
text
stringlengths 20
1.01M
| url
stringlengths 14
1.25k
| dump
stringlengths 9
15
⌀ | lang
stringclasses 4
values | source
stringclasses 4
values |
|---|---|---|---|---|
# «Распределение в запросе» или «избавляемся от перебора»
**Хороший перебор — это отсутствие перебора. Рассмотрим пример замены полного перебора запросом.**
В свое время, года 3 назад, возникла необходимость оптимизации конфигурации 1С и устранения ее узких мест в одной компании. Одним из таких узких мест оказался, казалось бы, безобидный, механизм распределения товаров в реализации по сериям. Суть в том, что строк распределялось достаточно много и было это очень медленно. Не миллионы за раз, конечно, но на это самое распределение для одного документа могло уходить до минуты.
Запрос специально привожу на T-SQL, т.к. думаю, что Хабравцам это будет ближе.
В общем от этого дела становилось всем очень грустно, т.к. параллельно бухгалтера препроводили документы, другие операторы тоже формировали документы отгрузки и когда отгружали «большого» клиента – жизнь на некоторое время замирала.
К слову сказать, размер базы 1С за 2-3 года на тот момент составлял ~500 Гб, заказов от одного клиента за день могло прийти десяток-другой, а в некоторых из них строк могло быть более 1000, в общем «Реализация товаров и услуг» на 1000 строк — это не было ничем сверхъестественным. Реиндексация, обновление статистики, шринк и другие необходимые процедуры проводились регулярно, но сейчас речь не об этом. Вернемся к нашему объекту оптимизации. На тот момент механизм распределения был до банального прост:
1. Запросом получали остатки по сериям (Номенклатура – Серия – Количество).
2. Другим запросом получали таблицу товаров к отгрузке (Номенклатура – Заказ покупателя – Количество).
3. Проходил обыкновенный перебор для каждой номенклатуры по принципу «**Пока** **КоличествоКРаспределению** > 0 **Цикл** ……… ».
Т.к. я всегда придерживался позиции, что сам факт перебора на больших объемах данных – это уже само по себе узкое место, то возможность «улучшения» алгоритма перебора я даже рассматривать не планировал. Нужна была альтернатива. Также на тот момент я уже давно набил руку в оптимизации сложных запросов и укрепился в выводе, что нет ни одной задачи, которую нельзя было бы решить исключительно запросом и точно знал, что качественный запрос (пакет запросов) в 99% случаев окажется самым эффективным решением, чем какая-либо пост-обработка результатов запроса. Вопрос оставался только в нахождении этого решения).
Выходил я на перекур с достаточно тривиальным условием задачи (распределить количество по измерениям одной таблицы на количество по измерениям из другой) и 2-мя тезисами:
* Мы имеем 2 таблицы, которые и так собираются запросом.
* SQL не знает никакого «Распределить». SQL знает только «больше», «меньше», «равно» (утрированно). Надо дать ему некий параметр для сравнения. Числовой параметр, по которому будет понятно какое количество **еще** можно распределить в условную строку.
И в этот самый момент, когда я мысленно проговаривал второй тезис, слово «**еще**» и натолкнуло меня на решение. Далее, рисуя палочкой на снегу, я не успел докурить, как уже побежал пробовать свою гипотезу в консоли запросов.
Рассмотрим ниже простой пример:
У нас есть складские ячейки с количеством вмещаемого в них товара с одной стороны (A, B, C, D) и сам товар (X, Y, Z), который необходимо «как-то» разложить по этим ячейкам, но так, чтоб в ячейку не положили больше товара, чем может быть в ней места.
> A – 10 мест
>
> B – 1 место
>
> C – 5 мест
>
> D – 8 мест
>
>
>
> X – 13 шт
>
> Y – 1 шт
>
> Z – 4 шт
Результатом должна стать таблица распределения:
> A-X-10
>
> B-X-1
>
> C-X-2
>
> C-Y-1
>
> C-Z-2
>
> D-Z-2
Для этого нам надо определить порядок распределения, сделать это оказалось до банального просто:
```
select
t1.Cell,
t1.Qty,
ISNULL(sum(t2.Qty),0)+1 as OrderBottom,
ISNULL(sum(t2.Qty),0)+t1.Qty as OrderTop
into OrderedCells
from Cells as t1
left join Cells as t2
on t1.Cell > t2.Cell
Group by
t1.Cell,
t1.Qty
```
Кстати, здесь же можно учесть и порядок распределения, если, например, в какие-то ячейки товар надо класть в первую очередь. Решается изменением условия в соединении.
Тоже самое и с товарами:
```
select
t1.Goods,
t1.Qty,
ISNULL(sum(t2.Qty),0)+1 as OrderBottom,
ISNULL(sum(t2.Qty),0)+t1.Qty as OrderTop
into OrderedGoods
from Goods as t1
left join Goods as t2
on t1.Goods > t2.Goods
Group by
t1.Goods,
t1.Qty
```
Для простоты понимания разложу все эти позиции поштучно в таблице и наложу одну на другую в порядке распределения:

Нам просто нужно написать граничные условия. А теперь осталось просто соединить эти таблицы и получим наш результат:
```
select
OrderedCells.Cell,
OrderedGoods.Goods,
case when OrderedGoods.OrderTop < OrderedCells.OrderTop
then OrderedGoods.OrderTop
else OrderedCells.OrderTop
end - case when OrderedGoods.OrderBottom > OrderedCells.OrderBottom
then OrderedGoods.OrderBottom
else OrderedCells.OrderBottom
end + 1 as Qty
from
OrderedCells
inner join OrderedGoods
on OrderedCells.OrderBottom <= OrderedGoods.OrderTop
and OrderedCells.OrderTop >= OrderedGoods.OrderBottom
```
Сразу оговорюсь, что в запросе умышленно добавлено большее количество полей, чем надо. Можно было бы обойтись и одной границей распределения (нарастающим итогом) и не делать «+1», но как мне показалось – в таком виде это более наглядно для понимания. Оптимизацию запросов мы в этой теме не рассматриваем, поэтому и индексы здесь тоже не описаны. Ну а более сложные алгоритмы распределения (по нескольким измерениям, например) решаются только изменением условий соединения и проверки границ.
Вот и все. В итоге вместо минут ожидания на тех же объемах данных этот запрос выполнялся считанные миллисекунды.
Прошу простить за обилие лирики в этой статье. Хотелось дать не математическое решение узкой задачи, а поделиться концептуальным подходом к решению подобных задач, именно ходом своих мыслей. | https://habr.com/ru/post/318240/ | null | ru | null |
# 12 возможностей ES10 в 12 простых примерах
*Перед вами перевод статьи из блога [Carlos Caballero](https://medium.com/better-programming/twelve-es10-features-in-twelve-simple-examples-6e8cc109f3d3) на сайте Medium.com. Автор расскажет нам о функциях, которые появились в версии ES10 2019 года.*

[ES10](https://www.ecma-international.org/ecma-262/10.0/index.html#Title) — это версия [ECMAScript](https://www.ecma-international.org/publications/standards/Ecma-262.htm), актуальная для 2019 года. Она содержит не так много нововведений, как версия [ES6](http://es6-features.org/#Constants), выпущенная в 2015 году, однако в нее включили несколько полезных функций.
В этой статье функции, представленные в ES10, описываются в виде примеров простого кода. Вы сможете быстро их понять без подробного разъяснения. Конечно же, для этого понадобятся базовые знания JavaScript.
Новыми функциями JavaScript в ES2019 являются:
* `Array#{flat,flatMap}`
* `Object.fromEntries`
* `String#{trimStart,trimEnd}`
* `Symbol#description`
* необязательная привязка `try { } catch {} //`
* JSON ⊂ ECMAScript
* хорошо сформированный `JSON.stringify`
* устойчивый `Array#sort`
* обновленная Function#toString
* `BigInt` — простой тип (3 стадия)
* динамический импорт (3 стадия)
* стандартизированный объект `global This` (3 стадия).
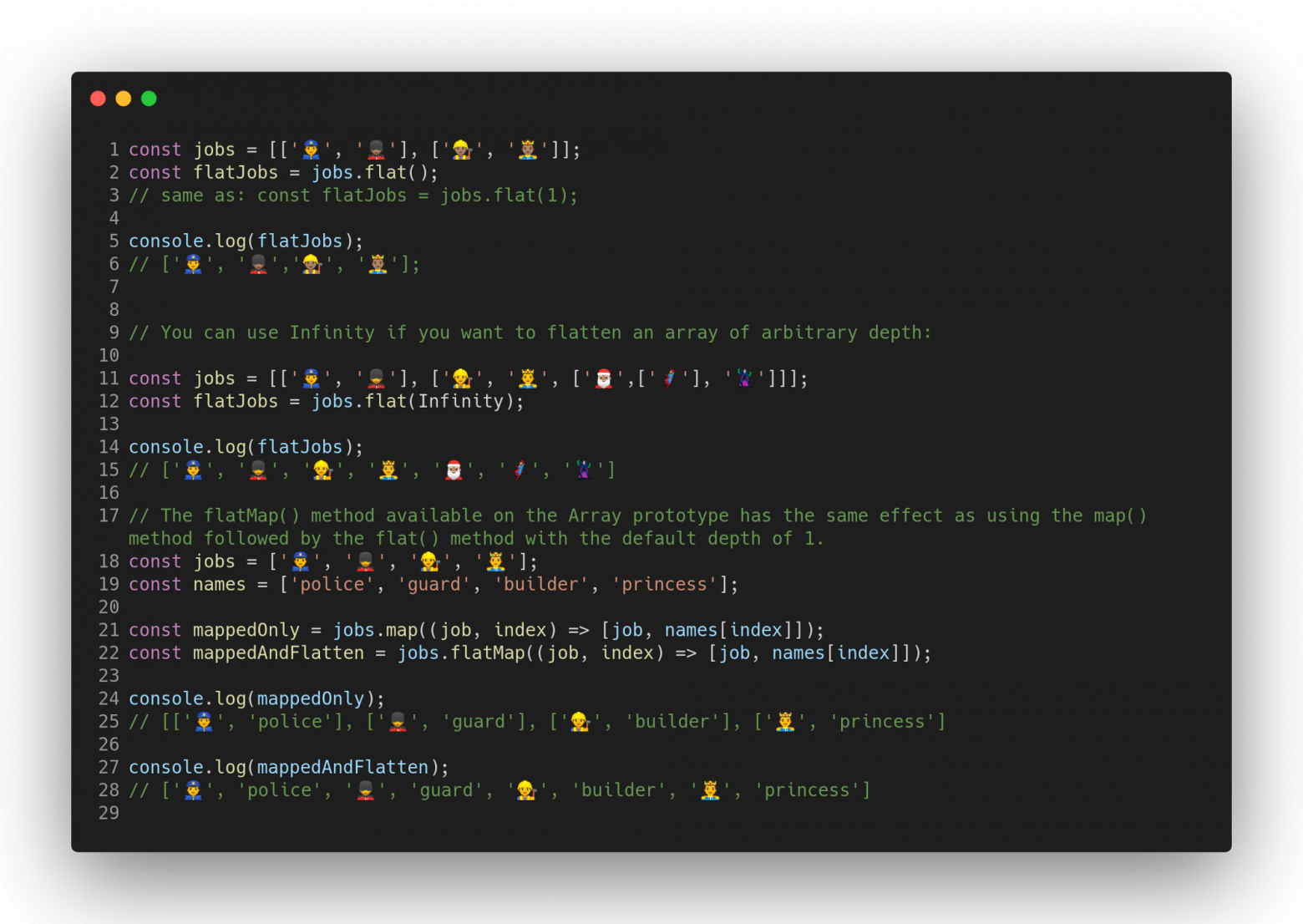
### Array.flat() и Array.flatMap()
Существует два новых метода `Array`:
* Метод `Array.flat()` возвращает новый массив, в котором все элементы вложенных подмассивов были рекурсивно подняты на указанный уровень depth.
* Метод `Array.flatMap()` сначала применяет функцию к каждому элементу, а затем преобразует полученный результат в плоскую структуру и помещает в новый массив. Это идентично функции `map()` с последующим применением функции `flat()` с параметром depth, равным 1, но `flatMap()` чаще более эффективен, поскольку совмещает в себе оба подхода в одном методе.
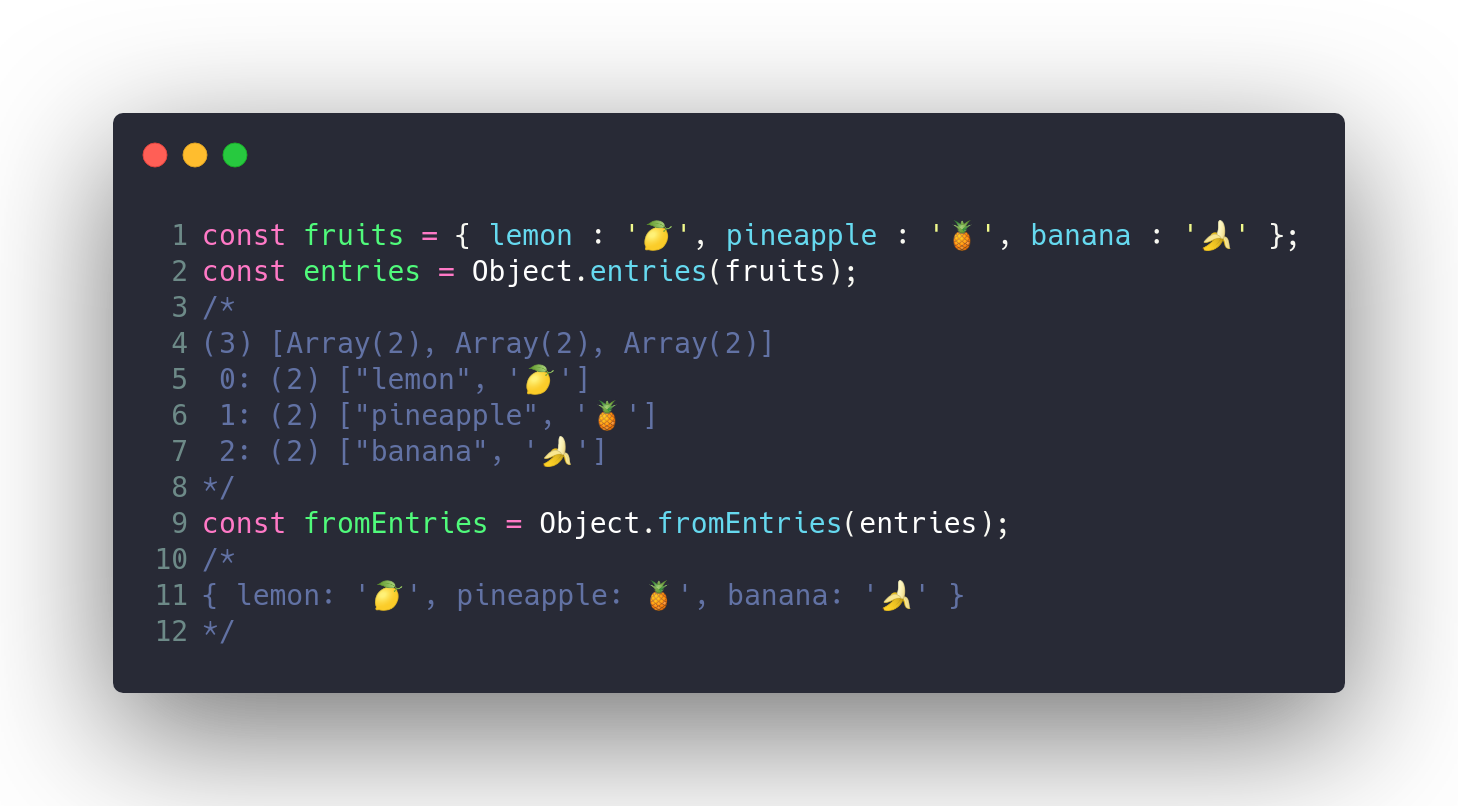
### Object.fromEntries()
Преобразует список кода и пары значений в объект.
### String.prototype.matchAll
При сопоставлении строки с регулярным выражением метод `matchAll()` возвращает итератор по всем результатам, включая группы захвата.

### String.trimStart() and String.trimEnd()
Появилось два новых метода `String` для удаления пробелов из строки:
* Метод `trimStart()` удаляет пробел в начале строки.
* Метод `trimEnd()` удаляет пробел в конце строки.

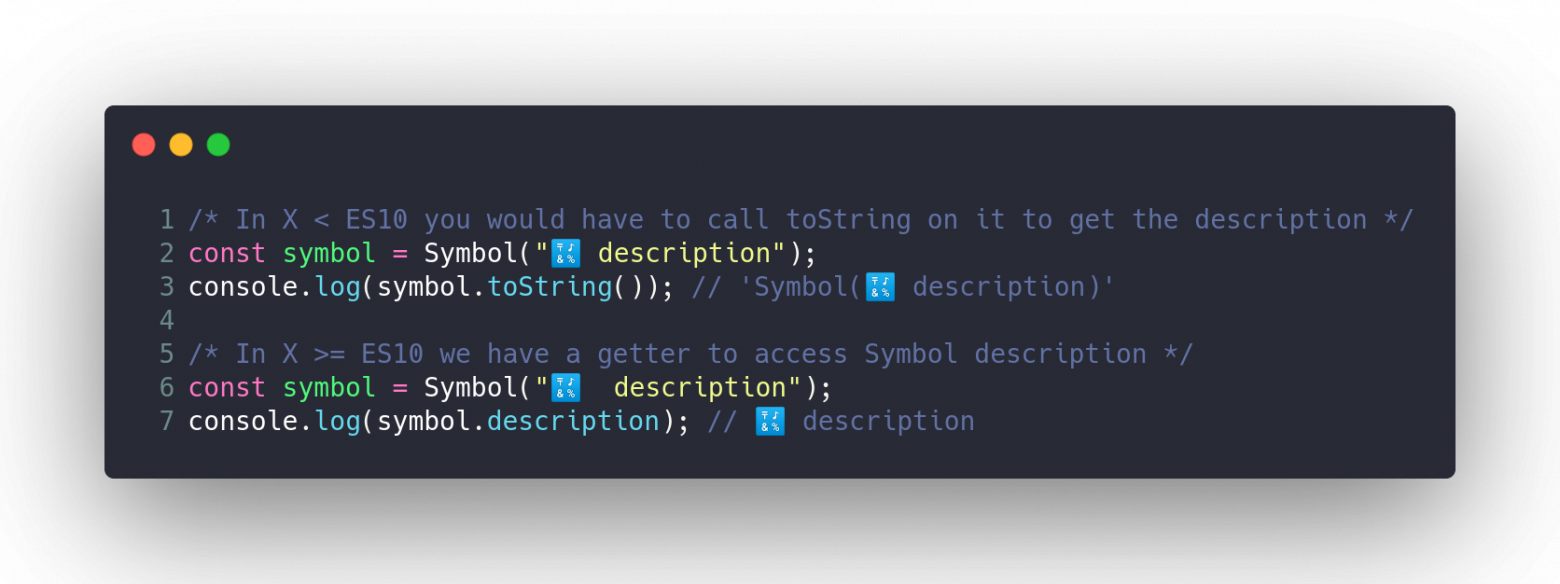
### Symbol.Description
Добавлен новый вариант получения описания `Symbol`. Теперь, создавая `Symbol`, вы можете добавить строку в качестве описания — в ES10 есть доступ к этому показателю.
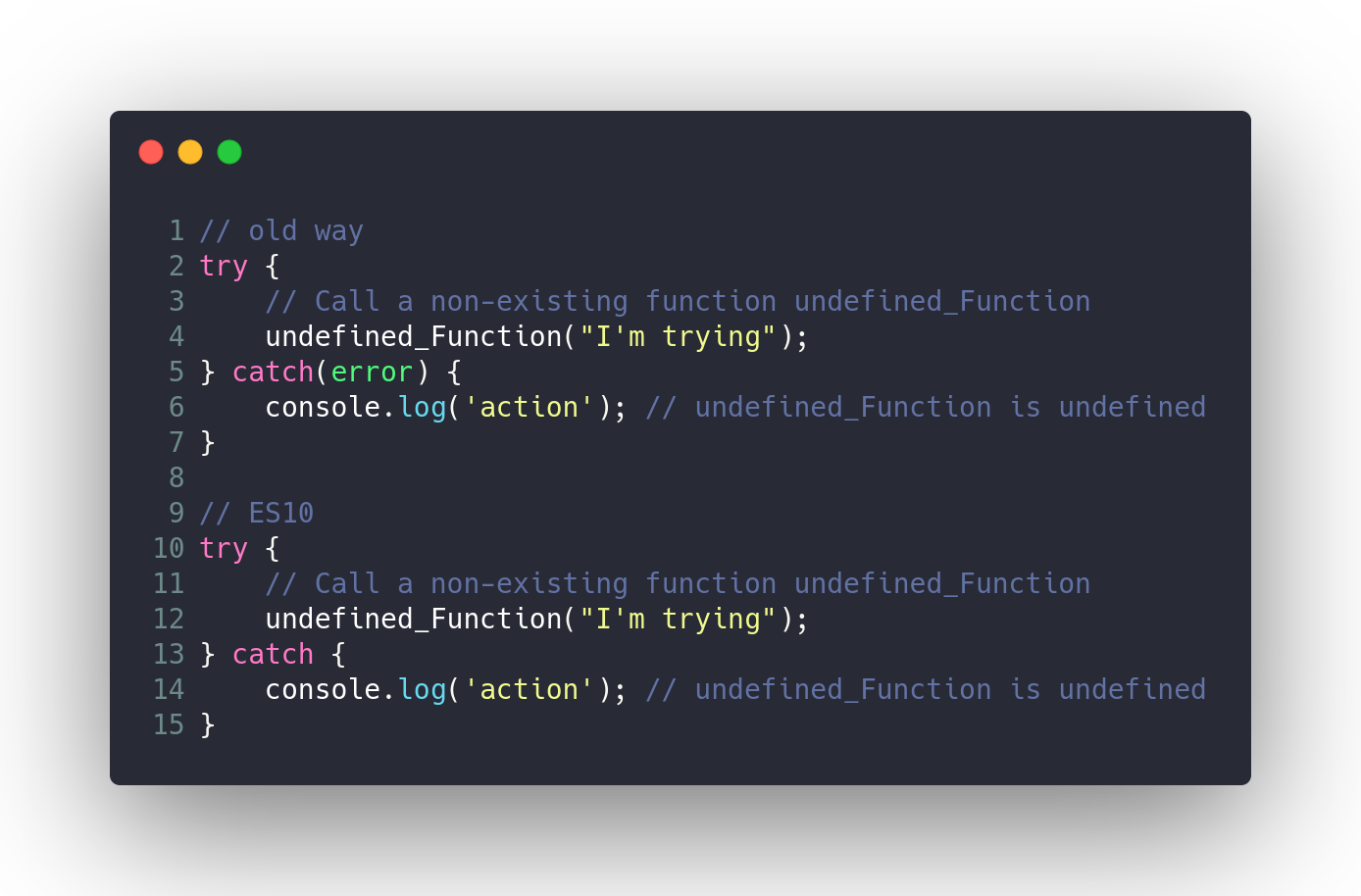
### Необязательная привязка `try/catch`
Раньше выражение `catch` из конструкции `try/catch` нуждалось в переменной. Сегодня разработчики могут использовать `try/catch` без создания ненужной привязки.
### JSON ⊂ ECMAScript
Символы неэкранированного разделителя строк `U+2028` и разделителя абзацев `U+2029` не были представлены в предыдущих версиях ECMAScript.
* U+2028 — разделитель абзацев.
* U+2029 — разделитель строк.

### Хорошо сформированный JSON.stringify()
`JSON.stringify()` может возвращать символы между `U+D800` и `U+DFFF` в качестве значений, для которых не существует эквивалента символов UTF-8. Однако формату JSON необходимо кодирование UTF-8. Было предложено решение представить непарные суррогатные кодовые точки в качестве экранированных последовательностей JSON вместо того, чтобы оставить их одиночными кодовыми единицами UTF-16.

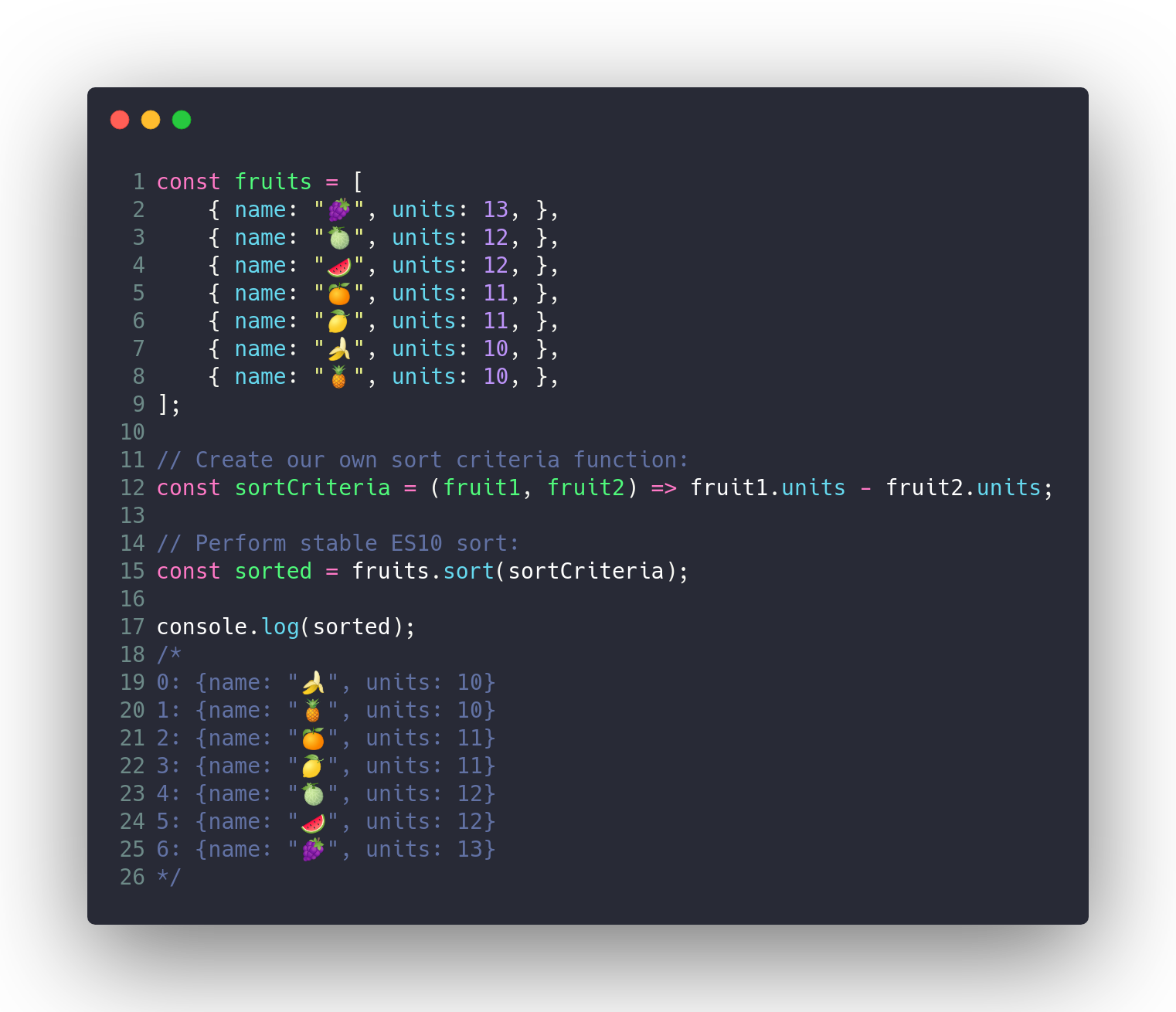
### Устойчивый Array.prototype.sort()
В предыдущей реализации движка V8 использовался нестабильный алгоритм быстрой сортировки для массивов, содержащих более 10 элементов.
*Алгоритм стабильной сортировки* — это алгоритм сортировки, при котором два объекта с одинаковыми ключами остаются в том же порядке, в котором они были до сортировки.
### Обновленная Function.toString()
Метод `toString()` возвращает строковое представление исходного кода функции. В ES6 при вызове `toString()` для функции он мог возвращать разный результат в зависимости от конкретной реализации движка ECMAScript. По возможности возвращался исходный код, в противном случае — стандартизированная заглушка.

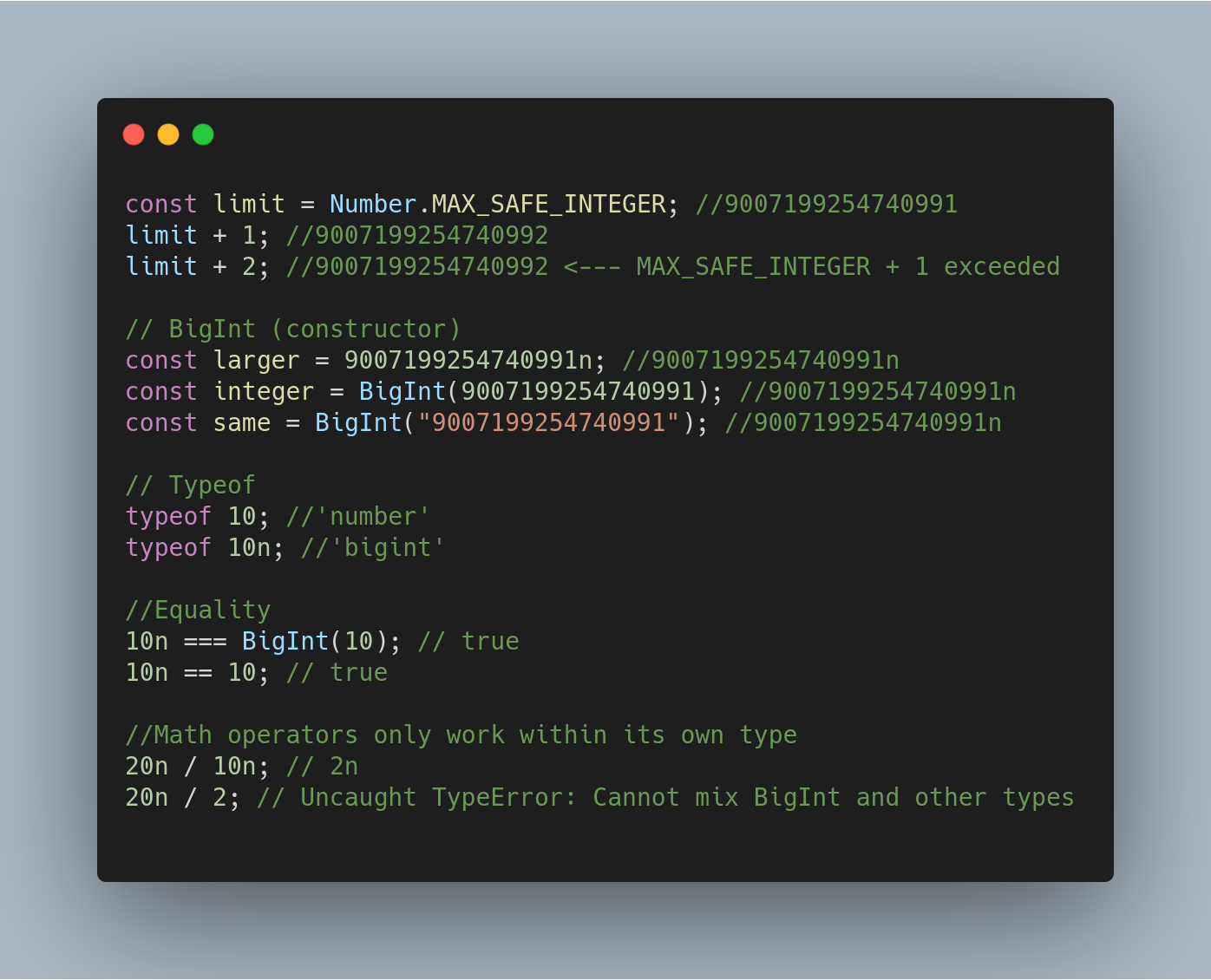
### BigInt — целые числа произвольной длины
`BigInt` — это 7-й примитивный тип, целое число произвольной длины. Переменные данного типа могут состоять из 253 числовых знаков, они не ограничены числовым значением `9007199254740992`.
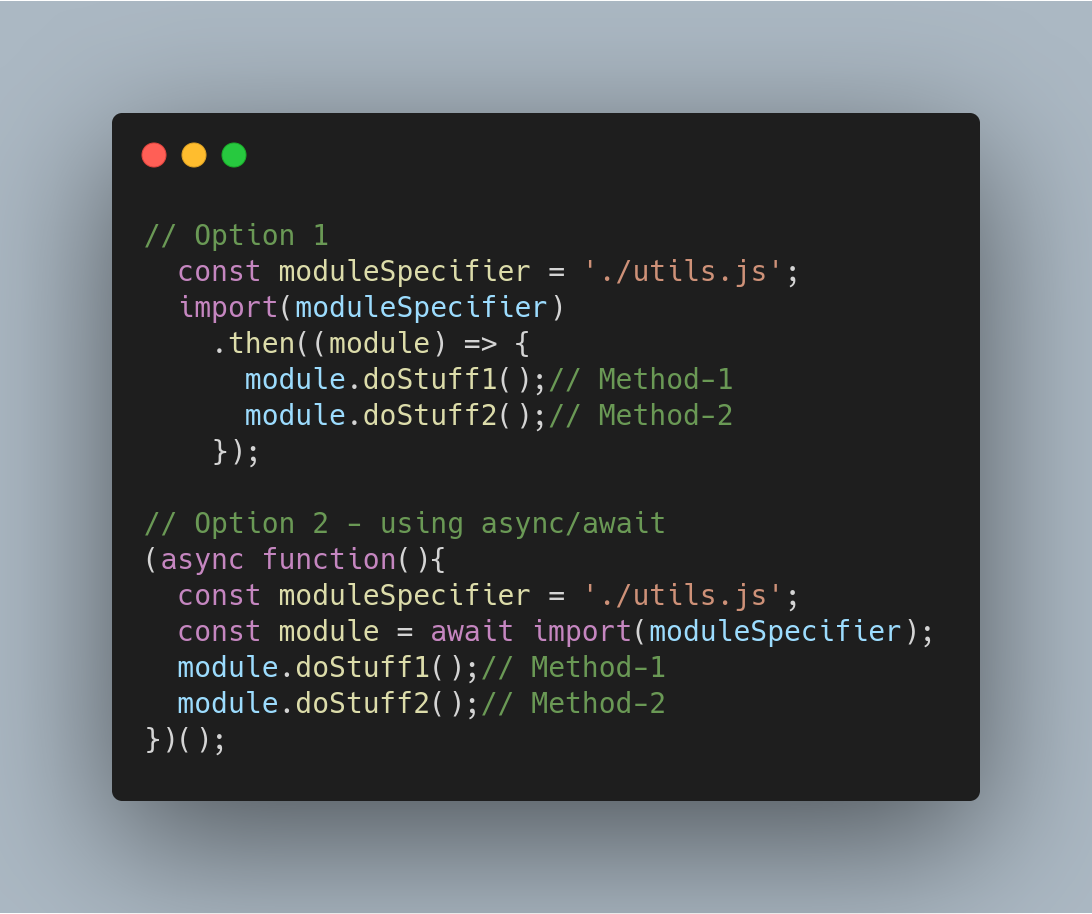
### Динамический импорт
Динамический `import()` возвращает промис для объекта пространства имен запрашиваемого модуля. Следовательно, теперь импорт можно назначить переменной, используя `async/await`.
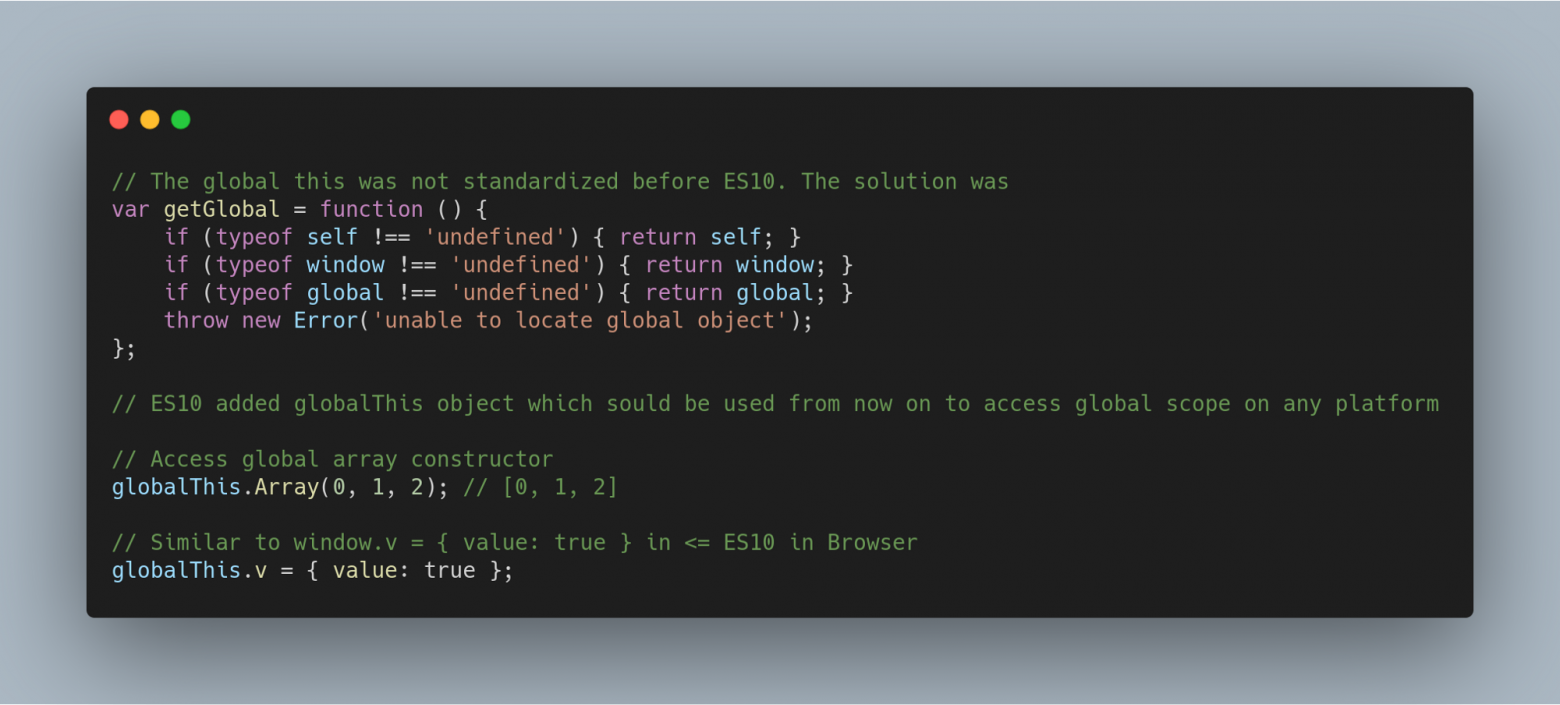
### Стандартизированный объект globalThis
Объект `globalThis` не был стандартизирован до появления ES10. В коде готового приложения его приходилось приводить к стандарту для различных платформ самостоятельно, прописывая нечто громоздкое, например:
### Заключение
JavaScript является живым языком, что очень благоприятно для веб-программирования. Мы наблюдаем его динамичное развитие с момента появления ES6 в 2015 году. В этой статье мы осветили функции, которые появились в версии ES10 2019 года. Также были представлены некоторые функции, которые обретут стабильность в ES11 (2020), поскольку они находятся в 3 стадии внедрения и, вероятно, в итоге будут стандартизированы для следующего выпуска.
Многие из этих функций могут оказаться ненужными для создания вашего веб-приложения. Однако все они дают возможность обойтись без хитроумных приемов или написания большого количества кода там, где это требовалось раньше. | https://habr.com/ru/post/471142/ | null | ru | null |
# Передача даты с формы в базу
**Дано**
Angular, PrimeNG, Spring Boot, JDBC, PostgreSQL
**Надо**
Передавать дату с формы в базу и обратно
#### Подготовка
```
create database test_date;
```
```
CREATE TABLE test_table (
test_date date NULL,
test_timestamp timestamp NULL,
test_timestamptz timestamptz NULL,
id serial2,
CONSTRAINT test_table_pk PRIMARY KEY (id)
);
```
java.util.Date
--------------
### Решение 1
Надо сохранять только дату без времени. Использую колонку с типом `date`.
Выбираю на форме дату `2020-12-22`. На сервер отправится `2020-12-21T21:00:00.000Z`. Это текущее время по `UTC`, так как браузер в зоне +3. Java сделает запрос
```
statement.setObject(1, entity.getTestDate(), Types.DATE)
```
```
insert into test_table (test_date) values ('2020-12-22 +03')
```
Java отбрасывает время и передает автоматически таймзону (по умолчанию зона сервера или `-Duser.timezone=Europe/Moscow`). Postgres не учитывает зону для типа данных `date`. Будет сохранено `2020-12-22`. При чтении из базы вернется эта же дата. В Json попадет
```
{ "testDate": "2020-12-22" }
```
Браузер прочитает такой формат, как начало дня по UTC.
```
new Date('2020-12-22')
new Date('2020-12-22T00:00:00.000+00:00')
Tue Dec 22 2020 03:00:00 GMT+0300 (Moscow Standard Time)
```
Т.е на форме отображается `2020-12-22 03:00` или просто без времени `2020-12-22`. Все верно.
Я встречал ситуацию , когда Chrome и Firefox интерпретировали дату без времени по-разному. Кто-то как начало дня по локальному времени. В данный момент такое не воспроизводится на обновленных версиях. Документация говорит, что сейчас такой формат стандартизирован. Но если строка отличается от формата `2020-12-22T00:00:00.000+00:00`, то поведение не гарантировано.
Ошибка всплывет только если начнет тестировать пользователь, который восточнее часового пояса сервера. Например Europe/Samara (+4). Выберет на форме `2020-12-22`. На сервер отправится `2020-12-21T20:00:00.000Z` (2020-12-22 00:00 +4). Сервер (работает в зоне +3) переведет это в `2020-12-21T23:00:00.000+03:00`, отбросит время и сохранит как
```
insert into test_table (test_date) values ('2020-12-21 +03')
```
При чтении сервер отдаст `2020-12-21`, что превратится в `2020-12-21 04:00`. На форме видим `2020-12-21`. Ошибка.
### Решение 2
При сохранении в БД указать временную зону пользователя, а не зону сервера.
```
statement.setDate(1, new java.sql.Date(entity.getTestDate().getTime()),
Calendar.getInstance(TimeZone.getTimeZone(userZoneId)));
```
Получить её можно отдельным параметром в запросе. Для этого в JS можно выполнить.
```
Intl.DateTimeFormat().resolvedOptions().timeZone;
```
Можно попробовать с полифилом новый API `Temporal.now().timeZone().id`. Этот параметр должен содержать зону по умолчанию. На старых браузерах может не работать или возвращать неправильную зону.
Запрос на сервер:
```
{"testDate":"2020-12-21T20:00:00.000Z","zoneId":"Europe/Samara"}
```
Сохранение:
```
insert into test_table (test_date) values ('2020-12-22 +04')
```
Зная зону, драйвер преобразовал `2020-12-21T23:00:00.000+03:00` в `2020-12-22T00:00:00.000+04:00`, и сформировал строку `2020-12-22 +04`. При чтении получится `2020-12-22` -> `2020-12-22 04:00:00`. На форме видим `2020-12-22`. Все верно.
Теперь протестируем ситуацию, когда пользователь к западу от UTC. Например America/Chicago (-6). Сохранится выбранная дата `2020-12-22`. При чтении сервер отдаст её обратно, но она превратится в `2020-12-21 18:00` по местному времени пользователя и отобразится как `2020-12-21`.
### Решение 3
Надо , чтобы сервер отдавал дату с временем `2020-12-22T00:00:00.000` и без зоны, тогда это будет преобразовано браузером в начало дня по местному времени. Для этого сделаю сериалайзер даты
```
import java.text.SimpleDateFormat;
import com.fasterxml.jackson.core.JsonGenerator;
import com.fasterxml.jackson.databind.JsonSerializer;
import com.fasterxml.jackson.databind.SerializerProvider;
public class DateSerializer extends JsonSerializer {
private final static SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd'T'HH:mm:ss");
@Override
public void serialize(Date value, JsonGenerator gen, SerializerProvider serializers) throws IOException {
gen.writeString(format.format(value));
}
}
```
Теперь все верно. Выбранная пользователем дата сохраняется в БД правильно. И возвращается на форму правильно. Проверено на разных таймзонах. Можно на прод.
С прода приходит баг. Пользователи видят неправильную дату. И смещение не на один день, а вообще не та дата.
### Решение 4
Метод `java.text.SimpleDateFormat.format()` не потокобезопасный. А я создал его один раз на все приложение. Надо для каждой сериализации делать свой экземпляр.
```
private static final String format = "yyyy-MM-dd'T'HH:mm:ss";
@Override
public void serialize(Date value, JsonGenerator gen, SerializerProvider serializers) throws IOException {
gen.writeString(new SimpleDateFormat(format).format(value));
}
```
Получился сервис со странным интерфейсом для сохранения даты. В другом клиенте придется передавать не только дату, но и рассчитывать время и передавать зону, для которой это время рассчитано. Если я захочу сохранить `2020-12-22`, то мне надо сначала определится с зоной. Если это +3, то надо передавать
```
{"testDate":"2020-12-21T21:00:00.000Z","zoneId":"Europe/Moscow"}
```
или
```
{"testDate":"2020-12-22T00:00:00.000+03:00","zoneId":"Europe/Moscow"}
```
В последнем варианте вообще получилось дублирование нужной информации о смещении. Надо убрать из запроса зону и оставить дату в формате `2020-12-22`. Если придет `2020-12-21T21:00:00.000Z`, то игнорировать время с зоной - сохранять как `2020-12-21`). Возвращаться результат должен тоже без времени.
### Решение 5
Убираю свой сериалайзер из java. На фронте надо обработать `2020-12-22` без времени, чтобы это было начало дня по локальному времени.
```
const ymd: string[] = obj.testDate.split('-');
const date: Date = new Date(ymd);
```
Это удобно и оно работает в Chrome и Firefox. Но конструктор с параметром `Array` не описан в стандарте. Поэтому параметр будет преобразован в строку и передан в `Date.parse()`. А этот метод стандартно работает только для `2020-12-22`.
Поэтому напишу по стандарту
```
const ymd: number[] = obj.testDate.split('-').map((s: string) => Number(s));
const date: Date = new Date(ymd[0], ymd[1] - 1, ymd[2])
```
Следующим шагом надо отбрасывать время при сохранении. Это уже делает JDBC. Но это вызывает ошибку для пользователей с востока. Так как время отбрасывается от даты по серверному времени. Поэтому время надо отбрасывать до конвертации строки в дату по серверному времени. Тут появляется ещё проблема: браузер отправляет дату, как начало дня по времени UTC. Т.е код надо писать ещё перед отправкой на фронте.
```
public saveEntity(entity: TestEntity): Observable {
const date: Date = entity.testDate;
const testDate: string = [date.getFullYear(), date.getMonth() + 1, date.getDate()]
.map(n => String(n).padStart(2, '0')).join('-');
const body: any = Object.assign({}, entity, {testDate});
return this.http.post(CONTROLLER, body);
}
```
Такой вариант работает, для пользователей из всех зон работает. И не надо ничего программировать на сервере.
Потом на проекте появляется разработчик из Чикаго. И тестирует приложение у себя. На сервер отправляется `2020-12-22`. Сервер превращает это в `2020-12-21 18:00:00` по местному времени. И сохраняет
```
insert into test_table (test_date) values ('2020-12-21 -06')
```
Ошибка. Решение работает только для сервера к востоку от UTC.
### Решение 6
Самое простое решение - захардкодить зону приложения.
```
System.setProperty("user.timezone", "UTC")
```
Но не совсем правильное. Что делать, если в приложении уже куча логики зависит от того, что сервер находится где-то по местному времени на западе? Проблема в том, что Jackson воспринимает полученную дату как начало дня по UTC. A я хотел, чтобы дата была началом дня для сервера.Тогда надо захардкодить эту зону и указать Jackson, что для конвертации надо использовать зону сервера.
```
public static final String APP_TIMEZONE = "America/Chicago";
public static void main(String[] args) {
System.setProperty("user.timezone", APP_TIMEZONE);
SpringApplication.run(TestDateApplication.class, args);
}
```
```
import com.fasterxml.jackson.annotation.JsonFormat;
public class TestEntity {
@JsonFormat(timezone = TestDateApplication.APP_TIMEZONE,
pattern = "yyyy-MM-dd")
private Date testDate;
```
Так как браузер теперь передает только дату без времени. То можно ограничить интерфейс и не позволять формат с временем. Если кто-то начнет передавать время, значит возможна ошибка с временными зонами.
### Решение 7
Jackson пропускает такие даты, не учитывая время. Поэтому надо писать свой десериалайзер. Он будет выбрасывать исключение, если строка длиннее заданного формата.
```
import java.io.IOException;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
import com.fasterxml.jackson.core.JsonParser;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.core.JsonToken;
import com.fasterxml.jackson.databind.DeserializationContext;
import com.fasterxml.jackson.databind.JsonDeserializer;
import com.fasterxml.jackson.databind.exc.InvalidFormatException;
public class DateDeserializer extends JsonDeserializer {
private static final String format = "yyyy-MM-dd";
@Override
public Date deserialize(JsonParser p, DeserializationContext ctxt)
throws IOException, JsonProcessingException {
if (p.hasToken(JsonToken.VALUE\_STRING)) {
String text = p.getText().trim();
if (text.length() != format.length()) {
throw new InvalidFormatException(p, "Wrong date", text, Date.class);
}
try {
Date result = new SimpleDateFormat(format).parse(text);
return result;
} catch (ParseException e) {
throw new InvalidFormatException(p, "Wrong date", text, Date.class);
}
}
return (Date) ctxt.handleUnexpectedToken(Date.class, p);
}
}
```
Если сохранить дату на востоке, а открыть на западе, то она будет одинакова. Но на западе может быть еще только вчера. Это может быть принято за ошибку. Зависит от задачи. Если речь о дате рождения, то ошибки нет. Если о дате публикации новости, то читатель на западе увидит новость из будущего. Это может выглядеть странно.
### Решение 8
Для такого случая придется сохранять время вместе с датой. От времени зависит, одинаковая дата для разных часовых поясов в это время или разная. Для сохранения можно использовать два типа: `timestamp` или `timestamp with time zone`. Зону мне хранить, вроде бы, не надо, поэтому сделаю `timestamp`.
```
private static final String COLUMN_LABEL = "test_timestamp";
entity.setTestDate(rs.getTimestamp(COLUMN_LABEL));
statement.setTimestamp(1, new Timestamp(entity.getTestDate().getTime()));
```
С фронта поступит дата `2020-12-21T20:00:00.000Z`. Будет передана в базу как
```
insert into test_table (test_timestamptz) values ('2020-12-21 14:00:00-06')
```
И сохранена в базе как время `2020-12-21 14:00:00`. На фронт придет время с указанием зоны `2020-12-21T20:00:00.000+00:00` и будет показано локальное время. Работает.
Беда придет, если изменится таймзона сервера. Время в базе сохранено по зоне сервера. При чтении на сервере с другой таймзоной будет неправильное время. Из `2020-12-21 14:00:00` на сервере `Europe/Moscow` получится `2020-12-21T11:00:00.000+00:00`. А должно было быть `2020-12-21T20:00:00.000+00:00`.
### Решение 9
Либо сервер должен быть всегда в одной зоне. Либо надо хранить даты в одной зоне и явно это указывать. Так как сервер был раньше в `America/Chicago` и время сохранено в такой зоне, то я укажу эту зону
```
private static final String COLUMN_TIMEZONE = "America/Chicago";
entity.setTestDate(rs.getTimestamp(COLUMN_LABEL,
Calendar.getInstance(TimeZone.getTimeZone(COLUMN_TIMEZONE))));
statement.setTimestamp(1, new Timestamp(entity.getTestDate().getTime()),
Calendar.getInstance(TimeZone.getTimeZone(COLUMN_TIMEZONE)));
```
Чтобы было легче дебажить, лучше сделать зону `UTC`. И в базе перевести время на `UTC`.
```
update test_table
set test_timestamp =
(test_timestamp at time zone 'America/Chicago') at time zone 'UTC';
```
```
private static final String COLUMN_TIMEZONE = "UTC";
```
С фронта поступит дата `2020-12-21T20:00:00.000Z`. Будет передана в базу как
```
insert into test_table (test_timestamp) values ('2020-12-21 20:00:00+00')
```
И сохранена в базе как время `2020-12-21 20:00:00`. При чтении сервер получит `2020-12-21 14:00:00` по своему времени (-6). На фронт придет время с указанием зоны `2020-12-21T20:00:00.000+00:00` и будет показано локальное время.
### Решение 10
Получилось тоже самое, что можно было сделать сразу, используя `timestamp with time zone`. Данный тип не хранит зону. Он хранит время для зоны `UTC` и автоматически конвертирует его во время для другой зоны. Поэтому код можно переписать без указания зоны при сохранении и чтении.
```
private static final String COLUMN_LABEL = "test_timestamptz";
entity.setTestDate(rs.getTimestamp(COLUMN_LABEL));
statement.setTimestamp(1, new Timestamp(entity.getTestDate().getTime()));
```
С фронта поступит дата `2020-12-21T20:00:00.000Z`. Будет передана в базу как
```
insert into test_table (test_timestamptz) values ('2020-12-21 14:00:00-06')
```
И сохранена в базе независимо от зоны сервера как время `2020-12-21T20:00:00.000Z`. При чтении сервер получит `2020-12-21 14:00:00` по своему времени. На фронт придет время с указанием зоны `2020-12-21T20:00:00.000+00:00` и будет показано локальное время.
### Решение 11
Надо чтобы время показывалось всегда то, что ввели, и не зависело от временной зоны браузера или сервера. Для передачи по сети буду использовать формат без указания зоны. Для хранения буду использовать колонку `timestamp`.
```
public saveEntity(entity: TestEntity): Observable {
const date: Date = entity.testDate;
const testDate: string = [date.getFullYear(), date.getMonth() + 1, date.getDate()]
.map(n => String(n).padStart(2, '0')).join('-')
+ 'T' + [date.getHours(), date.getMinutes(), date.getSeconds()]
.map(n => String(n).padStart(2, '0')).join(':');
const body: any = Object.assign({}, entity, {testDate});
return this.http.post(CONTROLLER, body);
}
```
```
@JsonDeserialize(using = DateDeserializer.class)
@JsonFormat(pattern = "yyyy-MM-dd'T'HH:mm:ss", timezone = TestDateApplication.APP_TIMEZONE)
private Date testDate;
```
В десериалайзере:
```
Date result = new SimpleDateFormat("yyyy-MM-dd'T'HH:mm:ss").parse(text);
```
При выборе на форме `2020-12-22 14:14` отправится `2020-12-22T14:14:00`. Это воспринимается как локальное время. И будет отправлено в базу.
```
insert into test_table (test_timestamp) values ('2020-12-22 14:14:00+04')
```
Так как тип колонки `timestamp without time zone`, то переданная зона просто будет отброшена, и дополнительной конвертации не будет. При чтении все также. Отобразится тоже, что сохраняли, в любом часовом поясе.
```
new Date('2020-12-22T14:14:00')
Tue Dec 22 2020 14:14:00 GMT-0600 (Central Standard Time)
```
Time API
--------
### Решение 1
Сохраняю только дату. Колонка `date`. Тип поля DTO `LocalDate`.
```
private LocalDate testDate;
statement.setObject(1, entity.getTestDate(), Types.DATE);
entity.setTestDate(rs.getObject("test_date", LocalDate.class));
```
Выберу на форме `2020-12-22`. От браузера придет `2020-12-21T21:00:00.000Z`. Jackson превратит это в `LocalDateTime` для зоны `UTC` и отбросит время.
```
insert into test_table (test_date) values ('2020-12-21'::date)
```
В браузер вернется `2020-12-21`. Неверно.
```
new Date('2020-12-21')
Mon Dec 21 2020 03:00:00 GMT+0300 (Moscow Standard Time)
```
### Решение 2
Надо делать десериализацию с таймзоной сервера.
```
public LocalDate deserialize(JsonParser p, DeserializationContext ctxt)
throws IOException, JsonProcessingException {
if (p.hasToken(JsonToken.VALUE_STRING)) {
String text = p.getText().trim();
try {
DateTimeFormatter formatter = new DateTimeFormatterBuilder()
.append(DateTimeFormatter.ISO_LOCAL_DATE_TIME)
.appendZoneId()
.toFormatter();
LocalDate result = ZonedDateTime.parse(text, formatter)
.withZoneSameInstant(ZoneId.systemDefault())
.toLocalDate();
return result;
} catch (Exception e) {
throw new InvalidFormatException(p, "Wrong date", text, Date.class);
}
}
return (LocalDate) ctxt.handleUnexpectedToken(LocalDate.class, p);
}
```
Теперь сохраняется введенная дата.
```
insert into test_table (test_date) values ('2020-12-22'::date)
```
Но это не будет работать для пользователя восточнее сервера.
### Решение 3
Можно пойти путем передачи зоны пользователя. Тогда надо сменить тип поля на тип с временем: `LocalDateTime`.
```
String zoneId = entity.getZoneId();
statement.setObject(1,
ZonedDateTime.of(entity.getTestDate(), ZoneId.systemDefault())
.withZoneSameInstant(ZoneId.of(zoneId))
.toLocalDate(),
Types.DATE);
entity.setTestDate(
LocalDateTime.of(rs.getObject(COLUMN_LABEL, LocalDate.class), LocalTime.MIN));
```
Обратно с сервера вернется дата уже с временем `2021-12-22T00:00:00`. Поэтому это решение будет работать и для пользователей с запада от UTC.
### Решение 4
Если формировать дату без времени на фронте, то на сервере можно оставить только поле с типом `LocalDate`. И больше не делать дополнительных конвертаций.
```
statement.setObject(1, entity.getTestDate(), Types.DATE);
entity.setTestDate(rs.getObject(COLUMN_LABEL, LocalDate.class));
```
Это решение работает, если даже переместить сервер в другую зону.
Чтобы предотвратить ошибку из-за передачи даты в формате ISO по времени UTC, достаточно указать формат. На дополнительные символы будет ругаться.
```
@JsonFormat(pattern = "yyyy-MM-dd")
private LocalDate testDate;
```
### Решение 5
Чтобы сохранить время можно использовать `LocalDateTime`. Но для конвертации строки `2020-12-21T20:00:00.000Z` в локальное время нужен десериалайзер с использованием `ZoneDateTime`. Поэтому буду использовать сразу его.
```
statement.setObject(1,
entity.getTestDate()
.withZoneSameInstant(ZoneId.systemDefault())
.toLocalDateTime(),
Types.TIMESTAMP);
entity.setTestDate(
ZonedDateTime.of(
rs.getObject(COLUMN_LABEL, LocalDateTime.class),
ZoneId.systemDefault()
)
);
```
При изменении зоны сервера даты поедут.
### Решение 6
Укажу явно зону `UTC` для хранения времени.
```
private static final String COLUMN_TIMEZONE = "UTC";
statement.setObject(1,
entity.getTestDate()
.withZoneSameInstant(ZoneId.of(COLUMN_TIMEZONE))
.toLocalDateTime(),
Types.TIMESTAMP);
entity.setTestDate(
ZonedDateTime.of(
rs.getObject(COLUMN_LABEL, LocalDateTime.class),
ZoneId.of(COLUMN_TIMEZONE)
)
);
```
### Решение 7
Теперь можно перейти на тип колонки `timestamptz`.
Чтобы сохранить `ZonedDateTime` в такую колонку, можно использовать `LocalDateTime`, но обязательно сконвертировав в зону сервера. Потому что JDBC сам добавит в запрос смещение на основе зоны сервера. Postgres его учтет для конвертации в UTC.
```
statement.setObject(1,
entity.getTestDate()
.withZoneSameInstant(ZoneId.systemDefault())
.toLocalDateTime());
```
```
insert into test_table (test_timestamptz) values ('2020-12-21 23:30:00+03'::timestamp)
```
Можно сохранять `OffsetDateTime`. Тогда будет передано то, что пришло из браузера.
```
statement.setObject(1, entity.getTestDate().toOffsetDateTime());
```
```
insert into test_table (test_timestamptz)
values ('2020-12-21 20:30:00+00'::timestamp with time zone)
```
Читать из базы драйвер позволяет только в `OffsetDateTime`.
```
entity.setTestDate(
rs.getObject(COLUMN_LABEL, OffsetDateTime.class).toZonedDateTime()
);
```
Поэтому поле DTO можно сразу переделать в `OffsetDateTime`.
### Решение 8
Для сохранение выбранного времени и отображения его независимо от зоны браузера достаточно передавать на сервер локальное время.
```
public saveEntity(entity: TestEntity): Observable {
const date: Date = entity.testDate;
const testDate: string =
[date.getFullYear(), date.getMonth() + 1, date.getDate()]
.map(n => String(n).padStart(2, '0')).join('-')
+ 'T'
+ [date.getHours(), date.getMinutes(), date.getSeconds()]
.map(n => String(n).padStart(2, '0')).join(':');
const body: any = Object.assign({}, entity, {testDate});
return this.http.post(CONTROLLER, body);
}
```
На сервере использовать `LocalDateTime` и `timestamp`. Дополнительная настройка Jackson не нужна. При передаче времени с зоной он будет ругаться.
```
statement.setObject(1, entity.getTestDate());
entity.setTestDate(rs.getObject(COLUMN_LABEL, LocalDateTime.class));
```
Заключение
----------
Чтобы избежать некоторых ошибок, надо изначально договорится о некоторых вещах. Формат даты в запросе и ответе. Зона, в которой будет запущен сервер. Зона, в которой хранится время.
Дополнительные ошибки могут появится, из-за устаревшей tzdata. PostgreSQL имеет свою tzdata. Если есть колонки `timestamptz`, то эта база используется. Надо обновлять минорные релизы. PostgreSQL может быть собран с флагом `with-system-tzdata`. Тогда надо обновлять системные зоны. Java имеет свою tzdata. Надо тоже обновлять. Можно отдельно от всей jre. Joda-time имеет свою tzdata.
Все решения доступны в [репозитории](https://github.com/Qwertovsky/test_date/commits/). Там две ветки. | https://habr.com/ru/post/536016/ | null | ru | null |
# Передача анонимных объектов в View

Идея состоит в том чтобы пользоваться моделью с новым более удобным dynamic синтаксисом. Главное ограничение тут в том, что нельзя просто передать анонимный объект как модель, потому что анонимные типы имеют модификатор доступа internal.
Предположим, что мы пытаемся написать этот код в контроллере:
> `public class HomeController : Controller
>
> {
>
> public ActionResult Index()
>
> {
>
> return View(
>
> new
>
> {
>
> Message = "Welcome to ASP.NET MVC!",
>
> Date = DateTime.Now
>
> });
>
> }
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Обратите внимание, что мы передаем анонимный объект в модель. Главная причина этого — это избежать создание необходимого внешнего ViewModel типа. Очевидно, что это несколько спорный момент, но оно должно выглядеть проще чем такая альтернатива:
> `ViewData["Message"] = "Welcome to ASP.NET MVC!";
>
> ViewData["Date"] = DateTime.Now;
>
> return View();
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Затем мы изменяем View таким образом, чтобы он имел
> `Inherits="System.Web.Mvc.ViewPage"
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
В идеале это должно позволить нам написать что-то типа этого:
> `<asp:Content ID="indexContent" ContentPlaceHolderID="MainContent" runat="server">
>
> <h2><%= Model.Message %>h2>
>
> <p>
>
> The date is <%= Model.Date %>
>
> p>
>
> asp:Content>
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Но по умолчанию dynamic binder не даст нам сделать это!
К сожалению, если вы попытаетесь запустить этот код, то будет:
**error: Microsoft.CSharp.RuntimeBinder.RuntimeBinderException: '<>f\_\_AnonymousType1.Message' is inaccessible due to its protection level**
Причина этого анонимный тип в контроллере является internal, так что он может быть доступен только из той сборки в которой он определен. Так как view компилируется отдельно, dynamic binder жалуется, что не может выйти за пределы этой сборки. Но достаточно просто можно написать свой DynamicObject, который связывает через private reflection.
Здесь мы собираеся написать не только свой DynamicObject, но также свой DynamicViewPage, который использует его. Вот полная реализация:
> `public class DynamicViewPage : ViewPage {
>
> // Скрываем модель класса предка и заменяем его на dynamic
>
> public new dynamic Model { get; private set; }
>
>
>
> protected override void SetViewData(ViewDataDictionary viewData) {
>
> base.SetViewData(viewData);
>
>
>
> // Создаем динамический объект, который использует private рефлексию над объектом модели
>
> Model = new ReflectionDynamicObject() { RealObject = ViewData.Model };
>
> }
>
>
>
> class ReflectionDynamicObject : DynamicObject {
>
> internal object RealObject { get; set; }
>
>
>
> public override bool TryGetMember(GetMemberBinder binder, out object result) {
>
> // Возвращаем значение свойства
>
> result = RealObject.GetType().InvokeMember(
>
> binder.Name,
>
> BindingFlags.GetProperty | BindingFlags.Instance | BindingFlags.Public | BindingFlags.NonPublic,
>
> null,
>
> RealObject,
>
> null);
>
>
>
> // Всегда возвращаем true, так как InvokeMember вызовет исключение, если что-то пойдет не так
>
> return true;
>
> }
>
> }
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Как вы видите здесь все просто. Все что нам нужно это узнать значение свойства используя private reflection. Вот и все, осталось только использовать это как наш базовый класс для View.
**<%@ Page Language=«C#» MasterPageFile="~/Views/Shared/Site.Master" Inherits=«MvcHelpers.DynamicViewPage» %>** | https://habr.com/ru/post/79363/ | null | ru | null |
# От UI-kit до дизайн-системы
*Опыт онлайн-кинотеатра Иви*
Когда в начале 2017 года мы впервые задумались о создании собственной системы доставки дизайна в код, об этом уже многие говорили и кто-то даже делал. Однако, об опыте построения кроссплатформенных дизайн-систем и по сей день мало что известно, а понятных и проверенных рецептов, описывающих технологии и способы подобной трансформации процесса имплементации дизайна в уже работающий продукт как не было, так и нет. Да и под «компонентами в коде» часто понимают очень разные вещи.
[](https://habr.com/ru/company/ivi/blog/456854/)
Меж тем компания год от года удваивала штат — нужно было масштабировать отдел дизайна и оптимизировать процессы создания и передачи макетов в разработку. Умножаем всё это на «зоопарк» платформ, которые нужно поддерживать, и получаем подобие вавилонского столпотворения, которое просто не способно «нормально делать» и приносить доход. Развитие платформ часто шло параллельно, и один и тот же функционал мог выходить на разных платформах с лагом в несколько месяцев.
*Отдельные наборы макетов для каждой платформы*
Традиционно, мы начали с проблем, которые помогла бы решить дизайн-система и сформулировали требования к её проектированию. Помимо создания единого визуального языка, увеличения скорости макетирования и разработки, повышения качества продукта в целом, было жизненно необходимо максимально унифицировать дизайн. Это нужно для того, чтобы развитие функционала стало возможным сразу на всех наших платформах одновременно: Web, iOS, Android, Smart TV, tvOS, Android TV, Windows 10, xBox One, PS4, Roku — не прорабатывая при этом каждую из них в отдельности. И это у нас получилось!
Дизайн → данные
---------------
Когда принципиальные договорённости отделов продукта и разработки были достигнуты, мы сели за подбор технологического стека и проработку деталей всего процесса — от макета до релиза. Чтобы полностью автоматизировать процесс передачи дизайна в разработку поисследовали вариант с парсером параметров компонентов прямо из Sketch-файлов с макетами. Оказалось, что находить нужные нам куски кода и извлекать нужные нам параметры — затея сложная и опасная. Во-первых, дизайнерам придётся быть крайне аккуратными в именовании всех слоёв исходника, во-вторых, это работает только для самых простых компонентов, а в-третьих, зависимость от чужой технологии и структуры кода исходного Sketch-макета ставит под угрозу будущее всего проекта. Мы решили отказаться от автоматизации на этом участке. Так в команде дизайн-системы появился первый человек, на вход которому подаются дизайн-макеты, а на выходе — данные, описывающие все параметры компонентов и иерархически упорядоченные по методологии атомарного дизайна.
Дело оставалось за малым: где и как хранить данные, как передавать в разработку и как интерпретировать в разработке на всех поддерживаемых нами платформах. Вечер переставал быть томным… Итогом регулярных встреч рабочей группы, состоящей из дизайнеров и тимлидов от каждой платформы стали договорённости о нижеследующем.
Вручную разбираем визуал на элементы-атомы: шрифты, цвета, прозрачности, отступы, скругления, иконки, картинки и длительности для анимаций. И собираем из этого кнопки, инпуты, чекбоксы, виджеты банковских карт и т. д. Стилям любого из уровней, кроме пиктограмм присваиваем несемантические имена, например названия городов, имена нимф, покемонов, марки автомобилей… Тут условие одно — список не должен исчерпаться раньше, чем закончатся стили — шоу маст гоу он! Семантикой же не стоит увлекаться, чтобы не пришлось добавлять среднюю кнопку между «small» и «medium», например.
Визуальный язык
---------------
Разработчики ушли думать, как хранить и передавать данные, чтобы это подходило всем платформам, а дизайну предстояло спроектировать элементы интерфейса, способные одинаково хорошо выглядеть и эффективно работать на всём парке поддерживаемых устройств.
Ранее мы уже успели «обкатать» большинство элементов дизайна в приложении под Windows 10, которое на тот момент являлось для нас новой платформой, то есть требовалась отрисовка и разработка «с нуля». Рисуя его, мы смогли подготовить и проверить большинство компонентов и понять, какие из них должны были войти в будущую дизайн-систему Иви. Без такой «песочницы» подобный опыт можно было получить только большим числом итераций на уже работающих платформах, а на это потребовалось бы больше года.
Переиспользование одинаковых компонентов на разных платформах уменьшает количество макетов и массив данных дизайн-системы в разы, поэтому дизайну предстояло решить ещё одну задачу, ранее не описанную в практиках продуктового дизайна и разработки — как, например кнопку для телефонов и планшетов переиспользовать на телевизорах? И как в принципе быть с размерами шрифтов и элементов на таких разных платформах?
Очевидно, требовалось спроектировать кроссплатформенную модульную сетку, которая будет задавать нужные нам размеры текста и элементов для каждой конкретной платформы. За точку отсчёта для сетки мы выбрали размер и количество постеров фильмов, которые хотим видеть на том или ином экране и, исходя из этого сформулировали правило построения колонок сетки, при условии — ширина одной колонки равна ширине постера.
Теперь нужно привести к одному размеру макета все большие экраны и вписать их в общую сетку. Apple TV и Roku разрабатываются в размер 1920x1080, Android TV — 960x540, Smart TV, в зависимости от вендора бывают такими же, а бывают 1280x720. Когда приложение рендерится и отображается на экранах Full HD, 960 умножается на 2, 1280 на 1,33, а 1920 выводится как есть.
Опуская скучные подробности, мы пришли к тому, что вообще все экраны, включая телеэкраны с точки зрения элементов и их размеров покрываются одним дизайн-макетом, а все телеэкраны являются частным случаем общей кроссплатформенной сетки, и состоят из пяти или шести колонок, как средний планшет или десктоп. Кому интересны подробности, го в комменты.
*Единый UI для всех платформ*
Теперь для отрисовки новой фичи нам не нужно рисовать макеты под каждую из платформ, плюс варианты адаптивности для каждой из них. Достаточно показать один макет и его адаптивность для всех платформ и устройств любой ширины: телефоны — 320–599, всё остальное — 600–1280.
Данные → разработка
-------------------
Конечно, как бы нам ни хотелось прийти к абсолютно унифицированному дизайну, каждая платформа имеет свои уникальные особенности. Несмотря на то, что и веб, и Smart TV используют стек ReactJS + TypeScript, приложение для Smart TV запускается на устаревших WebKit- и Presto-клиентах, и потому не может использовать общие стили с вебом. А email-рассылки и вовсе вынуждены работать с табличной вёрсткой. При этом ни одна из не-html-платформ не использует и не планирует использовать React Native или какие-то её аналоги, опасаясь ухудшения производительности, так как у нас слишком много кастомных лэйаутов, коллекций со сложной логикой обновления, изображений и видео. Поэтому для нас не подходит распространённая схема — поставлять готовые CSS-стили или React-компоненты. Поэтому мы решили передавать данные в формате JSON, описывая значения в абстрактном декларативном виде.
> Так свойство `rounding: 8` приложение Windows 10 преобразует в `CornerRadius="8"`, веб — `border-radius: 8px`, Android — `android:radius="8dp"`, iOS — `self.layer.cornerRadius = 8.0`.
>
> Cвойство `offsetTop: 12` один и тот же веб-клиент в разных случаях может интерпретировать как `top`, `margin-top`, `padding-top` или `transform`
Декларативность описания также предполагает, что если платформа технически не может использовать какое-либо свойство или его значение, она может его проигнорировать. С точки зрения терминологии мы сделали некое подобие языка эсперанто: что-то взяли из Android, что-то из SVG, что-то из CSS.
В случае если на той или иной платформе потребуется отображать элементы как-то иначе, мы реализовали возможность передачи соответствующей генерации данных в виде отдельного JSON-файла. Например, состояние «в фокусе» для Smart TV, диктует изменение позиции текста под постером, значит для этой платформы данный компонент в значении свойства «отступ» будет содержать необходимые ей 8 поинтов отступа. Хоть это и усложняет инфраструктуру дизайн-системы, зато даёт дополнительную степень свободы, оставляя нам возможность самим управлять визуальной «непохожестью» платформ, а не быть заложниками нами же созданной архитектуры.
Пиктограммы
-----------
Иконографика в цифровом продукте — это всегда объёмный и не самый простой подпроект, часто имеющий отдельного дизайнера. Глифов всегда много, каждый из них имеет несколько размеров и цветов, к тому же платформам они нужны, как правило в разных форматах. В общем, не было повода не завести всё это в дизайн-систему.

Глифы загружаются в векторном SVG-формате, а значения цветов автоматически заменяются переменными. Приложения-клиенты могут получать их уже готовыми к использованию — в любом формате и цвете.
Предпросмотр
------------
Поверх JSON’а с данными мы написали инструмент для предпросмотра компонентов — JS-приложение, на лету пропускающее JSON-данные через свои генераторы разметки и стилей, и отображающее в браузере различные вариации каждого из компонентов. По сути, предпросмотр является точно таким же клиентом, как и платформенные приложения, и работает с теми же данными.
Понять, как работает тот или иной компонент, проще всего путём взаимодействия с ним. Поэтому мы не стали использовать инструменты, подобные Storybook, а сделали интерактивный предпросмотр — можно пощупать, понаводить, покликать… При добавлении в дизайн-систему нового компонента он появляется в предпросмотре, чтобы платформам было на что ориентироваться при его внедрении.
Документация
------------
На основе тех данных, которые в виде JSON поставляются платформам, автоматически формируется документация по компонентам. Описывается перечень свойств и возможные типы значений в каждом из них. После автогенерации информацию можно уточнить в ручном режиме, добавить текстовое описание. Предпросмотр и документация снабжены перекрёстными ссылками друг на друга на уровне каждого компонента, а вся информация, попадающая в документацию, доступна разработчикам в виде дополнительных JSON-файлов.
Депрекатор
----------
Ещё одной необходимостью стала возможность со временем заменять и обновлять уже существующие компоненты. Дизайн-система научилась сообщать разработчикам, какие свойства или даже целые компоненты использовать нельзя и удалять их, как только они перестают использоваться на всех платформах. Пока в этом процессе ещё много «ручного» труда, но мы не стоим на месте.
Клиентская разработка
---------------------
Несомненно, самым масштабным по сложности этапом стала интерпретация данных дизайн-системы в коде всех поддерживаемых нами платформ. Если, например, модульные сетки на вебе не являются чем-то новым, то разработчики нативных мобильных приложений под iOS и Android изрядно попотели, прежде чем придумали, как с этим жить.
Для верстки экранов iOS-приложения мы используем два базовых механизма, которые предоставляет iviUIKit: cвободная компоновка элементов и компоновка коллекций элементов. Мы используем VIPER, и всё взаимодействие с iviUIKit сосредоточено во View, а большая часть взаимодействия с Apple UIKit сосредоточена в iviUIKit. Размеры и расположение элементов задаётся в терминах колонок и синтаксических конструкций, работающих поверх нативных констрейнтов iOS SDK, делающих их более прикладными. Особенно это упростило нам жизнь при работе с UICollectionView. Мы написали несколько настраиваемых обёрток для лэйаутов, в том числе довольно сложных. Клиентского кода получилось минимум и он стал декларативным.
Для генерации стилей в проекте Android мы используем Gradle, превращая данные дизайн-системы в стили формата XML. При этом у нас есть несколько генераторов различного уровня:
* **Базовые**. Парсят данные примитивов для генераторов более высокого уровня.
* **Ресурсные**. Скачивают картинки, иконки, и прочую графику.
* **Компонентные**. Пишутся для каждого компонента, где описано какие свойства и как перевести в стили.
Релизы приложений
-----------------
После того, как дизайнеры нарисовали новый компонент или переработали существующий, эти изменения попадают в дизайн-систему. Разработчики каждой из платформ дорабатывают свою кодогенерацию, обеспечивая поддержку изменений. После этого его можно использовать в реализации нового функционала, где этот компонент необходим. Таким образом, взаимодействие с дизайн-системой происходит не в реальном времени, а только в момент сборки новых релизов. Такой подход также позволяет лучше контролировать процесс передачи данных и гарантирует работоспособность кода в проектах клиентской разработки.
Итоги
-----
Скоро год как дизайн-система стала частью инфраструктуры, обслуживающей развитие онлайн-кинотеатра Иви, и уже можно делать кое-какие выводы:
* Это большой и сложный в реализации проект, требующий постоянных выделенных ресурсов.
* Это позволило нам создать свой уникальный кроссплатформенный визуальный язык, отвечающий задачам сервиса онлайн видео.
* У нас больше нет визуально и функционально отстающих платформ.
Предпросмотр компонентов дизайн-системы Иви — [design.ivi.ru](http://design.ivi.ru) | https://habr.com/ru/post/456854/ | null | ru | null |
# Практика в работе с нестандартными шинами комплекса Redd
В [прошлой статье](https://habr.com/ru/post/483724/) мы рассмотрели теорию по управлению тысячей мелочей в комплексе Redd, но чтобы не раздувать объём, отложили практику на следующий раз. Пришла пора провести практические опыты. Те же, кто не пользуется комплексом Redd, тоже смогут найти в этой статье полезные знания, а именно — методику подачи Vendor команд в USB накопители из ОС Linux, ведь как уже говорилось, контроллер STM32 в комплексе выполняет функцию SD-ридера, то есть — накопителя.

**Предыдущие статьи цикла**1. [Разработка простейшей «прошивки» для ПЛИС, установленной в Redd, и отладка на примере теста памяти.](https://habr.com/ru/post/452656/)
2. [Разработка простейшей «прошивки» для ПЛИС, установленной в Redd. Часть 2. Программный код.](https://habr.com/ru/post/453682/)
3. [Разработка собственного ядра для встраивания в процессорную систему на базе ПЛИС.](https://habr.com/ru/post/454938/)
4. [Разработка программ для центрального процессора Redd на примере доступа к ПЛИС.](https://habr.com/ru/post/456008/)
5. [Первые опыты использования потокового протокола на примере связи ЦП и процессора в ПЛИС комплекса Redd.](https://habr.com/ru/post/462253/)
6. [Веселая Квартусель, или как процессор докатился до такой жизни.](https://habr.com/ru/post/464795/)
7. [Методы оптимизации кода для Redd. Часть 1: влияние кэша.](https://habr.com/ru/post/467353/)
8. [Методы оптимизации кода для Redd. Часть 2: некэшируемая память и параллельная работа шин.](https://habr.com/ru/post/468027/)
9. [Экстенсивная оптимизация кода: замена генератора тактовой частоты для повышения быстродействия системы.](https://habr.com/ru/post/469985/)
10. [Доступ к шинам комплекса Redd, реализованным на контроллерах FTDI](https://habr.com/ru/post/477662/)
11. [Работа с нестандартными шинами комплекса Redd](https://habr.com/ru/post/483724/)
Классификация накопителей по системам команд
--------------------------------------------
При работе с накопителями следует различать физический интерфейс и систему команд. В частности, накопители CD/DVD/BD и прочая оптика. Традиционно они подключаются к кабелю SATA (ранее — IDE). Но конкретно по этому проводу во время работы бегают только команды PACKET, в блоке данных которых размещаются команды, закодированные по совершенно иному принципу (скоро мы узнаем, по какому). Поэтому сейчас мы будем говорить не столько о проводах, сколько о командах, которые в них бегают. Мне известно три распространённых системы команд для работы с накопителями.
* MMC. Её понимают SD-карты. Честно говоря, для меня это самая загадочная система команд. Как их подавать, вроде, ясно, но как управлять накопителем, не вчитываясь внимательно в документ, содержащий массу графов переходов, — я вечно путаюсь. К счастью, сегодня нас это не тревожит, так как хоть мы и работаем с SD-картой, но работу с ней осуществляет контроллер STM32 в режиме «чёрного ящика».
* ATA. Исходно эти команды бегали по шине IDE, затем — по SATA. Замечательная система команд, но сегодня мы также лишь упомянем, что она существует.
* SCSI. Эта система команд используется у широкого спектра устройств. Рассмотрим её применение в накопителях. Там сегодня SCSI-команды бегают, в первую очередь, по проводам шины SAS (кстати, сейчас в моду входят даже SSD с интерфейсом SAS). Как ни странно, оптические накопители, физически подключённые к шине SATA, также работают через SCSI-команды. По шине USB при работе по стандарту Mass Storage Device, также команды идут в формате SCSI. Микроконтроллер STM32 подключён к комплексу Redd через шину USB, то есть, в нашем случае, команды проходят по следующему пути:

От PC до контроллера, по шине USB, команды идут в формате SCSI. Контроллер перекодирует команды по правилу MMC и отправляет их по шине SDIO. Но нам предстоит писать программу для PC, поэтому от нас команды уходят именно в формате SCSI. Их готовит драйвер устройства Mass Storage Device, с которым мы общаемся через драйвер файловой системы. Можно ли к этим запросам подмешивать запросы к прочим устройствам? Давайте разбираться.
Детали системы команд SCSI
--------------------------
Если подходить к делу формально, то описание стандарта SCSI имеется на сайте t10.org, но будем реалистами. Никто добровольно читать его не станет. Точнее, не его, а их: там лежит целый ворох открытых документов и гора закрытых.Только крайняя необходимость заставит погрузиться в тот сложный язык, которым написан стандарт (это, кстати, касается и стандарта ATA на t13.org). Намного проще читать документацию на реальные накопители. Она написана более живым языком, а ещё из неё вырезаны гипотетические, но реально не используемые части. При подготовке статьи я наткнулся на довольно новый (2016 года) документ **SCSI Commands Reference Manual** фирмы Seagate (прямая ссылка [www.seagate.com/files/staticfiles/support/docs/manual/Interface%20manuals/100293068j.pdf](https://www.seagate.com/files/staticfiles/support/docs/manual/Interface%20manuals/100293068j.pdf) но, как всегда, я не знаю, сколько она проживёт). Думаю, если кто-то хочет освоить эту систему команд, ему лучше начать именно с этого документа. Помним только, что SD-ридеры реализуют ещё более мелкое подмножество команд из того описания.
Если же говорить совсем коротко, то в накопитель уходит командный блок, имеющий длину от 6 до 16 байт. К командному блоку может быть прикреплён блок данных либо от PC к накопителю, либо от накопителя к PC (стандарт SCSI допускает и двунаправленный обмен, но для Mass Storage Device через USB допускается только один блок, а значит, направление — только одно). В блоке команд первый байт — это всегда код команды. Остальные байты — её аргументы. Правила заполнения аргументов описываются исключительно деталями реализации команды.

Сначала я вставил в статью массу примеров, но потом понял, что они затрудняют чтение. Поэтому всем желающим я предлагаю сравнить поля команды READ CAPACITY (10) из таблицы 119 Сигейтовского документа и поля команды READ(10) из таблицы 97 того же документа (ссылку см. выше). Кто не нашёл никакой связи — не пугайтесь. Именно это я и хотел показать. Кроме поля «команда» в нулевом байте, назначение всех полей зависит исключительно от специфики конкретной команды. Всегда надо открывать документ и изучать назначение остальных полей в нём.
Итак:
* Для общения с накопителем следует сформировать блок команды длиной от 6 до 16 байт (зависит от формата команды, точное число указывается в документации на неё).
* Самым важным является нулевой байт блока: именно он задаёт код команды.
* Остальные байты блока не имеют чёткого назначения. Чтобы понять, как их заполнять, следует открыть документацию на конкретную команду.
* К команде может быть прикреплён блок данных, которые передаются в накопитель или из накопителя.
Собственно, всё. Мы изучили правила подачи SCSI-команд. Теперь мы можем их подавать, была бы на них документация. Но как это сделать на уровне операционной системы?
Подача SCSI команд в ОС Linux
-----------------------------
### Поиск целевого устройства
Для подачи команд следует открыть дисковое устройство. Давайте найдём его имя. Для этого мы пойдём абсолютно тем же путём, каким шли в [статье про последовательные порты](https://habr.com/ru/post/477662/). Посмотрим список «файлов» в каталоге **/dev** (помним, что в Linux устройства также показываются в виде файлов и их список отображается той же командой **ls**).
Сегодня обращаем внимание на виртуальный каталог **disk**:

Смотрим его содержимое:

Знакомый набор вложенных каталогов! Пробуем рассмотреть каталог **by-id**, применив уже знакомый нам по статье про последовательные порты ключ **–l** команды **ls**:

Выделенные слова говорят сами за себя. Это накопитель, содержащий внутреннюю SDшку комплекса Redd. Отлично! Теперь мы знаем, что устройству **MIR\_Redd\_Internal\_SD** соответствует устройства **/dev/sdb и /dev/sdb1**. То, которое без цифры, — это сам накопитель, работать мы будем именно с ним, а с цифрой — это файловая система, размещённая на вставленном в него носителе. В терминах работы с SD-картой, **/dev/sdb** — это ридер, а **/dev/sdb1** — файловая система на вставленной в него карточке.
### Функция операционной системы для подачи команд
Обычно в любой ОС все нестандартные вещи с устройствами делаются через прямые запросы к драйверу. В Linux для посылки таких запросов имеется функция **ioctl()**. Не исключение и наш случай. В качестве аргумента передаём запрос **SG\_IO**, описанный в заголовочном файле **sg.h**. Там же описана и структура **sg\_io\_hdr\_t**, содержащая параметры запроса. Полностью структуру приводить я не стану, так как далеко не все её поля подлежат заполнению. Приведу только наиболее важные из них:
```
typedef struct sg_io_hdr
{
int interface_id; /* [i] 'S' for SCSI generic (required) */
int dxfer_direction; /* [i] data transfer direction */
unsigned char cmd_len; /* [i] SCSI command length ( <= 16 bytes) */
unsigned char mx_sb_len; /* [i] max length to write to sbp */
unsigned short int iovec_count; /* [i] 0 implies no scatter gather */
unsigned int dxfer_len; /* [i] byte count of data transfer */
void * dxferp; /* [i], [*io] points to data transfer memory
or scatter gather list */
unsigned char * cmdp; /* [i], [*i] points to command to perform */
unsigned char * sbp; /* [i], [*o] points to sense_buffer memory */
unsigned int timeout; /* [i] MAX_UINT->no timeout (unit: millisec) */
```
Описывать те поля, которые хорошо документированы в комментариях (**interface\_id, dxfer\_direction, timeout**) нет смысла. Статья и так разрастается.
Поле **cmd\_len** содержит число байтов в блоке команды, а **cmdp** — указатель на этот блок. Без команды обойтись нельзя, поэтому число байтов должна быть не нулевым (от 6 до 16).
Данные же опциональны. Если они есть, то длина выделенного буфера задаётся в поле **dxfer\_len**, а указатель на него — в поле **dxferp**. Накопитель может физически передать меньше данных, чем указан размер буфера. Направление передачи задаётся в поле **dxfer\_direction**. Допустимые для USB Mass Storage Device значения: **SG\_DXFER\_NONE, SG\_DXFER\_TO\_DEV, SG\_DXFER\_FROM\_DEV**. В заголовочном файле есть ещё одно, но стандарт Mass Storage Device не позволяет реализовать это физически.
Также можно запросить возврат расширенного кода ошибки (**SENSE**). Что это такое, можно прочитать в Сигейтовском документе, раздел 2.4. Длина выделенного буфера указывается в поле **mx\_sb\_len**, а указатель на сам буфер — в поле **sbp**.
Как видим, в этой структуре заполняется всё то, о чём я говорил выше (плюс даётся возможность получить расширенные сведения об ошибке). Подробнее про работу с запросом **SG\_IO** можно прочитать здесь: [sg.danny.cz/sg/sg\_io.html](http://sg.danny.cz/sg/sg_io.html)
### Посылаем стандартную команду в накопитель
Ну что ж, мы выяснили формат команды, мы выяснили, в какое устройство её посылать, мы выяснили, какую функцию для этого вызывать. Давайте попробуем послать какую-нибудь стандартную команду в наше устройство. Пусть это будет команда получения имени накопителя. Вот так она описана в Сигейтовском документе:

Обратите внимание, что согласно SCSI-идеологии, все поля в стандартных командах заполняются в нотации Big Endian, то есть, старшим байтом вперёд. Поэтому поле с длиной буфера мы заполняем не в формате «0x80, 0x00», а наоборот – «0x00, 0x80». Но это – в стандартных командах. В нестандартных возможно всё, всегда надо сверяться с описанием. Собственно, только код команды (**12h**) и длину мы и должны заполнить. Страницу мы будем запрашивать нулевую, а остальные поля или зарезервированы, или устарели, или по умолчанию нулевые. Так что все их заполняем нулями.
**Делаем программку, которая подаёт эту команду:**
```
#include
#include
#include
#include // open
#include // close
#include
#include
#include
int main()
{
printf("hello from SdAccessTest!\n");
int s\_fd = open("/dev/sdb", O\_NONBLOCK | O\_RDWR);
if (s\_fd < 0)
{
printf("Cannot open file\n");
return -1;
}
sg\_io\_hdr\_t header;
memset(&header, 0, sizeof(header));
uint8\_t cmd12h[] = { 0x12,0x00,0x00,0x00,0x80,0x00};
uint8\_t data[0x80];
uint8\_t sense[0x80];
header.interface\_id = 'S'; // Обязательно 'S'
// Команда
header.cmd\_len = sizeof(cmd12h);
header.cmdp = cmd12h;
// Данные
header.dxfer\_len = sizeof(data);
header.dxferp = data;
header.dxfer\_direction = SG\_DXFER\_TO\_FROM\_DEV;
// Технологическая информация о результате
header.mx\_sb\_len = sizeof(sense);
header.sbp = sense;
//Таймаут
header.timeout = 100; // 100 мс
int res = ioctl(s\_fd, SG\_IO, &header);
close(s\_fd);
return 0;
}
```
Как такие программы запускать на удалённом устройства Redd, мы уже рассматривали в одной из [предыдущих статей](https://habr.com/ru/post/456008/). Правда, запустив её первый раз, я сразу получил ошибку вызова функции **open()**. Оказалось, что у пользователя по умолчанию не хватает прав для открытия дисковых устройств. Какой из меня специалист по Линуксу, я много раз писал, но в сети мне удалось найти, что для решения этой беды можно изменить права доступа к устройству, подав команду:
**sudo chmod 666 /dev/sdb**
Однако мой начальник (а вот он — большой специалист по этой ОС) позже отметил, что решение действует до перезагрузки операционной системы. Чтобы получить права наверняка, надо добавить пользователя в группу **disk**.
Каким бы из этих двух путей мы ни пошли, но после того, как всё заработало, ставим точку останова на строку **close(s\_fd);** и осматриваем результаты к моменту её достижения в среде разработки (так как программа — даже не однодневка, а значит — некогда нам тратить силы и время на вставку отображалок, если нам всё может показать среда разработки). Значение переменной **res** равно нулю. Значит, команда отработала без ошибок.

Что пришло в буфер? Когда я ввёл в адрес для дампа слово **data**, мне сказали, что не могут вычислить значение, пришлось вводить **&data**. Странно, ведь **data** – это указатель, при отладке под Windows всё работает, но просто отмечаю этот факт, работает так: смотрим на результат, полученный так:

Всё верно, нам вернули имя и ревизию накопителя. Подробнее с форматом полученной структуры можно ознакомиться в Сигейтовском документе (раздел 3.6.2, таблица 59). Буфер **sense** не заполнился, но и описание IOCTL запроса говорит, что он заполняется, только когда возникла ошибка, возвращающая что-то в этом буфере. Дословно: **Sense data (only used when 'status' is CHECK CONDITION or (driver\_status & DRIVER\_SENSE) is true)**.
Формат нестандартной команды для накопителя Redd Internal SD
------------------------------------------------------------
Теперь, когда мы не только изучили сухое описание стандарта, но и попробовали всё на практике, прочувствовав, что такое блок команды, уже можно показать формат команды, при помощи которой можно вызывать нестандартные функции, «прошитые» в контроллер STM32 на плате комплекса. Код команды я выбрал из начала диапазона **Vendor Specific** команд. Он равен 0xC0. Традиционно, в описаниях SCSI команд, пишут **C0h**. Длина команды всегда равна 10 байтам. Формат команды унифицирован и представлен в таблице ниже.
| | |
| --- | --- |
| **Байт** | **Назначение** |
| 0 | Код команды C0h |
| 1 | Код подкоманды |
| 2 | Аргумент arg1. Задаётся в нотации Little Endian (младшим байтом вперёд) |
| 3 |
| 4 |
| 5 |
| 6 | Аргумент arg2. Задаётся в нотации Little Endian (младшим байтом вперёд) |
| 7 |
| 8 |
| 9 |
Как видно, аргументы задаются в нотации Little Endian. Это позволит описать команду в виде структуры и обращаться к её полям напрямую, не прибегая к функции перестановки байт. Проблем выравнивания (двойные слова в структуре имеют смещения, не кратные четырём) на архитектурах x86 и x64 не стоит.
Коды подкоманд описаны следующим перечислением:
```
enum vendorSubCommands
{
subCmdSdEnable = 0, // 00 Switch SD card to PC or Outside
subCmdSdPower, // 01 Switch Power of SD card On/Off
subCmdSdReinit, // 02 Reinitialize SD card (for example, after Power Cycle)
subCmdSpiFlashEnable, // 03 Switch SPI Flash to PC or Outside
subCmdSpiFlashWritePage, // 04 Write Page to SPI Flash
subCmdSpiFlashReadPage, // 05 Read Page from SPI Flash
subCmdSpiFlashErasePage,// 06 Erase Pages on SPI Flash (4K block)
subCmdRelaysOn, // 07 Switch relays On by mask
subCmdRelaysOff, // 08 Switch relays off by mask
subCmdRelaysSet, // 09 Set state of all relays by data
subCmdFT4222_1_Reset, // 0A Activate Reset State or switch chip to normal mode
subCmdFT4222_2_Reset, // 0B Activate Reset State or switch chip to normal mode
subCmdFT4222_3_Reset, // 0C Activate Reset State or switch chip to normal mode
subCmdFT4232_Reset, // 0D Activate Reset State or switch chip to normal mode
subCmdFT2232_Reset, // 0E Activate Reset State or switch chip to normal mode
subCmdMAX3421_Reset, // 0F Activate Reset State or switch chip to normal mode
subCmdFT4222_1_Cfg, // 10 Write to CFG pins of FT4222_1
subCmdFT4222_2_Cfg, // 11 Write to CFG pins of FT4222_2
subCmdFT4222_3_Cfg, // 12 Write to CFG pins of FT4222_3
};
```
Их можно разбить на группы.
### Переключение устройств на внутренний и внешний режимы
Команды **subCmdSdEnable** и **subCmdSpiFlashEnable** коммутируют SD-карту и SPI-флэш соответственно. В параметре **arg1** передаётся одно из следующих значений:
```
enum enableMode
{
enableModeToPC = 0,
enableModeOutside
};
```
По умолчанию, оба устройства подключены к PC.
### Коммутация питания
Протокол SDIO требует достаточно больших манипуляций при инициализации. Иногда бывает полезно сбросить SD-карту к начальному состоянию (например, при переключении её линий на внешний разъём). Для этого надо отключить, затем — включить её питание. Это можно сделать при помощи команды **subCmdSdPower**. В аргументе **arg1** передаётся одно из следующих значений: 0 — выключение питания, 1 — включение. Не забудьте дать время на разрядку конденсаторов на линии питания.
После включения питания, карту, если она подключена к PC, следует переинициализировать. Для этого используйте команду **subCmdSdReinit** (у неё нет аргументов).
### Работа с SPI флэшкой
Если SD-карта подключается к системе как полноценный накопитель, микросхеме SPI Flash доступ в текущей версии сделан достаточно ограничено. Можно обращаться только к отдельным её страницам (256 байт) и только по одной. Объём памяти в микросхеме таков, что даже при работе по странице всё равно много времени процесс не займёт, но зато такой подход существенно упрощает «прошивку» микроконтроллера.
Команда **subCmdSpiFlashReadPage** считывает страницу. Адрес задаётся в параметре arg1, число страниц на передачу — в параметре arg2. Но в текущей версии число страниц должно быть равно единице. Команда вернёт 256 байт данных.
Зеркальная для неё — команда **subCmdSpiFlashWritePage**. Аргументы для неё заполняются по тому же принципу. Направление передачи данных — к устройству.
Особенностью флэш-памяти является то, что при записи можно заменять только единичные биты на нулевые. Чтобы вернуть их в единичное значение, страницы следует стереть. Для этого имеется команда **subCmdSpiFlashErasePage**. Правда, из-за особенностей применённой микросхемы, стирается не одиночная страница, адрес которой задан в параметре **arg1**, а блок размером 4 килобайта, содержащий её.
### Управление твердотельными реле
В комплексе установлено шесть твердотельных реле. Для управления ими имеется три команды.
**subCmdRelaysSet** — устанавливает значение всех шести реле одновременно. В параметре **arg1** передаётся значение, каждый бит которого соответствует своему реле (нулевой бит — реле с индексом 0, первый — с индексом 1 и т. д.). Единичное значение бита приводит к замыканию реле, нулевое — к размыканию.
Такой метод работы хорош, когда все реле работают, как единая группа. Если же они работают независимо друг от друга, при таком подходе приходится заводить буферную переменную, которая хранит значение состояний всех реле. Если же разными реле управляют разные программы, проблема хранения сводного значения становится крайне острой. В этом случае можно воспользоваться двумя другими командами:
**subCmdRelaysOn** — включает выбранные реле по маске. Те реле, которым соответствуют единичные биты в аргументе **arg1**, будут включены. Реле же, которым соответствуют нули в маске, сохранят своё текущее состояние.
Зеркальная ей команда **subCmdRelaysOff** выключит выбранные реле по маске. Те реле, которым соответствуют единичные биты в аргументе **arg1**, будут выключены. Реле же, которым соответствуют нули в маске, сохранят своё текущее состояние.
### Сброс контроллеров FTDI и Maxim
Для подачи сигналов сброса на микросхемы FTDI и Maxim, используется группа команд **subCmdFT4222\_1\_Reset**, **subCmdFT4222\_2\_Reset**, **subCmdFT4222\_3\_Reset**, **subCmdFT4232\_Reset**, **subCmdFT2232\_Reset** и **subCmdMAX3421\_Reset**. Из их имён видно, сигналами сброса каких микросхем они управляют. Мостов FT4222, как мы рассматривали ранее, в схеме два (их индексы 1 и 2), ещё один мост FT4222 передаёт данные в микросхему MAX3421, которую мы будем рассматривать в следующей статье.
В параметре **arg1** передаётся одно из следующих значений:
```
enum ResetState
{
resetStateActive =0,
resetStateNormalOperation
};
```
По умолчанию, все мосты находятся в нормальном рабочем состоянии. Как уже отмечалось в [прошлой статье](https://habr.com/ru/post/483724/), мы пока сами не уверены, понадобится ли эта функциональность, но когда нет прямого доступа к устройству — лучше иметь возможность дистанционно сбрасывать всё и вся.
### Переключение конфигурационных линий микросхем FT4222
Микросхемы FT4222 имеют четыре режима. Вряд ли кому-то понадобится режим, отличный от «00», но если вдруг понадобится — для переключения можно использовать команды **subCmdFT4222\_1\_Cfg**, **subCmdFT4222\_2\_Cfg** и **subCmdFT4222\_3\_Cfg** для первой, второй и третьей микросхем. Значение линий CFG0 и CFG1 задаётся в младших двух битах параметра **arg1**.
Практический опыт подачи команды в контроллер STM32
---------------------------------------------------
Для проверки полученного теоретического материала на практике попробуем переключить SD-карту наружу. Для этого надо подать команду **subCmdSdEnable**, имеющую код 0x00 с аргументом **enableModeOutside**, имеющим код 0x01. Прекрасно. Переписываем программу из прошлого опыта следующим образом.
**Переписанная программа:**
```
#include
#include
#include
#include // open
#include // close
#include
#include
#include
int main()
{
printf("hello from SdAccessTest!\n");
int s\_fd = open("/dev/sdb", O\_NONBLOCK | O\_RDWR);
if (s\_fd < 0)
{
printf("Cannot open file\n");
return -1;
}
sg\_io\_hdr\_t header;
memset(&header, 0, sizeof(header));
uint8\_t cmdSdToOutside[] = { 0xC0,0x00,0x01,0x00,0x00,0x00,0x00,0x00,0x00,0x00 };
uint8\_t cmdSdToPC[] = { 0xC0,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00 };
uint8\_t sense[32];
memset(sense, 0, sizeof(sense));
header.interface\_id = 'S'; // Обязательно 'S'
// Команда
header.cmd\_len = sizeof(cmdSdToOutside);
header.cmdp = cmdSdToOutside;
// Данные (их нет)
header.dxfer\_len = 0;
header.dxferp = 0;
header.dxfer\_direction = SG\_DXFER\_NONE;
// Технологическая информация о результате
header.mx\_sb\_len = sizeof(sense);
header.sbp = sense;
//Таймаут
header.timeout = 100; // 100 мс
int res = ioctl(s\_fd, SG\_IO, &header);
// Включаем обратно
header.cmdp = cmdSdToPC;
res = ioctl(s\_fd, SG\_IO, &header);
close(s\_fd);
return 0;
}
```
Мы изменили длину команды до десяти байт и убрали блок данных. Ну, и записали код команды с аргументами, согласно требованиям. В остальном, всё осталось то же самое. Запускаем… И… Ничего не работает. Функция **ioctl()** возвращает ошибку. Причина описана в документе на команду **SG\_IO**. Дело в том, что мы подаём Vendor Specific команду **C0h**, а про них там сказано дословно следующее:
> Any other SCSI command (opcode) not mentioned for the sg driver needs O\_RDWR. Any other SCSI command (opcode) not mentioned for the block layer SG\_IO ioctl needs a user with CAP\_SYS\_RAWIO capability.
Как объяснил мне начальник (я просто пересказываю его слова), значения **capabilities** назначаются на исполняемый файл. По этой причине трассировать из среды разработки мне пришлось, заходя под пользователем **root**. Не самое лучшее решение, но хоть что-то. На самом деле, в Windows запрос **IOCTL\_SCSI\_PASS\_THROUGH\_DIRECT** тоже требует администраторских прав. Возможно, в комментариях кто-то даст совет, как решить вопрос с трассировкой без таких радикальных шагов, но уже написанную программу можно запускать и не от имени **root**, если прописать ей правильные **capabilities**. А пока — меняем имя пользователя в среде разработки и ставим точку останова на строку:
```
int res = ioctl(s_fd, SG_IO, &header);
```
и перед вызовом функции **ioctl()** смотрим перечень запоминающих устройств:

Вызываем **ioctl()** и смотрим перечень ещё раз:

Устройство **/dev/sdb** осталось (грубо говоря, это сам считыватель SD-карт), а **/dev/sdb1** – исчезло. Это устройство соответствует файловой системе на носителе. Носитель отключился от ЭВМ – его стало не видно. Продолжаем трассировку. После вызова второй функции **ioctl()**, снова смотрим список устройств:

SD-карта снова подключена к системе, поэтому **/dev/sdb1** снова на месте. Собственно, мы научились подавать vendor specific команды и управлять устройством на базе микроконтроллера STM32 в комплексе Redd. Прочие команды оставим читателям для самостоятельного изучения. Контролировать срабатывание некоторых из них можно аналогичным образом. Если какая-то микросхема **ftdi** ушла в состояние сброса, из системы исчезнет соответствующее ей устройство. Срабатывание реле и управление ножками конфигурации придётся контролировать измерительными приборами. Ну, и работу с флэшкой можно проверять, записывая страницы с последующим их контрольным считыванием.
Заключение
----------
Мы рассмотрели две больших темы, не связанные с ПЛИС в комплексе Redd. Осталась третья — работа с микросхемой MAX3421, позволяющей реализовывать устройства USB 2.0 FS. На самом деле, хосты тоже, но хостов и на материнской плате имеется предостаточно. Функциональность Устройства же позволят комплексу прикидываться USB флэшкой (чтобы передавать обновления «прошивки»), USB клавиатурой (чтобы управлять внешними блоками) и т.п. Эту тему мы рассмотрим в следующей статье. | https://habr.com/ru/post/484706/ | null | ru | null |
# Новая большая книга CSS
Привет, Хаброжители! У нас вышла новая обновленная книга Дэвида Макфарланда:
 Технология CSS3 позволяет создавать профессионально оформленные сайты, но тонкости этого языка могут оказаться довольно сложными даже для опытных веб-разработчиков. Полностью переработанное четвертое издание этой книги поможет вам поднять навыки работы с HTML и CSS на новый уровень; она содержит множество ценных советов, описаний приемов, а также инструкции, написанные в стиле справочного руководства. Веб-дизайнеры, как начинающие, так и опытные, при помощи этой книги быстро научатся создавать красивые веб-страницы, которые при этом молниеносно загружаются как на ПК, так и на мобильных устройствах.
##### Что необходимо знать
Эта книга предполагает, что вы уже знакомы с языком HTML. Подразумевается, что вы создали пару сайтов (или по крайней мере несколько веб-страниц) и знакомы с основными элементами, такими как html, p, h1, table, составляющими основу языка гипертекстовой разметки документов. CSS бесполезен без HTML, поэтому вы должны знать, как создать простейшую веб-страницу с использованием основных HTML-элементов.
Если вы раньше создавали веб-страницы на HTML, но чувствуете, что знания требуется освежить, вам поможет следующий раздел книги.
##### HTML: структура языка
В языке гипертекстовой разметки HTML используются простые команды, именуемые тегами, для определения различных частей — фрагментов. Ниже приведен HTML-код простой веб-страницы:
```
Это заголовок веб-страницы
А это абзац этой веб-страницы
```
Конечно, пример очень простой, но демонстрирует все основные элементы, необходимые обычной веб-странице. В нем вы заметите то, что называется объявлением типа документа — doctype, за ним следует открывающий тег (со скобками), потом элемент head (голова, раздел заголовка), следом body (тело, раздел тела), а в нем непосредственно содержимое веб-страницы. Все это завершается закрывающим тегом . Открывающий и закрывающий теги образуют HTML-элемент.
##### Типы документов
Все веб-страницы начинаются с объявления типа документа — строки кода, определяющей разновидность HTML, которой вы пользовались при написании страницы. В течение многих лет использовались два типа документов — HTML 4.01 и XHTML 1.0, и каждый из них имеет два стиля: строгий и переходный. Например, объявление переходного типа документа HTML 4.01 имеет следующий вид (другие объявления типа документа для HTML 4.01 и XHTML 1.0 выглядят примерно так же):
```
```
Если посмотреть на код примера HTML-страницы, показанный в этом разделе, то вы увидите, что в нем используется краткая форма объявления типа документа:
```
```
Объявление типа документа появилось в языке HTML5. По сравнению с предшественниками, в HTML5 заложена простота и рациональность использования. В этой книге применяется объявление типа документа из HTML5, поддерживаемое любым популярным браузером (даже старым Internet Explorer 6). Применять другие объявления, отличные от простого doctype из HTML5, не имеет смысла.
Независимо от предпочитаемого типа документа, объявляемого с помощью doctype, важно, чтобы использовалось объявление хотя бы одного из них. Без этого ваши страницы будут выглядеть по-разному в зависимости от браузера вашего посетителя, поскольку браузеры, не имеющие в качестве руководства объявления типа документа, по-разному отображают информацию, форматированную с помощью CSS.
Каждое объявление типа документа требует от вас написания HTML-кода определенным образом. Например, элемент для разбиения строк имеет в HTML 4.01 следующий вид:
```
``` | https://habr.com/ru/post/280828/ | null | ru | null |
# Система для «Своей игры»

Привет, Хабр! Так получилось, что одним из моих увлечений являются интеллектуальные игры. Это «Что? Где? Когда?», «Своя игра», «Эрудит-квартет», «Брейн-ринг» и прочие. И вот, однажды мне захотелось сделать своими руками систему для этой игры. Если вам интересен процесс создания с нуля такого устройства — приглашаю под кат.
#### Предыстория
> **Коротко о правилах «Своей игры»:**
>
> *Группа игроков (как правило, до 4-х человек) садится за игровые места. Объявляется тема, состоящая из пяти вопросов. Вопросы идут по возрастанию сложности и соответственно оцениваются — от 10 до 50 баллов. Ведущий объявляет номинал вопроса и начинает его зачитывать. В любой момент чтения вопроса игрок подает сигнал, после которого ведущий прекращает читать вопрос и начинает отсчет времени — подавшему сигнал игроку дается 3-5 секунд на ответ. В случае правильного и своевременного ответа, игрок получает количество баллов, равное номиналу вопроса. В ином случае у игрока отнимается это количество баллов (Итоговый счет может быть глубоко отрицательным).*
Сигналом в этой игре может быть все что угодно — от хлопка в ладоши в простейшем случае, до нажатия кнопки специализированной системы для «Своей игры». Подавляющее большинство таких систем являются самодельными (не настолько интеллектуальные игры популярны, чтобы ставить это дело на поток). Кроме того, эти системы зачастую обладают различными недостатками.
Перечислю некоторые из недостатков в системах, с которыми мне приходилось иметь дело:
* большие габариты;
* работа только от сети 220В;
* работа только в связке с компьютером (взаимодействие со специальным Windows-приложением);
* некачественные, залипающие кнопки (например, от дверных звонков);
В нашем городе тренировки по интеллектуальным играм проходят каждую неделю, по воскресеньям. Причем, в зависимости от времени года и погоды, мы можем собраться в местном парке — это намного приятнее, чем коптиться в душном помещении. Из-за своих недостатков, имеющиеся в нашем распоряжении готовые системы было просто лень приносить из дому. Поэтому, зачастую приходилось играть «на хлопки». Точность определения первого, успевшего подать сигнал, оставляла желать лучшего. Часто бывало, что мнения присутствующих по этому поводу разделялись — казалось, что первым хлопнул тот, кто стоит к тебе ближе. Все эти факторы натолкнули меня на мысль о создании своей реализации игровой системы. Да и вообще, было интересно получить опыт создания устройства с нуля — от проекта до готового изделия.
#### Проект
Для начала, я решил определиться с основной концепцией устройства. Для себя отметил принципиальные пункты, которые должны быть реализованы в системе:
* Удобные пульты с надежными кнопками и светодиодной индикацией (подтверждение игроку, что он первый нажал на кнопку);
* Разъемное соединение пультов и устройства. Решено было сделать разъемы как на пультах, так и на самой системе. Был выбран разъем 4P4C (RJ11, обычно применяется в телефонных аппаратах). Такой выбор был сделан из-за небольших размеров и простоты ремонта кабеля — при наличии обжимного инструмента и коннекторов проблема решается в считанные минуты;
* Два возможных источника питания — внешний и внутренний. Забегая вперед — именно в реализации схемы питания я совершил наибольшее число ошибок;
* Система должна иметь разъем внутрисхемного программирования (ISP), чтобы можно было без лишних хлопот менять прошивку микроконтроллера;
* Не должно быть привязки к любым другим устройствам (компьютер и т.п.);
* Небольшие габариты.
В качестве «мозгов» устройства я выбрал чрезвычайно популярный у радиолюбителей микроконтроллер от Atmel — Atmega8. Хотя для функционала системы с головой хватило бы какого-нибудь Attiny, у него был фатальный недостаток — он не лежал у меня в столе. В отличие от вышеупомянутой Atmega.
Затем я на скорую руку набросал приблизительную принципиальную схему:
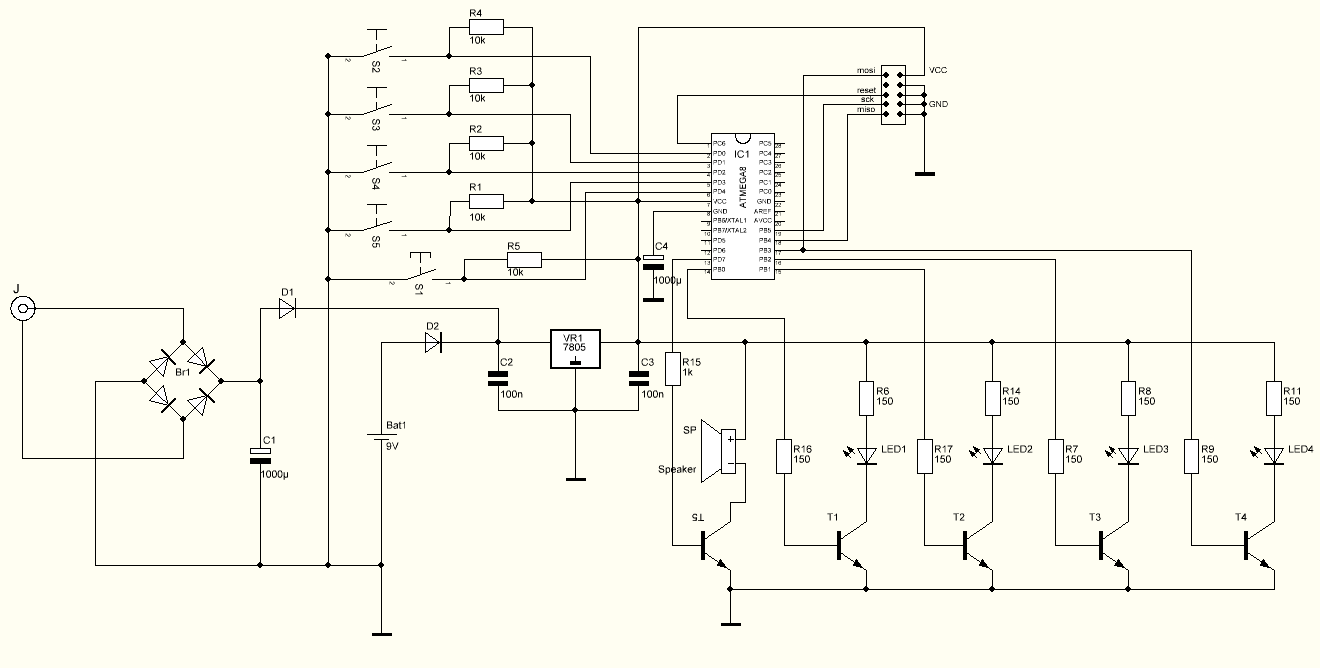
В качестве внешнего источника питания был выбран валявшийся без дела блок питания от старого модема — на выходе он имеет 12 В переменного напряжения. В роли внутреннего источника я выбрал батарейку типа «Крона» — ошибка №1. Для выработки необходимых для микроконтроллера 5 В я поставил линейный стабилизатор LM7805 — ошибка №2. О том, что это ошибки, я на практике узнал уже после сборки и тестирования устройства. Оказалось, что у «Кроны» весьма низкая емкость, да еще и почти половина ее уходила в никуда — на подогрев линейного стабилизатора. Однако, об этом позже.
Кнопки и разъемы, которые я выбрал для устройства, пришлось покупать на ebay — уж слишком высокие цены запрашивали местные торговцы. Правда, 10-миллиметровые светодиоды таки пришлось приобрести на радиорынке — ни на ebay, ни на aliexpress я не нашел индикаторных разноцветных светодиодов нужного диаметра.
Одним из важнейших и определяющих дальнейшее действие шагов был выбор корпуса. В своем городе ничего подходящего мне по качеству найти не удалось — пришлось воспользоваться торговыми площадками в Интернете. Устраивающий меня вариант нашелся в Киеве, там и были заказаны 5 корпусов — для основного блока и для пультов.
И вот, имея на руках все необходимые элементы, я стал продумывать дизайн устройства.
#### Печатные платы
Имея на руках корпуса, я приступил к разработке печатных плат. Вот, что у меня вышло:
**Печатная плата основного блока**
**Печатная плата блока светодиодов**
**Печатная плата кнопки**
Макеты печатных платы создавались в программе Sprint Layout, в конце будут ссылки на исходники. Используйте, модифицируйте — в общем, делайте с ними все что хотите.
Сами печатные платы я делал методом ЛУТ (лазерно-утюжная технология) — по моему скромному мнению, это наиболее простой и доступный простому смертному способ сделать печатную плату приемлемого качества.
#### Код
Тут, собственно, листинг программы микроконтроллера. Возможно, код не самый изящный, но он работает и свою функцию выполняет на ура.
**Код программы на языке C**
```
#define F_CPU 4000000UL
#define f 349
#define a 440
#define cH 523
#include // Ввод/вывод, все стандартно
#include // Нам будут нужны временные задержки
#include // Без прерываний тоже никуда
// Гасим засветившиеся светодиоды
void clear\_led(void)
{
PORTB = 0b00110000;
PORTC = 0xFF;
}
int blink\_led(int num)
{
clear\_led();
\_delay\_ms(100);
PORTB |= (1<
```
Если вдруг случится, что кто-то откроет кат и посмотрит на код, у этого человека наверняка возникнет вопрос — что за ерунда занимает большую его часть. Дело в том, что мне захотелось внести в устройство какую-нибудь изюминку, и в качестве этой изюминки я выбрал приветствие при включении. Сразу после того, как первые электроны побегут по цепи, эта черная коробочка с разноцветными светодиодами и красной кнопкой начинает весело играть отрывок из всем известного «Имперского марша».
**Вот как это выглядит:**
Кроме самой мелодии, на этом коротком видео можно лицезреть пример работы системы: по нажатию кнопки загорается соответствующий светодиод на основном устройстве и индикатор. В таком состоянии система блокируется до нажатия ведущим красной кнопки сброса системы. Вот, собственно, и вся логика работы.
#### Ошибки в проекте
Как я уже писал выше, основные ошибки на этапе проектирования касались системы питания устройства. Ужасный КПД линейного стабилизатора, который буквально превращает в тепло «лишние» 4В при питании от «Кроны» — апофеоз энергонеэффективности. Да и сама «Крона» — далеко не лучший выбор. Этот элемент питания обладает малой емкостью (около 600 мА\*ч), и его хватает очень ненадолго. С такой схемой питания система во время первого тестирования в боевых условиях проработала не больше часа. Меня это абсолютно не устраивало, поэтому пришлось переделывать эту часть схемы.
Незадолго до этого проекта я познакомился с литий-ионными аккумуляторами форм-фактора 18650. Они зарекомендовали себя с наилучшей стороны. Как минимум, даже у дешевых китайских аккумуляторов емкость в пересчете на единицу объема была значительно выше, чем у «Кроны».
Однако, с выбором этих элементов питания сразу появлялась другая проблема. Номинальное напряжение на таком аккумуляторе — 3.7 В. А этого недостаточно, чтобы запитать Atmega8. На помощь снова пришли ушлые китайцы — чтобы получить заветные 5 В я взял лежавший без дела повышающий преобразователь на LM2577. Вырвав с корнем злополучную LM7805 (оставшиеся в плате ножки можно будет увидеть на фото, размещенные дальше), я внедрил в систему питания аккуратную схемку, созданную трудолюбивыми жителями КНР.
Кроме того, на время тестирования этого варианта схемы я решил отказаться от возможности подключения внешнего источника питания. Полевые тесты прошли на ура — после многих часов эксплуатации не было никаких признаков разряда аккумулятора или просадки напряжения («Крона» просадки давала — видимо, не могла отдавать необходимый схеме ток). Я решил продолжать тесты до тех пор, пока мой доблестный noname 18650 не откажется запускать схему.
Кстати, в описании лота при покупке была заявлена емкость около 3700 мА\*ч — очень самоуверенно даже для китайцев, учитывая стоимость одной банки в районе 3$. Но вышло так, что за несколько месяцев работы (что говорит еще и о низком саморазряде аккумуляторов) батарейка так и не села. Потому я сдался раньше и зарядил аккумулятор для безотказной работы устройства на одном важном мероприятии, о котором будет упомянуто позже.
#### Фотографии
Здесь привожу фото получившегося аппарата, в том числе и вид изнутри. Это для того, чтобы было видно, что все сделано по-честному — никакой неонки внутре там нет.







#### Итог
Система получилась работоспособная, выполняющая свою функцию на 100%. Помимо тренировок, она была протестирована на ЧУСИ-2013 (Чемпионат Украины по «Своей игре» 2013-го года), на котором ваш покорный слуга был одним из ведущих.
Это был замечательный опыт, который, как известно, сын ошибок трудных. В итоговой реализации устройство потеряло часть функций, которые задумывались изначально. Например, я отказался от возможности подключения внешнего блока питания — даже при активном использовании системы, посредственного аккумулятора хватает на многие месяцы.
Ниже прилагаю ссылки, по которым можно скачать макеты печатных плат (в формате .lay) и готовую прошивку для микроконтроллера. Буду рад, если кому-нибудь пригодятся мои наработки.
[Печатная плата основной части](https://yadi.sk/d/-ickg2ZXcFEfG);
[Печатная плата блока светодиодов](https://yadi.sk/d/-Osg2H65cFEfa);
[Печатная плата кнопки](https://yadi.sk/d/HFAQboB0cFEgV);
[Прошивка](https://yadi.sk/d/VCqKWpa5cFEgs). | https://habr.com/ru/post/241407/ | null | ru | null |
# Прописываем процедуру экстренного доступа к хостам SSH с аппаратными ключами

В этом посте мы разработаем процедуру для экстренного доступа к хостам SSH, используя аппаратные ключи безопасности в автономном режиме. Это всего лишь один из подходов, и вы можете адаптировать его под себя. Мы будем хранить центр сертификации SSH для наших хостов на аппаратном ключе безопасности. Эта схема будет работать практически на любом OpenSSH, включая SSH с единым входом.
Зачем всё это? Ну, это вариант на крайний случай. Это бэкдор, который позволит вам получить доступ к своему серверу в том случае, когда по какой-то причине больше ничего не помогает.
Зачем использовать сертификаты вместо открытых / закрытых ключей для экстренного доступа?
* В отличие от открытых ключей, срок действия сертификатов может быть очень коротким. Вы можете сгенерировать сертификат, действительный в течение 1 минуты или даже 5 секунд. По истечении этого срока сертификат станет непригодным для новых подключений. Это идеально подходит для экстренного доступа.
* Вы можете создать сертификат для любой учётной записи на своих хостах и при необходимости отправлять такие вот «одноразовые» сертификаты коллегам.
Что вам понадобится
-------------------
* Аппаратные ключи безопасности, которые поддерживают резидентные ключи.
Резидентные ключи — это криптографические ключи, которые полностью хранятся внутри ключа безопасности. Иногда они защищены буквенно-цифровым PIN-кодом. Открытая часть резидентного ключа может быть экспортирована из ключа безопасности, при необходимости — вместе с дескриптором закрытого ключа. Поддержку резидентных ключей, имеют, например, USB-ключи серии Yubikey 5. Желательно, чтобы они предназначались только для экстренного доступа к хосту. Для этого поста я буду использовать только один ключ, но у вас должен быть дополнительный для резервного копирования.
* Безопасное место для хранения этих ключей.
* OpenSSH версии 8.2 или выше на вашем локальном компьютере и на серверах, к которым вы хотите получить экстренный доступ. Ubuntu 20.04 поставляется с OpenSSH 8.2.
* (необязательно, но желательно) Средство CLI для проверки сертификатов.
Подготовка
----------
Для начала нужно создать центр сертификации, который будет находиться на аппаратном ключе безопасности. Вставьте ключ и запустите:
```
$ ssh-keygen -t ecdsa-sk -f sk-user-ca -O resident -C [security key ID]
```
В качестве комментария (-C) я указал [email protected], чтобы не забыть, к какому ключу безопасности относится этот центр сертификации.
Кроме добавления ключа к Yubikey, локально будет сгенерировано два файла:
1. sk-user-ca, дескриптор ключа, который ссылается на закрытый ключ, хранящийся в ключе безопасности,
2. sk-user-ca.pub, который будет открытым ключом для вашего центра сертификации.
Но не волнуйтесь, на Yubikey хранится ещё один закрытый ключ, который невозможно извлечь. Поэтому тут всё надёжно.
На хостах от имени пользователя root добавьте (если ещё не добавили) в конфигурацию вашего SSHD (/etc/ssh/sshd\_config) следующее:
```
TrustedUserCAKeys /etc/ssh/ca.pub
```
Затем на хосте добавьте открытый ключ (sk-user-ca.pub) в /etc/ssh/ca.pub
Перезагрузите демон:
```
# /etc/init.d/ssh restart
```
Теперь мы можем попробовать получить доступ к хосту. Но сначала нам понадобится сертификат. Создайте пару ключей, которая будет связана с сертификатом:
```
$ ssh-keygen -t ecdsa -f emergency
```
> ***Сертификаты и SSH-пары***
>
> *Иногда так и тянет использовать сертификат как замену пары открытый / закрытый ключ. Но для аутентификации пользователя одного сертификата недостаточно. Каждый сертификат также имеет закрытый ключ, связанный с ним. Вот почему нам нужно сгенерировать эту пару «экстренных» ключей, прежде чем мы выдадим себе сертификат. Важно то, что подписанный сертификат мы показываем серверу, с указанием пары ключей, для которых у нас есть закрытый ключ.
>
>
>
> Таким образом, обмен открытыми ключами всё ещё жив-здоров. Это прокатывает даже с сертификатами. Сертификаты просто избавляют сервер от необходимости хранить открытые ключи.*
Далее создайте сам сертификат. Мне нужна авторизация пользователя ubuntu в 10-минутном интервале. Вы можете сделать по-своему.
```
$ ssh-keygen -s sk-user-ca -I test-key -n ubuntu -V -5m:+5m emergency
```
Вам будет предложено подписать сертификат с помощью отпечатка пальцев. Вы можете добавить дополнительные имена пользователей, разделенные запятыми, например, -n ubuntu,carl,ec2-user
Всё, теперь вас есть сертификат! Далее нужно указать правильные разрешения:
```
$ chmod 600 emergency-cert.pub
```
После этого вы можете ознакомится с содержимым вашего сертификата:
```
$ step ssh inspect emergency-cert.pub
```
Вот как выглядит мой:
```
emergency-cert.pub
Type: [email protected] user certificate
Public key: ECDSA-CERT SHA256:EJSfzfQv1UK44/LOKhBbuh5oRMqxXGBSr+UAzA7cork
Signing CA: SK-ECDSA SHA256:kLJ7xfTTPQN0G/IF2cq5TB3EitaV4k3XczcBZcLPQ0E
Key ID: "test-key"
Serial: 0
Valid: from 2020-06-24T16:53:03 to 2020-06-24T17:03:03
Principals:
ubuntu
Critical Options: (none)
Extensions:
permit-X11-forwarding
permit-agent-forwarding
permit-port-forwarding
permit-pty
permit-user-rc
```
Здесь открытый ключ — это созданный нами ключ emergency, а с центром сертификации связан sk-user-ca.
Наконец-то мы готовы запустить команду SSH:
```
$ ssh -i emergency ubuntu@my-hostname
ubuntu@my-hostname:~$
```
1. Теперь вы можете создавать сертификаты для любого пользователя на хосте, который доверяет вашему центру сертификации.
2. Вы можете удалить emergency. Вы можете сохранить sk-user-ca, но вам это не нужно, поскольку он также находится на ключе безопасности. Возможно, вы также захотите удалить исходный открытый ключ PEM со своих хостов (например, в ~/.ssh/authorized\_keys для пользователя ubuntu), если вы использовали его для экстренного доступа.
Экстренный доступ: план действий
--------------------------------
Вставьте ключ безопасности и запустите команду:
```
$ ssh-add -K
```
Таким образом вы добавите открытый ключ центра сертификации и дескриптор ключа в SSH-агент.
Теперь экспортируйте открытый ключ, чтобы сделать сертификат:
```
$ ssh-add -L | tail -1 > sk-user-ca.pub
```
Создайте сертификат со сроком годности, например, не более часа:
```
$ ssh-keygen -t ecdsa -f emergency
$ ssh-keygen -Us sk-user-ca.pub -I test-key -n [username] -V -5m:+60m emergency
$ chmod 600 emergency-cert.pub
```
И теперь вновь SSH:
```
$ ssh -i emergency username@host
```
Если ваш файл .ssh/config вызывает какие-то проблемы при подключении, вы можете запустить ssh с параметром -F none, чтобы обойтись без него. Если вам нужно отправить сертификат коллеге, самый простой и безопасный вариант — это [Magic Wormhole](https://github.com/warner/magic-wormhole). Для этого понадобится всего два файла — в нашем случае это emergency и emergency-cert.pub.
Что мне нравится в этом подходе, так это аппаратная поддержка. Вы можете поместить ключи безопасности в сейф, и они никуда не денутся.
---
#### На правах рекламы
**Эпичные серверы** — это [дешёвые VPS](https://vdsina.ru/cloud-servers?partner=habr34) с мощными процессорами от AMD, частота ядра CPU до 3.4 GHz. Максимальная конфигурация позволяет решить практически любые задачи — 128 ядер CPU, 512 ГБ RAM, 4000 ГБ NVMe. Присоединяйтесь!
[](https://vdsina.ru/cloud-servers?partner=habr34) | https://habr.com/ru/post/510546/ | null | ru | null |
# Хочется взять и расстрелять, или ликбез о том, почему не стоит использовать make install
| |
| --- |
| К написанию сей заметки меня сподвигло то, что я устал делать развёрнутые замечания на эту тему в комментариях к статьям, где в качестве части инструкции по сборке и настройке чего-либо для конкретного дистра предлагают выполнить make install. |
Суть сводится к тому, что эту команду в виде «make install» или «sudo make install» использовать в современных дистрибутивах нельзя.
Но ведь авторы программ в руководствах по установке пишут, что нужно использовать эту команду, возможно, скажете вы. Да, пишут. Но это лишь означает, что они не знают, какой у вас дистрибутив, и дистрибутив ли это вообще, может, вы вступили в секту и об~~курились~~читались LFS и теперь решили под свою хтоническую систему скомпилять их творение. А make install является универсальным, хоть и зачастую неправильным способом это сделать.
#### Лирическое отступление
Как известно, для нормальной работы большинство софта должно быть не только скомпилировано, но и правильно установлено в системе. Программы ожидают найти нужные им файлы в определённых местах, и места эти в большинстве \*nix-систем зашиты в код на этапе компиляции. Помимо этого аспекта основным отличием процесса установки в linux/freebsd/whatever от таковой в Windows и MacOS является то, что программа не просто складывает кучу файлов в отдельную директорию в Program Files или /Applications, а «размазывает» себя по всей файловой системе. Библиотеки идут в lib, исполняемые файлы в bin, конфиги в etc, разного рода данные в var и так далее. Если вам вдруг понадобится её обновить, то всё это надо сначала как-то вычистить, т. к. *при использовании новой версии остатки файлов от старой могут привести к совершенно непредсказуемым последствиям*, зачастую нехорошим. Вероятность этого события не так велика, но оно вам надо на боевом сервере?
#### И что с того?
Так вот, если вы делали установку напрямую через make install, то нормально удалить или обновить софтину вы, скорее всего, *не сможете*. Более того, установка новой версии поверх старой, скорее всего, *затрёт ваши изменения в конфигах*. make install делает ровно то, что ему сказано — производит установку файлов в нужные места, игнорируя тот факт, что там что-то уже есть. После этого процесса совершенно никакой информации о том, что и куда ставилось, получить в удобоваримом виде невозможно. Иногда, конечно, Makefile поддерживает действие uninstall, но это встречается не так часто, да и не факт, что корректно работает. Помимо этого хранить для деинсталяции распакованное дерево исходников и правил сборки как-то странно.
#### Как бороться?
Поскольку в дистрибутивах пакеты имеют свойство иногда всё-таки обновляться, для решения этой проблемы придумали такую штуку как пакетный менеджер. При его использовании установка происходит примерно так:
1. берётся определённым образом сформированный архив
2. из него извлекается информация о том, что это вообще такое, какой версии, от чего зависит, с чем конфликтует, надо ли для установки/удаления/настройки запускать какие-то скрипты, etc
3. Выполняются действия по непосредственной установке
4. Все данные о том, куда и что было поставлено добавляются в базу данных пакетного менеджера.
В этом случае при обновлении можно безболезненно поудалять лишнее, а заодно посмотреть, не поменялись ли в системе файлы, помеченные как конфигурационные и спросить, что делать, если в новой версии их содержимое отличается. Помимо этого, пакетный менеджер не даст затереть файлы одного пакета при установке другого. В общем, много полезных штук он может сделать.
Если вы по незнанию/лени скопипастили make install из инструкции, то *в системе появляются файлы, о которых пакетный менеджер не знает*. Со всеми вытекающими, если вам мало того, что было перечислено ранее.
#### Что делать?
Можно, конечно, сконфигурировать дерево исходников так, чтобы установка всего и вся шла куда-нибудь в /opt/mycoolapp/, а потом при необходимости руками удалить, но тут может вылезти масса неприятных вещей, начиная с того, что программа ожидает, что сможет загрузить свои библиотеки, а загрузчик о директории, где они лежат ничего не знает, заканчивая тем, что автор программы может рассчитывать, что например, если он кладёт файл, скажем в $prefix/share/xsessions/, то его подхватит менеджер дисплея. Не говоря уже о путях для pkgconfig и прочем.
Так что надо собирать пакет.
#### У меня нет времени, чтобы \*\*\*ться с этим, лучше ещё раз сделаю make install, всё просто и понятно!
Спокойно, спокойно. Он у нас за ноги привязан. Всё не так уж страшно и сложно, как кажется на первый взгляд.
##### checkinstall
Данная чудесная утилита, будучи запущенной вместо make install задаст несколько вопросов, после чего сама соберёт и установит пакет. Всё, при обновлении никаких проблем с вычисткой старого хлама у вас не будет.
##### Сборка deb-пакета вручную
Если вы не склонны доверять такой автоматике (которая иногда всё же косячит) или же хочется внести пару изменений, но разбираться с нормальным процессом сборки пакетов всё же лениво, то можно собрать пакет ручками. Я привожу способ, как соорудить его для систем на базе Debian, т. к. лучше всего знаком именно с ними. Он не является идеологически правильным, но на выходе получается вполне корректный пакет без задействования дополнительных сущностей. Делается это следующим образом.
Для начала собираем софт с предварительно указанными для configure или autogen.sh параметрами --prefix=/usr и --exec-prefix=/usr.
Далее производим установку во временную директорию. Пишем:
```
fakeroot
make install DESTDIR=`pwd`/tempinstall
```
После чего получаем в свежесозданной директории весь тот набор файлов. Кстати, мы сейчас находимся в fakeroot-окружении, т. е. можно невозбранно менять владельца и права доступа файлов, но физически в системе владельцем останетесь вы сами. Софт же внутри fakeroot-сессии будет получать изменённую информацию, что позволит упаковать в архив файлы с корректными правами.
Далее создадим в «корне пакета» директорию DEBIAN и сложим в DEBIAN/conffiles список всех файлов, которые должны попасть в /etc:
```
cd tempinstall
mkdir DEBIAN
find etc | sed "s/^/\//" > DEBIAN/conffiles
```
После чего создаём файл DEBIAN/control следующего содержания:
| |
| --- |
|
```
Package: имя_пакета
Version: 1.2.3
Architecture: amd64/i386/armel/all
Maintainer: Можете вписать своё имя, можете дребедень, но если оставить пустым, то dpkg будет ругаться
Depends: Тут можно вписать список пакетов через запятую.
Priority: optional
Description: Тоже надо что-нибудь вписать, чтобы не кидало предупреждения
```
|
При необходимости там же можно создать скрипты preinst, postinst, prerm и postrm.
Всё, делаем dpkg -b tempinstall и получаем на выходе tempinstall.deb, на который можно натравить dpkg -i и который корректно установится, обновится или удалится.
«Правильный» процесс с предварительным созданием пакета исходного кода выходит за рамки данной заметки, а потому описан не будет, но для ваших целей оно обычно и не нужно.
#### Заключение
Как видите, тут нет абсолютно ничего сложного, но выполнение этих действий избавит вас от огромного числа проблем в будущем.
*А авторам статей на хабре просьба: пишите checkinstall вместо make install. Не надо давать вредные советы.* | https://habr.com/ru/post/130868/ | null | ru | null |
# Сервис на языке Dart: доменное имя, SSL
**Оглавление**
1. 1. [Введение](https://habr.com/ru/company/surfstudio/blog/511880/)
2. 2. Backend
3. 2.1. [Инфраструктура](https://habr.com/ru/company/surfstudio/blog/511880/).
4. 2.2. Доменное имя. SSL (мы находимся здесь)
5. 2.3. Серверное приложение на Дарт.
6. ...
7. 3. Web
8. 3.1. Заглушка “Under construction”
9. ...
10. 4. Mobile
11. ...
**disclaimer (по комментариям к предыдущей статье)**
* Эта статья не является в полной мере самостоятельной и является продолжением серии Сервис на языке Дарт. [Начало здесь](https://habr.com/ru/company/surfstudio/blog/511880/).
* Предмет данной статьи только то, что вынесено в заголовок: доменное имя и шифрование соединения.
* Облаков, оркестрации, масштабирования, K8s, AWS, GKE здесь нет. Автору известно, что данный подход не является современным и модным. Более того, автор признаёт, что общается в окружении «ретроградов», многие из которых вообще считают неприемлемым передачу критических данных и сервисов за пределы контролируемого периметра.
* Автор не может отказаться от использования Дарт на сервере в пользу других языков и технологий, поскольку сама концепция данной серии статей заключается в реализации работоспособного сервиса [на языке Дарт](https://surf.ru/pochemu-flutter-ispolzuet-dart-a-ne-kotlin-ili-javascript/) для всех уровней приложения: сервера, веб и мобильных клиентов.
* Список подлежащих рассмотрению в ходе реализации приложений вопросов выбран автором по собственному усмотрению. Список может быть расширен читателем соответствующим комментарием к этой или последующим статьям. Предлагайте, попробуем сделать.
* **Список вопросов**
+ Декомпозиция приложения на компоненты и слои
+ Dependency injection (кодогенерация boilerplate)
+ Генерация нативного серверного приложения
+ ORM. Генерация схемы и миграций для БД.
+ oAuth2 + JWT авторизация. Изолированный сервер авторизации.
+ Deeplinks (Universal links/ App links). Бесшовная интеграция web/app
+ Маршрутизация в приложениях
+ Взаимодействие реального времени (websockets)
+ Адаптивная верстка flutter
Доменное имя
------------
В [прошлый раз](https://habr.com/ru/company/surfstudio/blog/511880/) мы закончили на том, что в докер контейнере запустили веб-сервер NGINX, раздающий статический файл index.html. В этот раз мы расширим функциональность веб-сервера, добавив шифрование данных и принудительную переадресацию с http на https.

Для этого понадобится решить организационную задачу: дело в том, что сертификат шифрования можно получить только на доменное имя или группу имён. По этой причине отправляемся к любому из регистраторов доменных имён и выбираем название, соответствующее бренду (назначению, слогану и т.д.) не забывая о назначении [доменных имён](https://ru.wikipedia.org/wiki/%D0%A1%D0%BF%D0%B8%D1%81%D0%BE%D0%BA_%D0%B4%D0%BE%D0%BC%D0%B5%D0%BD%D0%BE%D0%B2_%D0%B2%D0%B5%D1%80%D1%85%D0%BD%D0%B5%D0%B3%D0%BE_%D1%83%D1%80%D0%BE%D0%B2%D0%BD%D1%8F) верхнего уровня. В моём случае отлично подойдёт dartservice.ru. В процессе регистрации необходимо заполнить форму сведений о владельце включая ФИО, почтовый адрес и электронную почту. Затем необходимо в панели управления регистратора перейти к управлению записями DNS и сделать три записи:
* Не менее двух NS записей (NS records). Это имена серверов доменных имён регистратора и их наименование регистратор сообщает при покупке доменного имени.
* A запись (A record). Это непосредственно запись связи между доменным именем и IP-адресом сервера.
В моём случае DNS записи выглядят так:
Сделав это не стоит ожидать немедленного результата. Обмен сведениями между DNS серверами занимает обычно от 1 до 12 часов для зоны RU. После чего… добавим [в проект](https://github.com/AndX2/dart_server/tree/v0.2.2-pre) ещё один тест /test/http/client.http

SSL
---
Вообще, конечно, [протокол SSL](https://ru.wikipedia.org/wiki/SSL) — устаревшее наименование. Новые версии протокола называются TLS 1.0...1.3, но механизм остался прежним — шифрование данных при переходе между протоколом прикладного уровня (в нашем случае HTTP) и протоколом транспортного уровня (TCP/IP). Фактически необходимо:
* Получить сертификат шифрования от специального удостоверяющего центра, подтвердив владение соответствующим доменом.
* Передать сертификат серверу NGINX.
* Настроить конфигурацию веб сервера для шифрования соединения.
* Принудительно переключать соединения, устанавливаемые по http на https.
Общепринятым на данный момент является использование бесплатных сертификатов, автоматически выдаваемых сервисом [Let’s encrypt](https://letsencrypt.org/ru/getting-started/). Одним из ограничений таких сертификатов является срок действия. Всего 90 дней. После чего сертификат необходимо получить вновь. Для автоматического (без участия человека) получения сертификатов был разработан протокол [ACME](https://en.wikipedia.org/wiki/Automated_Certificate_Management_Environment) и приложения, периодически выполняющие действия по подтверждению владения доменом. Let’s encrypt рекомендует использовать приложение [certbot](https://certbot.eff.org/). Оно написанно на python и требует установки собственного репозитория и python3. Поэтому воспользуемся docker контейнером с установленным [certbot из регистра DockerHub](https://hub.docker.com/r/certbot/certbot). Выберем последнюю стабильную версию [certbot/certbot:v1.5.0](https://hub.docker.com/layers/certbot/certbot/v1.5.0/images/sha256-568b8ebd95641a365a433da4437460e69fb279f6c9a159321988d413c6cde0ba?context=explore).
Теперь разберёмся с механизмом получения сертификата по протоколу ACME:
* Certbot при первом запуске генерирует закрытый и открытый ключ, затем создаёт аккаунт администратора домена в сервисе Let’s encrypt, передавая открытый ключ и сведения о домене.
* После этого Let’s encrypt передаёт сообщение, которое certbot должен подписать закрытым ключом и вернуть обратно.
* Сertbot должен разместить на сервере специальный файл, доступный для чтения в [dartservice.ru/.well-known/acme-challenge](http://dartservice.ru/.well-known/acme-challenge) для подтверждения владения этим доменом.
* Certbot составляет [запрос сертификата](https://tools.ietf.org/html/rfc2986), отправляет его в Let’s encrypt и получает взамен сертификат для домена.
Добавим контейнер приложения в наш сценарий docker-compose.yaml:
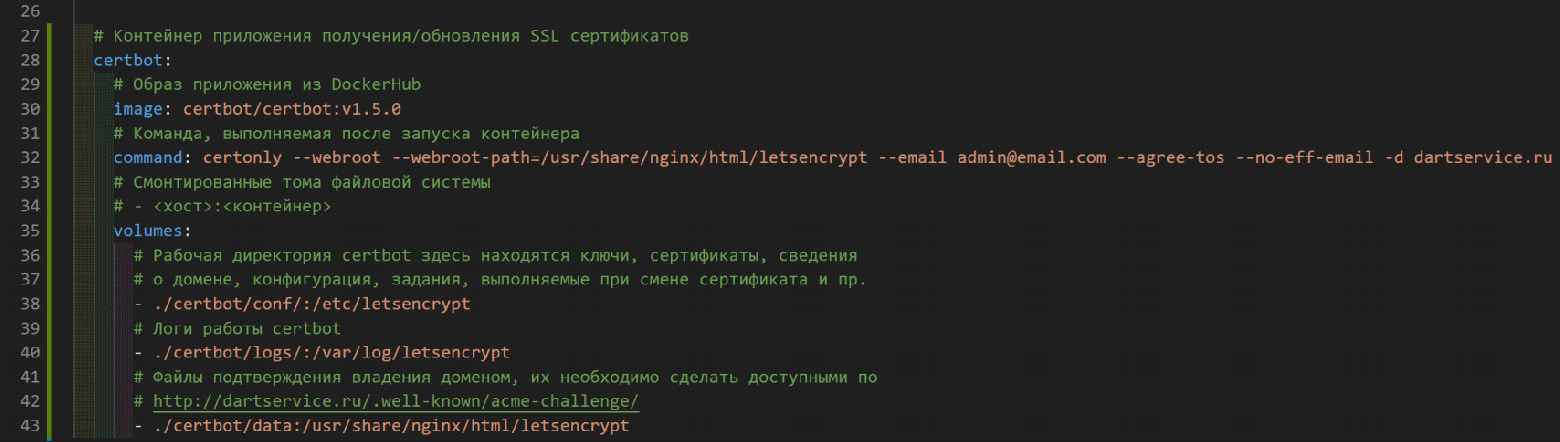
Новый параметр здесь **comand**: тут находится команда, которая будет выполнена после запуска контейнера. В данном случае certonly (получить сертификат). Получение сертификата происходит в интерактивном режиме, то есть необходимо последовательно ответить на несколько вопросов. Передача флагов после команды позволяет сделать это без участия человека: --webroot (способ подтверждения) --webroot-path=/usr/share/nginx/html/letsencrypt (путь, по которому будут размещены файлы подтверждения владения доменом) --email [email protected] (почта администратора домена) --agree-tos (принимаем условия лицензионного соглашения) --no-eff-email (не сообщать электронную почту разработчикам certbot) -d dartservice.ru (список доменов).
Настроим контейнер NGINX:

Изменения здесь заключаются в открытии порта https (443) и монтировании папок с SSL сертификатом и файлами подтверждения владения доменом.
Важным параметром является папка с ключом Диффи-Хеллмана. Если быть кратким: этот ключ нужен для того, чтобы безопасно обмениваться ключами шифрования между сервером и клиентом при установлении соединения. Более подробно [здесь](https://tproger.ru/translations/diffie-hellman-key-exchange-explained/).
Давайте сгенерируем такой ключ, однако мы столкнёмся со следующей проблемой: создание ключа выполняется программой **openssl**, это Linux консольная утилита, которая вряд ли обнаружится на нашей Windows машине. Самое простое решение — запустить наш сценарий, зайти в консоль контейнера **web** и там создать ключ, передав в выходном пути для файла папку хоста смонтированную в контейнер:
Запускаем сценарий:
```
docker-compose up -d
```
Запрашиваем список работающих контейнеров:
```
docker-compose ps
```

Открываем консоль контейнера:
```
docker exec -it srv_web_1 bash
```
Запускаем генерацию ключа в папку конфигурации NGINX (которая, как мы помним, смонтирована из хоста):
```
openssl dhparam -out /etc/nginx/conf.d/dhparams.pem 2048
```

Переместим ключ в ./dhparams/dhparam-2048.pem
Выходим из консоли контейнера Ctrl-D, останавливаем сценарий:
```
docker-compose down
```
Теперь изменим конфигурацию NGINX ./conf.d/defaulf.conf:
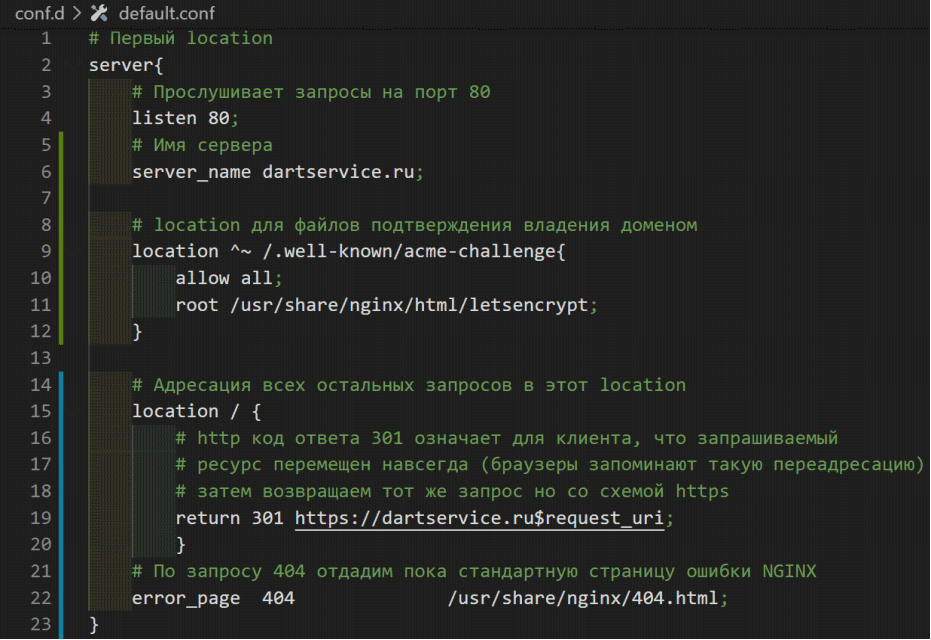
Добавим новый location ^~ /.well-known/acme-challenge для раздачи статических файлов из папки /usr/share/nginx/html/letsencrypt. Здесь будут размещаться файлы подтверждения certbot. Настроим переадресацию для всех остальных запросов на https.
Всё готово для первого получения SSL сертификата.
Скопируем наш проект на VPS в новую папку /opt/srv\_1/ командой:
```
scp -r ./* [email protected]:/opt/srv_1/
```
Подключимся из VScode по SSH к VPS.
Перейдём в папку работающего сервера:
```
cd /opt/srv_0/
```
и остановим сценарий:
```
docker-compose down
```
Теперь переходим в папку нового сервера cd /opt/srv\_1/ и запускаем сценарий:
```
docker-compose up
```
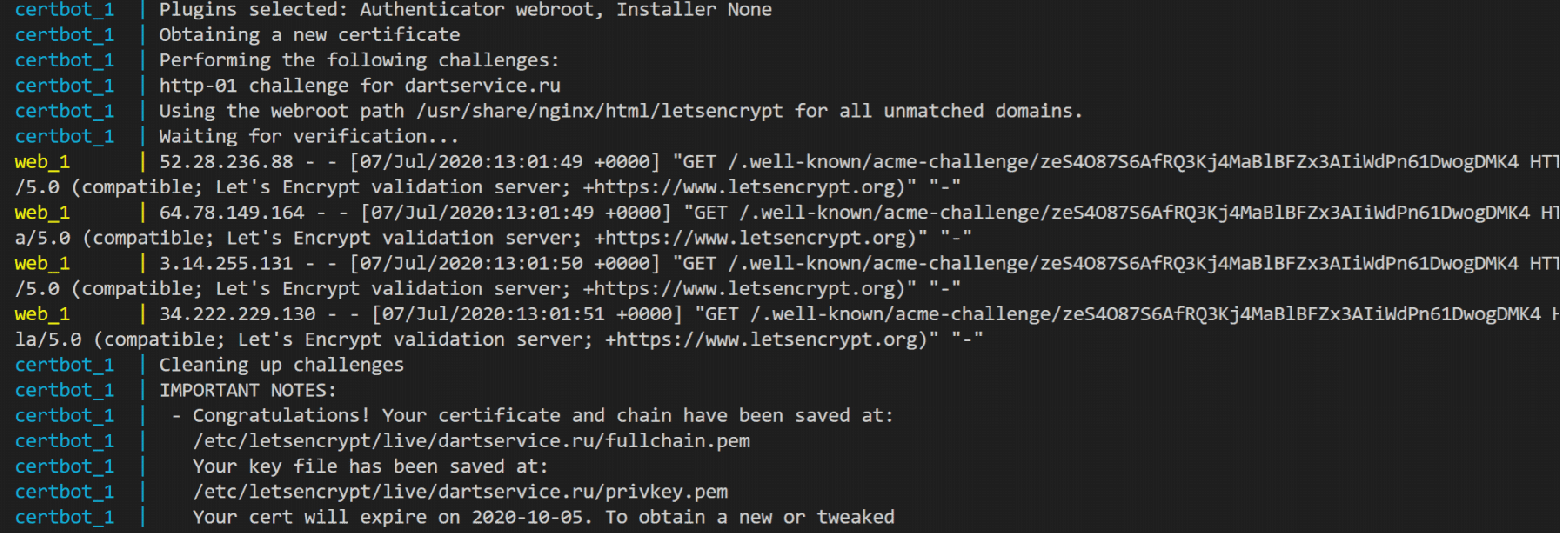
В консоли мы видим, что certbot создал файл подтверждения zeS4O87S6AfRQ3Kj4MaBlBFZx3AIiWdPn61DwogDMK4 и сообщил об этом сервису Let’s encrypt, который, в свою очередь, из четырёх разных IP адресов запросил данный файл после чего выдал сертификат. Сертификат в виде полной цепочки и приватного ключа были сохранены в соответствующей папке. Срок действия сертификата 90 дней (до 05.10.2020).
Самое время создать второй location для защищенного соединения в конфигурации NGINX на сервере ./conf.d/defaulf.conf:

Перезапустим сценарий
```
docker-compose restart
```
Посмотрим, как отреагирует браузер на наш сертификат:

Google Chrome нашим сертификатом доволен. Теперь задачка посложнее — протестируем безопасность и доступность для разных браузеров наше SSL соединение <https://www.ssllabs.com/ssltest/>. Вводим адрес, и получаем результат:

С сертификатом и обменом ключами (спасибо Диффи-Хеллману) всё отлично, однако тестовый робот снизил оценку («В» — это «4» по-нашему) за поддержку устаревших протоколов TLS1.0 и TLS1.1. Отключить их в конфигурации NGINX несложно, однако, просматривая тестовый отчет дальше, мы видим что, например, браузеры некоторых мобильных устройств в этом случае не смогут подключиться:


Осталось выполнить несколько служебных задач.
Число попыток получения сертификата для домена не должно превышать 5 в течение 7 дней. После этого сервис Let’s encrypt может нас заблокировать. Однако запуская сценарий при [разработке приложения](https://surf.ru/flutter/) каждый раз **certbot** будет делать такую попытку, поэтому в сценарии docker-compose.dev.yaml изменим параметр **command** контейнера **certbot**:

Флаг --dry-run — это тестовый прогон без получения сертификата.
Напишем тест:
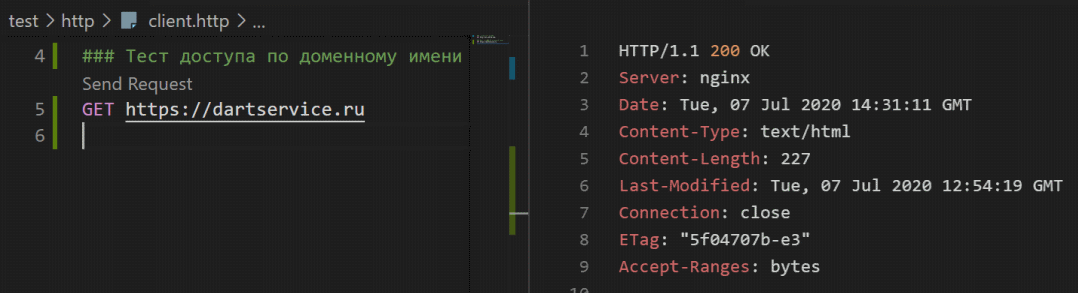
Исходный код [github](https://github.com/AndX2/dart_server/tree/v0.2.2-pre).
Заключение
----------
Итак, в этом шаге мы защитили коммуникации сервера с клиентскими приложениями и научили браузеры «доверять» нашему домену.
В следующей статье мы с [Surf](https://surf.ru/) напишем [flutter web](https://flutter.dev/web) страницу с обратным отсчетом времени до запуска нашего сервиса, соберём его и разместим на нашем сервере. | https://habr.com/ru/post/512528/ | null | ru | null |
# Низкоуровневая оптимизация параллельных алгоритмов или SIMD в .NET

В настоящее время огромное количество задач требует большой производительности систем. Бесконечно увеличивать количество транзисторов на кристалле процессора не позволяют физические ограничения. Геометрические размеры транзисторов нельзя физически уменьшать, так как при превышении возможно допустимых размеров начинают проявляться явления, которые не заметны при больших размерах активных элементов — начинают сильно сказываться квантовые размерные эффекты. Транзисторы начинают работать не как транзисторы.
А закон Мура здесь ни при чем. Это был и остается законом стоимости, а увеличение количества транзисторов на кристалле — это скорее следствие из закона. Таким образом, для того, чтобы увеличивать мощность компьютерных систем приходится искать другие способы. Это использование мультипроцессоров, мультикомпьютеров. Такой подход характеризуется большим количеством процессорных элементов, что приводит к независимому исполнение подзадач на каждом вычислительном устройстве.
### Параллельные методы обработки:
| Источник параллелизма | Ускорение | Усилие программиста | Популярность |
| --- | --- | --- | --- |
| Множество ядер | 2х-128х | Умеренное | Высокая |
| Множество машин | 1х-Бесконечность | Умеренно-Высокое | Высокая |
| Векторизация | 2х-8х | Умеренное | Низкая |
| Графические адаптеры | 128х-2048х | Высокое | Низкая |
| Сопроцессор | 40х-80х | Умеренно-высокое | Чрезвычайно-низкая |
Способов для повышения эффективности систем много и все довольно различны. Одним из таких способов является использование векторных процессоров, которые в разы повышают скорость вычислений. В отличие от скалярных процессоров, которые обрабатывают один элемент данных за одну инструкцию (SISD), векторные процессоры способны за одну инструкцию обрабатывать несколько элементов данных (SIMD). Большинство современных процессоров являются скалярными. Но многие задачи, которые они решают, требуют большого объема вычислений: обработка видео, звука, работа с графикой, научные расчеты и многое другое. Для ускорения процесса вычислений производители процессоров стали встраивать в свои устройства дополнительные потоковые SIMD-расширения.
Соответственно при определенном подходе программирования стало возможным использование векторной обработки данных в процессоре. Существующие расширения: MMX, SSE и AVX. Они позволяют использовать дополнительные возможности процессора для ускоренной обработки больших массивов данных. При этом векторизация позволяет добиться ускорения без явного параллелизма. Т.е. он есть с точки зрения обработки данных, но с точки зрения программиста это не требует каких-либо затрат на разработку специальных алгоритмов для предотвращения состояния гонки или синхронизации, а стиль разработки не отличается от синхронного. Мы получаем ускорение без особых усилий, почти совершенно бесплатно. И в этом нет никакой магии.
### Что такое SSE?
SSE (англ. Streaming SIMD Extensions, потоковое SIMD-расширение процессора) — это SIMD (англ. Single Instruction, Multiple Data, Одна инструкция — множество данных) набор инструкций. SSE включает в архитектуру процессора восемь 128-битных регистров и набор инструкций. Технология SSE была впервые введена в Pentium III в 1999 году. Со временем, этот набор инструкций был улучшен путем добавления более сложных операций. Восемь (в x86-64 — шестнадцать) 128-битовых регистров были добавлены к процессору: от xmm0 до xmm7.

Изначально эти регистры могли быть использованы только для одинарной точности вычислений (т.е. для типа float). Но после выхода SSE2, эти регистры могут использоваться для любого примитивного типа данных. Учитывая стандартную 32-разрядную машину таким образом, мы можем хранить и обрабатывать параллельно:
* 2 double
* 2 long
* 4 float
* 4 int
* 8 short
* 16 char
Если же использовать технологию AVX, то вы будете манипулировать уже 256-битными регистрами, соответственно больше чисел за одну инструкцию. Так уже есть и 512-битные регистры.
Сначала на примере С++ (кому не интересно, можете пропустить) мы напишем программу, которая будет суммировать два массива из 8 элементов типа float.
### Пример векторизации на С++
Технология SSE в С++ реализована низкоуровневыми инструкциями, представленные в виде псевдокода, которые отражают команды на ассемблере. Так, например, команда *\_\_m128 \_mm\_add\_ps(\_\_m128 a, \_\_m128 b );* преобразуется в инструкцию ассемблера *ADDPS операнд1, операнд2*. Соответственно команда *\_\_m128 \_mm\_add\_ss(\_\_m128 a, \_\_m128 b );* будет преобразовываться в инструкцию *ADDSS операнд1, операнд2*. Эти две команды делают почти одинаковые операции: складывают элементы массива, но немного по-разному. *\_mm\_add\_ps* складывает полностью регистр с регистром, так что:
* r0 := a0 + b0
* r1 := a1 + b1
* r2 := a2 + b2
* r3 := a3 + b3
При этом весь регистр \_\_m128 и есть набор r0-r3. А вот команда *\_mm\_add\_ss* складывает только часть регистра, так что:
* r0 := a0 + b0
* r1 := a1
* r2 := a2
* r3 := a3
По такому же принципу устроены и остальные команды, такие как вычитание, деление, квадратный корень, минимум, максимум и другие операции.
Для написания программы можно манипулировать 128-битовыми регистрами типа \_\_m128 для float, \_\_m128d для double и \_\_m128i для int, short, char. При этом можно не использовать массивы типа \_\_m128, а использовать приведенные указатели массива float к типу \_\_m128\*.
При этом следует учитывать несколько условий для работы:
* Данные float, загруженные и хранящиеся в \_\_m128 объекте должны иметь 16-байтовое выравнивание
* Некоторые встроенные функции требуют, чтобы их аргумент был типа констант целых чисел, в силу природы инструкции
* Результат арифметических операций, действующих на два NAN аргументов, не определен
Такой вот маленький экскурс в теорию. Однако, рассмотрим пример программы с использованием SSE:
```
#include "iostream"
#include "xmmintrin.h"
int main()
{
const auto N = 8;
alignas(16) float a[] = { 41982.0, 81.5091, 3.14, 42.666, 54776.45, 342.4556, 6756.2344, 4563.789 };
alignas(16) float b[] = { 85989.111, 156.5091, 3.14, 42.666, 1006.45, 9999.4546, 0.2344, 7893.789 };
__m128* a_simd = reinterpret_cast<__m128*>(a);
__m128* b_simd = reinterpret_cast<__m128*>(b);
auto size = sizeof(float);
void *ptr = _aligned_malloc(N * size, 32);
float* c = reinterpret_cast(ptr);
for (size\_t i = 0; i < N/2; i++, a\_simd++, b\_simd++, c += 4)
\_mm\_store\_ps(c, \_mm\_add\_ps(\*a\_simd, \*b\_simd));
c -= N;
std::cout.precision(10);
for (size\_t i = 0; i < N; i++)
std::cout << c[i] << std::endl;
\_aligned\_free(ptr);
system("PAUSE");
return 0;
}
```
* *alignas(#)* — стандартный для С++ переносимый способ задания настраиваемого выравнивания переменных и пользовательских типов. Используется в С++11 и поддерживается Visual Studio 2015. Можно использовать и другой вариант — *\_\_declspec( align( #)) declarator*. Данные средства для управления выравниванием при статическом выделении памяти. Если необходимо выравнивание с динамическим выделением, необходимо использовать *void\* \_aligned\_malloc(size\_t size, size\_t alignment);*
* Затем преобразуем указатель на массив a и b к типу \_m128\* при помощи reinterpret\_cast, который позволяет преобразовывать любой указатель в указатель любого другого типа.
* После динамически выделим выравненную память при помощи уже упомянутой выше функции *\_aligned\_malloc(N\*sizeof(float), 16);*
* Количество необходимых байт выделяем исходя из количества элементов с учетом размерности типа, а 16 это значение выравнивания, которое должно быть степенью двойки. А затем указатель на этот участок памяти приводим к другому типу указателя, чтобы с ним можно было бы работать с учетом размерности типа float как с массивом.
Таким образом все приготовления для работы SSE выполнены. Дальше в цикле суммируем элементы массивов. Подход основан на арифметике указателей. Так как *a\_simd*, *b\_simd* и *с* — это указатели, то их увеличение приводит к смещению на sizeof(T) по памяти. Если взять к примеру динамический массив *с*, то *с[0]* и *\*с* покажут одинаковое значение, т.к. *с* указывает на первый элемент массива. Инкремент *с* приведет к смещению указателя на 4 байта вперед и теперь указатель будет указывать на 2 элемент массива. Таким образом можно двигаться по массиву вперед и назад увеличивая и уменьшая указатель. Но при этом следует учитывать размерность массива, так как легко выйти за его пределы и обратиться к чужому участку памяти. Работа с указателями *a\_simd* и *b\_simd* аналогична, только инкремент указателя приведет к перемещению на 128-бит вперед и при этом с точки зрения типа float будет пропущено 4 переменных массива a и b. В принципе указатель *a\_simd* и *a*, как и *b\_simd* и *b* указывают соответственно на один участок в памяти, за тем исключением, что обрабатываются они по-разному с учетом размерности типа указателя:

```
for (int i = 0; i < N/2; i++, a_simd++, b_simd++, c += 4)
_mm_store_ps(c, _mm_add_ps(*a_simd, *b_simd));
```
Теперь понятно почему в данном цикле такие изменения указателей. На каждой итерации цикла происходит сложение 4-х элементов и сохранение полученного результата по адресам указателя *с* из регистра xmm0 (для данной программы). Т.е. как мы видим такой подход не изменяет исходных данных, а хранит сумму в регистре и по необходимости передает ее в нужный нам операнд. Это позволяет повысить производительность программы в тех случаях, когда необходимо повторно использовать операнды.
Рассмотрим код, который генерирует ассемблер для метода *\_mm\_add\_ps*:
```
mov eax,dword ptr [b_simd] ;// поместить адрес b_simd в регистр eax(базовая команда пересылки данных, источник не изменяется)
mov ecx,dword ptr [a_simd] ;// поместить адрес a_simd в регистр ecx
movups xmm0,xmmword ptr [ecx] ;// поместить 4 переменные с плавающей точкой по адресу ecx в регистр xmm0; xmm0 = {a[i], a[i+1], a[i+2], a[i+3]}
addps xmm0,xmmword ptr [eax] ;// сложить переменные: xmm0 = xmm0 + b_simd
;// xmm0[0] = xmm[0] + b_simd[0]
;// xmm0[1] = xmm[1] + b_simd[1]
;// xmm0[2] = xmm[2] + b_simd[2]
;// xmm0[3] = xmm[3] + b_simd[3]
movaps xmmword ptr [ebp-190h],xmm0 ;// поместить значение регистра по адресу в стеке со смещением
movaps xmm0,xmmword ptr [ebp-190h] ;// поместить в регистр
mov edx,dword ptr [c] ;// поместить в регистр ecx адрес переменной с
movaps xmmword ptr [edx],xmm0 ;// поместить значение регистра в регистр ecx или сохранить сумму по адресу памяти, куда указывает (ecx) или с. При этом xmmword представляет собой один и тот же тип, что и _m128 - 128-битовое слово, в котором 4 переменные с плавающей точкой
```
Как видно из кода, одна инструкция *addps* обрабатывает сразу 4 переменных, которая реализована и поддерживается аппаратно процессором. Система не принимает никакого участия при обработке этих переменных, что дает хороший прирост производительности без лишних затрат со стороны.
При этом хотел бы отметить одну особенность, что в данном примере и компилятором используется инструкция *movups*, для которой не требуются операнды, которые должны быть выровнены по 16-байтовой границе. Из чего следует, что можно было бы не выравнивать массив *a*. Однако, массив *b* необходимо выровнять, иначе в операции *addps* возникнет ошибка чтения памяти, ведь регистр складывается со 128-битным расположением в памяти. В другом компиляторе или среде могут быть другие инструкции, поэтому лучше в любом случае для всех операндов, принимающих участие в подобных операциях, делать выравнивание по границе. Во всяком случае во избежание проблем с памятью.
Еще одна причина делать выравнивание, так это когда мы оперируем с элементами массивов (и не только с ними), то на самом деле постоянно работаем с кэш-линиями размером по 64 байта. SSE и AVX векторы всегда попадают в одну кэш линию, если они выравнены по 16 и 32 байта, соответственно. А вот если наши данные не выравнены, то, очень вероятно, нам придётся подгружать ещё одну «дополнительную» кэш-линию. Процесс этот достаточно сильно сказывается на производительности, а если мы при этом и к элементам массива, а значит, и к памяти, обращаемся непоследовательно, то всё может быть ещё хуже.
### Поддержка SIMD в .NET
Впервые упоминание o поддержке JIT технологии SIMD было объявлено в блоге .NET в апреле 2014 года. Тогда разработчики анонсировали новую превью-версию RyuJIT, которая обеспечивала SIMD функциональность. Причиной добавления стала довольно высокая популярность запроса на поддержку C# and SIMD. Изначальный набор поддерживаемых типов был не большим и были ограничения по функциональности. Изначально поддерживался набор SSE, а AVX обещали добавить в релизе. Позже были выпущены обновления и добавлены новые типы с поддержкой SIMD и новые методы для работы с ними, что в последних версиях представляет обширную и удобную библиотеку для аппаратной обработки данных.

Такой подход облегчает жизнь разработчика, который не должен писать CPU-зависимый код. Вместо этого CLR абстрагирует аппаратное обеспечение, предоставляя виртуальную исполняющую среду, которая переводит свой код в машинные команды либо во время выполнения (JIT), либо во время установки (NGEN). Оставляя генерацию кода CLR, вы можете использовать один и тот же MSIL код на разных компьютерах с разными процессорами, не отказываясь от оптимизаций, специфических для данного конкретного CPU.
На данный момент поддержка этой технологии в .NET представлена в пространстве имен System.Numerics.Vectors и представляет собой библиотеку векторных типов, которые могут использовать преимущества аппаратного ускорения SIMD. Аппаратное ускорение может приводить к значительному повышению производительности при математическом и научном программировании, а также при программировании графики. Она содержит следующие типы:
* Vector — коллекцию статических удобных методов для работы с универсальными векторами
* Matrix3x2 — представляет матрицу 3х2
* Matrix4х4 — представляет матрицу 4х4
* Plane — представляет трехмерную плоскость
* Quaternion — представляет вектор, используемый для кодирования трехмерных физических поворотов
* Vector<(Of <(<'T>)>)> представляет вектор указанного числового типа, который подходит для низкоуровневой оптимизации параллельных алгоритмов
* Vector2 — представляет вектор с двумя значениями одинарной точности с плавающей запятой
* Vector3 — представляет вектор с тремя значениями одинарной точности с плавающей запятой
* Vector4 — представляет вектор с четырьмя значениями одинарной точности с плавающей запятой
Класс Vector предоставляет методы для сложения, сравнения, поиска минимума и максимума и многих других преобразований над векторами. При этом операции работают с использованием технологии SIMD. Остальные типы также поддерживают аппаратное ускорение и содержат специфические для них преобразования. Для матриц это может быть перемножение, для векторов евклидово расстояние между точками и т.д.
### Пример программы на C#
Итак, что необходимо для того, чтобы использовать данную технологию? Необходимо в первую очередь иметь RyuJIT компилятор и версию .NET 4.6. System.Numerics.Vectors через NuGet не ставится, если версия ниже. Однако, уже при установленной библиотеке я понижал версию и все работало как надо. Затем необходима сборка под x64, для этого необходимо убрать в свойствах проекта «предпочитать 32-разрядную платформу» и можно собирать под Any CPU.
Листинг:
```
using System;
using System.Numerics;
class Program
{
static void Main(string[] args)
{
const Int32 N = 8;
Single[] a = { 41982.0F, 81.5091F, 3.14F, 42.666F, 54776.45F, 342.4556F, 6756.2344F, 4563.789F };
Single[] b = { 85989.111F, 156.5091F, 3.14F, 42.666F, 1006.45F, 9999.4546F, 0.2344F, 7893.789F };
Single[] c = new Single[N];
for (int i = 0; i < N; i += Vector.Count) // Count возвращает 16 для char, 4 для float, 2 для double и т.п.
{
var aSimd = new Vector(a, i); // создать экземпляр со смещением i
var bSimd = new Vector(b, i);
Vector cSimd = aSimd + bSimd; // или так Vector c\_simd = Vector.Add(b\_simd, a\_simd);
cSimd.CopyTo(c, i); //копировать в массив со смещением
}
for (int i = 0; i < a.Length; i++)
{
Console.WriteLine(c[i]);
}
Console.ReadKey();
}
}
```
С общей точки зрения что С++ подход, что .NET довольно схожи. Необходимо преобразование/копирование исходных данных, выполнить копирование в конечный массив. Однако, подход с C# намного проще, многие вещи сделаны за Вас и Вам только остается пользоваться и наслаждаться. Нет необходимости думать о выравнивании данных, заниматься выделением памяти и делать это статически, либо динамически с определенными операторами. С другой стороны у вас больший контроль над происходящим с использованием указателей, но и больше ответственности за происходящее.
А в цикле происходит все так, как и в цикле в С++. И я не про указатели. Алгоритм расчета такой же. На первой итерации мы заносим первые 4 элемента исходных массивов в структуру *aSimd* и *bSimd*, затем суммируем и сохраняем в конечном массиве. Затем на следующей итерации заносим следующие 4 элемента при помощи смещения и суммируем их. Вот так все просто и быстро делается. Рассмотрим код, который генерирует компилятор для этой команды *var cSimd = aSimd + bSimd*:
```
addps xmm0,xmm1
```
Отличие от С++ версии только в том, что тут складываются оба регистра, в то время как там было складывание регистра с участком памяти. Помещение в регистры происходит при инициализации *aSimd* и *bSimd*. В целом данный подход, если сравнивать код компиляторов С++ и .NET не особо отличается и дает приблизительно равную производительность. Хотя вариант с указателями будет работать все равно быстрее. Хотелось бы отметить, что SIMD-инструкции генерируются при включенной оптимизации кода. Т.е. увидеть их в дизассемблере в Debug не получится: это реализовано в виде вызова функции. Однако в Release, где включена оптимизация, вы получите эти инструкции в явном(встроенном) виде.
### Напоследок
Что мы имеем:
* Во многих случаях векторизация дает 4-8× увеличение производительности
* Сложные алгоритмы потребуют изобретательность, но без этого никуда
* System.Numerics.Vectors в настоящее время обхватывает только часть simd-инструкций. Для более серьезного подхода потребуется С++
* Есть множество других способов помимо векторизации: правильное использование кэша, многопоточность, гетерогенные вычисления, грамотная работа с памятью(чтобы сборщик мусора не потел) и т.д.
В ходе краткой твиттер-переписки с Сашой Голдштейном(одного из авторов книги «Оптимизация приложений на платформе .NET»), который рассматривал аппаратное ускорение в .NET, я поинтересовался, что как на его взгляд реализована поддержка SIMD в .NET и какова она в сравнении с С++. На что он ответил: «Несомненно, вы можете сделать больше на С++, чем на C#. Но вы действительно получаете кросс-процессорную поддержку на С#. Например, автоматический выбор между SSE4 и AVX». В целом, это не может не радовать. Ценой малых усилий мы можем получать от системы как можно большей производительности, задействуя все возможные аппаратные ресурсы.
Для меня это очень хорошая возможность разрабатывать производительные программы. По крайней мере у себя в дипломной работе, по моделированию физических процессов, я в основном добивался эффективности путем создания некоторого количества потоков, а также при помощи гетерогенных вычислений. Использую как CUDA, так и C++ AMP. Разработка ведется на универсальной платформе под Windows 10, где меня очень привлекает WinRT, который позволяет писать программу как на C#, так и на С++/CX. В основном на плюсах пишу ядро для больших расчетов (Boost), а на C# уже манипулирую данными и разрабатываю интерфейс. Естественно, перегон данных через двоичный интерфейс ABI для взаимодействия двух языков имеет свою цену(хотя и не очень большую), что требует более разумной разработки библиотеки на С++. Однако у меня данные пересылаются только в случае необходимости и довольно редко, только для отображения результатов.
В случае надобности манипулирования данными в C#, я их преобразую в типы .NET, чтобы не работать с типами WinRT, тем самым увеличивая производительность обработки уже на C#. Так например, когда нужно обработать несколько тысяч или десятков тысяч элементов или требования к обработке не имеют никаких особых спецификаций, данные можно рассчитать в C# без задействования библиотеки (в ней считаются от 3 до 10 миллионов экземпляров структур, иногда только за одну итерацию). Так что подход с аппаратным ускорением упростит задачу и сделает ее быстрее.

