
text
stringlengths 20
1.01M
| url
stringlengths 14
1.25k
| dump
stringlengths 9
15
⌀ | lang
stringclasses 4
values | source
stringclasses 4
values |
|---|---|---|---|---|
# Анализ трафика приложений на Android Emulator. Причем здесь Root?
Привет! Я думаю, что наберется немало людей, перед которыми стоят интересные задачи по работе с приложениями. Например - анализ трафика для, разумеется, тестирования этих самых приложений! Вам выпало нелегкое бремя - необходимо отдебажить продовую сборку чего-либо и вы начинаете свои поиски решений проблем. А проблем у вас на этом пути будет много. О том, как их можно решить я и пишу.
Классический путь начинается с установки какого-нибудь Charles, настройки в нем proxy-сервера и попытки слушать трафик, однако мы быстро натыкаемся на проблему - все адекватные современные приложения используют HTTPS, а поэтому - на ваше устройство придется установить сертификат, который и позволит слушать трафик. Тут то и начинается самое интересное...
Давайте создадим чек-лист, на который будем ориентироваться в процессе:
* ⚑ Предварительные подготовления, позволяющие начать установку эмулятора
* ⚑ Вы находитесь здесь
* ⚐ Установка эмулятора
* ⚐ Установка сертификата для MITM
* ⚐ Проверка работоспособности прослушки трафика
* ⚐ Разочарование
* ⚐ Получение root-доступа
* ⚐ Перенос сертификата в системное хранилище
* ⚐ Разочарование(?)
* ⚐ SSL Unpinning
* ⚐ Profit!!!
### Установка Android Emulator
Я не буду описывать всю процедуру установки, надеюсь, вы сможете сделать [все](https://developer.android.com/studio/run/emulator) подготовительные [действия](https://developer.android.com/studio), чтобы оказаться в ситуации, когда вам осталось лишь выбрать определенный тип OS в эмуляторе, а все предыдущие шаги уже выполнены.
Итак:
1. Выбираем любой подходящий вариант, с важной оговоркой - это должна быть сборка без Google Play, но с Google Play Services (далее будет видно). Соответственно - выбираем устройство без треугольника
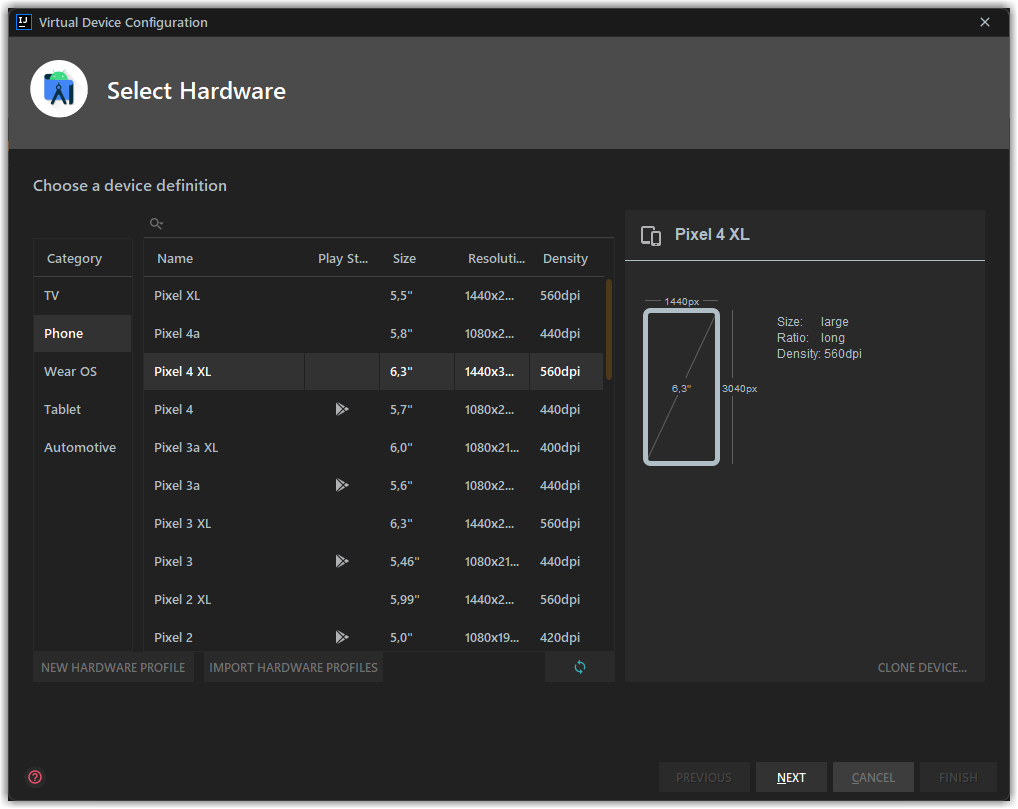2. Выбираем любой интересующий образ в котором есть Google Play APIs
3. Устанавливаем параметр Cold Boot
Готово!
* ⚑ Установка эмулятора
### Установка сертификата для proxy-sniffer
Для прослушки трафика я буду пользоваться Fiddler Everywhere. И покажу порядок настройки данной софтины, согласно которому мы закроем еще один пункт нашей дорожной карты.
*Тут я сделаю небольшое лирическое отступление - данная программа платная, да и еще по подписке, и стоить будет, в лучшем случае - 10$ в месяц. Но, у вас будет триал в 30 дней, после которого нужно больше золота, поэтому можно использовать любой другой инструмент. Сам я пытался заюзать Postman - в нем тоже есть proxy-tooling, однако, корневые сертификаты, которые генерирует Postman, не пригодны для установки в Android 10 / 11. Однако, служба поддержки уже бдит, и, надеюсь, за отведенные 30 дней триала все заработает как надо (в Postman) и вы сможете пользоваться наиболее удобным (с моей точки зрения) инструментом для решения данной задачи. Когда это случится - я дополню данную статью. А теперь возвращаемся к процессу установки сертификата на устройство (эмулятор).*
Нам необходимо раскрыть пункт **Advanced Settings** в настройках Fiddler, и экспортировать корневой сертификат. В данный момент я пользователь Windows и на данной ОС он окажется на рабочем столе, подсказка об этом показывается по наведению на значок вопроса.
После экспорта сертификата, плавным движением кистей рук, переносим его на запущенный эмулятор - файл окажется в папке `.../Downloads`. После чего можно сразу идти в настройки и устанавливать наш серт:
Отлично! Можем поставить галочку у еще одного пункта:
* ⚑ Установка сертификата для MITM
### Проверяем, все ли ок
Самое время проверить, принесли ли наши усилия хоть какие-то полезные плоды. Подопытным кроликом сегодняшнего эксперимента будет приложение **Reddit** и первое, что мы увидим, если попытаемся загрузить посты:
Пустота.
А также бесконечное количество попыток SSL-handshake в Fiddler. Кажется, пора поставить прочерк сразу напротив двух пунктов нашей дорожной карты:
* ⚑ Проверка работоспособности прослушки трафика
* ⚑ Разочарование
* ### Я есть root
Мне кажется, что наступил момент рассказать, для чего нам вообще рут? Все дело в том пресловутом изменении Android 7, после которого пользовательские сертификаты перестали быть доверенными. Посему - нам необходимо сделать что-то с нашим установленным сертификатом, чтобы мы смогли использовать его для изучения трафика нашего ~~рабочего~~ приложения. И сделать это можно, только если ваш девайс рутован. Тут же заключается и причина использования эмулятора, да и связанные с этим особенности: без эмулятора вам придется иметь постоянно рутованное устройство, если это отдельный выделенный смартфон - то проблем с этим особенно и нет (ну, кроме зарядки, постепенного устаревания и ограничений конкретной модели), однако, если у вас свой личный аппарат - то минусы от root могут быть существенными - не работающая система безопасности, сломанный Google Pay или отвалившиеся камеры... Ну и помимо всего прочего - эмулятор позволяет легко изменить версию Android (правда, придется повторить все действия, перечисленные тут, но у вас уже будет эта статья, а я вот это все пишу её не имея).
А теперь приступим. Благодаря прекраснейшему [проекту](https://github.com/newbit1/rootAVD) весь процесс сводится к запуску всего лишь одного скрипта, с небольшими подготовительными работами. Также, обращайте внимание на то, что выводится в консоль и если вы пользуетесь Windows - то запускайте не `.sh`, а `.bat`. Возможно, WSL будет тут как раз кстати, но моя система, скажем так, с некоторыми особенностями, которые WSL использовать не позволяют (если вы знаете, как завести на Ryzen 5000-серии и WSL и Android Emulator - то прошу написать об этом комментарий).
А вот и сами работы:
```
./rootAVD.sh ~/Library/Android/sdk/system-images/android-30/google_apis/x86_64/ramdisk.img
```
Плюс, нужно перезагрузить эмулятор. Ну и, у пользователей Windows путь до образа будет примерно таким:
```
C:\Users\Me\AppData\Local\Android\Sdk\system-images\android-30\google_apis\x86_64\ramdisk.img
```
На выходе мы получаем рут, который сохраняется при перезагрузке эмулятора, но wipe делать не стоит.
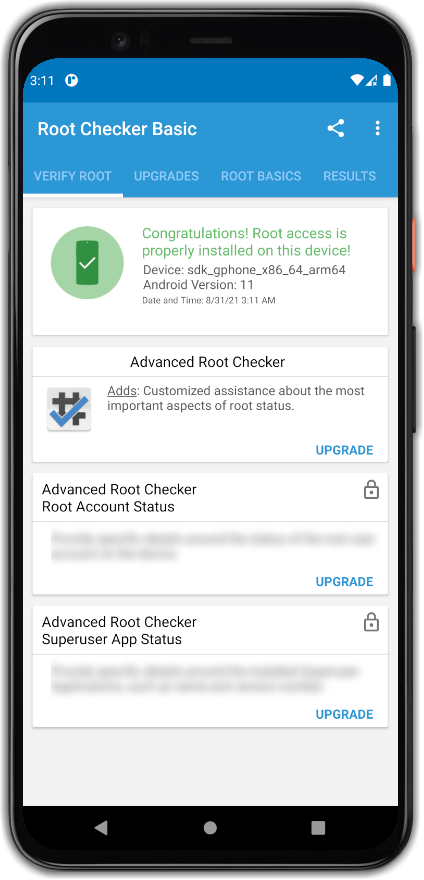Ставим галку:
+ ⚑ Получение root-доступа### Делаем сертификат доверенным
Для этого нам понадобится перенести его в хранилище доверенных сертификатов. Тут рут нам и нужен (не только тут, но это позже).
Для этого мы запускаем цепочку следующих команд:
```
adb shell
su
mkdir -m 700 /data/certs
cp /system/etc/security/cacerts/* /data/certs/
mount -t tmpfs tmpfs /system/etc/security/cacerts
cp /data/misc/user/0/cacerts-added/* /system/etc/security/cacerts/
mv /data/certs/* /system/etc/security/cacerts/
chown root:root /system/etc/security/cacerts/*
chmod 644 /system/etc/security/cacerts/*
chcon u:object_r:system_file:s0 /system/etc/security/cacerts/*
```
После чего наблюдаем следующую картинку в системных сертификатах:
Наш сертификат стал системным, поэтому закроем еще один пункт:
+ ⚑ Перенос сертификата в системное хранилищеИ давайте сразу проверим наше приложение:
Отлично! Теперь мы можем слушать HTTPS-трафик любых (ли?) приложений с эмулятора. Давайте, чтобы закрепить результат, попробуем еще одно приложение - **Avito** (как говорили Ник и Майк - это крепкий орешек).
Кажется, тут что-то пошло не так. Впрочем вы и так все знаете, так как видели гигантский спойлер в самом начале, поэтому ставим еще одну галку:
+ ⚑ Разочарование!### SSL-Unpinning
На данную тему есть множество решений, но, как правило, все они крутятся вокруг одной идеи - пересборки приложения, которое вы хотите изучить. Данный подход весьма громоздкий, сложный и может сподвигнуть к прокрастинации, поэтому нужно что-то такое, что позволит сделать все намного проще и универсальнее. И рецепт этого чего-то прямо тут, бесплатно и без СМС:
1. Благодаря наличию root установим Xposed
2. Благодаря Xposed установим модуль для отвязки SSL-привязки
3. Profit!!! (два пункта тут смотрелись бы уныло)А теперь давайте по порядку.
**Установка Xposed**
С учетом нашего изначального плана слушать всё и вся на эмуляторе на этом шаге появляются некоторые сложности - нужно подобрать удачную комбинацию программных решений, которые будут работать и на эмуляторе. Благодаря этой статье вам совершенно точно не придется тратить несколько часов на поиски этих решений и будет достаточно следовать простой инструкции:
1. Скачиваем [последнюю](https://github.com/RikkaApps/Riru/releases) версию Magisk-модуля с интересным названием Riru и устанавливаем его посредством Magisk
2. Закрываем эмулятор, а затем снова запускаем (данный шаг эмулирует перезагрузку, которая у меня, по каким-то причинам, не работает, если работает у вас - может быть достаточно и её)
3. Находим в репозитории Magisk модуль с названием `Riru - LSPosed` и устанавливаем его
4. Снова ребутим эмулятор
5. Открываем приложение LSPosed, в котором необходимо установить уже Xposed-модуль SSLUnpinning
6. Переключаем все галки в настройках данного модуля у всех приложений, которые хотим слушать и активируем сам модуль
7. Ребутим эмуляторПосле этого вы оказались в ситуации, когда у вас есть эмулятор с:
+ Полноценным рутом (Magisk)
+ Установленным MITM-сертификатом в User-space
+ Установленным Xposed (LSPosed)
+ Установленным модулем для SSL-UnpinningВ процессе имея следующий набор картинок:
Можно честно поставить галку:
+ ⚑ SSL UnpinningНастал час проверить, работает ли этот паровоз:
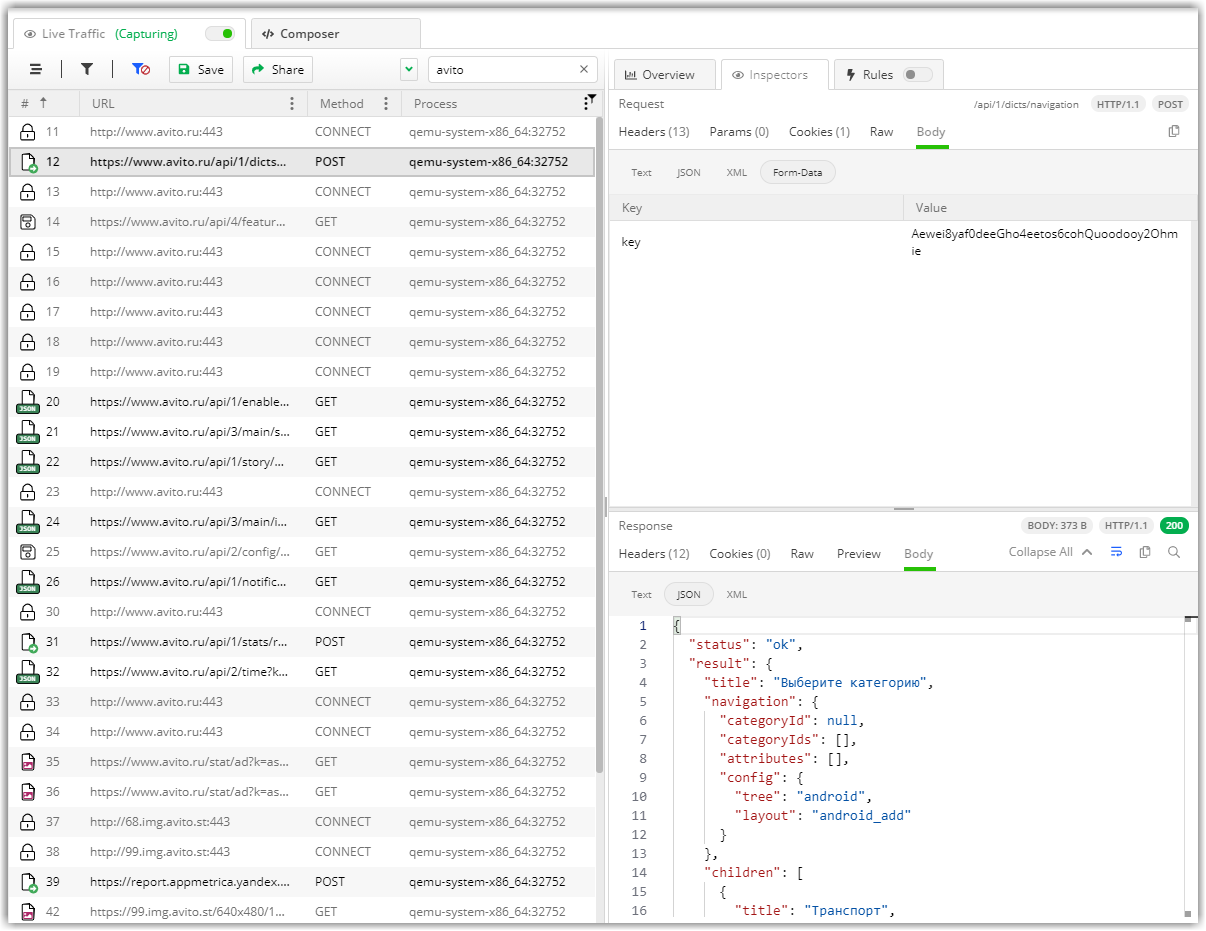Работает! Ник и Майк ошиблись! Можем ставить и последнюю галку:
+ ⚑ Profit!!!Какие есть нюансы? Во первых - при каждом включении эмулятора будет необходимо снова делать сертификаты доверенными (в принципе, после всех этих процедур можно отключить Cold Boot, и тогда не придется, но рано или вам придется перезагрузить эмулятор "жестко", и тогда потребуется поработать и с сертификатами). Возможно, тут есть постоянное решение или это можно, на худой конец, автоматизировать, но я устал. Во вторых - не все приложения в принципе хотят запускаться на эмуляторе. Самый надежный вариант - иметь набор выделенных телефонов на разных версиях Android, все из которых будут иметь весь арсенал инструментов из данного мануала (с небольшими изменениями), но он не всегда возможен.
Под конец - я еще раз продублирую всю инструкцию по пунктам, чтобы был понятен сам алгоритм:
+ Делаем приготовления (ставим Android Studio), чтобы иметь возможность установить / запустить эмулятор
+ Устанавливаем эмулятор с параметрами, определенными выше
+ Устанавливаем интересующие нас приложения на эмулятор методом перетаскивания курсором и убеждаемся, что они в принципе работают и все это будет не зря
+ Получаем root (Magisk) посредством инструкции, указанной выше
+ Перезагружаем эмулятор
+ Устанавливаем Riru
+ Перезагружаем эмулятор
+ Устанавливаем LSPosed
+ Перезагружаем эмулятор
+ Устанавливаем Xposed-модуль SSLUnpinning
+ Ставим все галки в модуле у интересующих нас приложений и у самого модуля (включаем его)
+ Закрываем эмулятор
+ Выключаем Cold Boot
+ Включаем эмулятор
+ Устанавливаем MITM CA-сертификат в User-space (считай - просто устанавливаем)
+ Делаем сертификат доверенным по инструкции выше
+ Настраиваем Proxy на эмуляторе согласно параметрам, указанным выше, или вашим собственным (в зависимости от того, каким инструментом для анализа трафика вы собираетесь пользоваться)
+ Анализируем работу приложенияЕсли будете устанавливать дополнительные приложения на эмулятор - то необходимо проставить галки напротив них в SSLUnpinning (через LSPosed) и жестко перезагрузить эмулятор, с последующим фиксом сертификатов после перезагрузки. На этом, собственно, все, до новых встреч! | https://habr.com/ru/post/575460/ | null | ru | null |
# Настройка ISCSI initiator в linux
Abstract: как работает open-iscsi (ISCSI initiator в linux), как его настраивать и чуть-чуть про сам протокол ISCSI.
Лирика: В интернете есть множество статей довольно хорошо объясняющих, как настроить ISCSI target, однако, почему-то, практически нет статей про работу с инициатором. Не смотря на то, что target технически сложнее, административной возни с initiator больше — тут больше запутанных концепций и не очень очевидные принципы работы.
ISCSI
=====
Перед тем, как рассказать про ISCSI — несколько слов о разных типах удалённого доступа к информации в современных сетях.
NAS vs SAN
----------
Существует два метода доступа к данным, находящимся на другом компьютере: файловый (когда у удалённого компьютера запрашивают файл, а какими файловыми системами это сделано — никого не волнует), характерные представители NFS, CIFS (SMB); и блочный — когда у удалённого компьютера запрашивают блоки с дискового носителя (аналогично тому, как их читают с жёсткого диска). В этом случае запрашивающая сторона сама себе делает на блочном устройстве файловую систему, а сервер, отдающий блочное устройство, знать не знает про файловые системы на нём. Первый метод называют NAS (network attached storage), а второй — SAN (storage area network). Названия вообще указывают на другие признаки (SAN подразумевает выделенную сеть до хранилищ), но так сложилось, что NAS — это файлы, а SAN — это блочные устройства по сети. И хотя все (?) понимают, что это неправильные названия, чем дальше, тем больше они закрепляются.
scsi over tcp
-------------
Одним из протоколов доступа к блочным устройствам является iscsi. Буква 'i' в названии относится не к продукции эппл, а к Internet ~~Explorer~~. По своей сути это 'scsi over tcp'. Сам протокол SCSI (без буквы 'i') — это весьма сложная конструкция, поскольку он может работать через разные физические среды (например, UWSCSI — параллельная шина, SAS — последовательная — но протокол у них один и тот же). Этот протокол позволяет делать куда больше, чем просто «подтыкать диски к компьютеру» (как это придумано в SATA), например, он поддерживает имена устройств, наличие нескольких линков между блочным устройством и потребителем, поддержку коммутации (ага, SAS-коммутатор, такие даже есть в природе), подключение нескольких потребителей к одному блочному устройству и т.д. Другими словами, этот протокол просто просился в качестве основы для сетевого блочного устройства.
Терминология
------------
В мире SCSI приняты следующие термины:
**target** — тот, кто предоставляет блочное устройство. Ближайший аналог из обычного компьютерного мира — сервер.
**initiator** — клиент, тот, кто пользуется блочным устройством. Аналог клиента.
**WWID** — уникальный идентификатор устройства, его имя. Аналог DNS-имени.
**LUN** — номер «кусочка» диска, к которому идёт обращение. Ближайший аналог — раздел на жёстком диске.
ISCSI приносит следующие изменения: WWID исчезает, на его место приходит понятие IQN (iSCSI Qualified Name) — то есть чистой воды имя, сходное до степени смешения с DNS (с небольшими отличиями). Вот пример IQN: iqn.2011-09.test:name.
IETD и open-iscsi (сервер и клиент под линукс) приносят ещё одну очень важную концепцию, о которой чаще всего не пишут в руководствах по iscsi — portal. Portal — это, если грубо говорить, несколько target'ов, которые анонсируются одним сервером. Аналогии с www нет, но если бы веб-сервер можно было попросить перечислить все свои virtualhosts, то это было бы оно. portal указывает список target'ов и доступные IP, по которым можно обращаться (да-да, iscsi поддерживает несколько маршрутов от initiator к target).
target
======
Статья не про target, так что даю очень краткое описание того, что делает target. Он берёт блочное устройство, пришлёпывает к нему имя и LUN и публикет его у себя на портале, после чего позволяет всем желающим (авторизация по вкусу) обращаться к нему.
Вот пример простенького файла конфигурации, думаю, из него будет понятно что делает target (файл конфигурации на примере IET):
```
Target iqn.2011-09.example:data
IncomingUser username Pa$$w0rd
Lun 0 Path=/dev/md1
```
(сложный от простого отличается только опциями экспорта). Таким образом, если у нас есть target, то мы хотим его подключить. И тут начинается сложное, потому что у initiator'а своя логика, он совсем не похож на тривиальное mount для nfs.
Initiator
=========
В качестве инициатора используется open-iscsi. Итак, самое важное — у него есть *режимы работы* и *состояние*. Если мы дадим команду не в том режиме или не учтём состояние, результат будет крайне обескураживающий.
Итак, режимы работы:* Поиск target'ов (discovery)
* Подключение к target'у
* Работа с подключенным target'ом
Из этого списка вполне понятен жизненный цикл — сначала найти, потом подключиться, потом отключиться, потом снова подключиться. Open-iscsi держит сессию открытой, даже если блочное устройство не используется. Более того, он держит сессию открытой (до определённых пределов, конечно), даже если сервер ушёл в перезагрузку. Сессия iscsi — это не то же самое, что открытое TCP-соединение, iscsi может прозрачно переподключаться к target'у. Отключение/подключение — операции, которыми управляют «снаружи» (либо из другого ПО, либо руками).
Немного о состоянии. После discovery open-iscsi *запоминает* все найденные target'ы (они хранятся в /etc/iscsi/), другими словами, discovery — операция постоянная, совсем НЕ соответствующая, например, dns resolving). Найденные target можно удалить руками (кстати, частая ошибка — когда у open-iscsi, в результате экспериментов и настройки, пачка найденных target'ов, при попытке логина в которые выползает множество ошибок из-за того, что половина target'ов — старые строчки конфига, которые уже давно не существуют на сервере, но помнятся open-iscsi). Более того, open-iscsi позволяет менять настройки запомненного target'а — и эта «память» влияет на дальнейшую работу с target'ами даже после перезагрузки/перезапуска демона.
Блочное устройство
==================
Второй вопрос, который многих мучает по-началу — куда оно попадает после подключения? open-iscsi создаёт хоть и сетевое, но БЛОЧНОЕ устройство класса SCSI (не зря же оно «я сказя»), то есть получает букву в семействе /dev/sd, например, /dev/sdc. Используется первая свободная буква, т.к. для всей остальной системы это блочное устройство — типичный жёсткий диск, ничем не отличающийся от подключенного через usb-sata или просто напрямую к sata.
Это часто вызывает панику «как я могу узнать имя блочного устройства?». Оно выводится в подробном выводе iscsiadm (# iscsiadm -m session -P 3).
Авторизация
===========
В отличие от SAS/UWSCSI, ISCSI доступно для подключения кому попало. Для защиты от таких, есть логин и пароль (chap), и их передача iscsiadm'у — ещё одна головная боль для начинающих пользователей. Она может осуществляться двумя путями — изменением свойств уже найденного ранее target'а и прописываем логина/пароля в файле конфигурации open-iscsi.
Причина подобных сложностей — в том, что пароль и процесс логина — это атрибуты не пользователя, а системы. ISCSI — это дешёвая версия FC-инфраструктуры, и понятие «пользователь» в контексте человека за клавиатурой тут неприменимо. Если у вас sql-база лежит на блочном устройстве iscsi, то разумеется, вам будет хотеться, чтобы sql-сервер запускался сам, а не после минутки персонального внимания оператора.
Файл конфигурации
=================
Это очень важный файл, потому что помимо логина/пароля он описывает ещё поведение open-iscsi при нахождении ошибок. Он может отдавать ошибку «назад» не сразу, а с некоторой паузой (например, минут в пять, чего достаточно для перезагрузки сервера с данными). Так же там контролируется процесс логина (сколько раз пробовать, сколько ждать между попытками) и всякий тонкий тюнинг самого процесса работы. Заметим, эти параметры довольно важны для работы и вам нужно обязательно понимать, как поведёт ваш iscsi если вынуть сетевой шнурок на 10-20с, например.
Краткий справочник
==================
Я не очень люблю цитировать легконаходимые маны и строчки, так что приведу типовой сценарий употребения iscsi:
сначала мы находим нужные нам target, для этого мы должны знать IP/dns-имя инициатора: `iscsiadm -m discovery -t st -p 192.168.0.1` -t st — это команда send targets.
`iscsiadm -m node` (список найденного для логина)
`iscsiadm -m node -l -T iqn.2011-09.example:data` (залогиниться, то есть подключиться и создать блочное устройство).
`iscsiadm -m session` (вывести список того, к чему подключились)
`iscsiadm -m session -P3` (вывести его же, но подробнее — в самом конце вывода будет указание на то, какое блочное устройство какому target'у принадлежит).
`iscsiadm - m session -u -T iqn.2011-09.example:data` (вылогиниться из конкретной )
`iscsiadm -m node -l` (залогиниться во все обнаруженные target'ы)
`iscsiadm -m node -u` (вылогиниться из всех target'ов)
`iscsiadm -m node --op delete -T iqn.2011-09.example:data` (удалить target из обнаруженных).
mulitpath
=========
Ещё один вопрос, важный в серьёзных решениях — поддержка нескольких маршрутов к источнику. Прелесть iscsi — в использовании обычного ip, который может быть обычным образом обработан, как и любой другой трафик (хотя на практике обычно его не маршрутизируют, а только коммутируют — слишком уж великая там нагрузка). Так вот, iscsi поддерживает multipath в режиме «не сопротивляться». Сам по себе open-iscsi не умеет подключаться к нескольким IP одного target'а. Если его подключить к нескольким IP одного target'а, то это приведёт к появлению нескольких блочных устройств.
Однако, решение есть — это multipathd, который находит диски с одинаковым идентифиатором и обрабатывает их как положено в multipath, с настраиваемыми политиками. Эта статья не про multipath, так что подробно объяснять таинство процесса я не буду, однако, вот некоторые важные моменты:
1. При использовании multipath следует ставить маленькие таймауты — переключение между сбойными путями должно происходить достаточно быстро
2. В условиях более-менее быстрого канала (10G и выше, во многих случаях гигабит) следует избегать параллелизма нагрузки, так как теряется возможность использовать bio coalesing, что в некоторых типах нагрузки может неприятно ударить по target'у. | https://habr.com/ru/post/97529/ | null | ru | null |
# Поиск в пространстве стратегий. AI водитель

Выкладываю отчёт о своём эксперименте в области машинного обучения. В этот раз темой эксперимента было создание AI для управления моделькой автомобиля.
Как написано на [умных сайтах](http://www.machinelearning.ru/wiki/index.php?title=%D0%9E%D0%B1%D1%83%D1%87%D0%B5%D0%BD%D0%B8%D0%B5_%D1%81_%D0%BF%D0%BE%D0%B4%D0%BA%D1%80%D0%B5%D0%BF%D0%BB%D0%B5%D0%BD%D0%B8%D0%B5%D0%BC), существует два основных способа сделать, чтобы объект управления максимизировал некую функцию оценки:
1) Запрограммировать обучение с подкреплением (привет собакам Павлова)
2) Провести прямой поиск в пространстве стратегий
Я решил выбрать второй вариант.
AI-водитель
------------
В качестве модельной задачи я выбрал подзадачу из одного чемпионата по ИИ (когда я её решал впервые, я ещё не умел machine learning).
Есть объект. Он может поворачиваться вправо-влево и ускоряться вперёд-назад (вперёд – побыстрее, назад – помедленнее). Как быстрее всего добраться этим объектом из пункта А в пункт Б?

**Программный код симуляции на Matlab**
```
function q = evaluateNN(input,nn)
unit.angle=0;
unit.x=0;
unit.y=0;
trg.x=input(1);
trg.y=input(2);
q=0;
rmin=1e100;
for i=1:20 %машина "живёт" 20 тактов
%работа сенсоров
tangle=180*atan2(-unit.y+trg.y,-unit.x+trg.x)/3.141-unit.angle;
if(tangle>180)
tangle=tangle-360;
end;
if(tangle<-180)
tangle=tangle+360;
end;
r=sqrt((unit.y-trg.y)^2+(unit.x-trg.x)^2);
%принятие решений
answArr=fastSim(nn,[tangle;r]);
answArr(1)=(10+(-2))/2+ answArr(1)*(10-(-2))/2;
answArr(2)=(30+(-30))/2+ answArr(2)*(30-(-30))/2;
%механика
vx=answArr(1)*cos(3.141*unit.angle/180);
vy=answArr(1)*sin(3.141*unit.angle/180);
unit.x=unit.x+vx;
unit.y=unit.y+vy;
unit.angle=unit.angle+answArr(2);
%да, машина у нас довольно простенькая.
if(r0)
q=0;
end;
end
```
Вообще-то задачу можно решить, записав дифференциальное уравнение движения и решив его… Но я в диффурах не силён. Поэтому регулярно сталкивался с такими проблемами:

Юнит повёрнут к цели спиной. Ему лучше развернуться и доехать, или доехать задним ходом?

Юнит повёрнут к цели под 70 градусов. Мне лучше ускоряться и одновременно поворачивать, или сначала повернуть, а потом ускоряться? Как выбрать порог, отделяющий одну стратегию от другой?
Теперь, когда у меня есть эффективный оптимизирующий алгоритм и скоростные нейросети, я решил задачу перебором стратегий. То есть я представил нашу задачу как функцию, где входные величины — это веса и сдвиги нейронов, а выходная величина — это численная оценка эффективности данной стратегии (эта численная оценка называется функцией качества или метрикой качества).
Входные данные нейросети:
1) Направление на цель (от -180 до 180 градусов)
2) Расстояние до цели
3) Курсовая скорость объекта управления
4) Боковая скорость объекта управления
Курсовая и боковая скорости – это вот эти штуки:

Выходные величины – положение руля (от -30 до +30 градусов за такт) и ускорение от движка (от -2 до +10 клеток/ход за ход).
В качестве функции качества в единичном испытании я выбрал q=(-минимальное расстояние до цели). Q всегда отрицательна, но чем больше Q, тем выше мы оцениваем качество алгоритма. Так как испытаний я провожу несколько, надо вывести из них какую-то единую метрику качества.
Я взял в качестве метрики наихудшее значение качества по всем испытаниям — то есть бот стремиться улучшить не средний, а худший из результатов. Я так сделал, чтобы AI не стремился оптимизировать результаты одних испытаний в ущерб результатам других испытаний.
Моя нейросеть состояла из 2 слоёв по 7 нейронов каждый, функция активации каждого нейрона – арктангенс.
Несколько минут обучения и…

AI стал наводиться на цель вот так. Красная стрелочка – это ориентация машины. То есть бот давал задний ход, одновременно разворачивался, а затем переходил с заднего хода на передний. При этом цели он достигал быстрее, чем стратегия «сначала хотя бы частично развернуться, потом ехать» и чем стратегия «ехать задом».
AI-собиратель
-------------
Немного меняем постановку задачи. Всё та же плоскость, всё те же возможности ускоряться/поворачивать (на этот раз ускорение от -3 до 7, а поворот от -30 до 30 градусов за ход). Каждое испытание ограничено 100 ходами.
Но теперь целей несколько. Каждая цель неподвижна. AI видит их таким образом:

Нейросети доступен угол обзора в 200 градусов, который разбит на 9 равных секторов (22 градуса каждый). Если в один из секторов попадает цель, то на соответствующий сенсор нейросети попадает число, равное расстоянию до цели. Если цели в секторе нет, то на сенсор попадает число 1000 (практически все расстояния в симуляции меньше этого числа).

Если управляемый объект подъезжает к цели на расстояние 10 или меньше, цель уничтожается, а AI получает 10 очков (типа съел цель).
Начальные координаты объекта управления нулевые (0,0). Координаты целей в первом испытании такие:
[50,100] [10,30] [100,-120] [60,75]
Это типичные координаты. Всего испытаний 6, и координаты примерно такого порядка. Целей всегда 4.
Ставлю ИИ на обучение. ИИ безуспешно пытается обучиться в течение нескольких часов. Он в среднем захватывает одну цель за испытание (даже чуть меньше). Полагаю, проблема в том, что функция зависимости награды от коэффициентов кусочно-постоянная.

В таких случаях мой оптимизатор работает довольно плохо (да и эволюция в таких случаях не особенно справляется).
Поэтому я совершаю небольшое читерство. Я делаю, чтобы каждый ход AI получал число очков, обратно пропорциональное расстоянию до каждой из неподобранных целей. Он получает по 0.1/r очков за каждую цель. То есть на расстоянии в 10 он будет получать 0.001 очко за цель, а «съедание» этой цели будет давать 10 очков. Число очков, получаемое AI, меняется очень слабо, но функция становится кусочно-переменной, то есть у неё появляется ненулевая производная.

**Исходный код симуляции с водителем, находящим ключевые точки**
```
function q = evaluateNN(input,nn)
unit.angle=0;
unit.x=0;
unit.y=0;
unit.vx=0;
unit.vy=0;
trg=[];
trg(1).x=input(1);
trg(1).y=input(2);
trg(1).pickable=1;
trg(2).x=input(3);
trg(2).y=input(4);
trg(2).pickable=1;
trg(3).x=input(5);
trg(3).y=input(6);
trg(3).pickable=1;
trg(4).x=input(7);
trg(4).y=input(8);
trg(4).pickable=1;
tsz=size(trg);
tangle=[];
r=[];
sensor=[];
sensorMax=5;
sensorBound=70;
sectorSize=2*sensorBound/sensorMax;
q=-100;
rmin=1e100;
for i=1:200
%работа сенсоров
for j=1:sensorMax
sensor(j)=1e4;
end;
for j=1:tsz(2)
tangle(j)=180*atan2(-unit.y+trg(j).y,-unit.x+trg(j).x)/3.141-unit.angle;
if(tangle>180)
tangle=tangle-360;
end;
if(tangle<-180)
tangle=tangle+360;
end;
r(j)=sqrt((unit.y-trg(j).y)^2+(unit.x-trg(j).x)^2);
if(tangle(j)>-sensorBound && tangle(j)r(j))
sensor(index)=r(j);
end;
end;
%даём подкрепление за подбор награды
if(r(j)<10 && trg(j).pickable==1)
%picked up
q=q+10;
trg(j).pickable=0;
end;
%даём подкрепление за близость к награде
if(r(j)<50 && trg(j).pickable==1)
q=q+1/r(j);
end;
end;
%сенсоры скорости: боковой и курсовой
vangle=180\*atan2(unit.vy,unit.vx)/3.141;
vr=unit.vy\*sin(3.141\*unit.angle/180)+unit.vx\*cos(3.141\*unit.angle/180);%v-radial. Scalar multing
vb=-unit.vx\*sin(3.141\*unit.angle/180)+unit.vy\*cos(3.141\*unit.angle/180);%v-back. vx\*(-y)+vy\*x
%принятие решений
answArr=fastSim(nn,[sensor'';vr;vb]);
answArr(1)=(4+(-1))/2+ answArr(1)\*(4-(-1))/2;
answArr(2)=(30+(-30))/2+ answArr(2)\*(30-(-30))/2;
%механическая модель
ax=answArr(1)\*cos(3.141\*unit.angle/180);
ay=answArr(1)\*sin(3.141\*unit.angle/180);
unit.vx=unit.vx+ax;
unit.vy=unit.vy+ay;
unit.x=unit.x+unit.vx;
unit.y=unit.y+unit.vy;
unit.angle=unit.angle+answArr(2);
end;
if(q>0)
q=0;
end;
end
```
При этом результаты нескольких испытаний я объединял следующим образом: я брал средний результат и наихудший, и брал от них среднее.
```
nnlocal=ktonn(nn,k);
arr=[1,2,3,4,1,2,3,4];
input=[[50,100,10,30,100,-120,60,75];[-50,50,-100,100,10,0,20,-90];[100,-60,-100,15,20,0,15,4];[-100,-10,-25,15,60,-5,-80,10];[-10,-70,0,-40,0,40,20,22]; [20,-100,-20,22,-30,0,100,-10];];
for (i=1:6)
nncopy=nnlocal;
val=evaluateNN(input(i,:),nncopy);
sum_=sum_+val;
arr(i)=val;
countOfPoints=countOfPoints+1;
end;
q=sum_/countOfPoints- sum(abs(k))*0.00001;
```
Работа пошла бодрее. Несколько десятков минут – и вуаля:

Так мы проходим 1-ое испытание. Все цели (синие крестики) успешно захвачены.

Так мы проходим 2-ое испытание. Захвачено 3 цели (для захвата той первой цели пришлось чуть проехать вперёд, а затем развернуться. Крупным планом это выглядит так:

В 3-ем испытании тоже 4 из 4:

И в 4-ом:

И в 5-ом:

А вот в 6-ом у нас уже 3 из 4.

Зададим теперь новые испытания – такие, которых не было в обучающей выборке (проведём кроссвалидацию).

3 из 4! Признаться, я до последнего сомневался, что AI сможет перенести опыт обучающей выборки на тестовую.

Отработал 3 цели, и мимо одной чуть-чуть промазал.

Ну а тут AI совсем облажался. Отработал 2 цели из 4.
Вывод
-----
Отчёт об эксперименте должен заканчиваться выводами. Выводы следующие:
1) Обучение методом перебора пространства стратегий — многообещающая методика. Но она требовательна к оптимизатору — я применял довольно замороченный алгоритм для подбора параметров.
2) Кусочно-постоянная функция качества — это зло. Если у функции нет чего-то, хоть отдалённо напоминающего производную, её очень тяжело будет оптимизировать.
3) 2 слоя по 7 нейронов — это достаточно, чтобы сделать простенький автопилот. Обычно 14 нейронов — это пшик, из которого не собрать никакую полезную функцию.
Буду благодарен за комментарии, товарищи!
Если статья понравится, я расскажу, как делал аналогичный AI для игры типа Mortal Kombat. | https://habr.com/ru/post/323424/ | null | ru | null |
# Создаем новогоднюю ёлку-таймер при помощи CSS3

Буквально неделю назад я загорелся идеей, максимально использовать для создания своих сайтов CSS3. И так как в последнее время меня мучает бессонница, я стал развивать эти навыки. Расслабляясь и смотря очередное видео, я пропитался новогодним настроением и решил сделать новогоднюю елку на CSS. Идея была в том, что все должно быть максимально простым, классическим и без использования картинок. В то время когда я делал елку, я решил сделать еще и таймер обратного отсчета к Новому году. На все это я потратил не очень много времени и масса удовольствия была мне обеспечена.
Итак, приступим.
HTML-код будет предельно простой:
```
До Нового Року залишилось...
$(function () {
var austDay = new Date(2011, 1, 1, 00, 00, 00) ;
austDay = new Date(austDay.getFullYear() + 1, 1 - 1, 1);
$('#defaultCountdown').countdown({until: austDay});
$('#year').text(austDay.getFullYear());
});
До
Нового Року
залишилось:
```
**Пишем стили**
Для начала мы создадим фон для нашей елки:
```
body {
background: #E8E8E8;
}
```
Для создания елки я использовал легкую схему из двенадцати треугольников, ножки, и подставки — придавая им соответствующие стили.
Получилось следующее:
```
.fir-tree {
position: absolute;
top: 80%;
left: 45%;
width: 100px;
height: 30px;
background: #222222;
-moz-border-radius: 4px;
-webkit-border-radius: 4px;
border-radius: 4px;
}
.fir-tree .conf-stem {
position: absolute;
top: 0%;
left: 10%;
width: 100px;
height: 30px;
background: #222222;
-moz-border-radius: 4px;
-webkit-border-radius: 4px;
border-radius: 4px;
}
.fir-tree .stem {
position: absolute;
top: -120%;
left: 41%;
width: 30px;
height: 60px;
background: #222222;
}
.fir-tree .a {
position: inherit;
top: -430%;
left: -65%;
width:0;
height: 0;
border-left: 120px solid transparent;
border-right: 120px solid transparent;
border-bottom: 120px solid #222222;
/* Only FF, Safari, Chrome (I don't use this in IE and Opera because this function doesn't work correctly) */
-moz-border-radius: 50px;
-webkit-border-radius: 50px;
}
.fir-tree .b {
position: inherit;
top: -485%;
left: -55%;
width:0;
height: 0;
border-left: 110px solid transparent;
border-right: 110px solid transparent;
border-bottom: 110px solid #222222;
/* Only FF, Safari, Chrome (I don't use this in IE and Opera because this function doesn't work correctly) */
-moz-border-radius: 50px;
-webkit-border-radius: 50px;
}
.fir-tree .c {
position: inherit;
top: -535%;
left: -45%;
width:0;
height: 0;
border-left: 100px solid transparent;
border-right: 100px solid transparent;
border-bottom: 100px solid #222222;
/* Only FF, Safari, Chrome (I don't use this in IE and Opera because this function doesn't work correctly) */
-moz-border-radius: 50px;
-webkit-border-radius: 50px;
}
.fir-tree .d {
position: inherit;
top: -585%;
left: -35%;
width:0;
height: 0;
border-left: 90px solid transparent;
border-right: 90px solid transparent;
border-bottom: 90px solid #222222;
/* Only FF, Safari, Chrome (I don't use this in IE and Opera because this function doesn't work correctly) */
-moz-border-radius: 50px;
-webkit-border-radius: 50px;
}
.fir-tree .e {
position: inherit;
top: -635%;
left: -25%;
width:0;
height: 0;
border-left: 80px solid transparent;
border-right: 80px solid transparent;
border-bottom: 80px solid #222222;
/* Only FF, Safari, Chrome (I don't use this in IE and Opera because this function doesn't work correctly) */
-moz-border-radius: 50px;
-webkit-border-radius: 50px;
}
.fir-tree .f {
position: inherit;
top: -685%;
left: -15%;
width:0;
height: 0;
border-left: 70px solid transparent;
border-right: 70px solid transparent;
border-bottom: 70px solid #222222;
/* Only FF, Safari, Chrome (I don't use this in IE and Opera because this function doesn't work correctly) */
-moz-border-radius: 50px;
-webkit-border-radius: 50px;
}
.fir-tree .g {
position: inherit;
top: -725%;
left: -5%;
width:0;
height: 0;
border-left: 60px solid transparent;
border-right: 60px solid transparent;
border-bottom: 60px solid #222222;
/* Only FF, Safari, Chrome (I don't use this in IE and Opera because this function doesn't work correctly) */
-moz-border-radius: 50px;
-webkit-border-radius: 50px;
}
.fir-tree .h {
position: inherit;
top: -765%;
left: 5%;
width:0;
height: 0;
border-left: 50px solid transparent;
border-right: 50px solid transparent;
border-bottom: 50px solid #222222;
/* Only FF, Safari, Chrome (I don't use this in IE and Opera because this function doesn't work correctly) */
-moz-border-radius: 50px;
-webkit-border-radius: 50px;
}
.fir-tree .i {
position: inherit;
top: -805%;
left: 15%;
width:0;
height: 0;
border-left: 40px solid transparent;
border-right: 40px solid transparent;
border-bottom: 40px solid #222222;
/* Only FF, Safari, Chrome (I don't use this in IE and Opera because this function doesn't work correctly) */
-moz-border-radius: 50px;
-webkit-border-radius: 50px;
}
.fir-tree .j {
position: inherit;
top: -835%;
left: 25%;
width:0;
height: 0;
border-left: 30px solid transparent;
border-right: 30px solid transparent;
border-bottom: 30px solid #222222;
/* Only FF, Safari, Chrome (I don't use this in IE and Opera because this function doesn't work correctly) */
-moz-border-radius: 50px;
-webkit-border-radius: 50px;
}
.fir-tree .k {
position: inherit;
top: -855%;
left: 35%;
width:0;
height: 0;
border-left: 20px solid transparent;
border-right: 20px solid transparent;
border-bottom: 20px solid #222222;
/* Only FF, Safari, Chrome (I don't use this in IE and Opera because this function doesn't work correctly) */
-moz-border-radius: 50px;
-webkit-border-radius: 50px;
}
.fir-tree .l {
position: inherit;
top: -872%;
left: 45%;
width:0;
height: 0;
border-left: 10px solid transparent;
border-right: 10px solid transparent;
border-bottom: 10px solid #222222;
/* Only FF, Safari, Chrome (I don't use this in IE and Opera because this function doesn't work correctly) */
-moz-border-radius: 50px;
-webkit-border-radius: 50px;
}
```
Елка у нас уже есть и теперь нужно сделать таймер. Для его создания я выбрал плагин для JS под названием [Countdown](http://keith-wood.name/countdown.html).
Что бы сделать обратный отсчет, я использовал такой шаблонный код:
```
$(function () {
var austDay = new Date(2011, 1, 1, 00, 00, 00) ;
austDay = new Date(austDay.getFullYear() + 1, 12 - 1, 32);
$('#defaultCountdown').countdown({until: austDay});
$('#year').text(austDay.getFullYear());
});
```
Для плагина конечно же можно добавить стили по вкусу, вот мои:
```
.countdown_show1 .countdown_section {
width: 200%;
}
.countdown_show2 .countdown_section {
width: 100%;
}
.countdown_show3 .countdown_section {
width: 100%;
}
.countdown_show4 .countdown_section {
width: 100%;
}
.countdown_show5 .countdown_section {
width: 100%;
}
.countdown_show6 .countdown_section {
width: 100%;
}
.countdown_show7 .countdown_section {
width: 60%;
}
.countdown_section {
display: block;
float: left;
font-size: 80%;
text-align: center;
}
.countdown_amount {
font-size: 200%;
}
.countdown_descr {
display: block;
width: 100%;
}
```
Полноценная елка у нас уже есть, осталось лишь сделать надпись. Для надписи можно использовать какой-нибудь красивый шрифт, но в данном примере я решил удержаться и следовать простоте.
```
.text {
position: absolute;
top: -800%;
left: -430%;
font-size: 40px;
color: #222222;
font-family: Verdana, Arial;
text-align: center;
font-weight:bold;
text-shadow: 4px 4px 7px rgba(0,0,0,0.2),
0px -6px 38px rgba(255,255,255,0.3);
}
```
И вот что у нас в результате получилось:
[Демонстрация](http://holovko.org.ua/newyear/)
**Заключение**
Итак, у нас получился красивый таймер в виде елки. Все довольно просто и красиво.
С наступающим! | https://habr.com/ru/post/135238/ | null | ru | null |
# Создание модулей с учётом новой структуры Joomla 4
Joomla 4 "под капотом" претерпела немало изменений относительно предыдущих версий. Её кодовую базу сообщество разработчиков регулярно подтягивают до современных реалий, вводя актуальные технологии в ядро CMS. Так, например, если раньше загрузка классов была вариациями на тему include, то в Joomla 4 появился лоадер, приведённый к PSR-4. Ядро CMS переводится на концепцию сервис-провайдеров, внедрены DI-контейнеры, переработанная система событий для плагинов позволила [увеличить производительность при генерации страниц более чем в два раза.](https://github.com/joomla/joomla-cms/discussions/38407#discussioncomment-3472706) Эти изменения влекут за собой изменения в структуре компонентов, модулей и плагинов.
В данной статье пойдёт речь о том, как создать модуль для Joomla 4 с новой структурой файлов и классов. К слову сказать, legacy ещё работает и многие расширения, созданные по канонам Joomla 3 (а не работавшие на Joomla 3, но написанные по канонам Joomla 1.5) ещё долго будут работать на Joomla 4.
Отступление
-----------
Я предполагаю, что часть читателей имеет опыт работы с Joomla, но не имеет опыта создания модулей, поэтому постараюсь описать создание модуля как можно подробнее. Статья имеет сугубо прикладной характер, без погружения в теорию ООП и его реализацию в Joomla. Основная цель - подсказать что "делать руками", когда поставлена определённая задача.
Рассказывать о создании модуля я буду на примере своего модуля **WT Yandex map items** - [модуля вывода материалов Joomla на Яндекс.карты](https://web-tolk.ru/dev/joomla-modules/wt-yandex-map-items.html) по координатам из пользовательских полей, который создавался под проект на Joomla 4, поэтому названия файлов, классов и namespace будут содержать название именно этого модуля. При создании своего модуля, естественно, нужно изменить их на свои.
Файловая структура модуля Joomla 3 vs Joomla 4 и распределение функционала
--------------------------------------------------------------------------
### Было (Joomla 3)
Старая файловая структура модуля Joomla 3Для создания модуля было необходимо как минимум 3 файла:
* **mod\_wtyandexmapitems.xml** - описание модуля для установщика расширений Joomla (системное имя, дата, версия, сайт разработчика и т.д.), параметры конфигурации, сервер обновлений и т.д.
* **mod\_wtyandexmapitems.php** - "точка входа" в модуль. С этого файла начинается работа Вашего кода.
* **tmpl/default.php** - макет вывода для модуля. Здесь находится HTML-вёрстка Вашего модуля. При необходимости, можно скопировать и переименовать этот файл, изменить вывод HTML по своему вкусу и выбрать в настройках свой новый макет вывода.
Этот же способ позволяет выполнять любой свой PHP-код в нужном месте и в нужное время.
Именно такую структуру мы видим в одном из простейших модулей Joomla - mod\_custom - "HTML-код".
Файловая структура модуля типа HTML-код в Joomla 3.#### Хелпер (helper) модуля Joomla
Если наш модуль делает что-то более сложное, чем просто вывод значений из настроек модуля, например:
* отображает список новых статей на сайте;
* показывает карусель товаров из компонента интернет-магазина;
* выводит популярные комментарии или фотографии из фото-галереи ;
* подтягивает данные модуля по ajax (ajax-корзина товаров, к примеру).
то все функции, выполняющие эту работу, помещаются в хелпер модуля. В Joomla 3 он помещался в файл helper.php, находящийся рядом с основным php-файлом. Подключение хелпера было в "точке входа" с помощью `JLoader::register('ModWtyandexmapitemsHelper', __DIR__ . '/helper.php');`
### Стало (Joomla 4)
Новая файловая структура модуля для Joomla 4Для создания модуля в Joomla 4 нужны следующие файлы (с меньшим количеством можно поэкспериментировать спортивного интереса ради):
#### Файл mod\_wtyandexmapitems.xml
Этот файл содержит описание модуля для установщика расширений Joomla (системное имя, дата, версия, сайт разработчика и т.д.), параметры конфигурации, сервер обновлений, **а также** **задаёт Namespace модуля и директории для автозагрузки классов**.
Namespace Joomla\Module\Wtyandexmapitems начинается в modules/mod\_wtyandexmapitems/src
```
xml version="1.0" encoding="utf-8"?
MOD\_WTYANDEXMAPITEMS
Sergey Tolkachyov
13/09/2022
(C) 2022 Sergey Tolkachyov.
GNU General Public License version 2 or later
[email protected]
https://web-tolk.ru
1.0.0
MOD\_WTYANDEXMAPITEMS\_DESC
Joomla\Module\Wtyandexmapitems
src
language
services
tmpl
language/en-GB/mod\_wtyandexmapitems.ini
language/en-GB/mod\_wtyandexmapitems.sys.ini
language/ru-RU/mod\_wtyandexmapitems.ini
language/ru-RU/mod\_wtyandexmapitems.sys.ini
```
**Также обратите внимание**, что для корректной установки и работы модуля нужно указывать атрибут `module="mod_wtyandexmapitems"` в xml-манифесте. Если в Joomla 3 этот атрибут указывался для файла "точки входа" (`mod\_wtyandexmapitems.php`), то сейчас он указывается для папки `src` модуля - `src` .
Ещё одно **нововведение связано с языковыми файлами**: теперь в именах файлов не обязательно дублировать префикс языка - "ru-RU.mod\_wtyandexmapitems.ini". Достаточно того, что файл лежит в папке "ru-RU".
#### Файл services/provider.php
Файл - сервис-провайдер Вашего модуля. Он сообщает Joomla, что Ваш модуль существует и регистрирует namespace модуля в глобальном пространстве имён.
```
php
/**
* @package WT Yandex Map items
*
* @copyright (C) 2022 Sergey Tolkachyov
* @link https://web-tolk.ru
* @license GNU General Public License version 2 or later
*/
defined('_JEXEC') or die;
use Joomla\CMS\Extension\Service\Provider\HelperFactory;
use Joomla\CMS\Extension\Service\Provider\Module;
use Joomla\CMS\Extension\Service\Provider\ModuleDispatcherFactory;
use Joomla\DI\Container;
use Joomla\DI\ServiceProviderInterface;
/**
* The WT Yandex map items module service provider.
*
* @since 1.0.0
*/
return new class implements ServiceProviderInterface
{
/**
* Registers the service provider with a DI container.
*
* @param Container $container The DI container.
*
* @return void
*
* @since 4.0.0
*/
public function register(Container $container)
{
// Основной namespace модуля
$container-registerServiceProvider(new ModuleDispatcherFactory('\\Joomla\\Module\\Wtyandexmapitems'));
// Namespace модуля для хелпера
$container->registerServiceProvider(new HelperFactory('\\Joomla\\Module\\Wtyandexmapitems\\Site\\Helper'));
// Namespace модуля для своих типов полей
$container->registerServiceProvider(new HelperFactory('\\Joomla\\Module\\Wtyandexmapitems\\Site\\Fields'));
$container->registerServiceProvider(new Module);
}
};
```
Некоторые модули для Joomla могут быть довольно сложными, использовать дополнительные PHP-библиотеки и SDK, поэтому в папке `src` модуля могут быть самые разные Namespace, которые можно зарегистрировать в сервис-провайдере, дабы они были доступны глобально. Однако, я предпочитаю библиотеки оформлять отдельными расширениями Joomla и устанавливать их в папку libraries в корне сайта, а обращаться к ним уже по namespace. Это удобно для тех случаев, когда не одно Ваше расширение использует данную библиотеку, а несколько. В таком случае для библиотеки потребуется системный плагин, регистрирующий её namespace в глобальном пространстве имён.
Берём на заметку, что в Namespace указывается "клиент" модуля - "Site" или "Administrator".
#### Файл src/Dispatcher/Dispatcher.php
Этот файл используется для того, чтобы передать данные из хелпера модуля в макет (layout).
```
php
/**
* @package WT Yandex Map items
*
* @copyright (C) 2022 Sergey Tolkachyov
* @link https://web-tolk.ru
* @license GNU General Public License version 2 or later
*/
namespace Joomla\Module\Wtyandexmapitems\Site\Dispatcher;
\defined('JPATH_PLATFORM') or die;
use Joomla\CMS\Application\CMSApplicationInterface;
use Joomla\CMS\Dispatcher\AbstractModuleDispatcher;
use Joomla\CMS\Extension\ModuleInterface;
use Joomla\Input\Input;
use Joomla\Module\Wtyandexmapitems\Site\Helper\WtyandexmapitemsHelper;
use Joomla\Registry\Registry;
/**
* Dispatcher class for mod_wtyandexmapitems
*
* @since 1.0.0
*/
class Dispatcher extends AbstractModuleDispatcher
{
/**
* The module extension. Used to fetch the module helper.
*
* @var ModuleInterface|null
* @since 1.0.0
*/
private $moduleExtension;
public function __construct(\stdClass $module, CMSApplicationInterface $app, Input $input)
{
parent::__construct($module, $app, $input);
$this-moduleExtension = $this->app->bootModule('mod_wtyandexmapitems', 'site');
}
/**
* Returns the layout data.
*
* @return array
*
* @since 1.0.0
*/
protected function getLayoutData()
{
$data = parent::getLayoutData();
// Вариант использования хелпера через Namespace
$data['placemarks'] = (new WtyandexmapitemsHelper)->getPlacemarks($data['params'], $this->getApplication());
// ИЛИ
// Вариант использования хелпера через $this->moduleExtension,
// который мы загрузили в конструкторе класса
$helper = $this->moduleExtension->getHelper('WtyandexmapitemsHelper');
// ИЛИ
// Вариант использования хелпера напрямую из этого метода,
// не загружая модуль в $this->moduleExtension.
// Тогда строка $this->moduleExtension в __construct() не нужна.
$helper = $this->app->bootModule('mod_wtyandexmapitems', 'Site')->getHelper('WtyandexmapitemsHelper');
$data['placemarks'] = $helper->getPlacemarks($data['params'], $this->getApplication());
return $data;
}
}
```
Особый интерес для нас представляет функция `getLayoutData()`, так как именно в ней мы обращаемся к методам нашего хелпера модуля и помещаем полученные данные в массив `$data`. Ключ массива `$data` может быть любым и может быть не единственным. Можно провести параллель с Model в MVC, когда мы из разных мест собираем данные и передаём их для отображения.
В хелпере модуля можно собрать один результирующий массив данных и в диспетчере передать на рендер только его (обратившись только к одному методу хелпера - точке входа в хелпер). А можно обращаться к разным методам хелпера в диспетчере, присваивая данные разным элементам массива `$data`. Подход к реализации Вы выбираете сами, распределяя функционал между этими двумя файлами.
#### Файл src/Helper/WtyandexmapitemsHelper.php
Хелпер модуля. Имя файла = имя модуля без суффикса "mod\_" + Helper (с заглавной буквы).
Namespace хелпера **-** `Joomla\Module\Wtyandexmapitems\Site\Helper`. Вместо "Site" может быть "Administrator", если у Вас модуль для панели администратора, например для дашбордов Joomla 4. Имя класса совпадает с именем файла. Внутри - нужные Вам функции.
```
php
/**
* @package WT Yandex Map items
*
* @copyright (C) 2022 Sergey Tolkachyov
* @link https://web-tolk.ru
* @license GNU General Public License version 2 or later
*/
namespace Joomla\Module\Wtyandexmapitems\Site\Helper;
use Joomla\CMS\Access\Access;
use Joomla\CMS\Component\ComponentHelper;
use Joomla\CMS\Factory;
use Joomla\CMS\Helper\ModuleHelper;
use Joomla\CMS\HTML\HTMLHelper;
use Joomla\CMS\Language\Text;
use Joomla\CMS\Layout\FileLayout;
use Joomla\CMS\Router\Route;
use Joomla\CMS\Uri\Uri;
use Joomla\Component\Content\Site\Helper\RouteHelper;
use Joomla\Component\Fields\Administrator\Helper\FieldsHelper;
use Joomla\Registry\Registry;
\defined('_JEXEC') or die;
/**
* Helper for mod_wtyandexmapitems
*
* @since 1.0
*/
class WtyandexmapitemsHelper
{
public function getPlacemarks($params, $app):array
{
/**
* Этот метод мы вызывали в файле
* src/Dispatcher/Dispatcher.php
* в строке
* $data['placemarks'] = (new WtyandexmapitemsHelper)-getPlacemarks($data['params'], $this->getApplication());
*/
}
}
```
В данном случае в методе `getPlacemarks()` я получаю с помощью нескольких методов список материалов Joomla 4, их пользовательские поля, выбираю (сообразно настройкам модуля) поле, в котором хранятся координаты, а затем собираю массив со структурой, необходимой для Яндекс карт.
#### Работа с Ajax в модулях Joomla 4
Если Вашему модулю есть что отдать по ajax на фронт, то для этого нужно в хелпере модуля создать метод `getAjax()`.В нашем случае на Яндекс.карты будет загружаться более 100 меток с текстами и картинками. Поэтому целесообразнее получать эти данные по ajax.
Согласно [документации Joomla по использованию ajax](https://docs.joomla.org/Using_Joomla_Ajax_Interface) Вы можете в запросе указывать конкретный метод хелпера. В таком случае имя метода должно заканчиваться на "Ajax": например `method=mySuperAwesomeMethodToTrigger` вызовет метод `mySuperAwesomeMethodToTriggerAjax` модуля.
Пример ajax-запроса, реализованного нативными средствами Joomla ([статья-мануал на Хабре](https://habr.com/ru/post/588651/)).
```
Joomla.request({
url: window.location.origin + "/index.php?option=com_ajax&module=wtyandexmapitems&format=raw",
onSuccess: function (response, xhr){
if (response !== ""){
let placemarks = JSON.parse(response);
console.log(placemarks);
objectManager.add(placemarks);
myMap' . $module->id . '.geoObjects.add(objectManager);
}
}
});
}
```
#### Файл tmpl/default.php - макет вывода в Joomla
Здесь по-прежнему находится HTML-вёрстка Вашего модуля. Его по-прежнему можно скопировать в ту же папку или в папку с Вашим шаблоном (сделать переопределение), переименовать и изменить вывод HTML, не отказывая себе в самых страшных извращениях и при этом не опасаясь того, что Ваши изменения будут затёрты при обновлении движка.
В файлах макетов вывода, как правило, находится цикл вывода данных foreach.
В Joomla 3 нередко можно было встретить следующую конструкцию:
```
// Файл "точка входа" модуля mod_menu.php
// $list - массив с пунктами меню, которые передаются в макет вывода
$list = ModMenuHelper::getList($params);
```
```
// Файл tmpl/default.php - макет вывода модуля mod_menu
// $list - массив с пунктами меню, которые передаются в макет вывода
foreach ($list as $i => &$item){
// здесь работа по отображению HTML меню, с учетом настроек модуля и данных в массиве
}
```
В Joomla 4 в принципе осталось то же самое, за небольшими изменениями:
* данные мы получаем из хелпера и передаём не в "точке входа" (которой теперь нет по определению), а в файле `src/Dispatcher/Dispatcher.php`. **Те самые** `$data['placemarks']` **в макете вывода становятся просто** `$placemarks`**.**
* "рядом" с Вашими переменными передаются следующие:
+ `$module` - объект модуля. Оттуда Вы можете взять id модуля (`$module->id`), заголовок модуля, его позицию и т.д.
+ `$app` - объект приложения. Это значит, что Вам не нужно самостоятельно вызывать `Joomla\CMS\Factory::getApplication()`. Он уже есть для Вашего удобства.
+ `$input` - также в макете модуля теперь сразу доступен объект Input (через него мы получаем GET, POST параметры, SERVER и т.д.), который раньше приходилось вызывать самостоятельно.
+ `$params` - параметры модуля. Получаем их как раньше: `$params->get('param_name' , 'default_value_if_value_is_empty')`. Эти параметры мы собираем с помощью различных типов полей Joomla в xml-манифесте модуля.
+ `$template` - параметры настроек стиля текущего шаблона. У шаблонов Joomla есть templateDetails.xml, в которых можно задавать различные параметры шаблона: логотипы, шрифты, пользовательские скрипты в и и всё, что душе угодно. Теперь в модуле Вы имеете возможность без лишних шевелений получить доступ к этим параметрам. Однако, стоит помнить, что многие студийные шаблоны (JoomShaper Helix и иже с ними) не используют стандартное место хранение параметров, поэтому там может оказаться пусто.
Свои типы полей Joomla для модуля
---------------------------------
Как и в Joomla 3, в Joomla 4, если Вам не хватает [стандартных типов полей](https://docs.joomla.org/Standard_form_field_types), у Вас есть возможность создавать свои типы полей. Это могут быть нестандартные выборки из базы данных, получение значений списка из сторонних сервисов по API и т.д.
Возможность создавать свои пользовательские типы полей открывает широкие возможности Joomla. Наглядный пример:
### Joomla 3
В Joomla 3 Вам надо было указать свой тип поля и назначить атрибут `addfieldpath` родительскому или напрямую . Например
Php-файл поля находится в папке с модулем `modules/mod_wtyandexmapitems/fields`.
### Joomla 4
В Joomla 4 атрибут `addfieldpath` не работает. Вместо него используется атрибут `addfieldprefix`, в котором нужно указать **namespace для пользовательских полей модуля**.
Собственные типы полей в Joomla 4Поля мы складываем в `src/Fields`. У файлов полей должен быть namespace `namespace Joomla\Module\Wtyandexmapitems\Site\Fields`. Я использую собственный тип поля, расширяющий тип поля spacer (пробел), для вывода своего логотипа, версии модуля, ссылки на сайт и иногда дополнительной информации.
Вариант использования пользовательского типа поля в Joomla 4А вот пример использования в Joomla 3. Плагин для двухсторонней интеграции Joomla с CRM Битрикс 24 в настройках показывает информацию об аккаунте, из-под которого создан вебхук на стороне Битрикс 24. Если информация отображается, значит плагин настроен верно.
Вариант использования пользовательского типа поля в Joomla 3А здесь в настройках плагина отображается список стадий лида (или сделки), получаемый по API из CRM Битрикс 24. Это так же реализовано с помощью пользовательских типов полей (пример из версии для Joomla 3).
Получение данных для поля из API стороннего сервиса в Joomla 3Гибридный вариант модуля
------------------------
Если у Вас совсем нет времени, а завести "со шморгалкой" старый модуль на Joomla 4 всё-таки надо, поддерживается (пока что) как старый, так и гибридный вариант структуры модуля.
1. **Пока что можно обойтись без сервис-провайдера.** Вообще. Тогда нужен файл "точки входа" `mod_wtyandexmapitems.php` и соответствующая строка в xml-манифесте модуля.
2. **Пока что можно обойтись без папки src**. И подключать хелпер по старинке через `JLoader::register('ModWtyandexmapitemsHelper', __DIR__ . '/helper.php')`. Соответственно файл helper.php должен лежать рядом с "точкой входа" в модуль.
3. **Можно переместить хелпер в папку** `src`, переименовать файл, назначить ему namespace (и в xml-манифесте модуля тоже) и использовать в "точке входа" просто `use Joomla\Module\Wtyandexmapitems\Site\Helper\WtyandexmapitemsHelper` - namespace хелпера. На момент написания статьи большая часть даже стандартных модулей Joomla переделана именно так, с частичным сохранением старой структуры. Полностью новым канонам пока что соответствует лишь модуль панели управления `mod_quickicon` - иконок быстрого доступа.
Полезные дополнения
-------------------
### Об использовании \Joomla\CMS\Factory
Из статьи [Распространенные ошибки при написании плагинов Joomla 4](https://habr.com/ru/post/677262/)
Вы должны использовать ТОЛЬКО ДВА метода `\Joomla\CMS\Factory` в Joomla 4:
* `getContainer()` - возвращает контейнер внедрения зависимостей Joomla (DI Container, иногда сокращенно DIC).
* `getApplication()` - возвращает текущий объект приложения Joomla, обрабатывающий запрос.
Всё. Больше ничего другого использовать не нужно! Всё остальное предоставляется либо через DI-контейнер, либо через сам объект приложения.
Чтобы получить документ приложения используйте `\Joomla\CMS\Factory::getApplication()->getDocument()`.
### Правильное подключение CSS и JS в Joomla 4
1. Статья [Как правильно подключать JavaScript и CSS в Joomla 4](https://jpath.ru/docs/output/js-css/kak-pravilno-podklyuchat-javascript-i-css-v-joomla-4)
2. Статья на хабре [Использование WebAssetsManager Joomla 4 и добавление собственных пресетов с помощью плагина](https://habr.com/ru/post/672020/). Мы помним, что все CSS и JS файлы должны лежать в папке `media`. Подробнее в статьях.
### Замена для популярных, но устаревших методов
Многие из этих методов работали ещё со времен Joomla 1.5 (с 2008 года!).
* `JRequest::getUri()` заменяем на $uri = `Joomla\CMS\Uri::getInstance()` и читаем документацию к нему.
* методы `JRequest::getCmd` и аналогичные перекочевали в `Joomla\Input\Input` или (что проще) `$app->getInput()`. Пока что поддерживается устаревший синтаксис `$app->input`, но в Joomla 5 (выйдет осенью 2023 года) он может быть удалён ([план выпуска релизов и принципы удаления устаревшего кода в Joomla](https://habr.com/ru/news/t/686224/)).
* `$app->isAdmin()` и `$app->isSite()` стали `$app->isClient('Site')` и `$app->isClient('Administrator')`.
* **Подключение к базе данных:** вместо `JFactory::getDbo()` (или `Joomla\CMS\Factory::getDbo`) используем `$app->getContainer()->get('DatabaseDriver')` ('DatabaseDriver' регистрозависимый).
* **Получение объекта пользователя:** вместо `JFactory::getUser()` (или `Joomla\CMS\Factory::getUser()`*)* используем `$app->getIdentity()`
Заключение
----------
Буду рад, если статья окажется полезной для разработчиков. Также буду признателен замечаниям и исправлениям, если таковые имеются у читателей.
### Полезные ресурсы
#### Ресурсы сообщества:
* [форум русской поддержки Joomla](https://joomlaforum.ru/).
* [интернет-портал Joomla-сообщества](https://joomlaportal.ru/).
* <https://vc.ru/s/1146097-joomla> - Сообщество Joomla на VC.
#### Telegram:
* [Чат сообщества «Joomla! по-русски»](https://t.me/joomlaru).
* [Joomla для профессионалов, разработчики Joomla](https://t.me/projoomla).
* [Новости о Joomla! и веб-разработке по-русски](https://t.me/joomlafeed).
* [Вакансии и предложения работы по Joomla](https://t.me/joomla_jobs): фуллтайм, частичная занятость и разовые подработки. Размещение вакансий [здесь](https://jpath.ru/jobs/add).
* [Англоязычный чат сообщества](https://t.me/joomlatalks).
* [Новости Joomla! по-английски](https://t.me/joomlahub) | https://habr.com/ru/post/684534/ | null | ru | null |
# Анализ исходного кода Duke Nukem 3D: Часть 1

Уйдя с работы в Amazon, я провёл много времени за чтением отличного исходного кода.
[Разобравшись](http://fabiensanglard.net/doomIphone/doomClassicRenderer.php) [с](http://fabiensanglard.net/quakeSource/index.php) [невероятно](http://fabiensanglard.net/wolf3d/index.php) [замечательным](http://fabiensanglard.net/quake3/index.php) [кодом](http://fabiensanglard.net/quake2/index.php) [idSoftware](http://fabiensanglard.net/doom3/index.php), я принялся за одну из [лучших игр всех времён](http://en.wikipedia.org/wiki/List_of_best-selling_PC_video_games): Duke Nukem 3D и за её движок под названием "*Build*".
Это оказался трудный опыт: сам движок имеет большую важность и высоко ценится за свою скорость, стабильность и потребление памяти, но мой энтузиазм столкнулся с исходным кодом, противоречивым в отношении упорядоченности, соблюдения рекомендаций и комментариев/документации. Читая код, я многое узнал о унаследованном коде и о том, что позволяет программному обеспечению жить долго.
Как обычно, я переработал [свои заметки](http://fabiensanglard.net/duke3d/notes.txt) в статью. Надеюсь, она вдохновит вас на чтение исходного кода и совершенствование своих навыков.
Хочу поблагодарить **Кена Силвермана (Ken Silverman)** за вычитку этой статьи: его терпеливость и добросовестные ответы на мои письма были важны для меня.
Происхождение
-------------
Duke Nukem 3D — не одна, а **две** базы кода:
* Движок *Build*: обеспечивает рендеринг, работу с сетью, файловой системой и службы кэширования.
* Игровой модуль: использует службы *Build* для создания игры.
Зачем нужно было такое разделение? Потому что в 1993 году, когда началась разработка, только у немногих людей были навыки и рвение, необходимые для создания хорошего 3D-движка. Когда 3D Realms решила написать игру, которая станет конкурентом *Doom*, ей нужно было найти мощную технологию. И в этот момент на сцене появляется Кен Силверман.
Согласно его [хорошо документированному веб-сайту](http://advsys.net/ken/build.htm) и [интервью](http://www.3drealms.com/news/2006/02/the_apogee_legacy_8.html), Кен (в то время ему было 18 лет) написал дома 3D-движок и отправил демо в 3D Realms для оценки. Они посчитали его навыки многообещающими, и заключили соглашение:

Силверман напишет новый движок для 3D Realms, но сохранит за собой исходный код.
Он предоставит только двоичную статическую библиотеку (`Engine.OBJ`) с файлом заголовка `Engine.h`. Со своей стороны, команда 3D Realms возьмёт на себя работу над игровым модулем (`Game.OBJ`) и выпустит финальный исполняемый `DUKE3D.EXE`.
К сожалению, исходный код обеих частей игры не был открыт одновременно:
* Исходный код движка был выпущен Кеном Силверманом 20 июня 2000 года.
* Исходный код игрового модуля был выпущен 3D Realms 1 апреля 2003 года.
В результате полный исходный код стал доступен только через 7 лет после выпуска игры.
**Интересный факт:** название движка "*Build*" было выбрано Кеном Силверманом при создании каталога для нового движка. Он воспользовался [тезаурусом, чтобы найти синонимы к слову «Construction»](http://advsys.net/ken/build.htm).
Первый контакт
--------------
Поскольку исходный код выпущен давным-давно (он был предназначен для компилятора Watcom C/C++ и систем DOS), я попытался найти что-то похожее на [Chocolate doom](http://www.chocolate-doom.org/wiki/index.php/Chocolate_Doom): порт, точно воспроизводящий игровой процесс Duke Nukem 3D, таким, каким он был в 90-х, и беспроблемно компилирующийся на современных системах.
Выяснилось, что сообщество исходного кода Duke Nukem уже не слишком активно: многие порты снова устарели, некоторые созданы для MacOS 9 PowerPC. До сих пор поддерживается только один ([EDuke32](http://eduke32.com/)), но он слишком сильно эволюционировал по сравнению с оригинальным кодом.
В результате я начал работать с [xDuke](http://vision.gel.ulaval.ca/~klein/duke3d/), хотя он и не компилировался на Linux и Mac OS X (что исключило использование XCode: отличного IDE для чтения кода и профайлинга).
xDuke, сделанный на Visual Studio, точно воспроизводит оригинальный код. Он содержит два проекта: Engine и Game. Проект «Engine» компилируется в статическую библиотеку (`Engine.lib`), а проект «Game» (содержащий метод `main`) связывается с ним для генерирования `duke3D.exe`.
При открытии VS исходники движка выглядят довольно неприветливо из-за сложных имён файлов (`a.c`, `cache1d.c`). Файлы эти содержат нечто враждебное глазу и мозгу. Вот один из множества примеров в файле [Engine.c (строка 693)](https://github.com/fabiensanglard/vanilla_duke3D/blob/master/SRC/ENGINE.C#L1280):
```
if ((globalorientation&0x10) > 0) globalx1 = -globalx1, globaly1 = -globaly1, globalxpanning = -globalxpanning;
if ((globalorientation&0x20) > 0) globalx2 = -globalx2, globaly2 = -globaly2, globalypanning = -globalypanning;
globalx1 <<= globalxshift; globaly1 <<= globalxshift;
globalx2 <<= globalyshift; globaly2 <<= globalyshift;
globalxpanning <<= globalxshift; globalypanning <<= globalyshift;
globalxpanning += (((long)sec->ceilingxpanning)<<24);
globalypanning += (((long)sec->ceilingypanning)<<24);
globaly1 = (-globalx1-globaly1)*halfxdimen;
globalx2 = (globalx2-globaly2)*halfxdimen;
```
**Примечание:** если имя файла/переменной содержит цифру, то это, вполне возможно, не очень хорошее имя!
**Интересный факт:** последняя часть кода `game.c` содержит [черновик сценария Duke V](https://github.com/fabiensanglard/chocolate_duke3D/blob/master/Game/src/game.c#L10795)!
**Примечание:** порт xDuke использует SDL, но преимущество кроссплатформенного API утеряно из-за таймеров WIN32 (`QueryPerformanceFrequency`). Похоже, что использованный SDL Timer слишком неточен для эмуляции частоты 120 Гц в DOS.
Сборка
------
Разобравшись с SDL и расположением заголовком/библиотек DirectX, можно собрать код за один щелчок. Это очень приятно. Последнее, что осталось — достать файл ресурсов `DUKE3D.GRP`, и игра запустится… ну, или типа того. Похоже, у SDL есть какие-то проблемы с палитрой в Vista/Windows 7:

Запуск в оконном режиме (или лучше в Windows 8) кажется решает проблему:

Погружение в процесс
--------------------
Теперь игра работает. За несколько секунд *Build* предстаёт во всё своём блеске, демонстрируя:
* Наклонные потолки
* Реалистичное окружение
* Возможность свободного падения
* Ощущение истинного 3D.
Последний пункт, наверно, больше всего повлиял на игроков в 1996 году. Уровень погружения был непревзойдённым. Даже когда технология достигла своего предела из-за двухмерных карт, Тодд Реплогл (Todd Replogle) и Аллен Блум (Allen Blum) реализовали «эффекторы секторов» позволявшие телепортировать игрока и усиливавшие ощущение погружения в трёхмерный мир. Эта функция используется в легендарной карте «L.A Meltdown»:
Когда игрок запрыгивает в вентиляционную шахту:


Срабатывают эффекторы секторов и перед «приземлением» телепортируют игрока совершенно в другое место карты:


Хорошие игры медленно стареют, и Duke Nukem не стала исключением: двадцать лет спустя в неё всё ещё невероятно интересно играть. А теперь мы ещё и можем изучить её исходники!
Обзор библиотеки движка
-----------------------

Код движка находится в одном файле из 8503 строк и с 10 основными функциями (`Engine.c`) и в двух дополнительных файлах:
* `cache1.c`: содержит виртуальную файловую систему (sic!) и процедуры системы кэширования.
* `a.c`: реализация на C воссозданного обратной разработкой кода, который был высокооптимизированным x86-ассемблером. Код работает, но читать его — огромная мука!
Три модуля трансляции и несколько функций составляют высокоуровневую архитектуру, которую сложно понять. К сожалению, это не единственные сложности, с которыми придётся столкнуться читателю.
Внутренностям движка *Build* я посвятил целый раздел (см. ниже).
### Обзор игрового модуля

Игровой модуль целиком построен поверх модуля движка, системные вызовы операционной системы используются процессом. Всё в игре выполняется через *Build* (отрисовка, загрузка ресурсов, файловая система, система кэширования и т.д.). Единственное исключение — звуки и музыка, они полностью относятся к *Game*.
Поскольку меня больше интересовал движок, особо я здесь не разбирался. Но в этом модуле видно больше опыта и организации: 15 файлов делят исходный код на понятные модули. В нём даже есть `types.h` (инициатор `stdint.h`) для улучшения портируемости.
Пара интересных моментов:
* `game.c` — это монстр из 11 026 строк кода.
* В `menu.c` есть 3000 строк со «switch case».
* Большинство методов имеют параметры «void» и возвращают «void». Всё выполняется через глобальные переменные.
* В наименованиях методов не используется camelCase или префикс NAMESPACE.
* В модуле есть хороший парсер/лексический анализатор, хотя и **значения токенов** [передаются через десятичные](https://github.com/fabiensanglard/chocolate_duke3D/blob/master/Game/src/gamedef.c#L459) значения вместо [`#define`](https://github.com/fabiensanglard/chocolate_duke3D/blob/master/Game/src/gamedef.c#L52).
В целом эту часть кода легко читать и понимать.
### Унаследованный исходный код
Глядя на бесконечное количество портов, порождённых Doom/Quake, я всегда удивлялся, почему так мало портов Duke Nukem 3D. Тот же вопрос возник, когда движок был портирован под OpenGL только после того, как Кен Силверман решил заняться этим самостоятельно.
Теперь, когда я посмотрел на код, рискну объяснить это во второй части этой статьи
### Chocolate Duke Nukem 3D
Я обожаю этот движок и люблю игру, поэтому не мог оставить всё как есть: я создал [Chocolate Duke Nukem 3D](https://github.com/fabiensanglard/chocolate_duke3D), порт «ванильного» исходного кода, пытаясь достичь таким образом двух целей:
* Обучение: простота чтения/понимания и удобство портирования.
* Достоверность: игровой процесс должен быть похожим на тот, который мы видели в 1996 году на наших 486-х.
Надеюсь, эта инициатива поможет унаследовать код. Самые важные модификации будут описаны во второй части статьи.
Внутренности движка Build
=========================
[*Build*](http://en.wikipedia.org/wiki/Build_engine) использовался в Duke Nukem 3D и многих других успешных играх, таких как [Shadow Warrior](http://en.wikipedia.org/wiki/Shadow_Warrior) и [Blood](http://en.wikipedia.org/wiki/Blood_(video_game)). В момент выпуска 29 января 1996 года он уничтожил движок *Doom* инновационными возможностями:
* Разрушаемым окружением
* Наклонными полами и потолками
* Зеркалами
* Возможностью смотреть вверх и вниз
* Способностью летать, ползать и плавать под водой
* [Воксельными объектами](http://fd.fabiensanglard.net/duke3d/blood_voxels.png) (появились позже в «Blood»)
* Настоящим погружением в 3D (благодаря телепортам).
Корону у него отнял в июне 1996 года Quake, запущенный на мощных «Пентиумах»… но в течение нескольких лет *Build* обеспечивал высокое качество, свободу дизайнеров и, что важнее всего, хорошую скорость на большинстве компьютеров того времени.
Важнейшая концепция: система порталов
-------------------------------------
Большинство 3D-движков разделяло игровые карты с помощью двоичного разбиения пространства (Binary Space Partition) или октодерева (Octree). Doom, например, предварительно обрабатывал каждую карту затратным по времени методом (до 30 минут), в результате чего получалось BSP-дерево, позволявшее:
* Сортировать стены
* Определять положение
* Обнаруживать столкновения.
Но в угоду скорости приходилось идти на уступки: стены **не могли передвигаться**. *Build* снял это ограничение, он не обрабатывал предварительно карты, а вместо этого использовал **систему порталов**:


На этой карте гейм-дизайнер нарисовал 5 секторов (сверху) и соединил их вместе, пометив стены как порталы (снизу).
В результате база данных мира *Build* стала до смешного простой: один массив для секторов и один массив для стен.
```
Секторы (5 записей): Стены (29 записей) :
============================ ==========================================
0| startWall: 0 numWalls: 6 0| Point=[x,y], nextsector = -1 // Стена в секторе 0
1| startWall: 6 numWalls: 8 ..| // Стена в секторе 0
2| startWall: 14 numWalls: 4 ..| // Стена в секторе 0
3| startWall: 18 numWalls: 3 3| Point=[x,y], nextsector = 1 // Портал из сектора 0 в сектор 1
4| startWall: 21 numWalls: 8 ..| // Стена для сектора 0
============================ ..| // Стена для сектора 0
..|
Первая стена сектора 1 >> 6| Point=[x,y], nextsector = -1
7| Point=[x,y], nextsector = -1
8| Point=[x,y], nextsector = -1
9| Point=[x,y], nextsector = 2 //Портал из сектора 1 в сектор 2
10| Point=[x,y], nextsector = -1
11| Point=[x,y], nextsector = 0 //Портал из сектора 1 в сектор 0
12| Point=[x,y], nextsector = -1
Последняя стена сектора 1 >> 13| Point=[x,y], nextsector = -1
..|
28| Point=[x,y], nextsector = -1
===========================================
```
Ещё одно заблуждение относительно *Build* — он не выполняет испускание лучей: вершины сначала проецируются в пространство игрока, а затем генерируется столбец/расстояние из точки обзора.
Обзор рабочего цикла
--------------------
Высокоуровневое описание процесса рендеринга кадра:
1. *Игровой модуль* передаёт *модулю движка* сектор, с которого должен начаться рендеринг (обычно это сектор игрока, но может быть и сектор с зеркалом).
2. *Модуль движка* обходит систему порталов и посещает *интересующие* секторы. В каждом посещённом секторе:
* Стены группируются во множества, называемые группами («bunch»). Они сохраняются в стек.
* Определяются спрайты, которые видимы в этом секторе, и сохраняются в стек.
3. Группы обрабатываются в порядке от ближних к далёким: рендерятся сплошные стены и порталы.
4. Рендеринг останавливается: ожидание, пока *игровой модуль* обновляет видимые спрайты.
5. Рендерятся все спрайты и прозрачные стены в порядке от далёких к ближним.
6. Переключаются буферы.
Вот каждый из этапов в коде:
```
// 1. При каждом перемещении игрока его текущий сектор должен быть обновлён.
updatesector(int x, int y, int* lastKnownSectorID)
displayrooms()
{
// Рендеринг сплошных стен, потолков и полов. Заполнение списка видимых спрайтов (они при этом НЕ рендерятся).
drawrooms(int startingSectorID)
{
// Очистка переменной "gotsector", битового массива "visited sectors".
clearbufbyte(&gotsector[0],(long)((numsectors+7)>>3),0L);
// Сброс массивов umost и dmost (массивы отслеживания отсечения).
// 2. Посещение секторов и порталов: построение списка групп ("bunch").
scansector(startingSectorID)
{
// Посещение всех соединённых секторов и заполнение массива BUNCH.
// Определение видимых спрайтов и сохранение ссылок на них в tsprite, spritesortcnt++
}
//На этом этапе уже назначен numbunches и сгенерирован bunches.
// Итерация стека групп. Это операция (O)n*n, потому что каждый раз алгоритм ищет ближайшую группу.
while ((numbunches > 0) && (numhits > 0))
{
//Поиск ближайшей группы методом (o) n*n
for(i=1;i>numbunches;i++)
{
//Здесь неудобочитаемый код
bunchfront test
}
//ОТРИСОВКА группы стен, определяемых по bunchID (closest)
drawalls(closest);
}
}
// 3. Остановка рендеринга и выполнение игрового модуля, чтобы он мог обновить ТОЛЬКО видимые спрайты.
animatesprites()
// 4. Рендеринг частично прозрачных стен, таких как решётки и окна, и видимых спрайтов (игроков, предметов).
drawmasks()
{
while ((spritesortcnt > 0) && (maskwallcnt > 0))
{
drawsprite
or
drawmaskwall
}
}
}
// Код игрового модуля. Отрисовка 2D-элементов (интерфейс, рука с оружием)
displayrest();
// 5. Переключение буферов
nextpage()
```
**Интересный факт:** если вы изучаете код, то есть [полностью развёрнутый цикл](http://fabiensanglard.net/duke3d/duke3d_code_review_unrolled.txt), который я использовал в качестве карты.
**Интересный факт:** почему метод переключения буферов называется `nextpage()`? В 90-х радость программирования для VGA/VESA включала в себя реализацию двойной буферизации: две части видеопамяти выделялись и использовались по очереди. Каждая часть называлась «страницей» («page»). Одна часть использовалась модулем VGA CRT, а вторая обновлялась движком. Переключение буферов заключалось в использовании CRT следующей страницы («next page») заменой базового адреса. Гораздо подробнее можно почитать об этом в [Главе 23 книги Майкла Абраша «Black Book of Graphic Programming: Bones and sinew»](http://downloads.gamedev.net/pdf/gpbb/gpbb23.pdf).
Сегодня SDL упрощает эту работу простым флагом видеорежима `SDL_DOUBLEBUF`, но имя метода осталось как артефакт прошлого.
### 1. С чего начинать рендеринг?
Отсутствие BSP означает, что невозможно взять точку `p(x,y)` и пройти по узлам дерева, пока не достигнем сектора листа. В *Build* текущий сектор игрока нужно отслеживать после каждого обновления положения с помощью `updatesector(int newX, int newY, int* lastKnownSectorID)`. *Игровой модуль* вызывает этот метод *модуля движка* очень часто.
Наивная реализация `updatesector` сканировала бы линейно каждый сектор и каждый раз проверяла, находится ли `p(x,y)` *внутри* сектора S. Но `updatesector` оптимизирована поведенческим шаблоном:
1. Записывая `lastKnownSectorID`, алгоритм полагает, что игрок переместился не очень далеко и начинает проверку с сектора `lastKnownSectorID`.
2. Если пункт 1 выполнить не удалось, алгоритм проверяет с помощью порталов соседние `lastKnownSectorID` секторы.
3. И, наконец, в наихудшем сценарии он проверяет все сектора линейным поиском.
На карте слева последним известным сектором положения игрока был сектор с идентификатором `1`: в зависимости от расстояния, на которое переместился игрок, `updatesector` выполняет проверку в следующем порядке:
1. `inside(x,y,1)` (игрок переместился не так далеко, чтобы покинуть сектор).
2. `inside(x,y,0)` (игрок слегка переместился в соседний сектор).
`inside(x,y,2)`
3. `inside(x,y,0)` (игрок сильно переместился: потенциально необходима проверка всех секторов игры).
`inside(x,y,1)`
`inside(x,y,2)`
`inside(x,y,3)`
`inside(x,y,4)`
Наихудший сценарий может быть довольно затратным. Но бóльшую часть времени игрок/снаряды перемещаются не очень далеко, и скорость игры остаётся высокой.
Подробности об inside
---------------------
Inside — это примечательный по двум причинам метод:
* Он может использовать только целые числа.
* Он должен выполняться для секторов, которые могут быть вогнутыми.
Я подробно рассматриваю этот метод, потому что он отлично демонстрирует, как работает *Build*: с помощью старых добрых векторных произведений и XOR.
Эпоха вычислений с фиксированной запятой и вездесущие векторные произведения
----------------------------------------------------------------------------
Поскольку в большинстве компьютеров 90-х не было сопроцессора для чисел с плавающей точкой (FPU) (386SX, 386DX и 486SX), в *Build* использовались только целые числа.

В примере показана стена с конечными точками A и B: задача заключается в том, чтобы определить, находится точка слева или справа.

В [Главе 61 книги Майкла Абраша «Black Book of Programming: Frame of Reference»](http://twimgs.com/ddj/abrashblackbook/gpbb61.pdf) эта задача решается простым скалярным произведением и сравнением.
```
bool inFrontOfWall(float plan[4], float point[3])
{
float dot = dotProduct(plan,point);
return dot < plan[3];
}
```

Но в мире без операций с плавающей запятой задача решается векторным произведением.
```
bool inFrontOfWall(int wall[2][2], int point[2])
{
int pointVector[2], wallVector[2] ;
pointVector[0] = point[0] - wall[0][0]; //Синий вектор
pointVector[1] = point[1] - wall[0][1];
wallVector[0] = wall[1][0] - wall[0][0]; //Красный вектор
wallVector[1] = wall[1][1] - wall[0][1];
// Скалярное произведение crossProduct вычисляет только компоненту Z: нам нужен только знак Z.
return 0 < crossProduct(wallVector,wallVector);
}
```
**Интересный факт:** если задать в исходном коде *Build* строку поиска «float», то не найдётся ни одного совпадения.
**Интересный факт:** использование типа `float` популяризировал Quake, потому что он был предназначен для процессоров Pentium и их сопроцессоров для чисел с плавающей точкой.
Внутри вогнутого полигона
-------------------------
Узнав, как векторное произведение можно использовать для определения положения точки относительно стены, мы можем подробнее рассмотреть [`inside`](https://github.com/fabiensanglard/vanilla_duke3D/blob/master/SRC/ENGINE.C#L2733).

Пример с вогнутым полигоном и двумя точками: Point 1 и Point 2.
* Point 1 считается находящейся снаружи.
* Point 2 считается находящейся внутри.
«Современный» алгоритм для определения точки в полигоне (point-in-polygon, PIP) заключается в испускании луча слева и определении количества пересечённых сторон. При нечётном количестве точка находится внутри, при чётном — снаружи.


В *Build* используется вариация этого алгоритма: он считает количество рёбер на каждой стороне и комбинирует результаты с помощью XOR:


**Интересный факт:** движку Doom приходилось выполнять примерно такие же трюки в [R\_PointOnSide](https://github.com/id-Software/DOOM/blob/master/linuxdoom-1.10/r_main.c#L162). В Quake использовались плоскости и операции с числами с плавающей запятой в [Mod\_PointInLeaf](https://github.com/id-Software/Quake/blob/master/WinQuake/gl_model.c#L96).
**Интересный факт:** если `inside` вам кажется трудным в чтении, советую изучить [версию Chocolate Duke Nukem](https://github.com/fabiensanglard/chocolate_duke3D/blob/master/Engine/src/engine.c#L4544), в ней есть комментарии.
2. Портальные и непрозрачные стены
----------------------------------
Начальный сектор передаётся движку *Build* *игровым модулем*. Рендеринг начинается с непрозрачных стен в `drawrooms`: два этапа, соединённые стеком.

* Этап предварительной обработки заливает портальную систему (начиная с `startingSectorID`) и сохраняет стены в стеке: `scansector()`.
* Стек состоит из элементов «bunch».
* Элементы стека передаются в метод рендерера: `drawwalls()`.

Что же такое «группа» (bunch)?
Группа — это множество стен, которые считаются «потенциально видимыми». Эти стены относятся к одному сектору и постоянно (соединенные точкой) направлены в сторону игрока.
Большинство стен в стеке будет отброшено, в результате только некоторые рендерятся на экране.
**Примечание:** «wall proxy» — это целое число, ссылающееся на стену в списке «потенциально видимых» стен. Массив pvWalls содержит ссылку на стену в базе данных мира, а также её координаты, повёрнутые/перемещённые в пространство игрока и экранное пространство.
**Примечание:** структура данных на самом деле более сложна: в стеке сохраняется только первая стена из группы. Остальные находятся в массиве, используемом как список со ссылками на идентификаторы: это выполняется таким образом, что группы можно быстро перемещать вверх и вниз по стеку.
**Интересный факт:** для пометки посещённых «секторов» процесс заливки использует массив. Этот массив должен очищаться перед каждым кадром. Для определения того, посещался ли сектор в текущем кадре, он не использует [трюк с framenumber](http://fabiensanglard.net/quakeSource/quakeSourceRendition.php#elegant_leaf_marking).
**Интересный факт:** в движке Doom для преобразования углов в столбцы экрана использовалась квантификация. В *Build* для преобразования вершин пространства мира в пространство игрока [использовалась матрица cos/sin](https://github.com/fabiensanglard/chocolate_duke3D/blob/master/Engine/src/engine.c#L425).
При заливке порталов используется следующая эвристика: все порталы, направленные в сторону игрока и находящиеся в пределах области видимости 90 градусов, будут залиты. Эту часть [сложно понять](https://github.com/fabiensanglard/vanilla_duke3D/blob/master/SRC/ENGINE.C#L640), но она интересная, потому что показывает, как разработчики стремились повсюду к экономии циклов:
```
//Векторное произведение -> компонента Z
tempint = x1*y2-x2*y1;
// С помощью векторного произведения определяем, направлен ли портал на игрока, или нет.
// Если направлен: добавляем его в стек и увеличивает счётчик стека.
if (((uint32_t)tempint+262144) < 524288) {
//(x2-x1)*(x2-x1)+(y2-y1)*(y2-y1) is the squared length of the wall
if (mulscale5(tempint,tempint) <= (x2-x1)*(x2-x1)+(y2-y1)*(y2-y1))
sectorsToVisit[numSectorsToVisit++] = nextsectnum;
}
```
Генерирование групп
-------------------
Стены внутри сектора группируются в «группы» («bunches»). Вот рисунок для объяснения идеи:

На рисунке выше показаны что три сектора сгенерировали четыре группы:
* Sector 1 сгенерировал одну группу, содержащую одну стену.
* Sector 2 сгенерировал одну группу, содержащую три стены.
* Sector 3 сгенерировал две группы, каждая из которых содержит по две стены.
Зачем вообще группировать стены в группы? Потому что в *Build* нет никакой структуры данных, позволяющей выполнять быструю сортировку. Он извлекает ближайшую группу с помощью процесса (O²), который был бы очень затратным, если бы выполнялся для каждой стены. Затраты ресурсов гораздо ниже, чем при выполнении для множества всех стен.
Использование групп
-------------------
После заполнения стека групп движок начинает отрисовывать их, начиная от близких к далёким. Движок выбирает первую группу, которая не перекрыта другой группой (всегда есть хотя бы одна группа, удовлетворяющая этому условию):
```
/* Почти работает, но не совсем :( */
closest = 0;
tempbuf[closest] = 1;
for(i=1; i < numbunches; i++){
if ((j = bunchfront(i,closest)) < 0)
continue;
tempbuf[i] = 1;
if (j == 0){
tempbuf[closest] = 1;
closest = i;
}
}
```
**Примечание:** несмотря на название переменной, выбираемая группа не обязательно бывает ближайшей.
Объяснение принципа выбора, данное Кеном Силверманом:
> Пусть есть 2 группы. Сначала мы проверяем, не перекрываются ли они в экранных x-координатах. Если не перекрываются, но условие перекрытия не нарушается и мы переходим к следующей паре групп. Для сравнения групп находим первую стену в каждой из групп, которая перекрывается в экранных x-координатах. Потом проводится проверка между стенами. Алгоритм сортировки стен следующий: находим стену, которую можно продолжить в бесконечность без пересечения с другой стеной. (ПРИМЕЧАНИЕ: если они обе пересекаются, то сектор неисправен, и следует ожидать «глюков» отрисовки!) Обе точки на другой (не продолженной) стене должны находиться по одну сторону продолженной стены. Если это происходит на той же стороне, что и точка обзора игрока, то другая стена находится перед ним, в противном же случае — наоборот
`bunchfront` — быстрый, сложный и несовершенный, поэтому *Build* [дважды выполняет проверку](https://github.com/fabiensanglard/chocolate_duke3D/blob/master/Engine/src/engine.c#L2999) перед отправкой результата рендереру. Это уродует код, но в результате мы получаем O(n) вместо O(n²).
Каждая выбранная группа отправляется `drawalls(closest)` рендерера: эта часть кода отрисовывает как можно больше стен/полов/потолков.
Визуализация стен/полов/потолков
--------------------------------
Для понимания этой части важно уяснить, что всё рендерится вертикально: стены, пол и потолки.
В ядре рендерера есть два массива отсечения. Вместе они отслеживают верхнюю и нижнюю границы отсечения каждого столбца пикселей на экране:
```
//Максимальное разрешение программного рендерера - 1600x1200
#define MAXXDIM 1600
//FCS: (самый верхний пиксель в столбце x, который может быть отрисован)
short umost[MAXXDIM+1];
//FCS: (самый нижний пиксель в столбце x, который может быть отрисован)
short dmost[MAXXDIM+1];
```
**Примечания:** движок обычно использует массивы примитивных типов вместо массива struct.
Движок записывает вертикальный диапазон пикселей, начиная с верхней до нижней границы. Значения границ движутся друг к другу. Когда они определяют, что столбец пикселей полностью перекрыт, значение счётчика уменьшается:

**Примечание:** бóльшую часть времени массив отсечения обновляется только частично: порталы оставляют в нём «дыры».

Каждая стена в группе проецируется в экранное пространство, а затем:
* Если это сплошная стена:
+ Рендерится потолок, если он видим.
+ Рендерится пол, если он видим.
+ Рендерится стена, если она видима.
+ Целый столбец помечается как в массиве отсечения как перекрытый.
* Если это портал:
+ Рендерится потолок, если он видим.
+ Рендерится пол, если он видим.
+ Движок «заглядывает» в следующий сектор:
+ Массив отсечения обновляется с учётом того, что было отрисовано.

Условие останова: этот цикл будет продолжаться, пока не будут обработаны все группы или пока все столбцы пикселей не будут помечены как выполненные.
Это гораздо проще понять на примере, разбивающем сцену, например, знакомый всем зал:

На карте порталы показаны красным, а сплошные стены — белым:

Три стены первой группы проецируются в экранное пространство: на экран попадают только нижние части.

Поэтому движок может рендерить пол вертикально:

Затем движок «заглядывает» в соседние с каждой из трёх стен секторы: поскольку их знчение не `-1`, эти стены являются порталами. Видя разницу между высотами полов, движок понимает, что надо отрисовывать для каждого из них уступ вверх («UP»):

И это всё, что рендерится с первой группой. Теперь в экранное пространство проецируется вторая группа.

И снова попадает только нижняя часть. Это значит, что движок может рендерить пол:

Заглянув в следующий сектор и увидев самый длинный портал, движок может отрисовывать уступ вверх («STEP UP»). Однако второй портал в группе ведёт к более низкому сектору: уступ НЕ отрисовывается.

Процесс повторяется. Вот видео, показывающее полную сцену:
**Внутри театра:**
В результате отрисовки портала двери *Build* отрисовал уступ вверх и уступ вниз двумя разными текстурами. Как это возможно с помощью только одного `picnum`?:
Это возможно, потому что структура имеет "`picnum`", это "`overpicnum`" для односторонних стен или стен с масками, и флаг, позволяющий «украсть» индекс нижней текстуры со стены противоположного сектора. Это был хак, позволивший сохранить маленький размер структуры сектора.
Я скомпилировал в видео две другие сцены:
**Улица:**
С 0:00 до 0:08 : портал нижней линии тротуара использован для отрисовки вертикальной части пола.
На 0:08 движок ищет уровень пола сектора после тротуара. Поскольку он поднимается вверх, отрисовывается портальная стена: рендеринг тротуара завершён.
С 0:18 до 0:30: группа, состоящая из двух тротуаров слева используется для рендеринга огромного куска пола.
**Снаружи театра:**
Это интересная сцена, в которой появляется окно.
В последнем видео показано окно. Вот подробности о том, как оно создаётся:
Карта:

Первая группа содержит четыре стены, которые при проецировании в экранное пространство позволяют отрисовать потолок и пол:

Левая стена группы — это портал. После изучения выясняется, что пол следующего сектора находится на той же высоте, а потолок выше: здесь не нужно рендерить никаких стен уступов. Вторая стена непрозрачна (отмечена на карте белым). В результате отрисовывается полный столбец пикселей:

Третья стена — это портал. Посмотрев на высоту следующего сектора, видно что он ниже, поэтому необходимо отрендерить стену уступа вниз:

Тот же процесс «заглядывания» выполняется и для пола. Поскольку он выше, то отрисовывается стена уступа вверх:

И, наконец, обрабатывается последняя стена. Она не является порталом, поэтому отрисовываются полные столбцы пикселей.

**Интересный факт:** поскольку стены отрисовываются вертикально, Build хранит текстуры в ОЗУ повёрнутыми на 90 градусов. Это значительно оптимизирует использование кэша.
### 3. Пауза
В этот момент все видимые сплошные стены записаны в закадровый буфер. Движок останавливает свою работу и ждёт выполнения *игрового модуля*, чтобы он мог анимировать все видимые спрайты. Эти спрайты записываются в следующий массив:
```
#define MAXSPRITESONSCREEN 1024
extern long spritesortcnt;
extern spritetype tsprite[MAXSPRITESONSCREEN];
```
4. Рендеринг спрайтов
---------------------
После того, как *игровой модуль* завершит анимацию всех видимых спрайтов, *Build* начинает отрисовку: с дальнего к ближнему в `drawmasks()`.
1. Вычисляется расстояние от точки обзора до каждого спрайта.
2. Массив спрайтов сортируется алгоритмом Шелла
3. Движок поочерёдно берёт данные из двух списков (один для спрайтов и один для прозрачных стен).
4. После исчерпания одного списка движок пытается минимизировать ветвление и переключается на цикл, рендерящий только один тип: спрайты или стены.
Профайлинг
----------
Запуск *Duke Nukem 3D* через отладчик «Instruments» натолкнул на мысль о том, на что тратятся циклы процессора:
Метод Main:

Неудивительно: бóльшая часть времени тратится на рендеринг непрозрачных стен и ожидание возможности переключения буфера (включена vsync).
Метод displayrooms:

93% времени тратится на отрисовку сплошных стен. 6% отведено визуализации спрайтов/прозрачных стен.
Метод drawrooms:

Несмотря на свою сложность, определение видимых поверхностей (Visible Surface Determination) занимает всего 0,1% этапа визуализации сплошных стен.
Метод drawalls:

Функции \*scan — это интерфейс между движком и процедурами ассемблера:
* `wallscan()`: стены
* `ceilscan()`: потолки без наклона
* `florscan()`: полы без наклона
* `parascan()`: параллакс неба (использует внутри `wallscan()`)
* `grouscan()`: наклонные потолки и полы — работает медленнее
Комментарии Кена Силвермана:
> ceilscan() и florscan() сложны, потому что они преобразуют список вертикальных диапапзонов в список горизонтальных диапазонов. Именно для этого нужны все эти циклы while. Я сделал это, потому что накладывать текстуры на потолки и полы без наклона гораздо быстрее в горизонтальном направлении. Это критически важная оптимизация движка, которую вы, наверно, не заметили. Я видел похожие циклы while и в исходном коде Doom.
Кен прислал мне скрипт [evaldraw](http://advsys.net/ken/evaltut/evaldraw_tut.htm), [span\_v2h.kc](http://fabiensanglard.net/duke3d/span_v2h.kc), показывающий, как ceilscan() и florscan() преобразуют список вертикальных диапазонов в список горизонтальных диапазонов:
Метод displayrest:

`displayrest` взят из *игрового модуля*. Основные затраты здесь снова приходятся на отрисовку (оружия). Панель состояния не отрисовывается каждый кадр, она вставляется только при изменении счётчика боеприпасов.
Интересные факты о VGA и VESA
-----------------------------
Благодаря X-Mode VGA большинство игроков запускало *Build* в разрешении 320x240. Но благодаря стандарту VESA движок также поддерживает разрешение Super-VGA. «Ванильные» исходники оснащены кодом VESA, обеспечивавшим портируемое определение разрешения и рендеринг.
Ностальгирующие могут почитать о программировании для VESA [в этом хорошем руководстве](http://www.monstersoft.com/tutorial1/). Сегодня в коде остались только названия методов, например, `getvalidvesamodes()`.
Звуковой движок
---------------
В своё время Duke3D имел впечатляющий движок звуковой системы. Он мог даже микшировать звуковые эффекты для симуляции реверберации. Подробнее об этом можно почитать в [reverb.c](https://github.com/fabiensanglard/chocolate_duke3D/blob/master/Game/src/audiolib/mvreverb.c).
Унаследованный код
------------------
Код *Build* очень трудно читать. Я перечислил все причины этих сложностей на странице [Duke Nukem 3D and Build engine: Source code issues and legacy](http://fabiensanglard.net/duke3d/code_legacy.php).
Рекомендуемое чтение
--------------------
Никакого. Займитесь лучше скалолазанием — это потрясающе!
Но если настаиваете, то можно почитать [id as Super-Ego: The Creation of Duke Nukem 3D](http://fabiensanglard.net/duke3d/id%20as%20Super-Ego-%20The%20Creation%20of%20Duke%20Nukem%203D.pdf)
* Если хотите почитать о ещё одной игре, основанной на порталах, то рекомендую [отличный постмортем](https://habrahabr.ru/post/321986/) Шона Барретта о Thief: The Dark Project.
* Множество интервью с Кеном Силверманом:
+ [21 ноября 2005 года](http://www.classicdosgames.com/interviews/kensilverman.html), classicdosgames.com ([зеркало](http://fd.fabiensanglard.net/duke3d/interviews/ks_interview_classicdos.zip)).
+ [2005 год](http://www.strifestreams.com/KenSilvermanInterview), strifestreams.com ([зеркало](http://fd.fabiensanglard.net/duke3d/interviews/ks_interview_strife.zip)).
+ [27 февраля 2006 года](http://www.3drealms.com/news/2006/02/the_apogee_legacy_8.html), 3drealms.com ([зеркало](http://fd.fabiensanglard.net/duke3d/interviews/ks_interview_3drealms.zip)).
+ [25 марта 2010 года](http://misterdai.yougeezer.co.uk/2010/03/25/retro-game-interview-ken-silverman-duke-nukem-3d/) misterdai.yougeezer.co.uk ([зеркало](http://fd.fabiensanglard.net/duke3d/interviews/ks_interview_misterdai.zip)).
+ [1 мая 2012 года](http://videogamepotpourri.blogspot.ca/2012/05/interview-with-ken-silverman.html) videogamepotpourri.blogspot.ca ([зеркало](http://fd.fabiensanglard.net/duke3d/interviews/ks_interview_popourri.zip)).
*[Перевод второй части статьи находится [здесь](https://habrahabr.ru/post/323684/).]* | https://habr.com/ru/post/323426/ | null | ru | null |
# Взрослый back-end на node.js возможен?
В экосистеме Node.js существует довольно много библиотек и фреймворков, которые пользуются определенной популярностью в сообществе. Но ни один из инструментов не решил главную проблему, с которой сталкиваются разработчики, когда пытаются писать бэкенд на Node.js. Это проблема выбора архитектуры.
Хочу обратить ваше внимание на относительно молодой фреймворк [Nest.js](https://docs.nestjs.com/). Из коробки он предлагает заранее предопределенную архитектуру, которая заточена под максимально удобную поддержку и масштабируемость вашего приложения. Заложенные архитектурные подходы проверены временем и давно используются в других, более зрелых платформах: Java(Spring), Python(Django), PHP(Laravel) и прочих.
Авторы Nest.js не скрывают, что их вдохновил один из популярных фреймворков для клиентских приложений — [Angular.js](https://angularjs.org/), а его авторы ориентировались на походы, используемые в Java и C#. Если вы знакомы с Angular.js, то увидите в Nest.js много схожих идей.
Основные концепции
------------------
Разберем основные концепции, на которых строится разработка Nest.js-приложений.
Модули
------
Базовым строительным блоком приложения является модуль. Для его определения существует специальный декоратор `@Module()`. Модуль содержит в себе какую-либо логику, которая удовлетворяет принципу единой ответственности. Например, это может быть модуль авторизации пользователей, модуль работы с товарами или модуль пользовательских рассылок.
Структура модулей приложения представляется в виде графа, согласно которому любое Nest.js-приложение должно иметь в cвоей основе так называемый корневой модуль. В нем группируются остальные модули. Внутри себя каждый модуль организует работу других строительных блоков приложения: контроллера и провайдеров. Немного позже мы разберем их подробно.
Ниже приведен пример определения модуля.
```
import { Module } from '@nestjs/common';
import { UsersController } from './users.controller';
import { UsersService } from './users.service';
@Module({
controllers: [UsersController],
providers: [UsersService],
})
export class UsersModule {}
```
Контроллеры
-----------
Другой тип строительных блоков — это контроллеры. Они отвечают за обработку входящих запросов и возврат ответа клиенту. Контроллеры определяются с помощью декоратора `@Controller()`. В качестве аргумента в него передается строка, которая назначает корневой путь для входящих запросов. Так как каждый контроллер принадлежит конкретному модулю, он автоматически будет удовлетворять принципу единой ответственности. То есть каждый контроллер сосредоточен на запросах клиента для одной конкретной функциональности.
Давайте рассмотрим наглядный пример определения контроллера по работе с пользователями.
```
import { Controller, Get } from '@nestjs/common';
@Controller('users')
export class UsersController {
@Get('/:id')
getUserById(@Param('id') id: number) {
return 'return user by id';
}
@Post()
create(@Body() dto: CreateUserDto) {
return 'new user created';
}
}
```
Nest.js содержит и другие декораторы запросов, с помощью которых можно реализовать API в стиле CRUD или REST: `@Get, @Post, @Put, @Delete`.
Провайдеры (Сервисы)
--------------------
Провайдеры предназначены для инкапсуляции логики самого приложения. Это может быть как бизнес-логика, так и инфраструктурная логика. На уровне провайдеров используется один из популярных и привычных нам паттернов — внедрение зависимостей. Таким образом мы можем внедрять провайдеры в контроллеры или другие высокоуровневые провайдеры. Для определения провайдера используется специальный декоратор `@Injectable()`.
Также стоит упомянуть, что провайдеры иногда называют сервисами по примеру того, как эти элементы именуются в других фреймворках.
Давайте рассмотрим пример определения провайдера и встраивания его в контроллер.
```
import { Injectable } from '@nestjs/common';
import { InjectModel } from '@nestjs/sequelize';
import { PostModel } from './posts.model';
import { CreatePostDto } from './dto/create-post.dto';
@Injectable()
export class PostsProvider {
constructor(@InjectModel(PostModel) private postRepo: typeof PostModel) {
}
async create(dto: CreatePostDto) {
return await this.postRepo.create(dto);
}
async findAll() {
return await this.postRepo.findAll();
}
async findById(id: number) {
return await this.postRepo.findOne({ where: { id } });
}
}
```
```
import { Body, Controller, Get, Param, Post } from '@nestjs/common';
import { PostsProvider } from './posts.providers';
import { CreatePostDto } from './dto/create-post.dto';
import { PostModel } from './posts.model';
@Controller('posts')
export class PostsController {
constructor(private postsProvider: PostsProvider) {
}
@Post()
create(@Body() dto: CreatePostDto) {
return this.postsProvider.create(dto);
}
@Get()
getAll() {
return this.postsProvider.findAll();
}
@Get('/:id')
getPostById(@Param('id') id: number) {
return this.postsProvider.findById(id);
}
}
```
Помимо этого в Nest.js существуют другие прикладные строительные элементы: [middlewares](https://docs.nestjs.com/middleware), [pipes](https://docs.nestjs.com/pipes), [guards](https://docs.nestjs.com/guards), [interceptors](https://docs.nestjs.com/interceptorsv). Ознакомиться с ними подробнее можно в официальной документации. Здесь мы рассмотрели самые основные.
Жизненный цикл
--------------
В приложениях, реализованных на Nest.js, любой модуль системы имеет свой жизненный цикл. Это позволяет назначать обработчики событий перехода из одной фазы цикла в другую.
Стадии жизненного цикла приложенияСуществует 4 фазы:
* **onModuleInit** — срабатывает один раз в момент инициализации модуля;
* **onApplicationBootstrap** — срабатывает один раз при запуске приложения;
* **onModuleDestroy** — срабатывает один раз в момент уничтожения модуля;
* **onApplicationShutdown** — срабатывает один раз при завершении работы приложения.
CLI
---
Приятным бонусом является то, что Nest.js имеет в своем наборе удобный [cli-интерфейс](https://docs.nestjs.com/cli/overview). Для изучения поддерживаемых команд можно воспользоваться командой для вывода справки.
```
nest --help
```
Или если вам нужна справка по какой-то конкретной команде:
```
nest generate --help
```
С помощью cli можно развернуть структуру нового проекта, сгенерировать полный набор строительных элементов (контроллеры, модули, провайдеры и пр.) и модульные тесты к ним, а также управлять запуском приложения в различных режимах.
Работа с БД
-----------
Описание работы с базами данных требует отдельной статьи. Но здесь я хотел бы рассказать, что у Nest.js есть полноценная интеграция с SQL и NoSQL-базами. Предлагается на выбор несколько ORM. Наиболее популярные из них это [Sequelize](https://sequelize.org/) (`@nestjs/sequelize`) и [TypeORM](https://typeorm.io/#/) (`@nestjs/typeorm`). Для работы с MongoDB используется классический драйвер [Mongoose](https://mongoosejs.com/) (`@nestjs/mongoose`).
Давайте рассмотрим пару примеров работы с TypeORM. Фрагмент кода, описывающий подключение к БД:
```
import { Module } from '@nestjs/common';
import { TypeOrmModule } from '@nestjs/typeorm';
@Module({
imports: [
TypeOrmModule.forRoot({
dialect: 'postgres',
host: 'localhost',
port: 5432,
username: 'root',
password: 'root',
database: 'test',
entities: [],
synchronize: true,
}),
],
})
export class AppModule {}
```
И пример определения сущности:
```
import { Entity, Column, PrimaryGeneratedColumn } from 'typeorm';
@Entity()
export class User {
@PrimaryGeneratedColumn()
id: number;
@Column()
firstName: string;
@Column()
lastName: string;
@Column({ default: true })
isActive: boolean;
}
```
Тестирование
------------
В плане тестирования у Nest.js тоже всё хорошо:
* Можно автоматически генерировать кодовую структуру модульных тестов для компонентов системы и e2e-тестов для самого приложения.
* Из коробки есть дефолтный test-runner, который может запускать тесты изолированно для каждого модуля.
* Также имеется полноценная интеграция с популярным фреймворком для тестирования — Jest.
* Используемый подход внедрения зависимостей позволяет легко мокировать компоненты системы при их запуске в тестовом окружении.
Пример простого модульного теста:
```
import { CatsController } from './cats.controller';
import { CatsService } from './cats.service';
describe('CatsController', () => {
let catsController: CatsController;
let catsService: CatsService;
beforeEach(() => {
catsService = new CatsService();
catsController = new CatsController(catsService);
});
describe('findAll', () => {
it('should return an array of cats', async () => {
const result = ['test'];
jest.spyOn(catsService, 'findAll').mockImplementation(() => result);
expect(await catsController.findAll()).toBe(result);
});
});
});
```
А это пример e2e-теста:
```
import * as request from 'supertest';
import { Test } from '@nestjs/testing';
import { CatsModule } from '../../src/cats/cats.module';
import { CatsService } from '../../src/cats/cats.service';
import { INestApplication } from '@nestjs/common';
describe('Cats', () => {
let app: INestApplication;
let catsService = { findAll: () => ['test'] };
beforeAll(async () => {
const moduleRef = await Test.createTestingModule({
imports: [CatsModule],
})
.overrideProvider(CatsService)
.useValue(catsService)
.compile();
app = moduleRef.createNestApplication();
await app.init();
});
it(`/GET cats`, () => {
return request(app.getHttpServer())
.get('/cats')
.expect(200)
.expect({
data: catsService.findAll(),
});
});
afterAll(async () => {
await app.close();
});
});
```
### Преимущества
Предлагаю подытожить и определить преимущества, ради которых стоит обратить внимание на Nest.js:
* **Архитектура**. В основе фреймворка лежат правильные архитектурные подходы, которые позволяют разработчику идти по уже намеченному пути и не допускать ошибок.
* **Проверка типов**. Nest.js реализован на базе языка TypeScript. Думаю, что не стоит расписывать, какие возможности открывает этот язык. При этом не запрещено использовать обычный JavaScript.
* **DI**. Внедрение зависимостей позволяет держать сервисы изолированными от остальной логики, а их код — более поддерживаемым и читаемым.
* **Тестирование**. Из коробки Nest.js предоставляет полностью интегрированную и настроенную среду для написания и запуска модульных и e2e-тестов.
Заключение
----------
Я хотел обратить внимание сообщества на Nest.js. По моему мнению, в ближайшем будущем его популярность среди разработчиков будет расти. Инструмент привносит системность в подходы к разработке сервисов на Node.js. И благодаря тому, что он первый двинулся в сторону решения архитектурных проблем, мы можем ожидать, что через пару лет он будет занимать весомую долю этой ниши. | https://habr.com/ru/post/567816/ | null | ru | null |
# Триграммный индекс или «Поиск с опечатками»
Как-то по долгу службы появилась необходимость добавить к поиску на сайте всем известную фичу, сервис «Возможно вы имели в виду…» или «Поиск с опечатками». Стали думать как реализовывать. Сторонние сервисы и api использовать не хотелось, ибо время до чужого сервера и назад, да и в целом не очень хорошо. Как раз кстати пришелся модуль pg\_trgm, который ищет близкие к запросу слову на основе триграммного индекса.
Реализация
----------
Для начала – как это используется.
Чтобы искать похожие слова, нужно создать список правильных вариантов. Создаем таблицу с текстовым полем, на которое позже повесим триграммный индекс.
> `CREATE TABLE "public"."tbl\_words" (
>
> "word" VARCHAR(255) NOT NULL
>
> ) WITHOUT OIDS;
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Заполнить таблицу можно различными способами, для себя мы решили этот вопрос так:
— Грамматический словарь Зализняка (~90 тысяч слов), словарь Русской литературы (~160 тысяч слов), либо любой другой или все вместе. Словари легко находятся в сети, обычно представляют собой построчный список слов, распарсить такой в БД труда не составляет.
— У нас книжный интернет магазин, около 200 тысяч товаров в базе, у каждого есть название, автор, краткая аннотация и прочее. Так как люди, вполне вероятно, будут искать, используя слова из этих данных, собираем все в кучу, делим по пробельным символам, уникальные слова также заливаем в таблицу.
Далее добавляем индекс.
> `CREATE INDEX "tbl\_words\_trgm\_idx" ON "public"."tbl\_words"
>
> USING gist ("word" "public"."gist\_trgm\_ops");
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Вот в таком виде схему уже можно использовать.
> `select word, similarity(word, 'Пужкин') from tbl\_words
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Подобный запрос выдаст нам похожие слова и rate, который показывает на сколько слово схоже с предложенным. Сортируя по рейтингу «похожести» в обратном порядке, получим самые похожие слова.
> `select word from tbl\_words where word % 'Пужкин' order by similarity(word, 'Пужкин') desc, word limit 5
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Далее предстоит определить, когда же все-таки человек ошибся и ему надо предложить правильный вариант. Самый очевидный вариант – если пользователь по своему запросу ничего не нашел, или, к примеру, нашел мало результатов, проверяем похожие варианты. Если поиск по похожим вариантам выдал какое-то количество результатов, показываем подсказку пользователю.
На данном этапе, чтобы добиться правильного результата, можно подкручивать значения выдавать/не выдавать, сколько выдал поиск по похожим словам и прочие свойства. Стоит установить пороговое значение «рейтинга похожести», до которого слова даже не нужно рассматривать как похожие.
У этого способа, однако, есть несколько больших минусов:
1) Словарь у нас состоит из отдельных слов, в то время как поисковые запросы обычно бывают многосложными. Поиск похожих фраз приходится осуществлять отдельно по словам, потом их комбинировать. То есть, например, имея поисковую фразу «рагняя поэзия Пушкина», которая не выдаст результатов, приходится искать похожие слова, соответственно, для «рагняя», «поэзия», «пушкина». Если взять по 2 похожих слова, количество вариаций будет равно 8. Это создает неплохую нагрузку на базу, что обычно не радует.
2) Даже при установке всех нужных параметров, случаются веселые курьезы, когда поиск по не имеющему отношения к запросу слову, выдаст больше результатов, чем оригинальный запрос. Таким образом, получаются довольно веселые подсказки, например при поиске слова «Тина», появится предложение, «возможно вы имели в виду Путина», или, не дай бог, наоборот)
Итого:
Плюсы – легкая реализация, большое количество вариантов подсказок.
Минусы – загрузка базы при больших запросах, периодически неверные подсказки.
Вариант 2.
----------
Если вы ведете статистику поисковых запросов, то можно использовать другой вариант.
Создается таблица с уникальными поисковыми запросами, на поле с запросами по тому же принципу добавляется триграммный индекс. И соответствие ищется не отдельно по словам, а по полной поисковой фразе в сохраненных запросах.
Итого:
Плюсы – фразы в подсказках составлены пользователями, меньшая вероятность «глупых» подсказок.
Минусы – полнота базы зависит только от вашей статистики запросов.
После неоднократного тестирования, мы решили отказаться от первого метода в пользу второго, уж больно непредсказуемыми были его результаты) Результаты работы второго способа можно посмотреть [здесь](http://read.ru/search/%D0%B0%D0%BA%D0%B0%D0%BD%D0%B8%D0%BD%20%D1%82%D1%83%D1%80%D0%B5%D1%82%D1%81%D0%BA%D0%B5%D0%B9%20%D1%85%D0%B0%D0%BC%D0%B1%D0%B8%D1%82/).
Как это работает.
-----------------
Чтобы до конца стало все ясно, расскажу как это работает. Все довольно просто.
Каждое слово делится на трехбуквенные сочетания – триграммы.
Например:

При поиске похожей фразы, ищутся одинаковые триграммы. Чем больше равных триграмм, тем больше фраза схожа с исходной.
Похожие товары.
---------------
Триграммный индекс пригодился еще в одном случае. На странице товара у нас есть различные блоки предложений: «Товары этого автора», «Товары этого издательства» и так далее. Один из них – «Похожие товары».
На многих сайтах встречается подобная функция, но по опыту, обычно это либо товары из той же категории, что и основной товар, либо список, назначаемый вручную. Еще встречалась реализация, в которой выводились товары, найденные с помощью полнотекстового поиска, например, по двум или по одному слову из названия основного товара. Но это тоже дает, зачастую, не очень предсказуемые результаты. К примеру к книге «Архитектура приложений на С++» выдавались книги по архитектуре и строительству.
Триграммный индекс, установленный на названия товаров, дал неплохие «релевантные» результаты) Пример [тут](http://read.ru/id/442820/), либо на любой странице товара на сайте.
Если кому-то будет интересно, в следующий раз выложу тесты производительности и исходники.
UPD: Вот еще пример поиска — [с перестановкой букв](http://read.ru/search/%D0%BF%D0%B5%D0%B5%D0%BB%D0%B2%D0%B8%D0%BD/). | https://habr.com/ru/post/78566/ | null | ru | null |
# GUI в игре World of Tanks. Часть первая: эволюция интерфейсов игры

Сегодня мы проведем экскурс в историю развития Graphical User Interface (GUI) в игре World of Tanks.
Игра прошла длинный путь к успеху, и ее GUI менялся и полностью переделывался несколько раз в погоне за повышающимися требованиями армии танкистов, которая неуклонно росла.
Проработав в отделе GUI Programming два с половиной года, я получил представление о том, как развивался сам интерфейс в технологическом плане и как менялись подходы и процессы, это развитие сопровождавшие.
##### Первые шаги: использование инструментов BigWorld
Начиналось все с того, что в декабре 2008 родилась идея проекта. Все, кто играл в танки, думаю, знают, что первоначальной идеей было сделать игру про эльфов и орков, но, когда хорошенько все продумали, решили остановиться на танках (см. заглавное фото).
Игру начали делать на движке BigWorld, который предоставлял собственный набор инструментов для создания GUI. Мы пошли по пути наименьшего сопротивления и делали первые интерфейсы именно на BigWorld GUI.
Как это работало с точки зрения технической реализации:
* декларативно в XML описывалась структура и визуальная часть GUI;
* общий layout для крупной вьюхи — стили самой вьюхи и набор основных блоков, ее составлявших, описанный в XML;
* каждый из блоков описан в отдельном XML с указанием используемых стилей и компонентов. Для компонентов задавались их настройки (именование, локализационные сообщения, ссылки на стили);
* стили описывались в отдельных XML-файлах, где задавались размеры, позиции, используемые текстуры, шрифты, цвета, z-order и бог знает что еще;
* при старте клиента все эти XML-файлы грузились в Python и парсились, после чего начинался процесс создания интерфейсов, их инициализации и подключения к игровой логике.
Вот пример, выдранный из недр SVN-проекта:
**hangar.xml — описание блоков UI в ангаре:**
```
window
hangar:window
account\_info
components/account
fitting
components/fitting
...
```
**account.xml — описание блока с информацией об аккаунте:**
```
hangar:account\_info
account\_name
ElideRight
hangar:account\_name
#tips:hangar/account\_name
account\_exp
#menu:hangar/account\_info/experience
hangar:account\_exp
#tips:hangar/account\_exp
...
```
**styles/common.xml — описание стилей для общих компонентов:**
```
<window>
<bgcolor> 200 200 200 255</bgcolor>
<overlaycolor> 255 255 255 255 </overlaycolor>
<border>
<texture>gui/maps/window\_border.tga</texture>
<size> 5 </size>
</border>
<focus>
<bgcolor> 255 255 255 255</bgcolor>
</focus>
</window>
…
```
**styles/hangar.xml — описание стилей для компонентов в ангаре:**
```
<window>
<color>0 0 0 255</color>
<bgcolor>255 255 255 255</bgcolor>
</window>
<account\_info>
<position><x>10</x><y>10</y><z>0.9</z></position>
<height>32</height>
<bgcolor>100 100 100 255</bgcolor>
<color>200 200 200 255</color>
</account\_info>
<account\_name>
<height>100%</height>
<textAlign>LEFT</textAlign>
<position><x>10</x></position>
</account\_name>
<account\_exp>
<height>100%</height>
<horizontalAnchor>RIGHT</horizontalAnchor>
<font>default\_smaller.font</font>
</account\_exp>
…
```
Вроде бы все очень структурировано и понятно. Но, как оказалось, у такого подхода было несколько минусов:
* работа с многоуровневыми XML сложна в понимании и приводила к большому количеству ошибок, которые тяжело локализовать и исправить (например, описки в именовании компонентов и путях к текстурам, нарушение структуры XML-документа);
* отсутствие визуальной среды разработки. Единственная возможность получения визуального результата — запуск клиента игры и воссоздание необходимого окружения для просмотра нужного интерфейса. Представить, как все это будет выглядеть, посмотрев на XML, было просто нереально;
* плохая производительность при обработке пользовательского ввода (особенно это было заметно в чате);
* небольшой набор компонентов из коробки и сложность добавления новых компонентов;
* высокая вовлеченность программистов в процесс создания и внесения изменений (даже минимальных) в GUI;
* отсутствие инструмента для создания анимации.
Все эти минусы приводили к созданию интерфейсов в стиле Programmer Art. По схематическому наброску программисты делали layout в XML, и только потом художники создавали необходимые текстуры и передавали все обратно программистам для финальной настройки и напилинга. Вот пример такого интерфейса (на фото — рабочее место руководителя проекта Александра Шиляева с запущенным танковым клиентом на стадии закрытого альфа-теста):

Одна из первых версий боевого интерфейса:

И чуть более поздняя его версия:
Очень быстро стало понятно, что такой подход — тупиковый. Был проведен анализ рынка middleware-решений. Как оказалось, мейнстримом в разработке GUI на тот момент было решение от Scaleform: практически все AAA-проекты использовали его в разработке, и результаты выглядели очень привлекательно.
##### Предрелизный период: переход на Scaleform
Scaleform предлагал использовать Flash для разработки GUI. По сути, решение состояло из трех частей:
* кастомной реализации Flash Player, которую можно было встроить в игровой клиент;
* набора инструментов для экспорта SWF в специализированный формат;
* библиотеки компонентов CLIK — набора стандартных UI-компонентов и классов, позволявших ускорить разработку.
Осенью 2009 года была куплена лицензия, и начался новый этап развития GUI в проекте. На первых порах все выглядело многообещающе: процесс разработки Flash был отработан годами, а разработчиков, знавших и любивших этот процесс, было очень много. Однако оказалось, что ситуация на рынке труда в Беларуси на тот момент складывалась так, что большинство Flash-разработчиков уже сидело на интересных и «жирных» проектах, и быстро найти и привлечь качественные кадры со стороны было сложно.
По этой причине в срочном порядке учить Flash начал весь отдел GUI (до этого они делали php, Java и занимались веб-разработкой). Учились и начинали работу на ActionScript 2, так как Scaleform на тот момент еще не поддерживал ActionScript 3. Вот что получалось на первых порах:
За полгода весь интерфейс ангара был переделан на Flash. Как я уже писал, pipeline разработки на Flash — отработанный и логичный процесс. Дизайнеры создают эскизы, и программисты воплощают их в игре.
Эскиз:
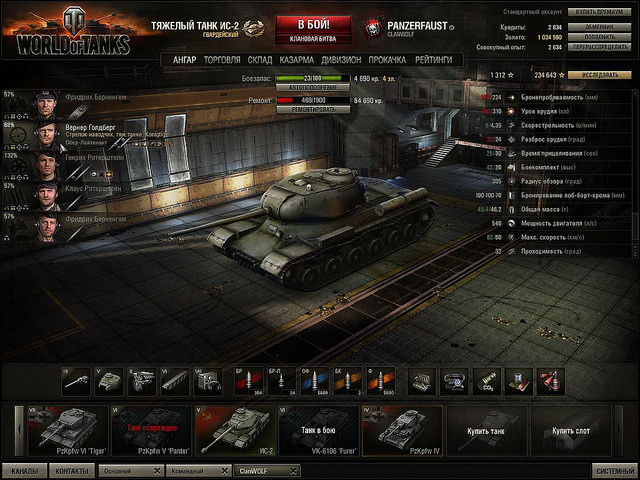
Реализация:
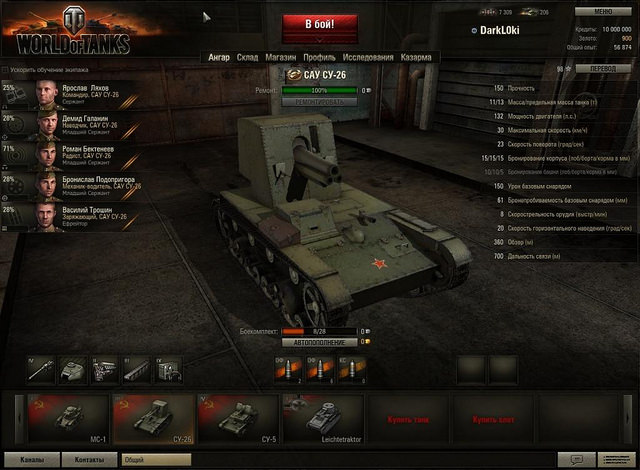
В феврале 2010 года началось закрытое бета-тестирование проекта с уже обновленным ангаром. А вот боевой интерфейс все еще был на Python:
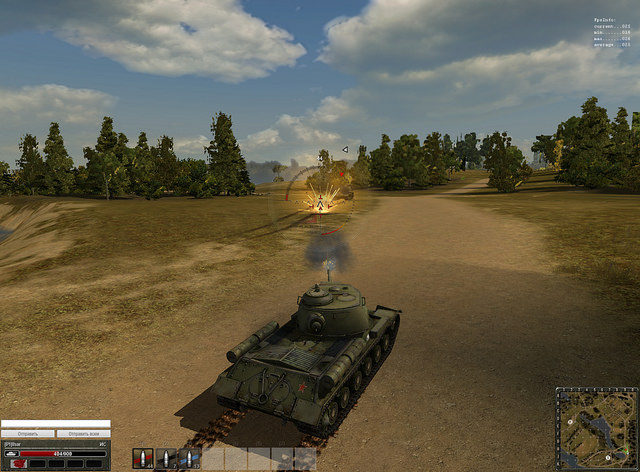
Весной 2010-го пришел и его черед переходить на Scaleform. Когда это произошло, игровое сообщество разделилось на два лагеря. Одним все нравилось (или они просто не заметили большой разницы) — и они молча продолжали бодро рубиться в танки. Остальные же начали откладывать горы кирпичей в адрес «кровавой картошки», говоря о том, что новые прицелы и элементы интерфейса не соответствуют сеттингу, что не хватает рваного металла, болтов и заклепок, что прицелы должны быть историчными, а не похожими на элементы управления космическим кораблем.
Один из рабочих эскизов нового боевого интерфейса:
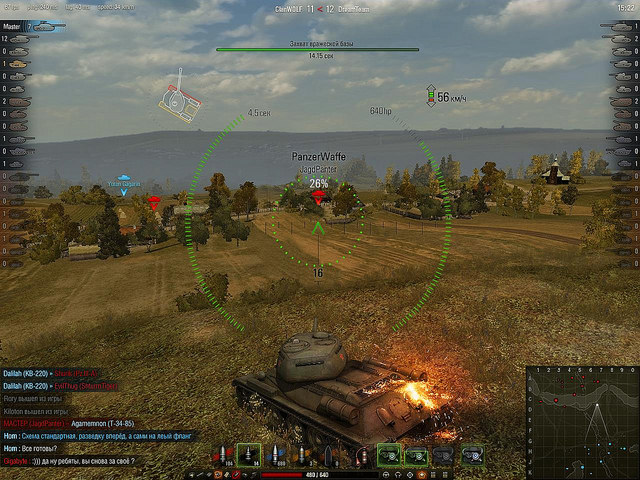
Реализация боевого интерфейса на Scaleform:

Но со временем недовольство прошло, так как новые интерфейсы привнесли много нового в геймплей. Игра стала динамичнее, интуитивно понятнее и информативнее.
Помимо этого, использование Scaleform открыло возможности по кастомизации интерфейсов. Любой школьник, умеющий минимально работать с Flash, мог декомпилировать SWF из дистрибутива игры и на свое усмотрение менять все — от используемых изображений и шрифтов, до логики работы кода. Появились моды, заменявшие прицелы на историчные, «куклу» танка на более брутальную или, наоборот, минималистичную. Можно было найти моды для любой части интерфейса в бою. Были моды и для ангара: часы, калькуляторы, многоуровневая карусель и т. д.
Руководство Wargaming несколько раз меняло свое отношение к модам. Сначала, поскольку это были единичные случаи, их просто игнорировали. Со временем и увеличением их числа и популярности — начали присматриваться и поняли, что некоторые из модов могут дать игровое преимущество использующему их игроку. Разработку стали вести по принципу «клиент в руках врага». Это, конечно, не значит, что игроки — наши враги. Нашей задачей стало максимально обезопасить игроков от чужих попыток получить игровое преимущество.
Ситуация на рынке модов стала тщательно мониториться. Теперь в случае обнаружения опасных или изменяющих игровой баланс модов мы оперативно реагируем и закрываем возможность их использования, меняя логику работы клиента. В последнее несколько лет изготовление честных модов поддерживается. По сути, это user generated content — игроки делают эти моды для себя и других игроков, что повышает ценность нашего продукта.
Но вернемся к истории. Работа со Scaleform очень освежила GUI и дала толчок к его развитию в проекте. Функционал разрастался и усложнялся за время прохождения закрытой и открытой беты и выхода проекта в релиз в августе 2010. Добавлялись новые фичи, дорабатывались и наворачивались уже существующие. Менялся дизайн, пробовались разные подходы к представлению информации в игре и организации взаимодействия с игроком.
Варианты реализации фильтра техники:

Изменения миникарты:

##### Пострелиз: проблемы роста и пути их решений
С ростом количества кода и ассетов стали выползать различные косяки.
Маркетинг Scaleform обгонял реальную разработку продукта и, как оказалось, многие из заявленных фич или работали не так, как хотелось, или сильно били по производительности, или вообще были в зачаточном состоянии. Была проделана огромная работа по улучшению производительности Scaleform-плеера, причем как с нашей стороны, так и со стороны разработчиков технологии.
Увеличившийся объем кода приводил к интересному спецэффекту. Каждая вьюха (или окно) лежала в своей FLA, содержала свои ассеты и код и компилировалась в отдельный SWF-файл. Таких SWF было очень много, и на рантайме они подгружались в клиент для показа нужного окошка или элемента управления, и, что характерно, порядок загрузки мог меняться в зависимости от того, что делал пользователь в игре.
Проблема заключалась в том, что если менялся код, который использовался в нескольких SWF, и после изменений не все эти SWF пересобирались, то на рантайме могло произойти следующее. Первой загружалась SWF с устаревшим кодом, и в лучшем случае все работало по старому, а в худшем — происходило падение клиента. Понять, что именно приводит к таким результатам, было трудно. Нам приходилось придумывать инструменты и методики, позволявшие отслеживать, что именно нужно пересобрать после изменений.
Также существовала проблема с качеством и консистентностью кода и использованием различных паттернов и стилей программирования. Так получилось потому, что разработку на Flash в проекте начинали люди, которые не были профессиональными Flash-разработчиками. Они учили Flash «в бою», и у каждого был свой бэкграунд (C++, php, Java). Получалось так, что при работе в разных частях проекта нужно было переключаться с одного подхода на другой.
Еще одной болью было взаимодействие Flash с Python. Передавать данные в любую сторону можно было только в виде примитивных типов, что, конечно же, не удовлетворяло нашим запросам. Путей решения было два: использовать JSON или же раскладывать все сложные типы в длинные массивы на одном конце и собирать из этих массивов объекты на другом.
Первый подход хорошо работал, когда объекты были маленькими. Но при росте размера объектов объемы результирующих строк росли, и это сказывалось на скорости выполнения кода — она падала. Второй подход быстро работал, но был сложен для понимания при прочтении кода и требовал титанических усилий при реализации изменений в структуре данных.
К тому моменту, когда все эти проблемы стали сильно тормозить разработку, Scaleform уже довел поддержку ActionScript 3 до приемлемого уровня. У нас вызревал план перевести интерфейсы ангара на новую версию языка и параллельно провести реструктуризацию проекта и создать свой framework, позволяющий быстро и по определенным правилам добавлять новую функциональность в проект.
Работы по подготовке перехода на ActionScript 3 начались в конце 2012 года. Как мы решали стоящие перед нами проблемы, и какие задачи ставили.
**Проблема:** проблемы с различными версиями кода в разных SWF.
**Решение:** весь код приложения вкомпиливается в один SWF-файл, который загружается при старте приложения.
**Проблема:** коммуникация Flash <-> Python.
**Решение:** переход на использование Direct Access API. Этот механизм позволяет передавать сложные объекты данных при помощи автоматической сериализации/десериализации их на уровне C++. Также использование этого подхода увеличивает производительность за счет того, что ссылки на Flash-объекты можно передавать в Python и производить манипуляции над ними в Python напрямую, вместо поиска нужного объекта во Flash по полному пути к нему при каждой необходимости передачи данных.
**Проблема:** стандартизация и унификация кода.
**Решение:** мы реализовали сервисную инфраструктуру и определили наборы интерфейсов и базовых классов, реализуя которые новая функциональность добавляется в проект.
**Проблема:** автоматизация сборки и добавления нового функционала в проект.
**Решение:** для сборки мы используем Maven. Проект был реструктурирован и разбит на более логичные подпроекты и подсистемы. Для автоматизации добавления нового функционала мы использовали YAML в качестве языка для описания интерфейсов взаимодействия Flash и Python. На базе YAML автоматически при сборке генерируется код и создаются необходимые сущности — как во Flash, так и в Python. Все, что остается сделать, это написать код и определить точку входа для запуска новой функциональности.
Так, в сентябре 2013 с выходом версии 8.8 лобби игры было полностью переделано на ActionScript 3.
Вот и все на сегодня. Детали о структуре проекта и планах на будущее читайте в следующей статье. | https://habr.com/ru/post/228309/ | null | ru | null |
# Привязка Request Traker 4.x на Ubuntu к ldap на примере ActiveDirectory
#### **Что это за RT**
Давно использую у себя в аутсорсерской компании трекер заявок от Secure Scout, который теперь называется BestPractical Request Tracker. Request Tracker хорош тем, что он опесорсовый, написан на Perl, нетребователен к ресурсам, гибок и позволяет прикрутить к себе какой угодно функционал. Больше рассказывать нет смысла, в свое время [zar0ku1](https://habrahabr.ru/users/zar0ku1/) написал неплохую [статью](https://habrahabr.ru/post/112348/) по установке RT 3.8, затем мануал [немного освежил](https://habrahabr.ru/sandbox/96505/) @Испанский лётчик, а [mister\_j](https://habrahabr.ru/users/mister_j/) даже [рассказал](https://habrahabr.ru/post/190822/) о программировании RT.
Мы шагнем немного дальше и выясним, как привязать авторизацию RT к ldap на примере AD, чтобы пользователи могли создавать заявки и отслеживать их выполнение, используя свою доменную учетку. Помимо индивидуализации трекера, появится возможность автоматического обновления информации (имя, email, подразделение и т.д.) о пользователях RT из службы каталогов.
#### **Какие возможности внешней авторизации встроены в RT**
BestPractical [предлагает](https://www.bestpractical.com/docs/rt/4.4/authentication.html) нам два вида аутентификации через внешний источник: используя форму входа (которая перекидывает запрос авторизации дальше) или минуя форму входа с использованием возможностей веб-сервера опознавать пользователя автоматически (например NTLM). Нужно сказать, что BestPractical рекомендует включать обе возможности, что мы и сделаем.
Чтобы не погружаться в пучину технический мануалов, скажу так: можно прикрутить аутентификацию к форме входа так, чтобы пользователь домена автоматически создавался в RT при входе на портал заявок, а можно создать скрипт, который будет периодически загружать новых пользователей из каталога. BestPractical, опять же, настаивает на обоих вариантах.
#### **Включение импорта учеток из LDAP**
Для подключения к домену нужно создать обычную пользовательскую учетку в AD (или в вашей реализации службы каталогов).
```
PS C:\> New-ADUser -Name "Request Tracker" -GivenName rt -SamAccountName rt -UserPrincipalName [email protected] -AccountPassword (Read-Host -AsSecureString "rt_password")
```
На хост RT нужно скачать специально созданный для целей импорта модуль Perl:
```
sudo cpan -i RT::Extension::LDAPImport
```
Затем добавить в конфигурационный файл RT (в моем случае это */opt/rt4/etc/RT\_SiteConfig.pm*) строки:
```
Set(@Plugins, qw(RT::Extension::LDAPImport));
Set($LDAPHost,'domaincontroller.example.com');
Set($LDAPUser,'example\rt');
Set($LDAPPassword,'rt_password');
Set($LDAPBase,'dc=example,dc=com');
Set($LDAPFilter, ' (&(objectCategory=person))');
Set($LDAPMapping, {Name => 'sAMAccountName',
RealName => 'cn',
EmailAddress => 'mail'
});
Set($LDAPCreatePrivileged, 1);
Set($LDAPUpdateUsers, 1);
```
В данном примере я указываю для импорта всех пользователей домена (*$LDAPFilter*), начиная с корня (*$LDAPBase*), подкачивая их имя, логин и email (*$LDAPMapping*). Учетные записи будут автоматически иметь доступ к RT (*$LDAPCreatePrivileged*) и информация о них будет обновляться при каждом новом запросе на импорт (*$LDAPUpdateUsers*).
Модуль импорта позволяет импортировать учетные записи из разных подразделений, импортировать группы, загружать больше информации об пользователях LDAP и т.д. Мне же достаточно того что я вам показал. Хотите знать больше — читайте [мануал](https://metacpan.org/pod/RT::Extension::LDAPImport) по модулю.
Процесс импорта сам по себе прост. Для начала можно запустить тестовый импорт и посмотреть, чем он закончился:
```
sudo /opt/rt4/local/plugins/RT-Extension-LDAPImport/bin/rtldapimport --debug > ldapimport.debug 2>&1
sudo cat ldapimport.debug
```
Как правило, ошибки возникают при включенных firewall и некорректно указанной базе поиска по LDAP. Если все прошло удачно, импорт можно запускать полноценно:
```
sudo /opt/rt4/local/plugins/RT-Extension-LDAPImport/bin/rtldapimport --import
```
Если вам, как и мне было достаточно не разделять пользователей по группам при импорте, то пользователи будут по умолчанию добавлены в RT в группу *Imported From LDAP*. Этой группе надо будет дать в RT соответствующие права на очереди, или вручную разобрать пользователей. Отдельно отмечу — никаких паролей у пользователей пока еще нет, входить в RT они не могут, мы просто импортировали информацию о них в RT и можем настраивать им уровни доступа.
Для того, чтобы информацию о пользователях обновлялась регулярно, можно создать задачу в планировщике, например:
```
sudo echo "01 1 * * * root /opt/rt4/local/plugins/RT-Extension-LDAPImport/bin/rtldapimport --import" >> /etc/crontab
```
#### **Авторизация через внешний источник**
Для фактической передачи запросов контроллеру домена или другому владельцу каталога ldap тоже нужен модуль Perl:
```
sudo cpan -i RT::Authen::ExternalAuth
```
В файл конфигурации *RT\_SiteConfig.pm* нужно добавить информацию о скачанном плагине:
```
Set(@Plugins, qw(RT::Extension::LDAPImport RT::Authen::ExternalAuth));
```
И указать информацию для доступа к каталогу ldap:
```
Set($ExternalAuthPriority, [ 'My_AD' ] );
Set($ExternalInfoPriority, ['My_AD'] );
Set( $UserAutocreateDefaultsOnLogin, { Privileged => 1 , Lang => 'ru'} );
Set($ExternalSettings, {
'My_AD' => {
'type' => 'ldap',
'server' => 'domaincontroller.example.com',
'user' => 'example\rt',
'pass' => 'rt_password',
'base' => 'dc=example,dc=com',
'filter' => '(objectCategory=person)',
'attr_match_list' => ['Name'],
'attr_map' => {
'Name' => 'sAMAccountName',
'EmailAddress' => 'mail',
'RealName' => 'cn',
},
},
} );
```
В этом примере я опять не делаю привязку групп, импортирую минимум информации и указываю базой для поиска информации весь домен, начиная с корня. Кому нужно больше — заходите и читайте [мануал](https://metacpan.org/pod/RT::Authen::ExternalAuth).
#### **Для самостоятельной работы**
~~Должен отметить, что после подключения к ldap создание локальных пользователей становится невозможным, но старые пользователи из внутренней БД продолжают успешно авторизоваться.~~ [Flashick](https://habrahabr.ru/users/flashick/) подсказал, что для возможности создания локальных учеток в RT нужно добавить в конфиг `Set($AutoCreateNonExternalUsers, 1);`
Еще один момент — если в домене для пользователей включен «Вход на», то пока отключайте, а в следующий раз расскажу, как поправить.
В следующий раз расскажу о том, как сделать авторизацию прозрачной для пользователя, не требуя от него пароля и логина, получая эту информацию автоматически.
UPD1: [Flashick](https://habrahabr.ru/users/flashick/) говорит что в версии RT 4.4 оба плагина уже есть по умолчанию и их не надо скачивать и ставить отдельно.
UPD2: по всему процессу, начиная с установки записал несколько видео в [плейлист](https://www.youtube.com/playlist?list=PLmxB7JSpraifsRUrtq2Y-il5NCLc3vKho) для тех, кто любит следить за процессом наглядно. | https://habr.com/ru/post/276597/ | null | ru | null |
# Доступность в Angular c помощью CDK A11y на реальных кейсах с FocusTrap и FocusMonitor
Мы привыкли слышать, что Angular - это фреймворк, который решает массу задач из коробки: свой CLI, встроенная сборка приложений, автоматическая миграция на новые версии с помощью schematic, работа с HTTP, DI, реактивные формы, работа с состоянием - все это удобные инструменты для разработчика. Обычно я сравниваю его с коробкой автомат: сел и поехал, не отвлекаясь на переключение передач.
Но в мире веба мы всегда должны думать о пользователях. И один из разделов, который заботится о них, называется доступность (Accessibility, A11y в англоязычной среде). И тут Angular позаботился о нас и дал мощнейший инструмент из коробки под названием **CDK A11y.** Предлагаюознакомиться с концепцией доступности и изучить применение этого инструмента в Angular.
Что такое доступность
---------------------
Существует множество способов взаимодействия с сайтом: мышь, клавиатура, голосовое управление, touch-устройства и т.д. Доступным будет считаться тот сайт, который максимально покрывает все варианты взаимодействия с ним. Независимо от пользовательских предпочтений, возможность дойти от точки действия А к Б не будет являться для него проблемой. Попробуйте навигацию клавиатурой по Github - в нем неплохо учтены пользовательские кейсы доступности.
Помимо способов взаимодействия с сайтом, в A11y можно выделить отдельное направление про контент на сайте. Сюда будут входить хорошие шрифты, цвета (возможны высокие контрасты для людей с нарушением зрения), скрытый/вспомогательный контент.
Также к доступности можно отнести: скорость загрузки сайта (возможно, есть пользователи, у которых ограничена пропускная способность интернета). А также работу сайта на различных устройствах.
Тема доступности очень важна для пользователей, ведь это связано с удобством. Это как доступная среда на улице: вход в подъезд без ступеней и лишних препятствий, велодорожки, светофоры и т.д. Более того, в некоторых странах доступность начинает входит в стандарты сайта по умолчанию, и в случае отсутствия, к владельцу могут быть применены штрафы. Кроме того, Google при индексации сайтов может учитывать и проверять состояние доступности на сайте.
CDK A11y в Angular
------------------
**Начнем с FocusTrap.** Это API предназначено, чтобы захватывать фокус в рамках определенного участка интерфейса. Такой захват нужен в случае, если нужно обеспечить навигацию через TAB.
Обычно выделяют следующие кейсы в интерфейсе для использования захвата фокуса:
* навигация в модальных окнах;
* навигация в меню;
* навигация в datepicker;
* различные пользовательские формы ввода, например, форма login;
Пример реализации захвата в календаре от Material.
Material Datepicker & FocusTrapИспользовать **cdkFocusTrap** просто - достаточно обернуть необходимую область для захвата и при перемещении по tab мы не будем вываливаться за пределы области.
```
Area 1
button 1
button 2
button 3
button 4
Area 2
button 1
button 2
button 3
button 4
```
**FocusMonitor -** это сервис, который предоставляет работу с фокусом. Он дает две возможности:
1. С помощью Monitor можно подписаться на Observable и получать состояния DOM элемента. Он отдаёт события focus и blur и возвращает, с помощью чего был установлен фокус (мышь, клавиатура, touch-устройство или установка через код)
В каких кейсах можно использовать **FocusMonitor**? Где угодно! Например:
* скрытие / открытие tooltip, [пример из material](https://github.com/angular/components/blob/81935ad7cf9bd1ac3843fe47c1a29b75303b47b0/src/material/tooltip/tooltip.ts);
* выполнение логики для перерисовки визуальных частей компонента таблиц при взаимодействии с компонентами сортировки, [пример из material](https://github.com/angular/components/blob/34dd468158ff11b95658c2a5ea662c4cd16afe68/src/material/sort/sort-header.ts);
* мониторинг списка с выделением, [пример из material](https://github.com/angular/components/blob/298da1cbc3b2d91d47e4d0a433ee0bd0f8439863/src/material/list/selection-list.ts);
Пример использования в коде:
```
export class FocusMonitorExample implements AfterContentInit, OnDestroy {
....
constructor(
private _element: ElementRef,
private \_focusMonitor: FocusMonitor
) {}
ngAfterContentInit(): void {
this.\_focusMonitor?.monitor(this.\_element)
.pipe(takeUntil(this.\_destroyed))
.subscribe(origin => {
if (origin === 'keyboard' || origin === 'program') {
// выполняем логику компонента
}
});
}
ngOnDestroy() {
this.\_focusMonitor?.stopMonitoring(this.\_element);
}
}
```
2. Он позволяет устанавливать фокус на указанные элементы через метод **focusVia**. При этом, в него можно передать параметр, с помощью чего был установлен фокус (мышь, клавиатура, через touch, через код)
В каких кейсах можно использовать **FocusMonitor** для установки фокуса:
* кнопка в форме - кнопка, которая получает фокус. Такую кнопку можно нажать сразу, без перевода на неё фокуса с помощью клавиатуры. Отличный кейс, когда требуется показывать на сайте onboarding/tutorial с кнопкой «далее»;
* поле ввода - при создании письма в gmail фокус, фокус сразу попадает в поле ввода почты получателя;
* чекбоксы, радиобаттоны на форме, можно управлять фокусом элемента по умолчанию;
* элементы меню;
Использование в коде:
```
export class FocusMonitorViaExample {
...
@ViewChild('btn') buttonElement: ElementRef;
constructor(
private _focusMonitor: FocusMonitor
) {}
focusElement() {
this._focusMonitor.focusVia(this.buttonElement, 'program');
}
}
```
**Если всё так просто – зачем нам FocusMonitor?**
Может показаться, что задачи сервиса довольно простые: обрабатывать события blur, focus или устанавливать фокус. Но данный сервис избавляет нас от рутины и потенциальных багов, которые могут возникнуть в ходе работы приложения. Можно выделить следующие плюсы:
* Переиспользуемый код. Так или иначе мы бы сами сделали что-то подобное для своих приложений, чтобы не дублировать код.
* Сервис работает в разном окружении, если приложение запущено за пределами браузера, эти кейсы предусмотрены (тесты, ssr и т.д.).
* Обработка ShadowRoot. Если элемент будет находиться внутри ShadowRoot, то обработчики focus/blur нужно привязывать к его корню, иначе мы не получим события.
* Оптимизация работы приложения. Используется runOutsideAngular для работы с нативными событиями addEventListener, чтобы лишний раз не тревожить Zone.js.
* Предусматривает мониторинг дочерних элементов.
Поэтому CDK FocusMonitor очень полезен в ваших приложениях. Многие задачи, с которыми вы можете столкнуться, уже решены в нём.
Заключение
----------
Мы рассмотрели понятие доступности. Узнали, какие инструменты существуют в Angular CDK. Подробно рассмотрели FocusMonitor и FocusTrap API для работы с доступностью. Но это далеко не весь функционал, который предоставляет нам CDK. Тема довольно обширная и выходит за рамки одной статьи. Если у вас есть опыт работы с остальным API доступности, напишите в комментариях, интересен ваш опыт и видение в этом направлении. | https://habr.com/ru/post/578856/ | null | ru | null |
# Управление Java Flight Recorder

Не так давно в мире Java случилось грандиозное событие. Во всех актуальных версиях OpenJDK стал доступен Java Flight Recorder (или просто JFR).
**Что такое Java Flight Recorder?**
JFR – это механизм легковесного профилирования Java-приложения. Он позволяет записывать и в последствии анализировать огромное количество метрик и событий, происходящих внутри JVM, что значительно облегчает анализ проблем. Более того, при определённых настройках его накладные расходы настолько малы, что многие (включая Oracle) рекомендуют держать его постоянно включённым везде, в том числе прод, чтобы в случае возникновения проблем сразу иметь полную картину происходившего с приложением. Просто мечта любого SRE!
Раньше этот механизм был доступен только в коммерческих версиях Java от корпорации Oracle версии 8 и более ранних. В какой-то момент его реимплементировали с нуля в OpenJDK 12, затем бекпортировали в OpenJDK 11, которая является LTS-версией. Однако вот OpenJDK 8 оставалась за бортом этого праздника жизни. Вплоть до выхода апдейта 8u272, в который наконец-то тоже бекпортировали JFR. Теперь все (за редким исключением) пользователи OpenJDK могут начинать использовать эту функциональность.
Но вот незадача: большая часть документации в интернете относится к старой, коммерческой, версии JFR и во многом не соответствует версии, которая присутствует в OpenJDK. Да и та, что есть, весьма скудная и не способствует пониманию того, как это всё использовать.
В предлагаемой вашему вниманию статье я расскажу, как управлять работой JFR и как его настраивать.
Активация через параметры JVM
-----------------------------
Активировать JFR можно несколькими путями. Один из них – задать соответствующие параметры при запуске Java-приложения. Для этого необходимо использовать два параметра:
* -XX:StartFlightRecording (активирует JFR и определяет основные параметры его работы),
* -XX:FlightRecorderOptions (задаёт дополнительные параметры работы).
Каждая из этих опций может быть дополнена настройками, например:
```
java -XX:StartFlightRecording=filename=/path/to/record/file.jfr
```
или
```
java -XX:StartFlightRecording:filename=/path/to/record/file.jfr
```
задаёт путь к файлу, куда будет записана вся собранная JFR информация после завершения записи (или остановки приложения).
Опций может быть несколько. В таком случае они разделяются запятыми (без пробелов!).
Посмотрим, какие есть настройки у каждой из этих опций и для чего они нужны.
### XX:StartFlightRecording
Посмотреть список опций можно в первоисточнике. В исходном файле OpenJDK. Для OpenJDK 11 это файл `src/hotspot/share/jfr/dcmd/jfrDcmds.cpp`.
| Опция | Описание | Умолчание |
| --- | --- | --- |
| name | Имя, по которому можно идентифицировать запись, например: "My Recording". Одновременно может быть запущено несколько разных записей. Чтобы их как-то различать и управлять ими независимо, используется это имя. | |
| settings | Файл(ы) с настройками, какие конкретно метрики и как профилировать. Это может быть или предопределённый профиль (см. JRE\_HOME/lib/jfr), или путь к своему файлу с настройками. Позже рассмотрим, как сформировать такой файл под себя. | |
| delay | Если требуется начать запись не в момент старта приложения, а позже, то можно задать задержку данным параметром. Размерности значения: (s)econds, (m)inutes), (h)ours) или (d)ays. Пример: `5h`. | 0 |
| duration | Промежуток времени, в течение которого будет происходить запись. Размерности значения: (s)econds, (m)inutes, (h)ours или (d)ays. Пример: `300s`. | 0 |
| filename | Файл, куда будет записан результат записи. Этот файл будет записан при завершении записи или при остановке приложения, если установлен флаг `dumponexit`. Пример: "/home/user/My Recording.jfr". | |
| disk | Флаг, обозначающий, что запись должна сохраняться на диске по мере работы. Если этот флаг не установлен, то вся записанная информация будет копиться в памяти. | false |
| maxage | Максимальное время, в течение которого будут сохраняться записанные данные. Если в ходе записи данные скидываются на диск, то будет производиться ротация записанных файлов. Размерности значения: (s)econds, (m)inutes, (h)ours или (d)ays. Пример: `60m` или `0` для безлимитной записи. | 0 |
| maxsize | Максимальное количество данных, которое будет сохраняться при записи. Если в ходе записи данные скидываются на диск, то будет производиться ротация записанных файлов. Размерности значений: (k)B, (M)B или (G)B. Пример: `500M` или `0` для безлимитной записи. | 0 |
| dumponexit | Флаг, обозначающий необходимость сброса записанных данных на диск при завершении работы JVM. Включая аварийное завершение. | false |
| path-to-gc-roots | Если в настройках JFR включена запись информации о живых объектах, то данным флагом можно включить запись ещё и маршрутов по ссылкам до корней сборки мусора. | false |
### XX:FlightRecorderOptions
Посмотреть список опций можно в исходном файле `src/hotspot/share/jfr/recorder/service/jfrOptionSet.cpp`.
| Опция | Описание | Умолчание |
| --- | --- | --- |
| repository | Каталог, в который будут по блокам записываться данные JFR, если указана опция `disk=true`. | |
| threadbuffersize | Размер буфера под запись данных JFR, выделяемого для каждого потока. Размерности значений: (k)B, (M)B или (G)B. | 8k |
| memorysize | Суммарное количество памяти, используемое JFR для записи данных. | 10m |
| globalbuffersize | Размер единичного глобального буфера для записи данных JFR, куда перекладывается информация из локальных буферов потоков. Размерности значений: (k)B, (M)B или (G)B. | 512k |
| numglobalbuffers | Количество глобальных буферов для записи данных JFR. | 20 |
| maxchunksize | Размер одного файлового блока в каталоге, заданном параметром `repository`. Размерности значений: (k)B, (M)B или (G)B. | 12m |
| old-object-queue-size | Максимальное количество наблюдаемых старых объектов. | 256 |
| samplethreads | Включение / выключение снятия дампов потоков (дампы снимаются, только если соответствующие настройки включены в файле настроек). | true |
| sampleprotection | Включение внутренней защиты для хождения по стеку при снятии дампов потоков. | false |
| stackdepth | Максимальная глубина снимаемых стектрейсов (минимум 1, максимум 2048) | 64 |
| retransform | Нужно ли инструментировать классы событий с использованием JVMTI? | true |
### Примеры использования
Минимально возможный пример запуска Java с JFR выглядит так:
```
java -XX:StartFlightRecording -version
```
В результате в консоль будет выдано сообщение:
```
Started recording 1. No limit specified, using maxsize=250MB as default.
Use jcmd 4787 JFR.dump name=1 filename=FILEPATH to copy recording data to file.
openjdk version "1.8.0_275"
OpenJDK Runtime Environment (build 1.8.0_275-b01)
OpenJDK 64-Bit Server VM (build 25.275-b01, mixed mode)
```
Тут мы видим, что, помимо версии Java, запрашиваемой параметром `-version`, выведены ещё две строки:
* сообщение о том, что JFR запущен и с каким идентификатором,
* подсказка, как получить результаты работы JFR через утилиту `jcmd`.
В параметрах мы не указали никаких настроек. Т.о., в силу быстрого завершения выполнения (сразу после вывода версии Java) мы не сможем получить результаты в виде файла. Данные JFR будут накапливаться в памяти и пропадут при остановке приложения.
Чтобы это исправить, можно задать дополнительные опции:
```
java -XX:StartFlightRecording=filename=recording.jfr -version
```
В результате по окончании работы приложения записанные данные будут сброшены в файл `recording.jfr` в текущем каталоге.
Вместо имени файла, можно указать имя каталога:
```
java -XX:StartFlightRecording=filename=./ -version
```
Тогда имя конкретного файла будет сгенерировано в момент записи, например: `hotspot-pid-16330-id-1-2020_11_30_17_16_49.jfr`. Это может быть полезно, если запускается много экземпляров JVM и не хочется перетирать данные предыдущих запусков.
Как было отмечено ранее, по умолчанию JFR накапливает все снятые данные в памяти в течение всей работы приложения. Полностью память при этом под записанные данные использоваться не будет. JFR имеет ряд настроек, ограничивающих максимальное использование памяти. Но что делать, если хочется производить запись в течение длительного времени, не забивая при этом память?
В таком случае можно использовать набор настроек, позволяющих сбрасывать записанные данные по частям на диск:
```
java \
-XX:StartFlightRecording=disk=true,maxsize=10g,maxage=24h,filename=./recording.jfr \
-XX:FlightRecorderOptions=repository=./diagnostics/,maxchunksize=50m,stackdepth=1024 \
-jar application.jar
```
Прежде всего необходимо установить опцию `disk=true`, чтобы переключить JFR из режима записи в память в режим записи на диск.
Далее необходимо указать каталог, в который будет производиться запись: `repository=./diagnostics/`. В этом каталоге начнут появляться файлы с фрагментами записи данных JFR. Размер каждого такого отдельного фрагмента задаётся опцией `maxchunksize=50m`, но не стоит обманываться. Этот параметр задаёт размер чистых данных JFR, но в каждый файл в конце будет дописываться ещё довольно много служебной информации, что в отдельных случаях может увеличить размер файла в разы. Зато каждый такой файл будет самодостаточным и доступным для независимого изучения.
По умолчанию файлы будут писаться до бесконечности, пока приложение не остановится. Но, если оно будет работать достаточно долго, место на диске может закончиться. Чтобы этого не произошло, можно ограничить количество сохраняемых данных по времени (`maxage=24h`) или объёму (`maxsize=10g`). Если один из этих параметров будет превышен, то старые файлы в каталоге `./diagnostics/` начнут стираться.
Ну и последний параметр из приведённого ранее примера — `stackdepth=1024`. Он необходим для приложений с глубокими стеками вызовов, чтобы стек захватывался полностью.
Т.о., мы получаем конфигурацию, которую можно задавать для долго работающих приложений и при этом иметь возможность ретроспективно увидеть, что конкретно происходило с приложением на момент, когда ему "поплохело".
Единственный существенный момент, который остался за скобками, — настройка снимаемых метрик JFR.
Файл конфигурации профиля JFR
-----------------------------
По умолчанию с OpenJDK поставляется два преднастроенных профиля:
* default.jfc (предназначен для мониторинга приложений на проде и дающий пенальти около 1% производительности),
* profile.jfc (предназначен для профилирования приложений на проде и дающий пенальти около 2% производительности и значительно больший объём снимаемых данных (больший размер jfr файлов).
Оба профиля тщательно подобраны разработчиками OpenJDK и лежат в каталоге `JAVA_HOME/jre/lib/jfr` для OpenJDK 8 или `JAVA_HOME/lib/jfr` для OpenJDK 11+.
Активировать их можно с помощью опции, например `settings=profile.jfc`:
```
java -XX:StartFlightRecording=settings=profile.jfc -version
```
Во многих ситуациях этого может оказаться достаточно, но не во всех. Дело в том, что в этих двух профилях остаётся отключённым очень большое количество метрик, которые могут очень помочь в тех или иных ситуациях. Например, в default.jfc практически отключён сбор информации о потреблении памяти, хотя он не даёт заметного пенальти, но при этом весьма полезен для понимания того, куда расходуется память приложения.
Т.о., становится понятно, что для своих частных случаев имеет смысл формировать отдельный, специально заточенный под себя файл с настройками. Но править его вручную – дело неблагодарное. Поэтому рекомендуется воспользоваться инструментом Java Mission Control (JMC), который умеет не только просматривать файлы, записанные JFR, но и управлять профилями записи этих файлов.
Скачать дистрибутив JMC можно, например, с сайта компании [BellSoft](https://bell-sw.com/pages/lmc-7.1.1/).
Если мы запустим JMC и выберем пункт меню `Window -> Flight Recording Template Manager`, то попадём в окно управления настройками профилей записи JFR:
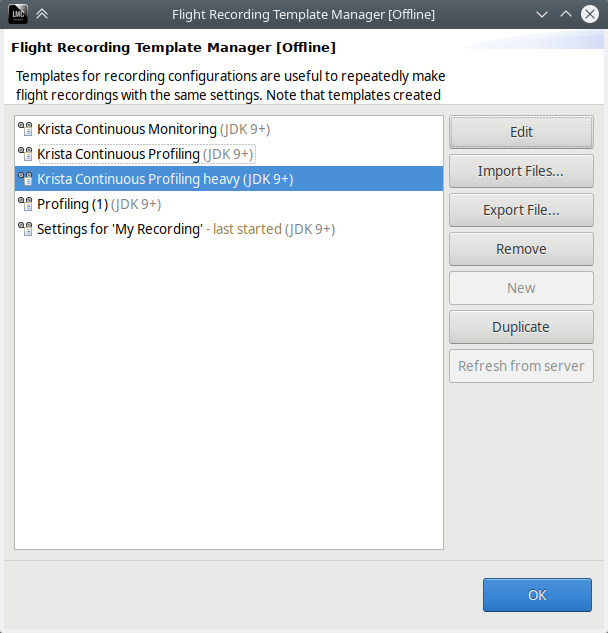
По умолчанию тут будут представлены два профиля, поставляемые с OpenJDK. Но мы можем создать свой профиль, если сначала продублируем имеющийся профиль с помощью кнопки `Duplicate`, а потом выберем копию и нажмём кнопку `Edit`:
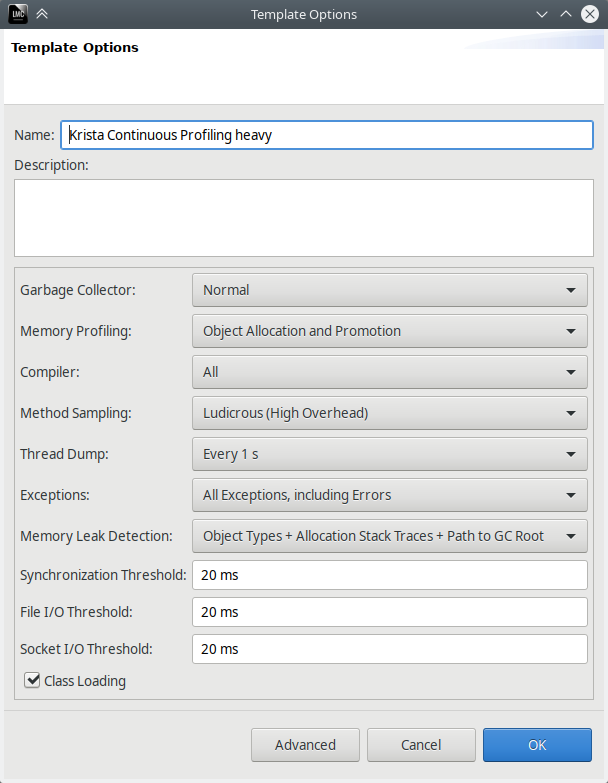
В открывшемся окне можно задать название профиля, его описание и настройки в упрощённом виде.
Но если упрощённых настроек не хватает, можно перейти в подробный режим, нажав кнопку `Advanced`:

Перейдя в такой режим настроек, можно включить дополнительные метрики для записи. Например, можно включить метрики:
* ObjectAllocationInNewTLAB
* ObjectAllocationOutsideTLAB
Как показано на скриншоте выше. Значимого пенальти по скорости это не создаёт, зато позволяет оценить, где и чем мусорит приложение в памяти, что часто позволяет находить весьма нетривиальные проблемы.
**Немного о метриках TLAB**
Важно понимать, как работает сбор данных метрик, чтобы правильно оценивать показываемые ими данные. JFR не пишет информацию о создании каждого объекта. Вместо этого, делается более хитрый ход: JVM не выделяет память напрямую из кучи, а отрезает от последней равные фрагменты и распределяет их по каждому потоку в отдельности. Локальное выделение объектов из таких локальных блоков происходит гораздо быстрее и без лишних блокировок. Так вот, в момент, когда очередной такой блок заканчивается, JFR записывает, при создании объекта какого класса это произошло, а также может записать стек, чтобы понять, в каком месте программы это произошло. Т.о., получается, что нельзя увидеть абсолютно всю информацию о выделяемых объектах, но при достаточно длительной работе приложения можно получить адекватную картину происходящего просто по закону больших чисел.
Также важно понимать, что если были внесены и сохранены какие-либо изменения в этом окне, доступ к простому виду настроек будет потерян. Настройки всегда будут открываться только в подробном виде.
После создания своего профиля работы JFR его можно экспортировать в отдельный файл и использовать в настройках запуска, указав путь к этому файлу:
```
java -XX:StartFlightRecording=settings=/path/to/custom/profile.jfc -version
```
Управление JFR через командную строку (jcmd)
--------------------------------------------
Но что делать, если приложение уже работает и надо запустить запись JFR? Или приостановить запись по какой-то причине? Или ещё что-то сделать?
Для этого можно воспользоваться штатной утилитой OpenJDK — jcmd. Например, запустить JFR можно следующей командой:
```
jcmd JFR.start duration=60s filename=myrecording.jfr settings=/path/to/custom/profile.jfc
```
Где — PID процесса JVM, в котором необходимо запустить JFR. В ответ будет выдана информация о том, что JFR запущено и куда именно будет записан файл с результатом:
```
19380:
Started recording 2. The result will be written to:
/media/data/java/OpenJDK/lmc7.1.1/myrecording.jfr
```
Данная команда запускает запись JFR на `60` секунд и указывает на то, чтобы записать результат в файл `myrecording.jfr`. Причём при таком указании файл будет записан по пути, локальному относительно не каталога запуска jcmd, а каталога, из которого была запущена JVM, в которой запускается JFR.
В целом видно, что при использовании jcmd доступны все те же самые опции, что и при запуске через параметры JVM, но некоторые опции имеют другие имена, поэтому далее они будут рассмотрены подробнее.
Также в ответе jcmd видна цифра `2`. Это имя записи. Если мы в дальнейшем захотим как-то повзаимодействовать с этой записью, нам необходимо будет использовать данное имя. Например, вот так можно остановить запись:
```
jcmd JFR.stop name=2
```
Утилита jcmd может выполнять несколько команд, связанных с JFR. Рассмотрим их по порядку.
### JFR.start
Запускает запись JFR с заданным именем, аналогично параметру запуска JVM `-XX:StartFlightRecording`. Если имя явно не задано, оно генерируется автоматически и выводится в консоль.
Можно использовать следующие опции:
| Опция | Описание | Умолчание |
| --- | --- | --- |
| name | Имя, которое может использоваться для идентификации запускаемой записи, например: "My Recording" | |
| settings | Имя или путь к конфигурации профиля записи. Имя может быть profile или default. См. JRE\_HOME/lib/jfr | |
| delay | Задержка перед началом записи. Размерности значения: (s)econds, (m)inutes), (h)ours) или (d)ays, например: 5h. | 0 |
| duration | Продолжительность записи. Размерности значения: (s)econds, (m)inutes, (h)ours или (d)ays, например: 300s. | 0 |
| filename | Файл, куда следует внести результат записи, например: "/home/user/My Recording.jfr". | |
| disk | Запись должна вестись на диск, а не в памяти. | |
| maxage | Максимальный промежуток времени, в течение которого будут сохраняться на диске записываемые данные. Размерности значения: (s)econds, (m)inutes, (h)ours или (d)ays, например: 60m или 0 для отсутствия ограничения | 0 |
| maxsize | Максимальное количество данных, сохраняемых при записи на диск. Размерности значения: (k)B, (M)B или (G)B, например: 500M или 0 для отсутствия ограничения. | 0 |
| dumponexit | Сбросить записанные данные на диск, если JVM прекращает работу. | |
| path-to-gc-roots | Сохранять пути до корней GC у объектов. | false |
### JFR.configure
Настраивает запись JFR аналогично параметру `-XX:FlightRecorderOptions`. Данная команда должна выполняться перед `JFR.start`, чтобы изменения вступили в силу.
| Опция | Описание | Умолчание |
| --- | --- | --- |
| repositorypath | Путь к каталогу репозитория, куда будет производиться запись данных JFR по мере работы, например, "/path/to/repository". Имеет смысл, если при старте будет указана опция `disk=true`. | |
| dumppath | Путь, куда будет сброшен результат записи при завершении работы JVM. Включая аварийное завершение. | |
| stackdepth | Глубина захватываемого стека при записи стектрейсов. | 64 |
| globalbuffercount | Количество глобальных буферов для записи данных JFR. | 20 |
| globalbuffersize | Размер единичного глобального буфера для записи данных JFR, куда перекладывается информация из локальных буферов потоков. Размерности значений: (k)B, (M)B или (G)B. | 512k |
| thread\_buffer\_size | Размер буфера под запись данных JFR, выделяемого для каждого потока. Размерности значений: (k)B, (M)B или (G)B. | 8k |
| memorysize | Суммарное количество памяти, используемое JFR для записи данных. | 10m |
| maxchunksize | Размер одного файлового блока в каталоге, заданном параметром `repository`. Размерности значений: (k)B, (M)B или (G)B. | 12m |
| samplethreads | Включение / выключение снятия дампов потоков (дампы снимаются, только если соответствующие настройки включены в файле настроек). | true |
### JFR.stop
Останавливает запись и сбрасывает записанные данные в файл, указанный при старте или непосредственно при вызове данной команды.
| Опция | Описание |
| --- | --- |
| name | Имя записи, которую необходимо остановить |
| filename | Файл, куда нужно записать результат записи, например: "/home/user/My Recording.jfr". |
### JFR.dump
Эта команда позволяет получить записанные данные, не останавливая саму запись. Ещё одной отличительной особенностью данной команды от JFR.stop является возможность сохранить не всю запись, а только интересующую её часть.
| Опция | Описание | Умолчание |
| --- | --- | --- |
| name | Имя записи, от которой необходимо получить данные. | |
| filename | Файл, в который необходимо записать выгружаемые данные. | |
| maxage | Максимальный промежуток времени, который будет выгружен в файл. Размерности значения: (s)econds, (m)inutes, (h)ours или (d)ays, например: 60m или 0 для отсутствия ограничения. | 0 |
| maxsize | Максимальное количество данных, которое будет выгружено в файл. Размерности значения: (k)B, (M)B или (G)B, например: 500M или 0 для отсутствия ограничения. | 0 |
| begin | Значение времени, начиная с которого нужно выгрузить данные записи, например: 09:00, 21:35:00, 2018-06-03T18:12:56.827Z, 2018-06-03T20:13:46.832, -10m, -3h или -1d. | |
| end | Значение времени, до которого необходимо выгрузить данные записи, например: 09:00, 21:35:00, 2018-06-03T18:12:56.827Z, 2018-06-03T20:13:46.832, -10m, -3h или -1d. | |
| path-to-gc-roots | Сохранять пути до корней GC у объектов. | false |
### JFR.check
Выводит информацию об активных записях JFR. Данная команда полезна, чтобы понять, запущена ли уже запись JFR в JVM и требуется ли её запускать или можно смотреть информацию в уже запущенной. А также чтобы убедиться, что записываются интересуемые события (метрики) JFR.
| Опция | Описание | Умолчание |
| --- | --- | --- |
| name | Имя записи, для которой запрашивается информация. Если не указано, то будет выведена информация для всех активных записей. | |
| verbose | Вывести полную информацию по записываемым событиям JFR. | false |
### Примеры использования
Разберём типовой сценарий использования jcmd для работы с JFR.
В качестве подопытного буду использовать запущенный Java Mission Control, который ранее использовался для формирования настроек записи.
Прежде всего посмотрим, не запущена ли уже запись JFR:
```
jcmd JFR.check
```
Получаю результат:
```
vektor@work$ jcmd 28534 JFR.check
28534:
Recording 1: name=JMC_Default maxsize=100,0MB (running)
```
Видно, что уже запущена запись с именем `JMC_Default`.
Допустим, мне необходимо посмотреть, как расходуется куча JVM. Как понять, снимается данная информация в запущенной записи или нет? Для этого можно посмотреть подробную информацию и найти в ней настройки для `jdk.ObjectAllocationInNewTLAB` и `jdk.ObjectAllocationOutsideTLAB`. Выполняем:
```
jcmd JFR.check name=JMC\_Default verbose=true
```
И получаем результат (сокращено для наглядности):
```
vektor@work$ jcmd 28534 JFR.check name=JMC_Default verbose=true
28534:
Recording 1: name=JMC_Default maxsize=100,0MB (running)
Flight Recording (jdk.ActiveRecording)
[enabled=true]
Recording Setting (jdk.ActiveSetting)
...
Allocation in new TLAB (jdk.ObjectAllocationInNewTLAB)
[enabled=false,stackTrace=true]
Allocation outside TLAB (jdk.ObjectAllocationOutsideTLAB)
[enabled=false,stackTrace=true]
...
```
Видно, что интересующие меня метрики отключены. Но не беда: можно запустить отдельную запись в том же процессе JVM с интересующими меня настройками:
```
jcmd JFR.start \
name=memory\_profile \
duration=10m \
filename=/path/to/recording.jfr \
settings=/path/to/memory\_profile.jfc
```
И получим вывод:
```
vektor@work$ jcmd 28534 JFR.start name=memory_profile duration=10m filename=/path/to/recording.jfr settings=/path/to/memory_profile.jfc
28534:
Started recording 4. The result will be written to:
/path/to/recording.jfr
```
Видно, что запись успешно запустилась.
Также можно посмотреть список всех записей:
```
jcmd JFR.check
```
И убедиться, что наша запись работает параллельно с ранее запущенной:
```
vektor@work$ jcmd 28534 JFR.check
28534:
Recording 1: name=JMC_Default maxsize=100,0MB (running)
Recording 4: name=memory_profile duration=10m (running)
```
Через 10 минут мы получим файл с результатами записи, который готов к открытию и изучению в Java Mission Control.
Но что делать, если есть необходимость включить запись на постоянной основе и иметь возможность анализировать результаты за сутки или более? В таком случае памяти на все записываемые данные может не хватить, а значит, нужно активировать их сброс на диск по мере записи. Для этого можно предварительно выполнить команду:
```
jcmd 28534 JFR.configure repositorypath=/path/to/disk/cahce maxchunksize=20m
```
Таким образом мы зададим каталог, куда будет скидываться записываемая информация. Плюс мы устанавливаем размер одного файла. Т.е. данные будут писаться фрагментами по 20 Мб, каждый из которых будет самодостаточным, и его можно будет просматривать в JMC независимо от всех остальных файлов.
В результате выполнения команды увидим следующий ответ:
```
vektor@work$ jcmd 28534 JFR.configure repositorypath=/path/to/disk/cahce maxchunksize=20m
28534:
Repository path: /path/to/disk/cahce/2020_12_03_16_58_40_28534
Max chunk size: 20,0 MB
```
Т.е. настройки установлены успешно. Теперь можно запускать непрерывную запись JFR:
```
jcmd 28534 JFR.start \
name=continuouse_record \
disk=true \
maxage=24h \
maxsize=10g \
settings=/path/to/memory_profile.jfc
```
Самым главным моментом в данном примере является включение записи на диск, вместо хранения данных в памяти. Также ограничиваем максимальное время хранения данных одними сутками, а размер – 10 Гб. Как минимум для того, чтобы диск не переполнился.
После этого в каталоге `/path/to/disk/cahce/2020_12_03_16_58_40_28534` начнут появляться файлы с записанными данными. А при превышении ограничений по времени или размеру старые файлы будут стираться.
Теперь, если мы захотим посмотреть на поведение JVM в какой-то момент времени, можно открыть соответствующий файл в JMC. Однако это не слишком удобно, т.к. нас может интересовать отрезок времени, не совпадающий с границами записи в файлах. Для решения этой проблемы мы можем выгрузить именно интересующий нас фрагмент записи:
```
jcmd 28534 JFR.dump \
name=continuouse_record \
begin=-10m \
filename=/path/to/recording.jfr
```
В результате получим вывод:
```
vektor@work$ jcmd 28534 JFR.dump name=continuouse_record begin=-10m filename=/path/to/recording.jfr
28534:
Dumped recording "continuouse_record", 13,1 MB written to:
/path/to/recording.jfr
```
Таким образом мы сохранили в файл данные за последние 10 минут. При этом сама запись не остановилась, и, если с приложением произойдёт ещё что-то интересное, мы сможем вытащить информацию за этот промежуток времени и проанализировать, что же с приложением случилось, во всех деталях.
Заключение
----------
В данной статье мы рассмотрели, как можно управлять записью Java Flight Recorder, и актуальный набор параметров для этого.
За скобками осталось ещё очень много интересного, т. к. управлять записью можно ещё и программно. А также добавлять свои типы событий и метрик, а потом анализировать всю собранную информацию в Java Mission Control.
Но это всё уже темы для других статей.
А тем, кого интересует, как использовать JFR для анализа и оптимизации приложения, я рекомендую серию статей от [Алексея Рагозина](https://training.ragozin.info/ru/java_profiling_classroom/):
* [JDK Flight Recorder – a gem hidden in OpenJDK](https://bell-sw.com/announcements/2020/06/24/Java-Flight-Recorder-a-gem-hidden-in-OpenJDK/)
* [Hunting down code hotspots with JDK Flight Recorder](https://bell-sw.com/announcements/2020/07/22/Hunting-down-code-hotspots-with-JDK-Flight-Recorder/)
* [Hunting down memory issues with JDK Flight Recorder](https://bell-sw.com/announcements/2020/09/02/Hunting-down-memory-issues-with-JDK-Flight-Recorder/) | https://habr.com/ru/post/532632/ | null | ru | null |
# Восстановление жёсткого диска iPod Classic
Попал ко мне iPod Classic 80 Gb с проблемой: «На экране надпись „Connect to iTunes to restore“, попытка восстановления через iTunes оканчивается ошибкой 1439». Перед этим его банально уронили. На лицо мертвый (или как оказалось позже частично мёртвый) жёсткий диск.
Как выяснить как дела у жёсткого диска и как вернуть iPod к жизни (хотя бы частично) читайте под катом.
**Внимание! Все действия с плеером вы производите на свой страх и риск. Если что-то пойдёт не так – ни автор статьи, ни авторы использованных инструментов не несут никакой ответственности.**
#### Диагностика
В первую очередь нам необходимо выяснить насколько плохо обстоят дела с жёстким диском. Для начала переведём iPod в режим диагностики. Для этого необходимо одновременно зажать кнопки «Menu» и «Select». Через несколько секунд плеер начнёт перезагружаться и на экране появиться яблочко. В этот момент зажимаем кнопку «Select» и кнопку перемотки назад. Откроется диагностическое меню iPod-а. Здесь можно проверить большинство функций плеера, но нас наиболее интересуют данные S.M.A.R.T. его жёсткого диска. Растущее число «Reallocated sector count» (я проверял этот параметр после каждой из нескольких попыток восстановления через iTunes) показывает нам что проблема действительно кроется в жёстком диске.
Для более детальной диагностики HDD переведём плеер в режим накопителя. Для этого снова зажимаем кнопки «Menu» и «Select» и так в момент появления яблочка на экране зажимаем уже «Menu» и «Play\Pause». После появления на экране надписи «OK to disconnect» кнопки отпускаем и подключаем плеер к компьютеру.
Далее нам понадобиться любая программа для тестирования поверхности жёсткого диска (я использовал Victoria) которой и проверяем поверхность жёсткого диска на битые сектора. Здесь необходимо отметить одну тонкость (возможно это не станет для кого чем-то новым, но я наступил на такие грабли, так что всё-таки отмечу на всякий случай): через некоторое количество bad-блоков жесткий диск отключается а в лог виктории падали ошибки «ABRT». В таких случаях приходится останавливать сканирование отключать и заново подключать плеер и запускать тест далее с места откуда начали сыпаться ошибки (или с места чуть дальше, что бы сразу отсечь мёртвый кусок диска). На данном этапе нам необходимо окончательно подтвердить, что проблема действительно в жёстком диске и найти самый большой живой кусок, что бы в последующем его вырезать для использования.
#### Восстановление. Попытка №1.
Единственный известный мне способ использования жёсткого диска с bad-блоками – вырезать мертвый кусок диска, и использовать диск уменьшенного объёма. Способ не самый надёжный – диск может отказать в любой момент – но в моём случае подходил, так как не хотелось раскошеливаться на новый (hdd для iPod classic стоит около 3300 рублей).
Поискав информации по поводу разбивки диска iPod-а нашёл только вот эту запись на форуме: [www.mobile-files.ru/forum/showthread.php?t=306330](http://www.mobile-files.ru/forum/showthread.php?t=306330). Попробовал. И не получилось. Связанно это с тем, что у моего экземпляра умерло в том числе почти самое начало диска вместе с файловой таблицей. Соответственно у меня не было того содержимого диска, которое создаёт iTunes при восстановлении плеера (это не указанно в сообщении форума, но после нарезания диска необходимо воссоздать содержимое диска как будто это сделал сам iTunes). И повторить я его не смог.
#### Восстановление. Попытка №2.
Я продолжил поиски способов восстановления и наткнулся на проект Rockbox (<http://www.rockbox.org/>). Rockbox – это альтернативная прошивка для множества плееров, в том числе и плееров компании Apple. Правда iPod Classic у них числится как неготовый к использованию. А именно если открыть таблицу списка платформ в разработке на их сайте (<http://www.rockbox.org/wiki/TargetStatus#New_Platforms_Currently_Under_Development>) и найти в списке iPod Classic то увидим, что не готовы только Dual Boot (возможность выбора между оригинальной прошивкой и Rockbox-ом) и установка через их собственную утилиту установки. Если вас это не смущает то продолжаем.
Установка Rockbox-а на плеер возможна благодаря проекту freemyipod (<http://www.freemyipod.org>) и их продукту emCore (<http://www.freemyipod.org/wiki/EmCORE>). Вкратце – freemyipod проект реверс инжиниринга iPod-ов с колёсиком Click Wheel. А emCore, как сказано на вики проекта, простенькая операционная система для них. А по факту является загрузчиком для Rockbox-а.
Начнём установку. Инструкция для пользователей Linux: <http://www.freemyipod.org/wiki/EmCORE_Installation/iPodClassic/PrepareDFULinux>. MacOs к сожалению не поддерживается. Инструкция для Windows (поддерживается XP/Vista/7/8) пользователей:
1. Устанавливаем iTunes если он ещё не установлен
2. Подключаем iPod к компьютеру
3. Закрываем iTunes если он запущен. Так же останавливаем процессы «AppleMobileDeviceService.exe» и «iTunesHelper.exe».
4. Скачиваем файл <http://files.freemyipod.org/misc/bootstrap_ipodclassic_itunes.exe>
5. Снимаем iPod с блокировки
6. Переводим плеер в режим DFU. Для этого одновременно зажимаем кнопки «Menu» и «Select». После того как на экране появится яблочко продолжаем держать кнопки. Отпускаем только когда экран плеера погаснет
7. Ждём пока установится всё новое оборудование
8. Запускаем скачанный файл до тех пор, пока программа не скажет, что всё установилось хорошо, а на экране iPod-а не появится маленькая картинка с текстом
9. Если в этот момент у вас не появился диск «UMSboot» объёмом 64 мегабайта то, после установки всех дополнительных драйверов на плеер, повторно запускаем bootstrap\_ipodclassic\_itunes.exe
На этом этапе у нас должен быть отдельный диск «UMSboot». Скачиваем файл <http://files.freemyipod.org/releases/20120102/installer-ipodclassic-r859-20120102.ubi> – это самый свежий релиз r859 на момент написания статьи. Самую свежую версию можно посмотреть на странице <http://www.freemyipod.org/wiki/EmCORE_Releases>. Скачанный файл просто копируем на диск «UMSboot». Теперь необходимо безопасно извлечь диск. В Linux просто отмонтируем папку. В Windows нажимаем правой кнопкой на диск в проводнике и нажимаем «Извлечь» (**сделать надо именно так – безопасное отсоединение устройства не работает!**). Теперь отключаем плеер от компьютера.
Теперь следуем инструкциям на экране плеера. Сначала необходимо прочитать отказ от гарантий и согласиться с ним одновременным нажатием «Menu» и «Play\Pause». Затем начнётся перепрошивка плеера. Тут я наткнулся на проблему о которой нигде не было написано – во время этого процесса происходит форматирование жесткого диска. А так, как он сильно повреждён то процесс этот затянулся. Первые два раза я даже думал, что плеер завис и перезагружал его (зажав «Menu» и «Select»). Однако я зря это делал. Просто надо подождать – у меня это заняло примерно 3-4 часа.
После перепрошивки и перезагрузки плеера появится меню загрузчика. В нём выбираем «Rock box». Загрузчик скажет, что не найден файл «rockbox.ipod» – не обращаем внимание. После того, как Rockbox запустился, снова подключаем плеер к компьютеру. Будет обнаружен жёсткий диск, который нам теперь предстоит переразбить чтобы вырезать мёртвый кусок.
Тут я столкнулся с новой проблемой – ни одна из утилит под Windows не хотела работать с этим диском. Кто-то его просто не видел. Кто-то зависал при попытке обращения. Можете предварительно сами попробовать – может быть и получится. Если нет – то следующий абзац для вас.
Меня спас старый добрый fdisk из Linux. Он без проблем переделал таблицу разделов в нужный мне вид. Для примера приведу список команд (подробнее в справке fdisk):
```
# sudo fdisk /dev/sdb
o
n
p
1
[здесь первый сектор живого куска (размер сектора на HDD плеера – 4096 байт]
[здесь последний сектор живого куска или +[размер]{K,M,G}]
t
c
w
# sudo mkfs.cfat /dev/sdb1
```
Здесь стоит обратить внимание что необходимо обязательно указать тип раздела как Windows (0x0C) иначе ни emCore ни Rockbox не увидят этот раздел.
После разбивки диска и форматирования закончим установку прошивки. Скачиваем архив <http://files.freemyipod.org/releases/20120102/rockbox-ipodclassic-r31516-20120102.zip> (опять же — самая свежая версия на странице <http://www.freemyipod.org/wiki/EmCORE_Releases>). Скачанный архив просто распаковываем на диск плеера. И всё – готово!
#### Небольшое заключение
Примерно неделя тестирования показала некоторую нестабильность прошивки – я не смог точно определить причину, но несколько раз плеер зависал совсем намертво. Гасла подсветка (изображение оставалось на экране) а в наушниках зацикливалось текущее содержимое аудио буфера. Одновременное зажатие «Menu» и «Select» не помогало (сочетание кнопок для перезагрузки). Единственный способ возвращения плеера в рабочее состояние либо дожидаться пока не сядет аккумулятор, либо вскрывать и отсоединять шлейф аккумулятора. Пока что предположение о причинах – воспроизведение FLAC. Именно при его воспроизведении в случайное время происходят такие зависания. Но пока информация не точная.
На этом всё. Надеюсь, что статья кому-нибудь помогла вернуть к жизни его iPod. | https://habr.com/ru/post/170151/ | null | ru | null |
# Как быстро и бесплатно получить доступ к windows на osx или linux
Среди разработчиков нередка ситуация, когда основной рабочий компьютер это mac или linux, но время от времени нужен доступ к windows: запустить специфичную программу, проверить верстку в internet explorer, поставить триальную версию corel draw для конвертации в .svg.
“Классический” способ решения этой задачи — установить одну из популярных виртуальных машин, скачать 90-дневную триал версию windows и установить ее в виртуальноый машине. Но у этого способа есть один большой минус — о необходимости деражать под рукой такую виртуальную машину разработчик обычно вспоминает в тот момент когда “о, тут нужна винда!”. А ставится windows не то чтобы очень быстро. И 90-дневный триал, что характерно, имеет обыкновение заканчиваться в самый неподходящий момент. Даже с rearm. Недавно Microsoft пошла на встречу разработчикам и сделала интересный сервис, позволяющий очень быстро и бесплатно получить доступ к нужной версии windows.
Сервис изначально был сделан для web разработчиков, чтобы они могли быстро тестировать свои сайты и приложения под разные версии браузеров, включая новый Microsoft Edge. Доступен сервис по адресу: [dev.modern.ie/tools/vms](http://dev.modern.ie/tools/vms)
С помощью этого сервиса можно скачать образ нужной версии windows с нужным internet explorer, полностью настроенный под одну из трех виртуальных машин: parallels, virtualbox или wmvare. Огромным плюсом является наличие версий Windows от XP до 10 и то, что скачанный образ запускается сразу же — не нужно ничего никуда устанавливать. При наличии быстрого интернета 1 гигабайт windows XP скачивается за пару минут, еще минуту образ подключается к виртуальной машине и через 3 минуты с момента “о, тут нужна винда!” у вас есть запущенная винда.
Проиллюстрирую как это работает на примере osx, виртуальной машины virtualbox (потому что наш технический евангелист сказал что так надо) и windows xp (потому что клиенты бывают странные). Вначале скачиваем zip архив с нужной версией образа для виртуальной машины:
Устанавливаем и запускаем oracle virtualbox. Можно с [официального сайта](https://www.virtualbox.org/), можно с помощью homebrew cask:
```
sudo brew cask install virtualbox
```
Выбираем File/Import Appliance и указываем **.ova** файл, распакованный из скачанного zip архива. Appliance — это экспортированные образы виртуальной машины для virtualbox, которые содержат не только содержимое жесткого диска, но и настройки. В процессе экспортирования можно указать произвольное имя виртуальной машины, поменять объем доступной памяти ну и остальные настройки, если вам не нравится что наконфигурили ребята из Microsoft:

Импортированная appliance повляется в списке виртуальных машин virtualbox и готова к запуску. Несколько секунд ожидания — и вот она, винда. Быстро и безболезнено:
Интересным моментом является то, что Microsoft сама рекомендует сделать snapshot виртуальной машины до первого запуска — это позволит восстановить ее после истечения триального периода. Как это стыкуется с их политикой лицензирования я не знаю, но факт остается фактом. Видимо, в целях отладки на internet explorer — можно. | https://habr.com/ru/post/265935/ | null | ru | null |
# Optional: Кот Шрёдингера в Java 8
Представим, что в коробке находятся кот, радиоактивное вещество и колба с синильной кислотой. Вещества так мало, что в течение часа может распасться только один атом. Если в течение часа он распадётся, считыватель разрядится, сработает реле, которое приведёт в действие молоток, который разобьёт колбу, и коту настанет карачун. Поскольку атом может распасться, а может и не распасться, мы не знаем, жив ли кот или уже нет, поэтому он одновременно и жив, и мёртв. Таков мысленный эксперимент, именуемый «Кот Шрёдингера».

Класс Optional обладает схожими свойствами — при написании кода разработчик часто не может знать — будет ли существовать нужный объект на момент исполнения программы или нет, и в таких случаях приходится делать проверки на null. Если такими проверками пренебречь, то рано или поздно (обычно рано) Ваша программа рухнет с NullPointerException.
*Коллеги! Статья, как и любая другая, не идеальна и может быть поправлена. Если Вы видите возможность существенного улучшения данного материала, укажите её в комментариях.*
Как получить объект через Optional?
-----------------------------------
Как уже было сказано, класс Optional может содержать объект, а может содержать null. К примеру, попытаемся извлечь из репозитория юзера с заданным ID:
```
User = repository.findById(userId);
```
Возможно, юзер по такому ID есть в репозитории, а возможно, нет. Если такого юзера нет, к нам в стектрейс прилетает NullPointerException. Не имей мы в запасе класса Optional, нам пришлось бы изобретать какую-нибудь такую конструкцию:
```
User user;
if (Objects.nonNull(user = repository.findById(userId))) {
(остальная борода пишется тут)
}
```
Согласитесь, не очень. Намного приятнее иметь дело с такой строчкой:
```
Optional user = Optional.of(repository.findById(userId));
```
Мы получаем объект, в котором может быть запрашиваемый объект — а может быть null. Но с Optional надо как-то работать дальше, нам нужна сущность, которую он содержит (или не содержит).
Cуществует всего три категории Optional:
* Optional.of — возвращает Optional-объект.
* Optional.ofNullable -возвращает Optional-объект, а если нет дженерик-объекта, возвращает пустой Optional-объект.
* Optional.empty — возвращает пустой Optional-объект.
Существует так же два метода, вытекающие из познания, существует обёрнутый объект или нет — isPresent() и ifPresent();
### .ifPresent()
Метод позволяет выполнить какое-то действие, если объект не пустой.
```
Optional.of(repository.findById(userId)).ifPresent(createLog());
```
Если обычно мы выполняем какое-то действие в том случае, когда объект отсутствует (об этом ниже), то здесь как раз наоборот.
### .isPresent()
Этот метод возвращает ответ, существует ли искомый объект или нет, в виде Boolean:
```
Boolean present = repository.findById(userId).isPresent();
```
Если Вы решили использовать нижеописанный метод get(), то не будет лишним проверить, существует ли данный объект, при помощи этого метода, например:
```
Optional optionalUser = repository.findById(userId);
User user = optionalUser.isPresent() ? optionalUser.get() : new User();
```
Но такая конструкция лично мне кажется громоздкой, и о более удобных методах получения объекта мы поговорим ниже.
Как получить объект, содержащийся в Optional?
---------------------------------------------
Существует три прямых метода дальнейшего получения объекта семейства orElse(); Как следует из перевода, эти методы срабатывают в том случае, если объекта в полученном Optional не нашлось.
* orElse() — возвращает объект по дефолту.
* orElseGet() — вызывает указанный метод.
* orElseThrow() — выбрасывает исключение.
### .orElse()
Подходит для случаев, когда нам обязательно нужно получить объект, пусть даже и пустой. Код, в таком случае, может выглядеть так:
```
User user = repository.findById(userId).orElse(new User());
```
Эта конструкция гарантированно вернёт нам объект класса User. Она очень выручает на начальных этапах познания Optional, а также, во многих случаях, связанных с использованием Spring Data JPA (там большинство классов семейства find возвращает именно Optional).
### .orElseThrow()
Очень часто, и опять же, в случае с использованием Spring Data JPA, нам требуется явно заявить, что такого объекта нет, например, когда речь идёт о сущности в репозитории. В таком случае, мы можем получить объект или, если его нет, выбросить исключение:
```
User user = repository.findById(userId).orElseThrow(() -> new NoEntityException(userId));
```
Если сущность не обнаружена и объект null, будет выброшено исключение NoEntityException (в моём случае, кастомное). В моём случае, на клиент уходит строчка «Пользователь {userID} не найден. Проверьте данные запроса».
### .orElseGet()
Если объект не найден, Optional оставляет пространство для «Варианта Б» — Вы можете выполнить другой метод, например:
```
User user = repository.findById(userId).orElseGet(() -> findInAnotherPlace(userId));
```
Если объект не был найден, предлагается поискать в другом месте.
Этот метод, как и orElseThrow(), использует Supplier. Также, через этот метод можно, опять же, вызвать объект по умолчанию, как и в .orElse():
```
User user = repository.findById(userId).orElseGet(() -> new User());
```
Помимо методов получения объектов, существует богатый инструментарий преобразования объекта, морально унаследованный от stream().
Работа с полученным объектом.
-----------------------------
Как я писал выше, у Optional имеется неплохой инструментарий преобразования полученного объекта, а именно:
* get() — возвращает объект, если он есть.
* map() — преобразовывает объект в другой объект.
* filter() — фильтрует содержащиеся объекты по предикату.
* flatmap() — возвращает множество в виде стрима.
### .get()
Метод get() возвращает объект, запакованный в Optional. Например:
```
User user = repository.findById(userId).get();
```
Будет получен объект User, запакованный в Optional. Такая конструкция крайне опасна, поскольку минует проверку на null и лишает смысла само использование Optional, поскольку Вы можете получить желаемый объект, а можете получить NPE. Такую конструкцию придётся оборачивать в .isPresent().
### .map()
Этот метод полностью повторяет аналогичный метод для stream(), но срабатывает только в том случае, если в Optional есть не-нулловый объект.
```
String name = repository.findById(userId).map(user -> user.getName()).orElseThrow(() -> new Exception());
```
В примере мы получили одно из полей класса User, упакованного в Optional.
### .filter()
Данный метод также позаимствован из stream() и фильтрует элементы по условию.
```
List users = repository.findAll().filter(user -> user.age >= 18).orElseThrow(() -> new Exception());
```
### .flatMap()
Этот метод делает ровно то же, что и стримовский, с той лишь разницей, что он работает только в том случае, если значение не null.
Заключение
----------
Класс Optional, при умелом использовании, значительно сокращает возможности приложения рухнуть с NullPoinerException, делая его более понятным и компактным, чем как если бы Вы делали бесчисленные проверки на null. А если Вы пользуетесь популярными фреймворками, то Вам тем более придётся углублённо изучить этот класс, поскольку тот же Spring гоняет его в своих методах и в хвост, и в гриву. Впрочем, Optional — приобретение Java 8, а это значит, что знать его в 2018 году просто обязательно. | https://habr.com/ru/post/346782/ | null | ru | null |
# Асинхронный удар
Как уже наверное кто-то догадался, в этой статье речь пойдет о сокетах, и фреймфорках облегчающих работу с ними. Недавно я начал работу надо новым проектом, онлайн игрой. Для таких проектов довольно критично время ответа от сервера, если это конечно не пошаговая стратегия, хотя и в этом случае пожалуй тоже. Так как же этого добиться при суровой ограниченности ресурсов?
* Облегчить сервер от ненужной работы, например отрисовки самой странички, используя вместо этого javascript шаблонизатор.
* Использовать хороший front-end, например nginx, учитывая пункт первый, динамики у нас нет, и это нам вполне подходит.
* Распределяя нагрузку на frontend, например используя Tornado.
Остался самый главный вопрос, что будет происходить когда пользователь совершает какое-либо действие? Обычные ajax запросы не подойдут, вполне понятно почему. Поэтому нам на помощь приходят сокеты.
##### Предыстоия
Игра построена не на флеше, а js не умеет работать с сокетами, поэтому можно использовать флеш подложку которая займется этим вопросом. Тут нам поможет небольшая библиотечка jsocket.
Для сервера первым делом внимание пало на Twisted, и уже даже начал кое что писать, как обнаружил для себя еще целую гору интересных инструментов, из которых больше всего приглянулись gevent и tornado. Поискав информацию про каждый из них обнаружил интересную [статью](http://oddments.org/?p=494), а позже [эту](http://nichol.as/asynchronous-servers-in-python). Однако там рассматривается немного другая задача, нежели нужна мне, поэтому я решил провести свое тестирование.
##### Скрипты
###### Пишем простой клиент для тестов на twisted.
```
from twisted.internet.protocol import ClientFactory
from twisted.protocols.basic import LineReceiver
from twisted.internet import epollreactor
epollreactor.install()
from twisted.internet import reactor
import sys,time
clients=30000
host='127.0.0.1'
port=8001
file = open( 'log.dat', 'w')
class glob():
connections=0
crefuse=0
clost=0
def enchant(self):
self.connections+=1
def refuse(self):
self.crefuse+=1
def lost(self):
self.clost+=1
a=glob()
class EchoClient(LineReceiver):
measure=True
def connectionMade(self):
self.sendLine("Hello, world!")
self.t1 = time.time()
def lineReceived(self, line):
if self.measure:
self.t2 = time.time() - self.t1
file.write('%s %s %s %s %s\n' % (a.connections+1,self.t2,a.crefuse,a.clost,line))
self.measure=False
if a.connections+1 < clients:
a.enchant()
reactor.connectTCP(host, port, EchoClientFactory())
else:
self.transport.loseConnection()
class EchoClientFactory(ClientFactory):
protocol = EchoClient
def clientConnectionFailed(self, connector, reason):
a.refuse()
def clientConnectionLost(self, connector, reason):
a.lost()
def main():
f = EchoClientFactory()
reactor.connectTCP(host, port, f)
reactor.run()
file.close()
if __name__ == '__main__':
main()
```
###### И сервер на каждом фреймворке.
###### gevent
```
clients=[]
host=''
port = 8001
def echo(socket, address):
clients.append(socket)
while True:
line = socket.recv(1024)
for client in clients:
try:
client.send(str(len(clients))+'\r\n')
except:
clients.remove(client)
if __name__ == '__main__':
from gevent.server import StreamServer
StreamServer((host, port), echo).serve_forever()
```
###### tornado
```
import errno
import functools
import socket
from tornado import ioloop, iostream
host=''
port = 8001
clients=[]
class Connection(object):
def __init__(self, connection):
clients.append(self)
self.stream = iostream.IOStream(connection)
self.read()
def read(self):
self.stream.read_until('\r\n', self.eol_callback)
def eol_callback(self, data):
for c in clients:
try:
c.stream.write(str(len(clients))+'\r\n')
except:
clients.remove(c)
self.read()
def connection_ready(sock, fd, events):
while True:
try:
connection, address = sock.accept()
except socket.error, e:
if e[0] not in (errno.EWOULDBLOCK, errno.EAGAIN):
raise
return
connection.setblocking(0)
Connection(connection)
if __name__ == '__main__':
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM, 0)
sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
sock.setblocking(0)
sock.bind((host, port))
sock.listen(30000)
io_loop = ioloop.IOLoop.instance()
callback = functools.partial(connection_ready, sock)
io_loop.add_handler(sock.fileno(), callback, io_loop.READ)
try:
io_loop.start()
except KeyboardInterrupt:
io_loop.stop()
print "exited cleanly"
```
###### twisted
```
from twisted.protocols import basic
class MyChat(basic.LineReceiver):
def connectionMade(self):
self.factory.clients.append(self)
def connectionLost(self, reason):
self.factory.clients.remove(self)
def dataReceived(self, line):
for c in self.factory.clients:
c.message(str(len(factory.clients))+'\r\n')
def message(self, message):
self.transport.write(message)
from twisted.internet import epollreactor
epollreactor.install()
from twisted.internet import reactor, protocol
from twisted.application import service, internet
factory = protocol.ServerFactory()
factory.protocol = MyChat
factory.clients = []
reactor.listenTCP(8001,factory)
reactor.run()
```
##### Небольшое пояснение
По сути мы создали чат сервер, Как только сервер получает строку от клиента, он рассылает эту строку всем подключенным клиентам (точнее вместо этого мы рассылаем количество подключенных клиентов). Таким образом нагрузка возрастает арифметически. Клиент в свою очередь измеряет время прошедшее между отправкой сообщения на сервер и получением ответа от него. Так как наш текущий клиент подключился последним, то все клиенты к этому моменту уже получат ответ.
При измерениях я снимал зависимость времени ответа от количества подключенных пользователей. Клиент и сервер запускались на локалхосте. Машина при этом используется как десктоп, так что результаты могут быть немного искажены, однако суть при этом ясна. Планировалось измерить зависимость вплоть до 30000 подлючений, но к сожалению для всех трех фреймворков это оказалось слишком долго.
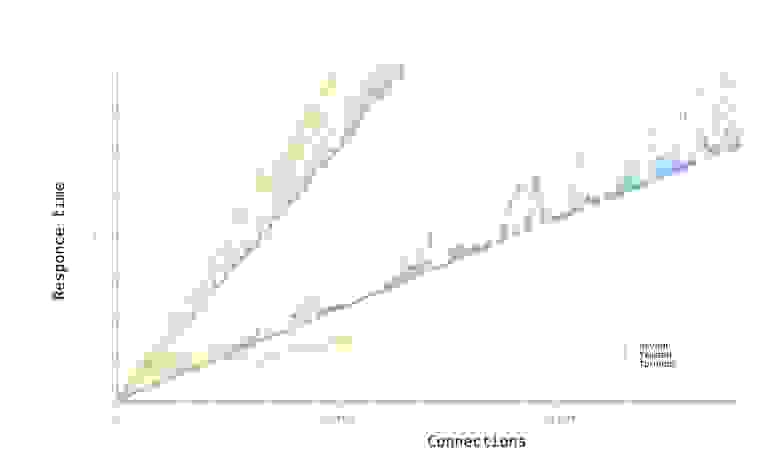
По оси отклика, время, разумеется, в секундах.
На графике у tornado видно две линии. Это не два теста, а один, просто результаты получились такого вида:
`11476 2.45670819283
11477 0.405035018921
11478 2.42619085312
11479 0.392680883408
11480 2.5216550827
11481 0.401995897293`
где первое число это количество коннектов, а второе время ответа. Я не знаю с чем это связано.
##### Выводы
Привожу список всех плюсов и минусов, в рамках поставленной задачи
###### Gevent
* + Высокая скорость работы.
* + Лаконичный код.
* — Не очень удобно.
###### Twisted
* + Понятный код.
* + Множество дополнительных функций.
* + Обширная документация.
* — Тормознутый домашний сайт.
* — Медленный.
###### Tornado
* + С ним быстрее всего получилось разобраться.
* — Нет документации
* — Не очень удобно.
* — Нестабильное время отклика.
Что-ж из всего вышесказаного, каждый сможет сделать выводы для себя сам. Я для себя и своих задач выберу gevent.
UPD. немного ошибся со скриптом на gevent. На него было меньше нагрузки. Перемерил, результат получился немного хуже, однако остался по прежнему лучшим. вот примерные результаты:
`10336 1.01536607742 0 0 10338
10337 0.955881118774 0 0 10339
10338 0.947958946228 0 0 10340
10339 1.02578997612 0 0 10341` | https://habr.com/ru/post/117918/ | null | ru | null |
# В DWH только Python
Вопреки названию, мы используем далеко не только Python. Но большой проект на любом языке требует к себе вдумчивый подход, особенно в плане учета особенностей языка и технологий.
Пройдя все стадии от отрицания до принятия в программировании на Python, могу сказать, что он нам подошел. Но будет неправдой сказать, что нас обошли стороной трудности и проблемы, связанные с особенностями разработки.
Про жизненные неурядицы и то, как мы их решали и продолжаем решать — об этом и немного об устройстве DWH в inDrive я и расскажу. А еще на примере кейсов разберу, что в проекте может пойти не так.
### Языки и технологии в нашем DWH
Наш DWH облачный и расположен в Google Cloud. Значительную часть технологий этой платформы мы используем для решения задач:
* BigQuery.
* Pub/Sub + Dataflow.
* Dataproc.
* Google Functions.
* Composer.
Помимо этого, есть опенсорсные технологии, которые активно используем — Livy и Presto.
Языки нашей разработки можно представить в виде небольшой таблицы:
| | | |
| --- | --- | --- |
| **Scala** | **SQL** | **Python** |
| General-purpose язык.Быстрый.Имеет небольшую распространенность. | Поддерживается для многих систем обработки/хранения данных.Скорость зависит от системы.Очень распространен (основные конструкции). | General-purpose язык.Не очень быстрый.Очень распространен. |
Подружить такое количество технологий с доставкой данных из API и бэкенда требует много усилий. Это выросло в целый проект, позволяющий автоматизировать выгрузки и сбор витрин данных. В качестве основного языка мы используем Python, в узких местах Scala. Проект, предоставляющий простой интерфейс для работы со сложными инструментами, мы назвали **de-core**.
### Что же могло пойти не так?
#### Кейс 1. Навигация в проекте
В начале проект писали два человека. Со временем команда подросла и встал вопрос, как ориентироваться в коде.
**Проблемы:**
* Непонятно, что и где лежит.
* `common.py` на 10 тысяч строк.
* IDE не помогает найти нужные файлы.
* Документации нет.
Эти проблемы могут привести к тому, что в какой-то момент возникнет дублирующий функционал, а новички начнут долго разбираться в проекте. А документацию никто писать не любит, плюс понятная документация — это трудно. А если существует часть проекта и его требуется ретроспективно задокументировать? Это уже задачка со звездочкой. В нашем кейсе проблемы подсветили новые коллеги — оказалось, что порог входа в проект очень высокий.
**Что можно сделать:**
* Закоммититься на определенную структуру проекта.
* Явно разделить функционал для общего использования и частного процесса.
* Описать базовые классы того, что ожидается от фичи.
* Начать вести документацию.
* Придумать нейминг.
Первым делом мы выделили «ядро» проекта. Это центральная часть, которая часто переиспользуется и должна быть написана наиболее качественно. Провели глубокий рефакторинг этой части, определили базовые структуры для того, чтобы унифицировать разрабатываемые модули. Ввели понятную структуру в проекте для поддержки ETL-процессов, завязались на нашу архитектуру DWH (raw-, ods-, dds-, cdm-слои), и поиск нужных файлов свелся к логическим единицам — источник и таблица.
Пример структуры для источника#### Кейс 2. Помоги себе сам
Больше человек в команде — больше работы с чужим кодом. Python часто используют для маленьких скриптов, где требования к коду ниже, так как сам скрипт легко влезает на экран. В большом проекте нужно писать код так, чтобы другой человек смог легко в нем разобраться.
Спор о необходимости типизации в Python**Проблемы:**
* IDE не подсказывает методы класса.
* Передал аргументы не того типа.
* Нейминг функций/методов/переменных не всегда помогает.
Типизация помогает понять, что ожидает функция или метод, IDE может подсказать атрибуты и методы. А линтеры автоматически проверят эти ожидания. Мы также определили базовые классы как стандарт написания ETL. Поддержка интерфейса классов позволяет быстрее ориентироваться в чужом коде.
**Что можно сделать:**
* Прописать типы.
* Определить интерфейс ответа функции/метода.
* Подготовить базовые классы.
* Настроить линтеры и хуки.
Функция с типизацией и базовым классом#### Кейс 3. Сложная схема зависимостей
В большом проекте возникает соблазн притянуть импорты из другого модуля и быстро решить проблему. Но подход может привести к тому, что возникнут сложные зависимости, которые будет сложно дебажить.
**Проблемы:**
* Всегда нужно деплоить проект целиком.
* Трудно вынести часть проекта в отдельную библиотеку.
* Пакеты зависят друг от друга циклически для разных файлов.
Здесь помогает регулярный рефакторинг, когда нужно пересматривать актуальность текущего кода после изменения требований. Как вариант разрыва зависимостей — определение объектов для передачи в функцию/метод/класс.
**Что можно сделать:**
* Переразбить проект на пакеты.
* Провести код-ревью и груминг.
* Заложить время на рефакторинг.
Можете ли вы позволить себе оформить часть проекта как отдельную библиотеку?#### Кейс 4. А у меня локально запускается
Одна из частых проблем — запуск в разных средах и локальное тестирование. Существует риск, что среда будет отличаться от продакшена при тесте. А это может привести к непредсказуемым ошибкам.
**Проблемы:**
* Разное поведение локально и на проде.
* Неправильные подсказки от IDE.
Здесь спасает Docker. Все тесты и проверки работы приложения нужно тестировать в виртуальной сред, соответствующей проду.
**Что можно сделать:**
* Сделать отдельное виртуальное окружение для проекта;
* Запускать тесты только в Docker.
Вам тоже выдали новый MacBook с M1?### Я пролистал текст, о чем он был?
Изначально простой и маленький проект вырос в сложный, с которым работает много разработчиков. Стандарты работы с этой кодовой базой постоянно эволюционировали. А про те кейсы, которые задели струны в моей душе, я написал выше.
**Главное, что стоит держать в голове, начиная большой проект на Python:**
* Промышленная разработка на Python — это сложно.
* IDE ваш друг, используйте возможности по максимуму.
* Есть много рекомендаций по тому, как писать код — лучше их изучить.
* Не поскупитесь на автоматизацию, линтеры, хуки, документацию.
В итоге задача разработчика — знать о разных практиках, уметь оценить полезность для вашего конкретного проекта и иметь волю по их внедрению при необходимости. Даже если вы пишете на Python.
 | https://habr.com/ru/post/706842/ | null | ru | null |
# Использование инерциальной навигационной системы (ИНС) с несколькими датчиками на примере задачи стабилизации высоты квадрокоптера
В данной статье я постараюсь рассказать о своем опыте создания и реализации алгоритма для обработки сигналов с нескольких стандартных датчиков, входящих в состав ИНС (в английской версии IMU), для решения задачи стабилизации высоты многороторного летательного аппарата (в моем случае — квадрокоптера). На хабре уже был [ряд статей](http://habrahabr.ru/blogs/DIY/120266/), описывающих, что это за игрушка и как её сделать самому. Как программисту по профессии, мне было интересно не только его собрать, но и поковыряться в «мозгах» и сделать что-то полезное для сообщества. В качестве «мозгов» я выбрал Arduino и замечательный проект [MultiWii](http://www.multiwii.com/). Он полностью открытый, динамично развивается, но в нем пока есть «белые пятна». Например, неудовлетворительно работает стабилизация положения по высоте. И я решил разобраться, можно ли с имеющимся оборудованием улучшить эту часть системы.
Для начала немного вводной информации, чтобы прояснить, с чем предстоит иметь дело.
Мультиротор — аппарат с несколькими (3, 4, 6, 8) моторами с пропеллерами, каждый из которых создает вертикальную регулируемую тягу. В отличие от вертолета, стабилизация тут полностью электронная, и занимается ей микропроцессор при помощи ИНС (полетный контроллер).
#### Какие задачи необходимо решать в полете?
* Определение ориентации (углов по трем осям относительно земли) и стабилизация по ним
* Определение высоты и стабилизация по ней
* Определение координат и полет по заданным точкам
* Прием команд с пульта управления и выдача управляющих сигналов на моторы
#### Что мы имеем в распоряжении?
На данный момент в легкой доступности имеем стандартный набор сенсоров:
* довольно хорошие 3-х осевые гироскопы.
* средние по качеству 3-х осевые акселерометры
* средний по качеству 3-х осевой магнетометр
* средний или плохой барометр
Такой набор в сборе с Arduino-подобным процессором или в виде отдельной платки можно найти за сумму 70-100$
У каждого датчика свои возможности и слабые стороны. По отдельности ни один из них не может решить ни одну и перечисленных выше задач, поэтому системы ИНС всегда строятся из комбинации датчиков, и самое интересное тут — это вычислительные алгоритмы, позволяющие соединить сильные стороны каждого из датчиков для устранения их недостатков.
Первая задача — стабилизация ориентации — довольно успешно решается гироскопами. Гироскопы очень точно меряют угловую скорость и после интегрирования можно получить углы. Но у них есть проблема — показания уплывают со временем. Для коррекции этого дрифта применяется акселерометр, который всегда (ну или почти всегда в долгосрочной перспективе) знает, где земля. Но акселерометр ничего не почувствует, если его крутить вокруг оси Z, поэтому нам нужен магнетометр, который всегда знает, где север.
Вторая задача — нахождение высоты — частично решается барометром. Если обнулить показания на земле, то при подъеме на каждый метр мы знаем, насколько изменятся его показания (естественно, если мы не летаем 12 часов и не начала меняться погода). Но по условию задачи барометр у нас плохой, и он выдает высоту +-1м с диким шумом амплитудой примерно в этих же пределах. В реальности мой датчик показывает следующее (на 10-й секунде перемещен на 1метр):

На помощь барометру может прийти сонар, который меряет высоту с очень высокой точностью (даже тот, что я приобрел за 5$, выдает точность ± 3мм по заявлению производителя). Но сонар способен работать только невысоко над землей (2-10м), меряет долго (до 200мс), чувствителен к качеству поверхности, к углу наклона, и может терять сигнал.
Третья задача — определение координат — не решается никак указанными выше датчиками. Акселерометр в комбинации с гироскопом может выдать линейные горизонтальные ускорения, но тут есть две проблемы: постоянно действующий огромный (по сравнению с тем, что будем измерять) вектор 1G, и отсутствие привязок для коррекции. Так что определение координат остается прерогативой GPS-сенсора, и на высокую точность тут рассчитывать не приходится.
Во всех любительских полетных контроллерах задача нахождения ориентации решена хорошо и на ней останавливаться не буду. Задача довольно простая и расписана в интернете ([один](http://www.starlino.com/imu_guide.html), [два](http://habrahabr.ru/blogs/augmented_reality/118192/)). В MultiWii используется красивое решение без сложностей типа кватернионов и матриц DCM (не забываем, что считать все это будет простенький 16-Мегагерцовый процессор), на основе упрощений для малых углов и комплементарного фильтра.
Итак, ориентацию аппарата в пространстве мы знаем с высокой степенью точности. Теперь можно перейти к основной теме статьи, т. е. постараться улучшить результаты, которые выдает барометр (или сонар), чтобы их можно было скормить [ПИД-регулятору](http://ru.wikipedia.org/wiki/ПИД-регулятор). Для этого показания должны поступать без задержек, быть точными в короткой перспективе и не сильно уплывать со временем. *Тема ПИД-регуляторов заслуживает отдельного пристального изучения, так как он широко используются в системах управления процессами. Я рекомендую сначала ознакомиться с их определением, чтобы лучше понять рассуждения, изложенные ниже.*
#### Сглаживаем
Чем нам не подходят показания барометра в текущем виде? Ну во первых, сильная зашумленность сигнала будет вызывать лишние управляющие воздействия на моторы. Применив фильтр низких частот, мы уменьшим шум, но потеряем быстроту измерения. А это значит, что любые кратковременные возмущения останутся без внимания, резкие возмущения отработаются с большой задержкой, и самое главное, мы не получим дифференциальную составляющую (D) для ПИД-регулятора. А как следует из теории, регулятор без этой составляющей склонен к слабозатухающим осцилляциям вокруг целевой величины, что и наблюдается на практике.
#### Интегрируем
Хорошо, оставим барометр и возьмем акселерометр. Вроде все просто — из значения по оси Z вычтем константу 1G, получим линейное вертикальное ускорение. Дважды проинтегрируем его (фактически просуммируем в измерительном цикле) и получим скорость и относительное смещение. Для ПИД-регулятора это лакомые показатели, с ними можно построить хорошую динамическую модель. Но и тут не все так хорошо, как хотелось бы. Наклон аппарата вызовет изменение проекции вектора ускорения А на ось Z. Вибрации от мотора или изменение температуры могут вызвать «сдвиг» чувствительности, и наша константа 1G уже не будет соответствовать реальности. Но даже в случае идеально неподвижного аппарата и точно выставленной 1G, любой сенсор выдает шум. А ведь даже крохотная ошибка в течение десятка секунд двойного интегрирования вырастает до размера слона, и вот мы видим скорость 10м/с и высоту 20м (хотя от земли ещё даже не оторвались).
#### Комплементарный фильтр
Если объяснять по простому — этот фильтр применяется к двум величинам, измеряемых разными датчиками, и корректирует одну из них так, что она медленно стремится ко второй. В измерительном цикле фильтр реализуется простой формулой:
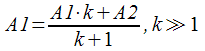
При этом влияние величины A2 на A1 пропорционально разнице между ними и определяется коэффициентом k (чем больше, тем слабее влияние).
Если применить этот фильтр к высоте, найденной акселерометром, и показаниям барометра, получится интересная штука: дрифт акселерометра будет постоянно корректироваться барометром, а показания барометра будут сглаживаться (так как для A2 этот фильтр работает как фильтр низких частот). Но корректироваться будет только второй интеграл, а первый по прежнему спокойно «дрейфовать» в бесконечность, и в итоге из-за малого коэффициента k барометр просто не сможет повлиять на ситуацию.
Почему этот фильтр прекрасно работает для пары гироскоп + акселерометр? Потому что там мы корректируем первый интеграл, и он в конце концов перестает «уплывать», когда величина коррекции за время одного цикла сравняется с величиной ошибки гироскопа, прибавляемой в этом же цикле при интегрировании.
#### ПИД-регулятор приходит на помощь
Но и из пары барометр+акселерометр можно извлечь нечто полезное, если применить к ним ПИД-регулятор (да-да, область их применения крайне обширна).
Итак, в чем главное слабое место нашего интегратора ускорения? В микро-ошибке, которая может возникнуть по разным причинам, описанным выше, при вычитании константы 1G. Если записать искомое ускорение в виде:
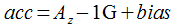
то, регулируя величину bias, можно управлять и первым интегралом (скоростью), и вторым (смещением). Итак, цель нашего ПИД-регулятора найдена. Но надо ещё знать ошибку. Сделаем допущение, что bias зафиксируется после наступлении некоей стабилизации параметров системы (температурных, вибрационных и т. д.). Когда bias будет найден, показания акселерометра станут очень близки к истине и можно применить комплементарный фильтр, скрестив их с барометром. Величина коррекции этого фильтра и будет ошибкой, от которой будет отталкиваться ПИД-регулятор (он стремится свести ошибку к 0 за счет регулирования целевой переменной).
Дальше находим все три составляющие ПИД-регулятора. Пропорциональная (P) — это сама ошибка. Интегральная (I) — просто интегрируем её. Дифференциальная (D) — по теории надо дифференцировать ошибку. Но в ней сидят ужасные шумы барометра и акселерометра. Такое дифференцировать страшно, поэтому применим хитрость — возьмем за D-составляющую найденную акселерометром скорость с отрицательным знаком. Так как D призвана ввести затухание в регулятор, скорость тут вполне сгодится — чем она больше, тем больше надо её «погасить».
Умножим каждый из компонентов на свои коэффициенты, сложим и получим bias. Но тут применим вторую хитрость — не будем прибавлять bias напрямую к ускорению, а прибавим только I-часть. Именно она описывает величину постоянно действующей ошибки, что соответствует нашему допущению о медленном изменении bias.
P и D части прибавим к скорости, умножив на dT (так как позаимствовали их из ускорения).
Так как основная задача регулятора — найти постоянную составляющую ошибки, я решил настроить его достаточно «мягко», чтобы по минимуму влиять на кратковременные изменения. Но тут остается широкое поле для экспериментов, и все буде определяться поведением реальных датчиков.
#### А как же гироскоп?
Выше я упомянул, что для определения высоты нам понадобится ещё и гироскоп. Действительно, описанный выше алгоритм будет работать, только если вектор A (в локальной системе) смотрит точно вдоль оси Z. Как только аппарат наклонится, произойдут две неприятные вещи: проекция A на ось Z изменится и ПИД-регулятор начнет заново медленно и мучительно искать bias. И вторая — любое горизонтальное ускорение начнет давать ненулевую проекцию на локальную ось Z. При углах наклона в 45° уже и не поймешь, где какое ускорение.
Но так как мы знаем точную ориентацию локальной системы относительно глобальной, нет ничего сложного восстановить справедливость — просто спроектируем локальный вектор A на локальный вектор G (изначально найденный акселерометром и заботливо вращаемый гироскопом), который всегда смотрит в землю.
Операция эта простая и вытекает из определения векторного произведения:
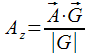
Сделать это надо до вычитания 1G.
Теперь можно посмотреть на код и результаты.
```
#define ACC_BARO_CMPF 300.0f
#define ACC_BARO_P 30.0f
#define ACC_BARO_I (ACC_BARO_P * 0.001f)
#define ACC_BARO_D (ACC_BARO_P * 0.001f)
#define VEL_SCALE ((1.0f — 1.0f/ACC_BARO_CMPF)/1000000.0f)
#define ACC_SCALE 9.80665f / acc_1G / 10000.0f
err = (alt - BaroAlt)/ACC_BARO_CMPF; // P term of error
errI+= err * ACC_BARO_I; // I term of error
accZ = (accADC[0]*EstG.V.X + accADC[1]*EstG.V.Y + accADC[2]*EstG.V.Z) *
InvSqrt(fsq(EstG.V.X) + fsq(EstG.V.Y) + fsq(EstG.V.Z))
- errI - acc_1G;
// Integrator - velocity, cm/sec
vel+= (accZ - err*ACC_BARO_P - vel*ACC_BARO_D) * cycleTime * ACC_SCALE;
// Integrator - altitude, cm
alt+= vel * cycleTime * VEL_SCALE;
// Apply ACC->BARO complementary filter
alt-= err;
errPrev = err;
```
Данные сенсоров приходят в следующих переменных:
EstG.V – вектор G (он получен ранее при нахождении ориентации)
accADC – чистые данные с акселерометра
BaroAlt – данные с барометра, конвертированные в cm
На выходе получаем accZ, vel, alt.
Как видно, вычислительная сложность алгоритма довольно простая и Arduino его «переварит» легко (особенно если перевести в целочисленную арифметику, но тогда код станет плохо читаем).
*PS: в видео есть фраза об отключении алгоритма при определенном угле наклона, и и-за этого возникает выброс ошибки. На самом деле это ограничение не нужно — алгоритм работает стабильно при любом угле от 0° до 360°*
Если к этому алгоритму подключить сонар (вмето BaroAlt взять SonarAlt), то кривая высоты выглядит практически идеально. Таким образом, на низкой высоте используем сонар, при появлении ошибок или близко к пределу измерений переключаемся на барометр (предварительно согласовав высоты в период поступления достоверных данных с сонара).
К сожалению, погода пока не дает провести полетные испытания нового алгоритма. Как только появятся результаты, выложу графики сонара, отлаженный исходный код всего проекта и полетное видео. | https://habr.com/ru/post/137595/ | null | ru | null |
# PocoCapsule: делаем «Hello world» проще
 Статья рассказывает об опыте знакомства с IoC-контейнером PocoCapsule (C++), возникших трудностях и способах их преодоления. Помимо прочего статья включает небольшой пример для быстрого старта с PocoCapsule (упрощенный проект [«Hello World» с официального сайта](http://www.pocomatic.com/docs/whitepapers/ioc-tutorial/)).
По моему скромному мнению технология IoC является важнейшей составляющей любого мало-мальски значимого проекта, посему правильное использование IoC-контейнера является критически важным. Поэтому, после знакомства с PocoCapsule, я решил написать эту статью. Не только ради того, чтобы поделиться своим опытом, но и для того, чтобы убедиться, что я все правильно сделал и все правильно понял, поскольку, как известно, лучший способ понять что-либо — попытаться объяснить это другому человеку.
Для того, чтобы запустить «Hello world»-приложение c использованием PocoCapsule, мне потребовалось порядка 6 часов. Причем, периодически хотелось послать все ко всем чертям, т.к. руки опускаются, когда видишь сообщение «failure: null», хотя делаешь все по учебнику. При том, что аналогичный старт в Spring IoC занимает от силы минут 30-60.
[PocoCapsule](http://code.google.com/p/pococapsule/) это [IoC](http://ru.wikipedia.org/wiki/Обращение_контроля)-контейнер, который работает со стандартными C++ объектами (POCO) и делает это он достаточно хитро. PocoCapsule не может, прочитав xml-файл конфигурации, напрямую создать требуемые POCO-объекты, т.к. в C++ отсутствуем механизм рефлексии.
Например, есть класс Foo:
> `class Foo {
>
> public:
>
> Foo() {};
>
> ~Foo() {};
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
и xml-конфигурация контейнера:
> `class="Foo"
>
> destroy-method="delete"
>
> lazy-init="false">
>
>
>
>
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Прочитав xml-конфигурацию, PocoCapsule должен создать объект класса Foo. Но как это сделать? Ведь PocoCapsule не зависит от ваших исходников и не может знать что это за класс такой Foo и как с ним обращаться, поэтому, естественно, он не может напрямую создать объект этого класса.
Для решения этой проблемы PocoCapsule генерирует для каждого вашего класса прокси-методы — методы, которые занимаются непосредственно работой с вашими классами (создание, удаление и пр.). Так, для вызова конструктора Foo будет сгенерирован метод:
> `// ---------------------------------------
>
> // Proxies of constructors and factories
>
> // ---------------------------------------
>
> //
>
> // new Foo()
>
> //
>
> static void\* \_poco\_proxy\_0(void\* \_poco\_this, void\* \_poco\_params[])
>
> {
>
> Foo\* \_poco\_var\_retv;
>
>
>
> \_poco\_var\_retv = new Foo();
>
>
>
> return (void\*)\_poco\_var\_retv;
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Для удаления соответственно:
> `// -------------------------------------
>
> // Proxies of dup and destroy methods
>
> // -------------------------------------
>
> //
>
> // delete(Foo\*)
>
> //
>
> static void\* \_poco\_proxy\_1(void\* \_poco\_this, void\* \_poco\_params[])
>
> {
>
> int \_poco\_i = 0;
>
> Foo\* \_poco\_var\_0 = (Foo\*)(\_poco\_params[\_poco\_i++]);
>
>
>
> delete(
>
> \_poco\_var\_0);
>
>
>
> return (void\*)0UL;
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Затем также генерируются методы регистрации этих «poco\_proxy» в контейнере. В конце концов эти прокси-методы обеъдиняются в общем исходном файле, который подключается к проекту и является связующим звеном между вашими классами и PocoCapsule.
**Проблемы с оригинальным «Hello word».** (Окружение Ubuntu 10.04 LTS)
Опишу по порядку проблемы, с которыми я столкунлся при знакомстве с PocoCapsule и которые отняли у меня так много времени.
1. После распаковки [бинарников](http://pococapsule.googlecode.com/files/pococapsule-cpp-1.0-Linux-x86-Install) генератор прокси не запускается (bin/pxgenproxy). Имеем следующее:
```
caiiiycuk@caiiiycuk-laptop:~/pococapsule-cpp/bin$ ./pxgenproxy
./pxgenproxy: undefined symbol: JNI_CreateJavaVM
```
При этом у меня установлено и JRE и JDK (pocoapsule использует Java для генерации прокси и не только).
Для решения этой проблемы необходимо установить переменную окружения POCOCAPSULE\_DIR=(папка с распакованным PocoCapsule). Очень старнно то, что данное требование нигде в документации не описанно. Предполагается, что должно работать из коробки, но у меня не пошло.
Правильный алгоритм:
> `caiiiycuk@caiiiycuk-laptop:~/pococapsule-cpp/bin$ export POCOCAPSULE\_DIR=/home/caiiiycuk/pococapsule-cpp/
>
> caiiiycuk@caiiiycuk-laptop:~/pococapsule-cpp/bin$ ./pxgenproxy
>
> ------------------------------------------------------------
>
> Pocomatic Software, Dynamic Proxy Generator, version 1.0
>
> ------------------------------------------------------------
>
>
>
> Usage:
>
>
>
> ./pxgenproxy (xml-file|option)\*
>
>
>
> options:
>
> -help : print this page
>
> -s=[name] : suffix and extend name of proxy file,
>
> default value is '\_reflx.cc'
>
> -H=[std-header-file] : use the specified standard header file
>
> -h=[usr-header-file] : use the specified user defined header file
>
> -r=[gather|scatte] : recursively step into imported resources and gather or scatte
>
> proxy generation result into one or multiple individual proxy file(s)
>
>
>
> caiiiycuk@caiiiycuk-laptop:~/pococapsule-cpp/bin$
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
2. При попытке поднять контекст ничего не происходит — получаем жизнерадостный null вместо контекста. Сделав все по [учебнику](http://pococapsule.googlecode.com/files/pococpp-iocdsm-dev-guide102.pdf) и запустив скомпилированный main.C, мы получаем «failure: null», поскольку cxtx == null:
> `/\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*/
>
> /\* \*/
>
> /\* Copyright 2006, by Pocomatic Software, LLC. All Rights Reserved. \*/
>
> /\* \*/
>
> /\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*/
>
> #include "pocoapp.h"
>
> #include
>
> #include <string.h>
>
>
>
> int main(int argc, char\*\* argv)
>
> {
>
> POCO\_AppEnv\* env = POCO\_AppContext::initDefaultAppEnv(argc, argv);
>
>
>
> POCO\_AppContext\* ctxt = POCO\_AppContext::create("setup.xml", "file");
>
>
>
> if( ctxt == NULL || !ctxt->initSingletons() ) {
>
> printf("failure: %s\n", env->get\_message());
>
> return -1;
>
> }
>
>
>
> ctxt->terminate();
>
> ctxt->destroy();
>
>
>
> return 0;
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
А причина все в том же «POCOCAPSULE\_DIR»: если перед запуском объявить эту перменную окружения, все начинает работать. Это связнано с тем, что для парсинга xml-файлов PocoCapsule использует по умолчанию JAXP. Sad but true :( Как вы понимаете, таскать с собой яву для парсинга xml-файлов не очень приятно… Благо есть два способа от нее отбиться: использовать нативыный xml-reader на базе Xerces-C++ или использовать encoded xml-дескрипторы. К сожалению, я пошел первым путем и это только добавило проблем. Всем рекомендую идти по второму пути.
3. PocoCapsule нативный xml-reader (libpocoxml.so) скомпилирован для Xerces-C++ версии 2.7, которая уже вышла из моды и нигде досатать ее не получится. Для решения этой проблемы качаем исходники pococapsule, устанавливаем xerces-c (dev) в систему, заходим в папочку pococapsule-cpp-1.1-src/src/xmlreader и выполняем make. После успешной компиляции забираем годный libpocoxml.so из папочки lib.
4. PocoCapsule игнорирует наше желание использовать Xerces-C++ (libpocoxml.so) и по-прежнему требует JAXP (libpocoxsl.so). Учебник нам говорит о том, что если мы подключим libpocoxml.so к нашему проекту, то PocoCapsule автоматически будет его использлвать вместо libpocoxsl.so. Да это так — на моем «Hello word»-проекте сроботало. Но в другом (более сложном) проекте, в котором подключены еще и другие библиотеки, подключение libpocoxml.so не дает эффекта — проект упорно требует libpocoxsl.so. После безуспешных танцев с бубном, я тупо перименовал libpocoxml.so в libpocoxsl.so и все заработало.
Помимо прочего, «Hello World»-проект по учебнику подразумевает динамическую линковку. Я считаю, что можно сделать гораздо проще для нужд знакомства-то.
**Простейший «Hello World»**
Для разработки я использую Ubuntu 10.04 LTS и [Netbeans 6.8](http://netbeans.org/downloads/index.html), а так же бинарники PocoCapsule 1.0.
1. Создаем новый C++ проект. Подключаем заголовочные файлы (Project properties->Build->С++ Сompiler->Include directories: pococapsule\_dir/include). Указываем линкеру где иcкать libpococapsule.so (Project properties->Build->Linker->Libraries: pococapsule\_dir/lib/libpococapsule.so).
2. Создадим класс Foo (Foo.h):
> `#ifndef \_FOO\_H
>
> #define \_FOO\_H
>
>
>
> #include
>
>
>
> class Foo {
>
> public:
>
> Foo() {
>
> std::cout << "Hello world!" << std::endl;
>
> }
>
> };
>
>
>
> #endif /\* \_FOO\_H \*/
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
3. Создадим xml-контекст (context.xml):
> `xml version=<font color="#A31515""1.0" encoding="iso-8859-1"?>
>
>
> SYSTEM "http://www.pocomatic.com/poco-application-context.dtd">
>
>
>
> class="Foo"
>
> destroy-method="delete"
>
> lazy-init="false">
>
>
>
>
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
4. Сгенерируем proxy-методы для нашего класса Foo. Откроем консоль в директории проекта и выполним:
> `export POCOCAPSULE\_DIR=(директория PocoCapsule)
>
> $POCOCAPSULE\_DIR/bin/pxgenproxy -h=Foo.h context.xml
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
После успешной генерации повяится файл context\_reflx.cc, добавим этот файл в проект, чтобы NetBeans его билдил (Sources Files->Add Exsisting Item). Проверим, что все успешно билдится.
5. Закодируем xml-контекст, чтобы избавиться от JAXP. Откроем консоль в директории проекта и выполним:
> `export POCOCAPSULE\_DIR=(директория PocoCapsule)
>
> $POCOCAPSULE\_DIR/bin/pxencode context.xml
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
На выходе получим context\_poco.ctx.
6. Отредактируем main.cpp:
> `#include "pocoapp.h"
>
> #include
>
> #include <string.h>
>
>
>
> int main(int argc, char\*\* argv)
>
> {
>
> POCO\_AppEnv\* env = POCO\_AppContext::initDefaultAppEnv(argc, argv);
>
>
>
> POCO\_AppContext\* ctxt = POCO\_AppContext::create("context\_poco.ctx", "file");
>
>
>
> if( ctxt == NULL || !ctxt->initSingletons() ) {
>
> printf("failure: %s\n", env->get\_message());
>
> return -1;
>
> }
>
>
>
> ctxt->terminate();
>
> ctxt->destroy();
>
>
>
> return 0;
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Запустив увидем «Hello World!»
Вот и все :)
Спасибо за внимание. | https://habr.com/ru/post/93081/ | null | ru | null |
# Удобное использование Redux в vue-компонентах
Недавно перешел с [PolymerJS](https://www.polymer-project.org/) на [VueJS](https://ru.vuejs.org/index.html) для некоторых задач. Совместно с *polymer* использовал [Redux](http://redux.js.org/dops/introduction/) через библиотеку [polymer-redux](https://github.com/tur-nr/polymer-redux). Поэтому вся бизнес-логика уже была сформирована на уровне *redux store*. Для связки *vue* и *redux* выбрал библиотеку [vuedeux](https://github.com/Vuedeux/vuedeux). В [awesome vue](https://github.com/vuejs/awesome-vue) в разделе [redux](https://github.com/vuejs/awesome-vue#redux) представлена еще одна библиотека для связки с redux — [revue](https://github.com/revue/revue), но мне показалось эффективней использовать именно *vuedeux*, за счет интеграции *redux store* непосредственно в *«свой redux»* для *vue* — [vuex](https://vuex.vuejs.org/ru/intro.html), для возможного использования его в будущем.
После создание *vuex store*, используя плагин [vuedeux](https://github.com/Vuedeux/vuedeux#inserting-the-plugin-into-a-vuex-store) доступ к необходимым разделам *redux store* может быть осуществлен через *computed* свойства экземпляра *vue*-компонента. Например, вот так (часть кода [из examples](https://github.com/Vuedeux/vuedeux/tree/master/examples/TodoMVC)):
```
...
computed: {
todos () {
return this.$store.state.redux.todos
},
...
}
...
```
А *action creators* попадают в экземпляр компонента через раздел *data*, [например](https://github.com/Vuedeux/vuedeux/blob/master/examples/TodoMVC/app.js):
```
new Vue({
...
data: {
reduxActions: actionCreators,
},
...
});
```
Диспатчить экшены можно, например, так:
```
methods: {
addTodo () {
this.$store.dispatch(this.$root.reduxActions.addingTodo(text))
},
...
}
```
Остальные *action creators* можно «прокинуть» напрямую в раздел *methods*:
```
methods: {
...mapActions({
toggleAll: 'COMPLETE_ALL',
clearCompleted: 'CLEAR_COMPLETED'
}),
...
}
```
Но как по мне это не очень удобно для использования, так как все *action creators* будут в корне контекста экземпляра компонента. И при их использовании будет не совсем понятно этот метод диспатчит экшен или просто выполняет какие-либо внутренние действия компонента. А хотелось бы сразу понимать, что данный метод является *action creators*.
Для этих целей я разработал [миксин](https://learn.javascript.ru/mixins) [redux-store-mixin](https://github.com/kolesoffac/redux-store-mixin) для интеграции с *redux actions* через единую точку входа в виде метода reduxActions *aka* метод *dispatch* из вышеупомянутой библиотеки [polymer-redux](https://github.com/tur-nr/polymer-redux).
### Использование
Подключаем сам миксин:
```
import reduxStoreMixin from "redux-store-mixin";
```
Подключаем свои *action creators*:
```
import {actionCreators} from "store/store";
```
И подключаем метод mapState из vuex для удобного «прокидывания» необходимых свойств из *redux store*:
```
import { mapState } from "vuex";
```
И создаем экземпляр *vue*-компонента с миксином и необходимыми свойствами:
```
new Vue({
mixins: [
...
reduxStoreMixin(actionCreators),
...
],
computed: {
...mapState({
prop1: state => state.redux.map.prop1,
...
propN: state => state.redux.map.propN
}),
...
},
...
});
```
После этого вызов экшена будет выглядеть следующим образом:
```
this.reduxActions(, ...args);
```
где *name action creator* — наименование *«action creator»*-функции,
*...args* — перечень аргументов для ее вызова.
Всю прелесть данного метода особенно прочувствуют те, кто пользовался библиотекой [polymer-redux](https://github.com/tur-nr/polymer-redux).
### Заключение
Подобные миксины уже существует, например: [Vue-Redux-Mixin-Generator](https://github.com/seanpar203/Vue-Redux-Mixin-Generator) и [vue-redux-mixin](https://github.com/exah/vue-redux-mixin). Но по сравнению с ними мое решение имеет более простую настройку и более наглядно в использовании, с учетом, что интеграция *vue* и *redux* будет осуществлена через [vuedeux](https://github.com/Vuedeux/vuedeux).
[GitHub](https://github.com/kolesoffac/redux-store-mixin)
**UPD:**Сделал фикс для возможности работы с [redux-wait-for-action](https://github.com/Chion82/redux-wait-for-action). Так же для этих целей пришлось пофиксить и [vuedeux](https://github.com/kolesoffac/vuedeux), пока форкнутая версия, но PR отправил, ждемс. | https://habr.com/ru/post/336352/ | null | ru | null |
# Директивы в Angularjs для начинающих. Часть 1
На мой взгляд, директивы являются основной изюминкой декларативного стиля Angularjs. Однако, если открыть комментарии пользователей в разделе официальной документации Angularjs, [посвященной директивам](http://docs.angularjs.org/guide/directive), то вы увидите, что [самый популярный из них](http://docs.angularjs.org/guide/directive#comment-838089804): «Пожалуйста, перепишите документацию, сделайте ее более доступной и структурированной. Начинающему разработчику на Angularjs сложно в ней разобраться» («Please rewrite a clearer well structured documentation of directives., this is not friendly to first time angular developers»). С этим трудно не согласится, документация пока еще сыровата и в некоторых моментах приходится прилагать большие усилия, чтобы разобраться в логике и сути функционала. Поэтому я предлагаю вам свой вольный пересказ данной главы в надежде, что кому-то это позволит сэкономить время, а так же рассчитываю на вашу поддержку и участие в комментариях. Итак, поехали!
#### Как писать директивы?
Директивы в Angularjs задаются вместе с другими конфигурациями модуля следующим образом:
```
angular.module('moduleName', [])
.directive('directiveName', function () {
/*Метод-фабрика для директивы*/
})
.directive('anotherDirectiveName', function () {
/*Метод-фабрика для директивы*/
});
```
При этом есть два варианта их объявления. Простой и более мощный длинный варианты.
#### Простой вариант создания директивы
Для того, чтобы написать директиву, которая будет вызываться при указании в HTML разметке, в простейшем случае вам нужно задать некую функцию (она называется Связующей *Linking*, но об этом чуть позже), возвращаемую фабрикой:
```
angular.module('moduleName', [])
.directive('directiveName', function () {
return function(scope,element,attrs){
}
});
```
Эта функция принимает следующие параметры:
* scope — область видимости, в которой вызывается директива
* element — элемент DOM, которому принадлежит директива, [обернутый в jQuery Lite](http://docs.angularjs.org/api/angular.element)
* attrs — объект со списком всех атрибутов тэга, в котором вызывается директива
Давайте на более развернутом примере. Напишем такую директиву (назовем **habra-habr**), которая будет складывать две строчки и выводить внутри элемента верстки, в котором вызывается. При этом одну строчку мы будем задавать в качестве переменной контролера(**forExampleController**), а вторую передавать атрибутом(**habra**) в этом же тэге. А также оставим за собой возможность определять имя переменной контролера при вызове директивы:
[[jsFiddle](http://jsfiddle.net/XtUdT/)]
```
```
```
function forExampleController($scope) {
$scope.word="Habrahabra"
}
angular.module('helloHabrahabr', [])
.directive('habraHabr', function() {
return function($scope, element, attrs) {
/*Задаем функцию, которая будет вызываться при изменении переменной word, ее имя находится в attrs.habraHabr*/
$scope.$watch(attrs.habraHabr,function(value){
element.text(value+attrs.habra);
});
}
});
```
Всё. Директива в примитивном виде у нас готова. Можно переходить к более развернутой форме.
#### Развернутый вариант
В своей полноценной форме задание директивы выглядит следующим образом:
```
angular.module('moduleName', [])
.directive('directiveName', function () {
return {
compile: function compile(temaplateElement, templateAttrs) {
return {
pre: function (scope, element, attrs) {
},
post: function(scope, element, attrs) {
}
}
},
link: function (scope, element, attrs) {
},
priority: 0,
terminal:false,
template: '',
templateUrl: 'template.html',
replace: false,
transclude: false,
restrict: 'A',
scope: false,
controller: function ($scope, $element, $attrs, $transclude, otherInjectables) {
}
}
});
```
Все эти свойства довольно тесно друг с другом связаны и переплетены. И для того, чтобы было проще в этом разобраться, их лучше рассматривать некими смысловыми группами.
##### Link и Compile
Метод Link это та самая функция, которую возвращала фабрика директивы в короткой версии. Здесь надо понять, что в Angularjs процесс компиляции разбит на два этапа:
* compile — анализ всех директив используемых в данном элементе DOM ( в том числе и в его потомках *child*)
* linking — связывание переменных используемых в шаблоне и переменных в scope
И при этом как в простейшей версии, так и в расширенной метод Link правильно будет называть **postLink**, поскольку он выполняется после того, как переменные уже сопоставлены. Рассмотрим примеры.
Сперва, я предлагаю переписать пример простой директивы на манер расширенной.
[[jsFiddle](http://jsfiddle.net/jx9mz/)]
```
angular.module('helloHabrahabr', [])
.directive('habraHabr', function() {
return {
link:function($scope, element, attrs) {
/*Задаем функцию, которая будет вызываться при изменении переменной word*/
$scope.$watch(attrs.habraHabr,function(value){
element.text(value+attrs.habra);
}
);
}
}
});
```
То есть всё, действительно, работает по-прежнему. Теперь можно усложнить задачу и сделать так, чтобы наша фраза выводилась не посредством прямого взаимодействия с DOM **element.text(...)**, а внутри директивы interpolate **"{{}}"**:
[[jsFiddle](http://jsfiddle.net/HQyyu/)]
```
angular.module('helloHabrahabr', [])
.directive('habraHabrNotwork', function() {
return {
link:function($scope, element, attrs) {
element.html("{{"+attrs.habraHabrWork+"}}"+attrs.habra+"");
}
}
})
.directive('habraHabrWork', function() {
return {
compile: function compile(templateElement, templateAttrs) {
templateElement.html("{{"+templateAttrs.habraHabrWork+"}}"+templateAttrs.habra+"");
},
link: function (scope, element, attrs) {
}
}
});
```
**Пример обновлен после [комментария](http://habrahabr.ru/post/179755/#comment_6250673) [tamtakoe](http://habrahabr.ru/users/tamtakoe/)**
В примере выше директива **habraHabrNotwork** не будет работать корректно, поскольку мы вставляем директиву "{{}}" с переменными в postLink, то есть, когда уже выполнены компиляця и линкование. Иными словами Angularjs даже не знает, что "{{}}" это директива, которая подлежит исполнению.
Другое дело, вторая директива. Там всё на своем месте, мы вставляем шаблон "{{"+attrs.habraHabrNotwork+"+"+attrs.habra+"}}" до компиляции, и он успешно проходит рендеринг.
Остановимся немного на методе **compile**. Он может возвращать, как функцию postLink, так и объект с двумя параметрами: pre и post. Где pre и post это методы preLink и postLink соответственно. Из названия методов может показаться, что речь идет о методах до и после *Link*а. Но это не совсем так, эти функции выполняются до и после *Link* а детей директивы в DOM. На примере:
[[jsFiddle](http://jsfiddle.net/KuUhN/)]
```
```
{{log}}
```
```
```
function forExampleController($scope) {
$scope.word="Habrahabra";
$scope.log="";
}
angular.module('helloHabrahabr', [])
.directive('habraHabrWork', function() {
return {
compile: function compile(templateElement, templateAttrs) {
templateElement.prepend("{{"+templateAttrs.habraHabrWork+"}}"+templateAttrs.habra+"");
return {
pre: function ($scope, element, attrs, controller) {
$scope.log+=templateAttrs.habra +' preLink \n';
},
post: function ($scope, element, attrs, controller) {
$scope.log+=templateAttrs.habra +' postLink \n';
}
}
}
}
});
```
На этом предлагаю сделать паузу. Если тема интересная, в ближайшие дни постараюсь написать продолжение про области видимости и шаблоны. | https://habr.com/ru/post/179755/ | null | ru | null |
# Что делать, если в PK Identity закончились значения?
Иногда, при дизайне БД разработчики недооценивают масштабы проекта. А потом, проект выстреливает и становится высоконагруженным. Затем, в какой-то момент, кто-то замечает, что в качестве первичного ключа большой таблицы выбран identity типа INT, с ограничением 2,147,483,647.
Изначально кажется, что 2 миллиарда записей – это много. Но если, у вас ежедневно добавляется 10 млн. новых записей? И уже израсходовано более 1 млрд. значений? У вас приложение, работающее в режиме 24/7? То у вас осталось всего 114 дней, чтобы это исправить тип первичного ключа. Это не так уж и много, если у вас используется значение ключа как в веб-приложении, так и в клиентском.

Если описанная ситуация вам знакома, и Вы заметили эту прискорбную деталь – у Вас заканчиваются значения первичного ключа – слишком поздно, то данная статья – для Вас. В статье Вы найдете скрипты, которые приведены для таблицы TableWithPKViolation, в которой поле TableWithPKViolationId вызывает проблему.
В худшем случае, Вы столкнулись с ошибкой “Arithmetic overflow error converting IDENTITY to data type int”. Это означает, что значения первичного ключа уже закончились, и Ваше приложение перестало работать. В данном случае Вы можете использовать следующие решения:
1. Поменять тип первичного ключа на BIGINT. Всем и каждому понятно, что лучший вариант — это сесть в машину времени и изменить INTна BIGINT там, в прошлом. Но Вы можете сделать это и сейчас, если поле TableWithPKViolationId не используется в серверном и клиентском приложении, то у вас есть возможность оперативно и безболезненно поменять тип. Сделайте это, и не тратьте время на остальную статью. Обратите внимание, что если в Вашей таблице больше 1 млрд. записей, то изменение будет применяться, т.е. может занять больше 3 часов, в зависимости от мощности вашего сервера, и потребует дополнительного места в логе транзакций (если можете, переключитесь на модель Recovery Mode в Simple). Скрипт для изменения следующий:
```
ALTER TABLE TableWithPKViolation ALTER COLUMN TableWithPKViolationId BIGINT;
```
Если данный способ Вам недоступен, необходимо запланировать переход ключа на BIGINT как можно быстрее.
2. Использовать отрицательные значения. Обычно, при использовании identity используется по умолчанию IDENTITY(1,1). Когда значение подходит к 2 миллиардам записей, Вы можете сделать сброс начального значения, используя следующую команду:
```
DBCC CHECKIDENT (TableWithPKViolation, - 2147483647, reseed)
```
и таким образом получить гораздо больше времени для перехода на BIGINT. Единственное неудобство данного решения – это отрицательные значения первичного ключа. Проверьте, что Ваша бизнес-логика допускает отрицательные значения. Пожалуй, это самое легкое решение.
3. III. Сформировать таблицу с неиспользованными значениями. Посчитайте значения, которые пропущены, и сформируйте таблицу со списком неиспользованных значений. Это даст Вам дополнительное время для перехода на BIGINT.
Данный способ Вам подойдет, если Вы не опираетесь на порядок записей в таблице, то есть не используете ORDERY BY Id. Либо мест, где есть такая сортировка не много, и Вы можете изменить сортировку на другое поле, например, на дате добавления записи.
Сформировать таблицу с неиспользованными значениями можно двумя способами:
**Способ А**. Пропущенные значения.
Когда вы используете Identity, у вас всегда есть пропущенные значения, так как, значения резервируются при начале транзакции, и, в случае ее отката, следующей транзакции присваивается новое, следующее за зарезервированным, значение первичного ключа. Зарезервированное значение, которое было сформировано для отмененной транзакции, так и останется неиспользованным. Данные неиспользованные значения можно сформировать в отдельную таблицу и применить, используя код, который будет приведен ниже.
**Способ В**. Удаленные значения.
Если Вы обычно удаляете записи из таблицы, в которой заканчиваются значения первичного ключа, то все удаленные значения можно использовать повторно в качестве свободных. Приведу пример кода для этого варианта ниже.
Исходная таблица TableWithPKViolation.
```
CREATE TABLE [dbo].[TableWithPKViolation](
[TableWithPKViolationId] [int] IDENTITY(1,1) NOT NULL
) ON [PRIMARY]
```
1. Создаем таблицу для хранение свободных ID
10-CreateNewId.sql
```
CREATE TABLE [dbo].[NewIds](
[NewId] [int] NOT NULL,
[DateUsedUtc] [datetime] NULL
) ON [PRIMARY]
```
Далее, в зависимости от способа:
Для генерации последовательности способом А. Пропущенные значения:
2. Генерируем последовательность из пропущенных идентификаторов
20-GenerateGaps.sql
«Option1 FindGaps\20-GenerateGaps.sql»
```
CREATE PROCEDURE [dbo].[spNewIDPopulateInsertFromGaps]
@batchsize INT = 10000,
@startFrom INT = NULL
AS
BEGIN
SET NOCOUNT ON;
SET XACT_ABORT ON;
IF @startFrom IS NULL
BEGIN
SELECT @startFrom = MAX([NewId])
FROM dbo.NewIds;
END;
DECLARE @startId INT = ISNULL(@startFrom,0);
DECLARE @rowscount INT = @batchsize;
DECLARE @maxId INT;
SELECT @maxId = MAX(TableWithPKViolationId)
FROM dbo.TableWithPKViolation;
WHILE @startId < @maxId
BEGIN
INSERT INTO dbo.NewIds
([NewId])
SELECT id
FROM (
SELECT TOP (@batchsize)
@startId + ROW_NUMBER()
OVER(ORDER BY TableWithPKViolationId) AS id
FROM dbo.TableWithPKViolation --any table where you have @batchsize rows
) AS genids
WHERE id < @maxId
AND NOT EXISTS
(
SELECT 1
FROM [dbo].[TableWithPKViolation] as Tb WITH (NOLOCK)
WHERE Tb.TableWithPKViolationId = genids.id
);
SET @rowscount = @@ROWCOUNT;
SET @startId = @startId + @batchsize;
PRINT CONVERT(VARCHAR(50),GETDATE(),121)+' '+ CAST(@startId AS VARCHAR(50));
END
END
```
Для генерации последовательности способом B Удаленные значения:
2. Создаем таблицу для генерации последовательности и заполняем ее данными от 1 до 2,147,483,647
15-CreateInt.sql
```
CREATE TABLE [dbo].[IntRange](
[Id] [int] NOT NULL
) ON [PRIMARY]
```
20-GenerateInt.sql
```
CREATE PROCEDURE [dbo].[spNewIDPopulateInsert]
@batchsize INT = 10000,
@startFrom INT = NULL
AS
BEGIN
SET NOCOUNT ON;
SET XACT_ABORT ON;
IF @startFrom IS NULL
BEGIN
SELECT @startFrom = MAX(id)
FROM dbo.IntRange;
END;
DECLARE @startId INT = ISNULL(@startFrom,0);
DECLARE @rowscount INT = @batchsize;
DECLARE @maxId INT = 2147483647;
WHILE @rowscount = @batchsize
BEGIN
INSERT INTO dbo.IntRange
(id)
SELECT id
FROM (
SELECT TOP (@batchsize)
@startId + ROW_NUMBER()
OVER(ORDER BY TableWithPKViolationId) AS id
FROM dbo.TableWithPKViolation --any table where you have @batchsize rows
) AS genids
WHERE id < @maxId;
SET @rowscount = @@ROWCOUNT;
SET @startId = @startId + @rowscount;
PRINT CONVERT(VARCHAR(50),GETDATE(),121)+' '+ CAST(@startId AS VARCHAR(50));
END
END
```
25-PopulateRange.sql
```
exec dbo.spNewIDPopulateInsert
@batchsize = 10000000
```
В скрипте используется таблица TableWithPKViolation для генерации последовательности, вы можете использовать любой способ для этого, в том числе, последовательность встроенную в MS SQL (Sequence). Данный способ был выбран, потому что работал быстрее по сравнению с другими.
30-CreateIndexOnInt.sql
```
ALTER TABLE [dbo].[IntRange] ADD PRIMARY KEY CLUSTERED
(
[Id] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = OFF) ON [PRIMARY]
```
и заполняем ее
50-GenerateNewId.sql
```
CREATE PROCEDURE [dbo].[spNewIDPopulateInsertFiltered]
@batchsize INT = 10000,
@startFrom INT = NULL,
@endTill INT = NULL
AS
BEGIN
SET NOCOUNT ON;
SET XACT_ABORT ON;
IF @startFrom IS NULL
BEGIN
SELECT @startFrom = MAX([NewId])
FROM dbo.NewIds;
END;
DECLARE @startId INT = ISNULL(@startFrom,0);
DECLARE @rowscount INT = @batchsize;
DECLARE @maxId INT = ISNULL(@endTill,2147483647);
DECLARE @endId INT = @startId + @batchsize;
WHILE @startId < @maxId
BEGIN
INSERT INTO [NewIds]
([NewId])
SELECT IR.id
FROM [dbo].[IntRange] AS IR
WHERE IR.id >= @startId
AND IR.id < @endId
AND NOT EXISTS
(
SELECT 1
FROM [dbo].[TableWithPKViolation] as Tb WITH (NOLOCK)
WHERE Tb.TableWithPKViolationId = IR.id
);
SET @rowscount = @@ROWCOUNT;
SET @startId = @endId;
SET @endId = @endId + @batchsize;
IF @endId > @maxId
SET @endId = @maxId;
PRINT CONVERT(VARCHAR(50),GETDATE(),121)+' '+ CAST(@startId AS VARCHAR(50));
END
END
```
55-ExecGeneration.sql
```
-----Run each part in separate window in parallel
-----
--part 1
exec dbo.spNewIDPopulateInsertFiltered @batchsize = 10000000,
@startFrom = 1, @endTill= 500000000
--end of part 1
--part 2
exec dbo.spNewIDPopulateInsertFiltered @batchsize = 10000000,
@startFrom = 500000000, @endTill= 1000000000
--end of part 2
--part 3
exec dbo.spNewIDPopulateInsertFiltered @batchsize = 10000000,
@startFrom = 1000000000, @endTill= 1500000000
--end of part 3
--part 4
DECLARE @maxId INT
SELECT @maxId = MAX(TableWithPKViolationId)
FROM dbo.TableWithPKViolation
exec dbo.spNewIDPopulateInsertFiltered @batchsize = 10000000,
@startFrom = 1500000000, @endTill= @maxId
--end of part 4
```
3. Таблица свободных идентификаторов, сгенерированная способом A или B готова. Создаем индексы на таблице со свободными ключами
60-CreateIndex.sql
```
ALTER TABLE [dbo].[NewIds] ADD CONSTRAINT [PK_NewIds] PRIMARY KEY CLUSTERED
(
[NewId] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
CREATE NONCLUSTERED INDEX [IX_NewIds_DateUsedUtc] ON [dbo].[NewIds]
(
[DateUsedUtc] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = OFF)
GO
ALTER TABLE [dbo].[NewIds] SET ( LOCK_ESCALATION = DISABLE )
GO
```
Проверяем, что все было правильно сгенерировано. Не должно быть ID в таблице NewId, которые есть в основной таблице TableWithPKViolation.
70-CheckData.sql
```
declare @maxId INT
select @maxId = max(TableWithPKViolationId)
from [dbo].[TableWithPKViolation]
IF EXISTS (select 1 from [dbo].[NewIds] WHERE [NewId] > @maxId)
BEGIN
PRINT 'PROBLEM. Wait for cleanup';
declare @batchsize INT = 10000
DECLARE @rowcount int = @batchsize;
while @rowcount = @batchsize
begin
delete top (@batchsize)
from [dbo].[NewIds]
where DFVId > @maxId;
SET @rowcount = @@rowcount;
end;
END
ELSE
PRINT 'OK';
```
Если вы генерируете последовательно на другом сервере (например на сервере с восстановленной резервной копией БД), то выгрузить данные в файл, можно с помощью скрипта:
80-BulkOut.sql
```
declare @command VARCHAR(4096),
@dbname VARCHAR(255),
@path VARCHAR(1024),
@filename VARCHAR(255),
@batchsize INT
SELECT @dbname = DB_NAME();
SET @path = 'D:\NewIds\';
SET @filename = 'NewIds-'+@dbname+'.txt';
SET @batchsize = 10000000;
SET @command = 'bcp "['+@dbname+'].dbo.NewIds" out "'+@path+@filename+'" -c -t, -S localhost -T -b '+CAST(@batchsize AS VARCHAR(255));
PRINT @command
exec master..xp_cmdshell @command
```
4. Создаем процедуру, которая помечает нужное количество доступный ID и возвращает их в результате
90-GetNewId.sql
```
create PROCEDURE [dbo].[spGetTableWithPKViolationIds]
@batchsize INT = 1
AS
BEGIN
SET NOCOUNT ON;
SET XACT_ABORT ON;
DECLARE @rowcount INT,
@now DATETIME = GETUTCDATE();
BEGIN TRAN
UPDATE TOP (@batchsize) dbo.NewIds
SET DateUsedUtc = @now
OUTPUT inserted.[NewId]
WHERE DateUsedUtc IS NULL;
SET @rowcount = @@ROWCOUNT;
IF @rowcount != @batchsize
BEGIN
DECLARE @msg NVARCHAR(2048);
SET @msg = 'TableWithPKViolationId out of ids. sp spGetTableWithPKViolationIds, table NewIds. '
+'Ids requested '
+ CAST(@batchsize AS NVARCHAR(255))
+ ', IDs available '
+ CAST(@rowcount AS NVARCHAR(255));
RAISERROR(@msg, 16,1);
ROLLBACK;
END
ELSE
BEGIN
COMMIT TRAN
END;
END
```
5. Добавляем во все процедуры, в которых была вставка данных, в таблицу и возвращался SCOPE\_IDENTITY(), вызов новой процедуры.
Если позволяет производительность или вам очень дорого время, а процедур нужно поменять много, можно сделать триггер instead of insert.
Вот, пример, как можно использовать процедуру для выдачи новых значений первичного ключа:
```
CREATE TABLE #tmp_Id (Id INT);
INSERT INTO #tmp_Id
EXEC spGetTableWithPKViolationIds @batchsize=@IDNumber;
SELECT @newVersionId = Id
FROM #tmp_Id;
SET IDENTITY_INSERT [dbo].[TableWithPKViolation] ON;
```
Обратите внимание, что для опции SET IDENTITY\_INSERT ON нужно, чтобы пользователь вызывающий процедуру имел разрешение на ALTER для таблицы TableWithPKViolation.
6. Затем можно настроить JOB, который будет очищать таблицу с используемыми идентификаторами
95-SPsCleanup.sql
```
create PROCEDURE dbo.spCleanupNewIds @batchSize INT = 4999
AS
BEGIN
SET NOCOUNT ON
DECLARE @minId INT
DECLARE @maxId INT
SELECT @minId = Min([NewId]), @maxId = MAX([NewId])
FROM dbo.NewIds WITH (NOLOCK)
WHERE DateUsedUtc IS NOT NULL;
DECLARE @totRowCount INT = 0
DECLARE @rowCount INT = @batchSize
WHILE @rowcount = @batchsize
BEGIN
DELETE TOP (@batchsize)
FROM dbo.NewIds
WHERE DateUsedUtc IS NOT NULL AND [NewId] >= @minId AND [NewId] <= @maxId
SET @rowcount = @@ROWCOUNT
SET @totRowCount = @totRowCount + @rowcount
END
PRINT 'Total records cleaned up - ' + CAST(@totRowCount AS VARCHAR(100))
END
```
JOB, который будет удалять использованные записи раз в сутки, не является обязательным. Если, Вы регулярно удаляете записи из основной таблицы, то Вы можете дополнять эту таблицу удаленными значениями.
Я бы все равно порекомендовала при этом запланировать переход на BIGINT.
Новые идентификаторы, конечно, будут выдаваться по нарастающей, однако, необходимо продумать логику сортировки новых идентификаторов таким образом, чтобы они шли после ранее выданных старых идентификаторов, даже если арифметические значение новых меньше.
Описанные в данной статье временные решения проблемы того, что значения первичного ключа внезапно закончились, помогают Вам выиграть время и поддержать систему в рабочем состоянии, пока Вы будете изменять систему и программу на новый тип данных.
Наилучшим решением является мониторинг пограничных значений и переход на соответствующие типы данных заранее.
[Архив с кодом](https://drive.google.com/file/d/0B2xL7TcM6ZSpcjRfSU51N25Dd0E/view?usp=sharing) | https://habr.com/ru/post/329506/ | null | ru | null |
# Проблема циклических зависимостей при инициализации типов
Некоторые из читателей, которые когда-либо сталкивались с проблемой, описанной в названии статьи, наверняка оставались на работе до поздна и проводили много часов в отладчике. Для других это может быть не более чем игрой слов и жаргонными словечками. Однако, давайте отойдем от жаргона в сторону и раскроем понятия:
* Инициализация типа: это код, который выполняется чтобы проинициализировать все статические переменные класса и выполнить статический конструктор;
* Циклическая зависимость: два кусочка кода, которые зависят друг от друга. В нашем случае это два класса, инициализация типов которых требует уже проинициализированного типа другого класса.
Ну и небольшой пример, чтобы показать, о чем идет речь:
```
using System;
class Test
{
static void Main()
{
Console.WriteLine(First.Beta);
}
}
class First
{
public static readonly int Alpha = 5;
public static readonly int Beta = Second.Gamma;
}
class Second
{
public static readonly int Gamma = First.Alpha;
}
```
**Результатом выполнения этого кода будет 0**
Конечно же, если не смотреть в спецификацию, то любые ожидания как это будет работать не более чем предположения. Потому посмотрим в спецификацию (section 10.5.5.1 of the C# 4 version ):
> The static field variable initializers of a class correspond to a sequence of assignments that are executed in the textual order in which they appear in the class declaration. If a static constructor (§10.12) exists in the class, execution of the static field initializers occurs immediately prior to executing that static constructor. Otherwise, the static field initializers are executed at an implementation-dependent time prior to the first use of a static field of that class.
Перевод:
> Порядок инициализации статических полей класса соответствует порядку их расположения в исходном тексте класса. Если в классе присутствует статический конструктор, выполнение кода инициализации статических полей класса располагается прямо перед вызовом статического конструктора. В противном случае, если статического конструктора не существует, инициализация статических полей выполняется в месте, зависящем от конкретной реализации: это происходит перед первым использованием статического поля.
В дополнение к спецификации языка, можно привести выдержку из спецификации `CLI`, которая раскрывает больше деталей о инициализации типов, особенно о циклических зависимостях и многопоточной работе. Однако, я не буду этого делать, а только напишу пару коротких выдержек:
* Гарантируется потокобезопасность при инициализации типов
* Если `CLI` замечает, что тип A необходимо проинициализировать и при этом он же находится в процессе инициализации в том же самом потоке, `CLI` продолжает работу таким образом, как будто тип A уже проинициализирован.
Итак, что бы могло случиться по вашему мнению:
1. Проинициализировать `Test`: никаких дальнейших действий не требуется
2. Начать выполнение `Main`
3. Начать инициализацию `First` (так как нам необходим `First.Beta`)
4. Установить `First.Alpha` в 5
5. Начать инициализацию `Second` (так как нам необходим `Second.Gamma`)
6. Установить `Second.Gamma` в `First.Alpha` (5)
7. Закончить инициализацию `Second`
8. Установить `First.Beta` в `Second.Gamma` (5)
9. Закончить инициализацию `First`
10. Напечатать «5»
А здесь описано то, что происходит в реальности — на моем компьютере, с установленным .Net Framework 4.5 beta (я знаю, что инициализация типов [была изменена в .NET 4](http://link:https://msmvps.com/blogs/jon_skeet/archive/2010/01/26/type-initialization-changes-in-net-4-0.aspx). Я не знаю, были ли изменения в .Net 4.5, но я не буду утверждать, что это не возможно)
1. Проинициализировать `Test`: никаких дальнейших действий не требуется
2. Начать выполнение `Main`
3. Начать инициализацию `First` (так как нам необходим `First.Beta`)
4. Начать иннициализацию `Second` (нам понадобится `Second.Gamma`)
5. Установить `Second.Gamma` в `First.Alpha` (0)
6. Закончить инициализацию `Second`
7. Установить `First.Alpha` в 5
8. Установить `First.Beta` в `Second.Gamma` (0)
9. Закончить инициализацию `First`
10. Напечатать 0
Шаг **(5)** очень интересен. Мы знаем, что нам необходимо проинициализировать `First` чтобы получить далее `First.Alpha`. Однако этот поток уже инициализирует `First`, потому мы пропускам инициализацию, надеясь что все в порядке. Однако в этой точке инициализации переменной еще не произошло. Упс…
(Существует одна тонкость, которая позволит избежать всех описанных проблем: использование ключевого слова const)
#### Назад в реальный мир
Надеюсь, мой пример прояснил для вас, почему использование циклических зависимостей при инициализации типов — дело которое вам сильно подпортит жизнь. Такие места очень трудно отлавливать и отлаживать. И по сути это классический [Гайзенбаг](http://ru.wikipedia.org/wiki/%D0%93%D0%B5%D0%B9%D0%B7%D0%B5%D0%BD%D0%B1%D0%B0%D0%B3). В нашем примере важно понимать, что если так случится что программа проинициализирует первым `Second` (например, чтобы получить доступ к другой переменной), то мы получим совершенно другой результат. И, на практике, можно получить такую ситуацию, когда запуск всех юнит-тестов приведет к тому что все они завалятся. Но если при этом запускать их по отдельности, они сработают (вполне возможно, кроме одного).
Один из путей, чтобы избегать подобных ситуаций — это отказаться от инициализации типов вообще. В большинстве случаев это как раз то что надо. Однако, обычно мы используем хорошо известные вещи. Такие как `**Encoding.Utf8**`, или `**TimeZoneInfo.Utc**`. Заметьте, что в обоих случаях это статические свойства, но мне кажется, они за собой несут использование статических полей. На первый взгляд кажется, что использование ``public static readonly` полей и public static get-only` свойств одинаково, однако, как мы увидим позже, использование свойств дает свои преимущества.
Моя библиотека **[Noda Time](http://code.google.com/p/noda-time/)** имеет несколько похожих на наш, моментов. И все потому что многие типы этой библиотеки *immutable*, т.е. неизменяемые. Это имеет смысл, когда необходимо создать свою временную зону `UTC`, или `ISO calendar system`. Причем в дополнении к публично-видимым значениям, мы имеем множество статических переменных, используемых внутри библиотеки (в основном для задач кэширования). Все это делает библиотеку сложнее и трудной для тестирования, однако бенефиты производительности в данном случае очень и очень значительные.
К сожалению, огромное количество этих полей и свойств имеют циклические зависимости. Как я упоминал ранее, когда мы добавляем новое статическое поле, это может привести к самым различным поломкам в программе. Я могу исправить непосредственную причину, однако это оставит во мне чувство обеспокоенности о целостности кода. Ведь если я устранил одну проблему, это не дает никаких гарантий что нет других.
#### Тестирование инициализации типов
Один из главных вопросов при инициализаии типов — это чувствительность к порядку инициализации в комбинации с гарантией того что тип в пределах `AppDomain` будет проинициализирован лишь однажды. Как я показал ранее, возможно, что при одном порядке инициализации это вызовет ошибку, а при каком-либо другом никакой ошибки не возникнет.
Для себя я решил что при разработке Noda Time, я хочу быть абсолютно уверенным что циклические зависимости не создадут для меня никаких проблем. Т.о. я хочу удостовериться что при инициализации типов не образуется циклов, причем независимо от того, в каком порядке они инициализируются. Если размышлять логически, мы можем определить циклическую зависимость, которая начинается с какого-то одного типа, начиная инициализацию с других типов, находящихся в этом же самом цикле. Я очень беспокоюсь чтобы не пропустить ни каких крайних случаев, и чтобы перебрать все варианты, которые возможны и не выпустить ничего из виду. Потому я применил метод грубой силы — полный перебор.
Вот наш грубый план:
* Начинаем с пустым списком зависимостей;
* Для каждого типа целевой сборки:
+ Создать новый AppDomain
+ Загрузить туда сборку
+ Инициализировать тип (выполнить над ним действие, чтобы запустить процесс инициализации)
+ Просмотреть Stack Trace от начала каждой инициализации типа и записать все зависимости.
* Просмотреть циклические зависимости в итоговом списке
Прошу заметить что у нас никогда не выйдет ситуации, когда мы сможем определить циклическую зависимость за одну загрузку домена приложения. Для этого необходимо обойти все типы и выявить циклы, анализируя результаты.
Описание того как работает код выйдет намного большим чем сам код и на самом деле он очень легок для понимания, так что я расположу его в конце статьи.
Это решение не является очень хорошим по нескольким причинам:
* Создание нового AppDomain и загрузка в него сборок из программы юнит-тестирования может оказаться не таким простым как могло бы быть. Мой код не корректно отрабатывает в связке с `NCrunch`.И я уверен, что если я это исправлю, остальные системы юнит-тестирования все равно будут ломать мою программу.
* Он основан на том, что каждый инициализатор типа будет содержать необходимую для работы системы строчку кода:
```
private static readonly int TypeInitializationChecking = NodaTime.Utility.TypeInitializationChecker.RecordInitializationStart();
```
* Плохо не только то что необходимо добавлять строку кода в каждый интересующий нас тип. Это плохо еще тем, что эта строчка будет вызываться каждый раз при инициализации типа. А также будет отбирать минимум 4 байта из кучи, а это очень плохо, если программа запущена не в режиме тестирования. Я, конечно, мог бы использовать директивы препроцессора для того чтобы убрать этот код из версии, не для тестирования. Но от этого код будет выглядеть еще более грязным;
* Этот метод находит циклические зависимости только для тех версий .Net, на которых были прогнаны тесты. Если учесть что существуют различия в различных версиях .Net Framework, я бы не был уверен в том что тесты покроют 100% ситауций. Аналогично, если мы сменим текущую CultureInfo, или любую другую, казалось бы, постояную, переменную окружения, тесты могут заработать совершенно иным образом.
* Также в данной реализации я не смотрю на ситуации, когда код многопоточен. Для таких ситуаций, я опять же, не уверен что это будет работать корректно.
И, учитывая все эти оговорки… Стоит ли это использовать? Однозначно, да. Эта методика помогла мне найти множество багов, которые были исправлены.
#### Исправление циклических зависимостей
В прошлом, я «исправлял» порядок инициализации типов просто перемещая по коду поля. Циклы все еще существовали, однако я вычислил как сделать их безвредными. Я могу сказать что этот подход не масштабируемый и стоит гораздо больших усилий чем кажется. Код становится трудным… И если вы однажды получите цикл в более чем из двух зависимостей, это будет задачка для ума, как сделать его безопасным. На данный момент я использую очень простую технику чтобы осущиствить отложенную инициализацию статических переменных.
Так что вместо того чтобы искать что за `static readonly field` создает вам циклическую зависимость, вы используете `static readonly property`, которое возвращает `internal static readonly field`, во вложенном, приватном статическом классе. Мы все еще имеем потоко-безопасную инициализацию с гарантией единичного вызова, однако `nested` тип не будет проинициализирован, пока в этом не появится нужда.
Таким образом, вместо этого:
```
// Requires Bar to be initialized - if Bar also requires Foo to be
// initialized, we have a problem...
public static readonly Foo SimpleFoo = new Foo(Bar.Zero);
```
Мы напишем:
```
public static readonly Foo SimpleFoo { get { return Constants.SimpleFoo; } }
private static class Constants
{
private static readonly int TypeInitializationChecking = NodaTime.Utility.TypeInitializationChecker.RecordInitializationStart();
// This requires both Foo and Bar to be initialized, but that's okay
// so long as neither of them require Foo.Constants to be initialized.
// (The unit test would spot that.)
internal static readonly Foo SimpleFoo = new Foo(Bar.Zero);
}
```
На данный момент я не могу определить, включать статические конструкторы в этих классах чтобы добиться ленивой инициализации или нет. Если инициализатор типа Foo вызовет инициализатор типа Foo.Constants, мы вернемся к исходной точке. Но добавление статических конструкторов в каждых из nested классов звучит ужасно.
#### Заключение
Я хочу вам сказать, что какая-то часть меня в реальности не любит писать тестирование кода или делать обходные пути и городить костыли. И определенно, стоит задуматься, можно ли на самом деле избавиться от инициализации типов (или его части), избегая хранения только в статических полях. Было бы совсем замечательно, если бы можно было найти все эти зависимости избегая запуска программы или юнит-тестов. Чтобы это можно было сделать при помощи статического анализатора. Когда у меня будет шанс, я попробую выяснить, может ли мне в этом помочь `NDepend`.
Тем не менее, в то время как этот подход выглядит как некоторое хакерство, он все же лучше чем альтернатива — код, полных ошибок. И… Мне стыдно сказать, но я не думаю что в `Noda Time` я нашел все циклические зависимости. Ее стоит опробовать на своем собственном коде — посмотрите, где у вас могут быть скрытые проблемы
#### Приложение: тестирующий код
##### TypeInitializationChecker
```
internal sealed class TypeInitializationChecker : MarshalByRefObject
{
private static List dependencies = null;
private static readonly MethodInfo EntryMethod = typeof(TypeInitializationChecker).GetMethod("FindDependencies");
internal static int RecordInitializationStart()
{
if (dependencies == null)
{
return 0;
}
Type previousType = null;
foreach (var frame in new StackTrace().GetFrames())
{
var method = frame.GetMethod();
if (method == EntryMethod)
{
break;
}
var declaringType = method.DeclaringType;
if (method == declaringType.TypeInitializer)
{
if (previousType != null)
{
dependencies.Add(new Dependency(declaringType, previousType));
}
previousType = declaringType;
}
}
return 0;
}
///
/// Invoked from the unit tests, this finds the dependency chain for a single type
/// by invoking its type initializer.
///
public Dependency[] FindDependencies(string name)
{
dependencies = new List();
Type type = typeof(TypeInitializationChecker).Assembly.GetType(name, true);
RuntimeHelpers.RunClassConstructor(type.TypeHandle);
return dependencies.ToArray();
}
///
/// A simple from/to tuple, which can be marshaled across AppDomains.
///
internal sealed class Dependency : MarshalByRefObject
{
public string From { get; private set; }
public string To { get; private set; }
internal Dependency(Type from, Type to)
{
From = from.FullName;
To = to.FullName;
}
}
}
```
##### TypeInitializationTest
```
[TestFixture]
public class TypeInitializationTest
{
[Test]
public void BuildInitializerLoops()
{
Assembly assembly = typeof(TypeInitializationChecker).Assembly;
var dependencies = new List();
// Test each type in a new AppDomain - we want to see what happens where each type is initialized first.
// Note: Namespace prefix check is present to get this to survive in test runners which
// inject extra types. (Seen with JetBrains.Profiler.Core.Instrumentation.DataOnStack.)
foreach (var type in assembly.GetTypes().Where(t => t.FullName.StartsWith("NodaTime")))
{
// Note: this won't be enough to load the assembly in all test runners. In particular, it fails in
// NCrunch at the moment.
AppDomainSetup setup = new AppDomainSetup { ApplicationBase = AppDomain.CurrentDomain.BaseDirectory };
AppDomain domain = AppDomain.CreateDomain("InitializationTest" + type.Name, AppDomain.CurrentDomain.Evidence, setup);
var helper = (TypeInitializationChecker)domain.CreateInstanceAndUnwrap(assembly.FullName,
typeof(TypeInitializationChecker).FullName);
dependencies.AddRange(helper.FindDependencies(type.FullName));
}
var lookup = dependencies.ToLookup(d => d.From, d => d.To);
// This is less efficient than it might be, but I'm aiming for simplicity: starting at each type
// which has a dependency, can we make a cycle?
// See Tarjan's Algorithm in Wikipedia for ways this could be made more efficient.
// http://en.wikipedia.org/wiki/Tarjan's\_strongly\_connected\_components\_algorithm
foreach (var group in lookup)
{
Stack path = new Stack();
CheckForCycles(group.Key, path, lookup);
}
}
private static void CheckForCycles(string next, Stack path, ILookup dependencyLookup)
{
if (path.Contains(next))
{
Assert.Fail("Type initializer cycle: {0}-{1}", string.Join("-", path.Reverse().ToArray()), next);
}
path.Push(next);
foreach (var candidate in dependencyLookup[next].Distinct())
{
CheckForCycles(candidate, path, dependencyLookup);
}
path.Pop();
}
}
```
 | https://habr.com/ru/post/143936/ | null | ru | null |
# Как создать кластер в JBoss AS 7.1 в автономном (standalone) режиме?
*Статья переведена и опубликована здесь с целью дополнить ее рецептом от себя, добытом на основе личного опыта. Есть надежда, что кто-то сэкономит полдня-день гугления и массу проб и ошибок, с которыми пришлось столкнуться мне. Далее следует вольный перевод и дополнение лично от меня. Основная решаемая задача: репликация сессий пользователей на все узлы кластера. За счет репликации сессий, в случае потери одного из узлов кластера балансировщик прозрачно для пользователя может переключить его на другой узел. Работа балансировщика выходит за рамки данного перевода и будет описана в следующей статье.*
JBoss AS 7 кардинально отличается от предыдущих версий JBoss, следовательно, если вы хотите создать кластер в JBoss AS 7, вам следует знать несколько вещей, чтобы не столкнуться с проблемами.
В JBoss AS 7 есть два режима: режим домена (**domain**) и автономный (**standalone**) режим, в этой статье мы расскажем о автономном режиме. В автономном режиме есть различные XML-файлы в папке конфигурации, но поддержка кластеризации включена только в **standalone-ha.xml** и **standalone-full-ha.xml**, поэтому убедитесь, что вы используете при старте один из них (см. ниже команду запуска).
##### Шаги для создания кластера в JBoss AS 7.1
После того как вы распаковали JBoss-как-7.1.1.Final.zip (от переводчика: проверено в версии 7.2.2), сделайте две копии папки standalone и переименуйте их, например, в **standalone-node1** и **standalone-node2**, как показано ниже:
1 Home/user/jboss-as-7.1.1.Final/standalone-node1
2 Home/user/jboss-as-7.1.1.Final/standalone-node2
**Примечание**: Убедитесь, что вы сохранили оригинальную копию папки **standalone** для возможного будущего использования.
Теперь вы должны запустить JBoss следующей командой, чтобы он работал как узел в кластере
**Node1**
./standalone.sh -c standalone-ha.xml -b 10.10.10.10 -u 230.0.0.4 -Djboss.server.base.dir=../standalone-node1 -Djboss.node.name=node1 -Djboss.socket.binding.port-offset=100
**Node2**
./standalone.sh -c standalone-ha.xml -b 10.10.10.10 -u 230.0.0.4 -Djboss.server.base.dir=../standalone-node2 -Djboss.node.name=node2 -Djboss.socket.binding.port-offset=200
Где:
-c = файл настроек сервера, который будет использоваться
-b = предназначен для указания адреса, который прослушивает JBoss
-u = групповой (multicast) адрес. (от переводчика: предполагается, что будет использоваться при объединение узлов в кластер, но с этим могут быть проблемы, см. ниже)
-Djboss.server.base.dir = путь к папке, в которой развернут узел
-Djboss.node.name = имя узла
-Djboss.socket.binding.port-offset = смещение по портам
**Примечание**: Обратите внимание на следующие вещи:
— Оба узла должны иметь одинаковый широковещательный адрес
— Оба узла должны иметь разные имена узлов
— В случае запуска на одном компьютере, оба узла должны иметь разные разное смещение по портам, во избежание конфликтов. Для одного из узлов параметр -Djboss.socket.binding.port-offset можно опустить, он запустится на портах по-умолчанию. Также этот параметр можно не использовать в случае запуска на разных компьютерах.
После запуска узлов в кластерной конфигурации вы не увидите никаких изменений. Чтобы убедиться в том, что оба узла объединились в кластер, вам нужно будет развернуть веб-приложение, которое имеет тег в web.xml. Вы можете скачать один из наших примеров кластерного приложения [здесь](https://github.com/jaysensharma/MiddlewareMagicDemos/blob/master/ClusterTest_WebApp/ClusterWebApp.war?raw=true).
После загрузки ClusterWebApp.war вы просто должны скопировать его в (/home/user/jboss-as-7.1.1.Final/standalone-nodeX/deployments) на обоих узлах, и сразу после этого вы увидите подобные сообщения:
**Лог JBoss**
```
18:32:46,863 INFO [stdout] (pool-13-thread-1) -------------------------------------------------------------------
18:32:46,863 INFO [stdout] (pool-13-thread-1) GMS: address=node1/web, cluster=web, physical address=10.10.10.10:55300
18:32:46,863 INFO [stdout] (pool-13-thread-1) -------------------------------------------------------------------
18:32:47,572 INFO [org.infinispan.configuration.cache.EvictionConfigurationBuilder] (MSC service thread 1-8) ISPN000152: Passivation configured without an eviction policy being selected. Only manually evicted entities will be pasivated.
18:32:47,581 INFO [org.infinispan.configuration.cache.EvictionConfigurationBuilder] (MSC service thread 1-1) ISPN000152: Passivation configured without an eviction policy being selected. Only manually evicted entities will be pasivated.
18:32:47,771 INFO [org.infinispan.remoting.transport.jgroups.JGroupsTransport] (pool-15-thread-1) ISPN000078: Starting JGroups Channel
18:32:47,791 INFO [org.infinispan.remoting.transport.jgroups.JGroupsTransport] (pool-15-thread-1) ISPN000094: Received new cluster view: [node1/web|1] [node1/web, node2/web]
```
##### От переводчика
Если дублировать папку JBoss целиком, а не только standalone, то можно не указывать параметр -Djboss.server.base.dir.
###### Несколько IP-адресов
В данной статье, и в большей части ресурсов в Сети не решается одна проблема. Многие (в т.ч. и я) при старте указывают параметр -b 0.0.0.0, который сообщает JBoss-у о том, что следует прослушивать все доступные сетевые интерфейсы. Это требуется если у вашего сервера, например, есть внешний и внутренний IP адреса, или требуется чтобы он был доступен также и по адресам по-умолчанию (например, localhost). Так вот, проблема в том, что jgroups, используемый JBoss-ом для объединения кластера отказывается работать если указан параметр -b 0.0.0.0. При старте узлов выводится сообщение:
```
GMS: address=node1/web, cluster=web, physical address=0.0.0.0:55200
```
а при попытке их объединения появляется ошибка:
```
[org.jgroups.protocols.UDP] (OOB-14,shared=udp) failed sending message to node2/web (117 bytes): java.lang.Exception: dest=/0.0.0.0:55500 (120 bytes), cause: java.net.BindException: Cannot assign requested address: Datagram send failed
```
Насколько я понял, jgroups требует конкретного IP-адреса, и отказывается работать с абстрактным 0.0.0.0, а параметр запуска -u 230.0.0.4 в этом случае просто игнорируется.
Судя по сообщениям на форумах, нет каких-либо других возможностей заставить JBoss прослушивать несколько адресов, кроме как указать параметр запуска -b 0.0.0.0. Можно в файле конфигурации standalone-ha.xml/standalone-full-ha.xml указать тэг для ``вместо` , но, как оказалось его действие аналогично параметру -b 0.0.0.0, т.е. кластер отказывается объединяться.
Долгий поиск по форумам дал в конце концов простое работающее решение: следует добавить параметр **-Djgroups.bind\_addr=IP-адрес**, чтобы указать jgroups по какому именно адресу ему объединяться. Если не уверены, осуществите запуск кластера без параметра -b 0.0.0.0, и в логе увидите какой адрес выберет jgroups, и сообщит об этом в логе. У меня под Windows я увидел следующее:
```
GMS: address=node1/web, cluster=web, physical address=127.0.0.1:55200
```
Соответственно, после этого возвращаем на место -b 0.0.0.0 и указываем в дополнение к нему -Djgroups.bind_addr=127.0.0.1.
###### Несколько кластеров в одной сети
Есть еще одна проблема: если кроме вашего кластера JBoss в той же сети доступны другие сервера/кластера JBoss 7, и на них развернуты distributable-приложения, то с высокой степенью вероятности "чужой" сервер подключится в ваш кластер. В предыдущих версиях проблема решалась путем указания уникального имени для каждого кластера. В 7-й версии этого нет, на форумах пишут о том, что теперь кластера следует разделять путем указания различных UDP адресов (параметр -u). Это обосновывается тем, что если идентифицировать группы серверов лишь на уровне их имен, то различные группы будут постоянно обрабатывать UDP-запросы от соседних групп, только для того, чтобы отвергнуть их. Указание же разных UPD адресов, насколько я понял, избавляет JBoss от обработки чужих запросов вообще.
UPD адрес по умолчанию для jgroups в конфигурации указан как 230.0.0.4, следует для разных групп серверов указать разные адреса групповой рассылки в параметре -u. Какой же адрес выбрать? [Википедия говорит](http://ru.wikipedia.org/wiki/Multicast) о том, что "*Технология IP Multicast использует адреса с 224.0.0.0 до 239.255.255.255*". При смене адреса по умолчанию, даже если он входит в этот диапазон, нет гарантии что кластер объединится, например, после указания адреса 230.0.0.**5**, мои два узла, работающие под Windows, перестали объединяться в кластер. Пара других адресов - 230.0.0.**3** и 23**1**.0.0.4 - прекрасно работают. Возможно, существуют средства для того, чтобы точно узнать какой адрес будет работать корректно, но я с ними незнаком, и мне, к сожалению, пришлось использовать метод "научного тыка".
С продолжением темы вы можете ознакомиться [в этой статье](http://habrahabr.ru/post/190196/).` | https://habr.com/ru/post/189588/ | null | ru | null |
# Просто и качественно определяем язык сообщений

У нас в компании [YouScan](http://youscan.io/) в день обрабатывается около 100 млн. сообщений, на которых применяется много правил и разных смарт-функций. Для корректной их работы нужно правильно определить язык, потому что не все функции можно сделать агностическими относительно языка. В данной статье мы коротко расскажем про наше исследование данной задачи и покажем оценку качества на датасете из соц. сетей.
#### План статьи
1. Проблемы определения языка
2. Доступные публичные решения
* Compact Language Detector 2
* FastText
3. Оценка качества
4. Выводы
1. Проблемы определения языка
-----------------------------
Определение языка достаточно старая проблема и многие ее пытаются решать в рамках мультиязычности своих продуктов. Более старые подходы используют решения основанные на н-граммах, когда считается к-во вхождений определенной н-граммы и на основе этого рассчитывается "скор" для каждого языка, после чего выбирается наиболее вероятный язык по нашей модели. Главный недостаток данных моделей в том, что абсолютно не учитывается контекст, поэтому определение языка для схожих языковых групп затрудняется. Но из-за простоты моделей мы получаем в итоге высокую скорость определения, что позволяет экономить ресурсы для высоконагруженных систем. Другой вариант, более современный, – решение на рекуррентных нейронных сетях. Данное решение уже строится не только на н-граммах, а и учитывает контекст, что должно дать прирост в качестве работы.
Сложность создания своего решения упирается в сбор данных для обучения и самом процессе обучения. Самый очевидный выход – обучить модель на статьях википедии, потому что мы точно знаем язык и там очень качественные проверенные тексты, которые относительно легко собрать. А для обучения своей модели нужно потратить достаточно много времени, чтобы собрать датасет, его обработать и потом выбрать лучшую архитектуру. Скорее всего кто-то уже сделал это раньше нас. В следующем блоке мы рассмотрим существующие решения.
2. Доступные публичные решения
------------------------------
### Compact Language Detector 2
[CLD2](https://github.com/CLD2Owners/cld2) – это вероятностная модель на основе машинного обучения (Наивный Баессовский классификатор), которая может определять 83 различных языка для текста в формате UTF-8 или html/xml. Для смешанных языков модель возвращает топ-3 языка, где вероятность расчитывается как приблизительный процент текста от общего числа байт. Если модель не уверена в своем ответе, то возвращает тег "unc".
Точность и полнота данной модели на достаточно хорошем уровне, но главное преимущество – это скорость. Создатели заявляют про 30кб в 1ms, на наших тестах питоновской обертки мы получили от 21 до 26кб в 1ms (70000-85000 сообщений в секунду, средний размер которых 0.8кб, а медиана – 0.3кб).
Данное решение очень простое в использовании. Для начала нужно установить его [питоновскую обертку](https://pypi.org/project/pycld2/) или воспользоваться [нашим докером](https://github.com/YouScan/language-identification-article).
Чтобы сделать прогноз, достаточно просто импортировать библиотеку `pycld2` и написать одну дополнительную строчку кода:
**Определение языка с помощью cld2**
```
import pycld2 as cld2
cld2.detect("Bonjour, Habr!")
# (True,
# 14,
# (('FRENCH', 'fr', 92, 1102.0),
# ('Unknown', 'un', 0, 0.0),
# ('Unknown', 'un', 0, 0.0)))
```
Ответ детектора – это tuple из трех элементов:
* определился язык или нет;
* к-во символов;
* tuple из трех наиболее вероятных языков, где на первом месте идет полное название,
на втором – сокращение по стандарту ISO 3166 Codes, на третьем – процент символов пренадлежащих данному языку, на четвертом – к-во байт.
### FastText
[FastText](https://github.com/facebookresearch/fastText) – это библиотека написанная фейсбуком для эффективного обучения и классификации текстов. В рамках данного проекта фейсбук ресерч представил эмбеддинги для 157 языков, которые показывают state-of-the-art результаты на разных задачах, а также модель для определения языка и другие супервайзд задачи.
Для [модели определения языка](https://fasttext.cc/docs/en/language-identification.html) они использовали данные Wikipedia, Tatoeba and SETimes, а в качестве классификатора – свое решение на фасттексте.
Разработчики фейсбук ресерч предоставляют две модели:
* [lid.176.bin](https://s3-us-west-1.amazonaws.com/fasttext-vectors/supervised_models/lid.176.bin), которая немного быстрее и точнее второй модели, но весит 128Мб;
* [lid.176.ftz](https://s3-us-west-1.amazonaws.com/fasttext-vectors/supervised_models/lid.176.ftz) – сжатая версия оригинальной модели.
Для использования этих моделей в питоне, сначала нужно установить [питоновскую обертку для фасттекста](https://github.com/vrasneur/pyfasttext). Могут возникнуть сложности по ее установке, поэтому нужно внимательно придерживаться инструкции на гитхабе или воспользоваться [нашим докером](https://github.com/YouScan/language-identification-article). А также необходимо скачать модель по вышеприведенной ссылке. Мы будем использовать оригинальную версию в данной статье.
Классифицировать язык с помощью модели от фейсбука немного сложнее, для этого нам понадобится уже три строки кода:
**Определение языка с помощью модели FastText**
```
from pyfasttext import FastText
model = FastText('../model/lid.176.bin')
model.predict_proba(["Bonjour, Habr!"], 3)
#[[('fr', 0.7602248429835308),
# ('en', 0.05550386696556002),
# ('ca', 0.04721488914800802)]]
```
Модель FastText'a позволяет предсказывать вероятность для n-языков, где по дефолту n=1, но в этом примере мы вывели результат для топ-3 языков. Для этой модели это уже общая вероятность предсказания языка для текста, а не к-во символов, которые пренадлежат определенному языку, как было в модели cld2. Скорость работы тоже достаточно высокая – больше 60000 сообщений в секунду.
3. Оценка качества
------------------
Оценивать качество работы алгоритмов будем на данных из соц.сетей за случайное время, взятых из системы [YouScan](https://youscan.io/) (приблизительно 500 тысяч упоминаний), поэтому в выборке будет больше русского и английского языков, 43% и 32% соответственно, украинского, испанского и португальского – около 2% каждого, из остальных языков меньше 1%. За правильный таргет мы будем брать разметку через google translate, так как на данный момент гугл очень хорошо справляется не только с переводом, а и с определением языка текстов. Конечно, его разметка неидеальна, но в большинстве случаев ей можно доверять.
Метриками для оценки качества определения языка будут точность, полнота и f1. Давайте их посчитаем и выведем в таблице:
**Сравнение качества двух алгоритмов**
```
with open("../data/lang_data.txt", "r") as f:
text_l, cld2_l, ft_l, g_l = [], [], [], []
s = ''
for i in f:
s += i
if ' |end\n' in s:
text, cld2, ft, g = s.strip().rsplit(" ||| ", 3)
text_l.append(text)
cld2_l.append(cld2)
ft_l.append(ft)
g_l.append(g.replace(" |end", ""))
s=''
data = pd.DataFrame({"text": text_l, "cld2": cld2_l, "ft": ft_l, "google": g_l})
def lang_summary(lang, col):
prec = (data.loc[data[col] == lang, "google"] == data.loc[data[col] == lang, col]).mean()
rec = (data.loc[data["google"] == lang, "google"] == data.loc[data["google"] == lang, col]).mean()
return round(prec, 3), round(rec, 3), round(2*prec*rec / (prec + rec),3)
results = {}
for approach in ["cld2", "ft"]:
results[approach] = {}
for l in data["google"].value_counts().index[:20]:
results[approach][l] = lang_summary(l, approach)
res = pd.DataFrame.from_dict(results)
res["cld2_prec"], res["cld2_rec"], res["cld2_f1"] = res["cld2"].apply(lambda x: [x[0], x[1], x[2]]).str
res["ft_prec"], res["ft_rec"], res["ft_f1"] = res["ft"].apply(lambda x: [x[0], x[1], x[2]]).str
res.drop(columns=["cld2", "ft"], inplace=True)
arrays = [['cld2', 'cld2', 'cld2', 'ft', 'ft', 'ft'],
['precision', 'recall', 'f1_score', 'precision', 'recall', 'f1_score']]
tuples = list(zip(*arrays))
res.columns = pd.MultiIndex.from_tuples(tuples, names=["approach", "metrics"])
```
| model | | cld2 | | | ft | | | ans | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| metrics | prec | rec | f1 | prec | rec | f1 | prec | rec | f1 |
| ar | **0.992** | 0.725 | 0.838 | 0.918 | 0.697 | 0.793 | 0.968 | **0.788** | **0.869** |
| az | **0.95** | 0.752 | 0.839 | 0.888 | 0.547 | 0.677 | 0.914 | **0.787** | **0.845** |
| bg | **0.529** | 0.136 | 0.217 | 0.286 | 0.178 | 0.219 | 0.408 | **0.214** | **0.281** |
| en | **0.949** | 0.844 | 0.894 | 0.885 | 0.869 | 0.877 | 0.912 | **0.925** | **0.918** |
| es | **0.987** | 0.653 | 0.786 | 0.709 | 0.814 | 0.758 | 0.828 | **0.834** | **0.831** |
| fr | **0.991** | 0.713 | **0.829** | 0.53 | 0.803 | 0.638 | 0.713 | **0.81** | 0.758 |
| id | **0.763** | 0.543 | **0.634** | 0.481 | 0.404 | 0.439 | 0.659 | **0.603** | 0.63 |
| it | **0.975** | 0.466 | 0.631 | 0.519 | 0.778 | 0.622 | 0.666 | **0.752** | **0.706** |
| ja | **0.994** | 0.899 | **0.944** | 0.602 | 0.842 | 0.702 | 0.847 | **0.905** | 0.875 |
| ka | **0.962** | 0.995 | **0.979** | 0.959 | 0.905 | 0.931 | 0.958 | **0.995** | 0.976 |
| kk | **0.908** | 0.653 | 0.759 | 0.804 | 0.584 | 0.677 | 0.831 | **0.713** | **0.767** |
| ko | **0.984** | 0.886 | 0.933 | 0.94 | 0.704 | 0.805 | 0.966 | **0.91** | **0.937** |
| ms | **0.801** | 0.578 | **0.672** | 0.369 | 0.101 | 0.159 | 0.73 | **0.586** | 0.65 |
| pt | **0.968** | 0.753 | 0.847 | 0.805 | 0.771 | 0.788 | 0.867 | **0.864** | **0.865** |
| ru | **0.987** | 0.809 | 0.889 | 0.936 | 0.933 | 0.935 | 0.953 | **0.948** | **0.95** |
| sr | 0.093 | 0.114 | 0.103 | **0.174** | 0.103 | 0.13 | 0.106 | **0.16** | **0.128** |
| th | **0.989** | 0.986 | **0.987** | 0.973 | 0.927 | 0.95 | 0.979 | **0.986** | 0.983 |
| tr | **0.961** | 0.639 | **0.768** | 0.607 | 0.73 | 0.663 | 0.769 | **0.764** | 0.767 |
| uk | **0.949** | 0.671 | **0.786** | 0.615 | 0.733 | 0.669 | 0.774 | **0.777** | 0.775 |
| uz | 0.666 | 0.512 | 0.579 | **0.77** | 0.169 | 0.278 | 0.655 | **0.541** | **0.592** |
По результатам хорошо видно, что у подхода cld2 очень высокая точность определения языка, только для непопулярных языков она падает ниже 90%, и в 90% случаев результат лучше, чем у fasttext'a. При примерно одинаковой полноте для двух подходов, f1 скор больше у cld2.
Особенность cld2 модели в том, что она выдает прогноз только для тех сообщений, где она достаточно уверена, это объясняет высокую точность. Модель fasttext'a выдает ответ для большинства сообщений, поэтому точность существенно ниже, но странно, что полнота не существенно выше, а в половине случаев – ниже. Но если "подкрутить" порог для модели fasttext'a, то можно улучшить точность.
4. Выводы
---------
В целом, обе модели дают хороший результат и могут быть использованы для решения задачи определения языка в разных доменах. Главное их преимущество – высокая скорость, которая дает возможность сделать так называемый "ансамбль" и добавить необходимый препроцессинг для повышения качества.
Весь код для воспроизведения экспериментов и тестирований вышеприведенных подходов вы можете найти в [нашем репозитории](https://github.com/YouScan/language-identification-article).
Также можете посмотреть тестирование этих решений в [другой статье](https://tech.people-doc.com/how-to-detect-western-language-with-python.html), где сравнивается точность и скорость на 6 западноевропейских языках. | https://habr.com/ru/post/423569/ | null | ru | null |
# Разработка умных устройств на примере контроллера теплого пола на ESP8266
Хочу поделиться своим опытом разработки умного устройства. В этой публикации я опишу аппаратное (кратко) и программное (более подробно) обеспечение.
Контроллер предназначен анализировать показания датчиков (проводных и беспроводных) и поддерживать заданную (с учетом расписания, в т.ч. по дням недели) температуру в каждой отдельной зоне, путем включения/выключения котла и управления петлями водяного теплого пола с помощью термоголовок на коллекторе.
Аппаратное обеспечение
----------------------
В качестве контроллера был выбран ESP8266 (WeMos D1 mini), как т.к. имеет WiFi на борту. Вместо ESP8266 может быть использован любой другой контроллер или микрокомпьютер – общие идеи останутся неизменными, главное чтобы на выбранной системе можно было бы развернуть WEB-сервер с поддержкой WEB-сокетов. В проекте так же были использованы:
* RTC: DS3231 – надо же определять день недели и текущее время. Проект задумывался как автономное устройство, способное работать без интернета, поэтому NTP не подходит.
* Беспроводные датчики температуры: NoName, 433МГц, от китайской метеостанции – готовое решение, работают от батареек. Что еще надо? А надо чтобы период передачи данных был не фиксированный. Проблема в том, что период передачи 35 секунд и не много плавает. И бывают ситуации, когда сигналы двух датчиков накладываются. В этом случае один или два датчика выпадают из системы на некоторое время. Проблему можно решить, используя похожие датчики, в которых переключение каналов так же изменяет период передачи данных.
* Приемник 433МГц: Rxb6 – по обзорам в интернетах и личному опыту не плохой приемник.
* Проводные датчики температуры: DS18B20 – очень удобны тем, что не требуется заранее знать количество датчиков.
* Мастер шины 1Wire: DS2482-100 – протокол 1Wire очень чувствителен к таймингам, поэтому все реализации программного мастера шины используют delay, что очень не хорошо для многозадачности. Используя эту микросхему, можно использовать преимущества шины 1Wire и избавиться от ее недостатков за счет трансляции 1Wire <-> i2c. Протокол i2c имеет линию синхронизации, за счет чего не критичен к таймингам и часто в контроллерах реализован аппаратно.
* Сторожевой таймер: TPL5000DGST – для данного проекта не столь важен непрерывный аптайм, однако доступность очень важна. В ESP8266 есть встроенный сторожевой таймер. Но как показала практика, иногда все же бывают ситуации, когда он не справляется и система зависает. Внешний аппаратный сторожевой таймер призван бороться с нештатными ситуациями. Сконфигурирован на задержку в 64сек. Присоединен к ноге TX – при работе система постоянно пишет в Serial отладочную информацию и отсутствие активности более одной минуты свидетельствует о зависании системы.
* Расширитель портов: 74HC595 – использование этого расширителя требует 4х ног контроллера – три на передачу состояния и одну для того, чтобы при подаче питания реле не щелкали. В следующий раз буду использовать PCF8574 – шина i2c все равно используются, т.е. дополнительных ног MCU не требуется и при подаче питания выходы в 1 установлены.
* Релейный модуль: NoName, 8-ми канальный, 5В – сказать нечего, кроме того, что включение реле происходит по низкому уровню на входах модуля. Твердотельные реле в данном проекте использовать недопустимо, т.к. коммутация контактов котла должна выполняться сухим контактом – в общем случае я не знаю напряжение и постоянный или переменный ток на контактах.
Операционная система
--------------------
Операционная система – все то ПО, которое обеспечивает работоспособность прикладной программы. Операционная система так же является прослойкой между железом и прикладной программой, предоставляя высокоуровневый интерфейс доступа к аппаратным ресурсам. В случае ESP компонентами операционной системы можно считать:
### Файловая система
В проекте используется SPIFFS, тут вроде все понятно, это самый простой путь. Для простого доступа к файлам на устройстве извне, я использую библиотеку nailbuster/esp8266FTPServer.
### Система распределения процессорного времени
Это одна из основных функций операционной системы и ESP не станет исключением. За параллельное выполнение различных потоков алгоритма отвечает глобальный объект (синглтон) Timers. Класс достаточно простой и предоставляет следующий функционал:
* Периодическое выполнение функции, с заданным интервалом. Пример инициализации таймера:
```
Timers.add(doLoop, 6000, F("OneWireSensorsClass::doLoop")); // третий параметр – отладочная информация
```
* Однократное выполнение функции через указанный промежуток времени. Например так выполняется отложенное сканирование WiFi сетей:
```
Timers.once([]() { WiFi.scanNetworks(true);}, 1);
```
Таким образом функция loop выглядит подобным образом:
```
void loop(void) {
ESP.wdtFeed();
Timers.doLoop();
CPULoadInfo.doLoop();
}
```
На практике функция loop содержит еще несколько строк, о них будет рассказано ниже.
Листинг класса Timers приложен.
### Учет процессорного времени
Сервисная функция, не имеющая практического применения. Тем не менее она есть. Реализуется сингтоном CPULoadInfo. При инициализации объекта, выполняется замер количества итераций пустого цикла за небольшой промежуток времени:
```
void CPULoadInfoClass::init() {
uint32_t currTime = millis();
// определяем максимальное число циклов в 1сек
while ((millis() - currTime) < 10) {
delay(0);
MaxLoopsInSecond++;
}
MaxLoopsInSecond *= 100;
}
```
Затем, считаем количество вызовов процедуры loop в секунду, считаем загрузку процессора в процентах и сохраняем данные в буфер:
```
void CPULoadInfoClass::doLoop() {
static uint32_t prevTime = 0;
uint32_t currTime = millis();
LoopsInSecond++;
if ((currTime - prevTime) > 1000) {
memmove(CPULoadPercentHistory, &CPULoadPercentHistory[1], sizeof(CPULoadPercentHistory) - 1);
int8_t load = ((MaxLoopsInSecond - LoopsInSecond) * 100) / MaxLoopsInSecond;
CPULoadPercentHistory[sizeof(CPULoadPercentHistory) - 1] = load;
prevTime = currTime;
LoopsInSecond = 0;
}
}
```
Использование этого подхода позволяет получить так же использование процессора каждым отдельным потоком (если соединить эту подсистему с классом Timers), но как я уже сказал – практического применения этому я не вижу.
### Система ввода-вывода
Для общения с пользователем используется UART-USB и WEB интерфейс. Про UART думаю подробно рассказывать не требуется. Единственно на что стоит обратить внимание – для удобства и совместимости с не ESP реализована функция serialEvent():
```
void loop(void) {
// …
if (Serial.available())
serialEvent();
// …
}
```
С WEB интерфейсом все гораздо интереснее. Посвятим ему отдельный раздел.
### WEB интерфейс
В случае с умными устройствами, по моему мнению, WEB интерфейс самое удобное для пользователя решение.
Использование экрана, подключенного к устройству, я считаю устаревшей практикой – невозможно при использовании небольшого экрана и ограниченного набора кнопок создать простой, удобный, красивый интерфейс.
Использование специфических программ для управления устройством – накладывает ограничения на пользователя, добавляет необходимость разработки и поддержки этих программ, а также требует от разработчика заботиться о доставке этих программ на терминальные устройства пользователя. По-хорошему, приложение должно быть опубликовано в магазинах приложений Google, Apple, Windows, а также доступно в репозиториях Linux в виде deb и rpm пакетов – в противном случае, для какой-то части аудитории может быть затруднен доступ к интерфейсу устройства.
Доступ к WEB интерфейсу устройства доступен с любой операционной системы – Linux, Windows, Android, MacOS, на десктопе, ноутбуке, планшете, смартфоне – лишь бы был браузер. Конечно разработчику WEB интерфейса необходимо учитывать особенности различных устройств, но это в основном касается размера и разрешения. Доступ к WEB интерфейсу умного устройства в доме/квартире/на даче легко обеспечивается извне через интернет – сейчас сложно представить дом/квартиру, в которых есть умные устройства и нет роутера и интернета, а в роутере такой доступ настраивается в несколько кликов (тем, кто совсем не в теме, помогут ключевые слова – «проброска портов» и «динамический DNS»). В случае дачи доступ можно обеспечить с помощью 3G роутера.
Для реализации WEB интерфейса необходим WEB сервер. Я использую библиотеку me-no-dev/ESPAsyncWebServer. Эта библиотека обеспечивает следующий функционал:
* Отдачу статического контента, в т.ч. с поддержкой сжатия gzip. Поддерживаются виртуальные каталоги, с возможностью указания главного файла (который обычно index.htm) для каждого каталога.
* Назначение callback функций на различные URL с учетом типа запроса (GET, POST, …)
* Поддержка WEB сокетов на том же порту (это имеет значение при проброске портов).
* BASIC авторизацию. Причем авторизация устанавливается индивидуально для каждого URL. Это важно, т.к. например Google Chrome при создании ярлыка страницы на главном экране, запрашивает иконку и файла манифеста и не передает данные авторизации. Поэтому часть файлов помещены в виртуальный каталог и для этого каталога авторизация отключена.
### HTTP сервисы операционной системы
В текущем проекте все настройки операционной системы выполняются с помощью HTTP сервисов. HTTP сервис – это небольшой независимый функционал получения/изменения данных, доступный по HTTP. Далее рассмотрим список этих сервисов.
#### HELP
Реализацию любого списка команд я считаю правильным начать с реализации команды HELP. Ниже блок инициализации WEB сервера:
```
void HTTPserverClass::init()
{
//SERVER INIT
help_info.concat(F("/'doc_hame.ext': load file from server. Allow methods: HTTP_GET\n"));
AsyncStaticWebHandler& handler = server.serveStatic("na/", SPIFFS, "na/");
serveStaticHandlerNA = &handler // виртуальный каталог в котором Нет Авторизации
server.serveStatic("/", SPIFFS, "/"); // все остальные файлы
//info
// перед реализацией сервиса сформируем его описание
help_info.concat(F("/info: get system info. Allow methods: HTTP_GET\n"));
server.on("/info", HTTP_GET, handleInfo);
…
server.on("/help", HTTP_GET, [](AsyncWebServerRequest *request) { request->send(200, ContentTypesStrings[ContentTypes::text_plain], help_info.c_str()); });
// устанавливаем параметры авторизации
setAuthentication(ConfigStore.getAdminName(), ConfigStore.getAdminPassword());
DefaultHeaders::Instance().addHeader("Access-Control-Allow-Origin", "*"); // разрешает кросс-доменные запросы
// запускаем сервер
server.begin();
// макросы отладочной информации будут приложены отдельно
DEBUG_PRINT(F("HTTP server started"));
}
```
Зачем нужна справочная система, рассказывать думаю не стоит. Некоторые разработчик откладывают реализацию справочной системы на потом, но этот «потом» как правило не наступает. Гораздо проще ее реализовать в начале проекта и при развитии проекта дополнять.
В моем проекте список возможных сервисов выводится так же и при ошибке 404 – страница не найдена. На данный момент реализованы следующие сервисы:
<http://tc-demo.vehs.ru/help>
```
/'doc_hame.ext': load file from server. Allow methods: HTTP_GET
/info: get system info. Allow methods: HTTP_GET
/time: get time as string (eg: 20140527T123456). Allow methods: HTTP_GET
/uptime: get uptime as string (eg: 123D123456). Allow methods: HTTP_GET
/rtc: set RTC time. Allow methods: HTTP_GET, HTTP_POST
/list ? [dir=...] & [format=json]: get file list as text or json. Allow methods: HTTP_GET
/edit: edit files. Allow methods: HTTP_GET, HTTP_PUT, HTTP_DELETE, HTTP_POST
/wifi: edit wifi settings. Allow methods: HTTP_GET, HTTP_POST
/wifi-scan ? [format=json]: get wifi list as text or json. Allow methods: HTTP_GET
/wifi-info ? [format=json]: get wifi info as text or json. Allow methods: HTTP_GET
/ap: edit soft ap settings. Allow methods: HTTP_GET, HTTP_POST
/user: edit user settings. Allow methods: HTTP_GET, HTTP_POST
/user-info ? [format=json]: get user info as text or json. Allow methods: HTTP_GET
/update: update flash. Allow methods: HTTP_GET, HTTP_POST
/restart: restart system. Allow methods: HTTP_GET, HTTP_POST
/ws: web socket url. Allow methods: HTTP_GET
/help: list allow URLs. Allow methods: HTTP_GET
```
Как видно, в списке сервисов отсутствуют какие-либо прикладные сервисы. Все HTTP сервисы относятся к операционной системе. Каждый сервис выполняет одну небольшую задачу. При этом если сервис требует ввода каких-либо данных, то по запросу GET возвращает минималистичную форму ввода:
```
#ifdef USE_RTC_CLOCK
help_info.concat(F("/rtc: set RTC time. Allow methods: HTTP_GET, HTTP_POST\n"));
const char* urlNTP = "/rtc";
server.on(urlNTP, HTTP_GET, [](AsyncWebServerRequest *request) { DEBUG_PRINT(F("/rtc")); request->send(200, ContentTypesStrings[ContentTypes::text_html], String(F("RTC timeset"))); });
server.on(urlNTP, HTTP_POST, handleSetRTC_time);
#endif // USE_RTC_CLOCK
```
В последствии этот сервис используется в более симпатичном интерфейсе:
Прикладное ПО
-------------
Наконец подошли к тому, ради чего система создавалась. А именно – к реализации прикладной задачи.
Любая прикладная программа должна получать исходные данные, обрабатывать их и выдавать результат. Так же, возможно, система должна сообщать текущее состояние.
Исходными данными для контроллера теплого пола являются:
* Данные датчиков – система не привязана к конкретным датчикам. Для каждого датчика формируется уникальный идентификатор. Для радио-датчиков их идентификатор дополняется до 16 бит нулями, для датчиков 1Wire на основании их внутреннего идентификатора вычисляется CRC16 и используется в качестве идентификатора датчика. Таким образом, все датчики имеют идентификаторы длиной 2 байта.
* Данные о зонах отопления – число зон не фиксировано, максимальное количество ограничено используемым модулем реле. С учетом этого ограничения так же разрабатывался WEB интерфейс.
* Целевая температура и расписание – я постарался сделать максимально гибкие настройки, можно создать несколько схем отопления и можно даже на каждую зону назначить свою схему настроек.
Таким образом есть некоторое количество настроек, которые надо как-то задавать, и есть некоторое количество параметров, которые система сообщает как текущее состояние.
Для общения контроллера с внешним миром я реализовал командный интерпретатор, который позволил реализовать как управление контроллером, так и получать данные о состоянии. Команды передаются контроллеру в человекочитаемом виде, и могут передаваться через UART или WEB сокет (при желании можно реализовать поддержку других протоколов, например telnet).
Строка команд начинается со знака '#' и оканчивается нулевым символом либо символом перевода строки. Все команды состоят из имени команды и операнда, разделенных двоеточием. Для некоторых команд операнд не обязателен, в этом случае двоеточие и операнд не указываются. Команды в строке разделяются запятой. Например:
```
#ZonesInfo:1,SensorsInfo
```
И конечно же список команд начинается с команды Help, которая выводит список всех допустимых команд (передаваемые команды для удобства восприятия начинаются со знака '>' вместо '#'):
```
>help
Help
SetZonesCount
Zone
SetName
SetSensor
...
LoadCfg
SaveCfg
#Cmd:Help,CmdRes:Ok
```
Особенностью реализации командного интерпретатора является то, что информация о результате выполнения команды выдается так же в виде команды или набора команд:
```
>help
…
#Cmd:Help,CmdRes:Ok
>zone:123
#Cmd:Zone,Value:123,CmdRes:Error,Error:Zone 123 not in range 1-5
>SchemasInfo
#SchemasCount:2
#Schema:1,Name:Основная,DOWs:0b0000000
#Schema:2,Name:Гараж,DOWs:0b0000000
#Cmd:SchemasInfo,CmdRes:Ok
```
На стороне WEB клиента так же реализован командный интерпретатор, который принимает эти команды и преобразует их в графический вид. Например:
```
>zonesInfo:3
#Zone:3,Name:Спальня,Sensor:0x5680,Schema:1,DeltaT:-20
#Cmd:ZonesInfo,CmdRes:Ok
```
WEB интерфейс передал запрос контроллеру о зоне номер 3, и получил в ответ название зоны, идентификатор датчика, привязанного к зоне, идентификатор схемы, назначенной зоне и коррекцию температуры для зоны. Командный интерпретатор не понимает дробных чисел, поэтому температура передается в десятых долях градуса, т.е. 12.3 градуса это 123 десятых долей.
Ключевой особенностью является то, что на любую команду, вне зависимости от способа ввода команды, контроллер отвечает сразу всем клиентам. Это позволяет отображать изменение состояния сразу во всех сеансах WEB интерфейса. Т.к. основной транспорт обмена между контроллером и WEB интерфейсом это WEB сокеты, то контроллер может передавать данные без запроса, например когда приходят новые данные от датчиков:
```
#sensor:0x5A20,type:w433th,battery:1,button_tx:0,channel:0,temperature:228,humidity:34,uptime_label:130308243,time_label:20180521T235126
```
Или о том например, что данные зоны необходимо актуализировать:
```
#Zone:2,TargetTemp:220,CurrentTemp:228,Error:Ok
```
WEB интерфейс контроллера построен на использовании текстовых команд. На одной из закладок интерфейса имеется терминал, с помощью которого можно вводить команды в текстовом виде. Так же эта закладка, в целях отладки, позволяет узнать какие команды отправляет и получает WEB интерфейс при различных действиях пользователя.
Командный интерпретатор позволяет легко менять и наращивать функционал устройства, за счет изменения существующих команд и добавления новых. При этом отладка подобной системы значительно упрощается, т.к. общение с контроллером происходит исключительно на человекочитаемом языке.
Заключение
----------
Использование подобного подхода, а именно:
* Разделение ПО на операционную систему и прикладную программу
* Реализация настроек операционной системы в виде минималистичных HTTP сервисов
* Отделение логики системы от представления данных
* Использование человекочитаемых протоколов обмена данными
позволяет создавать решения, которые понятны как пользователям, так и разработчикам. Подобные решения легко модифицировать. На базе подобных решений легко строить новые устройства, с совершенно другой логикой, но которые будут работать на тех же принципах. Можно создавать линейки устройств, с однотипным интерфейсом:
Как видно, в этом проекте только первые три страницы интерфейса непосредственно связаны с прикладной задачей, а остальные практически универсальны.
В этой публикации я описываю исключительно свой взгляд на построение умных устройств, и ни в коем случае не претендую на истину в последней инстанции.
Кому интересна данная тема – пишите, может я в чем-то не прав, а может быть какие-то детали имеет смысл описать более подробно.
Что получилось в итоге: [Фиаско. История одной самоделки IoT](https://habr.com/post/426235/) | https://habr.com/ru/post/412889/ | null | ru | null |
# Установка Asterisk 18 на Debian 11
Asterisk должен быть собран с поддержкой mysql (модули cdr\_mysql,res\_config\_mysql).
Сначала обновите вашу систему
```
sudo apt update && sudo apt full-upgrade -y
```
установите все необходимые пакеты зависимостей Asterisk:
```
sudo apt -y install build-essential git curl wget libnewt-dev libssl-dev libncurses5-dev subversion libsqlite3-dev libjansson-dev libxml2-dev uuid-dev default-libmysqlclient-dev
```
Убедитесь, что GCC и CMAKE установлены и работают в нашей локальной системе
```
make --version
```
```
gcc --version
```
```
cd /usr/src/ && sudo wget https://downloads.asterisk.org/pub/telephony/asterisk/asterisk-18-current.tar.gz &&
sudo tar xvf asterisk-18-current.tar.gz && cd asterisk-18*/ && sudo contrib/scripts/get_mp3_source.sh
```
Устанавливаем необходимые зависимости
```
sudo contrib/scripts/install_prereq install
```
в процессе предложить выбрать код страны ставим 7
Скрипт установит все необходимые пакеты и после успешного завершения выведет следующее сообщение:
```
#######################################
install completed successfully
#######################################
```
Очистим систему от временных файлов установочного пакета
```
make distclean
```
Теперь нам нужно проверить, присутствуют ли все зависимости в вашей системе, чтобы скомпилировать исходный код. Затем выполните следующую команду:
```
sudo ./configure
```
В конце вас встретит красивый логотип ASCII Asterisk.
Затем выберите модули, которые вы хотите скомпилировать и установить. Чтобы получить доступ к меню, введите следующее:
```
sudo make menuselect
```
выбираем следующие
```
Add-ons (See README-addons.txt)
[*] chan_ooh323
[*] format_mp3
[*] res_config_mysql
[*] cdr_mysql
Applications - добавить
[*] app_macro
Call Detail Recording
[ ] cdr_radius убрать
Channel Event Logging
[ ] cel_radius убрать
Core Sound Packages
[*] CORE-SOUNDS-RU-WAV
[*] CORE-SOUNDS-RU-ULAW
[*] CORE-SOUNDS-RU-ALAW
[*] CORE-SOUNDS-RU-GSM
[*] CORE-SOUNDS-RU-G729
[*] CORE-SOUNDS-RU-G722
[*] CORE-SOUNDS-RU-SLN16
[*] CORE-SOUNDS-RU-SIREN7
[*] CORE-SOUNDS-RU-SIREN14
Music On Hold File Packages
[*] MOH-OPSOUND-WAV
[*] MOH-OPSOUND-ULAW
[*] MOH-OPSOUND-ALAW
[*] MOH-OPSOUND-GSM
Extras Sound Packages
[*] EXTRA-SOUNDS-EN-WAV
[*] EXTRA-SOUNDS-EN-ULAW
[*] EXTRA-SOUNDS-EN-ALAW
[*] EXTRA-SOUNDS-EN-GSM
Save & Exit
```
По завершении должны получить:
```
menuselect changes saved!
make[1]: Leaving directory '/home/infoit/asterisk-18'
```
Чтобы начать компиляцию исходного кода, выполните команду
```
sudo make
```
Если все прошло успешно, вы должны получить:
```
+--------- Asterisk Build Complete ---------+
Asterisk has successfully been built, and +
can be installed by running: +
+
make install +
+-------------------------------------------+
```
После завершения компиляции установите Asterisk и его модули, набрав:
Затем установите Asterisk
```
sudo make install
```
Пример вывода:
```
+---- Asterisk Installation Complete ------+
+
YOU MUST READ THE SECURITY DOCUMENT +
+
Asterisk has successfully been installed. +
If you would like to install the sample +
configuration files (overwriting any +
existing config files), run: +
+
For generic reference documentation: +
make samples +
+
For a sample basic PBX: +
make basic-pbx +
+
+----------------- or ---------------------+
+
You can go ahead and install the asterisk +
program documentation now or later run: +
+
make progdocs +
+
Note This requires that you have +
doxygen installed on your local system +
+-------------------------------------------+
```
Установите документацию, как показано, если вы хотите
```
sudo make progdocs
```
Создание документации C-API. Это займет некоторое время.
Затем, наконец, используйте приведенные ниже команды для установки конфигураций и примеров
```
sudo make samples &&
sudo make config &&
sudo ldconfig
```
включить ротацию логов можно так
```
make install-logrotate
```
Создаем пользователя Asterisk и запускаем
```
sudo groupadd asterisk &&
sudo useradd -r -d /var/lib/asterisk -g asterisk asterisk &&
sudo usermod -aG audio,dialout asterisk &&
sudo chown -R asterisk.asterisk /etc/asterisk &&
sudo chown -R asterisk.asterisk /var/{lib,log,run,spool}/asterisk &&
sudo chown -R asterisk.asterisk /usr/lib/asterisk
```
Давайте подтвердим идентификатор пользователя Asterisk:
```
id asterisk
```
Чтобы настроить Asterisk для запуска от имени вновь созданного пользователя, откройте файл и раскомментируйте следующие две строки в начале (удалите # перед строками):
```
sudo sed -i 's/#AST_USER="asterisk"/AST_USER="asterisk"/' /etc/default/asterisk &&
sudo sed -i 's/#AST_GROUP="asterisk"/AST_GROUP="asterisk"/' /etc/default/asterisk &&
sudo sed -i 's/;runuser = asterisk/runuser = asterisk/' /etc/asterisk/asterisk.conf &&
sudo sed -i 's/;rungroup = asterisk/rungroup = asterisk/' /etc/asterisk/asterisk.conf
```
переместим и архивируем в домашнюю категорию
```
mv /etc/init.d/asterisk ~/asterisk.init.d.bak
```
Создайте свой новый сервис файл в`/etc/systemd/system/asterisk.service`
```
sudo tee /etc/systemd/system/asterisk.service<
```
проверить свой сервис файл
```
nano /etc/systemd/system/asterisk.service
```
После изменения
```
systemctl daemon-reload
```
После внесения изменений перезапустите службу asterisk
```
sudo systemctl restart asterisk && sudo systemctl enable asterisk && sudo systemctl status asterisk
```
Проверьте подключение к Asterisk CLI
```
sudo asterisk -rvvvv
```
Вы должны увидеть результат, подобный этому:
```
Connected to Asterisk GIT-18-804b1987fb currently running on infoit (pid = 31426)
infoit*CLI>
```
выйти
Попробуем ввести парочку команд для проверки работы.
```
core show channels
```
```
core show uptime
```
```
core show sysinfo
```
**Настройка межсетевого экрана**
```
sudo apt update
sudo apt install ufw -y
```
Разрешите доступ к портам на брандмауэре, выполнив следующую команду:
```
sudo ufw allow 80
```
```
sudo ufw allow 22
```
```
sudo ufw allow 10000:20000/udp
```
```
sudo ufw allow 5060:5061/udp
```
проверить статус
```
sudo ufw status verbose
```
Status: inactive
включить
```
sudo ufw enable
```
прописать порты в конфиге
```
sudo tee /etc/asterisk/rtp.conf<
```
проверить
```
nano /etc/asterisk/rtp.conf
```
просмотреть статус можно
```
sudo ufw status verbose
``` | https://habr.com/ru/post/692216/ | null | ru | null |
# Работа с GtkTreeView и GtkListStore с помощью редактора Glade для начинающих
В этом посте я хочу рассказать про работу с очень интересными виджетами (объектами) библиотеки графических интерфейсов GTK+: **GtkTreeView** и **GtkListStore**. GtkTreeView — виджет для отображения деревьев и списков. GtkListStore — виджет представляющий модель списка.
Создавать их я буду с помощью редактора Glade, в интернете очень мало материала именно по работе с виджетами GTK+ (и особенно с этими) с помощью этого редактора интерфейсов. Я уже писал немного про работу с ним. Те, кто никогда с ним не работал — советую прочитать [этот](http://habrahabr.ru/blogs/development/107403/) пост.
Возможностей работы с этими виджетами очень много и я планирую написать еще несколько статей по этой теме (если это конечно заинтересует читателей). Этот пост расчитан на начинающих еще только знакомиться с библиотекой GTK+ и её возможностями. Поэтому сегодня я рассмотрю достаточно простой пример.
Смысл его будет в том, что будем добавлять данные в объект класса GtkListStore (я буду иногда называть его хранилищем) о персонаже компьютерной игры и выводить их на экран в наглядной форме с помощью GtkTreeView.
Но добавлять в GtkListStore будем не только информацию о персонаже. Это хранилище позволяет хранить различные данные. Например стили шрифта, имя шрифта, цвета, картинки, различные настройки виджетов. В данном примере я покажу как можно для каждого отдельного персонажа задать отдельно цвет его написания в GtkTreeView (его еще называют виджет просмотра дерева, хотя в данном примеры мы будем просмотривать структуру списочного формата, а не древовидного).
Начнём с того, что рассмотрим хранилище данных — виджет GtkListStore. Он представляет структуру данных похожую на таблицу (точно так же как таблица в базе данных) каждая строка это запись, запись состоит из данных (атомарных) различных типов. Каждая колонка задаёт свой тип данных. Колонки идентифицируются порядковым номером: первая колонка — 0, вторая колонка — 1, третья колонка — 2 и т.д.
Обычно создают перечисление для более понятного обращения к колонкам хранилища:
```
enum
{
NAME = 0,
HEALTH,
POWER,
SELECTED,
FONT_COLOR
};
```
Для начала открываем Glade (я для примера буду использовать версию 3.6.7 — из репозитория Ubuntu, хотя есть более новые версии, поддерживающие GTK+ 3.0). Создаём форму, слева в панеле объектов ищем Window и кладём на рабочую область. Слева на панелей свойств во вкладке General ищем Window Title и задаём его как: *«Пример работы с GtkTreeView и GtkListStore»*, во вкладке Common задаём Width request и Height requst: *650* и *350* соответственно. Далее нужно будет положить на неё Horizontal Panes, в два отсека которых кладутся Scrolled Window. У Вас должно получится на данном шаге, как показано картинке ниже (кликабельно):
[](http://habrastorage.org/storage/habraeffect/dd/26/dd26b128eb0af7f948e88bce887af421.png)
теперь идём в панель объектов нажимаем на Tree Model и ищем там List Store — наше будущее хранилище (виджет GtkLitStore).
По нажатию по этому виджету он автоматически появится в дереве виджетов справо во вкладке Objects. Нажмаем на него и смотрим на свойства. Отобразятся вот такие настройки, правда можно еще ниже прокрутить и там будет Add and remove rows, но нам это не нужно, т.к. данные будем вводить из контролов (которые сделаем чуть позже).

Во-первых, меняем имя на *liststorePlayers*. Во-вторых, в Add and Remove Columns нам нужно добавить следующие колонки: Имя (name) — строка, Здоровье (неalth) — целочисленный, Сила (power) — целочисленный, Флаг выделения (seleted) — логический и цвет шрифта (colortext) — тип цвета.
Итак добавляем первую колонку имя — выбираем тип *gchararray* в Column type, а в Column name пишем *name*. Далее вторая колонка здоровье — в Column type пишем *gint*, в Column name *health*. Аналогично для *power* типа *gint*. Далее флаг выделение — выбираем тип *gboolean*, а в Column name *selected*. А далее… А далее нас ждёт небольшая неприятность. Нам нужен для цвета шрифта типа GdkColor (структура, используемая в GTK+ для представления цвета). Вы посмотрите на то большое количество возможных вариантов выбора типа, но GdkColor там нет. Видимо это недоработка разработчиков Glade и прийдёт добавить нам самим. Если попробуем вписать его туда — всё равно ничего не получится. Нужно вспомнить, что Glade сохраняет описание интефейса в XML файле, а следовательно его можно будет исправить. Значит, создаём еще одно поле типа *gchararray*, например, в Column type пишем *colortext*.
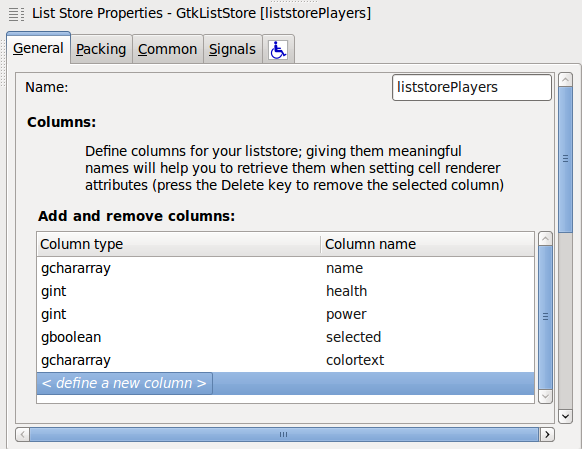
Сохраняем наше описание интерфейса с именем mainForm и открываем полученный файл. Ищем там GtkListStore.
```
```
Меняем наш *gchararray* на *GdkColor*
```
```
Сохраняемся и открываем снова в Glade. Смотрим тип колонки и видим, что всё так, как нам и нужно:
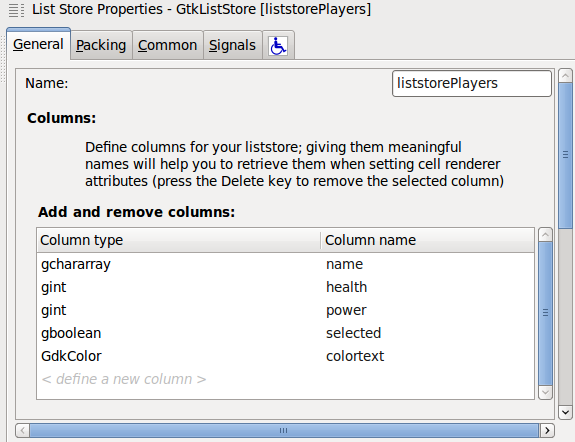
Настройка хранилища GtkListStore на этом завершена. Теперь нам необходимо сделать так, чтобы данные можно было отображать в более менее красивой форме. Для этого идём снова в панель объектов и ищем там Tree View — это виджет GtkTreeView.
Кладём его на левый scrolledwindow (у меня он называется scrolledwindow1, Вы можете вообще все объекты переименовывать, но я переименовываю только те, которые будут потом в коде использоваться, вообще желательного все переименовывать). После того как Вы взяли Tree View на панели объектов и щелкнув по левому scrolledwindow Вам вылетит сообщение о том, что следует указать TreeView Model.
В нашем случае TreeView Model это и есть наше хранилище — GtkListStore, а именно виджет liststorePlayers. Нажимаем **...** и выбираем там *liststorePlayers*.
Нажимаем OK для этого диалога и для предыдущего. Теперь нам необходимо настроить или правильнее будет сказать связать данные из хранилища с конкретного формой отображения их на экране. Нажимаем на treeview1 (а именно так он у Вас называется) на правой панеле объектов и идём в верхнее меню, где ищем Edit.

Откроется диалог редактирования нашего Tree View.
Во вкладке General находятся общие свойства для всего Tree View в целом. Во-первых, меняем Name на *treeviewPlayers*. А так же свойство Enable Grid Lines ставим в *Horizontal and Vertical* — отображение визуального разделения строк и колонок. Переходим во вкладку Hierarcy. В ней как раз мы и будем связать данные из хранилища с конкретной реализацией их отображения.
Немножко теории. Запомните, что колонки в List Store и колонки в Tree View — это абсолютно разные вещи и никакой связи между ними нет. Конкретные данные привязывают не к колонкам Tree View. Колонки Tree View больше служат каким-то логическо-визуальным разделением для выводимых данных. Для представления конкретных данных из хранилища используются объекты класса **GtkCellRenderer**.
В нашем примере будет использоваться 4 различных типов объектов представления:
**GtkCellRendererText** — обычный текст, для отображения name из хранилища;
**GtkCellRendererProgress** — шкала выполнения, а если более просто — это обычный ProgressBar, с помощью него мы будем отображать health и power из хранилища;
**GtkCellRendererSpin** — кнопка «карусель», с помощью неё мы сможем сможем изменять значение power прямо в Tree View;
**GtkCellRendererToggle** — кнопку переключения в ячейке, c помощью неё будем отображать флаг выделения записи.
Возвращаемся в Glade. Нажимаем кнопку Add и у нас появится одна колонка. Вообще можно колонок будет не добавлять в принципе. Одной хватит, но будет не очень красиво и не очень гибко в плане вывода. Поэтому сделаем следующим образом. У нас будет 4 колонки: Name, Health, Power, Seleted. Но в колонке Power мы выведем значение Power из хранилища и в GtkCellRendererSpin и в GtkCellRendererProgress.
Нажмём правой клавишей по добавленной строке: column column и выберем там Add child Text item. В итоге у Вас должно получится следующее:
Тем самым мы добавили GtkCellRendererText — для отображения текстового содержимого. Начинаем изменять свойства, которые располагаются справа. В Name ставим название *cellrenderertextName*. Далее свойство Text. Там где у написано unset нажимаем на стрелочки и в выпадающем меню выбираем *name — gchararray*. Ноль означает, что привязана из хранилища (GtkListStore) колонка с номером 0, с хранящимися там данными (строка имени персонажа, которую мы задали в GtkListStore: *name* типа *gchararray*).
Прокручиваем список свойств вниз и ищем Background colour. Я предлагаю его задать жестко, т.е. для всех строк этого GtkCellRendererText будет одинаковый цвет фона. Для этого снимаем галочку и появится кнопка выбора цвета. Нажимаете и на неё и выбираете цвет, который Вам больше по душе. А вот ниже идёт свойство Foreground colour. Его я уже предлагаю брать из хранилища. Тем самым для каждого конкретной строки можно будет разное свойство цвета шрифта. Для этого нажимаем справо на unset и выбираем там *colortext — GdkColor*. И у Вас должна появится цифра 4. т.е. номер колонки из хранилища GtkListStore, где мы храним цвет. Так же необходимо сделать так, чтобы можно было редактировать имя прямо в Tree View. Для этого прокручиваем свойства еще ниже и ищем там Editable. Снимаем галочку и нажимаем кнопку, так чтобы появилось Yes. У Вас должно получится так:
Я думаю стало уже более менее понятно в чём суть привязвки. Когда у свойства стоит галочка значит данные берутся из хранилища. По умолчанию у всех свойств стоит -1, т.е. не из какой колонки хранилища GtkListStore ничего не берётся. Наша задача указать номер колонки хранилища откуда будут браться значения для свойства. Если мы хотим сами жестко что-то задать — снимаем галочку и настраиваем как хотим. Но тогда уже эти настройки никак не будут зависеть от данных в хранилище GtkListStore и будут применены абсолютно ко всем строкам данного объекта представления.
Далее создаём еще одну колонку. Нажимаем на нашу первую колонку, она выделется и нажимаем Add. Добавится еще одна колонка. Если бы у нас был выделен наш GtkCellRendererText, то добавился бы еще один объект представления в первую колонку. Glade порой немного неудобен. Но ничего страшного.
Теперь добавим объект представления GtkCellRendererProgress, где будем отображать Health — здоровье нашего персонажа с помощью ProgressBar. Нажимаем правой клавишей по новой колонке и выбираем Add child Progress item. Устанавливаем свойство Name в *cellrendererprogressHealth*, в Value выбираем *health — gint*, появится цифра 1 — значит данные будут браться из первой колонки хранилища GtkListStore.
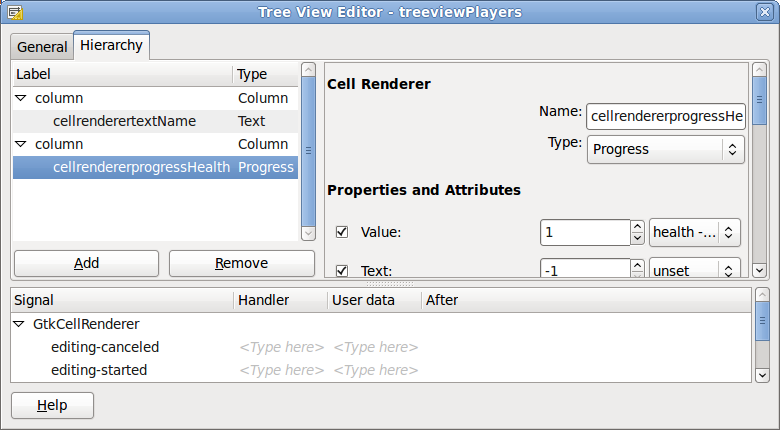
Устанавливаем свойство Background colour. Вы можете выбрать такой же цвет как и для GtkCellRendererText на предыдущем шаге (я именно так и сделал) а можете выбрать свой цвет. Может получится небольшой баг, когда вы выберете цвет на кнопке, он отобразится, а в строке код цвета будет #000000000000. Не расстраивайтесь. Цвет задан нормально, после того как вы закроете диалог редактирования этого Tree View и снова откроете, всё будет нормально. Небольшой глюк Glade.

Теперь добавляем еще один column и в него вставляем GtkCellRendererSpin и GtkCellRendererProgress (точно так же как мы выше вставляли GtkCellRendererText). Для первого Add child Spin item, для второго Add child Progress item. Назовём их соответственно *cellrendererspinPower* и *cellrendererprogressPower* (свойство Name).
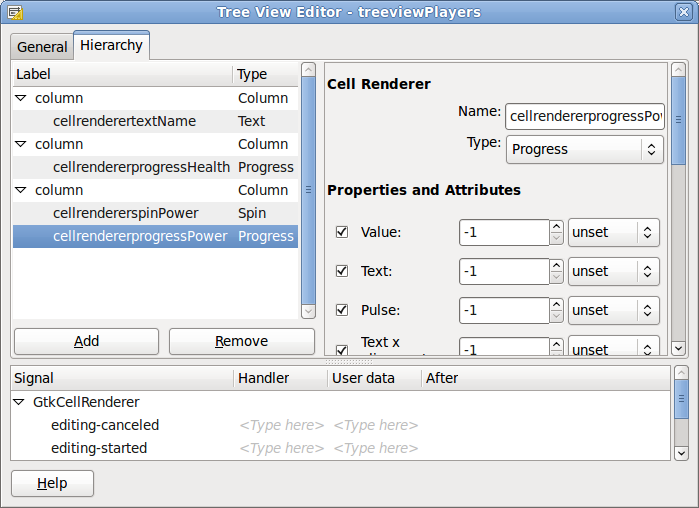
Теперь временно необходимо закрыть окно Tree View Editor и создать для cellrendererspinPower виджет GtkAdjustment под названием *adjCellRendererSpinPower*. На панели объектов выбираем Adjustment, как показано на рисунке ниже и он отобразиться в дереве виджетов в Objects.
В свойствах adjCellRendererSpinPower установим Maximum value: *100.00*, Page Size: *0.00*. Возвращаемся в режим редактирования нашего виджета GtkTreeView. Теперь необходимо определить adjCellRendererSpinPower для cellrendererspinPower. Снимаем галочку с Adjustment, нажимаем **...** и выбираем adjCellRendererSpinPower.
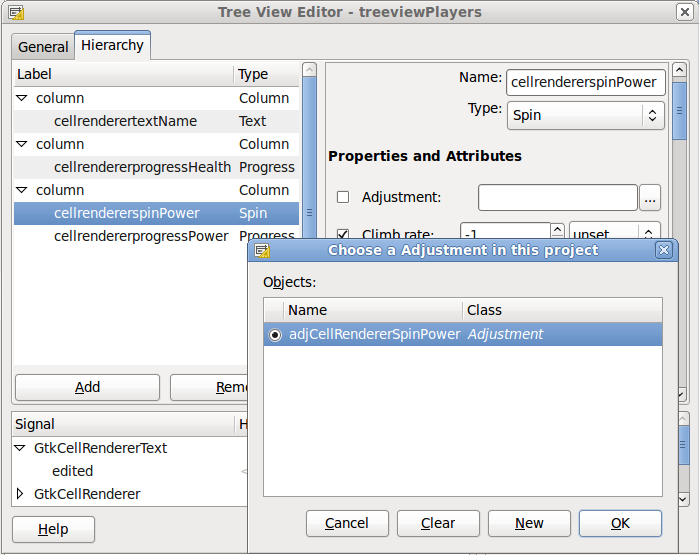
В Glade есть еще один нехороший баг. При новом открытии GladeXML файла с описанием интерфейса, который мы создаём сбрасывается вот этот самый флажок Adjustment. Не забывайте про это. Теперь устанавливаем другие свойства, начнём с Text. Выбираем из выпадаюшего списка *power — gint*, т.е. привязываем из хранилища колонка с номером 2 с данными, с данными о силе.

а так же Editable делаем *Yes*:

Еще необходимо установить, как и для прошлых объектов width: *60*; Cell background color: *#c0c0e5e5e7e7* (напоминаю, что у Вас может быть другой цвет) и Horizontal Padding: *5*. Теперь для cellrendererprogressPower устанавливаем Text (отображаемый текст на шкале) и Value (значение шкалы) тоже в *power — gint*.

И конечно же установливаем, как и для прошлых объектов width: *100*; Cell background color: *#c0c0e5e5e7e7* и Horizontal Padding: *5*.
Осталось добавить последний объект в GtkTreeView — cellrenderertoggleSelected — виджет типа Toggle (Add Toggle Item). Соотносим его свойство Toggle State с *selected gboolean*, с колонкой с номером 3 из хранилща с данными:

Так же устанавливаем Cell background color: *#c0c0e5e5e7e7*.
На последок необходимо подписать колонки, т.е. установать для всех Column свойство Title. В соответствующие значения: *Name*, *Health*, *Power*, *Selected*:
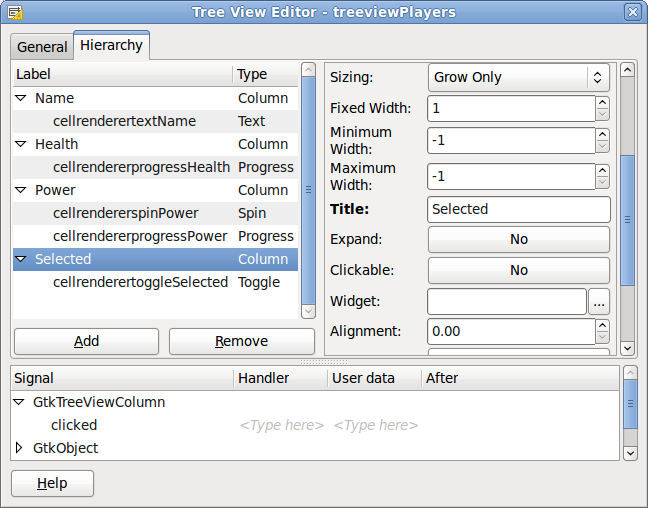
На этом настройка GtkTreeView почти завершена. Теперь дерево виджетов будет выглядеть следующим образом:
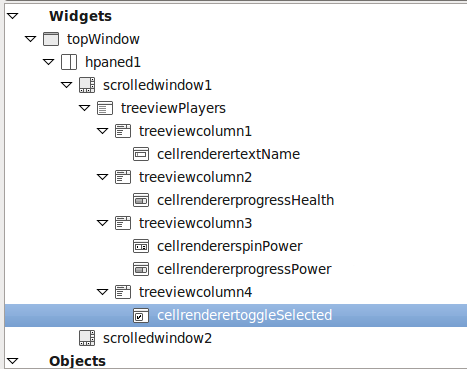
Далее необходимо прописать обработчики сигналов (событий) для некоторых виджетов GtkTreeView и для него самого. Нажимаем на виджет cellrenderertextName и переходим во вкладку Signals (сигналы), ищем там событие (я буду всё-таки сигналы называть как события) *edited* — редактирование текстового поля. С помощью выпадающего списка или в ручную пишем название обработчика этого события *on\_cellrenderertextName\_edited*, как показано на рисунке ниже:

Точно так же делаем для виджета cellrendererspinPower для события edited обработчик *on\_cellrendererspinPower\_edited* — изменение значения с помощью «карусели». Для виджета cellrenderertoggleSelected ищем событие toggled — изменение состояния переключателя и выбираем название обработчика *on\_cellrenderertoggleSelected\_toggled*. И теперь нажимаем на сам наш виджет treeviewPlayers и ищем там во вкладке Signals row\_activated. Пишем сами или выбираем название обработчика on\_treeviewPlayers\_row\_activated.
Хотя Вы в принципе можете как Вам больше нравится называть обработчики событий.Главное их так же как и в Glade указать далее в коде.
Теперь необходимо добавить небольшую диалоговую панель, с помощью которой можно будет быстро добавлять новых персожей и вызывать другие манипуляции. Я не буду подробно описывать процесс создания этого меню, т.к. цель поста рассказать про GtkTreeView и GtkListStore, просто вкратце скажу основые шаги и покажу, что в итоге должно получиться.
Сначала для scrolledwindow1 установим оба свойства Resize и Shrink в *Yes* (вкладка Packing) и Width request в *370* (вкладка Common). Для scrolledwindow2 свойство Resize в *No*, а Shrink в *Yes*, а Width request в *250*. Далее добавим виджет GtkViewport в scrolledwindow2, а в него уже виджет GtkVBox(вертикальный контейнер), состоящий из 8 ячеек. Первые четыре будут представлять собой виджеты GtkHBox (горизонтальный контейнер), состоящие из GtkLabel (подписи) и контролов: entryName (GtkEntry), spinbuttonHealth (GtkSpinButton), spinbuttonPower (GtkSpinButton) и colorbutFontColor (GtkColorButton). Поясняю: необходимо добавить 4 GtkHBox, состоящих из 2 двух ячеек: одна для подписи (левая), другая для контрола (правая), перечисленных ранее.
Четыре нижних это кнопки: butAdd, butDelete, butPrint, butQuit. Для всех виджетов внутри GtkVBox рекомендую установить во вкладке Packing свойства Expand и Fill в *No* (об этих свойствах рассказывается в моём предыдущем [посте](http://habrahabr.ru/blogs/development/107403/)). Так же виджеты spinbuttonHealth и spinbuttonPower необходимо связать с соответствующими виджетами GtkAdjustment. Я их назвал adjHealth и adjPower. И установился соответствующие настройки:
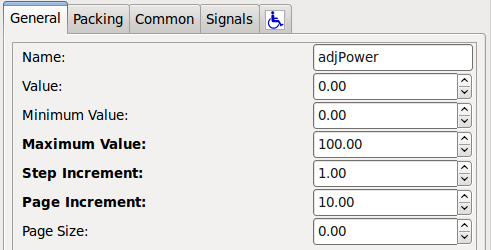
Связывание с spinbuttonHealth и spinbuttonPower происходит посредством выбора в их свойствах Adjustment созданных *adjHealth* и *adjPower*.
Всё, что осталось сделать в Glade — это определить обработчики для кнопок: butAdd, butDelete, butPrint, butQuit. Нажимаем на каждый виджет и во вкладке Event для свойства clicked выбираем *on\_butAdd\_clicked*, *on\_butDelete\_clicked*, *on\_butPrint\_clicked*, *on\_butQuit\_clicked*.
В итоге должно получиться следующее:

А в целом всё окно нашего тренировочного приложения выглядит так:
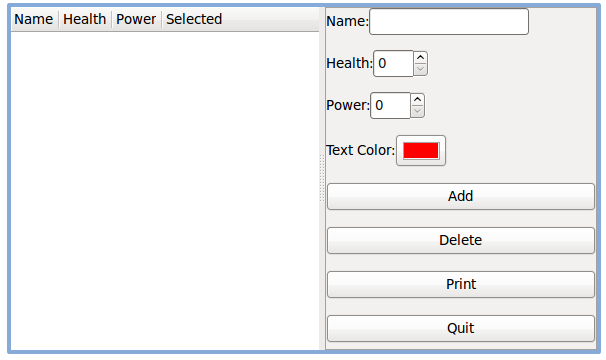
Теперь переходим к написанию кода. Весь код будет содержаться в файле Example1.cpp, хотя Вы можете назвать его как Вам больше нравится.
```
#include
#include
#define UI\_FILE "mainForm.glade"
```
Структура для работы с хранилищем, о которой было сказано в начале:
```
enum
{
NAME = 0,
HEALTH,
POWER,
SELECTED,
FONT_COLOR
};
```
Протопипы обработчиков событий, названия должно быть такими, как мы указали во вкладе Signals для виджетов в редакторе Glade. Т.к. используется C++ компилятор, то указываем, что они должны связываться согласно порядку связывания в языке С.
```
extern "C" void on_butQuit_clicked(GtkWidget *TopWindow, gpointer data);
extern "C" void on_butAdd_clicked(GtkWidget *window, gpointer data);
extern "C" void on_butDelete_clicked (GtkButton *remove, gpointer data);
extern "C" void on_butPrint_clicked(GtkWidget *button, gpointer data);
extern "C" void on_cellrendererspinPower_edited(GtkCellRendererText *render, gchar *path, gchar *new_text, gpointer data);
extern "C" void on_cellrenderertoggleSelected_toggled(GtkCellRendererToggle *render, gchar *path, gpointer data);
extern "C" void on_treeviewPlayers_row_activated(GtkTreeView *treeview, GtkTreePath *path, GtkTreeViewColumn *col, gpointer data);
extern "C" void on_cellrenderertextName_edited(GtkCellRendererText *renderer, gchar *path, gchar *new_text, gpointer data);
```
Структура, содержащая указатели на виджеты, которые был созданы в Glade и будут получены из GladeXML в функции main.
```
struct MainWindowObjects
{
GtkWindow *topWindow;
GtkTreeView *treeviewPlayers;
GtkListStore *liststorePlayers;
GtkEntry *entryName;
GtkAdjustment *adjHealth;
GtkAdjustment *adjPower;
GtkColorButton *colorbutFontColor;
} mainWindowObjects;
```
В main получаем виджеты из GladeXML-формата. С помощью gtk\_tree\_selection\_set\_mode устанавливаем возможность выделения в GtkTreeView нескольких строк. Связываем наши обработчики событий используя функцию gtk\_builder\_connect\_signals и заодно передаём указатели на виджеты с помощью ссылки mainWindowObjects. Тем самым, как вы увидите дальше с помощью указателя gpointer data можно будет обращаться ко всем виджетам из функции обработчика.
```
int main(int argc, char** argv)
{
GtkBuilder *builder;
GError *error = NULL;
gtk_init( &argc, &argv );
builder = gtk_builder_new();
if( ! gtk_builder_add_from_file( builder, UI_FILE, &error ) )
{
g_warning( "%s\n", error->message );
g_free( error );
return( 1 );
}
mainWindowObjects.topWindow = GTK_WINDOW(gtk_builder_get_object(builder, "topWindow"));
mainWindowObjects.treeviewPlayers = GTK_TREE_VIEW( gtk_builder_get_object( builder, "treeviewPlayers" ) );
mainWindowObjects.liststorePlayers = GTK_LIST_STORE( gtk_builder_get_object(builder, "liststorePlayers") );
mainWindowObjects.entryName = GTK_ENTRY( gtk_builder_get_object(builder, "entryName") );
mainWindowObjects.adjHealth = GTK_ADJUSTMENT( gtk_builder_get_object(builder, "adjHealth") );
mainWindowObjects.adjPower = GTK_ADJUSTMENT( gtk_builder_get_object(builder, "adjPower") );
mainWindowObjects.colorbutFontColor = GTK_COLOR_BUTTON( gtk_builder_get_object(builder, "colorbutFontColor") );
GtkTreeSelection *selection;
selection = gtk_tree_view_get_selection( GTK_TREE_VIEW(mainWindowObjects.treeviewPlayers) );
gtk_tree_selection_set_mode( selection, GTK_SELECTION_MULTIPLE );
gtk_builder_connect_signals (builder, &mainWindowObjects);
g_object_unref( G_OBJECT( builder ) );
gtk_widget_show_all ( GTK_WIDGET (mainWindowObjects.topWindow) );
gtk_main ();
}
```
Реализация обработчика добавления нового персонажа. gtk\_list\_store\_append — добавляет новую строку в модель (хранилище) и возвращает iter — ссылку на неё (или еще это называют итератором, указывающим на строку). А функция gtk\_list\_store\_set устанавливает значения ячеек в строке, на которую указывает iter. Значения указываются с помощью перечисления: NAME, HEALTH и т.д. Признак окончания это -1.
```
void on_butAdd_clicked(GtkWidget *button, gpointer data)
{
MainWindowObjects* mwo = static_cast( data );
GtkTreeIter iter;
GdkColor color;
gtk\_color\_button\_get\_color( mwo->colorbutFontColor, &color );
gtk\_list\_store\_append(GTK\_LIST\_STORE( mwo->liststorePlayers ), &iter);
gtk\_list\_store\_set(GTK\_LIST\_STORE( mwo->liststorePlayers ), &iter,
NAME, gtk\_entry\_get\_text(mwo->entryName),
HEALTH, static\_cast( gtk\_adjustment\_get\_value(mwo->adjHealth) ),
POWER, static\_cast( gtk\_adjustment\_get\_value(mwo->adjPower) ),
SELECTED, false,
FONT\_COLOR, &color,
-1 );
}
```
Реализация обработчика события редактирования ячейки с именем. С помощью функции gtk\_tree\_view\_get\_model получаем модель (хранилище), связанную с нашим GtkTreeView. Используя функцию gtk\_tree\_model\_get\_iter\_from\_string получаем ссылку на строку из пути path (который находится в сигнатуре функции, для данного представления хранилища этот путь — просто номер строки, которую изменили), а дальше с помощью уже знакомой нам gtk\_list\_store\_set устанавливаем новое значение, которое находится в new\_text. Вообще сигнатура данного обработчика (как и остальных обработчиков) взята из официальной [документации](http://developer.gnome.org/gtk/2.24/GtkCellRendererText.html) по Gtk+.
Т.е. для каждого виджета можно найти там сигнатуру события (или как там пишут signal — сигнатуру сигнала).
```
void on_cellrenderertextName_edited(GtkCellRendererText *renderer, gchar *path, gchar *new_text, gpointer data)
{
MainWindowObjects* mwo = static_cast( data );
if ( g\_ascii\_strcasecmp(new\_text, "") != 0 )
{
GtkTreeIter iter;
GtkTreeModel \*model;
model = gtk\_tree\_view\_get\_model (mwo->treeviewPlayers);
if (gtk\_tree\_model\_get\_iter\_from\_string(model, &iter, path) )
gtk\_list\_store\_set(GTK\_LIST\_STORE (model), &iter, NAME, new\_text, -1 );
}
}
```
Реализация обработчика события редактирвоания с помощью кнопки «карусель». Оно почти аналогично описанному выше. За исключением того, что нужно новое значение преобразовать в int. Для простоты я использовал старую Си-шную функцию atoi, хотя можно было реализовать это, используя stringstream.
```
void on_cellrendererspinPower_edited(GtkCellRendererText *renderer, gchar *path, gchar *new_text, gpointer data)
{
MainWindowObjects* mwo = static_cast( data );
if ( g\_ascii\_strcasecmp(new\_text, "") != 0 )
{
GtkTreeIter iter;
GtkTreeModel \*model;
model = gtk\_tree\_view\_get\_model (mwo->treeviewPlayers);
if (gtk\_tree\_model\_get\_iter\_from\_string(model, &iter, path) )
gtk\_list\_store\_set(GTK\_LIST\_STORE (model), &iter, POWER, atoi(new\_text), -1 );
}
}
```
Реализация обработчика нажатия по ячейке с переключателем (флагом) — 4я колонка. Получаем с помощью gtk\_tree\_model\_get текущение состояние переключателя и устанавливаем противоложное: !selected
```
void on_cellrenderertoggleSelected_toggled(GtkCellRendererToggle *render, gchar *path, gpointer data)
{
MainWindowObjects* mwo = static_cast( data );
GtkTreeIter iter;
GtkTreeModel \*model;
gboolean selected;
model = gtk\_tree\_view\_get\_model ( mwo->treeviewPlayers );
if (gtk\_tree\_model\_get\_iter\_from\_string(model, &iter, path) )
{
gtk\_tree\_model\_get( model, &iter, 3, &selected, -1 );
gtk\_list\_store\_set( GTK\_LIST\_STORE (model), &iter, SELECTED, !selected, -1 );
}
}
```
Реализация метода печати выделенных строк. С помощью функции gtk\_tree\_model\_get\_iter\_first получаем ссылку на первую строку и заодно проверяем: не пусто ли хранилище (флаг reader). С помощью метода gtk\_tree\_model\_get получаем интересующие нас значения ячеек для текущей строки, на которую «смотрит» iter. К следующей строке переходим с помощью gtk\_tree\_model\_iter\_next.
```
void on_butPrint_clicked(GtkWidget *button, gpointer data)
{
MainWindowObjects* mwo = static_cast( data );
GtkTreeIter iter;
gboolean reader = gtk\_tree\_model\_get\_iter\_first(GTK\_TREE\_MODEL( mwo->liststorePlayers ), &iter);
g\_print( "Selected rows:\n" );
while ( reader )
{
gboolean selected;
gtk\_tree\_model\_get (GTK\_TREE\_MODEL( mwo->liststorePlayers ), &iter,
SELECTED, &selected, -1);
if ( selected )
{
gchar\* name;
gint health;
gint power;
gtk\_tree\_model\_get (GTK\_TREE\_MODEL( mwo->liststorePlayers ), &iter,
NAME, &name,
HEALTH, &health,
POWER, &power,
-1);
g\_print( "%s %d %d\n", name, health, power );
}
reader = gtk\_tree\_model\_iter\_next(GTK\_TREE\_MODEL( mwo->liststorePlayers ), &iter);
}
}
```
Реализация метода, обрабатывающего двойной щелчок по строке в GtkTreeView. С помощью функции gtk\_tree\_model\_get\_iter получаем iter из path, а потом получаем интересующие нас данные с помощью gtk\_tree\_model\_get и выводим их в консоль.
```
void on_treeviewPlayers_row_activated(GtkTreeView *treeview, GtkTreePath *path, GtkTreeViewColumn *col, gpointer data)
{
GtkTreeModel *model;
GtkTreeIter iter;
model = gtk_tree_view_get_model( treeview );
if ( gtk_tree_model_get_iter(model, &iter, path) )
{
gchar* name;
gint health;
gint power;
gtk_tree_model_get(model, &iter,
NAME, &name,
HEALTH, &health,
POWER, &power,
-1);
g_print( "Current row: %s %d %d\n", name, health, power);
}
}
```
Данная функция является вспомогательной, для удаления выделенных строк в GtkTreeView. gtk\_list\_store\_remove — удаляет данную строку из списка, на которую ссылается iter. Перед этим извлекаем path с помощью gtk\_tree\_row\_reference\_get\_path, а потом преобразуем path в iter с помощью gtk\_tree\_model\_get\_iter.
```
static void remove_row (GtkTreeRowReference *ref, GtkTreeModel *model)
{
GtkTreeIter iter;
GtkTreePath *path;
path = gtk_tree_row_reference_get_path (ref);
gtk_tree_model_get_iter (model, &iter, path);
gtk_list_store_remove (GTK_LIST_STORE (model), &iter);
}
```
С помощью функции gtk\_tree\_selection\_get\_selected\_rows получаем список выделенных строк, потом с помощью цикла while проходим по каждой выделенной строке и создаем ссылку на основе пути с помощью функции gtk\_tree\_row\_reference\_new и добавляем эту ссылку в список references с помощью g\_list\_prepend.
Вызываем функцию remove\_row для каждой ссылки, с помощью g\_list\_foreach. И в конце, аналогично с помощью g\_list\_foreach освобождаем наши списки.
```
void on_butDelete_clicked (GtkButton *remove, gpointer data)
{
MainWindowObjects* mwo = static_cast( data );
GtkTreeSelection \*selection;
GtkTreeRowReference \*ref;
GtkTreeModel \*model;
GList \*rows, \*ptr, \*references = NULL;
selection = gtk\_tree\_view\_get\_selection ( mwo->treeviewPlayers );
model = gtk\_tree\_view\_get\_model ( mwo->treeviewPlayers );
rows = gtk\_tree\_selection\_get\_selected\_rows (selection, &model);
ptr = rows;
while (ptr != NULL)
{
ref = gtk\_tree\_row\_reference\_new (model, (GtkTreePath\*) ptr->data);
references = g\_list\_prepend (references, gtk\_tree\_row\_reference\_copy (ref));
gtk\_tree\_row\_reference\_free (ref);
ptr = ptr->next;
}
g\_list\_foreach ( references, (GFunc) remove\_row, model );
g\_list\_foreach ( references, (GFunc) gtk\_tree\_row\_reference\_free, NULL );
g\_list\_foreach ( rows, (GFunc) gtk\_tree\_path\_free, NULL );
g\_list\_free ( references );
g\_list\_free ( rows );
}
```
Реализация обработчика закрытия GTK+ приложения
```
void on_butQuit_clicked(GtkWidget *window, gpointer data)
{
gtk_main_quit();
}
```
Для компиляции необходимо создать makefile:
```
CC=g++
LDLIBS=`pkg-config --libs gtk+-2.0 gmodule-2.0`
CFLAGS=-Wall -g `pkg-config --cflags gtk+-2.0 gmodule-2.0`
example1: example1.o
$(CC) $(LDLIBS) example1.o -o example1
example1.o: example1.cpp
$(CC) $(CFLAGS) -c example1.cpp
clean:
rm -f example1
rm -f *.o
```
Теперь можно скомпилировать данный пример и попробовать «поиграться» с тем, что мы сделали. Советую запускать из консоли дистрибутива вашего дистрибутива Linux. Попробуйте добавить несколько персонажей, выбирая разные цвета их имени. Попробуйте выделить в 4ой колонке несколько строк и нажать Print, тогда в консоле напечатаются выделенные. Попробуйте изменить значение Power с помощью «карусели» (двойной щелчок по ней, левее Progress bar'a). Попробуйте с помощью зажатой клавишы Ctrl или Shift выделить несколько добавленных строк и удалить их, нажав Delete.
Данный пример можно скачать [отсюда](https://bitbucket.org/goran_src/example1/src).
Компиляция происходит командой:
```
$ make
```
Запуск:
```
$ ./example1
```
Я постарался максимально подробно описать многие вещи (некоторые может быть даже слишком), но всё это сделано для более быстрого понимания данной темы. | https://habr.com/ru/post/116268/ | null | ru | null |
# Неприятные ошибки при написании юнит тестов
На днях я буду делать внутренний доклад, на котором расскажу нашим разработчикам про неприятные ошибки, которые могут возникнуть при написании юнит тестов. Самые неприятные с моей точки зрения ошибки — когда тесты проходят, но при этом делают это настолько некорректно, что лучше бы не проходили. И я решил поделиться примерами таких ошибок со всеми. Наверняка ещё что-нибудь подскажете из этой области. Примеры написаны для Node.JS и Mocha, но в целом эти ошибки справедливы и для любой другой экосистемы.
Чтобы было интереснее, часть из них оформлена в виде проблемного кода и спойлера, открыв который, вы увидите, в чём была проблема. Так что рекомендую сначала смотреть на код, находить в нём ошибку, а затем открывать спойлер. Решения проблем указано не будет — предлагаю самим подумать над ним. Просто потому, что я ленивый. Порядок списка не имеет глубокого смысла — просто это очерёдность, в которой я вспоминал про всякие реальные проблемы, которые доводили нас до кровавых слёз. Наверняка многие вещи покажется вам очевидными — но даже опытные разработчики могут случайно написать такой код.
Итак, поехали.
### 0. Отсутствие тестов
Как ни странно, до сих пор многие считают, что написание тестов замедляет скорость разработки. Конечно, это очевидно, что больше времени приходится тратить на то, чтобы писать тесты, и чтобы писать код, который можно тестировать. Но на отладку и регрессы после этого придётся тратить в разы больше времени…
### 1. Отсутствие запуска тестов
Если у вас есть тесты, которые вы не запускаете, или запускаете от раза к разу — то это всё равно что отсутствие тестов. И это даже хуже — у вас есть устаревающий код тестов и ложное чувство безопасности. Тесты как минимум должны запускаться в CI процессах при пуше кода в ветку. А лучше — локально перед пушем. Тогда разработчику не придётся через несколько дней возвращаться к билду, который, как оказалось, не прошёл.
### 2. Отсутствие покрытия
Если вы ещё не знаете, что такое покрытие в тестах, то самое время во прямо сейчас пойти и прочитать. Хотя бы [википедию](https://ru.wikipedia.org/wiki/%D0%9F%D0%BE%D0%BA%D1%80%D1%8B%D1%82%D0%B8%D0%B5_%D0%BA%D0%BE%D0%B4%D0%B0). Иначе велики шансы того, что ваш тест будет проверять от силы 10% от того кода, который, как вы думаете, он проверяет. Рано или поздно вы на это обязательно наступите. Конечно, даже 100% покрытие кода никак не гарантирует его полную корректность — но это гораздо лучше, чем отсутствие покрытия так как покажет вам гораздо больше потенциальных ошибок. Недаром в последних версиях Node.JS даже появились встроенные инструменты для того, чтобы его считать. Вообще, тема покрытия глубокая и крайне холиварная, но не буду в неё слишком углубляться — хочется сказать по понемножку о многом.
### 3.
```
const {assert} = require('chai');
const Promise = require('bluebird');
const sinon = require('sinon');
class MightyLibrary {
static someLongFunction() {
return Promise.resolve(1); // just imagine a really complex and long function here
}
}
async function doItQuickOrFail()
{
let res;
try {
res = await MightyLibrary.someLongFunction().timeout(1000);
}
catch (err)
{
if (err instanceof Promise.TimeoutError)
{
return false;
}
throw err;
}
return res;
}
describe('using Timeouts', ()=>{
it('should return false if waited too much', async ()=>{
// stub function to emulate looong work
sinon.stub(MightyLibrary, 'someLongFunction').callsFake(()=>Promise.delay(10000).then(()=>true));
const res = await doItQuickOrFail();
assert.equal(res, false);
});
});
```
**Что тут не так**
> Таймауты в юнит тестах.
>
>
>
> Здесь хотели проверить, что установка таймаутов на долгую операцию действительно работает. В целом это и так имеет мало смысла — не стоит проверять стандартные библиотеки — но так же такой код приводит к другой проблеме — увеличению выполнения времени прохождения тестов на секунду. Казалось бы, это не так много… Но помножьте эту секунду на количество аналогичных тестов, на количество разработчиков, на количеств запусков в день… И вы поймёте, что из-за таких таймаутов вы можете терять впустую много часов работы еженедельно, если не ежедневно.
### 4.
```
const fs = require('fs');
const testData = JSON.parse(fs.readFileSync('./testData.json', 'utf8'));
describe('some block', ()=>{
it('should do something', ()=>{
someTest(testData);
})
})
```
**Что тут не так**
> Загрузка тестовых данных вне блоков теста.
>
>
>
> На первый взгляд кажется, что всё равно, где читать тестовые данные — в блоке describe, it или в самом модуле. На второй тоже. Но представьте, что у вас сотни тестов, и во многих из них используются тяжёлые данные. Если вы их грузите вне теста, то это приведёт к тому, что все тестовые данные будут оставаться в памяти до конца выполнения тестов, и запуск со временем будет потреблять всё больше и больше оперативной памяти — пока не окажется, что тесты больше вообще не запускаются на стандартных рабочих машинах.
### 5.
```
const {assert} = require('chai');
const sinon = require('sinon');
class Dog
{
// eslint-disable-next-line class-methods-use-this
say()
{
return 'Wow';
}
}
describe('stubsEverywhere', ()=>{
before(()=>{
sinon.stub(Dog.prototype, 'say').callsFake(()=>{
return 'meow';
});
});
it('should say meow', ()=>{
const dog = new Dog();
assert.equal(dog.say(), 'meow', 'dog should say "meow!"');
});
});
```
**Что тут не так**
> Код фактически заменён стабами.
>
>
>
> Наверняка вы сразу увидели эту смешную ошибку. В реальном коде это, конечно, не настолько очевидно — но я видел код, который был обвешан стабами настолько, что вообще ничего не тестировал.
### 6.
```
const sinon = require('sinon');
const {assert} = require('chai');
class Widget {
fetch()
{}
loadData()
{
this.fetch();
}
}
if (!sinon.sandbox || !sinon.sandbox.stub) {
sinon.sandbox = sinon.createSandbox();
}
describe('My widget', () => {
it('is awesome', () => {
const widget = new Widget();
widget.fetch = sinon.sandbox.stub().returns({ one: 1, two: 2 });
widget.loadData();
assert.isTrue(widget.fetch.called);
});
});
```
**Что тут не так**
> Зависимость между тестами.
>
>
>
> С первого взгляда понятно, что здесь забыли написать
>
>
>
>
> ```
> afterEach(() => {
> sinon.sandbox.restore();
> });
> ```
>
>
>
>
> Но проблема не только в этом, а в том, что для всех тестов используется один и тот же sandbox. И очень легко таким образом смутировать среду выполнения тестов таким образом, что они начнут зависеть друг от друга. После этого тесты начнут выполняться только в определённом порядке, и вообще непонятно что тестировать.
>
>
>
> К счастью, sinon.sandbox в какой-то момент был объявлен устаревшим и выпилен, так что с такой проблемой вы можете столкнуться только на легаси проекте — но есть огромное множество других способов смутировать среду выполнения тестов таким образом, что потом будет мучительно больно расследовать, какой код виновен в некорректном поведении. На хабре, кстати, недавно был пост про какой-то шаблон вроде «Ice Factory» — это не панацея, но иногда помогает в таких случаях.
### 7. Огромные тестовые данные в файле теста
Очень часто видел, как прямо в тесте лежали огромные JSON файлы, и даже XML. Думаю, очевидно, почему это не стоит делать — становится больно это смотреть, редактировать, и любая IDE не скажет вам за такое спасибо. Если у вас есть большие тестовые данные — выносите их вне файла теста.
### 8.
```
const {assert} = require('chai');
const crypto = require('crypto');
describe('extraTests', ()=>{
it('should generate unique bytes', ()=>{
const arr = [];
for (let i = 0; i < 1000; i++)
{
const value = crypto.randomBytes(256);
arr.push(value);
}
const unique = arr.filter((el, index)=>arr.indexOf(el) === index);
assert.equal(arr.length, unique.length, 'Data is not random enough!');
});
});
```
**Что тут не так**
> Лишние тесты.
>
>
>
> В данном случае разработчик был очень обеспокоен тем, что его уникальные идентификаторы будут уникальными, поэтому написал на это проверку. В целом понятное стремление — но лучше прочитать документацию или прогнать такой тест несколько раз, не добавляя его в проект. Запуск его в каждом билде не имеет никакого смысла.
>
>
>
> Ну и завязка на случайные значения в тесте — сама по себе является отличным способом выстрелить себе в ногу, сделав нестабильный тест на пустом месте.
### 9. Отсутствие моков
Гораздо проще запускать тесты с живой базой и сотальными сервисами, и гонять тесты на них.
Но рано или поздно это аукнется — тесты по удалению данных выполнятся на продуктовой базе, начнут падать из-за неработающего партнёрского сервиса, или в вашем CI просто не будет базы, на которой можно их прогнать. В общем, пункт достаточно холиварный, но как правило — если вы можете эмулировать внешние сервисы, то лучше это делать.
### 11.
```
const {assert} = require('chai');
class CustomError extends Error
{
}
function mytestFunction()
{
throw new CustomError('important message');
}
describe('badCompare', ()=>{
it('should throw only my custom errors', ()=>{
let errorHappened = false;
try {
mytestFunction();
}
catch (err)
{
errorHappened = true;
assert.isTrue(err instanceof CustomError);
}
assert.isTrue(errorHappened);
});
});
```
**Что тут не так**
> Усложнённая отладка ошибок.
>
>
>
> Всё неплохо, но есть одна проблема — если тест вдруг упал, то вы увидите ошибку вида
>
>
>
> `1) badCompare
>
> should throw only my custom errors:
>
>
>
> AssertionError: expected false to be true
>
> + expected - actual
>
>
>
> -false
>
> +true
>
>
>
> at Context.it (test/011_badCompare/test.js:23:14)`
>
>
>
> Дальше, чтобы понять, что за ошибка собственно случилась — вам придётся переписывать тест. Так что в случае неожиданной ошибки — постарайтесь, чтобы тест рассказал о ней, а не только сам факт того, что она произошла.
### 12.
```
const {assert} = require('chai');
function someVeryBigFunc1()
{
return 1; // imagine a tonn of code here
}
function someVeryBigFunc2()
{
return 2; // imagine a tonn of code here
}
describe('all Before Tests', ()=>{
let res1;
let res2;
before(async ()=>{
res1 = await someVeryBigFunc1();
res2 = await someVeryBigFunc2();
});
it('should return 1', ()=>{
assert.equal(res1, 1);
});
it('should return 2', ()=>{
assert.equal(res2, 2);
});
});
```
**Что тут не так**
> Всё в блоке before.
>
>
>
> Казалось бы, классный подход сделать все операции в блоке `before`, и таким образом оставить внутри `it` только проверки.
>
> На самом деле нет.
>
> Потому что в этом случае возникает каша, в которой нельзя ни понять время реального выполнения тестов, ни причину падения, ни то, что относится к одному тесту, а что к другому.
>
> Так что вся работа теста (кроме стандартных инициализаций) должна выполняться внутри самого теста.
### 13.
```
const {assert} = require('chai');
const moment = require('moment');
function someDateBasedFunction(date)
{
if (moment().isAfter(date))
{
return 0;
}
return 1;
}
describe('useFutureDate', ()=>{
it('should return 0 for passed date', ()=>{
const pastDate = moment('2010-01-01');
assert.equal(someDateBasedFunction(pastDate), 0);
});
it('should return 1 for future date', ()=>{
const itWillAlwaysBeInFuture = moment('2030-01-01');
assert.equal(someDateBasedFunction(itWillAlwaysBeInFuture), 1);
});
});
```
**Что тут не так**
> Завязка на даты.
>
>
>
> Тоже казалось бы очевидная ошибка — но тоже периодически возникает у уставших разработчиков, которые уже считают, что завтра никогда не наступит. И билд который отлично собирался вчера, внезапно падает сегодня.
>
>
>
> Помните, что любая дата наступит рано или поздно — так что или используйте эмуляцию времени штуками вроде `sinon.fakeTimers`, или хотя бы ставьте отдалённые даты вроде 2050 года — пускай голова болит у ваших потомков...
### 14.
```
describe('dynamicRequires', ()=>{
it('should return english locale', ()=>{
// HACK :
// Some people mutate locale in tests to chinese so I will require moment here
// eslint-disable-next-line global-require
const moment = require('moment');
const someDate = moment('2010-01-01').format('MMMM');
assert.equal(someDate, 'January');
});
});
```
**Что тут не так**
> Динамическая подгрузка модулей.
>
>
>
> Если у вас стоит Eslint, то вы наверняка уже запретили динамические зависимости. Или нет.
>
> Часто вижу, что разработчики стараются подгружать библиотеки или различные модули прямо внутри тестов. При этом они в целом знают, как работает `require` — но предпочитают иллюзию того, что им будто бы дадут чистый модуль, который никто пока что не смутировал.
>
> Такое предположение опасно тем, что загрузка дополнительных модулей во время тестов происходит медленнее, и опять же приводит к большему количеству неопределённого поведения.
### 15.
```
function someComplexFunc()
{
// Imagine a piece of really strange code here
return 1;
}
describe('cryptic', ()=>{
it('success', ()=>{
const result = someComplexFunc();
assert.equal(result, 1);
});
it('should not fail', ()=>{
const result = someComplexFunc();
assert.equal(result, 1);
});
it('is right', ()=>{
const result = someComplexFunc();
assert.equal(result, 1);
});
it('makes no difference for solar system', ()=>{
const result = someComplexFunc();
assert.equal(result, 1);
});
});
```
**Что тут не так**
> Непонятные названия тестов.
>
>
>
> Наверное, вы устали от очевидны вещей, да? Но всё равно придётся о ней сказать потому что многие не утруждаются написанием понятных названий для тестов — и в результате понять, что делает тот или иной тест, можно только после долгих исследований.
### 16.
```
const {assert} = require('chai');
const Promise = require('bluebird');
function someTomeoutingFunction()
{
throw new Promise.TimeoutError();
}
describe('no Error check', ()=>{
it('should throw error', async ()=>{
let timedOut = false;
try {
await someTomeoutingFunction();
}
catch (err)
{
timedOut = true;
}
assert.equal(timedOut, true);
});
});
```
**Что тут не так**
> Отсутствие проверки выброшенной ошибки.
>
>
>
> Часто нужно проверить, что в каком-то случае функция выкидывает ошибку. Но всегда нужно проверять, те ли это дроиды, которых мы ищем — поскольку внезапно может оказаться, что ошибка была выкинута другая, в другом месте и по другим причинам...
### 17.
```
function someBadFunc()
{
throw new Error('I am just wrong!');
}
describe.skip('skipped test', ()=>{
it('should be fine', ()=>{
someBadFunc();
});
});
```
**Что тут не так**
> Отключенные тесты.
>
>
>
> Конечно, всегда может появиться ситуация, когда код уже много раз протестирован руками, нужно срочно его катить, а тест почему-то не работает. Например, из-за не очевидной завязки на другой тест, о которой я писал ранее. И тест отключают. И это нормально. Не нормально — не поставить мгновенно задачу на то, чтобы включить тест обратно. Если это не сделать, то количество отключенных тестов будет плодиться, а их код — постоянно устаревать. Пока не останется единственный вариант — проявить милосердие и выкинуть все эти тесты нафиг, поскольку быстрее написать их заново, чем разбираться в ошибках.
Вот такая вот подборка вышла. Все эти тесты отлично проходят проверки, но они broken by design. Добавляйте свои варианты в комментарии, или в [репозиторий](https://github.com/jehy/unit-test-antipatterns), который я сделал для коллекционирования таких ошибок. | https://habr.com/ru/post/432092/ | null | ru | null |
# Platform V DataSpace: пишем код на Java при помощи удобного SDK
Привет, Хабр! Продолжаем рассказывать, как быстро и просто создавать микросервисные приложения. В [прошлой статье](https://habr.com/ru/company/sberbank/blog/655817/) мы написали frontend с помощью Platform V DataSpace. В примере был использован TypeScript, но, как мы и говорили, это необязательное требование.
Теперь рассмотрим, как разрабатывать backend-приложения на языке Java с помощью сервиса Platform V Functions и инструмента DataSpace SDK.
Platform V Functions — это FaaS-решение, позволяющее загружать исходный код сервиса в виде функции в OpenShift/k8s без создания docker-образов и настройки окружения.
Но основное внимание в статье уделим даже не Functions, а DataSpace SDK. Это инструмент для удобного взаимодействия с DataSpace по протоколу [JSON-RPC](https://www.jsonrpc.org/specification). По ходу статьи мы рассмотрим основные фичи, которые DataSpace SDK предоставляет Java-разработчику.
Приложение «Промоакция»
-----------------------
В качестве примера снова возьмём приложение «Промоакция» из предыдущей статьи.
Изменим архитектуру нашего приложения, разбив его на микросервисы. Теперь промокоды и подарки будут вестись раздельно разными сервисами, у каждого из которых будет свой DataSpace со своей моделью данных.
Архитектура приложения на этот раз будет выглядеть вот так:
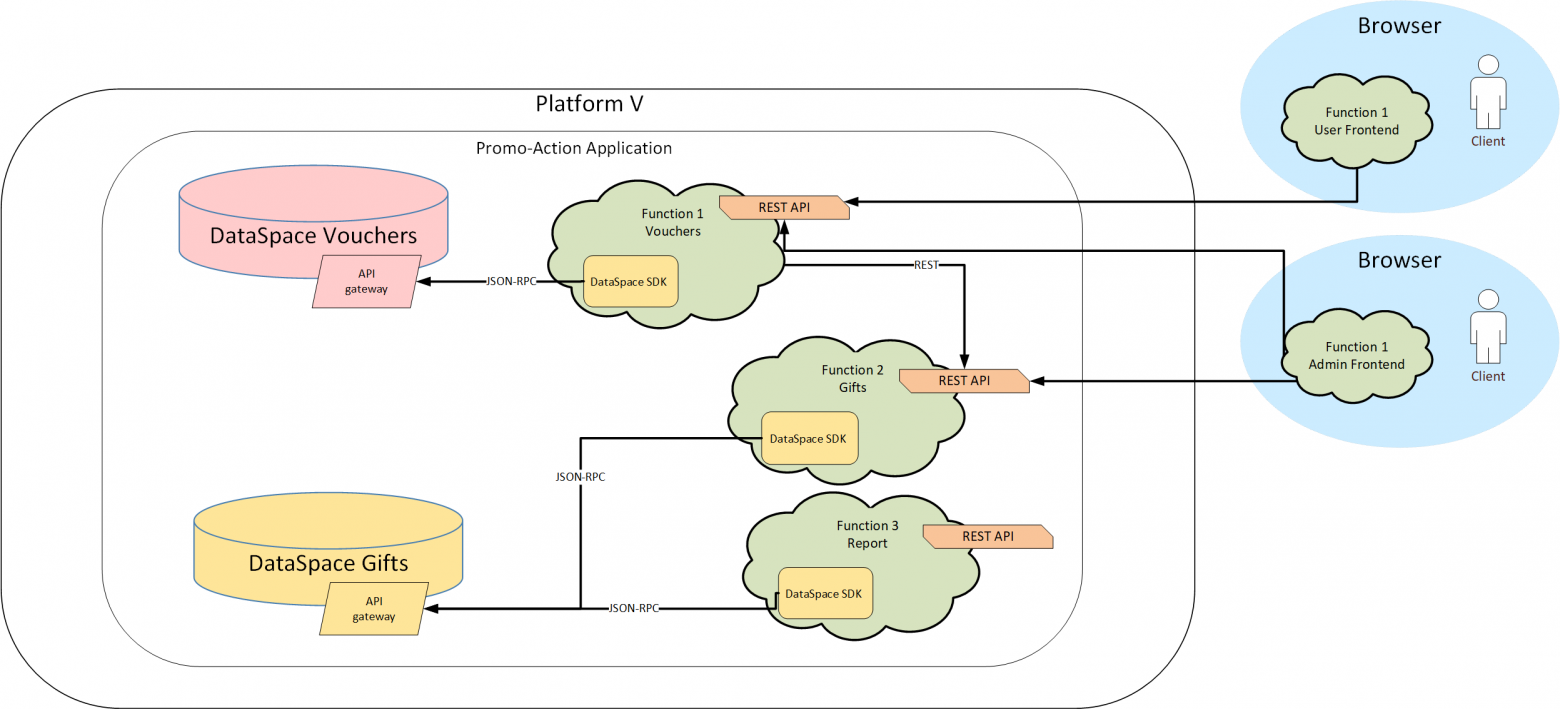**Function 1 Vouchers** — backend-сервис, отвечающий за ведение промокодов.
**Function 2 Gifts** — backend-сервис, отвечающий за ведение подарков.
**Function 3 Report** — backend-сервис, предоставляющий различные аналитические отчёты о подарках.
Разработка
----------
Представим, что разработкой данного приложения занимаются два разработчика:
* разработчик Vouchers реализует часть приложения, которая связана с управлением промокодами;
* разработчик Gifts реализует часть приложения, которая связана с управлением подарками.
Для начала работы каждому разработчику нужно развернуть сервис DataSpace в своем пространстве в SmartMarket Studio. Подробнее о том, как это сделать, мы рассказывали [здесь](https://habr.com/ru/company/sberbank/blog/655817/), в разделе «Как начать работу» в SmartMarket Studio.
У каждого DataSpace будет своя модель данных:
* [vouchers\_model.xml](https://github.com/MaximNavodnikov/promo-action/blob/main/vouchers_model.xml) — модель для DataSpace Vouchers;
* [gifts\_model.xml](https://github.com/MaximNavodnikov/promo-action/blob/main/gifts_model.xml) — модель для DataSpace Gifts.
Voucher и Gift теперь имеют связь OneToOne. Но тип этой связи «из внешней системы», так как они находятся в разных моделях данных.
Итак, сервисы DataSpace развёрнуты. Теперь создадим заготовки для наших сервисов.
Разработчик Vouchers создаёт в своём пространстве соответствующую функцию:
Разработчик Gifts создаёт в своём пространстве функции Gifts Function, Reports Function:
Теперь разработаем «начинки» для функций — это будут хорошо известные всем Spring Boot приложения.
Сервис Voucher
--------------
Переходим на вкладку «*Детали»* и скачиваем инструмент DataSpace SDK — он был сгенерирован после развёртывания сервиса DataSpace Vouchers.
Создадим проект со стандартной структурой. Для удобства можно взять за основу шаблонный проект в одной из наших функций-заготовок. Для этого в действиях выбираем пункт «Экспортировать»:
При этом добавим в src/libs jar, полученный из скачанного ранее архива.
Также нам потребуется java-sdk-core для подписи REST-запросов при помощи ak/sk. Скачиваем его по [ссылке](https://support.hc.sbercloud.ru/devg/apisign/api-sign-sdk-java.html), достаём из архива и добавляем в src/libs нашего проекта.
В pom.xml проекта необходимо добавить следующие зависимости:
```
Данная зависимость содержит служебные классы, сгенерированные под нашу модель данных.
Это позволяет достичь строгой типизации при написании прикладного кода.
sbp.com.sbt.dataspace
m7063364230573391874-model-sdk
0.0.1
system
${project.basedir}/src/libs/m7063364230573391874-model-sdk-0.0.3.jar
Зависимости необходимые для работы DataSpace SDK
org.apache.httpcomponents
httpclient
io.projectreactor.netty
reactor-netty
org.springframework
spring-webflux
org.apache.commons
commons-lang3
com.google.guava
guava
26.0-jre
io.grpc
grpc-stub
1.39.0
com.google.protobuf
protobuf-java
3.15.8
Зависимость нужна для осуществления подписи REST-запросов при помощи ak/sk
sbp.ts.faas
java-sdk-core
3.1.2
system
${project.basedir}/src/libs/java-sdk-core-3.1.2.jar
Зависимость необходимая для работы java-sdk-core
joda-time
joda-time
2.10.3
```
Сервис Vouchers будет предоставлять REST API, который принимает на вход промокод и тип подарка. В ответ он отдаёт сообщение с информацией о результате бронирования подарка.
Определим API в нашем контроллере:
```
@RestController
public class VouchersController {
@Autowired
private VouchersService vouchersService;
@RequestMapping(value = "/getGiftByPromoCode")
public ResponseEntity getGiftByPromoCode(@RequestParam String voucherCode, @RequestParam String giftKind) {
return ResponseEntity.ok()
.contentType(MediaType.TEXT\_PLAIN)
.body(vouchersService.getGift(voucherCode, giftKind));
}
}
```
Перейдём к конфигурации. Определим инстансы DataspaceCorePacketClient и DataspaceCoreSearchClient. Нам понадобится адрес сервиса DataSpace и ak/sk для авторизации на API gateway. Все эти значения мы получаем из соответствующих инфраструктурных переменных DATASPACE\_URL, APP\_KEY, APP\_SECRET.
Также нам потребуется RestTemplate для осуществления вызовов к сервису Gifts:
```
@Configuration
public class Config {
@Value("${DATASPACE_URL}")
private String dataSpaceUrl;
@Value("${APP_KEY}")
private String appKey;
@Value("${APP_SECRET}")
private String appSecret;
@Bean
public RestTemplate restTemplate() {
return new RestTemplate();
}
@Bean
public DataspaceCoreSearchClient searchClient() {
return new DataspaceCoreSearchClient(dataSpaceUrl,
DataspaceSdkApiClientConfiguration.of(builder ->
builder
.setApiGatewayConfiguration(AKSKApiGatewayConfiguration.of(appKey, appSecret))
)
);
}
@Bean
public DataspaceCorePacketClient packetClient() {
return new DataspaceCorePacketClient(dataSpaceUrl,
DataspaceSdkApiClientConfiguration.of(builder ->
builder
.setApiGatewayConfiguration(AKSKApiGatewayConfiguration.of(appKey, appSecret))
)
);
}
```
Также нам понадобятся:
* адрес проекта;
* appKey;
* appSecret.
Найти эти значения можно в настройках проекта:
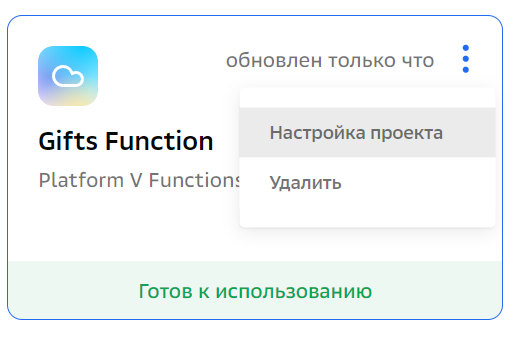В конфигурационном файле config.yaml определим необходимые настройки:
```
gifts.url: https://gw-ift-sm.pv-api-test.sbc.space/fn_fa969687_4694_4b3e_a871_5g42q56he710
gifts.appKey: d9ad1de7d38f493793c407061dc1111e
gifts.appSecret: a418e8315cf0222fbf4784811fe3dc8a
```
Перейдём к реализации VoucherService.
Алгоритм заказа подарка по промокоду будет выглядеть так:
1. Запрос клиента поступает с фронта в сервис Vouchers, который выполняет валидацию промокода.
2. Если валидация прошла успешно, сервис Vouchers вызывает сервис Gifts по REST.
3. Сервис Gifts должен найти подходящий подарок и забронировать его либо вернуть ответ, содержащий информацию о том, что доступные подарки отсутствуют.
4. Сервис Vouchers получает идентификатор подарка, привязывает его к промокоду и отправляет ответ с серийным номером подарка и наименованием компании клиенту.
5. Если подарок не был найден, сервис отправляет соответствующий ответ клиенту:
```
public String getGiftByPromoCode(String code,
String giftKind) {
try {
String voucherId = verifyPromoCode(code);
JsonNode giftResponse = getGift(giftKind, voucherId);
JsonNode error = giftResponse.get("error");
if (error != null) {
return error.textValue();
}
updateVoucher(voucherId, giftResponse.get("giftId").textValue());
return "You have been given a gift from " + giftResponse.get("vendor") + ". Serial number: " + giftResponse.get("serialNumber");
} catch (Exception e) {
LOG.error(e.getMessage());
return e.getMessage();
}
}
```
В основном методе getGiftsByPromoCode нам необходимо проверить, что переданный промокод валиден. Для этого нужно убедиться, что промокод с таким кодом присутствует в базе данных, и он не был использован ранее.
Рассмотрим метод verifyPromoCode:
```
public String verifyPromoCode(String code) throws SdkJsonRpcClientException {
try {
VoucherGet voucher = searchClient.getVoucher(voucherWith ->
voucherWith
.withCode()
.withStatusForVoucherMain(StatusWithLinkable::withCode)
.withGift()
.setWhere(where -> where.codeEq(code)));
if (voucher.getGift().getEntityId() != null ||
!voucher.getStatusForVoucherMain().getCode().equals(VoucherVoucherMainStatus.OPEN.getValue())) {
throw new GiftAlreadyIssuedException(code);
}
return voucher.getObjectId();
} catch (ObjectNotFoundException objectNotFoundException) {
throw new VoucherNotFoundException(code);
}
}
```
Метод DataspaceCoreSearchClient#getVoucher из состава DataSpace SDK позволяет построить в типизированном формате запрос к сервису DataSpace Vouchers.
В лямбда-выражении мы указываем спецификацию с набором полей, которые хотим получить в ответе, а также задаём условие поиска.
Get-метод предполагает возникновение ObjectNotFoundException в случае, если по запросу ничего не нашлось.
Далее нужно убедиться, что у запрашиваемого промокода нет ссылки на уже полученный подарок, а статус — «ОТКРЫТ». В противном случае отправляем сообщение о том, что данный промокод уже был использован.
Мы провели валидацию промокода и получили его идентификатор, теперь нужно забронировать подходящий подарок.
В **методе getGift** вызовем сервис Gifts по REST. При этом подпишем наш запрос при помощи ключей ak/sk для корректной авторизации на ApiGateway:
```
private JsonNode getGift(String giftKind, String voucherId) throws Exception {
final String GET_GIFT_URL = giftsFunctionUrl + GET_GIFT_ENDPOINT;
Request request = new Request();
request.setMethod("GET");
request.setBody("");
request.setKey(appKey);
request.setSecret(appSecret);
request.setUrl(GET_GIFT_URL);
request.addQueryStringParam("voucherId", voucherId);
request.addQueryStringParam("giftKind", giftKind);
new Signer().sign(request);
HttpHeaders requestHeaders = new HttpHeaders();
request.getHeaders().forEach((k, v) -> requestHeaders.put(k, Collections.singletonList(v)));
String urlTemplate = UriComponentsBuilder.fromHttpUrl(GET_GIFT_URL)
.queryParam("voucherId", "{voucherId}")
.queryParam("giftKind", "{giftKind}")
.encode()
.toUriString();
Map params = new HashMap<>();
params.put("voucherId", voucherId);
params.put("giftKind", giftKind);
ResponseEntity response = restTemplate.exchange(
urlTemplate, HttpMethod.GET, new HttpEntity<>(requestHeaders), JsonNode.class, params);
return response.getBody();
}
```
В ответ получаем ошибку, которую пробрасываем на фронт, или атрибуты забронированного подарка.
Если мы получили положительный ответ от Gifts, нужно отметить, что обрабатываемый промокод использован и за ним закреплён подарок.
Рассмотрим метод updateVoucher:
```
public void updateVoucher(String voucherId,
String giftId) throws SdkJsonRpcClientException {
UpdateVoucherParam updateVoucherParam =
UpdateVoucherParam.create()
.setStatusForVoucherMain(VoucherVoucherMainStatus.ISSUED)
.setGift(GiftReference.of(giftId));
Packet updatePacket = new Packet(voucherId);
updatePacket.voucher.update(VoucherRef.of(voucherId), updateVoucherParam);
packetClient.execute(updatePacket);
}
```
Метод DataspaceCorePacketClient#execute оперирует объектами типа Packet. Packet является реализацией паттерна UnitOfWork. Все команды, содержащиеся в рамках одного Packet, выполняются в одной транзакции на стороне сервиса DataSpace.
Создаём объект Packet. При этом задаём параметр *idempotencePacketId* — таким образом мы наделяем Packet свойством идемпотентности.
*IdempotencePacketId* выступает ключом идемпотентности. Это означает, что на все последующие вызовы Packet c таким же ключом DataSpace вернёт результат, который был получен при первом успешном вызове. При этом сами операции изменения состояния БД выполнены не будут. В качестве ключа идемпотентности используем идентификатор сущности Voucher.
Добавляем в Packet команду update сущности Voucher. При этом указываем идентификатор сущности, а также значения полей, которые нужно установить.
Вызываем метод DataspaceCorePacketClient#execute, чтобы отправить запрос в DataSpace.
В методе getGiftByPromoCode отправляем на фронт сообщение о полученном подарке или ошибку.
Сервис Gifts
------------
Скачиваем jar с DataSpace SDK, но на этот раз из сервиса DataSpace Gifts:
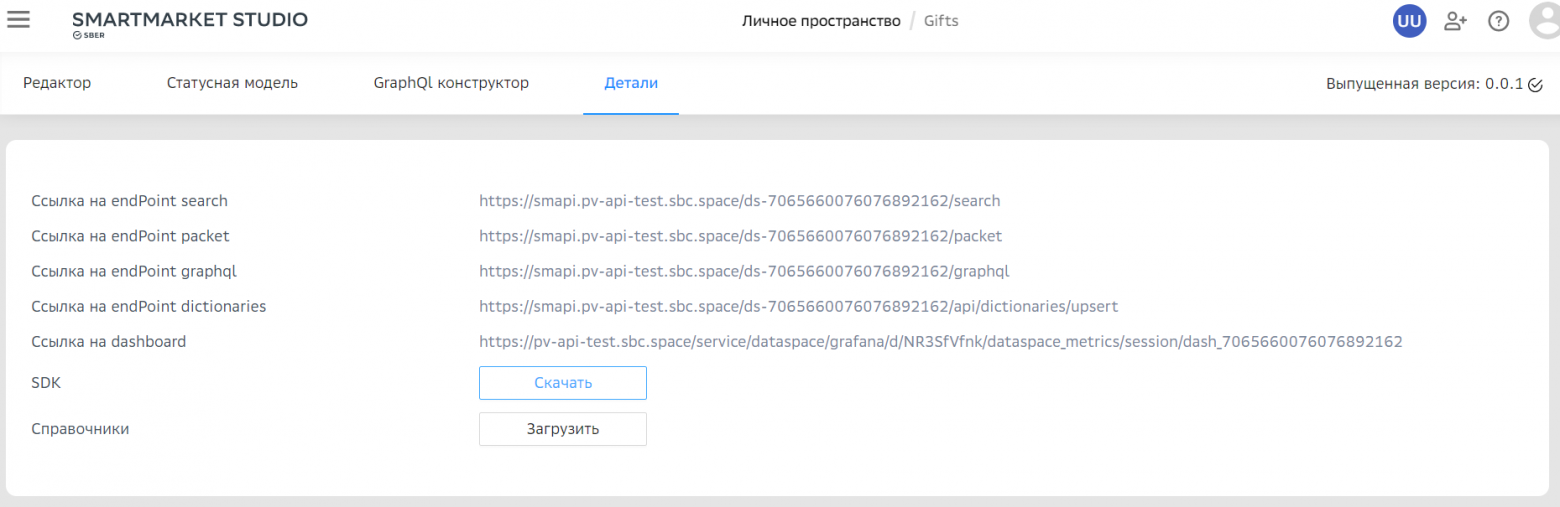Создаём проект, подключаем зависимости точно так же, как и в случае с сервисом Vouchers:
Сервис Gift будет предоставлять REST API, который принимает на вход идентификатор промокода и тип подарка.
В ответ он отдаёт JSON, в котором содержится информация о забронированном подарке или ошибка.
Определим API в нашем контроллере:
```
@RestController
public class GiftsController {
@Autowired
private GiftsService giftsService;
@RequestMapping(value = "/getGift")
public ResponseEntity getGift(@RequestParam String voucherId, @RequestParam String giftKind) {
return ResponseEntity.ok()
.contentType(MediaType.APPLICATION\_JSON)
.body(giftsService.getGift(voucherId, giftKind));
}
}
```
Определим инстансы DataspaceCorePacketClient и DataspaceCoreSearchClient. Получаем необходимые параметры из соответствующих инфраструктурных переменных DATASPACE\_URL, APP\_KEY, APP\_SECRET.
```
@Configuration
public class Config {
@Value("${DATASPACE_URL}")
private String dataSpaceUrl;
@Value("${APP_KEY}")
private String appKey;
@Value("${APP_SECRET}")
private String appSecret;
@Bean
public DataspaceCoreSearchClient searchClient() {
return new DataspaceCoreSearchClient(dataSpaceUrl,
DataspaceSdkApiClientConfiguration.of(builder ->
builder
.setApiGatewayConfiguration(AKSKApiGatewayConfiguration.of(appKey, appSecret))
)
);
}
@Bean
public DataspaceCorePacketClient packetClient() {
return new DataspaceCorePacketClient(dataSpaceUrl,
DataspaceSdkApiClientConfiguration.of(builder ->
builder
.setApiGatewayConfiguration(AKSKApiGatewayConfiguration.of(appKey, appSecret))
)
);
}
}
```
Перейдём к реализации GiftsService.
Рассмотрим основной метод GiftsService#getGift:
```
public JsonNode getGift(String voucherId, String kind) {
ObjectNode response = objectMapper.createObjectNode();
try {
updateRequestCount(voucherId, kind);
GraphCollection gifts = searchClient.searchGift(giftWith ->
giftWith
.withKind()
.withVendor(GiftVendorWithLinkable::withName)
.withSerialNumber()
.setWhere(where ->
where
.kindEq(GiftKind.valueOf(kind))
.and(where.voucherIsNull().or(where.voucherEq(voucherId)))
)
);
if (gifts.isEmpty()) {
LOG.error("Available gift not found");
response.put("error", "Available gift not found");
return response;
}
GiftGet gift = gifts.get(0);
String giftId = gift.getObjectId();
Packet packet = new Packet(giftId);
packet.gift.update(GiftRef.of(giftId),
update -> update
.setVoucher(VoucherReference.of(voucherId)));
packetClient.execute(packet);
response.put("giftId", giftId);
response.put("vendor", gift.getVendor().getName());
response.put("serialNumber", gift.getSerialNumber());
} catch (IdempotencyException idempotencyException) {
LOG.error(idempotencyException.getMessage());
return getGift(voucherId, kind);
} catch (Exception exception) {
LOG.error(exception.getMessage());
response.put("error", exception.getMessage());
}
return response;
}
```
Разберём его детально.
В сервисе Gifts помимо самих подарков и компаний ведётся сущность GiftRequestCounter, которая хранит количество поступивших запросов для каждого типа подарка.
Предполагается, что она будет использована в аналитических отчётах:
```
private void updateRequestCount(String voucherId, String kind) {
String idempotencePacketId = voucherId + kind;
Packet packet = new Packet(idempotencePacketId);
CreateGiftRequestCounterParam createGiftRequestCounterParam =
CreateGiftRequestCounterParam.create()
.setKind(GiftKind.valueOf(kind))
.setLastRequest(LocalDateTime.now());
GiftRequestCounterRef giftRequestCounter = packet.giftRequestCounter.updateOrCreate(
createGiftRequestCounterParam, KeyGiftRequestCounter.KIND);
UpdateGiftRequestCounterReq updateGiftRequestCounterReq =
UpdateGiftRequestCounterReq.create()
.setInc(IncGiftRequestCounterParam.create().setCounter(1));
packet.giftRequestCounter.update(giftRequestCounter, updateGiftRequestCounterReq);
packetClient.executeAsync(packet).subscribe();
}
```
В методе updateRequestCount мы отправляем асинхронно запрос на увеличение счётчика GiftRequestCounter в сервис DataSpace Gifts.
Создаём Packet с ключом идемпотентности, состоящим из идентификатора промокода и типа подарка, чтобы избежать лишнего накручивания счётчика при ретраях.
В Packet добавляем команду UpdateOrCreate. Эта команда позволяет за один вызов проверить наличие сущности в БД и обновить её, а если сущности нет, то создать. Также мы добавляем команду update с установленным параметром на увеличение счётчика. Затем отправляем запрос асинхронно при помощи метода DataspaceCorePacketClient#executeAsync.
Далее в основном методе сервиса getGift производим поиск доступного подарка, используя метод DataspaceCoreSearchClient#searchGift:
```
GraphCollection gifts = searchClient.searchGift(giftWith ->
giftWith
.withKind()
.withVendor(GiftVendorWithLinkable::withName)
.withSerialNumber()
.setWhere(where ->
where
.kindEq(GiftKind.valueOf(kind))
.and(where.voucherIsNull().or(where.voucherEq(voucherId)))
)
);
```
Если доступные подарки не были найдены, формируем ответ с ошибкой:
```
if (gifts.isEmpty()) {
LOG.error("Available gift not found");
response.put("error", "Available gift not found");
return response;
}
```
Если подходящие подарки нашлись, нам необходимо забронировать один из них, установив ссылку на соответствующий ваучер.
Снова воспользуемся функционалом DataspaceCorePacketClient. Создадим Packet и добавим в него команду на обновление сущности Gift.
Обратим внимание, что данный запрос мы выполняем идемпотентно, используя при этом в качестве ключа идентификатор подарка.
Данный подход позволяет нам не допустить ситуацию, в которой один и тот же подарок будет забронирован для нескольких разных ваучеров, а также избежать выполнения лишних операций при ретраях:
```
GiftGet gift = gifts.get(0);
String giftId = gift.getObjectId();
Packet packet = new Packet(giftId);
packet.gift.update(GiftRef.of(giftId),
update -> update
.setVoucher(VoucherReference.of(voucherId)));
packetClient.execute(packet);
```
Сервис Reports
--------------
Перейдём к реализации сервиса, который предоставляет API для получения отчётов.
Данный сервис будет предоставлять отчёты о подарках, поэтому нам потребуется jar DataSpace SDK из сервиса DataSpace Gifts.
Создадим проект, добавим необходимую зависимость:
Реализуем API получения следующего отчёта:
Компания | тип подарка | кол-во подарков:
```
@RestController
public class ReportController {
@Autowired
private ReportService reportService;
@RequestMapping(value = "/getGiftsReport")
public ResponseEntity getGiftsReport() {
return ResponseEntity.ok()
.contentType(MediaType.APPLICATION\_JSON)
.body(reportService.getGiftsReport());
}
}
```
Рассмотрим реализацию основного метода ReportService#getGiftsReport с применением DataSpace SDK:
```
public JsonNode getGiftsReport() {
ObjectNode response = objectMapper.createObjectNode();
try {
SelectionWith extends GiftGrasp selectionWith = GiftGraph.createSelection()
.$withGroup("vendor", groupSelector -> groupSelector.none(giftGrasp -> giftGrasp.vendor().name()))
.$withGroup("kind", groupSelector -> groupSelector.none(GiftGrasp::kind))
.$withGroup("giftsCount", groupSelector -> groupSelector.count(GiftGrasp::kind))
.$addGroupBy(groupBy -> groupBy.vendor().name())
.$addGroupBy(GiftGrasp::kind);
GraphCollection selections = searchClient.selectionSearch(selectionWith);
ArrayNode reportRows = objectMapper.createArrayNode();
selections.forEach(selection -> {
ObjectNode objectNode = objectMapper.createObjectNode();
objectNode.put("vendor", selection.$getCalculated("vendor", String.class));
objectNode.put("kind", selection.$getCalculated("kind", String.class));
objectNode.put("giftsCount", selection.$getCalculated("giftsCount", Integer.class));
reportRows.add(objectNode);
});
response.set("report", reportRows);
} catch (SdkJsonRpcClientException e) {
LOG.error(e.getMessage());
response.put("error", e.getMessage());
}
return response;
}
```
Конструкция SelectionWith позволяет построить запрос с группировками.
Метод $withGroup первым параметром принимает алиас поля, который будет отображён в результирующей выборке. Вторым параметром $withGroup принимает groupSelector, который позволяет указать выражение, на основе которого будут получены данные, будь то значение поля как оно есть или агрегирующая функция.
При помощи метода $addGroupBy мы добавляем поля, по которым будет выполнена группировка.
После формирования объекта SelectionWith выполняем вызов DataspaceCoreSearchClient#selectionSearch. Формируем JSON-ответ. Метод Selection#$getCalculated позволяет получить данные из объекта Selection, а также привести их к требуемому типу данных.
Публикация функций и тестирование
---------------------------------
Приложения готовы, теперь необходимо упаковать каждое в zip-архив и загрузить в соответствующую функцию в SmartMarket Studio:
* [vouchers.zip](https://github.com/MaximNavodnikov/promo-action/blob/main/vouchers.zip)
* [gifts.zip](https://github.com/MaximNavodnikov/promo-action/blob/main/gifts.zip)
* [report.zip](https://github.com/MaximNavodnikov/promo-action/blob/main/report.zip)
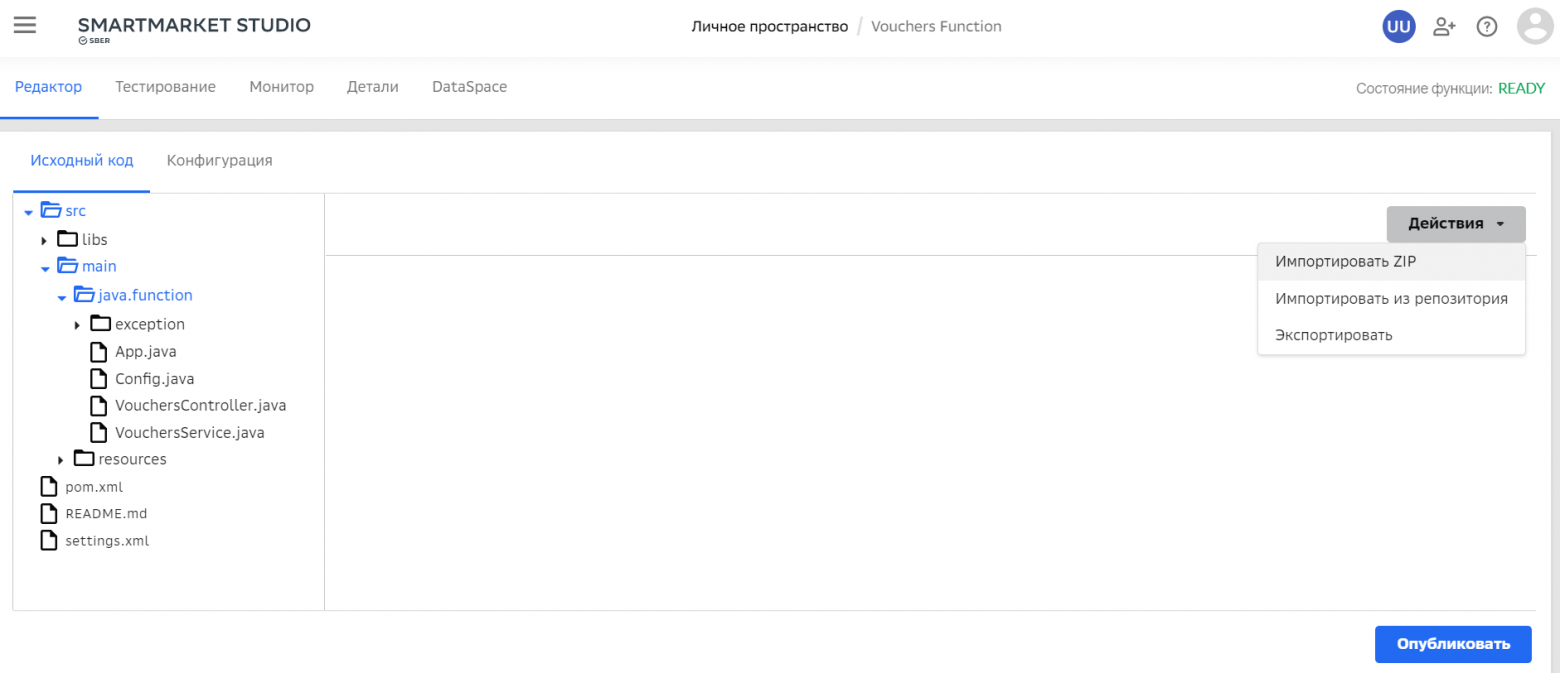Затем жмём кнопку «*Опубликовать»* и ждём, пока функции задеплоятся.
После успешного деплоя на вкладке «*Тестирование»*мы можем проверить работоспособность наших API:
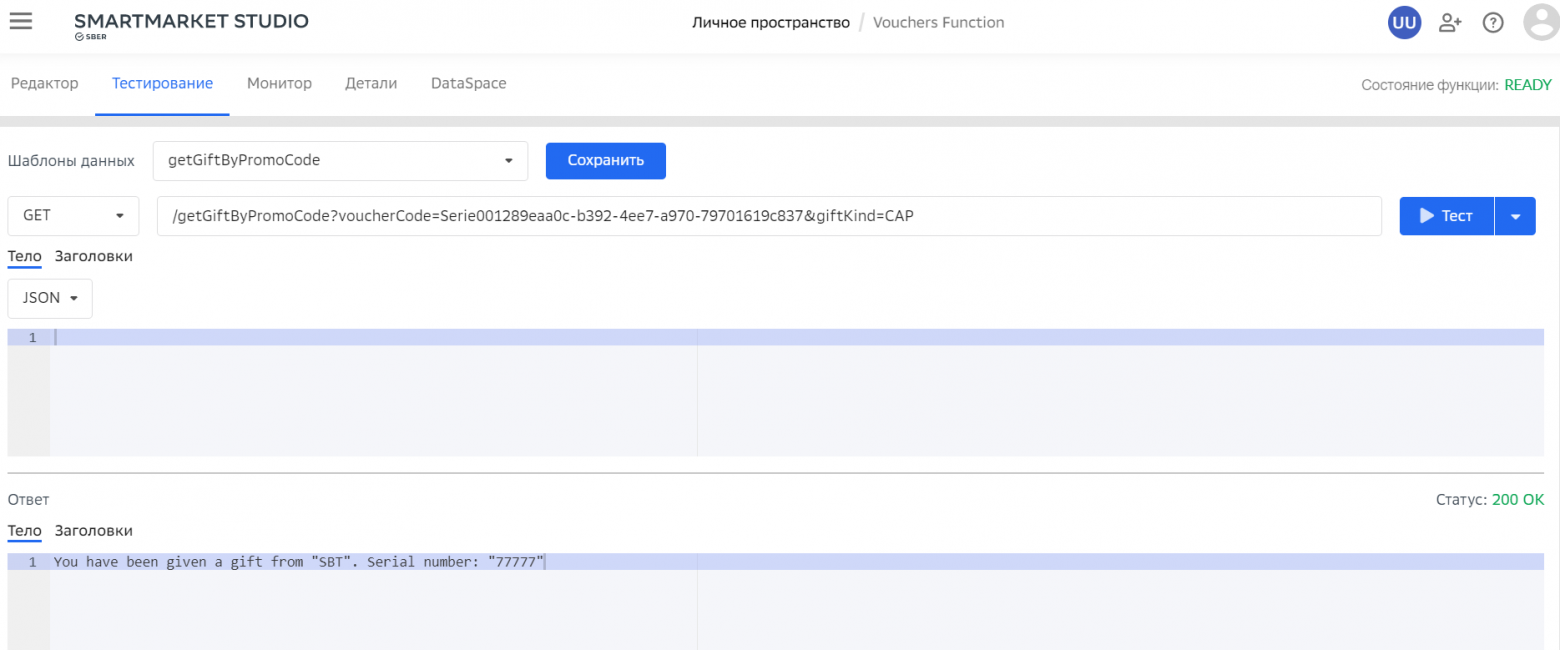Итог
----
С помощью Platform V Functions и DataSpace SDK мы создали и развернули два полноценных микросервиса:
* Подарки:
a) Ведение компаний-спонсоров и их подарков.
b) Аналитический учёт пользовательских запросов.
* ·Промоакции:
a) Ведение промоакций и ваучеров в рамках сервиса.
b) Резервирование подарков в рамках промоакций (интеграция с сервисом «Подарки»).
В следующих статьях подробнее раскроем фичи и возможности Platform V Functions и расскажем, как ещё можно сократить время на разработку и реализовать микросервисный подход, используя инструменты Platform V. | https://habr.com/ru/post/662397/ | null | ru | null |
# Собираем генератор данных на Blender. Часть 2: Камера
*Всем привет! На связи Глеб, в* [*предыдущей статье*](https://habr.com/ru/company/friflex/blog/666958/) *мы рассмотрели работу с объектами на Blender. Но для того, чтобы создать минимально жизнеспособный генератор, нужно разобраться в том, как работают камеры.*
### Получение доступа к камере
На сцене камера отображается, как обычный объект «bpy.types.Object». Мы можем менять стандартные свойства, которые рассмотрели в [предыдущей статье](https://habr.com/ru/company/friflex/blog/666958/). Но для камеры также определен набор специальных настроек: фокусное расстояние, размер сенсорной матрицы и прочие. Доступ к ним мы можем получить через класс «bpy.types.Camera».
В прошлой статье мы увидели, что у экземпляра «bpy.types.Object» есть свойство «data», в котором лежит экземпляр класса, предоставляющий доступ к специальным свойствам. Это как раз то, что нам нужно. Ведь в случае с камерой внутри «data» лежит тот самый объект с типом «bpy.types.Camera».
Поэтому, чтобы получить доступ к свойствам, которые мы упомянули ранее, нужно сделать следующее:
```
camera_object = bpy.data.objects['Camera']
camera = camera_object.data
```
Теперь через переменную «camera» мы можем получить доступ к следующим [свойствам и методам](https://docs.blender.org/api/current/bpy.types.Camera.html?highlight=camera#bpy.types.Camera). Часть из которых мы рассмотрим чуть позже.
### Выбор основной камеры
Так как на сцене может быть несколько камер, нам нужно выбрать основную, с которой будет вестись съемка.
```
# Получаем сцену, с которой работаем
scene = bpy.context.scene
# Получаем камеру, которую будет использовать, как основную
camera = bpy.data.objects['Camera']
# Устанавливаем камеру, как основную для этой сцены
scene.camera = camera
```
### Что видит камера?
Для настройки камеры полезно понять какие объекты попадают в её поле зрения. Для этого мы можем переключиться в режим «Camera view», которой покажет, что видит основная камера сцены.
Это гифка. Чтобы посмотреть, нажмите на изображение### Разрешение
В blender нет свойства, которое бы отвечало за разрешение конкретной камеры. Для этой цели мы будем использовать свойство рендеринга.
```
# Получаем настройки рендеринга для конкретной сцены
render = bpy.context.scene.render
# Меняем разрешение относительно осей x и y в пикселях
render.resolution_x = 1920
render.resolution_y = 1080
```
**Важно!** Новое разрешение автоматически применится **ко всем камерам**.
Это гифка. Чтобы посмотреть, нажмите на изображениеНа данный момент мы научились получать доступ к камере и менять разрешение. Пришло время разобраться со свойствами, которые предоставляет класс «bpy.types.Camera».
### lens
Это свойство отвечает за фокусное расстояние. Единицей измерения является миллиметр.
```
camera = bpy.data.cameras['Camera']
camera.lens = 10
```
Это гифка. Чтобы посмотреть, нажмите на изображение### sensor\_width / sensor\_height
Помимо фокусного расстояния мы можем взаимодействовать с размером сенсорной матрицы. Как и в случае с фокусным расстоянием, единицей измерения является миллиметр. Размер матрицы удобно использовать, когда у нас есть реальная камера, свойства которой мы хотим воспроизвести при генерации данных.
```
camera = bpy.data.cameras['Camera']
camera.sensor_width = 32
```
### shift\_x / shift\_y
Смысл этих свойств легче всего объяснить с помощью наглядного примера.
Это гифка. Чтобы посмотреть, нажмите на изображениеЭто гифка. Чтобы посмотреть, нажмите на изображениеЕдиницы измерения этих свойств рассчитываются относительно наибольшей стороны кадра:
*shift\_in\_pixels / max(resolution\_x, resolution\_y) <- Это формула*
Допустим, разрешение 1920x1080 и мы хотим сместить кадр на 100 пикселей вправо и 200 пикселей вниз.
```
resolution = (
bpy.context.scene.render.resolution_x,
bpy.context.scene.render.resolution_y
)
shift_x_in_px = 100
shift_y_in_px = -200
camera = bpy.data.cameras[‘Camera’]
camera.shift_x = shift_x_in_px / max(resolution)
camera.shift_y = shift_y_in_px / max(resolution)
```
### Проецирование точек на кадр
Зачастую, нам требуются получить координаты объектов изображенных на кадре. Для этой цели мы будем использовать функцию «world\_to\_camera\_view», находящуюся в библиотеке «bpy\_extras».
Эта функция получает на вход следующие аргументы:
* scene [ bpy.types.Scene ]: используется для определения размера кадра
* obj [ **bpy.types.Object** ]: Камера, с которой происходит съемка
* coord [ mathutils.Vector ]: Координаты точки, которую мы хотим отобразить на кадр
В результате использования «world\_to\_camera\_view» мы получим вектор, состоящий из 3 значений: координата по оси х, координата по оси y, дистанция от камеры до объекта.
```
from bpy_extras.object_utils import world_to_camera_view
cube = bpy.data.objects['Cube']
scene = bpy.context.scene
camera = bpy.data.objects['Camera']
world_to_camera_view(scene, camera, cube.location)
# Vector((0.4990274906158447, 0.513164222240448, 11.256155967712402))
```
### Наведение на объект
На этом этапе, мы хотим навести камеру на интересующий нас объект. Для решения этой задачи я нашел два решения.
#### Constraints
В blender есть встроенная возможность «приказать» камере отслеживать какой-то объект. Но стоит заметить, что камера будет наводиться на центр выбранного объекта.
```
# Получение доступа к объектам
camera = bpy.data.objects[‘Camera’]
target = bpy.data.objects[‘Cube’]
# Создание ограничения
constraint = camera.constraints.new(type=’TRACK_TO’)
constraint.target = target
```
Это гифка. Чтобы посмотреть, нажмите на изображениеЕсть и другие интересные ограничения, которые можно использовать при создании своего генератора. Подробнее об этом можно прочитать в [документации](https://docs.blender.org/manual/en/latest/animation/constraints/index.html).
#### mathutils.vector
Суть этого подхода в том, что мы рассчитываем угол, на который нужно повернуть камеру, чтобы она смотрела на точку, а затем производим поворот. В отличии от предыдущего подхода, мы передаем координату, а не объект. Это добавляет нам пространство для маневра. К примеру, мы можем навести камеру на один из углов куба.
```
# Функция для наведения
def point_camera_at(
camera: bpy.types.Object,
target: mathutils.Vector,
track_axis: str = 'Z',
up_axis: str = 'Y'
):
vector = camera.location - target
camera.rotation_euler = vector.to_track_quat(
track_axis,
up_axis
).to_euler()
# Получаем доступ к объектам
camera = bpy.data.objects['Camera']
cube = bpy.data.objects['Cube']
# Получаем точки контура объекта cube. Используем функцию из предыдущей статьи.
bbox = bounding_box_world(cube)
# Наводим камеру на угол
point_camera_at(camera, bbox[0])
```
**Важно!** Изменяя положение камеры через api, стоит обратить внимание на одну небольшую хитрость: после трансформации нужно вручную обновить состояние сцены. Если пропустить этот шаг, то функция «world\_to\_camera\_view» будет возвращать проекции относительно старого положения и поворота.
```
# Обновляем состояние сцены
bpy.context.view_layer.update()
```
### The end
Blender мы в [Friflex](https://friflex.com/) используем в рамках разработки наших продуктов по оцифровке спорта, в том числе [idChess](https://idchess.com). И в серии статей на Хабр я делюсь своим опытом. В следующих материалах мы рассмотрим свойства источников света и работу с материалами через пользовательские свойства и драйверы и научимся загружать объекты из разных файлов и запускать рендеринг сцены через консоль.
Если вы работали с blender и хотите обсудить прочитанное или поделиться своим опытом и знаниями, жду вас в комментариях! Сделаем статью более полной и полезной для новичков. | https://habr.com/ru/post/668978/ | null | ru | null |
# Создание микросервиса на Quarkus, Kotlin и Gradle