### Список источников при написании статьи
* [Перевод статьи блога .NET про новый JIT с поддержкой SIMD](http://habrahabr.ru/post/219841/)
* [Про System.Numerics.Vector в блоге .NET](http://blogs.msdn.com/b/dotnet/archive/2014/11/05/using-system-numerics-vector-for-graphics-programming.aspx)
* [Что такое выравнивание, и как оно влияет на работу ваших программ](http://konishchevdmitry.blogspot.ru/2010/01/blog-post.html)
* [Блог компании Intel про выравнивании данных при векторизации циклов](http://habrahabr.ru/company/intel/blog/262933/)
Ну и отдельное спасибо Саше Голдштейну за предоставленную помощь и информацию. | https://habr.com/ru/post/274605/ | null | ru | null |
# Альтернативный способ получить SID
Сложилось ситуация где необходимо было получить [Security Identifier (SID) винды](http://en.wikipedia.org/wiki/Security_Identifier) без использования стороннего софта и VB. Через командную строку оказалось вполне реально, мы создали велосипед.
`@echo off
dir "%SYSTEMROOT%\system32\appmgmt" /A>SID_DIR.txt
findstr /R S-.* "SID_DIR.txt">SID_STR.txt
for /f "tokens=5" %%A in (SID_STR.txt) do (@echo %%A>SID.txt)
del /f /q SID_DIR.txt
del /f /q SID_STR.txt`
Работает только в Win2k/XP/Vista. | https://habr.com/ru/post/75993/ | null | ru | null |
# Визуализация на карте распределения голосов по Москве на выборах президента 2018
Введение
--------
Выборы — крайне загадочный процесс, при просмотре значений результатов которого не совсем понятна общая картина. Я решил показать их на карте Москвы с делением по районам c помощью технологий InterSystems, которые обеспечивают и хранение, и анализ данных. В данном случае использовалась платформа для интеграции и разработки приложений InterSystems Ensemble, но с равным успехом можно развернуть описанное ниже решение и на [мультимодельной СУБД InterSystems Caché](http://www.intersystems.com/ru/our-products/cache/cache-overview/), и на новом продукте InterSystems IRIS Data Platform.
Этапы:
------
Для показа карты мы выполним следующие действия:
* сбор данных голосования, которые будут отображаться на карте;
* приведение собранных данных к необходимому формату;
* создание хранимых (persistent) классов и их заполнение;
* создание OLAP-куба;
* создание пивота (ов);
* создание и настройка дашборда;
* установка проектов MDX2JSON и DeepSeeWeb;
* сбор координат полигонов;
* создание термлистов и добавление элемента управления.
Сбор данных
-----------
Для отображения данных выборов президента нам необходима модель данных.
Создадим следующие классы:
* map.MoscowElections2018 — класс с данными результатов выборов
* map.MoscowRegion — справочник районов Москвы, на который будут ссылаться объекты класса map.MoscowElections2018
Начнем с создания класса map.MoscowRegion
Возьмем со страниц на википедии данные по [районам](https://ru.wikipedia.org/wiki/%D0%A1%D0%BF%D0%B8%D1%81%D0%BE%D0%BA_%D1%80%D0%B0%D0%B9%D0%BE%D0%BD%D0%BE%D0%B2_%D0%B8_%D0%BF%D0%BE%D1%81%D0%B5%D0%BB%D0%B5%D0%BD%D0%B8%D0%B9_%D0%9C%D0%BE%D1%81%D0%BA%D0%B2%D1%8B) и [административным округам](https://ru.wikipedia.org/wiki/%D0%90%D0%B4%D0%BC%D0%B8%D0%BD%D0%B8%D1%81%D1%82%D1%80%D0%B0%D1%82%D0%B8%D0%B2%D0%BD%D0%BE-%D1%82%D0%B5%D1%80%D1%80%D0%B8%D1%82%D0%BE%D1%80%D0%B8%D0%B0%D0%BB%D1%8C%D0%BD%D0%BE%D0%B5_%D0%B4%D0%B5%D0%BB%D0%B5%D0%BD%D0%25B), создадим для этих данных [XML-enabled](http://docs.intersystems.com/latest/csp/docbook/DocBook.UI.Page.cls?KEY=GXML_import) класс
**map.MoscowRegion**
```
Class map.MoscowRegion Extends (%Persistent, %XML.Adaptor)
{
Index idIndex On id [ IdKey, PrimaryKey, Unique ];
/// Код
Property id As %String [ Required ];
/// Название админ. единицы
Property name As %String(MAXLEN = 250);
/// Площадь, га
Property area As %Float;
/// Население
Property population As %Integer;
/// Название вышестоящей адм. единицы
Property parentName As %String;
/// Вышестоящая адм. единица
Property parent As map.MoscowRegion;
/// Вышестоящая адм. единица
Property parentId As %Integer;
ClassMethod populateRegions() As %Status
{
#dim sc As %Status = $$$OK
#dim stream As %Stream.Object = ##class(%Dictionary.CompiledXData).%OpenId(..%ClassName(1) _ "||" _ "regions").Data
#dim reader As %XML.Reader = ##class(%XML.Reader).%New()
set sc = ..%KillExtent()
if $$$ISERR(sc) quit sc
set sc = reader.OpenStream(stream, "literal")
if $$$ISERR(sc) quit sc
do reader.Correlate("region", ..%ClassName(1))
#dim obj As map.MoscowRegion
while reader.Next(.obj, .sc)
{
if $$$ISERR(sc) quit
if (obj.parentId) {
set obj.parent = ..%OpenId(obj.parentId)
}
set sc = obj.%Save()
if $$$ISERR(sc) quit
set obj = ""
}
quit sc
}
XData regions
{
}
}
```
И приведем полученные данные к формату XML
**XData из map.MoscowRegion**
```
Центральный округ
-
66.18
769630
1001
...
поселение Щербинка
Новомосковский административный округ
7.62
47504
2146
1012
```
За данными выборов я обратился на [сайт](http://www.izbirkom.ru/region/izbirkom) Центральной избирательной комиссии Российской Федерации. К сожалению нормального API с возможностью получить подходящий набор данных я не нашел, поэтому пришлось брать все из сводной таблицы результатов. Там при помощи фильтров можно найти результаты выборов не только президента РФ, но и выборы депутатов и глав различных административных единиц Российской Федерации. Так как нас интересуют именно выборы президента, то находим подходящую [сводную таблицу](http://www.vybory.izbirkom.ru/region/region/izbirkom?action=show&tvd=100100084849066&vrn=100100084849062®ion=0&global=1&sub_region=0&prver=0&pronetvd=null&vibid=100100084849200&type=227) результатов выборов по Москве, выгружаем, трансформируем к подходящему формату (для данного примера был выбран формат XML, так как данный формат легко можно использовать для импорта в нашу базу данных под управлением платформы InterSystems).
В итоге имеем примерно следующий формат данных:
**Данные выборов в формате XML**
```
район Богородское
2013
65519
58800
0
38056
1326
19418
1326
38003
538
38791
0
0
356
4738
2060
27833
1602
300
668
1234
...
поселение Сосенское
2142
103818
86145
0
63192
1123
21829
1123
63139
796
63466
1
0
439
8723
3110
47192
1860
345
734
1063
```
Создал для данных XML-enabled класс map.MoscowElections2018 на платформе InterSystems:
**Код класса map.MoscowElections2018**
```
Class map.MoscowElections2018 Extends (%Persistent, %XML.Adaptor)
{
/// Ссылка на регион
Property region As map.MoscowRegion;
/// Имя региона
Property regionName As %String;
/// ID региона
Property regionId As %Integer;
/// Число избирателей, включенных в список избирателей
Property votersIncludedInVotersList As %Integer;
/// Число избирательных бюллетеней, полученных участковой избирательной комиссией
Property ballotsReceivedByPrecinctElectionCommission As %Integer;
/// Число избирательных бюллетеней, выданных избирателям, проголосовавшим досрочно
Property ballotsIssuedToVotersWhoVotedEarly As %Integer;
/// Число избирательных бюллетеней, выданных в помещении для голосования в день голосования
Property ballotsIssuedInPollingStationOnElectionDay As %Integer;
/// Число избирательных бюллетеней, выданных вне помещения для голосования в день голосования
Property ballotsIssuedOutsidePollingStationOnElectionDay As %Integer;
/// Число погашенных избирательных бюллетеней
Property canceledBallots As %Integer;
/// Число избирательных бюллетеней в переносных ящиках для голосования
Property ballotsInMobileBallotBoxes As %Integer;
/// Число бюллетеней в стационарных ящиках для голосования
Property ballotsInStationaryBallotBoxes As %Integer;
/// Число недействительных избирательных бюллетеней
Property invalidBallots As %Integer;
/// Число действительных избирательных бюллетеней
Property validBallots As %Integer;
/// Число утраченных избирательных бюллетеней
Property lostBallots As %Integer;
/// Число избирательных бюллетеней, не учтенных при получении
Property ballotsNotRecorded As %Integer;
/// Бабурин Сергей Николаевич
Property Baburin As %Integer;
/// Грудинин Павел Николаевич
Property Grudinin As %Integer;
/// Жириновский Владимир Вольфович
Property Zhirinovsky As %Integer;
/// Путин Владимир Владимирович
Property Putin As %Integer;
/// Собчак Ксения Анатольевна
Property Sobchak As %Integer;
/// Сурайкин Максим Александрович
Property Suraykin As %Integer;
/// Титов Борис Юрьевич
Property Titov As %Integer;
/// Явлинский Григорий Алексеевич
Property Yavlinsky As %Integer;
ClassMethod populateElectionsData() As %Status
{
#dim sc As %Status = $$$OK
#dim stream As %Stream.Object = ##class(%Dictionary.CompiledXData).%OpenId(..%ClassName(1) _ "||" _ "elections").Data
#dim reader As %XML.Reader = ##class(%XML.Reader).%New()
set sc = ..%KillExtent()
if $$$ISERR(sc) quit sc
set sc = reader.OpenStream(stream, "literal")
if $$$ISERR(sc) quit sc
do reader.Correlate("region", ..%ClassName(1))
#dim obj As map.MoscowElections2018
while reader.Next(.obj, .sc)
{
if $$$ISERR(sc) quit
if (obj.regionId) {
set obj.region = ##class(map.MoscowRegion).%OpenId(obj.regionId)
}
set sc = obj.%Save()
if $$$ISERR(sc) quit
set obj = ""
}
quit sc
}
XData elections
{
}
}
```
Создание куба
-------------
Для создания OLAP-куба мы используем веб-приложение [DeepSee Architect](http://docs.intersystems.com/latest/csp/docbook/DocBook.UI.Page.cls?KEY=D2DT_ch_cube), чтобы перейти на него откроем Портал Управления Системой → DeepSee → Выбор области → Architect.
В том случае если вы не видите вашей области в списке доступных DeepSee областей — перейдите в Портал Управления Системой → Меню → Управление веб-приложениями → /csp/область, и там в поле «Включен» поставьте галочку «DeepSee» и нажмите кнопку сохранить. После этого выбранная область должна появиться в списке доступных DeepSee областей.
Создаем новый куб.
Нажав на кнопку «Создать» попадаем на экран создания нового куба, там необходимо установить следующие параметры:
* Имя куба — название куба используемое в запросах к нему
* Отображаемое Имя — локализуемое название куба (перевод осуществляется [стандартными механизмами](http://docs.intersystems.com/latest/csp/docbook/DocBook.UI.Page.cls?KEY=D2IMP_ch_localization) InterSystems)
* Источник Cube — использовать таблицу фактов или другой куб в качестве источника данных
* Исходный класс — если на предыдущем шаге был выбран класс, то указываем в качестве таблицы фактов класс map.MoscowElections2018.
* Имя класса для куба — имя класса, в котором будет храниться определение куба. Создается автоматически
* Описание класса — произвольное описание
Вот как выглядит наш новый куб:
### Определяем свойства куба.
После нажатия кнопки OK будет создан новый куб:
Слева выводятся свойства базового и связанных с ним по “снежинке” классов, которые можно использовать при построении куба.
Центральная часть экрана — это скелет куба. Его можно наполнить свойствами класса с помощью drag-n-drop из области базового класса, либо добавляя элементы вручную. Основными элементами куба являются измерения, показатели и списки.
### Измерения (Dimensions)
[Измерения](http://docs.intersystems.com/latest/csp/docbook/DocBook.UI.Page.cls?KEY=D2MODEL_ch_concepts) — это элементы куба, которые группируют записи таблицы фактов. В измерения обычно относят “качественные” атрибуты базового класса, которые разбивают все записи таблицы фактов по тем или иным срезам.
Например нам бы хотелось группировать все факты по Муниципальному образованию и при углублении — по району.
Для разбиения фактов по территориальной принадлежности прекрасно подойдет свойство Territory. Так как у нас иерархия начинается с муниципального образования, то на первом уровне должно быть измерение родителя региона, то есть — мы нажимаем на стрелочку у свойства region в левом списке, в раскрывшемся списке также раскрываем свойство parent и перетягиваем name на область измерений — в результате Архитектор добавит в куб измерение name с одной иерархией H1 и одним уровнем name. для удобства переименуем измерение из name в Territory и первый уровень в Region.
Измерения помимо группировки позволяют строить иерархии вложенности фактов от общего к частному. Для этого добавим уровень Subregion перетаскиванием имени региона на иерархию H1 добавим свойства население и имя в оба измерения и также пока магическое свойство coordsKey со значением имени измерения — данное свойство будет использовано для поиска координат соответствующего данному муниципальному образованию/району полигона для подсвечивания на карте. Укажем отображаемые названия в подписях к измерению и уровню.

### Показатели (Measures)
[Показатели](http://docs.intersystems.com/latest/csp/docbook/DocBook.UI.Page.cls?KEY=D2MODEL_ch_concepts#D2MODEL_concepts_measure) или метрики это такие элементы куба, куда относят какие-либо «количественные» данные, которые необходимо посчитать для «качественных» измерений куба (Dimensions).
Например в таблице фактов такими показателями могут быть свойства:
* population (Население),
* validBallots (Число действительных избирательных бюллетеней),
* votersIncludedInVotersList (Число избирателей),
* отдельные показатели по каждому из восьми кондидатов
* Baburin (Бабурин СН),
* Grudinin (Грудинин ПН),
* Putin (Путин ВВ),
* Sobchak (Собчак КА),
* Suraykin (Сурайкин МА),
* Titov (Титов БЮ),
* Yavlinsky (Явлинский ГА),
* Zhirinovsky (Жириновский ВВ).
Перетянем каждое свойство на область показателей и создадим числовой показатель типа Integer функцией SUM, которая будет считать общее количество голосов в текущем срезе. Также для каждого показателя укажем отображаемое имя.
### Компиляция куба
Итак мы добавили в куб восемь показателей, одно измерения — этого вполне достаточно и уже можно посмотреть, что получилось.
Скомпилируем класс куба (Кнопка «Компилировать»). Если ошибок компиляции нет, значит куб создан правильно и можно наполнить его данными.
Для этого нужно нажать «Построить куб» — в результате DeepSee загрузит данные из таблицы фактов в хранилище данных куба.
Для работы с данными куба нам пригодится другое веб-приложение — DeepSee Analyzer.
Построение сводной таблицы (Pivot)
----------------------------------
[DeepSee Analyzer](http://docs.intersystems.com/latest/csp/docbook/DocBook.UI.Page.cls?KEY=D2ANLY_ch_intro) — визуальное средство для непосредственного анализа данных кубов и подготовки источников данных для дальнейшей визуализации. Для перехода к DeepSee Analyzer откроем Портал Управления Системой → DeepSee → Выбор области → Analyzer, также можно перейти со страницы создания куба, нажав на вкладку «Инструменты» в левой панели и затем на кнопку «Analyzer». Открывается рабочее окно Аналайзера.
В рабочем окне Аналайзера слева мы видим элементы созданного куба: показатели и измерения. Комбинируя их мы строим запросы к кубу на языке [MDX](http://docs.intersystems.com/latest/csp/docbook/DocBook.UI.Page.cls?KEY=D2GMDX_ch_intro#D2GMDX_intro_mdx) — аналоге языка SQL для многомерных OLAP кубов.
Чтобы создать сводную таблицу перетянем в поле колонок измерения Бабурин СН, Грудинин ПН, Путин ВВ, Собчак КА, Сурайкин МА, Титов БЮ, Явлинский ГА, Жириновский ВВ. Показателем выберем «Административный округ». В результате получим таблицу количества по административному округу с возможностью углубления (DrillDown — переход по иерархии измерения от общего к частному) в районы.
В Аналайзере двойной щелчок по заголовку измерения приводит переходу к следующему по иерархии измерению (DrillDown). В данном случае двойной клик по административному округу приведет к переходу к районам этого административного округа. В итоге можно посмотреть сколько было отдано голосов в разрезе по районам.
Также для подсвечивания определенных АО/районов нам необходим показатель, по которому будет высчитываться цвет данного полигона — данное значение будет браться из колонки со спец. именем ColorHSLValue (ссылка на инструкцию по настройке виджетов использующих карты приведен в конце статьи) — чем выше значение чем ближе цвет будет к красному и к зеленому в обратном случае. Для выведения названия полигона при наведении на него курсора используется спец. имя колонки TooltipValue. Для текста в всплывающем окне, которое появляется при нажатии на определенный полигон используйте имя измерения PopupValue, есть возможность использовать html для разметки значения.
Данные спец. поля мы создадим как вычисляемые значения. Для этого нажмите на кнопку с калькулятором в левом меню , выберите тип элемента, имя измерения, имя элемента и выражение, по которому будет вычисляться значение данного элемента.
#### Список специальных полей для карт
ColorHSLValue:
Тип элемента: Показатель
Имя элемента: ColorHSLValue
Тип: Число
Описание: Определяет цвет полигона от зелёного к красному в зависимости от значения.
Выражение:
```
[Measures].[attandance]/[Measures].[votersIncludedInVotersList]
```
является количество явившихся на выборы результатом отношения количества проголосовавших в данном АО/районе, таким образом чем выше данная пропорция — тем ближе цвет к красному.
PopupValue:
Тип элемента: Измерение
Имя измерения: custom
Имя элемента: PopupValue
Тип: Строка
Описание: Определяет цвет полигона от зелёного к красному в зависимости от значения.
Выражение:
```
"**" + [Territory].[H1].[Region].CurrentMember.Properties("name") + "**
Население: " + [Measures].[Population] + " чел.
Число избирателей: " + [Measures].[votersIncludedInVotersList] + "чел."
```
будет выведено имя данного АО/региона, население, количество проголосовавших избирателей
TooltipValue:
Тип элемента: Измерение
Имя измерения: custom
Имя элемента: TooltipValue
Тип: Строка
Описание: Определяет сообщение появляющееся при наведении на полигон.
Выражение:
```
[Territory].[H1].[Region].CurrentMember.Properties("name")
```
И после добавления данных колонок пивот выглядит следующим образом:

Сохраним данный пивот как MoscowElections/mainPivot2018.
Также создадим еще один пивот с информацией по всем избираемым кандидатам для выведения в виде пай-чара.
Перенесем показатели всех кандидатов в колонку «Показатели» и выберите в параметрах показателей  — «Разместить показатели на» — «строки»

Сохраним получившийся пивот как MoscowElections/countPivot2018 и перейдем к созданию индикаторной панели
Построение панели индикаторов (Dashboard)
-----------------------------------------
Портал Пользователя — это веб-приложение для создания и использования дашбордов ([панелей индикаторов](https://ru.wikipedia.org/wiki/%D0%9F%D0%B0%D0%BD%D0%B5%D0%BB%D1%8C_%D0%B8%D0%BD%D0%B4%D0%B8%D0%BA%D0%B0%D1%82%D0%BE%D1%80%D0%BE%D0%B2)). Дашборды содержат виджеты: таблицы, графики и карты на основе сводных таблиц, созданных аналитиками в Аналайзере.
Для перехода к Порталу Пользователя DeepSee откроем Портал Управления Системой → DeepSee → Выбор области → Портал Пользователя.
Создадим новый дашборд нажав на стрелку справа → добавить → Добавить индикаторную панель.

Создадим три виджета.
Для создания — нажмем на стрелку справа → Виджеты → "+" → выберем тип виджета в левом списке → источник данных и имя виджета:
Виджет с картой:
Тип виджета — Карта → Карта
Источник данных — MoscowElections/mainPivot2018
Имя виджета — moscowElectionsMap
Табличный виджет с данными с карты:
Тип виджета — Сводные таблицы и диаграммы → Таблица
Ссылка на — moscowElectionsMap
Имя виджета — tableWidget
Пай-чарт виджет с данными кандитатов:
Тип виджета — Сводные таблицы и диаграммы → Круговая диаграмма
Источник данных — MoscowElections/countPivot2018
Для второго и третьего виджетов необходимо создать элементы управления. Для табличного виджета — элемент управления, с помощью которого мы определим какие из поступающих колоном мы будем отображать (Напомню, что в пивоте мы определили спец. колонки которые нужны для карты, но которые не стоит отображать в табличном виджете). Для третьего — фильтр по АО/районам, значение которого будет устанавливаться автоматически при нажатии на любой АО/район. Сделать это можно следующим образом — нажмем на стрелку справа → Виджеты → tableWidget → Элементы управления → "+"
Расположение — Виджет
Цель — tableWidget
Действие — Установить спец. столбца
Тип — hidden
После подтверждения создания элемента управления — определим показываемые столбцы — необходимый формат — MDX
```
{[Measures].[Baburin],[Measures].[Grudinin],[Measures].[Zhirinovsky],[Measures].[Putin],[Measures].[Sobchak],[Measures].[Suraykin],[Measures].[Titov],[Measures].[Yavlinsky]}
```

Элемент управления для пай-чар виджета мы создадим в виджете-карте.
Расположение — Щелчок мыши
Цель — Виджет3
Действие — Применить фильтр
После этого сохраним дашборд.
Установка MDX2JSON и DeepSeeWeb
-------------------------------
Для визуализации созданного дашборда можно использовать следующие OpenSource решения:
* [MDX2JSON](https://github.com/intersystems-ru/Cache-MDX2JSON) — REST API предоставляет информацию о кубах, пивотах, дашбордах и многих других элементах DeepSee, в частности — результатах исполнения MDX запросов, что позволяет встраивать пользовательский интерфейс аналитического решения на DeepSee в любое современное Web или мобильное приложение.
* [DeepSeeWeb](https://github.com/intersystems-ru/DeepSeeWeb) — AngularJS приложение, предоставляющее альтернативную реализацию портала пользователя DeepSee. Может быть легко кастомизирован. Использует MDX2JSON в качестве бэкэнда.
### Установка MDX2JSON
Для установки MDX2JSON надо:
1. Загрузить [Installer.xml](https://raw.githubusercontent.com/intersystems-ru/Cache-MDX2JSON/master/MDX2JSON/Installer.cls.xml) и импортировать его в любую область с помощью Studio, Портала Управления Системой или Do $System.OBJ.Load(file).
2. Выполнить в терминале (пользователем с ролью %ALL): Do ##class(MDX2JSON.Installer).setup()
Для проверки установки надо открыть в браузере страницу `http://server:port/MDX2JSON/Test?Debug`. Возможно потребуется ввести логин и пароль (в зависимости от настроек безопасности сервера). Должна открыться страница с информацией о сервере. В случае получения ошибки, можно почитать на [Readme](https://github.com/intersystems-ru/Cache-MDX2JSON) и [Wiki](https://github.com/intersystems-ru/Cache-MDX2JSON/wiki/Installation-Guide---RU).
### Установка DeepSeeWeb
Для установки DeepSeeWeb надо:
1. Загрузить [установщик](https://github.com/intersystems-ru/DeepSeeWeb/releases) и импортировать его в любую область с помощью Studio, Портала Управления Системой или Do $System.OBJ.Load(file).
2. Выполнить в терминале (пользователем с ролью %ALL): Do ##class(DSW.Installer).setup()
Для проверки установки надо открыть в браузере страницу `http://server:port/dsw/index.html`. Должна открыться страница авторизации. В области SAMPLES представлено множество уже готовых дашбордов и все они автоматически отображаются в DeepSeeWeb.
Сбор координат полигонов
------------------------
Для отображения собранных данных на карте нам необходим набор координат полигонов административных округов и районов Москвы. Взять их можно например на сайте [gis-lab](http://gis-lab.info/qa/moscow-atd.html). Далее так как эти данные будут использоваться DeepSeeWeb нам нужно их привести к формату, который сможет обработать DSW:
**Укороченный код moscowElectionsMap.js**
```
function loadCoordinates(polygonCoordsArray)
{
polygonCoordsArray['Троицкий административный округ'] =
'36.8031,55.44083,0 ... 37.37279,55.80868,0'
...
polygonCoordsArray['район Некрасовка'] =
'37.90613,55.70626,0 ... 37.37296,55.80745,0'
}
```
Сохраним полученный js файл в папку web приложения нашей области и вуаля.
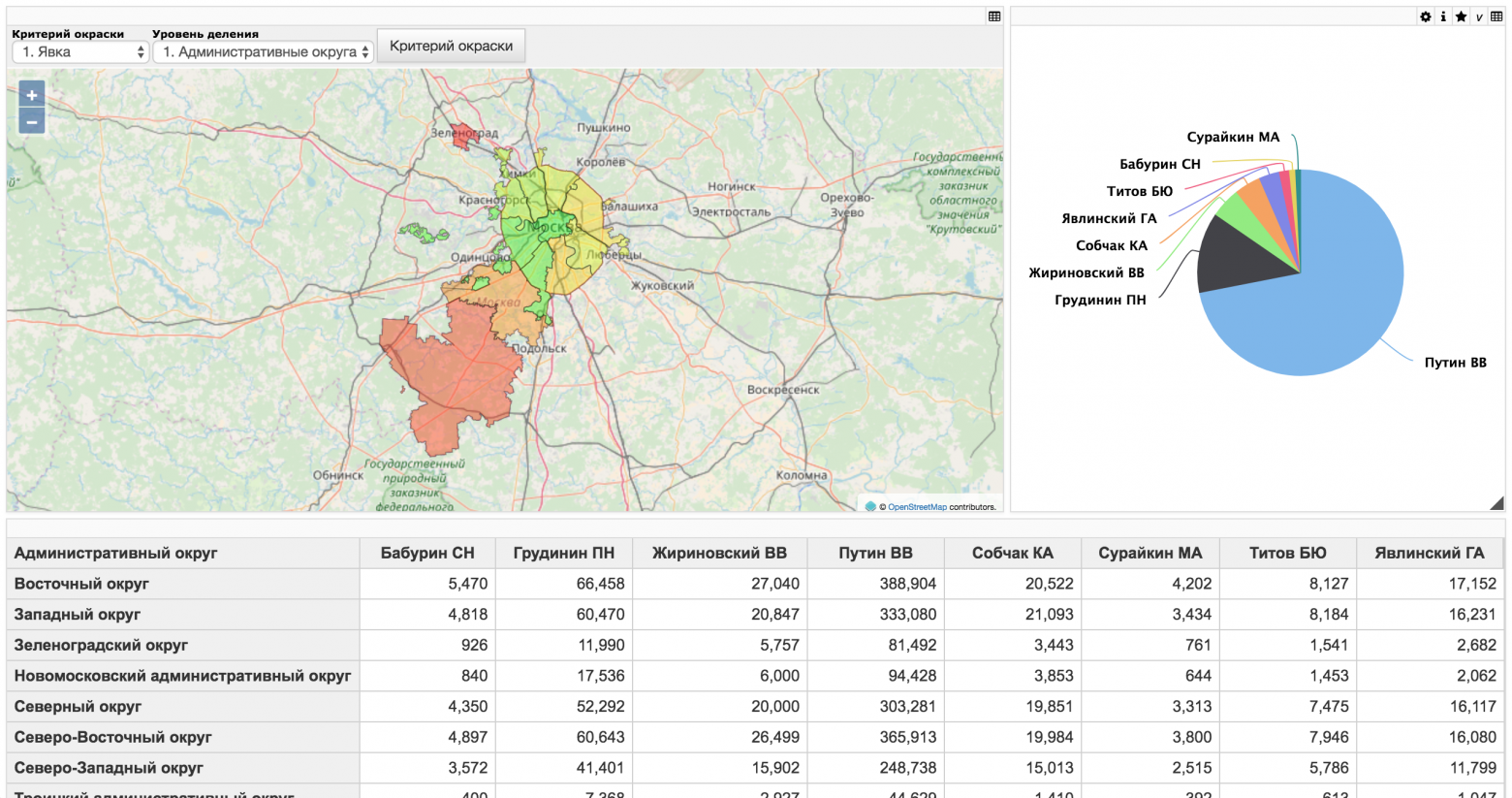
### Создание списка терминов
Также мы можем добавить возможность определения критерия окраски карты. если у нас сейчас окрашивается по отношения всего проголосовавших к населению АО/района, мы можем сделать окраску по отношению голосов за кандидата к населению. Сделать это можно следующим образом — мы создадим список терминов — список пар ключ-значение, при выборе ключа — значение будет подставляться в MDX выражение запроса. MDX выражение нашего пивота следующее:
```
SELECT NON EMPTY {[Measures].[Putin],[Measures].[Zhirinovsky],[Measures].[Baburin],[Measures].[Grudinin],[Measures].[Sobchak],[Measures].[Suraykin],[Measures].[Titov],[Measures].[Yavlinsky],[MEASURES].[COLORRGBVALUE],[CUSTOM].[TooltipValue],[CUSTOM].[PopupValue]} ON 0,NON EMPTY [Territory].[H1].[Region].Members ON 1 FROM [ELECTIONS2018CUBE]
```
Заменяться будет часть которая окружена фигурными скобками.
Создать список терминов можно в [Диспетчере списка терминов](http://docs.intersystems.com/latest/csp/docbook/DocBook.UI.Page.cls?KEY=D2MODADV_ch_term_list) — откройте портал пользователя → Инструменты → Диспетчер списка терминов
Для Путина будет следующая строка
Ключ: 2. Путин
Значение:
```
{[Measures].[Putin]\,%LABEL([Measures].[Putin]/[Measures].[votersIncludedInVotersList]\,"ColorRGBValue")\,[CUSTOM].[TooltipValue]\,%LABEL("**" + [Territory].[H1].[Region].CurrentMember.Properties("name") + "**
Население: " + [Measures].[Population] + " чел.
Число избирателей: " + [Measures].[votersIncludedInVotersList] + " чел.
За Путина проголосовало: " + [Measures].[Putin] + "чел."\,"PopupValue")}
```
Сохраним данный список терминов как MoscowElections2018.
Далее создадим элемент управления на странице настройки дашборда для пивота с картой:
Расположение — Щелчок мышки
Действие — Выбрать спец. строки
Нажимаем «OK»
Определяем имя и список спец. столбцов
Метка — Критерий окраски
Список спец. столбцов — MoscowElections2018.termlist
Готово!
### Дополнительная возможность: определение URL тайл-сервера
Также хотелось бы указать, что DeepSeeWeb поддерживает возможность указания определенного пути тайл сервера, который будет использоваться при запросах тайлов (картинок) для карты вместо используемого по умолчанию — `https://{a-c}.tile.openstreetmap.org/{z}/{x}/{y}.png`.
Мы опустим настройку тайл сервера, т. к. данная информация уже не раз была описана в [интернетах](https://switch2osm.org/manually-building-a-tile-server-16-04-2-lts/).
Для установки пути к желаемому тайл серверу необходимо выполнить следующие шаги:
1. Создать json файл с настройками DeepSeeWeb или сгенерировать уже готовый, который используется DeepSeeWeb
2. Указать узел “app.tileServer” со значением — url желаемого тайл сервера
3. Импортировать полученный json файл с настройками
#### Создание json файла с настройками DeepSeeWeb
Наилучшим способом создания является правки в json файле который уже используется вашим приложением. Для его получения нажмите на  в верхней части окна DeepSeeWeb — откроется окно с настройками DeepSeeWeb.
Нажмите “Export settings”. Откройте скачанный json файл и добавьте узел «tileServer» как подузел узла «app». Для данного примера будет использоваться URL OSM Wikipedia Maps — `https://maps.wikimedia.org/osm-intl/{z}/{x}/{y}.png`. Сохраните файл с настройками. Откройте окно с DeepSeeWeb и загрузите полученный json файл в окне настроек DeepSeeWeb. Готово!
Выводы:
-------
Мы показали пример использования мультимодельной СУБД InterSystems Caché, OLAP DeepSee, проектов DeepSeeWeb, MDX2JSON. Вы научились создавать хранимые классы, кубы, пивоты, индикаторные панели и осознали насколько прекрасны и удобны компоненты доступные как в платформе для интеграции и разработки приложений InterSystems Ensemble, так и в мультимодельной СУБД InterSystems Caché и на новом продукте InterSystems IRIS Data Platform.
Разработанные индикаторные панели были выложены на демо сервер:
→ [Демо сервер](http://37.139.6.217:57773/dsw/index.html#!/f/MoscowElections?ns=ELECTIONS)
Ссылки:
* [InterSystems IRIS Data platform](https://www.intersystems.com/resources/detail/intersystems-iris-data-platform/)
* [Репозиторий](https://github.com/intersystems-ru/MoscowElections)
* [Инструкция по настройке карт в DeepSeeWeb](https://www.intersystems.com/ru/wp-content/uploads/sites/11/DeepSeeWebMapsSetup.pdf)
* [DeepSeeWeb](https://github.com/intersystems-ru/DeepSeeWeb)
* [MDX2JSON](https://github.com/intersystems-ru/Cache-MDX2JSON)
* [Сведения о выборах Центральной избирательной комиссии Российской Федерации](http://www.izbirkom.ru/region/izbirkom)
* [gis-lab](http://gis-lab.info/qa/moscow-atd.html)
* [Список тайл серверов OSM](https://wiki.openstreetmap.org/wiki/Tile_servers) | https://habr.com/ru/post/351992/ | null | ru | null |
# Что такое скрипты и с чем их едят — Lua & C++
Добрый день, Хабрахабр!
Решил написать этот топик на тему скриптов
#### Что нужно знать?
* С++ на приличном уровне (в уроке будут шаблоны — template)
* Lua, очень легкий скриптовый язык. Советую [этот](http://tylerneylon.com/a/learn-lua/) урок.
#### Почему писать диалоги игры в .cpp файле было большой ошибкой
Если вы разрабатывали большие проекты (к примеру, масштабные игры), замечали, что с каждой новой сотней строк кода компиляция идет медленней?
В игре создается больше оружия, больше диалогов, больше меню, больше etc.
Одна из самых главных проблем, возникающих в связи с нововведениями — поддерживать бессчетное множество оружия и бейджиков довольно сложное занятие.
В ситуации, когда просьба друга/босса/напарника изменить диалог или добавить новый вид оружия занимает слишком много времени, приходится прибегать к каким-то мерам — например, записи всей этой фигни в отдельные текстовые файлы.
Почти каждый геймдевелопер когда-нибудь делал карту уровней или диалоги в отдельном текстовом файле и потом их считывал. Взять хотя бы простейший вариант — олимпиадные задачи по информатике с файлом ввода
Но есть способ, на голову выше — использование скриптов.
#### Решение проблемы
«Окей, для таких дел хватает обычного файла с описанием характеристиков игрока. Но что делать, если в бурно развивающемся проекте почти каждый день приходится немножко изменять логику главного игрока, и, следовательно, много раз компилировать проект?»
Хороший вопрос. В этом случае нам на помощь приходят скрипты, держащие именно логику игрока со всеми характеристиками либо какой-либо другой части игры.
Естественно, удобнее всего держать, логику игрока в виде кода какого-нибудь языка программирования.
Первая мысль — написать свой интерпретатор своего скриптового языка, выкидывается из мозга через несколько секунд. Логика игрока определенно не стоит таких жутких затрат.
К счастью, есть специальные библиотеки скриптовых языков для С++, которые принимают на вход текстовый файл и выполняют его.
Об одном таком скриптовом языке Lua пойдет речь.
#### Как это работает?
Прежде чем начать, важно понимать, как работает скриптовый язык. Дело в том, что в скриптовых языках есть очень мало функций, при наличии конструкций for, while, if, прочих.
В основном это функции вывода текста в консоль, математические функции и функции для работы с файлами.
Как же тогда можно управлять игроком через скрипты?
Мы в С++-программе делаем какие-либо функции, «регистрируем» их под каким-нибудь именем в скрипте и вызываем в скрипте. То есть если мы зарегистрировали функцию SetPos(x,y) для определения позиции игрока в С++-программе, то, встретив эту функцию в скрипте, «интерпретатор» из библиотеки скриптового языка вызывает эту функцию в С++-программе, естественно, с передачей всех методов.
Удивительно, да? :)
**UPD:** Внимание! Один юзер обратился мне с мейлом, что, когда я заливал код, я не полностью устранил все ошибки — [habrahabr.ru/post/196272/#comment\_6850016](http://habrahabr.ru/post/196272/#comment_6850016)
В коде с позволения хабра проникли жучки
Замените участки кода вроде
```
template
T MethodName();
```
На
```
template
T MethodName();
```
И еще вместо lua\_CFunction проскакивает lua\_cfunction
Спасибо!
#### Я готов!
Когда вы поняли преимущества скриптовых языков программирования, самое время начать работать!
Скачайте из репозитория на гитхабе (низ топика) lib'у и includ'ы Lua, либо возмите их на официальном сайте.
Создаем консольный проект либо Win32 (это неважно) в Visual Studio (у меня стоит версия 2012)
Заходим в Проект->Свойства->Свойства конфигурации->Каталоги VC++ и в «каталоги включения» и «каталоги библиотек» добавьте папку Include и Lib из репозитория соответственно.
Теперь создаем файл main.cpp, пишем в нем:
```
int main()
{
return 0;
}
```
Как вы догадались, у меня консольное приложение.
Теперь переходим к кодингу
Обещаю, что буду тщательно объяснять каждый момент
У нас за скрипты будет отвечать класс Script. Я буду объявлять и одновременно реализовывать функции в Script.h/.cpp
Создаем Script.cpp и пишем в нем
```
#include "Script.h"
```
Создаем Script.h и пишем в нем
```
#ifndef _SCRIPT_H_
#define _SCRIPT_H_
#endif
```
После 2 строчки и перед #endif мы определяем класс скриптов
Этот код пишется для предотвращения взаимного включения файлов. Допустим, что файл Game.h подключает Script.h, а Script.h подключает Game.h — непорядок! А с таким кодом включение выполняется только 1 раз
Теперь пишем внутри этого кода вот это
```
#pragma comment(lib,"lua.lib")
extern "C"
{
#include
#include
#include
}
```
Первая строчка подключает сам lua.lib из архива.
Для чего нужен extern «C»? Дело в том, что lua написан на С и поэтому такой код необходим для подключения библиотек.
Дальше идет подключение хорошо известных многим файлов для работы с консолью
```
#include
#include
#include
using namespace std;
```
Теперь приступим к определению класса
```
class Script
{
```
Самый главный объект библиотеки Lua для C++ — lua\_State, он необходим для выполнения скриптов
```
private:
lua_State *lua_state;
```
Дальше идут публичные функции
```
public:
void Create();
```
Эта функция инициализирует lua\_State
**Create()**Его определение в Script.cpp
```
void Script::Create()
{
lua_state = luaL_newstate();
static const luaL_Reg lualibs[] =
{
{"base", luaopen_base},
{"io", luaopen_io},
{NULL, NULL}
};
for(const luaL_Reg *lib = lualibs; lib->func != NULL; lib++)
{
luaL_requiref(lua_state, lib->name, lib->func, 1);
lua_settop(lua_state, 0);
}
}
```
Первой строчкой мы инициализируем наш lua\_State.
Потом мы объявляем список «подключенных библиотек». Дело в том, что в «чистом» виде в луа есть только функция print(). Для математических и прочих функций требуется подключать специальные библиотеки и потом вызывать их как math.foo, base.foo, io.foo. Для подключения других библиотек добавьте в lualibs, например, {«math», luaopen\_math}. Все названия библиотек начинаются с luaopen\_..., в конце lialibs должен стоять {NULL,NULL}
```
void Close();
```
Эта функция освобождает ресурсы Lua
**Close()**Ее определение
```
void Script::Close()
{
lua_close(lua_state);
}
```
Просто используем lua\_close()
```
int DoFile(char* ScriptFileName);
```
А эта функция выполняет файл. На вход она принимает название файла, например, «C:\\script.lua».
Почему она возвращает int? Просто некоторые скрипты могут содержать return, прерывая работу скрипта и возвращая какое-нибудь значение.
**DoFile()**Ее определение
```
int Script::DoFile(char* ScriptFileName)
{
luaL_dofile(lua_state,ScriptFileName);
return lua_tointeger(lua_state, lua_gettop(lua_state));
}
```
Как вы видите, я выполняю скрипт и возвращаю int. Но возращать функция может не только int, но еще и bool и char\*, просто я всегда возвращаю числа (lua\_toboolean, lua\_tostring)
Теперь мы сделаем функцию, регистрирующую константы (числа, строки, функции)
```
template
void RegisterConstant(T value, char\* constantname);
```
**RegisterConstant()**Мы действуем через шаблоны. Пример вызова функции:
```
RegisterConstant(13,"goodvalue");
```
Ее определение
```
template<>
void Script::RegisterConstant(int value, char\* constantname)
{
lua\_pushinteger(lua\_state, value);
lua\_setglobal(lua\_state,constantname);
}
template<>
void Script::RegisterConstant(double value, char\* constantname)
{
lua\_pushnumber(lua\_state, value);
lua\_setglobal(lua\_state,constantname);
}
template<>
void Script::RegisterConstant(char\* value, char\* constantname)
{
lua\_pushstring(lua\_state, value);
lua\_setglobal(lua\_state,constantname);
}
template<>
void Script::RegisterConstant(bool value, char\* constantname)
{
lua\_pushboolean(lua\_state, value);
lua\_setglobal(lua\_state,constantname);
}
template<>
void Script::RegisterConstant(lua\_CFunction value, char\* constantname)
{
lua\_pushcfunction(lua\_state, value);
lua\_setglobal(lua\_state,constantname);
}
```
Для каждого возможного значения class T мы определяем свои действия.
\*Капитан\* последнее определение — регистрация функции
Функции, годные для регистрации, выглядят так:
```
int Foo(lua_State*)
{
// ...
return n;
}
```
Где n — количество возвращаемых значений. Если n = 2, то в Луа можно сделать так:
```
a, b = Foo()
```
Читайте мануалы по Луа, если были удивлены тем, что одна функция возвращает несколько значений :)
Следующая функция создает *таблицу* для Луа. Если непонятно, что это значит, то тамошная таблица все равно что массив
```
void Array();
```
**Array()**Ее описание
```
void Script::Array()
{
lua_createtable(lua_state, 2, 0);
}
```
Следующая функция регистрирует элемент в таблице.
```
template
void RegisterConstantArray(T value, int index);
```
**RegisterConstantArray()**Ее описание
```
template
void Script::RegisterConstantArray(int value, int index)
{
lua\_pushnumber(lua\_state, index);
lua\_pushinteger(lua\_state, value);
lua\_settable(lua\_state, -3);
}
template
void Script::RegisterConstantArray(double value, int index)
{
lua\_pushnumber(lua\_state, index);
lua\_pushnumber(lua\_state, value);
lua\_settable(lua\_state, -3);
}
template
void Script::RegisterConstantArray(char\* value, int index)
{
lua\_pushnumber(lua\_state, index);
lua\_pushstring(lua\_state, value);
lua\_settable(lua\_state, -3);
}
template
void Script::RegisterConstantArray(bool value, int index)
{
lua\_pushnumber(lua\_state, index);
lua\_pushboolean(lua\_state, value);
lua\_settable(lua\_state, -3);
}
template
void Script::RegisterConstantArray(lua\_CFunction value, int index)
{
lua\_pushnumber(lua\_state, index);
lua\_pushcfunction(lua\_state, value);
lua\_settable(lua\_state, -3);
}
```
Если вы не знаете Lua, вы, наверное, удивлены тем, что в один массив помещается столько типов? :)
На самом деле в элементе таблицы может содержаться еще и таблица, я так никогда не делаю.
Наконец, заполненную таблицу нужно зарегистрировать
```
void RegisterArray(char* arrayname);
```
**RegisterArray()**Ее описание
```
void Script::RegisterArray(char* arrayname)
{
lua_setglobal(lua_state, arrayname);
}
```
Ничего особенного нет
Следующие функции предназначены в основном только для функций типа int foo(lua\_State\*), которые нужны для регистрации в Луа.
Первая из них — получает количество аргументов
```
int GetArgumentCount();
```
**Create()**Ее описание
```
int Script::GetArgumentCount()
{
return lua_gettop(lua_state);
}
```
Эта функция нужна, например, для функции Write(), куда можно запихать сколь угодно аргументов, а можно и ни одного
Подобную функцию мы реализуем позже
Следующая функция получает аргумент, переданный функции в скрипте
```
template
T GetArgument(int index);
```
**GetArgument()**Ее описание
```
template
int Script::GetArgument(int index)
{
return lua\_tointeger(lua\_state,index);
}
template
double Script::GetArgument(int index)
{
return lua\_tonumber(lua\_state,index);
}
template
char\* Script::GetArgument(int index)
{
return (char\*)lua\_tostring(lua\_state,index);
}
template
bool Script::GetArgument(int index)
{
return lua\_toboolean(lua\_state,index);
}
```
Можно получить все типы, описывавшиеся ранее, кроме таблиц и функций
index — это номер аргумента. И первый аргумент начинается с 1.
Наконец, последняя функция, которая возвращает значение в скрипт
```
template
void Return(T value);
```
**Return()**Ее описание
```
template<>
void Script::Return(int value)
{
lua\_pushinteger(lua\_state,value);
}
template<>
void Script::Return(double value)
{
lua\_pushnumber(lua\_state,value);
}
template<>
void Script::Return(char\* value)
{
lua\_pushstring(lua\_state,value);
}
template<>
void Script::Return(bool value)
{
lua\_pushboolean(lua\_state,value);
}
```
#### Боевой код
Пора что-нибудь сделать!
Изменяем main.cpp
```
#include "Script.h"
int main()
{
return 0;
}
```
Компилируем. Теперь можно приступить к тестированию нашего класса
Помните, я обещал сделать функцию Write? :)
Видоизменяем main.cpp
```
#include "Script.h"
// Нужен для _getch()
#include
// Объект скрипта
Script script;
// Функция Write для текста
int Write(lua\_State\*)
{
// Тут мы считываем количество аргументов и каждый аргумент выводим
for(int i = 1; i < script.GetArgumentCount()+1; i++)
cout << script.GetArgument(i);
// После вывода ставим консоль на паузу
\_getch();
return 0;
}
int main()
{
script.Create();
// Имя у луашной функции такое же, как у сишной
script.RegisterConstant(Write,"Write");
script.DoFile("script.lua");
script.Close();
}
```
А в папке с проектом создаем файл script.lua
```
Write(1,2,3,4)
```
Компилируем и запускаем проект.
Теперь изменяем script.lua
```
for i = 1, 4 do
Write(i, "\n", "Hier kommt die Sonne", "\n")
end
```
Теперь программа будет выводить по 2 строки ("\n" — создание новой строки), ждать нажатия Enter и снова выводить строки.

Экспериментируйте со скриптами!
Вот пример main.cpp с функциями и пример script.lua
```
#include "Script.h"
#include
#include
#include
Script script;
int Write(lua\_State\*)
{
// Тут мы считываем количество аргументов и каждый аргумент выводим
for(int i = 1; i < script.GetArgumentCount()+1; i++)
cout << script.GetArgument(i);
cout << "\n";
return 0;
}
int GetString(lua\_State\*)
{
// Считываем строку с помощью cin и возвращаем ее, используя методы Script
char\* str = "";
cin >> str;
script.Return(str);
// Не забудьте! У нас возвращается 1 результат -> return 1
return 1;
}
int Message(lua\_State\*)
{
// Выводим обычное сообщение MessageBox из Windows.h
// Кстати, вам домашнее задание - сделайте возможность вывода сообщений с несколькими аргументами :)
char\* msg = script.GetArgument(1);
MessageBox(0,msg,"Сообщение",MB\_OK);
return 0;
}
int GetTwoRandomNumbers(lua\_State\*)
{
// Возвращаем два рандомных числа до 1000
srand(time(NULL));
for(int i = 0; i < 2; i++)
script.Return(rand()%1000);
// Вовзращаем 2 значения
return 2;
}
int GetLotOfRandomNumbers(lua\_State\*)
{
// Возвращаем много рандомных чисел до 1000
srand(time(NULL));
for(int i = 0; i < script.GetArgument(1); i++)
script.Return(rand()%1000);
// Вовзращаем столько значений, сколько задано в аргументе
return script.GetArgument(1);
}
int main()
{
script.Create();
script.RegisterConstant(Write,"Write");
script.RegisterConstant(GetString,"GetString");
script.RegisterConstant(Message,"Message");
script.RegisterConstant(GetTwoRandomNumbers,"Rand1");
script.RegisterConstant(GetLotOfRandomNumbers,"Rand2");
script.Array();
script.RegisterConstantArray(1,1);
script.RegisterConstantArray(2,2);
script.RegisterConstantArray(3,3);
script.RegisterConstantArray(4,4);
script.RegisterArray("mass");
script.DoFile("script.lua");
script.Close();
// Пауза после скрипта
\_getch();
}
```
```
for i = 1, 4 do
Write(i, "\n", "Hier kommt die Sonne", "\n")
end
Write(2*100-1)
Message("Привет!")
a, b = Rand1()
Write(a, "\n", b, "\n")
Write(Rand1(), "\n")
a, b, c, d = Rand2(4)
Write(a, "\n", b, "\n", c, "\n", d, "\n")
return 1
```
##### Полезные советы
* Для класса Script все равно, в каком расширении находится скрипт, хоть в .txt, хоть в .lua, хоть в .bmp, просто .lua открывается множеством редакторов именно ЯП Луа
* Используйте редакторы Lua кода, очень трудно писать код, можно забыть написать end, do, либо что-нибудь еще. Программа из-за ошибки в луа скрипте не вылетит, но просто не выполнит код
* Lua может оказаться намного гибче, чем вам могло показаться. К примеру, числа свободно преобразуются в строки, он нетипизирован. Если передать в функцию 100 параметров, а она в С++ считывает только первые 2, то программа не вылетит. Есть еще много подобных допущений.
##### Вопросы и ответы
* **Вопрос:** Почему мы не используем луа стейт, который есть в каждой подобной функции — int foo(lua\_State\* L)?
**Ответ:** За всю программу мы используем только один стейт в Script, где регистрируем функции, инициализируем его и делаем прочие штучки. К тому же просто невыгодно было бы, написав целый класс, опять обращаться начистоту к lua\_State через lua\_pushboolean и прочие функции.
Полный листинг Script.h и Script.cpp
**Script.h**
```
#ifndef _SCRIPT_H_
#define _SCRIPT_H_
#pragma comment(lib,"lua.lib")
extern "C"
{
#include
#include
#include
}
class Script
{
private:
lua\_State \*lua\_state;
public:
void Create();
void Close();
int DoFile(char\* ScriptFileName);
template
void RegisterConstant(T value, char\* constantname);
void Array();
template
void RegisterConstantArray(T value, int index);
void RegisterArray(char\* arrayname);
int GetArgumentCount();
template
T GetArgument(int index);
template
void Return(T value);
};
#endif
```
Я удалил инклуды для работы с консолью
**Script.cpp**
```
#include "Script.h"
void Script::Create()
{
lua_state = luaL_newstate();
static const luaL_Reg lualibs[] =
{
{"base", luaopen_base},
{"io", luaopen_io},
{NULL, NULL}
};
for(const luaL_Reg *lib = lualibs; lib->func != NULL; lib++)
{
luaL_requiref(lua_state, lib->name, lib->func, 1);
lua_settop(lua_state, 0);
}
}
void Script::Close()
{
lua_close(lua_state);
}
int Script::DoFile(char* ScriptFileName)
{
luaL_dofile(lua_state,ScriptFileName);
return lua_tointeger(lua_state, lua_gettop(lua_state));
}
template<>
void Script::RegisterConstant(int value, char\* constantname)
{
lua\_pushinteger(lua\_state, value);
lua\_setglobal(lua\_state,constantname);
}
template<>
void Script::RegisterConstant(double value, char\* constantname)
{
lua\_pushnumber(lua\_state, value);
lua\_setglobal(lua\_state,constantname);
}
template<>
void Script::RegisterConstant(char\* value, char\* constantname)
{
lua\_pushstring(lua\_state, value);
lua\_setglobal(lua\_state,constantname);
}
template<>
void Script::RegisterConstant(bool value, char\* constantname)
{
lua\_pushboolean(lua\_state, value);
lua\_setglobal(lua\_state,constantname);
}
template<>
void Script::RegisterConstant(int(\*value)(lua\_State\*), char\* constantname)
{
lua\_pushcfunction(lua\_state, value);
lua\_setglobal(lua\_state,constantname);
}
void Script::Array()
{
lua\_createtable(lua\_state, 2, 0);
}
template<>
void Script::RegisterConstantArray(int value, int index)
{
lua\_pushnumber(lua\_state, index);
lua\_pushinteger(lua\_state, value);
lua\_settable(lua\_state, -3);
}
template<>
void Script::RegisterConstantArray(double value, int index)
{
lua\_pushnumber(lua\_state, index);
lua\_pushnumber(lua\_state, value);
lua\_settable(lua\_state, -3);
}
template<>
void Script::RegisterConstantArray(char\* value, int index)
{
lua\_pushnumber(lua\_state, index);
lua\_pushstring(lua\_state, value);
lua\_settable(lua\_state, -3);
}
template<>
void Script::RegisterConstantArray(bool value, int index)
{
lua\_pushnumber(lua\_state, index);
lua\_pushboolean(lua\_state, value);
lua\_settable(lua\_state, -3);
}
template<>
void Script::RegisterConstantArray(lua\_CFunction value, int index)
{
lua\_pushnumber(lua\_state, index);
lua\_pushcfunction(lua\_state, value);
lua\_settable(lua\_state, -3);
}
void Script::RegisterArray(char\* arrayname)
{
lua\_setglobal(lua\_state, arrayname);
}
int Script::GetArgumentCount()
{
return lua\_gettop(lua\_state);
}
template<>
int Script::GetArgument(int index)
{
return lua\_tointeger(lua\_state,index);
}
template<>
double Script::GetArgument(int index)
{
return lua\_tonumber(lua\_state,index);
}
template<>
char\* Script::GetArgument(int index)
{
return (char\*)lua\_tostring(lua\_state,index);
}
template<>
bool Script::GetArgument(int index)
{
return lua\_toboolean(lua\_state,index);
}
template<>
void Script::Return(int value)
{
lua\_pushinteger(lua\_state,value);
}
template<>
void Script::Return(double value)
{
lua\_pushnumber(lua\_state,value);
}
template<>
void Script::Return(char\* value)
{
lua\_pushstring(lua\_state,value);
}
template<>
void Script::Return(bool value)
{
lua\_pushboolean(lua\_state,value);
}
```
Репозиторий с lib'ой и includ'ами: <https://github.com/Izaron/LuaForHabr>
Все вопросы посылайте мне в ЛС, либо в этот топик, либо, если вам не повезло быть зарегистрированным на хабре — на мейл [email protected] | https://habr.com/ru/post/196272/ | null | ru | null |
# BrowserID: почтовый адрес как ID пользователя
Mozilla закончила разработку [BrowserID](https://github.com/mozilla/browserid) — единой децентрализованной системы аутентификации, которая использует HTML5, криптографию с открытым ключом и цифровые подписи. Она основана на упрощённой интерпретации [Verified Email Protocol](http://www.open-mike.org/entry/verified-email-protocol).
Даже сейчас, на первом этапе внедрения, система довольно проста для пользователя: ему нужно один раз [подтвердить email](https://browserid.org/signup), после чего он получает возможность безопасной авторизации на любом сайте в два клика мышкой, без ввода пароля. В будущем авторизация ещё более упростится, когда поддержку BrowserID внедрят в браузеры, а почтовые провайдеры станут центрами идентификации первого уровня.

Так будет работать система, если Gmail станет поддерживать BrowserID. В этом случае отпадёт необходимость подтверждать свой email на сайте Browserid.org, который сейчас является пока единственным центром идентификации первого уровня.
Кроме отсутствия паролей, ключевым преимуществом BrowserID является защита приватности — в отличие от OpenID и всех подобных систем, провайдер identity в BrowserID *не получает* данных о том, на каком сайте залогинился пользователь.
Для поддержки BrowserID достаточно включить библиотеку [include.js](https://github.com/mozilla/browserid/blob/dev/resources/static/include.js), добавив следующую строчку в заголовок страницы:
Вместо кастомной кнопки можно поставить одну из стандартных, которые предлагаются для BrowserID.
    
По нажатию на кнопку осуществляется вызов функции верификации адреса электронной почты.
```
navigator.id.getVerifiedEmail(function(assertion) {
if (assertion) {
// This code will be invoked once the user has successfully
// selected an email address they control to sign in with.
} else {
// something went wrong! the user isn't logged in.
}
});
```
После успешной проверки адреса электронной почты API возвращает вам подписанную строку `assertion`, которая подтверждает email пользователя.
На втором этапе вам нужно верифицировать `assertion` и получить email пользователя. Это делается запросом к <https://browserid.org/verify> с двумя параметрами `POST` (`assertion` и `audience`) — запрос подписан уже вашей подписью. Верификатор проверяет валидность `assertion`.
```
$ curl -d "assertion=&audience=https://mysite.com" "https://browserid.org/verify"
{
"status": "okay",
"email": "[email protected]",
"audience": "https://mysite.com",
"expires": 1308859352261,
"issuer": "browserid.org"
}
```
Проверку `assertion` можно осуществлять и на собственном сервере, см. [спецификации](https://wiki.mozilla.org/Identity/Verified_Email_Protocol) и [исходники верификатора](https://github.com/mozilla/browserid/blob/dev/bin/verifier). В этом случае обеспечивается абсолютная защита информации — провайдер identity не получает данных о том, на каком сайте залогинился пользователь.
Демо BrowserID (с конференции Mozilla All Hands в сентябре 2011 г.) | https://habr.com/ru/post/134762/ | null | ru | null |
# Python для математических вычислений
 Экосистема языка python стремительно развивается. Это уже не просто язык общего назначения. С его помощью можно успешно разрабатывать веб-приложения, системные утилиты и много другое. В этой заметке мы сконцентрируемся все же на другом приложении, а именно на научных вычислениях.
Мы попытаемся найти в языке функции, которые обычно требуем от математических пакетов. Рассмотрим сильные и слабые стороны идеи использования python вместо MATLAB, Maple, Mathcad, Mathematica.
Среда разработки
----------------
Код на python может быть помещен в файл с расширением .py и отправлен интерпретатору для выполнения. то классический подход, который обычно разбавляется использованием среды разработки, например pyCharm. Однако, для python ([и не только](https://github.com/ipython/ipython/wiki/IPython-kernels-for-other-languages)) существует другой способ взаимодействия с интерпретатором — интерактивные блокноты [jupyter](http://jupyter.org/), сохраняющие промежуточное состояние программы между выполнением различных блоков кода, которые могут быть выполнены в произвольном порядке. Этот способ взаимодействия позаимствован у блокнотов Mathematica, позже аналог появился и в MATLAB (Live script).
Таким образом вся работа с python-кодом переносится в браузер. Получившейся блокнот можно открыть с помощью [nbviewer.jupyter.org](http://nbviewer.jupyter.org/), [github](https://github.com/) (и [gist](https://gist.github.com)) умеют самостоятельно показывать содержимое таких файлов (преобразовывать).
Из браузерной природы jupyter следуют его недостатки: отсутствие отладчика и проблемы с печатью большого количества информации (зависание окна браузера). Последняя проблема решается расширением, которое ограничивает максимальное количество символов, которое можно вывести в результате выполнения одной ячейки.
Визуализация данных
-------------------
Для визуализации данных обычно используется библиотека [matplotlib](http://matplotlib.org/), команды которой очень похожи на MATLABовские. В Stanford'е была разработана библиотека, расширяющая возможности matplotlib — [seaborn](https://stanford.edu/~mwaskom/software/seaborn/) (необычные графики для статистики).
Рассмотрим пример построения гистограммы для сгенерированной выборки данных.
```
import numpy as np
import matplotlib.mlab as mlab
import matplotlib.pyplot as plt
# example data
mu = 100 # mean of distribution
sigma = 15 # standard deviation of distribution
x = mu + sigma * np.random.randn(10000)
num_bins = 50
# the histogram of the data
n, bins, patches = plt.hist(x, num_bins, normed=1, facecolor='green', alpha=0.5)
# add a 'best fit' line
y = mlab.normpdf(bins, mu, sigma)
plt.plot(bins, y, 'r--')
plt.xlabel('Smarts')
plt.ylabel('Probability')
plt.title(r'Histogram of IQ: $\mu=100$, $\sigma=15$')
# Tweak spacing to prevent clipping of ylabel
plt.subplots_adjust(left=0.15)
plt.show()
```
Мы видим, что синтаксис matplotlib очень похож на синтаксис MATLAB. Стоит так же заметить, что в заголовке графика используется latex.
Вычислительные математика
-------------------------
Для линейной алгебры в python принято использовать [numpy](http://www.numpy.org/), вектора и матрицы которого типизированы, в отличии от встроенный в язык списков. Для научных вычислений используется библиотека [scipy](https://www.scipy.org/).
Специально для пользователей MATLAB [написан гайд по переходу с MATLAB на numpy](http://docs.scipy.org/doc/numpy-dev/user/numpy-for-matlab-users.html).
```
import scipy.integrate as integrate
import scipy.special as special
result = integrate.quad(lambda x: special.jv(2.5,x), 0, 4.5)
```
В данном примере численно вычисляется значение определенного интеграла функции Бесселя на отрезке [0,0.45] с помощью библиотеки QUADPACK (Fortran).
Символьные вычисления
---------------------
Для использования символьных вычислений можно использовать библиотеку [sympy](http://www.sympy.org/). Однако, код, написанный с помощью sympy, уступает в красоте коду, написанному на Mathematica, которая специализирована на символьных вычислениях.
```
# python
from sympy import Symbol, solve
x = Symbol("x")
solve(x**2 - 1)
```

По функциональности Sympy уступает Mathematica, однако, с учетом ваших потребностей, может оказаться, что для вас их возможности приблизительно равны. Более подробное сравнение можно найти в [wiki репозитория sympy](https://github.com/sympy/sympy/wiki/SymPy-vs.-Mathematica).
Ускоряем код
------------
Для ускорения вашего кода за счет преобразования в C++ может быть реализовано по средствам библиотеки [theano](http://deeplearning.net/software/theano/). Платой за такое ускорение становится синтаксис, теперь вам требуется писать theano-ориентированные функции и указывать типы всех переменных.
```
import theano
import theano.tensor as T
x = T.dmatrix('x')
s = 1 / (1 + T.exp(-x))
logistic = theano.function([x], s)
logistic([[0, 1], [-1, -2]])
```
Некоторые библиотеки для сверточных нейронных сетей, такие как [Lasagne](https://github.com/Lasagne/Lasagne) и [Keras](https://keras.io/), используют theano для своих вычислений. Стоит так же добавить, что theano поддерживает ускорение за счет вычислений на GPU.
Машинное обучение
-----------------
Самой популярной библиотекой машинного обучения для python является [scikit-learn](http://scikit-learn.org/stable/), которая содержит все основные алгоритмы машинного обучения, а так же метрики качества, инструменты для валидации алгоритмов, инструменты для пред-обработки данных.

```
from sklearn import svm
from sklearn import datasets
clf = svm.SVC()
iris = datasets.load_iris()
X, y = iris.data, iris.target
clf.fit(X, y)
clf.predict(X)
```
Для работы загрузки данных из табличных форматов данных (excel, csv) обычно используется [pandas](http://pandas.pydata.org/). Загруженные данные представляются в памяти в виде DataFrame'ов, к которым можно применять различные операции: как строчные (построчная обработка), так и групповые (фильтры, группировки). Обзор основных функций pandas можно найти в презентации "[Pandas: обзор основных функций](http://www.slideshare.net/dyakonov/pandas-54795658)" (Автор: Александр Дьяконов, профессор МГУ).
Не все так гладко...
--------------------
Однако, не все так гладко в python. Например, сейчас уживается две версии языка 2. *и 3.*, обе они развиваются параллельно, однако синтаксис 2ой версии не совместим полностью с синтаксисом 3ей версии.
Еще одна проблема может возникнуть у вас, если вы не обладатель linux, в этом случае при установке ряда библиотек у вас могут возникнуть трудности, некоторые библиотеки будут полностью не совместимы, например [tensorflow](https://www.tensorflow.org/versions/r0.11/get_started/os_setup.html).
**Библиотеки, о которых шла речь*** [Jupyter](http://jupyter.org/) (онлайн блокноты)
* [Matplotlib](http://matplotlib.org/) (графики)
* [Seaborn](https://stanford.edu/~mwaskom/software/seaborn/) (графики)
* [Numpy](http://www.numpy.org/) (линейная алгебра)
* [Scipy](https://www.scipy.org/) (научные вычисления)
* [Sympy](http://www.sympy.org/en/index.html) (символьные вычисления)
* [Theano](http://deeplearning.net/software/theano/) (преобразование в C++, вычисления на GPU)
* [Scikit-learn](http://scikit-learn.org/stable/) (машинное обучение)
* [Pandas](http://pandas.pydata.org/) (загрузка данных и простые операции над ними)
**P.S:** все библиотеки для python, о которых говорилось данной статье, имеют открытый исходный код и распространяются бесплатно. Для их загрузки можно воспользоваться командой [pip](https://pypi.python.org/pypi/pip) или просто скачать сборку [Anaconda](https://www.continuum.io/downloads), которая содержит все основные библиотеки. | https://habr.com/ru/post/312268/ | null | ru | null |
# Как захватить мир, или javascript next уже сейчас (часть первая)
Доброго времени суток дорогой хабраюзер. Я очень люблю все новое и красивое и поэтому очень часто посматриваю за развитием ecma 6 aka Harmony. Да-да, вы не ошиблись, речь пойдет именно о новом javascript, хотя он еще в разработке, но многие фичи уже сейчас можно начать тестировать, так сказать, просто для своего удовольствия.
В помощь можно взять Firefox последней версии, но я нашел более другой способ для себя. Далее речь пойдет о новых возможностях javascript, что нас ждет и о [slimerjs](http://slimerjs.org).
Итак, что же такое slimerjs? Наверное стоит познакомиться с ним ближе, если мы хотим с ним работать. По сути slimerjs есть ни что иное что и [phantomjs](http://phantomjs.org). Это скриптовый браузер для разработчика имеющий в своем арсенале движок эквивалентный последнему Firefox. Это означает, что мы имеем полную возможность использовать его, как REPL.
Но оставим теорию на будущее и рассмотрим как же работать со slimerjs. Так как я любитель Windows, и часто сталкиваюсь с трудностью настроек, но я не унываю. Все свои действия я буду описывать для Windows, по сути особого труда настроить под другую OS нет. И так поехали.
Первым делом мы скачиваем [slimerjs](http://slimerjs.org/download.html), распаковываем в папку, и прописываем системные переменные. В моем случае это была папка C:/Tools/slimerjs, добавляем это в переменную path. Также нам нужно установить переменную для Firefox, так как slimerjs требует Firefox, для запуска. Переменную **SLIMERJSLAUNCHER** в моем случае я установил так: C:\Program Files (x86)\Mozilla Firefox\firefox.exe. Что же, на этом наши магические манипуляции заканчиваются. Приступим к написанию кода, для проверки фич ecma 6.
Первое, на что я обратил свое внимание это на короткую запись функции. Найдя в [просторах интернета](http://paulrouget.com/e/es6functions/), довольно подробно описанное использования, я решил проверить это. И о чудо, изумлению не было предела. Есть несколько вариантов записи, я приведу все.
```
1) var square = function(x) { return x * x; }
2) var square2 = function(x) x * x;
3) var square3 = x => { return x * x };
4) var square4 = x => x * x;
5) var squareAndCube = x => [x * x, x * x * x];
```
Четвертый вариант знаком многим разработчикам работающим с C#, Scala, Typescript. Это есть не что иное как лямбда оператор.
Пятый вариант интересен собой, тем, что это еще и деструктивная операция. Давай-те проверим все эти типы записей. Для этого нам надо создать файл, пусть он будет иметь название ecma6-test-features.js и записать в него функции описанные выше. Допишем к каждой функции console.log, и посмотрим результат запуском команды slimerjs ecma6-test-features.js. Поначалу нам откроется окошко, ясное дело, что оно нам будет мешать, но у него есть ряд назначений, о которых можно почитать в документации slimerjs. Для того чтобы избавится от нежелательного открытия окна, в конце нашего файла скрипта нужно дописать такой код slimer.exit(). Теперь мы имеем консоль похожую на nodejs, в которой мы можем выполнять свой код. Запустив наш скрипт, мы получим результат от всех выше написанных функций. Такая запись функций меня очень порадовала.
Что же на очереди еще одна возможность в ecma6 — это list comprehensions. Что такое list comprehensions известно многим, тем кому нет, я вкратце объясню. Это такая синтаксическая конструкция, которая служит для создания списков применением операций над существующими списками. Что же рассмотрим пример, чтобы понять как это.
```
var list = [1,2,3,4,5];
var newList = [x * x for(x of list) if(x % 2 === 0)];
```
Итак, что же тут происходит? Первым выражением есть функция, которая применяется к каждому элементу массива, эквивалент которой является map. Вторая запись является итератором, для прохода по элементам массива. Третья часть, которая содержит if — является эквивалентом filter. С учетом того, что было сказано, плюс возможность короткой записи функции, запишем этот кусок кода в более привычном виде.
```
var list = [1,2,3,4,5];
var newList = list.filter(x => x % 2 === 0).map(n => n * n);
```
Многим эта запись знакома. Да-да вы не ошиблись так можно писать в C#, Typescript И в других современных языках. Красиво не так-ли?
На этом, пока все, далее я хотел рассказать и показать (потом выложить исходники всех тестов) остальные возможности работы с ecma6 уже сейчас.
Это моя первая статья. У меня было много идей, что написать, но я решил начать с этого
Буду рад услышать замечания и пожелание, для дальнейшего совершенствования себя как писателя статей.
С уважением ко всем. До новых встреч. | https://habr.com/ru/post/187400/ | null | ru | null |
# Собираем и настраиваем DNS сервер BUNDY (BIND10). Часть 1
Как то незаметно дошли руки все таки потрогать BIND10. Для начала немного истории о данном продукте. Первый релиз BIND10 был представлен консорциумом ISC в феврале 2013. 17 апреля 2014 консорциум ISC выпустил последний релиз BIND10 1.2.0, после это передал все наработки сообществу независимых разработчиков. Данного решение было принято в связи с тем что у консорциума нет ресурсов для разработки двух альтернативных проектов. Поэтому они будут развивать только BIND9, а BIND10 полностью переходит в руки сообщества. Для уменьшения путаницы с BIND9, на GitHub был создан новый проект в который перенесли все наработки консорциума по BIND10 и данный проект получил название Bundy.
Ну что же, думаю можно приступать к эксперименту.
Создадим новый контейнер и подключаемся к нему:
```
$ docker run --name bundy --hostname=bundy -d -i -t sovicua:jessie
$ docker attach bundy
```
Как обычно обновляемся и устанавливаем нужные пакеты для сборки.
```
# apt-get update
# apt-get upgrade
# apt-get install git-core g++ make pkg-config python3-dev sqlite3 libsqlite3-dev libbotan1.10-dev liblog4cplus-dev libboost-dev python3-setproctitle dnsutils net-tools autoconf autoconf-archive automake libtool
```
Получаем исходные коды проекта и выполняем сборку:
```
# git clone https://github.com/bundy-dns/bundy.git
# cd bundy
# autoreconf --install --warnings=none
# ./configure --prefix=/usr --sysconfdir=/etc --without-werror --enable-experimental-resolver
# make
```
И получаем ошибку при сборке resolver…
Ошибку получаем из-за того что ветке master отсутствуют некоторые файлы, в частности в папки src/lib/xfr которая нужна для сборки resolver. Если собирать без этой опции то все собирается и работает. Но так как мне хотелось попробовать все, то мне пришлось загрузить исходные коды с другой ветки и собирать все снова.
Дополнительно включаем для сервера DHCP хранение базы в MySQL. В процессе инсталляции нам зададут несколько вопросов на которые думаю не сложно будет ответить.
```
# wget http://dev.mysql.com/get/mysql-apt-config_0.3.6-1debian8_all.deb
# dpkg -i mysql-apt-config_0.3.6-1debian8_all.deb
```
Выбираем самую последнюю версию (DRM — Developer milestone releases)
```
Configuring mysql-apt-config
----------------------------
MySQL APT Repo features MySQL Server along with a variety of MySQL components. You may select the appropriate product to choose the version that you wish to receive.
Once you are satisfied with the configuration then select last option 'Apply' to save the configuration. Advanced users can always change the configurations later,
depending on their own needs.
1. Server 2. Connector-Python 3. Utilities 4. Apply
Which MySQL product do you wish to configure? 1
This configuration program will detect the current state of your system, check for any installed MySQL Server packages, and try to select the most appropriate version
of MySQL Server to be installed. If you are not sure which version to choose for yourself, do not change the auto-selected version. Advanced users can always change
the version later, depending on their own needs.
1. mysql-5.6 2. mysql-5.7-dmr 3. none
Which server version do you wish to receive? 2
MySQL APT Repo features MySQL Server along with a variety of MySQL components. You may select the appropriate product to choose the version that you wish to receive.
Once you are satisfied with the configuration then select last option 'Apply' to save the configuration. Advanced users can always change the configurations later,
depending on their own needs.
1. Server 2. Connector-Python 3. Utilities 4. Apply
Which MySQL product do you wish to configure? 4
```
Если вы решили использовать стабильную версию, то нужно выполнить команду:
```
# dpkg-reconfigure mysql-apt-config
```
… и выбрать требуемую версию ПО которое вы хотите использовать.
После этого обновляем данные репозитория и устанавливаем MySQL сервер.
```
# apt-get update
# apt-get install mysql-server libmysqlclient-dev libz-dev
```
Запускаем сервер MySQL
```
# service mysql start
..
[info] MySQL Community Server 5.7.7-rc is started.
# service mysql status
[info] MySQL Community Server 5.7.7-rc is running.
```
Теперь мы готовы к повторной сборке, перед этим удаляем каталог с старыми исходниками.
```
# git clone --branch bundyfork --single-branch https://github.com/bundy-dns/bundy.git
# cd bundy
# autoreconf --install --warnings=none
# ./configure --prefix=/usr --sysconfdir=/etc --without-werror --with-dhcp-mysql --enable-experimental-resolver
# make
```
Итак, продолжим наши эксперименты.
После того как закончится сборка, выполняем инсталляцию:
```
# make install
```
**Подготовка к первому запуску.**
По умолчанию сервисы DNS и DHCP не запускаются, их нужно отдельно активировать при помощи утилиты bundyctl. Перед этим нам нужно добавить пользователя от которого мы будем управлять сервисом.
```
# bundy-cmdctl-usermgr add root
```
Так же стоит подготовить базу данных для DHCP сервера.
```
# mysql -u root -p
mysql> CREATE DATABASE bundy;
mysql> CONNECT bundy;
mysql> SOURCE /usr/share/bundy/dhcpdb_create.mysql
mysql> CREATE USER 'bundy'@'localhost' IDENTIFIED BY 'bundy';
mysql> GRANT ALL ON bundy.* TO 'bundy'@'localhost';
mysql> quit
```
Ну вот и все мы готовы к запуску и посмотреть что же это за зверь такой этот BUNDY
**Поехали...**
Из родительской системы выполняем команду запуска, для первого запуска можно даже добавить ключ --verbose
```
$ docker exec -i -t bundy /usr/sbin/bundy --verbose
```
В контейнере подключаемся к сервису используя утилиту bundyctl которая позволяет нам управлять и настраивать все сервисы bundy.
```
# bundyctl
Username: root
Password:
["login success"]
> help
usage: [param1 = value1 [, param2 = value2]]
Type Tab character to get the hint of module/command/parameters.
Type "help(? h)" for help on bundyctl.
Type " help" for help on the specific module.
Type " help" for help on the specific command.
Available module names:
help Get help for bundyctl.
config Configuration commands.
execute Execute a given set of commands
Stats Stats daemon
tsig\_keys The TSIG keyring is stored here
Init Init process
Logging Logging options
data\_sources
The sources of authoritative DNS data
Cmdctl Interface for command and control
Msgq The message queue
>
```
Как я и говорил выше, по умолчанию сервисы DNS и DHCP (и другие) не запущены, для их инициализации есть готовый скрип который выполняет инициализацию авторизированного DNS сервер. Итак, для начала посмотрим какие у нас процессы запущены до начала инициализации.
```
> Init show_processes
[
[
18493,
"Socket creator",
null
],
[
18494,
"msgq",
null
],
[
18496,
"cfgmgr",
"ConfigManager"
],
[
18498,
"bundy-stats",
"Stats"
],
[
18499,
"bundy-cmdctl",
"Cmdctl"
]
]
```
Выполняем скрипт инициализации и снова смотрим что у нас теперь с процессами:
```
> execute init_authoritative_server
adding Authoritative server component
adding Xfrin component
adding Xfrout component
adding Zone Manager component
Components added. Please enter "config commit" to
finalize initial setup and run the components.
> config commit
```
```
> Init show_processes
[
[
18493,
"Socket creator",
null
],
[
18494,
"msgq",
null
],
[
18496,
"cfgmgr",
"ConfigManager"
],
[
18498,
"bundy-stats",
"Stats"
],
[
18499,
"bundy-cmdctl",
"Cmdctl"
],
[
18559,
"bundy-xfrout",
"Xfrout"
],
[
18560,
"bundy-xfrin",
"Xfrin"
],
[
18561,
"bundy-zonemgr",
"Zonemgr"
],
[
18562,
"bundy-auth",
"Auth"
]
]
```
Думаю, что разница заметна :) У нас появились 4 новых процессов:
— bundy-xfrout
— bundy-xfrin
— bundy-zonemgr
— bundy-auth
Проверим работу DNS сервера через запрос его версии.
```
# dig @127.0.0.1 -c CH -t TXT version.bind
; <<>> DiG 9.9.5-9-Debian <<>> @127.0.0.1 -c CH -t TXT version.bind
; (1 server found)
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 27337
;; flags: qr aa rd; QUERY: 1, ANSWER: 1, AUTHORITY: 1, ADDITIONAL: 1
;; WARNING: recursion requested but not available
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 4096
;; QUESTION SECTION:
;version.bind. CH TXT
;; ANSWER SECTION:
version.bind. 0 CH TXT "bundy 1.2.0"
;; AUTHORITY SECTION:
bind. 0 CH NS bind.
;; Query time: 1 msec
;; SERVER: 127.0.0.1#53(127.0.0.1)
;; WHEN: Fri Jul 03 07:39:41 UTC 2015
;; MSG SIZE rcvd: 79
```
Ну что же нас можно поздравить — не взирая на всякие препятствия при компиляции, мы смогли запустить и инициализировать авторизированный DNS сервер BUNDY|BIND10. Думаю что на сегодня достаточно буковок.
В следующей части мы немного разберемся с модулями которые входят в bundy и кто за что отвечает, а так же продолжим настройку DHCP и других модулей. | https://habr.com/ru/post/261719/ | null | ru | null |
# Основы SQL на примере задачи
В этом руководстве мы рассмотрим основные sql команды на примере небольшой задачи. При прочтении желательно сидеть за консолью mysql и вводить все запросы для большей наглядности.
### Постановка задачи
Дана база данных, в ней 3 таблицы следующего вида:
table1: user\_id (INT(5), PRIMARY KEY), username (VARCHAR(50), INDEX)
table2: phone\_id (INT(5), PRIMARY KEY), user\_id (INT(5), INDEX), phone\_number (INT(10), INDEX)
table3: room\_id (INT(5), PRIMARY KEY), phone\_id (INT(5), INDEX), room\_number(INT(4) INDEX)
Необходимо выбрать номер комнаты в которой сидит пользователь с ником qux…
### Подготовка данных для задачи
Для создания баз данных и таблиц используются операторы CREATE DATABASE и CREATE TABLE, соответственно (для удаления DROP DATABASE и DROP TABLE). В конце каждой команды ставится точка с запятой (;). Сначала создадим базу с именем article:
```
CREATE DATABASE IF NOT EXISTS article;
```
Мы используем ключевые слова IF NOT EXISTS для того, чтобы не возникала ошибка, если указанная база данных или таблица уже существует (в дальнейшем IF NOT EXISTS для простоты будем опускать).
Теперь необходимо создать таблицы:
```
CREATE TABLE `table1` (`user_id` INT(5) NOT NULL AUTO_INCREMENT, `username` VARCHAR(50), PRIMARY KEY(`user_id`), INDEX(`username`));
CREATE TABLE `table2` (`phone_id` INT(5) NOT NULL AUTO_INCREMENT, `user_id` INT(5) NOT NULL, phone_number INT(10) NOT NULL, PRIMARY KEY (`phone_id`), INDEX(`user_id`, `phone_number`));
CREATE TABLE `table3` (`room_id` INT(5) NOT NULL AUTO_INCREMENT, `phone_id` INT(5) NOT NULL, `room_number` INT(4) NOT NULL, PRIMARY KEY(`room_id`), INDEX(`phone_id`, `room_number`));
```
Разберём эти команды по порядку. После CREATE TABLE указывается имя таблицы, далее в скобках следуют имена полей с типами и атрибутами, перечисленные через запятую и указания ключей. Первой командой мы создаём таблицу с именем table1 и полями user\_id, username. Поле user\_id имеет целочисленный тип (INT) и длину 5-ть знаков, не может равняться нулю и обладает атрибутом auto\_increment (при создании каждой записи, значение в этом поле создаётся автоматически и увеличивается на единицу), к тому же оно является первичным ключём. [ Первичный ключ (primary key) представляет собой один из примеров уникальных индексов и применяется для уникальной идентификации записей таблицы. Никакие из двух записей таблицы не могут иметь одинаковых значений первичного ключа. ] Поле username имеет символьный тип (длина 255 символов) и является индексом. Вторая и третья команды аналогичны первой.
Для проверки какие таблицы есть у Вас в базе можно использовать команду:
```
SHOW TABLES;
```
Теперь необходимо добавить данные в таблицы. Для добавления записей используется оператор INSERT.
```
INSERT INTO table1 (username) VALUE ('foo');
```
В поле user\_id мы ничего не добавляем так как оно автоматически создаётся при каждом INSERT`е (вспоминаем про магический атрибут auto\_increment). После названия таблицы в скобках (далее будем называть эти скобки кортежём) указывается список полей, которым мы будем присваивать значения. После VALUE указываются сами значения. Они должны стоять на соответствующих позициях в кортеже.
Такими же командами добавляем пользователей bar, baz, qux.
Для проверки используем команду:
[1]
```
SELECT * FROM table1;
```
Саму команду SELECT мы рассмотрим подробнее позже.
Далее заполним таблицы table2 и table3.
[2]
```
INSERT INTO table2 (user_id, phone_number) VALUE ('2','200');
```
Здесь полю user\_id присваивается значение 2, а полю phone\_number — 200. Если поменять местами названия полей или значения в кортежах, то результат измениться. Например:
[3]
```
INSERT INTO table2 (user_id, phone_number) VALUE ('200','2');
```
Теперь полю user\_id присваивается значение 200, а phone\_number – 2.
Предположим, мы ошиблись при добавлении значений (использовали команду [3] вместо [2]), не надо рваться удалять таблицу или всю базу — значение можно изменить с помощью оператора UPDATE.
```
UPDATE table2 SET user_id='2', phone_number='200' WHERE phone_id='1';
```
После SET мы указываем поля, значения которых необходимо изменить, и соответственно новые значения через знак равно. Оператор WHERE мы видим впервые. Он необходимо для наложения ограничений на запрос. В данном случае изменения будут применяться не ко всем строкам таблицы, а только к тем у которых значение поля phone\_id равно '1'.
Остальные данные добавляются по аналогии (что добавлять можно посмотреть вверху страницы).
### Решение
Базу данных и таблицы мы создали. Теперь можно заняться решением самой задачи. Выборка в базе данных производится с помощью оператора SELECT, с которым мы немного знакомы по команде [1]. Рассмотрим его подробнее. В общем виде он выглядит так:
SELECT названия\_полей FROM названия\_таблиц WHERE условие [ORDER BY, LIMIT]
Где ORDER BY и LIMIT дополнительные опции.
Попробуем применить его. Выберем все значения поля username из таблицы table1.
```
SELECT username FROM table1;
```
и отсортируем их
```
SELECT username FROM table1 ORDER BY username;
```
Как видно, ORDER BY используется для сортировки по одному из полей, указанных после оператора SELECT. По умолчанию делается возрастающая сортировка, если хотим использовать сортировку в обратном порядке то после поля необходимо добавить DESC:
```
SELECT username FROM table1 ORDER BY username DESC;
```
Так как нам нужны все значения, то оператор WHERE можно не использовать. Ещё один пример: выбираем значения полей phone\_id и user\_id из таблицы table2, где phone\_number равен '200'.
```
SELECT phone_id, user_id FROM table2 WHERE phone_number=200;
SELECT phone_id, user_id FROM table2 WHERE phone_number=200 LIMIT 1, 3;
```
LIMIT выводит строки в указанном диапазоне (нижняя граница не включается). Если первый аргумент не указан, то он считается равным 0.
Как мы можем видить, все три наши таблицы связаны. table1 и table2 через поле user\_id, а table2 и table3 через phone\_id. Для того, чтобы связать их в одно целое по указанным столбцам, необходимо воспользоваться оператором JOIN. JOIN, в переводе на великий и могучий, означает «объединять», то есть собирать из нескольких кусочков единое целое. В базе данных MySQL такими «кусочками» служат поля таблиц, которые можно объединять при выборке. Объединения позволяют извлекать данные из нескольких таблиц за один запрос. В зависимости от требований к результату, MySQL позволяет производить три разных типа объединения:
1. INNER JOIN (CROSS JOIN) — внутреннее (перекрёстное) объединение
2. LEFT JOIN — левостороннее внешнее объединение
3. RIGHT JOIN — правостороннее внешнее объединение
INNER JOIN позволяет извлекать строки, которые обязательно присутсвуют во всех объединяемых таблицах.
Попробуем написать запрос:
[4]
```
SELECT table3.room_number FROM table1 INNER JOIN table2 USING(user_id) INNER JOIN table3 USING(phone_id) WHERE table1.username = 'qux';
```
С помощью оператора USING мы указываем поле по которому будут связаны таблицы. Его использование возможно только если поля имеют одинаковое название. В противном случае необходимо использовать ON, так как показано ниже:
```
SELECT table3.room_number FROM table1 INNER JOIN table2 ON table1.user_id = table2.user_id INNER JOIN table3 ON table2.phone_id = table3.phone_id WHERE table1.username = 'qux';
```
LEFT/RIGHT JOIN позволяют извлекать данные из таблицы, дополняя их по возможности данными из другой таблицы. Чтобы показать разницу с INNER JOIN нам сначала необходимо будет добавить ещё одно поле в таблицу table1.
```
INSERT INTO table1 (username) VALUE ('quuz');
```
А теперь используем команду [4], только заменим INNER JOIN на LEFT JOIN, а qux на quuz:
```
SELECT table3.room_number FROM table1 LEFT JOIN table2 USING(user_id) LEFT JOIN table3 USING(phone_id) WHERE table1.username = 'quuz';
```
Мы получим следующий результат:
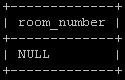
Новый пользователь получил user\_id=5. Это значение отсутствует в других таблицах, поэтому в результате мы получили NULL. При INNER JOIN результат был бы пустой, так как выводятся только значения, которые есть во всех таблицах. Здесь же таблицы table1 и table2 дополняются значением из table3, даже если его и нет.
### Аппендикс
Ниже приводятся примеры команд с небольшими пояснениями:
Удалить строку с user\_id равным 1 из таблицы table1:
```
DELETE FROM table1 WHERE user_id = 1;
```
Переименовываем таблицу table1 в nya:
```
RENAME TABLE table1 TO nya;
```
Переименовать поле user\_id в id (таблица table1):
```
ALTER TABLE table1 CHANGE user_id id INT;
```
Меняем тип и атрибут поля phone\_number:
```
ALTER TABLE table2 MODIFY phone_number VARCHAR(100) NOT NULL;
```
Просмотр описания таблицы table1:
```
DESCRIBE table1;
```
Добавляем поле abra типа DATE:
```
ALTER TABLE table3 ADD abra DATE;
```
Выбираем из table3 все значения поля room\_id, для которых room\_number начинается с цифры 3 (% означает любое количество любых символов; like проверяет совпадение символьной строки с заданным шаблоном):
```
SELECT room_id FROM table3 WHERE room_number LIKE '3%';
```
### P.S.
1. Часть материала про join`ы взята из статьи [MySQL немного о JOIN'ах](http://anton-pribora.ru/articles/mysql/mysql-join/).
2. Задача встретилась на одном из собеседований, которые я проходил. Она достаточно синтетическая, но хорошо подходит для описания материала.
3. Описания конструкций операторов намеренно упрощены для более лёгкого восприятия новичками. Для всех остальных есть [Справочное руководство по MySQL](http://mysql.ru/docs/man/Introduction.html) | https://habr.com/ru/post/123636/ | null | ru | null |
# PHP-Watcher: инструмент, который упрощает разработку долгоживущих приложений

Мы любим PHP за простоту: ты пишешь код, обновляешь страницу в браузере и сразу видишь изменения. Но если дело доходит до консольных команд, которые могут быть долгоживущими процессами, — например, если мы пишем асинхронный HTTP-сервер для загрузки файлов, — разработка может оказаться весьма болезненной.
В экосистеме PHP не было подходящего решения, чтобы автоматически перезапускать приложения при изменениях в исходном коде. Поэтому я решил сделать свой инструмент — на чистом PHP и с доступом через Composer.
Это как Nodemon, но на PHP
--------------------------
Некоторое время я сам использовал [Nodemon](https://github.com/remy/nodemon). Это инструмент из мира Node.js, однако если его немного поднастроить, можно использовать и с PHP-скриптами. Но ведь на самом деле я не хочу устанавливать Node.js и тащить кучу неизвестных мне NPM-пакетов в своё асинхронное PHP-приложение, чтобы перезапускать его.
Поскольку я активно общаюсь в твиттере, то спросил там, кто еще сталкивался с такой проблемой и хотел бы получить решение. Увидев интерес, сел писать инструмент, который предоставляет такой же функционал, что и Nodemon, ***только на PHP и для PHP***.

Прошел месяц: с [PHP-Watcher](https://github.com/seregazhuk/php-watcher) вам больше не нужно устанавливать Nodemon или любой другой пакет NPM для разработки вашего долгоживущего PHP-приложения.
Вот так это работает
--------------------
Библиотеку можно установить через Composer:
```
composer global require seregazhuk/php-watcher
```
Представим, что мы работаем над долгоживущим приложением на основе Symfony. Точка входа в наше приложение — файл public/index.php. Мы хотим отслеживать изменения в папках src и config. Еще мы хотим, чтобы приложение автоматически перезапускалось, как только мы изменим исходный код или параметры конфигурации. Вот как можно решить эту задачу:
```
php-watcher public/index.php --watch src --watch config
```
Команда запустит скрипт public/index.php, который начнёт отслеживать изменения в директориях src и config. Как только в любой из них изменится файл, PHP-Watcher перезапустит скрипт.
По умолчанию он отслеживает изменения только в PHP-файлах. Но Symfony хранит свои конфиги в yaml. Поэтому нам нужно явно указать “вотчеру”, чтобы он отслеживал как PHP, так и yaml-файлы. Делается это с помощью опции --ext:
```
php-watcher public/index.php --watch src --watch config --ext php,yaml
```
Допустим, мы поняли, что нам не нужно перезапускать приложения при любых изменениях внутри директории src. Например, нам бы хотелось игнорировать изменения в поддиректории src/Migrations. В этом случае можно воспользоваться опцией --ignore:
```
php-watcher public/index.php --watch src --watch config --ext php,yaml --ignore Migrations
```
Теперь PHP-Watcher начнёт отслеживать изменения в директориях src и config, но будет игнорировать любые изменения внутри поддиректории Migrations. Кроме того, он по умолчанию игнорирует изменения во всех dot- и VCS-файлах.
**“Вотчер” поддерживает настройку своего поведения не только через опции командной строки, но и через файлы конфигурации.** Если не хочется каждый раз в командной строке передавать кучу опций и параметров, то можно создать файл конфигурации .php-watcher.yml. Например, предыдущую команду можно заменить следующим конфигурационным файлом:
```
watch:
- src
- config
extensions:
- php
- yaml
ignore:
- Migrations
```
Имея такой файл, мы можем просто активировать “вотчер”, указав лишь PHP-скрипт, который нужно перезапускать. Все остальные настройки будут взяты из файла:
```
php-watcher public/index.php
```
Что будет, если у нас есть и файл конфигурации и аргументы командной строки? В таком случае все аргументы, переданные из командной строки, перезатрут соответствующие значения из файла конфигурации.
По умолчанию PHP-Watcher использует исполняемый файл PHP, чтобы запустить скрипт. Мы пишем в терминале команду:
```
php-watcher public/index.php
```
Под капотом создается дочерний процесс с командой php public/index.php. В большинстве случаев это то, что нужно. Однако если в вашем окружении иной исполняемый файл, можно явно указать, какую команду следует выполнить. Например, когда у нас есть несколько версий PHP в одной системе, а мы хотим запускать наше приложение с исполняемым файлом php7.4, можно воспользоваться опцией --exec и указать свой исполняемый файл:
```
php-watcher public/index.php --exec php7.4
```
То же самое через файл конфигурации:
```
watch:
- src
- config
executable: php7.4
```
PHP-Watcher автоматически не перезапускает приложение, если оно упало. В dev-окружении в этом и нет особой необходимости — ведь пока мы разрабатываем новое приложение, это нормально, что иногда оно будет крашиться. Если приложение упало (завершилось с кодом, отличным от 0), “вотчер” даст нам об этом знать. Как только мы пофиксим код, изменения будут обнаружены в исходниках — и приложение перезапустится.
**Спасибо за внимание!** Больше информации о PHP-Watcher можно найти на [домашней странице проекта на GitHub](https://github.com/seregazhuk/php-watcher). В документации описаны основные паттерны использования. Проект пока ещё находится в стадии разработки, но API уже довольно стабильный. Буду рад, если воспользуетесь.
**P.S.** Не стесняйтесь оставлять отзывы и пожелания через issue на GitHub. | https://habr.com/ru/post/475624/ | null | ru | null |
# Повесть о создании классической RTS в домашних условиях с нуля (часть 2: «Воскрешение»)

Примерно год назад вышла моя статья, которую можно назвать "[первой частью](https://habrahabr.ru/post/280520/)" данной статьи. В первой части я насколько смог подробно разобрал тернистый путь разработчика-энтузиаста, который мне удалось когда-то самостоятельно пройти от начала и до конца. Результатом этих усилий стала игра жанра **RTS** "*Земля онимодов*" созданная мною в домашних условиях без движков, конструкторов и прочих современных средств разработки. Для проекта использовались **C++** и **Ассемблер**, ну, и в качестве основного инструмента моя собственная голова.
В этой статье я постараюсь рассказать о том, как я решил взять на себя роль «реаниматора» и попытаться «воскресить» этот проект. Много внимания будет уделено написанию собственного игрового сервера.
[Продолжение статьи: GUI](https://habrahabr.ru/post/328116/)
[Конец статьи: Сеть](https://habrahabr.ru/post/328118/)
Короткое видео я прилагаю к статье, чтобы сразу было понятно о чем идет речь:
Вступление
----------
Вся эта история уходит корнями в 1998 год, когда мир IT был совсем иным. Игра, естественно, изначально проектировалась на существующие в тот момент условия. В частности, я бы сейчас навряд ли стал использовать ассемблер для вывода графики, но в тот момент это мне казалось чуть ли ни единственным решением. Если кому-то интересно, как всё это работает (игровая механика, AI и прочее) и каким было российское «издательство» игр в конце прошлого века, отсылаю вас к [первой части статьи](https://habrahabr.ru/post/280520/).
Также существует отдельное описание алгоритма поиска пути, который я когда-то разработал для своей RTS. Этой статье уже более 10 лет и писалась она, скорее, «для себя», но писалась достаточно подробно, чтобы я сам мог вспомнить как всё это работает. Использованное решение, на мой взгляд, обладает высокой эффективностью с точки зрения скорости работы и гарантированно строит путь до цели на клеточном поле с любой степенью сложности расположения препятствий. Ознакомиться с этим способом можно [тут](http://astralax.ru/articles/pathway).
Почему я решил продолжить всю эту «эпопею»? Мне всегда было больно осознавать, что работа такого масштаба была мною в своё время просто похоронена по экономическим причинам. И когда мне показалось, что есть хоть какой-то шанс дать этой игре вторую попытку, то я, естественно, попытался это сделать. Последний год своей жизни я почти полностью посвятил этому вопросу. Благодаря в основном поддержке читателей [первой части статьи](https://habrahabr.ru/post/280520/), игра прошла **Greenlight**, и я решил со свойственной мне целеустремленностью привести всё в порядок. И именно этой моей деятельности будет посвящена данная статья. В начале я думал описать подробно весь процесс, начиная с создания собственного **GUI** (графический интерфейс пользователя) и заканчивая написанием игрового сервера. Но, к сожалению, обнаружил, что этой информации получается слишком много. В результате я больше внимания уделил описанию сети, так как, мне показалось, что эта тема для многих более интересна. Я постарался дать объяснения в таком виде, чтобы это можно было как-то применить на практике. Однако у меня нет уверенности, что в результате статья не получилось слегка «тяжеловатой» для понимания.
«Оболочка» для игры или то, что можно скачать и посмотреть в исходном коде C++
------------------------------------------------------------------------------
Как ни странно, этот раздел, который находится в самом начале статьи, я написал в последнюю очередь. По ходу написания статьи я понял, что мне нужно хоть что-то показать «изнутри», иначе все мои объяснения не имеют большого практического смысла и на деле превращаются в словоблудие. А мне бы этого очень не хотелось.
Поэтому дополнительно я снабдил статью примером, по которому желающие могут ознакомиться с некоторыми аспектами моего подхода к написанию больших проектов:

Визуально этот пример мало похож на мою игру, но на деле игра использует именно этот код, только в ней применяется другая «оформляющая тема ». Настройка игрового сеанса выглядит в игре так:

Также на всякий случай уточняю, что это не «кнопки Windows-а», как кто-то может подумать, а мои собственные компоненты, которые я сделал в том объеме, который требовала моя игра.
Пример является не просто «формальным» примером, а содержит в себе оболочку, которую я создал, чтобы использовать её в составе игры. Названия сей продукт не имеет, но он создавался мною с учетом того, что возможно игре потребуется портирование на другую платформу. В настоящий момент в полностью работоспособном состоянии имеется только *Windows*-версия, однако все обращения к операционной системе выполнены через виртуальные функции, которые можно заменить. На практике мне это понадобилось, когда пришло время выкладывать игровой сервер на просторы Интернета. Для бесплатного тестирования мне был доступен только вариант сервера, которым управляла *Unix*-подобная ОС. В результате пришлось дописать в оболочку ветку для *Unix*-а. Сам сервер при этом я не менял вообще, только заменил функции, которые требовались серверу для взаимодействия с ОС. Я не особенно разбираюсь в **API** *Unix*-а, но у меня есть хороший знакомый программист (на данном ресурсе носящий кодовое имя [Komei](https://habr.com/ru/users/komei/)), который прекрасно понимает в этой теме. С его помощью портирование сервера было выполнено в течение нескольких дней. Кроме того мой приятель любезно предоставил мне свой *Unix*-сервер для запуска и тестирования моего игрового Интернет-сервера, а это, как минимум, была приличная материальная помощь моему проекту, так как держать собственный выделенный сервер не такое уж и дешевое удовольствие.
Пример в составе статьи мне понадобился по причине того, что вся вторая часть статьи посвящена устройству сетевой игры. И там я вынужден периодически переходить в объяснениях на код. А сами по себе отдельные куски кода представляются мне достаточно бессмысленными. Обнародовать исходный код игры я посчитал «перебором», всё же это для меня коммерческий продукт, кроме того, относительно небольшой пример представляется мне гораздо более понятным. Поэтому я решил обнародовать исходный код оболочки снабдив её для понятности собственным примером. Пример показывает работу с моим **GUI**, проигрывает звук и демонстрирует сетевое взаимодействие. Т.е. пользователь может нажать кнопку «Включить сеть», потом кнопку «Создать» и будет создан игровой сеанс, к которому можно присоединиться из примера, запущенного на другом компьютере. Конфигурация игрока в сеансе сводится к возможности менять его цвет, но для демонстрации принципа этого вполне достаточно.
Описывать подробно организацию **GUI** я уже не стал, так как я не уверен, что это сильно кому-то интересно, а статья и так получилась достаточно большой. В любом случае пример демонстрирует работу со всеми имеющимися в моем **GUI** компонентами.
Я не возражаю против того, чтобы кто-то воспользовался моей работой в своих корыстных или бескорыстных целях. Но я не обещаю, что буду развивать этот проект или что я буду поддерживать совместимость с текущей версией. Также я уточняю, что **GUI** проектировался не для скорости, а для универсальности, что и требовалось в моем случае. Кроме того, у меня реализована ветка, которая работает только с 16-битным цветом, который нужен моей игре, однако никто не мешает дописать ветку кода, которая будет работать с 32-битными цветами, а также использовать аппаратное ускорение **GPU** там, где это возможно. Скачать этот проект можно [здесь](http://astralax.ru/projects/others/ol_wrap).
Проект примера выполнен на **Visual Studio 2008** и использует язык **C++** и **DirectX9**.
Проблемы, которые мне предстояло решить
---------------------------------------
Для начала вот список проблем, которые существовали в игре год назад:
* Игра полноценно работала только под *Windows XP*. Под *Windows 7* игра нормально запускалась, но локальная сеть не функционировала вообще. А *Windows 8/10* просто отказывались запускать игру.
* Игра была намертво «прибита гвоздями» к платформе *Windows*. Активно использовался **DirectX**, а также **MFC**.
* Оформление меню было очень «стрёмным» даже на мой взгляд. Связано это было с тем, что я занимаюсь программированием и к рисованию имею весьма далекое отношение, а доделывал игру я уже в одиночку.
* Визуально с «иконками исследований» дело обстояло еще хуже, чем с меню.
* Голосовая озвучка оставляла, мягко говоря, желать лучшего.
* Не было интернет-сервера, который мне всегда хотелось иметь, так как я считаю, что самое интересное в **RTS** — это игра по сети.
Постепенно шаг за шагом я решал эти проблемы и сейчас чувствую, что наконец-то результат меня вполне устраивает. Однако так было не всегда…
С чего начать
-------------
Проект игры когда-то делался в **Visual Studio C++ 6.0**. Теперь же этот **Visual Studio C++ 6.0** даже не пожелал работать в *Windows 8*. Поэтому первым делом, мне нужно было перенести проект в новую для него среду. С одной стороны всё должно быть просто, так как **Visual Studio** умеет конвертировать проекты из прошлых версий в собственный формат, однако не тут-то было. Дело в том, что я использовал ассемблер **tasm32**, который создавал мне **obj**-файл. Этот файл без проблем линковался с **Visual Studio C++ 6.0**, но совсем не хотел линковаться с **Visual Studio 2008**. Новой версии **tasm32** на свете не оказалось, а другие ассемблеры типа **masm** почему-то пылали к синтаксису **tasm32** лютой ненавистью и выдавали множество ошибок при попытке подсунуть им мой **asm**-файл.
Поразмыслив, я решил, что не готов на данной стадии переписывать код ассемблера под другой синтаксис, так как по началу я вообще не был уверен, что я двигаюсь в правильном направлении. В результате я принял следующее решение: установил *Windows XP*, поставил в неё **Visual Studio C++ 6.0**, создал проект типа **DLL**, написал экспортируемые функции, которые просто вызывали через себя функции ассемблера и прилинковал к нему свой ассемблерный **obj**-файл, который в *Windows XP* прекрасно создавался через *tasm32.exe*. В результате я получил библиотеку **asm.dll**, которую я уже смог без проблем подключить к новому проекту в **Visual Studio 2008**. Такое решение заработало, практически, сразу и пока я решил остановится на нем. Я, естественно, понимаю, что это решение абсолютно не переносимо на другие платформы, но если уж действительно встанет вопрос о портировании, то можно «собрать волю в кулак » и перевести ассемблер в другой синтаксис. Пока же судьба этой игры для меня туманна, хотя определенно я её за последний год в прямом смысле реанимировал. В любом случае, я потратил на этот проект уже достаточно сил, чтобы наконец-то получить от вселенной четкий ответ по данному поводу.
После того, как я смог запустить игру в *Windows 8* с помощью **Visual Studio 2008** у меня в руках на-конец -то появился отладчик. Для начала мне нужно было разобраться в причинах, по которым новые версии *Windows* не желали запускать игру. Я давно не занимался играми и не особенно следил за той эволюцией ограничений, которую *Windows* стала накладывать на работу старых программ. Лично для меня эта причина оказалась очень неожиданной. Я обнаружил, что из *Windows 8/10* удален 16-битный цветовой режим, который использовался моей игрой. После нескольких «магических ритуалов» мне всё же удалось запустить игру и даже немного поиграть, но работало всё угрожающе медленно, а вместо ландшафта на основной части экрана был чистый и прекрасный черный цвет. Для себя я отметил, что 16-битный режим теперь эмулируется и имеет ограничения по использованию.
Битва за 16-битный видеорежим
-----------------------------
Как бороться с этой проблемой? Как минимум имеется 2 выхода:
1. Переделать всю графику в игре так, чтобы она могла работать в 24-битном разрешении. В моем случае этот вариант плох тем, что вся графика хранилась в сжатом виде и рисовалась ассемблером. Все функции ассемблера умели работать только с 16-битной графикой, самих функций было много и работали они достаточно быстро, предполагали много нюансов при рисовании и, главное, за эти годы я порядком забыл как всё это функционирует в деталях.
2. Создать в ОЗУ собственную поверхность, которая для игры будет являться экранной памятью. Рисовать всё на этой поверхности, а потом копировать её на реальный экран. Этот вариант я и выбрал в качестве единственно верного. При таком решении также появлялся жирнейший плюс — мне теперь почти не нужен **DirectX** для работы с графикой, так как единственное что он теперь должен был делать — это копировать мою поверхность на экран. Но есть в таком решении и не сразу очевидный минус — **DirectX** позволял мне запросто выводить текст, и я, естественно, так и делал. А теперь получалось: «нет **DirectX** — нет текста».
В результате я решил сделать следующее — написать что-то типа «оболочки», через которую игра общалась бы с операционной системой. Любые обращения к ресурсам ОС выполнять через виртуальные функции, чтобы в случае чего их можно было заменить. Практически, это даёт возможность относительно быстро портировать игру на другую ОС, но как всегда не всё так просто… почти любой программе, которая хоть как-то общается с пользователем нужен интерфейс. Интерфейс же состоит из разных маленьких (но милых) элементиков типа "*Текстовое поле*", "*Списочек*", "*Дерево*", "*Диалоговое окошечко*" и прочее. Иными словами, если идти таким путём, то нужно делать собственный **GUI**, который будет работать одинаково в условиях любой ОС. Кроме этого нужно как-то решить проблему с проигрыванием звуков и сетевым взаимодействием.
Для звуков я решил использовать библиотеку **Squall**. Плюсов её использования было несколько… во-первых, эта библиотека уже использовалась в старой версии игры, во-вторых, по сравнению с другими бесплатными аналогичными решениями она играла почти все **wav**-файлы, которые я ей подсовывал, в-третьих, я был лично знаком с автором [cesium](https://habr.com/ru/users/cesium/), что тоже немаловажно. Главный минус **Squall** — это то, что она уже давно не развивается и существует только под *Windows*. Однако в последнее время я стал стараться делать такую структуру у своих программ, чтобы можно было относительно без труда заменить внешнюю библиотеку каким-нибудь аналогом. В результате я сделал всё взаимодействие со **Squall** через небольшую прослойку из собственного класса. Чуть позже я в качестве эксперимента заменил **Squall** на **BASS**, однако не особенно ощутив пользу от этой замены, вернул **Squall** обратно. Зато теперь я знал, что если понадобиться другая платформа, то я смогу использовать **BASS**, который есть везде.
Так как мне предстояло, практически, избавиться от **DirectX** в составе игры, то для начала я просто закомментировал все **h**-файлы **DirectX**-а. Нажал на *Build* и приготовился оценить объем предполагаемой работы по замене функций **DirectX** на свои. Когда длинный «список проблем» наконец остановился, то внизу очень красноречиво отобразилось количество найденных ошибок в общей сложности чуть более 9 тысяч. Меньше всего ошибки касались **DirectInput**-а, так как ввод данных с мыши и клавиатуры — это относительно маленькая часть кода, а вот зато **DirectDraw** и **DirectPlay** отметились, как говорится, «по полной».
Существовала и еще одна мощная проблема. Дело в том, что к игре прилагается редактор карт и кампаний. А он был полностью написан с использованием **MFC**, а так как это, практически, оконное приложение *Windows*, то я сразу принял решение даже не думать о том, чтобы редактор в перспективе мог работать на другой платформе. Но дело в том, что и игра, и редактор — это, в моем случае, был один и тот же проект (в прямом смысле это был один и тот же **exe**-файл, который запускался в разными параметрами). Соответственно, мне нужно было разделить этот проект на 2 части: игра должна была работать почти полностью независимо от *Windows*, а редактор, напротив, оставался **MFC**-проектом. В результате когда я выдирал игру из фреймворка **MFC** я частенько натыкался на ситуацию, когда общие для этих проектов функции должны теперь выполнять свою задачу по-разному. Приходилось вставлять в код условную компиляцию и порождать вторую ветку кода.
Первым делом я стал создавать собственную оболочку, которая помогла бы мне освободиться от **DirectX**-зависимости. Мне было необходимо, чтобы оболочка умела работать с 16-битным разрешением, имела бы в своем составе стандартные компоненты для формирования интерфейса, а также позволяла бы выводить текст.
Структура «оболочки»
--------------------
Базовым классом всей оболочки я сделал класс **GGame**, который уже будет содержать в себе все остальные важные объекты. Класс **GPlatform** отвечает у меня за общение с ОС, исключая графические операции. Зато всё что касается работы с файловой системой, обработкой цикла сообщений, завершением работы приложения, запуском потоков и процессов относится к **GPlatform**. Класс **GSound** отвечает за звук, а класс **GNet** является либо сервером **GNetServer**, либо клиентом **GNetClient**, в зависимости от задачи. Самым сложным был класс **GDevice**, который заведует графикой.
Класс **GDevice** работает с поверхностями **GSurface**. Эти поверхности определены мною весьма абстрактно, т.е. там нет никаких намеков на количество битов на пиксель, зато определено множество абстрактных функций, которые должны были заменить мне стандартный **GDI**. Однако в реальности в игре никогда не создаются объекты типа **GSurface**, вместо этого используются дочерние объекты типа **GSurface16**, которые как раз умеют выполнять работу **GDI** применительно к 16-битным поверхностям. Я рассудил так, что если мне потребуется дать своей оболочке возможность работать с 24-битной графикой, то я всегда смогу создать аналогичный класс **GSurface24** и это не потребует каких-то глобальных изменений общей структуры оболочки.
Класс **GDevice** также отвечает за работу с разрешениями экрана, он имеет абстрактные функции, которые определяют доступные разрешения экрана, позволяет выбрать новое разрешение. **GDevice** также умеет масштабировать размер сцены под размер монитора. Например, игра использует любое разрешение просто за счёт увеличения видимой области игрового поля, а вот меню всегда работает только в разрешении **1920 x 1080**. Однако если реальное разрешение монитора меньше, то **GDevice** выполняет масштабирование меню под текущее разрешение монитора. Возможно, что более хорошим решением было бы сделать несколько видов меню под разные разрешения монитора, но я всё же не корпорация и подобные решения в моем случае, будут просто нерациональны. В любом случае, на ноутбуке с разрешением **1366 x 768** меню выглядит вполне приемлемо.
Все эти базовые классы **GPlatform**, **GDevice**, **GNet** и т.д. содержат множество абстрактных функций. В реальной программе вместо класса **GPlatform** используется дочерний класс **GPlatformWindows**, вместо класса **GDevice** — класс **GDeviceOnimodLandDX9**, вместо класса **GNet** — либо класс **GNetServerLibUV**, либо класс **GNetClientLibUV**, т.е. я использую объекты классов, которые уже приспособлены под нужную платформу и мою игру. Сама «оболочка», не имеет ни об игре, ни об ОС, ни малейшего понятия.
Да и самый основной класс на самом деле превращается из **GGame** в класс **GGameOnimodLandDX9**. Как же всё это связывается вместе? Ответ заключается в том, чтобы никогда не создавать в программе важные объекты напрямую через оператор **new**. Вместо этого существуют виртуальные функции, которые осуществляют создание объекта нужного типа. Например, абстрактные функции класса **GGame**:
```
// Создание платформы
virtual GPlatform* GGame::NewPlatform(GGame* owner, const char* game_name)=0;
// Создание звука
virtual GSound* GGame::NewSound()=0;
```
выглядят для класса **GGameOnimodLand** примерно так:
```
// Создание платформы
GPlatform* GGameOnimodLand::NewPlatform(GGame* owner, const char* game_name)
{
return new GPlatformWindows(owner, game_name);
}
// Создание звука
GSound* GGameOnimodLand::NewSound()
{
#ifdef SQUALL_SOUND
return new GSoundSquall();
#endif
#ifdef BASS_SOUND
return new GSoundBass();
#endif
}
```
А теперь как всё это создается через базовый класс:
```
// Создание всего, что есть в игре
bool GGame::CreateGame(void* init, int view_width, int view_height)
{
platform=NewPlatform(this, game_name.c_str());
platform->Create();
device=NewDevice(init);
device->Create(view_width, view_height);
sound=NewSound();
....
....
....
}
```
Таким образом, получается так, что базовый класс создает нужные ему объекты, не вникая в тонкости специфики ОС или графического **API**. Такой подход позволяет отделить основной код программы от особенностей среды выполнения. Также это позволяет относительно легко произвести портирование на другую платформу, а **DirectX** заменить на **OpenGL**, так как вся специфика среды выполнения вынесена в небольшие и полностью отделенные классы и их функции.
[Продолжение статьи: GUI](https://habrahabr.ru/post/328116/)
[Конец статьи: Сеть](https://habrahabr.ru/post/328118/) | https://habr.com/ru/post/327596/ | null | ru | null |
# Установка Sun System Portal Server 7.1 update 1 на Windows 2003
По просьбам трудящихся, пишу как установить портал на винду. К сожалению, я не осилил следующую проблему — как продеплоить сэмплы на портал, как запустить болг-портлет, вики-портлет и т.д. Исходя из логов, я пришел к выводу, что хардкод путей к файлам в билдовых скриптах не позволяет установить примеры и развернуть существующий функционал.
Тем не менее, портал ставится и работает.
Как я и обещал, через несколько дней будут готовы примеры портлетиков (через неделю диплом сдаю, пришлось отложить написание портлетов на «последипломие»). Затем поставлю портал 7.2 на линух и начну его ковырять.
### Установка Sun System Portal Server 7.1 update 1 на Windows 2003
1.Скачать дистрибутив портала с сайта Sun: Дистрибутивы порталов
2.Раскрыть архив на диске C:\
Путь к корню дистрибутива должен выглядеть следующим образом: C:\Sun. В папке находятся следующие каталоги и файлы:
3.Проверить, не заняты ли порты и освободить их.
`1527, 1389, 4848, 8080, 11161, 11162, 11163, 11164, 11165, 4443`
Для этого воспользуйтесь командой
````netstat –ano | findstr
последовательно подставляя порты из списка.
tasklist | findstr
чтобы выяснить, какой процесс занял порт
taskkill /PID
чтобы завершить процесс.
Порты 8080` и `4848` обычно занимает GlassFish, идущий в поставке с NetBeans. Самый простой способ освободить их – зайти в NetBeans, на вкладке Services выбрать правой кнопкой сервер GlassFish и остановить его. Если вы ставили J2EE расширение, то сервер, идущий в поставке так же оккупирует порты 8080 и 4848. Убедитесь, что он остановлен.
4.Запустить setup.bat.
Нажать «y» если вы собираетесь использовать localhost в качестве FQDN host name.
5.Выполнить команду
`C:\Sun\JavaES5\appserver\bin\asadmin list-instances --user admin --port 4848
Пароль = password
Примите сертификат, который вам предложат. Это действие необходимо для последующего развертывания портлетов.
Сам портал находится по адресу localhost:8080/portal/dt
Веб-интерфейс администратора портала: localhost:8080/psconsole
Логин = amadmin
Пароль = password
Консоль администратора сервера приложений: localhost:4848/
Логин = admin
Пароль = password
Портал ставится на сервер приложений.
Для запуска и остановки сервера используйте команды:
C:\Sun\startportal.bat
C:\Sun\stopportal.bat
Для указания другого FQDN нужно отредактировать файл
C:\Sun\env.bat
Пример отредактированного файла:
fqdn.host=plasma.red.iplanet.com
domainname=red.iplanet.com
root.domain=iplanet.com
Если портал установлен и требуется поменять FQDN, то нужно деинсталировать портал, записать конфигурацию env.bat, установить портал заново.
**Полные сведения, настройки по умолчанию:**
JDK Version: 1.6.0_02
Sun Java System Application Server
Version: 8.2
Admin User: admin
Password: password
Master Password: password
Admin Port: 4848
GF Domain: domain1
Port: 8080
Sun Java System Directory Server
Version: 6.0
Admin User: cn=Directory Manager
Password: password
Port: 1389
Instance: DSInstance
Root DN: dc=red,dc=iplanet,dc=com
Sun Java System Access Manager
Version: 7.1
Admin User: amadmin
Password: password
amldapuser password: adminadmin
Sun Java System Portal Server
Version: 7.1 Update 1
Admin User: amadmin
Password: password```` | https://habr.com/ru/post/26695/ | null | ru | null |
# Кэширование в Windows Azure
Проблема кэширования встает перед любым высоконагруженным приложением. В Windows Azure, где основным алгоритмом увеличения производительности является добавление экземпляров приложения, роль кэша становится еще более важной, т.к. с его помощью можно обеспечить «общую память» для всех экземпляров.
#### MemoryCache
Вообще, этот класс не имеет отношение к Azure, но не упомянуть его в статье о кэшировании просто нельзя.
Начиная с .Net 4 появилось новое пространство имен System.Runtime.Caching. Занимается MemoryCache, как следует из названия, созданием хранилища объектов в памяти. Для меня он важен тем, что работает гораздо быстрее, чем Cache из пространства System.Web.Caching. Еще приятной особенностью является то, что можно создать несколько кэшей с разными настройками.
Для простоты работы, можно сразу описать параметры кэша в конфигурации и потом обращаться к нему через MemoryCache.Default. Другие кэши нужно инициализировать принудительно и хранить ссылки на них. Параметры можно задать как в рантайме, так и в конфигурации:
```
```
#### In-Role Cache
Как правило, у каждого приложения в облаке есть несколько экземпляров: с одной стороны это обеспечивает отказоустойчивость (SLA Azure в принципе требует не мене двух экземпляров) и масштабируемость при росте-падении нагрузок.
Регулярно возникает желание, обеспечить единую «память» для всех экземпляров. Самым простым примером будет сессия. Для этого в Azure имеется механизм In-Role Cache, который позволяет выделить часть или всю память экземпляра под кэш, и он будет доступен из всех экземпляров приложения.
Для его использования необходимо добавить в решение пакет [Windows Azure Caching](https://www.nuget.org/packages/Microsoft.WindowsAzure.Caching/) и настроить роли для работы с ним.
Сначала нам нужно включить кэш на экземплярах или добавить выделенные под кэш экземпляры в решение.
> **Внимание**: кэш не поддерживается на сверхмалых (extra small) экземплярах.
**Картинки про включение кэша**Включение кэша на существующей роли
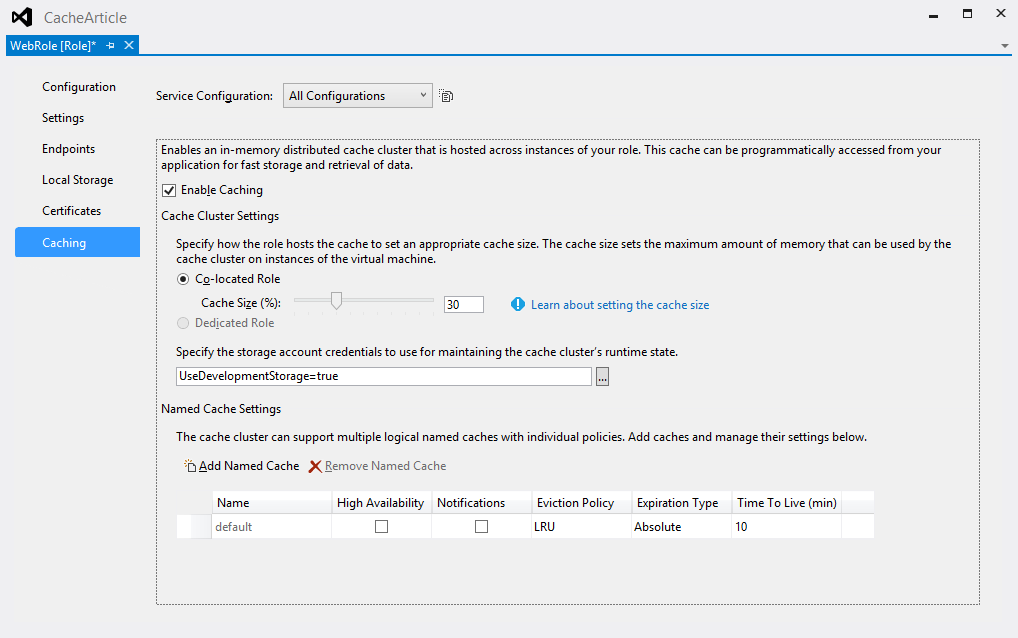
Создание роли, выделенной под кэш
Всегда будет присутствовать кэш с именем “default”. Мы можем добавить кэши со своими именами и различными настройками.
##### Настройки кэша
**Высокая доступность (High Availability).**
Требует, чтобы в решении было не менее двух экземпляров, на которых расположен кэш. Данные попадающие в кэш будут храниться минимум на двух экземплярах и выход из строя одного экземпляра не приведет к потере данных. Использовать эту опцию стоит осторожно, т.к. кэш начинает поглощать гораздо больше ресурсов.
**Оповещения (Notifications)**
Включить-выключить механизм оповещений для кэша. Появились они буквально только-что и реальных сценариев для них, я пока не придумал.
**Очистка (Eviction policy)**
Как будет очищаться кэш в случае переполнения. Для включения пока доступна только одна опция – LRU (Least recent use). Т.е. к какому объекту меньше всего обращались – тот и будет удален.
**Устаревание (Expiration Type) и время жизни (TTL, Time To Live)**
Два взаимосвязанных параметра, указывают, как и за какой срок (в минутах) будут устаревать в кэше и исчезать из него. Т.е. если параметр очистки является больше аварийным (ситуация переполнения кэша ни к чему хорошему обычно не приводит), то устаревание позволяет нам описать как объекты должны исчезать из кэша при нормальной работе.
**None.** Объекты будут храниться в кэше вечно (до перезагрузки). Требует, чтобы время жизни было установлено в ноль.
**Absolute.** Объект хранится в кэше определенное время после того, как туда попал.
**Sliding window.** Моя любимая опция. Объект исчезнет из кэша через указанное время после последнего обращения. Т.е. объекты, к которым обращаются постоянно будут жить в кэше.
#### Настройка клиента кэша
В целом, всё довольно просто: в конфигурационном файле описываем, какие кэши у нас есть и где расположены. Вставляем в конфигурационный файл в секцию configuration следующие строки (их шаблон должен был уже создать NuGet при установки пакета кэширования).
```
…
```
В качестве идентификатора нужно указывать имя роли содержащей кэш в проекте. В нашем случае – CacheWorkerRole. А не имя точки доступа в Azure, типа mycoolapp.cloudapp.net.
Пояснений, наверное, требует только тэг localCache, который указывает, что экземпляр может хранить объекты у себя локально и принцип хранения. objectCount определяет сколько объектов мы будем хранить локально, при достижении указанного количества, кэш удалит из локальной копии 20% объектов, к которым дольше всего не обращались.
Синхронизация по времени (TimeBased) указывает, что объекты будут храниться в локальном кэше указанное в ttlValue количество секунд. Синхронизации по оповещениям (NotificationBased) требует, чтобы механизм оповещений был включен в кэше. В этом случае параметр ttlValue указывает, с какой частотой локальный кэш будет проверять наличие изменений в кэше.
Базовые настройки завершены. Теперь, для примера, подключим сессии нашей веб-роли к кэшу. В IIS это делается очень просто, заменив стандартный InProc провайдер сессии на провайдер, использующий кэш.
```
```
Сессия является прекрасным примером того, где можно использовать кэш. Но не стоит ограничиваться только ей. Например, можно сложить в кэш страницы, тогда другим экземплярам не придется тратить время на их построение. И само-собой, в кэш можно и нужно складывать наши собственные данные.
Перед тем, как перейти к примерам работы с кэшем из кода, остановимся на совсем новом виде кэша.
#### Cache Service
Пока кэш как сервис доступен в режиме предварительного просмотра (preview). Востребован он может быть в сценариях, где разные решения должны иметь доступ к одним и тем же данным. In-Role кэш доступен только в пределах того решения, к которому он привязан. Кэш-сервис такого недостатка лишен.
Настройка кэш-сервиса один в один такая же, как и настройка In-Role кэша, но проводить её нужно не в студии, а на портале управления Azure. В конфигурацию роли добавится ключ доступа к кэшу.
Еще плюсам кэш-сервиса можно отнести:
— несколько меньшую цену;
— отсутствие головной боли при обновлениях развертываний (они не будут затрагивать кэш);
— поддержку протокола memcached, что позволяет подключить к нему не только PaaS решения, но и любой тип виртуалок.
#### Еще несколько слов по настройке
Создавая кэш стоит знать сколько объектов, в каком объеме будут в нём храниться и с какой частотой их будут читать и писать. Когда эти величины известны, данные нужно вбить в одну из эксельных табличек (для [сервиса](http://go.microsoft.com/fwlink/?LinkId=321182) или [ролей](http://go.microsoft.com/fwlink/?LinkId=254507)) и получить рекомендации по тому, сколько и чего вам нужно в терминах тарифицируемых единиц.
Объекты хранятся в кэше в серилизованном виде, потому для определения объема объекта нужно получить размер после серилизации собственно объекта и его ключа.
Размер объекта в кэше после серилизации ограничен 8 мегабайтами. Если вы выходите за лимит, можно включить компрессию для кэша, тогда перед попаданием в кэш объекты будут сжиматься. Вообще, компрессия может положительно сказаться на работе кэша, если расходы на упаковку-распаковку будут меньше, чем расходы на сетевую передачу. Выяснить это, к сожалению, можно только экспериментально.
Для увеличения пропускной способности кэша можно увеличить кол-во подключений к нему параметром maxConnectionsToServer. По умолчанию создается только одно подключение к кэшу.
#### Работа с кэшем из кода
Всё необходимое для работы с кэшем живет в Microsoft.ApplicationServer.Caching.
Для начала создать объект кэша и командами Add, Put, Get и Remove начать работать с данными.
```
DataCache dc = new DataCache("default");
dc.Add("test", DateTime.Now); //добавить объект в кэш
dc.Put("test", DateTime.Now); //добавить или заменить
DateTime dt=(DateTime)dc.Get("test"); //получить
dc.Remove("test"); //удалить
```
##### Гонка
Для предотвращения гонки, следует использовать GetAndLock, PutAndUnlock и Unlock. Оператор GetAndLock не блокирует обычный Get и не мешает «грязному» чтению.
```
try
{
DataCacheLockHandle lockHndl;
object value = dc.GetAndLock("test", new TimeSpan(0, 0, 5), out lockHndl);
//модифицируем объект
dc.PutAndUnlock("test", value, lockHndl);
//или dc.Unlock("test", lockHndl) если ничего не меняли
}
catch (DataCacheException de)
{
if (de.ErrorCode == DataCacheErrorCode.KeyDoesNotExist)
{
//объекта нет
}
}
```
##### Чтение обновлений
Нетрудно представить себе сценарий, при котором необходимо совершить какие-то действия при изменении объекта в кэше. Можно получать объект и сравнивать его с текущим значением, но можно снизить нагрузку на кэш используя метод GetIfNewer.
```
object val = DateTime.Now;
DataCacheItemVersion version = dc.Put("test", val);
while (true)
{
val = dc.GetIfNewer("test", ref version);
if (val != null)
{
//объект изменился
}
Thread.Sleep(1000);
}
```
Если объект появился в кэше, где-то в другом месте, можно получить его версию из объекта DataCacheItem.
```
DataCacheItem dci = dc.GetCacheItem("test");
DataCacheItemVersion version = dci.Version;
object val = dci.Value;
```
##### Регионы
Для группировки объектов, можно использовать регионы. В каждый из перечисленных выше методов вторым аргументом можно передать имя региона (предварительно его создав), в котором нужно создать объект. А после легко осуществлять перебор объектов в кэше.
```
if (dc.CreateRegion("region"))
{
//региона не было, он создан
}
dc.Put("test", DateTime.Now, "region");
foreach (KeyValuePair kvp in dc.GetObjectsInRegion("region"))
{
//обрабатываем объекты
}
```
У регионов есть пара особенностей, которые стоит учитывать при работе с ними.
Не стоит перебирать объекты в регионе напрямую как в коде выше. Если другой поток сложит или уберет в нем объект, нарвемся на исключение «коллекция изменилась».
Вторая особенность: регион живет в пределах одного экземпляра. Т.е. если распределение объектов по регионам неравномерно, то может возникнуть ситуация, когда один из экземпляров бездельничает, а другой кипит под нагрузкой.
#### О чём стоит помнить при работе с кэшем
— Размер объекта в кэше ограничен 8 мегабайтами
— Если используются регионы, они должны наполняться равномерно
— Кэшируйте объекты локально всегда, когда это возможно.
— Включайте высокую доступность только там, где это нужно.
— Используйте блокировки (GetAndLock) только там, где это необходимо
— Не читайте объекты, если они не обновлены (используйте GetIfNewer)
Надеюсь, эта статья поможет другим пройти по меньшему количеству граблей, чем собрал я. Успехов в разработке, пусть ваши приложения будут быстрыми.
[Google Plus](https://plus.google.com/107862204079203068843?rel=author) | https://habr.com/ru/post/200744/ | null | ru | null |
# HP Compaq T5000 — домашний seedbox

Хочу представить хабросообществу один старый, но занятный девайс, тонкий клиент HP Compaq T5000.
Под катом описание, фотографии и установка на него rtorrent + rutorrent.
HP Compaq t5000 это тонкий клиент, в моем случае выпущенный в 2003-ем году. Начинка тонкого клиента:
| | |
| --- | --- |
| processor | Transmeta(tm) Crusoe(tm) Processor TM5800 — 1000 MHz |
| memory | 128KiB L1 cache |
| memory | 512KiB L2 cache |
| memory | 256MiB SODIMM DDR |
| bridge | VT8231 [PCI-to-ISA Bridge] |
| bridge | VT8235 ACPI |
| storage | VT82C586A/B/VT82C686/A/B/VT823x/A/C PIPC Bus Master IDE |
| disk | 256MB 256MB ATA Flash |
| bus | VT82xxxxx UHCI USB 1.1 Controller |
| multimedia | VT82C686 AC97 Audio Controller |
| network | VT6102 [Rhine-II] |
В моем случае на тонком клиенте была установлена Windows XP embedded на одном и Windows CE .NET на другом. То какая операционная система установлена зависит только от размера ОЗУ и IDE DOM модуля.
Первое что пришло в голову это включить RDP (удаленное управление), поставить uTorrent, подключить USB жесткий диск и использовать всё это как торрентокачалку. Благо тонкий клиент потребляет в пределах 20Вт.
Немного поодумав, решил поставить Ubuntu. т.к. CD привода под рукой не оказалось, но был поднят tftp сервер, то решено было ставить Ubuntu по сети. А так как встроенного IDE DOM размером в 256MB явно маловато, систему ставил на 4 гиговую USB флешку. Подходящий мне вариант установки описан [здесь](https://help.ubuntu.com/community/Installation/Netboot)
упрощенно, я просто взял папку ubuntu-installer из [netboot.tar.gz](http://archive.ubuntu.com/ubuntu/dists/karmic/main/installer-i386/current/images/netboot/netboot.tar.gz), положил её в /tftpboot/ а в /tftpboot/pxelinux.cfg/01-00-0b-cd-6d-8e-58 добавил:
`include ubuntu-installer/i386/boot-screens/menu.cfg
default ubuntu-installer/i386/boot-screens/vesamenu.c32
prompt 0
timeout 0`
*01-00-0b-cd-6d-8e-58 это mac адрес тонкого клиента.*
#### Далее процесс установки rtorrent + rutorrent.
`apt-get install rtorrent wget libapache2-mod-scgi apache2 php5 php5-mysql php5-curl screen
wget rutorrent.googlecode.com/files/rtorrent-2.8.tar.gz
tar zxf rtorrent-2.8.tar.gz
mv rtorrent /var/www/
echo 'SCGIMount /RPC2 127.0.0.1:5000' >> /etc/apache2/apache2.conf
ln -s /etc/apache2/mods-available/scgi.load /etc/apache2/mods-enabled/
service apache2 restart
useradd torrent -d /torrents/
echo 'scgi_port = localhost:5000' > /torrents/.rtorrent.rc
echo 'port_range = 6925-6925' >> /torrents/.rtorrent.rc
echo 'schedule = watch_directory,5,5,load_start=/torrents/watch/*.torrent' >> /torrents/.rtorrent.rc
echo 'directory = /torrents/download/' >> /torrents/.rtorrent.rc
echo 'session = /torrents/session/' >> /torrents/.rtorrent.rc
echo 'hash_read_ahead = 32' >> /torrents/.rtorrent.rc
echo 'hash_max_tries = 1' >> /torrents/.rtorrent.rc
echo 'hash_interval = 1' >> /torrents/.rtorrent.rc
mkdir -p /torrents/{download,session,watch}
chown -R torrent:torrent /torrents/
wget libtorrent.rakshasa.no/attachment/wiki/RTorrentCommonTasks/rtorrentInit.sh?format=raw -O /etc/init.d/rtorrent
sed -i 's/user="user"/user="torrent"/' /etc/init.d/rtorrent
chmod +x /etc/init.d/rtorrent
update-rc.d rtorrent defaults
/etc/init.d/rtorrent start`
#### Теперь перейдем к железу (картинки кликабельны).
| | | | | | |
| --- | --- | --- | --- | --- | --- |
| [image](http://lh4.ggpht.com/_SI9MZ1NpKYE/S0tyN1GtvEI/AAAAAAAALeY/1lqpZnXVVzA/IMG_3603.JPG) | [image](http://lh5.ggpht.com/_SI9MZ1NpKYE/S0tykWuIYoI/AAAAAAAALeg/7mcOcW8hm5w/IMG_3604.JPG) | [image](http://lh4.ggpht.com/_SI9MZ1NpKYE/S0tyyJ9keiI/AAAAAAAALeo/MWzrX8jEtwU/IMG_3605.JPG) | [image](http://lh4.ggpht.com/_SI9MZ1NpKYE/S0tzH3aFcAI/AAAAAAAALew/UDfvIbQo5hk/IMG_3606.JPG) | [image](http://lh6.ggpht.com/_SI9MZ1NpKYE/S0tzSQNxJ6I/AAAAAAAALe0/xWVaYoK2B00/IMG_3607.JPG) | [image](http://lh5.ggpht.com/_SI9MZ1NpKYE/S0t1PioTjyI/AAAAAAAALfg/rZpilOTqDmI/IMG_3628.JPG) |
| [image](http://lh4.ggpht.com/_SI9MZ1NpKYE/S0tzktOKyOI/AAAAAAAALe4/L1kBInjeyGo/IMG_3609.JPG) | [image](http://lh6.ggpht.com/_SI9MZ1NpKYE/S0tz50o_IXI/AAAAAAAALfA/yt0k3R4n5C0/IMG_3618.JPG) | [image](http://lh3.ggpht.com/_SI9MZ1NpKYE/S0t0K3m8wOI/AAAAAAAALfE/4bQRu8040b0/IMG_3623.JPG) | [image](http://lh6.ggpht.com/_SI9MZ1NpKYE/S0t0cHySiKI/AAAAAAAALfI/R6IaXU3oJ9o/s720/IMG_3625.JPG) | [image](http://lh3.ggpht.com/_SI9MZ1NpKYE/S0t0xst1LAI/AAAAAAAALfY/mgwxePasFUI/IMG_3626.JPG) | [image](http://lh3.ggpht.com/_SI9MZ1NpKYE/S0t1ANRriKI/AAAAAAAALfc/1doyLjTuDuk/IMG_3627.JPG) |
Если плюнуть на эстетику то можно снять крышку и воткнуть SATA контроллер, к которому подключить обычные жесткие диски. | https://habr.com/ru/post/80803/ | null | ru | null |
# Войны с Citrix XenServer
#### Введение
На днях мой сотрудник удалил случайно несколько виртуалок в Citrix XenServer.
Все осложнилось тем что виртуальные машины оказались на snapshot дисках.
Под катом рассказываю как я их оттуда вынимал в отсутствии каких либо резервных копий и переносил на KVM.
Примеров команд много не делал, так как целью статьи было описание концепции. Внизу привел необходимые ссылки.
#### Подготовка
Забрал жесткие диски себе, поставил на тестовую машину.
Грузиться xen не захотел, уходил в циклический ребут.
Следовательно пришлось качать новую версию и ставить на другой диск.
Скачал, установил. Дальше необходимо было подключить старые диски.
Xen был в самой стандартной конфигурации, виртуалки на LVM.
#### Первое разочарование
Во всех статьях написано что LVM в XenServer должен делать резервные копии изменений в папочку
`/etc/lvm/archive`
Но не тут то было. В версии 5.5 в конфиге LVM автоматическое сохранение выключено.
Благо с LVM я уже дело имел и знаю что он хранит копии данных в начальных блоках PV.
С помощью команды:
`dd if=/dev/sda3 bs=512 count=255 skip=1 of=./lvmbackup.img`
скопировал первые блоки раздела
С помощью vim этот снимок можно прекрасно открыть и вытащить оттуда нужную информацию.
Там кстати можно увидеть множество конфигураций. Мне подошла предпоследняя. Так как в предудущих еще не было нужных разделов, а в следующих уже!
И так, найдя нужный кусок конфигурации, я выдрал его и скопировал в новый файл.
Далее немного переформатировав его и, если не ошибаюсь, поменяв uuid физических разделов, получил рабочую конфигурацию lvm тома.
После чего в папке /etc/lvm/backup заменил файлик описания lvm группы на свой.
И запустил vgcfgrestore с названием группы.
Как не странно но все разделы зацепились.
#### Второе разочарование
И так, радостный что все у меня удачно завелось, и диски видятся, я пытаюсь зацепить это хранилище в XenServer.
Такого облома я никак не ожидал. Подключение SR проходит успешно. Ни одной ошибочки. Но! Диски видятся только те что не были удалены. Удаленных нет.
Команда lvs при этом так же показала только новые диски. То есть XenServer нашел где-то описании репозитория.
Делать нечего, восстанавливаю lvm второй раз. (Если честно я это раз 10 сделал пока понял что зен считает диски удаленными и никак их видеть не хочет)
Так же дело осложнялось наличием снапшотов с этих дисков.
#### собственно восстановление
Примерно к 10 вечера мне пришло озарение что LVM тома зен сервера ни что иное как VHD диски.
Вооружившись блокнотом и vhd-util я записал данные о родителях всех снапшотов. Снапшоты в Зен сервере представляют собой дифференциальные VHD диски.
Далее dd в файлы всех нужных томов.
После чего проверка vhd-util check показала что все контролные суммы правильные и файлы рабочие.
Через эту же утилиту я указал новых родителей снапшотам и запустил сливание (параметр coalesce).
Тут кстати у меня остался вопрос: при создании одного снапшота зен делает 2 разностных диска. Один размером с оригинал, а второй очень небольшой. Мне хватило того что размером с оригинал. Мелкий сливать не стал.
#### Последний этап
Перелив файлы на сервер с KVM я попробовал скормить ему vhd. Есть его он естественно не стал.
Но меня выручила утилита qemu-img которая очень даже не плохо сконвертила мне файлы raw.
В общем все хорошо что хорошо кончается. Сейчас пользователи удачно работают.
Просьба сильно не пинать — первый опыт статьи на хабре.
По поводу отсутствия резервных копий — их отсутствие не случайность, и не халатность.
VHD у xen немного отличается и напрямую подключить их в Hyper-v не получится, так же надо конвертить.
#### Ссылки
1. [How to Reinstall XenServer and Preserve Virtual Machines on a Local Disk](http://support.citrix.com/article/CTX120962)
2. [Linux LVM: Recovering a lost volume.](http://www.microdevsys.com/WordPress/2011/09/19/linux-lvm-recovering-a-lost-volume/)
3. [Qemu disk image conversion](http://virtuallyfun.superglobalmegacorp.com/?p=436)
Спасбо за внимание! | https://habr.com/ru/post/141870/ | null | ru | null |
# Делаем обычную микроволновку умнее с IFTTT и OpenHAB

«Умные дома» и «умные офисы» сегодня тренд. А как сделать самое обычное бытовое устройство чуть «умнее»? А что если при этом вы не умеете или не хотите ничего паять? Я например отношусь к тем, кто паять не умеет, а пользу от умных устройств получать хочет.
Под катом я расскажу, как легко и без паяльника можно быстро превратить абсолютно любую микроволновку в самую настоящую smart-микроволновку, которая будет оповещать вас о готовности еды и своем текущем статусе самыми разнообразными способами.
Для чего?
=========
Так уж получилось, что в нашем офисе помещений несколько, а микроволновка одна. Собственно нужно как-то оповещать коллег, что еда разогрелась и пора идти на обед (ходим на обед мы все вместе, а еду разогревает только пара человек).
Во всех офисах у нас висит по телевизору, который подключен к самому обычному ПК (Mac Mini). Так что он мог бы выступить в качестве «рупора», оповещающего, когда микроволновка начала, а когда закончила свою работу. Вдобавок, можно было бы подключить какое-то световое оповещение, типа лампочек ~~ильича~~ Phillips Hue. Ну или посылать уведомление в мессенджер.
Что понадобится?
================
Как я уже сказал ранее, паяльник НЕ ПОНАДОБИТСЯ. А понадобится нам что-нибудь, что умеет мерять нагрузку на обычной 220 розетке, к которой подключена микроволновка, и сообщать об этом куда надо. А куда надо? Правильно — в [онлайн автоматизатор IFTTT](http://ifttt.com), который умеет отправлять [что-угодно куда-угодно](https://ifttt.com/channels).
Собственно алгоритм простой — когда микроволновка включится, то нагрузка на розетку возрастает, а когда микроволновка заканчивает греть — то снова становится равной нулю. Этот факт можно отследить и использовать как триггер в IFTTT, который и «дернет» нужный нам сервис, оповещающий нас о готовности.
Розетка
=======
Теперь пойдем в любой интернет магазин умных домов и купим там обычную Z-Wave розетку и контроллер к ней.
*Это не единственный способ, можно было бы выбрать и другой вариант, но этот лично для меня проще всего.*

Сама розетка — например вот эта (хотя можно купить и гораздо более дешевый вариант, но эта красиво светится :) )
Котроллер нужен, чтобы получать данные от розетки. С его помощью можно также и управлять умными устройствами, но сейчас не об этом.
Будем подключать нашу розетку к контроллеру MiCasa Vera Lite (или можно к Vera 3).

Контроллер подключается в локальную сеть через Ethernet или Wi-Fi (для Vera3). С ним один раз синхронизируется розетка с помощью одной-единственной кнопки, и все — теперь с помощью контроллера можно управлять розеткой и получать от нее данные. Сразу ее включим через веб-консоль контроллера и оставим включенной.
OpenHAB
=======
Чтобы не писать всякие скрипты на самом контроллере, а обойтись «малой кровью», установим на любой ПК под любой ОС [бесплатный сервер домашней автоматизации OpenHAB](http://openhab.org). Он позволяет унифицировать протоколы любых умных устройств в сети и связывать их в единую логику с помощью очень гибких и простых правил.
**Зачем он нам?** Все просто — он будет отслеживать состояние нашей розетки и в нужный момент отправлять на IFTTT запрос, чтобы тот в свою очередь отсылал данные в нужный нам канал нотификаций.
*Можно по-разному написать правило, включить например другое устройство, музыку, сказать что-то синтезатором речи и тд. Но в данном примере я покажу, как связать микроволновку именно с IFTTT, который открывает безграничные возможности по интеграции со сторонними сервисами без лишних заморочек.*
Установка
=========
Итак, скачаем OpenHAB и аддоны для него, среди которых отыщем jar файлы со словом «mios» в названии и положим их в папку «addons» нашего OpenHAB-а.
*Еще вам понадобится Oracle JDK последней версии, так как OpenHAB написан на Java*
Конфигурируем OpenHAB
=====================
Тут все просто. Идем в папку «configurations» и переименовываем «openhab\_default.cfg» в «openhab.cfg» и открвыаем его в редакторе.
В конец фала пишем строчку
```
mios:house.host=192.168.1.22
```
**естествнно заменив IP адрес на адрес вашего контроллера Vera**. Его кстати можно очень быстро получить, открыв в браузере вот такую ссылку <http://cp.mios.com/detect_unit.php>
*Подробное описание процесса настройки и конфигурации Vera в OpenHAB [описана на странице аддона github](https://github.com/openhab/openhab/wiki/MiOS-Binding).*
Далее идем в папку «items» и там в файле «test.items» пропишем настройку, чтобы OpenHAB знал, состояние какой розетки нам нужно отслеживать:
```
Number Microwave {mios="unit:house,device:11/service/urn:micasaverde-com:serviceId:EnergyMetering1/Watts"}
```
*Вместо цифры 11 пропишите идентификатор вашей розетки, который можно увидеть в веб-консоли вашего контроллера Vera.*
Ну и последнее — пишем небольшое правило, которое будет отслеживать состояние розетки и отправлять запрос на наш IFTTT.
В папке «rules» создаем файл «test.rules» и пишем там:
```
import org.openhab.core.library.types.*
import org.openhab.model.script.actions.*
rule "Microwave"
when
Microwave received update 0
then
sendHttpGetRequest("http://maker.ifttt.com/trigger/microwave/with/key/<тут должен быть ваш ключ от IFTTT>")
end
```
Правило реагирует, когда нагрузка от микроволновке становится равной нулю и шлет запрос на IFTTT. Адрес запроса нужно получить в вашей консоли IFTTT, туда сейчас и пойдем.
IFTTT
=====

IFTTT предоставляет возможность слать ему запросы от любых систем и перенаправлять их в нужный вам канал с помощью [канала Maker](https://ifttt.com/maker). Там можно получить свой уникальный идентификатор, который и подставить в приведенный выше скрипт OpenHAB.
По сути, это URL, на который нужно отправить GET или POST запрос, заодно можно туда передать параметры (в нашем примере это не нужно). IFTTT получает такой запрос и выполняет «then» — то есть запускает нужный вам канал с нужными параметрами.
*Кто-то обязательно скажет, что мол все придумано за нас, и OpenHAB уже давно работает с IFTTT, зачем нам костыль из Maker?
Отвечу сразу — IFTTT слишком редко получает статусы от OpenHAB (раз в 15 минут), что для нас **неприемлемо**. Поэтому OpenHAB будет сам «дергать» Maker — и тогда никаких задержек не будет, все будет происходить моментально.*
Итак, делаем рецепт:

*Этот рецепт для примера просто отправит нотификацию на ваш смартфон, когда микроволновка закончит свою работу. Как я уже сказал, можно создать любой другой рецепт, который сделает что-то более интересное, например слать сообщение в корпоративный Slack.*
Настройки самого триггера Maker будут вот такими:
**Собственно все!** В Maker можно проверить как это работает — на самой странице Maker можно нажать кнопку Test и получить результат.
***Не забудьте прописать ваш ключ от Maker в правило в OpenHAB!***
Запускаем!
==========
Остается только запустить OpenHAB с помощью одного из скриптов «start.sh» или «start.bat», в зависимости от того, на какой ОС у вас он установлен.
Теперь каждый раз, когда микроволновка будет заканчивать греть еду, вы будете получать от IFTTT нотификацию, которую настроили в своем рецепте. Причем моментально.
Так мы сделали из обчной микроволновки «умную», которая умеет немножко больше, чем только греть еду :) | https://habr.com/ru/post/384605/ | null | ru | null |
# Окей, Хабр, сделай мне интересно
Читать Хабр — важная часть моей работы. Ощущение от статей разное: одни статьи читаешь и жалеешь, что они заканчиваются; от других статей веет нафталиновым сборником вымученных статей аспирантов; третьи утомляют личностью автора; иные раздражают неприкрытой рекламой и т. д. Часто встречаются публикации, которые просто не вызывают никаких эмоций: они просто неинтересные. А ведь почти всегда можно сделать лучше, стоит потратить чуть больше времени, сил и вложить в статью часть души. Кто-то об этом не знает, кто-то ленится, а я печалюсь и пишу ~~ультимативный~~ гайд по тому, как сделать статью интереснее.
### Как найти интересную тему
У нас в Хабре среди рабочих инструментов и презентаций есть схема поиска идей для контента. Она универсальная, проверенная временем и неплохо работает, но при одном условии: если вы опытный автор Хабра, который буквально кончиками пальцев чувствует, какая тема зайдёт и как нужно её подать, чтобы зашло.
> 📢 А если вы уже гуру и нашли интересную тему, срочно подавайте статью на конкурс «[**Технотекст 2022**](https://u.habr.com/technotextmain_post_about)», в этом году он, как и планировалось, больше техно, чем текст. Do IT!
>
>
Схема изначально создавалась для обучения компаний, но и для обычных авторов она актуальнаКогда автор — новичок, найти классную тему невероятно сложно. Он погружается в дело и сразу совершает все самые распространённые ошибки.
* **Ударяется в креатив:** пишет излишне вычурно, с ненужными метафорами, сарказмом, в нестандартном и неподходящем для Хабра стиле.
* **Пытается соблюсти интересы всех сторон:** самого себя, аудитории Хабра, своей компании (если речь идёт о блоге компании). Увы, всем угодить не получится хотя бы потому, что интересы зачастую диаметрально противоположные. Выход очевиден: нужно ориентироваться на пользу и интерес для читателя, для аудитории, тогда и всё остальное подтянется.
* **Пишет честную статью с честной целью:** найти работу, найти сотрудников, прорекламировать свою компанию, продукт или блог, показать себя как эксперта или как причастного к какому-либо ИТ-сообществу. Честным быть выгодно, но излишняя прямолинейность в публикациях граничит с неуважением: «короче, есть тема, но я даже не постарался как-то вас заинтересовать, любите меня таким».
* **Занимается профессиональным копирайтингом:** пишет выверенные, старательные статьи с элементами SEO (кстати, ТЗ на такие статьи — просто отдельный вид искусства, правда, скорее, юмористического).
В итоге статьи получаются… бездушными. Вы легко узнаете их на Хабре: проходные, скучные, написанные как сочинение, с банальными картинками и осторожными посылами. Это не плохо и не хорошо, но, мне кажется, что это не тот результат, ради которого стоит работать несколько дней над статьёй. «Да я за 4 часа статью пишу, какие дни!» — воскликнет кто-то из авторов. И это тоже нюанс: если вы отлично знаете тему и не готовите сложные технические выкладки с фрагментами кода, статью действительно можно написать очень быстро. Если же вы пишете, потому что надо написать, это минимум 8 часов даже у очень опытного автора, а так — от 2 до 7 дней «перебежками» по 3-5 часов. Это, конечно, среднее время, многое зависит от автора, целей и условий.
В общем, всем нам нужен хороший текст.
### Формула хорошего текста
Формула хорошего текста состоит из 5 слагаемых:
> `интересный текст = хорошая тема + практика + знания автора + лицо автора + форма подачи`
>
>
где
* хорошая тема — тема, которая интересна узкому кругу профессионалов или, наоборот, каждому читателю; она актуальна, предполагает интересные подробности и почти всегда вызывает дискуссию;
* практика — та часть информации, которую автор предлагает читателям исходя из собственного опыта;
* знания автора — полная и достоверная информация по теме, которой автор уверенно владеет (здесь стоит упомянуть хороший фактчекинг, актуализацию информации и работу с различными источниками);
* лицо автора — личность и харизма автора, которые присутствуют в статье и помогают создать ощущения общения с живым человеком, а не с компилятором текстов всея интернета (кстати, в этом плане заполненный профиль с аватаркой будет восприниматься лучше, чем дефолтный юзерпик");
* форма подачи — стиль автора, оформление, иллюстрации, вёрстка, всё то, что делает статью читабельной, а автора запоминающимся.
Звучит просто, но на деле даже опытные авторы не всегда используют все пять компонентов.
### Почему бывает не очень интересно?
Едва ли не каждый день я получаю сообщения от авторов частных и корпоративных блогов с просьбой рассказать, почему у их статей мало просмотров, комментариев или низкий рейтинг (кстати, волнует авторов гораздо реже, чем другие показатели). Как правило, причин несколько.
1. **Много рекламы (саморекламы)** — с первых строчек видно, что автор стремится прежде всего продавить свой интерес и остальной текст выступает в роли маскировки рекламного сообщения. Далее может идти интересный и даже полезный контент, но на дочитывания и любовь аудитории можно не рассчитывать. Вот [отличный пример такого автора](https://habr.com/ru/users/tolstenkoaa/posts/): его задача — рассказать о своих услугах, и, несмотря на довольно дельные статьи, он проигрывает именно за счёт постоянных отсылок к коммерции (хотя формально правила и не нарушает). Увы, несмотря на многочисленные предупреждения, в корпоративных блогах бывает то же самое: компания решает не формировать среду нативным контентом, а рекламироваться в лоб, и чаще всего результат печальный.
2. **Узкая профильная тема**, которая точно не заинтересует широкую аудиторию. Как правило, такие публикации отлично написаны и содержат массу полезной и интересной информации, но рассчитаны на небольшой сегмент специалистов. Примеры можно взять в том же [хабе Rust](https://habr.com/ru/hub/rust/) — язык популярен в энтерпрайз-среде, статьи имеют стабильный, но невысокий уровень интереса (можете сравнить с «интересными всем» Python и JavaScript). Авторы таких статей получают небольшую, но свою, ядерную, аудиторию — и это дорогого стоит (кто заходит в статью о тестировании Rust, точно знает, за чем идёт). Хотя и здесь случаются огромные всплески интереса: [Rust должен умереть, МГУ сделал замеры](https://habr.com/ru/post/598219/).
3. **Скучная подача.** Тоже часто встречающийся паттерн публикации. Такие статьи трудно читаются, трудно воспринимаются, тяжело оформлены и нет никакого желания в них погружаться (даже модераторам). Я вам больше скажу, такие статьи ещё и тяжело пишутся: для галочки, для [зачёта](https://habr.com/ru/company/habr/blog/595067/), для KPI и т. д. Впрочем, иногда (почти всегда) автор искренне считает свою статью шедевром и не понимает, почему аудитория не разделяет его мнение. Примеры приводить не буду, их легко найти каждый день. И наверное, это единственная ситуация, когда уже ничем не помочь — если автор не захочет сделать хорошо, всё так и будет.
А теперь я приведу вам два примера.
* [Про злые угри и чёрные точки и добрые сальные нити (не путайте их)](https://habr.com/ru/company/geltek/blog/583402/) (+35, 61k просмотров) или [Как мы ели лубрикант](https://habr.com/ru/company/geltek/blog/695886/) (+251, 37k) — если разобраться формально, то статья мало соответствует тематике Хабра и рекламирует конкретные косметические средства. Однако живой язык, яркий заголовок, удержание интереса, важная тема, польза для читателей, прекрасная подача и даже юмор делают своё дело: публикация набирает отличный результат и более того, ты доверяешь тому, что в ней написано.
* [Гипотеза Коллатца — самый крутой математический фокус всех времён](https://habr.com/ru/post/597935/) (90k просмотров) — статья о не самой популярной математической теме, да ещё с реализацией на Delphi. Кажется, никаких шансов на успех на широкой аудитории. Но захватывающий язык автора, крутой заголовок и лаконичность буквально заставляют зайти в пост и заворожённо его дочитать. А вот [пример по той же теме с более сухой подачей](https://habr.com/ru/post/675594/) — комментариев много, но удовольствия от прочтения меньше (что видно и по рейтингу, и по просмотрам).
Таких примеров на Хабре очень много: известные и неизвестные авторы тщательно работают над своими материалами и делают публикации привлекательными и запоминающимися (например, я, проглядывающая и прочитывающая едва ли не все посты, легко извлекла эти два примера из головы и точно так же легко извлекаю другие удачные примеры на семинарах). Конечно, отчасти здесь вмешивается талант автора, но по большей части — опыт и практика и, что немаловажно, понимание того, о чём он пишет (это вообще главный ключ к успешной публикации, потому что ты не просто излагаешь, но и эмоционально связан с тем, о чём рассказываешь, а значит, можешь подобрать удачные и простые формулировки для сложных тезисов).
### Так как повернуть тему интересно?
#### Подобрать картинку и заголовок
Это буквально альфа и омега для хорошей публикации: во-первых, вам нужно выжить в ленте 60-75 статьями за сутки, во-вторых, в случае попадания на главную выделиться в топе 20 публикаций. Кроме этого, именно заголовок и КДПВ — тот единственный шанс произвести первое впечатление и заставить читателя «провалиться» в статью. На третьем месте по эффективности идёт докатный текст (он же лид-абзац): не игнорируйте его, сделайте небольшим и понятным, но в то же время интригующим.
Да, плохую статью ни один заголовок и ни одна картинка не вытянут (но это не точно), а вот хорошую статью плохое оформление может значительно испортить.
 и трендовостью (как раз был поток статей про Dalle-2). Есть мнение, что если в картинке фигурирует Хабр и в целом нет сомнений, что она делалась именно для Хабра, то это встречается более тепло, ну уж модераторами так точно :)")В данном случае заголовок немного желтоват, но в контексте содержания это именно авторский приём. Картинка, безусловно, привлекает внимание цветом, узнаваемым образом (маскот + название) и трендовостью (как раз был поток статей про Dalle-2). Есть мнение, что если в картинке фигурирует Хабр и в целом нет сомнений, что она делалась именно для Хабра, то это встречается более тепло, ну уж модераторами так точно :). Заголовок тоже хороший: распространённый и осмысленный, читатель сразу знает, за каким контентом он идёт.")Люблю такое: на картинку затрачено ровно 0 сил и 0 времени, но она однозначно передаёт содержание статьи, выглядит иронично и прямо вынуждает зайти под кат (шёпотом: хотя бы, чтобы найти ещё таких приколов). Заголовок тоже хороший: распространённый и осмысленный, читатель сразу знает, за каким контентом он идёт.#### Рассказать личную историю
В принципе, каждая история личная: авторы рассказывают о своей работе, своём DIY, своих исследованиях и находках, своих приключениях на входе в ИТ и при релокации, передают свои знания, делятся своими решениями. Другое дело, что часто статьи принципиально обезличиваются — примерно как научные статьи в ВАКовских журналах («мы провели», «было установлено», «выяснилось»), автор теряется и отдаёт аудитории безликий фактологический материал.
Хабр — блог, и вы имеете полное право писать от своего имени и рассказывать о своём опыте, показывать своё отношение к материалу, использовать свой стиль и характерные приёмы речи. Если долго читать Хабр, начинаешь ценить авторские образы, потому что узнаёшь отдельных пользователей, не глядя на никнейм. Поэтому мой совет: будьте собой и транслируйте текст от себя, со своими фишечками и эмоциями (конечно, цензурными, а то всякое бывает). Но опять же, если вам комфортно в рамках научного стиля, не принуждайте себя писать в публицистическом — доносите до аудитории тот контент, внутри которого вам комфортно как автору и как профессионалу.
. Простой посыл, простая интрига, человечная картинка «из жизни» и ты уже не можешь не погрузиться в историю. ")Наверное, за последнее время это одно из моих любимых вступлений (лид-абзацев, лидов). Простой посыл, простая интрига, человечная картинка «из жизни» и ты уже не можешь не погрузиться в историю.  А если серьёзно — пример, как сквозь призму исключительно личных историй и личного восприятия «продавать» аудитории интересные, актуальные темы. Но это тот случай, когда формат не для всех — либо вы с ним «пришёл и говорю», либо всё будет очень вымученно и неискренне.")Иван — один из мастеров «личного» жанра, гуру баек и джедай короткого формата :) А если серьёзно — пример, как сквозь призму исключительно личных историй и личного восприятия «продавать» аудитории интересные, актуальные темы. Но это тот случай, когда формат не для всех — либо вы с ним «пришёл и говорю», либо всё будет очень вымученно и неискренне.#### Подобрать байки и случаи из практики
Это очень хороший приём, который позволяет рассказывать интереснейшие технологические вещи, помогает упростить материал без ухода в примитивность, разбивает лонгриды на удобоваримые блоки. Кроме того, байки могут быть отдельным жанром, в рамках которого вы делитесь комплексным опытом: технологическим, управленческим, жизненным. Как правило, это всегда довольно захватывающее чтение. Хороший пример этого жанра из свежего контента — серия [«Made at Intel»](https://habr.com/ru/users/vvvphoenix/posts/) — читатель погружается в мир недоступной ему компании, ему интересно, даже если не всё до конца понятно.
На семинарах и обучении мы всегда призываем рассказывать байки, реальные истории, тру стори про факапы и озарения — это стабильно интересный и живой формат. Если есть такая фактура, используйте её по максимуму.#### Поработать над стилем
Я уже писала о том, что стоит писать примерно так, как вы говорите. НО. Если вы запишете себя на диктофон и расшифруете запись, вы заметите, насколько несовершенна даже самая крутая устная речь: неоправданные инверсии, разговорные обороты, сложные конструкции, длинные и иногда сбивающие с толку тезисы. Это нормально: с такими моментами сталкиваешься в интервью, при расшифровке докладов и видеоуроков. Поэтому стоит поработать над стилем, взяв за базу ваши персональные речевые особенности.
Работа над стилем — это выбор вашего образа человека пишущего: лёгкости изложения, структуры, общего набора оборотов и приёмов, тональности текста, отношения к аудитории (вы друзья, вы коллеги, вы над аудиторией, вы общаетесь панибратски). Главное, стиль должен быть адекватным и релевантным вашим публикациям. Буквально недавно столкнулась с примером не самого удачного, вычурного и наигранного стиля [вот в этом комментарии](https://habr.com/ru/news/t/698902/comments/#comment_24916666) — аудитория сразу среагировала негативно.
#### Выбрать удачный момент для публикации
Когда компании и частные авторы задают вопрос о времени публикации, они ждут волшебную таблетку. Долгое время среди авторов Хабра ходил сакральный миф про «вторник, 11», что приводило к дикому валу статей в один слот времени. Конечно, работает другая формула: «Хорошая статья зайдёт даже 1 января в 00:10, а неинтересная не взлетит и в прайм-тайм». Однако бывают темы, которые и хороши, и интересны, но тяжело конкурируют в ленте публикаций — такие можно оставить до выходных, когда конкуренция в ленте в три раза ниже. «Опасные» и провокационные темы можно подать как пятничный пост, а с хорошим научпопом можно зайти вечером в воскресенье. Это всё очень рамочные наблюдения, однако иногда действительно стоит выждать подходящее время для публикации, чтобы привлечь больше читателей и комментаторов.
### Главное правило хорошего текста
Главное правило хорошего текста — не пишите его по шаблонам и линейкам. Работайте с ним так, как нужно именно вам и так, чтобы было хорошо аудитории. Уважение к читателю, понимание его потребностей и ожиданий — отличный скил автора, который качается практикой работы над контентом и общей насмотренностью. На самом деле, Хабр динамично меняется, причём не только по пропорциям тем, но и по требованиям к глубине и грамотности раскрытия фактуры. Да, бывают провалы, особенно в каких-то новых и непонятных тематиках (сколько фигни про COVID сошло за крутой контент на волне пандемии!), но в целом запрос на качество остаётся высоким. Если вам важно быть не просто автором, а автором с репутацией, нужно работать над текстом с той же ответственностью, с которой вы подходите к рабочим задачам. А дальше задача автора — развиваться вместе с аудиторией, выделяя качественные запросы, а не мимолётные тренды.
И главное, не бойтесь писать!
**P.S.: ждём ваши статьи 2022 года на конкурсе «**[**Технотекст 2022**](https://u.habr.com/technotextmain_post_about)**»**
> Если нашли опечатку в тексте, выделите её и нажмите `CTRL/⌘+Enter`
>
> | https://habr.com/ru/post/699704/ | null | ru | null |
# Как мы делали студию для записи онлайн-курсов
 Если вкратце, то Stepic – это платформа, где каждый пользователь может создать и разместить свой собственный онлайн-курс. В прошлом году Стэпик использовался в курсе [Bioinformatics Algorithms](http://habrahabr.ru/company/stepic/blog/196870/) на Coursera как движок для проверки задач на программирование и анализ данных.
Через какое-то время мы поняли, что стоит посодействовать развитию онлайн-образования и в России. Что для этого надо? Хорошие преподаватели и хорошая студия, где можно записывать видео. Поскольку мы любим программировать, то и начать решили с курсов, так или иначе связанных с программированием, это [алгоритмы и структуры данных](https://stepic.org/course/%D0%90%D0%BB%D0%B3%D0%BE%D1%80%D0%B8%D1%82%D0%BC%D1%8B-%D0%B8-%D1%81%D1%82%D1%80%D1%83%D0%BA%D1%82%D1%83%D1%80%D1%8B-%D0%B4%D0%B0%D0%BD%D0%BD%D1%8B%D1%85-63), [операционные системы](https://stepic.org/course/%D0%92%D0%B2%D0%B5%D0%B4%D0%B5%D0%BD%D0%B8%D0%B5-%D0%B2-%D0%B0%D1%80%D1%85%D0%B8%D1%82%D0%B5%D0%BA%D1%82%D1%83%D1%80%D1%83-%D0%AD%D0%92%D0%9C-%D0%AD%D0%BB%D0%B5%D0%BC%D0%B5%D0%BD%D1%82%D1%8B-%D0%BE%D0%BF%D0%B5%D1%80%D0%B0%D1%86%D0%B8%D0%BE%D0%BD%D0%BD%D1%8B%D1%85-%D1%81%D0%B8%D1%81%D1%82%D0%B5%D0%BC-65) и [язык С++](https://stepic.org/course/%D0%9F%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5-%D0%BD%D0%B0-%D1%8F%D0%B7%D1%8B%D0%BA%D0%B5-%D0%A1++-7) от преподавателей Computer Science Center.
А еще через какое-то время мы поняли, что **чем больше будет хороших студий для записи, тем лучше же для всех нас и образования в целом**. Поэтому мы решили рассказать, показать и выложить в опенсорс все те небольшие наработки, которые на данный момент есть в Stepic по части видео-курсов и их производству.
#### Студия и оборудование
На этой схеме изображен автоматизированный процесс записи видео-лекций, к которому мы пришли:
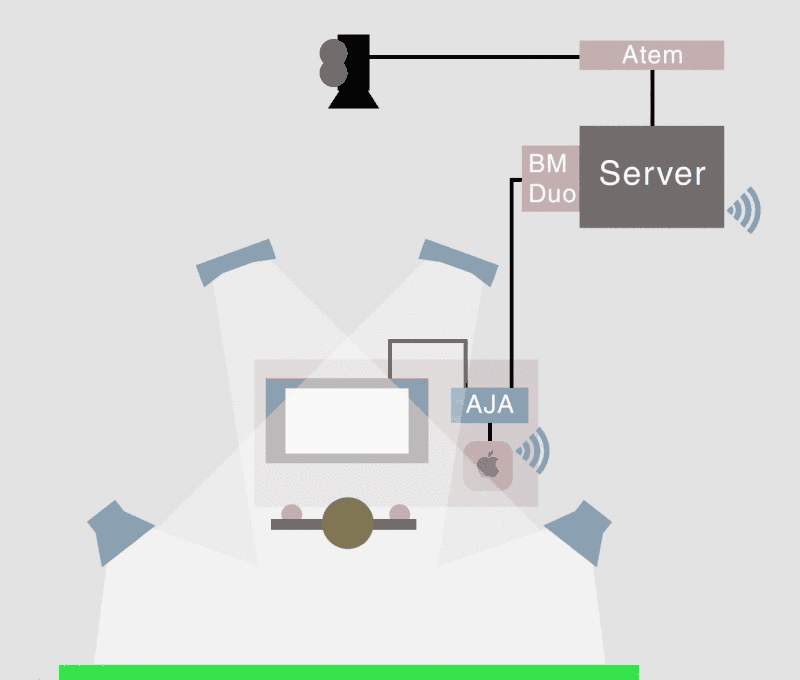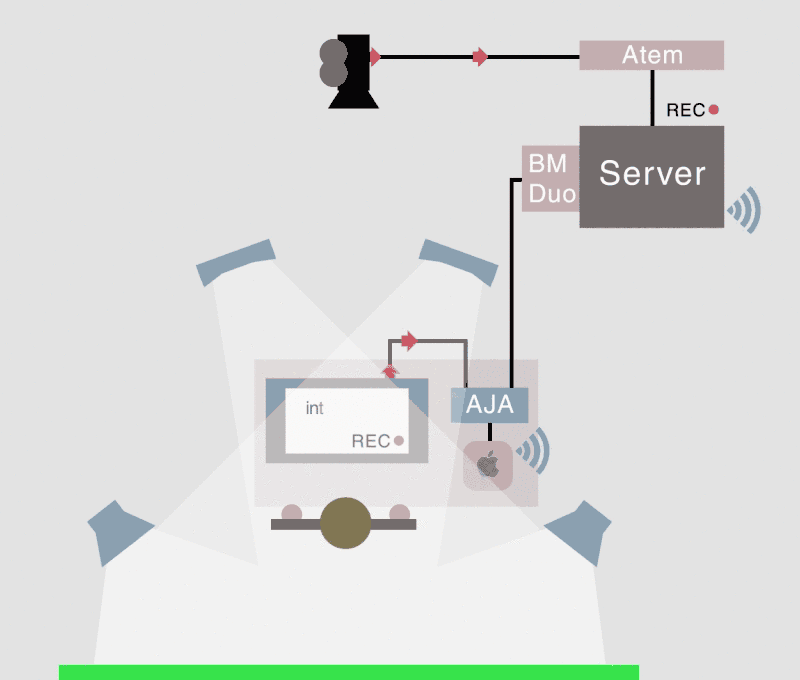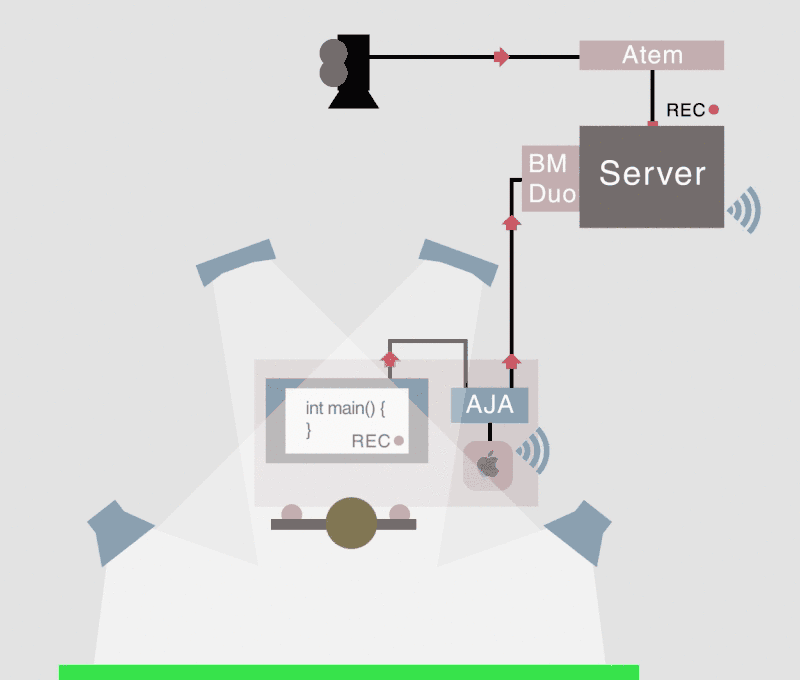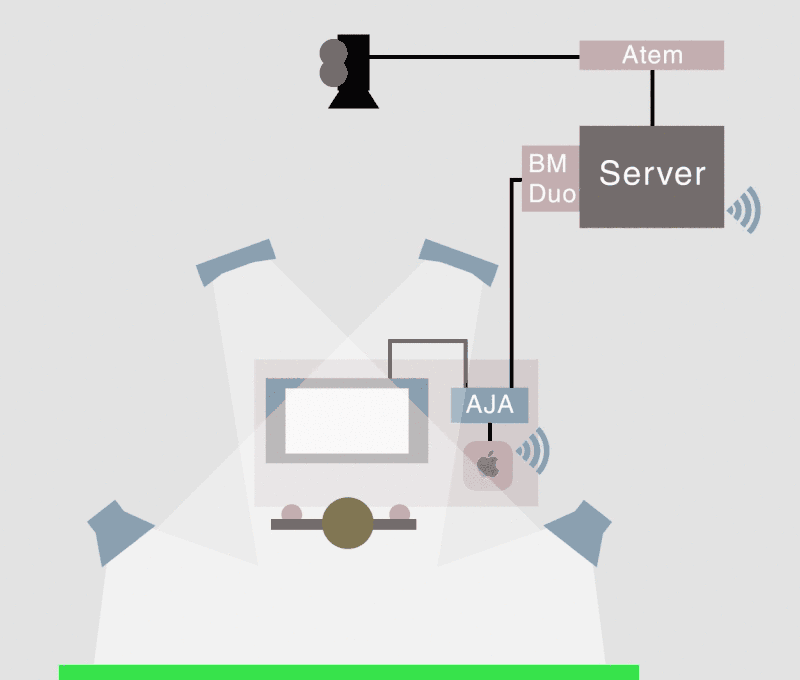
Мы решили не изобретать велосипед, а посмотреть, как оборудованы подобные проекты за границей. Отправной точкой послужила [студия в швейцарском EPFL](http://moocs.epfl.ch/production), где зимой проходила конференция EMOOCs 2014. Видео про студию в EPFL [можно посмотреть тут](http://www.youtube.com/watch?v=nmLcxftaU5Q).
Был составлен список необходимого оборудования (указаны приблизительные цены в России):
1. 2 стойки под фон (3'000 руб. за штуку)
2. 4 стойки под 4 источника света (1'500 руб. за штуку)
3. 2 источника FalconEyes с 5 энергосберегающими лампами холодного света на засвет фона (5'500 руб. за штуку)
4. 2 источника с лампами холодного света для освещения лектора (DFL-С556) (11'000 руб. за штуку)
5. Белый и зелёный фон (1'500 руб. за штуку)
6. Видеокамера Canon XA25 (90'000 руб.)
7. Штатив под камеру Libec TH-950DV (10'000 руб.)
8. Микрофон Audio-Technica AT2031 (8'000 руб.), втыкается в камеру
9. Стойка под микрофон Samson MB1 Mini Boom Stand (2'500 руб.)
10. Крепление под микрофон AT8410a Microphone Shock Mount (3'500 руб.)
11. Wacom Cintiq 24HD Interactive Pen Display DTK-2400 (120'000 руб.) – монитор, на котором можно рисовать от руки по слайдам
12. Apple Mac mini: i5, 2.5HGz (Late 2012) (~25'000 руб.) – компьютер преподавателя, к которому подключён монитором Wacom
13. PC (Server): i7, 3 TB HDD, 16 GB RAM, Win (~25'000 руб.) – компьютер, на котором запущен сервер и куда стекаются видеопотоки
14. AJA ROI (35'000 руб.)
15. BlackMagic DeckLink Duo (18'000 руб.)
Итого, приблизительно: 385 тысяч рублей.
Думаю, выбор всех пунктов, за исключением трёх, не вызывает вопросов. А вот про то, почему мы выбрали этот кэнон и зачем же нужны AJA ROI и DeckLink, я бы хотел рассказать ниже.
#### AJA ROI и DeckLink Duo

В нашей студии (как и в студии швейцарцев) мы используем провода BNC, которые выходят из камеры и AJA ROI и приходят в DeckLink Duo на PC. Который, в определенный момент, по желанию преподавателя, начинает записывать два потока и аккуратно складывать их в папочку на сервере. AJA ROI выполняет роль cплиттера сигнала, устанавливается она между Mac mini и Wacom, дублирует канал который получает Mac mini и передает его на сервер.
Выше был представлен cхематический вид студии, чтобы можно было понять, как у нас расположены источники света и как проведены провода.
#### Камера
Камера Canon XA25 была выбрана не случайно. Дело в том, что данная модель является единственной на рынке в подобном ценовом сегменте, которая имеет SDI выход, и это очень важно.
Что же это за такой SDI канал и почему про него так редко слышно, если он такой хороший?
SDI это стандарт передачи изображения который до сих пор используется на телевидении и средством передачи этого канала служит обычный коаксиальный кабель 75 Ом, который есть в каждом радиомагазине. Вот и всё. Так зачем же использовать этот SDI? Очень просто, если у вас 2 SDI канала кодируются в реальном времени, у вас нет проблем, если же использовать вместо SDI, протокол HDMI, то тут уже вам возможно потребуется дополнительное оборудование, способное в реальном времени обрабатывать эти потоки.
Также плюсами SDI является относительное отсутствие ограничений накладываемых на длинну кабеля и его надежное крепление
Итак, всё приехало, всё собрано, давайте запустим и посмотрим с камими проблемами мы можем столкнуться.
#### Проблемы
Первый неприятный сюрприз, который поджидал нас, – это ограничение на формат изображения по SDI каналу от камеры. Как я уже упоминал, камера является единственной в данном ценовом сегменте, которая умеет выдавать HD видео через аналоговый интерфейс. Но ложка дегтя заключается в том, что по SDI транслируется изображение в формате 1080i ([тут можно почитать про различия 1080i и 1080p](https://tech.ebu.ch/docs/techreports/tr005.pdf)).
Вторая проблема: сигнала нет! Дело в том, что интерфейс SDI очень чувствителен к частоте кадров и разрешению, поэтому если камера у вас выдает 1080i и 50 кадров в секунду (именно такой формат выдает камера кэнон), то и на сервере должно стоять ровно 1080i и 50, в противном случае вы увидите чёрный экран и будете думать, что проблема не в настройках.
Даже если настройки на камере и сервере совпадают, иногда может случиться так, что изображения нет, – дело может быть в самих проводах. В таком случае надо просто проверить все контакты и найти слабое звено. Хотя сами крепления SDI очень надёжны и никогда не выпадут, проблема может быть где-то посередине кабеля. Мы столкнулись с такой проблемой и методом проб и ошибок нашли и устранили слабое место.
#### Хорошо, если все работает, давайте двигаться дальше.

Как же теперь записывать лекции на сервер? Хочется какое-то простое решение. Однако самое очевидное решение (использовать софт, поставляющийся в комплекте с картой захвата BlackMagic DeckLink) оказывается далеко не самым удобным.
Во-первых, начинать запись сам лектор не может, а значит нужен человек который будет это делать.
Во-вторых, DeckLink Studio не позволяет кодировать в реальном времени, а значит мы будем получать некомпрессированное видео = 1 минута около 1 GB…
Ну и последнее неудобство заключается в том что необходимо открывать две копии приложения от разных пользователей. Это конечно решается написанием bat-скрипта (напоминаю: сервер виндовый), но нажимая запись в двух разных каналах вручную, мы получаем 2 несинхронизированных файла.
#### Синхронная запись двух видеопотоков
Очевидное решение – использовать Mac сервер и купить [Movie Recorder](http://www.softronmedia.com/products/movierecorder.html) по 1000$ на канал. Именно так сделано у наших коллег в Швейцарии. Но мы решили пойти по другому пути. Конечно, были идеи реализовать кастомный интерфейс с помощью DeckLink SDK, но потом у нас появился чудный девайс который очень помогает нам по сей день. Итак, встречайте:

ATEM Television Studio. Вообще, предназначение данной карточки: в реалтайме кодировать видео с разных камер и позволять оператору переключаться между ними. Как обычно, софт поставляющийся в комплекте не очень то удобен. Однако на просторах интернета была найдена уже готовая софтина ([MXLight](http://mxlight.co.uk/)) которая обладает интерфейсом командной строки и позволяет записывать изображение с канала подключенного к данной карте.
Итак, у нас есть bat-файл, который умеет начинать запись с камеры, и другой bat-файл, который умеет останавливать этот процесс:
```
set name=D:\VIDEO\CPP_Course\Week3\Professor\Step4
set TIMESTAMP=%TIME:~0,2%_%TIME:~3,2%_%TIME:~6,2%
if exist %name%.TS ( START D:\VIDEO\MXLight\MXLight.exe record-to-file=%name%_%TIMESTAMP%.TS record=on )
else ( START D:\VIDEO\MXLight\MXLight.exe record-to-file=%name%.TS record=on )
```
Осталось разобраться с интерфейсом карточки DeckLink. Решение нашлось очень быстро – ffmpeg для Windows поддерживает DirectShow, а карта DeckLink является ничем иным как DirectShow устройством.
И вуаля – вот он bat-файл который запускает запись экрана:
```
set name=D:\VIDEO\CPP_Course\Week3\ScreenCast\Final_ScreenCast_LAST
set EXT=mp4
set TIMESTAMP=%TIME:~0,2%_%TIME:~3,2%_%TIME:~6,2%
if exist %name%.%EXT% ( START D:\VIDEO\ffmpeg\bin\ffmpeg.exe -y -video_size 1920x1080 -pixel_format uyvy422 -rtbufsize 702000k -framerate 24 -f dshow -i video="Decklink Video Capture" %name%_%TIMESTAMP%.%EXT% )
else ( START D:\VIDEO\ffmpeg\bin\ffmpeg.exe -y -video_size 1920x1080 -pixel_format uyvy422 -rtbufsize 702000k -framerate 24 -f dshow -i video="Decklink Video Capture" %name%.%EXT% )
```
А вот с остановкой записи экрана пришлось немного повозиться, дело в том, что нельзя просто взять и закрыть ffmpeg. В этом случае файл захвата будет поврежден, и может воспроизводится с помехами. Для корректного завершения режима видеозахвата нам необходимо послать с клавиатуры keypressed event «q».
Таким образом, всё равно нужен человек, который запускает запись и корректно ее останавливает.
Мне это очень не нравилось, и я решил в качестве эксперимента поднять простенький Node.js сервер, а поскольку на JS я никогда не писал, то и убить двух зайцев.
Так родилось приложение epicStudio, запуск которого осуществляет сам лектор из браузера, открытого на Wacom (Mac mini). Ссылка на гихтаб – [epicStudio](https://github.com/StepicOrg/epicStudio).
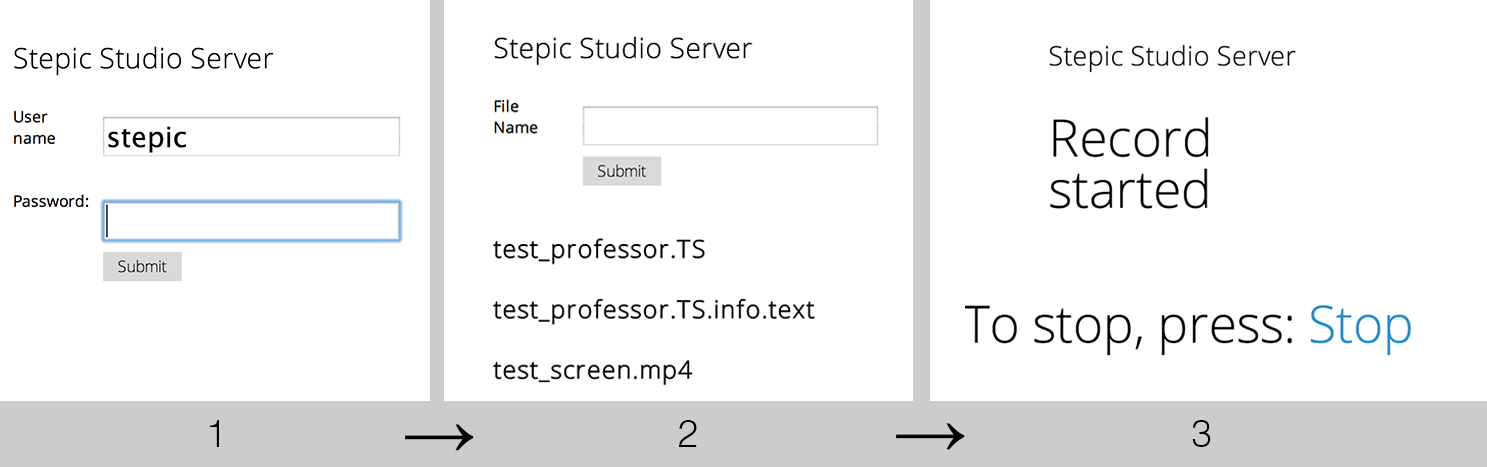
После запуска преподаватель начинает рассказывать лекцию и рисовать на слайдах. По окончании лекции, преподаватель самостоятельно останавливает запись и может начать запись новой темы. В конце дня мне остается только скачать файлы с сервера и склеить лекцию.
Этот процесс мы тоже постарались оптимизировать. Так, мной написаны различные инструменты для автоматического вырезания ненужных кусков, наложения ватермарков и приведения всех видеороликов к одинаковой громкости. Думаю, о них будет вкратце рассказано в следующий раз, в любом случае мои инструменты я выкладываю в [этот репозиторий](https://github.com/StepicOrg/epicTools) и там можно их посмотреть.
#### Напоследок, примеры получающихся видео:
**UPD:** В январе 2015 мы обновили конфигурацию нашей студии – стало удобнее, лучше и… дешевле. Подробнее ещё напишем пост, но если вы срочно заинтересованы в конфигурации и списке оборудования, спрашивайте по [[email protected]](mailto:[email protected]). Ещё мы собираем аналогичную студию в Москве, которая будет открыта для преподавателей, размещающих MOOC-и на [Stepic](https://stepic.org). Так что если вы хотели бы записать с нами курс, обращайтесь.
**UPD2:** Продолжение (апрель 2015): [habrahabr.ru/company/stepic/blog/255053](http://habrahabr.ru/company/stepic/blog/255053/) | https://habr.com/ru/post/235867/ | null | ru | null |
# Проблема глубинных ссылок в HATEOAS
> Внешнее связывание (глубинное связывание) — в интернете, это помещение на сайт гиперссылки, которая указывает на страницу, находящуюся на другом веб-сайте, вместо того, чтобы указать на начальную (домашнюю, стартовую) страницу того сайта. Такие ссылки называются внешними ссылками (глубинными ссылками).
>
> [Википедия](https://ru.wikipedia.org/wiki/%D0%92%D0%BD%D0%B5%D1%88%D0%BD%D0%B5%D0%B5_%D1%81%D0%B2%D1%8F%D0%B7%D1%8B%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5)
Дальше будет использоваться термин **«глубинные ссылки»**, как наиболее близкий к англоязычному «deep links». Речь в данной статье пойдет про REST API, поэтому под глубинными ссылками будут подразумеваться ссылки на HTTP-ресурсы. Например, глубинная ссылка [habr.com/ru/post/426691](https://habr.com/ru/post/426691/) указывает на конкретную статью на сайте habr.com.
**HATEOAS** – компонент REST-архитектуры, позволяющий предоставлять клиентам API информацию через гипермедиа. Клиенту известен единственный фиксированный адрес, точка входа API; все возможные действия он узнает из ресурсов, полученных от сервера. Представления ресурсов содержат ссылки на действия или другие ресурсы; клиент взаимодействует с API, динамически выбирая действие из доступных ссылок. Подробнее о HATEOAS можно прочитать на [Википедии](https://ru.wikipedia.org/wiki/HATEOAS) или в этой замечательной [статье](https://habr.com/ru/company/aligntechnology/blog/281206/) на Хабре.
HATEOAS – следующий уровень REST API. Благодаря использованию гипермедиа, он отвечает на многие вопросы, возникающие при разработке API: как управлять доступом к действиям на стороне сервера, как избавиться от жесткой связности между клиентом и сервером, как изменять адреса ресурсов в случае необходимости. Но он не дает ответа на вопрос о том, как должны выглядеть глубинные ссылки на ресурсы.
В «классической» реализации REST клиенту известна структура адресов, он знает, как по идентификатору получить ресурс в REST API. Например, пользователь переходит по глубинной ссылке на страницу книги в Интернет-магазине. В адресной строке браузера отображается URL `https://domain.test/books/1`. Клиент знает, что «1» – это идентификатор ресурса книги, и для его получения надо подставить этот идентификатор в URL REST API `https://api.domain.test/api/books/{id}`. Таким образом, глубинная ссылка на ресурс этой книги в REST API выглядит так: `https://api.domain.test/api/books/1`.
В HATEOAS же клиент не знает об идентификаторах ресурсов или структуре адресов. Он не хардкодит, а «обнаруживает» ссылки. Более того, структура URL-ов может измениться без ведома клиента, HATEOAS это позволяет. Из-за этих отличий не получится реализовать глубинные ссылки аналогично классическому REST API. Удивительно, но поиск в Интернете рецептов реализации таких ссылок в HATEOAS не дал большого количества результатов, только несколько недоуменных вопросов на Stackoverflow. Поэтому рассмотрим несколько возможных вариантов и попробуем выбрать лучший.
Нулевой вариант вне конкурса – не реализовывать глубинные ссылки. Это может подойти каким-нибудь админкам или мобильным приложениям, которым не требуется возможность прямого перехода на внутренние ресурсы. Это полностью в духе HATEOAS, пользователь может открывать страницы только последовательно, начиная с точки входа, потому что клиент не знает, как перейти на внутренний ресурс напрямую. Но этот вариант плохо подходит для веб-приложений – мы ожидаем, что ссылку на внутреннюю страницу можно добавить в закладки, а обновление страницы не перебросит нас обратно на главную страницу сайта.
Итак, первый вариант: хардкод URL-ов HATEOAS API. Клиент знает структуру адресов ресурсов, для которых нужны глубинные ссылки, и знает, как получить идентификатор ресурса для подстановки. Например, сервер в качестве ссылки на ресурс книги возвращает адрес `https://api.domain.test/api/books/1`. Клиент знает, что «1» – это идентификатор книги и может сформировать этот URL самостоятельно при переходе по глубинной ссылке. Это безусловно рабочий вариант, но нарушающий принципы HATEOAS. Структуру адреса и идентификатор ресурса изменить уже нельзя, иначе клиент сломается, налицо жесткая связность. Это не HATEOAS, а значит, вариант нам не подходит.
Второй вариант – подстановка URL REST API в URL клиента. Для примера с книгой глубинная ссылка будет выглядеть так: `https://domain.test/books?url=https://api.domain.test/api/books/1`. Здесь клиент берет полученную от сервера ссылку на ресурс и подставляет ее целиком в адрес страницы. Это уже больше похоже на HATEOAS, клиент не знает про идентификаторы и структуру адресов, он получает ссылку и использует ее как есть. При переходе по такой глубинной ссылке клиент получит нужный ресурс по ссылке REST API из параметра url. Казалось бы, решение рабочее, и вполне в духе HATEOAS. Но если добавить такую ссылку в закладки, в будущем мы уже не сможем изменить адрес ресурса в API (или придется вечно поддерживать переадресацию на новый адрес). Опять же теряется одно из преимуществ HATEOAS, этот вариант тоже не идеален.
Таким образом, мы хотим иметь постоянные ссылки, которые, тем не менее, могут измениться. Такое решение существует и широко используется в Интернете – многие сайты предоставляют короткие ссылки на внутренние страницы, которыми можно поделиться. Помимо краткости, их преимущество в том, что сайт может изменить реальный адрес страницы, но такие ссылки не сломаются. Например, Microsoft использует в Windows ссылки на страницы справки вида `http://go.microsoft.com/fwlink/?LinkId=XXX`. За эти годы сайты Microsoft были несколько раз переработаны, но ссылки в старых версиях Windows продолжают работать.
Осталось только приспособить это решение к HATEOAS. И это третий вариант – использование уникальных идентификаторов глубинных ссылок в REST API. Теперь адрес страницы с книгой будет выглядеть так: `https://domain.test/books?deepLinkId=3f0fd552-e564-42ed-86b6-a8e3055e2763`. При переходе по такой глубинной ссылке клиент должен спросить у сервера: какая ссылка на ресурс соответствует такому идентификатору `deepLinkId`? Сервер вернет ссылку `https://api.domain.test/api/books/1` (ну или сразу ресурс, чтобы два раза не ходить). Если адрес ресурса в REST API изменится, сервер просто вернет другую ссылку. В БД сохранена запись, что идентификатору ссылки 3f0fd552-e564-42ed-86b6-a8e3055e2763 соответствует идентификатор сущности книги 1.
Для этого ресурсы должны содержать поле `deepLinkId` с идентификаторами их глубинных ссылок, а клиент должен подставлять их в адрес страницы. Такой адрес можно спокойно сохранять в закладки и отправлять друзьям. Не совсем хорошо, что клиент самостоятельно работает с некими идентификаторами, но это позволяет сохранить преимущества HATEOAS для API в целом.
Пример
======
Эта статья была бы неполной без примера реализации. Для проверки концепции рассмотрим пример сайта-каталога гипотетического Интернет-магазина с бэкендом на Spring Boot/Kotlin и SPA-фронтендом на Vue/JavaScript. Магазин торгует книгами и карандашами, на сайте есть два раздела, в которых можно посмотреть список товаров и открыть их страницы.
Раздел «Книги»:

Страница одной книги:

Для хранения товаров определены сущности Spring Data JPA:
```
enum class EntityType { PEN, BOOK }
@Entity
class Pen(val color: String) {
@Id
@Column(columnDefinition = "uuid")
val id: UUID = UUID.randomUUID()
@OneToOne(cascade = [CascadeType.ALL])
val deepLink: DeepLink = DeepLink(EntityType.PEN, id)
}
@Entity
class Book(val name: String) {
@Id
@Column(columnDefinition = "uuid")
val id: UUID = UUID.randomUUID()
@OneToOne(cascade = [CascadeType.ALL])
val deepLink: DeepLink = DeepLink(EntityType.BOOK, id)
}
@Entity
class DeepLink(
@Enumerated(EnumType.STRING)
val entityType: EntityType,
@Column(columnDefinition = "uuid")
val entityId: UUID
) {
@Id
@Column(columnDefinition = "uuid")
val id: UUID = UUID.randomUUID()
}
```
Для создания и хранения идентификаторов глубинных ссылок используется сущность `DeepLink`, экземпляр которой создается с каждым доменным объектом. Сам идентификатор генерируется по стандарту UUID в момент создания сущности. В ее таблице хранится идентификатор глубинной ссылки, идентификатор и тип сущности, на которую ведет ссылка.
REST API сервера организовано по концепции HATEOAS, точка входа API содержит ссылки на коллекции товаров, а также ссылку `#deepLink` для формирования глубинных ссылок подстановкой идентификатора:
```
GET http://localhost:8080/api
{
"_links": {
"pens": {
"href": "http://localhost:8080/api/pens"
},
"books": {
"href": "http://localhost:8080/api/books"
},
"deepLink": {
"href": "http://localhost:8080/api/links/{id}",
"templated": true
}
}
}
```
Клиент при открытии раздела «Книги» запрашивает коллекцию ресурсов по ссылке `#books` в точке входа:
```
GET http://localhost:8080/api/books
...
{
"name": "Harry Potter",
"deepLinkId": "4bda3c65-e5f7-4e9b-a8ec-42d16488276f",
"_links": {
"self": {
"href": "http://localhost:8080/api/books/1272e287-07a5-4ebc-9170-2588b9cf4e20"
}
}
},
{
"name": "Cryptonomicon",
"deepLinkId": "a23d92c2-0b7f-48d5-88bc-18f45df02345",
"_links": {
"self": {
"href": "http://localhost:8080/api/books/5d04a6d0-5bbc-463e-a951-a9ff8405cc70"
}
}
}
...
```
В SPA используется Vue Router, для которого определен путь к странице книги `{ path: '/books/:deepLinkId', name: 'book', component: Book, props: true }`, а ссылки в списке книг выглядят так: `{{ book.name }}`.
То есть при открытии страницы конкретной книги вызывается компонент `Book`, которому передаются два параметра: `link` (ссылка на ресурс книги в REST API, значение поля `href` ссылки `#self`) и `deepLinkId` из ресурса).
```
const Book = {
template: `{{ 'Book: ' + book.name }}`,
props: {
link: null,
deepLinkId: null
},
data() {
return {
book: { name: "" }
}
},
mounted() {
let url = this.link == null ? '/api/links/' + this.deepLinkId : this.link;
fetch(url).then((response) => {
return response.json().then((json) => {
this.book = json
})
})
}
}
```
Значение `deepLinkId` Vue Router устанавливает в адрес страницы `/books/:deepLinkId`, а компонент запрашивает ресурс по прямой ссылке из свойства `link`. При принудительном обновлении страницы Vue Router устанавливает свойство компонента `deepLinkId`, получая его из адреса страницы. Свойство `link` остается равным `null`. Компонент проверяет: если есть прямая ссылка, полученная из коллекции, ресурс запрашивается по ней. Если же доступен только идентификатор `deepLinkId`, он подставляется в ссылку `#deepLink` из точки входа для получения ресурса по глубинной ссылке.
На бэкенде метод контроллера для глубинных ссылок выглядит так:
```
@GetMapping("/links/{id}")
fun deepLink(@PathVariable id: UUID?, response: HttpServletResponse?): ResponseEntity {
id!!; response!!
val deepLink = deepLinkRepo.getOne(id)
val path: String = when (deepLink.entityType) {
EntityType.PEN -> linkTo(methodOn(MainController::class.java).getPen(deepLink.entityId))
EntityType.BOOK -> linkTo(methodOn(MainController::class.java).getBook(deepLink.entityId))
}.toUri().path
response.sendRedirect(path)
return ResponseEntity.notFound().build()
}
```
По идентификатору находится сущность глубинной ссылки. В зависимости от типа прикладной сущности формируется ссылка на метод контроллера, который возвращает ее ресурс по `entityId`. Запрос редиректится на этот адрес. Таким образом, если в будущем ссылка на контроллер сущности изменится, можно будет просто изменить логику формирования ссылок в методе `deepLink`.
Полный исходный код примера доступен на [Github](https://github.com/johnspade/hateoas-deep-links-demo). | https://habr.com/ru/post/445092/ | null | ru | null |
# [boringssl] Failed to log metrics
Наверное, каждый iOS разработчик сталкивался с этой проблемой. Любое приложение, которое делает https запросы, получает в лог эти мистические сообщения от `boringssl`:
`[boringssl] boringssl_metrics_log_metric_block_invoke(151) Failed to log metrics`
Минимальный код для воспроизведения проблемы:
```
URLSession.shared
.dataTask(with: URL(string: "https://google.com")!)
.resume()
```
StackOverflow и другие ресурсы советуют установить переменную окружения `OS_ACTIVITY_MODE=disable`, но это порождает новую проблему: сообщения из `NSLog()` так же пропадут из консоли.
```
// OS_ACTIVITY_MODE=disable
URLSession.shared
.dataTask(with: URL(string: "https://google.com")!)
.resume()
NSLog("hello")
// ошибки boringssl пропадут,
// но и "hello" не напечатается
```
Полное отключение диагностических сообщений через `OS_ACTIVITY_MODE=disable` никогда не было выходом, так как это делает ситуацию только хуже. Удовлетворив разумное желание избавиться от мусора в логах, взамен мы получаем игнорирование других потенциально важных диагностических сообщений (в том числе своих же NSLog-ов).
Но раз логи нужны и полезны, то зачем тогда что-то отключать?
Спам в логах мне кажется контрпродуктивным. Когда логов так много, что ты даже не успеваешь прочитать сообщение, то в какой-то момент ты просто перестаёшь обращать на них внимание, и можешь пропустить важные сигналы. В идеале лог должен быть пустым, чтобы внезапно появившиеся диагностические сообщения были явно заметны, и можно было на них вовремя отреагировать – исправить, и снова сделать так, чтобы лог был чист.
Проблема неотключаемого мусорного логирования от boringssl мучала нас много лет, но, кажется, я нашёл приемлемое решение. Расскажу, как я до него дошёл.
Сперва я хотел понять, где же живёт код, который печатает эти логи. Я решил поискать функции с подстрокой "boringssl" в названии, чтобы узнать, из какой библиотеки или фреймворка они импортируются.
```
(lldb) image lookup -r -s "boringssl"
13 symbols match the regular expression 'boringssl' in /Applications/Xcode.app/Contents/Developer/Platforms/iPhoneOS.platform/Library/Developer/CoreSimulator/Profiles/Runtimes/iOS.simruntime/Contents/Resources/RuntimeRoot/usr/lib/libnetwork.dylib:
Address: libnetwork.dylib[0x0000000000090a78] (libnetwork.dylib.__TEXT.__text + 586400)
Summary: libnetwork.dylib`__nw_protocol_get_boringssl_identifier_block_invoke Address: libnetwork.dylib[0x0000000000090d1c] (libnetwork.dylib.__TEXT.__text + 587076)
...
1251 symbols match the regular expression 'boringssl' in /Applications/Xcode.app/Contents/Developer/Platforms/iPhoneOS.platform/Library/Developer/CoreSimulator/Profiles/Runtimes/iOS.simruntime/Contents/Resources/RuntimeRoot/usr/lib/libboringssl.dylib:
Address: libboringssl.dylib[0x0000000000001dd4] (libboringssl.dylib.__TEXT.__text + 3844)
Summary: libboringssl.dylib`boringssl_bio_create Address: libboringssl.dylib[0x0000000000001ea0] (libboringssl.dylib.__TEXT.__text + 4048)
...
```
`libboringssl.dylib` выглядит подходящим кандидатом для анализа. Я загрузил файл библиотеки в Hopper Disassembler, чтобы найти строковую константу и места её использования.
Строковая константа быстро нашлась, и используя "References To..." я сразу же нашёл функцию, которая использует эту строку – `boringssl_metrics_log_event`.
Не являясь экспертом в ассемблере, я переключил Hopper Disassembler в режим "Pseudo Code Mode", и увидел более-менее приличную версию этой функции на Си.
Если убрать всё лишнее, то увидим код:
```
int boringssl_metrics_log_event(...) {
// ...
if (g_boringssl_log != NULL
&& os_log_type_enabled(g_boringssl_log, OS_LOG_TYPE_ERROR))
{
os_log_with_type(
g_boringssl_log,
OS_LOG_TYPE_ERROR,
"%s(%d) Failed to log metrics",
"boringssl_metrics_log_metric_block_invoke",
0x12
)
}
// ...
}
```
Делаем вывод, что можно отключить логирование внутри boringssl установлением глобальной переменной `g_boringssl_log` в NULL. Останавливаем исполнение работающей программы, и проверяем доступность переменной в отладчике:
```
(lldb) p g_boringssl_log
(OS_os_log *) $2 = 0x0000600000ac9d80
```
Честно говоря, я не совсем понимаю почему эта переменная видна в lldb прямо по имени. Но тем не менее, можно изменить её значение:
```
(lldb) p g_boringssl_log = 0
(void *) $3 = 0x0000000000000000
```
Убеждаемся, что после этого логи от boringssl пропадают.
Теперь нужно найти способ автоматически обнулять эту переменную при каждом запуске приложения. Мне сразу пришёл в голову способ с установлением breakpoint, в котором есть action с телом `p g_boringssl_log = 0`, плюс `Automatically continue after evaluating actions`.
Однако же, создать такой breakpoint оказалось непросто, так как не совсем очевиден момент во времени, когда этот breakpoint должен сработать. Дело в том, что `libboringssl.dylib`, судя по всему, загружается динамически, и поставить breakpoint на самый старт приложения (например на `main`) не получится, т.к. `libboringssl` ещё не будет загружен, и `g_boringssl_log` ещё не будет проинициализирована.
Поэтому я стал искать точку инициализации `g_boringssl_log`.
Снова используя Hopper Disassembler я нашёл символ `g_boringssl_log` в `libboringssl.dylib`, и нашёл все его использования. Их оказалось довольно много, так как код проверки на `os_log_type_enabled` скорее всего оказывается заинлайнен благодаря макросу из :
```
#define os_log_with_type(log, type, format, ...) __extension__({ \
os_log_t _log_tmp = (log); \
os_log_type_t _type_tmp = (type); \
if (os_log_type_enabled(_log_tmp, _type_tmp)) { \
OS_LOG_CALL_WITH_FORMAT(_os_log_impl, \
(&__dso_handle, _log_tmp, _type_tmp), format, ##__VA_ARGS__); \
} \
})
#define os_log_error(log, format, ...) \
os_log_with_type(log, OS_LOG_TYPE_ERROR, format, ##__VA_ARGS__)
```
Пройдясь по списку функций, использующих эту переменную, я всё же нашёл функцию `boringssl_log_open`, которая и производит инициализацию `g_boringssl_log`.
Но был и другой способ найти место инициализации этой переменной: установить watchpoint на её адрес, и отладчик остановится в момент записи нового значения.
Открываем терминал и запускаем `lldb` отдельно от Xcode:
```
% lldb
# устанавливаем брейкпоинт на все функции из libboringssl
(lldb) breakpoint set -r '.' -s 'libboringssl.dylib'
Breakpoint 1: no locations (pending).
Breakpoint set in dummy target, will get copied into future targets.
# заставляем отладчик ждать запуска процесса $EXECUTABLE_NAME,
# затем подключиться к процессу, и остановиться
(lldb) process attach -n '$EXECUTABLE_NAME' -w
# после этого вручную запускаем приложение в симуляторе,
# lldb должен подключиться к новому процессу:
Process 25155 stopped
* thread #1, stop reason = signal SIGSTOP
frame #0: 0x0000000102a58560 dyld`_dyld_start
dyld`_dyld_start:
-> 0x102a58560 <+0>: mov x0, sp
0x102a58564 <+4>: and sp, x0, #0xfffffffffffffff0
0x102a58568 <+8>: mov x29, #0x0
0x102a5856c <+12>: mov x30, #0x0
Target 0: stopped.
Executable module set to "/path/to/executable".
Architecture set to: arm64e-apple-ios-simulator.
# продолжить исполнение до срабатывания breakpoint
# на любой функции из boringssl
(lldb) continue
Process 25155 stopped
* thread #5, queue = 'com.apple.CFNetwork.Connection', stop reason = breakpoint 1.233
frame #0: 0x0000000185e66c00 libboringssl.dylib`nw_protocol_boringssl_copy_definition
libboringssl.dylib`nw_protocol_boringssl_copy_definition:
-> 0x185e66c00 <+0>: stp x29, x30, [sp, #-0x10]!
0x185e66c04 <+4>: mov x29, sp
0x185e66c08 <+8>: adrp x8, 337146
0x185e66c0c <+12>: ldr x8, [x8, #0xc8]
Target 0: stopped.
# установить watchpoint на адрес g_boringssl_log
(lldb) watchpoint set expression &g_boringssl_log
Watchpoint created: Watchpoint 1: addr = 0x1d8360b28 size = 8 state = enabled type = w
new value: 0x0000000000000000
# отключить breakpoint, чтобы он больше не срабатывал
(lldb) breakpoint disable 1
1 breakpoints disabled.
# продолжить, чтобы сработал watchpoint
(lldb) continue
Process 25155 resuming
Watchpoint 1 hit:
old value: 0x0000000000000000
new value: 0x0000600000464880
Process 25155 stopped
* thread #5, queue = 'com.apple.CFNetwork.Connection', stop reason = watchpoint 1
frame #0: 0x0000000185e715dc libboringssl.dylib`__boringssl_log_open_block_invoke + 40
libboringssl.dylib`__boringssl_log_open_block_invoke:
-> 0x185e715dc <+40>: mov x0, x8
0x185e715e0 <+44>: bl 0x185ee4698 ; symbol stub for: objc_release
0x185e715e4 <+48>: adrp x8, 337135
0x185e715e8 <+52>: ldr x8, [x8, #0x228]
Target 0: stopped.
```
Таким образом удалось сразу найти нужную функцию – `__boringssl_log_open_block_invoke`.
Снова открываем Hopper Disassembler, находим эту функцию и её использования, и
видим следующую картину:
```
void boringssl_log_open() {
static dispatch_once_t onceToken;
dispatch_once(&onceToken, __boringssl_log_open_block_invoke);
// или в развёрнутом виде:
dispatch_once(&onceToken, ^{
g_boringssl_log = os_log_create("com.apple.network", "boringssl");
});
}
```
Подумав, я пришёл к выводу, что лучшее, что я могу сделать, это как-то заставить тело `dispatch_once` перестать выполняться, чтобы `g_boringssl_log` оставался неинициализированным (NULL).
Такого поведения можно добиться установив breakpoint на `__boringssl_log_open_block_invoke` и добавив action `thread return`. Это заставит lldb сразу же выйти из функции, и её тело не будет исполнено.
breakpoint, отключающий вывод логов от boringsslУ логов из boringssl есть "брат", живущий по соседству в `libnetwork.dylib`, и порождающий сообщения `[connection] ... [...] Client called nw_connection_copy_connected_path on unconnected nw_connection`.
Эти логи можно отключить тем же способом, добавив такой же брейкпоинт с `thread return` на `____nwlog_connection_log_block_invoke` из `libnetwork.dylib`.
Напоследок рекомендую создать shared breakpoint и сделать его "глобальным", используя пункт меню "Move Breakpoint to User". Xcode добавит эти брейкпоинты в `~/Library/Developer/Xcode/UserData/xcdebugger/Breakpoints_v2.xcbkptlist`, и они автоматически станут видны во всех проектах.
Shared User Breakpoints автоматически добавляются ко всем проектам**UPD**: как всегда, оказалось, что уже давно есть более человеческий способ заглушить те или иные `os_log`. Надо было лишь получше поискать.
```
xcrun simctl spawn booted log config --subsystem com.apple.network --category boringssl --mode "level:off"
``` | https://habr.com/ru/post/661039/ | null | ru | null |
# Взял видеоинтервью у вице-президента Ардуино и обсудил с ней преподавание школьникам ПЛИС-ов / FPGA и языка Verilog
На днях я встретился и взял короткое видеоинтервью у [Kathy Giori, Vice President Operations Arduino USA](https://www.crunchbase.com/person/kathy-giori). Мы обсудили с Кати новое веяние, которое уже коснулось и Ардуино-коммьюнити: так как программированию микроконтроллеров с помощью Ардуино уже все более-менее научены, то пора делать следующий шаг: учить школьников использовать язык описания аппаратуры Verilog и микросхемы ПЛИС / FPGA, матрицы логических элементов с изменяемыми функциями. А для того, чтобы сделать освоение FPGA проще, стоит воскресить упражнения с микросхемами малой степени интеграции, популярные в 1970-х, в качестве приквела к современным FPGA. Все это закроет брешь между физикой и программированием, дискретными элементами и микроконтроллерами, транзистором и Ардуино.
FPGA и платы можно использовать от любого производителя (Xilinx, Altera, Lattice, Digilent, Terasic), все что я пишу ниже, не имеет привязки к той или иной компании.
В разговоре с Кати принимала участие [преподаватель Стенфорда Светлана Хутка](http://stanford.academia.edu/SvitlanaKhutka), которая рассказала Кати об [эксперименте по бесплатному обучению школьников использованию FPGA в Киеве](http://www.silicon-russia.com/2017/04/19/kiev-april-2017/), силами преподавателей-энтузиатов из нескольких киевских вузов. После этого я поделился с Кати планами проведения следующего такого эксперимента на известной еще с советских времен [летней школе юных программистов в Новосибирске](http://school.iis.nsk.su/lshyup-2017/masterskie-6), а также поговорил с другими присутствующими товарищами из Ардуино-коммьюнити о внедрении FPGA в двух школах и одном коледже Silicon Valley.
Плата c FPGA, которую сейчас рекомендует Кати, и которую я несколько переделываю, чтобы приспособить к своим нуждам (про это будет отдельный пост):

Ниже я приведу как информацию по результатам киевского эксперимента, так и некоторые планы на будущее, которые сейчас разрабатывают активисты — преподаватели физматшкол и вузов Киева, Чернигова, Новосибирска, Москвы, Нижнего Новгорода, Самары, Санкт-Петербура, Алматы и других городов. На киевском семинаре участники дошли до создания конечных автоматов кодового замка и интеграции с простыми периферийными устройствами (16-кнопочная клавиатура, динамик). На летней школе в Новосибирске у нас времени будет больше и мы попробуем построить со школьниками процессор. В перспективе из этого планируется сделать годовой курс основ цифровой электроники на FPGA для физматшкол, который может обогатить школьное образование, как в 1980-х его обогатило введение элементов программирования.
Обсудим это детально:
**1. Зачем учить школьников языкам описания аппаратуры и использованию ПЛИС? Обоснование программы.**
В картине мира, представляемой школьным образованием, существует “слепое пятно” в области принципов проектирования цифровой электроники, между физикой и программированием. Курсы роботики и ардуино это слепое пятно не закрывают, так как сводятся к программированию готовых чипов. Упражнения с дискретными элементами и микросхемами малой степени интеграции, хотя и эффективны во введении в основные принципы, базируются на технологиях 1960-1970-х годов и не содержат привязки к современному проектированию. Слепое пятно можно закрыть с помощью введения элементов языков описания аппаратуры (ЯОА) и доступные для школьного экспериментирования микросхемы ПЛИС (программируемые логические интегральные схемы) — матрицы реконфигурируемых логических элементов. Тем самым картина мира становится цельной, и способствует созданию среды для появления большого количества молодых инженеров, имеющих представление о всех сторонах современных микросхем для приложений типа самоуправляемых автомобилей, и способных в будущем специализироваться для проектирования того или иного аспекта таких устройств.
Введение ЯОА и ПЛИС в школьную программу также хорошо привязывается к курсу математики и физики физматшкол — булевская алгебра, арифметические схемы, конечные автоматы.
Заметим, что ЯОА и ПЛИС, несмотря на поверхностное сходство с программированием, используют другие базовые концепции:
Программирование: последовательное исполнение, ветви выбора, циклы, переменные, выражения, массивы (c моделью плоской адресуемой памяти), функции (на основе использования стека), рекурсия.
Проектирование цифровой логики: комбинационный логический элемент; построение из этих элементов облаков комбинационной логики, включающей примитивы выбора с помощью мультиплексоров, а также блоки для реализации арифметических выражений; концепция тактового сигнала для синхронизации вычислений и повторения, концепция D-триггера для хранения текущего состояния между тактами; конечный автомат; параллельность операций, иерархия модулей, концепция конвейера (не только для процессора, но и для арифметических блоков).

**2. Общий план таких курсов:**
* Секция 1. Соединение с физикой, с лабораторными на дискретных компонентах.
* Секция 2. Основы цифровой логики и арифметики, с лабораторными на микросхемах малой степени интеграции.
* Секция 3. Проектирование схем на основе синтеза языка описания аппаратуры, с лабораторными на ПЛИС Xilinx или Altera.
* Секция 4. Архитектура процессора: вид со стороны программиста, с лабораторными с помощью симулятора RISC-процессора на уровне инструкций, например MARS MIPS.
* Секция 5. Микроархитектура: строим процессор.
* Индивидуальный проект: интеграция датчика или другого периферийного устройства с схемой, реализованной в ПЛИС.

**3. Итоги киевского эксперимента.**
[Развернутый текст с итогами киевского эксперимента](https://www.facebook.com/lampa.kpi/posts/1849260118666201) написал преподаватель Киевского Политехнического Института Евгений Короткий. Я дополню его своими личными выводами. Предыстория — посты на Хабре и Geektimes — [1](https://habrahabr.ru/post/250511/), [2](https://geektimes.ru/post/285778/), [3](https://geektimes.ru/post/287174/), [4](https://geektimes.ru/post/287396/)). В тех постах были заданы вопросы. Вот какие получились ответы:
1. Гипотеза, что школьники могут использовать Verilog, подтвердилась
2. Verilog также оказался достаточному количеству школьников интересен (до Киева некоторые коллеги в этом сомневались, утверждая, что детям более интересны проекты типа роботической руки с микроконтроллером)
3. Идея, что перед использованием Verilog полезно показать школьникам логические элементы и D-триггер на микросхемах малой степени интеграции — не то чтобы однозначно подтвердилась, но получила большее обоснование.
4. Всего после дня опыта с верилогом некоторые школьники начали задавать вразумительные вопросы — например когда применять блокирующее, а когда неблокирующее присваивание.
5. Довести школьников от нуля до конечных автоматов, реализующих протоколы типа SPI — за одну неделю по-видимому нереально, а вот до конечного автомата кодового замка или светофора — реально.
6. Также нереально довести за одну неделю по конструирования процессора, но мы попробуем это сделать за две недели в Новосибирске.
7. Во время киевского эксперимента мы пробовали рассказать и про FPGA, и про встроенные процессоры (MediaTek MT7688, находящийся где-то посередине между Ардуино и Интел Галилео или Расбери Пай по производительности). Потом мы сделали хакатон (в Киевско-Могилянской Академии) и пронаблюдали, сколько школьников выбрали для хакатона проект с FPGA и сколько — проект с встроенным процессором. Выяснилось — 50 на 50. Это интересно — до хакатона у меня не было вообще никакого предположения, какая будет разбивка.
8. У меня было опасение, что школьников может запутать пользовательский интерфейс в Xilinx Vivado, с кучей опций и элементов интерфейса. Но оказалось, что школьникам все равно — сложный GUI их не пугает.
9. Большинство школьников используют Windows. У меня вместе с моим коллегой [Александром Белицем](https://habrahabr.ru/users/abelits/) есть идея заготовить для таких мероприятий пару десятков bootable SSD-драйвов с Линуксом (Ubuntu или CentOS) и носить их от мероприятия к мероприятияю. Алекс даже написал скрипт для клонирования таких драйвов. Ubuntu более дружелюбен, но CentOS более официально поддерживается средствами автоматизации проектирования схем на FPGA, в частности Xilinx Vivado и Altera Quartus. Можно ли делать одновременно ликбез по Линуксу и ликбез по Verilog / FPGA во время летнего лагеря? Непонятно, но это можно попробовать.
10. Оказывается, Xilinx Vivado нещадно глючит приконфигурации Artix-7 FPGA, если использовать дешевые плохо экранированные микро-USB кабели. По какому-то мистическому наитию я перед поездкой в Киев засунул в чемодан дюжину качественных шнуров, и это спасло семинар.
11. У меня была идея, что использование breadboardable FPGA modules (FPGA плат, которые втыкаются в макетные платы), например [Digilent Cmod A7 35T](http://store.digilentinc.com/cmod-a7-breadboardable-artix-7-fpga-module/), может облегчить школьникам переход с упражнений с микросхемами малой степени интеграции на упражнения с FPGA. Верна ли эта идея, я так и не понял. Возможно использование более крупных плат с богатым набором периферии, например [Terasic DE10-Lite](http://de10-lite.terasic.com), будет ничуть не хуже. Все равно при переходе с микросхем малой степени интеграции (CMOS 4000 или 74HC) на FPGA — нужно менять напряжение питания (с 9 V или 5 V на 3.3 V), поэтому нельзя воткнуть Cmod A7 вместо скажем CMOD 4013 в одну и ту же макетную плату с лампочками и кнопками, и ожидать, что все будет продолжать работать.
12. Я подтвердил свое наблюдение, что для проведения краткосрочных (1 неделя) образовательных мероприятий критично, чтобы на месте находилась бригада студентов местного университета, которая бы осуществляла менторство школьников. В киевском случае такую бригаду обеспечил преподаватель Киевского Политехнического Института [Евгений Короткий](https://www.facebook.com/korotkiy.eugene).
13. Стало более-менее понятно, в каких случаях и в каком объеме стоит включать в программу подобных мероприятий часть про уровень транзисторов и про производства микросхем. Эту часть преподавал доцент Киевского Национального Университета [Александр Барабанов](http://ce.knu.ua/list/barabanov), переводчик материалов по курсу [Nanometer ASIC](https://habrahabr.ru/post/314892/) для студентов. По-видимому, этот материал стоит в полном объеме включать в годовой курс для школьников, в небольшом — в двухнедельный курс в формате летнего лагеря, но при продолжительности меньше недели нужно наверное сразу (в течение 1 часа после начала) давать школьникам микросхемы малой степени интеграции (например CMOS 4000) и про транзистор упомянуть вскользь, в виде «транзистор — это устройство, в котором ток течет из пукта A в пункт B, если в C стоит напряжение 1 (или 0). Из транзисторов можно строить логические элементы И, ИЛИ, НЕ (показать на картинку)».
14. Во время лекций перед большой аудиторией школьникам можно показывать схемы, собранные на макетной плате из микросхем малой степени интеграции. Это наглядно, вызывет интерес, а также не требует подключения конструкции к компьютеру — только с батарейке 9 V. Я показывал три таких схемы, наиболее критичных для понимания — логический элемент XOR, комбинационный 4-битный сумматори D-триггер с частотой порядка 1 Герц (т.е. такт в секунду).
15. Остается открытым вопрос, можно ли преподавать школьникам идею конвейерной обработки, одну из самых мощных идей в цифровом проектировании и организации вычислений вообще. Для этого необязательно строить конвейерный процессор, можно сделать и [конвейерное арифметическое устройство](http://www.silicon-russia.com/public_materials/2016_11_04_one_day_mipsfpga_connected_mcu_materials_public_for_the_website/06_optional_introductory_materials_if_necessary_for_the_audience/08_quizes/quiz_5_comb_seq_pipe_1.html). Наверное это можно упомянуть в самом конце курса, когда дети наиграются с простыми комбинационными и последовательностным схемами и конечными автоматами. Скорее всего это будет интересно очень небольшому подмножеству школьников, но попробовать стоит.
16. Для мероприятий подлиннее можно использовать [индивидуальные проекты](http://www.silicon-russia.com/public_materials/2016_11_04_one_day_mipsfpga_connected_mcu_materials_public_for_the_website/06_optional_introductory_materials_if_necessary_for_the_audience/06_exercises/exercise_3_counter_shift_fsm.html) и [проверочные работы](http://www.silicon-russia.com/public_materials/2016_11_04_one_day_mipsfpga_connected_mcu_materials_public_for_the_website/06_optional_introductory_materials_if_necessary_for_the_audience/08_quizes/).
[Код на GitHub использованный для киевского мероприятия](https://github.com/yuri-panchul/2017-kiev/tree/master/xilinx)

**4. Источники информации для разработки будущих материалов.**
Источники информации для преподавателей физматшкол, которые по-видимому будут разрабатывать большую часть детальных материалов, после начальных экспериментов со школьниками на Украине, в России и в Silicon Valley:
1. Учебник Дэвида Харриса и Сары Харрис “Цифровая схемотехника и архитектура компьютера”, 2-е издание, русский перевод. Этот учебник можно скачать бесплатно, см. статьи на Хабре о нем — [1](https://habrahabr.ru/post/317558/), [2](https://habrahabr.ru/post/306982/), [3](https://habrahabr.ru/post/259505/). Недавно также вышло [новое бумажное издание с улучшенной цветной полиграфией](http://dmkpress.com/catalog/electronics/circuit_design/978-5-97060-522-6/)
2. [Слайды для преподавателей, дополнение к учебнику Харрис & Харрис.](https://habrahabr.ru/post/308976/) Бесплатное скачивание.
3. Материалы по курсу [From NAND to Tetris](http://www.nand2tetris.org/), который был создан в Израиле и внедрен в некоторые американские университеты. При этом, имхо, от курса стоит использовать идеи и скелет, но реализацию делать на подмножествах “взрослых” средств проектирования, а не искуственных “детских” средствах, как делает это курс. [Ключевые части](http://www.nand2tetris.org/chapters/) скачиваются бесплатно.
4. Книга Чарльза Петзольда “Код”, которая адекватно объясняет на пальцах многие концепции и уровень которой соответствует школьному (идея подсказана преподавателем киевской школы ОРТ [Сергеем Дзюбой](https://vk.com/id2943004)). Опять же, с моей точки зрения, из книги стоит использовать идеи и скелет, но бОльшую часть материала заменить на более корректный (вместо защелок (D-latch) использовать D-триггеры (D-flip-flop)) и современный, например вместо accumulator-based 6800 и архаичного 8080 использовать подмножество RISC-архитектуры.
5. Наборы для конструирования схем на макетной плате на основе дискретных компонент и микросхем малой степени интеграции от американской компании ETron Circuit Labs, российской компании Киберфизика, украинской компании Радиомаг (я могу объяснить различия между этими наборами в комментариях, если кому интересно).
6. Материалы компаний-производителей микросхем ПЛИС (Xilinx, Altera) и образовательных плат с микросхемами ПЛИС (Digilent, Terasic).
7. Примеры кода, контрольные работы и рекомендации по проектам, разработанные Антоном Моисеевым, Юрием Панчулом, Евгением Коротким, Александром Барабановым и другими инженерами компаний и преподавателями университетов для различных мероприятий в Калифорнии, Казахстане, России и Украине.

**5. План на будущее номер 1. Формат годового курса на 35 учебных часов, раскиданных на учебный год по часу в неделю**
1. От физики к дискретным элементам
1. Что такое ток, напряжение и сопротивление. Как устроена макетная плата. Упражнение: первая схема с батарейкой, светодиодом и резистором. Зачем включать резистор в цепь со светодиодом. Чтение маркировки резисторов. Переменные резисторы, фоторезисторы.
2. Что такое транзистор. Обзор переключающих элементов от реле, радиоламп, дискретных транзисторов до транзисторов на микросхемах. Упражнения с тиристором (SCR — silicon controlled rectifier — нагляднее чем транзистор), биполярным p-n-p и n-p-n транзисторами.
3. Контрольная работа.
2. От дискретных элементов к комбинационной логике
1. Булева алгебра и алгебра логики. Операции, выражения, аксиомы и тождества, включая законы де Моргана. Таблицы истинности.
2. Комбинационные логические элементы И, ИЛИ, НЕ, И-НЕ, ИЛИ-НЕ, ИСКЛЮЧАЮЩЕЕ-ИЛИ (AND, OR, NOT, NAND, NOR, XOR). Как комбинационные элементы строятся из транзисторов. Упражнение: построить AND, NAND или NOR из дискретных элементов.
3. Логические элементы в микросхемах малой степени интеграции. Индивидуальное упражнение: каждому ученику выдается персональная микросхема логики серии CMOS 4000, с техническим описанием от производителя, с задачей нарисовать таблицу истинности, продемонстрировать ее работу и словесно описать функцию. Микросхемы содержат логические элементы AND, OR, XOR, NOR, NAND с различным числом входов. Что такое такое подтягивающие резисторы и зачем они нужны. Добавляем к предыдущему упражнению кнопки и подтягивающие резисторы.
4. Контрольная работа.
3. Двоичная арифметика и ее реализация
1. Двоичные числа. Преобразование из двоичных в десятичные числа и наоборот. Операции сложения и умножения. Отрицательные числа и дополнительный код.
2. Реализация полусумматора и полного сумматора с помощью логических элементов. Перенос. Многоразрядный сумматор с последовательным переносом. Упражнение на макетной плате. Упоминание о длинной временной задержке и схемах с более оптимальной задержкой.
3. Использование 4-битного полного сумматора CMOD 4008. Построение из него 8-битного сумматора и схемы вычитания. Домашнее задание для продвинутых студентов: изучить и сделать презентацию о реализации быстрых сумматоров с ускоренным групповым переносом.
4. Контрольная работа.
4. Последовательностная логика
1. Построение генератора тактового сигнала на основе микросхемы 555. Изучение влияния конденсаторов и сопротивлений на частоту и длительности высокого и низкого уровней.
Так как в обвязку 555 входят конденсаторы, могут понадобится дополнительные объяснения, что такое конденсаторы, зачем они нужны в обвязке 555 и как они маркируются. Также может быть полезным и вспомогательное упражнение с зарядкой и разрядкой конденсаторов разной емкости.
2. Схемы с внутренним состоянием. Построение RS-защелки из логических элементов NAND. Изучение поведения D-триггера с помощью микросхемы CMOS 4013 и тактового сигнала от 555 с частотой 1 Гц.
3. Последовательностные блоки — счетчик (CMOS 4029) и сдвиговый регистр (4015). Семисегментный индикатор и его драйвер 4511. Упражнения с этими микросхемами.
5. Экзамен.
6. От микросхем малой степени интеграции к ПЛИС — комбинационная логика
1. Понятие о ПЛИС (программируемой логической интегральной схеме) — матрице реконфигурируемых логических элементов. Понятие о языке описания аппаратуры Verilog, процедурах синтеза, размещения, трассировки и конфигурации. Упражнение: синтез простейшего комбинационного модуля с конфигурацией ПЛИС на учебной плате.
2. Продолжение изучения языка Verilog. Типы данных, выражения, присваивания. Always-блоки и основные операторы. Упражнение: вывод первых букв своего имени и фамилии на семисегментный индикатор, переключаясь между ними с помощью кнопки.
3. Продолжение изучения языка Verilog. Иерархия модулей. Упражнение: построение мультиплексоров и сумматоров из подмодулей. Домашнее задание для продвинутых студентов: изучить и сделать презентацию о реализации быстрых сумматоров с ускоренным групповым переносом.
4. Моделирование кода на Verilog без ПЛИС. Подмножества языка для реализации схемы и для ее тестирования / верификации. Моделирование временных задержек. Упражнение: создание среды для проверки работы схемы, описанной на языке Verilog. Использование симулятора Icarus Verilog для моделирования и программы GTKWave для просмотра временных диаграмм.
5. Презентация группы продвинутых студентов: реализация быстрых сумматоров с ускоренным групповым переносом, моделирование в них временных задержек и сравнение их с сумматорами с последовательным переносом (количество логических элементов и задержки).
6. Контрольная работа
7. Проектирование последовательностной логике на языке Verilog с реализацией на ПЛИС
1. Конструкции языка Verilog, которые порождают D-триггеры по время синтеза. Объяснение правил методологии проектирования на уровне регистровых передач: блокирующие и неблокирующие присваивания в различных always-блоках. Моделирование последовательностных схем на симуляторе Icarus Verilog.
2. Упражнения: реализация D-триггера, счетчика и сдвигового регистра на ПЛИС. Анализ результатов программы статического анализа о максимальной частоте. Демонстрация: использование последовательностной логики для генерации сигналов звуковой частоты и вывода их на динамик.
3. Концепция конечного автомата. Диаграммы изменения состояний. Упражнения: конечные автоматы светофора и кодового замка.
4. Конечные автоматы для протоколов шин. Выбор самостоятельного проекта (со сдачей в конце курса) по интеграции датчиков и других периферийных устройств с платой c ПЛИС. Самостоятельная работа: индивидуальный проект, модифицирующий поведение одного из примеров с последовательностной логикой: счетчика, сдвигового регистра или конечного автомата.
5. Концепция конвейерной обработки. Сравнение конвейерной реализации арифметических блоков, вычисляющих степень и квадратный корень.
6. Контрольная работа.
8. Архитектура процессора: вид со стороны программиста, с лабораторными с помощью симулятора RISC-процессора на уровне инструкций, например [MARS MIPS](http://courses.missouristate.edu/KenVollmar/mars/).
1. Концепция фон-Нейманновской машины. Введение в ассемблер: команды, операнды, регистры, константы. Арифметические и логические операции. Кодирование инструкций. Упражнение с симулятором процессора на уровне инструкций — MARS MIPS. Простые программы на ассемблере для вычисления выражений.
2. Условные и безусловные переходы, метки, циклы. Пример: вычисление чисел Фибоначчи. Индивидуальное упражнение на основе модификации примера.
3. Концепция адресуемой памяти. Инструкции загрузки и сохранения в память. Конструкции ассемблера для выделения памяти. Упражнение: программа, заполняющая память вычисленными данными. Индивидуальное упражнение на основе модификации примера.
4. Контрольная работа.
9. Микроархитектура: строим процессор
1. Реализация на Verilog подмножества архитектуры MIPS с памятью инструкций, с регистрами общего назначения, но без памяти данных. Минимальный набор инструкции, достаточный, чтобы вычислять числа Фибоначчи и целочисленный квадратный корень итеративным способом. Однотактовая микроархитектура. Простейшая среда тестирования с закодированным вручную массивом инструкций.
2. Продолжение 9.1
10. Представление студенческих проектов по интеграции с датчиками
11. Экзамен

**6. План на будущее номер 2. Формат двухнедельного летнего лагеря**
1. Знакомство с макетной платой, сопротивлениями и логическими элементами.
1. Первая схема с батарейкой, светодиодом и резистором. Зачем включать резистор в цепь со светодиодом. Чтение маркировки резисторов.
2. Комбинационные логические элементы. Каждому ученику выдается персональная микросхема логики серии CMOS 4000, с техническим описанием от производителя, с задачей нарисовать таблицу истинности, продемонстрировать ее работу и словесно описать функцию. Микросхемы содержат логические элементы AND, OR, XOR, NOR, NAND с различным числом входов. Входы подключаются к питанию и земле переходниками, и входы и выходы подключаются к светодиодам.
3. Вариант упражнения 2 с кнопками и подтягивающими резисторами, с объяснением их функции.
2. Знакомство с двоичной арифметикой
1. Использование 4-битного сумматора на микросхеме CMOD 4008.
Построение 8-битного сумматора из двух 4-битных.
2. Построение схемы вычитания используя тождество -a == ~ a + 1
3. Знакомство с последовательностной логикой
1. Построение генератора тактового сигнала на основе микросхемы 555. Изучение влияния конденсаторов и сопротивлений на частоту и длительности высокого и низкого уровней.
2. Изучение поведения D-триггера с помощью микросхемы CMOS 4013 и тактового сигнала от 555 с частотой 1 Гц.
3. Использование сдвигового регистра для генерации “бегущих огоньков” на основе микросхемы CMOS 4015.
4. Строим счетчик (CMOS 4029) и подсоединяем к нему семисегментный индикатор через драйвер 4511.
4. Знакомство с ПЛИС (программируемой логической интегральной схеме) — матрицей реконфигурируемых логических элементов. Понятие о языке описания аппаратуры Verilog, процедурах синтеза, размещения, трассировки и конфигурации. Типы данных языка Verilog, выражения, присваивания. Always-блоки и основные операторы.
1. Синтез простейшего комбинационного модуля с конфигурацией ПЛИС на учебной плате.
2. Вывод первых букв своего имени и фамилии на семисегментный индикатор, переключаясь между ними с помощью кнопки.
3. Продолжение изучения языка Verilog. Иерархия модулей. Моделирование кода на Verilog без ПЛИС. Подмножества языка для реализации схемы и для ее тестирования / верификации. Моделирование временных задержек.
4. Упражнение: построение мультиплексоров из подмодулей.
5. Создание среды для проверки работы схемы, описанной на языке Verilog. Использование симулятора Icarus Verilog для моделирования, а также программы GTKWave для просмотра временных диаграмм.
5. Проектирование последовательностной логике на языке Verilog. Конструкции языка Verilog, которые порождают D-триггеры по время синтеза. Объяснение правил методологии проектирования на уровне регистровых передач: блокирующие и неблокирующие присваивания в различных always-блоках. Моделирование последовательностных схем на симуляторе Icarus Verilog. Анализ результатов программы статического анализа о максимальной частоте.
1. Реализация счетчика на ПЛИС.
2. Реализация сдвигового регистра на ПЛИС.
3. Использование последовательностной логики для генерации сигналов звуковой частоты и вывода их на динамик.
4. Модификация упражнения 2 или упражнения 3 на основе индивидуального задания.
6. Концепция конечного автомата. Диаграммы изменения состояний. Конечные автоматы для протоколов шин. Выбор самостоятельного проекта (со сдачей в конце школы) по интеграции датчиков и других периферийных устройств с платой c ПЛИС.
1. Конечный автомат “улыбающаяся улитка”.
2. Конечный автомат кодового замка на основе индивидуального задания.
3. Конечный автомат для работы с датчиком освещения.
7. Архитектура процессора: вид вычислительной установки со стороны программиста. Концепция фон-Нейманновской машины. Использование симулятора процессора на уровне инструкций [MARS MIPS](http://courses.missouristate.edu/KenVollmar/mars/).
1. Введение в ассемблер: команды, операнды, регистры, константы. Арифметические и логические операции. Кодирование инструкций. Простые программы для вычисления выражений.
2. Условные и безусловные переходы, метки, циклы. Программа вычисляющая числа Фибоначчи.
3. Концепция адресуемой памяти. Инструкции загрузки и сохранения в память. Конструкции ассемблера для выделения памяти. Программа, заполняющая память вычисленными данными. Индивидуальное упражнение на основе модификации примера.
8. Микроархитектура: строим процессор.
1. Реализация на Verilog подмножества архитектуры MIPS с памятью инструкций, с регистрами общего назначения, но без памяти данных. Минимальный набор инструкции, достаточный, чтобы вычислять числа Фибоначчи и целочисленный квадратный корень итеративным способом. Однотактовая микроархитектура. Простейшая среда тестирования с закодированным вручную массивом инструкций.
2. Больше о процессорах.
9. Работа над индивидуальным проектом
10. Сдача индивидуального проекта

**Приложение A. Что такое язык описания аппаратуры Verilogи как он связан с проектированием микросхем**
Из поста на Geektimes [Оруженосцы микроэлектроники. Видеорепортаж с конференции по проектированию электроники в Сан-Франциско.](https://geektimes.ru/post/255122/)
> В последние 25 лет дизайн микросхемы чаще всего пишется на языке описания аппаратуры Verilog (в Европе и у военных — VHDL), после чего специальная программа (logic synthesis) превращает дизайн в граф из проводов и логических примитивов, другая программа (static timing analysis) сообщает дизайнеру, вписывается ли он в бюджет скорости, а третья программа (place-and-route) раскладывает этот дизайн по площадке микросхемы.
>
>
>
> Когда дизайн проходит все этапы: кодирование на верилоге, отладка, верификация, синтез, static timing analysis, floorplanning, place-n-route, parasitics extraction и т.д. — получается файл под названием GDSII, который отправляют на фабрику, и фабрика выпекает микросхемы. Самые известные фабрики этого типа принадлежат компании Taiwan Semiconductor Manufacturing Company или TSMC.
>
>

**Приложение B. Что такое ПЛИС / FPGA и почему изучение ПЛИС нельзя заменить более глубоким изучением Ардуино или Расберри Пай**
Из поста на Хабре [Как начать разрабатывать железо, используя ПЛИС — пошаговая инструкция](http://habrahabr.ru/post/250511/):
> В самом простом варианте FPGA состоит из матрицы однородных ячеек, в функцию каждой из которых можно поменять с помощью мультиплексоров, подсоединенных к битам конфигурационной памяти. Одна ячейка может стать гейтом AND с четырьмя вводами и одним выводом, другая — однобитным регистром и т.д. Загружаем в конфигурационную память последовательность битов из памяти — и в FPGA образуется заданная электронная схема, которая может быть процессором, контроллером дисплея и т.д.
>
>
>
> ПЛИС-ы / FPGA — не процессоры, «программируя» ПЛИС (заполняя конфигурационную память ПЛИС-а) вы создаете электронную схему (хардвер), в то время как при программировании процессора (фиксированного хардвера) вы подсовываете ему цепочку написанных в память последовательных инструкций программы (софтвер).
>
>
>
> Внизу — схема простейшего блока FPGA, в который входит look-up table (LUT) и flip-flop. Правда в этой схеме не показаны мультиплексоры, которые меняют функцию ячейки, и соединения с конфигурационной памятью.
>
>
>
> 
>
>
>
> Диаграммы, иллюстрирующие структуру FPGA:
>
>
>
> 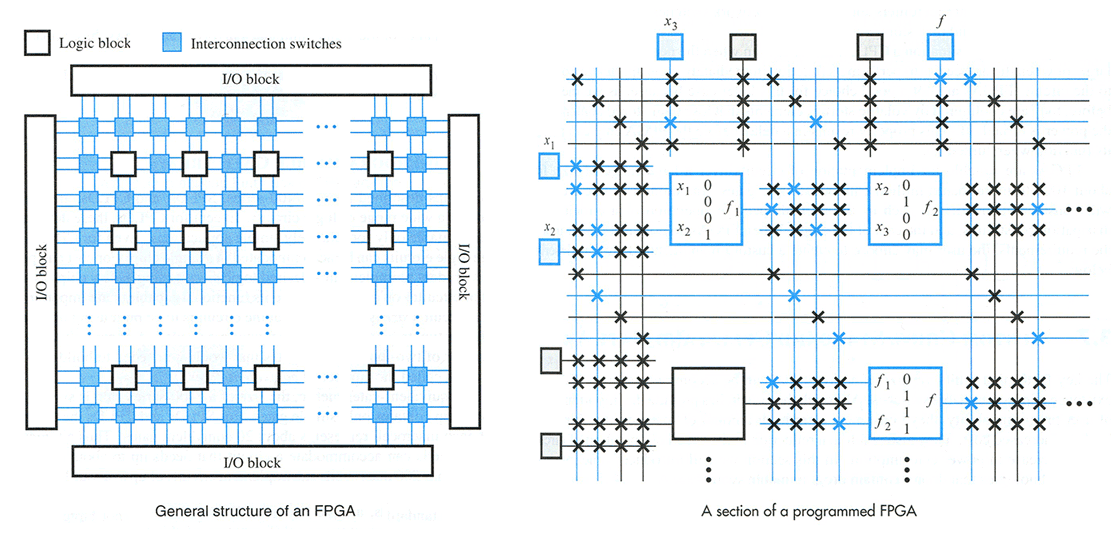
>
>
>
> И еще одна:
>
>
>
> 
>
>

**Приложение C. Отрывок из [заметки про конференции в Томске](http://www.silicon-russia.com/2017/05/17/tomsk-2017/) про то, как образование школьников в данной области привязано к образованию студентов**
> Системы на кристалле (system on chip, SoC), проектирование высокоинтегрированных микросхем с гетерогенными IP-блоками (CPU, GPU, DSP) — технологическая основа для многих культурных феноменов современного мира, включая смартфоны и быстрый интернет. Значение этой группы технологий еще больше увеличивается с лавинообразным внедрением в автомобильную промышленность чипов для ADAS (advanced driver-assistance systems) и последующим распостранением самоуправляемых автомобилей.
>
>
>
> К сожалению, появление ключевых технологий, на которых базируется проектирование систем на кристалле, в мире по времени пришлось аккурат на период коллапса СССР (конец 1980-х — начало 1990-х годов). Западные университеты довольно быстро внедрили в программу обучения языки описания аппаратуры (hardware description languages — HDL), методологию проектирования на уровне регистровых передач (register transfer level — RTL), маршрут проектирования RTL-to-GDSII, превращающий код на языках Verilog и VHDL в геометрическое представление дорожек и транзисторов на кремнии, а также лабораторные работы с использованием реконфигурируемых микросхем FPGA (field-programmable gate arrays). Все эти технологии были внедрены в России гораздо позже, и сейчас их преподавание сконцентрировано в небольшом количестве топ-университетов, таких как МИЭТ в Зеленограде и ИТМО в Санкт-Петербурге. Игнорируется возможность интеграции концепций HDL и RTL в программы физматшкол, где их можно было бы привязать к математической логике, теории конечных автоматов и электричеству, подобно тому, как обогатило советские школьные программы введение в середине 1980-х годов элементов программирования.
>
>
Помимо конференции в Томске и планируемого следующего эксперимента в июле а Новосибирске, который поддерживается Новосибирской Летней Школой Юных Программистов, есть еще ранний план организовывать такой эксперимент в Казахстане (этом в частности заинтересована [Венера Жаналина](https://www.facebook.com/venera.zhanalina) посещавшая киевский семинар).

**Приложение D. Примеры простейшего кода на Verilog и порождаемые им схемы**
```
module adder
(
input a,
input b,
input carry_in,
output reg sum,
output reg carry_out
);
reg p, q;
always @*
begin
p = a ^ b;
q = a & b;
sum = p ^ carry_in;
carry_out = q | (p & carry_in);
end
endmodule
```
```
module counter
(
input clock,
input resetn,
input load,
input [15:0] load_data,
output reg [15:0] count
);
always @ (posedge clock or negedge resetn)
begin
if (! resetn)
count <= 0;
else if (load)
count <= load_data;
else
count <= count + 1;
end
endmodule
```
Как оно работает:
Подробное объяснение — в тексте [«Введение в дизайн харвера микросхем для тех программистов, которые этим никогда не занимались»](http://panchul.com/2011/07/28/basics-of-hardware-design-for-software-engineers/).
Если вы преподаватель и хотите принять участие в разработке таких материалов (это все на общественных началах, без связи с той или иной компанией), сообщите мне в комментариях. Также интересна любая критика.
 | https://habr.com/ru/post/404387/ | null | ru | null |
# PostgreSQL 9.6: Параллелизация последовательного чтения
В течении долгого времени, одним из самых известных несовершенств PostgreSQL была возможность распараллеливания запросов. С выходом версии 9.6 это перестанет быть проблемой. Большая работа была проделана по этому вопросу, и уже начиная с коммита [80558c1](https://github.com/postgres/postgres/commit/80558c1f5aa109d08db0fbd76a6d370f900628a8), появляется параллелизация последовательного чтения, с которым мы и познакомимся по ходу этой статьи.

Во-первых, следует принять к сведению: разработка этого функционала велась непрерывно и некоторые параметры изменили свои имена между коммитами. Данная статья была написана после чекаута, совершенного 17 июня и некоторые особенности, описанные в этой статье, будут присутствовать только в версии 9.6 beta2.
Сравнивая с релизом 9.5, новые параметры были добавлены в конфигурационный файл. Вот они:
* **max\_parallel\_workers\_per\_gather**: количество воркеров, которые могут участвовать в последовательном сканировании таблицы;
* **min\_parallel\_relation\_size**: минимальный размер отношения, после которого планировщик начнет использовать дополнительных воркеров;
* **parallel\_setup\_cost**: параметр планировщика, который оценивает стоимость создания нового воркера;
* **parallel\_tuple\_cost**: параметр планировщика, который оценивает стоимость перевода кортежа от одного воркера к другому;
* **force\_parallel\_mode**: параметр полезный для тестирования, сильного параллелизма, а также запросов, в которых планировщик будет себя вести по-другому.
Давайте посмотрим, каким образом дополнительные воркеры могут быть использованы для ускорения выполнения наших запросов. Создадим тестовую таблицу с полем типа INT и ста миллионами записей:
```
postgres=# CREATE TABLE test (i int);
CREATE TABLE
postgres=# INSERT INTO test SELECT generate_series(1,100000000);
INSERT 0 100000000
postgres=# ANALYSE test;
ANALYZE
```
PostgreSQL имеет параметр ***max\_parallel\_workers\_per\_gather*** равным 2 по умолчанию, в этом случае будут активированы два воркера во время последовательного сканирования.
Обычное последовательное сканирование не несет в себе ничего нового:
```
postgres=# EXPLAIN ANALYSE SELECT * FROM test;
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------
Seq Scan on test (cost=0.00..1442478.32 rows=100000032 width=4) (actual time=0.081..21051.918 rows=100000000 loops=1)
Planning time: 0.077 ms
Execution time: 28055.993 ms
(3 rows)
```
По факту, присутствие условия ***WHERE*** необходимо для параллелизации:
```
postgres=# EXPLAIN ANALYZE SELECT * FROM test WHERE i=1;
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------
Gather (cost=1000.00..964311.60 rows=1 width=4) (actual time=3.381..9799.942 rows=1 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Parallel Seq Scan on test (cost=0.00..963311.50 rows=0 width=4) (actual time=6525.595..9791.066 rows=0 loops=3)
Filter: (i = 1)
Rows Removed by Filter: 33333333
Planning time: 0.130 ms
Execution time: 9804.484 ms
(8 rows)
```
Мы можем вернуться к прошлому действию и посмотреть на разницу выполнения, при ***max\_parallel\_workers\_per\_gather*** установленным в 0:
```
postgres=# SET max_parallel_workers_per_gather TO 0;
SET
postgres=# EXPLAIN ANALYZE SELECT * FROM test WHERE i=1;
QUERY PLAN
--------------------------------------------------------------------------------------------------------
Seq Scan on test (cost=0.00..1692478.40 rows=1 width=4) (actual time=0.123..25003.221 rows=1 loops=1)
Filter: (i = 1)
Rows Removed by Filter: 99999999
Planning time: 0.105 ms
Execution time: 25003.263 ms
(5 rows)
```
В 2.5 раза дольше.
Планировщик далеко не всегда считает параллелизацию последовательного чтения лучшим вариантом. Если запрос недостаточно избирателен и есть много кортежей, которые надо передавать от воркера к воркеру, он может предпочесть «классическое» последовательное сканирование:
```
postgres=# SET max_parallel_workers_per_gather TO 2;
SET
postgres=# EXPLAIN ANALYZE SELECT * FROM test WHERE i<90000000;
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------
Seq Scan on test (cost=0.00..1692478.40 rows=90116088 width=4) (actual time=0.073..31410.276 rows=89999999 loops=1)
Filter: (i < 90000000)
Rows Removed by Filter: 10000001
Planning time: 0.133 ms
Execution time: 37939.401 ms
(5 rows)
```
На самом деле, если мы попробуем заставить планировщик использовать параллелизацию последовательного чтения, мы получим худший результат:
```
postgres=# SET parallel_tuple_cost TO 0;
SET
postgres=# EXPLAIN ANALYZE SELECT * FROM test WHERE i<90000000;
QUERY PLAN
-------------------------------------------------------------------------------------------------------------------------------------
Gather (cost=1000.00..964311.50 rows=90116088 width=4) (actual time=0.454..75546.078 rows=89999999 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Parallel Seq Scan on test (cost=0.00..1338795.20 rows=37548370 width=4) (actual time=0.088..20294.670 rows=30000000 loops=3)
Filter: (i < 90000000)
Rows Removed by Filter: 3333334
Planning time: 0.128 ms
Execution time: 83423.577 ms
(8 rows)
```
Количество воркеров может быть увеличено до ***max\_worker\_processes*** (по умолчанию: 8). Восстановим значение ***parallel\_tuple\_cost*** и посмотрим что будет, если увеличить ***max\_parallel\_workers\_per\_gather*** до 8:
```
postgres=# SET parallel_tuple_cost TO DEFAULT ;
SET
postgres=# SET max_parallel_workers_per_gather TO 8;
SET
postgres=# EXPLAIN ANALYZE SELECT * FROM test WHERE i=1;
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------
Gather (cost=1000.00..651811.50 rows=1 width=4) (actual time=3.684..8248.307 rows=1 loops=1)
Workers Planned: 6
Workers Launched: 6
-> Parallel Seq Scan on test (cost=0.00..650811.40 rows=0 width=4) (actual time=7053.761..8231.174 rows=0 loops=7)
Filter: (i = 1)
Rows Removed by Filter: 14285714
Planning time: 0.124 ms
Execution time: 8250.461 ms
(8 rows)
```
Даже учитывая, что PostgreSQL может использовать вплоть до 8 воркеров, он воспользовался только шестью. Это связано с тем, что Postgres кроме того оптимизирует количество воркеров зависимо от размера таблицы и параметра ***min\_parallel\_relation\_size***. Количество воркеров доступных постгресу основано на геометрической прогрессии со знаменателем 3 и ***min\_parallel\_relation\_size*** в качестве масштабирующего фактора. Вот пример. Учитывая что 8Мб является параметром по умолчанию:
| | |
| --- | --- |
| **Size** | **Worker** |
| <8Мб | 0 |
| <24Мб | 1 |
| <72Мб | 2 |
| <216Мб | 3 |
| <648Мб | 4 |
| <1944Мб | 5 |
| <5822Мб | 6 |
| … | … |
Размер нашей таблицы 3548Мб, соответственно 6 является максимальным количеством доступных воркеров.
```
postgres=# \dt+ test
List of relations
Schema | Name | Type | Owner | Size | Description
--------+------+-------+----------+---------+-------------
public | test | table | postgres | 3458 MB |
(1 row)
```
Наконец, я дам краткую демонстрацию улучшений, достигнутых с помощью этого патча. Запуская наш запрос с растущим числом воркеров, мы получим следующие результаты:
| | |
| --- | --- |
| **Size** | **Worker** |
| <0 | 24767.848 мс |
| <1 | 14855.961 мс |
| <2 | 10415.661 мс |
| <3 | 8041.187 мс |
| <4 | 8090.855 мс |
| <5 | 8082.937 мс |
| <6 | 8061.939 мс |
Можно видеть, что время выполнения значительно улучшается, пока не достигнет одной трети от исходного значения. Также легко объяснить тот факт, что мы не видим улучшений при использовании 6 воркеров вместо 3: машина, на которой выполнялись тесты имеет 4 процессора, так что результаты стабильны после добавления 3 дополнительных воркеров к оригинальному процессу.
Наконец, PostgreSQL 9.6 вышел на новый этап параллелизации запросов, в котором параллелизация последовательного чтения это только первый отличный результат. Кроме того, в версии 9.6 было распараллелено агрегирование, но это уже тема для другой статьи, которая выйдет в ближайшие недели! | https://habr.com/ru/post/305662/ | null | ru | null |
# Знакомство с гео-библиотекой S2 от Google и примеры использования
Привет, Хабр!
Меня зовут Марко, я работаю в [Badoo](https://badoo.com/) в команде «Платформа». Не так давно на [GopherCon Russia 2018](https://www.gophercon-russia.ru/) я рассказывал, как работать с координатами. Для тех, кто не любит смотреть видео (и всех интересующихся, конечно), публикую текстовый вариант своего доклада.
Введение
--------
Сейчас у большинства людей в мире есть смартфон с постоянным доступом в Интернет. Если говорить в цифрах, то в 2018 году смартфон [будет](https://www.statista.com/statistics/274774/forecast-of-mobile-phone-users-worldwide/) у почти 5 млрд людей, и 60% из них [пользуются](https://www.statista.com/statistics/284202/mobile-phone-internet-user-penetration-worldwide/) мобильным Интернетом.
Это огромные числа. Компаниям получать координаты пользователей стало легко и просто. Эти лёгкость и доступность породили (и продолжают порождать) огромное количество сервисов, основанных на координатах.
Всем нам известны компании типа [Uber](https://www.uber.com/), игры, покорившие мир, такие как [Ingress](https://www.ingress.com/) и [Pokemon Go](https://www.pokemongo.com/). Да что уж там, в любом банковском приложении есть возможность увидеть банкоматы или скидки поблизости.
Мы в Badoo также очень активно используем координаты, чтобы предоставлять своим пользователям лучший, актуальный и интересный для них сервис. Но о каком именно использовании идёт речь? Давайте посмотрим на примеры сервисов, которые у нас есть.
Geo-сервисы в Badoo
-------------------
### Первый пример: Meetmaker и Geousers
Badoo — это в первую очередь дейтинг. Место, где люди знакомятся друг с другом. Одним из важных критериев при поиске людей является расстояние. Ведь в большинстве случаев девушке из Москвы хочется познакомиться с мальчиком, который находится в паре километров от неё или по крайней мере тоже живёт в Москве, а не в далёком Владивостоке.
Сервисы, которые подбирают вам людей для «игры» «Да/нет» или показывают пользователей вокруг, занимаются поиском людей с подходящими вам критериями в каком-то радиусе от вас.
### Второй пример: Geoborder
Для того чтобы ответить на вопросы, в каком городе находится пользователь, в какой стране или, ещё более точно, к примеру, в каком аэропорту или в каком университете, мы используем сервис Geoborder, который занимается так называемым [geofencing-ом](https://en.wikipedia.org/wiki/Geo-fence).
Самым простым способом ответить на эти вопросы было бы считать расстояние от пользователя до центра города или центра университета, но этот подход очень неточен и зависит от большого количества граничных условий.
Поэтому у нас расчерчены очень точные границы стран, городов, важных объектов (например, университетов и аэропортов, о которых я говорил). Эти границы задаются полигонами. Имея набор таких границ, мы можем понять, находится ли пользователь внутри полигона, или найти ближайший к нему полигон. Соответственно, мы можем сказать, в каком он городе, или найти ближайший к нему город.
### Третий пример: Bumpd
У нас есть очень популярная фича под названием Bumped Into, которая в фоновом режиме постоянно ищет пересечения пользователей во времени и в пространстве и показывает вам, что вот с этим мальчиком или с этой девушкой вы регулярно бываете в одном месте в одно и то же время или регулярно ходите одной дорогой. Эта фича очень нравится пользователям, поскольку является ещё одним поводом познакомиться и темой, с которой можно начать разговор.
### Четвёртый пример: Geocache — кеширование гео-информации, которую дорого «доставать»
Ну и последний пример, о котором я упомяну, связан с кешированием гео-информации. Представьте себе, что вы используете данные из, например, Booking.com, который предоставляет вам информацию о гостиницах вокруг, но лезть в Booking.com каждый раз — слишком долго. Ваша труба в Интернет, возможно, довольно узкая, как яма у этого гофера. Возможно, сервис, в который вы идёте за данными, берёт деньги за каждый запрос, и вам хочется немного сэкономить.

В этом случае неплохо бы иметь кеширующий слой, который заметно уменьшит количество запросов в медленный или дорогой сервис, а наружу будет предоставлять очень похожий API. Сервис, который будет понимать, что обо всех или о большинстве гостиниц в данной области он уже знает, эти данные относительно свежи, и, соответственно, можно не лезть за ними во внешний сервис. Такого рода задачи у нас решаются сервисом под названием Geocache.
Особенности geo-сервисов
------------------------
Мы с вами уже поняли, что координат много, координаты — это важно, и на основе них можно сделать очень много интересных сервисов. Ну и что дальше? В чём, собственно, дело? Чем координаты отличаются от любой другой информации, полученной от пользователя?
А особенностей, я бы сказал, две.
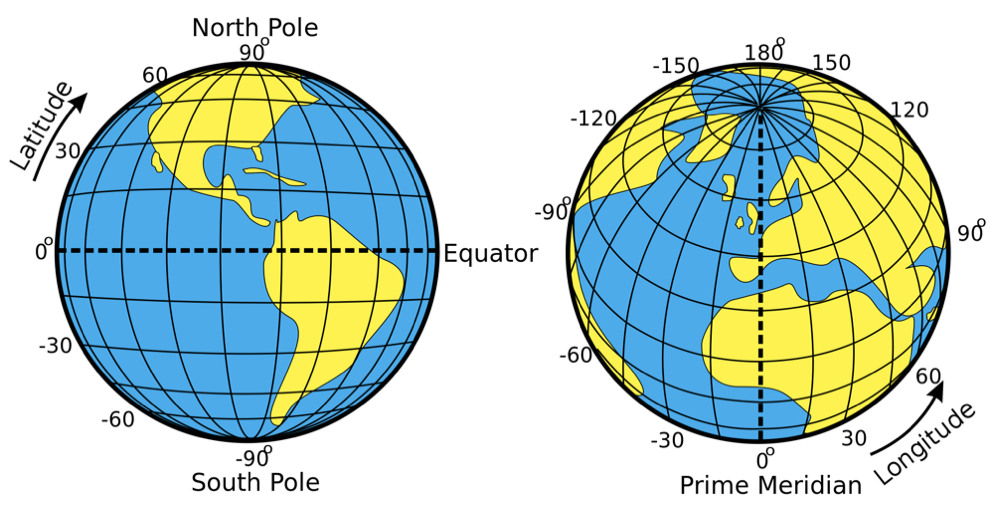
Во-первых, гео-данные трёхмерны, а точнее двумерны, так как в общем случае нас не интересует высота. Они состоят из широты и долготы, и поиск чаще всего идёт одновременно по обеим. Представьте себе поиск в какой-либо области. Стандартные индексы в распространённых СУБД неоптимальны для такого использования.
Во-вторых, многие задачи требуют более сложных типов данных типа полигонов, о которых мы говорили выше на примере сервиса Geoborder в Badoo. Полигоны, конечно, состоят из координат вершин, но требуют дополнительной обработки, и поисковые запросы на таких типах данных тоже сложнее. Мы уже видели запросы «Найти ближайший полигон к точке» или «Найти полигон, который включает данную точку».
Зачем писать свой сервис
------------------------
Для того чтобы соответствовать этим особенностям, многие СУБД включают в поставку [специальные индексы,](https://en.wikipedia.org/wiki/R-tree) заточенные под многомерные данные, и дополнительные функции, которые позволяют работать с такими объектами, как полигоны или ломаные.
Наверное, самым ярким примером является [PostGIS](https://postgis.net/) — расширение к популярной СУБД [PostgreSQL](https://www.postgresql.org/), обладающее широчайшими возможностями для работы с координатами и географией.
Но использовать готовую СУБД — не единственное и не всегда лучшее решение.

Если вы не хотите делить бизнес-логику вашего сервиса между ним и СУБД, если вы хотите чего-то, что недоступно в СУБД, если вы хотите полноценно управлять вашим сервисом и не быть ограниченным возможностями масштабирования какой-либо СУБД, например, то вы можете захотеть встроить возможности поиска и работы с geo-данными в свой сервис.
Такой подход, бесспорно, гибче, но может быть и значительно сложнее, потому что СУБД — это решение формата «всё в одном», и многие инфраструктурные вещи типа репликации уже сделаны за вас. Репликации и, собственно, алгоритмов и индексов для работы с координатами.
Но не всё так страшно. Я хотел бы познакомить вас с библиотекой, которая реализует большую часть из того, что вам понадобится. Которая является своеобразным кубиком, легко встраиваемым везде, где вам нужно работать с геометрией на сфере или искать по координатам. С библиотекой под названием [S2](https://s2geometry.io/).
S2
--
[S2](https://s2geometry.io/) — библиотека для работы с геометрией (в том числе на сфере), предоставляющая очень удобные возможности для создания geo-индексов.
До недавнего времени S2 была практически неизвестна и обладала совсем скудной документацией, но не так давно Google решила "[перевыпустить](https://opensource.googleblog.com/2017/12/announcing-s2-library-geometry-on-sphere.html)" её в open-source, дополнив выкладку обещанием поддерживать и развивать продукт.
Главная версия библиотеки написана на C++ и имеет несколько официальных портов или версий на других языках, включая Go-версию. Go-версия на сегодняшний день не на 100% реализует всё то, что есть в C++-версии, но того, что есть, достаточно для реализации большинства вещей.
Помимо Google, библиотеку активно используют в таких компаниях, как [Foursquare](https://foursquare.com/), [Uber](https://www.uber.com/), [Yelp](https://www.yelp.com/), ну и [Badoo](https://badoo.com/), конечно. А среди продуктов, использующих библиотеку внутри, можно выделить всем вам известную MongoDB.
Но пока я не сказал ничего дельного о том, почему именно S2 удобна и почему позволяет легко писать сервисы c geo-поиском. Давайте я исправлюсь и немного погружусь во внутренности, прежде чем мы рассмотрим два примера.
### Проекция
Обычно география подразумевает использование одной из распространённых проекций земного шара на плоскость. Например, всем нам известной [проекции Меркатора](https://en.wikipedia.org/wiki/Mercator_projection). Недостаток такого подхода заключается в том, что любая проекция так или иначе имеет искажения. Наш с вами земной шар не очень-то похож на плоскость.
Вспомните знаменитую картинку с сравнением России и Африки. На картах Россия огромна, а на самом деле площадь Африки аж в два раза больше площади России! Это как раз пример искажения проекции Меркатора.

S2 решает эту проблему использованием исключительно сферической проекции и сферической геометрии. Конечно, Земля — тоже не совсем сфера, но искажениями в случае сферы можно пренебречь для большинства задач.
Работать мы будем с единичной, или [unit- сферой](https://en.wikipedia.org/wiki/Unit_sphere), то есть со сферой радиусом 1 и будем использовать такие понятия, как [центральный угол](https://en.wikipedia.org/wiki/Central_angle), сферический прямоугольник и [сферический сегмент](https://en.wikipedia.org/wiki/Spherical_cap).
Название S2 как раз происходит из математической нотации, обозначающей unit-сферу.
Но пугаться не стоит, так как практически всю математику берёт на себя библиотека.
### Иерархические клетки (cells)
Второй (и самой важной) особенностью библиотеки является понятие иерархического разбиения земного шара на клетки (по-английски — cells).
Разбиение иерархично, то есть присутствует такое понятие, как уровень (или level) клетки. И на одном уровне клетки имеют примерно одинаковый размер.
Клетками можно задать любую точку на Земле. Если воспользоваться клеткой максимального, 30-го, уровня, которая имеет размер меньше сантиметра по ширине, то точность, как вы понимаете, будет очень высокой. Клетками более низкого уровня можно задать ту же самую точку, но точность уже будет меньше. Например, 5 м на 5 м.
Клетками можно задавать не только точки, но и более сложные объекты типа полигонов и каких-то областей (на картинке вы, например, видите Гавайи). В этом случае такие фигуры будут заданы наборами клеток (возможно, разных уровней).
Такое разбиение очень компактно: каждая клетка может быть закодирована одним 64-битным числом.
### Кривая Гильберта
Я упомянул о том, что клетка задаётся одним 64-битным числом. Вот оно! Получается, что координата или точка на Земле, которая по умолчанию задаётся двумя координатами, с которыми нам неудобно работать стандартными методами, может быть задана одним числом. Но как этого добиться? Давайте посмотрим…
Как происходит то самое иерархическое разбиение сферы?
Мы сначала окружаем сферу кубом и проецируем её на все шесть его граней, чуть-чуть подправив проекцию на ходу, чтобы убрать искажения. Это level 0. Затем мы каждую из шести граней куба можем разбить на четыре равные части — это level 1. И каждую из получившихся четырёх частей можно разбить ещё на четыре равные части — level 2. И так далее до level 30.

Но на данном этапе у нас всё ещё присутствует двумерность. И здесь на подмогу нам приходит математическая идея из далёкого прошлого. В конце XIX века Дейвид Гильберт придумал способ заполнения любого пространства одномерной линией, которая поворачивает, сворачивается и таким образом заполняет пространство. [Гильбертовая кривая](https://en.wikipedia.org/wiki/Hilbert_curve) рекурсивна, а это значит, что точность или плотность заполнения можно выбирать. Любой мелкий кусок мы можем при необходимости заполнить плотнее.
Мы можем заполнить такой кривой наше двумерное пространство. И если теперь взять эту кривую и растянуть её в прямую (как будто мы вытягиваем ниточку), то мы получим одномерный объект, описывающий многомерный объект, — одномерный объект или координату на этой линии, с которой удобно и просто работать.
Примерно так выглядит заполнение Гильбертовой кривой Земли на одном из срединных уровней:

Ещё одной особенностью Гильбертовой кривой является тот факт, что точки, находящиеся рядом на кривой, находятся рядом и в пространстве. Обратное не всегда, но в основном тоже верно. И вот эту особенность мы тоже будем активно применять.
Кодирование в 64-битную переменную
----------------------------------
Но почему мы можем любую клетку закодировать одним 64-битным числом, которое, кстати, называется CellID? Давайте посмотрим.
У нас шесть граней куба. Шесть разных значений можно закодировать тремя битами. Вспоминаем [логарифмы](https://en.wikipedia.org/wiki/Binary_logarithm).
Затем мы каждую из шести граней разбиваем на четыре равные части 30 раз. Чтобы задать одну из четырёх частей, на которые мы разбиваем клетку на каждом из уровней, нам хватит двух бит.
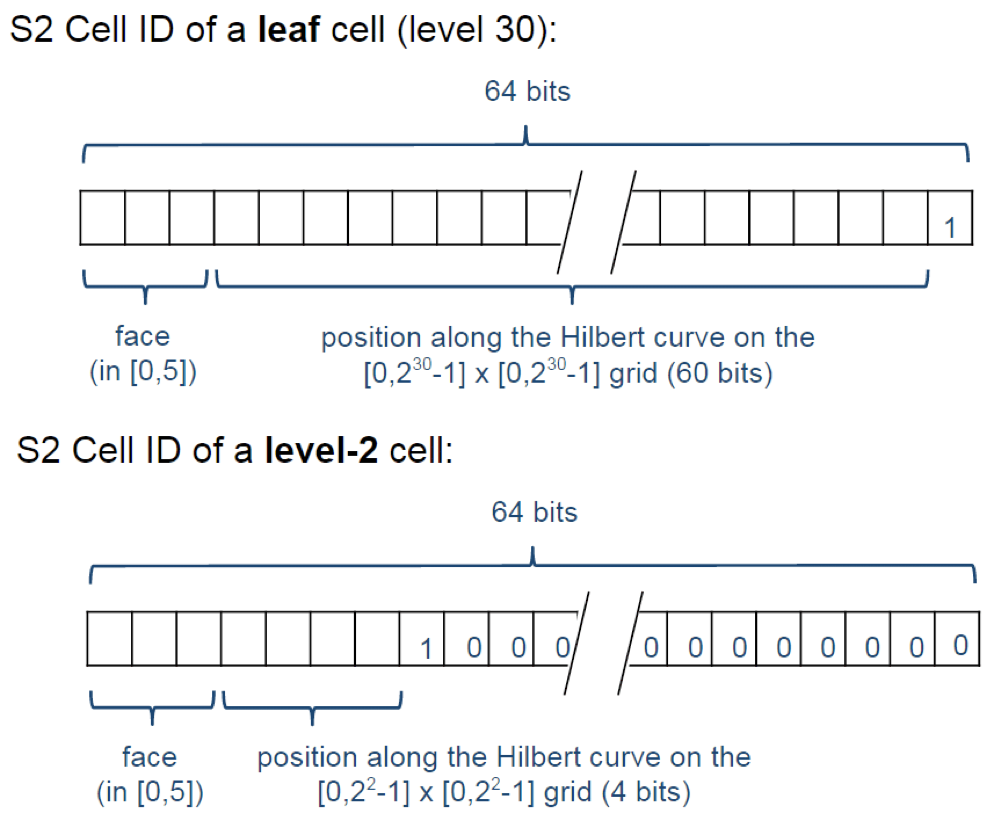
Итого 3 + 2\*30 = 63. А один лишний бит мы выставим в конце, чтобы знать и быстро понимать, какого уровня клетка задаётся данным CellID.

Что нам дают все эти разбиения и кодирование Гильбертовой кривой в одно число?
1. Мы можем любую точку на земном шаре закодировать одним CellID. В зависимости от уровня мы получаем разную точность.
2. Любой двумерный объект на земном шаре мы можем закодировать одним или несколькими CellID. Аналогично мы можем играть с точностью, варьируя уровни.
3. Свойство Гильбертовой кривой, заключающееся в том, что точки, которые находятся рядом на ней, находятся рядом и в пространстве, и тот факт что CellID у нас — просто число, позволяют нам для поиска пользоваться обычным деревом типа B-дерева. В зависимости от того, что мы ищем (точку или область), мы будем пользоваться или get, или range scan, то есть поиском «от» и «до».
4. Разбиение земного шара на уровни даёт нам простой фреймворк для шардинга нашей системы. К примеру, на нулевом уровне мы можем разделить наш сервис на шесть инстансов, на первом уровне — на 24 и т. д.
Теперь, чтобы закрепить эти теоретические знания, давайте рассмотрим два примера. Мы напишем два простых сервиса, и первый из них — просто поиск «вокруг».
Примеры
-------
### Напишем сервис поиска людей вокруг
Мы сделаем поисковый индекс. Нам понадобится функция для создания индекса, функция для добавления человека в индекс и, собственно, функция поиска. Ну и тест.
```
type Index struct {}
func NewIndex(storageLevel int) *Index {}
func (i *Index) AddUser(userID uint32, lon, lat float64) error {}
func (i *Index) Search(lon, lat float64, radius uint32) ([]uint32, error) {}
func TestSearch(t *testing.T) {}
```
Пользователь задаётся своим ID и координатами, а поиск — координатами центра поиска и радиусом поиска.
В индексе нам понадобится [B-tree,](https://en.wikipedia.org/wiki/B-tree) в узлах которого мы будем хранить ячейку уровня storageLevel и список пользователей в данной ячейке. Уровень ячейки storageLevel — это выбор между точностью первоначального поиска и производительностью. В этом примере мы воспользуемся ячейкой размера примерно 1 км на 1 км. Функция Less необходима для работы B-tree, для того, чтобы дерево могло понять, какое из наших значений меньше, а какое — больше.
```
type Index struct {
storageLevel int
bt *btree.BTree
}
type userList struct {
cellID s2.CellID
list []uint32
}
func (ul userList) Less(than btree.Item) bool {
return uint64(ul.cellID) < uint64(than.(userList).cellID)
}
```
Теперь давайте посмотрим на функцию добавления пользователя.
```
func (i *Index) AddUser(userID uint32, lon, lat float64) error {
latlng := s2.LatLngFromDegrees(lat, lon)
cellID := s2.CellIDFromLatLng(latlng)
cellIDOnStorageLevel := cellID.Parent(i.storageLevel)
// ...
}
```

Здесь мы впервые видим S2 в деле. Мы преобразовываем наши координаты, заданные в градусах, в радианы, а затем — в CellID, который соответствует этим координатам на максимальном 30-м уровне (то есть с минимальным размером клетки), и преобразуем полученный CellID в CellID того уровня, на котором мы будем хранить людей. Если заглянуть «внутрь» этой функции, мы увидим просто обнуление нескольких бит. Вспомните, как у нас кодируется CellID.
```
func (i *Index) AddUser(userID uint32, lon, lat float64) error {
// ...
ul := userList{cellID: cellIDOnStorageLevel, list: nil}
item := i.bt.Get(ul)
if item != nil {
ul = item.(userList)
}
ul.list = append(ul.list, userID)
i.bt.ReplaceOrInsert(ul)
return nil
}
```
Затем нам всего лишь нужно добавить данного пользователя в соответствующую клетку в B-tree. Или первым, или в конец списка, если там кто-то уже есть. Наш простой индекс готов.
Переходим к функции поиска. Первые преобразования похожи, но вместо клетки мы по координатам получаем объект «точка». Это центр нашего поиска.
```
func (i *Index) Search(lon, lat float64, radius uint32) ([]uint32, error) {
latlng := s2.LatLngFromDegrees(lat, lon)
centerPoint := s2.PointFromLatLng(latlng)
centerAngle := float64(radius) / EarthRadiusM
cap := s2.CapFromCenterAngle(centerPoint, s1.Angle(centerAngle))
// ...
return result, nil
}
```
Далее по радиусу, заданному в метрах, мы получаем центральный угол. Это угол, исходящий из центра сферы. Преобразование в данном случае простое: достаточно разделить наш радиус в метрах на радиус Земли в метрах.
По точке центра поиска и по углу, которые мы только что получили, мы можем вычислить сферический сегмент (или «шапочку»). По сути, это окружность на сфере, но только трёхмерная.
Отлично, у нас есть «шапочка», внутри которой нам нужно искать. Но как? Для этого мы попросим S2 дать нам список клеток уровня storageLevel, которые полностью покрывают наш круг или нашу «шапочку».
```
func (i *Index) Search(lon, lat float64, radius uint32) ([]uint32, error) {
// ...
rc := s2.RegionCoverer{MaxLevel: i.storageLevel, MinLevel: i.storageLevel}
cu := rc.Covering(cap)
// ...
return result, nil
}
```
Выглядит это примерно так:
Осталось лишь пройтись по полученным клеткам и get-ами в B-tree получить всех пользователей, что находятся внутри.
```
func (i *Index) Search(lon, lat float64, radius uint32) ([]uint32, error) {
// ...
var result []uint32
for _, cellID := range cu {
item := i.bt.Get(userList{cellID: cellID})
if item != nil {
result = append(result, item.(userList).list...)
}
}
return result, nil
}
```
Для теста мы создадим индекс и несколько пользователей. Трёх поближе, двух — подальше. И проверим, чтобы в случае маленького радиуса возвращались только три пользователя, а в случае большего радиуса — все. Ура! Наша простенькая программка работает.
```
func prepare() *Index {
i := NewIndex(13 /* ~ 1km */)
i.AddUser(1, 14.1313, 14.1313)
i.AddUser(2, 14.1314, 14.1314)
i.AddUser(3, 14.1311, 14.1311)
i.AddUser(10, 14.2313, 14.2313)
i.AddUser(11, 14.0313, 14.0313)
return i
}
func TestSearch(t *testing.T) {
indx := prepare()
found, _ := indx.Search(14.1313, 14.1313, 2000)
if len(found) != 3 {
t.Fatal("error while searching with radius 2000")
}
found, _ = indx.Search(14.1313, 14.1313, 20000)
if len(found) != 5 {
t.Fatal("error while searching with radius 20000")
}
}
$ go test -run 'TestSearch$'
PASS
ok github.com/mkevac/gophercon-russia-2018/geosearch 0.008s
```
Но в ней есть один довольно очевидный недостаток. В случае большого радиуса поиска и маленькой плотности заполнения людьми, нужно будет get-ами проверять очень и очень много клеток. Это не так быстро.
Вспомните, что мы просили S2 покрыть нашу «шапочку» именно клетками уровня storageLevel. Но поскольку эти клетки довольно маленькие, то их получается много.
Мы можем попросить S2 покрыть «шапочку» клетками разного уровня; тогда получится что-то вроде этого:
```
rc := s2.RegionCoverer{MaxLevel: i.storageLevel}
cu := rc.Covering(cap)
```
Как видите, S2 использует внутри круга клетки большего размера, а по краям — меньшего. В сумме же клеток становится меньше.
Но для того чтобы в нашем B-дереве найти пользователей из бОльших клеток, мы уже не можем пользоваться Get. Нам нужно спросить у S2 для каждой большой клетки номер первой внутренней клетки нашего уровня storageLevel и номер последней и искать уже с помощью range scan, то есть запросом «от» и «до».
```
func (i *Index) SearchFaster(lon, lat float64, radius uint32) ([]uint32, error) {
// ...
for _, cellID := range cu {
if cellID.Level() < i.storageLevel
begin := cellID.ChildBeginAtLevel(i.storageLevel)
end := cellID.ChildEndAtLevel(i.storageLevel)
i.bt.AscendRange(userList{cellID: begin}, userList{cellID: end.Next()},func(item btree.Item) bool {
result = append(result, item.(userList).list...)
return true
})
} else {
// ...
}
}
return result, nil
}
```
Изменение совсем незначительное, но давайте посмотрим на него в процессе работы. Напишем простенькие бенчмарки, которые в цикле занимаются поиском, и запустим их.
```
var res []uint32
func BenchmarkSearch(b *testing.B) {
indx := prepare()
for i := 0; i < b.N; i++ {
res, _ = indx.Search(14.1313, 14.1313, 50000)
}
}
func BenchmarkSearchFaster(b *testing.B) {
indx := prepare()
for i := 0; i < b.N; i++ {
res, _ = indx.SearchFaster(14.1313, 14.1313, 50000)
}
}
```
Наше маленькое изменение привело к ускорению на три порядка. Неплохо!
```
$ go test -bench=.
goos: darwin
goarch: amd64
pkg: github.com/mkevac/gophercon-russia-2018/geosearch
BenchmarkSearch-8 500 3097564 ns/op
BenchmarkSearchFaster-8 200000 7198 ns/op
PASS
ok github.com/mkevac/gophercon-russia-2018/geosearch 3.393s
```
### Давайте напишем geofencing-сервис
Мы с вами рассмотрели суперпростую реализацию поиска по радиусу. Давайте теперь быстренько пройдёмся по такой же простой реализации geofencing-а, то есть определения, в каком полигоне мы находимся или какой полигон ближайший к нам.
Здесь в нашем индексе нам аналогично понадобится B-tree, но в дополнение к нему у нас будет глобальный map всех добавленных полигонов.
```
type Index struct {
storageLevel int
bt *btree.BTree
polygons map[uint32]*s2.Polygon
}
func NewIndex(storageLevel int) *Index {
return &Index{
storageLevel: storageLevel,
bt: btree.New(35),
polygons: make(map[uint32]*s2.Polygon),
}
}
```
В узлах B-дерева, как и раньше, мы будем хранить список, но только теперь уже полигонов, которые находятся в ячейке уровня storageLevel.
```
type IndexItem struct {
cellID s2.CellID
polygonsInCell []uint32
}
func (ii IndexItem) Less(than btree.Item) bool {
return uint64(ii.cellID) < uint64(than.(IndexItem).cellID)
}
```
В данном примере у нас будут функции добавления полигона в индекс, поиска полигона, в котором мы находимся, и поиска ближайшего полигона.
```
func (i *Index) AddPolygon(polygonID uint32, vertices []s2.LatLng) error {}
func (i *Index) Search(lon, lat float64) ([]uint32, error) {}
func (i *Index) SearchNearest(lon, lat float64) ([]uint32, error) {}
```
Начнём с добавления полигона. Полигон задаётся списком вершин, причём S2 ожидает, что порядок вершин будет против часовой стрелки. Но в случае ошибки у нас будет функция «нормализации», которая как бы выворачивает его наизнанку.
```
func (i *Index) AddPolygon(polygonID uint32, vertices []s2.LatLng) error {
points := func() (res []s2.Point) {
for _, vertex := range vertices {
point := s2.PointFromLatLng(vertex)
res = append(res, point)
}
return
}()
loop := s2.LoopFromPoints(points)
loop.Normalize()
polygon := s2.PolygonFromLoops([]*s2.Loop{loop})
// ...
return nil
}
```
Список точек-вершин мы преобразуем в Loop, а затем и в полигон. Разница между ними в том, что полигон может состоять из нескольких loop-ов, иметь дырку, например, как пончик.
Как и в прошлом примере, мы попросим S2 покрыть наш полигон клетками и каждую из возвращённых клеток добавим в B-tree. Ну и в глобальный map.
```
func (i *Index) AddPolygon(polygonID uint32, vertices []s2.LatLng) error {
// ...
coverer := s2.RegionCoverer{MinLevel: i.storageLevel, MaxLevel: i.storageLevel}
cells := coverer.Covering(polygon)
for _, cell := range cells {
// ...
ii.polygonsInCell = append(ii.polygonsInCell, polygonID)
i.bt.ReplaceOrInsert(ii)
}
i.polygons[polygonID] = polygon
return nil
}
```
Функция поиска полигона, в котором мы находимся, в данном примере тривиальна. Как и раньше, преобразуем координату поиска в CellID на уровне storageLevel и находим или не находим эту клетку в B-дереве.
```
func (i *Index) Search(lon, lat float64) ([]uint32, error) {
latlng := s2.LatLngFromDegrees(lat, lon)
cellID := s2.CellIDFromLatLng(latlng)
cellIDOnStorageLevel := cellID.Parent(i.storageLevel)
item := i.bt.Get(IndexItem{cellID: cellIDOnStorageLevel})
if item != nil {
return item.(IndexItem).polygonsInCell, nil
}
return []uint32{}, nil
}
```
Поиск ближайшего полигона чуть сложнее. Сначала мы попробуем определить, вдруг мы уже находимся в каком-то полигоне. Если нет, то мы будем искать по увеличивающемуся радиусу (ниже я покажу, как это выглядит). Ну и когда мы найдём ближайшие полигоны, мы отфильтруем их и найдём самый ближайший, вычислив расстояние до каждого из найденных и взяв тот, расстояние до которого наименьшее.
```
func (i *Index) SearchNearest(lon, lat float64) ([]uint32, error) {
// ...
alreadyVisited := []s2.CellID{cellID}
var found []IndexItem
searched := []s2.CellID{cellID}
for {
found, searched = i.searchNextLevel(searched, &alreadyVisited)
if len(searched) == 0 {
break
}
if len(found) > 0 {
return i.filter(lon, lat, found), nil
}
}
return []uint32{}, nil
}
```
Что значит «по увеличивающемуся радиусу»? На первой картинке вы видите оранжевую клетку — центр нашего поиска. Сначала мы попробуем найти ближайший полигон во всех соседних клетках (на картинке они серые). Если мы ничего там не найдём, то отдалимся ещё на один уровень, как на второй картинке. И так далее.


«Соседей» нам даёт функция AllNeighbors. Разве что нужно полученные клетки отфильтровать и убрать те, которые мы уже просмотрели.
```
func (i *Index) searchNextLevel(radiusEdges []s2.CellID,
alreadyVisited *[]s2.CellID) (found []IndexItem, searched []s2.CellID) {
for _, radiusEdge := range radiusEdges {
neighbors := radiusEdge.AllNeighbors(i.storageLevel)
for _, neighbor := range neighbors {
if in(*alreadyVisited, neighbor) {
continue
}
*alreadyVisited = append(*alreadyVisited, neighbor)
searched = append(searched, neighbor)
item := i.bt.Get(IndexItem{cellID: neighbor})
if item != nil {
found = append(found, item.(IndexItem))
}
}
}
return
}
```
Вот, собственно, и всё. Для этого примера я также написал тест, и он успешно проходит.
Если вам интересно взглянуть на него или на полные примеры, то их можно найти [здесь](https://github.com/mkevac/gophercon-russia-2018) вместе со слайдами.
Заключение
----------
Если вам когда-нибудь понадобится написать поисковый сервис, работающий с координатами или какими-то более сложными географическими объектами, и вы не захотите или не сможете использовать готовые СУБД типа PostGIS, вспомните об S2.
Это классный и простой инструмент, который даст вам базовые вещи и фреймворк для работы с координатами и земным шаром. Мы в Badoo очень любим S2 и всячески её рекомендуем.
Спасибо!
Upd: А вот и видео подоспело! | https://habr.com/ru/post/352754/ | null | ru | null |
# Решение японских кроссвордов c P̶y̶t̶h̶o̶̶n̶ Rust и WebAssembly

Как сделать решатель (солвер) нонограмм на Python, переписать его на Rust, чтобы запускать прямо в браузере через WebAssembly.
[TL;DR](https://tsionyx.github.io/nono/?id=32480)
Начало
------
Про японские кроссворды (нонограммы) на хабре было уже несколько постов. [Пример](https://habr.com/ru/post/418069/)
и [еще один](https://habr.com/ru/post/433330/).
> Изображения зашифрованы числами, расположенными слева от строк, а также сверху над столбцами. Количество чисел показывает, сколько групп чёрных (либо своего цвета, для цветных кроссвордов) клеток находятся в соответствующих строке или столбце, а сами числа — сколько слитных клеток содержит каждая из этих групп (например, набор из трёх чисел — 4, 1, и 3 означает, что в этом ряду есть три группы: первая — из четырёх, вторая — из одной, третья — из трёх чёрных клеток). В чёрно-белом кроссворде группы должны быть разделены, как минимум, одной пустой клеткой, в цветном это правило касается только одноцветных групп, а разноцветные группы могут быть расположены вплотную (пустые клетки могут быть и по краям рядов). Необходимо определить размещение групп клеток.
Одна из наиболее общепринятых точек зрения — что "правильными" кроссвордами можно называть только те, которые решаются "логическим" путем. Обычно так называют способ решения, при котором не принимаются во внимание зависимости между разными строками и/или столбцами. Иначе говоря, решение представляет собой последовательность **независимых** решений отдельных строк или столбцов, пока все клетки не окажутся закрашены (подробнее об алгоритме далее). Например только такие нонограммы можно найти на сайте <http://nonograms.org/> (<http://nonograms.ru/>). Нонограммы с этого сайта уже приводились в качестве примера в статье [Решение цветных японских кроссвордов со скоростью света](https://habr.com/ru/post/418069/). Для целей сравнения и проверки в моем солвере также добавлена поддержка скачивания и парсинга кроссвордов с этого сайта (спасибо [KyberPrizrak](https://habr.com/ru/users/kyberprizrak/) за разрешение использовать материалы с его сайта).
Однако можно расширить понятие нонограмм до более общей задачи, когда обычный "логический" способ заводит в тупик. В таких случаях для решения приходится делать предположение о цвете какой-нибудь клетки и после, доказав, что этот цвет приводит к противоречию, отмечать для этой клетки противоположный цвет. Последовательность таких шагов может (если хватит терпения) выдать нам все решения. О решении такого более общего случая кроссвордов и будет главным образом эта статья.
Python
------
Около полутора лет назад я случайно наткнулся на [статью](http://window.edu.ru/resource/781/57781), в которой рассказывался метод решения одной строки (как оказалось позднее, метод был довольно медленным).
Когда я реализовал этот метод на Python (мой основной рабочий язык) и добавил последовательное обновление всех строк, то увидел, что решается все это не слишком быстро. После изучения матчасти обнаружилось, что по этой теме существует масса работ и реализаций, которые предлагают разные подходы для этой задачи.
Как мне показалось, наиболее масштабную работу по анализу различных реализаций солверов провел Jan Wolter, опубликовав на своем сайте (который, насколько мне известно, остается самым крупным публичным хранилищем нонограмм в интернете) [подробное исследование](https://webpbn.com/survey/), содержащее огромное количество информации и ссылок, которые могут помочь в создании своего солвера.
Изучая многочисленные источники (будут в конце статьи), я постепенно улучшал скорость и функциональность моего солвера. В итоге меня затянуло и я занимался реализацией, рефакторингом, отладкой алгоритмов около 10 месяцев в сводобное от работы время.
### Основные алгоритмы
Полученный солвер можно представить в виде четырех уровней решения:
* (**line**) линейный солвер: на входе строка из клеток и строка описания (clues), на выходе — частично решенная строка. В python-решении я реализовал 4 различных алгоритма (3 их них адаптированы для цветных кроссвордов). Самым быстрым оказался алгоритм BguSolver, названный в честь [первоисточника](https://www.cs.bgu.ac.il/~benr/nonograms/). Это очень эффективный и фактически стандартный метод решения нонограмм-строки при помощи динамического программирования. Псевдокод этого метода можно найти например [в этой статье](https://habr.com/ru/post/418069/#odna-stroka-dva-cveta).
* (**propagation**) все строки и столбцы складываем в очередь, проходим по ней линейным солвером, при получении новой информации при решении строки (столбца) обновляем очередь, соответственно, новыми столбцами (строками). Продолжаем, пока очередь не опустеет.
**Пример и код**
Берем очередную задачу для решения из очереди. Пусть это будет пустая (нерешенная) строка длины 7 (обозначим ее как `???????`) с описанием блоков `[2, 3]`. Линейный солвер выдаст частично решенную строку `?X??XX?`, где `X` — закрашенная клетка. При обновлении строки видим, что изменились столбцы с номерами 1, 4, 5 (индексация начинается с 0). Значит в указанных столбцах появилась новая информация и их можно заново отдавать "линейному" солверу. Складываем эти столбцы в очередь задач с повышенным приоритетом (чтобы отдать их линейному солверу следующими).
```
def propagation(board):
line_jobs = PriorityDict()
for row_index in range(board.height):
new_job = (False, row_index)
line_jobs[new_job] = 0
for column_index in range(board.width):
new_job = (True, column_index)
line_jobs[new_job] = 0
for (is_column, index), priority in line_jobs.sorted_iter():
new_jobs = solve_and_update(board, index, is_column)
for new_job in new_jobs:
# upgrade priority
new_priority = priority - 1
line_jobs[new_job] = new_priority
def solve_and_update(board, index, is_column):
if is_column:
row_desc = board.columns_descriptions[index]
row = tuple(board.get_column(index))
else:
row_desc = board.rows_descriptions[index]
row = tuple(board.get_row(index))
updated = line_solver(row_desc, row)
if row != updated:
for i, (pre, post) in enumerate(zip(row, updated)):
if _is_pixel_updated(pre, post):
yield (not is_column, i)
if is_column:
board.set_column(index, updated)
else:
board.set_row(index, updated)
```
* (**probing**) для каждой нерешенной клетки перебираем все варианты цветов и пробуем propagation с этой новой информацией. Если получаем противоречие — выкидываем этот цвет из вариантов цветов для клетки и пытаемся извлечь из этого пользу снова при помощи propagation. Если решается до конца — добавляем решение в список решений, но продолжаем эксперименты с другими цветами (решений может быть несколько). Если приходим к ситуации, где дальше решить невозможно — просто игнорируем и повторяем процедуру с другим цветом/клеткой.
**Код**
Возвращает True, если в результате пробы было получено противоречие.
```
def probe(self, cell_state):
board = self.board
pos, assumption = cell_state.position, cell_state.color
# already solved
if board.is_cell_solved(pos):
return False
if assumption not in board.cell_colors(pos):
LOG.warning("The probe is useless: color '%s' already unset", assumption)
return False
save = board.make_snapshot()
try:
board.set_color(cell_state)
propagation(
board,
row_indexes=(cell_state.row_index,),
column_indexes=(cell_state.column_index,))
except NonogramError:
LOG.debug('Contradiction', exc_info=True)
# rollback solved cells
board.restore(save)
else:
if board.is_solved_full:
self._add_solution()
board.restore(save)
return False
LOG.info('Found contradiction at (%i, %i)', *pos)
try:
board.unset_color(cell_state)
except ValueError as ex:
raise NonogramError(str(ex))
propagation(
board,
row_indexes=(pos.row_index,),
column_indexes=(pos.column_index,))
return True
```
* (**backtracking**) если при пробинге не игнорировать частично решенный пазл, а продолжать рекурсивно вызывать эту же процедуру — получим бэктрэкинг (иначе говоря — полный обход в глубину дерева потенциальных решений). Здесь начинает играть большую роль, какая из клеток будет выбрана в качестве следующего расширения потенциального решения. Хорошее исследование на эту тему есть [в этой публикации](https://ir.nctu.edu.tw/bitstream/11536/22772/1/000324586300005.pdf).
**Код**
Бэктрэкинг у меня довольно неряшливый, но вот эти две функции приблизительно описывают, что происходит при рекурсивном поиске
```
def search(self, search_directions, path=()):
"""
Return False if the given path is a dead end (no solutions can be found)
"""
board = self.board
depth = len(path)
save = board.make_snapshot()
try:
while search_directions:
state = search_directions.popleft()
assumption, pos = state.color, state.position
cell_colors = board.cell_colors(pos)
if assumption not in cell_colors:
LOG.warning("The assumption '%s' is already expired. "
"Possible colors for %s are %s",
assumption, pos, cell_colors)
continue
if len(cell_colors) == 1:
LOG.warning('Only one color for cell %r left: %s.',
pos, assumption)
try:
self._solve_without_search()
except NonogramError:
LOG.warning(
"The last possible color '%s' for the cell '%s' "
"lead to the contradiction. "
"The path %s is invalid", assumption, pos, path)
return False
if board.is_solved_full:
self._add_solution()
LOG.warning(
"The only color '%s' for the cell '%s' "
"lead to full solution. No need to traverse "
"the path %s anymore", assumption, pos, path)
return True
continue
rate = board.solution_rate
guess_save = board.make_snapshot()
try:
LOG.warning(
'Trying state: %s (depth=%d, rate=%.4f, previous=%s)',
state, depth, rate, path)
success = self._try_state(state, path)
finally:
board.restore(guess_save)
if not success:
try:
LOG.warning(
"Unset the color %s for cell '%s'.",
assumption, pos)
board.unset_color(state)
self._solve_without_search()
except ValueError:
LOG.warning(
"The last possible color '%s' for the cell '%s' "
"lead to the contradiction. "
"The whole branch (depth=%d) is invalid. ",
assumption, pos, depth)
return False
if board.is_solved_full:
self._add_solution()
LOG.warning(
"The negation of color '%s' for the cell '%s' "
"lead to full solution. No need to traverse "
" the path %s anymore", assumption, pos, path)
return True
finally:
# do not restore the solved cells on a root path
# they are really solved!
if path:
board.restore(save)
return True
def _try_state(self, state, path):
board = self.board
full_path = path + (state,)
probe_jobs = self._get_all_unsolved_jobs(board)
try:
# update with more prioritized cells
for new_job, priority in self._set_guess(state):
probe_jobs[new_job] = priority
__, best_candidates = self._solve_jobs(probe_jobs)
except NonogramError as ex:
LOG.warning('Dead end found (%s): %s', full_path[-1], str(ex))
return False
rate = board.solution_rate
LOG.info('Reached rate %.4f on %s path', rate, full_path)
if rate == 1:
return True
cells_left = round((1 - rate) * board.width * board.height)
LOG.info('Unsolved cells left: %d', cells_left)
if best_candidates:
return self.search(best_candidates, path=full_path)
return True
```
Итак, мы начинаем решать наш кроссворд со второго уровня (первый годится только для вырожденного случая, когда во всем кроссворде только одна строка или столбец) и постепенно продвигаемся вверх по уровням. Как можно догадаться, каждый уровень несколько раз вызывает нижележащий уровень, поэтому для эффективного решения крайне необходимо иметь быстрые первый и второй уровень, которые для сложных пазлов могут вызываться миллионы раз.
На этом этапе выясняется (довольно ожидаемо), что python — это совсем не тот инструмент, который подходит для максимальной производительности в такой CPU-intensive задаче: все расчеты в нем крайне неэффективны по сравнению с более низкоуровневыми языками. Например, наиболее алгоритмически близкий BGU-солвер (на Java) по результатам замеров оказался в 7-17 (иногда до 27) раз быстрее на самых разных задачах.
**Подробнее**
```
pynogram_my BGU_my speedup
Dancer 0.976 0.141 6.921986
Cat 1.064 0.110 9.672727
Skid 1.084 0.101 10.732673
Bucks 1.116 0.118 9.457627
Edge 1.208 0.094 12.851064
Smoke 1.464 0.120 12.200000
Knot 1.332 0.140 9.514286
Swing 1.784 0.138 12.927536
Mum 2.108 0.147 14.340136
DiCap 2.076 0.176 11.795455
Tragic 2.368 0.265 8.935849
Merka 2.084 0.196 10.632653
Petro 2.948 0.219 13.461187
M&M 3.588 0.375 9.568000
Signed 4.068 0.242 16.809917
Light 3.848 0.488 7.885246
Forever 111.000 13.570 8.179808
Center 5.700 0.327 17.431193
Hot 3.150 0.278 11.330935
Karate 2.500 0.219 11.415525
9-Dom 510.000 70.416 7.242672
Flag 149.000 5.628 26.474769
Lion 71.000 2.895 24.525043
Marley 12.108 4.405 2.748695
Thing 321.000 46.166 6.953169
Nature inf 433.138 inf
Sierp inf inf NaN
Gettys inf inf NaN
```
Замеры проводились на моей машине, пазлы взяты из стандартного набора, который использовал Jan Wolter в своем [сравнении](https://webpbn.com/survey/#samptime)
И это уже после того, как я начал использовать PyPy, а на стандартном CPython время расчетов было выше, чем на PyPy в 4-5 раз! Можно сказать, что производительность похожего солвера на Java оказалась выше кода на CPython в 28-85 раз.
Попытки улучшить производительность моего солвера при помощи профайлинга (cProfile, SnakeViz, line\_profiler) привели к некоторому ускорению, но сверхъестественного результата конечно не дали.
### [Итоги](https://github.com/tsionyx/pynogram):
**+** солвер умеет решать все пазлы с сайтов <https://webpbn.com>, <http://nonograms.org> и свой собственный (ini-based) формат
**+** решает черно-белые и цветные нонограммы с любым количеством цветов (максимальное количество цветов, которое встречалось — 10)
**+** решает пазлы с пропущенными размерами блоков (blotted). [Пример такого пазла](https://webpbn.com/19407).
**+** умеет рендерить пазлы в консоль / в окно curses / в браузер (при установке дополнительной опции *pynogram-web*). Для всех режимов поддерживается просмотр прогресса решения в реальном времени.
**-** медленные расчеты (в сравнении с реализациями, описанными в статье-сравнении солверов, см. [таблицу](https://webpbn.com/survey/#samptime)).
**-** неэффективный бэктрэкинг: некоторые пазлы могут решаться часами (когда дерево решений очень большое).
Rust
----
В начале года я начал изучать Rust. Начал я, как водится, с [The Book](https://doc.rust-lang.org/book/), узнал про WASM, прошел [предлагаемый туториал](https://rustwasm.github.io/docs/book/). Однако хотелось какой-то настоящей задачи, в которой можно зайдействовать сильные стороны языка (в первую очередь его супер-производительность), а не выдуманных кем-то примеров. Так я снова вернулся к нонограммам. Но теперь у меня уже был работающий вариант всех алгоритмов на Python, его осталось "всего лишь" переписать.
С самого начала меня ожидала приятная новость: оказалось что Rust с его системой типов отлично описывает структуры данных для моей задачи. Так например одно из базовых соответствий *BinaryColor + BinaryBlock* / *MultiColor + ColoredBlock* позволяет навсегда разделить черно-белые и цветные нонограммы. Если где-то в коде мы попытаемся решить цветную строку при помощи обычных бинарных блоков описания, то получим ошибку компиляции про несоответствие типов.
**Базовые типы выглядят примерно так**
```
pub trait Color
{
fn blank() -> Self;
fn is_solved(&self) -> bool;
fn solution_rate(&self) -> f64;
fn is_updated_with(&self, new: &Self) -> Result;
fn variants(&self) -> Vec;
fn as\_color\_id(&self) -> Option;
fn from\_color\_ids(ids: &[ColorId]) -> Self;
}
pub trait Block
{
type Color: Color;
fn from\_str\_and\_color(s: &str, color: Option) -> Self {
let size = s.parse::().expect("Non-integer block size given");
Self::from\_size\_and\_color(size, color)
}
fn from\_size\_and\_color(size: usize, color: Option) -> Self;
fn size(&self) -> usize;
fn color(&self) -> Self::Color;
}
#[derive(Debug, PartialEq, Eq, Hash, Clone)]
pub struct Description
where
T: Block,
{
pub vec: Vec,
}
// for black-and-white puzzles
#[derive(Debug, PartialEq, Eq, Hash, Copy, Clone, PartialOrd)]
pub enum BinaryColor {
Undefined,
White,
Black,
BlackOrWhite,
}
impl Color for BinaryColor {
// omitted
}
#[derive(Debug, PartialEq, Eq, Hash, Default, Clone)]
pub struct BinaryBlock(pub usize);
impl Block for BinaryBlock {
type Color = BinaryColor;
// omitted
}
// for multicolor puzzles
#[derive(Debug, PartialEq, Eq, Hash, Default, Copy, Clone, PartialOrd, Ord)]
pub struct MultiColor(pub ColorId);
impl Color for MultiColor {
// omitted
}
#[derive(Debug, PartialEq, Eq, Hash, Default, Clone)]
pub struct ColoredBlock {
size: usize,
color: ColorId,
}
impl Block for ColoredBlock {
type Color = MultiColor;
// omitted
}
```
При переносе кода некоторые моменты явно указывали на то, что статически типизированный язык, такой как Rust (ну или, например C++) — более подходящий для этой задачи. Точнее говоря, дженерики и трэйты лучше описывают предметную область чем иерархии классов. Так в Python-коде у меня было два класса для линейного солвера, `BguSolver` и `BguColoredSolver` которые решали, соответственно, черно-белую строку и цветную строку. В Rust-коде у меня осталась единственная generic-структура `struct DynamicSolver::Color>`, которая умеет решать оба типа задач, в зависимости от переданного при создании типа (`DynamicSolver, DynamicSolver`). Это, конечно, не значит, что в Python что-то похожее невозможно сделать, просто в Rust система типов явно указала мне, что если не пойти эти путем, то придется написать тонну повторяющегося кода.
К тому же любой кто пробовал писать на Rust, несомненно заметил эффект "доверия" к компилятору, когда процесс написания кода сводится к следующему псевдометаалгоритму:
```
write_initial_code
while (compiler_hints = $(cargo check)) != 0; do
fix_errors(compiler_hints)
end
```
Когда компилятор перестанет выдавать ошибки и предупреждения, ваш код будет согласован с системой типов и borrow checker-ом и вы заранее предупредите возникновение кучи потенциальных багов (конечно, при условии тщательного проектирования типов данных).
Приведу пару примеров функций, которые показывают насколько лаконичен может быть код на Rust (в сравнении с Python-аналогами).
**unsolved\_neighbours**
Выдает список нерешенных "соседей" для данной точки (x, y)
```
def unsolved_neighbours(self, position):
for pos in self.neighbours(position):
if not self.is_cell_solved(*pos):
yield pos
```
```
fn unsolved_neighbours(&self, point: &Point) -> impl Iterator + '\_ {
self.neighbours(&point)
.into\_iter()
.filter(move |n| !self.cell(n).is\_solved())
}
```
**partial\_sums**
Для набора блоков, описывающих одну строку, выдать частичные суммы (с учетом обязательных промежутков между блоками).Полученные индексы будут указывать минимальную позицию, на которой блок может закончиться (эта информация используется далее для линейного солвера).
Например для такого набора блоков `[2, 3, 1]` имеем на выходе `[2, 6, 8]`, что означает, что первый блок может быть максимально сдвинут влево настолько, чтобы его правый край занимал 2-ую клетку, аналогично и для остальных блоков:
```
1 2 3 4 5 6 7 8 9
_ _ _ _ _ _ _ _ _
2 3 1 |_|_|_|_|_|_|_|_|_|
^ ^ ^
| | |
конец 1 блока | | |
конец 2 блока -------- |
конец 3 блока ------------
```
```
@expand_generator
def partial_sums(blocks):
if not blocks:
return
sum_so_far = blocks[0]
yield sum_so_far
for block in blocks[1:]:
sum_so_far += block + 1
yield sum_so_far
```
```
fn partial_sums(desc: &[Self]) -> Vec {
desc.iter()
.scan(None, |prev, block| {
let current = if let Some(ref prev\_size) = prev {
prev\_size + block.0 + 1
} else {
block.0
};
\*prev = Some(current);
\*prev
})
.collect()
}
```
При портировании я допустил несколько изменений
* ядро солвера (алгоритмы) подверглись незначительным изменениям (в первую очередь для поддержки generic-типов для клеток и блоков)
* оставил единственный (самый быстрый) алгоритм для линейного солвера
* вместо ini формата ввел чуть измененный TOML-формат
* не добавил поддержку blotted-кроссвордов, потому что, строго говоря, это уже другой класс задач
* оставил единственный способ вывода — просто в консоль, но теперь цветные клетки в консоли рисуются действительно цветными (благодаря [этому крэйту](https://crates.io/crates/colored))
**вот так**

### Полезные инструменты
* [clippy](https://github.com/rust-lang/rust-clippy) — стандартный статический анализатор, который иногда даже может дать советы, слегка увеличивающие производительность кода
* [valgrind](http://www.valgrind.org/) — инструмент для динамического анализа приложений. Я использовал его как профайлер для поиска боттлнеков (`valrgind --tool=callgrind`) и особо прожорливых по памяти участков кода (`valrgind --tool=massif`). Совет: устанавливайте *[profile.release] debug=true* в Cargo.toml перед запуском профайлера. Это позволит оставить debug-символы в исполняемом файле.
* [kcachegrind](https://github.com/KDE/kcachegrind) для просмотра файлов callgrind. Очень полезный инструмент для поиска наиболее проблемных с точки зрения производительности мест.
### Производительность
То, ради чего и затевалось переписывание на Rust. Берем кросвворды из уже упомянутой [таблицы сравнения](https://webpbn.com/survey/#samptime) и прогоняем их через лучшие, описанные в оригинальной статье, солверы. Результаты и описание прогонов [здесь](https://github.com/tsionyx/nonogrid/tree/master/benches). Берем полученный [файл](https://github.com/tsionyx/nonogrid/blob/master/benches/perf.csv) и строим на нем пару графиков.Так как время решения варьируется от миллисекунд до десятков минут, график выполнен с логарифмической шкалой.
**запускать в Jupyter-ноутбуке**
```
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
# strip the spaces
df = pd.read_csv('perf.csv', skipinitialspace=True)
df.columns = df.columns.str.strip()
df['name'] = df['name'].str.strip()
# convert to numeric
df = df.replace('\+\ *', np.inf, regex=True)
ALL_SOLVERS = list(df.columns[3:])
df.loc[:,ALL_SOLVERS] = df.loc[:,ALL_SOLVERS].apply(pd.to_numeric)
# it cannot be a total zero
df = df.replace(0, 0.001)
#df.set_index('name', inplace=True)
def is_my_solver(solver_name):
return solver_name.endswith('_my') or solver_name.endswith('_sat')
SURVEY_SOLVERS = [s for s in ALL_SOLVERS if not is_my_solver(s)]
MY_MACHINE_SOLVERS = [s for s in ALL_SOLVERS if is_my_solver(s) and s[:-3] in SURVEY_SOLVERS]
MY_SOLVERS = [s for s in ALL_SOLVERS if is_my_solver(s) and s[:-3] not in SURVEY_SOLVERS]
bar_width = 0.17
df_compare = df.replace(np.inf, 10000, regex=True)
plt.rcParams.update({'font.size': 20})
def solver_name_in_plot(solver_name):
if solver_name.endswith('_my'):
return solver_name[:-3]
return solver_name
def compare(first, others):
bars = [first] + list(others)
index = np.arange(len(df))
fig, ax = plt.subplots(figsize=(30,10))
df_compare.sort_values(first, inplace=True)
for i, column in enumerate(bars):
ax.bar(index + bar_width*i, df_compare[column], bar_width, label=solver_name_in_plot(column))
ax.set_xlabel("puzzles")
ax.set_ylabel("Time, s (log)")
ax.set_title("Compare '{}' with others (lower is better)".format(solver_name_in_plot(first)))
ax.set_xticks(index + bar_width / 2)
ax.set_xticklabels("#" + df_compare['ID'].astype(str) + ": " + df_compare['name'].astype(str))
ax.legend()
plt.yscale('log')
plt.xticks(rotation=90)
plt.show()
fig.savefig(solver_name_in_plot(first) + '.png', bbox_inches='tight')
for my in MY_SOLVERS:
compare(my, MY_MACHINE_SOLVERS)
compare(MY_SOLVERS[0], MY_SOLVERS[1:])
```
##### Python-солвер
[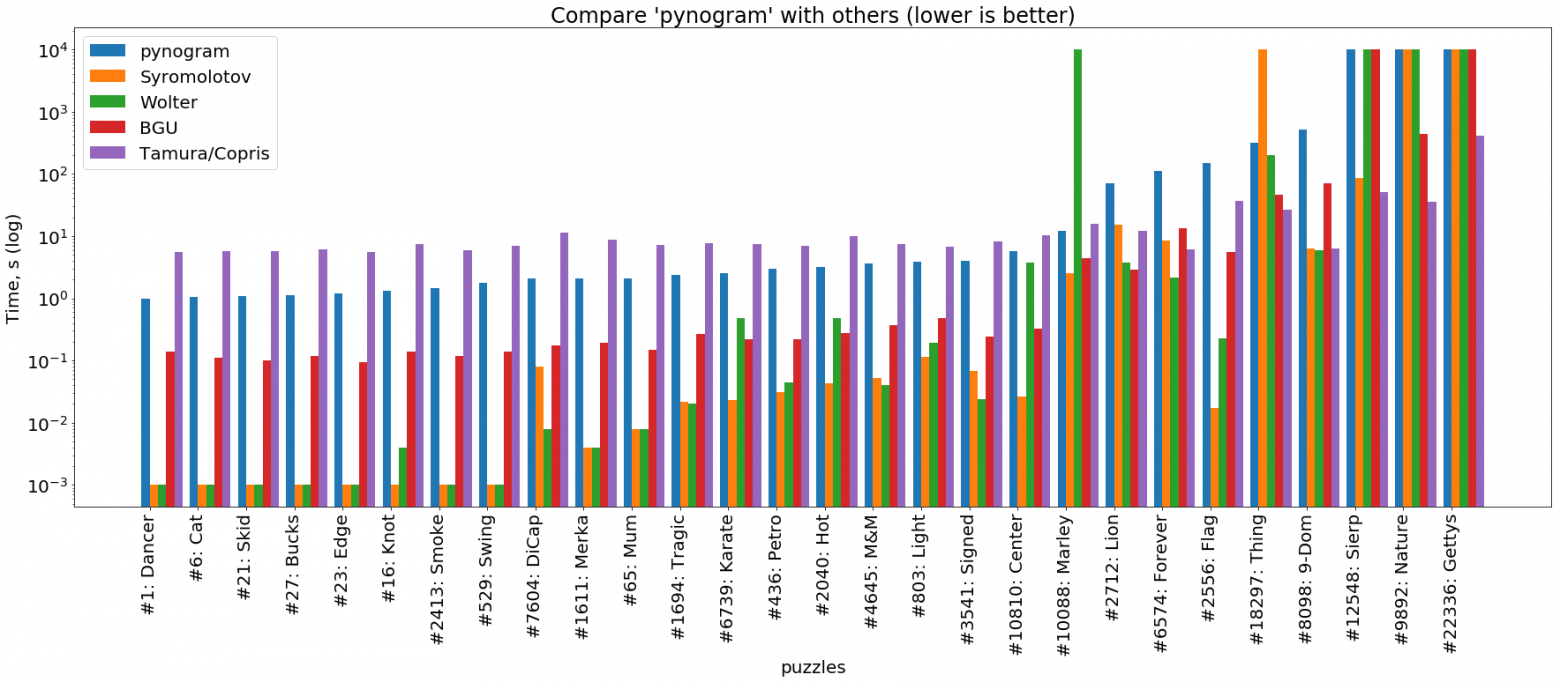](https://habrastorage.org/webt/si/qb/5o/siqb5ohxk_bjjaulmkohy1uhzkw.png)
(*картинка кликабельна*)
Видим, что *pynogram* здесь медленнее всех представленных солверов. Единственное исключение из этого правила — солвер [Tamura/Copris](http://bach.istc.kobe-u.ac.jp/copris/puzzles/nonogram/), основанный на SAT, который самые простые пазлы (левая часть графика) решает дольше, чем наш. Однако такова уж особенность SAT-солверов: они предназначены для супер сложных кроссвордов, в которых обычный солвер надолго застревает в бэктрэкинге. Это отчетливо видно на правой части графика, где *Tamura/Copris* решает самые сложные пазлы в десятки и сотни раз быстрее всех остальных.
##### Rust-солвер
[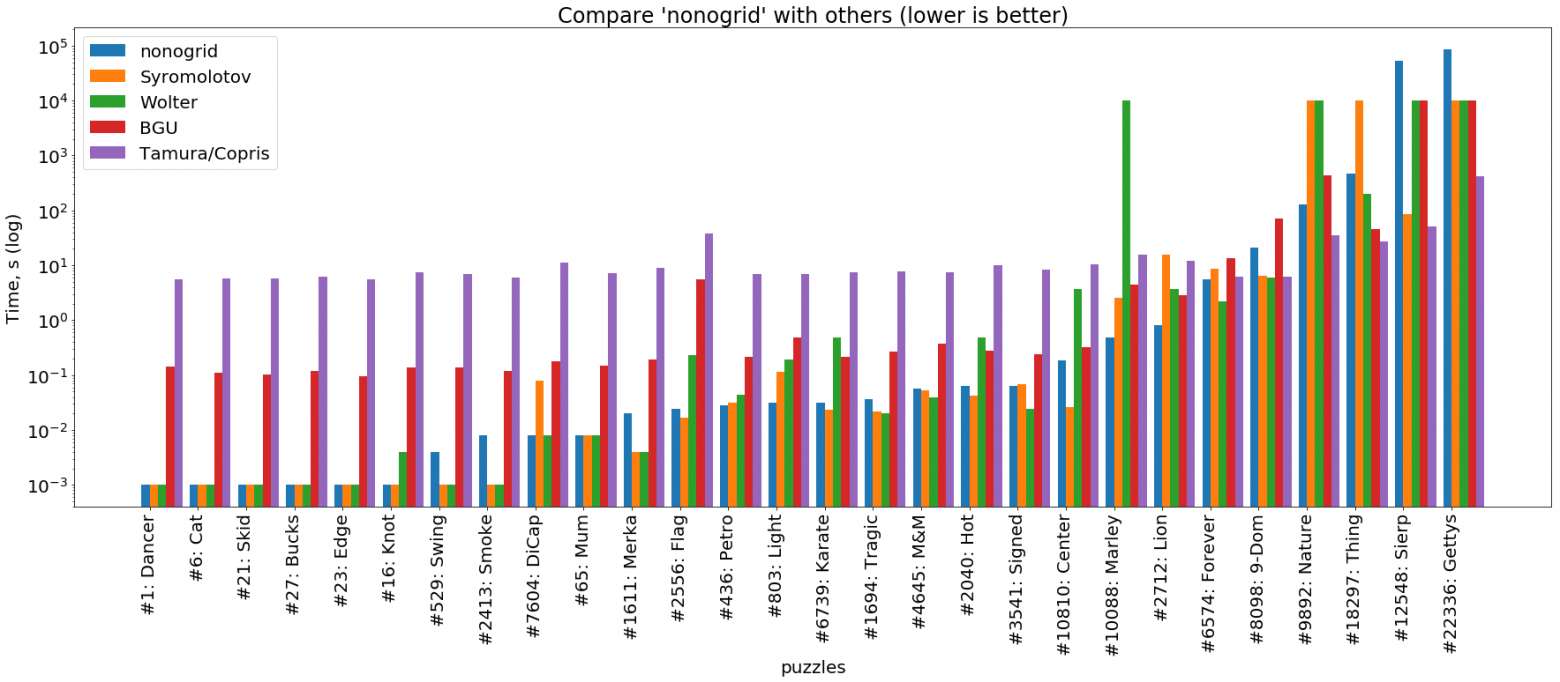](https://habrastorage.org/webt/ec/n0/a1/ecn0a1itxkvhoqlmfyxcluey9nq.png)
(*картинка кликабельна*)
На этом графике видно, что *nonogrid* на простых задачах справляется также или чуть хуже, чем высокопроизводительные солверы, написанные на C и С++ (*Wolter* и *Syromolotov*). С усложнением задач, наш солвер примерно повторяет траекторию *BGU*-солвера (Java), но почти всегда опережает его примерно на порядок. На самых сложных задачах *Tamura/Copris* как всегда впереди всех.
##### Rust-солвер (с включенным в него SAT-солвером)
[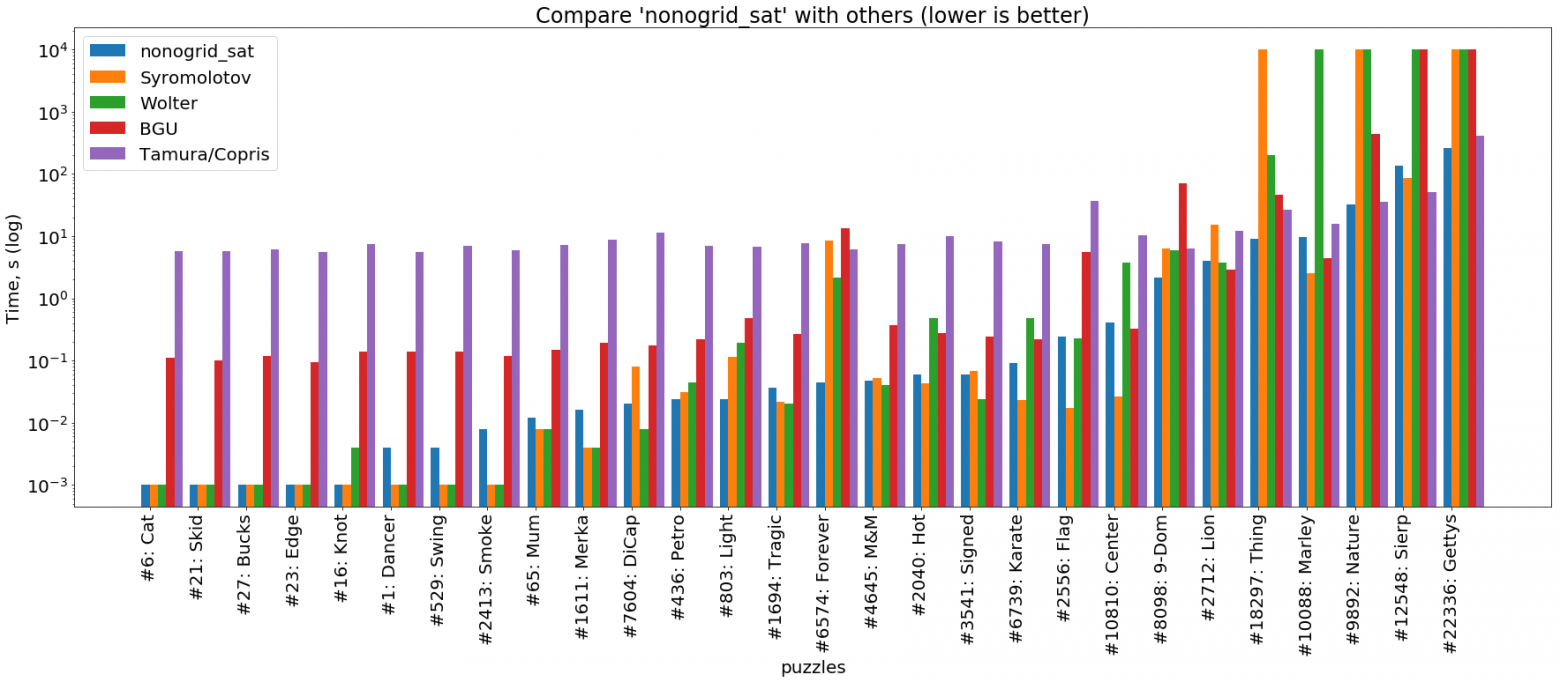](https://habrastorage.org/webt/5s/ii/io/5siiioqv2y8o1rojqkjawjup4g4.png)
(*картинка кликабельна*)
*nonogrid(sat)* (бэктрэкинг заменен на SAT-поиск) на простых задачах продолжает работать также или чуть хуже, чем высокопроизводительные солверы, написанные на C и С++ (*Wolter* и *Syromolotov*). На самых сложных задачах, где почти все солверы уходят в таймаут, как и ожидается, наш солвер по производительности становится очень похож на *Tamura/Copris*, уступая ему лишь на одной задаче (#12548). Таким образом, эта версия берет лучшее из двух миров: быстро справляется с легкими задачами при помощи специальных алгоритмов и подключает эффективный SAT-солвер, когда задача становится слишком сложной.
##### Rust vs python
[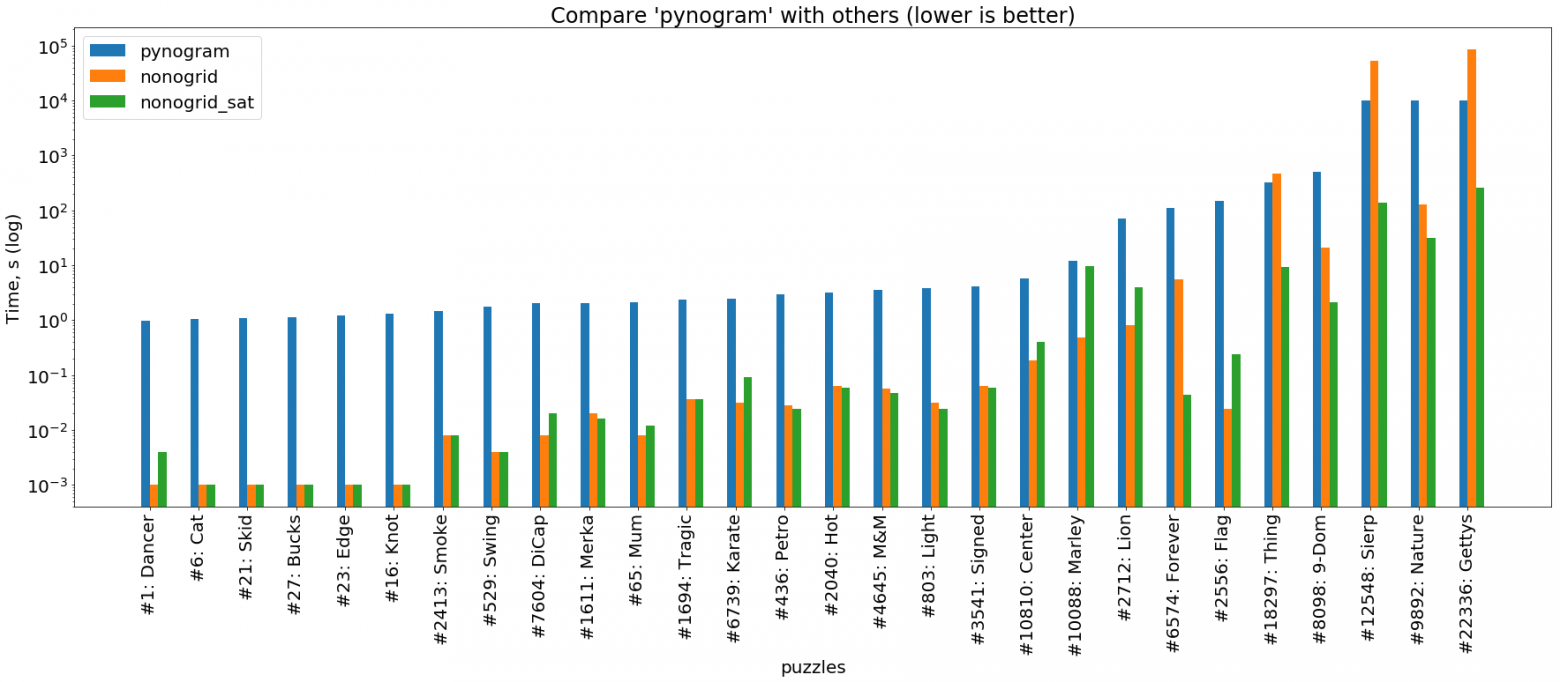](https://habrastorage.org/webt/my/kn/r_/myknr_ffdcoe6ytrqspa5s0ej7e.png)
(*картинка кликабельна*)
Ну и наконец сравнение двух наших солверов, описанных здесь. Видно, что Rust-солвер почти всегда опережает на 1-3 порядка питоновский солвер.
Сравнивая две версии Rust-солвера, использующих SAT и собственный бэктрэкинг, можно заметить, что на легких задачах они ведут себя практически одинаково, в пределах погрешности замеров. На задачах среднего уровня (в которых поиск решения занимает несколько секунд), где необходимо проводить поиск по дереву возможных решений, но решение лежит довольно близко, SAT-солвер может уступать самописному бэктрэкингу примерно на порядок (#10088, #2712, #2556). Однако на сложных задачах SAT берет свое и там, где бэктрэкинг уходит в практически бесконечный поиск, который может длиться часами, SAT находит пару решений уже через несколько минут.
### [Итоги](https://github.com/tsionyx/nonogrid):
**+** солвер умеет решать все пазлы с сайтов <https://webpbn.com> (кроме blotted — c частично скрытыми размерами блоков), <http://nonograms.org> и свой собственный (TOML-based) формат
**+** решает черно-белые и цветные нонограммы с любым количеством цветов
**+** умеет рендерить пазлы в консоль (цветные c webpbn.com рисует по настоящему цветными)
**+** работает быстро (в сравнении с реализациями, описанными в статье-сравнении солверов, см. таблицу).
**-** бэктрэкинг остался неэффективным, как и в Python-решении: некоторые пазлы (например [вот такой безобидный 20x20](https://webpbn.com/3620)) могут решаться часами (когда дерево решений очень большое). ~~Возможно вместо бэктрэкинга стоит воспользоваться уже упоминавшимися на хабре [SAT-солверами](https://habr.com/ru/post/433330/). Правда единственный найденный мною [SAT-солвер на Rust](https://github.com/kmcallister/sat) на первый взгляд кажется недописанным и заброшенным.~~ **UPDATE:** использование [SAT-солвера](https://github.com/jix/varisat) позволило улучшить производительность на сложных задачах на несколько порядков (включается при компиляции вот так: `cargo build --features=sat`, включен по умолчанию в WASM-версии).
WebAssembly
-----------
Итак, переписывание кода на Rust дало свои плоды: солвер стал намного быстрее. Однако Rust нам предлагает еще одну невероятно крутую фичу: компиляцию в WebAssembly и возможность запускать свой код прямо в браузере.
Для реализации этой возможности существует специальный инструмент для Rust, который обеспечивает необходимые биндинги и генерирует за вас boilerplate для безболезненного запуска Rust функций в JS-коде — это *wasm-pack* (+*wasm-bindgen*). Большая часть работы c ним и другими важными инструментами уже описана в [туториале Rust and WebAssembly](https://rustwasm.github.io/docs/book/). Однако есть пара моментов, которые пришлось выяснять самостоятельно:
* при чтении создается ощущение, что туториал в первую очередь написан для JS-девелопера, который хочет ускорить свой код при помощи Rust. Ну или по крайней мере, для того кто знаком с *npm*. Для меня же, как человека, далекого от фронтэнда, было удивлением обнаружить, что даже стандартный пример из книги никак не хочет работать со сторонним web-сервером, отличающимся от `npm run start`.
К счастью в wasm-pack есть режим, позволяющий генерировать обычный JS-код (не являющийся npm-модулем). `wasm-pack build --target no-modules --no-typescript` на выходе даст всего два файла: *project-name.wasm* — бинарник Rust-кода, скомпилированного в WebAssembly и *project-name.js*. Последний файл можно добавить на любую HTML-страницу и использовать WASM-функции, не заморачиваясь с npm, webpack, ES6, модулями и прочими радостями современного JS-разработчика. Режим `no-modules` идеально подходит для не-фронтэндеров в процессе разработки WASM-приложения, а также для примеров и демонстраций, потому что не требует никакой дополнительной frontend-инфраструктуры.
* WebAssembly хорош для задач, которые слишком тяжелы для JavaScript. В первую очередь это задачи, которые выполняют множество расчетов. А раз так, такая задача может выполняться долго даже с WebAssembly и тем самым нарушить асинхронный принцип работы современного веба. Я говорю про всевозможные *Warning: Unresponsive script*, которые мне случилось наблюдать при работе моего солвера. Для решения этой проблемы можно использовать механизм *Web worker*. В таком случае схема работы с "тяжелыми" WASM-функциями может выглядеть так:
1. из основного скрипта по событию (например клику на кнопке) послать сообщение воркеру с заданием запустить тяжелую функцию.
2. воркер принимает задание, запускает функцию и по ее окончанию возвращает результат.
3. основной скрипт принимает результат и как-то его обрабатывает (отрисовывает)
При создании WASM-интерфейса нет возможности передавать все создаваемые типы данных в JS, к тому же это противоречит [практике использования WASM](https://rustwasm.github.io/docs/book/game-of-life/implementing.html#interfacing-rust-and-javascript). Однако между вызовами функций нужно как-то хранить состояние (внутреннее представление нонограмм с описанием клеток и блоков), поэтому я использовал глобальный `HashMap` для хранения нонограмм по их порядковым номерам, который никак не виден снаружи. При запросе извне (из JS) передается только номер кроссворда, по которому затем восстанавливается сам кроссворд для запуска решения / запроса результатов решения.
Для обеспечения безопасного доступа к глобальному словарю, он [заворачивается в Mutex](https://github.com/tsionyx/nono/blob/8e2f8f27cce70492b66a929287e011b1ce357324/src/lib.rs#L45), что заставляет заменить все используемые структуры на thread-safe. Изменения в таком случае касаются использования smart-указателей в основном коде солвера. Для поддержки thread-safe операций пришлось заменить все *Rc* на *Arc* и *RefCell* на *RwLock*. Однако эта операция тут же сказалась на производительности солвера: время выполнения по самой оптимистичной оценке увеличилось на 30%. Для обхода этого ограничения я добавил специальную опцию `--features=threaded` при необходимости использовать солвер в thread-safe среде, которая и необходима в WASM-интерфейсе.
В результате проведенных замеров на кроссвордах [6574](https://tsionyx.github.io/nono/?id=6574) и [8098](https://tsionyx.github.io/nono/?id=8098) получился следующий результат (лучшее время в секундах из 10 запусков):
| # | console | console thread-safe | browser (WASM) |
| --- | --- | --- | --- |
| 6574 | 5.4 | 7.4 | 9.2 |
| 8098 | 21.5 | 28.4 | 29.9 |
Видно, что в веб-интерфейсе пазл решается на 40..70% медленнее, чем при запуске нативного приложения в консоли, причем большую часть этого замедления (32..37%) берет на себя запуск в thread-safe режиме (`cargo build --release --features=threaded`). **UPDATE:** таблица выше больше не отражает истинное состояние: при [включении в WASM-версии SAT-поиска](https://github.com/tsionyx/nono/commit/6391e42d191c44226e471cb595c8c7cd700f4ef0) вместо бэктрэкинга, решение указанных задач ускорилось на порядок или более.
Тесты проводились в Firefox 67.0 и Chromium 74.0.
WASM-солвер можно попробовать [здесь](https://tsionyx.github.io/nono/) ([исходники](https://github.com/tsionyx/nono)). Интерфейс позволяет выбрать кроссворд по его номеру с одного из сайтов <https://webpbn.com/> или <http://www.nonograms.org/> **UPDATE:** или ввести исходный текст задачи вручную в одном из множеста поддерживаемых форматов (см. [документацию](https://github.com/tsionyx/nono/blob/master/README.md)).
### TODO
* "выкидывание" решенных строк/столбцов, чтобы облегчить/ускорить решение на этапе бэктрэкинга.
* если солвер находит несколько решений, то интерфейс их не показывает. Вместо этого он показывает максимально "общее" решение, то есть неполное решение, в котором незакрашенные клетки могут иметь разные значения. Нужно добавить показ всех найденных решений.
* нет ограничения по времени (некоторые пазлы считаются очень долго, традиционно я запускал с таймаутом 3600 секунд). В WASM невозможно использовать системный вызов времени, чтобы запустить ограничивающий таймер (на самом деле, это единственное (!) [изменение](https://github.com/tsionyx/nonogrid/commit/47b48109927e3146455636df2c32efc44232733b), которое пришлось сделать, чтобы солвер заработал в WASM). Это, я уверен, как-то можно пофиксить, но возможно придется в основной крэйт nonogrid вносить изменения.
* невозможно отслеживать прогресс. Здесь у меня есть некоторые наработки: коллбэки, которые могут срабатывать при изменении состояния клеток, но как их пробросить в WASM пока не думал. Возможно стоит создать очередь, привязанную к пазлу и писать в нее все (или основные) изменения на этапе решения, а со стороны JS сделать цикл, вычитывающий эту очередь и рендерящий изменения.
* уведомления об ошибках в JS. Например при запросе несуществующего пазла в консоль вываливается backtrace, но на странице просто ничего не происходит.
* ~~добавить поддержку других источников и внешних нонограмм (например возможность загружать файлы в [TOML-формате](https://github.com/tsionyx/nonogrid/blob/master/examples/hello.toml))~~ **UPDATE:** теперь есть возможность задавать исходный текст нонограммы в более простых форматах, [например так](https://tsionyx.github.io/nono/?s=1%201%0A0%0A1%201%0A%0A1%201%0A0%0A1%201).
Итоги
-----
* задача решения нонограмм позволила мне получить массу новых знаний об алгоритмах, языках и инфраструктуре (профайлерах, анализаторах, etc).
* солвер на Rust на 1-3 порядка быстрее солвера на PyPy при увеличении количества кода всего в 1.5-2 раза (точно не замерял).
* переносить код с Python на Rust достаточно просто, если он разбит на достаточно мелкие функции и использует функциональные возможности Python (итераторы, генераторы, comprehensions), которые замечательно транслируются в идиоматичный Rust-код.
* писать на Rust под WebAssembly можно уже сейчас. При этом производительность исполнения Rust кода, скомпилированного в WASM, довольно близка к нативному приложению (на моей задаче примерно в 1.5 раза медленнее).
Основные источники
------------------
1. [The 'pbnsolve' Paint-by-Number Puzzle Solver by Jan Wolter](http://webpbn.com/pbnsolve.html) and the [survey](http://webpbn.com/survey/)
2. [The BGU Nonograms Project](https://www.cs.bgu.ac.il/~benr/nonograms/)
3. [Solving Nonograms by combining relaxations](http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.177.76&rep=rep1&type=pdf)
4. [An Efficient Approach to Solving Nonograms](https://ir.nctu.edu.tw/bitstream/11536/22772/1/000324586300005.pdf)
5. [Решение цветных японских кроссвордов со скоростью света](https://habr.com/post/418069)
6. [Color and black and white Japanese crosswords on-line](http://www.nonograms.org/)
7. [Решение японских кроссвордов с использованием конечных автоматов](http://window.edu.ru/resource/781/57781)
8. ['Nonolib' library by Dr. Steven Simpson](http://www.lancaster.ac.uk/~simpsons/nonogram/howitworks)
9. [Rust and WebAssembly](https://rustwasm.github.io/docs/book/)
10. [Решение японских кроссвордов с помощью SAT солвера](https://habr.com/ru/post/433330/) | https://habr.com/ru/post/454586/ | null | ru | null |
# Библиотеки для конвертирования PDF документа в картинку
«Клавиша Print Screen отлично справляется с поставленной задачей. Что может быть проще, чем сохранить документ как изображение?» — спросите вы. Долгое время я работал над задачами сохранения отчётов и форм в формате PDF. Но даже с простыми многостраничными таблицами цифр не все PDF генераторы справлялись одинаково успешно.
Не так давно, мне попался проект, заказчик которого хотел свои сохранённый в PDF маркетинговые шедевры конвертировать в один из графических форматов, например PNG. После долгих уговоров и приведения контраргументов, бюджет проекта позволял купить недорогой .NET компонент.
Оставалось выбрать самый подходящий под требования заказчика и, по-возможности, с хорошей англоговорящей, англо пишущей службой поддержки (не с полуострова Индостан):
##### Требования к PDF конвертерам
Основное внимание уделялось таким особенностям конвертеров как:
* Простотой API, с том числе, для настройки шрифтов (помимо встроенных шрифтов, должна быть возможность добавить недостающий системный шрифт или ссылку на него)
* Возможность экспорта в TIFF, PNG, JPEG, BMP форматы
* Поддержка прозрачных картинок внутри PDF документа
* Поддержка цветовых масок
* Поддержка азиатских шрифтов
* Аннотации должны конвертироваться вместе с документом (возможность отключить эту опцию)
* Различные режимы смешивания цветов (blending modes)
* Различные шаблоны заливки (tiling patterns)
* Различные цветовые пространства RGB, CMYK, Gray, DeviceN
* Прозрачные группы для документов, созданных при помощи Adobe Illustrator
После нескольких запросов, поисковик выдал группу подходящих .NET компонентов:
| | |
| --- | --- |
| ABCpdf | 6.1.1.5 |
| Adobe Acrobat (Interop.Acrobat) | Adobe Acrobat 10.0 Type Library |
| Apitron.PDF.Rasterizer | 3.0.1.0 |
| O2S.Components.PDFRender4NET | 4.5.1.0 |
| PDFLibNET | |
| PDFSharp | 1.31.1789.0 |
| SautinSoft.PdfFocus | 2.2.2.2 |
| TallCоmponents.PDF.Rasterizer | 3.0.91.0 |
##### Начало испытаний
Для тестовых целей был выбран одностраничный PDF файл 3BigPreview.pdf (взят с официального сайта компании Adobe). Он включает в себя большое количество графических элементов, демонстрируя возможности визуализации компонентой графических объектов PDF и их свойств.
##### ABCPDF
Запустить пример для данной библиотеки на 64-разрядной машине удалось не сразу, лишь поменяв платформу с AnyCPU на x86 был получен результат. Проблема возникла с выставлением правильного разрешения картинки. Картинку правильного размера 612 x 792 пикселей удалось получить только явно выставив разрешение результирующей картинки в 72 точки на дюйм, что странно, так как другие компоненты выставляют 96dpi (для Win7). Правильное отображение иероглифов [Kinsoku Shori](http://en.wikipedia.org/wiki/Line_breaking_rules_in_East_Asian_languages) порадовало. Некоторые буквы выглядят более яркими чем остальные, что говорит о не совсем честном использовании сглаживания (antialiasing). Результат хороший для тех кому не важно, что используется не 100% managed код, а мы идём дальше.
Кусок кода для ABCpdf:
```
public static void ConvertPDFToImage(string pdfInputPath, string imageOutputPath, string imageName, ImageFormat imageFormat)
{
FileStream fs = new FileStream(pdfInputPath, FileMode.Open);
Doc document = new Doc();
document.Read(fs);
document.Rendering.DotsPerInch = 72;
document.Rendering.DrawAnnotations = true;
document.Rendering.AntiAliasImages = true;
document.Rect.String = document.CropBox.String;
document.Rendering.Save(Path.ChangeExtension(Path.Combine(imageOutputPath ,imageName), imageFormat.ToString()));
}
```
Результат: 
##### Adobe Acrobat 10.0 Type Library
Нетрудно понять, что нативная библиотека Adobe не может быть не в фаворитах. Но вызовы com объектов, это не совсем то, чего нам хотелось получить, тем более, что для этого нужна установленная Pro версия продукта.
Кусок кода для Adobe:
```
public static void ConvertPDFToImage(string pdfInputPath, string imageOutputPath, string imageName, ImageFormat imageFormat)
{
CAcroPDDoc pdfDoc = (CAcroPDDoc) Interaction.CreateObject("AcroExch.PDDoc", "");
pdfDoc.Open(pdfInputPath);
CAcroPDPage pdfPage = (CAcroPDPage) pdfDoc.AcquirePage(0);
CAcroPoint pdfPoint = (CAcroPoint) pdfPage.GetSize();
CAcroRect pdfRect = (CAcroRect) Interaction.CreateObject("AcroExch.Rect", "");
pdfRect.Left = pdfRect.Top = 0;
pdfRect.right = pdfPoint.x;
pdfRect.bottom = pdfPoint.y;
pdfPage.CopyToClipboard(pdfRect, 0, 0, 100);
IDataObject clipboardData = Clipboard.GetDataObject();
if (clipboardData.GetDataPresent(DataFormats.Bitmap))
{
using(Bitmap pdfBitmap = (Bitmap) clipboardData.GetData(DataFormats.Bitmap))
{
pdfBitmap.Save(Path.ChangeExtension(Path.Combine(imageOutputPath, imageName), imageFormat.ToString()), imageFormat);
}
}
pdfDoc.Close();
Marshal.ReleaseComObject(pdfPage);
Marshal.ReleaseComObject(pdfRect);
Marshal.ReleaseComObject(pdfDoc);
Marshal.ReleaseComObject(pdfPoint);
}
```
Результат: 
##### Apitron.PDF.Rasterizer for .NET
Компонент хорошо справился с тестовым испытанием. Удобный API, есть возможность настраивать шрифты и отключаемое рисование аннотаций. Изображение выглядит чётким. Все элементы оригинального PDF документа нарисованы. Заметил, что при конвертировании документа все восемь ядер рабочей машины были задействованы, скорее всего это будет удобно для тех, кто хочет увеличить производительность приложения увеличением оперативной памяти и количества процессоров рабочей системы.
Кусок кода для Apitron:
```
public static void ConvertPDFToImage(string pdfInputPath, string imageOutputPath, string imageName, ImageFormat imageFormat)
{
FileStream fs = new FileStream(pdfInputPath, FileMode.Open);
Document doc = new Apitron.PDF.Rasterizer.Document(fs);
RenderingSettings option = new RenderingSettings();
option.DrawAnotations = true;
doc.Pages[0].Render((int) doc.Pages[0].Width, (int) doc.Pages[0].Height, option).Save(Path.ChangeExtension(Path.Combine(imageOutputPath, imageName), imageFormat.ToString()), imageFormat);
}
```
Результат: 
##### O2S.Components.PDFRender4NET
Румынский компонент удовлетворительно справился с тестовым испытанием. Не все элементы документа сохраняются правильно. Как видно из результирующего файла все элементы спецификации поддерживаются. Есть явные проблемы с рисованием текста.
Кусок кода для O2S:
```
public static void ConvertPDFToImage(string pdfInputPath, string imageOutputPath, string imageName, ImageFormat imageFormat)
{
PDFFile pdfFile = O2S.Components.PDFRender4NET.PDFFile.Open(pdfInputPath);
using (Bitmap pageImage = pdfFile.GetPageImage(0, 300))
{
pageImage.Save(Path.ChangeExtension(Path.Combine(imageOutputPath, imageName), imageFormat.ToString()), imageFormat);
}
}
```
Результат: 
##### xPDF Wrapper Library (PDFLibNET)
Генерация тестового примера не удалась. Изображение выглядит размытым, текст не читается. При конвертировании тестового файла получили ошибки.
Кусок кода для PDFLibNET:
```
public static void ConvertPDFToImage(string pdfInputPath, string imageOutputPath, string imageName, ImageFormat imageFormat)
{
PDFWrapper pdfWrapper = new PDFWrapper();
pdfWrapper.LoadPDF(pdfInputPath);
pdfWrapper.ExportJpg(Path.ChangeExtension(Path.Combine(imageOutputPath, imageName), imageFormat.ToString()), 10);
pdfWrapper.Dispose();
}
```
Результат: 
##### PDFSharp (GhostScript и другие обёртки)
PDFSharp, как и другие обёртки известного инструмента GhostScript (например gouda, GhostscriptSharp) работает специфично и не всегда предсказуемо. Потратив несколько часов времени получилось сделать только извлечение картинок, целиком документ сохранить в виде картинки не получилось. Отмечу как хорошую идею для новой статьи.
Можно здесь же отметить, всеми любимый, iTextSharp. Удобный инструмент, но не для нашей задачи.
##### PdfFocus от SautinSoft
В мой обзор попался также отечественный компонент. Но, к сожалению, с испытаниями он не справился.
На тестовом файле он выдал NRE ошибку. Зато, на других файлах он неплохо показал себя.
(Автору: «Максим, я уверен, что у Вас отличный софт и эта мелочь будет быстро исправлена.»)
Кусок кода для SautinSoft:
```
public static void ConvertPDFToImage(string pdfInputPath, string imageOutputPath, string imageName, ImageFormat imageFormat)
{
PdfFocus pdfFocus = new PdfFocus();
pdfFocus.OpenPdf(pdfInputPath);
pdfFocus.ImageOptions.Dpi = 96;
pdfFocus.ImageOptions.ImageFormat = imageFormat;
using (Image bitmap = pdfFocus.ToDrawingImage(1))
{
bitmap.Save(Path.ChangeExtension(Path.Combine(imageOutputPath, imageName), imageFormat.ToString()), imageFormat);
}
pdfFocus.ClosePdf();
}
```
##### TallCompоnents.PDF.Rаsterizer
Нидерландский компонент хорошо справился с тестовым испытанием. Сложности специфичного API были компенсированы базовыми знаниями Graphics. Видны небольшие проблемы с рисованием текста.
Кусок кода для TаllCоmponents:
```
public static void ConvertPDFToImage(string pdfInputPath, string imageOutputPath, string imageName, ImageFormat imageFormat)
{
FileStream fs = new FileStream(pdfInputPath, FileMode.Open);
Document document = new Document(fs);
Page page = document.Pages[0];
RenderSettings renderSettings = new RenderSettings();
renderSettings.GdiSettings.WorkAroundImageTransparencyPrintSize = true;
using (Bitmap bitmap = new Bitmap((int) page.Width, (int) page.Height))
{
using (Graphics graphics = Graphics.FromImage(bitmap))
{
graphics.SmoothingMode = SmoothingMode.AntiAlias;
graphics.CompositingQuality = CompositingQuality.HighQuality;
graphics.Clear(Color.White);
page.Draw(graphics, renderSettings);
}
bitmap.Save(Path.ChangeExtension(Path.Combine(imageOutputPath, imageName), imageFormat.ToString()), imageFormat);
}
}
```
Результат: 
##### Итог
Сохранение PDF документов в изображение BMP, JPEG, TIFF задача нетривиальная, как это может показаться на первый взгляд. Можно найти массу программных утилит, библиотек и коммерческих сервисов и их условно бесплатных аналогов, но в маленьком стартапе не обойтись без надежных компонентов сторонних разработчиков. Проанализировав результаты, перечитав документацию, примеры кода и цены на сайтах, я выбрал компонент для своего проекта. По производительности, все библиотеки находятся на одном уровне, возможно, из-за специфики считывания PDF документа в один поток. При выборе я не учёл возможность использования продуктов на мобильных устройствах, так как не все компоненты из-за ограничений GDI+ смогут работать корректно под платформу Android или совместимы с Mono.Xamarin. | https://habr.com/ru/post/182800/ | null | ru | null |
# Как Project Infer от Facebook помогает искать баги в мобильных приложениях перед деплоем

Несколько дней назад команда инженеров Facebook отличилась — ее удостоили награды [Most Influential POPL Paper Award](https://www.sigplan.org/Awards/POPL/). В среде специалистов по машинному обучению это весьма почетно. Награду вручили за работу [Compositional Shape Analysis by Means of Bi-abduction](http://www0.cs.ucl.ac.uk/staff/p.ohearn/papers/popl09.pdf), которая раскрывает нюансы Project Infer. Сам проект предназначен для обнаружения и ликвидации багов в коде мобильного приложения перед его деплоем.
Баги в программном обеспечении для мобильных устройств обходятся очень дорого как разработчикам, так и пользователям. Что касается первых, то обнаружение проблемы в уже размещенном в каталогах приложении — ночной кошмар для любого специалиста. Конечно, софт тестируется, работу программ проверяют по определенным шаблонам. Но чаще разработчики не могут предусмотреть всего, и баги в приложении обнаруживаются уже после деплоя.
> **Напоминаем:** *для всех читателей «Хабра» — скидка 10 000 рублей при записи на любой курс Skillbox по промокоду «Хабр».*
>
>
>
> **Skillbox рекомендует:** Онлайн-курс [«Аналитик данных на Python»](https://skillbox.ru/python-data/?utm_source=skillbox.media&utm_medium=habr.com&utm_campaign=PTNANA&utm_content=articles&utm_term=projectinfer).
>
>
Project Infer сканирует код мобильных приложений и позволяет найти разного рода проблемы, паттерны которых хранятся в базе (а она все время обновляется). Сам проект был представлен три года назад. Почти сразу после анонса Facebook открыл код, после чего его стали использовать в таких компаниях, как Amazon Web Services, Spotify и Uber.
### Как это работает?
Project Infer использует специализированный набор алгоритмов для анализа работы кода. В исходном коде любого крупного приложения могут быть миллионы комбинаций, которые приводят к появлению ошибок. Традиционные процедуры анализа кода не могут помочь обнаружить все. Infer от Facebook, самообучаясь, расширяет свою базу, так проект позволяет обнаружить массу проблем в коде.
В общем смысле процесс работы Facebook Infer можно разделить на два этапа: сбор данных и их анализ. Жизненный цикл (lifecycle) также разделяется на две части: глобальную и дифференциальную.
На этапе сбора данных Infer переводит исходный код в собственный язык. Этап анализа посвящается изучению мельчайших деталей структуры кода, которые могут потенциально привести к появлению ошибки. Если Infer встречает уже знакомое сочетание факторов, идентифицируемое как паттерн ошибки, анализ останавливается для конкретного метода или функции, но остальные методы и функции продолжают анализироваться. Вот пример работы Infer.

C точки зрения исполнения Infer может работать в двух модальностях — Global и Differential, как и говорилось выше. В первом случае Infer анализирует все файлы. Для проекта, который компилируется с использованием Gradle, запуск Infer производится командой
```
infer run -- gradle build
```
Дифференциальный процесс используется в инкрементных системах сборки, характерных для мобильных приложений. В этом случае нужно сначала запустить сбор данных Infer, чтобы получить все команды компиляции, а затем провести анализ только изменений. Для этого используется такой набор команд:
```
gradle clean
infer capture -- gradle build
edit some/File.java
# make some changes to some/File.java
infer run --reactive -- gradle build
```
Отчеты Infer можно просмотреть при помощи команды InferTraceBugs.
```
infer run -- gradle build
inferTraceBugs
```
### Основа Project Infer
Infer от Facebook основан на двух новых математических методах: [логике разделения](https://ru.wikipedia.org/wiki/%D0%9B%D0%BE%D0%B3%D0%B8%D0%BA%D0%B0_%D1%80%D0%B0%D0%B7%D0%B4%D0%B5%D0%BB%D0%B5%D0%BD%D0%B8%D1%8F) и [Bi-abduction](https://fbinfer.com/docs/separation-logic-and-bi-abduction.html).
Ключевая особенность логики разделения — возможность локальных рассуждений (local reasoning). Она появилась благодаря наличию в утверждениях пространственных связок (англ. spatial connectives) между частями кучи. В этом случае нет необходимости учитывать весь объем памяти на каждом из этапов.
Основной элемент логики разделения — оператор \* (и отдельно), который называется разделяющим соединением. Формула X↦Y ∗ Y↦X может быть прочитана как «X указывает на Y, а отдельно Y указывает на X», что очень похоже на то, как работают указатели памяти.
В контексте Infer Bi-abduction можно рассматривать как метод логического вывода, который дает платформе возможность обнаруживать свойства, касающиеся поведения независимых частей кода приложения. Bi-abduction совместно выводит антифреймы (отсутствующие части состояния) и фреймы (те части, которые не затронуты операцией). Математически проблема Bi-abduction выражается с использованием следующего синтаксиса: A ∗? Antiframe⊢B ∗? Frame.
В Infer от Facebook метод дает возможность вывести спецификации pre/post из чистого кода при условии, что мы знаем спецификации для примитивов на базовом уровне кода.
Создание FI стало возможно благодаря анализу работы специалистов по машинному обучению, который проводился много лет. В ходе работы над Infer были опубликованы такие ключевые для всей сферы статьи:
* [**Compositional Shape Analysis by means of Bi-abduction**](http://www0.cs.ucl.ac.uk/staff/p.ohearn/papers/popl09.pdf). Как раз за эту работу была получена премия, о которой говорится выше. Работа знакомит читателя с композиционным анализом формы. Это дополнение к традиционному анализу формы (shape analysis), дающее возможность применить метод для анализа исходного кода приложений.
* [**A Local Shape Analysis Based on Separation Logic**](https://link.springer.com/chapter/10.1007%2F11691372_19)**:** эта статья описывает логику разделения в качестве механизма анализа исходного кода приложений. Авторы показывают возможность изучения отдельных ячеек в куче памяти, без изучения всей кучи целиком. Таким образом, определенные ячейки составляют связанный список и без полного анализа.
* **[Smallfoot: Modular Automatic Assertion Checking with Separation Logic](https://link.springer.com/chapter/10.1007/11804192_6)**: в этой работе описывается предшественник Facebook Infer, который называется Smallfoot.
* **[AL: A new declarative language for detecting bugs with Infer](https://code.fb.com/developer-tools/al-a-new-declarative-language-for-detecting-bugs-with-infer/)**: AL позволяет любому разработчику проектировать новые чекеры без полного понимания внутренней кухни Infer. AL — это декларативный язык.
* **[Moving Fast with Software Verification](https://research.fb.com/publications/moving-fast-with-software-verification/)**: Наконец, статья, которая раскрывает, как Facebook использует Project Infer для собственных нужд. В документе рассказывается о том, как разработчики Facebook интегрировали Infer в свой процесс разработки для обеспечения статического анализа для мобильных приложений, таких как Instagram, Facebook Messenger и приложения Facebook для Android и iOS.
Пока что Infer может использоваться лишь для мобильных приложений. Но некоторые его принципы применимы к приложениям общего назначения. Возможно, в будущем возможности Infer станут шире, и с его помощью разработчики смогут анализировать десктопные или серверные приложения.
> **Skillbox рекомендует:**
>
>
>
> * Практический курс [«Мобильный разработчик PRO»](https://skillbox.ru/agima/?utm_source=skillbox.media&utm_medium=habr.com&utm_campaign=AGIMA&utm_content=articles&utm_term=projectinfer).
> * Онлайн-курс [«Профессия Frontend-разработчик»](https://skillbox.ru/frontend-developer/?utm_source=skillbox.media&utm_medium=habr.com&utm_campaign=FRENDEV&utm_content=articles&utm_term=projectinfer).
> * Практический годовой курс [«PHP-разработчик с 0 до PRO»](https://skillbox.ru/php/?utm_source=skillbox.media&utm_medium=habr.com&utm_campaign=PHPDEV&utm_content=articles&utm_term=projectinfer).
> | https://habr.com/ru/post/440536/ | null | ru | null |
# Как мы учились эксплуатировать Java в Docker
Под капотом hh.ru — большое количество Java-сервисов, запущенных в докер-контейнерах. За время их эксплуатации мы столкнулись с большим количеством нетривиальных проблем. Во многих случаях чтобы докопаться до решения приходилось долго гуглить, читать исходники OpenJDK и даже профилировать сервисы на продакшене. В этой статье я постараюсь передать квинтэссенцию полученного в процессе знания.
* [CPU лимиты](https://habr.com/ru/company/hh/blog/450954#cpu)
* [Docker и server class machine](https://habr.com/ru/company/hh/blog/450954#server-class)
* [CPU лимиты (да, опять) и фрагментация памяти](https://habr.com/ru/company/hh/blog/450954#malloc)
* [Обрабатываем Java-OOM](https://habr.com/ru/company/hh/blog/450954#oom)
* [Оптимизируем потребление памяти](https://habr.com/ru/company/hh/blog/450954#opt-mem)
* [Ограничиваем потребление памяти: heap, non-heap, direct memory](https://habr.com/ru/company/hh/blog/450954#lim-mem-1)
* [Ограничиваем потребление памяти: Native Memory Tracking](https://habr.com/ru/company/hh/blog/450954#lim-mem-2)
* [Java и диски](https://habr.com/ru/company/hh/blog/450954#disks)
* [Как за всем уследить?](https://habr.com/ru/company/hh/blog/450954#monitor)
#### CPU лимиты
Раньше мы жили в kvm-виртуалках с ограничениями CPU и памяти и, переезжая в Docker, выставили похожие ограничения в cgroups. И первой неувязкой, с которой мы столкнулись, были именно CPU лимиты. Сразу скажу, что эта проблема уже не актуальна для свежих версий Java 8 и Java ≥ 10. Если вы идёте в ногу со временем, можете смело пропускать этот раздел.
Итак, мы запускаем небольшой сервис в контейнере и видим, что он плодит огромное количество тредов. Или потребляет CPU гораздо больше, чем ожидалось, таймаутится почём зря. Или вот ещё реальная ситуация: на одной машине сервис нормально запускается, а на другой, с теми же настройками — падает, прибитый OOM-киллером.
Разгадка оказывается очень простой — просто Java не видит ограничений `--cpus`, выставленных в докере и считает, что ей доступны все ядра хост-машины. А их может быть очень много (в нашем стандартном сетапе — 80).
Библиотеки подстраивают размеры тред-пулов под количество доступных процессоров — отсюда огромное количество тредов.
Сама Java таким же образом масштабирует количество тредов GC, отсюда потребление CPU и таймауты — сервис начинает тратить большое количество ресурсов на сборку мусора, используя львиную долю отпущенной ему квоты.
Также библиотеки (в частности Netty) могут в определённых случаях подстраивать размеры офф-хип памяти под количество CPU, что приводит к большой вероятности выхода за выставленные контейнеру лимиты при запуске на более мощном железе.
Сначала, по мере проявления этой проблемы, мы пытались использовать следующие воркэраунды:
— пробовали использовать в паре сервисов [libnumcpus](https://github.com/dekobon/libnumcpus) — библиотеку, которая позволяет «обмануть» Java, задав иное число доступных процессоров;
— явно указывали количество GC-тредов,
— явно задавали лимиты на использование direct byte buffers.
Но, конечно же, с такими костылями передвигаться не очень удобно, и настоящим решением стал переезд на Java 10 (а затем и Java 11), в котором все эти проблемы [отсутствуют](https://bugs.openjdk.java.net/browse/JDK-8146115). Справедливости ради, стоит сказать, что в восьмёрке тоже всё стало хорошо с [апдейта 191](https://www.oracle.com/technetwork/java/javase/8u191-relnotes-5032181.html#JDK-8146115), выпущенного в октябре 2018 года. К тому времени для нас это было уже неактуально, чего и вам желаю.
Это один из примеров, когда обновление версии Java даёт не только моральное удовлетворение, но и реальный ощутимый профит в виде упрощения эксплуатации и повышения производительности сервиса.
#### Docker и server class machine
Итак, в Java 10 появились (и были бекпортированы в Java 8) опции `-XX:ActiveProcessorCount` и `-XX:+UseContainerSupport`, учитывающие по умолчанию лимиты cgroups. Теперь-то всё стало замечательно. Или нет?
Через некоторое время после того как мы пересели на Java 10 / 11, мы стали замечать некоторые странности. Почему-то в некоторых сервисах графики GC выглядели так, будто в них не использовался G1:
Это было, мягко говоря, немного неожиданно, так как мы точно знали, что G1 является дефолтным коллектором, начиная с Java 9. При этом в каких-то сервисах этой проблемы нет — включается G1, как и ожидалось.
Начинаем разбираться и натыкаемся на [интересную вещь](https://github.com/AdoptOpenJDK/openjdk-jdk11/blob/999dbd4192d0f819cb5224f26e9e7fa75ca6f289/src/hotspot/share/runtime/os.cpp#L1627). Оказывается, если Java запущена меньше чем на 3 процессорах и с лимитом памяти меньше 2 ГБ, то она считает себя клиентской и не даёт использовать ничего, кроме SerialGC.
К слову, это затрагивает только [выбор GC](https://github.com/AdoptOpenJDK/openjdk-jdk11/blob/8dba7453f0628759b83d77df87690b95047295a8/src/hotspot/share/gc/shared/gcConfig.cpp#L103) и никак не связано с параметрами -client / -server и JIT-компиляцией.
Очевидно, когда мы пользовались Java 8, она не учитывала лимиты докера и считала, что у неё много процессоров и памяти. После обновления на Java 10 многие сервисы, у которых лимиты выставлены ниже, внезапно стали использовать SerialGC. К счастью, лечится это очень просто — явным выставлением опции `-XX:+AlwaysActAsServerClassMachine`.