Введение
--------
В [предыдущей статье](https://romankudryashov.com/blog/2020/01/heterogeneous-microservices/) было приведено краткое описание процесса создания микросервиса на современных JVM фреймворках, а также их сравнение. В этой статье будет более детально рассмотрен недавно вышедший [Quarkus](https://quarkus.io/) на примере создания микросервиса с использованием упомянутых технологий и в соответствии с требованиями, указанными в основной статье. Полученное приложение станет частью следующей микросервисной архитектуры:
Исходный код проекта, как обычно, доступен на [GitHub](https://github.com/rkudryashov/heterogeneous-microservices/tree/master/quarkus-service).
Перед началом работы с проектом должны быть установлены:
* JDK 13
* [Consul](https://www.consul.io)
Создание нового проекта
-----------------------
Для генерации нового проекта используйте [web starter](https://code.quarkus.io) или Maven (для создания [Maven](https://quarkus.io/guides/getting-started) проекта или [Gradle](https://quarkus.io/guides/gradle-tooling) проекта). Стоит отметить, что фреймворк поддерживает языки Java, Kotlin и Scala.
Зависмости
----------
В этом проекте в качестве системы сборки используется Gradle Kotlin DSL. Скрипт сборки должен содержать:
* плагины
*Листинг 1. [build.gradle.kts](https://github.com/rkudryashov/heterogeneous-microservices/blob/master/quarkus-service/build.gradle.kts)*
```
plugins {
kotlin("jvm")
kotlin("plugin.allopen")
id("io.quarkus")
}
```
Разрешение версий плагинов выполняется в [`settings.gradle.kts`](https://github.com/rkudryashov/heterogeneous-microservices/blob/master/settings.gradle.kts).
* зависимости
*Листинг 2. [build.gradle.kts](https://github.com/rkudryashov/heterogeneous-microservices/blob/master/quarkus-service/build.gradle.kts)*
```
dependencies {
...
implementation(enforcedPlatform("io.quarkus:quarkus-bom:$quarkusVersion"))
implementation("io.quarkus:quarkus-resteasy-jackson")
implementation("io.quarkus:quarkus-rest-client")
implementation("io.quarkus:quarkus-kotlin")
implementation("io.quarkus:quarkus-config-yaml")
testImplementation("io.quarkus:quarkus-junit5")
...
}
```
Информация по поводу импорта Maven BOM доступна в [документации Gradle](https://docs.gradle.org/current/userguide/platforms.html#sub:bom_import).
Также требуется сделать некоторые Kotlin классы `open` (по умолчанию они `final`; больше информации по конфигурированию Gradle в [Quarkus Kotlin guide](https://quarkus.io/guides/kotlin#important-gradle-configuration-points):
*Листинг 3. [build.gradle.kts](https://github.com/rkudryashov/heterogeneous-microservices/blob/master/quarkus-service/build.gradle.kts)*
```
allOpen {
annotation("javax.enterprise.context.ApplicationScoped")
}
```
Конфигурирование
----------------
Фреймворк поддерживает конфигурирование с использованием properties и YAML файлов
(подробнее в [Quarkus config guide](https://quarkus.io/guides/config)). Конфигурационный файл располагается в папке `resources` и выглядит так:
*Листинг 4. [application.yaml](https://github.com/rkudryashov/heterogeneous-microservices/blob/master/quarkus-service/src/main/resources/application.yaml)*
```
quarkus:
http:
host: localhost
port: 8084
application-info:
name: quarkus-service
framework:
name: Quarkus
release-year: 2019
```
В этом фрагменте кода конфигурируются стандартные и кастомные параметры микросервиса. Последние могут быть прочитаны так:
*Листинг 5. Чтение кастомных параметров приложения ([исходный код](https://github.com/rkudryashov/heterogeneous-microservices/blob/master/quarkus-service/src/main/kotlin/io/heterogeneousmicroservices/quarkusservice/config/ApplicationInfoProperties.kt))*
```
import io.quarkus.arc.config.ConfigProperties
@ConfigProperties(prefix = "application-info")
class ApplicationInfoProperties {
lateinit var name: String
lateinit var framework: FrameworkConfiguration
class FrameworkConfiguration {
lateinit var name: String
lateinit var releaseYear: String
}
}
```
Бины
----
Перед тем как начать работать с кодом, надо отметить, что в исходном коде приложения на Quarkus нет main метода (хотя, возможно, [появится](https://github.com/quarkusio/quarkus/issues/6499)).
Внедрение `@ConfigProperties` бина с предыдущего листинга в другой бин выполняется с использованием аннотации `@Inject`:
*Листинг 6. Внедрение `@ConfigProperties` бина ([исходный код](https://github.com/rkudryashov/heterogeneous-microservices/blob/master/quarkus-service/src/main/kotlin/io/heterogeneousmicroservices/quarkusservice/service/ApplicationInfoService.kt))*
```
@ApplicationScoped
class ApplicationInfoService(
@Inject private val applicationInfoProperties: ApplicationInfoProperties,
@Inject private val serviceClient: ServiceClient
) {
...
}
```
`ApplicationInfoService` бин, аннотированный `@ApplicationScoped`, в свою очередь, внедряется так:
*Листинг 7. Внедрение `@ApplicationScoped` бина ([исходный код](https://github.com/rkudryashov/heterogeneous-microservices/blob/master/quarkus-service/src/main/kotlin/io/heterogeneousmicroservices/quarkusservice/web/ApplicationInfoResource.kt))*
```
class ApplicationInfoResource(
@Inject private val applicationInfoService: ApplicationInfoService
)
```
Больше информации по Contexts and Dependency Injection в [Quarkus CDI guide](https://quarkus.io/guides/cdi-reference).
REST контроллер
---------------
В REST контроллере нет ничего необычного для тех, кто работал с Spring Framework или Java EE:
*Листинг 8. REST контроллер ([исходный код](https://github.com/rkudryashov/heterogeneous-microservices/blob/master/quarkus-service/src/main/kotlin/io/heterogeneousmicroservices/quarkusservice/web/ApplicationInfoResource.kt))*
```
@Path("/application-info")
@Produces(MediaType.APPLICATION_JSON)
@Consumes(MediaType.APPLICATION_JSON)
class ApplicationInfoResource(
@Inject private val applicationInfoService: ApplicationInfoService
) {
@GET
fun get(@QueryParam("request-to") requestTo: String?): Response =
Response.ok(applicationInfoService.get(requestTo)).build()
@GET
@Path("/logo")
@Produces("image/png")
fun logo(): Response = Response.ok(applicationInfoService.getLogo()).build()
}
```
REST клиент
-----------
Для работы в микросервисной архитектуре Quarkus сервис должен уметь выполнять запросы к другим сервисам. Т. к. все сервисы имеют одинаковый API, имеет смысл создать единый интерфейс для общего кода и пачку наследующих его REST клиентов:
*Листинг 9. REST клиенты ([исходный код](https://github.com/rkudryashov/heterogeneous-microservices/blob/master/quarkus-service/src/main/kotlin/io/heterogeneousmicroservices/quarkusservice/service/ExternalServiceClients.kt))*
```
@ApplicationScoped
@Path("/")
interface ExternalServiceClient {
@GET
@Path("/application-info")
@Produces("application/json")
fun getApplicationInfo(): ApplicationInfo
}
@RegisterRestClient(baseUri = "http://helidon-service")
interface HelidonServiceClient : ExternalServiceClient
@RegisterRestClient(baseUri = "http://ktor-service")
interface KtorServiceClient : ExternalServiceClient
@RegisterRestClient(baseUri = "http://micronaut-service")
interface MicronautServiceClient : ExternalServiceClient
@RegisterRestClient(baseUri = "http://quarkus-service")
interface QuarkusServiceClient : ExternalServiceClient
@RegisterRestClient(baseUri = "http://spring-boot-service")
interface SpringBootServiceClient : ExternalServiceClient
```
Как видите, создание REST клиента к другим сервисам представляет собой всего лишь создание интерфейса с соответствующими JAX-RS и MicroProfile аннотациями.
Service Discovery
-----------------
Как было видно в предыдущем разделе, значениями параметра `baseUri` являются названия сервисов. Но пока что в Quarkus нет встроенной поддержки Service Discovery ([Eureka](https://github.com/quarkusio/quarkus/issues/2052)) или она не работает ([Consul](https://github.com/quarkusio/quarkus/issues/5812)), т. к. фреймворк в перую очередь направлен на работу в облачных средах. Поэтому паттерн Service Discovery реализован с использованием библиотеки [Consul Client for Java](https://github.com/rickfast/consul-client).
Клиент к Consul включает два метода, `register` и `getServiceInstance` (использующий алгоритм Round-robin):
*Листинг 10. Клиент к Consul ([исходный код](https://github.com/rkudryashov/heterogeneous-microservices/blob/master/quarkus-service/src/main/kotlin/io/heterogeneousmicroservices/quarkusservice/servicediscovery/ConsulClient.kt))*
```
@ApplicationScoped
class ConsulClient(
@ConfigProperty(name = "application-info.name")
private val serviceName: String,
@ConfigProperty(name = "quarkus.http.port")
private val port: Int
) {
private val consulUrl = "http://localhost:8500"
private val consulClient by lazy {
Consul.builder().withUrl(consulUrl).build()
}
private var serviceInstanceIndex: Int = 0
fun register() {
consulClient.agentClient().register(createConsulRegistration())
}
fun getServiceInstance(serviceName: String): Service {
val serviceInstances = consulClient.healthClient().getHealthyServiceInstances(serviceName).response
val selectedInstance = serviceInstances[serviceInstanceIndex]
serviceInstanceIndex = (serviceInstanceIndex + 1) % serviceInstances.size
return selectedInstance.service
}
private fun createConsulRegistration() = ImmutableRegistration.builder()
.id("$serviceName-$port")
.name(serviceName)
.address("localhost")
.port(port)
.build()
}
```
Сначала надо зарегистрировать приложение:
*Листинг 11. Регистрация в Consul ([исходный код](https://github.com/rkudryashov/heterogeneous-microservices/blob/master/quarkus-service/src/main/kotlin/io/heterogeneousmicroservices/quarkusservice/servicediscovery/ConsulRegistrationBean.kt))*
```
@ApplicationScoped
class ConsulRegistrationBean(
@Inject private val consulClient: ConsulClient
) {
fun onStart(@Observes event: StartupEvent) {
consulClient.register()
}
}
```
Далее требуется преобразовать названия сервисов в реальное расположение. Для этого используется класс, расширяющий `ClientRequestFilter` и аннотированный `@Provider`:
*Листинг 12. Фильтр для работы с Service Discovery ([исходный код](https://github.com/rkudryashov/heterogeneous-microservices/blob/master/quarkus-service/src/main/kotlin/io/heterogeneousmicroservices/quarkusservice/servicediscovery/ConsulFilter.kt))*
```
@Provider
@ApplicationScoped
class ConsulFilter(
@Inject private val consulClient: ConsulClient
) : ClientRequestFilter {
override fun filter(requestContext: ClientRequestContext) {
val serviceName = requestContext.uri.host
val serviceInstance = consulClient.getServiceInstance(serviceName)
val newUri: URI = URIBuilder(URI.create(requestContext.uri.toString()))
.setHost(serviceInstance.address)
.setPort(serviceInstance.port)
.build()
requestContext.uri = newUri
}
}
```
В фильтре всего лишь осуществляется замена URI объекта `requestContext` на расположение сервиса, полученное от клиента к Consul.
Тестирование
------------
Тесты для двух методов API реализованы с использованием библиотеки REST Assured:
*Листинг 13. Тесты ([исходный код](https://github.com/rkudryashov/heterogeneous-microservices/blob/master/quarkus-service/src/test/kotlin/io/heterogeneousmicroservices/quarkusservice/QuarkusServiceApplicationTest.kt))*
```
@QuarkusTest
class QuarkusServiceApplicationTest {
@Test
fun testGet() {
given()
.`when`().get("/application-info")
.then()
.statusCode(200)
.contentType(ContentType.JSON)
.body("name") { `is`("quarkus-service") }
.body("framework.name") { `is`("Quarkus") }
.body("framework.releaseYear") { `is`(2019) }
}
@Test
fun testGetLogo() {
given()
.`when`().get("/application-info/logo")
.then()
.statusCode(200)
.contentType("image/png")
.body(`is`(notNullValue()))
}
}
```
Во время тестирования нет необходимости регистрировать приложение в Consul, поэтому в исходном коде проекта рядом с тестом находится `ConsulClientMock`, расширяющий `ConsulClient`:
*Листинг 14. Мок для `ConsulClient` ([исходный код](https://github.com/rkudryashov/heterogeneous-microservices/blob/master/quarkus-service/src/test/kotlin/io/heterogeneousmicroservices/quarkusservice/ConsulClientMock.kt))*
```
@Mock
@ApplicationScoped
class ConsulClientMock : ConsulClient("", 0) {
// do nothing
override fun register() {
}
}
```
Сборка
------
Во время Gradle задачи `build` вызывается задача `quarkusBuild`. По умолчанию она генерирует *runner* JAR и папку `lib`, где находятся зависимости. Для создания uber-JAR задача `quarkusBuild` долна быть сконфигурирована следующим образом:
*Листинг 15. Настройка генерации uber-JAR ([исходный код](https://github.com/rkudryashov/heterogeneous-microservices/blob/master/build.gradle.kts))*
```
tasks {
withType {
isUberJar = true
}
}
```
Для сборки выполните в корне проекта `./gradlew clean build`.
Запуск
------
Перед запуском микросервиса надо стартовать Consul (описано в [основной статье](https://romankudryashov.com/blog/2020/01/heterogeneous-microservices/#_launch)).
Микросервис можно запустить, используя:
* Gradle задачу `quarkusDev`
Выполните в корне проекта:
`./gradlew :quarkus-service:quarkusDev`
или запустите задачу в IDE
* uber-JAR
Выполните в корне проекта:
`java -jar quarkus-service/build/quarkus-service-1.0.0-runner.jar`
Теперь можно использовать REST API, например, выполните следующий запрос:
`GET http://localhost:8084/application-info`
Результатом будет:
*Листинг 16. Результат вызова API*
```
{
"name": "quarkus-service",
"framework": {
"name": "Quarkus",
"releaseYear": 2019
},
"requestedService": null
}
```
Совместимость с Spring
----------------------
Фреймворк обеспечивает совместимость с несколькими технологиями Spring: [DI](https://quarkus.io/guides/spring-di), [Web](https://quarkus.io/guides/spring-web), [Security](https://quarkus.io/guides/spring-security), [Data JPA](https://quarkus.io/guides/spring-data-jpa).
Заключение
----------
В статье был рассмотрен пример создания простого REST сервиса на Quarkus с использованием Kotlin и Gradle. В [основной статье](https://romankudryashov.com/blog/2020/01/heterogeneous-microservices/#_comparison_of_applications_parameters) вы можете видеть, что полученное приложение имеет сопоставимые параметры с приложениями на других современных JVM фреймворках. Таким образом у Quarkus есть серьёзные конкуренты, такие как Helidon MicroProfile, Micronaut и Spring Boot (если речь идёт о fullstack фреймворках). Поэтому, думаю, нас ждёт интересное развитие событий, которое будет полезно для всей экосистемы Java.
Полезные ссылки
---------------
* [Quarkus — Get Started](https://quarkus.io/get-started/)
* [Quarkus — Creating Your First Application](https://quarkus.io/guides/getting-started)
* [Quarkus for Spring Developers](https://quarkus.io/blog/quarkus-for-spring-developers/)
P.S. Спасибо [vladimirsitnikov](https://habr.com/en/users/vladimirsitnikov/) за помощь в подготовке статьи. | https://habr.com/ru/post/484320/ | null | ru | null |
# Gimpbox — Однооконный Gimp
Сегодня я хотел бы рассказать Вам о замечательном дополнении для Gimp'а под названием Gimpbox.
Многим уже порядком поднадоел многооконный режим Gimp'a и пока все в ожидании стабильного релиза 2.8 где разработчики обещали сделать возможность выбора между многооконным и однооконным режимом, китайские разработчики подумали как можно решить эту проблему малой кровью и сделали дополнение Gimpbox, смысл которого заключается в том что бы объединить все окна Gimp'а в одно окно как это сделано например в Adobe Photoshop, Paint.net и других редакторах.
**Gimpbox является frontendом для Gimp'а, т.е. он будет работать только с уже установленным Gimp'ом.**
Под катом инструкция по установки.
Было:

[Полноразмерная картинка](http://habrastorage.org/storage/7160a6f4/d2a8c464/bf630d9a/ae3b528c.png)
Стало:

[Полноразмерная картинка](http://habrastorage.org/storage/28f9132a/98c58bac/67533e3d/00728b51.png)
**Установка и требования:**
— Gimp 2.6.10 или новее.
— Установленный python-wnck
Для удобства пользователей оформил установку одной коммандой.
`sudo wget gimpbox.googlecode.com/hg/gimpbox.py -O /usr/local/bin/gimpbox && sudo chmod +x /usr/local/bin/gimpbox`
После этого просто меняем пункт меню в настройках меню с gimp-2.6 %U на gimpbox %U
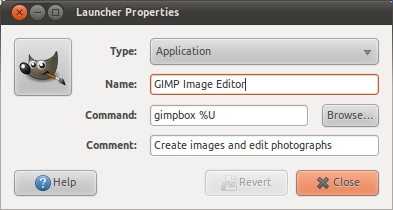
Готово, теперь у Вас однооконный Gimp.
Хочу отметить что этот frontend всё ещё работает немного не стабильно, например я так и не смог до конца разобраться как перемещаются доки, но в целом получилось довольно мило.
Дерзайте :)
[Проект на code.google.com](http://translate.google.com/translate?hl=en&sl=zh-CN&tl=ru&u=http://code.google.com/p/gimpbox/) (Переведён с помощью Google Translate) | https://habr.com/ru/post/107680/ | null | ru | null |
# Трекерная музыка. Приобщаемся к великому
Представляю вашему вниманию подборку из 15 моих любимых V2M-композиций от [товарищей](http://ru.wikipedia.org/wiki/Farbrausch) [Farbrausch](http://www.1337haxorz.de/products.html). Для прослушивания достаточно запустить Exe-шник. *Обращаем внимание на его размер и на качество звучания!*
[narod.ru/disk/9788383000/q.exe.html](http://narod.ru/disk/9788383000/q.exe.html)
(Это не вирус, клянусь кармой, сам лично компилил)
**Сразу оговорюсь, не работает в Висте и Windows 7**, почему — не знаю =(, т.к. не использую и полный профан в системном программировании, если кто подскажет, почему — буду благодарен. В \*nix под Wine должно работать.
Прежде чем начать повествование рекомендую освежить в памяти эти хабратопики
[Music. The code inside. Razor 1911, Farbrausch…](http://habrahabr.ru/blogs/music/7748/)
[Деморолики. Искусство программирования.](http://habrahabr.ru/blogs/demoscene/27952/)
Как то так случилось, что я увлекся всякими трекерными мелодиями.
У меня в универе был лектор (по ТФКП), который любил на лекциях пофилософствовать о связи музыки и математики, и довольно интересно, надо сказать. И, по-моему, трекерная музыка — это именно та музыка, которая ближе всего находится к математике.
Для непосвещенных скажу, что это музыка, звучащая в кряках/кейгенах, многих компьютерных играх, демосценерских роликах… По правде сказать, я искренне не понимаю, почему, например, именно midi-мелодии так прочно укоренились в мобильниках, ведь трекерная музычка весит примерно столько же, а звучит гораздо лучше. Форматов трекерного музона очень много: .mod, .it, .xm, .s3m, ..., и т.д. Основная их особенность — очень малый «вес» (десятки-сотни килобайт, хотя зависит от битности семплов, могут быть и мегабайты), при этом красивое (по сравнению с миди-музоном, а, имхо, и просто красивое) звучание. Более подробную информацию можно с легкостью отыскать на бескрайних просторах интернета.
Опять отвлекусь и дам ссылку на другие «самые-самые» трекерные композиции: <http://websound.ru/tracked-music.htm> (и вообще всячески рекомендую этот сайт о музыке [websound.ru](http://websound.ru)). Только убедительно заклинаю слушать их не через Winamp (а он может), а через [XMPlay](http://support.xmplay.com/) — по моему опыту — самое адекватное воспроизведение модулей.
Ребята из Farbrausch (в лице [kb](http://www.kebby.org/)) пошли дальше и создали свой музыкальный движок [v2](http://www.1337haxorz.de/products.html). Музыка, созданная в нем и звучит в [потрясающих демках](http://www.farb-rausch.com/productions.php) этого демомейкерского коллектива. Собственно, я подозреваю, самой v2m-музыки в природе существует не так много (если неправ — поправьте, буду приятно удивлен и благодарен), но то что есть можно скачать, например, [тут](http://trackers.fmf.ru/music/arc/v2m.rar) (около 200 изумительно звучащих мелодий размером всего 1 Мб) для проигрывания рекомендую in\_v2m.dll плагин для винампа [отсюда](http://www.scene.org/file.php?file=/demos/groups/farb-rausch/farbrausch_v2_plugins_1.0.zip&fileinfo) (т.к. сдается, что новая версия 1.5 плагина, доступная на авторском [сайте](http://www.1337haxorz.de/products.html) у меня проигрывала некоторые v2m-ки некорректно). Отличие этого формата от классических трекерных мелодий в том, что в нем совершенно не используются семплы, а все инструменты и эффекты, включая синтез голоса, программно генерируются движком.
Ну и вот мне захотелось немножко «приобщиться к великому» и попробовать скомпилять экзешник с музычкой, во-первых чтоб узнать, как же эти гении-демосценеры добиваются таких крошечных размеров демок, а во-вторых просто чтоб поделиться с вами своими любимыми v2m-композициями.
Я взял за основу файлик tinyplayer.cpp приведенный как пример использования API ([отсюда](http://www.scene.org/file.php?file=%2Fdemos%2Fgroups%2Ffarb-rausch%2Flibv2_1.0.zip&fileinfo)). Он представлял собой исходник проигрывания одной музычки, которая вкомпилировалась в него прямо в коде типа такого:
`const unsigned char theTune[] = {
0xe0, 0x01, 0x00, 0x00, 0xd7, 0x84, 0x02, ...`
подключаемом в .h файле. Мне надо было создать аналогичный .h-файл но с нужными мне композициями.
Скопировал нужные v2m-ки в папку, создал там скриптик gen\_tunes.py содержанием:
> `import glob
>
>
>
> out = open('tune1.h', 'w')
>
> listOut = open('list.txt','w')
>
>
>
> def writeTune(i, data):
>
> out.write('\nconst unsigned char tune\_%s[] = {\n\t' % i)
>
>
>
> t = 0
>
>
>
> lst = []
>
> for b in data:
>
> lst.append(hex(ord(b)))
>
> t+=1
>
> if t % 16 == 0:
>
> lst[-1] += '\n\t'
>
>
>
> out.write(', '.join(lst))
>
> out.write('};\n\n')
>
>
>
> def main():
>
> i = 0
>
>
>
> for fn in glob.glob('\*.v2m'):
>
> f = open(fn, 'rb')
>
> data = f.read()
>
>
>
> writeTune(i, data)
>
> listOut.write("%s, %s\n" % (i, fn))
>
>
>
> i += 1
>
>
>
> main()
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
и запустив его, получил файл tune1.h «весом» 7.84 Мб, суммарный вес файликов .v2m же был 1.46 Мб.
И как я уже говорил, tinyplayer.cpp был дополнен следующим образом:
> `//
>
> // tinyplayer: An example for using libv2 and a lesson in getting
>
> // Win32 executables small. Written by Tammo "kb"
>
> // Hinrichs in 2004. This file (as well as the .sln
>
> // and the .vcproj file) is in the public domain,
>
> // do with it what you want.
>
> //
>
> // farbrausch consumer consulting, Dec. 2004
>
> //
>
>
>
> // it is advised to look into the compiler settings to see why the
>
> // final exe takes only 52k (or 12.5k after being packed with an
>
> // executable packer)
>
>
>
> // we need: windows...
>
> #define WIN32\_LEAN\_AND\_MEAN
>
> #include
>
>
>
> // ... the libv2 ...
>
> #include "libv2.h"
>
>
>
> // ... and our tune.
>
> //#include "tune.h"
>
> #include "tune1.h"
>
>
>
> // --------------------------------------------------------------------------------
>
>
>
> // a few fakes coming up because this gets compiled without any stdlib and so
>
> // we don't even have printf() :
>
>
>
> static HANDLE stdout;
>
>
>
> static void print(const char \*text)
>
> {
>
> unsigned long bw;
>
> int len=0;
>
> while (text[len]) len++; // yeah, strlen() also is a luxury. :)
>
> WriteFile(stdout,text,len,&bw,0);
>
> }
>
>
>
> static const char\* digits[]={"0","1","2","3","4","5","6","7","8","9"};
>
> static void print(long num) {
>
> int nums[20];
>
> int n = 0;
>
>
>
> if (num == 0) {
>
> print("0");
>
> }
>
>
>
> while (num != 0) {
>
> nums[n++] = num % 10;
>
> num = num / 10;
>
> };
>
> n--;
>
>
>
> for (int nn=n;nn>=0;nn--) {
>
> print(digits[nums[nn]]);
>
> }
>
> }
>
>
>
> // VC needs this symbol as soon as something uses floating point numbers
>
> // (and libv2 does):
>
> extern "C" int \_fltused;
>
> int \_fltused;
>
>
>
> // --------------------------------------------------------------------------------
>
> const char\* songs[] = {
>
> "acid in space",
>
> "agony remix",
>
> "breeze",
>
> "chiptown",
>
> "cracked zone",
>
> "fr-014 garbage collection - main",
>
> "fr-037 the code inside",
>
> "full access",
>
> "gamma projection",
>
> "josie3",
>
> "multiscenist",
>
> "trance style",
>
> "ultra short",
>
> "welcome to vectronix disco",
>
> "zuibath"
>
> };
>
>
>
> long songDurations[] = { // in sec
>
> 233,
>
> 296,
>
> 181,
>
> 157,
>
> 267,
>
> 128,
>
> 211,
>
> 225,
>
> 152,
>
> 207,
>
> 177,
>
> 465,
>
> 186,
>
> 208,
>
> 170
>
> };
>
>
>
> const unsigned char\* songData[] = {
>
> tune\_0,tune\_1,tune\_2,tune\_3,tune\_4,tune\_5,tune\_6,tune\_7,
>
> tune\_8,tune\_9,tune\_10,tune\_11,tune\_12,tune\_13,tune\_14
>
> };
>
>
>
> static void writeSongLine(int current) {
>
> print(current+1);print(" - ");print(songs[current]);print(" (");
>
> long duration = songDurations[current];
>
> print(duration/60); // min
>
> print(":");
>
> long sec = duration%60;
>
> if (sec<10)
>
> print("0");
>
> print(sec);
>
> print(")");
>
> }
>
>
>
> static void playSong(int current) {
>
> print("\r \r");
>
> writeSongLine(current);
>
> ssStop();
>
> ssClose();
>
> ssInit(songData[current],GetForegroundWindow());
>
> ssPlay();
>
> }
>
>
>
> int SONG\_NUM\_MAX = 14;
>
>
>
> int main(int argc, char \*argv[])
>
> {
>
> // we need this for print() to work
>
> stdout=GetStdHandle(STD\_OUTPUT\_HANDLE);
>
>
>
> // print a bunch of senseless info..
>
> print("Farbrausch Tiny Music Player v0.2\n");
>
> print("Code and Synthesizer (C) 2000-2004 kb/Farbrausch\n");
>
>
>
> print("Compiled by: Xonix\n\n");
>
>
>
> print("Tunes:\n\n");
>
>
>
> for (int i=0; i<=SONG\_NUM\_MAX; i++) {
>
> writeSongLine(i);
>
> print("\n");
>
> }
>
>
>
> print("\n\n");
>
>
>
> int current = 0;
>
>
>
> print("Now playing (ESC to quit, UP/DOWN to select):\n");
>
> playSong(current);
>
>
>
> for ( ; ; ) {
>
> if ( GetAsyncKeyState ( VK\_ESCAPE ) != 0 )
>
> break;
>
> else if ( GetAsyncKeyState ( VK\_UP ) != 0 ) {
>
> if (current > 0)
>
> current--;
>
> else
>
> current = SONG\_NUM\_MAX;
>
>
>
> playSong(current);
>
>
>
> while(GetAsyncKeyState ( VK\_UP ) != 0) {Sleep(10);}
>
> }
>
> else if ( GetAsyncKeyState ( VK\_DOWN ) != 0 ) {
>
> if (current < SONG\_NUM\_MAX)
>
> current++;
>
> else
>
> current = 0;
>
>
>
> playSong(current);
>
>
>
> while(GetAsyncKeyState ( VK\_DOWN ) != 0) {Sleep(10);}
>
> }
>
>
>
> if (ssGetTime() > (songDurations[current] + 1) \* 1000) { // song ended
>
> if (current < SONG\_NUM\_MAX)
>
> current++;
>
> else
>
> current = 0;
>
>
>
> playSong(current);
>
> }
>
> Sleep ( 10 );
>
> }
>
>
>
> // stop and deinit the player
>
> ssStop();
>
> ssClose();
>
>
>
> // ... and we're done.
>
> ExitProcess(0);
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Обращаю ваше внимание, что в программе используется только windows.h (помимо, собственно, libv2.h и tune1.h), и ничего более (все для компактности получаемого .exe, поэтому print и форматирование мы вынуждены писать собственноручно).
Для компиляции использовал как ни странно QtCreator + Mingw, ибо Visual Studio, простите, не осилил (люблю когда все явно, т.е. я вижу что запускается при компиляции и т.д.).
Тут обращаю внимание товарищей, потянувшихся к кнопочке "-", что это пожалуй первый, осознанно скомпиленный мною C++ код =)
Проект выглядел так:
`# -------------------------------------------------
# Project created by QtCreator 2009-06-10T03:58:51
# -------------------------------------------------
QT -= core \
gui
TARGET = v2m_palyer_qt
CONFIG += console
CONFIG -= app_bundle
TEMPLATE = app
SOURCES += main.cpp
HEADERS += tune.h tune1.h \
libv2.h
OTHER_FILES +=
LIBS += -L"C:\Program Files\Microsoft Visual Studio .NET 2003\Vc7\PlatformSDK\Lib" \
-L"D:/TEST/v2m/libv2_1.0/v2m_palyer_qt" -llibv2 -ldsound -luser32 -lkernel32`
В результате компиляции получаем файлик v2m\_palyer\_qt.exe. Но это еще не все ). Теперь надо «ужать» этот файлик. Для этого я использовал обычный для таких задач executables compressor [upx](http://upx.sourceforge.net/) с настройкой --best, ужавший мой экзешник с 1.48 Мб до 72 Кб.
Так же пробовал beroexepacker — ужал лучше, но остановился на первом варианте, т.к. антивирусы знают upx и умеют его распаковывать в поисках вирусов, а после этого товарища — не умеют.
И наконец пробовал «ужиматор» [kkrunchy](http://www.farbrausch.de/~fg/kkrunchy/) — именно им пользуются сами ребята из Farbrausch, и действительно он ужал ровнехонько до 64000 байт, но при этом exe-шник ну ооооочень долго стартовал.
Из недостатков: екзешник использует глобальные хуки для перелистывания/выхода. Как сделать иначе — не знаю, а автор kb по этому поводу оставил комментарий
`// yep, I know this will stop even if we don't have focus. I simply don't care.`
я тоже не стал заморачиваться.
Спасибо за внимание. | https://habr.com/ru/post/66585/ | null | ru | null |
# Сжатие данных в Apache Ignite. Опыт Сбера
При работе с большими объемами данных иногда может остро встать проблема нехватки места на дисках. Одним из способов решения данной проблемы является сжатие, благодаря которому, на том же оборудовании, можно себе позволить увеличить объемы хранения. В данной статье мы рассмотрим, как работает сжатие данных в Apache Ignite. В статье будут описаны только реализованные внутри продукта способы сжатия на диске. Другие способы сжатия данных (по сети, в памяти) как реализованные, так и нет останутся за рамками.
Итак, при включенном persistence режиме, в результате изменения данных в кэшах, Ignite начинает записывать на диск:
1. Содержимое кэшей
2. Журнал упреждающей записи (Write Ahead Log, далее просто WAL)
Для сжатия WAL уже довольно давно существует механизм, который называется WAL compaction. В недавно вышедшем Apache Ignite 2.8 появилось еще два механизма позволяющих сжимать данные на диске, это disk page compression для сжатия содержимого кэшей и WAL page snapshot compression для сжатия некоторых записей WAL. Подробнее о всех этих трех механизмах ниже.
### Disk page compression
#### Как это работает
Для начала очень коротко остановимся на том как Ignite хранит данные. Для хранения используется страничная память. Размер страницы задается на старте узла и не может быть изменен на более поздних этапах, также размер страницы должен быть степенью двойки и кратен размеру блока файловой системы. Страницы подгружаются в RAM с диска по мере необходимости, размер данных на диске может превышать объем выделенной RAM. В случае нехватки места в RAM для подгрузки страницы с диска старые, уже не используемые страницы будут вытеснены из RAM.
На диске данные хранятся в следующем виде: на каждую партицию каждой кэш-группы создается отдельный файл, в этом файле, в порядке возрастания индекса, одна за другой идут страницы. Полный идентификатор страницы содержит идентификатор кэш-группы, номер партиции и индекс страницы в файле. Таким образом по полному идентификатору страницы мы можем однозначно определить файл и оффсет в файле для каждой страницы. Более подробно об устройстве страничной памяти можно прочитать в статье на Apache Ignite Wiki: [Ignite Persistent Store — under the hood](https://cwiki.apache.org/confluence/display/IGNITE/Ignite+Persistent+Store+-+under+the+hood).
Механизм disk page compression, как можно догадаться из названия, работает на страничном уровне. При включении данного механизма работа с данными в RAM выполняется как есть, без какой-либо компрессии, но в момент сохранения страниц из RAM на диск выполняется их сжатие.
Но сжать каждую страницу в отдельности это еще не решение проблемы, нужно как-то уменьшить размер итоговых файлов с данными. Если размер страницы перестает быть фиксированным, мы уже не можем писать страницы в файл одну за другой, так как это может породить целый ряд проблем:
* Мы не сможем с помощью индекса страницы вычислить оффсет по которому она располагается в файле.
* Не понятно, что делать со страницами, которые находятся не в конце файла и меняют свой размер. Если размер страницы уменьшается, место которое она высвободила пропадает. Если размер страницы увеличивается, для нее нужно искать уже новое место в файле.
* Если страница сместится на не кратное размеру блока файловой системы число байт, то для ее чтения или записи, потребуется затронуть на один блок файловой системы больше, что может привести к деградации производительности.
Чтобы не решать эти проблемы на своем уровне самостоятельно disk page compression в Apache Ignite использует механизм файловой системы под названием sparse файлы. Sparse (разреженный) файл — это такой файл, в котором некоторые, заполненные нулями регионы могут быть помечены как «дыры». При этом блоков файловой системы для хранения этих дыр выделено не будет, в результате чего достигается экономия места на диске.
Логично, что чтобы высвободить блок файловой системы, размер дыры должен быть больше либо равен блоку файловой системы, что накладывает дополнительное ограничение на размер страницы в Apache Ignite: чтобы сжатие давало хоть какой-то эффект необходимо чтобы размер страницы был строго больше размера блока файловой системы. Если размер страницы будет равен размеру блока, то мы никогда не сможем освободить ни одного блока, так как чтобы высвободить единственный блок нужно чтобы сжатая страница занимала 0 байт. Если же размер страницы будет равен размеру 2-х либо 4-х блоков, мы уже сможем высвободить как минимум один блок если наша страница сожмется как минимум до 50% либо до 75% соответственно.
Таким образом, итоговое описание работы механизма: При записи страницы на диск, производится попытка сжать страницу. Если размер сжатой страницы позволяет высвободить один или более блок файловой системы, то страница записывается в сжатом виде, на месте высвобожденных блоков пробивается «дырка» (выполняется системный вызов `fallocate()` с флагом «punch hole»). Если размер сжатой страницы не позволяет высвободить блоки, страница сохраняется как есть, в несжатом виде. Все оффсеты страниц считаются также как и без компрессии, умножением индекса страницы на размер страницы. Никакой релокации страниц своими силами не требуется. Оффсеты страниц как и без компрессии попадают на границы блоков файловой системы.
В текущей реализации Ignite умеет работать со sparse файлами только под ОС Linux, соответственно disk page compression может быть включен только при использовании Ignite на этой операционной системе.
Алгоритмы сжатия, которые могут быть использованы для disk page compression: ZSTD, LZ4, Snappy. Кроме того есть режим работы (SKIP\_GARBAGE), при котором только выкидывается неиспользуемое в странице место без применения компрессии на оставшихся данных, что позволяет снизить нагрузку на CPU по сравнению с перечисленными ранее алгоритмами.
#### Влияние на производительность
К сожалению фактического замера производительности на реальных стендах я не проводил, так как у нас не планируется использовать этот механизм в продакшне, но можно порассуждать теоретически, где мы потеряем, а где выиграем.
Для этого нам необходимо вспомнить о том как выполняется чтение и запись страниц при обращении к ним:
* При выполнении операции чтения сначала выполняется ее поиск в RAM, если поиск завершился неудачно страница подгружается в RAM c диска тем же потоком, который выполняет чтение.
* При выполнении операции записи, страница в RAM помечается как грязная, при этом физическое сохранение страницы на диск сразу в потоке выполняющим запись не происходит. Все грязные страницы сохраняются на диск позднее в процессе чекпоинта отдельными потоками.
Таким образом, влияние на операции чтения:
* Положительное (disk IO), за счет уменьшения количества прочитанных блоков файловой системы.
* Отрицательное (CPU), за счет дополнительной нагрузки необходимой операционной системе для работы со sparse файлами. Также возможно здесь неявно появятся дополнительные IO операции для сохранения более сложной структуры sparse файла (со всеми деталями работы sparse файлов я, к сожалению, не знаком).
* Отрицательное (CPU), за счет необходимости декомпрессии страниц.
* Влияния на операции записи нет.
* Влияние на процесс чекпоинта (здесь все аналогично операциям чтения):
* Положительное (disk IO), за счет уменьшения количества записанных блоков файловой системы.
* Отрицательное (CPU, возможно disk IO), за счет работы со sparse файлами.
* Отрицательное (CPU), за счет необходимости сжатия страниц.
Какая чаша весов перевесит? Это все очень зависит от окружения, но я склоняюсь к тому, что disk page compression приведет скорее к деградации производительности на большинстве систем. Тем более что тесты на других СУБД использующих подобный подход со sparse файлами показывают падение производительности при включенном сжатии.
#### Как включить и настроить
Как уже было сказано выше, минимальная версия Apache Ignite, поддерживающая disk page compression: 2.8 и поддерживается только операционная система Linux. Включение и настройка выполняется следующим образом:
* В class-path должен быть модуль ignite-compression. По умолчанию он находится в дистрибутиве Apache Ignite в директории libs/optional и не включается в class-path. Можно просто перенести директорию на один уровень вверх в libs и тогда при запуске через ignite.sh он автоматически будет включен.
* Persistence должен быть включен (Включается через `DataRegionConfiguration.setPersistenceEnabled(true))`.
* Размер страницы должен быть больше размера блока файловой системы (задать можно с помощью `DataStorageConfiguration.setPageSize()` ).
* Для каждого кэша, данные которого требуется сжимать необходимо в конфигурации настроить метод сжатия и (опционально) уровень сжатия (методы `CacheConfiguration.setDiskPageCompression() , CacheConfiguration.setDiskPageCompressionLevel()`).
### WAL compaction
#### Как это работает
Что такое WAL и зачем он нужен? Очень коротко: это журнал в который попадают все события меняющие в итоге страничное хранилище. Нужен он в первую очередь для возможности восстановления в случае падения. Любая операция прежде чем отдать управление пользователю должна сначала записать событие в WAL, чтобы в случае падения иметь возможность проиграть по журналу и восстановить все операции, по которым пользователь получил успешный ответ, даже если эти операции не успели отразится в страничном хранилище на диске (выше уже было описано, что фактическая запись в страничное хранилище выполняется в процессе, который называется «чекпоинт» с некоторым запозданием отдельными потоками).
Записи в WAL делятся на логические и физические. Логические — это сами ключи и значения. Физические — отражают изменения страниц в страничном хранилище. Если логические записи могут быть полезны еще для каких-нибудь случаев, физические записи нужны только для восстановления в случае падения и нужны записи только с момента последнего успешного чекпоинта. Здесь мы не будем вдаваться в подробности и объяснять почему это работает именно так, но кому интересно, могут обратиться к уже упомянутой статье на Apache Ignite Wiki: [Ignite Persistent Store — under the hood](https://cwiki.apache.org/confluence/display/IGNITE/Ignite+Persistent+Store+-+under+the+hood).
На одну логическую запись часто приходится несколько физических записей. То есть, например, одна операция put в кэш затрагивает несколько страниц в страничной памяти (страницу с самими данными, страницы с индексами, страницы с free-list'ами). На некоторых синтетических тестах у меня получалось, что физические записи занимали до 90% объема WAL файла. При этом нужны они очень непродолжительное время (по умолчанию интервал между чекпоинтами — 3 минуты). Логично было бы от этих данных после потери их актуальности избавляться. Именно это и выполняет механизм WAL compaction, избавляется от физических записей и сжимает с помощью zip оставшиеся логические записи, при этом размер файла уменьшается очень значительно (иногда в десятки раз).
Физически WAL состоит из нескольких сегментов (по умолчанию 10) фиксированного размера (по умолчанию 64Мб), которые перезаписываются по кругу. Как только текущий сегмент заполняется, текущим назначается следующий за ним сегмент, а заполненный сегмент копируется в архив отдельным потоком. WAL compaction уже работает с архивными сегментами. Также отдельным потоком он отслеживает выполнение чекпоинта и начинает сжатие по архивным сегментам, физические записи для которых уже не нужны.

#### Влияние на производительность
Поскольку WAL compaction работает отдельным потоком, то прямого влияния на выполняемые операции быть не должно. Но он все таки дает дополнительную фоновую нагрузку на CPU (сжатие) и диск (чтение каждого WAL сегмента из архива и запись сжатых сегментов), поэтому если система работает на пределе возможностей, он также приведет к деградации производительности.
#### Как включить и настроить
Включить WAL compaction можно с помощью свойства `WalCompactionEnabled` в `DataStorageConfiguration (DataStorageConfiguration.setWalCompactionEnabled(true)`). Также, с помощью метода DataStorageConfiguration.setWalCompactionLevel() можно задать степень сжатия, если не устраивает значение по умолчательнию (BEST\_SPEED).
### WAL page snapshot compression
#### Как это работает
Ранее уже выяснили, что в WAL записи делятся на логические и физические. На каждое изменение каждой страницы в страничной памяти формируется физическая запись WAL. Физические записи в свою очередь тоже делятся на 2 подвида: page snapshot record и delta record. Каждый раз когда мы меняем что-то на странице и переводим ее из чистого состояния в грязное, в WAL сохраняется полная копия этой страницы (page snapshot record — снэпшот страницы). Даже если мы поменяли только один байт в WAL сохранится запись размером чуть более размера страницы. Если же мы меняем что-то на уже грязной странице то в WAL формируется delta record, в которой отражены только изменения по сравнению с предыдущим состоянием страницы, но не вся страница целиком. Поскольку сброс состояния страниц с грязного на чистый выполняется в процессе чекпоинта, сразу после начала чекпоинта практически все физические записи будут состоять только из снэпшотов страниц (так как все страницы сразу после начала чекпоинта чистые), затем по мере приближения к следующему чекпоинту доля delta record начинает расти и опять сбрасывается на начале следующего чекпоинта. Замеры на некоторых синтетических тестах показывали, что доля снэпшотов страниц в общем объеме физических записей достигает 90%.
Идея WAL page snapshot compression заключается в том, чтобы сжимать снэпшоты страниц используя уже готовый инструмент для сжатия страниц (см. disk page compression). При этом в WAL записи сохраняются последовательно в append-only режиме и нет необходимости привязки записей к границам блоков файловой системы, поэтому здесь, в отличии от механизма disk page compression, нам совершенно не нужны sparse файлы, соответственно работать этот механизм будет не только на ОС Linux. Кроме того, нам уже не важно как сильно мы смогли сжать страницу. Даже если мы высвободили 1 байт это уже положительный результат и мы можем сохранять в WAL сжатые данные, в отличие от disk page compression, где мы сохраняем сжатую страницу только если освободили более 1 блока файловой системы.
Страницы — хорошо сжимаемые данные, их доля в общем объеме WAL очень высока, таким образом не меняя формат WAL файла мы можем получить значительное сокращение его размера. Сжатие в том числе логических записей потребовало бы изменение формата и потерю совместимости, например, для внешних потребителей, которым могут быть интересны логические записи, при этом не принесло бы значительного уменьшения объема файла.
Как и для disk page compression для WAL page snapshot compression могут быть использованы алгоритмы сжатия ZSTD, LZ4, Snappy, а также режим SKIP\_GARBAGE.
#### Влияние на производительность
Как не трудно заметить, напрямую включение WAL page snapshot compression влияет только на потоки которые записывают данные в страничную память, то есть на те потоки которые изменяют данные в кэшах. Чтение из WAL физических записей происходит только единоразово, в момент поднятия узла после падения (и только в случае падения в процессе чекпоинта).
На потоки изменяющие данные это влияет следующим образом: мы получаем отрицательный эффект (CPU) за счет необходимости каждый раз сжимать страницу перед записью на диск и положительный эффект (disk IO) за счет уменьшения количества записываемых данных. Соответственно, здесь все просто, если производительность системы упирается в CPU, получаем небольшую деградацию, если в дисковый ввод/вывод — получаем прирост.
Косвенно уменьшение размера WAL также влияет (положительно) на потоки которые скидывают в архив сегменты WAL и на потоки WAL compaction.
Реальные тесты производительности на нашем окружении на синтетических данных показали небольшой прирост (на 10%-15% вырос throughput, на 10%-15% уменьшилось latency).
#### Как включить и настроить
Минимальная версия Apache Ignite: 2.8. Включение и настройка выполняется следующим образом:
* В class-path должен быть модуль ignite-compression. По умолчанию он находится в дистрибутиве Apache Ignite в директории libs/optional и не включается в class-path. Можно просто перенести директорию на один уровень вверх в libs и тогда при запуске через ignite.sh он автоматически будет включен.
* Persistence должен быть включен (Включается через `DataRegionConfiguration.setPersistenceEnabled(true)`).
* Должен быть задан режим сжатия с помощью метода `DataStorageConfiguration.setWalPageCompression()`, по умолчанию сжатие отключено (режим DISABLED).
* Опционально можно задать степень сжатия с помощью метода `DataStorageConfiguration.setWalPageCompression()`, допустимые значения для каждого из режимов смотри в javadoc к методу.
### Заключение
Рассмотренные механизмы сжатия данных в Apache Ignite могут использоваться независимо друг от друга, но также допустимы и любые их комбинации. Понимание принципов их работы позволит определить насколько они подходят под ваши задачи на вашем окружении и чем придется пожертвовать при их использовании. Disk page compression предназначен для сжатия основного хранилища и может дать среднюю степень сжатия. WAL page snapshot compression даст среднюю степень сжатия уже WAL файлов, при этом вероятнее всего даже повысит производительность. WAL compaction на производительность положительно не повлияет, но максимально сократит размер WAL файлов за счет удаления физических записей. | https://habr.com/ru/post/502136/ | null | ru | null |
# Подбираем сервер для 1000 WebRTC стримов
В любом проекте большое внимание уделяется подбору серверного оборудования и WebRTC стриминг не исключение. При подборе сервера один из главных принципов --- достичь баланса, чтобы и оборудование в пустую не работало и качество контента от несостоятельности железа не страдало. Итак, как же все таки выбрать правильный сервер?
[Раньше](https://flashphoner.com/kak-zapustit-webrtc-skrinsharing-v-2020/?lang=ru) в нашем блоге мы уже обсуждали тему выбора сервера в зависимости от количества подписчиков. Кратко напомню основные тезисы:
1. При выборе серверов с балансировкой или без нее для потоковой передачи видео необходимо учитывать профили нагрузки:
* просто стримы;
* потоки с транскодированием;
* [микширование потоков](https://flashphoner.com/mikshirovanie-potokov/?lang=ru).
2. Потоки с транскодированием и микшированием требуют больше ресурсов ЦП и ОЗУ, чем просто стримы. Нагрузка на системные ресурсы сервера не должна превышать 80%. В этом случае, все подписчики получат видеопотоки с приемлемым качеством.
3. На практике часто видно, что качество стриминга упирается не в характеристики сервера, а в пропускную способность сети.
Примерные расчеты количества стримов исходя из пропускной способности канала:
Один стрим 480p это примерно 0.5 - 1 Mbps трафика. Битрейт WebRTC потоков плавающий, поэтому возьмем 1 Mbps. Соответственно 1000 стримов — 1000 Mbps.
4. Количество зрителей и качество трансляции в том числе зависят от [правильных настроек на стороне сервера](https://docs.flashphoner.com/pages/viewpage.action?pageId=23036804) — количества медиапортов и использования ZGC.
В этой статье мы рассмотрим, как провести нагрузочное тестирование сервера и на практике убедимся в справедливости утверждений выше.
### План тестирования
1. Опубликовать поток с камеры на сервере WCS #1 с помощью стандартного примера Two Way Streaming
2. С помощью веб-приложение Console запустить нагрузочное тестирование, в котором сервер WCS#2 будет имитировать подключение 1000 зрителей к WCS#1.
3. С помощью метрик, получаемых от системы мониторинга Prometheus, оценить нагрузку на сервер и количество исходящих WebRTC стримов от WCS#2.
4. Если, при нагрузочном тестировании, сервер отправит заданное количество потоков, выбрать случайный стрим и визуально оценить деградацию потока (или ее отсутствие).
Будем считать тестирование успешным, если к WCS#1 удастся подключиться 1000 зрителей и при этом не будет видимой деградации потоков.
### Подготовка к тестированию
Для тестирования нам понадобятся:
* два WCS-сервера;
* стандартный пример Two-Way Streaming для публикации потока;
* веб-приложение Console для проведения теста;
* браузер Google Chrome и [расширение Allow-Control-Allow-Origin](https://chrome.google.com/webstore/detail/allow-cors-access-control/lhobafahddgcelffkeicbaginigeejlf?hl) для работы веб-приложения Console.
Если в вашем браузере не установлено расширение Access-Control-Allow-Origin, то установите его и запустите:
Предполагаем, что у вас уже есть установленный и настроенный экземпляр WCS. Если нет, то устанавливаем по [этой инструкции](https://docs.flashphoner.com/pages/viewpage.action?pageId=9241019).
Чтобы тестирование прошло успешно, и для того, чтобы оценить результаты, нужно выполнить следующие подготовительные этапы.
1. Увеличьте в файле [flashphoner.properties](https://docs.flashphoner.com/pages/viewpage.action?pageId=1049300) диапазон портов для WebRTC подключений
```
media_port_from = 20001
media_port_to = 40000
```
При расширении диапазона медиапортов, проверьте, что диапазон не пересекается с [другими портами](https://docs.flashphoner.com/pages/viewpage.action?pageId=9241054), используемыми в работе сервера и [диапазоном динамических портов Linux](https://docs.flashphoner.com/pages/viewpage.action?pageId=9241213#id-%D0%A0%D0%B5%D0%BA%D0%BE%D0%BC%D0%B5%D0%BD%D0%B4%D0%B0%D1%86%D0%B8%D0%B8%D0%BF%D0%BE%D1%82%D0%BE%D0%BD%D0%BA%D0%BE%D0%B9%D0%BD%D0%B0%D1%81%D1%82%D1%80%D0%BE%D0%B9%D0%BA%D0%B5%D1%81%D0%B5%D1%80%D0%B2%D0%B5%D1%80%D0%B0-%D0%98%D0%B7%D0%BC%D0%B5%D0%BD%D0%B5%D0%BD%D0%B8%D0%B5%D0%B4%D0%B8%D0%B0%D0%BF%D0%B0%D0%B7%D0%BE%D0%BD%D0%B0%D0%B4%D0%B8%D0%BD%D0%B0%D0%BC%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B8%D1%85%D0%BF%D0%BE%D1%80%D1%82%D0%BE%D0%B2%D0%B2Linux) (при необходимости можно его изменить)
2. В том же файле укажите настройку, которая увеличивает время на прохождение теста и настройку, которая будет выводить на страницу статистики информацию о загруженности сети:
```
wcs_activity_timer_timeout=86400000
global_bandwidth_check_enabled=true
```
3. При большом количестве подписчиков на один поток (от 100 и более) и достаточных ресурсах процессора сервера и канала связи качество воспроизведения потока может падать: низкий FPS,могут появляться фризы. Что бы избежать такого поведения рекомендуется включить распределение доставки стримов подписчикам по процессорным потокам при помощи настройки в файле [flashphoner.properties](https://docs.flashphoner.com/pages/viewpage.action?pageId=1049300):
```
streaming_distributor_subgroup_enabled=true
```
В этом случае клиентские аудио и видео сессии будут распределяются по группам.
Максимальное количество видео сессий в группе задается настройкой:
```
streaming_distributor_subgroup_size=50
```
Максимальное количество аудио сессий в группе задается настройкой:
```
streaming_distributor_audio_subgroup_size=500
```
Размеры очередей пакетов на группу и максимальное время ожидания фрейма для отправки (в миллисекундах) задаются настройками:
```
streaming_distributor_subgroup_queue_size=300
streaming_distributor_subgroup_queue_max_waiting_time=5000
streaming_distributor_audio_subgroup_queue_size=300
streaming_distributor_audio_subgroup_queue_max_waiting_time=5000
```
4. Включить аппаратное ускорение шифрования WebRTC трафика. По умолчанию, для шифрования WebRTC трафика используется библиотека BouncyCastle, но, если процессор сервера поддерживает инструкции [AES](https://en.wikipedia.org/wiki/AES_instruction_set), целесообразно переключиться на использование [Java Cryptography Extension](https://ru.wikipedia.org/wiki/Java_Cryptography_Extension) при помощи настройки в файле flashphoner.properties
```
webrtc_aes_crypto_provider=JCE
```
и включить поддержку AES в настройках Java Virtual Machine в файле wcs-core.properties
```
-server
-XX:+UnlockDiagnosticVMOptions
-XX:+UseAES
-XX:+UseAESIntrinsics
```
В этом случае производительность шифрования за счет аппаратного ускорения увеличивается в 1,8-2 раза, что может снизить нагрузку на процессор сервера.
Проверить, поддерживает ли процессор сервера инструкции AES, можно при помощи команды:
```
lscpu | grep -o aes
```
5. Включите ZGC в JavaVM. Рекомендованные версии JDK, с которыми протестирована работа WCS, это 12 или 14 ([Инструкция по установке](https://docs.flashphoner.com/pages/viewpage.action?pageId=9241028#id-%D0%A2%D1%80%D0%B5%D0%B1%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F%D0%B8%D0%BF%D0%BE%D0%B4%D0%B3%D0%BE%D1%82%D0%BE%D0%B2%D0%BA%D0%B0%D0%BA%D1%83%D1%81%D1%82%D0%B0%D0%BD%D0%BE%D0%B2%D0%BA%D0%B5-%D0%A0%D1%83%D1%87%D0%BD%D0%B0%D1%8F%D1%83%D1%81%D1%82%D0%B0%D0%BD%D0%BE%D0%B2%D0%BA%D0%B0))
Для настройки ZGC выполните следующие действия:
* Нужно закомментировать в файле wcs-core.properties следующие строки:
```
-XX:+UseConcMarkSweepGC
-XX:+UseCMSInitiatingOccupancyOnly
-XX:CMSInitiatingOccupancyFraction=70
-XX:+PrintGCDateStamps
-XX:+PrintGCDetails
```
* Поправить настройки для логов
```
-Xlog:gc*:/usr/local/FlashphonerWebCallServer/logs/gc-core.log
-XX:ErrorFile=/usr/local/FlashphonerWebCallServer/logs/error%p.log
```
* Выставить размер хипа не менее, чем 1/2 физической памяти сервера
```
### JVM OPTIONS ###
-Xmx16g
-Xms16g
```
* Включаем ZGC
```
# ZGC
-XX:+UnlockExperimentalVMOptions -XX:+UseZGC -XX:+UseLargePages -XX:ZPath=/hugepages
```
* Настраиваем страницы памяти. Обязательно нужно рассчитать число страниц под размер выделенного хипа:
```
(1,125*heap_size*1024)/2. Для -Xmx16g это число (1,125*16*1024)/2=9216
```
```
mkdir /hugepages
echo "echo 9216 >/sys/kernel/mm/hugepages/hugepages-2048kB/nr_hugepages" >>/etc/rc.local
echo "mount -t hugetlbfs -o uid=0 nodev /hugepages" >>/etc/rc.local
chmod +x /etc/rc.d/rc.local
systemctl enable rc-local.service
systemctl restart rc-local.service
```
После выполнения настроек для ZGC нужно перезапустить WCS.
6. Для удобного отслеживания работы сервера во время тестирования предлагаем развернуть систему мониторинга [Prometheus+Grafana](https://flashphoner.com/10-vazhnyh-metrik-webrtc-striminga-i-nastrojka-monitoringa-prometheus-grafana/?lang=ru).
Будем отслеживать следующие метрики:
* Загрузка процессора:
```
node_load1
node_load5
node_load15
```
* Использование физической памяти для Java:
```
core_stats{instance="your.WCS.server.name:8081", job="flashphoner", param="core_java_freePhysicalMemorySize"}
core_stats{instance="your.WCS.server.name:8081", job="flashphoner", param="core_java_totalPhysicalMemorySize"}
```
* Паузы в работе ZGC:
```
custom_stats{instance="your.WCS.server.name:8081", job="flashphoner", param="gc_pause"}
```
* Пропускная способность сети:
```
network_stats
```
* Количество стримов. При нагрузочном тестировании будем считать исходящие WebRTC подключения:
```
streams_stats{instance="your.WCS.server.name:8081", job="flashphoner", param="streams_webrtc_out"}
```
* Количество и процент деградировавших стримов:
```
degraded_streams_stats{instance="your.WCS.server.name:8081", job="flashphoner", param="degraded_streams"}
degraded_streams_stats{instance="your.WCS.server.name:8081", job="flashphoner", param="degraded_streams_percent"}
```
### Тестирование первое — слабые серверы
Для первого тестирования будем использовать два сервера со следующими техническими характеристиками: 1x Intel Atom C2550 @ 2.4Ghz (4 ядра, 4 потока) 8GB RAM 2x 1Gbps
Пропускная способность канала заявлена как 2x 1Gbps. Давайте проверим, как это обстоит на самом деле.
Измерить пропускную способность канала можно при помощи утилиты iperf. Эта программа выпущена под все основные операционные системы: Windows, MacOS, Ubuntu/Debian, CentOS. iperf в режиме сервера может быть установлена вместе с WCS, что позволяет тестировать канал целиком, от паблишера до зрителя.
Запуск iperf в режиме сервера:
```
iperf3 -s -p 5201
```
здесь: **5201** - порт, на который iperf ожидает соединений от тестирующих клиентов.
Запуск iperf в режиме клиента для тестирования отправки данных от клиента к серверу по TCP:
```
iperf3 -c test.flashphoner.com -p 5201
```
здесь: **test.flashphoner.com** - WCS сервер; **5201** - порт iperf в режиме сервера.
Устанавливаем и запускаем iperf в режиме сервера на первом сервере:
Затем устанавливаем и запускаем iperf в режиме клиента на втором сервере и получаем данные о пропускной способности канала:
Итак, между паблишером (первый север) и зрителем (второй сервер) ширина канала составляет в среднем 2.25 Gbps, а это значит, что, теоретически, мы можем подключить 2000 зрителей.
Теперь проверим это на практике.
Запустим [нагрузочное тестирование](https://docs.flashphoner.com/pages/viewpage.action?pageId=3049870#id-%D0%9D%D0%B0%D0%B3%D1%80%D1%83%D0%B7%D0%BE%D1%87%D0%BD%D0%BE%D0%B5%D1%82%D0%B5%D1%81%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5%D1%81%D0%B8%D1%81%D0%BF%D0%BE%D0%BB%D1%8C%D0%B7%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5%D0%BC%D0%B7%D0%B0%D1%85%D0%B2%D0%B0%D1%82%D0%B0%D0%BF%D0%BE%D1%82%D0%BE%D0%BA%D0%BE%D0%B2%D0%BF%D0%BEWebRTC-%D0%A2%D0%B5%D1%81%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5).
На первом сервере откройте приложение Console через HTTP <http://your.WCS.server.name:9091/client2/examples/demo/streaming/console/console.html>
Укажите доменное имя или IP адрес первого сервера и нажмите кнопку "Add node". Это будет тестируемый сервер, который будет источником потоков. Затем аналогично подключите второй сервер, который будет имитировать подписчиков и захватывать потоки.
Для первого сервера запустите стандартный пример Two-way Streaming и опубликуйте поток с веб камеры. Имя потока может быть любым.
В приложении Console выберите сервер второй сервер, нажмите кнопку 'Pull streams', задайте параметры теста:
* Choose node - выберите первый сервер;
* Local stream name, Remote stream name - укажите имя опубликованного на первом сервере потока;
* Qty - укажите количество зрителей (для нашего тестирования 1000)
После чего нажмите кнопку "Pull":
Во время тестирования будем отслеживать изменение метрик по графикам в Grafana:
Как видите, при тестировании возросла нагрузка на CPU сервера. Значение Load Averrage более 5 единиц для 4 ядерного процессора означает, что процессор загружен на 100%:
Уменьшилось количество свободной оперативной памяти:
Паузы для работы ZGC достигали 5 мс, что достаточно приемлемо:
График пропускной способности сетевого канала. Здесь мы видим, что основной трафик приходился на исходящие потоки. Скорость не превышала 100 Mbps (меньше 5% от заявленной пропускной способности, которую мы подтвердили тестом iperf ):
Число исходящих WebRTC стримов. Как видите, наше тестирование практически провалилось. За время тестирования нам не удалось отдать потоки больше, чем 260 пользователям из запрошенной 1000.
Деградировавшие стримы. Ближе к завершению тестирования появились деградировавшие потоки. Это вполне объяснимо, т.к. значение Load Average более 5 единиц для 4 ядерного процессора означает, что процессор загружен на 100% и деградация потоков в таких условиях неизбежна:
Вывод к первому тестированию напрашивается сам собой:
Как бы не хотелось сэкономить на железе, но, к сожалению, слабый сервер, как и слабый виртуальный инстанс, не потянет серьезной нагрузки при использовании в продакшене. Хотя, если для вашей задачи не требуется подключать к потоку 1000 зрителей, то и этот вариант можно считать жизнеспособным. Например, на "маленьком" сервере можно:
* организовать простую систему видеонаблюдения — раздавать по WebRTC поток с IP-камеры небольшому количеству подписчиков;
* организовать систему проведения вебинаров для сотрудников небольшой компании;
* проводить трансляции только звука (аудиопоток требует меньше ресурсов процессора).
А теперь возьмем серверы помощнее и посмотрим, удастся ли подключить 1000 зрителей?
### Тестирование второе — мощные серверы
Для второго тестирования будем использовать два сервера со следующими техническими характеристиками: 2x Intel(R) Xeon(R) Silver 4214 CPU @ 2.20GHz (суммарно 24 ядра, 48 потоков) 192GB RAM 2x 10Gbps
Как и в первом тестировании проверим пропускную способность канала между серверами с помощью iperf:
В этом случае, между паблишером (первый сервер) и зрителем (второй сервер) ширина канала составила в среднем 9.42 Gbps, а это значит, что, теоретически, мы можем подключить 9000 зрителей.
Запустим [нагрузочное тестирование](https://docs.flashphoner.com/pages/viewpage.action?pageId=3049870#id-%D0%9D%D0%B0%D0%B3%D1%80%D1%83%D0%B7%D0%BE%D1%87%D0%BD%D0%BE%D0%B5%D1%82%D0%B5%D1%81%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5%D1%81%D0%B8%D1%81%D0%BF%D0%BE%D0%BB%D1%8C%D0%B7%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5%D0%BC%D0%B7%D0%B0%D1%85%D0%B2%D0%B0%D1%82%D0%B0%D0%BF%D0%BE%D1%82%D0%BE%D0%BA%D0%BE%D0%B2%D0%BF%D0%BEWebRTC-%D0%A2%D0%B5%D1%81%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5) точно так же, как и для первого тестирования с помощью веб приложения Console.
Отслеживаем изменение метрик по графикам в Grafana:
Рассмотрим графики подробнее.
При запуске тестирования ожидаемо возросла нагрузка на CPU, но для 48 потоков процессора пиковое значение индекса Load Average чуть больше 11 единиц не сигнализирует о высокой нагрузке. Процессор сервера, конечно, работает, но до полной загрузки еще далеко:
Количество свободной памяти ощутимо не изменялось:
Паузы для работы ZGC достигали 2,5 мс, что достаточно приемлемо:
График пропускной способности сетевого канала. Здесь мы видим, что основной трафик приходился на исходящие потоки. Загрузка не превышала 500 Mbps (около 5% от заявленной пропускной способности, которую мы подтвердили тестом iperf ):
Количество исходящих WebRTC стримов. Тестирование на мощных серверах завершилось успешно. Нам удалось подключить 1000 зрителей.
Деградировавшие стримы. Сервер успешно отработал, и деградировавших потоков за время тестирования не было:
Для проверки успешности тестирования нужно в процессе тестирования подключиться к серверу и просмотреть стрим, так же как и подписчики, которых мы имитируем в тесте.
Открываем на тестируемом сервере плеер и воспроизводим наш тестовый стрим. Стрим должен проигрываться без видимой потери качества - без заиканий, фризов или артефактов:
Тестирование на мощных серверах можно считать успешным. Мы подключили 1001 зрителя на просмотр потока и отдали этот поток в приемлемом качестве.
### Тестирование третье - мощные серверы, толстые потоки
В предыдущих двух тестах мы использовали в качестве потока источника небольшой поток с разрешением всего лишь 240p. Как показывает практика, такие потоки в современном мире мало кому интересны. Гораздо интереснее смотреть видео в формате от fullHD и выше. Итак, давайте проверим, справятся ли наши "большие" сервера с потоками 720p.
Для публикации потока нам понадобится пример "[Media Devices](https://flashphoner.com/testirovanie-upravleniya-kameroj-mikrofonom-i-parametrami-potoka/?lang=ru)" с помощью которого мы сможем опубликовать поток с заданными характеристиками:
Тест запустим прежним способом с помощью веб приложения Console. Результаты будем оценивать с помощью графиков в Grafana и контрольного воспроизведения опубликованного стрима.
В первом тесте прошло более 8 часов, прежде, чем смогли подключиться 1000 подписчиков, при этом по графикам видно, что нагрузка на сервер была совсем не большой:
Такое поведение прежде всего связано с мощностью тестирующего сервера, который захватывает потоки и имитирует подписчиков. В таком тестировании на тестирующий сервер тоже падает большая нагрузка, и, по всей видимости, сервер с ней не справился. Что бы проверить эту теорию добавим к условиям теста еще один тестирующий сервер, что бы разделить подписчиков и создаваемую ими нагрузку по 500 стримов на каждый сервер:
Запускаем тест точно так же как и в прошлых вариантах.
Теперь тест запустился гораздо быстрее. Менее чем через 10 минут от начала теста у нас уже было 1000 подписчиков:
Судя по графикам тест был пройден - загрузка процессора по метрике Load Average1 была в пределах 40 единиц. Единичный пик до 60 единиц не привел к снижению производительности. Паузы в работе ZGC не превышали 8 мс. Деградировавших стримов зарегистрировано не было. Воспроизведение публикуемого потока тоже прошло гладко - без фризов, артефактов и проблем со звуком.
Получается, что для успешного тестирования сервер, который будет захватывать потоки должен быть как минимум в два раза мощнее чем тестируемый сервер. Или можно использовать несколько серверов меньшей мощности.
Результаты тестирования могут меняться в зависимости от окружения, географического размещения серверов и пользователей - как подписчиков, так и стримеров.
В этой статье мы рассмотрели одну из методик проведения нагрузочного тестирования. По анализу результатов тестирования можно подобрать оптимальную конфигурацию сервера именно под вашу задачу, чтобы не допускать простоев или перегрузки оборудования.
Хорошего стриминга!
Ссылки[Наш демо сервер](https://demo.flashphoner.com/admin/login.html)
[WCS на Amazon EC2](https://flashphoner.com/podderzhka-oblachnyh-serverov-amazon-ec2-v-web-call-server/?lang=ru) - Быстрое развертывание WCS на базе Amazon
[WCS на DigitalOcean](https://flashphoner.com/podderzhka-web-call-server-v-digital-ocean-marketplace/?lang=ru) - Быстрое развертывание WCS на базе DigitalOcean
[WCS в Docker](https://flashphoner.com/podderzhka-web-call-server-v-docker/?lang=ru) - Запуск WCS как Docker контейнера
[Документация по быстрому развертыванию и тестированию WCS сервера](https://docs.flashphoner.com/pages/viewpage.action?pageId=9241019)
[Документация по мониторингу информации о нагрузке и ресурсах](https://docs.flashphoner.com/pages/viewpage.action?pageId=9241112)
[Документация по организации мониторинга с помощью Prometheus](https://docs.flashphoner.com/pages/viewpage.action?pageId=14256163)
[Описание файла настроек flashphoner.properties](https://docs.flashphoner.com/pages/viewpage.action?pageId=9241061)
[Описание файла настроек wcs-core.properties](https://docs.flashphoner.com/pages/viewpage.action?pageId=9241071)
[Документация по управлению памятью в Java](https://docs.flashphoner.com/pages/viewpage.action?pageId=14255501)
[Рекомендации по тонкой настройке сервера](https://docs.flashphoner.com/pages/viewpage.action?pageId=9241213)
[Документация по подготовке к промышленной эксплуатации WCS](https://docs.flashphoner.com/pages/viewpage.action?pageId=23036804)
[Документация по проведению нагрузочного тестирования с использованием захвата потоков по WebRTC/RTMP](https://docs.flashphoner.com/pages/viewpage.action?pageId=9241723) | https://habr.com/ru/post/570266/ | null | ru | null |
# Опасно ли держать открытым RDP в Интернете?
Нередко я читал мнение, что держать RDP (Remote Desktop Protocol) порт открытым в Интернет — это весьма небезопасно, и делать так не надо. А надо доступ к RDP давать или через VPN, или только с определённых "белых" IP адресов.
Я администрирую несколько Windows Server для небольших фирм, в которых мне поставили задачу обеспечить удалённый доступ к Windows Server для бухгалтеров. Такой вот современный тренд — работа из дома. Достаточно быстро я понял, что мучить бухгалтеров VPN — неблагодарное занятие, а собрать все IP для белого списка не получится, потому что IP адреса у народа — динамические.
Поэтому я пошёл самым простым путём — пробросил RDP порт наружу. Теперь для доступа бухгалтерам нужно запустить RDP и ввести имя хоста (включая порт), имя пользователя и пароль.
В этой статье я поделюсь опытом (положительным и не очень) и рекомендациями.
### Риски
Чем вы рискуете открывая порт RDP?
**1) Неавторизованный доступ к чувствительным данным**
Если кто-то подберёт пароль к RDP, то он сможет получить данные, которые вы хотите держать приватными: состояние счетов, балансы, данные клиентов, ...
**2) Потеря данных**
Например в результате работы вируса-шифровальщика.
Или целенаправленного действия злоумышленника.
**3) Потеря рабочей станции**
Работникам нужно работать, а система — скомпроментирована, нужно переустанавливать / восстанавливать / конфигурировать.
**4) Компроментация локальной сети**
Если злоумышленник получил доступ к Windows-компьютеру, то уже с этого компьютера он сможет иметь доступ к системам, которые недоступны извне, из Интернета. Например к файл-шарам, к сетевым принтерам и т.д.
**У меня был случай, когда Windows Server словил шифровальщика**и этот шифровальщик сначала зашифровал большинство файлов на диске C:, а затем начал шифровать файлы на NAS по сети. Так как NAS была Synology, с настроенными snapshots, то NAS я восстановил за 5 минут, а Windows Server переустанавливал с нуля.
### Наблюдения и Рекомендации
Я мониторю Windows Servers с помощью [Winlogbeat](https://www.elastic.co/beats/winlogbeat), которые шлют логи в ElasticSearch. В Kibana есть несколько визуализаций, а я ещё настроил себе кастомную дэшборд.
Сам мониторинг не защищает, но помогает определиться с необходимыми мерами.
Вот некоторые наблюдения:
**a) RDP будут брут-форсить.**
На одном из серверов я RDP повесил не на стандартный порт 3389, на 443 — ну типа замаскируюсь под HTTPS. Порт сменить со стандартного, наверное стоит, но толку от этого немного. Вот статистика с этого сервера:
Видно, что за неделю было почти 400 000 неудачных попыток зайти по RDP.
Видно, что попытки зайти были с 55 001 IP адресов (некоторые IP адреса уже были заблокированы мной).
Тут прямо напрашивается вывод о том, что нужно ставить fail2ban, но
**для Windows такой утилиты - нету.**Есть пара заброшенных проектов на Гитхабе, которые вроде бы это делают, но я даже не пробовал их ставить:
<https://github.com/glasnt/wail2ban>
<https://github.com/EvanAnderson/ts_block>
Ещё есть платные утилиты, но я их не рассматривал.
Если вы знаете открытую утилиту для этой цели — поделитесь в комментариях.
**Update**: В комментариях подсказали, что порт 443 — неудачный выбор, а лучше выбирать высокие порты (32000+), потому что 443 сканируется чаще, и распознать RDP на этом порту — не проблема.
**Update:** В комментариях подсказали, что такая утилита есть:
<https://github.com/digitalruby/ipban>
После запуска IPBan, количество неуспешных логинов радикально упало:

**Логи IPBan на этом сервере**2020-02-11 00:01:18.2517|WARN|DigitalRuby.IPBanCore.Logger|Login failure: 31.131.251.228,, RDP, 1
2020-02-11 00:01:18.2686|WARN|DigitalRuby.IPBanCore.Logger|Login failure: 31.131.251.228, Administrator, RDP, 2
2020-02-11 00:02:49.7098|WARN|DigitalRuby.IPBanCore.Logger|Login failure: 95.213.143.147,, RDP, 3
2020-02-11 00:02:49.7098|WARN|DigitalRuby.IPBanCore.Logger|Login failure: 95.213.143.147, Administrator, RDP, 4
2020-02-11 00:04:20.9878|WARN|DigitalRuby.IPBanCore.Logger|Login failure: 95.213.184.20,, RDP, 5
2020-02-11 00:04:20.9878|WARN|DigitalRuby.IPBanCore.Logger|Banning ip address: 95.213.184.20, user name:, config black listed: False, count: 5, extra info:
2020-02-11 00:04:20.9878|WARN|DigitalRuby.IPBanCore.Logger|Login failure: 95.213.184.20, Administrator, RDP, 5
2020-02-11 00:04:21.0040|WARN|DigitalRuby.IPBanCore.Logger|IP 95.213.184.20, Administrator, RDP ban pending.
2020-02-11 00:04:21.1237|WARN|DigitalRuby.IPBanCore.Logger|Updating firewall with 1 entries…
2020-02-11 00:05:36.6525|WARN|DigitalRuby.IPBanCore.Logger|Login failure: 31.131.251.24,, RDP, 3
2020-02-11 00:05:36.6566|WARN|DigitalRuby.IPBanCore.Logger|Login failure: 31.131.251.24, Administrator, RDP, 4
2020-02-11 00:07:22.4729|WARN|DigitalRuby.IPBanCore.Logger|Login failure: 82.202.249.225, Administrator, RDP, 3
2020-02-11 00:07:22.4894|WARN|DigitalRuby.IPBanCore.Logger|Login failure: 82.202.249.225,, RDP, 4
2020-02-11 00:08:53.1731|WARN|DigitalRuby.IPBanCore.Logger|Login failure: 45.141.86.141,, RDP, 3
2020-02-11 00:08:53.1731|WARN|DigitalRuby.IPBanCore.Logger|Login failure: 45.141.86.141, Administrator, RDP, 4
2020-02-11 00:09:23.4981|WARN|DigitalRuby.IPBanCore.Logger|Login failure: 68.129.202.154,, RDP, 1
2020-02-11 00:09:23.5022|WARN|DigitalRuby.IPBanCore.Logger|Login failure: 68.129.202.154, ADMINISTRATOR, RDP, 2
2020-02-11 00:10:39.0282|WARN|DigitalRuby.IPBanCore.Logger|Login failure: 95.213.143.147,, RDP, 5
2020-02-11 00:10:39.0336|WARN|DigitalRuby.IPBanCore.Logger|Banning ip address: 95.213.143.147, user name:, config black listed: False, count: 5, extra info:
2020-02-11 00:10:39.0336|WARN|DigitalRuby.IPBanCore.Logger|Login failure: 95.213.143.147, Administrator, RDP, 5
2020-02-11 00:10:39.0336|WARN|DigitalRuby.IPBanCore.Logger|IP 95.213.143.147, Administrator, RDP ban pending.
2020-02-11 00:10:39.1155|WARN|DigitalRuby.IPBanCore.Logger|Updating firewall with 1 entries…
2020-02-11 00:12:09.6470|WARN|DigitalRuby.IPBanCore.Logger|Login failure: 82.202.249.225,, RDP, 5
2020-02-11 00:12:09.6470|WARN|DigitalRuby.IPBanCore.Logger|Banning ip address: 82.202.249.225, user name:, config black listed: False, count: 5, extra info:
**b) Есть определённые username, которые злоумышленники предпочитают**
Видно, что перебор идёт по словарю с разными именами.
Но вот что я заметил: значительное количество попыток — это использование имени сервера, как логина. Рекомендация: не используйте одинаковое имя для компьютера и для пользователя. Причём, иногда похоже имя сервера пытаются как-то распарсить: например для системы с именем DESKTOP-DFTHD7C больше всего попыток зайти с именем DFTHD7C:
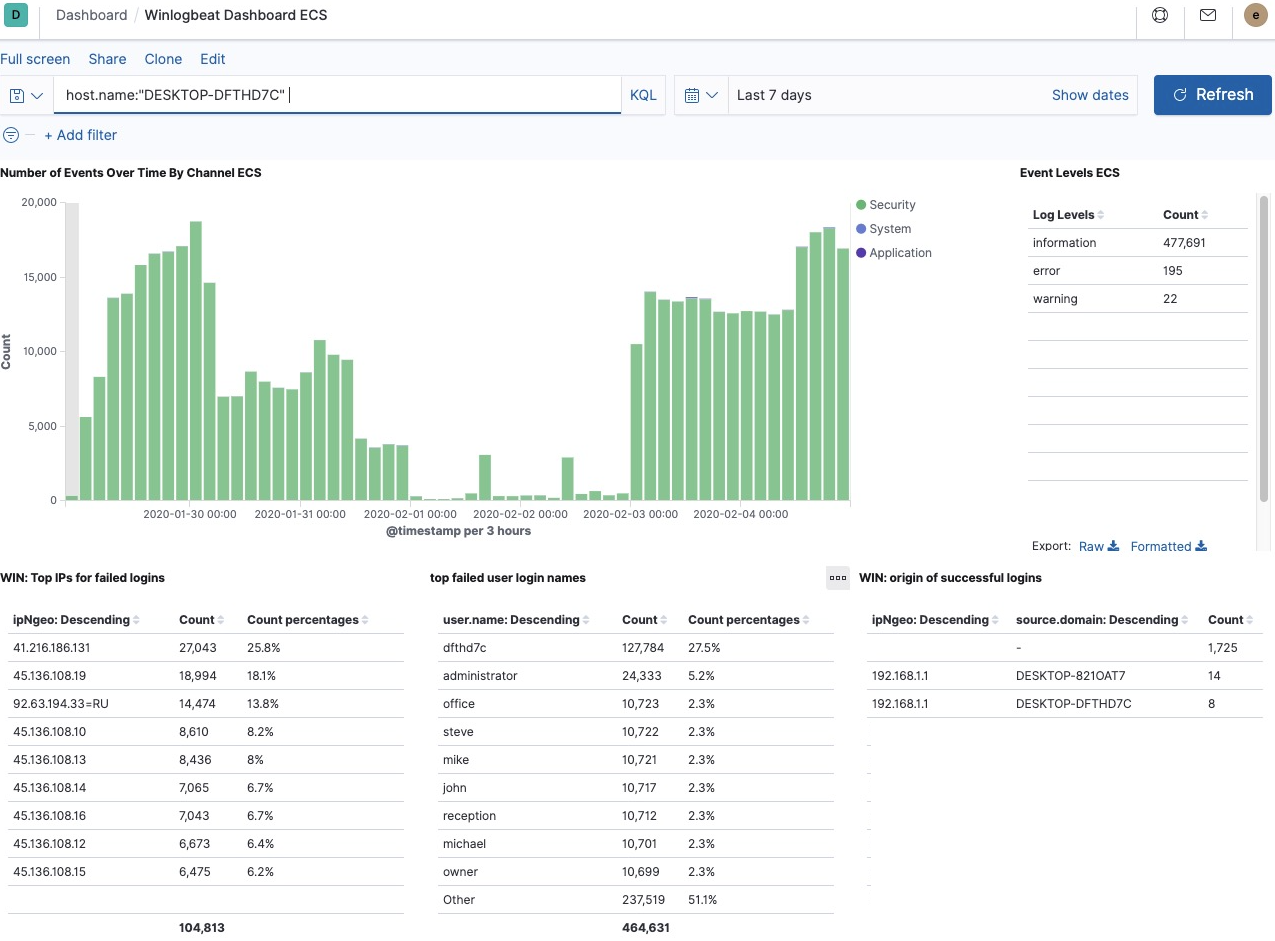
Соответственно, если у вас будет компьютер DESKTOP-MARIA, то вероятно будут идти попытки заходить под пользователем MARIA.
Ещё, что я заметил из логов: на большинстве систем, большинство попыток зайти — это с именем "administrator". И это неспроста, потому что во многих версиях Windows, это пользователь существует.
**Более того - его нельзя удалить.**<https://docs.microsoft.com/en-us/windows/security/identity-protection/access-control/local-accounts#administrator-account>
Administrator account
The default local Administrator account is a user account for the system administrator. Every computer has an Administrator account (SID S-1-5-domain-500, display name Administrator). The Administrator account is the first account that is created during the Windows installation.
The Administrator account has full control of the files, directories, services, and other resources on the local computer. The Administrator account can create other local users, assign user rights, and assign permissions. The Administrator account can take control of local resources at any time simply by changing the user rights and permissions.
The default Administrator account cannot be deleted or locked out, but it can be renamed or disabled.
Это упрощает задачу для злоумышленников: вместо подбора имени и пароля нужно только подобрать пароль.
Кстати та система, которая у меня словила шифровальщика имела пользователя Administrator и пароль Murmansk#9. Я до сих не уверен, как взломали ту систему, потому что мониторить я начал как раз после того случая, но думаю, что перебор — вероятен.
Так если пользователя Administrator нельзя удалить, то что же делать? Его можно переименовать!
Рекомендации из этого пункта:
* не используйте имя пользователя в названии компьютера
* удостоверьтесь, что на системе нет пользователся Administrator
* используйте надёжные пароли
Вот таким образом, я наблюдаю, как несколько Windows Server под моим контролем брут-форсятся уже где-то пару лет, и безуспешно.
Откуда я знаю, что безуспешно?
Потому что на скриншотах выше видно, что есть логи успешных заходов по RDP, в которых есть информация:
* с какого IP
* с какого компьютера (hostname)
* имя пользователя
* GeoIP информация
И я регулярно туда посматриваю — аномалий не обнаружено.
Кстати, если с какого-то IP брут-форсят особо усердно, то заблокировать отдельные IP (или подсети) можно вот так в PowerShell:
```
New-NetFirewallRule -Direction Inbound -DisplayName "fail2ban" -Name "fail2ban" -RemoteAddress ("185.143.0.0/16", "185.153.0.0/16", "193.188.0.0/16") -Action Block
```
Кстати у Elastic, помимо Winlogbeat ещё есть [Auditbeat](https://www.elastic.co/beats/auditbeat), который может следить за файлами и процессами на системе. Ещё есть SIEM (Security Information & Event Management) приложение в Kibana. Я пробовал и то и другое, но пользы особо не увидел — похоже Auditbeat будет более полезен для Linux систем, а SIEM ничего внятного мне пока не показал.
Ну и финальные рекомендации:
* делайте регулярные автоматические бэкапы.
* своевременно ставьте Security Updates
**Бонус: список из 50 пользователей, которые чаще использовались для попыток входа по RDP**
| "user.name: Descending" | Count |
| --- | --- |
| dfthd7c (hostname) | 842941 |
| winsrv1 (hostname) | 266525 |
| ADMINISTRATOR | 180678 |
| administrator | 163842 |
| Administrator | 53541 |
| michael | 23101 |
| server | 21983 |
| steve | 21936 |
| john | 21927 |
| paul | 21913 |
| reception | 21909 |
| mike | 21899 |
| office | 21888 |
| scanner | 21887 |
| scan | 21867 |
| david | 21865 |
| chris | 21860 |
| owner | 21855 |
| manager | 21852 |
| administrateur | 21841 |
| brian | 21839 |
| administrador | 21837 |
| mark | 21824 |
| staff | 21806 |
| ADMIN | 12748 |
| ROOT | 7772 |
| ADMINISTRADOR | 7325 |
| SUPPORT | 5577 |
| SOPORTE | 5418 |
| USER | 4558 |
| admin | 2832 |
| TEST | 1928 |
| MySql | 1664 |
| Admin | 1652 |
| GUEST | 1322 |
| USER1 | 1179 |
| SCANNER | 1121 |
| SCAN | 1032 |
| ADMINISTRATEUR | 842 |
| ADMIN1 | 525 |
| BACKUP | 518 |
| MySqlAdmin | 518 |
| RECEPTION | 490 |
| USER2 | 466 |
| TEMP | 452 |
| SQLADMIN | 450 |
| USER3 | 441 |
| 1 | 422 |
| MANAGER | 418 |
| OWNER | 410 | | https://habr.com/ru/post/487056/ | null | ru | null |
# Unix как IDE: Работа с текстом
Текстовый редактор — это основной инструмент для любого программиста, вот почему вопрос его выбора становится причиной яростных дебатов. Unix традиционно тесно связан с двумя своими многолетними фаворитами, **Emacs** и **Vi**, и их современными версиями **GNU Emacs** и **Vim**. Эти редакторы имеют очень разный подход к редактированию текста, но при этом сравнимы по мощи.
Поскольку я отношусь к секте **Vim**, далее мы обсудим неисчерпаемые возможности этого редактора, а также инструменты командной строки, вызываемые прямо из **Vim** для расширения встроенной функциональности. Некоторые из обсуждаемых дальше принципов могут быть применимы и для **Emacs**, но не для простых редакторов, вроде **Nano**.
Это будет очень поверхностный обзор, поскольку возможности **Vim** в деле программирования поистине неисчислимы, и при этом все равно он получится довольно длинным. Команда **Vim** *:help* известна среди новичков как качественный и полезный источник информации, поэтому не пренебрегайте ей.
#### Определение типа файла
**Vim** имеет множество настроек, влияющих на его поведение. Например, легко настроить подсветку кода в зависимости от типа загружаемого файла. Таким образом, в частности, можно установить стиль отступов, соответствующий нормам используемого языка программирования. Эту настройку лучше поместить одной из первых в вашем *.vimrc* файле.
```
if has("autocmd")
filetype on
filetype indent on
filetype plugin on
endif
```
#### Подсветка синтаксиса
Даже если вы работаете с 16-цветным терминалом, смело включайте подсветку в вашем *.vimrc* файле:
```
syntax on
```
Цветовые схемы стандартного 16-цветного терминала внешне не слишком хороши, но решают поставленные перед ними задачи, если подцепить правильные синтаксические файлы. Есть огромное множество цветовых схем, поэтому не составит труда настроить их под себя, а 256-цветный терминал или **gVim** дадут еще более широкие возможности. Хорошие синтаксические файлы подсветят ошибки ярким красным цветом фона.
#### Нумерация строк
Если вы привыкли к нумерации строк в традиционных IDE, то включить ее можно, набрав:
```
set number
```
Можно попробовать такой трюк, если у вас **Vim** не старее 7.3, и вы хотите нумеровать строки не абсолютно, а по отношению к текущей:
```
set relativenumber
```
#### Тег-файлы
**Vim** очень хорошо работает с данными, генерируемыми утилитой **ctags**. Это позволяет быстро найти все вхождения нужного идентификатора в пределах проекта, или перейти прямо к объявлению переменной с места ее использования в коде, даже если она находится в другом файле. Для больших проектов на C, содержащих множество файлов, можно сэкономить огромное количество впустую потраченного времени, и это, возможно, теснее всего сближает **Vim** с мейнстримными IDE.
Вы можете запустить *:!ctags -R* в корневой директории проекта на одном их поддерживаемых языков, и в результате получите тег-файл с определениями и ссылками на расположение идентификаторов в вашем проекте. По готовности тег-файла искать использование тега в проекте можно так:
```
:tag someClass
```
Команды *:tn* и *:tp* позволяют перемещаться между вхождениями тега по всему проекту. Встроенный механизм тегов покрывает большую часть наиболее используемых возможностей, но если хочется более навороченных фишек, вроде окна со списком тегов, можно установить очень популярный плагин **Taglist**. Плагин **Unimpaired** за авторством Tim Pope тоже содержит несколько важных командных переназначений.
#### Вызов внешних программ
Есть 2 основных метода вызова внешних команд из сессии **Vim**:
* *:!!* — используется в случаях, когда нужно сохранить вывод программы в буфер
* *:shell* — Запустить shell как дочерний процесс **Vim**. Подходит для интерактивного выполнения команд.
Третий способ, здесь подробно не обсуждаемый, подразумевает использование плагинов вроде **Conque** для эмуляции shell прямо в буфере **Vim**. Сам я пробовал его в действии, но плагин показался мне непригодным к использованию. Возможно, дело просто в неверном авторском замысле (см. *:help design-not*).
**Vim** — это не консоль и не операционная система. У вас вряд ли получится запустить консоль внутри **Vim** или использовать его для управления отладчиком. У него другая модель использования: применяйте его в качестве компонента командной строки или как составную часть IDE.
#### Lint-подобные программы и проверка синтаксиса
Проверка синтаксиса или компиляция через вызов внешней программы (например, `perl -c`, `gcc`) может быть запущена из редактора при помощи *!: commands*. Если редактируется файл Perl, то можно выполнить следую команду:
```
:!perl -c %
/home/tom/project/test.pl syntax OK
Press Enter or type command to continue
```
Символ "%" — это знак подстановки файла, загруженного в текущий буфер. Результатом является текстовый вывод команды, если таковой имеется, под введенной командной строкой. Если нужно вызывать внешнюю программу постоянно, то лучше замапить ее как команду, или даже как комбинацию клавиш в файле *.vimrc*. Ниже мы определим команду *:PerlLint*, вызываемую из нормального режима при помощи *\l*:
```
command PerlLint !perl -c %
nnoremap l :PerlLint
```
Для многих языков есть еще один способ сделать то же самое, прибегнув к помощи встроенного в **Vim** окна quicklist. Установить настройку *makeprg* для типа файла, включив туда вызов модуля, формирующего читабельный для **Vim** вывод:
```
:set makeprg=perl\ -c\ -MVi::QuickFix\ %
:set errorformat+=%m\ at\ %f\ line\ %l\.
:set errorformat+=%m\ at\ %f\ line\ %l
```
Предварительно нужно установить нужный модуль через CPAN. По завершении можно вводить команду *:make* и проверять синтаксис файла. Если найдены ошибки, можно открыть окно quicklist (*:copen*), проверять их описание и перемещаться между ними при помощи *:cn* и *:cp*.
Подобные трюки аналогично работают с выводом gcc, да и вообще с любой программой проверки синтаксиса, которая оперирует в результатах своей работы именами файлов, номерами строк и сообщениями об ошибках. Точно так же можно работать и с веб-ориентироваными языками вроде PHP, и с JSLint для Javascript. Существует также отличный плагин **Syntastic**, предназначенный для так же целей.
#### Чтение вывода других команд
Чтобы вызвать команду и направить ее вывод прямо в текущий буфер, используется *:r!*. Для примера, чтобы получить быстрый список содержимого директории, можно напечатать:
```
:r!ls
```
Командами, конечно, дело не ограничивается; при помощи *:r* можно считывать считывать любые файлы, например, открытые ключи или шаблонные тексты:
```
:r ~/.ssh/id_rsa.pub
:r ~/dev/perl/boilerplate/copyright.pl
```
#### Фильтрация вывода через другие команды
Если смотреть на заговолок шире, то речь пойдет вообще о фильтрации текста в буфере через внешние команды. Поскольку визуальный режим **Vim** отлично подходит для работы с данными, разбитыми на столбцы, нередко имеет смысл применить команды **column**, **cut**, **sort** или **awk**.
Для примера можно отсортировать весь файл по второму столбцу следующей командой:
```
:%!sort -k2 -r
```
Можно выводить только третью колонку выбранного текста, где строка совпадает с шаблоном "/vim/":
```
:'<,'>!awk '/vim/ {print $3}'
```
Можно расположить ключевые слова в строках с 1 по 10 по колонкам:
```
:1,10!column -t
```
Любой текстовый фильтр или команда могут быть применены таким образом в **Vim**, и это на порядок увеличивает размах возможностей текстового редактора. При этом буфер **Vim** рассматривается как текстовый поток, а уж на этом языке легко общаются все классические утилиты.
#### Встроенные альтернативы
Стоит отметить, что для самых распространенных операций, таких как сортировка и поиск, **Vim** имеет встроенные методы *:sort* и *:grep*. Они полезны, если *Vim* используется под Windows, однако даже близко не сравнимы с адаптивностью консольных вызовов.
#### Сравнение файлов
**Vim** имеет инструмент сравнения **vimdiff**, позволяющий не только смотреть различия в разных версиях файла, но и разрешать конфликты через трехстороннее слияние, заменять разницу между кусками текста командами *:diffput* и *:diffget*. **Vimdiff** вызывается из командной строки для по крайней мере двух файлов вот так:
```
$ vimdiff file-v1.c file-v2.c
```
#### Контроль версий
Запускать методы контроля версий можно прямо из **Vim**, и этого чаще всего достаточно. При этом нужно помнить, что "%" — всегда место подстановки файла из текущего буфера:
```
:!svn status
:!svn add %
:!git commit -a
```
Действующий чемпион по Git-функциональности — это плагин **Fugitive** за авторством Tim Pope, который я настоятельно рекомендую всем, кто использует Git совместно с **Vim**. Более подробное освещение истории и основ систем контроля версий в Unix ищите в 7 части данной серии статей.
#### Большая разница
Программисты, привыкшие к графическим IDE, нередко считают **Vim** игрушкой или пережитком. Отчасти причиной служит тот факт, что **Vim** привыкли видеть в качестве средства редактирования конфигурационных файлов на сервере, а вовсе не как удобный текстовый редактор командной строки. Его встроенные инструменты так хорошо совмещаются с внешними Unix-командами, что нередко способны удивить даже опытных пользователей.
***Продолжение следует...***
[**Unix как IDE: Введение**](http://habrahabr.ru/post/150930/)
[**Unix как IDE: Файлы**](http://habrahabr.ru/post/151064/)
[**Unix как IDE: Работа с текстом**](http://habrahabr.ru/post/151128/)
[**Unix как IDE: Компиляция**](http://habrahabr.ru/post/151314/) | https://habr.com/ru/post/151128/ | null | ru | null |
# Что же не так с любыми электронными голосованиями?
Данная публикация написана по мотивам поста «[Что же не так с ДЭГ в Москве?](https://habr.com/ru/post/579350/)». Его автор описывает, как можно выгрузить и расшифровать данные по электронному голосованию, а также приводит целый список замечаний к его текущей системе.
Статья хорошая, её выводы и замечания я полностью поддерживаю, но мне захотелось дополнить её в обеих частях. Первая — с анализом того, как в процессе голосования менялись отданные за различных кандидатов голоса; вторая — моя позиция о фундаментальных недостатках **любого электронного голосования**, которые неустранимы на практике (особенно в современной России).
**UPD**: Добавил также [графики по партийным спискам](https://denull.github.io/elections-2021/parties.html) + отметил некоторые [странности в соотношении выданных/полученных транзакций](https://habr.com/ru/post/579968/comments/#comment_23526024) в самом начале (возможно, это объяснимо техническими проблемами).
Аномалии в динамике распределения голосов
-----------------------------------------
Во-первых, я последовал инструкции, выгрузил дамп с голосами по одномандатному голосованию в Москве, и сделал [вот такие интерактивные визуализации](https://denull.github.io/elections-2021/index.html) по каждому московскому округу:
Как менялось распределение голосов за три дня голосования в Ленинградском округе МосквыОбратите внимание, что по вертикали здесь отложены проценты голосов за каждый 20-минутный период, а не абсолютное число голосов. Поэтому в ночные периоды эти проценты сильно «скачут» — просто из-за того, что голосов там мало. А вот что более интересно — это **динамика доли голосов за административного кандидата**. Во-первых, виден **скачок в самом начале**, который постепенно **убывает с течением времени** (то есть по какой-то причине сторонникам провластного кандидата хотелось проголосовать как можно раньше — особенно в самые первые часы первого дня голосования). Во-вторых, в третий день наблюдается ещё более заметный **«горб» с 2 часов ночи до примерно 2 часов дня — с перерывом с 12 до 13**. Какая естественная причина могла сподвигнуть избирателей дружно выбрать такой период для голосования за подобных кандидатов — остается лишь гадать.
На приведённых графиках можно спрятать любой из сегментов, и вот как меняются соотношения, если спрятать кандидата, занявшего первое место:
Динамика распределения голосов без учета голосов за административного кандидатаВидно, что странный горб в третий день бесследно исчезает, а соотношения между голосами выравниваются. Важно отметить, что я тут привожу пример только одного округа, но самое интересное, что подобные аномалии видно [**на каждом из 15 округов Москвы**](https://denull.github.io/elections-2021/index.html). В каждом округе именно у провластного кандидата (и только у него) есть скачок в начале графика, и везде странный горб в третий день. Если просуммировать данные по каждому округу, эти аномалии видны ещё лучше (заодно сглаживаются ночные флуктуации):
Суммарное соотношение голосов за кандидатов на 1-м, 2-м и т.д. местах в каждом округе МосквыДобавлю, что я не первый, кто провёл этот анализ — я лишь перепроверил (и чуть иначе визуализировал) наблюдения, сделанные командой Анастасии Брюхановой, которая побеждала в Ленинградском округе, но (как и ряд кандидатов в других округах) была лишена победы из-за этих необъяснимых аномалий. Вот их видео с разбором этих проблем:
Отмечу, что я также обнаружил на Гитхабе [ещё один инструмент](https://github.com/kbespalov/voting2021) для выгрузки этих данных по Москве, и ещё одни [графики](https://datalens.yandex/pzbi5cq6nd08i), построенные по ним в DataLens. Можно убедиться, что они совпадают с моими наблюдениями и наблюдениями команды Брюхановой. ЦИК же, ожидаемо, никаких проблем в них не увидел.
Почему электронное голосование всегда будет хуже бумажного
----------------------------------------------------------
Критики в сторону текущей реализации ДЭГ очень много. Напомню вкратце основные отмеченные проблемы:
* В базе голосов присутствуют как актуальные, так и отменённые из-за переголосований бюллетени. Сейчас нет никакого публичного способа их отличить, а следовательно корректно перепроверить итоги выборов.
* На выборах в Госдуму даже не была публично завершена расшифровка всех бюллетеней — хотя их и возможно дорасшифровать самостоятельно. Отдельно замечу, что один бюллетень (с хэшом `f07ee512b57bc7d6176592ee6a4ab2526c025af2d57cd9e636c038e61b57db06`) не удается расшифровать в принципе. Я пока объяснений не видел (и у меня нет гипотез), как он попал в блокчейн, но это выглядит нехорошим звоночком.
* Итоги были подведены спустя значительное время после завершения выборов. При этом наблюдатели лишились возможности следить за процессом непосредственно в момент окончания приема голосов (19 сентября в 20:00) из-за истекшего сертификата. То есть никакого контроля за работой системы не осуществлялось, а результаты были просто представлены позднее независимо от неё.
* Не скрывается, что за выдачу вышеупомянутых сертификатов была ответственна ФСБ. Не удивлюсь, если в целом их позиция в том, что в любой окологосударственной электронной системе, использующей криптографию, должны быть предусмотрены бэкдоры для них. Это вызывает опасения как в плане предвзятости самой службы в пользу текущей власти, так и потенциального использования бэкдоров третьими лицами.
* Наблюдатели, следившие за ходом электронного голосования, слабо понимали технический смысл происходящего — и их сложно в этом винить, так как система сделана переусложнённой и малопонятной даже для IT-специалистов.
* Нет никакого способа удостовериться, что [опубликованные исходные коды ДЭГ](https://github.com/moscow-technologies/blockchain-voting_2021) соответствуют тем, которые применяются фактически. Я не слышал, чтобы кто-то проводил её независимый аудит.
* Возможность убедиться, что голос был сохранён в блокчейне, хотя и присутствует у избирателей, однако требует выполнения [ряда неочевидных действий](https://grigorysherstyuk.medium.com/%D0%BA%D0%B0%D0%BA-%D0%BF%D1%80%D0%BE%D0%B2%D0%B5%D1%80%D0%B8%D1%82%D1%8C-%D0%B3%D0%BE%D0%BB%D0%BE%D1%81-%D0%BF%D0%BE%D0%B4%D0%B0%D0%BD%D0%BD%D1%8B%D0%B9-%D1%87%D0%B5%D1%80%D0%B5%D0%B7-%D1%81%D0%B8%D1%81%D1%82%D0%B5%D0%BC%D1%83-%D0%B4%D1%8D%D0%B3-%D0%B8%D0%BD%D1%81%D1%82%D1%80%D1%83%D0%BA%D1%86%D0%B8%D1%8F-7e40500ac0f8), о которых нужно знать заранее. Очевидно, что не сильно подкованный технически избиратель данной возможностью не воспользуется, в интерфейсе она не представлена, а разработчики и вовсе говорят, что «[*нормативно это вообще запрещено*](https://youtu.be/_jsRVlwsBj8?t=13958)». То есть это действие, которое реализуемо технически, но запрещённое некими формальными правилами.
Всё это абсолютно валидные претензии к системе (в дополнение к вышеупомянутым аномалиям, а также [традиционным статистически выявляемым фальсификациям](https://www.facebook.com/sergey.shpilkin/posts/4398836840204918) на обычных участках). Однако я хочу (и даже вынес это в заголовок) взглянуть на более общую картину, касающуюся различий между электронными и «бумажными» голосованиями.
Если послушать интервью с главным «локомотивом» ДЭГ Алексеем Венедиктовым, то можно понять, что все замечания к этой системе он воспринимает как обычные багрепорты, которые просто можно пофиксить в следующей версии (и тогда у нас наступит светлое электронное будущее). Тех же, кто выступает против электронных голосований как таковых, он приравнивает к антиваксерам и прочим маргиналам, выступающим против прогресса.
Поэтому я считаю очень важным обсуждать именно этот момент: Венедиктов заблуждается, у **любого** электронного голосования остаются неразрешимые фундаментальные проблемы, которых нет у физического. С одной стороны, позицию его можно в чём-то понять: он представляет команду, которая пилит какой-то продукт, и конечно им хочется верить, что его можно отточить и наладить — и внутренне это действительно так. Но важно помнить, что этот продукт — лишь часть цельной системы, и пока у неё остаются более слабые места, она останется слабой в целом.
> Лично это мне видится как производство супер-навороченного замка, который хоть и красиво блестит (и может даже быть исследован и оттестирован изнутри), но повешен на сарай с дырами в стенах (через которые и полезут злоумышленники).
>
>
Здесь таким замком выступает хвалёный блокчейн, который якобы нельзя подделать (хотя с учётом переголосований выходит, что и можно). Даже если он решит задачу надёжного хранения отданных голосов, это не даст никаких возможностей проверить, **откуда они поступают**.
Сравните роль наблюдателей на традиционном и электронном голосованиях. Наблюдатель на участке видит живого человека, с паспортом, который получает бюллетень, ставит в нём галочку, опускает в опечатанную урну, а затем следит за тем, как эти бюллетени подсчитывают. Что видит наблюдатель в электронном голосовании? Как в некую базу данных откуда-то прилетают некие бюллетени. Продолжая аналогии, **это как если бы наблюдение велось не за всем происходящим на участке, а только за содержимым урны — мы только видим, что в неё неизвестно откуда сыпятся бюллетени** (и вроде ничего не высыпается — но в текущей системе даже это неверно).
Если максимально упрощать, избиратель — это всегда объект физического мира. Чтобы взаимно однозначно перевести его в электронное представление, необходим какой-то компонент, которому мы **доверяем**. В Эстонии, например, государство выдает ID-карты для этой цели, а у нас — насколько я понимаю, Госуслуги передают информацию об авторизованном избирателе в ГАС Выборы. Когда мы сравниваем такие системы, нужно сравнивать и степень доверия, соответственно, этим компонентам. Но самое важное это то, что традиционное голосование не требует такого доверия к единому компоненту — процесс можно контролировать независимо извне (наблюдатель видит именно **живого человека**, а не заверенную кем-то цифровую подпись).
Ещё один тонкий момент, которого я коснулся выше — **анонимность**. Голосование, с одной стороны, должно быть тайным, чтобы на избирателя нельзя было оказать административное давление, а с другой — желательно быть уверенным, что каждый отданный голос будет учтён в подсчёте. В текущей реализации получается так, что, с одной стороны, проверить свой голос вроде как можно, но по сложной инструкции (т.е. избиратель должен либо понимать, что делает, либо доверять составителю). Но ничего не мешает принуждать людей пользоваться этой инструкцией, а после расшифровки проверять, *правильно* ли они голосовали. Да, я уже предвижу комментарии о том, что это исправимо с помощью [гомоморфного шифрования](https://ru.wikipedia.org/wiki/%D0%93%D0%BE%D0%BC%D0%BE%D0%BC%D0%BE%D1%80%D1%84%D0%BD%D0%BE%D0%B5_%D1%88%D0%B8%D1%84%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5) и прочих весёлых криптографических ухищрений. Я соглашусь, что это красивые математические решения и они даже могут работать в теории — но только если допустить, что страна населена роботами, каждый из которых способен вникнуть в суть этих непростых криптографических схем. К сожалению, в реальности я бы на это не рассчитывал.
И, наконец, вредоносное программное обеспечение. Если бы речь шла лишь о применении КОИБов для «цифровизации» выборов, можно было бы надеяться, что их начинка не искажает подсчёт голосов (хотя это тоже требует доверия к её разработчикам, а по факту в ней уже находили ряд уязвимостей). Но сейчас для голосования применяются компьютеры самих избирателей, которые вполне могут быть подвержены заражению вирусами. **Компроментация конечного устройства сводит на нет всю защиту «по пути»** — если, скажем, у пользователя стоит расширение, переставляющее на веб-страничке галочки местами, то никакая криптография его не спасёт. И это фальсификации, которые возможно делать не в масштабах одного участка, а в масштабах всей страны. Что характерно, заниматься этим может уже не только государство, а **любые злоумышленники** (привет государственной паранойе на тему иностранных вмешательств :)
Заключение
----------
Нынешняя реализация ДЭГ — **плохая**. К ней зафиксировано много претензий, а в результатах — много фальсификаций. Все, кстати, обращают внимание на московскую, а шесть других регионов (в которых использовалась несколько другая реализация) остаются в тени. **Но проблема не столько с текущей реализацией, сколько с электронными голосованиями в принципе**. В отличие от бумажных голосований, они требуют **гораздо больше доверия** к организаторам выборов и собственному государству, поскольку не дают даже **теоретических инструментов для независимого наблюдения в той степени, в которой оно возможно в традиционных выборах**.
Это не значит, конечно, что бумажные выборы идеальны — но там хотя бы есть понятные пути для предотвращения вбросов и фальсификаций. Эти пути нужно применять (идти в наблюдатели) и усиливать (а не отбирать, например, [публичный доступ к видеонаблюдению](https://novayagazeta.ru/articles/2021/07/16/videonabliudenie-eto-ne-prazdnoe-liubopytstvo-pamfilova-ob-otkaze-na-vyborakh-ot-obshchedostupnykh-transliatsii-s-uchastkov), и не [обфусцировать результаты выборов](https://habr.com/ru/post/579492/)). Это будет прогрессивно. А переход к электронному голосованию — это регресс, как бы противоречиво на первый взгляд это ни казалось.
Напоследок предлагаю также посмотреть вот это видео Тома Скотта с критикой электронных голосований — в первую очередь в Великобритании, но он приводит те же аргументы, что привёл и я, которые распространяются на любую такую систему: | https://habr.com/ru/post/579968/ | null | ru | null |
# Как создать проект на ассемблере в STM32CubeIDE
Доброго времени суток, сегодня я хотел бы поделиться своим опытом создания шаблона проекта в CubeIDE для программирование на Ассемблере.
Так как CubeIDE использует средства GNU то и синтаксис ассемблера у нас будет советующий. Для начала откроем CubeIDE и создадим новый проект. В качестве испытуемого микроконтроллера возьму STM32G030F6P6 уж очень мне они нравятся. А так данный способ работает и с другими сериями микроконтроллера STM32.
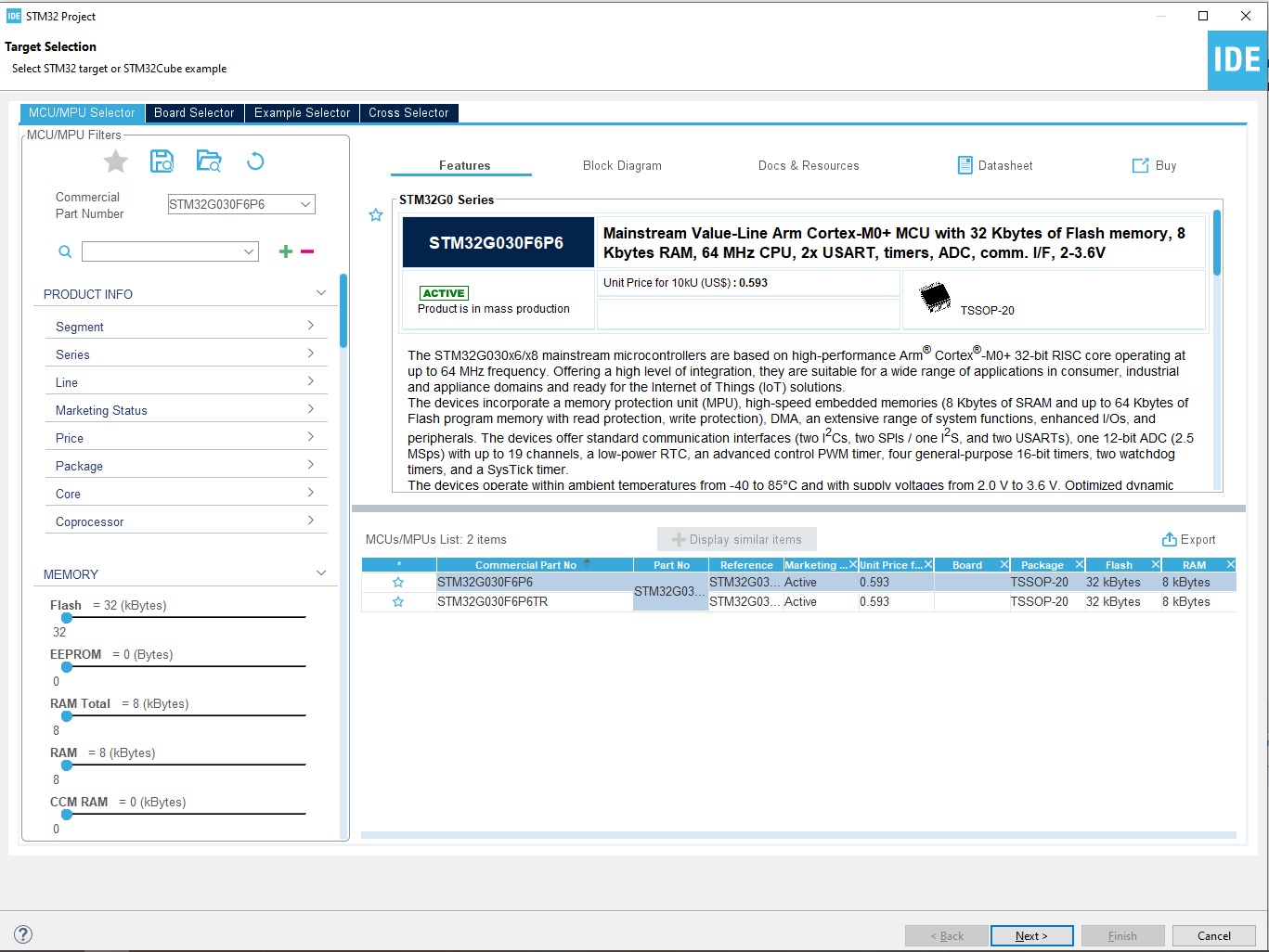Далее необходимо дать название проекту и выбрать пустой проект и жмем завершить.
Теперь необходимо удалить лишние файлы и переименовать main.c в main.s.
Очищаем main.s и удаляем syscall.c и sysmem.c. , но startup файл мы оставим обязательно, так как там прописаны первоначальная настройка стека и таблицы векторов после чего вызывается main, в рамках данной статьи автор рассчитывает на новичков которые только познают азы ассемблера. Должно получиться примерно так.
Теперь нам необходимо открыть файл startup\_stm32....s и скопировать директивы среды. Находим данные строки ниже и копируем в наш main.s
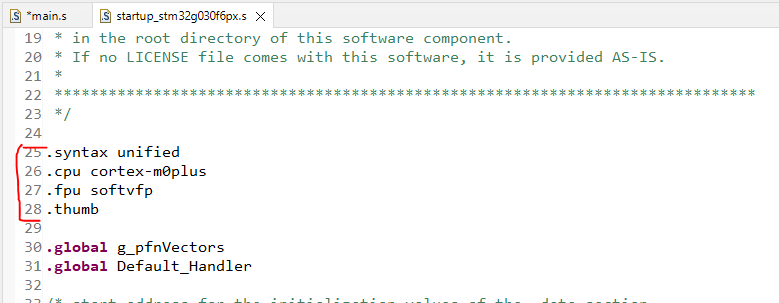После чего необходимо создать точку входа в программу, для этого нам необходимо создать метку main и сделать ее глобальной, что бы была видна из других файлов. Так же пропишем бесконечный цикл, для избежание перехода в другие области памяти. После чего компилируем и как видим проект собрался.
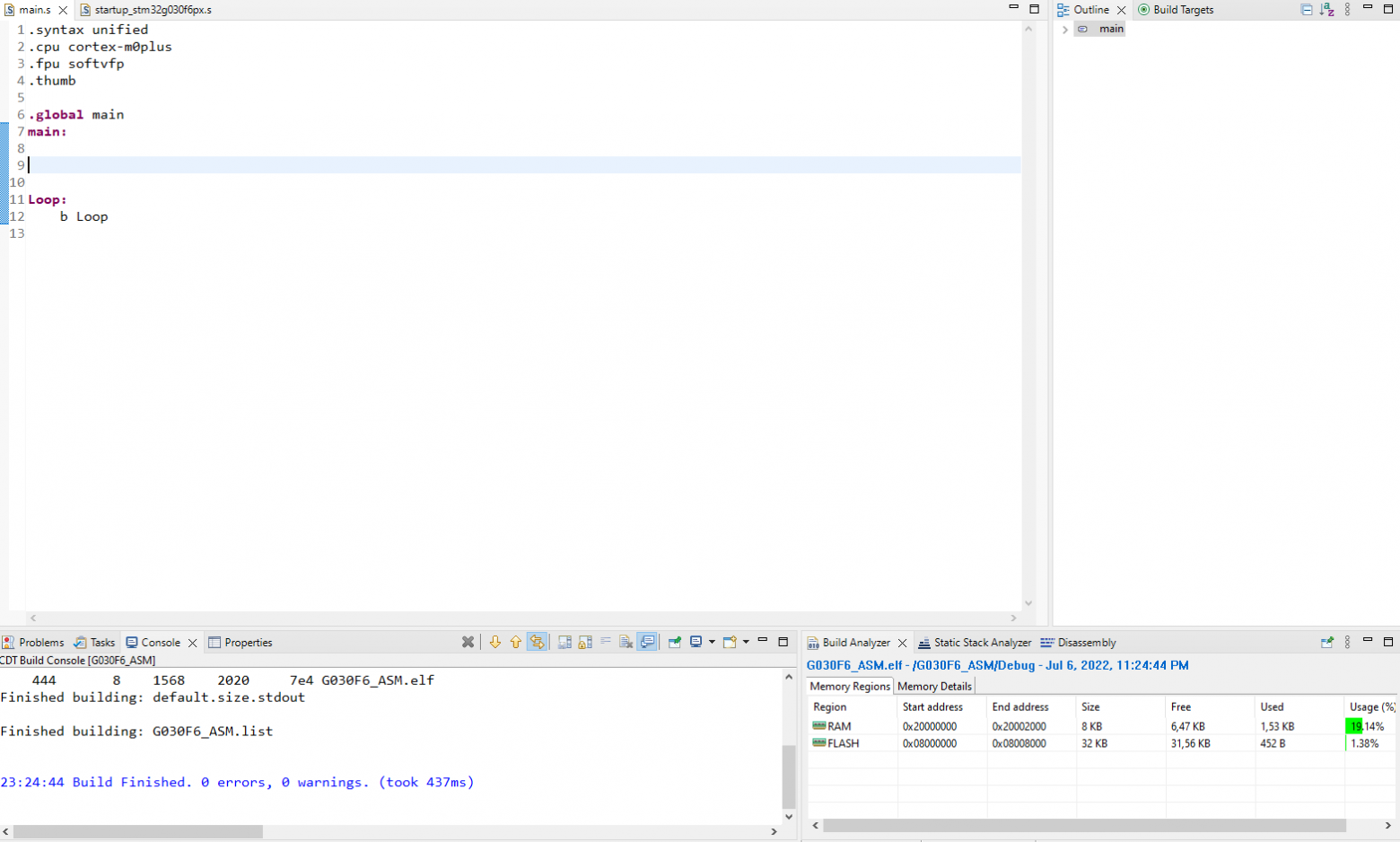Теперь давайте напишем небольшой код, в самых лучших традициях помигаем светодиодом) , для этого нам понадобиться два адреса RCC и GPIO. Можно взять из datasheet их, но мне лень поэтому немного схитрим. Необходимо войти в режим отладки.
Тут просто жмем Ок.
после чего начнет загружаться прошивка и нам предложат подключиться на что мы соглашаемся и жмем Switch.
В правом окне нам необходимо найти раздел SFRs и выбрать нам интересную периферию. Тут мы находим наш начальный адрес, для RCC он находиться 0x40021000 а для GPIOB 0x50000400. Желтым подсвечивается изменение содержимого регистра. Так как мы только что открыли их, для нас все эти значения новые.
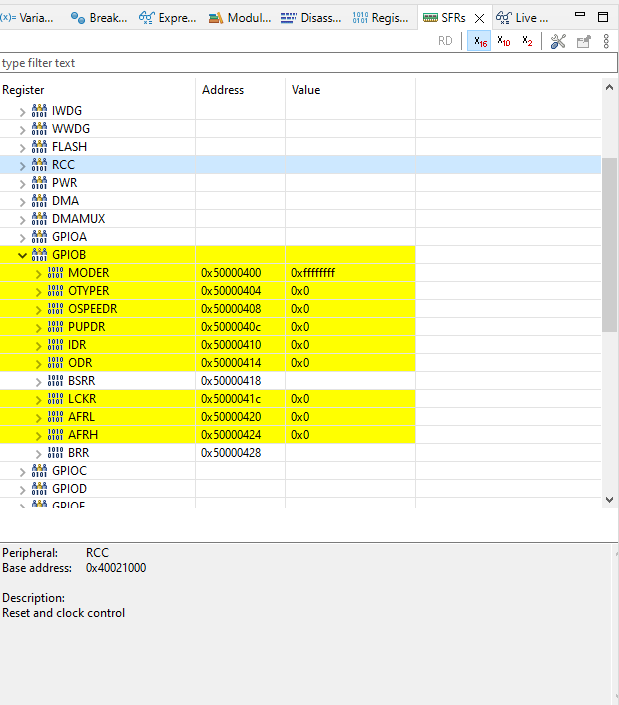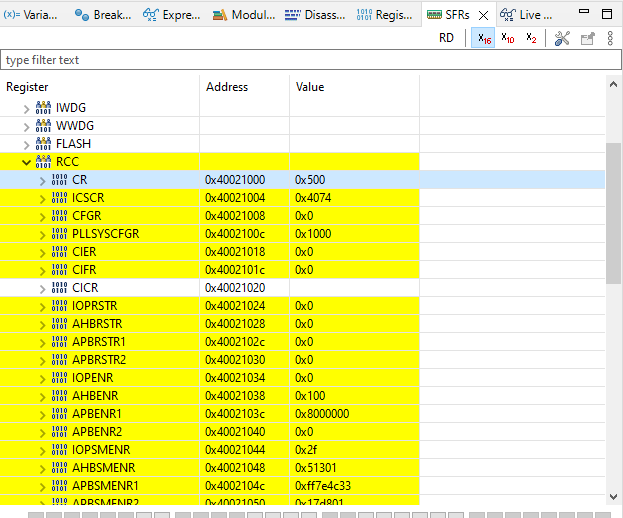В этом разделе можно посмотреть текущее состояние битов периферии. Так же нам понадобиться раздел Registers в котором находиться регистры общего назначения.
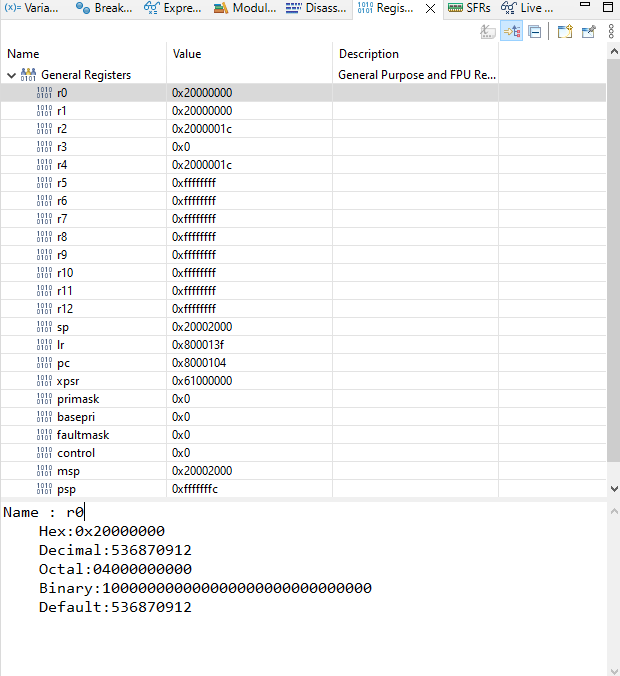После чего напишем простой скетч.
```
.syntax unified
.cpu cortex-m0plus
.fpu softvfp
.thumb
.equ RCC_BASE, 0x40021000
.equ GPIOB_BASE, 0x50000400
.global delay
.global main
main:
//Включения тактирования GPIOB
ldr r0, =RCC_BASE
ldr r1, [r0, #0x34]
movs r2, #0b10
adds r1, r2
str r1, [R0, #0x34]
//Настройка GPIOB_PIN_0 как выход
ldr r0, =GPIOB_BASE
ldr r1, [r0, #0x0]
movs r2, #0b11
bics r1, r2
adds r1, #1
str r1, [r0, #0x0]
Loop:
//Установка PIN_0 в лог. ед.
ldr r1, [r0, #0x18]
movs r2, #1
orrs r1, r2
str r1, [r0, #0x18]
bl delay
//Установка PIN_0 в лог. ноль
ldr r1, [r0, #0x18]
movs r2, #1
lsls r2, #16
orrs r1, r2
str r1, [r0, #0x18]
bl delay
b Loop
//задержка
delay:
push {r3}
ldr r3, =#0x00100000;
delay_loop:
subs r3, #1
bne delay_loop
pop {r3}
bx lr
```
Скомпилируем наш код и зашьем его. В качестве примера использую китайскую плату. У данной платы к ножке 0 порта В подлечен светодиод катодом т.е. когда мы подаем лог. ед. на вывод светодиод не горит, когда подаем лог. ноль то светодиод загорается.
Подключаемся в режиме отладки и начинаем идти по коду. Сначала отработает код startup файла. В нем процессор сначала вызывает обработчик сброса в котором формирует стек и векторы прерываний а после вызывает наш main. В первом блоке кода происходит включение тактирования GPIOB.
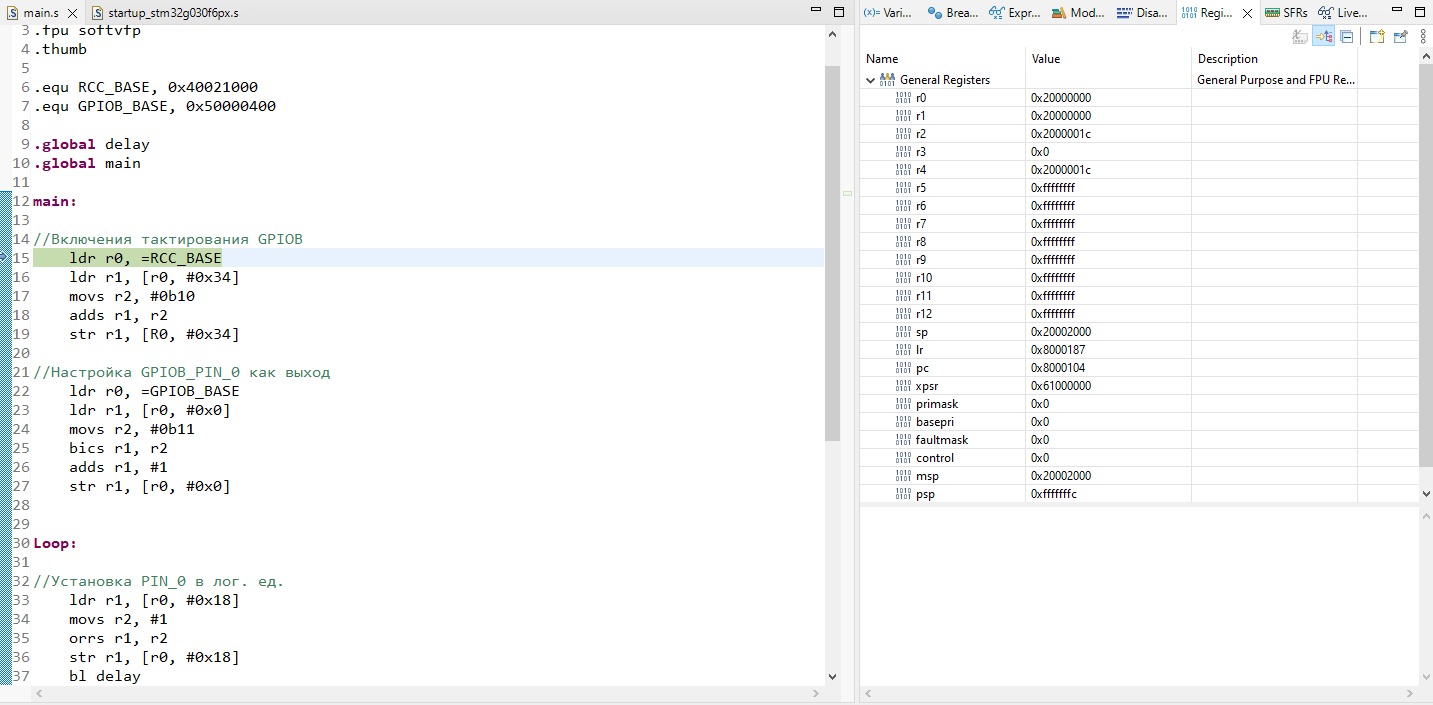 Команда LDR загружает в R0 базовый адрес RCC который объявлен у нас константой. как можно видеть после выполнения команды в регистр был положен адрес. Так же можно будет заметить что счетчик команд постоянно смещается. Если перейти в окно disassembly можно сопоставить данные адреса.
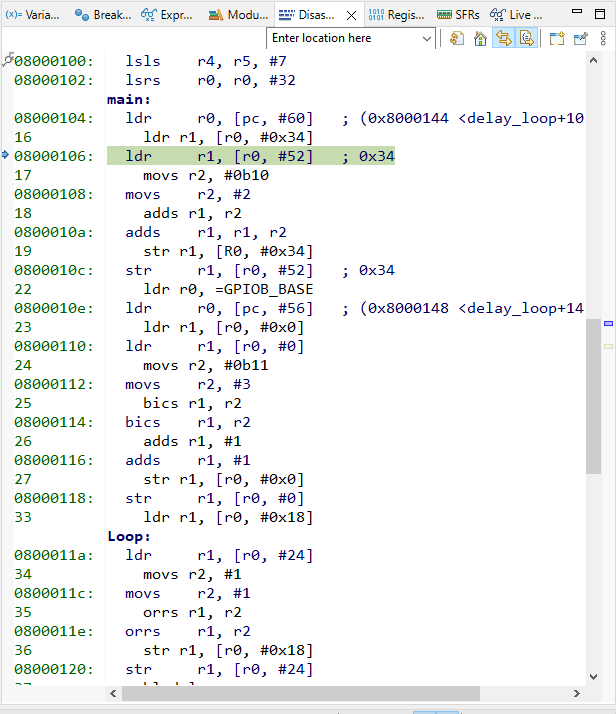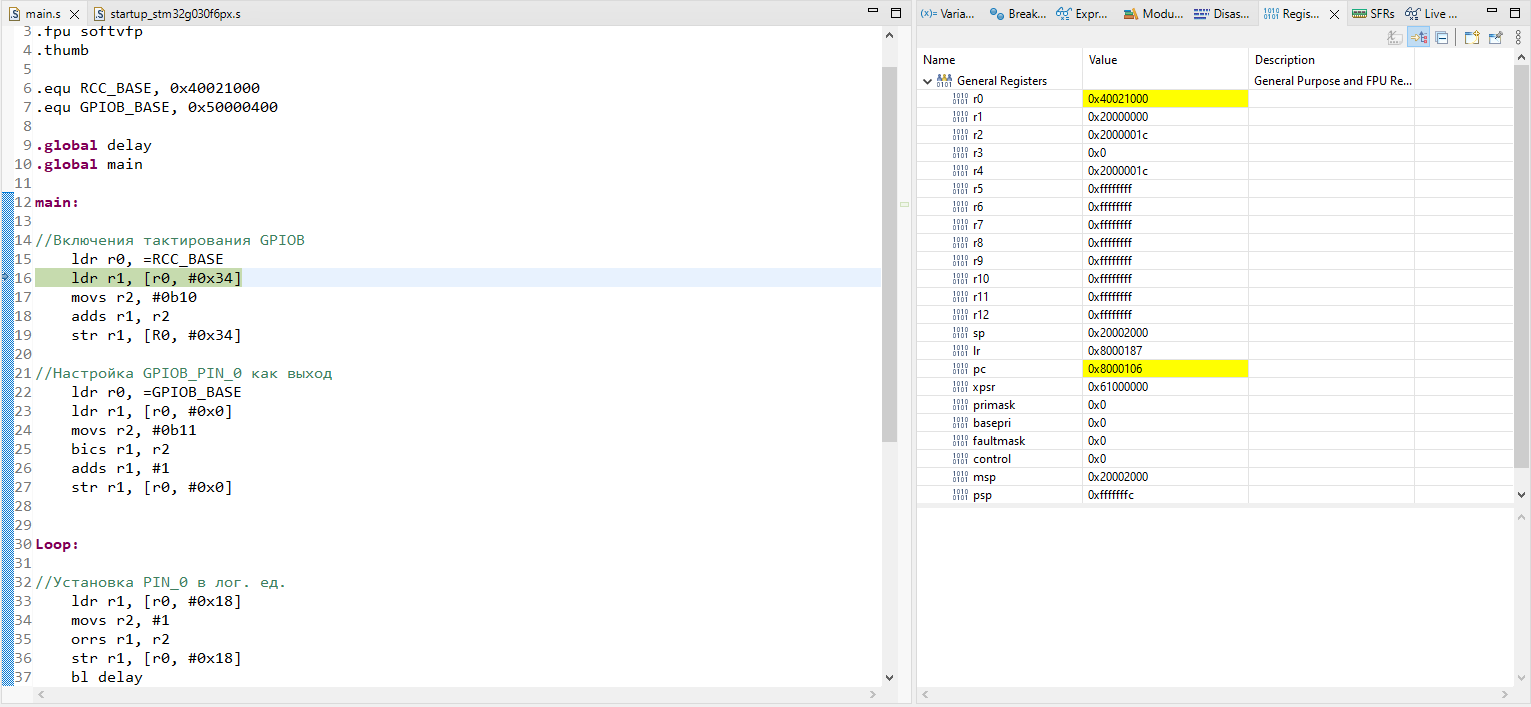после чего следующей командой LDR мы загружаем значение в регистр R1 находящееся по адресу R0 смешенное на 0x34. Для проверки сравним считанное значение и посмотренное через средства отладки. Для этого откроем окно SFRs и посмотрим значения регистра RCC\_IOPENB.
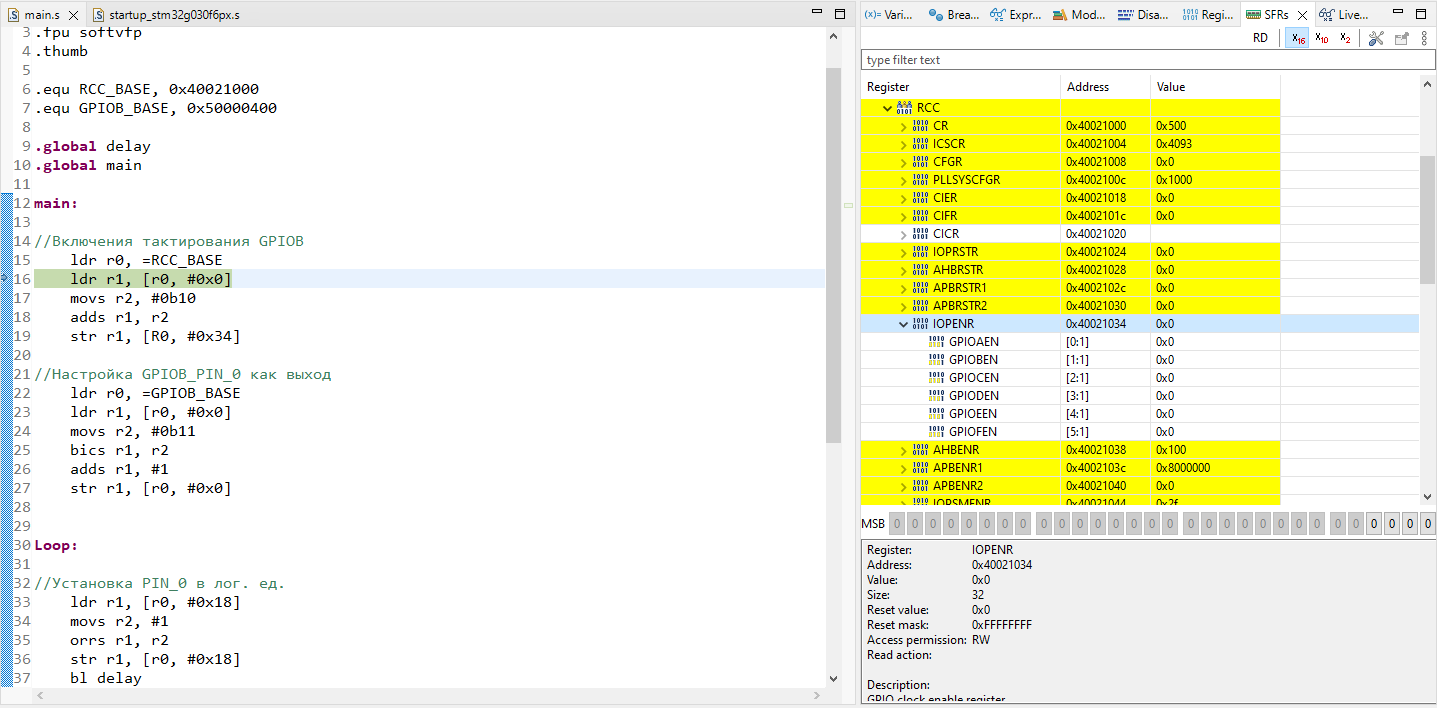И жмем дальше шаг дальше. И переходим снова в окно регистров общего назначения и убеждаемся, что загруженное число советует.
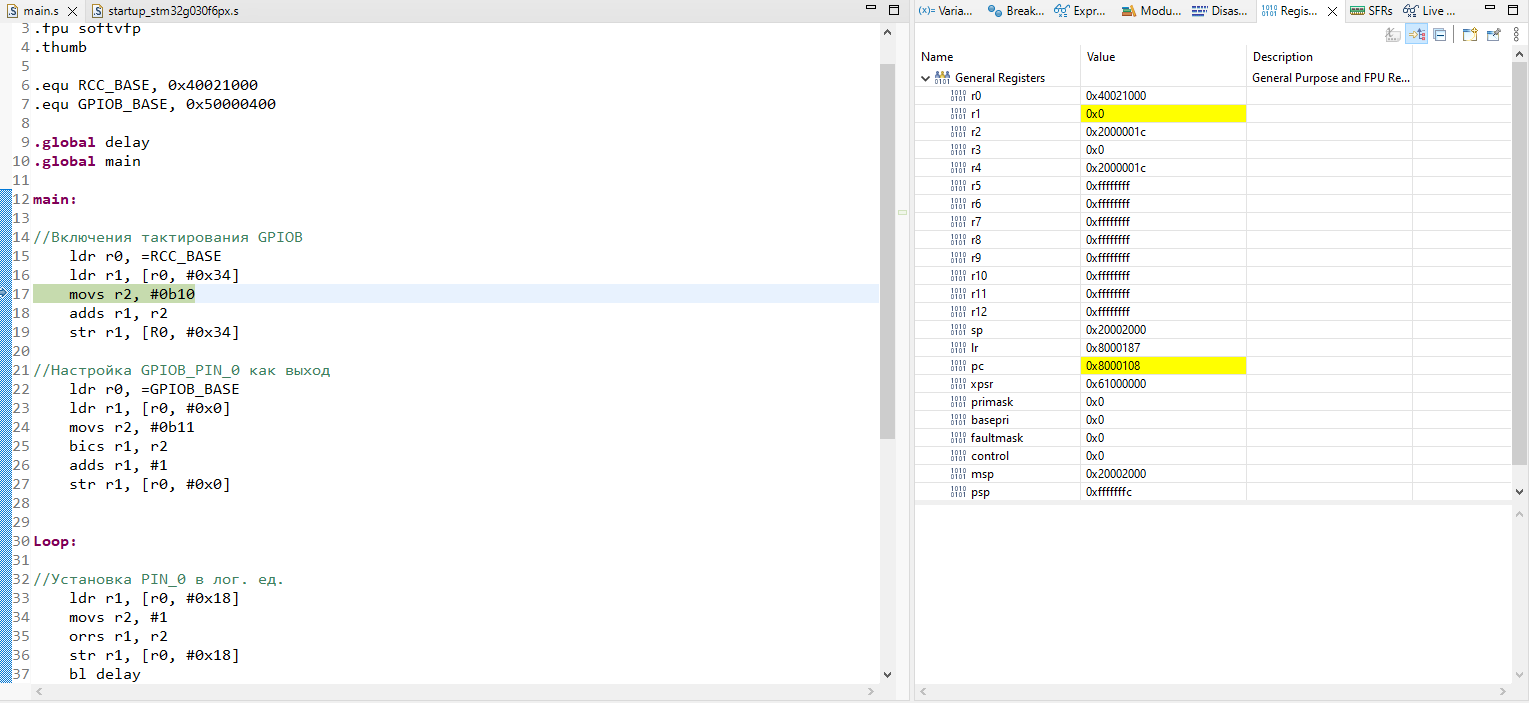Далее нам надо произвести манипуляции над значениями, мы загружаем чисто 2 в регистр r2 или же во второй бит записываем единицу, и потом просто складываем значения регистра r1 и r2, значения запишется в регистр r1.
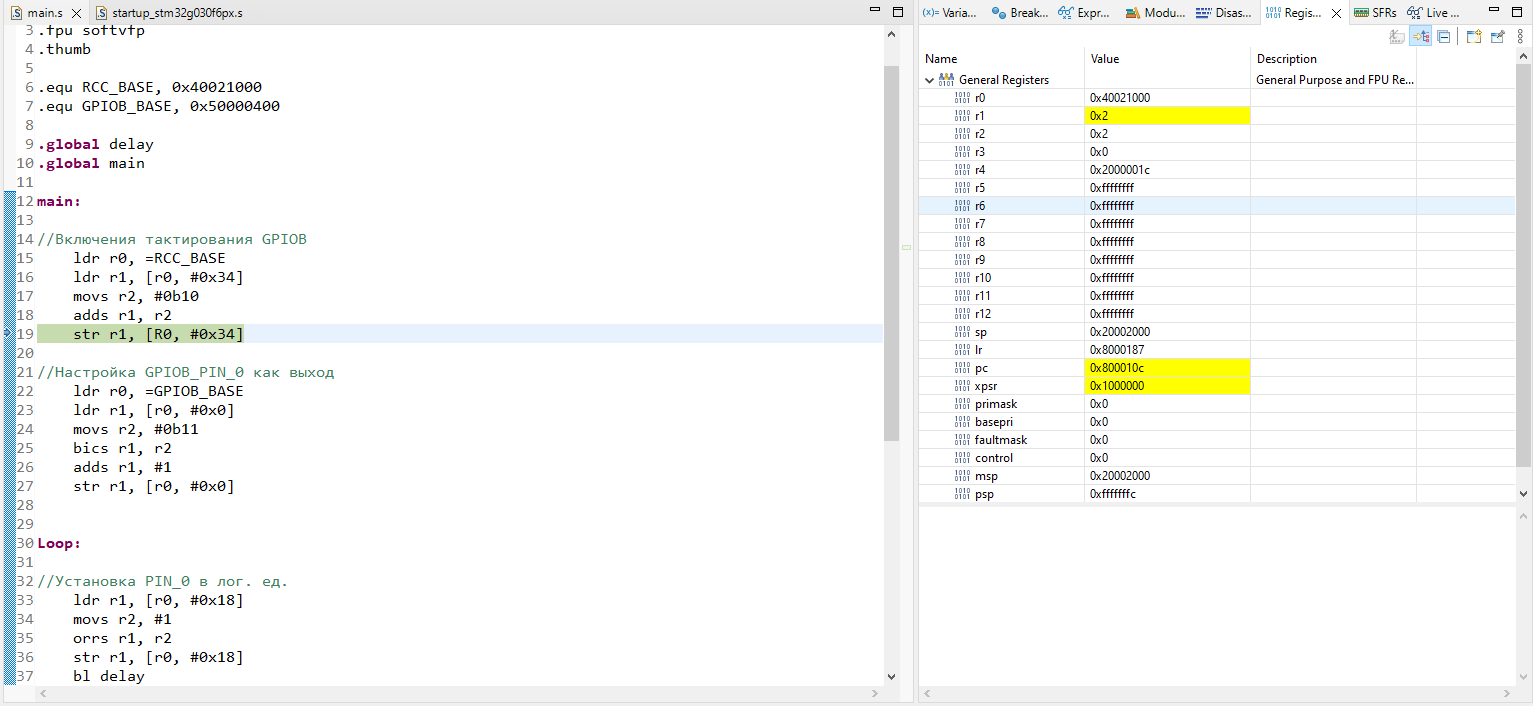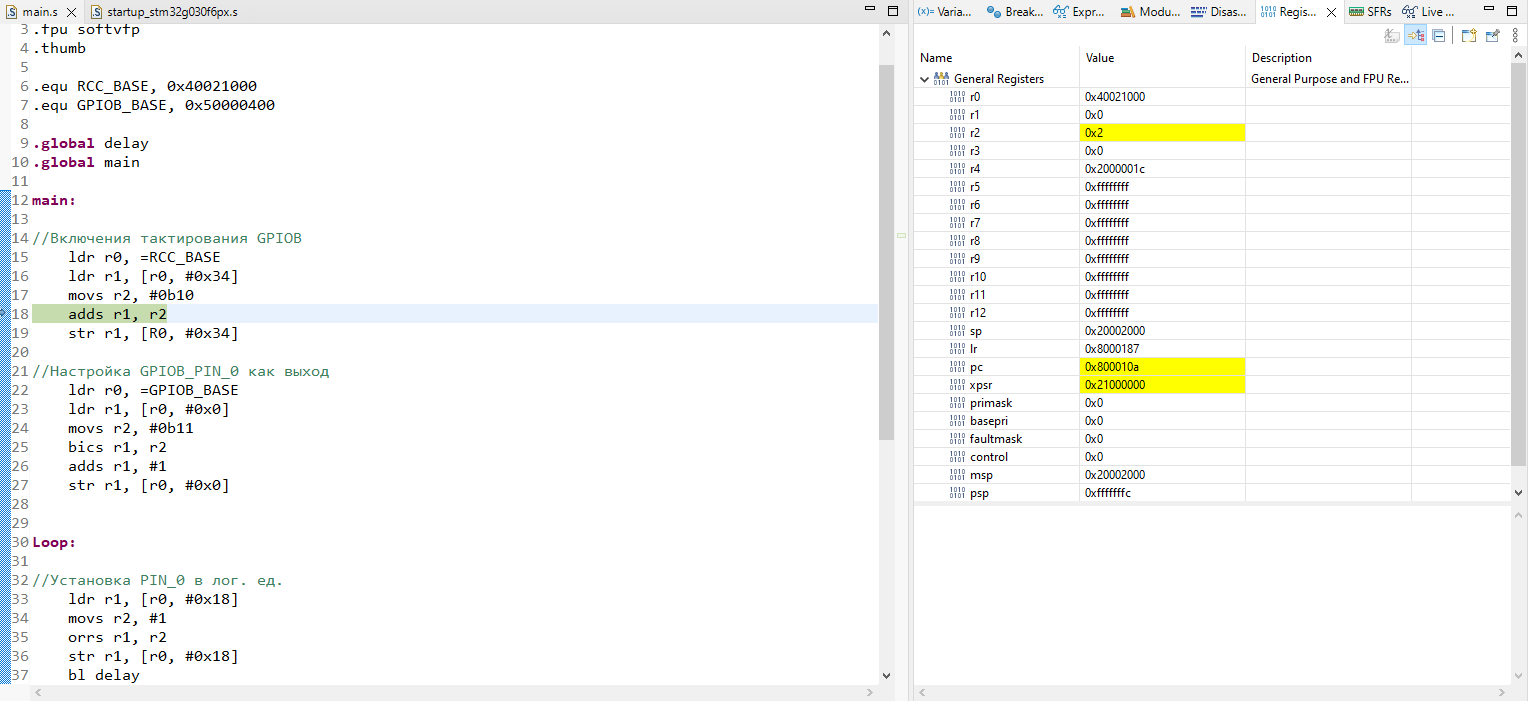Команда STR обратная LDR, т.е. она выгружает значения из регистра общего назначения в регистр памяти по адресу R0 + смещение. Значит наше число которое должно будет оказаться в регистре RCC\_IOPENB, жмем далее и убеждаемся в этом.
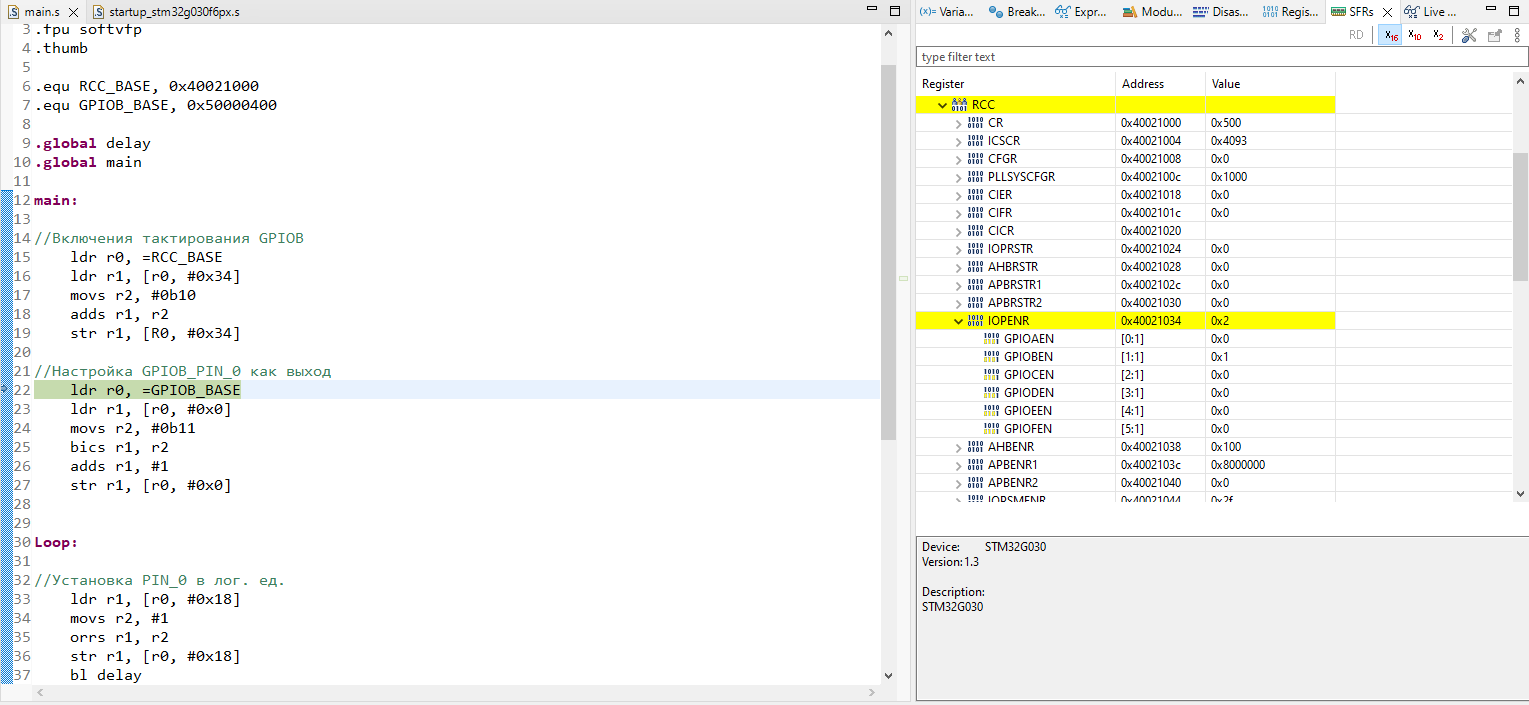Далее такими таким же способом работаем с остальными регистрами. Алгоритм таков, сначала выгружаем значение, изменяем его и загружаем обратно. Только если вы не включите тактирование периферии то значения регистров меняться не будут, можно будет только читать. Сейчас мы перейдем в установку выхода вывода в лог. ед. так как у нас сейчас вывод стянут к нулю второй светодиод горит.
 Теперь шагами проходим и устанавливаем вывод в лог. ед. и можем убедиться наглядно.
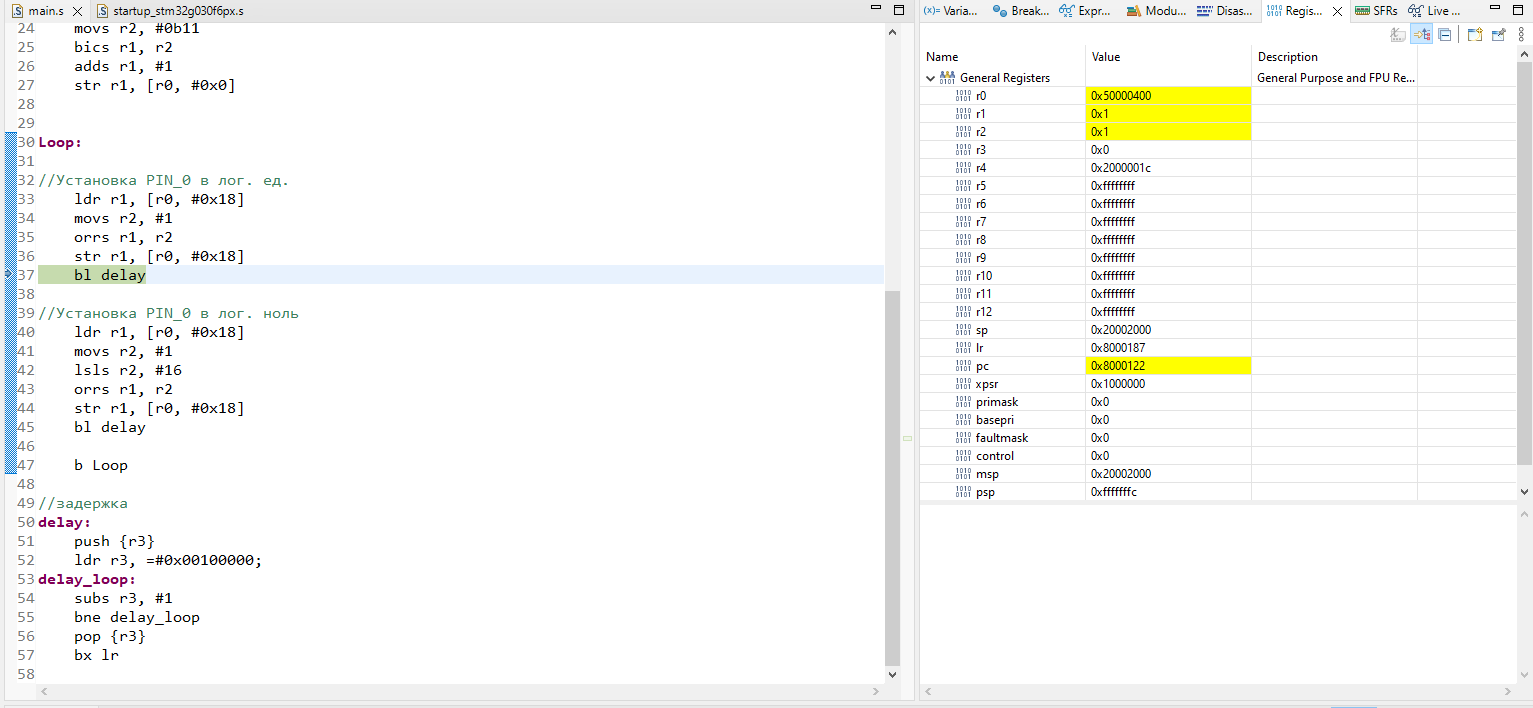Теперь у нас вызывается подпрограмма задержки, нажимаем на следящий шаг и переходим в подпрограмму, как можно заметить у нас изменился регистр LR, он сохранил адрес возврата из подпрограммы, т.е. адрес следующей команды после bl delay. Тут мы впервые используем команды для работы с стеком, условно PUSH загружает значения регистров в стек а POP выгружает, но нам это в данной программе не особо и нужно, но в качестве примера.
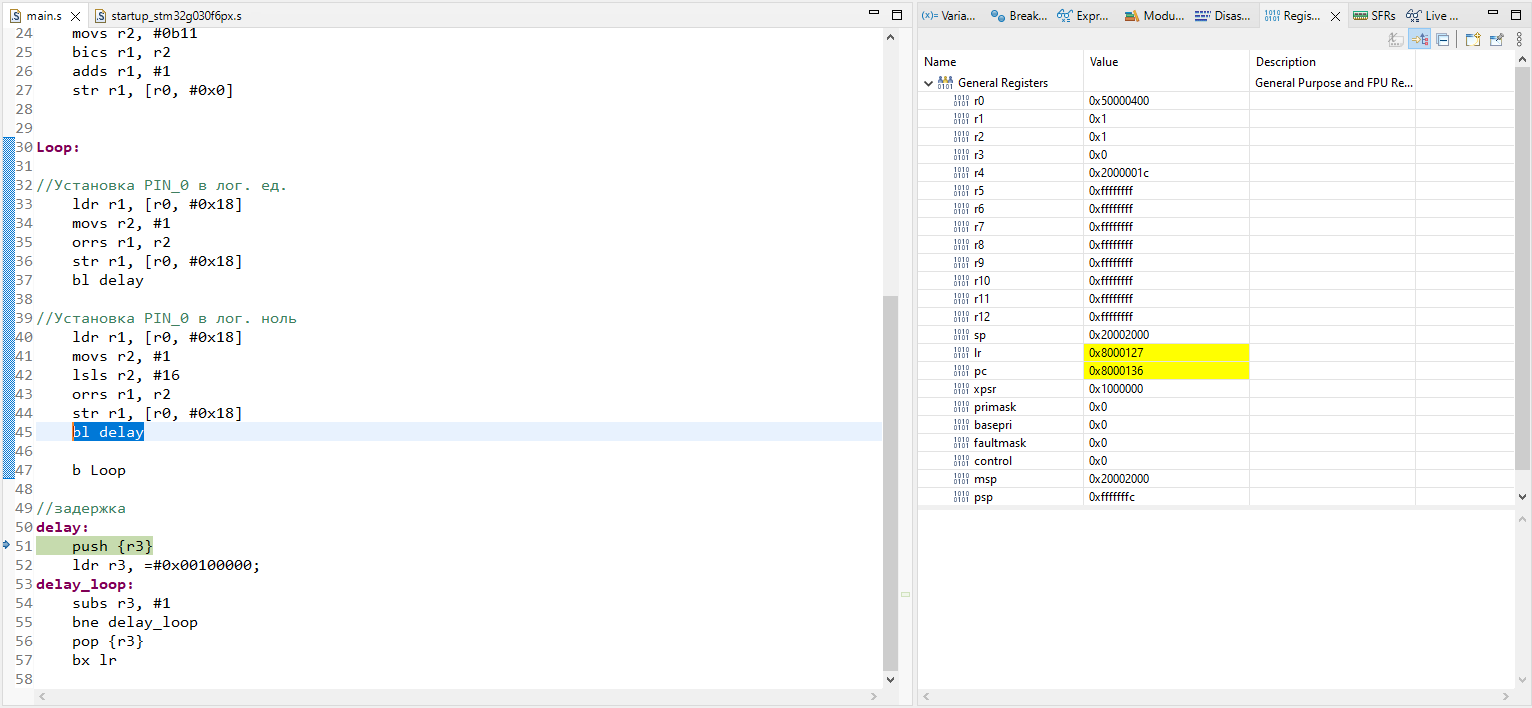Задержка работает следующим образом. Загружается некоторое число в регистр R3, после чего из него вычитается единица, если результат вычета не равен нулю то переходим по метке иначе выполняем следующую команду. Можно в отладке потыкать и посмотреть как он отнимает число. Но смотреть как число отнимается несколько миллионов раз не интересно) поэтому можно пойти двумя путями, поставить точку останова на следующей команде или же изменить значения регистра R3 на удобное нам. Как использовать отладку и точки остановки есть куча информации в интернете, поэтому я на этом не особо заостряю внимание. А вот изменения значения регистров мало можно встретить поэтому попробуем второй вариант.
Для этого нам надо тыкнуть на значения регистра исправить его и нажать enter.
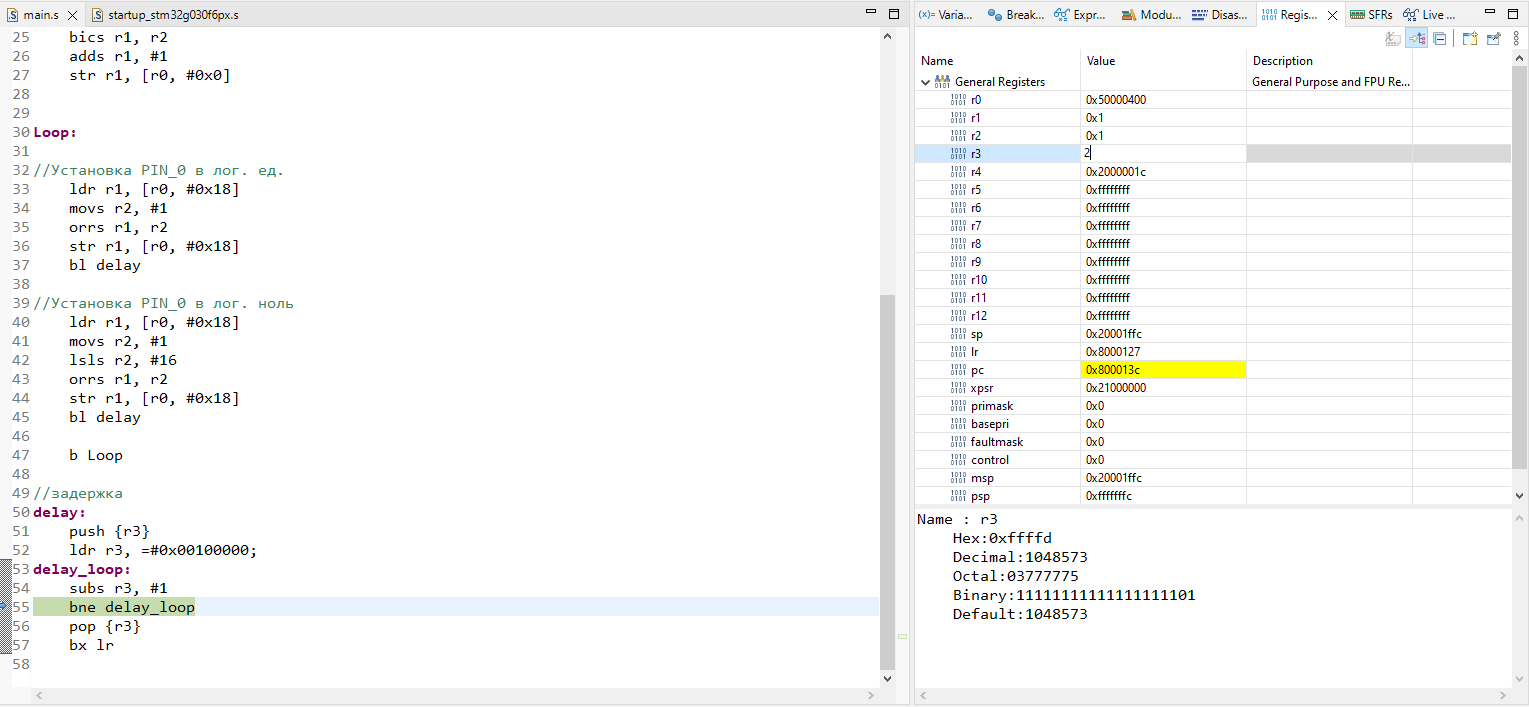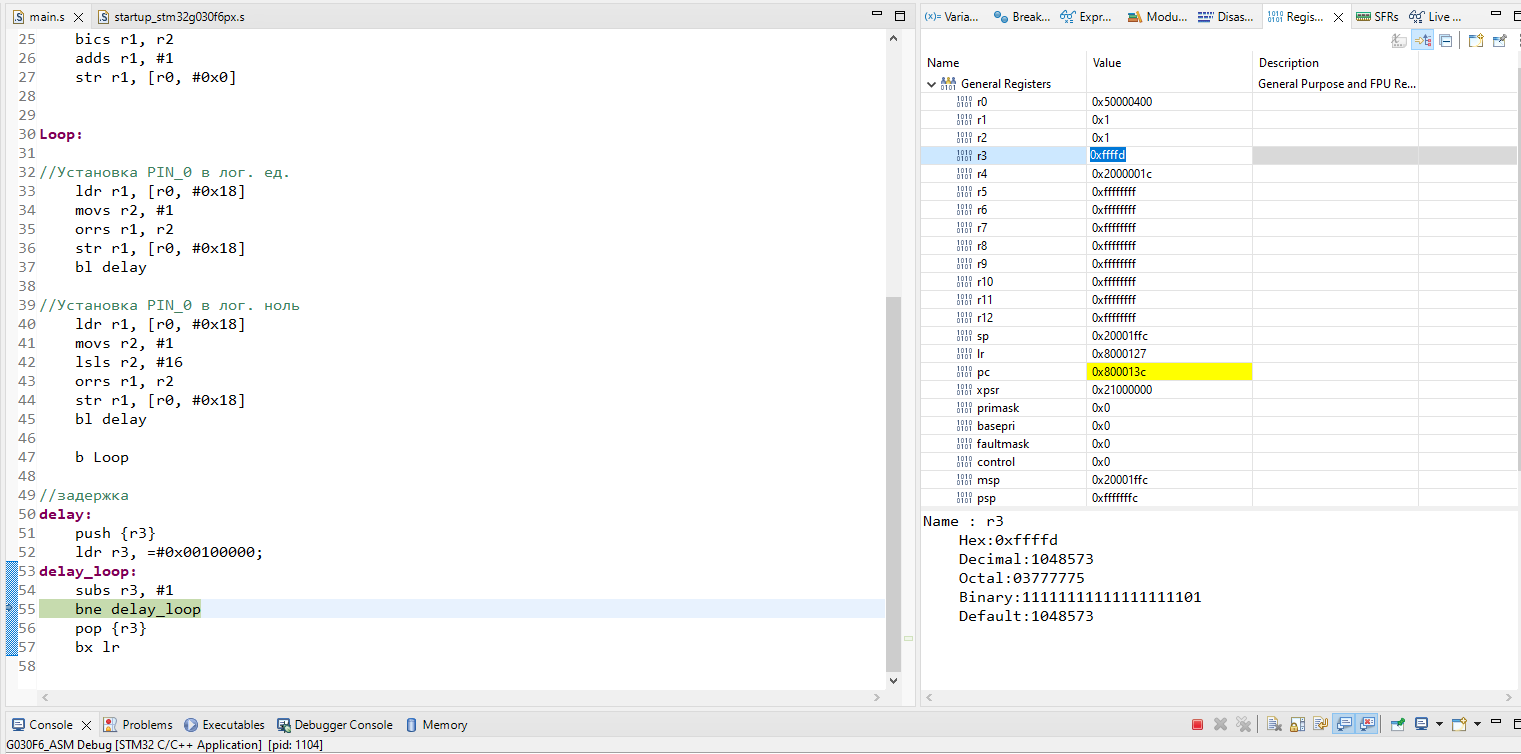После чего мы просто делаем два шага и выходим из цикла, после чего загружаем значения из стека обратно в регистр R3 и командой BX выходим из подпрограммы, обратим внимание что в качестве метки используем регистр LR. Можно сказать что метка это и есть адрес, удобный для нашего восприятия. На ,а далее все циклично думаю разобраться можно.
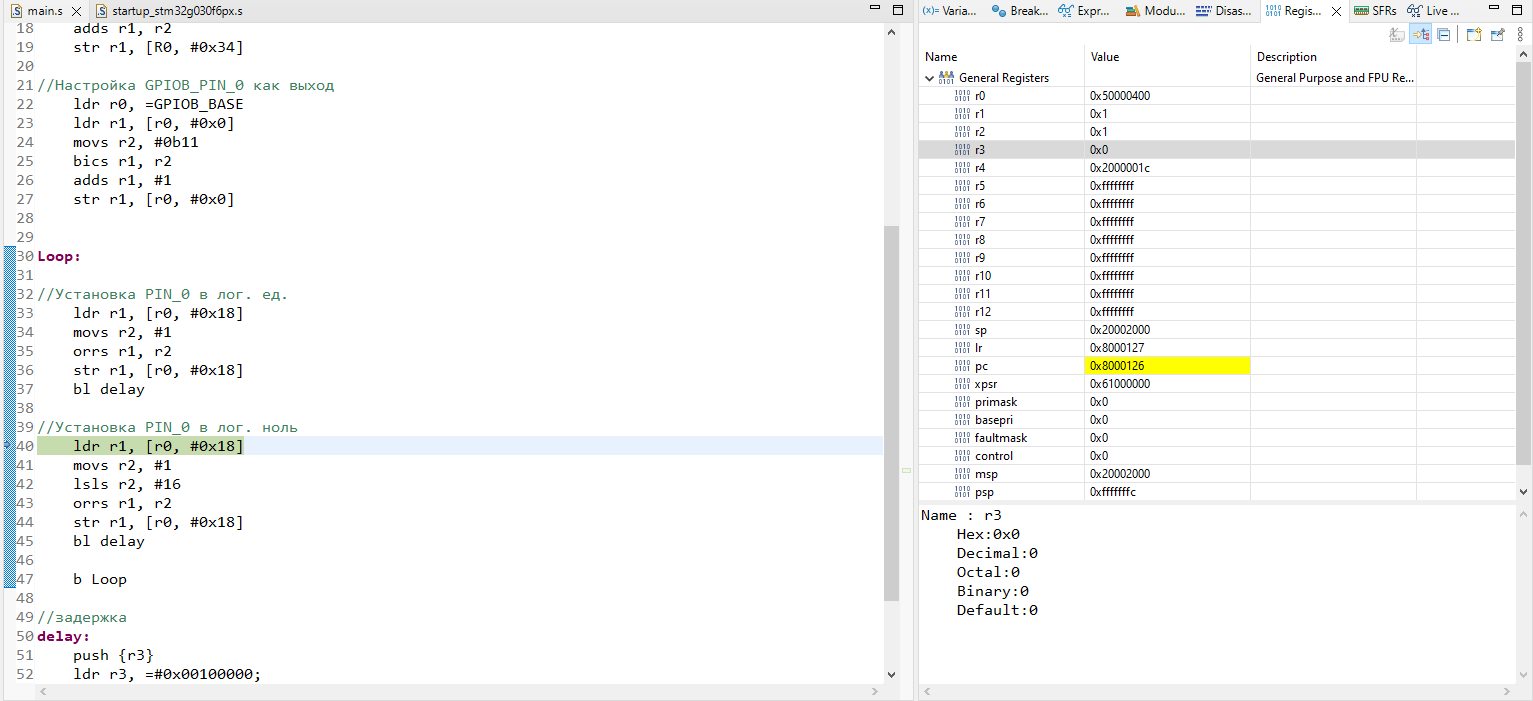Надеюсь данная статья кому ни будь окажется полезной. Это моя первая статья так что не судите строго. В качестве литературы могу порекомендовать:
1. Джозеф Ю: Ядро Cortex-M3 компании ARM. Полное руководство
2. Харрис, Харрис: Цифровая схемотехника и архитектура компьютера
3. Харрис, Харрис: Цифровая схемотехника и архитектура компьютера. Дополнение по архитектуре ARM | https://habr.com/ru/post/677292/ | null | ru | null |
# Обработка строк в Java. Часть II: Pattern, Matcher
### Вступление
Что Вы знаете о обработке строк в Java? Как много этих знаний и насколько они углублены и актуальны? Давайте попробуем вместе со мной разобрать все вопросы, связанные с этой важной, фундаментальной и часто используемой частью языка. Наш маленький гайд будет разбит на две публикации:
1. [String, StringBuffer, StringBuilder (реализация строк)](http://habrahabr.ru/post/260767/)
2. [Pattern, Matcher (регулярные выражения)](http://habrahabr.ru/post/260773/)
Сегодня поговорим о регулярных выражениях в Java, рассмотрим их механизм и подход к обработке. Также рассмотрим функциональные возможности пакета **java.util.regex**.
---
### Регулярные выражения
Регулярные выражения (*regular expressions*, далее РВ) — мощное и эффективное средство для обработки текста. Они впервые были использованы в текстовых редакторах операционной системы UNIX ([ed](https://en.wikipedia.org/wiki/Ed_%28text_editor%29) и [QED](https://en.wikipedia.org/wiki/QED_%28text_editor%29)) и сделали прорыв в электронной обработке текстов конца XX века. В 1987 году более сложные РВ возникли в первой версии языка Perl и были основаны на пакете Henry Spencer (1986), написанном на языке С. А в 1997 году, Philip Hazel разработал [Perl Compatible Regular Expressions](http://www.pcre.org/) (PCRE) — библиотеку, что точно наследует функциональность РВ в Perl. Сейчас PCRE используется многими современными инструментами, например [Apache HTTP Server](http://httpd.apache.org/).
Большинство современных языков программирования поддерживают РВ, Java не является исключением.
### Механизм
Существует две базовые технологии, на основе которых строятся механизмы РВ:
* Недетерминированный конечный автомат (НКА) — «механизм, управляемый регулярным выражением»
* Детерминированный конечный автомат (ДКА) — «механизм, управляемый текстом»
НКА — механизм, в котором управление внутри РВ передается от компонента к компоненту. НКА просматривает РВ по одному компоненту и проверяет, совпадает ли компонент с текстом. Если совпадает — проверятся следующий компонент. Процедура повторяется до тех пор, пока не будет найдено совпадение для всех компонентов РВ (пока не получим общее совпадение).
ДКА — механизм, который анализирует строку и следит за всеми «возможными совпадениями». Его работа зависит от каждого просканированного символа текста (то есть ДКА «управляется текстом»). Даний механизм сканирует символ текста, обновляет «потенциальное совпадение» и резервирует его. Если следующий символ аннулирует «потенциальное совпадение», то ДКА возвращается к резерву. Нет резерва — нет совпадений.
Логично, что ДКА должен работать быстрее чем НКА (ДКА проверяет каждый символ текста не более одного раза, НКА — сколько угодно раз пока не закончит разбор РВ). Но НКА предоставляет возможность определять ход дальнейших событий. Мы можем в значительной степени управлять процессом за счет правильного написания РВ.
**Регулярные выражения в Java используют механизм НКА.**
*Эти виды конечных автоматов более детально рассмотрены в статье [«Регулярные выражения изнутри»](http://habrahabr.ru/post/166777/).*
### Подход к обработке
В языках программирования существует три подхода к обработке РВ:
* интегрированный
* процедурный
* объектно-ориентированный
Интегрированный подход — встраивание РВ в низкоуровневый синтаксис языка. Этот подход скрывает всю механику, настройку и, как следствие, упрощает работу программиста.
Функциональность РВ при процедурном и объектно-ориентированном подходе обеспечивают функции и методы соответственно. Вместо специальных конструкций языка, функции и методы принимают в качестве параметров строки и интерпретируют их как РВ.
**Для обработки регулярных выражений в Java используют объектно-ориентированный подход.**
### Реализация
Для работы с регулярными выражениями в Java представлен пакет **java.util.regex**. Пакет был добавлен в версии 1.4 и уже тогда содержал мощный и современный прикладной интерфейс для работы с регулярными выражениями. Обеспечивает хорошую гибкость из-за использования объектов, реализующих интерефейс **CharSequence**.
Все функциональные возможности представлены двумя классами, интерфейсом и исключением:

#### Pattern
Класс **Pattern** представляет собой скомпилированное представление РВ. Класс не имеет публичных конструкторов, поэтому для создания объекта данного класса необходимо вызвать статический метод **compile** и передать в качестве первого аргумента строку с РВ:
```
// XML тэг в формате
Pattern pattern = Pattern.compile("^<([a-z]+)([^>]+)*(?:>(.*)<\\/\\1>|\\s+\\/>)$");
```
Также в качестве второго параметра в метод **compile** можно передать флаг в виде статической константы класса **Pattern**, например:
```
// email адрес в формате [email protected] (регистр букв игнорируется)
Pattern pattern = Pattern.compile("^([a-z0-9_\\.-]+)@([a-z0-9_\\.-]+)\\.([a-z\\.]{2,6})$", Pattern.CASE_INSENSITIVE);
```
Таблица всех доступных констант и эквивалентных им флагов:
| № | Constant | Equivalent Embedded Flag Expression |
| --- | --- | --- |
| 1 | Pattern.CANON\_EQ | - |
| 2 | Pattern.CASE\_INSENSITIVE | (?i) |
| 3 | Pattern.COMMENTS | (?x) |
| 4 | Pattern.MULTILINE | (?m) |
| 5 | Pattern.DOTALL | (?s) |
| 6 | Pattern.LITERAL | - |
| 7 | Pattern.UNICODE\_CASE | (?u) |
| 8 | Pattern.UNIX\_LINES | (?d) |
Иногда нам необходимо просто проверить есть ли в строке подстрока, что удовлетворяет заданному РВ. Для этого используют статический метод **matches**, например:
```
// это hex код цвета?
if (Pattern.matches("^#?([a-f0-9]{6}|[a-f0-9]{3})$", "#8b2323")) { // вернет true
// делаем что-то
}
```
Также иногда возникает необходимость разбить строку на массив подстрок используя РВ. В этом нам поможет метод **split**:
```
Pattern pattern = Pattern.compile(":|;");
String[] animals = pattern.split("cat:dog;bird:cow");
Arrays.asList(animals).forEach(animal -> System.out.print(animal + " "));
// cat dog bird cow
```
#### Matcher и MatchResult
**Matcher** — класс, который представляет строку, реализует механизм согласования (*matching*) с РВ и хранит результаты этого согласования (используя реализацию методов интерфейса **MatchResult**). Не имеет публичных конструкторов, поэтому для создания объекта этого класса нужно использовать метод **matcher** класса **Pattern**:
```
// будем искать URL
String regexp = "^(https?:\\/\\/)?([\\da-z\\.-]+)\\.([a-z\\.]{2,6})([\\/\\w \\.-]*)*\\/?$";
String url = "http://habrahabr.ru/post/260767/";
Pattern pattern = Pattern.compile(regexp);
Matcher matcher = pattern.matcher(url);
```
Но результатов у нас еще нет. Чтобы их получить нужно воспользоваться методом **find**. Можно использовать **matches** — этот метод вернет true только тогда, когда вся строка соответствует заданному РВ, в отличии от **find**, который пытается найти подстроку, которая удовлетворяет РВ. Для более детальной информации о результатах согласования можно использовать реализацию методов интерфейса **MatchResult**, например:
```
// IP адрес
String regexp = "(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)";
// для сравнения работы find() и matches()
String goodIp = "192.168.0.3";
String badIp = "192.168.0.3g";
Pattern pattern = Pattern.compile(regexp);
Matcher matcher = pattern.matcher(goodIp);
// matches() - true, find() - true
matcher = pattern.matcher(badIp);
// matches() - false, find() - true
// а теперь получим дополнительную информацию
System.out.println(matcher.find() ?
"I found '"+matcher.group()+"' starting at index "+matcher.start()+" and ending at index "+matcher.end()+"." :
"I found nothing!");
// I found the text '192.168.0.3' starting at index 0 and ending at index 11.
```
Также можно начинать поиск с нужной позиции используя **find(int start)**. Стоит отметить что существует еще один способ поиска — метод **lookingAt**. Он начинает проверку совпадений РВ с начала строки, но не требует полного соответствия, в отличии от **matches**.
Класс предоставляет методы для замены текста в указанной строке:
| | |
| --- | --- |
| appendReplacement(StringBuffer sb, String replacement) | Реализует механизм «добавление-и-замена» (*append-and-replace*). Формирует обьект **StringBuffer** (получен как параметр) добавляя replacement в нужные места. Устанавливает позицию, которая соответствует **end()** последнего результата поиска. После этой позиции ничего не добавляет. |
| appendTail(StringBuffer sb) | Используется после одного или нескольких вызовов **appendReplacement** и служит для добавления оставшейся части строки в объект класса **StringBuffer**, полученного как параметр. |
| replaceFirst(String replacement) | Заменяет **первую** последовательность, которая соответствует РВ, на replacement. Использует вызовы методов **appendReplacement** и **appendTail**. |
| replaceAll(String replacement) | Заменяет **каждую** последовательность, которая соответствует РВ, на replacement. Также использует методы **appendReplacement** и **appendTail**. |
| quoteReplacement(String s) | Возвращает строку, в которой коса черта (**' \ '**) и знак доллара (**' $ '**) будут лишены особого смысла. |
```
Pattern pattern = Pattern.compile("a*b");
Matcher matcher = pattern.matcher("aabtextaabtextabtextb the end");
StringBuffer buffer = new StringBuffer();
while (matcher.find()) {
matcher.appendReplacement(buffer, "-");
// buffer = "-" -> "-text-" -> "-text-text-" -> "-text-text-text-"
}
matcher.appendTail(buffer);
// buffer = "-text-text-text- the end"
```
#### PatternSyntaxException
Неконтролируемое (*unchecked*) исключение, возникает при синтаксической ошибке в регулярном выражении. В таблице ниже приведены все методы и их описание.
| | |
| --- | --- |
| getDescription() | Возвращает описание ошибки. |
| getIndex() | Возвращает индекс строки, где была найдена ошибка в РВ |
| getPattern() | Возвращает ошибочное РВ. |
| getMessage() | getDescription() + getIndex() + getPattern() |
Спасибо за внимание. Все дополнения, уточнения и критика приветствуются. | https://habr.com/ru/post/260773/ | null | ru | null |
# Redis на практических примерах

Redis — достаточно популярный инструмент, который из коробки поддерживает большое количество различных типов данных и методов работы с ними. Во многих проектах он используется в качестве кэшируещего слоя, но его возможности намного шире. Мы в ManyChat очень любим Redis и активно используем его в нашем продукте для решения огромного количества задач. Про некоторые интересные кейсы использования этой in-memory key-value базы данных я расскажу на примерах. Надеюсь, вам они будут полезны, и вы сможете применить что-то в своих проектах.
Рассмотрим следующие кейсы:
* Кэширование данных (да, банально и скучно, но это классный инструмент для кэширования и обойти стороной этот кейс, кажется будет не правильно)
* Работа с очередями на базе redis
* Организация блокировок (mutex)
* Делаем систему rate-limit
* Pubsub — делаем рассылки сообщений на клиенты
Буду работать с сырыми redis командами, чтобы не завязываться на какую-либо конкретную библиотеку, предоставляющую обертку над этими командами. Код буду писать на PHP с использованием ext-redis, но он здесь для наглядности, использовать представленные подходы можно в связке с любым другим языком программирования.