#### CPU лимиты (да, опять) и фрагментация памяти
Рассматривая графики в мониторинге, мы как-то заметили, что Resident Set Size контейнера чересчур большой — аж в три раза больше чем максимальный размер хипа. Не может ли здесь быть дело в каком-то очередном хитром механизме, который масштабируется по числу процессоров в системе и не знает об ограничениях докера?
Оказывается, механизм вовсе не хитрый — это всем хорошо известный malloc из glibc. Если коротко, то в glibc для выделения памяти используются так называемые арены. При создании каждому треду присваивается одна из арен. Когда тред с помощью glibc хочет выделить определённое количество памяти в нативном хипе под свои нужды и вызывает malloc, то память выделяется в присвоенной ему арене. Если арена обслуживает несколько тредов, то эти треды будут за неё конкурировать. Чем больше арен, тем меньше конкуренции, но тем больше фрагментации, так как у каждой арены свой список свободных областей.
На 64-битных системах количество арен по умолчанию выставляется в 8 \* количество CPU. Очевидно, для нас это огромный оверхед, потому что контейнеру доступны не все CPU. Более того, для Java-приложений конкуренция за арены не так актуальна, так как большинство аллокаций делается в Java-хипе, память под который можно целиком выделить при старте.
Эта особенность malloc известна уже [очень](https://www.ibm.com/developerworks/community/blogs/kevgrig/entry/linux_glibc_2_10_rhel_6_malloc_may_show_excessive_virtual_memory_usage?lang=en) [давно](https://devcenter.heroku.com/articles/tuning-glibc-memory-behavior#what-value-to-choose-for-malloc_arena_max), как и её решение — использовать переменную окружения `MALLOC_ARENA_MAX` для явного указания числа арен. Это очень легко сделать для любого контейнера. Вот эффект от указания `MALLOC_ARENA_MAX = 4` для нашего основного бэкенда:
На графике RSS двух инстансов: в одном (синий) включаем `MALLOC_ARENA_MAX`, другой (красный) просто рестартуем. Разница очевидна.
Но после этого возникает резонное желание разобраться, на что Java вообще тратит память. Можно ли запустить на Java микросервис с лимитом памяти в 300-400 мегабайт и не бояться, что он упадёт с Java-OOM или не будет прибит системным OOM-киллером?
#### Обрабатываем Java-OOM
Прежде всего, надо подготовиться к тому, что OOM неизбежны, и надо их правильно обрабатывать — как минимум сохранять хип-дампы. Как ни странно, даже в этой простой затее есть свои нюансы. К примеру, хип-дампы не перезаписываются — если уже сохранён хип-дамп с тем же именем, то новый просто не будет создан.
Java умеет [автоматически добавлять](https://github.com/AdoptOpenJDK/openjdk-jdk11/blob/999dbd4192d0f819cb5224f26e9e7fa75ca6f289/src/hotspot/share/services/heapDumper.cpp#L2028) порядковый номер дампа и process id в название файла, но это нам ничем не поможет. Порядковый номер не пригодится, потому что это OOM, а не штатно запрошенный хипдамп — приложение после него рестартует, обнуляя счётчик. А process id не подходит, так как в докере он всегда одинаковый (чаще всего 1).
Поэтому мы пришли к такому варианту:
`-XX:+HeapDumpOnOutOfMemoryError
-XX:+ExitOnOutOfMemoryError
-XX:HeapDumpPath=/var/crash/java.hprof
-XX:OnOutOfMemoryError="mv /var/crash/java.hprof /var/crash/heapdump.hprof"`
Он довольно прост и при некоторых доработках можно даже научить хранить его не только последний хипдамп, но для наших нужд и этого более чем достаточно.
Java OOM — это не единственное, с чем нам придётся столкнуться. У каждого контейнера есть ограничение на занимаемую им память, и оно может быть превышено. Если так происходит, то контейнер убивается системным OOM-киллером и рестартует (мы используем `restart_policy: always`). Естественно, это нежелательно, и мы хотим научиться правильно выставлять лимиты на используемые JVM ресурсы.
#### Оптимизируем потребление памяти
Но прежде чем настраивать лимиты, нужно убедиться, что JVM не тратит ресурсы впустую. Мы уже сумели сократить потребление памяти с помощью лимита на количество CPU и переменной `MALLOC_ARENA_MAX`. Есть ли ещё какие-то «почти бесплатные» способы это сделать?
Оказывается, есть ещё пара трюков, которые позволят сэкономить немного памяти.
Первый — это использование опции `-Xss` (или `-XX:ThreadStackSize`), контролирующей размер стека для тредов. По умолчанию для 64-битной JVM это 1 МБ. Мы выяснили, что нам хватает и 512 КБ. StackOverflowException пока из-за этого ни разу не ловили, но допускаю, что подойдёт это далеко не всем. Да и профит от этого совсем небольшой.
Второй — флаг `-XX:+UseStringDeduplication` (при включённом G1 GC). Он позволяет сэкономить на памяти, схлопнув дублирующиеся строки за счёт дополнительной нагрузки на процессор. Трейдоф между памятью и CPU зависит только от конкретного приложения и настройки самого механизма дедупликации. Читайте [доку](http://openjdk.java.net/jeps/192) и тестируйте в своих сервисах, у нас эта опция пока не нашла своего применения.
И, наконец, способ, который тоже подойдёт не всем (но нам зашло) — использовать [jemalloc](http://jemalloc.net/) вместо родного malloc. Эта имплементация заточена на уменьшение фрагментации памяти и лучшую поддержку многопоточности по сравнению с malloc из glibc. Для наших сервисов jemalloc дал немного больше выигрыша по памяти, чем malloc с `MALLOC_ARENA_MAX=4`, при этом не сказавшись сколько-нибудь заметно на производительности.
Остальные варианты, в том числе описанные у Алексея Шипилёва в [JVM Anatomy Quark #12: Native Memory Tracking](https://shipilev.net/jvm/anatomy-quarks/12-native-memory-tracking/), показались довольно опасными либо приводили к заметной деградации производительности. Тем не менее, в образовательных целях рекомендую прочесть эту статью.
А пока двинемся к следующей теме и, наконец, попробуем научиться ограничивать потребление памяти и подбирать правильные лимиты.
#### Ограничиваем потребление памяти: heap, non-heap, direct memory
Чтобы всё правильно сделать, надо вспомнить, из чего вообще состоит память в Java. Для начала посмотрим на пулы, состояние которых можно замониторить через JMX.
Первое, само собой, **хип**. Тут всё просто: задаём `-Xmx`, но как сделать это правильно? К сожалению, универсального рецепта тут нет, всё зависит от приложения и профиля нагрузки. Для новых сервисов мы начинаем с относительно разумного размера хипа (128 Мб) и при необходимости увеличиваем или уменьшаем его. Для поддержки уже существующих есть мониторинг с графиками потребления памяти и метриками GC.
Одновременно с `-Xmx` мы выставляем `-Xms == -Xmx`. У нас нет оверселлинга памяти, поэтому в наших интересах, чтобы сервис по максимуму использовал те ресурсы, которые мы ему выдали. В дополнение, в рядовых сервисах мы включаем `-XX:+AlwaysPreTouch` и механизм Transparent Huge Pages: `-XX:+UseTransparentHugePages -XX:+UseLargePagesInMetaspace`. Однако, прежде чем включать THP, внимательно прочитайте [документацию](https://www.kernel.org/doc/html/latest/admin-guide/mm/transhuge.html) и протестируйте, как сервисы ведут себя с этой опцией в течение длительного времени. Не исключены сюрпризы на машинах с недостаточным запасом оперативной памяти (к примеру, нам пришлось выключить THP на тестовых стендах).
Далее — **non-heap**. В non-heap память входят:
— Metaspace и Compressed Class Space,
— Code Cache.
Рассмотрим эти пулы по порядку.
Про **Metaspace**, конечно же, все слышали, не буду подробно про него рассказывать. В нём хранятся метаданные классов, байткод методов и так далее. По сути, использование Metaspace напрямую зависит от числа и размера загруженных классов и определить его можно, как и хип, только запустив приложение и сняв метрики через JMX. По умолчанию Metaspace ничем не ограничен, но сделать это довольно легко с помощью опции `-XX:MaxMetaspaceSize`.
**Compressed Class Space** входит в состав Metaspace и появляется, когда включена опция `-XX:+UseCompressedClassPointers` (включена по умолчанию для хипов меньше 32 ГБ, то есть когда она может дать реальный выигрыш по памяти). Размер этого пула можно ограничить опцией `-XX:CompressedClassSpaceSize`, но особого смысла в этом нет, так как Compressed Class Space включается в Metaspace и суммарный объём закоммиченной памяти для Metaspace и Compressed Class Space в итоге ограничивается одной опцией `-XX:MaxMetaspaceSize`.
Кстати, если смотреть на показания JMX, то там объём non-heap памяти всегда рассчитывается как [сумма](https://github.com/AdoptOpenJDK/openjdk-jdk11/blob/999dbd4192d0f819cb5224f26e9e7fa75ca6f289/src/hotspot/share/services/management.cpp#L724) Metaspace, Compressed Class Space и Code Cache. На самом деле надо суммировать только Metaspace и CodeCache.
Итак, в non-heap остался только **Code Cache** — хранилище скомпилированного JIT-компилятором кода. По умолчанию его максимальный размер выставлен в 240 МБ и для небольших сервисов это в несколько раз больше, чем нужно. Размер Code Cache можно выставить опцией `-XX:ReservedCodeCacheSize`. Правильный размер можно определить, только запустив приложение и проследив за ним под типичным профилем нагрузки.
Тут важно не ошибиться, так как недостаточный размер Code Cache приводит к удалению из кеша холодного и старого кода (опция `-XX:+UseCodeCacheFlushing` включена по умолчанию), а это, в свою очередь, может привести к более высокому потреблению CPU и к деградации производительности. Было бы здорово, если можно было кидать OOM при переполнении Code Cache, для этого даже есть флаг `-XX:+ExitOnFullCodeCache`, но, к сожалению, он доступен только в [девелоперской версии](https://github.com/AdoptOpenJDK/openjdk-jdk11/blob/999dbd4192d0f819cb5224f26e9e7fa75ca6f289/src/hotspot/share/runtime/globals.hpp#L1944) JVM.
Последний пул, о котором есть информация в JMX, — **direct memory**. По умолчанию его размер не ограничен, поэтому важно задать ему какой-то лимит — как минимум на него будут ориентироваться библиотеки вроде Netty, активно использующие direct byte-буфферы. Задать лимит несложно при помощи флага `-XX:MaxDirectMemorySize`, а в определении правильного значения нам, опять же, поможет только мониторинг.
Итак, что у нас пока получается?
```
Java process memory =
Heap + Metaspace + Code Cache + Direct Memory =
-Xmx +
-XX:MaxMetaspaceSize +
-XX:ReservedCodeCacheSize +
-XX:MaxDirectMemorySize
```
Давайте попробуем нарисовать всё на графике и сравнить с RSS докер-контейнера.
Линия сверху — это RSS контейнера и он раза в полтора больше, чем потребление памяти JVM, которое мы можем замониторить через JMX.
Копаем дальше!
#### Ограничиваем потребление памяти: Native Memory Tracking
Разумеется, помимо heap, non-heap и direct memory, JVM использует целую кучу других пулов памяти. Разобраться с ними нам поможет флаг `-XX:NativeMemoryTracking=summary`. Включив эту опцию, мы сможем получать информацию о пулах, известных JVM, но недоступных в JMX. Подробнее об использовании этой опции можно почитать в [документации](https://docs.oracle.com/en/java/javase/12/troubleshoot/diagnostic-tools.html#GUID-FB0581EA-2F91-4093-B2FA-46687F7AB081).
Начнём с самого очевидного — памяти, занимаемой **стеками тредов**. NMT выдаёт для нашего сервиса примерно следующее:
```
Thread (reserved=32166KB, committed=5358KB)
(thread #52)
(stack: reserved=31920KB, committed=5112KB)
(malloc=185KB #270)
(arena=61KB #102)
```
Кстати, её размер можно узнать и без Native Memory Tracking, воспользовавшись jstack и немного поковырявшись в `/proc//smaps`. Андрей Паньгин выкладывал [специальную утилиту](https://github.com/apangin/jstackmem) для этого.
Размер **Shared Class Space** оценить ещё проще:
```
Shared class space (reserved=17084KB, committed=17084KB)
(mmap: reserved=17084KB, committed=17084KB)
```
Это механизм Class Data Sharing, включаемый опциями `-Xshare` и `-XX:+UseAppCDS`. В Java 11 опция `-Xshare` по умолчанию выставлена в auto, а это значит, что если у вас есть архив `$JAVA_HOME/lib/server/classes.jsa` (в официальном докер-образе OpenJDK он есть), то он будет загружаться memory map-ом при старте JVM, ускоряя время запуска. Соответственно, размер Shared Class Space легко определить, если вы знаете размер jsa-архивов.
Далее идут нативные структуры **сборщика мусора**:
```
GC (reserved=42137KB, committed=41801KB)
(malloc=5705KB #9460)
(mmap: reserved=36432KB, committed=36096KB)
```
У Алексея Шипилёва в уже упомянутом руководстве по Native Memory Tracking [сказано](https://shipilev.net/jvm/anatomy-quarks/12-native-memory-tracking/#_slimdown_sane_parts), что они занимают примерно 4-5% от размера хипа, но в нашем сетапе для небольших хипов (до нескольких сотен мегабайт) оверхед доходил до 50% от размера хипа.
Довольно много места могут занимать **таблицы символов**:
```
Symbol (reserved=16421KB, committed=16421KB)
(malloc=15261KB #203089)
(arena=1159KB #1)
```
В них хранятся названия методов, сигнатуры, а также ссылки на интернированные строки. К сожалению, оценить размер таблицы символов представляется возможным только пост-фактум, с помощью Native Memory Tracking.
Что остаётся? Согласно Native Memory Tracking довольно много всего:
```
Compiler (reserved=509KB, committed=509KB)
Internal (reserved=1647KB, committed=1647KB)
Other (reserved=2110KB, committed=2110KB)
Arena Chunk (reserved=1712KB, committed=1712KB)
Logging (reserved=6KB, committed=6KB)
Arguments (reserved=19KB, committed=19KB)
Module (reserved=227KB, committed=227KB)
Unknown (reserved=32KB, committed=32KB)
```
Но на всё это уходит довольно мало места.
К сожалению, многие из упомянутых областей памяти нельзя ни ограничить, ни контролировать, а если и можно было бы, то конфигурация превратилась бы в сущий ад. Даже наблюдение за их состоянием — нетривиальная задача, так как включение Native Memory Tracking немного просаживает производительность приложения и включать его на продакшене в критичном сервисе — не лучшая идея.
Всё же, ради интереса попробуем отразить на графике всё, о чём сообщает Native Memory Tracking:

Неплохо! Оставшаяся разница — это оверхед на фрагментацию / аллокацию памяти (он совсем небольшой, так как мы используем jemalloc) или память, которую выделили нативные либы. Мы как раз пользуемся одной такой для эффективного хранения префиксного дерева.
Итак, для наших нужд достаточно ограничить то, что можно: Heap, Metaspace, Code Cache, Direct Memory. На всё остальное мы оставляем некий разумный задел, определяемый по результатам практических замеров.
Разобравшись с CPU и памятью, переходим к следующему ресурсу, за который могут конкурировать приложения — к дискам.
#### Java и диски
И с ними всё очень плохо: они медленные и могут приводить к ощутимым затупам приложения. Поэтому мы максимально отвязываем Java от дисков:
* Все логи приложения мы пишем в локальный сислог по UDP. Это оставляет некоторую вероятность, что нужные логи потеряются где-то по пути, но, как показала практика, такие случаи очень редки.
* Логи JVM будем писать в tmpfs, для этого нужно всего лишь подмонтировать в докере в нужное место волюмом `/dev/shm`.
Если мы пишем логи в сислог или в tmpfs, а само приложение ничего, кроме хип-дампов, на диск не пишет, то выходит, что на этом историю с дисками можно считать закрытой?
Конечно же, нет.
Обращаем внимание на график длительности stop-the-world пауз и видим печальную картину — Stop-The-World-паузы на хостах по сотням миллисекунд, а на одном хосте вообще могут доходить до секунды:
Надо ли говорить, что это негативно сказывается на работе приложения? Вот, к примеру, график, отражающий время ответа сервиса по мнению клиентов:
Это очень простой сервис, по большей части отдающий закешированные ответы, так откуда там такие запредельные тайминги, начиная с 95 персентили? В других сервисах аналогичная картина, к тому же с завидным постоянством сыпятся таймауты при взятии коннекшена из пула соединений к базе, при выполнении запросов и так далее.
При чём же тут диски? — спросите вы. Оказывается, очень даже при чём.
Детальный разбор проблемы показал, что долгие STW-паузы возникают из-за того, что треды долго идут до сейфпойнта. Почитав код JVM, мы поняли, что во время синхронизации тредов на сейфпойнте JVM может записывать через memory map файл `/tmp/hsperfdata*`, в который она экспортирует некоторую статистику. Этой статистикой пользуются утилиты типа `jstat` и `jps`.
Отключаем её на одной машине опцией `-XX:+PerfDisableSharedMem` и…
Метрики тредпула Jetty стабилизируются:
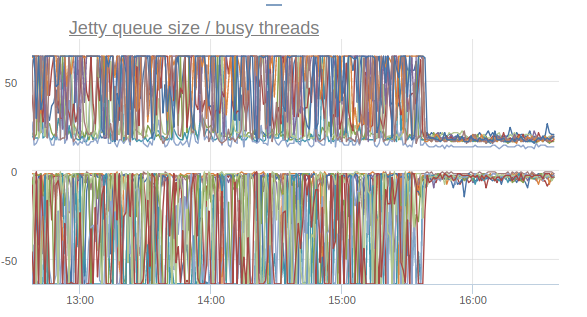
А персентили времени ответа начинают приходить в норму (повторюсь, это эффект от включения опции только на одной машине):
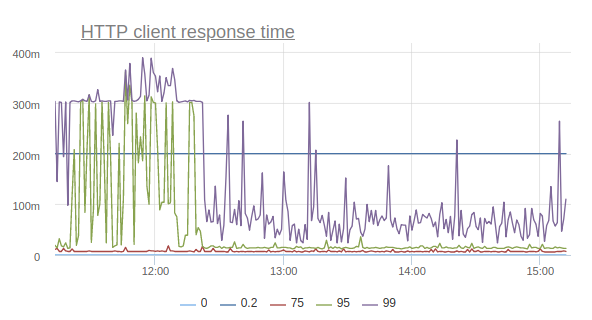
Таким образом, благодаря выключению одной опции мы сумели снизить количество таймаутов, количество ретраев, и даже поправить общие персентили времени ответа сайта.
#### Как за всем уследить?
Для того чтобы поддерживать Java-сервисы в докере, нужно, прежде всего, научиться за ними следить.
Мы запускаем свои сервисы на базе собственного фреймворка [Nuts and Bolts](https://github.com/hhru/nuts-and-bolts), и поэтому можем обвесить все критичные места нужными нам метриками. В дальнейшем это очень сильно помогает при расследовании инцидентов и вообще в понимании того, как сервис живёт на продакшене. Метрики мы посылаем в статсд, на практике это оказывается более удобно, чем JMX.
По метрикам мы стараемся строить графики, отражающие внутреннее состояние сервиса и позволяющие быстро диагностировать причины аномалий. Некоторые из подобных графиков я уже приводил в пример выше.
Мы также отправляем в statsd и внутренние метрики JVM, например потребление памяти (heap, верно посчитанный non-heap и общую картину):
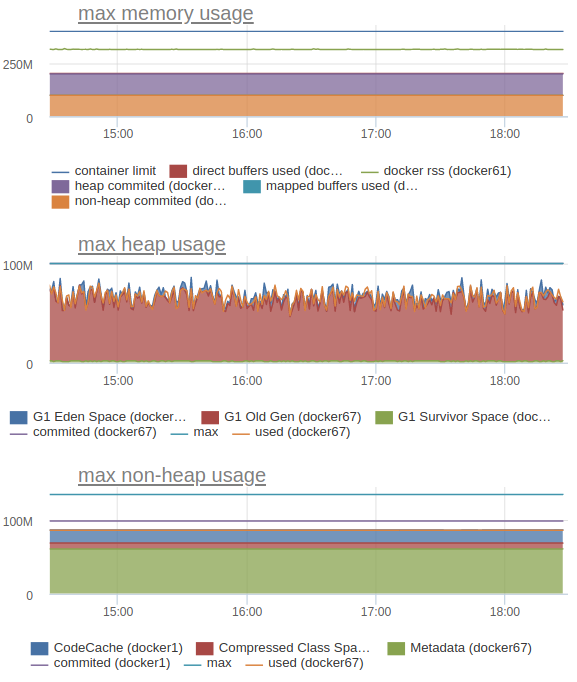
В частности, это позволяет нам понимать, какие лимиты выставлять для каждого конкретного сервиса.
Ну и напоследок — как на постоянной основе следить за тем, что лимиты выставлены грамотно, а сервисы, живущие на одном хосте, не мешают друг другу? В этом нам сильно помогает ежедневное нагрузочное тестирование. Так как у нас (пока) два дата-центра, то нагрузочное тестирование настроено так, чтобы увеличивать RPS на сайте вдвое.
Механизм нагрузочного тестирования очень прост: утром запускается крон, который парсит логи за предыдущий час и формирует из них профиль типичной анонимной нагрузки. К анонимной нагрузке добавляется ряд работодательских и соискательских страниц. После этого профиль нагрузки экспортируется в формат ammo-файлов для [Яндекс.Танка](https://github.com/yandex/yandex-tank). В заданное время Яндекс.Танк стартует:
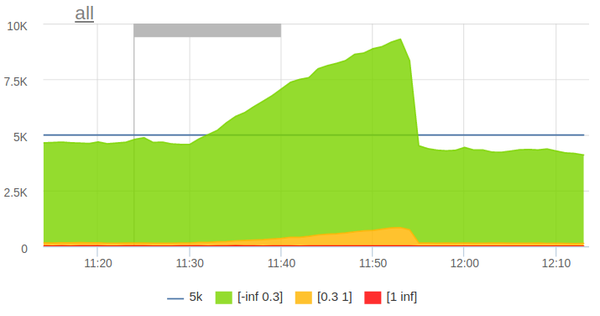
Нагрузка автоматически останавливается при превышении небольшого порога пятисоток.
За время своего существования нагрузочное тестирование позволило нам выявить целый ряд проблем ещё до того, как они зааффектили реальных пользователей. Кроме того, оно даёт нам уверенность в том, что при выпадении одного дата-центра другой, оставшийся в живых, выдержит всю нагрузку.
#### В заключение
Наш опыт показывает, что Java в Docker — это не только удобно, но и в итоге довольно экономично. Надо только научиться их готовить. | https://habr.com/ru/post/450954/ | null | ru | null |
# XMonad + XMobar = ❤
Многие слышали про тайловые оконные менеджеры, некоторые даже слышали о XMonad. А ребята из Google даже [променяли](http://habrahabr.ru/post/143734/) Unity/Gnome на XMonad. Что же это такое, как это настраивать и как с этим жить? Краткий workaround для любителей кастомизировать всё подряд.
Дружище, зачем же оно мне?
--------------------------
Для себя я выделил несколько ситуаций, когда он особенно полезен особенно полезен:
* Рабочий стол ноутбука для разработки. Места не хватает, очень хочется использовать его максимально эффективно;
* Многомониторные рабочие места. XMonad позволяет во всю использовать преимущества нескольких мониторв с помощью xinerma;
* Частое переключение контекстов задач. Например, разработчику часто приходится переключаться между IDE, файловым менеджером, консолью и прочими инструментами. Этот процесс можно ускорить;
* Надоел визуальный шум от стандартных оконных менеджеров.
В общем, меньше слов, больше дела! Если хочешь управляться с рабочим окружением так же ловко, как герой сериала Kopps управляется с преступниками , то ты не зря зашёл.
Немного о коде и примерах
-------------------------
Я использую archlinux, поэтому все примеры будут в разрезе archlinux. Но на других линукса все действия производятся похожим образом.
Все примеры я старался оформить в виде скриптов, чтобы потом можно было развернуть на новой системе. Буду оставлять ссылки на github.
Шаг 1: Установка XMonad
-----------------------
*Данное действие специфичено для archlinux*
Первое, что нужно сделать — это поставить yaourt, если он не стоит конечно же. Не буду утомлять, я делаю это скриптом [install-01-yaourt.sh](https://github.com/lavcraft/xmonad-config/blob/master/install-01-yaourt.sh). (Когда нашел на просторах интернета, спасибо автору.)
Ставим XMonad:
```
yaourt -S xmonad xmonad-contrib xmobar dmenu2
```
Или, если хотим поставить из haskell-core репозитория:
```
yaourt -S haskell-xmonad haskell-xmonad-contrib xmobar dmenu2
```
Так же можно поставить через yaourt darcs версию, но этот вирант мы опустим.
Шаг 2: Минимальная настройка XMonad
-----------------------------------
Конфигурирование XMonad производится с помощью файла ~/.xmonad/xmonad.hs. Как вы уже наверно догадались, конфигурация пишется на Haskell.
Если вы не знаете Haskell, это не беда, польюзуйтесь чужими конфигами. Когда конфиг работает, понять что к чему можно и на понятийном уровне.
Минимальный .xmonad/xmonad.hs:
```
import XMonad
main = xmonad defaultConfig
{ modMask = mod4Mask -- Use Super instead of Alt
, terminal = "urxvt"
}
```
### Курс молодого бойца по управлению XMonad
При использовании тайлового оконного менеджера, окон как таковых — нет. Есть тайлы. Тайлы ведут себя в соответсвии с текущем Layout автоматически располагаясь так или иначе (например, Layout Grid — тупо отображает таблицой или же Full — отобразить одно главное окно).
#### Layout
Компанует тайлы. По умолчанию переключение между Layout`s производится с помощью сочетания modKey+space.
В нашем случае modKey = клавише Windows(Super).
#### Тайл
Это и есть те самые, привычные нам окошки.
В Layout может быть настроена поддержка изменения размера тайлов и количества *мастер окон*. Так же можно «отсоединить» тайл, зажав кнопку modKey и потянув за окно мышкой. А modKey+RightMouseButton будет изменять размер окошка. Перевести тайл из режима doFloat в стандартный можно комбинацией modKey+t.
*Мастер тайл* — тайл, или группа тайлов, которые будут отображаться на «самом видном месте». На скришоте в шапке, master тайл самый большой, его сразу видно.
Между тайлами можно переключаться сочетаниями **modKey+tab** или **modKey+j/modKey+k** — фокус на предыдущий/следующий тайл. Так же тайлы можно менять местами с мастер тайлом или предыдущими: **modKey+entеr** — поменять местами текущий тайл и мастер тайл. **modKey+J/modKey+K** — поменять местами со следующим/предыдущим
#### Workspace
Это по сути, рабочие столы, для каждого workspace Layout свой и сохраняется при переключении на другие рабочие столы по возвращению. Хотя это поведение можно изменить, но это уже другая история.
Переключаться между Wokspace можно с помощью сочетания modKey+#, где # — номер рабочего стола (не на цифровой клавиатуре).
Подведём итог:
**modKey+tab** — фокус на следующий (или modKey+shift+tab на предыдущий);
**modKey+j/modKey+k** — фокус на следующий/предыдущий;
**modKey+J/modKey+K** — поменять текущий и следующий/предыдущий;
**modKey+entеr** — поменять текущий тайл и мастер тайл местами;
**modKey+m** — фокус на мастер тайл;
**modKey+#** — рабочий стол №#;
**modKey+t** — перевести тайл из режима doFloat в стандартный.
Оставлю это тут: [xmonad cheatsheet](https://www.haskell.org/wikiupload/b/b8/Xmbindings.png)
Шаг 3: Запуск
-------------
Есть много способов запустить XMonad, рассмотрим парочку.
### 1. Чистый запуск
У нас установлены только XMonad, нам не нужен ни Gnome, ни KDE, ни XFCE. Мы сами по себе.
В этом случае для запуска достаточно сконфигурировать запуск xmonad в файле инициализации X системы: .xinitrc:
```
setxkbmap -layout "us,ru"
setxkbmap -option "grp:caps_toggle,grp_led:scroll"
xsetroot -cursor_name left_ptr &
export PATH=~/bin:$PATH
#exec startxfce4
#exec startkde
#exec gnome-session
exec dbus-launch xmonad
```
Полезняшка: [мой .xinitrc](https://github.com/lavcraft/xmonad-config/blob/master/home/.xinitrc)
Теперь при запуске startx запустется xmonad (конечно же, эта команда исполняется, когда ещё нет X сессии).
### 2. Замена текущего оконного менеджера
XMonad умеет нагло заменять текущий window manager. Для этого достаточно выполнить простую команду:
```
xmonad --replace
```
### 3. Интеграция с \_\_ПодставитьЧтоНужно\_\_
А подставить можно, например, GNOME ([дока для archlinux](https://wiki.archlinux.org/index.php/xmonad#GNOME_3_and_xmonad)).
Тут, я думаю, каждый найдёт то, что ему нужно, мы же двинемся к самому интересному.
Шаг 4: Нескучные обои
---------------------
Если вы запустили xmonad с минимальным конфигом, то уже, наверно, заметили, что там чёрный экран. Обоев нет!
Как же так, подумали мы, в gnome есть, в kde есть… И тут сделаем!
Быстро исправляем это недоразумение:
```
sudo pacman -S feh
feh --bg-center /usr/share/backgrounds/gnome/Bokeh_Tails.jpg # Тут можно подставить путь до любой картинки. Или, о господи, даже http урл!
feh --bg-center http://habrastorage.org/files/c1a/90a/763/c1a90a763acc48a083a325d42f86f8ad.jpg # да да, даже так!
```
Вам, наверно, понравилось, да? Можно поставить любимую картинку из интернета прямо на рабочий стол, зафиксируем результат:
```
echo "feh --bg-center http://habrastorage.org/files/c1a/90a/763/c1a90a763acc48a083a325d42f86f8ad.jpg &">>~/.xinitrc
```
Шаг 5: Рашпиль
--------------
Ну вот теперь можно работать, возьмём в руки инструмент и начнём допиливать XMonad.
Тут можно было бы приложить конфиг и сказать — готово, но нет. Мы же здесь чтобы хоть чуть чуть разобраться.
Поработаем над нашим конфигом, преобразуем его к следующему виду:
```
defaults = defaultConfig {
terminal = "urxvt"
, workspaces = myWorkspaces
, modMask = mod4Mask
, borderWidth = 2
}
myWorkspaces :: [String]
myWorkspaces = ["1:web","2:dev","3:term","4:vm","5:media"] ++ map show [6..9]
main = do
xmonad defaults
```
Теперь наши рабочие столы с названиями, но ты, дядя Фёдор, этого всё равно не увидишь, ведь у тебя xmobar не настроен!
Ладно, отложим xmobar, сделаем нечто более существенное:
```
defaults = defaultConfig {
terminal = "urxvt"
, workspaces = myWorkspaces
, modMask = mod4Mask
, layoutHook = myLayoutHook
, handleEventHook = fullscreenEventHook -- для корректного отображения окон в полно экранном режиме
, startupHook = setWMName "LG3D" -- для совместимости определёных приложений, java например(IntelliJ IDEA)
, borderWidth = 2
, normalBorderColor = "black"
, focusedBorderColor = "orange"
}
myWorkspaces :: [String]
myWorkspaces = ["1:web","2:dev","3:term","4:vm","5:media"] ++ map show [6..9]
myLayoutHook = spacing 6 $ gaps [(U,15)] $ toggleLayouts (noBorders Full) $
smartBorders $ Mirror tiled ||| mosaic 2 [3,2] ||| tabbed shrinkText myTabConfig
where
tiled = Tall nmaster delta ratio
nmaster = 1
delta = 3/100
ratio = 3/5
main = do
xmonad defaults
```
Теперь посмотрим что получилось, для этого:
* перекомпилим командой xmonad --recompile
* если нет ошибок перезапустим xmonad --restart
И, вуаля, изменения должны вступить в силу.
Выполним комбинацию modKey+shift+enter. Должнен открыться тайл с консолью. Если не открылся, возможно, проблема в строчке конфига xmonad.hs:
```
terminal = "urxvt"
```
Укажите терминал, которые есть в системе, или установите urxvt:
```
sudo pacman -S rxvt-unicode
```
Сочетанием **modKey+p** можно вызвать dmenu (откроется сверху, набирая команду, там будет отобажён список приложений, которые можно запустить). Вызовем gvim, например, modKey+p -> печатаем gvim (если он, конечно, есть в системе) жмакаем enter.
Итак, у нас есть рабочие столы, тайлы, лайауты… Так давайте же автоматически направлять приложения на разные рабочие столы? Давайте.
Идём в наш конфиг xmonad.hs и добавляем следующее:
```
...
defaults = defaultConfig {
terminal = "urxvt"
, workspaces = myWorkspaces
, modMask = mod4Mask
, layoutHook = myLayoutHook
, handleEventHook = fullscreenEventHook -- для корректного отображения окон в полно экранном режиме
, startupHook = setWMName "LG3D" -- для совместимости определёных приложений, java например(IntelliJ IDEA)
, borderWidth = 2
, manageHook = myManageHook -- Добавили ХУК Сюда
, normalBorderColor = "black"
, focusedBorderColor = "orange"
}
-- Добавим хуук с реализацией
myManageHook :: ManageHook
myManageHook = composeAll . concat $
[ [className =? c --> doF (W.shift "1:web") | c <- myWeb]
, [className =? c --> doF (W.shift "2:dev") | c <- myDev]
, [className =? c --> doF (W.shift "3:term") | c <- myTerm]
, [className =? c --> doF (W.shift "4:vm") | c <- myVMs]
, [manageDocks]
]
where
myWeb = ["Firefox","Chromium","Chrome"]
myDev = ["Eclipse","Gedit","sublime-text"]
myTerm = ["Terminator","xterm","urxvt"]
myVMs = ["VirtualBox"]
....
```
Теперь
```
xmonad --recompile && xmonad --restart
```
Через dmenu запускаем например sublime-text, и вот она! Вот она магия! Он сразу оказался на рабочем столе с пометкой 2:dev.
Нажмём modKey+shift+enter для запуска терминала и, о чудо! Он окажется на 3-м рабочем столе.
### А как же мне узнать className тайла для отправки на нужный рабочий стол?
Это очень просто. Открываем консоль, набираем команду xprop, дальше тыркаем мышкой в нужное окно и в консоле отобразится информация о нём. Нас интересует поле WM\_CLASS(STRING).
Впринципе, не обязательно именно по className фильтровать окна, можно и по другим параметрам. Можно увидеть, что, например, по полю [title](http://xmonad.org/xmonad-docs/xmonad/XMonad-ManageHook.html) так же можно отправить окошко куда душе угодно.
Это то, к чему мы так долго шли…
И тут мы вспомнили о дяде Фёдоре. Точнее — о xmobar. Давайте сделаем статус бар. Для тех, кто ещё не понял, это чёрная панелька сверху (скриншот в шапке).
Шаг 6: Напильник
----------------
Итак, xmobar уже должен быть установлен. Поэтому открываем наш конфиг xmonad.hs и меняем:
```
main = do
xmonad defaults
```
На:
```
main = do
xmproc <- spawnPipe "/usr/bin/xmobar ~/.xmonad/xmobar.hs"
xmonad $ defaults {
logHook = dynamicLogWithPP $ defaultPP {
ppOutput = System.IO.hPutStrLn xmproc
, ppTitle = xmobarColor xmobarTitleColor "" . shorten 100
, ppCurrent = xmobarColor xmobarCurrentWorkspaceColor "" . wrap "[" "]"
, ppSep = " "
, ppWsSep = " "
, ppLayout = (\ x -> case x of
"Spacing 6 Mosaic" -> "[:]"
"Spacing 6 Mirror Tall" -> "[M]"
"Spacing 6 Hinted Tabbed Simplest" -> "[T]"
"Spacing 6 Full" -> "[ ]"
_ -> x )
, ppHiddenNoWindows = showNamedWorkspaces
}
} where showNamedWorkspaces wsId = if any (`elem` wsId) ['a'..'z']
then pad wsId
else ""
```
Нет времени ничего объяснять, просто создаём дальше конфиги, а именно ~./xmonad/xmobar.hs:
```
Config {
font = "xft:Droid Sans Mono:size=9:bold:antialias=true"
bgColor = "#000000",
fgColor = "#ffffff",
position = Static { xpos = 0, ypos = 0, width = 1920, height = 16 },
lowerOnStart = True,
commands = [
Run Weather "UUDD" ["-t","°C","-L","18","-H","25","--normal","green","--high","red","--low","lightblue"] 36000
,Run Memory ["-t","/M (M)","-H","8192","-L","4096","-h","#FFB6B0","-l","#CEFFAC","-n","#FFFFCC"] 10
,Run Network "enp6s0" [
"-t" ,"rx:, tx:"
,"-H" ,"200"
,"-L" ,"10"
,"-h" ,"#FFB6B0"
,"-l" ,"#CEFFAC"
,"-n" ,"#FFFFCC"
, "-c" , " "
, "-w" , "2"
] 10
,Run Date "%Y.%m.%d %H:%M:%S" "date" 10
,Run MultiCpu [ "--template" , ""
, "--Low" , "50" -- units: %
, "--High" , "85" -- units: %
, "--low" , "gray"
, "--normal" , "darkorange"
, "--high" , "darkred"
, "-c" , " "
, "-w" , "3"
] 10
,Run CoreTemp [ "--template" , " °C"
, "--Low" , "70" -- units: °C
, "--High" , "80" -- units: °C
, "--low" , "darkgreen"
, "--normal" , "darkorange"
, "--high" , "darkred"
] 50
,Run StdinReader
],
sepChar = "%",
alignSep = "}{",
template = "%StdinReader% }{ %coretemp% | %multicpu% | %memory% | %enp6s0% | %UUDD% | %date% "
}
```
Ух, теперь можно присесть и выполнить уже знакомую команду:
```
xmonad --recompile && xmonad --restart
```
Должен был появится наш долгожданный бар и теперь, %USERNAME%, должен наконец увидеть, на каком он рабочем сталое находится. Так же вынесли заголовок текущего окна в наш бар (прям как в mac os x, только гибче). За это отвечает [dynamicLogWithPP](http://xmonad.org/xmonad-docs/xmonad-contrib/XMonad-Hooks-DynamicLog.html), который копирует информацию в stdin xmobar, предварительно форматируя её.
Очень подробно о xmobar и его плагинах [тут](http://projects.haskell.org/xmobar/).
Будьте внимательны, в font нужно указать существущий шрифт в вашей системе. Его можно найти в выводе команды fc-list.
Шаг 7: Надфиль
--------------
Вроде всё работает, но как-то не уютно. Чего бы ещё такого сделать? Давайте отобразим Volume Level в нашем баре! Хм, ХМобаре! Сказал — делай.
#### Изменяем ~/.xmonad/xmobar.hs
Добрые люди уже написали для нас плагин PipeReader, который тупо вычитывает pipe и отображает это дело в баре.
Добавим вызов плагина PipeReader и изменим шаблон добавив в него отображение громкости:
```
,Run PipeReader "/tmp/.volume-pipe" "vol"
template = "%StdinReader% }{ %vol% | %coretemp% | %multicpu% | %memory% | %enp6s0% | %UUDD% | %date% "
```
#### Создадим pipe
```
export _volume_pipe=/tmp/.volume-pipe
[[ -S $_volume_pipe ]] || mkfifo $_volume_pipe
```
Теперь у нас есть pipe, сливаем в него нужные данные. Попробуем узнать уровень громкости следующей командой:
```
amixer sget Master | grep -o -m 1 '[[:digit:]]*%' | tr -d '%'
Отлично, вот его и "сольём":
echo `amixer sget Master | grep -o -m 1 '[[:digit:]]*%' | tr -d '%'`>/tmp/.volume-pipe
Обновленные данные отобразились в xmobar.. Вё равно как то счастья не видно. Может дело в этих сухих цифрах? Так давайте сделаем бар громкости в xmobar! Ух, повеселело сразу.
Создаем скрипт ./xmonad/getvolume.sh:
#!/bin/sh
vol=`amixer sget Master | grep -o -m 1 '[[:digit:]]*%' | tr -d '%'`
level=`expr $vol / 10`
bars=$level
case $bars in
0) bar='[----------]' ;;
1) bar='[|---------]' ;;
2) bar='[||--------]' ;;
3) bar='[|||-------]' ;;
4) bar='[||||------]' ;;
5) bar='[|||||-----]' ;;
6) bar='[||||||----]' ;;
7) bar='[|||||||---]' ;;
8) bar='[||||||||--]' ;;
9) bar='[|||||||||-]' ;;
10) bar='[||||||||||]' ;;
*) bar='[----!!----]' ;;
esac
echo $bar
exit 0
```
Примерно так, зато быстро. Проверяем:
```
echo `~/.xmonad/getvolume.sh`>/tmp/.volume-pipe
```
Не знаю как у вас, а у меня работает. Но как то оно… не автоматически. Хочется ещё вкусняшек, а если хочется, зачем останавливаться?
### Бонусные вкусняшки
Редактируем наш ~/.xmonad/xmonad.hs.
Добавим следующее:
```
defaults = defaultConfig {
...
}`additionalKeys` myKeys -- добавили к дефолтной конфигурации новые кнпоки!
myKeys = [
((mod4Mask, xK_g), goToSelected defaultGSConfig)
, ((mod4Mask, xK_s), spawnSelected defaultGSConfig ["chromium","idea","gvim"])
, ((mod4Mask, xK_KP_Add), spawn "amixer set Master 10%+ && ~/.xmonad/getvolume.sh >> /tmp/.volume-pipe")
, ((mod4Mask, xK_KP_Subtract), spawn "amixer set Master 10%- && ~/.xmonad/getvolume.sh >> /tmp/.volume-pipe")
]
```
Теперь при нажатии на modKey+ -/+ (это — и + на NumKeyboard) будет изменяться громкость и её уровень сразу отобразится в нашей панельке.
Ещё не уснувший читатель мог заметить дополнительную вкусняшку в виде строчки:
```
((mod4Mask, xK_s), spawnSelected defaultGSConfig ["chromium","idea","gvim"])
```
В качестве вознаграждения он может исполнить хитрую комбинацию клавиш и увидеть результат.
Как заметили в комментария, хорошо было бы добавить определение цветов темы myTabConfig:
```
myTabConfig = defaultTheme {
activeColor = "#6666cc"
, activeBorderColor = "#000000"
, inactiveColor = "#666666"
, inactiveBorderColor = "#000000"
, decoHeight = 10
}
```
Заключение
----------
Хочу лишь сказать, что я не претендую на какую либо исключительность этого материала. Да и правильным его не назовешь, наверняка всё можно сделать лучше. Я всего лишь хотел показать путь, по которому можно пойти для настройки собственного окружения так, чтобы этой холодной осенью на душе было тепло и приятно.
Надеюсь, было интересно и полезно, с радостью обсужу тематику рабочего окружения, xmonad и всего, что связанно с Linux.
PS: Для экономии места все примеры конфигов не снабжены необходимыми директивами import. Импорты можно стянуть с гитхаба.
#### Материалы
[Сайт XMonad](http://xmonad.org/) — много инфы и доки по API;
[Xmobar Reference](http://projects.haskell.org/xmobar/) — дока по Xmobar и его плагинам;
[Архив конфигураций XMonad](https://www.haskell.org/haskellwiki/Xmonad/Config_archive) — примеры кофнигов с прилагающимися картинками результата;
[XMonad hotkey cheatsheet](https://www.haskell.org/wikiupload/b/b8/Xmbindings.png) — все хоткеи на одной страничке. Для начала советую feh --bg-center [www.haskell.org/wikiupload/b/b8/Xmbindings.png;](https://www.haskell.org/wikiupload/b/b8/Xmbindings.png;)
[GitHub xmonad-config](https://github.com/lavcraft/xmonad-config/tree/9703376ee2b23241bbd2b55d4c7950c9ec48e1cb) — Все конфиги, которые тут использовал, в кучку собрал да на гитхабе разместил. | https://habr.com/ru/post/242351/ | null | ru | null |
# Прикручиваем ИИ: оптимизация работы банкоматов
Всем привет! Это небольшой рассказ про то, как команда Центра компетенции больших данных и искусственного интеллекта в [ЛАНИТ](http://www.lanit.ru) оптимизировала работу банкоматной сети. Упор в статье сделан не на описание подбора параметров и выбор лучшего алгоритма прогнозирования, а на рассмотрение концепции нашего подхода к решению поставленной задачи. Кому интересно, добро пожаловать под кат.
[*источник*](https://www.sondakika.com/haber/haber-tek-bir-sms-in-marifetleri-5835560/)
Банки теряют довольно много денег из-за того, что они просто лежат в банкоматах. Вместо этого деньги можно было бы успешно вложить и получать доход. Сегодня крупные банки с сильными аналитическими центрами имеют свои решения для того, чтобы рассчитать количество купюр и время, на которое их нужно заложить в банкоматы до следующей инкассации. Небольшие же игроки, не имея таких решений, просто ориентируются на средние значения, полученные в ходе предыдущих поездок инкассаторов.
Таким образом, формальная постановка задачи выглядит так.
**На входе:**
* есть история снятия/приема наличности в банкоматах (в нашем случае это были данные за полтора года);
* стоимость потерь от нахождения денег в банкоматах (от простаивающих запасов) зависит от ставки рефинансирования (параметр *q*); стоимость можно оценить как , где *S* — сумма, *X*— количество дней;
* стоимость поездки инкассаторов, *si* (меняется со временем и зависит от местоположения банкомата и маршрута инкассаторов).
**На выходе** ожидается:
* система рекомендаций по количеству купюр и времени, на которое их нужно заложить;
* экономический эффект от предлагаемого решения.
Разработка велась совместно с @[vladbalv](https://habr.com/users/vladbalv/), от которого поступило множество предложений, в том числе ключевых, которые легли в основу описываемого решения.
Общая идея основана на нахождении минимума затрат как функции от количества дней между инкассациями. Для объяснения конечного решения можно сначала рассмотреть упрощенный вариант — в предположении, что сумма снимаемых денег не меняется изо дня в день и равна *S*, и что она только убывает. В таком случае сумма денег в банкомате является убывающей арифметической прогрессией.
Предположим, что в день снимают *S* руб. Помимо суммы снятий, введем также переменную X — число дней между инкассациями, меняя которую будем дальше искать минимум затрат банка. Логично, что сумма, которую выгоднее всего положить в банкомат, зная, что инкассация будет через *X* дней это *S\*X*. При таком подходе за день до инкассации в банкомате будет находиться *S* руб., за два дня — *2\*S* руб., за три дня — *3\*S* руб. и т. д. Другими словами, наш ряд можно рассматривать, двигаясь от конца к началу, тогда это будет возрастающая арифметическая прогрессия. Поэтому за период между двумя инкассациями в банкомате будет лежать *(S+S\*X)/2* руб. Теперь, исходя из ставки рефинансирования, остаётся посчитать стоимость простаивающих запасов этой суммы за *X* дней и дополнительно прибавить стоимость совершённых инкассаторских поездок. Если между инкассациями *X* дней, то за *n* дней будет совершено ![$[\frac{n}{X}]+1$](https://habrastorage.org/getpro/habr/formulas/f29/b3b/56c/f29b3b56ceca48c8f46f4401ea4b868f.svg) (где ![$[\frac{n}{X}]$](https://habrastorage.org/getpro/habr/formulas/706/b6d/d42/706b6dd42693d732aa6c8714a8136d10.svg) — это целочисленное деление) инкассаций, поскольку ещё один раз придётся приехать, чтобы вывести остаток денег.
Таким образом, получившаяся функция выглядит так:
![$TotalCost(S, X, n, q, si) = (S + S*X)/2*\frac{q}{365}+si*([\frac{n}{X}]+1)$](https://habrastorage.org/getpro/habr/formulas/55c/52f/043/55c52f04300e0ddc6e543e15758f39f8.svg)
где:
* *S* — сумма снятий, руб./день,
* *X* — количество дней между инкассациями,
* *n* — рассматриваемый период в днях,
* *q* — ставка рефинансирования,
* *si* — стоимость инкассации.
Однако в реальности каждый день снимают разные суммы, поэтому у нас есть ряд снятий/внесений купюр, каждый день этот ряд пополняется новыми значениями. Если это учесть, функция примет следующий вид:
![$TotalCost = \sum_{i=1}^{n}Q_{i}*\frac{q}{365} + si*([\frac{n}{X}]+1) \\ q - ставка\, рефинансирования, \\ n - количество\, рассматриваемых\, дней, \\ X - количество\, дней\, между\, инкассациями, \\ Q_{i} - сумма\, в\, банкомате\, на\, iй\, день,\, Q_{i} = encash_{i} - \sum_{k=[\frac{i}{X}]*X}^{i}S_{k} \\ S_{k} - изменение\, суммы\, в\, банкомате\, на\, kй\, день, \\ encash_{i} - сумма\, последней\, на\, iй\, день\, инкассации, \\ encash_{i} = \begin{cases} \sum_{k=[\frac{i}{X}]*X}^{([\frac{i}{X}]*X+1)*X}S_{k}, \,\,\, если\,сумма\, убывающая \\ \\ \sum_{k=[\frac{i}{X}]*X}^{[\frac{i}{X}]*X+3}S_{k}^{-}, \,\,\, если\,сумма\, возрастающая \end{cases} \\ S_{k}^{-} - сумма\, снятий\, за\, kй\, день \\$](https://habrastorage.org/getpro/habr/formulas/da7/1f2/5f7/da71f25f7bfa959f05f35d31cc1b986e.svg)
Что такое убывающие и возрастающие суммы: в зависимости от того, больше кладут или больше снимают, есть купюры, по которым сумма в банкомате накапливается, а есть купюры, по которым сумма в банкомате убывает. Таким образом формируются возрастающие и убывающие суммы купюр. В реализации было сделано три ряда: incr\_sums — возрастающие купюры, decr\_sums — убывающие купюры и withdrawal\_sums — ряд сумм выдач банкомата (там присутствуют купюры, которые идут только на выдачу).
Также важный момент: если сумма возрастающая, то нам не нужно закладывать целиком всю сумму целого ряда, это необходимо делать только для убывающих сумм, поскольку они должны полностью исчезнуть к концу периода инкассации. Для возрастающих сумм мы решили закладывать сумму на три дня в качестве подушки безопасности, если что-то пойдёт не так.
Помимо прочего, чтобы применить описанную функцию, нужно учесть следующие моменты.
* Самое главное, сложное, и интересное — в момент инкассации мы не знаем, какие это будут суммы, их нужно прогнозировать (об этом ниже).
* Банкоматы бывают следующих типов:
○ только на внос/вынос,
○ на внос и вынос одновременно,
○ на внос и вынос одновременно + ресайклинг (за счёт ресайклинга у банкомата есть возможность выдавать купюры, которые в него вносят другие клиенты).
* Описанная функция также зависит от *n* — количества рассматриваемых дней. Если подробнее рассмотреть эту зависимость на реальных примерах, то получится следующая картинка:
*Рис. 1.* *Значения функции TotalCost в зависимости от X (Days betw incas) и n (Num of considered days)*
Чтобы избавиться от *n*, можно воспользоваться простым трюком — просто разделить значение функции на *n*. При этом мы усредняем и получаем среднюю величину стоимости затрат в день. Теперь функция затрат зависит только от количества дней между инкассациями. Это как раз тот параметр, по которому мы будем её минимизировать.
Учитывая вышесказанное, реальная функция будет иметь следующий шаблон:
*TotalCost(n, x, incr\_sums, decr\_sums, withdrawal\_sums, si),* где
* *x* —максимальное количество дней между инкассациями
* *n* — количество дней, которые отслеживаем, то есть мы смотрим последние *n* значений подаваемых на вход временных рядов (как написано выше, функция не зависит от *n*, этот параметр добавлен, чтобы можно было экспериментировать с длиной подаваемого временного ряда)
* *incr\_sums* — ряд спрогнозированных сумм *по* *купюрам только на внос,*
* *decr\_sums* — ряд спрогнозированных сумм *по* *купюрам только на вынос,*
* *withdrawal\_sums* — ряд спрогнозированных сумм выдач банкомата (т.е. здесь сумма по купюрам in минус сумма по out), заполняется *0* для всех банкоматов кроме ресайклинговых,
* *si* — стоимость инкассации.
Функция проходит непересекающимся окном величиной *X* по входным рядам и считает суммы внесенных денег внутри окна. В отличие от первоначальной функции сумма арифметической прогрессии здесь превращается в обычную сумму (это та сумма, которая была заложена при инкассации). Далее внутри окна в цикле по дням происходит кумулятивное суммирование/вычитание сумм, которые ежедневно клались/снимались из банкомата. Это делается для того, чтобы получить сумму, которая лежала в банкомате на каждый день.
Затем из полученных сумм при помощи ставки рефинансирования рассчитывается стоимость затрат на простаивающие запасы, а также в конце прибавляются затраты от инкассаторских поездок.
**Реализация**
```
def process_intervals(n, x, incr_sums, decr_sums, withdrawal_sums):
# генератор количества сумм, которые
# остаются в банкомате на каждый день
# incr_sums — ряд возрастающих сумм
# decr_sums — ряд убывающих сумм
# withdrawal_sums — ряд сумм выдач банкомата (там присутствуют купюры, которые идут только на выдачу)
# заполняется 0 для всех банкоматов кроме ресайклинговых
# x — количество дней между инкассациями
# n — количество дней, которые отслеживаем
if x>n: return
for i in range(n//x):
decr_interval = decr_sums[i*x:i*x+x]
incr_interval = incr_sums[i*x:i*x+x]
withdrawal_interval = withdrawal_sums[i*x:i*x+x]
interval_sum = np.sum(decr_interval)
interval_sum += np.sum(withdrawal_interval[:3])
for i, day_sum in enumerate(decr_interval):
interval_sum -= day_sum
interval_sum += incr_interval[i]
interval_sum += withdrawal_interval[i]
yield interval_sum
# остаток сумм. Берется целый интервал.
# но yield только для остатка ряда
decr_interval = decr_sums[(n//x)*x:(n//x)*x+x]
incr_interval = incr_sums[(n//x)*x:(n//x)*x+x]
withdrawal_interval = withdrawal_sums[(n//x)*x:(n//x)*x+x]
interval_sum = np.sum(decr_interval)
interval_sum += np.sum(withdrawal_sums[:3])
for i, day_sum in enumerate(decr_interval[:n-(n//x)*x]):
interval_sum -= day_sum
interval_sum += incr_interval[i]
interval_sum += withdrawal_sums[i]
yield interval_sum
def waiting_cost(n, x, incr_sums, decr_sums, withdrawal_sums, si):
# incr_sums — ряд возрастающих сумм
# decr_sums — ряд убывающих сумм
# withdrawal_sums — ряд сумм выдач банкомата (там присутствуют купюры, которые идут только на выдачу)
# заполняется 0 для всех банкоматов кроме ресайклинговых
# si — стоимость инкассации
# x — количество дней между инкассациями
# n — количество дней, которое отслеживаем
assert len(incr_sums)==len(decr_sums)
q = 4.25/100/365
processed_sums = list(process_intervals(n, x, incr_sums, decr_sums, withdrawal_sums))
# waiting_cost = np.sum(processed_sums)*q + si*(x+1)*n//x
waiting_cost = np.sum(processed_sums)*q + si*(n//x) + si
# делим на n, чтобы получить среднюю сумму в день (не зависящее от количества дней)
return waiting_cost/n
def TotalCost (incr_sums, decr_sums, withdrawal_sums, x_max=14, n=None, si=2500):
# x — количество дней между инкассациями
# n — количество дней, которое отслеживаем
assert len(incr_sums)==len(decr_sums) and len(decr_sums)==len(withdrawal_sums)
X = np.arange(1, x_max)
if n is None: n=len(incr_sums)
incr_sums = incr_sums[-n:]
decr_sums = decr_sums[-n:]
withdrawal_sums = withdrawal_sums[-n:]
waiting_cost_sums = np.zeros(len(X))
for i, x in enumerate(X):
waiting_cost_sums[i] = waiting_cost(n, x, incr_sums, decr_sums, withdrawal_sums, si)
return waiting_cost_sums
```
Теперь применим эту функцию к историческим данным наших банкоматов и получим следующую картинку:
*Рис. 2. Оптимальное количество дней между инкассациями*
Резкие перепады на некоторых графиках объясняются провалами в данных. А то, что они произошли в одинаковое время, скорее всего можно объяснить техническими работами, на время которых банкоматы не работали.
Дальше нужно сделать прогноз снятия/зачисления наличности, применить к нему эту функцию, найти оптимальный день инкассации и загрузить определенное количество купюр по сделанному прогнозу.
В зависимости от суммы денег, находящейся в обращении (чем меньше денег проходит через банкомат, тем дольше оптимальный срок инкассации), меняется количество оптимальных дней между инкассациями. Бывают случаи, когда это количество больше 30. Прогноз на такой большой период времени будет слишком большой ошибкой. Поэтому вначале происходит оценка по историческим данным, если она меньше 14 дней (это значение было выбрано эмпирически, потому что оптимальное количество дней до инкассации у большинства банкоматов меньше 14 дней, а также потому, что чем дальше горизонт прогнозирования, тем больше его ошибка), то в дальнейшем для определения оптимального количества дней между инкассациями используется прогноз по временному ряду, иначе по историческим данным.
Подробно останавливаться на том, как делается прогноз снятий и зачислений не буду. Если есть интерес к этой теме, то можно посмотреть видеодоклад о решении подобной задачи исследователями из Сбербанка ([Data Science на примере управления банкоматной сетью банка](https://www.youtube.com/watch?v=s7cYqaiA2mE)).
Из всего опробованного нами лучше всего показал себя CatBoostRegressor, регрессоры из sklearn немного отставали по качеству. Возможно, здесь не последнюю роль сыграло то, что после всех фильтраций и отделения валидационной выборки, в обучающей выборке осталось всего несколько сотен объектов.
Prophet показал себя плохо. SARIMA не стали пробовать, поскольку в видео выше о нем плохие отзывы.
**Используемые признаки** (всего их было 139, после признака приведено его обозначение на графике feature importance ниже)
* Временные лаги целевых значений переменной, lag\_\* (их количество можно варьировать, но мы остановились на 31. К тому же, если мы хотим прогнозировать не на день вперед, а на неделю, то и первый лаг смотрится не за вчерашний день, а за неделю назад. Таким образом, максимально далеко мы смотрели на 31+14=45 дней назад).
* Дельты между лагами, delta\_lag\*-lag\*.
* Полиномиальные признаки от лагов и их дельт, lag\_\*^\* (использовались только первые 5 лагов и их дельт, обозначались).
* День недели, месяца, номер месяца, weekday, day, month (категориальные переменные).
* Тригонометрические функции от временных значений из пункта выше, weekday\_cos и т.д.
* Статистика (max, var, mean, median) для этого же дня недели, месяца, weekday\_max, weekday\_mean,… (брались только дни, находящиеся раньше рассматриваемого в обучающей выборке).
* Бинарные признаки выходных дней, когда банкоматы не работают, is\_weekend
* Значения целевой переменной за этот же день предыдущей недели/месяца, y\_prev\_week, y\_prev\_month.
* Двойное экспоненциальное сглаживание + сглаживание по значениям целевой функции за те же дни предыдущих недели/месяца, weekday\_exp\_pred, monthday\_exp\_pred.
* Попробовали tsfresh, tsfresh+PCA, но потом отказались от этого, поскольку этих признаков очень много, а объектов в обучающей выборке у нас было мало.
Важность признаков для модели следующая (приведена модель для прогноза снятий купюры номиналом в 1000 руб. на один день вперед):
*Рис. 3.**Feature importance используемых признаков*
Выводы по картинкам выше — наибольший вклад сделали лаговые признаки, дельты между ними, полиномиальные признаки и тригонометрические функции от даты/времени. Важно, что в своём прогнозе модель не опирается на какую-то одну фичу, а важность признаков равномерно убывает (правая часть графика на рис. 2).
Сам график прогноза выглядит следующим образом (по оси *x* отложены дни, по оси *y* количество купюр):
*Рис. 4* *—* *Прогноз CatBoostRegressor*
По нему видно, что CatBoost всё же плохо выделяет пики (несмотря на то, что в ходе предварительной обработки выбросы были заменены на 95 перцентиль), но общую закономерность отлавливает, хотя случаются и грубые ошибки, как на примере провала в районе шестидесяти дней.
Ошибка по MAE там колеблется в примерном диапазоне от нескольких десятков до ста. Успешность прогноза сильно зависит от конкретного банкомата. Соответственно, величину реальной ошибки определяет номинал купюры.
Общий пайплайн работы выглядит следующим образом (пересчёт всех значений происходит раз в день).
1. Для каждой купюры каждого atm на каждый прогнозируемый день своя модель (поскольку прогнозировать на день вперед и на неделю вперед *—* разные вещи и снятия по различным купюрам также сильно разнятся), поэтому на каждый банкомат приходится около 100 моделей.
2. По историческим данным банкомата при помощи функции *TotalCost* находится оптимальное количество дней до инкассации.
3. Если найденное значение меньше 14 дней, то следующий день инкассации и закладываемая сумма подбираются по прогнозу, который кладется в функцию *TotalCost*, иначе по историческим данным.
4. На основе прогноза либо исторических данных снятий/внесений наличности рассчитывается сумма, которую нужно заложить (т.е. количество закладываемых купюр).
5. В банкомат закладывается сумма + ошибка.
6. Ошибка: при закладывании денег в банкомат необходимо заложить больше денег, оставив подушку безопасности, на случай, если вдруг люди дружно захотят обналичить свои сбережения (чтобы перевести их во что-то более ценное). В качестве такой суммы можно брать средние снятия за последние 2-3 дня. В усложнённом варианте можно прогнозировать снятия за следующие 2-3 дня и дополнительно класть эту сумму (выбор варианта зависит от качества прогноза на конкретном банкомате)
7. Теперь с каждым новым днём приходят значения реальных снятий, и оптимальный день инкассации пересчитывается. Чем ближе день инкассации, полученный по предварительному прогнозу, тем больше реальных данных мы кладём в *TotalCost* вместо прогноза, и точность работы увеличивается.
Полученный профит мы посчитали следующим образом: взяли данные по снятиям/внесениям за последние три месяца и из этого промежутка по дню, как если бы к нам приходили ежедневные данные от банкоматов.
Для этих трёх месяцев рассчитали стоимость простаивающих запасов денег и инкассаторских поездок для исторических данных и для результата работы нашей системы. Получился профит. Усредненные за день величины приведены в таблице ниже (названия банкоматов заменены на латинские символы):
| | | |
| --- | --- | --- |
| **atm** | **profit****(relative)** | **≈****profit/day (руб.)** |
| *a* | 0.61 | 367 |
| *b* | 0.68 | 557 |
| *с* | 0.70 | 470 |
| *d* | 0.79 | 552 |
| *e* | -0.30 | -66 |
| *f* | 0.49 | 102 |
| *g* | 0.41 | 128 |
| *h* | 0.49 | 98 |
| *i* | 0.34 | 112 |
| *j* | 0.48 | 120 |
| *k* | -0.01 | -2 |
| *l* | -0.43 | -26 |
| *m* | 0.127 | 34 |
| *n* | -0.03 | -4 |
| *o* | -0.21 | -57 |
| *p* | 0.14 | 24 |
| *q* | -0.21 | -37 |
Подходы и улучшения, которые интересно рассмотреть, но пока не реализованы на практике (в силу комплексности их реализации и ограниченности во времени):
* использовать нейронные сети для прогноза, возможно даже RL агента,
* использовать одну модель, просто подавая в неё дополнительный признак, отвечающий за горизонт прогнозирования в днях.
* построить эмбеддинги для банкоматов, в которых сагрегировать информацию о географии, посещаемости места, близости к магазинам/торговым центрам и т. д.
* если оптимальный день инкассации (на втором шаге пайплайна) превышает 14 дней, рассчитывать оптимальный день инкассации по прогнозу другой модели, например, Prophet, SARIMA, или брать для этого не исторические данные, а исторические данные за прогнозируемый период с прошлого года/усредненный за последние несколько лет.
* для банкоматов, у которых отрицательный профит, можно пробовать настраивать различные триггеры, при срабатывании которых работа с банкоматами ведется в старом режиме, либо инкассаторские поездки совершаются чаще/реже.
В заключение можно отметить, что временные ряды снятий/внесений наличности поддаются прогнозированию, и что в целом предложенный подход к оптимизации работы банкоматов является довольно успешным. При грубой оценке текущих результатов работы в день получается сэкономить около 2400 руб., соответственно, в месяц это — 72 тыс. руб., а в год — порядка 0,9 млн руб. Причём чем больше суммы денег, находящихся в обращении у банкомата, тем большего профита можно достичь (поскольку при небольших суммах профит нивелируется ошибкой от прогноза).
За ценные советы при подготовке статьи большая благодарность [vladbalv](https://habr.com/ru/users/vladbalv/) и [art\_pro](https://habr.com/ru/users/art_pro/).
Спасибо за внимание! | https://habr.com/ru/post/552732/ | null | ru | null |
# Рендеринг диаграмм: не так просто, как кажется
Что сложнее: отрендерить сцену со взрывающимися вертолётами или нарисовать унылый график функции *y=x*2? Да, верно, вертолёты взрывать дорого и сложно — но народ справляется, используя для этого такие мощные штуки, как OpenGL или DirectX. А рисовать график, вроде, просто. А если хочется красивый интерактивный график — можно его нарисовать теми же мощными штуками? Раз плюнуть, наверное?
А вот и нет. Чтобы заставить унылые графики вменяемо выглядеть и при этом работать без тормозов, нам пришлось попотеть: едва ли не на каждом шагу подстерегали неожиданные трудности.
**Задача:** разработать кроссплатформенную библиотеку для построения диаграмм, которая была бы интерактивной, из коробки поддерживала анимационные переходы и, главное, не тормозила.
#### Проблема 1: float и пиксельные соответствия
[](http://habrastorage.org/getpro/habr/post_images/010/cb3/d0a/010cb3d0af651d944d22c6007e0c484f.png)
Казалось бы, поделить отрезок на n равных частей сможет и первоклассник. В чём же наша проблема? Математически тут всё верно. Жизнь портит точность float’a. Совместить две линии пиксель в пиксель, если на них действуют эквивалентные, но разные преобразования, оказывается практически невозможно: в недрах графического процессора возникают погрешности, которые проявляются в процессе растеризации, каждый раз по-разному. А пиксель влево-пиксель вправо — весьма заметно, когда речь идёт о контурах, отметках на осях и т.п. Отладить это практически невозможно, так как невозможно ни предсказать наличие погрешности, ни повлиять на механизм растеризации, в котором она возникает. При этом погрешность оказывается разной в зависимости от того, включен ли [Scissor Test](http://www.opengl.org/wiki/Scissor_Test) (который мы используем для ограничения области отрисовки графика).
Приходится делать костыли. Например, мы округляем значение смещений в преобразовании переноса до 10–4. Откуда такое число? Подобрали! Код выглядит страшно, зато работает:
```
const float m[16] = {
1.0f, 0.0f, 0.0f, 0.0f,
0.0f, 1.0f, 0.0f, 0.0f,
0.0f, 0.0f, 1.0f, 0.0f,
(float)(ceil(t.x() * 10000.0f) / 10000.0),
(float)(ceil(t.y() * 10000.0f) / 10000.0),
(float)(ceil(t.z() * 10000.0f) / 10000.0),
1.0f
};
```
В итоге для большинства случаев, возникающих на практике, мы подобрали нужные значения, компенсирующие погрешности. Остаётся надеяться, что ничего критичного не пропустили.
#### Проблема 2: стыковка перпендикулярных линий
[](http://habrastorage.org/getpro/habr/post_images/bf3/447/596/bf344759632128845463f72a36015019.png)
Тут уже дело не в погрешности, а в том, как реализуются «аппаратно ускоренные» линии. Толщина 2 px, координаты одинаковые, пересечение в центре. И — великолепный «выкушенный» угол, как следствие. Решение — опять же, костыльное смещение Х- или Y-координаты одного из концов на один пиксель. Но сместить что-то на пиксель, работая с координатами полигонов — целая проблема. Координаты сцены и координаты экрана связаны друг с другом преобразованиями, пронизанными погрешностью — особенно если размер области видимости, которую описывает матрица проекции, не равен размеру экрана.
В конце концов, мы подобрали смещения, которые дают приемлемые результаты, «но осадочек остался»: решение всё-таки ненадёжное и всегда есть вероятность, что у юзеров уголки окажутся щербатыми. Выглядит это примерно так:
```
m_border->setFrame(NRect(rect.origin.x + 0.5f, rect.origin.y + 0.5f, rect.size.width - 3.5f, rect.size.height - 3.0f));
m_xAxisLine->setFrame(NRect(rect.origin.x, rect.origin.y, rect.size.width - 1.5f, rect.size.height - 1.0f));
m_yAxisLine->setFrame(NRect(rect.origin.x, rect.origin.y, rect.size.width - 1.5f, rect.size.height - 0.5f));
```
#### Проблема 3: линии вообще
И снова линии. В любой диаграмме присутствует довольно много линий — обычных линий, без излишеств. Это и оси, и сетка, и деления на осях, и границы элементов графика, иногда и сам график. И эти линии надо как-то рисовать. Казалось бы, что проще? Как это ни парадоксально, современные графические API чем дальше, тем увереннее выкидывают поддержку обычных линий: [пруф для OpenGL](http://stackoverflow.com/questions/8791531/opengl-3-2-core-profile-gllinewidth), [пруф для Direct3D](http://stackoverflow.com/questions/2280077/direct3d-line-thickness).
Пока что линии ещё поддерживаются, но сильно ограничена их допустимая толщина. Практика показала, что на iOS-устройствах это 8 px, а на некоторых андроидах и того меньше. Когда-то бывшая в спецификации OpenGL функция установки шаблона пунктира ([glLineStipple](https://www.opengl.org/sdk/docs/man2/xhtml/glLineStipple.xml)) более не поддерживается, на мобильных устройствах в OpenGLES 2.0 она не доступна. Сами же линии — даже те, которые по толщине вписываются в допустимые границы — выглядят ужасающе:
[](http://habrastorage.org/getpro/habr/post_images/9de/8ac/a9e/9de8aca9ed785e7825a558c9faf06760.png)
Пока мы миримся с тем, что есть, но всё идёт к тому, что придётся писать свой визуализатор линий, который сохранял бы постоянную толщину на экране, не зависящую от масштаба контура (как сейчас делает GL\_LINES), но умел бы делать красивые сочленения на изгибах. Вероятно, для этого придётся строить их из полигонов:

#### Проблема 4: дырки между полигонами
[](http://habrastorage.org/files/30e/c0e/626/30ec0e626aa64f14bd0f83dc7a15e0b0.png)
И снова проблема точности. На скриншоте видны светлые «вкрапления» на круговой диаграмме. Это не что иное, как результат погрешности растеризации (опять!), и здесь никакие костыли уже не спасают. Чуть лучше становится, если включить сглаживание границ:
[](http://habrastorage.org/getpro/habr/post_images/f8c/488/662/f8c48866249f00f636fc28d24bfa7980.png)
На данный момент смирились и оставили в таком виде.
#### Проблема 5: особенности системного антиалиасинга
Совсем без сглаживания границ результат рендеринга режет глаз даже на ретина-дисплеях. Но системный алгоритм сглаживания MSAA, доступный на любой современной платформе, имеет три серьёзных проблемы:
1. Снижение производительности: по нашим наблюдениям, на мобилках она падает в среднем в три раза, и при воспроизведении анимации на сложных сценах появляются ощутимые лаги.
2. Затруднение мультиплатформенности (а мы за ней гоняемся): на разных платформах системный антиалиасинг включается по-разному, мы же пытаемся по максимуму унифицировать код.
3. Артефакты изображения: объекты, стороны которых параллельны сторонам экрана (например, линии сетки на графике) размываются под действием системного антиалиасинга (если у них в итоге всех преобразований получились дробные координаты), хотя должны оставаться резкими:
[](https://habrastorage.org/getpro/habr/post_images/888/f8d/b38/888f8db38908227556ea2de759c84f02.png)
Из-за всего этого нам пришлось отказаться от стандартного сглаживания и ~~изобретать очередной велосипед~~ реализовать собственный алгоритм. В итоге, мы собрали оптимизированный под мобилки гибрид [SSAA](http://en.wikipedia.org/wiki/Supersampling) и [FXAA](http://en.wikipedia.org/wiki/Fast_approximate_anti-aliasing), который:
1. Умеет автоматически отключаться на периоды воспроизведения анимации (при анимации пользователю нужна плавность движения, а в статике — сглаженность границ).
2. По производительности сглаживания совпадает с системным антиалиасингом, при этом реализуется исключительно внутренними механизмами нашего графического движка (то есть сохраняет мультиплатформенность).
3. Может воздействовать на часть сцены, а не на всю целиком (так удаётся избежать артефактов размытия: просто исключаем из множества сглаживаемых объектов те, которым оно заведомо не пойдёт на пользу).
Воздействие на часть сцены организуется через «послойный» рендеринг, когда всё множество объектов делится на группы (слои) по их взаимному расположению (передний, средний, задний план и т.д.) и необходимости сглаживания. Слои отрисовываются последовательно, и сглаживание применяется только к тем, у которых выставлен соответствующий атрибут.
[](https://habrastorage.org/getpro/habr/post_images/1fb/7ec/baa/1fb7ecbaacebad71ffa5ec11d24ee6de.png)
#### Проблема 6: Многопоточность и экономия энергии
Хороший тон — обрабатывать события пользовательского интерфейса и рендеринг графической сцены в разных потоках. Однако, действия пользователя влияют на внешний вид сцены, а значит, необходима синхронизация. Мы решили, что расставлять мьютексы во всех визуальных объектах — это чересчур, и вместо этого реализовали транзакционную память.
Идея состоит в том, что есть две хеш-таблицы свойств: для главного потока (Main thread table, MTT) и для потока рендеринга (Render thread table, RTT). Все изменения настроек внешнего вида объектов попадают в MTT. Попадание в неё очередной записи приводит к планированию «тика синхронизации» (если он ещё не был запланирован), который произойдёт в начале следующей итерации главного потока (предполагается, что обработка пользовательского интерфейса происходит именно в главном потоке). Во время тика синхронизации содержимое MTT перемещается в RTT (это действие защищено мьютексом — единственным на всю графическую сцену). В начале каждой итерации потока рендеринга проверяется, нет ли записей в RTT, и если они есть — они применяются к соответствующим объектам.
Здесь же реализуется установка тех или иных свойств с анимацией. Например, можно указать изменение масштаба от 0 до 1 за определённое время, и запись из RTT применится не сразу, а за несколько шагов, на каждом из которых конкретное значение будет результатом интерполяции значения масштаба от 0 до 1 по заданному закону.
И этот же механизм обеспечивает возможность визуализации по требованию: фактический рендеринг выполняется только в том случае, если в RTT есть записи (то есть состояние сцены изменилось). Визуализация по требованию очень актуальна для мобильных устройств, так как разгружает процессор и тем самым позволяет экономить драгоценный заряд аккумулятора.
Как-то так. Хватало, конечно, и задач на умение пользоваться гуглом — но самые неожиданные грабли мы вроде перечислили. В итоге, несмотря на усилия организаторов, ~~праздник состоялся~~ удалось-таки получить картинки, за которые не очень стыдно:
[](//habrastorage.org/files/4aa/b17/a9c/4aab17a9cdf84543a199413edc830c90.PNG) [](//habrastorage.org/files/e84/41d/b17/e8441db17252410294069a05416f59f0.PNG)
[](//habrastorage.org/files/cc8/541/ef4/cc8541ef49174389ae3a5ac5f528fc9b.PNG) [](//habrastorage.org/files/a25/ac9/ee8/a25ac9ee88e041e69711ede97f26dafe.PNG) | https://habr.com/ru/post/230671/ | null | ru | null |
# Yandex Map Kit for Android. Поворот карты
Здравствуйте!
В этом сообщении опишу включение функции вращения карты в приложении использующем [Yandex Map Kit for Android](https://github.com/yandexmobile/yandexmapkit-android). Сообщение написано по мотивам [Issue #99](https://github.com/yandexmobile/yandexmapkit-android/issues/99), которое осталось без решения.
Маленькое отступление. Начать работать с картой по описанию в разделе Wiki [«Как начать работу»](https://github.com/yandexmobile/yandexmapkit-android/wiki/%D0%9A%D0%B0%D0%BA-%D0%BD%D0%B0%D1%87%D0%B0%D1%82%D1%8C-%D1%80%D0%B0%D0%B1%D0%BE%D1%82%D1%83) не удалось. Приложение падало при старте с ошибкой «Caused by: android.view.InflateException: Binary XML file line #7: Error inflating class ru.yandex.yandexmapkit.MapView». Помогло подключение к проекту classes.jar, располагается в yandexmapkit-library\libs.
Как и у автора [Issue #99](https://github.com/yandexmobile/yandexmapkit-android/issues/99) метод **МapController** **setRotateAnimtionTo** повернул карту, но вместо тайлов карты получил тайлы с надписью «Для этого участка нет данных».
Воспользовавшись подсказкой поддержки
> По вращение оно делалось для моего место положения и как бы представляет внутрений функционал.
>
> Проблема у Вас в повороте это то что не выставлена точка центра вращение. Но все эти АПИ пока увы закрыты
исследовал класс **MyLocationOverlay**(байт код можно посмотреть в Eclipse), были найдены следующие строчки
```
223 aload_0 [this]
224 invokevirtual ru.yandex.yandexmapkit.overlay.location.MyLocationOverlay.f() : boolean [168]
227 ifeq 258
230 aload_0 [this]
231 getfield ru.yandex.yandexmapkit.overlay.location.MyLocationOverlay.y : al [78]
234 aload_0 [this]
235 invokevirtual ru.yandex.yandexmapkit.overlay.location.MyLocationOverlay.getMyLocationItem() : ru.yandex.yandexmapkit.overlay.location.MyLocationItem [171]
238 invokevirtual ru.yandex.yandexmapkit.overlay.location.MyLocationItem.getBearing() : float [154]
241 invokevirtual al.a(float) : void [79]
244 aload_0 [this]
245 getfield ru.yandex.yandexmapkit.overlay.location.MyLocationOverlay.y : al [78]
248 aload_0 [this]
249 invokevirtual ru.yandex.yandexmapkit.overlay.location.MyLocationOverlay.getMyLocationItem() : ru.yandex.yandexmapkit.overlay.location.MyLocationItem [171]
252 invokevirtual ru.yandex.yandexmapkit.overlay.location.MyLocationItem.getPoint() : cp [156]
255 invokevirtual al.a(cp) : void [80]
258 aload_0 [this]
259 invokevirtual ru.yandex.yandexmapkit.overlay.location.MyLocationOverlay.getMapController() : ru.yandex.yandexmapkit.MapController [170]
262 invokevirtual ru.yandex.yandexmapkit.MapController.notifyRepaint() : void [140]
```
где **al** — это то, что возвращает метод **MapController getMapRotator()**. **MyLocationItem** — расширение **OverlayItem**, метод **getPoint()** которого наследуется в **MyLocationItem** (потребуется для получения недоступного экземпляра класса **cp**). Увидев все это, нетрудно догадаться, что метод класса **al a(cp point)** задает координаты оси вокруг которой вращается карта, а **al.a(float bearing)** угол поворота. У класса **al** (напомню, что экземпляр получен методом **getMapRotator()** класса **MapController** ) есть еще один метод **a(boolean enableRotation)** относительно которого была догадка, что он разрешает вращение карты, которая впоследствии подтвердилась.
Теперь все готово, чтобы вращать карту, например, при изменении азимута. Как получать значения азимута при изменении положения устройства в пространстве хорошо описано в [книге](http://books.google.ru/books?id=g3hAdK1IBkYC&printsec=frontcover&dq=professional+android+4+application+development&hl=ru&sa=X&ei=TqQKUcvTHpCN4gSriYCACg&ved=0CDEQ6AEwAA). Остается только вставить в обработчик события изменения азимута следующий код
```
GeoPoint geoPoint = mMapController.getMapCenter(); //получает географические координаты центра карты
OverlayItem overlayItem = new OverlayItem(geoPoint, null); // необходимо для получения недоступного экземпляра класса cp, представляет внутренние координаты центра карты библиотеки
mMapController.getMapRotator().a(bearing); //задаем угол поворота
mMapController.getMapRotator().a(overlayItem.getPoint()); //задаем точку относительно которой производится вращение
```
где
```
MapController mMapController;
MapView mMapView;
mMapView = (MapView) findViewById(R.id.map);
mMapController = mMapView.getMapController();
mMapController.getMapRotator().a(true); // разрешаем вращение
```
Результат
 | https://habr.com/ru/post/167807/ | null | ru | null |
# Terrasoft CRM: руководство разработчика
По долгу работы в последние несколько месяцев мне пришлось столкнуться с разработкой инфраструктуры CRM для одного издательского дома. Руководство компании выбрало именно десктопную версию CRM, т.к. на тот момент web версия bpm'online была достаточно сырой. До начала разработки были проработаны и согласованы основные сущности, специфические для издательства, которые не имели аналогов из коробки (такие как «Издания», «Форматы», «Номера», для рекламы в журналах «Заказы», «Размещения» и т.д., тесно взаимодействующие между собой). Но каково было мое удивление, когда, приступив к разработке я не нашел адекватной документации для разработчиков, а точнее и вовсе ничего не нашел. Все что удалось откопать это ответы на вопросы и блоги самих разработчиков CRM, на форуме. Скудную документацию можно найти на [terrasoft.ru/sdk](http://terrasoft.ru/sdk/), однако в самом начале знакомства с системой мне это не очень то и помогло. Поэтому я потратил достаточно много времени, чтобы понять, что и как работает.
Итак, всю систему можно разделить на разделы (Контакты, Контрагенты, Банки и детали к этим разделам, например Адреса, Договоры, Карьера для Контактов, Бренды, Платежные реквизиты для Контрагентов и т.д.)
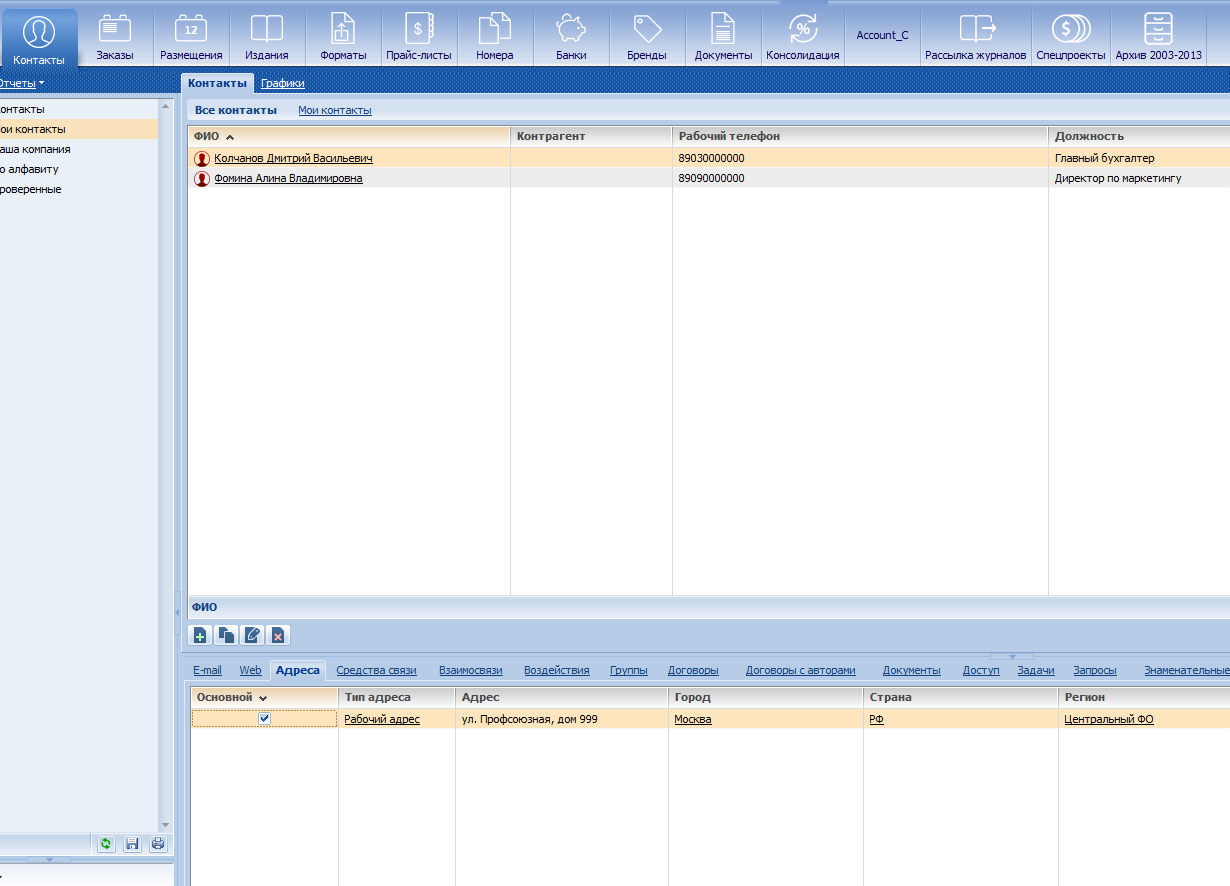
Вот пример раздела «Контакты» и детали «Адреса» Хочется отметить, что разделы создаются с помощью специальной утилиты.
**Как создать раздел**Для этого необходимо прописать специальный ключ для ярлыка запуска Terrasoft Client в поле «Объект»:
```
\wnd=wnd_CreateNewWorkspace
```
Должно получиться что-то вроде этого:
```
"C:\Program Files (x86)\Terrasoft Press\Bin\TSClient.exe" \wnd=wnd_CreateNewWorkspace
```
Кстати, таким же образом с помощью другого ключа можно включать профайлер запросов к БД, который бывает незаменим при поиске ошибок:
```
"C:\Program Files (x86)\Terrasoft Press\Bin\TSClient.exe" /profiler
```
Собственно самое важное для разработчика это как раз добавление, редактирование и структуризация данных, проработка связей всех сущностей между собой. Поэтому создадим раздел (или также Workspace) **MyWorkspace** и наладим добавление данных.

После чего надо добавить только что созданный раздел на рабочее место:
```
Файл -> Настройки -> Рабочие места
```

После этого мы можем открыть Terrasoft Administrator и найти все сервисы, необходимые для работы нашего раздела (воркспейса).
Найти его можно в дереве сервисов:
```
Custom -> Workspaces -> myworkspace -> General -> Main Grid
```
Теперь коротко о сервисах, из которых состоит наш воркспейс.
* *tbl\_myworkspace* (tbl\_ = Table) Таблица с описанием полей, индексов и связей;
* *sq\_myworkspace* (sq\_ = Select Query) Запрос, который достает данные из таблицы (или нескольких таблиц с использованием JOIN’ов);
* *ds\_myworkspace* (ds\_ = Data Set) Набор данных, позволяет добавлять, удалять или изменять данные в таблице;
* *wnd\_myworkspaceEdit* (wnd\_ = Window) Окно редактирования, с помощью которого пользователь добавляет данные в данный раздел;
* *wnd\_myworkspaceGridArea* Это грид, в котором отображаются все наши записи из данного раздела;
* *wnd\_myworkspaceWorkspace* Главное окно раздела, которое содержит как основной грид, так детали, связанные с ним. Также, при необходимости здесь можно добавлять новые детали (получается связь один-ко-многим, т.е. одна запись грида может иметь несколько записей в детали, как я писал раньше «Контакт» может иметь несколько адресов и т.д.);
### Добавление данных
Попробуем создать раздел с информацией о сотрудниках. Добавим несколько новых полей:
* E-mail
* Должность
* Зарплата
Сначала необходимо создать все эти поля в таблице **tbl\_myworkspace**. Ни каких сложностей возникнуть не должно. После сохранения поля обновятся в БД которую вы используете (у меня Microsoft SQL). Здесь же мы можем добавить индексы по полям или связи при необходимости.
Теперь надо обновить запрос **sq\_myworkspace**, который отвечает за выборку данных из этой таблицы.
Добавляем необходимые поля и сохраняем. При желании можно просмотреть SQL, запрос нажав ctrl + P.
В конце добавляем все эти поля в датасет **ds\_myworkspace**, чтобы можно было работать с данными через специальный объект.
Тоже самое можно проделать гораздо проще, надо найти справочник нашего раздела (myworkspace) и изменить структуру полей:
```
Инструменты -> Справочники
```
Теперь, когда мы добавили необходимые поля, можно отобразить их на форме добавления/редактирования данных **wnd\_myworkspaceEdit**.
Из множества доступных элементов, выбираем **TextDataControl.** В свойствах необходимо указать следующие параметры:
* DatasetLink — обычно он всего один на форме dlData (находится на вкладке «Невизуальные»);
* DataFieldName – выбираем поле, которое мы хотим отобразить (если наших добавленных полей не видно, попробуйте закрыть и заново открыть окно wnd\_myworkspaceEdit)
* Name – можно оставить стандартное название, но лучше использовать определенный стиль для таких элементов (например edtNameOfField).
Для зарплаты выбираем **IntegerDataControl** и проделываем все то же самое. Теперь мы можем открыть Terrasoft Client и добавить запись, используя окно редактирования данных раздела. Запись без проблем добавляется, но в гриде не отображаются наши пользовательские поля. Почему? Да потому что мы не добавили их в этот самый грид. Поэтому открываем **wnd\_myworkspaceGridArea**, находим элемент grdData -> gdvData, щелкаем правой кнопкой мыши, выбираем пункт «Определить колонки» и добавляем наши поля. После чего они станут видны в гриде в клиенте (возможно вам понадобится добавить их, нажав плюсик в правом верхнем углу грида, там вы можете добавлять или наоборот прятать необходимые колонки).
### Выпадающие списки
Довольно часто приходится иметь дело с выпадающими списками. Гораздо удобнее внести, например, список должностей один раз в справочник, а потом просто выбирать название должности из этого списка. Это гораздо удобнее и правильнее с точки зрения проектирования БД.
Предположим, мы уже создали справочник со списком должностей **MyWorkspaceAppointments**. Создаем поле AppointmentID в таблице **tbl\_myworkspace**, где будет храниться ID должности. Добавляем его в **sq\_myworkspace**, и также нам надо будет делать выборку поля «Название должности», которое будет отображаться в выпадающем списке. Поэтому делаем JOIN с таблицей должностей по полю AppointmentID. И добавляем в блок SELECT это поле. Извлекаем его как AppointmentName.
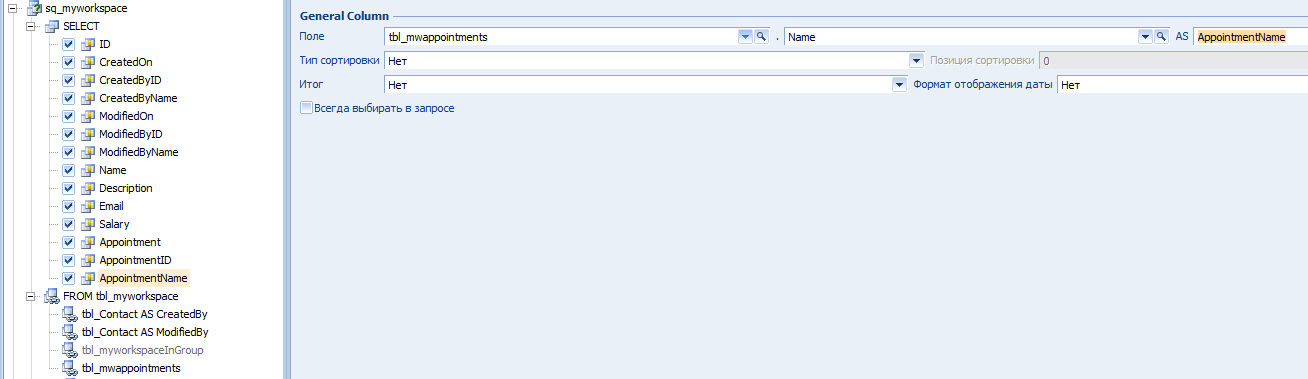
Теперь добавляем поле «Поле справочника» в датасет. Выбираем колонку AppointmentID, в источнике данных справочника выбираем датасет справочника должностей, а в поле «Колонка для отображения» выбираем поле AppointmentName, выбранное нами ранее. Внизу ставим галочку «Отображать как выпадающий список в карточках». На окно добавляем элемент LookupDataControl и выбираем в DataFieldName. Все, можно проверять.
Собственно, это и есть самые основы на которых построена система Terrasoft (по моему личному мнению).
### Работа с набором данных Dataset
Как я уже говорил, работа с БД происходит через набор данных dataset. Получить текущий dataset для окна, в котором мы работаем, можно через DataLink:
```
var Dataset = dlData.Dataset;
```
Получить любой другой набор данных можно также по его названию:
```
var TestDataset = Services.GetNewItemByUSI('ds_Test');
```
**Добавление записи в коде**
```
TestDataset.Append();
TestDataset.Values('Name') = 'Василий Иванов';
TestDataset.Values('Salary') = 30000;
TestDataset.Post();
```
ID – уникальный идентификатор добавлять не надо, это произойдет автоматически.
**Редактирование записи**
Для редактирования конкретной записи применяем фильтр (далее фильтры будут более подробно рассмотрены) к набору данных:
```
ApplyDatasetFilter(TestDataset, 'ID', '{e2ad6e6f-481a-40d0-abb6-50e4b19a43d6}', true);
TestDataset.Open(); // открываем набор
if(!TestDataset.IsEmptyPage) {
TestDataset.Edit();
TestDataset.Values('Salary') = 35000; // изменяем нужные поля
TestDataset.Post(); // сохраняем
}
TestDataset.Close(); // закрываем по завершении работы
```
Если необходимо отредактировать более одной записи:
```
TestDataset.Open();
while (!TestDataset.IsEOF) {
TestDataset.Edit();
TestDataset.Values('Salary') = 40000;
TestDataset.Post();
TestDataset.GotoNext(); // переходим к следующей записи
}
TestDataset.Close();
```
**Удаление**
```
// не забывайте применять соответствующие фильтры, чтобы не удалить все записи
TestDataset.Open();
while(!TestDataset.IsEOF) {
TestDataset.Delete();
TestDataset.Open();
}
TestDataset.Close();
```
Посчитать количество записей в наборе можно с помощью свойства RecordsCount.
```
var Records = TestDataset.RecordsCount;
```
### Select Query и Dataset: пользовательские фильтры
Получаемые с помощью датасетов данные, можно фильтровать с помощью пользовательских фильтров. Они задаются в сервисах **sq\_**. В нашем случае это **sq\_myworkspace**. По умолчанию будет создан фильтр по ID, который сразу можно использовать в коде.
Применяется обычный фильтр с помощью функции ApplyDatasetFilter:
```
ApplyDatasetFilter(Dataset, 'ID', id, true);
```
* Dataset – датасет, к которому надо применить фильтр
* 'ID' – название фильтра в блоке WHERE
* id – идентификатор по которому будет производится поиск
* true – данный параметр говорит о том, что фильтр надо включить
Создадим простой фильтр по полю «Зарплата»:
1) создаем параметр, который будет передаваться в фильтр (SalarySum);
2) в блок WHERE добавляем «Фильтр сравнения», указываем название такое же, как и у параметра (SalarySum). Выбираем поле (*tbl\_myworkspace.Salary*) для сравнения с параметром, который мы будем передавать из функции ApplyDatasetFilter.

Теперь можем применить его в коде и найти всех сотрудников с зарплатой 30000.
```
var ds = Services.GetNewItemByUSI('ds_myworkspace');
ApplyDatasetFilter(ds, 'SalarySum', 30000, true);
ds.Open();
Log.Write(2, ds.ValAsStr('Name'));
ds.Close();
```
Можно также применять несколько фильтров. Например, найти всех директоров с зарплатой больше 30000 и т.д.
### События dataset
Также хочется отметить наиболее используемые события dataset:
*OnDatasetAfterOpen* — возникает после открытия набора данных;
*OnDatasetAfterPositionChange* — возникает после перехода на другую запись (бывает полезно при отслеживании смены выделенной записи в гриде);
*OnDatasetAfterPost* — возникает после добавления/изменения записи (бывает полезно, когда надо изменить связанные данные в другой таблице);
*OnDatasetBeforePost* — возникает перед добавлением/изменением записи (бывает полезно для пользовательской проверки данных, перед сохранением). Также в событие передается параметр DoPost, если по какой-то причине нужно отменить добавление (например, данные не прошли пользовательскую проверку) просто делаем:
```
DoPost.Value = false;
```
*OnDatasetDataChange* — возникает при изменении данных датасета. Например нужна какая-то логика при изменении поля должность из нашего выпадающего списка.
```
function dlDataOnDatasetDataChange(DataField) {
var FieldName = DataField.Name;
switch(FieldName) {
case 'EditionID':
// организуем необходимую логики при каждом изменении поля
break;
}
}
```
*OnDatasetBeforeDelete* — возникает перед удалением записи (например можно повесить пользовательскую проверку данных, и при необходимости отменить удалить используя параметр DoDelete).
```
DoDelete.Value = false;
```
*OnDatasetAfterDelete* — возникает после удаления записи (например можно проверить, обновить или удалить связанные данные с данной записью).
### События окна, обращение к элементам
Иногда нужно прописать определенную логику при открытии окна, сделать это можно в событии **OnPrepare**.
По умолчанию у окна, в событии, будет прописана функция **wnd\_BaseDBEditOnPrepare**, которая должна вызываться для правильной инициализации каждого окна. Но нам необходимо добавить свою логику, поэтому переименуем функцию в **wnd\_MyWorkspaceDBEditOnPrepare** и дважды нажмем на нее. Откроется (или создастся новый) скрипт окна.
```
function wnd_MyWorkspaceDBEditOnPrepare(Window) {
scr_BaseDBEdit.wnd_BaseDBEditOnPrepare(Window);
}
```
Не забываем вызвать данную функцию для корректной инициализации и добавляем свою логику. Предположим, что нам надо высчитывать подоходный налог с зарплаты сотрудника. Добавляем в окно новый элемент NumericEdit.
Определяем события для поля *Salary* OnKeyDown и OnKeyUp, эти события буду срабатывать при вводе данных или при стирании. Напишем функцию, которая будет обновлять при каждом изменении поля *Salary* поле *Tax* (налог). Должно получиться что-то вроде этого:
```
function edtSalaryOnKeyDown(Control, Key, Shift) {
calculateTax();
}
function edtSalaryOnKeyUp(Control, Key, Shift) {
calculateTax();
}
function calculateTax() {
var Dataset = dlData.Dataset; // получаем набор данных для текущего окна
edtTax.Value = dlData.Dataset.ValAsInt('Salary') * 0.13;
}
```
Все отлично работает. Однако при открытии окна поле «Налог» не будет заполнено. Это можно исправить с помощью события окна OnPrepare.
```
function wnd_MyWorkspaceDBEditOnPrepare(Window) {
scr_BaseDBEdit.wnd_BaseDBEditOnPrepare(Window);
calculateTax(); // просчитываем и заполняем поле налог
}
```
В процессе работы появились некоторые наработки, которые мне не раз пригодились.
**Посмотреть**
```
//изменение цвета и текста в ячейке у DataGrid
function grdDataOnGetRowDrawInfo(DataGrid, Color, TextColor, ImageName, Font) {
if (/* условие */) {
Color.Value= clRed; // цвет ячейки
TextColor.Value = clYellow; // цвет текста
}
}
```
```
//фильтрация значений выпадающего списка по определенном полю
function edtContactOnPrepareSelectWindow(LookupDataControl, SelectWindow) {
ApplyDatasetFilter(LookupDataControl.DataField.LookupDataset, 'IsActive', true, true);
}
// сбрасывает выпадающий список, и при следующем обращении опять вызовет событие OnPrepareSelectWindow< (например если данные в списке зависят от другого поля, которое изменилось, и необходимо обновить фильтр)
edtContact.UnprepareDropDownList();
```
```
// открытие любого окна
var EditWindowUSI = 'wnd_OpportunityEdit';
var Attributes = GetNewDictionary();
Attributes.Add('RecordID', GUID_NULL); // если не указываем RecordID то открывается окно для добавления данных, если указываем, то запись с ID = RecordID открывается для редактирование
var DefaultValues = GetNewDictionary(); // значения по умолчанию
DefaultValues.Add('CustomerID', AccountID);
ShowEditWindowEx(EditWindowUSI, Attributes, DefaultValues);
```
```
// что-то вроде глобальной области видимости, можно таким образом передавать данные из одного окна в другое
Connector.Attributes('DatasetToSave') = object;
```
```
// обращение к родительскому окну (также можно обратиться к элементам на этом окне)
var ParentWindow = Self.Attributes('NotifyObject').ParentContainer.ParentWindow.ComponentsByName('edtPriceListsEditionID');
// обращение к элементу родительского окна (текущее окно находится в контейнере)
var ParentWindow = Self.ParentContainer.ParentWindow.ComponentsByName('edtName’);
// обращение к одному гриду из другого через workspace
var grd = Self.ParentContainer.ParentWindow.ComponentsByName('wndGridData').Window.ComponentsByName('grdData');
```
```
// проверка, является ли данная запись новой, или она открыта на редактирование
Window.Attributes('IsNewRecordAppend')
```
```
// получить выделенные записи грида
var ArrayIDs = GetArrayByCollection(grdData.SelectedIDs);
```
```
// вывод каких либо данных в консоль
Log.Write(2, 'Text');
// например при отладке, удобно использовать исключение
try {
// ваш код
} catch(e) {
Log.Write(2, e.message);
}
```
Собственно, я описал все ключевые моменты по работе с системой. Думаю, что для начала разработки под данную CRM (актуально для версии 3.4, на счет других не знаю) этого будет вполне достаточно. | https://habr.com/ru/post/242081/ | null | ru | null |
# Смелый стайлгайд по AngularJS для командной разработки [2/2]
*Первая часть перевода [тут](http://habrahabr.ru/post/235873/).*
После прочтения [Google's AngularJS Guidelines](http://google-styleguide.googlecode.com/svn/trunk/angularjs-google-style.html), у меня создалось впечатление о его незавершённости, а ещё в нём часто намекали на профит от использования библиотеки Closure. Ещё [они заявили](http://blog.angularjs.org/2014/02/an-angularjs-style-guide-and-best.html), «Мы не думаем, что эти рекомендации одинаково хорошо применимы для всех проектов, использующих AngularJS. Мы будем рады видеть инициативу от сообщества за более общий стайлгайд, применимый как для небольших так и крупных проектов».
Отталкиваясь от личного опыта работы с Angular, [нескольких выступлений](http://speakerdeck.com/toddmotto), а также имеющемуся опыту командной разработки, представляю Вашему вниманию этот смелый стайлгайд по синтаксису, написанию кода и структуре приложений на AngularJS.
Директивы
---------
Все манипуляции с DOM следует производить исключительно из директив. Весь код, который годится для повторного использования должен быть при этом инкапсулирован (это касается и действий и разметки).
### Манипуляции с DOM
Манипуляциям с DOM следует находиться в методе `link` директивы.
##### Плохо:
```
// не используем контроллер
function MainCtrl (SomeService) {
this.makeActive = function (elem) {
elem.addClass('test');
};
}
angular
.module('app')
.controller('MainCtrl', MainCtrl);
```
##### Хорошо:
```
// используем директиву
function SomeDirective (SomeService) {
return {
restrict: 'EA',
template: [
'',
'',
''
].join(''),
link: function ($scope, $element, $attrs) {
// DOM manipulation/events here!
$element.on('click', function () {
$(this).addClass('test');
});
}
};
}
angular
.module('app')
.directive('SomeDirective', SomeDirective);
```
### Соглашение об именовании
Пользовательские директивы не должны иметь префикса `ng-*` в названии, во избежании возможного переназначения кода будущими релизами Angular. Наверняка, на момент появления `ng-focus`, было написано много директив, с таким-же названием, чья работа в приложениях была парализована только из-за использования такого же названия. Также, использование этого префикса запутывает, и внешне из кода представления не понятно, какие из директив написаны пользователем, а какие пришли с библиотекой.
##### Плохо:
```
function ngFocus (SomeService) {
return {};
}
angular
.module('app')
.directive('ngFocus', ngFocus);
```
##### Хорошо:
```
function focusFire (SomeService) {
return {};
}
angular
.module('app')
.directive('focusFire', focusFire);
```
Для именования директив используется camelCase. Первая буква в названии директивы при этом строчная. Стоит также заметить, что в коде представления (view) мы орудуем уже названием директивы, написанным через дефис. Так, для использования директивы `focusFire` в представлении мы обращаемся через .
### Ограничения в использовании
Если Вам важна поддержка IE8, то для директив необходимо использовать синтаксис с комментариями. По правда говоря, нет других причин использовать такую форму вызова директив. По возможности даже этот синтаксис лучше не использовать, потому что в последствии может возникнуть путаница, где настоящий комментарий, а где вызов директивы.
##### Плохо:
Это очень путает.
```
```
##### Хорошо:
Декларативные пользовательские директивы выглядят более выразительно.
```
```
Разрешение promise в роутере, а defer в контроллере
---------------------------------------------------
После создания сервисов, наверняка нам захочется воспользоваться ими в контроллерах для работы с данными. Потому со временем поддержание опрятного вида контроллеров может стать проблемой, наряду с получением правильных данных.
Благодаря `angular-route.js` (либо аналогичным сторонним дополнениям, таким как `ui-router.js`), мы получаем возможность использовать свойство `resolve`, для разрешения promise'ов следующего представления до момента отображения нам готовой страницы. Это означает, что контроллер для данного представления будет создан сразу после получения всех данных, а это в свою очередь значит, что до этого момента не будет вызовов функций.
##### Плохо:
```
function MainCtrl (SomeService) {
var self = this;
// не будет разрешён
self.something;
// будет разрешён асинхронно
SomeService.doSomething().then(function (response) {
self.something = response;
});
}
angular
.module('app')
.controller('MainCtrl', MainCtrl);
```
##### Хорошо:
```
function config ($routeProvider) {
$routeProvider
.when('/', {
templateUrl: 'views/main.html',
resolve: {
doSomething: function (SomeService) {
return SomeService.doSomething();
}
}
});
}
angular
.module('app')
.config(config);
```
На данном этапе внутри нашего сервиса произойдёт привязка promise к отдельному объекту, который в свою очередь, может быть передан «отложенному» контроллеру:
##### Хорошо:
```
function MainCtrl (SomeService) {
// будет разрешён!
this.something = SomeService.something;
}
angular
.module('app')
.controller('MainCtrl', MainCtrl);
```
Но здесь есть ещё кое-что, что можно улучшить. Можно перенести свойство `resolve` прямо в код контроллера, что позволит избежать наличия какой-либо логики в коде маршрутизатора.
##### Отлично:
```
// конфигурация, где resolve ссылается на метод в соответствующем контроллере
function config ($routeProvider) {
$routeProvider
.when('/', {
templateUrl: 'views/main.html',
controller: 'MainCtrl',
controllerAs: 'main',
resolve: MainCtrl.resolve
});
}
// собственно, контроллер
function MainCtrl (SomeService) {
// будет разрешён!
this.something = SomeService.something;
}
// описываем свойство resolve прямо в контроллере
MainCtrl.resolve = {
doSomething: function (SomeService) {
return SomeService.doSomething();
}
};
angular
.module('app')
.controller('MainCtrl', MainCtrl)
.config(config);
```
### Изменение маршрута и спиннер
В процессе разрешения нового маршрута, наверняка нам захочется показать что-нибудь для индикации прогресса. По обыкновению Angular создаёт событие `$routeChangeStart`, когда мы покидаем текущую страницу. В этот самый момент можно показать спиннер. А убрать его можно в момент возникновения события `$routeChangeSuccess` ([подробнее здесь](https://docs.angularjs.org/api/ngRoute/service/$route)).
Избегайте $scope.$watch
-----------------------
Используйте `$scope.$watch` только тогда, когда нет возможности обойтись без него. Стоит помнить, что по производительности он значительно уступает решениям `ng-change`.
##### Плохо:
```
$scope.$watch('myModel', callback);
```
##### Хорошо:
```
```
Структура проекта
-----------------
Каждый контроллер, сервис или директиву следует помещать в отдельный файл. Не стоит запихивать все контроллеры в один файл хотя бы по той причине, что в последствии будет крайне сложно там что-либо найти.
##### Плохо:
```
|-- app.js
|-- controllers.js
|-- filters.js
|-- services.js
|-- directives.js
```
##### Хорошо:
Придерживайтесь ёмких и говорящих названий файлов, чтобы иметь максимальное представление о его содержимом отталкиваясь только от названия.
```
|-- app.js
|-- controllers/
| |-- MainCtrl.js
| |-- AnotherCtrl.js
|-- filters/
| |-- MainFilter.js
| |-- AnotherFilter.js
|-- services/
| |-- MainService.js
| |-- AnotherService.js
|-- directives/
| |-- MainDirective.js
| |-- AnotherDirective.js
```
В зависимости от размера кодовой базы вашего проекта, возможно вам больше подойдёт функциональный подход в именовании файлов.
##### Хорошо:
```
|-- app.js
|-- dashboard/
| |-- DashboardService.js
| |-- DashboardCtrl.js
|-- login/
| |-- LoginService.js
| |-- LoginCtrl.js
|-- inbox/
| |-- InboxService.js
| |-- InboxCtrl.js
```
Соглашения об именовании и конфликты
------------------------------------
В Angular есть множество объектов, чьё название начинается со знака `$`, например `$scope` или `$rootScope`. Этот символ как бы намекает нам на то, что тот или иной объект является публичным и с ним можно взаимодействовать из разных мест. Мы также знакомы с такими вещами как `$$listeners`, которые также доступны в коде, но считаются приватными.
Всё вышесказанное говорит только о том, что следует избегать использования `$` и `$$` в качестве префиксов в названиях ваших собственных директив/сервисов/контроллеров/провайдеров/фабрик.
##### Плохо:
Здесь мы задаём `$$SomeService` в качестве определения, название функции при этом оставляем без префиксов.
```
function SomeService () {
}
angular
.module('app')
.factory('$$SomeService', SomeService);
```
##### Хорошо:
Здесь мы задаём `SomeService` в качестве определения **и** названия самой функции для более выразительного stack trace.
```
function SomeService () {
}
angular
.module('app')
.factory('SomeService', SomeService);
```
Минификация и аннотация
-----------------------
### Порядок аннотации
Считается хорошей практикой указывать в списке зависимостей модуля сначала провайдеры Angular, а уже после – свои.
##### Плохо:
```
// зависимости указаны беспорядочно
function SomeCtrl (MyService, $scope, AnotherService, $rootScope) {
}
```
##### Хорошо:
```
// сначала провайдеры Angular -> свои
function SomeCtrl ($scope, $rootScope, MyService, AnotherService) {
}
```
### Автоматизируйте минификацию
Используйте `ng-annotate` для автоматической аннотации зависимостей, ведь `ng-min` [устарел и больше не поддерживается](https://github.com/btford/ngmin). Что касается `ng-annotate`, так подробнее о нём [здесь](https://github.com/olov/ng-annotate).
В нашем случае, когда мы описываем код модуля в отдельной функции, для корректной минификации необходимо будет использовать комментарий `@ngInject` перед теми функциями с зависимостями. Этот комментарий является инструкцией `ng-annotate` для автоматического описания зависимостей того или иного модуля.
##### Плохо:
```
function SomeService ($scope) {
}
// ручное описание зависимостей – это пустая трата времени
SomeService.$inject = ['$scope'];
angular
.module('app')
.factory('SomeService', SomeService);
```
##### Хорошо:
```
/**
* @ngInject
*/
function SomeService ($scope) {
}
angular
.module('app')
.factory('SomeService', SomeService);
```
В итоге это превратится в следующее:
```
/**
* @ngInject
*/
function SomeService ($scope) {
}
// следующую строчку ng-annotate создаст автоматически
SomeService.$inject = ['$scope'];
angular
.module('app')
.factory('SomeService', SomeService);
```
Данный стайлгайд находится в процессе доработки. Всегда актуальные рекомендации Вы найдёте на [Github](https://github.com/toddmotto/angularjs-styleguide). | https://habr.com/ru/post/237279/ | null | ru | null |
# Настройка VPN-сервера SoftEtherVPN под Linux

Как уже [писалось](http://habrahabr.ru/post/208782/) на хабре, буквально в начале января сего года под лицензию GPL2 перешел очень интересный и, в своем роде, уникальный проект — [SoftEther VPN](http://www.softether.org/). Написали его студенты японского University of Tsukuba. Данный продукт позиционирует себя как VPN-сервер с поддержкой огромного количества туннельных протоколов: L2TP, L2TP/IPsec, L2TPv3/IPsec, MS-SSTP, EtherIP/IPsec, OpenVPN, SSL-VPN (собственной разработки), L2VPN, а также такие хитрые штуки как туннелирование через ICMP и DNS. Поддерживает туннелирование как на третьем, так и на втором уровне, умеет VLAN и IPv6. Работает практически на всех известных платформах (даже ARM и MIPS) и к тому же не требует рутовых прав. С полной спецификацией можно ознакомиться вот [тут](http://www.softether.org/3-spec). Если честно, когда я увидел список возможностей этой проги — я просто не поверил своим глазам и подумал: «Если ЭТО работает, то я ДОЛЖЕН это потестить!»
Эта статья будет описывать процесс установки и настройки SoftEther VPN Server под Линукс. В следующей статье постараюсь нарисовать красивые сравнительные графики производительности.
Данная софтина обладает на редкость приятным [интерфейсом](http://www.softether.org/3-screens/1.vpnserver) под Винду, однако под Линуксом вся настройка осуществляется через CLI. [Мануал](http://www.softether.org/4-docs/1-manual) безусловно хорош, но мне например показался чересчур подробным, и к тому же с перекосом в сторону графического интерфейса и излишне красочных японских картинок. Поэтому решил выложить основные команды CLI для тех, кому лень лопатить много английских букв.
Для начала — установим это чудо. У меня под рукой был VPS с 64-битным Дебиан 7 на борту, поэтому выбор был очевиден. Сразу предупреждаю: устанавливать нужно только с [GitHub'a](https://github.com/SoftEtherVPN/SoftEtherVPN/) (на текущий момент версия релиза 4.04 build 9412)! На оффициальном [сайте](http://www.softether-download.com/) можно скачать исходники под разные платформы, однако засада в том, что makefile'ы там сгенерированы каким-то садистки-западлистским способом, и на выходе вы получаете всего два файла — сам бинарник сервера и его CLI-шка. Никакого копирования в /usr/bin/ и прочих цивилизованных вещей там не прописано. В отличие от этого, makefile на Гитхабе ведет себя гораздо более дружелюбно (хотя инит-скрипт все равно не делает, зараза).
Прежде чем поставить прогу, рекомендую сходить [сюда](http://www.softether.org/4-docs/1-manual/7._Installing_SoftEther_VPN_Server/7.3_Install_on_Linux_and_Initial_Configurations) и узнать, что ей нужно для установки. Мне, например, понадобилось поставить ряд библиотек (потом их можно снести):
> `# apt-get install libreadline-dev libssl-dev libncurses5-dev zlib1g-dev`
Дальнейшая установка не проста, а очень проста, однако хочу обратить внимание, что вместо «make install» я пишу «checkinstall», дабы менеджер пакетов apt знал о новой программулине и мог потом ее корректно удалить (подробнее [здесь](https://debian.pro/628)).
> `# git clone github.com/SoftEtherVPN/SoftEtherVPN.git`
>
> `# cd SoftEtherVPN\`
>
> `# ./configure`
>
> `# make`
>
> `# checkinstall`
В процессе установщик попросит вас прочитать Лицензионное соглашение, а также указать вашу платформу и разрядность ОС. Кстати, прогу он поставит по-любому в /usr/vpnserver/, а бинарники в /usr/bin/, имейте ввиду. Если путь установки не нравится, это можно руками поменять в makefile'е. В конце установки он скажет:
> — Installation completed successfully.
>
>
>
> Execute 'vpnserver start' to run the SoftEther VPN Server background service.
>
> Execute 'vpnbridge start' to run the SoftEther VPN Bridge background service.
>
> Execute 'vpnclient start' to run the SoftEther VPN Client background service.
>
> Execute 'vpncmd' to run SoftEther VPN Command-Line Utility to configure VPN Server, VPN Bridge or VPN Client.
>
> --------------------------------------------------------------------
Отсюда можно логически понять, как это волшебство запускается и останавливается. Можно оставить и так, а можно взять с офф. сайта простенький [init-скрипт](http://www.softether.org/4-docs/1-manual/7._Installing_SoftEther_VPN_Server/7.3_Install_on_Linux_and_Initial_Configurations), который будет более привычным нам способом делать то же самое.
Итак, VPN-сервер установлен и его можно запустить:
> `# vpnserver start`
>
> `SoftEther VPN Server Service Started.`
Приступаем к конфигурированию. Вообще, мануал предлагает нам два способа это сделать: через его собственную командную строку **vpncmd** или через конфигурационный файл **vpn\_server.config**, причем огромное предпочтение отдается первому способу. Операции с конфигурационным файлом производитель считает рискованным занятием и всячески пытается нас от этого [отговорить](http://www.softether.org/4-docs/1-manual/3._SoftEther_VPN_Server_Manual/3.3_VPN_Server_Administration#3.3.7_Configuration_File). Дело в том, что сервер непрерывно читает этот файл и любые изменения в нем мгновенно отражаются на работе сервера. Единственный случай, когда настройка из конфиг-файла оправдана — это когда VPN-сервер выключен. Не знаю, зачем так сделано, но автору, в любом случае, виднее. Да и вообще, у проги хорошая CLI, после работы с которой о существовании конфиг-файла просто забываешь за ненадобностью.
Кстати, сразу после установки обратил внимание, что прога зачем-то стукнулась по адресу 130.158.6.77:80. Оказалось в этом нет ничего подозрительного, просто таким образом сервер посылает keepalive-пакеты на свой сайт (keepalive.softether.org:80), чтобы не рвались по таймауту разные PPP-сессии. Сразу после установки я эту функцию отключил командой **KeepDisable**.
Итак, сразу после запуска VPN-сервер уже работает и принимает подключения на порты TCP 443 (SSL VPN), 992, 1194 (OpenVPN) и 5555 (номера портов можно поменять командами **ListenerCreate** и **ListenerDelete**), однако чтобы начать использовать его необходимо сделать ряд простых настроек. Заходим в CLI командой **vpncmd**:
> `# vpncmd`
>
> `vpncmd command - SoftEther VPN Command Line Management Utility`
>
> `SoftEther VPN Command Line Management Utility (vpncmd command)`
>
> `Version 4.04 Build 9412 (English)`
>
> `Compiled 2014/01/15 17:22:14 by yagi at pc25`
>
> `Copyright (c) SoftEther VPN Project. All Rights Reserved.`
>
>
>
> `By using vpncmd program, the following can be achieved.`
>
>
>
> `1. Management of VPN Server or VPN Bridge`
>
> `2. Management of VPN Client`
>
> `3. Use of VPN Tools (certificate creation and Network Traffic Speed Test Tool)`
>
>
>
> `Select 1, 2 or 3:`
Выбор 1 перенесет нас в режим редактирования сервера, выбор 2 — в режим редактирования свойств клиента, а выбор 3 — режим тестирования и создания сертификатов сервера. Выбираем 1, сервер предложит ввести айпи адрес сервера, к которому мы хотим подключиться (Hostname of IP Address of Destination:), просто нажимаем Enter, т.к. собираемся редактировать локальный сервер. В третий и последний раз прога спросит нас имя виртуального хаба (Specify Virtual Hub Name:), с которым мы будем работать. Мы пока что не собираемся работать с виртуальными хабами, поэтому снова нажимаем Enter и попадаем в командную строку самого сервера.
Необходимо пояснить, что такое виртуальные хабы в терминологии разработчика. Виртуальный хаб — это некая довольно самостоятельная инстанция VPN-сервера, обладающая собственным набором настроек виртуальных интерфейсов, политик безопасности и протоколов VPN. Всего можно создать до 4096 виртуальных хабов, при этом они никак не будут пересекаться друг с другом ни на 2-ом, ни на 3-ем уровне — то есть будут полностью изолированы друг от друга. Каждый виртуальный хаб работает со своим набором пользователей и ничего не знает про пользователей другого виртуального хаба, хоть они и находятся на одном физическом сервере. С другой стороны, если мы захотим, мы можем настроить их взаимодействие друг с другом, в терминологии автора это называется Virtual bridge/router. Таким образом, виртуальный хаб — это и есть то, с чем мы будем работать после указания определенных глобальных настроек сервера.
После входа в vpncmd перед нами возникнет приглашение:
> `Connection has been established with VPN Server "localhost" (port 443).`
>
>
>
> `You have administrator privileges for the entire VPN Server.`
>
>
>
> `VPN Server>`
Можно ввести help и почитать список команд.
Первое, что мы должны сделать — это задать рутовый пароль сервера. Делается это командой **ServerPasswordSet**. Далее, как я уже писал командой **KeepDisable** отключаем keepalive-пакеты.
Далее, создаем виртуальный хаб командой **HubCreate <имя виртуального хаба>**, например
> `VPN Server>hubcreate vpn`
>
> `HubCreate command - Create New Virtual Hub`
>
> `Please enter the password. To cancel press the Ctrl+D key.`
>
>
>
> `Password:`
Можно задать админский пароль для нового хаба, тогда можно будет делегировать администрирование этого хаба другому человеку. А можно для простоты нажать Enter и не делать этого (для этого в дальнейшем есть команда **SetHubPassword**). После создания хаба мы должны перейти в режим администрирования этого хаба командой **Hub vpn**. Посмотреть статус хаба можно командой **StatusGet**. Не буду приводить здесь вывод этой команды, т.к. он длинный и довольно понятный. Хаб можно выключить командой **Offline** и вернуть обратно командой **Online**.
Мне понравилась команда **SetEnumDeny**. Дело в том, что когда в VPN-клиенте вводишь адрес VPN-сервера, он сразу же сдает тебе имена всех виртуальных хабов, зарегенных на сервере, как на картинке. Эта команда запрещает выводить имя данного хаба в списке. Типа небольшой, но бонус к безопасности.
Ладно, займемся более интересными вещами. Создаем пользователя командой **UserCreate** и задаем ему пароль при помощи **UserPasswordSet**. Команды очень простые, достаточно минимального знания английского, чтобы понять диалоговые сообщения сервера. На данном этапе для простоты не будем возиться с сертификатами, а доверимся самоподписанному сертификату сервера, который он сгенерил на этапе установки.
Вот в принципе и все, минимальная установка завершена и мы можем прицепиться к нашему серверу, указав его IP-адрес и любой из портов списка **ListenerList**. Автор рекомендует порт 5555, поскольку данный порт не требует рутовых прав в системе. Окно VPN клиента я уже приводил выше, там все интуитивно понятно и очень красиво. Аутентификация проходит и устанавливается VPN-туннель. Однако, в таком виде пользы от туннеля мало, т.к. он позволяет обращаться только к самому серверу и больше никуда.
Допустим, наша задача более широка, и мы хотим использовать VPN-сервер для доступа в корпоративную сеть. Для этого нам понадобиться настроить NAT. Делается это довольно просто командой **SecureNATEnable**. Автоматом вместе с NAT включается и DHCP.
Вообще, SecureNAT — это довольно интересная технология от авторов SoftEtherVPN. Как мы знаем, трансляция сетевых адресов в \*NIX-системах осуществляется в ядре, соответственно для настройки NAT нужно иметь права суперпользователя. Создатели SoftEtherVPN решили, что это слишком излишне и написали свой собственный кастомный стек TCP/IP для того, чтобы фильтрация и натирование [осуществлялось](http://www.softether.org/index.php?title=4-docs/1-manual/3._SoftEther_VPN_Server_Manual/3.7_Virtual_NAT_%26_Virtual_DHCP_Servers) в userspace. Прикольная задумка, не знаю стоило ли оно того, но работает — это факт!
Сменить адрес интерфейса SecureNAT'a можно командой **SecureNatHostSet** (по умолчанию 192.168.30.1/24), а диапазон выдаваемых адресов и другие опции DHCP (например, основной шлюз и DNS-сервера) — командой **DhcpSet**. Не правда ли, дружелюбная CLI? Например если ввести «secure?» и нажать Enter, то выведется список возможных автодополнений:
> `VPN Server/vpn>secure?`
>
> `"secure": The command-name is ambiguous.`
>
> `The specified command name matches the following multiple commands.`
>
> `SecureNatDisable - Disable the Virtual NAT and DHCP Server Function (SecureNat Function)`
>
> `SecureNatEnable - Enable the Virtual NAT and DHCP Server Function (SecureNat Function)`
>
> `SecureNatHostGet - Get Network Interface Setting of Virtual Host of SecureNAT Function`
>
> `SecureNatHostSet - Change Network Interface Setting of Virtual Host of SecureNAT Function`
>
> `SecureNatStatusGet - Get the Operating Status of the Virtual NAT and DHCP Server Function (SecureNat Function)`
>
> `Please re-specify the command name more strictly.`
По умолчанию никакая фильтрация пакетов не применяется, т.е. впн-клиенты могут неограниченно ходить в корпоративную подсеть и пользоваться корпоративным Интернетом, если таковой имеется. При желании можно добавить правила файрволла командой **AccessAdd**. В качестве критериев файрволла можно указать имя пользователя, MAC и IP адреса источника и назначения, порты, протоколы и флаги TCP. И самое главное, что это работает, я проверял! Учтите еще, что правила фильтрации разных виртуальных хабов никак не влияют друг на друга, что позволяет гибко управлять доступом к корпоративной среде.
В качестве приятного бонуса доступен Dynamic DNS от softether.net. Свой VPN-сервер можно зарегить в DDNS командой **DynamicDnsSetHostname**, после чего нужно ввести желаемое имя домена 3-го уровня. Получится что-то вроде myvpn.softether.net. Согласитесь, мелочь, а приятно и притом совершенно бесплатно!
Поговорим о протоколах VPN. Я протестил L2TP/IPsec и OpenVPN. Настройка двух, казалось бы, таких разных протоколов оказалась довольно простой. OpenVPN включен изначально на порту 1194 UDP, но чтобы оно заработало нужно в режиме глобального сервера (команда **Hub** без параметров) ввести **IPsecEnable**, после чего ответить на ряд вопросов на предмет того, хотим ли мы включить голый L2TP, шифрованный L2TP/IPsec, а также L2TPv3/IPsec. Самые главные вопросы — это Pre-shared key (PSK) для IPsec и Default Hub. С PSK все понятно, это ключ, который необходимо ввести на клиентском устройстве, а вот про Default Hub расскажу поподробнее.
Дело в том, что тот же OpenVPN работает не через IPsec, но наследует политику учетных записей из IPsec. Поэтому при попытке коннекта по протоколу OpenVPN будет запрошено имя пользователя и пароль. Имя пользователя обязательно нужно вводить в формате «пользователь@хаб», но если мы указываем, какой хаб использовать по умолчанию, то "@хаб" можно опустить.
Сгенерировать конфиг-файл для OpenVPN можно командой **OpenVpnMakeConfig**, после чего указать местоположение, куда сохранить сгенереный файл. Этот файл можно тут же скормить OpenVPN клиенту и коннект пойдет. Файл предоставляется сразу в двух вариантах — Layer2VPN и Layer3VPN, то бишь VPN-сервер как свич, и VPN-сервер как роутер. И то, и другое прекрасно работает. Удобно!
Настройка L2TP/IPsec оказалась вообще тривиальной: на сервере после команды **IPsecEnable** ничего менять уже не надо, а в настройках например виндового встроенного VPN-клиента нужно указать протокол «L2TP IPsec VPN», в дополнительных параметрах указать предварительный ключ (PSK), который мы уже устанавливали, ну и, само собой, ввести учетные данные в формате, о котором я упоминал выше.
Аналогичным образом все настраивается на Андроиде. Было проверено на 4.2.1, все работает с использованием только стандартных инструментов.
**Вывод:** SoftEtherVPN — очень мощное и, самое главное, удобное средство построения VPN-туннелей. Конечно, я протестировал далеко не все возможности, но в большинстве случаев хватает и тех, что я написал. В ближайшем будущем постараюсь выложить сравнительные тесты производительности, а также тесты таких смешных штук как VPN over ICMP и DNS. С протоколами SSL VPN и MS SSTP пока связываться не хочу, т.к. неохота возиться с сертификатами, к тому же надо еще посмотреть на такие фичи проги, как Load Balancing aka кластеризация, отказоустойчивость, авторизация из RADIUS и AD и Layer2 VPN, включая VLAN-транкинг!
Так что, мне кажется, софтина стоит, как минимум, того, чтобы приглядеться к ней повнимательнее. Производитель позиционирует свой продукт, как во всем превосходящий OpenVPN, даже обещает throughput под гигабит. В общем, надо тестить! На данном этапе мне эта штукенция очень даже нравится. | https://habr.com/ru/post/211136/ | null | ru | null |
# 10 типичных ошибок при использовании Kubernetes
***Прим. перев.**: авторы этой статьи — инженеры из небольшой чешской компании pipetail. Им удалось собрать замечательный список из [местами банальных, но всё ещё] столь актуальных проблем и заблуждений, связанных с эксплуатацией кластеров Kubernetes.*

За годы использования Kubernetes нам довелось поработать с большим числом кластеров (как управляемых, так и неуправляемых — на GCP, AWS и Azure). Со временем мы стали замечать, что некоторые ошибки постоянно повторяются. Однако в этом нет ничего постыдного: мы сами совершили большинство из них!
В статье собраны наиболее распространенные ошибки, а также упомянуто о том, как их исправлять.
1. Ресурсы: запросы и лимиты
----------------------------
Этот пункт определенно заслуживает самого пристального внимания и первого места в списке.
CPU request обычно **либо вообще не задан, либо имеет очень низкое значение** (чтобы разместить как можно больше pod'ов на каждом узле). Таким образом, узлы оказываются перегружены. Во время высокой нагрузки процессорные мощности узла полностью задействованы и конкретная рабочая нагрузка получает только то, что «запросила» путем **троттлинга CPU**. Это приводит к повышению задержек в приложении, таймаутам и другим неприятным последствиям. *(Подробнее об этом читайте в другом нашем недавнем переводе: «[CPU-лимиты и агрессивный троттлинг в Kubernetes](https://habr.com/ru/company/flant/blog/489668/)» — прим. перев.)*
**BestEffort** (крайне **не** рекомендуется):
```
resources: {}
```
Экстремально низкий запрос CPU (крайне **не** рекомендуется):
```
resources:
Requests:
cpu: "1m"
```
С другой стороны, наличие лимита CPU может приводить к необоснованному пропуску тактов pod'ами, даже если процессор узла загружен не полностью. Опять же, это может привести к увеличению задержек. Продолжаются споры вокруг параметра *CPU CFS quota* в ядре Linux и троттлинга CPU в зависимости от установленных лимитов, а также отключении квоты CFS… Увы, лимиты CPU могут вызвать больше проблем, чем способны решить. Подробнее об этом можно узнать по ссылке ниже.
Чрезмерное выделение *(overcommiting)* памяти может привести к более масштабным проблемам. Достижение предела CPU влечет за собой пропуск тактов, в то время как достижение предела по памяти влечет за собой «убийство» pod’а. Наблюдали когда-нибудь **OOMkill**? Да, речь идет именно о нем.
Хотите свести к минимуму вероятность этого события? Не распределяйте чрезмерные объемы памяти и используйте Guaranteed QoS (Quality of Service), устанавливая memory request равным лимиту (как в примере ниже). Подробнее об этом читайте в [презентации Henning Jacobs](https://www.slideshare.net/try_except_/optimizing-kubernetes-resource-requestslimits-for-costefficiency-and-latency-highload) (ведущий инженер Zalando).
**Burstable** (более высокая вероятность получить OOMkilled):
```
resources:
requests:
memory: "128Mi"
cpu: "500m"
limits:
memory: "256Mi"
cpu: 2
```
**Guaranteed**:
```
resources:
requests:
memory: "128Mi"
cpu: 2
limits:
memory: "128Mi"
cpu: 2
```
Что потенциально поможет при настройке ресурсов?
С помощью *metrics-server* можно посмотреть текущее потребление ресурсов CPU и использование памяти pod'ами (и контейнерами внутри их). Скорее всего, вы уже им пользуетесь. Просто выполните следующие команды:
```
kubectl top pods
kubectl top pods --containers
kubectl top nodes
```
Однако они показывают только текущее использование. С ним можно получить приблизительное представление о порядке величин, но в конечном итоге понадобится **история изменения метрик во времени** (чтобы ответить на такие вопросы, как: «Какова была пиковая нагрузка на CPU?», «Какой была нагрузка вчера утром?» — и т.д.). Для этого можно использовать *Prometheus*, *DataDog* и другие инструменты. Они просто получают метрики с metrics-server и хранят их, а пользователь может запрашивать их и строить соответствующие графики.
[VerticalPodAutoscaler](https://cloud.google.com/kubernetes-engine/docs/concepts/verticalpodautoscaler) позволяет **автоматизировать** этот процесс. Он отслеживает историю использования процессора и памяти и настраивает новые request'ы и limit'ы на основе этой информации.
Эффективное использование вычислительных мощностей — непростая задача. Это все равно что постоянно играть в тетрис. Если вы слишком много платите за вычислительные мощности при низком среднем потреблении (скажем, ~10 %), рекомендуем обратить внимание на продукты, основанные на AWS Fargate или Virtual Kubelet. Они построены на модели биллинга serverless/pay-per-usage, что в таких условиях может оказаться дешевле.
2. Liveness и readiness probes
------------------------------
По умолчанию проверки состояния liveness и readiness в Kubernetes не включены. И порой их забывают включить…
Но как еще можно инициировать перезапуск сервиса в случае неустранимой ошибки? И как балансировщик нагрузки узнает, что некий pod готов принимать трафик? Или что он способен обработать больше трафика?
Часто эти пробы путают между собой:
* **Liveness** — проверка «живучести», которая перезапускает pod при неудачном завершении;
* **Readiness** — проверка готовности, она при неудаче отключает pod от сервиса Kubernetes (это можно проверить с помощью `kubectl get endpoints`) и трафик на него не поступает до тех пор, пока очередная проверка не завершится успешно.
Обе эти проверки **ВЫПОЛНЯЮТСЯ В ТЕЧЕНИЕ ВСЕГО ЖИЗНЕННОГО ЦИКЛА POD'А**. Это очень важно.
Распространено заблуждение, что readiness-пробы запускаются только на старте, чтобы балансировщик мог узнать, что pod готов (`Ready`) и может приступить к обработке трафика. Однако это лишь один из вариантов их применения.
Другой — возможность узнать, что трафик на pod чрезмерно велик и **перегружает его** (или pod проводит ресурсоемкие вычисления). В этом случае readiness-проверка помогает *снизить нагрузку на pod и «остудить» его*. Успешное завершение readiness-проверки в будущем позволяет **опять повысить нагрузку на pod**. В этом случае (при неудаче readiness-пробы) провал liveness-проверки был бы очень контрпродуктивным. **Зачем перезапускать pod, который здоров и трудится изо всех сил?**
Поэтому в некоторых случаях полное отсутствие проверок лучше, чем их включение с неправильно настроенными параметрами. Как было сказано выше, если **liveness-проверка копирует readiness-проверку**, то вы в большой беде. Возможный вариант — настроить [только readiness-тест](https://twitter.com/sszuecs/status/1175803113204269059), а [опасный liveness](https://habr.com/ru/company/flant/blog/470958/) оставить в стороне.
Оба типа проверок не должны завершаться неудачей при падении общих зависимостей, иначе это приведет к каскадному (лавинообразному) отказу всех pod'ов. Другими словами, [не вредите самому себе](https://blog.colinbreck.com/kubernetes-liveness-and-readiness-probes-how-to-avoid-shooting-yourself-in-the-foot/).
3. LoadBalancer для каждого HTTP-сервиса
----------------------------------------
Скорее всего, у вас в кластере есть HTTP-сервисы, которые вы хотели бы пробросить во внешний мир.
Если открыть сервис как `type: LoadBalancer`, его контроллер (в зависимости от поставщика услуг) будет предоставлять и согласовывать внешний LoadBalancer (не обязательно работающий на L7, скорее даже на L4), и это может сказаться на стоимости (внешний статический адрес IPv4, вычислительные мощности, посекундная тарификация) из-за необходимости создания большого числа подобных ресурсов.
В данном случае гораздо логичнее использовать один внешний балансировщик нагрузки, открывая сервисы как `type: NodePort`. Или, что еще лучше, развернуть что-то вроде **nginx-ingress-controller** (или *traefik*), который выступит единственным *NodePort* endpoint'ом, связанным с внешним балансировщиком нагрузки, и будет маршрутизировать трафик в кластере с помощью **ingress**-ресурсов Kubernetes.
Другие внутрикластерные (микро)сервисы, взаимодействующие друг с другом, могут «общаться» с помощью сервисов типа **ClusterIP** и встроенного механизма обнаружения сервисов через DNS. Только не используйте их публичные DNS/IP, так как это может повлиять на задержку и привести к росту стоимости облачных услуг.
4. Автомасштабирование кластера без учета его особенностей
----------------------------------------------------------
При добавлении узлов в кластер и их удалении из него не стоит полагаться на некоторые базовые метрики вроде использования CPU на этих узлах. Планирование pod'а должно производиться с учетом множества **ограничений**, таких как affinity pod'ов/узлов, taints и tolerations, запросы ресурсов, QoS и т.д. Использование внешнего autoscaler'а, не учитывающего эти нюансы, может привести к проблемам.
Представьте, что некий pod должен быть запланирован, но все доступные мощности CPU запрошены/разобраны и pod **застревает в состоянии `Pending`**. Внешний autoscaler видит среднюю текущую загрузку CPU (а не запрашиваемую) и не инициирует расширение *(scale-out)* — не добавляет еще один узел. В результате данный pod не будет запланирован.
При этом обратное масштабирование *(scale-in)* — удаление узла из кластера — всегда сложнее реализовать. Представьте, что у вас stateful pod (с подключенным постоянным хранилищем). **Persistent-тома** обычно принадлежат к **определенной зоне доступности** и не реплицируются в регионе. Таким образом, если внешний autoscaler удалит узел с этим pod'ом, то планировщик не сможет запланировать данный pod на другой узел, так как это можно сделать только в той зоне доступности, где находится постоянное хранилище. Pod зависнет в состоянии `Pending`.
В Kubernetes-сообществе большой популярностью пользуется [**cluster-autoscaler**](https://github.com/kubernetes/autoscaler/tree/master/cluster-autoscaler). Он работает в кластере, поддерживает API от основных поставщиков облачных услуг, учитывает все ограничения и умеет масштабироваться в вышеперечисленных случаях. Он также способен выполнять scale-in при сохранении всех установленных ограничений, тем самым экономя деньги (которые иначе были бы потрачены на невостребованные мощности).
5. Пренебрежение возможностями IAM/RBAC
---------------------------------------
Остерегайтесь использовать IAM-пользователей с постоянными секретами для *машин и приложений*. Организуйте временный доступ, используя роли и учетные записи служб *(service accounts)*.
Мы часто сталкиваемся с тем, что ключи доступа (и секреты) оказываются за'hardcode'ны в конфигурации приложения, а также с пренебрежением ротацией секретов несмотря на имеющийся доступ к Cloud IAM. Используйте роли IAM и учетные записи служб вместо пользователей, где это уместно.

Забудьте о kube2iam и переходите сразу к ролям IAM для service accounts (как это описывается в [одноименной заметке](https://blog.pipetail.io/posts/2020-04-13-more-eks-tips/) Štěpán Vraný):
```
apiVersion: v1
kind: ServiceAccount
metadata:
annotations:
eks.amazonaws.com/role-arn: arn:aws:iam::123456789012:role/my-app-role
name: my-serviceaccount
namespace: default
```
Одна аннотация. Не так уж сложно, правда?
Кроме того, не наделяйте service accounts и профили инстансов привилегиями `admin` и `cluster-admin`, если они в этом не нуждаются. Это реализовать чуть сложнее, особенно в RBAC K8s, но определенно стоит затрачиваемых усилий.
6. Не полагайтесь на автоматическое anti-affinity для pod'ов
------------------------------------------------------------
Представьте, что у вас три реплики некоторого deployment'а на узле. Узел падает, а вместе с ним и все реплики. Неприятная ситуация, так? Но почему все реплики находились на одном узле? Разве Kubernetes не должен обеспечивать высокую доступность (HA)?!
Увы, планировщик Kubernetes по своей инициативе не соблюдает правила раздельного существования *(anti-affinity)* для pod'ов. Их необходимо явно прописать:
```
// опущено для краткости
labels:
app: zk
// опущено для краткости
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: "app"
operator: In
values:
- zk
topologyKey: "kubernetes.io/hostname"
```
Вот и все. Теперь pod'ы будут планироваться на различные узлы (это условие проверяется только во время планирования, но не их работы — отсюда и `requiredDuringSchedulingIgnoredDuringExecution`).
Здесь мы говорим о `podAntiAffinity` на разных узлах: `topologyKey: "kubernetes.io/hostname"`, — а не о разных зонах доступности. Чтобы реализовать полноценную HA, придется копнуть поглубже в эту тему.
7. Игнорирование PodDisruptionBudget'ов
---------------------------------------
Представьте, что у вас production-нагрузка в кластере Kubernetes. Периодически узлы и сам кластер приходится обновлять (или выводить из эксплуатации). PodDisruptionBudget (PDB) — это нечто вроде гарантийного соглашения об обслуживании между администраторами кластера и пользователями.
PDB позволяет избежать перебоев в работе сервисов, вызванных недостатком узлов:
```
apiVersion: policy/v1beta1
kind: PodDisruptionBudget
metadata:
name: zk-pdb
spec:
minAvailable: 2
selector:
matchLabels:
app: zookeeper
```
В этом примере вы, как пользователь кластера, заявляете администраторам: «Эй, у меня есть сервис zookeeper, и независимо от того, что вы делаете, я бы хотел, чтобы по крайней мере 2 реплики этого сервиса всегда были доступны».
Подробнее об этом можно почитать [здесь](https://blog.marekbartik.com/posts/2018-06-29_kubernetes-in-production-poddisruptionbudget/).
8. Несколько пользователей или окружений в общем кластере
---------------------------------------------------------
Пространства имен Kubernetes *(namespaces)* **не обеспечивают сильную изоляцию**.
Распространено заблуждение, что если развернуть не-prod-нагрузку в одно пространство имен, а prod-нагрузку в другое, то они **никак не будут влиять друг на друга**… Впрочем, некоторый уровень изоляции можно достичь с помощью запросов/ограничений ресурсов, установки квот, задания priorityClass'ов. Некую «физическую» изоляцию в data plane обеспечивают affinities, tolerations, taints (или nodeselectors), однако подобное разделение довольно **сложно** реализовать.
Тем, кому необходимо совмещать оба типа рабочих нагрузок в одном кластере, придется мириться со сложностью. Если же такой потребности нет, и вам по карману завести **еще один кластер** (скажем, в публичном облаке), то лучше так и сделать. Это позволит достичь гораздо более высокого уровня изоляции.
9. externalTrafficPolicy: Cluster
---------------------------------
Очень часто мы наблюдаем, что весь трафик внутрь кластера поступает через сервис типа NodePort, для которого по умолчанию установлена политика `externalTrafficPolicy: Cluster`. Это означает, что *NodePort* открыт на каждом узле в кластере, и можно использовать любой из них для взаимодействия с нужным сервисом (набором pod'ов).

При этом реальные pod'ы, связанные с вышеупомянутым NodePort-сервисом, обычно имеются лишь на неком **подмножестве этих узлов**. Другими словами, если я подключусь к узлу, на котором нет нужного pod'а, он будет перенаправлять трафик на другой узел, **добавляя транзитный участок (hop)** и увеличивая задержку (если узлы находятся в разных зонах доступности/дата-центрах, задержка может оказаться довольно высокой; кроме того, вырастут расходы на egress-трафик).
С другой стороны, если для некоего сервиса Kubernetes задана политика `externalTrafficPolicy: Local`, то NodePort открывается только на тех узлах, где фактически запущены нужные pod'ы. При использовании внешнего балансировщика нагрузок, проверяющего состояния *(healthchecking)* endpoint'ов (как это делает *AWS ELB*), он **будет отправлять трафик только на нужные узлы**, что благоприятно скажется на задержках, вычислительных потребностях, счетах за egress (да и здравый смысл диктует то же самое).
Высока вероятность, что вы уже используете что-то вроде *traefik* или *nginx-ingress-controller* в качестве конечной NodePort-точки (или LoadBalancer, который тоже использует NodePort) для маршрутизации HTTP ingress-трафика, и установка этой опции может значительно снизить задержку при подобных запросах.
В [этой публикации](https://www.asykim.com/blog/deep-dive-into-kubernetes-external-traffic-policies) можно более подробно узнать об externalTrafficPolicy, ее преимуществах и недостатках.
10. Не привязывайтесь к кластерам и не злоупотребляйте control plane
--------------------------------------------------------------------
Раньше серверы было принято называть именами собственными: [*Anton*](https://twitter.com/vorobiev_cloud), HAL9000 и Colossus… Сегодня на смену им пришли случайно сгенерированные идентификаторы. Однако привычка осталась, и теперь собственные имена достаются кластерам.
Типичная история (основанная на реальных событиях): все начиналось с доказательства концепции, поэтому кластер носил гордое имя *testing*… Прошли годы, и он ДО СИХ пор используется в production, и все боятся к нему прикоснуться.
Нет ничего забавного в том, что кластеры превращаются в питомцев, поэтому рекомендуем периодически удалять их, попутно практикуясь в **восстановлении после сбоев** *(в этом поможет [chaos engineering](https://habr.com/ru/company/flant/blog/477994/) — прим. перев.)*. Кроме того, не помешает заняться и управляющим слоем *(control plane)*. Боязнь прикоснуться к нему — не очень хороший знак. *Etcd* мертв? Ребята, вы влипли по-настоящему!
С другой стороны, не стоит увлекаться манипуляциями с ним. Со временем **управляющий слой может стать медленным**. Скорее всего, это связано с большим количеством создаваемых объектов без их ротации (обычная ситуация при использовании Helm с настройками по умолчанию, из-за чего не обновляется его состояние в configmap'ах/секретах — как результат, в управляющем слое скапливаются тысячи объектов) или с постоянным редактированием объектов kube-api (для автоматического масштабирования, для CI/CD, для мониторинга, логи событий, контроллеры и т.д.).
Кроме того, рекомендуем проверить соглашения SLA/SLO с поставщиком managed Kubernetes и обратить внимание на гарантии. Вендор может гарантировать **доступность управляющего слоя** (или его субкомпонентов), но не p99-задержку запросов, которые вы ему посылаете. Другими словами, можно ввести `kubectl get nodes`, а ответ получить лишь через 10 минут, и это не будет являться нарушением условий соглашения об обслуживании.
11. Бонус: использование тега latest
------------------------------------
А вот это уже классика. В последнее время мы встречаемся с подобной техникой не так часто, поскольку многие, наученные горьким опытом, перестали использовать тег `:latest` и начали закреплять (pin) версии. Ура!
ECR [поддерживает неизменность тегов образов](https://aws.amazon.com/about-aws/whats-new/2019/07/amazon-ecr-now-supports-immutable-image-tags/); рекомендуем ознакомиться с этой примечательной особенностью.
Резюме
------
Не ждите, что все заработает по мановению руки: Kubernetes — это не панацея. Плохое приложение [останется таким даже в Kubernetes](https://twitter.com/sadserver/status/1032704897500598272?s=20) (и, возможно, станет еще хуже). Беспечность приведет к избыточной сложности, медленной и напряженной работе управляющего слоя. Кроме того, вы рискуете остаться без стратегии аварийного восстановления. Не рассчитывайте, что Kubernetes «из коробки» возьмет на себя обеспечение изоляции и высокой доступности. Потратьте некоторое время на то, чтобы сделать свое приложение по-настоящему cloud native.
Познакомиться с неудачным опытом различных команд можно в [этой подборке историй](https://k8s.af/) от Henning Jacobs.
Желающие дополнить список ошибок, приведенный в этой статье, могут связаться с нами в Twitter ([@MarekBartik](https://twitter.com/MarekBartik), [@MstrsObserver](https://twitter.com/MstrsObserver)).
P.S. от переводчика
-------------------
Читайте также в нашем блоге:
* «[Проектирование Kubernetes-кластеров: сколько их должно быть?](https://habr.com/ru/company/flant/blog/498100/)»;
* «[Азбука безопасности в Kubernetes: аутентификация, авторизация, аудит](https://habr.com/ru/company/flant/blog/468679/)»;
* «[Автомасштабирование и управление ресурсами в Kubernetes](https://habr.com/ru/company/flant/blog/459326/)» (обзор и видео доклада);
* «[ConfigMaps в Kubernetes: нюансы, о которых стоит знать](https://habr.com/ru/company/flant/blog/498970/)». | https://habr.com/ru/post/504396/ | null | ru | null |
# Одна история с оператором Redis в K8s и мини-обзор утилит для анализа данных этой БД

Что будет, если использовать всем известное in-memory-хранилище ключей и значений в качестве персистентной базы данных, не используя TTL? А если оно запущено с помощью надёжного, казалось бы, оператора в Kubernetes? А если в процессе увеличения реплик Redis мы внесём ещё одно маленькое и безобидное изменение?.. Отвечая на эти вопросы в данной статье, мы попутно расскажем, какие утилиты помогут найти пути к оптимизации размеров большой БД в Redis.
Проблемный кейс
---------------
Redis у нас используется внутри кластера Kubernetes в разных проектах. Для удобства управления и применения единых практик в рамках компании мы остановились на [операторе от Spotahome](https://github.com/spotahome/redis-operator). По нашему опыту, это наиболее стабильный вариант, хотя и у него есть свои проблемы, некоторые из которых будут затронуты далее в статье.
Простое описание логики работы этого оператора Redis можно найти в [документации проекта](https://github.com/spotahome/redis-operator/blob/master/docs/logic.md). По сути он создаёт комплект ресурсов для запуска *Redis failover* (отказоустойчивый Redis) на основе заданного пользователем ресурса `RedisFailover`. Этот комплект состоит из:
* ConfigMap’ов с конфигурацией Redis,
* StatefulSet’ов с самими Redis,
* Deployment’а из нужного количества реплик Sentinel.
Спецификация в ресурсе `RedisFailover` позволяет:
* настроить как количество реплик, так и requests/limits;
* сделать конкретные правки в конфигах запускаемых pod’ов *([простой пример](https://github.com/spotahome/redis-operator/blob/master/example/redisfailover/custom-config.yaml))*;
* сделать неудаляемые PVC, чтоб данные сохранились не только после удаления *Redis failovers*, но и даже после удаления самого оператора *([пример](https://github.com/spotahome/redis-operator/blob/master/example/redisfailover/persistent-storage-no-pvc-deletion.yaml))*;
* да даже просто поменять пользователя, из-под которого мы хотим запустить Redis *([пример](https://github.com/spotahome/redis-operator/blob/master/example/redisfailover/security-context.yaml))*.
Создавая много ресурсов `RedisFailover`, можно создать и конфигурировать отдельно такое количество взаимосвязанных *Redis failovers*, какое необходимо.
***Примечание**: Тем, кто не свыкся с понятием Kubernetes-оператора и/или к данному моменту запутался в ресурсах для Redis failover и ресурсе `RedisFailover`, рекомендуем прочитать [эту вводную статью](https://habr.com/ru/company/flant/blog/326414/).*
В одном достаточно нагруженном проекте, состоящем из нескольких подпроектов *(речь про популярный в рунете веб-сайт)*, Redis исторически используется не только как in-memory data store и хранилище кэша, но и как полноценное stateful-хранилище. В связи с этим, размеры отдельных инсталляций Redis во всех подпроектах превратились из «редисок» в «тыквы». Если говорить точнее, то размер .rdb-файла\* самого «толстого» Redis в подпроектах составил 5 Гб.
*\* Снапшот базы данных Redis — один из двух встроенных в Redis вариантов [сохранения состояния на диск](https://redis.io/topics/persistence).*
Изначально для него использовался уже упомянутый ресурс [`RedisFailover`](https://github.com/spotahome/redis-operator/tree/master/example/redisfailover) с одной репликой Redis. Инстанс — довольно крупный, потребляющий на пике (т.е. в момент сохранения данных на диск) примерно 16 Гб оперативной памяти. Больше реплик просто не помещалось на узлы.
Затем, по мере роста потребления ресурсов и в процессе переезда подпроектов в Kubernetes, в используемый ЦОД были добавлены серверы. Благодаря этому появилась возможность увеличить количество реплик Redis до двух, чтобы повысить надёжность БД, учитывая важность сохранения состояния Redis.
Попутно с изменением количества реплик было принято решение изменить requests и limits контейнеров по памяти, уменьшив их с 22 гигабайт до 19, поскольку итоговые pod’ы получались большими (ведь хочется увеличить шанс комфортного переезда pod’ов при отказе на другие узлы). И решение делать это *одновременно* с увеличением количества реплик стало фатальным.
Подготовив бэкап для оперативного восстановления, был выкачен `RedisFailover` с обновлённой конфигурацией, в результате чего произошло следующее:
* StatefulSet расширился до двух;
* новый инстанс стал slave’ом и запустилась репликация;
* сразу же прошла readiness-проба у нового инстанса (там используется обычный ping!);
* из-за этого начался перекат единственного pod’а с данными, поскольку поменялись ресурсы;
* sentinel'ы мигом «сообразили», что мастера уже и нет и назначили мастером пустую реплику (на тот момент мастер едва ли успел сделать начальный для репликации `BGSAVE`);
* после переката нулевой реплики она подключилась к новоиспеченному пустому мастеру; репликация произошла молниеносно и уничтожила все данные.
Итог понятен: катастрофа (простой и восстановление данных из бэкапа).
Поскольку основным виновником произошедшего был оператор (а точнее — его readiness probe), по итогам инцидента мы создали [issue в GitHub проекта](https://github.com/spotahome/redis-operator/issues/205), а в процессе подготовки/публикации статьи получили [ответ](https://github.com/spotahome/redis-operator/issues/205#issuecomment-562350538) и [исправление](https://github.com/spotahome/redis-operator/releases/tag/v1.0.0-rc.3) от разработчиков оператора, с успехом проверили его.
Более общий вывод таков: **будьте бдительны при использовании Kubernetes-операторов** для управления критичными компонентами инфраструктуры! Применяя конкретно этот оператор, Redis-конфигурация с изначально одной репликой является даже более устойчивой к потере данных, чем в нескольких. В момент расширения кластера с одного узла Redis’а до двух и более система переходит в нестабильное состояние, при котором перезапуск мастера по любой причине гарантированно приведёт к потере данных — основной причиной этому будет некорректная проба. И, конечно, перед проведением таких работ нужно всегда сохранять копию `dump.rbd`.
Анализ данных
-------------
Дело пошло дальше. Увидев на этом примере, какие могут возникать проблемы при работе с Redis подобных размеров, мы решили выделить время на анализ данных в БД.
Для начала мы воспользовались [latency doctor](https://redis.io/topics/latency) — встроенной функцией Redis — и увидели следующее:
```
127.0.0.1:6379> LATENCY doctor
Dave, I have observed latency spikes in this Redis instance. You don't mind talking about it, do you Dave?
1. command: 3 latency spikes (average 237ms, mean deviation 19ms, period 67.33 sec). Worst all time event 256ms.
I have a few advices for you:
- Check your Slow Log to understand what are the commands you are running which are too slow to execute. Please check http://redis.io/commands/slowlog for more information.
- Deleting, expiring or evicting (because of maxmemory policy) large objects is a blocking operation. If you have very large objects that are often deleted, expired, or evicted, try to fragment those objects into multiple smaller objects.
127.0.0.1:6379> LATENCY latest
1) 1) "fork"
2) (integer) 1574513316
3) (integer) 308
4) (integer) 308
2) 1) "command"
2) (integer) 1574513311
3) (integer) 214
4) (integer) 256
```
Заметно, что при выполнении `fork` и `command` в Redis наблюдаются пики-задержки. Предполагаем, что эти пики как раз связаны с процессом сохранения rbd из-за его размера.
В Grafana, что показывает метрики Redis, полученные через Prometheus, следующая картина:
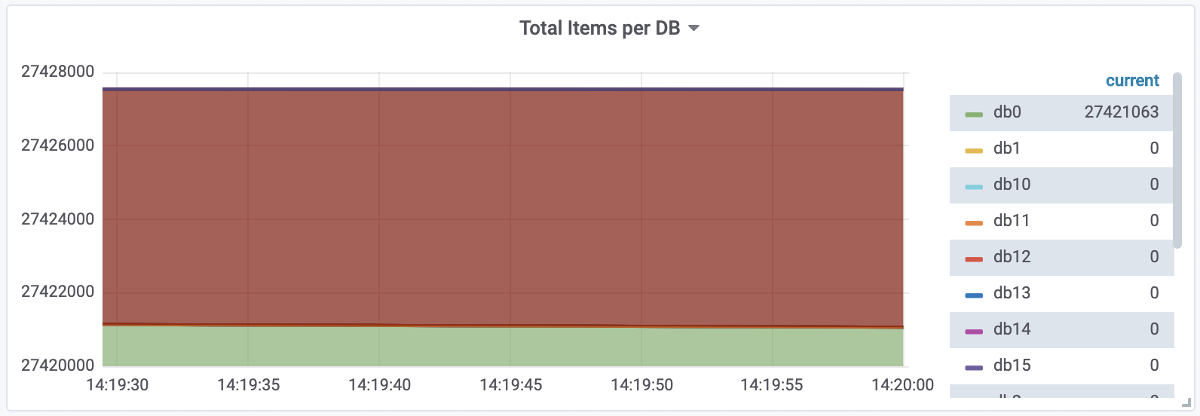
Иными словами: и огромный размер базы, и весьма большое количество QPS.
Следующий этап — более детальное изучение баз Redis. Хотелось получить агрегированный вывод, сколько места занимают БД и сколько времени они живут. Разобраться, что именно можно вычистить из Redis, а что — поменять в коде, чтобы избегать «раздутия» базы. Для этого мы вооружились бесплатными Open Source-инструментами. Предлагаем вниманию их краткий обзор на нашем конкретном примере.
### 1. Redis-memory-analyzer (RMA)
* [GitHub](https://github.com/gamenet/redis-memory-analyzer).
Эта утилита написана на Python, устанавливается из PyPI с помощью pip. Для запуска стоит запустить на отдельном (от production'а) узле Kubernetes или же просто с помощью Docker-контейнера с Redis, которому в `/data` надо поместить файл со снапшотом `dump.rdb`. Например, вот так (`docker-compose.yml`):
```
redis:
container_name: redis
image: redis
ports:
- "127.0.0.1:6379:6379"
volumes:
- ./:/data
restart: always
```
Далее достаточно запустить на узле: `rma -f json` — и получить вывод в формате JSON (нам это показалось более удобным для парсинга, чем plain text).
Сокращенный и слегка обфусцированный вывод самой проблемной базы:
```
{
"keys": [
{
"count": 16236021,
"name": "The:most:evil:set:*",
"percent": "59.24%",
"type": "set"
},
{
"count": 2463064,
"name": "likes:*:*",
"percent": "8.98%",
"type": "set"
},
{
"count": 2422160,
"name": "notifications:*",
"percent": "8.83%",
"type": "zset"
},
{
"count": 2102164,
"name": "YYY:*",
"percent": "7.67%",
"type": "set"
},
"nodes": [
{
"info": {
"active_defrag_running": 0,
"allocator_active": 16108007424,
"allocator_allocated": 16027311240,
"allocator_frag_bytes": 80696184,
"allocator_frag_ratio": 1.01,
"allocator_resident": 16336216064,
"allocator_rss_bytes": 228208640,
"allocator_rss_ratio": 1.01,
"lazyfree_pending_objects": 0,
"maxmemory": 0,
"maxmemory_human": "0B",
"maxmemory_policy": "noeviction",
"mem_allocator": "jemalloc-5.1.0",
"mem_aof_buffer": 0,
"mem_clients_normal": 49694,
"mem_clients_slaves": 0,
"mem_fragmentation_bytes": 308401864,
"mem_fragmentation_ratio": 1.02,
"mem_not_counted_for_evict": 0,
"mem_replication_backlog": 0,
"number_of_cached_scripts": 18,
"rss_overhead_bytes": -606208,
"rss_overhead_ratio": 1.0,
"total_system_memory": 67552931840,
"total_system_memory_human": "62.91G",
"used_memory": 16027240832,
"used_memory_dataset": 14661812642,
"used_memory_dataset_perc": "91.49%",
"used_memory_human": "14.93G",
"used_memory_lua": 1277952,
"used_memory_lua_human": "1.22M",
"used_memory_overhead": 1365428190,
"used_memory_peak": 16027625216,
"used_memory_peak_human": "14.93G",
"used_memory_peak_perc": "100.00%",
"used_memory_rss": 16335609856,
"used_memory_rss_human": "15.21G",
"used_memory_scripts": 35328,
"used_memory_scripts_human": "34.50K",
"used_memory_startup": 791264
},
"redisKeySpaceOverhead": null,
"totalKeys": 27402900,
"used": {
"active-defrag-max-scan-fields": "1000",
"hash-max-ziplist-entries": "512",
"hash-max-ziplist-value": "64",
"list-max-ziplist-size": "-2",
"proto-max-bulk-len": "536870912",
"set-max-intset-entries": "512",
"zset-max-ziplist-entries": "128",
"zset-max-ziplist-value": "64"
}
}
],
"stat": {
"hash": [
{
"Avg field count": 273.9381613257764,
"Count": 92806,
"Encoding": "ziplist [85.3%] / hashtable [14.6%]",
"Key mem": 127070103,
"Match": "YYY:*",
"Ratio": 4.11216105916338,
"Real": 1374780864,
"System": 899529088,
"TTL Avg.": -1,
"TTL Max": -1,
"TTL Min": -1,
"Total aligned": 2961700368,
"Total mem": 461390876,
"Value mem": 334320773
},
{
"Avg field count": 16.630734258229428,
"Count": 102498,
"Encoding": "ziplist [72.0%] / hashtable [27.9%]",
"Key mem": 51729452,
"Match": "ZZZ:*",
"Ratio": 3.4048548273474686,
"Real": 97797080,
"System": 63099024,
"TTL Avg.": -1,
"TTL Max": -1,
"TTL Min": -1,
"Total aligned": 265209096,
"Total mem": 80452286,
"Value mem": 28722834
},
{ … и так далее }
```
Увидев `"totalKeys": 27402900` и `{ "count": 16236021, "name": "The:most:evil:set:*", "percent": "59.24%", "type": "set" }`, разработчики схватились за голову. Довольно быстро были обнаружены проблемные участки кода, а в момент написания статьи уже шла подготовка к очистке всех Redis, после чего будет задеплоен код с исправлениями.
На этом можно было бы остановиться, но поскольку мы посмотрели и другие утилиты, расскажем и про них.
### 2. Redis-rdb-tools
* [GitHub](https://github.com/sripathikrishnan/redis-rdb-tools).
Для установки достаточно выполнить `pip install rdbtools python-lzf`. Затем, используя тот же стенд, что для RMA, можно выполнить:
```
rdb -c memory dump.rdb --bytes 100 -f memory.csv
```
… получив в ответ:
```
database,type,key,size_in_bytes,encoding,num_elements,len_largest_element,expiry
0,sortedset,notification:user:50242,26844,skiplist,262,8,
0,set,zz:yy:35647,30692,hashtable,760,8,
0,set,pp:646064c2170c2e1d:item:a15671709071,39500,hashtable,319,64,
0,hash,comments:93250,7224,ziplist,353,15,
0,hash,comments2:90667,3715,ziplist,179,14,
0,sortedset,yy:94224,67972,skiplist,544,15,
0,hash,comments3:135049,70764,hashtable,1150,15,
0,hash,ll-date:2018-10-20 12:00:00:count,2043,ziplist,61,49,
0,set,likes:57513,2064,intset,498,8,
0,hash,ll-date:2018-09-29 04:00:00:summ,2091,ziplist,53,49,
0,hash,ll-date:2018-09-25 22:00:00:count,2243,ziplist,68,49,
```
В целом, это неплохой инструмент, который даже умеет [сравнивать](https://github.com/sripathikrishnan/redis-rdb-tools#comparing-rdb-files) конкретные rdb-снапшоты между собой или «[излучать](https://github.com/sripathikrishnan/redis-rdb-tools#emitting-redis-protocol)» в протокол Redis в нужное место.
Однако делать заключение по его выводу очень сложно, поскольку потребуется дополнительный парсинг результатов. Авторы инструмента создали ещё и [rdbtools.com](https://rdbtools.com/) — платный GUI для визуализации данных Redis. В конце минувшего года он прекратил своё существование (EOL), перейдя в Redis Labs, тоже в виде платного продукта ([RedisInsight](https://redislabs.com/redisinsight/)). Рассмотрение таких решений остаётся за рамками этой статьи.
### 3. Redis-audit
* [GitHub](https://github.com/snmaynard/redis-audit).
Следующий инструмент написан на Ruby и, мягко говоря, устарел. Для его установки нужно скопировать репозиторий из GitHub, поставить Ruby и совершить пару простейших действий в каталоге инструмента:
```
sudo apt-get install ruby-full
gem install bundler
bundle install
```
Запуск:
```
./redis-audit.rb -h 127.0.0.1
```
… однако он зачастую падает с ошибкой:
```
Auditing 127.0.0.1:6379 dbnum:0 sampling 50000 keys
Sampling 50000 keys...
5000 keys sampled - 10% complete - 2019-11-26 14:16:16 +0300
10000 keys sampled - 20% complete - 2019-11-26 14:16:18 +0300
./redis-audit.rb:144:in `delete': invalid byte sequence in US-ASCII (ArgumentError)
from ./redis-audit.rb:144:in `group_key'
from ./redis-audit.rb:130:in `audit_key'
from ./redis-audit.rb:99:in `block in audit_keys'
from ./redis-audit.rb:97:in `times'
from ./redis-audit.rb:97:in `audit_keys'
from ./redis-audit.rb:358:in `'
```
Поскольку ресурсы на изучение каждой утилиты были довольно ограниченными, воспользовались «костылем»:
```
until ./redis-audit.rb -h 127.0.0.1 -s 50000 > dtf-audit; do echo "Try again"; sleep 1; done
Auditing 127.0.0.1:6379 dbnum:0 sampling 50000 keys
Sampling 50000 keys...
5000 keys sampled - 10% complete - 2019-11-24 22:18:26 +0300
10000 keys sampled - 20% complete - 2019-11-24 22:18:28 +0300
15000 keys sampled - 30% complete - 2019-11-24 22:18:29 +0300
20000 keys sampled - 40% complete - 2019-11-24 22:18:31 +0300
25000 keys sampled - 50% complete - 2019-11-24 22:18:32 +0300
30000 keys sampled - 60% complete - 2019-11-24 22:18:34 +0300
35000 keys sampled - 70% complete - 2019-11-24 22:18:35 +0300
40000 keys sampled - 80% complete - 2019-11-24 22:18:37 +0300
45000 keys sampled - 90% complete - 2019-11-24 22:18:38 +0300
50000 keys sampled - 100% complete - 2019-11-24 22:18:40 +0300
DB has 27402893 keys
Sampled 6.25 MB of Redis memory
Found 90 key groups
==============================================================================
```
Результат:
```
Found 107 key groups
==============================================================================
Found 1 keys containing strings, like:
ooo:04-01-2019
These keys use 0.0% of the total sampled memory (2 bytes)
None of these keys expire
Average last accessed time: 12 hours, 3 minutes, 22 seconds - (Max: 12 hours, 3 minutes, 22 seconds Min:12 hours, 3 minutes, 22 seconds)
==============================================================================
Found 1 keys containing sets, like:
ttt:fff:8aa26e6f8f7a232bd80877ddb4e3b7a4c7706be0031ab0a8f76adfb3e5448783
These keys use 0.0% of the total sampled memory (13 bytes)
None of these keys expire
Average last accessed time: 10 hours, 26 minutes, 34 seconds - (Max: 10 hours, 26 minutes, 34 seconds Min:10 hours, 26 minutes, 34 seconds)
==============================================================================
Found 1 keys containing hashs, like:
zz:yy:vv:b45c247c-bcc4ae1b-fdacd2da-471e6cba-b82b9a20-a32255df-caa95a8a-a2533c7c
These keys use 0.0% of the total sampled memory (24 bytes)
None of these keys expire
Average last accessed time: 11 hours, 46 minutes, 54 seconds - (Max: 11 hours, 46 minutes, 54 seconds Min:11 hours, 46 minutes, 54 seconds)
```
Таким образом, добиться нужного можно, но для этого придётся разобраться с ошибкой, что в нашем случае (т.е. имея результаты от RMA) показалось лишней тратой времени.
### 4. Redis-sampler
* [GitHub](https://github.com/antirez/redis-sampler).
Для запуска этой утилиты, тоже написанной на Ruby, достаточно взять ранее сделанный стенд, скачать скрипт из репозитория и запустить, например, с миллионом сэмплов:
```
./redis-sampler.rb 127.0.0.1 6379 0 1000000
```
**Большой ответ**
```
Sampling 127.0.0.1:6379 DB:0 with 1000000 RANDOMKEYS
TYPES
=====
set: 864532 (86.45%) zset: 116538 (11.65%) hash: 16761 (1.68%)
string: 2055 (0.21%) list: 114 (0.01%)
EXPIRES
=======
unknown: 1000000 (100.00%)
Average: 0.00 Standard Deviation: 0.00
Min: 0 Max: 0
Powers of two distribution: (NOTE <= p means: p/2 < x <= p)
Note: 'unknown' expire means keys with no expire
STRINGS, SIZE OF VALUES
=======================
1: 1096 (53.33%) 4: 485 (23.60%) 5: 182 (8.86%)
6: 180 (8.76%) 7: 60 (2.92%) 3: 21 (1.02%)
2: 21 (1.02%) 342: 7 (0.34%) 8: 2 (0.10%)
32: 1 (0.05%)
Average: 3.89 Standard Deviation: 19.88
Min: 1 Max: 342
Powers of two distribution: (NOTE <= p means: p/2 < x <= p)
<= 1: 1096 (53.33%) <= 4: 506 (24.62%) <= 8: 424 (20.63%)
<= 2: 21 (1.02%) <= 512: 7 (0.34%) <= 32: 1 (0.05%)
LISTS, NUMBER OF ELEMENTS
=========================
4: 86 (75.44%) 1: 14 (12.28%) 3: 7 (6.14%)
2: 7 (6.14%)
Average: 3.45 Standard Deviation: 1.05
Min: 1 Max: 4
Powers of two distribution: (NOTE <= p means: p/2 < x <= p)
<= 4: 93 (81.58%) <= 1: 14 (12.28%) <= 2: 7 (6.14%)
LISTS, SIZE OF ELEMENTS
=======================
482: 2 (1.75%) 491: 2 (1.75%) 674: 2 (1.75%)
666: 2 (1.75%) 449: 2 (1.75%) 515: 2 (1.75%)
561: 2 (1.75%) 558: 2 (1.75%) 590: 2 (1.75%)
483: 2 (1.75%) 631: 2 (1.75%) 527: 2 (1.75%)
777: 2 (1.75%) 633: 1 (0.88%) 456: 1 (0.88%)
604: 1 (0.88%) 606: 1 (0.88%) 498: 1 (0.88%)
710: 1 (0.88%) 1946: 1 (0.88%) 481: 1 (0.88%)
(suppressed 80 items with perc < 0.5% for a total of 70.18%)
Average: 699.10 Standard Deviation: 387.90
Min: 207 Max: 3686
Powers of two distribution: (NOTE <= p means: p/2 < x <= p)
<= 1024: 72 (63.16%) <= 512: 30 (26.32%) <= 2048: 10 (8.77%)
<= 256: 1 (0.88%) <= 4096: 1 (0.88%)
SETS, NUMBER OF ELEMENTS
========================
1: 38506 (33.04%) 2: 20277 (17.40%) 3: 11991 (10.29%)
4: 7695 (6.60%) 5: 5456 (4.68%) 6: 4097 (3.52%)
7: 3171 (2.72%) 8: 2559 (2.20%) 9: 2112 (1.81%)
10: 1767 (1.52%) 11: 1527 (1.31%) 12: 1223 (1.05%)
13: 1060 (0.91%) 14: 1030 (0.88%) 15: 860 (0.74%)
16: 775 (0.67%) 17: 706 (0.61%) 18: 608 (0.52%)
19: 576 (0.49%) 21: 519 (0.45%) 20: 502 (0.43%)
(suppressed 924 items with perc < 0.5% for a total of 8.17%)
Average: 2.89 Standard Deviation: 64.09
Min: 1 Max: 55774
Powers of two distribution: (NOTE <= p means: p/2 < x <= p)
<= 2: 631053 (72.99%) <= 1: 186025 (21.52%) <= 4: 15631 (1.81%)
<= 8: 13305 (1.54%) <= 16: 8311 (0.96%) <= 32: 5008 (0.58%)
<= 64: 2845 (0.33%) <= 128: 1319 (0.15%) <= 256: 581 (0.07%)
<= 512: 282 (0.03%) <= 1024: 117 (0.01%) <= 2048: 35 (0.00%)
<= 4096: 16 (0.00%) <= 8192: 3 (0.00%) <= 65536: 1 (0.00%)
SETS, NUMBER OF ELEMENTS
========================
1: 38506 (33.04%) 2: 20277 (17.40%) 3: 11991 (10.29%)
4: 7695 (6.60%) 5: 5456 (4.68%) 6: 4097 (3.52%)
7: 3171 (2.72%) 8: 2559 (2.20%) 9: 2112 (1.81%)
10: 1767 (1.52%) 11: 1527 (1.31%) 12: 1223 (1.05%)
13: 1060 (0.91%) 14: 1030 (0.88%) 15: 860 (0.74%)
16: 775 (0.67%) 17: 706 (0.61%) 18: 608 (0.52%)
19: 576 (0.49%) 21: 519 (0.45%) 20: 502 (0.43%)
(suppressed 924 items with perc < 0.5% for a total of 8.17%)
Average: 2.89 Standard Deviation: 64.09
Min: 1 Max: 55774
Powers of two distribution: (NOTE <= p means: p/2 < x <= p)
<= 2: 631053 (72.99%) <= 1: 186025 (21.52%) <= 4: 15631 (1.81%)
<= 8: 13305 (1.54%) <= 16: 8311 (0.96%) <= 32: 5008 (0.58%)
<= 64: 2845 (0.33%) <= 128: 1319 (0.15%) <= 256: 581 (0.07%)
<= 512: 282 (0.03%) <= 1024: 117 (0.01%) <= 2048: 35 (0.00%)
<= 4096: 16 (0.00%) <= 8192: 3 (0.00%) <= 65536: 1 (0.00%)
SETS, SIZE OF ELEMENTS
======================
41: 250500 (28.98%) 32: 215070 (24.88%) 33: 142136 (16.44%)
5: 71140 (8.23%) 37: 54151 (6.26%) 40: 45521 (5.27%)
31: 28938 (3.35%) 36: 18885 (2.18%) 6: 18383 (2.13%)
4: 9766 (1.13%) 30: 2513 (0.29%) 44: 1967 (0.23%)
35: 1025 (0.12%) 3: 729 (0.08%) 43: 387 (0.04%)
26: 372 (0.04%) 34: 334 (0.04%) 8: 318 (0.04%)
29: 242 (0.03%) 71: 233 (0.03%) 28: 224 (0.03%)
(suppressed 129 items with perc < 0.5% for a total of 0.20%)
Average: 32.53 Standard Deviation: 10.91
Min: 1 Max: 151
Powers of two distribution: (NOTE <= p means: p/2 < x <= p)
<= 64: 515245 (59.60%) <= 32: 247497 (28.63%) <= 8: 90055 (10.42%)
<= 4: 10495 (1.21%) <= 128: 966 (0.11%) <= 2: 100 (0.01%)
<= 256: 76 (0.01%) <= 16: 50 (0.01%) <= 1: 48 (0.01%)
SORTED SETS, NUMBER OF ELEMENTS
===============================
1: 38506 (33.04%) 2: 20277 (17.40%) 3: 11991 (10.29%)
4: 7695 (6.60%) 5: 5456 (4.68%) 6: 4097 (3.52%)
7: 3171 (2.72%) 8: 2559 (2.20%) 9: 2112 (1.81%)
10: 1767 (1.52%) 11: 1527 (1.31%) 12: 1223 (1.05%)
13: 1060 (0.91%) 14: 1030 (0.88%) 15: 860 (0.74%)
16: 775 (0.67%) 17: 706 (0.61%) 18: 608 (0.52%)
19: 576 (0.49%) 21: 519 (0.45%) 20: 502 (0.43%)
(suppressed 924 items with perc < 0.5% for a total of 8.17%)
Average: 23.62 Standard Deviation: 374.23
Min: 1 Max: 33340
Powers of two distribution: (NOTE <= p means: p/2 < x <= p)
<= 1: 38506 (33.04%) <= 2: 20277 (17.40%) <= 4: 19686 (16.89%)
<= 8: 15283 (13.11%) <= 16: 10354 (8.88%) <= 32: 6220 (5.34%)
<= 64: 3085 (2.65%) <= 128: 1445 (1.24%) <= 256: 702 (0.60%)
<= 512: 388 (0.33%) <= 1024: 235 (0.20%) <= 2048: 148 (0.13%)
<= 4096: 107 (0.09%) <= 8192: 57 (0.05%) <= 16384: 31 (0.03%)
<= 32768: 13 (0.01%) <= 65536: 1 (0.00%)
SORTED SETS, SIZE OF ELEMENTS
=============================
7: 52226 (44.81%) 8: 45833 (39.33%) 6: 8702 (7.47%)
15: 2971 (2.55%) 5: 2896 (2.49%) 4: 484 (0.42%)
18: 448 (0.38%) 21: 445 (0.38%) 16: 348 (0.30%)
20: 274 (0.24%) 12: 272 (0.23%) 22: 227 (0.19%)
14: 204 (0.18%) 13: 191 (0.16%) 17: 150 (0.13%)
10: 94 (0.08%) 11: 71 (0.06%) 3: 37 (0.03%)
9: 36 (0.03%) 19: 26 (0.02%) 2: 21 (0.02%)
(suppressed 188 items with perc < 0.5% for a total of 0.50%)
Average: 9.16 Standard Deviation: 22.30
Min: 1 Max: 722
Powers of two distribution: (NOTE <= p means: p/2 < x <= p)
<= 8: 109657 (94.10%) <= 16: 4187 (3.59%) <= 32: 1610 (1.38%)
<= 4: 521 (0.45%) <= 512: 489 (0.42%) <= 128: 30 (0.03%)
<= 2: 21 (0.02%) <= 64: 13 (0.01%) <= 256: 5 (0.00%)
<= 1024: 3 (0.00%) <= 1: 2 (0.00%)
HASHES, NUMBER OF FIELDS
========================
1: 3261 (19.46%) 3: 2763 (16.48%) 2: 1521 (9.07%)
4: 1361 (8.12%) 5: 1289 (7.69%) 6: 611 (3.65%)
7: 238 (1.42%) 8: 236 (1.41%) 18: 173 (1.03%)
9: 173 (1.03%) 16: 160 (0.95%) 12: 160 (0.95%)
13: 158 (0.94%) 15: 157 (0.94%) 17: 157 (0.94%)
10: 155 (0.92%) 14: 154 (0.92%) 22: 141 (0.84%)
11: 140 (0.84%) 20: 137 (0.82%) 19: 123 (0.73%)
(suppressed 830 items with perc < 0.5% for a total of 20.84%)
Average: 71.88 Standard Deviation: 397.44
Min: 1 Max: 10869
Powers of two distribution: (NOTE <= p means: p/2 < x <= p)
<= 4: 4124 (24.60%) <= 1: 3261 (19.46%) <= 8: 2374 (14.16%)
<= 2: 1521 (9.07%) <= 32: 1418 (8.46%) <= 64: 1329 (7.93%)
<= 16: 1257 (7.50%) <= 128: 429 (2.56%) <= 512: 274 (1.63%)
<= 256: 238 (1.42%) <= 1024: 236 (1.41%) <= 2048: 181 (1.08%)
<= 4096: 84 (0.50%) <= 8192: 29 (0.17%) <= 16384: 6 (0.04%)
HASHES, SIZE OF FIELDS
======================
unknown: 13916 (83.03%) 5: 1570 (9.37%) 24: 244 (1.46%)
32: 225 (1.34%) 22: 127 (0.76%) 29: 86 (0.51%)
43: 82 (0.49%) 26: 60 (0.36%) 25: 47 (0.28%)
30: 42 (0.25%) 27: 41 (0.24%) 12: 40 (0.24%)
36: 34 (0.20%) 23: 34 (0.20%) 39: 31 (0.18%)
21: 23 (0.14%) 8: 23 (0.14%) 28: 17 (0.10%)
34: 15 (0.09%) 16: 15 (0.09%) 64: 15 (0.09%)
(suppressed 19 items with perc < 0.5% for a total of 0.44%)
Average: 15.12 Standard Deviation: 12.77
Min: 2 Max: 64
Powers of two distribution: (NOTE <= p means: p/2 < x <= p)
<= 8: 1600 (56.24%) <= 32: 969 (34.06%) <= 64: 201 (7.07%)
<= 16: 59 (2.07%) <= 4: 15 (0.53%) <= 2: 1 (0.04%)
HASHES, SIZE OF VALUES
======================
unknown: 13916 (83.03%) 13: 768 (4.58%) 14: 624 (3.72%)
6: 394 (2.35%) 12: 192 (1.15%) 3: 172 (1.03%)
4: 153 (0.91%) 7: 119 (0.71%) 2: 98 (0.58%)
5: 90 (0.54%) 21: 75 (0.45%) 20: 57 (0.34%)
16: 33 (0.20%) 1: 30 (0.18%) 15: 18 (0.11%)
9: 12 (0.07%) 22: 3 (0.02%) 19: 2 (0.01%)
8: 2 (0.01%) 71: 1 (0.01%) 32: 1 (0.01%)
(suppressed 1 items with perc < 0.5% for a total of 0.01%)
Average: 10.52 Standard Deviation: 5.05
Min: 1 Max: 71
Powers of two distribution: (NOTE <= p means: p/2 < x <= p)
<= 16: 1647 (57.89%) <= 8: 605 (21.27%) <= 4: 325 (11.42%)
<= 32: 138 (4.85%) <= 2: 98 (3.44%) <= 1: 30 (1.05%)
<= 128: 1 (0.04%) <= 64: 1 (0.04%)
```
Вывод показывает распределение по типам объектов в базе Redis на основе миллиона сэмплов. В нашей конкретной задаче не помогло в достаточной мере.
### 5. RedisDesktop
* [GitHub](https://github.com/uglide/RedisDesktopManager);
* [Сайт](https://redisdesktop.com/).
Эта утилита — простой GUI для Redis. Функция анализа памяти в ней присутствует, однако на достаточно мощном ноутбуке (с 32 Гб памяти) её запуски на наших объёмах привели лишь к падению самой утилиты… Не стали глубоко погружаться в детали, т.к. нашли иное решение проблемы, а наличие GUI как таковое большого интереса для нас не представляет.
### 6. Harvest
* [GitHub](https://github.com/31z4/harvest).
Инструмент написан на Go и запускается максимально просто:
```
# docker run --link redis:redis -it --rm 31z4/harvest redis://redis
t:: 12.65% (697)
tl:i:n:: 10.75% (592)
tl:i:n:1: 5.68% (313)
t:n:: 1.91% (105)
t:n:i:: 1.87% (103)
c: 1.63% (90)
c:: 1.60% (88)
n:: 1.52% (84)
n:f:: 1.49% (82)
c:l:: 1.34% (74)
```
Попробуем с большим количеством сэмплов, чем количество ключей в базе:
```
docker run --link redis:redis -it --rm 31z4/harvest redis://redis -s 3000000
warning: database size (27402892) is less than the number of samples (30000000)
t: 6.35% (20471794)
tl:: 6.35% (20471508)
tl:i:: 5.52% (17777810)
tl:i:n:: 5.52% (17777693)
tl:i:n:1: 2.89% (9302664)
c: 1.06% (3398834)
c:: 1.02% (3297466)
c:c:: 0.84% (2697278)
tl:n:: 0.84% (2693697)
tl:n:i:: 0.82% (2649015)
```
Тут мы сильно удивились…
Увеличение количества выводимых результатов просто увеличивает количество выводимых результатов. Агрегации — нет. Анализировать такой вывод без дополнительного инструмента анализа (или длинной команды агрегации) — сложно. В общем, инструмент нам не подошёл.
### Итоги анализа
Главным помощником в анализе стал RMA (redis-memory-analyzer): его вывод был не только проще всего в получении, но и в прочтении/понимании. Благодаря этим результатам, команда разработчиков нашла 18 миллионов ключей, которые предположительно были порождены неудачным архитектурным решением в приложении и будут исправлены. Мы же надеемся, что в итоге наши БД «похудеют», что позволит проектам клиента работать быстрее и принимать больше трафика и пользователей.
Заключение
----------
В статье рассматривался «классический» кластер Redis, который по сути является комплектом из Sentinel, Redis master и Redis slave. Решение [Redis Enterprise Operator](https://docs.redislabs.com/latest/platforms/kubernetes/kubernetes-with-operator/) не применялось по причине полной непрозрачности его [цены](https://redislabs.com/redis-enterprise-cloud/essentials-pricing/), а [оператор от Amadeus IT Group](https://github.com/AmadeusITGroup/Redis-Operator) — из-за недостаточной зрелости.
Схемы с использованием встроенной кластеризации, шардирования и failover’а мы также не затрагивали в статье, поскольку их поддержка требует переработки кода и больших ресурсов. Однако, пользуясь результатами уже проделанной работы, теперь можно двигаться и в этом направлении. Благодаря достигнутой экономии, вопросы использования встроенной кластеризации и шардирования в самой Redis актуальны и рассматриваются как ключевые дальнейшие шаги.
После анализа случившегося мы также планируем пересмотреть практики использования оператора от Spotahome. По рассмотренным инструментам сделали вывод, что RMA — самый простой, понятный и эффективный инструмент для быстрого анализа базы Redis. Он помог нам сходу разобраться, почему Redis стал большим и куда стоит направить усилия в вопросах переписывания кода. Остальные утилиты требовали больших трудозатрат для получения такого же результата.
P.S.
----
Читайте также в нашем блоге:
* «[KeyDB как [потенциальная] замена Redis](https://habr.com/ru/company/flant/blog/478404/)»;
* «[Базы данных и Kubernetes (обзор и видео доклада)](https://habr.com/ru/company/flant/blog/431500/)»;
* «[Миграция Cassandra в Kubernetes: особенности и решения](https://habr.com/ru/company/flant/blog/475036/)»;
* «[Беспростойная миграция MongoDB в Kubernetes](https://habr.com/ru/company/flant/blog/461149/)»;
* «[Беспростойная миграция RabbitMQ в Kubernetes](https://habr.com/ru/company/flant/blog/450662/)». | https://habr.com/ru/post/480722/ | null | ru | null |
# Колдовской NeoVIM. Часть вторая. “Конфиг Всевластья”
Никто не любит конфиги (я уж точно). Они скучные и нединамичные.
Но со своим конфигом Nvim’а я ношусь, как Голлум с кольцом Всевластья. *Моя прелесссссть*. Я боюсь потерять свой конфиг, боюсь, что с ним что-то случится. *Другие хотят забрать тебя, моя прелессссть. Саша тебя им не отдаст, нет-нет...*
Если кто-то отнимет мой конфиг - я буду гнаться за ним до Роковой Горы и даже прыгну в жерло вулкана.
В этой статье я расскажу, как создать такой *Конфиг Всевластья* ~~и как завоевать Гондор~~.
Зачем возиться с файлом конфигурации?
-------------------------------------
Потому что ничего, кроме файла конфигурации, вам не нужно.
Моя прелессстьКонфиг является полным хранилищем всех необходимых плагинов, настроек, горячих клавиш, скриптов. Это сердце колдовского редактора.
**Установка Neovim обычно выглядит так:**
1. Одной командой устанавливаем Neovim.
2. Копируем свой конфиг в папку с конфигами редактора.
3. Устанавливаем менеджер пакетов (одна команда)
4. Устанавливаем плагины (одна команда)
5. ОПЦИОНАЛЬНО: Подключаем LSP-сервер. Одна команда.
6. Всё
Спустя пару минут вы готовы к работе. И не просто готовы! Вы только что получили идеально точную копию той рабочей среды, к которой вы привыкли. Абсолютно всё, начиная с темы, используемых плагинов, и заканчивая горячими клавишами и нюансами настройки, будет повторять все ваши другие Nvim’ы. Рай для людей с обсессивно-компульсивным расстройством и программистов…
С недавнего времени все любители колдовского редактора дружно пересели на конфиги, написанные на Lua. А чем мы хуже?
Чуть-чуть про Lua
-----------------
[Lua](https://www.lua.org/) - это простой скриптовый язык. Он предназначен для пользователей, не являющихся профессиональными программистами. Большое внимание уделено простоте дизайна и лёгкости обучения.
С помощью этого языка пишут скрипты для игр, некоторые интерфейсы, а еще пишут модульные и удобные конфиги колдовского редактора.
На Хабре про **Lua** есть даже [целый канал](https://habr.com/ru/hub/lua/).
Устанавливаем Nvim
------------------
Я разверну новую версию Neovim на **Ubuntu 22.04 LTS**, а конфиг будет заточен под Python. Но вы сможете легко его перенастроить под свои любимые языки программирования.
**ОПЦИОНАЛЬНО:** Для лучшей работы конфигурационного файла и плагинов вам понадобится Neovim как минимум 8й версии. Установить ее можно [здесь](https://github.com/neovim/neovim/wiki/Installing-Neovim) (я сейчас использую Nvim 9й версии, скачиваю его через PPA).
Старые версии устанавливаются проще:
```
$ sudo apt install neovim
```
Установили? Теперь убедимся, что колдовской редактор попал в **$PATH**:
```
$ nvim --version
```
Откройте любой файл через:
```
$ nvim
```
Выглядеть должно примерно так:
Не пугайтесь. Это чистый Nvim. Он удобен, когда вы хотите быстро отредактировать файл на сервере, но для разработки все-таки нужно что-то пофункциональнее. Для того, чтобы выйти из колдовского редактора, наберите команду `ZQ` (обратите внимание, что команда написана прописными буквами).
Затем создайте каталог по адресу `~/.config/nvim/` . А в нем разверните следующую структуру файлов:
nvim/
├── init.lua
├── lua/
│ ├── keymaps.lua
│ ├── plugins.lua
│ ├── settings.lua
│ └── treesitter.lua
То есть у нас в каталоге `nvim/` есть отдельный файл `init.lua` и каталог `lua/` с 4мя файлами-модулями.
Заполните все файлы:
init.lua Точка входа. Отсюда Nvim начинает читать конфигурацию.
```
-----------------------------------------------------------
-- Импорт модулей Lua
-----------------------------------------------------------
require('plugins')
require('settings')
require('keymaps')
require('treesitter')
```
plugins.lua Подключаемые плагины
```
vim.cmd [[packadd packer.nvim]]
return require('packer').startup(function(use)
-- Автоустановка пакетного менеджера
use 'wbthomason/packer.nvim'
---------------------------------------------------------
-- ПЛАГИНЫ ВНЕШНЕГО ВИДА
---------------------------------------------------------
-- Информационная строка внизу
use "kyazdani42/nvim-web-devicons"
use { 'nvim-lualine/lualine.nvim',
requires = {'kyazdani42/nvim-web-devicons', opt = true},
config = function()
require('lualine').setup()
end, }
-- Тема в стиле Rose Pine
use({
'rose-pine/neovim',
as = 'rose-pine',
config = function()
vim.cmd('colorscheme rose-pine')
end
})
---------------------------------------------------------
-- МОДУЛИ РЕДАКТОРА
---------------------------------------------------------
-- Табы с вкладками сверху
use {'akinsho/bufferline.nvim',
requires = 'kyazdani42/nvim-web-devicons',
config = function()
require("bufferline").setup{}
end, }
-- Структура классов и функций в файле
use 'majutsushi/tagbar'
-- Файловый менеджер
use { 'kyazdani42/nvim-tree.lua',
requires = 'kyazdani42/nvim-web-devicons',
config = function()
require'nvim-tree'.setup {}
end, }
--- popup окошки
use 'nvim-lua/popup.nvim'
---------------------------------------------------------
-- ПОИСК
---------------------------------------------------------
-- Наш FuzzySearch
use { 'nvim-telescope/telescope.nvim',
requires = { {'nvim-lua/plenary.nvim'} },
config = function()
require'telescope'.setup {}
end, }
---------------------------------------------------------
-- КОД
---------------------------------------------------------
-- автоматические закрывающиеся скобки
use { 'windwp/nvim-autopairs',
config = function()
require("nvim-autopairs").setup()
end}
-- Комментирует по все, вне зависимости от языка программирования
use { 'numToStr/Comment.nvim',
config = function()
require('Comment').setup()
end }
---------------------------------------------------------
-- LSP И АВТОДОПОЛНЯЛКИ
---------------------------------------------------------
-- Collection of configurations for built-in LSP client
use 'neovim/nvim-lspconfig'
use 'williamboman/nvim-lsp-installer'
-- Автодополнялка
use 'hrsh7th/nvim-cmp'
use 'hrsh7th/cmp-nvim-lsp'
use 'hrsh7th/cmp-buffer'
use 'saadparwaiz1/cmp\_luasnip'
--- Автодополнлялка к файловой системе
use 'hrsh7th/cmp-path'
-- Snippets plugin
use 'L3MON4D3/LuaSnip'
-- Highlight, edit, and navigate code using a fast incremental parsing library
use 'nvim-treesitter/nvim-treesitter'
-- Линтер, работает для всех языков
use 'dense-analysis/ale'
---------------------------------------------------------
-- РАЗНОЕ
---------------------------------------------------------
-- Даже если включена русская раскладка, то nvim-команды будут работать
use 'powerman/vim-plugin-ruscmd'
end)
```
settings.lua Настройки редактора
```
local opt = vim.opt
-----------------------------------------------------------
-- ОБЩИЕ ОПЦИИ
-----------------------------------------------------------
opt.mouse = 'a' --Включит мышь
opt.encoding = 'utf-8' --Кодировка
opt.showcmd = true --Отображение команд
vim.cmd([[
filetype indent plugin on
syntax enable
]])
opt.swapfile = false --Не создаем свап файлы
-----------------------------------------------------------
-- ВИЗУАЛЬНЫЕ ОПЦИИ
-----------------------------------------------------------
opt.number = true --Номер строк сбоку
opt.wrap = true --Длинные линии будет видно
opt.expandtab = true --???
opt.tabstop = 4 --1 tab = 4 пробела
opt.smartindent = true
opt.shiftwidth = 4 --Смещаем на 4 пробела
-- 2 spaces for selected filetypes
vim.cmd [[
autocmd FileType xml,html,xhtml,css,scss,javascript,lua,yaml,htmljinja setlocal shiftwidth=2 tabstop=2
]]
opt.so = 5 --Отступ курсора от края экрана
opt.foldcolumn = '2' --Ширина колонки для фолдов
opt.colorcolumn = '119' --Расположение цветной колонки
-- remove line lenght marker for selected filetypes
vim.cmd [[autocmd FileType text,markdown,html,xhtml,javascript setlocal cc=0]]
opt.cursorline = true -- Подсветка строки с курсором
opt.termguicolors = true
-- Компактный вид у тагбара и Отк. сортировка по имени у тагбара
vim.g.tagbar_compact = 1
vim.g.tagbar_sort = 0
-----------------------------------------------------------
-- НАСТРОЙКИ ПОИСКА
-----------------------------------------------------------
-- Будет игнорировать размер букв при поиске
opt.ignorecase = true --Игнорировать размер букв
opt.smartcase = true --Игнор прописных буквj
-----------------------------------------------------------
-- ПОЛЕЗНЫЕ ФИШКИ
-----------------------------------------------------------
-- Подсвечивает на доли секунды скопированную часть текста
vim.api.nvim_exec([[
augroup YankHighlight
autocmd!
autocmd TextYankPost * silent! lua vim.highlight.on_yank{higroup="IncSearch", timeout=300}
augroup end
]], false)
-----------------------------------------------------------
-- НАСТРОЙКИ ПЛАГИНОВ
-----------------------------------------------------------
-- LSP settings
local lsp_installer = require("nvim-lsp-installer")
lsp_installer.on_server_ready(function(server)
local opts = {}
if server.name == "sumneko_lua" then
-- only apply these settings for the "sumneko_lua" server
opts.settings = {
Lua = {
diagnostics = {
-- Get the language server to recognize the 'vim', 'use' global
globals = {'vim', 'use'},
},
workspace = {
-- Make the server aware of Neovim runtime files
library = vim.api.nvim_get_runtime_file("", true),
},
-- Do not send telemetry data containing a randomized but unique identifier
telemetry = {
enable = false,
},
},
}
end
server:setup(opts)
end)
-- nvim-cmp supports additional completion capabilities
local capabilities = vim.lsp.protocol.make_client_capabilities()
capabilities = require('cmp_nvim_lsp').default_capabilities(capabilities)
vim.o.completeopt = 'menuone,noselect'
-- luasnip setup
local luasnip = require 'luasnip'
-- nvim-cmp setup
local cmp = require 'cmp'
cmp.setup {
snippet = {
expand = function(args)
luasnip.lsp_expand(args.body)
end,
},
sources = {
{ name = 'nvim_lsp' },
{ name = 'luasnip' },
{ name = 'path' },
{ name = 'buffer', option = {
get_bufnrs = function()
return vim.api.nvim_list_bufs()
end
},
},
},
}
```
keymaps.lua Переназначенные клавиши и скрипты
```
local map = vim.api.nvim_set_keymap
local default_opts = {noremap = true, silent = true}
-----------------------------------------------------------
-- НАВИГАЦИЯ
-----------------------------------------------------------
-- Отключаем стрелочки в Нормальном Режиме. Хардкор!
map('', '', ':echoe "Use hjkl, bro"', {noremap = true, silent = false})
map('', '', ':echoe "Use hjkl, bro"', {noremap = true, silent = false})
map('', '', ':echoe "Use hjkl, bro"', {noremap = true, silent = false})
map('', '', ':echoe "Use hjkl, bro"', {noremap = true, silent = false})
-- Переключение вкладок с помощью TAB или shift-tab (akinsho/bufferline.nvim)
map('n', '', ':BufferLineCycleNext', default\_opts)
map('n', '', ':BufferLineCyclePrev', default\_opts)
-- разные вариации нумераций строк, можно переключаться на ходу
map('n', '', ':exec ν==&rnu? "se nu!" : "se rnu!"', default\_opts)
-----------------------------------------------------------
-- РЕЖИМЫ
-----------------------------------------------------------
-- Выходим в нормальный режим через , чтобы не тянуться
map('i', 'jk', '', {noremap = true})
-----------------------------------------------------------
-- ПОИСК
-----------------------------------------------------------
-- Выключить подсветку поиска через комбинацию ,+
map('n', ',', ':nohlsearch', {noremap = true})
-- Fuzzy Search. CTRL+a для поиска по файлам, CTRL+p для поиска по буфферам
map('n', '', [[ lua require('telescope.builtin').find\_files() ]], default\_opts)
map('n', '', [[ lua require('telescope.builtin').buffers() ]], default\_opts)
-- Греповский поиск слова под курсором
map('n', '', [[lua require('telescope.builtin').grep\_string()]], default\_opts)
-- Греповский поиск слова в модальном окошке
map('n', '', [[lua require('telescope.builtin').live\_grep()]], default\_opts)
-----------------------------------------------------------
-- ФАЙЛЫ
-----------------------------------------------------------
-- Показ дерева классов и функций, плагин majutsushi/tagbar
map('n', '', ':TagbarToggle', default\_opts)
-- Дерево файлов. Для иконок следует установить Nerd Font
map('n', '', ':NvimTreeRefresh:NvimTreeToggle', default\_opts)
```
treesitter.lua Настройки отдельного плагина Treesitter
```
require'nvim-treesitter.configs'.setup {
-- Парсеры, которые мы собираемся использовать
ensure_installed = { "lua", "python", "javascript", "typescript"},
sync_install = false,
-- Automatically install missing parsers when entering buffer
-- Recommendation: set to false if you don't have `tree-sitter` CLI installed locally
auto_install = true,
highlight = {
-- `false` will disable the whole extension
enable = true,
-- Setting this to true will run `:h syntax` and tree-sitter at the same time.
-- Set this to `true` if you depend on 'syntax' being enabled (like for indentation).
-- Using this option may slow down your editor, and you may see some duplicate highlights.
-- Instead of true it can also be a list of languages
additional_vim_regex_highlighting = false,
},
}
```
Конфиг небольшой и несложный, а еще максимально подробно закомментирован для вашего удобства! Советую почитать про синтаксис Lua, а затем попытаться разобраться в самом конфиге самостоятельно.
Пакетный менеджер
-----------------
И тем не менее редактор пока не изменился, ведь мы не установили плагины! Для этого мы используем самый популярный менеджер плагинов/пакетов [“Packer”](https://github.com/wbthomason/packer.nvim).
Устанавливаем (для Ubuntu):
```
$ git clone --depth 1 https://github.com/wbthomason/packer.nvim\
~/.local/share/nvim/site/pack/packer/start/packer.nvim
```
После установки откроем в nvim файл `plugins.lua` и установим плагины командой `:PackerSync`
Да, нужно набрать двоеточие и “PackerSync” вместе. Для удобства Nvim покажет набираемую команду в левом-нижнем углу.
Подробнее о том, как в колдовском редакторе работает режим командной строки мы поговорим в следующей части.
После набора команды Packer установит плагины.
Затем выйдем из nvim, зайдем заново и полюбуемся результатом. Должно получиться как-то так:
То есть красивый темный фон, нет ошибок и есть распознавание синтаксиса.
**Если не получилось:**
* Внимательно читайте описание ошибок. Почти всегда они прямо укажут на проблему.
* Проверьте, что в вашем терминале установлен один из [Nerd Fonts](https://www.nerdfonts.com/). Конфиг должен работать и без них (хотя иконки не смогут отображаться), но вы предупреждены.
* Используйте команду `:checkhealth` . Она даст исчерпывающий перечень проблем, которые видит Nvim. Для большинства проблем он сразу предложит решение (например у меня стоял жутко старый node, и Nvim посоветовал обновиться).
LSP
---
Одна из важных механик колдовского редактора (да и почти любой IDE) - это работа с **LSP**.
**Language Server Protocol -** это формат общения Сервер-Клиент, который помогает работать с конкретным языком программирования. Благодаря **LSP** наш маленький (но гордый) Nvim научится делать автозаполнение, находить определения функций/классов и многое другое.
В упрощенном виде LSP-коммуникация выглядит примерно так:
> **Клиент → JavaScriptLanguageServer:** *"Расскажи, а вот в JavaScript мы блоки кода выделяем индентацией?"*
>
> **JavaScriptLanguageServer → Клиент:** *"Нет, у нас в JS фигурные скобки."*
>
> **Клиент → JavaScriptLanguageServer:** *"А это что такое?"*
>
> **JavaScriptLanguageServer → Клиент:** *"Это глобальная переменная."*
>
>
**LSP** помогает нашему редактору работать с любыми языками программирования.
Для установки серверов наберите команду `:LspInstall` и следуйте инструкциям. Советую для работы с Python выбрать сервер Pyright.
После этого мы получим поддержку для `.lua` и `.py` файлов.
Особенности данного конфига
---------------------------
* Через мы получаем доступ к файловому менеджеру, а через к структуре нашего файла.
* Даст доступ к fuzzy search, и позволит очень быстро находить и открывать файлы.
* У нас есть линтинг.
* С помощью можно выбрать формат нумерации строк в редакторе.
* и позволят переключаться между табами. И у нас вообще появятся табы!
* И многое другое
---
Конфигурация колдовского редактора - невероятно объемная тема. Надеюсь, что мне удалось помочь начинающим запустить Nvim в удобном виде, который сделает переход с привычной IDE чуть легче!
И хочу поблагодарить людей, благодаря которым мне удалось хотя бы немного освоить конфигурирование Nvim:
* Пользователь Хабра с ником [Rilkener](https://habr.com/ru/users/Rilkener/)
* Самый быстрый Nvim'ист на свете [Primeagen](https://www.youtube.com/@ThePrimeagen)
**А в следующей части мы познакомимся с Режимами в Nvim!** | https://habr.com/ru/post/706110/ | null | ru | null |
# IPC::Open3. Решение проблемы с STDERR
Когда мы пишем графическое приложение, бывает что требуется вызывать внешние программы и читать из STDOUT/STDERR.
С этим прекрасно справляется модуль [IPC::Open3](http://search.cpan.org/~nwclark/perl-5.8.9/lib/IPC/Open3.pm).
Однако, программу Вы написали, все работает, но Вы не хотите чтобы пользователь (или Вы) видели ненужное окно терминала.
Есть несколько вариантов его скрыть:
1. Запускать скрипт через wperl.exe, а не через perl.exe
2. ???
Рассмотрим программу
```
use strict;
use Tkx;
use IPC::Open3;
my $mw = Tkx::widget->new('.');
my $tw = $mw->new_text();
my $bt = $mw->new_ttk__button(
-text => 'dir',
-command => sub {
my($rdr, $pid);
$pid = open3( undef, $rdr, undef, 'dir' );
$tw->insert( 'end', do { local $/; <$rdr> } );
},
);
Tkx::pack( $tw );
Tkx::pack( $bt );
Tkx::MainLoop;
```

Вызывается команда dir, и выводится ее результат. (не обращайте внимания на кодировку).
Все работает, но если Вы запустите скрипт через wperl.exe, то при вызове open3 получите ошибку:
```
open3: Can't call method "close" on an undefined value at C:/perl5.8/lib/IPC/Open3.pm line 368.
open3: Can't call method "close" on an undefined value at C:/perl5.8/lib/IPC/Open3.pm line 368.
```
Проблема в том что, wperl не создает стандартные [потоки](http://win32.perl.org/wiki/index.php?title=Win32_Idiosyncrasies#wperl_and_STDERR_from_children) (STDIN, STDOUT, STDERR).
Я долго ломал голову, как заставить работать программу. Пробовал вызывать WINAPI внутри тела программы, запускать через bat файл (работает, но не со всеми программами), однако решение оказалось наудивление простым.
Необходимо использовать функцию ShellExecute из shell32.dll c аттрибутом SW\_HIDE.
Ниже код лоадера на Си.
```
#include
#include
static char \*ldr\_file = "app.pl";
static char \*ldr\_path = "";
int main(int argc, char \*argv[])
{
int code;
LoadLibrary("shell32.dll");
code = (int) ShellExecute(NULL, "open", ldr\_file, ldr\_path, NULL, SW\_HIDE);
if (code <= 32)
{
char buf[200];
sprintf(buf, "Cannot run application. Code: %d", code);
MessageBox(
NULL,
buf,
"Dynld Error",
MB\_ICONERROR | MB\_OK
);
}
return code;
}
```
Компилировать gcc из MinGW.
`gcc -mwindows loader.c -o loader.exe` | https://habr.com/ru/post/67712/ | null | ru | null |
# Как мы делали мониторинг запросов mongodb

Использование монги в production — достаточно спорная тема.
С одной стороны все просто и удобно: положили данные, настроили репликацию, понимаем как шардировать базу при росте объема данных. С другой стороны существует достаточно много [страшилок](https://habrahabr.ru/post/231213/), Aphyr в своем последнем [jepsen тесте](https://aphyr.com/posts/322-jepsen-mongodb-stale-reads) сделал не очень позитивные выводы.
По факту оказывается, что есть достаточно много проектов, где mongo является основным хранилищем данных, и нас часто спрашивали про поддержку mongodb в окметр. Мы долго тянули с этой задачей, потому что сделать "осмысленный" мониторинг на порядок сложнее, чем просто собрать какие-то метрики и настроить какие-нибудь алерты. Нужно сначала разобраться в особенностях поведения софта, чтобы понять, какие именно показатели отслеживать.
Как раз про сложности и проблемы я и хочу рассказать на примере реализации мониторинга запросов к mongodb.
На любую базу данных нужно смотреть с трех сторон:
* Мониторинг ресурсов сервера (процессор, память, дисковая подсистема, сеть). Тут нет ничего сложного, большинство систем мониторинга с этим справляются достаточно хорошо.
* Мониторинг внутренностей БД (соединения, индексы, кэши, работа с диском, временные таблицы, репликация, сортировки, ...). Такие метрики обычно нужны для понимания, как перенастроить БД, каких ресурсов сервера не хватает, какие индексы создать.
* Мониторинг запросов (сколько каких, какие запросы создают нагрузку, трафик, времена запросов). По нашему опыту большинство проблем с базой возникают при изменении профиля нагрузки/запросов от приложения, например:
+ появился какой-то новый неоптимальный запроса от приложения
+ изменились условия запроса и индекс перестал эффективно работать
+ выросла таблица и последовательное чтение перестало быть быстрым
Мы пока ограничились только мониторингом запросов.
Так как мы говорим о мониторинге, нас не интересует каждый конкретный запрос, мы скорее хотим все запросы сгруппировать по некоторому одинаковому плану выполнения (например postgresql в [pg\_stat\_statements](https://www.postgresql.org/docs/9.4/static/pgstatstatements.html) группирует запросы по реальному плану).
Для mongodb идентификатором запроса является тип запроса (find, insert, update, findAndModify, aggregate и другие), база данных, коллекция и bson документ с самим запросом.
Для простоты мы решили, что запросы можно сгруппировать, заменив все значения полей из запроса на "?" и отсортировав по полям.
Например запрос:
```
{"country": "RU", "city": "Moscow", "$orderby": {"age": -1}}
```
превращаем в
```
{country: ?, city: ?, $orderby: {age: ?}}
```
а потом сортируем по ключам
```
{$orderby: {age: ?}, city: ?, country: ?}
```
Скорее всего подобные запросы будут использовать одни и те же индексы вне зависимости от конкретных условий.
Следующий большой вопрос: как получать в реальном времени весь поток запросов.
Единственный штатный способ в mongodb — это [profiler](https://docs.mongodb.com/manual/administration/analyzing-mongodb-performance/#database-profiling). Он записывает статистику по каждому запросу в ограниченную по размеру коллекцию (capped collection). Профайлер может записывать или только медленные запросы (если время исполнения больше заданного в [slowOpThresholdMs](https://docs.mongodb.com/manual/reference/configuration-options/#operationProfiling.slowOpThresholdMs)) или записывать абсолютно все запросы. Во втором случае может просесть производительность самой mongodb.
К преимуществам данного подхода стоит отнести очень подробную статистику о выполнении каждого запроса.
Но для нас очень критично не оказать негативного влияния на производительность серверов наших клиентов, поэтому использовать профайлер в режиме записи всех запросов мы не можем. Только "медленных" запросов нам недостаточно, так как мы не увидим полной картины:
* какие запросы создают наибольшую нагрузку на сервер
* какие запросы создают основной входящий/исходящий трафик на сервер
* по интересующим запросам посмотреть распределение времени ответа
* каких запросов сколько в штуках в секунду
По нашему опыту проблемы чаще создают высокочастотные запросы, которые раньше выполнялись 1ms, а потом по какой-то причине стали выполняться к примеру 5ms. А запросы >100ms (дефолтный slowOpThresholdMs) обычно служебные (админка/статистика) и очень редкие.
Так как стандартный профайлер не подошел, мы стали копать в сторону сниффинга трафика. На первом этапе было необходимо выяснить ряд вопросов:
* библиотеки для go (наш агент написан на golang) для сниффинга
* производительность (сколько агент будет потреблять ресурсов при прослушивании большого потока трафика)
* разбор [протокола mongodb](https://docs.mongodb.com/manual/reference/mongodb-wire-protocol/)
Прототип нашего плагина mongodb был написан за несколько дней с использование библиотеки [gopacket](https://github.com/google/gopacket). Мы перехватывали пакеты через libpcap, разбирали протокол, bson документы десериализовались с использованием [mgo](https://godoc.org/labix.org/v2/mgo/bson).
Так как у нас нет инсталяции mongodb под нагрузкой, мы сделали стенд и запустили готовый [benchmark](https://github.com/tmcallaghan/sysbench-mongodb). В нашем случае mongodb и грузилка жили на одной виртуальной машине с 2 ядрами и 2Gb памяти. По нагрузкой мы видели около 10 тысяч пакетов в секунду при трафике ~60Mbit/s.
Наш прототип под такой нагрузкой утилизировал около 70% одного процессорного ядра. Стало понятно, что необходимо профилировать и оптимизировать код. Тут стоит отдать должное стандартному [профайлеру](https://blog.golang.org/profiling-go-programs) golang, нам не нужно было ничего изобретать, а просто тюнить самые прожорливые по CPU участки кода и стараться как можно меньше аллоцировать память для снижения нагрузки на GC.
В точности процесс оптимизации я уже воспроизвести не смогу, но приведу примеры самых значительных изменений:
bson.Unmarshal медленный
------------------------
Bson документ запроса в mongo — это грубо говоря словарь, значения которого могут быть в том числе и такими же словарями.
Так как с самого начала мы решили, что будем нормализовывать запросы, можем вообще не читать значения элементов исходного словаря, если они не являются словарями.
Берем [спецификацию](http://bsonspec.org/spec.html) и пишем свой примитивный десериализатор. В итоге получилась функция ~100 строк
**для примера приведу кусок разбора элемента словаря**
```
elementValueType, err = reader.ReadByte()
if err != nil {
break
}
payload, err = reader.ReadBytes(nullByte)
if err != nil {
break
}
elementName = string(payload)
switch elementValueType {
case bsonDouble, bsonDatetime, bsonTimestamp, bsonInt64:
if _, err = reader.ReadN(8); err != nil {
break
}
case bsonString:
l, err = reader.ReadInt()
if err != nil {
break
}
payload, err = reader.ReadN(l)
if err != nil {
break
}
elementValue = string(payload[:len(payload)-1])
case bsonJsCode, bsonDeprecated, bsonBinary, bsonJsWithScope, bsonArray:
l, err = reader.ReadInt()
if err != nil {
break
}
if _, err = reader.ReadN(l - 4); err != nil {
break
}
case bsonDoc:
elementValue, _, _, err = readDocument(reader)
if err != nil {
break
}
case bsonObjId:
if _, err = reader.ReadN(12); err != nil {
break
}
case bsonBool:
if _, err = reader.ReadByte(); err != nil {
break
}
case bsonRegexp:
if _, err = reader.ReadBytes(nullByte); err != nil {
break
}
if _, err = reader.ReadBytes(nullByte); err != nil {
break
}
case bsonDbPointer:
l, err = reader.ReadInt()
if err != nil {
break
}
if _, err = reader.ReadN(l - 4 + 12); err != nil {
break
}
case bsonInt32:
if _, err = reader.ReadN(4); err != nil {
break
}
}
```
Из всех вариантов полей мы читаем значения только для bsonDocument (рекурсивно вызывая себя же) и bsonString (у нас есть дополнительная логика по определению коллекции и типа запроса), остальные поля мы просто пропускаем.
Как ловить пакеты
-----------------
На наших тестах использование [raw sockets](http://man7.org/linux/man-pages/man7/packet.7.html) напрямую оказалось быстре, чем через pcap.
Возможно это было из-за старой версии libpcap, но мы планировали делать сниффер только под linux, поэтому решили не разбираться, а использовать [gopacket.af\_packet](https://github.com/google/gopacket/blob/master/afpacket/afpacket.go) (тем более не нужно линковать агента с libpcap).
Raw sockets — это специльные сокеты в linux, через которые можно отправить полностью сформированный в userspace (а не ядре) пакет или получить пакеты с определенного сетевого интерфейса. Если говорить про сниффинг, пакеты от ядра попадают в userspace через циклический буфер, что позволяет не делать syscall на перехват каждого пакета. На эту тему есть подробный [хардкор](http://lxr.free-electrons.com/source/Documentation/networking/packet_mmap.txt) в документации ядра.
ZeroCopy
--------
Так как мы обрабатываем пакеты в один поток, то можем использовать "[ZeroCopy](https://github.com/google/gopacket/blob/master/afpacket/afpacket.go#L241)" интерфейс сниффера. Но при этом нужно помнить, что ссылок на данный участок памяти дальше в коде оставлять нельзя.
Разбор пакетов
--------------
Интерфейс разбора пакетов в gopacket устроен довольно гибко, поддерживает из коробки много разных протоколов, пользователю не нужно думать о том, как инкапсулированы данные верхнего уровня. Но вместе с этим этот интерфейс навязывает необходимость большого числа копирований данных и как следствие большую нагрузку как на CPU так и на GC.
Мы опять решили откинуть все лишнее:)
Наша задача из исходного ethernet фрэйма (а на выходе AF\_PACKET мы получаем всегда ethernet) получить:
* source ip
* destination ip
* source port
* destination port
* TCP seq (ниже объясню, зачем он нужен)
* TCP payload (собственно данные протокола верхнего уровня)
Для простоты было решено пока не поддерживать IPv6.
**В итоге получилась вот такая страшная функция**
```
func DecodePacket(data []byte, linkType layers.LinkType, packet *TcpIpPacket) (err error) {
var l uint16
switch linkType {
case layers.LinkTypeEthernet:
if len(data) < 14 {
ethernetTooSmall.Inc(1)
err = errors.New("Ethernet packet too small")
return
}
l = binary.BigEndian.Uint16(data[12:14])
switch layers.EthernetType(l) {
case layers.EthernetTypeIPv4:
data = data[14:]
case layers.EthernetTypeLLC:
l = uint16(data[2])
if l&0x1 == 0 || l&0x3 == 0x1 {
data = data[4:]
} else {
data = data[3:]
}
default:
ethernetUnsupportedType.Inc(1)
err = errors.New("Unsupported ethernet type")
return
}
default:
unsupportedLinkProto.Inc(1)
err = errors.New("Unsupported link protocol")
return
}
//IP
var cmp int
if len(data) < 20 {
ipTooSmallLength.Inc(1)
err = errors.New("Too small IP length")
return
}
version := data[0] >> 4
switch version {
case 4:
if binary.BigEndian.Uint16(data[6:8])&0x1FFF != 0 {
ipNonFirstFragment.Inc(1)
err = errors.New("Non first IP fragment")
return
}
if len(data) < 20 {
ipTooSmall.Inc(1)
err = errors.New("Too small IP packet")
return
}
hl := uint8(data[0]) & 0x0F
l = binary.BigEndian.Uint16(data[2:4])
packet.SrcIp[0] = data[12]
packet.SrcIp[1] = data[13]
packet.SrcIp[2] = data[14]
packet.SrcIp[3] = data[15]
packet.DstIp[0] = data[16]
packet.DstIp[1] = data[17]
packet.DstIp[2] = data[18]
packet.DstIp[3] = data[19]
if l < 20 {
ipTooSmallLength.Inc(1)
err = errors.New("Too small IP length")
return
} else if hl < 5 {
ipTooSmallHeaderLength.Inc(1)
err = errors.New("Too small IP header length")
return
} else if int(hl*4) > int(l) {
ipInvalieHeaderLength.Inc(1)
err = errors.New("Invalid IP header length > IP length")
return
}
if cmp = len(data) - int(l); cmp > 0 {
data = data[:l]
} else if cmp < 0 {
if int(hl)*4 > len(data) {
ipTruncatedHeader.Inc(1)
err = errors.New("Not all IP header bytes available")
return
}
}
data = data[hl*4:]
case 6:
ipV6IsNotSupported.Inc(1)
err = errors.New("IPv6 is not supported")
return
default:
ipInvalidVersion.Inc(1)
err = errors.New("Invalid IP packet version")
return
}
//TCP
if len(data) < 13 {
tcpTooSmall.Inc(1)
err = errors.New("Too small TCP packet")
return
}
packet.SrcPort = binary.BigEndian.Uint16(data[0:2])
packet.DstPort = binary.BigEndian.Uint16(data[2:4])
packet.Seq = binary.BigEndian.Uint32(data[4:8])
dataOffset := data[12] >> 4
if dataOffset < 5 {
tcpInvalidDataOffset.Inc(1)
err = errors.New("Invalid TCP data offset")
return
}
dataStart := int(dataOffset) * 4
if dataStart > len(data) {
tcpOffsetGreaterThanPacket.Inc(1)
err = errors.New("TCP data offset greater than packet length")
return
}
packet.Payload = data[dataStart:]
return
}
```
Для подобных функций всегда стоит писать [бенчмарки](http://dave.cheney.net/2013/06/30/how-to-write-benchmarks-in-go), на этот раз получилась достаточно приятная картина:
```
Benchmark_DecodePacket-4 50000000 27.9 ns/op
Benchmark_Gopacket-4 1000000 3351 ns/op
```
То есть мы получили ускорение больше чем в 100 раз.
Значительнуя часть кода этой функции занимает обработка ошибок, там же видно инкременты разных счетчиков из которых мы потом делаем служебные метрики агента и можем легко понять, почему у нас как-то не так работает сниффер. Например, о необходимости добавить поддержку IPv6 мы планируем узнать именно по такой метрике.
Еще мы не пытаемся склеивать tcp payload из разных пакетов, в случае когда данные не влезают в 1 ethernet фрэйм.
Если такой пакет — ответ mongodb, нас интересует только заголовок, а для больших insert запросов например, мы просто возьмем часть запроса из первого пакета.
Дубли пакетов
-------------
Выяснилось, что если клиент и сервер находятся на одном сервере, то мы ловим один и тот же пакет 2 раза.
Пришлось делать простой дедубликатор пакетов на основе src ip+port, dest ip+port и TCP seq.
Итого
-----
* В результате на нашем бенчмарке агент стал потреблять ~5% ядра вместо 70%
* На этом мы пока решили остановиться с оптимизациями, но осталось несколько идей, как еще немного ускориться
* Под реальной нагрузкой у клиентов агент работает примерно с теми же показателями (потребление cpu в той же пропорции к количеству пакетов, что и на бенчмарке) | https://habr.com/ru/post/308328/ | null | ru | null |
# Управление облаком с помощью API и CLI. Основы
В этой статье объясняем, зачем нужны инструменты автоматизации API и CLI и как с их помощью управлять инфраструктурой на примере Serverspace.
Что такое CLI?
--------------
CLI (Command Line Interface) или интерфейс командной строки – инструмент для работы пользователя с программой с помощью команд.
Что такое API?
--------------
API (Application Programming Interface) или программный интерфейс приложений – это способ взаимодействия одной программы с другой, когда элементы одного приложения используются внутри другого.
Из определений сложно понять, что же делать дальше с этими инструментами, поэтому рассмотрим подробнее каждый из них.
CLI
---
Язык команд был единственным способом взаимодействия с компьютером до появления всем знакомых графических интерфейсов. Несмотря на это сегодня командная строка по-прежнему остается важным инструментом, как быстрый доступ к необходимым функциям компьютера / сервера.
Принцип работы CLI
------------------
Пользователь вводит текстовые команды в строку интерфейса и ждет ответ от компьютера. В это время инструмент переводит запросы в понятные для операционной системы функции и выдает ответ. Команды в [CLI](https://serverspace.ru/services/cli/) могут состоять как из одного слова, так и из нескольких строк, известных как сценарии.
Например, с помощью интерфейса командной строки Serverspace вы можете получить объем созданного диска:
```
>s2ctl server get-volume l1s12345 --volume-id 20210
```
\*s2ctl – название утилиты Serverspace, которая дает возможность контролировать вашу инфраструктуру в терминале.
В результате, вы получите подробные данные о сервере:
```
id: 20210
name: boot
server_id: l1s12345
size_mb: 25600
created: '1970-01-01T0:00:00.0000000Z'
```
Инструмент CLI полезен для автоматизации рутинных задач. Вы или ваша команда разработчиков можете написать список команд, которые компьютер будет выполнять в выбранное время или в ситуации по вашему выбору.
CLI позволяет делать все, что доступно в графическом интерфейсе панели управления Serverspace, только с помощью быстрых команд и строки ввода.
API
---
[API](https://serverspace.ru/services/api/) выступает посредником между двумя программами и позволяет им взаимодействовать друг с другом, используя определенный набор протоколов. Разработчикам необязательно знать, как реализован сторонний API; они могут использовать интерфейс для связи с другими продуктами и услугами.
API можно рассматривать как договор между двумя сервисами, который определяет, как им работать друг с другом. В качестве договора выступает документация, содержащая информацию о том, как разработчики должны структурировать запросы и ответы. Например, вы можете ознакомиться с документацией [Serverspace API](https://docs.serverspace.ru/public_api.html), где найдете описание API, структуры запросов и ответов, коды ошибок и примеры операций.
Для начала работы необходимо получить доступ к API с помощью данных для авторизации (API-ключ, пароль, Secret key). Например, для работы с Serverspace API пользователем создается API-ключ для проекта, который в дальнейшем необходимо передавать при каждом запросе в заголовке X-API-KEY:
```
-H "X-API-KEY: lmGwbvllpIqIrKROOCLgE5Z941MKP5EYfbkgwtqJZGigfXUTpuYRpNQkCqShmm6r"
```
Принцип работы
--------------
Специалисты компании [mulesoft](https://www.mulesoft.com/resources/api/what-is-an-api) приводят наглядный пример, как работает API – его сравнивают с рестораном. Представьте, вы сидите за столом и выбираете блюдо. Кухня выступает частью «системы», которая будет готовить ваш заказ. Но не хватает связующего звена, чтобы передать заказ на кухню и доставить еду к вашему столу. Здесь появляется официант, в нашем случае API, который принимает ваш запрос или заказ и сообщает кухне (т.е. системе), что делать. Затем он отдает вам ответ в виде вкусной еды.
Например, вы хотите получить детальную информацию о сервере. Вы делаете «заказ» с помощью запроса:
```
curl -X GET \
https://api.serverspace.ru/api/v1/servers/{server_id} \
-H 'content-type: application/json' \
-H 'x-api-key: lmGwbvllpIqIrKROOCLgE5Z941MKP5EYfbkgwtqJZGigfXUTpuYRpNQkCqShmm6r'
```
Serverspace API принимает этот запрос, относит на «кухню» и возвращает ответ в виде информации про сервер.
```
{
"server": {
"id": "l1s2400",
"location_id": "am2",
"cpu": 1,
"ram_mb": 1024,
"volumes": [
{
"id": 2977,
"name": "boot",
"size_mb": 25600,
"created": "2020-11-12T09:09:30.46252"
},
{
"id": 2978,
"name": "additional",
"size_mb": 30720,
"created": "2020-11-12T09:36:34.376165"
}
],
"nics": [
{
"id": 3024,
"network_id": "l1n1",
"mac": "ca:05:27:ff:56:89",
"ip_address": "45.14.48.218",
"mask": 28,
"gateway": "45.14.48.209",
"bandwidth_mbps": 50
},
{
"id": 3025,
"network_id": "l1n368",
"mac": "ca:05:1a:50:f6:07",
"ip_address": "10.0.0.1",
"mask": 24,
"bandwidth_mbps": 1024
}
],
"image_id": "CentOS-7.7-X64",
"is_power_on": true,
"name": "public-api",
"login": "root",
"password": "EuvzlqK6pv",
"ssh_key_ids": [
223,
224
],
"state": "Active",
"created": "2020-11-12T09:09:54.6478655Z",
"tags": [
"production",
"elastic"
],
"application_ids": [
"nginx",
"gitlab",
"wordpress"
]
}
}
```
Или например, чтобы изменить конфигурацию сервера, необходимо ввести более сложный запрос, так как здесь передается тело запроса (CPU и RAM). Запрос будет выглядеть так:
```
curl -X PUT \
https://api.serverspace.ru/api/v1/servers/{server_id} \
-H 'content-type: application/json' \
-H 'x-api-key: lmGwbvllpIqIrKROOCLgE5Z941MKP5EYfbkgwtqJZGigfXUTpuYRpNQkCqShmm6r' \
-d '{
"cpu": 4,
"ram_mb": 4096
}’
```
В результате возвращается ID задачи, по которой можно отследить процесс изменения настроек VPS и его ID.
```
{
"task_id": "lt17499"
}
```
\* Используя API нескольких сервисов, отправляя запросы и анализируя их ответы, можно настроить автоматическое взаимодействие приложений. Автоматизация использования API может помочь сделать процессы более гибкими, позволив разработчикам сосредоточиться на важных задачах.
Сегодня каждое второе приложение использует API от добавления календаря и погоды до настройки биржевой торговли. Интересно, что если однажды будут удалены все API в мире, то почти все сервисы и большинство приложений просто перестанут работать.
Оба инструмента позволяют автоматизировать процесс работы с виртуальными машинами Serverspace и получать быстрые ответы на запросы, не заходя в панель управления. Вот, что вы можете делать с их помощью:
* управлять виртуальными машинами;
* просматривать детали сервера и управлять его питанием;
* масштабировать конфигурацию виртуальной машины;
* подключать сети;
* управлять SSH-ключами;
* управлять снимками;
* создавать и удалять пограничные шлюзы, настраивать правила NAT и Firewall;
* просматривать детали проекта в панели управления;
* создавать и удалять доменное имя;
* управлять DNS-записями. | https://habr.com/ru/post/692122/ | null | ru | null |
# Модальные окна и нотификация в Angular
В Angular (версии 2+) столкнулся с задачей создания модальных окон, но готовые решения мне не подходили либо из-за жестко заданного функционала (негибкие), либо они не обновлены до последней версии и по этой причине не работают. Но продираясь через дебри официальной документации решил рассказать о двух способах работы с модальными окнами (или нотификаций), которые я посчитал лучшими.
В данной статье я хочу рассказать о двух способах работы с модальными окнами:
1. «Обычное» добавление компонентов
2. Динамическое добавление компонентов
В одной из [статей](https://habrahabr.ru/post/305892/) на Хабре дается неплохой, на мой взгляд, способ решения данной проблемы, но он перестал работать после введения NgModule (а может и раньше). С данной статьей материал будет пересекаться, поэтому советую ознакомится и с ней.
Сразу скажу что есть еще несколько способов добавления модальных окон, такие как добавление в стиле [bootstrap](http://www.w3schools.com/bootstrap/bootstrap_modal.asp) (похоже на 1 способ, только в 1 способе модальное окно вынесли в отдельный компонент), так же никто не мешает использовать typescript чтоб напрямую в dom добавить какое-либо модальное окно, хоть этот способ мне и не нравится, но он существует.
Во всех примерах я буду опускать css и html в тех местах, где это не будет влиять на логику. Ссылка на репозиторий с исходным кодом будет приведена в конце статьи.
### «Обычное» добавление компонентов
Создадим, для начала, компонент, который будет простым диалоговым окном для подтверждения:
```
@Component({
selector : 'modal-dialog',
...
})
export class ModalDialogComponent {
@Input() header: string;
@Input() description: string;
@Output() isConfirmed: EventEmitter = new EventEmitter();
private confirm() {
this.isConfirmed.emit(true);
}
private close() {
this.isConfirmed.emit(false);
}
}
```
Мы создали компонент с входными значениями header и description и в ответ получаем одно значение boolean переменной с результатом работы окна. Если будет необходимость вернуть какие-либо значения с модального окна в компонент, который его вызвал, можно создать класс для представления результата выполнения:
```
export class ModalDialogResult {
public isConfirmed: boolean;
public data:any;
}
```
И возвращать данные через него.
Теперь для использованием диалогового окна нам необходимо добавить его в какой-либо модуль. Тут есть несколько способов:
1. Объединить модальные окна в один модуль
2. Добавить в тот модуль, где он будет использоваться
Для данного способа создания модального окна я выбрал добавить его в тот модуль, где он будет использоваться:
```
@NgModule({
imports : [BrowserModule],
declarations: [SimpleModalPageComponent, ModalDialogComponent],
bootstrap : [SimpleModalPageComponent]
})
export class SimpleModalPageModule {
}
```
ModalDialogComponent — это собственно сам компонент диалогового окна.
SimpleModalPageComponent — это компонент (далее компоненты, которые имеют в названии слово Page буду называть страницы), где будем отображать диалоговое окно.
Теперь добавим модальное окно в template страницы:
```
Заголовок:
Содержимое:
Show Dialog
```
Управлять видимостью модального окна будем через ngIf. При желании эту логику можно перенести внутрь диалогового окна, либо объединить кнопку для отображения окна с самим окном в один компонент.
Код страницы для отображения диалогового окна:
```
....
export class SimpleModalPageComponent {
private isModalDialogVisible: boolean = false;
public showDialog() {
this.isModalDialogVisible = true;
}
public closeModal(isConfirmed: boolean) {
this.isModalDialogVisible = false;
...
}
}
```
Диалоговое окно готово для использования. Для работы с всплывающей нотификацией (Toast, popup и т.п) работа будет происходить несколько иначе. Для работы с нотификицией нужен стек (если необходимо более чем одно всплывающее сообщение на экране), который должен быть общим для всего приложения. Далее рассмотрим как это можно сделать.
Для начала давайте создадим сервис, который будет отвечать за доступ к нотификации и модель нотификации:
```
@Injectable()
export class TinyNotificationService {
private notifications: Subject = new Subject();
public getNotifications(): Subject {
return this.notifications;
}
public showToast(info: TinyNotificationModel) {
this.notifications.next(info);
}
}
export class TinyNotificationModel {
public header: string;
public description: string;
constructor(header: string, description: string) {
this.header = header;
this.description = description;
}
}
```
В модели мы определяем заголовок и описание. В сервисе мы определили метод для отображения нотификации и метод для получения моделей нотификации.
Теперь определим компонент нотификации:
```
@Component({
selector : "notifications",
template : `
### {{notification.header}}
x
{{notification.description}}
`
})
export class TinyNotificationComponent {
notifications: Set = new Set();
constructor(private \_notificationService: TinyNotificationService) {
this.\_notificationService.getNotification()
.subscribe((notification: TinyNotificationModel)=> {
this.notifications.add(notification);
setTimeout(()=> {
this.closeNotification(notification);
}, 5000);
});
}
public closeNotification(notification: TinyNotificationModel) {
this.notifications.delete(notification);
}
}
```
В конструкторе мы подписываемся на добавление нотификации и задаем автозакрытие нотификации по истечении 5 секунд.
Для использования такой нотификации необходимо добавить компонент нотификации, желательно, как можно выше в иерархии компонентов (в главный компонент).
Для использования добавляем в template страницы (SimpleModalPageComponent)
После этого можно будет вызывать нотификацию через сервис, к примеру, следующим способом
```
...
constructor(private notificationService: TinyNotificationService) {}
public showToast(header: string, description: string) {
this.notificationService.showToast(new TinyNotificationModel(header, description));
}
...
```
Не забываем добавлять компоненты и сервисы в модули.
### Динамическое добавление компонентов
Думаю нужно сразу сказать почему я решил не создавать очередной ~~модный и молодеждый~~ пакет в npm и просто описать подход для создания модальных окон. Причина в том, что создать универсальный пакет сложно и все равно он будет подходить малому количеству пользователей (вспоминается история про то, что усредненное и универсальное решение рискует не подойти никому).
А теперь перейдем к тому из-за чего я затеял написание этой статьи. Добавить компонент динамически «из воздуха» в Angular не получится (скорее всего можно, но это сложно и рискует часто ломаться с обновлениями). Поэтому все должно быть где-то определено явно (на мой взгляд это хорошо).
Для динамического добавления компонентов должно быть известно куда мы их планируем добавлять. Для этого нам необходимо получить объект [ViewContainerRef](https://angular.io/docs/ts/latest/api/core/index/ViewContainerRef-class.html).
Получить его можно следующим способом:
```
@Component({
...
template: `
...
`,
...
})
export class DynamicModalPageComponent implements OnInit {
@ViewChild('notificationBlock', { read: ViewContainerRef }) notificationBlock: ViewContainerRef;
constructor(private notificationManager: NotificationManager) { }
public ngOnInit(): void {
this.notificationManager.init(this.notificationBlock);
}
..
}
```
Таким образом мы получаем объект ViewContainerRef. Как вы могли заметить помимо этого объекта мы используем NotificationManager и инициализируем его значением ViewContainerRef.
NotificationManager предназначен для работы с модальными окнами и нотификацией. Далее мы определим данный класс:
```
@Injectable()
export class NotificationManager {
private notificationBlock: ViewContainerRef;
...
constructor(private componentFactoryResolver: ComponentFactoryResolver) { }
public init(notificationBlock: ViewContainerRef) {
this.notificationBlock = notificationBlock;
...
}
...
private createComponent(componentType: {new (...args: any[]): T;}): ComponentRef {
const injector = ReflectiveInjector.fromResolvedProviders([], this.notificationBlock.parentInjector);
const factory = this.componentFactoryResolver.resolveComponentFactory(componentType);
return factory.create(injector);
}
private createNotificationWithData(componentType: {new (...args: any[]): T;}, data: any): ComponentRef {
const component = this.createComponent(componentType);
Object.assign(component.instance, data);
return component;
}
}
```
В предыдущем листинге я намеренно пропустил некоторые части кода, чтоб ввести их после некоторых объяснений. До того как добавлять компонент куда-либо нам необходимо его вначале создать. Методы createComponent и createNotificationWithData это внутренние методы класса и предназначены для создания компонента и инициализации его какими-либо данными соответственно.
Рассмотрим метод createComponent:
```
private createComponent(componentType: {new (...args: any[]): T;}): ComponentRef {
const injector = ReflectiveInjector.fromResolvedProviders([], this.notificationBlock.parentInjector);
const factory = this.componentFactoryResolver.resolveComponentFactory(componentType);
return factory.create(injector);
}
```
На вход мы подаем класс компонента, далее используем метод fromResolvedProviders из [ReflectiveInjector](https://angular.io/docs/ts/latest/api/core/index/ReflectiveInjector-class.html) для получения объекта ReflectiveInjector. Далее через [ComponentFactoryResolver](https://angular.io/docs/ts/latest/api/core/index/ComponentFactoryResolver-class.html) создаем фабрику для компонента и собственно создаем компонент.
Метод createNotificationWithData создает компонент и добавляет к нему данные:
```
private createNotificationWithData(componentType: {new (...args: any[]): T;}, data: any): ComponentRef {
const component = this.createComponent(componentType);
Object.assign(component.instance, data);
return component;
}
```
После того, как мы разобрали методы для создания компонентов необходимо рассмотреть как эти объекты использовать. Добавим в NotificationManager метод для отображения модального окна:
```
@Injectable()
export class NotificationManager {
...
public showDialog(componentType: {new (...args: any[]): T;},
header: string,
description: string): Subject {
const dialog = this.createNotificationWithData(componentType, {
header : header,
description: description
});
this.notificationBlock.insert(dialog.hostView);
const subject = dialog.instance.getDialogState();
const sub = subject.subscribe(x=> {
dialog.destroy();
sub.unsubscribe();
});
return subject;
}
...
}
```
ModalDialogBase это базовый класс для модели. Спрячу его под спойлер вместе с ModalDialogResult
**ModalDialogBase and ModalDialogResult**
```
export abstract class ModalDialogBase {
public abstract getDialogState(): Subject;
}
export enum ModalDialogResult{
Opened,
Confirmed,
Closed
}
```
Метод showDialog принимает класс компонента, данные для его инициализации и возвращает Subject для получения результата выполнения модального окна.
Для добавления компонента используем метод insert у notificationBlock
```
this.notificationBlock.insert(dialog.hostView);
```
Данный метод добавляет компонент и после этого он будет отображен пользователю. Через dialog.instance мы получаем объект компонента и можем обращается к его методам и полям. Например мы можем подписаться на получение результата и удалить данное диалоговое окно из dom после закрытия:
```
const subject = dialog.instance.getDialogState();
const sub = subject.subscribe(x=> {
dialog.destroy();
sub.unsubscribe();
});
```
Если вызвать у объекта [ComponentRef](https://angular.io/docs/ts/latest/api/core/index/ComponentRef-class.html) метод destroy компонент удалится не только из dom, но и из notificationBlock, что очень удобно.
Под спойлером код модального окна:
**ModalDialog**
```
@Component({
selector : 'modal-dialog',
template : `
### {{header}}
x
{{description}}
ОК
Отмена
`
})
export class ModalDialogComponent extends ModalDialogBase {
private header: string;
private description: string;
private modalState: Subject;
constructor() {
super();
this.modalState = new Subject();
}
public getDialogState(): Subject {
return this.modalState;
}
private confirm() {
this.modalState.next(ModalDialogResult.Confirmed);
}
private close() {
this.modalState.next(ModalDialogResult.Closed);
}
}
```
Далее давайте рассмотрим создание нотификации. Мы может добавлять ее так же, как и модальные окна, но на мой взгляд их лучше выделить в отдельное место, поэтому давайте создадим компонент NotificationPanelComponent:
```
@Component({
selector : 'notification-panel',
template : `
})
export class NotificationPanelComponent {
@ViewChild('notifications', { read: ViewContainerRef }) notificationBlock: ViewContainerRef;
public showNotification(componentRef: ComponentRef, timeOut: number) {
const toast = componentRef;
this.notificationBlock.insert(toast.hostView);
let subscription = toast.instance.getClosedEvent()
.subscribe(()=> {
this.destroyComponent(toast, subscription);
});
setTimeout(()=> {
toast.instance.close();
}, timeOut);
}
private destroyComponent(componentRef: ComponentRef, subscription: Subscription) {
componentRef.destroy();
subscription.unsubscribe();
}
}
```
В методе showNotification мы добавляем компонент для отображения, подписываемся на событие закрытия окна и задаем таймаут для закрытия окна. Для простоты закрытие реализовано через метод close у компонента нотификации.
Все нотификации должны наследоваться от класса NotificationBase.
**NotificationBase**
```
export abstract class NotificationBase {
protected closedEvent = new Subject();
public getClosedEvent(){
return this.closedEvent;
}
public abstract close(): void;
}
```
И приведем код самого компонента нотификации:
```
@Component({
selector : 'tiny-notification',
template : `
### {{header}}
x
{{description}}
`
})
export class TinyNotificationComponent extends NotificationBase {
public header: string;
public description: string;
close() {
this.closedEvent.next();
this.closedEvent.complete();
}
}
```
Для использования нотификации необходимо добавить метод showToast и NotificationPanelComponent в NotificationManager:
```
@Injectable()
export class NotificationManager {
private notificationBlock: ViewContainerRef;
private notificationPanel: NotificationPanelComponent;
constructor(private componentFactoryResolver: ComponentFactoryResolver) { }
public init(notificationBlock: ViewContainerRef) {
this.notificationBlock = notificationBlock;
const component = this.createComponent(NotificationPanelComponent);
this.notificationPanel = component.instance;
this.notificationBlock.insert(component.hostView);
}
...
public showToast(header: string, description: string, timeOut: number = 3000) {
const component = this.createNotificationWithData(TinyNotificationComponent, {
header : header,
description: description
});
this.notificationPanel.showNotification(component, timeOut);
}
...
```
Если попробовать сделать все, что было приведено до этого, то ничего работать не будет, ведь есть нюанс, а именно в том, как все это объединять в модули. Например если вы попробуете найти информацию где-либо, кроме оф. документации по [NgModule](https://angular.io/docs/ts/latest/api/core/index/NgModule-interface.html), то рискуете не увидеть информацию про такую вещь, как [entryComponents](https://angular.io/docs/ts/latest/api/core/index/NgModule-interface.html#!#entryComponents-anchor).
В оф. документации написано:
```
entryComponents : Array|any[]>
Specifies a list of components that should be compiled when this module is defined. For each component listed here, Angular will create a ComponentFactory and store it in the ComponentFactoryResolver.
```
То есть если мы хотим создавать компоненты через ComponentFactory и ComponentFactoryResolver нам необходимо указывать наши компоненты помимо declarations еще и в entryComponents.
Пример модуля:
```
@NgModule({
declarations : [TinyNotificationComponent, NotificationPanelComponent, ModalDialogComponent],
entryComponents: [TinyNotificationComponent, NotificationPanelComponent, ModalDialogComponent],
providers : [NotificationManager]
})
export class NotificationModule {
}
```
По поводу объединения в модули. Я считаю неплохим вариантов объединять схожий функционал модальных окон в модули и импортировать их в NotificationModule.
Теперь для использования модальных окон необходимо только указать NotificationModule в imports и можно использовать.
Пример использования:
```
...
export class DynamicModalPageComponent implements OnInit {
....
constructor(private notificationManager: NotificationManager) { }
public ngOnInit(): void {
this.notificationManager.init(this.notificationBlock);
}
public showToast(header: string, description: string) {
this.notificationManager.showToast(header, description, 3000);
}
public showDialog(header: string, description: string) {
this.notificationManager.showDialog(ModalDialogComponent, header, description)
.subscribe((x: ModalDialogResult)=> {
if (x == ModalDialogResult.Confirmed) {
this.showToast(header, "modal dialog is confirmed");
}
else {
this.showToast(header, "modal dialog is closed");
}
});
}
}
```
В данной статье мы рассмотрели способы создания модальных окон, в том числе динамически.
→ Исходный код по статье находится в данном [репозитории](https://github.com/boykovdmitriy/angular2modal/). | https://habr.com/ru/post/319386/ | null | ru | null |
# Microdata & the microdata DOM API
#### Введение
Одной из проблем, на решение которой был направлен HTML5, было повышение логичности (и, следовательно, машиночитаемости) разметки, о чем свидетельствует введение стандартных семантических элементов, таких как , и . Это все хорошо, но иногда возникает потребность добавить определенные машиночитаемые атрибуты для элементов контента, так чтобы их можно бы использовать в каком-либо скрипте предсказуемо, даже если разметка используемая для различного контента различается между собой. Эта потребность уже удовлетворена, в определенной степени, с помощью простых и обратно совместимых [Микроформатов](http://microformats.org/), и с помощью более эзотерического [RDFa](http://www.w3.org/TR/xhtml-rdfa-primer/).
В связи с этим, нет ничего удивительного, что решение этой проблемы было добавлено в спецификацию HTML5 в виде спецификации [микроданных](http://www.whatwg.org/specs/web-apps/current-work/multipage/microdata.html)(далее Microdata), включающей в себя набор атрибутов, которые могут быть добавлены к любому элементу и связанное DOM API для обработки/агрегирования микроданных на странице.
Microdata пытается улучшить то, что мы уже имели в прошлом: обеспечить встроенный механизм, который также легко понять, как и микроформаты, и который позволяет обрабатывать данные без необходимости писать свой собственный парсер. Вы, конечно же, можете создать свой [собственный парсер Microdata для поддержки в браузерах без нативной поддержки Microdata DOM API, используя JavaScript](https://github.com/termi1uc1/Microdata-JS), если это необходимо. В этой статье мы пройдёмся по HTML-аттрибутам Microdata и синтаксису DOM API.
`Примечание: Экспериментальная сборка Opera с поддержкой Microdata может быть найдена тут.`
#### HTML синтаксис
Microdata состоит из набора элементов, каждый из которых имеет набор свойств представленных парами ключ-значение. Собственно, как настоящие web-гики, давайте опишем себя в формате микроданных. Вы можете написать свой собственный пример, по моему образцу.
`Примечание: Вы можете проверить правильность синтаксиса Microdata с помощью экспериментально HTML5-валидатора. Также вы можете открыть мой пример использования Microdata и поглядывать на него, пока читаете текст данной статьи.`
Прежде всего, мы можем отметить любой подходящий элемент как контейнер элементов, используя **itemscope** атрибут
```
```
Очевидно, что вы должны выбрать элемент содержащий нужные вам данные, при этом, не важно, какие данные вы отмечаете. В данном случае, я размечу карточку биографии: первым свойством будет наше имя, а отметим мы его с помощью аттрибута **itemprop**:
```
Chris Mills
-----------
```
Атрибут **itemprop** выделяет элемент содержащий данные. Значение атрибута — это имя свойства, а содержимое элемента — это значение свойства. Давайте добавим еще несколько свойств, чтобы убедиться, что вы уловили суть:
```
Chris Mills
-----------
* Nationality: British
* Age: 33
* Hair colour: Brown
```
В некоторых случаях, значением свойства является не текстовое содержимое элемента, а значение некоторого атрибута у того же элемента. Например:
1. Для тега значением свойства является значение атрибута «src».
2. Для тега — значение атрибута «href».
3. Для тега — значение атрибута «datetime».
(Прим. переводчика: значения других элементов можно посмотреть в [спецификации](http://www.w3.org/TR/html5/microdata.html#values))
С другой стороны, если значением свойства является URL, то оно должно быть выражено через соответствующий элемент, который указывает на или загружает внешний ресурс, например, через элемент . Если значение свойства — дата или время (или оба сразу), то свойство должно быть выражено через элемент и атрибут «datetime». Атрибут **itemprop** добавляется точно также, но, при этом, значением свойства будет значение атрибута, вместо текстового контента элемента.
Несколько примеров:
```
Chris Mills
-----------

* Nationality: British
* Age: 33
* Date of birth: June 27th 1978
* Hair colour: Brown
```
`Примечание: На момент публикации этой статьи (10 августа 2011), ведутся разговоры о замене элемента на элемент , поэтому данный пример может потребовать изменений.`
##### Вложенные узлы Microdata
Вы также можете совершенно спокойно внедрять Microdata элементы (Прим. переводчика: далее, чтобы не запутаться в терминах: «узлы Microdata») внутри друг друга. Самый верхний узел Microdata помечается атрибутом **itemscope**, а затем любые вложенные узлы Microdata также помечаются атрибутом **itemscope**. Давайте добавим некоторую информацию о своей группе в карточку биографии:
```
...
- ### My band
* Name: Conquest of Steel
* Band: Heavy metal
* Members: 5
...
```
##### Разные свойства, одно имя; одно свойство, разные имена
Вы можете указать у нескольких элементов одно и тоже название свойства, например:
```
- Members:
* Claymore Clark
* DD Danger
* Dan Durrant
* Chris Mills
* Vic Victory
```
Результатом будет узел Microdata с пятью свойствами, все с именем «memeber» и каждое со своим значением.
И наоборот, вы также можете поместить несколько свойств в одном элементе, тем самым давая этим свойствам одинаковое значение:
```
- Band: Heavy metal
```
##### Указание на свойства вне itemscope элемента
Могут быть случаи, когда вы хотите, чтобы ваши узлы Microdata включали свойства, которые на самом деле определены не в пределах этого пункта(элемента). Вы можете сделать это, ссылаясь на **ID** внешних свойств внутри атрибута **itemref**. Рассмотрим следующий пример, в котором я перенёс участников моей группы за пределы моего элемента, в отдельное место в html-разметки:
```
...
- ### My band
* Name: Conquest of Steel
* Band: Heavy metal
* Members: 5
* Claymore Clark
* DD Danger
* Dan Durrant
* Chris Mills
* Vic Victory
```
В этом случае «member» свойства находятся внутри элемента с идентификатором на который ссылается атрибут **itemref** нашего Microdata пункта.
`Примечание: Вы можете указать несколько ID в атрибуте itemref разделённых символом пробела. Например: itemref="members instruments gigdates"`
##### Определение словаря свойств для узлов Microdata, которые могут быть использованы в дальнейшем
Всё хорошо, пока вы используете свою Microdata разметку сами — вы сами определяете набор свойств для ваших узлов Microdata. Но, при совместной работе с другими веб-разработчиками возникает необходимость в определении словаря свойство для определённого узла Microdata. Вы можете сделать это, указав каждому узлу тип, используя **itemtype** атрибут. Значение этого атрибута имеет форму URL, ресурс на который ссылается данный URL может существовать, а может и не существовать. Хорошо, если вы указываете URL на реальную страницу в Интернете, которая информирует других пользователей о словаре свойств, но вы не обязаны этого делать.
Вернемся к нашему примеру:
```
...
...
...
```
Узел Microdata может иметь только один тип, а тип определяет словарь свойств. Таким образом, в нашем примере, элемент типа [example.org/biography](http://example.org/biography) имеет четыре свойства — name, style, bandsize и member. Это помогает избежать путаницы с аналогичным названием свойства. Можно также использовать Microdata для разметки информации о присяжных в суде, с аналогичным свойством itemprop=«member», но это будет другое свойство, т.к. узел Microdata имеет другой **itemtype** — «[example.org/jury](http://example.org/jury)», или любой другой по вашему выбору.
Вы должны хорошо подумать, какой словарь свойств вы будете использовать, чтобы выбрать надежный, гибкий и расширяемый: для получения дополнительной информации и советов, читайте раздел спецификации [Выбор имен при определении словарей](http://www.whatwg.org/specs/web-apps/current-work/multipage/microdata.html#selecting-names-when-defining-vocabularies). Вы также должны поискать в вебе, может быть кто-то уже написал подходящий словарь для ваших целей. Посмотрите раздел спецификации [словари Microdata](http://www.whatwg.org/specs/web-apps/current-work/multipage/microdata.html#mdvocabs) для получения информации о существующих словарях, перенесенных из микроформатов, таких как vCard и vEvent.
##### Назначение глобального идентификатора для узла Midrodata
Некоторые вещи уже имеют идентификатор назначенный по мировым соглашениям об идентификаторах, таких как [ISBN](http://en.wikipedia.org/wiki/Isbn) для книг и [UPC](http://en.wikipedia.org/wiki/Universal_Product_Code) для продуктов в магазине. Некоторые словари Microdata поддерживают такие идентификаторы (вы должны сами выяснять такие вопросы, именно поэтому мы рекомендуем при написании собственных словарей свойств документировать их по URL-адресу указанному в атрибуте **itemtype**). Если вы используете подобные идентификаторы, укажите его в атрибуте **itemid** в том же элементе, где вы указали **itemscope** и **itemtype**. Кроулер или поисковый движок, который понимает подобную разметку (пока таких нету) поймёт, что ваш контент — это тот же ISBN/UPC объект, как и любой другой контент с каким же **itemid**. Далее они смогут плавно накапливать информацию до тех пор, пока сеть не обретет сознание и машины не восстанут.
Например, следующая разметка будет обработана, только при условии, что *[example.com/book](http://example.com/book)* словарь явно указывает использовать ISBN идентификатор (больше деталей об этом позже):
```
InterACT with web standards
---------------------------
Authors:
* Leslie Jensen-Inman
* Chris Mills
* Glenda Sims
* Aarron Walter
...
```
#### Microdata DOM API
Microdata становится еще более полезной, когда вы начинаете использовать её DOM API для манипуляций с узлами и их свойствами на странице используя javascript, возможно, для представления информации в поисковой манере или для доставки его в какое-либо другое приложение.
API очень простое — вы используете функцию document.getItems() для получения объекта Nodelist, содержащего все узлы Microdata на странице (Прим. переводчика: только все узлы **верхнего** уровня, т.е. не вложенные в другие узлы и не имеющие **itemprop** атрибута). Если вы вызываете функцию без аргументов, то вы получите список из всех узлов Microdata; или же, вы можете указать, какой **itemtype** вы ищите, передав его в качестве параметра вызова, в этом случае функция вернет Nodelist только с узлами Microdata у которых **itemtype** равен вашему параметру. Например:
```
var biography = document.getItems("http://example.org/biography");
```
Вернёт биографический узел и сохранит его в переменную. После получения узла, вы можете манипулировать его свойствами через свойство **properties**:
```
var biography = document.getItems("http://example.org/biography")[0];
alert('Hi there ' + biography.properties['name'][0].textContent + '!');
```
И в этом нету ничего сложного, серьёзно. Вы можете найти больше примеров для изучения в разделе [Using the microdata DOM API](http://www.whatwg.org/specs/web-apps/current-work/multipage/microdata.html#using-the-microdata-dom-api) спецификации. Кроме того, [Philip Jägenstedt](http://blog.foolip.org/) создал довольно изящный [live microdata viewer](http://foolip.org/microdatajs/live/), который весьма полезен для проверки вашего кода, а также может быть использован для быстрой конвертации Microdata в различные форматы, например, JSON.
`Вы можете посмотреть на мой пример использования Microdata. Также, зацените набор тестов от Opera для Microdata, мы только что запостили его в набор тестов W3C`
Наш краткий обзор микроданных завершился. Я надеюсь, что это помогло вам понять эту новую интересную технологию. Дайте нам знать, что вы думаете, и зацените нашу [экспериментальную сборку Opera с поддержкой микроданных](http://my.opera.com/desktopteam/blog/2011/07/27/latency-microdata-qresync).
*От переводчика:
Статья пролежала на [Dev.Opera](http://dev.opera.com/) с августа и никто её так и не перевёл. Т.к. статья достойна внимания и будет интересна большому количеству разработчиков, я взял на себя смелость исправить данную несправедливость. Я не обладаю ни хорошими знаниями английского языка, ни опытом переводов, так что, если вы обнаружили неточность в переводе — напишите мне в личку. Если вы считаете, что статья достойна какого-либо другого блога — также, пишите мне в личку* | https://habr.com/ru/post/133961/ | null | ru | null |
# Несоответствия исторических пластов Windows 11 — если копнуть, на дне сохранились даже элементы Windows 3.1

Спустя несколько лет Windows 11 доросла до более-менее нормального состояния, так что ею с удовольствием пользуется большинство людей. В сентябре вышло обновление [Sun Valley](https://thewincentral.com/windows-11-sun-valley-2-22h2-may-bring-missing-taskbar-features-back-along-with-other-new-features/) (22H2) с давно назревшими изменениями в дизайне. Но достаточно ли их, чтобы устранить исторические несоответствия в UI?
Давайте посмотрим.
*Примечание. В данном исследовании используется Windows 11 build 25267, последняя сборка Insider Dev на данный момент (01.01.2023 г).*
Первый слой: элементы Windows 11/WinUI3
---------------------------------------
Windows 11 реализовала новый язык дизайна: акцент на закруглённые углы и градиенты, с прозрачным фоном. Новый дизайн Mica призван заменить старый Acrylic.
Если сравнить приложения Windows 10 и 11, то впервые за многие годы (для некоторых вроде «Блокнота» даже десятилетия) пользовательский интерфейс значительно переработан в соответствии с новым языком дизайна.

Другим фундаментальным изменением в Windows 11 является расположение кнопки «Пуск», которая спустя 27 лет перемещена из левого угла к центру экрана, как в операционной системе [Windows 10X](https://ru.wikipedia.org/wiki/Windows_10X) (проект уже отменён — *прим. пер.*).

По сравнению с Windows 10 изменились контекстные меню, «Проводник» (в нём наконец-то появились вкладки!) и приложение «Настройки».
И последнее. Дизайнеры переработали меню «Пуск», убрав оттуда «живые плитки» образца Windows 8.
Ещё одним значительным улучшением Windows 11 стало обновление редких элементов элементов интерфейса. Они спрятаны в глубине настроек и обычный пользователь редко (случайно) туда добирается. Например, подсказки файрвола (которые не обновлялись со времен Vista!).
Также разработчики заменили многие элементы Metro UI…

… включая ползунок громкости, наконец-то.
На загрузочный экран поместили новый логотип Windows, а также новый кружок загрузки WinUI, который заменил устаревшие вращающиеся точки.

Как видим, дизайн Windows 11 значительно лучше согласован. Обновилось большинство распространённых элементов UI, а с появлением WinUI 3 разработчики смогут легче интегрировать эти элементы в свои приложения.
Теперь копнём глубже.
Второй слой: элементы Windows 10
--------------------------------
Во-первых, безотносительно дизайна, у Windows 10 и 11 одинаковая версия ядра — 10.0.

Некоторые приложения («Почта» и «Календарь») не перешли на новый дизайн Windows 11. Есть информация, что в 2023 году их заменят другим приложением под кодовым названием Project Monarch.

Некоторые элементы настроек тоже не обновились в соответствии с новым дизайном. Например, окно на этапе изменения профиля пользователя.

Дизайн Windows Defender тоже не обновили. В результате он выглядит значительно более устаревшим, чем остальные элементы UI.
На удивление, Кортана тоже сохранилась в Windows 11, но уже не так тщательно интегрирована в ОС. А помните, как она помогала голосовыми подсказками во время установки системы? (Это особенно раздражало системных администраторов, которые [накатывали десятки образов](https://www.windowscentral.com/watch-bemusement-dozens-instances-cortana-annoy-it-department?amp) одновременно, [видео](https://www.youtube.com/watch?v=Rp2rhM8YUZY) — *прим. пер*).
*Я вообще забыл о существовании Кортаны, пока не увидел её в меню «Пуск»*
Как видите, в ОС ещё довольно много остатков Windows 10, но они не бросаются в глаза, за исключением Windows Defender, который выглядит довольно странно на общем фоне.
Теперь перейдём к самому интересному.
Третий слой: Windows 8
----------------------
Похоже, мы никак не избавимся от проклятия Metro. И хотя Microsoft уже официально прекратила поддержку Windows 8.1, этот дизайн продолжает отравлять интерфейс всех последующих версий Windows.
В системе по-прежнему много элементов Windows 8. Например, окошко Autorun для выбора действия…
… или ошибка при запуске несовместимой программы.
Это довольно заметные элементы ОС, и они определенно придают Windows ощущение половинчатости и непоследовательности.
Также хорошо заметны экраны загрузки. Хотя в WinUI3 они обновились, но Metro-аналоги по-прежнему преобладают по всей системе:


*Одно приложение, разные круги загрузки*
Ещё один сохранившийся элемент Metro — среда восстановления Windows Recovery Environment, которая выглядит почти так же, как и в Windows 8:
Экран копирования остался таким же, как в Windows 8:
Несмотря на заметный прогресс в де-метро-фикации Windows 11, некоторые важные элементы выявить и обновить не удалось. Очевидно, очистка UI будет продолжаться.
Четвёртый слой: Windows 7
-------------------------
Если в Windows 10 большинство встроенных приложений идентичны Windows 7, то в Windows 11 этот аспект значительно улучшен. Большинство приложений («Блокнот», Paint, «Ножницы» и др.) переработаны, чтобы соответствовать новым принципам дизайна Windows 11. Но поскольку мы говорим о Microsoft, не обошлось без ляпов.
Программа *Remote Desktop Connection* осталась точно такой же, как и 14 лет назад, с иконками Aero и скеоморфными общими элементами управления.
Старый интерфейс Windows Media Player 12 тоже сохранился, хотя вместо него уже используется новое приложение Media Player.

Как и в Windows 10, некоторые диалоговые окна файлов сохранили дизайн Windows 7.
Переходим к пятому слою.
Пятый слой: Windows Vista
-------------------------
Являясь краеугольным камнем современной Windows, Vista привнесла в ОС множество новых функций. Одной из них стало внедрение Aero-мастеров, которые сохранились в Windows 11 без изменений, как и в Windows 10.
Любимая «Панель управления» всё еще здесь, хотя большинство общих функций теперь перенаправляются в приложение «Настройки».
Последняя странность Vista — это программа поиска, которая выглядит совершенно прекрасно в современном дизайне «Проводника».
*Великолепно, да?*
Шестой слой: Windows XP
-----------------------
Как и в Windows 10, окошко копирования драйверов не обновили. В нём по-прежнему используются иконки Windows XP.

Седьмой слой: Windows 2000
--------------------------
И снова, как и раньше, почти полностью совпадают *MMC*, *winver* и программа установки *Windows Installer*. За исключением того факта, что в инсталляторе впервые за двадцать лет поменяли иконки!

*Какое замечательное попурри иконок!*
Восьмой слой: Windows 95/NT 4.0
-------------------------------
Хотя меню «Пуск» впервые сместили из левого нижнего угла в центр, всё остальное осталось прежним.
Как и в Windows 10, параметры папок, настройки мыши и многие другие элементы пользовательского интерфейса практически не изменились на протяжении последних 27 лет.

Наконец, девятый слой.
Девятый слой: Windows 3.1
-------------------------
В системе по-прежнему сохранилась возможность выбирать иконки, которым более тридцати лет, включая важнейшую и абсолютно критическую для правильной работы ОС библиотеку `moricons.dll` (вероятно, это сарказм — *прим. пер.*.
И последнее, но не менее важное: в утилите *ODBC Data Sources* сохранилось окно выбора папок в стиле Windows 3.1!
Заключение
----------
Как видим, в Windows 11 дизайн стал слегка более согласованным. Хотя сделанные улучшения несколько поверхностны, они всё же более основательны, чем те, что были представлены в Windows 10. В то же время осталось много возможностей для улучшения. Но хотя бы «повседневный» UI по большей части согласован и последователен, в отличие от Windows 10.
В 2023 году Windows 11 получит три небольших обновления ("moment updates") с новыми функциями и исправлениями UI. По слухам, Microsoft хочет ещё больше отделить элементы UI от остальной части операционной системы. Так что ждём очередных изменений.
Спасибо за внимание. 😏 | https://habr.com/ru/post/711684/ | null | ru | null |
# Передача табличных данных из хранимой процедуры
Речь пойдет о методах получения результатов работы процедуры в виде таблиц для последующей работы с ними в SQL. Думаю, большинство здесь изложенного может пригодиться только в приложениях со сложной SQL логикой и объемными процедурами. Не берусь утверждать, что данные методы самые эффективные. Это всего лишь то, что я использую в своей работе. Всё это работает под Microsoft SQL Server 2008.
Тем, кто знаком с темой предлагаю пролистать пост до пятого метода.
Пусть процедура, из которой нам нужно получить данные будет такой:
```
create procedure Proc1
as
begin
select 1 p1, 'b' p2
end
```
#### 1 Метод
Один из самых простых методов. Используем конструкцию `insert ... exec ...`
```
if object_id(N'tempdb..#t1',N'U') is not null drop table #t1
create table #t1(p1 int, p2 varchar(max))
insert #t1
exec Proc1
select * from #t1
```
##### Плюсы и минусы:
* Передаваемые поля перечисляются 2 раза (это внутренний `select`, внешнее создание таблицы и `insert`). Плюс перечисление полей происходит при каждом новом аналогичном вызове. (Я добавляю данный критерий, т.к. при большом количестве правок и множестве мест вызова процедуры, процесс изменения выводимых данных становится очень трудоемким)
* Имеет серьезное ограничение – мы можем получить только одну таблицу
* Для работы процедуры в режиме простого вывода не требуются дополнительные действия, достаточно запустить `exec Proc1` без `insert`
#### 2 Метод
С помощью записи в ранее созданную таблицу. Здесь придется добавлять insert в процедуру:
```
create procedure Proc1
as
begin
insert #t1(p1, p2)
select 1 p1, 'b' p2
end
```
По сути мы перенесли строку insert внутрь процедуры.
```
if object_id(N'tempdb..#t1',N'U') is not null drop table #t1
create table #t1(p1 int, p2 varchar(max))
exec Proc1
select * from #t1
```
##### Плюсы и минусы:
* Передаваемые поля перечисляются 2 раза, и еще по одному перечислению на каждое новое использование
* Для работы процедуры в режиме простого вывода потребуется либо писать отдельную процедуру, выводящую принятые от `Proc1` таблицы, либо определять, когда их выводить внутри `Proc1`. Например, по признаку не существования таблицы для вставки:
```
alter procedure Proc1
as
begin
declare @show bit
if object_id(N'tempdb..#t1',N'U') is null
begin
set @show = 1
create table #t1(p1 int, p2 varchar(max))
end
insert #t1(p1, p2)
select 1 p1, 'b' p2
if (@show = 1)
begin
select * from #t1
end
end
```
Я не рассматриваю возможность передачи через постоянные таблицы, т.к. если это требуется, то задача не относиться к данной теме. Если же нет, то мы получаем лишние проблемы с блокировкой и идентификацией между сессиями.
#### 3 Метод
По сути, является доработкой второго метода. Чтобы упростить поддержку создаем пользовательский тип таблицы. Выглядит это примерно так:
```
create type tt1 as table(p1 int, p2 varchar(max))
go
create procedure Proc1
as
begin
insert #t1(p1, p2)
select 1 p1, 'b' p2
end
go
-- используем:
declare @t1 tt1
if object_id(N'tempdb..#t1',N'U') is not null drop table #t1
select *
into #t1
from @t1
exec Proc1
select * from #t1
```
##### Плюсы и минусы:
* Передаваемые поля перечисляются 2 раза, при этом каждое новое использование не добавляет сложности
* Для организации непосредственного вывода результата также требуются дополнительные действия
* Есть небольшие сложности с созданием индексов и ограничений, т.к. их мы не можем создать с помощю конструкции `select ... into`
#### 4 Метод
Усложнение третьего метода, позволяющее создавать таблицу с ограничениями и индексами. В отличии от предыдущего работает под Microsoft SQL Server 2005.
```
create procedure Proc1
as
begin
insert #t1(p1, p2)
select 1 p1, 'b' p2
end
go
create procedure Proc1_AlterTable
as
begin
alter table #t1 add p1 int, p2 varchar(max)
alter table #t1 drop column delmy
end
go
-- используем:
if object_id(N'tempdb..#t1',N'U') is not null drop table #t1
create table #t1(delmy int)
exec Proc1_AlterTable
exec Proc1
select * from #t1
```
Однако обычно временная колонка delmy не используется, вместо неё таблица создается просто с одним первым столбцом (здесь с p1).
##### Плюсы и минусы:
* Передаваемые поля перечисляются 2 раза, при этом каждое новое использование не добавляет сложности
* Для непосредственного вывода результата также требуются дополнительные действия
* Неожиданно обнаружилось, что иногда, по непонятным причинам, возникают блокировки на конструкции `alter table #t1`, и процесс ожидает полного завершения `Proc1` (не `Proc1_AlterTable`!) параллельного запроса. Если кто-нибудь знает, с чем это связанно — поделитесь, буду рад услышать:)
#### 5 Метод
Этот метод использует предварительно созданные процедуры. Он основан на включении динамического SQL-запроса в запускаемую процедуру. Однако является достаточно простым в использовании.
Для его использования процедуры необходимо обработать следующим образом:
1. В начало процедуры включить строки:
```
if object_id('tempdb..#ttInclusion', 'U') is null create table #ttInclusion(lvl int, i int)
exec util.InclusionBegin
```
2. Все выводящие select'ы процедуры переделать на создание временных таблиц начинающихся с `#Output` (Например `into #Output`, `into #Output5`, `into #OutputMySelect`). Если процедура не создает результирующего набора, то действие не требуется
3. В конец процедуры включить строку:
```
exec util.InclusionEnd --выводит все таблицы, начинающиеся с #Output, в порядке их создания после запуска util.InclusionBegin
```
Для нашего примера мы получаем:
```
create procedure Proc1
as
begin
if object_id('tempdb..#ttInclusion', 'U') is null create table #ttInclusion(lvl int, i int)
exec util.InclusionBegin
select 1 p1, 'b' p2
into #Output1
exec util.InclusionEnd --выводит все таблицы, начинающиеся с #Output, в порядке их создания после запуска util.InclusionBegin
end
```
Запуск осуществляется так:
```
if object_id('tempdb..#ttInclusionParameters', 'U') is null create table #ttInclusionParameters(lvl int, pr int, val varchar(max))
exec util.InclusionRun'
select * from #InclusionOutput1
', 1, '#InclusionOutput'
exec Proc1
```
Поскольку генерируемый SQL это не всегда хорошо, то приведенный пример лучше подходит для небольших инструкций. Если кода достаточно много, то можно либо вынести его в отдельную процедуру и из динамической части осуществлять только exec вызов, либо перезалить данные в новые временные таблицы. В последнем случае, конечно, происходит ещё одно «лишнее» копирование, но часто бывает так, что на этом этапе мы можем предварительно сгруппировать результат и выбрать только нужные поля для дальнейшей обработки (например, если в каком-либо случае не требуется все возвращаемые данные).
Функции `util.InclusionRun` передаются 3 параметра:
* `@sql` – SQL-скрипт, который выполниться внутри вызываемой процедуры
* `@notShowOutput` – если = 1, то блокировать вывод таблиц, начинающихся с `#Output`
* `@replaceableTableName` – (по умолчанию = `'#Output'`) задать префикс в имени таблиц используемых в `@sql`, для замены его на соответствующую `#Output*` таблицу в скрипте. Например, если задать `#InclusionOutput`, и в процедуре созданы две таблицы `#Output55` и `#Output0A`, то в `@sql` можно обратиться к `#Output55` как к `#InclusionOutput1`, а к `#Output0A` как к `#InclusionOutput2`
Работа построена таким образом, что запуск `Proc1`, без предварительного запуска `util.InclusionRun` приводит к естественной работе процедуры с выводом всех данных, которые она выводила до обработки.
##### Нюансы использования:
* Накладывает ограничения на использование инструкции `return` в процедуре, т.к. перед ней необходим запуск `util.InclusionEnd`
* Выводящие результат select'ы из запускаемых процедур выводят результат раньше, чем даже те #Output-таблицы, которые были созданы до их вызова (это логично, т.к. вывод происходит только в `util.InclusionEnd`)
##### Плюсы и минусы:
* Передаваемые поля перечисляются один раз, при этом каждое новое использование не добавляет сложности
* Для непосредственного вывода результата не требуется никаких действий
* Необходимо помнить и учитывать нюансы использования
* Из-за дополнительных процедур выполняется больше инструкций, что может снизить быстродействие при частых вызовах (я думаю, что при запуске реже одного раза в секунду этим можно пренебречь)
* Возможно, может усложнить понимание кода для сотрудников не знакомых с данным методом: процедура приобретает два exec-вызова и неочевидность того, что все `#Output`-таблицы будут выведены
* Позволяет легко организовать модульное тестирование без внешних инструментов
##### Демонстрация использования:
**Скрытый текст**Код:
```
if object_id('dbo.TestInclusion') is not null drop procedure dbo.TestInclusion
go
create procedure dbo.TestInclusion
@i int
as
begin
if object_id('tempdb..#ttInclusion', 'U') is null create table #ttInclusion(lvl int, i int)
exec util.InclusionBegin
if object_id('tempdb..#tmp2', 'U') is not null drop table #tmp2
select @i myI
into #tmp2
if object_id('tempdb..#tmp3', 'U') is not null drop table #tmp3
select @i + 1 myI
into #tmp3
select *
into #Output0 --На вывод (выводится в util.InclusionEnd)
from #tmp2
union all
select *
from #tmp3
select 'процедура TestInclusion' alt
into #OutputQwerty --На вывод (выводится в util.InclusionEnd)
exec util.InclusionEnd --выводит все таблицы начинающиеся с #Output в порядке из создания после запуска util.InclusionBegin
end
go
set nocount on
set ansi_warnings off
if object_id('tempdb..#ttInclusionParameters', 'U') is not null drop table #ttInclusionParameters
go
select 'Тест 1: запуск TestInclusion. Ниже должен быть вывод таблицы с одной колонкой myI и двумя строками: 2 и 3. И таблица с 1 строкой: "процедура TestInclusion"'
exec dbo.TestInclusion 2
go
select 'Тест 2: тест TestInclusion. Ниже должен быть вывод таблицы с одной колонкой testSum и одной строкой: 5'
if object_id('tempdb..#ttInclusionParameters', 'U') is null create table #ttInclusionParameters(lvl int, pr int, val varchar(max))
exec util.InclusionRun '
select sum(myI) testSum
from #InclusionOutput1
', 1, '#InclusionOutput'
exec dbo.TestInclusion 2
```
Результат:
```
-----------------------------------------------------------------------------------------------------------------------------------------------------------
Тест 1: запуск TestInclusion. Ниже должен быть вывод таблицы с одной колонкой myI и двумя строками: 2 и 3. И таблица с 1 строкой: "процедура TestInclusion"
myI
-----------
2
3
alt
-----------------------
процедура TestInclusion
------------------------------------------------------------------------------------------------------
Тест 2: тест TestInclusion. Ниже должен быть вывод таблицы с одной колонкой testSum и одной строкой: 5
testSum
-----------
5
```
##### Сами функции:
**Скрытый текст**
```
if not exists(select top 1 null from sys.schemas where name = 'util')
begin
exec ('create schema util')
end
go
alter procedure util.InclusionBegin
as
begin
/*
Инструкция для использования:
1. Обработка процедуры данные которой необходимо использовать
1.1. В начало процедуры включить строки:
if object_id('tempdb..#ttInclusion', 'U') is null create table #ttInclusion(lvl int, i int)
exec util.InclusionBegin
1.1. Все выводящие select'ы процедуры переделать на создание временных таблиц начинающихся с #Output (Например into #Output, into #Output5, into #OutputMySelect)
1.2. В конец процедуры включить строку:
exec util.InclusionEnd --выводит все таблицы, начинающиеся с #Output, в порядке из создания после запуска util.InclusionBegin
2. В месте, где вызывается обработанная процедура, непосредственно до её запуска включить строки (иначе процедура будет просто выводить все #Output* таблицы):
if object_id('tempdb..#ttInclusionParameters', 'U') is null create table #ttInclusionParameters(lvl int, pr int)
exec util.InclusionRun('')
Дополнительно см. коментарии внутри util.InclusionRun
\*/
set nocount on
set ansi\_warnings off
declare @lvl int
if object\_id('tempdb..#ttInclusionParameters', 'U') is not null
begin
select @lvl = max(lvl)
from #ttInclusionParameters
--Добавляем null задание, для предотвращения запуска скрипта во вложенных процедурах с данным механизмом
if (@lvl is not null)
begin
insert #ttInclusionParameters(lvl, pr)
select @lvl+1 lvl, null pr
end
end
if object\_id('tempdb..#ttInclusion', 'U') is not null
begin
--запоминаем все уже существующие таблицы #Output, чтобы в util.InclusionEnd не выводить их
insert #ttInclusion(lvl, i)
select isnull(@lvl, 0), so.object\_id i
from tempdb.sys.objects so
where so.type = 'U'
and so.name like '#[^#]%'
and object\_id('tempdb..' + so.name, 'U') is not null
and not exists (select top 1 null from #ttInclusion where i = so.object\_id)
end
end
GO
go
alter procedure util.InclusionEnd
as
begin
/\*
Инструкция для использования:
1. Обработка процедуры данные которой необходимо использовать
1.1. В начало процедуры включить строки:
if object\_id('tempdb..#ttInclusion', 'U') is null create table #ttInclusion(lvl int, i int)
exec util.InclusionBegin
1.1. Все выводящие select'ы процедуры переделать на создание временных таблиц начинающихся с #Output (Например into #Output, into #Output5, into #OutputMySelect)
1.2. В конец процедуры включить строку:
exec util.InclusionEnd --выводит все таблицы, начинающиеся с #Output, в порядке из создания после запуска util.InclusionBegin
2. В месте, где вызывается обработанная процедура, непосредственно до её запуска включить строки (иначе процедура будет просто выводить все #Output\* таблицы):
if object\_id('tempdb..#ttInclusionParameters', 'U') is null create table #ttInclusionParameters(lvl int, pr int)
exec util.InclusionRun('')
Дополнительно см. коментарии внутри util.InclusionRun
\*/
set nocount on
set ansi\_warnings off
----------------------------------------------------------------------------------------------------
--считываем параметры
declare @lvl int
, @p0 varchar(max) --(@sql) sql скрипт который необходимо выполнить
, @p1 varchar(max) --(@notShowOutput) если равно '1' хотя бы у одного из существующих вложенности заданий, то НЕ выводим #Output, иначе селектим их
, @p2 varchar(max) --(@replaceableTableName) заменяемый префекс таблицы
if object\_id('tempdb..#ttInclusionParameters', 'U') is not null
begin
--считываем глобальные параметры
select @p1 = max(val)
from #ttInclusionParameters
where pr = 1
--находим уровень на котором наше задание (max(lvl) - это уровень с null который мы добавили в util.InclusionBegin)
select @lvl = max(lvl) - 1
from #ttInclusionParameters
if @lvl is not null
begin
--считываем
select @p0 = max(case when pr = 0 then val end)
, @p2 = max(case when pr = 2 then val end)
from #ttInclusionParameters
where lvl = @lvl
having max(pr) is not null
--удаляем задание на скрипт, а если его нет, то только null-задание
delete #ttInclusionParameters
where lvl >= @lvl and (lvl > @lvl or @p0 is not null)
end
end
----------------------------------------------------------------------------------------------------
--выбираем все созданные таблицы #Output
if object\_id('tempdb..#InclusionOutputs', 'U') is not null drop table #InclusionOutputs
create table #InclusionOutputs(i int, tableName varchar(max), num int)
if object\_id('tempdb..#ttInclusion', 'U') is not null
begin
insert #InclusionOutputs(i, tableName, num)
select so.object\_id i, left(so.name, charindex('\_', so.name)-1) tableName, row\_number() over (order by so.create\_date) num
from tempdb.sys.objects so
where so.type = 'U'
and so.name like '#[^#]%'
and object\_id('tempdb..' + so.name, 'U') is not null
and so.name like '#Output%'
and not exists (select top 1 null from #ttInclusion where i = so.object\_id and lvl <= isnull(@lvl, lvl))
--очищаем список созданных таблиц, которые принадлежат обрабатываемому уровню
delete #ttInclusion
where lvl <= @lvl
end
else
begin
insert #InclusionOutputs(i, tableName, num)
select so.object\_id i, left(so.name, charindex('\_', so.name)-1) tableName, row\_number() over (order by so.create\_date) num
from tempdb.sys.objects so
where so.type = 'U'
and so.name like '#[^#]%'
and object\_id('tempdb..' + so.name, 'U') is not null
and so.name like '#Output%'
end
----------------------------------------------------------------------------------------------------
--Выполнение заданий (если его не было - вывод всех #Output)
declare @srcsql varchar(max)
--Выполняем заданный скрипт в util.InclusionRun
if (@p0 is not null and @p0 <> '')
begin
--заменяем псевдонимы @replaceableTableName
if (@p2 is not null and @p2 <> '')
begin
select @p0 = replace(@p0, @p2 + cast(num as varchar(10)), replace(tableName, '#', '#'))
from #InclusionOutputs
order by num desc
select @p0 = replace(@p0, '', '')
end
--добавляем в скрипт
select @srcsql = isnull(@srcsql + ' ' + char(13), '')
+ @p0 + ' ' + char(13)
end
--Выводим созданные #Output таблицы
if (@p1 is null or @p1 <> '1') --если равно 1, то не выполняем!
begin
--отступ от прошлого скрипта
select @srcsql = isnull(@srcsql + ' ' + char(13), '')
--добавляем в скрипт
select @srcsql = isnull(@srcsql + ' ', '') +
'select \* from ' + tableName
from #InclusionOutputs
order by num asc
end
if (@srcsql is not null)
begin
exec (@srcsql)
end
end
go
alter procedure util.InclusionRun
@sql varchar(max), --sql скрипт который выполниться внутри вызываемой процедуры (содержащей util.InclusionEnd)
@notShowOutput bit, --если = 1, то блокировать вывод таблиц начинающихся с #Output
@replaceableTableName varchar(100) = '#Output' -- задать префикс в имени таблиц используемых в @sql, для замены его на соответствующую #Output\* таблицу в скрипте.
-- Например, если задать #InclusionOutput, и в процедуре созданы две таблицы #Output55 и #Output0A,
-- то в @sql можно обратиться к #Output55 как к #InclusionOutput1, а к #Output0A как к #InclusionOutput2
as
begin
set nocount on
set ansi\_warnings off
if object\_id('tempdb..#ttInclusionParameters', 'U') is null
begin
print 'Процедура util.InclusionRun не выполнена, т.к. для неё не созданна таблица #ttInclusionParameters! '
return
end
declare @lvl int
select @lvl = isnull(max(lvl), 0) + 1
from #ttInclusionParameters
insert #ttInclusionParameters(lvl, pr, val)
select @lvl, 0, @sql
union all
select @lvl, 1, '1' where @notShowOutput = 1
union all
select @lvl, 2, @replaceableTableName
end
```
#### Другие методы
Можно воспользоваться передачей параметра из функции (`OUTPUT`) и на основе его значения восстановить таблицу. Например, можно передать курсор или XML.
На эту тему существует [статья](http://technet.microsoft.com/ru-ru/library/ms188655.aspx).
Использовать курсор для этой задачи я не вижу смысла, только если изначально требуется именно курсор. А вот XML выглядит перспективным. [Здесь](http://habrahabr.ru/post/96145/) очень интересные результаты тестов на производительность.
Интересно услышать какие вы используете способы упрощения этой задачи :)
**UPD 31.03.2014:** Скорректировал пост по идеям из комментариев | https://habr.com/ru/post/217649/ | null | ru | null |
# Создание анализатора Roslyn на примере проверки инкапсуляции
Что такое Roslyn?
-----------------
Roslyn – это набор компиляторов с открытым исходным кодом и API для анализа кода для языков C# и VisualBasic .NET от Microsoft.
Анализатор Roslyn – мощный инструмент для анализа кода, нахождения ошибок и их исправления.
Синтаксическое дерево и семантическая модель
--------------------------------------------
Для анализа кода, нужно иметь представление о синтаксическом дереве и семантической модели, так как это два основных компонента для статического анализа.
Синтаксическое дерево — это элемент, который строится на основании исходного кода программы, и необходимый для анализа кода. В ходе анализа кода по нему происходит перемещение.
Каждый код обладает синтаксическим деревом. Для следующего объекта класса
```
class A
{
void Method()
{
}
}
```
синтаксическое дерево будет выглядеть так:

Объект типа SyntaxTree представляет собой синтаксическое дерево. В дереве можно выделить три основных элемента: SyntaxNodes, SyntaxTokens, SyntaxTrivia.
Syntaxnodes описывают синтаксические конструкции, а именно: объявления, операторы, выражения и т.п. В C# синтаксические конструкции представляют класс типа SyntaxNode.
Syntaxtokens описывает такие элементы, как: идентификаторы, ключевые слова, специальные символы. В C# является типом класса SyntaxToken.
Syntaxtrivia описывает элементы, которые не будут скомпилированы, а именно: пробелы, символы перевода строки, комментарии, директивы препроцессора. В C# определяется классом типа SyntaxTrivia.
Семантическая модель представляет информацию об объектах и об их типах. Благодаря этому инструменту можно проводить глубокий и сложный анализ. В C# определяется классом типа SemanticModel.
Создание анализатора
--------------------
Для создания статического анализатора требуется установить следующий компонент .NETCompilerPlatformSDK.
К основным функциям, входящим в состав любого анализатора, относятся:
1. Регистрация действий.
Действия представляют собой изменения кода, которые должны инициировать анализатор для проверки кода на наличие нарушений. Когда VisualStudio обнаруживает изменения кода, соответствующие зарегистрированному действию, она вызывает зарегистрированный метод анализатора.
2. Создание диагностики.
При обнаружении нарушения анализатор создает диагностический объект, используемый VisualStudio для уведомления пользователя о нарушении.
Существует несколько шагов для создания и проверки анализатора:
1. Создайте решение.
2. Зарегистрируйте имя и описание анализатора.
3. Предупреждения и рекомендации анализатора отчетов.
4. Выполните исправление кода, чтобы принять рекомендации.
5. Улучшение анализа с помощью модульных тестов.
Действия регистрируются в переопределении метода DiagnosticAnalyzer.Initialize (AnalysisContext), где AnalysisContext метод в котором фиксируется поиск анализируемого объекта.
Анализатор может предоставить одно или несколько исправлений кода. Исправление кода определяет изменения, которые обращаются к сообщенной проблеме. Пользователь сам выбирает изменения из пользовательского интерфейса (лампочки в редакторе), а VisualStudio изменяет код. В методе RegisterCodeFixesAsync описывается изменение кода.
Пример
------
Для примера напишем анализатор публичных полей. Это приложение должно предупредить пользователя о публичных полях и предоставить возможность инкапсулировать поле свойством.
Вот что должно получиться:

### Разберем, что для этого нужно сделать
Для начала следует создать решение.

После создания решение видим, что уже есть три проекта.

Нам потребуется два класса:
1) Класс AnalyzerPublicFieldsAnalyzer, в котором указываем критерии анализа кода для нахождения публичных полей и описание предупреждения для пользователя.
Укажем следующие свойства:
```
public const string DiagnosticId = "PublicField";
private const string Title = "Filed is public";
private const string MessageFormat = "Field '{0}' is public";
private const string Category = "Syntax";
private static DiagnosticDescriptor Rule = new DiagnosticDescriptor(DiagnosticId, Title, MessageFormat, Category, DiagnosticSeverity.Warning, isEnabledByDefault: true);
public override ImmutableArray SupportedDiagnostics
{
get
{
return ImmutableArray.Create(Rule);
}
}
```
После этого укажем, по каким критериям будет происходить анализ публичных полей.
```
private static void AnalyzeSymbol(SymbolAnalysisContext context)
{
var fieldSymbol = context.Symbol as IFieldSymbol;
if (fieldSymbol != null && fieldSymbol.DeclaredAccessibility == Accessibility.Public
&& !fieldSymbol.IsConst && !fieldSymbol.IsAbstract && !fieldSymbol.IsStatic
&& !fieldSymbol.IsVirtual && !fieldSymbol.IsOverride && !fieldSymbol.IsReadOnly
&& !fieldSymbol.IsSealed && !fieldSymbol.IsExtern)
{
var diagnostic = Diagnostic.Create(Rule, fieldSymbol.Locations[0], fieldSymbol.Name);
context.ReportDiagnostic(diagnostic);
}
}
```
Мы получаем поле объекта типа IFieldSymbol, который обладает свойствами для определения модификаторов поля, его имени и локации. Что нам и нужно для диагностики.
Остается инициализировать анализатор, указав в переопределённом методе
```
public override void Initialize(AnalysisContext context)
{
context.RegisterSymbolAction(AnalyzeSymbol, SymbolKind.Field);
}
```
2) Теперь перейдем к изменению предлагаемого кода пользователем на основе анализа кода. Это происходит в классе AnalyzerPublicFieldsCodeFixProvider.
Для этого указываем следующее:
```
private const string title = "Encapsulate field";
public sealed override ImmutableArray FixableDiagnosticIds
{
get { return ImmutableArray.Create(AnalyzerPublicFieldsAnalyzer.DiagnosticId); }
}
public sealed override FixAllProvider GetFixAllProvider()
{
return WellKnownFixAllProviders.BatchFixer;
}
public sealed override async Task RegisterCodeFixesAsync(CodeFixContext context)
{
var root = await context.Document.GetSyntaxRootAsync(context.CancellationToken)
.ConfigureAwait(false);
var diagnostic = context.Diagnostics.First();
var diagnosticSpan = diagnostic.Location.SourceSpan;
var initialToken = root.FindToken(diagnosticSpan.Start);
context.RegisterCodeFix(
CodeAction.Create(title,
c => EncapsulateFieldAsync(context.Document, initialToken, c),
AnalyzerPublicFieldsAnalyzer.DiagnosticId),
diagnostic);
}
```
И определяем возможность инкапсулировать поле свойством в методе EncapsulateFieldAsync.
```
private async Task EncapsulateFieldAsync(Document document, SyntaxToken declaration, CancellationToken cancellationToken)
{
var field = FindAncestorOfType(declaration.Parent);
var fieldType = field.Declaration.Type;
ChangeNameFieldAndNameProperty(declaration.ValueText, out string fieldName, out string propertyName);
var fieldDeclaration = CreateFieldDecaration(fieldName, fieldType);
var propertyDeclaration = CreatePropertyDecaration(fieldName, propertyName, fieldType);
var root = await document.GetSyntaxRootAsync();
var newRoot = root.ReplaceNode(field, new List { fieldDeclaration, propertyDeclaration });
var newDocument = document.WithSyntaxRoot(newRoot);
return newDocument;
}
```
Для этого необходимо создать приватное поле.
```
private FieldDeclarationSyntax CreateFieldDecaration(string fieldName, TypeSyntax fieldType)
{
var variableDeclarationField = SyntaxFactory.VariableDeclaration(fieldType)
.AddVariables(SyntaxFactory.VariableDeclarator(fieldName));
return SyntaxFactory.FieldDeclaration(variableDeclarationField)
.AddModifiers(SyntaxFactory.Token(SyntaxKind.PrivateKeyword));
}
```
Затем создать публичное свойство, возвращающее и принимающее это приватное поле.
```
private PropertyDeclarationSyntax CreatePropertyDecaration(string fieldName, string propertyName, TypeSyntax propertyType)
{
var syntaxGet = SyntaxFactory.ParseStatement($"return {fieldName};");
var syntaxSet = SyntaxFactory.ParseStatement($"{fieldName} = value;");
return SyntaxFactory.PropertyDeclaration(propertyType, propertyName)
.AddModifiers(SyntaxFactory.Token(SyntaxKind.PublicKeyword))
.AddAccessorListAccessors(
SyntaxFactory.AccessorDeclaration(SyntaxKind.GetAccessorDeclaration).WithBody(SyntaxFactory.Block(syntaxGet)),
SyntaxFactory.AccessorDeclaration(SyntaxKind.SetAccessorDeclaration).WithBody(SyntaxFactory.Block(syntaxSet)));
}
```
При этом сохраняем тип и имя исходного поля. Имя поля строится следующим образом «\_name», а имя свойства «Name».
Ссылки
------
1. [Исходники на GitHub](https://github.com/Nemo-Illusionist/Roslyn-Encapsulation-check)
2. [The .NET Compiler Platform SDK](https://docs.microsoft.com/en-us/dotnet/csharp/roslyn-sdk/) | https://habr.com/ru/post/455844/ | null | ru | null |
# CI/CD для AWS Lambda через GitHub Actions
AWS Lambda это бессерверная вычислительная платформа от Amazon, часть Amazon Web Services (AWS). Суть такая: сервис выполняет код в ответ на события, при этом полностью управляет масштабированием ресурсов. Событиями могут быть запросы, cron-расписание и многое другое. С помощью AWS Lambda делают, наверное, все, что должно крутиться в облаке и что-то делать. По возрастанию сложности:
* [Telegram](https://habr.com/ru/post/555518/) и [Slack](https://habr.com/ru/company/first/blog/667204/) ботов
* [Парсеры](https://github.com/bdrgn/hardwax2vk)
* ETL-процессы
* [Модели машинного обучения](https://towardsdatascience.com/how-to-deploy-a-machine-learning-model-on-aws-lambda-24c36dcaed20)
* И даже тяжелые [микросервисы](https://docs.aws.amazon.com/whitepapers/latest/serverless-multi-tier-architectures-api-gateway-lambda/microservices-with-lambda.html)
Для начинающих разработчиков или просто желающих попробовать бессерверный подход приятной неожиданностью [станет](https://aws.amazon.com/ru/free/?all-free-tier.sort-by=item.additionalFields.SortRank&all-free-tier.sort-order=asc&awsf.Free%20Tier%20Types=*all&awsf.Free%20Tier%20Categories=*all) довольно высокий уровень бесплатного доступа, который не ограничивается по времени. Каждый месяц 1 миллион запросов в AWS Lambda доступно бесплатно. Если вспомнить, что AWS также предоставляет до 25 ГБ бесплатного хранения данных в супер быстрой NoSQL базе данных [DynamoDB](https://aws.amazon.com/ru/dynamodb/), то предложение становится супер привлекательным для pet project’а или экспериментов.
Сегодня я расскажу, как без лишних усилий настроить CI/CD pipeline из GitHub в AWS Lambda с помощью GitHub Actions. Логика такая — когда мы пушим изменения в master-ветку репозитория на GitHub они прорастают в AWS и обновляет продовую версию функции.
1. Регистрация на AWS.
Очевидно, первое, что необходимо сделать это зарегистрировать аккаунт AWS. [Здесь](https://habr.com/ru/post/448528/) подробно описано, как это сделать и ничего при этом не заплатить.
2. Создание функции.
Сделали аккаунт AWS, переходим к созданию функции.
Набираем в строке поиска ‘lambda’ и переходим в соответствующий раздел:
Нажимаем ‘Create function’.
Function name = ‘habr\_function’
Runtime = ‘Python 3.9’ или более поздняя версия.
Готово, функция создана. На экране вы сможете видеть дефолтный код для функции. Его можно поменять прямо в браузере, но это очень неудобно. Гораздо лучше, чтобы этот код обновлялся автоматически при коммите в репозиторий. Это мы и сделаем.
3. Создание репозитория.
Создадим для этих нужд репозиторий на [github.com](http://github.com):
Чтобы протестировать GitHub Actions создадим файл с помощью браузера. В дальнейшем вы сможете использовать любую удобную вам IDE, чтобы коммитить файлы в репозиторий.
Создадим новый файл `lambda_function.py`, так как именно файл с таким названием по умолчанию выполняется в AWS Lambda:
Немного модифицируем код из дефолтного значения AWS Lambda, чтобы понять, когда он обновится:
import json
`def lambda_handler(event, context):`
`# comment passed from GitHub Actions`
`return {`
`'statusCode': 200,`
`'body': json.dumps('Hello from GitHub Actions!')`
`}`
4. Получаем ключи AWS.
Чтобы обновлять код в AWS нам нужно дать GitHub доступ к нашему аккаунту. Для этого используются специальные ключи. Получим ключи AWS. Для этого перейдем в `Security credentials` с любой страницы AWS, открыв боковое меню справа:
Откроем раздел `Access keys (access key ID and secret access key)` и нажмем `Create New Access Key`:
При нажатии на кнопку `Download Key File` мы получаем .csv-файл с ключами. Его можно открыть с помощью любого текстового редактора или Microsoft Excel.
В файле будут два ключа `Access key ID` и `Secret access key`. Их нужно сохранить, они понадобятся нам в следующем этапе. Кроме того, нужно помнить, что ключи дают неограниченный доступ к части функционала вашего аккаунта AWS, в т. ч. к платным функциям. По этой причине их не стоит разглашать. Также не нужно хранить ключи в репозиториях на GitHub. (это распространенная ошибка)
5. Задаем 'секреты' в GitHub.
Возвращаемся на GitHub. Переходим в раздел `Settings` нашего репозитория. Далее `Secrets` -> `Actions` -> `New repository secret`. Этот раздел позволяет создавать 'секреты' в репозиториях GitHub. Именно здесь хранить ключи AWS наиболее безопасно. Отсюда ключи, токены или пароли могут быть безопасно использованы в процессах CI/CD и прочем.
Создаем новый `секрет` с названием `AWS_ACCESS_KEY_ID`. Значение берем из поля `Access key ID` из полученного ранее .csv-файла с ключами:
Аналогично создаем `секрет` с именем `AWS_SECRET_ACCESS_KEY` и заполняем значение ключем из поля `Secret access key` из файла:
6. Создаем конфиг процесса.
Переходим в раздел `Actions` и нажимаем `set up a workflow yourself`:
Дальше откроется редактор конфига процесса GitHub Actions. Необходимо заполнить его с помощью кода ниже:
`name: deploy-py-lambda`
`on:`
`push:`
`branches:`
`- main`
`jobs:`
`build:`
`runs-on: ubuntu-latest`
`steps:`
`- uses: actions/checkout@master`
`- name: Deploy code to Lambda`
`uses: mariamrf/[email protected]`
`with:`
`lambda_function_name: 'habr_example_function'`
`env:`
`AWS_ACCESS_KEY_ID: ${{ secrets.AWS_ACCESS_KEY_ID }}`
`AWS_SECRET_ACCESS_KEY: ${{ secrets.AWS_SECRET_ACCESS_KEY }}`
`AWS_DEFAULT_REGION: 'us-east-2'`
В коде процесса мы указываем, что хотим выполнять процесс как только происходит push в main ветку нашего репозитория. Также мы указываем имя нашей фукнции `habr_example_function`, регион AWS `us-east-2` и передаем ключи из 'секретов' GitHub Actions с помощью конструкции вида `${{ secrets.AWS_ACCESS_KEY_ID }}`.
В GitHub предусмотрен механизм для переиспользования действий, поэтому в конфиге мы указываем, что берем код из [этого](https://github.com/mariamrf/py-lambda-action) репозитория. В этом репозитории добрый человек за нас прописал последовательность Shell-скриптов, которые нужно выполнить, чтобы обновить код AWS Lambda из командной строки.
Когда все готово нажимаем `Start commit` -> `Commit new file`:
Как только создан новый файл процесс начинает работу, поскольку создание файла это тоже push-реквест. Чтобы наблюдать за ходом процесса переходим в раздел `Actions`. Перейдем внутрь процесса, нажав на `Update lambda_function.py`:
Можем видеть как на серверах GitHub создается Unix-окружение, устанавливаются зависимости, а затем запускаются Shell-скрипты с нашими ключами и от нашего лица обновляют код лямбда-функции:
Когда все будет готово экран будет выглядеть следующим образом:
Переходим в AWS Lambda, видим изменившийся код и наш комментарий `comment passed from GitHub Actions`.
Готово! Теперь все изменения из main-ветки репозитория попадают напрямую в AWS Lambda. Можно забыть про браузер и уходить в любимую IDE.
 | https://habr.com/ru/post/703416/ | null | ru | null |
# Память: LOH и Chunked Lists
Управляемая память в .Net поделена на стек и несколько хипов. Самые важные из хипов – это обычная (эфемерная) куча и LOH. Эфемерная куча – это то место, где живут все обычные объекты. LOH – это то место где живут большие (больше 85000 байт) объекты.
LOH обладает некоторыми особенностями:
* Объекты в LOH никогда не перемещаются
* LOH только растет и никогда не уменьшается (т.е. если объект собран сборщиком мусора, размер LOH все равно остается неизменным)
* Хип LOH освобождается только тогда, когда LOH **полностью** пуст
Из этих двух особенностей LOH происходят два важных следствия, про которые часто забывают:
* Память в LOH может оказаться фрагментированной. Т.е. происходит то, с чем так боролись в unmanaged мире: в какой-то момент у вас может быть 10Mb свободной памяти, но вы не сможете выделить память под объект размером 1Mb
* Если вы однажды выделили память под большой объект, а потом используете только маленькие, то вы фактически лишаете себя большого куска памяти. При чем, если у вас в LOH был список или хэш-таблица размером N, а вы добавили в него один элемент, то список реаллоцируется и растет в два раза, сответственно размер LOH составит как минимум 3\*N (N – исходные данные, 2N – копия данных и резерв под новый размер). Следующий рост потребует в LOH непрерывный кусок памяти размером в 4\*N, а так как такого куска в LOH у нас нет (есть только N), его придется позаимствовать из адресного пространства процесса. В итоге размер LOH вырастет до 7\*N, и так далее.
Если вспомнить, что LOH аллоцируется кусками по 16Mb, то все происходящее покажется еще более разрушительными. С первым следствием можно бороться аккуратно переиспользуя объекты. Со вторым — не используя большие объекты. Получается как-то не очень, особенно если с большими коллекциями работать все-таки хочется. Посмотрим, что как можно решить эту проблему.
#### Реализация контейнеров на chunk-ах
Можно попытаться реализовать свои контейнеры на chunk-ак (на кусках, т.е. выделять память под массив не целиком, а небольшими частями, которые не попадут в LOH). При чем непосредственно на chunk-ах надо делать надо реализовать только `IList`, все остальные контейнеры будут использовать `IList` как хранилище для своих данных.
Начнем реализовывать такой список:
> `public class ChunkList : IList
>
> {
>
> private readonly int \_ChunkSize = 4096;
>
>
>
> private int \_Count;
>
> private T[][] \_Chunks;
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
В `_Chunks` будем хранить `N` страниц по `_ChunkSize` объектов в каждой, динамически удаляя или добавляя новые страницы. Собственно, саму реализацию я оставлю желающим в качестве домашнего задания. Она не так и сложна, надо только аккуратно написать все операции.
Но уже в том коде, который я привел, есть ошибка. Ошибка в значении по-умолчанию для `_ChunkSize`. Дело в том, что для reference-типов это значение адекватно, а для структур – нет. Ведь структура будет занимать в массиве `_Chunks` столько памяти, сколько ее данные. Значит надо как-то узнать размер данных типа `T`, а количество chunks посчитать как `85000/sizeof(T)`. Но не смотря на кажущуюся простоту, эта задача легко не решается.
Если обратиться к статье [Computing the Size of a Structure](http://www.informit.com/guides/content.aspx?g=dotnet&seqNum=698), то можно найти такое решение задачи поиска размера:
> `public static int GetSize()
>
> {
>
> Type tt = typeof(T);
>
> int size;
>
> if (tt.IsValueType)
>
> {
>
> if (tt.IsGenericType)
>
> {
>
> var t = default(T);
>
> size = Marshal.SizeOf(t);
>
> }
>
> else
>
> {
>
> size = Marshal.SizeOf(tt);
>
> }
>
> }
>
> else
>
> {
>
> size = IntPtr.Size;
>
> }
>
> return size;
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Таким образом можно дополнить наш `ChunkList`:
> `public class ChunkList : IList
>
> {
>
> static ChunkList()
>
> {
>
> \_ChunkSize = 80000 / GetSize();
>
> }
>
>
>
> private static readonly int \_ChunkSize = 4096;
>
>
>
> private int \_Count;
>
> private T[][] \_Chunks;
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Все хорошо, но только в каких-то случаях (достаточно редких) этот код будет создавать экземпляр структуры. Если это неважно, то можно так и оставить. Если важно, то придется создать конструктор, в который каждый пользователь списка сможет самостоятельно передавать размер объекта или желаемый размер chunk-ов.
А вы как боретесь с большими объектами? | https://habr.com/ru/post/83929/ | null | ru | null |
# BpfTrace — наконец, полноценная замена Dtrace в Linux
Бывает, что системы глючат, тормозят, ломаются. Чем больше система, тем сложнее найти причину. Чтобы узнать, почему что-то работает не так, как ожидалось, исправить или предотвратить будущие проблемы, нужно посмотреть внутрь. Для этого системы должны обладать свойством **наблюдаемости**, которая достигается инструментацией в широком смысле этого слова.
На [HighLoad++](https://www.highload.ru/) Пётр Зайцев (Percona) сделал обзор доступной инфраструктуры для трейсинга в Linux и рассказал о bpfTrace, который (как видно из названия) дает много преимуществ. Мы сделали текстовую версию доклада, чтобы вам было удобно пересмотреть детали и дополнительные материалы всегда были под рукой.
Инструментацию можно разделить на два больших блока:
* **Статическая**, когда сбор информации зашит в код: запись логов, счетчиков, времени и т.д.
* **Динамическая**, когда код не инструментируется сам по себе, но есть возможность сделать это, когда понадобится.
Другой вариант классификации основан на подходе к регистрации данных:
* **Tracing** — события генерируются, если сработал определенный код.
* **Sampling** — статус системы проверяется, например, 100 раз в секунду и по нему определяется, что в ней происходит.
Статическая инструментация существует многие годы и есть практически во всем. В Linux её используют многие стандартные инструменты типа Vmstat или top. Они читают данные из procfs, куда, грубо говоря, записываются разные таймеры и счётчики из кода ядра.
Но слишком много таких счётчиков не вставишь, всё на свете ими не покроешь. Поэтому бывает полезна динамическая инструментация, которая позволяет смотреть именно то, что нужно. Например, если есть какие-то проблемы с TCP/IP стеком, то можно идти очень глубоко и инструментировать конкретные детали.

DTrace
------
DTrace — один из первых известных фреймворков для динамического трейсинга, созданный компанией Sun Microsystems. Его начали делать еще в 2001 году, и впервые он вышел в Solaris 10 в 2005 году. Подход оказался весьма популярным и в дальнейшем вошел во многие другие дистрибутивы.
Интересно, что DTrace позволяет инструментировать как kernel space, так и user space. Можно ставить трейсы на любые вызовы функции и специально инструментировать программы: ввести специальные DTrace tracepoints, которые для пользователей могут быть более понятны, чем служебные названия функций.
Особенно важно это было для Solaris, потому что это не открытая операционная система. Не было возможности просто посмотреть в код и понять, что tracepoint нужно поставить на такую-то функцию, как сейчас можно сделать в новом открытом программном обеспечении Linux.
Одна из уникальных, особенно на тот момент, особенностей DTrace в том, что **пока трейсинг не включен, он ничего не стоит**. Он работает таким образом, что просто заменяет некоторые CPU-инструкции на вызов DTrace, который при возврате эти инструкции выполняет.
В DTrace инструментация записывается на специальном языке D, похожим на C и Awk.
В дальнейшем DTrace появился практически везде, кроме Linux: в MacOS в 2007, во FreeBSD в 2008, в NetBSD в 2010. Oracle в 2011 включил DTrace в Oracle Unbreakable Linux. Но Oracle Linux используют мало людей, а в основной Linux DTrace так и не вошел.
Интересно, что в 2017 году Oracle наконец лицензировал DTrace под GPLv2, что в принципе сделало возможным включение его в mainline Linux без лицензионных сложностей, но было уже слишком поздно. На тот момент в Linux был хороший BPF, который в основном и использовался для стандартизации.
DTrace даже собираются включить в Windows, сейчас он доступен в некоторых тестовых версиях.
Трейсинг в Linux
----------------
Что же есть в Linux вместо DTrace? На самом деле в Linux в лучшем (или худшем) проявлении духа open source есть много всего, куча разных tracing frameworks накопилась за это время. Поэтому разобраться, что там к чему, не так просто.
Если вы хотите познакомиться с этим многообразием и вам интересна история, посмотрите [статью](https://jvns.ca/blog/2017/07/05/linux-tracing-systems/) с картинками и подробным описанием подходов для трейсинга в Linux.
Если говорить про инфраструктуру для трейсинга в Linux в общем, можно выделить три ее уровня:
1. **Интерфейс для инструментации ядра:** Kprobe, Uprobe, Dtrace probe и т.д.
2. **«Программа», работающая с этим интерфейсом.** События, создаваемые probe, могут происходить миллионы раз в секунду, записывать их все в файл или просто гнать в user space обычно слишком дорого. Для обработки таких событий есть разные подходы: буферизировать в ядре, чтобы потом читать из user space, использовать Kernel Module, чтобы их как-то обрабатывать, и eBPF.
3. **Фронтенд-инструменты**, чтобы работать с данными, полученными на предыдущих уровнях: Perf, SystemTap, SysDig, BCC и т.д. bpfTtrace на самом деле один из так фреймворков, если разобраться, что к чему.
eBPF — новый стандарт Linux
---------------------------
Со всеми этими фреймворками в последние годы eBPF становится стандартом в Linux. Это более продвинутый, весьма гибкий и эффективный инструмент, который позволяет практически всё.
Что же такое eBPF и откуда он взялся? На самом деле, eBPF — это Extended Berkeley Packet Filter, а BPF был разработан в 1992 году как виртуальная машина для эффективной фильтрации пакетов файрволлом. Никакого отношения к мониторингу, наблюдаемости, трейсингу он изначально не имел.
В более современных версиях eBPF был расширен (отсюда слово extended), как общий **фреймворк для обработки событий**. Текущие версии интегрированы с JIT-компилятором для большей эффективности.
**Отличия eBPF от классического BPF:**
* добавлены регистры;
* появился стек;
* есть дополнительные структуры данных (maps).
Сейчас люди чаще всего забывают, что был старый BPF, и называют eBPF просто BPF. В большинстве современных выражений eBPF и BPF — это одно и то же. Поэтому же и инструмент называется bpfTrace, а не eBpfTrace.
eBPF включен в mainline Linux начиная с 2014 года и постепенно входит в многий инструментарий около Linux, в том числе Perf, SystemTap, SysDig. Происходит стандартизация.
Интересно, что по-прежнему идет разработка. Современные ядра поддерживают eBPF все лучше и лучше.

Посмотреть, что в каких современных версиях ядра появилось, можно [здесь](https://github.com/iovisor/BCC/blob/master/docs/kernel-versions.md).
### Программы eBPF
Итак, что такое eBPF и чем он интересен?
**eBPF — это программа в своем специальном байт-коде**, которая включается непосредственно в ядро и выполняет обработку трейс-эвентов. Причем то, что она сделана в специальном байт-коде, позволяет ядру провести определенную верификацию, что код достаточно безопасный. Например, проверить, что в нём не используются циклы, потому что цикл в critical-секции в ядре может повесить всю систему.
Но полностью обезопаситься это не позволяет. Например, если написать очень сложную eBPF-программу, всунуть ее в эвент в ядре, который происходит 10 млн раз в секунду, то все может очень сильно затормозиться. Но при этом eBPF куда более безопасен, чем старый подход, когда просто какие-то Kernel Modules вставлялись через insmod, и в этих модулях могло быть все что угодно. Если кто-то допустил ошибку, или просто из-за бинарной несовместимости все ядро могло упасть.
eBPF-код можно скомпилировать LLVM Clang, то есть по большому счету использовать подмножество C для создания eBPF-программ, что, конечно, достаточно сложно. И важно, что компиляция зависит от ядра: используются хэдеры, чтобы понимать, какие структуры и для чего используются и т.д. Это не очень удобно в том плане, что всегда поставляются либо какие-то модули, связанные с конкретным ядром, либо нужно перекомпилировать.
На схеме представлено, как работает eBPF.
<http://www.brendangregg.com/ebpf.html>
Пользователь создает eBPF-программу. Дальше ядро со своей стороны ее проверяет и загружает. После этого eBPF может подключиться к разным инструментам для трейсов, обрабатывать информацию, сохранять ее в maps (структуру данных для временного хранения). Потом user program может читать статистику, получать perf-эвенты и т.д.
Здесь показано, какие функции eBPF в каких версиях ядрах Linux есть.
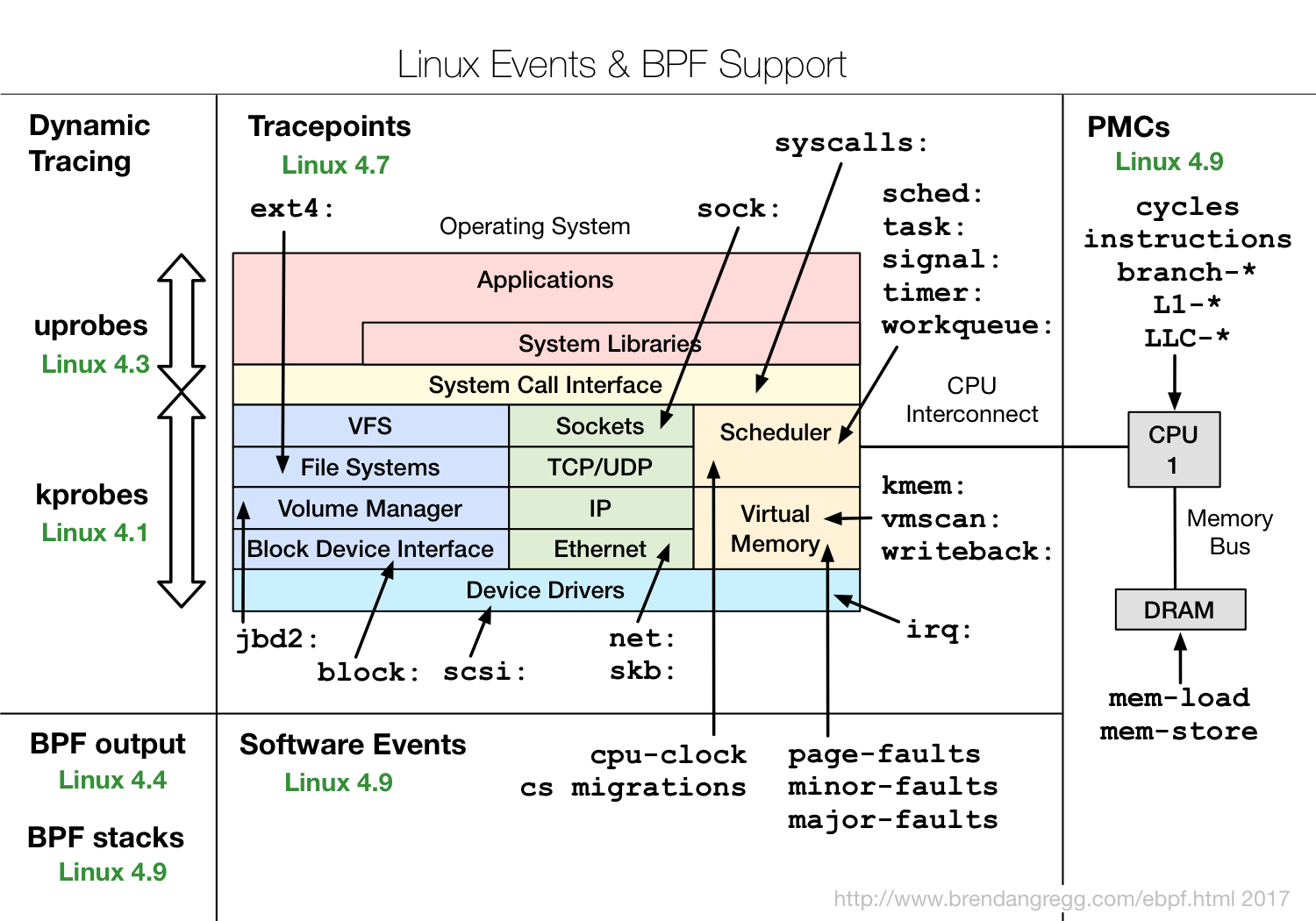
Видно, что покрываются практически все подсистемы ядра Linux, плюс есть хорошая интеграция с hardware-данными, у eBPF есть доступ ко всяким cache miss или branch miss prediction и т.д.
Если вам интересен eBPF, обратите внимание на проект [IO Visor](https://github.com/iovisor), в нём собрано большинство инструментов. Компания IO Visor занимается их разработкой, у них вы найдете последние версии и очень хорошую документацию. В дистрибутивах Linux появляется все больше и больше eBPF-инструментов, поэтому я бы рекомендовал всегда использовать последние доступные версии.
### Производительность eBPF
По производительности eBPF достаточно эффективный. Чтобы понять, насколько и есть ли overhead, можно добавить probe, который дергается несколько раз в секунду, и проверить, сколько требуется времени на его выполнение.

Ребята из Cloudflare сделали [бенчмарк](https://github.com/cloudflare/ebpf_exporter/tree/master/benchmark). Простой eBPF probe занимал у них около 100 нс, более сложный — 300 нс. Это означает, что даже сложный probe может вызываться на одном ядре около 3 млн раз в секунду. Если probe дергается 100 тысяч или миллион раз в секунду на многоядерном процессоре, то это не слишком скажется на производительности.
Фронтенд для eBPF
-----------------
Если вы интересуетесь eBPF и темой Observability вообще, то наверняка слышали о Брендане Грегге (Brendan Gregg). Он много об этом [пишет](http://www.brendangregg.com/ebpf.html) и рассказывает и сделал такую красивую картинку, на которой представлены инструменты для eBPF.

Здесь видно, что, например, можно использовать Raw BPF — просто писать байт-код — это даст полный набор возможностей, но работать с этим будет очень тяжело. Raw BPF это примерно как писать веб-приложение на ассемблере — в принципе можно, но без необходимости делать этого не стоит.
Интересно, что bpfTrace, с одной стороны, по возможностям позволяет получить практически всё, что и BCC, и сырой BPF, но при этом значительно проще в использовании.
На мой взгляд, наиболее полезны два инструмента:
* **BCC.** Несмотря на то, что по схеме Грегга BCC сложный, он включает в себя [множество готовых функций](https://github.com/iovisor/bcc#tools), которые можно просто запустить из командной строки.
* **BpfTrace**. Позволяет достаточно просто писать свой инструментарий или же использовать готовые решения.
Насколько проще писать на bpfTrace можно представить, если посмотреть на код одного и того же инструмента в двух вариантах.

DTrace vs bpfTrace
------------------
В общем и целом DTrace и bpfTrace используется для одного и того же.
<http://www.brendangregg.com/blog/2018-10-08/dtrace-for-linux-2018.html>
Разница в том, что в BPF-экосистеме есть еще и BCC, который можно использовать для сложных инструментов. В DTrace эквивалента BCC нет, поэтому, чтобы делать сложный инструментарий, обычно используют связку Shell + DTrace.
Когда создавали bpfTrace, не было задачи полностью эмулировать DTrace. То есть нельзя взять DTrace-скрипт и запустить его на bpfTrace. Но в этом и нет особого смысла, потому что в инструментарии нижнего уровня логика достаточно простая. Обычно важнее понять, к каким tracepoints нужно подсоединиться, а названия системных вызовов и то, что они непосредственно делают на низком уровне, отличаются в Linux, Solaris, FreeBSD. Именно в этом возникает разница.
При этом bpfTrace сделан через 15 лет после DTrace. В нём есть некоторые дополнительные возможности, которых в DTrace нет. Например, он может делать стек-трейсы.
Но, конечно, многое унаследовано от DTrace. Например, **названия функций и синтаксис похожи**, хотя не полностью эквивалентны.
Скрипты DTrace и bpfTrace близки по объему кода и похожи по сложности и возможностям языка.
bpfTrace
--------
Посмотрим подробнее, что есть в bpfTrace, как его можно использовать и что для этого нужно.
[Требования к Linux](https://tracingsummit.org/w/images/8/82/Tracingsummit2018-bpftrace-robertson.pdf) для использования bpfTrace:

Чтобы использовать все фичи, нужна версия, как минимум, 4.9. BpfTrace позволяет делать очень много разных probes, начиная с uprobe для инструментирования вызова функции в user-приложении, kernel-probes и т.д.
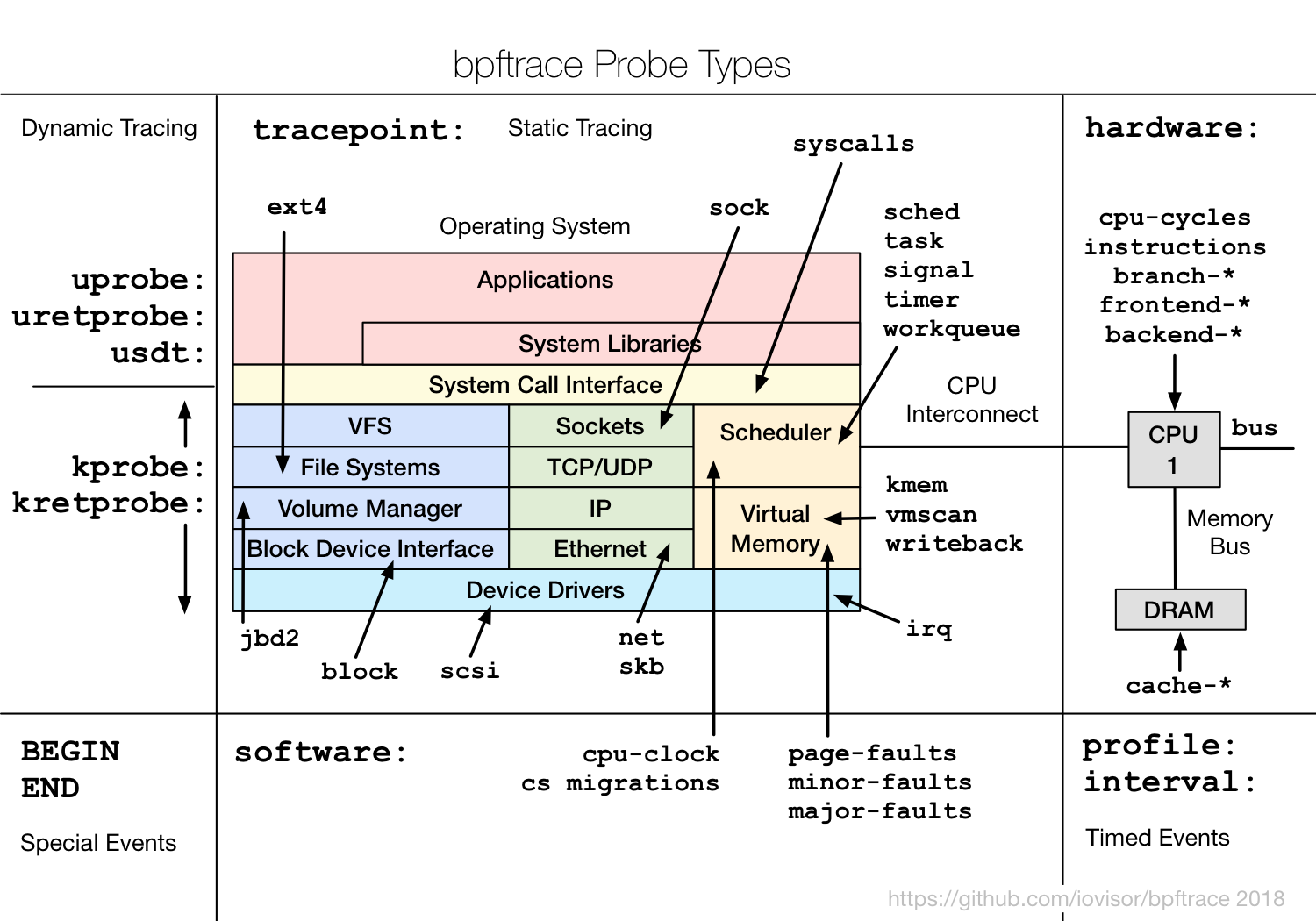
Интересно, что для пользовательской функции uprobe есть эквивалент uretprobe. Для kernel то же самое — есть kprobe и kretprobe. Это означает, что на самом деле в трейсинг-фреймворке можно генерировать события по вызову функции и по завершению этой функции — это часто используется для тайминга. Или можно анализировать значения, которые функция вернула, и группировать их по параметрам, с которыми функция была вызвана. Если ловить и вызов функции, и возврат из нее, можно делать много классных вещей.
Внутри bpfTrace работает так: пишем bpf-программу, которая парсится, конвертируется в C, потом обрабатывается через Clang, который генерирует bpf-байт-код, после этого программа загружается.
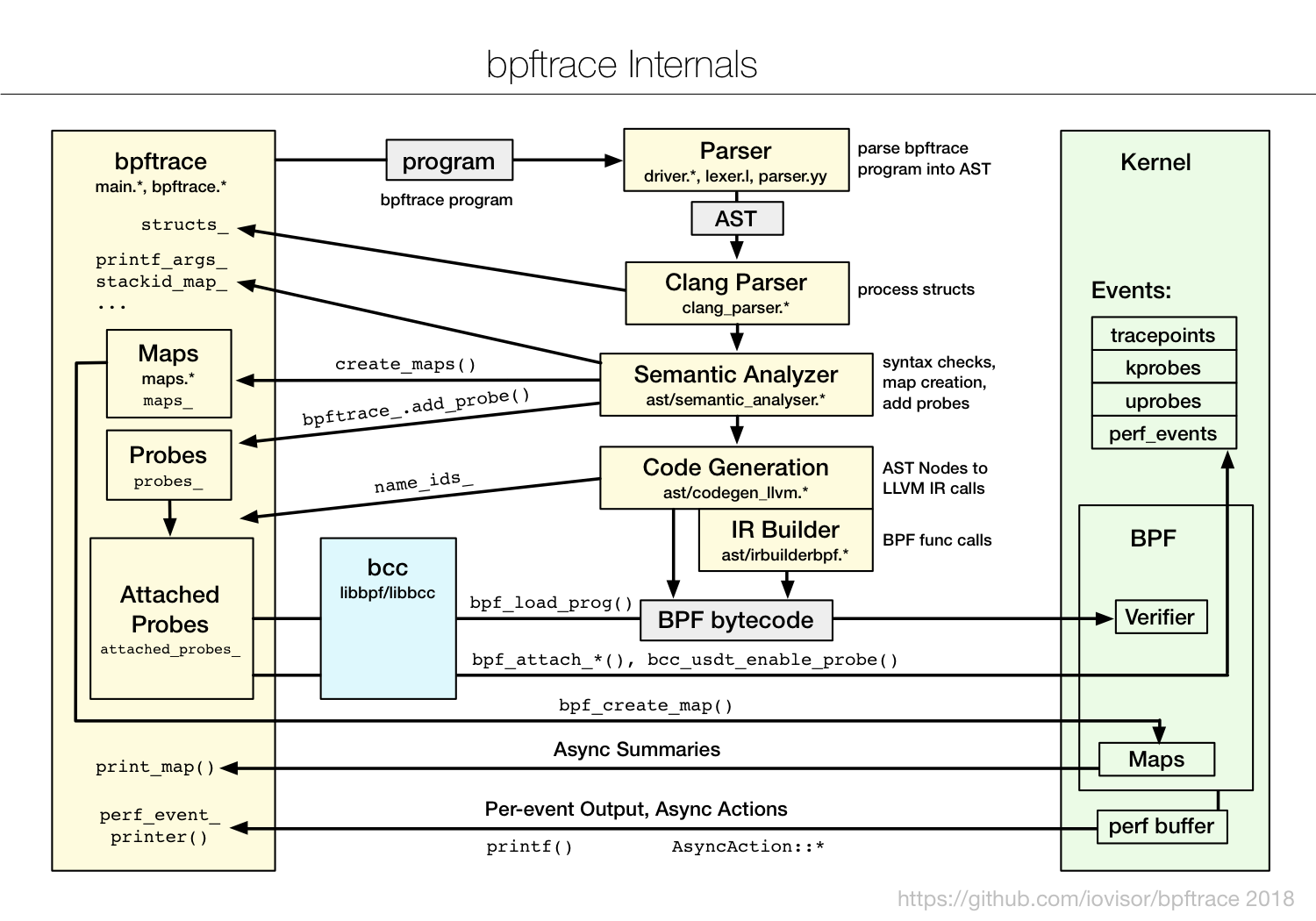
Процесс достаточно тяжелый, поэтому есть ограничения. На мощных серверах bpfTrace работает хорошо. Но тащить Clang на маленький embedded-девайс, чтобы разобраться, что там происходит, не лучшая идея. Для этого подойдет [Ply](https://github.com/iovisor/ply). У него, конечно, нет всех возможностей bpfTrace, но он генерирует байт-код напрямую.
### Поддержка в Linux
Стабильная версия bpfTrace вышла около года назад, поэтому в старых дистрибутивах Linux его нет. Лучше всего брать пакеты или компилировать последнюю версию, которую распространяет IO Visor.
Интересно, что в последнем Ubuntu LTS 18.04 нет bpfTrace, но его можно поставить с помощью snap-пакета. С одной стороны это удобно, но с другой стороны из-за того, как сделаны и изолируются snap-пакеты, будут работать не все функции. Для kernel-трейсинга пакет со snap работает хорошо, для user-трейсинга — может работать неправильно.

### Пример трейсинга процесса
Рассмотрим простейший пример, который позволяет получить статистику IO-запросов:
```
bpftrace -e 'kprobe:vfs_read { @start[tid] = nsecs; }
kretprobe:vfs_read /@start[tid]/ { @ns[comm] = hist(nsecs - @start[tid]); delete(@start[tid]); }'
```
Здесь мы подключаемся к функции `vfs_read`, причем как kretprobe, так и kprobe. Дальше для каждого thread ID (tid), то есть для каждого запроса отслеживаем начало и окончание его выполнения. Данные можно сгруппировать не только по совокупности всей системы, но и по разным процессам. Ниже вывод по IO для MySQL.
Видно классическое бимодальное распределение ввода/вывода. Большое число быстрых запросов — это данные, которые читаются из кэша. Второй пик — чтение данных с диска, где latency значительно выше.
Можно сохранить это как скрипт (обычно используется bt-расширение), написать комментарии, отформатировать и просто дальше использовать `#bpftrace read.bt`.
```
// read.bt file
tracepoint:syscalls:sys_enter_read
{
@start[tid] = nsecs;
}
tracepoint:syscalls:sys_exit_read / @start[tid]/
{
@times = hist(nsecs - @start[tid]);
delete(@start[tid]);
}
```
Общий концепт языка достаточно простой.
* **Синтаксис:** выбираем probe для подсоединения `probe[,probe,...] /filter/ { action }`.
* **Filter:** указываем фильтр, например, только данные по данному процессу данного Pid.
* **Action:** мини-программа, которая конвертируется непосредственно в bpf-программу и выполняется при вызове bpfTrace.
Более детально можно познакомиться [здесь](https://github.com/iovisor/bpftrace/blob/master/docs/reference_guide.md).
### BpfTrace Tools
В bpfTrace тоже есть набор инструментов. Многие достаточно простые инструменты на BCC сейчас реализуются на bpfTrace.

[Коллекция](https://github.com/iovisor/bpftrace) пока небольшая, но там есть кое-что, чего нет в BCC. Например, killsnoop позволяет отслеживать сигналы, вызванные kill().
Если интересно посмотреть bpf-код, то в bpfTrace можно через `-v` посмотреть сгенерированный байт-код. Это полезно, если хотите понять, тяжелый probe или не очень. Посмотрев код и просто прикинув его размер (одна страница или две), можно понять, насколько он сложный.
### Пример трейсинга MySQL
Покажу на примере MySQL, как это работает. В MySQL есть функция `dispatch_command`, в которой происходят все выполнения запросов MySQL.
```
bpftrace -e 'uprobe:/usr/sbin/mysqld:dispatch_command { printf("%s\n", str(arg2)); }'
failed to stat uprobe target file /usr/sbin/mysqld: No such file or directory
```
Я хотел просто подсоединить uprobe, чтобы распечатать текст запросов, которые приходят к MySQL — примитивная задача. Получил проблему — говорит, что нет такого файла. Как нет, когда вот он:
```
root@mysql1:/# ls -la /usr/sbin/mysqld
-rwxr-xr-x 1 root root 60718384 Oct 25 09:19 /usr/sbin/mysqld
```
Это как раз сюрпризы со snap. Если ставить через snap, то могут быть проблемы трейсинга на уровне приложений.
Тогда поставил через apt-версию, более новую Ubuntu, запустил снова:
```
root@mysql1:~# bpftrace -e 'uprobe:/usr/sbin/mysqld:dispatch_command { printf("%s\n", str(arg2)); }'
Attaching 1 probe...
Could not resolve symbol: /usr/sbin/mysqld:dispatch_command
```
«Нет такого символа», — как нет?! Смотрю через `nm`, есть такой символ или нет:
```
root@mysql1:~# nm -D /usr/sbin/mysqld | grep dispatch_command
00000000005af770 T
_Z16dispatch_command19enum_server_commandP3THDPcjbb
root@localhost:~# bpftrace -e 'uprobe:/usr/sbin/mysqld:_Z16dispatch_command19enum_server_commandP3THDPcjbb { printf("%s\n", str(arg2)); }'
Attaching 1 probe...
select @@version_comment limit 1
select 1
```
Такой символ есть, но поскольку MySQL скомпилирован из C++, там используется mangling. На самом деле настоящее имя функции, которое используется в этой команде, такое: `_Z16dispatch_command19enum_server_commandP3THDPcjbb`. Если именно его использовать в функции, то можно подключиться и получить результат. В perf-экосистеме многие инструменты делают unmangling автоматом, а bpfTrace пока не умеет.
Еще обратите внимание на флаг `-D` для `nm`. Он важен, потому что MySQL, а сейчас и многие другие пакеты, поставляются без динамических символов (debug symbols) — они идут в других пакетах. Если хочется использовать эти символы, нужен флаг `-D`, иначе nm их не увидит.
**Полезные ссылки**
* [github.com/zoidbergwill/awesome-ebpf](https://github.com/zoidbergwill/awesome-ebpf)
* [slideplayer.com/slide/12710510](https://slideplayer.com/slide/12710510/)
* [www.brendangregg.com/ebpf.html](http://www.brendangregg.com/ebpf.html)
* [vger.kernel.org/netconf2018\_files/BrendanGregg\_netconf2018.pdf](http://vger.kernel.org/netconf2018_files/BrendanGregg_netconf2018.pdf)
* [www.brendangregg.com/Slides/Velocity2017\_BPF\_superpowers.pdf](http://www.brendangregg.com/Slides/Velocity2017_BPF_superpowers.pdf)
* [lwn.net/Articles/740157](https://lwn.net/Articles/740157/)
* [tracingsummit.org/w/images/8/82/Tracingsummit2018-bpftrace-robertson.pdf](https://tracingsummit.org/w/images/8/82/Tracingsummit2018-bpftrace-robertson.pdf)
> *Хорошая новость номер раз:* на РИТ++ 25–26 мая Пётр Зайцев [расскажет](https://ritfest.ru/2020/abstracts/6876) о технологиях и тенденциях на рынке баз данных, которые изменят бизнес через год. Это отличная возможность узнать, какие конкретные решения подойдут в разных ситуациях, от человека с невероятной экспертизой в области БД и оптимизации их производительности.
>
>
>
> *Хорошая новость номер два:* [РИТ++ Online](https://ritfest.ru/2020) стал намного доступнее. Билет для физлиц сейчас стоит всего 5 900 и позволяет разобраться в тенденциях не только БД, но и многих других актуальных технологий, и подробно познакомиться с их применением на мастер-классах.
>
>
>
> *Хорошая новость номер три:* мы открыли видео всех докладов [DevOpsConf 2019](https://www.youtube.com/playlist?list=PLknJ4Vr6efQGklXoJ-eedKMQOaV7DWwsA) и [HighLoad++ 2019](https://www.youtube.com/playlist?list=PLknJ4Vr6efQGzsPS-6UzydF7Sj4bnqFMS) — хотите больше хардкора, вам [сюда](https://habr.com/ru/company/oleg-bunin/blog/497154/).
>
>
>
> Подобные полезности мы собираем в нашей рассылке — [подпишитесь](http://eepurl.com/VYVaf), пригодится. | https://habr.com/ru/post/500456/ | null | ru | null |
# Вы не сможете решить эту задачу на собеседовании
Привет, Habr. Хочу поделиться с вами одной интересной задачей, которую многие из нас получали на собеседовании, но, вероятно, даже и не догадывались о том, что решаем ее неправильно.
Прежде всего — немного истории. Работая на должностях тимлида и техлида мне порой приходилось проводить собеседования, соответственно нужно подготовить несколько теоретических вопросов, ну и пару несложных задач, на решение которых не должно было бы уйти больше 2х-3х минут. Если с теорией все просто — мой любимый вопрос это: «чему равен typeof null?», по ответу сразу можно понять, кто сидит перед тобой, джун — просто правильно ответит, а претендент на сеньера, еще и объяснит почему. То с практикой — сложнее. Я долго не мог придумать нормальное задание, не изъезженное, типа fizz-buzz, а что-нибудь свое. Поэтому я на собеседованиях давал задания, которые сам проходил, устраиваясь на текущую работу. О первом из них и пойдет речь.
### Текст задачи
> Напишите функцию, которая принимает на вход строку, а возвращает эту строку «задом наперед»
```
function strReverse(str) {};
strReverse('Habr') === 'rbaH'; // true
```
Очень простая задача, решений для которой масса, самым оптимальным для себя я долго считал такое решение:
```
const strReverse = str => str.split('').reverse().join('');
```
Но что-то меня в этом решении смущало всегда, а именно ненадежность «split('')». И вот после одного из собеседований, я задумался: «Что же такое я могу передать в строке, что сломает мой способ...?». Ответ пришел очень быстро.
О, да, вы уже могли понять о чем я, emoji! Эти чертовы смайлики, их придумал сам дьявол, вы только посмотрите, во что превращается палец вверх, если его перевернуть (нет, не в палец вниз).
> Сразу хочу извиниться, редактор разметки убирает emoji из кода, поэтому вставляю картинки.

Окей, задача простая, нужно просто нормально разбить строку по символам. Вперед, команда, пара часов мозгового штурма команды и у нас есть решение, если честно, удивлен, что раньше так не додумались делать, теперь это будет моя любимая реализация!

Огонь, работает, супер, но… Подождите ка, с недавних пор мы можем указать цвет для смайла, и что же будет, если мы передадим такой emoji в функцию?
> Это фиаско, братан!

Вот тут то я и сел в лужу. Если честно, я пару раз предлагал еще на собеседованиях решить эту задачу, в основном, надеясь что мне предложат то решение, которое сможет это сделать — нет, претенденты разводили руками и не могли мне ничем помочь.
> Помог случай, ну или спортивный интерес. Со словами «Хочешь задачку со специальной олимпиады?» я отправил ее моему бывшему коллеге. «Ок, к вечеру попробую сделать» — последовал ответ, и я напрягся… «А что если сделает? А что если реально сможет? Он сможет, а я — нет? Так дела не пойдут!» — так подумал я и начал шерстить интернет.
Тут я перейду к теоретической части, которая некоторым из вас может показаться интересной и полезной, а некоторым — повторением пройденного материала.
### Что нам нужно знать о Emoji?
Во первых, это — **стандарт**! Стандарт, который хорошо [описан](https://unicode.org/Public/emoji/).
Решающим моментом в жизни emoji можно считать день принятия стандарта unicode 8.0 и стандарта emoji 2.0 в нем, тогда и были описаны первые последовательности юникода и последовательности emoji.
Давайте вот тут остановимся чуть подольше и разберем вопрос подробнее.
Согласно первой версии стандарта emoji является представлением одного символа юникода

[И так далее](https://www.unicode.org/Public/emoji/1.0/emoji-data.txt)…
Вторая версия стандарта позволяет нам взять несколько симовлов юникода в определенной последовательности, чтобы получить emoji

→ [Полный список](https://www.unicode.org/Public/emoji/2.0/emoji-sequences.txt)
Это и есть простые **последовательности** в emoji, но простые они только потому что есть еще и zwj — последовательности.
> ZERO WIDTH JOINER (ZWJ) — соединитель с нулевой шириной, это та ситуация, когда между несколькими emoji вставляется специальный символ юникода ZWJ (200D), который «схлопывает» emoji по обе стороны от него и вот что мы получаем в итоге:

→ [Полный список](https://www.unicode.org/Public/emoji/2.0/emoji-zwj-sequences.txt)
В последующих стандартах эти последовательности только дополнялись, так что количество комбинаций emoji только росло со временем.
Что ж, с мат частью разобрались, но что же нам делать, чтобы перевернуть строку и при этом сохранить последовательность?
### Регулярные выражения.
> Если у вас есть проблема и вы захотели решить ее с помощью регулярных выражений, то теперь у вас две проблемы.
Углубляясь в изучение стандарта юникода находим отдельный раздел о [последовательностях emoji](https://unicode.org/reports/tr51/#Emoji_Sequences), в котором говорится о том, как должны быть реализованы последовательности, и все оказывается достаточно просто.
#### Последовательность может быть составлена по следующей формуле
```
emoji_sequence :=
emoji_core_sequence
| emoji_zwj_sequence
| emoji_tag_sequence
# по пунктам
emoji_core_sequence :=
emoji_character
| emoji_presentation_sequence
| emoji_keycap_sequence
| emoji_modifier_sequence
| emoji_flag_sequence
emoji_presentation_sequence :=
emoji_character emoji_presentation_selector
emoji_presentation_selector := \x{FE0F}
emoji_keycap_sequence := [0-9#*] \x{FE0F 20E3}
emoji_modifier_sequence :=
emoji_modifier_base emoji_modifier
emoji_modifier_base := \p{Emoji_Modifier_Base}
emoji_modifier := \p{Emoji_Modifier}
# к этому вернемся чуть позже
emoji_flag_sequence :=
regional_indicator regional_indicator
regional_indicator := \p{Regional_Indicator}
emoji_zwj_sequence :=
emoji_zwj_element ( ZWJ emoji_zwj_element )+
emoji_zwj_element :=
emoji_character
| emoji_presentation_sequence
| emoji_modifier_sequence
emoji_tag_sequence :=
tag_base tag_spec tag_term
tag_base :=
emoji_character
| emoji_modifier_sequence
| emoji_presentation_sequence
tag_spec := [\x{E0020}-\x{E007E}]+
tag_term := \x{E007F}
```
В принципе, этого уже достаточно, чтобы грамотно(нет) составить регулярное выражение, но еще немного слов про юникод.
### Unicode Categories
В юникоде определены категории, используя которые мы можем в регулярных выражениях находить, например, все заглавные буквы, или, например, все буквы латинского алфавита. Более подробно со списком можно ознакомиться [здесь](https://www.regular-expressions.info/unicode.html#category). Что важно для нас: в стандарте определены категории для emoji: *{Emoji}, {Emoji\_Presentation}, {Emoji\_Modifier}, {Emoji\_Modifier\_Base}*, и казалось бы, все хорошо, давайте использовать, но в реализацию ECMAScript они еще не вошли. Точнее — вошла только одна категория — *{Emoji}*

Остальные на данный момент находятся на [рассмотрении](https://github.com/tc39/proposal-regexp-unicode-sequence-properties#matching-all-emoji-including-emoji-sequences) в tc-39 (stage-2 на момент 10.04.2019).
«Что ж, придется писать регулярку» — подумал и примерно через час мой бывший коллега кидает мне ссылку на гитхаб [github.com/mathiasbynens/emoji-regex](https://github.com/mathiasbynens/emoji-regex), ну да, на гитхабе всегда найдется то, что ты только собирался написать… А жаль, но речь не об этом… Библиотека реализует и импортирует регулярное выражение для поиска эмоджи, в принципе то что надо! Наконец то можно попробовать написать реализацию нужной нам функции!
```
const emojiRegex = require('emoji-regex');
const regex = emojiRegex();
function stringReverse(string) {
let match;
const emojis = [];
const separator = `unique_separator_${Math.random()}`;
const reversedSeparator = [...separator].reverse().join('');
while (match = regex.exec(string)) {
const emoji = match[0];
emojis.push(emoji);
}
return [...string.replace(regex, separator)].reverse().join('').replace(new RegExp(reversedSeparator, 'gm'), () => emojis.pop());
}
```

#### Подводя небольшой итог
Я обожаю задачи со "*специальной*" олимпиады, они заставляют меня узнавать что-то новое, каждый раз расширяя границы знаний. Я не понимаю людей, которые говорят: «Я не понимаю, зачем нужно знать, что null >= 0? Мне это не пригодится!». Пригодится, 100% пригодится, в тот момент, когда ты будешь выяснять причину того-или иного явления — ты прокачаешь себя, как программиста и станешь лучше. Не лучше кого-то, а лучше себя, который еще пару часов назад не знал, как решить какую-то задачу.
Спасибо за прочтение, всем спасибо, буду рад любым комментариям.
Необходимый постскриптум:
Все сломала буква \u{0415}\u{0308}. Это буква ё, состоящая из 2х символов, оказывается в стандарте юникода есть вариант объединения не только emoji, но и просто символов… Но это — совсем другая история.
UPD: Речь идет не о букве «Ё», а о сочетании 2х символов Юникода u{0415}(Е) и u{0308}("̈), которые идя друг за другом образуют последовательность юникода и мы видим букву «Ё» на экране. | https://habr.com/ru/post/447614/ | null | ru | null |
# Знакомство с библиотекой libevent на примере создания простейшего Web-сервера картинок
В данной статье я покажу как используя библиотеку [libevent](http://www.monkey.org/~provos/libevent/), написать простейший Web-сервер, который будет по запросу клиентов выдавать файлы jpeg картинок.
Библиотека *libevent* предоставляет программистам доступ к кроссплатформенному асинхронному сетевому API. На основе данной библиотеки можно создавать высокопроизводительные сетевые приложения. Например, *libevent* используется в таких известных приложениях как [Memcached](http://memcached.org/) (распределённая система кэширования) и [TOR](http://www.torproject.org/) (распределённая анонимная сеть).
Скачать код сервера можно [тут](http://www.ionkin.com/misc/main.c).
**Начнем рассмотрение кода с функции main ():**
`75:int main (int argc, char *argv[])
76:{
77: struct event_base *ev_base;
78: struct evhttp *ev_http;
79:
80: if (argc != 3) {
81: printf ("Usage: %s host port\n", argv[0]);
82: exit (1);
83: }
84:
85: ev_base = event_init ();
86:
87: ev_http = evhttp_new (ev_base);
88: if (evhttp_bind_socket (ev_http, argv[1], (u_short)atoi (argv[2]))) {
89: printf ("Failed to bind %s:%s\n", argv[1], argv[2]);
90: exit (1);
91: }
92: evhttp_set_cb (ev_http, "/img", http_img_cb, NULL);
93:
94: event_base_dispatch (ev_base);
95:
96: return 0;
97:}`
Наш Web-сервер будет принимать два параметра из командной строки: IP адрес и порт, которые будет прослушивать сервер. В строках 80-83 идет проверка количества переданных параметров из командной строки. Не забывайте, что первым элементом массива *argv[]* всегда является имя самого приложения.
Строка 85 производит инициализацию библиотеки *libevent*, возвращает указатель на структуру данных «*struct event\_base*». Во все дальнейшие вызовы функций библиотеки *libevent* должна будет передаваться эта переменная.
С 87 по 92 строку создается HTTP сервер, вызывается функция, которая инициализирует прослушку на переданном в командной строке адресе. Если вдруг данный адрес уже прослушивается каким-то другим приложением или у нас нет прав на занятие данного адреса (на забывайте, что порты до 1024 может занимать только приложение запущенное с правами пользователя root), то программа выводит сообщение на экран и завершает выполнение. Далее мы устанавливаем callback-функцию для «/img» URI.
Вся библиотека *libevent* построена на основе так называемых «callback»-функций (функций обратного вызова), они работают следующим образом: допустим мы хотим, чтобы при наступлении какого-то события («event» — англ. «событие», отсюда и название библиотеки) вызывалась наша функция. Для этого мы, использую API *libevent*, регистрируем нашу функцию для конкретного события (это может быть событие таймера, готовность сокета к приему данных, запрос URI и т.д). В дальнейшем, при наступлении этого события, происходит вызов нашей функции, которой передаются все необходимые параметры.
Строка 94 запускает цикл обработки событий. В нашем примере цикл будет выполнятся бесконечное количество раз, так как мы не предусмотрели завершение работы HTTP сервера. Для того чтобы выйти из этого цикла и завершить работу сервера, нужно будет в консоли нажать CTRL+C.
**Теперь рассмотрим обработку «/img» HTTP запроса:**
`13:static void http_img_cb (struct evhttp_request *request, void *ctx)
14:{
15: struct evbuffer *evb;
16: int fd;
17: const char *fname;
18: struct stat stbuf;
19: int total_read_bytes, read_bytes;
20: struct evkeyvalq uri_params;
21:
22: evb = evbuffer_new ();
23:
24: printf ("Request from: %s:%d URI: %s\n", request->remote_host, request->remote_port, request->uri);
25:
26: evhttp_parse_query (request->uri, &uri_params);
27: fname = evhttp_find_header (&uri_params, "name");
28:
29: if (!fname) {
30: evbuffer_add_printf (evb, "Bad request");
31: evhttp_send_reply (request, HTTP_BADREQUEST, "Bad request", evb);
32: evhttp_clear_headers (&uri_params);
33: evbuffer_free (evb);
34: return;
35: }`
Сторка 13 объявляет «callback» функцию *http\_img\_cb ().* При вызове функции, ей, в качестве аргументов, передастся указатель на структуру «*struct evhttp\_request*», в которой содержится вся необходимая информация о HTTP запросе и указатель на пользовательские данные. В нашем примере переменная «*ctx*» не используется.
Строка 22 инициализирует переменную с типом «*struct evbuffer* \*».
В *libevent* структура «*struct evbuffer*» является основным типом для работы с данными Ввода/Вывода («I/O»). API для работы с «*struct evbuffer*» позволяет эффективно считывать, записывать и производить поиск данных.
Строка 26 вызывает *libevent* функцию «*evhttp\_parse\_query* ()», которая принимает строку URI и возвращает список со значениями «ключ» → «значение» из параметров URI. Например, если произошел запрос «http://serverIP:port/img?aa=bb&cc=dd» и вызвали функцию «*evhttp\_parse\_query (request->uri, &uri\_params)*», то в «uri\_params» будут содержаться пары «aa» → «bb», «cc» → «dd». API *libevent* содержит несколько функций для работы с типом «*struct evkeyvalq*».
Строка 27 вызывает одну из таких функций, которая принимает указатель на структуру «*struct evkeyvalq*» и строку с ключом. Функция возвращает значение ключа или «*NULL*», если такой ключ не найден. В нашем случае мы будем принимать в URI параметрах ключ «name», в котором будет содержаться имя требуемого файла.
Строки 29-35 проверяют, чтобы ключ «name» был указан в URI параметрах. Если он не указан, мы, используя функцию «*evhttp\_send\_reply* ()», отсылаем ответ клиенту с HTTP кодом 400 и сообщением для пользователя «Bad request». Далее вызываем функцию «*evhttp\_clear\_headers* ()» для очистки списка «ключ» → «значение» и функцию «*evbuffer\_free* ()» для освобождения памяти, занимаемой структурой «*struct evbuffer*» и выходим из функции.
Функция «*evhttp\_send\_reply* ()» является основным способом отсылки HTTP сообщений клиентам, в параметрах она принимает указатель на структуру «*struct evhttp\_request*», HTTP код (в *libevent* есть несколько предопределённых констант с HTTP кодами), строку с коротким текстовым сообщением для броузера и указатель на структуру «*struct evbuffer*» — эти данные будут непосредственно отображены клиенту.
`37: if ((fd = open (fname, O_RDONLY)) < 0) {
38: evbuffer_add_printf (evb, " File %s not found", fname);
39: evhttp_send_reply (request, HTTP_NOTFOUND, "File not found", evb);
40: evhttp_clear_headers (&uri_params);
41: evbuffer_free (evb);
42: return;
43: }
44: if (fstat (fd, &stbuf) < 0) {
45: evbuffer_add_printf (evb, "File %s not found", fname);
46: evhttp_send_reply (request, HTTP_NOTFOUND, "File not found", evb);
47: evhttp_clear_headers (&uri_params);
48: evbuffer_free (evb);
49: close (fd);
50: return;
51: }`
Строки 37-51 открывают файл для чтения. Имя файла берется из параметра «name». Далее вызывается функция «*fstat* ()», которая возвращает различную системную информацию о файле. Если в любой из функций произошла ошибка, то мы отсылаем ответ клиенту с HTTP кодом 404 и сообщением для пользователя «File not found», освобождаем память и выходим из функции.
`53: total_read_bytes = 0;
54: while (total_read_bytes < stbuf.st_size) {
55: read_bytes = evbuffer_read (evb, fd, stbuf.st_size);
56: if (read_bytes < 0) {
57: evbuffer_add_printf (evb, "Error reading file %s", fname);
58: evhttp_send_reply (request, HTTP_NOTFOUND, "File not found", evb);
59: evhttp_clear_headers (&uri_params);
60: evbuffer_free (evb);
61: close (fd);
62: return;
63: }
64: total_read_bytes += read_bytes;
65: }`
Строки 53-65 считывают данные из открытого файла в структуру «*struct evbuffer*». Функция «*evbuffer\_read* ()» принимает в параметрах указатель на структуру «*struct evbuffer*», десктриптор открытого файла и сколько байтов нужно считать. Функция возвращает количество считанных байтов из файла. Возможна такая ситуация, что файл слишком большой, и его нельзя считать одним вызовом «*evbuffer\_read* ()», тогда мы в цикле сверяем количество уже считанных байтов с размером файла, полученного из вызова «*fstat* ()» и при необходимости повторяем считывание.
`66: evhttp_add_header (request->output_headers, "Content-Type", "image/jpeg");
67: evhttp_send_reply (request, HTTP_OK, "HTTP_OK", evb);
68:
69: evhttp_clear_headers (&uri_params);
70: evbuffer_free (evb);
71: close (fd);
72:}`
Строки 66-72 отсылают содержание файла клиенту с HTTP кодом 200. Предварительно добавив к ответу HTTP заголовок «Content-Type: image/jpeg», это необходимо для того, чтобы броузер клиента правильно отобразил содержание картинки. После этого освобождаем память, закрываем файл и выходим из функции.
**Сборка и тестирование.**
Скопируйте в текущую директорию пару jpeg картинок и запомните имена файлов.
Чтобы скомпилить данный код, вам нужно на своем компьютере установить библиотеку *libevent* версии 1.4.XX (замените XX на последнюю доступную версию). На некоторых Linux дистрибутивах надо будет установить пакет «*libevent-dev*» Примеры:
для Gentoo: `emerge libevent`
для Ubuntu: `aptitude install libevent-dev`
После того, как библиотека установлена, сохраните код программы в файл main.c и можно попробовать скомпилить:
`gcc main.c -o web_server -levent`
Если ни каких ошибок не было, то у вас в текущей директории появится файл «web\_server». Запускаем его с параметрами IP адрес и порт, например:
`./web_server 127.0.0.1 8090`
Теперь на своей машине откройте любой броузер и введите такой URL: `http://127.0.0.1:8090/img?name=имя_jpeg_картинки`
Должна показаться картинка. Ура, вы только что создали web сервер!
**Немного о безопасности.**
Web-сервер в данном виде не пригоден для использования в Интернете, так как нет проверки к какому файлу идет обращение. Допустим, можно послать такой запрос: «`http://serverIP:port/img?name=/etc/passwd`» и клиенту отошлется файл со списком пользователей системы. Я специально опустил рассмотрение безопасности, так как это тема целой отдельной статьи. Могу лишь посоветовать, что вполне безопасно запускать такой Web-сервер в «*chroot*» среде, предварительно скомпилив его с флагом «*-static*».
**Что дальше.**
Возможно, я в скором времени напишу продолжение о разработке простейшего Web-сервера, где покажу как можно кэшировать файлы картинок. Так же недавно начал писать статейку, где хочу рассказать, как можно организовать взаимодействие сервера и Flash клиента посредством двоичного протокола и API *libevent*.
Есть много разных интересный вещей, что можно сделать используя API *libevent*. Главное что отличает разработку программ с используя *libevent* — это простота и в то же время эффективность и скорость выполнения полученных программ. Обязательно почитайте книгу [Learning Libevent](http://www.wangafu.net/~nickm/libevent-book/TOC.html). Успешного кодинга!
P.S. Подсветка кода почему-то не отображается ;/ | https://habr.com/ru/post/84509/ | null | ru | null |
# Печатные формы документов для Eloquent в 0 строчек кода
Недавно в проекте на Laravel+Eloquent понадобилось сделать печатные формы документов — счетов, договоров в формате Word. Так как в системе много разных документов, то решил сделать универсально, чтобы можно было потом использовать и в других проектах.
В итоге получилась реализация, которая требует минимум затрат на интеграцию в проект.

Как я раньше делал печатные формы. Использовал разные подходы
* В шаблон документа размещал теги и заменял их при генерации.
* Генерировал текст документа с нуля.
* Генерировал html и конвертировал его в word.
* Делал свою систему для генерации документов по аналогии с той, что описана в этой статье, но на других технологиях.
Каждый вариант хорош для своей задачи. Но если у вас Eloquent, то весьма рекомендую вариант, описанный в этой статье.
Итак, подключаем пакет
```
composer require mnvx/eloquent-print-form
```
И описываем модели Eloquent, если они еще не описаны. Допустим, есть следующие модели.
```
use Illuminate\Database\Eloquent\Model;
/**
* @property string $number
* @property string $start_at
* @property Customer $customer
* @property ContractAppendix[] $appendixes
*/
class Contract extends Model
{
public function customer()
{
return $this->belongsTo(Customer::class);
}
public function appendixes()
{
return $this->hasMany(ContractAppendix::class);
}
}
/**
* @property string $name
* @property CustomerCategory $category
*/
class Customer extends Model
{
public function category()
{
return $this->belongsTo(CustomerCategory::class);
}
}
/**
* @property string $number
* @property string $date
* @property float $tax
*/
class ContractAppendix extends Model
{
public function getTaxAttribute()
{
$tax = 0;
foreach ($this->items as $item) {
$tax += $item->total_amount * (1 - 100 / (100+($item->taxStatus->vat_rate ?? 0)));
}
return $tax;
}
}
```
Для наглядности, диаграмма связей

То есть описана таблица с договорами (`Contract`), у договора может быть заполнен контрагент (`Customer`), у контрагента может быть заполнена категория. У договора может быть несколько приложений (`ContractAppendix`).
Все что нужно для генерации печатной формы — описать поля в шаблоне печатной формы. Создаем docx файл с таким содержимым

В переменных указываем названия полей сущностей Eloquent. Если нужно добраться по связям до соседних таблиц, используем точку, как в примере выше, в `${customer.category.name}`.
Если необходимо обработать данные из базы, используем оператор конвейер `|`, как в примере `${number|placeholder}`. Если нужно выполнить несколько обработок, строим цепочку конвейеров, например `${start_at|date|placeholder}`.
Примеры готовых операций
* `placeholder` — заменяет пустое значение на "********\_\_\_\_********",
* `date` — приводит дату к формату 24.12.2020,
* `dateTime` — приводит дату-время к формату 24.12.2020 23:11,
* `int` — приводит целое число к формату 2`145,
* `decimal` — приводит дробное число к формату 2`145.07.
Для заполнения табличных данных вставляем переменные в таблицу как в примере документа выше. Для нумерации строк таблицы можно использовать отдельную конструкцию `${entities.#row_number}`.
Теперь, когда документ описан, остается просто запустить генерацию печатной формы
```
use Mnvx\EloquentPrintForm\PrintFormProcessor;
$entity = Contract::find($id);
$printFormProcessor = new PrintFormProcessor();
$templateFile = resource_path('path_to_print_forms/your_print_form.docx');
$tempFileName = $printFormProcessor->process($templateFile, $entity);
```
В сгенерированном файле `$tempFileName` будет лежать подготовленная печатная форма.
В проекте на Laravel метод контроллера, отвечающий за генерацию печатной формы, может выглядеть так
```
public function downloadPrintForm(FormRequest $request)
{
$id = $request->get('id');
$entity = Contract::find($id);
$printFormProcessor = new PrintFormProcessor();
$templateFile = resource_path('path_to_print_forms/your_print_form.docx');
$tempFileName = $printFormProcessor->process($templateFile, $entity);
$filename = 'contract_' . $id;
return response()
->download($tempFileName, $filename . '.docx')
->deleteFileAfterSend();
}
```
Резюмируя, скажу, что я прилично разгрузил себя, сделав эту небольшую библиотеку в проекте, где довольно много печатных форм. Мне не надо для каждой из них писать свой уникальный код. Я просто описываю переменные как сказано выше и весьма быстро получаю результат. Буду рад, если и вам пакет поможет сэкономить время.
[Ссылка на проект на гитхабе](https://github.com/mnvx/eloquent-print-form) | https://habr.com/ru/post/527356/ | null | ru | null |
# Как Python помогает заменить финконсультантов
В продолжение [статьи](https://habr.com/post/419313/) о вреде избыточной диверсификации создадим полезный инструментарий по подбору акций. После этого сделаем простую ребалансировку и добавим уникальные условия технических индикаторов, которых так часто не хватает в популярных сервисах. А затем сравним доходность отдельных активов и различных портфелей.
Во всём этом задействуем Pandas и минимизируем количество циклов. Погруппируем времянные ряды и порисуем графиков. Познакомимся с мультииндексами и их поведением. И всё это в Jupyter на Python 3.6.
> Если хочешь сделать что-то хорошо, сделай это сам.
>
> Фердинанд Порше
Описанный инструмент позволит подобрать оптимальные активы для портфеля и исключить инструменты, навязываемые консультантами. Но мы увидим лишь общую картину — без учёта ликвидности, времени набора позиций, комиссий брокера и стоимости одной акции. В целом, при ежемесячной или ежегодной ребалансировке у крупных брокеров это будут незначительные затраты. Однако перед применением выбранную стратегию всё же стоит проверить в event-driven бэктестере, например, Quantopian (QP), дабы исключить потенциальные ошибки.
Почему не сразу в QP? Время. Там самый простой тест длится около 5 минут. А текущее решение позволит вам за минуту проверить сотни разных стратегий с уникальными условиями.
Загрузка сырых данных
---------------------
Для загрузки данных возьмем метод, описанный в этой [статье](https://habr.com/post/416681/). Для хранения дневных цен я использую PostgreSQL, но сейчас полно бесплатных источников, из которых можно сформировать необходимый DataFrame.
Код загрузки истории цен из БД доступен в репозитории. Ссылка будет в конце статьи.
Структура DataFrame
-------------------
При работе с историей цен, для удобной группировки и доступа ко всем данным, лучшим решением является использование мильтииндекса (MultiIndex) с датой и тикерами.
```
df = df.set_index(['dt', 'symbol'], drop=False).sort_index()
df.tail(len(df.index.levels[1]) * 2)
```

Используя мультииндекс, мы можем легко получить доступ ко всей истории цен для всех активов и можем группировать массив отдельно по датам и активам. Также можем получить историю цен для одного актива.
Вот пример, как можно легко группировать историю по неделям, месяцам и годам. И всё это показать на графиках силами Pandas:
```
# Правила обработки колонок при группировке
agg_rules = {
'dt': 'last', 'symbol': 'last',
'open': 'first', 'high': 'max', 'low': 'min', 'close': 'last',
'volume': 'sum', 'adj': 'last'
}
level_values = df.index.get_level_values
# Графики
fig = plt.figure(figsize=(15, 3), facecolor='white')
df.groupby([pd.Grouper(freq='W', level=0)] + [level_values(i) for i in [1]]).agg(
agg_rules).set_index(['dt', 'symbol'], drop=False
).close.unstack(1).plot(ax=fig.add_subplot(131), title="Weekly")
df.groupby([pd.Grouper(freq='M', level=0)] + [level_values(i) for i in [1]]).agg(
agg_rules).set_index(['dt', 'symbol'], drop=False
).close.unstack(1).plot(ax=fig.add_subplot(132), title="Monthly")
df.groupby([pd.Grouper(freq='Y', level=0)] + [level_values(i) for i in [1]]).agg(
agg_rules).set_index(['dt', 'symbol'], drop=False
).close.unstack(1).plot(ax=fig.add_subplot(133), title="Yearly")
plt.show()
```

Для корректного отображения области с легендой графика мы переносим уровень индекса с тикерами на второй уровень над колонками, используя команду Series().unstack(1). С DataFrame() такой номер не пройдёт, но решение есть ниже.
При группировке по стандартным периодам Pandas использует в индексе последнюю календарную дату группы, которая часто отличается от фактических дат. Для того чтобы это исправить, обновим индекс.
```
monthly = df.groupby([pd.Grouper(freq='M', level=0), level_values(1)]).agg(agg_rules) \
.set_index(['dt', 'symbol'], drop=False)
```
Пример получения истории цен определённого актива (берём все даты, тикер QQQ и все колонки):
```
monthly.loc[(slice(None), ['QQQ']), :] # история одно актива
```
Ежемесячная волатильность активов
---------------------------------
Теперь мы в несколько строк можем посмотреть на графике изменение цены каждого актива за интересующий нас период. Для этого получим процент изменения цены, группируя dataframe по уровню мультииндекса с тикером актива.
```
monthly = df.groupby([pd.Grouper(freq='M', level=0), level_values(1)]).agg(
agg_rules).set_index(['dt', 'symbol'], drop=False)
# Ежемесячные изменения цены в процентах. Первое значение обнулим.
monthly['pct_close'] = monthly.groupby(level=1)['close'].pct_change().fillna(0)
# График
ax = monthly.pct_close.unstack(1).plot(title="Monthly", figsize=(15, 4))
ax.axhline(0, color='k', linestyle='--', lw=0.5)
plt.show()
```

Сравним доходность активов
--------------------------
Теперь воспользуемся оконным методом Series().rolling() и выведем доходность активов за определённый период:
**Код на Python**
```
rolling_prod = lambda x: x.rolling(len(x), min_periods=1).apply(np.prod) # кумулятивный доход
monthly = df.groupby([pd.Grouper(freq='M', level=0), level_values(1)]).agg(
agg_rules).set_index(['dt', 'symbol'], drop=False)
# Ежемесячные изменения цены в процентах. Первое значение обнулим. И прибавим 1.
monthly['pct_close'] = monthly.groupby(level=1)['close'].pct_change().fillna(0) + 1
# Новый DataFrame без данных старше 2007 года
fltr = monthly.dt >= '2007-01-01'
test = monthly[fltr].copy().set_index(['dt', 'symbol'], drop=False) # обрежем dataframe и обновим индекс
test.loc[test.index.levels[0][0], 'pct_close'] = 1 # устанавливаем первое значение 1
# Получаем кумулятивный доход
test['performance'] = test.groupby(level=1)['pct_close'].transform(rolling_prod) - 1
# График
ax = test.performance.unstack(1).plot(title="Performance (Monthly) from 2007-01-01", figsize=(15, 4))
ax.axhline(0, color='k', linestyle='--', lw=0.5)
plt.show()
# Доходность каждого инструмента в последний момент
test.tail(len(test.index.levels[1])).sort_values('performance', ascending=False)
```
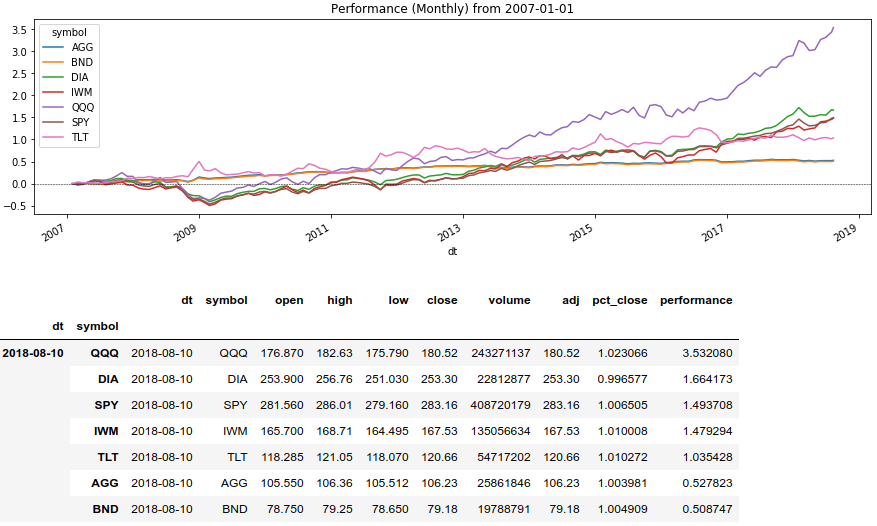
Методы ребалансировки портфелей
-------------------------------
Вот мы и подобрались к самому вкусному. В примерах мы посмотрим результаты портфлеля при распределении капитала по заранее определённым долям между несколькими активами. А также добавим уникальные условия, по которым будем отказываться от некоторых активов в момент распределения капитала. Если подходящих активов не будет, то будем считать, что капитал лежит у брокера в кэше.
Для того чтобы при ребалансировке использовать методы Pandas, нам необходимо хранить доли распределения и условия ребалансировки в DataFrame с группированными данными. Теперь рассмотрим функции ребалансировок, которые будем передавать в метод DataFrame().apply():
**Код на Python**
```
def rebalance_simple(x):
# Простая ребалансировка по долям
data = x.unstack(1)
return (data.pct_close * data['size']).sum() / data['size'].sum()
def rebalance_sma(x):
# Ребалансировка по активам, у которых SMA50 > SMA200
data = x.unstack(1)
fltr = data['sma50'] > data['sma200']
if not data[fltr]['size'].sum():
return 1 # Баланс без изменений, если нет подходящих
return (data[fltr].pct_close * data[fltr]['size']).sum() / data[fltr]['size'].sum()
def rebalance_rsi(x):
# Ребалансировка по активам, у которых RSI100 > 50
data = x.unstack(1)
fltr = data['rsi100'] > 50
if not data[fltr]['size'].sum():
return 1 # Баланс без изменений, если нет подходящих
return (data[fltr].pct_close * data[fltr]['size']).sum() / data[fltr]['size'].sum()
def rebalance_custom(x, df=None):
# Медленная ребалансировка с уникальными условиями и внешними данными
data = x.unstack(1)
for s in data.index:
if data['dt'][s]:
fltr_dt = df['dt'] < data['rebalance_dt'][s] # исключим будущее
values = df[fltr_dt].loc[(slice(None), [s]), 'close'].values
data.loc[s, 'custom'] = 0 # обнулим значение фильтра
if len(values) > len(values[np.isnan(values)]):
# Получим RSI за 100 дней
data.loc[s, 'custom'] = talib.RSI(values, timeperiod=100)[-1]
fltr = data['custom'] > 50
if not data[fltr]['size'].sum():
return 1 # Баланс без изменений, если нет подходящих
return (data[fltr].pct_close * data[fltr]['size']).sum() / data[fltr]['size'].sum()
def drawdown(chg, is_max=False):
# Максимальная просадка доходности
total = len(chg.index)
rolling_max = chg.rolling(total, min_periods=1).max()
daily_drawdown = chg/rolling_max - 1.0
if is_max:
return daily_drawdown.rolling(total, min_periods=1).min()
return daily_drawdown
```
По порядку:
* rebalance\_simple — самая простая функция, которая будет распределять доходность каждого актива по долям.
* rebalance\_sma — функция, распределяющая капитал по активам, у которых скользящая средняя за 50 дней выше значения за 200 дней на момент ребалансировки.
* rebalance\_rsi — функция, распределяющая капитал по активам, у которых значение индикатора RSI за 100 дней выше 50.
* rebalance\_custom — самая медленная и самая универсальная функция, где мы будем высчитывать значения индикатора из дневной истории цен актива на момент ребалансировки. Здесь можно использовать любые условия и данные. Даже загружать каждый раз из внешних источников. Но без цикла уже не обойтись.
* drawdown — вспомогательная фукция, показывающая максимальную просадку по портфелю.
В функциях ребалансировки нам необходим массив всех данных на дату в разрезе активов. Метод DataFrame().apply(), которым мы будем рассчитывать результаты портфелей, передаст в нашу функцию массив, где колонки станут индексом строк. А если мы сделаем мультииндекс, где нулевым уровнем будут тикеры, то к нам придёт мультииндекс. Этот мультииндекс мы сможем развернуть в двумерный массив и получить на каждой строке данные соответствующего актива.

Ребалансировка портфелей
------------------------
Теперь достаточно подготовить необходимые условия и сделать в цикле расчёт для каждого портфеля. Первым делом рассчитаем индикаторы на дневной истории цен:
```
# Смещаем данные на 1 день вперед, чтобы не заглядывать в будущее
df['sma50'] = df.groupby(level=1)['close'].transform(lambda x: talib.SMA(x.values, timeperiod=50)).shift(1)
df['sma200'] = df.groupby(level=1)['close'].transform(lambda x: talib.SMA(x.values, timeperiod=200)).shift(1)
df['rsi100'] = df.groupby(level=1)['close'].transform(lambda x: talib.RSI(x.values, timeperiod=100)).shift(1)
```
Теперь сгруппируем историю под нужный период ребалансировки, используя методы, описанные выше. Будем брать при этом значения индикаторов в начале периода, чтобы исключить заглядывание в будущее.
Опишем структуру портфелей и укажем нужную ребалансировку. Портфели рассчитаем в цикле, так как нам необходимо указывать уникальные доли и условия:
**Код на Python**
```
# Условия портфелей: доли активов, функция ребалансировки, название
portfolios = [
{'symbols': [('SPY', 0.8), ('AGG', 0.2)], 'func': rebalance_sma, 'name': 'Portfolio 80/20 SMA50x200'},
{'symbols': [('SPY', 0.8), ('AGG', 0.2)], 'func': rebalance_rsi, 'name': 'Portfolio 80/20 RSI100>50'},
{'symbols': [('SPY', 0.8), ('AGG', 0.2)], 'func': partial(rebalance_custom, df=df), 'name': 'Portfolio 80/20 Custom'},
{'symbols': [('SPY', 0.8), ('AGG', 0.2)], 'func': rebalance_simple, 'name': 'Portfolio 80/20'},
{'symbols': [('SPY', 0.4), ('AGG', 0.6)], 'func': rebalance_simple, 'name': 'Portfolio 40/60'},
{'symbols': [('SPY', 0.2), ('AGG', 0.8)], 'func': rebalance_simple, 'name': 'Portfolio 20/80'},
{'symbols': [('DIA', 0.2), ('QQQ', 0.3), ('SPY', 0.2), ('IWM', 0.2), ('AGG', 0.1)],
'func': rebalance_simple, 'name': 'Portfolio DIA & QQQ & SPY & IWM & AGG'},
]
for p in portfolios:
# Обнуляем размер долей
rebalance['size'] = 0.
for s, pct in p['symbols']:
# Устанавливаем свои доли для каждого актива
rebalance.loc[(slice(None), [s]), 'size'] = pct
# Подготовим индекс для корректной ребалансировки и получим доходность за каждый период
rebalance_perf = rebalance.stack().unstack([1, 2]).apply(p['func'], axis=1)
# Кумулятивная доходность портфеля
p['performance'] = (rebalance_perf.rolling(len(rebalance_perf), min_periods=1).apply(np.prod) - 1)
# Максимальная просадка портфеля
p['drawdown'] = drawdown(p['performance'] + 1, is_max=True)
```
В этот раз нам потребуется провернуть хитрость с индексами колонок и строк, чтобы получить нужный мультииндекс в функции ребалансировки. Добьёмся этого, вызвав последовательно методы DataFrame().stack().unstack([1, 2]). Данный код перенесет колонки в строчный мультииндекс, а затем вернет обратно мультииндекс с тикерами и колонками в нужном порядке.
Готовые портфели на графики
---------------------------
Теперь осталось всё нарисовать. Для этого ещё раз запустим цикл по портфелям, который выведет данные на графики. В конце нарисуем SPY в качестве бенчмарка для сравнения.
**Код на Python**
```
fig = plt.figure(figsize=(15, 4), facecolor='white')
ax_perf = fig.add_subplot(121)
ax_dd = fig.add_subplot(122)
for p in portfolios:
p['performance'].rename(p['name']).plot(ax=ax_perf, legend=True, title='Performance')
p['drawdown'].rename(p['name']).plot(ax=ax_dd, legend=True, title='Max drawdown')
# Вывод доходности и просадки перед графиками
print(f"{p['name']}: {p['performance'][-1]*100:.2f}% / {p['drawdown'][-1]*100:.2f}%")
# SPY, как бенчмарк
rebalance.loc[(slice(None), ['SPY']), :].set_index('dt', drop=False).performance. \
rename('SPY').plot(ax=ax_perf, legend=True)
drawdown(rebalance.loc[(slice(None), ['SPY']), :].set_index('dt', drop=False).performance + 1,
is_max=True).rename('SPY').plot(ax=ax_dd, legend=True)
ax_perf.axhline(0, color='k', linestyle='--', lw=0.5)
ax_dd.axhline(0, color='k', linestyle='--', lw=0.5)
plt.show()
```

Заключение
----------
Рассмотренный код позволяет подбирать различные структуры портфелей и условия ребалансировок. С его помощью можно быстро проверить, стоит ли, например, держать в портфеле золото (GLD) или развивающиеся рынки (EEM). Попробуйте его сами, добавьте свои условия индикаторов или подберите параметры уже описанных. (Но помните об ошибке выжившего и о том, что подгонка под прошлые данные, может не оправдать ожидания в будущем.) А после этого решите, кому вы доверите свой портфель — Python-у или финкосультантy?
Репозиторий: [rebalance.portfolio](https://github.com/iamraa/rebalance.portfolio.python) | https://habr.com/ru/post/419979/ | null | ru | null |
# Нативные приложения обречены (часть 1)

Отныне я не буду больше создавать нативные приложения. Все мои приложения в дальнейшем будут прогрессивными веб-приложениями (PWA, Progressive Web Apps). Это такие приложения, которые предназначены для еще более органичной работы на мобильных устройствах, чем нативные приложения.
Что я имею ввиду под «более органичной работой»? Большая часть веб-траффика исходит от мобильных устройств и пользователи устанавливают в среднем от 0 до 3 новых приложений в месяц. Это означает, что люди не тратят много времени на поиск новых приложений в App store, но они проводят много времени в сети, где могут найти и использовать ваше приложение.
Прогрессивные веб-приложения начинают свою работу как любое другое веб-приложение, но когда пользователь возвращается в приложение и показывает (фактом использования), что он заинтересован в более регулярном обращении к приложению, браузеры предложат пользователю установить приложение на свой домашний экран. PWA также могут использовать [push-уведомления](https://developers.google.com/web/fundamentals/engage-and-retain/push-notifications/) как и нативные приложения.
> [](https://www.edsd.ru/ "EDISON Software - web-development")
>
> Компании EDISON разрабатывает и [нативные мобильные приложения](https://www.edsd.ru/ru/proekty/mobilnye_prilozhenija), но мы делаем это прогрессивно ;-)
>
>
>
> [](https://www.edsd.ru/ru/proekty/mobilnye_prilozhenija)
>
> Вот здесь можно поглядеть наше [портфолио мобильных приложений под iOS](https://www.edsd.ru/ru/portfolio/tehnologiya/ios).
>
>
>
> Разумеется, для тех же проектов реализуем и [мобильные приложения на Android](https://www.edsd.ru/ru/portfolio/tehnologiya/android).
>
>
>
>
>
>
>
>
>
>
И тут-то начинается интересная часть. Как и любое нативное приложение, прогрессивное веб-приложение будет обладать собственной иконкой для домашнего экрана и когда вы нажимаете на нее приложение запускается без оболочки браузера Chrome. Это означает отсутствие адресной строки и кнопок навигации. Только обычная строка состояния телефона и ваше приложение во всем своем почти полноэкранном великолепии.
К этому уже давно шло. Ни одна из технологий не является особо новой, за примечательным исключением развивающегося кросс-платформенного стандарта.
Немного истории
---------------
На заре iPhone не существовало app store. Стив Джобс хотел, чтобы разработчики создавали приложения для iPhone, используя стандартные веб-технологии.
Иногда мечтатели правы, но они на 10 лет опережают свое время. Оглядываясь назад на 2 года, рекомендация Стива Джобса о создании веб-приложений для iPhone была названа журналом Forbes его “[крупнейшей ошибкой](http://www.forbes.com/sites/markrogowsky/2014/07/11/app-store-at-6-how-steve-jobs-biggest-blunder-became-one-of-apples-greatest-strengths/)”, поскольку нативные приложения приобрели сокрушительный успех.
Сегодня, оглядываясь назад, кажется очевидным, что он действительно что-то нащупал, но только далеко впереди возможностей существующий веб-стандартов того времени.
Сейчас десятилетие спустя, мобильные веб-стандарты поддерживают многие функции, которые были нужны разработчикам нативных приложений и первоначальное видение мобильных веб-приложений Стива Джобса теперь воспринимается серьезно всем миром. Практически с самого начала Apple поддерживал “apple-mobile-web-capable” веб-приложения, которые вы можете добавить себе на домашний экран, используя мета тэги, которые помогают устройствам iOS находить такие вещи как подходящие иконки.
Другие производители последовали примеру, каждый создавал свою собственную коллекцию мета тэгов для объявления возможностей мобильных веб-приложений. Но недавно была введена кросс-платформеная спецификация и теперь кросс-платформенные мобильные веб-приложения наконец-то становятся реальностью.
Приложения, выполняющие стандарт называются прогрессивными веб-приложениями, не путать с такими сбивающими с толку, похожими терминами как прогрессивное усовершенствование или отзывчивые приложения.
Что такое прогрессивные веб-приложения
--------------------------------------
Прогрессивные веб-приложения являются веб-приложениями, разработанными и адаптированными под мобильные устройства. Если браузер отмечает, что пользователь хочет продолжить использование приложения, то он может предложить ему установить приложение на свой домашний экран. Но для того чтобы он это сделал, приложения должны удовлетворять специфическим критериям:
* Должны быть HTTPS (смотри let's encrypt)
* Валидный манифест с обязательными свойствами ( Web Manifest Validator)
* Должны иметь service worker
* start\_url прописанный в манифесте, должен всегда загружаться даже в offline (используя service worker)
* Должны предоставлятьсвою собственную навигацию
* Должны быть отзывчивыми к разным размерам экрана и ориентациям
Конечно, использование HTTPS и service worker для оффлайн пользователей является сегодня рекомендуемой нормой для любого современного приложения.
Что забывают многие создатели приложений так это то, что если вы делаете прогрессивное веб-приложение, то вы должны иметь возможность управлять приложением без браузерной оболочки и навигационных жестов. Мобильные устройства полагают, что вы встроили собственную навигацию в приложение.
Например, если у вас есть страница, то эта страница должна иметь обратную ссылку на пользовательский интерфейс приложения, или пользователям придется закрывать и повторно открывать приложение, чтобы вернуться обратно к главному экрану.
Прогрессивные приложения — инструкция
-------------------------------------
В сети существует множество информации о создании прогрессивных веб-приложений, но по большей части она устаревшая, а многие источники содержат только фрагменты того, что вам нужно чтобы создать приложение. Давайте исправим это.
Включить HTTPS
--------------
Чтобы включить HTTPS вам понадобится:
* Веб-сервер (я рекомендую DigitalOcean)
* [SSL сертификат](https://certbot.eff.org/all-instructions/#ubuntu-16-04-xenial-nginx)
* Сильная группа Diffie-Hellman (`sudo openssl dhparam -out /etc/ssl/certs/dhparam.pem 2048`)
* TLS/SSL конфигурация для вашего веб-сервера ([инструкции для Nginx на Ubuntu](https://www.digitalocean.com/community/tutorials/how-to-secure-nginx-with-let-s-encrypt-on-ubuntu-14-04))
Манифест
--------
Файл манифеста называется `manifest.json` и он достаточно простой. Он состоит из имени (`short_name` для иконки домашнего экрана и опционального `name` для более полного названия), начального url, большого списка иконок чтобы вы могли поддерживать широкий спектр если для разных платформ нужны разные размеры иконки. Для Android и iOS вам понадобится:
* 36\*36
* 48\*48
* 60\*60 (значок Apple touch на iPhone)
* 72\*72
* 76\*76 (значок Apple touch на iPad)
* 96\*96
* 120\*120 (значок Apple touch на iPhone retina)
* 152\*152 (значок Apple touch на iPad retina)
* 180\*180 (значок Apple touch для iOS 8+ )
* 192\*192
* 512\*512
Я выделил значки Apple touch потому что у них известные имена:
`apple-touch-icon-180x180.png`
Где 180\*180 может быть заменено на любое нужное разрешение. Использование известных имен не обязательно, но если вы забудете включить тэги, iOS все-равно сможет найти иконки, ища их в корневой директории вашего веб-приложения, если вы будете использовать известные имена.
**Иконки iOS не поддерживают прозрачность.**
#### Простой manifest.json:
```
{
"name": "My Progressive Web Application",
"short_name": "Progressive",
"start_url": "/?home=true",
"icons": [
{
"src": "/icons/icon36.png",
"sizes": "36x36",
"type": "image/png"
},
{
"src": "/icons/icon48.png",
"sizes": "48x48",
"type": "image/png"
},
{
"src": "/icons/icon60.png",
"sizes": "60x60",
"type": "image/png"
},
{
"src": "/icons/icon72.png",
"sizes": "72x72",
"type": "image/png"
},
{
"src": "/icons/icon76.png",
"sizes": "76x76",
"type": "image/png"
},
{
"src": "/icons/icon96.png",
"sizes": "96x96",
"type": "image/png"
},
{
"src": "/icons/icon120.png",
"sizes": "120x120",
"type": "image/png"
},
{
"src": "/icons/icon152.png",
"sizes": "152x152",
"type": "image/png"
},
{
"src": "/icons/icon180.png",
"sizes": "180x180",
"type": "image/png"
},
{
"src": "/icons/icon192.png",
"sizes": "192x192",
"type": "image/png"
},
{
"src": "/icons/icon512.png",
"sizes": "512x512",
"type": "image/png"
}
],
"theme_color": "#000000",
"background_color": "#FFFFFF",
"display": "fullscreen",
"orientation": "portrait"
}
```
Существуют некоторые функции, о которых вам следует знать. `theme_color` устанавливает цвет статусной строки, а заголовок окна используется при переключении между приложениями на Android.
`background_color` устанавливает цвет заставки. На Android заставка будет состоять из свойства `name` (длинное имя) и большой иконки поверх `background_color`.
#### Манифест есть не везде
Когда с создал первое прогрессивное веб-приложение, я был потрясен тем, что оно работало как и предполагалось в Chrome на Android, но не в Safari /iOS. Причина в том, что мобильный Safari, несмотря на десятилетнюю поддержку этих функций, используя свои специфичные тэги не поддерживает до сих пор спецификацию веб-манифеста.
Поэтому в дополнение к файлу манифеста для поддерживаемых браузеров вам также понадобятся специальные мета тэги для iOS, начиная с этого, который будет запускать приложение без оболочки браузера:

Существует множество тэгов, о которых надо помнить, хотя есть и другой способ. Есть [web manifest polyfill](https://github.com/boyofgreen/manUp.js/), который прочтет ваш manifest.json файл и добавит тэги производителей для более старых мобильных браузеров, iOS и даже для Windows phone и Firefox OS.
*Перевод: Ольга Чернопицкая*
**Продолжение следует**
*Поддержка публикации — компания [Edison](https://www.edsd.com/), которая разрабатывает [автоматическую систему сборки прошивки для сетевой техники](https://www.edsd.ru/avtomaticheskaya-sistema-sborki-proshivki), а так же делает [перевод ПО на русский для транснациональной промышленной корпорации](https://www.edsd.ru/kalkulyator-dlya-podbora-avtopokryshek).* | https://habr.com/ru/post/316000/ | null | ru | null |
# Multiple Delegate
В Cocoa очень популярен [паттерн делегирование](http://en.wikipedia.org/wiki/Delegation_pattern). Стандартный способ реализации этого паттерна — добавление к делегатору weak свойства, которое хранит ссылку на делегат.
У делегирования много различных применений. Например, реализация какого-то поведения в другом классе без наследования. Еще делегирование используется как способ передачи уведомлений. Например, UITextField вызывает у делегата метод textFieldDidEndEditing:, который информирует его о том, что редактирование закончено, и т.д.
А теперь представьте задачу: надо сделать так, чтобы делегатор посылал сообщения не одному делегату, а нескольким, причем делегирование реализовано стандартным методом через свойство.
#### Пример
Пример немного притянутый, но все же.
Нужно сделать кастомный UITextField, который будет проверять введенный в него текст, и если текст невалидный, то контрол будет менять цвет. Плюс надо сделать так, чтобы пользователь мог ввести только заданное число символов.
Т.е хотим что-то вроде этого:
```
@protocol PTCTextValidator
- (BOOL)textIsValid:(NSString \*)text;
- (BOOL)textLengthIsValid:(NSString \*)text;
@end
@interface PTCVerifiableTextField : UITextField
@property (nonatomic, weak) IBOutlet id validator;
@property (nonatomic, strong) UIColor \*validTextColor UI\_APPEARANCE\_SELECTOR;
@property (nonatomic, strong) UIColor \*invalidTextColor UI\_APPEARANCE\_SELECTOR;
@property (nonatomic, readonly) BOOL isValid;
@end
```
И тут возникает проблема. Чтобы PTCVerifiableTextField реализовал кастомное поведение, нужно чтобы он был делегатом своего суперкласса (UITextField). Но если так сделать, то нельзя будет трогать свойство delegate извне.
Т.е. нижеприведенный код поломает внутреннюю логику PTCVerifiableTextField
```
PTCVerifiableTextField *textField = [PTCVerifiableTextField alloc] initWIthFrame:CGrectMake(0, 0, 100 20)];
textField.delegate = self;
[self.view addSubview:textField];
```
Таким образом, получаем задачу: сделать так, чтобы свойству
```
@property(nonatomic, assign) id delegate
```
можно было присвоить несколько объектов.
#### Решение
Решение напрашивается само собой. Надо сделать контейнер, который будет хранить несколько делегатов и сообщения, которые будут приходить не в него, а в объекты, которые хранятся в контейнере.
Т.е нужен контейнер, проксирующий запросы к хранящимся в нем элементам.
У такого решения есть один большой недостаток — если делегируемая функция возвращает значение, то надо как-то определить, результат вызова какого делегата считать за возвращаемое значение.
Итак, перед тем, как что-то проксировать, надо разобраться, что такое Message Forwarding и NSProxy.
#### Message Forwarding
Objective-C работает с сообщениями. Мы не вызываем метод на объекте. Вместо этого, мы шлем ему сообщение. Таким образом, под Message Forwarding понимается редирект сообщения другому объекту, т.е. его проксирование.
Важно отметить, что отправка объекту сообщения, на которое он не отвечает, дает ошибку. Однако перед тем, как ошибка будет сгенерирована, рантайм даст объекту еще один шанс, чтобы обработать сообщение.
Давайте рассмотрим, что происходит при отправке объекту сообщения.
1. Если объект реализует метод, т.е можно получить IMP (например, при помощи `method_getImplementation(class_getInstanceMethod(subclass, aSelecor))`), то рантайм вызывает метод. В противном случае, идем дальше.
2. Вызывается `+(BOOL)resolveInstanceMethod:(SEL)aSEL` или `+(BOOL)resolveClassMethod:(SEL)name`, если шлем сообщение классу. Этот метод дает возможность добавить нужный селектор динамически. Если возвращается YES, то рантайм сново пытается получить IMP и вызвать метод. В противном случае, идем дальше.
Еще данный метод вызывается при `+(BOOL)respondsToSelector:(SEL)aSelector` и `+(BOOL)instancesRespondToSelector:(SEL)aSelector`, если селектор не реализован. Причем, данный метод вызывается только один раз для каждого селектора, второго шанса добавить метод не будет!
Пример динамического добавления метода:
```
+ (BOOL)resolveInstanceMethod:(SEL)aSEL
{
if (aSEL == @selector(resolveThisMethodDynamically))
{
class_addMethod([self class], aSEL, (IMP) dynamicMethodIMP, "v@:");
return YES;
}
return [super resolveInstanceMethod:aSel];
}
```
3. Выполняется так называемый Fast Forwarding. А именно, вызывается метод `-(id)forwardingTargetForSelector:(SEL)aSelector`
Этот метод возвращает объект, который надо использовать вместо текущего. В общем-то, очень удобная штука для имитации множественного наследования. Fast он, потому что на данном этапе можно сделать форвардинг без создания NSInvoacation.
Для возвращенного этим методом объекта будут повторены все шаги. Согласно документации, если вернуть self, то будет бесконечный цикл. На практике, бесконечного цикла не возникает: видимо, в рантайм внесли поправки.
4. Два предыдущих шага являются оптимизацией форвардинга. После них рантайм создает NSInvocation.
Создание NSInvocation рантаймом выглядит примерно так:
```
NSMethodSignature *sig = ...
NSInvocation* inv = [NSInvocation invocationWithMethodSignature:sig];
[inv setSelector:selector];
```
Т.е для создания NSInvocation, рантайму надо получить сигнатуру метода (NSMethodSignature). Поэтому у объекта вызывается `- (NSMethodSignature *)methodSignatureForSelector:(SEL)aSelector`. Если метод вместо NSMethodSignature вернет nil, то рантайм вызовет у объекта `-(void)doesNotRecognizeSelector:(SEL)aSelector`, т.е. произойдет крэш.
Создать NSMethodSignature можно следующими способами:
* использовать метод `+(NSMethodSignature *)instanceMethodSignatureForSelector:(SEL)aSelector`
Заметьте, если класс всего лишь заявляет, что реализует протокол (`@interface MyClass : NSObject ), то этот методу уже вернет не nil, а сигнатуру.`
использовать метод `-(NSMethodSignature *)methodSignatureForSelector:(SEL)aSelector`
Внутри вызывает [[self class] instanceMethodSignatureForSelector:...]
использовать метод `+(NSMethodSignature *)signatureWithObjCTypes:(const char *)types` принадлежащий классу NSMethodSignature и собрать NSMethodSignature самому
. | https://habr.com/ru/post/227321/ | null | ru | null |
# Недостающее введение в контейнеризацию
Эта [статья](https://medium.com/faun/the-missing-introduction-to-containerization-de1fbb73efc5) помогла мне немного углубится в устройство и принцип работы контейнеров. Поэтому решил ее перевести. "Экосистема контейнеров иногда может сбивать с толку, этот пост может помочь вам понять некоторые запутанные концепции Docker и контейнеров. Мы также увидим, как развивалась экосистема контейнеров". Статья 2019 года.
Docker - одна из самых известных платформ контейнеризации в настоящее время, она была выпущена в 2013 году. Однако использование изоляции и контейнеризации началось раньше. Давайте вернемся в 1979 год, когда мы начали использовать Chroot Jail, и посмотрим на самые известные технологии контейнеризации, появившиеся после. Это поможет нам понять новые концепции.
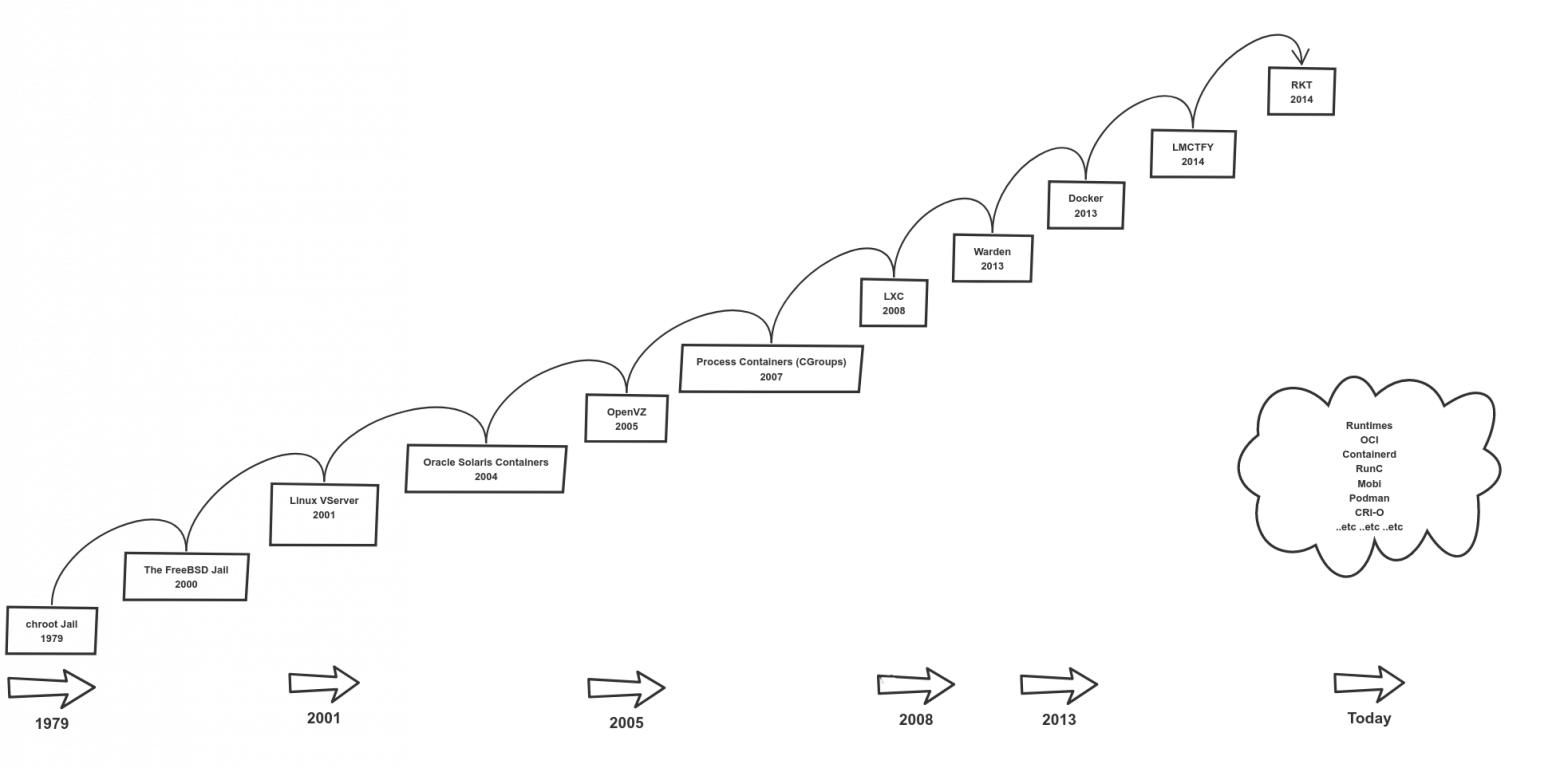Все началось с того, что **Chroot Jail** и системный вызов Chroot были введены во время разработки версии [7 Unix](https://en.wikipedia.org/wiki/Version_7_Unix) в 1979 году. Chroot jail предназначен для «Change Root» и считается одной из первых технологий контейнеризации. Он позволяет изолировать процесс и его дочерние элементы от остальной части операционной системы. Единственная проблема с этой изоляцией заключается в том, что корневой процесс может легко выйти из chroot. В нем никогда не задумывались механизмы безопасности. **FreeBSD Jail** была представлена в ОС FreeBSD в 2000 году и была предназначена для обеспечения большей безопасности простой изоляции файлов Chroot. В отличие от Chroot, реализация FreeBSD также изолирует процессы и их действия от Файловой системы.
Chroot Jail. Источник: https://linuxhill.wordpress.com/2014/08/09/014-setting-up-a-chroot-jail-in-crunchbang-11debian-wheezyКогда в ядро Linux были добавлены возможности виртуализации на уровне операционной системы, в 2001 году был представлен **Linux VServer**, который использовал chroot-подобный механизм в сочетании с «security contexts (контекстами безопасности)», так и виртуализацию на уровне операционной системы. Он более продвинутый, чем простой chroot, и позволяет запускать несколько дистрибутивов Linux на одном VPS.
В феврале 2004 года Sun (позже приобретенная Oracle) выпустила (Oracle) Solaris Containers, реализацию Linux-Vserver для процессоров X86 и SPARC. Контейнер Solaris - это комбинация элементов управления ресурсами системы и разделения ресурсов, обеспечиваемых «zone».
Подобно контейнерам Solaris, первая версия **OpenVZ** была представлена в 2005 году. OpenVZ, как и Linux-VServer, использует виртуализацию на уровне ОС и был принят многими хостинговыми компаниями для изоляции и продажи VPS. Виртуализация на уровне ОС имеет некоторые ограничения, поскольку контейнеры и хост используют одну и ту же архитектуру и версию ядра, недостаток возникает в ситуациях, когда гостям требуются версии ядра, отличные от версии на хосте. Linux-VServer и OpenVZ требуют патча ядра, чтобы добавить некоторые механизмы управления, используемые для создания изолированного контейнера. Патчи OpenVZ не были интегрированы в ядро.
В 2007 году Google выпустил **CGroups** - механизм, который ограничивает и изолирует использование ресурсов (ЦП, память, дисковый ввод-вывод, сеть и т. д.) для набора процессов. CGroups были, в отличие от ядра OpenVZ, встроены в ядро Linux в 2007 году.
В 2008 году была выпущена первая версия LXC (Linux Containers). LXC похож на OpenVZ, Solaris Containers и Linux-VServer, однако он использует CGroups, которые уже реализованы в ядре Linux. Затем в 2013 году компания CloudFoundry создала Warden - API для управления изолированными, эфемерными средами с контролируемыми ресурсами. В своих первых версиях Warden использовал LXC.
В 2013 году была представлена первая версия **Docker**. Он выполняет виртуализацию на уровне операционной системы, как и контейнеры OpenVZ и Solaris.
В 2014 году Google представил **LMCTFY**, версию стека контейнеров Google с открытым исходным кодом, которая предоставляет контейнеры для приложений Linux. Инженеры Google сотрудничают с Docker над libcontainer и переносят основные концепции и абстракции в libcontainer. Проект активно не развивается, и в будущем ядро этого проекта, вероятно, будет заменено libcontainer.
LMCTFY запускает приложения в изолированных средах на том же ядре и без патчей, поскольку он использует CGroups, namespases и другие функции ядра Linux.
Фото Павла Червиньского для UnsplashGoogle - лидер в контейнерной индустрии. Все в Google работает на контейнерах. Каждую неделю в инфраструктуре Google работает [более 2 миллиардов контейнеров](https://speakerdeck.com/jbeda/containers-at-scale).
В декабре 2014 года CoreOS выпустила и начала поддерживать rkt (первоначально выпущенную как Rocket) в качестве альтернативы Docker.
Jails, VPS, Zones, контейнеры и виртуальные машины
--------------------------------------------------
Изоляция и управление ресурсами являются общими целями использования Jail, Zone, VPS, виртуальных машин и контейнеров, но каждая технология использует разные способы достижения этого, имеет свои ограничения и свои преимущества.
До сих пор мы вкратце видели, как работает Jail, и представили, как Linux-VServer позволяет запускать изолированные пользовательские пространства, в которых программы запускаются непосредственно в ядре операционной системы хоста, но имеют доступ к ограниченному подмножеству его ресурсов.
Linux-VServer позволяет запускать VPS, и для его использования необходимо пропатчить ядро хоста.
Контейнеры Solaris называются Zones.
«Виртуальная машина» - это общий термин для описания эмулируемой виртуальной машины поверх «реальной аппаратной машины». Этот термин был первоначально определен Попеком и Голдбергом как эффективная изолированная копия реальной компьютерной машины.
Виртуальные машины могут быть «**System Virtual Machines** (системными виртуальными машинами)» или «**Process Virtual Machines (**процессными виртуальными машинами)». В повседневном использовании под словом «виртуальные машины» мы обычно имеем в виду «системные виртуальные машины», которые представляют собой эмуляцию оборудования хоста для эмуляции всей операционной системы. Однако «Process Virtual Machines», иногда называемый «Application Virtual Machine (Виртуальной машиной приложения)», используется для имитации среды программирования для выполнения отдельного процесса: примером является виртуальная машина Java.
Виртуализация на уровне ОС также называется контейнеризацией. Такие технологии, как Linux-VServer и OpenVZ, могут запускать несколько операционных систем, используя одну и ту же архитектуру и версию ядра.
Совместное использование одной и той же архитектуры и ядра имеет некоторые ограничения и недостатки в ситуациях, когда гостям требуются версии ядра, отличные от версии хоста.
Источник: https://fntlnz.wtf/post/why-containersСистемные контейнеры (например, LXC) предлагают среду, максимально приближенную к той, которую вы получаете от виртуальной машины, но без накладных расходов, связанных с запуском отдельного ядра и имитацией всего оборудования.
VM vs Container. Источник: Docker BlogКонтейнеры ОС vs контейнеры приложений
--------------------------------------
Виртуализация на уровне ОС помогает нам в создании контейнеров. Такие технологии, как LXC и Docker, используют этот тип изоляции.
Здесь у нас есть два типа контейнеров:
* Контейнеры ОС, в которые упакована операционная система со всем стеком приложений (пример LEMP).
* Контейнеры приложений, которые обычно запускают один процесс для каждого контейнера.
В случае с контейнерами приложений у нас будет 3 контейнера для создания стека LEMP:
* сервер PHP (или PHP FPM).
* Веб-сервер (Nginx).
* Mysql.
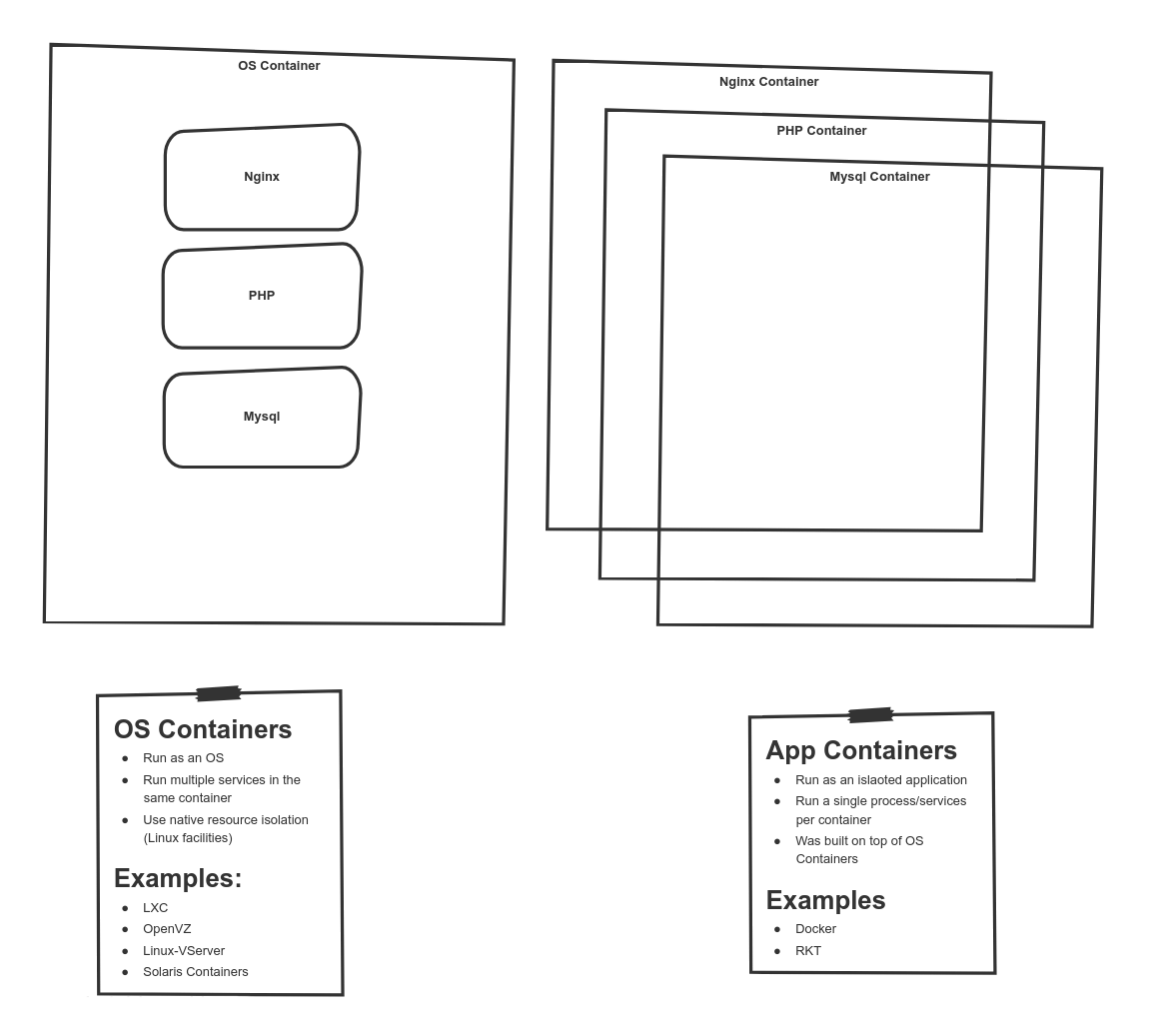Докер: контейнер или платформа?
-------------------------------
**Коротко:** и то и другое
**Подробный ответ:**
Когда Docker начал использовать LXC в качестве среды выполнения контейнера, идея заключалась в том, чтобы создать API для управления средой выполнения контейнера, изолировать отдельные процессы, выполняющие приложения, и контролировать жизненный цикл контейнера и ресурсы, которые он использует. В начале 2013 года проект Docker должен был создать «стандартный контейнер», как мы можем видеть в этом [манифесте](https://github.com/moby/moby/commit/0db56e6c519b19ec16c6fbd12e3cee7dfa6018c5).
Манифест стандартного контейнера [был удален](https://github.com/docker/docker/commit/eed00a4afd1e8e8e35f8ca640c94d9c9e9babaf7).
Docker начал создавать монолитное приложение с множеством функций - от запуска облачных серверов до создания и запуска образов / контейнеров. Docker использовал **libcontainer** для взаимодействия с такими средствами ядра Linux, как **Control Groups** и **Namespaces**.
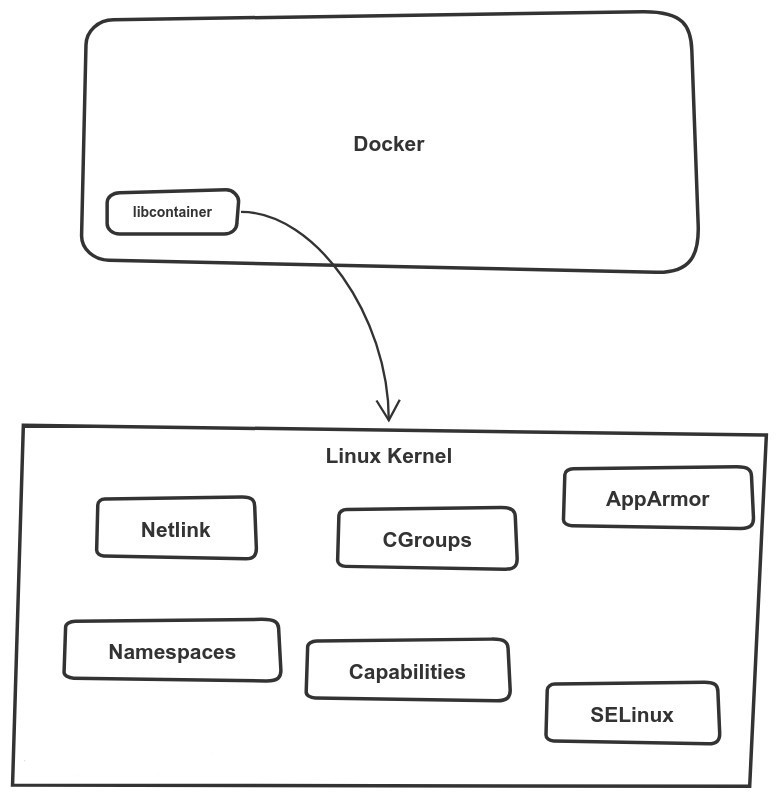 **Давайте создадим контейнер с использованием СGroups и Namespaces**
В этом примере я использую Ubuntu, но это должно работать для большинства дистрибутивов. Начните с установки CGroup Tools and утилиты stress, поскольку мы собираемся выполнить некоторые стресс-тесты.
```
sudo apt install cgroup-tools
sudo apt install stress
```
Эта команда создаст новый контекст исполнения:
```
sudo unshare --fork --pid --mount-proc bash
ps aux
```
Команда "[unshare](http://man7.org/linux/man-pages/man2/unshare.2.html)" разъединяет части контекста исполнения процесса
Теперь, используя *cgcreate*, мы можем создать группы управления и определить два контроллера: один в памяти, а другой - в процессоре.
```
cgcreate -a $USER -g memory:mygroup -g cpu:mygroup
ls /sys/fs/cgroup/{memory,cpu}/mygroup
```
 Следующим шагом будет определение лимита памяти и его активация:
```
echo 3000000 > /sys/fs/cgroup/memory/mygroup/memory.kmem.limit_in_bytes
cgexec -g memory:mygroup bash
```
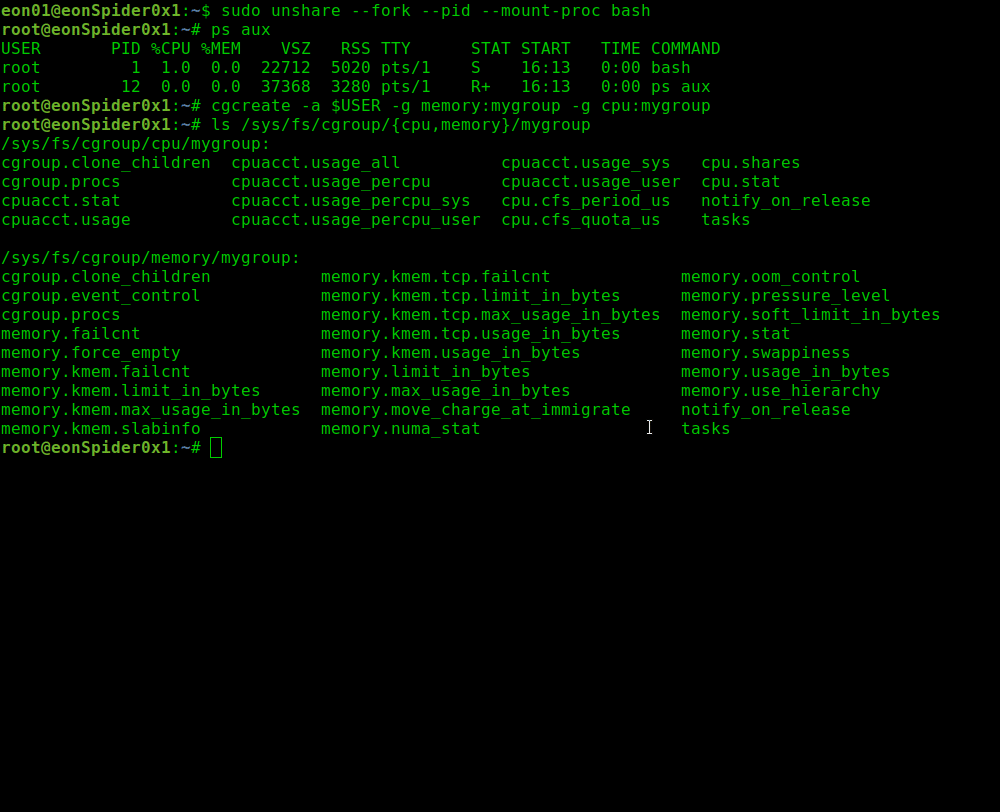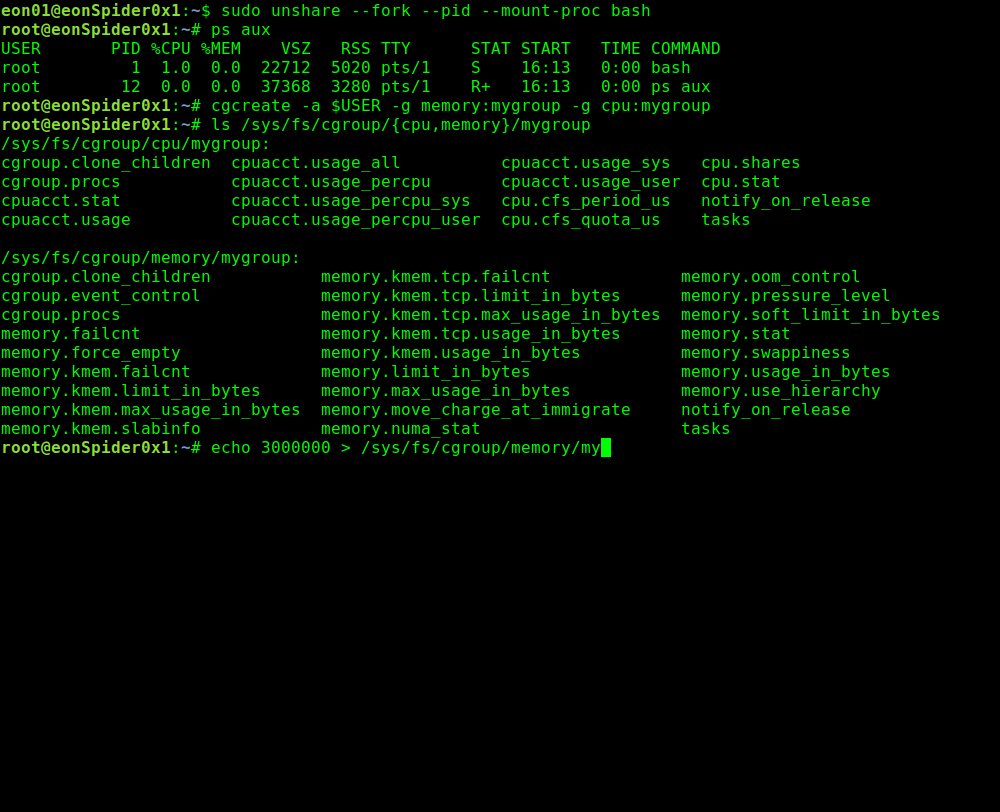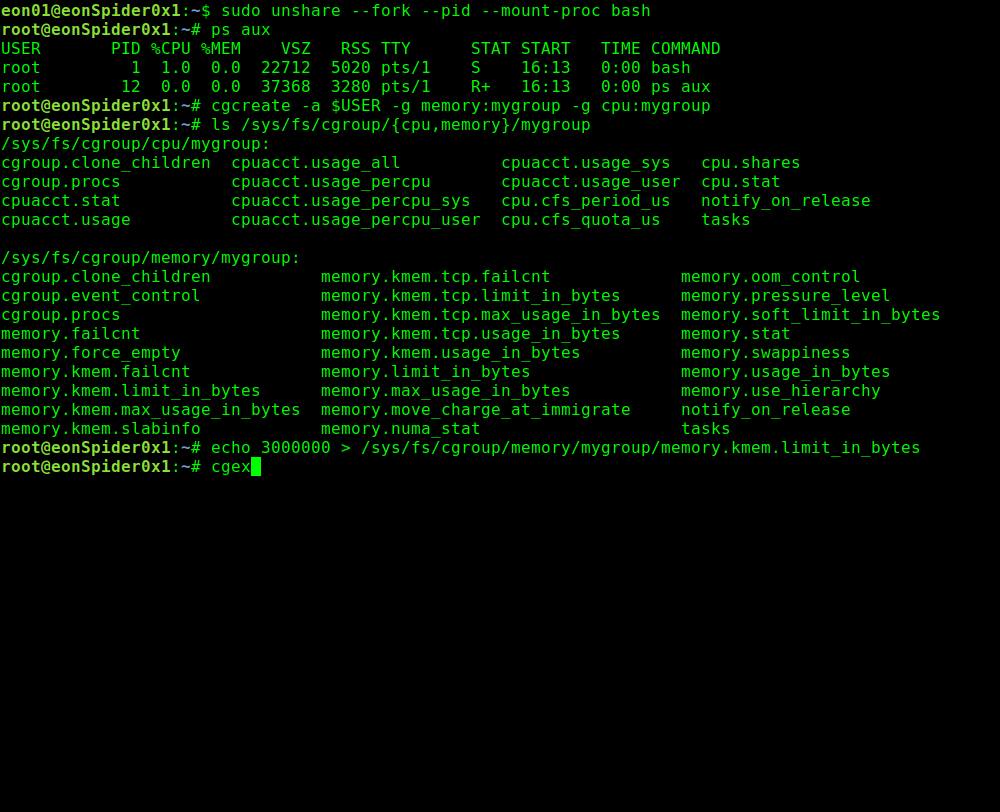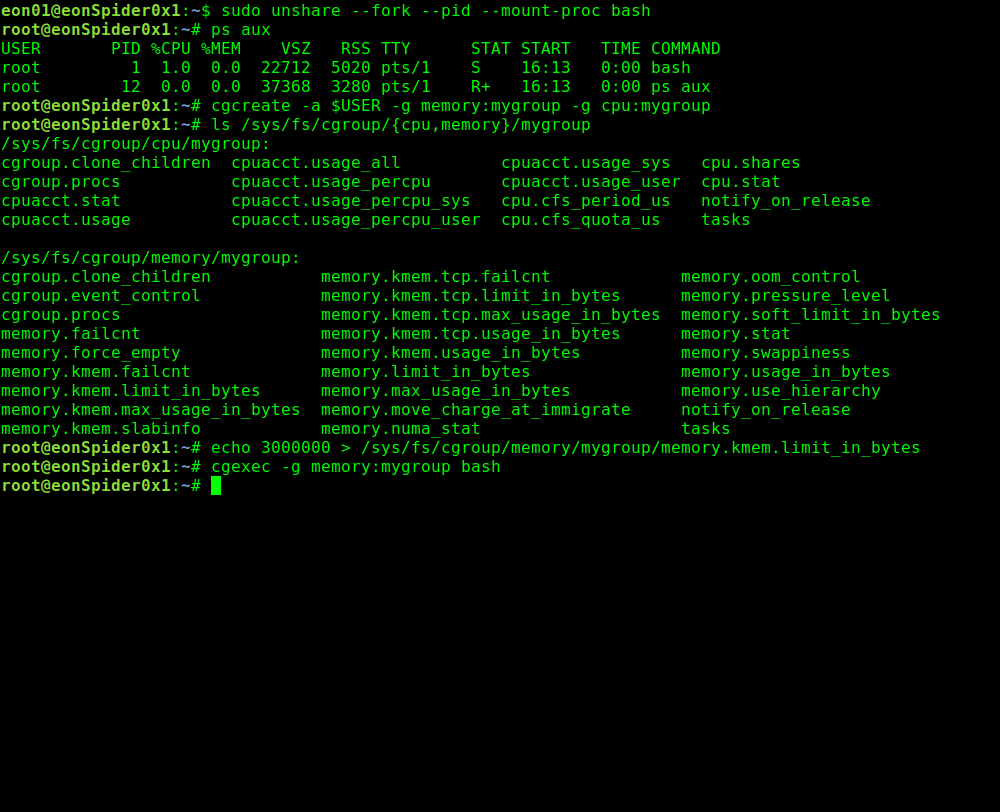Теперь давайте запустим stress для изолированного namespace, которое мы создали с ограничениями памяти.
```
stress --vm 1 --vm-bytes 1G --timeout 10s
```
Мы можем заметить, что выполнение не удалось, значит ограничение памяти работает. Если мы сделаем то же самое на хост-машине, тест завершится без ошибки, если у вас действительно достаточно свободной памяти:
Выполнение этих шагов поможет понять, как средства Linux, такие как CGroups и другие функции управления ресурсами, могут создавать изолированные среды в системах Linux и управлять ими.
Интерфейс **libcontainer** взаимодействует с этими средствами для управления контейнерами Docker и их запуска.
runC: Использование libcontainer без Docker
-------------------------------------------
В 2015 году Docker анонсировал runC: легкую портативную среду выполнения контейнеров.
runC - это, по сути, небольшой инструмент командной строки для непосредственного использования libcontainer, без использования Docker Engine.
Цель runC - сделать стандартные контейнеры доступными повсюду.
Этот проект был передан в дар Open Container Initiative (OCI).
Репозиторий libcontainer сейчас заархивирован. На самом деле, libcontainer не забросили, а перенесли в репозиторий runC.
Перейдем к практической части и создадим контейнер с помощью runC. Начните с установки среды выполнения runC (прим. переводчика: если стоит docker то этого можно (нужно) не делать):
```
sudo apt install runc
```
Давайте создадим каталог (/mycontainer), в который мы собираемся экспортировать содержимое образа [Busybox](https://hub.docker.com/_/busybox).