### Кэширование данных
Давайте начнем с самого простого, один из самых популярных кейсов использования Redis — кэширование данных. Будет полезно для тех, кто не работал с Redis. Для тех, кто уже давно пользуется этим инструментом — можно смело переходить к следующему кейсу. Для того, чтобы снизить нагрузку на БД, иметь возможность запрашивать часто используемые данные максимально быстро, используется кэш. Redis — это in-memory хранилище, то есть данные хранятся в оперативной памяти. Ещё это key-value хранилище, где доступ к данным по их ключу имеет сложность O(1) — поэтому данные мы получаем очень быстро.
Получение данных из хранилища выглядит следующим образом:
```
public function getValueFromCache(string $key)
{
return $this->getRedis()->rawCommand('GET', $key);
}
```
Но для того, чтобы данные из кэша получить, их нужно сначала туда положить. Простой пример записи:
```
public function setValueToCache(string $key, $value)
{
$this->getRedis()->rawCommand('SET', $key, $value);
}
```
Таким образом, мы запишем данные в Redis и сможем их считать по тому же самому ключу в любой нужный нам момент. Но если мы будем все время писать в Redis, данные в нем будут занимать все больше и больше места в оперативной памяти. Нам нужно удалять нерелевантные данные, контролировать это вручную достаточно проблематично, поэтому пускай redis занимается этим самостоятельно. Добавим к нашему ключу TTL (время жизни ключа):
```
public function setValueToCache(string $key, $value, int $ttl = 3600)
{
$this->getRedis()->rawCommand('SET', $key, $value, 'EX', $ttl);
}
```
По истечении времени ttl (в секундах) данные по этому ключу будут автоматически удалены.
Как говорят, в программировании существует две самых сложных вещи: придумывание названий переменных и инвалидация кэша. Для того, чтобы принудительно удалить значение из Redis по ключу, достаточно выполнить следующую команду:
```
public function dropValueFromCache(string $key)
{
$this->getRedis()->rawCommand('DEL', $key);
}
```
Также редис позволяет получить массив значений по списку ключей:
```
public function getValuesFromCache(array $keys)
{
return $this->getRedis()->rawCommand('MGET', ...$keys);
}
```
И соответственно массовое удаление данных по массиву ключей:
```
public function dropValuesFromCache(array $keys)
{
$this->getRedis()->rawCommand('MDEL', ...$keys);
}
```
### Очереди
Используя имеющиеся в Redis структуры данных, мы можем запросто реализовать стандартные очереди FIFO или LIFO. Для этого используем структуру List и методы по работе с ней. Работа с очередями состоит из двух основных действий: **отправить** задачу в очередь, и **взять** задачу из очереди. Отправлять задачи в очередь мы можем из любой части системы. Получением задачи из очереди и ее обработкой обычно занимается выделенный процесс, который называется консьюмером (consumer).
Итак, для того, чтобы отправить нашу задачу в очередь, нам достаточно использовать следующий метод:
```
public function pushToQueue(string $queueName, $payload)
{
$this->getRedis()->rawCommand('RPUSH', $queueName, serialize($payload));
}
```
Тем самым мы добавим в конец листа с названием $queueName некий $payload, который может представлять из себя JSON для инициализации нужной нам бизнес логики (например данные по денежной транзакции, данные для инициализации отправки письма пользователю, etc.). Если же в нашем хранилище не существует листа с именем $queueName, он будет автоматически создан, и туда попадет первый элемент $payload.
Со стороны консьюмера нам необходимо обеспечить получение задач из очереди, это реализуется простой командой чтения из листа. Для реализации FIFO очереди мы используем чтение с обратной записи стороны (в нашем случае мы писали через RPUSH), то есть читать будем через LPOP:
```
public function popFromQueue(string $queueName)
{
return $this->getRedis()->rawCommand('LPOP', $queueName);
}
```
Для реализации LIFO очереди, нам нужно будет читать лист с той же стороны, с которой мы в него пишем, то есть через RPOP.
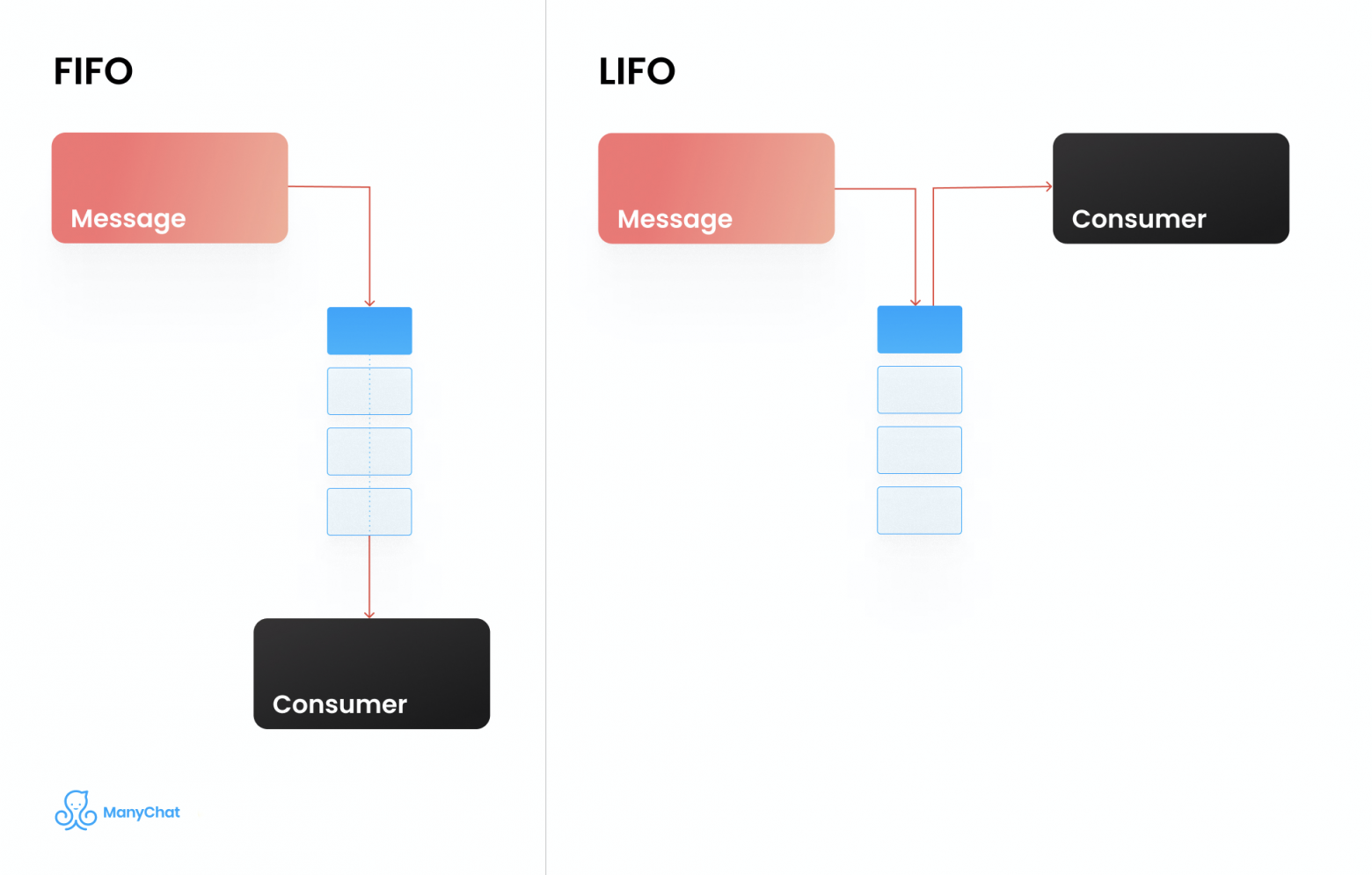
Тем самым мы вычитываем по одному сообщению из очереди. В случае если листа не существует (он пустой), то мы получим NULL. Каркас консьюмера мог бы выглядеть так:
```
class Consumer {
private string $queueName;
public function __construct(string $queueName)
{
$this->queueName = $queueName;
}
public function run()
{
while (true) { //Вычитываем в бесконечном цикле нашу очередь
$payload = $this->popFromQueue();
if ($payload === null) { //Если мы получили NULL, значит очередь пустая, сделаем небольшую паузу в ожидании новых сообщений
sleep(1);
continue;
}
//Если очередь не пустая и мы получили $payload, то запускаем обработку этого $payload
$this->process($payload);
}
}
private function popFromQueue()
{
return $this->getRedis()->rawCommand('LPOP', $this->queueName);
}
}
```
Для того, чтобы получить информацию о глубине очереди (сколько значений хранится в нашем листе), можем воспользоваться следующей командой:
```
public function getQueueLength(string $queueName)
{
return $this->getRedis()->rawCommand('LLEN', $queueName);
}
```
Мы рассмотрели базовую реализацию простых очередей, но Redis позволяет строить более сложные очереди. Например, мы хотим знать о времени последней активности наших пользователей на сайте. Нам не важно знать это с точностью вплоть до секунды, приемлемая погрешность — 3 минуты. Мы можем обновлять поле last\_visit пользователя при каждом запросе на наш бэкенд от этого пользователя. Но если этих пользователей большое количество в онлайне — 10,000 или 100,000? А если у нас еще и SPA, которое отправляет много асинхронных запросов? Если на каждый такой запрос обновлять поле в бд, мы получим большое количество тупых запросов к нашей БД. Эту задачу можно решать разными способами, один из вариантов — это сделать некую отложенную очередь, в рамках которой мы будем схлопывать одинаковые задачи в одну в определенном промежутке времени. Здесь на помощь нам придет такая структура, как Sorted SET. Это взвешенное множество, каждый элемент которого имеет свой вес (score). А что если в качестве score мы будем использовать timestamp добавления элемента в этот sorted set? Тогда мы сможем организовать очередь, в которой можно будет откладывать некоторые события на определенное время. Для этого используем следующую функцию:
```
public function pushToDelayedQueue(string $queueName, $payload, int $delay = 180)
{
$this->getRedis()->rawCommand('ZADD', $queueName, 'NX', time() + $delay, serialize($payload))
}
```
В такой схеме идентификатор пользователя, зашедшего на сайт, попадет в очередь $queueName и будет висеть там в течение 180 секунд. Все другие запросы в рамках этого времени будут также отправляться в эту очередь, но они не будут туда добавлены, так как идентификатор этого пользователя уже существует в этой очереди и продублирован он не будет (за это отвечает параметр 'NX'). Так мы отсекаем всю лишнюю нагрузку и каждый пользователь будет генерить не более одного запроса в 3 минуты на обновление поля last\_visit.
Теперь возникает вопрос о том, как читать эту очередь. Если методы LPOP и RPOP для листа читают значение и удаляют его из листа атомарно (это значит, что одно и тоже значение не может быть взято несколькими консьюмерами), то sorted set такого метода из коробки не имеет. Мы можем сделать чтение и удаление элемента только двумя последовательными командами. Но мы можем выполнить эти команды атомарно, используя простой LUA скрипт!
```
public function popFromDelayedQueue(string $queueName)
{
$command = 'eval "
local val = redis.call(\'ZRANGEBYSCORE\', KEYS[1], 0, ARGV[1], \'LIMIT\', 0, 1)[1]
if val then
redis.call(\'ZREM\', KEYS[1], val)
end
return val"
';
return $this->getRedis()->rawCommand($command, 1, $queueName, time());
}
```
В этом LUA скрипте мы пытаемся получить первое значение с весом в диапазоне от 0 до текущего timestamp в переменную val с помощью команды ZRANGEBYSCORE, если нам удалось получить это значение, то удаляем его из sorted set командой ZREM и возвращаем само значение val. Все эти операции выполняются атомарно. Таким образом мы можем вычитывать нашу очередь в консьюмере, аналогично с примером очереди построенной на структуре LIST.
Я рассказал про несколько базовых паттернов очередей, реализованных в нашей системе. На текущий момент у нас в продакшене существуют более сложные механизмы построения очередей — линейных, составных, шардированных. При этом Redis позволяет все это делать при помощи смекалки и готовых круто работающих структур из коробки, без сложного программирования.
### Блокировки (Mutex)
Mutex (блокировка) — это механизм синхронизации доступа к shared ресурсу нескольких процессов, тем самым гарантируя, что только один процесс будет взаимодействовать с этим ресурсом в единицу времени. Этот механизм часто применяется в биллинге и других системах, где важно соблюдать потоковую безопасность (thread safety).
Для реализации mutex на базе Redis прекрасно подойдет стандартный метод SET с дополнительными параметрами:
```
public function lock(string $key, string $hash, int $ttl = 10): bool
{
return (bool)$this->getRedis()->rawCommand('SET', $key, $hash, 'NX', 'EX', $ttl);
}
```
где параметрами для установки mutex являются:
* $key — ключ идентифицирующий mutex;
* $hash — генерируем некую подпись, которая идентифицирует того, кто поставил mutex. Мы же не хотим, чтобы кто-то в другом месте случайно снял блокировку и вся наша логика рассыпалась.
* $ttl — время в секундах, которое мы отводим на блокировку (на тот случай, если что-то пойдет не так, например процесс, поставивший блокировку, по какой-то причине умер и не снял ее, чтобы это блокировка не висела бесконечно).
Основное отличие от метода SET, используемого в механизме кэширования — это параметр NX, который говорит Redis о том, что значение, которое уже хранится в Redis по ключу $key, не будет записано повторно. В результате, если в Redis нет значения по ключу $key, туда произведется запись и в ответе мы получим 'OK', если значение по ключу уже есть в Redis, оно не будет туда добавлено (обновлено) и в ответе мы получим NULL. Результат метода lock(): bool, где `true` – блокировка поставлена, `false` – уже есть активная блокировка, создать новую невозможно.
Чаще всего, когда мы пишем код, который пытается работать с shared ресурсом, который заблокирован, мы хотим дождаться его разблокировки и продолжить работу с этим ресурсом. Для этого можем реализовать простой метод для ожидания освободившегося ресурса:
```
public function tryLock(string $key, string $hash, int $timeout, int $ttl = 10): bool
{
$startTime = microtime(true);
while (!this->lock($key, $hash, $ttl)) {
if ((microtime(true) - $startTime) > $timeout) {
return false; // не удалось взять shared ресурс под блокировку за указанный $timeout
}
usleep(500 * 1000) //ждем 500 миллисекунд до следующей попытки поставить блокировку
}
return true; //блокировка успешно поставлена
}
```
Мы разобрались как ставить блокировку, теперь нам нужно научиться ее снимать. Для того, чтобы гарантировать снятие блокировки тем процессом, который ее установил, нам понадобится перед удалением значения из хранилища Redis, сверить хранимый хэш по этому ключу. Для того, чтобы сделать это атомарно, воспользуемся LUA скриптом:
```
public function releaseLock(string $key, string $hash): bool
{
$command = 'eval "
if redis.call("GET",KEYS[1])==ARGV[1] then
return redis.call("DEL",KEYS[1])
else
return 0
end"
';
return (bool) $this->getRedis()->rawCommand($command, 1, $key, $hash);
}
```
Здесь мы пытаемся найти с помощью команды GET значение по ключу $key, если оно равно значению $hash, то удаляем его при помощи команды DEL, которая вернет нам количество удаленных ключей, если же значения по ключу $key не существует, или оно не равно значению $hash, то мы возвращаем 0, что значит блокировку снять не удалось. Базовый пример использования mutex:
```
class Billing {
public function charge(int $userId, int $amount)
{
$mutexName = sprintf('billing_%d', $userId);
$hash = sha1(sprintf('billing_%d_%d'), $userId, mt_rand()); //генерим некий хэш запущенного потока
if (!$this->tryLock($mutexName, $hash, 10)) { //пытаемся поставить блокировку в течение 10 секунд
throw new Exception('Не получилось поставить lock, shared ресурс занят');
}
//lock получен, процессим бизнес-логику
$this->doSomeLogick();
//освобождаем shared ресурс, снимаем блокировку
$this->releaseLock($mutexName, $hash);
}
}
```
### Rate limiter
Достаточно частая задача, когда мы хотим ограничить количество запросов к нашему апи. Например на один API endpoint от одного аккаунта мы хотим принимать не более 100 запросов в минуту. Эта задача легко решается с помощью нашего любимого Redis:
```
public function isLimitReached(string $method, int $userId, int $limit): bool
{
$currentTime = time();
$timeWindow = $currentTime - ($currentTime % 60); //Так как наш rate limit имеет ограничение 100 запросов в минуту,
//то округляем текущий timestamp до начала минуты — это будет частью нашего ключа, //по которому мы будем считать количество запросов
$key = sprintf('api_%s_%d_%d', $method, $userId, $timeWindow); //генерируем ключ для счетчика, соответственно каждую минуту он будет меняться исходя из $timeWindow
$count = $this->getRedis()->rawCommand('INCR', $key); //метод INCR увеличивает значение по указанному ключу, и возвращает новое значение.
//Если ключа не существует, он будут инициализирован со значением 0 и после этого увеличен
$this->getRedis()->rawCommand('EXPIRE', $key, 60); // Обновляем TTL нашему ключу, выставляя его в минуту, для того, чтобы не накапливать не актуальные данные
if ($count > $limit) { //limit достигнут
return true;
}
return false;
}
```
Таким простым методом мы можем лимитировать количество запросов к нашему API, базовый каркас нашего контроллера мог бы выглядеть следующим образом:
```
class FooController {
public function actionBar()
{
if ($this->isLimitReached(__METHOD__, $this->getUserId(), 100)) {
throw new Exception('API method max limit reached');
}
$this->doSomeLogick();
}
}
```
### Pub/sub
Pub/sub — интересный механизм, который позволяет, с одной стороны, подписаться на канал и получать сообщения из него, с другой стороны — отправлять в этот канал сообщение, которое будет получено всеми подписчиками. Наверное у многих, кто работал с вебсокетами, возникла аналогия с этим механизмом, они действительно очень похожи. Механизм pub/sub не гарантирует доставки сообщений, он не гарантирует консистентности, поэтому не стоит его использовать в системах, для которых важны эти критерии. Однако рассмотрим этот механизм на практическом примере. Предположим, что у нас есть большое количество демонизированных команд, которыми мы хотим централизованно управлять. При инициализации нашей команды мы подписываемся на канал, через который будем получать сообщения с инструкциями. С другой стороны у нас есть управляющий скрипт, который отправляет сообщения с инструкциям в указанный канал. К сожалению, стандартный PHP работает в одном блокирующем потоке; для того, чтобы реализовать задуманное, используем [ReactPHP](https://github.com/reactphp/event-loop) и реализованный под него [клиент Redis](https://github.com/clue/reactphp-redis).
Подписка на канал:
```
class FooDaemon {
private $throttleParam = 10;
public function run()
{
$loop = React\EventLoop\Factory::create(); //инициализируем event-loop ReactPHP
$redisClient = $this->getRedis($loop); //инициализируем клиента Redis для ReactPHP
$redisClient->subscribe(__CLASS__); // подписываемся на нужный нам канал в Redis, в нашем примере название канала соответствует названию класса
$redisClient->on('message', static function($channel, $payload) { //слушаем события message, при возникновении такого события, получаем channel и payload
switch (true) { // Здесь может быть любая логика обработки сообщений, в качестве примера пускай будет так:
case \is_int($payload): //Если к нам пришло число – обновим параметр $throttleParam на полученное значение
$this->throttleParam = $payload;
break;
case $payload === 'exit': //Если к нам пришла команда 'exit' – завершим выполнение скрипта
exit;
default: //Если пришло что-то другое, то просто залогируем это
$this->log($payload);
break;
}
});
$loop->addPeriodicTimer(0, function() {
$this->doSomeLogick(); // Здесь в бесконечном цикле может выполняться какая-то логика, например чтение задач из очереди и их процессинг
});
$loop->run(); //Запускаем наш event-loop
}
}
```
Отправка сообщения в канал — более простое действие, мы можем сделать это абсолютно из любого места системы одной командой:
```
public function publishMessage($channel, $message)
{
$this->getRedis()->publish($channel, $message);
}
```
В результате такой отправки сообщения в канал, все клиенты, которые подписаны на данный канал, получат это сообщение.
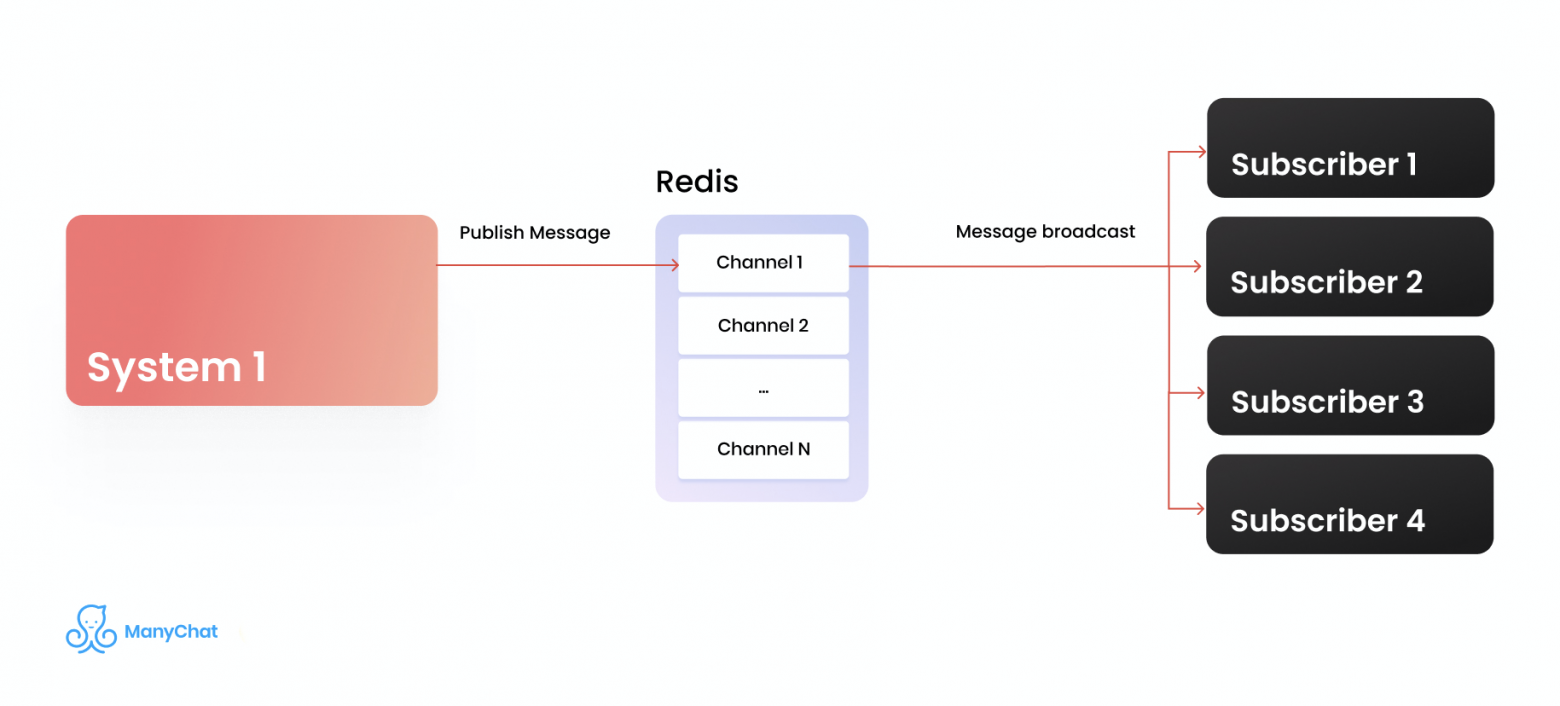
### Итог
Мы рассмотрели 5 примеров использования Redis на практике, надеюсь что каждый найдет для себя что-то интересное. В нашем стэке технологий Redis занимает важное место, мы любим этот инструмент за его скорость и гибкость. Мы используем Redis в продакшене уже много лет, и он зарекомендовал себя как очень крутой и надежный инструмент, который лежит в основе многих частей нашего продукта. Наш небольшой кластер Redis серверов обрабатывает около 1 миллиона запросов в секунду. А как вы используете Redis в своем проекте? Делитесь опытом в комментариях! | https://habr.com/ru/post/507136/ | null | ru | null |
# Скорочтение по технологии spritz на любом сайте

Совсем недавно, была представлена технология скорочтения spritz ([500 слов в минуту без подготовки](http://habrahabr.ru/post/213721/)) она позволяет вам читать тексты намного быстрее, но, к сожалению, разработчик не реализовал тогда её в виде приложения для прочтения собственных текстов.
Теперь же, появился проект Squirt, который позволяет читать **любой** текст по технологии скорочтения от spritz, установив только 1 букмарклет.
Сам скрипт который предлагается добавить в закладки:
```
javascript:(function(){if(window.sq){window.sq.closed&&window.document.dispatchEvent(new Event('squirt.again'));}else{window.sq={};window.sq.userId='78410c39-0bc7-450f-99ac-8f65ece0a7ec';s=document.createElement('script');s.src='http://www.squirt.io/bm/squirt.js';s.s=window.location.search;s.idx=s.s.indexOf('sq-dev');if(s.idx!=-1){s.ampIdx=s.s.indexOf('&');s.host=s.s.substring(s.idx+7,s.ampIdx==-1?s.s.length:s.ampIdx);s.src='http://'+(s.host?s.host:'localhost')+':4000/bm/squirt.js';}document.body.appendChild(s);}})();
```
После его добавления в закладки, вам потребуется зайти на любой сайт с обилием текста и нажать на закладку, текст автоматически будет отображаться в режиме скорочтения. Кроме того, вы можете выделить желаемый текст на странице и нажать на закладку, таким образом, только выделенный вами текст будет прочитан в режиме скорочтения.
Проект является открытым и доступен на Github [github.com/cameron/squirt](https://github.com/cameron/squirt)
Основной сайт проекта [www.squirt.io](http://www.squirt.io)
Установка букмарклета [www.squirt.io/install.html](http://www.squirt.io/install.html)
*Если вам нравится технология, то лучше скачать репозиторий себе, так, как в данный момент патент на технологию еще не подтвержден, но вполне вероятно это произойдет и тогда, ситуация с репозиториями повториться как и с WhatsApp* | https://habr.com/ru/post/215603/ | null | ru | null |
# Dagaz: От простого к сложному
***かたつぶりそろそろ登れ富士の山
Тихо-тихо ползи, улитка, по склону Фудзи,
вверх, до самых высот
[小林一茶 (Кобаяси Исса)](https://ru.wikipedia.org/wiki/%D0%98%D1%81%D1%81%D0%B0,_%D0%9A%D0%BE%D0%B1%D0%B0%D1%8F%D1%81%D0%B8)***
Я много [писал](https://habrahabr.ru/post/320474/) о том, что хочу получить в итоге. [Рассказал](https://habrahabr.ru/post/322212/), как этим можно пользоваться, но оставил без ответа один простой вопрос. Почему я **убеждён** в том, что всё [это](https://github.com/GlukKazan/JoclyGames/tree/master/Z2J/src) (ладно-ладно, **почти** всё это) работает? У меня есть секретное оружие! И сегодня я хочу о нём рассказать.
Проект, который я пишу сложен. Я разрабатываю универсальную модель, потенциально пригодную для описания **любых** настольных игр. Нечего и думать о том, чтобы разработать такой проект «с нуля», запустить и проверить, работает ли он. Тем более, что и запускать-то пока нечего. Нет ни контроллера ни сколь нибудь завалящего представления, под которыми эту модель можно было бы запустить. Но я должен уже сейчас проверять и отлаживать написанный код! Потом, когда контроллер и представление появятся, отладить его весь, целиком, будет попросту невозможно!
Я не первый, кто сталкивается с такой проблемой и способ её решения давно [придуман](https://ru.wikipedia.org/wiki/%D0%9C%D0%BE%D0%B4%D1%83%D0%BB%D1%8C%D0%BD%D0%BE%D0%B5_%D1%82%D0%B5%D1%81%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5). Для тестирования своего кода, я использую [QUnit](https://qunitjs.com/), но конечно же, это не единственное подобное решение в мире JavaScript. Я не придерживаюсь методологии [TDD](https://ru.wikipedia.org/wiki/%D0%A0%D0%B0%D0%B7%D1%80%D0%B0%D0%B1%D0%BE%D1%82%D0%BA%D0%B0_%D1%87%D0%B5%D1%80%D0%B5%D0%B7_%D1%82%D0%B5%D1%81%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5), в том отношении, что не стараюсь предварять написание кода тестами, но стараюсь максимально покрыть тестами весь код модели. Это помогает мне решить следующие задачи:
* Поиск и исправление глупых ошибок и опечаток в коде
* Проверка совместимости используемых решений с различными платформами (браузерами)
* [Регрессионное тестирование](https://ru.wikipedia.org/wiki/%D0%A0%D0%B5%D0%B3%D1%80%D0%B5%D1%81%D1%81%D0%B8%D0%BE%D0%BD%D0%BD%D0%BE%D0%B5_%D1%82%D0%B5%D1%81%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5) (изменяя что-то, я должен быть уверен, что ничего не сломал)
* Минимальное документирование (тесты фиксируют способы использования интерфейсов модели)
**Подход уже успел себя оправдать**
В самом начале разработки, когда с JavaScript-ом я был ещё очень сильно «на Вы», я брал за основу код [Jocly](https://www.jocly.com/#/about). Сейчас, мне приходится избавляться от много из того, что было написано тогда, но на тот момент, надо было с чего-то начинать. Я хорошо (как показало время, недостаточно хорошо) понимал задачу, но очень плохо знал язык. Вот один из образчиков кода тех времён:
**Поиск элемента в массиве**
```
if ([].indexOf) {
Model.find = function(array, value) {
return array.indexOf(value);
}
} else {
Model.find = function(array, value) {
for (var i = 0; i < array.length; i++) {
if (array[i] === value) return i;
}
return -1;
}
}
```
Да-да, преждевременная оптимизация. Если массивы поддерживают "**indexOf**", пользуемся им, в противном случае, ищем вручную, в цикле. Поскольку я с самого начала строил модель таким образом, чтобы работать только с числовыми значениями, по прошествии некоторого времени, я решил соптимизировать кое что ещё:
**Массивы целочисленных значений**
```
if (typeof Int32Array !== "undefined") {
Model.int32Array = function(array) {
var a = new Int32Array(array.length);
a.set(array);
return a;
}
} else {
Model.int32Array = function(array) {
return array;
}
}
```
Логика та же. Те кто могут — пользуются числовыми массивами, остальные пользуются тем чем могут. Некоторое время всё это прекрасно работало. На тех браузерах, которыми я пользовался. Но в один прекрасный момент, я запустил свои тесты на IE11. И творение Microsoft-а не замедлило нанести свой удар. Тесты не отработали. Всё вылилось в [это](https://github.com/GlukKazan/JoclyGames/commit/87032851ad1fed49e219935755dd26d1797ed99b) исправление. Я не хочу сказать, что этот код сильно лучше (сейчас он уже переписан), но если бы я не запускал тесты регулярно и на разных платформах, то попросту не узнал бы о проблеме! Unit-тесты действительно работают.
Разрабатывая тесты, я двигаюсь от простого кода к более сложному. Перед тем как проверять сложную логику генерации хода (это главное из того чем занимается модель), я должен убедиться в правильности работы всех используемых ей частей. Все классы, используемые в моей модели, можно ранжировать по нарастанию «сложности»:
* **ZrfPiece** — описание фигуры (объекта на доске)
* **ZrfDesign** — описание топологии доски и игровых правил
* **ZrfMove** — описание хода, изменяющего состояние игры
* **ZrfMoveGenerator** — генератор возможных ходов «по шаблону»
* **ZrfBoard** — хранилище игрового состояния и генератор всех допустимых ходов
Класс **ZrfPiece** настолько прост, что его тестирование даже не требует наличия полноценного игрового [дизайна](https://github.com/GlukKazan/JoclyGames/blob/master/Z2J/src/zrf/turkish-dama.js). Тем не менее, у него имеются некоторые не очевидные особенности, которые необходимо проверить. Например, логика создания нового объекта при изменении типа, владельца либо какого-то из атрибутов фигуры.
**Всё это элементарно проверяется**
```
QUnit.test( "Piece", function( assert ) {
var design = Model.Game.getDesign();
design.addPlayer("White", []);
design.addPlayer("Black", []);
design.addPiece("Man", 0);
design.addPiece("King", 1);
var man = Model.Game.createPiece(0, 1);
assert.equal( man.toString(), "White Man", "White Man");
var king = man.promote(1);
assert.ok( king !== man, "Promoted Man");
assert.equal( king.toString(), "White King", "White King");
assert.equal( man.getValue(0), null, "Non existent value");
var piece = man.setValue(0, true);
assert.ok( piece !== man, "Non mutable pieces");
assert.ok( piece.getValue(0) === true, "Existent value");
piece = piece.setValue(0, false);
assert.ok( piece.getValue(0) === false, "Reset value");
var p = piece.setValue(0, false);
assert.equal( piece, p, "Value not changed");
Model.Game.design = undefined;
});
```
Создаём вручную самый минимальный «дизайн» (два игрока, два типа фигур и никакого намёка на доску) и вручную же выполняем все интересующие нас проверки. После этого спокойно пользуемся **ZrfPiece**, не ожидая от него никаких подвохов. Даже если впоследствии выяснится, что что-то проверить забыли, просто добавим ещё несколько проверок. Далее тестируем более сложный код:
**Дизайн игры**
```
QUnit.test( "Design", function( assert ) {
var design = Model.Game.getDesign();
design.addDirection("w");
design.addDirection("e");
design.addDirection("s");
design.addDirection("n");
assert.equal( design.dirs.length, 4, "Directions");
design.addPlayer("White", [1, 0, 3, 2]);
design.addPlayer("Black", [0, 1, 3, 2]);
assert.equal( design.players[0].length, 4, "Opposite");
assert.equal( design.players[2].length, 4, "Symmetry");
design.addPosition("a2", [ 0, 1, 2, 0]);
design.addPosition("b2", [-1, 0, 2, 0]);
design.addPosition("a1", [ 0, 1, 0, -2]);
design.addPosition("b1", [-1, 0, 0, -2]);
var pos = 2;
assert.equal( design.positionNames.length,4, "Positions");
assert.equal( Model.Game.posToString(pos), "a1", "Start position");
pos = design.navigate(1, pos, 3);
assert.equal( Model.Game.posToString(pos), "a2", "Player A moving");
pos = design.navigate(2, pos, 3);
assert.equal( Model.Game.posToString(pos), "a1", "Player B moving");
...
Model.Game.design = undefined;
});
```
**ZrfDesign** — это на 99% навигация по игровой доске. Её и проверяем. Дизайн снова создаём вручную (теперь уже с небольшой доской), после чего прогоняем наиболее типичные тест-кейсы. И не забываем, в конце, очистить созданный дизайн! Чтобы он не ломал другие тесты.
**Кстати, вот прямо сейчас выяснилось**
Я был сильно не прав, когда посчитал дизайн игры [синглтоном](https://ru.wikipedia.org/wiki/%D0%9E%D0%B4%D0%B8%D0%BD%D0%BE%D1%87%D0%BA%D0%B0_(%D1%88%D0%B0%D0%B1%D0%BB%D0%BE%D0%BD_%D0%BF%D1%80%D0%BE%D0%B5%D0%BA%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F))! Не говоря уже о серверной версии, которой попросту необходимо уметь работать с несколькими различными моделями игр одновременно, существует ещё один любопытный кейс. Работая над простейшими игровыми [ботами](https://github.com/GlukKazan/JoclyGames/tree/master/Z2J/src/js/debug/ai), я вспомнил о [замечательной игре](http://www.battlevschess.com/en/).
По полю разбросаны мины, но как заманить на них противника, при условии, что он про них знает? Ему ведь нет абсолютно никакого резона просто терять фигуру, встав на «заминированное» поле. Задача решается просто. Бот, с которым мы играем, может получить слегка отличающийся дизайн игры. Доска, правила хода фигур — всё будет тем же, за одним маленьким исключением. О минах он не будет знать ничего.
Фактически, это единственный адекватный способ реализации игр с неполной информацией, таких как [Kriegspiel](http://www.zillions-of-games.com/cgi-bin/zilligames/submissions.cgi?do=show;id=554) или [Luzhanqi](http://www.zillions-of-games.com/cgi-bin/zilligames/submissions.cgi?do=show;id=2515), конечно, если мы не хотим, чтобы компьютер видел все наши фигуры, а мы его нет. В любом случае, сейчас я над этим работаю. И в этом мне вновь помогают unit-тесты! При выполнении столь обширного рефакторинга, жизненно необходимо знать, что у тебя ничего не развалилось!
Далее, тесты становятся всё более и более высокоуровневыми. Генерация отдельного хода по шаблону классом **ZrfMoveGenerator**, применение хода к игровому состоянию и, наконец, генерация набора ходов определённой позицией:
**Бой нескольких фигур дамкой**
```
QUnit.test( "King's capturing chain", function( assert ) {
Model.Game.InitGame();
var design = Model.Game.getDesign();
var board = Model.Game.getInitBoard();
board.clear();
assert.equal( board.moves.length, 0, "No board moves");
design.setup("White", "King", Model.Game.stringToPos("d4"));
design.setup("Black", "Man", Model.Game.stringToPos("c4"));
design.setup("Black", "Man", Model.Game.stringToPos("a6"));
design.setup("Black", "Man", Model.Game.stringToPos("f8"));
board.generate();
assert.equal( board.moves.length, 2, "2 moves generated");
assert.equal( board.moves[0].toString(), "d4 - a4 - a8 - g8 x c4 x a6 x f8", "d4 - a4 - a8 - g8 x c4 x a6 x f8");
assert.equal( board.moves[1].toString(), "d4 - a4 - a8 - h8 x c4 x a6 x f8", "d4 - a4 - a8 - h8 x c4 x a6 x f8");
Model.Game.design = undefined;
Model.Game.board = undefined;
});
```
При всей лаконичности теста, это уже, практически, полноценная игра! Во всяком случае, один ход из неё. Здесь тестируются и составные ходы и ход «скользящей» фигурой и приоритет взятия и даже [правило большинства](https://github.com/GlukKazan/JoclyGames/blob/master/Z2J/src/js/debug/kernel/model/maximal-captures.js), реализованное как игровое расширение и предписывающее взятие максимально-возможного количества вражеских фигур! Этот небольшой тест покрывает практически всю функциональность модели. И когда что-то ломается, мы это видим, и сразу же [исправляем](https://github.com/GlukKazan/JoclyGames/commit/ff74cedd4e25fb4acdb8e9a87e461e474853abbe).
Ещё одна вещь, в которой помогают unit-тесты — это рефакторинг! В какой-то момент, мы решили, что в проекте **будет** использоваться [Underscore](http://underscorejs.ru/). Эта замечательная библиотека помогает писать код в [функциональном стиле](https://ru.wikipedia.org/wiki/%D0%A4%D1%83%D0%BD%D0%BA%D1%86%D0%B8%D0%BE%D0%BD%D0%B0%D0%BB%D1%8C%D0%BD%D0%BE%D0%B5_%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5), делая его более лаконичным и сопровождаемым. Чтобы было понятнее, приведу один пример «из жизни» проекта.
Функциональное программирование тем полезнее, чем сложнее задача. Если код совсем простой, переписывание его в функциональном стиле мало что даст. Но если задачка чуть посложнее, преимущества функционального подхода становятся более очевидными.
Помните эту [игру](http://www.iggamecenter.com/info/ru/ninemenmorris.html)? У неё есть два забавных правила:
* Если перемещение камня создает новый ряд, то игрок получает право захватить **любой** из камней противника
* Когда игрок остается всего с тремя камнями, его камни превращаются в «летающие». Эти камни могут перемещаться («перелетать») не только в одну из соседних, но вообще в **любую** свободную клетку на доске.
Я отметил ключевое слово. Что значит «игрок может захватить любой камень противника»? Если у противника **N** фигур на доске, то ровно такое количество раз мы обязаны продублировать каждый ход, приводящий к построению «ряда». Эти ходы будут отличаться лишь взятой фигурой! В [Zillions of Games](http://zillions-of-games.com/) всё именно так и делается. И это невообразимо усложняет реализацию игры! А ведь есть ещё правило «летающих» камней…
Есть другое решение. Мы можем сформировать всего **один** ход, перечислив в нём все позиции потенциального взятия. Разумеется, это не означает, что мы возьмём **все** камни, вовсе нет! Взят будет лишь один из перечисленных. Ход станет недетерминированным. То же с перемещениями. Если «летающий» камень может построить «ряд», получается декартово произведение всех результативных ходов на множество позиций занятых вражескими фигурами.
Я придумал хороший [способ](https://habrahabr.ru/post/320474/), при помощи которого пользовательский интерфейс может работать с такими ходами, но для AI-ботов он неприменим! AI должен получать на вход строго детерминированные ходы! Это означает, что должен быть механизм, превращающий недетерминированные ходы в детерминированные.
**Вот первый вариант того, что я когда-то написал**
```
var getIx = function(x, ix, mx) {
if (ix > x.length) {
x = [];
return null;
}
if (ix == x.length) {
c.push(0);
return 0;
}
var r = x[ix];
if (r >= mx) {
if (ix + 1 >= x.length) {
x = [];
return null;
}
for (var i = 0; i <= ix; i++) {
x[ix] = 0;
}
x[ix + 1]++;
}
return r;
}
ZrfMove.prototype.determinate = function() {
var r = [];
for (var x = [0]; x.length > 0; x[0]++) {
var m = Model.Game.createMove();
var ix = 0;
for (var i in this.actions) {
var k = 0;
var fp = this.actions[i][0];
if (fp !== null) {
k = getIx(x, ix++, fp.length);
if (k === null) {
break;
}
fp = [ fp[k] ];
}
var tp = this.actions[i][1];
if (tp !== null) {
k = getIx(x, ix++, tp.length);
if (k === null) {
break;
}
tp = [ tp[k] ];
}
var pc = this.actions[i][2];
if (pc !== null) {
k = getIx(x, ix++, pc.length);
if (k === null) {
break;
}
pc = [ pc[k] ];
}
var pn = this.actions[i][3];
m.actions.push([fp, tp, pc, pn]);
}
r.push(m);
}
return r;
}
```
60 строк совершенно непонятного и абсолютно неподдерживаемого кода! Скорее всего, он даже не работает! Я так и не протестировал его.
**Вместо этого, я его переписал**
```
ZrfMove.prototype.getControlList = function() {
return _.chain(this.actions)
.map(function (action) {
return _.chain(_.range(3))
.map(function (ix) {
if (action[ix] === null) {
return 0;
} else {
return action[ix].length;
}
})
.filter(function (n) { return n > 1; })
.value();
})
.flatten()
.map(function (n) { return _.range(n); })
.cartesian()
.value();
}
ZrfMove.prototype.determinate = function() {
var c = this.getControlList();
if (c.length > 1) {
return _.chain(c)
.map(function (l) {
var r = new ZrfMove();
var pos = 0;
_.each(this.actions, function (action) {
var x = [];
_.each(_.range(3), function (ix) {
pos = pushItem(this, action[ix], l, pos);
}, x);
x.push(action[3]);
if (isValidAction(x)) {
this.actions.push(x);
}
}, r);
return r;
}, this)
.filter(isValidMove)
.value();
} else {
return [ this ];
}
}
```
Код стал длиннее и, на первый взгляд, не выглядит более понятным. Но давайте присмотримся к нему повнимательнее. Для начала, попробуем разобраться в задаче. Описание хода (**ZrfMove**) состоит из набора действий (**actions**), каждое из которых представляет собой кортеж из четырёх элементов:
1. Начальная позиция (**from**)
2. Конечная позиция (**to**)
3. Фигура (**piece**)
4. Номер частичного хода (**num**)
Поскольку превращение фигур в «Мельнице» отсутствует и составные ходы не используются, для нас важны только первые два из этих значений. Их достаточно, чтобы описать любое выполняемое действие:
* Добавление фигуры на доску (сброс) — **from == null && to != null**
* Удаление фигуры (захват) — **from != null && to == null**
* Перемещение фигуры — **from != null && to != null && from != to**
Но это только половина дела! На самом деле и **from** и **to** (и даже **piece**, но речь не о ней) — тоже массивы! В случае, если ход детерминированный, каждый из таких массивов содержит ровно по одному элементу. Наличие в любом из них большего количества значений означает возможность выбора (с которой мы и должны разобраться).
**Недетерминированный ход**
```
var m = [ [ [0], [1, 2] ], [ [3, 4, 5], null ] ]; // Незначимые элементы опущены
```
Имеется перемещение фигуры с позиции **0** на любую из двух позиций (**1** или **2**) и захват одной фигуры противника с позиций **3**, **4** или **5**. Для начала, можно выбрать размер всех «недетерминированных» позиций (содержащих более одного элемента):
**Код**
```
m = _.map(m, function(action) {
return _.chain(_.range(2))
.map(function (ix) {
if (action[ix] === null) {
return 0;
} else {
return action[ix].length;
}
})
.filter(function (n) { return n > 1; })
.value();
});
```
**Результат**
```
m == [ [2], [3] ] // Только "недетерминированные" позиции
```
Этот массив «сглаживаем», после чего, превращаем каждое числовое значение в range:
**Код**
m = \_.chain(m)
.flatten()
.map(function (n) { return \_.range(n); })
.value();
**Результат**
```
m == [ [0, 1], [0, 1, 2] ]
```
Теперь нам понадобится операция, в базовой комплектации [Underscore.js](http://underscorejs.ru/) не предусмотренная. Что-то вроде [декартова произведения](http://www.wikiwand.com/bg/%D0%94%D0%B5%D0%BA%D0%B0%D1%80%D1%82%D0%BE%D0%B2%D0%BE_%D0%BF%D1%80%D0%BE%D0%B8%D0%B7%D0%B2%D0%B5%D0%B4%D0%B5%D0%BD%D0%B8%D0%B5). Ничего страшного.
**Напишем его сами**
```
var cartesian = function(r, prefix, arr) {
if (arr.length > 0) {
_.each(_.first(arr), function (n) {
var x = _.clone(prefix);
x.push(n);
cartesian(r, x, _.rest(arr));
});
} else {
r.push(prefix);
}
}
```
**И встроим в Underscore.js**
```
_.mixin({
cartesian: function(x) {
var r = [];
cartesian(r, [], x);
return r;
}
});
```
Допускаю, что моё решение не вполне «кошерно». Если кто нибудь знает, как сделать лучше, пишите в комментарии. Применим его:
**Код**
```
_.chain(m)
.map(function(action) {
return _.chain(_.range(2))
.map(function (ix) {
if (action[ix] === null) {
return 0;
} else {
return action[ix].length;
}
})
.filter(function (n) { return n > 1; })
.value();
})
.flatten()
.map(function (n) { return _.range(n); })
.cartesian()
.value();
```
**Результат**
```
[ [0, 0], [0, 1], [0, 2], [1, 0], [1, 1], [1, 2] ]
```
Оставшаяся часть задачи немногим сложнее. Необходимо выбрать из исходного варианта хода «недетерминированные» позиции, в соответствии с имеющейся шпаргалкой. Не стану утруждать этим читателя, задача чисто техническая. Самое главное то, что использование функционального подхода позволило разделить довольно сложную задачу на части, которые можно решать и отлаживать по отдельности.
Разумеется, использование функционального подхода не всегда связано с решением подобных головоломок. Обычно, всё несколько проще. В качестве характерного примера могу привести модуль **[maximal-captures](https://github.com/GlukKazan/JoclyGames/blob/master/Z2J/src/js/debug/kernel/model/maximal-captures.js)**, реализующий унаследованную от Zillions of Games опцию, обеспечивающую взятие максимального количества фигур в играх семейства шашек.
**Так было**
```
Model.Game.PostActions = function(board) {
PostActions(board);
if (mode !== 0) {
var moves = [];
var mx = 0;
var mk = 0;
for (var i in board.moves) {
var vl = 0;
var kv = 0;
for (var j in board.moves[i].actions) {
var fp = board.moves[i].actions[j][0];
var tp = board.moves[i].actions[j][1];
if (tp === null) {
var piece = board.getPiece(fp[0]);
if (piece !== null) {
if (piece.type > 0) {
kv++;
}
vl++;
}
}
}
if (vl > mx) {
mx = vl;
}
if (kv > mk) {
mk = kv;
}
}
for (var i in board.moves) {
var vl = 0;
var kv = 0;
for (var j in board.moves[i].actions) {
var fp = board.moves[i].actions[j][0];
var tp = board.moves[i].actions[j][1];
if (tp === null) {
var piece = board.getPiece(fp[0]);
if (piece !== null) {
if (piece.type > 0) {
kv++;
}
vl++;
}
}
}
if ((mode === 2) && (mk > 0)) {
if (kv == mk) {
moves.push(board.moves[i]);
}
} else {
if (vl == mx) {
moves.push(board.moves[i]);
}
}
}
board.moves = moves;
}
}
```
**... и так стало**
```
Model.Game.PostActions = function(board) {
PostActions(board);
var captures = function(move) {
return _.chain(move.actions)
.filter(function(action) {
return (action[0] !== null) && (action[1] === null);
})
.map(function(action) {
return board.getPiece(action[0]);
})
.compact()
.map(function(piece) {
return piece.type;
})
.countBy(function(type) {
return (type === 0) ? "Mans" : "Kings";
})
.defaults({ Mans: 0, Kings: 0 })
.value();
};
if (mode !== 0) {
var caps = _.map(board.moves, captures);
var all = _.chain(caps)
.map(function(captured) {
return captured.Mans + captured.Kings;
})
.max()
.value();
var kings = _.chain(caps)
.map(function(captured) {
return captured.Kings;
})
.max()
.value();
board.moves = _.chain(board.moves)
.filter(function(move) {
var c = captures(move);
if ((mode === 2) && (kings > 0)) {
return c.Kings >= kings;
} else {
return c.Mans + c.Kings >= all;
}
})
.value();
}
}
```
И тот и другой вариант вполне работающие (на момент рефакторинга код был уже покрыт тестами), но функциональный вариант короче, легче понимается и собран из унифицированных блоков. Поддерживать его, безусловно, гораздо проще.
В заключение статьи, я хочу озвучить несколько принципов, которыми я стараюсь руководствоваться в работе. Я, ни в коем случае, не хочу делать из них догму, но мне они помогают.
**Ни дня без строчки**
Работа над проектом не должна прерываться! Во всяком случае, на сколь нибудь продолжительное время. Чем дольше перерыв — тем сложнее вернуться к работе. Работа отнимает гораздо меньше времени и сил, если заниматься ей каждый день. Хотя бы понемногу! Это не означает, что нужно «выдавливать» из себя код «через не могу» (так недолго и перегореть). Если проект сложен и интересен, всегда можно найти работу под настроение.
**Утром код, вечером тесты**
Да-да, знаю, это идёт в полный разрез с методологией [TDD](https://ru.wikipedia.org/wiki/%D0%A0%D0%B0%D0%B7%D1%80%D0%B0%D0%B1%D0%BE%D1%82%D0%BA%D0%B0_%D1%87%D0%B5%D1%80%D0%B5%D0%B7_%D1%82%D0%B5%D1%81%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5). Но кто сказал, что я её придерживаюсь? **Unit-test**-ы (очень) полезны, даже если не ставить их во главу угла! Любой код, и простой и сложный, должен быть покрыт тестами, насколько это возможно! При этом, желательно двигаться от простого к сложному, тестируя более сложную функциональность после того как не остаётся сомнений в работоспособности той, на которой она построена. Не следует удалять тесты, пока они не потеряли свою актуальность! Напротив, надо стараться запускать их как можно чаще, в различных окружениях. Я нашёл несколько серьёзных и очень нетривиальных ошибок таким образом!
**Не навреди**
Любые изменения не должны ломать код уже покрытый тестами! Не надо **commit**-ить код со сломанными тестами. Даже если занимался этим кодом весь день! Даже если очень устал, чтобы разобраться с проблемой «здесь и сейчас»! Не работающий код — это мусор. Это бомба, которая может взорваться в любой момент! Если нет сил с ним разобраться, лучше полностью его удалить, чтобы потом переписать заново.
**Никогда не сдавайся**
Не надо бояться переписывать код снова и снова! Небольшой рефакторинг, или даже полное переписывание проекта с нуля — это не повод для паники! Это возможность решить задачу лучше.
**Если не можешь победить честно - просто победи**
Хороший код решает задачу. Хороший код — понятен и сопровождаем. На этом, всё! Не надо выворачиваться наизнанку просто для того, чтобы «подогнать» его под идеологию [ООП](https://ru.wikipedia.org/wiki/%D0%9E%D0%B1%D1%8A%D0%B5%D0%BA%D1%82%D0%BD%D0%BE-%D0%BE%D1%80%D0%B8%D0%B5%D0%BD%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%BD%D0%BE%D0%B5_%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5), [ФП](https://ru.wikipedia.org/wiki/%D0%A4%D1%83%D0%BD%D0%BA%D1%86%D0%B8%D0%BE%D0%BD%D0%B0%D0%BB%D1%8C%D0%BD%D0%BE%D0%B5_%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5) или чего-то там ещё! Используя какие-то возможности языка или его окружения, надо думать не о моде, а лишь о полезности этих «фич» для проекта. За модой всё равно не угонишься!
Безусловно, мне ещё есть куда расти. Я не вижу в этом проблемы. Меняется (надеюсь, что в лучшую сторону) моё понимание языка, а вместе с ним, меняется и код. А unit-тесты просто помогают мне в этом. | https://habr.com/ru/post/323198/ | null | ru | null |
# Начало разработки для Sailfish OS
Sailfish OS — это мобильная платформа, основанная на ядре Linux. Прочитать о ней можно на [официальном сайте](https://sailfishos.org/about/) или в одном из обзоров платформы в сети. Например, один из них [был опубликован на GeekTimes](https://geektimes.ru/post/260512/). В данной статье я хотел бы затронуть сам процесс разработки приложений для Sailfish OS, рассказать о том как начать программировать под данную платформу, а также поделиться некоторыми особенностями разработки.
Для написания приложений для платформы Sailfish OS используется язык С++ и библиотеки Qt, а также язык QML для описания графического интерфейса приложений. Поэтому, если вы уже имеете опыт написания приложений с использованием Qt и QML, разработка для Sailfish OS не вызовет у вас затруднений. Кроме того, Sailfish OS позволяет разрабатывать нативные приложения на языке Python. Однако, данная тема выходит за рамки данной статьи и не будет в ней описана (подробнее про это можно почитать, например, [тут](https://sailfishos.org/develop/tutorials/creating-application-in-python/)).
Как и для других мобильных платформ, разработка для Sailfish OS ведется с использованием SDK, предоставляемого создателями платформы. SailfishOS SDK включает в себя:
* QtCreator — IDE, в которой собственно и предлагается вести весь процесс разработки.
* Mer Build Engine, который необходим для сборки приложений.
* Эмулятор Sailfish OS.
* Примеры, руководства и документация к API.
Mer Build Engine и эмулятор платформы поставляются в виде образов виртуальных машин для VirtualBox. Однако, сам VirtualBox в состав SailfishOS SDK не входит. Поэтому, перед непосредственной установкой SDK, необходимо вначале установить VirtualBox версии не ниже чем 4.1.18. Кроме того, при работе в Windows, перед установкой SDK так же необходимо установить пакет Windows Microsoft Visual C++ 2010 redistributable (x86).
Сам SailfishOS SDK доступен для Linux, Windows и Max OS X, его можно [скачать тут](https://sailfishos.org/wiki/Application_SDK#Latest_SDK_Release). SDK поставляется в виде графического инсталлятора, поэтому установка SDK не вызывает никаких трудностей. Однако, при установке вас спросят альтернативный путь для проектов. Этот параметр необходим для того, чтобы виртуальная машина с Mer Build Engine имела доступ к исходным кодам вашего проекта. По умолчанию это ваша домашняя директория. В последствии данный параметр можно изменить в настройках Qt Creator.
После установки SDK вы полностью готовы к разработке приложений для платформы Sailfish OS.
Создание Hello World! приложения так же не вызывает каких либо трудностей. Просто запускаем Qt Creator, нажимаем на кнопку «Новый проект» на главном экране (или через меню Файл -> Создать файл или проект...) и настраиваем проект:
1. Выбираем в качестве типа приложения SailfishOS Qt Quick Application:

2. Указываем название и директорию, в которой следует сохранить данные проекта (помните, что проект следует сохранять только в вашей домашней директории или по альтернативному путю для проектов, указанному при установке либо в настройках Qt Creator, поскольку для сборки проекта Mer Build Engine должен иметь доступ к нему):
3. Выбираем необходимые комплекты, которые будет использоваться для сборки приложения.
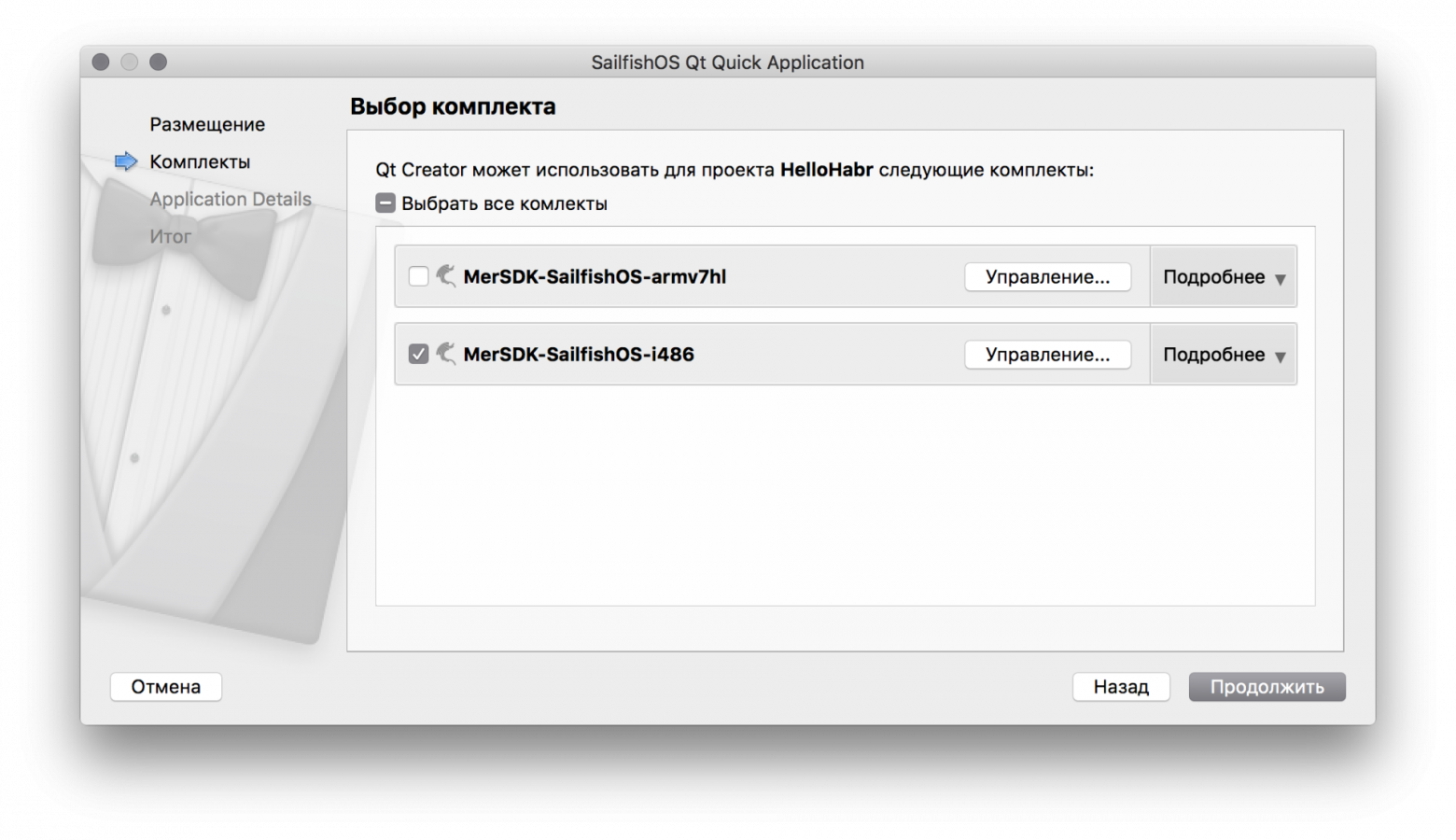
Всего, как видно из скриншота выше, доступно два комплекта:
* MerSDK-SailfishOS-armv7hl — для устройств на базе архитектуры ARM (например, смартфон Jolla),
* MerSDK-SailfishOS-i486 — для устройств на базе архитектуры Intel.
Здесь также стоит отметить, что эмулятор работает только с комплектом i486. Поэтому, если вы планируете тестировать свое приложение в эмуляторе, выбирать на данном шаге нужно второй комплект.
4. Указываем дополнительную информацию о проекте:
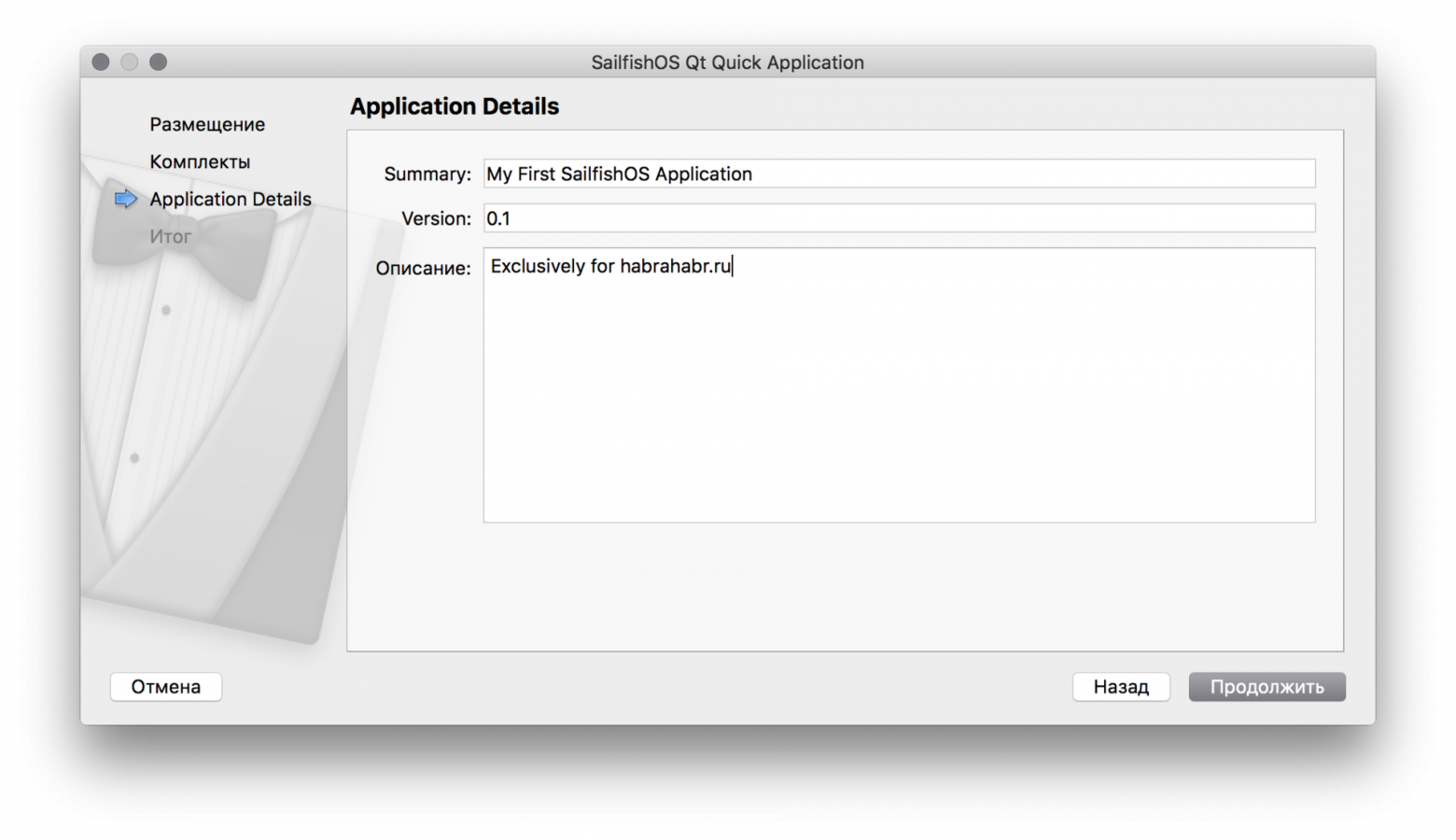
5. И всё, SDK сгенерировала нам Hello World проект.
Автоматически сгенерированный проект немного сложнее, чем стандартный одностраничный Hello World. Это позволяет сразу же раскрыть некоторые особенности Sailfish OS. На главное странице отображается стандартное приветствие. Однако, если на этом экране выполнить жест swipe вниз (стандартное управление для данной платформы), вверху появится меню, позволяющее перейти на вторую страницу приложения, где расположен список элементов.
Ниже приведены скриншоты Hello World приложения:
| | | |
| --- | --- | --- |
| | | |
Теперь давайте взглянем на код. Здесь все стандартно для QML приложений и поэтому знакомо любому, кто когда-либо писал приложения используя данный язык. Единственный *.cpp* файл описывает, какой *.qml* следует отобразить при запуске приложения. В нашем случае это *HelloWorld.qml*. Кроме того, в проекте содержатся 2 страницы, а также Cover Page, которая определяет вид приложения на домашнем экране Sailfish OS, который отображает миниатюры всех запущенных приложений и позволяет переключаться между ними, либо закрывать их.
*HelloWorld.qml* описывает главное окно приложения. В нем указывается начальная страница приложения и Cover Page, а также дополнительные параметры приложения (в нашем случае это разрешенные ориентации экрана и ориентация экрана, которая будет использована по умолчанию):
```
ApplicationWindow
{
initialPage: Component { FirstPage { } }
cover: Qt.resolvedUrl("cover/CoverPage.qml")
allowedOrientations: Orientation.All
_defaultPageOrientations: Orientation.All
}
```
*FirstPage.qml* описывает начальную страницу приложения. Здесь все стандартно для QML приложений, однако есть некоторая особенность Sailfish OS, на которую следует обратить внимание:
```
//...
SilicaFlickable {
anchors.fill: parent
PullDownMenu {
MenuItem {
text: qsTr("Показать вторую страницу")
onClicked: pageStack.push(Qt.resolvedUrl("SecondPage.qml"))
}
}
//...
```
Здесь используется элемент *SilicaFlickable*, который, во первых, позволяет сделать контент внутри самого элемента прокручиваемым, в случае если он полностью не влезает внутрь элемента. А во вторых, позволяет использовать *PullDownMenu* — то самое меню приложения, открываемое свайпом вниз.
Кроме того, хотелось бы так же обратить внимание на *CoverPage.qml*, который описывает Cover Page приложения. Он содержит следующий элемент:
```
CoverActionList {
id: coverAction
CoverAction {
iconSource: "image://theme/icon-cover-next"
}
CoverAction {
iconSource: "image://theme/icon-cover-pause"
}
}
```
Данный элемент позволяет помимо вывода информации также предоставить пользователю возможность управления приложением непосредственно с его миниатюры на домашнем экране.
Для запуска приложения в эмуляторе необходимо в боковом меню выбрать комплект i486, нужный тип сборки (релиз или отладка) и способ установки *Deploy as RPM Package*:
После этого просто нажать на зеленую стрелочку в боковом меню. Это действие соберет приложение, запустит эмулятор, установит и запустит ваше приложение на эмуляторе.
Кроме того, можно просто запустить эмулятор нажав на кнопку  в боковом меню. Это позволит вам просто исследовать Sailfish OS не имея устройства на данной платформе.
На этом все, в будущем я постараюсь более подробно описать некоторые особенности разработки под платформу Sailfish OS.
Автор статьи: Денис Лаурэ
*UPD:* Большое спасибо @kirikch за замечания и комментарии, они были учтены в обновленном тексте статьи. | https://habr.com/ru/post/305510/ | null | ru | null |
# Обзор инструментов для визуального сравнения и разрешения конфликтов слияния
На хабре уже было много статей о распределенных системах управления версиями ([DVCS](http://ru.wikipedia.org/wiki/DVCS)), их сравнений, а также сравнений GUI-клиентов для них. Также были обсуждения плагинов к IDE для работы с git и mercurial. Но практически **не было информации** об инструментах визуального сравнения и разрешения конфликтов слияния.

Недавно я «перескочил» с mercurial (который до сих пор считаю более удобным и логичным) на git, потому что, подавляющее большинство проектов, которые мне интересны, используют git и хостятся на github. В связи с этим, встал вопрос о пересмотре арсенала инструментов, в частности вопрос **выбора инструмента** визуального сравнения и слияния (diff and merge). Дабы восполнить недостаток информации на хабре, я решил написать этот мини-обзор. Как говориться — по горячим следам.
Под катом Вы также найдете примеры настроек Git для использования с DiffMerge и WinMerge под Windows. Думаю многим сэкономит время.
| | | |
| --- | --- | --- |
| **Название** | **Особенности** | **Платформа** |
| KDiff3
<http://kdiff3.sourceforge.net/>
[[скриншот](http://habrastorage.org/storage2/c3b/9a0/c95/c3b9a0c9517dfd0f23b936ee9155ab80.png)] | С этим инструментом скорее всего сталкивались как пользователи git, так и пользователи системы mercurial, тем не менее пару строк не помешает.
*Плюсы*:* бесплатен;
* поддерживает трехстороннее слияние;
* умеет сравнивать директории;
* с различными кодировками работает нормально;
*Минусы*:* без дополнений не подсвечивает синтаксис.
Примечание: устанавливается вместе с [TortoiseHg.](http://ru.wikipedia.org/wiki/TortoiseHg) | Windows, Mac OS X, Linux |
| DiffMerge
<http://www.sourcegear.com/diffmerge/index.html>
[[скриншот](http://habrastorage.org/storage2/170/795/08f/17079508fdfe75a5bd35d98d189c684a.png)] | *Плюсы*:* бесплатен;
* поддерживает трехстороннее слияние;
* умеет сравнивать директории.
*Минусы*:* бывают проблемы при работе с кириллицей. Думаю, со временем, исправят.
* DiffMerge по умолчанию, не поддерживает подсветку синтаксиса языков программирования.
| Windows, Mac OS X, Linux |
| WinMerge
<http://www.winmerge.org>
<http://ru.wikipedia.org/wiki/Winmerge>
[[скриншот](http://habrastorage.org/storage2/e97/f4a/7fb/e97f4a7fbb6d402666cfff67985a3939.png)] | *Плюсы*:* Open Source;
* никаких проблем с кодировками;
* подсветка синтаксиса без лишних телодвижений;
* сравнение директорий.
*Минусы*:* инструмент слияния является двусторонним, что может создавать неудобства в некоторых случаях;
* Windows only.
*Примечание*: этим инструментом я начал пользоваться очень давно (еще до того, как стал использовать mercurial и git) и тот факт, что инструмент слияния является двусторонним в большинстве случаев не доставляет особых неудобств. | Windows |
| Meld
<http://meld.sourceforge.net/>
[[скриншот](http://habrastorage.org/storage2/f86/c20/09e/f86c2009e9ea4fdc0ab9016df7417579.png)] | *Плюсы*:* GPL v2;
* двустороннее и трехстороннее слияние файлов;
* сравнение директорий;
* подсветка синтаксиса (при установленном GtkSourceView).
*Минусы*:* для установки под Windows требуется установить Python, GTK+, Glib, GtkSourceView, что не каждому понравиться.
| Windows, Mac OS X, Linux
Инструкция по установке под Windows:
<https://live.gnome.org/Meld/Windows> |
| Diffuse
<http://diffuse.sourceforge.net/>
[[скриншот](http://habrastorage.org/storage2/fc1/80f/46d/fc180f46dee8efeeae79c7aed90d783f.png)] | *Плюсы*:* GPL;
* поддержка 2-way, 3-way и n-way (произвольное количество файлов) слияния;
* подсветка синтаксиса;
* отлично работает с UTF-8;
* неограниченная глубина отмен (Undo);
* удобная навигация по коду.
*Минусы*:* разве что, невозможность сравнивать директории.
*Примечаие*: при слиянии с помощью команды git mergetool через Git Bash под Windows открывается четвертое — «лишнее» окно.
Убрать можно, подправив конфиг c:/Git/libexec/git-core/mergetools/diffuse | Windows, Mac OS X, Linux
*Примечание*: при установке под Windows уже включает в себя все зависимости (в отличие от Meld), а именно Python и пакет PyGTK. |
| TKDiff
<http://sourceforge.net/projects/tkdiff/>
[[скриншот](http://habrastorage.org/storage2/2d9/98f/c04/2d998fc045f5c7edd05b6afc54165722.png)] | *Плюсы*:* GPLv2;
* можно добавлять закладки для различий;
* с кодировками работает нормально;
*Минусы*:* интерфейс менее удобен и выглядит очень бедно (см. скриншот), чем у других продуктов.
* нет подсветки синтаксиса;
* не умеет сравнивать директории.
| Windows, Mac OS X, Linux |
| SmartSynchronize
<http://www.syntevo.com/smartsynchronize/index.html>
[[скриншот](http://habrastorage.org/storage2/ea1/850/0df/ea18500dfefe73954345423adb70b61e.png)] | *Плюсы*:* трехстороннее слияние;
* нет проблем с кодировками;
* помимо файлов, может сравнивать директории.
*Минусы*:* для коммерческого использования требуется лицензия;
* подсветка синтаксиса для языков программирования по умолчанию не предусмотрена. Не исключено, что можно как-то сделать.
*Примечание*: SmartySynctonize встроен в программу [SmartGit](http://www.syntevo.com/smartgit/index.html) — удобный GUI-инструмент для работы с Git (тоже бесплатен для некоммерческого использования). | Windows, Mac OS X, Linux |
| BeyondCompare
<http://www.scootersoftware.com/>
<http://en.wikipedia.org/wiki/Beyond_Compare>
[[скриншот](http://habrastorage.org/storage2/312/718/899/3127188994f31320d3ea9d48bee4d702.png)] | *Плюсы*:* трехстороннее слияние;
* может сравнивать файлы, директории, удаленные директории, архивы, а также MP3-файлы, изображения и др. Но последние пункты — это в принципе не нужный функционал.
*Минусы*:* ShareWare;
* нет версии под Mac.
| Windows, Linux |
| Araxis Merge
<http://www.araxis.com/merge/>
[[скриншот](http://habrastorage.org/storage2/c77/714/512/c777145121ac926447b4f79b448a68bf.png)] | *Плюсы*:* трехстороннее слияние;
* нет проблем с кодировками;
* подсвечивает синтаксис;
* помимо файлов, может сравнивать директории и синхронизировать их;
* хорошо работает на сравнении больших файлов (гигабайты) и больших директорий;
* генерация отчётов по результатам сравнения.
* [Ribbon-интерфейс](http://ru.wikipedia.org/wiki/Ribbon) (если это можно назвать плюсом).
*Минусы*:* ShareWare;
* нет версии под Linux.
*Примечание*: в комментариях многие расхваливают и советуют этот инструмент, несмотря на высокую стоимость. | Windows, Mac OS X |
В принципе, все перечисленные инструменты хорошо справляются со своими задачами и данный обзор **не тема для спора**, т.к. каждый выбирает инструмент по вкусу.
Далее приводятся примеры настроек Git для работы с DiffMerge и WinMerge. По аналогии можно настроить взаимодействие Git с другими инструментами.
Git и DiffMerge
---------------
1) Добавим в директорию *c:/Git/libexec/git-core/mergetools/*
файл diffmerge следующего содержания:
```
diff_cmd () {
"c:/Program Files/SourceGear/Common/DiffMerge/sgdm.exe" \
"$LOCAL" "$REMOTE" >/dev/null 2>&1
}
merge_cmd () {
"c:/Program Files/SourceGear/Common/DiffMerge/sgdm.exe" \
--merge --result="$MERGED" "$LOCAL" "$BASE" "$REMOTE" >/dev/null 2>&1
status=$?
}
```
2) Теперь добавим в файл *c:/Users/swipe/.gitconfig*
следующие строки:
```
[diff]
tool = diffmerge
[merge]
tool = diffmerge
[mergetool "diffmerge"]
cmd = "diffmerge"
trustExitCode = true
```
3) Создадим конфликт и вызовем DiffMerge для его разрешения
```
git init // инициализируем репозиторий
создадим пустой файл readme.txt
git add . // добавим созданный файл в индекс
git commit -m "empty readme" // зафиксируем изменения
git branch new // создадим новую ветку
git checkout new // переключимся на новую ветку
добавим строку в файл readme.txt
git add . // добавим изменения в индекс
git commit -m "new string" // зафиксируем изменения в новой ветке
git checkout master // переключися на master ветку
добавим изменения в файл readme.txt
git add . // добавим изменения в индекс
git commit -m "master string" // зафиксируем их
git hist --all // посмотрим на дерево
```

```
git difftool master new // сравним две ветви
```
```
git merge new // сольем изменения в new с веткой master
```

Выводится сообщение о конфликте слияния, чего мы и добивались.
```
git mergetool // разрешим этот конфликт
```

В среднем окне, приведем файл к требуемому состоянию и сохраним изменения.
Конфликт разрешен.
Настройку DiffMegre подсмотрел тут:
<http://twobitlabs.com/2011/08/install-diffmerge-git-mac-os-x/>
Git и WinMerge
--------------
1) Добавим в директорию *c:/Git/libexec/git-core/mergetools/*
файл winmerge следующего содержания:
```
diff_cmd () {
"c:/Program Files (x86)/WinMerge/WinMergeU.exe" \
"$LOCAL" "$REMOTE" >/dev/null 2>&1
}
merge_cmd () {
"c:/Program Files (x86)/WinMerge/WinMergeU.exe" \
"$PWD/$LOCAL" "$PWD/$REMOTE" "$PWD/$MERGED" >/dev/null 2>&1
status=$?
}
```
Когда Git не может автоматически объединить изменения, происходит конфликт слияния и в конфликтующий файл добавляются маркеры слияния (<<<<<<<, =======, и >>>>>>>). Они необходимы для разрешения конфликта с помощью сторонних инструментов.
Рассмотрим файл *readme.txt* который образуется в результате выполнения слияния веток *master и new* в приведенном выше примере:
```
<<<<<<< HEAD
master str
=======
new str
>>>>>>> new
```
Мы можем открыть файл конфликтов с помощью программы WinMerge для разрешения конфликта.
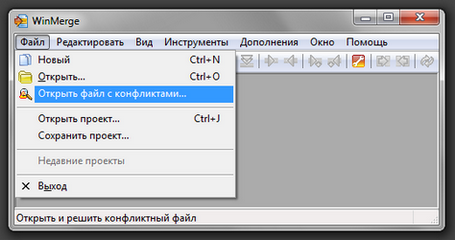
После этого откроется средство двухстороннего слияния:

Исходя из описанной логики перепишем команду слияния *merge\_cmd* следующим образом:
```
merge_cmd () {
"c:/Program Files (x86)/WinMerge/WinMergeU.exe" \
"$MERGED" >/dev/null 2>&1
status=$?
}
```
По сути, оба приведенных варианта эквивалентны.
2) Отредактируем *.gitconfig*
```
[diff]
tool = winmerge
[difftool "winmerge"]
cmd = "winmerge"
[merge]
tool = winmerge
[mergetool "winmerge"]
cmd = "winmerge"
trustExitCode = false
keepBackup = false
```
последняя строчка отменяет сохранение backup-файлов в директории репозитория.
3) Создадим конфликт при слиянии двух веток (см. пример с использованием DiffMerge).
```
git difftool master new // сравним две ветви
```
Для разрешения конфликта при слиянии веток, воспользуемся командой
```
git mergetool
```

Отредактируем наш файл. После сохранения изменений, конфликт будет разрешен.
Настройки WinMerge подсмотрел тут:
<http://stackoverflow.com/questions/636253/msys-git-merge-tool-command-options-issue> | https://habr.com/ru/post/150001/ | null | ru | null |
# Моя реализация Java библиотеки для биржи BTC-e
После начала торговли на BTC-e я заметил довольно удачное API. Его возможности вполне можно направить на благое дело. А именно — на создание торговых ботов и мобильные клиенты. Про ботов понятно, а вот клиент под Android понадобился довольно скоро, но на маркете тогда их вообще не нашлось. А когда библиотека была дописана (да да, кода в ней мало, но получился долгострой), приложения хоть и появились, но были все равно какие-то не такие. Итак, если вам интересно узнать, что же у меня получилось и насколько это может быть полезно вам — прошу под кат.
Перед написанием я поставил перед собой ряд задач, а именно:
* реализовать в библиотеке все возможности api;
* название методов и возвращаемые значения должны точно соответствовать методам из официальной документации;
* сделать её удобной для модификации, в том числе другими людьми;
* возвращаемые значения должны быть, по возможности, готовыми к употреблению;
* добавить дополнительную функциональность, основанную на методах api;
* сделать её совместимой с Andoid.
Для хостинга был выбран GitHub, ссылки вы можете найти в конце статьи.
Размышления о том, как все это скомпоновать привели к следующей иерархии классов:

Две основные группы классов, это PrivateBaseClass и PublicBaseClass, для приватного и публичного раздела api, соответственно. PrivateBaseClass разделен на методы, возвращающие итерируемые результаты и неитерируемые. В их основе лежит CommonClass, содержащий общие для всех вещи. Private Network служит для работы с ключами при отправке приватных запросов, а так же шифровки в 3DES, для хранения на устройстве. StringCrypter ему в этом как раз и помогает. А завершает композицию класс TradeApi, вобравший в себя все их возможности и служащий точкой взаимодействия с пользователем. Правда, никто не запрещает использовать отдельно классы вродe Ticker или Info, если кроме их функциональности вам больше ничего и не нужно.
Для работы с json была выбрана Jackson library, а для всего остального Apache Commons Codec.
А теперь на примере, что же из всего этого получилось и как ~~с этим бороться~~ этим пользоваться.
Алгоритм будет примерно следующим: выбираем из официальной документации нужный нам метод, устанавливаем ему параметры, запускаем, получаем результаты.
Самое первое что вам, возможно, захочется — узнать цены любимых пар. И сделать это будет довольно просто:
```
TradeApi tradeApi = new TradeApi();
tradeApi.ticker.addPair("btc_usd");//добавляем пары
tradeApi.ticker.addPair("ltc_usd");
tradeApi.ticker.addPair("nmc_usd");
tradeApi.ticker.runMethod();//запускаем метод
while (tradeApi.ticker.hasNextPair()) {//если есть следующая пара
tradeApi.ticker.switchNextPair();//переключаемся на следующую пару
System.out.println(tradeApi.ticker.getCurrentLast());//выводим на экран
}
```
Результатом будет:
368.98
4.216
1.02
Следующим на очереди у нас будет получение баланса, ключи можно взять в личном кабинете (эти, естественно, не валидны):
```
String aKey = "TK8HD88A-ENLZZBCW-P4L5JYVR-18K9NZZP-CYQ7WKKH";//API-ключ
String aSecret = "b7738a9f4d62da1b6ebdcd7ff2d7b5ddb93de88b71f017ae600b7ab3ed5b7015";//SECRET
TradeApi tradeApi = new TradeApi(aKey,aSecret);//передаем их конструктору
tradeApi.getInfo.runMethod();//запускаем метод, который возвращает нужную информацию
System.out.println(tradeApi.getInfo.getBalance("usd"));//выводим долларовый баланс на экран
```
Результатом будет:
0.25
В случае, если вы не хотите в своей конечной реализации вводить ключи каждый раз, но и хранить в открытом виде их тоже не хотите, возможно использовать встроенное шифрование. Код будет тем же за исключением передачи ключей. В этом случае конструктору нужно будет передать зашифрованный api-ключ, секрет а так же пароль для их расшифровки:
```
String aKey = "TK8HD88A-ENLZZBCW-P4L5JYVR-18K9NZZP-CYQ7WKKH";//API-ключ
String aSecret = "b7738a9f4d62da1b6ebdcd7ff2d7b5ddb93de88b71f017ae600b7ab3ed5b7015";//SECRET
String password = "12345";// пароль
String encryptedKey = tradeApi.encodeString(aKey, password);// шифруем ключ
String encryptedSecret = tradeApi.encodeString(aSecret, password);// шифруем секрет
tradeApi.setKeys(encryptedKey, encryptedSecret, password);//передаем конструктору зашифрованные ключ, секрет и пароль для их расшифровки
```
В случае если пароль неверен, будет выброшено исключение. В случае если были установлены валидные ключ и секрет, но после была попытка установить зашифрованные ключи с неправильным паролем, исключение будет так же выброшено, но прежние ключи останутся работать дальше.
А теперь, возможно, самое интересное: дополнительные фичи, созданные с помощью официального API.
Начнем с торговли. Кроме родного метода Trade, описанного в документации, мною был добавлен метод немного умнее. В нем используются сразу два метода: Trade и Info. Он автоматически округляет цену до допустимых пределов и выбрасывает исключения с разными сообщениями для быстрой диагностики причины ошибки:
```
String aKey = "TK8HD88A-ENLZZBCW-P4L5JYVR-18K9NZZP-CYQ7WKKH";//API-ключ
String aSecret = "b7738a9f4d62da1b6ebdcd7ff2d7b5ddb93de88b71f017ae600b7ab3ed5b7015";//SECRET
TradeApi tradeApi = new TradeApi(aKey,aSecret);//передаем их конструктору
Trade trade = tradeApi.extendedTrade("btc_usd", false, "600", "0.01");//false - продажа, true - покупка :)
if (trade.isSuccess()){
System.out.println(trade.getReceived());//выводим полученное
}
```
Результат: 0
то есть мы ничего не получили т. к. продать сейчас 0.01 биткоина за 600 долларов на момент написания статьи было нельзя.
Следующий на очереди приятный для использования во всяческих будильниках метод priceDifference:
```
TradeApi tradeApi = new TradeApi();
for (int i = 0; i < 3; i++) {
System.out.println(tradeApi.priceDifference("btc-usd", 600.0, 10000));
}
```
Результат:
233.39
233.39
233.103
Метод принимает на вход имя пары и ценовую границу, с которой необходимо выполнить сравнение текущей цены, а так же время задержки в миллисекундах, это может быть полезно, если метод используется в цикле, например для построения будильников.
А напоследок остаются tryMaximumBuy(String pairName, long reuseAgeMillis) и tryMaximumSell(String pairName). Наиболее интересен из этих двоих метод tryMaximumBuy. Он пытается выполнить максимально возможную покупку валюты по выбранной паре. Вторым параметром является время, через которое данные, используемые в методе, считаются устаревшими и подлежат обновлению. Показать пример работы, к сожалению не смогу, по причине того что это будет не бесплатно для меня.
Разумеется, на этом возможности данной бибилиотеки не ограничены и, возможно, вы найдете в ней ещё какие-то полезные мелочи для себя, например, округление чисел до выбранного знака после запятой, полезно при работе с количеством и ценами при покупке. С библиотекой вы так же можете скачать Javadoc, описывающий многие методы.
В заключение надеюсь, что эта библиотека окажется вам полезна и послужит дальнейшему развитию криптовалютного сообщества, а так же снимет проблему поддержания вашего набора классов для работы с API биржи в актуальном состоянии т.к. этим буду заниматься я.
#### Обещанные в начале статьи ссылки
Ссылка на репозиторий с библиотекой: [github.com/alexandersjn/btc\_e\_assist\_api](https://github.com/alexandersjn/btc_e_assist_api)
Ссылка на документацию по приватной части API: [btc-e.com/tapi/docs#Trade](https://btc-e.com/tapi/docs#Trade)
Ссылка на документацию по публичной части API: [btc-e.com/api/3/docs](https://btc-e.com/api/3/docs)
Так же в качестве примера использования, вы можете найти ссылку на мой андроид клиент для btc-e в описании репозитория библиотеки. Его исходный код вы тоже найдете в моём репозитории.
Благодарю за внимание. | https://habr.com/ru/post/239073/ | null | ru | null |
# DigestSDK — автоматизация работы с MSSQL на Delphi
#### Вступление
Несколько лет назад мне пришлось реализовать работу с таблицами базы данных MSSQL сервера. После написания некоторого количества, фактически однотипного кода, пришла мысль автоматизировать эти «рутинные» действия.
Согласитесь, что написание одного и того же кода, отличающегося только структурой таблиц БД, не может никого вдохновить. К тому же, если кол-во таблиц, с которыми приходиться работать переваливает за десяток, то занятие из разряда скучное — переходит в разряд трудоемкое.
Поиск в интернете на тот момент не дал результатов, поэтому реализацию пришлось взять на себя. .
В результате был создан набор модулей (в дальнейшем *DigestSDK*) на языке Delphi, позволяющих избавить программиста от написания «стандартного» кода по работе с БД и сосредоточиться на логике самого приложения. .
Демонстрационные примеры, исходные коды и видео по работе с DigestSDK выложил на [SourceForge](http://sourceforge.net/projects/digestsdk/) (авось еще кому да и пригодится, заодно и хабр эффект проверим в очередной раз:-))..
Итак, DigestSDK позволяет отобразить содержимое таблиц MSSQL сервера (в дальнейшем планируется реализация для остальных популярных БД) и автоматически предоставляет следующие возможности:
#### Перечень стандартных функций
После создания справочник автоматически содержит следующие функции:
* добавление;
* удаление (в том числе групповое);
* редактирование (в том числе групповое);
* поиск (с возможностью частичного соответствия);
* сортировка (при нажатии на заголовке DBGrid)
* сортировка (с указанием множества полей и порядка сортировки);
* выделение записей;
* подсчет кол-ва записей для текущей выборки и выделенных записей;
* быстрый переход на указанную запись;
* задание максимального кол-ва отображаемых записей;
* сохранение последнего состояния справочника в БД или в файле (настройки колонок, последний запрос, условия отбора и сортировки, положение формы);
* настройка отображаемых колонок (видимость, ширина, положение);
* автоматический перевод английских наименований в соответствии с пользовательским справочником.
#### Дополнительные возможности
Перечисленные выше возможности могут расширены программистом следующими возможностями:
* изменение любого набора полей (с указанием собственных функций отображения, проверки и т.д.)
* переопределение стандартных процедур добавления, удаления, редактирования;
* добавление в справочник собственных процедур, не входящих в список, поддерживаемых справочником;
* задание списка полей запрещенных для редактирования и удаления;
* задание внешнего вида справочника (цвет выделенных записей, набор отображаемых кнопок, добавление собственных кнопок и панелей и т.д.);
* задание начальных поисковых значений.
Представленный перечень функций и возможностей далеко не полный и может быть расширен программистом за счет переопределения и/или написания собственных дополнительных функций.
Приведу фрагмент кода по созданию справочника с выборкой данных из таблицы Production.Product (из демонстрационной БД AdventureWorks к MSSQL 2005).
В данном примере вызывается конструктор класса TSimpleDigest, которому передается: sql запрос, имя таблицы в БД (к которой будут применяться операции добавления, изменения и удаления), обычная строка подключения ADO, указание где создавать справочник (TWinControl или nil, если на новой форме) и идентификатор оператора – некоторое целое число – код, под которым справочник будет сохранять свое последнее состояние.
#### Пример использования с демонстрацией результатов.
Пример программы создания:
```
//создаем основой справочник
DigestProducts := TSimpleDigestR.Create(
'select top 10 * from Production.Product',//произвольный запрос
'Production.Product',//Имя таблицы для изменения
ConnectionString, //Строка подключения
nil, //Где создавать справочник
0 //Идентификатор оператора (для сохранения настроек)
);
//открываем справочник
DigestProducts.Open();
DigestProducts.ShowModal;
```
Результат выполнения:

#### Небольшой ролик по созданию справочника
Пример как подключить файлы к проекту и написать простейший код для отображения содержимого БД cars (находится в папке Demos\Cars\DataBase")
#### Ролик, демонстрирующий основные возможности DigestSDK
Показано использование различных операций (добавление, удаление, поиск, сортировка, сохранение последнего состояния ну и т.д.)
Исходные коды. примеры и демонстрационную БД (cars) можно скачать [тут](http://sourceforge.net/projects/digestsdk/files/Projects/DIgestSDK_Demo.zip/download)
Остальные видео-примеры по работе [тут](http://sourceforge.net/projects/digestsdk/files/Video/)
Достаточно просто создать нужный и работа всех функций, а также перевод наименований таблиц и полей, будет производен автоматически.
DigestSDK поддерживает с MSSQL 2005, 2008, 2008 R2.
Работостпосбность проверена для Delphi 7, 2007, XE2
Более подробное ознакомление: <http://sourceforge.net/projects/digestsdk/> | https://habr.com/ru/post/134901/ | null | ru | null |
# Юлия → Iuliia. Всё о транслитерации

Транслитерация — это запись кириллических слов латиницей (*Анна → Anna*, *Самара → Samara*). Её используют в загранпаспортах, водительских удостоверениях, трансграничной доставке, библиотечных каталогах и множестве других международных процессов.
Так вышло, что я недавно окунулся в эту тему, а в Википедии она раскрыта слабо. Поэтому расскажу, что к чему (спойлер — если вы думаете, что с транслитерацией всё плохо, то на самом деле всё ещё хуже).
И конечно, поскольку это Хабр — предложу open-source библиотеки для решения проблемы.
Оглавление:
* [Кто виноват](#kto-vinovat)
* [Как выбрать схему (быстрый вариант)](#kak-vybrat-shemu-bystryy-variant)
* [Как выбрать схему (для дотошных)](#kak-vybrat-shemu-dlya-dotoshnyh)
* [Как транслитерировать](#kak-transliterirovat)
Кто виноват
-----------
Транслит — это хрестоматийная ситуация «у нас 14 плохих стандартов, давайте придумаем ещё один». Весь 20 век солидные, уважаемые люди придумывали всё новые и новые стандарты транслитерации.

Как приумножаются стандарты // [xkcd](https://xkcd.com/927/)
Получалось у них очень, очень плохо. Например, в загранпаспорте пишут *Юлия → Iuliia* не потому, что МИД хочет сделать вам больно, а потому что это международный стандарт ICAO Doc 9303 [[1]](#ft-icao-doc-9303) — Machine Readable Travel Documents.
Такое ощущение, что все стандарты писались людьми, которые ненавидят русский язык. Если для англо-американского творчества это объяснимо, то что заставило советских учёных превратить *Лёгкий* в *Ljogkijj* (ГОСТ 16876-71[[2]](#ft-gost-16876)) — решительно непонятно.
> *Zato naši kosmičeskie korabli borozdili prostory vselennoj.*
В 21 веке человечество оказалось с двумя наиболее распространёнными стандартами: ICO Doc 9303 (*Юлия → Iuliia*) и ISO 9:1995 (*Юлия → Ûliâ*), он же отечественный ГОСТ 7.79-2000[[3]](#ft-gost-779). Достойный результат для столетних усилий, ничего не скажешь.
Посмотрев на эту «красоту», ребята из Википедии взялись за голову и сделали нормальную схему транслитерации[[4]](#ft-wikipedia), благодаря которой у несчастной *Юлии* остаётся слабый шанс быть *Yuliya*. Международные и отечественные институты эту работу проигнорировали, к сожалению.
> *Yuliya, syesh yeshchyo etikh myagkikh frantsuzskikh bulok iz Yoshkar-Oly, da vypey altayskogo chayu.*
Конечно, нельзя было делать совсем уж хорошо (а то кто тогда станет придумывать новые стандарты). Поэтому у Википедии *ещё* превращается в *yeshchyo*. Схема хорошо передаёт фонетику, а вот выглядит иногда не очень — оцените *E → YE*, *Щ → SHCH* и *Ё → YO* в этом примере.
Не остался в стороне и Яндекс. У него две схемы — отдельно для ФИО[[5]](#ft-yandex-money), отдельно для адресов[[6]](#ft-yandex-maps). Здесь наконец-то сделали *Щ → SCH*. Но *Юрий → Yurii*, а *Усолье → Usole*, что понравится не всем. Не забываем оставлять пространство для новых стандартов!
И Студия Лебедева туда же (в рунете ничего без неё не обходится). Когда дизайнили схему московского метро, ребята отвергли стандарт ISO, а прочие, похоже, даже не смотрели. Ну и придумали свой вариант — Мосметро[[7]](#ft-mosmetro).
Чтобы вы представляли масштаб бедствия. Я насчитал 20 схем транслитерации, некоторые из которых предусматривают альтернативные наборы правил (например, с диакритикой и без). Из них 14 считаются действующими. **Четырнадцать** действующих «стандартов», прямо как в комиксе xkcd.
> Кстати, на Хабре тоже есть транслитерация — например, для генерации id заголовков из текста. И угадайте что? Ну да: она не следует ни одному из официальных стандартов.
>
> Habr, chto ty delaesh, ahaha, prekrati
В качестве вишенки на торте в рунете несметное количество сервисов типа «транслитерация онлайн», которые мало того что перевирают существующие схемы, так ещё и придумывают собственные. Исходники у них закрыты, разумеется.
> Есть ещё такая штука — «обратная транслитерация», когда вы восстанавливаете справедливость и превращаете *Iuliia → Юлия*. Тут ситуация даже хуже, чем в прямой транслитерации, потому что при записи латиницей никто никаких стандартов не соблюдает, и встречаются жуткие монстры.
>
>
>
> Обратная транслитерация — отдельная большая тема, здесь я её не рассматриваю. Но есть отличная статья [DaryaRodionova](https://habr.com/ru/users/daryarodionova/) — «Как написать свой транслитератор»[[8]](#ft-lat2cyr).
Теперь несколько практических рекомендаций.
Как выбрать схему (быстрый вариант)
-----------------------------------
**Загранпаспорт или в/у**. По умолчанию используйте *ICAO Doc 9303* — это требование закона. Впрочем, есть лайфхак: если написать отдельное заявление при подаче документов, сделают паспорт с нормальной транслитерацией. Тогда подойдёт старый стандарт *МВД-310*[[9]](#ft-mvd-310) или *Мосметро*.
```
import iuliia
source = "Юлия Щеглова"
iuliia.translate(source, schema=iuliia.ICAO_DOC_9303)
# Iuliia Shcheglova
```
**Если нужно обратимое преобразование (cyr–lat)**. Используйте *ГОСТ 7.79-2000* (aka ISO 9:1995). Там есть вариант с диакритикой и без.
```
import iuliia
source = "Юлия, съешь ещё этих мягких французских булок из Йошкар-Олы"
iuliia.translate(source, schema=iuliia.GOST_779)
# Ûliâ, sʺešʹ eŝё ètih mâgkih francuzskih bulok iz Joškar-Oly
iuliia.translate(source, schema=iuliia.GOST_779_ALT)
# Yuliya, s``esh` eshhyo е`tix myagkix franczuzskix bulok iz Joshkar-Oly`
```
**Если визуальная красота превыше всего**. Используйте схему *Мосметро*, она сама лаконичная и приятная на вид.
```
import iuliia
source = "Юлия Щеглова"
iuliia.translate(source, schema=iuliia.MOSMETRO)
# Yuliya Scheglova
```
**В остальных случаях**. Используйте схему *Википедии*. Она лучше всех по фонетике и лишь немного уступает *Мосметро* визуально.
```
import iuliia
source = "Россия, город Йошкар-Ола, улица Яна Крастыня"
iuliia.translate(source, schema=iuliia.WIKIPEDIA)
# Rossiya, gorod Yoshkar-Ola, ulitsa Yana Krastynya
```
Как выбрать схему (для дотошных)
--------------------------------
Чтобы не раздувать статью до неприличия, я сделал страницу со всеми схемами [[10]](#ft-iuliia). Там и сценарии использования, и фильтры, и подробные описания, и примеры. Читайте, выбирайте, что больше нравится. Все схемы уже реализованы на JavaScript, Python и Go, подключить библиотеку — минутное дело.
Здесь же перечислю вкратце только актуальные схемы с моими комментариями.
### ГОСТ 7.79-2000
Универсальная схема транслитерации, международный стандарт ISO 9:1995. Громоздкая, зато обратимая. Есть вариант с диакритикой.
```
Юлия, съешь ещё этих мягких французских булок из Йошкар-Олы,
да выпей алтайского чаю
↓ ↓ ↓
Ûliâ, sʺešʹ eŝё ètih mâgkih francuzskih bulok iz Joškar-Oly,
da vypej altajskogo čaû
или
Yuliya, s``esh` eshhyo е`tix myagkix franczuzskix bulok iz Joshkar-Oly`,
da vy`pej altajskogo chayu
```
### ГОСТ Р 52290-2004
Стандарт для транслитерации имён собственных на дорожных знаках. Неплохая, с одинарными апострофами. Много внимания написанию Е и Ё.
```
Юлия, съешь ещё этих мягких французских булок из Йошкар-Олы,
да выпей алтайского чаю
↓ ↓ ↓
Yuliya, syesh' eshche etikh myagkikh frantsuzskikh bulok iz Yoshkar-Oly,
da vypey altayskogo chayu
```
### ГОСТ Р 7.0.34-2014
Правила упрощенной транслитерации русского письма латинским алфавитом. Для библиотек и издательств. В меру приятная. Расслабленная: есть альтернативы для многих букв, можно без апострофов.
```
Юлия, съешь ещё этих мягких французских булок из Йошкар-Олы,
да выпей алтайского чаю
↓ ↓ ↓
Yuliya, s''esh' eshhyo etix myagkix francuzskix bulok iz Joshkar-Oly,
da vypej altajskogo chayu
или
Yuliya, sesh eshhyo etikh myagkikh francuzskikh bulok iz Yoshkar-Oly,
da vypey altayskogo chayu
```
### Телеграммы
Инструкция Минсвязи о порядке обработки международных телеграмм. Некрасивая, зато без апострофов.
```
Юлия, съешь ещё этих мягких французских булок из Йошкар-Олы,
да выпей алтайского чаю
↓ ↓ ↓
Iuliia, sesh esce etih miagkih francuzskih bulok iz Ioshkar-Oly,
da vypei altaiskogo chaiu
```
### ICAO DOC 9303
Стандарт Международной организации гражданской авиации. Используется МВД для ФИО в водительских удостоверениях, а МИД — в загранпаспортах. Подходит для гринкарты и вида на жительство. Используется некоторыми платёжными системами.
```
Юлия, съешь ещё этих мягких французских булок из Йошкар-Олы,
да выпей алтайского чаю
↓ ↓ ↓
Iuliia, sieesh eshche etikh miagkikh frantsuzskikh bulok iz Ioshkar-Oly,
da vypei altaiskogo chaiu
```
### UNGEGN 1987 V/18
Схема транслитерации ООН для географических названий. Основана на ГОСТ 16876-71. Такая же страшная, но до сих пор не отменена.
```
Юлия, съешь ещё этих мягких французских булок из Йошкар-Олы,
да выпей алтайского чаю
↓ ↓ ↓
Julija, sʺešʹ eščё ètih mjagkih francuzskih bulok iz Joškar-Oly,
da vypej altajskogo čaju
```
### BGN/PCGN
Древняя схема транслитерации ООН для географических названий. Почти без диакритики, но зачем-то оставила Ё с точками.
```
Юлия, съешь ещё этих мягких французских булок из Йошкар-Олы,
да выпей алтайского чаю
↓ ↓ ↓
Yuliya, s”yesh’ yeshchё etikh myagkikh frantsuzskikh bulok iz Yoshkar-Oly,
da vypey altayskogo chayu
```
### ALA-LC
Схема транслитерации американской Библиотеки Конгресса. Страшноватая. Есть варианты с диакритикой и без.
```
Юлия, съешь ещё этих мягких французских булок из Йошкар-Олы,
да выпей алтайского чаю
↓ ↓ ↓
I͡ulii͡a, sʺeshʹ eshchё ėtikh mi͡agkikh frant͡suzskikh bulok iz Ĭoshkar-Oly,
da vypeĭ altaĭskogo chai͡u
или
Iuliia, s"esh' eshche etikh miagkikh frantsuzskikh bulok iz Ioshkar-Oly,
da vypei altaiskogo chaiu
```
BS 2979:1958
------------
Схема транслитерации Британской библиотеки. Используется издательством Oxford University Press. Изящно схлопывает окончания ИЙ и ЫЙ, в остальном так себе.
```
Юлия, съешь ещё этих мягких французских булок из Йошкар-Олы,
да выпей алтайского чаю
↓ ↓ ↓
Yuliya, sʺeshʹ eshchё étikh myagkikh frantsuzskikh bulok iz Ĭoshkar-Olȳ,
da vȳpeĭ altaĭskogo chayu
или
Yuliya, s"esh' eshche etikh myagkikh frantsuzskikh bulok iz Ioshkar-Oly,
da vypei altaiskogo chayu
```
### Научная
Великая праматерь всех схем. Используется в научных работах. Из неё вырос ГОСТ 16876-71. Достойна уважения за вклад в историю, но страшная.
```
Юлия, съешь ещё этих мягких французских булок из Йошкар-Олы,
да выпей алтайского чаю
↓ ↓ ↓
Julija, sʺešʹ eščё ètix mjagkix francuzskix bulok iz Joškar-Oly,
da vypej altajskogo čaju
```
### Википедия
Схема транслитерации, которую использует Википедия. Сделана на основе BGN/PCGN со значительными модификациями. Самая продуманная, звучит лучше всех и выглядит приятнее большинства прочих схем.
```
Юлия, съешь ещё этих мягких французских булок из Йошкар-Олы,
да выпей алтайского чаю
↓ ↓ ↓
Yuliya, syesh yeshchyo etikh myagkikh frantsuzskikh bulok iz Yoshkar-Oly,
da vypey altayskogo chayu
```
### Мосметро
Схема транслитерации, которую использует Московский метрополитен. Визуально самая приятная из всех, хотя уступает Википедии по фонетической точности. Придумана в Студии Лебедева, официально нигде не описана.
```
Юлия, съешь ещё этих мягких французских булок из Йошкар-Олы,
да выпей алтайского чаю
↓ ↓ ↓
Yuliya, syesh esche etikh myagkikh frantsuzskikh bulok iz Yoshkar-Oly,
da vypey altayskogo chayu
```
### Яндекс.Деньги
Правила Яндекса для банковских карт. Простая и удобная схема.
```
Юлия, съешь ещё этих мягких французских булок из Йошкар-Олы,
да выпей алтайского чаю
↓ ↓ ↓
Yuliya, sesh esche etikh myagkikh frantsuzskikh bulok iz Ioshkar-Oly,
da vypei altaiskogo chayu
```
### Яндекс.Карты
Правила Яндекса для адресов. Слегка улучшенная версия Яндекс.Денег.
```
Юлия, съешь ещё этих мягких французских булок из Йошкар-Олы,
да выпей алтайского чаю
↓ ↓ ↓
Yuliya, syesh eschyo etikh myagkikh frantsuzskikh bulok iz Yoshkar-Oly,
da vypey altayskogo chayu
```
Как транслитерировать
---------------------
Не пишите логику транслитерации с нуля — велик шанс ошибиться и получить очередную (N+1) схему транслитерации, «спасибо» за которую вам не скажут.
Не берите библиотеки с гитхаба без проверки. Все, что я смотрел — реализуют стандарт некорректно, если он чуть сложнее таблицы с однозначным соответствием.
Мы с [mehanizm](https://habr.com/ru/users/mehanizm/) сделали аккуратные библиотеки с нормальными тестами для [Python](https://github.com/nalgeon/iuliia-py), [JavaScript](https://github.com/nalgeon/iuliia-js) и [Go](https://github.com/mehanizm/iuliia-go). Но лучше дополнительно проверьте на паре примеров, а то вы ведь знаете этих программистов ツ
*UPD* Больше библиотек!
* [C#](https://github.com/belianin/iuliia-cs), Андрей Белянин
* [Java](https://github.com/Homyakin/iuliia-java), Антон Лаврентьев aka [Homyakin](https://habr.com/ru/users/homyakin/)
* [Java](https://github.com/massita99/iuliia-java), [Massita](https://habr.com/ru/users/massita/)
* [Java](https://github.com/radist-nt/iuliia-java), [rrrad](https://habr.com/ru/users/rrrad/)
* [PHP](https://github.com/perevoshchikov/iuliia-php), Антон Перевощиков aka [Fett](https://habr.com/ru/users/fett/)
* [PostgreSQL](https://github.com/rin-nas/postgresql-patterns-library/blob/master/functions/iuliia_translate.sql), [RinNas](https://habr.com/ru/users/rinnas/)
* [Ruby](https://github.com/adnikiforov/iuliia-rb), Андрей Никифоров
* [Rust](https://github.com/massita99/iuliia-rust), [Massita](https://habr.com/ru/users/massita/)
* [Swift](https://github.com/petertretyakov/Iuliia), [petertretyakov](https://habr.com/ru/users/petertretyakov/)
Пример использования (Python):
```
import iuliia
# list all supported schemas
for schema_name in iuliia.Schemas.names():
print(schema_name)
# transliterate using specified schema
source = "Юлия Щеглова"
iuliia.translate(source, schema=iuliia.ICAO_DOC_9303)
# "Iuliia Shcheglova"
# or pick schema by name
schema = iuliia.Schemas.get("wikipedia")
iuliia.translate(source, schema)
# "Yuliya Shcheglova"
```
Или Go:
```
import iuliia "github.com/mehanizm/iuliia-go"
func main() {
translated, err := iuliia.Wikipedia.Translate("Юлия Щеглова")
if err != nil {
log.Fatal(err)
}
fmt.Println(translated)
}
>> 'Yuliya Shcheglova'
```
Схемы транслитерации описаны декларативно в JSON, лежат [в отдельном репозитории](https://github.com/nalgeon/iuliia). Если я какую-то пропустил — вы знаете, что делать ツ
И поделитесь в комментариях — приходилось вам сталкиваться с транслитерацией по работе или в жизни? Какие впечатления?
---
Ссылки по тексту:
1. [ICAO Doc 9303](https://iuliia.ru/icao-doc-9303/)
2. [ГОСТ 16876-71](https://iuliia.ru/gost-16876/)
3. [ГОСТ 7.79-2000, он же ISO 9:1995](https://iuliia.ru/gost-779/)
4. [Схема Википедии](https://iuliia.ru/wikipedia/)
5. [Схема Яндекс.Денег](https://iuliia.ru/yandex-money/)
6. [Схема Яндекс.Карт](https://iuliia.ru/yandex-maps/)
7. [Схема Мосметро](https://iuliia.ru/mosmetro/)
8. [Как написать свой транслитератор](https://habr.com/ru/company/JetBrains-education/blog/479542/)
9. [МВД 310](https://iuliia.ru/mvd-310/)
10. [Полное руководство по транслитерации](https://iuliia.ru/) | https://habr.com/ru/post/499574/ | null | ru | null |
# Установка расширений OCI8 и PDO_OCI для PHP5
В настоящее время я работаю в компании, которая очень любит использовать в проектах на PHP СУБД Oracle, причем иногда версии 11g.
Большая часть разработчиков этой компании работает под ОС Windows. За последний месяц несколько из них решили приобщиться к Linux и поставили себе Ubuntu. По прошествии нескольких дней после установки самой ОС, ребята столкнулись с задачей установки драйверов PHP для работы с СУБД Oracle — OCI8 и PDO\_OCI на базе Oracle instant client 11.2, которую не смогли решить самостоятельно.
Я не нашел подробного, полностью рабочего мануала на русском, по которому новичок в Linux смог бы выполнить все манипуляции сам. В результате мне пришлось несколько раз проделать серию одних и тех же действий на их машинах и написать мануал, который я вам и представляю.
Мануал написан для пользователей Ubuntu Linux, но с некоторыми изменениями подойдет для пользователей большинства Linux'ов.
#### Подготовка к установке
1. У вас должна быть возможность выполнять команды под администратором;
2. У вас должен быть установлен php5 со следующими пакетами (команда установки со списком):
`sudo apt-get install php5 php5-dev php-pear php5-cli
sudo pecl install pdo`
3. У вас должна быть установлена библиотека libaio1:
`sudo apt-get install libaio1`
#### Установка Oracle instant client
Скачиваем instant client Oracle с официального сайта [http://oracle.com](http://www.oracle.com/technetwork/database/features/instant-client/index-097480.html) для своей архитектуры процессора и ОС.
Для Linux instant client поставляется в двух вариантах:
* RPM пакет — Linux, CentOS, Fedora, Red Hat Enterprise Linux, Mandriva Linux, SUSE Linux и д.р. у кого есть поддержка RPM;
* ZIP архив — всем остальным.
Необходимо скачать 2 файла:
* instantclient-basic — сам Oracle instant client
* instantclient-sdk — набор библиотек для разработки приложений под Oracle instant client
Также можете скачать:
* instantclient-sqlplus — [SQL\*Plus](http://ru.wikipedia.org/wiki/SQL*Plus)
Создаем директорию, в которой будут лежать файлы Oracle instant client (каталог /opt, зарезервированный для дополнительных пакетов программного обеспечения, хорошо для этого подходит):
`sudo mkdir -p /opt/oracle/`
Перемещаем скачанные файлы в /opt/oracle и переходим в папку назначения (допустим что вы скачали «zip архивы» в папку «downloads» Вашего пользователя):
`sudo mv ~/downloads/instantclient-*.zip /opt/oracle/
cd /opt/oracle/`
Разархивируем все скачанные архивы:
`sudo unzip instantclient-basic-*-*.zip
sudo unzip instantclient-sdk-*-*.zip`
Если вы скачивали [SQL\*Plus](http://ru.wikipedia.org/wiki/SQL*Plus):
`sudo unzip instantclient-sqlplus-*-*.zip`
В итоге в каталоге /opt/oracle был создан, для Oracle instant client 11.2.0.2.0, каталог instantclient\_11\_2. Переименуем этот каталог в instantclient (если у вас другая версия/каталог измените команду) и перейдем в него:
`sudo mv instantclient_11_2 instantclient
cd instantclient`
Далее необходимо создать несколько дополнительных каталогов и символьных ссылок для нормальной работы клиента (обратите внимание на версию и если она у вас другая измените команды):
`sudo ln -s /opt/oracle/instantclient/libclntsh.so.* /opt/oracle/instantclient/libclntsh.so
sudo ln -s /opt/oracle/instantclient/libocci.so.* /opt/oracle/instantclient/libocci.so
sudo ln -s /opt/oracle/instantclient/ /opt/oracle/instantclient/lib
sudo mkdir -p include/oracle/11.2/
cd include/oracle/11.2/
sudo ln -s ../../../sdk/include client
cd -
sudo mkdir -p lib/oracle/11.2/client
cd lib/oracle/11.2/client
sudo ln -s ../../../ lib
cd -`
Создаем конфигурационный файл, в котором будет указан каталог для поиска библиотек Oracle instant client, и подключаем его:
`echo /opt/oracle/instantclient/ | sudo tee -a /etc/ld.so.conf.d/oracle.conf
sudo ldconfig`
Так как в Ubuntu нет каталога /usr/include/php, а клиент его все равно ищет создадим символьную ссылку на его эквивалент php5:
`sudo ln -s /usr/include/php5 /usr/include/php`
#### Устанавливаем OCI8
После всех наших манипуляций расширение oci8 замечательно устанавливается с помощью команды [pecl](http://www.php.net/manual/ru/install.pecl.php):
`sudo pecl install oci8`
нас просят ввести путь к Oracle instant client, на что необходимо ответить:
`instantclient,/opt/oracle/instantclient`
Создаём файл подключения расширения:
`echo "; configuration for php oci8 module" | sudo tee /etc/php5/conf.d/oci8.ini
echo extension=oci8.so | sudo tee -a /etc/php5/conf.d/oci8.ini`
#### Устанавливаем PDO\_OCI
Для установки PDO\_OCI нам сначала необходимо его скачать из [репозитория pear](http://pear.php.net/).
Обновим список пакетов pear:
`sudo pecl channel-update pear.php.net`
Скачаем и поместим архив во временную директорию:
`sudo mkdir -p /tmp/pear/download/
cd /tmp/pear/download/
sudo pecl download pdo_oci`
Извлечем содержимое архива и перейдем к нему:
`sudo tar xvf PDO_OCI*.tgz
cd PDO_OCI*`
Здесь нам необходимо скорректировать файл config.m4, так как в нем нет данных о нашей версии Oracle instant client, последние изменения датируются 2005 годом. Запускаем любимый редактор и вносим изменения отмеченные "+" (обратите внимание на версию и если она у вас другая измените строчки):
`sudo vim config.m4`
Далее приведен diff двух файлов:
`***************
*** 7,12 ****
--- 7,14 ----
if test -s "$PDO_OCI_DIR/orainst/unix.rgs"; then
PDO_OCI_VERSION=`grep '"ocommon"' $PDO_OCI_DIR/orainst/unix.rgs | sed 's/[ ][ ]*/:/g' | cut -d: -f 6 | cut -c 2-4`
test -z "$PDO_OCI_VERSION" && PDO_OCI_VERSION=7.3
+ elif test -f $PDO_OCI_DIR/lib/libclntsh.$SHLIB_SUFFIX_NAME.11.2; then
+ PDO_OCI_VERSION=11.2
elif test -f $PDO_OCI_DIR/lib/libclntsh.$SHLIB_SUFFIX_NAME.10.1; then
PDO_OCI_VERSION=10.1
elif test -f $PDO_OCI_DIR/lib/libclntsh.$SHLIB_SUFFIX_NAME.9.0; then
***************
*** 119,124 ****
--- 121,129 ----
10.2)
PHP_ADD_LIBRARY(clntsh, 1, PDO_OCI_SHARED_LIBADD)
;;
+ 11.2)
+ PHP_ADD_LIBRARY(clntsh, 1, PDO_OCI_SHARED_LIBADD)
+ ;;
*)
AC_MSG_ERROR(Unsupported Oracle version! $PDO_OCI_VERSION)
;;
***************`
Подготавливаем окружение для расширения php c помощью команды [phpize](http://php.net/manual/ru/install.pecl.phpize.php) (обратите внимание на версию, если она у вас другая измените):
`sudo phpize`
Конфигурируем установщик пакета и устанавливаем пакет (обратите внимание на версию, если она у вас другая измените):
`sudo ./configure --with-pdo-oci=instantclient,/opt/oracle/instantclient/,11.2
sudo make
sudo make install`
Создаём для него файл подключения:
`echo "; configuration for php PDO_OCI module" | sudo tee /etc/php5/conf.d/pdo_oci.ini
echo extension=pdo_oci.so | sudo tee -a /etc/php5/conf.d/pdo_oci.ini`
#### Подводим итоги
Перезапускаем apache и проверяем наличие установленных расширений:
`sudo /etc/init.d/apache2 restart
php -m`
#### Заключение
Мануал основан на вот этом [посте](http://ubuntuforums.org/showthread.php?t=1207665), который был несколько переработан — исправлены ошибки и внесены дополнения.
Надеюсь, статья будет полезной не только моим коллегам по работе. | https://habr.com/ru/post/116474/ | null | ru | null |
# Создание и тестирование неблокирующих веб-приложений с помощью Spring WebFlux, Kotlin и Coroutines
Когда поступает HTTP-запрос, «обычное» веб-приложение сопоставляет запрос с конкретным потоком из пула потоков. Этот назначенный поток остается с запросом до тех пор, пока ответ не будет возвращен в сокет запроса. Попутно нам может потребоваться получить данные из некоторой веб-службы или базы данных, прочитать или записать в файл или выполнить другие вызовы ввода-вывода, во время которых поток блокируется и должен ждать, пока не получит ответ. Для приложений с высокой частотой запросов пул потоков может в какой-то момент исчерпаться, и тогда новые запросы больше не будут обрабатываться.
Здесь нам может помочь реактивное программирование. Вместо того, чтобы иметь большой пул потоков и модель «поток на запрос», реактивное приложение имеет только один поток на каждое ядро ЦП, которое продолжает работать, и, если оно попадает в операцию ввода-вывода, оно разгружает эту операцию и работает над чем-то еще до тех пор, пока IO завершено. Мы говорим, что такое приложение неблокирующее.
Подход появился, когда группа компаний объединилась в инициативе Reactive Streams, чтобы определить ключевые принципы и четыре интерфейса JVM. После этого они практически каждый пошли своим путем, чтобы создать реактивную библиотеку на основе этих соглашений. Одна из этих библиотек, Project Reactor, является основой, на которой Spring построил свою реактивную веб-платформу Spring WebFlux.
Этот реактивный стек позволяет нам создавать неблокирующие веб-приложения в структуре, которая выглядит знакомой с точки зрения классов, методов и аннотаций, если вы работали с Spring MVC, но фактическая реализация методов может быть с довольно сложной кривой обучения.
Взгляните на контроллер ниже.
```
@RestController
@RequestMapping("/cats")
class CatController(
@Autowired val catRepository: CatRepository
) {
@PutMapping("{id}")
fun updateProduct(@PathVariable(value = "id") id: Long, @RequestBody newCat: Cat): Mono> {
return catRepository
.findById(id)
.flatMap { existingCat ->
catRepository.save(
existingCat.copy(
name = newCat.name,
type = newCat.type,
age = newCat.age
)
)
}
.map { updatedCat -> ResponseEntity.ok(updatedCat) }
.defaultIfEmpty(ResponseEntity.notFound().build())
}
}
```
Как видите, полюбившийся нам императивный стиль заменен декларативной парадигмой с множеством комбинаторов. Наш код внезапно состоит из функциональных цепочек вызовов, которые передают информацию от издателей подписчикам. Кроме того, теперь нам внезапно нужно иметь дело с абстракциями, такими как Mono и Flux, на всех уровнях нашего приложения, и, как таковая, наша кодовая база становится связанной с реактивной библиотекой, которую мы используем. В конце концов, кажется, что мы должны оставить все, что мы знаем, только для того, чтобы получить неблокирующие вкусности. Кажется, это высокая цена, можем ли мы поступить иначе?
Да мы можем! Kotlin предоставляет нам языковую функцию, называемую Coroutines (корутины), которые концептуально представляют собой легкие потоки, которые позволяют выполнять асинхронное выполнение кода, даже если код по-прежнему выглядит так, как мы привыкли к последовательному выполнению. Мы можем реагировать, не подвергая нашу кодовую базу полной декларативной переработке, потому что наши друзья из Spring проделали очень хорошую работу по интеграции Kotlin, и особенно корутин, в свою структуру. Интеграция позволяет нам использовать корутины на уровне общедоступного API, в то время как мы по-прежнему используем Reactor под капотом.
Заинтересовались? В этой статье мы разработаем простой веб-API с использованием Spring WebFlux и постараемся максимально использовать специальные расширения Kotlin в Spring WebFlux. Эти расширения включают `coRouter` (подсказка, 'co' для корутин) DSL возвращает в наш маршрутизатор значение типа `Flow`, и использует адаптированные методы WebClient с 'await'.
Вместо модели на основе аннотаций `@RestController`, `@RequestMapping` и `@Service` мы используем функциональную веб-платформу, представляющую новую модель программирования, в которой мы используем функции для маршрутизации (Router) и обработки запросов (Handler).
Мы следуем за входящим запросом и поэтому начинаем извне. Запрос начинается с функций маршрутизатора, которые являются функциональной альтернативой контроллера `@RequestMapping`. Затем запрос передается функциональному варианту сервиса, который мы называем обработчиком. Наконец, мы приходим к уже знакомому репозиторию. Этот последний слой имеет то же имя, что и в Spring MVC, но технология, лежащая в его основе, совсем другая, чтобы сделать все неблокирующим. Если вы хотите придерживаться своих контроллеров и сервисов, тогда это также полностью поддерживается WebFlux, и большинство статей действительно демонстрирует этот подход. Однако я хотел бы изучить подход, который является более идиоматическим для Kotlin. Все примеры кода можно найти в [этом репозитории GitHub](https://github.com/BjornvdLaan/spring-boot-webflux-kotlin-h2-example).
### Наш пример
В качестве примера мы создаем API для нашей собственной CMS (Cat Management System), которая может выполнять операции создания, чтения, обновления и удаления (CRUD). Ниже вы приведен обзор маршрутов, которые мы определим, и возможные ответы, которые возвращает приложение.
| **HTTP** метод | **Route** | **HTTP** Статус ответа | Описание |
| --- | --- | --- | --- |
| GET | /api/cats | 200 Ok | Все cat возвращены |
| GET | /api/cats/{id} | 200 Ok | Требуется cat с существующим идентификатором |
| GET | /api/cats/{id} | 404 Not Found | Запрашен cat с несуществующим идентификатором |
| POST | /api/cats | 201 Created | Новый cat создан успешно |
| POST | /api/cats | 400 Bad Request | Невозможно создать новый cat |
| PUT | /api/cats/{id} | 200 Ok | Существующий cat обновлен |
| PUT | /api/cats/{id} | 400 Bad Request | Cat не может быть обновлен |
| PUT | /api/cats/{id} | 404 Not Found | Запрос на обновление несуществующего cat |
| DELETE | /api/cats/{id} | 204 No Content | Существующий cat теперь удален |
| DELETE | /api/cats/{id} | 404 Not Found | Запрошено удаление несуществующего cat |
### Настройка проекта
Начнем с создания нового проекта Spring Boot с помощью [Spring Initializr](https://start.spring.io/). Мы говорим, что это проект Gradle, использующий Kotlin и упакованный в виде jar-файла. Мы также добавляем необходимые зависимости: Spring Reactive Web, который включает WebFlux и Netty, Spring Data R2DBC для наших репозиториев и H2 для создания простой базы данных в памяти для тестирования нашего приложения.
Затем нам нужно добавить еще две тестовые зависимости для Mockk и SpringMockk:
```
dependencies {
...
testImplementation("io.mockk:mockk:1.10.2")
testImplementation("com.ninja-squad:springmockk:3.0.1")
...
}
```
Они не являются строго обязательными для запуска нашего приложения, но используются в тестах. Я рекомендую вам проверить Maven Central на наличие последних версий.
### Router
Функции Router (маршрутизатор) принимают аргумент типа `ServerRequest` и возвращают `ServerResponse`. Это варианты WebFlux для Spring MVC `RequestEntity` и `ResponseEntity`, соответственно. Мы используем router DSL Kotlin для определения наших маршрутов:
```
@Configuration
class CatRouterConfiguration(
private val catHandler: CatHandler
) {
@Bean
fun apiRouter() = coRouter {
"/api/cats".nest {
accept(APPLICATION_JSON).nest {
GET("", catHandler::getAll)
contentType(APPLICATION_JSON).nest {
POST("", catHandler::add)
}
"/{id}".nest {
GET("", catHandler::getById)
DELETE("", catHandler::delete)
contentType(APPLICATION_JSON).nest {
PUT("", catHandler::update)
}
}
}
}
}
}
```
Функция `coRouter` создает RouterFunction на основе дальнейших вложенных операторов. Вы можете использовать функцию расширения `String.nest` для группировки маршрутов с общим префиксом пути. Подобные группировки могут быть сделаны на основе заголовков accept и contentType, а также других предикатов. Фактические маршруты добавляются через функции, которые соответствуют HTTP методам: `GET`, `POST`, `PUT`, `DELETE` и другие. Фактической обработкой занимается Handler.
### Handler
Реализации `HandlerFunction` представляет функции, которые принимают запросы и генерируют ответы на них. Подобно методам сервиса, соответствующие функции обработчика сгруппированы в класс Handler с использованием специфичного для Kotlin DSL. Эти функции читают и анализируют переменные пути и тела запросов, обращаются к репозиториям и создают объект `ServerResponse` для передачи в router
```
suspend fun getById(req: ServerRequest): ServerResponse {
val id = Integer.parseInt(req.pathVariable("id"))
val existingCat = catRepository.findById(id.toLong())
return existingCat?.let {
ServerResponse
.ok()
.contentType(MediaType.APPLICATION_JSON)
.bodyValueAndAwait(it)
} ?: ServerResponse.notFound().buildAndAwait()
}
suspend fun add(req: ServerRequest): ServerResponse {
val receivedCat = req.awaitBodyOrNull(CatDto::class)
return receivedCat?.let {
ServerResponse
.ok()
.contentType(MediaType.APPLICATION_JSON)
.bodyValueAndAwait(
catRepository
.save(it.toEntity())
.toDto()
)
} ?: ServerResponse.badRequest().buildAndAwait()
}
suspend fun update(req: ServerRequest): ServerResponse {
val id = req.pathVariable("id")
val receivedCat = req.awaitBodyOrNull(CatDto::class)
?: return ServerResponse.badRequest().buildAndAwait()
val existingCat = catRepository.findById(id.toLong())
?: return ServerResponse.notFound().buildAndAwait()
return ServerResponse
.ok()
.contentType(MediaType.APPLICATION_JSON)
.bodyValueAndAwait(
catRepository.save(
receivedCat.toEntity().copy(id = existingCat.id)
).toDto()
)
}
suspend fun delete(req: ServerRequest): ServerResponse {
val id = req.pathVariable("id")
return if (catRepository.existsById(id.toLong())) {
catRepository.deleteById(id.toLong())
ServerResponse.noContent().buildAndAwait()
} else {
ServerResponse.notFound().buildAndAwait()
}
}
```
Здесь мы также видим расширения Kotlin, которые Spring встроил в WebFlux. По соглашению, builder методы `ServerResponse`, основанные на Reactor, имеют префикс «await» или суффикс «AndAwait» для формирования методов приостановки, при использовании корутин. Чтобы увидеть, что внутри это тот же механизм, давайте рассмотрим метод `bodyValueAndAwait`:
```
suspend fun ServerResponse.BodyBuilder.bodyValueAndAwait(body: Any): ServerResponse =
bodyValue(body).awaitSingle()
```
Как мы видим, метод Reactor `bodyValue` вызывается в цепочке `awaitSingle` из пакета `kotlinx.coroutines`, который ожидает единственное значение от Publisher и возвращает результирующее значение для создания корутины типа `bodyValueAndAwait`.
### Repository
Последняя "остановка" перед базой данных - это Repository (репозиторий) на уровне инфраструктуры персистентности. Как и в случае с другими слоями, здесь нам нужно быть неблокирующими. Поэтому мы не можем использовать блокирующий JDBC и должны использовать реактивную альтернативу, называемую [R2DBC](https://r2dbc.io/).
Spring Data Reactive, к счастью, предлагает интерфейсы для неблокирующих репозиториев, которые очень похожи на их блокирующие аналоги `JpaRepository` или `CrudRepository`.
Если мы решим реализовать тип R2DBC, называемый `ReactiveCrudRepository,` указанные выше методы будут возвращать типы данных Reactor `Mono` и `Flux`. К счастью для нас, как и в случае с другими слоями, WebFlux предоставляет расширения для Kotlin и корутины типа `CoroutineCrudRepository`, которая возвращают только сущности:
```
interface CatRepository : CoroutineCrudRepository {
override fun findAll(): Flow
override suspend fun findById(id: Long): Cat?
override suspend fun existsById(id: Long): Boolean
override suspend fun ~~save(entity: S): Cat
override suspend fun deleteById(id: Long)
}~~
```
### Тесты
Как хорошо обученные практики программной инженерии, мы хотим тщательно протестировать наши приложения. Ниже приведены два набора тестов, один из которых имитирует, что репозиторий не зависит от реальной базы данных, а другой использует базу данных H2 в памяти. Оба они предоставляют простой тест для каждого HTTP статуса, которым может отвечать каждый маршрут.
Оба теста включают две вспомогательных функций `aCat()` и `anotherCat()`, которые создают новый `Cat` с некоторыми значениями по умолчанию и дают возможность передавать другие значения. Такой подход к созданию объектов для наших тестов скрывает все детали реализации объекта `Cat`, кроме тех, которые имеют отношение к тесту, и в этом случае вы должны определить пользовательское значение для этих соответствующих полей.
#### 1. Тесты с mocking
Этот подход я чаще всего вижу в других статьях: мы имитируем `CatRepository`, чтобы протестировать Router и Handler без зависимости от базы данных. Мы используем комбинацию Spring WebFlux аннотаций `@WebFluxTest` вместе с `@Import` и добавляем ее в классы Router и Handler. Мы могли бы использовать `@SpringBootTest` и `@AutoConfigureWebTestClient` для достижения того же без необходимости вручную импортировать классы с помощью `@Import`. Тем не менее, в этом случае наши тесты проходят быстрее, и мне также нравится если конкретный тестируемый Router и Handler явно упоминаются вверху.
Мы [имитируем](https://mockk.io/) репозиторий, используя Mockk, фреймворк для имитации, созданный специально для Kotlin. Он хорошо подходит для приложения, которое мы создали, поскольку Mockk имеет встроенную поддержку корутин. Подробное описание Mockk выходит за рамки этой статьи. Что вы должны знать, так это то, что мы можем использовать комбинацию `coEvery` и `coAnswers` для установки возвращаемых значений для методов `CatRepository`, которые мы хотим имитировать. Кроме того, Spring (пока) не предлагает поддержку имитации beans с Mockk, как будто он дает нам аннотацию `@MockBean` для Mockito. Поэтому мы используем [SpringMockk](https://github.com/Ninja-Squad/springmockk) и его аннотацию `@MockkBean` для достижения того же.
```
@WebFluxTest
@Import(CatRouterConfiguration::class, CatHandler::class)
class MockedRepositoryIntegrationTest(
@Autowired private val client: WebTestClient
) {
@MockkBean
private lateinit var repository: CatRepository
private fun aCat(
name: String = "Obi",
type: String = "Dutch Ringtail",
age: Int = 3
) =
Cat(
name = name,
type = type,
age = age
)
private fun anotherCat(
name: String = "Wan",
type: String = "Japanese Bobtail",
age: Int = 5
) =
aCat(
name = name,
type = type,
age = age
)
@Test
fun `Retrieve all cats`() {
every {
repository.findAll()
} returns flow {
emit(aCat())
emit(anotherCat())
}
client
.get()
.uri("/api/cats")
.exchange()
.expectStatus()
.isOk
.expectBodyList()
.hasSize(2)
.contains(aCat().toDto(), anotherCat().toDto())
}
@Test
fun `Retrieve cat by existing id`() {
coEvery {
repository.findById(any())
} coAnswers {
aCat()
}
client
.get()
.uri("/api/cats/2")
.exchange()
.expectStatus()
.isOk
.expectBody()
.isEqualTo(aCat().toDto())
}
@Test
fun `Retrieve cat by non-existing id`() {
coEvery {
repository.findById(any())
} returns null
client
.get()
.uri("/api/cats/2")
.exchange()
.expectStatus()
.isNotFound
}
@Test
fun `Add a new cat`() {
val savedCat = slot()
coEvery {
repository.save(capture(savedCat))
} coAnswers {
savedCat.captured
}
client
.post()
.uri("/api/cats/")
.accept(MediaType.APPLICATION\_JSON)
.contentType(MediaType.APPLICATION\_JSON)
.bodyValue(aCat().toDto())
.exchange()
.expectStatus()
.isOk
.expectBody()
.isEqualTo(savedCat.captured.toDto())
}
@Test
fun `Add a new cat with empty request body`() {
val savedCat = slot()
coEvery {
repository.save(capture(savedCat))
} coAnswers {
savedCat.captured
}
client
.post()
.uri("/api/cats/")
.accept(MediaType.APPLICATION\_JSON)
.contentType(MediaType.APPLICATION\_JSON)
.body(fromValue("{}"))
.exchange()
.expectStatus()
.isBadRequest
}
@Test
fun `Update a cat`() {
coEvery {
repository.findById(any())
} coAnswers {
aCat()
}
val savedCat = slot()
coEvery {
repository.save(capture(savedCat))
} coAnswers {
savedCat.captured
}
val updatedCat = aCat(name = "New fancy name").toDto()
client
.put()
.uri("/api/cats/2")
.accept(MediaType.APPLICATION\_JSON)
.contentType(MediaType.APPLICATION\_JSON)
.bodyValue(updatedCat)
.exchange()
.expectStatus()
.isOk
.expectBody()
.isEqualTo(updatedCat)
}
@Test
fun `Update cat with non-existing id`() {
val requestedId = slot()
coEvery {
repository.findById(capture(requestedId))
} coAnswers {
nothing
}
val updatedCat = aCat(name = "New fancy name").toDto()
client
.put()
.uri("/api/cats/2")
.accept(MediaType.APPLICATION\_JSON)
.contentType(MediaType.APPLICATION\_JSON)
.bodyValue(updatedCat)
.exchange()
.expectStatus()
.isNotFound
}
@Test
fun `Update cat with empty request body id`() {
coEvery {
repository.findById(any())
} coAnswers {
aCat()
}
client
.put()
.uri("/api/cats/2")
.accept(MediaType.APPLICATION\_JSON)
.contentType(MediaType.APPLICATION\_JSON)
.body(fromValue("{}"))
.exchange()
.expectStatus()
.isBadRequest
}
@Test
fun `Delete cat with existing id`() {
coEvery {
repository.existsById(any())
} coAnswers {
true
}
coEvery {
repository.deleteById(any())
} coAnswers {
nothing
}
client
.delete()
.uri("/api/cats/2")
.exchange()
.expectStatus()
.isNoContent
coVerify { repository.deleteById(any()) }
}
@Test
fun `Delete cat by non-existing id`() {
coEvery {
repository.existsById(any())
} coAnswers {
false
}
client
.delete()
.uri("/api/cats/2")
.exchange()
.expectStatus()
.isNotFound
coVerify(exactly = 0) { repository.deleteById(any()) }
}
}
```
#### 2. Тесты без mocking
Мы также можем выполнить интеграционный тест с реальной базой данных. Нет ничего лучше настоящего, правда? Существуют различные варианты для тестирования, такие как testcontainers, реальные базы данных и базы данных в памяти. Мы выберем третий вариант и воспользуемся `@DirtiesContext` для воссоздания контекста приложения, включая базу данных, после каждого теста.
Важное отличие от предыдущего набора тестов заключается в том, что мы используем `@AutoConfigureWebTestClient` вместо `@WebFluxTest`. Последний отключает полную автоконфигурацию и настраивает только подмножество, которое считает актуальным, но теперь нам также нужно настроить наши репозитории.
Кроме того, поскольку мы больше не можем имитировать ответы репозитория, нам нужен другой способ установить его состояние в начале теста.
Я определил метод расширения `CatRepository.seed` для сохранения `Cat` в базе данных и `@AfterEach` метод очистки после теста. Оба используют `runBlocking` для создания coroutine, которая блокирует прерываемый текущий поток до его завершения. Если мы не заблокируем поток, JUnit продолжит собственно тест до того, как `Cat` будут фактически вставлены в базу данных или удалены из нее.
```
@SpringBootTest
@AutoConfigureWebTestClient
@DirtiesContext(classMode = DirtiesContext.ClassMode.AFTER_EACH_TEST_METHOD)
class InMemoryDatabaseIntegrationTest(
@Autowired val client: WebTestClient,
@Autowired val repository: CatRepository
) {
private fun aCat(
name: String = "Obi",
type: String = "Dutch Ringtail",
age: Int = 3
) =
Cat(
name = name,
type = type,
age = age
)
private fun anotherCat(
name: String = "Wan",
type: String = "Japanese Bobtail",
age: Int = 5
) =
aCat(
name = name,
type = type,
age = age
)
private fun CatRepository.seed(vararg cats: Cat) =
runBlocking {
repository.saveAll(cats.toList()).toList()
}
@AfterEach
fun afterEach() {
runBlocking {
repository.deleteAll()
}
}
@Test
fun `Retrieve all cats`() {
repository.seed(aCat(), anotherCat())
client
.get()
.uri("/api/cats")
.exchange()
.expectStatus()
.isOk
.expectBodyList()
.hasSize(2)
.contains(aCat().toDto(), anotherCat().toDto())
}
@Test
fun `Retrieve cat by existing id`() {
repository.seed(aCat(), anotherCat())
client
.get()
.uri("/api/cats/2")
.exchange()
.expectStatus()
.isOk
.expectBody()
.isEqualTo(anotherCat().toDto())
}
@Test
fun `Retrieve cat by non-existing id`() {
client
.get()
.uri("/api/cats/2")
.exchange()
.expectStatus()
.isNotFound
}
@Test
fun `Add a new cat`() {
client
.post()
.uri("/api/cats")
.accept(MediaType.APPLICATION\_JSON)
.contentType(MediaType.APPLICATION\_JSON)
.bodyValue(aCat().toDto())
.exchange()
.expectStatus()
.isOk
.expectBody()
.isEqualTo(aCat().toDto())
}
@Test
fun `Add a new cat with empty request body`() {
client
.post()
.uri("/api/cats")
.accept(MediaType.APPLICATION\_JSON)
.contentType(MediaType.APPLICATION\_JSON)
.body(fromValue("{}"))
.exchange()
.expectStatus()
.isBadRequest
}
@Test
fun `Update a cat`() {
repository.seed(aCat(), anotherCat())
val updatedCat = aCat(name = "New fancy name").toDto()
client
.put()
.uri("/api/cats/2")
.accept(MediaType.APPLICATION\_JSON)
.contentType(MediaType.APPLICATION\_JSON)
.bodyValue(updatedCat)
.exchange()
.expectStatus()
.isOk
.expectBody()
.isEqualTo(updatedCat)
}
@Test
fun `Update cat with non-existing id`() {
val updatedCat = aCat(name = "New fancy name").toDto()
client
.put()
.uri("/api/cats/2")
.accept(MediaType.APPLICATION\_JSON)
.contentType(MediaType.APPLICATION\_JSON)
.bodyValue(updatedCat)
.exchange()
.expectStatus()
.isNotFound
}
@Test
fun `Update cat with empty request body id`() {
client
.put()
.uri("/api/cats/2")
.accept(MediaType.APPLICATION\_JSON)
.contentType(MediaType.APPLICATION\_JSON)
.body(fromValue("{}"))
.exchange()
.expectStatus()
.isBadRequest
}
@Test
fun `Delete cat with existing id`() {
repository.seed(aCat(), anotherCat())
client
.delete()
.uri("/api/cats/2")
.exchange()
.expectStatus()
.isNoContent
}
@Test
fun `Delete cat by non-existing id`() {
client
.delete()
.uri("/api/cats/2")
.exchange()
.expectStatus()
.isNotFound
}
}
```
### Вывод
В этой статье мы рассмотрели, как создать неблокирующее веб-приложение с помощью Spring WebFlux, используя расширения для Kotlin.
В результате создается кодовая баз, не замусоренная `Mono` и `Flux` (хотя мы взамен получаем несколько `suspend` и `Flow`).
Описанный выше подход позволяет нам продолжать писать наш код в императивном стиле, как мы привыкли.
Мы также рассмотрели два способа тестирования нашего приложения: один с использованием mocking, а второй - без него. | https://habr.com/ru/post/594625/ | null | ru | null |
# Шифрование сообщений в Python. От простого к сложному. Шифр Цезаря
Немного о проекте
-----------------
Мне, лично, давно была интересна тема шифрования информации, однако, каждый раз погрузившись в эту тему, я осознавал насколько это сложно и понял, что лучше начать с чего-то более простого. Я, лично, планирую написать некоторое количество статей на эту тему, в которых я покажу вам различные алгоритмы шифрования и их реализацию в *Python*, продемонстрирую и разберу свой проект, созданный в этом направлении. Итак, начнем.
---
Для начала, я бы хотел рассказать вам какие уже известные алгоритмы мы рассмотрим, в моих статьях. Список вам представлен ниже:
* Шифр Цезаря
* Шифр Виженера
* Шифр замены
* Омофонический шифр
* RSA шифрование
Шифр Цезаря
-----------
Итак, после небольшого введения в цикл, я предлагаю все-таки перейти к основной теме сегодняшней статьи, а именно к *Шифру Цезаря.*
#### Что это такое?
Шифр Цезаря - это простой тип подстановочного шифра, где каждая буква обычного текста заменяется буквой с фиксированным числом позиций вниз по алфавиту. Принцип его действия можно увидеть в следующей иллюстрации:
#### Какими особенностями он обладает?
У Шифра Цезаря, как у алгоритма шифрования, я могу выделить две основные особенности. Первая особенность - это *простота* и *доступность* метода шифрования, который, возможно поможет вам погрузится в эту тему, вторая особенность - это, собственно говоря, сам метод шифрования.
#### Программная реализация
В интернете существует огромное множество уроков, связанных с криптографией в питоне, однако, я написал максимально простой и интуитивно понятный код, структуру которого я вам продемонстрирую.
Начнем, пожалуй, с создания алфавита. Для этого вы можете скопировать приведенную ниже строку или написать все руками.
```
alfavit = 'ABCDEFGHIJKLMNOPQRSTUVWXYZABCDEFGHIJKLMNOPQRSTUVWXYZАБВГДЕЁЖЗИЙКЛМНОПРСТУФХЦЧШЩЪЫЬЭЮЯАБВГДЕЁЖЗИЙКЛМНОПРСТУФХЦЧШЩЪЫЬЭЮЯ'
# Создаем алфавит
```
Далее, нам нужно обозначить программе шаг, то есть смещение при шифровании. Так, например, если мы напишем букву *"а"* в сообщении, тот при шаге *"2"*, программа выведет нам букву *"в".*
Итак, создаем переменнуюsmeshenie*,* которая будет вручную задаваться пользователем, и *message*, куда будет помещаться наше сообщение, и, с помощью метода `upper(),` возводим все символы в нашем сообщении в верхний регистр, чтобы у нас не было ошибок. Потом создаем просто пустую переменную itog, куда мы буем выводить зашифрованное сообщение. Для этого пишем следующее:
```
smeshenie = int(input('Шаг шифровки: ')) #Создаем переменную с шагом шифровки
message = input("Сообщение для шифровки: ").upper() #создаем переменнную, куда запишем наше сообщение
itog = '' #создаем переменную для вывода итогового сообщения
```
Итак, теперь переходим к самому алгоритму шифровки. Первым делом создаем цикл`for`, где мы определим место букв, задействованных в сообщении, в нашем списке *alfavit,* после чего определяем их новые места(далее я постараюсь насытить код с пояснениями):
```
for i in message:
mesto = alfavit.find(i) #Вычисляем места символов в списке
new_mesto = mesto + smeshenie #Сдвигаем символы на указанный в переменной smeshenie шаг
```
Далее, мы создаем внутри нашего цикла условие `if` , в нем мы записываем в список *itog* мы записываем наше сообщение уже в зашифрованном виде и выводим его:
```
for i in message:
mesto = alfavit.find(i)
new_mesto = mesto + smeshenie
if i in alfavit:
itog += alfavit[new_mesto] # Задаем значения в итог
else:
itog += i
print (itog)
```
**Модернизация**
Вот мы и написали программу, однако она имеет очень большой недостаток: "При использовании последних букв(русских), программа выведет вам английские буквы. Давайте это исправим.
Для начала создадим переменную *lang*, в которой будем задавать язык нашего шифра, а так же разделим английский и русский алфавиты.
```
alfavit_EU = 'ABCDEFGHIJKLMNOPQRSTUVWXYZABCDEFGHIJKLMNOPQRSTUVWXYZ'
alfavit_RU = 'АБВГДЕЁЖЗИЙКЛМНОПРСТУФХЦЧШЩЪЫЬЭЮЯАБВГДЕЁЖЗИЙКЛМНОПРСТУФХЦЧШЩЪЫЬЭЮЯ'
smeshenie = int(input('Шаг шифровки: '))
message = input("Сообщение для шифровки: ").upper()
itog = ''
lang = input('Выберите язык RU/EU: ') #Добавляем возможность выбора языка
```
Теперь нам надо создать условие, которое проверит выбранный язык и применит его, то есть обратится к нужному нам алфавиту. Для этого пишем само условие и добавляем алгоритм шифрования, с помощью которого будет выполнено шифрование:
```
if lang == 'RU':
for i in message:
mesto = alfavit_RU.find(i) # Алгоритм для шифрования сообщения на русском
new_mesto = mesto + smeshenie
if i in alfavit_RU:
itog += alfavit_RU[new_mesto]
else:
itog += i
else:
for i in message:
mesto = alfavit_EU.find(i) # Алгоритм для шифрования сообщения на английском
new_mesto = mesto + smeshenie
if i in alfavit_EU:
itog += alfavit_EU[new_mesto]
else:
itog += i
```
#### Дешифровка сообщения
Возможно это прозвучит несколько смешно, но мы смогли только зашифровать сообщение, а насчет его дешифровки мы особо не задумывались, но теперь дело дошло и до неё.
По сути, дешифровка - это алгоритм обратный шифровке. Давайте немного переделаем наш код (итоговый вид вы можете увидеть выше).
Для начала, я предлагаю сделать "косметическую" часть нашей переделки. Для этого перемещаемся в самое начало кода:
```
alfavit = 'ABCDEFGHIJKLMNOPQRSTUVWXYZABCDEFGHIJKLMNOPQRSTUVWXYZАБВГДЕЁЖЗИЙКЛМНОПРСТУФХЦЧШЩЪЫЬЭЮЯАБВГДЕЁЖЗИЙКЛМНОПРСТУФХЦЧШЩЪЫЬЭЮЯ'
smeshenie = int(input('Шаг шифровки: '))
message = input("Сообщение для ДЕшифровки: ").upper() #заменяем слово шифровка, на дешифровка
itog = ''
```
Остальное можно оставить так же, но если у вас есть желание, то можете поменять названия переменных.
По большому счету, самые 'большие' изменения у нас произойдут в той части кода, где у нас находится алгоритм, где нам нужно просто поменять знак "+" на знак "-". Итак, переходим к самому циклу:
```
if lang == 'RU':
for i in message:
mesto = alfavit_RU.find(i)
new_mesto = mesto + smeshenie # Меняем знак + на знак -
if i in alfavit_RU:
itog += alfavit_RU[new_mesto]
else:
itog += i
else:
for i in message:
mesto = alfavit_EU.find(i) # Меняем знак + на знак -
new_mesto = mesto + smeshenie
if i in alfavit_EU:
itog += alfavit_EU[new_mesto]
else:
itog += i
```
Итоговый вид программы
----------------------
Итак, вот мы и написали простейшую программу для шифрования методом Цезаря. Ниже я размещу общий вид программы без моих комментариев, чтобы вы еще раз смогли сравнить свою программу с моей:
```
alfavit_EU = 'ABCDEFGHIJKLMNOPQRSTUVWXYZABCDEFGHIJKLMNOPQRSTUVWXYZ'
alfavit_RU = 'АБВГДЕЁЖЗИЙКЛМНОПРСТУФХЦЧШЩЪЫЬЭЮЯАБВГДЕЁЖЗИЙКЛМНОПРСТУФХЦЧШЩЪЫЬЭЮЯ'
smeshenie = int(input('Шаг шифровки: '))
message = input("Сообщение для ДЕшифровки: ").upper()
itog = ''
lang = input('Выберите язык RU/EU: ')
if lang == 'RU':
for i in message:
mesto = alfavit_RU.find(i)
new_mesto = mesto + smeshenie
if i in alfavit_RU:
itog += alfavit_RU[new_mesto]
else:
itog += i
else:
for i in message:
mesto = alfavit_EU.find(i)
new_mesto = mesto + smeshenie
if i in alfavit_EU:
itog += alfavit_EU[new_mesto]
else:
itog += i
print (itog)
```
Итог
----
Вы успешно написали алгоритм шифровки и дешифровки сообщения на Python с помощью метода Цезаря. В следующей статье мы с вами рассмотрим Шифр Виженера, а также разберем его реализацию на Python, а пока я предлагаю вам написать в комментариях варианты модернизации программы(код или просо предложения и пожелания). Я обязательно учту ваше мнение. | https://habr.com/ru/post/552212/ | null | ru | null |
# Web Storage API: примеры использования

Доброго времени суток, друзья!
В данной статье мы рассмотрим парочку примеров использования Web Storage API или объекта «Storage».
Что конкретно мы будем делать?
* Научимся запоминать время воспроизведения видео.
* Поработаем с формой входа на страницу.
* Напишем логику списка задач.
* Реализуем чат.
* Схематично набросаем корзину для товаров.
Итак, поехали.
### Краткий обзор
Объект «Storage» используется для хранения данных на стороне клиента и в этом смысле выступает альтернативой cookies. Преимущество Storage состоит в размере хранилища (от 5 Мб, зависит от браузера, при превышении лимита выбрасывается ошибка «QUOTA\_EXCEEDED\_ERR») и отсутствии необходимости обращаться к серверу. Существенный недостаток — безопасность: стоит вредоносному скрипту получить доступ к странице, и пиши пропало. Поэтому крайне не рекомендуется хранить в Storage конфиденциальную информацию.
Справедливости ради стоит отметить, что на сегодняшний день существуют более продвинутые решения для хранения данных на стороне клиента — это IndexedDB, Service Workers + Cache API и др.
О сервис-воркерах можно почитать [здесь](https://habr.com/ru/post/491840/).
Web Storage API включает в себя localStorage и sessionStorage. Разница между ними состоит во времени хранения данных. В localStorage данные хранятся постоянно до их «явного» удаления (ни перезагрузка страницы, ни ее закрытие не приводят к удалению данных). Время хранения данных в sessionStorage, как следует из названия, ограничено сессией браузера. Поскольку sessionStorage на практике почти не используется, мы будет рассматривать только localStorage.
#### Что необходимо знать о localStorage?
* При использовании localStorage создается представление объекта «Storage».
* Данные в localStorage хранятся в виде пар ключ/значение.
* Данные хранятся в виде строк.
* Данные не сортируются, что иногда приводит к их перемешиванию (в чем мы убедимся на примере списка задач).
* При включении в браузере режима инкогнито или приватного режима использование localStorage может стать невозможным (зависит от браузера).
localStorage обладает следующими методами:
* Storage.key(n) — имя ключа с индексом n
* Storage.getItem() — получить элемент
* Storage.setItem() — записать элемент
* Storage.removeItem() — удалить элемент
* Storage.clear() — очистить хранилище
* Storage.length — длина хранилища (количество элементов — пар ключ/значение)
В спецификации это выглядит так:
```
interface Storage {
readonly attribute unsigned long length;
DOMString? key(unsigned long index);
getter DOMString? getItem(DOMString key);
setter void setItem(DOMString key, DOMString value);
deleter void removeItem(DOMString key);
void clear();
};
```
Данные в хранилище записываются одним из следующих способов:
```
localStorage.color = 'deepskyblue'
localStorage[color] = 'deepskyblue'
localStorage.setItem('color', 'deepskyblue') // рекомендуется использовать этот способ
```
Получить данные можно так:
```
localStorage.getItem('color')
localStorage['color']
```
#### Как перебрать ключи хранилища и получить значения?
```
// способ 1
for (let i = 0; i < localStorage.length; i++) {
let key = localStorage.key(i)
console.log(`${key}: ${localStorage.getItem(key)}`)
}
// способ 2
let keys = Object.keys(localStorage)
for (let key of keys) {
console.log(`${key}: ${localStorage.getItem(key)}`)
}
```
Как мы отмечали выше, данные в хранилище имеют строковый формат, поэтому с записью объектов возникают некоторые трудности, которые легко решаются с помощью тандема JSON.stringify() — JSON.parse():
```
localStorage.user = {
name: 'Harry'
}
console.dir(localStorage.user) // [object Object]
localStorage.user = JSON.stringify({
name: 'Harry'
})
let user = JSON.parse(localStorage.user)
console.dir(user.name) // Harry
```
Для взаимодействием с localStorage существует специальное событие — storage (onstorage), которое возникает при записи/удалении данных. Оно имеет следующие свойства:
* key — ключ
* oldValue — старое значение
* newValue — новое значение
* url — адрес хранилища
* storageArea — объект, в котором произошло изменение
В спецификации это выглядит так:
```
[Constructor(DOMString type, optional StorageEventInit eventInitDict)]
interface StorageEvent : Event {
readonly attribute DOMString? key;
readonly attribute DOMString? oldValue;
readonly attribute DOMString? newValue;
readonly attribute DOMString url;
readonly attribute Storage? storageArea;
};
dictionary StorageEventInit : EventInit {
DOMString? key;
DOMString? oldValue;
DOMString? newValue;
DOMString url;
Storage? storageArea;
};
```
#### Допускает ли localStorage прототипирование?
```
Storage.prototype.removeItems = function() {
for (item in arguments) {
this.removeItem(arguments[item])
}
}
localStorage.setItem('first', 'some value')
localStorage.setItem('second', 'some value')
localStorage.removeItems('first', 'second')
console.log(localStorage.length) // 0
```
#### Как проверить наличие данных в localStorage?
```
// способ 1
localStorage.setItem('name', 'Harry')
function isExist(name) {
return (!!localStorage[name])
}
isExist('name') // true
// способ 2
function isItemExist(name) {
return (name in localStorage)
}
isItemExist('name') // true
```
В браузере localStorage можно найти здесь:
Довольно слов, пора переходить к делу.
### Примеры использования
#### Запоминаем время воспроизведения видео
```
window.onload = () => {
// находим элемент
let video = document.querySelector('video')
// если localStorage содержит значение currentTime (текущее время), присваиваем это значение video.currentTime
if(localStorage.currentTime) {
video.currentTime = localStorage.currentTime
}
// при каждом изменении video.currentTime, записываем его значение в localStorage.currentTime
video.addEventListener('timeupdate', () => localStorage.currentTime = video.currentTime)
}
```
Результат выглядит так:

Запускаем видео и останавливаем воспроизведение на третьей секунде, например. Время, на котором мы остановились, хранится в localStorage. Чтобы в этом убедиться, перезагружаем или закрываем/открываем страницу. Видим, что текущее время воспроизведения видео остается прежним.
[Codepen](https://codepen.io/igor_agapov/pen/GRpKYaO)
[Github](https://github.com/harryheman/web-storage-api-examles/blob/master/video.html)
#### Работаем с формой для входа
Разметка выглядит так:
```
Login:
Password:
```
У нас имеется форма и три «инпута». Для пароля мы используем , поскольку если использовать правильный тип (password), Chrome будет пытаться сохранять введенные данные, что помешает нам реализовать собственный функционал.
JavaScript:
```
// находим форму и инпуты для ввода логина и пароля
let form = document.querySelector('form')
let login = document.querySelector('input')
let password = document.querySelector('input + input')
// если localStorage не пустой
// получаем из него необходимые данные
// и присваиваем их инпутам
if (localStorage.length != 0) {
login.value = localStorage.login
password.value = localStorage.password
}
// вешаем на форму обработчик события "submit"
form.addEventListener('submit', () => {
// записываем введенные пользователем данные в localStorage
localStorage.login = login.value
localStorage.password = password.value
// если пользователем введены hello и world в качестве логина и пароля, соответственно
// используем древний метод для вывода сообщения "welcome" на страницу
if (login.value == 'hello' && password.value == 'world') {
document.write('welcome')
}
})
```
Обратите внимание, что мы не «валидируем» форму. Это, в частности, позволяет записывать пустые строки в качестве логина и пароля.
Результат выглядит так:
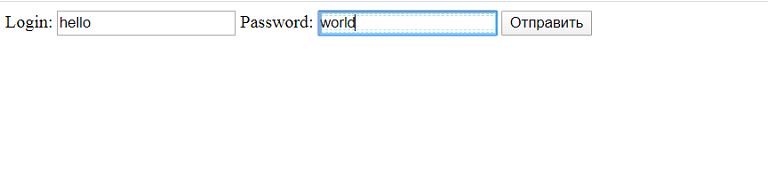
Вводим волшебные слова.
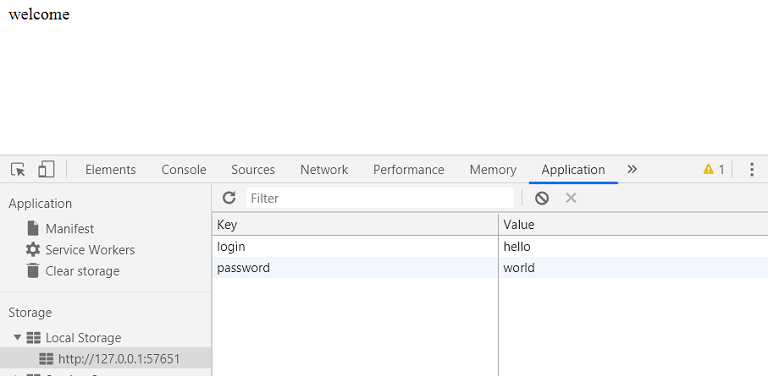
Данные записываются в localStorage, а на страницу выводится приветствие.
[Codepen](https://codepen.io/igor_agapov/pen/YzyKRzQ)
[Github](https://github.com/harryheman/web-storage-api-examles/blob/master/form.html)
#### Пишем логику списка задач
Разметка выглядит так:
```
add taskclear storage
```
У нас имеется «инпут» для ввода задачи, кнопка для добавления задачи в список, кнопка для очистки списка и хранилища и контейнер для списка.
JavaScript:
```
// находим инпут и фокусируемся на нем
let input = document.querySelector('input')
input.focus()
// находим кнопку для добавления задачи в список
let addButton = document.querySelector('.add')
// находим контейнер для списка
let list = document.querySelector('ul')
// если в localStorage имеются данные
if (localStorage.length != 0) {
// цикл по количеству пар ключ/значение
for (let i = 0; i < localStorage.length; i++) {
let key = localStorage.key(i)
// получаем шаблон - элемент списка
let template = `${localStorage.getItem(key)}`
// помещаем задачу в список
list.insertAdjacentHTML('afterbegin', template)
}
// находим все кнопки с классом "close" - галочки для выполненных задач
document.querySelectorAll('.close').forEach(b => {
// для каждой кнопки
b.addEventListener('click', e => {
// получаем родительский элемент "li"
let item = e.target.parentElement
// удаляем задачу из списка
list.removeChild(item)
// удаляем данные из localStorage
localStorage.removeItem(`${item.dataset.id}`)
})
})
}
// добавляем задачу в список при нажатии "Enter"
window.addEventListener('keydown', e => {
if (e.keyCode == 13) addButton.click()
})
// вешаем на кнопку для добавления задачи в список обработчик события "клик"
addButton.addEventListener('click', () => {
// получаем строку - задачу
let text = input.value
// формируем шаблон, запись и идентификация значений по ключам осуществляется через атрибут "data-id"
let template = `- V${new Date().toLocaleDateString()} ${text}
`
// добавляем шаблон - задачу в список
list.insertAdjacentHTML('afterbegin', template)
// записываем данные в localStorage
localStorage.setItem(`${++localStorage.length}`, template)
// сбрасываем значение инпута
input.value = ''
// вешаем на кнопку для удаления задачи из списка обработчик события "клик"
document.querySelector('.close').addEventListener('click', e => {
// получаем элемент списка - родительский элемент кнопки
let item = e.target.parentElement
// удаляем задачу из списка
list.removeChild(item)
// удаляем данные из localStorage
localStorage.removeItem(`${item.dataset.id}`)
})
})
// вешаем на кнопку для очистки обработчик события "клик"
document.querySelector('.clear').onclick = () => {
// очищаем хранилище
localStorage.clear()
// удаляем задачи из списка
document.querySelectorAll('li').forEach(item => list.removeChild(item))
// фокусируемся на инпуте
input.focus()
}
```
Результат выглядит так:
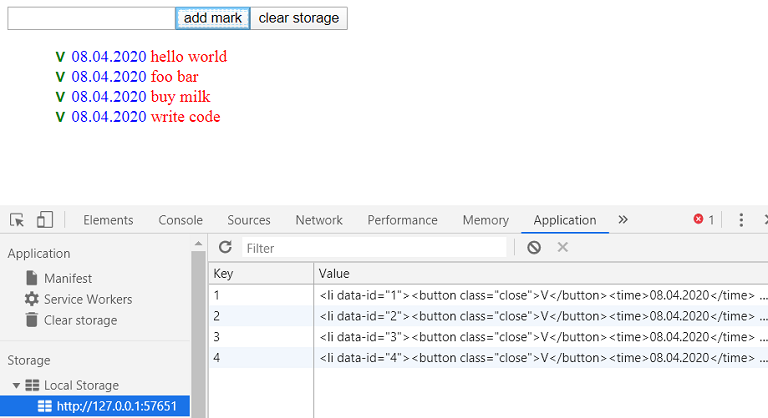
Задачи, добавляемые в список, сохраняются в localStorage в виде готовой разметки. При перезагрузке страницы список формируется из данных хранилища (имеет место перемешивание, о котором упоминалось выше).

Удаление задачи из списка посредством нажатия зеленой галочки приводит к удалению соответствующей пары ключ/значение из хранилища.
[Codepen](https://codepen.io/igor_agapov/pen/VwvZVLW)
[Github](https://github.com/harryheman/web-storage-api-examles/blob/master/toDoList.html)
#### Реализация чата
Разметка выглядит так:
```
send message
save chat
clear chat
```
У нас имеется инпут для ввода сообщения, три кнопки: для отправки сообщения, для сохранения переписки и для очистки чата и хранилища, а также контейнер для сообщений.
JavaScript:
```
// находим инпут и фокусируемся на нем
let input = document.querySelector('input')
input.focus()
// находим кнопки
let sendButton = document.querySelector('.send')
let saveButton = document.querySelector('.save')
let clearButton = document.querySelector('.clear')
// находим контейнер
let box = document.querySelector('div')
// если в хранилище имеется ключ "messages"
if (localStorage.messages) {
// формируем переписку
localStorage.messages
.split(',')
.map(p => box.insertAdjacentHTML('beforeend', p))
}
// обрабатываем отправку сообщений
sendButton.addEventListener('click', () => {
// получаем текст сообщения
let text = document.querySelector('input').value
// формируем шаблон
let template = `${new Date().toLocaleTimeString()} ${text}
`
// добавляем шаблон в контейнер
box.insertAdjacentHTML('afterbegin', template)
// сбрасываем значение инпута
input.value = ''
// записываем сообщение в хранилище
localStorage.message = template
})
// добавляем задачу в список при нажатии "Enter"
window.addEventListener('keydown', e => {
if (e.keyCode == 13) sendButton.click()
})
// обрабатываем событие "storage"
window.addEventListener('storage', event => {
// если ключом события является "messages"
// игнорируем его
if (event.key == 'messages') return
// если новое значение события равняется null
// нажимаем кнопку для очистки хранилища
// иначе добавляем сообщение в контейнер
event.newValue == null ? clearButton.click() : box.insertAdjacentHTML('afterbegin', event.newValue)
})
// сохраняем переписку
saveButton.addEventListener('click', () => {
// массив сообщений
let messages = []
// заполняем массив
document.querySelectorAll('p').forEach(p => messages.push(p.outerHTML))
// записываем данные в хранилище
localStorage.messages = messages
})
// очищаем хранилище и контейнер
clearButton.addEventListener('click', () => {
localStorage.clear()
document.querySelectorAll('p').forEach(p => box.removeChild(p))
input.focus()
})
```
Результат выглядит так:
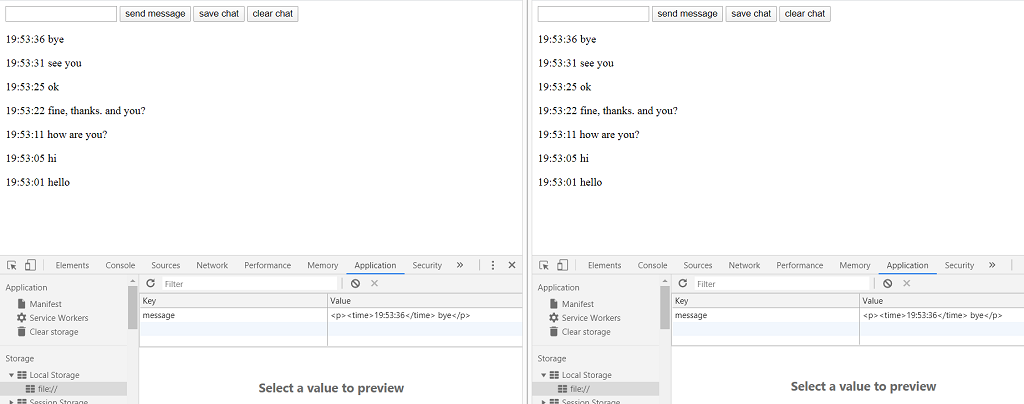
Отправляемое сообщение записывается в localStorage.message. Событие «storage» позволяет организовать обмен сообщениями между вкладками браузера.
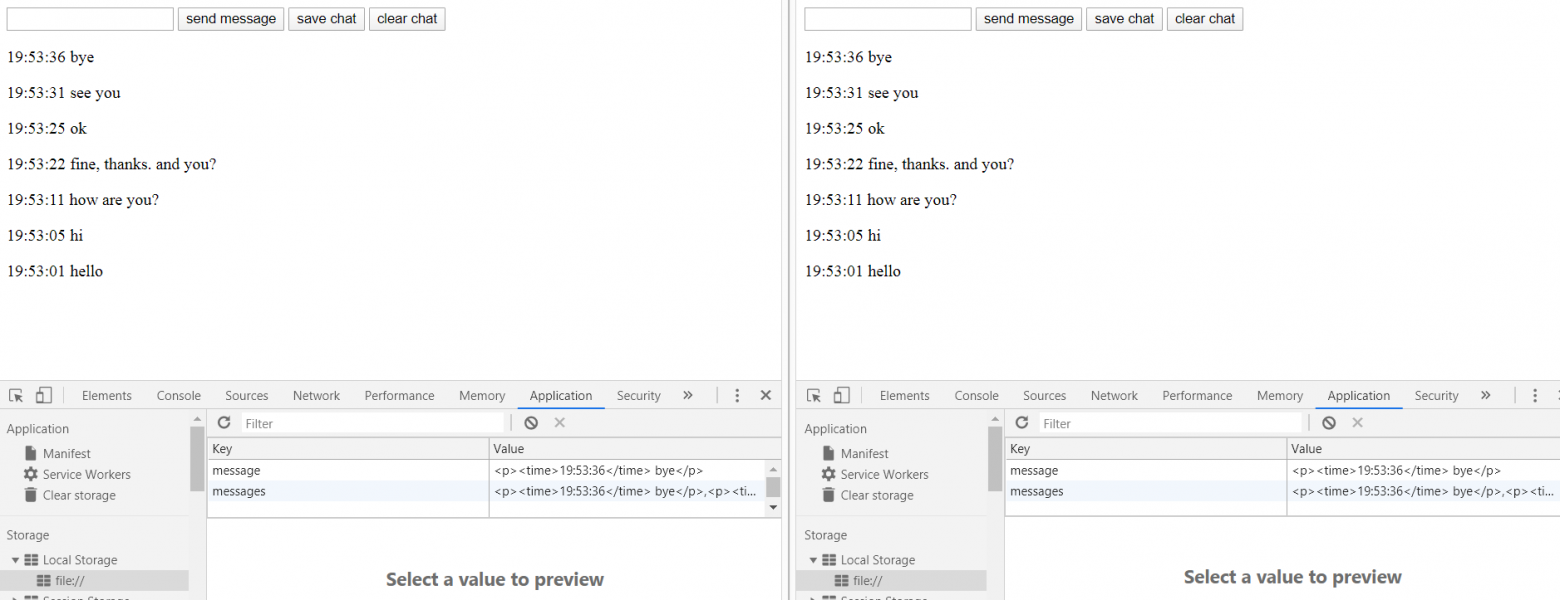
При сохранении чата все сообщения записываются в localStorage.messages. При перезагрузке страницы из записанных сообщений формируется переписка.
[Codepen](https://codepen.io/igor_agapov/pen/dyYyZvW)
[Github](https://github.com/harryheman/web-storage-api-examles/blob/master/chat.html)
#### Схема корзины для товаров
Мы не преследуем цель создать полнофункциональную корзину, поэтому код будет написан «в старом стиле».
Разметка одного товара выглядит так:
```
### Item1

Price: 1000
Buy
```
У нас имеется контейнер для товара, наименование, изображение и цена товара, а также кнопка для добавления товара в корзину.
Также у нас имеется контейнер для кнопок отображения содержимого корзины и очистки корзины и хранилища и контейнер для корзины.
```
Cart
Clear
```
JavaScript:
```
// находим товары и корзину
let itemBox = document.querySelectorAll('.item'),
cart = document.getElementById('content');
// получаем данные из localStorage
function getCartData() {
return JSON.parse(localStorage.getItem('cart'));
}
// записываем данные в хранилище
function setCartData(o) {
localStorage.setItem('cart', JSON.stringify(o));
}
// добавление товара в корзину
function addToCart() {
// блокируем кнопку на время работы с корзиной
this.disabled = true;
// получаем данные из корзины или создаем новый объект, если данные отсутствуют
let cartData = getCartData() || {},
// родительский элемент кнопки "Buy"
parentBox = this.parentNode,
// id товара
itemId = this.getAttribute('data-id'),
// название товара
itemTitle = parentBox.querySelector('.title').innerHTML,
// стоимость товара
itemPrice = parentBox.querySelector('.price').innerHTML;
// +1 к товару
if (cartData.hasOwnProperty(itemId)) {
cartData[itemId][2] += 1;
} else {
// + товар
cartData[itemId] = [itemTitle, itemPrice, 1];
}
// обновляем данные в localStorage
if (!setCartData(cartData)) {
// снимаем блокировку кнопки
this.disabled = false;
}
}
// устанавливаем обработчик события "клик" на каждую кнопку "Buy"
for (let i = 0; i < itemBox.length; i++) {
itemBox[i].querySelector('.add').addEventListener('click', addToCart)
}
// содержимое корзины
function openCart() {
// получаем данные из хранилища
let cartData = getCartData(),
totalItems = '',
totalGoods = 0,
totalPrice = 0;
// формируем данные для вывода
if (cartData !== null) {
totalItems = '
| Name | Price | Amount |
| --- | --- | --- |
';
for (let items in cartData) {
totalItems += '|';
for (let i = 0; i < cartData[items].length; i++) {
totalItems += ' ' + cartData[items][i] + ' |';
}
totalItems += '
';
totalGoods += cartData[items][2];
totalPrice += cartData[items][1] \* cartData[items][2];
}
totalItems += '
';
cart.innerHTML = totalItems;
cart.append(document.createElement('p').innerHTML = 'Goods: ' + totalGoods + '. Price: ' + totalPrice);
} else {
// если в корзине пусто
cart.innerHTML = 'empty';
}
}
// открываем корзину
document.getElementById('open').addEventListener('click', openCart);
// очищаем корзину
document.getElementById('clear').addEventListener('click', () => {
localStorage.removeItem('cart');
cart.innerHTML = 'сleared';
});
```
Результат выглядит так:
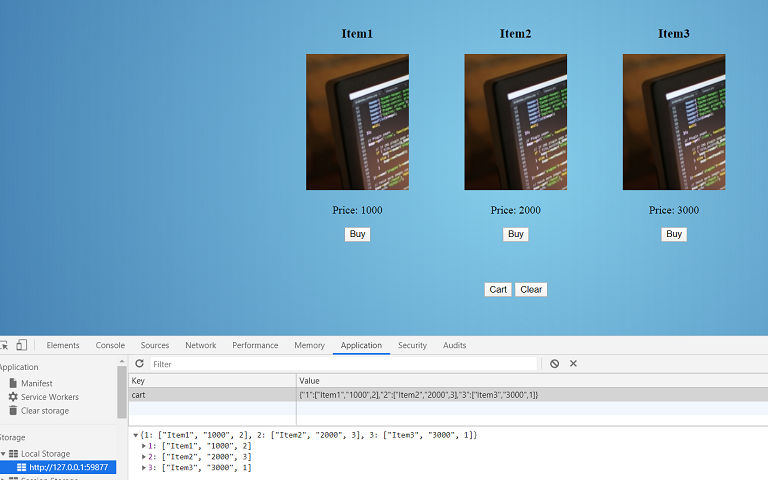 | https://habr.com/ru/post/496348/ | null | ru | null |
# Полиморфные структуры данных и производительность
В этой статье мы рассмотрим как обычно происходит работа с динамическим полиморфизмом, где теряется производительность и как её можно улучшить, используя интересные структуры данных.
В С++ не так чтобы много способов получить из коробки динамический полиморфизм. Способов буквально два: виртуальные функции и std::variant.
про std::anystd::any неприменим нигде кроме каких-то костылей в dll и про него лучше забыть, благо есть аналоги с гораздо большим потенциалом, но об этом в другой статье
Рассмотрим эти способы подробнее:
1. виртуальные функции:
позволяют создать контейнер указателей на базовый тип, а потом складывать туда любых наследников.
```
struct base {
virtual ~base() = default;
};
...
std::vector things;
```
Сразу проблемы:
* если нужен указатель, то как управлять памятью?
* если нужно копирование контейнера, то оно будет неправильным(скопируются указатели). И так как контейнер использует внутри конструкторы, нам ничего не остаётся кроме как написать свою обёртку или функцию копирования - что, вообще-то, крайне неудобно, затратно и опасно в плане багов
* так как в контейнере лежат элементы с разными указателями на vtable, процессор и компилятор не состоянии предугадать vtable какого типа лежит следующим и это приводит к постоянным кеш-мисам, что значительно замедляет и итерацию и в целом использование подобного контейнера.
нестандартные альтернативыпроблемы с лишними аллокациями памяти и копированием/удобством в целом отлично решаются решениями основанными на стирании типов, например <https://github.com/kelbon/AnyAny>, но это не тема этой статьи
2. std::variant
позволяет складывать любые из \*известных заранее\* типов в контейнер
```
using myvar = std::variant;
...
std::vector things;
```
Это решает проблемы с конструкторами и выделением памяти, к тому же элементы теперь расположены более менее локально. Но это вносит кучу своих проблем:
* типы должны быть известны заранее, невозможны "рекурсивные" структуры данных, например AST на варианте уже не напишешь
* Любое увеличение количества типов должно изменить ВСЕ сигнатуры всех функций использующих этот вариант. Как минимум придётся перекомпилирвать весь проект
void foo(const std::variant&);
просто сломается при введении ещё одного типа
* Проблемы с исключениями и неэффективность при большой разнице sizeof
К тому же у обоих рассмотренных вариантов нет опции быстро посмотреть только интересующие типы, придётся идти и к тому же заниматься динамическим кастом/визитом
Заметим, что часто нам нужен именно контейнер полиморфных типов, а не просто одна штука. Также я уже упомянул про то, что неплохо бы уметь предсказывать какой тип будет следующим. Это приводит нас к идее сортировать значения внутри контейнера по типу! Хм, интересно. И это действительно значительно улучшает производительность при итерации, но согласитесь как-то неудобно и затратно, к тому же придётся каждый раз при вставке и удалении думать об этом.
А как это исправлять?
---------------------
Я пошёл дальше, почему бы не сделать контейнер ведущий себя как контейнер из variant, но на самом деле хранящий каждый тип в отдельном контейнере? Тогда мы сразу совершенно избавились бы от кастов/прыжков по vtable, std::visit и прочего. В действительности мы избавились бы от полиморфизма вообще, хотя он и оставался бы со стороны публичного интерфейса.
Кстати, об интерфейсе, нам нужны операции:
* вставка для каждого типа T из Ts...
* удаление для каждого типа T из Ts...
* просмотр контейнера для типа T
* аналог посещения(visit) для всех значений контейнера
К тому же кажется, что контейнер может быть разным в зависимости от задачи, так что сделаем его кастомизируемым. Назвал я это чудо variant\_swarm (буквально рой вариантов)
Итак, как реализовать это? Всё довольно просто:
```
// БАЗА с настомизируемым контейнером
template typename Container, typename... Ts>
struct basic\_variant\_swarm {
private:
std::tuple...> containers;
public:
// операция "посмотреть контейнеры для типов Types..."
auto& view();
// операция "посетить все типы из контейнеров для Types..."
void visit(visitor);
// операция вставки, перегруженная для каждого из типов Ts...
auto insert(\*сложный момент\* auto value)
// операция вставки, перегруженная для каждого из типов Ts...
auto erase(\*сложный момент\* auto iterator)
};
// алиас для самого частого случая
template
using variant\_swarm = basic\_variant\_swarm;
```
Конечно всё немного сложнее и это очень условный минимальный набор. Но в целом всё понятно - у нас есть tuple из контейнеров для каждого типа и перегруженные под каждый тип операции. Это интуитивно и просто.
Использовать это можно примерно так:
```
variant_swarm f;
// в операции вставки нет никакого динамического полиморфизма,
// всё решено на компиляции
f.insert("hello");
f.insert(155);
f.insert(3.14);
// должно вывести "hello" 155 3.14 в КАКОМ-ТО порядке
f.visit\_all([](auto& v) { std::cout<< v << std::endl;});
```
[Полный код можно посмотреть здесь](https://github.com/kelbon/AnyAny/blob/main/include/variant_swarm.hpp)
Обратите внимание, значения будут появляется в visit\_all упорядоченно по типам. А что если хочется упорядочить по индексу?
На самом деле ничего сложного, в самом деле достаточно заменить контейнер на unordered\_map и вставлять вместе со значением текущее количество элементов в контейнере как ключ. Тогда операция find(index) определяется за ожидаемое время O(1).
Но двинемся дальше.
Получается, что мы определили контейнер сумтипов, если говорить терминами высших эльфов. Сразу хочется подумать, а какой аналог такой вещи был бы для типа-произведения, также известного в C++ как std::tuple? Не буду долго томить, просто ПОЧЕМУ БЫ НЕ хранить каждое поле tuple или агрегата как отдельный контейнер и так организовать data parallel контейнер?
Опять сразу определимся с интерфейсом, кажется эта штука должна вести себя практически также как std::vector снаружи, уметь хранить агрегаты и туплы, но просто делать это более эффективно и также поддерживать операцию "посмотреть филд №3 для всех сразу". И сразу заметим, что наш контейнер не сможет быть contiguous ренжом, только random\_access всилу того как элементы располагаются в памяти.
Ну и с точки зрения эстетической красоты хотелось бы, чтобы это просто работало:
```
struct mytype {
int i;
float d;
char x;
};
...
data_parallel_vector things;
// использование structured binding из С++17
auto [a, b, c] = things;
// реализуемо?)
```
Итак, посмотрим как выглядит каркас реализации:
```
// конечно мы поддерживаем аллокаоры, мы же серьёзные люди!
template >
struct data\_parallel\_vector {
private:
// как доставать поля?
std::tuple...> field\_containers;
public:
using iterator; // как делать итератор?
// операция "посмотреть поля по номерам Nbs..."
// Отмечу, что она не может возвращать ссылку на контейнер,
// потому что тогда юзер может сломать инварианты нашего контейнера
// например удалить элементы
template
constexpr std::span<...> view();
// тут все операции которые поддерживаются вектором
// и могут поддерживаться нашим контейнером, а их крайне много...
};
```
Тут С++ явно бросает нам вызов, чего только стоит специализация std::vector, которая может сломать нам буквально всё.
Для реализации итератора достаточно заметить, что для I-того элемента в каждом контейнере лежит I-тое его поле. Поэтому мы можем создать random access итератор состоящий из тупла итераторов на контейнеры.
Остальное - лучше смотреть в реализации, иначе статья будет больше хабра. Кстати, [реализация полностью тут](https://github.com/kelbon/AnyAny/blob/main/include/data_parallel_vector.hpp).
Пример использования (да, это работает):
```
struct mytype {
int i;
float d;
bool x;
};
...
data_parallel_vector things;
// a, b, c это здесь std::span span и span
auto [a, b, c] = things;
// А вы что, думали это нереализуемо?
```
Итоги
-----
Мы реализовали контейнер сум-типов, который позволяет совершенно без оверхеда и удобно использовать рантайм полиморфизм подобный контейнеру std::variant
И контейнер-тип-произведение, который ведёт себя как std::vector, но позволяет делать параллельные вычисления или, например, ECS систему в играх гораздо удобнее и эффективнее
Надеюсь статья была для вас интересна, предлагайте свои улучшения/идеи в комментариях! | https://habr.com/ru/post/703666/ | null | ru | null |
# Любопытные извращения из мира ИТ — 4

Сайт [The Daily WTF](http://thedailywtf.com/) уже 15 лет собирает курьёзные, дикие и/или печальные истории из мира ИТ. Я перевёл несколько рассказов, показавшихся мне интересными. Все имена и названия компаний изменены. Предыдущие выпуски можно найти по метке "[любопытные извращения](https://habr.com/ru/search/?q=%5B%D0%BB%D1%8E%D0%B1%D0%BE%D0%BF%D1%8B%D1%82%D0%BD%D1%8B%D0%B5%20%D0%B8%D0%B7%D0%B2%D1%80%D0%B0%D1%89%D0%B5%D0%BD%D0%B8%D1%8F%5D&target_type=posts)".
История первая. Конец ~~света~~ месяца
--------------------------------------
[[Оригинал]](http://thedailywtf.com/articles/it-s-the-end-of-the-month-as-we-know-it)
Если спросить инженера-разработчика, безопасно ли ходить по мосту, то он с удовольствием расскажет вам, насколько надёжны мосты, как в них работает математика, как далеко мы продвинулись в вопросах строительной безопасности. После разговора с ним у вас создастся впечатление, что ни один мост на Земле ни за что не развалится. Но если спросить у инженера-разработчика ПО о банках, то вы скорее всего будете в ужасе, и с вероятностью 50/50 убедите себя вложить все деньги в биткоин. Банки печально известны своими плохими решениями при создании ПО — не потому, что эти решения отвратительны, а потому, что большинство людей предполагает, что банки более аккуратны и внимательны к безопасности.
**Като** работает в Inibank, где в качестве ядра банковской системы используется коммерческий продукт под названием T24. Система T24 используется сотнями банков по всему миру. Её можно настраивать под широкий диапазон банковских решений. Как и в случае с большинством настраиваемых пакетов. существуют программисты, специализирующиеся в написании кода для него, и консультанты, помогающие банкам в выполнении крупных обновлений.
Персонал Inibank был загружен работой, поэтому банк пригласил для участия в особом проекте консультанта. В конце рабочего дня банк проводил процесс завершения работы, который необходим для того, чтобы все деньги попадали туда, куда направлялись, пересчитывались все необходимые выходные данные и выполнялись все требуемые отчёты. В банках этот процесс также меняет системную дату на ближайший рабочий день. Именно поэтому когда вы занимаетесь онлайн-банкингом в воскресенье, ни одна операция не начинает обрабатываться до утра понедельника. Консультант должен был создать новый отчёт, который бы выполнялся во время процесса завершения работы и включал в себя дополнительную обработку, если дата соответствовала концу месяца.
Като показал новому консультанту, как в банке настраиваются отчёты конца дня. «Видите, у нас есть глобальные переменные для предыдущего рабочего дня, для сегодняшнего дня, и для следующего рабочего дня. Они имеют формат YYMMDD, чтобы с ними было проще работать».
«Ага, ага, понял. Понял. А в каком они формате?»
"… Э-э-э… могу только предположить, что это год, месяц и день".
«Ага, ага, ладно. Отлично. Тогда я приступаю к работе».
После этого разговора у Като появилось нехорошее предчувствие. но он попытался от него избавиться. Консультант сказал, что всё настроено и готово. Он ведь точно знает, что делает, верно? Като выбросил это из головы и перестал беспокоиться, пока не настало время code review и он не обнаружил такой перл:
````
TH.DATE = R.DATES(EB.DAT.NEXT.WORKING.DAY)[1,6]:"01"
CALL CDT('ES00',TH.DATE,"-1C")
WTODAY = OCONV(DATE(),"DY") : FMT(OCONV(DATE(),"DM"),'R%2') : FMT(OCONV(DATE(),"DD"),'R%2')
IF TH.DATE EQ WTODAY THEN
````
Объясним вкратце, что здесь происходит:
1. Берём следующий рабочий день и изменяем день на 01, чтобы получить первый день месяца.
2. Меняем эту дату, вычитая 1 календарный день по календарю Испании.
3. Берём дату с сервера и переводим её в формат YYYYMMDD, трижды вызывая команду Date.
4. Если дата, вычисленная на этапе 2, равна дате, вычисленной на этапе 3, запускаем процесс.
Ну, вообще это… работает. По большей части. Если только по какой-то причине завершение дня не произойдёт после полуночи предпоследнего дня месяца — а это бывает не так редко. В таком случае код будет ошибочно думать, что это последний день месяца, и запустит создание отчёта. Что хорошо сочетается с ещё одной проблемой: если то же самое произойдёт в последний день месяца, то создание отчёта ошибочно не будет запущено. И самый лучший баг: если последний день месяца оказался воскресеньем, то календарь сервера никогда не будет устанавливаться на него, потому что он пропускает нерабочие дни.
Кстати о нерабочих днях: так как Inibank находится в США, нет никакой причины использовать календарь Испании. Да, месяца и недели будут такими же, но в испанском календаре ПО нужно указать банковские выходные в США, иначе программа будет продолжать работу. Наконец, как будто всего этого ещё не было достаточно, тройной вызов Date означает, что могут возникнуть разногласия при запуске ровно в полночь: значение месяца запрашивается перед полуночью, а день после неё.
Като добавил комментарий, предложив способ изменения кода:
````
IF R.DATES(EB.DAT.TODAY)[5,2] # R.DATES(EB.DAT.LAST.WORKING.DAY)[5,2] THEN
````
Пять минут спустя консультант подошёл к его столу. «Что означает эта правка?»
У Като в этот момент не было настроения спорить. «Твой код поломан, друг. Всё это не нужно».
«Понятно, понятно. Вообще-то это просто стандартная рабочая процедура для нашей отрасли. Ну да ладно».
Като сильно в этом сомневался, но просто пожал плечами. «Тогда отрасль ошибается. Я всё объяснил в комментарии».
«Ага. Да, я прочитал его. Но я прочитаю ещё раз». И он пропал столь же внезапно, как и появился.
Правки были внесены, Като одобрил код и консультант растворился в тумане.
Иногда, лёжа в кровати по ночам, Като задавался вопросом: действительно ли консультант понял, что сделал не так, или он просто согласился для вида, получил свой чек и продолжил где-то писать ужасный код за цену, вдвое превышающую зарплату Като? В тех банках, где нет сотрудников, способных проверить код.
Но не стоит вкладывать все деньги в биткоин. Там всё ещё хуже.
История вторая. Как это сделано
-------------------------------
[[Оригинал]](http://thedailywtf.com/articles/how-it-s-made)
Люди любят есть хот-доги, пока не узнают, как они готовятся. Большинство этого не спрашивает, потому что не хочет знать и продолжает есть хот-доги. При разработке ПО нам иногда *приходится* спрашивать. Не только для того, чтобы решать проблемы, но и потому, что некоторые программисты боятся, что ПО в их автомобилях, несущихся по трассе со скоростью 100 км/ч, собрано из изоленты и палок. [Вся наша отрасль плохо справляется со своими задачами](https://xkcd.com/2030/).
**Бретт** работал системным аналитиком в медицинском исследовательском центре MedStitute. Для хранения и анализа данных MedStitute использовал проприетарное ПО под названием MedTech. Врачам и исследователям нравились результаты MedTech, но коллега Бретта Тайри знал, как они создавались.
У ПО не было доступа к бэкенду, и весь процесс разработки происходил в «программируемом мышью» GUI. Этот интерфейс выглядел так, как будто был написан человеком, изучавшим программирование копипастингом веб-сайтов эпохи 90-х, посмотревшим десять минут *«Парка юрского периода»* и искавшего ответы на StackOverflow, пока что-нибудь не удавалось скомпилировать. «Язык программирования» тоже демонстрировал аналогичный уровень продуманности философии дизайна. У каждого `if` *обязательно* должен был быть `else`. В некоторых модулях использовались булевы значения, другие для обозначения значений false возвращали пустые строки. Из документации было непонятно, в какой ситуации случалось одно или другое. По сути, каждый оператор `if` превращался в три оператора.
Бретту нужно было начать новое исследование. Оно основывалось на простом множестве статистических данных и группировала пациентов с помощью рандомизированной переменной. Бретт поискал в списке переменную, которую можно было бы рандомизировать, но не нашёл нужной. Он предположил, что совершил ошибку и вернулся на несколько экранов назад, чтобы проверить её имя, скопировав его для поиска. Бретт вернулся к списку рандомизируемых переменных. Её там не было. Он присмотрелся к списку повнимательнее и заметил, что список рандомизируемых переменных содержал данные из полей с множественным выбором. Поле, которое ему нужно было рандомизировать, было основано на вычисляемом поле.
Бретт знал, что Тайри работал над другим проектом, который рандомизировался по вычисляемому полю, поэтому связался с ним в Slack. «Как ты закодировал эту случайную переменную? Medtech ведь этого не позволяет сделать?»
«Я говорю по конференц-связи, перезвоню позже», — написал Тайри.
Несколько минут спустя Тайри позвонил Бретту.
«Тебе нужно начать с двух полей. Допустим. назовём их `$variable_choice`, то есть вопрос с множественным выбором, и `$variable_calced`, то есть твоё вычисляемое поле. Когда ты хочешь создать переменную, которая выполняет случайный выбор на основании вычисляемого поля, ты сообщаешь Medtech, что эта случайная переменная основана на `$variable_choice`. Затем ты удаляешь `$variable_choice`, и переименовываешь `$variable_calced` в `$variable_choice`»
«Стоп, система позволяет сделать это, но не разрешает рандомизировать вычисленные поля каким-то другим способом? И она этого не проверяет?»
«Надеюсь, ничего не изменится, и она не начнёт проверять этого до завершения моего проекта», — ответил Тайри.
«Это исследование должно проходить в течение десяти лет. И его успешное завершение зависит от того, не посчитают ли разработчики эту уловку багом?»
«Мне удалось найти только такое решение. Дай знать, если найдёшь что-то получше».
Бретта не удовлетворил такой хак, и он вернулся к изучению документации. Он обнаружил решение «получше»: можно создать поле множественного выбора только для чтения с единственным вариантом значения по умолчанию — значением вычисляемого поля. К сожалению пользователь мог ненамеренно изменить список, ответив на вопрос с множественным выбором *до* вычисления значения вычисляемого поля.
В конце концов, единственное, что оставалось Бретту — сделать перерыв, пойти в кафетерий и купить пару хот-догов.
История третья. Портативность и крепёж
--------------------------------------
[[Оригинал]](http://thedailywtf.com/articles/portage-and-portability)

Много лун назад, когда PC имели тяжёлые корпуса из металла и пластика, **Мэтту** и его коллеге поручили оценить пакет ПО для грядущей операции отдела продаж. К сожалению, они с коллегой работали в разных офисах в пределах одного города. В ту эпоху ещё не существовало эффективных онлайн-инструментов для совместной работы, поэтому Мэтту регулярно приходилось ездить в другой офис, беря с собой PC. Это означало, что каждый раз нужно было отключать от корпуса 473 кабеля периферии, нести компьютер по коридорам и вниз по лестницам, ловить автобус, чтобы добраться до другого офиса, в котором он проделывал всё это в обратном порядке. Иногда неправильная организация труда заставляла эту пару работать по выходным, а значит, носить рабочие машины домой.
В процессе работы жёсткий диск на 20 МБ в компьютере Мэтта переполнился. Из своего офиса он отправил заявку в отдел ИТ. Для выполнения заявки назначили техника Гари, который спустя какое-то время появился в кубикле Мэтта, держа в руках новый жёсткий диск и отвёртку. Гари отправил Мэтта за кофе, чтобы сосредоточиться на своём «пациенте». После небольшого хирургического вмешательства PC Мэтта включился и заработал с большим жёстким диском.
За день до дедлайна проекта Мэтт почти завершил свою долю работы. Ему оставалось внести всего несколько дополнений в свой отчёт, а потом скопировать его на гибкие диски и отправить в отдел продаж. Вернув свой PC в кубикл и подсоединив провода, он включил питание и услышал хлопок. PC был мёртв и не подавал признаков жизни.
После панического звонка в отдел ИТ, в его кабинете снова появился Гари с отвёрткой. Вскрыв корпус PC, он сразу же завопил: «Постойте-ка! Вы что, куда-то таскали компьютер?»
Мэтт нахмурился. «Ну да. А что, в этом дело?»
«Да уж конечно! Вы не должны были этого делать!», — начал ругаться Гари. «Жёсткий диск начал болтаться и закоротил всё внутри!»
Мэтт наклонился над Гари, чтобы самому увидеть внутренности компьютера. Он сразу заметил, что новый жёсткий диск был «закреплён» на скотч.
«Стоп! Это *вы* не должны были этого делать!» Мэтт показал на кусок скотча. «Мне что, на всякий случай стоит обратиться к вашему руководителю?»
Лицо Гари сморщилось. «Мне не дают нужные крепления!»
«Тогда найдите того, у кого они есть!»
Учитывая надвигающийся дедлайн, с разрешения начальника Мэтт передал свою заявку ещё выше. Почти сразу же клейкую ленту заменили на настоящий крепёж. Он так никогда и не понял, *почему* у сотрудников отдела ИТ не было доступа к необходимому оборудованию; он предположил, что это была блестящая идея какого-то идиота для экономии средств. Мэтт мог только догадываться, какие ещё отчаянные импровизации позволяли обеспечивать работоспособность их ИТ-инфраструктуры, и как долго бы они оставались незамеченными, если бы не сломался его PC.
История четвёртая. Вот как на твой мозг влияет PL/SQL
-----------------------------------------------------
[[Оригинал]](https://thedailywtf.com/articles/this-is-your-brain-on-pl-sql)
Вечным чемпионом среди самых странных и неудачных решений навсегда будет оставаться *Oracle*. Сегодня мы рассмотрим небольшой код на PL/SQL.
PL/SQL — это странный язык, смесь SQL и **P**rocedural (процедурного) **L**anguage (языка) с приклееной сбоку объектно-ориентированностью. Синтаксису превосходно удаётся создать впечатление, что он был разработан в 1970-х, и каждая новая функция или изменение языка продолжают эту традицию.
Структура каждого модуля кода на PL/SQL строится на основе *блоков*. Каждый блок представляет собой самостоятельное пространство имён. Вкратце его анатомия выглядит так:
```
DECLARE
-- variable declarations go here
BEGIN
-- code goes here
EXCEPTIONS
-- exception handling code goes here, using WHEN clauses
END;
```
Если вы пишете хранимую процедуру или обработчик событий, то заменяете ключевое слово `DECLARE` на `CREATE [OR REPLACE]`. Также можно вкладывать блоки внутрь других блоков, поэтому довольно часто можно увидеть код, структурированный таким образом:
```
BEGIN
DECLARE
--stuff
BEGIN
--actions
END;
--more actions
END;
```
Да, довольно быстро это начинает запутывать. И да, если вы хотите обеспечить хотя бы приблизительно структурированную обработку ошибок, то *обязаны* начинать вкладывать блоки друг в друга.
Язык и база данных имеют и другие забавные особенности. До версии 12c у них не было типа столбца `IDENTITY`. В предыдущих версиях необходимо было использовать объект `SEQUENCE` и писать процедуры или обработчики событий, выполняющих принудительное автоматическое нумерование. Обычно для присваивания значения переменной использовался оператор `SELECT INTO…`. Бонус: Oracle SQL *всегда* требует указания таблицы в операторе `FROM`, поэтому необходимо использовать придуманную таблицу `dual`, например так:
```
CREATE TRIGGER "SOME_TABLE_AUTONUMBER"
BEFORE INSERT ON "SOME_TABLE"
FOR EACH ROW
BEGIN
SELECT myseq.nextval INTO :new.id FROM dual;
END;
```
`:new` в данном контексте обозначает строку, для которой мы выполняем автоматическую нумерацию. В старых версиях Oracle это был «обычный» способ создания столбцов с автоматической нумерацией. **Бенуа** обнаружил другой, немного менее обычный способ выполнения той же операции:
```
CREATE OR REPLACE TRIGGER "SCHEMA1"."TABLE1_TRIGGER"
BEFORE INSERT ON "SCHEMA1"."TABLE1"
FOR EACH ROW
BEGIN
DECLARE
pl_error_id table1.error_id%TYPE;
CURSOR get_seq IS
SELECT table1_seq.nextval
FROM dual;
BEGIN
OPEN get_seq;
FETCH get_seq
INTO pl_error_id;
IF get_seq%NOTFOUND
THEN
raise_application_error(-20001, 'Sequence TABLE1_SEQ does not exist');
CLOSE get_seq;
END IF;
CLOSE get_seq;
:new.error_id := pl_error_id;
END;
END table1_trigger;
```
Тут происходит очень многое. Для начала заметьте, что в разделе `DECLARE` содержится оператор `CURSOR`. Курсоры позволяют итеративно переходить между записями. Они очень затратны и в мире Oracle это ресурс, который нужно освобождать.
Этот обработчик событий (триггер) использует вложенный блок безо всяких на то причин. Также он использует дополнительную переменную `pl_error_id`, без которой можно обойтись.
Но по-настоящему странная часть заключается в блоке `IF get_seq%NOTFOUND`. Всё довольно просто: он проверяет условие, что курсор не вернул строку. Такого для этого курсора не может случиться даже *теоретически*, поэтому операции внутри никогда не выполняются. Последовательность всегда возвращает значение. И это *хорошо*, учитывая тот код, который идёт дальше.
`raise_application_error` — это аналог «throw» в Oracle. Этот оператор поднимается по стеку из выполняемых блоков, пока не находит раздел `EXCEPTIONS` для обработки ошибки. Заметьте, что мы закрываем курсор *после* этого оператора — то есть, на самом деле мы *никогда* не закрываем курсор. Курсоры, как сказано выше, затратны, и Oracle позволяет использовать только ограниченное их количество.
Здесь мы видим странный пример того, как разработчик пытается защититься от ошибки, которая не может произойти, таким образом, которая со временем приведёт к новым ошибкам.
История пятая. Логины с двойным шифрованием
-------------------------------------------
[[Оригинал]](https://thedailywtf.com/articles/doubly-encrypted-logins)
Создание аутентификации для веб-API — это *сложная* задача, но она имеет *множество* устоявшихся решений. Самое трудное на самом деле — выбрать один из различных вариантов, после чего достаточно просто добавить компонент.
При правильной реализации система не зависит от типа клиента. Я могу получать доступ к сервису через браузер, в толстом клиенте или через cURL. При неправильной реализации вы получаете то, что случилось с **Амирой**.
Она решала задачу вытягивания из бэкенда нужной ей статистики, но не могла разобраться в способе аутентификации. Поэтому она изучила код фронтенда, чтобы понять, как он выполняет аутентификацию:
```
crypt = new JSEncrypt();
crypt.setPublicKey('');
challenge = "";
function doChallengeResponse()
{
document.loginForm.password.value.replace(/&/g, '%26');
document.loginForm.password.value.replace(/\\+/g, '%2B');
document.loginForm.password.value = crypt.encrypt(document.loginForm.password.value);
document.loginForm.response.value = document.loginForm.password.value;
document.loginForm.password.value = '';
document.loginForm.submit();
}
```
С одной стороны, я могу предположить, что этот код очень стар, учитывая `document.loginForm`, используемый для взаимодействиями с DOM-элементами. С другой стороны, `JSEncrypt` был впервые выпущен в 2013 году, что даёт нам максимальную планку возраста.
Мы передаём параметры доступа бэкенду с помощью отправки формы, которая, по мнению разработчика кода требовала очистки — все `&` и `+` в пароле заменяются, но… это необязательно, потому что форма должна выполнять запрос `POST` и, кроме того, *мы зашифровали данные*.
Вот что я думаю. Код *и в самом деле* довольно стар. Разработчик скопировал его из поста на StackOverflow примерно за 2005 год, в котором не использовалось шифрование и отправка формы через `POST`. Год за годом в него добавлялись небольшие изменения. но базовый механизм никогда не менялся.
Амира проверила историю, и обнаружила, что в предыдущей версии шифрование не использовалось. Код конкатенировал пароль с переменной `challenge`, оба они хешировались MD5, после чего он передавал *это* в сеть, и всё как бы работало, если слишком сильно над этим не задумываться.
Была и хорошая сторона дела: когда Амира разобралась, как получать нужные ей куки, срок жизни этого токена на сервере никогда не истекал, поэтому она могла хранить его, отправлять запросы через cURL и больше не связываться с веб-формой. Ей не нужно было беспокоиться о компрометировании куки при передаче, потому что приложение *использует и всегда использовало SSL/TLS*. | https://habr.com/ru/post/446714/ | null | ru | null |
# Как новичку сделать вклад в open source проект с 20К звездами?
На хабре публикуют перевод статей про участие в open source продуктах и складывается впечатление что жизнь, полная энтузиастов, где-то за границей. Что новичку страшно участвовать в крупных проектах, что у него обязательно должны быть там кураторы и его pull request вместе с ним точно пройдет [через все круги ада](https://habrahabr.ru/post/346558/).
Опыт друга, новичка в open source, говорит об обратном. Первый его pull request [#11680](https://github.com/spring-projects/spring-boot/pull/11680) приняли в звездный spring-boot без обсуждения и без единого комментария от мейнтейнеров. Его исправления будут доступны уже в версии 2.0.0.RC1
Не боги горшки обжигают. Рассуждения о возможности стать контрибьютором крупного проекта на github…
Первое что останавливает от действия взрослого человека — это страх и неуверенность. А вдруг у меня не получится, а вдруг меня засмеют — посещали ли вас такие мысли, когда вы делали впервые что-то новое в большом коллективе?
А удерживает ли это интернет тролля от публикации? И что такое бокс по переписке? Все эти ютуб видеобатлы всерьез? Среда виртуальная, вряд ли мейнтейнер проекта — необузданный психопат и знает где ты живёшь… **Все еще страшно?**
У медиков есть шутка что нет здоровых людей, есть недообследованные. Так же и в мире open source — нет идеального кода, в каждом модуле есть душок — code smell. Как обнаружить его новичку, всегда ли субъективны критерии чистоты кода? Есть инструменты статического анализа кода sonarqube, pvs-studio, SpotBugs, code inspection в Idea. Попробуйте запустить их на знакомом проекте и вы и удивитесь! **Вам это лень?**
Наконец, вы придумали «инновационный JS фреймвор с виджетами». Думаете, выложив на github, его сразу украдут, обфусцируют и продадут в Сколково? Понимаю что вы тратили свое свободное время. Воображение рисует как будете привлекать инвестиции и покупать себе красную Ferrari. У вас есть модель монетизации и план развития вашего «секретного» проекта? Насколько востребована и уникальна эта идея. Как быстро устареет код и идея? Сможет ли проект развиваться без вас? **Жалко отдавать его бесплатно?**
Для некоторых отдать свой код в общественное достояние — новый шанс получить интересную работу, багфиксы от сообщества и обратную связь от профессионалов. Конечно само собой это не случится и нужно прилагать усилия. По мне, так лучше принципа «Собака на сене». Может стоит рискнуть, снабдив проект нужной вирусной лицензией?
Возвращаясь к истории [Андрея](https://github.com/andrey916) и его вклад в open source.
Мы учились вместе в университете, он с нашей кафедры, на 3 курса младше меня. С интересом делал лабораторные задания по программированию и профильным дисциплинам, тратил свободное время за компилятором и книгами.
Но после университета и военной кафедры его призвали служить. Это время из его карьеры разработчика было потеряно. Вернувшись, ему было непросто найти работу по специальности без опыта работы после университета. Опыт не наберешь без работы, на работу не берут без опыта — замкнутый круг. Маленький городок, где живут они с женой не изобилует IT вакансиями. Поработал в банке сисадмином. Потом ради работы программистом, стал ездить на работу за 80км от дома. И до сих пор так ездит на работу… На работе совсем нет времени на open source — был проект в крупном интеграторе копать от забора до обеда. Развитие и обучение было, в основном, в его свободное время. Он очень умный и целеустремленный, но резюме и время службы оборачиваются против него, когда проходит через жернова формальностей у HR.
Недавно разговорился с Андреем и рассказал ему про результаты анализа кода spring boot в sonarcloud. У нас время от времени бывают дискуссии про технологии и процесс разработки.
Предложил помочь с улучшением кода boot. Он сомневался, что его pull request примут в такой крупный проект. Я порекомендовал ему сконцентрироваться на исправлении одного типа дефектов и взять в работу не очень сложный code smell. Он выбрал **«String function use should be optimized for single characters»**.
Суть этого «запаха кода» в том что, в объекте **java.lang.String** есть методы **indexOf** и **lastIndexOf**, которые можно вызвать с параметром char вместро String из одного символа и для случая строки с одним символом они работают эффективнее.
Не эффективно:
```
String myStr = "Hello World";
// ...
int pos = myStr.indexOf("W"); // Noncompliant
// ...
int otherPos = myStr.lastIndexOf("r"); // Noncompliant
// ...
```
Лучше написать так:
```
String myStr = "Hello World";
// ...
int pos = myStr.indexOf('W');
// ...
int otherPos = myStr.lastIndexOf('r');
// ...
```
Как результат — он немного улучшил то, чем пользуются многие java разработчики в повседневной работе. Надеюсь, что у Андрея в будущем появится возможность улучшать на работе open source инструменты и фреймворки, которые он использует, вместе с коллегами!