```
sudo su
mkdir /mycontainer
cd /mycontainer/
mkdir rootfs
docker export $(docker create busybox) | tar -C rootfs -xvf -
```
Используя команду runC, мы можем запустить контейнер busybox, который использует извлеченный образ и файл спецификации (config.json).

```
runc spec
runc run mycontainerid
```
Команда *runc spec* изначально создает этот файл JSON:
```
{
"ociVersion": "1.0.1-dev",
"process": {
"terminal": true,
"user": {
"uid": 0,
"gid": 0
},
"args": [
"sh"
],
"env": [
"PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin",
"TERM=xterm"
],
"cwd": "/",
"capabilities": {
"bounding": [
"CAP_AUDIT_WRITE",
"CAP_KILL",
"CAP_NET_BIND_SERVICE"
],
"effective": [
"CAP_AUDIT_WRITE",
"CAP_KILL",
"CAP_NET_BIND_SERVICE"
],
"inheritable": [
"CAP_AUDIT_WRITE",
"CAP_KILL",
"CAP_NET_BIND_SERVICE"
],
"permitted": [
"CAP_AUDIT_WRITE",
"CAP_KILL",
"CAP_NET_BIND_SERVICE"
],
"ambient": [
"CAP_AUDIT_WRITE",
"CAP_KILL",
"CAP_NET_BIND_SERVICE"
]
},
"rlimits": [
{
"type": "RLIMIT_NOFILE",
"hard": 1024,
"soft": 1024
}
],
"noNewPrivileges": true
},
"root": {
"path": "rootfs",
"readonly": true
},
"hostname": "runc",
"mounts": [
{
"destination": "/proc",
"type": "proc",
"source": "proc"
},
{
"destination": "/dev",
"type": "tmpfs",
"source": "tmpfs",
"options": [
"nosuid",
"strictatime",
"mode=755",
"size=65536k"
]
},
{
"destination": "/dev/pts",
"type": "devpts",
"source": "devpts",
"options": [
"nosuid",
"noexec",
"newinstance",
"ptmxmode=0666",
"mode=0620",
"gid=5"
]
},
{
"destination": "/dev/shm",
"type": "tmpfs",
"source": "shm",
"options": [
"nosuid",
"noexec",
"nodev",
"mode=1777",
"size=65536k"
]
},
{
"destination": "/dev/mqueue",
"type": "mqueue",
"source": "mqueue",
"options": [
"nosuid",
"noexec",
"nodev"
]
},
{
"destination": "/sys",
"type": "sysfs",
"source": "sysfs",
"options": [
"nosuid",
"noexec",
"nodev",
"ro"
]
},
{
"destination": "/sys/fs/cgroup",
"type": "cgroup",
"source": "cgroup",
"options": [
"nosuid",
"noexec",
"nodev",
"relatime",
"ro"
]
}
],
"linux": {
"resources": {
"devices": [
{
"allow": false,
"access": "rwm"
}
]
},
"namespaces": [
{
"type": "pid"
},
{
"type": "network"
},
{
"type": "ipc"
},
{
"type": "uts"
},
{
"type": "mount"
}
],
"maskedPaths": [
"/proc/kcore",
"/proc/latency_stats",
"/proc/timer_list",
"/proc/timer_stats",
"/proc/sched_debug",
"/sys/firmware",
"/proc/scsi"
],
"readonlyPaths": [
"/proc/asound",
"/proc/bus",
"/proc/fs",
"/proc/irq",
"/proc/sys",
"/proc/sysrq-trigger"
]
}
}
```
Альтернативой для создания кастомной спецификации конфигурации является использование «oci-runtime-tool», подкоманда «oci-runtime-tool generate» имеет множество опций, которые можно использовать для выполнения разных настроек.
Для получения дополнительной информации см. [Runtime-tools](https://github.com/opencontainers/runtime-tools).
Используя сгенерированный файл спецификации JSON, вы можете настроить время работы контейнера. Мы можем, например, изменить аргумент для выполнения приложения.
 Давайте посмотрим, чем отличается исходный файл config.json от нового:
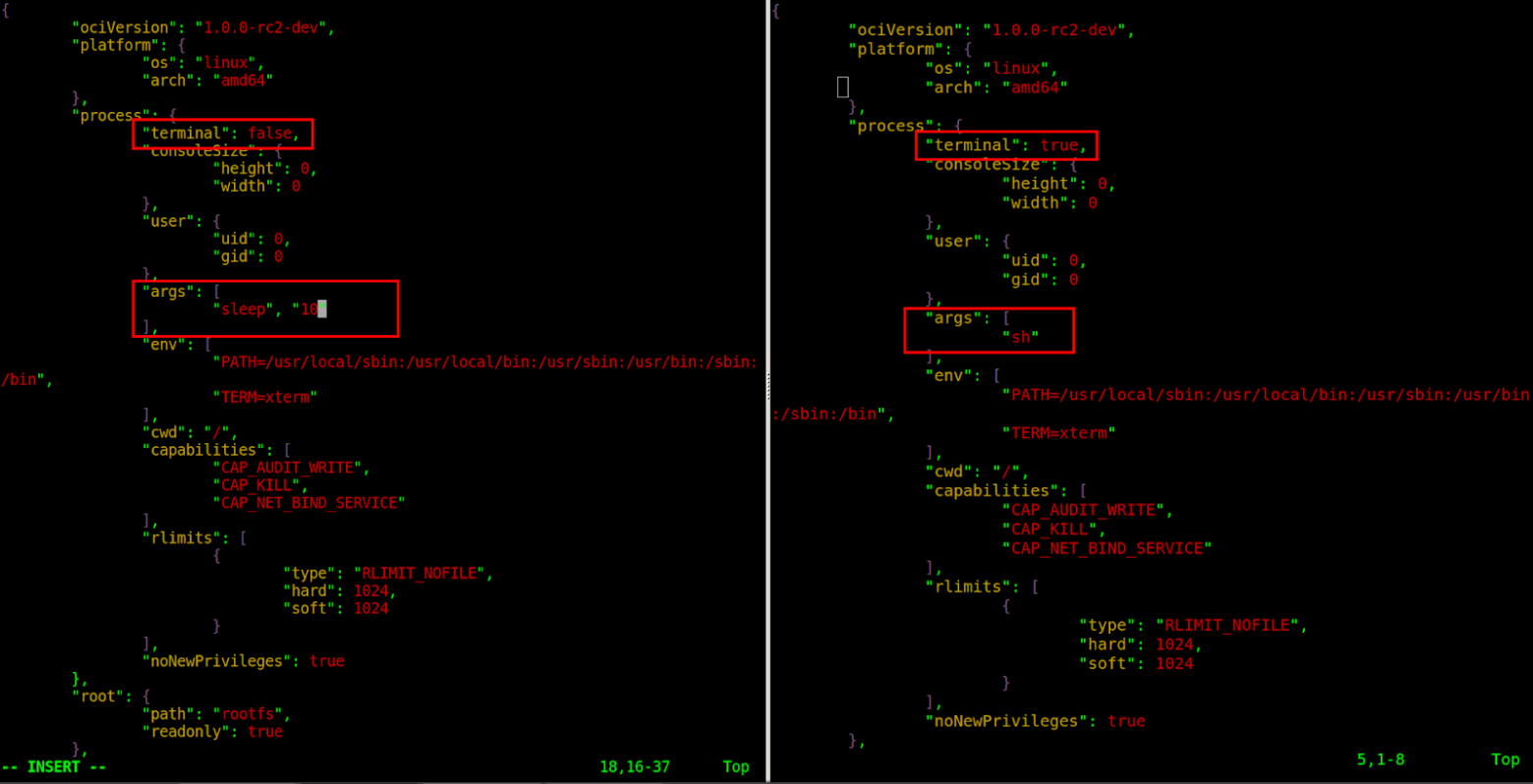 Давайте теперь снова запустим контейнер и заметим, как он ожидает 10 секунд, прежде чем завершится.
Стандарты сред исполнения контейнеров
-------------------------------------
С тех пор, как контейнеры стали широко распространенными, различные участники этой экосистемы работали над стандартизацией. Стандартизация - ключ к автоматизации и обобщению передового опыта. Передав проект runC OCI, Docker начал использовать containerd в 2016 году в качестве среды выполнения контейнера, взаимодействующей с базовой средой исполнения низкого уровня runC.
```
docker info | grep -i runtime
```
Containerd полностью поддерживает запуск пакетов OCI и управление их жизненным циклом. Containerd (как и другие среды выполнения, такие как cri-o) использует runC для запуска контейнеров, но реализует также другие высокоуровневые функции, такие как управление образами и высокоуровневые API.
Интеграция containerd со средами выполнения Docker и OCIСontainerd, Shim и RunC, как все работает вместе
------------------------------------------------
runC построен на libcontainer, который является той же библиотекой, которая ранее использовалась для Docker Engine.
До версии 1.11 Docker Engine использовался для управления томами, сетями, контейнерами, образами и т. д.
Теперь архитектура Docker разбита на четыре компонента:
* Docker engine
* containerd
* containerd-shim
* runC
Бинарные файлы соответственно называются docker, docker-containerd, docker-containerd-shim и docker-runc.
Давайте перечислим этапы запуска контейнера с использованием новой архитектуры docker:
1. Docker engine создает контейнер (из образа) и передает его в containerd.
2. Containerd вызывает containerd-shim
3. Containerd-shim использует runC для запуска контейнера
4. Containerd-shim позволяет среде выполнения (в данном случае runC) завершиться после запуска контейнера
Используя эту новую архитектуру, мы можем запускать «контейнеры без служб» (“daemon-less containers”), и у нас есть два преимущества:
1. runC может завершиться после запуска контейнера, и нам не нужны запущенными все процессы исполнения.
2. containerd-shim сохраняет открытыми файловые дескрипторы, такие как stdin, stdout и stderr, даже когда Docker и /или containerd завершаются.
«Если runC и Containerd являются средами исполнения, какого черта мы используем оба для запуска одного контейнера?»
-------------------------------------------------------------------------------------------------------------------
Это, наверное, один из самых частых вопросов. Поняв, почему Docker разбил свою архитектуру на runC и Containerd, вы понимаете, что оба являются средами исполнения.
Если вы следили за историей с самого начала, вы, вероятно, заметили использование сред исполнения высокого и низкого уровня. В этом практическая разница между ними.
Обе они могут называться средами исполнения, но каждая среда исполнения имеет разные цели и функции. Чтобы сохранить стандартизацию экосистемы контейнеров, среда исполнения низкоуровневых контейнеров позволяет запускать только контейнеры.
Среда исполнения низкого уровня (например, runC) должна быть легкой, быстрой и не конфликтовать с другими более высокими уровнями управления контейнерами. Когда вы создаете контейнер Docker, он фактически управляет двумя средами исполнения containerd и runC.
Вы можете найти множество сред исполнения контейнеров, некоторые из них стандартизированы OCI, а другие нет, некоторые являются средами исполнения низкого уровня, а другие представляют собой нечто большее и реализуют уровень инструментов для управления жизненным циклом контейнеров и многое другое:
* передача и хранение образов,
* завершение и наблюдение за контейнерами,
* низкоуровневое хранилище,
* сетевые настройки,
* и т.п.
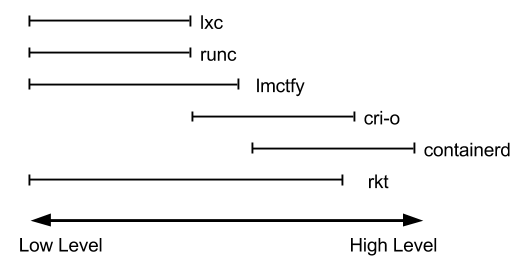Мы можем добавить новую среду исполнения с помощью Docker, выполнив:
```
sudo dockerd --add-runtime==
```
Например:
```
sudo apt-get install nvidia-container-runtime
sudo dockerd --add-runtime=nvidia=/usr/bin/nvidia-container-runtime
```
Интерфейс среды исполнения контейнера (Container Runtime Interface)
-------------------------------------------------------------------
Kubernetes - одна из самых популярных систем оркестровки. С ростом числа сред выполнения контейнеров Kubernetes стремится быть более расширяемым и взаимодействовать с большим количеством сред выполнения контейнеров, помимо Docker.
Первоначально Kubernetes использовал среду исполнения Docker для запуска контейнеров, и она по-прежнему остается средой исполнения по умолчанию.
Однако CoreOS хотела использовать Kubernetes со средой исполнения RKT и предлагала патчи для Kubernetes, чтобы использовать эту среду исполнения в качестве альтернативы Docker.
Вместо изменения кодовой базы kubernetes в случае добавлении новой среды исполнения контейнера создатели Kubernetes решили создать CRI (Container Runtime Interface), который представляет собой набор API-интерфейсов и библиотек, позволяющих запускать различные среды исполнения контейнеров в Kubernetes. Любое взаимодействие между ядром Kubernetes и поддерживаемой средой выполнения осуществляется через CRI API.
Вот некоторые из плагинов CRI:
**CRI-O:**
CRI-O - это первая среда исполнения контейнера, созданная для интерфейса CRI kubernetes. Cri-O не предназначен для замены Docker, но его можно использовать вместо среды исполнения Docker в Kubernetes.
**Containerd CRI :**
С cri-containerd пользователи могут запускать кластеры Kubernetes, используя containerd в качестве базовой среды исполнения без установленного Docker.
**gVisor CRI:**
gVisor - это проект, разработанный Google, который реализует около 200 системных вызовов Linux в пользовательском пространстве для дополнительной безопасности по сравнению с контейнерами Docker, которые работают непосредственно поверх ядра Linux и изолированы с помощью namespace.
Google Cloud App Engine использует gVisor CRI для изоляции клиентов.
Среда исполнения gVisor интегрируется с Docker и Kubernetes, что упрощает запуск изолированных контейнеров.
**CRI-O Kata Containers**
Kata Containers - это проект с открытым исходным кодом, создающий легкие виртуальные машины, которые подключаются к экосистеме контейнеров. CRI-O Kata Containers позволяет запускать контейнеры Kata в Kubernetes вместо среды выполнения Docker по умолчанию.
Проект Moby
-----------
От проекта создания Docker как единой монолитной платформы отказались и родился проект Moby, в котором Docker состоит из множества компонентов, таких как RunC.
Источник: Solomon Hykes TwitterMoby - это проект по организации и разделения на модули Docker. Это экосистема разработки. Обычные пользователи Docker не заметят никаких изменений.
Источник: Solomon Hykes TwitterMoby помогает в разработке и запуске Docker CE и EE (Moby - это исходный код Docker), а также в создании среды разработки для других сред исполнения и платформ.
Open Containers Initiative
--------------------------
Как мы видели, Docker пожертвовал RunC Open Container Initiative (OCI), но что это?
OCI - это открытая структура, запущенная в 2015 году Docker, CoreOS и другими лидерами контейнерной индустрии.
Open Container Initiative (OCI) направлена на установление общих стандартов для контейнеров, чтобы избежать потенциальной фрагментации и разделения внутри экосистемы контейнеров.
Он содержит две спецификации:
* runtime-spec: спецификация исполнения
* image-spec: спецификация образов
Контейнер, использующий другую среду исполнения, можно использовать с Docker API. Контейнер, созданный с помощью Docker, должен работать с любым другим движком.
На этом статья заканчивается.
Буду рад замечаниям и возможно неточностям в статье оригинального автора. Это позволит избежать заблуждений в понимании внутреннего устройства контейнеров. Если нет возможности комментирования на Хабре, можете обсудить [тут](https://t.me/orangedevops) в комментариях. | https://habr.com/ru/post/541288/ | null | ru | null |
# Кодирование бинарных данных в строку с алфавитом произвольной длины (BaseN)
[](http://habrahabr.ru/post/219993/)Всем хорошо известен алгоритм преобразования массива байт в строку base64. Существует большое количество разновидностей данного алгоритма с различными алфавитами, с хвостовыми символами и без. Есть модификации алгоритма, в котором длина алфавита равна другим степеням двойки, например 32, 16. Однако существуют и более интересные модификации, в которых длина алфавита не кратна степени двойки, такими являются алгоритмы [base85](http://ru.wikipedia.org/wiki/ASCII85), [base91](http://sourceforge.net/projects/base91/). Однако мне не попадался алгоритм, в котором алфавит мог бы быть произвольным, в том числе большей длины, чем 256. Задача показалась мне интересной, и я решил ее реализовать.
Сразу выкладываю ссылку на [**исходники**](https://github.com/KvanTTT/BaseNcoding) и [**демо на js**](http://kvanttt.github.io/BaseNcoding/). Хотя и разработанный алгоритм имеет скорее теоретическое значение, я посчитал нужным описать детали его реализации. Практически его можно использовать, например, для случаев, когда меньшая длина строки актуальней, чем ее размер в байтах (например, в квайнах).
##### Произвольный алфавит
Чтобы понять как можно синтезировать такой алгоритм, я решил разобраться в частном случае, а именно алгоритме base85. Идея у этого алгоритма следующая: входной поток данных разделяется на блоки по 4 байта, затем каждый их них рассматривается как 32-битное число со старшим байтом в начале. Последовательным делением каждого блока на 85 получается 5 цифр 85-ричной системы счисления. Далее каждая цифра кодируется печатным символом из алфавита, размером 85 символов, и выводится в выходной поток, с сохранением порядка, от старшего разряда к младшему.
Но почему был выбран размер 4 байта, т.е. 32 бита? А потому что при этом достигается оптимальное сжатие, т.е. задействовано минимальное количество бит (2^32 = 4294967296) при максимальном количестве символов (85^5 = 4437053125). Однако данную методику можно расширить и для любого другого алфавита. Таким образом была составлена математическая система для поиска количества бит, при котором сжатие будет максимальным:
**a** — размер алфавита **A**.
**k** — количество кодируемых символов.
**b** — основание системы счисления.
**n** — количество бит в системе счисления **b** для представления **k** символов алфавита **A**.
**r** — коэффициент сжатия (чем больше — тем лучше).
**mbc** — максимальный размер блока в битах.
**⌊x⌋** — наибольшее целое, меньшее x (floor).
**⌈x⌉** — наименьшее целое, большее x (ceiling).
Далее с помощью данной методики были найдены оптимальные комбинации бит и закодированных в них символов, которые были изображены на рисунке ниже. Максимальный размер блока — 64 бита (такое число было выбрано из-за того, что при большем количестве необходимо использовать большие числа). Как видим, коэффициент сжатия не всегда увеличивается при увеличении количества символов (это видно в области от 60 и от 91). Красными столбиками изображены известные кодировки (85 и 91). Собственно из диаграммы можно сделать вывод, что такое количество символов для этих кодировок было выбрано не зря, поскольку при этом используется минимальное количество бит при хорошем коэффициенте сжатия. Стоит отметить, что при увеличении максимального размера блока, диаграмма может и измениться (например, для кодировки base85 при 64 битах размер блока будет равен 32 битам, а количество символов — 5 при избыточности 1.25. Если же максимальный размер блока увеличить до 256 бит, то размер блока будет равен 141 биту при 22 символах и избыточности 1.2482).

##### Этапы кодирования
Итак, поэтапно процесс кодирования выглядит следующим образом:
1. Расчет оптимального размера блока (количество бит **n**) и количества соответствующих ему символов (**k**).
2. Представление исходной строки в виде последовательности байтов (используется UTF8).
3. Разбиение исходной последовательности байтов на группы по **n** бит.
4. Преобразование каждой группы бит в число с системой счисления с основанием **a**.
5. Просчет хвостовых бит.
Выполнение первого этапа было рассмотрено выше. Для второго этапа использовался метод для представления строки в виде массива байт (в C# он встроенный *Encoding.UTF8.GetBytes()*, а для JS он был написан вручную *strToUtf8Bytes* и *bytesToUtf8Str*). Далее последующие три этапа будут рассмотрены подробней. Обратное преобразование последовательности символов в массив байт выглядит аналогичным образом.
##### Кодирование блока бит
```
private void EncodeBlock(byte[] src, char[] dst, int ind)
{
int charInd = ind * BlockCharsCount;
int bitInd = ind * BlockBitsCount;
BigInteger bits = GetBitsN(src, bitInd, BlockBitsCount);
BitsToChars(dst, charInd, (int)BlockCharsCount, bits);
}
private void DecodeBlock(string src, byte[] dst, int ind)
{
int charInd = ind * BlockCharsCount;
int bitInd = ind * BlockBitsCount;
BigInteger bits = CharsToBits(src, charInd, (int)BlockCharsCount);
AddBitsN(dst, bits, bitInd, BlockBitsCount);
}
```
**GetBitsN** возвращает число длины *BlockBitsCount* бит и начинающееся с бита под номером *bitInd*.
**AddBitsN** присоединяет число *bits* длины *BlockBitsCount* бит к массиву байт *dst* на позиции *bitInd*.
##### Конвертация блока бит в систему счисления с произвольным основанием и обратно
**Alphabet** — произвольный алфавит. Для обратного преобразования используется заранее просчитанный обратный алфавит **InvAlphabet**. Стоит отметить, что, например, для base64 используется прямой порядок бит, а для base85 — обратный (**ReverseOrder**), **\_powN** — степени длины алфавита.
```
private void BitsToChars(char[] chars, int ind, int count, BigInteger block)
{
for (int i = 0; i < count; i++)
{
chars[ind + (!ReverseOrder ? i : count - 1 - i)] = Alphabet[(int)(block % CharsCount)];
block /= CharsCount;
}
}
private BigInteger CharsToBits(string data, int ind, int count)
{
BigInteger result = 0;
for (int i = 0; i < count; i++)
result += InvAlphabet[data[ind + (!ReverseOrder ? i : count - 1 - i)]] * _powN[BlockCharsCount - 1 - i];
return result;
}
```
##### Обработка хвостовых бит
На решение данной проблемы было потрачено больше всего времени. Однако в итоге получилось создать код для расчета основных и хвостовых бит и символов без использования вещественных чисел, что позволило легко распараллелить алгоритм.
* **mainBitsLength** — основное количество бит.
* **tailBitsLength** — хвостовое количество бит.
* **mainCharsCount** — основное количество символов.
* **tailCharsCount** — хвостовое количество символов.
* **globalBitsLength** — общее количество бит (mainBitsLength + tailBitsLength).
* **globalCharsCount** — общее количество символов (mainCharsCount + tailCharsCount).
###### Расчет основного и хвостового количества бит и символов при кодировании.
```
int mainBitsLength = (data.Length * 8 / BlockBitsCount) * BlockBitsCount;
int tailBitsLength = data.Length * 8 - mainBitsLength;
int globalBitsLength = mainBitsLength + tailBitsLength;
int mainCharsCount = mainBitsLength * BlockCharsCount / BlockBitsCount;
int tailCharsCount = (tailBitsLength * BlockCharsCount + BlockBitsCount - 1) / BlockBitsCount;
int globalCharsCount = mainCharsCount + tailCharsCount;
int iterationCount = mainCharsCount / BlockCharsCount;
```
###### Расчет основного и хвостового количества бит и символов при декодировании.
```
int globalBitsLength = ((data.Length - 1) * BlockBitsCount / BlockCharsCount + 8) / 8 * 8;
int mainBitsLength = globalBitsLength / BlockBitsCount * BlockBitsCount;
int tailBitsLength = globalBitsLength - mainBitsLength;
int mainCharsCount = mainBitsLength * BlockCharsCount / BlockBitsCount;
int tailCharsCount = (tailBitsLength * BlockCharsCount + BlockBitsCount - 1) / BlockBitsCount;
BigInteger tailBits = CharsToBits(data, mainCharsCount, tailCharsCount);
if (tailBits >> tailBitsLength != 0)
{
globalBitsLength += 8;
mainBitsLength = globalBitsLength / BlockBitsCount * BlockBitsCount;
tailBitsLength = globalBitsLength - mainBitsLength;
mainCharsCount = mainBitsLength * BlockCharsCount / BlockBitsCount;
tailCharsCount = (tailBitsLength * BlockCharsCount + BlockBitsCount - 1) / BlockBitsCount;
}
int iterationCount = mainCharsCount / BlockCharsCount;
```
##### JavaScript реализация
Я решил создать портировать данный алгоритм и на JavaScript. Для работы с большими числами использовалась библиотека [jsbn](https://github.com/andyperlitch/jsbn). Для интерфейса использовался bootstrap. Результат можно посмотреть тут: [kvanttt.github.io/BaseNcoding](http://kvanttt.github.io/BaseNcoding/)
##### Заключение
Данный алгоритм написан так, что его легко портировать на другие языки и распараллелить (это есть в C# версии), в том числе и на GPU. Кстати, про модифицирование алгоритма base64 под GPU с использованием C# хорошо написано здесь: [Base64 Encoding on a GPU](http://www.codeproject.com/Articles/276993/Base-Encoding-on-a-GPU).
Корректность разработанного алгоритма была проверена на алгоритмах base32, base64, base85 (последовательности получившихся символов получались одинаковыми за исключением хвостов). | https://habr.com/ru/post/219993/ | null | ru | null |
# Создаём интерактивный выставочный экспонат с .NET, Azure Functions и магией когнитивных сервисов
В начале января [Электромузей Москвы](http://electromuseum.ru) объявил открытый отбор экспонатов для участия в выставке [Open Museum 2020](http://electromuseum.ru/event/otkrytyj-muzej-2020/). В этой заметке я расскажу, как превратил идею когнитивного портрета, [о которой я уже писал](https://habr.com/ru/company/microsoft/blog/478356/), в интерактивный экспонат, и как после закрытия музея на карантин этот экспонат стал виртуальным. Под катом — экскурс в [Azure Functions](https://docs.microsoft.com/azure/developer/python/tutorial-vs-code-serverless-python-01/?WT.mc_id=aiapril-blog-dmitryso), [Bot Framework](https://docs.microsoft.com/ru-ru/azure/bot-service/?view=azure-bot-service-4.0&WT.mc_id=aiapril-blog-dmitryso), [когнитивные сервисы](http://aka.ms/coserv) и [обнаружение лиц в UWP-приложениях](https://docs.microsoft.com/windows/uwp/audio-video-camera/detect-and-track-faces-in-an-image/?WT.mc_id=aiapril-blog-dmitryso).

> Этот пост является частью инициативы [AI April](http://aka.ms/AIApril). В течение всего апреля, мои коллеги из Microsoft каждый день пишут интересные статьи на тему AI и машинного обучения. Посмотрите на [календарь](http://aka.ms/AIApril) — вдруг вы найдёте там другие интересующие вас темы. Статьи преимущественно на английском.
Ранее я писал про [технику когнитивного портрета](/scienceart/peopleblending/), которая позволяет создавать смешанные портреты людей из серии фотографий:
| Cognitive Portrait | Cogntive Protrait |
| --- | --- |
| *Ольга*, 2019, [People Blending](http://aka.ms/peopleblending) | *Круговорот людей*, 2020, [Cognitive Portrait](http://aka.ms/cognitiveportrait) |
Когда был объявлен открытый конкурс работ для предстоящей выставки [OpenMuseum](http://electromuseum.ru/event/otkrytyj-muzej-2020/), и я сразу же подумал о том, чтобы воплотить идею когнитивного портрета в виде какого-нибудь интерактивного экспоната. Мне пришла в голову идея интерактивного стенда, который захватывал бы фотографии посетителей выставки и превращал их в "усреднённый" когнитивный портрет посетителей.
Поскольку техника когнитивного портрета использует [когнитивные сервисы](https://docs.microsoft.com/azure/cognitive-services/?WT.mc_id=aiapril-blog-dmitryso) для извлечения [ключевых точек лица](https://docs.microsoft.com/azure/cognitive-services/face/concepts/face-detection#face-landmarks?WT.mc_id=aiapril-blog-dmitryso), экспонату потребуется подключение к интернет. Вообще говоря, "подключенный" к сети экспонат, в котором логика оформлена в виде облачного сервиса, позволит делать намного больше интересного:
* Он сможет записывать в облако фотографии, чтобы затем использовать их для последующей экспозиции.
* Можно получить демографический портрет посетителей выставки, включая распределение по полу, возрасту и эмоциям.
* Отслеживание посетителей позволит нам понимать, сколько времени они проводят перед экспонатом, а также какой эмоциональный эффект имеют те или иные фотографии на посетителей.
* Впоследствии, чтобы задействовать новые [техники когнитивного портрета](http://github.com/CloudAdvocacy/CognitivePortrait), достаточно будет всего лишь изменить программный код в облаке, при этом экспонат "поменяется" без всякой необходимости личного посещения музея.
Архитектура
-----------
С точки зрения архитектуры, экспонат будет состоять из двух частей:
* **Клиентское UWP-приложение**, работающее на компьютере в музее, с веб-камерой и дисплеем. [UWP-приложение](https://docs.microsoft.com/windows/uwp/get-started/universal-application-platform-guide/?WT.mc_id=aiapril-blog-dmitryso) может также работать на Raspberry Pi на [Windows IoT Core](https://docs.microsoft.com/windows/iot-core/tutorials/rpi/?WT.mc_id=aiapril-blog-dmitryso). Клиентское приложение делает следующее:
+ Обнаруживает, есть ли перед камерой человек (face detection).
+ Если человек стоит относительно неподвижно около секунды — оно делает фотографию и посылает её в облако.
+ В ответ на фотографию приложение получает из облака ссылку на изображение, которое оно отображает на экране.
* **Облачный сервис**, который собственно и определяет логику экспоната и отвечает за рисование когнитивного портрета:
+ Получает изображение от клиентского приложения.
+ Вызывает когнитивные сервисы для извлечения ключевых точек лица, применяет аффинное преобразование и выравнивает изображение таким образом, чтобы глаза и середина рта были расположены в точках с фиксированными координатами.
+ Сохраняет выровненное изображение в [Azure Storage](https://docs.microsoft.com/azure/storage/?WT.mc_id=aiapril-blog-dmitryso).
+ Получает несколько последних выровненных изображений, усредняет их для получения портрета, сохраняет его в Azure Storage и возвращает полученную ссылку.
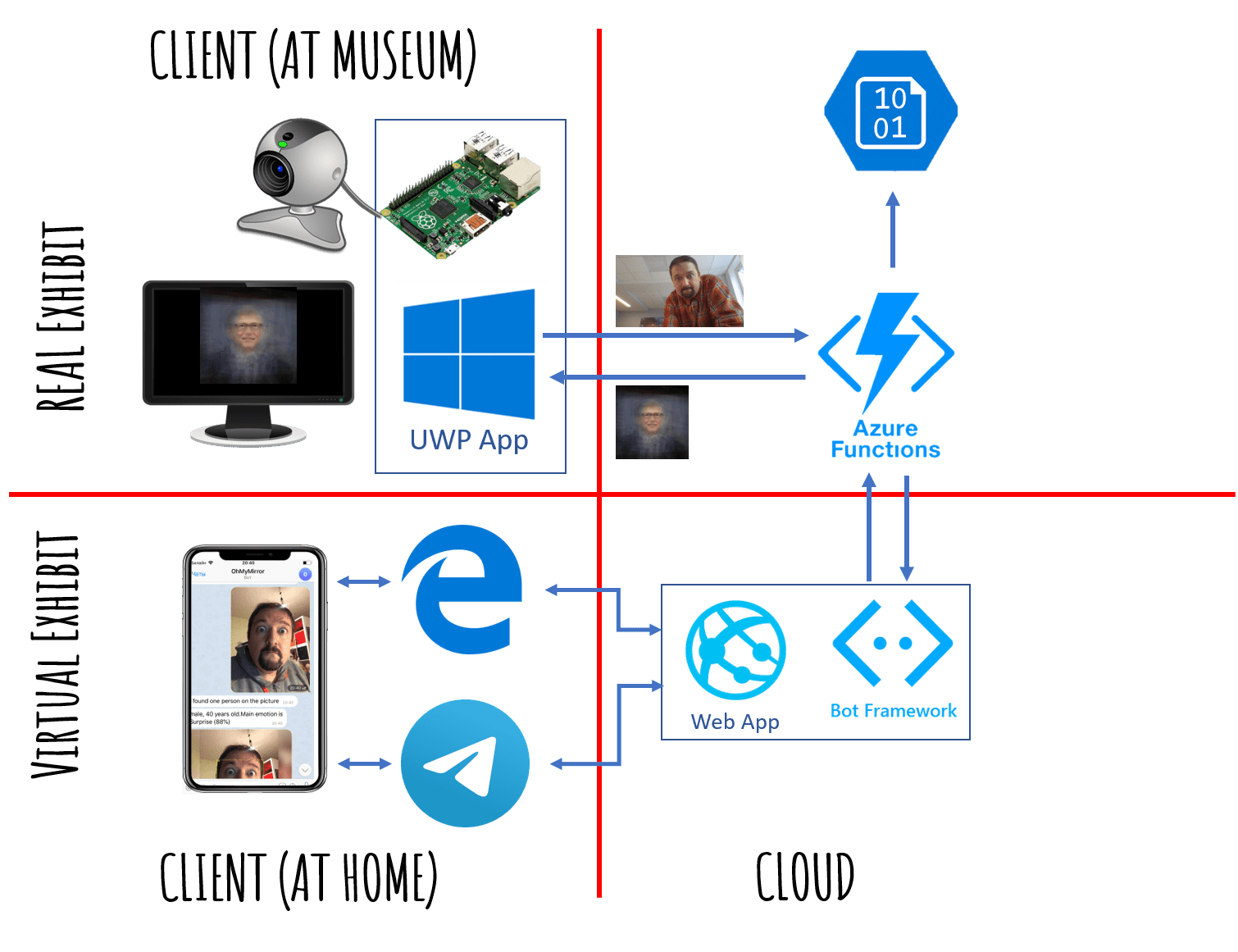
Виртуальный экспонат в условиях самоизоляции
--------------------------------------------
Через несколько недель после открытия выставки, на которой был представлен экспонат, работа музея была временно приостановлена из-за карантина. Однако, учитывая клиент-серверную архитектуру решения, оказалось возможным заменить клиентскую часть приложения, и создать **интерактивный музейный бот-экспонат**.
Бот доступен а телеграм как [@PeopleBlenderBot](http://t.me/peopleblenderbot). Он вызывает тот же самый облачный сервис через REST API, и показывает пользователю полученное изображение. Пользователь посылает боту свою фотографию, и получает в ответ когнитивный портрет со своим участием, и с участием нескольких других "посетителей виртуальной выставки", которые посылали свои фотографии до этого. При этом, если в это время работала бы реальная выставка, то изображения бы смешивались ещё и с теми посетителями, которые пришли посмотреть на экспонат "в реальном мире".
> Интерактивный бот [**@PeopleBlenderBot**](http://t.me/peopleblenderbot) стирает границы между реальным и виртуальным миром, смешивая фотографии посетителей реальной выставки (или нескольких выставок) и людей, посещающих её из дома с помощью бота, в единый когнитивный портрет. Он являет собой **искусство без границ**, в прямом смысле объединяя людей из разных городов и стран. Вы можете протестировать бота в телеграм, или [в моём виртуальном музее](http://soshnikov.com/museum/peopleblenderbot).
Далее поговорим подробнее про техническое устройство экспоната.
Клиентское приложение UWP
-------------------------
Одна из основных причин, по которой я выбрал технологию [универсальных приложений Windows](https://docs.microsoft.com/windows/uwp/get-started/universal-application-platform-guide/?WT.mc_id=aiapril-blog-dmitryso) в качестве клиента — это наличие функции распознавания лиц прямо "из коробки". Универсальное приложение может быть запущено как на персональном компьютере, так и на микроконтроллере Raspberry Pi с операционной системой [Windows 10 IoT Core](https://docs.microsoft.com/windows/iot-core/tutorials/rpi/?WT.mc_id=aiapril-blog-dmitryso). Конечно, Raspberry на Windows не слишком шустр, поэтому я использовал компактный компьютер [Intel NUC](https://www.intel.ru/content/www/ru/ru/products/boards-kits/nuc.html).
Примерно так выглядит пользовательский интерфейс приложения:
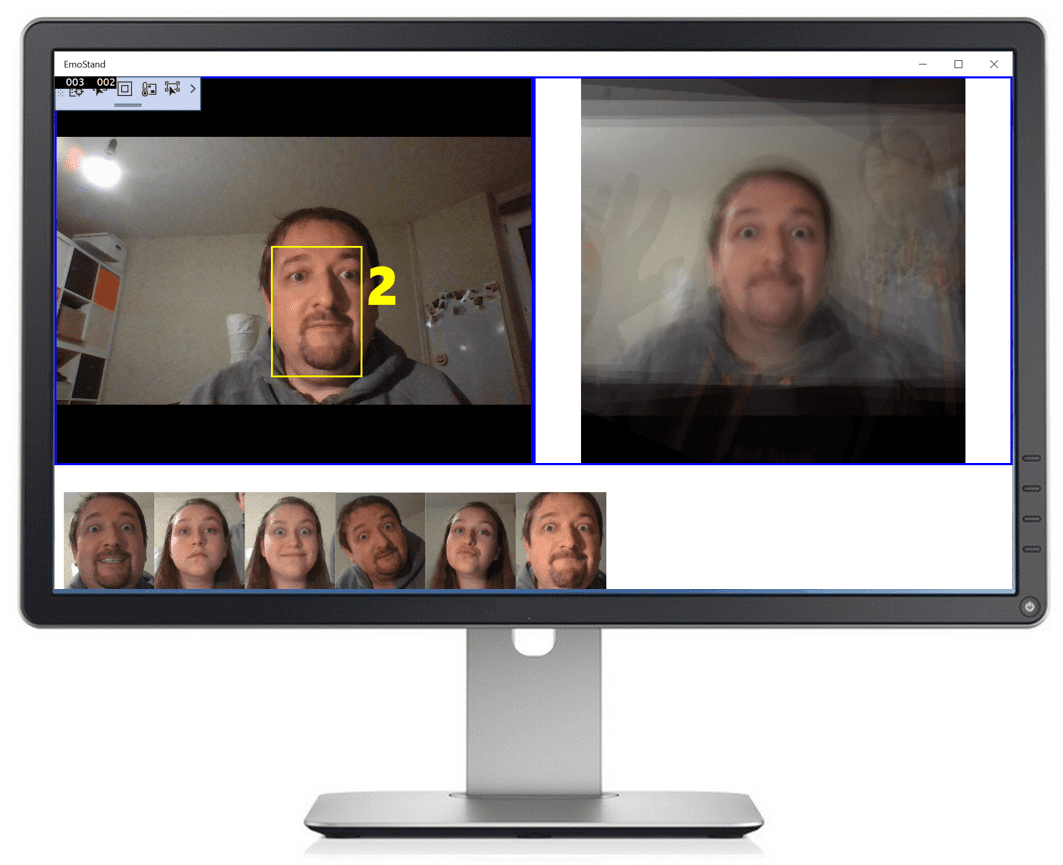
Такой интерфейс описывается на XAML следующим образом (с незначительными упрощениями):
```
```
Наиболее интересны для нас следующие элементы управления:
* `ViewFinder` показывает живое потоковое видео с камеры.
* `FaceRect` и `Counter` находятся поверх `ViewFinder`, чтобы показывать прямоугольник поверх обнаруженного лица и счетчик обратного отсчета 3-2-1, после чего производится фотографирование.
* `ResultImage` — это основная область экрана, показывающая полученный из облака смешанный когнитивный портрет.
* `FacesLine` показывает несколько последних фотографий посетителей, сделанных экспонатом. Этот элемент управления декларативно привязан к коллекции `Faces`, которая является `Observable`. Таким образом, чтобы добавить в интерфейс новое лицо, достаточно просто добавить изображение в коллекцию `Faces`.
* Остальной код XAML используется для правильного позиционирования элементов на экране.
Пример реализации обнаружения лиц в UWP можно найти [в этом примере](https://docs.microsoft.com/en-us/samples/microsoft/windows-universal-samples/camerafacedetection/?WT.mc_id=aiapril-blog-dmitryso), или [в документации](https://docs.microsoft.com/windows/uwp/audio-video-camera/detect-and-track-faces-in-an-image/?WT.mc_id=aiapril-blog-dmitryso). Он слегка сложноват, я позволил себе его немного упростить (и в статье для простоты также его немного сокращу).
Для начала, запустим камеру, и добьемся того, что изображение в реальном времени отображается в окне `ViewFinder`:
```
MC = new MediaCapture();
var cameras = await DeviceInformation.FindAllAsync(
DeviceClass.VideoCapture);
var camera = cameras.First();
var settings = new MediaCaptureInitializationSettings()
{ VideoDeviceId = camera.Id };
await MC.InitializeAsync(settings);
ViewFinder.Source = MC;
```
Теперь займёмся трекингом лиц. Для этого создадим объект `FaceDetectionEffect`, который будет вызывать метод `FaceDetectedEvent` при обнаружении лица:
```
var def = new FaceDetectionEffectDefinition();
def.SynchronousDetectionEnabled = false;
def.DetectionMode = FaceDetectionMode.HighPerformance;
FaceDetector = (FaceDetectionEffect)
(await MC.AddVideoEffectAsync(def, MediaStreamType.VideoPreview));
FaceDetector.FaceDetected += FaceDetectedEvent;
FaceDetector.DesiredDetectionInterval = TimeSpan.FromMilliseconds(100);
FaceDetector.Enabled = true;
await MC.StartPreviewAsync();
```
Когда в кадре обнаруживается лицо, вызывается `FaceDetectedEvent`, которая запускает таймер обратного отсчета, срабатывающий раз в секунду. По таймеру обновляется содержимое текстового поля `Counter`, показывающее обратный отсчет 3, 2 и 1. Когда счетчик достигает 0, изображение с камеры сохраняется в `MemoryStream`, и затем вызывается функция `CallCognitiveFunction`, которую мы реализуем позже:
```
var ms = new MemoryStream();
await MC.CapturePhotoToStreamAsync(
ImageEncodingProperties.CreateJpeg(), ms.AsRandomAccessStream());
var cb = await GetCroppedBitmapAsync(ms,DFace.FaceBox);
Faces.Add(cb);
var url = await CallCognitiveFunction(ms);
ResultImage.Source = new BitmapImage(new Uri(url));
```
Мы ожидаем, что веб-сервис REST получит на вход изображение в виде потока методом POST, сделает всю основную магию по созданию портрета, сохранит его где-нибудь в облаке в открытом хранилище, и вернёт общедоступный URL изображения. Чтобы отобразить изображение в нашем интерфейсе, мы просто присваиваем этот URL свойству `Source` элемента управления `ResultImage`, что приводит к отображению результата на экране (при этом фреймворк UWP сам скачивает изображение по сети).
Также для красоты мы хотим показывать внизу экрана несколько предыдущих фотографий. Для этого вызывается функция `GetCroppedBitmapAsync`, вырезающая фрагмент изображения, и он добавляется в коллекцию `Faces`, в результате чего лицо отображается на экране (здесь нам помогает магия DataBinding).
Функция `CallCognitiveFunction` вызывает наш облачный сервис, который нам ещё предстоит реализовать, по протоколу REST с использованием объекта `HttpClient`:
```
private async Task CallCognitiveFunction(MemoryStream ms)
{
ms.Position = 0;
var resp = await http.PostAsync(function\_url,new StreamContent(ms));
return await resp.Content.ReadAsStringAsync();
}
```
Azure Function для создания когнитивного портрета
-------------------------------------------------
Для выполнения основной работы мы используем технологию Azure Functions и реализуем код на Python. Использование Azure Functions имеет несколько преимуществ:
* Нет необходимости думать о том, где и как ваш код будет выполняться. Поэтому Azure Functions называют **[бессерверными вычислениями](https://ru.wikipedia.org/wiki/%D0%91%D0%B5%D1%81%D1%81%D0%B5%D1%80%D0%B2%D0%B5%D1%80%D0%BD%D1%8B%D0%B5_%D0%B2%D1%8B%D1%87%D0%B8%D1%81%D0%BB%D0%B5%D0%BD%D0%B8%D1%8F)** (*serverless*).
* Если мы используем план [*functions consumption plan*](https://docs.microsoft.com/azure/azure-functions/functions-scale#consumption-plan/?WT.mc_id=aiapril-blog-dmitryso), то мы платим только за количество вызовов функции, а не за время работы сервера. Единственным существенным минусом является ограничение на время работы функции (15 секунд), при превышении которого функция принудительно завершается. В нашем случае это не проблема, алгоритм должен уложиться в это время.
* Функция автоматически масштабируется в зависимости от нагрузки, не нужно думать про автомасштабирование.
* Azure Function может запускаться в ответ на различные события в облаке. В нашем примере мы будем явно запускать функцию по REST-запросу, но возможно также привязать запуск функции к появлению нового объекта в хранилище, нового сообщения в очереди, или сделать автозапуск по таймеру.
* Azure Function может быть легко интегрирована с хранилищем декларативным способом, при этом объект будет автоматически извлечен из хранилища и передан в функцию в качестве параметра. Мы можем концентрироваться на логике, а не на том, как работать с облачным хранилищем.
В качестве примера рассмотрим задачу, когда нам нужно наносить текущую дату поверх фотографий, присылаемых пользователем. Мы можем создать Azure Function, которая будет срабатывать автоматически при помещении фотографии в блоб-хранилище, и которая будет размещать результат в другом хранилище. Нам останется лишь написать код для импринтинга даты, входное изображение мы получим автоматически в качестве параметра, а выходное — вернем как результат функции. Минимум *boilerplate code*!
> Azure Functions настолько полезны, что я рассматриваю их как основной выбор во всех случаях, когда мне нужно запускать какой-то код для обработки данных в облаке, включая чат-ботов, обработку IoT-сообщений и т.д.
В нашем случае алгоритм рисования портрета реализован на Python с использованием OpenCV — я описывал реализации [в своей более ранней заметке](/scienceart/peopleblending/). Раньше считалось, что Azure Functions очень неэффективны при работе с Python, но эта информация устарела — вторая версия (V2) работает как часы.
Проще всего начать разрабатывать функцию локально. Этот процесс [хорошо описан в документации](https://docs.microsoft.com/azure/azure-functions/functions-create-first-azure-function-azure-cli?pivots=programming-language-python&tabs=bash%2Cbrowser&WT.mc_id=aiapril-blog-dmitryso), но я тоже коротко на нём остановлюсь. Если вы хотите сделать больше операций из VS Code, а не из командной строки — смотрите [это пошаговое руководство](https://docs.microsoft.com/azure/developer/python/tutorial-vs-code-serverless-python-01/?WT.mc_id=aiapril-blog-dmitryso).
Для начала создадим новую функцию с помощью CLI:
```
func init coportrait –python
cd coportrait
func new --name pdraw --template "HTTP trigger"
```
Конечно, предварительно нам потребуется установить [Azure Functions Core Tools](https://docs.microsoft.com/azure/azure-functions/functions-run-local?tabs=windows%2Ccsharp%2Cbash&WT.mc_id=aiapril-blog-dmitryso).
Функция описывается двумя основными файлами:
* Основной код функции на Python (в нашем случае, он будет в файле `__init__.py`).
* Файл описания `function.json`, который описывает все **интеграции**, т.е. связь функции с хранилищами, её входные и выходные параметры и критерии срабатывания.
В нашем случае функция срабатывает по HTTP-запросу, и `function.json` выглядит так:
```
{
"scriptFile": "__init__.py",
"bindings": [
{
"authLevel": "function",
"type": "httpTrigger",
"direction": "in",
"name": "req",
"methods": [ "post" ]},
{
"type": "http",
"direction": "out",
"name": "$return"
}]}
```
Здесь указывается имя скрипта, имя входного параметра `req` связывается с входящим HTTP-триггером, а выход функции — это HTTP response, возвращаемый из функции как результат (`$return`). Мы также указываем, что функция поддерживает лишь **POST**-запросы. Изначально в шаблоне был также указан метод `"get"`, который я удалил.
Если мы посмотрим в `__init__.py`, то там будет изначально содержаться примерно такой шаблон кода (который я для наглядности ещё немного упростил):
```
def main(req:func.HttpRequest) -> func.HttpResponse:
logging.info('Execution begins…')
return func.HttpResponse(f"Hello {name}!")
```
Здесь, `req` — это наш запрос. Чтобы получить изображение, закодированное как двоичный поток в формате JPEG, мы сначала получаем данные через `get_body`, а затем преобразуем их в `numpy`-массив с помощью OpenCV:
```
body = req.get_body()
nparr = np.fromstring(body, np.uint8)
img = cv2.imdecode(nparr, cv2.IMREAD_COLOR)
```
Для работы с хранилищем мы будем использовать объект `azure.storage.blob.BlockBlobService`. Альтернативой было бы использовать интеграции, но в моём примере мне показалось, что проще включить код для работы с хранилищем внутрь функции, поскольку нам нужно работать сразу с несколькими контейнерами в рамках одного хранилища, и прописывать доступ ко всем этим контейнерам с помощью интеграции было бы дольше. Про работу с хранилищами в Azure из Python можно подробнее [прочитать в документации](https://docs.microsoft.com/azure/storage/blobs/storage-quickstart-blobs-python?WT.mc_id=aiapril-blog-dmitryso).
Для начала сохраним входное изображение в контейнер `cin`:
```
blob = BlockBlobService(account_name=..., account_key=...)
sec_p = int((end_date-datetime.datetime.now()).total_seconds())
name = f"{sec_p:09d}-{time.strftime('%Y%m%d-%H%M%S')}"
blob.create_blob_from_bytes("cin",name,body)
```
Здесь мы делаем один очень важный трюк с именованием файла. Поскольку далее нам потребуется обращаться к 10 последним фотографиям, нам хотелось бы иметь возможность это делать, не считывая все файлы в хранилище. Поскольку имена объектов в хранилище возвращаются *в алфавитном порядке*, нам необходимо придумать такое именование файлов, чтобы они были отсортированы в порядке **убывания дат**. В этом примере я просто вычисляю количество секунд от текущего момента времени до 1 января 2021 года, и добавляю соответствующее число (с лидирующими нулями) в начало имени файла, которое формируется стандартным образом из текущей даты и времени в формате *YYYYMMDD-HHMMSS*. При этом наш код будет страдать от **проблемы 2021 года**...
Далее будем вызывать [Face API](https://docs.microsoft.com/azure/cognitive-services/face/overview/?WT.mc_id=aiapril-blog-dmitryso) для извлечения опорных точек лица, и применять к изображению аффинное преобразование для совмещения глаз с предопределёнными позициями:
```
cogface = cf.FaceClient(cognitive_endpoint,
CognitiveServicesCredentials(cognitive_key))
res = cogface.face.detect_with_stream(io.BytesIO(body),
return_face_landmarks=True)
if res is not None and len(res)>0:
tr = affine_transform(img,res[0].face_landmarks.as_dict())
body = cv2.imencode('.jpg',tr)[1]
blob.create_blob_from_bytes("cmapped",name,body.tobytes())
```
Код функции `affine_transform` можно взять [из моего предыдущего поста](/scienceart/peopleblending/). После того, как изображение повёрнуто, оно сохраняется как JPEG-картинка в контейнер `cmapped`.
Наконец, нам надо подготовить очередной когнитивный портрет, а для этого взять 10 последних выровненных изображений из `cmapped` и наложить их друг на друга. Для этого мы используем функцию `list_blobs` для получения генератора всех имен файлов в блобе, берем из него 10 первых элементов с помощью `islice`, и затем применяем к ним `imdecode` для получения `numpy`-массивов изображений:
```
imgs = [ imdecode(blob.get_blob_to_bytes("cmapped",x.name).content)
for x in itertools.islice(blob.list_blobs("cmapped"),10) ]
imgs = np.array(imgs).astype(np.float)
```
Для наложения всех фотографий, нам необходимо провести усреднение массива по первой оси. Единственная важная тонкость здесь состоит в том, что нам надо привести изображения к `float`, а затем — обратно к `np.uint8`:
```
res = (np.average(imgs,axis=0)).astype(np.uint8)
```
В завершение, мы сохраняем результат в контейнере `out`, сначала превращая изображение в байтовый поток с помощью `cv2.imencode`, а затем вызывая `create_blob_from_bytes`:
```
b = cv2.imencode('.jpg',res)[1]
r = blob.create_blob_from_bytes("out",f"{name}.jpg",b.tobytes())
result_url = f"https://{act}.blob.core.windows.net/out/{name}.jpg"
return func.HttpResponse(result_url)
```
Важный момент — мы должны заранее создать контейнер `out`, и пометить его как открытый блоб, чтобы доступ к нему был возможен снаружи из интернет, без указания дополнительных параметров.
После написания кода функции в `__init__.py`, нам также важно правильно указать все зависимости в `requirements.txt`:
```
azure-functions
opencv-python
azure-cognitiveservices-vision-face
azure-storage-blob==1.5.0
```
Сделав это, мы можем запустить функцию локально:
```
func start
```
При этом запустится локальный веб-сервер, и на экране будет напечатана локальная URL функции, которую мы можем для проверки попробовать вызвать с помощью Postman. Мы должны использовать метод **POST**, и передать какое-нибудь изображение в теле запроса.
Мы также можем указать эту же URL в переменной `function_url` в нашем UWP-приложении, после чего весь экспонат должен успешно запуститься и заработать на локальном компьютере.
Для публикации кода Azure Function в облако, нам сначала необходимо создать Python Azure Function через [Azure Portal](http://portal.azure.com/?WT.mc_id=aiapril-blog-dmitryso), или из командной строки Azure CLI:
```
az functionapp create --resource-group PeopleBlenderBot
--os-type Linux --consumption-plan-location westeurope
--runtime python --runtime-version 3.7
--functions-version 2
--name coportrait --storage-account coportraitstore
```
Делать это через Azure Portal поначалу безусловно проще, поскольку ряд вещей (вроде создания хранилища данных) будет сделан автоматически. Azure CLI полезен в том случае, если вы хотите автоматизировать процесс.
После того, как функция создана, её развёртывание делается совсем просто:
```
func azure functionapp publish coportrait
```
После публикации нам нужно пойти на [Azure Portal](http://portal.azure.com/?WT.mc_id=aiapril-blog-dmitryso), и посмотреть там соответствующий функции URL:
Этот URL будет выглядеть примерно так: `https://coportrait.azurewebsites.net/api/pdraw?code=geE..e3P==`, т.е. он будет содержать в себе код для вызова функции. Присвойте этот адрес (вместе с ключом) переменной `function_url` в нашем UWP-приложении, запустите его, и наслаждайтесь!
Создаём чат-ботный экспонат
---------------------------
> Во время социальной изоляции, очень важно дать людям возможность наслаждаться искусством из дома. Лучший способ сделать экспонат доступным отовсюду — использовать [Microsoft Bot Framework](https://docs.microsoft.com/ru-ru/azure/bot-service/?view=azure-bot-service-4.0&WT.mc_id=aiapril-blog-dmitryso) для создания чат-бота.
В описанной архитектуре, вся основная работа делается в облаке, поэтому очень легко создавать дополнительные интерфейсы к тому же экспонату. Например, интерфейс в виде чат-бота.
Процесс создания чат-бота на C# [хорошо описан в документации](https://docs.microsoft.com/azure/bot-service/dotnet/bot-builder-dotnet-sdk-quickstart?view=azure-bot-service-4.0&WT.mc_id=aiapril-blog-dmitryso), или [вот в этом пошаговом руководстве](https://docs.microsoft.com/ru-ru/azure/bot-service/bot-builder-tutorial-basic-deploy?view=azure-bot-service-4.0&tabs=csharp&WT.mc_id=aiapril-blog-dmitryso). Вы также можете [создать чат-бота на Python](https://docs.microsoft.com/azure/bot-service/python/bot-builder-python-quickstart?view=azure-bot-service-4.0&WT.mc_id=aiapril-blog-dmitryso), но использование .NET сильно лучше документировано, поэтому мы пойдём именно таким путём.
Для начала, нам надо установить [VS Bot Template](https://marketplace.visualstudio.com/items?itemName=BotBuilder.botbuilderv4) для Visual Studio, и затем создать новый проект из шаблона **Echo**:
Я назову этого бота `PeopleBlenderBot`.
Основная логика бота содержится в файле `Bots\EchoBot.cs`, внутри функции `OnMessageActivityAsync`. Эта функция получает на вход т.н. `turnContext`. Главная составляющая этого контекста — поле `Activity`, которое в свою очередь содержит текст сообщения в поле `Text`, а также присоединенные файлы в объекте `Attachments`. Для начала нам надо проверить, содержится ли в сообщении пользователя картинка:
```
if (turnContext.Activity.Attachments?.Count>0)
{
// do the magic
}
else
{
await turnContext.SendActivityAsync("Please send picture");
}
```
Если пользователь добавил картинку, то ссылка на неё будет доступна в поле `ContentUrl` объекта `Attachment`. Внутри `if`-блока, поместим код для считывания входного изображения в http-поток:
```
var http = new HttpClient();
var resp = await http.GetAsync(Attachments[0].ContentUrl);
var str = await resp.Content.ReadAsStreamAsync();
```
Далее нам нужно передать этот поток на вход нашей Azure Function, в теле POST-запроса. Этот код выглядит очень похожим образом на код из нашего UWP-приложения:
```
resp = await http.PostAsync(function_url, new StreamContent(str));
var url = await resp.Content.ReadAsStringAsync();
```
В результате вызова функции мы получаем URL результирующего изображения, которое необходимо вернуть пользователю. Для этого мы используем **карточки**, а именно Hero-card, которая передаётся назад в виде attachment-а:
```
var msg = MessageFactory.Attachment(
(new HeroCard()
{ Images = new CardImage[] { new CardImage(url) } }
).ToAttachment());
await turnContext.SendActivityAsync(msg);
```
Написав код бота, мы можем запустить и отладить его локально с помощью [Bot Framework Emulator](https://github.com/microsoft/BotFramework-Emulator):
Убедившись, что бот работает, мы можем опубликовать код в облако, как это [описано в документации](https://docs.microsoft.com/en-us/azure/bot-service/bot-builder-deploy-az-cli?view=azure-bot-service-4.0&tabs=csharp&WT.mc_id=aiapril-blog-dmitryso) через Azure CLI и ARM-шаблон. Однако, тоже самое можно сделать через Azure Portal:
1. Создайте новый объект **Web App Bot** на портале, выбрав **Echo Bot** в качестве начального шаблона. Это приведёт к созданию двух объектов в вашей подписке:
* **Bot Connector App**, который описывает взаимодействие вашего бота в различными каналами связи, такими, как Telegram
* **Bot Web App**, веб-приложение, в рамках которого работает написанный вами код бота
2. Скачайте код вашего бота из облака и скопируйте файл `appsettings.json` из него в наш проект `PeopleBlenderBot`. Этот файл содержит **App Id** и **App Password**, которые необходимы для безопасного подключения к bot connector.
3. Из Visual Studio нажмите правой кнопкой на проект `PeopleBlenderBot` и выберите **Publish**. Выберите пункт *Existing Web App*, и приложение, созданное на шаге 1. Это позволит вам развернуть код вашего бота в облако.
После этого, переходите на страничку объекта **Bot Connector App** на портале Azure Portal, и убедитесь, что бот работает в режиме Web Chat:
Теперь развернуть бота в телеграмм — это пара кликов! Этот процесс [детально описан в документации](https://docs.microsoft.com/azure/bot-service/bot-service-channel-connect-telegram?view=azure-bot-service-4.0&WT.mc_id=aiapril-blog-dmitryso), да и на самом портале при добавлении канала **Telegram** в разделе **Channels** предложат пошаговую инструкцию:
Заключение
----------
Я поделился своим опытом создания интерактивного экспоната, основная логика которого реализована в виде облачного сервиса. Такой подход оказывается очень плодотворным, мы ранее уже успешно использовали его для создания экспонатов в компании [Mechanium](http://mechanium.ru/), и на Moscow Maker Faire 2019. Я призываю вас использовать такой подход, если вы делаете какие-то музейные экспонаты или выставки. Ну а если нет — призываю вас присмотреться к направлению Science Art, поскольку это прекрасная возможность для нас — технарей — приобщиться к художественному творчеству. В качестве отправной точки приглашаю вас в [репозиторий техник когнитивного портрета](http://github.com/CloudAdvocacy/CognitivePortrait), в котором собраны разные техники, основанные на извлечении опорных точек лица! Попробуйте сделать что-то своё — я буду очень рад получить **pull request** от вас! В моей [другой заметке](http://aka.ms/creative_ai) я обсуждаю искусственный интеллект и искусство, и показываю примеры того, как ИИ может быть ещё более креативным. Если вас интересует эта тема — давайте [поговорим](http://soshnikov.com/contact), и возможно сделаем что-нибудь совместно!
> Чат-бот, описанный в этой статье, доступен в Telegram как [@peopleblenderbot](http://ttttt.me/peopleblenderbot), а также в моём [виртуальном музее](/museum/peopleblenderbot). Попробуйте его сами! Помните, что вы не просто переписываетесь в ботом, а получаете опыт созерцания **удалённого виртуального экспоната**, который делает людей ближе, несмотря на расстояния и на период самоизоляции. Посылая фотографии, имейте в виду, что **ваши фотографии будут сохраняться в облаке и отправляться другим людям в усреднённом виде**.
Следите за новостями! Очень надеюсь, что в скором времени мы сможем насладиться этим экспонатом не только виртуально, но и на реальной выставке! | https://habr.com/ru/post/498224/ | null | ru | null |
# Переход через NULL
Многие знают и используют встроенную функцию ISNULL(X, Y), которая заменяет первый аргумент на второй в случае, если он (первый) NULL. Менее употребима обратная встроенная функция NULLIF(X, Y), которая возвращает NULL, если первый аргумент равен второму. Комбинация этих двух функций позволяет избежать использования конструкций IF-ELSE или CASE-WHEN, что делает код компактнее. Если интересно посмотреть пару примеров — добро пожаловать под кат.
Например, вот код, который выводит 10 случайных целых чисел в диапазоне от 1 до 37, и ближайшее большее или равное выведенному числу значение, кратное 6.
```
SELECT
Q.Src,
CASE
WHEN Q.Src % 6 = 0 THEN Q.Src
ELSE Q.Src + (6 - Q.Src % 6)
END AS NextTimes6
FROM (
SELECT TOP 10
CONVERT(INT, 1 + 37 * RAND(CHECKSUM(NEWID()))) Src
FROM SYSOBJECTS S
) Q
```
От CASE..WHEN можно избавиться, проделав следующий трюк — обратив в NULL результат выражения Q.Src % 6 в случае, если остаток равен 0, зная, что результат любой операции с NULL равен NULL, и восстанавливая затем обратно NULL до 0 внешней функцией ISNULL:
```
SELECT
Q.Src,
Q.Src + ISNULL(6 - NULLIF(Q.Src % 6, 0), 0) AS NextTimes6
FROM (
SELECT TOP 10
CONVERT(INT, 1 + 37 * RAND(CHECKSUM(NEWID()))) Src
FROM SYSOBJECTS S
) Q
```
Еще один пример — разделение строки на две части по пробелу (например, имени из строки Имя<пробел>Фамилия. Типичная проблема здесь при решении «в лоб» — падение функции LEFT при передаче ей аргумента -1 в качестве значения количества отрезаемых символов в случае, когда пробела в исходной строке не находится (CHARINDEX возвращает 0):
```
SELECT
Q.Src,
CASE
WHEN CHARINDEX(' ', Q.Src) > 0 THEN LEFT(Q.Src, CHARINDEX(' ', Q.Src) - 1)
ELSE Q.Src
END AS NameOnly
FROM (
SELECT N'Петр Иванов' AS Src
UNION ALL
SELECT N'Иван'
) Q
```
Превращается в:
```
SELECT
Q.Src,
LEFT(Q.Src, ISNULL(NULLIF(CHARINDEX(' ', Q.Src), 0) - 1, LEN(Q.Src))) AS NameOnly
FROM (
SELECT N'Петр Иванов' AS Src
UNION ALL
SELECT N'Иван'
) Q
```
Приятного SQL-программирования! | https://habr.com/ru/post/413747/ | null | ru | null |
# Распознавание речи в ROS при помощи Pocketsphinx и Kinect
Распознавание речи является одной из самых важных способностей для робота поскольку позволяет управлять роботом посредством голоса. Можно дать роботу простую команду “Принеси пиво из холодильника” и при достаточных навыках робот может выполнить все необходимые операции, связанные с извлечением пива из холодильника и доставки его в нужное место.
В этой статье я хочу рассказать об установке и настройке всех необходимых драйверов и библиотек для распознавания голоса с использованием Pocketsphinx и сенсора Kinect Xbox 360 в качестве микрофона. Я выбрал пакет Pocketsphinx поскольку он является одним из самых популярных, имеет официальный пакет для ROS и имеет хорошие рекомендации.
Все описанные шаги я выполнял на системе Ubuntu 12.04.
#### Установка OpenKinect
Во-первых, для использования сенсора Kinect в качестве микрофона необходимо установить библиотеку OpenKinect (Libfreenect): <http://openkinect.org/wiki/Main_Page>. К счастью он доступен в виде бинарных пакетов в Ubuntu, поэтому здесь проблем никаких не должно возникнуть:
```
sudo apt-get install freenect
```
Вместе с драйвером будут установлены и демо приложения.
При установке libfreenect в Ubuntu 12.04 также советуют удалить модули gspca, поскольку они не позволяют libfreenect работать в режиме пользователя (user-mode). Последуем рекомендации:
```
$ sudo modprobe -r gspca_kinect
$ sudo modprobe -r gspca_main
```
Для проверки работоспособности драйвера можно запустить демо командой:
```
freenect-glview
```
Появится изображение с камеры и карта глубины.
#### Проверка подключения Kinect
Во-вторых, для корректной работы Kinect в качестве приемника звука сенсор Kinect должен быть подключен к компьютеру через USB только версии 2.0 или 1.0, через USB 3.0 работать не будет. Проверить, что аудио устройство Kinect доступно, можно командой:
```
cat /proc/asound/cards
```
Вы должны увидеть подобный вывод команды:
```
0 [AudioPCI ]: ENS1371 - Ensoniq AudioPCI
Ensoniq AudioPCI ENS1371 at 0x2080, irq 16
1 [Audio ]: USB-Audio - Kinect USB Audio
Microsoft Kinect USB Audio at usb-0000:02:03.0-1, high speed
…
```
Если вы не увидели запись об устройстве Kinect, то возможно Kinect подключен через порт USB 3.0. Также проверьте, что микрофон Kinect доступен как входное аудио устройство в настройках звука Ubuntu.
Теперь Kinect готов к работе и можно приступить к настройке Pocketsphinx.
#### Установка Pocketsphinx
Установка Pocketsphinx очень проста. Нужно установить пакет для ROS:
```
sudo apt-get install ros-"groovy или hydro"-pocketsphinx
```
Для пользователей других систем (не Ubuntu) установка будет такой:
```
git clone https://github.com/mikeferguson/pocketsphinx
sudo apt-get install gstreamer0.10-pocketsphinx
```
Существует несколько мануалов по использованию этой библиотеки. Их можно найти [здесь](http://robotica.unileon.es/mediawiki/index.php/Voice_control_(sphinx%2Bfestival)) и [здесь](http://www.pirobot.org/blog/0022/). Я попробовал первый. Руководства очень простые и с ними у вас никаких сложностей не возникнет.
Желаю удачи в распознавании речи с помощью Pocketsphinx! | https://habr.com/ru/post/246781/ | null | ru | null |
# Сегментация фона в Intel RealSense SDK
В этом документе описывается, как разработчики могут использовать сегментацию фона (background segmentation, BGS) в [Intel RealSense SDK](https://software.intel.com/en-us/intel-realsense-sdk) для создания новых увлекательных приложений для совместной работы. Описывается предполагаемое поведение программ и их производительность в разных сценариях, оговариваются ограничения, о которых следует помнить разработчикам перед поставкой продуктов клиентам. Основная аудитория этой статьи — группы разработки, использующие BGS, и ОЕМ-производители.
На КДПВ — приложение [Cyberlink YouCam RX](http://www.cyberlink.com/stat/product/youcamrx/enu/YouCamRX.jsp) как пример применения BGS.
Область применения
------------------
Сегментация фона (технология BGS) — важная отличительная особенность [камеры Intel RealSense](https://software.intel.com/en-us/realsense/devkit) для приложений для совместной работы и создания контента. Возможность отделения фона в реальном времени без особого оборудования или постобработки — очень интересная дополнительная функция для существующих приложений для телеконференций.
Существует огромный потенциал доработки существующих приложений или создания новых с использованием технологии BGS. Например, потребители могут просматривать общий контент вместе с друзьями на YouTube\* через другую программу в ходе сеанса видеочата. Сотрудники могут видеть изображение друг друга, наложенное на общую рабочую область при виртуальном собрании. Разработчики могут интегрировать BGS для создания новых сценариев использования, таких как изменяющийся фон или фоновое видео в приложениях, где используется камера или общий доступ к экрану. Выше и ниже показаны приложения, использующие камеру Intel RealSense. Кроме того, разработчики могут изобретать и другие сценарии использования, например съемку селфи и изменение фона, использование средств совместной работы (браузеры, офисные приложения) для совместного доступа и совместного редактирования, скажем, для создания видео караоке с разным фоном.

*Приложение [Personify](http://www.personify.com/realsense), использующее BGS*
Создание образца приложения с сегментацией фона
-----------------------------------------------
Требования
* Платформа с процессором Intel Core с включенным рутовым портом USB3.0
* Память: 4 ГБ
* [Камера Intel RealSense F200](https://software.intel.com/en-us/RealSense/F200Camera)
* [Intel RealSense SDK](https://software.intel.com/en-us/intel-realsense-sdk)
* Программное обеспечение [Intel Depth Camera Manager](https://software.intel.com/en-us/intel-realsense-sdk/download) или система, в которой этот компонент уже установлен OEM-производителем
* Microsoft Windows\* 8.1, 64-разрядная версия
* Microsoft Visual Studio\* 2010–2013 с последней версией пакета обновления
В этой статье мы поясняем, как разработчики могут заменить фон на видео или другие изображения в образце приложения. Мы также приводим фрагмент кода для смешения выходного изображения с любым фоновым изображением и рассказываем о влиянии на производительность.
Текущая [реализация сегментации фона](https://software.intel.com/sites/landingpage/realsense/camera-sdk/v1.1/documentation/html/index.html?manuals_user_segmentation.html) поддерживает форматы YUY2 и RGB. Допустимое разрешение — от 360p до 720p (для цветного изображения) и 480p (для изображения глубины).
На рисунке ниже показано общее представление конвейера BGS. Кадры глубины и цвета записываются камерой Intel RealSense и передаются в основной SDK (то есть в среду выполнения Intel RealSense SDK). На основе запроса, поступающего от приложения, кадры доставляются в блок User Extraction, где образуется сегментированное изображение в формате RGBA. К этому изображению можно применить альфа-смешение с любым другим изображением RGB для получения итогового фонового изображения на выходе. Разработчики могут использовать любые механизмы для смешения изображений на экране, но наилучшая производительность достигается при использовании графического процессора.
*Конвейер BGS*
Ниже поясняется, как интегрировать трехмерную сегментацию в приложение разработчика.
1. Установите следующие компоненты Intel RealSense SDK.
* Основная среда выполнения Intel RealSense SDK
* Модуль сегментации фона
2. Используйте веб-установщик или автономный установщик, чтобы установить только основные и индивидуальные компоненты. Среду выполнения можно установить только в режиме UAC.
*intel\_rs\_sdk\_runtime\_websetup\_x.x.x.xxxxxx --silent --no-progress --accept-license=yes --finstall=core,personify --fnone=all”*
Можно определить, какая среда выполнения установлена в системе, с помощью следующего API Intel RealSense SDK:
```
// session is a PXCSession instance
PXCSession::ImplVersion sdk_version=session->QueryVersion();
```
3. Создайте экземпляр для использования трехмерной камеры. При этом создается конвейер для работы любого трехмерного алгоритма.
```
PXCSenseManager* pSenseManager = PXCSenseManager::CreateInstance();
```
4. Включите нужный промежуточный модуль. Рекомендуется включать только модуль, необходимый приложению.
```
pxcStatus result = pSenseManager->Enable3DSeg();
```
5. Укажите профиль, нужный для вашего приложения. Запуск с более высоким разрешением и с более высокой кадровой скоростью приведет к повышению нагрузки. Передайте профили, чтобы получить с камеры нужный поток.
```
PXC3DSeg* pSeg = pSenseManager->Query3DSeg();
pSeg->QueryInstance()->QueryCaptureProfile(profile, &VideoProfile);
pSenseManager->EnableStreams(&VideoProfile);
```
6. Инициализируйте конвейер камеры и передайте первый кадр на промежуточный уровень. Этот этап требуется для всех промежуточных уровней, он необходим для работы конвейера.
```
result = pSenseManager->Init();
```
7. Получите сегментированное изображение с камеры. Выходное изображение выводится с промежуточного уровня в формате RGBA, оно содержит только сегментированную часть.
```
PXCImage *image=seg->AcquireSegmentedImage(...);
```
8. Смешайте сегментированное изображение с собственным фоном.
Примечание. Смешение значительно влияет на производительность, если оно осуществляется на ЦП, а не на ГП. Образец приложения работает на ЦП.
* Можно использовать любую методику для смешения сегментированного изображения RGBA с другим растровым изображением.
* Можно использовать нулевое копирование данных в системную память при использовании ГП вместо ЦП.
* Для смешения можно использовать Direct3D\* или OpenGL\*.
Вот фрагмент кода для получения передачи изображения в системную память, где srcData имеет тип pxcBYTE.
```
segmented_image->AcquireAccess(PXCImage::ACCESS_READ,
PXCImage::PIXEL_FORMAT_RGB32, &segmented_image_data);
srcData = segmented_image_data.planes[0] + 0 * segmented_image_data.pitches[0];
```
#### Смешение и рендеринг
* Запись: чтение потоков данных цвета и глубины с камеры.
* Сегментация: разделение на фон и пиксели переднего плана.
* Копирование цвета и сегментированного изображения (маски глубины) в текстуры.
* Изменение размера сегментированного изображения (маски глубины) до такого же разрешения, как у цветного изображения.
* (Необязательно) Загрузка или обновление фонового изображения (при замене) в текстуру.
* Компиляция/загрузка шейдера.
* Установка цвета, глубины и (необязательно) фоновых текстур для шейдера.
* Запуск шейдера и показ.
* (В приложениях для видеоконференций) Копирование объединенного изображения на поверхность NV12 или YUY2.
* (В приложениях для видеоконференций) Передача поверхности в аппаратный кодировщик Intel Media SDK H.264.
#### Производительность
На работу приложения влияют следующие факторы.
* Кадровая скорость
* Смешение
* Разрешение
В приведенной ниже таблице показана нагрузка на процессор Intel Core i5 5-го поколения.
| | Без рендеринга | Рендеринг с помощью ЦП | Рендеринг с помощью ГП |
| --- | --- | --- | --- |
| 720p, 30 кадр./с. | 29,20 % | 43,49 % | 31,92 % |
| 360p, 30 кадр./с. | 15,39 % | 25,29 % | 16,12 % |
| 720p, 15 кадр./с. | 17,93 % | 28,29 % | 18,29 % |
Чтобы проверить влияние рендеринга на вашем собственном компьютере, запустите образец приложения с параметром -noRender, а затем без этого параметра.
Ограничения технологии BGS
--------------------------
Сегментация пользователей по-прежнему развивается, и с каждой новой версией SDK качество повышается.
О чем следует помнить при оценке качества.
* Избегайте наличия на теле предметов такого же цвета, как у фонового изображения. Например, черная футболка при черном фоне.
* Слишком яркое освещение головы может повлиять на качество изображения волос.
* Если лежать на кровати или на диване, система может работать неправильно. Для видеоконференций лучше подходит сидячее положение.
* Прозрачные и светопроницаемые объекты (например, стеклянный стакан) будут отображаться неправильно.
* Точное отслеживание руки вызывает затруднения, качество может быть нестабильным.
* Челка на лбу может привести к проблемам при сегментации.
* Не двигайте головой слишком быстро. Ограничения камеры влияют на качество.
Отзывы корпорации Intel о технологии BGS
----------------------------------------
Как повысить качество программного обеспечения? Лучше всего — оставлять отзывы. Выполнение сценариев в схожей среде может быть затруднено, если разработчик захочет повторить тестирование с новым выпуском Intel RealSense SDK.
Чтобы снизить расхождение между разными запусками, рекомендуется снимать входные последовательности, использующиеся для воспроизведения проблем, чтобы увидеть, улучшается ли качество.
Пакет Intel RealSense SDK поставляется с образцом приложения, помогающим собирать последовательности для воспроизведения.
* Важно для предоставления отзывов о качестве
* Не для анализа производительности
При установке по умолчанию образец приложения находится в папке *C:\Program Files (x86)\Intel\RSSDK\bin\win32\FF\_3DSeg.cs.exe*. Запустите приложение и выполните действия, показанные на приведенных ниже снимках экрана.
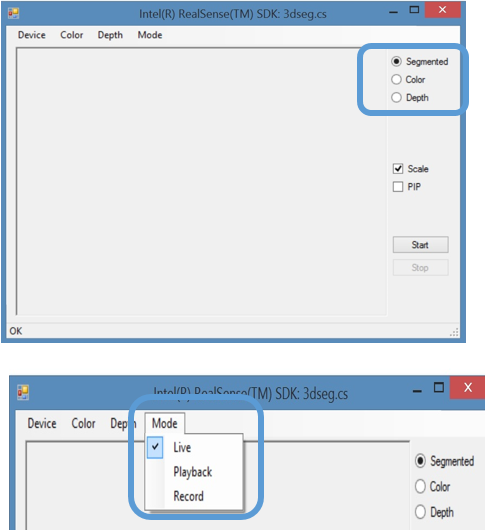
Вы увидите на экране самого себя, при этом фон будет удален.
#### Воспроизведение последовательностей
Если выбрать режим Record, можно сохранить копию вашего сеанса. Теперь можно открыть приложение FF\_3DSeg.cs.exe и выбрать режим воспроизведения для просмотра записи.
Заключение
----------
Промежуточный модуль сегментации фона технологии Intel RealSense предоставляет пользователям новые интересные возможности. Среди новых моделей использования — изменение фона на видео или другое изображение, создание селфи с сегментированным изображением.
Справочные материалы
* [Камера Intel RealSense (F200)](https://software.intel.com/en-us/realsense/home)
* [Intel RealSense SDK](https://software.intel.com/en-us/intel-realsense-sdk/download)
* [Программное обеспечение Intel Depth Camera Manager или система, в которой этот компонент уже установлен OEM-производителем](https://software.intel.com/en-us/intel-realsense-sdk/download)
* [Советы и рекомендации по использованию сегментации фона Intel RealSense](https://software.intel.com/en-us/articles/realsense-bgs)
* [Демонстрационные приложения Intel Real Sense](https://appshowcase.intel.com/en-us/realsense) | https://habr.com/ru/post/273663/ | null | ru | null |
# Новые возможности от Google Buzz — кнопки, размещение и написание материалов

Гугл продолжает наступление по всем фронтам на распространённые социальные сервисы. Встретить его иконку Buzz («баззика») среди твиттеров-фейсбуков-рсс можно всё чаще и чаще. Вчера очередной большой шаг вперёд — официальные кнопки с нормальной функциональностью, «чистый» механизм закидывания поста, «чистое» окошко для изложения своих мыслей, счётчики проделанных читателями репостов и… появляющиеся в конце каждой статьи ссылки «следуйте за нами в Баззе» от техкранча и многих других.
Объявленный некоторыми «мёртвым при рождении» Google Buzz всё активней появляется перед глазами пользователей Интернета, вне зависимости от их технонаклонностей, гламурности и прочего. Впечатляют сайты, первыми внедрившие возможности репоста в «баззик»: The Washington Post, The Huffington Post, Glamour, YouTube, Blogger, MySpace, GigaOM, PBS Parents, PBS NewsHour, The Next Web, TweetDeck, SocialWok, Disqus, Vinehub, Buzzzy. И это только первый день.

Множество людей при появлении нового сервиса от Гугла были непрочь туда что-нибудь запостить из понравившегося. Однако ограниченная функциональность возможностей репоста позволяли это сделать далеко не всем. Да и на фоне ретвитов, кнопки для которых содержали информацию о количестве проделанных репостов говорили также о количестве сторонников в Твиттере, которые сочли данный материал интересным. В сравнении с этим «баззик» казался непрозрачным и неживым.
Cайты техногиков типа Mashable и TechCrunch быстро организовали собственные кнопки, которые использовали для постинга возможности Google Reader. И хотя подобный путь выглядит извращением, многие пользовались им. Предположу, что таких людей становилось всё меньше.
Реализацией нормальной работы репостов и постов в «баззик» Гугл хочет восстановить прирост армии своих сторонников, и совместить это с ростом сторонников его социальных сервисов.
Новая возможность репостов добавлена в сервисы ShareThis, Meebo, Shareholic, AddThis и AddtoAny (взамен тех «костылей» через почту или Reader), так что у множества пользователей интернета теперь появится удобная возможность закинуть понравившийся материал к себе в «баззик» и обсудить его с друзьями-знакомыми.
Для того чтобы добавить кнопку Google Buzz на свой сайт зайдите на страницу [buzz.google.com/stuff](http://buzz.google.com/stuff) и настройте в пару кликов её параметры. Скопируйте получившийся небольшой код на JavaScript и добавьте его в нужное место на сайт.
Если Вы хотите раскручивать свой собственный «баззик» — воспользуйтесь другим вариантом кнопки, которая позволяет людям последовать за вами в Buzz прямо из вашего блога или с сайта:

Чтобы подготовить репост в свой «баззик» достаточно перейти по ссылке `www.google.com/buzz/post?url=http://АДРЕС-СТРАНИЦЫ-КОТОРУЮ-РЕПОСТИМ`
Открытие окна редактирования «с чистого листа» [www.google.com/buzz/post](http://www.google.com/buzz/post) являет нам чистый интерфейс размещения новых материалов, которого раньше так не хватало.
[](http://picasaweb.google.com/lh/photo/aqFdIBdIxdnHKWbQMprUcA?feat=embedwebsite)
От себя добавлю, что вышеуказанные возможности просто замечательны как для адептов Гугла так и для множества новых людей, которые могут пополнить ряды лояльных пользователей сервисов поискового гиганта.
Однако от себя хочу спросить у представителей Гугла: «Ребята! А вы сами пробовали искать в своём баззике какой-нибудь конкретный материал, который вы разместили месяц назад?!»
Полагаю, что радикально изменить удобство использования истории баззика может введение тэгов и блока индикации количества постов по каждому, аналогично их нынешнему удобному использованию в Блогспоте. Сделайте, пожалуйста, эту штуку!
И некоторые мои знакомые впервые начнут постить понравившиеся им материалы именно в свой «баззик», как в маленькое и удобное средство для новичков. | https://habr.com/ru/post/90969/ | null | ru | null |
# ServerSideJS: теперь проще просто. Встречайте v8cgi!
[v8cgi](http://code.google.com/p/v8cgi/) — обертка для JS-движка [v8](http://code.google.com/p/v8/) от гугла. Меня попросили его поставить на сервер и он меня приятно удивил непредсказуемо малой прожорливостью и удобством эксплуатации.
Итак, задачи:
1. Собрать v8
2. Собрать v8cgi в том числе как модуль апача
3. Настроить апач.
4. Выпить чаю с карамельками по этому поводу.
#### v8
Необходимо: питон, subversion и scons(gcc есть везде).
Для неопытных: в debian подойдут пакеты svn, scons, python-minimal
Забираем исходный код с SVN
`svn checkout v8.googlecode.com/svn/trunk v8-read-only`
и, перейдя в полученную папку, запускаем конструктор.
`scons library=shared`
Копируем свежесобранный файл (libv8\*.so) в /usr/lib/libv8.so
#### cgi
Надо: библиотеки apache, mysql и GD
(пакеты deb: libmysqlclient15-dev libgd2-dev apache2-threaded-dev )
Опционально: sqlite и fastcgi ( libfcgi-dev libsqlite3-dev)
Обязательно исправляем примерно на 58 строке файла Sconfigure ../v8 на ../V8, иначе конструктор будет недоволен.
Собираем:
`scons module=1 sqlite=0 fcgi=0`
Собрано. Имеем 2 файла: mod\_v8cgi.so и v8cgi, копируем их в /home/v8, а содержимое каталога lib в /usr/lib/v8cgi.
Конфиг libv8cgi.conf.posix скопируем в /etc/v8cgi.conf
#### Apache
добавим 3 строчки с кофиг и модуль заработал.
`LoadModule v8cgi_module /home/v8/mod_v8cgi.so
v8cgi_Config /etc/v8cgi.conf
AddHandler v8cgi-script .ssjs`
По поводу запуска как cgi программы.
`ScriptAlias /ssjs/ /home/lazutov/ssjs/
AddHandler v8cgi-handler .ssjs
Action v8cgi-handler /ssjs/v8cgi`
В еррорлоге v8cgi ругается на неверные заголовки и ожидаемо падает 500 ошибкой. Руки, что поделаешь :)
#### Заключение
v8cgi заработал с непредсказуемо малым расходом памяти — 20-30 мб, против ожидаемых 70-100.
JS получил еще одно пинковое ускорение в развитии уже в совершенно другом качестве. Перспективы? Горизонты? Время покажет.
##### Чай
.
Ой. карамелек нет. Нет и чая.
Есть очень кислая вишня. Зальем ее кипятком и отправим в организм немного витаминов :) Кстати неплохо, рекомендую. | https://habr.com/ru/post/66455/ | null | ru | null |
# Учебник по Solidity. Всё про библиотеки
### Что такое библиотеки в Solidity?
“Библиотеки можно рассматривать, как неявные базовые смарт-контракты для смарт-контрактов, которые их используют” из [документации](https://docs.soliditylang.org/en/latest/contracts.html#libraries) языка Solidity
Библиотека в Solidity - это тип смарт-контракта, содержащий многократно используемый код. После развертывания в блокчейне (развёртывается только один раз) ему присваивается определённый адрес, а его свойства / методы могут многократно использоваться другими смарт-контрактами в сети Ethereum.
Они позволяют вести разработку более модульным способом. Иногда полезно думать о библиотеке как о куске кода, который можно вызвать из любого смарт-контракта без необходимости его повторного развертывания.
#### Преимущества
Однако библиотеки в Solidity не ограничиваются только одной возможностью по повторному использованию. Вот некоторые другие преимущества:
* **Удобство использования:** функции в библиотеке могут использоваться многими смарт-контрактами. Если у вас много смарт-контрактов, которые содержат некоторый общий для каждого смарт-контракта код, то вы можете вынести этот общий код в библиотеку.
* **Экономично:** использование кода в виде библиотеки сэкономит вам gas, так как расход gas’а также зависит от размера смарт-контракта. Использование базового смарт-контракта вместо библиотеки для разделения общего кода не сэкономит gas, потому что в Solidity наследование работает путем копирования кода.
* **Дополнения:** библиотеки в Solidity можно использовать для добавления функций к типам данных. Например, подумайте о библиотеках как о *стандартных библиотеках* или *пакетах*, которые вы можете использовать в других языках программирования для выполнения сложных математических операций над числами.
#### Ограничения
В Solidity библиотеки не имеют своего состоянияи, следовательно, имеют следующие ограничения:
* Они не имеют хранилища (поэтому не могут иметь изменяемых переменных состояния)
* Они не могут хранить `ether` (поэтому не могут иметь функцию **отката (**`fallback`**)**)
* Не позволяет использовать `payable` функции (так как они не могут хранить ether)
* Не могут ни наследовать, ни быть наследуемыми
* Не могут быть уничтоженными (нет функции `selfdestruct()` с версии 0.4.20)
*"Библиотеки не предназначены для изменения состояния смарт-контракта, они должны использоваться только для выполнения простых операций на основе входных данных и возврата результата".*
Однако библиотеки позволяют сэкономить значительное количество газа (и, следовательно, не загрязнять блокчейн повторяющимся кодом), поскольку один и тот же код не нужно развертывать снова и снова. Различные смарт-контракты на Ethereum могут просто полагаться на одну и ту же уже развернутую библиотеку.
Тот факт, что несколько смарт-контрактов зависят от одного и того же фрагмента кода, может сделать среду более безопасной. Представьте себе, что у вас есть не только хорошо проверенный код для ваших проектов (как например заготовки кодов [OpenZeppelin](https://github.com/OpenZeppelin/zeppelin-solidity)), но и возможность полагаться на уже развернутый в блокчейне библиотечный код, который уже используют другие смарт-контракты. Это, безусловно, помогло бы в данном [случае](https://github.com/ether-camp/virtual-accelerator/issues/8).
### 2. Как создать библиотечный смарт-контракт?
#### Определите библиотеку и допустимые переменные
Вы определяете библиотечный смарт-контракт с помощью ключевого слова `library` вместо традиционного ключевого слова `contract`, используемого для стандартных смарт-контрактов. Просто объявите libary под оператором **pragma solidity (версия компилятора)**. Смотрите пример кода ниже.
```
library libraryName {
// объявление переменной struct, enum или constant
// определение функции с телом
}
```
Как мы уже видели, библиотечные смарт-контракты не имеют хранилища. Поэтому они не могут хранить переменные состояния (переменные состояния, которые не являются константами). Однако библиотеки все же могут реализовать некоторые типы данных:
* `struct` и `enum`: это переменные, определяемые пользователем.
* любая другая переменная, определенная как `constant` (неизменяемая), поскольку неизменяемые переменные хранятся в байткоде смарт-контракта, а не в памяти.
Начнем с простого примера: *библиотека для математических операций*.
Ниже мы создали простую математическую библиотеку MathLib, которая содержит базовую арифметическую операцию, принимающую на вход 2 беззнаковых целых числа и возвращающую результат арифметической операции.
```
library MathLib {
struct MathConstant {
uint256 Pi; // π (Pi) ≈ 3.1415926535...
uint256 Phi; // Золотая пропорция ≈ 1.6180339887...
uint256 Tau; // Tau (2pi) ≈ 6.283185...
uint256 Omega; // Ω (Omega) ≈ 0.5671432904...
uint256 ImaginaryUnit; // i (мнимая единица) = √-1
uint256 EulerNb; // Число Эйлера ≈ 2.7182818284590452...
uint256 PythagoraConst; // Константа Пифагора (√2) ≈ 1.41421...
uint256 TheodorusConst; // Константа Теодоруса (√3) ≈ 1.73205...
}
}
```
Библиотека [SafeMath](https://docs.openzeppelin.org/docs/math_safemath), доступная в [коллекции смарт-контрактов OpenZeppelin,](https://openzeppelin.org/) используется многими проектами для защиты от [переполнения](https://ethereumdev.io/safemath-protect-overflows/).
### 3. Как развернуть библиотеки?
Развертывание библиотеки немного отличается от развертывания обычного смарт-контракта. Вот два сценария:
1. **Встроенная библиотека:** если смарт-контракт использует библиотеку, которая имеет только **внутренние (**`internal`**) функции,** то EVM просто встраивает библиотеку в смарт-контракт. Вместо того чтобы использовать `delegatecall` для вызова функции, он просто использует оператор `JUMP` (обычный вызов метода). В этом сценарии нет необходимости в отдельном развертывании библиотеки.
2. **Связанная библиотека:** с другой стороны, если библиотека содержит **публичные (**`public`**) или внешние (**`external`**) функции,** то ее необходимо развернуть как отдельный смарт-контракт. При развертывании библиотеки генерируется уникальный адрес в блокчейне. Этот адрес должен быть связан с вызывающим смарт-контрактом.
### 4. Как использовать библиотеку в смарт-контракте?
#### Шаг 1: Импорт библиотеки
Под pragma просто укажите следующее утверждение:
`import "./libfile.sol" as LibraryName;`
Файл library-file может содержать несколько библиотек. Используя фигурные скобки {} в операторе import, вы можете указать, какую библиотеку вы хотите импортировать. Представьте, что у вас есть файл libfile.sol следующего вида :
```
library Library1 {
// Код из библиотеки 1
}
library Library2 {
// Код из библиотеки 2
}
library Library3 {
// Код из библиотеки 3
}
```
Вы можете указать, какую библиотеку вы хотите использовать в вашем основном смарт-контракте, следующим образом:
```
// Мы решили использовать здесь только библиотеки 1 и 3, и исключить библиотеку 2
import {Library1, Library3} from "./libfile.sol";
contract MyContract {
// Код вашего контракта здесь
}
```
#### Шаг 2: Использование библиотеки
Чтобы использовать библиотеку в смарт-контракте, мы используем синтаксис
`using LibraryName for Type.`
Эта указание используется для присоединения библиотечных функций (из библиотеки `LibraryName`) к любому типу (`Type`).
* **LibraryName** - имя библиотеки, которую мы хотим импортировать.
* **Type** - тип переменной, для которой мы собираемся использовать библиотеку. (Мы также можем использовать оператор подстановки \*, чтобы прикрепить функции из библиотеки ко всем типам).
```
// Использовать библиотеку для целых беззнаковых чисел
using MathLib for uint256;
// Использовать библиотеку для любого типа данных
using MathLib for *;
```
В этих случаях к смарт-контракту присоединяются *все* функции из библиотеки, включая те, где тип первого параметра не совпадает с типом объекта. Тип проверяется в момент вызова функции, и **выполняется перегрузка функции.**
При добавлении библиотеки её типы данных, включая библиотечные функции, становятся доступными в контакте без необходимости добавления дополнительного кода. Когда вы вызываете библиотечную функцию, библиотечные функции получают объект, на котором они вызываются, в качестве первого параметра, подобно переменной self в Python.
```
using MathLib for uint256;
uint256 a = 10;
uint256 b = 10;
uint256 c = a.subUint(b);
```
Мы все еще можем выполнить uint c = a - b; Это вернет тот же результат - 0. Однако библиотека MathLib имеет некоторые дополнительные свойства для защиты от переполнения, например, assert(a >= b); которая проверяет, что первый операнд **a** больше или равен второму операнду **b**, чтобы операция вычитания не привела к отрицательному значению.
Еще один хороший приём, который делает наш код понятнее - это использование ключевого слова using с библиотечной информацией в качестве метода. В нашем примере с **MathConstant** это будет:
`using MathLib for MathLib.MathConstant;`
### 5. Как взаимодействовать с библиотеками?
#### Немного теории
Если вызываются библиотечные функции, их код выполняется в контексте вызывающего смарт-контракта.
Давайте немного углубимся в документацию Solidity. В которой говорится следующее: *"Библиотеки можно рассматривать как неявные базовые смарт-контракты для смарт-контрактов, которые их используют":*
* Они не будут явно видны в иерархии наследования
* ...но вызовы библиотечных функций выглядят так же, как вызовы функций явных базовых смарт-контрактов (L.f(), если L - имя библиотеки).
Вызов функции из библиотеки использует специальную инструкцию в EVM: [опкод DELEGATECALL](https://ethervm.io/#F4). Это приведет к тому, что контекст вызова будет передан библиотеке, **как если бы это был код, выполняемый в самом смарт-контракте**. Рассмотрим пример кода:
```
library MathLib {
function multiply(uint256 a, uint256 b)
public
view
returns (uint256, address)
{
return (a * b, address(this));
}
}
contract Example {
using MathLib for uint256;
address owner = address(this);
function multiplyExample(uint256 _a, uint256 _b)
public
view
returns (uint256, address)
{
return _a.multiply(_b);
}
}
```
Если мы вызовем функцию `multiply()` библиотеки MathLib из нашего смарт-контракта (через функцию `multiplyExample`), будет **возвращен адрес Example,** а не адрес библиотеки. Функция multiply() компилируется как внешний вызов (`DELEGATECALL`), но если мы проверим адрес, возвращаемый в операторе `return`, то увидим адрес нашего смарт-контракта (а не адрес смарт-контракта библиотеки).
**Исключение:** библиотечные функции можно вызывать напрямую (без использования DELEGATECALL), только если они не изменяют состояние (`view` или `pure` функции).
Более того, внутренние функции библиотек видны во всех смарт-контрактах, как если бы библиотека была базовым смарт-контрактом.
Давайте изучим процесс вызова внутренней (`internal`) библиотечной функции, чтобы понять, что именно происходит:
* Контракт A вызывает внутреннюю функцию B из библиотеки L.
* Во время компиляции EVM **подтягивает** внутреннюю функцию B в смарт-контракт A. Это было бы похоже на то, как если бы функция B была жестко закодирована в смарт-контракте A.
* Вместо DELEGATECALL будет использоваться обычный вызов JUMP.
Вызовы внутренних функций используют ту же конвенцию внутреннего вызова:
* могут быть переданы все внутренние типы.
* типы, [хранящиеся в памяти](https://docs.soliditylang.org/en/latest/types.html#data-location), будут передаваться по ссылке и не копироваться.
Несмотря на то, что у библиотек нет хранилища, они могут модифицировать хранилище своего связанного смарт-контракта, передавая аргумент хранилища в параметры своей функции. Таким образом, любое изменение, сделанное библиотекой через свою функцию, будет сохранено в собственном хранилище смарт-контракта.
Поэтому ключевое слово `this` будет указывать на смарт-контракт вызова, а точнее, **ссылаться на хранилище вызывающего смарт-контракта.**
Поскольку библиотека - это изолированный кусок кода, она может получить доступ к переменным состояния из вызывающего смарт-контракта, только если они явно предоставлены. В противном случае у нее не было бы возможности назвать их.
#### Как использовать библиотечную функцию
Чтобы использовать библиотечную функцию, мы выбираем переменную, к которой хотим применить библиотечную функцию, и добавляем символ `.`, за которым следует имя библиотечной функции, которую мы хотим использовать.
`Type variable = variable.libraryFunction(Type argument);`
Ниже приведен пример.
```
contract MyContract {
using MathLib for uint256;
uint256 a = 10;
uint256 b = 10;
uint256 c = a.add(b);
}
library MathLib {
function add(uint256 a, uint256 b) external pure returns (uint256) {
uint256 c = a + b;
assert(c >= a);
return c;
}
}
```
### 6. Понимание функций в библиотеках
В библиотеке могут быть нереализованные функции (как в интерфейсах). В результате, функции такого типа должны быть объявлены как публичные или внешние. Нереализованные фукнции не могут быть приватными или внутренними.
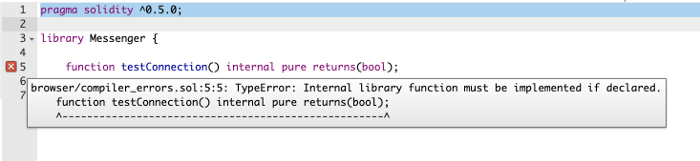Вот внутренняя функция, реализованная в функции `testConnection()`:
```
function testConnection(address _from, address _to)
internal
returns (bool)
{
if (true) {
emit testConnection(_from, _to, connection_success_message);
return true;
}
}
```
Примером нереализованных функций в нашей ситуации могут быть функции обратного вызова при подключении и отключении. При этом вы можете реализовать свой собственный код в теле функции основного смарт-контракта.
`function onConnect() public;`
`function onDisconnect() public;`
### 7. События и библиотеки
Точно так же, как у библиотек нет своего хранилища, у них нет и журнала событий. Однако библиотеки могут отправлять события.
Любое событие, созданное библиотекой, будет сохранено в журнале событий того смарт-контракта, который вызывает функцию, создающую событие в библиотеке.
Единственная проблема заключается в том, что на данный момент ABI смарт-контракта не отражает события, которые могут создавать используемые им библиотеки. Это сбивает с толку клиентов, таких как web3, которые не могут декодировать вызванное событие или понять, как декодировать его аргументы.
### 8. Отображения в библиотеках
Использование типа отображения (`mapping`) внутри библиотек отличается от использования этого типа в традиционных смарт-контрактах Solidity. Здесь мы поговорим об использовании этого типа в качестве параметра функции.
Вы можете использовать **отображение** в качестве параметра функции с любой видимостью: **публичной (**`public`**), частной (**`private`**), внешней (**`internal`**) и внутренней (**`external`**).**
Для сравнения, отображения можно передавать в качестве параметра только для `internal` или `private` функций внутри смарт-контрактов.
**Предупреждение:** местоположение данных **может быть только в хранилище,** если отображение передается в качестве параметров функции.
Поскольку мы используем отображение внутри библиотеки, мы не можем создать его внутри библиотеки (помните, что библиотеки не могут хранить переменные состояния). Давайте рассмотрим *"возможный"* пример того, как это может выглядеть:
```
library Messenger {
event LogFunctionWithMappingAsInput(
address from,
address to,
string message
);
function sendMessage(address to, mapping(string => string) storage aMapping)
public
{
emit LogFunctionWithMappingAsInput(msg.sender, to, aMapping["test1"]);
}
}
```
### 9. Использование структур внутри библиотек
```
library Library3 {
struct hold {
uint256 a;
}
function subUint(hold storage s, uint256 b) public view returns (uint256) {
// Make sure it doesn’t return a negative value.
require(s.a >= b);
return s.a - b;
}
}
```
***Обратите внимание****, как функция* subUint *получает struct в качестве аргумента. В Solidity v0.4.24 это невозможно в смарт-контрактах, но возможно в Solidity библиотеках.*
### 11. Использование модификаторов внутри библиотек
В библиотеках можно использовать модификаторы. Однако мы не можем экспортировать их в наш смарт-контракт, поскольку модификаторы являются функциями времени компиляции (своего рода макросами).
Смотрите здесь: [Solidity modifiers in library?](https://ethereum.stackexchange.com/questions/68529/solidity-modifiers-in-library)
Поэтому модификаторы применяются только к функциям самой библиотеки и не могут быть использованы внешним смарт-контрактом библиотеки.
### 12. Что нельзя делать с библиотеками в Solidity?
1. Библиотеки не могут содержать изменяемые переменные. Если вы попытаетесь добавить переменную, которую можно изменить, вы получите следующую ошибку в Remix: `TypeError: library can't have non-constant state variable`
2. Библиотеки не имеют журналов событий.
3. Уничтожить библиотеку невозможно.
4. Библиотека не может наследоваться.
### 13. Некоторые популярные существующие библиотеки
Вот список некоторых библиотек, написанных на Solidity, и их авторов:
* [Modular network](https://github.com/modular-network/ethereum-libraries): включает несколько библиотечных инструментов, таких как [ArrayUtils](https://github.com/modular-network/ethereum-libraries/blob/master/ArrayUtilsLib/Array256Lib.sol), [BasicMath](https://github.com/modular-network/ethereum-libraries/blob/master/BasicMathLib/BasicMathLib.sol), [CrowdSale](https://github.com/modular-network/ethereum-libraries/blob/master/CrowdsaleLib/CrowdsaleLib.sol), [LinkedList](https://github.com/modular-network/ethereum-libraries/blob/master/LinkedListLib/LinkedListLib.sol), [StringUtils](https://github.com/modular-network/ethereum-libraries/blob/master/StringUtilsLib/StringUtilsLib.sol), [Token](https://github.com/modular-network/ethereum-libraries/blob/master/TokenLib/TokenLib.sol), [Vesting](https://github.com/modular-network/ethereum-libraries/blob/master/VestingLib/VestingLib.sol) и [Wallet](https://github.com/modular-network/ethereum-libraries/tree/master/WalletLib)
* OpenZeppelin: библиотеки, такие как [AccessControl](https://github.com/OpenZeppelin/openzeppelin-contracts/blob/master/contracts/access/AccessControl.sol), [ECDSA](https://github.com/OpenZeppelin/openzeppelin-contracts/blob/master/contracts/utils/cryptography/ECDSA.sol), [MerkleProof](https://github.com/OpenZeppelin/openzeppelin-contracts/blob/master/contracts/utils/cryptography/MerkleProof.sol), [SafeERC20](https://github.com/OpenZeppelin/openzeppelin-contracts/blob/master/contracts/token/ERC20/utils/SafeERC20.sol), [ERC165Checker](https://github.com/OpenZeppelin/openzeppelin-contracts/blob/master/contracts/utils/introspection/ERC165Checker.sol), [Math](https://github.com/OpenZeppelin/openzeppelin-contracts/blob/master/contracts/utils/math/Math.sol), [SafeMath](https://github.com/OpenZeppelin/openzeppelin-contracts/blob/master/contracts/utils/math/SafeMath.sol) (для защиты от переполнения), [Address](https://github.com/OpenZeppelin/openzeppelin-contracts/blob/master/contracts/utils/Address.sol), [Arrays](https://github.com/OpenZeppelin/openzeppelin-contracts/blob/master/contracts/utils/Arrays.sol)
* Dapp-bin от Ethereum: включает такие интересные библиотеки, как [IterableMapping](https://github.com/ethereum/dapp-bin/blob/master/library/iterable_mapping.sol), [DoublyLinkedList](https://github.com/ethereum/dapp-bin/blob/master/library/linkedList.sol), и еще одну [StringUtils](https://github.com/ethereum/dapp-bin/blob/master/library/stringUtils.sol)
### Ссылки
1. [All you should know about libraries in solidity](https://medium.com/coinmonks/all-you-should-know-about-libraries-in-solidity-dd8bc953eae7)
2. [Library Driven Development in Solidity](https://blog.aragon.org/library-driven-development-in-solidity-2bebcaf88736/)
3. [Contracts — Solidity 0.8.6 documentation](https://docs.soliditylang.org/en/latest/contracts.html#libraries) | https://habr.com/ru/post/572894/ | null | ru | null |
# TypeScript в React-приложениях. 4. Глубокая типизация
Глубокая типизация предполагает обеспечение кода достаточно точными типами. Статья рассматривает эти подходы на примерах, встречающихся в приложениях на React.
Содержание[1. Как типизировать данные](https://habr.com/ru/post/693558/)
[2. Как понимать типы](https://habr.com/ru/post/693590/)
[3. Как использовать типизацию](https://habr.com/ru/post/694832/)
**4. Глубокая типизация**
[5. Связанная типизация](https://habr.com/ru/post/697548/)
[6. Изящная типизация](https://habr.com/ru/post/697564/)
Код требует более точный тип, чем string
----------------------------------------
Каждый раз когда функция принимает строчные данные и в зависимости от их содержимого включает в выполнение определённое поведение, то разработчик вынужден писать логику проверки этих данных. Использование TypeScript по назначению позволяет избегать лишнего кода, контролируя данные на входе функции.
Рассмотрим пример с компонентом иконки:
```
import React from 'react';
import * as icons from './icons'
type Props = {
name: string;
}
const Icon: FC => {
const Component = icons[name]
return Components ? (
) : null
}
```
*Код 4.1. Компонента иконки с недостаточно точным типом Props*
Мы не можем гарантировать, что для переданного имени иконки найдется соответствующая иконка, поэтому делаем проверку и не рендерим иконку с неправильными пропсами. Если мы через TypeScript обяжем код, использующий компонент иконки, передавать только правильные имена, то внутри компонента не потребуются дополнительные проверки.
```
import React from 'react';
import * as icons from './icons'
type Props = {
name: 'add' | 'remove' | 'edit';
}
const Icon: FC => {
const Component = icons[name]
return (
)
}
```
*Код 4.2. Компонент с более узким типом Props не требует дополнительной логики*
Уменьшение логики за счёт контроля типов анализатором - очень важный плюс использования TypeScript в проекте, которым разработчики забывают пользоваться. Кроме того здесь связаны имена файлов иконок с их именами в коде, что вынуждает разработчиков добавлять файлы с именами соответствующими именам иконок в коде и наоборот.
Как это работает? Когда мы импортируем через звёздочку \*, то получаем объект со всеми файлами в папке.
Файлы
add.svg
remove.svg
edit.svg
преобразуются в объект:
```
{
add: add.svg
remove: add.svg
remove: edit.svg
}
```
Анализатор TypeScript типизирует его как объект с конкретными свойствами. Зная это, мы можем получить его тип через typeof и связать имена иконок с именами файлов через **keyof**
```
import * as icons from './icons'
type Props = {
name: keyof typeof icons;
}
```
*Код 4.3. Тип иконок привязан к именам файлов*
Теперь разработчику не придётся добавлять в тип новые имена иконок — они автоматически берут тип из имён файлов.
Подобная привязка работает не только для файлов в папке, но и для отдельных экспортов внутри файла.
```
// файл utils
export const fn1 = () => {
// некая логика
}
export const fn2 = () => {
// некая логика
}
// файл импортирующий функции из utils
import * as utils from './utils'
type UtilNames = keyof typeof utils // 'fn1' | 'fn2'
```
*Код 4.4. Тип имён функций привязан к именам функций в другом файле*
Эта возможность позволяет типизировать паттерны фабрики и стратегии (когда вызывающему коду должно быть известно имя функции) без дополнительного обслуживания типа.
Авторское отступлениеЕсли вы захотите вспомнить (или познакомиться) с паттерном фабрики и заглянете [сюда](https://javarush.ru/groups/posts/2370-pattern-proektirovanija-factory), то увидите, что там так же предлагается более точная типизация на языке Java. Таким образом подходы в подробной типизации давно существуют, а понятие *глубокой* типизации нужно только для того, чтобы акцентировать на этом внимание разработчиков JavaScript, привыкших проверять данные, вместо того, чтобы правильно их типизировать.
Потребность в более точных типах вынуждает писать больше кода в контексте типов. Для того, чтобы избежать нужно использовать различные уловки.
Выведение типа из строки
------------------------
Рассмотрим на примере с иконками более широкие возможности языка TypeScript.
Обобщённо, чтобы типы работали правильно, нам нужно структуру приложения и имена файлов подгонять под способ типизации. Предположим, что имена файлов иконок не соответствуют имени, передаваемому в пропсах:
addIcon.svg
removeIcon.svg
editIcon.svg
Здесь нам помогут шаблонные литеральные типы, которые через шаблоны типизируют множества различных строк. В именах файлах прослеживается следующий литеральный шаблонный тип:
```
type IconNames = 'add' | 'remove' | 'edit';
type FileNames = `${IconNames}Icon`; // 'addIcon' | 'removeIcon' | 'editIcon'
```
*Код 4.5. Пример литерального шаблонного типа*
С помощью таких типов разработчик может создавать интересные типы, более узкие чем string и при этом завязанные на некие исходные типы. Но наша задача извлечь тип из существующих. Для этого воспользуемся ключевым словом **infer**:
```
import * as icons from './icons';
type FileNames = keyof typeof icons; // 'addIcon' | 'removeIcon' | 'editIcon'
type ParametrizedIconNames = T extends `${infer IconNames}Icons` ? IconNames : never;
type IconNames = ParametrizedIconNames; // 'add' | 'remove' | 'edit'
```
*Код 4.6 Извлечение типа из шаблонной строки*
Большинству разработчиков, пишущих приложения на TypeScript, данный код скорее всего сложно понять. Здесь есть дженерик, условный тип, шаблонный литеральный тип и ключевое слово infer.
```
type ParametrizedIconNames = T extends `${infer IconNames}Icons` ? IconNames : never;
```
Тип ParametrizedIconNames через дженерик принимает некий тип **T** внутрь себя. Тернарный оператор в TypeScript, определяет, принадлежит ли данный тип определённому множеству и в зависимости от ответа возвращает другой тип. Так реализуются условные типы в TypeScript:
```
type MyType = T extends 'str' ? string : number;
type MyString = MyType<'str'>; // string
type MyNumber = MyType; // number
type MyNumber1 = MyType; // number, так как множество string не принадлежит
// множеству из одного значения 'str'
```
*Код 4.7. Условный тип*
В условии типа ParametrizedIconNames, мы проверяем, принадлежит ли переданный тип T к шаблонной строке
```
`${string}Icons`
```
На данный момент в переменную шаблонной строки записан тип string, потому что там может быть какая угодно строка. Мы не можем знать, что это строка, но TypeScript сможет проанализировать соответствует ли тип **T** некой строке, которая оканчивается на **'Icons'**.
Так как ему доступен исходный тип, он предоставляет разработчику возможность определить множество строк, которые предшествуют **'Icons'** в исходном типе. И делается это с помощью ключевого слова infer. infer создаёт новую переменную, в которую записывается тип, то есть множество всех значений строк, подходящих под описание типа.
```
`${infer IconNames}Icons` // в переменной IconNames находится множество
// 'add' | 'remove' | 'edit'
```
Если входной тип T не включается во множество 'addIcon' | 'removeIcon' | 'editIcon', то в результате получится тип **never**. Этот тип пишется просто потому, что нам не нужны альтернативные типы. Мы можем что угодно сюда написать, но передать в дженерик такой тип, чтобы извлечь нужный тип.
Резюмируем тем, что извлечение типа из строки имеет важное значение, так как на строках строятся поля объекта, объекты получаются из импорта через звёздочку, различные паттерны проектирования используют строки. Глубокая типизация вертится вокруг строк.
Точность типов в реальной жизни
-------------------------------
После сложных объяснений типизации настало время аллегорий. Наверняка вы помните фразу из советского кино:
> *Детям – мороженое, его бабе – цветы.*..
>
>
Здесь можно провести интересную параллель с глубокой типизацией. Дети и их мать функции, которые принимают некие данные — подарки — и в результате должны проявить нужное поведение, то есть благосклонность к незнакомому дяде.
Можно заметить, что мороженое и цветы - это не данные, а тип данных. Мороженое может быть пломбиром, разливным, в стаканчиках и так далее. То же самое с многообразием видов цветов. Если дети будут рады любому мороженому, то с цветами не всё так просто. Функция женщины имеет довольно-таки сложную логику и если мы нарвём ей одуванчиков, то реакция может быть не такой, как ожидается.
Можно сказать, что типизация функции женщины не достаточно точная. И если герой Миронова не знаком с работой этой функции, то может передать совсем не те цветы. Более узкий тип для цветов — это, например: розы или фиалки или орхидеи.
Изображение 4.1. Разработчик передаёт функции woman данные типа FlowersАх, если бы вся жизнь была точно типизирована!..
Коду требуется более точный тип констант
----------------------------------------
Когда мы создаём константы, анализатор TypeScript сам определяет их тип. Иногда он это делает более точно, чем нам нужно, а иногда недостаточно точно.
Предположим, что нашему коду достаточно типа:
```
Record
```
Мы создаём константу этого типа без явной типизации:
```
const config = {
isActive: true,
hasLink: false,
}
// тип { isActive: boolean; hasLink: boolean}
// является подтипом Record
```
Анализатор определил тип как более точный, что по большому счёту не является проблемой. Согласно [принципу подстановки Барбары Лисков](https://ru.wikipedia.org/wiki/%D0%9F%D1%80%D0%B8%D0%BD%D1%86%D0%B8%D0%BF_%D0%BF%D0%BE%D0%B4%D1%81%D1%82%D0%B0%D0%BD%D0%BE%D0%B2%D0%BA%D0%B8_%D0%91%D0%B0%D1%80%D0%B1%D0%B0%D1%80%D1%8B_%D0%9B%D0%B8%D1%81%D0%BA%D0%BE%D0%B2) код, который использует более широкий тип, так же будет работать с более узким типом.
Код принимающий более широкий тип не сможет правильно работать с более узким типом, поэтому придётся дописывать в него логику проверки для сужения типа. В неизменных константах разработчики могли бы изначально описывать более точный тип явно и тогда это упростило код, который использует данные этого типа.
Эту проблему хорошо иллюстрируют константы массивы:
```
const steps = ['steps1', 'steps2'] // тип string[]
```
Если принимающий код будет обращаться к конкретным индексам, то тип данных станет более широким и его придётся сужать.
```
const currentSteps = steps[0] // string | undefined
```
Особенность массива в том, что не смотря на то, что он хранится в константе, он может изменить число элементов. И по этой причине TypeScript не может гарантировать, что в текущем элементе обнаружится строка, а не undefined.
Справиться с этой проблемой поможет кортеж — частный случай типа массива. Он будет защищать изменение числа элементов в массиве и соответственно гарантировать, что в нужных индекса содержатся заданные типы.
```
const steps: [string, string] = ['steps1', 'steps2'];
```
Передаваемый индекс так же должен соответствовать длине кортежа, то есть быть более узким типом, чем number:
```
const getStep = (index: 0 | 1) => steps[index];
```
В связке с кортежами неплохо работают типы enum. Они документируют код и ограничивают тип индекса:
```
enum StepNames {
FIRST,
SECOND
}
const currentStep = getStep(StepNames.FIRST);
```
Типизация кортежей может выглядеть громоздкой в месте объявления константы и логично заранее типизировать их различные размеры:
```
type TupleLength = 2 | 3 | 4 | 5;
type Tuple =
N extends 2 ? [T, T] :
N extends 3 ? [T, T, T] :
N extends 4 ? [T, T, T, T] :
N extends 5 ? [T, T, T, T, T] : never
type TupleOfFive = Tuple<2, string>; // тип [string, string, string, string, string]
```
*Код 4.8. Типизация кортежей различной длины и типа*
Типы аргументов функции зависят друг от друга
---------------------------------------------
Некоторые функции в приложениях при своих компактных размерах имеют очень мощные возможности. В эти функции нужно передавать правильные данные, чтобы они сработали, либо писать логику внутри, чтобы функция не ломалась. Используя глубокую типизацию разработчики могут столкнуться с проблемой зависимости типа одних аргументов от типа других.
Представим в React-приложении какой-нибудь сложный конфиг, который редактируется с помощью подобной функции:
```
// Внимание! Данный код демонстрирует только необходимость глубокой типизации,
// но не демонстрирует правильность подходов в проектировании логики
let initialConfig = {
total: 1,
isActive: true,
role: 'senior'
}
const setConfig = (param, value) => {
initialConfig = {
...initialConfig,
[param]: value
}
}
```
Функция setConfig не защищена от неверных входных данных. Можно легко задать правильный тип первого аргумента:
```
type ConfigParams = keyof typeof initialConfig; // 'total' | 'isActive' | 'role'
```
Но типизировать второй аргумент не так просто:
```
type ConfigValues = typeof initialConfig[ConfigParams];
// тип string | number | boolean
```
Значения переменной initialConfig вкупе действительно относятся к такому широкому типу. Чтобы заложить в тип аргументов зависимость друг от друга, нужно типизировать их через кортеж способом, показанным в прошлой [статье](https://habr.com/ru/post/694832/) в коде 3.8:
```
type SetFilterArgs = [
T, // тип относящийся ко множеству параметров ConfigParams
typeof initialConfig[T] // тип, соответствующий переданному параметру в initialConfig
]
// функция принимает тип T и передаёт его в тип SetFilterArgs
// здесь прописывается extends, чтобы отличить дженерик от JSX
const setConfig = (...args: SetFilterArgs) => {
const [param, value] = args;
initialConfig = {
...initialConfig,
[param]: value
}
}
// при вызове функции тип T передаётся с первым аргументом
setConfig('total', 3);
// если передать неверные типы аргументов будет ошибка
setConfig('role', true); // ошибка переданный тип boolean не соответствует
// типу string (который должен быть у полей с role)
setConfig('name', 'junior'); // ошибка 'name' не соответствует типу ConfigParams
```
*Код 4.9. Типизация аргументов функции с зависимыми типами*
Примеров необходимости глубокой типизации может быть ещё больше. Признаки того, что возможно данные требуют более точного типа:
* код нуждается в логике проверки данных:
+ ветвления (if, switch) сужают тип входных данных;
+ обращение к полям объектам или элементам массива требует проверки на null и undefined (операторы ??, ||);
* поведение функций меняется вплоть до их поломки, если передать неверные данные;
* чтобы получить тип из исходного, нужно писать много логики в контексте типов.
Следующая статья: [TypeScript в React-приложениях. 5. Связанная типизация](https://habr.com/ru/post/697548/) | https://habr.com/ru/post/696294/ | null | ru | null |
# Заметка о восстановлении Grub UEFI для Proxmox 7.xx (Debian 11)
Доброго времени суток, Хабр!
В своей работе IT-специалист иногда сталкивается с задачами, которые входят только в общий кругозор на уровне "читал, осознал", требующими срочного решения.
Недавно, после установки драйверов видеокарты NVIDIA для XFCE4 на Proxmox 7.xx перестал пинговаться гипервизор с роутера и компов сети. После его перезагрузки я увидел черный экран и надписью "grub disk native sectors not found".
Загрузившись с LiveUSB Ubuntu я прочитал разделы диска, убедился, что данные целы, проблема в загрузчике. Стало ясно, что проблема с разделом Grub BIOS, так как разделы диска EFI и рабочий монтировались корректно.
Надо сказать, что я устанавливал Proxmox 7.xx со стандартными настройками разбиения диска, то есть три раздела GPT-диска /dev/nvmes0n1: /dev/nvmes0n1p1 - GrubBIOS; /dev/nvmes0n1p2 - EFI диск; /dev/nvmes0n1p3 - LVM раздел, в котором Proxmox по-умолчанию задает два LVM диска /dev/pve/root и /dev/pve/swap
Убедившись, что данные корректны, диски fsck - тест проходят приступил к восстановлению. Я вставил поисковик текст ошибки и [открыл статью-инструкцию на сайте Proxmox](https://pve.proxmox.com/wiki/Recover_From_Grub_Failure).
Смысл ясен: грузим Linux-ОС с поддержкой LVM, активируем диск LVM с загрузчиком гипервизора, монтируем в папку, заходим chroot и восстанавливаем загрузчик (ничего сложного). Ниже листинг до проблемы, которая возникла у меня:
```
#Использую права админа постоянно, чтобы не писать везде sudo
sudo su -
#Сканирую LVM диски
vgscan
Found volume group "pve" using metadata type lvm2
#Активирую Volume Group (VG) "pve"
vgscan -ay pve
#Смотрим, что есть
lsblk
nvmes0
├─nvmes0n1p1
├─nvmes0n1p2 vfat
└─nvmes0n1p3 LVM2_member
└──pve-swap swap
└─pve-root ext4
#монтируем в директорию /mnt
mount /dev/pve/root /mnt
mount /dev/nvmes0n1 /mnt/boot
```
Ошибка следующая: диск уже активен, смонтировать его нельзя. Естественно активен, ведь он активирован как том VG (LVM). То есть, один шаг инструкции не работает. Иду дальше:
```
mount /dev/nvmes0n1p2 /mnt/boot
ls /mnt/boot
EFI
```
Вывод показывает, что мы смонтировали EFI - раздел с загрузчиком Debian. Перемонтируем его правильно:
```
umount /mnt/boot
mount /mnt/boot/efi
ls /mnt/boot
config-5.15.30-2-pve initrd.img-5.15.74-1-pve System.map-5.15.74-1-pve
config-5.15.74-1-pve initrd.img-5.15.83-1-pve System.map-5.15.83-1-pve
config-5.15.83-1-pve memtest86+.bin vmlinuz-5.15.30-2-pve
efi memtest86+_multiboot.bin vmlinuz-5.15.74-1-pve
grub pve vmlinuz-5.15.83-1-pve
initrd.img-5.15.30-2-pve System.map-5.15.30-2-pve
```
Ясно, что в /mnt/boot есть необходимые файлы-образы ядра для загрузки, следовательно монтировать туда диск нет необходимости. Действуем дальше:
```
mount -t proc proc /mnt/proc
mount -t sysfs sys /mnt/sys
mount -o bind /dev /mnt/dev
mount -o bind /run /mnt/run
chroot /mnt
update-grub
```
Апгрейд grub произведен, загрузочные файлы сформированы по необходимым им путям, необходимо восстановить загрузчик. Изучаем предметную область:
```
fdisk -l /dev/nvmes0n1p1
Disk /dev/nvmes0n1p1: 1 MiB, 1048576 bytes, 2048 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
fsck -N /dev/nvmes0n1p1
root@pve:~# fsck -n /dev/nvme0n1p1
fsck from util-linux 2.36.1
e2fsck 1.46.5 (30-Dec-2021)
ext2fs_open2: Bad magic number in super-block
fsck.ext2: Superblock invalid, trying backup blocks...
fsck.ext2: Bad magic number in super-block while trying to open /dev/nvme0n1p1
The superblock could not be read or does not describe a valid ext2/ext3/ext4
filesystem. If the device is valid and it really contains an ext2/ext3/ext4
lsblk -no name,fstype
nvmes0n1
├─nvmes0n1p1
├─nvmes0n1p2 vfat
└─nvmes0n1p3 LVM2_member
├─pve-swap swap
└─pve-root ext4
gdisk /dev/nvmes0n1
GPT fdisk (gdisk) version 1.0.6
Partition table scan:
MBR: protective
BSD: not present
APM: not present
GPT: present
Found valid GPT with protective MBR; using GPT.
Command (? for help): i
Partition number (1-3): 1
Partition GUID code: 21686148-6449-6E6F-744E-656564454649 (BIOS boot partition)
Partition unique GUID: AEC0785C-ECA8-0C4C-A7AD-C5C11F0B2B20
First sector: 34 (at 17.0 KiB)
Last sector: 2047 (at 1023.5 KiB)
Partition size: 2014 sectors (1007.0 KiB)
Attribute flags: 0000000000000004
Partition name: ''
# Следовательно, файловая система BIOS boot partition, размер диска 1Мб
#диск /dev/nvmes0n1p2 - vfat, EFI загрузчик
#напомню, мы в chroot, поэтому тут каталог /mnt свободен
mount /dev/nvmes0n1p1 /mnt
mount: /mnt: wrong fs type, bad option, bad superblock on /dev/nvmes0n1p1, missing codepage or helper program, or other error.
```
Если кратко, то по запросу UEFI boot Debian 11 [получил статью, где описывается](https://tanguy.ortolo.eu/blog/article51/debian-efi), что есть некий efi-boot debian, который необходимо установить в загрузочный раздел с типом vfat, в дальнейшем монтируемый в /boot/efi. Начал подозревать, что /dev/nvmes0n1p1 и является таким разделом, в отличие от заявленного в статье о восстановлении загрузки /dev/sda.
Читателю рекомендую произвести перед каждым действием с изменением данными бекап "оперируемого" диска, например на внешний диск. Самое простое, но и длительное, это зацепить внешний HDD (предполагаю, что он примонтирован в каталог /backup) и на него выполнить клон диска утилитой DD:
```
dd if=/dev/nvmes0n1 of=/backup/nvmes0n1.img
```
Begin: UPD#1 19.01.2023
-----------------------
Озадачился поиском оптимального использования дампа через "dd'. [В статье "Команда dd и все, что с ней связано" описан механизм бекапа mbr](https://habr.com/ru/post/117050/):
```
# dd if=/dev/sda of=mbr.img bs=512 count=1
```
Для бекапа загрузки GPT, взято [из этого источника](http://www.techpository.com/linux-copy-gpt-partition-table-with-dd/)
```
dd if=/dev/nvmes0n1 of=/backup/gpt_table_nvmes0n1 bs=1 count=1536
```
### End: UPD#1 19.01.2023
Я же сделал бекап сразу после запуска LiveCD, поэтому продолжаю:
```
grub-install /dev/nvmes0n1p1
```
После выхода из chroot, выключения ОС LiveUSB, изъятия флеш-диска из системного блока, произошла корректная загрузка моего Proxmox 7.xx со всеми виртуальными машинами и настройками.
В течение недели, до 24 января 2023 года напишу еще пару статей о:
* зачем IT-специалисту вообще дома гипервизор Proxmox 7.xx
* как запустить в Proxmox 7.xx гостевую машину в окне Proxmox 7.xx и для чего это мне понадобилось
Очень надеюсь, что описание данного кейса сэкономит коллегам кучу нервных клеток и время на поиск решения (спасибо, Хабр, что ты есть). Комментарии к статье приветствуются | https://habr.com/ru/post/711466/ | null | ru | null |
# Смена регистра букв при автозамене в NetBeans
Всем привет! Хочу поделиться решением одной проблемы, связанной с авто-заменой по регулярному выражению в [NetBeans](http://www.netbeans.org/).
#### Описание проблемы
При реализации многих проектов программисту приходится решать проблему [локализации](http://ru.wikipedia.org/wiki/%D0%9B%D0%BE%D0%BA%D0%B0%D0%BB%D0%B8%D0%B7%D0%B0%D1%86%D0%B8%D1%8F), а в частности реализации многоязычной поддержки пользовательского интерфейса. Я часто сталкивался с этой задачей и раньше использовал для этого список(массив) лексем, которые в нужном месте вызывались по ключу (здесь и далее речь пойдет о проектах на [PHP](http://www.php.net/), но статья поможет любым разработчикам, которые используют IDE NetBeans):
`php<br/
$_CONFIG['errors'] = array();
$_CONFIG['errors']['db_connection'] = "Database connection error:";
$_CONFIG['errors']['no_user'] = "No user with this e-mail and password.";
$_CONFIG['errors']['wrong_user_data'] = "Wrong user data.";
...
?>`
Но у такого решения есть ряд недостатков:
1. для того чтобы видеть, какое именно значение вставляется в код нужно постоянно переключаться во вкладку с языковым файлом и искать нужное значение;
2. неудобства, возникающие при множественном вложении массивов (в примере вложенность 2 уровня, но может быть и больше);
3. данная структура данных является переменной, а для такой задачи логичнее было бы использовать константы, так как значение этих лексем в процессе выполнения сценария не меняются.
#### Постановка задачи
Для решения описанной выше задачи [декомпозируем](http://ru.wikipedia.org/wiki/%D0%94%D0%B5%D0%BA%D0%BE%D0%BC%D0%BF%D0%BE%D0%B7%D0%B8%D1%86%D0%B8%D1%8F) ее на подзадачи, согласно описанным проблемам:
1. реализовать возможность быстрого перехода на значение лексемы из любой части кода в среде разработки;
2. выделить основные типы лексем и построить максимально удобную и понятную структуру их представления (в крупных проектах количество лексем может достигать нескольких тысяч)
3. использовать константы вместо переменных;
Таким образом удобнее всего решить эту задачу с помощью классов констант:
`php<br/
class __ERRORS {
/**
* Database errors
*/
const DB_CONNECTION = "Database connection error:";
const NO_USER = "No user with this e-mail and password.";
const WRONG_USER_DATA = "Wrong user data.";
/**
* Forms validation errors
*/
const WRONG_CAPTCHA = "Wrong captcha code";
.....
?>`
Такой подход позволит разбить лексемы на необходимые классы. Просто можно создать классы **\_\_TIPS**, **\_\_MESSAGES**, **\_\_WARNINGS** и т.д. Также при клике по константе класса в любой части кода в IDE с нажатым **Ctrl** мы сразу переходим на ее декларацию, что очень ускоряет процесс разработки.
#### Проблема с которой я столкнулся
Но все-таки остается одна проблема, что делать если мы уже имеем огромный файл с лексемами в массивах. Многие системы написаны именно с таким подходом к локализации. Лексем очень много, естественно перебивать их в новую структуру зачастую очень сложно и долго. Логичным решением представляется автозамена в самой IDE.
Вот мы и подошли к тому, из-за чего я пишу статью. Первым делом для того чтобы изменить структуру хранения лексем я воспользовался автозаменой в NetBeans по регулярному выражению **\$\\_CONFIG\['errors'\]\['(.+)'\]**.
Далее мне было нужно переименовать все константы в верхний регистр и тут то я зашел в тупик. Начал искать как это можно сделать в NetBeans. И даже на [официальных источниках](http://forums.netbeans.org/topic32881.html). Оказалось что автозаменой этого сделать нельзя. Тут я вспомнил про [макросы](http://rmcreative.ru/playground/netbeans_macro/). Осталось только написать еще одно регулярное выражение для поиска в коде имен констант и написать макрос, который будет переводить найденные имена констант в верхний регистр.
Для этого идем в *Edit -> Start Macro Recording* и ищем по регулярному выражению **([a-z]{1}[a-z\_]\*) =**

Останавливаем запись макроса *Edit -> Stop Macro Recording* и даем ему имя.
Идем в панель управления макросами *Tools -> Options -> Editor -> Macros* и находим наш макрос.
Дописываем команду перевода в верхний регистр **to-upper-case** и назначаем комбинацию клавиш для быстрого вызова макроса. Теперь мы имеем возможность быстро выполнить [рефакторинг](http://ru.wikipedia.org/wiki/%D0%A0%D0%B5%D1%84%D0%B0%D0%BA%D1%82%D0%BE%D1%80%D0%B8%D0%BD%D0%B3) нашего кода.

#### Заключение
В данной статье рассматривается решение конкретной практической задачи. Но она выбрана просто как пример, скорее даже так исторически сложилось, она была толчком для поиска такого решения. Но описанные выше действия могут помочь при решении многих подобных задач, связанных с необходимостью быстрого поиска и замены большого количества кода в IDE NetBeans. Надеюсь что эта статья кому-то поможет.
#### Литература
* [Макросы в NetBeans](http://rmcreative.ru/playground/netbeans_macro/)
**P.S.** Автору статьи просто необходим инвайт.
**UPD** Автор [dzarezenko](https://habrahabr.ru/users/dzarezenko/) получил инвайт. Огромное спасибо! | https://habr.com/ru/post/108272/ | null | ru | null |
# MaskJS, поговорим о шаблонном движке, или новом велосипеде

Вот, наконец дошли руки поделиться с людьми одним из множества велосипедов (как сейчас называют личные наработки). До хабраката пару плюсов и минусов этого решения:
Из плюсов:
* скорость [jsperf](http://jsperf.com/javascript-template-engine-compare/2) (тест с прекомпилированными шаблонами: [jsperf](http://jsperf.com/javascript-template-engine-compare/9))
* расширяемость := кастомные контролы, трансформация шаблонных данных
* data bindings
* компиляция в json для дальнейшего кэширования
* приятный синтаксис (без мешанины логики и структуры)
Из недостатков:
* шаблонные данные могут находиться только в атрибутах и литералах (хотя, поверте — этого достаточно)
Если тема интересная —
###### Вступление
Давайте я сразу принесу свои извинения за грамматику/стилистику. Хочется написать все очень кратко, но в тоже время, чтобы все меня поняли, и к тому же правильно поняли. Вы же не компиляторы, которые всё «понимают» буквально — а каждый со своим опыт, суждением и прочим. А так как опыта в написании статей у меня мало, как и опыта в писании на русском — то это в корни перечёркивает надежду написать всё так, как я это представляю. Но я попробую, а вы не ругайтесь.
###### Немного истории
Пару лет назад мне понадобилась функция вида `String.format('N: #{a} : #{b}',{a:1,b:2})`.
Вскоре я понял, что используя её для форматирования html, у меня, по большей части, связаны руки. Ведь так хочется форматирование по условию, условной видимости и списков. Посмотрев на разные шаблонные движки, ощутил дикое отвращение к смеси *html* и *javascript*, плюс использование `with(){}` и `eval/new Function('')` тоже не радовало. Подумав, что «мне то совсем чуть-чуть надо» и решил написать для себя сам. Так родились два тэга `list` и `visible` и формат вида `#{a==1?1:-1}`. Mне достаточно было лишь найти рэгэкспом эти тэги, ну а дальше `String.format`. И вот полтора года этот движок отлично нёс свою службу — был шустрее шустрых и надёжнее надёжных.
###### «А нам всегда мало...»
Как не прискорбно, но мы так устроены — ну, по крайней мере, я. Захотелось ещё быстрее, ещё более расширяемо и чтобы дальше без месива *html/javascript*. На этот момент я знал точно: хочу кастомные тэги — что бы по десять раз не писать одну и ту же html структуру и без *placeholder*-ов*(что бы после вставки в дом туда рэндерить)*. И вот как только я сел допиливать парсер для обработки дополнительных тэгов, тут как назло проснулось стремление к искусству, которое начало мусолить — "*Перепиши. Перепиши код. Это же Ford Mondeo 93-го. А сейчас уже даже миллениум давно был. Да вот ещё и синтаксис шаблонов другой надо. Ты что не видел CoffeeScript Sass/Less ZenCoding? Перепиши, кому говорят, иначе уснуть не дам — так и знай*". И под этим давлением я не устоял. Но все же главным приоритетом, это была скорость движка — никому не нужен красивый, но со 100 л.с. болид на старте.
###### Переходим к делу: Дерево
Так как используем свой синтаксис, его надо преобразовывать в дерево. Имеем два типа узлов: Тэг = `{tagName:'someTagName', attr: { key:'value'}, nodes:[] }` и Литерал = `{content:'Some String'}`. А так как за 1.5 года использования старого шаблонизатора, я ни разу не помню, что бы подставлял шаблонные данные в название тэга, или названия атрибута, то для простоты шаблона и анализатора, сделаем возможным вставки данных только в них. Поэтому узлы будут следующего вида: Тэг := `{tagName:'name', attr: { key:('value'||function)}, nodes:[] }` и Литерал := `{content:('Some String'||function)}`. Где `function` — это функция которая подставляет шаблонные данные и она только у тех значениях, которые их требуют. Вот мы и посадили дерево, пока что ничего сложного( *дальше сложнее тоже не будет*).
###### Анализатор/Парсер
Интересные моменты:
* анализируем линейно, по возможности даже перепрыгнем участки, для дальнейшего «substring»
* минимально используем вызовы функций, рекурсию совсем не используем
* для анализа используем объект: `var T = {index:0 /* currentIndex */, length:template.length, template:template}`. При вызове дополнительных функций, передаём его(вернее передаётся ссылка на него). Таким образом `template string` не копируется
* charCodeAt — не особо быстрее charAt или [], но дальнейшая робота с number быстрее
Сам парсинг до боли прост — составляет 40 строк. (парсинг атрибутов надо было бы не выносить в отдельную функцию, но потерялась бы наглядность)
**Кусок кода**
```
var current = T;
for (; T.index < T.length; T.index++) {
var c = T.template.charCodeAt(T.index);
switch (c) {
case 32: //" "
continue;
case 39: // "'" парсим литерал
T.index++;
var content = T.sliceToChar("'");
// в sliceToChar используется indexOf с проверкой на 'escape character'
// поэтому след. indexOf имеет смысл, так как, это быстрее чем линейно проверять charCodeAt/charAt/[]
if (~content.indexOf('#{')) content = T.serialize == null ? this.toFunction(content) : {
template: content
};
current.nodes.push({
content: content
});
if (current.__single) {
//если это одинарный тэг, переходим к предку, который не одинарный; пример div > ul > li > span > 'Some'
if (current == null) continue;
do (current = current.parent)
while (current != null && current.__single != null);
}
continue;
case 62: /* '>' */
current.__single = true;
continue;
case 123: /* '{' */
continue;
case 59: /* ';' */
case 125: /* '}' */
if (current == null) continue;
// тэг закрыт ; , или закончился } - переходим к предку
do(current = current.parent)
while (current != null && current.__single != null);
continue;
}
//знакомые символы не встретились - парсим tag с атрибутами
var start = T.index;
do(c = T.template.charCodeAt(++T.index))
while (c !== 32 && c !== 35 && c !== 46 && c !== 59 && c !== 123); /** while !: ' ', # , . , ; , { */
var tag = {
tagName: T.template.substring(start, T.index),
parent: current
};
current.nodes.push(tag);
current = tag;
this.parseAttributes(T, current);
//парсинг атрибута закончится на ; > {, чуть чуть назад отступим
T.index--;
}
```
###### Конструктор
Имея дерево, негоже строить `html string` для вставки в документ, надо строить сразу `documentFragment` (хотя `function renderHtml` тоже оставил, на всякий случай). Этим мы сильно компенсируем затраченное время на парсинг.
Сам процесс снова тривиальный:
**Часть кода**
```
function buildDom(node, values, container) {
if (container == null) container = document.createDocumentFragment();
if (node instanceof Array) {
for (var i = 0, length = node.length; i < length; i++) buildDom(node[i], values, container);
return container;
}
if (CustomTags.all[node.tagName] != null) {
var custom = new CustomTags.all[node.tagName]();
for (var key in node) custom[key] = node[key];
custom.render(values, container);
return container;
}
if (node.content != null) {
//это литерал
container.appendChild(document.createTextNode(typeof node.content === 'function' ? node.content(values) : node.content));
return container;
}
var tag = document.createElement(node.tagName);
for (var key in node.attr) {
var value = typeof node.attr[key] == 'function' ? node.attr[key](values) : node.attr[key];
if (value) tag.setAttribute(key, value);
}
if (node.nodes != null) {
buildDom(node.nodes, values, tag);
}
container.appendChild(tag);
return container;
}
```
###### Кастомные контролы
Как видно выше из кода, здесь на сцену выходят кастомные контролы. Если конструктор встретит зарегистрированный обработчик тэга, он создаст объект обработчика, сделает `shallow copy` значений `attr` и `nodes` и передаст контекст сборки в функцию render. То есть наш контрол должен реализовать в прототипе функцию `.render(currentValues, container)`
###### toFunction(templateString)
Собственно это то место, где происходит магия. Правда магией это не назовёшь, а так хотелось бы. На самом деле тут получаем части для вставки наших данных, это
* или ключи к свойствам входных данных, возможна «рекурсия» `#{obj.other.value}`
* или обращение к функции трансформаторе `#{fnName:line}`. Если fnName пустая строка считается что line это условие и будет выполнено функцией `ValueUtilities.condition(line, values)`
, обрабатываем их и вставляем в template.
Ну вот, кажется все осветил. В примерах можно больше интересного увидеть, там же реализация дата биндингов, через контролы. Посмотрите также исходники страницы примеров.
---
[Примеры](http://tenbits.github.com/MaskJS/)
[Исходники](https://github.com/tenbits/MaskJS)
---
оффтоп:
В арсенале много ещё каких «великов», например, IncludeJS — похоже на Require, но со своей кучей «вкусняшек». Если будет интерес к подобным вещам (это ведь не зарелизеные библиотеки для продакшн) тоже выложу на гитхаб, и напишу статью.
Удачи! | https://habr.com/ru/post/149509/ | null | ru | null |
# Лишние элементы или как мы балансируем между серверами
**Привет, Хабр!** Какое-то время назад люди осознали, что увеличивать мощность сервера в соответствии с ростом нагрузки просто невозможно. Тогда-то мы и узнали слово «кластер». Но как бы красиво это слово не звучало, всё равно приходится технически объединять разрозненные серверы в единое целое – тот самый кластер. [По городам и весям](http://habrahabr.ru/company/ivi/blog/237349/) мы добрались до наших узлов в моём предыдущем опусе. А сегодня мой рассказ пойдёт о том, как делят нагрузку между членами кластера системные интеграторы, и как это сделали мы.
[](http://habrahabr.ru/company/ivi/blog/240237/)
Внутри публикации вас также ждёт бонус в виде трёх сертификатов на [месячную подписку ivi+](http://www.ivi.ru/plus/).
Делай как все
-------------
Какие задачи ставят для кластера?
**1.** Много трафика
**2.** Высокая надёжность
03d63a0996fb
Как этого добиться? Самый простой способ поделить нагрузку между серверами – не делить её. Вернее так: дадим полный список серверов – пусть клиенты сами разбираются. Как? Да просто прописав все IP-адреса серверов в DNS для заданного имени. Древняя и знаменитейшая балансировка [round-robin DNS](https://ru.wikipedia.org/wiki/Round_robin_DNS). И в целом неплохо работает, пока не возникает потребность добавить узел – я уже [писал](http://habrahabr.ru/company/ivi/blog/237349/) про инертность DNS-кэшей. Выглядит DNS-балансировка так:
А если надо убрать сервер из кластера (ну, сломался он), наступает каюк. Чтобы каюк на нас не наступил, надо куда-то быстро повесить IP сломавшегося сервера. Куда? Ну, допустим, на соседа. Окей, а как мы это можем автоматизировать? Для этого придумана куча протоколов вроде VRRP, CARP со своими достоинствами и недостатками.
Первое, во что обычно упираются, это ARP-кэш на роутере, который не хочет понимать, что IP-адрес переехал на другой MAC. Впрочем, современные реализации либо «пингуют» роутер с нового MAC'а (обновляя кэш таким образом), либо вообще используют виртуальный MAC, который не меняется во время работы.
Второе, что бьёт по голове – это серверные ресурсы. Мы ведь не будем держать один сервер из двух в горячем standby? Сервер должен работать! Поэтому мы будет резервировать по VRRP два адреса на каждом сервере: один – primary и один backup. Если один из серверов пары сломается, второй примет на себя всю его нагрузку… может быть… если справится. И вот такая «парность» и будет главным недостатком, ибо не всегда есть возможность или целесообразность держать двойной запас серверной мощности.
Также нельзя не заметить, что каждый сервер требует своего собственного, глобально маршрутизируемого IP-адреса. В наше нелёгкое время это может стать большой проблемой.
В целом, мне скорее не нравится такой способ балансировки и резервирования, но для целого ряда задач и объёмов трафика он хорош. Прост. Не требует дополнительного оборудования – всё делается серверным софтом.
На шару
-------
Продолжая перечисление простых решений, а может, стоит просто навесить один и тот же IP-адрес на несколько серверов? Ну, в IPv6 есть возможность сделать anycast в одном домене (и то балансировка там будет только для хостов внутри него, а для внешних – совсем не так), а вот в IPv4 такая штука просто создаст ARP-конфликт (более известный как конфликт адресов). Но это если «в лоб».
А если использовать небольшой наворот под кодовым названием «shared address» (разделяемый адрес), то такое возможно. Суть трюка заключается в том, чтобы сначала превратить входящий уникаст в броадкаст (ладно, если кто хочет – пусть делает мультикаст), а затем только один из серверов отвечает на пакеты от данного клиента. Как осуществляется превращение? Очень просто: все серверы кластера в ответ на ARP-запрос возвращают один и тот же MAC: либо несуществующий на сети, либо мультикастовый. После этого сеть сама размножит входящие пакеты на все члены кластера. А как серверы договариваются о том, кто отвечает? Для простоты скажем так: по остатку от деления srcIP на количество серверов в кластере. Дальше – дело техники.
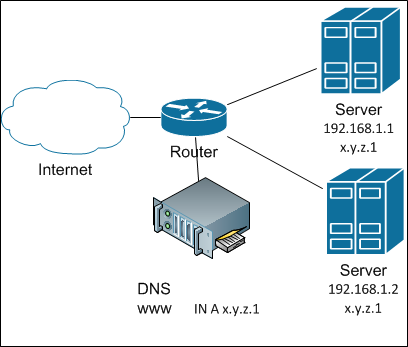
*Балансировка с разделяемым адресом*
Такую технику реализуют разные модули и разные протоколы. Для FreeBSD такая возможность реализована в [CARP](https://www.freebsd.org/doc/handbook/carp.html). Для Linux в прошлой жизни мне доводилось использовать [ClusterIP](http://www.linux-ha.org/ClusterIP). Сейчас он, видимо, не развивается. Но я уверен, что есть и другие реализации. Для Windows такая штука есть во встроенных средствах кластеризации. В общем, выбор есть.
Преимуществом такой балансировки всё так же является чисто серверная реализация: никакой особой настройки со стороны сети не требуется. Публичный адрес используется всего один. Добавление или отключение одного сервера в кластере происходит быстро.
В недостатках же, во-первых, числится необходимость дополнительной проверки на уровне приложения, а во-вторых (и даже «в главных») – это ограничение по входящей полосе: количество входящего трафика не может превышать полосу в физическом подключении серверов. И это очевидно: ведь входящий трафик попадает на все серверы одновременно.
Так что в целом это неплохой способ балансировать трафик, если у вас немного входящего трафика, но употреблять его следует с умом. И тут я скромно скажу, что сейчас мы этот метод не используем. Как раз из-за проблемы входящего трафика.
Никогда не заговаривайте с интеграторами
----------------------------------------
Мне почему-то кажется, что задача балансировки между серверами должна быть типовой. А для типовой задачи должны быть типовые решения. А кто хорошо продаёт типовые решения? Интеграторы! И мы спросили…
Надо ли говорить, что нам предложили решения из вагонов самого разного оборудования? От [Cisco ACE](http://habrahabr.ru/post/143564/) и до всяческих [F5 BigIP LTM](https://f5.com/products/modules/local-traffic-manager). Дорого. Но хорошо ли? Ладно, есть ещё прекрасный бесплатный софтовый L7-балансировщик [haproxy](http://www.haproxy.org/).
В чём же смысл этих штучек? Смысл в том, что балансировку они делают на уровне приложения – Layer 7. Фактически, такие балансировщики являются полными прокси (full proxy): они устанавливают соединение с клиентом и с сервером от своего имени. В теории это хорошо тем, что они могут осуществлять прилипание клиента к определённому серверу (server affinity) и даже выбирать бэкэнд в зависимости от запрошенного контента (крайне полезная штука для такого ресурса как [ivi.ru](http://www.ivi.ru/)). А при определённой настройке – и фильтровать запросы по URL, защищаясь от различного рода атак. Главное же преимущество – такие балансировщики могут определять жизнеспособность каждого узла в кластере самостоятельно.
*Балансировщики включаются в сеть как-то так*
Признаюсь, мой прошлый опыт кричал «Без балансировщиков сделать ничего не возможно». Мы посчитали… И ужаснулись.
Самые производительные балансировщики, которые нам предложили, имели пропускную способность 10Гбит/с. По нашим меркам не смешно (серверы с тяжелым контентом у нас подключаются 2 \* 10Гбит/с). Соответственно, чтобы получить нужную полосу, надо было бы набить целую стойку такими балансировщиками, с учётом резервирования. Посмотрите вот на эту схему:
*Так выглядит физическое подключение балансировщика.*
Конечно, есть ещё режим частичного прокси (half-proxy), когда через балансировщик проходит только половина трафика: от клиента к серверу, а обратно от сервера – идёт напрямую. Но такой режим отключает L7 функциональность, и балансировщик становится L3-L4, что резко снижает его ценность. А дальше последовательно возникает две проблемы: сначала нужно сделать достаточную мощности сети (в первую очередь – по портам, потом – по надёжности). Затем возникает вопрос: а как балансировать нагрузку между балансировщиками? В Москве поставить стойку с оборудованием для балансировки, в теории, наверно, можно. А вот в регионах, где наши узлы минималистичны (серверы да циска) добавление нескольких балансировщиков уже как-то не смешно. К тому же, чем длиннее цепочка, тем ниже надёжность. А оно нам надо?
ECMP или ничего лишнего
-----------------------
Решение нагуглилось почти случайно. Оказывается, современный роутер сам по себе умеет балансировать трафик. Если подумать, это разумно: ведь одна и та же подсеть может быть доступна через разные каналы с одинаковым качеством. Такая функция называется **ECMP** – Equal Cost Multiple Paths. Видя одинаковые по своей метрике (в общем смысле этого слова) маршруты, роутер просто делит пакеты между этими маршрутами.
ОК, идея интересная, но будет ли это работать? Тестовый запуск мы провели, прописывая статические маршруты с роутера в сторону нескольких серверов. Концепт оказался работоспособным, но потребовалась дополнительная проработка.
**Во-первых**, необходимо обеспечить попадание всех IP-пакетов, относящихся к одной TCP-сессии на один и тот же сервер. Ведь иначе TCP-сессия просто не состоится. Это так называемый режим «per-flow» (или «per-destination»), и он вроде как включен по умолчанию на роутерах Cisco.
**Во-вторых**, статические маршруты не подходят – ведь нам надо иметь возможность автоматически убирать сломанный сервер из кластера. Т.е. надо применять какой-либо протокол динамической маршрутизации. Для единообразия мы выбрали BGP. На серверах установлен программный роутер (сейчас это [quagga](http://www.nongnu.org/quagga/), но в ближайшем будущем перейдём на [BIRD](http://bird.network.cz/)), который анонсирует «серверную» сеть на роутер. Как только сервер перестаёт слать анонсы, роутер перестаёт распределять трафик. Соответственно, для балансировки на роутере настроено значение `maximum-paths ibgp` равное количеству серверов в кластере (с некоторыми оговорками):
```
router bgp 57629
address-family ipv4
maximum-paths ibgp 24
```
Но сам BGP гарантирует только сетевую доступность сервера, но не прикладную. Чтобы проверять работоспособность прикладного софта, на сервере запущен скрипт, который осуществляет ряд проверок, и если что-то пошло не так, просто гасит BGP. Дальше дело роутера – перестать слать пакеты на этот сервер.
**В третьих**, была замечена неоднородность распределения запросов между серверами. Небольшая, и компенсируемая нашим ПО кластеризации, Но хотелось-то равномерности. Выяснилось, что по умолчанию роутер балансирует пакеты исходя из адресов отправителя и получателя пакета, то есть L3-балансировка. Исходя из того, что адрес получателя (сервера) всегда один и тот же, это указывает на неоднородность в адресах-источниках. Учитывая массовую NAT'изацию интернета, это неудивительно. Решение оказалось простым – заставить роутер учитывать порты получателя и источника (L4-балансировка) при помощи команды вроде
```
platform ip cef load-sharing full
```
или
```
ip cef load-sharing algorithm include-ports source destination
```
в зависимости от IOS. Главное только, чтобы у вас не было такой команды:
```
ip load-sharing per-packet
```
Итоговая схема выглядит вот так:
Ничего знакомого не заметили? Ну там, что это фактически anycast, только не между регионами, а внутри одного узла? Так это он и есть!
Преимуществами L3-L4 балансировки можно назвать эффективность: роутер должен быть, без него никак. Надёжность тоже на должном уровне – если вдруг сломается роутер, то дальше уже неважно. Дополнительное оборудование не приобретается – это хорошо. Публичные адреса тоже не расходуются – один и тот же IP обслуживается сразу несколькими серверами.
Есть, увы, и недостатки.
**1.** На сервер приходится ставить дополнительный софт, настраивать его и т.п. Правда, этот софт достаточно скромен, и не расходует ресурсы сервера. Так что – терпимо.
**2.** Переходные процессы одного сервера (включение в кластер или исключение) влияют на весь кластер. Ведь роутер ничего не знает о серверах – он думает, что имеет дело с роутерами и каналами. Соответственно, все соединения распределяются на все доступные каналы. Никакого server-affinity. В результате при выключении сервера все соединения перетасовываются между всеми оставшимися серверами. И все активные TCP-сессий разрываются (строго говоря – не все, есть шанс, что часть вернётся на тот же сервер). Это плохо, но учитывая нашу защиту от таких ситуаций (плеер перезапрашивает контент при разрыве соединений) и некоторые финты ушами (о которых я ещё расскажу), жить можно.
**3.** Существуют ограничения, на сколько равных маршрутов роутер может разделить трафик: на cisco 3750X и 4500-X это 8, на 6500+Sup2T – это 32 (но там есть один прикол). В целом этого достаточно, к тому же есть трюки, которые позволяют раскрутить это ограничение.
**4.** При такой схеме нагрузка на все серверы распределяется равномерно, что накладывает требование одинаковости на все серверы. И если добавлять в кластер более современный, мощный, сервер, нагрузка на него будет не больше, чем на соседа. К счастью, наш софт кластеризации эту проблему в значительной степени нивелирует. К тому же, в роутерах еще есть функция *unequal cost multiple paths*, которую мы пока не задействовали.
**5.** Типовые таймауты BGP могут приводить к таким ситуациям, когда сервер уже недоступен, а балансирующий роутер всё ещё распределяет на него нагрузку. Но с этим нам поможет справиться BFD. Подробнее о протоколе — [читайте wikipedia.](http://en.wikipedia.org/wiki/Bidirectional_Forwarding_Detection) Собственно, именно из-за BFD мы и решили перейти на BIRD.
Промежуточный итог
------------------
Исключение балансировщиков из цепочки прохождения трафика позволило сэкономить на оборудовании, повысило надёжность системы и сохранило минималистичность наших региональных узлов. Нам пришлось применить несколько трюков, чтобы компенсировать недостатки такой схемы балансировки (надеюсь, у меня ещё будет шанс рассказать об этих трюках). Но в существующей схеме всё ещё есть лишний элемент. И я очень надеюсь убрать его в этом году и рассказать, как нам это удалось.
Кстати, пока я писал (точнее, черновик вылёживался) эту статью, коллеги на Хабре написали очень неплохую [статью про алгоритмы балансировки](http://habrahabr.ru/company/selectel/blog/250201/). Рекомендую к прочтению!
**P.S.** Сертификаты одноразовые, так что «кто первый встал, тот и ~~посс~~ попал в душ».
Наши предыдущие публикации:
» [Blowfish на страже ivi](http://habrahabr.ru/post/249359/)
» [Неперсонализированные рекомендации: метод ассоциаций](http://habrahabr.ru/post/247813/)
» [По городам и весям или как мы балансируем между узлами CDN](http://habrahabr.ru/post/237349/)
» [I am Groot. Делаем свою аналитику на событиях](http://habrahabr.ru/post/236253/ "b706a658aa01")
» [Все на одного или как мы построили CDN](http://habrahabr.ru/post/236065/) | https://habr.com/ru/post/240237/ | null | ru | null |
# Почему Kotlin лучше Java?
Это ответ на переведенную публикацию [«Почему Kotlin хуже, чем Java?»](https://habr.com/ru/company/funcorp/blog/558412/). Поскольку исходная аргументация опирается всего на два примера, то не теряя времени пройдем по этим «недостаткам» Kotlin.
Проприетарные метаданные?
-------------------------
> изрядное количество подробностей внутренней работы kotlinc скрыто внутри сгенерированных файлов классов...без IDEA Kotlin немедленно умрет
>
>
Это не проприетарный код, а просто способ для компилятора дописать дополнительные данные в жестко заданном формате .class-файлов, который ранее был заточен только под javac. Метаданные нужны для рефлексии и их можно удалить при компиляции. Исходный код метаданных [открыт и общедоступен](https://github.com/JetBrains/kotlin/blob/master/core/metadata/src/metadata.proto).
Kotlin будет отставать?
-----------------------
Вкратце, посыл исходной статьи таков, что Kotlin был инновационным, но Java добавит все те же языковые возможности, только продуманее и лучше, и уже Kotlin-вариант выпадет из мейнстрима.
В качестве примера автор приводит`instanceof`:
> В Kotlin сделали примерно так
>
>
```
if (x instanceof String) {
// теперь x имеет тип String!
System.out.println(x.toLowerCase());
}
```
> Но в Java версии 16+ стало так:
>
>
```
if (x instanceof String y) {
System.out.println(y.toLowerCase());
}
```
> Получается, что оба языка имеют способ обработать описанный сценарий, но разными способами. **Я уверен, что если бы мог вдавить огромную кнопку «сброс», разработать Kotlin с нуля и снова выпустить сегодня бета-версию, то в Kotlin было бы сделано так же, как сейчас в Java. Учитывая, что синтаксис Java более мощный**: мы можем сделать с ним намного больше, чем просто «проверить тип» (например, «деконструировать» типы-значения).
> ...
> Ему придётся опираться только на себя и перестать рекламировать доступность всех преимуществ Java и её экосистемы. Пример с instanceof уже демонстрирует, почему я думаю, что Kotlin не будет лучше Java: **почти каждая новая фича, которая появилась в Java недавно или вот-вот появится (в смысле, имеет активный JEP и обсуждается в рассылках) выглядит более продуманной, чем любая фича Kotlin.**
>
>
Этот аргумент вызван плохим знанием Kotlin. Автор использовал неидиоматичный подход, и вся его критика по сути направлена против своего же неверно написаного Kotlin кода. На самом деле, стоит прочесть лишь вводную страницу документации по базовым инструкциям (чего автор видимо не сделал), чтобы понять что Kotlin вариант не только более лаконичный, но и намного функциональнее, судите сами:
```
when(val v = calcValue()) {
is String -> processString(v)
}
```
Здесь в одной области можно проверить *сразу несколько типов* вместе со значениями, без создания дополнительных переменных. Попробуйте повторить в Java c if/instanceof/switch:
```
when(val v = calcValue()) {
is String -> processString(v)
42 -> prosess42()
is Int -> processInt(v)
else -> processElse(v)
}
```
Остается разобраться с аргументом, что Kotlin, якобы, придется что-то делать с изменениями вносимыми Java, адаптироваться или расходиться, что это, якобы, создает проблему развития для Kotlin.
> Прямо сейчас Kotlin оседлал волну успеха, но со временем жизнь его будет тем тяжелее, чем шире будет зазор между ним и Java, и чем сложнее будет преодолеть этот зазор.
>
>
Здесь автор путает местами причину и следствие, пытаясь выдать Kotlin за догоняющий язык. На самом деле, адаптация новых возможностей это в первую очередь проблема именно для Java. Уже давно C# и Kotlin подстегивают Java изменяться, и для Java изменения даются гораздо сложнее по причине изначально тяжеловесного и сложившегося за десятилетия синтаксиса, не предусматривавшего появление новых, функциональных возможностей. В Java для них попросту осталось не так много места, где их можно прикрутить к синтаксису, и именно поэтому они выглядят чужеродно и обременительно для восприятия.
> Нативная поддержка null, которая греет душу любого котлиниста, легко заменяется в Java на обёртку из `Optional.ofNullable`. Data-объекты могут быть заменены более богатым функционалом `record`.
>
>
Многие догоняющие возможности Java содержат изъяны по умолчанию, все больше заставляют прибегать к соглашениям, а не к дизайну языка. Вместо громоздкой в коде обертки Optional можно просто передать null, а record ничуть не более богатый чем data class.
> Как думаете, сохранит Kotlin свою популярность через пять лет и почему?
>
>
Отвечая на этот вопрос, некоторые в комментариях к исходной статье вспомнили историю Scala и Java. Но есть и другая история, история того что сделал С++ со старым Си.
Несомненно, Java останется там где нужно поддерживать старые решения. Однако новые решения будут все больше писаться на Kotlin, пока он не станет языком по умолчанию, как это уже произошло в Android экосистеме, и прямо сейчас происходит для backend разработки в jvm экосистеме. Kotlin не просто лучше, он страхует от старых ошибок на этапе компиляции, дает думать в другой парадигме, открыт для новых возможностей. | https://habr.com/ru/post/558892/ | null | ru | null |
# Управление списком баз 1С 8.2 с помощью Active Directory
Приветствую тебя, уважаемый читатель!
По традиции, прошу слишком сильно не пинать, т.к. это мой первый пост.
Итак, приблизительно с полгода назад, встала задача автоматизировать управление списком баз 1С (коих развелось уже более 20 штук) у пользователей домена.
Делалось это не только удобства ради, но и в рамках проекта по внедрению «ролевой модели доступа». Вкратце, смысл этой модели в том, что каждый пользователь в домене является членом определенной группы (именуемой согласно должности), которая имеет заранее определенный набор привилегий, в том числе и список информационных баз.
Т.к. у нас имеется домен Active Directory, логично использовать групповые политики для выполнения нашей задачи.
Гугление выдавало достаточно много реализаций (и даже платных), но все они, чаще всего, сводились к заранее сформированным файлам со списками баз (ibases.v8i). Нам же хотелось:
a) Централизованно управлять настройками подключения к информационным базам (у нас клиент-серверный вариант с SQL базами).
б) Централизованно управлять списком, доступных пользователю, информационных баз, согласно его «роли».
В итоге я расскажу о решении которое работает уже больше полугода в нашей компании.
Итак, приступим.
**Шаг 1**.
1С 8.2 хранит список информационных баз в файле ibases.v8i, такой файл присутствует в профиле у каждого пользователя. Формат и принцип работы этого файла отлично описаны [тут](http://habrahabr.ru/post/179405/) и [тут](http://infostart.ru/public/104469/), поэтому я не вижу смысла здесь это повторять.
Также, в одном каталоге с файлом ibases.v8i, находится файл 1CEStart.cfg, особенностью этого файла является то, что в нем можно прописать пути к отдельным файлам \*.v8i, содержащим параметры подключения к конкретным информационным базам.
При запуске, 1С берет параметры подключений к информационным базам из файлов, прописанных в 1CEStart.cfg и помещает их в ibases.v8i. Эту-то особенность мы и будем использовать.
Сначала, сформируем файл v8i для каждой информационной базы.
Самый простой способ сформировать такой файлик — это кликнуть правой кнопкой на нужной базе в списке, и выбрать пункт «Сохранить ссылку в файл»:
Однако, следует иметь ввиду, что сформированный таким образом файл v8i содержит некоторые «лишние» строки, которые нам не нужны. Для нормальной работы достаточно оставить только следующее:
```
[%NAME% ]
Connect=Srvr="%server%";Ref="%base%";
ClientConnectionSpeed=Normal
App=Auto
WA=1
Version=8.2
```
Далее, необходимо разместить эти файлы в общедоступном, для пользователей локальной сети, месте, и дать права на «чтение». Я не стал заморачиваться, и просто разместил их в папке NETLOGON контроллера домена. Тому есть несколько причин — это и репликация каталога между контроллерами домена, и отказоустойчивость (в силу того, что контроллеров три, и в каждый момент времени хотя-бы один из них доступен).
**Шаг 2**.
Раз мы собираемся управлять списком информационных баз на основе принадлежности пользователя к той или иной группе AD, создадим в ней необходимое количество групп безопасности согласно имеющимся у нас базам 1С:
Префикс «1C\_82» является обязательным, и далее будет понятно для чего.
Теперь, в каждой вновь созданной группе безопасности, в поле «заметки», укажем путь к соответствующему ей файлу v8i:
На этом с группами закончили.
**Шаг 3**.
Создаем групповую политику, которая будет запускать следующий vbs скрипт каждый раз при логоне пользователя:
**Код на vbs**
```
On Error Resume Next
Const PROPERTY_NOT_FOUND = &h8000500D
Dim sGroupNames
Dim sGroupDNs
Dim aGroupNames
Dim aGroupDNs
Dim aMemof
Dim oUser
Dim tgdn
Dim fso
Dim V8iConfigFile
Dim dir
Const ForReading = 1, ForWriting = 2, ForAppending = 8
'Настраиваем лог файл
Set fso = CreateObject("Scripting.FileSystemObject")
Set WshShell = WScript.CreateObject("Wscript.Shell")
strSysVarTEMP = WshShell.ExpandEnvironmentStrings("%TEMP%")
Set oScriptLog = fso.OpenTextFile(strSysVarTEMP + "\_dbconn.log",ForWriting,True)
oScriptLog.Write ""
strToLog = CStr(Date())+" "+CStr(Time()) + " - " + "Start..."
oScriptLog.WriteLine(strToLog)
'Проверяем, что 1С установлена
Set objFSO = CreateObject("Scripting.FileSystemObject")
If Not (objFSO.FolderExists("C:\Program Files\1cv82") Or objFSO.FolderExists("C:\Program Files (x86)\1cv82")) Then
strToLog = CStr(Date())+" "+CStr(Time()) + " - " + "1C 8.2 not installed... Quit..."
oScriptLog.WriteLine(strToLog)
WScript.quit
End If
'Проверяем есть ли старый файл и удаляем в случае наличия'
APPDATA = WshShell.ExpandEnvironmentStrings("%APPDATA%")
v8i = APPDATA + "\1C\1CEStart\ibases.v8i"
If fso.FileExists(v8i) Then
fso.DeleteFile(v8i)
Set V8iConfigFile = fso.CreateTextFile(v8i ,True)
strToLog = CStr(Date())+" "+CStr(Time()) + " - " + "Удален файл v8i и создан новый"
oScriptLog.WriteLine(strToLog)
' Если файла нет (1С только установлена), то создаем файла по указанному пути
Else
Set dir = fso.CreateFolder(APPDATA + "\1C")
Set dir = fso.CreateFolder(dir + "\1CEStart")
Set V8iConfigFile = fso.CreateTextFile(v8i ,True)
strToLog = CStr(Date())+" "+CStr(Time()) + " - " + "Создан файл v8i"
oScriptLog.WriteLine(strToLog)
End if
'
' Initialise strings. We make the assumption that every account is a member of two system groups
'
sGroupNames = "Authenticated Users(S),Everyone(S)"
'
' Enter the DN for the user account here
Set objSysInfo = CreateObject("ADSystemInfo")
strUserName = objSysInfo.UserName
strToLog = CStr(Date())+" "+CStr(Time()) + " - " + "Logged user DN: "+strUserName
oScriptLog.WriteLine(strToLog)
' Получаем имя залогиненного пользователя
Set oUser = GetObject("LDAP://" + strUserName)
If Err.Number <> 0 Then
strToLog = CStr(Date())+" "+CStr(Time()) + " - " + "There is an error retrieving the account. Please check your distinguished name syntax assigned to the oUser object."
oScriptLog.WriteLine(strToLog)
WScript.quit
End If
'
' Determine the DN of the primary group
' We make an assumption that every user account is a member of a primary group
'
iPgid = oUser.Get("primaryGroupID")
sGroupDNs = primgroup(iPgid)
tgdn = sGroupDNs
'
' Call a subroutine to extract the group name and scope
' Add the result to the accumulated group name String
'
Call Getmemof(tgdn)
'
' Check the direct group membership for the User account
'
aMemOf = oUser.GetEx("memberOf")
If Err.Number <> PROPERTY_NOT_FOUND Then
'
' Call a recursive subroutine to retrieve all indirect group memberships
'
Err.clear
For Each GroupDN in aMemof
Call AddGroups(GroupDN)
Call Getmemof(GroupDN)
Next
End If
aGroupNames = Split(sGroupNames,",")
aGroupDNs = Split(sGroupDNs,":")
'Откидываем все группы, кроме начинающихся с 1C_82
For Each strGroupDN in aGroupDNs
if StrComp(Mid(strGroupDN,1,8), "CN=1C_82", vbTextCompare) = 0 Then
strToLog = CStr(Date())+" "+CStr(Time()) + " - " + "User is member of: " + strGroupDN
oScriptLog.WriteLine(strToLog)
Set objGroup = GetObject("LDAP://" & strGroupDN)
If Err.Number <> 0 Then
strToLog = CStr(Date())+" "+CStr(Time()) + " - " + "There is an error retrieving the group. Please check your distinguished name syntax assigned to the objGroup object: " + strGroupDN
oScriptLog.WriteLine(strToLog)
WScript.quit
End If
strInfo = objGroup.Get("info")
strToLog = CStr(Date())+" "+CStr(Time()) + " - " + "Group " + strGroupDN +" info field: " + strInfo
oScriptLog.WriteLine(strToLog)
strAllInfo = strAllInfo & ":" & strInfo
End If
Next
aInfoStrings = Split(strAllInfo,":")
Call WriteDBSettings()
Sub WriteDBSettings()
'Прописываем ссылки на v8i файлы в 1CEStart.cfg
strSysVarAPPDATA = WshShell.ExpandEnvironmentStrings("%APPDATA%")
strDBConfigFilePath = strSysVarAPPDATA + "\1C\1CEStart\1CEStart.cfg"
strToLog = CStr(Date())+" "+CStr(Time()) + " - " + "1C Config file is: " + strDBConfigFilePath
oScriptLog.WriteLine(strToLog)
If (fso.FileExists(strDBConfigFilePath)) Then
Set objDBConfigFile = fso.OpenTextFile(strDBConfigFilePath,ForWriting,True)
objDBConfigFile.Write ""
For each strInfo in aInfoStrings
objDBConfigFile.WriteLine("CommonInfoBases=" + strInfo)
strToLog = CStr(Date())+" "+CStr(Time()) + " - " + "Add Line: " + "CommonInfoBases=" + strInfo
oScriptLog.WriteLine(strToLog)
next
'Изменить на 0, если аппаратные лицензии не используются
objDBConfigFile.WriteLine("UseHWLicenses=1")
strToLog = CStr(Date())+" "+CStr(Time()) + " - " + "Add Line: " + "UseHWLicenses=1"
oScriptLog.WriteLine(strToLog)
strToLog = CStr(Date())+" "+CStr(Time()) + " - " + "Ready"
oScriptLog.WriteLine(strToLog)
objDBConfigFile.Close
Else
Set fso = CreateObject("Scripting.FileSystemObject")
Set WshShell = WScript.CreateObject("Wscript.Shell")
Set objDBConfigFile = fso.OpenTextFile(strDBConfigFilePath,ForWriting,True)
objDBConfigFile.Write ""
For each strInfo in aInfoStrings
objDBConfigFile.WriteLine("CommonInfoBases=" + strInfo)
strToLog = CStr(Date())+" "+CStr(Time()) + " - " + "Add Line: " + "CommonInfoBases=" + strInfo
oScriptLog.WriteLine(strToLog)
next
strToLog = CStr(Date())+" "+CStr(Time()) + " - " + "1C Config file" + strDBConfigFilePath + " Not Exist! Create!"
oScriptLog.WriteLine(strToLog)
WScript.Quit
End If
End Sub
'*************************************************************************************************
' End of mainline code
'*************************************************************************************************
Function primgroup(groupid)
' This function accepts a primary group id
' It binds to the local domain and returns the DN of the primary group
' David Zemdegs 6 May 2008
'
Dim oRootDSE,oConn,oCmd,oRset
Dim ADDomain,srchdmn
' Bind to loca domain
Set oRootDSE = GetObject("LDAP://RootDSE")
ADDomain = oRootDSE.Get("defaultNamingContext")
srchdmn = ""
'
' Initialise AD search and obtain the recordset of groups
'
Set oConn = CreateObject("ADODB.Connection")
oConn.Open "Provider=ADsDSOObject;"
Set oCmd = CreateObject("ADODB.Command")
oCmd.ActiveConnection = oConn
oCmd.CommandText = srchdmn & ";(objectCategory=Group);" & \_
"distinguishedName,primaryGroupToken;subtree"
Set oRset = oCmd.Execute
'
' Loop through the recordset and find the matching primary group token
' When found retrieve the DN and exit the loop
'
Do Until oRset.EOF
If oRset.Fields("primaryGroupToken") = groupid Then
primgroup = oRset.Fields("distinguishedName")
Exit Do
End If
oRset.MoveNext
Loop
'
' Close and tidy up objects
'
oConn.Close
Set oRootDSE = Nothing
Set oConn = Nothing
Set oCmd = Nothing
Set oRset = Nothing
End Function
Sub Getmemof(sDN)
'
' This is recursive subroutine that calls itself for memberof Property
' David Zemdegs 6 May 2008
'
On Error Resume Next
Dim oGrp
Dim aGrpMemOf
Dim sGrpDN
Set oGrp = GetObject("LDAP://" & sDN)
aGrpMemOf = oGrp.GetEx("memberOf")
If Err.Number <> PROPERTY\_NOT\_FOUND Then
'
' Call a recursive subroutine to retrieve all indirect group memberships
'
Err.clear
For Each sGrpDN in aGrpMemOf
Call AddGroups(sGrpDN)
Call Getmemof(sGrpDN)
Next
End If
Err.clear
Set oGrp = Nothing
End Sub
Sub AddGroups(sGdn)
'
' This subroutine accepts a disguished name
' It extracts the RDN as the group name and determines the group scope
' This is then appended to the group name String
' It also appends the DN to the DN String
'
Const SCOPE\_GLOBAL = &h2
Const SCOPE\_LOCAL = &h4
Const SCOPE\_UNIVERSAL = &h8
Dim SNewgrp
'
' Retrieve the group name
'
iComma = InStr(1,sGdn,",")
sGrpName = Mid(sGdn,4,iComma-4)
'
' Add the results to the group name String
' Check that the group doesnt already exist in the list
'
sNewgrp = sGrpName
If InStr(1,sGroupNames,SNewgrp,1) = 0 Then
sGroupNames = sGroupNames & "," & SNewgrp
End If
'
' Add the Groups DN to the string if not duplicate
'
If InStr(1,sGroupDNs,sGdn,1) = 0 Then
sGroupDNs = sGroupDNs & ":" & sGdn
End If
End Sub
```
Логика работы скрипта следующая:
1. Проверяет установлена ли 1С, если нет — скрипт завершается.
2. Проверяет существует ли файл ibases.v8i, и перезаписывает его пустым (или создает в случае отсутствия).
3. Извлекает все группы из AD, членом которых является пользователь.
4. Отбрасывает все, кроме тех, которые начинаются с 1C\_82.
5. Получает значение атрибута «Notes».
6. Прописывает значение этого атрибута в файл 1CEStart.cfg
Попутно пишется лог:
Для Windows 7 — C:\Users\username\appdata\Local\Temp\\_dbconn.log
Для Windows XP — C:\Documents and Settings\username\Local Settings\Temp\\_dbconn.log
**Шаг 4**.
«Вешаем» групповую политику на необходимую OU или весь домен. Стоит отметить, для того, чтоб скрипт не применялся всем подряд без разбора (не все пользователи работают с 1С), я добавил в фильтр безопасности групповой политики только те группы, которые мы создавали на шаге 2, таким образом скрипт будет отрабатывать только у пользователей включенных в хотя-бы одну из этих групп:
**Шаг 5**.
Включаем группу (читай должность) пользователя в те группы 1С, которые предусмотрены ролевой моделью доступа (хотя можно и отдельно взятого пользователя — бывают исключения). После перезагрузки у пользователя будет индивидуальный именно его должности список информационных баз.
Ну вот вроде-бы и все.
Кстати, для применения изменений, пользователю не обязательно перелогиниваться, нужно просто заставить пользователя выполнить этот скрипт любым удобным способом, к примеру, отправив скрипт по электронной почте.
Спасибо за внимание, буду очень рад, если статья кому-то поможет. | https://habr.com/ru/post/231119/ | null | ru | null |
# Switch для строк в C++11
К сожалению, стандарт C++ не допускает применения операторов switch-case к строковым константам. Хотя в других языках, вроде C#, такая возможность имеется прямо «из коробки». Поэтому, понятное дело, многие C++ программисты пытались написать свою версию «switch для строк» — и я не исключение.
Для C++03 решения не отличались красотой и лишь усложняли код, дополнительно нагружая приложение в рантайме. Однако с появлением C++11 наконец-то появилась возможность реализовать такой код:
```
std::string month;
std::string days;
std::cout << "Enter month name: ";
std::cin >> month;
SWITCH (month)
{
CASE("february"):
days = "28 or 29";
break;
CASE("april"):
CASE("june"):
CASE("september"):
CASE("november"):
days = "30";
break;
CASE("january"):
CASE("march"):
CASE("may"):
CASE("july"):
CASE("august"):
CASE("october"):
CASE("december"):
days = "31";
break;
DEFAULT:
days = "?";
break;
}
std::cout << month << " has " << days << " days." << std::endl;
```
Реализация этой конструкции весьма проста. Она основана на constexpr-функциях из C++11, благодаря чему почти все вычисления производятся ещё на этапе компиляции. Если кого-то интересуют её детали, добро пожаловать под кат — благо на Хабре о «switch для строк» почему-то ничего не сказано.
Чего же мы хотим?
-----------------
Прежде всего — чтобы это был полноценный **switch**, а не его «эмуляция» путём скрытия **if**-операторов и функций для сравнения строк внутри макросов, поскольку сравнение строк в рантайме — дорогостоящая операция, и проводить её для каждой строки из CASE слишком расточительно. Поэтому [такое решение](http://ghodbane.web.cern.ch/ghodbane/tpc/doc/html/string__switch_8h-source.html) нас не устроит — к тому же, в нём неизбежно появляются непонятные макросы типа END\_STRING\_SWITCH.
Кроме того, очень желательно по-максимуму задействовать компилятор. Например, что будет с «обычным» switch-case в случае, когда аргументы двух **case** окажутся одинаковыми? Правильно, компилятор тут же обругает нас: *«duplicate case value»*, и прекратит компиляцию. А в примере по вышеуказанной ссылке, разумеется, ни один компилятор не сможет заметить эту ошибку.
Важен и итоговый синтаксис, простой и без лишних конструкций. Именно поэтому [известный вариант](http://www.codeguru.com/cpp/cpp/cpp_mfc/article.php/c4067/Switch-on-Strings-in-C.htm) "**std::map** со строковым ключом" нас тоже не устраивает: во-первых, аргументы **case** в нём не выглядят наглядными — а во-вторых, он требует обязательной инициализации используемого **std::map** в рантайме. Функция этой инициализации может находиться где угодно, постоянно глядеть в неё слишком утомительно.
Начинаем вычислять хэш
----------------------
Остаётся последний вариант: вычислять хэш строки в **switch**, и сравнивать его с хэшем каждой строки в **case**. То есть, всё сводится к сравнению двух целых чисел, для которых switch-case прекрасно работает. Однако стандарт C++ говорит, что аргумент каждого **case** должен быть известен ещё при компиляции — поэтому функция «вычисления хэша от строки» должна работать именно в compile-time. В C++03 её можно реализовать лишь с помощью шаблонов, наподобие вычисления CRC в [этой статье](http://habrahabr.ru/post/38622/). Но в C++11, к счастью, появились более понятные **constexpr**-функции, значения которых также могут вычисляться компилятором.
Итак, нам нужно написать constexpr-функцию, которая бы оперировала числовыми кодами **char**-символов. Как известно, тело такой функции представляет из себя "**return** *<известное в compile-time выражение>*". Попробуем реализовать самый «вырожденный» её вариант, а именно — функцию вычисления длины **const char\*** строки. Но уже здесь нас поджидают первые трудности:
```
constexpr unsigned char str_len(const char* const str)
{
return *str ? (1 + str_len(str + 1)) : 0;
}
std::cout << (int) str_len("qwerty") << " " << (int) str_len("йцукен") << std::endl; // проверяем
```
Компилятор не ругается, функция корректна. Однако у меня она почему-то вывела не «6 6», а «6 12». Отчего так? А всё дело в том, что я набрал этот исходный код под Windows в «линуксовой» кодировке UTF-8, а не в стандартной Win-1251 — и поэтому каждый «кириллический» символ воспринялся как два. Вот если сменить кодировку на стандартную, тогда действительно выведется «6 6». Что ж получается, наша задумка потерпела крах? Ведь это не дело, когда при разных кодировках получаются разные хэши…
Проверяем содержимое строки
---------------------------
Но зачем нам кириллица или азиатские иероглифы? В подавляющем большинстве случаев, для исходников достаточно лишь английских букв и стандартных знаков пунктуации — то есть символов, умещающихся в диапазоне от 0 до 127 в [ASCII-таблице](http://ru.wikipedia.org/wiki/ASCII). А их **char**-коды при смене кодировки не изменятся — и поэтому хэш от строки, составленной лишь из них, *всегда* будет одинаков. Но как быть, если программист случайно всё же введёт один из таких символов? На помощь нам приходит следующая compile-time функция:
```
constexpr bool str_is_correct(const char* const str)
{
return (static_cast(\*str) > 0) ? str\_is\_correct(str + 1) : (\*str ? false : true);
}
```
Она проверяет, содержит ли известная на стадии компиляции строка только символы из диапазона 0-127, и возвращает **false** в случае нахождения «запретного» символа. Зачем нужен принудительный каст к **signed char**? Дело в том, что в стандарте C++ не определено, чем же именно является тип **char** — он может быть как знаковым, так и беззнаковым. А вот его **sizeof** всегда будет равен 1, отчего мы смещаемся вправо на единицу. Таким образом, нужный нам макрос CASE будет иметь вид:
```
#define CASE(str) static_assert(str_is_correct(str), "CASE string contains wrong characters");\
case str_hash(...)
```
Тут используется ещё одна фича C++11 — **assert** при компиляции. То есть, если строка-аргумент макроса CASE будет содержать хотя бы один «запретный» символ — компиляция остановится со вполне понятной ошибкой. Иначе, будет вычислен хэш, значение которого подставится в **case**. Это решение избавит нас от проблем с кодировкой. Осталось лишь написать саму функцию str\_hash(), которая и вычислит нужный хэш.
Возвращаемся к вычислению хэша
------------------------------
Выбрать хэш-функцию можно по-разному, и самый главный вопрос тут — это возможность коллизий. Если хэши двух различных строк совпадут, то программа может перепрыгнуть со **switch** на ложную **case**-ветку. И спутник упадёт в океан… Поэтому будем использовать хэш-функцию, не имеющую коллизий вообще. Так как уже установлено, что все символы строки расположены в диапазоне 0-127, то функция будет иметь вид: . Её реализация такова:
```
typedef unsigned char uchar;
typedef unsigned long long ullong;
constexpr ullong str_hash(const char* const str, const uchar current_len)
{
return *str ? (raise_128_to(current_len - 1) * static_cast(\*str)
+ str\_hash(str + 1, current\_len - 1)) : 0;
}
```
Здесь raise\_128\_to() — это compile-time функция возведения 128 в степень, а **current\_len** — это длина текущей строки. Конечно, длину можно вычислять и на каждом шаге рекурсии, но это лишь замедлит компиляцию — лучше сосчитать её до первого запуска str\_hash(), и затем всегда подставлять как дополнительный аргумент. При какой же максимальной длине строки эта функция не будет иметь коллизий? Очевидно, лишь тогда, когда полученное ею значение всегда уместится в диапазоне типа **unsigned long long** (также окончательно введённого в C++11), то есть если оно не превышает 264-1.
Можно подсчитать, что эта максимальная длина будет равна 9 (обозначим это число как MAX\_LEN). А вот максимально возможное значение хэша составит ровно 263 для строки, все символы которой имеют код 127 (и [являются нечитаемыми](http://mmb.mediachance.com/mmbhelp/ru/index.html?asciitable.htm) в ASCII, так что под CASE мы её всё равно не загоним). Но как быть, если под CASE будет стоять строка из 10 символов? Если мы действительно не хотим возникновения коллизий, то нужно запретить и такую возможность — то есть, расширить уже используемый нами **static\_assert**:
```
#define CASE(str) static_assert(str_is_correct(str) && (str_len(str) <= MAX_LEN),\
"CASE string contains wrong characters, or its length is greater than 9");\
case str_hash(str, str_len(str))
```
Производим финальные штрихи
---------------------------
Всё, с макросом CASE покончено. Он либо выдаст нам ошибку компиляции, либо вычислит уникальное значение хэша. Вот для подсчёта хэша в макросе SWITCH нам придётся сделать отдельную функцию, поскольку она будет работать уже в рантайме. А если её строка-аргумент будет иметь длину более 9 символов, то договоримся возвращать 264-1 (обозначим это число как N\_HASH). Итак:
```
#define SWITCH(str) switch(str_hash_for_switch(str))
const ullong N_HASH = static_cast(-1); // по аналогии с std::string::npos
inline ullong str\_hash\_for\_switch(const char\* const str)
{
return (str\_is\_correct(str) && (str\_len(str) <= MAX\_LEN)) ? str\_hash(str, str\_len(str)) : N\_HASH;
}
```
Собственно, вот и всё. В рантайме вычислится хэш для строки в SWITCH, и если одна строк в CASE имеет такой же хэш, исполнение пойдёт на неё. Если какая-то строка из CASE содержит «запретные» символы, или её длина больше 9 символов — мы получим надёжную ошибку компиляции. Нагрузки в рантайме почти нет (за исключением однократного вычисление хэша для SWITCH), читаемость кода не страдает. Осталось лишь перегрузить функцию str\_hash\_for\_switch() для строк **std::string**, и заключить всё внутрь namespace.
Итоговый h-файл исходников [лежит на Гитхабе](https://github.com/Efrit/str_switch/blob/master/str_switch.h). Он подойдёт для любого компилятора с поддержкой C++11. Для использования «switch для строк» просто сделайте инклуд *str\_switch.h* куда хотите, и всё — макросы SWITCH, CASE и DEFAULT перед вами. Не забудьте про ограничение на длину строки в CASE (9 символов).
В общем — надеюсь, что кому-нибудь эта реализация пригодится ;)
**P. S.** *Upd:* в коде была обнаружена пара неточностей — поэтому сейчас он обновлён, вместе со статьёй. В комментариях также предлагалось использовать другую функцию для вычисления хэша — разумеется, каждый может написать свою её реализацию. | https://habr.com/ru/post/166201/ | null | ru | null |
# «Теперь он и тебя сосчитал» или Наука о данных с нуля (Data Science from Scratch)
Не так давно я рассказывал о том, как случайно познакомился с понятием Data Science, благодаря курсам от [Cognitive Class](https://habrahabr.ru/post/331118/). Кратко резюмируя ту статью скажу, что по результатам курса я толком ничему не научился, но мне стало любопытно, поэтому спустя какое-то время я побежал в магазин и купил книгу, которой и посвящён данный материал.
Не знаю на сколько уместно на Хабре описывать возможность обучения по печатному самоучителю, но в конце концов этот хаб же про учебный процесс в IT и поэтому если вам интересно, чему может научить эта книга полного новичка в области Data Science и стоит ли тратить на этот этап время и деньги, то милости прошу под кат.

Часть 1. «Я — это раз» — немного о навыках
------------------------------------------
Надо сказать, что до прочтения данной книги, мое представление о пользе Data Science не далеко ушло от заглавной картинки, позаимствованной из любимого мультфильма.
Для того, чтобы заглянувший сюда читатель мог спроецировать мой опыт на себя, придется мне немного поведать о своих стартовых навыках. Итак, как и в прошлый раз, досье осталось практически без изменений:
1. В связах с мат. анализом и статистикой замечен не был;
2. Навыками программирования на Python не владеет;
3. Владеет знанием о существовании Data Science, практических навыков не имеет.
4. Характер стойкий нордический, не женат.
Собственно, почему я решил изучить эту книгу, и поделится впечатлениями о ней?
Просто после курсов Cognitive Class, я решил заглянуть на Kaggle и понял, что даже в туториале по решению задачи про [Титаник](https://www.kaggle.com/c/titanic#description), я сути почти всех приемов и определений не понимаю.
Данная книга не требовала никаких стартовых навыков и обещала приятное погружение в мир науки о данных. Есть ли у меня теперь уверенность, что после прочтения книги я смогу решить эту задачу с Титаником? Ответ в конце статьи.
Часть 2. «Два — это Телёнок» — общие сведения о книге
-----------------------------------------------------
Книга «Data Science. Наука о данных с нуля» — на отечественном рынке похоже появилась совсем недавно, о чем как минимум свидетельствует, то что её электронную версию мне не удалось ни скачать, ни купить. Сам же оригинал был выпущен в 2015 г. Само собой за 2 года в мире IT много чего меняется, например, выходят новые версии библиотек для анализа данных в Python. И тут надо отдать должное автору (Джоэл Грас) и локализатору книги. Изначально, книга писалась с расчетом на Python 2, но автор не оставил свое детище и адаптировал исходные тексты программ, для Python 3 (и кстати выложил это на [GitHub](https://github.com/joelgrus/data-science-from-scratch)), ну а переводчик слава богу разместил в книге уже адаптированные тексты программ (похоже, что с небольшими корректировками).
Также спасибо переводчикам, за краткую инструкцию по установке Anaconda и/или настройки среды для случая если вы не хотите ставить Анаконду.
И так начнём повествование о книге. На обороте обложки размещена цитата, действительно четко описывающая размещенный в ней материал: «Джоэл проведет для вас экскурсию по науке о данных. В результате вы перейдете от простого любопытства к глубокому пониманию насущных алгоритмов, которые должен знать любой аналитик данных.» — Роит Шивапрасад. Ну по крайней мере первая часть этой цитаты на 100% верна, книга действительно напоминает экскурсию, когда вам надо за 2 часа осмотреть Эрмитаж и все, что вы успеваете это бежать за экскурсоводом, ловя краткую справку о каждом шедевре. Как ни странно, не могу сказать, что это плохо, по крайней мере книгу успеваешь прочесть раньше, чем она надоест.
Надо отметить, что кого-то, как и меня может **ввести в заблуждение** название книги.
Важно отметить, что в данном случае «с нуля» подразумевает **не с нуля знаний** до какого-то практического уровня, а то, что все **примеры функций** для анализа и визуализации **будут написаны в процессе** изложения материала. Это напоминает аналогию с книгой «Linux from scratch», которая направлена не на то, чтобы вы прям вот сразу начали пользоваться каким-нибудь дистрибутивом Linux «с интересными обоями», а планомерно, собрали, свою систему с нуля (даже если вы ей потом не будете пользоваться).
У такого подхода есть свои плюсы и есть свои минусы. С одной стороны вы вряд ли в дальнейшем будете пользоваться теми функциями, которые позаимствуете из книги, с другой стороны, возможно к вам придет понимание общих принципов (ко мне с первого раза много где не пришло)
Итак, как пишут в рапортах представители силовых структур: «по существу вопроса, докладываю следующее:»
Часть 3. «Три — это Python» — содержание и общий подход.
--------------------------------------------------------
Надо сказать, что с форматом «экскурсии» книга действительно справляется. В ней кратко изложены, наверное, почти все базовые концепции, которые можно встретить в иных курсах по Data Science (например, на той же [Coursera](https://www.coursera.org/specializations/machine-learning-data-analysis)). У краткости есть достоинства и недостатки, с одной стороны прочитать книгу при желании можно за 2-3 дня и она не успевает надоесть, с другой стороны материала реально мало и читая «по диагонали» можно, что-то пропустить, в таком случае чтобы что-то понять придется возвращаться и перечитывать главу еще раз.
Автор проявил фантазию и привязал изучаемый материал, к вашей работе в условной соцсети для ученых по данным — “DataSciencester”. Надо сказать, что это приятный подход, задачи выглядят из далека похожими на житейские. И сложность решаемых вами «рабочих» задач постепенно возрастает от главы к главе.
В первой главе обучение стартует с места в карьер, автор покажет, вам как с помощью Питона решить несколько условных задач, на малом объеме данных, например, построить граф отражающей количество друзей в нашей «условной» соцсети или выявить и графически отобразить связь между стажем работы и уровнем зарплаты, для ученого по данным.
Дальше будет изложен интенсив по Python, избыточным его точно не назовешь, но надо отдать автору должное, за рамки того, что дано в главе 2, он далее по тексту сильно не выходит, поэтому если вникнуть один раз в базовые типы данных и другие понятия, то по идее представленный в книге код проблем вызывать не должен (хотя у меня вызывал).
После вводной части и азов Python, остальные направления книги можно поделить на 3 части:
1. Очень краткие основы мат. анализа и статистики;
2. Сбор, обработка, хранение данных;
3. Машинное обучение (математические модели и алгоритмы для обработки данных и предсказания);
Фрагмент книги и оглавление можно посмотреть на [Ozon](http://www.ozon.ru/context/detail/id/140943923/) (не реклама), там как раз содержание и первая глава.
От текстовой части перейдем к практической, выше по тексту была ссылка на страничку автора на [GitHub](https://github.com/joelgrus/data-science-from-scratch), где размещен код представленный в книге и необходимые данные.
В локализованной версии книги есть ссылка на архив с адаптированной (русифицированной) версией кода, чтобы не нарушать ни чьи права, воздержусь от ее размещения.
Весь код представлен в виде исходников на Python 2 и 3, а также в виде блокнотов для Jupyter notebook. Надо сказать, большое спасибо этой книге, потому что благодаря ей я открыл для себя [Anaconda](https://www.continuum.io/downloads) (удобная вещь). На мой взгляд удобней всего экспериментировать с кодом, представленным в книге именно в версии блокнотов Jupyter (который по умолчанию установлен в Анакодне). Хотя с другой стороны по сути в записной книжке весь код вбит в одну ячейку без разбивки и без отдельных текстовых вставок, так что это скорее вопрос вкуса, чем явного преимущества. Кстати если вдруг вас не устроит корневая директорию откуда Jupyter «видит» файлы, то вот действительно [рабочий совет](https://stackoverflow.com/questions/15680463/change-ipython-working-directory) (есть варианты и для Windows и для Linux)
Надо отметить, что блокноты идут с заранее подготовленными результатами, чтобы вы могли посмотреть их без запуска кода, а вот после перезапуска расчётов в некоторых местах могут потребоваться маленькие «пляски с бубном» в виде установки библиотек или еще каких-то мелочей (например, подключение к API сервисов).
Не хочу быть голословным поэтому надеюсь автор не обидится если я продемонстрирую кусочек кода из его книги.
Вот, например, фрагмент кода посвященный линейной алгебре (чтобы не нарушать права переводчика возьмем оригинал с GitHub). В книге данный код перемешан с изложением материала, в блокноте и исходниках идет в сплошном виде.
```
# -*- coding: utf-8 -*-
# linear_algebra.py
import re, math, random # regexes, math functions, random numbers
import matplotlib.pyplot as plt # pyplot
from collections import defaultdict, Counter
from functools import partial, reduce
#
# functions for working with vectors
#
def vector_add(v, w):
"""adds two vectors componentwise"""
return [v_i + w_i for v_i, w_i in zip(v,w)]
def vector_subtract(v, w):
"""subtracts two vectors componentwise"""
return [v_i - w_i for v_i, w_i in zip(v,w)]
def vector_sum(vectors):
return reduce(vector_add, vectors)
def scalar_multiply(c, v):
return [c * v_i for v_i in v]
def vector_mean(vectors):
"""compute the vector whose i-th element is the mean of the
i-th elements of the input vectors"""
n = len(vectors)
return scalar_multiply(1/n, vector_sum(vectors))
def dot(v, w):
"""v_1 * w_1 + ... + v_n * w_n"""
return sum(v_i * w_i for v_i, w_i in zip(v, w))
def sum_of_squares(v):
"""v_1 * v_1 + ... + v_n * v_n"""
return dot(v, v)
def magnitude(v):
return math.sqrt(sum_of_squares(v))
def squared_distance(v, w):
return sum_of_squares(vector_subtract(v, w))
def distance(v, w):
return math.sqrt(squared_distance(v, w))
#
# functions for working with matrices
#
def shape(A):
num_rows = len(A)
num_cols = len(A[0]) if A else 0
return num_rows, num_cols
def get_row(A, i):
return A[i]
def get_column(A, j):
return [A_i[j] for A_i in A]
def make_matrix(num_rows, num_cols, entry_fn):
"""returns a num_rows x num_cols matrix
whose (i,j)-th entry is entry_fn(i, j)"""
return [[entry_fn(i, j) for j in range(num_cols)]
for i in range(num_rows)]
def is_diagonal(i, j):
"""1's on the 'diagonal', 0's everywhere else"""
return 1 if i == j else 0
identity_matrix = make_matrix(5, 5, is_diagonal)
# user 0 1 2 3 4 5 6 7 8 9
#
friendships = [[0, 1, 1, 0, 0, 0, 0, 0, 0, 0], # user 0
[1, 0, 1, 1, 0, 0, 0, 0, 0, 0], # user 1
[1, 1, 0, 1, 0, 0, 0, 0, 0, 0], # user 2
[0, 1, 1, 0, 1, 0, 0, 0, 0, 0], # user 3
[0, 0, 0, 1, 0, 1, 0, 0, 0, 0], # user 4
[0, 0, 0, 0, 1, 0, 1, 1, 0, 0], # user 5
[0, 0, 0, 0, 0, 1, 0, 0, 1, 0], # user 6
[0, 0, 0, 0, 0, 1, 0, 0, 1, 0], # user 7
[0, 0, 0, 0, 0, 0, 1, 1, 0, 1], # user 8
[0, 0, 0, 0, 0, 0, 0, 0, 1, 0]] # user 9
```
Автор, как и обещал пишет все функции с нуля и старается объяснить их работу, после чего в конце каждой главы честно информирует вас о том, что существуют те или иные библиотеки, где это реализовано лучше.
Объяснение процесса разработки функций ближе к концу неподготовленному читателю (например, мне) кажутся зубодробительными и где-то после середины книги уже понимается, не вся логика работы кода (думаю придется однажды перечитывать), но зато таким путем вы вместе с автором посмотрите, как сделать своими руками очередные ~~гребаные велосипеды~~, полезные базовые решения в куче областей например, свой примитивный аналог СУДБ, все базовые функции и модели анализа, нейронные сети, деревья принятия решений, генераторы текста, распознаватели «капчи». Даже просто беглое знакомство со всем этим набором вполне может развить у вас интерес к предмету.
Часть 4. «Ура козлёнку!» — Заключение.
--------------------------------------
Итак, что у нас в сухом остатке?
Поскольку на текущий момент все мои знания о Data Science ограничиваются этой книгой и курсами от Cognitive class (СС), то для начала с ними и сравню.
Не знаю может фактор родного языка, может, то, что в отличие от курсов СС автор хотя бы нормально оси на графиках подписал в примерах, но в плане общего представления книга дала намного больше, при тех же затратах времени (и там и там 2 чистых дня), не смотря на отсутствие видео, лабораторных, экзаменов и так далее. И даже отсутствие «сертификатов» и «бейджиков» ничуть не дает плюсов CC (ибо грош им цена).
Сможет ли полный новичок, что-то понять об основных подходах в области науки о данных? Скорее да, чем нет. Сможет ли он по окончанию книги сразу сделать что-то путное, скорее нет, чем да. Все же, наверное, будет плохой практикой применять для постоянной работы те примеры, что указаны в книге, а значит необходимо выучить основные библиотеки для анализа данных (сам автор тоже об этом говорит по ходу изложения материала). Причем могу предположить, что будет полезно однажды вернуться к примерам «с нуля», когда уже набьется рука на готовых библиотеках.
Полезна ли книга новичку? Я думаю, что да. Наверное, если представить, что ваш мозг дискутирует сам с собой, то можно получить что-то вроде «окон Овертона», ну то есть вначале само осознание того, что надо вникать в какое-нибудь понятие типа дисперсии или регрессии, или нейронных сетей, кажется недопустимым, но с каждым разом потихонечку приходишь к мысли, что это не так и страшно.
Поэтому в качестве экскурсии в мир Data Science книга вполне подойдет, по крайней мере, в процессе прочтения интерес к вопросу только возрастает и думаю, что при прохождении более основательных учебных курсов будет намного проще более детально рассмотреть ранее изученные с помощью данной книги концепции.
Стоит ли в итоге 550 рублей книга из 300 с небольшим страниц, напечатанных на газетной бумаге, решать вам. Могу сказать одно, данная книга вселила в меня уверенность, что теперь я смогу худо-бедно решить задачку про Титаник на kaggle, думаю как раз об этом и будет следующий мой материал. | https://habr.com/ru/post/331794/ | null | ru | null |
# Что можно и нельзя выжать из веб-компонентов
Это не туториал и не вполне обзор — скорее заметки по горячим следам после собирания библиотеки компонентов. Начиналось всё с обычной обыденной истории: есть легаси-код, к легаси нужно прикрутить пипмочек и финтифлюшек, переписывать ничего нельзя, некогда, и вообще не трогайте тут ничего руками; большие и страшные пакеты тоже на всякий случай не трогайте, да и вообще, почему бы вам просто не взять самый прекрасный фреймворк [Vanilla JS](http://vanilla-js.com/) и не начать на нём писать, как завещали деды?
Но поскольку объем работ предвиделся очень заметный, то творческих порывов от идеи писать всё в голом JS никто почему-то не испытал. Пошли смотреть на инструменты и выбирать из них такие, которые бы не напугали потребителей наших компонентов до дрожи в коленках.
Инструменты
-----------
Хоть я и уже проспойлерил весь этот раздел, кое-что сказать тут нужно. Во-первых, веб-компоненты сразу же стали абсолютно безальтернативными: когда результатом творчества — предполагается библиотека компонентов, и нельзя тащить большого монстра а-ля Angular, который разрулит модульность полностью внутри себя, то остаётся то, что вообще не требует тащить библиотечного кода, и работает «прям так» в современных браузерах. Сами по себе веб-компоненты — это всё тот же удивительный фреймворк Vanilla JS, только с немного решенными вопросами модульности. Руками писать остаётся всё еще слишком много — нужна обертка с шаблонизацией, да еще и желательно, чтоб на каждый компонент было минимум бойлерплейта.
Таковых обёрток, да еще и достаточно зрелых для использования в серьезном проде — не так уж много: [Hybrids,](https://hybrids.js.org/) [LitElement,](https://lit-element.polymer-project.org/) [Stencil.](https://stenciljs.com/) И они все делают примерно одно и то же примерно одним и тем же способом, разница — в малозначимых рюшечках. Hybrids пытается быть модным и безклассовым, Stencil — модным и реактоподобным, LitElement — вроде бы даже особо и не пытается. И по результатам выбирания из малозначимых мелочей на выходе остался LitElement — ООПшники поворотили нос от Hybrids, а нелюбители реакта — от Stencil, в котором JSX и вообще чувствуется повторение не самых бесспорных идей реакта.
В бой?
------
Говорить о том, что можно — не так уж интересно, это всё есть в документации, поэтому далее я буду говорить в основном о том, что нельзя: об этом в документации обычно не пишут.
### Шаблоны
С точки зрения шаблонизации LitElement пользуется lit-html, которая отлично минималистична:
```
const template = html`
`;
```
Это не html, но запомнить тут нужно ровно три конструкции в один символ — ".", "?", и "@". Всё остальное — таки html. Отностительно JSX с его className и прочим — это немного приятнее и законно отделено от кода JS/TS. Но, впрочем, отсюда и вытекает первое «нельзя» — биндить что попало куда попало не выйдет, биндить можно только в значения атрибутов и свойств, и в текстовое содержимое. Разумеется, в tagged template literals нет магии, и ценой некоторого количества извращений можно собрать строку в рантайме и в рантайме же к ней приделать биндинги lit-html, но это фактически влезание в рендер руками, и с тем же успехом можно собирать строки и отправлять их в innerHTML. Нормальным же образом это всё делается через композицию шаблонов и разбиение сложных компонентов на более простые составляющие. Бойлерплейта довольно-таки мало — обвязка шаблонов фактически отсутствует, поскольку это просто переменная, а для создания компонента потребуется пять «лишних» строк.
### Компоненты
Единственная (но весомая) проблема компонентов — в том, что для полноценного «замешивания» компонентов с рендером детей где-то внутри шаблона родителя нужен Shadow DOM. Который, конечно, включён в LitElement по умолчанию, и вообще вроде бы как неплох. Но теневой DOM в настоящее время имеет одну большую проблему со стилями, аналогично css modules: изолировать стили оно прекрасно изолирует, но попутно это рубит на корню всю каскадность. Влезть в изолированные стили снаружи попросту нельзя. Вообще (почти) никак.
Это сильно мешает, например, возможности накатывания на компоненты разных тем. Всё, что можно делать с теневым DOM — это или упаковать все варианты стилизации внутрь компонента, или пытаться сделать тему полностью зависимой от переменных css — это то самое «почти», с которым таки можно подёргать изолированные стили. Но с которым придётся предусмотреть переменные буквально на любой разумный чих стилизации, и, с большой вероятностью, всё равно потом добавлять еще.
К счастью, Shadow DOM в LitElement можно просто отключить в компоненте. К несчастью, это также отключит и возможность адресно отрендерить детей элемента в нужных местах шаблона через . К счастью, немного извратившись, можно получить и первое и второе: для этого *всего лишь* нужно завести теневой корень на каждый необходимый слот, и не держать в нём ничего, кроме, собственно, . Таким образом и стилизация компонента будет открытой, и слоты будут наличествовать. Я хотел привести кратенький пример, но к сожалению код по манипулированию слотами кратеньким не выходит в любом случае — очень интересующиеся могут почитать [вот этот вот issue.](https://github.com/Polymer/lit-element/issues/553) Я вдохновлялся идеями именно оттуда.
Ну и еще стоит упомянуть, что в обозримом будущем скорее всего заколосится браузерная поддержка и полифиллы [::part](https://developer.mozilla.org/en-US/docs/Web/CSS/::part) и ::theme, и вот с ними теневой DOM наконец-то станет тем решением, которого все ждут уже много лет — чтоб и изолировано, и расширяемо/изменяемо. Но пока этого всего еще нет.
### Деплой
На этом пункте писать про «что нельзя» уже не выходит, потому что дальше можно всё — библиотеки lit существуют в виде ES modules, и поэтому без каких-либо проблем подхватываются чем угодно и как угодно (хоть голым браузером, который умеет в модули сам). Для IE и нынешнего Edge нужно подключать полифилл веб-компонентов, для модулей, если есть желание поднять их прямо из браузера, нужно что-то избавляющее от боли браузерных импортов, например [es-module-shims.](https://github.com/guybedford/es-module-shims) Ну или же бандлер.
Подцепленные в приложение веб-компоненты просто и банально доступны к применению, можно начинать использовать их в html и дёргать их методы и свойства в коде. Посмотреть, насколько хорошо это всё может быть прицеплено к другой либе или фреймворку — можно [вот здесь](https://custom-elements-everywhere.com/) (реакт отличился, но в среднем всё очень хорошо). Мы цеплялись в AngularJS, и всё было банально: ng-prop позволяет передать что-нибудь в компонент, а ng-on — слушать события.
Итог
----
Если нужно наваять компонентный UI и прикрутить его к чему-то, во что ты совершенно не хочешь влезать (в легаси код, в немодный страшный фреймворк, и в прочие плохие места) — веб-компоненты выручают просто прекрасно. Основные «зрелые» библиотеки, с ними управляющиеся — мелкие по размеру, серьезных технических проблем модульности и компоновки — уже нет, и можно просто брать и делать. Какую именно библиотеку вы возьмете — даже и не так важно, различий между ними на данный момент очень мало; конкретно LitElement, который взяли мы — не создал нам ни одной дополнительной проблемы, и отработал ожидаемым образом во всех случаях. | https://habr.com/ru/post/467403/ | null | ru | null |
# Универсальная система управления данными на базе технологий скаффолдинга и платформы .NET Core
Несколько лет назад я реализовал ряд проектов, для управления которыми использовалась система управления основанная на [ASP.NET Dynamic Data](https://habrahabr.ru/post/181804/). В свое время эта система сэкономила достаточно много времени и ресурсов. Но как известно, в ИТ все развивается очень стремительно. Не так давно вышла в релиз платформа .NET Core, основным нововведением которой была поддержка кроссплатформенности. Это в свою очередь позволило мне мигрировать ряд небольших проектов, а также проектов, которые я поддерживаю на некоммерческой основе на бюджетные сервера от Digital Ocean, которые, как известно, поддерживают только ОС семейства Linux. Когда дело дошло до системы управления передо мной стоял выбор — с минимальным изменением кода портировать проект под Mono, или переписать с нуля использую новые возможности .NET Core. Взвесив все за и против, я выбрал второй вариант. Что из этого вышло и что я собираюсь получить вы можете узнать под катом.

Для для тех кто не в курсе, что такое скаффолдинг, краткое описание этого подхода:
> "**Скаффолдинг** — это метод метапрограммирования для создания веб-приложений, взаимодействующих с базой данных. Этот метод поддерживается некоторыми современными MVC-фреймворками (Grails, Yii, Ruby on Rails, Django, CakePHP, Phalcon PHP, Symfony, ASP.NET Dynamic Data и другими.). Разработчик в них задает спецификации, по которым в дальнейшем генерируется программный код для операций создания определенных записей в базе данных, их чтения, обновления и удаления."[1]
Вдохновившись примером Ruby on Rail в 2007 году компания Майкрософт разработала свой инструмент для быстрого проектирования веб-приложения работающих с данными.
> "**ASP.NET Dynamic Data** – это фреймворк, который позволяет быстро разрабатывать полнофункциональные data-driven приложения, используя LINQ to SQL или Entity Framework, а также расширяет возможности элементов управления DetailsView, FormView, GridView и ListView в плане функциональности, проверки данных и отображения.
>
> Если говорить по простому, то Dynamic Data предназначен для быстрой генерации фронт-эндов для баз данных Microsoft SQL Server."[2]
И сам подход и инструмент ASP.NET Dynamic Data мне понравились. Причем на столько, что как я уже писал выше, я создал свою систему на их основе. Однако, за время использования этого решения у меня появляли различные идеи о том, как можно было бы улучшить этот продукт. И так, к тому, чтобы переписать проект с нуля меня подтолкнул ряд недостатков решения на базе ASP.NET Dynamic Data, среди которых основные:
* Построение модели не напрямую из базы данных, а по сгенерированной модели Entity Framework, что в свою очередь влечет необходимость переброски проекта, содержащего модель в случае изменения структуры базы.
* Проект был основан на устаревшей на сегодняшний день технологии WebForms
* Поддерживался только SQL Server
Исходя из этих недостатков я выделил для себя ряд возможностей, которые я бы хотел реализовать в новом проекте:
* Поддержка кроссплатформенности
* Поддержка различных баз данных (на данный момент реализована поддержка SQL Server и идет работа над реализацией поддержки MySQL. В планах также: PostgreSQL, Oracle Database, SQLite).
* Генерация модели базы данных напрямую из базы.
* Lookup с расширенными возможностями поиска
#### Общий принцип работы системы
На данный момент уже написана основная часть кода, которая позволяет работать с данными несложных по структуре баз.
Процедура работы следующая:
1. Для базы данных создается рабочая директория, которая указывается в базовом файле конфигурации приложения.
2. В этой директории создается файл с информацией о параметрах подключения к базе и параметрах подключения к файловому хранилищу, а также конфигурируются учетные записи пользователей системы.
3. Далее, после первого запуска системы, пользователь переходит в раздел Administration и запускает процесс построения модели базы данных, которая будет сохранена в рабочую директорию в файл **db.json**.
4. После того, как модель построена, в принципе, с системой можно уже работать. Однако для полностью комфортной работы может понадобиться уточнить параметры некоторых полей. Чтобы упростить процедуру поддержки конфигурационного файла в будущем, я предусмотрел возможность описывать уточненную конфигурацию в отдельном файле **db\_ex.json**. Это файл по структуре аналогичен **db.json**, но в нем необходимо указывать только имя поля, которое требует дополнительной настройки и указать те параметры, которые отличаются от сгенерированных по умолчанию. Разбиение конфигурации на два отельных файла позволяет не беспокоиться о том, что если в будущем придется обновить модель данных то все кастомные настройки будут потеряны. А это может произойти, например, если в таблицу были добавлены новые поля, или была создана новая таблица в базе.
##### Конфигурация
* **db.json** – файл с описанием схемын базы данных
* **db\_ex.json** – файл с расширенным описания схемы. Позволяет переопределять типы полей и другую мета-информацию.
* **configuration.json** – файл содержащий информацию о подключении к базе данных, пользователям системы и информацию для подключения к файловым хранилищам
**Структура описания базы**###### Схема
* Name – системное название схемы.
* Title – заголовок. Отображается в интерфейсе системы
* Tables – список таблиц
###### Таблица
* ShowInList – параметр указывает, будет ли отображаться таблица в навигационном меню
* Name – системное имя таблицы. Соответствует имени таблицы в базе данных.
* Title – заголовок таблицы. Оторажется в навигационном меню и на странице редактирования таблицы.
* Description – описание. Отображается на странице редактирования таблицы
* Columns – список полей
###### Поле
* Position – позиция поля в гриде и редакторе.
* IsKey – является ли поле ключевым полем в базе данных
* IsNullable – допустимы ли NULL-значения в поле
* Reference – ...
* ShowInGrid – отображать, или не поле в гриде
* AutoIncrement – является ли поле автоинкрементным
* MaxValue – максимальное значение поля
* MinValue – максимальное значение поля
* MaxLength – максимальная длинна поля
* Readonly – является ли поле доступным только для чтения
* Type – тип поля
* Name – системное название поля, соответствует имени поля в таблице базы данных
* Title – название поля, тображается в редакторе и гриде
* Description – описание поля
##### Поддержка типов данных
На данный момент в системе предусмотрены (но еще не все реализованы) следующие редакторы для различных типов полей:
* Text — обычное текстовое поле
* Email — поле для ввода почтового адреса
* Url — поле для ввода url
* Phone — поле для ввода телефона
* HTML — поле содержащее полноценный WYSIWYG редактор.
* Password — поле для ввода пароля
* Date — поле для ввода даты
* Time — поле для ввода времени
* DateTime — поле для ввода времени и даты
* File — поле для загрузки файла и сохранения идентификатора загруженного файла в таблицу
* Integer — поле для ввода целых чисел
* Double — поле для ввода дробных чисел
* Image — поле для загрузки изображения, предпросмотра загруженного изображения и сохранения идентификатора загруженного изображения в таблицу
* Binary — поле для загрузки файла и сохранения содержимого в таблицу,
* Reference — выпадающий список, или всплывающее окно с возможностью поиска для выбора связанного значения
* Boolean — чекбокс
**Пример файла конфигурации db.json**
```
{
"Tables": [
{
"Columns": [
{
"Position": 1,
"IsKey": true,
"IsNullable": false,
"Reference": null,
"ShowInGrid": false,
"AutoIncrement": true,
"MaxValue": null,
"MinValue": null,
"MaxLength": null,
"Readonly": true,
"Type": 40,
"Name": "Id",
"Title": "Id",
"Description": ""
},
{
"Position": 2,
"IsKey": true,
"IsNullable": false,
"Reference": null,
"ShowInGrid": false,
"AutoIncrement": true,
"MaxValue": null,
"MinValue": null,
"MaxLength": null,
"Readonly": true,
"Type": 40,
"Name": "Name",
"Title": "Name",
"Description": ""
},
{
"Position": 3,
"IsKey": true,
"IsNullable": false,
"Reference": null,
"ShowInGrid": false,
"AutoIncrement": true,
"MaxValue": null,
"MinValue": null,
"MaxLength": null,
"Readonly": true,
"Type": 40,
"Name": "Value",
"Title": "Value",
"Description": ""
}
],
"ShowInList": false,
"Name": "Setting",
"Title": "Настройки",
"Description": "Системные настройки"
}
],
"Generated": "2016-09-27T00:40:48.9189786+03:00",
"ExtendedConfigurationLoaded": false,
"Name": "Database",
"Title": "Database"
}
```
**Пример файла конфигурации db\_ex.json**
```
{
"Tables": [
{
"Columns": [
{
"Type": 40,
"ShowInGrid": false,
"AutoIncrement": true,
"Readonly": true,
"Name": "Id",
"Title": "Системный идентификатор"
},
{
"Type": 10,
"Name": "Name",
"Title": "Название"
},
{
"Type": 10,
"Name": "Value",
"Title": "Значение"
}
],
"ShowInList": false,
"Name": "Setting",
"Title": "Настройки",
"Description": "Системные настройки"
}
],
"Name": "Описание проекта",
"Title": "База данных"
}
```
**Пример файла конфигурации configuration.json**
```
{
"ConnectionString": "Server=...;Database=...;User Id=...;Password=..;",
"SecretKey": "secret-key-123",
"ApplicationRestartCommand": "",
"StorageConfiguration": {
"Type": 0,
"Url": "http://static.exapmle.com/user_upload/",
"Connection": {
"Path": "/var/www/example.com/user_upload/"
}
},
"Users": [{
"Login": "admin",
"Password": "admin",
"Administrator": true
}
]
}
```
#### Файловые хранилища
* **FileSystem** – наиболее частый вариант, когда файловое хранилище располагается на том же сервере, где запущена система управления. В этом случае указаывается путь к файлу.
* **FTP** – файловое хранилище располагается на удаленном сервере, загрузка файлов происходит по протоколу FTP*(реализация в планах)*
* **AzureStorage** – файловое хранилище располагается в Microsoft Azure, загрузка файлов производится в Azure Blob Storage *(реализация в планах)*
* **SSH** – файловое хранилище располагается на удаленном сервере, загрузка файлов производится по SSH-протоколу *(реализация в планах)*
В планах также реализация интеграции с хранилищем Amazon S3.
#### Послесловие
Хочу выразить благодарность [gelas](https://habrahabr.ru/users/gelas/) за помощь в работе над проектом и здравую критику.
Отдельно хочу отметить, что проект создавался мною в рамках комьюнити украинских разработчиков .NET Core — [.NET Core Ukrainian User Group](http://dot-net.in.ua). На данный момент наибольшая активность участников наблюдается в группе в Facebook, но и группу в ВК мы также планируем наполнять. Если у вас есть вопросы по .NET Core, идеи которыми вы хотите поделиться, или вы только присматриваетесь к этой технологии – присоединяйтесь, будет интересно!
Проект доступен под лицензией MIT на [GitHub](https://github.com/dncuug/scaffolder).
---
1. *[Руководство по ASP.NET Dynamic Data.](http://appclub.im/archive/details/2396)*
2. *[Википедия. Скаффолдинг.](https://uk.wikipedia.org/wiki/%D0%A1%D0%BA%D0%B0%D1%84%D1%84%D0%BE%D0%BB%D0%B4%D0%B8%D0%BD%D0%B3)* | https://habr.com/ru/post/311822/ | null | ru | null |
# Взлёты и падения строительной отрасли Сан-Франциско. Тенденции и история развития строительной активности
Это серия статей посвящена исследованию строительной активности главного города Кремниевой Долины — Сан-Франциско. Сан-Франциско — технологическая «Москва» нашего мира, на примере которого (при помощи открытых данных) можно наблюдать за развитием строительной отрасли в больших городах и столицах.
Построение графиков и расчётов проводилось в [Jupyter Notebook](https://www.kaggle.com/artemboiko/san-francisco-building-sector-1980-2019) (на платформе Kaggle.com).
Данные о более чем миллионе разрешений на строительство (записей в двух датасетах) от департамента по строительству Сан-Франциско — позволяют **проанализировать не только строительную активность в городе**, но и критически рассмотреть **последнии тенденции и историю развития строительной отрасли за последние 40 лет**, в период с 1980 по 2019 год.
Открытые данные дают возможность исследовать **основные факторы, которые влияли и будут влиять на развитие строительной отрасли** в городе, разделив их на “внешние” (экономические бумы и кризисы) и “внутренние” (влияние праздников и сезонно-годовых циклов).
### Содержание
[Открытые данные и обзор исходных параметров](#op)
[Годовая строительная активность в Сан-Франциско](#year)
[Ожидание и реальность при составлении сметной стоимости](#excep)
[Активность строительства в зависимости от сезона года](#aktiv)
[Общий объём инвестиций в недвижимость Сан-Франциско](#sum)
[В какие районы инвестировали за последние 40 лет](#distr)
[Средняя сметная стоимость заявки по районам города](#mean)
[Статистика по общему количеству заявок по месяцам и дням](#stat)
[Будущее строительной отрасли Сан-Франциско](#future)
Открытые данные и обзор исходных параметров.
--------------------------------------------
Это не перевод статьи. Я пишу на LinkedIn и чтобы не создавать графики на нескольких языках — все графики на английском. [Ссылка на английскую версию: The Ups and Downs of the San Francisco Construction Industry. Trends and History of Construction.](https://www.linkedin.com/pulse/ups-downs-san-francisco-construction-industry-trends-history-artem)
Ссылка на вторую часть:
[Хайповые строительные сектора и стоимость работ в Большом городе. Инфляция и рост чека в Сан-Франциско](https://habr.com/ru/post/513716/)
Данные о разрешениях на строительство в городе Сан-Франциско — взяты с портала открытых данных — [data.sfgov.org](http://data.sfgov.org). На портале есть несколько датасетов по теме строительства. В двух таких датасетах хранятся и обновляются данные по разрешениям, выданным на строительство или ремонт объектов в городе:
* [Разрешения на строительство в период 1980-2013 год](https://data.sfgov.org/Housing-and-Buildings/Building-Permits-before-January-1-2013/4jpb-z4kk) (850 тыс. записей)
* [Разрешения на строительство в период после 2013 года](https://data.sfgov.org/Housing-and-Buildings/Building-Permits-on-or-after-January-1-2013/p4e4-a5a7) (280 тыс. записей, данные загружаются и обновляются еженедельно)
В данных датасетах содержится информация о выданных разрешениях на строительство, с различными характеристиками объекта, на который выдается разрешение. Общее количество записей (разрешений), полученных **в период 1980-2019 год — 1 137 695 разрешений**.

Основные параметры из этого датасет, которые были использованы для анализа:
* **permit\_creation\_date** — дата создания заявки (по факту день с которого начинаются строительные работы)
* **desctription** — описание заявки (два-три ключевых слова, описывающих объект строительства (работы) на которое создавалось разрешение)
* **estimated\_cost** — сметная (предположительная) стоимость строительных работ
* **revised\_cost** — пересмотренная стоимость (стоимость работ после переоценки, увеличения или уменьшения первоначальных объёмов по заявке)
* **existing\_use** — тип жилья (один-, двух-фамильный дом, апартаменты, офисы, производство и др.)
* **zipcode, location** — почтовый индекс и координаты объекта
Годовая строительная активность в Сан-Франциско
-----------------------------------------------
На графике ниже данные по параметрам **estimated\_cost** и **revised\_cost** представлены в виде распределения общей стоимости работ по месяцам.
```
data_cost_m = data_cost.groupby(pd.Grouper(freq='M')).sum()
```
Для уменьшения месячных “выбросов” месячные данные сгруппированы по годам. График количества инвестированных денег по годам получил более логичный, и поддающийся анализу, — вид.
```
data_cost_y = data_cost.groupby(pd.Grouper(freq='Y')).sum()
```
По годовому движению суммы стоимостей (всех разрешений за год) в городские объекты **хорошо видны экономические факторы, которые с 1980 по 2019 года влияли** на количество и стоимость строительных объектов, или по другому на инвестиции в недвижимость Сан-Франциско.
Количество разрешений на строительство (количество строительных работ или количество инвестиций) за последние 40 лет было тесно связано с экономической активностью в кремниевой долине.
Первый пик строительной активности был связан с хайпом электроники середины 80 х годов в долине. Последовавший спад в области электроники и банковского дела в 1985 году привел к тому, что региональный рынок недвижимости пришел в упадок, от которого он не восстанавливался почти десять лет.
После этого ещё два раза (в 1993-2000 и 2009-2016 гг.) перед схлопыванием пузыря Доткомов и технологическим бумом последних лет **строительная отрасль Сан-Франциско прошла через параболический рост в несколько тысяч процентов**.
Убрав промежуточные пики и спады и оставив минимальные и максимальные значения на каждом экономическом цикле, видно на сколько большие колебания рынка преследовали отрасль последние 40 лет.

Самый большой рост инвестиций в строительство пришёлся на время бума доткомов, когда за период с 1993 по 2001 год в ремонт и строительство было проинвестировано — $ 10 млрд. или примерно по $ 1 млрд. в год. Если считать в квадратных метрах ( стоимость 1м² в 1995 году — $3000) — это примерно по 350 000 м2 в год в течении 10 лет, начиная с 1993 года.
> Рост ежегодных суммарных инвестиций за этот период составил 1215%.
Фирмы, которые в этот период занимались сдачей в аренду строительной техники, были похоже на конторы, которые продавали лопаты во времена золотой лихорадки (в этом же регионе в середине 19 века). Только вместо лопат — в 2000-е уже были краны и бетононасосы, для только что образовавшихся строительных фирм, которые хотели заработать на строительном буме.

После каждого из многочисленных кризисов, которые пережила строительная отрасль за эти годы, **в течении последующих двух послекризисных лет инвестиции** (сумма заявок по разрешениям) в строительство **каждый раз падали минимум на 50%**.
Самые крупные кризисы в строительной отрасли Сан-Франциско пришлись на 90-е годы. Где с периодичностью в 5 лет, отрасль то падала (-85% в период 1983-1986 гг.), то опять поднималась (+895% в период 1988-1992 гг.), оставаясь в ежегодном выражение в 1981, 1986, 1988, 1993 — на одном уровне.
Уже после 1993 года все последующие спады в строительной отрасли составляли не больше 50%. Но **приближающийся экономический кризис** (из за COVID-19) **может создать рекордный кризис в строительной отрасли** в период 2017-2021 год, падение которой уже за период 2017-2019 года составляет суммарно больше 60%.

**Рост населения Сан-Франциско** по динамике в период 1980-1993 годов также **показывал почти экспоненциальный рост**. Экономическая сила и инновационная энергия кремниевой долины были прочной основой, на которой строилась гипербола новой экономики, американского возрождения и доткомов. Это был эпицентр новой экономики. Но в отличие от роста инвестиций в недвижимость, после пика доткомов, численность населения фактически вышла на плато.
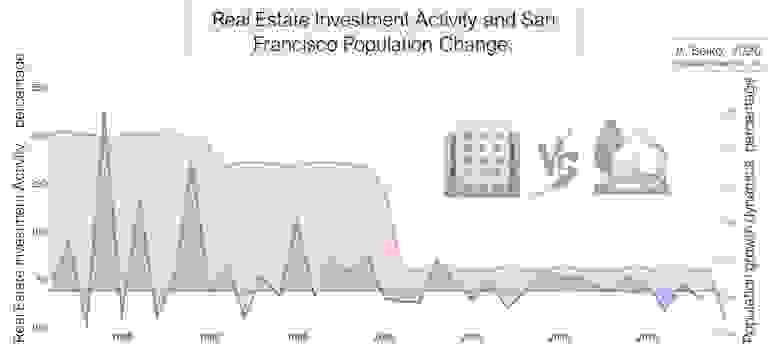
Если до пика доткомов в 2001 году, с 1950 года ежегодный прирост населения составлял примерно 1% в год. То после схлопывания пузыря, приток нового населения затормозился и с 2001 года составляет только 0.2 процента в год.
B 2019 (впервые с 1950 года) динамика прироста показала отток населения (-0.21% или 7000 человек) из города Сан-Франциско.
Ожидание и реальность при составлении сметной стоимости
-------------------------------------------------------
В использованных датасетах данные по стоимости разрещения на строительный объект разделены на:
* изначальную сметную стоимость (**estimated\_cost**)
* стоимость работ после переоценки (**revised\_cost**)
Во времена бума основная цель переоценки — это увеличение изначальной стоимости, когда у инвестора (заказчик строительства) проявляется аппетит уже после начала строительства.
**Во время же кризиса сметные стоимости, стараются не превышать, и изначальные сметы практически не претерпевают изменений** (исключение землетрясение 1989 года).
По графику построенного на разности переоцененной и сметной стоимости (revised\_cost — estimated\_cost) можно наблюдать, что:
> Сумма увеличения стоимости при переоценке объема строительных работ — прямо зависит от циклов экономического бума
```
data_spread = data_cost.assign(spread = (data_cost.revised_cost-data_cost.estimated_cost))
```

В периоды стремительного экономического роста, заказчики работ (инвесторы) достаточно щедро расходуют свои средства, увеличивая свои запросы уже после начала работ.
Заказчик (инвестор), чувствуя свою финансовую уверенность, просит строительного подрядчика или архитектора расширить уже выданное разрешение на строительство. Это может быть решение об увеличение первоначальной длины бассейна или увеличение площади дома (уже после начала работ и выдачи разрешения на строительство).
> В пик доткомов такие “дополнительные” расходы доходили до «лишних» 1 млрд. в год.
>
>

Если посмотреть на эту таблицу уже в процентном изменении, то пик увеличение сметы (в 100% или в 2 раза от первоначальной сметной стоимости) пришелся на год, перед землетрясением, произошедшего в 1989 года недалеко от города. Предполагаю, что после землетрясения объекты строительства которые были начаты в 1988 требовали после землетрясения в 1989 — большего количество времени и средств на реализацию.
И наоборот, пересмотр сметной стоимости в меньшую сторону (что произошло только один раз за период с 1980 по 2019 год) за несколько лет до землетрясения, предположительно связан с тем, что некоторые объекты начатые в 1986-1987 году были заморожены или инвестиции по этим объектам были урезаны. По графику **в среднем на каждый объект начатый в 1987 году — снижение сметной стоимости составило -20% от первоначального плана**.
```
data_spred_percent = data_cost_y.assign(spred = ((data_cost_y.revised_cost-data_cost_y.estimated_cost)/data_cost_y.estimated_cost*100))
```
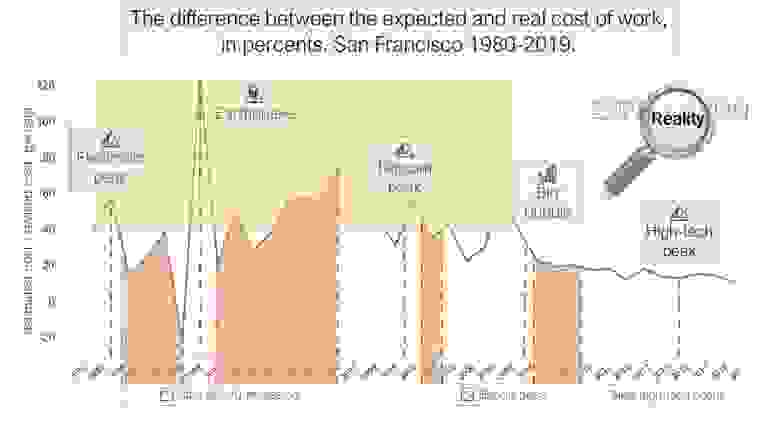
> Увеличение начальной сметной стоимости на больше чем 40%, указывало или возможно было следствием приближающегося пузыря на финансовом и в последующем — строительном рынке.
С чем связано уменьшение спреда (разницы) между сметной и пересмотренной стоимостью после 2007 года?
Возможно инвесторы начали тщательно смотреть на цифры (средняя сумма за 20 лет выросла со $ 100 тыс. до $ 2 млн.) или возможно департамент по строительству, предупреждая и тормозя возникающие пузыри на рынке недвижимости, ввело новые правилы и ограничения, чтобы снизить возможные манипуляции и возможные риски, которые возникнут в кризисные годы.
Активность строительства в зависимости от сезона года
-----------------------------------------------------
Сгруппировав данные по календарным неделям в году (54 недели), можно наблюдать за строительной активностью города Сан-Франциско в зависимости от сезонности и времени года.
**К рождеству все строительные организации стараются успеть получить разрешение на новые “крупные” объекты** (при этом! количество! разрешений в эти же месяцы находится на одном уровне в течении всего года). Инвесторы, планируя получить свой объект в течении следующего года заключают договора в зимние месяцы, рассчитывая на большие скидки (так как летние договора, в большей части, к концу года подходят к окончанию и строительные фирмы заинтересованы в поступление новых заявок).
**Перед рождеством, подаются самые большие суммы в заявках** (увеличение со средних 1-1,5 млрд. в месяц. до 5 млрд. за один только декабрь). **При этом общее количество заявок по месяцам остаётся на одном уровне** (см. Ниже раздел: статистика по общему количеству заявок по месяцам и дням)
После зимних каникул строительная отрасль активно (почти без роста количества разрешений) занимается планированием и реализацией “рождественских” заказов, чтобы к середине года (до праздника “Дня независимости”) — успеть освободить ресурсы перед начинающийся сразу после июньских праздников — новой волной летних договоров.
```
data_month_year = data_month_year.assign(week_year = data_month_year.permit_creation_date.dt.week)
data_month_year = data_month_year.groupby(['week_year'])['estimated_cost'].sum()
```
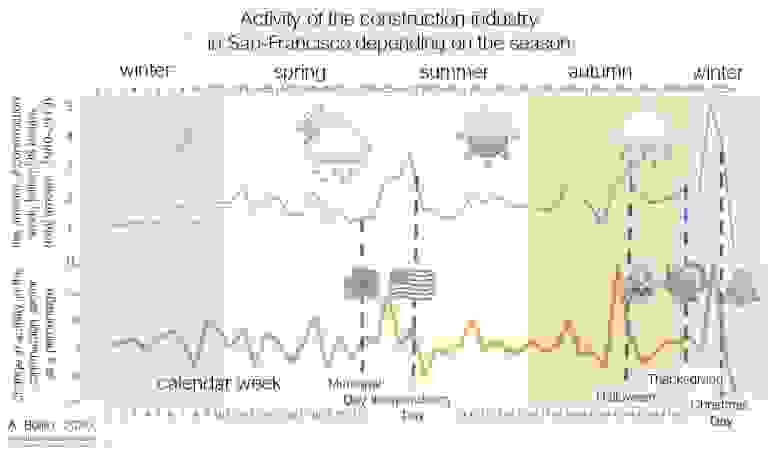
Эти же данные в процентах (оранжевая линия) так же показывают, что отрасль работает “ровно” в течении года, но перед и после праздников активность по разрешениям увеличивается до 150% в период между week 20-24 (перед Днём Независимости), и снижается сразу после праздника до -70%.
Перед Хэллоином и Рождеством активность в строительной отрасли Сан-Франциско week 43-44 возрастает на 150% (от дна до пика) и после уменьшается на каникулах до нуля.
> Таким образом отрасль находится в полугодовом цикле, который разделён праздниками “Днём независимости США” (week 20) и “Рождеством” (week 52).
Общий объём инвестиций в недвижимость Сан-Франциско
---------------------------------------------------
Исходя из данных по разрешениям на строительство в городе:
> Общий объём инвестиций в строительные объекты Сан-Франциско в период с 1980 года по 2019 года составляет 91,5 млрд. долларов.
```
sf_worth = data_location_lang_long.cost.sum()
```

Общая рыночная стоимость всей жилой недвижимости в Сан-Франциско, оцененная по налогу на имущество (является оценочной стоимостью всей недвижимости и всей личной собственности, принадлежащей Сан-Франциско) [**достигла в 2016 году — 208 миллиардов долларов**](https://www.sfassessor.org/news/san-francisco%e2%80%99s-total-property-assessment-above-200-billion-first-time).
В какие районы Сан-Франциско инвестировали за последние 40 лет
--------------------------------------------------------------
При помощи библиотеки Folium посмотрим куда были инвестированы эти $91,5 млрд. по районам. Для этого сгруппировав данные по почтовому индексу (zipcode), представим полученные значение при помощи кругов (функции Circle из библиотеки Folium).
```
import folium
from folium import Circle
from folium import Marker
from folium.features import DivIcon
# map folium display
lat = data_location_lang_long.lat.mean()
long = data_location_lang_long.long.mean()
map1 = folium.Map(location = [lat, long], zoom_start = 12)
for i in range(0,len(data_location_lang_long)):
Circle(
location = [data_location_lang_long.iloc[i]['lat'], data_location_lang_long.iloc[i]['long']],
radius= [data_location_lang_long.iloc[i]['cost']/20000000],
fill = True, fill_color='#cc0000',color='#cc0000').add_to(map1)
Marker(
[data_location_mean.iloc[i]['lat'], data_location_mean.iloc[i]['long']],
icon=DivIcon(
icon_size=(6000,3336),
icon_anchor=(0,0),
html='%s'
%("$ "+ str((data_location_lang_long.iloc[i]['cost']/1000000000).round()) + ' mlrd.'))).add_to(map1)
map1
```

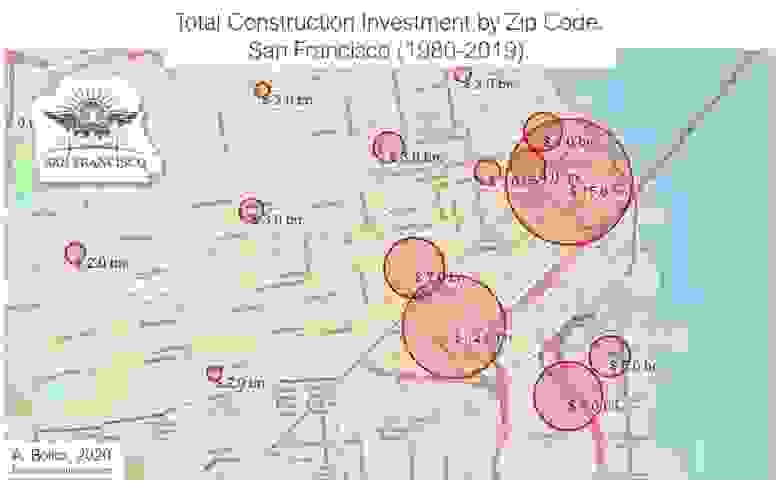
По районам видно, что **большая часть пирога логично досталась DownTown.** Упрощенно сгруппировав все объекты по расстоянию до центра города и времени, которые необходимо чтобы добраться до центра города (конечно дорогие дома строятся также на побережье), все разрешения были разделены на 4 группы: 'Downtown', '<0.5H Downtown', '<1H Downtown', 'Outside SF'.
```
from geopy.distance import vincenty
def distance_calc (row):
start = (row['lat'], row['long'])
stop = (37.7945742, -122.3999445)
return vincenty(start, stop).meters/1000
df_pr['distance'] = df_pr.apply (lambda row: distance_calc (row),axis=1)
def downtown_proximity(dist):
'''
< 2 -> Near Downtown, >= 2, <4 -> <0.5H Downtown
>= 4, <6 -> <1H Downtown, >= 8 -> Outside SF
'''
if dist < 2:
return 'Downtown'
elif dist < 4:
return '<0.5H Downtown'
elif dist < 6:
return '<1H Downtown'
elif dist >= 6:
return 'Outside SF'
df_pr['downtown_proximity'] = df_pr.distance.apply(downtown_proximity)
```
**Из 91,5 млрд. инвестированных в город — почти 70 миллиардов (75% всех инвестиций) инвестированных в ремонт и строительство приходятся на центр города** (зелёная зона) и в район города в радиусе 2 км. от центра (синяя зона).
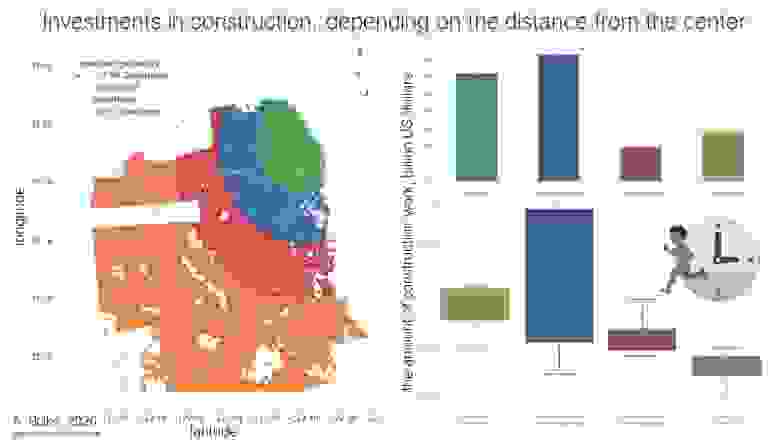
Средняя сметная стоимость заявки на строительство по районам города
-------------------------------------------------------------------
Все данные, как и в случае с общей суммой инвестиций, были сгруппированы по почтовому индексу. Только в данном случае со средней (.mean()) сметной стоимостью заявки по почтовому индексу.
```
data_location_mean = data_location.groupby(['zipcode'])['lat','long','estimated_cost'].mean()
```
В обычных районах города (больше 2 км. от центра города) — средняя сметная стоимость заявки на строительство составляет $ 50 тыс.

**Средняя сметная стоимость в районе центра города выше примерно в три раза** ($ 150 тыс. до $ 400 тыс.) чем в остальных районах ($30-50 тыс.).
Помимо стоимости земли, три фактора определяют общую стоимость при строительстве жилья: труд, материалы и государственные сборы. Эти три компонента в Калифорнии выше, чем в остальной части страны. Строительные нормы и стандарты Калифорнии считаются одними из самых всеобъемлющих и строгих в стране (из за землетрясений и экологических норм), часто требуя более дорогих материалов и рабочей силы.
Например, государство требует, чтобы строители использовали строительные материалы (окна, изоляция, системы отопления и охлаждения) более высокого качества — для достижения высоких стандартов в области энергоэффективности.

Из общей статистики по средней стоимости заявки на разрешение — выбиваются две локации:
* **Treasure Island** — искусственный остров в заливе Сан-Франциско. Средняя сметная стоимость разрешения на строительства — $ 6,5 миллионов.
* **Mission Bay** — (проживает 2926 человек) Средняя сметная стоимость разрешения на строительства — $ 1,5 миллионов.

На самом деле высокая средняя заявка в этих двух районах связана **с наименьшем количеством заявок по этим почтовым локациям** (145 и 3064 соответственно, строительство на острове сильно ограничено), тогда как по остальным почтовым индексам — з**а период 1980-2019 год поступало примерно по 1300 заявлений в год** (всего в среднем 30 -50 тыс. Заявлений за весь период).
> По параметру “количество заявок” заметно идеально-ровное распределение количества заявок, приходящихся на один почтовый индекс, по всей территории города.
Статистика по общему количеству заявок по месяцам и дням
--------------------------------------------------------
Общая статистика по общему количеству заявок по месяцам и дням недели в период с 1980 по 2019 год показывает, что **самые “спокойные” месяцы для департамента по строительству — это весенние и зимние месяцы. При этом сумма инвестиций, указанных в заявках сильно варьируется, и отличает от месяца к месяцу в разы** (см. дополнительно “Активность строительства в зависимости от сезона года”). Среди дней недели в понедельник нагрузка на департамент примерно на 20% меньше чем в остальные дни недели.
```
months = [ 'January', 'February', 'March', 'April', 'May','June', 'July', 'August', 'September', 'October', 'November', 'December' ]
data_month_count = data_month.groupby(['permit_creation_date']).count().reindex(months)
```

Тогда как по количеству заявок Июнь и Июль практически не отличаются, по общей сметной стоимости разница достигает 100% (4,3 млрд. в Мае и Июле и 8,2 млрд. в Июне).
```
data_month_sum = data_month.groupby(['permit_creation_date']).sum().reindex(months)
```
Будущее строительной отрасли Сан-Франциско, предсказание активности по паттернам.
---------------------------------------------------------------------------------
В заключении сравним график активности строительства в Сан-Франциско с графиком цены на Биткоин (2015-2018 гг.) и графиком цены на золото (1940 — 1980 гг.)
**Паттерн** (от англ. pattern — модель, образец) — в техническом анализе называются устойчивые повторяющиеся сочетания данных цены, объёма или индикаторов. Анализ паттернов основывается на одной из аксиом технического анализа: «история повторяется» — считается, что повторяющиеся комбинации данных приводят к аналогичному результату.
Основной паттерн который угадывается на графике годовой активности — **это “Голова и плечи” — паттерн разворота тренда.** Назван так, поскольку график похож на человеческую голову (пик) и плечи по бокам (меньшие пики). Когда цена прорывает линию, соединяющую впадины, паттерн считается завершенным, а движение, скорее всего, будут происходить вниз.
> Движения активности в строительной отрасли Сан-Франциско, практически полностью совпадает с графиком роста цены на золото и биткоин. Исторические показатели этих трёх графиков движения цен и активности демонстрируют заметные сходства.
Чтобы можно было предсказать поведение строительного рынка в будущем, **необходимо рассчитать коэффициент коррелированности** с каждым из этих двух трендов.
Две случайные величины называются коррелированными, если их корреляционный момент (или коэффициент корреляции) отличен от нуля; и называют некоррелированными величинами, если их корреляционный момент равен нулю.
Если полученное значение будет ближе к 0, чем к 1, то говорить о четкой закономерности не имеет смысла. Это сложная математическая задача, за которую возможно возьмутся старшие товарищи, которых может заинтересовать эта тема.
**Если! ненаучно!** посмотреть на тему дальнейшего развития строительной отрасли Сан-Франциско: при совпадении паттерна и дальше с ценой биткоина, то **по этому пессимистичному варианту** — выйти из кризиса строительной отрасли в Сан-Франциско будет непросто ближайшее посткризисное время.

**При более “оптимистичном” варианте** развития, возможен повторный экспоненциальный рост строительной отрасли, если активность здесь пойдет по сценарию “цены на золото”. В этом варианте через 20-30 лет (возможно через 10) строительную сферу ожидает новый всплеск занятости и развития.

[В следующей части](https://habr.com/ru/post/513716/) я подробнее рассмотрю отдельные отрасли строительства (ремонт крыш, кухонь, строительство лестниц, ванных комнат, если у вас есть пожелания по отраслям или другим данным — напишите пожалуйста в комментарии) и сравню инфляцию по отдельным типам работ с фиксированные ставкой по ипотечным кредитам и доходностью государственных облигаций США (Fixed Mortgage Rates & US Treasury Yield).
Ссылка на вторую часть:
[Хайповые строительные сектора и стоимость работ в Большом городе. Инфляция и рост чека в Сан-Франциско](https://habr.com/ru/post/513716/)
Ссылка на Jupyter Notebook: [San Francisco. Building sector 1980-2019.](https://www.kaggle.com/artemboiko/san-francisco-building-sector-1980-2019)
Пожалуйста тем, кто с Kaggle — поставьте плюс Notebook (Спасибо!).
(В Notebook позже будут добавлены комментарии и пояснения по коду)
Ссылка на английскую версию: [The Ups and Downs of the San Francisco Construction Industry. Trends and History of Construction.](https://www.linkedin.com/pulse/ups-downs-san-francisco-construction-industry-trends-history-artem) | https://habr.com/ru/post/508854/ | null | ru | null |
# Kali Linux: мониторинг и логирование
→ Часть 1. [Kali Linux: политика безопасности, защита компьютеров и сетевых служб](https://habrahabr.ru/company/ruvds/blog/338338/)
→ Часть 2. [Kali Linux: фильтрация трафика с помощью netfilter](https://habrahabr.ru/company/ruvds/blog/338480/)
→ Часть 3. [Kali Linux: мониторинг и логирование](https://habrahabr.ru/company/ruvds/blog/338668/)
→ Часть 4. [Kali Linux: упражнения по защите и мониторингу системы](https://habrahabr.ru/company/ruvds/blog/338712/)
В предыдущих двух статьях из этой серии мы говорили о политике безопасности, о защите компьютеров и сетевых служб, о фильтрации трафика в Kali Linux. Благодарим наших читателей за полезные дополнения к этим материалам. В частности — пользователя [imbasoft](https://habrahabr.ru/users/imbasoft/) за ссылку на [SANS Best Practices](https://www.sans.org/reading-room/whitepapers/bestprac) и за рекомендацию ознакомиться с комплексом стандартов [СТО БР ИББС](https://ru.wikipedia.org/wiki/%D0%A1%D0%A2%D0%9E_%D0%91%D0%A0_%D0%98%D0%91%D0%91%D0%A1) для погружения в тему бизнес-процессов управления безопасностью. Этот комментарий дан к [первому](https://habrahabr.ru/company/ruvds/blog/338338/) материалу. Спасибо пользователю [loginsin](https://habrahabr.ru/users/loginsin/), который сделал ценные замечания ко [второму](https://habrahabr.ru/company/ruvds/blog/338480/) материалу, касающиеся правил `iptables` и некоторых других тонкостей фильтрации трафика в Linux.
[](https://habrahabr.ru/company/ruvds/blog/338668/)
Сегодня мы хотим поделиться с вами переводом раздела 7.5. главы 7 книги «[Kali Linux Revealed](https://kali.training/introduction/kali-linux-revealed-book/)», который посвящён мониторингу и ведению журналов.
7.5. Мониторинг и логирование
-----------------------------
Конфиденциальность и защита данных — это важные аспекты информационной безопасности, но не менее важно обеспечивать бесперебойную и правильную работу системы. Если вы играете роль системного администратора и специалиста в области безопасности, вы должны обеспечить надёжную и предсказуемую работу инфраструктуры. В вашей сфере ответственности находится своевременное обнаружение аномального поведения и ухудшения качества работы служб.
Программы для мониторинга и логирования играют здесь ключевую роль, позволяя анализировать то, что происходит в системе и в сети.
В этом разделе мы рассмотрим некоторые инструменты, которые можно использовать для мониторинга Kali Linux.
7.5.1. Мониторинг журналов с использованием logcheck
----------------------------------------------------
Утилита `logcheck` предназначена для мониторинга лог-файлов, которые она, по умолчанию, ежечасно просматривает и отправляет необычные записи журналов на электронную почту администратора для дальнейшего анализа.
Список файлов, за которыми наблюдает программа, хранится в файле `/etc/logcheck/logcheck.logfiles`. Стандартные настройки позволяют `logcheck` нормально работать, при условии, если файл `/etc/rsyslog.conf` не был полностью изменён.
`Logcheck` поддерживает три уровня фильтрации: `paranoid`, `server` и `workstation`. Использование уровня `paranoid` приводит к тому, что `logcheck` отправляет администратору чрезвычайно длинные отчёты. Вероятно, его стоит использовать лишь на отдельных серверах, вроде тех, которые играют роль файрволов. Уровень `server` применяется по умолчанию, его рекомендовано использовать на большинстве серверов. Уровень `workstation`, что вполне очевидно из его названия, создан для рабочих станций, благодаря его использованию программа выдаёт краткие отчёты, отфильтровывая гораздо больше сообщений, чем при использовании других уровней фильтрации.
Во всех трёх случаях `logcheck` стоит настроить так, чтобы исключить из отчётов некоторые явно лишние сообщения (какие именно — зависит от служб, установленных в системе). Иначе приготовьтесь к тому, что каждый час вам будут приходить длинные неинтересные электронные письма. Механизм отбора сообщений для включения в отчёты довольно сложен, поэтому рекомендуется запастись терпением и осилить `/usr/share/doc/logcheck-database/README.logcheck-database.gz`.
Применяемые правила можно разделить на несколько типов:
* Правила, которые анализируют сообщения на предмет поиска попыток взлома системы. Эти правила хранятся в файле, расположенном в директории `/etc/logcheck/cracking.d/`;
* Правила для сообщений о попытках взлома, которые нужно игнорировать, описаны в `/etc/logcheck/cracking.ignore.d/`;
* Правила для сообщений, оцениваемых как предупреждения безопасности, хранятся в `/etc/logcheck/violations.d/`;
* Правила, для предупреждений безопасности, которые нужно игнорировать, хранятся в `/etc/logcheck/violations.ignore.d/`;
* И, наконец, правила, которые применяются к остальным сообщениям (они рассматриваются как системные события).
Файлы `ignore.d` используются для игнорирования сообщений. Например, сообщение, помеченное как попытка взлома или предупреждение безопасности (в соответствии с правилом, хранящимся в файле `/etc/logcheck/violations.d/myfile`) может быть проигнорировано только при применении правила, которое хранится в файле `/etc/logcheck/violations.ignore.d/myfile`, или в файле `/etc/logcheck/violations.ignore.d/myfile-extension`.
`Logcheck` всегда сообщает о системных событиях, если только в директориях, схема именования которых показана ниже, не будет указано, что эти события нужно игнорировать:
```
/etc/logcheck/ignore.d.{paranoid,server,workstation}/
```
Естественно, во внимание принимаются только те директории, которые соответствуют уровню фильтрации, равному или превышающему выбранный.
7.5.2. Мониторинг в режиме реального времени
--------------------------------------------
Программа `top —` это интерактивный инструмент, который выводит список выполняющихся процессов. Стандартная сортировка списка процессов основана на объёме потребляемых ресурсов процессора. При необходимости её можно активизировать с помощью ключа `P`. Другие способы сортировки процессов включают сортировку по занимаемому объёму оперативной памяти (ключ `M`), по общему времени использования процессора (ключ `T`), и по идентификатору процесса (ключ `N`). Ключ `k` позволяет завершить процесс, введя его идентификатор. Ключ `r` позволяет изменить приоритет процесса.
Если система выглядит перегруженной, `top —` это отличное средство, которое помогает узнать, какие процессы потребляют больше всего процессорного времени или занимают слишком много памяти. В частности, обычно полезно бывает проверить, соответствует ли потребление ресурсов процессами той роли, которую играет компьютер, тем службам, для поддержки которых он предназначен. Например, на неизвестный процесс, выполняющийся под пользователем «www-data», стоит обратить внимание. Его нужно исследовать, так как, возможно, это некая программа, установленная и запущенная в системе через уязвимость в веб-приложении.
Инструмент `top` весьма гибок, из его справки можно узнать подробности о том, как настроить выводимые им данные и приспособить его к вашим личным нуждам и предпочтениям.
Графическое средство `gnome-system-monitor` похоже на `top`, оно обладает примерно такими же возможностями.
7.5.3. Обнаружение изменений в системе
--------------------------------------
После того, как система установлена и настроена, большинство системных файлов не должно меняться до обновления системы. Таким образом, полезно отслеживать изменения в системных файлах, так как любое неожиданное изменение может стать основанием для беспокойства и для исследования причины такого изменения. В этом разделе показаны несколько распространённых инструментов, подходящих для мониторинга системных файлов, для обнаружения их изменений, и, при необходимости, для организации оповещения администратора.
### ▍7.5.3.1. Аудит пакетов с помощью dpkg --verify
Команда `dpkg --verify` (или `dpkg -V`) — это интересный инструмент, который позволяет выводить сведения о системных файлах, которые были модифицированы (возможно — злоумышленниками), но вывод этой команды стоит рассматривать с долей скептицизма. Для того, чтобы сделать своё дело, утилита `dpkg` полагается на контрольные суммы, хранящиеся в её собственной базе данных на жёстком диске (её можно найти по пути `/var/lib/dpkg/info/package.md5sums`). Квалифицированный взломщик вполне может модифицировать эти файлы так, чтобы они содержали новые контрольные суммы для изменённых файлов. Если атакующий пойдёт ещё дальше — он подменит пакет на вашем зеркале Debian. Для того, чтобы защититься от подобных атак, используйте систему подтверждения цифровой подписи APT (подробнее об этом — в разделе 8.3.6. «[Проверка подлинности пакета](https://kali.training/8-debian-package-management/advanced-apt-configuration-and-usage/#sect.package-authentication)») для надёжной проверки пакетов.
> ### ▍Что такое контрольная сумма файла?
>
>
>
> Хотим напомнить о том, что контрольная сумма — это значение, часто являющееся числом (хотя и в шестнадцатеричной записи), которое содержит нечто вроде сигнатуры для содержимого файла. Сигнатура вычисляется с помощью некоего алгоритма (среди них — широко известные MD5 и SHA1), которые, в целом, гарантируют, что даже мельчайшее изменение в файле приведёт к изменению контрольной суммы. Это явление известно как «эффект лавины». Простая цифровая сигнатура затем служит средством для проверки того, изменилось ли содержимое файла. Эти алгоритмы не поддаются обратному преобразованию. Другими словами, для большинства из них, знание сигнатуры не позволяет восстановить данные, на основе которых эта сигнатура создана. Последние исследования в области математики ставят под вопрос абсолютность этого принципа, но до сих пор на практике подобное не используется, так как создание различных наборов данных, имеющих одинаковую контрольную сумму всё ещё остаётся весьма сложной задачей.
Выполнение команды `dpkg -V` приведёт к проверке всех установленных пакетов и выводу сведений о тех из них, которые проверку не прошли. Каждый символ в строке сведений о пакете указывает на проверку некоторых метаданных. К сожалению, `dpkg` не хранит метаданные, необходимые для большинства тестов, и, таким образом, выводит для них знаки вопроса. В настоящее время только если пакет не проходит испытание контрольной суммой, на третьей позиции появляется цифра 5.
```
# dpkg -V
??5?????? /lib/systemd/system/ssh.service
??5?????? c /etc/libvirt/qemu/networks/default.xml
??5?????? c /etc/lvm/lvm.conf
??5?????? c /etc/salt/roster
```
В этом примере `dpkg` сообщает об изменении в файле `ssh.service`, которое сделал администратор, вместо того, чтобы использовать переопределение правил для `/etc/systemd/system/ssh.service`, (которое сохранилось бы в директории `/etc`, где и должны храниться файлы, задающие изменения конфигурации). Кроме того, команда выводит несколько конфигурационных файлов (для таких файлов во второй колонке отчёта выводится буква «c»), которые были модифицированы вполне обоснованно.
### ▍7.5.3.2. Мониторинг файлов: AIDE
Средство Advanced Intrusion Detection Environment (AIDE) позволяет проверять целостность файлов и обнаруживает любые изменения в сравнении с ранее сохранённым образом правильно сконфигурированной системы. Образ хранится в виде базы данных (`/var/lib/aide/aide.db`) и содержит соответствующие данные (контрольные суммы, разрешения, отметки времени) обо всех файлах системы.
Установить AIDE можно так:
```
apt update
apt install aide
```
После установки нужно инициализировать базу данных командой `aideinit`. Эта операция затем будет выполняться ежедневно (с помощью скрипта `/etc/cron.daily/aide`) для проверки того, что системные файлы не изменились. В случае обнаружения изменений, AIDE записывает их в лог-файлы (`/var/log/aide/*.log`) и отправляет отчёт администратору по электронной почте.
> ### ▍Защита базы данных AIDE
>
>
>
> Так как AIDE использует локальную базу данных для сравнения состояния файлов, корректность таких сравнений полностью привязана к состоянию базы данных. Если атакующий получит права суперпользователя на скомпрометированной системе, он сможет заменить базу данных и скрыть следы взлома. Один из способов предотвращения подобной атаки заключается в хранении эталонных данных на носителе, предназначенном только для чтения.
Для настройки пакета `aide` можно воспользоваться параметрами в `/etc/default/aide`. А именно, внутренние настройки программы хранятся в файлах `/etc/aide/aide.conf` и `/etc/aide/aide.conf.d/` (на самом деле, это — единственные файлы, используемые `update-aide.conf` для формирования `/var/lib/aide/aide.conf.autogenerated`). Конфигурация указывает на то, какие свойства каких файлов должны быть проверены. Например, состояние файлов журналов постоянно меняется, подобные изменения можно игнорировать, до тех пор, пока разрешения, заданные для этих файлов не меняются. Однако, в случае с исполняемыми файлами, и их содержимое, и разрешения, должны оставаться неизменными. Хотя эти настройки не так уж и сложны, синтаксис конфигурационных файлов AIDE нельзя назвать полностью интуитивно понятным, поэтому тем, кто хочет разобраться с настройкой AIDE, рекомендуем почитать `man` `aide.conf(5)`.
Новая версия базы данных создаётся ежедневно по адресу `/var/lib/aide/aide.db.new`. Если все зафиксированные изменения допустимы, ей можно заменить эталонную базу данных.
Инструмент Tripwire очень похож на AIDE. Даже синтаксис конфигурационных файлов практически тот же самый. Главное улучшение, которое даёт `tripwire`, заключается в механизме подписывания конфигурационного файла, в результате чего атакующий не может изменить его так, чтобы он указывал на другую версию эталонной базы данных.
Средство Samhain так же даёт похожие возможности, равно как и некоторые функции, предназначенные для выявления руткитов (этому посвящена следующая врезка). Эту программу, кроме того, можно развернуть глобально, в масштабах сети, и записывать результаты её работы на сервер (с цифровой подписью).
> ### ▍Пакеты checksecurity и chkrootkit/rkhunter
>
>
>
> Пакет `checksecurity` представляет собой набор небольших скриптов, которые выполняют основные проверки системы (поиск пустых паролей, новых файлов `setuid`, и так далее) и выдают предупреждения, если удаётся найти что-то подозрительное. Название пакета, `checksecurity`, может создать у администратора впечатление о том, что проверив систему с помощью этого пакета можно гарантировать её защищённость. Однако, не стоит всецело полагаться на этот пакет.
>
>
>
> Пакеты `chkrootkit` и `rkhunter` предназначены для обнаружения конкретных руткитов, которые могут быть установлены в системе. Руткиты — это программы, которые созданы для того, чтобы не привлекая внимания администратора, незаметно использовать компьютер. Испытания, которые выполняют вышеупомянутые пакеты, нельзя назвать на 100% надёжными, но обычно если они что-то находят — на это стоит обратить внимание.
Итоги
-----
Сегодня мы поговорили о мониторинге и логировании в Kali Linux. Рассмотренные здесь инструменты позволяют поддерживать уровень защиты системы и её работоспособность в хорошем состоянии, однако, всегда стоит помнить о том, что у атакующих есть средства противодействия многим системам контроля. В следующем материале мы подведём итоги 7-й главы и предложим вам несколько упражнений, которые позволят вам проверить свои знания и узнать что-то новое о Kali Linux.
Уважаемые читатели! Как вы организуете мониторинг ваших Linux-систем? | https://habr.com/ru/post/338668/ | null | ru | null |
# Структурное/визуальное программирование
Исторически сложилось что разработка программного обеспечения проводится посредством набора обычного текста. Вот уже несколько десятилетий основной подход к программированию состоит в последовательном наборе символов, которые должны формировать структуры более высокого уровня чем эти символы. Программисту приходится не просто раз за разом набирать одни и те же сочетания клавиш, но и следить за правильностью форматирования кода, иначе компьютер просто откажется понимать, что в коде написано. Один забытый символ ";" может выдать совершенно невнятные ошибки компиляции/интерпретации. Более того - использование текстового представления программы не просто ставит дополнительные требования к программированию, но и сильно ограничивает возможности программиста для эффективного написания и использования кода. Также текстовое представление информации сильно усложняет анализ этой информации программным способом. Давайте разберемся с альтернативным подходом к написанию программ.
---
Знакомьтесь - это MetaIDE. Один из представителей визуального/структурного подхода к обработке и хранению информации. Любой оператор (наподобие for, if, while) это не набор простых текстовых символов, а конкретный цельный элемент в памяти компьютера. Любой код программы - это набор из фиксированных операторов, которые составляют структурное представление программы. При использовании большинства обычных языков программирования, компилятор парсит исходный текст программы и строит AST - Abstract syntax tree (Абстрактное синтаксическое дерево). В MetaIDE вся программа уже являет собой AST, что сильно упрощает написание кода и последующее его использование.
Создание программного кода
--------------------------
Написание программного кода напоминает обычное текстовое программирование. Разве что вместо полнотекстового ввода операторов, в MetaIDE можно ограничиться всего парой клавиш: wh для while, fo для for и т.п. Также все операторы уже имеют необходимую разметку, что ускоряет набор кода. Среди программистов часто говорят, что скорость набора якобы не важна, но на практике, пока держишь в голове все детали алгоритма, очень желательно поскорее внести его в компьютер. Необходимость форматирования текста при этом только отвлекает. Структурное программирование позволяет более быстрее набирать исходные код. Особенно учитывая, что у IDE гораздо больше возможностей помочь программисту. Также стоит заметить, что для создания структурной программы, клавиатура не обязательна. Все основные операторы можно вводить с помощью меню. Простой текстовый ввод в основном необходим для задания имен переменным, функциям и т.п. Такой подход может хорошо зарекомендовать себя в случаях, когда нет полноценного доступа к клавиатуре - например на планшете (телефоне) или устройстве VR. Да и вообще - кто бы не хотел писать программу попивая чай одной рукой, а второй - спокойно и эффективно набирать код.
Отображение кода
----------------
Scratch, UML, Unreal EngineКак и в визуальном программировании, структурный код может быть представлен в любом формате. Например, как пазлы (Scratch, Blockly), как блоксхемы (UML, Дракон), как чертежи (blueprints - Unreal, Unity). Конкретно в MetaIDE используется представление кода максимально близкое к обычному текстовому представлению. Это позволяет разместить максимум информации на экране к чему привыкли опытные программисты.
Свобода в представлении информации позволяет делать локализованные версии кода, что может быть удобно в учебных целях. Не смотря на разное представление, исходный код при этом остается без изменений, и на других платформах может выглядеть по-другому, адаптируясь под конкретную платформу.
Также такой подход к отображению кода упрощает чтение и разработку программы. Например, большинство программ требуют локализации. Чаще всего для локализации используют перечисления (enum) которые имеют краткое описание текста. Но для программиста такой подход не совсем удобен - перечисление может не полностью отображать суть текста что приводит к ошибкам в использовании не тех строк, а добавление нового текстового значения требует перекомпиляции всей программы. В структурной программе можно создать специальное значение для локализованной строки - это позволит отображать текст строки прямо в коде (с возможностью выбора локали), упростит компиляцию (хранится обычное цифровое представление вместо перечисления), сделает более удобную локализацию (новые строки для локали можно добавлять прямо "из кода" не прибегая к дополнительным инструментам).
Как это все работает
--------------------
На самом деле очень просто. В основе всех данных в MetaIDE лежат ноды (узлы дерева), которые формируют дерево или граф - структуру данных, знакомую большинству программистов. Каждая нода может иметь базовое значение (число, строку, указатель на другую ноду), дочерние ноды, и указатель на своего родителя. Такой подход позволяет очень просто читать и модифицировать данные с помощью скриптов, что в свою очередь позволяет автоматизировать любую рутинную работу с данными. Для отображения нод используются виджеты. Каждый виджет привязывается к ноде, получая от нее сообщения о изменении данных самой ноды, и отображает эти данные в соответствии с своим кодом. Как не сложно догадаться, виджет может иметь любую форму и представление. В основе MetaIDE уже лежат готовые видежеты для представления информации в виде текста. Для оперирования нодами и виджетами используются меню и скрипты. Для создания меню уже есть готовые инструменты, также есть множество готовых скриптов для базового управления нодами.
Таким образом MetaIDE реализует популярный архитектурный шаблон MVC (Model-View-Controller, Модель-Представление-Контроллер) и обеспечивает максимальную гибкость при работе с данными. На каждую ноду можно создать множество разных виджетов и это активно используется в представлении кода. Например, декларация локальной переменной (или функции, класса, типа) содержит в себе имя, а все места где эта переменная используется - на самом деле указатели на декларацию и используют виджет для отображения имени по этому указателю. Так что изменив имя переменной, изменится также выводимый текст всюду, где встречается эта переменная.
Как с этим работать
-------------------
Здесь все еще проще - активировав ноду (вернее виджет представляющий ноду), слева в меню появятся все возможные действия, которые можно выполнить с этой нодой. За каждым пунктом меню стоит скрипт изменяющий ноду. Также в меню можно ознакомиться с комбинациями клавиш необходимыми для выполнения конкретного пункта меню.
Единое пространство
-------------------
Поскольку почти все в MetaIDE состоит из нод, значит любой скрипт может получить доступ к любой части данных IDE, и прочитать или модифицировать их на свое усмотрение. Даже модифицировать свой собственный исходный код. Таким образом, написать дополнение к структурной IDE в разы легче чем для обычной IDE - фактически достаточно знать какие ноды нужно изменить и как это сделать (никаких SDK или ограниченных API, как в случае с текстовым исходным кодом).
Генерация кода, метапрограммирование и DSL
------------------------------------------
```
fix code main table
name: varLocal node: var get local fn: varLocal switch: ndPtr
name: varMember node: var get member fn: varMember switch: ndPtr
name: varGlobal node: var get global fn: varGlobal switch: ndPtr
name: varUnkn node: var unknown fn: varUnkn switch: ndPtr
name: call node: call fn fn: call switch: ndPtr
name: inline node: inlineCall fn: inline switch: ndPtr
name: subClass node: getSubClass fn: subClass switch: ndPtr
name: subNode node: var get subnode fn: subNode switch: ndPtr
name: nextFn node: nextFn fn: nextFn switch: ndPtr
```
Часто бывают ситуации, когда в исходный код нужно добавить новую сущность что тянет за собой создание нового класса для этой сущности, пары функций для обработки сущности, значение в enum, текстовое описание, добавление указателей в массивы и т.п. И все это раскидано по разным файлам и даже проектам. Один раз прописывать весь код не составляет особых проблем, но вот если таких сущностей десятки, а то и сотни, ручная прописка всех необходимых мест начинает сильно усложнять разработку. К тому же спустя некоторое время все нюансы создания кода забываются, и добавление чего-либо нового в программу занимает уйму времени. Обычный подход к программированию мало приспособленный к такой проблеме. В языках программирования могут быть макросы и темплейты, которые лишь частично помогают в организации однотипного кода. MetaIDE предлагает другой подход к решению - создание DSL (или даже обычного UI) который в краткой форме описывает необходимые данные, и пары скриптов которые будут генерировать финальный код и прописывать его во все нужные места. Создание такого генератора в структурном коде на порядки проще чем создание его менее удобного аналога для обычных текстовых исходников.
Больше чем IDE
--------------
Карта памятиНа самом деле MetaIDE это не только среда для разработки программ, но и среда для работы этих же программ. Так в MetaIDE разработаны дополнительные инструменты для организации рабочего процесса (пока в очень базовой форме) - карты памяти (mind map), текстовый структурный редактор (outliner), скрипты и виджеты для подбора цветов (в пространствах HSB, LCH, HSLuv, HPLuv). Кроме того, разрабатывая программы для MetaIDE, можно сразу использовать набор готовых виджетов, стандартные скрипты и разметки для более простой работы с нодами, готовую систему истории изменений (undo/redo) и сохранения данных на диск. В будущем планируется добавить систему контроля версий для нод (такой себе git), возможность создавать любые виджеты с помощью скриптов, а также компиляция готовых программ в исполняемые файлы под разные ОС.
Выбор цветов для менюПомощь с легаси
---------------
Важной составляющей структурного представления кода, является простота чтения и модификации кода с помощью скриптов. Фактически весь код – это набор объектов, которыми легко манипулировать, в том числе транслировать старый код под новые требования, что сильно облегчает работу с устаревшими данными. Вместо ручного переписывания старых данных под новый формат, можно написать скрипт, который выполнит большую часть работы автоматически.
Язык Delight
------------
Список операторовДля написания скриптов в MetaIDE используется структурный язык программирования Delight. По синтаксису он ближе всего к Паскалю и С++, однако имеет множество нововведений, в том числе компонентно-ориентированное программирование (вместо ООП), но это уже тема другой статьи.
История разработки
------------------
Описание нод, виджетов и менюЛучше всего использование всех возможностей структурного подхода к организации информации просматривается на истории создания самой MetaIDE. Изначально весь код писался в Lazarus, соответственно существовал только код паскаля. На паскале был написан язык описания шаблонов нод, с помощью которого было легко создавать новые типы нод. Поскольку сам язык описания нод был вполне самодостаточен, то уже мог описать сам себя. Был написан скрипт, который прокидывал все существующие ноды на уже созданные шаблоны нод (созданные уже на нодах, а не на паскале). Фактически новая структура нод начала ссылаться сама на себя, и стала менее зависима от паскаля, что позволило выкинуть большую часть паскалевского кода. Общее количество кода сильно сократилось, при том что старые данные нод успешно конвертировались в новую структуру в автоматическом режиме. На новой структуре нод начал создаваться язык программирования Delight, и здесь проявились недостатки в шаблонном описании нод – на тот момент нода описывалась своим визуальным представлением вперемешку со своими данными, что было крайне неудобно для интеграции с Delight. Было решено сделать описание нод в виде близком к описанию классов (как в обычных ЯП), а визуальное представление ноды вынести в отдельные виджеты. Однако на тот момент уже существовали сотни описаний нод на которых держалась вся IDE и Delight. Задачу можно сравнить с необходимостью разделения кода декларации класса на несколько частей, а таких классов в программе - сотни. Фактически требовалось переписывание всего кода с нуля. К счастью, имея дело с структурированной информацией, всего за два вечера были написаны скрипты, которые конвертировали устаревшее представление данных в новый формат. Ручное переписывание заняло бы пару недель. В последствии, автоматическое переписывании кода с помощью скриптов использовалось регулярно. Так в один момент, данные уже созданных библиотек нод были разделены на две части, проводились тотальные изменения в синтаксисе и архитектуре Delight - чего только стоил перевод всех существующих исходных кодов с ООП и интерфейсами на КОП. Все эти задачи успешно решались написанием скриптов вместо ручного переписывание всего существующего кода. Фактически вся разработка MetaIDE и Delight напоминала эволюционное программирование - когда все старые данные без проблем эволюционировали в новые, более эффективные представления.
Ложка дегтя
-----------
Конечно работа со структурными данными довольно сильно отличается от обычной работы с текстом. Если при оперировании с текстовым представлением, достаточно любого текстового редактора со стандартным и знакомым всем функционалом, то работа со структурными данными практически не возможна без использования скриптов и знания как эти скрипты функционируют. С другой стороны, если для текстового программированная нужно досконально знать синтаксис языка программирования, то для структурного программирования можно просто пользоваться подсказками IDE для создания кода.
Ложка дегтя №2
--------------
На текущий момент MetaIDE и Delight находятся в стадии разработки и доступны только в качестве предварительного просмотра (даже не как альфа версия). Далеко не все еще доработано и не все вещи сделаны удобно. Масштабы разработки слишком громадны и на проработку всех деталей за раз не хватает времени.
Обширный todo listВыводы
------
На данный момент MetaIDE представляет собой совершенно новый подход к написанию программ, открывая для программиста новые горизонты в организации всего рабочего процесса. Сильно упрощается как работа с кодом в целом, так и отдельные аспекты программирования. | https://habr.com/ru/post/532914/ | null | ru | null |
# Еще одно Canvas руководство [4]: The end
В этой части
------------
[Трансформации,
Композиции,
Анимации,
Манипуляция пикселями]
Трансформации
-------------
### Вспомним некоторые методы
Во первых нам понадобится вспомнить два метода которые были упомянуты в прошлой главе.
save — сохраняет текущее состояние на вершине стека
restore — устанавливает состояние с вершины стека
Под состоянием стоит понимать: матрицу трансформации, область рисования, и следующие свойства: strokeStyle, fillStyle, globalAlpha, lineWidth, lineCap, lineJoin, miterLimit, shadowOffsetX, shadowOffsetY, shadowBlur, shadowColor, globalCompositeOperation, font, textAlign, textBaseline.
### Сместим
```
translate(float x, float y)
```
— сместим текущее положение начала координат на x и y от предыдущего положения.
Рассмотрим следующий пример:
```
ctx.save() //Сохраним состояние
ctx.translate(100,100) //Сместим начало координат
ctx.textBaseline = 'top'
ctx.font = "bold italic 30px sans-serif"
ctx.strokeText("Привет Хабр",0,0) //Казалось бы рисуем в точке (0;0), а текст рисуется не в угле холста
ctx.restore() //Восстановим состояние, на самом деле не обязательно, но лучше восстановить
```
### Повернем
[](http://jsfiddle.net/r2Gr7/)
```
rotate(float angle)
```
— повернет оси абсцисс и ординат на угол angle, также не стоит забывать что угол измеряется в радианах, чтобы преобразовать угол в радианы из градусов нужно умножить градусы на Pi и разделит на 180, то есть: rad = deg \* Math.PI // 180
Для примера добавим после ctx.translate(100,100) строку: ctx.rotate(45\*Math.PI/180)
### Уменьшим/увеличим
[](http://jsfiddle.net/P3ec8/1/)
```
scale(float x, float y)
```
— применит новый масштаб к осям x и y.
Для примера заменим ctx.rotate(45\*Math.PI/180) на ctx.scale(0.65,1.5)
### Перемножим матрицу
```
transform(float m11, float m12, float m21, float m22, float dx
, float dy)
```
— перемножит старую матрицу на новую матрицу.
### Применим матрицу