На Хабре точно есть люди, которые смогут вам помочь советом. Так познакомился с [raiym](https://habrahabr.ru/users/raiym/) сначала на github, а потом и здесь. [lany](https://habrahabr.ru/users/lany/) рассказывал о судьбе его проекта HuntBugs и как можно использовать статический анализ кода из Idea в командной строке.
Мой главный совет новичкам — не бояться open source и пробовать исправлять код «с душком». Следуйте примеру Андрея!
А что удерживает вас от вклада в open source? | https://habr.com/ru/post/347402/ | null | ru | null |
# Сравнительный анализ Docker Engine на платформах Windows Server и Linux
Конференция Ignite в Атланте, которая проводилась в конце сентября сего года, стала важным событием для Microsoft и Docker Inc. А именно, тогда был выпущен финальный общедоступный релиз Windows Server 2016, в котором можно найти массу новых возможностей. Windows Server стал интеллектуальнее, в нём улучшили систему безопасности и поддержку облачных решений, повысили производительность, усовершенствовали сетевые инструменты. Нельзя забывать и об улучшенной поддержке кластеризации. Весьма интересна новая облегчённая версия ОС – Nano Server. Этот дистрибутив предназначен для использования в облачных службах. Тогда же был анонсирован Microsoft System Center 2016, стало известно кое-что о новой облачной платформе [Azure Stack](https://azure.microsoft.com/en-us/overview/azure-stack/), возможностями которой можно будет воспользоваться в следующем году. Эта платформа позволит организациям размещать основные службы Azure в собственных дата-центрах.
[](https://habrahabr.ru/company/ruvds/blog/315220/)
На конференции было много новостей. Но, пожалуй, самой горячей стала новость о партнёрстве Docker Inc. и Microsoft в области поддержки Docker Engine на платформе Windows Server 2016.
В рамках этого партнёрства Microsoft позволит пользователям Windows Server 2016 бесплатно работать с Docker Engine и обеспечит базовую техническую поддержку. Сложными проблемами будет заниматься техподдержка Docker Inc.
В Windows Server 2016 теперь имеется встроенная поддержка контейнеров Docker и предлагается два способа развёртывания контейнеров: Windows Server Containers и Hyper-V Containers, что предусматривает дополнительный уровень изоляции для многоарендных сред. Поддержка Docker интегрирована в широкий набор средств разработки от Microsoft, в операционные системы и облачную инфраструктуру, в том числе в следующие технологии:
* Windows Server 2016
* Hyper-V
* Visual Studio
* Microsoft Azure
Если вы – приверженец Linux, вроде меня, то вам, должно быть, не терпится узнать, насколько различается Docker Engine на платформах Windows Server и Linux. В этом материале я собираюсь рассказать об архитектурных различиях, об интерфейсе командной строки, который работает под обеими платформами, о сборке образов с помощью Dockerfile, о некоторых других особенностях работы с Docker на платформе Windows.
Начнём с архитектурных различий контейнеров Windows и Linux.
Docker Engine на платформе Linux
--------------------------------
Если рассмотреть Docker Engine на платформе Linux, то сразу бросаются в глаза инструменты командной строки вроде Docker Compose, Docker Client, Docker Registry, и так далее, которые используют Docker REST API. Пользователи взаимодействуют с Docker Engine, а, в свою очередь, Docker Engine работает с демоном containerd. Демон использует runC или другую OCI-совместимую среду выполнения для запуска контейнеров.
В основе этой архитектуры находятся функции ядра, наподобие пространств имён, которые обеспечивают изоляцию контейнеров. Тут же находятся контрольные группы и другие низкоуровневые механизмы. Всё это позволяет реализовать изоляцию контейнеров, распределение и ограничение ресурсов. В результате каждому контейнеру можно выделить необходимую ему долю памяти, процессорного времени, ресурсов дискового накопителя. При этом, что очень важно, отдельный контейнер не может нарушить работу системы, единолично захватив один из этих ресурсов.
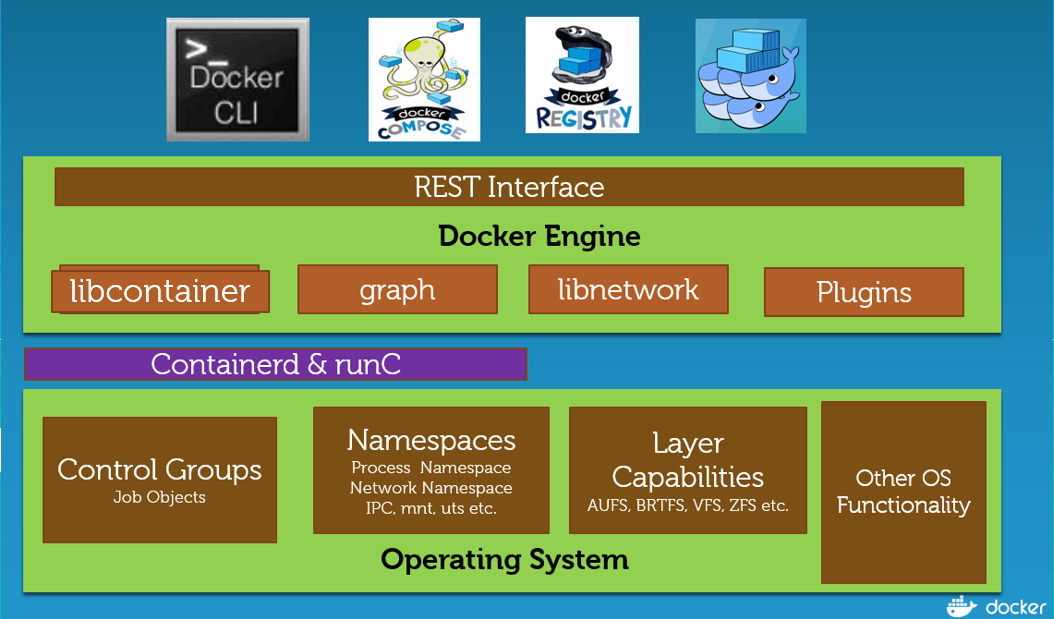
*Docker Engine на платформе Linux*
Docker Engine на платформе Windows
----------------------------------
В Windows всё устроено несколько иначе. Архитектура большинства высокоуровневых компонентов выглядит точно так же, как на Linux. Это и то же самое Remote API, те же рабочие инструменты (Docker Compose, например), но глубже, ближе к ядру, всё уже не так, как в Linux. Тут, для тех, кто не очень хорошо ориентируется в вопросах, связанных с ядром Windows, хочу отметить, что ядра Windows и Linux – это далеко не одно и то же. Дело в том, что Microsoft применяет несколько иной подход к проектированию ядра, нежели тот, которому следует сообщество разработчиков Linux. А именно, термин «режим ядра» на языке Microsoft относится не только к самому ядру системы, но и к уровню аппаратных абстракций (hal.dll), и к различным системным службам. Здесь имеются модули, предназначенные для управления объектами, процессами, памятью, безопасностью, кэшем, технологией PnP, электропитанием, настройками, операциями ввода-вывода. Всё вместе это называется исполнительной системой Windows (Windows Executive, ntoskrnl.exe).
Среди возможностей ядра в Windows нет пространств имён и контрольных групп. Вместо этого команда Microsoft, работая над новой версией Windows Server 2016, представила так называемый «Compute Service Layer», дополнительный слой служб на уровне операционной системы, который предоставляет функции пространств имён, управление ресурсами, и возможности, похожие на UFS. Кроме того, как вы увидите ниже, на платформе Windows нет чего-либо, соответствующего демону containerd и среде runC. Compute Service Layer предоставляет общедоступный интерфейс к контейнеру и несёт ответственность за управление контейнерами, за выполнение операций вроде их запуска и остановки, но он не контролирует их состояние, как таковое. Если в двух словах, то он заменяет containerd на Windows и абстрагирует низкоуровневые возможности, которые предоставляет ядро.
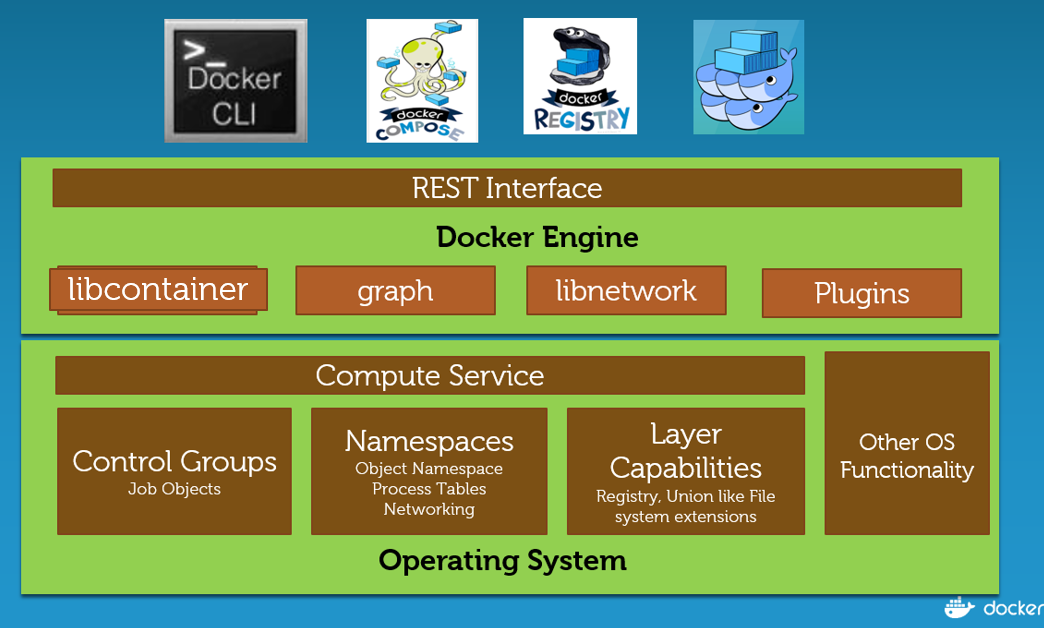
*Docker Engine на платформе Windows*
На рисунке ниже показаны механизмы ядра Windows, созданные для поддержки контейнеров. В самом низу – совместно используемое ядро, то же самое мы уже видели на Linux. Блок Host User Mode – это хост-система Windows, в основном – системные процессы. Гораздо более важные компоненты размещены в правой части рисунка – это System Processes и Application Processes, системные процессы и процессы приложений в контейнерах Windows Server, которые, в сравнении с Linux, работают иначе. Обычная для Linux практика – хорошее документирование механизма вызова системы, а также гарантия его стабильности для разных версий ядра. В Windows механизм вызова системы не документирован, при этом речь не идёт и о гарантиях его единообразного поведения. Единственный способ сделать системный вызов в Windows заключается в обращении к ntdll.dll. В контейнеры Windows входит множество взаимосвязанных процессов, вызывающих друг друга, поэтому они имеют довольно большой размер.
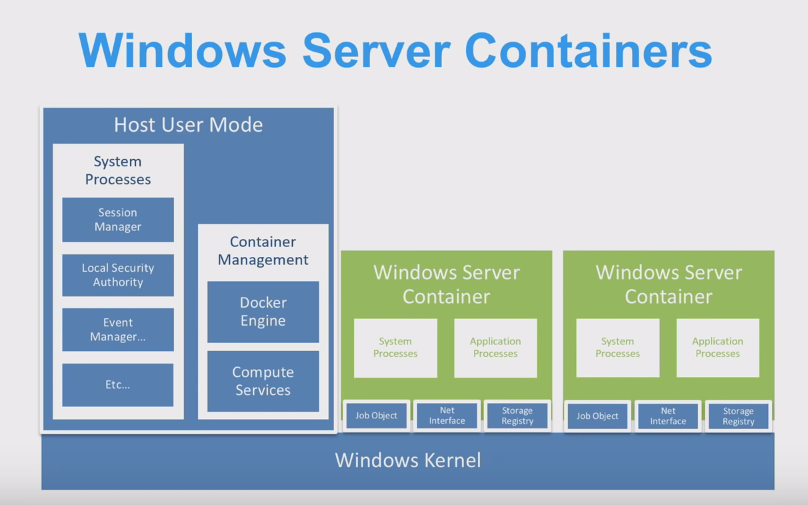
*Контейнеры в Windows Server (источник: DockerCon 2016)*
Важно отметить, что в файлах Dockerfile для Windows не используется команда «FROM scratch», то есть, нет такого понятия, как «пустой образ». Это так из-за большого числа взаимосвязанных системных процессов, необходимых для предоставления базовой функциональности. Microsoft сделала свои базовые образы в следующих двух вариантах:
1. Microsoft/windowsservercore – это обычный Windows Server с .NET 4.5, он занимает 9.3 Гб, что немало, поддерживает существующие приложения Windows.
2. Microsoft/nanoserver – размер этого образа значительно меньше, около 600 Мб, здесь не предусмотрено графической среды. Этот сервер работает быстро, требует меньше памяти, но предоставляет меньше API и может быть несовместим с некоторыми существующими приложениями.
Пара слов о пространствах имён в Windows
----------------------------------------
В Windows нет концепции «пространств имён», соответствующей пространствам имён в Linux. Однако, на пространства имён Linux здесь весьма похожа концепция приёмников команд (silos) — расширение к объектам-заданиям Windows (Windows Job objects) – набору процессов, ресурсами которых можно управлять. При этом появляется то, что называется пространством имён процесса, пользователя, объекта, сети, и так далее. Пространство имён объекта – это пространство имён системного уровня, скрытое от пользователя. Так же, как и Linux, Windows имеет корневую папку (\) на уровне NT для всех устройств. Например, «C\Windows» отображается на \DosDevices\C:\Windows, или на \Device\Tcp, если речь идёт о сети.
Начало работы с Docker на Windows 2016 Server
---------------------------------------------
Обратите внимание на то, что для того, чтобы опробовать то, о чём я сейчас расскажу, вам понадобится Windows 2016 Server Evaluation сборки 14393. Если попытаться выполнить стандартную процедуру установки Docker на старую версию Windows 2016 TP5, появится сообщение об ошибке.

*Сообщение об ошибке*
Не забудьте и о том, что обновить систему TP5 на новую версию не получится. Поэтому для того, чтобы попробовать новейший Docker 1.12.2, понадобится установить ОС Windows Server Evaluation, которую можно загрузить [отсюда](http://tinyurl.com/jb4axm9).
Когда нужная версия Windows Server будет установлена, выполните нижеприведённые команды, соблюдая их последовательность:
```
Invoke-WebRequest "https://download.docker.com/components/engine/windows-server/cs-1.12/docker.zip" -OutFile "$env:TEMP\docker.zip" -UseBasicParsing
Expand-Archive -Path "$env:TEMP\docker.zip" -DestinationPath $env:ProgramFiles
[Environment]::SetEnvironmentVariable("Path", $env:Path + ";C:\Program Files\Docker", [EnvironmentVariableTarget]::Machine)
dockerd --register-service
Start-Service Docker
```
Этих команд в большинстве случаев будет вполне достаточно для того, чтобы установить Docker и не столкнуться при этом с какими-либо проблемами.
Кстати, 10 ноября я узнал, что Windows 2016 Final Release и Nano Server доступны на платформе Azure.
Приступая к работе с контейнерами в Windows Server 2016, в которой установлен соответствующий компонент, проверьте, запущен ли сервис Docker:
```
docker version
```
Если вы столкнулись с сообщениями об ошибках, наподобие показанных ниже, которые довелось увидеть мне, выполните такую команду:
```
Start-Service Docker
```
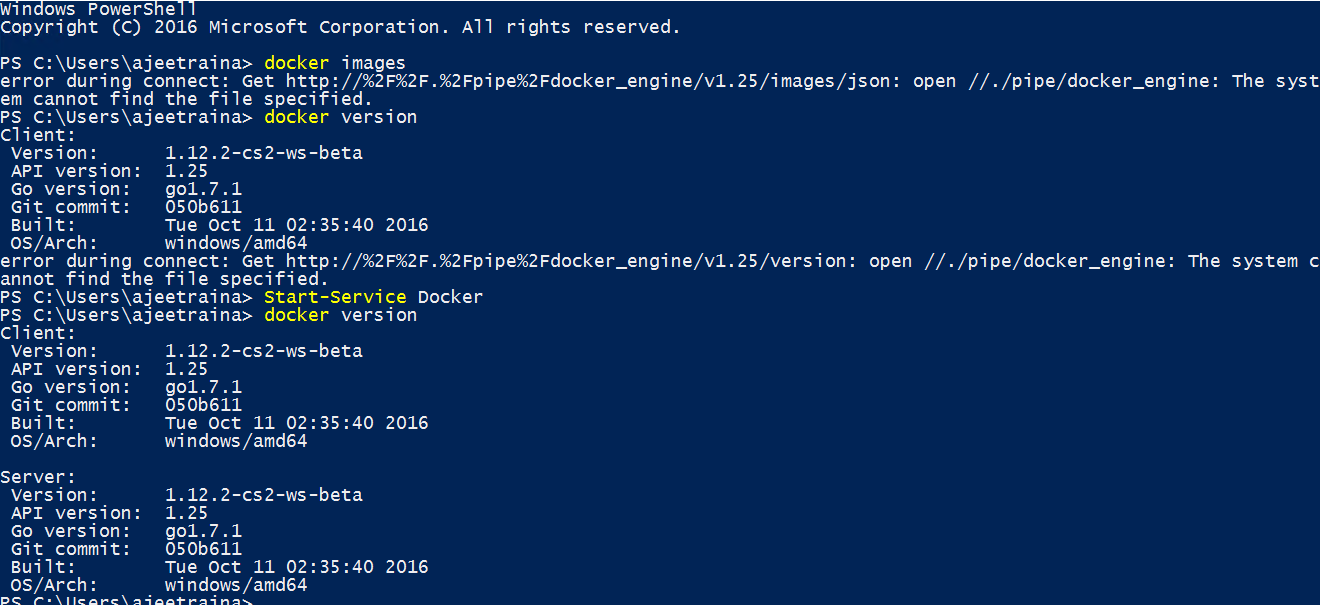
*Сообщения об ошибках и запуск Docker*
Теперь вы можете найти Windows-приложения, подготовленные для Docker, используя такую команду:
```
docker search microsoft
```
Вот, например, что удалось найти мне.

*Результаты поиска приложений*
Ещё можно воспользоваться такой командой:
```
docker search windows
```
В ответ система выведет примерно такой список:
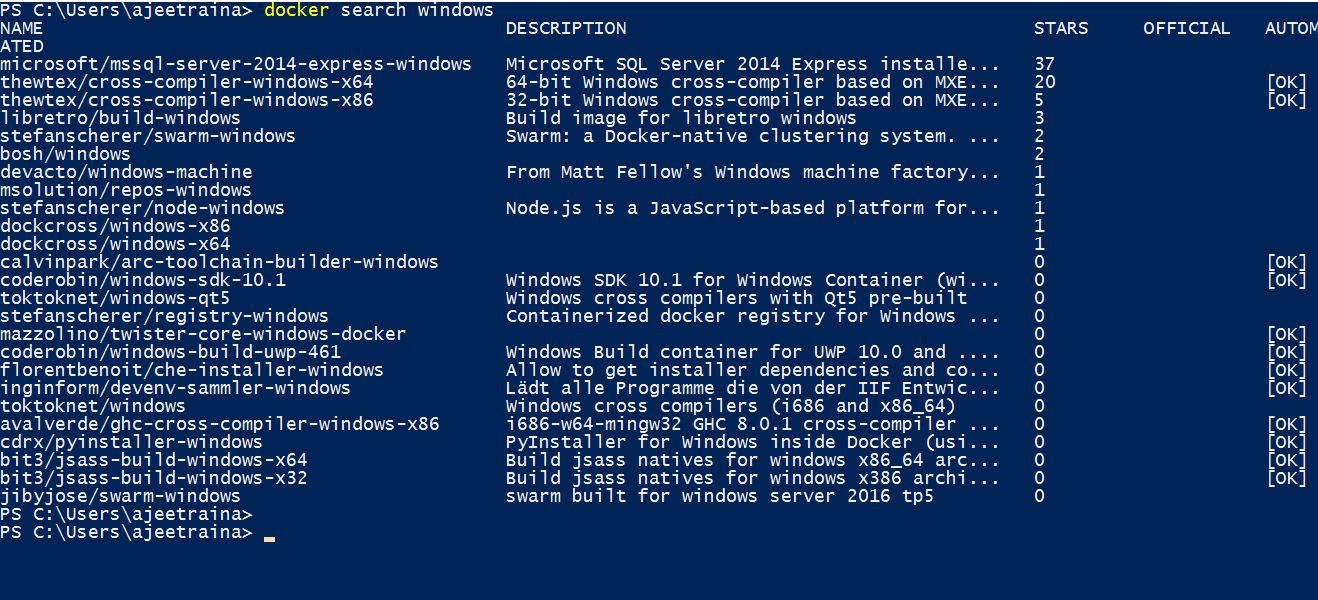
*Результаты поиска приложений*
Об ограничениях Docker на Windows
---------------------------------
1. На платформе Windows Linux-контейнеры работать не будут. Вот что система сообщает по этому поводу:

*Docker на Windows и Linux-контейнеры*
2. На платформе Windows всё ещё не поддерживается DTR.
3. Нельзя, с помощью команды `docker commit`, зафиксировать изменения в исполняющемся контейнере и создать на его основе новый образ (на Linux это – обычное дело).
4. Docker для Windows пока не поддерживает Swarm Mode.
Использование Dockerfile в Windows и образ с MySQL
--------------------------------------------------
На платформе Windows Server можно создавать контейнеры с использованием файлов Dockerfile. Возьмём пример такого файла для MySQL и соберём на его основе контейнер MySQL. Мне подходящий файл попался где-то на GitHub и я решил взглянуть на то, как механизм создания образов с помощью Dockerfile работает на Windows. Этот файл выглядит так:
```
FROM microsoft/windowsservercore
LABEL Description="MySql" Vendor="Oracle" Version="5.6.29″
RUN powershell -Command \
$ErrorActionPreference = ‘Stop’; \
Invoke-WebRequest -Method Get -Uri https://dev.mysql.com/get/Downloads/MySQL-5.6/mysql-5.6.29-winx64.zip -OutFile c:\mysql.zip ; \
Expand-Archive -Path c:\mysql.zip -DestinationPath c:\ ; \
Remove-Item c:\mysql.zip -Force
RUN SETX /M Path %path%;C:\mysql-5.6.29-winx64\bin
RUN powershell -Command \
$ErrorActionPreference = ‘Stop’; \
mysqld.exe –install ; \
Start-Service mysql ; \
Stop-Service mysql ; \
Start-Service mysql
RUN type NUL > C:\mysql-5.6.29-winx64\bin\foo.mysql
RUN echo UPDATE user SET Password=PASSWORD(‘mysql123′) WHERE User=’root’; FLUSH PRIVILEGES; .> C:\mysql-5.6.29-winx64\bin\foo.mysql
RUN mysql -u root mysql < C:\mysql-5.6.29-winx64\bin\foo.mysql
```
Всё сработало как ожидалось, образ MySQL был собран быстро и без проблем. [Вот](https://hub.docker.com/r/ajeetraina/windows-mysql/) мой репозиторий «докеризованного» MySQL для Windows (правда, мне ещё надо заполнить его описание).
*MySQL для Windows*
Итоги
-----
Docker для Windows – технология очень молодая, поэтому она пока не поддерживает все те возможности, которые имеются у Linux-версии. Однако, существующие наработки, усилия компаний и сообществ независимых разработчиков, вселяют надежду в то, что полноценное использование Docker на платформе Windows – дело недалёкого будущего.
Кстати, если вы хотите продолжить знакомство с Docker для Windows – взгляните на [этот](https://msdn.microsoft.com/virtualization/windowscontainers/containers_welcome) регулярно пополняемый и обновляемый набор материалов от Microsoft. | https://habr.com/ru/post/315220/ | null | ru | null |
# Вышел релиз GitLab 13.6 с автоматическим развёртыванием в EC2 и статистикой использования для инстанса

Команда GitLab стремится к повышению производительности и степени удовлетворённости разработчиков. Релиз 13.6 содержит все необходимые ингредиенты, которые помогут вам достичь этого и, возможно, чего-то ещё! Мы надеемся, что вам пригодятся основные фичи релиза, а также ещё **более 60 новых фич и улучшений**, добавленных в этом релизе.
Простота использования и автоматизация для повышения эффективности
------------------------------------------------------------------
Чтобы вам было проще начать работу с CI/CD GitLab на Amazon Web Services (AWS), мы добавили поддержку AWS к нашей фиче Auto DevOps, так что теперь вы можете [запускать автоматические развёртывания на EC2](#avtomaticheskoe-razvyortyvanie-v-ec2), используя Auto DevOps без Kubernetes (который ранее требовался в Auto DevOps).
Docker Hub ввёл ограничения по количеству запросов `docker pull` для бесплатных планов. Мы [постарались смягчить последствия этих ограничений](https://about.gitlab.com/blog/2020/10/30/mitigating-the-impact-of-docker-hub-pull-requests-limits/) для наших SaaS- и самостоятельных установок, а также мы предлагаем способы [отслеживания этих лимитов с помощью с Prometheus](https://about.gitlab.com/blog/2020/11/18/docker-hub-rate-limit-monitoring/) в ваших окружениях. Мы хотим, чтобы все наши пользователи могли безопасно использовать CI/CD конвейеры (в русской локализации GitLab «сборочные линии») и кластеры Kubernetes, поэтому мы переводим [прокси зависимостей](#proksi-zavisimostey-teper-s-otkrytym-ishodnym-kodom) (Dependency Proxy) в план Core, доступный для всех.
Мы прислушались к мнению сообщества о том, что имя ветки по умолчанию должно быть настраиваемым, и теперь владельцы групп могут указать для новых репозиториев [исходное имя ветки по умолчанию](#nastroyte-nachalnoe-imya-vetki-dlya-novyh-proektov-v-gruppe), отличное от `master`. Кстати о настройках по умолчанию, теперь вы можете задать [шаблон мерж-реквеста](#shablon-opisaniya-merzh-rekvesta-dlya-redaktora-staticheskih-saytov) (в русской локализации GitLab «запрос на слияние») для редактора статических сайтов, благодаря чему вам больше не придется переходить к свежепредложенному мерж-реквесту только ради добавления описания.
Большая наглядность для более быстрого принятия решений
-------------------------------------------------------
Нельзя исправить то, что нельзя найти. С релизом 13.6 мы внесли улучшения в несколько панелей и отчётов, чтобы повысить наглядность и помочь вам быстрее принимать решения.
С помощью [данных о степени качества кода](#otobrazhenie-dannyh-o-stepeni-kachestva-koda), включённых в мерж-реквест, и [полного отчёта о качестве кода](#generaciya-html-otchyotov-dlya-kachestva-koda), вы сможете быстро определить, какие проблемы, связанные с качеством кода, необходимо решить до мержа. Спасибо нашему сообществу, а именно [Vicken Simonian](https://gitlab.com/vicken.papaya), за вклад с отчётом по качеству кода!
Мы обновили [панель безопасности проекта](https://docs.gitlab.com/ee/user/application_security/security_dashboard/#project-security-dashboard), добавив [результаты последнего сканирования безопасности конвейера](#status-konveyera-na-paneli-bezopasnosti-proekta), а также [динамический график тенденций уязвимостей](#novyy-grafik-tendenciy-uyazvimostey), чтобы вы были в курсе трендов развития уязвимостей в реальном времени и в прошлом. Мы также добавили [результаты фаззинг-тестирования в виджет мерж-реквеста](#artefakty-fazzing-testirovaniya-na-osnove-pokrytiya-dostupny-v-vidzhete-merzh-rekvesta) вместе с другими отчётами по безопасности и улучшили читаемость этого отчёта, добавив имя исходного файла и номер строки, чтобы вы могли быстро найти точное место падения приложения и исправить его.
Администраторы инстансов GitLab с самостоятельным управлением теперь могут [отслеживать тенденции использования в своей организации](#statistika-polzovateley-proektov-grupp-tiketov-merzh-rekvestov-i-aktivnosti-konveyera) разных фич, например, количество пользователей, проекты, группы, тикеты и конвейеры за последние 12 месяцев.
Улучшили работу с другими сервисами
-----------------------------------
Мы считаем, что GitLab должен [хорошо взаимодействовать с другими популярными инструментами](https://about.gitlab.com/handbook/product/gitlab-the-product/#plays-well-with-others), которыми часто пользуются совместно с GitLab, чтобы обеспечить органичное взаимодействие, даже если вы используете не все возможности GitLab. Чтобы обеспечить лёгкий доступ и совместную работу в VS Code, в релизе 13.6 мы улучшили наше [расширение для VS Code](https://docs.gitlab.com/ee/user/project/#gitlab-workflow---vs-code-extension). Теперь вы сможете [вставлять сниппеты](#vstavka-snippetov-gitlab-pryamo-v-vs-code), а также просматривать и комментировать мерж-реквесты и тикеты непосредственно из VS Code, вместо того, чтобы переключаться в интерфейс GitLab.
[Интеграции](#upravlenie-integraciyami-proektov-na-urovne-grupp) теперь могут быть настроены на уровне группы наряду с уровнем инстанса и уровнем проекта, что поможет владельцам групп легко управлять интеграциями.
И это ещё не всё
----------------
Для того чтобы вы могли преодолеть ограничение в [10 ГБ на проект](https://about.gitlab.com/pricing/), мы недавно ввели возможность [приобретать дополнительное место](https://customers.gitlab.com/). В дополнение к [прокси зависимостей](#proksi-zavisimostey-teper-s-otkrytym-ishodnym-kodom), мы также переместили [трассировку](#trassirovka-teper-v-core) в Core в рамках этого релиза.
Это всего лишь несколько новых фич и улучшений производительности из этого релиза, об остальных мы расскажем подробнее далее в статье. Если вы хотите заранее узнать, что вас ждёт в следующем месяце, загляните на страницу [будущих релизов](https://about.gitlab.com/upcoming-releases/), а также посмотрите [видео по релизу 13.7](https://www.youtube.com/playlist?list=PL05JrBw4t0KoDQr8x2MaumyU7d8_6icNH), где наши менеджеры рассказывают о ключевых фичах следующего релиза.
[Приглашаем на наши встречи](https://about.gitlab.com/events/).

[MVP](https://about.gitlab.com/community/mvp/) этого месяца — [Sashi](https://gitlab.com/ksashikumar)
-----------------------------------------------------------------------------------------------------
Sashi [добавил ключевой набор возможностей для веб-хука GitLab](https://gitlab.com/gitlab-org/gitlab/-/merge_requests/41863), который добавляет события, когда [изменена подключаемая фича](https://gitlab.com/gitlab-org/gitlab/-/issues/220898) или [запустилось развёртывание](https://gitlab.com/gitlab-org/gitlab/-/issues/235474). Sashi также добавил в чат [уведомление о начале установки](https://gitlab.com/gitlab-org/gitlab/-/issues/235475).
Огромное спасибо [Sashi](https://gitlab.com/ksashikumar) за эти вклады!
Основные фичи релиза GitLab 13.6
--------------------------------
### Автоматическое развёртывание в EC2
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Release](https://about.gitlab.com/stages-devops-lifecycle/release/)
Теперь Auto DevOps поддерживает развёртывание в Amazon Web Services. Вы можете развёртывать в AWS Cloud Compute (EC2) и использовать при этом все преимущества Auto DevOps от GitLab, даже без использования Kubernetes. Для этого необходимо включить Auto DevOps и определить переменные окружения для AWS: `AWS_ACCESS_KEY_ID`, `AWS_SECRET_ACCESS_KEY` и `AWS_DEFAULT_REGION`. Это позволяет создать собственную инфраструктуру, используя API [AWS CloudFormation](https://aws.amazon.com/cloudformation/). После этого вы можете отправить ранее собранный артефакт в корзину [AWS S3](https://aws.amazon.com/s3/) и развернуть его содержимое на инстансе [AWS EC2](https://aws.amazon.com/ec2/). Ваше развёртывание EC2 автоматически соберёт полный автоматический конвейер поставки без каких-либо дополнительных ручных действий.
[Документация по настраиваемым сборкам в Auto DevOps](https://docs.gitlab.com/ee/ci/cloud_deployment/#custom-build-job-for-auto-devops) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/216008).
### Поддержка коллекций Postman для фаззинг-тестирования API
(ULTIMATE, GOLD) [Стадия цикла DevOps: Secure](https://about.gitlab.com/stages-devops-lifecycle/secure/)
Теперь вы можете использовать [коллекции Postman](https://www.postman.com) для тестирования API фаззингом! Коллекции Postman — это предустановленные описания ваших API, которые вы, вероятно, уже создавали в процессе тестирования. А если вы этого ещё не делали, создать их очень просто.
Это отличный способ использовать фаззинг-тестирование с уже имеющимися у вас ресурсами. Чтобы использовать коллекцию Postman для фаззинг-тестирования, добавьте её в ваш репозиторий и укажите её расположение в файле `.gitlab-ci.yml`. После чего движок фаззинга будет ссылаться на эту коллекцию для проведения фаззинг-тестирования.
Тестирование API фаззингом с использованием коллекции Postman выполняет все те же проверки, что и тестирование фаззингом с помощью спецификации OpenAPI или HAR-записи. У нас есть [пример проекта](https://gitlab.com/gitlab-org/security-products/demos/api-fuzzing/postman-api-fuzzing-example), к которому вы можете обратиться, чтобы быстрее начать работу.

[Документация по использованию коллекций Postman для фаззинг-тестирования](https://docs.gitlab.com/ee/user/application_security/api_fuzzing/index.html#postman-collection) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/249838).
### Отображение данных о степени качества кода
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Verify](https://about.gitlab.com/stages-devops-lifecycle/verify/)
Фича «качество кода» (code quality) в GitLab позволяет узнать, какие нарушения качества кода существуют в проекте на данный момент или же вносятся в мерж-реквесте. Однако понимание того, какие из этих нарушений являются наиболее существенными, ранее не было очевидным при работе в интерфейсе GitLab.
Благодаря полному отчёту о качестве кода в виджете мерж-реквеста вы сможете увидеть оценку степени серьёзности нарушений. Теперь вы сможете понять, какие нарушения качества кода наиболее важны и требуют устранения до мержа, и сократить технический долг в вашем проекте.

[Документация по виджету качества кода](https://docs.gitlab.com/ee/user/project/merge_requests/code_quality.html#code-quality-widget) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/2529).
### Отображение покрытия кода тестами для выбранных проектов
(PREMIUM, ULTIMATE, SILVER, GOLD) [Стадия цикла DevOps: Verify](https://about.gitlab.com/stages-devops-lifecycle/verify/)
В 13.4 мы выпустили первую итерацию [данных о покрытии кода для проектов группы](https://habr.com/ru/post/522792/#dannye-o-pokrytii-koda-testami-po-vsem-proektam-gruppy), которая позволяла сравнить покрытие кода тестами среди нескольких проектов и загрузить данные в общем файле с того же экрана. Однако для анализа данных необходимо было открыть файл и самостоятельно просмотреть его, а затем, возможно, импортировать данные в электронную таблицу для дальнейшего анализа. В GitLab 13.6 вы можете выбрать конкретные проекты группы, чтобы просмотреть последние значения их покрытия непосредственно в интерфейсе GitLab, без необходимости загружать файл и тратить время на получение доступа к данным о покрытии кода. Мы будем рады, если вы напишете отзывы о том, как эта фича работает, и что можно было бы улучшить в будущих итерациях в специальном [тикете для фидбэка](https://gitlab.com/gitlab-org/gitlab/-/issues/231515).
[Документация по проверке покрытия кода проектов тестами](https://docs.gitlab.com/ee/user/group/repositories_analytics/index.html#latest-project-test-coverage-list) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/215135).
### Создавайте тест-кейсы в GitLab
(ULTIMATE, GOLD) [Стадия цикла DevOps: Plan](https://about.gitlab.com/stages-devops-lifecycle/plan/)
Мы сделали первый шаг к управлению качеством на уровне проекта. В этом первом релизе вы можете создавать и просматривать тест-кейсы в GitLab.
Объединение всех ваших инструментов управления качеством в единой системе DevOps необходимо, чтобы создать главный источник информации и общее место для всех участников, где они могут взаимодействовать друг с другом и отслеживать контекст. Возможность создавать тест-кейсы в GitLab — первый шаг в этом направлении. Мы намерены продолжать работу на этой базе, добавив тестовые сессии, панель управления качеством и возможность просматривать историю тестов по нескольким целям развёртывания, например staging и production.
Чтобы узнать больше о том, как мы планируем развивать эту фичу, или внести свой вклад, посетите страницу [«Управление качеством»](https://about.gitlab.com/direction/plan/quality_management/).
[Документация по тест-кейсам](https://docs.gitlab.com/ee/ci/test_cases/index.html) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/233479).
### Управление интеграциями проектов на уровне групп
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Create](https://about.gitlab.com/stages-devops-lifecycle/create/)
В релизе 13.3 мы добавили возможность [подключить интеграцию для всего инстанса](https://habr.com/ru/post/518382/#upravlenie-integraciyami-proektov-na-urovne-instansa-dlya-vneshnih-servisov). В GitLab 13.6 мы добавили возможность управлять интеграциями и на групповом уровне!
Теперь владельцы группы могут добавить в группу интеграцию, которая будет унаследована всеми проектами, входящими в эту группу. Это может сэкономить огромное количество времени, так как многие организации используют определённые интеграции, которые необходимо внедрить в каждый проект, над которым они работают.
Отличный пример использования этой фичи — подключение нашей [интеграции с Jira](https://docs.gitlab.com/ee/user/project/integrations/jira.html). Если вы используете Jira, то она почти всегда используется везде в компании. Некоторые из компаний работают с *тысячами проектов* и ранее были вынуждены настраивать интеграцию для каждого по отдельности.
С помощью управления интеграциями проектов на уровне группы вы сможете добавить интеграцию в родительскую группу, уменьшив количество необходимых настроек на порядок!
Узнайте больше в [соответствующем анонсе в блоге GitLab](https://about.gitlab.com/blog/2020/11/19/integration-management/).

[Документация по управлению интеграциями проекта](https://docs.gitlab.com/ee/user/admin_area/settings/project_integration_management.html) и [оригинальный эпик](https://gitlab.com/groups/gitlab-org/-/epics/2543).
### Графики выполнения работ и точные отчёты
(STARTER, PREMIUM, ULTIMATE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Plan](https://about.gitlab.com/stages-devops-lifecycle/plan/)
График выполнения работ (burndown chart) по майлстоуну (в русской локализации GitLab «этап») или итерации помогает отслеживать прогресс в выполнении общего объёма работ, но не даёт представления о том, как менялся объём работ в течение временного блока (timebox). Кроме того, в нём не сохранялась историческая точность в отношении того, какая часть изначально выделенного объёма работ по этапу или итерации была фактически выполнена.
Чтобы решить эти проблемы и предоставить командам лучшее представление о причинах разрастания сроков, майлстоуны и итерации теперь показывают график выполнения работ в виде burnup chart, в котором отображается общее количество и вес тикетов, добавленных и решённых в течение заданного временного блока.
Мы также переработали графики выполнения работ для использования неизменяемых [событий состояния ресурса](https://docs.gitlab.com/ee/api/resource_state_events.html#issues), что гарантирует, что графики выполнения работ в майлстоунах и итерациях останутся исторически точными[1] даже после того, как вы переместили тикеты в другое временное окно.
[1] Это относится только к майлстоунам и итерациям, созданным в GitLab 13.6 или более поздних версиях. Созданные до 13.6 майлстоуны по-прежнему будут иметь доступ к [старым графикам выполнения работ](https://docs.gitlab.com/ee/user/project/milestones/burndown_and_burnup_charts.html#fixed-burndown-charts).
[Документация по графикам выполнения работ](https://docs.gitlab.com/ee/user/project/milestones/burndown_and_burnup_charts.html#burnup-charts) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/6903).
### Меняйте значение canary-weight через API
(PREMIUM, ULTIMATE, SILVER, GOLD) [Стадия цикла DevOps: Release](https://about.gitlab.com/stages-devops-lifecycle/release/)
Добавление поддержки аннотации canary-weight — это первая итерация в реализации балансировщика нагрузки в GitLab. Наша цель — предоставить простой способ конфигурации аннотаций NGINX, чтобы вы могли легко настроить их поведение. Проще говоря, это даст вам дополнительную гибкость при настройке сложных развёртываний. Ранее изменение canary-weight поддерживалось только через файл `.gitlab-ci.yml`. Теперь у вас будет больше контроля над вашими развёртываниями, а также возможность внедрять развёртывания по триггеру.
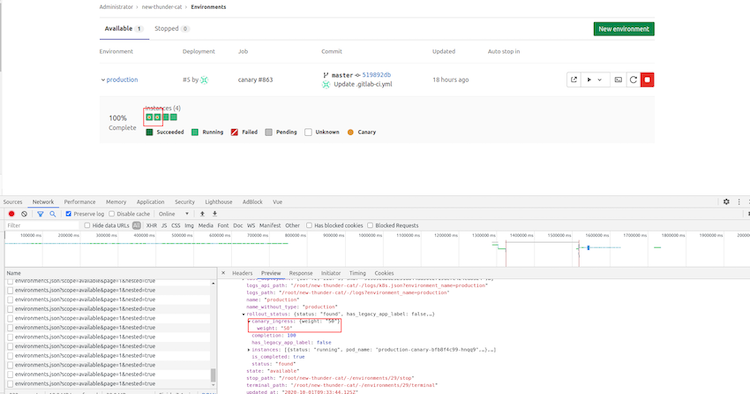
[Документация по canary-развёртываниям](https://docs.gitlab.com/ee/user/project/canary_deployments.html) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/215501).
### Запускайте веб-хук при переключении подключаемой фичи
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Release](https://about.gitlab.com/stages-devops-lifecycle/release/)
Как разработчик вы можете использовать веб-хуки GitLab для различных событий, таких как события мерж-реквестов, конвейера, заданий и развёртывания. С этого релиза вы также можете запускать веб-хук, когда была переключена подключаемая фича (feature flag). Это упрощает процесс обновления CI/CD конвейеров, получения в Slack уведомлений о событиях и не только. Огромное спасибо [Sashi](https://gitlab.com/ksashikumar) за этот вклад от сообщества!
[Документация по веб-хукам](https://docs.gitlab.com/ee/user/project/integrations/webhooks.html#feature-flag-events) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/220898).
### Сортировка релизов по имени на странице релизов
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Release](https://about.gitlab.com/stages-devops-lifecycle/release/)
Страница релизов может быть запутанной и трудной для навигации, если у вас сотни тегов релизов с примечаниями к ним. С введением нового механизма сортировки вам больше не придётся вручную просматривать релизы каждый раз перед развёртыванием. Теперь вы можете сортировать релизы по дате и названию, чтобы находить нужную информацию более эффективно.
[Документация по релизам](https://docs.gitlab.com/ee/user/project/releases/#sort-releases) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/26413).
Другие улучшения в GitLab 13.6
------------------------------
### Требование подтверждения новых учётных записей администратором включено по умолчанию
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Manage](https://about.gitlab.com/stages-devops-lifecycle/manage/)
В GitLab 13.5 мы ввели возможность [требовать подтверждения администратором регистрации новых пользователей](https://habr.com/ru/post/527208/#nastroyka-podtverzhdeniya-pri-registracii-novogo-polzovatelya). Для повышения безопасности нашей конфигурации по умолчанию, GitLab 13.6 включает эту опцию для всех новых инстансов. Мы также добавили уведомления для администраторов по электронной почте при новых регистрациях и уведомления для пользователей, когда их регистрация одобрена. Уведомления по электронной почте на этих важных этапах помогают сократить время оформления новых пользователей, если требуется одобрение администратора.
[Документация по подтверждению регистраций администраторам](https://docs.gitlab.com/ee/user/admin_area/settings/sign_up_restrictions.html#require-administrator-approval-for-new-sign-ups) и [оригинальный эпик](https://gitlab.com/groups/gitlab-org/-/epics/4491).
### Экспорт мерж-реквестов в CSV
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Manage](https://about.gitlab.com/stages-devops-lifecycle/manage/)
Многие организации обязаны документировать изменения (мерж-реквесты) и данные по ним, например, кто является автором мерж-реквеста, кто его одобрил и когда эти изменения были отправлены в продакшен. Хотя этот список и не является исчерпывающим, он подчёркивает необходимость отслеживаемости и удобного экспорта этих данных из GitLab для выполнения требований аудита или других нормативных требований.
Раньше вам нужно было использовать наш [API мерж-реквестов](https://docs.gitlab.com/ee/api/merge_requests.html#merge-requests-api), чтобы собрать эти данные с помощью пользовательских инструментов. Теперь же вы можете нажать одну кнопку и получить CSV-файл, содержащий всю необходимую информацию.

[Документация по экспорту в CSV](https://docs.gitlab.com/ee/user/project/merge_requests/csv_export.html) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/3619).
### Улучшили список членов группы
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Manage](https://about.gitlab.com/stages-devops-lifecycle/manage/)
Список членов группы был переработан с использованием нашей [системы дизайна Pajamas](https://design.gitlab.com/). Обновления включают в себя более понятную терминологию, новую компоновку, заголовки для всех столбцов, подсказки для ключевых элементов и не только! Новое представление поможет администраторам групп быстрее определять ключевые атрибуты участников группы для более эффективного управления группой.

[Документация по работе с группой](https://docs.gitlab.com/ee/user/group/#add-users-to-a-group) и [оригинальный эпик](https://gitlab.com/groups/gitlab-org/-/epics/4600).
### Фильтрация по итерациям для досок и списков задач
(STARTER, PREMIUM, ULTIMATE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Plan](https://about.gitlab.com/stages-devops-lifecycle/plan/)
В рамках наших непрерывных усилий по улучшению использования временных блоков (timeboxes) для планирования и отслеживания работы в GitLab, мы добавили фильтрацию по итерации для списков задач и досок. Например, команда, использующая итерации для двухнедельного спринта, теперь может использовать ограниченный список заданий или доску как единый источник информации о задачах в конкретном спринте.
[Документация по использованию фильтров в списках тикетов и мерж-реквестов](https://docs.gitlab.com/ee/user/search/#filtering-issue-and-merge-request-lists) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/118742).
### Отслеживайте состояние тикетов из списка тикетов
(ULTIMATE, GOLD) [Стадия цикла DevOps: Plan](https://about.gitlab.com/stages-devops-lifecycle/plan/)
Если вам приходится управлять большим количеством тикетов в работе, может быть трудно отследить их состояние здоровья, особенно если вы работаете с несколькими эпиками (в русской локализации GitLab «цели»). Теперь в интерфейсе списка тикетов отображается их состояние, что позволит вам быстро получить краткое представление о текущем состоянии работы. В следующей итерации мы также [добавим фильтрацию](https://gitlab.com/gitlab-org/gitlab/-/issues/218711).
[Документация по состоянию здоровья тикетов](https://docs.gitlab.com/ee/user/project/issues/#health-status) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/218330).
### Настраивайте место назначения для изображений, загруженных из редактора статических сайтов
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Create](https://about.gitlab.com/stages-devops-lifecycle/create/)
В GitLab 13.6 появилась возможность [загружать графические ресурсы через статический редактор сайтов непосредственно в ваш проект](#zagruzka-izobrazheniy-v-redaktor-staticheskih-saytov). Изображения, загружаемые с вашего компьютера, включаются в итоговый мерж-реквест, и по умолчанию для загружаемых ресурсов используется каталог `source/images`. Однако, в зависимости от структуры вашего проекта, вы можете захотеть хранить свои изображения в другом месте. А каталог по умолчанию может даже не существовать.
Файл `.gitlab/static-site-editor.yml` позволяет настроить поведение редактора. Укажите в `image_upload_path` абсолютный путь к каталогу ваших ресурсов, чтобы наш редактор статических сайтов знал, где вы хотите хранить изображения в вашем проекте.
[Документация по файлу конфигурации](https://docs.gitlab.com/ee/user/project/static_site_editor/index.html#static-site-editor-configuration-file) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/216641).
### Фильтр мерж-реквестов по окружению и времени развёртывания
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Create](https://about.gitlab.com/stages-devops-lifecycle/create/)
Теперь вы можете фильтровать мерж-реквесты по окружению и времени развёртывания в дополнение к уже существующим фильтрам по ID развёртывания. Это означает, что теперь вы можете находить мерж-реквесты по имени окружения, ID развёртывания или времени развёртывания (до или после определённого момента). Использование комбинации этих фильтров может помочь вам понять, какие развёртывания были запущены в окружении за определённый период времени.
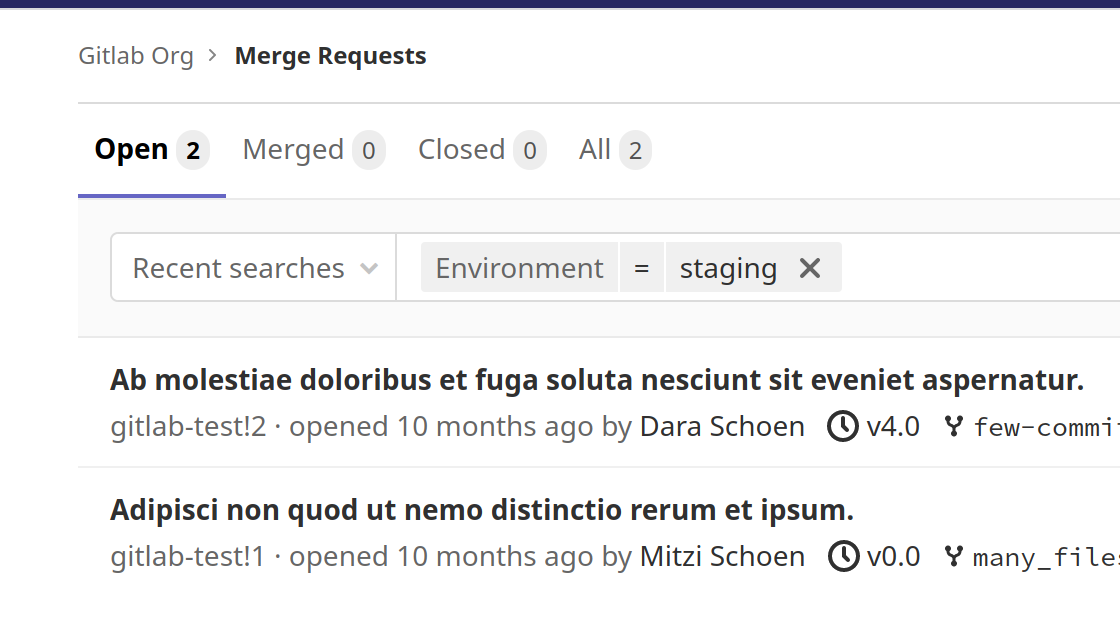
[Документация по фильтрации мерж-реквестов по окружению и дате развёртывания](https://docs.gitlab.com/ee/user/search/#filtering-merge-requests-by-environment-or-deployment-date) и [оригинальный тикет](https://gitlab.com/gitlab-com/gl-infra/delivery/-/issues/1246).
### Добавление LFS-файлов Git в архив репозитория
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Create](https://about.gitlab.com/stages-devops-lifecycle/create/)
Хранилище крупных файлов LFS — это одно из решений Git для работы с крупными файлами. Оно заменяет крупные файлы на указатели на них. Содержимое файлов хранится на удалённом сервере, например GitLab. Это позволяет разработчикам управлять версиями для очень больших файлов, при этом операции Git между локальным хостом и сервером остаются быстрыми и эффективными.
Ранее при скачивании из GitLab архива с исходниками, который содержит LFS-файлы, экспортировался указатель на файл вместо самого файла. Это уменьшало размер архива, но при этом архив не содержал полный снимок репозитория. Это значит, что пользователям приходилось делать много ручной работы, добавляя каждый LFS-файл в отдельности, чтобы получить полную копию репозитория.
GitLab 13.6 будет экспортировать LFS файлы целиком, а не только указатели на них, что позволит получать полную копию содержимого вашего репозитория.
[Документация по LFS-объектам в архивах проекта](https://docs.gitlab.com/ee/topics/git/lfs/#lfs-objects-in-project-archives) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/15079).
### Тикеты и мерж-реквесты в VS Code
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Create](https://about.gitlab.com/stages-devops-lifecycle/create/)
Тикеты являются источником достоверной информации по тому, что необходимо сделать в проекте, и подходящим местом для совместной работы. Чтобы ссылаться на истории пользователей, дизайны и обсуждения к тикетам, приходится переключаться между редактором и браузером. В комментариях к мерж-реквестам вы получаете обратную связь по предлагаемым изменениям. Чтобы ссылаться на эту обратную связь и продолжать вносить изменения, вам также приходится переключать контекст между редактором и браузером.
Уменьшение задержки, связанной с переключением контекста, делает более эффективным внесение изменений в проект. С [релизом 3.6.0](https://gitlab.com/gitlab-org/gitlab-vscode-extension/-/blob/main/CHANGELOG.md#360-2020-10-26) [GitLab Workflow](https://marketplace.visualstudio.com/items?itemName=GitLab.gitlab-workflow), вы можете работать с тикетами и мерж-реквестами напрямую в VS Code. Вы можете искать тикеты и мерж-реквесты, назначенные вам или созданные вами, получать доступ к необходимой информации в тикетах и мерж-реквестах и комментировать их.
Это первый шаг к возможности проводить более полные [ревью мерж-реквестов в VS Code](https://gitlab.com/groups/gitlab-org/-/epics/4607).
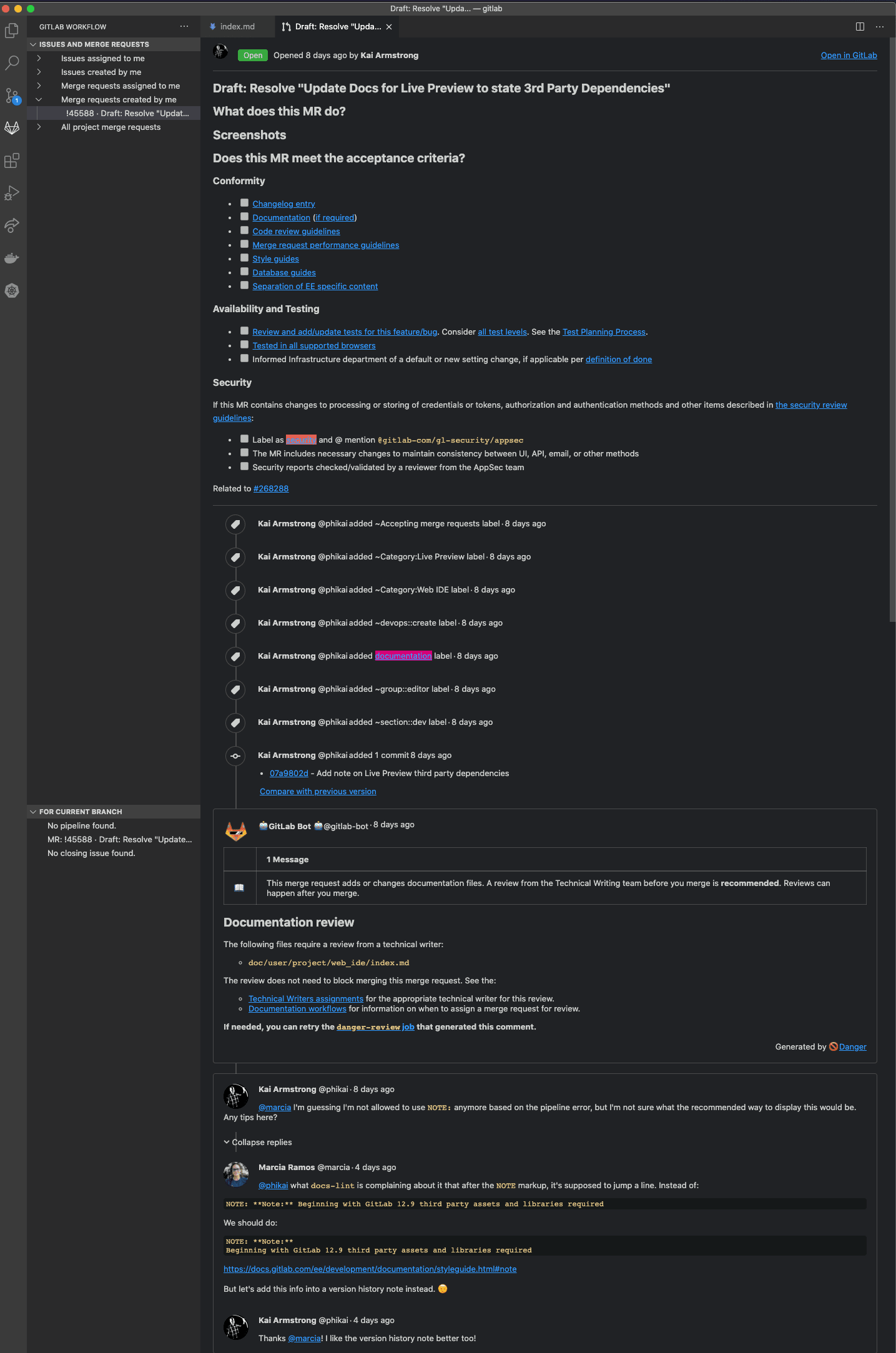
[Документация по интеграции с VS Code](https://gitlab.com/gitlab-org/gitlab-vscode-extension#view-issue-and-mr-details-and-comments-in-vs-code) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab-vscode-extension/-/issues/53).
### Уникальный идентификатор дизайна
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Create](https://about.gitlab.com/stages-devops-lifecycle/create/)
Изначально все дизайны относились к тикетам и имели URL, который включает ID и имя файла дизайна. Это накладывает много ограничений на архитектуру управления дизайнами, так как вы не можете ссылаться на поле внутреннего идентификатора дизайна.
Хотя эта фича носит чисто технический характер, она создаёт основу для использования дизайнов во многих местах в GitLab. С уникальными внутренними идентификаторами мы сможем добавить привязку дизайнов к [мерж-реквестам](https://gitlab.com/groups/gitlab-org/-/epics/3035), [эпикам](https://gitlab.com/groups/gitlab-org/-/epics/2565) и [на уровне проекта](https://gitlab.com/groups/gitlab-org/-/epics/3033).
[Документация по управлению дизайнами](https://docs.gitlab.com/ee/user/project/issues/design_management.html#adding-designs) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/214978).
### Генерация HTML-отчётов для качества кода
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Verify](https://about.gitlab.com/stages-devops-lifecycle/verify/)
Отчёты о качестве кода (Code Quality) дают вам много различной информации о нарушениях в качестве кода, найденных в текущей ветке, однако они генерируются в довольно неудобном для чтения формате.
Теперь этот вид отчёта доступен в формате файла `.html`, так что вам будет удобнее просматривать нарушения в качестве кода вашего проекта и определять их значимость. Вы даже можете хостить этот файл на GitLab Pages для ещё более удобного ревью.
Спасибо [Vicken Simonian](https://gitlab.com/vicken.papaya) за эту фичу!
[Документация по генерации HTML-отчётов по качеству кода](https://docs.gitlab.com/ee/user/project/merge_requests/code_quality.html#generating-an-html-report) и [оригинальный тикет](https://gitlab.com/gitlab-org/ci-cd/codequality/-/issues/10).
### Добавление нескольких файлов конфигурации CI/CD в виде списка
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Verify](https://about.gitlab.com/stages-devops-lifecycle/verify/)
Ранее при добавлении нескольких файлов для вашей конфигурации CI/CD с использованием синтаксиса `include:file`, вы должны были задавать проект и ссылку для каждого файла. Начиная с этого релиза у вас появляется возможность передавать проект, ссылку и список файлов одновременно. Это позволит вам не повторять одни и те же действия несколько раз и сделает конфигурацию вашего конвейера менее запутанной.

[`Документация по синтаксису include:file`](https://docs.gitlab.com/ee/ci/yaml/#includefile) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/26793).
### Отображение данных покрытия при неудачном завершении конвейера
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Verify](https://about.gitlab.com/stages-devops-lifecycle/verify/)
Мейнтейнеры проекта (в русской локализации GitLab «сопровождающие») могут выбрать использование бейджей отображения текущего покрытия проекта тестами. К сожалению, если конвейер выполняется долго, в нём есть ручные шаги или он завершается с ошибкой для ветки, связанной с бейджем, значение покрытия будет отображаться как «неизвестно». Это делает бейджи менее полезными для вас.
Теперь ваш конвейер не должен быть полностью успешным, чтобы отображалось значение покрытия, благодаря чему вам будет проще увидеть его статус. Вы можете быть уверены в значении покрытия тестами для вашего проекта (например, перед шагом ручного релиза), без необходимости разбираться в списке заданий.
[Документация по бейджам для конвейера](https://docs.gitlab.com/ee/ci/pipelines/settings.html#pipeline-badges) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/27090).
### Улучшенная работа с отчётами по юнит-тестам
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Verify](https://about.gitlab.com/stages-devops-lifecycle/verify/)
Отчёты по юнит-тестам — это отличный способ проводить ревью результатов тестов через конвейер. Однако наличие крупных кусков логов может сделать страницу очень длинной и неудобной для навигации. Также вам может быть сложно найти тест, который вы хотели проверить в отчёте по юнит-тестам, так как имя файла теста отсутствовало на странице отчёта.
С релизом GitLab 13.6 имя файла, которое находится в файле отчёта по юнит-тесту, становится доступным на странице, что упрощает поиск. Также содержимое логов удаляется из основного списка и становится доступным в модальном окне, что значительно улучшает работу со списком.
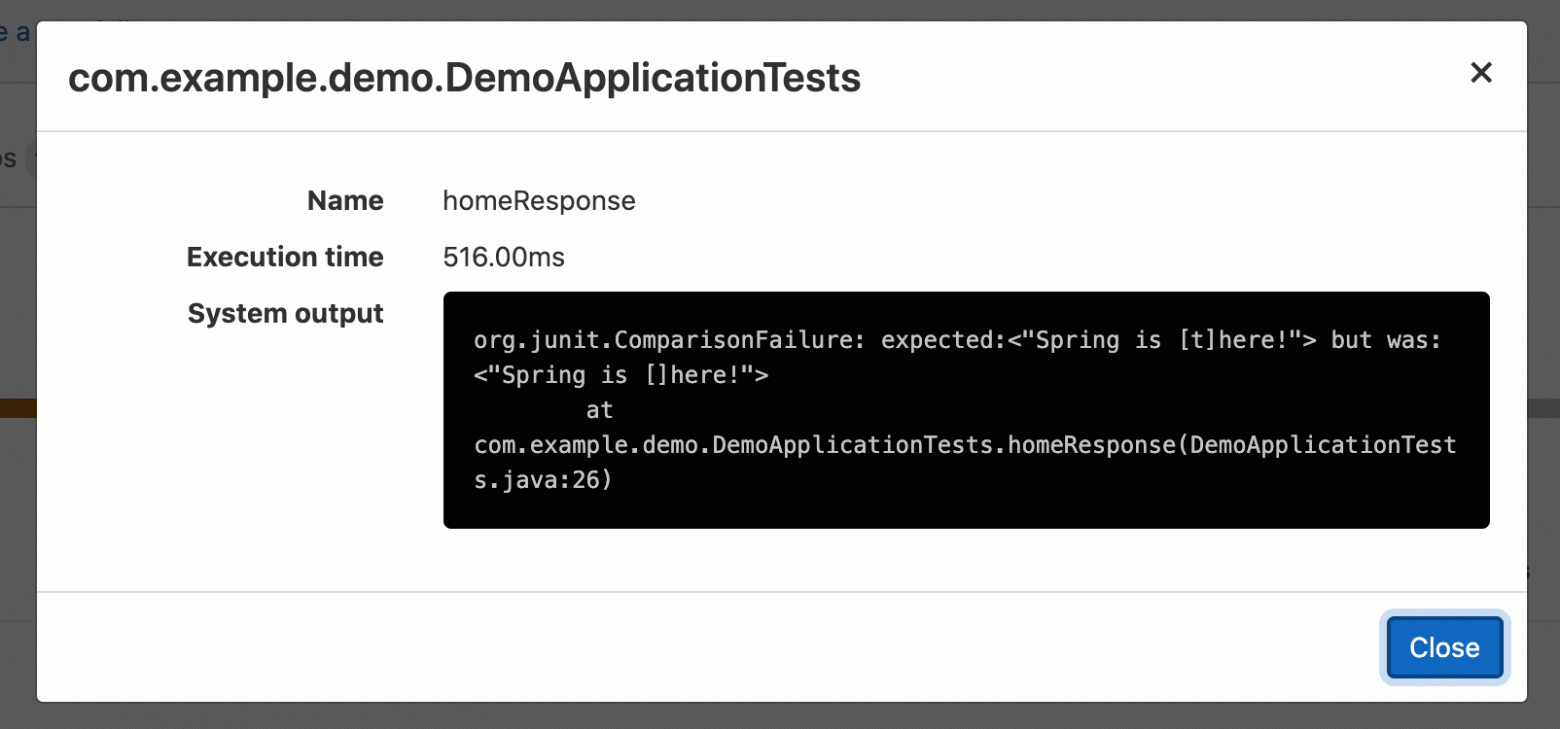
[Документация по отчётам по юнит-тестам в GitLab](https://docs.gitlab.com/ee/ci/unit_test_reports.html#viewing-unit-test-reports-on-gitlab) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/241534).
### Конечная точка npm на уровне проекта работает со всеми командами npm
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Package](https://about.gitlab.com/stages-devops-lifecycle/package/)
Когда вы используете реестр пакетов для публикации и распространения пакетов Node, вы можете выбирать использование конечной точки на уровне инстанса или на уровне проекта. Конечная точка на уровне проекта наиболее полезна, когда у вас есть несколько пакетов в одной группе; конечная точка на уровне инстанса удобна, когда у вас есть несколько пакетов в разных группах.
Проблема заключалась в том, что конечная точка проекта не поддерживала многие распространённые команды npm, включая `npm dist-tag`, `npm add` и `npm view`. В качестве обходного пути вы могли задавать `publishConfig` в каждом `package.json`. Хотя этот обходной путь и работал, у него было несколько недостатков:
* Вам приходилось выполнять дополнительные действия при публикации пакетов, так как каждый пакет нужно было настраивать для публикации в реестре проекта.
* Это усложняло автоматизацию. Например, переменные окружения можно было заменять внутри `.npmrc`, но не в `package.json`. Из-за этого вам приходилось хардкодить ID проекта GitLab в вашем `package.json`.
* Это не соответствовало ожиданиям разработчиков, которые не привыкли к такому рабочему процессу.
Чтобы решить эти проблемы, мы сделали все поддерживаемые конечные точки доступными для использования в инстансах и проектах. Теперь вы можете использовать ваш файл `.npmrc`, чтобы настроить реестр пакетов. Вы больше не должны добавлять и поддерживать `publishConfig` в каждом `package.json` со следующими исключениями:
* Конечная точка загрузки должна быть на уровне проекта. Она не может находиться на уровне инстанса, так как серверная часть получит запрос на загрузку без привязки к группе или проекту и не будет знать, где хранить загружаемый пакет.
* Конечная точка файла архива остаётся на уровне проекта. В ходе выполнения команды `npm install` npm запрашивает URL архива. Реестр пакетов должен в ответ передать локацию, которая может быть где угодно. Чтобы не усложнять этот процесс, мы оставим её там, где она находится сейчас: на уровне проекта.
[Документация по конечной точке npm на уровне проекта](https://docs.gitlab.com/ee/user/packages/npm_registry/#project-level-npm-endpoint) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/220985).
### Артефакты фаззинг-тестирования на основе покрытия доступны в виджете мерж-реквеста
(ULTIMATE, GOLD) [Стадия цикла DevOps: Secure](https://about.gitlab.com/stages-devops-lifecycle/secure/)
Результаты фаззинг-тестирования на основе покрытия теперь отображаются в результатах сканирования безопасности наряду с результатами других сканирований безопасности мерж-реквеста. Это позволит вам быстро понимать, были ли найдены проблемы в ходе тестирования, получать детальную информацию о них и скачивать артефакты, необходимые для воспроизведения проблемы локально до того, как код будет смержен.
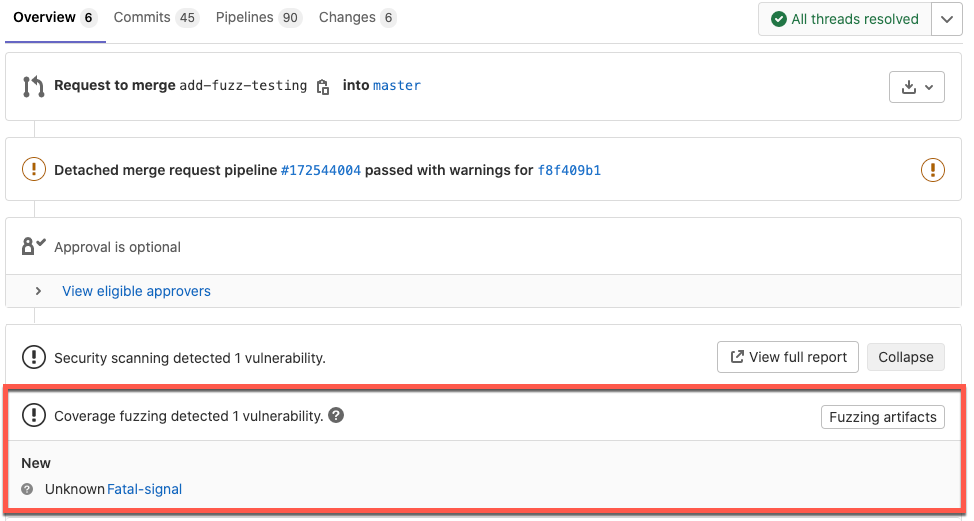
[Документация по взаимодействию с уязвимостями при фаззинг-тестированиях](https://docs.gitlab.com/ee/user/application_security/coverage_fuzzing/#interacting-with-the-vulnerabilities) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/254652).
### Новый механизм для фаззинг-тестирования проектов на Java
(ULTIMATE, GOLD) [Стадия цикла DevOps: Secure](https://about.gitlab.com/stages-devops-lifecycle/secure/)
Мы представляем новый механизм фаззинг-тестирования на основе покрытия для кода на Java. Это базовый механизм, который лежит в основе ваших фаззинг-тестирований на конвейере, он называется [`javafuzz`](https://gitlab.com/gitlab-org/security-products/analyzers/fuzzers/javafuzz) и его можно использовать, задав переменную `--engine javafuzz` в вашем файле конвейера.
Мы рекомендуем в будущем использовать новый механизм `javafuzz` вместо существующего механизма `JQF`. Новый механизм поддерживает фреймворк Java Spring, где, как мы ожидаем, он будет очень полезен.
Кроме того, у нового механизма открытый исходный код, он распространяется под лицензией Apache. Мы будем рады узнать, что вы думаете, и рассмотреть любые улучшения, которые вы предложите.
[Документация по поддерживаемым механизмам и языкам для фаззинг-тестирования](https://docs.gitlab.com/ee/user/application_security/coverage_fuzzing/#supported-fuzzing-engines-and-languages) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/249663).
### Статус конвейера на панели безопасности проекта
(ULTIMATE, GOLD) [Стадия цикла DevOps: Secure](https://about.gitlab.com/stages-devops-lifecycle/secure/)
Панель безопасности проекта является центральным местом управления уязвимостями для команд безопасности и разработчиков. Так как отчёты по безопасности основаны на последнем успешном сканировании конвейера текущей ветки, очень важно быть уверенным в том, что результаты сканирования являются актуальными. Ранее не было никакого способа узнать время или статус последнего сканирования конвейера по умолчанию с этих страниц. Для этого вам приходилось возвращаться к списку конвейеров и искать необходимую информацию там.
Теперь вы можете видеть время последнего сканирования конвейера по умолчанию сверху на панели безопасности проекта, а также ссылку на страницу этого конвейера. Вы также увидите число неудачных завершений конвейера, если они были. Кликнув на ссылку с числом неудачных завершений, вы попадёте на вкладку **Неудачные задания** (**Failed jobs**) на странице конвейера. После того как вы разберётесь с причинами неудачи, новый запуск конвейера обновит данные об уязвимостях для проекта, а также область статуса конвейера на панели безопасности.

[Документация по отчётам об уязвимостях на панели безопасности](https://docs.gitlab.com/ee/user/application_security/security_dashboard/#vulnerability-report) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/249767).
### Поддержка пост-обработки слитых секретных ключей
(FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Secure](https://about.gitlab.com/stages-devops-lifecycle/secure/)
GitLab.com теперь поддерживает веб-хуки для пост-обработки [поиска секретных ключей](https://docs.gitlab.com/ee/user/application_security/secret_detection/). Их можно использовать, например, для отправки уведомлений в облачный сервис, который выдал секретный ключ. Провайдер сервиса может подтвердить учётные данные и быстро отозвать ключ или выдать новый, а также уведомить владельца слитого ключа. Рабочие процессы пост-обработки у разных провайдеров отличаются. С этим релизом GitLab начинает поддерживать пост-обработку для секретных ключей от Amazon Web Services (AWS).
Мы планируем расширить эту интеграцию до других сторонних провайдеров облачных сервисов и SaaS. Если вы как провайдер заинтересованы в интеграции с вашим сервисом, вы можете [заполнить эту анкету](https://forms.gle/wWpvrtLRK21Q2WJL9). Также вы можете узнать больше [технических подробностей пост-обработки секретных ключей](https://gitlab.com/groups/gitlab-org/-/epics/4639).
[Документация по пост-обработке секретных ключей](https://docs.gitlab.com/ee/user/application_security/secret_detection/#post-processing) и [оригинальный эпик](https://gitlab.com/groups/gitlab-org/-/epics/4639).
### Уведомления в чате о начале развёртывания
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Release](https://about.gitlab.com/stages-devops-lifecycle/release/)
В предыдущих релизах GitLab мы добавили поддержку уведомлений для успешных, отменённых и неудачно завершённых развёртываний. В этом релизе вы также сможете получать уведомления в чат при запуске развёртывания. Эта фича стала доступной благодаря потрясающему вкладу от [Sashi](https://gitlab.com/ksashikumar)! С ней вы сможете удобно отслеживать статус развёртываний, не нарушая привычный вам рабочий процесс.
[Документация по триггерам для уведомлений в Slack](https://docs.gitlab.com/ee/user/project/integrations/slack.html#triggers-available-for-slack-notifications) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/235475).
### Остановка приложений для ревью при развёртывании через ECS
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Release](https://about.gitlab.com/stages-devops-lifecycle/release/)
Недавно мы добавили поддержку сервиса AWS ECS для развёртываний в него через Auto DevOps. Однако приложения для ревью для целей ECS ранее не останавливались автоматически. Чтобы исправить это, мы расширили шаблон `Deploy_ECS`, добавив автоматическую остановку приложений для ревью как часть рабочего процесса Auto DevOps, чтобы ресурсы не тратились впустую. Таким образом, опыт работы с Auto DevOps для пользователей, развёртывающих в ECS, и пользователей, использующих Kubernetes, будет одинаковым: операции будут выполняться автоматически, без необходимости вручную останавливать процесс и следить за приложениями для ревью.
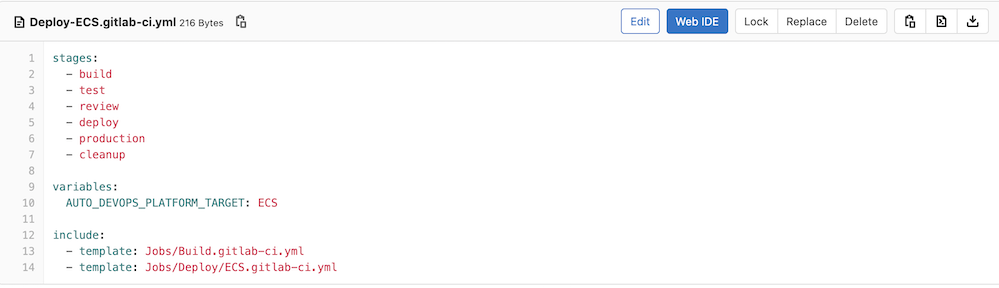
[Документация по развёртыванию приложений через ECS](https://docs.gitlab.com/ee/ci/cloud_deployment/#deploy-your-application-to-the-aws-elastic-container-service-ecs) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/218167).
### Возможность задавать период истечения срока действия окружения при его создании
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Release](https://about.gitlab.com/stages-devops-lifecycle/release/)
В этом релизе у вас появилась возможность задавать время истечения срока действия приложений для ревью при создании окружения. Ранее срок действия был привязан ко времени начала развёртывания, однако в некоторых окружениях развёртывания никогда не происходят. Эта новая фича позволяет автоматически останавливать окружения на основе времени создания, независимо от статуса развёртывания в нем.
[Документация по истечению срока действия окружений](https://docs.gitlab.com/ee/ci/environments/#environments-auto-stop) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/214606).
### Предупреждение при запуске устаревших заданий
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Release](https://about.gitlab.com/stages-devops-lifecycle/release/)
Если вы повторно запустите неудачно завершённое задание развёртывания, в окружение может быть записан старый исходный код. Чтобы это не происходило случайно, мы добавили сообщение, которое предупреждает о том, что вы запускаете устаревшее задание.
[Документация по настройкам конвейера](https://docs.gitlab.com/ee/ci/pipelines/settings.html#retry-outdated-jobs) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/211339).
### Уведомления на пользовательских панелях
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Monitor](https://about.gitlab.com/stages-devops-lifecycle/monitor/)
Уведомления помогают разработчикам и специалистам по эксплуатации наблюдать за состоянием сервисов и прерываниями в их работе. Ранее вы могли создавать уведомления только для метрик на стандартных панелях GitLab. Начиная с этой версии GitLab вы можете настраивать уведомления для любых метрик на любых панелях, которые создаёт и использует ваша команда.
[Документация по уведомлениям для метрик](https://docs.gitlab.com/ee/operations/metrics/alerts.html) и [оригинальный эпик](https://gitlab.com/groups/gitlab-org/-/epics/3971).
### Автоматические фоновые миграции для индексации расширенного поиска
(STARTER, PREMIUM, ULTIMATE, BRONZE, SILVER, GOLD) [Доступность](https://about.gitlab.com/handbook/engineering/development/enablement/)
Добавление новых фич для расширенного поиска зачастую означает также добавление или изменение способа индексации контента, и это изменение индекса выполняется постепенно в течение нескольких дней. На протяжении последних нескольких релизов мы добавили много новых фич для расширенного поиска, и поэтому администраторам GitLab пришлось бы вручную производить переиндексацию после каждого обновления.
Начиная с GitLab 13.6 при добавлении новых фич для расширенного поиска переиндексация будет автоматически запускаться в фоне. При необходимости переиндексацию также можно будет запускать [вручную](https://docs.gitlab.com/ee/integration/elasticsearch.html#trigger-the-reindex-via-the-advanced-search-administration).
[Документация по фоновым миграциям для Elasticsearch](https://docs.gitlab.com/ee/integration/elasticsearch.html#background-migrations) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/234046).
### Повышение скорости веб-интерфейса GitLab с автоматическим изменением размера изображений
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Доступность](https://about.gitlab.com/handbook/engineering/development/enablement/)
GitLab отображает множество изображений, добавленных пользователями, таких как фото профиля или вложения в тикетах и комментариях. До релиза GitLab 13.6 этот контент поставлялся пользователям без изменений независимо от того, как изображение было использовано на странице. Например, мы позволяем добавлять изображения профиля размером до 200 КБ, и на страницах аналогичным [списку коммитов](https://gitlab.com/gitlab-org/gitlab/-/commits/master) мы можем отображать более 20 таких изображений одновременно. Если каждое изображение в среднем занимает 100 КБ, то в сумме получается 20 МБ данных, что значительно замедляет загрузку страницы.
Для улучшения производительности GitLab теперь автоматически изменяет размер аватаров до размера, используемого на странице, что значительно уменьшает размер контента, который необходимо загрузить. На страницах, которые мы использовали для теста, нам удалось уменьшить размер контента в 10 раз. Это не только ускоряет загрузку страницы, но и использует меньше сетевого трафика.
Вы можете узнать больше о нашем подходе и результатах в [этом посте](https://about.gitlab.com/blog/2020/11/02/scaling-down-how-we-prototyped-an-image-scaler-at-gitlab/) из нашего блога.
[Документация по настройкам изменения размера изображений](https://docs.gitlab.com/omnibus/settings/image_scaling.html) и [оригинальный эпик](https://gitlab.com/groups/gitlab-org/-/epics/3822).
### Фильтрация по дате и улучшенные таблицы данных для аналитики мерж-реквестов
(STARTER, PREMIUM, ULTIMATE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Manage](https://about.gitlab.com/stages-devops-lifecycle/manage/)
В GitLab 13.3 мы представили аналитику мерж-реквестов, которая помогает лучше оценивать эффективность и продуктивность пропускной способности мерж-реквестов. GitLab 13.6 представляет новые улучшения в аналитике мерж-реквестов: теперь у вас есть возможность фильтровать [по диапазонам дат](https://gitlab.com/gitlab-org/gitlab/-/issues/262061), а также данные [по количеству подтверждений](https://gitlab.com/gitlab-org/gitlab/-/issues/251079). А ещё мы добавили [пагинацию](https://gitlab.com/gitlab-org/gitlab/-/issues/229842) для таблиц данных.
[Документация по аналитике мерж-реквестов](https://docs.gitlab.com/ee/user/analytics/merge_request_analytics.html) и [оригинальный эпик](https://gitlab.com/groups/gitlab-org/-/epics/3925).
### Создание отчёта для коммита по его SHA
(ULTIMATE, GOLD) [Стадия цикла DevOps: Manage](https://about.gitlab.com/stages-devops-lifecycle/manage/)
В 13.4 мы добавили отчёт [“chain of custody”](https://docs.gitlab.com/ee/user/compliance/compliance_dashboard/#chain-of-custody-report) для всех коммитов мержа в группе. С тех пор ваши отзывы вдохновили нас добавить поддержку экспорта этого отчёта на основе SHA начального коммита. Теперь при экспорте отчёта у вас будет возможность ввести SHA коммита, для которого вы хотите сгенерировать отчёт.

[Документация по генерированию отчёта по SHA коммита](https://docs.gitlab.com/ee/user/compliance/compliance_dashboard/#commit-specific-chain-of-custody-report) и [оригинальный эпик](https://gitlab.com/groups/gitlab-org/-/epics/4608).
### Статистика пользователей, проектов, групп, тикетов, мерж-реквестов и активности конвейера
(CORE, STARTER, PREMIUM, ULTIMATE) [Стадия цикла DevOps: Manage](https://about.gitlab.com/stages-devops-lifecycle/manage/)
Администраторам часто требуется с одного взгляда понять, как используется GitLab. Статистика инстанса поможет администраторам понять тенденции использования ключевых фич во всем инстансе. Администраторы теперь могут видеть графики, отображающие пользователей, проекты, группы, тикеты и конвейеры за последние 12 месяцев.
В своей первой итерации статистика инстансов требует прав доступа администратора, что означает, что она доступна только в инстансах GitLab, размещённых на собственных серверах. В следующей итерации [эти данные станут более доступными для других пользователей](https://gitlab.com/gitlab-org/gitlab/-/issues/233855), включая пользователей GitLab.com, с возможностью ограничения доступа. Обратите внимание, что статистика инстансов будет переименована в «Тренды использования» в 13.7 в рамках дорожной карты, направленной на то, чтобы сделать эту фичу более доступной.
[Документация по статистике инстанса](https://docs.gitlab.com/ee/user/admin_area/analytics/instance_statistics.html) и [оригинальный эпик](https://gitlab.com/groups/gitlab-org/-/epics/4147).
### Новый способ организации досок задач: группировка по эпикам
(PREMIUM, ULTIMATE, SILVER, GOLD) [Стадия цикла DevOps: Plan](https://about.gitlab.com/stages-devops-lifecycle/plan/)
Часто при просмотре доски задач бывает трудно определить задачи, которые связаны с конкретной работой. Чтобы обеспечить большую ясность и помочь вам организовать работу в ваших командах, мы выпускаем эпик с первым вариантом «плавательной дорожки» для доски задач. Быстро группируйте свои задачи в горизонтальную дорожку по столбцам доски задач, что позволит вам легко увидеть всю работу, связанную с эпиком, а также в каком состоянии она находится!
Пожалуйста, расскажите: [как вам «плавательные дорожки»](https://gitlab.com/groups/gitlab-org/-/epics/328)?
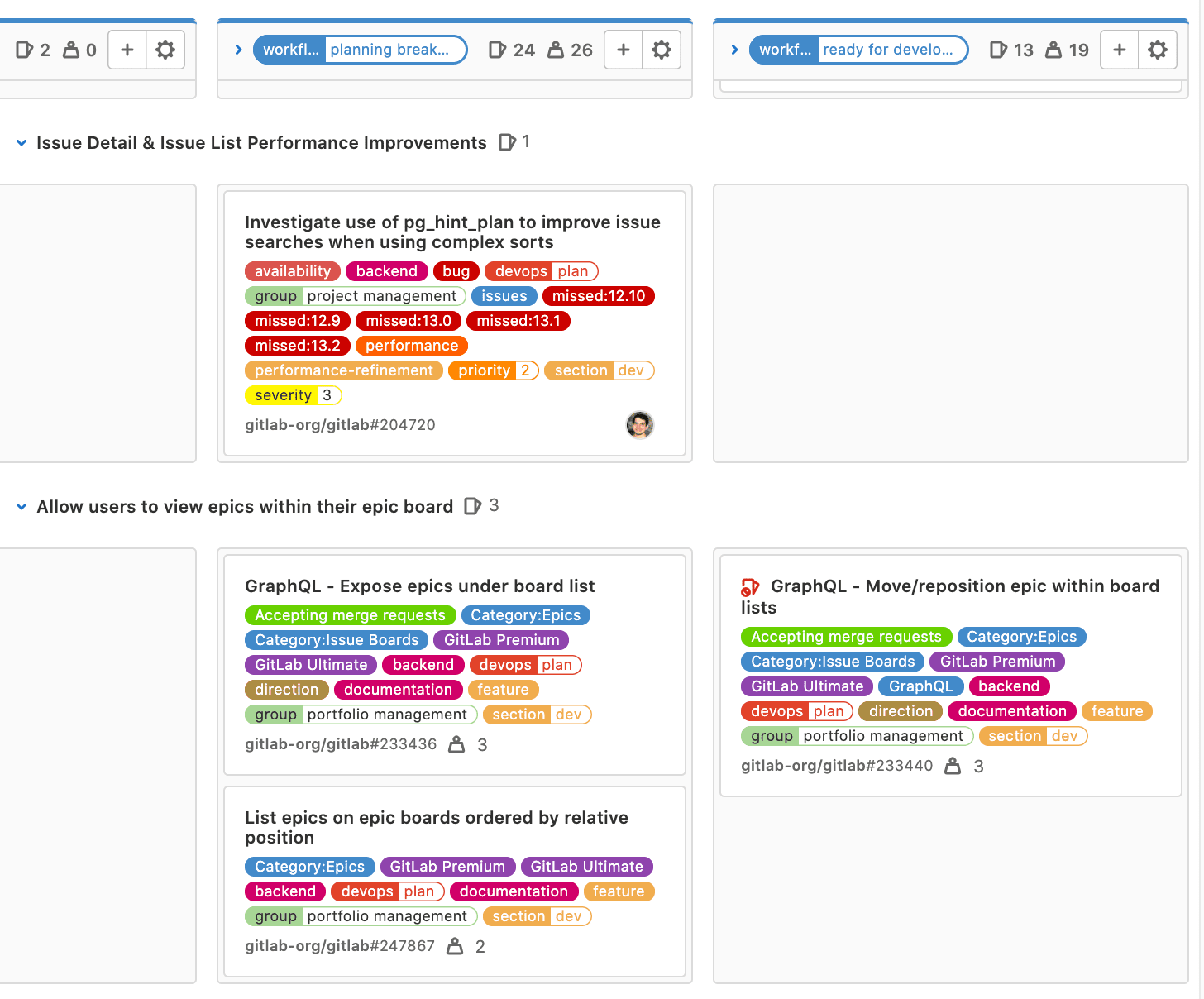
[Документация по «плавательным дорожкам» в досках задач](https://docs.gitlab.com/ee/user/project/issue_board.html#group-issues-in-swimlanes) и [оригинальный эпик](https://gitlab.com/groups/gitlab-org/-/epics/3352).
### Используйте кнопку, чтобы превратить тикет в эпик
(PREMIUM, ULTIMATE, SILVER, GOLD) [Стадия цикла DevOps: Plan](https://about.gitlab.com/stages-devops-lifecycle/plan/)
Ранее превращение тикета в эпик совершалось [быстрым действием](https://docs.gitlab.com/ee/user/project/quick_actions.html) `/promote` в описании или комментарии тикета, что несколько замедляло это частое и важное действие. Чтобы сделать это действие более заметным, мы представили новое меню дополнительных действий в заголовке тикета и добавили кнопку, с помощью которой можно быстро перевести тикет в эпик одним щелчком мыши.

[Документация по управлению тикетами](https://docs.gitlab.com/ee/user/project/issues/managing_issues.html#promote-an-issue-to-an-epic) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/233974).
### Настройте начальное имя ветки для новых проектов в группе
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Create](https://about.gitlab.com/stages-devops-lifecycle/create/)
При создании нового репозитория Git первая созданная ветка по умолчанию называется `master`. В сотрудничестве с проектом Git, обширным сообществом пользователей и другими поставщиками Git, GitLab прислушивается к отзывам сообщества разработчиков по поводу определения более информативного имени для ветки по умолчанию, и теперь предлагает пользователям возможность изменения имени ветки по умолчанию для своих репозиториев.
Ранее мы предоставляли возможность [настраивать начальное имя ветки на уровне инстанса](https://gitlab.com/gitlab-org/gitlab/-/issues/221013), а теперь, начиная с 13.6, GitLab позволяет администраторам групп настраивать имя ветки по умолчанию и для новых репозиториев, созданных через интерфейс GitLab.
[Документация по настройке имени ветки по умолчанию](https://docs.gitlab.com/ee/user/group/#custom-initial-branch-name) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/221014).
### Улучшенные уведомления для управления дизайнами
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Create](https://about.gitlab.com/stages-devops-lifecycle/create/)
До сих пор уведомления о дизайне не очень согласованы с другими уведомлениями GitLab, потому что вы не получали электронное письмо, если вы не были напрямую `@упомянуты`. Из-за этого было очень трудно отслеживать обсуждения в дизайнах.
В 13.6 мы сделали уведомления по дизайнам единообразными со всеми остальными уведомлениями, поэтому, если вы каким-либо образом участвовали в дизайне (оставили комментарий, ответили или были `@упомянуты`), вы получите электронное письмо для каждого нового комментария.
[Документация по настройке уведомлений по электронной почте](https://docs.gitlab.com/ee/user/profile/notifications.html#gitlab-notification-emails) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/217095).
### Вставка сниппетов GitLab прямо в VS Code
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Create](https://about.gitlab.com/stages-devops-lifecycle/create/)
Сниппеты проекта — это место для обмена фрагментами кода, которые повторно используются в нескольких местах или помогают настроить аналогичные страницы и компоненты.
Когда вы вносите свой вклад в проект, вам может понадобиться найти эти фрагменты и вставить их содержимое в ваш рабочий файл. Для их поиска требуется переключение контекста из вашего редактора, а затем копирование/вставка правильной информации.
Используя расширение для VS Code [GitLab Workflow v3.5.0](https://marketplace.visualstudio.com/items?itemName=GitLab.gitlab-workflow), вы сможете вставлять фрагменты в свой рабочий файл, причём поддерживаются как одиночные, так и [мультифайловые](https://habr.com/ru/post/527208/#snippety-s-neskolkimi-faylami) сниппеты.
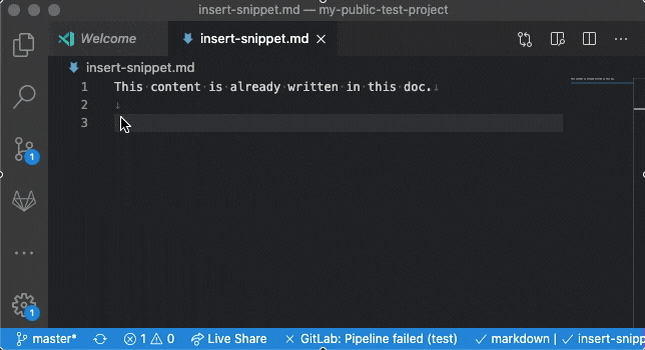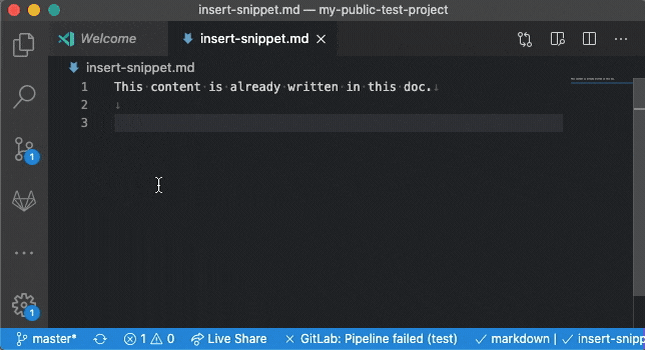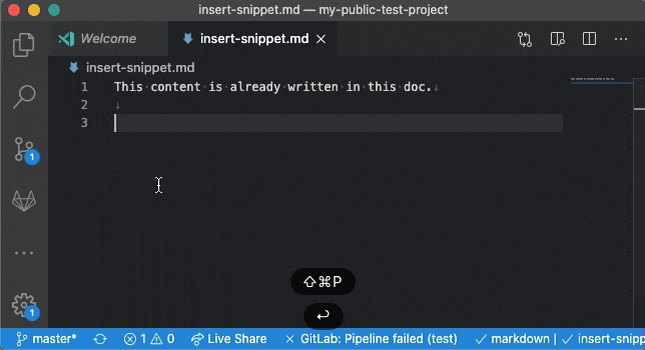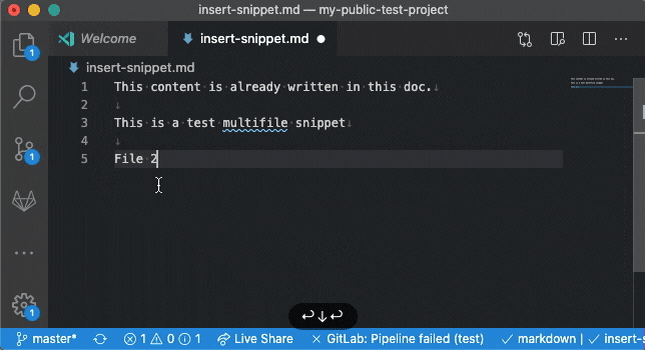
[Документация по вставке сниппетов через расширение для VS Code](https://gitlab.com/gitlab-org/gitlab-vscode-extension#insert-snippet) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab-vscode-extension/-/issues/129).
### Шаблон описания мерж-реквеста для редактора статических сайтов
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Create](https://about.gitlab.com/stages-devops-lifecycle/create/)
Для веб-сайтов, созданных с помощью генератора статических сайтов, редактор статических сайтов можно использовать для быстрого редактирования содержимого страницы в знакомом и интуитивно понятном интерфейсе. После завершения редактирования вы даже можете создать мерж-реквест прямо из редактора. В GitLab 13.5 мы добавили возможность задать [название и описание](https://gitlab.com/gitlab-org/gitlab/-/issues/216861) мерж-реквеста, но шаблоны описания мерж-реквеста были недоступны. Это означало, что у мерж-реквестов, созданных в статическом редакторе сайтов, были противоречивые описания, и в них не было никакой полезной информации из шаблонов, например чеклистов.
В GitLab 13.6 мерж-реквесты, созданные в редакторе статических сайтов, будут использовать шаблон описания мерж-реквеста по умолчанию, если он был настроен. Кроме того, вы можете выбрать и применить любые другие шаблоны описания, определённые в `.gitlab/merge_request_templates`, обеспечивая согласованную связь для рецензентов и снижая вероятность того, что вам придётся переходить на страницу мерж-реквеста, чтобы обновить описание после отправки.
[Документация по редактору статических сайтов](https://docs.gitlab.com/ee/user/project/static_site_editor/#edit-content) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/263252).
### Загрузка изображений в редактор статических сайтов
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Create](https://about.gitlab.com/stages-devops-lifecycle/create/)
В GitLab 13.1 добавлена поддержка ссылок на изображения и их предварительного просмотра в редакторе статических сайтов, что отлично подходит, если ваши изображения уже размещены где-то в Интернете. Однако для добавления новых изображений на ваш сайт по-прежнему приходилось использовать альтернативные методы для загрузки ресурсов в репозиторий проекта.
В GitLab 13.6 вы можете не только ссылаться на изображение, но и загружать его в свой проект в статическом редакторе сайтов, и сразу же просматривать его вместе с вашими правками. Щелчок по значку **Добавить изображение** (**Add Image**) на панели форматирования теперь открывает и новый вариант — выбор файла с вашего компьютера. После загрузки изображение отображается в режиме WYSIWYG редактора, а после сохранения изменений сам файл включается в мерж-реквест.
[Документация по вставке изображений в редакторе статических сайтов](https://docs.gitlab.com/ee/user/project/static_site_editor/#images) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/218529).
### Статус конвейера в списках веток и тегов
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Verify](https://about.gitlab.com/stages-devops-lifecycle/verify/)
Если вы используете конвейеры CI/CD с тегами или ветками и хотите узнать последнее состояние конвейера, ранее вам приходилось переходить от списка веток или тегов к странице конвейера. Теперь значки состояния конвейера отображаются для каждой ветки или тега в соответствующих списках, так что вы можете быстро получить эту информацию для многих тегов или веток за меньшее количество щелчков мышью.
Спасибо [Lee Tickett](https://gitlab.com/leetickett) за эту фичу!
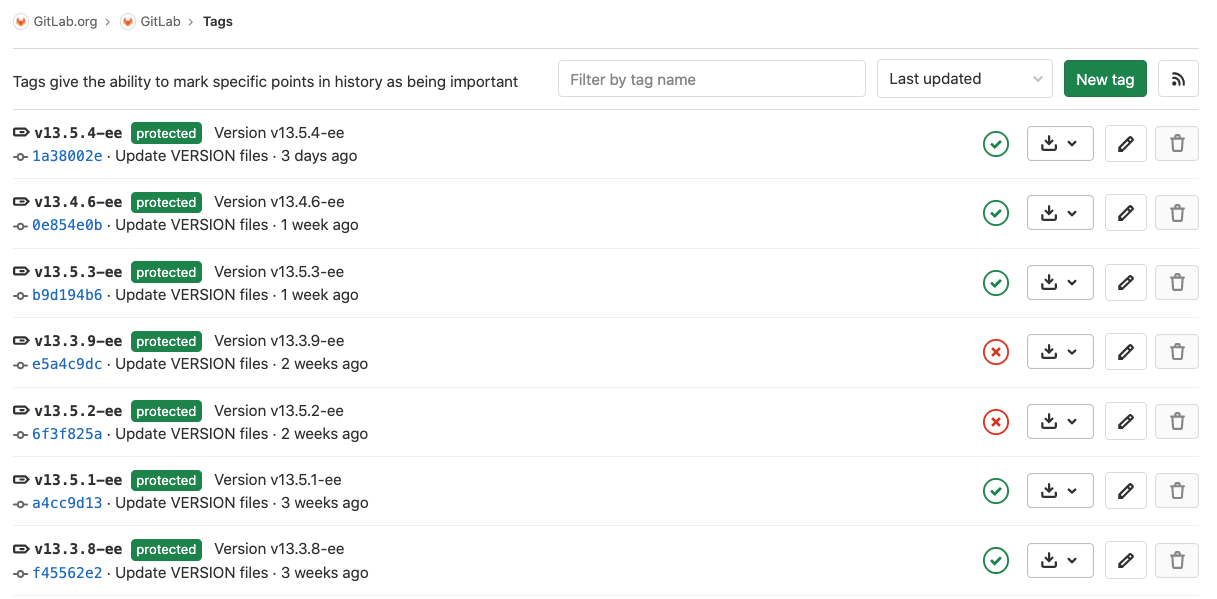
[Документация по просмотру конвейеров](https://docs.gitlab.com/ee/ci/pipelines/#view-pipelines) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/14124).
### Поддержка переменных в `rules:changes`
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Verify](https://about.gitlab.com/stages-devops-lifecycle/verify/)
Чем длиннее ваши скрипты `gitlab-ci.yml`, тем сложнее их поддерживать и масштабировать. Мы добавили поддержку переменных окружения в ключевое слово `rules:changes`, так что вы теперь можете использовать переменные для путей или имён файлов, не раздувая ваш CI-файл. Переменные помогают уменьшить общую длину файла конфигурации при выполнении одних и тех же заданий CI для проверки изменений в разных наборах файлов.
[Документация по использованию переменных в rules:changes](https://docs.gitlab.com/ee/ci/yaml/README.html#variables-in-ruleschanges) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/34272).
### Прокси зависимостей теперь с открытым исходным кодом
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Package](https://about.gitlab.com/stages-devops-lifecycle/package/)
Docker Hub недавно начал применять [`ограничения частоты запросов docker pull` из Docker Hub](https://docs.docker.com/docker-hub/download-rate-limit). Частота выполнения таких запросов теперь ограничена в зависимости от вашего индивидуального IP-адреса для анонимных пользователей или вашего тарифного плана, если вы прошли аутентификацию и вошли в систему.
Прокси зависимостей может помочь уменьшить количество запросов `docker pull`, которые вы делаете из Docker Hub, путём кэширования образов, ранее загруженных через прокси. Чтобы помочь нашим пользователям работать в рамках этих новых ограничений, мы переносим прокси зависимостей в Core. Благодаря поддержке проксирования и кэширования в Core теперь вы можете повысить надёжность и производительность своих конвейеров.
[Документация по прокси зависимостей](https://docs.gitlab.com/ee/user/packages/dependency_proxy/) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/273655).
### Результаты фаззинг-тестирования теперь более читаемые
(ULTIMATE, GOLD) [Стадия цикла DevOps: Secure](https://about.gitlab.com/stages-devops-lifecycle/secure/)
После того как фаззинг-тестирование находит сбой, следующим шагом будет отладка и определение места сбоя. Это может быть сложно сделать, если есть только шестнадцатеричный адрес, поэтому мы рады сообщить, что теперь мы предоставляем удобочитаемые результаты фаззинг-тестирования с учётом покрытия для всех поддерживаемых языков.
Это значит, что когда вы смотрите на логи падения, вы можете увидеть сопутствующее имя файла и номер строки. Это позволяет легко добраться до места, где произошёл сбой, и исправить его.
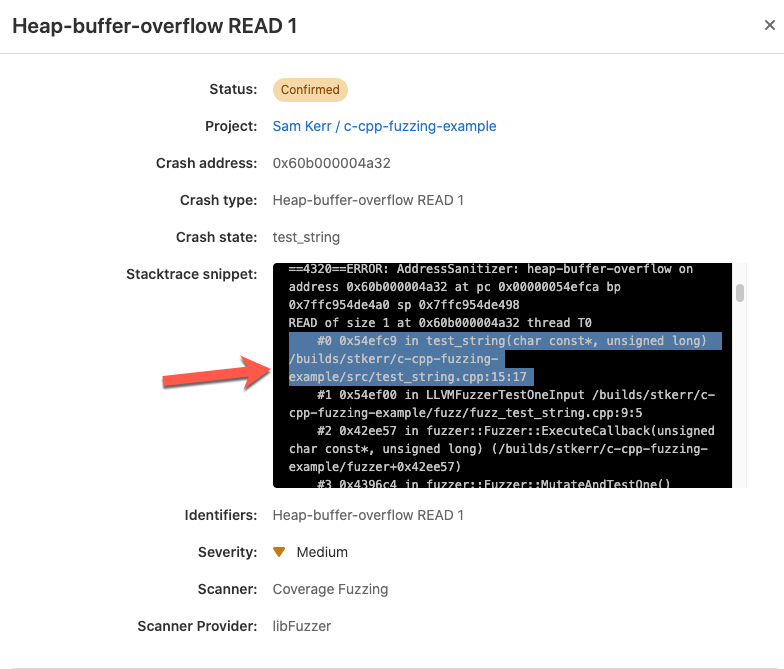
[Документация по фаззинг-тестированию](https://docs.gitlab.com/ee/user/application_security/coverage_fuzzing/#coverage-guided-fuzz-testing-ultimate) и [оригинальный эпик](https://gitlab.com/groups/gitlab-org/-/epics/4784).
### Данные в SAST об уровне серьёзности для уязвимостей Rails
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Secure](https://about.gitlab.com/stages-devops-lifecycle/secure/)
[Статическое тестирование безопасности приложений (SAST) в GitLab](https://docs.gitlab.com/ee/user/application_security/sast/) предоставляет данные о серьёзности выявленных уязвимостей, когда эту информацию можно получить от наших сканеров безопасности. Недавно мы обновили наш анализатор Brakeman, чтобы добавить поддержку данных о серьёзности уязвимостей. Эти данные помогут повысить удобство использования и точность [правил подтверждения](https://docs.gitlab.com/ee/user/application_security/#security-approvals-in-merge-requests), так как меньшее количество уязвимостей будет сообщать о «неизвестной» серьёзности. В будущем мы [дополним другие анализаторы недостающими метаданными уязвимостей](https://gitlab.com/groups/gitlab-org/-/epics/4004) и добавим механизм, позволяющий [настроить метаданные уязвимостей](https://gitlab.com/gitlab-org/gitlab/-/issues/235359), чтобы организации могли адаптировать результаты в соответствии с их профилями рисков.

[Документация по данным об уязвимостях для анализаторов SAST](https://docs.gitlab.com/ee/user/application_security/sast/analyzers.html#analyzers-data) и [оригинальный тикет](https://gitlab.com/gitlab-org/security-products/analyzers/brakeman/-/merge_requests/49).
### Новый график тенденций уязвимостей
(ULTIMATE, GOLD) [Стадия цикла DevOps: Secure](https://about.gitlab.com/stages-devops-lifecycle/secure/)
Визуализация основных тенденций уязвимостей уже давно доступна на панелях безопасности группы и в центре безопасности инстанса. Однако на панели безопасности проекта их нет, что затрудняет понимание тенденций на уровне проекта в отношении количества и типов уязвимостей с течением времени.
Наш новый график тенденций уязвимостей обеспечивает эту необходимую видимость на уровне проекта. Кроме того, этот новый график за счёт своей интерактивности ещё более функционален, чем существующие визуализации групп и центра безопасности. Включайте или выключайте линии тенденций серьёзности одним щелчком мыши, чтобы отобразить только те данные, которые вам нужны. Вы также можете изменить временные рамки, чтобы просмотреть данные за год. График тенденций является динамическим, поэтому он обновляется в реальном времени, чтобы отражать ваши изменения.
С включением этого графика вы также заметите, что одностраничная панель безопасности проекта теперь разделена на отдельные страницы для графиков и для списков уязвимостей, что соответствует виду страниц центра безопасности группы и инстанса. Страница отчёта об уязвимостях содержит все функции, которые ранее находились на панели безопасности проекта. Страница «Панель управления безопасностью» останется, но теперь будет содержать новый график тенденций уязвимостей. Разделение этих функций даёт нам отдельное пространство для добавления новых метрик и визуализаций для отслеживания безопасности на уровне проекта в будущем.
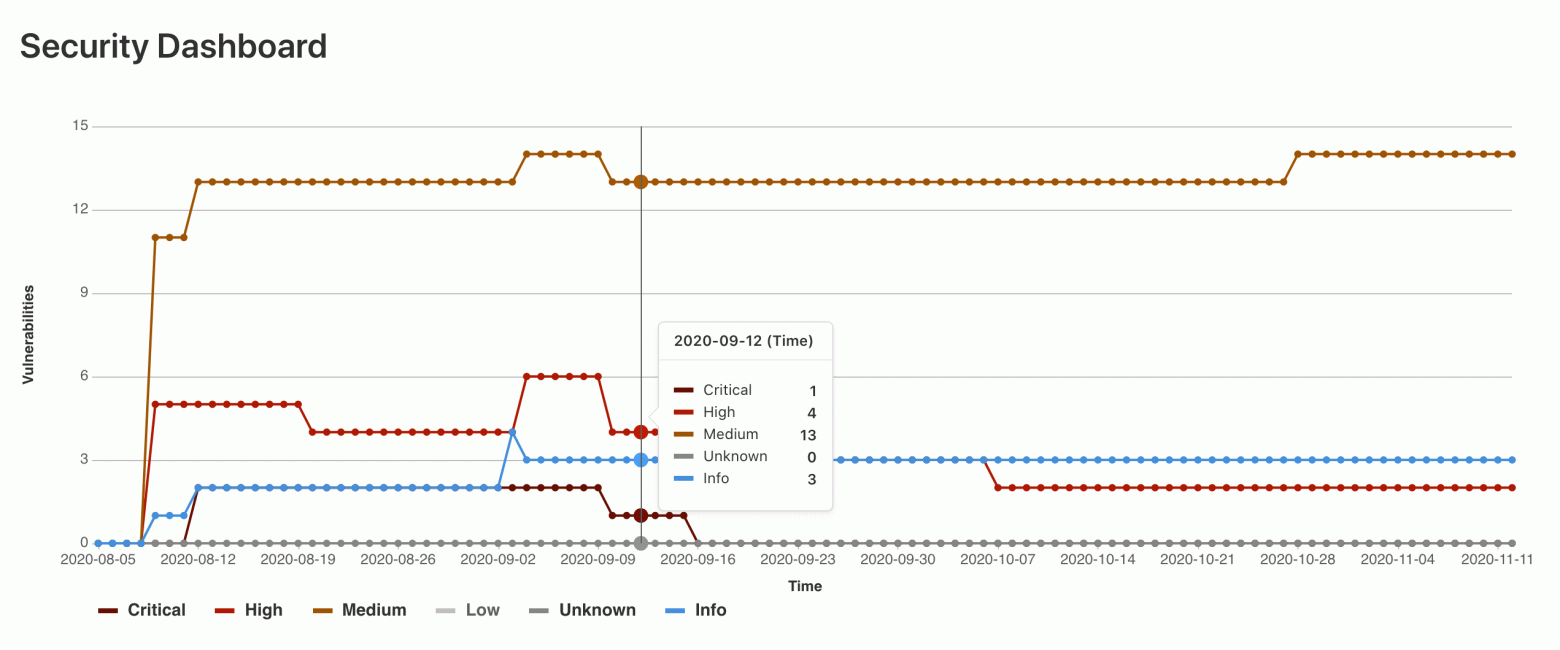
[Документация по панели управления безопасностью на уровне проекта](https://docs.gitlab.com/ee/user/application_security/security_dashboard/#project-security-dashboard) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/235558).
### Отключение ранее существовавших правил SAST
(ULTIMATE, GOLD) [Стадия цикла DevOps: Secure](https://about.gitlab.com/stages-devops-lifecycle/secure/)
[Статическое тестирование безопасности приложений в GitLab](https://docs.gitlab.com/ee/user/application_security/sast/) теперь поддерживает отключение предопределённых правил обнаружения. Изменяя параметры обнаружения уязвимостей по умолчанию, организации могут адаптировать результаты сканирования безопасности. Отключение предопределённых правил исключит обнаружение нерелевантных уязвимостей, что поможет уменьшить количество ложных срабатываний и повысить точность таких шлюзов безопасности, как [правила подтверждения безопасности мерж-реквеста](https://docs.gitlab.com/ee/user/application_security/#security-approvals-in-merge-requests), а также уменьшить количество уязвимостей, о которых сообщается на [панелях безопасности](https://docs.gitlab.com/ee/user/application_security/security_dashboard/). Чтобы отключить наборы правил по умолчанию, добавьте в папку `.gitlab` новый файл с именем `sast-rulesets.toml`, в котором будут настройки в правильной нотации. Вы можете узнать больше об этом формате файла и посмотреть примеры в нашей документации для [пользовательских наборов правил SAST](https://docs.gitlab.com/ee/user/application_security/sast/#customize-rulesets). В будущем мы собираемся представить [дополнительные улучшения](https://gitlab.com/groups/gitlab-org/-/epics/4179), такие как импорт пользовательских наборов правил в файлы `.gitlab-ci.yml`.

[Документация по настройке наборов правил безопасности](https://docs.gitlab.com/ee/user/application_security/sast/#customize-rulesets) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/235358).
### Используйте список путей URL для управления сканированием DAST
(ULTIMATE, GOLD) [Стадия цикла DevOps: Secure](https://about.gitlab.com/stages-devops-lifecycle/secure/)
Веб-тестирование DAST в GitLab всегда зависело от успешного сеанса поискового робота для сканирования сайта и поиска страниц, которые должен тестировать сканер DAST. Он хорошо работает во многих случаях, но может вызвать проблемы, когда на сайте есть скрытые страницы, разделы сайта не связаны друг с другом, или если робот-паук достигает лимита по времени и перестаёт искать страницы. Если время отклика сайта велико из-за того, что он находится в инстансе разработки или по любой другой причине, последний сценарий может значительно уменьшить охват теста DAST при сканировании на наличие уязвимостей.
Чтобы уменьшить проблемы, связанные с обходом сайта, и позволить пользователям точно контролировать, какие части сайта проверяются во время сканирования DAST, мы ввели использование списка URL, которые надо сканировать, вместо набора адресов, получаемых в результатов обхода пауком DAST. Используя новую переменную `DAST_PATHS`, вы можете включить для сканирования список путей на сайте, указанный в переменной `DAST_WEBSITE`. Этот список, разделённый запятыми, будет действовать как инструкция и позволит охватить страницы, которые, возможно, не были бы обнаружены поисковым роботом. Это также позволит вам использовать существующие карты сайтов, экспортированные в виде списка, чтобы убедиться, что сканирование DAST охватывает каждую страницу, которую вы хотите протестировать.
[Документация по переменным для DAST](https://docs.gitlab.com/ee/user/application_security/dast/#available-variables) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/214120).
### Свяжите релиз с групповым майлстоуном
(PREMIUM, ULTIMATE, SILVER, GOLD) [Стадия цикла DevOps: Release](https://about.gitlab.com/stages-devops-lifecycle/release/)
В GitLab 13.0 вы могли [связать релиз с майлстоуном](https://docs.gitlab.com/ee/user/project/releases/#associate-milestones-with-a-release), выбрав этот вариант в пользовательском интерфейсе Gitlab. Однако пользователи, использующие [групповые майлстоуны](https://docs.gitlab.com/ee/user/project/milestones/#project-milestones-and-group-milestones) не могли связать релиз с таким майлстоуном. Теперь у вас есть возможность легко связать свои групповые планы майлстоунов с релизами.
[Документация по связи релизов с майлстоунами](https://docs.gitlab.com/ee/user/project/releases/#associate-milestones-with-a-release) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/121476).
### Поиск списка пользователей по имени в стратегии переключаемых фич
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Release](https://about.gitlab.com/stages-devops-lifecycle/release/)
Ранее мы добавили поддержку списков пользователей в качестве стратегии переключаемых фич. Если у вас уже есть множество списков пользователей, может быть очень трудно найти тот, который вы хотите применить к конкретной стратегии. Чтобы упростить поиск и использование списков пользователей, мы добавили поиск по спискам пользователей при выборе списка для стратегии.

[Документация по списку пользователей в качестве стратегии переключаемых фич](https://docs.gitlab.com/ee/operations/feature_flags.html#user-list) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/218669).
### Используйте специальный ключ подписи CI\_JOB\_JWT для интеграции Vault
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Release](https://about.gitlab.com/stages-devops-lifecycle/release/)
Ваша безопасность имеет первостепенное значение для нас в GitLab. Поддержка актуальности функций, на которые вы полагаетесь, обеспечивает не только новейшую и лучшую функциональность, но и безопасность и защиту ваших конфиденциальных данных. Чтобы повысить общую безопасность, теперь вы можете использовать специальный ключ подписи для метода аутентификации HashiCorp Vault JSON Web Token (JWT). Вы можете быть уверены в безопасности, зная, что JWT нельзя использовать для того, чтобы выдавать одного пользователя за другого через OpenID Connect.
[Документация по методу аутентификации HashiCorp Vault](https://docs.gitlab.com/ee/ci/examples/authenticating-with-hashicorp-vault/#how-it-works) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/214607).
### Установка обработчиков заданий с помощью GitLab Kubernetes Agent
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Configure](https://about.gitlab.com/stages-devops-lifecycle/configure/)
Для настройки пользовательских обработчиков заданий (runners) GitLab вы можете использовать приложения, управляемые GitLab, или ручную установку. Хотя управляемые GitLab приложения просты в использовании, этот подход недостаточно гибок для сложных случаев, а ручная установка приводит к тому, что пользователи сами выполняют задачи обслуживания, поскольку она не интегрирована с GitLab. GitLab Kubernetes Agent можно использовать для превращения любого проекта GitLab в проект управления Kubernetes, поэтому мы создали [пример репозитория и документации](https://docs.gitlab.com/ee/user/clusters/agent/#example-projects), чтобы показать вам, как использовать его для установки обработчика заданий GitLab. Это предоставит вам интегрированный, ориентированный на GitLab рабочий процесс GitOps для управления вашими настраиваемыми обработчиками заданий.
[Документация по GitLab Kubernetes Agent](https://docs.gitlab.com/ee/user/clusters/agent/#example-projects) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/250286).
### Трассировка теперь в Core
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD) [Стадия цикла DevOps: Monitor](https://about.gitlab.com/stages-devops-lifecycle/monitor/)
Поскольку мы хотели [сделать три столпа наблюдаемости доступными в плане Core](https://gitlab.com/groups/gitlab-org/-/epics/2310), мы завершили последнюю часть и переместили трассировку в GitLab Core. Чтобы узнать больше о возможностях трассировки, [загляните в документацию](https://docs.gitlab.com/ee/operations/tracing.html).
[Документация по трассировке](https://docs.gitlab.com/ee/operations/tracing.html) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/42645).
---
Полный текст релиза и инструкции по обновлению/установке вы можете найти в оригинальном англоязычном посте: [GitLab 13.6 released with Auto Deploy to EC2 and Usage Trends Dashboard](https://about.gitlab.com/releases/2020/11/22/gitlab-13-6-released/).
Над переводом с английского работали [cattidourden](https://habr.com/ru/users/cattidourden/), [maryartkey](https://habr.com/ru/users/maryartkey/), [ainoneko](https://habr.com/ru/users/ainoneko/) и [rishavant](https://habr.com/ru/users/rishavant/). | https://habr.com/ru/post/531934/ | null | ru | null |
# PyQt4 — Меню и панели инструментов
**Главное окно**
Класс QMainWindow представляет собой главное окно приложения. С его помощью можно создавать классический вид со строкой состояния, панелями инструментов и меню.
**Строка состояния**
Строка состояния это виджет, который используется для отображения статусной информации.
`#!/usr/bin/python
import sys
from PyQt4 import QtGui
class MainWindow(QtGui.QMainWindow):
def __init__(self):
QtGui.QMainWindow.__init__(self)
self.resize(250, 150)
self.setWindowTitle('statusbar')
self.statusBar().showMessage('Ready')
app = QtGui.QApplication(sys.argv)
main = MainWindow()
main.show()
sys.exit(app.exec_())`
`self.statusBar().showMessage('Ready')`
Чтобы создать строку состояния мы вызываем метод statusBar() класса QApplication. ShowMessage() показывает сообщение на строке состояния.
**Меню**
Меню это один из самых видных частей GUI приложения. Это группа команд расположенных в различных меню. Тогда как в консольных приложениях вам необходимо помнить все тайные команды, здесь вам доступно большинство команд сгруппированных логически. Это принятый стандарт, который уменьшает время на изучение нового приложения.
`#!/usr/bin/python
import sys
from PyQt4 import QtGui, QtCore
class MainWindow(QtGui.QMainWindow):
def __init__(self):
QtGui.QMainWindow.__init__(self)
self.resize(250, 150)
self.setWindowTitle('menubar')
exit = QtGui.QAction(QtGui.QIcon('icons/exit.png'), 'Exit', self)
exit.setShortcut('Ctrl+Q')
exit.setStatusTip('Exit application')
self.connect(exit, QtCore.SIGNAL('triggered()'), QtCore.SLOT('close()'))
self.statusBar()
menubar = self.menuBar()
file = menubar.addMenu('&File')
file.addAction(exit)
app = QtGui.QApplication(sys.argv)
main = MainWindow()
main.show()
sys.exit(app.exec_())`
`self.statusBar().showMessage('Ready')`
Во-первых, мы создаём меню c помощью метода menuBar() класса QMainWindow. Затем, используя метод addMenu(), добавляем пункт меню File, после чего подключаем объект exit к созданному пункту.
Панель инструментов
Меню объединяет все команды, которые мы можем использовать в приложении. Панели инструментов, в свою очередь, предоставляют быстрый доступ к наиболее часто употребляемым командам.
`#!/usr/bin/python
import sys
from PyQt4 import QtGui, QtCore
class MainWindow(QtGui.QMainWindow):
def __init__(self):
QtGui.QMainWindow.__init__(self)
self.resize(250, 150)
self.setWindowTitle('toolbar')
self.exit = QtGui.QAction(QtGui.QIcon('icons/exit.png'), 'Exit', self)
self.exit.setShortcut('Ctrl+Q')
self.connect(self.exit, QtCore.SIGNAL('triggered()'), QtCore.SLOT('close()'))
self.toolbar = self.addToolBar('Exit')
self.toolbar.addAction(self.exit)
app = QtGui.QApplication(sys.argv)
main = MainWindow()
main.show()
sys.exit(app.exec_())`
`self.exit = QtGui.QAction(QtGui.QIcon('icons/exit.png'), 'Exit', self)
self.exit.setShortcut('Ctrl+Q')`
GUI приложения управляются командами, и эти команды могут быть запущены из меню, контекстного меню, панели инструментов или с помощью горячих клавиш. PyQt упрощает разработку с введением действий (actions). Объект action может иметь текст меню, иконку, ярлык (клавиатурное сочетание), статусный текст, текст «What's This?» и всплывающую подсказку. В нашем примере мы определим объект action с иконкой, ярлыком и всплывающей подсказкой.
`self.connect(self.exit, QtCore.SIGNAL('triggered()'),
QtCore.SLOT('close()'))`
Здесь мы соединяем сигнал triggered() объекта action с предопределённым сигналом close().
`self.toolbar = self.addToolBar('Exit')
self.toolbar.addAction(self.exit)`
Создаём панель инструментов и устанавливаем на неё объект action.
**Совмещаем вместе**
В поседнем примере, мы создадим окно и расположим на нём меню, панель инструментов и статусную строку, а также добавим центральный виджет.
`#!/usr/bin/python
import sys
from PyQt4 import QtGui, QtCore
class MainWindow(QtGui.QMainWindow):
def __init__(self):
QtGui.QMainWindow.__init__(self)
self.resize(350, 250)
self.setWindowTitle('mainwindow')
textEdit = QtGui.QTextEdit()
self.setCentralWidget(textEdit)
exit = QtGui.QAction(QtGui.QIcon('icons/exit.png'), 'Exit', self)
exit.setShortcut('Ctrl+Q')
exit.setStatusTip('Exit application')
self.connect(exit, QtCore.SIGNAL('triggered()'), QtCore.SLOT('close()'))
self.statusBar()
menubar = self.menuBar()
file = menubar.addMenu('&File')
file.addAction(exit)
toolbar = self.addToolBar('Exit')
toolbar.addAction(exit)
app = QtGui.QApplication(sys.argv)
main = MainWindow()
main.show()
sys.exit(app.exec_())`
`self.toolbar = self.addToolBar('Exit')
self.toolbar.addAction(self.exit)`
Здесь мы создаём виджет QtextEdit, который устанавливаем центральным на QMainWindow. Центральный виджет занимает все свободное пространство.
 | https://habr.com/ru/post/31685/ | null | ru | null |
# Небольшой Add-In для Visual Studio
Когда solution-файл содержит достаточно большое число проектов, сборка бинарных файлов превращается в процесс, требующий ощутимого количества времени, а отчет о сборке в простыню размером в несколько мегабайт. Лично у меня подобная строка в самом конце при таких масштабах вызывает недоумение:
`========== Build: 258 succeeded, 1 failed, 40 up-to-date, 1 skipped ==========`
А помимо недоумения закономерный вопрос: а что, собственно, сломалось? Есть, конечно, вкладка «Error list», но она к сожалению не показывает названий проектов — только файлы, а при таком объеме исходного кода, да с учетом того факта, что над этим solution'ом работает большая команда, довольно проблематично определять на память принадлежность того или иного файла к определенному проекту (читай определять виновных в сломанной сборке). Пролистывать же отчет в поисках имени проекта, содержащего ошибки, на мой взгляд, не совсем целесообразно.
Принимая во внимание всё вышесказанное, я решил совместить приятное с полезным, получив небольшое представление о том, что же такое VS Exstensibility, снабдив при этом студию маленьким «удобством». «Удобство» должно позволять одним кликом мыши отсеять все ненужное из отчета о сборке, оставив только сообщения об ошибках и имена проектов, их содержащие.
Всё оказалось довольно просто. Начиная с готового шаблона проекта:
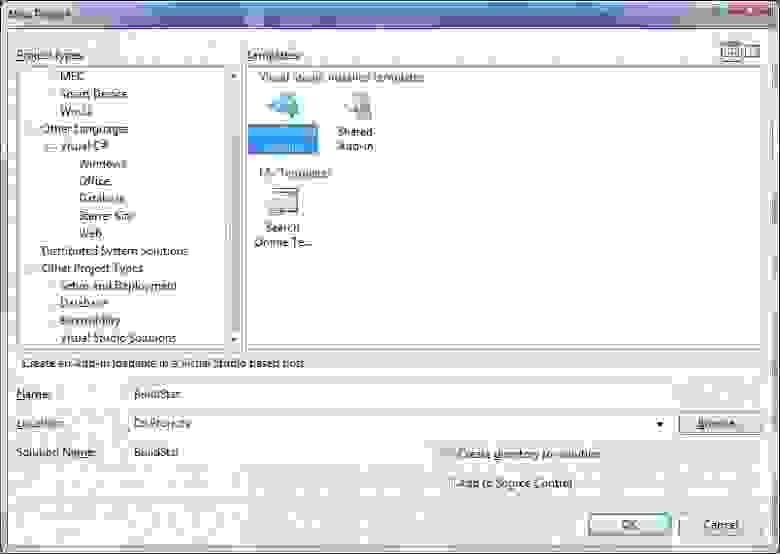
и заканчивая довольно очевидным набором классов, который позволяет практически не заглядывать в документацию, пользуясь лишь подсказками редактора.
После создания проекта генерируется довольно много кода (выбор языка предоставляется; в моем случае — C#). По сути интересны там только два места: методы OnConnect и Exec, где первый, как несложно догадаться инициализация, а второй непосредственная реализация нашей логики.
OnConnect нам необходим только для того, чтобы сделать новый пункт в меню «Tools». По факту, в сгенерированном для нас коде всё это уже есть, нам остаётсяь только подкорректировать само создание команды:
``> try
>
> {
>
> //Add a command to the Commands collection:
>
> Command command = commands.AddNamedCommand2(\_addInInstance,
>
> "BuildStat",
>
> "Show failed build parts",
>
> "Provides information about failed parts of performed solution build",
>
> true,
>
> 56,
>
> ref contextGUIDS,
>
> (int)vsCommandStatus.vsCommandStatusSupported + (int)vsCommandStatus.vsCommandStatusEnabled,
>
> (int)vsCommandStyle.vsCommandStylePictAndText,
>
> vsCommandControlType.vsCommandControlTypeButton);
>
>
>
> //Add a control for the command to the tools menu:
>
> if((command != null) && (toolsPopup != null))
>
> {
>
> command.AddControl(toolsPopup.CommandBar, 1);
>
> }
>
> }
>
> catch(System.ArgumentException)
>
> {
>
> //If we are here, then the exception is probably because a command with that name
>
> // already exists. If so there is no need to recreate the command and we can
>
> // safely ignore the exception.
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
В итоге получим:

Остается реализовать фильтрацию отчета о сборке. Для этого, нам необходимо получить сам отчет из окна «Output/Build», оставить только необходимое, создать в окне «Output» новую панель и заполнить ее результатами работы. Соответственно, метод Exec примет следующий вид:
``> public void Exec(string commandName, vsCommandExecOption executeOption, ref object varIn, ref object varOut, ref bool handled)
>
> {
>
> handled = false;
>
> if(executeOption == vsCommandExecOption.vsCommandExecOptionDoDefault)
>
> {
>
> if(commandName == "BuildStat.Connect.BuildStat")
>
> {
>
> handled = true;
>
>
>
> foreach (OutputWindowPane pane in \_applicationObject.ToolWindows.OutputWindow.OutputWindowPanes)
>
> {
>
> if(pane.Name == "Build")
>
> {
>
> // нашлась нужная нам вкладка
>
>
>
> TextDocument textDocument = pane.TextDocument;
>
> textDocument.Selection.StartOfDocument(false);
>
> textDocument.Selection.EndOfDocument(true);
>
>
>
> String buildLog = textDocument.Selection.Text;
>
> if(buildLog.Length > 0)
>
> {
>
> string parsedLog = Parse(buildLog);
>
> if (parsedLog.Length > 0)
>
> Output(parsedLog);
>
> }
>
>
>
> break;
>
> }
>
> }
>
>
>
> return;
>
> }
>
> }
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Немного работы со строками:
``> private string Parse(string buildLog)
>
> {
>
> String parseResult = "";
>
> StringReader logReader = new StringReader(buildLog);
>
>
>
> Regex failedProjects = new Regex("[1-9][0-9]\* error\\(s\\), [0-9]+ warning\\(s\\)");
>
>
>
> for (string line = logReader.ReadLine(); line != null; line = logReader.ReadLine())
>
> {
>
> if(failedProjects.IsMatch(line))
>
> {
>
> parseResult += line;
>
> parseResult += "\r\n";
>
> }
>
>
>
> if ((line.IndexOf(": error") != -1) || (line.IndexOf(": fatal error") != -1))
>
> {
>
> parseResult += line;
>
> parseResult += "\r\n";
>
> }
>
> }
>
>
>
> return parseResult;
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
И сам вывод на экран:
``> private void Output(string outputString)
>
> {
>
> OutputWindowPane myPane = null;
>
>
>
> foreach (OutputWindowPane pane in \_applicationObject.ToolWindows.OutputWindow.OutputWindowPanes)
>
> {
>
> if (pane.Name == "Build [failed]")
>
> {
>
> myPane = pane;
>
> break;
>
> }
>
> }
>
>
>
> if (myPane == null)
>
> myPane = \_applicationObject.ToolWindows.OutputWindow.OutputWindowPanes.Add("Build [failed]");
>
>
>
> myPane.Clear();
>
> myPane.OutputString(outputString);
>
>
>
> myPane.Activate();
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
И вот он результат:

Для установки модуля необходимо присутствующий в проекте .AddIn файл скопировать в «Мои документы\Visual Studio <версия>\Addins», не забыв при этом поправить в нем необходимые поля, например, пути.
P.S. Ощущение того, что изобрел велосипед, присутствует, но совокупность таких факторов, как всего 30 минут потраченного времени и небольшая порция полученного удовольствия все компенсирует.```` | https://habr.com/ru/post/91276/ | null | ru | null |
# О Dependency Injection в Magento 2
В предыдущей статье мы рассмотрели базовую структуру модуля в M2: [читать тут](https://habr.com/ru/post/674316/). В этой статье поговорим об инъекции (внедрении) зависимостей в Magento 2. Как ее использовать и для чего она нужна.
Итак, внедрение зависимостей — это паттерн проектирования предназначенный для того, чтобы предоставлять какому-либо объекту зависимости, необходимые для его работы. Это более совершенная альтернатива наследованию, позволяющая уменьшить связанность классов и компонентов между собой.
В основе этого подхода лежит принцип **Dependency Inversion** (инверсия зависимостей) из принципов [**SOLID**](https://ru.wikipedia.org/wiki/SOLID_%28%D0%BE%D0%B1%D1%8A%D0%B5%D0%BA%D1%82%D0%BD%D0%BE-%D0%BE%D1%80%D0%B8%D0%B5%D0%BD%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%BD%D0%BE%D0%B5_%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5%29), который предполагает использование абстракций вместо конкретных классов, где детали реализации должны зависеть от абстракций, а абстракции не должны зависеть от деталей реализации.
### ObjectManager
За инъекцию зависимостей в M2 отвечает специальный класс **ObjectManager** (далее OM), который создается при инициализации приложения. OM вызывается автоматически и его запрещено использовать напрямую, поскольку тогда зависимости перестают быть явными и весь смысл использования Dependency Injection теряется, однако, бывают и исключения, которые будут приведены ниже. А вот и код самого OM:
```
php
/**
* Magento object manager. Responsible for instantiating objects taking into account:
* - constructor arguments (using configured, and provided parameters)
* - class instances life style (singleton, transient)
* - interface preferences
*
* Intentionally contains multiple concerns for best performance
*
* Copyright © Magento, Inc. All rights reserved.
* See COPYING.txt for license details.
*/
namespace Magento\Framework\ObjectManager;
class ObjectManager implements \Magento\Framework\ObjectManagerInterface
{
/**
* @var \Magento\Framework\ObjectManager\FactoryInterface
*/
protected $_factory;
/**
* List of shared instances
*
* @var array
*/
protected $_sharedInstances = [];
/**
* @var ConfigInterface
*/
protected $_config;
/**
* @param FactoryInterface $factory
* @param ConfigInterface $config
* @param array &$sharedInstances
*/
public function __construct(FactoryInterface $factory, ConfigInterface $config, &$sharedInstances = [])
{
$this-_config = $config;
$this->_factory = $factory;
$this->_sharedInstances = &$sharedInstances;
$this->_sharedInstances[\Magento\Framework\ObjectManagerInterface::class] = $this;
}
/**
* Create new object instance
*
* @param string $type
* @param array $arguments
* @return mixed
*/
public function create($type, array $arguments = [])
{
return $this->_factory->create($this->_config->getPreference($type), $arguments);
}
/**
* Retrieve cached object instance
*
* @param string $type
* @return mixed
*/
public function get($type)
{
$type = ltrim($type, '\\');
$type = $this->_config->getPreference($type);
if (!isset($this->_sharedInstances[$type])) {
$this->_sharedInstances[$type] = $this->_factory->create($type);
}
return $this->_sharedInstances[$type];
}
/**
* Configure di instance
* Note: All arguments should be pre-processed (sort order, translations, etc) before passing to method configure.
*
* @param array $configuration
* @return void
*/
public function configure(array $configuration)
{
$this->_config->extend($configuration);
}
}
```
Приложение использует конструктор класса, чтобы получить информацию о зависимостях объекта. При инициализации, **OM** заполняет объект его зависимостями, определенными в специальном конфигурационном файле **di.xml** ([тут](https://habr.com/ru/post/674316/) про di.xml) и помещает их в конструктор класса. Если класс не найден, то возвращается исключение (Exception). Аргументы собираются рекурсивно, то есть зависимости заполняются не только на верхнем уровне, но и на всех низ лежащих (зависимости зависимостей) до того момента пока не будут подгружены все.
**Итак, основные задачи OM:**
1. Создание объектов в фабриках и прокси-классах
2. Возвращение singleton-инстанса класса, т.е. единственного экземпляра класса
3. Автоматическая инициализация аргументов в конструкторах классов
**А в файле di.xml:**
1. Происходит настройка OM для работы с зависимостями.
2. Указывается предпочтительный класс реализации интерфейса ([Service Contract](https://habr.com/ru/post/674316/)), который потом передается в конструктор класса, а также позволяет подменять классы другими.
3. Можно подменять аргументы классов своими, использовать [прокси](https://ru.wikipedia.org/wiki/%D0%97%D0%B0%D0%BC%D0%B5%D1%81%D1%82%D0%B8%D1%82%D0%B5%D0%BB%D1%8C_%28%D1%88%D0%B0%D0%B1%D0%BB%D0%BE%D0%BD_%D0%BF%D1%80%D0%BE%D0%B5%D0%BA%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F%29), виртуальные типы, плагины и т.д.
### Когда можно использовать Object Manager?
Бывают случаи, когда использование OM оправдано:
* при использовании магических методов \_\_wakeup() и \_\_sleep();
* в тестах;
* в классах-фабриках и прокси-классах.
### Как быть, когда нужно несколько экземпляров класса?
Для таких случаев нужно применять **фабрики**. Фабрики необходимы для создания объектов.
Для того, чтобы ее использовать, нужно добавить нужный класс через **use** и в конце дописать ключевое слово **Factory** вот так:
```
use Magento\Framework\Controller\Result\RawFactory;
```
А затем просто подключить данный класс через конструктор.
```
public function __construct(RawFactory $resultRawFactory) {
$this->resultRawFactory = $resultRawFactory;
}
```
Далее, чтобы получить новый экземпляр класса, необходимо использовать публичный метод фабрики под названием **create()**.
```
$resultRaw = $this->resultRawFactory->create();
```
Таким образом, мы получим необходимый экземпляр класса, а M2 сама создаст нужные объекты при переходе в **production mode**, либо на лету, если активен **developer mode** и положит его в папку **/generated/code**. Выглядеть сгенерированный класс будет таким образом:
```
php
namespace Magento\Framework\Controller\Result;
/**
* Factory class for @see \Magento\Framework\Controller\Result\Raw
*/
class RawFactory
{
/**
* Object Manager instance
*
* @var \Magento\Framework\ObjectManagerInterface
*/
protected $_objectManager = null;
/**
* Instance name to create
*
* @var string
*/
protected $_instanceName = null;
/**
* Factory constructor
*
* @param \Magento\Framework\ObjectManagerInterface $objectManager
* @param string $instanceName
*/
public function __construct(
\Magento\Framework\ObjectManagerInterface $objectManager,
$instanceName = '\\Magento\\Framework\\Controller\\Result\\Raw'
) {
$this-_objectManager = $objectManager;
$this->_instanceName = $instanceName;
}
/**
* Create class instance with specified parameters
*
* @param array $data
* @return \Magento\Framework\Controller\Result\Raw
*/
public function create(array $data = [])
{
return $this->_objectManager->create($this->_instanceName, $data);
}
}
```
Как можно заметить из кода выше, в созданном классе используется **object manager**. Как упоминалось ранее, в классах-фабриках это допустимо.
### Что такое preference?
**Preference** — это переопределение класса или интерфейса, а также связь интерфейса и его конкретной реализации.
Бывают случаи, когда мы хотим заменить какой-либо класс своей собственной имплементацией, что не очень желательно и лучше использовать плагины, когда это возможно, но тем не менее.
**Preference** также используется для определения **Service Contract**, чтобы при подключении класса в конструкторе мы использовали абстракцию, а не конкретный класс.
Выглядит это так, где **for** — это класс, который переопределяем, а **type** — класс, которым заменяем:
```
```
### Что такое Proxy?
Proxy (Заместитель) — это паттерн проектирования, который предполагает создание суррогата объекта и контроль доступа к нему.
В M2 данный подход применяется, если объект слишком “тяжелый”. Это позволяет подгружать его только в случае необходимости (ленивая загрузка), тем самым ускоряя работу приложения.
Для того, чтобы применить данный подход, нужно выполнить его настройку в di.xml. Например:
```
Magento\Framework\DataObject\Copy\Config\Data\Proxy
```
В узле указывается класс, в конструктор которого передается объект, на который будет создан прокси.
Далее в узле мы перечисляем необходимые подменяемые на прокси аргументы. В данном случае аргумент **dataStorage**. В значении ноду указывается путь к классу и в конце через слеш добавляется **\Proxy**
Изменения выполняются только в конфигурационном файле **di.xml**. Внутри класса ничего делать не надо. M2 сама сгенерирует нужные классы и положит их в папку **/generated**
### Что такое Virtual Type и Type?
Подход, который позволяет создавать существующий класс с кастомными аргументами конструктора. Таким образом, мы создаем как бы “виртуальный” класс, который имеет все те же свойства и методы родительского класса, но с новыми элементами конструктора без какого-либо влияния на изначальный класс, т.е “старый” класс может использоваться как и ранее. Определяется Virtual Type в конфигурационном файле **di.xml**:
```
layout
```
В узле атрибут name содержит имя нашего виртуального типа, в атрибуте type указан “родительский” класс, в котором будут заменяться аргументы.
В узле перечисляются аргументы, значения которых мы хотим заменить на свои. В данном случае аргумент **subDir** будет иметь значение layout.
Затем этот виртуальный тип можно подключить в какой-нибудь класс через тот же **di.xml** через узел в качестве аргумента subject класса *Magento\Framework\View\File\Collector\Decorator\ModuleOutput* следующим образом:
```
layoutFileSourceBase
```
В отличие от Virtual Type, Type добавляет аргументы к реальному классу.
---
Мы рассмотрели как в Magento 2 используется Dependency Injection и основные способы его применения на практике. Такой подход упрощает процесс разработки, структурирует приложение. | https://habr.com/ru/post/697140/ | null | ru | null |
# Поддержка нестандартного XMPP-протокола с помощью Smack
В одном из недавних проектов мы реализовывали взаимодействие Android-приложения с ejabberd-сервером через кастомизированный XMPP-протокол.
В этой статье приведены примеры как можно отправлять/получать кастомизированные пакеты XMPP-протокола в Android-приложении.
Для работы с XMPP протоколом была выбрана библиотека Smack 4.1.8.
**Первая задача** — отправка на сервер Message-пакетов с дополнительными атрибутами в родительском элементе и нестандартными дочерними элементами.
Сразу оговорюсь, с точки зрения XMPP-протокола изменять родительский элемент некорректно. Но в этом проекте нам пришлось так сделать, т.к. сервер к моменту старта разработки Android-приложения был уже реализован и не было возможности его изменить.
Xml для отправки Message-пакета:
```
```
Атрибута ’company’ и элемента “read” нет в XMPP-протоколе.
Стандартная реализация классов IQ, Message, Stanza не предоставляют возможность что-либо добавлять в родительский элемент xml. А для классов IQ, Message даже в случае наследования нет возможности изменять родительский элемент.
Решением является наследование от класса “Stanza” и переопределение метода toXML:
```
// Класс “ReadMessageStanza” служить для передачи уведомлений, что другой участник
// переписки прочитал сообщение
public class ReadMessageStanza extends Stanza {
@Override
public CharSequence toXML() {
XmlStringBuilder buf = new XmlStringBuilder();
// Добавляем открывающую скобку “<” и название элемента родительского элемента
// rootElement может быть “iq”, “message”, “stanza”.
buf.halfOpenElement(rootElement);
// Добавляем атрибуты "to", "from", "id", "lang" через стандартную функцию.
// Для задания значения "to" необходимо вызвать метод “setTo” класса “Stanza”
// "id", "lang" задаются автоматически по умолчанию в классе “Stanza”
// Значение для "from" будет браться автоматически текущего пользователя, если
// у объекта XMPPTCPConnection вызвать
// “setFromMode(XMPPConnection.FromMode.USER);“
addCommonAttributes(buf);
for (String key : attributes.keySet()) {
// Добавляем свои атрибуты в родительский элемент
buf.attribute(key, attributes.get(key));
}
// Закрываем скобку родительского элемента “/>”
buf.rightAngleBracket();
// Добавляем свои дочерние элементы. Данного метода нет в классе “Stanza”
buf.append(getChildElementXML());
// Стандартная функция для добавления Extensions. По сути это добавление
// стандартных дочерних элементов в xml
buf.append(getExtensionsXML());
// Добавляем закрывающий элемент “”, “”, “”
buf.closeElement(rootElement);
return buf;
}
}
```
Отправить такой пакет можно как обычный Stanza-пакет без обработки результата:
```
xmppTCPConnection.sendStanza(new ReadMessageStanza());
```
В обработчике исходящих пакетов объекта `“xmppTCPConnection”` тип класса будет `“ReadMessageStanza”`:
```
xmppTCPConnection.addPacketSendingListener(new StanzaListener() {
@Override
public void processPacket(Stanza packet) throws SmackException.NotConnectedException {
Map map =((ReadMessageStanza )packet).getAttributes();
// Работа с объектом класса “ReadMessageStanza”...
}
}, new StanzaFilter() {
@Override
public boolean accept(Stanza stanza) {
// Фильтруем нужные пакеты
return stanza instanceof ReadMessageStanza;
}
});
```
Реализация `“ReadMessageStanza”` приведена выше в демонстративных целях. Правильнее вынести код в базовый класс `“CustomStanza”` или использовать паттерн `“Builder”` для построения пакетов.
Если сообщение не дошло до сервера или сервер вернул ошибку, то отправленное сообщение возвращается с информацией об ошибке. Парсер в Smack не сможет обработать такой формат данных и выдаст ошибку. Эту проблему можно решить только внося изменения в исходники библиотеки Smack.
**Вторая задача** — парсинг входящих Message-пакетов из приведенного выше xml.
Для решения этой задачи необходимо создать и зарегистрировать провайдер (парсер).
Для класса `"ReadMessageStanza"` провайдер будет следующий:
```
public class ReadMessageProvider extends ExtensionElementProvider {
// Дочерний элемент пакета
public static final String ELEMENT\_NAME = ”read”;
// namespace дочернего элемента пакета
public static final String NAMESPACE = ”urn:xmpp:receipts”;
// Класс для дочернего элемента реализует стандартный интерфейс
// “ExtensionElement” библиотеки Smack.
// Переназначив метод toXML, объект данного класса можно добавлять в качестве
// “Extensions” для отправляемых ReadMessageStanza-пакетов
public static class Element implements ExtensionElement {
private final String id;
Element(String id) { this.id = id; }
public String getId() { return id; }
// В данном примере объект этого класса не используется в качестве “Extension”
// у отправляемых пакетов, потому можно вернуть null в методе toXML
@Override public CharSequence toXML() { return null; }
@Override public String getNamespace() { return NAMESPACE; }
@Override public String getElementName() { return ELEMENT\_NAME; }
}
// Парсинг дочерних элементов пакета
@Override
public ReadMessageProvider .Element parse(XmlPullParser parser, int initialDepth) throws XmlPullParserException, IOException, SmackException {
// Получаем идентификатор прочитанного сообщения
return new ReadMessageProvider .Element(parser.getAttributeValue("", "id"));
}
}
```
Регистрируем свой провайдер:
```
static {
ProviderManager.addExtensionProvider(ReadMessageProvider.ELEMENT_NAME, ReadMessageProvider.NAMESPACE, new ReadMessageProvider());
}
```
Создаем обработчик входящих пакетов:
```
private StanzaListener inComingChatListener = new StanzaListener() {
@Override
public void processPacket(Stanza packet) throws SmackException.NotConnectedException{
Message message = (Message) packet;
// Проверяем, что сообщение содержит нужный дочерний элемент
if(message.hasExtension(ReadMessageProvider.ELEMENT_NAME, ReadMessageProvider.NAMESPACE)) {
ReadMessageProvider.Element element = message.getExtension(ReadMessageProvider.ELEMENT_NAME, ReadMessageProvider.NAMESPACE);
int id = element.getId();
// Обрабатываем сообщение ...
}
};
}
```
Регистрируем обработчик входящих сообщений с использованием стандартного фильтра `MessageTypeFilter.NORMAL_OR_CHAT`:
```
xmppTCPConnection.addSyncStanzaListener(inComingChatListener, MessageTypeFilter.NORMAL_OR_CHAT);
```
**Третья задача** — отправка и получение кастомизированных IQ-пакетов.
Xml для отправки IQ-пакета:
```
'userJIdTo/Resource'
```
Здесь атрибуты “xmlns” и “type” принимаю значения, которых нет в XMPP-протоколе. Такой пакет можно формировать по аналогии с `“ReadMessageStanza”`.
Xml входящего IQ-пакета:
```
Message
1482729259000000
```
Для парсинга дочерних элементов нужно создать и зарегистрировать провайдер:
```
// Провайдер для парсинга IQ-пакета с историей переписки
public class MyMessagesProvider extends IQProvider {
// Дочерний элемент пакета. В качестве значения берем enum из библиотеки Smack
public static final String ELEMENT\_NAME = IQ.Type.result.name();
// namespace элемента пакета
public static final String NAMESPACE = ”xep:mymessages”;
// Класс для дочерних элементов
public static class Result extends IQ
{
// Хранит полученные сообщения
private List mItems = new ArrayList<>();
private Result() { super("items"); }
@Override
protected IQChildElementXmlStringBuilder getIQChildElementBuilder(IQChildElementXmlStringBuilder xml) { return null; }
public List getValue() { return mItems; }
}
@Override
public MyMessagesProvider.Result parse(XmlPullParser parser, int initialDepth) throws XmlPullParserException, IOException, SmackException {
MyMessagesProvider.Result result = new MyMessagesProvider.Result();
result.mItems = new ArrayList<>();
// Парсинг элементов “message” из parser
// ...
return result;
}
}
```
Регистрируем провайдер:
```
static { ProviderManager.addIQProvider(MyMessagesProvider.ELEMENT_NAME, MyMessagesProvider.NAMESPACE, new MyMessagesProvider());
}
```
Отправляем IQ-пакет с обработкой результата:
```
xmppTCPConnection.sendStanzaWithResponseCallback(
// Исходящий IQ-пакет
new CustomStanza(),
// Фильтр для входящих IQ-пакетов. Если не настроить правильно фильтр, то можно
// получать пакеты от любых других запросов или вообще не получить ничего.
new StanzaFilter() {
@Override
public boolean accept(Stanza stanza) {
return stanza instanceof MyMessagesProvider.Result;
}
},
// Обрабатываем входящий IQ-пакет, который удовлетворяет фильтру
new StanzaListener() {
@Override
public void processPacket(Stanza packet) throws SmackException.NotConnectedException {
List value = ((MyMessagesProvider.Result) packet).getValue();
// Обрабатываем входящие сообщения
}
},
// Обрабатываем ошибки
new ExceptionCallback() {
@Override
public void processException(Exception exception) { }
}
);
```
**Итого:** отправили на сервер кастомизированные IQ и Message пакеты, получили и распарсили кастомизированные IQ и Message пакеты не меняя исходников библиотеки Smack.
Весь приведенный выше код носит демонстрационный характер. В проекте мы используем retrolambda, RxJava и дополнительные классы, чтобы код был универсальным и красивым. | https://habr.com/ru/post/319150/ | null | ru | null |
# Немного о деревьях
#### Вступление
Встречалась ли вам ситуация, когда необходимо реализовать хранение древовидной структуры в реляционной БД?

Примеров можно привести множество. Это и древовидные комментарии, и каталог продукции, и населенные пункты, разделенные по странам и областям. Я думаю, что каждый сможет самостоятельно привести несколько примеров.
В данном топике мы с вами поговорим об одной из тех возможностей, которые существуют для организации хранения деревьев в PostgreSQL — **ltree**.
#### Установка
Процесс установки будет описан для debian-подобных систем.
1. необходимо установить пакет postgresql-contrib;
2. psql -U postgres -d database-name -1 -f SHAREDIR/contrib/ltree.sql — вливаем в базу database-name содержимое модуля (SHAREDIR — каталог с разделяемыми данными PostgreSQL)
3. …
4. PROFIT!
#### Краткое описание
**ltree** позволяет хранить древовидные структуры в виде *меток*, а так же предоставляет широкие возможности поиска по ним. [1, 2].
*Метка* может состоять из букв латинского алфавита, цифр и нижнего подчеркивания. Из меток можно составлять *пути*, которые и хранятся в ltree.
*Путь меток* — это совокупность из 0 и более меток, разделенных точками. Для поиска по путям используется специальные запросы — *lquery*.
Примеры lquery:
1. foo — записи с путем меток в точности равным foo;
2. foo.\* — записи у которых путь меток начинается с foo;
3. \*.foo.\* — любые записи путь меток которых содержит foo.
Модификаторы lquery:
1. \*{n} — путь содержит в точности n меток;
2. \*{n,} — путь содержит как минимум n меток;
3. \*{n,m} — путь содержит от n до m меток;
4. \*{,m} — путь содержит не более m меток.
Кроме того, существуют модификаторы для меток:
1. foo\* — любая метка начинающаяся на foo;
2. foo@ — метка без учета регистра, например: Foo, FOO, FoO — подойдут;
3. foo% — выберет foo\_bar, но не выберет foo и foobar.
Модификаторы можно комбинировать.
ltree можно сравнивать между собой и c lquery, т.е. стандартные операции сравнения =, <>, >, <, >=, <= полностью поддерживаются. Помимо них, введены еще несколько операций:
1. ltree @> ltree — является ли левый член выражения предком правого;
2. ltree <@ ltree — является ли левый член выражения потомком правого;
3. ltree ~ lquery или lquery ~ ltree — соответствует ли ltree запросу в lquery.
С полным списком операций и функций можно ознакомиться в официальной документации [2].
#### Пример использования
О деревьях мы немного узнали. Давайте попробуем реализовать на примере.
Перед нами стоит задача реализовать хранение территориальных единиц в виде: страна — регион — город.
Создадим таблицу:
```
create table "world" (
"id" serial primary key,
"name" varchar(150) not null,
"tree" ltree not null
);
```
Наполним данными:
```
id | name | tree
----+----------------+-------
1 | Россия | 1
2 | США | 2
3 | Канада | 3
4 | Москва | 1.4
5 | Химки | 1.4.5
6 | Мытищи | 1.4.6
```
И теперь у нас с вами, есть простой способ получить информацию. Например для получения списка всех стран достаточно выполнить следующий запрос:
```
select "id", "name" from "world" where "tree" ~ '*{1}'
```
Для получения всех регионов России:
```
select "id", "name" from "world" where "tree" ~ '1.*{1}'
```
Примеров применения данного инструмента можно привести множество. Но в силу обзорности данного топика остановимся на этом.
#### Заключение
Как мне кажется, ltree — является отличным способом организации древовидных структур. Благодаря простым и удобным методам поиска и сортировки информации, он подойдет для широкого круга задач.
В данной статье, я перечислил далеко не все возможности ltree. Совсем не был рассмотрен вопрос о индексировании, функциях и вопросы полнотекстового поиска ltxtquery. С полной документацией можно ознакомится по приведенным ниже ссылкам [1, 2].
А вообще, у PostgreSQL есть много дополнительных полезных модулей [3]. Приятного изучения!
#### Ссылки
1. [Описание ltree на сайте разработчика](http://www.sai.msu.su/~megera/postgres/gist/ltree/)
2. [Описание ltree на сайте PostgreSQL](http://www.postgresql.org/docs/9.0/static/ltree.html)
3. [Contrib-модули PostgreSQL](http://www.postgresql.org/docs/9.0/static/contrib.html) | https://habr.com/ru/post/130371/ | null | ru | null |
# Знакомство с jabber ботами
Длительное время я использовал джаббер только в роли меседжера, однако несколько недель назад мне попался адрес джаббер бота, который был словарем, что представилось мне крайне удобным в использовании. В скором времени мой ростер пополнился десятком удобных ботов, и в поиске новых я, в том числе, исследовал хабр, но не нашел ничего. Я решил заполнить эту нишу и создать сводный список ботов, известных мне, которые, по-моему мнению, могут заинтересовать.
Начну с исторически первого бота и раздела ботов, относящихся к нему: со словарей и переводчиков.
Первым ботом, *JID* (jabber id), который я случайно нашел был
**[email protected]**
Суть простая – высылаете ему слово или фразу на английском языке, и он пытается ее перевести на русский язык, но результат не всегда бывает удачным. Например:
> `[00:34:18] **Dark Dimius** this is an example of the translation made by the bot [email protected]
>
> [00:34:19] **English-Russian** это - пример перевода, сделанного личинкой [email protected]`
>
>
На [jrudevels.org](http://jrudevels.org) размещено много различных словарей-переводчиков, и многие «знакомы» с русским языком, что не может не радовать.
Однако, если мне нужен именно словарь, то я предпочитаю боты, о которых можно узнать у «главного» **[email protected]**
> `[00:37:55] **Dark Dimius** !help
>
> [00:37:56] **[email protected]** !list - dictionaries list
>
> !stat - show statistics
>
> !help - this help
>
> syntax: dictionary word
>
> [00:38:39] **Dark Dimius** !list
>
> [00:38:40] **[email protected]** 1000pbio: 1000+ biography
>
> aviation: Russian abbreviations for aviation
>
> beslov: Большой Энциклопедический Словарь
>
> biology:
>
> brok_and_efr: Энциклопедический словарь Брокгауза и Ефрона
>
> compbe: English-Belarusian Computer Dictionary
>
> deutsch:
>
> en-ru-bars:
>
> engcom: The Open English-Russian Computer Dictionary
>
> ethnographic: Этнографический словарь
>
> findict: Словарь финансовых терминов
>
> geology_enru: English-Russian Geological
>
> idioms: Русско-английский словарь идиом
>
> korolew_enru: Англо-русский словарь Королева
>
> korolew_ruen: Русско-английский словарь Королева
>
> mech: Mechanical
>
> mueller7: Mueller English-Russian Dictionary
>
> ozhegov: Толковый словарь Ожегова
>
> religion: История религии
>
> sc-abbr: Computer Science Abbreviations
>
> sinyagin_abbrev:
>
> sinyagin_alexeymavrin:
>
> sinyagin_business:
>
> sinyagin_computer:
>
> sinyagin_general_er:
>
> sinyagin_general_re:
>
> sinyagin_unsorted:
>
> slovnyk_be-en:
>
> slovnyk_be-pl:
>
> slovnyk_be-ru:
>
> slovnyk_be-uk:
>
> slovnyk_en-be:
>
> slovnyk_en-pl:
>
> slovnyk_en-ru:
>
> slovnyk_en-uk:
>
> slovnyk_pl-be:
>
> slovnyk_pl-en:
>
> slovnyk_pl-ru:
>
> slovnyk_pl-uk:
>
> slovnyk_ru-be:
>
> slovnyk_ru-en:
>
> slovnyk_ru-pl:
>
> slovnyk_ru-uk:
>
> slovnyk_uk-be:
>
> slovnyk_uk-en:
>
> slovnyk_uk-pl:
>
> slovnyk_uk-ru:
>
> smiley:
>
> sokrat_enru:
>
> sokrat_ruen:
>
> swedish:
>
> teo: Теософский словарь
>
> ushakov: Толковый словарь Ушакова
>
> zhelezyaki_abbr: USSR abbreviations for chips
>
> zhelezyaki_analogs: Analogs for USSR chips`
>
>
>
> Как видите, список действительно внушительный. Но это только словари, не переводчики.Переводят только слова. Например:
>
> `[18:10:04] **Dark Dimius** словарь
>
> [18:10:05] **[email protected]**
>
> словарь
>
> dictionary
>
>
>
> словарь
>
> dictionary;
>
> vocabulary, glossary;
>
> lexicon
>
>
>
> словарь
>
> dictionary
>
> glossary
>
> lexicon
>
> thesaurus
>
> vocabulary
>
> word-book
>
> wordbook`
>
>
Также стоит отметить переводчики семейства **@bot.talk.google.com**, «гугловские». Но это семейство предлагает только два переводчика знакомых с русским языком: русско-английский и англо-русский.
Теперь поговорим об информационных ботах.
**gism.portal-on.ru** – удобный транспорт, пересылающий пользователю погоду с [gismeteo.ru](http://gismeteo.ru). Например, [email protected] — погода в Москве. [Здесь](http://www.portal-on.ru/jabber/?q=content/bots/weather) находится хорошее описание.
На любое сообщение отвечает погодой
**[email protected]** – бот, собирающий RSS новости и пересылающий их пользователю. Например:
> `[00:58:56] **Dark Dimius** subscribe habrahabr.ru/rss
>
> [00:58:59] **JabRSS** You have been subscribed to habrahabr.ru/rss`
>
>
После этого мне сразу пришли новости, которые не выкладываю, так как их очень много. Бот сделан очень хорошо, при добавлении его в контакт лист сам присылает собственное описание. Список команд с описанием можно найти [здесь](http://cmeerw.org/dev/book/view/30).
Следующим, простым в выполнении, ботом является бот выполнения whois запросов — **[email protected]**. Отсылаете ему адрес – получаете ответ.
Далее бот, который мне очень понравился – удобная программа теле передач: **[email protected]**. По [этому](http://www.portal-on.ru/jabber/?q=service/tv) адресу можно найти хороший руководство к нему.
Теперь перечислю полезные бот-сервисы:
**[email protected]** — Сократитель ссылок.
Просто добавляем его в ростер бота и отсылаем ему длинную ссылку. В ответ получаем короткую ссылку.
**presence.jabberfr.org** — Сервис отображения статуса.
Заходим в обзоре сервисов на него, регистрируемся. После этого заходим на сайт [presence.jabberfr.org](http://presence.jabberfr.org/). Вводим свой JID, выбираем тип отображения.
Полученную ссылку можно добавить в свою подпись на форумах и сервисах.
Теперь все смогут увидеть ваш статус. Пример: мой статус 
**disk.jabbim.cz** – джаббер-сервис для хранения файлов до 100 Мб. [Здесь](http://www.jabber.ru/node/418) вы найдете описание. Джаббер-сервис состоит из трех ботов: первый предоставляет публичный доступ к файлам (с веб ссылкой), второй – личное хранение, третий – фотоальбом сразу выкладывающий картинки на сайт.
И последний, самый «вкусный», бот **[email protected]**
Это бот, *менеджер персональной информации,* который можно расширять виджетами (я бы назвал их плагинами). Чтобы активировать виджет, следует зайти в раздел меню «My Account», прислав «4». Виджеты содержат все, что может душа пожелать:
виджет постинга в [blogger](https://www.imified.com/settings/widgets.cfm?widgetKey=28) из джаббера.
блогилка в [твиттер и jaiku](https://www.imified.com/settings/widgets.cfm?widgetKey=21) одновременно. В них отдельно также есть постилки([Twitter](https://www.imified.com/settings/widgets.cfm?widgetKey=18),[Jaiku](https://www.imified.com/settings/widgets.cfm?widgetKey=20))
постилка в [ЖЖ](https://www.imified.com/settings/widgets.cfm?widgetKey=17)
постилка в [Wordpress](https://www.imified.com/settings/widgets.cfm?widgetKey=11).
[набор сетевых утилит](https://www.imified.com/settings/widgets.cfm?widgetKey=26)… ping, traceroute и т.д.
А также еще более 20 виджетов.
Выше описаны те боты, которые меня наиболее заинтересовали. Буду рад узнать от сообщества о других ботах, которые я не встречал.
~~Хорошо бы опубликовать в тематическом блоге, но это первый пост на хабре — кармы недостаточно.~~ Большое спасибо!
**Update 1** Сокращалка ссылок( **[email protected]**) похоже перестала работать, во всяком случае у меня.
**Update 2** [Найдена](http://habrahabr.ru/blogs/im/51328/#comment_1358962) достойная замена | https://habr.com/ru/post/51328/ | null | ru | null |
# Использование Простой электронной подписи в документах
Цель написания статьи – популяризировать использование **Простой электронной подписи** (пЭП) в документах. Чем больше людей пользуется, тем более популярен механизм, тем меньше у всех страхов, подозрений и вопросов. Очень удобно, подписал счет и акты пЭП и передал по email в бухгалтерию контрагента.
Простая электронная подпись не требует получения ее в удостоверяющем центре, не требует специальных технических или программных средств, однако она при соблюдении определенных условий признается нашим законодательством равнозначной собственноручной подписи.

Более того, при наличии своего сервиса проверки, пЭП гарантирует достоверность подписи, в отличии от собственноручной подписи. Например третьему лицу, взявшему в руки документ, неизвестно, закорючка напротив ФИО это реальная подпись того человека или нет. А здесь зашел на указанный сервис, вбил номер подписи и ты точно знаешь, что именно данный документ подписал именно данный человек.
Как сделать такой сервис проверки, и как организовать свою пЭП и будет описано в данной статье.
PS: **Данный способ не подходит для подписи счет-фактур. По счету-фактуре установлены жесткие требования — подпись либо живая, либо ЭП у оператора.** А счет, акт и т.п. можно.
> Комментарий юриста по данному поводу: "*По счету-фактуре установлены жесткие требования — подпись либо живая, либо ЭП у оператора.
>
> Была даже в свое время практика, можно ли подписывать сф факсимиле, вроде как примерно то же, что и живая подпись.
>
> Суды сказали нельзя.
>
> С ЭП будет то же самое. Слишком много бюджет теряет из-за сф*."
Сначала немного законодательной теории.
Наше законодательство однозначно определяет условия признания электронных документов, подписанных простой электронной подписью, равнозначными документам на бумажном носителе, подписанным собственноручной подписью. Это определяется ФЗ №63 от 06.04.2011 статья 9 “Использование простой электронной подписи”. Данный закон голосит:
> 1. Электронный документ считается подписанным простой электронной подписью при выполнении в том числе одного из следующих условий:
>
>
>
> 1) простая электронная подпись содержится в самом электронном документе;
>
> …
>
>
>
> 2. Нормативные правовые акты и (или) соглашения между участниками электронного взаимодействия, устанавливающие случаи признания электронных документов, подписанных простой электронной подписью, равнозначными документам на бумажных носителях, подписанным собственноручной подписью, должны предусматривать, в частности:
>
>
>
> 1) правила определения лица, подписывающего электронный документ, по его простой электронной подписи;
>
> 2) обязанность лица, создающего и (или) использующего ключ простой электронной подписи, соблюдать его конфиденциальность.
Т.е. для законного использования пЭП нам необходимо:
1. код подписи вписать в документ (что и так понятно)
2. придумать правила определения подписавшего лица
3. способ обеспечения конфиденциальности
Правила определения подписавшего лица и способ обеспечения конфиденциальности удобнее всего описывать в договоре. В теле договора должно быть описано что стороны признают пЭЦП равнозначной собственноручной подписи при соблюдении правил описанных в Приложении 1. В Приложении 1 соответственно должны быть описаны правила и порядок формирования пЭП.
Приведу пример как это сделано у меня в [договоре оферте](https://erp-platform.com/dog.pdf). Я не претендую на то, что это идеальный вариант, но думаю в качестве живого примера читателям будет интересно.
В разделе 1, Термины и определения вводится понятие пЭП.
> 1.6. «Простая электронная подпись» — подпись на электронной версии документов, передаваемых между Сторонами и определяемая правилами в Приложении 1 Данного договора, пунктами 4.2 и 4.3 данного Договора и статьей 9 Федерального закона от 06.04.2011 N 63-ФЗ «Об электронной подписи».
Далее раздел 4. Соглашение об использовании пЭП.
> 4. СОГЛАШЕНИЕ ОБ ИСПОЛЬЗОВАНИИ ПРОСТОЙ ЭЛЕКТРОННОЙ ПОДПИСИ.
>
>
>
> 4.1. Стороны, в соответствии с Федеральным законом от 06.04.2011 N 63-ФЗ «Об электронной подписи», дают согласие на использовании простой электронной подписи документах передаваемых между Сторонами, в том числе в закрывающих документах.
>
>
>
> 4.2. Правила и порядок формирования ключа простой электронной подписи и правила определения лица, подписывающего электронный документ, по его простой электронной подписью, определяются в Приложении 1 к данному Договору. Приложение 1 является неотъемлемой частью данного Договора.
>
>
>
> 4.3. Стороны обязуются соблюдать конфиденциальность ключа своей простой электронной подписи.
>
>
>
> 4.4. На основании п.4.2 и п.4.3. данного договора и положений п.2 статьи 9 Федерального закона от 06.04.2011 N 63-ФЗ «Об электронной подписи», электронные версии документов размещаемые в личном кабинете Лицензиата, либо предаваемые посредством электронной почты между Сторонами, признаются равнозначными документам на бумажных носителях, подписанным собственноручной подписью.
Далее раздел 6. Порядок взаиморасчетов. Тут сказано, что закрывающие документы могут удостоверяться пЭП.
> 6.7. Закрывающие документы между сторонами передаются в электронном виде посредством размещения в личном кабинете Лицензиата и (или) через электронную почту и удостоверяются Простой электронной подписью.
И наконец Приложение 1, где описываются правила и порядок формирования пЭП.
> **Правила и порядок формирования Простой электронной подписи.**
>
>
>
> 1. Правила формирования подписи.
>
>
>
> 1.1. **Ключ подписи** – кодовое слово или любая последовательность символов от 6 до 64 знаков известная только владельцу.
>
>
>
> *Например: «Ключ Лицензиата»*
>
>
>
> 1.2. **Hash ключа подписи** – ключ подписи обработанный hash функцией с длинной ключа от 64 до 256 бит.
>
>
>
> Пример получения:
>
>
>
> 1. hash('sha256','Ключ Лицензиата') = **cf7f0afbad1857c1da38477d79889cb378d33dee5430e9e7bf4cc04f0e3354f8**
> 2. hash('sha1','Ключ Лицензиата') = **7e3ecf5ab5ad710573a028d1a383355293b75438**
> 3. md5('Ключ Лицензиата') = **822f424c94ffbe1e9b0e53df6d851da4**
>
>
>
> 1.3. Hash ключа подписи, для возможности автоматической проверки документов системой, пользователю необходимо внести в личном кабинете на сайте [https://erp-platform.com](https://erp-platform.com/?i=1) в разделе Настройки-ЭП.
>
>
>
> 1.4. В целях безопасности, 5-10 символы значения хеша ключа пользователя при выводе на экран заменяются звездочками (например: вместо 822f424c94ffbe1e9b0e53df6d851da4 на экран будет выведено 822f4\*\*\*\*\*ffbe1e9b0e53df6d851da4). Данная процедура исключает копирование ключа пользователя злоумышленником, даже в случае взлома логина-пароля аккаунта пользователя. Оригинал ключа должен храниться исключительно у пользователя.
>
>
>
> 1.5. Алгоритм получения простой электронной подписи документа:
>
>
>
> «Простая электронная подпись» = hash\_sha1(«Тип документа»+«Номер документа»+«Дата документа»+«Ключ Лицензиата»)
>
>
>
> *PS: ключ лицензиата в данной системе является “солью”.*
>
>
>
> Например:
>
>
>
> **b554f464d3cf1b128b07e96b960b7bb4a19a3c95** = hash('sha1','1'.'№03452'.'09.11.2016'.'822f424c94ffbe1e9b0e53df6d851da4')
>
>
>
> Типы документов:
>
>
>
> 1 – Счет
>
> 2 – Акт
>
> 3 – Договор
>
> 4 – Приложение к договору
>
>
>
> 1.6. Для улучшения читабельности Электронная подпись может представляться в виде по 5 символов разделенных дефисами. Данная процедура необязательна. Дефисы при вводе подписи программой автоматически удалятся.
>
>
>
> b554f464d3cf1b128b07e96b960b7bb4a19a3c95 = **b554f-464d3-cf1b1-28b07-e96b9-60b7b-b4a19-a3c95**
>
>
>
> **2. Правила проверки подписи**
>
>
>
> 2.1. Удостоверение подлинности Простой электронной подписи Лицензиара.
>
>
>
> Лицензиар на своем официальном сайте [erp-platform.com](https://erp-platform.com) предоставляет возможность проверки подписи любого документа по адресу [erp-platform.com/ecp](https://erp-platform.com/ecp). Для проверки необходимо ввести Простую электронную подпись из документа в поле «Простая электронная подпись», ввести код капчи и нажать на кнопку «Проверить подпись документа». В ответ программа выдаст реквизиты документа, либо напишет «Документ не найден, подпись не подтверждена».
>
>
>
> Данную процедуру проверки подлинности Простой электронной подписи Лицензиата может проводить как Лицензиат, так и третьи лица, которым Лицензиат передал документы.
>
>
>
> 2.2. Удостоверение подлинности Простой электронной подписи Лицензиата.
>
> Удостоверить подпись Лицензиата Лицензиар может 4 способами:
>
>
>
> 1) В личном кабинете Лицензиата должен быть внесен Hash ключа подписи пользователя, подписавшего документ. В этом случае при получении документов по электронной почте у Лицензиара появляется возможность автоматической проверки подлинности подписи зная тип документа, номер документа, дату подписи и hash ключа подписи пользователя.
>
>
>
> 2) В случае если Лицензиат производит подпись документ в личном кабинете, и внесен hash ключа подписи пользователя, то необходимо внести сформированную Простую электронную подпись для данного Акта в соответствующую графу документ и нажать на кнопку «ЭП». Программа автоматически произведет проверку подписи и поставит ее в документ.
>
>
>
> 3) В случае если Лицензиат не вносит hash ключа подписи пользователя в личном кабинете, но хочет передавать подписанные Простой электронной подписью документы через электронную почту, Лицензиат должен доставить Лицензиару hash ключа подписи пользователя, подписывающего документы на любом носителе, в том числе на бумажном
>
>
>
> 4) В случае если Лицензиат не желает сообщать лицензиару hash ключа подписи пользователя, он вправе сделать на своих технических средствах сервис проверки подписи аналогичный [erp-platform.com/ecp](https://erp-platform.com/ecp) и вместе с документами присылать ссылку на данный сервис, чтобы у Лицензиара была возможность проверки подлинности Простой электронной подписи документа.
Код сервиса проверки
```
//Сначала отбрасываем всех кто неправильно ввел капчу
if ($_POST['capcha']==$_SESSION['captcha'])
{
//Потом отбрасываем если неверный формат ЭП, на остольное даже не будем таратить ресурсы.
if ((strlen($_POST['ep'])==47)or(strlen($_POST['ep'])==40))
{
//Если есть девисы то удаляем опять проверяем
$ep=str_replace('-','',$_POST['ep']);
if (strlen($ep)==40)
{
//Здесь дожен быть запрос в БД и проверка ЭП, вывод результата проверки
}
else
echo '
Неверный формат ЭП.'.strlen($ep).'';
}
else
echo '
Неверный формат ЭП. Должно быть 40 либо 47 символов.';
}
else
{
if (isset($_POST['capcha']))
echo '
Текст на рисунке не совпадает с введенным.';
}
``` | https://habr.com/ru/post/323364/ | null | ru | null |
# Знак рубля и XHTML 1.0 Strict. Что общего?
Речь пойдёт о Document Type Definition (или DTD, короче говоря).
На пути к совсем семантической вёрстке, нам понадобится DTD или же стандарт XML Schema. В данной статье я рассмотрю первое и покажу, как с помощью 2 строк и одного CSS-стиля сделать кроссбраузерный, W3-валидный документ с использованием собственного тэга —
Разобравшись с изложенным мною методом, любой может создавать валидные документы с использованием собственных тэгов, которые могут не только сделать макет документа более гибким, но и более семантически-правильным, логичным и понятным, как для роботов, так и для людей, которые будут заниматься дальнейшей его поддержкой.
Итак, нам требуется внедрить в XHTML свой тэг, который обозначал бы знак рубля. Для того, чтобы страница была одобрена валидатором, она должна быть не только well-formed (*Прим.:* синтаксически правильной в терминах «XMLSpec»), но и валидной, т.е. составленной в соответствии с дескриптором типа документа, известным, как DTD.
Я пользуюсь DTD XHTML 1.0 Strict, описание валидных документов для которого можно найти по знакомому URL <http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd>
Изучив структуру документа, мы найдём следующие строки:
> `1.
> 2.
> 3. ENTITY % special.pre
> 4. "br | span | bdo | map">
> \* This source code was highlighted with Source Code Highlighter.`
Эти строки показывают, что в документе могут быть использованы тэги br, span, bdo, map. Наш тэг называется rur. Теперь осталось как-то внедрить его в уже созданный DTD. Стандарт DTD позволяет наращивать дескрипторы типов документов. Я не буду на это останавливаться, а покажу сразу код DOCTYPE-заголовка для валидного XHTML 1.0 — Strict документа:
> `1. DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd"
> 2. [<!ENTITY % special.pre "br | span | bdo | map | rur">
> 3. ELEMENT rur (#PCDATA)>
> 4. ATTLIST rur>]>
> \* This source code was highlighted with Source Code Highlighter.`
Приведенный код означает, что мы добавляем для сущности special.pre тип тэга rur, который не имеет параметров и может содержать Parsed Character Data.
Для проверки работоспособности кода, вживим в любой валидный XHTML-макет указанный выше заголовок и следующий код:
> `1. Знак рубля (<rur>руб.rur>) появился в обращении 1 июля 2007 года.
> 2.
> 3. <script type="text/javascript">
> 4. //</font></li>
> <li>i=0;</li>
> <li><font color="#0000ff">while</font> (<font color="#0000ff">true</font>)</li>
> <li>{</li>
> <li> <font color="#0000ff">var</font> elem = <font color="#0000ff">document</font>.getElementsByTagName (<font color="#A31515">'rur'</font>)[i]; </li>
> <li> </li>
> <li> <font color="#0000ff">if</font> (!elem) {<font color="#0000ff">break</font>;}</li>
> <li> elem.innerHTML = <font color="#A31515">"Р"</font>;</li>
> <li> i++;</li>
> <li> </li>
> <li>} </li>
> <li><font color="#008000">//
> 5. script>
> \* This source code was highlighted with Source Code Highlighter.`
JS-код, я думаю вполне понятен — он ищет тэги в теле документа и подставляет в них контент — букву «Р», которая является графической основой знака рубля. Если у клиента нет JS, то выводится остаётся просто «руб.»
Да! И совсем забыл CSS для нашего рубля!
> `1. /\*знак рубля\*/
> 2. rur
> 3. {
> 4. text-decoration: line-through;
> 5. margin: 0.1em;
> 6. }
> \* This source code was highlighted with Source Code Highlighter.`
Кстати, он у вас может быть совсем другим!
Вот как-то так. Я думаю, Хабролюди с полна оценят эту скромную работку и поймут её ценность. Спасибо за внимание!
Для проверки, Вы можете открыть исходный код с моего сервера по адресу: [http://www.ridev.ru/valid-rur.htm](http://www.ridev.ru/valid-rur.htm "Ссылка на HTML-код")
Я намеряно запихнул CSS внутрь, чтобы был один файл. | https://habr.com/ru/post/63647/ | null | ru | null |
# Вся правда об ОСРВ. Статья #28. Программные таймеры
Идея программных таймеров была введена в одной из [предыдущих статей](https://habr.com/ru/post/418677/). Они являются объектами ядра, предоставляющими задачам простой способ запуска событий по времени, или, чаще всего, способ выполнять действия на регулярной основе. Все детали функционала, связанного со временем (точность, обработка прерываний и т.д.) в Nucleus SE были рассмотрены в [предыдущей статье](https://habr.com/ru/post/454272/).

**Предыдущие статьи серии:**[Статья #27. Системное время](https://habr.com/ru/post/454272/)
[Статья #26. Каналы: вспомогательные службы и структуры данных](https://habr.com/ru/post/433374/)
[Статья #25. Каналы передачи данных: введение и основные службы](https://habr.com/ru/post/433046/)
[Статья #24. Очереди: вспомогательные службы и структуры данных](https://habr.com/ru/post/432804/)
[Статья #23. Очереди: введение и базовые службы](https://habr.com/post/431378/)
[Статья #22. Почтовые ящики: вспомогательные службы и структуры данных](https://habr.com/post/431118/)
[Статья #21. Почтовые ящики: введение и базовые службы](https://habr.com/post/430856/)
[Статья #20. Семафоры: вспомогательные службы и структуры данных](https://habr.com/post/429588/)
[Статья #19. Семафоры: введение и базовые службы](https://habr.com/post/429156/)
[Статья #18. Группы флагов событий: вспомогательные службы и структуры данных](https://habr.com/post/428890/)
[Статья #17. Группы флагов событий: введение и базовые службы](https://habr.com/post/428131/)
[Статья #16. Сигналы](https://habr.com/post/427439/)
[Статья #15. Разделы памяти: службы и структуры данных](https://habr.com/post/426477/)
[Статья #14. Разделы памяти: введение и базовые службы](https://habr.com/post/426425/)
[Статья #13. Структуры данных задач и неподдерживаемые вызовы API](https://habr.com/post/425353/)
[Статья #12. Службы для работы с задачами](https://habr.com/post/424713/)
[Статья #11. Задачи: конфигурация и введение в API](https://habr.com/post/424481/)
[Статья #10. Планировщик: дополнительные возможности и сохранение контекста](https://habr.com/post/423967/)
[Статья #9. Планировщик: реализация](https://habr.com/post/422615/)
[Статья #8. Nucleus SE: внутреннее устройство и развертывание](https://habr.com/post/422617/)
[Статья #7. Nucleus SE: введение](https://habr.com/post/418601/)
[Статья #6. Другие сервисы ОСРВ](https://habr.com/post/418677/)
[Статья #5. Взаимодействие между задачами и синхронизация](https://habr.com/post/415429/)
[Статья #4. Задачи, переключение контекста и прерывания](https://habr.com/post/415427/)
[Статья #3. Задачи и планирование](https://habr.com/post/415329/)
[Статья #2. ОСРВ: Структура и режим реального времени
Статья #1. ОСРВ: введение.](https://habr.com/post/414093/)
Использование таймеров
----------------------
Программные таймеры могут быть настроены на однократное срабатывание, то есть они запускаются, а затем, после указанного периода времени, просто завершают цикл. Либо таймер может быть настроен на перезапуск: после завершения счета таймер автоматически перезапускается. Время работы после перезапуска может отличаться от первичного времени работы. Кроме того, таймер можно опционально настроить на выполнение специальной функции завершения, которая выполняется когда (или каждый раз когда) таймер завершает рабочий цикл.
Настройка таймеров
------------------
### Количество таймеров
Как и для большинства аспектов Nucleus SE, настройка таймеров управляется директивами **#define** в **nuse\_config.h**. Основным параметром является **NUSE\_TIMER\_NUMBER**, который определяет сконфигурированные в приложении таймеров. По умолчанию это значение равно нулю (то есть в приложении таймеры не используются), и может принимать значения вплоть до 16. Некорректное значение приведет к ошибке компиляции, которая будет сгенерирована проверкой в файле **nuse\_config\_check.h** (этот файл входит в **nuse\_config.c** и компилируется вместе с ним), что приведет к срабатыванию директивы **#error**.
Выбор ненулевого значения является главным активатором таймеров. Этот параметр используется при определении структур данных, и от его значения зависит их размер. Кроме того, ненулевое значение активирует настройки API.
### Активация функции завершения
В Nucleus SE я пытался найти возможность сделать функционал опциональным, там, где это позволит сэкономить память. Хорошим примером является поддержка функций завершения таймеров. Помимо того, что эта возможность опциональна для каждого таймера, механизм может быть активирован (или нет) для всего приложения при помощи параметра **NUSE\_TIMER\_EXPIRATION\_ROUTINE\_SUPPORT** в **nuse\_config.h**. Присвоение этому параметру значения **FALSE** блокирует определение двух структур данных в ПЗУ, которые будут подробно описаны в этой статье.
### Активация API
Каждая функция API (служебный вызов) в Nucleus SE имеет активирующую директиву #define в nuse\_config.h. Для таймеров к таким символам относятся:
**NUSE\_TIMER\_CONTROL
NUSE\_TIMER\_GET\_REMAINING
NUSE\_TIMER\_RESET
NUSE\_TIMER\_INFORMATION
NUSE\_TIMER\_COUNT**
По умолчанию, всем активаторам присвоено значение **FALSE**, таким образом, все служебные вызовы отключены, блокируя включение реализующего их кода. Для настройки таймеров в приложении нужно выбрать необходимые служебные вызовы API и присвоить им значение **TRUE**.
Ниже приведен фрагмент кода из файла **nuse\_config.h** по умолчанию.
```
#define NUSE_TIMER_NUMBER 0/* количество таймеров приложения в системе 0-16 */
/* Активаторы служебного вызова */
#define NUSE_TIMER_CONTROL FALSE
#define NUSE_TIMER_GET_REMAINING FALSE
#define NUSE_TIMER_RESET FALSE
#define NUSE_TIMER_INFORMATION FALSE
#define NUSE_TIMER_COUNT FALSE
```
Если функция API, связанная с таймерами, активирована, а в приложении нет сконфигурированных таймеров (кроме функции **NUSE\_Timer\_Count()**, которая разрешена всегда), возникнет ошибка компиляции. Если ваш код использует вызов API, который не был активирован, произойдет ошибка компоновки, так как код реализации не был включен в приложение.
Служебные вызовы таймеров
-------------------------
Nucleus RTOS поддерживает восемь служебных вызовов, связанных с таймерами, которые предоставляют следующий функционал:
* Управление (запуск/остановка) таймером. В Nucleus SE реализовано в функции **NUSE\_Timer\_Control()**.
* Получение оставшегося времени таймера. В Nucleus SE реализовано в **NUSE\_Timer\_Get\_Remaining()**.
* Восстановление таймера в исходное состояние (сброс). В Nucleus SE реализовано в **NUSE\_Timer\_Reset()**.
* Предоставление информации о конкретном таймере. В Nucleus SE реализовано в **NUSE\_Timer\_Information()**.
* Возврат количества сконфигурированных (на данный момент) таймеров в приложении. В Nucleus SE реализовано в **NUSE\_Timer\_Count()**.
* Добавление нового таймера в приложение (создание). В Nucleus SE не реализовано.
* Удаление таймера из приложения. В Nucleus SE не реализовано.
* Возвращение указателей на все таймеры в приложении. В Nucleus SE не реализовано.
Реализация каждого служебного вызова будет подробно рассмотрена далее.
Службы таймеров
---------------
Фундаментальные операции, которые можно выполнять с таймером, это управление (запуск и остановка) и считывание текущего значения. Nucleus RTOS и Nucleus SE предоставляют два базовых служебных вызова API для этих операций.
### Управление таймером
Служебный вызов Nucleus RTOS API для управления таймером позволяет активировать и деактивировать таймер (запускать и останавливать). Nucleus SE предоставляет аналогичный функционал.
***Вызов для управления таймером в Nucleus RTOS***
Прототип служебного вызова:
**STATUS NU\_Control\_Timer (NU\_TIMER \*timer, OPTION enable);**
Параметры:
**timer** – указатель на предоставляемый пользователем блок управления таймером;
**enable** – требуемая функция, может принимать значения **NU\_ENABLE\_TIMER** или **NU\_DISABLE\_TIMER**.
Возвращаемое значение:
**NU\_SUCCESS** – вызов был успешно завершен;
**NU\_INAVLID\_TIMER** – некорректный указатель на таймер;
**NU\_INAVLID\_ENABLE** – некорректная функция.
***Вызов для управления таймером в Nucleus SE***
Этот вызов API поддерживает полный функционал Nucleus RTOS API.
Прототип служебного вызова:
**STATUS NUSE\_Timer\_Control (NUSE\_TIMER timer, OPTION enable);**
Параметры:
**timer** – индекс (ID) используемого таймера;
**enable** – требуемая функция, может принимать значения **NUSE\_ENABLE\_TIMER** или **NUSE\_DISABLE\_TIMER**.
Возвращаемое значение:
**NUSE\_SUCCESS** – вызов был успешно завершен;
**NUSE\_INCALID\_TIMER** – некорректный индекс таймера;
**NUSE\_INVALID\_ENABLE** – некорректная функция.
***Реализация управления таймеров в Nucleus SE***
Код функции API **NUSE\_Timer\_Control()** (после проверки параметров), достаточно прост:
```
NUSE_CS_Enter();
if (enable == NUSE_ENABLE_TIMER)
{
NUSE_Timer_Status[timer] = TRUE;
if (NUSE_Timer_Expirations_Counter[timer] == 0)
{
NUSE_Timer_Value[timer] = NUSE_Timer_Initial_Time[timer];
}
else
{
NUSE_Timer_Value[timer] = NUSE_Timer_Reschedule_Time[timer];
}
}
else /* enable == NUSE_DISABLE_TIMER */
{
NUSE_Timer_Status[timer] = FALSE;
}
NUSE_CS_Exit();
```
Если была указана функция **NUSE\_DISABLE\_TIMER**, статусу таймера (параметр **NUSE\_Timer\_Status[]**) присваивается значение **FALSE**, что приводит к игнорированию таймера обработчиком прерываний.
При выборе функции **NUSE\_ENABLE\_TIMER** счетчик таймера (**NUSE\_Timer\_Value[]**) устанавливается в значение **NUSE\_Timer\_initial\_Time[]**, при условии что таймер ни разу не останавливался с момента последнего сброса. В противном случае ему присваивается значение **NUSE\_Timer\_Reschedule\_Time[]**. Затем статусу таймера (параметр **NUSE\_Timer\_Status[]**) присваивается значение **TRUE**, что приводит к тому, что таймер обрабатывается обработчиком прерываний.
### Считывание таймера
Для получения оставшегося времени таймера служебный вызов Nucleus RTOS API возвращает количество тактов до истечения срока его действия. Nucleus SE предоставляет аналогичный функционал.
***Вызов для получения оставшегося времени в Nucleus RTOS***
Прототип служебного вызова:
**STATUS NU\_Get\_Remaining\_Time (NU\_TIMER \*timer, UNSIGNED \*remaining\_time);**
Параметры:
**timer** – указатель на предоставленный пользователем блок управления таймером;
**remaining\_time** – указатель на хранилище значения оставшегося времени, которое является переменной типа **UNSIGNED**.
Возвращаемое значение
**NU\_SUCCESS** – вызов был успешно завершен;
**NU\_INVALID\_TIMER** – некорректный указатель на таймер.
***Вызов для получения оставшегося времени в Nucleus SE***
Этот вызов API поддерживает полный функционал Nucleus RTOS API.
Прототип служебного вызова:
**STATUS NUSE\_Timer\_Get\_Remaining(NUSE\_TIMER timer, U16 \*remaining\_time);**
Параметры:
**timer** – индекс (ID) используемого таймера;
**remaining\_time** – указатель на хранилище значения оставшегося времени, которое является переменной типа **U16**.
Возвращаемое значение:
**NUSE\_SUCCESS** – вызов был успешно завершен;
**NUSE\_INVALID\_TIMER** – некорректный индекс таймера;
**NUSE\_INVALID\_POINTER** – нулевой указатель на оставшееся время (**NULL**).
***Реализация считывания таймера в Nucleus SE***
Вариант кода функции API **NUSE\_Timer\_Get\_Remaining()** (после проверки параметров) тривиально прост. Значение **NUSE\_Timer\_Value[]** получается, а затем возвращается в критической секции.
Вспомогательные службы таймеров
-------------------------------
Nucleus RTOS имеет четыре вызова API, которые предоставляют вспомогательные функции, связанные с таймерами: сброс таймера, получение информации о таймере, получение количества таймеров в приложении и получение указателей на все таймеры в приложении. Первые три функции реализованы в Nucleus SE.
### Сброс таймера
Этот вызов API сбрасывает таймер в исходное, неиспользуемое состояние. Таймер может быть активирован или деактивирован после завершения этого вызова. Его можно использовать только после того, как таймер был отключен (при помощи **NUSE\_Timer\_Control()**). В следующий раз когда таймер будет активирован, он будет инициализирован с параметром **NUSE\_Timer\_Initial\_Time[]**. Nucleus RTOS позволяет предоставить новое исходное состояние и провести перепланирование времени, а также указать функцию завершения при сбросе таймера. В Nucleus SE эти значения устанавливаются во время настройки и не могут быть изменены, поскольку они хранятся в ПЗУ.
***Вызов для сброса таймера в Nucleus RTOS***
Прототип служебного вызова:
**STATUS NU\_Reset\_Timer (NU\_TIMER \*timer, VOID (\*expiration\_routine) (UNSIGNED), UNSIGNED initial\_time, UNSIGNED reschedule\_time, OPTION enable);**
Параметры:
**timer** – указатель на сбрасываемый таймер;
**expiration\_routine** – указывает функцию, которая будет выполнена при завершении цикла;
**initial\_time** – исходное количество тактов таймера до завершения цикла;
**reschedule\_time** – количество тактов таймера до завершения второго и последующих циклов;
**enable** – требуемое состояние таймера после сброса, может принимать значения **NU\_ENABLE\_TIMER** или **NU\_DISABLE\_TIMER**.
Возвращаемое значение:
**NU\_SUCCESS** – вызов был успешно завершен;
**NU\_INVALID\_TIMER** – некорректный указатель на блок управления таймера;
**NU\_INVALID\_FUNCTION** – нулевой указатель на функцию завершения (**NULL**);
**NU\_INVALID\_ENABLE** – указанное состояние некорректно;
**NU\_NOT\_DISABLED** – таймер уже запущен (его следует остановить перед вызовом этой функции).
***Вызов для сброса таймера в Nucleus SE***
Этот служебный вызов API поддерживает упрощенную версию ключевого функционала Nucleus RTOS API.
Прототип служебного вызова:
**STATUS NUSE\_Timer\_Reset (NUSE\_TIMER timer, OPTION enable);**
Параметры:
**timer** – индекс (ID) сбрасываемого таймера;
**enable** – требуемое состояние после сброса, может принимать значения **NUSE\_ENABLE\_TIMER** или **NUSE\_DISABLE\_TIMER**.
Возвращаемое значение:
**NUSE\_SUCCESS** – вызов был успешно завершен;
**NUSE\_INVALID\_TIMER** – некорректный индекс таймера;
**NUSE\_INVALID\_ENABLE** – указанное состояние некорректно;
**NUSE\_NOT\_DISABLED** – таймер уже запущен (его следует остановить перед вызовом этой функции).
***Реализация сброса таймера в Nucleus SE***
Вариант кода функции API **NUSE\_Timer\_Reset()** (после проверки параметров и текущего состояния) довольно прост:
```
NUSE_CS_Enter();
NUSE_Init_Timer(timer);
if (enable == NUSE_ENABLE_TIMER)
{
NUSE_Timer_Status[timer] = TRUE;
}
/* иначе enable == NUSE_DISABLE_TIMER а статус остается FALSE */
NUSE_CS_Exit();
```
Вызов **NUSE\_Init\_Timer()** инициализирует значение времени и очищает счетчик завершения. После этого при необходимости проверятся значение требуемого состояния и включен ли таймер.
### Информация о таймере
Этот служебный вызов позволяет получить набор информации о таймере. Реализация Nucleus SE отличается от Nucleus RTOS тем, что она возвращает меньше информации, так как именование объектов не поддерживается.
***Вызов для получения информации о таймере в Nucleus RTOS***
Прототип служебного вызова:
**STATUS NU\_Timer\_Information (NU\_TIMER \*timer, CHAR \*name, OPTION \*enable, UNSIGNED \*expirations, UNSIGNED \*id, UNSIGNED \*initial\_time, UNSIGNED \*reschedule\_time);**
Параметры:
**timer** – указатель на таймер, о котором запрашивается информация;
**name** – указатель на 8-символьную область для имени таймера;
**enable** – указатель на переменную, принимающую текущее состояние активатора таймера: **NU\_ENABLE\_TIMER** или **NU\_DISABLE\_TIMER**;
**expirations** – указатель на переменную, принимающую счетчик количества завершений цикла таймера с момента его последнего сброса;
**id** – указатель на переменную, принимающую значение параметра, переданного в функцию завершения цикла таймера;
**initial\_time** – указатель на переменную, принимающую значение, в которое будет инициализирован таймер после сброса;
**reschedule\_time** – указатель на переменную, принимающую значение, в которое будет инициализирован таймер после завершения.
Возвращаемое значение:
**NU\_SUCCESS** – вызов был успешно завершен;
**NU\_INVALID\_TIMER** – некорректный указатель на таймер.
***Вызов для получения информации о таймере в Nucleus SE***
Этот вызов API поддерживает основной функционал Nucleus RTOS API.
Прототип служебного вызова:
**STATUS NUSE\_Timer\_Information (NUSE\_TIMER timer, OPTION \*enable, U8 \*expirations, U8 \*id, U16 \*initial\_time, U16 \*reschedule\_time);**
Параметры:
**timer** – индекс таймера, о котором запрашивается информация;
**enable** – указатель на переменную, принимающую значение **TRUE** или **FALSE** в зависимости от того, активирован таймер или нет;
**expirations** – указатель на переменную типа **U8**, принимающую значение количества завершений таймера с момента его последнего сброса;
**id** – указатель на переменную типа **U8**, принимающую значение параметра, переданного в функцию завершения таймера (вернет пустое значение, если функции завершения отключены);
**initial\_time** – указатель на переменную типа **U16**, принимающую значение, которым будет инициализирован таймер после сброса;
**reschedule\_time** – указатель на переменную типа **U16**, принимающую значение, которым будет инициализирован таймер после завершения.
Возвращаемое значение:
**NUSE\_SUCCESS** – вызов был успешно завершен;
**NUSE\_INVALID\_TIMER** – некорректный индекс таймера;
**NUSE\_INVALID\_POINTER** – один или несколько параметров-указателей некорректны.
***Реализация получения информации о таймере в Nucleus SE***
Реализация этого вызова API довольно проста:
```
NUSE_CS_Enter();
if (NUSE_Timer_Status[timer])
{
*enable = NUSE_ENABLE_TIMER;
}
else
{
*enable = NUSE_DISABLE_TIMER;
}
*expirations = NUSE_Timer_Expirations_Counter[timer];
#if NUSE_TIMER_EXPIRATION_ROUTINE_SUPPORT
*id = NUSE_Timer_Expiration_Routine_Parameter[timer];
#endif
*initial_time = NUSE_Timer_Initial_Time[timer];
*reschedule_time = NUSE_Timer_Reschedule_Time[timer];
NUSE_CS_Exit();
```
Функция возвращает статус таймера. Значение параметра функции завершения возвращается, только если их поддержка была активирована в приложение.
### Получение количества таймеров
Этот служебный вызов возвращает количество таймеров, сконфигурированных в приложении. В Nucleus RTOS это значение может меняться со временем, и возвращаемое значение будет отображать текущее количество таймеров. В Nucleus SE возвращаемое значение задается на этапе сборки и не может изменяться.
***Вызов для счетчика таймеров в Nucleus RTOS***
Прототип служебного вызова:
**UNSIGNED NU\_Established\_Timers(VOID);**
Параметры: отсутствуют
Возвращаемое значение: количество созданных таймеров в системе.
***Вызов для счетчика таймеров в Nucleus SE***
Этот вызов API поддерживает ключевой функционал Nucleus RTOS API.
Прототип служебного вызова:
**U8 NUSE\_Timer\_Count(void);**
Параметры: отсутствуют
Возвращаемое значение:
количество сконфигурированных таймеров в приложении
### Реализация счетчика таймеров
Реализация этого вызова API достаточно проста: возвращается значение символа #define **NUSE\_TIMER\_NUMBER**.
Структуры данных
----------------
Таймеры используют пять или семь структур данных (находящихся в ОЗУ или в ПЗУ) которые (как и другие объекты Nucleus SE) являются набором таблиц, размер и количество которых соответствует количеству сконфигурированных таймеров и выбранных параметров.
Настоятельно рекомендую, чтобы код приложения не использовал прямой доступ к этим структурам данных, а обращался к ним через предоставляемые функции API. Это позволит избежать несовместимости с будущими версиями Nucleus SE и нежелательных побочных эффектов, а также упростит портирование приложений на Nucleus RTOS. Ниже приведен подробный обзор структур, чтобы упростить понимание работы кода служебных вызовов и для отладки.
### Данные ОЗУ
Эти данные имеют следующую структуру:
**NUSE\_Timer\_Status[]** – массив типа **U8**, имеющий одну запись для каждого сконфигурированного таймера и хранящий статус таймера (работает или остановлен: **TRUE** или **FALSE**).
**NUSE\_Timer\_Value[]** – массив типа **U16**, имеющий одну запись для каждого сконфигурированного таймера и хранящий текущее значение счетчика таймера.
**NUSE\_Timer\_Expirations\_Counter[]** – массив типа **U8**, содержащий счетчик количества случаев, когда таймеры достигали завершения цикла с момента их последнего сброса.
Все эти структуры данных инициализируются функцией **NUSE\_Init\_Timer()** при запуске Nucleus SE. Одна из следующих статей будет содержать полное описание процедур запуска Nucleus SE.
Ниже приведены определения этих структур данных в файле **nuse\_init.c**:
**RAM U8 Timer\_Status[NUSE\_TIMER\_NUMBER];
RAM U16 NUSE\_Timer\_Value[NUSE\_TIMER\_NUMBER];
RAM U8 NUSE\_Timer\_Expirations\_Counter[NUSE\_TIMER\_NUMBER];**
### Данные ПЗУ
Структура этих данных:
**NUSE\_Timer\_Initial\_Time[]** – массив типа **U16**, имеющий одну запись для каждого сконфигурированного таймера и хранящий значение каждого таймера.
**NUSE\_Timer\_Reschedule\_Time[]** – массив типа **U16**, имеющий одну запись для каждого сконфигурированного таймера и хранящий значение, в которое таймер будет установлен после завершения. Нулевое значение говорит о том, что таймер «одноразовый» и не должен перезапускаться автоматически.
**NUSE\_Timer\_Expiration\_Routine\_Address[]** – массив типа **ADDR**, содержащий адрес процедур истечения таймеров. Этот массив существует, только если поддержка процедуры истечения таймера была активирована.
**NUSE\_Timer\_Expiration\_Routine\_Parameter[]** – массив типа **U8**, содержащий значения параметра, который передается в функции завершения таймеров. Этот массив существует, только если поддержка функций завершения была активирована.
Эти структуры данных объявляются и инициализируются (статически) в файле **nuse\_config.c**, таким образом:
```
ROM U16 NUSE_Timer_Initial_Time[NUSE_TIMER_NUMBER] =
{
/* исходное время таймера------ */
};
ROM U16 NUSE_Timer_Reschedule_Time[NUSE_TIMER_NUMBER] =
{
/* время таймеров после первого завершения ------ */
};
#if NUSE_TIMER_EXPIRATION_ROUTINE_SUPPORT || NUSE_INCLUDE_EVERYTHING
/* прототипы функций завершения */
ROM ADDR
NUSE_Timer_Expiration_Routine_Address[NUSE_TIMER_NUMBER] =
{
/* адреса функций завершения таймеров ------ */
/* может быть NULL */
};
ROM U8
NUSE_Timer_Expiration_Routine_Parameter[NUSE_TIMER_NUMBER] =
{
/* параметры функции завершения таймера ------ */
};
#endif
```
### Объём памяти для таймера
Как и у всех других объектов Nucleus SE, объем данных, необходимый для таймеров, предсказуем.
Объём данных в ОЗУ (в байтах) для всех таймеров в приложении может быть вычислен следующим образом:
**NUSE\_TIMER\_NUMBER \* 4**
Объём данных в ПЗУ (в байтах) для всех таймеров в приложении, если поддержка функций завершения отключена, может быть вычислен следующим образом:
**NUSE\_TIMER\_NUMBER \* 4**
В противном случае он равен:
**NUSE\_TIMER\_NUMBER \* (sizeof(ADDR) + 5)**
Нереализованные вызовы API
--------------------------
В Nucleus SE не реализованы три вызова API, которые можно найти в RTOS.
### Создание таймера
Этот вызов API создает таймер. В Nucleus SE в нем нет необходимости, так как таймеры создаются статически.
Прототип служебного вызова:
**STATUS NU\_Create\_Timer(NU\_TIMER \*timer, CHAR \*name, VOID (\*expiration\_routine)(UNSIGNED), UNSIGNED id, UNSIGNED initial\_time, UNSIGNED reschedule\_time, OPTION enable);**
Параметры:
**timer** – указатель на предоставляемый пользователем блок управления таймером; он будет использоваться для управления таймерами в других вызовах API;
**name** – указатель на 7-символьное имя таймера с терминирующим нулем;
**expiration\_routine** – указывает функцию, которая должна выполняться после завершения таймера;
**id** – элемент данных типа **UNSIGNED**, передаваемый на функцию завершения: этот параметр может использоваться для идентификации таймеров с одинаковой функцией завершения;
**initial\_time** – указывает исходное количество тактов таймера до завершения таймера;
**reschedule\_time** – указывает количество тактов таймера до завершения второго и последующих циклов; если этот параметр равен нулю, таймер останавливается только один раз;
**enable** – этот параметр может принимать значения **NU\_ENABLE\_TIMER** и **NU\_DISABLE\_TIMER**; **NU\_ENABLE\_TIMER** активирует таймер после его создания; **NU\_DISABLE\_TIMER** оставляет таймер отключенным; таймеры, созданные с параметром **NU\_DISABLE\_TIMER**, должны быть активированы при помощи вызова **NU\_Control\_Timer**.
Возвращаемое значение:
**NU\_SUCCESS** – вызов был успешно завершен;
**NU\_INVALID\_TIMER** – нулевой указатель на блок управления таймером (**NULL**), или блок управления уже используется;
**NU\_INVALID\_FUNCTION** – нулевой указатель на программу завершения (**NULL**);
**NU\_INVALID\_ENABLE** – некорректный параметр **enable**;
**NU\_INVALID\_OPERATION** – параметр **initial\_time** был равен нулю.
### Удаление таймера
Этот вызов API удаляет ранее созданный таймер. В Nucleus SE в нем нет необходимости, так как таймеры создаются статически и не могут быть удалены.
Прототип служебного вызова:
**STATUS NU\_Delete\_Timer(NU\_TIMER \*timer);**
Параметры:
**timer** – указатель на блок управления таймером.
Возвращаемое значение:
**NU\_SUCCESS** – вызов был успешно завершен;
**NU\_INVALID\_TIMER** – некорректный указатель на таймер;
**NU\_NOT\_DISABLED** – указанный таймер не отключен.
### Указатели на таймеры
Этот вызов API формирует последовательный список указателей на все таймеры в системе. В Nucleus SE в нем нет необходимости, так как таймеры определяются простым индексом, а не указателем.
Прототип служебного вызова:
**UNSIGNED NU\_Timer\_Pointers(NU\_TIMER \*\*pointer\_list, UNSIGNED maximum\_pointers);**
Параметры:
**pointer\_list** – указатель на массив указателей **NU\_TIMER**; он будет заполнен указателями на сконфигурированные в системе таймеры;
**maximum\_pointers** – максимальное количество указателей в массиве.
Возвращаемое значение:
Количество указателей **NU\_TIMER**, помещенных в массив.
Совместимость с Nucleus RTOS
----------------------------
Как и в случае со всеми другими объектами Nucleus SE, моей целью было обеспечение максимальной совместимости кода приложений с Nucleus RTOS. Таймеры не являются исключением и, с точки зрения пользователя, они реализованы так же, как и в Nucleus RTOS. Есть и определенная несовместимость, которую я посчитал допустимой, с учетом того, что в результате код станет более понятным и более эффективным с точки зрения объема требуемой памяти. В остальном, вызовы API Nucleus RTOS могут быть практически напрямую перенесены на Nucleus SE.
### Идентификаторы объектов
В Nucleus RTOS, все объекты описываются структурой данных — управляющим блоком, который имеет определенный тип данных. Указатель на этот блок управления служит идентификатором таймера. Я решил, что в Nucleus SE для эффективного использования памяти необходим другой подход: все объекты ядра описываются набором таблиц в ОЗУ и/или ПЗУ. Размер этих таблиц определяется количеством сконфигурированных объектов каждого типа. Идентификатор конкретного объекта – индекс в этой таблице. Таким образом, я определил **NUSE\_TIMER** в качестве эквивалента **U8**, переменная (а не указатель) этого типа служит идентификатором таймера. С этой небольшой несовместимостью легко справиться, если код портируется с Nucleus SE на Nucleus RTOS и наоборот. Обычно над идентификаторами объектов не выполняются никакие операции, кроме перемещения и хранения.
Nucleus RTOS также поддерживает присвоение имен таймерам. Эти имена используются только при отладке. Я исключил их из Nucleus SE, чтобы сэкономить память.
### Размер таймера
В Nucleus RTOS таймеры реализованы при помощи 32-битных счетчиков. Я решил уменьшить это значение до 16 бит в Nucleus SE. Это привело к значительному улучшению эффективного использования памяти и времени выполнения. Nucleus SE может быть модифицирована, если приложению требуется более длительное время выполнения.
### Функции завершения
Nucleus SE реализует функции завершения похожим с Nucleus RTOS образом, только они могут быть отключены полностью (что позволяет сохранить память), а также они определяются статически. Функцию завершения нельзя изменить, когда таймер сброшен.
### Нереализованные вызовы API
Nucleus RTOS поддерживает восемь служебных вызовов для работы с таймерами. Из них три не реализованы в Nucleus SE. Подробное описание этих вызовов, а также причины такого решения можно найти выше в этой статье, в разделе «Нереализованные вызовы API».
В следующей статье будут рассматриваться прерывания. | https://habr.com/ru/post/455072/ | null | ru | null |
# Редактирование конфигов в Python

Вам когда-нибудь приходилось парсить и программно вносить изменения в чужие конфигурационные файлы? А в файлы с ненормальными форматами вроде того, что у NSD или BIND9? А если формат предусматривает переносы строк, смысловые отступы и сохранение комментариев, задача быстро покидает категорию тривиальных.
Вот почему я делюсь с вами библиотекой [python-reconfigure](http://github.com/Eugeny/reconfigure).
Библиотека предоставляет object mapping между текстом конфиг-файла и python-объектами.
Reconfigure никогда не «ломает» файлы, и не стесняется незнакомых блоков и опций внутри, а также сохраняет комментарии.
Сразу перейдем к примеру:
```
>>> from reconfigure.configs import FSTabConfig
>>> from reconfigure.items.fstab import FilesystemData
>>>
>>> config = FSTabConfig(path='/etc/fstab')
>>> config.load()
>>> print config.tree
{
"filesystems": [
{
"passno": "0",
"device": "proc",
"mountpoint": "/proc",
"freq": "0",
"type": "proc",
"options": "nodev,noexec,nosuid"
},
{
"passno": "1",
"device": "UUID=dfccef1e-d46c-45b8-969d-51391898c55e",
"mountpoint": "/",
"freq": "0",
"type": "ext4",
"options": "errors=remount-ro"
}
]
}
>>> tmpfs = FilesystemData()
>>> tmpfs.mountpoint = '/srv/cache'
>>> tmpfs.type = 'tmpfs'
>>> tmpfs.device = 'none'
>>> config.tree.filesystems.append(tmpfs)
>>> config.save()
>>> quit()
$ cat /etc/fstab
proc /proc proc nodev,noexec,nosuid 0 0
UUID=dfccef1e-d46c-45b8-969d-51391898c55e / ext4 errors=remount-ro 0 1
none /srv/cache tmpfs none 0 0
```
Reconfigure — модульная система, и классы \*Config скрывают некоторую внутреннюю логику.
Рассмотрим, как предыдущий пример работает «под капотом».
Сначала текст файла преобразуется парсером в абстрактное синтаксическое дерево.
```
>>> from reconfigure.parsers import SSVParser
>>> from reconfigure.builders import BoundBuilder
>>> content = open('/etc/fstab').read()
>>> syntax_tree = SSVParser().parse(content)
>>> syntax_tree
>>> print syntax\_tree
(None)
(line)
(token)
value = proc
(token)
value = /proc
(token)
value = proc
(token)
value = nodev,noexec,nosuid
(token)
value = 0
(token)
value = 0
(line)
(token)
value = UUID=83810b56-ef4b-44de-85c8-58dc589aef48
(token)
value = /
(token)
value = ext4
(token)
value = errors=remount-ro
(token)
value = 0
(token)
value = 1
```
Затем, класс-строитель (Builder) создает обычные python-объекты и привязывает их к синтаксическому дереву.
```
>>> builder = BoundBuilder(FSTabData)
>>> data_tree = builder.build(syntax_tree)
>>> print data_tree
{
"filesystems": [
{
"passno": "0",
"device": "proc",
"mountpoint": "/proc",
"freq": "0",Ц
"type": "proc",
"options": "nodev,noexec,nosuid"
},
{
"passno": "1",
"device": "UUID=83810b56-ef4b-44de-85c8-58dc589aef48",
"mountpoint": "/",
"freq": "0",
"type": "ext4",
"options": "errors=remount-ro"
}
]
}
```
На самом деле, созданные объекты — это proxy-классы, все поля которых являются свойствами, и при изменении изменяют значения в синтаксическом дереве.
```
>>> syntax_tree.children[0]
>>> print syntax\_tree.children[0]
(line)
(token)
value = proc
(token)
value = /proc
(token)
value = proc
(token)
value = nodev,noexec,nosuid
(token)
value = 0
(token)
value = 0
>>> data\_tree.filesystems[0].options += ',rw'
>>> print syntax\_tree.children[0]
(line)
(token)
value = proc
(token)
value = /proc
(token)
value = proc
(token)
value = nodev,noexec,nosuid,rw
(token)
value = 0
(token)
value = 0
```
Правила привязки элементов дерева к полям классов задаются в классах \*Data.
Пример привязок для данных файла /etc/resolv.conf:
```
from reconfigure.nodes import Node, PropertyNode
from reconfigure.items.bound import BoundData
class ResolvData (BoundData):
pass
class ItemData (BoundData):
def template(self):
return Node('line', children=[
Node('token', children=[PropertyNode('value', 'nameserver')]),
Node('token', children=[PropertyNode('value', '8.8.8.8')]),
])
ResolvData.bind_collection('items', item_class=ItemData)
ItemData.bind_property('value', 'name', path=lambda x: x.children[0])
ItemData.bind_property('value', 'value', path=lambda x: x.children[1])
```
Содержимое, синтаксическое и дерево данных этого файла:
```
>>> print open('/etc/resolv.conf').read()
# Dynamic resolv.conf(5) file for glibc resolver(3) generated by resolvconf(8)
# DO NOT EDIT THIS FILE BY HAND -- YOUR CHANGES WILL BE OVERWRITTEN
nameserver 127.0.0.1
>>> print syntax_tree
(None)
(line) (Dynamic resolv.conf(5) file for glibc resolver(3) generated by resolvconf(8)
DO NOT EDIT THIS FILE BY HAND -- YOUR CHANGES WILL BE OVERWRITTEN)
(token)
value = nameserver
(token)
value = 127.0.0.1
>>> print data_tree
{
"items": [
{
"name": "nameserver",
"value": "127.0.0.1"
}
]
}
```
Кроме того, Reconfigure осведомлена о наличии include-директив в некоторых файлах, и запоминает, что в каком файле находилось.
Reconfigure легко [расширить](http://eugeny.github.io/reconfigure/docs/architecture/components.html) собственными парсерами, builder'ами и includer'ами.
В настоящий момент Reconfigure — это сердце [Ajenti 1.0 Beta](http://ajenti.org), но об этом в следующий раз :)
[Github](https://github.com/Eugeny/reconfigure)
[PYPI](https://pypi.python.org/pypi/reconfigure/%28latest%20release%29)
[Документация](http://eugeny.github.io/reconfigure/)
DEB и RPM пакеты доступны в [репозиториях Ajenti](http://docs.ajenti.org/man/install/general.html) | https://habr.com/ru/post/188248/ | null | ru | null |
# Автоматизация тестирования программных систем
##### Приветственное слово
Здравствуйте, уважаемые хабрапользователи! Хочу представить вашему вниманию статью, в которой речь пойдёт о тестировании программных систем, его автоматизации, а также средствах для этого используемых.
На сегодняшний день уже мало кто сомневается в целесообразности проведения процесса тестирования разрабатываемых программных продуктов, но, к сожалению, не все ясно себе представляют как тестирование грамотно внедрять и применять. Корифеям-тестировщикам моя статья не принесёт практической пользы, а вот интересующихся тематикой новичков порадовать есть чем.
Изначально я не ставлю своей целью охватить всю проблемную область. На это не хватит и серии книг, которую мне, к тому же, не хватит знаний и опыта написать. Основная задача статьи — не растекаясь мыслью по древу, создать у читателя достаточно чёткую картину того, что вообще из себя представляет автоматизация тестирования и когда, а также с чем её едят.
##### Основные понятия
Начну с небольшого теоретического экскурса.
Итак, под тестированием принято понимать деятельность, выполняемую для оценки и улучшения качества ПО. В общем случае тестирование базируется на обнаружении дефектов и проблем в программных системах.
Автоматизированное тестирование ПО — процесс тестирования программного обеспечения, при котором основные функции и шаги теста, такие как запуск, инициализация, выполнение, анализ и выдача результата, производятся автоматически с помощью инструментов для автоматизированного тестирования.
В свою очередь, инструмент для автоматизированного тестирования — это программное обеспечение, посредством которого осуществляется создание, отладка, выполнение и анализ результатов прогона тест-скриптов (Test Scripts — это наборы инструкций для автоматической проверки определенной части программного обеспечения).
Тестирование программных систем состоит из динамической верификации поведения программ на конечном наборе тестов. При этом тесты выбираются из обычно выполняемых действий прикладной области и обеспечивают проверку соответствия ожидаемому поведению системы.
##### Применение автоматизированного тестирования
Первым пунктом в этом списке стоит тестирование производительности. Нагрузочное, стрессоустойчивое, тестирование на стабильность… Без автоматизации его выполнение трудно себе представить. По этой причине имеется широкий выбор продуктов от разных производителей и столь же высокие цены, даже в случае неудобного и слабо функционального инструмента.
Следом идёт регрессионное тестирование. Означает оно проверку ПО на корректность функциональности, выпущенной и протестированной в предыдущей версии. Выполняется с регулярной частотой, задаваемой в зависимости от условий: у кого-то с каждым новым билдом, а у кого-то с каждой версией для заказчика.
Конфигурационное тестирование – выполнение одних и тех же тестов в разных условиях. То есть когда один или несколько компонентов архитектуры системы требуется проверить в разном окружении, обычно заявленном в изначальных требованиях. Например: поддержка СУБД от разных производителей, работа в разных клиентских браузерах, использование в нескольких ОС и т.п. То есть некий аналог регрессионного тестирования, но в рамках одной версии системы.
Функциональное тестирование. Ясно, что здесь речь идёт о проверке нового функционала. Иногда бывает, что без автоматизации никак не обойтись. Даже если нужно выполнить тестирование только один раз. Обычно, впоследствии эти тесты и используются для регресса.
Установочное тестирование, выполняется для проверки условий инсталляции (и настройки) продукта с учётом тех или иных требований к системе от заказчика.
##### «А зачем?»
…спросит кто-то. Вопрос очень даже резонный. Тестировать, как вы понимаете, можно вручную, а можно с использованием средств автоматизации. Чтобы сделать выбор в сторону того или иного подхода, следует разобраться в его плюсах и минусах.
Какие же преимущества даёт тестировщику автоматизация? А вот какие:
* Исключен «человеческий фактор». Сильное достоинство. Все мы люди и никто из нас не застрахован от ошибок. Выполняемый же тест-скрипт не пропустит тест по неосторожности и ничего не напутает в результатах.
* Быстрое выполнение – автоматизированному скрипту не нужно сверяться с инструкциями и документациями.
* Меньшие затраты на поддержку – когда скрипты уже написаны, на их поддержку и анализ результатов требуется, как правило, меньшее время чем на проведение того же объема тестирования вручную.
* Отчеты – автоматически рассылаемые и сохраняемые отчеты о результатах тестирования.
* Выполнение без вмешательства – во время выполнения тестов инженер-тестировщик может заниматься другими полезными делами, или тесты могут выполняться в нерабочее время.
Вместе с тем имеет место и ряд недостатков, таких как:
* Повторяемость – все написанные тесты всегда будут выполняться однообразно. Это одновременно является и недостатком и преимуществом, так как тестировщик, выполняя тест вручную, может обратить внимание на некоторые детали и найти возникший дефект. Скрипт этого, увы, сделать не может.
* Затраты на поддержку – чем чаще изменяется приложение, тем они выше.
* Большие затраты на разработку – разработка автоматизированных тестов это сложный процесс, так как фактически идет разработка приложения, которое тестирует другое приложение.
* Стоимость инструмента для автоматизации – в случае, если используется лицензионное ПО, его стоимость может быть достаточно высока. Свободно распространяемые инструменты, как правило, отличаются более скромным функционалом и меньшим удобством работы.
* Пропуск мелких ошибок — автоматический скрипт может пропускать мелкие ошибки, на проверку которых он не запрограммирован.
##### Как автоматизировать тестирование?
Вернее даже будет сказать так: как подойти к внедрению процесса автоматизации тестирования в своей деятельности?
Во-первых, следует обратить внимание, насколько хорошо инструмент для автоматизации распознает элементы управления в приложении. В случае, когда элементы не распознаются, стоит поискать плагин, либо соответствующий модуль. Если такового нет – от инструмента лучше отказаться.
Во-вторых, нужно иметь в виду, сколько времени требуется на поддержку скриптов, написанных с помощью выбранного инструмента. Для этого можно записать простой скрипт, который выбирает пункт меню, а потом представить, что изменился пункт меню, который необходимо выбрать. Если для восстановления работоспособности сценария придется перезаписать скрипт целиком, то инструмент не оптимален, так как реальные сценарии гораздо сложнее.
И последний момент, на который надо обратить внимание – насколько удобен инструмент для написания новых скриптов. Сколько требуется на это времени, насколько можно структурировать код, насколько код читаем, и т.д.
##### На финишной прямой
Чтобы принять окончательное решение о целесообразности применения автоматизации, обычно советуют ответить на возникающий естественным образом в данной ситуации вопрос: «превалируют ли в нашем случае преимущества над недостатками?». Если недостатки в конкретном случае неприемлемы, то от автоматизации стоит воздержаться.
##### Выбор инструмента
Чаще всего зависит от объекта тестирования и требований к тестовым сценариям, т.к., разумеется, инструменты тестирования не могут поддерживать полный объём технологий, используемых при разработке приложений. Таким образом, выбор инструмента сводится к банальному методу проб и ошибок. В итоге, нередко тестировщики выбирают несколько инструментов для тестирования функций приложения.
Логично теперь будет поближе рассмотреть некоторые популярные средства автоматизации тестирования и привести пример написания простого тест-скрипта.
##### HP QuickTest Professional
Средство автоматизации от кампании Hewlett-Packard. Распространяется на платной основе (8000-10000 USD). Является основным инструментом автоматизации функционального тестирования от данного производителя. Позволяет автоматизировать функциональные и регрессионные тесты через записи действий пользователя при работе с тестируемым приложением, а потом исполнять записанные действия с целью проверки работоспособности ПО.
Записанные действия сохраняются в виде скриптов.
Скрипты могут быть отображенные в инструменте как VBScript (expert view), или же как визуальные последовательные шаги с действиями (keyword view).
Каждый шаг может быть отредактирован и на него можно добавить точки проверки (checkpoint), которые сравнивают ожидаемый результат с полученным.
##### IBM Rational Functional Tester
Тоже платный, но не настолько («всего-то» 6000 USD).
Rational Functional Tester предоставляет тестировщикам средства автоматизированного тестирования, позволяющие выполнять функциональное тестирование, регрессивное тестирование, тестирование пользовательского интерфейса и тестирование управляемое данными.
Много описательной информации о нём не дам, а лучше приведу практический пример.
##### Пример использования
Будет использована интеграция IBM Rational Functional Tester со средой разработки Microsoft Visual Studio. Для создания функционального теста необходимо выполнить следующие действия:
**1) В среде разработки Microsoft Visual Studio создать новый проект «Functional Test Project»:**
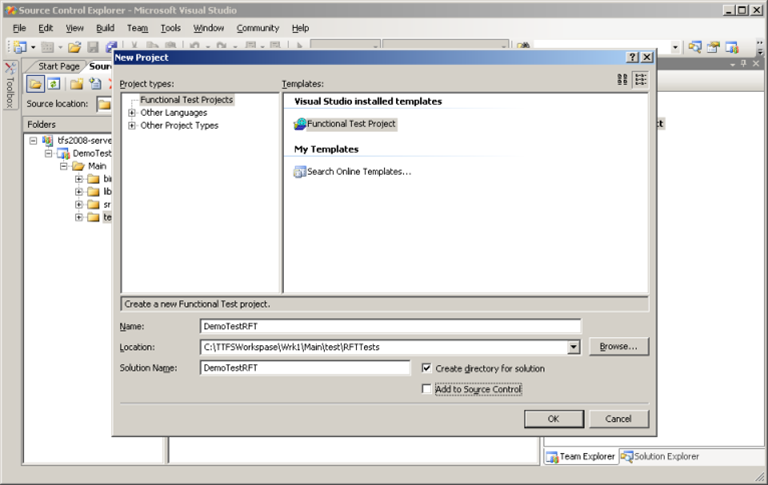
**2) Выполнить запись пользовательских действий с тестируемым приложением:**
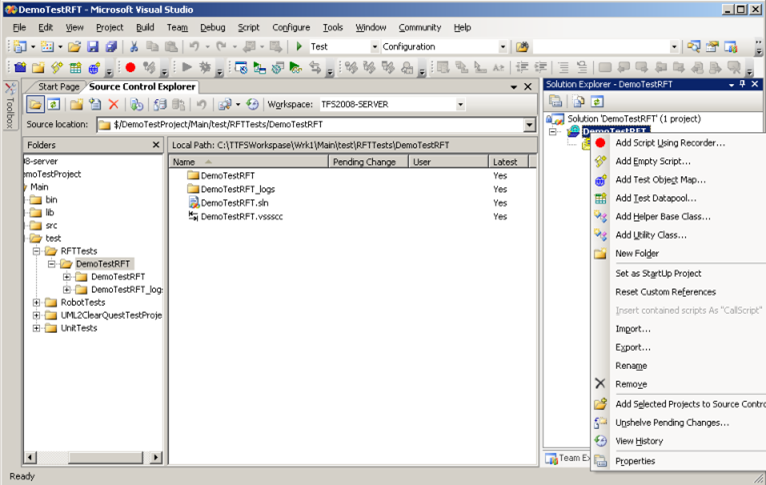
**3) Создать проверочную точку в процессе выполнения записи. Проверочная точка также будет выполнять проверку значения в выпадающем списке:**
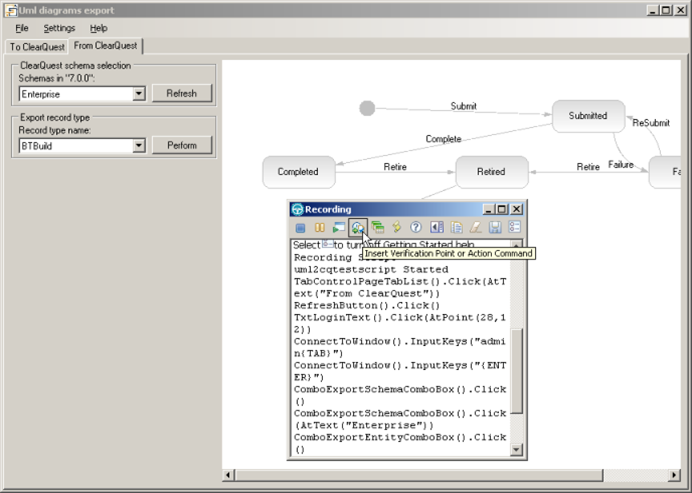
**4) Сохранить результаты записи:**
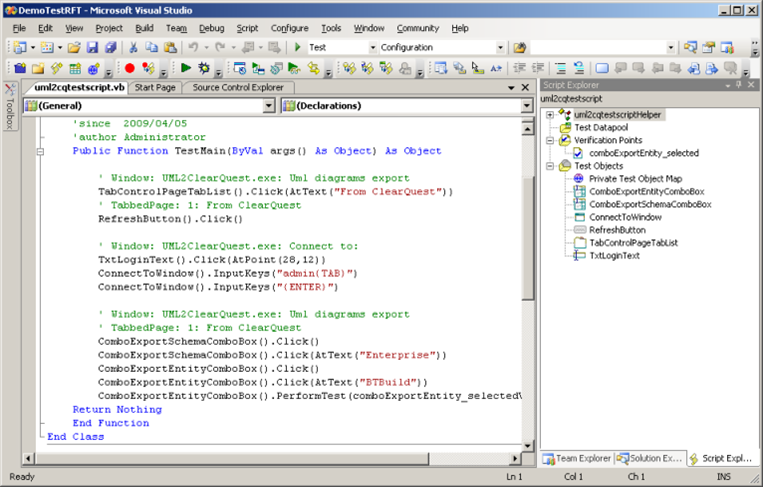
Далее необходимо сформировать bat-файл, который будет вызывать скрипт тестирования на выполнение и проверять результат:
`rational_ft.exe -datastore “<путь к каталогу проекта VS>\DemoTestRFT” -playback uml2cqtestscript
findstr failed “<путь к каталогу проектаVS>\DemoTestRFT_logs\uml2cqtestscript\rational_ft_logframe.html”
if %errorlevel% == 1 goto end
exit -1
:end
exit 0`
Bat-файл выполняет следующие действия:
Вызывается IBM Rational Functional Tester со следующими параметрами:
`-datastore “<путь к каталогу проекта VS>\DemoTestRFT”` – путь к каталогу с проектом.
`-playback uml2cqtestscript` – выполнить скрипт тестирования.
IBM Rational Functional Tester записывает свои результаты в отчет в формате HTML. Для того, чтоб определить был ли провален хоть один шаг в процессе выполнения скрипта тестирования, необходимо найти слово «failed» в отчете.
В зависимости от результата поиска возвращается результат 0 или -1.
**Результат выполнения**
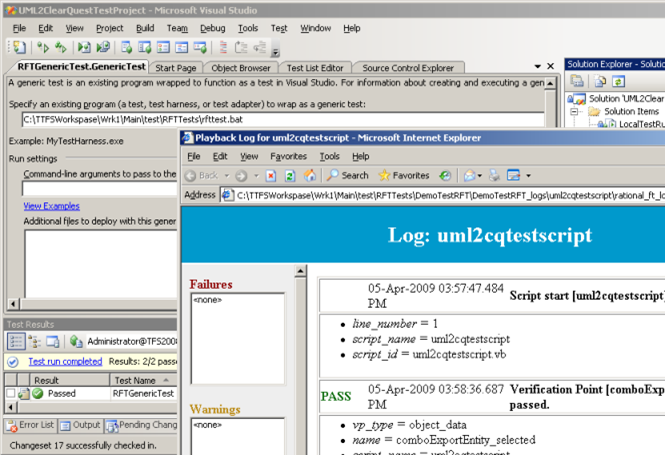
##### Selenium
А это уже бесплатный пакет от компании OpenQA.org.
В основе Selenium лежит среда для тестирования web-приложений, реализованная на JavaScript и выполняющая проверки непосредственно средствами браузера. В рамках проекта Selenium выпускается 3 инструмента, каждый из которых имеет свои особенности и область применения: Selenium Core, Selenium IDE, Selenium RC и Selenium GRID.
Поддерживаемые технологии: DHML, JavaScript, Ajax
Поддерживаемые ОС: Mac OS, Microsoft Windows, Linux, Solaris
Язык тестов: HTML, Java, C#, Perl, PHP, Python, и Ruby
Тестируемые приложения: веб-приложения. | https://habr.com/ru/post/160257/ | null | ru | null |
# Мерцание видео при использовании Qt widget и Directshow
Занимаюсь сейчас разработкой проигрывателя видео под Windows. И «завис» на некоторое время над задачей — после перехода на Qt, видео в проигрывателе начинает моргать и исчезать (см. видео).
Попытки переопределить QWidget::paintEvent невозможны из-за того, что Qt выполняет заливку на (https://qt-project.org/doc/qt-4.8/qwidget.html#autoFillBackground-prop) перед QWidget::paintEvent.
Попытка переопределить WM\_PAINT и WM\_ERASEBACKGOUND в QWidget::winEvent тоже не удалась, т.к. paintEvent может вызываться не только из WM\_PAINT, но и другими сервисами по неизвестному мне алгоритму.
Поэтому ниже приведу решение как выходил из этой ситуации.
Итак, решение:
Решил не изобретать велосипед, а использовать нативные виджеты вместе с Qt. Сам нативный виджет будет находиться внутри QWidget. Схематично в окне плеера это можно представить так:

Сначала создаем обработчик для окон. Он возьмет на себя регистрацию класса окна и пересылку сообщений виджетам.
Также необходимо запретить QApplication обрабатывать сообщения для нативных виджетов. У нас в проекте используется libqxt, поэтому необходимо добавить фильтр с помощью QxtApplication:: installNativeEventFilter. Другой вариант – переопределить QCoreApplication::winEventFilter.
Для начала я написал класс WindowProcMapper для того, чтобы сопоставить HWND с объектом.
nativewidgetimpl.h
```
namespace Native
{
class NativeWndFilter : public QxtNativeEventFilter
{
public:
inline NativeWndFilter() { }
inline void insert(HWND h) { m_wnds.insert(h); }
inline void remove(HWND h) { m_wnds.remove(h); }
inline bool contains(HWND h) { return m_wnds.contains(h); }
bool winEventFilter(MSG * msg, long *result) override;
private:
QSet m\_wnds;
};
template
class WindowProcMapper
{
public:
WindowProcMapper(const wchar\_t \*className);
~WindowProcMapper();
inline T \*getWindow(HWND hwnd) const;
inline void insertWindow(HWND hwnd, T \*ptr);
inline void removeWindow(HWND hwnd);
ATOM getRegisterResult();
bool registerWindowClass();
inline static WindowProcMapper \*instance()
{ return self; }
private:
QHash m\_hash;
LPCWSTR m\_className;
ATOM m\_registerResult;
static WindowProcMapper \*self;
static LRESULT CALLBACK WindowProc(\_In\_ HWND hwnd, \_In\_ UINT uMsg,
\_In\_ WPARAM wParam, \_In\_ LPARAM lParam);
NativeWndFilter \*m\_filter;
};
}
```
Создаем обертку для нативного виджета:
nativewidget.h
```
namespace Native
{
struct NativeWidgetPrivate;
class NativeWidget : public QWidget
{
Q_OBJECT
public:
NativeWidget(QWidget *parent = nullptr);
NativeWidget(const QString &wndName, QWidget *parent = nullptr);
~NativeWidget();
WId nativeHWND() const;
HDC getNativeDC() const;
void releaseNativeDC(HDC hdc) const;
QString wndName() const;
protected:
NativeWidget(NativeWidgetPrivate *p, const QString &wndName,
QWidget *parent = nullptr);
void paintEvent(QPaintEvent *ev) override;
void resizeEvent(QResizeEvent *ev) override;
virtual bool nativeWinEvent(MSG *msg, long *result);
QScopedPointer d\_ptr;
private:
void init();
Q\_DECLARE\_PRIVATE(NativeWidget);
};
void NativeWidget::paintEvent(QPaintEvent \*ev)
{
Q\_D(NativeWidget);
SendMessage(d->m\_hwnd, WM\_PAINT, 0, 0);
ev->accept();
}
void NativeWidget::resizeEvent(QResizeEvent \*ev)
{
Q\_D(NativeWidget);
const QSize &sz = ev->size();
SetWindowPos(d->m\_hwnd, NULL, 0, 0, sz.width(), sz.height(), 0);
QWidget::resizeEvent(ev);
}
}
```
Для поведения нативного виджета переопределяем функции resizeEvent и paintEvent. Они будут пересылать события в нативный виджет при изменении QWidget.
Приватный класс возьмет на себя обязанности по управлению нативным виджетом. Он принимает сообщения с помощью метода windowsEvent и, передает их NativeWidget:: nativeWinEvent, который может быть легко переопределен в классах-наследниках.
```
namespace Native
{
struct NativeWidgetPrivate
{
NativeWidgetPrivate(NativeWidget *q);
~NativeWidgetPrivate();
inline HWND winID() const;
HDC getDC() const;
void releaseDC(HDC hdc) const;
QRect windowPlacement() const;
virtual bool createWindow(QWidget *parent);
void sendEvent(QEvent *ev);
inline bool isCreating() const { return m_creating; }
LRESULT windowsEvent(_In_ HWND hwnd, _In_ UINT msg,
_In_ WPARAM wParam, _In_ LPARAM lParam);
HWND m_hwnd;
mutable HDC m_hdc;
bool m_creating;
void sendToWidget(uint msg, WPARAM wparam, LPARAM lparam);
QString m_wndName;
NativeWidget *const q_ptr;
Q_DECLARE_PUBLIC(NativeWidget);
};
}
```
Для реализации виджета с видео необходимо перехватить сообщения WM\_PAINT и WM\_ERASEBACKGROUND.
Примерная реализация приведена ниже:
```
bool MovieScreen::nativeWinEvent(MSG *msg, long *result)
{
Q_D(MovieScreen);
//qDebug() << __FUNCTION__;
switch (msg->message)
{
case WM_ERASEBKGND:
case WM_PAINT:
d->updateMovie();
break;
case WM_SHOWWINDOW:
{
auto r = NativeWidget::nativeWinEvent(msg, result);
if (msg->wParam == TRUE)
d->updateMovie();
return r;
}
case WM_SIZE:
case WM_MOVE:
case WM_MOVING:
case WM_SIZING:
{
auto r = NativeWidget::nativeWinEvent(msg, result);
d->resizeVideo();
return r;
}
}
return NativeWidget::nativeWinEvent(msg, result);
}
```
Примерная реализация:
```
IVMRWindowlessControl9 *m_pVideoRenderer9;
MovieScreenPrivate:: updateMovie()
{
If (isPaused())
{
HDC hdc = getHDC();
m_pVideoRenderer9->Repaint_Video(winID(), hdc);
releaseHDC(hdc);
}
}
MovieScreenPrivate::resizeVideo()
{
long lWidth, lHeight;
HRESULT hr = m_pVideoRenderer9->GetNativeVideoSize(&lWidth, &lHeight, NULL, NULL);
if (SUCCEEDED(hr))
{
RECT rcSrc, rcDest;
// Set the source rectangle.
SetRect(&rcSrc, 0, 0, lWidth, lHeight);
// Get the window client area.
GetClientRect(winID(), &rcDest);
// Set the destination rectangle.
SetRect(&rcDest, 0, 0, rcDest.right, rcDest.bottom);
m_pVideoRenderer9->SetVideoPosition(&rcSrc, &rcDest);
}
}
```
Ну вот, в итоге получаем:
Исходники можно скачать [здесь](http://ompldr.org/iaHJqbw) | https://habr.com/ru/post/172869/ | null | ru | null |
# Аппликация Expressions
Добрый день.
Просматривая недавно чужой код, наткнулся на довольно интересную задачу о IQueryable и Expession trees. Надеюсь, решение будет кому-нибудь полезно.
Задача заключается в том, чтобы повторно использовать некоторый Expression внутри другого Expression, например, у нас есть некий *f*:
```
Expression> f = (a, b) => a + b;
```
И мы бы хотели использовать этот *f* внтури другого expression, например так:
```
Expression> g = (a, b, c) => f(a+b,b)\*c;
```
Причем необходимо, чтобы результирующий expression был «чистым», т.е. пригодным для использования внутри IQueryable (без скомпилированных функций и т.п.)
Если попробовать скомпилировать эти две строчки, то окажется, что определение g ошибочно: *'f' is a 'variable' but is used like a 'method'*, что, в общем-то и понятно, f — это корень дерева выражений, а ни как не функция или функтор. Можно попробовать написать так:
```
Expression> g = (a, b, c) => f.Compile()(a+b,b)\*c;
```
Но тогда наше выражение в итоге будет выглядеть так:
`(a, b, c) => (Invoke(value(ExpressionReducer.Program+<>c__DisplayClass0).f.Compile(), (a + b), b) * c)`
Естественно, наш IQueryable такого не поймет.
Самая простая и очевидная идея — просто подставить вместо f само ее тело — грубо говоря, сделать «аппликацию» терма f в g (Честно говоря, я совсем не силен в лямбда-исчеслении, но по-моему это будет именно аппликация).
Для такой «аппликации» нам нужно немного переписать дерево выражения для g, конкретно — заменить вызов Invoke(Compile()) на тело функции f, и в самом теле f заменить ее параметры на значения аргументов Invoke, то есть из:
```
(a, b, c) => f.Compile()(a+b,b)*c
```
получить
```
(a, b, c) => ((a+b)+b)*c
```
Для начала, давайте избавимся от громоздкого Invoke(Compile) и заменим его на такой вот метод-расширение:
```
public static T Apply(this Expression> expression, T1 t1, T2 t2)
{
return expression.Compile()(t1, t2);
}
//...
Expression> g = (a, b, c) => f.Apply(a + b, b) \* c;
```
На самом деле тело функции Apply не важно — оно никогда не будет вызвано при преобразовании, но полезно иметь валидное тело, если кто-то будет использовать g без упрощения.
Теперь внимательно приглядимся к получившемуся дереву:
Собственно вот шаги, которые надо сделать:
1. Найти вызов метода Apply.
2. Получить лямбда-функцию f из первого аргумента функции Apply.
3. Заменить в теле лямбды аргументы на остальные параметры функции Apply.
4. Заменить в дереве .Call на тело f.
Первый пункт сделать достаточно легко — используем класс ExpressionVisitor из пространства имен System.Linq.Expressions. Это очень удобный класс, который позволяет не только посетить все узлы дерева выражений, но и переписать его часть (подробнее — <http://msdn.microsoft.com/en-us/library/bb546136%28v=vs.90%29.aspx>) Мы предполагаем, что метод Apply находится в классе ExpressionReductor:
```
private class InvokerVisitor : ExpressionVisitor
{
protected override Expression VisitMethodCall(MethodCallExpression node)
{
if (node.Method.DeclaringType == typeof (ExpressionReductor) && node.Method.Name == "Apply")
{
// Тут будут остальные пункты
}
return base.VisitMethodCall(node);
}
}
```
Второй пункт несколько сложнее. Как видно из дерева, f стало полем автогенерированного класса ExpressionReducer.Program+<>c\_\_DisplayClass0 — так C# поступает со всеми функторами или выражениями, объявленными в теле методов или пришедшими как параметры методов. Из других возможных вариантов — это поле или свойство именованного класса или результат вызова функции.
Для простоты будем рассматривать только первый случай (остальные можно реализовать аналогично): f — это поле некоего класса.
```
class FieldLambdaFinder : ExpressionVisitor
{
protected override Expression VisitMember(MemberExpression node)
{
var constantExpression = (ConstantExpression) node.Expression;
var info = (FieldInfo) node.Member;
var fieldValue = (Expression)info.GetValue(constantExpression.Value);
return fieldValue;
}
public Expression Find(Expression expression)
{
return Visit(expression);
}
}
```
Третий пункт достаточно прост — составим Dictionary (параметр f -> параметр Apply) и заменим все ParameterExpression в теле f:
```
internal class Replacer : ExpressionVisitor
{
private Dictionary \_replacements;
public Replacer(IEnumerable what, IEnumerable with)
{
\_replacements = what.Zip(with, (param, expr) => new { param, expr }).ToDictionary(x => x.param, x => x.expr);
}
public Expression Replace(Expression body)
{
return Visit(body);
}
protected override Expression VisitParameter(ParameterExpression node)
{
Expression replacement;
return \_replacements.TryGetValue(node, out replacement) ? replacement : base.VisitParameter(node);
}
}
```
Последний пункт покажет все в сборе:
```
private class InvokerVisitor : ExpressionVisitor
{
protected override Expression VisitMethodCall(MethodCallExpression node)
{
if (node.Method.DeclaringType == typeof (ExpressionReductor) && node.Method.Name == "Apply")
{
var lambda = GetLambda(node.Arguments[0]);
return Replace(lambda, node.Arguments.Skip(1));
}
return base.VisitMethodCall(node);
}
private Expression Replace(LambdaExpression lambda, IEnumerable arguments)
{
var replacer = new Replacer(lambda.Parameters, arguments);
return replacer.Replace(lambda.Body);
}
private LambdaExpression GetLambda(Expression expression)
{
var finder = new FieldLambdaFinder();
return (LambdaExpression) finder.Find(expression);
}
}
```
Cам метод Simplify:
```
public static Expression Simplify(this Expression expression)
{
var invoker = new InvokerVisitor();
return (Expression) invoker.Visit(expression);
}
```
Все и сразу можно найти [здесь](http://dl.dropbox.com/u/2562253/ExpressionReducer.cs).
В итоге мы получили то, что хотели:
```
Expression> f = (a, b) => a + b;
Expression> g = (a, b, c) => f.Apply(a + b, b)\*c;
g = g.Simplify();
```
Оставшиеся проблемы:
1. Как достать f в других случаях.
2. Если параметры Apply — это вызовы других функций, у которых есть side-эффекты, то подстановка некорректна. В нашем случае такого быть не может, так как мы оперируем с IQueryable, но стоит иметь это ввиду.
3. Функция Simplify не сворачивает вычисления: f.Apply(5, 5) упростится до (5+5), а не до (10).
4. Функция Simplify не рекурсивна, то есть на таких примерах — f.Apply(a, f.Apply(b,c)) — ее придется вызывать несколько раз. | https://habr.com/ru/post/130347/ | null | ru | null |
# Получаем музыку Вк через сторонний API
В этот раз дело начиналось после закрытия методов [audio в методе execute.](https://habr.com/post/429504/)
----------------------------------------------------------------------------------------------------------
Я решил посмотреть, как получают музыку сайты, которые предоставляют возможность ее скачать. Меня заинтересовал сайт vrit.me.
Я залез во вкладку network и увидел интересный запрос:
**фото**
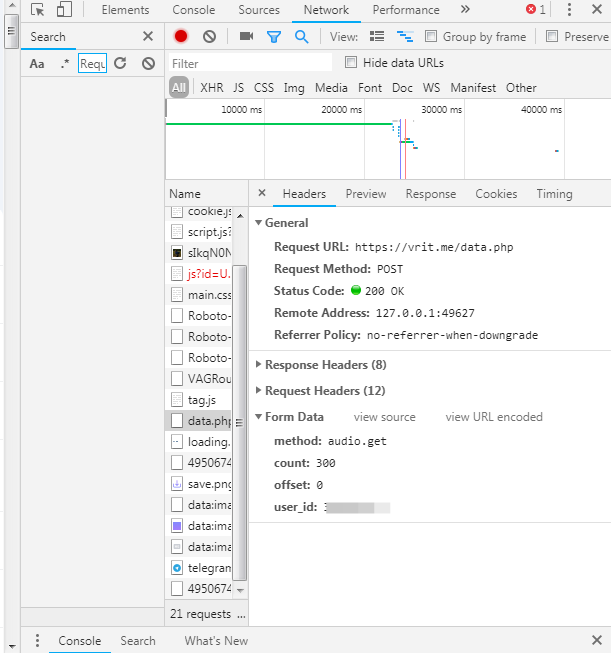
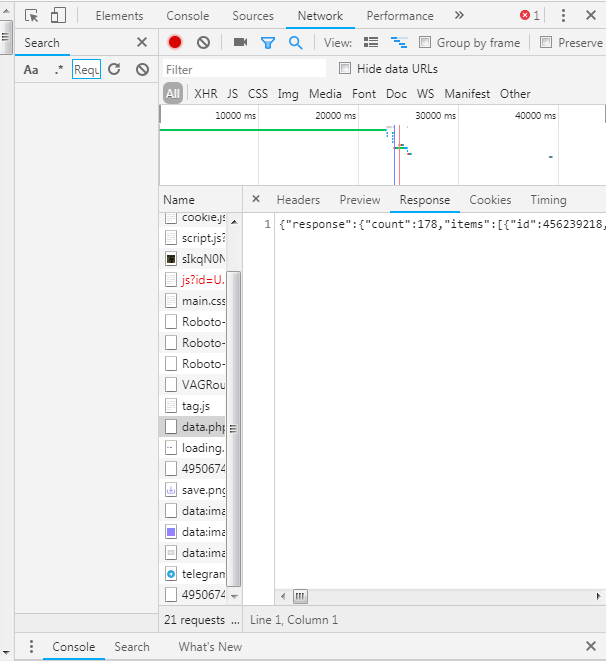
То есть, можно подделать POST запрос к этому сайту, и использовать его, как API для музыки vk, что я сразу и реализовал:
```
import json,requests
s = requests.post("https://vrit.me/data.php",data={
"method": "audio.get",
"count": 1000000000,
"offset": 0,
"user_id":-52922518})
s = json.loads(s.text)
print(s)
```
В результате получил такой ответ:
```
{'response': {'count': 2, 'items': [{'id': 456239018, 'owner_id': -52922518, 'artist': 'CORVUS', 'title': 'Осеннее смятение [ЗС]', 'duration': 126, 'date': 1474194635, 'url': 'https://cs1-81v4.vkuseraudio.net/p18/894f30b49d3571.mp3?extra=5xovvbyqXrdr0Ixl9FLteg-pRRC29pGr_yO8mDgqNN_4kLlxJe1gHST8S8bVy2IQt0wYFAC1tMCnF7p5ujeB7K1jFPfYSCaEuxjh5P92VT81AMd9AlIJx2GQp613xHxCRbXCynv6fqdhFcPwvyZaRvg', 'lyrics_id': 370291093, 'genre_id': 18, 'is_licensed': True, 'is_hq': True, 'track_genre_id': 11, 'access_key': '7b762a5b22b452d0ca'}, {'id': 456239017, 'owner_id': -52922518, 'artist': 'CORVUS', 'title': 'Записки сумасшедших [ЗС]', 'duration': 132, 'date': 1470474699, 'url': 'https://cs1-81v4.vkuseraudio.net/p4/7f6c08b134e0a7.mp3?extra=MgBr8oDpO-7f2l_qmtHZGAMD608vcqWxA8OLNgcyZDdA8aVc2Jlj9bDW48FW8S5zDA9jO-geAEUaF_LvFUP_DFiGZEFo-5B92YhcMYMpyuvi6tFt_nO4QVwjJjNhG-Ln3dOfkC4KY2Cywk_attG5fSQ', 'lyrics_id': 370291112, 'genre_id': 18, 'is_licensed': True, 'is_hq': True, 'track_genre_id': 11, 'access_key': '8717a672801e7a15fa'}]}}
```
**НО!** т.к. любая ссылка на аудио вк привязывается к IP адресу компьютера,
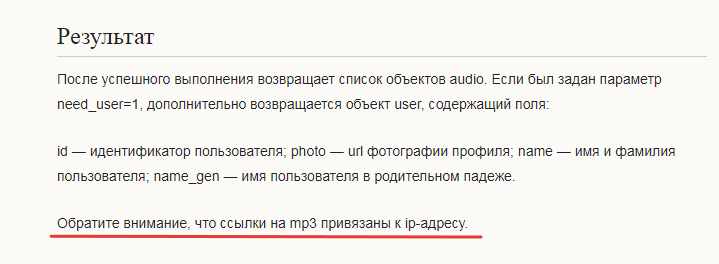
то когда я открыл ее на своем пк, то получил ошибку:
Дальше я все-таки решил посмотреть, как на самом сайте vrit.me генерируется ссылка. Оказалось, что **эта** ссылка подставляется в **другую** ссылку и в результате на выходе получается ссылка вида
```
https://vrit.me/download?artist=Егор Крид&title=ЭТОМОЕ&url=https://cs1-60v4.vkuseraudio.net/p20/6d11e54193b7e0.mp3?extra=CZi_FWKxxoYdOTg7Sz4cksgJ_l12bqsxH8wZFPRoN6t7qf4at_MDouTA6MDmsLiaoFrDJDswVzKozagVNVCskf3LiR3ry-JvP9WHgisWn7nq7BradXYcffgAlQH2VTWoTFDgpVwhdRZMUV6ATpr6KQ
```

То есть нам надо всего лишь полученную ссылку «вписать» в другую ссылку. Реализация:
```
for i in range(len(data["response"]["items"])):
url = data["response"]["items"][i]["url"]
title = data["response"]["items"][i]["title"]
artist = data["response"]["items"][i]["artist"]
data["response"]["items"][i]["url"] = "https://vrit.me/download?title={title}&artist={artist}&url={url}".format(url=url,title=title,artist=artist)
```
### Другие методы с аудио
Еще я попытался вызвать такие методы как «audio.getById», «audio.search», «audio.getCount», «audio.getLyrics», «audio.getAlbums» но из них работает только один метод «audio.search», и то, искать по музыке пользователя нельзя, можно только в глобальном поиске. Код:
```
s = requests.post("https://vrit.me/data.php",data={
"method": "audio.search",
"count": 3,
"offset": 0,
"q":q})
data = json.loads(s.text)
if "response" in data:
data = data["response"]
for i in range(len(data["items"])):
url = data["items"][i]["url"]
title = data["items"][i]["title"]
artist = data["items"][i]["artist"]
data["items"][i]["url"] = "https://vrit.me/download?title={title}&artist={artist}&url={url}".format(url=url,title=title,artist=artist)
```
**Финальный код**
```
import requests,json
class audio():
def get(owner_id):
s = requests.post("https://vrit.me/data.php",data={
"method": "audio.get",
"count": 1000000000,
"offset": 0,
"user_id": owner_id})
data = json.loads(s.text)
if "response" in data:
data = data["response"]
for i in range(len(data["items"])):
url = data["items"][i]["url"]
title = data["items"][i]["title"]
artist = data["items"][i]["artist"]
data["items"][i]["url"] = "https://vrit.me/download?title={title}&artist={artist}&url={url}".format(
url=url,
title=title,artist=artist)
return data
def search(q):
s = requests.post("https://vrit.me/data.php",data={
"method": "audio.search",
"count": 300,
"offset": 0,
"q":q})
data = json.loads(s.text)
if "response" in data:
data = data["response"]
for i in range(len(data["items"])):
url = data["items"][i]["url"]
title = data["items"][i]["title"]
artist = data["items"][i]["artist"]
data["items"][i]["url"] = "https://vrit.me/download?title={title}&artist={artist}&url={url}".format(
url=url,
title=title,artist=artist)
return data
```
Вызывать этот класс можно так:
```
import bot_vk#pip install bot_vk==1.7
info1 = bot_vk.audio.get(owner_id=1234567)
info2 = bot_vk.audio.search(q="imagine dragons")
```
P.S. В этой статье представлен пример получения музыки одного из сайтов. Есть еще много подобных сайтов, из которых тоже можно сделать «API». Скорее всего сайт [vrit.me](https://vrit.me) скоро перестанет быть действительным, и надо будет пользоваться другими сайтами.
> ВНИМАНИЕ! Автор этого поста не несет ответственности за какие-либо Ваши действия. Этот пост создан только с ознакомительными целями! | https://habr.com/ru/post/429942/ | null | ru | null |
# Generative adversarial networks
В [прошлой статье](https://habrahabr.ru/post/347184/) мы рассмотрели простейшую линейную генеративную модель PPCA. Вторая генеративная модель, которую мы рассмотрим — Generative Adversarial Networks, сокращенно GAN. В этой статье мы рассмотрим самую базовую версию этой модели, оставив продвинутые версии и сравнение с другими подходами в генеративном моделировании на следующие главы.
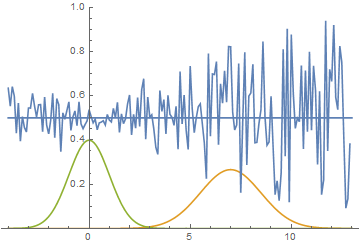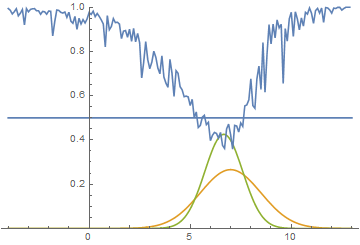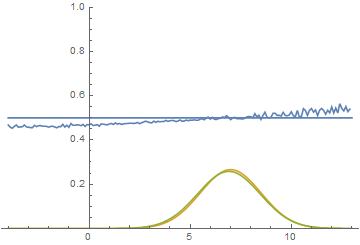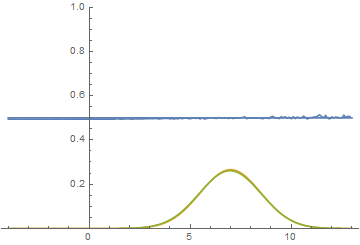
История
-------
Генеративное моделирование предполагает аппроксимацию невычислимых апостериорных распределений. Из-за этого большинство эффективных методов, разработанных для обучения дискриминативных моделей, не работают с генеративными моделями. Существующие в прошлом методы для решения этой задачи вычислительно трудны и, в основном, основаны на использовании [Markov Chain Monte Carlo](https://en.wikipedia.org/wiki/Markov_chain_Monte_Carlo), который плохо масштабируем. Поэтому для обучения генеративных моделей нужен был метод, основанный на таких масштабируемых техниках, как [Stochastic Gradient Descent (SGD)](https://en.wikipedia.org/wiki/Stochastic_gradient_descent) и [backpropagation](https://en.wikipedia.org/wiki/Backpropagation). Один из таких методов — Generative Adversarial Networks (GAN). Впервые GANы были предложены [в этой](https://arxiv.org/pdf/1406.2661.pdf) статье в 2014 году. Высокоуровнево эта модель может быть описана, как две подмодели, которые соревнуются друг с другом, и одна из этих моделей (генератор), пытается научиться в некотором смысле обманывать вторую (дискриминатор). Для этого генератор генерирует случайные объекты, а дискриминатор пытается отличить эти сгенерированные объекты от настоящих объектов из тренировочной выборки. В процессе обучения генератор генерирует все более похожие на выборку объекты и дискриминатору становится все сложнее отличить их от настоящих. Таким образом, генератор превращается в генеративную модель, которая генерирует объекты из некого сложного распределения, например, из распределения фотографий человеческих лиц.
Модель
------
Для начала введем необходимую терминологию. Через 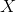 мы будем обозначать некоторое пространство объектов. Например, картинки  пикселя. На некотором вероятностном пространстве 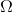 задана векторная случайная величина 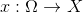 с распределением вероятностей, имеющим плотность 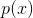 такую, что подмножество пространства 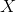, на котором 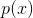 принимает ненулевые значения — это, например, фотографии человеческих лиц. Нам дана случайная i.i.d. выборка фотографий лиц для величины 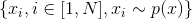. Дополнительно определим вспомогательное пространство 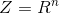 и случайную величину 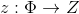 с распределением вероятностей, имеющим плотность 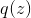. 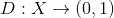 — функция-дискриминатор. Эта функция принимает на вход объект 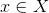 (в нашем примере — картинку соответствующего размера) и возвращает вероятность того, что входная картинка является фотографией человеческого лица. 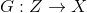 — функция-генератор. Она принимает значение 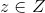 и выдает объект пространства 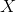, то есть, в нашем случае, картинку.
Предположим, что у нас уже есть идеальный дискриминатор 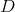. Для любого примера 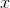 он выдает истинную вероятность принадлежности этого примера заданному подмножеству 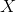, из которого получена выборка 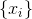. Переформулируя задачу обмана дискриминатора на вероятностном языке мы получаем, что необходимо максимизировать вероятность, выдаваемую идеальным дискриминатором на сгенерированных примерах. Таким образом оптимальный генератор находится как 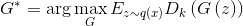. Так как 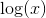 — монотонно возрастающая функция и не меняет положения экстремумов аргумента, эту формулу переписать в виде 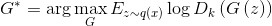, что будет удобно в дальнейшем.
В реальности обычно идеального дискриминатора нет и его надо найти. Так как задача дискриминатора — предоставлять сигнал для обучения генератора, вместо идеального дискриминатора достаточно взять дискриминатор, идеально отделяющий настоящие примеры от сгенерированных текущим генератором, т.е. идеальный только на подмножестве 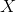 из которого генерируются примеры текущим генератором. Эту задачу можно переформулировать, как поиск такой функции 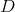, которая максимизирует вероятность правильной классификации примеров как настоящих или сгенерированных. Это называется задачей бинарной классификации и в данном случае мы имеем бесконечную обучающую выборку: конечное число настоящих примеров и потенциально бесконечное число сгенерированных примеров. У каждого примера есть метка: настоящий он или сгенерированный. В [первой статье](https://habrahabr.ru/post/343800/) было описано решение задачи классификации с помощью метода максимального правдоподобия. Давайте распишем его для нашего случая.
Итак, наша выборка 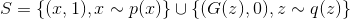. Определим плотность распределения 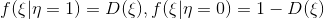, тогда 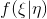 — это переформулировка дискриминатора 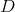, выдающего вероятность класса  (настоящий пример) в виде распределения на классах . Так как , это определение задает корректную плотность вероятности. Тогда оптимальный дискриминатор можно найти как:
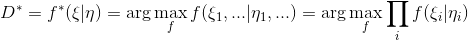
Сгруппируем множители для 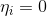 и 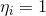:
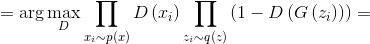
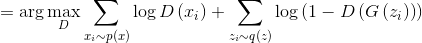
И при стремлении размера выборки в бесконечность, получаем:
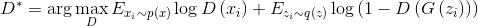
Итого, получаем следующий итерационный процесс:
1. Устанавливаем произвольный начальный .
2. Начинается -я итерация, 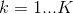.
3. Ищем оптимальный для текущего генератора дискриминатор:
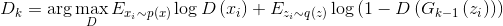.
4. Улучшаем генератор, используя оптимальный дискриминатор:
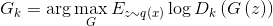. Важно находиться в окрестности текущего генератора. Если отойти далеко от текущего генератора, то дискриминатор перестанет быть оптимальным и алгоритм перестанет быть верным.
5. Задача обучения генератора считается решенной, когда  для любого 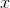. Если процесс не сошелся, то переходим на следующую итерацию в пункт (2).
В оригинальной статье этот алгоритм суммаризируется в одну формулу, задающую в некотором смысле минимакс-игру между дискриминатором и генератором:
Обе функции  могут быть представлены в виде нейросетей: 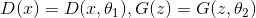, после чего задача поиска оптимальных функций сводится к задаче оптимизации по параметрам и ее можно решать с помощью традиционных методов: backpropagation и SGD. Дополнительно, так как нейросеть — это универсальный аппроксиматор функций, 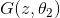 может приблизить произвольное распределение вероятностей, что снимает вопрос выбора распределения 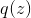. Это может быть любое непрерывное распределение в некоторых разумных рамках. Например, 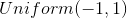 или 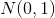. Корректность этого алгоритма и сходимость 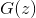 к 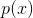 при достаточно общих предположениях доказана в оригинальной статье.
Нахождение параметров нормального распределения
-----------------------------------------------
С математикой мы разобрались, давайте теперь посмотрим, как это работает. Допустим, 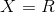, т.е. решаем одномерную задачу. 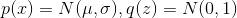. Давайте использовать линейный генератор 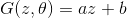, где 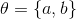. Дискриминатор будет полносвязной трехслойной нейронной сетью с бинарным классификатором на конце. Решением этой задачи является 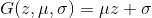, то есть, 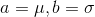. Попробуем теперь запрограммировать численное решение этой задачи с помощью Tensorflow. Полный код можно найти [тут](https://github.com/Monnoroch/generative/tree/master/gan_model_data), в статье же освещены только ключевые моменты.
Первое, что нужно задать, это входную выборку: 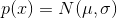. Так как обучение идет на минибатчах, мы будем за раз генерировать вектор чисел. Дополнительно, выборка параметризуется средним и стандартным отклонением.
```
def data_batch(hparams):
"""
Input data are just samples from N(mean, stddev).
"""
return tf.random_normal(
[hparams.batch_size, 1], hparams.input_mean, hparams.input_stddev)
```
Теперь зададим случайные входы для генератора 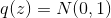:
```
def generator_input(hparams):
"""
Generator input data are just samples from N(0, 1).
"""
return tf.random_normal([hparams.batch_size, 1], 0., 1.)
```
Определим генератор. Возьмем абсолютное значение второго параметра для придания ему смысла стандартного отклонения:
```
def generator(input, hparams):
mean = tf.Variable(tf.constant(0.))
stddev = tf.sqrt(tf.Variable(tf.constant(1.)) ** 2)
return input * stddev + mean
```
Создадим вектор реальных примеров:
```
generator_input = generator_input(hparams)
generated = generator(generator_input)
```
И вектор сгенерированных примеров:
```
generator_input = generator_input(hparams)
generated = generator(generator_input)
```
Теперь прогоним все примеры через дискриминатор. Тут важно помнить о том, что мы хотим не два разных дискриминатора, а один, потому Tensorflow нужно попросить использовать одни и те же параметры для обоих входов:
```
with tf.variable_scope("discriminator"):
real_ratings = discriminator(real_input, hparams)
with tf.variable_scope("discriminator", reuse=True):
generated_ratings = discriminator(generated, hparams)
```
Функция потерь на реальных примерах — это кросс-энтропия между единицей (ожидаемым ответом дискриминатора на реальных примерах) и оценками дискриминатора:
```
loss_real = tf.reduce_mean(
tf.nn.sigmoid_cross_entropy_with_logits(
labels=tf.ones_like(real_ratings),
logits=real_ratings))
```
Функция потерь на поддельных примерах — это кросс-энтропия между нулем (ожидаемым ответом дискриминатора на поддельных примерах) и оценками дискриминатора:
```
loss_generated = tf.reduce_mean(
tf.nn.sigmoid_cross_entropy_with_logits(
labels=tf.zeros_like(generated_ratings),
logits=generated_ratings))
```
Функция потерь дискриминатора — это сумма потерь на реальных примерах и на поддельных примерах:
```
discriminator_loss = loss_generated + loss_real
```
Функция потерь генератора — это кросс-энтропия между единицей (желаемым ошибочным ответом дискриминатора на поддельных примерах) и оценками этих поддельных примеров дискриминатором:
```
generator_loss = tf.reduce_mean(
tf.nn.sigmoid_cross_entropy_with_logits(
labels=tf.ones_like(generated_ratings),
logits=generated_ratings))
```
К функции потерь дискриминатора опционально добавляется L2-регуляризация.
Обучение модели сводится к поочередному обучению дискриминатора и генератора в цикле до сходимости:
```
for step in range(args.max_steps):
session.run(model.discriminator_train)
session.run(model.generator_train)
```
Ниже приведены графики для четырех моделей дискриминатора:
* трехслойная нейронная сеть.
* трехслойная нейронная сеть с L2-регуляризацией..
* трехслойная нейронная сеть с dropout-регуляризацией.
* трехслойная нейронная сеть с L2- и dropout-регуляризацией.
Рис. 1. Вероятность классификации дискриминатором реального примера как реального.
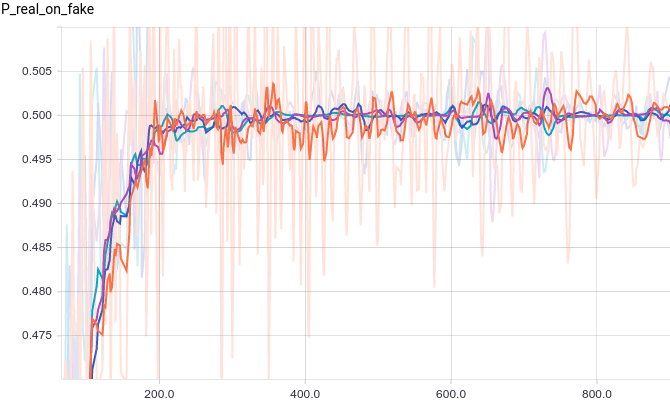
Рис. 2. Вероятность классификации дискриминатором сгенерированного примера как реального.
Все четыре модели достаточно быстро сходятся к тому, что дискриминатор выдает  на всех входах. Из-за простоты задачи, которую решает генератор, между моделями почти нет разницы. Из графиков видно, что среднее и стандартное отклонение довольно быстро сходятся к значениям из распределения данных:
Рис. 3. Среднее сгенерированных распределений.
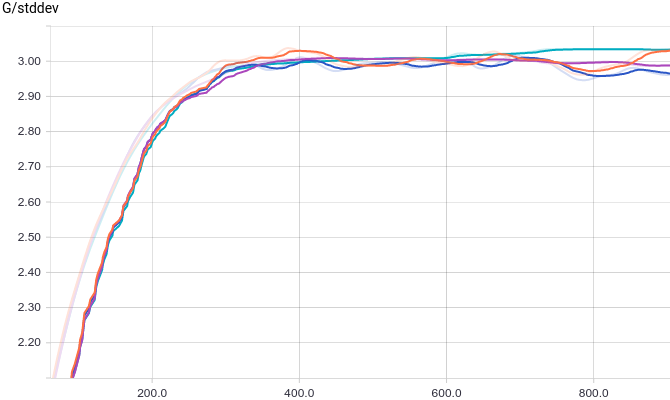
Рис. 4. Среднеквадратичное отклонение сгенерированных распределений.
Ниже приведены распределения настоящих и сгенерированных примеров в процессе обучения. Видно, что сгенерированные примеры к концу обучения практически не отличимы от настоящих (они отличимы на графиках потому, что Tensorboard выбрал разные масштабы, но, если посмотреть на значения, то они одинаковые).
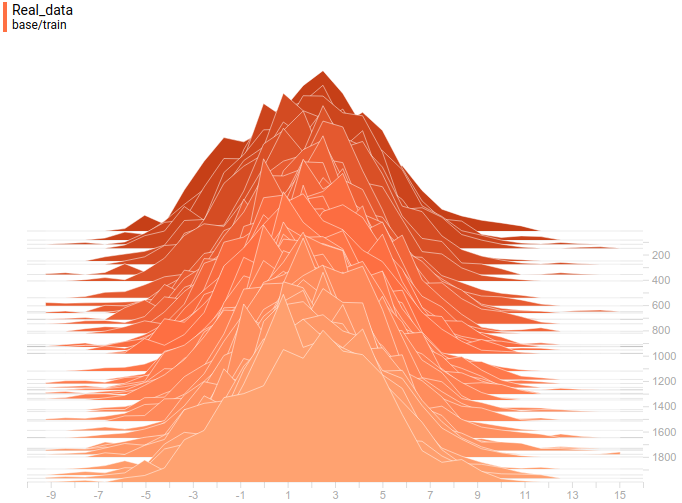
Рис. 5. Распределение реальных данных. Не меняется во времени. Шаг обучения отложен на вертикальной оси.
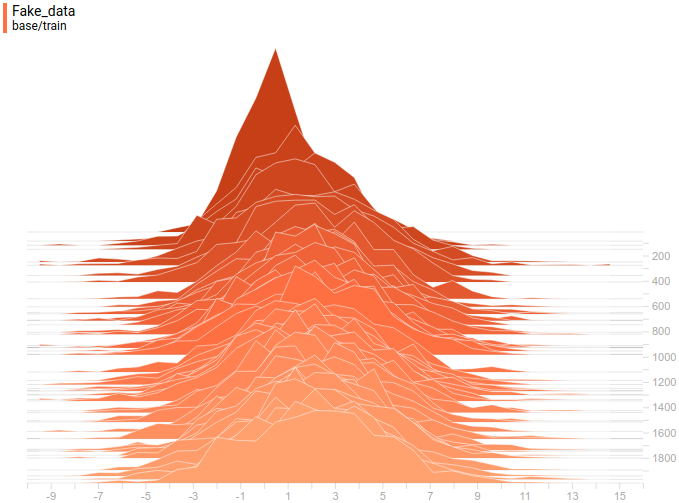
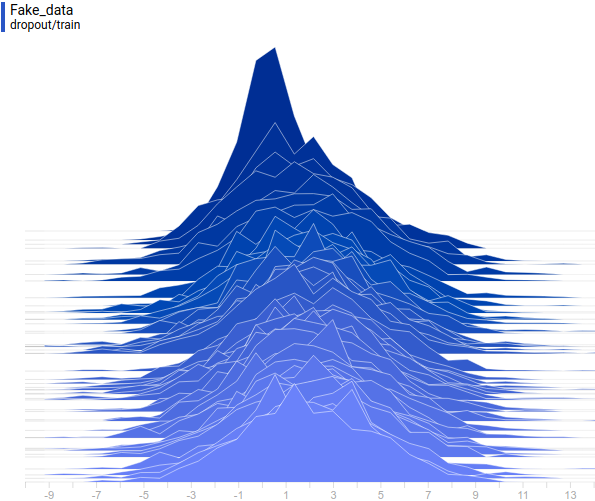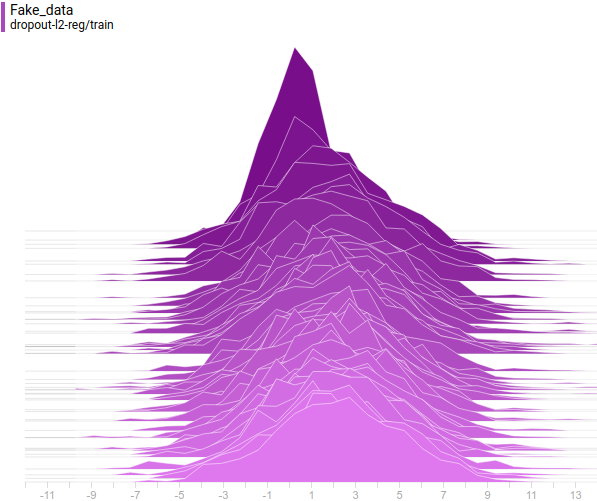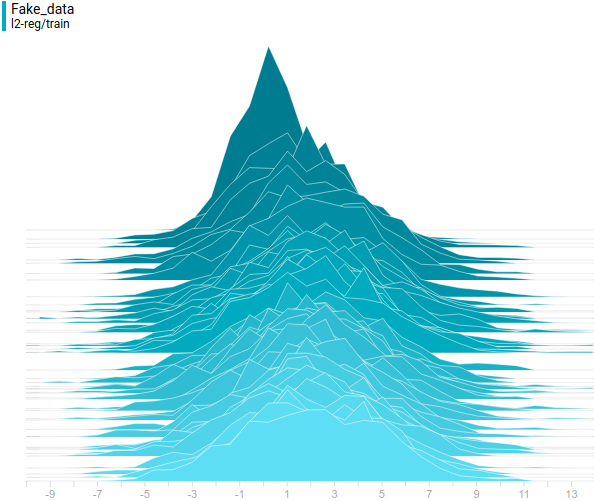
Рис. 6. Распределение реальных данных. Не меняется во времени. Шаг обучения отложен на вертикальной оси.
Давайте посмотрим на процесс обучения модели:

Рис. 7. Визуализация процесса обучения модели. Неподвижная гауссиана — плотность распределения реальных данных, движущаяся гауссиана — плотность распределения генерируемых примеров, синяя кривая — результат работы дискриминатора, т.е. вероятность примера быть настоящим.
Видно, что дискриминатор в начале обучения очень хорошо разделяет данные, но распределение генерируемых примеров очень быстро буквально “подползает” к распределению настоящих примеров. В конце концов, генератор настолько хорошо приближает данные, что дискриминатор становится константой 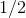 и задача сходится.
Приближение смеси нормальных распределений I
--------------------------------------------
Попробуем заменить 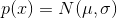 на 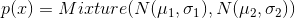, тем самым смоделировав мультимодальное распределение исходных данных. Для этой модели нужно изменить только код генерации реальных примеров. Вместо возвращения нормально распределенной случайной величины мы возвращаем смесь нескольких:
```
def data_batch(hparams):
count = len(hparams.input_mean)
componens = []
for i in range(count):
componens.append(
tf.contrib.distributions.Normal(
loc=hparams.input_mean[i],
scale=hparams.input_stddev[i]))
return tf.contrib.distributions.Mixture(
cat=tf.contrib.distributions.Categorical(
probs=[1./count] * count),
components=componens)
.sample(sample_shape=[hparams.batch_size, 1])
```
Ниже приведены графики для тех же самых моделей, что и в прошлом эксперименте, но для данных с двумя модами:
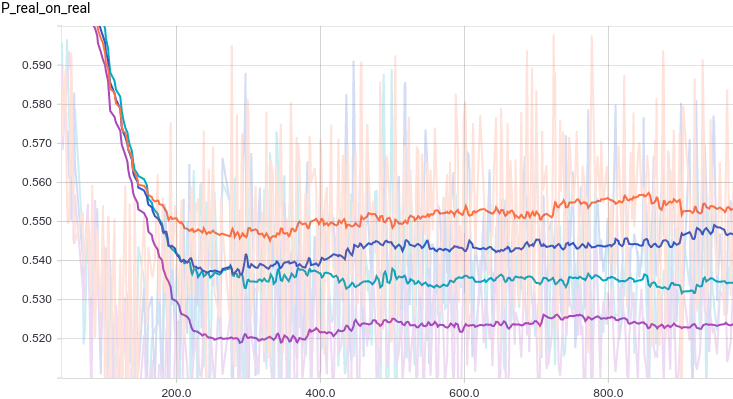
Рис. 8. Вероятность классификации дискриминатором реального примера как реального.
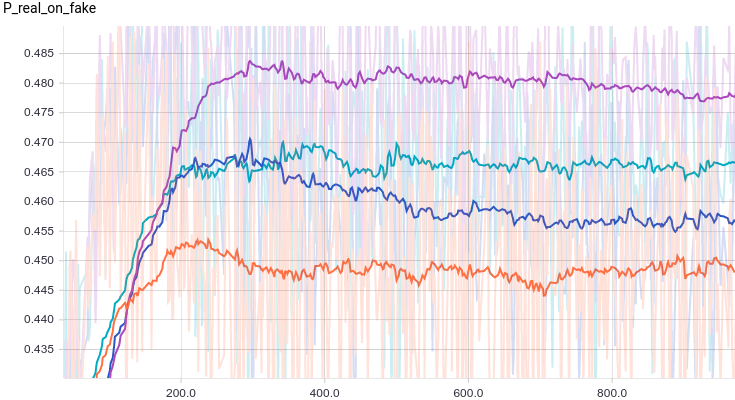
Рис. 9. Вероятность классификации дискриминатором сгенерированного примера как реального.
Интересно заметить, что регуляризованные модели показывают себя существенно лучше нерегуляризованных. Однако, независимо от модели видно, что теперь генератору не удается так хорошо обмануть дискриминатор. Давайте поймем, почему так получилось.
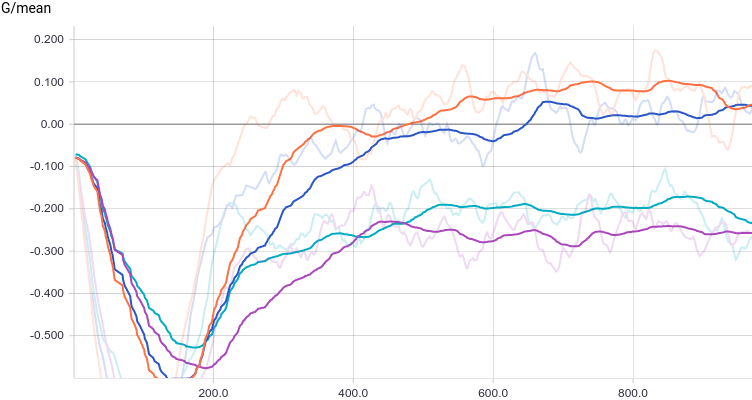
Рис. 10. Среднее сгенерированных распределений.
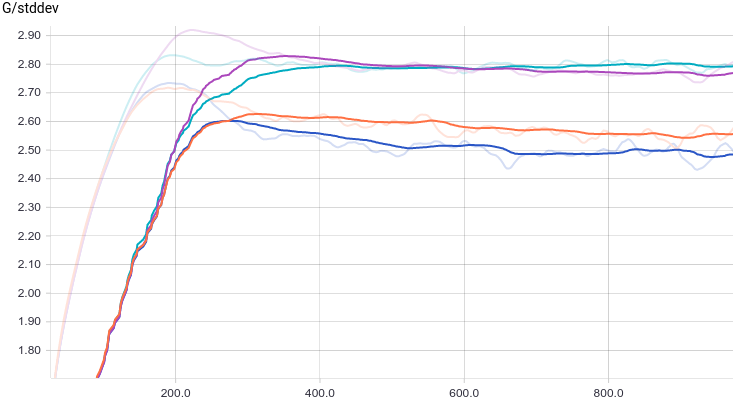
Рис. 11. Среднеквадратичное отклонение сгенерированных распределений.
Как и в первом эксперименте, генератор приближает данные нормальным распределением. Причина снижения качества в том, что теперь данные нельзя точно приблизить нормальным распределением, ведь они сэмплируются из смеси двух нормальных. Моды смеси симметричны относительно нуля, и видно, что все четыре модели приближают данные нормальным распределением с центром рядом с нулем и достаточно большой дисперсией. Давайте посмотрим на распределения настоящих и поддельных примеров, чтобы понять, что происходит:
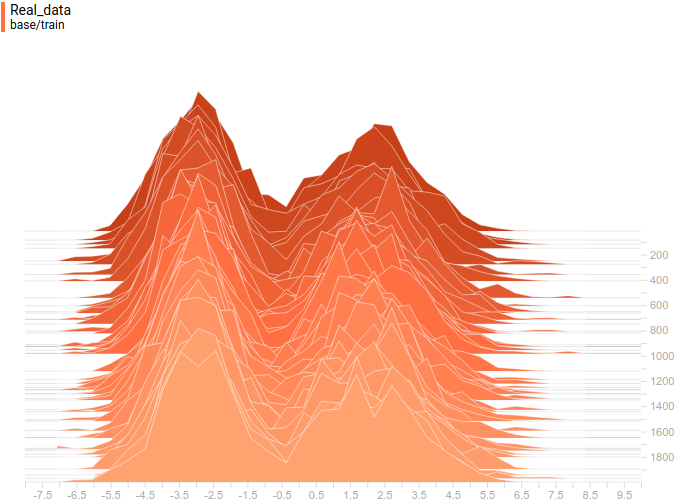
Рис 12. Распределение реальных данных. Не меняется во времени. Шаг обучения отложен на вертикальной оси.
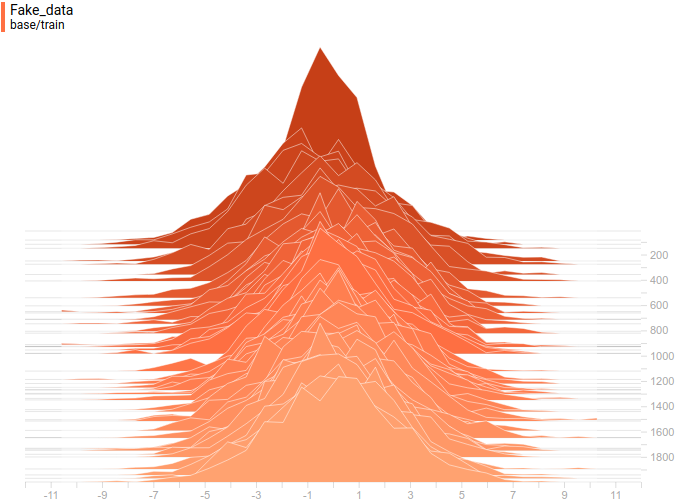
Рис 13. Распределения сгенерированных данных от четырех моделей. Шаг обучения отложен на вертикальной оси.
Так проходит процесс обучения модели:
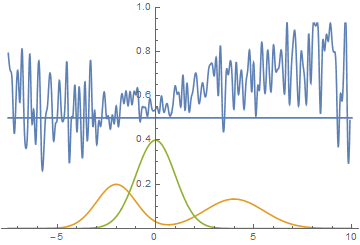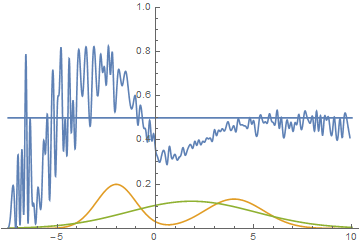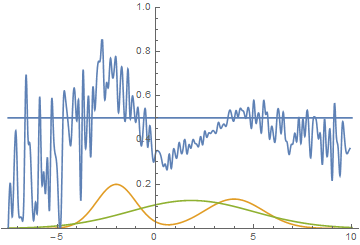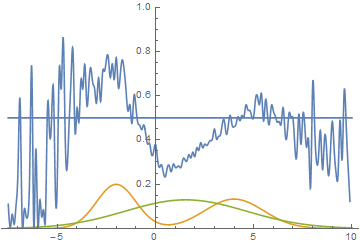
Рис. 14. Визуализация процесса обучения модели. Неподвижная смесь гауссиан — плотность распределения реальных данных, движущаяся гауссиана — плотность распределения генерируемых примеров, синяя кривая — результат работы дискриминатора, т.е. вероятность примера быть настоящим.
Эта анимация подробно показывает изученный выше случай. Генератор, не обладая достаточной экспрессивностью и имея возможность приближать данные только гауссианой, расплывается в широкую гауссиану, пытаясь охватить обе моды распределения данных. В результате генератор достоверно обманывает дискриминатор только в местах, где площади под кривыми генератора и исходных данных близки, то есть в районе пересечений этих кривых.
Однако, это не единственный возможный случай. Давайте подвинем правую моду еще немного правее, чтобы начальное приближение генератора ее не захватывало.
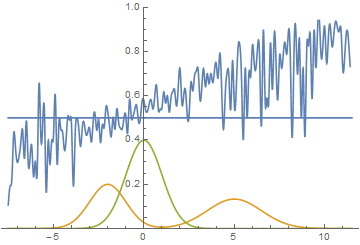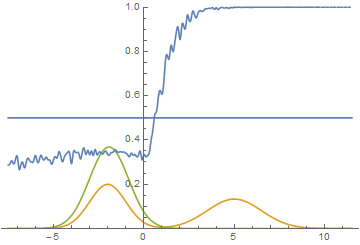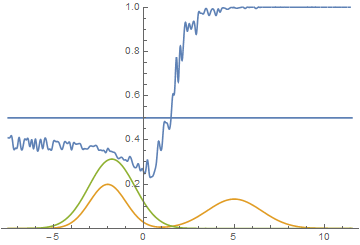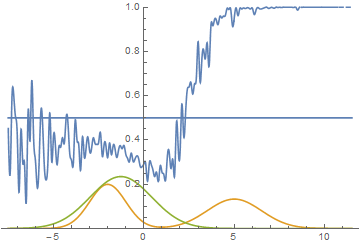
Рис. 15. Визуализация процесса обучения модели. Неподвижная смесь гауссиан — плотность распределения реальных данных, движущаяся гауссиана — плотность распределения генерируемых примеров, синяя кривая — результат работы дискриминатора, т.е. вероятность примера быть настоящим.
Видно, что в этом случае генератору выгоднее всего попытаться приблизить левую моду распределения. После того, как это происходит, генератор пытается предпринять попытки захватить и левую моду. Это выглядит, как осцилляции стандартного отклонения генератора во второй половине анимации. Но все эти попытки проваливаются, так как дискриминатор как-бы “запирает” генератор и для захвата левой моды ему необходимо преодолеть барьер из высокой функции потерь, чего он не может сделать из-за недостаточно большой скорости обучения. Данный эффект называется коллапсированием моды.
На двух вышеописанных примерах мы увидели два типа проблем, возникающих в том случае, если генератор недостаточно мощный, чтобы выразить исходное распределение данных: усреднение мод, когда генератор приближает все распределение, но везде достаточно плохо; и коллапсирование моды, когда генератор выучивает подмножество мод, а те, которые он не выучил, никак на него не влияют.
Помимо того, что обе этих проблемы приводят к несходимости дискриминатора к , они также приводят к снижению качества генеративной модели. Первая проблема приводит к тому, что генератор выдает примеры “между” мод, которых не должно быть, вторая проблема приводит к тому, что генератор выдает примеры только из некоторых мод, тем самым снижая богатство исходного распределения данных.
Приближение смеси нормальных распределений II
---------------------------------------------
Причиной того, что в предыдущем разделе не получилось до конца обмануть дискриминатор была тривиальность генератора, который просто делал линейное преобразование. Попробуем теперь в качестве генератора использовать полносвязную трехслойную нейронную сеть:
```
def generator(self, input, hparams):
# Первый полносвязный слой с 256 фичами.
input_size = 1
features = 256
weights = tf.get_variable(
"weights_1", initializer=tf.truncated_normal(
[input_size, features], stddev=0.1))
biases = tf.get_variable(
"biases_1", initializer=tf.constant(0.1, shape=[features]))
hidden_layer = tf.nn.relu(tf.matmul(input, weights) + biases)
# Второй полносвязный слой с 256 фичами.
features = 256
weights = tf.get_variable(
"weights_2", initializer=tf.truncated_normal(
[input_size, features], stddev=0.1))
biases = tf.get_variable(
"biases_2", initializer=tf.constant(0.1, shape=[features]))
hidden_layer = tf.nn.relu(tf.matmul(input, weights) + biases)
# Последний линейный слой, генерирующий пример.
output_size = 1
weights = tf.get_variable(
"weights_out", initializer=tf.truncated_normal(
[features, output_size], stddev=0.1))
biases = tf.get_variable(
"biases_out",
initializer=tf.constant(0.1, shape=[output_size]))
return tf.matmul(hidden_layer, weights) + biases
```
Давайте посмотрим на графики обучения.
Рис. 16. Вероятность классификации дискриминатором реального примера как реального.
Рис. 17. Вероятность классификации дискриминатором сгенерированного примера как реального.
Видно, что из за большого количества параметров обучение стало гораздо более шумным. Дискриминаторы всех моделей сходятся к результату около , но ведут себя нестабильно вокруг этой точки. Давайте посмотрим на форму генератора.

Рис 18. Распределение реальных данных. Не меняется во времени. Шаг обучения отложен на вертикальной оси.
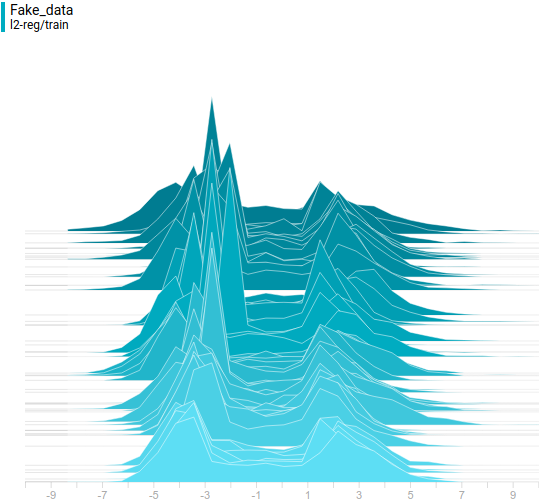
Рис 19. Распределения сгенерированных данных от четырех моделей. Шаг обучения отложен на вертикальной оси.
Видно, что распределение генератора хоть не совпадает с распределением данных, но достаточно сильно похоже на него. Самая регуляризованная модель опять показала себя лучше всех. Видно, что она выучила две моды, примерно совпадающие с модами распределения данных. Размеры пиков тоже не очень точно, но приближают распределение данных. Таким образом, нейросетевой генератор способен выучить мультимодальное распределение данных.
Так проходит процесс обучения модели:
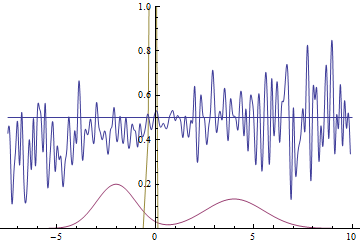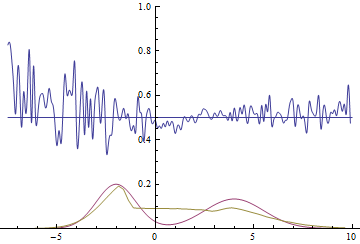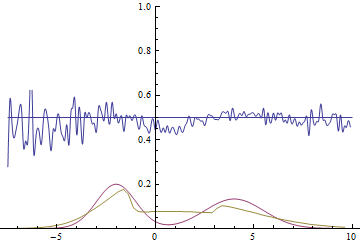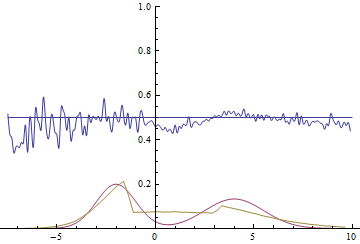
Рис. 20. Визуализация процесса обучения модели с близкими модами. Неподвижная смесь гауссиан — плотность распределения реальных данных, движущаяся гауссиана — плотность распределения генерируемых примеров, синяя кривая — результат работы дискриминатора, т.е. вероятность примера быть настоящим.
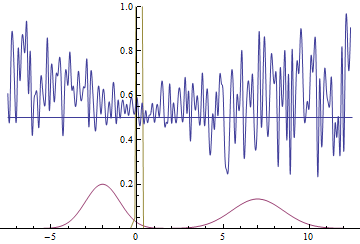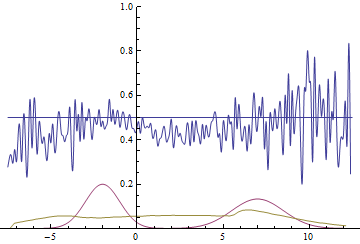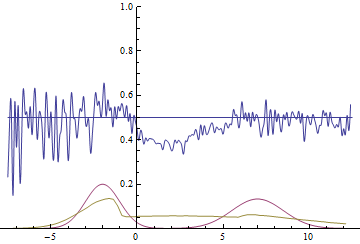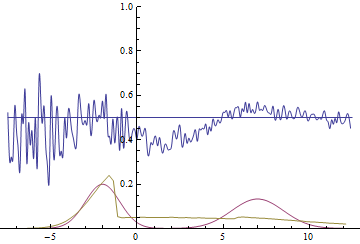
Рис. 21. Визуализация процесса обучения модели с далекими модами. Неподвижная смесь гауссиан — плотность распределения реальных данных, движущаяся гауссиана — плотность распределения генерируемых примеров, синяя кривая — результат работы дискриминатора, т.е. вероятность примера быть настоящим.
Эти две анимации показывают обучение на распределениях данных из предыдущего раздела. Из этих анимаций видно, что при использовании достаточно большого генератора с множеством параметров он, пусть и довольно грубо, но способен приближать мультимодальное распределение, тем самым косвенно подтверждая то, что проблемы из предыдущего раздела возникают из-за недостаточно сложного генератора. Дискриминаторы на этих анимациях гораздо более шумные, чем в разделе про нахождение параметров нормального распределения, но, тем не менее, к концу обучения начинают напоминать зашумленную горизонтальную прямую .
Итоги
-----
GAN — это модель, для приближения произвольного распределения только с помощью сэмплирования из этого распределения. В этой статье мы посмотрели в деталях, как модель работает на тривиальном примере поиска параметров нормального распределения и на более сложном примере аппроксимации бимодального распределения нейронной сетью. Обе задачи были с хорошей точностью решены, для чего потребовалось только использовать достаточно сложную модель генератора. В следующей статье мы перейдем от этих модельных примеров к реальным примерам генерации сэмплов из сложных распределений на примере распределения изображений.
Благодарности
-------------
Спасибо [Olga Talanova](https://www.linkedin.com/in/olga-talanova-b319b761/) и [Ruslan Login](https://www.linkedin.com/in/ruslan-login-68bb2676/) за ревью текста. Спасибо [Ruslan Login](https://www.linkedin.com/in/ruslan-login-68bb2676/) за помощь в подготовке изображений и анимаций. Спасибо [Andrei Tarashkevich](https://github.com/andrewtar) за помощь с версткой этой статьи. | https://habr.com/ru/post/352794/ | null | ru | null |
# Новый метод замены текста картинкой, или избавляемся от -9999px
Хотелось бы поговорить о техниках замены текста изображением. Думаю, практически все сталкивались с моментами в верстке, когда, к примеру, для заголовка страницы нужно использовать графический объект, при этом сохранив под ним текст и для поисковых роботов, и для печатной версии. Да и в принципе, никогда не хочется ломать семантинку страницы.

#### Немного об истории решения этого вопроса.
Самой первой популярной техникой была так называемая FIR (она же — Fahrner Image Replacement), которая [появилась](http://www.zeldman.com/daily/0703b.shtml#firflies) в 2003-м году. Она проста как пень, и многие начинающие верстальщики ее до сих пор используют:
```
h1.text-hide span { display: none; }
h1.text-hide {
height: 35px; /\* height of the replacement image \*/
background-image: url("hello-world.gif");
background-repeat: no-repeat;
}
Hello world!
============
```
Знакомая штука? По сути, внутрь тега, в фоне которого лежит наша картинка, мы добавляем инлайновый тег, который дублирует текст на картинке, а потом его скрываем с помощью display:none;
Многие сразу же признали кривизну этой техники, как с точки зрения семантики, так и с точки зрения утяжеления html лишними тегами. Ко всему прочему, ее полюбили серые оптимизаторы, в результате чего некоторые поисковые системы применяли санкции к страницам, перегруженным такими объектами.
#### В том же году [появилась](http://www.kryogenix.org/code/browser/lir/) еще одна техника замены. Работала она примерно так:
```
#ID_OF_ELEMENT {
padding: HEIGHT_OF_IMAGEpx 0 0 0;
overflow: hidden;
background-image: url("hello_world.gif");
background-repeat: no-repeat;
height: 0px !important;
height /**/:HEIGHT_OF_IMAGEpx;
}
```
Как видно, здесь был использован хак для IE5.5, в котором совсем все плохо было с блочной моделью. Впоследствии, эта техника не прижилась, так как переставала работать в ряде случаев, плюс многие не любят хаки.
#### -9999px
После всего этого появилась на свет техника [Phark’s Accessible Image Replacement](http://www.zeldman.com/daily/0703b.shtml#au1103), которая является самой популярной на текущий момент и состоящая всего из одной строки:
```
.text-hide {
text-indent: -9999px (или -999em);
}
```
Техника не идеальна, однако если не забывать о некоторых нюансах ее работы, то она сойдет для большинства случаев. В частности, проверять, чтобы text-align был направлен в ту же сторону, что и text-indent (в большинстве случаев — text-align:left). А также, не забывать, что применив ее на элемент со свойством display: inline-block;, этот элемент улетит в IE7 вслед за скрываемым текстом.
Я, как и многие, был приверженцем "-9999px", но в то же время понимал, что это не самый лучший вариант и что должно быть более красивое решение этой задачи. Каждый раз, прописывая -9999px, я задумывался а не повлияют ли эти пиксели на сайт в будущем.
#### Новое решение
И вот, несколько дней назад товарищ [Zeldman](http://www.zeldman.com/about/) предложил такой вариант:
```
.text-hide {
text-indent: 100%;
white-space: nowrap;
overflow: hidden;
}
```
Такой способ решает сразу несколько проблем:
* Во-первых, можно быть уверенными, что даже самый длинный текст, который скрывается, никогда не достигнет видимого контейнера, даже если длина этого текста будет превышать 9999px
* Во-вторых, сначала обнаружилась, а потом этим же способом решилась проблема, которая состояла в следующем: каждый раз при задании -9999px в dom-дереве добавлялся невидимый блок такой ширины. И если на обычных браузерах это сказывалось мало, то на iPAD обнаружились серьезные проблемы с производительностью анимации ([демо для проверки](http://lab.pgdn.us/hidden-text-performance/))
Однако этот способ также не идеален — если на элементе есть padding, то часть текста будет из него выглядывать. Проблема решается обнулением паддингов для тех блоков, где скрывается текст.
Вариант Зелдмана немного оживил ведущих фронт-енд разработчиков, которые ведут оживленные дискуссии в комментах и блогах.
Также, он был замечен командой разработчиков html5boilerplate, которые сейчас [активно дискутируют на github](https://github.com/h5bp/html5-boilerplate/issues/1005) на тему включения нового способа скрытия текста в набор вспомогательных классов своего бойлерплейта.
#### В той же ветке был предложен еще один способ, который имеет право на жизнь:
```
.text-hide {
font: 0/0 serif;
text-shadow: none;
color: transparent;
}
```
Этот способ тоже кроссбраузерен — проверено в IE7-10, Opera 11.61, Chrome 17.0, Firefox 10.0, и Safari 5.1.2. Правда, для старых браузеров такой вариант не прокатит — многие из них не понимают нулевое значение шрифта. Например, какой-то из старых Safari вместо нуля может принять значение 6 или 8.
Большую часть информации об истории и новом способе почерпнул из [этого поста](http://www.zeldman.com/2012/03/01/replacing-the-9999px-hack-new-image-replacement/)
**UPD:** [Еще один интеренсный метод от Николаса Галлахера с псевдоэлементом](http://nicolasgallagher.com/css-image-replacement-with-pseudo-elements/), спасибо за [подсказку](http://habrahabr.ru/blogs/css/139311/#comment_4655801) [SelenIT2](https://habrahabr.ru/users/selenit2/)
**UPD2:** В комментах к html5-boilerplate на гитхабе появились результаты теста трех способов IR (отрицательный text-indent, положительный text-indent и font: 0/0 a) в нескольких скринридерах. Вариант с font: 0/0 a не фурычит в Window-Eyes (как я понял, вымирающем, его сравнивают с IE5.5), остальное работает везде (хотя при положительном text-indent текст становится видимым во время его озвучки в старых версиях JAWS).
Спасибо [SelenIT2](https://habrahabr.ru/users/selenit2/), [ссылка на комментарий](http://habrahabr.ru/blogs/css/139311/#comment_4663071)
**UPD3:**Chris Coyier проделал огромную работу и собрал целый музей, посвященный техникам Image Replacement: [CSS Image Replacement Museum](http://css-tricks.com/examples/ImageReplacement/) | https://habr.com/ru/post/139311/ | null | ru | null |
# VKPLS — Генерация потокового аудио-плейлиста из vk.com

Хочу поделиться с читателями «Хабрахабра» небольшим веб-сервисом (скриптом), который написал для себя.
С появлением социальных сетей и их широким распространением пользователи довольно много времени проводят в онлайне. Все любят музыку, а лично я без нее жить не могу. Так вышло, что всю свою музыкальную коллекцию храню в профайле «Вконтакте». Поскольку всегда в курсе новинок, не трачу свое время на поиск и скачивание, а возможность доступа к своей музыке почти с любого гаджета в любом месте где есть интернет придает максимум удобства. Я очень рад, что прошли те деревянные времена, когда хороший интернет был роскошью. Больше нет необходимости хранить такую информацию на своем жестком диске. Все, что не конфиденциально, выбрасываю в облако.
Большую часть своей работы я выполняю за компьютером, а это значит, что музыка мне необходима как кислород — чтобы сконцентрироваться на поставленных задачах. Врубаешь любимый альбом в 5.1 и творишь. Но есть одно но: чтобы послушать музыку в VK.com, я должен зайти в онлайн, а если заходишь в онлайн — то непременно получаешь кучу сообщений и затягиваешься в нежелательные беседы. Я человек добрый и отзывчивый, поэтому не могу игнорировать своих друзей с их постоянными проблемами. Но ведь мне нужно сконцентрироваться на работе, а вся моя музыка там, где меня всегда что-то отвлекает.
Я обожаю Linux, но нормальных плагинов для музыкальных плееров или самих плееров для прослушивания музыки с VK.com так и не встретил. Тогда решил, что с этим нужно что-то делать и накидал за пару часов небольшой php скрипт, который и назвал vkpls (не трудно догадаться, что я имел ввиду).
Суть скрипта в получении прямых ссылок на аудиозаписи и генерации потокового плейлиста, алгоритм до безобразия прост, я завязал его на VK.API:
Для начала я создал Standalone приложение в разделе [«Для разработчиков»](http://vk.com/dev/standalone) и получил для него [права](http://vk.com/dev/permissions) на доступ к аудиозаписям. После этого мне необходимо было пройти авторизацию для создания ACCESS\_TOKEN, т.к. доступ к информации об аудиозаписях (метод audio.get в vk.api) невозможен по простому POST или GET запросу.
Теперь я мог с помощью средств старенького PHP направлять запрос с интересующими меня параметрами без ограничений, а в ответ получать интересующую меня информацию в формате JSON. Функция audio.get возвращает список аудиозаписей пользователя или сообщества со всей дополнительной информацией. Бинго, это-то мне и было нужно.
Так, например, в ответ такого запроса:
```
https://api.vk.com/method/audio.get?user_id=ВАШ_ID&v=5.28&access_token=ВАШ_ACCESS_TOKEN
```
мы получаем массив в формате JSON со следующей информацией:
**Ответ на audio.get в JSON**response: {
count: 505,
items: [{
id: '34',
photo: 'http://cs7009.vk....2/rj4RvYLCobY.jpg',
name: 'Tatyana Plutalova',
name\_gen: 'Tatyana'
}, {
id: 232745053,
owner\_id: 34,
artist: 'Ambassadeurs',
title: 'Sparks',
duration: 274,
url: 'http://cs6164.vk....lGEJhqRK8d5OQZngI',
lyrics\_id: 120266970,
genre\_id: 18
}, {
id: 232733966,
owner\_id: 34,
artist: 'Aloe Blacc',
title: 'Can You Do This ',
duration: 176,
url: 'http://cs6157.vk....erOa0DvsyOCYTPO1w',
genre\_id: 2
}, {
id: 232735496,
owner\_id: 34,
artist: 'Aloe Blacc',
title: 'Wake Me Up',
duration: 224,
url: 'http://cs6109.vk....FzHJU55ixz8Av8ujc',
lyrics\_id: 119056069,
genre\_id: 2
}]
}
Посмотрите — интересующие нас ключи artist, title, duration, url присутствуют для каждой аудиозаписи. Воспользовавшись функцией json\_decode я преобразовал полученный массив в понятный для php формат. Все, что мне осталось для достижения результата — это сгенерировать файл плейлиста.
**Структура M3U плэйлиста:**#EXTM3U
#EXTINF:**duration,artist — title**
**url**
…
Не было ничего проще записать в файл с помощью цикла foreach все полученные данные и сохранить его в m3u.
Ура, все получилось, теперь я могу слушать музыку в любом музыкальном плеере без необходимости авторизации вконтакте.
#### Резюме
Я решил поделиться своей идеей и сделать ее доступной для таких же, как я. С помощью CSS фрэймворка Maxmertkit (представленного одним из пользователей «Хабрахабра» [здесь](http://habrahabr.ru/post/225309/)) сверстал небольшую страницу для удобства использования скрипта. Для всех желающих она доступна по следующей ссылке — [VKPLS](http://vkpls.boutnew.ru). Там же вы можете прочитать инструкцию или посмотреть видео.
Следует отметить, что существует одно но. В связи с тем, что ссылки на аудиозаписи на серверах «Вконтакте» меняются с переодичностью в 0,5 — 3 дня, рекомендую чаще обновлять свой плэйлист.
На этом все, спасибо за внимание. | https://habr.com/ru/post/250251/ | null | ru | null |
# .NET Core Workers as Windows Services
In .NET Core 3.0 we are introducing a new type of application template called Worker Service. This template is intended to give you a starting point for writing long running services in .NET Core. In this walkthrough we will create a worker and run it as a Windows Service.
Create a worker
---------------
***Preview Note: In our preview releases the worker template is in the same menu as the Web templates. This will change in a future release. We intend to place the Worker Service template directly inside the create new project wizard.***
### Create a Worker in Visual Studio
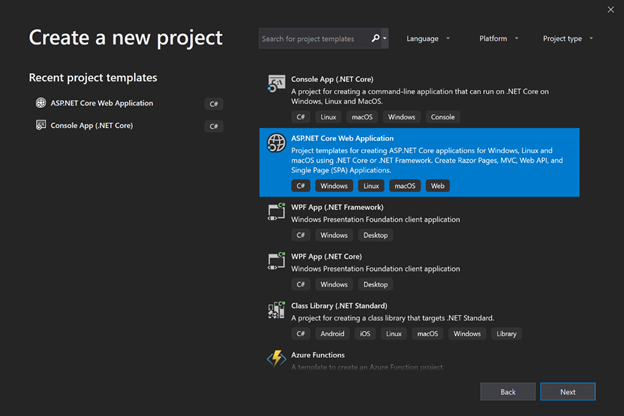
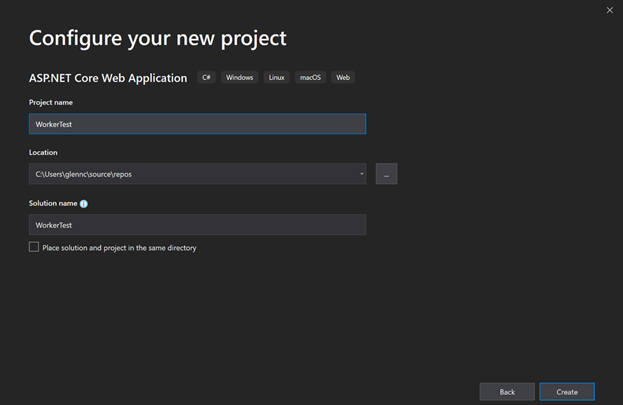
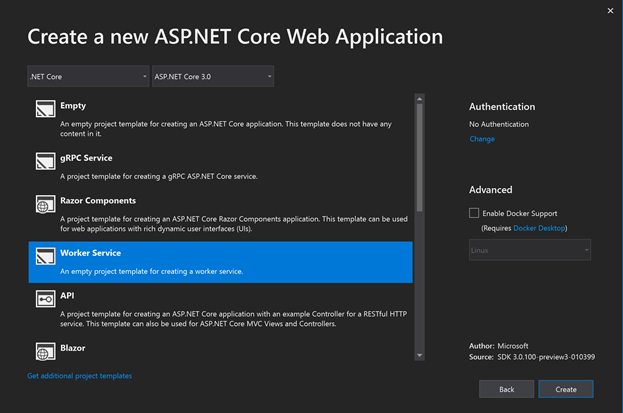
### Create a Worker on the command line
Run `dotnet new worker`
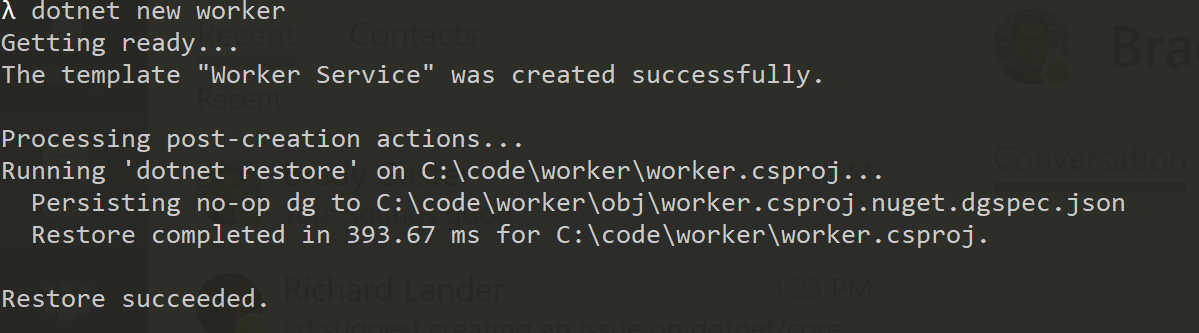
Run as a Windows Service
------------------------
In order to run as a Windows Service we need our worker to listen for start and stop signals from `ServiceBase` the .NET type that exposes the Windows Service systems to .NET applications. To do this we want to:
Add the `Microsoft.Extensions.Hosting.WindowsServices` NuGet package
Add the `UseServiceBaseLifetime` call to the `HostBuilder` in our Program.cs
```
public class Program
{
public static void Main(string[] args)
{
CreateHostBuilder(args).Build().Run();
}
public static IHostBuilder CreateHostBuilder(string[] args) =>
Host.CreateDefaultBuilder(args)
.UseServiceBaseLifetime()
.ConfigureServices(services =>
{
services.AddHostedService();
});
}
```
This method does a couple of things. First, it checks whether or not the application is actually running as a Windows Service, if it isn’t then it noops which makes this method safe to be called when running locally or when running as a Windows Service. You don’t need to add guard clauses to it and can just run the app normally when not installed as a Windows Service.
Secondly, it configures your host to use a `ServiceBaseLifetime`. `ServiceBaseLifetime` works with `ServiceBase` to help control the lifetime of your app when run as a Windows Service. This overrides the default `ConsoleLifetime` that handles signals like CTL+C.
### Install the Worker
Once we have our worker using the `ServiceBaseLifetime` we then need to install it:
First, lets publish the application. We will install the Windows Service in-place, meaning the exe will be locked whenever the service is running. The publish step is a nice way to make sure all the files I need to run the service are in one place and ready to be installed.
```
dotnet publish -o c:\code\workerpub
```
Then we can use the [sc utility](https://docs.microsoft.com/en-us/windows/desktop/services/controlling-a-service-using-sc) in an admin command prompt
```
sc create workertest binPath=c:\code\workerpub\WorkerTest.exe
```
For example:

***Security note:** This command has the service run as local system, which **isn’t something you will generally want to do**. Instead you should create a service account and run the windows service as that account. We will not talk about that here, but there is some documentation on the ASP.NET docs talking about it here: <https://docs.microsoft.com/en-us/aspnet/core/host-and-deploy/windows-service?view=aspnetcore-2.2>*
Logging
-------
The logging system has an Event Log provider that can send log message directly to the Windows Event Log. To log to the event log you can add the `Microsoft.Extensions.Logging.EventLog` package and then modify your `Program.cs`:
```
public static IHostBuilder CreateHostBuilder(string[] args) =>
Host.CreateDefaultBuilder(args)
.ConfigureLogging(loggerFactory => loggerFactory.AddEventLog())
.ConfigureServices(services =>
{
services.AddHostedService();
});
```
Future Work
===========
In upcoming previews we plan to improve the experience of using Workers with Windows Services by:
1. Rename UseWindowsServiceBaseLifetime to UseWindowsService
2. Add automatic and improved integration with the Event Log when running as a Windows Service.
Conclusion
==========
We hope you try out this new template and want you to let us know how it goes, you can file any bugs or suggestions here: <https://github.com/aspnet/AspNetCore/issues/new/choose>
##### [Glenn Condron](https://devblogs.microsoft.com/aspnet/author/glenncmicrosoft-com/) | https://habr.com/ru/post/446508/ | null | en | null |
# Нестандартное применение IT в быту: парсинг, перцептивный хеш, сравнение изображений = оптимизация расходов
В этой статье хочу поделиться интересной историей, о необычном решении одной интересной задачи, которая попалась мне год назад. Всё описанное в статье делалось, прежде всего, «just for fun» и из чистого академического интереса…
Дело было год назад, как раз было свободное время и желание сделать что-нибудь полезное. Явно был некоторый интеллектуальный голод и острая нехватка чего-нибудь нового, какой-нибудь интересной задачи… Отсюда и попытки прилепить велосипед даже туда, куда он вообще не требовался… Собственно, таковым велосипедом и является всё нижеописанное…
#### 1. Задача
На одном торгово-закупочном предприятии, достаточно остро стоял вопрос оптимизации закупок. У предприятия было несколько десятков основных поставщиков, но при этом у многих поставщиков пересечение товаров достигало 20-30%, а цены у всех разные. К сожалению, большинство товаров закупалось «по старой памяти», например привыкли, что товары группы A поставляет поставщик X, а товары группы Б поставщик Y, хотя если отбирать товары не группами, а штучно, то можно не слабо экономить. Для наглядности, покажу на примере:
```
У поставщика X:
Товар A1 - 11 руб.
Товар A2 - 10 руб.
Товар Б1 - 10 руб.
Товар Б2 - 11 руб.
У поставщика Y:
Товар A1 - 10 руб.
Товар A2 - 11 руб.
Товар Б1 - 11 руб.
Товар Б2 - 10.5 руб.
```
Из таблицы очевидно, что A1 и Б2 выгоднее закупать у «Y», а A2 и Б1 у «X». Но легко и просто это на примере из 4-х позиций номенклатуры и 2-х поставщиков, а если номенклатура в сумме насчитывает десятки тысяч позиций, а поставщиков десятки?
Казалось бы, в чём проблема — задача элементарная, но требует много несложных вычислений, руками объём не подъёмный, значит её нужно быстро переложить на плечи ПК и пожинать плоды? Всё было бы так, если бы была одна единая база со всей номенклатурой и ценами. Но увы, это утопия… база была в обычном, ужасном состоянии помойки, в котором могли кое-как разобраться только те кто каждый день и сваливал эту кучу мусора. С ценами всё ещё хуже, они вообще размазаны по разным каталогам, прайсам, сайтам. При попытке как-нибудь это каталогизировать и собрать воедино, становится очевидно, что это крайне трудно без ручного вмешательства. Один поставщик использует артикул производителя, другой ставит свой, а третий вообще не указывает их в прайсах. Названия практически нигде не совпадают, например один и тот же товар может называться: «Ваза с рисунком 'узор треугольный'», «Ваза А-563», «Ваза с рисунком», наконец, просто «Ваза» :)
Значит, по названиям соединять было тоже абсолютно бесполезно.
#### 2. Безумная идея
И тут появилась безумная идея. Специфика товара была таковой, что практически везде была картинка, притом, картинки очень часто поставщики брали в одном месте, или вообще друг у друга. Было одно «НО», картинки естественно были разного размера, могли даже отличаться пропорции. Значит сравнение «в лоб» нам не поможет. Но, ведь, Яндекс же как-то находит похожие изображения? А почему бы и нам не попробовать?!? Решено!
Изучение литературы, чтение гугла, статей, дало представление о том, как работает поиск похожих изображений. Вкратце: строятся хеши изображений, а потом уже хэши между собой и сравниваются. Основные различия именно в хеш-функциях. Самый простой и быстрый, как в реализации, так и в самой сложности расчётов — перцептивный хеш «по среднему значению».
Вкратце принцип работы: изображение сжимается в квадрат, например 16x16, затем из цветного изображения получаем изображение в градациях серого, затем, по точкам квадрата считаем среднее значение цвета, а потом во второй проход для каждой точки ставим 0 или 1, в зависимости от того, цвет этой точки меньше или больше среднего значения. Полученная последовательность 0-ей и 1-иц и есть искомый нами хеш.
Для того чтобы сделать быстро прототип было решено использовать ImageMagick для обработки картинок, а в качестве скриптового языка был выбран php.
В качестве материала для тестов я взял изображение «Хризантема.jpg», из стандартного набора Windows. Первый файл я назвал test1.jpg, потом взял исходный файл и исказил пропорции, сохранив под именем test2.jpg. В качестве 3-его образца я взял «Пустыня.jpg» и назвал его test3.jpg. Вот они:
**Изображения для теста**


Далее вызываем ImageMagick для предварительной обработки:
```
E:\ImageMagick\convert.exe E:\Article\img\test1.jpg -resize 16x16! -colorspace gray E:\Article\img\_test1.jpg
E:\ImageMagick\convert.exe E:\Article\img\test2.jpg -resize 16x16! -colorspace gray E:\Article\img\_test2.jpg
E:\ImageMagick\convert.exe E:\Article\img\test3.jpg -resize 16x16! -colorspace gray E:\Article\img\_test3.jpg
```
Получаем:
**Изображения 16x16 grayscale**


Далее считаем сам хеш:
```
function getPerceptHash($imgName) {
$im = imagecreatefromjpeg($imgName);
//В первом проходе считаем сумму, которую потом делим на 256 (16*16), чтобы получить среднее значение
$summ = 0;
for($i=0;$i<8;$i++){
for($j=0;$j<8;$j++){
$summ += imagecolorat($im, $i, $j);
}
}
$sred = $summ/64;
//При втором проходе сравниваем значение цвета каждой точки со средним значением и записываем в результат 0 или 1
$str='';
for($i=0;$i<8;$i++){
for($j=0;$j<8;$j++){
if(imagecolorat($im, $i, $j)=$sred){ $str .= '1'; }else{ $str .= '0'; }
}
}
//Переводим в 16-ю систему, для удобства
$str = base_convert($str, 2, 16);
return $str;
}
echo '_test1.jpg '.getPerceptHash("E:\Denwer3\home\imagecomparer.loc\www\Article\img\_test1.jpg").'
';
echo '_test2.jpg '.getPerceptHash("E:\Denwer3\home\imagecomparer.loc\www\Article\img\_test2.jpg").'
';
echo '_test3.jpg '.getPerceptHash("E:\Denwer3\home\imagecomparer.loc\www\Article\img\_test3.jpg").'
';
?>
``` | https://habr.com/ru/post/210388/ | null | ru | null |
# Обработка критических ошибок в PHP
В статье описан функционал, который доступен в PHP (актуально для 5.3.х) для обработки ошибок всех типов, включая ошибки интерпретации кода (E\_ERROR, E\_PARSE, E\_WARNING, etc). Эта обработка поможет вам для управляемого отображения страницы в случае возникновения таких проблем. В статье присутствует множество описаний и рабочих примеров(архитектуры) для того, что бы сразу воспользоваться в своем программном продукте. В конце концов, ну немного сломали сайт, ну надо же, об этом сообщить поисковику с заголовком 4хх или 5хх и повеселить пользователя, вместо возврата белого экрана (или что хуже экрана со священной информацией, для хакеров) с ответом 200 Ok.

Идея написать этот топик возникла, когда я на храбре задал 2 вопроса:
* Вопрос о [перехвате предупреждений и вывод ошибок в указанное место шаблона](http://habrahabr.ru/qa/13273/)
* Вопрос о [перехвате критических ошибок, заставляющие выполнение скрипт только остановиться](http://habrahabr.ru/qa/14388/)
По моей карме и добавление в избранное я понял, что они оказались интересные для PHP хабрасообщества. По этой причине я решил оформить решения этих вопросов в виде статьи, да бы людям и поисковикам было проще и комплексно находить нужную информацию.
Если заинтересовались, то подробности под катом…
#### Причины использования
Пользователю/поисковику, требуется внятно ответить, что на сервере проблемы. Без использования определенного фен-шуя, этого добиться достаточно трудно, а порой невозможно. Тут я проливаю свет на все это, ну и себе заметочку оставляю, так как еще неделю назад я не знал за что взяться, и, наверное, многие новички тоже будут обескуражены.
#### Описания функций
Данный функционал доступен в PHP для того, что бы обрабатывать ошибки и контролировать вывод. Вот описание их вкусностей и недостатков. Документацию я приводить не буду, я только сошлюсь её страницы и опишу свое мнение. Все что будет приведено это только малая доля, ссылки на соответствующие разделы документации я приведу в конце статьи. Итак встречаем:
**— Контроль некритических ошибок:** замечания, предупреждения, пользовательские ошибки. В общем все то, что не завершает интерпретацию аварийно.
[set\_error\_handler](http://www.php.net/manual/ru/function.set-error-handler.php) — Задает определенный пользователем обработчик ошибок.
Нужен для того, что бы писать в лог все такие ошибки. Если её не задать, то в лог это не пишется, а мне вот всегда хочется узнать при каких боевых ситуациях могут вызываться замечания и предупреждения. То есть позволяет автоматически тестировать продукт пользователем и он даже не будет замечать этого.
Если функция не задана, то PHP лишь пытается вывести данные на экран, а если ему и это не дают, то вообще никаких признаков жизни от этих типов ошибок не возникает.
**— Контроль, исключений:** является ошибкой типа E\_ERROR.
[set\_exception\_handler](http://www.php.net/manual/ru/function.set-exception-handler.php) — Задает пользовательский обработчик исключений
Ну не знаю, зачем это вообще было придумано, когда есть то, что описано ниже и просто обработка ошибки типа Exception. Так что сообщаю что оно просто существует. Она перехватывает критическую ошибку «исключение» и позволяет что-то с ней делать. В любом случае скрипт завершается. Её работы по умолчанию лично для меня достаточно (пишет в логи, пытается вывести на экран). Я бы её вообще не переопределял, а то придется в логи о случившимся исключении самому писать.
**— Функции контроля вывода:** Тут я опишу 3 функции, которые следует знать по разным причинам. Например, для [проблем производительности](http://habrahabr.ru/blogs/php/45016/) или для проблем вывода заголовков. В нашем случае требуется выводить заголовки ошибок.
[ob\_start](http://www.php.net/manual/ru/function.ob-start.php) — Включение буферизации вывода
[ob\_flush](http://www.php.net/manual/ru/function.ob-flush.php) — Сброс (отправка) буфера вывода
[ob\_end\_clean](http://www.php.net/manual/ru/function.ob-end-flush.php) — Очищает (стирает) буфер вывода и отключает буферизацию вывода
Если вкратце, то данные функции позволяют записывать все данные выводимые через echo в некий буфер. Это функционал позволяют отправлять заголовки в любой части кода, а так же многие другие вещи, темы которых не относится к данной статье. А если вдруг случилась беда. То можно сбрасывать весь буфер и весь стек (об этом не в этой статье), писать заголовок ошибки и выводить уведомление пользователю.
**— Получение последней произошедшей ошибки:** её надо использовать вместе с другими перехватывающими функциями, которые тут описаны.
[error\_get\_last](http://www.php.net/manual/ru/function.error-get-last.php) — Получение информации о последней произошедшей ошибке
С помощью нее, возможно вернуть последнюю ошибку. Ей очень удобно ловить критические ошибки и код становится оптимальным (появилась с 5.2.х если что).
**— Функция которая запускается после того как все отработало:** Барабанная дробь.
[register\_shutdown\_function](http://php.net/manual/ru/function.register-shutdown-function.php) — Регистрирует функцию, которая выполнится по завершении работы скрипта. Завершение может быть штатным или аварийным, без разницы.
Много плюсов и никаких минусов:
* Данная функция не переопределяется, а определяется дополнительно, и определить вы её можете много раз
* Так как она не переопределяется, то все ошибки уже пишутся в лог так или иначе, их не требуется переопределять
* Данная функция, не еще отправляет контент, о чем написано в документации, и соотвественно можно пользоваться функциями буферизации
#### Многие Объектно Ориентированные люди обрадуются
Что все вышеизложенные функции можно зарегистрировать даже на методы классов, а также, наверняка, на статические методы классов по той же схеме. Правда способ очень не очевиден для глаза обычного не PHP программиста.
Параметр handler требуется задать через массив, с элементами «название класса|объекта», «метод объекта». Устанавливаемый метод обязательно должен быть public. Пример для функции set\_error\_handler:
```
php
class BaseErrorCatcher
{
public function __construct()
{
set_error_handler(array($this, 'ErrorCatcher'));
echo "друг, я создался\n";
$errorVarArray['real index'] = true;
echo $errorVarArray['error index'];
}
public function ErrorCatcher($errno, $errstr)
{
echo "друг, да ты вероянто напортачил где-то в этом: $errstr\n";
}
}
error_reporting(E_ALL | E_STRICT); // включаем замечания у кого они выключены
ini_set('display_errors','On'); // ну уж что бы точно вы увидели результат
new BaseErrorCatcher(); // начало теста
?
```
Результат:
```
друг, я создался
друг, да ты вероянто напортачил где-то в этом: Undefined index: error index
```
#### Рабочий пример
Пример работы, архитектура класса для универсального и полного контроля ошибок. Я исследовал этот вопрос очень досконально и составил гибридный метод, из ответов на [заданные мною вопросы](http://habrahabr.ru/qa/14388/).
##### Условия
Есть файл с кодом, который запускается первым или перед кодом в котоом может появиться ошибка и этот файл и все файлы до него 100% отлаженные с невозможностью появления ошибки. Вот такое вот условие, что бы было проще — без ошибок до того пока не пройдут все регистрации вышеизложенных функций. В данном файле описаны данные методики контроля ошибок в комплексе. Контролируется буфер, если ошибка, то сбросить буфер и вывести ошибку.
##### Код с комментариями
*От себя добавлю, что код не тестировал, так как это упрощенная схема того, что у меня в коде, замечания принимаются*
```
php
class ErrorSupervisor
{
public function __construct()
{
// регистрация ошибок
set_error_handler(array($this, 'OtherErrorCatcher'));
// перехват критических ошибок
register_shutdown_function(array($this, 'FatalErrorCatcher'));
// создание буфера вывода
ob_start();
}
public function OtherErrorCatcher($errno, $errstr)
{
// контроль ошибок:
// - записать в лог
return false;
}
public function FatalErrorCatcher()
{
$error = error_get_last();
if (isset($error))
if($error['type'] == E_ERROR
|| $error['type'] == E_PARSE
|| $error['type'] == E_COMPILE_ERROR
|| $error['type'] == E_CORE_ERROR)
{
ob_end_clean(); // сбросить буфер, завершить работу буфера
// контроль критических ошибок:
// - записать в лог
// - вернуть заголовок 500
// - вернуть после заголовка данные для пользователя
}
else
{
ob_end_flush(); // вывод буфера, завершить работу буфера
}
else
{
ob_end_flush(); // вывод буфера, завершить работу буфера
}
}
}
// запуск контроллера
$errorController = new ErrorSupervisor();
// генерируем контент
// изменяем заголовки, в обещм делаем много чего
echo "генерация простейшего контента";
// тестируем систему (не тестировал, но у меня в более сложном варианте работает)
include 'null'; // запускается OtherErrorCatcher
// require 'null'; // запустится FatalErrorCatcher
// require 'foobar.php'; // а внутри этого файла вообще ошибка компиляции
?
```
#### Ссылки
##### Разделы документации
* [Функции обработки ошибок](http://www.php.net/manual/ru/ref.errorfunc.php)
* [Функции контроля вывода](http://www.php.net/manual/ru/ref.outcontrol.php)
* [Управление функциями](http://www.php.net/manual/ru/ref.funchand.php) — невзрачно оформлено правда? Без помощи [Aco](http://habrahabr.ru/users/aco/) я бы еще очень долго читал документацию и решал задачу.
##### Другая полезная информация
* [Функция echo в PHP может выполняться более 1 секунды](http://habrahabr.ru/blogs/php/45016/)
* [Предопределенные константы](http://www.php.net/manual/ru/errorfunc.constants.php) — они же типы ошибок
Спасибо за внимание.
UPD: По советам из комментариев, дополнил класс ErrorSupervisor новой функциональностью, исправил пару заблуждений, добавил дополнительную интересную информацию по теме, немного отладил код
**UPD2 Внимание: Товарищ по PHP-разуму написал хорошую статью** про [битовые операции в PHP](http://habrahabr.ru/blogs/php/134557/) как раз к теме данной статьи, советую почитать. Эти знания позволяют более элегантно писать код. Менять текст данной статьи уже не стал для того, что бы сохранился смысл. | https://habr.com/ru/post/134499/ | null | ru | null |
# Требования к разработке приложения в Kubernetes
Сегодня я планирую рассказать, как нужно писать приложения и какие есть требования для того, чтобы ваше приложение хорошо работало в Kubernetes. Чтобы с приложением не было никакой головной боли, чтобы не приходилось придумывать и выстраивать какие-то «костыли» вокруг него — и работало всё так, как это задумывалось самим Kubernetes.
Эта лекция в рамках «[Вечерней школы Слёрма по Кубернетес](http://to.slurm.io/53txdA)». Вы можете просмотреть открытые теоретические лекции Вечерней Школы [на Youtube, сгруппированные в плейлист](https://www.youtube.com/playlist?list=PL8D2P0ruohOA4Y9LQoTttfSgsRwUGWpu6). Для тех же, кому удобнее текст, а не видео, мы подготовили эту статью.
Зовут меня Павел Селиванов, на текущий момент я являюсь ведущим DevOps инженером компании Mail.ru Cloud Solutions, мы делаем «облака», мы делаем мэнедж-кубернетисы и так далее. В мои задачи сейчас как раз-таки входит помощь в разработке, раскатывание эти облаков, раскатывание приложения, которые мы пишем и непосредственно разработка инструментария, который мы предоставляем для наших пользователей.

Я DevOps-ом занимаюсь, думаю, что последние, наверное, года три. Но, в принципе, то, чем занимается DevOps, я занимаюсь, наверное, лет пять уже точно. До этого я занимался скорей больше админскими вещами. С Kubernetes я начал работать очень давно — уже, наверное, прошло порядка четырех лет с тех пор, как я начал с ним работать.
Вообще начинал я, когда у Kubernetes была версии 1.3, наверное, а может быть и 1.2 — когда он был еще в зачаточном состоянии. Сейчас он уже совсем не в зачаточном состоянии находится — и очевидно, что на рынке есть огромный спрос на инженеров, которые в Kubernetes хотели бы уметь. И у компаний есть очень большой спрос на таких людей. Поэтому, собственно, и появилась эта лекция.
Если говорить по плану того, о чем я буду рассказывать, это выглядит вот так, в скобочках написано (TL;DR) – «too long; don’t read». Моя сегодняшняя презентация будет представлять из себя бесконечные списки.

На самом деле, я сам не люблю такие презентации, когда их делают, но тут такая тема, что я когда готовил эту презентацию, я просто не придумал на самом деле, как по-другому организовать эту информацию.
Потому что по большому счету эта информация — это «ctrl+c, ctrl+v», из, в том числе нашей Вики в разделе DevOps, где у нас написаны требования к разработчикам: «ребята, чтобы ваше приложение мы запустили в Kubernetes, оно должно быть вот таким».
Поэтому получилась презентация таким большим списком. Извините. Постараюсь рассказывать максимально, чтобы было нескучно по возможности.
Что мы с вами сейчас будем разбирать:
* это, во-первых, логи (журналы приложения?), что с ними делать в Kubernetes, как с ними быть, какими они должны быть;
* что делать с конфигурациями в Kubernetes, какие для Kubernetes лучшие-худшие способы конфигурировать приложение;
* поговорим о том, что такое проверки доступности вообще, как они должны выглядеть;
* поговорим о том, что такое graceful shutdown;
* поговорим еще раз про ресурсы;
* еще раз затронем тему хранения данных;
* и в конце я расскажу, что такое термин этот загадочный cloud-native приложение. Cloudnativeness, как прилагательное от этого термина.
Логи
----
Я предлагаю начать с логов — с того, куда эти логи нужно в Kubernetes пихать. Вот вы запустили в Kubernetes приложение. По классике, раньше приложения всегда писали логи куда-нибудь в файлик. Плохие приложения писали логи в файлик в домашней директории разработчика, который запустил это приложение. Хорошие приложения писали логи в файлик куда-нибудь в `/var/log`.

Соответственно, дальше, у хороших админов в инфраструктурах были настроены какие-нибудь штуки, которые эти логи могут ротировать — тот же самый rsyslog элементарно, который смотрит на эти логи и когда с ними что-то происходит, их становится много, он создает резервные копии, складывает туда логи, удаляет старые файлики, больше, чем за неделю, за полгода и еще за сколько-нибудь. По идее, у нас должно быть предусмотрено, чтобы просто тупо из-за того, что приложение пишет логи, место на серверах продакшна (боевых серверах?) не кончалось. И, соответственно, весь продакшн не останавливался из-за логов.
Когда мы переходим в мир Kubernetes и запускаем там все то же самое, первое, на что можно обратить внимание – это на то, что люди, как писали логи в файлике, так и продолжают их писать.
Оказывается, если мы будем говорить про Kubernetes, что правильным местом для того, чтобы из докер-контейнера куда-то написать логи, это просто писать их из приложения в так называемые Stdout/Stderr, то есть потоки стандартного вывода операционной системы, стандартного вывода ошибок. Это самый правильный, самый простой и самый логичный способ, куда девать логи в принципе в докере и конкретно в Кубернетисе. Потому что, если ваше приложение пишет логи в Stdout/Stderr, то дальше это уже задача докера и надстройки над ним Kubernetes, что с этими логами делать. Докер по умолчанию будет складывать свои специальные файлики в JSON формате.
Тут уже возникает вопрос, что вы с этими логами будете делать дальше. Самый простой способ, понятно, у нас есть возможность сделать `kubectl logs` и посмотреть эти логи этих «подов». Но, наверное, это не очень хороший вариант — с логами нужно что-то дальше делать.
Пока еще поговорим заодно, раз уж мы затронули тему логов, о такой штуке, как логи должны выглядеть. То есть, это не относится напрямую к Kubernetes, но когда мы начинаем задумываться о том, что делать с логами, хорошо бы задуматься и об этом тоже.
Нам нужен какой-то инструмент, по-хорошему, который эти логи, которые у нас докер складывает в свои файлики, возьмет и куда-то их отправит. По большому счету, обычно мы внутри Kubernetes запускаем в виде DaemonSet какой-нибудь агент – сборщик логов, которому просто сказано, где лежат логи, которые складывает докер. И этот агент-сборщик их просто берет, возможно, даже по пути как-то парсит, возможно обогащает какой-то дополнительной метаинформацией и, в итоге, отправляет на хранение куда-то. Там уже возможны вариации. Самое распространенное, наверное, Elasticsearch, где можно хранить логи, их можно оттуда удобно доставать. Потом с помощью запроса, с помощью Kibana, например, строить по ним графики, строить по ним алерты и так далее.
Самая главная мысль, еще раз ее хочу повторить, о том, что внутри докера, в частности, внутри Kubernetes, складывать ваши логи в файлик – это очень плохая идея.
Потому что во-первых, логи внутри контейнера в файлике проблематично доставать. Нужно сначала зайти в контейнер, сделать туда exec, а потом уже смотреть логи. Следующий момент – если у вас логи в файлике, то в контейнерах обычно минималистичное окружение и там нет утилит, которые нужны обычно для нормальной работы с логами. Их погрепать, посмотреть, открыть в текстовом редакторе. Следующий момент, когда у нас логи лежат в файлике внутри контейнера, в случае, если этот контейнер удалится, вы понимаете, логи погибнут вместе с ним. Соответственно, любой рестарт контейнера — и логов уже нет. Опять же, плохой вариант.
И последний момент – это то, что внутри контейнеров у вас обычно существует ваше приложение и все – оно обычно является единственным запущенным процессом. Ни о каком процессе, который бы ротировал файлы с вашими логами, речи вообще не идет. Как только логи начинают записываться в файлик, это значит, что, извините, продакшн сервера мы начнем терять. Потому что, во-первых, их проблематично найти, их никто не отслеживает, плюс их никто не контролирует — соответственно, файлик растет бесконечно, пока просто место на сервере не кончится. Поэтому, еще раз говорю, что логи в докере, в частности, в Kubernetes, в файлик – это затея плохая.
Следующий момент, тут я хочу опять же об этом поговорить – раз уж мы затрагиваем тему логов, то хорошо бы поговорить и о том, как логи должны выглядеть, для того, чтобы с ними было удобно работать. Как я говорил, тема не относится напрямую к Kubernetes, но зато очень хорошо относится к теме DevOps. К теме культуры разработки и дружбы двух этих разных отделов – Dev и Ops, чтобы всем было удобно.
Значит в идеале, на сегодняшний день, логи нужно писать в JSON формате. Если у вас какое-нибудь непонятное приложение ваше самописное, которое пишет логи в непонятных форматах, потому что вы там вставляете какой-нибудь print или что-то типа того, то самое время уже нагуглить какой-нибудь фрэймворк, какую-нибудь обертку, которая позволяет реализовывать нормальное логирование; включить там параметры логирования в JSON, потому что JSON простой формат, его парсить просто элементарно.
Если у вас JSON не прокатывает по каким-нибудь критериям, неизвестно каким, то хотя бы пишите логи в том формате, который можно парсить. Тут, скорее, стоит задумываться о том, что, например, если у вас запущена куча каких-нибудь контейнеров или просто процессов с nginx, и у каждого свои настройки логирования, то, наверное, кажется, вам парсить их будет очень неудобно. Потому что на каждую новый nginx instance вам нужно написать собственный парсер, потому что они пишут логи по-разному. Опять же, наверное, тут стоило задуматься о том, чтобы все эти nginx instance имели одну и ту же конфигурацию логирования, и абсолютно единообразно писали все свои логи. То же самое касается абсолютно всех приложений.
Я в итоге еще хочу масла в огонь добавить, о том, что в идеале, логов многострочного формата стоит избегать. Тут какая штука, если вы когда-то работали со сборщиками логов, то, скорее всего, вы видели, что они вам обещают, что они умеют работать с многострочными логами, умеют их собирать и так далее. На самом деле, нормально, полноценно и без ошибок собирать многострочные логи, не умеет, по-моему, на сегодняшний день ни один сборщик. По-человечески, чтобы это было удобно и без ошибок.

Но stack trace — это всегда многострочные логи и как их избегать. Тут вопрос в том, что лог – это запись о событии, а стактрэйс фактически логом не является. Если мы логи собираем и складываем их куда-нибудь в Elasticsearch и по ним потом рисуем графики, строим какие-нибудь отчеты работы пользователей на вашем сайте, то когда у вас вылазит stack trace – это значит, что у вас происходит какая-то непредвиденная, необработанная ситуация в вашем приложении. И stack trace имеет смысл закидывать автоматически куда-нибудь в систему, которая их умеет трэкать.
Это то ПО (то же Sentry), которое сделано специально для того, чтобы работать со stack trace. Оно может создавать сразу же автоматизированно задачи, назначать на кого-то, аллертить, когда стактрейсы происходят, группировать эти стактрэйсы по одному типу и так далее. В принципе, не имеет особого смысла говорить о стактрэйсах, когда мы говорим о логах, потому что это, все-таки, разные вещи с разным предназначением.
Конфигурация
------------
Дальше у нас по поводу конфигурации в Kubernetes: что с этим делать и как приложения внутри Kubernetes должны конфигурироваться. Вообще, я обычно говорю о том, что докер – он не про контейнеры. Все знают, что докер – это контейнеры, даже те, кто особо с докером не работал. Повторюсь, Докер это не про контейнеры.
Докер, по моему мнению, это про стандарты. И там стандарты всего практически: стандарты сборки вашего приложения, стандарты установки вашего приложения.

И эта штука — мы ей пользовались и раньше, просто с приходом контейнеров это стало особо популярно — эта штука называется ENV (environment) переменные, то есть переменные окружения, которые есть в вашей операционной системе. Это вообще идеальный способ конфигурировать ваше приложение, потому что, если у вас есть приложения на JAVA, Python, Go, Perl не дай бог, и они все могут читать переменные database host, database user, database password, то идеально. У вас приложения на четырех разных языках конфигурируются в плане базы данных одним и тем же способом. Нет больше никаких разных конфигов.
Все можно сконфигурировать с помощью ENV переменных. Когда мы говорим про Kubernetes, там есть прекрасный способ объявлять ENV переменные прямо внутри Deployment. Соотвественно, если мы говорим про секретные данные, то секретные данные из ENV переменных (пароли к базам данных и т.д.), мы можем сразу запихать в секрет, создать секрет кластер и в описании ENV в Deployment указать, что мы не непосредственно объявляем значение этой переменной, а значение этой переменной database password будем читать из секрета. Это стандартное поведение Kubernetes. И это самый идеальный вариант конфигурировать ваши приложения. Просто на уровне кода, опять же к разработчикам это относится. Если вы DevOps, можно попросить: «Ребята, пожалуйста, научите ваше приложение читать переменные окружения. И будет нам счастье всем».
Если еще и все будут читать одинаково названные переменные окружения в компании, то это вообще шикарно. Чтобы не было такого, что одни ждут postgres database, другие database name, третьи database еще что-нибудь, четвертые dbn какой-нибудь там, чтобы, соответственно, единообразие было.
Проблема наступает, когда у вас переменных окружения становится так много, что просто открываешь Deployment — а там пятьсот строчек переменных окружения. В таком случае, переменные окружения вы уже просто переросли — и дальше уже не надо себя мучить. В таком случае, имело бы смысл начать пользоваться конфигами. То есть, обучить ваше приложение использовать конфиги.
Только вопрос в том, что конфиги – это не то, что вы думаете. Config.pi – это не тот конфиг, которым удобно пользоваться. Или какой-нибудь конфиг в вашем собственном формате, альтернативно одаренном – это тоже не тот конфиг, который я подразумеваю.
То, о чем я говорю, это конфигурация в приемлемых форматах, то есть, на сегодняшний день самым популярным стандартом является стандарт .yaml. Его понятно, как читать, он человекочитаемый, его понятно, как читать из приложения.
Соответственно, помимо YAML, можно еще, например, попользоваться JSON, парсить примерно так же удобно, как YAML в плане чтения оттуда конфигурации приложения. Читать людьми заметно неудобнее. Можно попробовать формат, а-ля ini. Его читать прям совсем удобно, с точки зрения человека, но его может быть неудобно автоматизированно обрабатывать, в том плане, если вы когда-то захотите генерить свои конфиги, вот ini формат уже может быть неудобно генерить.
Но в любом случае, какой бы формат вы ни выбрали, суть в том, что с точки зрения Kubernetes — это очень удобно. Вы весь свой конфиг можете положить внутри Kubernetes, в ConfigMap. И потом этот configmap взять и попросить внутри вашего пода замонтировать в какую-нибудь определенную директорию, где ваше приложение будет конфигурацию из этого configmap читать так, как будто бы это просто файлик. Это, собственно, то, что хорошо делать, когда у вас в приложении становится конфигурационных опций много. Или просто структура какая-нибудь сложная, вложенность есть.
Если у вас есть configmap, то очень прекрасно вы можете научить свое приложение, например, автоматически отслеживать изменения в файле, куда замонтирован configmap, и еще и автоматически релоадить ваше приложение при изменении конфигов. Это вообще идеальный вариант был бы.
Об этом я уже тоже, опять же, говорил — секретную информацию не в конфигмап, секретную информацию не в переменные, секретную информацию в секреты. Оттуда эту секретную информацию подключать в диплойменты. Обычно мы все описания кубернетовских объектов, диплойменты, конфигмапы, сервисы храним в git. Соответственно, запихивать пароль к базе данных в git, даже если это ваш git, который у вас внутренний в компании – плохая идея. Потому что, как минимум, git помнит все и удалить просто оттуда пароли не так просто.
Health check
------------
Следующий момент – это о такая штука, которая называется Health check. Вообще, Health check – это просто проверка того, что ваше приложение работает. При этом мы чаще всего говорим о неких веб-приложениях, у которых, соответственно, с точки зрения хэлсчека(лучше не переводить здесь и далее) это будет какой-нибудь специальный URL, который они обрабатывают стандартно, обычно делают `/health`.
При обращении на этот URL, соответственно, наше приложение говорит или «да, окей, у меня все хорошо 200» или «нет, у меня всё не хорошо, какой-нибудь 500». Соответственно, если у нас приложение не http, не веб-приложение, мы сейчас говорим какой-нибудь демон, мы можем придумать, как делать хэлсчеки. То есть, необязательно, если приложение не http, то все работает без хэлсчека и сделать это никак нельзя. Можно обновлять периодически информацию в файлике какую-нибудь, можно придумать к вашему daemon специальную какую-нибудь команду, типа, `daemon status`, которая будет говорить «да, все нормально, daemon работает, он живой».
Для чего это нужно? Первое самое очевидное, наверное, для чего нужен хэлсчек — для того, чтобы понимать, что приложение работает. То есть, просто тупо, когда оно сейчас поднято, оно выглядит как рабочее, чтобы точно быть уверенным, что оно работает. А то получается так, что под с приложением запущен, контейнер работает, инстенс работает, все нормально — а там пользователи уже оборвали все телефоны у техподдержки и говорят «вы что там, ..., заснули, ничего не работает».
Вот хэлсчек — это как раз-таки такой способ увидеть с точки зрения пользователя, что оно работает. Один из способов. Давайте говорить так. С точки зрения Kubernetes, это еще и способ понимать, когда приложение запускается, потому что мы понимаем, что есть разница между тем, когда запустился контейнер, создался и стартанул и когда непосредственно в этом контейнере запустилось приложение. Потому что если мы возьмем какое-нибудь среднестатистическое java-приложение и попробуем его запустить в доке, то секунд сорок, а то и минуту, а то и десять, оно может прекрасно стартовать. При этом можно хоть обстучаться в его порты, оно там не ответит, то есть оно еще не готово принимать трафик.
Опять же, с помощью хэлсчека и с помощью того, что мы обращаемся сюда, мы можем понимать в Kubernetes, что в приложении не просто контейнер поднялся, а прям приложение стартануло, оно на хэлсчек уже отвечает, значит туда можно запускать трафик.

То, о чем я говорю сейчас, называется Readiness/Liveness пробы в рамках Kubernetes, соответственно, readiness пробы у нас как раз-таки отвечают за доступность приложения в балансировке. То есть если readiness пробы выполняются в приложении, то значит все окей, на приложение идет клиентский трафик. Если readiness пробы не выполняются, то приложение просто не участвует, конкретно этот instance, не участвует в балансировке, оно убирается с балансировки, клиентский трафик не идет. Соответственно, Liveness пробы в рамках Kubernetes нужны для того, чтобы в случае, если приложение «залипло», его «рестартануть». Если liveness проба не работает у приложения, которое объявлено в Kubernetes, то приложение не просто убирается с балансировки, оно именно рестартится.
И тут такой важный момент, о котором хотелось бы сказать, с точки зрения практики, обычно все-таки чаще используется и чаще нужна readiness проба, чем liveness проба. То есть просто бездумно объявлять и readiness, и liveness пробы, потому что Kubernetes так умеет, а давайте использовать всё, что он умеет – не очень хорошая идея. Объясню почему. Потому что есть пунктик номер два в пробах – это о том, что неплохо было бы проверять нижележащий сервис в ваших хэлсчеках. Это значит, что если у вас есть веб-приложение, отдающее какую-то информацию, которую в свою очередь оно, естественно, должно где-то взять. В базе данных, например. Ну, и сохраняет в эту же базу данных информацию, которая в это REST API поступает. То соответственно, если у вас хэлсчек отвечает просто типа обратились на слешхэлс, приложение говорит «200, окей, все хорошо», а при этом у вас у приложения база данных недоступна, а приложение на хэлсчек говорит «200, окей, все хорошо» — это плохой хэлсчек. Так не должно работать.
То есть, ваше приложение, когда к нему приходит запрос на `/health`, оно не просто отвечает, «200, ок», оно сначала сначала идет, например, в базу данных, пробует подключиться к ней, делает там что-нибудь совсем элементарное, типа селект один, просто проверяет, что в базе данных коннект есть и в базу данных можно выполнить запрос. Если это все прошло успешно, то отвечает «200, ок». Если не прошло успешно, то говорит, что ошибка, база данных недоступна.
Поэтому, в связи с этим, опять же возвращаюсь к Readiness/Liveness пробам — почему readiness проба скорее всего вам нужна, а liveness проба под вопросом. Потому что, если вы будете описывать хэлсчеки именно так, как я сейчас сказал, то получится у нас недоступна в части instance`в или со всех instance`в база данных, к примеру. Когда у вас объявлена readiness проба, у нас хэлсчеки начали фэйлиться, и приложения соответственно все, с которых недоступна база данных, они выключаются просто из балансировки и фактически «висят» просто в запущенном состоянии и ждут, пока у них базы данных заработают.
Если у нас объявлена liveness проба, то представьте, у нас сломалась база данных, а у вас в Kubernetes половина всего начинает рестартовать, потому что liveness-проба падает. Это значит, нужно рестартовать. Это совсем не то, что вы хотите, у меня даже был в практике личный опыт. У нас было приложение, которое было чатом и которое было написано в JS и входило в базу данных Mongo. И была как раз-таки проблема в том, что это было на заре моей работы с Kubernetes, мы описывали readiness, liveness пробы по принципу того, что Kubernetes умеет — значит будем использовать. Соответственно, в какой-то момент Mongo немножко «затупила» и проба начала фэйлиться. Соответственно, по ливнесс пробе поды начали «убиваться».
Как вы понимаете, они когда «убиваются», это чат, то есть, к нему висят куча соединений от клиентов. Они тоже «убиваются» — нет не клиенты, только соединения — все не одновременно и из-за того, что не одновременно убиваются, кто-то раньше, кто-то позже, они не одновременно стартуют. Плюс стандартный рандом, мы не можем предсказать с точностью до миллисекунды время старта каждый раз приложения, поэтому они это делают по одному instance. Один инфоспот поднимается, добавляется в балансировку, все клиенты приходят туда, он не выдерживает такой нагрузки, потому что он один, а их там работает, грубо говоря, десяток, и падает. Поднимается следующий, на него вся нагрузка, он тоже падает. Ну, и каскадом просто продолжаются эти падения. В итоге чем это решилось – просто пришлось прям жестко остановить трафик пользователей на это приложение, дать всем instance подняться и после этого разом запустить весь трафик пользователей для того, чтобы он уже распределился на все десять instances.
Не будь бы это liveness проба объявленной, которая заставила бы это все рестартовать, приложение бы отлично с этим справилось. Но у нас отключается все из балансировки, потому что базы данных недоступны и все пользователи «отвалились». Потом, когда эта база данных стала доступна, все включается в балансировку, но приложениям не нужно заново стартовать, не нужно тратить на это время и ресурсы. Они все уже здесь, они готовы к трафику, соответственно, просто открывается трафик, все отлично – приложение на месте, все продолжает работать.
Поэтому, readiness и liveness пробы это разное, даже более того, можно теоретически делать разные хэлсчеки, один типа рэди, один типа лив, например, и проверять разные вещи. На readiness пробах проверять бэкенды ваши. А на liveness пробе, например, не проверять, с точки зрения того, что liveness пробы это вообще просто приложение отвечает, если вообще оно в состоянии ответить.
Потому что liveness проба по большому счету это когда мы «залипли». Бесконечный цикл начался или еще что-нибудь — и больше запросы не обрабатываются. Поэтому имеет смысл даже их разделять — и разную логику в них реализовывать.
По поводу того, чем нужно отвечать, когда у вас происходит проба, когда вы делаете хэлсчеки. Просто это боль на самом деле. Те, кто знаком с этим, наверное, будут смеяться — но серьезно, я видел сервисы в своей жизни, которые в ответ на запросы в стопроцентных случаях отвечают «200». То есть, который успешен. Но при этом в теле ответа они пишут «ошибка такая-то».
То есть статус ответа вам приходит — все успешно. Но при этом вы должны пропарсить тело, потому что в теле написано «извините, запрос завершился с ошибкой» и это прям реальность. Это я видел в реальной жизни.
И чтобы кому-то не было смешно, а кому-то очень больно, все-таки стоит придерживаться простого правила. В хэлсчеках, да и в принципе в работе с веб-приложениями.
Если все прошло успешно, то отвечайте двухсотым ответом. В принципе, любой двухсотый ответ устроит. Если вы очень хорошо читали рэгси и знаете, что одни статусы ответа отличаются от других, отвечайте подходящим: 204, 5, 10, 15, что угодно. Если не очень хорошо, то просто «два ноль ноль». Если все пошло плохо и хэлсчек не отвечает, то отвечаете любым пятисотым. Опять же, если вы понимаете, как нужно отвечать, чем отличаются разные статусы ответа друг от друга. Если не понимаете, то 502 – ваш вариант отвечать на хэлсчеки, если что-то пошло не так.
Такой еще момент, хочу немного вернуться по поводу проверки нижележащих сервисов. Если вы начнете, например, проверять все нижележащие сервисы, которые стоят за вашим приложением — вообще все. То у нас получается с точки зрения микросервисной архитектуры, у нас есть такое понятие, как «низкое зацепление» — то есть, когда ваши сервисы между собой минимально зависимы. В случае выхода одного из них из строя, все остальные без этого функционала просто продолжат работать. Просто часть функционала не работает. Соответственно, если вы все хэлсчеки завяжете друг на друга, то у вас получится, что в инфраструктуре упало что-то одно, а из-за того, что оно упало, все хэлсчеки всех сервисов тоже начинают фэйлиться — и инфраструктуры вообще всей микросервисной архитектуры больше нет. Там все вырубилось.
Поэтому я хочу повторить это еще раз, что проверять нижележащие сервисы нужно те, без которых ваше приложение в ста процентах случаях не может выполнять свою работу. То есть, логично, что если у вас REST API, через который пользователь сохраняет в базу или достает из базы, то в случае отсутствия базы данных, вы не можете работать гарантированно с вашими пользователями.
Но если у вас пользователи, когда вы их достаете из базы данных, дополнительно обогащаются еще какими-нибудь метаданными, еще из одного бэкенда, в который вы входите перед тем, как отдать ответ на фронтенд — и этот бэкенд недоступен, это значит, что вы отдадите ваш ответ без какой-то части метаданных.
Дальше у нас тоже одна из больных тем при запуске приложений.
На самом деле, это не только Kubernetes касается по большому счету, просто так совпало, что культура какая-то разработки массово и DevOps в частности начала распространяться примерно в то же время, что и Kubernetes. Поэтому по большому счету, что оказывается нужно корректно (graceful) завершать работу вашего приложения и без Kubernetes. И до Kubernetes люди так делали, но просто с приходом Kubernetes мы про это начали массово говорить.
Graceful Shutdown
-----------------
В общем, что такое Graceful Shutdown и вообще для чего это нужно. Это о том, что когда ваше приложение по какой-то причине завершает свою работу, вам нужно выполнить `app stop` — или вы получаете, например, сигнал операционной системы, ваше приложение его должно понимать и что-то с этим делать. Самый плохой вариант, конечно, это когда ваше приложение получает SIGTERM и такой типа «SIGTERM, висим дальше, работаем, ничего не делаем». Это прям откровенно плохой вариант.

Практически настолько же плохой вариант, это когда ваше приложение получает SIGTERM и такой типа «сказали же сегтерм, все значит завершаемся, не видел, не знаю никаких пользовательских запросов, не знаю что у меня там за запросы сейчас в работе, сказали SIGTERM, значит завершаемся». Это тоже плохой вариант.
А какой вариант хороший? Первым пунктом, учитываем завершение операций. Хороший вариант – это когда ваш сервер все-таки учитывает то, что он делает, если ему приходит SIGTERM.
SIGTERM – это мягкое завершение работы, оно специально такое, его можно перехватить на уровне кода, его можно обработать, сказать о том, что сейчас, подождите, мы сначала закончим ту работу, которая у нас есть, после этого завершимся.
С точки зрения Kubernetes, как это выглядит. Когда мы говорим поду, который работает в кластере Kubernetes, «пожалуйста, остановись, удались» или у рестарт нас происходит, или обновление, когда Kubernetes пересоздает поды — Kubernetes присылает в под сообщение как раз-таки SIGTERM, ждет какое-то время, причем, вот это время, которое он ждет, оно тоже конфигурируется, есть такой специальный параметр в диплойментах и он называется Graceful ShutdownTimeout. Как вы понимаете, неспроста он так называется и неспроста мы об этом сейчас говорим.
Там можно конкретно сказать, сколько нужно подождать между тем, когда мы послали в приложение SIGTERM и когда мы поймем, что приложение кажется от чего-то офигело или, «залипло» и не собирается завершаться — и нужно послать ему SIGKILL, то есть, жестко завершить его работу. То есть, соответственно, у нас работает какой-то демон, он обрабатывает операции. Мы понимаем, что в среднем у нас операции, над которыми работает демон, не длятся больше 30 секунд за раз. Соответственно, когда приходит SIGTERM, мы понимаем, что наш демон максимум может после SIGTERM дорабатывать 30 секунд. Мы его пишем, например, 45 секунд на всякий случай и говорим, что SIGTERM. После этого 45 секунд ждем. По идее, за это время демон должен был завершить свою работу и завершиться сам. Но если вдруг он не смог, значит, он, скорее всего, залип — он больше не обрабатывает наши запросы нормально. И его можно через 45 секунд смело, собственно, прибить.
Причем тут, на самом деле, даже 2 аспекта можно учитывать. Во-первых, понимать, что, если у вас запрос пришел, вы начали с ним как-то работать и не дали ответ пользователю, а вам пришел SIGTERM, например. То имеет смысл доработать и дать ответ пользователю. Это пункт номер раз в этом плане. Пункт номер два тут будет то, что если вы пишите свое приложение, вообще архитектуру строите таким образом, что у вас пришел запрос на ваше приложение, дальше вы запустили какую-то работу, файлики начали откуда-то качать, базу данных перекачивать и еще что-то. В общем, ваш пользователь, ваш запрос висит полчаса и ждет, пока вы ему ответите — то, скорее всего, вам нужно над архитектурой поработать. То есть просто учитывать даже здравый смысл, что если у вас операции короткие, то имеет смысл SIGTERM игнорировать и дорабатывать. Если у вас операции длинные, то не имеет смысла в данном случае игнорировать SIGTERM. Имеет смысл переработать архитектуру так, чтобы таких длинных операций избежать. Чтобы пользователи просто не висели, не ждали. Не знаю, сделать там какой-нибудь websocket, сделать обратные хуки, которые ваш сервер уже будет отправлять клиенту, что угодно другое, но не заставлять пользователя полчаса висеть и ждать просто сессию, пока вы ему ответите. Потому что непредсказуемо, где она может порваться.
Когда ваше приложение завершается, следует отдавать какой-нибудь адекватный exit-код. То есть если ваше приложение попросили закрыться, остановиться, и оно нормально само смогло остановиться, то не нужно возвращать какой-нибудь там типа exit-код 1,5,255 и так далее. Все что не нулевой код, по крайней мере, в Linux системах, я в этом точно уверен, считается неуспешным. То есть считается, что ваше приложение в таком случае завершилось с ошибкой. Соответственно, по-хорошему, если ваше приложение завершилось без ошибки, вы говорите 0 на выходе. Если ваше приложение завершилось с ошибкой по каким-то там поводам, вы говорите не 0 на выходе. И с этой с информацией можно работать.
И последний вариант. Плохо, когда у вас пользователь кидает запрос и полчаса висит, пока вы его обработаете. Но в целом еще хочется сказать о том, что вообще стоит со стороны клиента. Неважно у вас мобильное приложение, фронтенд и так далее. Необходимо учитывать, что вообще сессия пользователя может оборваться, может произойти, что угодно. Может быть запрос послан, например, недообработаться и не вернуться ответ. Ваш фронтенд или ваше мобильное приложение — вообще любой фронтенд, давайте говорить так — должны это учитывать. Если вы работаете с websocket`ами, это вообще самая страшная боль, которая была в моей практике.
Когда разработчики каких-нибудь очередных чатов не знают, что, оказывается, websocket может порваться. У них когда там элементарно на проксе что-нибудь происходит, мы просто конфиг меняем, и она делает reload. Естественно, все долгоживущие сессии рвутся при этом. К нам прибегают разработчики и говорят: «Ребята, вы чего, у нас там у всех клиентов чат поотваливался!». Мы им говорим: «Вы чего? Ваши клиенты не могут переподключаться?». Они говорят: «Нет, нам надо, чтобы сессии не рвались». Короче говоря, это бред на самом деле. Нужно учитывать сторону клиента. Особенно, я же говорю, с долгоживущими сессиями типа websocket, что она может порваться и незаметно для пользователя нужно уметь такие сессии переустановить. И тогда вообще все идеально.
Ресурсы
-------
Вообще, тут я давайте расскажу вам просто прям историю. Опять же из реальной жизни. Самую больную, которую я слышал про ресурсы.
Ресурсы в данном случае, я имею в виду, какие-то реквесты, лимиты, которые вы можете ставить на поды в ваших Kubernetes кластерах. Самое смешное, что я слышал от разработчика… Как-то один из коллег разработчиков на предыдущем месте работы сказал: «У меня приложение в кластере не запускается». Я посмотрел, что оно не запускается, а там оно то ли не влазило по ресурсам, то ли они очень маленькие лимиты поставили. Короче, приложение не может запуститься из-за ресурсов. Я говорю: «Из-за ресурсов не запускается, вы определитесь сколько вам нужно и поставьте адекватное значение». Он говорит: «Что за ресурсы?». Я ему начал объяснять, что вот Kubernetes, лимиты в реквестах и бла, бла, бла их нужно ставить. Человек слушал пять минут, кивал и говорит: «Я пришел сюда работать разработчиком, не хочу знать ничего ни про какие ресурсы. Я пришел типо сюда писать код и все». Это грустно. Это очень грустная концепция с точки зрения разработчика. Особенно в современном мире, так сказать, прогрессирующего девопса.
Для чего вообще нужны ресурсы? Ресурсы в Kubernetes бывают 2 типов. Одни называются реквестами, вторые – лимитами. Под ресурсами мы будем понимать, в основном всегда всего два ограничения базовых. То есть ограничения по процессорному времени и ограничения по оперативной памяти для контейнера, который запущен в Kubernetes.
Лимит ограничивает верхнюю границу для использования ресурса в вашем приложении. То есть, соответственно, если вы говорите 1Гб ОП в лимитах, то больше 1Гб ОП ваше приложение использовать не сможет. А если вдруг захочет и попытается это сделать, то придет процесс, который называется oom killer, out of memory то есть, и убьет ваше приложение — то есть оно просто рестартанет. По CPU приложения не рестартятся. По CPU, если приложение пытается использовать сильно много, больше, чем указано в лимитах, CPU будет просто жёстко отбираться. К рестартам это не приводит. Это вот лимит – это верхняя граница.
А есть реквест. Реквест – это то, благодаря чему Kubernetes понимает, как ноды в вашем кластере Kubernetes заполнены приложениями. То есть реквест – это такой некий commit вашего приложения. Оно говорит, что я хочу использовать: «Я хотело бы, чтобы ты под меня зарезервировал вот столько CPU и вот столько памяти». Такая простая аналогия. Что если у нас есть node, которой всего доступно, не знаю, 8 CPU. И туда приезжает под, у которого в реквестах написано 1 CPU, значит у нода осталось 7 CPU. То есть, соответственно, как только на эту ноду приедет 8 подов, у которых у каждого в реквестах стоит под 1 цпу — на ноде, как бы с точки зрения Kubernetes, CPU кончилось и больше подов с реквестами на эту ноду запустить нельзя. Если на всех нодах CPU кончится, то Kubernetes начнет говорить, что в кластере нет подходящих нод, для того чтобы запустить ваши поды, потому что кончилось CPU.
Для чего нужны реквесты и почему без реквестов, я думаю, что в Kubernetes запускать ничего не нужно? Давайте представим, себе гипотетическую ситуацию. Вы запускаете без реквестов ваше приложениие, Kubernetes не знает, сколько у вас чего, на какие ноды можно запихивать. Ну и пихает, пихает, пихает на ноды. В какой-то момент у вас на ваше приложение начнет приходить трафик. И одно из приложений начинает внезапно вдруг использовать ресурсы до лимитов, которые по лимитам у него есть. Оказывается, что рядом еще одно приложение и ему тоже нужны ресурсы. На ноде начинает реально физически кончаться ресурсы, например, ОП. На ноде начинают реально физически кончаться ресурсы, например, оперативная память (ОП). Когда у ноды кончается ОП, у вас перестанут отвечать в первую очередь докер, потом кублет, потом ОС. Они просто уйдут в несознанку и работать у вас ВСЕ перестанет точно. То есть это приведет к тому, что у вас залипнет нода, и ее нужно будет рестартануть. Короче, ситуация не очень хорошая.
А когда у вас реквесты, лимиты еще не очень сильно отличаются, хотя бы не в разы лимитов больше или реквестов, то у вас может быть такое нормальное рациональное заполнение приложений по нодам кластеров Kubernetes. При этом Kubernetes примерно в курсе, сколько чего он куда положил, сколько где чего используется. То есть это просто такой момент. Его важно понимать. И важно контролировать, что это проставляется.
Хранение данных
---------------
Следующий пунктик у нас это про хранение данных. Что с ними делать и вообще, как быть с persistence в Kubernetes?
Я думаю, опять же у нас, в рамках [Вечерней Школы](http://to.slurm.io/53txdA), тема про базу данных в Kubernetes была. И мне кажется, что я даже примерно знаю, что сказали вам коллеги на вопрос: «Можно ли запускать в Kubernetes базу данных?». Мне почему-то, кажется, что коллеги вам должны были сказать, что, если вы задаете вопрос, можно ли в Kubernetes запускать базу данных, значит нельзя.
Тут логика простая. На всякий случай еще раз поясню, если вы прям крутой чувак, который может построить достаточно отказоустойчивую систему распределенного сетевого хранения, понять, как подтянуть под это дело базу данных, как вообще cloud native в контейнерах должны в базе данных работать. Скорее всего, у вас нет вопроса, как это запускать. Если у вас такой вопрос есть, и вы хотите сделать так, чтобы это все развернулось и стояло прям насмерть в продакшене и никогда не падало, то такого не бывает. Вот прям прострелите себе ногу гарантировано при таком подходе. Поэтому лучше не надо.
Что делать с данными, которые наше приложение хотело бы хранить, какие-нибудь картинки, которые загружают пользователи, какие-нибудь штуки, которые в процессе работы генерирует наше приложение, при старте, например? Что с ними в Kubernetes делать?
Вообще в идеале, да, конечно, Kubernetes очень хорошо предусмотрен и вообще изначально задумывался под stateless приложения. То есть под те приложения, которые вообще не хранят информацию. Это идеальный вариант.
Но, естественно, идеальный вариант, он как бы существует далеко не всегда. Поэтому ну что? Пункт первый и самый простой – возьмите какой-нибудь S3, только не самопальное, которое тоже непонятно как работает, а от какого-нибудь провайдера. Хорошего нормального провайдера — и научите ваше приложение пользоваться S3. То есть когда у вас пользователь хочет загрузить файлик, скажите «вот сюда, пожалуйста, в S3 его загрузи». Когда он захочет его получить, скажите: «Вот тебе ссылочка на S3 бэк и вот отсюда его возьми». Это идеальный вариант.
Если вдруг по каким-то причинам такой идеальный вариант не подходит, у вас приложение, которое не вы пишите, не вы разрабатываете, или оно какое-нибудь жуткое легаси, оно не может по S3 протоколу, но должно работать с локальными директориями в локальных папочках. Возьмите что-нибудь более-менее простое, разверните это дело Kubernetes. То есть сразу городить Ceph под какие-то минимальные задачи, мне кажется, идея плохая. Потому что Ceph, конечно, хорошо и модно. Но если вы не очень понимаете, что делаете, то сложив что-то на Ceph, можно очень легко и просто это оттуда потом больше никогда не достать. Потому что, как известно, Ceph хранит данные у себя в кластере в бинарном виде, а не в виде простых файликов. Поэтому если вдруг кластер Ceph сломается, то есть полная и большая вероятность оттуда данные свои больше никогда не достать.
У нас будет курс по Ceph, можете [ознакомиться с программой и оставить заявку](http://to.slurm.io/hxLz1Q).
Потому лучше что-нибудь простое типа на NFS сервера. Kubernetes умеет с ними работать, вы можете подмонтировать директорию под NFS сервер — ваше приложение просто как локальную директорию. При этом, естественно, нужно понимать, что опять же, с вашим NFS нужно что-то делать, нужно понимать, что иногда, возможно, оно станет недоступным и предусмотреть вопрос, что вы будете делать в таком случае. Возможно, его стоит бэкапить куда-то на отдельный машину.
Следующий момент, о котором я говорил, это что делать, если в процессе работы ваше приложение генерирует какие-нибудь файлики. К примеру, оно, запускаясь, генерирует какой-нибудь статический файлик, который основан на какой-нибудь информации, которое приложение получает только в момент запуска. Тут какой момент. Если таких данных немного, то можно вообще не заморачиваться, просто под себя это приложение положить и работать. Только тут вопрос какой, смотрите. Очень часто легаси всякие системы, типа вордпресса и прочее, особенно с доработанными хитроумными какими-нибудь плагинами, хитроумными пхп-разработчиками, они часто умеют делать так, что они генерят какой-нибудь файлик под себя. Соответственно, один генерирует один файлик, второй генерит второй файлик. Они разные. Балансировка происходит в кластере Kubernetes клиентов просто случайно. Соответственно, вместе получается в instance работать не умеют. Один отдает одну информацию, другой отдает пользователю другую информацию. Вот такого стоит избегать. То есть в Kubernetes все, что вы запускаете, гарантировано должно уметь работать в несколько instances. Потому что Kubernetes штука подвижная. Соответственно, подвинуть он может что угодно, когда угодно, ни у кого не спрашивая в целом. Поэтому на это нужно рассчитывать. Все запущенное в один instance рано или поздно когда-нибудь упадет. Чем больше, соответственно, у вас резервирования, тем лучше. Но опять же, я говорю, если у вас таких файликов немного, то их можно прям под себя положить, они небольшой объем весят. Если их становится чуть больше, внутрь контейнера их, наверное, пихать не стоит.
Я бы посоветовал, есть в Kubernetes такая прекрасная штука, вы можете использовать volume. В частности, есть volume типа empty dir. То есть это просто Kubernetes автоматически на том сервере, где вы запустились, создаст директорию у себя в служебных директориях. И даст вам ее, чтобы вы ей пользовались. Тут только один важный момент. То есть ваши данные будут храниться не внутри контейнера, а как бы на хосте, на котором вы запущены. Kubernetes более того такие empty dirs при нормальной настройке умеет контролировать и умеет контролировать их максимальный размер и не давать его превышать. Единственный момент то, что у вас записано в empty dir, при рестартах пода не теряется. То есть если ваш под по ошибке упадет и поднимется снова, информация в empty dir никуда не денется. Под ею снова при новом старте может воспользоваться — и это хорошо. Если ваш под куда-то уедет, то естественно, он уедет без данных. То есть, как только под с нода, где он был запущен с empty dir, пропадает, empty dir удаляется.
Чем еще хорош empty dir? Например, им можно пользоваться как кэшем. Давайте представим, что у нас приложение генеририт что-то на лету, отдает пользователям и это делает долго. Поэтому приложение, например, генерит и отдает пользователям, и заодно складывает под себя куда-нибудь, чтобы в следующий раз, когда пользователь за тем же самым придет, отдать это сразу сгенерированное быстрее. Empty dir можно попросить Kubernetes создать в памяти. И таким образом, у вас кэши вообще могут просто молниеносно работать — в плане скорости обращения к диску. То есть у вас empty dir в памяти, в ОС он хранится в памяти, а при этом для вас, для пользователя внутри пода это выглядит, как просто локальная директория. Вам не нужно приложение специально учить какой-то магии. Вы просто прям берете и кладете в директорию ваш файлик, но, на самом деле, в память на ОС. Это тоже очень удобная фишка в плане Kubernetes.
Какие проблемы у Minio существуют? Главная проблема Minio – это в том, что для того, чтобы эта штука работала, ей нужно где-то быть запущенной, и по ней должна быть какая-нибудь файловая система, то есть хранилище. А тут мы встречаемся с теми же самыми проблемами, которые есть у Ceph. То есть Minio где-то должно хранить свои файлы. Оно просто HTTP интерфейс к вашим файлам. Причем с функционалом явно победнее, чем у амазоновской S3. Раньше оно не умело нормально авторизовывать пользователя. Сейчас оно, насколько я знаю, оно уже умеет делать buckets с разной авторизацией, но опять же, мне кажется, главная проблема – это, так сказать, нижележащая система хранения под минимум.
Empty dir в памяти как влияет на лимиты? Никак не влияет на лимиты. Он лежит в памяти, получается, хоста, а не в памяти вашего контейнера. То есть ваш контейнер не видит empty dir в памяти, как часть занятой своей памяти. Это видит хост. Соответственно, да, с точки зрения kubernetes, когда вы начинаете такое использовать, хорошо бы понимать, что вы часть своей памяти отдаете под empty dir. И соответственно, понимать, что память может кончиться не только из-за приложений, но и из-за того, кто-то в эти empty dir пишет.
Cloudnativeness
---------------
И заключительная подтема, что такое Cloudnative. Зачем оно нужно. Cloudnativeness и так далее.
То есть те приложения, которые умеют и написаны для того, чтобы работать в современной облачной инфраструктуре. Но, на самом деле, у Cloudnative есть еще один такой аспект. Что это не только приложение, которое учитывает все требования современной облачной инфраструктуры, но и умеет с этой современной облачной инфраструктурой работать, использовать плюсы и преимущества того, что оно в этих облаках работает. Не просто перебарывать себя и работать в облаках, а прям использовать плюсы от того, что вы работаете в облаке.

Давайте возьмем для примера просто Kubernetes. У вас приложение запущено в Kubernetes. У вас всегда ваше приложение может, точнее админы для вашего приложения, всегда могут сделать сервис-аккаунт. То есть учетку для авторизации в самом Kubernetes в его сервере. Накрутить туда какие-нибудь права, которые нам нужны. И вы можете обращаться в Kubernetes из вашего приложения. Что таким образом можно делать? Например, из приложения получать данные о том, где находятся другие ваши приложения, другие такие же инстансы и вместе как-нибудь кластеризоваться поверх Kubernetes, если такая необходимость есть.
Опять же, недавно буквально у нас был кейс. У нас есть один контролер, который занимается тем, что мониторит очередь. И когда в этой очереди появляются какие-то новые задачи, он идет в Kubernetes — и внутри Kubernetes создает новый под. Дает этому поду какую-то новую задачу и в рамках этого пода, под выполняет задачу, отправляет ответ в сам контролер, и контролер потом с этой информацией что-то делает. Базу данных, к примеру, складывает. То есть это опять же плюс того, что наше приложение работает в Kubernetes. Мы можем использовать сам встроенный функционал Kubernetes для того, чтобы как-то расширить и сделать более удобным функционал нашего приложения. То есть не городить какую-то магию того, как запускать приложение, как запускать воркер. В Kubernetes просто закинуть запрос в аппе, если приложение написано на питоне.
То же самое касается, если мы выйдем за пределы Kubernetes. У нас где-то наш Kubernetes запущен — хорошо, если в каком-то облаке. Опять же, мы можем использовать, и даже должны, я считаю, использовать возможности самого облака, где мы запущены. Из элементарного, что нам облако предоставляет. Балансировка, то есть мы можем создавать балансировщики облачные, их использовать. Это прям преимущество того, чем мы можем пользоваться. Потому что облачная балансировка, во-первых, просто тупо снимает ответственность с нас за то, как оно работает, как оно настраивается. Плюс очень удобно, потому что обычный Kubernetes с облаками умеет интегрироваться.
Тоже самое касается масштабирования. Обычный Kubernetes умеет интегрироваться с облачными провайдерами. Умеет понимать, что если в кластере закончились ноды, то есть место нода закончилось, то нужно добавить — сам Kubernetes добавит вам новых нод в свой кластер и начнет на них запускать поды. То есть когда у вас нагрузка приходит, у вас подов начинает количество увеличиваться. Когда ноды в кластере заканчиваются для этих подов, то Kubernetes запускает новые ноды и, соответственно, количество подов еще может увеличиваться. И это очень удобно. Это прям возможность на лету масштабировать кластер. Не очень быстро, в плане того, что это не секунда, это скорее минута, для того чтобы добавлять новые ноды.
Но из моего опять же опыта, самое такое клевое, что я видел. Когда на основе времени суток кластер Cloudnative скейлился. Это был такой бэкенд сервис, которым пользовались люди в бэкофисе. То есть они приходят на работу в 9 утра, начинают заходить в систему, соответственно, кластер Cloudnative, где это все запущено, начинает пухнуть, запускать новые поды, для того чтобы все, кто пришел на работу, могли с приложением работать. Когда они в 8 вечера или в 6 вечера уходят с работы, кластеры Kubernetes замечают, что больше никто не пользуется приложением и начинают уменьшаться. Экономия прям процентов 30 гарантированная. Это тогда работало в Амазоне, в России на тот момент не было вообще никого, кто бы так круто умел делать.
Я прям говорю, экономия процентов 30 просто из-за того, что мы пользуемся Kubernetes, пользуемся возможностями облака. Сейчас такое можно делать в России. Я не буду никого рекламировать, конечно, но скажем так, есть провайдеры, которые такое умеют делать, предоставлять прямо с коробки по кнопке.
Последний момент, на который тоже хочу обратить внимание. Для того, чтобы ваше приложение, ваша инфраструктура была Cloudnative, имеет смысл уже начать наконец-то адаптировать подход, который называется Infrastructure as a Code.То есть это о том, что ваше приложение, точнее вашу инфраструктуру нужно точно так же, как и код вашего приложения, вашей бизнес логики описывать в виде кода. И работать с ним как с кодом, то есть его тестировать, раскатывать, хранить в git, CI\CD к нему применять.
И это прям то, что позволяет вам, во-первых, всегда иметь контроль над вашей инфраструктурой, всегда понимать в каком она состоянии. Во-вторых, избегать ручных операций, которые вызывают ошибки. В-третьих, избегать просто того, что называется текучкой, когда вам постоянно нужно выполнять одни и те же ручные операции. В-четвертых, это позволяет гораздо быстрее восстанавливаться в случае сбоя. Вот в России каждый раз, когда я об этом говорю, находятся обязательно огромное количество человек, которые говорят: «Ага, понятно, да у вас подходы, короче, ничего чинить не надо». Но это правда. Если у вас что-то сломалось в инфраструктуре, то с точки зрения Cloudnative подхода и с точки зрения Infrastructure as a Code, чем это починить, пойти на сервер, разобраться, что сломалось и починить, проще сервер удалить и создать заново. И у меня все это восстановится.
Более подробно все эти вопросы рассматриваются на [видеокурсах по Kubernetes: Джуниор, Базовый, Мега](http://to.slurm.io/Lkn6kg). По ссылке вы можете ознакомиться с программой и условиями. Удобно то, что можете освоить Kubernetes, занимаясь из дома или с работы по 1-2 часа в день. | https://habr.com/ru/post/513886/ | null | ru | null |
# Тестируем не совсем реальный (или совсем нереальный) мониторинг от New Relic и Appdynamics
Привет, хабранарод! Почему совсем нереальный? Да потому что мониторинг имитирует действия реальных пользователей, но выполняется по специальному алгоритму из заданных локаций. Сами вендоры называют этот механизм Synthetics, поэтому дальше в статье будем стараться придерживаться именно такой терминологии – синтетический мониторинг.
New Relic и Appdynamics – прямые конкуренты, являются лидерами [квадранта Gartner](https://www.gartner.com/doc/reprints?id=1-2UCRVMU&ct=151217&st=sb) и реализуют достаточно схожий функционал. У обоих вендоров есть возможность мониторинга транзакций в приложениях, они умеют выполнять проверки на стороне браузера конечного пользователя, умеют встраиваться в мобильные приложения и, наконец, обладают одной из ключевых возможностей современного мониторинга – умеют выполнять алгоритмизированные действия в веб-интерфейсе приложения.
В предыдущих статьях по [основным принципам мониторинга бизнес-приложений](https://habrahabr.ru/company/jetinfosystems/blog/243991/) и [расширению функционала Zabbix](https://habrahabr.ru/company/jetinfosystems/blog/311640/) мы уже касались синтетического мониторинга и, нужно сказать, если ваш бизнес растет и веб-приложение обслуживает большое количество клиентов, Synthetics для вас must have. Либо он есть, либо будет. Вы же не хотите жалоб от клиентов (а в худшем случае – отказа от использования вашего сервиса), правда?

Как известно, ключевым отличием двух вендоров является наличие on-premise версии у Appdynamics (New Reliс работает только из облака). Но в случае с Synthetics все переворачивается с ног на голову. Appdynamics может выполнять алгоритмы проверки только из облака: на выбор разные континенты, разумеется, кроме Антарктиды (смотрите метки на карте). Небольшое примечание: это может показаться костылем, но Appdynamics предлагает использовать для мониторинга внутренних ресурсов три специальные точки наблюдения со статичными IP-адресами.

А вот с New Relic вы можете развернуть точку наблюдения как в облаке, так и у себя локально на полярной станции и проверять закрытые корпоративные ресурсы (например, заводить кредитные заявки в CRM):
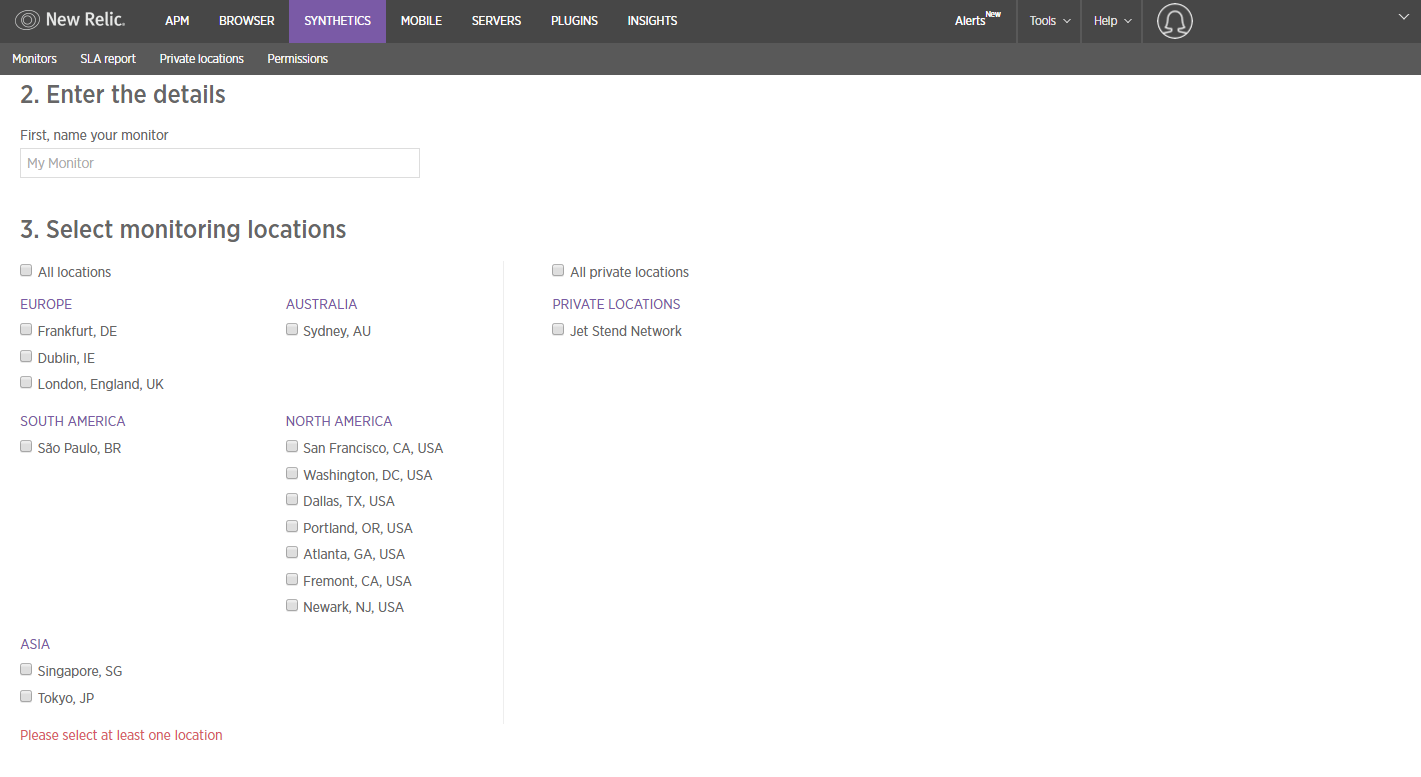
Следующим отличием двух решений является используемый язык для алгоритмизации. Если в [NewRelic это JavaScript](https://github.com/seleniumhq/selenium-google-code-issue-archive), который выполняет эмуляцию браузера Google Chrome на базе Selenium, то в [Appdynamics это Python](http://selenium-python.readthedocs.io/getting-started.html) также основанный на Selenium, но браузер можно выбрать из распространенных. И тут стоит добавить небольшой нюанс: оба решения используют Webdriver, но параметры этой штуки (user-agent, разрешение экрана и прочее) позволяет настраивать только New Relic, в Appdynamics используются параметры по умолчанию.
New Relic по умолчанию игнорирует [системы аналитики](http://pgl.yoyo.org/adservers/serverlist.php?hostformat=nohtml&showintro=0), поэтому если нужно что-то включить, используйте следующий алгоритм:
**Обход аналитики**
```
//Allow Google Analytics scripts to run
$browser.addHostnameToWhitelist(hostnameArr: ['google-analytics.com']);
//Visit https://docs.newrelic.com
$browser.get('https://docs.newrelic.com');
```
В Appdynamics такого функционала из коробки нет, но в случае необходимости его возможно реализовать внутри вашего скрипта.
После каждого шага транзакции Appdynamics сохраняет скриншот веб-страницы. New Relic сохраняет только последний экран. На просторах интернета нашелся один японский способ, который будет актуален для обоих решений. Умелец из страны восходящего солнца [описывает способ загрузки файлов на Google Drive через API](http://masashi-k.blogspot.ru/2013/08/upload-image-file-to-google-drive.html).
В Appdynamics есть возможность использовать только стандартные библиотеки Python. New Relic позволяет использовать также [популярные модули Node.js](https://docs.newrelic.com/docs/synthetics/new-relic-synthetics/scripting-monitors/import-nodejs-modules).
И основные выжимки в табличном виде:
| | | |
| --- | --- | --- |
| **Особенность** | **New Relic** | **Appdynamics** |
| Синтетический мониторинг из облака | да | да |
| Произвольный выбор точки наблюдения | да | нет |
| Язык алгоритмизации | JavaScript | Python |
| Настройка Webdriver | да | нет |
| Коробочное игнорирование систем аналитики | да | нет |
| Сохранение скриншотов экрана после каждого шага транзакции | нет | да |
| Возможности расширения алгоритмов с помощью внешних библиотек/модулей | да | нет |
Конечно, систем транзакционного мониторинга на рынке вагон и маленькая тележка и определить, какая подойдет именно вам, может оказаться не так-то просто. Кроме систем по работе с вебом, существуют также те, которые умеют запускать толстые клиенты, проводить OCR-анализ интерфейса и выдавать прочие радости.
Пожалуйста, обращайтесь с вопросами в комментариях. А если задача требует чуть более вдумчивого подхода, [наш консалтинг он, как светлое будущее,](http://www.jet.msk.su/services/upravlenie-it-uslugami-i-it-infrastrukturoy/) – совсем не за горами.
Автор статьи: **Антон Касимов**, архитектор систем управления | https://habr.com/ru/post/313210/ | null | ru | null |
# Nhibernate: Варианты маппингов, варианты запросов
В этой статье я решил собрать воедино всю ту информацию, к которой я регулярно обращаюсь, роясь в интернете либо в коде. Это маппинги и связи в NHibernate. Этакая статья-памятка будет. Я решил её слишком сильно не перегружать, (к примеру про NHibernate Queries я написал очень мало), и поэтому в каждом заголовке будет ссылка на статью (на английском), на которую я опирался, создавая статью-памятку. Надеюсь, она будет полезна и вам.
Я буду приводить примеры для ASP.NET MVC 4 и SQL Server 2008 (кстати, к последнему мы будем обращаться очень редко, лишь проверять, как там сохранились наши данные, да строкой подключения упомним). Постараюсь писать конкретно и емко, а если будут непонятные моменты, прошу на статью [Уроки по FluentNHibernate c ASP.NET MVC и SQL Server. Часть 1](http://habrahabr.ru/post/264907/) где более подробно все описано. Итак, приступим, для начала, запускаем Visual Studio и:
1. Создаем новый проект *File->New->Project*.
2. Выберем ASP.NET MVC 4 (.Net Framework 4) и назовем его *NHibernateMVC*.
3. В папке *Models* создайте папку NHibernate
4. В *Package Manager Console* пропишем **install-package nhibernate** (приведенные ниже примеры работает и в FluentNhibernate, (проверено!): install-package Fluentnhibernate).
После того, как установили Nhibernate, возникает вопрос, по какому пути мы будем связывать (маппить) классы из приложения с таблицами из БД. NHibernate припас для нас аж три вида маппинга, такие как:
* XML. Создаем \*.hbm.xml маппинг-файл
* Attributes. Является дополнением (add-in) для xml-маппинга. Маппинг выглядит, как аттрибуты .NET
* Mapping by code. — вместо xml-файлов используются \*.cs ConfORM маппинг-классы
* Fluent. Создаем \*.cs fluent маппинг-классы
**Варианты маппингов.**
**1.XML — файлы**
Самый первый из разработанных маппингов.
Плюсы:
+ Есть множество примеров в интернете.
+ Все остальные способы (Attributes и Fluent) сводятся к получению этих xml файлов.
Минусы:
— Полностью отсутствует intellisense(!).
— Отсутствует валидация во время компиляции.
Ну что ж, давайте рассмотрим его.
После установки NHibernate, добавьте в папку Models->NHibernate файл Nhibernate.cfg.xml
```
xml version="1.0" encoding="utf-8" ?
NHibernate.Connection.DriverConnectionProvider
NHibernate.Driver.SqlClientDriver
Server=...\SQLENTERPRISE; database=NhibernateTutor; Integrated Security=SSPI;
NHibernate.Dialect.MsSql2008Dialect
```
Я работаю с SQL Server, поэтому выбрал SqlClientDriver. Если вы работаете с другой базой данных, то список NHibernate.Driver'ов можно посмотреть тут [NHibernate.Driver](http://www.nudoq.org/#!/Packages/NHibernate/NHibernate/NHibernate.Driver)
Так как у меня SQL Server 2008 стоит, я выбрал MsSql2008Dialect, все диалекты можно посмотреть тут [SQL Dialects](http://nhibernate.info/doc/nh/en/index.html#configuration-optional-dialects)
Создайте в SQL Server БД NhibernateTutor и пропишите строку подключения. В этой статье я не буду создавать таблицы, они будут генерироваться сами, NHibernate'ом.
Далее добавим в папку Models класс Book.cs
```
public class Book {
public virtual int Id { get; set; }
public virtual string Name { get; set; }
public virtual string Description { get; set; }
}
```
(P.S. Все его поля должы быть virtual – это требование необходимо для lazy load (ленивой загрузки) и для отслеживания NHibnerate’ом всех изменений в объектах.)
После того, как создали класс, пришло время создать для него маппинг. Для этого создадим в папке Models->NHibernate xml-файл — «Book.hbm.xml». (**Внимание!**.
1. Все маппинг файлы должны иметь расширение \*.hbm.xml.
2. Перейдите в свойства этого файла (правой кнопкой по Book.hbm.xml -> Properties), и в списке «Advanced» измените свойство *Build Action* на *Embedded Resource*. Тоже самое нужно будет проделать еще раз и для других \*.hbm.xml-файлов. Если же его не указать, то в строке configuration.AddAssembly(typeof(Book).Assembly); класса NhibernateHelper (который будет создан позже) будет ошибка, что невозможно для класса Book найти его маппинг файл.)
```
xml version="1.0" encoding="utf-8" ?
```
На что тут следует обратить внимание. Во-первых, assembly и namespace должен быть такой же, как и у класса Book. Id я сделал потому что мне не нравятся guid, и он сам определяет, какой из типов (identity, sequence или hilo) использовать, в зависимости от возможностей БД (у Sql Server это identity).
* Полный список генераторов здесь [IdGenerator](http://nhibernate.info/doc/nh/en/index.html#mapping-declaration-id-generator).
* Список свойств класса [Class](http://nhibernate.info/doc/nh/en/index.html#mapping-declaration-class).
* Список свойств Id можно прочитать здесь [Id](http://nhibernate.info/doc/nh/en/index.html#mapping-declaration-id).
* Список свойств Property [Property](http://nhibernate.info/doc/nh/en/index.html#mapping-declaration-property).
После того, как создали xml-маппинг, создадим в корневом каталоге класс NHibernateHelper.cs.
```
public class NHibernateHelper {
public static ISession OpenSession() {
var configuration = new Configuration();
var configurePath = HttpContext.Current.Server.MapPath(@"~\Models\Nhibernate\nhibernate.cfg.xml");
configuration.Configure(configurePath);
//Если бы не сделали Book.hbm.xml Embedded Resource, то он бы написал ошибку о невозможности найти файл
configuration.AddAssembly(typeof(Book).Assembly);
ISessionFactory sessionFactory = configuration.BuildSessionFactory();
//Позволяет Nhibernate самому создавать в БД таблицу и поля к ним.
new SchemaUpdate(configuration).Execute(true, true);
return sessionFactory.OpenSession();
}
}
```
Более подробная информация про настройку ISessionConfiguration здесь [ISessionFactory Configuration](http://nhibernate.info/doc/nh/en/index.html#session-configuration)
В конце всех этих операций, должны были быть созданы следующие файлы.