```
setTransform(float m11, float m12, float m21, float m22, float dx
, float dy)
```
— применит новую матрицу, для примера посмотрим на следующий код.
```
var img = new Image();
img.onload = function(){
ctx.save()
ctx.setTransform(1,0.5,0,1,1,1)
ctx.drawImage(img,0,0,78,50)
ctx.restore()
}
img.src = 'brick.jpg';
```
Я использовал картинку кирпичной стены и [shearing трансформацию](http://en.wikipedia.org/wiki/Transformation_matrix#Shearing).
Кроме того о трансформациях можно почитать более подробно в [топике от Nutochka](http://habrahabr.ru/blogs/html5/104718/)
Композиции
----------
### Виды операции композиции

За тип операции композиции отвечает свойство globalCompositeOperation, можно было бы расписать все его возможные значения, но есть [Canvas Cheat Sheet](http://www.selfhtml5.org/wp-content/uploads/2010/07/HTML5_Canvas_Cheat_Sheet.png) и лучше показать часть картинки с него, синий прямоугольник был нарисован первым, а красный круг вторым и в зависимости от значения globalCompositeOperation мы получим разные результаты.
### Свойство globalAlpha
[](http://jsfiddle.net/5GT78/)
Свойство globalAlpha — фактически является множителем на которые умножается прозрачность каждого изображения, при этом только в том случае если 0 <= globalAlpha <= 1. Для примера рассмотрим код:
```
ctx.globalAlpha = 0.6;
ctx.fillRect(0,0,100,100)
ctx.fillRect(50,50,100,100)
```
Анимация
--------
requestAnimationFrame
---------------------
Если раньше для анимации использовались таймеры то теперь появилась специальная функция requestAnimationFrame, тема уже освещенная так что лучше прочитать [хабраперевод от azproduction](http://habrahabr.ru/blogs/javascript/114358/).
Основной принцип анимации
-------------------------
Основной принцип анимации это стереть старый кадр и нарисовать новый. Чтобы стереть старый кадр легче всего воспользоваться функцией clearRect. Для примера рассмотрим следующий код, для начала добавьте определение requestAnimationFrame в ваш код:
```
var x = 400,
y = 300;
(function loop(){
ctx.clearRect(0,0,800,600);
ctx.beginPath();
ctx.arc(x++,y++,50,0,Math.PI*2,false);
ctx.fill()
requestAnimFrame(loop);
})();
```
Также об анимации можно почитать в [топике от trickii](http://habrahabr.ru/blogs/canvas/119585/)
1 игра != 1 canvas
------------------
Это правило я увидел в презентации про ускорение canvas и понял что это самое простое правило.
Вместо того чтобы рисовать сложные изображения при каждом кадре можно сохранить это изображение в виртуальный canvas и затем рисовать его при каждом кадре, но однако стоит заметить что не надо всё пихать в виртуальный canvas, стоит пихать только действительно сложные для рисования фигуры (например текст или градиент). [Для примера я сделал небольшой тест на jsperf.com](http://jsperf.com/cache-canvas-test), не идеал, но думаю смысл понятен.
Манипулируем пикселями
----------------------
В canvas кроме высокоуровневых методов присутствует еще и полноценный доступ к пикселям, с помощью него можно творить замечательный вещи (я имею ввиду фильтры и подобное), а также рисовать простые вещи очень быстро. Для работы с пикселями существует специальный тип ImageData, он обладает тремя свойствам width,height (думаю не нуждаются в объяснении) и data — массив значений r,g,b,a для каждого пикселя.
### Как хранятся данные о пикселях

Данные о пикселях как говорилось ранее хранятся в массиве, при этом количество элементов в массиве равно количеству пикселей умноженному на 4. Все элементы принимают значения в диапазоне 0..255.
В том числе alpha канал хранится в значениях от 0..255. На картинке показано что четыре значения r,g,b,a формируют сегмент, сегмент в свою очередь является единой неделимой ячейкой хранящей параметры одного пикселя.
### Создание пустого ImageData
```
ImageData = context.createImageData(int w, int h)
```
— создаст пустой ImageData с шириной и высотой w и h соответственно.
```
ImageData = context.createImageData(imageData)
```
— создаст пустой ImageData с шириной и высотой переданного imageData, заметьте: данные не копируются.
### Применение ImageData
```
context.putImageData(imageData imgd, int x, int y)
```
— изменит массив пикселей canvas в области из точки x y с шириной и высотой imageData.
### Простой пример
Но хватит теории, приступим к делу давайте попробуем нарисовать график функции y = x\*x, без сглаживания:
```
var imgd = ctx.createImageData(800, 600);
var x,y,segment,xround,yround;
for (x=-40 ; x<=40 ; x+=0.01) {
y = x*x;
xround = ~~(x+0.5);
yround = ~~(y+0.5);
segment = ((-yround+400)*imgd.width + xround + 40)*4;
imgd.data[segment+3] = 255;
}
ctx.putImageData(imgd, 0, 0);
```
Для сравнения производительности я написал подобный [код с использованием fillRect, опять на jsperf](http://jsperf.com/imagedata-vs-fillrect), однако чтобы нарисовать одну точку лучше использовать fillRect так как создание imageData тоже отнимает ресурсы.
### Манипуляция пикселями изображения