Давайте сейчас посмотрим, как NHibernate создаст в БД таблицу Book. Создадим в папке Controllers класс HomeController и напишем следующий код.
```
public ActionResult Index()
{
var session = NHibernateHelper.OpenSession();
return View();
}
```
Как будет выглядет View нас сейчас не интересует, пусть будет пустой. Запускаем приложения, заходим в БД SQL Server и (вуаля!) видим в БД NhibernateTutor таблицу Book. Там можно поменять типы данных по своему усмотрению (nvarchar(255) сделать nvarchar(MAX), но не int!). Пока не будем заполнять её данными, давайте вначале настроим связи (когда появится связь один-к-одному, будет вылетать ошибка о том, что таблице Mind не соответсвует таблица Book) или заполните данными а затем удалите.

Теперь перейдем к настройке отношений между таблицами.
**1.1 Отношения**
**Многие-ко-многим**
| Book.cs | Author.cs |
| --- | --- |
|
```
private ISet \_authors;
public virtual ISet Authors {
get {
return \_authors ?? (\_authors = new HashSet());
}
set { \_author = value; }
}
```
|
```
private ISet \_books;
public virtual ISet Books{
get {
return \_books?? (\_books= new HashSet());
}
set { \_books= value; }
}
```
|
| Book.hbm.xml | Author.hbm.xml |
|
```
...........................................
```
|
```
...........................................
```
|
Давайте разберем xml-маппинги этих классов. Начнем с тега set, он применяется для .NET ISet. Более подробную информацию, какие бывают теги для коллекций, можно прочитать здесь [Collection of Values](http://nhibernate.info/doc/nh/en/index.html#collections-ofvalues), а я ниже предоставлю таблицу коллекций и какие теги применяются к ним.
| .Net Collection | Mapping |
| --- | --- |
| IEnumerable/ICollection/IList | bag |
| IList with order | list |
| ISet | set |
| IDictionary | map |
* table=«Book\_Author» — аттрибут, создающий промежуточную таблицу Book\_Author, необходимую для отношения многие-ко-многим.
* name=«Books/Authors» — указывает на название коллекции
* cascade=«save-update» — указывает, что при сохранении и обновлении также сохраняются и обновляются связанные с ним таблицы. Виды cascade=«all|none|save-update|delete|all-delete-orphan», более подробно здесь [LifeCycles and object graphs](http://nhibernate.info/doc/nh/en/index.html#manipulatingdata-graphs)
* inverse=«true» означает, что противоположная таблица Book является родителем (несет ответственность за отношения) и будет обновлен. Более подробно можно узнать здесь [inverse true example](http://www.mkyong.com/hibernate/inverse-true-example-and-explanation/)
* key column=«BookId» — указывает что таблица Book будет связана с таблицей Book\_Author по ключу BookId
* many-to-many class=«Author» column=«AuthorId» — указывает, что таблица Book будет связана с таблицей Author по ключу «AuthorId»
**Многие-к-одному (один-ко-многим)**
| Book.cs | Series.cs |
| --- | --- |
|
```
public virtual Series Series { get; set; }
```
|
```
private IList \_books;
public virtual IList Books {
get {
return \_books ?? (\_books = new List());
}
set { \_books = value; }
}
```
|
| Book.hbm.xml | Series.hbm.xml |
|
```
```
|
```
```
|
Так, ну что тут можно сказать? Мы использовали тег «bag» так как у нас IList, column=«Series\_id» создает в таблице Book столбец Series\_Id, остальное было сказано выше.
**Один-к-Одному**
| Book.cs | Mind.cs |
| --- | --- |
|
```
private Mind _mind;
public virtual Mind Mind {
get { return _mind ?? (_mind = new Mind()); }
set { _mind = value; }
}
```
|
```
public virtual Book Book { get; set; }
```
|
| Book.hbm.xml | Mind.hbm.xml |
|
```
```
|
```
```
|
А вот тут уже интересно! constrained=«true» означает, что для каждой записи таблицы Book должна существовать запись в таблице Mind, то есть Id таблицы Book должен быть равен Id таблицы Mind. Если вы попытаетесь сохранить объект Book, забыв про таблицу Mind, то Nhibernate выдаст исключение, что он не может сохранить данные. То есть предварительно нужно создать объекту Book объект Mind. Постоянно создавать объект Mind очень утомительно, поэтому при создании объекта Book при сохранении у меня инициализирует объект Mind кодом ниже, а заполнить таблицу Mind я всегда успею.
```
private Mind _mind;
public virtual Mind Mind {
get { return _mind ?? (_mind = new Mind()); }
set { _mind = value; }
}
```
Cascade = «All» При сохранении, изменении, удалении таблицы Book также сохраняется, изменяется, удаляется таблица Mind. Итак, мы создали все связи, пора проверить их, сохранив, отредактировав или удалив данные. Подробная информация под спойлером ниже.
**Проверка работы маппингов: Операции CRUD**Давайте создадим тестовое приложение, которое будет сохранять данные в БД, обновлять и удалять их, изменив HomeController следующим образом (Ненужные участки кода комментируем):
```
public ActionResult Index()
{
using (ISession session = NHibernateHelper.OpenSession()) {
using (ITransaction transaction = session.BeginTransaction()) {
//Создать, добавить
var createBook = new Book();
createBook.Name = "Metro2033";
createBook.Description = "Постапокалипсическая мистика";
createBook.Authors.Add(new Author { Name = "Глуховский" });
createBook.Series = new Series { Name = "Метро" };
createBook.Mind = new Mind { MyMind = "Постапокалипсическая мистика" };
session.SaveOrUpdate(createBook);
//Обновить (По идентификатору)
var updateBook = session.Get(1);
updateBook.Name = "Metro2033";
updateBook.Description = "Постапокалипсическая мистика";
updateBook.Authors.ElementAt(0).Name = "Петров";
updateBook.Series.Name = "Метроном";
updateBook.Mind.MyMind = "11111";
session.SaveOrUpdate(updateBook);
//Удаление (По идентификатору)
var deleteBook = session.Get(1);
session.Delete(deleteBook);
transaction.Commit();
}
var criteria = session.CreateCriteria();
criteria.CreateAlias("Series", "series", JoinType.LeftOuterJoin);
criteria.CreateAlias("Authors", "author", JoinType.LeftOuterJoin);
criteria.CreateAlias("Mind", "mind", JoinType.LeftOuterJoin);
criteria.SetResultTransformer(new DistinctRootEntityResultTransformer());
var books = criteria.List();
return View(books);
}
}
```
и изменим представление следующим образом:
```
@model IEnumerable
@{ Layout = null; }
Index
th, td {
border: 1px solid;
}
@Html.ActionLink("Create New", "Create")
| @Html.DisplayNameFor(model => model.Name) | @Html.DisplayNameFor(model => model.Mind) | @Html.DisplayNameFor(model => model.Series) | @Html.DisplayNameFor(model => model.Authors) | Операции |
| --- | --- | --- | --- | --- |
@foreach (var item in Model) {
| @Html.DisplayFor(modelItem => item.Name) | @Html.DisplayFor(modelItem => item.Mind.MyMind) |
@{string strSeries = item.Series != null ? item.Series.Name : null;}
@Html.DisplayFor(modelItem => strSeries) |
@foreach (var author in item.Authors) {
string strAuthor = author != null ? author.Name : null;
@Html.DisplayFor(modelItem => strAuthor)
}
|
@Html.ActionLink("Edit", "Edit", new { id = item.Id }) |
@Html.ActionLink("Details", "Details", new { id = item.Id }) |
@Html.ActionLink("Delete", "Delete", new { id = item.Id })
|
}
```
Думаю, вы сами справитесь, создав соответсвующие поля для Author, Mind и Series. Проверив поочередно все операции, мы заметим, что:
* При операциях Create и Update обновляются все данные, связанные с таблицей Book (уберите Cascade=«save-update» или cascade=«all» и связанные данные не будут сохранены)
* При удалении удаляются данные из таблиц Book, Mind, Book\_Author, а остальные данные не удаляются, потому что у них Cascade=«save-update»
* При удалении удаляются данные из таблиц Book, Mind, Book\_Author, а остальные данные не удаляются, потому что у них Cascade=«save-update»
Далее для проверки связей в остальных вариантах маппингов можете использовать этот код, потому что *Criteria* работает и в Attributes и в Fluent'e. И не забудьте проверить ключи в БД, мало ли какую ошибку вы допустили, о которой узнаете в последствии. К примеру, таблица Book ссылается ключом на AuthorId таблицы Book\_Author, вместо ключа BookId.
**Подробную информацию можно прочесть здесь.**
[NHibernate Reference Documentation](http://nhibernate.info/doc/nh/en/index.html)
**2. АТРИБУТЫ**
Является Дополнением (add-in) к Nhibernate.
Плюсы:
+ Не нужно создавать отдельные файлы (\*.hbm.xml), пишите атрибуты сразу над полями класса, то есть сущности и маппинги находятся рядом.
+ Поддрежка Intellisense 50/50(!). Есть подсказки для написания аттрибутов (таких как Name), но нет для его свойств, которые представлены в виде строки.
+ Легко перейти с xml-файлов на Атрибуты.
Минусы:
— Ухудшается удобочитаемость кода.
— Отсутсвие валидации во время компиляции.
— У свойств, состоящих из более 1 атрибута следует прописывать индексы.
В интернете материалов по NHibernate.Mapping.Attributes мало, даже на сайте [nhibernate.info](http://nhibernate.info) ему отведена всего ОДНА глава(!) [NHibernate.Mapping.Attributes](http://nhibernate.info/doc/nhibernate-reference/mapping-attributes.html) и этому есть простое объяснение: он является дополнением (Add-in) к NHibernate, и поэтому фактически имеет такие же настройки, как Nhibernate \*.hbm.xml-файлы. Таким образом, вы используете Attributes вместо ~~nasty~~ \*.hbm.xml-файлов. Поэтому, если вы используете Атрибуты и у вас возникли проблемы, смело применяйте решения, которые применимы для \*.hbm.xml-файлов, благо синтаксис у них одинаков, разобраться не составит труда.
1. Прежде чем использовать аттрибуты, удалим вначале все маппинг (\*.hbm.xml) файлы, они нам больше не понадобятся. (**Nhibernate.cfg.xml** оставляем!)
2. Для работы с аттрибутами нам понадобится NHibernate.Mapping.Attribute.dll, устанавливаем его через *Package Manager Console*, где пропишем **Install-Package NHibernate.Mapping.Attributes** .
3. Изменим NHibernateHelper класс следующим образом
```
public class NHibernateHelper {
public static ISession OpenSession() {
var configuration = new Configuration();
var configurePath = HttpContext.Current.Server.MapPath(@"~\Models\Nhibernate\nhibernate.cfg.xml");
configuration.Configure(configurePath);
//configuration.AddAssembly(typeof(Book).Assembly); заменяем вот на этот код\\
HbmSerializer.Default.Validate = true;
var stream = HbmSerializer.Default.Serialize(Assembly.GetAssembly(typeof(Book)));
configuration.AddInputStream(stream);
//*****************************************************************************************************\\
ISessionFactory sessionFactory = configuration.BuildSessionFactory();
//Позволяет Nhibernate самому создавать в БД таблицу и поля к ним.
new SchemaUpdate(configuration).Execute(true, true);
return sessionFactory.OpenSession();
}
}
```
* configurePath -Указываеn путь к конфигурации файла Nhibernate
* HbmSerializer.Default.Validate — включает или отключает проверку генерируемых xml-потоков
* HbmSerializer.Default.Serialize — сериализует классы в xml-файлы
Теперь настало время прописать Атрибуты. Изменим класс Book, добавив туда аттрибуты следующим образом
```
[Class]
public class Book {
[Id(0, Name = "Id")]
[Generator(1, Class = "native")]
public virtual int Id { get; set; }
[Property]
public virtual string Name { get; set; }
[Property]
public virtual string Description { get; set; }
}
```
Что следует заметить? Первое, над каждым свойством, который вы хотите замапить, должны быть атрибуты. Второе, вы обратили внимание на индексы Id(0...) и Generator(1...)? Индексы нужно применять для свойств, которые состоят из более чем одного атрибута. Это связано с тем, что NHMA генерирует \*.hbm.xml файлы на «лету» из атрибутов, и он должен знать в каком порядке выписывать xml-элементы. (К сожалению, порядок атрибут не поддерживается с помощью reflection).
Удалим из БД таблицу Book (можно и не удалять, это для проверки.) Запустим проект, и если в БД не было таблицы Book, то она создастся.
Про отношения не буду писать, так как синтаксис такой же как и у \*.hbm.xml файлов, единственное различие, что для коллекций нужно прописывать индексы.
**2.1 Отношения (В таблицах)**
**Многие-ко-многим**
| Book.cs | Author.cs |
| --- | --- |
|
```
[Set(0, Table = "Book_Author", Cascade = "save-update")]
[Key(1, Column = "BookId")]
[ManyToMany(2, ClassType = typeof(Author), Column = "AuthorId")]
private ISet \_authors;
public virtual ISet Authors {
get {
return \_authors ?? (\_authors = new HashSet());
}
set { \_author = value; }
}
```
|
```
[Set(0, Table = "Book_Author", Inverse = true, Cascade = "save-update")]
[Key(1, Column = "AuthorId")]
[ManyToMany(2, ClassType = typeof(Book), Column = "BookId")]
private ISet \_books;
public virtual ISet Books{
get {
return \_books?? (\_books= new HashSet());
}
set { \_books= value; }
}
```
|
**Многие-к-одному, один-ко-многим**
| Book.cs | Series.cs |
| --- | --- |
|
```
[ManyToOne(Name = "Series", Column = "SeriesId",
ClassType = typeof(Series), Cascade = "save-update")]
public virtual Series Series { get; set; }
```
|
```
[Bag(0, Name = "Books", Inverse = true)]
[Key(1, Column = "SeriesId")]
[OneToMany(2, ClassType = typeof(Book))]
private IList \_books;
public virtual IList Books{
get {
return \_books?? (\_books= new List());
}
set { \_books= value; }
}
```
|
**Один-к-одному**
| Book.cs | Mind.cs |
| --- | --- |
|
```
[OneToOne(Name = "Mind", ClassType = typeof(Mind),
Constrained = true, Cascade = "All")]
private Mind _mind;
public virtual Mind Mind {
get { return _mind ?? (_mind = new Mind()); }
set { _mind = value; }
}
```
|
```
[OneToOne(Name = "Book", ClassType = typeof(Book))]
public virtual Book Book { get; set; }
```
|
**3. Mapping ByCode**
Плюсы:
+ Не требуются дополнительных библиотек (как в случае с аттрибутами)
+ Поддрежка Intellisense 100(!).
+ Не требуются \*.hbm.xml-файлы и Nhibernate.cfg.xml
+ Взяли лучшее у Fluent-Nhibernate, (лямбда-выражения) и сделали синтаксис под \*.hbm.xml — файлы.
Минусы:
— Убрали у cascade Save-Update свойство (можно использовать Cascade.Persist, но всё-таки).
— Структура (в частности отношения между классами) не совсем точно соответствует элементам \*.hbm.xml — файлов.
*Будет обновлена...*
1. Удалим файл nhibernate.cfg.xml
2. Изменим NHibernateHelper класс следующим образом
```
public class NHibernateHelper {
public static ISession OpenSession() {
var cfg = new Configuration()
.DataBaseIntegration(db => {
db.ConnectionString = @"Server=..\SQLENTERPRISE;initial catalog=NhibernateTutor;Integrated Security=SSPI;";
db.Dialect();
});
var mapper = new ModelMapper();
mapper.AddMappings(Assembly.GetExecutingAssembly().GetExportedTypes());
HbmMapping mapping = mapper.CompileMappingForAllExplicitlyAddedEntities();
cfg.AddMapping(mapping);
new SchemaUpdate(cfg).Execute(true, true);
ISessionFactory sessionFactory = cfg.BuildSessionFactory();
return sessionFactory.OpenSession();
}
}
```
Заметили тенденцию? С каждым способом убирается один из файлов для Nhibernate. В xml-файлах были \*.hbm.xml файлы и nhibernate.cfg.xml файл, в Attributes стали не нужны \*.hbm.xml файлы, в Mapping byCode уже стал не нужен nhibernate.cfg.xml. Интересно, что будет уберут в новом способе (да и будет ли он вообще?).
Класс Book и его маппинг должны выглядеть следующим образом.
```
public class Book {
public virtual int Id { get; set; }
public virtual string Name { get; set; }
public virtual string Description { get; set; }
}
public class BookMap : ClassMapping {
public BookMap() {
Id(x => x.Id, map => map.Generator(Generators.Native));
Property(x=>x.Name);
Property(x=>x.Description);
}
```
**3.1 Отношения (В таблицах)**
**Многие-ко-многим**
| Book.cs | Author.cs |
| --- | --- |
|
```
private ISet \_authors;
public virtual ISet Authors {
get {
return \_authors ?? (\_authors = new HashSet());
}
set { \_author = value; }
}
```
|
```
private ISet \_books;
public virtual ISet Books{
get {
return \_books?? (\_books= new HashSet());
}
set { \_books= value; }
}
```
|
| BookMap.cs | AuthorMap.cs |
|
```
Set(a => a.Authors,
c => { c.Cascade(Cascade.Persist);
c.Key(k => k.Column("BookId"));
c.Table("Book_Author");},
r=>r.ManyToMany(m=>m.Column("AuthorId")));
```
|
```
Set(a => a.Books,
c => { c.Cascade(Cascade.All);
c.Key(k => k.Column("AuthorId"));
c.Table("Book_Author"); c.Inverse(true); },
r => r.ManyToMany(m => m.Column("BookId")));
```
|
**Многие-к-одному, один-ко-многим**
| Book.cs | Series.cs |
| --- | --- |
|
```
public virtual Series Series { get; set; }
```
|
```
private IList \_books;
public virtual IList Books{
get {
return \_books?? (\_books= new List());
}
set { \_books= value; }
}
```
|
| BookMap.cs | SeriesMap.cs |
|
```
ManyToOne(x => x.Series,
c => { c.Cascade(Cascade.Persist);
c.Column("Series_Id"); });
```
|
```
Bag(x => x.Books,
c => { c.Key(k => k.Column("Series_Id")); c.Inverse(true); },
r => r.OneToMany());
```
|
**Один-к-одному**
| Book.cs | Mind.cs |
| --- | --- |
|
```
private Mind _mind;
public virtual Mind Mind {
get { return _mind ?? (_mind = new Mind()); }
set { _mind = value; }
}
```
|
```
public virtual Book Book { get; set; }
```
|
| BookMap.cs | MindMap.cs |
|
```
OneToOne(x=>x.Mind, c=>{c.Cascade(Cascade.All);
c.Constrained(true);});
```
|
```
OneToOne(x=>x.Book,
c=>c.Cascade(Cascade.None));
```
|
Подробная информация здесь [StackOverflow Mapping-By-Code](http://stackoverflow.com/questions/5777898/docs-examples-for-nhibernate-3-2-mapping-by-code)
**4. FLUENT**
Он предлагает альтернативу стандартным отображения XML- файлов NHibernate. Вместо того, чтобы писать XML-файлы, вы пишете маппинги в строго типизированных C# коде (через лямбда-выражения). Благодаря этому есть рефакторинг, улучшается читаемость и легкость написания кода.
Плюсы:
+ 100% поддержка intellisense!
+ Великолепная документация [Fluent-Nhibernate](https://github.com/jagregory/fluent-nhibernate/wiki)
+ Валидация во время компиляции
+ Не нужно создавать файл Nhibernate.cfg.xml, все настройки, включая строку подключения, можно прописать в NhibernateHelper.
Минусы:
— По сравнению с другими версиями NHibernate немного непривычный синтаксис маппинга.
Так как FluentNhibernate и Nhibernate немного различаются, давайте я напишу так, будто заново создаю приложение? Итак начнем, создаем новое приложение.
1. В *Package Manager Console* пропишем install-package fluentnhibernate
2. В папке «Models» создадим класс «Book.cs» (Models->Book.cs)
3. Добавим в Models папку NHibernate и создадим класс NHibernateHelper.cs (Models->NHibernate->NHibernateHelper.cs)
```
public class NHibernateHelper {
public static ISession OpenSession() {
ISessionFactory sessionFactory = Fluently.Configure()
.Database(MsSqlConfiguration.MsSql2008.ConnectionString(@"Server=..\SQLENTERPRISE; initial catalog= Biblioteca; Integrated Security=SSPI;").ShowSql()
)
.Mappings(m =>m.FluentMappings.AddFromAssemblyOf())
.ExposeConfiguration(cfg => new SchemaUpdate(cfg).Execute(false, true))
.BuildSessionFactory();
return sessionFactory.OpenSession();
}
}
```
В этом NhibernateHelper.cs следует отметить, что теперь строку подключения к БД мы прописываем здесь. И да, тут присутсвеют лямбда-выражения.
Заполним класс Book.cs
```
public class Book {
public virtual int Id { get; set; }
public virtual string Name { get; set; }
public virtual string Description { get; set; }
}
```
и создадим к нему маппинг-класс
```
public class BookMap : ClassMap {
public BookMap() {
Id(x => x.Id);
Map(x => x.Name);
Map(x => x.Description);
}
}
```
Далее создадите в папке Controllers класс HomeController и напишем следующий код.
```
public ActionResult Index()
{
var session = NHibernateHelper.OpenSession();
return View();
}
```
Создайте любую View, и после запуска приложения в SQL Server будет создана таблица Book.
**4.1 Отношения (В таблицах)**
**Многие-ко-многим**
| Book.cs | Author.cs |
| --- | --- |
|
```
private ISet \_authors;
public virtual ISet Authors {
get {
return \_authors ?? (\_authors = new HashSet());
}
set { \_author = value; }
}
```
|
```
private ISet \_books;
public virtual ISet Books{
get {
return \_books?? (\_books= new HashSet());
}
set { \_books= value; }
}
```
|
| BookMap.cs | AuthorMap.cs |
|
```
HasManyToMany(x => x.Authors)
.Cascade.SaveUpdate()
.Table("Book_Author");
```
|
```
HasManyToMany(x => x.Books)
.Cascade.All()
.Inverse().Table("Book_Author");
```
|
**Многие-к-одному, один-ко-многим**
| Book.cs | Series.cs |
| --- | --- |
|
```
public virtual Series Series { get; set; }
```
|
```
private IList \_books;
public virtual IList Books{
get {
return \_books?? (\_books= new List());
}
set { \_books= value; }
}
```
|
| BookMap.cs | SeriesMap.cs |
|
```
References(x => x.Series).Cascade.SaveUpdate();
```
|
```
HasMany(x => x.Books)
.Inverse();
```
|
Метод References применяется на стороне «Многие-к-одному», на другой стороне «Один-ко-многим» будет метод HasMany.
**Один-к-одному**
| Book.cs | Mind.cs |
| --- | --- |
|
```
private Mind _mind;
public virtual Mind Mind {
get { return _mind ?? (_mind = new Mind()); }
set { _mind = value; }
}
```
|
```
public virtual Book Book { get; set; }
```
|
| BookMap.cs | MindMap.cs |
|
```
HasOne(x => x.Mind).Cascade.All().Constrained();
```
|
```
HasOne(x => x.Book);
```
|
Метод .Constrained() говорит NHibernate, что для записи из таблицы Book должна соответствовать запись из таблицы Mind (id таблицы Mind должен быть равен id таблицы Book)
**Варианты запросов (NHibernate Queries)**
NHibernate обладает мощными инструментами для создания запросов, такие как.
* Методы session.Get и session.Load. Получение (списка) объекта(ов) по первичному ключу.
* SQL (метод CreateSQLQuery) — в основном используется для преобразования SQL-скрипта к определенному классу
* HQL — это SQL-подобный язык, хорошо подходит для статических запросов.
* LINQ to NHibernate — В NHibernate 2x linq-запросы задавались интерфейсом ISession.Linq, который хорошо работал для простых запросов. C выходом Nhibernate 3 (интерфейс изменился на ISession.Query) получил более широкие возможности, хотя и не получил широкое распространение среди программистов
* Criteria (Часто используемый) — хорошо подходит для построения динамических запросов, свойства задаются в виде строки.
* QueryOver (Часто используемый) — Впервые появился в версии NHibernate 3. Также хорошо подходит для построения динамический запросов, поддерживается intellisense
**Запрос по идентификатору**
```
//Выбор объекта по иденитфикатору, (методы Get и Load)
var book = session.Get(1);
```
**Метод SQLCreateQuery**
```
//SQl-запрос
var queryBook = string.Format(@"select Id, Name, Description from Book");
//Вывод списка всех книг
var books = session.CreateSQLQuery(queryBook)
//SQl-запрос ассоциирует с классом
.SetResultTransformer(Transformers.AliasToBean(typeof(Book)))
.List().ToList();
```
**Lists with restrictions**
```
//hql
var hqlQuery = session.CreateQuery("from Book b where b.Series.Id = ? order by p.Id")
//Указывает 0 параметру значение int=2
.SetInt32(0,2);
var books = hqlQuery.List();
//NHibernate.Linq (session.Linq in NH 2/session.Query in NH3)
var linq = (from book in session.Query()
where book.Series.Id == 2
orderby book.Id
select book);
var books = linq.ToList();
return View(books);
//criteria
var criteria = session.CreateCriteria()
//"Restrictions" используется как "Expression"
.Add(Restrictions.Eq("Series.Id", 3))
//Order
.AddOrder(Order.Asc("Id"));
var books = criteria.List();
//query over
var queryOver = session.QueryOver()
.Where(x => x.Series.Id == 2)
.OrderBy(x => x.Id).Asc;
var books = queryOver.List();
return View(books);
```
Я хотел сделать аналогичные запросы по NHibernate Query, такие как Joinы, Projecting и другие, но оказалось, что про это уже есть превосходнейшие статьи [NHibernate Queries](http://www.martinwilley.com/net/code/nhibernate/query.html) и [NHibernate More Queries](http://www.martinwilley.com/net/code/nhibernate/query2.html)
Если вам интересен QueryOver, то виды его запросов можно посмотреть тут [QueryOver in NH3](http://nhibernate.info/blog/2009/12/17/queryover-in-nh-3-0.html)
Статья подходит к концу, и мне хотелось завершить её следующим материалом.
**Lazy и eager-loading («Ленивые» и «Жадные» загрузки)**
Lazy loading и eager loading — это методы, которыми пользуется NHibernate для загрузки необходимых данных в navigation properties сущности
->**Lazyloading — ленивая загрузка**. При первом обращении к сущности (Book), соответствующие связанные данные не загружаются. Однако, при первом обращении к navigation property (Book.Genres), связанные данные загружаются автоматически. При этом к базе совершается множество запросов: один для сущности и по одному каждый раз при загрузке данных.
```
//Код в представлении (View)
@foreach (var item in Model) { //Загружены ТОЛЬКО все записи таблицы Book
@foreach (var genre in item.Genres) { //Теперь загрузились поля Genres, связанные с таблицей Book
@Html.DisplayFor(modelItem => genre.Name)
}
}
```
-> **Eagerloading — жадная загрузка**. Данные загружаются при обращении к сущности. Обычно это сопровождается запросом join, который возвращает все данные.
```
//Код в представлении (View)
@foreach (var item in Model) { //Загружены ВСЕ записи таблицы Book и связанных с ним таблиц.
@foreach (var genre in item.Genres) {
@Html.DisplayFor(modelItem => genre.Name)
}
}
```
Для «жадной» загрузки NHibernate использует Fetch strategies.
Давайте рассмотрим EagerLoading и LazyLoading загрузки, на примере Query Over.
---Query Over — код Lazyloading загрузки---
```
using (ISession session = NHibernateHelper.OpenSession()) {
Genre genreAl = null; Author authorAl = null; Series seriesAl = null;
var books = session.QueryOver()
//Left Join с таблицей Genres
.JoinAlias(p => p.Authors, () => authorAl, JoinType.LeftOuterJoin)
.JoinAlias(p => p.Series, () => seriesAl, JoinType.LeftOuterJoin)
//Убирает повторяющиеся id номера таблицы Book.
.TransformUsing(Transformers.DistinctRootEntity).List();
return View(books);
}
```
---Query Over — код EagerLoading загрузки---
```
using (ISession session = NHibernateHelper.OpenSession()) {
var books = session.QueryOver()
.Fetch(a => a.Authors).Eager.Fetch(s => s.Series).Eager
.TransformUsing(Transformers.DistinctRootEntity).List();
return View(books);
```
как вы видете, мы не использовали LeftJoin как в предыдущем примере, потому что Fetch сразу привязывает к объекту Book все данные.
Про Fecth — стратегию вы можете почитать здесь [Nhibernate Fetch strategy](http://blog.raffaeu.com/archive/2014/07/04/nhibernate-fetch-strategies.aspx) а про маппингы с использованием lazy или eager loading — здесь [Аттрибуты lazy, fetch и batch-size](http://ser4ik.livejournal.com/2505.html). Также есть статья на [NhibernateInfo — lazy-eager loading](http://nhibernate.info/doc/howto/various/lazy-loading-eager-loading.html)
Статья подошла к концу, спасибо за внимание. | https://habr.com/ru/post/265371/ | null | ru | null |
# Рисуем снежинки с помощью SVG
Идею создания снежинок использованную в этом посте я позаимствовал из детского сада. Там складывают лист бумаги в несколько раз, вырезают ножницами дырочки и после разворачивания получают снежинку. В данном случае нам потребуется нарисовать одну шестую и потом её копии повернуть на 60 градусов 5 раз.
Такие снежинки можно использовать в новогодних поздравлениях. Для затравки я сделал [вот такую открытку](http://y3x.ru/sandbox/svg-newyear/happyNewYear.svg).
Для рисования можно использовать группу элементов (*g*) или один элемент *path*
```
```
в данном случае у нас есть одна основная линия (M0,0 L40,40) и дополнительные.
Для сборки снежинки сделаем группу:
```
```
Использовать снежинку можно следующим образом:
```
```
Я уже сделал [несколько снежинок](http://y3x.ru/sandbox/svg-snowflake/snowflakes.svg), а какие снежинки получатся у Вас? | https://habr.com/ru/post/164477/ | null | ru | null |
# Как самостоятельно изготовить электронную подпись
Оговорюсь сразу — я почти дилетант в вопросах, связанных с электронной цифровой подписью (ЭЦП). Недавно, движимый естественным любопытством, я решил немного разобраться в этом и нашел в Интернете 100500 статей на тему получения сертификатов ЭЦП в различных удостоверяющих центрах, а также многочисленные инструкции по использованию различных готовых приложений для подписания документов. Кое-где при этом вскользь упоминалось, что неквалифицированную подпись можно изготовить самостоятельно, если воспользоваться услугами «опытного программиста».
Мне тоже захотелось стать хоть немного «опытным» и разобраться в этой кухне изнутри. Для интереса я научился генерировать PGP-ключи, подписывать документы неквалифицированной подписью и проверять ее достоверность. Понимая, что никакой Америки не открыто, я, тем не менее, предлагаю этот краткий туториал для таких же, как и я, дилетантов в вопросах работы с ЭЦП. Я постарался особо не углубляться в теорию и в детали, а написать именно небольшое и краткое введение в вопрос. Тем, кто уже работает с ЭЦП, это вряд ли будет интересно, а вот новичкам, для первого знакомства — в самый раз.
Что такое электронная подпись
-----------------------------
Все термины и определения приведены в [законе](https://legalacts.ru/doc/FZ-ob-jelektronnoj-podpisi/), поэтому изложим всё, как говорится, своими словами, не претендуя при этом на абсолютную юридическую точность формулировок.
**Электронная цифровая подпись (ЭЦП)** — это совокупность средств, позволяющих однозначно удостовериться в том, что автором документа (или исполнителем какого-то действия) является именно то лицо, которое называет себя автором. В этом смысле ЭЦП полностью аналогична традиционной подписи: если в обычном «бумажном» документе указано, что его автор Иванов, а внизу стоит подпись Петрова, вы справедливо можете усомниться в авторстве Иванова.
Электронная подпись бывает *простая* и *усиленная*. **Простая** подпись не предполагает использование стандартных криптографических алгоритмов; все способы аутентификации (установления авторства), которые были придуманы до эпохи ЭЦП — это по сути и есть простая электронная подпись. Если вы, например, зарегистрировались на сайте госуслуг, удостоверили свою личность путем явки в многофункциональный центр, а затем направляете через этот сайт обращения в различные государственные органы, то ваши логин и пароль от сайта госуслуг и будут в данном случае вашей простой электронной подписью.
Мне однажды встречался такой способ удостоверения подлинности электронных документов в одной организации: перед рассылкой документа изготавливался его [хэш](https://ru.wikipedia.org/wiki/Хеш-функция) и подписывался в базу хэшей (обычный текстовый файл, лежащий на сервере). Далее любой желающий удостовериться в подлинности электронного документа заходил на официальный сайт этой организации (в официальности которого ни у кого сомнений не возникало) и с помощью специального сервиса проверял, содержится ли хэш проверяемого документа в базе. Замечательно при этом, что сам документ даже не нужно было загружать на сервер: хэш можно вычислить на клиентской стороне в браузере, а на сервер послать только маленький fetch- или ajax-запрос с этим хэшем. Безусловно, этот немудрёный способ можно с полным основанием назвать простой ЭЦП: подписью в данном случае является именно хэш документа, размещенный в базе организации.
Поговорим теперь об **усиленной** электронной подписи. Она предполагает использование стандартных криптографических алгоритмов; впрочем, таких алгоритмов существует достаточно много, так что и здесь единого стандарта нет. Тем не менее де-факто усиленная ЭЦП обычно основана на [асимметричном шифровании](https://ru.wikipedia.org/wiki/Криптосистема_с_открытым_ключом) (абсолютно гениальном, на мой взгляд, изобретении [Ральфа Меркла](https://ru.wikipedia.org/wiki/Меркл,_Ральф)), идея которого чрезвычайно проста: для шифрования и расшифровывания используются *два разных ключа*. Эти два ключа всегда генерируются парой; один называется *открытым ключом* (public key), а второй — *секретным ключом* (private key). При этом, имея один из двух ключей, второй ключ воспроизвести за разумное время невозможно.
Представим себе, что Аня хочет послать Боре (почему в литературе по криптографии обычно фигурируют Алиса и Боб? пусть будут Аня и Боря) секретную посылочку, закрытую на висячий замочек, и при этом на почте работают злые люди, которые хотят эту посылочку вскрыть. Других каналов связи, кроме почты, у Ани и Бори нет, так что ключ от замочка Аня передать Боре никак не может. Если она пошлет ключ по почте, то злые люди его, конечно, перехватят и вскроют посылочку.
Ситуация кардинально меняется, если изобретен замок *с двумя ключами*: один только для закрывания, а второй — только для открывания. Боря генерирует себе пару таких ключей (открытый и секретный) и открытый ключ шлет по почте Ане. Работники почты, конечно, потирая руки, делают себе копию этого ключа, но не тут-то было! Аня закрывает замок на посылке открытым ключом Бори и смело идет на почту. Работники почты вскрыть посылку открытым ключом не могут (он использовался *для закрывания*), а Боря спокойно открывает ее своим секретным ключом, который он бережно хранил у себя и никуда не пересылал.
Вернемся к усиленной электронной подписи. Предположим, некий Иван Иванович Иванов захотел подписать документ с помощью ЭЦП. Он генерирует себе два ключа: открытый и секретный. После этого изготавливает (стандартным способом) хэш документа и шифрует его с использованием своего *секретного* ключа. Можно, конечно, было зашифровать и весь документ, но полученный в результате такого шифрования файл может оказаться очень большим, поэтому шифруется именно небольшой по размеру хэш.
*Полученный в результате такого шифрования файл и будет являться усиленной электронной подписью.* Её еще называют *отсоединенной* (detach), так как она хранится в отдельном от документа файле. Такой вариант удобен тем, что подписанный отсоединенной ЭЦП файл можно спокойно прочитать без какой-либо расшифровки.
Что же теперь отправляет Иван Иванович получателям? А отправляет он три файла: сам документ, его электронную подпись и *открытый* ключ. Получатель документа:
* изготавливает его хэш с помощью стандартного алгоритма;
* расшифровывает электронную подпись, используя имеющийся у него открытый ключ Ивана Ивановича;
* убеждается, что хэш совпадает с тем, что указан в расшифрованной электронной подписи (то есть документ не был подменен или отредактирован). Вуаля!
Всё, казалось бы, хорошо, но есть одно большое «но». Предположим, что некий злодей по фамилии Плохиш решил прикинуться Ивановым и рассылать документы от его имени. Ничто не мешает Плохишу сгенерировать два ключа, изготовить с помощью секретного ключа электронную подпись документа и послать это всё получателю, назвавшись Ивановым. Именно поэтому описанная выше ЭЦП называется **усиленной неквалифицированной**: невозможно достоверно установить, кому принадлежит открытый ключ. Его с одинаковым успехом мог сгенерировать как Иванов, так и Плохиш...
Из этой коллизии существует два выхода. Первый, самый простой, заключается в том, что Иванов может разместить свой открытый ключ на своем персональном сайте (или на официальном сайте организации, где он работает). Если подлинность сайта не вызывает сомнений (а это отдельная проблема), то и принадлежность открытого ключа Иванову сомнений не вызовет. Более того, на сайте можно даже разметить не сам ключ, а его *отпечаток* (fingerprint), то есть, попросту говоря, хэш открытого ключа. Любой, кто сомневается в авторстве Иванова, может сверить отпечаток ключа, полученного от Иванова, с тем отпечатком, что опубликован на его персональном сайте. В конце концов, отпечаток можно просто продиктовать по телефону (обычно это 40 шестнадцатеричных цифр).
Второй выход, стандартный, состоит в том, что открытый ключ Иванова тоже должен быть подписан электронной подписью — того, кому все доверяют. И здесь мы приходим к понятию **усиленной квалифицированной** электронной подписи. Смысл ее очень прост: Иванов идет в специальный аккредитованный *удостоверяющий центр*, который подписывает открытый ключ Иванова *своей* электронной подписью (присоединив предварительно к ключу Иванова его персональные данные). То, что получилось, называется *сертификатом открытого ключа* Иванова.
Теперь любой сомневающийся может проверить подлинность открытого ключа Иванова с помощью любого из многочисленных сервисов Интернета, то есть расшифровать его сертификат (онлайн, с помощью открытого ключа удостоверяющего центра) и убедиться, что ключ принадлежит именно Иванову. Более того, Иванову теперь достаточно послать своим корреспондентам только сам документ и его отсоединенную подпись (содержащую и сведения о сертификате): все необходимые проверки будут сделаны желающими онлайн.
Справедливости ради необходимо отметить, что и неквалифицированная ЭЦП может быть сертифицирована: никто не мешает какому-то третьему лицу (например, *неаккредитованному удостоверяющему центру*) подписать открытый ключ Иванова своей ЭЦП и получить таким образом сертификат открытого ключа. Правда, если удостоверяющий центр не аккредитован, степень доверия к подписи Иванова будет полностью зависеть от степени доверия к этому центру.
Всё замечательно, да вот только услуги удостоверяющих центров по изготовлению для вас подписанных (снабженных сертификатом центра) ключей стоят денег (обычно несколько тысяч рублей в год). Поэтому ниже мы рассмотрим, как можно *самостоятельно* изготовить усиленную ЭЦП (неквалифицированную, не снабженную сертификатом открытого ключа от аккредитованного удостоверяющего центра). Юридической силы (например, в суде) такая подпись иметь не будет, так как принадлежность открытого ключа именно вам никем не подтверждена, но для повседневной переписки деловых партнеров или для документооборота внутри организации эту подпись вполне можно использовать.
Генерирование открытого и секретного ключей
-------------------------------------------
Итак, вы решили самостоятельно изготовить усиленную неквалифицированную электронную подпись и научиться подписывать ею свои документы. Начать необходимо, конечно, с генерирования пары ключей, открытого (public key) и секретного (private key).
Существует множество стандартов и алгоритмов асимметричного шифрования. Одной из библиотек, реализующих эти алгоритмы, является PGP (Pretty Good Privacy). Она была выпущена в 1991 году под проприетарной лицензией, поэтому имеются полностью совместимые с ней свободные библиотеки (например, OpenPGP). Одной из таких свободных библиотек является выпущенная в 1999 году GNU Privacy Guard (GnuPG, или GPG). Утилита GPG традиционно входит в состав почти всех дистрибутивов Линукса; для работы из-под Windows необходимо установить, например, [gpg4win](https://gpg4win.org/download.html). Ниже будет описана работа из-под Линукса.
Сначала сгенерируем собственно ключи, подав (из-под обычного юзера, не из-под root'а) команду
```
gpg --full-generate-key
```
В процессе генерирования вам будет предложено ответить на ряд вопросов:
* тип ключей можно оставить «RSA и RSA (по умолчанию)»;
* длину ключа можно оставить по умолчанию, но вполне достаточно и 2048 бит;
* в качестве срока действия ключа для личного использования можно выбрать «не ограничен»;
* в качестве идентификатора пользователя можно указать свои фамилию, имя и отчество, например, `Иван Иванович Иванов`; адрес электронной почты можно не указывать;
* в качестве примечания можно указать город, либо иную дополнительную информацию.
После ввода вами всех запрошенных данных утилита GPG попросит вас указать пароль, необходимый для доступа к секретному ключу. Дело в том, что сгененрированный секретный ключ будет храниться на вашем компьютере, что небезопасно, поэтому GPG дополнительно защищает его паролем. Таким образом, не знающий пароля злоумышленник, даже если и получит доступ к вашему компьютеру, подписать документы от вашего имени не сможет.
Сгенерированные ключи (во всяком случае, открытый, но можно также и секретный, на тот случай, если ваш компьютер внезапно сломается) необходимо экспортировать в текстовый формат:
```
gpg --export -a "Иван Иванович Иванов" > public.key
gpg --export-secret-key -a "Иван Иванович Иванов" > private.key
```
Понятно, что `private.key` вы должны хранить в секрете, а вот `public.key` вы можете открыто публиковать и рассылать всем желающим.
Подписание документа
--------------------
Нет ничего проще, чем создать отсоединенную ЭЦП в текстовом (ASCII) формате:
```
gpg -ba имя_подписываемого_файла
```
Файл с подписью будет создан в той же папке, где находится подписываемый файл и будет иметь расширение `asc`. Если, например, вы подписали файл `privet.doc`, то файл подписи будет иметь имя `privet.doc.asc`. Можно, следуя традиции, переименовать его в `privet.sig`, хотя это непринципиально.
Если вам не хочется каждый раз заходить в терминал и вводить руками имя подписываемого файла с полным путем, можно написать простейшую графическую утилиту для подписания документов, например, такую:
```
#!/usr/bin/python
# -*- coding: utf-8 -*-
from Tkinter import *
from tkFileDialog import *
import os, sys, tkMessageBox
def die(event):
sys.exit(0)
root = Tk()
w = root.winfo_screenwidth()//2 - 400
h = root.winfo_screenheight()//2 - 300
root.geometry("800x600+{}+{}".format(w, h))
root.title("Подписать документ")
flName = askopenfilename(title="Что подписываем?")
if flName:
os.system("gpg -ba " + flName)
button = Button(text="ЭЦП создана")
button.bind("", die)
button.pack(expand=YES, anchor=CENTER)
else:
die()
root.mainloop()
```
Проверка подписи
----------------
Вряд ли, конечно, вам самому придется проверять достоверность собственной электронной подписи, но если вдруг (на всякий случай) вам захочется это сделать, то нет ничего проще:
```
gpg --verify имя_файла_подписи имя_файла_документа
```
В реальности гораздо полезнее опубликовать где-нибудь в открытом доступе (например, на вашем персональном сайте или на сайте вашей организации):
* открытый ключ `public.key` для того, чтобы все желающие могли проверить (верифицировать) вашу подпись с использованием, например, той же GPG;
* веб-интерфейс для проверки вашей подписи всеми желающими, не являющимися специалистами.
Описанию такого веб-интерфейса (причем без использования серверных технологий, с проверкой подписи исключительно на клиентской стороне) и будет посвящена последняя часть моего краткого туториала.
К счастью для нас, имеется свободная библиотека [OpenPGP.js](https://github.com/openpgpjs/openpgpjs); скачиваем самый маленький по размеру (на момент написания данного туториала — 506 КБ) файл `dist/lightweight/openpgp.min.js` и пишем несложную html-страничку (для упрощения восприятия я удалил все описания стилей и очевидные meta-тэги):
```
Загрузите файл с документом
Загрузите файл с подписью
Проверить
```
Понятно, что файл с открытым ключом `public.key` и файл библиотеки `openpgp.min.js` должны лежать в той же папке, что и эта страничка.
Вся работа по верификации подписей будет производиться подключенным скриптом `validate.js`:
```
"use strict";
let cont = {doc:'', sig:''},
flag = {doc:false, sig:false},
pubkey = '',
mess = '';
// Чтение файлов документа (как бинарного),
// ключа и подписи (как текстовых)
const readDoc = contKey => {
let reader = new FileReader();
reader.onload = async e => {
cont[contKey] = contKey == "sig" ?
e.target.result :
new Uint8Array(e.target.result);
flag[contKey] = true;
pubkey = await (await fetch("public.key")).text();
if (flag["doc"] && flag["sig"])
document.querySelector("button").disabled = false;
}
reader.onerror = err => alert("Ошибка чтения файла");
let fileObj = document.querySelector(`#${contKey}`).files[0];
if (contKey == "sig") reader.readAsText(fileObj);
else reader.readAsArrayBuffer(fileObj);
}
// Верификация подписи
const check = async () => {
try {
const verified = await openpgp.verify({
message: openpgp.message.fromBinary(cont["doc"]),
signature: await openpgp.signature.readArmored(cont["sig"]),
publicKeys: (await openpgp.key.readArmored(pubkey)).keys
});
const {valid} = verified.signatures[0];
mess = "Электронная подпись НЕ является подлинной!";
if (valid) mess = "Электронная подпись является подлинной.";
} catch(e) {mess = "Файл подписи имеет недопустимый формат.";}
document.querySelector("output").innerHTML = mess;
}
```
Вот, собственно, и всё. Теперь вы можете в соответствии с пунктом 5.23 [ГОСТ 7.0.97–2016](http://docs.cntd.ru/document/1200142871) разместить на документе (в том месте, где должна стоять собственноручная подпись) вот такую красивую картинку:
 | https://habr.com/ru/post/502992/ | null | ru | null |
# Пример создания на Node.js спортивного приложения, работающего в режиме реального времени

В этой статье я покажу, как создать веб-приложение с использованием Node.js, которое позволяет отслеживать результаты матчей NHL в реальном времени. Показатели обновляются в соответствии с изменениями счета по ходу игр.
Мне очень понравилось писать эту статью, поскольку работа над ней включала две любимые мною вещи: разработку ПО и спорт.
В ходе работы мы будем использовать следующие инструменты:
* Node.js;
* Socket.io;
* MySportsFeed.com.
Если у вас нет установленного Node.js, посетите страницу загрузки и установите, а потом мы продолжим.
### Что такое Socket.io?
Это технология, которая соединяет клиента с сервером. В текущем примере клиент — веб-браузер, а сервер — приложение Node.js. Сервер может работать одновременно с несколькими клиентами в любое время.
Как только соединение установлено, сервер может отправлять сообщения всем клиентам или же всего одному из них. Тот, в свою очередь, может отправлять сообщениея на сервер, обеспечивая связь в двух направлениях.
До Socket.io веб-приложения обычно работали на AJAX. Его использование предусматривало необходимость опроса клиентом сервера и наоборот в поисках новых событий. К примеру, такие опросы могли выполняться каждые 10 секунд для проверки наличия новых сообщений.
Это давало дополнительную нагрузку, поскольку поиск новых сообщений велся даже тогда, когда их не было вовсе.
При использовании Socket.io сообщения получаются в режиме реального времени без необходимости постоянно проверять их наличие, что снижает нагрузку.
### Пример приложения Socket.io
Прежде чем мы начнем собирать данные соревнований в реальном времени, давайте сделаем приложение-пример для демонстрации принципа работы Socket.io.
Вначале я собираюсь создать приложение Node.js. В окне консоли нужно перейти к каталогу C:\GitHub\NodeJS, создать новую папку для приложения и в ней — новое приложение:
```
cd \GitHub\NodeJS
mkdir SocketExample
cd SocketExample
npm init
```
Я оставил настройки по умолчанию, вы можете поступить так же.
Поскольку мы создаем веб-приложение, для упрощения установки я буду использовать пакет NPM, который называется Express. В командной строке выполняем следующие команды: npm install express --save.
Конечно, мы должны установить и пакет Socket.io package: npm install socket.io --save
Теперь нужно запустить веб-сервер. Для этого создаем новый файл index.js и размещаем следующий участок кода:
```
var app = require('express')();
var http = require('http').Server(app);
app.get('/', function(req, res){
res.sendFile(__dirname + '/index.html');
});
http.listen(3000, function(){
console.log('HTTP server started on port 3000');
});
```
Если Express вам не знаком, то пример кода выше включает библиотеку Express, здесь идет создание нового HTTP-сервера. В примере HTTP-сервер слушает порт 3000, т.е. [localhost](http://localhost):3000. Путь идет к корню, “/”. Результат возвращается в виде HTML-файла index.html.
Прежде чем создать этот файл, давайте завершим запуск сервера, настроив Socket.io. Для создания сервера Socket выполняем следующие команды:
```
var io = require('socket.io')(http);
io.on('connection', function(socket){
console.log('Client connection received');
});
```
Как и в случае с Express, код начинается с импорта библиотеки Socket.io. Это указывается переменной io. Далее, используя эту переменную, создаем обработчик события с функцией on. Это событие вызывается каждый раз, когда клиент подключается к серверу.
Теперь давайте создадим простенький клиент. Для этого нужно сделать файл index.html и разместить внутри такой код:
```
Socket.IO Example
var socket = io();
```
HTML выше загружает клиент Socket.io JavaScript и инициализирует подключение к серверу. Для того, чтобы увидеть пример, запускаем Node: node index.js.
Далее в браузере вводим [localhost](http://localhost):3000. Страница останется пустой, но если вы посмотрите на консоль во время выполнения Node, то увидите два сообщения:
*HTTP server started on port 3000
Client connection received*
Сейчас, когда мы успешно соединились, давайте продолжим работу. Например, отправим сообщение в клиент с сервера. Затем, когда клиент получит его, отправится ответное сообщение:
```
io.on('connection', function(socket){
console.log('Client connection received');
socket.emit('sendToClient', { hello: 'world' });
socket.on('receivedFromClient', function (data) {
console.log(data);
});
});
```
Предыдущая функция io.on обновлена включением нескольких новых строк кода. Первая, socket.emit, отправляет сообщение клиенту. sendToClient — имя события. Именуя события, вы получаете возможность отправлять разные типы сообщений, так что клиент сможет интерпретировать их по-разному. Еще одно обновление — socket.on, где тоже есть название события: receivedFromClient. Все это создает функцию, которая принимает данные от клиента. В этом случае они также записываются в окне консоли.
Выполненные действия завершают подготовку сервера. Теперь он может принимать и отправлять данные от любого подключенного клиента.
Давайте завершим этот пример, обновив клиент путем получения ивента sendToClient. Когда событие получено, дается ответ receivedFromClient.
На этом завершаем JavaScript-часть HTML. В index.html добавляем:
```
var socket = io();
socket.on('sendToClient', function (data) {
console.log(data);
socket.emit('receivedFromClient', { my: 'data' });
});
```
Используя встроенную переменную сокета, получаем похожую логику на сервере с функцией socket.on. Клиент прослушивает событие sendToClient. Как только клиент подключен, сервер отправляет это сообщение. Клиент, получая его, записывает событие в консоли браузера. После этого клиент использует тот же socket.emit, что ранее сервер для отправки оригинального события. В этом случае клиент отправляет полученное событие FromClient на сервер. Когда тот получает сообщение, это логируется в окне консоли.
Попробуйте сами. Сначала, в консоли, запустите ваше Node-приложение: node index.js. Затем загрузите в браузере [localhost](http://localhost):3000.
Проверьте консоль браузера, и вы увидите в логах JSON следующее: {hello: «world»}
Затем, пока выполняется приложение Node, вы увидите следующее:
*HTTP server started on port 3000
Client connection received
{ my: 'data' }*
Как клиент, так и сервер могут использовать JSON-данные для выполнения специфических задач. Давайте посмотрим, как можно работать с данными соревнований в реальном времени.
### Информация с соревнований
После того как мы поняли принципы отправки и получения данных клиентом и сервером, стоит попробовать обеспечить выполнение обновлений в реальном времени. Я использовал данные соревнований, хотя то же самое можно проделывать не только с информацией спортивного характера. Но раз уж работаем с ней, то нужно найти источник. Им послужит [MySportsFeeds](https://www.mysportsfeeds.com/). Сервис платный — от $1 в месяц, имейте в виду.
Как только учетная запись настроена, вы можете начать работу с их API. Для этого можно использовать пакет NPM: npm install mysportsfeeds-node --save.
После установки пакета подключаем API:
```
var MySportsFeeds = require("mysportsfeeds-node");
var msf = new MySportsFeeds("1.2", true);
msf.authenticate("********", "*********");
var today = new Date();
msf.getData('nhl', '2017-2018-regular', 'scoreboard', 'json', {
fordate: today.getFullYear() +
('0' + parseInt(today.getMonth() + 1)).slice(-2) +
('0' + today.getDate()).slice(-2),
force: true
});
```
В примере выше замените мои данные своими.
Код выполняет вызов API для получения сегодняшних результатов соревнований NHL. Переменная fordate — то, что определяет дату. Также я использовал force и true для того, чтобы получать в ответ данные даже в том случае, если результаты прежние.
При текущей настройке результаты вызова API записываются в текстовый файл. В последнем примере мы это поменяем; для демонстрационных же целей файл результатов можно просмотреть в текстовом редакторе, чтобы понять содержимое ответа. В нашем результате мы видим объект таблицы результатов. Этот объект содержит массив, называемый gameScore. Он сохраняет результат каждой игры. Каждый объект в свою очередь содержит дочерний объект, называемый игрой. Этот объект предоставляет информацию о том, кто играет.
За пределами игрового объекта имеется несколько переменных, которые обеспечивают отображение текущего состояния игры. Данные меняются в зависимости от ее результатов. Когда игра еще не началась, используются переменные, которые позволяют получить информацию о том, когда это случится. Когда игра началась, предоставляются дополнительные данные о результатах, включая информацию о том, какой сейчас период и сколько времени осталось. Для того чтобы лучше понять, о чем идет речь, давайте перейдем к следующему разделу.
### Обновления в режиме реального времени
У нас есть все части пазла, поэтому давайте его собирать! К сожалению, у MySportsFeeds ограниченная поддержка выдачи данных, поэтому придется постоянно запрашивать информацию. Здесь есть положительный момент: мы знаем, что данные меняются только раз в 10 минут, поэтому слишком часто опрашивать сервис не нужно. Получаемые данные можно отправлять с сервера на все подключенные клиенты.
Для получения нужных данных я буду использовать функцию setInterval JavaScript, которая позволяет обращаться к API (в моем случае) каждые 10 минут для поиска обновлений. Когда данные приходят, событие отправляется всем подключенным клиентам. Далее результаты обновляются посредством JavaScript в веб-браузере.
К MySportsFeeds также идет обращение, когда приложение Node запускается первым. Полученные результаты будут использоваться для любых клиентов, которые подключаются до первого 10-минутного интервала. Информация об этом сохраняется в глобальной переменной. Она, в свою очередь, обновляется как часть интервального опроса. Это дает гарантию того, что у каждого из клиентов будут актуальные результаты.
Для того, чтобы в основном файле index.js все было хорошо, я создал новый файл с именем data.js. Он содержит функцию, экспортирующуюся из index.js, которая выполняет предыдущий вызов API MySportsFeeds. Вот полное содержание этого файла:
```
var MySportsFeeds = require("mysportsfeeds-node");
var msf = new MySportsFeeds("1.2", true, null);
msf.authenticate("*******", "******");
var today = new Date();
exports.getData = function() {
return msf.getData('nhl', '2017-2018-regular', 'scoreboard', 'json', {
fordate: today.getFullYear() +
('0' + parseInt(today.getMonth() + 1)).slice(-2) +
('0' + today.getDate()).slice(-2),
force: true
});
};
```
Функция getData экспортируется и возвращает результаты вызова. Давайте посмотрим на то, что у нас содержится в файле index.js.
```
var app = require('express')();
var http = require('http').Server(app);
var io = require('socket.io')(http);
var data = require('./data.js');
// Global variable to store the latest NHL results
var latestData;
// Load the NHL data for when client's first connect
// This will be updated every 10 minutes
data.getData().then((result) => {
latestData = result;
});
app.get('/', function(req, res){
res.sendFile(__dirname + '/index.html');
});
http.listen(3000, function(){
console.log('HTTP server started on port 3000');
});
io.on('connection', function(socket){
// when clients connect, send the latest data
socket.emit('data', latestData);
});
// refresh data
setInterval(function() {
data.getData().then((result) => {
// Update latest results for when new client's connect
latestData = result;
// send it to all connected clients
io.emit('data', result);
console.log('Last updated: ' + new Date());
});
}, 300000);
```
Первые семь строк кода выше обеспечивают инициализацию требуемых библиотек и вызов глобальной переменной latestData. Последний список используемых библиотек таков: Express, Http Server, созданный с помощью Express, Socket.io плюс только что созданный файл data.js.
С учетом потребностей приложение заполняет последние данные (latestData) для клиентов, которые подключатся при первом запуске сервера:
```
// Global variable to store the latest NHL results
var latestData;
// Load the NHL data for when client's first connect
// This will be updated every 10 minutes
data.getData().then((result) => {
latestData = result;
});
```
Следующие несколько строк устанавливают путь для главной страницы сайта (в нашем случае [localhost](http://localhost):3000/) и дают команду HTTP-серверу слушать порт 3000.
Затем Socket.io настраивается для поиска новых подключений. Когда они обнаруживаются, сервер отправляет данные событий с содержимым переменной latestData.
И, наконец, последний фрагмент кода создает необходимый интервал опроса. Когда он обнаружен, переменная latestData обновляется с результатами вызова API. Эти данные затем передают одно и то же событие всем клиентам.
```
// refresh data
setInterval(function() {
data.getData().then((result) => {
// Update latest results for when new client's connect
latestData = result;
// send it to all connected clients
io.emit('data', result);
console.log('Last updated: ' + new Date());
});
}, 300000);
```
Как мы видим, когда клиент подключается и определяется событие, оно выдается с переменной сокета. Это позволяет отправить событие определенному подключившемуся клиенту. Внутри интервала глобальная io используется для отправки события. Она отправляет данные всем клиентам. Настройка сервера завершена.
### Как это будет выглядеть
Теперь поработаем над фронтендом клиента. В раннем примере я создал базовый файл index.html, который устанавливает связь с клиентом, чтобы записывать события сервера и отправлять их. Теперь я расширю возможности файла.
Поскольку сервер отправляет нам объект JSON, я буду использовать jQuery и расширение jQuery, которое называется JsRender. Это шаблонная библиотека. Она позволит мне создать шаблон c HTML, который будет использоваться для отображения содержимого каждой игры NHL в удобной форме. Сейчас вы сможете убедиться в широте ее возможностей. Код содержит более 40 строк, поэтому я разделю его на несколько меньших участков, а в конце покажу все содержимое HTML.
Вот что используется для отображения игровых данных:
```
<div class="game">
<div>
{{:game.awayTeam.City}} {{:game.awayTeam.Name}} at {{:game.homeTeam.City}} {{:game.homeTeam.Name}}
</div>
<div>
{{if isUnplayed == "true" }}
Game starts at {{:game.time}}
{{else isCompleted == "false"}}
<div>Current Score: {{:awayScore}} - {{:homeScore}}</div>
<div>
{{if currentIntermission}}
{{:~ordinal\_suffix\_of(currentIntermission)}} Intermission
{{else currentPeriod}}
{{:~ordinal\_suffix\_of(currentPeriod)}}<br/>
{{:~time\_left(currentPeriodSecondsRemaining)}}
{{else}}
1st
{{/if}}
</div>
{{else}}
Final Score: {{:awayScore}} - {{:homeScore}}
{{/if}}
</div>
</div>
```
Шаблон определяется с помощью тега script. Он содержит идентификатор шаблона и специальный тип сценария, называемый text / x-jsrender. Шаблон определяет контейнер div для каждой игры, который содержит класс игры для применения определенного базового стиля. Внутри этого div и содержится начало шаблона.
В следующем div отображаются гостевая команда и команда-хозяйка. Это реализовано объединением названия города и имени команды вместе с игровым объектом из данных MySportsFeeds.
{{: game.awayTeam.City}} — это то, как я определяю объект, который будет заменен физическим значением при визуализации шаблона. Этот синтаксис определяется библиотекой JsRender.
Когда игра unPlayed, появится строка, в которой игра начнется с {{: game.time}}.
Пока игра не завершена, отображается текущий счет: {{: awayScore}} — {{: homeScore}}. И, наконец, небольшой прием, который позволит определить, какой сейчас период, и уточнить, не перерыв ли сейчас.
Если переменная currentIntermission появляется в результатах, то я использую функцию I, определяемую ordinal\_suffix\_of, которая преобразует номер периода в следующий текст: 1-й (2-й, 3-й и т. д.) Перерыв.
Когда перерыва нет, я ищу значение currentPeriod. Здесь также используется ordinal\_suffix\_of, чтобы показать, что игра находится в 1-м (2-м, 3-м и т. д.) периодах.
Кроме того, другая функция, которую я определил как time\_left, используется для преобразования количества секунд, оставшихся до конца периода. Например: 10:12.
Последняя часть кода отображает финальный результат, когда игра завершена.
Вот пример того, как это выглядит, когда есть смешанный список завершенных игр, игр, которые еще не завершены, и и игр, которые еще не начались (я не очень хороший дизайнер, поэтому результат и выглядит так, как должен, когда разработчик создает пользовательский интерфейс для приложения своими руками):

Далее -—фрагмент JavaScript, который создает сокет, вспомогательные функции ordinal\_suffix\_of и time\_left и переменную, которая ссылается на созданный шаблон jQuery.
```
var socket = io();
var tmpl = $.templates("#gameTemplate");
var helpers = {
ordinal\_suffix\_of: function(i) {
var j = i % 10,
k = i % 100;
if (j == 1 && k != 11) {
return i + "st";
}
if (j == 2 && k != 12) {
return i + "nd";
}
if (j == 3 && k != 13) {
return i + "rd";
}
return i + "th";
},
time\_left: function(time) {
var minutes = Math.floor(time / 60);
var seconds = time - minutes \* 60;
return minutes + ':' + ('0' + seconds).slice(-2);
}
};
```
Последним фрагментом является код для приема события сокета и рендера шаблона:
```
socket.on('data', function (data) {
console.log(data);
$('#data').html(tmpl.render(data.scoreboard.gameScore, helpers));
});
```
У меня есть разделитель с идентификатором данных. Результат рендера шаблона (tmpl.render) записывает HTML в этот контейнер. Что действительно круто — библиотека JsRender может принимать массив данных, в данном случае data.scoreboard.gameScore, который выполняет итерацию через каждый элемент в массиве и создает одну игру на элемент.
Вот обещанный выше окончательный вариант, где HTML и JavaScript собраны вместе:
```
Socket.IO Example
<div class="game">
<div>
{{:game.awayTeam.City}} {{:game.awayTeam.Name}} at {{:game.homeTeam.City}} {{:game.homeTeam.Name}}
</div>
<div>
{{if isUnplayed == "true" }}
Game starts at {{:game.time}}
{{else isCompleted == "false"}}
<div>Current Score: {{:awayScore}} - {{:homeScore}}</div>
<div>
{{if currentIntermission}}
{{:~ordinal\_suffix\_of(currentIntermission)}} Intermission
{{else currentPeriod}}
{{:~ordinal\_suffix\_of(currentPeriod)}}<br/>
{{:~time\_left(currentPeriodSecondsRemaining)}}
{{else}}
1st
{{/if}}
</div>
{{else}}
Final Score: {{:awayScore}} - {{:homeScore}}
{{/if}}
</div>
</div>
var socket = io();
var helpers = {
ordinal\_suffix\_of: function(i) {
var j = i % 10,
k = i % 100;
if (j == 1 && k != 11) {
return i + "st";
}
if (j == 2 && k != 12) {
return i + "nd";
}
if (j == 3 && k != 13) {
return i + "rd";
}
return i + "th";
},
time\_left: function(time) {
var minutes = Math.floor(time / 60);
var seconds = time - minutes \* 60;
return minutes + ':' + ('0' + seconds).slice(-2);
}
};
var tmpl = $.templates("#gameTemplate");
socket.on('data', function (data) {
console.log(data);
$('#data').html(tmpl.render(data.scoreboard.gameScore, helpers));
});
.game {
border: 1px solid #000;
float: left;
margin: 1%;
padding: 1em;
width: 25%;
}
```
Теперь самое время запустить приложение Node и открыть [localhost](http://localhost):3000 для того, чтобы увидеть результат!
Через каждые X минут сервер отправляет событие клиенту. Клиент, в свою очередь, будет перерисовывать элементы игры с обновленными данными. Поэтому, когда вы оставляете сайт открытым, результаты игр будут постоянно обновляться.
### Вывод
Конечный продукт использует Socket.io для создания сервера, к которому подключаются клиенты. Сервер извлекает данные и отправляет их клиенту. Когда клиент получает данные, он может обновлять результаты постепенно. Это уменьшает нагрузку на сервер, поскольку клиент действует, только когда получает событие от сервера.
Сервер может отправлять сообщения клиенту, а клиент, в свою очередь, — серверу. Когда сервер получает сообщение, он выполняет обработку данных.
Чат-приложения работают примерно так же. Сервер получит сообщение от клиента, а затем передаст все данные подключенным клиентам, чтобы показать, что кто-то отправил новое сообщение.
Надеюсь, вам понравилась эта статья, так как я при разработке этого спортивного приложения, работающего в реальном времени, получил просто гору удовольствия, которым мне и хотелось поделиться вместе со знаниями. Ведь хоккей — один из моих любимых видов спорта!
[](https://skillbox.ru/javascript/?utm_source=skillbox.media&utm_medium=habr.com&utm_campaign=jsdev&utm_content=articles&utm_term=sportapp) | https://habr.com/ru/post/413957/ | null | ru | null |
# Что лучше: Spark Structured Streaming или полное прекращение работы прода?
Правильное построение ETL-процессов (преобразования данных) — сложная задача, а при большом объёме обрабатываемых данных неизбежно возникают проблемы с ресурсами. Поэтому нам требуется выискивать новые архитектурные решения, способные обеспечить стабильность расчётов и доступность данных, а при необходимости и масштабируемость — с минимальными усилиями.
Когда я пришел в Ozon, мне пришлось столкнуться с огромным количеством ETL-джоб. Прежде чем применить модель машинного обучения, сырые данные проходят множество этапов обработки. А само применение модели (то, ради чего существует команда) занимает всего 5% времени.
Всем привет! Меня зовут Алексей, и в Ozon я занимаюсь матчингом. Что такое матчинг и зачем он нужен, мой коллега **[@alex\_golubev13](/users/alex_golubev13)** объяснил в статье «[Векторное представление товаров Prod2Vec](https://habr.com/ru/company/ozontech/blog/648231/)».
Ежедневно у нас добавляются сотни тысяч новых товаров, а также меняются те, которые уже есть на сайте. Это могут быть изменения картинок, описаний, названий или цен. Процесс ETL в данном случае заключается в извлечении признаков из товаров, которые появились или обновились в течение заданного промежутка времени (на данный момент за день). Данные мы забираем из HDFS и Hive, а для работы с ними используем PySpark.
Сразу скажу, что большую часть ресурсов и времени в ETL занимает обработка изображений и текстовых данных. Так, каждое изображение проходит через несколько свёрточных нейронных сетей, которые возвращают векторное представление для картинки (эмбеддинг). Для текста — та же схема.
Сначала ETL-процесс состоял из batch-джоб, которые брали партиции данных за конкретную дату и целиком её обрабатывали. Понятно, что с ростом числа товаров они будут работать всё дольше и дольше, а объём потребляемых ресурсов будет только расти. Особенно заметно это во время действия акций и сезонных распродаж — тогда часто меняется цена и добавляется много новых товаров. В такие моменты приходилось значительно поднимать память для приложения. К тому же процесс стал занимать слишком много времени — и весь остальной пайплайн был вынужден ждать завершения ETL. Всё закончилось тем, что на количество товаров, проходящих через ETL, выставлялся лимит, и максимально туда шла треть всех обновившихся товаров. Понятно, что при таком подходе очередь товаров, которые не проходят через пайплайн, будет стремительно расти.
Для того чтобы избежать большой очереди, мы решили никогда не останавливать наш пайплайн ETL — он теперь работает постоянно. Так мы пришли к Spark Structured Streaming.
Как у нас всё работает
----------------------
Spark Structured Streaming позволяет работать с потоковыми данными, при этом можно использовать все преимущества Spark SQL. Теперь все обновления едут в Kafka-топик, а Streaming Session читает данные из него, обрабатывает и складывает в HDFS. Затем раз в день мы забираем эти данные и обновляем таблицы, которые являются результатом ETL. Таким образом, можем не выставлять лимит на количество обрабатываемых товаров в день, получая обновления равномерно в течение суток. Эмпирическим путём выяснили, что за день стриминг способен обрабатывать около 20 млн изображений и 50 млн текстовых объектов.
В качестве нейросетей для получения эмбеддингов используем BERT, ResNet50, fastText, NFNet, а с недавнего времени также считаем эмбеддинги для модели [Prod2Vec](https://habr.com/ru/company/ozontech/blog/648231/).
Если вы работаете с PySpark (или просто со Spark), то наверняка знаете о возможности создания пользовательских функций (user-defined functions, UDF). На данный момент PySpark позволяет использовать три вида таких функций: Python UDF, Pandas UDF, Scala UDF. Об основных отличиях и бенчмарках можно прочитатьв этой [статье](https://medium.com/quantumblack/spark-udf-deep-insights-in-performance-f0a95a4d8c62), а я лишь скажу, что для инференса моделей используем Pandas UDF.
Давайте на примере рассмотрим, как можно выполнять инференс ML-моделей с использованием PySpark Structured Streaming и Pandas UDF, а в качестве источника сообщения используем Kafka. Весь код ниже актуален для PySpark 3.X.
Для начала — небольшой ликбез по основной терминологии Kafka.Kafka — это инструмент, который позволяет работать с потоками событий. Например, есть приложение, которое пишет много логов. Хочется иметь к ним быстрый доступ, чтобы анализировать и делать какие-то выводы или просто сохранять в базу данных. Kafka в этом случае — посредник между приложением, которое пишет логи, и приложением или человеком, читающим эти логи.
Чтобы ориентироваться в Kafka-терминологии из данной статьи, необходимо знать про три вещи. На примере приложения с логами определим Producer, Consumer и Topic:
1. **Topic** показывает, где будут храниться логи в Kafka. Можно представить, что Topic — это папка, а каждый лог в нём —файл из этой папки. У каждого объекта (лога, сообщения) есть свой индекс (offset). Kafka также партиционирует топик, разбивая его на несколько частей и раскидывая по Kafka-кластеру.
2. **Producer** в данном случае будет записывать логи в Topic. Он создаётся в логируемом приложении и пишет всё, что ему скажет пользователь.
1. log = get\_log()
2. producer.produce(log, topic)
3. **Consumer** будет читать сообщения, которые находятся в топике. Он создаётся в приложении для чтения и обработки логов. При этом один топик могут читать сразу несколько консьюмеров.
Начинаем
--------
Представим, что есть Kafka-топик, куда поступает событие изменения описания товара на сайте или добавления нового. Необходимо обрабатывать все такие события и извлекать необходимую информацию из текстов. Скажем, что известна схема сообщений (protobuf-схема), которые находятся в топике (ID и описание товара), а к текстам мы хотим применять какую-то ML-модель, которая возвращает эмбеддинг из текста.
```
syntax = "proto3";
message ItemText{
int64 item_id = 1;
string item_text = 2;
}
```
Чтобы десериализовывать proto-сообщения в Python, необходимо создать .py-файл из .proto-файла. Я это делаю командой `protoc --python_out=. .proto`.
Если вы не знакомы с Protobuf, то можно перейти по [ссылке](https://developers.google.com/protocol-buffers/) — и буквально за 30 секунд понять, что это :)
Объявим функцию, которая будет создавать и возвращать текстовую модель:
```
class TextModel:
...
def predict(self, x):
# your code
return model_prediction
...
def get_text_model(**kwargs) -> TextModel:
# your code
return text_model
```
Определим функции `process_text`, которая будет добавлять колонку “embedding” к входным данным, и `get_dataframe_from_messages`, которая десериализует сообщения.
```
# types_pb2 как раз создается из .proto
from types_pb2 import ItemText
def get_dataframe_from_messages(messages: pd.Series) -> pd.DataFrame:
proto_buffer = ItemText()
schema = [
"item_id",
"item_text",
]
columns = {col: [] for col in schema}
for msg in data:
data = proto_buffer.FromString(msg)
for col in columns:
columns[col].append(getattr(data, col))
return pd.DataFrame(columns)
@F.pandas_udf("item_id int, item_text string, embedding array")
def process\_text(data: pd.Series) -> pd.DataFrame:
model = get\_text\_model(\*\*kwargs)
data = get\_dataframe\_from\_messages(data)
data["embedding"] = data["item\_text"].apply(lambda x: model.predict(x))
return data
```
Функция обработки сообщения моделью готова. Теперь нужно научиться работать с топиком и поднять Spark Session для стриминга.
Создадим сессию и подпишемся на конкретный топик:
```
spark = SparkSession.builder.getOrCreate()
df = (
spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", bootstrap_servers)
.option("subscribe", topic)
)
```
Для контроля сессии также рекомендуется выставлять дополнительные параметры. Список таких параметров доступен в [документации](https://spark.apache.org/docs/latest/structured-streaming-kafka-integration.html). Наиболее важными, на мой взгляд, являются:
* **maxOffsetsPerTrigger** — отвечает за количество сообщений, которые попадают в батч;
* **minPartitions** — указывает число партиций, на которое разбивается этот самый батч. Неправильный выбор этого параметра может значительно замедлять стриминг в micro-batch режиме.
Рассмотрим пример, когда у топика есть три партиции. Тогда по умолчанию в параметрах контекста будет `minPartitions = 3`. Это значит, что на каждый экзекутор прилетит по одной партиции, и текущий батч будет состоять из трёх задач.
Так, а что делать, если хочется повысить производительность стриминг-джобы? Какой параметр нужно изменить?
Окей, вы добавляете больше экзекуторов в Spark-приложение в надежде, что оно ускорится. К сожалению, оно не ускоряется ☹️ Что же происходит в действительности?
Добавляется один экзекутор, для которого просто нет данных, так как в параметрах контекста значение `minPartitions` выставлено по умолчанию. В итоге такой экзекутор простаивает. Можно ли тогда изменить число партиций в Kafka, чтобы оно совпадало с количеством экзекуторов? Да, так тоже можно сделать, но только если у вас есть доступ к настройкам топика 🙂
Поэтому лучше сделать по-другому: выставить значение `minPartitions = 6` и количество экзекуторов тоже 6 — тогда каждая партиция в Kafka будет разбиваться Spark’ом на две подпартиции и спокойно скейлиться на шесть экзекуторов, которые смогут параллельно выполнять задачи. Здесь важно отметить, что сами сообщения из топика не шафлятся. Драйвер просто отдаёт офсеты каждому экзекутору, где создаётся консьюмер для их чтения.
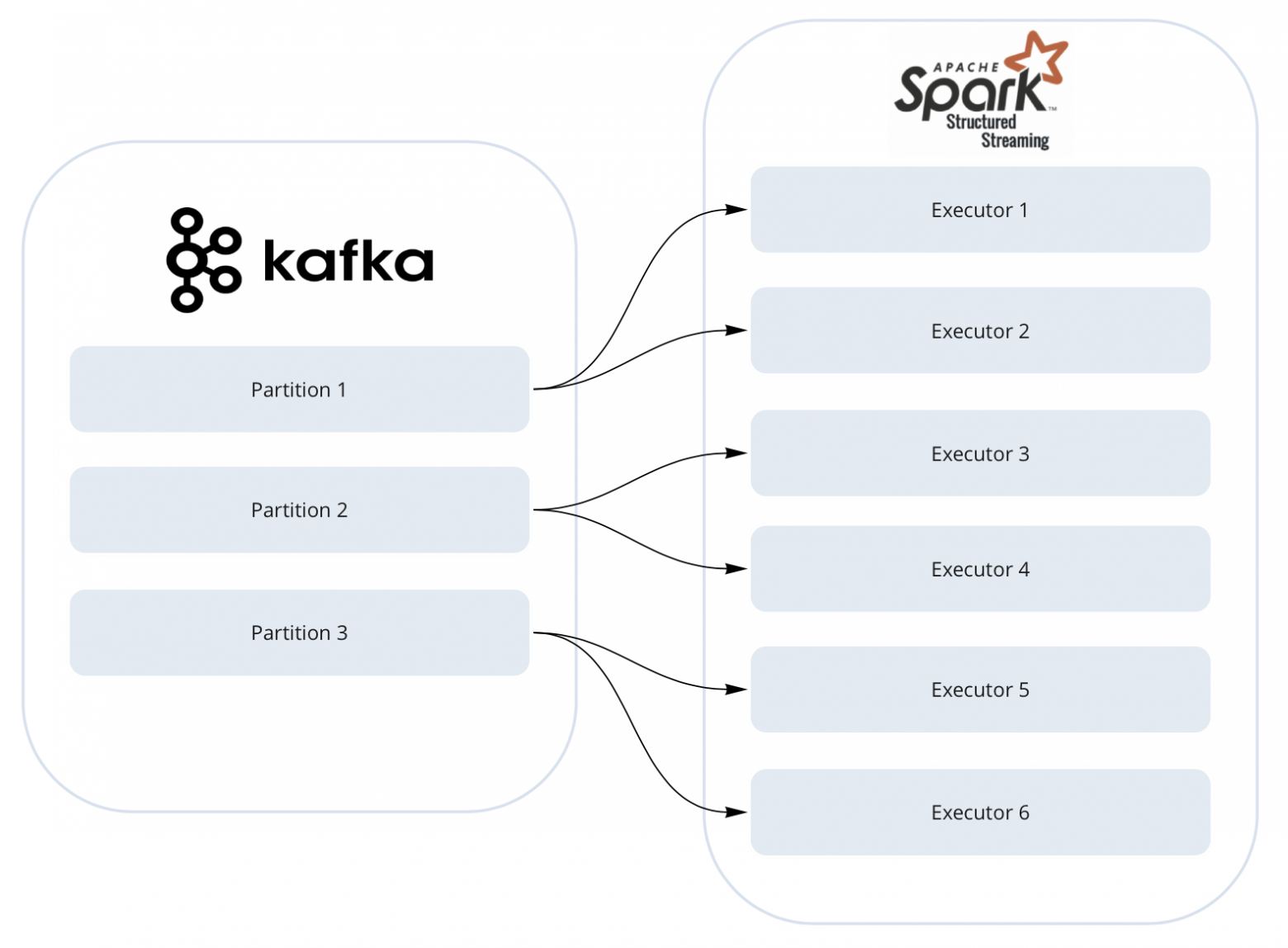Параметр `maxOffsetPerTrigger` позволяет контролировать, сколько сообщений (офсетов) из топика попадёт в текущий батч. Здесь тоже важно соблюдать баланс, так как слишком большой батч может долго обрабатываться (и в случае падения придётся его пересчитывать), а слишком маленький батч создаст много маленьких файлов, что не очень хорошо для HDFS и нагружает неймноду.
Что за неймнода?[Неймнода](https://hadoop.apache.org/docs/r1.2.1/hdfs_design.html#NameNode+and+DataNodes) на Hadoop-кластере хранит информацию о дереве файлов и директорий, а также знает, где лежит тот или иной файл. В случае если неймнода перестаёт работать, падает весь кластер :)
Зададим и применим указанные параметры:
```
kafka_params = {
"maxOffsetPerTrigger": 100_000,
"minPartitions": 6
}
for k, v in kafka_params.items():
df = df.option(k, v)
df = df.load()
```
После выполнения `load()` можно работать с `df` как с обычным DataFrame, применяя к нему привычные SQL-трансформации.
Посмотрим на схему df:
```
root
|-- key: binary (nullable = true)
|-- value: binary (nullable = true)
|-- topic: string (nullable = true)
|-- partition: integer (nullable = true)
|-- offset: long (nullable = true)
|-- timestamp: timestamp (nullable = true)
|-- timestampType: integer (nullable = true)
```
В данный момент нас интересуют сами сообщения. Они лежат в поле `value`. К этому полю мы применяем Pandas UDF. UDF вернёт структуру, которую можно распаковать через звёздочку, — и получить готовый для записи DataFrame.
```
query = (
df.withColumn("result", process_text(F.col("value").cast("binary")))
.select("result.*")
.writeStream
.foreachBatch(do_smth)
)
```
Чтобы записывать данные в HDFS или просто увидеть результат в логах, можно создать функцию, которая будет вызываться для каждого кусочка данных, и передать её в `foreachBatch`.
```
def do_smth(df, *args):
df.show(10)
```
В этой функции просто смотрим на десять строк данных, которые приезжают из Pandas UDF. Теперь метод `start()` начинает чтение из потокового источника информации (в данном случае — из Kafka-топика).
```
query = query.start()
```
Существует множество способов завершения Spark Structured Streaming — от перезагрузки кернела (в случае Jupyter Notebook) до graceful shutdown c реализацией на Scala ([тык](https://habr.com/ru/post/569898/)). В этой статье я не буду подробно разбирать каждый, а просто покажу тот, который используем мы.
```
is_stopped = False
while not is_stopped:
is_stopped = query.awaitTermination(timeout=timeout)
if not is_stopped and exists(indicator_path):
logger.info("Received stop indicator, stopping query...")
query.stop()
```
Что здесь происходит? Каждые `timeout` секунд идём в HDFS и смотрим, есть ли там файл-индикатор `indicator_path`. Как только он появляется, стриминг завершается.
Таким образом, получаем работающее Spark Structured Streaming приложение, где в качестве источника данных выступает Kafka-топик с обновлениями, а для обработки используется текстовая ML-модель.
---
#### Daemon Module
*Данный кусок относится не только к Spark Structured Streaming, но и к работе с Pandas UDF в целом.*
Внимательный читатель может заметить следующее: Pandas UDF работает батчами, размер которых контролируется через `spark.sql.execution.arrow.maxRecordsPerBatch`. Неужели на каждом батче приходится инициализировать модель заново? Хорошо, если загрузка модели занимает одну-две секунды. Но при работе с тяжёлыми моделями (например, из Hugging Face) или загрузке больших структур данных инициализация может занимать гораздо больше времени.
Да, в этом месте возникает большой оверхед, но его можно избежать :)
Было бы хорошо единожды создать объект на экзекуторе, а потом передавать ссылку на него в каждый дочерний процесс (на воркеры). Такая стратегия называется [copy-on-write](https://en.wikipedia.org/wiki/Copy-on-write). Как понятно из названия, копирование объекта происходит, только когда дочерний процесс пытается изменить объект по ссылке. Также у Spark Session есть параметр `spark.python.daemon.module`. Он указывает на модуль, который стартует при появлении нового экзекутора. Данный модуль запустится один раз на экзекуторах и форкнет процесс для запуска воркеров.
Для загрузки ML-модели как раз используем свой daemon-модуль. Чтобы организовать copy-on-write, необходимо ограничить запуск дочернего процесса [форком](https://docs.python.org/3/library/multiprocessing.html#contexts-and-start-methods), а также заимпортить модуль, в котором лежит загрузка модели.
Например, так:
```
multiprocessing.set_start_method("fork")
module = importlib.import_module(module_path)
```
Важно, чтобы при импорте модуля сама загрузка модели триггернулась.
Затем кладём в [кэш](https://docs.python.org/3/reference/import.html#the-module-cache) импортированный модуль через sys.modules:
```
sys.modules[module_name] = module
```
Теперь можно запустить стандартный [daemon manager](https://github.com/apache/spark/blob/master/python/pyspark/daemon.py#L85), который будет форкать родительский процесс. При этом пространство `sys.modules` у дочерних процессов будет идентично родительскому.
После этого можно импортировать нужную модель прямо из модуля, избегая процесса её инициализации (благодаря [системе импортов в Python](https://docs.python.org/3/reference/import.html#the-import-system), когда первым делом проверяется `sys.modules`).
```
@F.pandas_udf("item_id int, item_text string, embedding array")
def process\_text(data: pd.Series) -> pd.DataFrame:
from daemon\_module import model
data = get\_dataframe\_from\_messages(data)
data["embedding"] = data["item\_text"].apply(lambda x: model.predict(x))
return data
```
Таким образом можно реализовать потоковую обработку данных в PySpark с использованием Pandas UDF. Такой подход позволяет не только ускорить инициализацию модели, но и уменьшить потребление памяти (!), поскольку все дочерние процессы используют объект из родительского процесса без копирования.
---
Что в итоге
-----------
Так, обработка данных происходит постоянно, а затраты памяти не зависят от количества новых и обновившихся товаров, поскольку есть ограничение на число объектов сверху в одном батче (`maxOffsetsPerTrigger`). При возникновении большого лага (в топик идёт слишком много товаров, стриминг не успевает их обработать) можно увеличить количество экзекуторов, тем самым ускорив обработку батча.
Но как определить, что лаг увеличивается или уменьшается? :/ Можно воспользоваться стандартными средствами Spark UI. Идём в Application Master и видим такую картину:
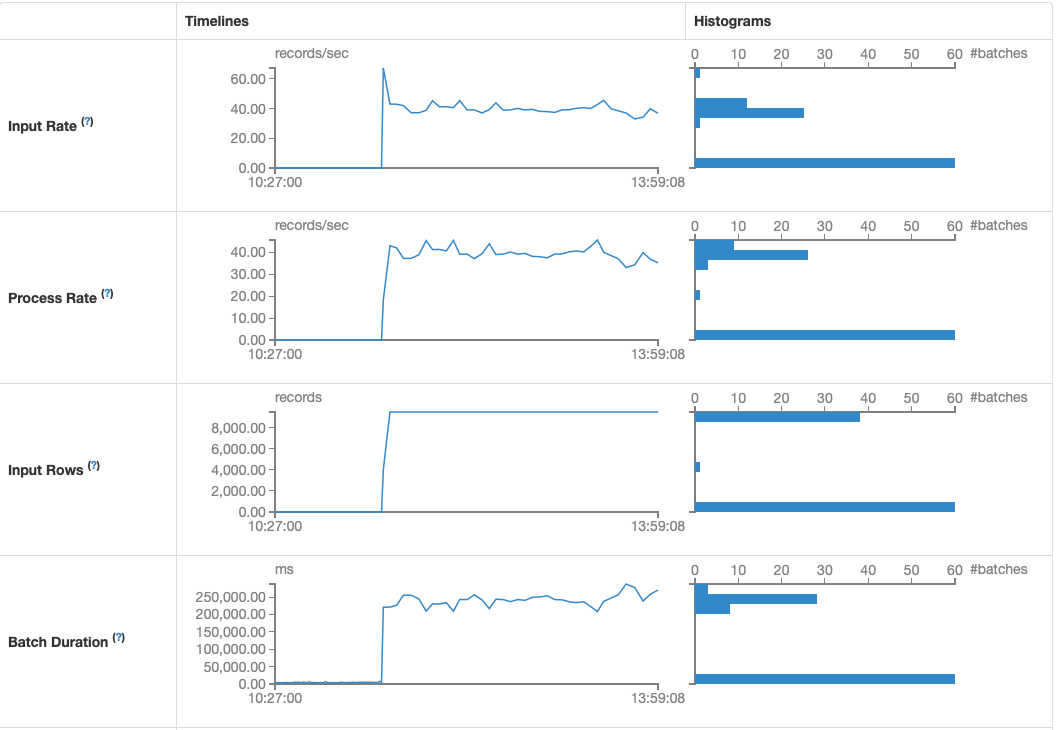Окей, вроде понятно, че-то считаем :)
Но как быть, если хотим сделать мониторинг стриминга в Grafana или, например, алерты, которые скажут о критическом значении лага для консьюмера в топике? Об этом поговорим во второй части 👋
#### Полезные материалы
1. [Дока по Spark Structured Streaming](https://spark.apache.org/docs/latest/structured-streaming-programming-guide.html#overview)
2. [Интеграция с Kafka](https://spark.apache.org/docs/latest/structured-streaming-kafka-integration.html)
3. [Про память в Spark приложениях](https://medium.com/analytics-vidhya/apache-spark-memory-management-49682ded3d42) (немного оффтоп, но если часто работаете со Спарком — тут много полезной инфы)
> А пока приглашаю вас на **открытый Data Science Meetup** в апреле, где обсудим мироустройство DS в крупной IT-компании.
>
> Следите за анонсами здесь, в [Телеграме](https://t.me/ozon_tech) или на [Таймпеде](https://ozontech.timepad.ru/events/) и приходите в гости!
>
> | https://habr.com/ru/post/656883/ | null | ru | null |
# Простой симулятор лидара автомобильного базирования на Unity
Хотите просто и быстро получить данные трехмерного сканирования улицы? Нет желания тратить тысячи долларов на покупку лидара? Давайте я предложу вам попробовать симулятор!
Все знают, что главная цель бережливого стартапа - дать умереть проекту как можно раньше. Без мучений. Если будет крохотный шанс, то можно получить финансирование и жить дальше долго и счастливо. Я участвовал в проекте лидарного картографирования, где руководство не торопилось покупать дорогую технику. Перед тем как начать работать с реальным железом, я предложил попробовать свои силы на симуляторах данных, проверить узкие места. Идея проекта - устанавливать лидар на автомобиль и сканировать городскую инфраструктуру в реальном времени. Немного об этой задаче я рассказывал в [предыдущей статье](https://habr.com/ru/post/582926/). В начале проекта возникали следующие вопросы: сколько каналов должно быть в лидаре? Какой угол установки? Какой алгоритм лучше справится в реальном времени или близком к нему?
Попробуем сформулировать требования для софта, который помог бы ответить на эти вопросы:
* Размещение лидара на автомобиле.
* Opensource, мало ли что надо подкрутить.
* Популярная 3D-платформа для визуализации, не надо экзотики.
* Простой в редактировании окружающей обстановки - добавляем людей, животных, машин. Статические и динамические объекты.
* Не привязан к конкретному производителю лидара, мы пока не определились.
Какие есть на просторах сети симуляторы с наличием лидарной обстановки:
* [CARLA Simulator](https://carla.org/). Хардкорный симулятор на базе Unreal Engine. На хабре попадалась [статья о нем](https://habr.com/ru/company/pvs-studio/blog/590305/). Детально моделирует окружающую обстановку для беспилотного авто. Для моей узкой задачи - явный перебор.
* [LGSVL](https://www.svlsimulator.com/). С 1 января заброшенный проект от компании LG. Когда [открываешь документацию](https://www.svlsimulator.com/docs/), то становиться не по себе. Надо очень много страдать, чтобы это всё запустить на локальной машине. Сделан на базе движка Unity.
* [Airsim](https://microsoft.github.io/AirSim/). Перспективный Unreal-симулятор для дронов. Можно подключать разнообразные примочки, достаточно удобно скачиваются модели городов и подключаются к движку. На хабре давным-давно её уже [упоминали](https://habr.com/ru/post/401639/). Неплохая вещь, правда больше заточена под дроны, а не автомобили и есть только оффлайновый редактор сцен.
* [Gazebo](https://github.com/ntnu-arl/lidar_simulator). Ну если вы начнёте на ROS моделировать лидар, то та же система будет работать и в реальном окружении. Мы пока не определились с экосистемой, поэтому переезжать на ROS будет тяжело, придётся много кодировать и допиливать.
Для нашего случая я обнаружил [простенький лидарный симулятор](https://github.com/ptibom/Lidar-Simulator) для авто. Мне он понравился тем, что написан на Unity и сразу завёлся. После запуска встречает двухрежимный интерфейс - редактирование сцены и запуск симуляции. Элементарно. Пришлось движок доработать под себя в [этом форке](https://github.com/antlas1/Lidar-Simulator). Я добавил управление наклонами платформы для установки лидара, а также вывод в результирующий CSV углов эйлера.
Вы можете собрать проект из исходников (я проверял под Windows) или взять уже [готовый бинарник в релизах](https://github.com/antlas1/Lidar-Simulator/releases/download/first/build.7z). Давайте подробнее остановимся на интерфейсе. После запуска `LidarSimulator.exe` нажимаем кнопку `Simulation` и попадаем в режим редактирования.
Основные настройки в нижней части экрана для лидарного датчика. Вверху находится ползунок, который определяет частоту выдачи облаков точек. Для добавления динамических объектов, двигающихся по маршруту, надо нажать кнопку с человечком-велосипедом. Порядок работы простой:
1. Выбор объекта на ленте, ЛКМ
2. Выбор места на сцена, ЛКМ
3. Выбор угла установки, ЛКМ
4. Установка маршрута планеткой, каждая точка ЛКМ, по завершению ПКМ
Для добавления статических объектов выбрать нижнюю иконку с домом. Расставляются аналогично динамическим, за исключением маршрута.
Для запуска имитации нажать кнопку Play.
Чтобы увидеть изображение облаков точек, необходимо нажать кнопку вверху "Point Cloud". Автомобилем можно управлять как в игре. Основные команды:
* W,A,S,D - движение вперед, влево, назад, вправо.
* R,F - управление креном.
* T,G - управление тангажом.
* Z - сброс в 0 всех углов.
После окончания симуляции нажать Stop, для приостановки Pause.
Сохранение облаков происходит автоматически после старта симуляции. Для того, чтобы их экспортировать в текстовый файл необходимо остановить симуляцию и нажать кнопку с иконкой папка в левом нижнем углу. Затем выбрать место сохранения и имя файла. Пример выдачи:
| Time | x | y | z | radius | inclination | azimuth | laserId | roll | yaw | pitch |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 9,6552 | -15,87924 | 2,004592 | -2,004201 | 155,0499 | 157,1568 | 1,968 | 36 | 0 | 0 | 0 |
| 9,6552 | -16,65221 | 2,102172 | -2,0042 | 155,0499 | 157,1568 | 1,968 | 37 | 0 | 0 | 0 |
| 9,6552 | -17,50305 | 2,209582 | -2,004201 | 155,0499 | 157,1568 | 1,968 | 38 | 0 | 0 | 0 |
| 9,6552 | -18,44423 | 2,328396 | -2,004199 | 155,0499 | 157,1568 | 1,968 | 39 | 0 | 0 | 0 |
Для компиляции оригинальной версии использовался Unity 5.6, после адаптации работает на Unity 2019.4.10f1.
В результате у меня получился компактный инструмент, который хорошо справился с проверкой гипотез лидарного проекта. Я отработал построение карты для разного количества лучей и нескольких вариантов углов установки. На самом деле, если используются алгоритмы SLAM, то надо устанавливать лидар параллельно дорожному полотну чтобы "зацепление" между облаками точек было лучше.
Кому интересно, вот ссылка на мой форк [на гитхаб](https://github.com/antlas1/Lidar-Simulator). | https://habr.com/ru/post/680212/ | null | ru | null |
# Высокая производительность и нативное партиционирование: Zabbix с поддержкой TimescaleDB
Zabbix — это система мониторинга. Как и любая другая система, она сталкивается с тремя основными проблемами всех систем мониторинга: сбор и обработка данных, хранение истории, ее очистка.
Этапы получения, обработки и записи данных занимают время. Немного, но для крупной системы это может выливаться в большие задержки. Проблема хранения — это вопрос доступа к данным. Они используются для отчетов, проверок и триггеров. Задержки при доступе к данным также влияют на производительность. Когда БД разрастаются, неактуальные данные приходится удалять. Удаление — это тяжелая операция, которая также съедает часть ресурсов.

Проблемы задержек при сборе и хранении в Zabbix решаются кэшированием: несколько видов кэшей, кэширование в БД. Для решения третьей проблемы кэширование не подходит, поэтому в Zabbix применили TimescaleDB. Об этом расскажет **Андрей Гущин** — инженер технической поддержки [Zabbix SIA](https://habr.com/ru/company/zabbix/). В поддержке Zabbix Андрей больше 6 лет и напрямую сталкивается с производительностью.
Как работает TimescaleDB, какую производительность может дать по сравнению с обычным PostgreSQL? Какую роль играет Zabbix для БД TimescaleDB? Как запустить с нуля и как мигрировать с PostgreSQL и производительность какой конфигурации лучше? Обо всем этом под катом.
Вызовы производительности
-------------------------
Каждая система мониторинга встречается с определенными вызовами производительности. Я расскажу о трех из них: сбор и обработка данных, хранение, очистка истории.
**Быстрый сбор и обработка данных.** Хорошая система мониторинга должна оперативно получать все данные и обрабатывать их согласно триггерным выражениям — по своим критериям. После обработки система должна также быстро сохранить эти данные в БД, чтобы позже их использовать.
**Хранение истории.** Хорошая система мониторинга должна хранить историю в БД и предоставлять удобный доступ к метрикам. История нужна, чтобы использовать ее в отчетах, графиках, триггерах, пороговых значениях и вычисляемых элементах данных для оповещения.
**Очистка истории.** Иногда наступает день, когда вам не нужно хранить метрики. Зачем вам данные, которые собраны за 5 лет назад, месяц или два: какие-то узлы удалены, какие-то хосты или метрики уже не нужны, потому что устарели и перестали собираться. Хорошая система мониторинга должна хранить исторические данные и время от времени их удалять, чтобы БД не разрослась.
> Очистка устаревших данных — острый вопрос, который сильно отражается на производительности базы данных.
Кэширование в Zabbix
--------------------
В Zabbix первый и второй вызовы решены с помощью кэширования. Для сбора и обработки данных используется оперативная память. Для хранения — истории в триггерах, графиках и вычисляемых элементах данных. На стороне БД есть определенное кэширование для основных выборок, например, графиков.
Кэширование на стороне самого Zabbix-сервера это:
* ConfigurationCache;
* ValueCache;
* HistoryCache;
* TrendsCache.
Рассмотрим их подробнее.
### ConfigurationCache
Это основной кэш, в котором мы храним метрики, хосты, элементы данных, триггеры — все, что нужно для PreProcessing и для сбора данных.
Все это хранится в ConfigurationCache, чтобы не создавать лишних запросов в БД. После старта сервера мы обновляем этот кэш, создаем и периодически обновляем конфигурации.
### Сбор данных
Схема достаточно большая, но основное в ней — это **сборщики**. Это различные «pollers» — процессы сборки. Они отвечают за разные виды сборки: собирают данные по SNMP, IPMI, и передают это все на PreProcessing.
*Сборщики обведены оранжевой линией.*
В Zabbix есть вычисляемые агрегационные элементы данных, которые нужны, чтобы агрегировать проверки. Если у нас они есть, мы забираем данные для них напрямую из ValueCache.
### PreProcessing HistoryCache
Все сборщики используют ConfigurationCache, чтобы получать задания. Дальше они передают их на PreProcessing.
PreProcessing использует ConfigurationCache, чтобы получать шаги PreProcessing. Он обрабатывает эти данные различными способами.
После обработки данных с помощью PreProcessing, сохраняем их в HistoryCache, чтобы обработать. На этом заканчивается сбор данных и мы переходим к главному процессу в Zabbix — **history syncer**, так как это монолитная архитектура.
*Примечание: PreProcessing достаточно тяжелая операция. С v 4.2 он вынесен на proxy. Если у вас очень большой Zabbix с большим количеством элементов данных и частотой сбора, то это сильно облегчает работу.*
### ValueCache, history & trends cache
> History syncer — это главный процесс, который атомарно обрабатывает каждый элемент данных, то есть каждое значение.
History syncer берет значения из HistoryCache и проверяет в Configuration наличие триггеров для вычислений. Если они есть — вычисляет.
History syncer создает событие, эскалацию, чтобы создать оповещения, если требуется по конфигурации, и записывает. Если есть триггеры для последующей обработки, то это значение он запоминает в ValueCache, чтобы не обращаться в таблицу истории. Так ValueCache наполняется данными, которые необходимы для вычисления триггеров, вычисляемых элементов.
History syncer записывает все данные в БД, а она — в диск. Процесс обработки на этом заканчивается.
### Кэширование в БД
На стороне БД есть различные кэши, когда вы хотите смотреть графики или отчеты по событиям:
* `Innodb_buffer_pool` на стороне MySQL;
* `shared_buffers` на стороне PostgreSQL;
* `effective_cache_size` на стороне Oracle;
* `shared_pool` на стороне DB2.
Есть еще много других кэшей, но это основные для всех БД. Они позволяют держать в оперативной памяти данные, которые часто необходимы для запросов. У них свои технологии для этого.
### Производительность БД критически важна
Zabbix-сервер постоянно собирает данные и записывает их. При перезапуске он тоже читает из истории для наполнения ValueCache. Скрипты и отчеты использует **Zabbix API**, который построен на базе Web-интерфейса. Zabbix API обращается в базу данных и получает необходимые данные для графиков, отчетов, списков событий и последних проблем.

Для визуализации — **Grafana**. Среди наших пользователей это популярное решение. Она умеет напрямую отправлять запросы через Zabbix API и в БД, и создает определенную конкурентность для получения данных. Поэтому нужна более тонкая и хорошая настройка БД, чтобы соответствовать быстрой выдаче результатов и тестирования.
Housekeeper
-----------
Третий вызов производительности в Zabbix — это очистка истории с помощью Housekeeper. Он соблюдает все настройки — в элементах данных указано, сколько хранить динамику изменений (трендов) в днях.
TrendsCache мы вычисляем на лету. Когда поступают данные, мы их агрегируем за один час и записываем в таблицы для динамики изменений трендов.
Housekeeper запускается и удаляет информацию из БД обычными «selects». Это не всегда эффективно, что можно понять по графикам производительности внутренних процессов.
Красный график показывает, что History syncer постоянно занят. Оранжевый график сверху — это Housekeeper, который постоянно запускается. Он ждет от БД, когда она удалит все строки, которые он задал.
Когда стоит отключить Housekeeper? Например, есть «Item ID» и нужно удалить последние 5 тысяч строк за определенное время. Конечно, это происходит по индексам. Но обычно dataset очень большой, и БД все равно считывает с диска и поднимает в кэш. Это всегда очень дорогая операция для БД и, в зависимости от размеров базы, может приводить к проблемам производительности.

Housekeeper просто отключить. В Web-интерфейсе есть настройка в «Administration general» для Housekeeper. Отключаем внутренний Housekeeping для внутренней истории трендов и он больше не управляет этим.
Housekeeper отключили, графики выровнялись — какие в этом случае могут быть проблемы и что может помочь в решении третьего вызова производительности?
Partitioning — секционирование или партиционирование
----------------------------------------------------
Обычно партиционирование настраивается различным способом на каждой реляционной БД, которые я перечислил. У каждой своя технология, но они похожи, в целом. Создание новой партиции часто приводит к определенным проблемам.
Обычно партиции настраивают в зависимости от «setup» — количества данных, которые создаются за один день. Как правило, Partitioning выставляют за один день, это минимум. Для трендов новой партиции — за 1 месяц.
Значения могут изменяться в случае очень большого «setup». Если малый «setup» — это до 5 000 nvps (новых значений в секунду), средний — от 5 000 до 25 000, то большой — выше 25 000 nvps. Это большие и очень большие инсталляции, которые требуют тщательной настройки именно базы данных.
На очень больших инсталляциях отрезок в один день может быть не оптимальным. Я видел на MySQL партиции по 40 ГБ и больше за день. Это очень большой объем данных, который может приводить к проблемам, и его нужно уменьшать.
### Что дает Partitioning?
**Секционирование таблиц**. Часто это отдельные файлы на диске. План запросов более оптимально выбирает одну партицию. Обычно партиционирование используется по диапазону — для Zabbix это тоже верно. Мы используем там «timestamp» — время с начала эпохи. У нас это обычные числа. Вы задаете начало и конец дня — это партиция.
**Быстрое удаление** — `DELETE`. Выбирается один файл/субтаблица, а не выборка строк на удаление.
**Заметно ускоряет выборку данных** `SELECT` — использует одну или более партиций, а не всю таблицу. Если вы обращаетесь за данными двухдневной давности, они выбираются из БД быстрее, потому что нужно загрузить в кэш и выдать только один файл, а не большую таблицу.
Зачастую многие БД также ускоряет `INSERT` — вставки в child-таблицу.
TimescaleDB
-----------
Для v 4.2 мы обратили внимание на TimescaleDB. Это расширение для PostgreSQL с нативным интерфейсом. Расширение эффективно работает с time series данными, при этом не теряя преимуществ реляционных БД. TimescaleDB также автоматически партицирует.
В TimescaleDB есть понятие **гипертаблица** (hypertable), которую вы создаете. В ней находятся **чанки** — партиции. Чанки — это автоматически управляемые фрагменты гипертаблицы, который не влияет на другие фрагменты. Для каждого чанка свой временной диапазон.
### TimescaleDB vs PostgreSQL
TimescaleDB работает действительно эффективно. Производители расширения утверждают, что они используют более правильный алгоритм обработки запросов, в частности, `inserts`. Когда размеры dataset-вставки растут, алгоритм поддерживает постоянную производительность.
После 200 млн строк PostgreSQL обычно начинает сильно проседать и теряет производительность до 0. TimescaleDB позволяетэффективно вставлять «inserts» при любом объеме данных.
### Установка
Установить TimescaleDB достаточно просто для любых пакетов. В [документации](https://docs.timescale.com/v1.3/getting-started) все подробно описано — он зависит от официальных пакетов PostgreSQL. TimescaleDB также можно собрать и скомпилировать вручную.
Для БД Zabbix мы просто активируем расширение:
```
echo "CREATE EXTENSION IF NOT EXISTS timescaledb CASCADE;" | sudo -u postgres psql zabbix
```
Вы активируете `extension` и создаете его для БД Zabbix. Последний шаг — создание гипертаблицы.
### Миграция таблиц истории на TimescaleDB
Для этого есть специальная функция `create_hypertable`:
```
SELECT create_hypertable(‘history’, ‘clock’, chunk_time_interval => 86400, migrate_data => true);
SELECT create_hypertable(‘history_unit’, ‘clock’, chunk_time_interval => 86400, migrate_data => true);
SELECT create_hypertable(‘history_log’, ‘clock’, chunk_time_interval => 86400, migrate_data => true);
SELECT create_hypertable(‘history_text’, ‘clock’, chunk_time_interval => 86400, migrate_data => true);
SELECT create_hypertable(‘history_str’, ‘clock’, chunk_time_interval => 86400, migrate_data => true);
SELECT create_hypertable(‘trends’, ‘clock’, chunk_time_interval => 86400, migrate_data => true);
SELECT create_hypertable(‘trends_unit’, ‘clock’, chunk_time_interval => 86400, migrate_data => true);
UPDATE config SET db_extension=’timescaledb’, hk_history_global=1, hk_trends_global=1
```
У функции три параметра. Первый — **таблица в БД**, для которой нужно создать гипертаблицу. Второй — **поле**, по которому надо создать `chunk_time_interval` — интервал чанков партиций, которые нужно использовать. В моем случае интервал это один день — 86 400.
Третий параметр — `**migrate\_data**`. Если выставить `true`, то все текущие данные переносятся в заранее созданные чанки. Я сам использовал `migrate_data`. У меня было около 1 ТБ, что заняло больше часа. Даже в каких-то случаях при тестировании я удалял необязательные к хранению исторические данные символьных типов, чтобы их не переносить.
Последний шаг — `**UPDATE**`: в `db_extension` ставим `timescaledb`, чтобы БД понимала, что есть это расширение. Zabbix его активирует и правильно использует синтаксис и запросы уже к БД — те фичи, которые необходимы для TimescaleDB.
Конфигурация железа
-------------------
Я использовал два сервера. Первый — **VMware-машина**. Она достаточно маленькая: 20 процессоров Intel® Xeon® CPU E5-2630 v 4 @ 2.20GHz, 16 ГБ оперативной памяти и SSD-диск на 200 ГБ.
Я установил на ней PostgreSQL 10.8 с ОС Debian 10.8-1.pgdg90+1 и файловой системой xfs. Все минимально настроил, чтобы использовать именно эту базу данных, за вычетом того, что будет использовать сам Zabbix.
На этой же машине стоял Zabbix-сервер, PostgreSQL и **нагрузочные агенты**. У меня было 50 активных агентов, которые использовали `LoadableModule`, чтобы очень быстро генерировать различные результаты: числа, строки. Я забивал базу большим количеством данных.
Изначально конфигурация содержала **5 000 элементов** данных на каждый хост. Почти каждый элемент содержал триггер, чтобы это было схоже с реальными инсталляциями. В некоторых случаях было больше одного триггера. На один узел сети приходилось **3 000-7 000 триггеров**.
Интервал обновления элементов данных — **4-7 секунд**. Саму нагрузку я регулировал тем, что использовал не только 50 агентов, но добавлял еще. Также, с помощью элементов данных я динамических регулировал нагрузку и снижал интервал обновления до 4 с.
### PostgreSQL. 35 000 nvps
Первый запуск на этом железе у меня был на чистом PostgreSQL — 35 тыс значений в секунду. Как видно, вставка данных занимает фракции секунды — все хорошо и быстро. Единственное, что SSD диск на 200 ГБ быстро заполняется.

Это стандартный dashboard производительности Zabbix — сервера.

Первый голубой график — количество значений в секунду. Второй график справа — загрузка процессов сборки. Третий — загрузка внутренних процессов сборки: history syncers и Housekeeper, который здесь выполнялся достаточное время.
Четвертый график показывает использование HistoryCache. Это некий буфер перед вставкой в БД. Зеленый пятый график показывает использование ValueCache, то есть сколько хитов ValueCache для триггеров — это несколько тысяч значений в секунду.
### PostgreSQL. 50 000 nvps
Дальше я увеличил нагрузку до 50 тыс значений в секунду на этом же железе.
При загрузке с Housekeeper вставка 10 тыс значений записывалась 2-3 с.

*Housekeeper уже начинает мешать работе.*
По третьему графику видно, что, в целом, загрузка трапперов и history syncers пока еще на уровне 60%. На четвертом графике HistoryCache во время работы Housekeeper уже начинает достаточно активно заполняться. Он заполнился на 20% — это около 0,5 ГБ.
### PostgreSQL. 80 000 nvps
Дальше я увеличил нагрузку до 80 тыс значений в секунду. Это примерно 400 тыс элементов данных и 280 тыс триггеров.

*Вставка по загрузке тридцати history syncers уже достаточно высокая.*
Также я увеличивал различные параметры: history syncers, кэши.
На моем железе загрузка history syncers увеличивалась до максимума. HistoryCache быстро заполнился данными — в буфере накопились данные для обработки.
Все это время я наблюдал, как используется процессор, оперативная память и другие параметры системы, и обнаружил, что утилизация дисков была максимальна.

Я добился использования **максимальных возможностей диска** на этом железе и на этой виртуальной машине. При такой интенсивности PostgreSQL начал сбрасывать данные достаточно активно, и диск уже не успевал работать на запись и чтение.
### Второй сервер
Я взял другой сервер, который имел уже 48 процессоров и 128 ГБ оперативной памяти. Затюнинговал его — поставил 60 history syncer, и добился приемлемого быстродействия.
Фактически, это уже предел производительности, где необходимо что-то предпринимать.
### TimescaleDB. 80 000 nvps
Моя главная задача — проверить возможности TimescaleDB от нагрузки Zabbix. 80 тыс значений в секунду — это много, частота сбора метрик (кроме Яндекса, конечно) и достаточно большой «setup».
На каждом графике есть провал — это как раз миграция данных. После провалов в Zabbix-сервере профиль загрузки history syncer очень сильно изменился — упал в три раза.
> TimescaleDB позволяет вставлять данные практически в 3 раза быстрее и использовать меньше HistoryCache.
Соответственно, у вас своевременно будут поставляться данные.
### TimescaleDB. 120 000 nvps
Дальше я увеличил количество элементов данных до 500 тыс. Главная задача была проверить возможности TimescaleDB — я получил расчетное значение 125 тыс значений в секунду.
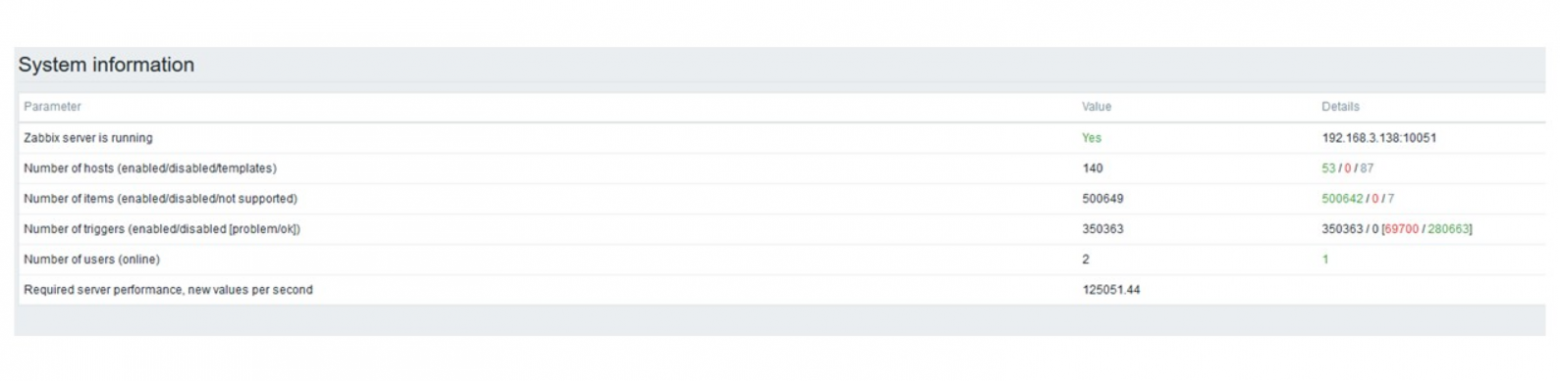
Это рабочий «setup», который может долго работать. Но так как мой диск был всего на 1,5 ТБ, то я его заполнил за пару дней.
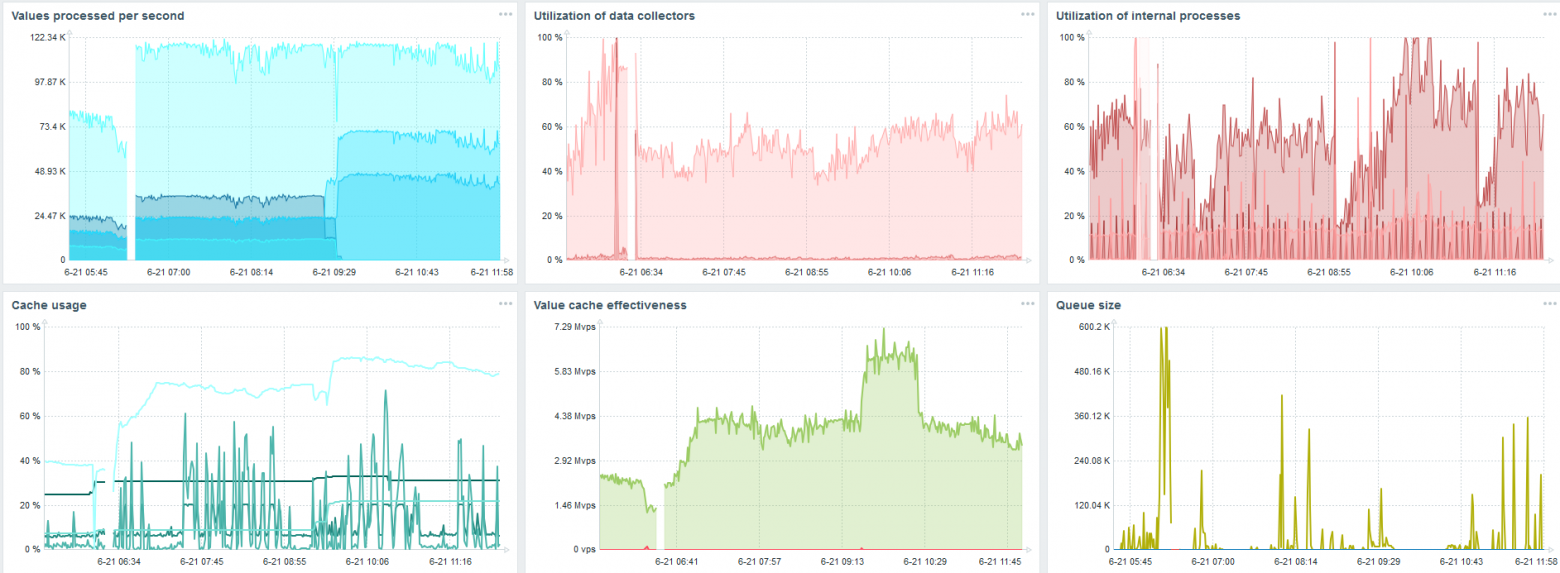
Самое важное, что в это же время создавались новые партиции TimescaleDB.
Для производительности это совершенно незаметно. Когда создаются партиции в MySQL, например, все иначе. Обычно это происходит ночью, потому что блокирует общую вставку, работу с таблицами и может создавать деградацию сервиса. В случае с TimescaleDB этого нет.
Для примера покажу один график из множества в community. На картинке включен TimescaleDB, благодаря этому загрузка по использованию io.weight на процессоре упала. Использование элементов внутренних процессов тоже снизилось. Причем это обычная виртуалка на обычных блинных дисках, а не SSD.

Выводы
------
**TimescaleDB хорошее решение для маленьких «setup»**, которые упираются в производительность диска. Оно позволит неплохо продолжать работать до миграции БД на железо побыстрее.
TimescaleDB прост в настройке, дает прирост производительности, хорошо работает с Zabbix и **имеет преимущества по сравнению с PostgreSQL**.
Если вы применяете PostgreSQL и не планируете его менять, то рекомендую **использовать PostgreSQL с расширением TimescaleDB в связке с Zabbix**. Это решение эффективно работает до средних «setup».
> Говорим «высокая производительность» — подразумеваем [HighLoad++](https://www.highload.ru/moscow/2019). Ждать, чтобы познакомиться с технологиями и практиками, позволяющими сервисам обслуживать миллионы пользователей, совсем недолго. Список [докладов](https://www.highload.ru/moscow/2019/abstracts) на 7 и 8 ноября мы уже составили, а вот [митапы](https://www.highload.ru/moscow/2019/meetups) еще можно предложить.
>
>
>
> Подписывайтесь на нашу [рассылку](http://eepurl.com/VYVaf) и [telegram](https://t.me/HighLoadChannel), в которых мы раскрываем фишки предстоящей конференции, и узнайте, как извлечь максимум пользы.
>
> | https://habr.com/ru/post/470902/ | null | ru | null |
# Генератор случайных двумерных пещер
Предисловие
-----------
Если вы тоже ~~ленитесь~~ заботитесь о своём времени, делая уровень для своей игры, то вы попали куда надо.
Эта статья подробно расскажет вам как можно использовать один из [множества других](https://habr.com/post/321210/) методов генерации на примере горной местности и пещер. Мы будем рассматривать алгоритм *Олдоса-Бродера* и то, как сделать сгенерированную пещеру красивее.
По завершении чтения статьи у вас должно получиться что-то такое:
**Итог**
Теория
------
#### Гора
Если честно, то пещеру можно сгенерировать и на пустом месте, но ведь это будет как-то некрасиво? В роли *«площадки»* для размещения шахт я выбрал горный массив.
Эта гора генерируется достаточно просто: пускай у нас будет *двумерный массив* и *переменная высоты*, изначально равная половине длины *массива* по второму измерению; мы просто пройдемся по его столбикам и будем заполнять чем-то все строчки в столбике до значения *переменной высоты*, изменяя ее со случайным шансом в большую или меньшую сторону.
#### Пещера
Для генерации самих подземелий я выбрал — *как мне показалось* — отличный алгоритм. Простым языком его можно объяснить так: пускай у нас будут две (можно даже десять) переменные **X** и **Y**, и двумерный массив 50 на 50, мы задаем этим переменным случайные значения в пределах нашего массива, например, **X = 26**, а **Y = 28**. После чего мы некоторое количество раз делаем однообразные действия: получаем случайное число от нуля до 
, в нашем случае до *четырех*; а потом в зависимости от выпавшего числа меняем
наши переменные:
```
switch (Random.Range(0, 4))
{
case 0: X += 1; break;
case 1: X -= 1; break;
case 2: Y += 1; break;
case 3: Y -= 1; break;
}
```
Потом мы, разумеется, проверяем не выпала-ли какая-нибудь переменная за границы нашего поля:
```
X = X < 0 ? 0 :
(X >= 50 ? 49 : X);
Y = Y < 0 ? 0 :
(Y >= 50 ? 49 : Y);
```
После всех этих проверок, мы в новых значениях **X** и **Y** для нашего массива что-нибудь выполняем *(например: прибавляем к элементу единицу)*.
```
array[X, Y] += 1;
```
Подготовка
----------
Давайте для простоты реализации и наглядности наших методов мы будем рисовать получившиеся объекты? Я так рад, что вы не против! Мы будем делать это с помощью [Texture2D](https://docs.unity3d.com/ScriptReference/Texture2D.html).
Для работы нам потребуется всего два скрипта:
> **ground\_libray** — это то, вокруг чего будет крутиться статья. Тут мы и генерируем, и чистим, и рисуем
> **ground\_generator** — это то, что будет пользоваться нашим ground\_libray
Пускай первый будет *статичным* и ни от чего не будет наследоваться:
```
public static class ground_libray
```
А второй обычный, только метод **Update** нам не понадобится.
Так же давайте создадим на сцене игровой объект, с компонентом **SpriteRenderer**
Практическая часть
------------------
#### Из чего всё состоит?
Для работы с данными мы будем использовать двумерный массив. Можно взять массив разных типов, от **byte** или **int**, до **Color**, но я считаю, что сделать так будет лучше всего:
**Новый тип**Эту штуку мы пишем в **ground\_libray**.
```
[System.Serializable]
public class block
{
public float[] color = new float[3];
public block(Color col)
{
color = new float[3]
{
col.r,
col.g,
col.b
};
}
}
```
Объясню это тем, что это позволит нам как *сохранять* наш массив, так и *модифицировать* его, если будет нужно.
#### Горный массив
Давайте, прежде чем начнем генерировать гору, обозначим место, где мы будем ее *хранить*.
В скрипте **ground\_generator** я написал так:
```
public int ground_size = 128;
ground_libray.block[,] ground;
Texture2D myT;
```
**ground\_size** — размер нашего поля (то есть массив будет состоять из 16384-х элементов).
**ground\_libray.block[,]** *ground* — это и есть наше поле для генерации.
**Texture2D** *myT* — это то, на чем мы будем рисовать.
**Как это будет работать?**Принцип работы у нас будет такой — мы будем вызывать какие-нибудь методы **ground\_libray** из **ground\_generator**, отдавая первому наше поле **ground**.
Давайте создадим первый метод в скрипте ground\_libray:
**Создание горы**
```
public static float mount_noise = 0.02f;
public static void generate_mount(ref block[,] b)
{
int h_now = b.GetLength(1) / 2;
for (int x = 0; x < b.GetLength(0); x++)
for (int y = 0; y < h_now; y++)
{
b[x, y] = new block(new Color(0.7f, 0.4f, 0));
h_now +=
Random.value > (1.0f - mount_noise) ?
(Random.value > 0.5 ? 1 : -1) : 0;
}
}
```
И сразу же попытаемся понять, что тут происходит: как я уже сказал, мы просто пробегаемся по столбикам нашего массива **b**, параллельно изменяя переменную высоты **h\_now**, которая изначально была равна половине **128** *(64)*. Но есть тут еще кое-что новое — **mount\_noise**. Это переменная отвечает за шанс смены **h\_now**, ибо если менять высоту очень часто, то гора будет смотреться как *расческа*.
**Цвет**Я сразу задал слегка *коричневатый* цвет, пускай хотя бы какой-нибудь будет — в дальнейшем он нам не понадобится.
Теперь давайте перейдем в **ground\_generator** и в методе **Start** напишем вот это:
```
ground = new ground_libray.block
[ground_size, ground_size];
ground_libray.generate_mount(ref ground);
```
Мы инициализируем переменную **ground** ~~когда-то это нужно было сделать~~.
После без объяснений отправляем ее **ground\_libray-ю**.
Так мы сгенерировали гору.
#### Почему я не вижу свою гору?
Давайте теперь нарисуем то, что у нас получилось!
Для рисования мы напишем в нашем **ground\_libray** такой метод:
**Рисование**
```
public static void paint(block[,] b, ref Texture2D t)
{
t = new Texture2D(b.GetLength(0), b.GetLength(1));
t.filterMode = FilterMode.Point;
for (int x = 0; x < b.GetLength(0); x++)
for (int y = 0; y < b.GetLength(1); y++)
{
if (b[x, y] == null)
{
t.SetPixel(x, y, new Color(0, 0, 0, 0));
continue;
}
t.SetPixel(x, y,
new Color(
b[x, y].color[0],
b[x, y].color[1],
b[x, y].color[2]
)
);
}
t.Apply();
}
```
Тут мы уже не будем отдавать кому-то свое поле, дадим только его копию *(правда, из-за слова class, мы дали чуточку больше, чем просто копию)*. А так же подарим этому методу нашу **Texture2D**.
Первые две строки: мы создаем нашу текстуру **размером с поле** и **убираем фильтрацию**.
После чего мы проходимся по всему нашему поле-массиву и там, где мы ничего не создали *(class нужно инициализировать)* — мы рисуем пустой квадратик, в ином случае, если там не пусто — мы рисуем то, что сохранили в элемент.
И, конечно, по завершении мы идем в **ground\_generator** и дописываем это:
```
ground = new ground_libray.block
[ground_size, ground_size];
ground_libray.generate_mount(ref ground);
//вот тут дописываем
ground_libray.paint(ground, ref myT);
GetComponent().sprite =
Sprite.Create(myT,
new Rect(0, 0, ground\_size, ground\_size),
Vector3.zero
);
```
Но сколько бы мы не рисовали на нашей текстуре, в игре мы это сможем увидеть, только наложив этот холст на что-нибудь:
**SpriteRenderer** нигде не принимает **Texture2D**, но нам ничего не мешает создать из этой текстуры *спрайт* — **Sprite.Create**(**текстура**, **прямоугольник с координатами нижнего левого угла и верхнего правого**, **координата оси**).
Эти строчки будут вызываться самыми последними, все остальное мы будем дописывать выше метода **paint**!
#### Шахты
Теперь нужно заполнить наше поля случайными пещерами. Для подобных действий мы тоже создадим отдельный метод в **ground\_libray**. Я бы хотел сразу объяснить параметры метода:
```
ref block[,] b - это мы отдаем наше поле.
int thick - толщина краев пещеры
int size - в некотором роде это можно назвать размером пещеры
Color outLine - цвет краев
```
**Пещера**
```
public static void make_cave(ref block[,] b,
int thick, int size, Color outLine)
{
int xNow = Random.Range(0, b.GetLength(0));
int yNow = Random.Range(0, b.GetLength(1) / 2);
for (int i = 0; i < size; i++)
{
b[xNow, yNow] = null;
make_thick(ref b, thick, new int[2] { xNow, yNow }, outLine);
switch (Random.Range(0, 4))
{
case 0: xNow += 1; break;
case 1: xNow -= 1; break;
case 2: yNow += 1; break;
case 3: yNow -= 1; break;
}
xNow = xNow < 0 ? 0 :
(xNow >= b.GetLength(0) ? b.GetLength(0) - 1 : xNow);
yNow = yNow < 0 ? 0 :
(yNow >= b.GetLength(1) ? b.GetLength(1) - 1 : yNow);
}
}
```
Для начала мы объявили наши переменные **X** и **Y**, вот только назвал я их **xNow** и **yNow** соответственно.
Первая, а именно **xNow** — получает случайное значение от нуля до размера поля по первому измерению.
А вторая — **yNow** — так же получает случайное значение: от нуля, до середины поля по второму измерению. *Почему?* Мы генерируем нашу гору с середины, шанс того, что она будет дорастать до «потолка» — *не большой*. Исходя из этого я не считаю релевантным генерировать пещеры в воздухе.
После сразу идет цикл, количество тиков которого зависит от параметра **size**. Каждый тик мы обновляем поле в позиции **xNow** и **yNow**, а уже потом обновляем их самих *(обновления поля можно поставить в конец — разницы вы не ощутите)*
Так же тут есть метод **make\_thick**, в параметры которого мы передаем наше **поле**, **ширину обводки пещеры**, **текущую позицию обновления пещеры** и **цвет обводки**:
**Обводка**
```
static void make_thick (ref block[,] b, int t, int[] start, Color o)
{
for (int x = (start[0] - t); x < (start[0] + t); x++)
{
if (x < 0 || x >= b.GetLength(0))
continue;
for (int y = (start[1] - t); y < (start[1] + t); y++)
{
if (y < 0 || y >= b.GetLength(1))
continue;
if (b[x, y] == null)
continue;
b[x, y] = new block(o);
}
}
}
```
Метод берет переданную ему координату **start**, и вокруг нее на расстоянии **t** перекрашивает все блоки в цвет **o** — все очень просто!
Теперь давайте допишем в наш **ground\_generator** эту строчку:
```
ground_libray.make_cave(ref ground, 2, 10000,
new Color(0.3f, 0.3f, 0.3f));
```
Вы можете установить скрипт **ground\_generator** как компонент на наш объект и проверить как это работает!

**Еще о пещерах...*** Чтобы сделать больше пещер, вы можете вызвать метод **make\_cave** несколько раз *(использовать цикл)*
* Изменение параметра **size** не всегда увеличивает размер пещеры, но зачастую она становится больше
* Изменяя параметр **thick** — вы значительно увеличиваете количество операций:
если параметр равен 3, то количество квадратиков в радиусе **3** будет **36**, значит при параметре **size = 40000** — количество операций будет **36\* 40000 = 1440000**
#### Коррекция пещер

Вы не замечали, что в этом виде пещера выглядит не лучшим образом? Слишком много лишних деталей *(возможно, вы считаете иначе)*.
Чтобы избавиться от вкраплений какого-то *#4d4d4d* мы напишем в **ground\_libray** вот этот метод:
**Чистильщик**
```
public static void clear_caves(ref block[,] b)
{
for (int x = 0; x < b.GetLength(0); x++)
for (int y = 0; y < b.GetLength(1); y++)
{
if (b[x, y] == null)
continue;
if (solo(b, 2, 13, new int[2] { x, y }))
b[x, y] = null;
}
}
```
Но будет сложно понять, что тут происходит, если вы не будете знать, что делает функция **solo**:
```
static bool solo (block[,] b, int rad, int min, int[] start)
{
int cnt = 0;
for (int x = (start[0] - rad); x <= (start[0] + rad); x++)
{
if (x < 0 || x >= b.GetLength(0))
continue;
for (int y = (start[1] - rad); y <= (start[1] + rad); y++)
{
if (y < 0 || y >= b.GetLength(1))
continue;
if (b[x, y] == null)
cnt += 1;
else
continue;
if (cnt >= min)
return true;
}
}
return false;
}
```
В параметрах у этой функции обязано находиться наше **поле**, **радиус проверки точки**, **«порог уничтожения»** и **координаты проверяемой точки**.
Вот подробное объяснение того, что делает эта функция:
> int cnt — то счетчик текущего «порога»
>
> Далее идут два цикла, которые проверяют все точки вокруг той, координаты которой переданы в **start**. Если находится **пустая точка**, то мы прибавляем к **cnt** единицу, по достижении *«порога уничтожения»* мы возвращаем истину — точка *является лишней*. Иначе мы ее не трогаем.
>
>
>
> Порог уничтожения я установил в *13* пустых точек, а радиус проверки *2* *(то есть проверит он 24 точки, не включая центральную)*
>
>
**Пример**Вот эта останется невредимой, так как всего **9** пустых точек.

А вот этой не повезло — вокруг целых **14** пустых точек

Краткое описание алгоритма: *мы проходимся по всему полю и проверяем все точки на то, нужны они ли нет.*
Далее мы просто добавляем в наш **ground\_generator** такую строчку:
```
ground_libray.clear_caves(ref ground);
```
**Итог**
*Как мы видим — большая часть ненужных частичек просто ушло.*
#### Добавим немного красок
Наша гора выглядит очень монотонно, я считаю это скучным.
Давайте добавим немного красок. Добавим метод **level\_paint** в **ground\_libray**:
**Закрашивание горы**
```
public static void level_paint(ref block[,] b, Color[] all_c)
{
for (int x = 0; x < b.GetLength(0); x++)
{
int lvl_div = -1;
int counter = 0;
int lvl_now = 0;
for (int y = b.GetLength(1) - 1; y > 0; y--)
{
if (b[x, y] != null && lvl_div == -1)
lvl_div = y / all_c.Length;
else if (b[x, y] == null)
continue;
b[x, y] = new block(all_c[lvl_now]);
lvl_now += counter >= lvl_div ? 1 : 0;
lvl_now = (lvl_now >= all_c.Length) ?
(all_c.Length - 1) : lvl_now;
counter = counter >= lvl_div ? 0 : (counter += 1);
}
}
}
source>
В параметры к методу мы передаем нашу гору и массив красок. Цвета будут использовать так, чтобы нулевой элемент массива красок был сверху, а последний снизу.
Мы проходимся по всем столбикам нашего поля, а обход по строчкам начинаем сверху. Найдя первую строчку с существующим элементом мы делим значение **Y** на количество цветов, чтобы поровну разделить цвета на столбик.
После мы дописываем в **ground\_generator** вот это:
ground_libray.level_paint(ref ground,
new Color[3]
{
new Color(0.2f, 0.8f, 0),
new Color(0.6f, 0.2f, 0.05f),
new Color(0.2f, 0.2f, 0.2f),
});
```
Я выбрал всего 3 цвета: *Зеленый*, *темно-красный* и *темно-серый*.
Вы, разумеется, можете изменить как количество цветов, так и значения каждого. У меня получилось так:
**Итог**
Но все же это выглядит слишком строго, чтобы добавить немного хаотичности цветам, мы напишем в **ground\_libray** вот такое свойство:
**Случайные цвета**
```
public static float color_randomize = 0.1f;
static float crnd
{
get
{
return Random.Range(1.0f - color_randomize,
1.0f + color_randomize);
}
}
```
И теперь в методах **level\_paint** и **make\_thick**, в строчках, где мы присваиваем цвета, например в **make\_thick**:
```
b[x, y] = new block(o);
```
Мы напишем так:
```
b[x, y] = new block(o * crnd);
```
А в **level\_paint**
```
b[x, y] = new block(all_c[lvl_now] * crnd);
```
В итоге у вас должно все выглядеть примерно так:
**Итог**
Недостатки
----------
Предположим, что у нас поле 1024 на 1024, нужно сгенерировать 24 пещеры, толщина края которых будет 4, а размер 80000.
1024 \* 1024 + 24 \* 64 \* 80000 = **5 368 832 000 000** операций.
Этот способ подходит только для генерации небольших модулей для игрового мира, сгенерировать что-то очень большое **за раз** — **нельзя**. | https://habr.com/ru/post/416419/ | null | ru | null |
# Zip-файлы: история, объяснение и реализация

Мне давно было интересно, как сжимаются данные, в том числе в Zip-файлах. Однажды я решил удовлетворить своё любопытство: узнать, как работает сжатие, и написать собственную Zip-программу. Реализация превратилась в захватывающее упражнение в программировании. Получаешь огромное удовольствие от создания отлаженной машины, которая берёт данные, перекладывает их биты в более эффективное представление, а затем собирает обратно. Надеюсь, вам тоже будет интересно об этом читать.
В статье очень подробно объясняется, как работают Zip-файлы и схема сжатия: LZ77-сжатие, алгоритм Хаффмана, алгоритм Deflate и прочее. Вы узнаете историю развития технологии и посмотрите довольно эффективные примеры реализации, написанные с нуля на С. Исходный код лежит тут: [hwzip-1.0.zip](https://www.hanshq.net/files/hwzip/hwzip-1.0.zip).
Я очень благодарен [Ange Albertini](https://twitter.com/angealbertini), [Gynvael Coldwind](https://gynvael.coldwind.pl), [Fabian Giesen](https://fgiesen.wordpress.com), [Jonas Skeppstedt](https://www.instagram.com/dr.jonas.skeppstedt) ([web](https://www.jonasskeppstedt.net)), [Primiano Tucci](https://primianotucci.com) и [Nico Weber](https://twitter.com/thakis), которые дали ценные отзывы на черновики этой статьи.
Содержание
----------
* [История](#1)
+ [PKZip](#2)
+ [Info-ZIP and zlib](#3)
+ [WinZip](#4)
* [Сжатие Lempel-Ziv (LZ77)](#5)
* [Код Хаффмана](#6)
+ [Алгоритм Хаффмана](#7)
+ [Канонические коды Хаффмана](#8)
+ [Эффективное декодирование Хаффмана](#9)
* [Deflate](#10)
+ [Битовые потоки](#11)
+ [Распаковка (Inflation)](#12)
- [Несжатые Deflate-блоки](#13)
- [Deflate-блоки с применением фиксированных кодов Хаффмана](#14)
- [Deflate-блоки с применением динамических кодов Хаффмана](#15)
+ [Сжатие (Deflation)](#16)
* [Формат Zip-файлов](#17)
+ [Обзор](#18)
+ [Структуры данных](#19)
- [Конец записи центрального каталога](#20)
- [Центральный заголовок файла](#21)
- [Локальный заголовок файла](#22)
+ [Реализация Zip-считывания](#23)
+ [Реализация Zip-записи](#24)
* [HWZip](#25)
+ [Инструкции по сборки](#26)
* [Заключение](#27)
* [Упражнения](#28)
* [Полезные материалы](#29)
История
-------
### PKZip
В восьмидесятых и начале девяностых, до широкого распространения интернета, энтузиасты-компьютерщики использовали dial-up-модемы для подключения через телефонную сеть к сети Bulletin Board Systems (BBS). BBS представляла собой интерактивную компьютерную систему, которая позволяла пользователям отправлять сообщения, играть в игры и делиться файлам. Для выхода в онлайн достаточно было компьютера, модема и телефонного номера хорошей BBS. Номера [публиковались в компьютерных журналах](https://archive.org/details/Boardwatch_Magazine_Vol_06_10_1992_Dec/page/n81) и на других BBS.
Важным инструментом, облегчающим распространение файлов, был *архиватор*. Он позволяет сохранять один или несколько файлов в едином файле-*архиве*, чтобы удобнее хранить или передавать информацию. А в идеале архив ещё и сжимал файлы для экономии места и времени на передачу по сети. Во времена BBS был популярен архиватор Arc, написанный Томом Хендерсоном из System Enhancement Associates (SEA), маленькой компании, которую он основал со своим шурином.
В конце 1980-х программист Фил Катц выпустил собственную версию Arc — PKArc. Она была совместима с SEA Arc, но работала быстрее благодаря подпрограммам, написанным на ассемблере, и использовала новый метод сжатия. Программа стала популярной, Катц ушёл с работы и создал компанию PKWare, чтобы сосредоточиться на дальнейшей разработке. Согласно легенде, большая часть работы проходила на кухне его матери в Глендейле, штат Висконсин.

*Фотография Фила Катца [из статьи в Milwaukee Sentinel](https://www.hanshq.net/files/katz_article.png), 19 сентября 1994.*
Однако SEA не устраивала инициатива Катца. Компания обвинила его в нарушении товарного знака и авторских прав. Разбирательства и споры в сети BBS и мире ПК стали известны как [Arc-войны](http://catb.org/jargon/chaff.html#arc-wars). В конце концов, спор был [урегулирован](http://www.bbsdocumentary.com/library/CONTROVERSY/LAWSUITS/SEA/release.txt) в пользу SEA.
Отказавшись от Arc, Катц в 1989 создал новый формат архивирования, который он назвал Zip и [передал в общественное пользование](https://groups.google.com/d/msg/comp.sys.ibm.pc/0tun_9sqKYU/RNeLTza9fAEJ):
> Формат файлов, создаваемых этими программами, является оригинальным с первого релиза этого программного обеспечения, и настоящим передаётся в общественное пользование. Кроме того, расширение ".ZIP", впервые использованное в контексте ПО для сжатия данных в первом релизе этого ПО, также настоящим передаётся в общественное пользование, с горячей и искренней надеждой, что никто не попытается присвоить формат для своего исключительного использования, а, скорее, что он будет использоваться в связи с ПО для сжатия данных и создания библиотек таких классов или типов, которые создают файлы в формате, в целом совместимом с данным ПО.
Программа Катца для создания таких файлов получила название PKZip и скоро распространилась в мире BBS и ПК.
Одним из аспектов, который с наибольшей вероятностью поспособствовал успеху Zip-формата, является то, что с PKZip шла документация, [Application Note](https://www.pkware.com/documents/APPNOTE/APPNOTE-2.0.txt), в которой подробно объяснялось, как работает формат. Это позволило другим изучить формат и создать программы, которые генерируют, извлекают или как-то иначе взаимодействуют с Zip-файлами.
Zip — это формат сжатия *без потерь*: после распаковки данные будут такими же, как перед сжатием. Алгоритм ищет избыточности в исходных данных и эффективнее представляет информацию. Этот подход отличается от сжатия *с потерями*, который используется в таких форматах, как JPEG и MP3: при сжатии выбрасывается часть информации, которая менее заметна для человеческого глаза или уха.
PKZip распространялась как Shareware: её можно было свободно использовать и копировать, но автор предлагал пользователям «зарегистрировать» программу. За $47 можно было получить распечатанную инструкцию, премиальную поддержку и расширенную версию приложения.

Одной из ключевых версий PKZip стала 2.04c, вышедшая 28 декабря 1992 (вскоре после неё вышла [версия 2.04g](https://www.hanshq.net/files/pkz204g.exe)). В ней по умолчанию использовался алгоритм сжатия Deflate. Версия определила дальнейший путь развития сжатия в Zip-файлах ([статья, посвящённая релизу](https://archive.org/details/Boardwatch1993-03/page/n21)).

С тех пор Zip-формат используется во многих других форматах файлов. Например, Java-архивы (.jar), Android Application Packages (.apk) и .docx-файлы Microsoft Office используют Zip-формат. Во многих форматах и протоколах применяется тот же алгоритм сжатия, Deflate. Скажем, веб-страницы наверняка передаются в ваш браузер в виде gzip-файла, формат которого использует Deflate-сжатие.
Фил Катц умер в 2000-м. PKWare всё ещё существует и поддерживает Zip-формат, хотя компания сосредоточена в основном на ПО для защиты данных.
### Info-ZIP и zlib
Вскоре после выхода PKZip в 1989-м начали появляться другие программы для распаковки Zip-файлов. Например, программа *unzip*, которая могла распаковывать на Unix-системах. В марте 1990-го был создан список рассылки под названием Info-ZIP.
Группа [Info-ZIP](http://www.info-zip.org) выпустила бесплатные программы с открытым исходным кодом *unzip* и *zip*, которые использовались для распаковки и создания Zip-файлов. Код портировали во многие системы, и он до сих пор является стандартом для Zip-программ под Unix-системы. Позднее это помогло росту популярности Zip-файлов.
Однажды код Info-ZIP, который выполнял Deflate-сжатие и распаковку, был вынесен в отдельную библиотеку [zlib](https://www.zlib.net/), которую написали [Jean-loup Gailly](http://gailly.net/) (сжатие) и [Mark Adler](https://madler.net/madler/) (распаковка).

*Jean-loup Gailly (слева) и Mark Adler (справа) на вручении им премии [USENIX STUG Award](https://www.usenix.org/about/stug) в 2009-м.*
Одна из причин создания библиотеки заключалась в том, что это обеспечивало удобство использования Deflate-сжатия в других приложениях и форматах, например, в новых [gzip](https://ru.wikipedia.org/wiki/Gzip) и [PNG](https://ru.wikipedia.org/wiki/PNG). Эти новые форматы были призваны заменить [Compress](https://en.wikipedia.org/wiki/Compress) и [GIF](https://ru.wikipedia.org/wiki/GIF), в которых применялся защищённый патентом алгоритм LZW.
В рамках создания этих форматов Питер Дойч написал спецификацию Deflate и опубликовал под названием [Internet RFC 1951](https://tools.ietf.org/html/rfc1951) в мае 1996-го. Это оказалось более доступное описание по сравнению с исходным PKZip Application Note.
Сегодня zlib используется повсеместно. Возможно, он сейчас отвечает за сжатие этой страницы на веб-сервере и её распаковки в вашем браузере. Сегодня сжатие и распаковка большинства Zip-файлов выполняется с помощью zlib.
### WinZip
Многие из тех, кто не застал PKZip, пользовались WinZip. Пользователи ПК перешли как с DOS на Windows, так и с PKZip на WinZip.
Всё началось с проекта программиста Нико Мака, который создавал ПО для OS/2 в компании Mansfield Software Group в городе Сторрс-Мансфилд, штат Коннектикут. Нико использовал Presentation Manager, это графический пользовательский интерфейс в OS/2, и его расстраивало, что приходится переходить от файлового менеджера к DOS-командам каждый раз, когда он хотел создать Zip-файлы.
Мак написал простую программу с графическим интерфейсом, которая работала с Zip-файлами прямо в Presentation Manager, назвал её [PMZip](http://cd.textfiles.com/sigserieswin/0WINRUN/2785/PMZIP.TXT) и выпустил в качестве shareware в 1990-м.
OS/2 так и не добилась успеха, а мир ПК захватывала Microsoft Windows. В 1991-м Мак решил научиться писать Windows-программы, и его первым проектом стало портирование своего Zip-приложения под новую ОС. В апреле 1991-го вышла [WinZip 1.00](https://www.hanshq.net/files/winzip1.zip). Она распространялась в качестве shareware с 21-дневным пробным периодом и стоимостью регистрации $29. Выглядела она так:
В первых версиях WinZip под капотом использовалась PKZip. Но с версии 5.0 в 1993-м для прямой обработки Zip-файлов стал использоваться код из Info-ZIP. Пользовательский интерфейс тоже постепенно эволюционировал.

*[WinZip 6.3](https://ftp.sunet.se/mirror/archive/ftp.sunet.se/pub/simtelnet/win3/compress/wz16v_63.exe) под Windows 3.11 for Workgroups.*
WinZip была одной из самых популярных shareware-программ в 1990-е. Но в конце концов она потеряла актуальность из-за встраивания поддержки Zip-файлов в операционные системы. Windows работает с ними как со «сжатыми папками» начиная с 2001-го (Windows XP), для этого используется библиотека [DynaZip](http://www.innermedia.com/).
Изначально компания Мака называлась Nico Mak Computing. В 2000-м её переименовали в WinZip Computing, и примерно в те годы Мак её покинул. В 2005-м компанию [продали Vector Capital](https://www.businesswire.com/news/home/20050718005297/en/Vector-Capital-Buys-WinZip-Private-Equity-Firm), и в конце концов ею стала владеть [Corel](https://www.corel.com), которая до сих пор выпускает WinZip в качестве продукта.
Сжатие Lempel-Ziv (LZ77)
------------------------
Zip-сжатие состоит из двух основных ингредиентов: сжатия Lempel-Ziv и кода Хаффмана.
Один из способов сжатия текста заключается в создании списка частых слов или фраз с заменой разновидностей этих слов в рамках текста ссылками на словарь. Например, длинное слово «compression» в исходном тексте можно представить как #1234, где 1234 ссылается на позицию слова в списке. Это называется *сжатием с использованием словаря*.
Но с точки зрения сжатия универсального назначения у такого метода есть несколько недостатков. Во-первых, что именно должно попасть в словарь? Исходные данные могут быть на разных языках, это может быть даже не человеко читаемый текст. И если заранее не согласовать словарь между сжатием и распаковкой, то его придётся хранить и передавать вместе со сжатыми данными, что снижает выгоду от сжатия.
Элегантным решением этой проблемы является использование в качестве словаря самих исходных данных. В работе "[A Universal Algorithm for Sequential Data Compression](https://www2.cs.duke.edu/courses/spring03/cps296.5/papers/ziv_lempel_1977_universal_algorithm.pdf)" 1977 года Якоб Зив и Абрахам Лемпел (работавшие в компании Technion), предложили схему сжатия, при которой исходные данные представляются в виде последовательности триплетов:
```
(указатель, длина, следующий)
```
где `указатель` и `длина` формируют обратную ссылку на последовательность символов, которую нужно скопировать из предыдущей позиции в оригинальном тексте, а `следующий` — это следующий символ в генерируемых данных.

*Абрахам Лемпел и Якоб Зив.*
Рассмотрим такие строки:
```
It was the best of times,
it was the worst of times,
```
Во второй строке последовательность «t was the w» можно представить как (26, 10, w), поскольку она воссоздаётся копированием 10 символов с позиции в 26 символов назад и до буквы «w». Для символов, которые до этого ещё не появлялись, используются обратные ссылки нулевой длины. Например, начальная «I» может быть представлена как (0, 0, I).
Эта схема получила название сжатие Lempel-Ziv, или сжатие LZ77. Однако в практических реализациях алгоритма обычно не используется часть триплета `следующий`. Вместо этого символы генерируются по-одиночке, а для обратных ссылок используются пары (`расстояние`, `длина`) (этот вариант называется сжатием [LZSS](https://ru.wikipedia.org/wiki/LZSS)). Как *кодируются* литералы и обратные ссылки — это отдельный вопрос, мы рассмотрим его ниже, когда будем разбирать алгоритм [Deflate](https://www.hanshq.net/zip.html#deflate).
Этот текст:
```
It was the best of times,
it was the worst of times,
it was the age of wisdom,
it was the age of foolishness,
it was the epoch of belief,
it was the epoch of incredulity,
it was the season of Light,
it was the season of Darkness,
it was the spring of hope,
it was the winter of despair,
we had everything before us,
we had nothing before us,
we were all going direct to Heaven,
we were all going direct the other way
```
Можно сжать в такой:
```
It was the best of times,
i(26,10)wor(27,24)age(25,4)wisdom(26,20)
foolishnes(57,14)epoch(33,4)belief(28,22)incredulity
(33,13)season(34,4)Light(28,23)Dark(120,17)
spring(31,4)hope(231,14)inter(27,4)despair,
we had everyth(57,4)before us(29,9)no(26,20)
we(12,3)all go(29,4)direct to Heaven
(36,28)(139,3)(83,3)(138,3)way
```
Одним из важных свойств обратных ссылок является то, что они могут перекрывать друг друга. Такое случается тогда, когда длина больше расстояния. Например:
```
Fa-la-la-la-la
```
Можно сжать в:
```
Fa-la(3,9)
```
Вам это может показаться странным, но метод работает: после того, как скопированы байты первых трёх «-la», копирование продолжается уже с использованием недавно сгенерированных байтов.
По сути, это разновидность [кодирования длин серий](https://en.wikipedia.org/wiki/Run-length_encoding), при котором часть данных многократно копируется для получения нужной длины.
Интерактивный пример использования сжатия Lempel-Ziv для текстов песен показан в статье Колина Морриса [Are Pop Lyrics Getting More Repetitive?](https://pudding.cool/2017/05/song-repetition/).
Ниже приведён пример копирования обратных ссылок на языке С. Обратите внимание, что из-за возможного перекрытия мы не можем использовать `memcpy` или `memmove`.
```
/* Output the (dist,len) backref at dst_pos in dst. */
static inline void lz77_output_backref(uint8_t *dst, size_t dst_pos,
size_t dist, size_t len)
{
size_t i;
assert(dist <= dst_pos && "cannot reference before beginning of dst");
for (i = 0; i < len; i++) {
dst[dst_pos] = dst[dst_pos - dist];
dst_pos++;
}
}
```
Генерировать литералы легко, но для полноты воспользуемся вспомогательной функцией:
```
/* Output lit at dst_pos in dst. */
static inline void lz77_output_lit(uint8_t *dst, size_t dst_pos, uint8_t lit)
{
dst[dst_pos] = lit;
}
```
Обратите внимание, что вызывающий эту функцию должен удостовериться, что в `dst` достаточно места для генерируемых данных и что обратная ссылка не обращается к позиции до начала буфера.
Сложно не генерировать данные с помощью обратных ссылок в ходе распаковки, а создавать их первым делом при сжатии исходных данных. Это можно сделать по-разному, но мы воспользуемся методикой на основе хэш-таблиц из zlib, который предлагается в RFC 1951.
Будем применять хэш-таблицу с позициями трёхсимвольных префиксов, которые ранее встречались в строке (более короткие обратные ссылки пользы не приносят). В Deflate допускаются обратные ссылки в рамках предыдущих 32 768 символов — это называется *окном*. Это обеспечивает потоковое сжатие: входные данные подвергаются небольшой обработке за раз, при условии, что окно с последними байтами хранится в памяти. Однако наша реализация предполагает, что нам доступны все входные данные и мы можем обработать их целиком за раз. Это позволяет сосредоточиться на сжатии, а не на учёте, который необходим для потоковой обработки.
Воспользуемся двумя массивами: в `head` содержится хэш-значение трёхсимвольного префикса для позиции во входных данных, а в `prev` содержится позиция предыдущей позиции с этим хэш-значением. По сути, `head[h]` — это заголовок связного списка позиций префиксов с хэшем `h`, а `prev[x]` получает элемент, предшествующий `x` в списке.
```
#define LZ_WND_SIZE 32768
#define LZ_MAX_LEN 258
#define HASH_SIZE 15
#define NO_POS SIZE_MAX
/* Perform LZ77 compression on the len bytes in src. Returns false as soon as
either of the callback functions returns false, otherwise returns true when
all bytes have been processed. */
bool lz77_compress(const uint8_t *src, size_t len,
bool (*lit_callback)(uint8_t lit, void *aux),
bool (*backref_callback)(size_t dist, size_t len, void *aux),
void *aux)
{
size_t head[1U << HASH_SIZE];
size_t prev[LZ_WND_SIZE];
uint16_t h;
size_t i, j, dist;
size_t match_len, match_pos;
size_t prev_match_len, prev_match_pos;
/* Initialize the hash table. */
for (i = 0; i < sizeof(head) / sizeof(head[0]); i++) {
head[i] = NO_POS;
}
```
Для вставки в хэш-таблицу новой строковой позиции `prev` обновляется, чтобы указывать на предыдущую `head`, а затем обновляется сама `head`:
```
static void insert_hash(uint16_t hash, size_t pos, size_t *head, size_t *prev)
{
prev[pos % LZ_WND_SIZE] = head[hash];
head[hash] = pos;
}
```
Обратите внимание на операцию по модулю при индексировании в `prev`: нас интересуют только те позиции, которые попадают в текущее окно.
Вместо того, чтобы с нуля вычислять хэш-значение для каждого трёхсимвольного префикса, мы воспользуемся [кольцевым хэшем](https://ru.wikipedia.org/wiki/%D0%9A%D0%BE%D0%BB%D1%8C%D1%86%D0%B5%D0%B2%D0%BE%D0%B9_%D1%85%D0%B5%D1%88) и будем постоянно обновлять его, чтобы в его значении отражались только три последних символа:
```
static uint16_t update_hash(uint16_t hash, uint8_t c)
{
hash <<= 5; /* Shift out old bits. */
hash ^= c; /* Include new bits. */
hash &= (1U << HASH_SIZE) - 1; /* Mask off excess bits. */
return hash;
}
```
Хэш-карту потом можно использовать для эффективного поиска предыдущих совпадений с последовательностью, как показано ниже. Поиск совпадений — самая ресурсозатратная операция сжатия, поэтому мы ограничим глубину поиска по списку.
Изменение различных параметров, вроде глубины поиска по списку префиксов и выполнения ленивого сравнения, как будет описано ниже, — это способ повышения скорости за счёт снижения степени сжатия. Настройки в нашем коде выбраны так, чтобы соответствовать максимальному уровню сжатия в zlib.
```
/* Find the longest most recent string which matches the string starting
* at src[pos]. The match must be strictly longer than prev_match_len and
* shorter or equal to max_match_len. Returns the length of the match if found
* and stores the match position in *match_pos, otherwise returns zero. */
static size_t find_match(const uint8_t *src, size_t pos, uint16_t hash,
size_t prev_match_len, size_t max_match_len,
const size_t *head, const size_t *prev,
size_t *match_pos)
{
size_t max_match_steps = 4096;
size_t i, l;
bool found;
if (prev_match_len == 0) {
/* We want backrefs of length 3 or longer. */
prev_match_len = 2;
}
if (prev_match_len >= max_match_len) {
/* A longer match would be too long. */
return 0;
}
if (prev_match_len >= 32) {
/* Do not try too hard if there is already a good match. */
max_match_steps /= 4;
}
found = false;
i = head[hash];
while (max_match_steps != 0) {
if (i == NO_POS) {
/* No match. */
break;
}
assert(i < pos && "Matches should precede pos.");
if (pos - i > LZ_WND_SIZE) {
/* The match is outside the window. */
break;
}
l = cmp(src, i, pos, prev_match_len, max_match_len);
if (l != 0) {
assert(l > prev_match_len);
assert(l <= max_match_len);
found = true;
*match_pos = i;
prev_match_len = l;
if (l == max_match_len) {
/* A longer match is not possible. */
return l;
}
}
/* Look further back in the prefix list. */
i = prev[i % LZ_WND_SIZE];
max_match_steps--;
}
if (!found) {
return 0;
}
return prev_match_len;
}
/* Compare the substrings starting at src[i] and src[j], and return the length
* of the common prefix. The match must be strictly longer than prev_match_len
* and shorter or equal to max_match_len. */
static size_t cmp(const uint8_t *src, size_t i, size_t j,
size_t prev_match_len, size_t max_match_len)
{
size_t l;
assert(prev_match_len < max_match_len);
/* Check whether the first prev_match_len + 1 characters match. Do this
* backwards for a higher chance of finding a mismatch quickly. */
for (l = 0; l < prev_match_len + 1; l++) {
if (src[i + prev_match_len - l] !=
src[j + prev_match_len - l]) {
return 0;
}
}
assert(l == prev_match_len + 1);
/* Now check how long the full match is. */
for (; l < max_match_len; l++) {
if (src[i + l] != src[j + l]) {
break;
}
}
assert(l > prev_match_len);
assert(l <= max_match_len);
assert(memcmp(&src[i], &src[j], l) == 0);
return l;
}
```
Можно завершить функцию `lz77_compress` этим кодом для поиска предыдущих совпадений:
```
/* h is the hash of the three-byte prefix starting at position i. */
h = 0;
if (len >= 2) {
h = update_hash(h, src[0]);
h = update_hash(h, src[1]);
}
prev_match_len = 0;
prev_match_pos = 0;
for (i = 0; i + 2 < len; i++) {
h = update_hash(h, src[i + 2]);
/* Search for a match using the hash table. */
match_len = find_match(src, i, h, prev_match_len,
min(LZ_MAX_LEN, len - i), head, prev,
&match_pos);
/* Insert the current hash for future searches. */
insert_hash(h, i, head, prev);
/* If the previous match is at least as good as the current. */
if (prev_match_len != 0 && prev_match_len >= match_len) {
/* Output the previous match. */
dist = (i - 1) - prev_match_pos;
if (!backref_callback(dist, prev_match_len, aux)) {
return false;
}
/* Move past the match. */
for (j = i + 1; j < min((i - 1) + prev_match_len,
len - 2); j++) {
h = update_hash(h, src[j + 2]);
insert_hash(h, j, head, prev);
}
i = (i - 1) + prev_match_len - 1;
prev_match_len = 0;
continue;
}
/* If no match (and no previous match), output literal. */
if (match_len == 0) {
assert(prev_match_len == 0);
if (!lit_callback(src[i], aux)) {
return false;
}
continue;
}
/* Otherwise the current match is better than the previous. */
if (prev_match_len != 0) {
/* Output a literal instead of the previous match. */
if (!lit_callback(src[i - 1], aux)) {
return false;
}
}
/* Defer this match and see if the next is even better. */
prev_match_len = match_len;
prev_match_pos = match_pos;
}
/* Output any previous match. */
if (prev_match_len != 0) {
dist = (i - 1) - prev_match_pos;
if (!backref_callback(dist, prev_match_len, aux)) {
return false;
}
i = (i - 1) + prev_match_len;
}
/* Output any remaining literals. */
for (; i < len; i++) {
if (!lit_callback(src[i], aux)) {
return false;
}
}
return true;
}
```
Этот код ищет самую длинную обратную ссылку, которая может быть сгенерирована на текущей позиции. Но прежде чем её выдать, программа решает, можно ли на следующей позиции найти ещё более длинное совпадение. В zlib это называется *оценкой с помощью ленивого сравнения*. Это всё ещё *жадный* алгоритм: он выбирает самое длинное совпадение, даже если текущее более короткое позволяет позднее получить совпадение ещё длиннее и достичь более сильного сжатия.
Сжатие Lempel-Ziv может работать как быстро, так и медленно. [Zopfli](https://github.com/google/zopfli) потратил много времени на поиски оптимальных обратных ссылок, чтобы выжать дополнительные проценты сжатия. Это полезно для данных, которые сжимаются один раз и потом многократно используются, например, для статичной информации на веб-сервере. На другой стороне шкалы находятся такие компрессоры, как [Snappy](https://github.com/google/snappy) и [LZ4](https://lz4.github.io/lz4/), которые сравнивают только с последним 4-байтным префиксом и работают очень быстро. Такой тип сжатия полезен в базах данных и RPC-системах, в которых время, потраченное на сжатие, окупается экономией времени при отправке данных по сети или на диск.
Идея использовать исходные данные в качестве словаря очень элегантна, но и от статичного словаря можно получить пользу. [Brotli](https://github.com/google/brotli) — алгоритм на основе LZ77, но он также использует большой [статичный словарь](https://gist.github.com/klauspost/2900d5ba6f9b65d69c8e) из строковых, которые часто встречаются в сети.
Код LZ77 можно посмотреть [в lz77.h](https://www.hanshq.net/files/hwzip/lz77.h) и [lz77.c](https://www.hanshq.net/files/hwzip/lz77.c).
Код Хаффмана
------------
Вторым алгоритмом Zip-сжатия является код Хаффмана.
Термин *код* в данном контексте является отсылкой к системе представления данных в какой-то другой форме. В данном случае нас интересует код, с помощью которого можно эффективно представлять литералы и обратные ссылки, сгенерированные алгоритмом Lempel-Ziv.
Традиционно англоязычный текст представляют с помощью [American Standard Code for Information Interchange (ASCII)](https://ru.wikipedia.org/wiki/ASCII). Эта система присваивает каждому символу число, которые обычно хранятся в 8-битном представлении. Вот ASCII-коды для прописных букв английского алфавита:
| | | | |
| --- | --- | --- | --- |
| **A** | 01000001 | **N** | 01001110 |
| **B** | 01000010 | **O** | 01001111 |
| **C** | 01000011 | **P** | 01010000 |
| **D** | 01000100 | **Q** | 01010001 |
| **E** | 01000101 | **R** | 01010010 |
| **F** | 01000110 | **S** | 01010011 |
| **G** | 01000111 | **T** | 01010100 |
| **H** | 01001000 | **U** | 01010101 |
| **I** | 01001001 | **V** | 01010110 |
| **J** | 01001010 | **W** | 01010111 |
| **K** | 01001011 | **X** | 01011000 |
| **L** | 01001100 | **Y** | 01011001 |
| **M** | 01001101 | **Z** | 01011010 |
Один байт на символ — это удобный способ хранения текста. Он позволяет легко обращаться к частям текста или изменять их, и всегда понятно, сколько байтов требуется для хранения N символов, или сколько символов хранится в N байтов. Однако это не самый эффективный способ с точки зрения занимаемого объёма. Например, в английском языке буква E используется чаще всего, а Z — реже всего. Поэтому с точки зрения объёма эффективнее использовать более короткое битовое представление для E и более длинное для Z, а не присваивать каждому символу одинаковое количество битов.
Код, который разным исходным символам задаёт кодировки разной длины, называется *кодом переменной длины*. Самый известный пример — [азбука Морзе](https://ru.wikipedia.org/wiki/%D0%90%D0%B7%D0%B1%D1%83%D0%BA%D0%B0_%D0%9C%D0%BE%D1%80%D0%B7%D0%B5), в которой каждый символ кодируется точками и тире, изначально передававшимися по телеграфу короткими и длинными импульсами:
| | | | |
| --- | --- | --- | --- |
| **A** | **• −** | **N** | **− •** |
| **B** | **− • • •** | **O** | **− − −** |
| **C** | **− • − •** | **P** | **• − − •** |
| **D** | **− • •** | **Q** | **− − • −** |
| **E** | **•** | **R** | **• − •** |
| **F** | **• • − •** | **S** | **• • •** |
| **G** | **− − •** | **T** | **−** |
| **H** | **• • • •** | **U** | **• • −** |
| **I** | **• •** | **V** | **• • • −** |
| **J** | **• − − −** | **W** | **• − −** |
| **K** | **− • −** | **X** | **− • • −** |
| **L** | **• − • •** | **Y** | **− • − −** |
| **M** | **− −** | **Z** | **− − • •** |
Одним из недостатков азбуки Морзе является то, что одно кодовое слово может быть префиксом другого. Например, • • − • не имеет уникального декодирования: это может быть F или ER. Это решается с помощью пауз (длиной в три точки) между буквами в ходе передачи. Однако было бы лучше, если бы кодовые слова не могли являться префиксами других слов. Такой код называется *беспрефиксным*. ASCII-код фиксированной длины является беспрефиксным, потому что кодовые слова всегда одной длины. Но коды переменной длины тоже могут быть беспрефиксными. Телефонные номера чаще всего беспрефиксные. Прежде чем в Швеции ввели телефон экстренной помощи 112, пришлось поменять все номера, начинавшиеся со 112. А в США нет ни одного телефонного номера, начинающегося с 911.
Для минимизации размера закодированного сообщения лучше использовать беспрефиксный код, в котором часто встречающиеся символы имеют более короткие кодовые слова. Оптимальным кодом будет такой, который генерирует самый короткий возможный результат — сумма длин кодовых слов, умноженная на их частоту появления, будет минимально возможной. Это называется *беспрефиксным кодом с минимальной избыточностью*, или *кодом Хаффмана*, в честь изобретателя эффективного алгоритма для генерирования таких кодов.
### Алгоритм Хаффмана
Изучая материалы для написания своей докторской диссертации по электронной инженерии в MIT, Дэвид Хаффман прослушал курс по теории информации, который читал Роберт Фано. [Согласно легенде](https://www.huffmancoding.com/my-uncle/scientific-american), Фано позволил своим слушателям выбирать: писать финальный экзамен или курсовую. Хаффман выбрал последнее, и ему дали тему поиска беcпрефиксных кодов с минимальной избыточностью. Предполагается, что он не знал о том, что над этой задачей в то время работал сам Фано (самым известный методом в те годы был [алгоритм Шеннона-Фано](https://ru.wikipedia.org/wiki/%D0%90%D0%BB%D0%B3%D0%BE%D1%80%D0%B8%D1%82%D0%BC_%D0%A8%D0%B5%D0%BD%D0%BD%D0%BE%D0%BD%D0%B0_%E2%80%94_%D0%A4%D0%B0%D0%BD%D0%BE)). Работа Хаффмана была опубликована в 1952-м под названием [A Method for the Construction of Minimum-Redundancy Codes](https://www.ic.tu-berlin.de/fileadmin/fg121/Source-Coding_WS12/selected-readings/10_04051119.pdf) in 1952. И с тех пор его алгоритм получил широкое распространение.

*Дэвид Хаффман [пресс-релиз](https://www.cise.ufl.edu/~manuel/huffman/press.release.html) UC Santa Cruz.*
Алгоритм Хаффмана создаёт беспрефиксный код с минимальной избыточностью для набора символов и их частоты использования. Алгоритм многократно выбирает два символа, которые реже всего встречаются в исходных данных, — допустим, Х и Y — и заменяет их на *составной символ*, означающий «X или Y». Частотой появления составного символа является сумма частот двух исходных символов. Кодовые слова для X и Y могут быть любыми кодовыми словами, которые присвоены составному символу «X или Y», за которым идёт 0 или 1, чтобы отличать друг от друга исходные символы. Когда входные данные уменьшаются до одного символа, алгоритм прекращает работу ([видеообъяснение](https://www.youtube.com/watch?v=ZdooBTdW5bM)).
Вот пример работы алгоритма на маленьком наборе символов:
| | |
| --- | --- |
| **Символ** | **Частота** |
| A | 6 |
| B | 4 |
| C | 2 |
| D | 3 |
Первая итерация обработки:
Два самых редких символа, C и D, убираются из набора и заменяются составным символом, частота которого является суммой частот C и D:

Теперь самыми редкими символами стали B и составной символ с частотой 5. Они убираются из набора и заменяются составным символом с частотой 9:

Наконец, A и составной символ с частотой 9 объединяются в новый символ с частотой 15:

Весь набор свёлся к одному символу, обработка завершена.
Алгоритм создал структуру, которая называется *деревом Хаффмана*. Входные символы — это листья, а чем больше частота у символа, тем выше он расположен. Начиная от корня дерева можно сгенерировать кодовые слова для символов, добавляя 0 или 1, когда переходим влево или вправо соответственно. Получится так:
| | |
| --- | --- |
| **Символ** | **Кодовое слово** |
| A | 0 |
| B | 10 |
| C | 110 |
| D | 111 |
Ни одно кодовое слово не является префиксом для какого-то другого. Чем чаще встречается символ, тем короче его кодовое слово.
Дерево можно использовать и для декодирования: начинаем с корня и идём направо или налево для значение с 0 или 1 перед символом. Например, строка 010100 декодируется в ABBA.
Обратите внимание, что длина каждого кодового слова эквивалентна глубине соответствующего узла дерева. Как мы увидим в следующей части, нам не нужно настоящее дерево для присвоения кодовых слов. Достаточно знать длину самих слов. Таким образом, результатом работы нашей реализации алгоритма Хаффмана будут длины кодовых слов.
Для хранения набора символов и эффективного нахождения наименьших частот мы воспользуемся структурой данных [двоичная куча](https://ru.wikipedia.org/wiki/%D0%94%D0%B2%D0%BE%D0%B8%D1%87%D0%BD%D0%B0%D1%8F_%D0%BA%D1%83%D1%87%D0%B0). В частности, нас интересует *min-куча*, поскольку минимальное значение должно быть наверху.
```
/* Swap the 32-bit values pointed to by a and b. */
static void swap32(uint32_t *a, uint32_t *b)
{
uint32_t tmp;
tmp = *a;
*a = *b;
*b = tmp;
}
/* Move element i in the n-element heap down to restore the minheap property. */
static void minheap_down(uint32_t *heap, size_t n, size_t i)
{
size_t left, right, min;
assert(i >= 1 && i <= n && "i must be inside the heap");
/* While the ith element has at least one child. */
while (i * 2 <= n) {
left = i * 2;
right = i * 2 + 1;
/* Find the child with lowest value. */
min = left;
if (right <= n && heap[right] < heap[left]) {
min = right;
}
/* Move i down if it is larger. */
if (heap[min] < heap[i]) {
swap32(&heap[min], &heap[i]);
i = min;
} else {
break;
}
}
}
/* Establish minheap property for heap[1..n]. */
static void minheap_heapify(uint32_t *heap, size_t n)
{
size_t i;
/* Floyd's algorithm. */
for (i = n / 2; i >= 1; i--) {
minheap_down(heap, n, i);
}
}
```
Чтобы отслеживать частоту `n` символов, будем использовать кучу из `n` элементов. Также при каждом создании составного символа мы хотим «связывать» с ним оба исходных символа. Поэтому каждый символ будет иметь «элемент связи».
Для хранения `n`-элементной кучи и `n` элементов связи будем использовать массив из `n * 2 + 1` элементов. Когда два символа в куче заменяются одним, мы будем использовать второй элемент для сохранения ссылки на новый символ. Этот подход основан на реализации [Managing Gigabytes](https://people.eng.unimelb.edu.au/ammoffat/mg/) Уиттена, Моффата и Белла.
В каждом узле куче мы будем использовать 16 старших битов для хранения частоты символа, а 16 младших — для хранения индекса элемента связи символа. За счёт использования старших битов разница частот будет определяться результатом 32-битного сравнения между двумя элементами кучи.
Из-за такого представления нам нужно удостовериться, что частота символов всегда укладывается в 16 битов. После завершения работы алгоритма финальный составной символ будет иметь частоту всех объединённых символов, то есть эта сумма должна помещаться в 16 битов. Наша реализация Deflate будет проверять это с помощью одновременной обработки до 64 535 символов.
Символы с нулевой частотой будут получать кодовые слова нулевой длины и не станут участвовать в составлении кодировки.
Если кодовое слово достигнет заданной максимальной глубины, мы «сгладим» распределение частот, наложив частотное ограничение, и попробуем опять (да, с помощью `goto`). Есть и более сложные способы выполнения ограниченного по глубине кодирования Хаффмана, но этот прост и эффективен.
```
#define MAX_HUFFMAN_SYMBOLS 288 /* Deflate uses max 288 symbols. */
/* Construct a Huffman code for n symbols with the frequencies in freq, and
* codeword length limited to max_len. The sum of the frequencies must be <=
* UINT16_MAX. max_len must be large enough that a code is always possible,
* i.e. 2 ** max_len >= n. Symbols with zero frequency are not part of the code
* and get length zero. Outputs the codeword lengths in lengths[0..n-1]. */
static void compute_huffman_lengths(const uint16_t *freqs, size_t n,
uint8_t max_len, uint8_t *lengths)
{
uint32_t nodes[MAX_HUFFMAN_SYMBOLS * 2 + 1], p, q;
uint16_t freq;
size_t i, h, l;
uint16_t freq_cap = UINT16_MAX;
#ifndef NDEBUG
uint32_t freq_sum = 0;
for (i = 0; i < n; i++) {
freq_sum += freqs[i];
}
assert(freq_sum <= UINT16_MAX && "Frequency sum too large!");
#endif
assert(n <= MAX_HUFFMAN_SYMBOLS);
assert((1U << max_len) >= n && "max_len must be large enough");
try_again:
/* Initialize the heap. h is the heap size. */
h = 0;
for (i = 0; i < n; i++) {
freq = freqs[i];
if (freq == 0) {
continue; /* Ignore zero-frequency symbols. */
}
if (freq > freq_cap) {
freq = freq_cap; /* Enforce the frequency cap. */
}
/* High 16 bits: Symbol frequency.
Low 16 bits: Symbol link element index. */
h++;
nodes[h] = ((uint32_t)freq << 16) | (uint32_t)(n + h);
}
minheap_heapify(nodes, h);
/* Special case for less than two non-zero symbols. */
if (h < 2) {
for (i = 0; i < n; i++) {
lengths[i] = (freqs[i] == 0) ? 0 : 1;
}
return;
}
/* Build the Huffman tree. */
while (h > 1) {
/* Remove the lowest frequency node p from the heap. */
p = nodes[1];
nodes[1] = nodes[h--];
minheap_down(nodes, h, 1);
/* Get q, the next lowest frequency node. */
q = nodes[1];
/* Replace q with a new symbol with the combined frequencies of
p and q, and with the no longer used h+1'th node as the
link element. */
nodes[1] = ((p & 0xffff0000) + (q & 0xffff0000))
| (uint32_t)(h + 1);
/* Set the links of p and q to point to the link element of
the new node. */
nodes[p & 0xffff] = nodes[q & 0xffff] = (uint32_t)(h + 1);
/* Move the new symbol down to restore heap property. */
minheap_down(nodes, h, 1);
}
/* Compute the codeword length for each symbol. */
h = 0;
for (i = 0; i < n; i++) {
if (freqs[i] == 0) {
lengths[i] = 0;
continue;
}
h++;
/* Link element for the i'th symbol. */
p = nodes[n + h];
/* Follow the links until we hit the root (link index 2). */
l = 1;
while (p != 2) {
l++;
p = nodes[p];
}
if (l > max_len) {
/* Lower freq_cap to flatten the distribution. */
assert(freq_cap != 1 && "Cannot lower freq_cap!");
freq_cap /= 2;
goto try_again;
}
assert(l <= UINT8_MAX);
lengths[i] = (uint8_t)l;
}
}
```
Элегантной альтернативой варианту с двоичной кучей является сохранение символов в двух очередях. Первая содержит исходные символы, отсортированные по частоте. Когда создаётся составной символ, он добавляется во вторую очередь. Таким образом символ с наименьшей частотой всегда будет на первой позиции одной из очередей. Этот подход описан [Jan van Leeuwen](https://www.staff.science.uu.nl/~leeuw112/) в [On the Construction of Huffman Trees](https://www.staff.science.uu.nl/~leeuw112/huffman.pdf) (1976).
Кодирование Хаффмана оптимально для беспрефиксных кодов, но в других случаях есть более эффективные способы: [арифметическое кодирование](https://ru.wikipedia.org/wiki/%D0%90%D1%80%D0%B8%D1%84%D0%BC%D0%B5%D1%82%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%BE%D0%B5_%D0%BA%D0%BE%D0%B4%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5) и [асимметричные системы счисления](https://ru.wikipedia.org/wiki/Asymmetric_numeral_systems).
### Канонические коды Хаффмана
В примере выше мы построили дерево Хаффмана:

Если идти от корня и использовать 0 для левой ветки и 1 для правой, то мы получим такие коды:
| | |
| --- | --- |
| **Символ** | **Кодовое слово** |
| A | 0 |
| B | 10 |
| C | 110 |
| D | 111 |
Решение об использовании 0 для левой ветки и 1 для правой выглядит произвольным. Если сделать наоборот, то получим:
| | |
| --- | --- |
| **Символ** | **Кодовое слово** |
| A | 1 |
| B | 01 |
| C | 001 |
| D | 000 |
Мы можем произвольно помечать две ветки, исходящие из ноды, нулём и единицей (главное, чтобы метки были разными), и всё равно получим эквивалентный код:
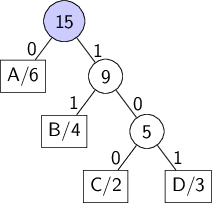
| | |
| --- | --- |
| **Символ** | **Кодовое слово** |
| A | 0 |
| B | 11 |
| C | 100 |
| D | 101 |
Хотя алгоритм Хаффмана дает требуемые длины кодовых слов для беспрефиксного кода с минимальной избыточностью, есть множество способов присвоения отдельных кодовых слов.
Учитывая длину кодового слова, вычисляемую по алгоритму Хаффмана, канонический код Хаффмана присваивает символам кодовые слова определённым образом. Это полезно, поскольку позволяет хранить и передавать длины кодовых слов со сжатыми данными: декодер сможет восстановить кодовые слова на основе их длин. Конечно, можно хранить и передавать частоты символов и запускать в декодере алгоритм Хаффмана, но это потребует от декодера больше работы и больше места для хранения. Другим очень важным свойством является то, что структура канонических кодов использует эффективное декодирование.
Идея заключается в том, чтобы присваивать символам кодовые слова последовательно, под одному за раз. Первым кодовым словом является 0. Следующим будет слово длиной предыдущее слово + 1. Первое слово длиной N составляется из последнего слова длиной N-1, добавления единицы (чтобы получилось новое кодовое слово) и смещения на один шаг влево (для увеличения длины).
В терминологии дерева Хоффмана кодовые слова последовательно присваиваются листьям в порядке слева-направо, по одному уровню за раз, смещаясь влево при переходе на следующий уровень.
В нашем примере A-B-C-D алгоритм Хаффмана присвоил кодовые слова с длинами 1, 2, 3 и 3. Первым словом является 0. Это также последнее слово длиной 1. Для длины 2 мы берём 0 и добавляем 1 для получения следующего кода, который станет префиксом двухбитных кодов, смещаемся влево и получаем 10. Это теперь последнее слово длиной 2. Для получения длины 3 мы добавляем 1 и смещаемся: 110. Для получения следующего слова длиной 3 мы добавляем 1: 111.
| | |
| --- | --- |
| **Символ** | **Кодовое слово** |
| A | 0 |
| B | 10 |
| C | 110 |
| D | 111 |
Ниже показана реализация генератора канонических кодов. Обратите внимание, что алгоритм Deflate ожидает, что кодовые слова будут генерироваться по принципу LSB-first (сначала младшим значащим битом). То есть первый бит кодового слова должен храниться в наименьшем значащем бите. Это означает, что нам нужно поменять порядок битов, например, с помощью поисковой таблицы.
```
#define MAX_HUFFMAN_BITS 15 /* Deflate uses max 15-bit codewords. */
static void compute_canonical_code(uint16_t *codewords, const uint8_t *lengths,
size_t n)
{
size_t i;
uint16_t count[MAX_HUFFMAN_BITS + 1] = {0};
uint16_t code[MAX_HUFFMAN_BITS + 1];
int l;
/* Count the number of codewords of each length. */
for (i = 0; i < n; i++) {
count[lengths[i]]++;
}
count[0] = 0; /* Ignore zero-length codes. */
/* Compute the first codeword for each length. */
code[0] = 0;
for (l = 1; l <= MAX_HUFFMAN_BITS; l++) {
code[l] = (uint16_t)((code[l - 1] + count[l - 1]) << 1);
}
/* Assign a codeword for each symbol. */
for (i = 0; i < n; i++) {
l = lengths[i];
if (l == 0) {
continue;
}
codewords[i] = reverse16(code[l]++, l); /* Make it LSB-first. */
}
}
/* Reverse the n least significant bits of x.
The (16 - n) most significant bits of the result will be zero. */
static inline uint16_t reverse16(uint16_t x, int n)
{
uint16_t lo, hi;
uint16_t reversed;
assert(n > 0);
assert(n <= 16);
lo = x & 0xff;
hi = x >> 8;
reversed = (uint16_t)((reverse8_tbl[lo] << 8) | reverse8_tbl[hi]);
return reversed >> (16 - n);
}
```
Теперь соберём всё вместе и напишем код инициализации кодировщика:
```
typedef struct huffman_encoder_t huffman_encoder_t;
struct huffman_encoder_t {
uint16_t codewords[MAX_HUFFMAN_SYMBOLS]; /* LSB-first codewords. */
uint8_t lengths[MAX_HUFFMAN_SYMBOLS]; /* Codeword lengths. */
};
/* Initialize a Huffman encoder based on the n symbol frequencies. */
void huffman_encoder_init(huffman_encoder_t *e, const uint16_t *freqs, size_t n,
uint8_t max_codeword_len)
{
assert(n <= MAX_HUFFMAN_SYMBOLS);
assert(max_codeword_len <= MAX_HUFFMAN_BITS);
compute_huffman_lengths(freqs, n, max_codeword_len, e->lengths);
compute_canonical_code(e->codewords, e->lengths, n);
}
```
Также сделаем функцию для настройки кодировщика с помощью уже вычисленных длин кодов:
```
/* Initialize a Huffman encoder based on the n codeword lengths. */
void huffman_encoder_init2(huffman_encoder_t *e, const uint8_t *lengths,
size_t n)
{
size_t i;
for (i = 0; i < n; i++) {
e->lengths[i] = lengths[i];
}
compute_canonical_code(e->codewords, e->lengths, n);
}
```
### Эффективное декодирование Хаффмана
Самый простой способ декодирования Хаффмана заключается в обходе дерева начиная с корня, считывая по одному биту входных данных за раз и решая, какую ветку брать следующей, левую или правую. Когда достигается листовой узел, это декодированный символ.
Этому методу часто учат в университетах и книгах. Он прост и элегантен, но обрабатывать по одному биту за раз слишком медленно. Гораздо быстрее декодировать с помощью поисковой таблицы. Для вышеприведённого примера, в котором максимальная длина кодового слова равна трём битам, можно использовать такую таблицу:
| | | |
| --- | --- | --- |
| **Биты** | **Символ** | **Длина кодового слова** |
| **0**00 | A | 1 |
| **0**01 | A | 1 |
| **0**10 | A | 1 |
| **0**11 | A | 1 |
| **10**0 | B | 2 |
| **10**1 | B | 2 |
| **110** | C | 3 |
| **111** | D | 3 |
Хотя символов всего четыре, нам нужна таблица с восемью записями, чтобы охватить все возможные трёхбитные комбинации. Символы с кодовыми словами короче трёх битов имеют в таблице по несколько записей. Например, слово 10 было «дополнено» **10**0 и **10**1, чтобы охватить все трёхбитные комбинации, начинающиеся с 10.
Чтобы декодировать таким образом, нужно проиндексировать в таблице с помощью следующих трёх входных битов и немедленно найти соответствующий символ и длину его кодового слова. Длина важна, потому что несмотря на то, что мы смотрели на следующие три бита, нам нужно получить такое же количество входных битов, какова длина кодового слова.
Метод на основе поисковой таблицы работает очень быстро, но у него есть недостаток: размер таблицы удваивается при каждом дополнительном бите в длине кодового слова. То есть построение таблицы замедляется экспоненциально, и если она перестаёт помещаться в кэш процессора, то метод начинает работать медленно.
Из-за этого таблицу поиска обычно используют только для кодовых слов не больше определённой длины. А для более длинных слов применяют другой подход. Как при кодировании Хаффмана более частым символами присваиваются более короткие кодовые слова, так и использование поисковой таблицы для коротких кодовых слов является во многих случаях прекрасной оптимизацией.
[В zlib](https://github.com/madler/zlib/blob/v1.2.11/doc/algorithm.txt#L58) используется несколько уровней поисковых таблиц. Если кодовое слово слишком длинное для первой таблицы, то поиск перейдёт во вторичную таблицу, чтобы проиндексировать оставшиеся биты.
Но есть и другой, очень элегантный метод, основанный на свойствах канонических кодов Хаффмана. Он описывается в статье *On the Implementation of Minimum Redundancy Prefix Codes* (Моффат и Турпин, 1997-й), а также объясняется в статье [The Lost Huffman Paper](http://cbloomrants.blogspot.com/2010/08/08-12-10-lost-huffman-paper.html) Чарльза Блума.
Возьмём кодовые слова из канонической версии: 0, 10, 110, 111. Будем отслеживать первые кодовые слова каждой из длин, а также номер каждого кодового слова в общей последовательности — «символьный индекс».
| | | |
| --- | --- | --- |
| **Длина кодового слова** | **Первое кодовое слово** | **Первый символьный индекс** |
| 1 | 0 | 1 (A) |
| 2 | 10 | 2 (B) |
| 3 | 110 | 3 (С) |
Поскольку кодовые слова присваиваются последовательно, то если нам известно количество битов, мы можем в вышеприведённой таблице найти символ, который представляют эти биты. Например, для трёхбитного 111 мы видим, что это смещение на единицу от первого кодового слова этой длины (110). Первым символьным индексом такой длины является 3, а смещение на единицу даёт нам индекс 4. Другая таблица сопоставляет символьный индекс с символом:
```
sym_idx = d->first_symbol[len] + (bits - d->first_code[len]);
sym = d->syms[sym_idx];
```
Маленька оптимизация: вместо раздельного хранения первого символьного индекса и первого кодового слова мы можем хранить в таблице первый индекс минус первое кодовое слово:
```
sym_idx = d->offset_first_sym_idx[len] + bits;
sym = d->syms[sym_idx];
```
Чтобы понять, сколько битов нужно оценить, мы снова воспользуемся свойством последовательности кода. В нашем примере все валидные однобитные кодовые слова строго меньше 1, двухбитные — строго меньше 11, трёхбитные — меньше 1000 (по сути, верно для всех трёхбитных значений). Иными словами, валидное N-битное кодовое слово должно быть строго меньше первого N-битного кодового слова плюс количество N-битных кодовых слов. Более того, мы можем смещать влево эти границы, чтобы все они были трёхбитной ширины. Давайте назовём это *ограничительными битами* для каждой из длин кодовых слов:
| | |
| --- | --- |
| **Длина кодового слова** | **Ограничительные биты** |
| 1 | 100 |
| 2 | 110 |
| 3 | 1000 |
*Ограничитель для длины 3 переполнился до 4 битов, но это лишь означает, что подойдёт любое трёхбитное слово.*
Мы можем искать среди трёхбитных входных данных и сравнивать с ограничительными битами, чтобы понять, какой длины наше кодовое слово. После завершения мы смещаем входные биты, только чтобы вычислить их правильное количество, а затем находим символьный индекс:
```
for (len = 1; len <= 3; len++) {
if (bits < d->sentinel_bits[len]) {
bits >>= 3 - len; /* Get the len most significant bits. */
sym_idx = d->offset_first_sym_idx[len] + bits;
}
}
```
Временная сложность процесса линейная относительно количества битов в кодовых словах, но зато место расходуется эффективно, на каждом шаге требуется только загрузка и сравнение, а поскольку более короткие кодовые слова встречаются чаще, метод позволяет оптимизировать сжатие во многих ситуациях.
Полный код декодера:
```
#define HUFFMAN_LOOKUP_TABLE_BITS 8 /* Seems a good trade-off. */
typedef struct huffman_decoder_t huffman_decoder_t;
struct huffman_decoder_t {
/* Lookup table for fast decoding of short codewords. */
struct {
uint16_t sym : 9; /* Wide enough to fit the max symbol nbr. */
uint16_t len : 7; /* 0 means no symbol. */
} table[1U << HUFFMAN_LOOKUP_TABLE_BITS];
/* "Sentinel bits" value for each codeword length. */
uint16_t sentinel_bits[MAX_HUFFMAN_BITS + 1];
/* First symbol index minus first codeword mod 2**16 for each length. */
uint16_t offset_first_sym_idx[MAX_HUFFMAN_BITS + 1];
/* Map from symbol index to symbol. */
uint16_t syms[MAX_HUFFMAN_SYMBOLS];
#ifndef NDEBUG
size_t num_syms;
#endif
};
/* Get the n least significant bits of x. */
static inline uint64_t lsb(uint64_t x, int n)
{
assert(n >= 0 && n <= 63);
return x & (((uint64_t)1 << n) - 1);
}
/* Use the decoder d to decode a symbol from the LSB-first zero-padded bits.
* Returns the decoded symbol number or -1 if no symbol could be decoded.
* *num_used_bits will be set to the number of bits used to decode the symbol,
* or zero if no symbol could be decoded. */
static inline int huffman_decode(const huffman_decoder_t *d, uint16_t bits,
size_t *num_used_bits)
{
uint64_t lookup_bits;
size_t l;
size_t sym_idx;
/* First try the lookup table. */
lookup_bits = lsb(bits, HUFFMAN_LOOKUP_TABLE_BITS);
assert(lookup_bits < sizeof(d->table) / sizeof(d->table[0]));
if (d->table[lookup_bits].len != 0) {
assert(d->table[lookup_bits].len <= HUFFMAN_LOOKUP_TABLE_BITS);
assert(d->table[lookup_bits].sym < d->num_syms);
*num_used_bits = d->table[lookup_bits].len;
return d->table[lookup_bits].sym;
}
/* Then do canonical decoding with the bits in MSB-first order. */
bits = reverse16(bits, MAX_HUFFMAN_BITS);
for (l = HUFFMAN_LOOKUP_TABLE_BITS + 1; l <= MAX_HUFFMAN_BITS; l++) {
if (bits < d->sentinel_bits[l]) {
bits >>= MAX_HUFFMAN_BITS - l;
sym_idx = (uint16_t)(d->offset_first_sym_idx[l] + bits);
assert(sym_idx < d->num_syms);
*num_used_bits = l;
return d->syms[sym_idx];
}
}
*num_used_bits = 0;
return -1;
}
```
Для настройки декодера мы заранее вычислим канонические коды, как для [huffman\_encoder\_init](https://www.hanshq.net/zip.html#huffman_encoder_init), и заполним разные таблицы:
```
/* Initialize huffman decoder d for a code defined by the n codeword lengths.
Returns false if the codeword lengths do not correspond to a valid prefix
code. */
bool huffman_decoder_init(huffman_decoder_t *d, const uint8_t *lengths,
size_t n)
{
size_t i;
uint16_t count[MAX_HUFFMAN_BITS + 1] = {0};
uint16_t code[MAX_HUFFMAN_BITS + 1];
uint32_t s;
uint16_t sym_idx[MAX_HUFFMAN_BITS + 1];
int l;
#ifndef NDEBUG
assert(n <= MAX_HUFFMAN_SYMBOLS);
d->num_syms = n;
#endif
/* Zero-initialize the lookup table. */
for (i = 0; i < sizeof(d->table) / sizeof(d->table[0]); i++) {
d->table[i].len = 0;
}
/* Count the number of codewords of each length. */
for (i = 0; i < n; i++) {
assert(lengths[i] <= MAX_HUFFMAN_BITS);
count[lengths[i]]++;
}
count[0] = 0; /* Ignore zero-length codewords. */
/* Compute sentinel_bits and offset_first_sym_idx for each length. */
code[0] = 0;
sym_idx[0] = 0;
for (l = 1; l <= MAX_HUFFMAN_BITS; l++) {
/* First canonical codeword of this length. */
code[l] = (uint16_t)((code[l - 1] + count[l - 1]) << 1);
if (count[l] != 0 && code[l] + count[l] - 1 > (1U << l) - 1) {
/* The last codeword is longer than l bits. */
return false;
}
s = (uint32_t)((code[l] + count[l]) << (MAX_HUFFMAN_BITS - l));
d->sentinel_bits[l] = (uint16_t)s;
assert(d->sentinel_bits[l] == s && "No overflow.");
sym_idx[l] = sym_idx[l - 1] + count[l - 1];
d->offset_first_sym_idx[l] = sym_idx[l] - code[l];
}
/* Build mapping from index to symbol and populate the lookup table. */
for (i = 0; i < n; i++) {
l = lengths[i];
if (l == 0) {
continue;
}
d->syms[sym_idx[l]] = (uint16_t)i;
sym_idx[l]++;
if (l <= HUFFMAN_LOOKUP_TABLE_BITS) {
table_insert(d, i, l, code[l]);
code[l]++;
}
}
return true;
}
static void table_insert(huffman_decoder_t *d, size_t sym, int len,
uint16_t codeword)
{
int pad_len;
uint16_t padding, index;
assert(len <= HUFFMAN_LOOKUP_TABLE_BITS);
codeword = reverse16(codeword, len); /* Make it LSB-first. */
pad_len = HUFFMAN_LOOKUP_TABLE_BITS - len;
/* Pad the pad_len upper bits with all bit combinations. */
for (padding = 0; padding < (1U << pad_len); padding++) {
index = (uint16_t)(codeword | (padding << len));
d->table[index].sym = (uint16_t)sym;
d->table[index].len = (uint16_t)len;
assert(d->table[index].sym == sym && "Fits in bitfield.");
assert(d->table[index].len == len && "Fits in bitfield.");
}
}
```
Deflate
-------
Алгоритм Deflate, представленный в PKZip 2.04c в 1993-м, это стандартный метод сжатия в современных Zip-файлах. Он также применяется в gzip, PNG и многих других форматах. В нём используется сочетание сжатия LZ77 и кодирования Хаффмана, которое мы рассмотрим и реализуем в этом разделе.
До Deflate в PKZip использовались методы сжатия Shrink, Reduce и Implode. Сегодня они встречаются редко, хотя после появления Deflate ещё какое-то время были в ходу, потому что потребляли меньше памяти. Но мы их рассматривать не будем.
### Битовые потоки
Deflate сохраняет кодовые слова Хаффмана в битовом потоке по принципу LSB-first. Это означает, что первый бит потока сохраняется в наименее младшем значащем бите первого байта.
Рассмотрим битовый поток (читается слева направо) 1-0-0-1-1. Когда он сохраняется по принципу LSB-first, то значение байта становится 0b00011001 (двоичное) или 0x19 (шестнадцатеричное). Может показаться, что поток просто представлен задом наперёд (в некотором смысле так и есть), но преимущество заключается в том, что так нам проще получить первые N битов из компьютерного слова: просто скрываем N младших битов.
Эти процедуры взяты из [bitstream.h](https://www.hanshq.net/files/hwzip/bitstream.h):
```
/* Input bitstream. */
typedef struct istream_t istream_t;
struct istream_t {
const uint8_t *src; /* Source bytes. */
const uint8_t *end; /* Past-the-end byte of src. */
size_t bitpos; /* Position of the next bit to read. */
size_t bitpos_end; /* Position of past-the-end bit. */
};
/* Initialize an input stream to present the n bytes from src as an LSB-first
* bitstream. */
static inline void istream_init(istream_t *is, const uint8_t *src, size_t n)
{
is->src = src;
is->end = src + n;
is->bitpos = 0;
is->bitpos_end = n * 8;
}
```
Нашему декодеру Хаффмана нужно смотреть на следующие биты в потоке (достаточно битов для самого длинного возможного кодового слова), а затем продолжать поток на количество битов, использованных декодированным символом:
```
#define ISTREAM_MIN_BITS (64 - 7)
/* Get the next bits from the input stream. The number of bits returned is
* between ISTREAM_MIN_BITS and 64, depending on the position in the stream, or
* fewer if the end of stream is reached. The upper bits are zero-padded. */
static inline uint64_t istream_bits(const istream_t *is)
{
const uint8_t *next;
uint64_t bits;
int i;
next = is->src + (is->bitpos / 8);
assert(next <= is->end && "Cannot read past end of stream.");
if (is->end - next >= 8) {
/* Common case: read 8 bytes in one go. */
bits = read64le(next);
} else {
/* Read the available bytes and zero-pad. */
bits = 0;
for (i = 0; i < is->end - next; i++) {
bits |= (uint64_t)next[i] << (i * 8);
}
}
return bits >> (is->bitpos % 8);
}
/* Advance n bits in the bitstream if possible. Returns false if that many bits
* are not available in the stream. */
static inline bool istream_advance(istream_t *is, size_t n) {
if (is->bitpos + n > is->bitpos_end) {
return false;
}
is->bitpos += n;
return true;
}
```
Суть в том, что на 64-битных машинах `istream_bits` обычно можно исполнять как инструкцию одиночной загрузки и каких-то арифметических действий, учитывая, что элементы структуры `istream_t` находятся в регистрах. read64le реализован в [bits.h](https://www.hanshq.net/files/hwzip/bits.h) (современные компиляторы преобразуют его в одиночную 64-битную загрузку по принципу little-endian):
```
/* Read a 64-bit value from p in little-endian byte order. */
static inline uint64_t read64le(const uint8_t *p)
{
/* The one true way, see
* https://commandcenter.blogspot.com/2012/04/byte-order-fallacy.html */
return ((uint64_t)p[0] << 0) |
((uint64_t)p[1] << 8) |
((uint64_t)p[2] << 16) |
((uint64_t)p[3] << 24) |
((uint64_t)p[4] << 32) |
((uint64_t)p[5] << 40) |
((uint64_t)p[6] << 48) |
((uint64_t)p[7] << 56);
}
```
Также нам нужна функция для продолжения битового потока к границе следующего байта:
```
/* Round x up to the next multiple of m, which must be a power of 2. */
static inline size_t round_up(size_t x, size_t m)
{
assert((m & (m - 1)) == 0 && "m must be a power of two");
return (x + m - 1) & (size_t)(-m); /* Hacker's Delight (2nd), 3-1. */
}
/* Align the input stream to the next 8-bit boundary and return a pointer to
* that byte, which may be the past-the-end-of-stream byte. */
static inline const uint8_t *istream_byte_align(istream_t *is)
{
const uint8_t *byte;
assert(is->bitpos <= is->bitpos_end && "Not past end of stream.");
is->bitpos = round_up(is->bitpos, 8);
byte = is->src + is->bitpos / 8;
assert(byte <= is->end);
return byte;
}
```
Для исходящего битового потока мы пишем биты с помощью последовательности операций чтение-модификация-запись. В быстром случае записать бит можно с помощью 64-битного чтения, какой-то битовой операции и 64-битной записи.
```
/* Output bitstream. */
typedef struct ostream_t ostream_t;
struct ostream_t {
uint8_t *dst;
uint8_t *end;
size_t bitpos;
size_t bitpos_end;
};
/* Initialize an output stream to write LSB-first bits into dst[0..n-1]. */
static inline void ostream_init(ostream_t *os, uint8_t *dst, size_t n)
{
os->dst = dst;
os->end = dst + n;
os->bitpos = 0;
os->bitpos_end = n * 8;
}
/* Get the current bit position in the stream. */
static inline size_t ostream_bit_pos(const ostream_t *os)
{
return os->bitpos;
}
/* Return the number of bytes written to the output buffer. */
static inline size_t ostream_bytes_written(ostream_t *os)
{
return round_up(os->bitpos, 8) / 8;
}
/* Write n bits to the output stream. Returns false if there is not enough room
* at the destination. */
static inline bool ostream_write(ostream_t *os, uint64_t bits, size_t n)
{
uint8_t *p;
uint64_t x;
int shift, i;
assert(n <= 57);
assert(bits <= ((uint64_t)1 << n) - 1 && "Must fit in n bits.");
if (os->bitpos_end - os->bitpos < n) {
/* Not enough room. */
return false;
}
p = &os->dst[os->bitpos / 8];
shift = os->bitpos % 8;
if (os->end - p >= 8) {
/* Common case: read and write 8 bytes in one go. */
x = read64le(p);
x = lsb(x, shift);
x |= bits << shift;
write64le(p, x);
} else {
/* Slow case: read/write as many bytes as are available. */
x = 0;
for (i = 0; i < os->end - p; i++) {
x |= (uint64_t)p[i] << (i * 8);
}
x = lsb(x, shift);
x |= bits << shift;
for (i = 0; i < os->end - p; i++) {
p[i] = (uint8_t)(x >> (i * 8));
}
}
os->bitpos += n;
return true;
}
/* Write a 64-bit value x to dst in little-endian byte order. */
static inline void write64le(uint8_t *dst, uint64_t x)
{
dst[0] = (uint8_t)(x >> 0);
dst[1] = (uint8_t)(x >> 8);
dst[2] = (uint8_t)(x >> 16);
dst[3] = (uint8_t)(x >> 24);
dst[4] = (uint8_t)(x >> 32);
dst[5] = (uint8_t)(x >> 40);
dst[6] = (uint8_t)(x >> 48);
dst[7] = (uint8_t)(x >> 56);
}
```
Также нам нужно эффективно записывать в поток байты. Конечно, можно многократно выполнять 8-битные записи, но гораздо быстрее будет использовать `memcpy`:
```
/* Align the bitstream to the next byte boundary, then write the n bytes from
src to it. Returns false if there is not enough room in the stream. */
static inline bool ostream_write_bytes_aligned(ostream_t *os,
const uint8_t *src,
size_t n)
{
if (os->bitpos_end - round_up(os->bitpos, 8) < n * 8) {
return false;
}
os->bitpos = round_up(os->bitpos, 8);
memcpy(&os->dst[os->bitpos / 8], src, n);
os->bitpos += n * 8;
return true;
}
```
### Распаковка (Inflation)
Поскольку алгоритм сжатия называется *Deflate* — сдувание, извлечение воздуха из чего-либо, — то процесс распаковки иногда называют *Inflation* (накачивание). Если первым делом изучить этот процесс, то мы поймём, как работает формат. Код можно посмотреть в первой части [deflate.h](https://www.hanshq.net/files/hwzip/deflate.h) и [deflate.c](https://www.hanshq.net/files/hwzip/deflate.c), [bits.h](https://www.hanshq.net/files/hwzip/bits.h), [tables.h](https://www.hanshq.net/files/hwzip/tables.h) и [tables.c](https://www.hanshq.net/files/hwzip/tables.c) (сгенерирован с помощью [generate\_tables.c](https://www.hanshq.net/files/hwzip/generate_tables.c)).
Данные, сжатые с помощью Deflate, хранятся в виде серии *блоков*. Каждый блок начинается с 3-битного заголовка, в котором первый (младший значимый) бит задаётся в том случае, если это финальный блок серии, а остальные два бита обозначают его тип.

Есть три типа блоков: несжатый (0), сжатый с помощью фиксированных кодов Хаффмана (1) и сжатый с помощью «динамических» кодов Хаффмана (2).
Этот код выполняет распаковку с использованием вспомогательных функций для разных типов блоков, которые мы реализуем позднее:
```
typedef enum {
HWINF_OK, /* Inflation was successful. */
HWINF_FULL, /* Not enough room in the output buffer. */
HWINF_ERR /* Error in the input data. */
} inf_stat_t;
/* Decompress (inflate) the Deflate stream in src. The number of input bytes
used, at most src_len, is stored in *src_used on success. Output is written
to dst. The number of bytes written, at most dst_cap, is stored in *dst_used
on success. src[0..src_len-1] and dst[0..dst_cap-1] must not overlap.
Returns a status value as defined above. */
inf_stat_t hwinflate(const uint8_t *src, size_t src_len, size_t *src_used,
uint8_t *dst, size_t dst_cap, size_t *dst_used)
{
istream_t is;
size_t dst_pos;
uint64_t bits;
bool bfinal;
inf_stat_t s;
istream_init(&is, src, src_len);
dst_pos = 0;
do {
/* Read the 3-bit block header. */
bits = istream_bits(&is);
if (!istream_advance(&is, 3)) {
return HWINF_ERR;
}
bfinal = bits & 1;
bits >>= 1;
switch (lsb(bits, 2)) {
case 0: /* 00: No compression. */
s = inf_noncomp_block(&is, dst, dst_cap, &dst_pos);
break;
case 1: /* 01: Compressed with fixed Huffman codes. */
s = inf_fixed_block(&is, dst, dst_cap, &dst_pos);
break;
case 2: /* 10: Compressed with "dynamic" Huffman codes. */
s = inf_dyn_block(&is, dst, dst_cap, &dst_pos);
break;
default: /* Invalid block type. */
return HWINF_ERR;
}
if (s != HWINF_OK) {
return s;
}
} while (!bfinal);
*src_used = (size_t)(istream_byte_align(&is) - src);
assert(dst_pos <= dst_cap);
*dst_used = dst_pos;
return HWINF_OK;
}
```
#### Несжатые Deflate-блоки
Это «хранимые» блоки, простейший тип. Он начинается со следующей 8-битной границы битового потока с 16 битного слова (len), обозначающего длину блока. За ним идёт другое 16-битное слово (nlen), которое дополняет (порядок битов инвертирован) слов len. Предполагается, что nlen действует как простая контрольная сумма len: если файл повреждён, то, вероятно, значения уже не будут взаимодополняющими и программа сможет обнаружить ошибку.

После len и nlen идут несжатые данные. Поскольку длина блока представляет собой 16-битное значение, размер данных ограничен 65 535 байтами.
```
static inf_stat_t inf_noncomp_block(istream_t *is, uint8_t *dst,
size_t dst_cap, size_t *dst_pos)
{
const uint8_t *p;
uint16_t len, nlen;
p = istream_byte_align(is);
/* Read len and nlen (2 x 16 bits). */
if (!istream_advance(is, 32)) {
return HWINF_ERR; /* Not enough input. */
}
len = read16le(p);
nlen = read16le(p + 2);
p += 4;
if (nlen != (uint16_t)~len) {
return HWINF_ERR;
}
if (!istream_advance(is, len * 8)) {
return HWINF_ERR; /* Not enough input. */
}
if (dst_cap - *dst_pos < len) {
return HWINF_FULL; /* Not enough room to output. */
}
memcpy(&dst[*dst_pos], p, len);
*dst_pos += len;
return HWINF_OK;
}
```
#### Deflate-блоки с применением фиксированных кодов Хаффмана
Сжатые Deflate-блоки используют код Хаффмана для представления последовательности LZ77-литералов. Обратные ссылки прерываются с помощью маркеров конца блока. Для литералов, длин обратных ссылок и маркеров используется код Хаффмана *litlen*. А для расстояний обратных ссылок используется код *dist*.

С помощью litlen кодируются значения в диапазоне 0-285. Значения 0-255 используются для байтов литералов, 256 — маркер конца блока, а 257-285 используются для длин обратных ссылок.
Обратные ссылки бывают длиной 3-258 байтов. Litlen-значение определяет базовую длину, к которой из потока добавляется ноль или больше *дополнительных битов*, чтобы получилась полная длина согласно нижеприведённой таблице. Например, litlen-значение 269 означает базовую длину 19 и два дополнительных бита. Прибавка двух битов из потока даёт финальную длину от 19 до 22.
| | | |
| --- | --- | --- |
| **Litlen** | **Дополнительные биты** | **Длины** |
| 257 | 0 | 3 |
| 258 | 0 | 4 |
| 259 | 0 | 5 |
| 260 | 0 | 6 |
| 261 | 0 | 7 |
| 262 | 0 | 8 |
| 263 | 0 | 9 |
| 264 | 0 | 10 |
| 265 | 1 | 11–12 |
| 266 | 1 | 13–14 |
| 267 | 1 | 15–16 |
| 268 | 1 | 17–18 |
| 269 | 2 | 19–22 |
| 270 | 2 | 23–26 |
| 271 | 2 | 27–30 |
| 272 | 2 | 31–34 |
| 273 | 3 | 35–42 |
| 274 | 3 | 43–50 |
| 275 | 3 | 51–58 |
| 276 | 3 | 59–66 |
| 277 | 4 | 67–82 |
| 278 | 4 | 83–98 |
| 279 | 4 | 99–114 |
| 280 | 4 | 115–130 |
| 281 | 5 | 131–162 |
| 282 | 5 | 163–194 |
| 283 | 5 | 195–226 |
| 284 | 5 | 227–257 |
| 285 | 0 | 258 |
Обратите внимание, что litlen-значение 284 плюс 5 дополнительных битов может представлять длины от 227 до 258, однако в спецификации указано, что длина 258 — максимальная длина обратной ссылки — должна быть представлена с помощью отдельного litlen-значения. Предполагается, что это позволяет сократить кодирование в ситуациях, когда часто встречается максимальная длина.
Декомпрессор использует использует таблицу для получения из litlen-значения (минус 257) базовой длины и дополнительных битов:
```
/* Table of litlen symbol values minus 257 with corresponding base length
and number of extra bits. */
struct litlen_tbl_t {
uint16_t base_len : 9;
uint16_t ebits : 7;
};
const struct litlen_tbl_t litlen_tbl[29] = {
/* 257 */ { 3, 0 },
/* 258 */ { 4, 0 },
...
/* 284 */ { 227, 5 },
/* 285 */ { 258, 0 }
};
```
Фиксированный litlen-код Хаффмана является каноническим и использует следующие длины кодовых слов (286–287 не являются корректными litlen-значениями, но они участвуют в генерировании кодов):
| | |
| --- | --- |
| **Litlen-значения** | **Длина кодового слова** |
| 0–143 | 8 |
| 144–255 | 9 |
| 256–279 | 7 |
| 280–287 | 8 |
Декомпрессор сохраняет эти длины в таблицу, удобную для передачи в `huffman_decoder_init`:
```
const uint8_t fixed_litlen_lengths[288] = {
/* 0 */ 8,
/* 1 */ 8,
...
/* 287 */ 8,
};
```
Расстояния обратных ссылок меняются от 1 до 32 768. Они кодируются с помощью схемы, которая аналогична схеме кодирования длин. Код Хаффмана dist кодирует значения от 0 до 29, каждое из которых соответствует базовой длине, к которой добавляются дополнительные биты для получения финального расстояния:
| | | |
| --- | --- | --- |
| **Dist** | **Дополнительные биты** | **Расстояния** |
| 0 | 0 | 1 |
| 1 | 0 | 2 |
| 2 | 0 | 3 |
| 3 | 0 | 4 |
| 4 | 1 | 5–6 |
| 5 | 1 | 7–8 |
| 6 | 2 | 9–12 |
| 7 | 2 | 13–16 |
| 8 | 3 | 17–24 |
| 9 | 3 | 25–32 |
| 10 | 4 | 33–48 |
| 11 | 4 | 49–64 |
| 12 | 5 | 65–96 |
| 13 | 5 | 97–128 |
| 14 | 6 | 129–192 |
| 15 | 6 | 193–256 |
| 16 | 7 | 257–384 |
| 17 | 7 | 385–512 |
| 18 | 8 | 513–768 |
| 19 | 8 | 769–1024 |
| 20 | 9 | 1025–1536 |
| 21 | 9 | 1537–2048 |
| 22 | 10 | 2049–3072 |
| 23 | 10 | 3073–4096 |
| 24 | 11 | 4097–6144 |
| 25 | 11 | 6145–8192 |
| 26 | 12 | 8193–12288 |
| 27 | 12 | 12289–16384 |
| 28 | 13 | 16385–24576 |
| 29 | 13 | 24577–32768 |
Фиксированный код Хаффмана dist является каноническим. Все кодовые слова длиной 5 битов. Он прост, декомпрессор хранит коды в таблице, которую можно использовать с `huffman_decoder_init` (dist-значения 30–31 не являются корректными. Указано, что они участвуют в генерировании кодов Хаффмана, но на самом деле не оказывают никакого эффекта):
```
const uint8_t fixed_dist_lengths[32] = {
/* 0 */ 5,
/* 1 */ 5,
...
/* 31 */ 5,
};
```
Код декомпрессии, или распаковки — Deflate-блок с использованием фиксированных кодов Хаффмана:
```
static inf_stat_t inf_fixed_block(istream_t *is, uint8_t *dst,
size_t dst_cap, size_t *dst_pos)
{
huffman_decoder_t litlen_dec, dist_dec;
huffman_decoder_init(&litlen_dec, fixed_litlen_lengths,
sizeof(fixed_litlen_lengths) /
sizeof(fixed_litlen_lengths[0]));
huffman_decoder_init(&dist_dec, fixed_dist_lengths,
sizeof(fixed_dist_lengths) /
sizeof(fixed_dist_lengths[0]));
return inf_block(is, dst, dst_cap, dst_pos, &litlen_dec, &dist_dec);
}
#define LITLEN_EOB 256
#define LITLEN_MAX 285
#define LITLEN_TBL_OFFSET 257
#define MIN_LEN 3
#define MAX_LEN 258
#define DISTSYM_MAX 29
#define MIN_DISTANCE 1
#define MAX_DISTANCE 32768
static inf_stat_t inf_block(istream_t *is, uint8_t *dst, size_t dst_cap,
size_t *dst_pos,
const huffman_decoder_t *litlen_dec,
const huffman_decoder_t *dist_dec)
{
uint64_t bits;
size_t used, used_tot, dist, len;
int litlen, distsym;
uint16_t ebits;
while (true) {
/* Read a litlen symbol. */
bits = istream_bits(is);
litlen = huffman_decode(litlen_dec, (uint16_t)bits, &used);
bits >>= used;
used_tot = used;
if (litlen < 0 || litlen > LITLEN_MAX) {
/* Failed to decode, or invalid symbol. */
return HWINF_ERR;
} else if (litlen <= UINT8_MAX) {
/* Literal. */
if (!istream_advance(is, used_tot)) {
return HWINF_ERR;
}
if (*dst_pos == dst_cap) {
return HWINF_FULL;
}
lz77_output_lit(dst, (*dst_pos)++, (uint8_t)litlen);
continue;
} else if (litlen == LITLEN_EOB) {
/* End of block. */
if (!istream_advance(is, used_tot)) {
return HWINF_ERR;
}
return HWINF_OK;
}
/* It is a back reference. Figure out the length. */
assert(litlen >= LITLEN_TBL_OFFSET && litlen <= LITLEN_MAX);
len = litlen_tbl[litlen - LITLEN_TBL_OFFSET].base_len;
ebits = litlen_tbl[litlen - LITLEN_TBL_OFFSET].ebits;
if (ebits != 0) {
len += lsb(bits, ebits);
bits >>= ebits;
used_tot += ebits;
}
assert(len >= MIN_LEN && len <= MAX_LEN);
/* Get the distance. */
distsym = huffman_decode(dist_dec, (uint16_t)bits, &used);
bits >>= used;
used_tot += used;
if (distsym < 0 || distsym > DISTSYM_MAX) {
/* Failed to decode, or invalid symbol. */
return HWINF_ERR;
}
dist = dist_tbl[distsym].base_dist;
ebits = dist_tbl[distsym].ebits;
if (ebits != 0) {
dist += lsb(bits, ebits);
bits >>= ebits;
used_tot += ebits;
}
assert(dist >= MIN_DISTANCE && dist <= MAX_DISTANCE);
assert(used_tot <= ISTREAM_MIN_BITS);
if (!istream_advance(is, used_tot)) {
return HWINF_ERR;
}
/* Bounds check and output the backref. */
if (dist > *dst_pos) {
return HWINF_ERR;
}
if (round_up(len, 8) <= dst_cap - *dst_pos) {
output_backref64(dst, *dst_pos, dist, len);
} else if (len <= dst_cap - *dst_pos) {
lz77_output_backref(dst, *dst_pos, dist, len);
} else {
return HWINF_FULL;
}
(*dst_pos) += len;
}
}
```
Обратите внимание на такую оптимизацию: когда в исходящем буфере недостаточно места, мы выдаём обратные ссылки с помощью нижеприведённой функции, которая копирует по 64 бита за раз. Это «неаккуратно» в том смысле, что при этом часто копируется несколько дополнительных байтов (до следующего значения, кратного 8). Но работает гораздо быстрее `lz77_output_backref`, потому что требует меньше циклических итераций и обращений к памяти. По сути, короткие обратные ссылки теперь будут обрабатываться за одну итерацию, что очень хорошо для прогнозирования ветвления.
```
/* Output the (dist,len) backref at dst_pos in dst using 64-bit wide writes.
There must be enough room for len bytes rounded to the next multiple of 8. */
static void output_backref64(uint8_t *dst, size_t dst_pos, size_t dist,
size_t len)
{
size_t i;
uint64_t tmp;
assert(len > 0);
assert(dist <= dst_pos && "cannot reference before beginning of dst");
if (len > dist) {
/* Self-overlapping backref; fall back to byte-by-byte copy. */
lz77_output_backref(dst, dst_pos, dist, len);
return;
}
i = 0;
do {
memcpy(&tmp, &dst[dst_pos - dist + i], 8);
memcpy(&dst[dst_pos + i], &tmp, 8);
i += 8;
} while (i < len);
}
```
#### Deflate-блоки с применением динамических кодов Хаффмана
Deflate-блоки, использующие динамические коды Хаффмана, работают так же, как описано выше. Но вместо заранее определённых кодов для litlen и dist они используют коды, хранящиеся в самом Deflate-потоке, в начале блока. Название, пожалуй, неудачное, поскольку динамическими кодами Хаффмана также называют коды, которые меняются в ходе кодирования — это [адаптивное кодирование Хаффмана](https://ru.wikipedia.org/wiki/%D0%90%D0%B4%D0%B0%D0%BF%D1%82%D0%B8%D0%B2%D0%BD%D1%8B%D0%B9_%D0%B0%D0%BB%D0%B3%D0%BE%D1%80%D0%B8%D1%82%D0%BC_%D0%A5%D0%B0%D1%84%D1%84%D0%BC%D0%B0%D0%BD%D0%B0). Описанные здесь коды не имеют к той процедуре никакого отношения. Они динамические лишь в том смысле, что разные блоки могут использовать разные коды.
Генерирование динамических litlen- и dist-кодов является самой сложной частью Deflate-формата. Но как только коды сгенерированы, декомпрессия выполняется так же, как описано в предыдущей части, с использованием `inf_block`:
```
static inf_stat_t inf_dyn_block(istream_t *is, uint8_t *dst,
size_t dst_cap, size_t *dst_pos)
{
inf_stat_t s;
huffman_decoder_t litlen_dec, dist_dec;
s = init_dyn_decoders(is, &litlen_dec, &dist_dec);
if (s != HWINF_OK) {
return s;
}
return inf_block(is, dst, dst_cap, dst_pos, &litlen_dec, &dist_dec);
}
```
Litlen- и dist-коды для динамических Deflate-блоков хранятся в виде серий длин кодовых слов. Сами длины закодированы с помощью третьего кода Хаффмана — *codelen*. Этот код определяется длиной кодовых слов (`codelen_lens`), которые хранятся в блоке (я уже говорил, что это сложно?).

В начале динамического блока находятся 14 битов, которые определяют количество litlen-, dist- и codelen-длин кодовых слов, которые нужно прочитать из блока:
```
#define MIN_CODELEN_LENS 4
#define MAX_CODELEN_LENS 19
#define MIN_LITLEN_LENS 257
#define MAX_LITLEN_LENS 288
#define MIN_DIST_LENS 1
#define MAX_DIST_LENS 32
#define CODELEN_MAX_LIT 15
#define CODELEN_COPY 16
#define CODELEN_COPY_MIN 3
#define CODELEN_COPY_MAX 6
#define CODELEN_ZEROS 17
#define CODELEN_ZEROS_MIN 3
#define CODELEN_ZEROS_MAX 10
#define CODELEN_ZEROS2 18
#define CODELEN_ZEROS2_MIN 11
#define CODELEN_ZEROS2_MAX 138
/* RFC 1951, 3.2.7 */
static const int codelen_lengths_order[MAX_CODELEN_LENS] =
{ 16, 17, 18, 0, 8, 7, 9, 6, 10, 5, 11, 4, 12, 3, 13, 2, 14, 1, 15 };
static inf_stat_t init_dyn_decoders(istream_t *is,
huffman_decoder_t *litlen_dec,
huffman_decoder_t *dist_dec)
{
uint64_t bits;
size_t num_litlen_lens, num_dist_lens, num_codelen_lens;
uint8_t codelen_lengths[MAX_CODELEN_LENS];
uint8_t code_lengths[MAX_LITLEN_LENS + MAX_DIST_LENS];
size_t i, n, used;
int sym;
huffman_decoder_t codelen_dec;
bits = istream_bits(is);
/* Number of litlen codeword lengths (5 bits + 257). */
num_litlen_lens = lsb(bits, 5) + MIN_LITLEN_LENS;
bits >>= 5;
assert(num_litlen_lens <= MAX_LITLEN_LENS);
/* Number of dist codeword lengths (5 bits + 1). */
num_dist_lens = lsb(bits, 5) + MIN_DIST_LENS;
bits >>= 5;
assert(num_dist_lens <= MAX_DIST_LENS);
/* Number of code length lengths (4 bits + 4). */
num_codelen_lens = lsb(bits, 4) + MIN_CODELEN_LENS;
bits >>= 4;
assert(num_codelen_lens <= MAX_CODELEN_LENS);
if (!istream_advance(is, 5 + 5 + 4)) {
return HWINF_ERR;
}
```
Затем идут длины кодовых слов для codelen-кода. Эти длины представляют собой обычные трёхбитные значения, но записанные в особом порядке, который задан в `codelen_lengths_order`. Поскольку нужно определить 19 длин, из потока будет прочитан только `num_codelen_lens`; всё остальное является неявно нулевым. Длины перечисляются в определённом порядке, чтобы нулевые длины с большей вероятностью попадали в конец списка и не сохранялись в блоке.
```
/* Read the codelen codeword lengths (3 bits each)
and initialize the codelen decoder. */
for (i = 0; i < num_codelen_lens; i++) {
bits = istream_bits(is);
codelen_lengths[codelen_lengths_order[i]] =
(uint8_t)lsb(bits, 3);
if (!istream_advance(is, 3)) {
return HWINF_ERR;
}
}
for (; i < MAX_CODELEN_LENS; i++) {
codelen_lengths[codelen_lengths_order[i]] = 0;
}
if (!huffman_decoder_init(&codelen_dec, codelen_lengths,
MAX_CODELEN_LENS)) {
return HWINF_ERR;
}
```
С помощью настройки codelen-декодера мы можем считывать из потока длины кодовых слов litlen и dist.
```
/* Read the litlen and dist codeword lengths. */
i = 0;
while (i < num_litlen_lens + num_dist_lens) {
bits = istream_bits(is);
sym = huffman_decode(&codelen_dec, (uint16_t)bits, &used);
bits >>= used;
if (!istream_advance(is, used)) {
return HWINF_ERR;
}
if (sym >= 0 && sym <= CODELEN_MAX_LIT) {
/* A literal codeword length. */
code_lengths[i++] = (uint8_t)sym;
}
```
16, 17 и 18 не являются настоящими длинами, это индикаторы того, что предыдущую длину нужно повторить какое-то количество раз, или что нужно повторить нулевую длину:
```
else if (sym == CODELEN_COPY) {
/* Copy the previous codeword length 3--6 times. */
if (i < 1) {
return HWINF_ERR; /* No previous length. */
}
n = lsb(bits, 2) + CODELEN_COPY_MIN; /* 2 bits + 3 */
if (!istream_advance(is, 2)) {
return HWINF_ERR;
}
assert(n >= CODELEN_COPY_MIN && n <= CODELEN_COPY_MAX);
if (i + n > num_litlen_lens + num_dist_lens) {
return HWINF_ERR;
}
while (n--) {
code_lengths[i] = code_lengths[i - 1];
i++;
}
} else if (sym == CODELEN_ZEROS) {
/* 3--10 zeros. */
n = lsb(bits, 3) + CODELEN_ZEROS_MIN; /* 3 bits + 3 */
if (!istream_advance(is, 3)) {
return HWINF_ERR;
}
assert(n >= CODELEN_ZEROS_MIN &&
n <= CODELEN_ZEROS_MAX);
if (i + n > num_litlen_lens + num_dist_lens) {
return HWINF_ERR;
}
while (n--) {
code_lengths[i++] = 0;
}
} else if (sym == CODELEN_ZEROS2) {
/* 11--138 zeros. */
n = lsb(bits, 7) + CODELEN_ZEROS2_MIN; /* 7 bits +138 */
if (!istream_advance(is, 7)) {
return HWINF_ERR;
}
assert(n >= CODELEN_ZEROS2_MIN &&
n <= CODELEN_ZEROS2_MAX);
if (i + n > num_litlen_lens + num_dist_lens) {
return HWINF_ERR;
}
while (n--) {
code_lengths[i++] = 0;
}
} else {
/* Invalid symbol. */
return HWINF_ERR;
}
}
```
Обратите внимание, что litlen- и dist-длины считываются одна за другой в массив `code_lengths`. Они не могут считываться отдельно, потому что прогоны длин кода могут переноситься с последних litlen-длин на первые dist-длины.
Подготовив длины кодовых слов, мы можем настроить декодеры Хаффмана и вернуться к задаче декодирования литералов и обратных ссылок:
```
if (!huffman_decoder_init(litlen_dec, &code_lengths[0],
num_litlen_lens)) {
return HWINF_ERR;
}
if (!huffman_decoder_init(dist_dec, &code_lengths[num_litlen_lens],
num_dist_lens)) {
return HWINF_ERR;
}
return HWINF_OK;
}
```
### Сжатие (Deflation)
В предыдущих частях мы создали все инструменты, необходимые для Deflate-сжатия: Lempel-Ziv, кодирование Хаффмана, битовые потоки и описание трёх типов Deflate-блоков. А в этой части мы соберём всё вместе, чтобы получилось Deflate-сжатие.
Сжатие Lempel-Ziv парсит исходные данные в последовательность обратных ссылок и литералов. Эту последовательность нужно разделить и закодировать в Deflate-блоки, как описано в предыдущей части. Выбор способа разделения часто называют *разбиением на блоки*. С одной стороны, каждый новый блок означает какие-то накладные расходы, объём которых зависит от типа блока и его содержимого. Меньше блоков — меньше накладных расходов. С другой стороны, эти расходы на создание нового блока могут окупаться. Например, если характеристики данных позволяют эффективнее выполнять кодирование Хаффмана и уменьшать общий объём генерируемых данных.
Разбиение на блоки — сложная задача по оптимизации. Некоторые компрессоры (например, [Zopfli](https://github.com/google/zopfli)) стараются лучше других, но большинство просто используют жадный подход: выдают блоки, как только те достигают определённого размера.
У разных типов блоков свои ограничения размеров:
* Несжатые блоки могут содержать не больше 65 535 байтов.
* Фиксированные коды Хаффмана не имеют максимального размера.
* Динамические коды Хаффмана в целом не имеют максимального размера, но поскольку наша реализация алгоритма Хаффмана используется 16-битные последовательности символов, мы ограничены 65 535 символами.
Чтобы свободно использовать блоки любого типа, ограничим их размер 65 534 байтами:
```
/* The largest number of bytes that will fit in any kind of block is 65,534.
It will fit in an uncompressed block (max 65,535 bytes) and a Huffman
block with only literals (65,535 symbols including end-of-block marker). */
#define MAX_BLOCK_LEN_BYTES 65534
```
Для отслеживания исходящего битового потока и содержимого текущего блока в ходе сжатия будем использовать структуру:
```
typedef struct deflate_state_t deflate_state_t;
struct deflate_state_t {
ostream_t os;
const uint8_t *block_src; /* First src byte in the block. */
size_t block_len; /* Number of symbols in the current block. */
size_t block_len_bytes; /* Number of src bytes in the block. */
/* Symbol frequencies for the current block. */
uint16_t litlen_freqs[LITLEN_MAX + 1];
uint16_t dist_freqs[DISTSYM_MAX + 1];
struct {
uint16_t distance; /* Backref distance. */
union {
uint16_t lit; /* Literal byte or end-of-block. */
uint16_t len; /* Backref length (distance != 0). */
} u;
} block[MAX_BLOCK_LEN_BYTES + 1];
};
static void reset_block(deflate_state_t *s)
{
s->block_len = 0;
s->block_len_bytes = 0;
memset(s->litlen_freqs, 0, sizeof(s->litlen_freqs));
memset(s->dist_freqs, 0, sizeof(s->dist_freqs));
}
```
Чтобы добавлять в блок результаты работы `lz77_compress` будем использовать функции обратного вызова, и по достижении максимального размера запишем блок в битовый поток:
```
static bool lit_callback(uint8_t lit, void *aux)
{
deflate_state_t *s = aux;
if (s->block_len_bytes + 1 > MAX_BLOCK_LEN_BYTES) {
if (!write_block(s, false)) {
return false;
}
s->block_src += s->block_len_bytes;
reset_block(s);
}
assert(s->block_len < sizeof(s->block) / sizeof(s->block[0]));
s->block[s->block_len ].distance = 0;
s->block[s->block_len++].u.lit = lit;
s->block_len_bytes++;
s->litlen_freqs[lit]++;
return true;
}
static bool backref_callback(size_t dist, size_t len, void *aux)
{
deflate_state_t *s = aux;
if (s->block_len_bytes + len > MAX_BLOCK_LEN_BYTES) {
if (!write_block(s, false)) {
return false;
}
s->block_src += s->block_len_bytes;
reset_block(s);
}
assert(s->block_len < sizeof(s->block) / sizeof(s->block[0]));
s->block[s->block_len ].distance = (uint16_t)dist;
s->block[s->block_len++].u.len = (uint16_t)len;
s->block_len_bytes += len;
assert(len >= MIN_LEN && len <= MAX_LEN);
assert(dist >= MIN_DISTANCE && dist <= MAX_DISTANCE);
s->litlen_freqs[len2litlen[len]]++;
s->dist_freqs[distance2dist[dist]]++;
return true;
}
```
Самое интересное — запись блоков. Если блок не сжат, то всё просто:
```
static bool write_uncomp_block(deflate_state_t *s, bool final)
{
uint8_t len_nlen[4];
/* Write the block header. */
if (!ostream_write(&s->os, (0x0 << 1) | final, 3)) {
return false;
}
len_nlen[0] = (uint8_t)(s->block_len_bytes >> 0);
len_nlen[1] = (uint8_t)(s->block_len_bytes >> 8);
len_nlen[2] = ~len_nlen[0];
len_nlen[3] = ~len_nlen[1];
if (!ostream_write_bytes_aligned(&s->os, len_nlen, sizeof(len_nlen))) {
return false;
}
if (!ostream_write_bytes_aligned(&s->os, s->block_src,
s->block_len_bytes)) {
return false;
}
return true;
}
```
Для записи статичного блока Хаффмана мы сначала сгенерируем канонические коды на основе фиксированных длин кодовых слов для litlen- и dist-кодов. Затем итерируем блок, записывая символы, которые используют эти коды:
```
static bool write_static_block(deflate_state_t *s, bool final)
{
huffman_encoder_t litlen_enc, dist_enc;
/* Write the block header. */
if (!ostream_write(&s->os, (0x1 << 1) | final, 3)) {
return false;
}
huffman_encoder_init2(&litlen_enc, fixed_litlen_lengths,
sizeof(fixed_litlen_lengths) /
sizeof(fixed_litlen_lengths[0]));
huffman_encoder_init2(&dist_enc, fixed_dist_lengths,
sizeof(fixed_dist_lengths) /
sizeof(fixed_dist_lengths[0]));
return write_huffman_block(s, &litlen_enc, &dist_enc);
}
static bool write_huffman_block(deflate_state_t *s,
const huffman_encoder_t *litlen_enc,
const huffman_encoder_t *dist_enc)
{
size_t i, nbits;
uint64_t distance, dist, len, litlen, bits, ebits;
for (i = 0; i < s->block_len; i++) {
if (s->block[i].distance == 0) {
/* Literal or EOB. */
litlen = s->block[i].u.lit;
assert(litlen <= LITLEN_EOB);
if (!ostream_write(&s->os,
litlen_enc->codewords[litlen],
litlen_enc->lengths[litlen])) {
return false;
}
continue;
}
/* Back reference length. */
len = s->block[i].u.len;
litlen = len2litlen[len];
/* litlen bits */
bits = litlen_enc->codewords[litlen];
nbits = litlen_enc->lengths[litlen];
/* ebits */
ebits = len - litlen_tbl[litlen - LITLEN_TBL_OFFSET].base_len;
bits |= ebits << nbits;
nbits += litlen_tbl[litlen - LITLEN_TBL_OFFSET].ebits;
/* Back reference distance. */
distance = s->block[i].distance;
dist = distance2dist[distance];
/* dist bits */
bits |= (uint64_t)dist_enc->codewords[dist] << nbits;
nbits += dist_enc->lengths[dist];
/* ebits */
ebits = distance - dist_tbl[dist].base_dist;
bits |= ebits << nbits;
nbits += dist_tbl[dist].ebits;
if (!ostream_write(&s->os, bits, nbits)) {
return false;
}
}
return true;
}
```
Конечно, записывать динамические блоки Хаффмана сложнее, потому что они содержат хитрое кодирование litlen- и dist-кодов. Для представления этого кодирования воспользуемся такой структурой:
```
typedef struct codelen_sym_t codelen_sym_t;
struct codelen_sym_t {
uint8_t sym;
uint8_t count; /* For symbols 16, 17, 18. */
};
```
Сначала мы отбрасываем хвост их нулевых длин кодовых слов litlen и dist, а потом копируем их в обычный массив для последующего кодирования. Мы не можем отбросить все нули: невозможно закодировать Deflate-блок, если в нём ни одного dist-кода. Также невозможно иметь меньше 257 litlen-кодов, но поскольку у нас всегда есть маркер окончания байта, то всегда будут ненулевая длина кода для символа 256.
```
/* Encode litlen_lens and dist_lens into encoded. *num_litlen_lens and
*num_dist_lens will be set to the number of encoded litlen and dist lens,
respectively. Returns the number of elements in encoded. */
static size_t encode_dist_litlen_lens(const uint8_t *litlen_lens,
const uint8_t *dist_lens,
codelen_sym_t *encoded,
size_t *num_litlen_lens,
size_t *num_dist_lens)
{
size_t i, n;
uint8_t lens[LITLEN_MAX + 1 + DISTSYM_MAX + 1];
*num_litlen_lens = LITLEN_MAX + 1;
*num_dist_lens = DISTSYM_MAX + 1;
/* Drop trailing zero litlen lengths. */
assert(litlen_lens[LITLEN_EOB] != 0 && "EOB len should be non-zero.");
while (litlen_lens[*num_litlen_lens - 1] == 0) {
(*num_litlen_lens)--;
}
assert(*num_litlen_lens >= MIN_LITLEN_LENS);
/* Drop trailing zero dist lengths, keeping at least one. */
while (dist_lens[*num_dist_lens - 1] == 0 && *num_dist_lens > 1) {
(*num_dist_lens)--;
}
assert(*num_dist_lens >= MIN_DIST_LENS);
/* Copy the lengths into a unified array. */
n = 0;
for (i = 0; i < *num_litlen_lens; i++) {
lens[n++] = litlen_lens[i];
}
for (i = 0; i < *num_dist_lens; i++) {
lens[n++] = dist_lens[i];
}
return encode_lens(lens, n, encoded);
}
```
Сложив длины кодов в один массив, мы выполняем кодирование, применяя специальные символы для прогона одинаковых длин кодов.
```
/* Encode the n code lengths in lens into encoded, returning the number of
elements in encoded. */
static size_t encode_lens(const uint8_t *lens, size_t n, codelen_sym_t *encoded)
{
size_t i, j, num_encoded;
uint8_t count;
i = 0;
num_encoded = 0;
while (i < n) {
if (lens[i] == 0) {
/* Scan past the end of this zero run (max 138). */
for (j = i; j < min(n, i + CODELEN_ZEROS2_MAX) &&
lens[j] == 0; j++);
count = (uint8_t)(j - i);
if (count < CODELEN_ZEROS_MIN) {
/* Output a single zero. */
encoded[num_encoded++].sym = 0;
i++;
continue;
}
/* Output a repeated zero. */
if (count <= CODELEN_ZEROS_MAX) {
/* Repeated zero 3--10 times. */
assert(count >= CODELEN_ZEROS_MIN &&
count <= CODELEN_ZEROS_MAX);
encoded[num_encoded].sym = CODELEN_ZEROS;
encoded[num_encoded++].count = count;
} else {
/* Repeated zero 11--138 times. */
assert(count >= CODELEN_ZEROS2_MIN &&
count <= CODELEN_ZEROS2_MAX);
encoded[num_encoded].sym = CODELEN_ZEROS2;
encoded[num_encoded++].count = count;
}
i = j;
continue;
}
/* Output len. */
encoded[num_encoded++].sym = lens[i++];
/* Scan past the end of the run of this len (max 6). */
for (j = i; j < min(n, i + CODELEN_COPY_MAX) &&
lens[j] == lens[i - 1]; j++);
count = (uint8_t)(j - i);
if (count >= CODELEN_COPY_MIN) {
/* Repeat last len 3--6 times. */
assert(count >= CODELEN_COPY_MIN &&
count <= CODELEN_COPY_MAX);
encoded[num_encoded].sym = CODELEN_COPY;
encoded[num_encoded++].count = count;
i = j;
continue;
}
}
return num_encoded;
}
```
Использованные для кодирования символы будут записаны с помощью кода Хаффмана — codelen. Длины кодовых слов из кода codelen записываются в блок в определённом порядке, чтобы нулевые длины с большей вероятностью оказывались в конце. Вот функция, подсчитывающая, сколько длин нужно записать:
```
static const int codelen_lengths_order[19] =
{ 16, 17, 18, 0, 8, 7, 9, 6, 10, 5, 11, 4, 12, 3, 13, 2, 14, 1, 15 };
/* Count the number of significant (not trailing zeros) codelen lengths. */
size_t count_codelen_lens(const uint8_t *codelen_lens)
{
size_t n = MAX_CODELEN_LENS;
/* Drop trailing zero lengths. */
while (codelen_lens[codelen_lengths_order[n - 1]] == 0) {
n--;
}
/* The first 4 lengths in the order (16, 17, 18, 0) cannot be used to
encode any non-zero lengths. Since there will always be at least
one non-zero codeword length (for EOB), n will be >= 4. */
assert(n >= MIN_CODELEN_LENS && n <= MAX_CODELEN_LENS);
return n;
}
```
Допустим, мы уже задали litlen- и dist-коды, настроили кодирование длин их кодовых слов и код для этих длин. Теперь можем записать динамический блок Хаффмана:
```
static bool write_dynamic_block(deflate_state_t *s, bool final,
size_t num_litlen_lens, size_t num_dist_lens,
size_t num_codelen_lens,
const huffman_encoder_t *codelen_enc,
const codelen_sym_t *encoded_lens,
size_t num_encoded_lens,
const huffman_encoder_t *litlen_enc,
const huffman_encoder_t *dist_enc)
{
size_t i;
uint8_t codelen, sym;
size_t nbits;
uint64_t bits, hlit, hdist, hclen, count;
/* Block header. */
bits = (0x2 << 1) | final;
nbits = 3;
/* hlit (5 bits) */
hlit = num_litlen_lens - MIN_LITLEN_LENS;
bits |= hlit << nbits;
nbits += 5;
/* hdist (5 bits) */
hdist = num_dist_lens - MIN_DIST_LENS;
bits |= hdist << nbits;
nbits += 5;
/* hclen (4 bits) */
hclen = num_codelen_lens - MIN_CODELEN_LENS;
bits |= hclen << nbits;
nbits += 4;
if (!ostream_write(&s->os, bits, nbits)) {
return false;
}
/* Codelen lengths. */
for (i = 0; i < num_codelen_lens; i++) {
codelen = codelen_enc->lengths[codelen_lengths_order[i]];
if (!ostream_write(&s->os, codelen, 3)) {
return false;
}
}
/* Litlen and dist code lengths. */
for (i = 0; i < num_encoded_lens; i++) {
sym = encoded_lens[i].sym;
bits = codelen_enc->codewords[sym];
nbits = codelen_enc->lengths[sym];
count = encoded_lens[i].count;
if (sym == CODELEN_COPY) { /* 2 ebits */
bits |= (count - CODELEN_COPY_MIN) << nbits;
nbits += 2;
} else if (sym == CODELEN_ZEROS) { /* 3 ebits */
bits |= (count - CODELEN_ZEROS_MIN) << nbits;
nbits += 3;
} else if (sym == CODELEN_ZEROS2) { /* 7 ebits */
bits |= (count - CODELEN_ZEROS2_MIN) << nbits;
nbits += 7;
}
if (!ostream_write(&s->os, bits, nbits)) {
return false;
}
}
return write_huffman_block(s, litlen_enc, dist_enc);
}
```
Для каждого блока мы хотим использовать тот тип, которому требуется наименьшее количество битов. Длину несжатого блока можно вычислить быстро:
```
/* Calculate the number of bits for an uncompressed block, including header. */
static size_t uncomp_block_len(const deflate_state_t *s)
{
size_t bit_pos, padding;
/* Bit position after writing the block header. */
bit_pos = ostream_bit_pos(&s->os) + 3;
padding = round_up(bit_pos, 8) - bit_pos;
/* Header + padding + len/nlen + block contents. */
return 3 + padding + 2 * 16 + s->block_len_bytes * 8;
}
```
Для блоков, закодированных по Хаффману, можно вычислить длину тела с помощью litlen- и dist-частот символов и длин кодовых слов:
```
/* Calculate the number of bits for a Huffman encoded block body. */
static size_t huffman_block_body_len(const deflate_state_t *s,
const uint8_t *litlen_lens,
const uint8_t *dist_lens)
{
size_t i, freq, len;
len = 0;
for (i = 0; i <= LITLEN_MAX; i++) {
freq = s->litlen_freqs[i];
len += litlen_lens[i] * freq;
if (i >= LITLEN_TBL_OFFSET) {
len += litlen_tbl[i - LITLEN_TBL_OFFSET].ebits * freq;
}
}
for (i = 0; i <= DISTSYM_MAX; i++) {
freq = s->dist_freqs[i];
len += dist_lens[i] * freq;
len += dist_tbl[i].ebits * freq;
}
return len;
}
```
Общая длина статичного блока равна 3 битам заголовка плюс длина тела. Вычисление размера заголовка динамического блока требует гораздо больше работы:
```
/* Calculate the number of bits for a dynamic Huffman block. */
static size_t dyn_block_len(const deflate_state_t *s, size_t num_codelen_lens,
const uint16_t *codelen_freqs,
const huffman_encoder_t *codelen_enc,
const huffman_encoder_t *litlen_enc,
const huffman_encoder_t *dist_enc)
{
size_t len, i, freq;
/* Block header. */
len = 3;
/* Nbr of litlen, dist, and codelen lengths. */
len += 5 + 5 + 4;
/* Codelen lengths. */
len += 3 * num_codelen_lens;
/* Codelen encoding. */
for (i = 0; i < MAX_CODELEN_LENS; i++) {
freq = codelen_freqs[i];
len += codelen_enc->lengths[i] * freq;
/* Extra bits. */
if (i == CODELEN_COPY) {
len += 2 * freq;
} else if (i == CODELEN_ZEROS) {
len += 3 * freq;
} else if (i == CODELEN_ZEROS2) {
len += 7 * freq;
}
}
return len + huffman_block_body_len(s, litlen_enc->lengths,
dist_enc->lengths);
}
```
Теперь соберём всё воедино и создадим главную функцию записи блоков:
```
/* Write the current deflate block, marking it final if that parameter is true,
returning false if there is not enough room in the output stream. */
static bool write_block(deflate_state_t *s, bool final)
{
size_t old_bit_pos, uncomp_len, static_len, dynamic_len;
huffman_encoder_t dyn_litlen_enc, dyn_dist_enc, codelen_enc;
size_t num_encoded_lens, num_litlen_lens, num_dist_lens;
codelen_sym_t encoded_lens[LITLEN_MAX + 1 + DISTSYM_MAX + 1];
uint16_t codelen_freqs[MAX_CODELEN_LENS] = {0};
size_t num_codelen_lens;
size_t i;
old_bit_pos = ostream_bit_pos(&s->os);
/* Add the end-of-block marker in case we write a Huffman block. */
assert(s->block_len < sizeof(s->block) / sizeof(s->block[0]));
assert(s->litlen_freqs[LITLEN_EOB] == 0);
s->block[s->block_len ].distance = 0;
s->block[s->block_len++].u.lit = LITLEN_EOB;
s->litlen_freqs[LITLEN_EOB] = 1;
uncomp_len = uncomp_block_len(s);
static_len = 3 + huffman_block_body_len(s, fixed_litlen_lengths,
fixed_dist_lengths);
/* Compute "dynamic" Huffman codes. */
huffman_encoder_init(&dyn_litlen_enc, s->litlen_freqs,
LITLEN_MAX + 1, 15);
huffman_encoder_init(&dyn_dist_enc, s->dist_freqs, DISTSYM_MAX + 1, 15);
/* Encode the litlen and dist code lengths. */
num_encoded_lens = encode_dist_litlen_lens(dyn_litlen_enc.lengths,
dyn_dist_enc.lengths,
encoded_lens,
#_litlen_lens,
#_dist_lens);
/* Compute the codelen code. */
for (i = 0; i < num_encoded_lens; i++) {
codelen_freqs[encoded_lens[i].sym]++;
}
huffman_encoder_init(&codelen_enc, codelen_freqs, MAX_CODELEN_LENS, 7);
num_codelen_lens = count_codelen_lens(codelen_enc.lengths);
dynamic_len = dyn_block_len(s, num_codelen_lens, codelen_freqs,
&codelen_enc, &dyn_litlen_enc,
&dyn_dist_enc);
if (uncomp_len <= dynamic_len && uncomp_len <= static_len) {
if (!write_uncomp_block(s, final)) {
return false;
}
assert(ostream_bit_pos(&s->os) - old_bit_pos == uncomp_len);
} else if (static_len <= dynamic_len) {
if (!write_static_block(s, final)) {
return false;
}
assert(ostream_bit_pos(&s->os) - old_bit_pos == static_len);
} else {
if (!write_dynamic_block(s, final, num_litlen_lens,
num_dist_lens, num_codelen_lens,
&codelen_enc, encoded_lens,
num_encoded_lens, &dyn_litlen_enc,
&dyn_dist_enc)) {
return false;
}
assert(ostream_bit_pos(&s->os) - old_bit_pos == dynamic_len);
}
return true;
}
```
Наконец, инициатор всего процесса сжатия должен задать начальное состояние, запустить сжатие Lempel-Ziv и записать получившийся блок:
```
/* Compress (deflate) the data in src into dst. The number of bytes output, at
most dst_cap, is stored in *dst_used. Returns false if there is not enough
room in dst. src and dst must not overlap. */
bool hwdeflate(const uint8_t *src, size_t src_len, uint8_t *dst,
size_t dst_cap, size_t *dst_used)
{
deflate_state_t s;
ostream_init(&s.os, dst, dst_cap);
reset_block(&s);
s.block_src = src;
if (!lz77_compress(src, src_len, &lit_callback,
&backref_callback, &s)) {
return false;
}
if (!write_block(&s, true)) {
return false;
}
/* The end of the final block should match the end of src. */
assert(s.block_src + s.block_len_bytes == src + src_len);
*dst_used = ostream_bytes_written(&s.os);
return true;
}
```
Формат Zip-файлов
-----------------
Выше мы рассмотрели, как работает Deflate-сжатие, используемое в Zip-файлах. А что насчёт самого формата файлов? В этой части мы подробно рассмотрим его устройство и реализацию. Код доступен в [zip.h](https://www.hanshq.net/files/hwzip/zip.h) и [zip.c](https://www.hanshq.net/files/hwzip/zip.c).
### Обзор
Формат файлов описан в PKZip [Application Note](https://www.pkware.com/documents/APPNOTE/APPNOTE-2.0.txt):
1. Каждый файл, или элемента архива, в Zip-файле имеет *локальный заголовок файла* с метаданными об элементе.
2. *Центральный каталог* служит индексом архива. Он содержит центральный заголовок файла для каждого элемента архива, копию метаданных из локального заголовка файла, а также дополнительную информацию, такую как смещение элемента в Zip-файле.
3. В конце файла, сразу после центрального каталога *конец записи центрального каталога*. Она содержит размер и позицию центрального каталога, а также может содержать комментарии обо всём архиве. Это начальная точка чтения Zip-файла.

Каждый элемент архива сжимается и хранится индивидуально. Это означает, что даже если между файлами в архиве есть совпадения, они не будут учитываться для улучшения сжатия.
Расположение центрального каталога в конце позволяет постепенно достраивать архив. По мере сжатия файлов элементов они дописываются в архив. Индекс записывается после всех сжатых размеров, что позволяет узнать смещения всех файлов. Добавлять файлы в существующий архив довольно легко, он помещается после последнего элемента, а центральный каталог перезаписывается.
Возможность постепенно создавать архивы была особенно важна для распространения информации на многочисленных дискетах или томах. По мере сжатия PKZip предлагал пользователям вставлять новые дискеты, а на последнюю (последние) записывал центральный каталог. Для распаковки многотомного архива PKZip сначала спрашивал последнюю дискету, чтобы записать прочитать центральный каталог, а затем остальные дискеты, необходимые для извлечения запрошенных файлов.
Вас это может удивить, но не существовало правила, запрещающего иметь в архиве несколько файлов с одинаковыми именами. Это могло приводить к большой путанице при распаковке: если есть несколько файлов с одинаковыми именами, то какой из них нужно распаковать? В свою очередь это могло приводить к проблемам в безопасности. Из-за бага «Master Key» в Android ([CVE-2013-4787](https://nvd.nist.gov/vuln/detail/CVE-2013-4787), [слайды](https://media.blackhat.com/us-13/US-13-Forristal-Android-One-Root-to-Own-Them-All-Slides.pdf) и [видео](https://www.youtube.com/watch?v=mCF5kaCt4NI) с доклада на Black Hat) злоумышленник мог при установке программ обходить проверки операционной системой криптоподписей. Android-программы распространяются в [APK](https://ru.wikipedia.org/wiki/APK)-файлах, которые представляют собой Zip-файлы. Как выяснилось, если APK содержал несколько файлов с одинаковыми именами, код проверки подписи выбирал *последний* файл с таким именем, а инсталлятор выбирал *первый* файл, то есть проверка не выполнялась. Иными словами, это небольшое различие между двумя Zip-библиотеками позволяло обойти всю модель безопасности операционной системы.
В отличие от большинства форматов, Zip-файлы не должны начинаться с сигнатуры или [магического числа](https://ru.wikipedia.org/wiki/%D0%A4%D0%BE%D1%80%D0%BC%D0%B0%D1%82_%D1%84%D0%B0%D0%B9%D0%BB%D0%B0#%D0%9C%D0%B0%D0%B3%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B8%D0%B5_%D1%87%D0%B8%D1%81%D0%BB%D0%B0). Вообще не указано, что Zip-файл должен начинаться каким-то конкретным образом, что легко позволяет создавать файлы, одновременно валидные и как Zip, и как другой формат — *файлы-полиглоты*. Например, самораспаковывающиеся Zip-архивы (например, [pkz204g.exe](https://www.hanshq.net/files/pkz204g.exe)) обычно одновременно и исполняемые, и Zip-файлы: первая часть является исполняемой, а за ней идёт Zip-файл (который распаковывается исполняемой частью). ОС может выполнять его как исполняемый, но Zip-программа откроет его как Zip-файл. Такая особенность могла стать причиной не требовать сигнатуру в начале файла.
Хотя такие файлы-полиглоты и умны, но они могут приводить к проблемам в безопасности, поскольку способны обмануть программы, старающиеся определить содержимое файла, а также позволяют доставлять зловредный код в месте с файлами разных типов. Например, в эксплойтах использовались [GIFAR](https://en.wikipedia.org/wiki/Gifar)-файлы, которые одновременно являются корректными GIF-изображениями и Java-архивами (JAR, разновидность Zip-файлов). Подробнее об этой проблеме рассказывается в статье [Abusing file formats](https://www.alchemistowl.org/pocorgtfo/pocorgtfo07.pdf) (начиная со страницы 18).
Как мы увидим ниже, Zip-файлы используют для смещений и размеров 32-битные поля, чтобы ограничивать размер архива и его элементов четырьмя гигабайтами. В [Application Note 4.5](https://pkware.cachefly.net/webdocs/APPNOTE/APPNOTE-4.5.0.txt) PKWare добавила расширения формата, позволяющие использовать 64-битные смещения и размеры. Файлы, использующие эти расширения, относят к формату Zip64, но мы не будем их рассматривать.
### Структуры данных
#### Конец записи центрального каталога
Конец записи центрального каталога (EOCDR) обычно используется в качестве начальной точки для чтения Zip-файла. В ней содержится расположение и размер центрального каталога, а также опциональные комментарии обо всём архиве.
В Zip-файлах, которые занимали несколько дискет — или томов, — EOCDR также содержала информацию о том, какой диск мы сейчас используем, на каком диске начинается центральный каталог и т.д. Сегодня эта функциональность используется редко, и код из этой статьи такие файлы не обрабатывает.
EOCDR определяется по сигнатуре 'P' 'K', за которой идут байты 5 и 6. За ней следует нижеприведённая структура, числа хранятся по принципу little-endian:
```
/* End of Central Directory Record. */
struct eocdr {
uint16_t disk_nbr; /* Number of this disk. */
uint16_t cd_start_disk; /* Nbr. of disk with start of the CD. */
uint16_t disk_cd_entries; /* Nbr. of CD entries on this disk. */
uint16_t cd_entries; /* Nbr. of Central Directory entries. */
uint32_t cd_size; /* Central Directory size in bytes. */
uint32_t cd_offset; /* Central Directory file offset. */
uint16_t comment_len; /* Archive comment length. */
const uint8_t *comment; /* Archive comment. */
};
```
EOCDR должна располагаться в конце файла. Но поскольку в её хвосте может быть комментарий произвольной 16-битной длины, может потребоваться находиться конкретную позицию:
```
/* Read 16/32 bits little-endian and bump p forward afterwards. */
#define READ16(p) ((p) += 2, read16le((p) - 2))
#define READ32(p) ((p) += 4, read32le((p) - 4))
/* Size of the End of Central Directory Record, not including comment. */
#define EOCDR_BASE_SZ 22
#define EOCDR_SIGNATURE 0x06054b50 /* "PK\5\6" little-endian. */
static bool find_eocdr(struct eocdr *r, const uint8_t *src, size_t src_len)
{
size_t comment_len;
const uint8_t *p;
uint32_t signature;
for (comment_len = 0; comment_len <= UINT16_MAX; comment_len++) {
if (src_len < EOCDR_BASE_SZ + comment_len) {
break;
}
p = &src[src_len - EOCDR_BASE_SZ - comment_len];
signature = READ32(p);
if (signature == EOCDR_SIGNATURE) {
r->disk_nbr = READ16(p);
r->cd_start_disk = READ16(p);
r->disk_cd_entries = READ16(p);
r->cd_entries = READ16(p);
r->cd_size = READ32(p);
r->cd_offset = READ32(p);
r->comment_len = READ16(p);
r->comment = p;
assert(p == &src[src_len - comment_len] &&
"All fields read.");
if (r->comment_len == comment_len) {
return true;
}
}
}
return false;
}
```
Записывать EOCDR несложно. Эта функция записывает и возвращает количество записанных байтов:
```
/* Write 16/32 bits little-endian and bump p forward afterwards. */
#define WRITE16(p, x) (write16le((p), (x)), (p) += 2)
#define WRITE32(p, x) (write32le((p), (x)), (p) += 4)
static size_t write_eocdr(uint8_t *dst, const struct eocdr *r)
{
uint8_t *p = dst;
WRITE32(p, EOCDR_SIGNATURE);
WRITE16(p, r->disk_nbr);
WRITE16(p, r->cd_start_disk);
WRITE16(p, r->disk_cd_entries);
WRITE16(p, r->cd_entries);
WRITE32(p, r->cd_size);
WRITE32(p, r->cd_offset);
WRITE16(p, r->comment_len);
assert(p - dst == EOCDR_BASE_SZ);
if (r->comment_len != 0) {
memcpy(p, r->comment, r->comment_len);
p += r->comment_len;
}
return (size_t)(p - dst);
}
```
#### Центральный заголовок файла
Центральный каталог состоит из центральных заголовков файлов, записанных друг за другом, по одному для каждого элемента архива. Каждый заголовок начинается с сигнатуры 'P', 'K', 1, 2, а потом идёт такая структура:
```
#define EXT_ATTR_DIR (1U << 4)
#define EXT_ATTR_ARC (1U << 5)
/* Central File Header (Central Directory Entry) */
struct cfh {
uint16_t made_by_ver; /* Version made by. */
uint16_t extract_ver; /* Version needed to extract. */
uint16_t gp_flag; /* General purpose bit flag. */
uint16_t method; /* Compression method. */
uint16_t mod_time; /* Modification time. */
uint16_t mod_date; /* Modification date. */
uint32_t crc32; /* CRC-32 checksum. */
uint32_t comp_size; /* Compressed size. */
uint32_t uncomp_size; /* Uncompressed size. */
uint16_t name_len; /* Filename length. */
uint16_t extra_len; /* Extra data length. */
uint16_t comment_len; /* Comment length. */
uint16_t disk_nbr_start; /* Disk nbr. where file begins. */
uint16_t int_attrs; /* Internal file attributes. */
uint32_t ext_attrs; /* External file attributes. */
uint32_t lfh_offset; /* Local File Header offset. */
const uint8_t *name; /* Filename. */
const uint8_t *extra; /* Extra data. */
const uint8_t *comment; /* File comment. */
};
```
`made_by_ver` и `extract_ver` кодируют информацию об ОС и версии программы, использованной для добавления этого элемента, а также о том, какая версия нужна для его извлечения. Самые важные восемь битов кодируют операционную систему (например, 0 означает DOS, 3 — Unix, 10 — Windows NTFS), а младшие восемь битов кодируют версию ПО. Зададим десятичное значение 20, что означает совместимость с PKZip 2.0.
`gp_flag` содержит разные флаги. Нас интересуют:
* Бит 0, обозначающий факт зашифровки элемента (мы это не будем рассматривать);
* И биты 1 и 2, кодирующие уровень Deflate-сжатия (0 — нормальное, 1 — максимальное, 2 — быстрое, 3 — очень быстрое).
`method` кодирует метод сжатия. 0 — данные не сжаты, 8 — применён Delate. Другие значения относятся к старым или новым алгоритмам, но почти все Zip-используют эти два значения.
`mod_time` и `mod_date` содержат дату и время изменения файла, закодированные в [MS-DOS-формате](http://www.ctyme.com/intr/rb-2992.htm#table1665). С помощью этого кода мы преобразуем обычные временные метки С `time_t` в MS-DOS-формат и из него:
```
/* Convert DOS date and time to time_t. */
static time_t dos2ctime(uint16_t dos_date, uint16_t dos_time)
{
struct tm tm = {0};
tm.tm_sec = (dos_time & 0x1f) * 2; /* Bits 0--4: Secs divided by 2. */
tm.tm_min = (dos_time >> 5) & 0x3f; /* Bits 5--10: Minute. */
tm.tm_hour = (dos_time >> 11); /* Bits 11-15: Hour (0--23). */
tm.tm_mday = (dos_date & 0x1f); /* Bits 0--4: Day (1--31). */
tm.tm_mon = ((dos_date >> 5) & 0xf) - 1; /* Bits 5--8: Month (1--12). */
tm.tm_year = (dos_date >> 9) + 80; /* Bits 9--15: Year-1980. */
tm.tm_isdst = -1;
return mktime(&tm);
}
/* Convert time_t to DOS date and time. */
static void ctime2dos(time_t t, uint16_t *dos_date, uint16_t *dos_time)
{
struct tm *tm = localtime(&t);
*dos_time = 0;
*dos_time |= tm->tm_sec / 2; /* Bits 0--4: Second divided by two. */
*dos_time |= tm->tm_min << 5; /* Bits 5--10: Minute. */
*dos_time |= tm->tm_hour << 11; /* Bits 11-15: Hour. */
*dos_date = 0;
*dos_date |= tm->tm_mday; /* Bits 0--4: Day (1--31). */
*dos_date |= (tm->tm_mon + 1) << 5; /* Bits 5--8: Month (1--12). */
*dos_date |= (tm->tm_year - 80) << 9; /* Bits 9--15: Year from 1980. */
}
```
Поле `crc32` содержит [значение циклического избыточного кода](https://en.wikipedia.org/wiki/Cyclic_redundancy_check) несжатых данных. Он используется для проверки целостности данных после извлечения. Реализация здесь: [crc32.c](https://www.hanshq.net/files/hwzip/crc32.c).
`comp_size` и `uncomp_size` содержат сжатый и несжатый размер данных файла элемента. Следующие три поля содержат длины имени, комментарий и дополнительные данные, которые идут сразу после заголовка. `disk_nbr_start` предназначено для архивов, использующих несколько дискет.
`int_attrs` и `ext_attrs` описывают внутренние и внешние атрибуты файла. Внутренние относятся к содержимому файла, например, младший бит обозначает, содержит ли файл только текст. Внешние атрибуты показывают, является ли файл скрытым, только для чтения и т.д. Содержимое этих полей зависит от ОС, в частности, от `made_by_ver`. В DOS младшие 8 битов содержат байт атрибутов файла, который можно получить из системного вызова [Int 21/AX=4300h](http://www.ctyme.com/intr/rb-2802.htm). К примеру, бит 4 означает, что это директория, а бит 5 — что установлен атрибут «архив» (верно для большинства файлов в DOS). Насколько я понял, ради совместимости эти биты аналогично задаются и в других ОС. В Unix старшие 16 битов этого поля содержат биты режима файла, которые возвращаются [stat(2)](https://linux.die.net/man/2/stat) в `st_mode`.
`lfh_offset` говорит нам, где искать локальный заголовок файла. `name` — имя файла (C-строка), а `comment` — опциональный комментарий для этого элемента архива (С-строка). `extra` может содержать опциональные дополнительные данные вроде информации о владельце Unix-файла, более точные дату и время изменения или Zip64-поля.
Эта функция используется для чтения центральных заголовков файлов:
```
/* Size of a Central File Header, not including name, extra, and comment. */
#define CFH_BASE_SZ 46
#define CFH_SIGNATURE 0x02014b50 /* "PK\1\2" little-endian. */
static bool read_cfh(struct cfh *cfh, const uint8_t *src, size_t src_len,
size_t offset)
{
const uint8_t *p;
uint32_t signature;
if (offset > src_len || src_len - offset < CFH_BASE_SZ) {
return false;
}
p = &src[offset];
signature = READ32(p);
if (signature != CFH_SIGNATURE) {
return false;
}
cfh->made_by_ver = READ16(p);
cfh->extract_ver = READ16(p);
cfh->gp_flag = READ16(p);
cfh->method = READ16(p);
cfh->mod_time = READ16(p);
cfh->mod_date = READ16(p);
cfh->crc32 = READ32(p);
cfh->comp_size = READ32(p);
cfh->uncomp_size = READ32(p);
cfh->name_len = READ16(p);
cfh->extra_len = READ16(p);
cfh->comment_len = READ16(p);
cfh->disk_nbr_start = READ16(p);
cfh->int_attrs = READ16(p);
cfh->ext_attrs = READ32(p);
cfh->lfh_offset = READ32(p);
cfh->name = p;
cfh->extra = cfh->name + cfh->name_len;
cfh->comment = cfh->extra + cfh->extra_len;
assert(p == &src[offset + CFH_BASE_SZ] && "All fields read.");
if (src_len - offset - CFH_BASE_SZ <
cfh->name_len + cfh->extra_len + cfh->comment_len) {
return false;
}
return true;
}
static size_t write_cfh(uint8_t *dst, const struct cfh *cfh)
{
uint8_t *p = dst;
WRITE32(p, CFH_SIGNATURE);
WRITE16(p, cfh->made_by_ver);
WRITE16(p, cfh->extract_ver);
WRITE16(p, cfh->gp_flag);
WRITE16(p, cfh->method);
WRITE16(p, cfh->mod_time);
WRITE16(p, cfh->mod_date);
WRITE32(p, cfh->crc32);
WRITE32(p, cfh->comp_size);
WRITE32(p, cfh->uncomp_size);
WRITE16(p, cfh->name_len);
WRITE16(p, cfh->extra_len);
WRITE16(p, cfh->comment_len);
WRITE16(p, cfh->disk_nbr_start);
WRITE16(p, cfh->int_attrs);
WRITE32(p, cfh->ext_attrs);
WRITE32(p, cfh->lfh_offset);
assert(p - dst == CFH_BASE_SZ);
if (cfh->name_len != 0) {
memcpy(p, cfh->name, cfh->name_len);
p += cfh->name_len;
}
if (cfh->extra_len != 0) {
memcpy(p, cfh->extra, cfh->extra_len);
p += cfh->extra_len;
}
if (cfh->comment_len != 0) {
memcpy(p, cfh->comment, cfh->comment_len);
p += cfh->comment_len;
}
return (size_t)(p - dst);
}
```
#### Локальный заголовок файла
Данные каждого элемента архива предваряются локальным заголовком файла, который повторяет большую часть информации из центрального заголовка.
Вероятно, дублирование данных в центральном и локальном заголовках было введено для того, чтобы PKZip при распаковке не держал в памяти весь центральный каталог. Вместо этого по мере извлечения каждого файла его имя и прочая информация может быть считана из локального заголовка. Кроме того, локальные заголовки полезны для восстановления файлов из Zip-архивов, в которых центральный каталог отсутствует или повреждён.
Однако эта избыточность является и главным источником неопределённости. Например, что будет, если имена файлов в центральном и локальном заголовках не совпадают? Это часто приводит к багам и проблемам в безопасности.
Дублируется не вся информация из центрального заголовка. Например, поля с атрибутами файлов. Кроме того, если задан третий младший значимый бит `gp_flags` (CRC-32), то поля сжатого и несжатого размера будут обнулены, а эту информацию можно будет найти в блоке *Data Descriptor* после данных самого файла (рассматривать не будем). Это позволяет записывать локальный заголовок до того, как станет известен размер файла элемента или до какого размера он будет сжат.
Локальный заголовок начинается с сигнатуры 'P', 'K', 3, 4, а потом идёт такая структура:
```
/* Local File Header. */
struct lfh {
uint16_t extract_ver;
uint16_t gp_flag;
uint16_t method;
uint16_t mod_time;
uint16_t mod_date;
uint32_t crc32;
uint32_t comp_size;
uint32_t uncomp_size;
uint16_t name_len;
uint16_t extra_len;
const uint8_t *name;
const uint8_t *extra;
};
```
Эти функции считывают и записывают локальные заголовки, как и другие структуры данных:
```
/* Size of a Local File Header, not including name and extra. */
#define LFH_BASE_SZ 30
#define LFH_SIGNATURE 0x04034b50 /* "PK\3\4" little-endian. */
static bool read_lfh(struct lfh *lfh, const uint8_t *src, size_t src_len,
size_t offset)
{
const uint8_t *p;
uint32_t signature;
if (offset > src_len || src_len - offset < LFH_BASE_SZ) {
return false;
}
p = &src[offset];
signature = READ32(p);
if (signature != LFH_SIGNATURE) {
return false;
}
lfh->extract_ver = READ16(p);
lfh->gp_flag = READ16(p);
lfh->method = READ16(p);
lfh->mod_time = READ16(p);
lfh->mod_date = READ16(p);
lfh->crc32 = READ32(p);
lfh->comp_size = READ32(p);
lfh->uncomp_size = READ32(p);
lfh->name_len = READ16(p);
lfh->extra_len = READ16(p);
lfh->name = p;
lfh->extra = lfh->name + lfh->name_len;
assert(p == &src[offset + LFH_BASE_SZ] && "All fields read.");
if (src_len - offset - LFH_BASE_SZ < lfh->name_len + lfh->extra_len) {
return false;
}
return true;
}
static size_t write_lfh(uint8_t *dst, const struct lfh *lfh)
{
uint8_t *p = dst;
WRITE32(p, LFH_SIGNATURE);
WRITE16(p, lfh->extract_ver);
WRITE16(p, lfh->gp_flag);
WRITE16(p, lfh->method);
WRITE16(p, lfh->mod_time);
WRITE16(p, lfh->mod_date);
WRITE32(p, lfh->crc32);
WRITE32(p, lfh->comp_size);
WRITE32(p, lfh->uncomp_size);
WRITE16(p, lfh->name_len);
WRITE16(p, lfh->extra_len);
assert(p - dst == LFH_BASE_SZ);
if (lfh->name_len != 0) {
memcpy(p, lfh->name, lfh->name_len);
p += lfh->name_len;
}
if (lfh->extra_len != 0) {
memcpy(p, lfh->extra, lfh->extra_len);
p += lfh->extra_len;
}
return (size_t)(p - dst);
}
```
### Реализация Zip-считывания
С помощью вышеописанных функций мы реализуем чтение Zip-файла в память и получаем итератор для доступа к элементам архива:
```
typedef size_t zipiter_t; /* Zip archive member iterator. */
typedef struct zip_t zip_t;
struct zip_t {
uint16_t num_members; /* Number of members. */
const uint8_t *comment; /* Zip file comment (not terminated). */
uint16_t comment_len; /* Zip file comment length. */
zipiter_t members_begin; /* Iterator to the first member. */
zipiter_t members_end; /* Iterator to the end of members. */
const uint8_t *src;
size_t src_len;
};
/* Initialize zip based on the source data. Returns true on success, or false
if the data could not be parsed as a valid Zip file. */
bool zip_read(zip_t *zip, const uint8_t *src, size_t src_len)
{
struct eocdr eocdr;
struct cfh cfh;
struct lfh lfh;
size_t i, offset;
const uint8_t *comp_data;
zip->src = src;
zip->src_len = src_len;
if (!find_eocdr(&eocdr, src, src_len)) {
return false;
}
if (eocdr.disk_nbr != 0 || eocdr.cd_start_disk != 0 ||
eocdr.disk_cd_entries != eocdr.cd_entries) {
return false; /* Cannot handle multi-volume archives. */
}
zip->num_members = eocdr.cd_entries;
zip->comment = eocdr.comment;
zip->comment_len = eocdr.comment_len;
offset = eocdr.cd_offset;
zip->members_begin = offset;
/* Read the member info and do a few checks. */
for (i = 0; i < eocdr.cd_entries; i++) {
if (!read_cfh(&cfh, src, src_len, offset)) {
return false;
}
if (cfh.gp_flag & 1) {
return false; /* The member is encrypted. */
}
if (cfh.method != ZIP_STORED && cfh.method != ZIP_DEFLATED) {
return false; /* Unsupported compression method. */
}
if (cfh.method == ZIP_STORED &&
cfh.uncomp_size != cfh.comp_size) {
return false;
}
if (cfh.disk_nbr_start != 0) {
return false; /* Cannot handle multi-volume archives. */
}
if (memchr(cfh.name, '\0', cfh.name_len) != NULL) {
return false; /* Bad filename. */
}
if (!read_lfh(&lfh, src, src_len, cfh.lfh_offset)) {
return false;
}
comp_data = lfh.extra + lfh.extra_len;
if (cfh.comp_size > src_len - (size_t)(comp_data - src)) {
return false; /* Member data does not fit in src. */
}
offset += CFH_BASE_SZ + cfh.name_len + cfh.extra_len +
cfh.comment_len;
}
zip->members_end = offset;
return true;
}
```
Как я упоминал выше, итераторы элементов — это просто смещения центрального заголовка файла, через которые можно обращаться к данным элементов:
```
typedef enum { ZIP_STORED = 0, ZIP_DEFLATED = 8 } method_t;
typedef struct zipmemb_t zipmemb_t;
struct zipmemb_t {
const uint8_t *name; /* Member name (not null terminated). */
uint16_t name_len; /* Member name length. */
time_t mtime; /* Modification time. */
uint32_t comp_size; /* Compressed size. */
const uint8_t *comp_data; /* Compressed data. */
method_t method; /* Compression method. */
uint32_t uncomp_size; /* Uncompressed size. */
uint32_t crc32; /* CRC-32 checksum. */
const uint8_t *comment; /* Comment (not null terminated). */
uint16_t comment_len; /* Comment length. */
bool is_dir; /* Whether this is a directory. */
zipiter_t next; /* Iterator to the next member. */
};
/* Get the Zip archive member through iterator it. */
zipmemb_t zip_member(const zip_t *zip, zipiter_t it)
{
struct cfh cfh;
struct lfh lfh;
bool ok;
zipmemb_t m;
assert(it >= zip->members_begin && it < zip->members_end);
ok = read_cfh(&cfh, zip->src, zip->src_len, it);
assert(ok);
ok = read_lfh(&lfh, zip->src, zip->src_len, cfh.lfh_offset);
assert(ok);
m.name = cfh.name;
m.name_len = cfh.name_len;
m.mtime = dos2ctime(cfh.mod_date, cfh.mod_time);
m.comp_size = cfh.comp_size;
m.comp_data = lfh.extra + lfh.extra_len;
m.method = cfh.method;
m.uncomp_size = cfh.uncomp_size;
m.crc32 = cfh.crc32;
m.comment = cfh.comment;
m.comment_len = cfh.comment_len;
m.is_dir = (cfh.ext_attrs & EXT_ATTR_DIR) != 0;
m.next = it + CFH_BASE_SZ +
cfh.name_len + cfh.extra_len + cfh.comment_len;
assert(m.next <= zip->members_end);
return m;
}
```
### Реализация Zip-записи
Чтобы записать Zip-файл в буфер памяти, сначала нужно узнать, сколько памяти под него выделить. А раз мы не знаем, сколько данных сожмём, прежде чем попытаемся записать, то вычислим верхнюю границу на основе размеров несжатых элементов:
```
/* Compute an upper bound on the dst size required by zip_write() for an
* archive with num_memb members with certain filenames, sizes, and archive
* comment. Returns zero on error, e.g. if a filename is longer than 2^16-1, or
* if the total file size is larger than 2^32-1. */
uint32_t zip_max_size(uint16_t num_memb, const char *const *filenames,
const uint32_t *file_sizes, const char *comment)
{
size_t comment_len, name_len;
uint64_t total;
uint16_t i;
comment_len = (comment == NULL ? 0 : strlen(comment));
if (comment_len > UINT16_MAX) {
return 0;
}
total = EOCDR_BASE_SZ + comment_len; /* EOCDR */
for (i = 0; i < num_memb; i++) {
assert(filenames[i] != NULL);
name_len = strlen(filenames[i]);
if (name_len > UINT16_MAX) {
return 0;
}
total += CFH_BASE_SZ + name_len; /* Central File Header */
total += LFH_BASE_SZ + name_len; /* Local File Header */
total += file_sizes[i]; /* Uncompressed data size. */
}
if (total > UINT32_MAX) {
return 0;
}
return (uint32_t)total;
}
```
Этот код записывает Zip-файл с помощью Deflate-сжатия каждого элемента, уменьшая их размер:
```
/* Write a Zip file containing num_memb members into dst, which must be large
enough to hold the resulting data. Returns the number of bytes written, which
is guaranteed to be less than or equal to the result of zip_max_size() when
called with the corresponding arguments. comment shall be a null-terminated
string or null. callback shall be null or point to a function which will
get called after the compression of each member. */
uint32_t zip_write(uint8_t *dst, uint16_t num_memb,
const char *const *filenames,
const uint8_t *const *file_data,
const uint32_t *file_sizes,
const time_t *mtimes,
const char *comment,
void (*callback)(const char *filename, uint32_t size,
uint32_t comp_size))
{
uint16_t i;
uint8_t *p;
struct eocdr eocdr;
struct cfh cfh;
struct lfh lfh;
bool ok;
uint16_t name_len;
uint8_t *data_dst;
size_t comp_sz;
uint32_t lfh_offset, cd_offset, eocdr_offset;
p = dst;
/* Write Local File Headers and deflated or stored data. */
for (i = 0; i < num_memb; i++) {
assert(filenames[i] != NULL);
assert(strlen(filenames[i]) <= UINT16_MAX);
name_len = (uint16_t)strlen(filenames[i]);
data_dst = p + LFH_BASE_SZ + name_len;
if (hwdeflate(file_data[i], file_sizes[i], data_dst,
file_sizes[i], ∁_sz) &&
comp_sz < file_sizes[i]) {
lfh.method = ZIP_DEFLATED;
assert(comp_sz <= UINT32_MAX);
lfh.comp_size = (uint32_t)comp_sz;
} else {
memcpy(data_dst, file_data[i], file_sizes[i]);
lfh.method = ZIP_STORED;
lfh.comp_size = file_sizes[i];
}
if (callback != NULL) {
callback(filenames[i], file_sizes[i], lfh.comp_size);
}
lfh.extract_ver = (0 << 8) | 20; /* DOS | PKZIP 2.0 */
lfh.gp_flag = (lfh.method == ZIP_DEFLATED ? (0x1 << 1) : 0x0);
ctime2dos(mtimes[i], &lfh.mod_date, &lfh.mod_time);
lfh.crc32 = crc32(file_data[i], file_sizes[i]);
lfh.uncomp_size = file_sizes[i];
lfh.name_len = name_len;
lfh.extra_len = 0;
lfh.name = (const uint8_t*)filenames[i];
p += write_lfh(p, &lfh);
p += lfh.comp_size;
}
assert(p - dst <= UINT32_MAX);
cd_offset = (uint32_t)(p - dst);
/* Write the Central Directory based on the Local File Headers. */
lfh_offset = 0;
for (i = 0; i < num_memb; i++) {
ok = read_lfh(&lfh, dst, SIZE_MAX, lfh_offset);
assert(ok);
cfh.made_by_ver = lfh.extract_ver;
cfh.extract_ver = lfh.extract_ver;
cfh.gp_flag = lfh.gp_flag;
cfh.method = lfh.method;
cfh.mod_time = lfh.mod_time;
cfh.mod_date = lfh.mod_date;
cfh.crc32 = lfh.crc32;
cfh.comp_size = lfh.comp_size;
cfh.uncomp_size = lfh.uncomp_size;
cfh.name_len = lfh.name_len;
cfh.extra_len = 0;
cfh.comment_len = 0;
cfh.disk_nbr_start = 0;
cfh.int_attrs = 0;
cfh.ext_attrs = EXT_ATTR_ARC;
cfh.lfh_offset = lfh_offset;
cfh.name = lfh.name;
p += write_cfh(p, &cfh);
lfh_offset += LFH_BASE_SZ + lfh.name_len + lfh.comp_size;
}
assert(p - dst <= UINT32_MAX);
eocdr_offset = (uint32_t)(p - dst);
/* Write the End of Central Directory Record. */
eocdr.disk_nbr = 0;
eocdr.cd_start_disk = 0;
eocdr.disk_cd_entries = num_memb;
eocdr.cd_entries = num_memb;
eocdr.cd_size = eocdr_offset - cd_offset;
eocdr.cd_offset = cd_offset;
eocdr.comment_len = (uint16_t)(comment == NULL ? 0 : strlen(comment));
eocdr.comment = (const uint8_t*)comment;
p += write_eocdr(p, &eocdr);
assert(p - dst <= zip_max_size(num_memb, filenames, file_sizes,
comment));
return (uint32_t)(p - dst);
}
```
HWZip
-----
Теперь мы знаем, как читать и записывать Zip-файлы, как сжимать и распаковывать хранящиеся в них данные. Теперь напишем простую Zip-программу, содержащую все эти инструменты. Код доступен в [hwzip.c](https://www.hanshq.net/files/hwzip/hwzip.c).
Воспользуемся макросом для простой обработки ошибок и несколькими вспомогательными функциями для проверенного выделения памяти:
```
#define PERROR_IF(cond, msg) if (cond) { perror(msg); exit(1); }
static void *xmalloc(size_t size)
{
void *ptr = malloc(size);
PERROR_IF(ptr == NULL, "malloc");
return ptr;
}
static void *xrealloc(void *ptr, size_t size)
{
ptr = realloc(ptr, size);
PERROR_IF(ptr == NULL, "realloc");
return ptr;
}
```
Другие две функции используются для чтения и записи файлов:
```
static uint8_t *read_file(const char *filename, size_t *file_sz)
{
FILE *f;
uint8_t *buf;
size_t buf_cap;
f = fopen(filename, "rb");
PERROR_IF(f == NULL, "fopen");
buf_cap = 4096;
buf = xmalloc(buf_cap);
*file_sz = 0;
while (feof(f) == 0) {
if (buf_cap - *file_sz == 0) {
buf_cap *= 2;
buf = xrealloc(buf, buf_cap);
}
*file_sz += fread(&buf[*file_sz], 1, buf_cap - *file_sz, f);
PERROR_IF(ferror(f), "fread");
}
PERROR_IF(fclose(f) != 0, "fclose");
return buf;
}
static void write_file(const char *filename, const uint8_t *data, size_t n)
{
FILE *f;
f = fopen(filename, "wb");
PERROR_IF(f == NULL, "fopen");
PERROR_IF(fwrite(data, 1, n, f) != n, "fwrite");
PERROR_IF(fclose(f) != 0, "fclose");
}
```
Наша Zip-программ может выполнять три функции: составлять список содержимого Zip-файлов и извлекать его, а также создавать Zip-файлы. Составление списка проще некуда:
```
static void list_zip(const char *filename)
{
uint8_t *zip_data;
size_t zip_sz;
zip_t z;
zipiter_t it;
zipmemb_t m;
printf("Listing ZIP archive: %s\n\n", filename);
zip_data = read_file(filename, &zip_sz);
if (!zip_read(&z, zip_data, zip_sz)) {
printf("Failed to parse ZIP file!\n");
exit(1);
}
if (z.comment_len != 0) {
printf("%.*s\n\n", (int)z.comment_len, z.comment);
}
for (it = z.members_begin; it != z.members_end; it = m.next) {
m = zip_member(&z, it);
printf("%.*s\n", (int)m.name_len, m.name);
}
printf("\n");
free(zip_data);
}
```
Извлечение чуть сложнее. Мы будем использовать вспомогательные функции для нуль-терминирования имени файла (чтобы передавать его в `fopen`) и распаковки:
```
static char *terminate_str(const char *str, size_t n)
{
char *p = xmalloc(n + 1);
memcpy(p, str, n);
p[n] = '\0';
return p;
}
static uint8_t *inflate_member(const zipmemb_t *m)
{
uint8_t *p;
size_t src_used, dst_used;
assert(m->method == ZIP_DEFLATED);
p = xmalloc(m->uncomp_size);
if (hwinflate(m->comp_data, m->comp_size, &src_used, p, m->uncomp_size,
&dst_used) != HWINF_OK) {
free(p);
return NULL;
}
if (src_used != m->comp_size || dst_used != m->uncomp_size) {
free(p);
return NULL;
}
return p;
}
```
Наша программа будет пропускать любые элементы архива, которые есть директории. Это делается для того, чтобы избежать так называемых [path traversal-атак](https://www.owasp.org/index.php/Path_Traversal): зловредный архив используется для записи файла извне директории, указанной пользователем. Подробности читайте в [Info-ZIP FAQ](http://infozip.sourceforge.net/FAQ.html#corruption).
```
static void extract_zip(const char *filename)
{
uint8_t *zip_data;
size_t zip_sz;
zip_t z;
zipiter_t it;
zipmemb_t m;
char *tname;
uint8_t *inflated;
const uint8_t *uncomp_data;
printf("Extracting ZIP archive: %s\n\n", filename);
zip_data = read_file(filename, &zip_sz);
if (!zip_read(&z, zip_data, zip_sz)) {
printf("Failed to read ZIP file!\n");
exit(1);
}
if (z.comment_len != 0) {
printf("%.*s\n\n", (int)z.comment_len, z.comment);
}
for (it = z.members_begin; it != z.members_end; it = m.next) {
m = zip_member(&z, it);
if (m.is_dir) {
printf(" (Skipping dir: %.*s)\n",
(int)m.name_len, m.name);
continue;
}
if (memchr(m.name, '/', m.name_len) != NULL ||
memchr(m.name, '\\', m.name_len) != NULL) {
printf(" (Skipping file in dir: %.*s)\n",
(int)m.name_len, m.name);
continue;
}
assert(m.method == ZIP_STORED || m.method == ZIP_DEFLATED);
printf(" %s: %.*s",
m.method == ZIP_STORED ? "Extracting" : " Inflating",
(int)m.name_len, m.name);
fflush(stdout);
if (m.method == ZIP_STORED) {
assert(m.uncomp_size == m.comp_size);
inflated = NULL;
uncomp_data = m.comp_data;
} else {
inflated = inflate_member(&m);
if (inflated == NULL) {
printf("Error: inflation failed!\n");
exit(1);
}
uncomp_data = inflated;
}
if (crc32(uncomp_data, m.uncomp_size) != m.crc32) {
printf("Error: CRC-32 mismatch!\n");
exit(1);
}
tname = terminate_str((const char*)m.name, m.name_len);
write_file(tname, uncomp_data, m.uncomp_size);
printf("\n");
free(inflated);
free(tname);
}
printf("\n");
free(zip_data);
}
```
Чтобы создать Zip-архив, мы прочитаем входные файлы и скормим их `zip_write`. Поскольку стандартная библиотека C не позволяет получить время изменения файла, мы воспользуемся текущим временем (исправление этой особенности оставляю вам в качестве домашнего задания).
```
void zip_callback(const char *filename, uint32_t size, uint32_t comp_size)
{
bool deflated = comp_size < size;
printf(" %s: %s", deflated ? "Deflated" : " Stored", filename);
if (deflated) {
printf(" (%u%%)", 100 - 100 * comp_size / size);
}
printf("\n");
}
static void create_zip(const char *zip_filename, const char *comment,
uint16_t n, const char *const *filenames)
{
time_t mtime;
time_t *mtimes;
uint8_t **file_data;
uint32_t *file_sizes;
size_t file_size, zip_size;
uint8_t *zip_data;
uint16_t i;
printf("Creating ZIP archive: %s\n\n", zip_filename);
if (comment != NULL) {
printf("%s\n\n", comment);
}
mtime = time(NULL);
file_data = xmalloc(sizeof(*file_data) * n);
file_sizes = xmalloc(sizeof(*file_sizes) * n);
mtimes = xmalloc(sizeof(*mtimes) * n);
for (i = 0; i < n; i++) {
file_data[i] = read_file(filenames[i], &file_size);
if (file_size >= UINT32_MAX) {
printf("%s is too large!\n", filenames[i]);
exit(1);
}
file_sizes[i] = (uint32_t)file_size;
mtimes[i] = mtime;
}
zip_size = zip_max_size(n, filenames, file_sizes, comment);
if (zip_size == 0) {
printf("zip writing not possible");
exit(1);
}
zip_data = xmalloc(zip_size);
zip_size = zip_write(zip_data, n, filenames,
(const uint8_t *const *)file_data,
file_sizes, mtimes, comment, zip_callback);
write_file(zip_filename, zip_data, zip_size);
printf("\n");
free(zip_data);
for (i = 0; i < n; i++) {
free(file_data[i]);
}
free(mtimes);
free(file_sizes);
free(file_data);
}
```
Наконец, `main` проверяет аргументы командной строки и решает, что делать:
```
static void print_usage(const char *argv0)
{
printf("Usage:\n\n");
printf(" %s list \n", argv0);
printf(" %s extract \n", argv0);
printf(" %s create [-c ] \n", argv0);
printf("\n");
}
int main(int argc, char \*\*argv) {
printf("\n");
printf("HWZIP " VERSION " -- A very simple ZIP program ");
printf("from https://www.hanshq.net/zip.html\n");
printf("\n");
if (argc == 3 && strcmp(argv[1], "list") == 0) {
list\_zip(argv[2]);
} else if (argc == 3 && strcmp(argv[1], "extract") == 0) {
extract\_zip(argv[2]);
} else if (argc >= 3 && strcmp(argv[1], "create") == 0) {
if (argc >= 5 && strcmp(argv[3], "-c") == 0) {
create\_zip(argv[2], argv[4], (uint16\_t)(argc - 5),
(const char \*const \*)&argv[5]);
} else {
create\_zip(argv[2], NULL, (uint16\_t)(argc - 3),
(const char \*const \*)&argv[3]);
}
} else {
print\_usage(argv[0]);
return 1;
}
return 0;
}
```
### Инструкции по сборке
Полный набор исходных файлов доступен в [hwzip-1.0.zip](https://www.hanshq.net/files/hwzip/hwzip-1.0.zip). Как скомпилировать HWZip под Linux или Mac:
```
$ clang generate_tables.c && ./a.out > tables.c
$ clang -O3 -DNDEBUG -march=native -o hwzip crc32.c deflate.c huffman.c \
hwzip.c lz77.c tables.c zip.c
```
Под Windows, в командной строке разработчика в Visual Studio (если у вас нет Visual Studio, скачайте [инструменты для сборки](https://aka.ms/buildtools)):
```
cl /TC generate_tables.c && generate_tables > tables.c
cl /O2 /DNDEBUG /MT /Fehwzip.exe /TC crc32.c deflate.c huffman.c hwzip.c
lz77.c tables.c zip.c /link setargv.obj
```
Setargv.obj для [расширяющих wildcard-аргументов командной строки](https://docs.microsoft.com/en-us/cpp/c-language/expanding-wildcard-arguments).)
Заключение
----------
Удивительно, как одновременно быстро и медленно развивается технология. Формат Zip был создан 30 лет назад на основе технологий пятидесятых и семидесятых годов. И хотя с тех пор многое изменилось, Zip-файлы, по сути, остались теми же и сегодня более распространены, чем когда-либо. Думаю, будет полезно хорошо разбираться в том, как они работают.
Упражнения
----------
* Сделайте так, чтобы HWZip записывал время изменения каждого файла, а не текущее время создания архива. Используйте [stat(2)](https://linux.die.net/man/2/stat) на Linux или Mac и [GetFileTime](https://docs.microsoft.com/en-us/windows/win32/api/fileapi/nf-fileapi-getfiletime) на Windows. Или добавьте флаг командной строки, который позволяет пользователю задавать определённое время изменения файлов.
* С помощью кода сжатия и распаковки из этой статьи напишите программу создания и распаковки gzip-файлов. Этот формат — простая обёртка вокруг данных, сжатых с помощью Deflate (обычно всего один файл). Он описан в [RFC 1952](https://tools.ietf.org/html/rfc1952).
* Реализации чтения и записи Zip-файлов спроектированы для работы с [отображением файлов в памяти](https://en.wikipedia.org/wiki/Memory-mapped_file). Измените HWZip так, чтобы вместо `read_file` использовать [mmap(2)](https://linux.die.net/man/2/mmap) под Linux или Mac и [CreateFileMapping](https://docs.microsoft.com/en-us/windows/win32/memory/creating-a-file-mapping-object) под Windows.
* Измените HWZip так, чтобы он поддерживал извлечение и создание архивов в формате Zip64. Подробности ищите в [последнем appnote.txt](https://pkware.cachefly.net/webdocs/APPNOTE/APPNOTE-6.3.6.TXT).
Полезные материалы
------------------
* Подробнее о BBS-культуре рассказывается в [BBS: The Documentary](http://www.bbsdocumentary.com/). Видео можно найти [на YouTube](https://www.youtube.com/playlist?list=PLgE-9Sxs2IBVgJkY-1ZMj0tIFxsJ-vOkv). В [Part 8: Compression](https://www.youtube.com/watch?v=MLNXmrF3a9c) рассказывается о противостоянии SEA и PKWare. На сайте есть [архив исторических материалов](http://www.bbsdocumentary.com/library/CONTROVERSY/LAWSUITS/SEA/).
* В статье [A better Zip bomb](https://www.bamsoftware.com/hacks/zipbomb/) прекрасно объясняется создание Zip-файла, который при распаковке «взрывается» в огромный объём данных.
* В статье [Zip Files All The Way Down](https://research.swtch.com/zip) показано, как создать *Zip-квайн* — файл, содержащий копию самого себя.
* [ascii-zip](https://github.com/molnarg/ascii-zip) — это программа, генерирующая Deflate-поток полностью в ASCII-кодировке. Она использовалась в эксплойте [Rosetta Flash](https://blog.miki.it/2014/7/8/abusing-jsonp-with-rosetta-flash/).
* [Ten Thousand Security Pitfalls: the Zip File Format](https://gynvael.coldwind.pl/?id=682) — подробная презентация о формате с точки зрения безопасности.
* [Reading bits in far too many ways part 1](https://fgiesen.wordpress.com/2018/02/19/reading-bits-in-far-too-many-ways-part-1/), [part 2](https://fgiesen.wordpress.com/2018/02/20/reading-bits-in-far-too-many-ways-part-2/) и [part 3](https://fgiesen.wordpress.com/2018/09/27/reading-bits-in-far-too-many-ways-part-3/) — отличный источник информации о реализации битовых потоков.
* Статья [Understanding Compression](http://shop.oreilly.com/product/0636920052036.do) является введением в тему сжатия данных. | https://habr.com/ru/post/490790/ | null | ru | null |
# Content editable в HTML5

Одним из нововведений HTML5 стала возможность редактировать часть страницы прямо в браузере. Эта фича получила название *content editable*. Она работает во всех современных браузерах. Чтобы сделать часть страницы редактируемой, нужно поставить тегу атрибут `contenteditable="true"`. Под тегом может стоять практически всё: текст с форматированием, картинки, списки и даже flash-ролики. Но пользователь может добавлять толко текст, остольное он может только удалять. В этом посте я покажу пример использования content editable на веб-сайте.
#### HTML-код
```
Редактируемый список в HTML5
</code></pre><br/>
В функции <code>buttonClick()</code> обрабатывается нажатие на кнопку «Сохранить» («Редактировать»): меняется атрибут <code>contentEditable</code>, надпись на кнопке и содержимое cписка копируется в текстовое поле.<br/>
<br/>
<pre><code class="html"> function buttonClick ()
{
var div = document.getElementById ("myDiv");
var button = document.getElementById ("myButton");
var content\_div = document.getElementById ("ListContent");
var textarea = document.getElementById ("myTextarea");
if (div.contentEditable == "true")
{
div.contentEditable = "false";
content\_div.style.display = "inline";
textarea.innerHTML = div.innerHTML;
button.value = "Редактировать";
}
else
{
div.contentEditable = "true";
content\_div.style.display = "none";
button.value = "Сохранить";
}
}
**Что нужно сделать?** (список можно редактировать)
```
Редактируемый `div`. Обратите в нимание на `contenteditable="true"`.
```
* Купить молоко
* Купить яйца
* Починить дверь
* Отредактировать список!
```
Кнопка «Сохранить» («Редактировать»). По нажатию вызывается функция `buttonClick()`.
```
``` | https://habr.com/ru/post/126877/ | null | ru | null |
# Elm. Удобный и неловкий
Поговорим о [Elm](http://elm-lang.org).
Elm — функциональный язык программирования для frontend-разработки. Синтаксис похож на Haskell, но значительно упрощен и специализирован. Исходный код на Elm компилируется в нативный JavaScript. Скомпилированный JavaScript содержит код приложения, которое управляют поддеревом DOM.
[Elm. Удобный и неловкий. Композиция](https://habr.com/post/424341/)
[Elm. Удобный и неловкий. Json.Encoder и Json.Decoder](https://habr.com/post/424437/)
[Elm. Удобный и неловкий. Http, Task](https://habr.com/post/424979/)
Основным элементом в [архитектуре языка Elm](https://guide.elm-lang.org/architecture/) является приложение. В общем случае каждое приложение содержит:
1. Состояние или модель. Данные описывающее текущее состояние приложения;
2. Множество допустимых сообщений. Сообщения отправляются при наступлении событий (допустим клик по кнопке) и доставляются в функцию update;
3. Функцию view, которая на основании состояния генерирует новое DOM дерево;
4. Функция update, которая принимает модель и сообщение, а возвращает новую модель и требуемые эффекты;
5. Функция subscribe, подписка на уведомления о событиях. В ядре языка имеются подписки на таймер, WebSocket и прочее.
Типизация
---------
Все должно быть типизировано. Как следствие статическая проверка согласованности кода. Если скомпилировалось, то должно работать. А вот будет оно работать как вы ожидаете или нет — никаких гарантий. Это значительно упрощает рефакторинг.
Модель
------
Модель является пользовательским типом. Пользовательские типы строятся из:
1. [Type Aliases](https://guide.elm-lang.org/types/type_aliases.html) для описания структур;
2. [Union Types](https://guide.elm-lang.org/types/union_types.html) для описания допустимых объединений типов;
3. базовые типы Int, String и прочие.
Union Types позволяют объявлять тегированные типы. Возьмем для примера описания типа User:
```
type User = Anonymous | User String
```
Объявленный тип содержит информацию о типе пользователя и его данные, если он авторизован. Иначе пользователь анонимный.
Граница
-------
Граница между Elm runtime и внешним окружением через декодеры. [Декодер (Json.Decode)](http://package.elm-lang.org/packages/elm-lang/core/5.1.1/Json-Decode) — функция, которая принимает на вход JSON и возвращает Elm тип. В процессе выполнения [Json.Decode.decodeString](http://package.elm-lang.org/packages/elm-lang/core/5.1.1/Json-Decode#decodeString) или [Json.Decode.decodeValue](http://package.elm-lang.org/packages/elm-lang/core/5.1.1/Json-Decode#decodeValue) проверяется структура входных данных и соответствие типам.
Декодер возвращает тип [Result](http://package.elm-lang.org/packages/elm-lang/core/5.1.1/Result), который содержит данные, в случае успеха, или ошибку.
Представление (view)
--------------------
Представление является функций от состояния, которая возвращают информацию для генерации DOM дерева. Пример:
```
view : Model -> Html.Html Msg
view model =
case model.user of
Anonymous ->
Html.div [] [ Html.text “Anonymous” ]
User name ->
Html.div [] [ Html.text (“Welcome ” ++ name) ]
```
Для генерации DOM узлов используются функции. В боевых проектах view представляет собой композицию из функций более общего порядка. Например:
```
view : Model -> Html.Html Msg
view model =
case model.user of
Anonymous ->
anonymousView
User name ->
userView name
```
anonymousView и userView пользовательские функции, которые генерируют небольшие части интерфейса.
Мутации (update)
----------------
Все события (действия пользователя, сетевые и тп) генерируют сообщения, которые доставляются в зарегистрированную при инициализации функцию. По умолчанию, эта функция имеет имя update. Функция принимает событие и модель, а возвращает новую модель и команды. Команды выполняются в Elm runtime и также могут генерировать события.
Для примера, инкремент переменной при нажатии кнопки:
```
update : Model -> Msg -> (Model, Cmd Msg)
update model msg =
case msg of
OnClick ->
({model | clicked = model.clicked + 1}, Cmd.none)
```
Подписка (subscribe)
--------------------
Подписка на события происходит при старте приложения и повторно вызывается при каждом изменении модели.
В случае возникновения события они доставляются в функцию update.
Для примера, подписка на таймер с периодом 10 секунд. При достижении 10 секунд генерируется сообщение Tick и доставляется в функцию update:
```
subscribe : Model -> Sub Msg
subscribe model =
Time.every 10 Tick
```
Источники
---------
* <http://elm-lang.org> — сайт языка
* <http://elm-lang.org/examples> — примитивные примеры
* <https://github.com/evancz/elm-todomvc> — пример TODO приложения
* <https://guide.elm-lang.org/install.html> — официальная документация
* <https://www.elm-tutorial.org/en/> — сторонний учебник языка
* <https://github.com/isRuslan/awesome-elm> — коллекция различных материалов о языке
* <https://github.com/rtfeldman/elm-spa-example> — пример среднего размера приложения | https://habr.com/ru/post/424215/ | null | ru | null |
# Digispark на Attiny85 — подключение под Windows 10

Если Вы читаете эти строки, значит что-то пошло не так… с подключением данного микроконтроллера. Знаю, у меня самого за сутки до написания статьи было так-же, но техноманьяки — народ ~~упоротый~~ упертый
Можно было спокойно заюзать любую из трех имеющихся ардуин или "голую" Atmega328P-PU/Atmega8-16PU
В конце концов, ПРОСТО загрузить USB-Linux c arduino ide под него.

Нет-же, в этот раз свет клином сошелся на Диджиспарке и ДЕСЯТКЕ — зря что-ли платил $3 за ESD-лицензию?.
"Уж если я чего решил, то выпью обязательно" пел Высоцкий, и как Вы поняли — таки да!
**Ладно, с присказками закончили — бутаем комп, заходим в биос.**
Находим пункт устройства/порты — USB — да, Digispark не работает с USB-3
Отключаем совместимось USB3-Disable (У некоторых просто может выставляться режим порта — ставим USB-2 Compatible)
У меня этот пункт назывался xHCI — Disable
Не торопитесь выходить — включите отладку — Debug-Enable
Опять на моем биосе эта функция зовется иначе — EHCI — Enable
Save&Exit
Гуд? Загрузили винду?
Не торопитесь входить в ArduinoIde!
**Снесите для начала Все установленные ранее дрова под digistump/digispark!**
Готово?
WIN-x — выполнить — regedit — поиск ищем digistump в реестре и беспощадно удаляем, F3 — поиск дальше!
Повторяем процедуру со словом digispark.
Контролный reboot ~~в голову~~ — винда все-же ;-)
**Теперь нам нужно сделать две закачки — правильный комплект дров с лоадером — micronucleus по ссылке**
[Страница загрузки github.com](https://github.com/digistump/DigistumpArduino/releases)
У меня это была версия micronucleus-2.0a4-win.zip
**Еще нужна прога ArduinoIde с предустановленной поддержкой Digispark-a — идем сюда:**
[Запиленный под Attiny85 софт](https://sourceforge.net/projects/digistump/files/)
качаем последний ArduinoIDE, моя версия(на 07.06.2018) — DigisparkArduino-Win32-1.0.4-May19.zip, извлекаем содержимое.
На 64-битке — работает!
Распаковываем/сетапим наш микронуклеус драйвер.
Окей, запускаем DigisparkArduino версии 1.0.4!
**Старый? А Вам Шашечки или Ехать?**
~~Its a Sparta~~ — это винда!

Лулзов добавляет, трейдмарк Sparta, под которым у меня импульсный паяльник и набор отверточек.
Но не торопитесь подключать плату в Usb порт!
Выбираем (в ArduinoIDE ) Сервис-Плата-Digispark (Tiny Core)
Далее Сервис-Программатор-Digispark
Наконец пришло время поморгать светодиодом ;-)
```
void setup()
{
//Set Pins 0 and 1 as outputs.
//Some Digisparks have a built-in LED on pin 0, while some have it on
//pin 1. This way, we can all Digisparks.
pinMode(0, OUTPUT);
pinMode(1, OUTPUT);
}
void loop()
{
//Set the LED pins to HIGH. This gives power to the LED and turns it on
digitalWrite(0, HIGH);
digitalWrite(1, HIGH);
//Wait for a second
delay(1000);
//Set the LED pins to LOW. This turns it off
digitalWrite(0, LOW);
digitalWrite(1, LOW);
//Wait for a second
delay(1000);
}
```
Компилируем Ctrl-R
Загружаем Ctrl-U (ведь правда мы еще не вставляли плату в ЮСБ? ЭТО ВАЖНО!!)

Вот только после такой надписи внизу — включаем Digispark в порт.

иначе он будет бесцельно блинкать появляясь и исчезая в устройствах — как первый спутник земли!
Если ВСЕ пункты выполнялись внимательно и последовательно, то мы получим подобную картинку

И мигающий на плате светодиод — WIN!
Успешных Вам проектов!
Андрей. | https://habr.com/ru/post/413927/ | null | ru | null |
# Один пиксель вместо тысячи слов
Пару месяцев назад, отдыхая от реализации [новых возможностей](http://cloudinary.com/blog/introducing_smart_cropping_intelligent_quality_selection_and_automated_responsive_images) вроде q\_auto и g\_auto, я прикалывался в нашем командном чате по поводу того, как различные форматы хранения изображений будут сжимать однопиксельную картинку. В ответ Orly, редактор блога, попросила меня написать пост об этом. Я сказал: «Конечно, почему бы и нет. Но это будет очень короткий пост. Ведь что можно рассказать про один пиксель».
Похоже, я был сильно неправ.
Что можно сделать с одним пикселем?
===================================
В ранние годы веба однопиксельные картинки часто использовались как костыли для вещей, которые сейчас делаются через CSS. Создание отступов, линий, прямоугольников, полупрозрачных фонов – много чего можно сделать, просто масштабируя пиксель до нужных размеров. Ещё одно использование пикселей, дожившее до наших дней – маячки, средства для отслеживания и аналитики.
В отзывчивом веб-дизайне однопиксельные картинки используются как временные заглушки в ожидании загрузки страницы. Большинство браузеров не поддерживают [HTTP Client Hints](http://httpwg.org/http-extensions/client-hints.html), поэтому некоторые варианты с отзывчивыми изображениями ждут полной загрузки страницы, чтобы подсчитать актуальный размер картинок, а затем заменяют однопиксельные картинки нужными изображениями при помощи JavaScript.
*Сломанная картинка*
Есть и ещё одно применение однопиксельных картинок: их можно использовать в качестве картинок «по умолчанию». Если нужное изображение по каким-то причинам невозможно найти, в некоторых случаях лучше показать один прозрачный пиксель, чем выдавать «404 — Not Found», которая будет видна в браузерах как «сломанная картинка». Нужное изображение вы в любом случае не увидите, но профессиональнее будет не акцентировать на этом внимание, выдавая иконку «сломанной картинки».
Хорошо, значит, однопиксельные картинки бывают полезными. И как же наилучшим образом закодировать изображение размера 1х1?
Очевидно, что для форматов сжатия изображений это пограничный случай. Если изображение состоит из одного пикселя, сжимать тут особенно нечего. Несжатых данных тут будет содержаться от одного бита до четырёх байт – в зависимости от интерпретации: черно-белый (1 бит), оттенки серого (1 байт), оттенки серого с альфой (2 байта), RGB (3 байта), RGBA (4 байта).
Но нельзя закодировать только лишь данные – в любом формате изображений нужно задать интерпретацию данных. По меньшей мере, нужно знать высоту и ширину изображения и количество бит на пиксель.
Заголовки
=========
Обычно для кодирования высоты и ширины используется четыре байта: два на число (если бы это был один байт, то максимальная размерность картинки была бы 255x255). Допустим, нужен ещё байт для задания типа цветопередачи (оттенки серого, RGB или RGBA). В таком минималистичном формате однопиксельная картинка занимала бы не менее 6 байт (для белого пикселя), а максимум – 9 байт (для полупрозрачного пикселя произвольного цвета).
Но в заголовках реальных форматов обычно содержится гораздо больше информации. Первые несколько байт любого формата содержат уникальный идентификатор нужный лишь для того, чтобы сообщить, что «Эй! Я — файл вот конкретно такого формата!». Эта последовательность байт также известна, как «волшебное число». К примеру, GIF всегда начинается с GIF87a или GIF89a, в зависимости от версии спецификаций, PNG – с 8-байтной последовательности, включающей PNG, у JPEG есть заголовок, содержащий строку JFIF или Exif, и т.д.
В заголовках может содержаться мета-информация. Это специфичные для данного формата данные, необходимые для раскодирования, определяющие, какой из подвидов формата используется. Некоторые из мета-данных не обязательно нужны для раскодирования, но тем не менее, используются для определения того, как показывать их на экране: цветовой профиль, ориентация, гамма, количество точек на пиксель. Это могут также быть производльные данные – комментарии, временные отметки, отметки об авторских правах, GPS-координаты. Это могут быть необязательные или обязательные данные, в зависимости от спецификации. Конечно, эти данные увеличивают объём файла. Давайте поэтому остановимся на минимальных файлах, откуда удалена вся необязательная информация – или мы будем тратить драгоценные байты на ерунду.
Кроме заголовков, в файлах может встречаться и другая дополнительная информация – маркеры, контрольные суммы (используемые для проверки правильности передачи или результата работы других процессов, которые могут испортить файл). Бывает, что требуется включить в файл отступы, чтобы выровнять все данные.
Однопиксельные, минимально возможные картинки, показывают, сколько «лишней» информации содержится в формате файла. Смотрим.
Вот шестнадцатеричный дамп 67-байтного PNG-файла с одним белым пикселем.
```
00000000 89 50 4e 47 0d 0a 1a 0a 00 00 00 0d 49 48 44 52 |.PNG........IHDR|
00000010 00 00 00 01 00 00 00 01 01 00 00 00 00 37 6e f9 |.............7n.|
00000020 24 00 00 00 0a 49 44 41 54 78 01 63 68 00 00 00 |$....IDATx.ch...|
00000030 82 00 81 4c 17 d7 df 00 00 00 00 49 45 4e 44 ae |...L.......IEND.|
00000040 42 60 82 |B`.|
```
Файл состоит из 8-байтного «волшебного числа» PNG, за которым следует отрезок заголовка IHDR из 13 байт, отрезок с данными об изображении IDAT с 10 байтами «сжатых» данных, и отметка об окончании IEND. Каждый отрезок данных начинается с 4-байтного отрезка с длиной и 4-байтного отрезка-идентификатора, и заканчивается контрольной суммой из 4 байт. Эти три отрезка данных обязательны, так что они в любом случае отъедают 36 байт у 67-байтного файла.
Чёрный пиксель тоже занимает 67 байт, прозрачный – 68, а произвольный цвет RGBA займёт от 67 до 70 байт.
Заголовок у JPEG длиннее. Минимальный однопиксельный JPEG занимает 141 байт, и он не бывает прозрачным, т.к. JPEG не поддерживает альфа-канал.
В смысле заголовков GIF самый компактный из трёх универсальных форматов. Белый пиксель можно закодировать в GIF 35 байтами:
```
00000000 47 49 46 38 37 61 01 00 01 00 80 01 00 00 00 00 |GIF87a..........|
00000010 ff ff ff 2c 00 00 00 00 01 00 01 00 00 02 02 4c |...,...........L|
00000020 01 00 3b |..;|
```
а прозрачный – 43:
```
00000000 47 49 46 38 39 61 01 00 01 00 80 01 00 00 00 00 |GIF89a..........|
00000010 ff ff ff 21 f9 04 01 0a 00 01 00 2c 00 00 00 00 |...!.......,....|
00000020 01 00 01 00 00 02 02 4c 01 00 3b |.......L..;|
```
Для всех перечисленных форматов можно изготовить и файлы поменьше, которые будут показываться в большинстве браузеров, но они будут сделаны с нарушением спецификаций, так что декодер изображений может в любой момент пожаловаться на то, что файл битый (и будет прав), и показать иконку «сломанной картинки» – а мы именно её и пытаемся избежать.
Так какой же наилучший формат однопиксельной картинки для веба? Есть варианты. Если пиксель непрозрачный, то GIF. Если прозрачный – тоже GIF. Если полупрозрачный, то PNG, поскольку у GIF прозрачность задаётся только как «да» или «нет».
Всё это мало что значит. Любой из этих файлов уместится в один сетевой пакет, поэтому разницы в скорости не будет, а разница для хранилища вообще пренебрежимо мала. Но тем не менее, с этим забавно разбираться – по крайней мере, любителям форматов.
Что же насчёт более экзотических форматов?
==========================================
Используя формат WebP, выбирайте его версию без потерь качества. Однопиксельная картинка без потери качества в формате WebP занимает от 34 до 38 байт. С потерей – от 44 до 104 байт, в зависимости от наличия альфа-канала. К примеру, вот полностью прозрачный пиксель в 34-байтном WebP без потери качества:
```
00000000 52 49 46 46 1a 00 00 00 57 45 42 50 56 50 38 4c |RIFF....WEBPVP8L|
00000010 0d 00 00 00 2f 00 00 00 10 07 10 11 11 88 88 fe |..../...........|
00000020 07 00 |..|
```
а вот тот же пиксель с потерей качества (по умолчанию) WebP, занимающий 82 байта:
```
00000000 52 49 46 46 4a 00 00 00 57 45 42 50 56 50 38 58 |RIFFJ...WEBPVP8X|
00000010 0a 00 00 00 10 00 00 00 00 00 00 00 00 00 41 4c |..............AL|
00000020 50 48 0b 00 00 00 01 07 10 11 11 88 88 fe 07 00 |PH..............|
00000030 00 00 56 50 38 20 18 00 00 00 30 01 00 9d 01 2a |..VP8 ....0....*|
00000040 01 00 01 00 02 00 34 25 a4 00 03 70 00 fe fb fd |......4%...p....|
00000050 50 00 |P.|
```
Разница в том, что WebP с потерей качества и прозрачностью хранится как две картинки в одном файле-контейнере: одна картинка с потерей качества, хранящая данные для RGB, и другая, без потери, с данными альфа-канала.
BPG
===
У [формата BPG](http://bellard.org/bpg/) также есть режимы с потерей из без потери качества, и для него действует обратная закономерность. BPG с потерей хранит 1 пиксель в 31 байте – наименьший показатель из всех:
```
00000000 42 50 47 fb 00 00 01 01 00 03 92 47 40 44 01 c1 |BPG........G@D..|
00000010 71 81 12 00 00 01 26 01 af c0 b6 20 bc b6 fc |q.....&.... ...|
```
BPG без потерь качества занимает 59 байт. Прозрачный пиксель займёт 57 байт в BPG
с потерями и 113 байт в BPG без потерь. Интересно, что в случае с одним белым пикселем BPG выиграет у WebP (31 байт против 38), а с одним прозрачным пикселем WebP выигрывает у BPG (34 байта против 57).
FLIF
====
А ещё есть FLIF. Я, конечно, не могу забыть о нём, являясь главным автором бесплатного формата изображений без потери качества (Free Lossless Image Format). Вот 15-байтный FLIF для одного белого пикселя:
```
00000000 46 4c 49 46 31 31 00 01 00 01 18 44 c6 19 c3 |FLIF11.....D...|
```
А вот 14-байтный для чёрного:
```
00000000 46 4c 49 46 31 31 00 01 00 01 1e 18 b7 ff |FLIF11........|
```
Чёрный пиксель получился меньше, потому что ноль сжимается лучше, чем 255. Заголовок простой: первые 4 байта всегда «FLIF», следующий – человеко-читаемое обозначение цвета и интерлейсинга. В нашем случае это «1», что значит, один канал для цвета (оттенки серого). Следующий байт – глубина цвета. «1» значит один байт на канал. Следующие четыре байта – размерность картинки, 0x0001 на 0x0001. Следующие 4 или 5 – сжатые данные.
Полностью прозрачный пиксель тоже занимает 14 байт в FLIF:
```
00000000 46 4c 49 46 34 31 00 01 00 01 4f fd 72 80 |FLIF41....O.r.|
```
В этом случае у нас 4 цветовых канала (RGBA) вместо одного. Можно было бы ожидать, что раздел с данными будет длиннее (всё-таки каналов в четыре раза больше), но это не так: поскольку значение альфа равно нулю (пиксель прозрачный), значения RGB считаются неважными, и их просто не включают в файл.
Для произвольного цвета RGBA файл FLIF может занять до 20 байт.
Хорошо, значит FLIF лидер в категории «один пиксель» в соревновании на кодирование изображений. Если бы ещё это было какое-то важное соревнование :)
Но тем не менее, FLIF не будет лидером. Помните упомянутый мною минималистичный формат? Тот, который закодирует один пиксель в размер от 6 до 9 байт? Такого формата нет, поэтому он в счёт не идёт. Но есть существующий формат, который довольно близко подходит к этому.
Он называется [Portable Bitmap format](https://en.wikipedia.org/wiki/Netpbm_format) (PBM), и представляет собою несжатый формат изображений из 1980-х. Вот как можно было бы закодировать один белый пиксель в PBM всего 8-ю байтами:
```
00000000 50 31 0a 31 20 31 0a 30 |P1.1 1.0|
```
Да тут и шестнадцатиричный дамп не нужен, этот формат человеко-читаемый. Его можно открыть в текстовом редакторе.
```
P1
1 1
0
```
Первая линия (P1) обозначает, что картинка двухцветная. Не оттенки серого, а только два цвета – чёрный (цифра 1) и белый (0). Вторая линия – размерность картинки. А затем идёт разделённый пробелами список чисел, одно число на пиксель. В нашем случае 0.
Если вам нужно что-то другое, кроме чёрного и белого, можно использовать формат PGM для представления одного пикселя любого цвета всего 12-ю байтами, или PPM размером 14 байт. Это всегда меньше, чем соответствующий FLIF (или любой другой формат со сжатием).
В традиционном семействе форматов PNM (PBM, PGM и PPM) не поддерживается прозрачность. Существует дополнение PNM под названием [Portable Arbitrary Map](https://en.wikipedia.org/wiki/Netpbm#PAM_graphics_format) (PAM), где есть прозрачность. Но для нас он не подходит из-за многословности. Самый маленький из файлов PAM, представляющий прозрачный пиксель, такой:
```
P7
WIDTH 1
HEIGHT 1
DEPTH 4
MAXVAL 1
TUPLTYPE RGB_ALPHA
ENDHDR
\0\0\0\0
```
На последней строке идёт четыре нулевых байта. Всего получается 67 байт. Можно было бы использовать оттенки серого с альфа-каналом вместо RGBA, это бы сберегло два байта в секции данных. Но получится файл из 71 байта, поскольку нужно будет сменить TUPLTYPE с RGB\_ALPHA на GRAYSCALE\_ALPHA. Кроме того, программе обработки может не понравится MAXVAL 1, и придётся поменять его на MAXVAL 255 (ещё два байта).
В общем, для однопиксельных изображений без прозрачности, самым маленьким будет PNM (от 8 до 14 байт для PNM против от 14 до 18 для FLIF), а с прозрачностью самым мелким будет FLIF (от 14 до 20 байт для FLIF против от 67 до 69 байт для PAM).
Вот сравнительная табличка с оптимальными размерами файлов для разных однопиксельных картинок:
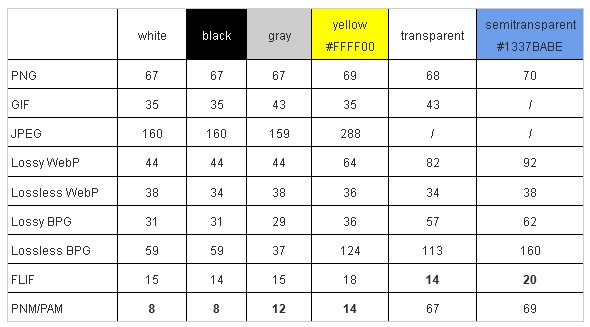
Может показаться странным, что формат без сжатия выигрывает у форматов со сжатием. Но если подумать, однопиксельные картинки – это наихудший вариант для сжатия изображений. Весь файл состоит из заголовка и дополнительной информации, и в нём очень мало данных. А очень мало данных нельзя сжать, поскольку сжатие основано на предсказуемости, и как можно предсказать единственный пиксель? | https://habr.com/ru/post/306210/ | null | ru | null |
# Git rebase «по кнопке»

Когда мы говорим об автоматизации процесса разработки и тестирования, мы подразумеваем, что это очень масштабное действие, и это действительно так. А если разложить его по частям, то станут видны отдельные фрагменты всей картины ― такая фрагментация процесса очень важна в двух случаях:
* действия выполняются вручную, что требует сосредоточенности и аккуратности;
* жёсткие временные рамки.
В нашем случае налицо лимит по времени: релизы формируются, тестируются и выкатываются на продакшн-сервер два раза в день. При ограниченных сроках в жизненном цикле релиза процесс удаления (отката) из релизной ветки задачи, содержащей ошибку, имеет важное значение. Для её выполнения мы используем git rebase. Так как git rebase ― это полностью ручная операция, которая требует внимательности и скрупулезности и занимает продолжительное время, мы автоматизировали процесс удаления задачи из релизной ветки.

#### Git flow
На данный момент Git является одной из самых распространённых систем контроля версий, и мы её успешно используем в Badoo.
Процесс работы с Git довольно прост.

Особенность нашей модели состоит в том, что каждую задачу мы разрабатываем и тестируем в отдельной ветке. Имя этой ветки состоит из номера тикета в JIRA и свободного описания задачи. Например:
> BFG-9000\_All\_developers\_should\_be\_given\_a\_years\_holiday\_(paid)
Релиз мы собираем и тестируем из отдельной ветки (release), в которую сливаются завершённые и протестированные задачи на devel-окружении. Так как мы выкладываем код на продакшн-сервер дважды в день, то, соответственно, ежедневно мы создаём две новые ветки релиза.
Релиз формируется путём сливания задач в релизную ветку с помощью инструмента automerge. Также у нас есть ветка master, которая является копией продакшн-сервера. После этапа интеграционного тестирования релиза и каждой отдельной задачи код отправляется на продакшн-сервер и сливается в ветку master.
Когда релиз тестируется на staging-окружении и обнаруживается ошибка в одной из задач, а времени на исправление нет, мы просто удаляем данную задачу из релиза, используя git rebase.

*Примечание.* Функцию git revert мы не используем в релизной ветке, потому что если удалить задачу из релизной ветки с помощью git revert и релизная ветка сольётся в master, из которого разработчик потом подтянет свежий код в ветку, в которой возникла ошибка, то ему придётся делать revert на revert, чтобы вернуть свои изменения.
На следующем этапе мы собираем новую версию релиза, выкатываем её на staging-окружение, проверяем на отсутствие ошибок, запускаем автотесты и при положительном результате выкладываем код на продакшн-сервер.
Основные моменты этой схемы полностью автоматизированы и работают в процессе непрерывной интеграции (до настоящего момента только удаление задачи из релизной ветки выполнялось вручную).


#### Постановка задачи
Рассмотрим, что можно использовать для автоматизации процесса:
1. Ветка релиза, из которой мы собираемся откатывать тикет, состоит из коммитов двух категорий:
* мерженный коммит, который получается при сливании в релизную ветку ветки задачи, содержит имя тикета в коммит-месседже, так как ветки именуются с префиксом задачи;
* мерженный коммит, который получается в результате сливания ветки master в ветку релиза в автоматическом режиме. На master мы накладываем патчи в полуавтоматическом режиме через наш специальный инструмент DeployDashboard. Патчи прикладываются к соответствующему тикету, при этом в коммит-месседже указывается номер этого тикета и описание патча.
2. Встроенный инструмент git rebase, который лучше всего использовать в интерактивном режиме благодаря удобной визуализации.
Проблемы, с которыми можно столкнуться:
1. При выполнении операции git rebase происходит перемерживание всех коммитов в ветке, начиная с того, который откатывается.
2. Если при формировании ветки какой-либо конфликт слияния был разрешён вручную, то Git не сохранит решение данного конфликта в памяти, поэтому при выполнении операции git rebase нужно будет повторно исправить конфликты слияния в ручном режиме.
3. Конфликты в конкретном алгоритме делятся на два вида:
* простые ― такие конфликты возникают из-за того, что функциональность системы контроля версий не позволяет запоминать решённые ранее конфликты слияния;
* сложные ― возникают из-за того, что код исправлялся в конкретной строке (файле) не только в коммите, который удаляется из ветки, но и в последующих коммитах, которые перемерживаются в процессе git rebase. При этом разработчик исправлял данный конфликт вручную и выполнял push в релизную ветку.
> У Git есть интересная функция git rerere, которая запоминает решение конфликтов при мерже. Она включается в автоматическом режиме, но, к сожалению, не может нам помочь в данном случае. Эта функция работает только тогда, когда есть две долгоживущие ветки, которые постоянно сливаются ― такие конфликты Git запоминает без проблем.
>
> У нас же всего одна ветка, и если не используется функция -force при выполнении git push изменений в репозиторий, то после каждого git rebase придётся создавать новую ветку с новым стволом изменений. Например, мы прописываем постфикс \_r1,r2,r3 … после каждой успешной операции git rebase и выполняем git push новой релизной ветки в репозиторий. Таким образом, история решения конфликтов не сохраняется.
Что же мы в итоге хотим получить?
По нажатию определённой кнопки в нашем багтрекере:
1. Задача будет автоматически удалена из релиза.
2. Создастся новая ветка релиза.
3. Статус у задачи будет переведен в Reopen.
4. В процессе удаления задачи из релиза будут решены все простые конфликты слияния.
К сожалению, в любой из схем невозможно решить сложные конфликты слияния, так что при возникновении такого конфликта мы будем уведомлять разработчика и релиз-инженера.

#### Основные функции
1. Наш скрипт использует интерактивный rebase и отлавливает в ветке релиза коммиты с номером задачи, которую нужно откатить.
2. При нахождении нужных коммитов он удаляет их, при этом запоминает имена файлов, которые в них изменялись.
3. Далее он перемерживает все коммиты, начиная с последнего удалённого нами в стволе ветки.
4. Если возникает конфликт, то он проверяет файлы, которые участвуют в данном конфликте. Если эти файлы совпадают с файлами удалённых комиттов, то мы уведомляем разработчика и релиз-инженера о том, что возник сложный конфликт, который нужно решить вручную.
5. Если файлы не совпадают, но конфликт возник, то это простой конфликт. Тогда мы берём код файлов из коммита, в котором разработчик уже решал этот конфликт, из origin-репозитория.
Так «бежим до головы ветки».
Вероятность того, что мы попадём на сложный конфликт, ничтожно мала, то есть 99% выполнений данного процесса будут проходить в автоматическом режиме.

#### Реализация
Теперь пошагово рассмотрим, что же будет делать наш скрипт (в примере используется только автоматический rebase и можно использовать скрипт просто в консоли):
**1.** Очищаем репозиторий и вытягиваем последнюю версию ветки релиза.
**2.** Получаем верхний коммит в стволе со слиянием в релиз ветки, которую хотим откатить.
а. Если коммита нет, то сообщаем, что откатывать нечего.
**3.** Генерируем скрипт-редактор, который только удаляет из ствола ветки хеши мержевых коммитов, таким образом удаляя их из истории.
**4.** В окружение скрипта-ревертера задаем скрипт-редактор (EDITOR), который мы сгенерили на предыдущем этапе.
**5.** Выполняем git rebase -ip для релиза. Проверяем код ошибки.
а. Если 0, то все прошло хорошо. Переходим к пункту 2, чтобы найти возможные предыдущие коммиты удаляемой ветки задачи.
b.Если не 0, значит, возник конфликт. Пробуем решить:
i. Запоминаем хэш коммита, который не удалось наложить.
Он лежит в файле .git/rebase-merge/stopped-sha
ii. Разбираем вывод команды rebase, чтобы выяснить, что не так.
1. Если Git нам говорит “CONFLICT (content): Merge conflict in ”, то сравниваем этот файл с предыдущей ревизией от удаляемой, и если он не отличается (файл не менялся в коммите), то просто берём этот файл с головы ветки билда и коммитим. Если отличается, то выходим, а разработчик разрешает конфликт вручную.
2. Если Git говорит “fatal: Commit is a merge but no -m option was given”, то просто повторяем rebase с флажком --continue. Мержевый коммит пропустится, но изменения не потеряются. Обычно такое бывает с веткой master, но он уже подтягивался в голову ветки и данный мержевый коммит не нужен.
3. Если Git говорит “error: could not apply… When you have resolved this problem run «git rebase --continue”, то делаем git status, чтобы получить список файлов. Если хоть один файл из статуса есть в коммите, который мы откатываем, то пропускаем коммит (rebase --skip), который мы запомнили на шаге 5.b.i, написав об этом в лог, чтобы релиз-инженер это увидел и решил, нужен этот коммит или нет.
4. Если ничего из перечисленного не случилось, то выходим из скрипта и говорим, что произошло что-то необъяснимое.
**6.** Повторяем пункт 5, пока не появится exit code 0 на выходе, либо счётчик в цикле не будет > 5, чтобы избежать ошибок зацикливания.
**Код скрипта**
```
/**
* Код выдран из библиотеки деплоя, поэтому при копипасте не заработает.
* Предназначен для ознакомления.
*/
function runBuildRevert($args)
{
if (count($args) != 2) {
$this->commandUsage(" ");
return $this->error("Unknown build!");;
}
$build\_name = array\_shift($args);
$ticket\_key = array\_shift($args);
$build = $this->Deploy->buildForNameOrBranch($build\_name);
if (!$build) return false;
if ($this->directSystem("git reset --hard && git clean -fdx")) {
return $this->error("Can't clean directory!");
}
if ($this->directSystem("git fetch")) {
return $this->error("Can't fetch from origin!");
}
if ($this->directSystem("git checkout " . $build['branch\_name'])) {
return $this->error("Can't checkout build branch!");
}
if ($this->directSystem("git pull origin " . $build['branch\_name'])) {
return $this->error("Can't pull build branch!");
}
$commit = $this->\_getTopBranchToBuildMergeCommit($build['branch\_name'], $ticket\_key);
$in\_stream\_count = 0;
while (!empty($commit)) {
$in\_stream\_count += 1;
if ($in\_stream\_count >= 5) return $this->error("Seems rebase went to infinite loop!");
$editor = $this->\_generateEditor($build['branch\_name'], $ticket\_key);
$output = '';
$code = 0;
$this->exec(
'git rebase -ip ' . $commit . '^^',
$output,
$code,
false
);
while ($code) {
$output = implode("\n", $output);
$conflicts\_result = $this->\_resolveRevertConflicts($output, $build['branch\_name'], $commit);
if (self::FLAG\_REBASE\_STOP !== $conflicts\_result) {
$command = '--continue';
if (self::FLAG\_REBASE\_SKIP === $conflicts\_result) {
$command = '--skip';
}
$output = '';
$code = 0;
$this->exec(
'git rebase ' . $command,
$output,
$code,
false
);
} else {
unlink($editor);
return $this->error("Giving up, can't resolve conflicts! Do it manually.. Output was:\n" . var\_export($output, 1));
}
}
unlink($editor);
$commit = $this->\_getTopBranchToBuildMergeCommit($build['branch\_name'], $ticket\_key);
}
if (empty($in\_stream\_count)) return $this->error("Can't find ticket merge in branchdiff with master!");
return true;
}
protected function \_resolveRevertConflicts($output, $build\_branch, $commit)
{
$res = self::FLAG\_REBASE\_STOP;
$stopped\_sha = trim(file\_get\_contents('.git/rebase-merge/stopped-sha'));
if (preg\_match\_all('/^CONFLICT\s\(content\)\:\sMerge\sconflict\sin\s(.\*)$/m', $output, $m)) {
$conflicting\_files = $m[1];
foreach ($conflicting\_files as $file) {
$output = '';
$this->exec(
'git diff ' . $commit . '..' . $commit . '^ -- ' . $file,
$output
);
if (empty($output)) {
$this->exec('git show ' . $build\_branch . ':' . $file . ' > ' . $file);
$this->exec('git add ' . $file);
$res = self::FLAG\_REBASE\_CONTINUE;
} else {
return $this->error("Can't resolve conflict, because file was changed in reverting branch!");
}
}
} elseif (preg\_match('/fatal\:\sCommit\s' . $stopped\_sha . '\sis\sa\smerge\sbut\sno\s\-m\soption\swas\sgiven/m', $output)) {
$res = self::FLAG\_REBASE\_CONTINUE;
} elseif (preg\_match('/error\:\scould\snot\sapply.\*When\syou\shave\sresolved\sthis\sproblem\srun\s"git\srebase\s\-\-continue"/sm', $output)) {
$files\_status = '';
$this->exec(
'git status -s|awk \'{print $2;}\'',
$files\_status
);
foreach ($files\_status as $file) {
$diff\_in\_reverting = '';
$this->exec(
'git diff ' . $commit . '..' . $commit . '^ -- ' . $file,
$diff\_in\_reverting
);
if (!empty($diff\_in\_reverting)) {
$this->warning("Skipping commit " . $stopped\_sha . " because it touches files we are reverting!");
$res = self::FLAG\_REBASE\_SKIP;
break;
}
}
}
return $res;
}
protected function \_getTopBranchToBuildMergeCommit($build\_branch, $ticket)
{
$commit = '';
$this->exec(
'git log ' . $build\_branch . ' ^origin/master --merges --grep ' . $ticket . ' -1 --pretty=format:%H',
$commit
);
return array\_shift($commit);
}
protected function \_generateEditor($build\_branch, $ticket, array $exclude\_commits = array())
{
$filename = PHPWEB\_PATH\_TEMPORARY . uniqid($build\_branch) . '.php';
$content = <<<'CODE'
#!/local/php5/bin/php
php
$build = '%s';
$ticket = '%s';
$commits = %s;
$file = $\_SERVER['argv'][1];
if (!empty($file)) {
$content = file\_get\_contents($file);
$build = preg\_replace('/\_r\d+$/', '', $build);
$new = preg\_replace('/^.\*Merge.\*branch.\*' . $ticket . '.\*into\s' . $build . '.\*$/m', '', $content);
foreach ($commits as $exclude) {
$new = preg\_replace('/^.\*' . preg\_quote($exclude, '/') . '$/m', '', $new);
}
file\_put\_contents($file, $new);
}
CODE;
$content = sprintf($content, $build\_branch, $ticket, var\_export($exclude\_commits, 1));
file\_put\_contents($filename, $content);
$this-exec('chmod +x ' . $filename);
putenv("EDITOR=" . $filename);
return $filename;
}
```

#### Заключение
В итоге мы получили скрипт, который удаляет задачу из релизной ветки в автоматическом режиме. Мы сэкономили время в процессе формирования и тестирования релиза, при этом почти полностью исключили человеческий фактор.
Конечно же, наш скрипт подойдет не всем пользователям Git. В некоторых случаях проще использовать git revert, но лучше им не увлекаться (revert на revert на revert...). Мы надеемся, что не самая простая операция git rebase стала вам более понятной, а тем, кто постоянно использует git rebase в процессе разработки и формирования релиза, пригодится и наш скрипт.
**Илья Агеев**, QA Lead и **Владислав Чернов**, Release engineer | https://habr.com/ru/post/193258/ | null | ru | null |
# Стандартный калькулятор в Win
А вы знали, что в стандартный калькулятор Windows можно вставлять арифметические выражение из буфера обмена и программа вычислит результат?
например:
* скопируйте строку `125/25*10=`
* запустите калькулятор (win+R, 'calc', Enter)
* нажмите Ctrl + V
А вот использование неверных с арифметической точки зрения выражений, например `10art` приводит к тому, что отображается какое-то число. У меня — `0.0017453310241888003447792279227637`. Баг?
**UPD:**как заметил [khim](https://geektimes.ru/users/khim/)
> Он просто как бы вбивает всё это с клавиатуры. 10 => 10, «a» => beep, «r» => 1/x (результат 0.1), «t» => tan(0.1), то есть 0.0017453310241888003447792279227637
>
>
>
> Всё правильно… Заметьте что результат будет отличаться в разных режимах (простой калькулятор не имеет приоритетов, «научный» — имеет).
>
> | https://habr.com/ru/post/37663/ | null | ru | null |
# Нативный шаблонизатор
Я довольно давно уже использую нативные шаблоны, но, почему-то, у многих людей нативные шаблоны ассоциируются с конструкциями типа:
> `1. $title = 'My title';
> 2. include('templates/index.html');
> \* This source code was highlighted with Source Code Highlighter.`
> `1. <html><head><title></fontphp echo $title ?>title>head>
> 2.
> \* This source code was highlighted with Source Code Highlighter.`
То есть, переменную определили и приинклюдили html-файл. Я считаю, что это в корне неверный подход. Почему?
Во-первых, все переменные, переданные в шаблон, должны храниться в одном месте (свойстве класса шаблонизатора).
Во-вторых, в шаблонизаторе не должно быть доступа к переменным, которые в него не переданы, и к функциям, которые в нем не определены.
В-третьих, должен быть определен набор функций, необходимых для работы.
Таким образом, я пришел к выводу, что шаблонизатор нужен, но он не должен быть навороченным тормозом типа Smarty.
Идеология блочных шаблонизаторов (XTemplate, например) мне не импонирует потому, что в них нет ветвлений как таковых, есть только циклы.
Потому я написал свой.
Начнем с того, что нам нужно разобраться с обработкой ошибок. Я использую для этой цели исключения, потому определяем класс исключений:
> `1. class STempException extends Exception {}
> \* This source code was highlighted with Source Code Highlighter.`
Тут нам больше ничего не нужно. Переходим к самому шаблонизатору (о том, что делают методы, кратко написано в комментариях, более подробно опишу ниже):
> `1. class STemp
> 2. {
> 3. /\*\*
> 4. \* The name of the directory where templates are located.
> 5. \*
> 6. \* @var string.
> 7. \* @access private.
> 8. \*/
> 9. private $path;
> 10.
> 11. /\*\*
> 12. \* Name of the template.
> 13. \*
> 14. \* @var string.
> 15. \* @access private.
> 16. \*/
> 17. private $template;
> 18.
> 19. /\*\*
> 20. \* Where assigned template vars are kept.
> 21. \*
> 22. \* @var array.
> 23. \* @access private.
> 24. \*/
> 25. private $variables = array();
> 26.
> 27. /\*\*
> 28. \* Parameters of the template engine.
> 29. \*
> 30. \* @var array.
> 31. \* @access private
> 32. \*/
> 33. private $params = array(
> 34. 'xss\_protection' => true,
> 35. 'exit\_after\_display' => true,
> 36. 'endofline\_to\_br' => false
> 37. );
> 38.
> 39. /\*\*
> 40. \* File that include in template.
> 41. \*
> 42. \* @var string.
> 43. \* @access private.
> 44. \*/
> 45. private $include\_file;
> 46.
> 47. /\*\*
> 48. \* The class constructor. Set name of the directory where templates are located.
> 49. \*
> 50. \* @param string $path name of the directory where templates are located, default 'templates/'.
> 51. \* @access public.
> 52. \*/
> 53. public function \_\_construct($path = 'templates/')
> 54. {
> 55. $this->path = $path;
> 56. }
> 57.
> 58. /\*\*
> 59. \* Set parameters of template engine.
> 60. \*
> 61. \* @param string $param name of the parameter.
> 62. \* @param bool $value value of the parameter.
> 63. \* @return bool TRUE if parameter set, FALSE if didn't set.
> 64. \* @access public.
> 65. \*/
> 66. public function setParam($param, $value)
> 67. {
> 68. if (isset($this->params[$param])) {
> 69. $this->params[$param] = $value;
> 70. return true;
> 71. }
> 72.
> 73. return false;
> 74. }
> 75.
> 76. /\*\*
> 77. \*
> 78. \* @param string $include\_file path to include file.
> 79. \* @access public.
> 80. \*/
> 81. public function setIncludeFile($include\_file)
> 82. {
> 83. $this->include\_file = $this->path.$include\_file;
> 84.
> 85. if (!file\_exists($this->path.$include\_file))
> 86. throw new STempException('Include file '.$this->include\_file.' not exitst');
> 87. }
> 88.
> 89. /\*\*
> 90. \* Assigns values to template variables.
> 91. \*
> 92. \* @param string $name the template variable name.
> 93. \* @param mixed $value the value to assign.
> 94. \* @access public.
> 95. \*/
> 96. public function assign($name, $value)
> 97. {
> 98. $this->variables[$name] = $value;
> 99. }
> 100.
> 101. /\*\*
> 102. \* Executes and displays the template results.
> 103. \*
> 104. \* @param string $template the template name.
> 105. \* @access public.
> 106. \*/
> 107. public function display($template)
> 108. {
> 109. $this->template = $this->path.$template;
> 110.
> 111. if (!file\_exists($this->template))
> 112. throw new STempException('Template file '.$template.' not exitst');
> 113.
> 114. require\_once($this->template);
> 115.
> 116. if ($this->params['exit\_after\_display'])
> 117. exit;
> 118. }
> 119.
> 120. /\*\*
> 121. \* Get value of template variable.
> 122. \*
> 123. \* @param string $name the template variable name.
> 124. \* @return mixed value of template variable with this name. FALSE if variable not set.
> 125. \* @access private.
> 126. \*/
> 127. private function \_\_get($name)
> 128. {
> 129. if (isset($this->variables[$name])) {
> 130. $variable = $this->variables[$name];
> 131.
> 132. if ($this->params['xss\_protection'])
> 133. $variable = $this->xssProtection($variable);
> 134.
> 135. if ($this->params['endofline\_to\_br'])
> 136. $variable = $this->endoflineToBr($variable);
> 137.
> 138. return $variable;
> 139. }
> 140.
> 141. return NULL;
> 142. }
> 143.
> 144. /\*\*
> 145. \* Include file
> 146. \*
> 147. \* @access private
> 148. \*/
> 149. private function includeFile()
> 150. {
> 151. if (!file\_exists($this->include\_file))
> 152. throw new STempException('Include file '.$this->include\_file.' not found');
> 153.
> 154. require\_once($this->include\_file);
> 155. }
> 156.
> 157. /\*\*
> 158. \* For the formation of endings of words.
> 159. \*
> 160. \* @param int $value number.
> 161. \* @param string $word0 word in the singular.
> 162. \* @param string $word1 word in the plural (2, 3).
> 163. \* @param string $word2 word in the plural.
> 164. \* @param string $separator separator, default ' '.
> 165. \* @return string formed words
> 166. \* @access private.
> 167. \*/
> 168. private function morph($value, $word0, $word1, $word2, $separator = ' ')
> 169. {
> 170. if (preg\_match('/1\d$/', $value))
> 171. return $value.$separator.$word2;
> 172. elseif (preg\_match('/1$/', $value))
> 173. return $value.$separator.$word0;
> 174. elseif (preg\_match('/(2|3|4)$/', $value))
> 175. return $value.$separator.$word1;
> 176. else
> 177. return $value.$separator.$word2;
> 178. }
> 179.
> 180. /\*\*
> 181. \* For protection from XSS.
> 182. \*
> 183. \* @param mixed $variable data for protection.
> 184. \* @return mixed protected data.
> 185. \* @access private.
> 186. \*/
> 187. private function xssProtection($variable)
> 188. {
> 189. if (is\_array($variable)) {
> 190. $protected = array();
> 191. foreach ($variable as $key=>$value)
> 192. $protected[$key] = $this->xssProtection($value);
> 193. return $protected;
> 194. }
> 195.
> 196. return htmlspecialchars($variable);
> 197. }
> 198.
> 199. /\*\*
> 200. \* Inserts HTML line breaks before all newlines in a string.
> 201. \*
> 202. \* @param mixed $variable data for protection.
> 203. \* @return mixed data where string with
> inserted before all newlines.
> 204. \* @access private.
> 205. \*/
> 206. private function endoflineToBr($variable)
> 207. {
> 208. if (is\_array($variable)) {
> 209. $protected = array();
> 210. foreach ($variable as $key=>$value)
> 211. $protected[$key] = $this->endoflineToBr($value);
> 212. return $protected;
> 213. }
> 214.
> 215. return nl2br($variable);
> 216. }
> 217. }
> \* This source code was highlighted with Source Code Highlighter.`
В конструкторе мы можем указать путь к директории шаблонов (по умолчанию temlates/).
С помощью метода setParam мы можем установить параметры шаблонизатора. Их всего три (мне этого достаточно, при необходимости можно добавлять параметры). Первый параметр — xss\_protection — как понятно из названия, нужен для защиты от уязвимости xss. Если значение параметра установлено как true, все переменные, которые мы используем в шаблоне, перед отдачей автоматически обрабатываются функцией htmlspecialchars (в том числе элементы массивов). Второй параметр — exit\_after\_display — нужен для того, чтобы, при потребности, мы могли остановить выполнение сценария после отображения шаблона. Третий параметр — endofline\_to\_br — обрабатывает все переменные перед отдачей (в том числе элементы массивов) функцией nl2br.
Методом setIncludeFile мы можем установить подключаемый шаблон. Очень часто используется общий шаблон index.tpl.php и в него, в зависимости от условий, подключают изменямую часть. Вот для автоматизации данного процесса и нужен этот метод. Если подключаемый файл не существует, выбрасыватся исключение.
Метод assign служит для передачи переменных в шаблон.
Метод display отображает шаблон. Если файл шаблона не существует, выбрасывается исключение. Если параметр exit\_after\_display установлен как true, этот метод также завершает работу сценария (практически всегда отображение шаблона является последним действием).
«Магический» метод \_\_get возвращает значение переданной в шаблон переменной. Если переменная не определена, возвращает NULL. В зависимости от параметров, переменные перед отдачей могут обрабатываться.
Метод includeFile инклюдит файл, назначенный методом setIncludeFile и выбрасывает исключение, если этот файл не найден.
Метод morph, не совсем «шаблонизаторный», служит для формирования правильных окончание слов, относящихся к числительным. То есть, 1 комментарий, 2 комментария, 5 комментариев. В метод нужно передать само число, три разных варианта и, опционально, разделитель слов (по умолчанию неразрывный пробел).
Метод xssProtection обрабатывает данные функцией htmlspecialchars. Если на входе массив, то он рекурсивно перебирается и обрабатываются все его элементы.
Метод endoflineToBr обрабатывает данные функцией nl2br. Если на входе массив, то он, как и в предыдущем методе, рекурсивно перебирается и обрабатываются все его элементы.
Как это выглядит на практике? Предположим, нам нужно распечатать статью и комментарии к ней. Данные по статье в массиве $article, комменты — в $comments.
Контроллер:
> `1. $stemp = new STemp();
> 2.
> 3. $stemp->assign("title", $article['title']);
> 4.
> 5. $stemp->assign("article", $article);
> 6. $stemp->assign("comments", $comments);
> 7.
> 8. try {
> 9. $stemp->setIncludeFile("article.tpl.php");
> 10. $stemp->display("index.tpl.php");
> 11. } catch (STempException $e) {
> 12. die('STemp error: '.$e->getMessage());
> 13. }
> \* This source code was highlighted with Source Code Highlighter.`
Шаблон index.tpl.php:
> `1. <html>
> 2. <head>
> 3. <title></fontphp echo $this->title ?>title>
> 4. head>
> 5. <body>
> 6. </fontphp $this->includeFile() ?>
> 7. body>
> 8. html>
> \* This source code was highlighted with Source Code Highlighter.`
Шаблон article.tpl.php:
> `1. <h1></fontphp echo $this->article['title'] ?>h1>
> 2. </fontphp $this->setParam('xss\_protection', false); $this->setParam('endofline\_to\_br', true) ?>
> 3. <div class="content">
> 4. </fontphp echo $this->article['content'] ?>
> 5. div>
> 6. <p></fontphp echo $this->morph(count($this->comments), 'комментарий', 'комментария', 'комментариев') ?>:p>
> 7. </fontphp $this->setParam('xss\_protecttion', true) ?>
> 8. </fontphp foreach ($this->comments as $key=>$value) { ?>
> 9. <p class="user"></fontphp echo $value['username'] ?>:p>
> 10. <p class="comment"></fontphp echo $value['text'] ?>p>
> 11. </fontphp } ?>
> \* This source code was highlighted with Source Code Highlighter.`
[Скачать класс](http://s-a-p.in/download/stemp/).
Использование класса в личных нуждах разрешено без ограничений. При перепечатке статьи или исходного кода, в том числе, частично, ссылка на меня (на [мой сайт](http://s-a-p.in/)) обязательна. | https://habr.com/ru/post/45259/ | null | ru | null |
# Методы, как first class citizens в C++
На днях, гуляя по багтрекеру gcc наткнулся на [интересный баг](http://gcc.gnu.org/bugzilla/show_bug.cgi?id=51927), в нем используется сразу несколько возможностей C++11:
* **std::function** — механизм для создания функторов — объектов функций
* **non static member initialisation** — [механизм для инициализации членов класса вне конструктора](http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2008/n2628.html)
* **lambda** — тут и так все ясно. Исчерпывающие статьи были [здесь](http://habrahabr.ru/post/66021/).
Анализируя этот баг, я подумал, что теперь можно удобно реализовать методы как first class citizens
Собственно, википедия объясняет нам, что такое [first class citizens](http://en.wikipedia.org/wiki/First-class_citizen) — это некая сущность, которая может быть создана в процессе работы программы, передана как параметр, присвоена переменной, может быть результатом работы функции.
#### Подготовка
##### Выбираем компилятор
Так как под рукой у меня не было свежего gcc или msvc, я решил собрать свежий clang-3.1:
```
mkdir llvm
cd llvm
svn co http://llvm.org/svn/llvm-project/llvm/tags/RELEASE_31/final ./
cd tools
svn co http://llvm.org/svn/llvm-project/cfe/tags/RELEASE_31/final clang
cd ../../
mkdir build
cd build
cmake ../llvm -DCMAKE_INSTALL_PREFIX=/home/pixel/fakeroot -DCMAKE_BUILD_TYPE=Release
make -j4
make check-all
make install
```
##### Выбираем библиотеку libcxx
Также я решил собрать библиотеку libcxx для использования всех возможностей нового компилятора:
```
mkdir libcxx
cd libcxx
svn co http://llvm.org/svn/llvm-project/libcxx/trunk ./
cd ../
mkdir build_libcxx
cd build_libcxx
CC=clang CXX=clang++ cmake ../libcxx -DCMAKE_INSTALL_PREFIX=/home/pixel/fakeroot -DCMAKE_BUILD_TYPE=Release
make -j4
make install
```
Несколько слов о сборке libcxx: я решил взять последнюю версию из trunk, так как последний релиз не захотел у меня собираться (разбираться не хотелось, поэтому взял trunk). Также libcxx должна собираться с помощью clang, для этого я ставлю переменные окружения CC и CXX для замены компилятора на clang. Также у меня почему-то не захотели запускаться тесты (**make check-libcxx**)
##### Пример CMakeLists.txt для использования свежесобранного clang и libcxx
```
cmake_minimum_required(VERSION 2.8)
project (clang_haxxs)
add_definitions(-std=c++11 -nostdinc++)
include_directories(/home/pixel/fakeroot/lib/clang/3.1/include)
include_directories(/home/pixel/fakeroot/include/c++/v1)
link_directories(/home/pixel/fakeroot/lib)
add_executable(clang_haxxs main.cpp)
set_target_properties(clang_haxxs PROPERTIES LINK_FLAGS -stdlib=libc++)
```
Соответственно, для cmake переопределяем переменные окружения CC и CXX аналогично, как при сборке libcxx.
#### Поясняющий пример
Итак, подготовительный процесс закончен, переходим к примеру:
```
#include
#include
using namespace std;
struct FirstClass
{
FirstClass(): x(0)
{
}
int get\_x() const
{
return x;
}
function f1 = [this]() -> int
{
cout << "called member function f1..." << endl;
++x;
f1 = f2;
return 5;
};
private:
function f2 = [this]() -> int
{
cout << "called member function f2..." << endl;
return x;
};
int x;
};
int main()
{
FirstClass m;
m.f1();
m.f1();
function f3 = []() -> int
{
cout << "called free function f3..." << endl;
return 100500;
};
m.f1 = f3;
m.f1();
return 0;
}
```
Вывод программы:
`called member function f1...
called member function f2...
called free function f3...`
На самом деле, аналогичную функциональность можно реализовать и без c++11, но будет это выглядеть менее читабельно. Основной вклад в читабельность кода вносит **non-static member initialisation** — мы получаем декларацию и реализацию метода аналогичную обычным методам в C++-03. Остальные возможности более-менее эмулируются средствами C++-03 и сторонними библиотеками: boost::function, boost::lambda.
#### Погружение
Рассмотрим подробнее, что мы можем делать с такими объектами:
##### Эмуляция статических и нестатических методов
Здесь все просто, метод не является статическим, если он имеет доступ к **this**. Соответственно, при определении лямбда функции в теле класса, мы добавляем в capture list **this**. Теперь из лямбда функции мы можем обращаться ко всем членам класса (в том числе и приватным).
Здесь есть она особенность: на самом деле, здесь не совсем корректно используется понятие статических функций, так как изначально в C++ они определяются как функции, которые можно вызывать без созданного объекта, здесь мы все же вынуждены создать объект, чтобы достучаться до функции.
##### Настройка методов вне класса
Как нестатическую определить функцию мы разобрались, теперь осталось понять, как это сделать вне класса, очень просто — необходимо в capture list передать по ссылке объект, к которому прицепляется данная функция:
```
function f4 = [&m]() ->int
{
cout << "called free function f4 with capture list..." << endl;
return m.get\_x() + 1;
};
m.f1 = f4;
m.f1();
```
Здесь мы должны соблюдать аккуратность при передаче ссылки на объект в capture list, так как операция определения функции и привязки ее к объекту разнесена по времени, можно допустить следующую ошибку:
«Привязать не к тому объекту, который указан в capture list».
Также, еще одно ограничение которое здесь присутствует, если мы прицепляем функцию вне декларации класса, то мы теряем доступ к приватным переменным класса:
```
function err = [&m]() ->int
{
cout << "called free function err with capture list..." << endl;
return m.x + 1;
};
```
При этом компилятор ругается: `/usr/src/projects/clang/usage/main.cpp:64:12: error: 'x' is a private member of 'FirstClass'`
##### Запрещение переопределения метода
Здесь все просто, так как метод является обычным членом класса, то добавив const к его описанию, мы как раз получаем то что нужно:
```
struct FirstClassConst
{
const function f1 = []() -> int
{
return 1;
};
};
FirstClassConst mc;
mc.f1 = f3;
```
Компилятор ругает нас: `/usr/src/projects/clang/usage/main.cpp:70:8: error: no viable overloaded '='
mc.f1 = f3;
~~~~~ ^ ~~`
##### Отсутствие const методов
У честных C++ методов есть возможность определения, что метод не меняет членов класса, и его можно применять к константному объекту, такие методы помечаются квалификатором const. В примере — это метод get\_x.
Если мы реализуем методы, как объекты, то такая возможность пропадает, вместо этого мы можем менять члены у константного объекта:
```
struct MutableFirstClass
{
int x;
MutableFirstClass(): x(0){}
int nonConstMethod()
{
++x;
return x;
}
function f1 = [this]() -> int
{
this->x = 100500;
return x;
};
};
const MutableFirstClass mm;
mm.f1();
//mm.nonConstMethod();
```
Если раскомментировать последний вызов, то компилятор ругается следующим образом:`/usr/src/projects/clang/usage/main.cpp:93:2: error: member function 'nonConstMethod' not viable: 'this' argument has type 'const MutableFirstClass', but function is not marked const
mm.nonConstMethod();
^~`
Скорее всего присходит следующая последовательность действий:
**non static member initialisation** не более чем синтаксический сахар, и поэтому захват **this** в **capture list** происходит в конструкторе, а в конструкторе this имеет тип **MutableFirstClass \* const**, и поэтому мы можем менять значения переменных.
Насколько я помню, в константных объектах менять значения членов — UB (кроме членов, помеченных квалификатором mutable), поэтому необходимо осторожно использовать такие методы в константных объектах.
#### Что дальше
На самом деле, возможность применения этого функционала довольно спорна — с одной стороны, мы легко можем реализовать паттерн «Декоратор» почти как в питоне, и это одна из сильных сторон: мы избавляемся от утомительной реализации кучи классов наследников, как в GoF. Также мы можем декорировать каждый объект индивидуальным способом: например, мы можем написать функцию **decorate**, которая получает на вход объект, и добавляет декоратор к одному из методов. Такое невозможно сделать, используя данный паттерн так, как он описан в GoF.
С другой стороны, отсутствие защиты членов константных объектов — это очень серьезный недостаток, поэтому необходимо серьезно подумать перед применением данного решения.
Также возрастает потребление памяти, в имплементации от libcxx каждый такой метод занимает 16 байт, таким образом, с увеличением количества методов, мы будем получать все более жирные объекты.
Также следует провести замеры времени и сравнить скорость вызова таких методов по сравнению с нативными методами C++ (можно сравнить скорость с виртуальными методами). | https://habr.com/ru/post/145673/ | null | ru | null |
# Wi-Fi розетка с управлением через Интернет за 60 минут
В этом материале мы покажем, что Интернет вещей — это не так уж и сложно. Для этого за 60 минут соберем и оживим простейшую Wi-Fi розетку с управлением через Интернет.
5 минут: размышляем над задачей
-------------------------------
Почему Wi-Fi? Потому что он у всех есть и не требует проводов, а значит, в пределах нашего помещения розетку можно будет перемещать в любой угол.
Раз розетка у нас смотрит в интернет, то помимо самой аппаратуры нам понадобится еще и нечто в этом самом Интернете. Причем разрабатывать что-то с нуля мы вот вообще не хотим, хотим максимально готовое.
Первое, что приходит в голову — для розетки берем микроконтроллер с ESP8266/ESP32, так как это очень известная и популярная платформа со встроенным Wi-Fi, а для бекэнда в Интернете готовый облачный сервис [Azure IoT Central](https://www.quarta-embedded.ru/products/microsoft-azure/central/), для которого код писать вообще не надо.
Ну раз это первое пришло в голову — так и сделаем, у нас же всего 60 минут!
У автора была плата с обтекаемым названием ESP32 Dev Board, на которой установлен USB-UART конвертер CP2102 и модуль ESP-WROOM-3. Плату можно опознать по картинке ниже и по ключевику "ESP32" найти на известном китайском сайте.

Что еще нужно?
* собственно сами розетки. Так как мы хотим больше приключений, возьмем сразу две штуки, ведь тогда продукт получится более конкурентоспособный! Автор статьи использовал корпус удлинителя с двумя гнездами.
* модуль реле на 220 В — возьмем готовый, двухканальный, с гальванической развязкой. Нам важно, чтобы реле переключались логическими сигналами с уровнем 3.3В. Выглядит так:

* пара кнопок, мы ведь не только из Интернета хотим включать/выключать розетки, но и кнопками на них;
* любой AC-DC преобразователь 220В — 5В для питания ESP32 Dev Board, например, такой:

* провода, чтобы все это соединить.
> Впрочем, необходимый минимум из этого всего — только сама плата ESP32: можно просто подключить ее по USB, от которого и питать, и посмотреть по отладочному выводу или мультиметром на выводах, как она работает совместно с облаком. Правда, в этом случае такая "розетка" не будет выполнять свою основную функцию собственно розетки.
Для ESP32 понадобится прошивка. Вариантов для ее разработки немного:
* взять стандартный тулчейн от производителя. Установка несложная, но и не особо простая. Подчеркиваю также то неприятное обстоятельство, что IDE в этом случае в комплект средств разработки не входит, и собирать все нужно будет с командной строки.
* прослойка для Arduino. Это очевидно проще и быстрее, все ставится и настраивается из самой IDE Arduino. В качестве минуса — не вдаваясь в подробности, нет полноценной готовой библиотеки для работы именно с IoT Central, но мы это обстоятельство обойдем.
20 минут: подготовим облачный сервис
------------------------------------
Заходим [по ссылке](https://apps.azureiotcentral.com/). Понадобится учетная запись Microsoft, с которой следует залогиниться. Подписка Azure для пробной 7-дневной версии — не нужна, но лучше все-таки ее оформить, чтобы взять один из стандартных ценовых планов, где время использования не ограничено и есть два бесплатных устройства.
Выбираем слева **Мои приложения — Новое приложение**, далее **Пользовательские приложения** и заполняем поля:
* Имя приложения: любое удобное;
* URL-адрес: любой, но он должен быть уникальным;
* Шаблон приложения: пользовательское приложение;
* Ценовой план: стандартный 1 или бесплатный;
Если выбрали стандартный ценовой план, ниже создайте подписку Azure и выберите расположение, ближайшее к вам (для России — Европа).
Нажмите кнопку **Создать**
В меню выберите **Шаблоны устройств — Создать**, как показано на рисунке ниже.

Далее **Устройство IoT — Следующий: Настроить**. В поле **Имя шаблона устройства** введите **Socket**. Нажмите **Далее: проверка**, **Создать**.
В появившемся диалоге выберите **Импорт модели** и выберите файл **Socket.json**, прилагающийся к данной статье.
Видим следующую картину:
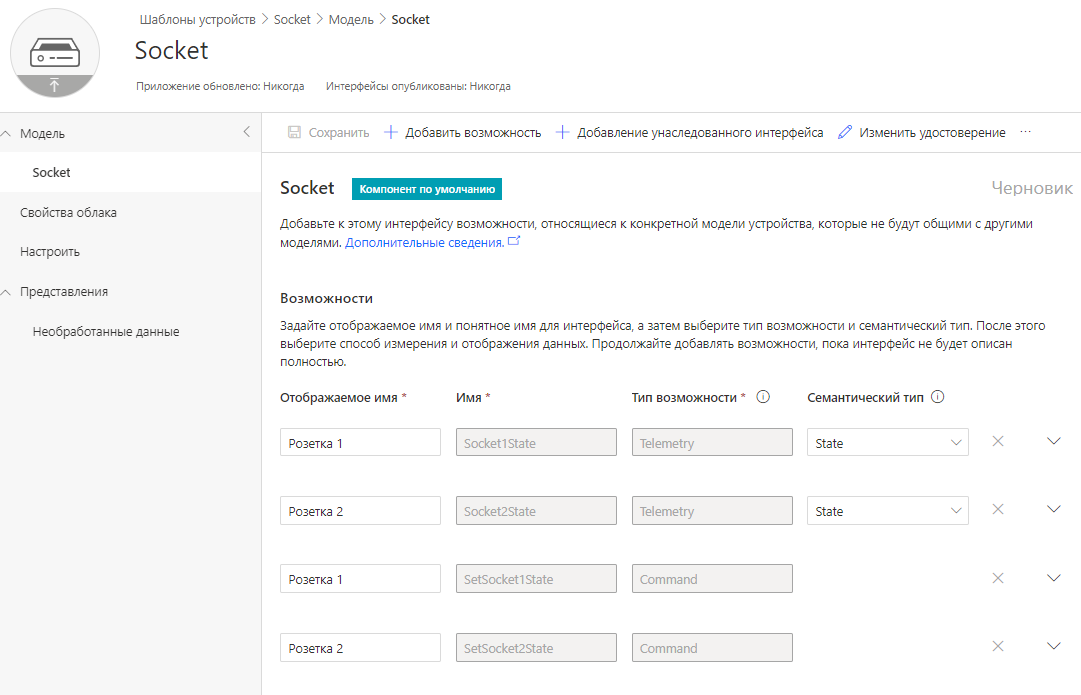
Что только что произошло? Фактически, мы объявили для IoT Central "язык" ("шаблон"), на котором говорит наша розетка при обмене данными с облаком, а именно, если развернем параметры каждой *возможности* (в оригинале — Capability), увидим следующее:
* каждая из двух розеток передает сообщение телеметрии, в котором закодировано состояние: 0 — выключено, 1 — включено;
* каждая из двух розеток принимает команду с параметром типа Boolean (true — включено, false — выключено).
Почему в телеметрии 0/1, а в команде true/false? Это связано с особенностями визуализации в IoT Central, короче говоря, телеметрию в виде 0/1 на картинках можно отобразить нагляднее, чем true/false.
Откуда взялся файл **Socket.json**? Автор подготовил его заранее, введя описание всех возможностей розетки в самом IoT Central, затем просто сохранил шаблон в файл, используя встроенную функцию экспорта.
Теперь по поводу визуализации. Нашему устройству неплохо бы сделать красивый дашборд, с которого мы будем посылать на него команды включения/выключения и видеть его состояния. Для этого нажмем в списке возможностей устройства пункт **Представления** и выберем плитку **Визуализация устройства**.
В разделе **Телеметрия** выберите **Socket1State**, нажмите **+ Телеметрия** и выберите **Socket2State**, затем нажмите **Добавить плитку**. На появившейся плитке нажмите иконку  и выберите **Диаграмма состояний** из меню. Нажмите **Сохранить**.
Теперь нам нужно "опубликовать" наш шаблон, т.е. перевести его из черновика в состояние, когда им можно будет пользоваться. Для этого нажмите соответствующую кнопку (**Опубликовать**). Подтвердите публикацию, нажав в появившемся окне кнопку **Опубликовать**.
Пока что мы только опубликовали шаблон устройства, теперь заведем запись для нашего конкретного устройства. Для этого переходим в главном меню в раздел **Устройства** и нажимаем кнопку **+ Создать**. В появившемся окне изменяем только **шаблон устройства** на **Socket**. Нажимаем кнопку **Создать** и кликаем по имени появившегося устройства. Нажмем кнопку **Подключить** в верхней части окна и в появившемся окне видим всю необходимую информацию, которую нам нужно будет использовать в прошивке устройства, чтобы оно могло "разговаривать" с IoT Central. В поле **Тип проверки подлинности** выберем **Подписанный URL-адрес (SAS)** (так проще). Итого нам понадобятся:
* **Область идентификатора** — это идентификатор нашего приложения IoT Central;
* **Идентификатор устройства** — не требует пояснений;
* **Первичный ключ** — считаем, что это "пароль" этого конкретного устройства.
С этими данными устройство должно обратиться к сервису регистрации устройств (Device Provisioning Service, DPS) для получения адреса IoT Hub, еще одного сервиса Azure. Зачем еще IoT Hub? Дело в том, что IoT Central работает "поверх" IoT Hub, являясь как бы "оберткой" для него. Вся последующая коммуникация будет происходить именно с этим IoT Hub.
Проблема в том, что простые в использовании библиотеки Arduino не включают готового клиента DPS. Ну раз так, то возьмем систему с [Windows 10](https://www.quarta-embedded.ru/we/10/), и получим этот адрес IoT Hub вручную. Утилита [dps-keygen](https://github.com/Azure/dps-keygen) умеет это делать, правда для ее запуска понадобится node.js.
Раз так, установим последнюю версию node.js с [официального сайта](https://nodejs.org/en/download/) с параметрами по умолчанию, затем запустим стандартную командную строку Windows и выполним команды (естественно, подставив нужные данные из нашего приложения IoT Central):
```
npm i -g dps-keygen
dps-keygen -si:область_идентификатора -di:идентификатор_устройства -dk:первичный_ключ_устройства
```
Порядок аргументов в последней строке не имеет значения.
Нас предупредят, что эта возможность "deprecated" и не "best practices", но нам очень надо, и не "best", а "fast", иначе не уложимся за 60 минут, которые обещал автор, поэтому продолжаем. На выходе будет строка подключения, которую мы позже укажем в прошивке розетки:

Отлично! Мы готовы к сборке стенда.
15 минут: достаем компоненты из ящика и собираем стенд
------------------------------------------------------
Сгребаем в охапку все провода, компоненты, и собираем их, как показано на схеме ниже. Можно как припаивать провода, так и соединять через разъемы — дело вкуса. В любом случае особое внимание уделяем высоковольтной части. Автор сделал разъемные соединения, где это было возможно, остальное — припаял.
Схема:

Результат немного угрожающий, но для стенда вполне работоспособный:

Такой вид в общем-то вполне нормален для всяких самоделок, но если под рукой (совершенно случайно!) есть 3D-принтер, можно сделать что-то более презентабельное:

Как и обещал, две кнопки, две розетки.
Между прочим, если задумаете поменять пины на Dev Board, рекомендую эту картинку для понимания, что на каких пинах есть:

Также из-за ошибки трассировки на плате автора был не подключен пинов GND около кнопки EN (RST), так что такие моменты тоже неплохо бы проверить (на вашей плате).
Ну и для справки, схема соединений **сигнальных** проводов в виде таблицы (для удобства сборки):
| Контакт | Контакт |
| --- | --- |
| ESP32 GPIO16 | Кнопка 1 |
| ESP32 GPIO17 | Кнопка 2 |
| ESP32 GPIO5 | Реле 1 |
| ESP32 GPIO18 | Реле 2 |
15 минут: подготовка инструментов и сборка прошивки
---------------------------------------------------
Будем собирать прошивку на Windows 10 (любой сборки, но авторы категорически рекомендуют [LTSC](https://www.quarta-embedded.ru/we/10/)).
1. [Загрузим и установим Arduino IDE](https://www.arduino.cc/en/software).
2. Загрузим и установим драйверы моста UART-USB, распаянного на плате. В случае автора это был [CP2102](https://www.silabs.com/developers/usb-to-uart-bridge-vcp-drivers) (на нем самом написано).
3. Запустим Arduino IDE и перейдем в меню **Файл — Настройки**. В поле **Дополнительные ссылки для Менеджера плат** вводим <https://dl.espressif.com/dl/package_esp32_index.json>. Это позволит установить поддержку ESP32 прямо из Arduino с сайта производителя чипа. Нажмем **OK** и закроем диалог.
4. Перейдем в меню **Инструменты — Плата — Менеджер плат**, в поиске введем **esp32**. В появившемся пункте нажимаем **Установить**.
5. Из прилагающегося архива распаковываем каталог **GetStarted** и открываем скетч **GetStarted.ino**.
6. Находим следующие строки и внутри кавычек соответственно прописываем SSID Wi-Fi сети и пароль:
```
const char* ssid = "";
const char* password = "";
```
7. Находим строку и внутри кавычек вставляем строку соединения, которую мы получили ранее при помощи утилиты **dps-keygen**.
```
static const char* connectionString = "";
```
8. Находим строку и внутри кавычек вставляем идентификатор нашего устройства:
```
#define DEVICE_ID ""
```
9. В настройках платы (**Инструменты — Плата**) устанавливаем параметры, как на рисунке ниже.

10. Поправим баг библиотеки SNTP, приводящий к перезагрузке ESP32 при пропадании соединения, для чего откроем файл C:\Users\имя\_пользователя\AppData\Local\Arduino15\packages\esp32\hardware\esp32\1.0.5\libraries\AzureIoT\src\az\_iot\c-utility\pal\lwip\sntp\_lwip.c и в самое начало функции SNTP\_Init() вставим код:
```
if (sntp_enabled()) sntp_stop();
```
> Версия библиотеки может отличаться. Замените 1.0.5 на ту, которая применяется в вашем случае.
>
>
11. Подключаем плату и выбираем появившийся последовательный порт в том же меню (номер порта можно уточнить в диспетчере устройств).
12. Нажимаем **Ctrl + U**, чтобы собрать и загрузить скетч в плату. Если все прошло успешно (как и должно быть), нажимаем кнопки на плате и видим, как переключаются реле.
13. Из меню **Инструменты** — **Монитор порта** можно посмотреть отладочный вывод платы.
> Если хотите больше двух розеток — без проблем! Внесите изменения в схему и добавьте номера пинов кнопки и сокета в массивы **BUTTON\_PIN** и **SWITCH\_PIN**.
5 минут: наслаждаемся собранным устройством
-------------------------------------------
Теперь вернемся в IoT Central, чтобы потестировать наше устройство.
1. На дашборде устройства есть закладка **Необработанные данные**, где можно увидеть сообщения телеметрии, отправляемые розеткой. Здесь же можно увидеть, что поля **deviceId** и **messaageId** не соответствуют модели. Так и есть — в шаблоне устройства их нигде нет, они добавлены только для отладочной телеметрии.
1. На закладке **Команды** можно включать и отключать каждую из двух розеток отдельно:
1. Также можно включать и отключать каждую розетку кнопкой на ней. В любом случае, все изменения отражаются на в телеметрии вкладке **Состояние** при любом переключении. Причем телеметрия отсылается не реже, чем раз в час, так что можно, например, в IoT Central создать правило, отслеживающее наличие подключения розетки: если за последний час не было ни одного сообщения, розетка потеряла связь. При срабатывании правила можно предпринять ряд действий, например, отправить e-mail и т.п.

Пример создания правила (высылает e-mail с предупреждением на заданный адрес, если не было ни одного сообщения телеметрии за последние 60 минут, другими словами, розетка "не в сети"):

Вместо заключения
-----------------
Это еще не все, и мы планируем продолжить эксперименты в подобном формате, а именно:
* Сделать поддержку DPS в прошивке;
* Добавить поддержку [IoT Plug and Play](https://www.quarta-embedded.ru/about/news/current/iot-plug-play/), тогда на стороне IoT Central не нужно будет регистрировать устройство, и оно все сделает само;
* Сделать голосовое управление розеткой ("Эй Кварта Технологии! Включи розетку 1!").
О нас
-----
Компания [Кварта Технологии](http://www.quarta-embedded.ru) была основана в 1997 году и сегодня является лидирующим поставщиком программного обеспечения и облачных сервисов для рынка встраиваемых систем и IoT в России, Украине, Грузии и странах СНГ.
Мы предоставляем услуги по лицензированию, разработке и обучению в области встраиваемых решений, помогая производителям из разных стран создавать передовые интеллектуальные системы и устройства в кратчайшие сроки.
С 2004 года компания является авторизованным дистрибутором и тренинг-партнером Microsoft Windows Embedded (IoT) на территории России и СНГ. Последние несколько лет входит в Топ-5 лучших дистрибуторов Microsoft по Embedded-продуктам в регионе EMEA (Европа, Ближний Восток, Африка) и обладает статусом «Windows Embedded Partner Gold Level».
*Автор статьи — Сергей Антонович, ведущий инженер Кварта Технологии. Связаться с ним можно по адресу sergant (at) quarta.ru.*
[Архив с файлами к статье](https://ln.sync.com/dl/bc5223720/xetu7he9-35cdubtb-3kbrx8qu-mnf7k75n) | https://habr.com/ru/post/547172/ | null | ru | null |
# Выпуск#8: ITренировка — актуальные вопросы и задачи от ведущих компаний
Продолжаем публиковать интересные задачи от ведуших IT-компаний.
В подборку попали задачи, задаваемые на собеседованиях (обычно на должность инженера-разработчика) в Yahoo! Предлагаем Вам попробовать свои силы и постараться решить задачи самостоятельно — тогда вопросы на собеседовании вряд ли застанут Вас врасплох.
#### Вопросы
1. **Total distance travelled by bee**
> Two trains are on same track and they are coming toward each other. The speed of first train is 50 KMs/h and the speed of second train is 70 KMs/h. A bee starts flying between the trains when the distance between two trains is 100 KMs. The bee first flies from first train to second train. Once it reaches the second train, it immediately flies back to the second train … and so on until trains collide. Calculate the total distance traveled by the bee. Speed of bee is 40 KMs/h.
**Перевод**Два поезда на одном пути едут навстречу друг другу. Скорость первого поезда — 50 км/ч, скорость второго — 70 км/ч. Пчела начинает летать между поездами, когда расстояние между ними равно 100 км. Пчела летит от первого поезда ко второму. Когда достигнет второго, немедленно летит обратно к первому… и продолжает так летать, пока поезда не столкнутся.
Посчитайте дистанцию, пройденную пчелой, если её скорость 40 км/ч.
2. **Poisoned wine**
> The King of a small country invites 240 senators to his annual party. As a tradition, each senator brings the King a bottle of wine. Soon after, the Queen discovers that one of the senators is trying to assassinate the King by giving him a bottle of poisoned wine. Unfortunately, they do not know which senator, nor which bottle of wine is poisoned, and the poison is completely indiscernible. However, the King has 5 prisoners he plans to execute. He decides to use them as taste testers to determine which bottle of wine contains the poison. After drinking the poisoned wine, one dies within 24 hours. The King needs to determine which bottle of wine is poisoned in 2 days so that the festivities can continue as planned. How can the King administer the wine to the prisoners to ensure that 48 hours from now he is guaranteed to have found the poisoned wine bottle?
>
>
**Перевод**Король небольшой страны пригласил 240 сенаторов на ежегодное празднование. По традиции, каждый сенатор преподносит королю бутылку вина. Однако, вскоре королева узнала, что один из сенаторов пытается отравить короля, подарив ему отравленную бутылку вина. К несчастью, они не знают, ни кто этот сенатор, ни что за бутыль отравлена, к тому же, яд невозможно обнаружить. В королевской тюрьме есть 5 заключенных, приговоренных к скорой смерти. Король решает с их помощью вычислить отравленную бутылку вина. Яд подействует только через 24 часа — выпивший его умирает. Королю необходимо выявить, какая бутылка отравлена, за 2 дня, чтобы продолжить запланированные мероприятия. Как он может распределить вино между заключенными, чтобы гарантированно найти отравленную бутылку за 48 часов?
#### Задачи
1. **Largest subarray with equal number of 0s and 1s**
> Given an array containing only 0s and 1s, find the largest subarray which contain equal number of 0s and 1s.
>
>
>
> Examples:
>
> Input: arr[] = {1, 0, 1, 1, 1, 0, 0}
>
> Output: 1 to 6 (Starting and Ending indexes of output subarray)
>
>
>
> Input: arr[] = {1, 1, 1, 1}
>
> Output: No such subarray
>
>
>
> Input: arr[] = {0, 0, 1, 1, 0}
>
> Output: 0 to 3 Or 1 to 4
>
>
**Перевод**Дан массив, содержащий нули и единицы. Необходимо найти наибольший подмассив, содержащий одинаковое количество 0 и 1.
Примеры:
Вход: arr[] = {1, 0, 1, 1, 1, 0, 0}
Выход: 1 to 6 (Индексы входного массива)
Вход: arr[] = {1, 1, 1, 1}
Выход: No such subarray
Вход: arr[] = {0, 0, 1, 1, 0}
Выход: 0 to 3 Or 1 to 4
2. **Count total set bits**
> Given a positive integer n, count the total number of set bits in binary representation of all numbers from 1 to n.
>
>
>
> Examples:
>
>
>
> Input: n = 3
>
> Output: 4
>
>
>
> Input: n = 6
>
> Output: 9
>
>
>
> Input: n = 7
>
> Output: 12
>
>
>
> Input: n = 8
>
> Output: 13
>
>
**Перевод**Дано положительное целое число n, необходимо вычислить сумму битов всех чисел от 1 до n в двоичном представлении.
Примеры:
Вход: n=3
Выход: 4
Вход: n=6
Выход: 9
Вход: n=7
Выход: 12
Вход: n=8
Выход: 13
3. **Find the repeating and the missing**
> Given an unsorted n-sized array of integers. Array elements are in range from 1 to n. One number from set {1, 2, …n} is missing and one number occurs twice in array. Find these two numbers.
>
>
>
> Examples:
>
>
>
> arr[] = {3, 1, 3}
>
> Output: 2, 3 // 2 is missing and 3 occurs twice
>
>
>
> arr[] = {4, 3, 6, 2, 1, 1}
>
> Output: 1, 5 // 5 is missing and 1 occurs twice
>
>
>
>
**Перевод**Дан неотсортированный массив целых чисел размерностью n. Элементы массива — последовательность чисел от 1 до n. Одно число в последовательности пропущено и одно — повторяется. Необходимо найти эти числа.
Примеры:
arr[] = {3, 1, 3}
Output: 2, 3 // 2 пропущено, 3 повторяется
arr[] = {4, 3, 6, 2, 1, 1}
Output: 1, 5 // 5 пропущено, 1 повторяется
Ответы будут даны в течение следующей недели — успейте решить. Удачи!
#### Решения
1. **Вопрос 1**Верный ответ был [найден](https://habrahabr.ru/company/spice/blog/347636/#comment_10638322) — 33, 3 км.
2. **Вопрос 2**Решение состоит в том, чтобы пронумеровать бутылки числом в троичной системе, где каждый разряд соответствует действию каждого заключенного по отношению к бутылке:
0 — не пил,
1 — выпил в первый день
2 — выпил во второй день.
Так, например бутыль с кодом 11201 будет означать, что 1,2 и 5 заключенные выпили в первый день, третий заключенный выпил во второй день, а четвертый не пил — соответственно, если 1,2 и 5 умерли в первый день, а третий во — второй день, то эта бутыль отравлена.
Всего уникальных комбинаций 3^5 = 243, т.е. по состоянию заключенный к истечению 48 часов можно будет однозначно определить какая бутыль отравлена.
Решение тоже было предложено в комментариях.
3. **Задача 1**Решение предполагает последовательное суммирование значений, причём, 0 рассматриваются как "-1". Один из вариантов был предложен [тут](https://habrahabr.ru/company/spice/blog/347636/#comment_10638574)
4. **Задача 2**Вариант верного решения был предложени в [комментарии](https://habrahabr.ru/company/spice/blog/347636/#comment_10638514)
5. **Задача 3**Один из вариантов решения — пройтись по массиву, используя абсолютное значение элемента как индекс и меняя знак у элемента под этим индексом. Тогда индекс элемента, который уже был помечен отрицательным — является повторяющимся значением.
За второй проход нужно найти положительное значение:
```
#include
#include
void printTwoElements(int arr[], int size)
{
int i;
printf("\n The repeating element is");
for(i = 0; i < size; i++)
{
if(arr[abs(arr[i])-1] > 0)
arr[abs(arr[i])-1] = -arr[abs(arr[i])-1];
else
printf(" %d ", abs(arr[i]));
}
printf("\nand the missing element is ");
for(i=0; i0)
printf("%d",i+1);
}
}
/\* Driver program to test above function \*/
int main()
{
int arr[] = {7, 3, 4, 5, 5, 6, 2};
int n = sizeof(arr)/sizeof(arr[0]);
printTwoElements(arr, n);
return 0;
}
```
Сложность алгоритма — О(n). | https://habr.com/ru/post/347636/ | null | ru | null |
# Unity3d. Уроки от Unity 3D Student (B09-B12)
Добрый день.
Предыдущие уроки вы можете найти по следующим ссылкам:
[Уроки B01-B03](http://habrahabr.ru/post/141362/)
[Уроки B04-B08](http://habrahabr.ru/post/142845/)
#### Базовый Урок 09 — Добавление материалов
---
*В уроке рассказывается, как добавлять текстуру к объекту используя материал.*
Когда вы работает с игровыми объектами в Unity3d, вам потребуется также использовать материалы. Например, мы хотим добавим материал с текстурой к кубу.
[Загрузить текстуру (\*.png, 256px x 256px, 98.4KB).](http://habrastorage.org/storage2/4ff/57d/254/4ff57d2540479c6f456b55b6394a1964.png)
Для начала сохраним нашу текстуру в папку **Assets** (в корневой папке проекта).
Добавим директорию **Materials** (мы помним, что всегда удобно поддерживать «иерархический порядок» в проекте) и назовем наш файл **bulb texture** (расширение \*.png (в оригинальном уроке \*.psd), см. примечание).

Переключимся назад в Unity3d, убедимся что в **Project View** появилась папка **Materials** c нашей текстурой.
Создадим куб. Добавить нашу текстуру к кубу, можно просто перетащив ее из **Project View** на куб (материал создастся автоматический). Но, возможно, вы захотите настроить его заранее, тогда выбираем **Create->Material.**

Назовем его **bulb** и положим в папку **Materials.**
Выберем **buld** и перенесем нашу текстуру из **Project View** на пустой серый квадрат в **Inspector View** (с надписью **none(Texture 2D)**), либо нажав на **Select** все в том же квадрате и выбрав ее из появившегося списка.

Взамен серого квадрата появится иконка с текстурой.
Перетяним наш материал на куб. Куб сразу станет текстурированным.
При выборе материала в **Inspector View** вы так же можете выбрать [шейдер](http://ru.wikipedia.org/wiki/%D0%A8%D0%B5%D0%B9%D0%B4%D0%B5%D1%80), по которому будет расчитываться его конечный вид
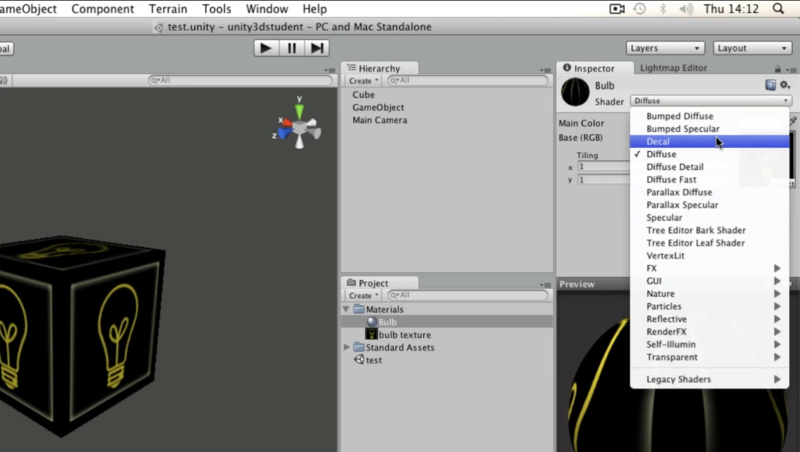
PS: О шейдерах мы обязательно поговорим отдельно, но много позже.
Так же у материала можно настраивать **tiling (мозаичное размещение текстуры)**. Чем больше значения tiling по x-ой или y-ой координате, тем больше раз она повторяется по соответствующей стороне. Чтобы понять как это работает — поставте значения по x и y равным 10 (при изменении значения текстура на кубе будет обновляться в реалтайме).
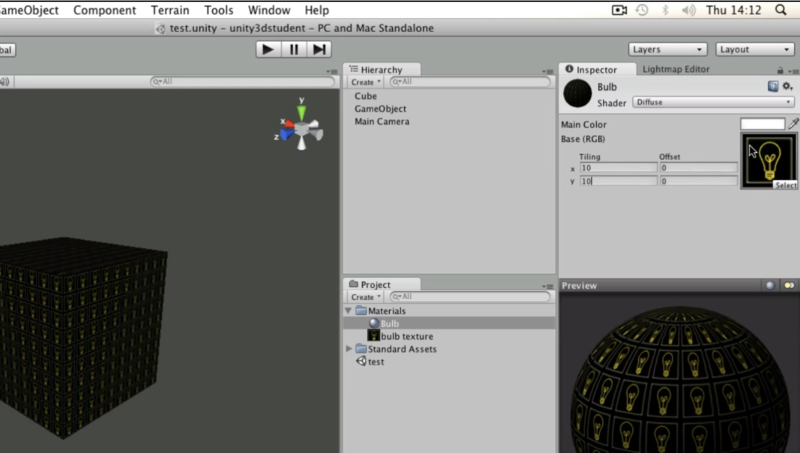
Параметр **offset (смещение)** отвечает за сдвиг текстуры «по кругу». Чтобы лучше понять как он работает, поэкспериментируйте c ним.
**Дополнительные материалы**[Информация о материалах из официального справочника о компонентах Unity3d](http://docs.unity3d.com/Documentation/ScriptReference/Material.html)
[Информация о классе Material из официального справочника о скриптах Unity3d](http://unity3d.com/support/documentation/Components/class-Material.html)
**Примечание**Помимо **PSD,** **Unity3d** так же поддерживает импорт следующих форматов:
**TIFF, JPG, TGA, PNG, GIF, BMP, IFF, PICT.**
Как и при всяком наложении текстур, наиболее эффективным (для производительности) будет, если стороны текстуры являются степенью двойки (128, 256, 512, и т.д.). Но при этом не обязательно чтоб текстура была двадратной (к примеру, 256x512 допустимый размер текстуры).
#### Базовый Урок 10 — Основы работы с аудио
---
*В уроке рассказывается, как проигрывать компонент Audio Source (аудио ресурс) и вызывать звуковые клипы с помощью скриптинга.*
Для работы со звуком в Unity3d вам потребуются два компонента:
* **AudioListener (аудио приемник)**
* **AudioSource (аудио ресурс)**
Обычно **AudioListener** является компонентом у камеры. Выберем камеру и убедимся в этом, посмотрев в **Inspector View.**
Для того чтобы слушать звуки вы должны иметь хотя бы один **AudioListener** в каждой сцене.
Добавим пустой **GameObject** и добавим к нему компонент **Audio Source.**
Добавить аудио-клип можно либо через **Inspector View,** либо с помощью скрипта.
В нашем проекте есть два аудио-файла — моно и стерео.

Моно обычно используется для звуковых эффектов. Только для него можно использовать затухание или другие 3d-эффекты.
Стерео, соответственно, для музыки, т.к. стереозвук прогирывается как есть.
В окне **Preview** можно проиграть выбранный файл.

Добавим наш клип (**GreenadeLaunch**) в поле **Audio Clip.** Если включен параметр **Play On Awake,** то звук будет проигрываться сразу после запуска сцены.
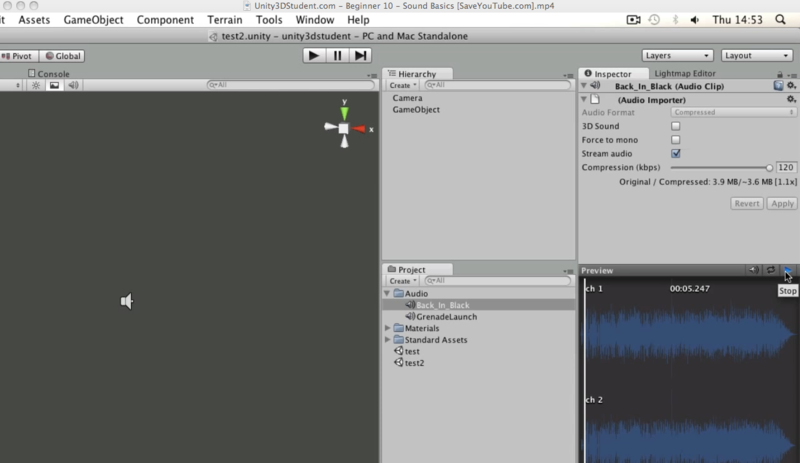
Если же мы хотим, чтоб аудио-клип прозвучал в нужный нам момент, нужно написать скрипт. Оставим поле **Audio Clip** у **Audio Source** пустым и добавим c#-скрипт, назвав его **PlaySounds.** Добавим в скрипт следующий код:
```
// открытая переменная для аудиоклипа
public AudioClip myClip;
void Start () {
// проигрываем наш аудиоклип
audio.PlayOneShot(myClip);
}
```
Добавим скрипт к пустому **GameObject,** а значение переменной **myClip** у скрипта проиницилизируем звуковым файлом (**GreenadeLaunch**). Теперь нажав на **play** вы снова усшылите звук.
Проигрывать аудио можно и без использования **Audio Source**. Удалим компонент **Audio Source** c нашего **GameObject,** а код в теле метода **Start()** заменим следующим:
```
AudioSource.PlayClipAtPoint(myClip, transform.position);
```
Тут, **PlayClipAtPoint** — статическая функция класса **AudioSource,** которая создает новый **GameObject,** с соответствующим **Audio Source** (в нашем случае это **myClip**) и после проигрывания аудио-клипа удаляет данный **GameObject.**
Сохраните скрипт и убедитесь что он есть у нашего **GameObject,** а значение **myClip** равно **GreenadeLaunch.**
Жмем **Play** и сразу после загрузки сцены жмем на **Pause** чтобы убедиться что на сцене появился новый игровой объект с именем **One Shot Audio.**
**Дополнительные материалы**[Информация о классе AudioClip из официального справочника о скриптах Unity3d](http://unity3d.com/support/documentation/ScriptReference/AudioClip.html)
[Информация о компоненте Audio Source из официального справочника о компонентах> Unity3d](http://unity3d.com/support/documentation/Components/class-AudioSource.html)
#### Базовый Урок 11 — Основы соединений
---
*В уроке рассказывается, как использовать Fixed joint (неподвижное соединение) и Hinge joint (шарнирное соединение) для создания цепи у «шара для разрушения зданий»*
Для создания интересной физики в Unity3d воспользуемся **«соединениями» (joints).** И для илюстрации этого создадим модель шара для разрушения зданий.
Исходная сцена содержит плоскрость **(Floor)**, камеру **(Main Camera)** и точечный источник света **(Point light).**
Для начала создадим cферу, добавим к ней компонент **Rigidbody** и назовем ее **Ball**.
Добавим на сцену цилиндр, так же добавив к нему **Rigidbody**. Размер и положения цилиндра и сферы указанны на рисунке ниже. Для цилиндра **scale** равно 0.15, 0.25 и 0.15, для x, y и z соответственно, цилиндр свинут «вверх» к «краю» шара (грани при этом пересекаются).

Чтобы связать сферу и цилиндр — выбирете сферу **(Ball)** и добавьте к ней компонент **Fixed Joint.** Переменную **Connected Body** проинициализируем значением **Cylinder.rigidbody.** Напомню, что для этого достаточно перетащить **Cylinder** из **Hierarchy view** в **Inspector View,** на поле напротив **Connected Body**.
Переименуем Cylinder на более подходящее названия для крепежа шара, например, **Ballstem**. Значение переменной **Connected Body** поменяется автоматический.
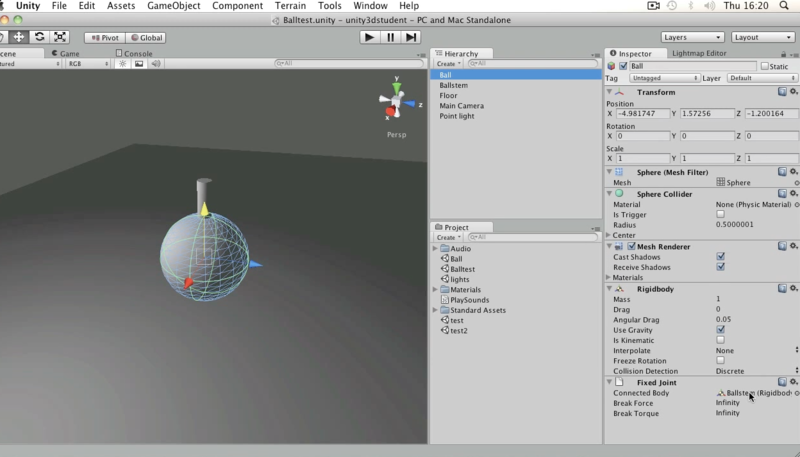
Нажмите **play** и увидите как шар падает вместе с прикрепленным к нему цилиндром.
Теперь начнем создавать подвижные участки цепи.
Создадим капсулу (назовем ее **Chain1**), при этом размеры ее будут аналогичны размерам **Ballstem'а,** а находится она будет чуть выше него, чтоб крайние грани объектов пересекались. **Chain1** так же будет с компонентом **rigidbody.**
А к **Ballstem'у** добавим компонент **Hinge Joint**, у которого
**Connected Body** мы инициализируем **Chain1.rigidbody**.
Место закрепление обозначенно ораньжевой стрелкой.
Нам потребуется еще один участок цепи. Выберем **Chain1** и сделаем его дубликат (**ctrl+D** или **cmd + D**). Переименуем его в **Chain2,** так же сдвинув его к верхушке **Chain1**. К **Сhain1** добавим **Hinge Joint**, с
**Connected Body** равным **Chain2.rigidbody.**
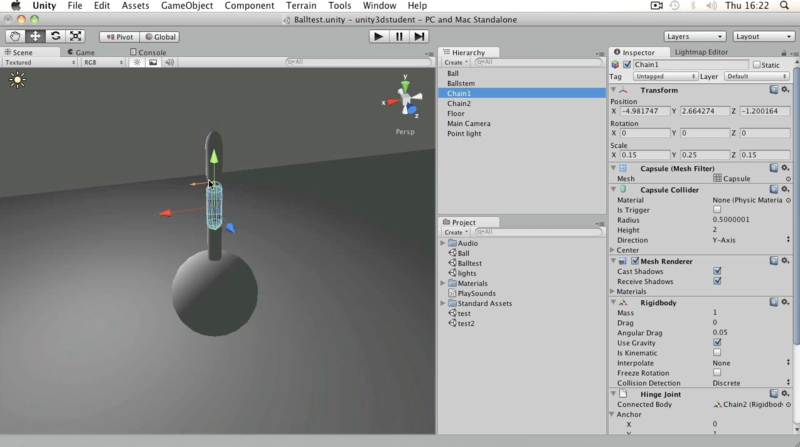
Аналогично добавим **Chain3.**
В конце, мы добавим **HingeJoint** к **Chain3**, при этом мы не будем задавать значение **Connected Body.** В этом случае объект будет прикрепленн «сам к себе» (точнее сказать к пустому месту в сцене).

Выделем **Ball, Ballstem, Chain1, Chain2, Chain3** и наклоним их.
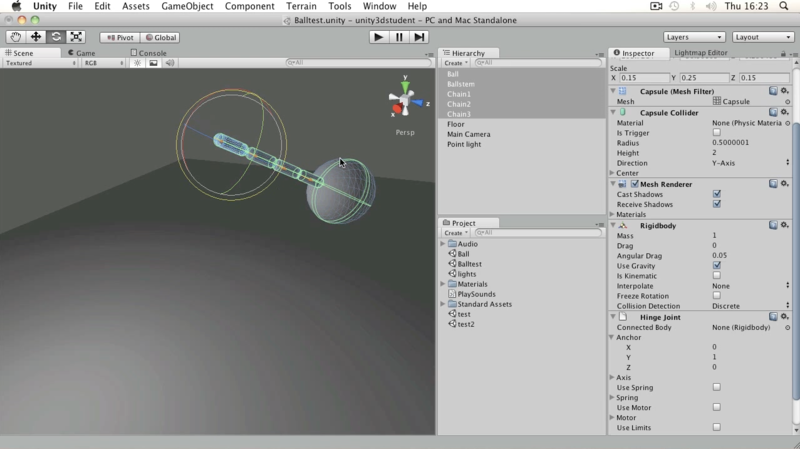
Жмем **play** и смотрим как перемещаются наш шар с цепью.
**Дополнительные материалы**[Информация о компоненте Hinge Joints из официального справочника о компонентах Unity3d](http://unity3d.com/support/documentation/Components/class-HingeJoint.html)
[Информация о компоненте Fixed Joints из официального справочника о компонентах Unity3d](http://docs.unity3d.com/Documentation/Components/class-FixedJoint.html)
[Информация о классе Joint из официального справочника о скриптах Unity3d](http://unity3d.com/support/documentation/ScriptReference/Joint.html)
#### Базовый Урок 12 — Ввод с использованием виртуальных осей
---
*В уроке рассказывается, как использовать стрелки (arrow keys), для перемещения влево и вправо, с помощью «осей» (axes)*
На это раз на сцене у нас есть плоскость **(floor)**, камера **(Main Camera)**, источник света **(Point light)** и пустой **gameObject.**
Еще один вариант ввода — использование **«осей» (Axes).**
Откроем **Input Manager (Edit->Project settings->Input)**. Разверните **Axis** и затем **Horizontal.**
Посмотрим на некоторые дефолтные параметры:
| | | |
| --- | --- | --- |
| Параметр | Значение | Комментарий |
| Negative Button | left | Клавиша для перемещения в отрицательном направлении |
| Positive Button | right | Клавиша для перемещения в положительном направлении |
| Alt Negative Button | a | Альтернативная клавиша для перемещения в отрицательном направлении |
| Alt Possitive Button | d | Альтернативная клавиша для перемещения в положительном направлении |
| Type | Key or Mouse Button | Тип ввода, для перемещения вдоль данной оси (в нашем случае X) |
| Axis | X axis | Ось объекта, вдоль которой мы будем перемещаться |
Для того, чтобы использовать данное перемещение **(Horizontal),** нам потребуется метод **GetAxis()** класса **Input.**
**Небольшой комментарий**Дальше, чтоб каждый раз не указывать на то, что метод статический, вводятся следующие соглашения:
1. если написано «метод класса», то предполагается что он **static.**
2. если написано «метод объекта», тогда метод принадлежит конкретному объекту.
Добавим C#-скрипт, назовем его **GetAxis.cs** и напишем:
```
private float horiz;
void Update () {
horiz = Input.GetAxis("Horizontal");
Debug.Log(horiz);
}
```
Добавим скрипт к пустому **gameObject'у,** и нажмем **play.** Если зажать стрелку влево/вправо (или же a/d), в **status bar'е** вы увидите как меняется значение переменной **horiz**:

Значение этой переменной может меняться от -1 до 1 (в зависимости от зажатой клавиши). Как только вы отпустите клавишу, **horiz** станет снова равен 0.
Добавим еще строчку кода в **Update(),** сразу за **Debug.Log():**
```
transform.Translate(new Vector3(horiz, 0.0f, 0.0f));
```
Запустим сцену и нажмем на стрелку — вы увидите, как наш **gameObject** начнет перемещаться вдоль оси X.
**Дополнительные материалы**[Информация о классе Input из официального справочника о скриптах Unity3d](http://unity3d.com/support/documentation/ScriptReference/Input.html)
[Информация о вводе с различных устройст из официального мануала Unity3d](http://unity3d.com/support/documentation/Manual/Android-Input.html) | https://habr.com/ru/post/145565/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.