```
ImageData = context.createImageData(int x, int y, int w, int h)
```
— вернет объект imageData с данными из canvas в прямоугольной области с левой верхней вершиной в (x;y) и шириной, высотой w и h соответственно. Для примера попробуем выделить на фотографии участки белого цвета:
```
var img = new Image();
img.src = 'test.jpg'; //Или что там у вас
img.onload = function(){
//netscape.security.PrivilegeManager.enablePrivilege("UniversalBrowserRead"); -- раскомментируйте если запускаете код в FireFox из локалки
ctx.drawImage(img, 0, 0, 160, 120);
var imgd = ctx.getImageData(0, 0, 160, 120); //Получаем imageData
for (var i=0 ; i
``` | https://habr.com/ru/post/119621/ | null | ru | null |
# Создание генератора мира для minecraft
#### Введение
Думаю, почти все читатели Хабра слышали про майнкрафт, кто-то играл в сингле, кто-то на одном из многочисленных серверов, был даже небольшой сервер у кого-то из хабраюзеров. После двух месяцев игры я задумался — а реально ли написать свой генератор карты? Как оказалось, это вполне возможно сделать за несколько дней неторопливого гугления и кодинга.
##### Немного технической части
Согласно [вики-проекту](http://www.minecraftwiki.net/wiki/Beta_Level_Format) майна, карты хранятся в файлах регионов (32x32 блока по 16x16x128 кубов, итого 262144 квадратных блоков на регион), имеющих следующую структуру:
1. 4096 байт, содержащих оффсеты **чанков** (так называются блоки 16x16x128) и их размер в блоках по 4кб, округляя вверх, 3 байта оффсет, 1 — размер
2. 4096 байт timestamp'ов чанков, по 4 байта на каждый
3. Оставшееся место до конца файла — собственно, данные чанков, сжатые Zlib. 4 байта — размер сжатых данных, 1 — способ сжатия (по умолчанию 2, Zlib (RFC1950)), размер-1 запакованная злибом [NBT-структура](http://www.minecraftwiki.net/wiki/Alpha_Level_Format/Chunk_File_Format), т.е сам контейнер кубов
Если упакованные данные занимают меньше целого числа секторов по 4 кб, то остаток сектора заполняется нулями, т.к каждый чанк должен начинаться с оффсета, выраженного целым числом секторов по 4096 байт
##### Выбор языка
Реализовать такую структуру можно на любом языке, я остановился Delphi 7. Во-первых, это пока единственный язык, который я знаю, во-вторых, именно на 7 версии года 4 назад я начинал писать блокноты по мануалам из Игромании.
##### Код
Так как данные хранятся в сжатом виде, нам необходим модуль **zlib**.
Я использовал [ZlibEx](http://www.base2ti.com/)
Для начала создадим класс чанка, в который будем впоследствии писать данные
```
Tchunk = class(TObject)
private
public
Data: tmemorystream;
c_data: tmemorystream;
c_stream: tzcompressionstream;
constructor Create;
procedure writeblock(x, y, z, block: integer); overload;
procedure writeblock(x, y, z, block, color: integer); overload;
procedure compress;
end;
```
##### Код этого класса:
```
constructor tchunk.Create;
begin
Data := TMemoryStream.Create;
Data.size := 82360;
Data.LoadFromFile('data.bin');
c_data := TMemoryStream.Create;
c_stream := tzcompressionstream.Create(c_data, zcdefault, 15, 8, zsdefault);
end;
procedure tchunk.writeblock(x, y, z, block: integer);
begin
Data.Seek(form1.getoffset(x, y, z) + 16487, 0);
Data.Write(block, 1);
end;
procedure tchunk.compress;
var
buffer: array [0..82360] of byte;
begin
c_data.Position := 0;
Data.Position := 0;
Data.Read(buffer, 82360);
c_stream.writebuffer(buffer, 82360);
c_stream.Free;
c_data.SaveToFile('file' + IntToStr(n));
end;
```
Функция **getoffset** выдает нужое смещение по формуле `y + ( z *128 + ( x * 128 * 16 ) )`
```
function tform1.getoffset(x, y, z: integer): integer;
begin
Result := y + (z * 128 + (x * 128 * 16));
end;
```
Добавим в var пару переменных:
```
chunks:array[0..32] of array[0..32] of tchunk;
n: integer=0;
```
Процедура для сборки всех чанков в готовый файл:
```
procedure tform1.SwapEndiannessOfBytes(var Value: cardinal);
var
tmp: cardinal;
i: integer;
begin
tmp := 0;
for i := 0 to sizeof(Value) - 1 do
Inc(tmp, ((Value shr (8 * i)) and $FF) shl (8 * (sizeof(Value) - i - 1)));
Value := tmp;
end;
procedure tform1.generatefile;
var
fileoffset: integer;
time, compressiontype, counter: integer;
filename: string;
regionfile: tfilestream;
tmp: cardinal;
size: integer;
n_x, n_z: integer;
bu: array[0..99999] of byte;
n: integer;
roundedsize: integer;
neededsize: integer;
d: byte;
begin
fileoffset := 2;
time := $d8de2f4e;
compressiontype := $02;
filename := GetVar('Appdata') + '\.minecraft\saves\NewWorld\region\r.0.0.mcr';
regionfile := tfilestream.Create(filename, fmcreate);
n := 0;
for n_x := 0 to 31 do
for n_z := 0 to 31 do
begin
chunks[n_x][n_z].compress;
roundedsize := ((chunks[n_x][n_z].c_data.Size) div 4096);
if (((chunks[n_x][n_z].c_data.Size) mod 4096) > 0) then
Inc(roundedsize);
regionfile.seek((4 * ((n_x mod 32) + (n_z mod 32) * 32)), 0);
tmp := fileoffset;
SwapEndiannessOfBytes(tmp);
tmp := tmp shr 8;
regionfile.Write(tmp, 4);
regionfile.seek(4 * ((n_x mod 32) + (n_z mod 32) * 32) + 3, 0);
regionfile.Write(roundedsize, 1);
size := chunks[n_x][n_z].c_data.Size + 1;
regionfile.seek(fileoffset * 4096, 0);
tmp := size;
SwapEndiannessOfBytes(tmp);
regionfile.Write(tmp, 4);
regionfile.Write(compressiontype, 1);
chunks[n_x][n_z].c_data.Position := 0;
chunks[n_x][n_z].c_data.readbuffer(bu, chunks[n_x][n_z].c_data.size);
regionfile.Writebuffer(bu, chunks[n_x][n_z].c_data.size);
regionfile.seek((n) * 4 + 4096, 0);
regionfile.Write(time, 4);
fileoffset := fileoffset + ((chunks[n_x][n_z].c_data.Size) div 4096);
if (((chunks[n_x][n_z].c_data.Size) mod 4096) > 0) then
fileoffset := fileoffset + 1;
Inc(n);
end;
neededsize := 4096 * fileoffset - regionfile.Size - 1;
regionfile.Seek(regionfile.Size, 0);
d := 00;
for n := 0 to neededsize do
regionfile.Write(d, 1);
regionfile.Free;
end;
```
Всё, теперь мы имеем метод записи любого блока по любой координате, в пределах региона. При желании, несложно повторить то же для остальных регионов, надо строк 10 кода.
Обертка для writeblock:
```
procedure tform1.writeworld(x, y, z, block: integer);
var
xw, zw: integer;
begin
xw := (x div 16);
zw := (z div 16);
chunks[xw][zw].writeblock(x mod 16, y, z mod 16, block);
end;
```
Генерация мира, его сжатие и сохранение.
```
procedure TForm1.Button4Click(Sender: TObject);
var
x, y, z: integer;
xx, zz: integer;
image: tbitmap;
begin
for xx := 0 to 31 do
for zz := 0 to 31 do
begin
chunks[xx][zz] := tchunk.Create;
end;
image := tbitmap.Create;
image.LoadFromFile('image.bmp');
for x:=0 to 127 do
for y:=0 to 116 do
begin
if image.Canvas.Pixels[x,y]=clblack then
form1.writeworld(x,117-y,0,49);
if image.Canvas.Pixels[x,117-y]=clwhite then
form1.writeworld(x,y,0,80);
end;
form1.generatefile;
```
Результат:


Можно генерировать не только пиксельарт, но произвольные фигуры, все, что можно задать какой-либо формулой. Например, пол в виде синусоиды:

Проект можно скачать [тут](http://dl.dropbox.com/u/33756134/minegen_0.2.zip).
Known bugs:
* Невозможно сохранять изменения в сгенерированном регионе (возможно, из-за того, что пишется одинаковый timestamp, который не совпадает с временем последнего сохранения в level.dat, как разберусь с форматом последнего — попробую реализовать)
* Спавн лучше переставить с помощью McEdit, т.к вполне возможно, что после генерации он окажется в сотне блоков над землей, что чревато летальным исходом(тоже можно менять в level.dat)
* Нет генерации света, вместо этого освещены все блоки, даже под землей(Рассчет освещения — отдельная серьёзная задача, пока не готов ее решать)
ToDo:
* **Починить сохранение, т.к без этого теряется половина смысла**
* Сделать поддержку записи дополнительной инфы(цвет шерсти, листвы, ориентация печек, etc) // частично готово
* Какое-то подобие ландшафта(холмы/дома/озера)
**Update:**
* Доработал `generatefile`, сделал нормальный разворот
* Форматирование кода
* Наброски a`dditional block data`, см. в проекте, ссылка обновлена
Ссылки:
* [Описание формата карт](http://www.minecraftwiki.net/wiki/Beta_Level_Format)
* [ID блоков для функции writeblock/writeworld](http://www.minecraftwiki.net/wiki/Data_values)
* [Zlib для Delphi](http://www.base2ti.com/) | https://habr.com/ru/post/125621/ | null | ru | null |
# Excel как транслятор в ассемблер AVR
Предпосылки
-----------
Ряд статей ([раз](https://habr.com/ru/post/345320/), [два](https://habr.com/ru/post/80893/), [три](https://habr.com/ru/post/246975/)) навел на мысли о том, что Excel можно использовать как транслятор в ассемблерный код AVR.
Сопоставим Excel с основными фичами «обычного» редактора кода. Список самых популярных фич следующий:
| Фича редактора кода | Как реализовать в Excel | Как реализовано в Atmel Studio |
| --- | --- | --- |
| Подсветка синтаксиса | Условное форматирование ячеек в зависимости от содержания | Подсветка команд |
| Автодополнение | Пользовательские функции VBA;
Именованные диапазоны;
Ячейка как миниконсоль с макросом на cобытие Change; | Нет |
| Отступы | Вручную переход в соседний столбец | Вручную |
| Проверка правильности расстановки скобок | Есть встроенный контроль | Только при сборке |
| Контекстная помощь по коду | Нет | Есть список имен меток |
| Сворачивание блока кода | Функция группировки столбцов и строк | Нет |
| Статический анализатор | На ходу показывает ошибки в ссылках | Нет |
Выглядит приемлемо. Кое-что достается «даром», кое-что надо доработать.
Но главное отличие табличного процессора от текстового – пользователь может размещать блок информации в произвольном месте пространства, а не только друг под другом. Эту особенность мы используем, чтобы превратить плоский код в почти полноценную блок-схему.
Первоначальные соглашения
-------------------------
[Общий подход и терминологию примем отсюда.](https://habr.com/ru/post/345320/)
Весь алгоритм разделим на ветки. Ветка играет роль самостоятельного программного блока.
У каждой ветки есть имя, которое является точкой входа в нее. Оно должно быть уникальным и осмысленным. Все имена веток размещаются в верхней строке, которую так и назовем – «строка имен».
Ветка заканчивается одним или несколькими переходами к другим веткам. Переходы от одной ветки к другой размещаются в самой нижней строке. Назовем ее «строка переходов».
Также принимаем правило, что изнутри одной ветки нельзя переходить внутрь другой.
**Общая схема алгоритма**
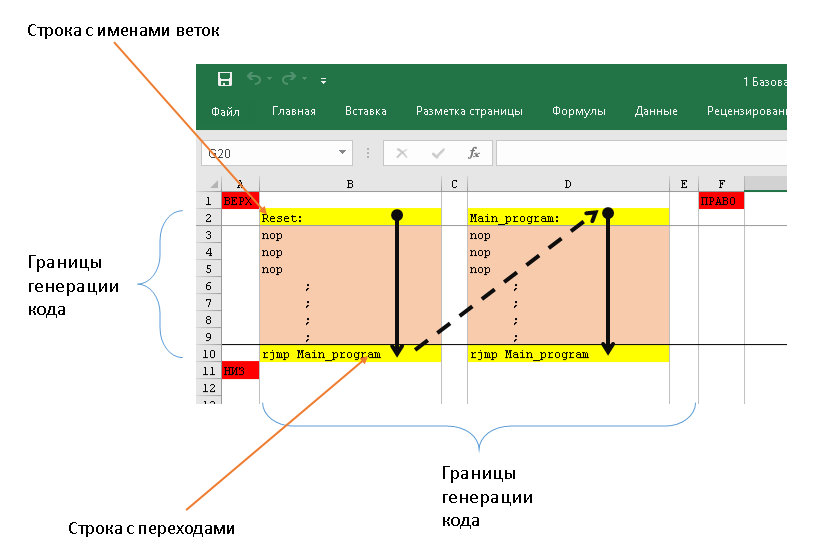
Для ветвлений и циклов внутри ветки также применяются метки. То есть меток в программе очень много. Каждый раз придумывать новое уникальное имя – это рутина. Здесь на помощь приходит базовая функциональность Excel. Каждая ячейка уже имеет уникальное имя, состоящее из имени столбца и номера строки.
На VBA создадим функцию **label** с аргументом типа **Range**. Метка в ассемблере AVR должна иметь на конце двоеточие. Т.е. наша функция **label**получает на вход ссылку на ячейку, в которой размещается сама и вычисляет ее адрес в формате A1. Затем добавляет к ней текст «\_M:». Фрагмент «\_M» не случаен, мы будем использовать это дальше – в форматировании ячеек.
Визуализация переходов
----------------------
В настоящих визуальных средах переходы обозначаются стрелками. Это удобно и наглядно.
В табличном процессоре вместо стрелочек можно подкрашивать ячейки, образующие путь к метке от команды перехода. В примерах так и сделано.
Если получается уместить весь код ветки на один экран, то можно не отрисовывать маршруты. Все команды перехода и метки будут перед глазами.
Для блок-схем существуют стандарты на обозначения отдельных элементов. Например, прямоугольник – это вычисление; ромб – условие и т.д. При работе с табличным процессором нам доступны управление цветом, начертанием и границами.
В Excel есть удобная функция условного форматирования. Использовать ее можно по-разному, но мы введем всего три простых правила:
1. Непустая ячейка в строке имен и в строке переходов красится в желтый цвет;
2. Непустая ячейка в теле ветки красится в оранжевый;
3. Ячейки с «локальными» метками и командами перехода красятся в синий. Это непустая ячейка, которая содержит символы «\_М», о которых упоминалось выше.
На гифке ниже представлено, как работа с метками и переходами выглядит после всех настроек.
**Работа с метками и командами перехода**
Порядок формирования конечного листинга
---------------------------------------
Сборщик листинга обходит итоговую программу сверху вниз и слева направо. По одной ячейке за раз.
**Как формируется конечный листинг**
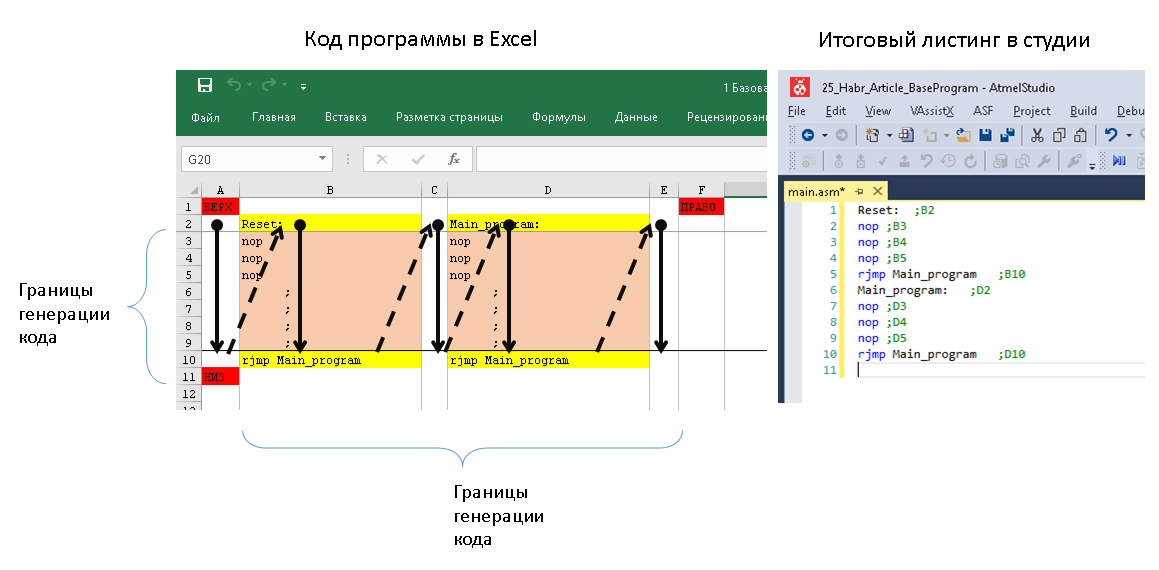
Алгоритм сборки пропускает пустые ячейки и ячейки, которые содержат символ «;», т.е. комментарии.
Отладка алгоритма и окончательная сборка проекта происходит в студии. Обратная связь кода в студии с ячейками Excel отсутствует. Поэтому для ловли ошибок в итоговый листинг напротив каждой команды указываем ссылку на ячейку. По этой ссылке мы находим проблемную команду на схеме в Excel.
Ветвление
---------
Базовое алгоритмическое решение – это ветвление вида:
```
If <условие> then
<действие>
Else
<действие>
End if
```
Для него в ассемблере AVR есть команды условного перехода (breq, brne, sbic и прочие). Эти команды указывают программе, куда перейти при выполнении условия.
Теперь представим, как должна выглядеть программа такого ветвления с учетом озвученных выше принципов:
**Простое ветвление**

У команды **brne** и ее аналогов есть ограничение. Дальность перехода составляет 64 слова в каждую сторону. Поэтому длинный макрос, вставленный в ответвление «Нет» может вызвать out of range.
Для обхода этого ограничения обработку «Нет» производить в отдельной ветке, которая будет правее метки перехода от **brne**. Либо использовать подпрограмму, в которой вызывается макрос.
Select Case
-----------
Если выбирать приходится из большого количества вариантов, в ЯВУ используется Select Case:
```
Select Case <переменная>
Case <условие1>
Case <условие2>
Case <условие3>
Case else
End select
```
На ассемблере под AVR доступны индексные переходы. Покажем вариант реализации.
**Select Case**
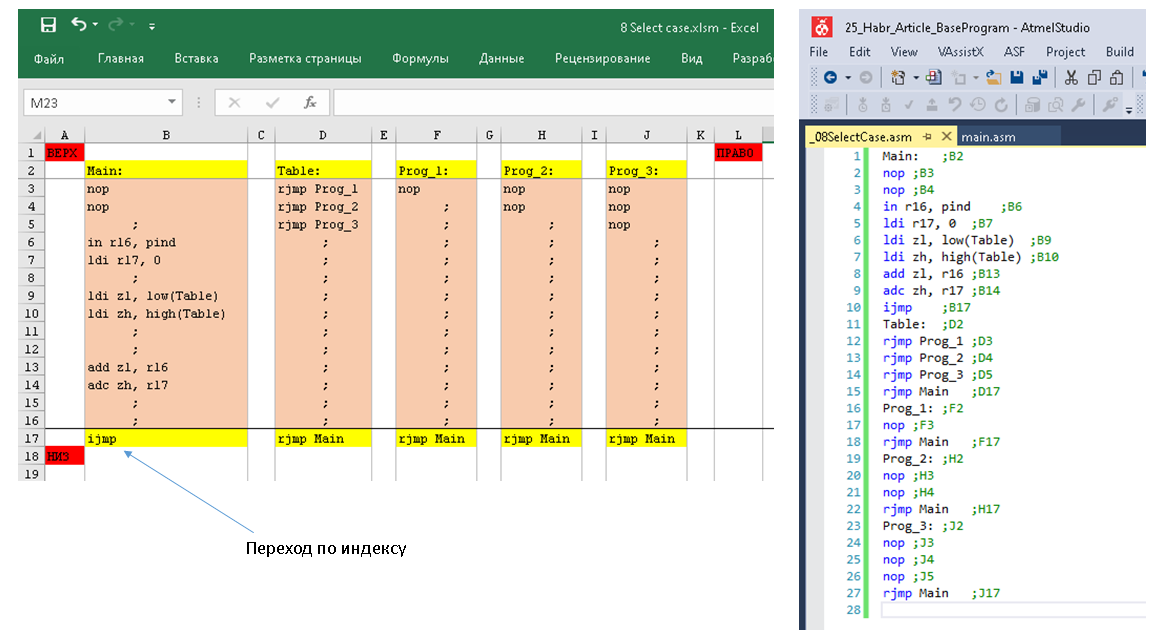
Здесь видно, что нарушен запрет прыжка из тела ветки к другой ветке. Это сделано преднамеренно, иначе программа займет слишком много места по горизонтали.
По этой же причине вектор прерываний следует выполнить в один столбик.
Цикл с постусловием
-------------------
Цикл, когда необходимо минимум одно повторение, в нотации ЯВУ выглядит следующим образом:
```
Do
<действие>
Loop while <условие>
```
Пример, как это выглядит в Excel и итоговый код в студии:
**Цикл с постусловием**
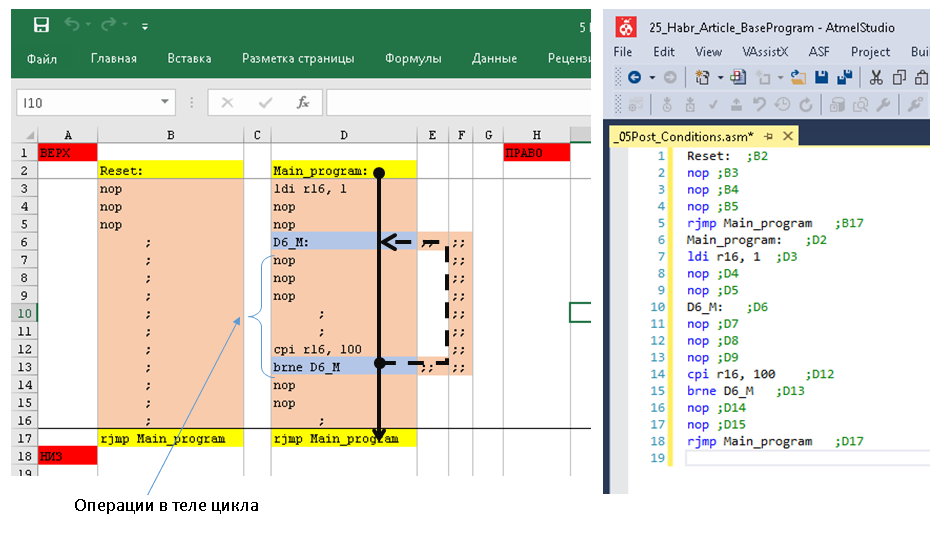
Цикл с предусловием
-------------------
Пример на ЯВУ:
```
Do while <условие>
<Действие>
Loop
```
Пример, как это выглядит в Excel и итоговый код в студии:
**Цикл с предусловием**
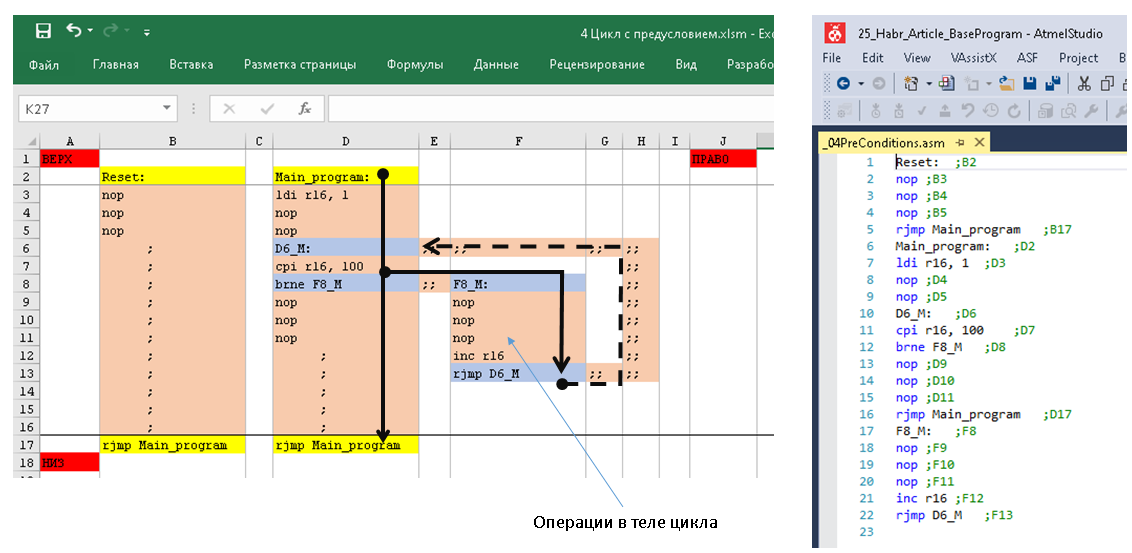
Цикл со вложенным циклом
------------------------
Обработка массивов или работа с числами предполагает использование вложенных циклов.
Общий вид на ЯВУ:
```
Do
Do
<действие>
Loop while <условие 2-го уровня>
<действие>
Loop while <условие 1-го уровня>
```
Реализовать вложенный цикл можно двумя путями: либо внутри одной ветки, либо с помощью нескольких веток. Покажем оба варианта.
**Вложенные циклы внутри одной ветки**
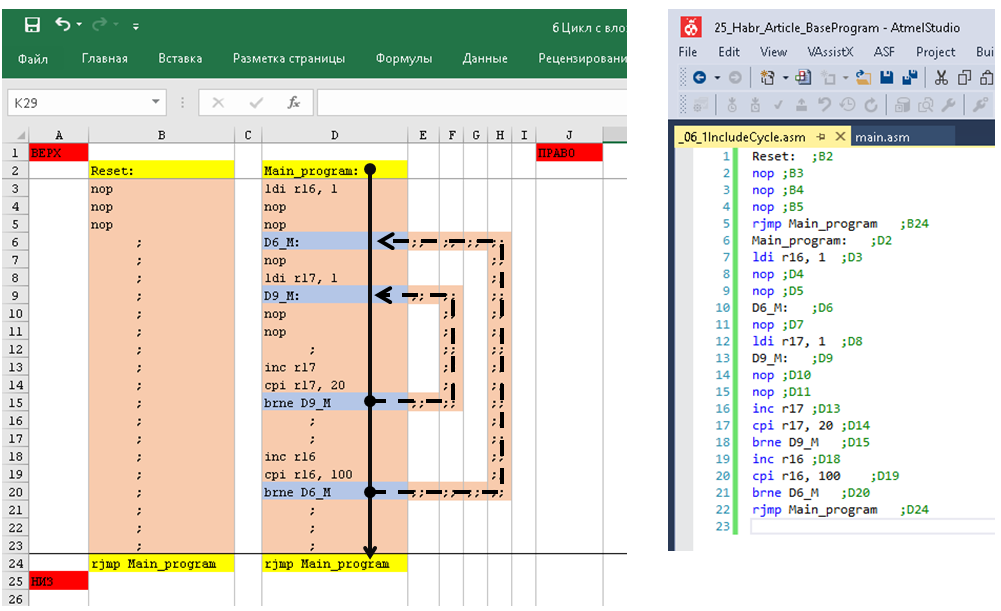
**Вложенные циклы с реализацией через ветки**
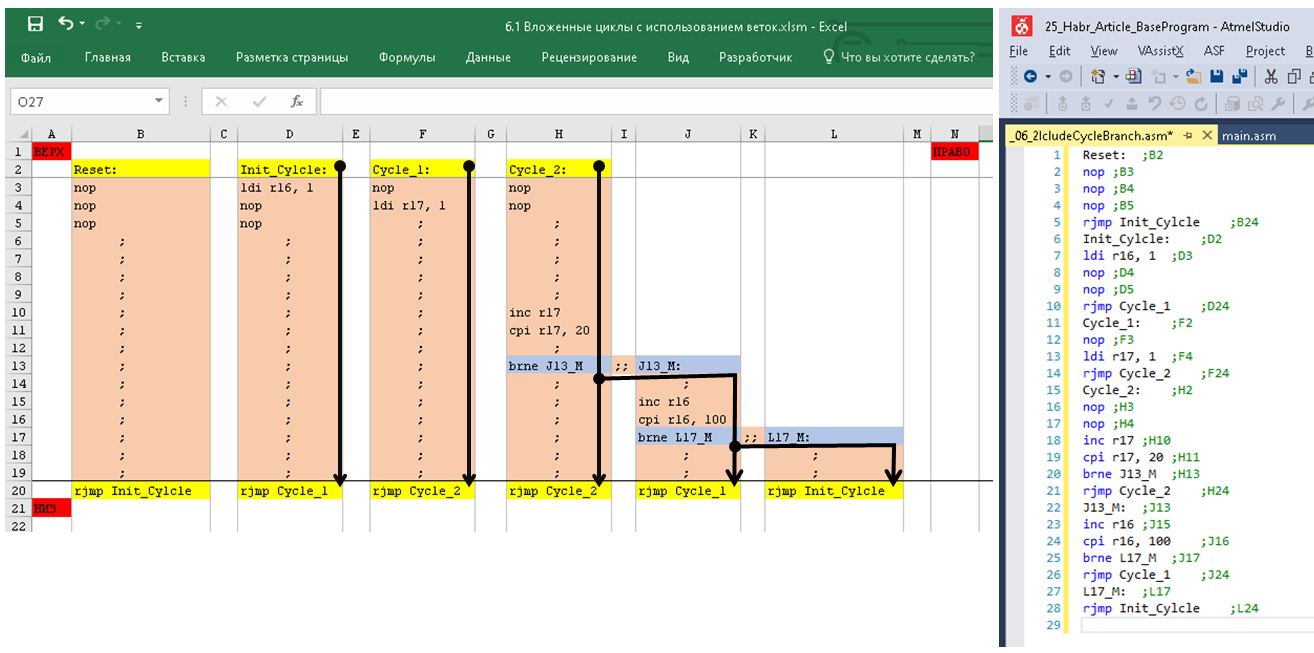
Цикл с выходом по условию
-------------------------
Есть ситуации, когда из цикла необходимо выйти до его окончания. Например, логический ноль на 0-вой ножке **порта D** может говорить о какой-то неисправности. Программа должна покинуть основной цикл и запустить тревогу.
В ЯВУ используется команда **break**, а общий алгоритм имеет следующий вид:
```
Do
<действие>
If <условие прерывания> then break
Loop while <условие>
```
Снова покажем, как будет выглядеть алгоритм без веток и с ветками.
**Прерывание цикла внутри одной ветки**
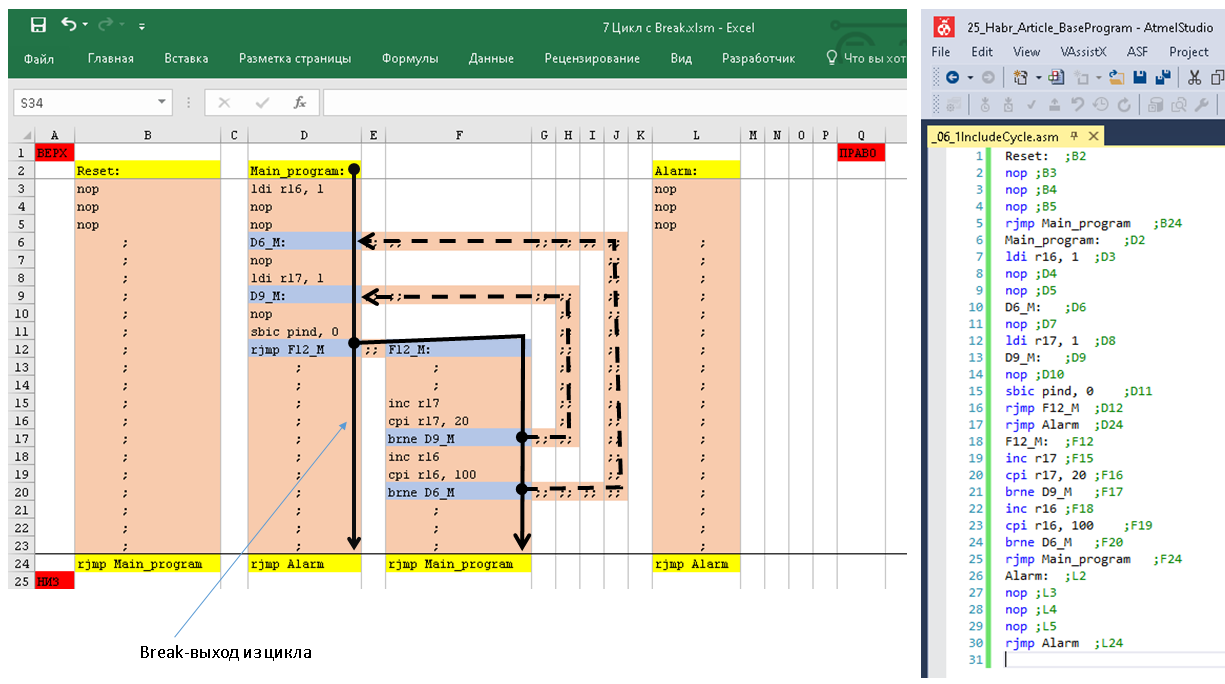
**Прерывание цикла, реализованного через ветки**
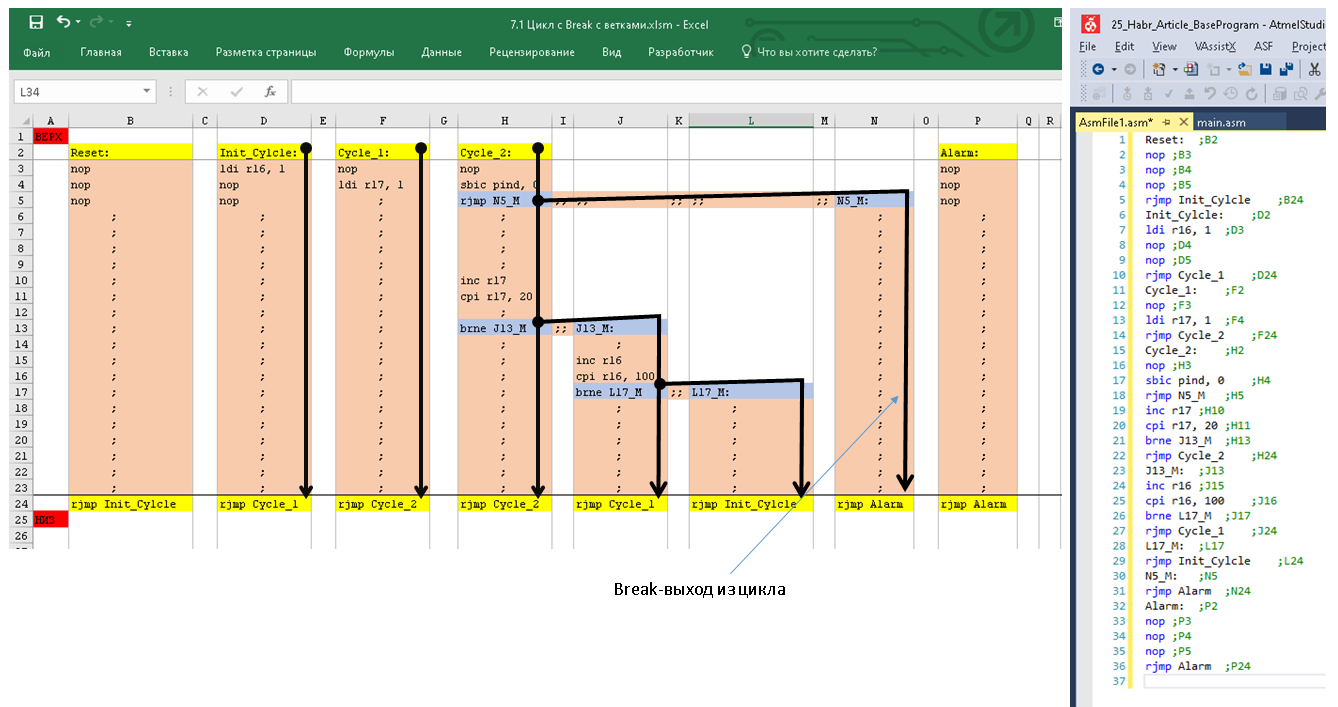
Вызов подпрограмм
-----------------
Подпрограммы вызываются командами **call**, **icall**, **rcall**. Тут есть важная особенность. Подпрограмму необходимо вызывать строго из тела ветки. Если же вызов разместить в строке переходов, возврат из подпрограммы почти гарантированно произойдет в неверное место.
Обязательные требования к подпрограмме:
* сама подпрограмма обязательно начинается с имени-метки;
* последняя команда подпрограммы обязательно должна быть **ret** и размещаться в строке переходов.
Внутренняя структура подпрограммы может быть произвольной – применяем все те же автоматические метки **label** для реализации логики.
Пример с бегущим огоньком
-------------------------
Приведем код тестовой программы с бегущим огоньком. Пример включает циклы, ветвления и вызов подпрограммы.
Конечный результат выглядит так:
**Схема бегущего огонька**
Листинг всей программы в Excel со скрипом уместился на один экран:
**Бегущий огонек. Код в Excel**

**Бегущий огонек. Итоговый листинг**
Итоги
-----
### Что не понравилось
1. Изложенный метод вряд ли подойдет для работы над большим проектом с участием целой команды. Контроль версий, диффы и т.д. все равно придется решать на стороне.
2. В режиме отладки очень неудобно без двух мониторов. Сама отладка ведется в студии, а блок-схема в Excel. Это разные окна, требуются переключения.
3. Программа быстро пухнет в горизонтальном направлении. При этом в Excel прокрутка в сторону грубая и неудобная.
4. Болезнь блок-схема как таковых – много пустого места. Для комфортной работы на одном экране разрешением 1280х1024 должно быть около 5 столбиков и 45 строк с информативными ячейками. Не более 20% от этого количества будет заполнено самими командами (это 45 команд). Остальное пространство – жертва визуальному представлению и комментариям. Примерно столько же команд помещается в окно студии на один экран.
### Что понравилось
1. Проектирование алгоритма «сверху вниз» складывается очень естественно. Объявляем только имена и переходы.
2. Код в Excel можно открыть в несколько окон. В Atmel Studio доступно только разделение экрана по горизонтали.
3. Сокращение рутинных действий при работе с именованными сущностями.
4. Контроль меток не требует внимания. Переместили или переименовали метку – все переходы автоматически получат изменения. Удаление метки приведет к ошибке, которую легко найти визуально.
5. Excel как транслятор очень просто расширять новыми функциями. Что-то доступно через формулы, что-то – через макросы VBA.
### Точки роста
1. Оптимизация работы с метками и переходами. Если в итоговом листинге команда «Переход на метку» расположена прямо над самой меткой, команду с переходом можно убрать. Освободим 4-5 тактов. Если конструкция вида «Переход на метку А – Метка А – Переход на метку Б – Метка Б» не содержит внутри никаких команд, то «Переход на метку Б» убираем, а «Переход на метку А» меняем на «Переход на метку Б». Также сэкономим 4-5 тактов.
2. Дополнительные проверки на ошибки. Макросом легко организовать проверку, нет ли «висящих» блоков, которые не кончаются переходами. Также макросом можем найти и удалить неиспользованные метки, которые при отладке отвлекают внимание.
3. Можно ввести собственные правила раскрашивания ячеек.
4. Если бы табличный процессор был встроен в студию как редактор кода, то производить отладку сразу на такой блок-схеме было бы очень удобно. | https://habr.com/ru/post/526838/ | null | ru | null |
# Flame-графики: «огонь» из всех движков
> ***Всем снова привет!*** *Приглашаем на* [*онлайн-встречу с Василием Кудрявцевым*](https://otus.pw/T1iB/) *(директором департамента обеспечения качества в АО «РТЛабс»), которая пройдёт в рамках курса «Нагрузочное тестирование». И публикуем перевод статьи Michael Hunger — software developer and editor of Neo4j Developer Blog and GRANDstack!*
>
>
Стандартные профайлеры Java используют либо инструментарий байткода, либо сэмплинг (рассматривая трассировки стека через короткие промежутки времени), чтобы определить, где было потрачено время. В обоих подходах есть свои недостатки и странности. Понимание результатов работы таких профайлеров само по себе искусство и требует большого опыта.
К счастью, [Брендан Грегг](https://twitter.com/brendangregg), инженер по производительности в Netflix, придумал [flame-графики](http://www.brendangregg.com/flamegraphs.html), гениального вида диаграммы для трассировки стека, которые можно собрать практически из любой системы.
Flame-график сортирует и агрегирует трассировки на каждом уровне стека, таким образом их количество отражает процент от общего времени, затраченного в этой части кода. Визуализация этих блоков в виде прямоугольников с шириной, пропорциональной проценту от общего времени работы и укладка их друг на друга оказалась крайне полезной визуализацией. (Обратите внимание на то, что порядок слева направо не имеет принципиального значения, часто это просто сортировка по алфавиту. То же самое и с цветами. Значение имеют только относительная ширина и глубина стека)
Flame-график бенчмарка заполнения непредаллоцированного ArrayListFlame'ы снизу вверх отражают прогрессию от точки входа программы или потока (`main` или цикл событий) до листьев выполнения на концах flame'ов.
Вы сразу увидите, если некоторые части программы будут занимать неожиданно большое количество времени. Чем выше на диаграмме вы это видите, тем хуже. А если у вас есть очень широкий flame сверху, то вы точно нашли узкое место, где работа не делегируется куда-либо еще. После устранения проблемы, измерьте время работы еще раз, если проблема с производительностью сохранится, вернитесь к диаграмме, чтобы понять, где осталась проблема.
Для устранения недостатков стандартных профайлеров многие современные инструменты используют внутреннюю функцию JVM (`AsyncGetCallTrace`), которая позволяет собирать трассировки стека независимо от безопасных точек. Помимо этого, они объединяют измерение JVM-операций с нативным кодом и системных вызовов операционной системы, так что время, проведенное в сети, ввод/вывод или сборка мусора, также может стать частью flame-графа.
Такие инструменты, как Honest Profiler, perf-map-agent, async-profiler или даже IntelliJ IDEA, умеют захватывать информацию и с легкостью делать flame-графики.
В большинстве случаев вы просто скачиваете инструмент, предоставляете PID вашего Java-процесса и говорите инструменту работать в течение определенного периода времени и генерировать интерактивный SVG.
```
# download and unzip async profiler for your OS from:
# https://github.com/jvm-profiling-tools/async-profiler
./profiler.sh -d -f flamegraph.svg -s -o svg && \
open flamegraph.svg -a "Google Chrome"
```
SVG, создаваемый этими инструментами, не просто красочный, но и интерактивный. Вы можете увеличивать секции, искать посимвольно и т.д.
Flame-графики — впечатляющий и мощный инструмент для быстрого обзора характеристик производительности ваших программ. С ними вы можете сразу увидеть проблемные места и сосредоточиться на них, а обзор аспектов, не связанных с JVM, помогает получить более полную картину.
---
***Интересно развиваться в данном направлении?*** *Запишитесь на бесплатный Demo-урок* [*«Скрипты и сценарии нагрузочного тестирования- Performance center (PC) и Vugen»*](https://otus.pw/T6KA/)*!* | https://habr.com/ru/post/523148/ | null | ru | null |
# Пишем голосовое IVR меню на языке TCL, с использованием Cisco IVR API
Сегодня речь о голосовом меню (**IVR**) для маршрутизаторов Cisco, которое мы будем писать на языке TCL, и подключать на Cisco 3845.
Итак, для начала давайте разберемся в азах
==========================================
Cisco начиная с версии **IOS** 12 поддерживает как **VXML** так и **TCL** скрипты для работы с голосовым меню. Однако, в отличии от **VXML**, скрипты на **TCL** имеют гораздо больше возможностей взаимодействия с **Cisco IVR API**. Так же существует возможность подключать гибридные **IVR** скрипты, со встроенными кусками **VXML** кода внутри **TCL** скрипта.
Все документы, связанные с IVR от Cisco, которые мне довелось получить можно скачать [здесь](https://cloud.mail.ru/public/FFBy/ZEujVorKp).
### FSM
Первое это **FSM** переходы.
Finite-State Machines — абстрактный автомат, число возможных внутренних состояний которого конечно.
Выглядит это примерно так:
```
set ivr_fsm(CALLCOMES,ev_setup_indication) "act_Setup same_state"
```
Переходов таких может быть сколько угодно, и расположены они в конце **TCL** скрипта.
Давайте разберемся, что это вообще такое.
Общий синтаксис этой команды таков:
```
set array(CURRSTATE, curr_event) “act_proc NEXTSTATE”
```
где:
**array** – это имя ***FSM*** массива.
**CURRSTATE** – имя текущего состояния, при котором получено событие ***curr\_event***.
**act\_proc** – имя функции, которую необходимо выполнить при поступлении события ***curr\_event***.
**NEXTSTATE** – имя состояния, которое установится после выполнения ***act\_proc***.
Другими словами, **FSM** это маркер, по которому Cisco сравнивает полученное от API событие с **curr\_event** и текущий статус с **CURRSTATE**, если в каком либо FSM переходе они описаны, вызывается процедура **act\_proc** и состояние изменяется на **NEXTSTATE**.
Самое главное в этом — это то, что текущее событие и состояние сравниваются со всеми описанными **FSM** переходами **одновременно**. Т.е. для Cisco не имеет значения порядок, в котором расположены FSM переходы, все они обрабатываются асинхронно.
### Функции
Второй момент, это сами функции, которые должны быть описаны до инициализации скрипта.
Назначение всех команд и состояний подробно описано в файле tcl\_ivr\_2.0\_programming\_guide, который вы можете скачать [здесь](https://cloud.mail.ru/public/FFBy/ZEujVorKp), я поподробнее остановлюсь только на тех, которые буду использовать непосредственно в скрипте
1) Инициализация скрипта
========================
Начало любого TCL IVR скрипта содержит процедуру ***init***, в моем примере эта функция выглядит так:
```
proc init { } {
puts "\n proc Init start"
global param
}
```
Здесь по сути выполняется вывод на экран командой ***puts "..."*** и определение глобальной переменной ***param***
Инициализация скрипта происходит после описания всех функций, и начинается с запуска функции ***init***. На этом простые вещи закончились, дальше все гораздо интереснее.
Последней исполняемой строкой скрипта должна быть строка определения стартового **FSM** перехода и стартового состояния. В нашем случае это:
```
fsm define ivr_fsm CALLCOMES
```
Это значит, что имя **FSM** массива задано как **ivr\_fsm**, и стартовое состояние **CALLCOMES**. С инициализацией закончим, дальше будет понятнее, что происходит (я надеюсь).
2) Приветствие
==============
```
proc Play_Welcome { } {
puts "\n\n IVR - proc Play_Welcome start \n\n"
global playng_files
global param
global pattern
global numbers
global workingtime
#Вызываем процедуру, где описаны все переменные
init_perCallVars
#Получаем время
GetDate
#В зависимости рабочее сейчас время или нет, устанавливаем приветствие
if {$workingtime} {
set after_welcome $playng_files(takenumber)
} else {
set after_welcome $playng_files(noworking)
}
#Устанавливаем параметры подключения входящего вызова
set param(interruptPrompt) true
set param(abortKey) *
set param(terminationKey) #
#Подключаем входящий вызов
leg setupack leg_incoming
leg proceeding leg_incoming
leg connect leg_incoming
#Запускаем процедуру сбора нажатых цифр со стороны звонящего
leg collectdigits leg_incoming param pattern
#Запускаем проигрыш файлов звонящему абоненту, после их окончания
#начнет действовать таймер param(interDigitTimeout), по истечении которого
#Произойдет событие ev_collectdigits_done
media play leg_incoming %s500 $playng_files(welcome) $after_welcome $playng_files(onhold)
#Запускаем таймер, по истечении которого произойдет событие ev_named_timer
timer start named_timer $numbers(waiting_time) t1
}
```
Здесь довольно подробно все описано.
Результатом выполнения данной процедуры будет подключение входящей линии к Cisco за счет команд ***leg setupack, leg proceeding, leg connect,*** и проигрыш музыкальных файлов по очереди во входящую линию за счет команды ***media play leg\_incoming***.
Тут же запускается процесс сбора нажатых клавиш ***leg collectdigit*** и таймер командой ***timer start***.
И проверяется рабочее сейчас время или нет, вызывая функцию ***GetDate***:
```
proc GetDate { } {
global workingtime
#Час
set houris [clock format [clock seconds] -format %H]
#День недели
set dayis [clock format [clock seconds] -format %A]
#Проверяем рабочее время
if {$houris > 17 || $houris < 8 || $dayis=="Sunday" || $dayis=="Saturday"} {
set workingtime 0
} else {
set workingtime 1
}
}
```
В зависимости от того рабочее время или нет мы меняем музыкальный файл, который будет проигран звонящему абоненту.
Так как стартовое состояние задано в нашем случае как ***fsm define ivr\_fsm CALLCOMES***, в него попадают сразу 3 **FSM**:
```
set ivr_fsm(CALLCOMES,ev_setup_indication) "Play_Welcome, same_state"
set ivr_fsm(CALLCOMES,ev_collectdigits_done) "CheckDestanation, same_state"
set ivr_fsm(CALLCOMES,ev_named_timer) "GoToReception, same_state"
```
Событие ***ev\_setup\_indication*** произойдет при поступлении звонка, и будет запущена процедура ***Play\_Welcome***, в которой описан старт процесса сбора нажатых цифр и старт таймера.
После окончания проигрывания музыки абоненту, начнется обратный отчет таймера, который задается параметром ***param(initialDigitTimeout)*** (который можно было задать чуть выше строкой ***set param(initialDigitTimeout) 15*** и установить значение 15 секунд), т.к. он у нас не указан, его стандартное значение 10 секунд, после чего скрипт получит событие ***ev\_collectdigits\_done***, при наступлении которого, как мы описали в **FSM** переходе, будет выполнена функция ***CheckDestanation***.
Таймер, запущенный в ***Play\_Welcome*** командой:
```
#Тип таймера named_timer, длительность, взята из переменной numbers(waiting_time), имя таймера t1
timer start named_timer $numbers(waiting_time) t1
```
После своего окончания сгенерирует событие ***ev\_named\_timer***, которое будет обработано следующим **FSM** переходом:
```
set ivr_fsm(CALLCOMES,ev_named_timer) "GoToReception, same_state"
```
и вызовется процедура ***GoToReception***.
3) Проверка введенного номера
=============================
```
proc CheckDestanation { } {
puts "\n\n IVR - proc CheckDestanation start \n\n"
global playng_files
global numbers
global digit
#Останавливаем проигрыш медиа
media stop leg_incoming
#Определяем значение переменным
set status [infotag get evt_status]
set digit [infotag get evt_dcdigits]
#Сравниваем полученные цифры и статусы
#Если введенная цифра соответствует той, что задана в $numbers(fast_reception),
#изменяем digit на номер ресепшн и передаем $digit в функцию CheckCallersAndConnect,
# предварительно изменив статус на CALLCONNECTED,
# благодаря которому, при наступлении события ev_setup_done (подключение к номеру секретаря)
# будет отработана процедура CallIsConnect
if {$digit == $numbers(fast_reception)} {
puts "\n\n IVR - proc CheckDestanation digit = $digit\nGoing to next reception \n\n"
fsm setstate CALLCONNECTED
set digit $numbers(reception)
#Передаем $digit в функцию CheckCallersAndConnect
CheckCallersAndConnect $digit
#Если введенная цифра соответствует той, что задана в $numbers(fast_ckp), подключаем на ЦКП
#через CheckCallersAndConnect
} elseif {$digit == $numbers(fast_ckp)} {
puts "\n\n IVR - proc CheckDestanation digit = $digit\nGoing to next CKP \n\n"
fsm setstate CALLCONNECTED
set digit $numbers(ckp)
#Передаем $digit в функцию CheckCallersAndConnect
CheckCallersAndConnect $digit
#Если введенная цифра соответствует той, что задана в $numbers(fast_fax), подключаем на факс
#через CheckCallersAndConnect
} elseif {$digit == $numbers(fast_fax)} {
puts "\n\n IVR - proc CheckDestanation digit = $digit\nGoing to next fax \n\n"
fsm setstate CALLCONNECTED
set digit $numbers(fax)
#Передаем $digit в функцию CheckCallersAndConnect
CheckCallersAndConnect $digit
#Если статус = cd_004 (введены корректные цифры номера) - подключаем к нужному номеру
#через CheckCallersAndConnect
} elseif {$status == "cd_004"} {
puts "\n\n IVR - proc CheckDestanation status = $status digit = $digit \n\n"
fsm setstate CALLCONNECTED
#Передаем $digit в функцию CheckCallersAndConnect
CheckCallersAndConnect $digit
#Если статус = cd_005 (совпадение с dial plan) - подключаем к нужному номеру
#через CheckCallersAndConnect
} elseif {$status == "cd_005"} {
puts "\n\n IVR - proc CheckDestanation status = $status digit = $digit \n\n"
fsm setstate CALLCONNECTED
#Передаем $digit в функцию CheckCallersAndConnect
CheckCallersAndConnect $digit
#Если статус = cd_006 (набран не существующий номер) - играем в линию $playng_files(noexist)
# и изменяем статус на TORECEPTION, при действии которого и наступлении события
#ev_media_done (конец проигрывания звукового файла) вызовется процедура Play_TakeNumber
} elseif {$status == "cd_006"} {
puts "\n\n IVR - proc CheckDestanation status = $status digit = $digit \n\n"
fsm setstate TRYAGAIN
media play leg_incoming $playng_files(noexist)
#Во всех остальных случаях изменяем статус на TORECEPTION, при действии которого
#и наступлении события ev_media_done (конец проигрывания звукового файла) вызовется
#процедура GoToReception
} else {
#Проигрываем "Ваш вызов переадресовывается на секретаря"
fsm setstate TORECEPTION
media play leg_incoming $playng_files(toreception)
puts "\n\n IVR - proc CheckDestanation status = $status \n\n"
}
}
```
В процедуре CheckDestanation, которая будет вызвана после набора номера звонящим абонентом, мы сравниваем полученные при наборе цифры с настройками и переводим скрипт в соответствующее состояние командой ***fsm setstate***.
Все состояния, попавшие в функцию, попадают под следующие FSM переходы:
```
set ivr_fsm(CALLCONNECTED,ev_setup_done) "CallIsConnect, same_state"
set ivr_fsm(TORECEPTION,ev_media_done) "GoToReception, same_state"
set ivr_fsm(TRYAGAIN,ev_media_done) "Play_TakeNumber, TRYING"
set ivr_fsm(TRYING,ev_collectdigits_done) "CheckDestanation, same_state"
set ivr_fsm(TRYING,ev_named_timer) "GoToReception, same_state"
```
Давайте по порядку.
1) Итак, изначально функция ***CheckDestanation*** вызывается после окончания процедуры сбора нажатия клавиш.
2) Информацию о нажатых клавишах мы записываем в переменную digit с помощью команды set digit [infotag get evt\_dcdigits]
Аналогично записываем состояние линии в переменную status
3) Затем сравниваем полученные результаты с заданными переменными и изменяем состояние скрипта при совпадении:
```
if {$digit == $numbers(fast_reception)} {
puts "\n\n IVR - proc CheckDestanation digit = $digit\nGoing to next reception \n\n"
fsm setstate CALLCONNECTED
leg setup $numbers(reception) callinfo leg_incoming
}
```
4) Проверка номера звонящего абонента
=====================================
```
proc CheckCallersAndConnect {digit} {
puts "\n\n IVR - proc CheckCallersAndConnect start \n\n"
set callernumber [infotag get leg_ani]
switch $callernumber {
"9120000000" {set callInfo(displayInfo) "Director(mobile)"}
"9130000000" {set callInfo(displayInfo) "Buhgalter(mobile)"}
default {}
}
puts "\n\n IVR - caller is $callernumber connect with $digit\n\n"
leg setup $digit callInfo leg_incoming
}
```
Данная функция позволяет изменить поле, отвечающее за написание имени звонящего. Просто ради эстетики, будет приятнее, когда на телефоне будет написан не только номер но и ID абонента. После изменения ID абонента происходит подключение линии к требуемому номеру.
5) Подключение номера
=====================
```
proc CallIsConnect { } {
puts "\n\n IVR - proc CallIsConnect start \n\n"
global playng_files
#Определяем чему равен status
set status [infotag get evt_status]
#Если статус равен ls_000 (успешное соединение с требуемым номером), изменяем состояние на CALLACTIVE
if {$status == "ls_000"} {
fsm setstate CALLACTIVE
#Если статус равен ls_002 (никто не ответил на звонок), запускаем процедуру запроса номера
} elseif {$status == "ls_002"} {
fsm setstate TRYAGAIN
media play leg_incoming $playng_files(noanswer)
#Если статус - неверный номер, запускаем процедуру запроса номера
} elseif {$status == "ls_004" || $status == "ls_005" || $status == "ls_006"} {
fsm setstate TRYAGAIN
media play leg_incoming $playng_files(noexist)
#Если статус равен ls_007 (абонент занят), запускаем процедуру запроса номера
} elseif {$status == "ls_007"} {
fsm setstate TRYAGAIN
media play leg_incoming $playng_files(busy)
}
}
```
Данная функция вызывается следующим FSM переходом:
```
set ivr_fsm(CALLCONNECTED,ev_setup_done) "CallIsConnect, same_state"
```
Событие ***ev\_setup\_done*** наступает после подключения звонящего к требуемой линии.
6) Повторный запрос номера
==========================
```
proc Play_TakeNumber { } {
puts "\n\n IVR - proc Play_TakeNumber start \n\n"
global playng_files
global numbers
global param
global pattern
#Проверяем какой раз абонент пытается набрать номер
if {$numbers(cur_try) <= $numbers(max_try)} {
puts "\n\n IVR - proc Play_TakeNumber current try is: $numbers(cur_try) \n\n"
incr numbers(cur_try)
#Запускаем процедуру сбора нажатых цифр со стороны звонящего
leg collectdigits leg_incoming param pattern
#Запускаем проигрыш файлов
media play leg_incoming $playng_files(takenumber)
#Запускаем таймер, по истечении которого произойдет событие ev_named_timer
timer start named_timer $numbers(waiting_time) t1
#Если попытка больше чем $numbers(max_try) - разъединяем
} else {
fsm setstate CALLDISCONNECTED
media play leg_incoming $playng_files(callafter)
}
}
```
Данная функция проверяет какой раз ошибается звонящий, и если значение меньше чем ***$numbers(max\_try)*** просит ввести номер еще раз.
Данная функция вызывается следующими **FSM**:
```
set ivr_fsm(TRYAGAIN,ev_media_done) "Play_TakeNumber, TRYING"
set ivr_fsm(TRYING,ev_collectdigits_done) "CheckDestanation, same_state"
set ivr_fsm(TRYING,ev_named_timer) "GoToReception, same_state"
```
7) Разрыв соединения
====================
```
proc AbortCall { } {
puts "\n\n IVR - proc AbortCall start \n\n"
call close
}
```
Вызывается следующими **FSM**:
```
set ivr_fsm(any_state,ev_disconnected) "AbortCall, same_state"
set ivr_fsm(CALLACTIVE,ev_disconnected) "AbortCall, CALLDISCONNECTED"
set ivr_fsm(CALLDISCONNECTED,ev_disconnected) "AbortCall, same_state"
set ivr_fsm(CALLDISCONNECTED,ev_media_done) "AbortCall, same_state"
set ivr_fsm(CALLDISCONNECTED,ev_disconnect_done) "AbortCall, same_state"
```
8) Подключение скрипта
======================
Подключение на маршрутизаторе Cisco проходит в 2 этапа.
**Первое**, что нужно сделать это определить **application**:
```
application
service voicemunu flash:voicemenu.tcl
param allowed_pattern 5[5-7]..
param fastto_reception 1
param reception_number 5501
param fastto_ckp 2
param ckp_number 5604
param fastto_fax 3
param fax_number 5555
param waiting_time 20
param max_try 3
param file_noanswer flash:en_noanswer.au
param file_after flash:en_after.au
param file_noexist flash:en_noexist.au
param file_busy flash:en_busy.au
param file_welcome flash:en_welcome.au
param file_onhold flash:music-on-hold.au
param file_noworking flash:en_takenumber2.au
param file_takenumber flash:en_takenumber2.au
```
**Второе**, подключить ***service*** к ***dial-peer***:
```
dial-peer voice 200 pots
description -= ISP Beeline - INcoming call to number 3300100 =-
service voicemunu
incoming called-number 3300100
```
Таким образом, при поступлении звонка на номер 3300100, произойдет вызов нашего голосового меню ***voicemunu***.
9) Полная версия скрипта
========================
Выше были рассмотрены только основные функции скрипта, далее полный текст, имейте в виду, это практически самый простой вариант:
```
#######################################################
# Cisco IVR TCL script by Konovalov D.A. v.2
#######################################################
#
# Для дебага скрипта
# debug voip application script
# Более полный дебага (не рекомендуется, может привести к перегрузке)
# debug voip ivr
#
# Скрипт должен быть запущен со следующими параметрами:
# param allowed_pattern 5[5-7]..
# param fastto_reception 1
# param reception_number 5501
# param fastto_ckp 2
# param ckp_number 5604
# param fastto_fax 3
# param fax_number 5555
# param waiting_time 20
# param max_try 3
# param file_welcome flash:en_welcome.au
# param file_takenumber flash:en_takenumber.au
# param file_after flash:en_after.au
# param file_busy flash:en_busy.au
# param file_noexist flash:en_noexist.au
# param file_noanswer flash:en_noanswer.au
# param file_onhold flash:music-on-hold.au
# param file_noworking flash:music-on-hold.au
#Процедура инициализации скрипта
proc init { } {
puts "\n proc Init start"
global param
}
#Процедура с переменными
proc init_perCallVars { } {
global pattern
global numbers
global playng_files
#####Допустимая нумерация
#Если в параметрах скрипта не указана допустимая нумерация, будет установлено значение .... - 4 любых цифры
if {[infotag get cfg_avpair_exists allowed_pattern]} {
set pattern(1) [string trim [infotag get cfg_avpair allowed_pattern]]
puts "\n\n IVR - Allowed pattern set as: $pattern(1) \n\n"
} else {
set pattern(1) ....
puts "\n\n IVR - Allowed pattern set as DEFAULT: $pattern(1) \n\n"
}
#####Номера
#Секретарь. Если в параметрах скрипта не указан номер секретаря, номер будет установлен в 0000
if {[infotag get cfg_avpair_exists reception_number]} {
set numbers(reception) [string trim [infotag get cfg_avpair reception_number]]
puts "\n\n IVR - reception number set as: $numbers(reception) \n\n"
} else {
set numbers(reception) 0000
puts "\n\n IVR - reception number set as DEFAULT: $numbers(reception) \n\n"
}
#ЦКП
if {[infotag get cfg_avpair_exists ckp_number]} {
set numbers(ckp) [string trim [infotag get cfg_avpair ckp_number]]
puts "\n\n IVR - ckp number set as: $numbers(ckp) \n\n"
} else {
set numbers(ckp) 0000
puts "\n\n IVR - ckp number set as DEFAULT: $numbers(ckp) \n\n"
}
#Факс
if {[infotag get cfg_avpair_exists fax_number]} {
set numbers(fax) [string trim [infotag get cfg_avpair fax_number]]
puts "\n\n IVR - fax number set as: $numbers(fax) \n\n"
} else {
set numbers(fax) 0000
puts "\n\n IVR - fax number set as DEFAULT: $numbers(fax) \n\n"
}
#Быстрый перевод на Ресепшн
if {[infotag get cfg_avpair_exists fastto_reception]} {
set numbers(fast_reception) [string trim [infotag get cfg_avpair fastto_reception]]
puts "\n\n IVR - fast to reception set as: $numbers(fast_reception) \n\n"
} else {
set numbers(fast_reception) 1
puts "\n\n IVR - fast to reception set as DEFAULT: $numbers(fast_reception) \n\n"
}
#Быстрый перевод на ЦКП
if {[infotag get cfg_avpair_exists fastto_ckp]} {
set numbers(fast_ckp) [string trim [infotag get cfg_avpair fastto_ckp]]
puts "\n\n IVR - fast to ckp set as: $numbers(fast_ckp) \n\n"
} else {
set numbers(fast_ckp) 2
puts "\n\n IVR - fast to ckp set as DEFAULT: $numbers(fast_ckp) \n\n"
}
#Быстрый перевод на факс
if {[infotag get cfg_avpair_exists fastto_fax]} {
set numbers(fast_fax) [string trim [infotag get cfg_avpair fastto_fax]]
puts "\n\n IVR - fast to fax set as: $numbers(fast_fax) \n\n"
} else {
set numbers(fast_fax) 3
puts "\n\n IVR - fast to fax set as DEFAULT: $numbers(fast_fax) \n\n"
}
#Время ожидания введения номера (должно быть больше времени проигрыша всех файлов приветствия)
if {[infotag get cfg_avpair_exists waiting_time]} {
set numbers(waiting_time) [string trim [infotag get cfg_avpair waiting_time]]
puts "\n\n IVR - wait number set as: $numbers(waiting_time) \n\n"
} else {
set numbers(waiting_time) 10
puts "\n\n IVR - wait number set as DEFAULT: $numbers(waiting_time) \n\n"
}
#Количество попыток ввести правильный номер, прежде чем звонок будет переведен на секретаря
if {[infotag get cfg_avpair_exists max_try]} {
set numbers(max_try) [string trim [infotag get cfg_avpair max_try]]
puts "\n\n IVR - max try set as: $numbers(max_try) \n\n"
set numbers(cur_try) 0
} else {
set numbers(max_try) 5
puts "\n\n IVR - max try set as DEFAULT: $numbers(max_try) \n\n"
set numbers(cur_try) 0
}
#####Музыкальные файлы, которые будут проигрываться
#Файл приветствия
if {[infotag get cfg_avpair_exists file_welcome]} {
set playng_files(welcome) [string trim [infotag get cfg_avpair file_welcome]]
puts "\n\n IVR - file_welcome set as: $playng_files(welcome) \n\n"
} else {
#Если файл не найден, он будет заменен на тишину в 1мс
set playng_files(welcome) %s1
puts "\n\n IVR - file_welcome set as DEFAULT: $playng_files(welcome) \n\n"
}
#Файл запроса ввести требуемый номер
if {[infotag get cfg_avpair_exists file_takenumber]} {
set playng_files(takenumber) [string trim [infotag get cfg_avpair file_takenumber]]
puts "\n\n IVR - file_takenumber set as: $playng_files(takenumber) \n\n"
} else {
#Если файл не найден, он будет заменен на тишину в 1мс
set playng_files(takenumber) %s1
puts "\n\n IVR - file_takenumber set as DEFAULT: $playng_files(takenumber) \n\n"
}
#Файл "Пожалуйста перезвоните позднее"
if {[infotag get cfg_avpair_exists file_after]} {
set playng_files(callafter) [string trim [infotag get cfg_avpair file_after]]
puts "\n\n IVR - file_after set as: $playng_files(callafter) \n\n"
} else {
#Если файл не найден, он будет заменен на тишину в 1мс
set playng_files(callafter) %s1
puts "\n\n IVR - file_after set as DEFAULT: $playng_files(callafter) \n\n"
}
#Файл "Номер занят"
if {[infotag get cfg_avpair_exists file_busy]} {
set playng_files(busy) [string trim [infotag get cfg_avpair file_busy]]
puts "\n\n IVR - file_busy set as: $playng_files(busy) \n\n"
} else {
#Если файл не найден, он будет заменен на тишину в 1мс
set playng_files(busy) %s1
puts "\n\n IVR - file_busy set as DEFAULT: $playng_files(busy) \n\n"
}
#Файл "Номер не существует"
if {[infotag get cfg_avpair_exists file_noexist]} {
set playng_files(noexist) [string trim [infotag get cfg_avpair file_noexist]]
puts "\n\n IVR - file_noexist set as: $playng_files(noexist) \n\n"
} else {
#Если файл не найден, он будет заменен на тишину в 1мс
set playng_files(noexist) %s1
puts "\n\n IVR - file_noexist set as DEFAULT: $playng_files(noexist) \n\n"
}
#Файл "Соеденяю с секретарем/оператором"
if {[infotag get cfg_avpair_exists file_toreception]} {
set playng_files(toreception) [string trim [infotag get cfg_avpair file_toreception]]
puts "\n\n IVR - file_toreception set as: $playng_files(toreception) \n\n"
} else {
#Если файл не найден, он будет заменен на тишину в 1мс
set playng_files(toreception) %s1
puts "\n\n IVR - file_toreception set as DEFAULT: $playng_files(toreception) \n\n"
}
#Файл "Номер не отвечает, перезвоните позднее"
if {[infotag get cfg_avpair_exists file_noanswer]} {
set playng_files(noanswer) [string trim [infotag get cfg_avpair file_noanswer]]
puts "\n\n IVR - file_noanswer set as: $playng_files(noanswer) \n\n"
} else {
#Если файл не найден, он будет заменен на тишину в 1мс
set playng_files(noanswer) %s1
puts "\n\n IVR - file_noanswer set as DEFAULT: $playng_files(noanswer) \n\n"
}
#Файл музыки, которая будет проигрываться при ожидании
if {[infotag get cfg_avpair_exists file_onhold]} {
set playng_files(onhold) [string trim [infotag get cfg_avpair file_onhold]]
puts "\n\n IVR - file_onhold set as: $playng_files(onhold) \n\n"
} else {
#Если файл не найден, он будет заменен на тишину в 1мс
set playng_files(onhold) %s1
puts "\n\n IVR - file_onhold set as DEFAULT: $playng_files(onhold) \n\n"
}
#Файл музыки, которая будет проигрываться В нерабочее время
if {[infotag get cfg_avpair_exists file_noworking]} {
set playng_files(noworking) [string trim [infotag get cfg_avpair file_noworking]]
puts "\n\n IVR - file_noworking set as: $playng_files(noworking) \n\n"
} else {
#Если файл не найден, он будет заменен на тишину в 1мс
set playng_files(noworking) %s1
puts "\n\n IVR - file_noworking set as DEFAULT: $playng_files(noworking) \n\n"
}
}
proc GetDate { } {
global workingtime
#Час
set houris [clock format [clock seconds] -format %H]
#День недели
set dayis [clock format [clock seconds] -format %A]
#Проверяем рабочее время
if {$houris > 17 || $houris < 8 || $dayis=="Sunday" || $dayis=="Saturday"} {
set workingtime 0
} else {
set workingtime 1
}
}
#Процедура проигрыша приветствия
proc Play_Welcome { } {
puts "\n\n IVR - proc Play_Welcome start \n\n"
global playng_files
global param
global pattern
global numbers
global workingtime
#Вызываем процедуру, где описаны все переменные
init_perCallVars
#Получаем время
GetDate
#В зависимости рабочее сейчас время или нет, устанавливаем приветствие
if {$workingtime} {
set after_welcome $playng_files(takenumber)
} else {
set after_welcome $playng_files(noworking)
}
#Устанавливаем параметры подключения входящего вызова
set param(interruptPrompt) true
set param(abortKey) *
set param(terminationKey) #
#Подключаем входящий вызов
leg setupack leg_incoming
leg proceeding leg_incoming
leg connect leg_incoming
#Запускаем процедуру сбора нажатых цифр со стороны звонящего
leg collectdigits leg_incoming param pattern
#Запускаем проигрыш файлов звонящему абоненту, после их окончания начнет
#действовать таймер param(interDigitTimeout), по истечении которого
#будет событие ev_collectdigits_done
media play leg_incoming %s500 $playng_files(welcome) $after_welcome $playng_files(onhold)
#Запускаем таймер, по истечении которого произойдет событие ev_named_timer
timer start named_timer $numbers(waiting_time) t1
}
#Процедура запроса ввести номер
proc Play_TakeNumber { } {
puts "\n\n IVR - proc Play_TakeNumber start \n\n"
global playng_files
global numbers
global param
global pattern
#Проверяем какой раз абонент пытается набрать номер
if {$numbers(cur_try) <= $numbers(max_try)} {
puts "\n\n IVR - proc Play_TakeNumber current try is: $numbers(cur_try) \n\n"
incr numbers(cur_try)
#Запускаем процедуру сбора нажатых цифр со стороны звонящего
leg collectdigits leg_incoming param pattern
#Запускаем проигрыш файлов
media play leg_incoming $playng_files(takenumber)
#Запускаем таймер, по истечении которого произойдет событие ev_named_timer
timer start named_timer $numbers(waiting_time) t1
#Если попытка больше чем $numbers(max_try) - разъединяем
} else {
fsm setstate CALLDISCONNECTED
media play leg_incoming $playng_files(callafter)
}
}
#Процедура перевода звонка на секретаря
proc GoToReception { } {
puts "\n\n IVR - proc GoToReception start \n\n"
global numbers
#Останавливаем проигрыш медиа
media stop leg_incoming
#Меняем состояние
fsm setstate CALLCONNECTED
set digit $numbers(reception)
#Передаем $digit в функцию CheckCallersAndConnect
CheckCallersAndConnect $digit
}
#Здесь проверяем введенные или не введенные звонящим цифры
proc CheckDestanation { } {
puts "\n\n IVR - proc CheckDestanation start \n\n"
global playng_files
global numbers
global digit
#Останавливаем проигрыш медиа
media stop leg_incoming
#Определяем значение переменным
set status [infotag get evt_status]
set digit [infotag get evt_dcdigits]
#Сравниваем полученные цифры и статусы
#Если введенная цифра соответствует той, что задана в $numbers(fast_reception),
#изменяем digit на номер ресепшн и передаем $digit в функцию CheckCallersAndConnect,
# предварительно изменив статус на CALLCONNECTED,
# благодаря которому, при наступлении события ev_setup_done (подключение к номеру секретаря)
# будет отработана процедура CallIsConnect
if {$digit == $numbers(fast_reception)} {
puts "\n\n IVR - proc CheckDestanation digit = $digit\nGoing to next reception \n\n"
fsm setstate CALLCONNECTED
set digit $numbers(reception)
#Передаем $digit в функцию CheckCallersAndConnect
CheckCallersAndConnect $digit
#Если введенная цифра соответствует той, что задана в $numbers(fast_ckp), подключаем на ЦКП
#через CheckCallersAndConnect
} elseif {$digit == $numbers(fast_ckp)} {
puts "\n\n IVR - proc CheckDestanation digit = $digit\nGoing to next CKP \n\n"
fsm setstate CALLCONNECTED
set digit $numbers(ckp)
#Передаем $digit в функцию CheckCallersAndConnect
CheckCallersAndConnect $digit
#Если введенная цифра соответствует той, что задана в $numbers(fast_fax), подключаем на факс
#через CheckCallersAndConnect
} elseif {$digit == $numbers(fast_fax)} {
puts "\n\n IVR - proc CheckDestanation digit = $digit\nGoing to next fax \n\n"
fsm setstate CALLCONNECTED
set digit $numbers(fax)
#Передаем $digit в функцию CheckCallersAndConnect
CheckCallersAndConnect $digit
#Если статус = cd_004 (введены корректные цифры номера) - подключаем к нужному номеру
#через CheckCallersAndConnect
} elseif {$status == "cd_004"} {
puts "\n\n IVR - proc CheckDestanation status = $status digit = $digit \n\n"
fsm setstate CALLCONNECTED
#Передаем $digit в функцию CheckCallersAndConnect
CheckCallersAndConnect $digit
#Если статус = cd_005 (совпадение с dial plan) - подключаем к нужному номеру
#через CheckCallersAndConnect
} elseif {$status == "cd_005"} {
puts "\n\n IVR - proc CheckDestanation status = $status digit = $digit \n\n"
fsm setstate CALLCONNECTED
#Передаем $digit в функцию CheckCallersAndConnect
CheckCallersAndConnect $digit
#Если статус = cd_006 (набран не существующий номер) - играем в линию $playng_files(noexist)
#и изменяем статус на TRYAGAIN, при действии которого и наступлении события ev_media_done
#(конец проигрывания звукового файла) вызовется процедура Play_TakeNumber
} elseif {$status == "cd_006"} {
puts "\n\n IVR - proc CheckDestanation status = $status digit = $digit \n\n"
fsm setstate TRYAGAIN
media play leg_incoming $playng_files(noexist)
#Во всех остальных случаях изменяем статус на TORECEPTION, при действии которого и
#наступлении события ev_media_done (конец проигрывания звукового файла) вызовется процедура GoToReception
} else {
#Проигрываем "Ваш вызов переадресовывается на секретаря"
fsm setstate TORECEPTION
media play leg_incoming $playng_files(toreception)
puts "\n\n IVR - proc CheckDestanation status = $status \n\n"
}
}
#Проверяем звонящего, если совпадает, будем менять отображаемое имя
proc CheckCallersAndConnect {digit} {
puts "\n\n IVR - proc CheckCallersAndConnect start \n\n"
set callernumber [infotag get leg_ani]
switch $callernumber {
"9120000000" {set callInfo(displayInfo) "Director(mobile)"}
"9130000000" {set callInfo(displayInfo) "Buhgalter(mobile)"}
default {}
}
leg setup $digit callInfo leg_incoming
}
#Процедура проверки состоянии линии после подключения звонящего к требуемому номеру
proc CallIsConnect { } {
puts "\n\n IVR - proc CallIsConnect start \n\n"
global playng_files
#Определяем чему равен status
set status [infotag get evt_status]
#Если статус равен ls_000 (успешное соединение с требуемым номером), изменяем состояние на CALLACTIVE
if {$status == "ls_000"} {
fsm setstate CALLACTIVE
#Если статус равен ls_002 (никто не ответил на звонок), запускаем процедуру запроса номера
} elseif {$status == "ls_002"} {
fsm setstate TRYAGAIN
media play leg_incoming $playng_files(noanswer)
#Если статус - неверный номер, запускаем процедуру запроса номера
} elseif {$status == "ls_004" || $status == "ls_005" || $status == "ls_006"} {
fsm setstate TRYAGAIN
media play leg_incoming $playng_files(noexist)
#Если статус равен ls_007 (абонент занят), запускаем процедуру запроса номера
} elseif {$status == "ls_007"} {
fsm setstate TRYAGAIN
media play leg_incoming $playng_files(busy)
}
}
#Процедура прерывания звонка
proc AbortCall { } {
puts "\n\n IVR - proc AbortCall start \n\n"
call close
}
#Исполнение скрипта
init
#init_perCallVars
#Это набор состояний и возникающих при данных состояних событий
#По сути именно это и описывает работу скрипта
#Если в любом состоянии возникнет событие отключения ev_disconnected, вызвать AbortCall
set ivr_fsm(any_state,ev_disconnected) "AbortCall, same_state"
#Если в состоянии CALLCOMES возникнет событие ev_setup_indication (входящий вызов)
#запускается Play_Welcome, и состояние меняется на same_state (т.е. остается прежним)
set ivr_fsm(CALLCOMES,ev_setup_indication) "Play_Welcome, same_state"
#Если в состоянии CALLCOMES возникнет событие ev_collectdigits_done (закончен ввод цифр)
#запускается CheckDestanation, и состояние остается прежним
set ivr_fsm(CALLCOMES,ev_collectdigits_done) "CheckDestanation, same_state"
#Если в состоянии CALLCOMES возникнет событие ev_named_timer (закончился таймер ожидания ввода цифр)
#запускается GoToReception, и состояние остается прежним
set ivr_fsm(CALLCOMES,ev_named_timer) "GoToReception, same_state"
#Если в состоянии TORECEPTION возникнет событие ev_media_done (закончился проигрыш файла)
#запускается GoToReception, и состояние остается прежним
set ivr_fsm(TORECEPTION,ev_media_done) "GoToReception, same_state"
#Данные настройки описывают поведение скрипта при ошибке в номере
set ivr_fsm(TRYAGAIN,ev_media_done) "Play_TakeNumber, TRYING"
set ivr_fsm(TRYING,ev_collectdigits_done) "CheckDestanation, same_state"
set ivr_fsm(TRYING,ev_named_timer) "GoToReception, same_state"
#Если в состоянии CALLCONNECTED возникнет событие ev_setup_done
#(установлено/неустановлено соединение с требуемым номером) запускается CallIsConnect, и состояние остается прежним
set ivr_fsm(CALLCONNECTED,ev_setup_done) "CallIsConnect, same_state"
#Эти события отрабатывают отключение линии
set ivr_fsm(CALLACTIVE,ev_disconnected) "AbortCall, CALLDISCONNECTED"
set ivr_fsm(CALLDISCONNECTED,ev_disconnected) "AbortCall, same_state"
set ivr_fsm(CALLDISCONNECTED,ev_media_done) "AbortCall, same_state"
set ivr_fsm(CALLDISCONNECTED,ev_disconnect_done) "AbortCall, same_state"
fsm define ivr_fsm CALLCOMES
``` | https://habr.com/ru/post/265453/ | null | ru | null |
# Используем Raw Data в Google Analytics на практике
Мы долго считали, что стандартные инструменты Google Analytics – лучший способ получить полезную информацию. Временами приходилось сталкиваться с некоторыми ограничениями и весьма странными результатами, и казалось, этому нет конца и края, пока некоторые аналитики не открыли для себя Google Analytics 360 и механизмы экспорта необработанных данных в Google BigQuery.
Спустя всего несколько часов работы с более продвинутыми инструментами и SQL-запросами, мы смогли извлечь информацию, которую бы никогда не получили, используя только сводные отчеты Google Analytics. С того момента мы сосредоточились на изучении особенностей необработанных («сырых») данных и на том, какую практическую пользу из них могут извлечь специалисты в области веб-аналитики.
В этой статье есть ответы на следующие вопросы:
* В чем разница между необработанными и сводными данными?
* Какую пользу можно извлечь от использования необработанных данных?
* Как получить доступ к необработанным данным?
* Как использовать эти новые данные (практические примеры)?
### Чем отличаются raw и сводные данные в Google Analytics
Используя бесплатную версию сервиса Google Analytics, можно получать только сводные данные. То есть, полная информация о просмотрах для конкретного визита и события будет недоступна. Разумеется, отчет User Explorer содержит много полезной информации, которую могут использовать веб-аналитики. Однако на этот файл наложены определенные ограничения: он не масштабируется и недоступен для скачивания.
В большинстве случаев наличия лишь сводных данных достаточно для получения ответов на распространенные вопросы:
* Какая кампания приносит наибольшее число конверсий?
* Насколько распространенной является технология машинного обучения Feature X (растет ли число ее пользователей)?
* Откуда приходят посетители (основные источники трафика)?
* С каких устройств пользователи переходят на сайт?

Вам не нужно анализировать необработанные данные, чтобы получить ответы на вопросы выше. С этим легко справятся кастомизированные или настроенные по умолчанию инструменты для формирования отчетов в Google Analytics. Основная проблема сводных данных состоит в том, что они агрегированы. Вы сопоставляете множество типов пользовательских действий, за которыми может скрываться весьма полезная информация. Приведем пример с просмотрами нескольких страниц за один сеанс. Имеем два источника с шестью сеансами со следующим количеством просмотренных страниц за один сеанс:
* Источник А: 1, 1, 2, 2, 2, 10;
* Источник Б: 2, 2, 3, 3, 4, 4.
Методом статистического выброса можно определить, что источник А характеризует пользователя с меньшей степенью вовлеченности. Но если учитывать только усредненные данные, можно сделать вывод об одинаковой вовлеченности для обоих источников, так как число страниц совпадает (медиана может быть любой).
Почему стандартные отчеты Google Analytics не содержат этих данных? Основная причина заключается в вычислительных затратах. Предоставляя только выборочные сводные данные, отпадает необходимость в обработке миллионов строк, содержащихся в отчете. Поэтому бесплатная версия Google Analytics не содержит инструментов для выполнения расширенных вычислений на бесплатной основе.
Какую информацию можно извлечь из необработанных данных
-------------------------------------------------------
Понимая ограниченность сводных данных, пришло время узнать, как можно использовать необработанные данные. Рассмотрим несколько вариантов их применения.
### Длительность ивентов
Одно из ограничений, с которым сталкивается любой веб-аналитик, использующий стандартные инструменты Google Analytics – нельзя определить временной интервал между помещением товара в корзину и оформлением покупки, независимо от того, происходит это действие в рамках одного сеанса или нет. Разумеется, для этого можно использовать cookies и проводить собственные расчеты. Но это бессмысленно, тем более что Google Analytics уже проделали эту работу за нас.
Проведя анализ необработанных данных, можно легко определить точное время возникновения события для конкретного пользователя, провести сравнительный анализ с другим событием для этого же пользователя. Также можно агрегировать данные на свое усмотрение, получив среднее, медианное или процентильное распределение, или использовать другую продвинутую статистическую модель. Разве тот факт, что 20% пользователей выполняют целевое действие за 2 минуты, а 10% — в течение целой недели, не имеет никакого значения? С этими знаниями вы будете использовать различные подходы для взаимодействия с этими двумя категориями пользователей.
### Анализ объема аудитории
В отчетах как Google Analytics, так и Google Analytics 360 содержатся данные о сегментации посетителей на протяжении последних 90 дней. Зачастую для получения достоверных данных требуется проведение анализа на более длинных дистанциях (особенно это касается крупных компаний). На основе анализа необработанных данных можно получать ответы на следующие вопросы:
1. Выше ли вероятность того, что пользователи, привлеченные в сезон праздников, будут приобретать продукт в сентябре, чем вероятность совершения покупки другими категориями пользователей в этом же месяце?
2. Каков эффект от просмотра видеороликов на протяжении года и как это отражается на количестве конверсий?
Используя необработанные данные, вы сможете хранить логи событий на протяжении неограниченного времени и удалять их только тогда, когда эти данные уже безнадежно устареют.
### Взаимосвязи между данными
Коэффициент корреляции вводят для определения статистической взаимосвязи между двумя переменными значениями. При анализе больших объемов данных можно определять взаимоотношения между двумя типами поведения пользователей:
* Как влияют просмотры тематических страниц на выполнение целевого действия?
* Существует ли связь между типом потребляемого контента и продуктом, который приобретает пользователь в конечном итоге?
* Существуют ли связанные товары? Например, если кто-то покупает продукт А, какая категория продуктов связана с ним?
### Сторонние данные
Последнее, но не менее важное, — необработанные данные позволяют получать намного больше информации, если подключить другие источники данных. Ниже приведены несколько наглядных примеров:
**Данные электронной коммерции**. Инструмент приносит наибольшую пользу в том случае, если вы сохраняете идентификатор клиента в Google Analytics, выполнявшим любые действия по добавлению в корзину или оформлению заказа. Это позволит рассчитать точное значение коэффициента конверсии, даже если инструменты Google Analytics не сработали (из-за используемых клиентами блокировщиков рекламы, отсутствия редиректа со страницы оплаты, длительного времени ожидания загрузки страницы и прочих причин). Кроме того, основываясь на собственных данных, вы сможете исключить отмененные целевые действия и возвраты для перерасчета реальной прибыли. Также это позволяет рассчитывать более сложные и закрытые показатели, например, маржу вместо дохода.
**Данные CRM**. Что может быть хуже, чем то, что в огромном множестве лидов содержится большое количество нерелевантных лидов? Это распространенная проблема для B2B онлайн сервисов. Экспортируя данные CRM с уникальными идентификаторами лидов (идентификатор клиента, зашифрованный с помощью SHA-256 e-mail, сгенерированный идентификатор и прочие), можно легко связывать их с идентификаторами клиентов в Google Analytics. Это позволит рассчитывать не только процент сгенерированных лидов, а и коэффициент конверсии. Для многоканального анализа потребуются более сложные запросы, однако вы сможете полностью контролировать процессы вычислений.
**Оффлайн события**. Бизнес в сфере онлайн подвержен влиянию множества внешних факторов: праздники, погодные условия, забастовки, смертельный вирус, который отправил на самоизоляцию половину населения планеты. Google Analytics не предусматривает возможность введения новых параметров для изучения на определенный промежуток времени. Что касается аннотаций, они не участвуют в вычислениях и используются исключительно как элемент пользовательского интерфейса. Однако было бы полезно узнать, как праздники влияют на число продаж.

Для проведения такого анализа необходимо собрать информацию и предоставить ее в удобочитаемом формате. Выполнив это, вы будете обладать актуальными и востребованными данными.
**Объявления, поисковые роботы, логи** – все эти данные следует хранить в едином хранилище.
Научившись сопоставлять их с аналитическими данными, вы сможете воплотить в реальность самые смелые мечты:
* Способствует ли более длинный контент привлечению пользователей? Правильно подобрав поискового робота (например, Screaming Frog) можно установить взаимосвязь между длиной текстового контента и числом просмотров страниц.
* Влияет ли поведение поисковых роботов на SEO-оптимизацию? Используя данные лога BigQuery, можно установить, как влияет частота посещения поискового робота на поисковую выдачу.
Какова реальная рентабельность вашего бизнеса? Внеся настройки в алгоритм расчета атрибуции, можно измерить отдачу от инвестиций в рекламные кампании по всем используемым платформам.
Инструменты для извлечения необработанных данных
------------------------------------------------
Информация, представленная выше, говорит в пользу необработанных данных. Но как их получить? Рассмотрим несколько наиболее распространенных способов.
### Google Analytics 360
Если вам повезло получить доступ к этому сервису или вы располагаете достаточным бюджетом для оплаты стоимости его использования, в ваших руках находится лучший инструмент для извлечения необработанных данных в Google BigQuery. Он позволяет экспортировать любую информацию, включая расширенные данные электронной коммерции. Каждой строке соответствует определенный сеанс, и вы сможете использовать огромное количество параметров и метрик.
### Google Analytics App+Web и Firebase
С недавнего времени веб-аналитики получили возможность экспортировать данные в Google BigQuery без необходимости покупки Google Analytics 360. Firebase, который является ядром Google Analytics App+Web, поддерживает функционал экспорта в Google BigQuery. Вам будет выставлен счет Blaze, который использует подход «оплата по мере использования». Если у вас крупный интернет портал, вам придется следить за своим бюджетом. Для небольших сайтов затраты составят от совсем ничего до всего нескольких долларов в месяц.
Каждой строке соответствует событие, содержащее скрин или просмотр страницы. Вам придется привыкнуть к этому весьма специфическому способу представления данных, который отличается от используемого в Google Analytics. Однако, этот сервис может стать лучшим решением для тех, кто желает использовать необработанные данные.
### Прочие бесплатные инструменты: Яндекс.Метрика и Matomo
Я не смог опробовать каждый инструмент, поскольку многие из них являются платными. Каждый из них содержит функционал экспорта необработанных данных. Однако, существует два абсолютно бесплатных онлайн сервиса, которые предлагают тот же функционал и не взимают плату за их использование.
Яндекс.Метрика – абсолютно бесплатный инструмент, который предоставляет доступ к необработанным данным через API его логов. Matomo – инструмент аналитики с открытым исходным кодом, который необходимо устанавливать непосредственно на ваш сервер, на котором находятся файлы сайта. Он экспортирует необработанные данные непосредственно в вашу БД.
### Конвейер данных
Еще один способ выгрузки данных Google Analytics непосредственно в ваше хранилище данных – конвейер данных. OWOX BI организовывает мощный поток данных между Google Analytics и BigQuery. Для реализации функционала необходимо создать кастомную задачу в Google Analytics. Он формирует копии полезной нагрузки Google Analytics и переносит в конечное хранилище данных.
Имея достаточный опыт, вы сможете самостоятельно создать собственную конечную точку выгрузки данных с использованием функционала облачного сервиса и на основе анализа лога. Ниже приведены два полезных ресурса, которые помогут вам разобраться в этом:
Симо Ахава – «Как сформировать GTM-монитор». После прочтения этой статьи вы узнаете, как отправлять данные в BigQuery с помощью облачных функций. Объемы передаваемых данных ограничены 100000 строк в секунду, которые можно интегрировать в сервис BigQuery. Если количество строк превышает указанное выше максимальное значение, вам придется группировать данные из нескольких логов.
Справочный центр Google Cloud – «Serverless Pixel Tracking Architecture». В этом источнике рассмотрен механизм создания собственного пикселя отслеживания с последующей интеграцией в BigQuery.
### Примеры и частные случаи использования BigQuery
Теперь вы знаете о преимуществах использования необработанных данных и способах получения доступа к ним. Теперь рассмотрим несколько примеров, которые наглядно демонстрируют принципы работы с этими данными.
Установление взаимосвязи между тематиками и целевыми действиями в Google Analytics 360
Анализ был проведен для новостного сайта с онлайн подписчиками. Основная задача анализа состояла в том, чтобы установить взаимосвязь (корреляцию) между тематикой новостей, которые читают пользователи, и выполняемыми целевыми действиями.
Полученный результат и выводы:
`corr_culture 0.397
corr_opinion 0.305
corr_lifestyle 0.0468
corr_sport 0.009`
Наиболее вероятная категория тех, кто оформит подписку на сайт, — это пользователи, интересующиеся рубриками «Культура» и «Мнения». С другой стороны, если пользователь интересуется рубриками «Стиль жизни» или «Спорт», вероятность оформления им подписки является минимальной.
**Запрос для BigQuery**
```
SELECT
CORR(culture,transac) AS corr_culture,
CORR(opinion,transac) AS corr_opinion,
CORR(lifestyle,transac) AS corr_lifestyle,
CORR(sport,transac) AS corr_sport
FROM(
SELECT
SUM(IF(hit.page.pagePath LIKE'/culture%',
1,
0)) AS culture,
SUM(IF(hit.page.pagePath LIKE'/opinion%',
1,
0)) AS opinion,
SUM(IF(hit.page.pagePath LIKE'/lifestyle%',
1,
0)) AS lifestyle,-
SUM(IF(hit.page.pagePath LIKE'/sport%',
1,
0)) AS sport,
COUNT(hit.transaction.transactionId) AS transac
FROM
`mydatabase.view_id.ga_sessions_*`,
UNNEST(hits) AS hit
WHERE
_TABLE_SUFFIX BETWEEN '20191201' AND '20200301'
GROUP BY
fullVisitorId
ORDER BY
transac DESC
)
```
### Когортный анализ с использованием Firebase
Для проведения анализа было взято приложение с регулярно обновляемым контентом и высоким показателем сезонности. Анализ проводится для поиска ответов на следующие вопросы:
Как ведут себя пользователи, которые впервые установили это приложение?
Какой момент времени является наилучшим для привлечения клиентов, которые будут использовать приложение на регулярной основе?
Полученный результат и выводы:

Судя по полученным данным, приложение чаще всего используют клиенты, которые загрузили его впервые в сентябре и декабре.
**Запрос для BigQuery**
```
# change my-app.analytics_123456789 to your ID
WITH cohorte_september
AS
(
WITH
user_september AS
(
SELECT DISTINCT user_pseudo_id AS user
FROM `my-app.analytics_123456789.events_*`
WHERE
_table_suffix between '20190901' AND '20190930'
AND
event_name="first_open"
)
SELECT sessions, month
FROM
(
(SELECT COUNT(DISTINCT user_pseudo_id) AS sessions,"201909" AS month
FROM `my-app.analytics_123456789.events_*`
WHERE
_table_suffix between '20190901' AND '20190930'
AND event_name="session_start"
AND user_pseudo_id IN (SELECT user FROM user_september)
)
UNION ALL
(SELECT COUNT(DISTINCT user_pseudo_id),"201910"
FROM `my-app.analytics_123456789.events_*`
WHERE
_table_suffix between '20191001' AND '20191031'
AND event_name="session_start"
AND user_pseudo_id IN (SELECT user FROM user_september)
)
UNION ALL
(
SELECT COUNT(DISTINCT user_pseudo_id),"201911"
FROM `my-app.analytics_123456789.events_*`
WHERE
_table_suffix between '20191101' AND '20191130'
AND event_name="session_start"
AND user_pseudo_id IN (SELECT user FROM user_september)
)
UNION ALL
(
SELECT COUNT(DISTINCT user_pseudo_id),"201912"
FROM `my-app.analytics_123456789.events_*`
WHERE
_table_suffix between '20191201' AND '20191231'
AND event_name="session_start"
AND user_pseudo_id IN (SELECT user FROM user_september)
)
UNION ALL
(
SELECT COUNT(DISTINCT user_pseudo_id),"202001"
FROM `my-app.analytics_123456789.events_*`
WHERE
_table_suffix between '20200101' AND '20200131'
AND event_name="session_start"
AND user_pseudo_id IN (SELECT user FROM user_september)
)
UNION ALL
(
SELECT COUNT(DISTINCT user_pseudo_id),"202002"
FROM `my-app.analytics_123456789.events_*`
WHERE
_table_suffix between '20200201' AND '20200229'
AND event_name="session_start"
AND user_pseudo_id IN (SELECT user FROM user_september)
)
UNION ALL
(
SELECT COUNT(DISTINCT user_pseudo_id),"202003"
FROM `my-app.analytics_123456789.events_*`
WHERE
_table_suffix between '20200301' AND '20200331'
AND event_name="session_start"
AND user_pseudo_id IN (SELECT user FROM user_september)
)
)
ORDER BY month ASC
),
#october
cohorte_october AS
(
WITH
user_october AS
(
SELECT DISTINCT user_pseudo_id AS user
FROM `my-app.analytics_123456789.events_*`
WHERE
_table_suffix between '20191001' AND '20191031'
AND
event_name="first_open"
)
SELECT sessions, month
FROM
(
(SELECT COUNT(DISTINCT user_pseudo_id) AS sessions,"201909" AS month
FROM `my-app.analytics_123456789.events_*`
WHERE
_table_suffix between '20190901' AND '20190930'
AND event_name="session_start"
AND user_pseudo_id IN (SELECT user FROM user_october )
)
UNION ALL
(SELECT COUNT(DISTINCT user_pseudo_id),"201910"
FROM `my-app.analytics_123456789.events_*`
WHERE
_table_suffix between '20191001' AND '20191031'
AND event_name="session_start"
AND user_pseudo_id IN (SELECT user FROM user_october )
)
UNION ALL
(
SELECT COUNT(DISTINCT user_pseudo_id),"201911"
FROM `my-app.analytics_123456789.events_*`
WHERE
_table_suffix between '20191101' AND '20191130'
AND event_name="session_start"
AND user_pseudo_id IN (SELECT user FROM user_october )
)
UNION ALL
(
SELECT COUNT(DISTINCT user_pseudo_id),"201912"
FROM `my-app.analytics_123456789.events_*`
WHERE
_table_suffix between '20191201' AND '20191231'
AND event_name="session_start"
AND user_pseudo_id IN (SELECT user FROM user_october )
)
UNION ALL
(
SELECT COUNT(DISTINCT user_pseudo_id),"202001"
FROM `my-app.analytics_123456789.events_*`
WHERE
_table_suffix between '20200101' AND '20200131'
AND event_name="session_start"
AND user_pseudo_id IN (SELECT user FROM user_october )
)
UNION ALL
(
SELECT COUNT(DISTINCT user_pseudo_id),"202002"
FROM `my-app.analytics_123456789.events_*`
WHERE
_table_suffix between '20200201' AND '20200229'
AND event_name="session_start"
AND user_pseudo_id IN (SELECT user FROM user_october )
)
UNION ALL
(
SELECT COUNT(DISTINCT user_pseudo_id),"202003"
FROM `my-app.analytics_123456789.events_*`
WHERE
_table_suffix between '20200301' AND '20200331'
AND event_name="session_start"
AND user_pseudo_id IN (SELECT user FROM user_october)
)
)
ORDER BY month ASC
),
#november
cohorte_november AS
(
WITH
user_november AS
(
SELECT DISTINCT user_pseudo_id AS user
FROM `my-app.analytics_123456789.events_*`
WHERE
_table_suffix between '20191101' AND '20191130'
AND
event_name="first_open"
)
SELECT sessions, month
FROM
(
(SELECT COUNT(DISTINCT user_pseudo_id) AS sessions,"201909" AS month
FROM `my-app.analytics_123456789.events_*`
WHERE
_table_suffix between '20190901' AND '20190930'
AND event_name="session_start"
AND user_pseudo_id IN (SELECT user FROM user_november )
)
UNION ALL
(SELECT COUNT(DISTINCT user_pseudo_id),"201910"
FROM `my-app.analytics_123456789.events_*`
WHERE
_table_suffix between '20191001' AND '20191031'
AND event_name="session_start"
AND user_pseudo_id IN (SELECT user FROM user_november )
)
UNION ALL
(
SELECT COUNT(DISTINCT user_pseudo_id),"201911"
FROM `my-app.analytics_123456789.events_*`
WHERE
_table_suffix between '20191101' AND '20191130'
AND event_name="session_start"
AND user_pseudo_id IN (SELECT user FROM user_november )
)
UNION ALL
(
SELECT COUNT(DISTINCT user_pseudo_id),"201912"
FROM `my-app.analytics_123456789.events_*`
WHERE
_table_suffix between '20191201' AND '20191231'
AND event_name="session_start"
AND user_pseudo_id IN (SELECT user FROM user_november )
)
UNION ALL
(
SELECT COUNT(DISTINCT user_pseudo_id),"202001"
FROM `my-app.analytics_123456789.events_*`
WHERE
_table_suffix between '20200101' AND '20200131'
AND event_name="session_start"
AND user_pseudo_id IN (SELECT user FROM user_november )
)
UNION ALL
(
SELECT COUNT(DISTINCT user_pseudo_id),"202002"
FROM `my-app.analytics_123456789.events_*`
WHERE
_table_suffix between '20200201' AND '20200229'
AND event_name="session_start"
AND user_pseudo_id IN (SELECT user FROM user_november )
)
UNION ALL
(
SELECT COUNT(DISTINCT user_pseudo_id),"202003"
FROM `my-app.analytics_123456789.events_*`
WHERE
_table_suffix between '20200301' AND '20200331'
AND event_name="session_start"
AND user_pseudo_id IN (SELECT user FROM user_november )
)
)
ORDER BY month ASC
),
#decembre
cohorte_decembre AS
(
WITH
user_decembre AS
(
SELECT DISTINCT user_pseudo_id AS user
FROM `my-app.analytics_123456789.events_*`
WHERE
_table_suffix between '20191201' AND '20191231'
AND
event_name="first_open"
)
SELECT sessions, month
FROM
(
(SELECT COUNT(DISTINCT user_pseudo_id) AS sessions,"201909" AS month
FROM `my-app.analytics_123456789.events_*`
WHERE
_table_suffix between '20190901' AND '20190930'
AND event_name="session_start"
AND user_pseudo_id IN (SELECT user FROM user_decembre )
)
UNION ALL
(SELECT COUNT(DISTINCT user_pseudo_id),"201910"
FROM `my-app.analytics_123456789.events_*`
WHERE
_table_suffix between '20191001' AND '20191031'
AND event_name="session_start"
AND user_pseudo_id IN (SELECT user FROM user_decembre )
)
UNION ALL
(
SELECT COUNT(DISTINCT user_pseudo_id),"201911"
FROM `my-app.analytics_123456789.events_*`
WHERE
_table_suffix between '20191101' AND '20191130'
AND event_name="session_start"
AND user_pseudo_id IN (SELECT user FROM user_decembre )
)
UNION ALL
(
SELECT COUNT(DISTINCT user_pseudo_id),"201912"
FROM `my-app.analytics_123456789.events_*`
WHERE
_table_suffix between '20191201' AND '20191231'
AND event_name="session_start"
AND user_pseudo_id IN (SELECT user FROM user_decembre )
)
UNION ALL
(
SELECT COUNT(DISTINCT user_pseudo_id),"202001"
FROM `my-app.analytics_123456789.events_*`
WHERE
_table_suffix between '20200101' AND '20200131'
AND event_name="session_start"
AND user_pseudo_id IN (SELECT user FROM user_decembre )
)
UNION ALL
(
SELECT COUNT(DISTINCT user_pseudo_id),"202002"
FROM `my-app.analytics_123456789.events_*`
WHERE
_table_suffix between '20200201' AND '20200229'
AND event_name="session_start"
AND user_pseudo_id IN (SELECT user FROM user_decembre )
)
UNION ALL
(
SELECT COUNT(DISTINCT user_pseudo_id),"202003"
FROM `my-app.analytics_123456789.events_*`
WHERE
_table_suffix between '20200301' AND '20200331'
AND event_name="session_start"
AND user_pseudo_id IN (SELECT user FROM user_decembre )
)
)
ORDER BY month ASC
)
SELECT cohorte_september.sessions AS september_cohort,
cohorte_october.sessions AS october_cohort,
cohorte_november.sessions AS november_cohort,
cohorte_decembre.sessions AS december_cohort,
month
FROM cohorte_september
JOIN cohorte_october USING (month)
JOIN cohorte_november USING (month)
JOIN cohorte_decembre USING (month)
ORDER BY month ASC
```
Выводы
------
Скорее всего в ближайшем будущем грядут серьезные изменения, и Google App+Web станет чем-то вроде отраслевого стандарта. Этот подход обеспечивает более тесную интеграцию между сервисами Google, такими как Marketing Platform и Google Cloud Platform, и особенно BigQuery. Если вы утратили навыки по созданию SQL-запросов (язык для работы с СУБД), я настоятельно рекомендую вам освежить информацию в своей памяти и потренироваться на практике.
Расширенная цифровая аналитика данных становится все более мощным инструментом благодаря простому доступу к необработанным данным, быстрым и эффективным вычислительным процессам, а также хорошей визуализации информации. В ближайшем будущем будет реализована еще более тесная интеграция с другими типами бизнес-данных.
Уже на протяжении многих лет эксперты утверждают, что цифровая и бизнес аналитика должны работать сообща. Медленно, но уверенно мы идем по пути воплощения этой идеи в реальность. | https://habr.com/ru/post/503702/ | null | ru | null |
# Инженерные системы наших дата-центров и их мониторинг, часть первая
Привет, Хабр! Я инженер компании «Миран», которая занимается выдачей в аренду различных серверов, размещением клиентского оборудования в своих дата-центрах и прочими подобными делами.

Меня продолжительное время уговаривали написать обзорную статью о нашей инженерной инфраструктуре и о том, как мы ее мониторим. Статья долго и упорно не хотела появляться на свет, но все же родилась. Поздравьте меня с почином!
*Осторожно, много картинок!*
[1. Введение в ЦОДоведение](#1)
[2. ТП, ВРУ, PDU](#2)
[3. Окунись в прохладу ©](#3)
[4. От клеммного зажима до ПЛК](#4)
Введение в ЦОДоведение
----------------------
Что есть центр обработки данных? Говорим «ЦОД» — представляем себе бескрайние ангары, заполненные бесчисленными рядами стоек с мерно гудящими железками. Железки загадочно перемигиваются разноцветными огоньками из полумрака. С лицевой стороны их обдувает прохладным бризом от промышленных кондиционеров. В холодных зонах можно наотличненько просквозить себе шею и простудиться. Поэтому админы всегда носят свитера.
Нашей компанией построены два отдельно стоящих дата-центра, бесхитростно именуемые «Миран-1» и «Миран-2». Первый представляет собой вполне привычный тип, с одним большим машинным залом и несколькими поменьше этажом выше. Второй ЦОД представляет из себя ангар, в котором на данный момент установлены два мобильных малых ЦОДа, а также строится третий. Мобильные ЦОДы — двухэтажные конструкции-контейнеры, первый этаж которых есть серверный зал со стойками и кондиционерами, он еще именуется серверным блоком, на втором же смонтированы ВРУ, установлены ИБП и различные щиты управления.
Так исторически сложилось, что «Миран-1» не имел единого мониторинга инженерной инфраструктуры (посыпаем голову пеплом) и мы стремимся исправить этот недостаток. Посему речь большей частью пойдет о втором дата-центре.
*Все картинки взяты из нашей системы мониторинга!*
*P.S.: фотографии щитов и их внутренностей тоже наши!*
ТП, ВРУ, PDU
------------
В «Миран-2» реализована система гарантированного электроснабжения (СГЭ). Как видно из схемы ниже, в обычных условиях дата-центр питается от двух независимых внешних вводов от ТП; в случае пропадания напряжения на внешних вводах (а такое у нас иногда случается) — питание идет от дизель-генераторной установки ДГУ2, фактически; под будущий задел предусмотрено место для еще двух.
*Общая мнемосхема ввода электропитания «Миран-2»*
Идем дальше. ВРУ выполнено двухсекционным с секционным выключателем под управлением АВР1. Контроллер АВР замкнет секционник в случае пропадания напряжения на одном или обоих вводах, в последнем случаем через 15 секунд будет дан сигнал на запуск ДГУ. Все эти неприятности «Модуль-1 и «Модуль-2» переживают на своих внутренних ИБП.
[](https://habrastorage.org/web/3d3/807/468/3d380746863a442eace61cc56b6b0fce.jpg)
*Фото ВРУ «Миран-2». Кликабельно*
Основное назначение секций и их автоматов, помимо питания различных вспомогательных щитов освещения, управления вентиляцией и прочего — исполнять роль вводов электропитания для «Модуль-1» и «Модуль-2» (QF1.1-.2 и QF2.1-.2 на схеме, соответственно). Каждый модульный ЦОД имеет внутри себя свое собственное ВРУ.
*Мнемосхема главного распределительного щита «Модуль-2»*
[](https://habrastorage.org/web/fff/685/28b/fff68528b6cb44d88168555390763035.jpg)
*Фото главного распределительного щита «Модуль-2». Кликабельно*
*Мнемосхема энергоблока «Модуль-1»*

*Мнемосхема стоек «Модуль-1»*
Большая часть стоек в «Модуль-1» и «Модуль-2» — производителей Rittal и RiT. Из PDU используем: в «Модуль-1» — сборную солянку из Eurolan, APC, DELTA. «Модуль-2» — целиком на PDU фирмы RiT.
Окунись в прохладу ©
--------------------
Все клиентское железо, а также инженерная инфраструктура в процессе своей работы выделяют много тепла. Это тепло необходимо отводить, иначе железо быстро умрет. Отводом у нас занимаются шесть инверторных фреоновых кондиционеров фирмы Daikin. Вся их деятельность гордо называется «фреоновым режимом», который обеспечивает сухой ~~тропический~~ прохладный климат от +15 до +23 С° в холодном коридоре. Данная система охлаждения применяется и в «Модуле-1», и в «Модуле-2».
Также в «Модуле-1» существует еще один режим охлаждения, «режим фрикулинга». Его должны обеспечивать четыре приточных установки и дюжина вытяжек. В теории. К сожалению, на практике отвод тепла таким образом был не слишком эффективным, если внутри было задействовано чуть больше половины стоек. Поэтому данный режим для первого модульного ЦОДа так и не используется, оставаясь, по сути, резервным.
*Мнемосхема серверного блока «Модуль-1»*
*Мнемосхема серверного блока «Модуль-2». Никаких приточек, только ~~хардкор!~~ фреон!*
От клеммного зажима до ПЛК
--------------------------
Опросом и агрегацией информации от всей периферии дата-центра «Миран-2» занимаются три ПЛК: по одному на «Модуль» и один общий. Эти вундержелезки носят имя небезызвестной компании WAGO.
Рассмотрим структуру системы опроса на основе решения для «Модуль-2».
*Схема шины ПЛК с модулями, скриншот из WAGO-IO-Check*
[](https://habrastorage.org/web/240/b84/7dd/240b847dda6d4ecf9f3965cd3b88fe42.jpg)
*Фото щита диспетчеризации «Модуль-2». Кликабельно*
Как видно из схемы, на шине установлен сам ПЛК серии **750-881**, четыре дискретных модуля **750-1405** на 16 каналов каждый и один аналоговый модуль **750-455** на четыре канала. Через дискретные модули ПЛК получает данные о состоянии автоматических выключателей питания («сухие» дополнительные контакты) в обеих секциях ГРЩ, о состоянии автоматов в собственном щите, а также о состоянии вентиляции энергоблока. Посредством аналогового модуля — получает данные от двух датчиков температуры и влажности (4-20 мА) здесь же, внутри энергоблока.
ПЛК также оснащен двумя Ethernet-портами и через них он общается по **Modbus TCP/IP** с еще несколькими железяками, как то:
* два вводных автомата фирмы Schneider Electric, от них же получается информация о входных мощностях, напряжениях, токах и прочем;
* две системы измерения токов фирмы АВВ в тандеме с двумя модулями ввода от фирмы ОВЕН — результатом их совместного труда есть вычисление по-стоечной мощности;
* контроллеры CAREL и 6 их подопечных — кондиционеры Daikin;
* и, наконец, младший братик — каплер **750-342** c семью дискретными модулями. Их задача отслеживать состояние 48 выключателей + 12 резервных в серверном блоке на 24 стойки.
[](https://habrastorage.org/web/e13/065/3bf/e130653bf8094bf48a6a1f04face90a0.jpg)
*Фото ABB CMS-600 и трансформаторов тока. Кликабельно*
[](https://habrastorage.org/web/cb8/7a4/4ae/cb87a44aef8149459e770430c1f43c0d.jpg)
*Фото ОВЕН МЭ110-220.3М. Кликабельно*
[](https://habrastorage.org/web/e7a/4cd/bce/e7a4cdbceb1b4e05bb3dd01e7d277463.jpg)
*Фото ПЛК CAREL. Кликабельно*
[](https://habrastorage.org/web/a64/863/319/a648633199f64537813f407c00269c4c.jpg)
*Фото щита слаботочных систем «Модуль-2». Кликабельно*
> Отдельно стоит упомянуть ИБП, они опрашиваются непосредственно SCADA, минуя ПЛК, по SNMP-протоколу.
[](https://habrastorage.org/web/d38/ce5/af6/d38ce5af672e486f89a99b1310072910.jpg)
*Фото ИБП «Модуль-2». Кликабельно*
Вся получаемая информация посредством программы формируется в собственный список Modbus-регистров, которая уже опрашивается SCADA.
**Небольшой кусочек из основной программы**
```
(* PLC_A2 *)
%QX256.0 := A2_1QF1; //присваиваем каждому биту 256го слова
%QX256.1 := A2_1QF2; //текущее состояние различных автоматов
%QX256.2 := A2_QS1;
%QX256.3 := A2_QS2;
%QX256.4 := A2_3QF1;
%QX256.5 := A2_3QF2;
%QX256.6 := A2_3QF3;
%QX256.7 := A2_3QF4;
%QX256.8 := A2_3QF5;
%QX256.9 := A2_3QF6;
%QX256.10 := A2_3QF7;
%QX256.11 := A2_3QF8;
%QX256.12 := A2_3QF9;
%QX256.13 := A2_3QF10;
%QX256.14 := A2_KM1;
%QX256.15 := A2_KM2;
(* QF1 *) //вводной автоматический выключатель № 1
%QW332 := QF1_I_L1; //токи по фазам
%QW333 := QF1_I_L2;
%QW334 := QF1_I_L3;
%QW335 := QF1_U_L12; //линейные (межфазные) напряжения
%QW336 := QF1_U_L23;
%QW337 := QF1_U_L31;
%QW338 := QF1_U_L1; //фазные (фаза-нуль) напряжения
%QW339 := QF1_U_L2;
%QW340 := QF1_U_L3;
%QW341 := QF1_P_L1; //активная мощность по фазам
%QW342 := QF1_P_L2;
%QW343 := QF1_P_L3;
%QW344 := QF1_P_Sum; //суммарная активная мощность (кВт)
%QW345 := QF1_Q_L1; //реактивная мощность по фазам
%QW346 := QF1_Q_L2;
%QW347 := QF1_Q_L3;
%QW348 := QF1_Q_Sum; //суммарная реактивная мощность (квар)
%QW349 := QF1_S_Sum; //полная мощность (кВА)
%QW350 := QF1_CosF; //коэффициент мощности
```
**Еще один кусочек из другой подпрограммы**
```
//Это работа кодогенератора CODESYS, в котором есть удобный настройщик связи
//с периферией по Modbus TCP/IP. Эта подпрограмма, в частности, отвечает
//за получение от ОВЕН МЭ110-220.3М показаний
//по трем напряжениям фаза-нейтраль
PROGRAM MBCFG_subCMS_1(* generated by config one prg for each slave *)
VAR_OUTPUT
U_L1 : WORD; (**)
U_L2 : WORD; (**)
U_L3 : WORD; (**)
/*--- system variables (read only) ----------------------------------------*/
MBCFG_IpAddress : STRING(12) := 'XXX.XXX.XXX.XXX';//IP-адрес Slave-устройства
MBCFG_Port : UINT := 502; //Порт, дефолтный
MBCFG_UnitID : BYTE := 2; //ID Slave-устройства
MBCFG_TimeOut : TIME := t#300ms; //Таймаут на получение ответа
MBCFG_RequestDelay : TIME := t#1000ms; //Задержка до следующего опроса
MBCFG_Error : MBCFG_eERROR := MBCFG_START_UP;
MBCFG_LastJob : MBCFG_typCOM_JOB;
/*-------------------------------------------------------------------------*/
END_VAR
VAR CONSTANT
zz_VARIABLECOUNT: INT := 3; (* number of variables *)
zz_JOBCOUNT : INT := 1; (* number of jobs *)
END_VAR
VAR
/*=== VARIABLE LIST =============*/
zz_VariableList : ARRAY[1..zz_VARIABLECOUNT] OF MBCFG_typVARIABLE :=
( DataType := MBCFG_TYPE_WORD,
ByteOrder := MBCFG_BYTE_ORDER_0,
BitSize := 16,
ptVar := 0,
ReadJobIndex := 1,
ReadStartBitNo := 0,
WriteJobIndex := 0,
WriteStartBitNo := 0 ),
( DataType := MBCFG_TYPE_WORD,
ByteOrder := MBCFG_BYTE_ORDER_0,
BitSize := 16,
ptVar := 0,
ReadJobIndex := 1,
ReadStartBitNo := 32,
WriteJobIndex := 0,
WriteStartBitNo := 0 ),
( DataType := MBCFG_TYPE_WORD,
ByteOrder := MBCFG_BYTE_ORDER_0,
BitSize := 16,
ptVar := 0,
ReadJobIndex := 1,
ReadStartBitNo := 64,
WriteJobIndex := 0,
WriteStartBitNo := 0
);
/*=== JOB LIST ==================*/
zz_JobList : ARRAY[1..zz_JOBCOUNT] OF MBCFG_typCOM_JOB :=
( Functioncode := 3, //Номер функции, 0x03, Read Holding Registers
ReadStartAddress := 26,//Адрес первого регистра
ReadQuantity := 5, //Кол-во регистров, которые следует прочесть
WriteStartAddress := 0,
WriteQuantity := 0,
ptReadData := 0,
ptWriteData := 0
);
zz_DataField_1_Read : ARRAY[1..5] OF WORD;
/*=== MODBUS MASTER ==============*/
zz_MBCFG_MASTER_ETH : MBCFG_MASTER_TCP;
END_VAR
/*--- for each variable -------------------------*/
zz_VariableList[1].ptVar := ADR(U_L1);
zz_VariableList[2].ptVar := ADR(U_L2);
zz_VariableList[3].ptVar := ADR(U_L3);
/*-----------------------------------------------*/
/*--- for each job -----------------------------------*/
zz_JobList[1].ptReadData := ADR(zz_DataField_1_Read);
/*----------------------------------------------------*/
/*#### START OF FIXED CODE #####################################*/
zz_MBCFG_MASTER_ETH( strIpAddress := MBCFG_IpAddress,
uiPort := MBCFG_Port,
bUnitID := MBCFG_UnitID,
tTimeOut := MBCFG_TimeOut,
iVariableCount := zz_VARIABLECOUNT,
ptVariableList := ADR(zz_VariableList),
iJobCount := zz_JOBCOUNT,
ptJobList := ADR(zz_JobList),
tRequestDelay := MBCFG_RequestDelay,
eError => MBCFG_Error,
LastJob => MBCFG_LastJob
);
%QW377 := U_L1;
%QW378 := U_L2;
%QW379 := U_L3;
```
[Фигура вторая, софтварная](https://habrahabr.ru/company/dcmiran/blog/336222/) | https://habr.com/ru/post/336134/ | null | ru | null |
# PayPal или все-таки РауРаl?
 Наверно все хорошо помнят, что ICANN одобрила внедрение нелатинских доменных имен([хабр](http://habrahabr.ru/blogs/it-politics/73870/)), в том числе и состоящих из букв русского алфавита. И совсем недавно большинство американских ресурсов, в том числе и небезызвестный **Mashable** опубликовал шокирующую для американского интернета [новость](http://mashable.com/2010/01/01/idn-phishing/).
Cчитается, что в русском алфавите есть много букв очень схожих латиницей. Вот что пишет Mashable:
`Cyrillic scripts, which is the basis for the Russian language, shares some of the same letterforms as the Latin alphabet. What this means is that potential evil-doers could register a domain using non-Latin characters that appears to spell out a Latin word.`
В качестве примера, на который обращает внимание Mashable, потенциальный злоумышленник регистрирует домен раураl.com (в домене буквы на русском) и ловит дешевую рыбу (её данные кредитной карточки и т.п.), которая не замечает отличий в написании фальшивого домена и оригинального paypal:

**А теперь мое представление дела**:
Насколько мне известно, в интернете не гуляло никаких новостей от ICANN по поводу гибридных доменов — если в их именах можно будет использовать как русские так и английские буквы. Иначе — да, существует вероятность подмены домена( обратите внимание на два примера — paypal.com, написанное при помощи русского языка и латыни и на обычное раураl.com ). Я не думаю, что в интернете действительно найдутся люди которые не смогут отличить обычное paypal.com от раурал.com. Тем более регистрацию кириллических доменов разрешили только в .eu,.рф, .su, но не в .com.
Т.е. в ближайшее время такой проблемы не должно возникнуть, особенно в домене .com.
И если посмотреть, то разрешения на кириллические поддомены в .eu,.рф, .su есть лишь потому, что для этих доменов нет других идентичных буквенных эквивалентов на кириллице/латыне.
Таким образом, мы имеем дело с тем, когда кто-то начал сеять панику, не разобравшись в деле. **Mashable**, поверив другому, похоже менее популярному источнику, [TimesOnline](http://technology.timesonline.co.uk/tol/news/tech_and_web/article6971724.ece), опубликовало информацию о возможных фишинговых кириллических доменах. Даже в качестве примера приводится пресловутое «paypal», которое кириллицей никак нельзя написать, чтобы выглядело идентично.
На самом деле, удивительно что такой «горячей» новости все верят — у топика на mashable более тысячи ретвитов и ~2000 diggs. Я кстати, давно уже отписался от Mashable, потому как это уже не тот ресурс на котором рассказывают об новых интересных вещах. Слишком много «паники», рекламы и вебдванольного подобия контента.
Кстати, тестовый русский домен ICANN с их вики:
[IDNwiki](http://пример.испытание/%D0%97%D0%B0%D0%B3%D0%BB%D0%B0%D0%B2%D0%BD%D0%B0%D1%8F_%D1%81%D1%82%D1%80%D0%B0%D0%BD%D0%B8%D1%86%D0%B0) | https://habr.com/ru/post/79991/ | null | ru | null |
# Корутинная эволюция в Kotlin. Чем отличаются Channels, Broadcast channels, Shared flows, State flows
Эта публикация — перевод поста [Романа Елизарова](https://twitter.com/relizarov) [«Shared flows, broadcast channels»](https://elizarov.medium.com/shared-flows-broadcast-channels-899b675e805c). Опубликовано с одобрения автора оригинала. Примечания переводчика выделены *курсивом*.
Давным-давно в Kotlin были представлены корутины, одной из особенностей которых является легковесность (*создание корутин дешевле, чем с запуск новых Threads*). Мы можем запускать несколько корутин, и нам нужен способ взаимодействия между ними избегая “mutable shared state” (*неконсистентности данных при записи и чтении из разных корутин*).
Для этого был придуман Channel как примитив для связи между корутинами. Channels — отличное изобретение. Они поддерживают связь между корутинами «один к одному», «один ко многим», «многие к одному» и «многие ко многим», но каждое значение, отправляемое в Channel, принимается один раз (*в одной из корутин с запущенной подпиской*).

Вы не можете использовать Channel для распространения событий или обновлений состояния так, чтобы несколько подписчиков могли независимо получать и реагировать на них.
Для решения этой проблемы был дополнительно добавлен интерфейс BroadcastChannel, хранящий состояние, доступное каждому подписчику, и его реализацию — ConflatedBroadcastChannel. Некоторое время они хорошо выполняли свою задачу, но их развитие оказалось тупиковым. Начиная с версии kotlinx-coroutines 1.4, мы представили новое решение — shared flows. Это была предыстория, а теперь поехали!
#### Flows are simple
В ранних версиях библиотеки у нас были только Channels, и мы пытались реализовать различные преобразования последовательностей данных как функции, которые принимают один Channel в качестве аргумента и в результате возвращают другой Channel. Это означает, что, например, оператор filter будет работать в своей собственной корутине.

Производительность такого подхода была далека от идеала, особенно по сравнению с простым написанием оператора **if**. И это неудивительно, потому что Channel — это примитив синхронизации доступа к данным (*в общем случае из разных потоков*). Любой Channel, даже реализация, оптимизированная для одного producer и одного consumer, должен поддерживать консистентный доступ к данным из разных потоков, а значит между ними требуется синхронизация, которая в современных многоядерных системах обходится дорого. Когда вы начинаете строить архитектуру приложения на основе асинхронных потоков данных, почти сразу возникает необходимость в преобразованиях данных, приходящих от producer. Тяжеловесность решения с каждым преобразованием возрастает.
Первым решением это проблемы можно назвать Flow, который позволяет эффективно добавлять операторы преобразования. По умолчанию данные передаются, преобразуются и собираются в одной корутине без необходимости в синхронизации.

Синхронизация возникает только в том случае, когда [producer и consumer работают в разных корутинах](https://elizarov.medium.com/kotlin-flows-and-coroutines-256260fb3bdb) (*при этом emit и filter из примера на картинке будут работать в одной корутине, что лучше ситуации, описанной двумя абзацами выше*).
#### Flows are cold
Однако вычисления данных для Flow обычно холодные (cold) — Flow, созданный билдером flow {…}, является пассивной сущностью. Рассмотрим следующий код:
```
val coldFlow = flow {
while (isActive) {
emit(nextEvent)
}
}
```
Сами Flow не начинают вычисляться и не хранят состояния пока на них не подпишется collector. Каждая корутина с collector-ом создает новый экземпляр кода, упаковывающего данные во Flow. Статья [“Cold flow, hot channels”](https://elizarov.medium.com/cold-flows-hot-channels-d74769805f9) описывает причины, лежащие в основе такой работы Flows, и показывает примеры использования, для которых они подходят лучше, чем Channels.

Но что насчет таких событий, как действия пользователя, события из операционной системы от датчиков устройства или о изменении состояния? Они появляются независимо от того, есть ли сейчас какой-либо collector, который в них потенциально заинтересован. Они также должны поддерживать нескольких collectors внутри приложения. Это так называемые горячие источники данных…
#### Shared flows
Вот здесь-то и появляется концепция SharedFlow. Shared Flow существует независимо от того, есть-ли сейчас collectors или нет. Collector у SharedFlow называется подписчиком (observer). Все observers получают одинаковую последовательность значений. Он работает как BroadcastChannel, но эффективнее и делает концепцию BroadcastChannel устаревшей.

SharedFlow — это легковесная широковещательный event bus, который вы можете создать и использовать в своей архитектуре приложения.
```
class BroadcastEventBus {
private val _events = MutableSharedFlow()
val events = \_events.asSharedFlow() // read-only public view
suspend fun postEvent(event: Event) {
\_events.emit(event) // suspends until subscribers receive it
}
}
```
Он имеет параметры для настройки, такие как количество старых событий, которые нужно сохранить и воспроизвести для новых подписчиков, и extraBufferCapacity, чтобы настроить поведение в случае быстрых emmiters и медленных observers.
Все observers SharedFlow асинхронно собирают данные в своем собственном coroutine context. Emmiter не ждет, пока подписчики закончат обработку данных. Однако, когда общий буфер SharedFlow заполнен, emmiter приостанавливается, пока в буфере не появится место. Альтернативные стратегии работы с переполненным буфером настраиваются параметром BufferOverlow.
#### State flows
Частый способ справиться с переполнением буфера — отбрасывать старые данные и сохранять только новые. В частности, при единичном размере буфера мы имеем дело со state variable. Это настолько распространенный вариант использования, что у него есть собственный специализированный тип — StateFlow. Он служит заменой ConflatedBroadcastChannel, который также устарел.
```
class StateModel {
private val _state = MutableStateFlow(initial)
val state = _state.asStateFlow() // read-only public view
fun update(newValue: Value) {
_state.value = newValue // NOT suspending
}
}
```
Смотрите на StateFlow как на изменяемую переменную, на изменения которой можно подписаться. Его последнее значение всегда доступно, и, фактически, последнее значение — единственное, что важно для observers.
Разница в производительности StateFlow с Channel и обычным Flow становится очевидной — StateFlow обновляет состояние без выделения памяти.
#### Что будет с Channels
По мере того, как разные виды Flow заменяют разные виды BroadcastChannel, возникает популярный вопрос: что произойдет с Channels? Они останутся в следующих версиях языка по многим причинам. Одна из причин заключается в том, что Channels представляют из себя низкоуровневые примитивы, которые используются для реализации многих сложных операторов, на которых базируется Flow.
Но у Channels также есть свои варианты использования. Channels могут быть использованы для обработки событий, которые должны быть обработаны ровно один раз. Это происходит в проекте с типом события, которое обычно имеет одного подписчика, но периодически (при запуске или во время некоторой реконфигурации) подписчиков вообще нет, и есть требование, чтобы все опубликованные события сохранялись до тех пор, пока не появился подписчик.
```
class SingleShotEventBus {
private val _events = Channel()
val events = \_events.receiveAsFlow() // expose as flow
suspend fun postEvent(event: Event) {
\_events.send(event) // suspends on buffer overflow
}
}
```
Оба примера, BroadcastEventBus, который написан с SharedFlow, и этот SingleShotEventBus, который написан с Channel, выставляют наружу данные в виде Flow , но у них есть важное отличие.
В SharedFlow события транслируются неизвестному количеству (⩾0) подписчиков. При отсутствии подписчика любое опубликованное событие немедленно удаляется. Это шаблон проектирования можно использовать для событий, которые должны обрабатываться немедленно или не обрабатываться вообще.
С помощью Channel каждое событие доставляется только одному подписчику. Попытка опубликовать событие без подписчиков будет приостановлена, как только буфер канала заполнится, ожидая появления подписчика. По умолчанию опубликованные события не удаляются.
#### Заключение
Знайте разницу и правильно используйте как SharedFlow, так и Channels. Они оба полезны и предназначены для совместной работы. Однако BroadcastChannels — это пережитки прошлого, которые в будущем будут удалены. | https://habr.com/ru/post/529944/ | null | ru | null |
# Как обхитрить тайм трекер при помощи Arduino
Здравствуйте!
Вся моя семья работает удалённо. Супруга работает в крупной организации, в которой осуществляется мониторинг рабочего времени. Мониторинг реагирует на нажатие кнопок клавиатуры и колесо прокрутки мыши, с таймаутом 5 минут. Жена переболела COVID-19 и после болезни стала сильно уставать во время работы, поэтому позволяет себе небольшие перерывчики. На время этих перерывчиков она просит меня покрутить колесико мыши, но я бывает так увлекусь работой, что забываю это сделать. В связи с этим у меня возникло желание автоматизировать этот процесс.
---
Я вспомнил что у меня валяется Arduino Leonardo, а его легко запрограммировать на имитацию клавиатуры и мыши. Покопавшись в ящиках нашел его и запрограммировал на имитацию колесика мыши. Но жена меня раскритиковала, так как у них запрещается пользоваться не зарегистрированными USB устройствами (а Arduino обязательно вызовет вопросы). Поэтому было решено крутить колесико мыши механически, для чего был заказан шаговый двигатель 28BYJ-48 в комплекте с драйвером двигателя на микросхеме ULN2003 и взят из другого «пыльного» ящика Arduino Nano.
Рисунок 1. Шаговый двигатель 28BYJ-48 с драйвером на микросхеме ULN2003.Подключил двигатель и кнопку к Arduno, двигатель запитывал как напрямую через Arduino, так и через внешний источник питания. Сейчас двигатель запитывается через Arduino (так меньше проводов висит, а Аrduino это терпит). Написал скетч (как смог) имитирующий прокрутку документа человеком при изучении сложного документа. Прокрутка осуществляется группами то в одну, то в другую сторону через разные промежутки времени. Запустить/остановить процесс скроллинга можно нажатием на кнопку или командами «START», «STOP» переданными по последовательному порту.
 с питанием от Arduino.")Рисунок 2. Схема подключения шагового двигателя (через драйвер) с питанием от Arduino. с внешним питанием.")Рисунок 3. Схема подключения шагового двигателя (через драйвер) с внешним питанием.
```
#include
#include
#define HALFSTEP 8
// Определение пинов для управления двигателем
#define motorPin1 2 // IN1 на 1-м драйвере ULN2003
#define motorPin2 3 // IN2 на 1-м драйвере ULN2003
#define motorPin3 4 // IN3 на 1-м драйвере ULN2003
#define motorPin4 5 // IN4 на 1-м драйвере ULN2003
// Инициализируемся с последовательностью выводов IN1-IN3-IN2-IN4
// для использования AccelStepper с 28BYJ-48
AccelStepper stepper1(HALFSTEP, motorPin1, motorPin3, motorPin2, motorPin4);
String str = "START";
const int buttonPin = 12; // Номер пина кнопки
const int minMaxSpeed = 800;
const int maxMaxSpeed = 1300;
const int minAcceleration = 500;
const int maxAcceleration = 700;
const int minSpeed = 700;
const int maxSpeed = 1000;
const int move = 600; // примерная длина одного перемещения
const int minPause = 1; // Минимальная пауза между группами прокруток (секунды)
const int maxPause = 3\*60; // Максимальная пауза между группами прокруток (секунды)
long pos = 0;
int smove = move;
int sMaxSpeed = maxMaxSpeed;
int sAcceleration = maxAcceleration;
int sSpeed = maxSpeed;
unsigned msec = 1000;
bool PREV = false;
int dir = 50;
int count = 5;
void setup(){
pinMode(LED\_BUILTIN, OUTPUT); // Светодиод (красный) для сигнализации (светит - стоп, не светит - работа)
Serial.begin(9600);
Serial.println("start");
stepper1.setMaxSpeed(sMaxSpeed);
stepper1.setAcceleration(sAcceleration);
stepper1.setSpeed(sSpeed);
pinMode(buttonPin, INPUT\_PULLUP); // Настройка кнопки
stepper1.move(move);
}
int inputHandler(){ // Чтение команд из порта и отслеживание нажатия кнопки
int res = 0;
if (Serial.available() > 0) {
str=Serial.readString();
str.trim();
Serial.println(">>>>>>>>>>>>>>>>>");
Serial.println(str);
res = 1;
}
buttonState = digitalRead(buttonPin);
if (buttonState == LOW && PREV == HIGH ) {
if (str=="START") {
str = "STOP";
Serial.println("Press button to 'STOP'");
stepper1.move(0);
res = 1;
} else {
str = "START";
Serial.println("Press button to 'START'");
res = 1;
}
delay(150);
}
if (str!="START") {
digitalWrite(LED\_BUILTIN, HIGH);
} else {
digitalWrite(LED\_BUILTIN, LOW);
}
PREV = buttonState;
return res;
}
int delayWithRead(unsigned ms){ // Пауза с обработкой ввода
Serial.print("Delay = ");
Serial.print(ms);
Serial.println(" msec.");
int time = 0;
while (time100){ // Крутить только если чуть ниже стартовой позиции
stepper1.move(smove); // Задать поворот относительно текущей позиции
}
}
void loop(){ // Основной цикл
inputHandler(); // Обработка ввода
if(stepper1.distanceToGo()==0) { // Если поворот закончили
if (str=="START") goNewPosition(); // Получаем следующую позицию
}
if (str=="START"){ // Если нет команды стоять то
stepper1.run(); // Крутим движок
}
}
```
Из картона сделал футляр для мыши, к которому прикрепил Arduino и двигатель с ведущим колесом которое кладется на колесико мыши и вращает его.
Рисунок 4. Вид гаджета с одной стороны.Рисунок 5. Вид гаджета с другой стороны.")Рисунок 6. Гаджет с подопытной мышью:)Рисунок 7. Мышь в гаджете.Как работает устройство можно посмотреть в видео.
Теперь, когда жене надо отлучиться, она вкладывает мышь в футляр и просто включает этот девайс. | https://habr.com/ru/post/593697/ | null | ru | null |
# Нумерология: никакого гадания, только теория чисел
В данной статье речь пойдёт о таких понятиях теории чисел, как цифровой корень и ведический квадрат.
Данная статья ничего не говорит о нумерологии, кроме того, что это псевдонаучная концепция.
Цель данной статьи: показать математические закономерности вокруг вычисления цифрового корня и его связь с циклическими числами.
Введение
--------
Несколько дней назад я решил написать незатейливую статью про нумерологическое сложение. Моей целью было показать, что даже такая незамысловатая операция может иметь большое количество интересных закономерностей. Многие из этих закономерностей я нашёл ещё в школьное время, когда скучал на уроках географии. При внимательном рассмотрении я нашёл больше закономерностей, чем ожидал, и это привело меня назад к моей любимой теме [full reptend prime](http://Full%20reptend%20prime).
После я внимательно изучил то, что нашёл, узнал, что многие из этих понятий уже существуют, и решил переписать статью заново, чтобы опираться на общеизвестные понятия. Помимо известных понятий я добавил собственные визуализации, чтобы сделать чтение немного более увлекательным.
Сумма цифр и цифровой корень
----------------------------
[Цифровой корень](https://en.wikipedia.org/wiki/Digital_root) натурального числа в заданной системе счисления — это значение, получаемое итеративным расчётом [суммы цифр](https://en.wikipedia.org/wiki/Digit_sum), где на первой итерации происходит расчёт суммы цифр натурального числа, а на каждой следующей - расчёт суммы цифр результата предыдущей итерации. Операция выполняется до тех пор, пока вычисленное значение не становится меньше заданной системы счисления, т.е. до тех пор, пока оно не равняется одной-единственной цифре.
[Аддитивная стойкость](https://en.wikipedia.org/wiki/Digital_root#Additive_persistence) натурального числа — это количество итераций, на которых нужно применить операцию суммы цифр, для того чтобы получить цифровой корень.
Пример: Цифровая сумма числа 142857 равна 1 + 4 + 2 + 8 + 5 + 7 = 27
Цифровая сумма числа 27 равна 2 + 7 = 9
Как следствие, цифровой корень числа 142857 = 9, аддитивная стойкость 142857 = 2.
Код для вычисления цифрового корня в произвольной системе счисления на языке Python:
```
def digitalRootRecurrent(number, base):
digitSum = 0
while number > 0:
digitSum += number % base
number //= base
if digitSum >= base:
digitSum = digitalRootRecurrent(digitSum, base)
return digitSum
```
Применение цифровой суммы
-------------------------
Цифровые суммы применялись при расчёте контрольных сумм для проверки арифметических операций ранних компьютеров. Ранее, в эпоху ручного счета, [Фрэнсис Исидор Эджуорт](https://ru.wikipedia.org/wiki/%D0%AD%D0%B4%D0%B6%D1%83%D0%BE%D1%80%D1%82,_%D0%A4%D1%80%D1%8D%D0%BD%D1%81%D0%B8%D1%81_%D0%98%D1%81%D0%B8%D0%B4%D0%BE%D1%80) предложил использовать суммы 50 цифр, взятых из математических таблиц логарифмов, в качестве формы генерации случайных чисел; если предположить, что каждая цифра случайна, то по центральной предельной теореме эти цифровые суммы будут иметь случайное распределение, близкое к [гауссову распределению](https://ru.wikipedia.org/wiki/%D0%9D%D0%BE%D1%80%D0%BC%D0%B0%D0%BB%D1%8C%D0%BD%D0%BE%D0%B5_%D1%80%D0%B0%D1%81%D0%BF%D1%80%D0%B5%D0%B4%D0%B5%D0%BB%D0%B5%D0%BD%D0%B8%D0%B5).
Цифровая сумма двоичного представления числа известна как [вес Хэмминга](https://en.wikipedia.org/wiki/Hamming_weight) или численность населения. Алгоритмы выполнения этой операции были изучены, и она была включена в качестве встроенной операции в некоторые компьютерные архитектуры и некоторые языки программирования. Эти операции используются в вычислительных приложениях, включая криптографию, теорию кодирования и компьютерные шахматы.
Улучшение алгоритма вычисления цифрового корня
----------------------------------------------
При расчёте цифрового корня можно воспользоваться небольшой хитростью: если значение не равно нулю, и не равно основанию системы счисления - 1, можно получить значение цифрового корня просто операцией взятия остатка от деления на основание системы счисления - 1.
Модифицированный код:
```
def digitalRoot(number, base):
if number == 0:
return 0
dR = number % (base - 1)
if dR == 0:
dR = base - 1
return dR
```
Свойства цифрового корня
------------------------
Операция сложения
-----------------
Сделаем небольшую таблицу, для того чтобы изучить закономерности, каким образом вычисляется цифровой корень суммы двух чисел:
Таблица для анализа операции цифрового корня суммы двух чисел. Код для построения таблицы суммы:
```
firstTermRangeStart = 2
firstTermRangeEnd = 8
secondTermRangeStart = 1
secondTermRangeEnd = 9
base = 10
for j in range(firstTermRangeStart, firstTermRangeEnd + 1):
print()
for i in range(secondTermRangeStart, secondTermRangeEnd + 1):
if i % (secondTermRangeEnd + 1) == 0:
print()
print('dr(',j,'+', i, ') =', digitalRoot(j + i, base), ' ', end='')
```
Как можно увидеть, цифровой корень суммы чисел равен цифровому корню суммы цифровых корней этих чисел:
Операция вычитания
------------------
Формула похожа на предыдущую, однако совпадает не полностью.
Приведем контрпример: 455 - 123 = 332.
Как можно отметить, выражение 4 - 6 не даёт в результате 8, потому формулу сложения нужно модифицировать, чтобы она работала для операции вычитания:
Операция умножения
------------------
Выведем вариацию таблицы умножения, для того чтобы исследовать эту операцию:
Расчет цифрового корня от двух множителейКод для вывода таблицы умножения:
```
firstTermRangeStart = 1
firstTermRangeEnd = 8
secondTermRangeStart = 1
secondTermRangeEnd = 9
base = 10
for i in range(secondTermRangeStart, secondTermRangeEnd + 1):
print()
for j in range(firstTermRangeStart, firstTermRangeEnd + 1):
print('dr(',j,'*', i, ') =', digitalRoot(i * j, base), ' ', end='')
```
Запишем значения для каждого множителя:
1) [1, 2, 3, 4, 5, 6, 7, 8, 9]
2) [2, 4, 6, 8, 1, 3, 5, 7, 9]
3) [3, 6, 9, 3, 6, 9, 3, 6, 9]
4) [4, 8, 3, 7, 2, 6, 1, 5, 9]
5) [5, 1, 6, 2, 7, 3, 8, 4, 9]
6) [6, 3, 9, 6, 3, 9, 6, 3, 9]
7) [7, 5, 3, 1, 8, 6, 4, 2, 9]
8) [8, 7, 6, 5, 4, 3, 2, 1, 9]
9) [9, 9, 9, 9, 9, 9, 9, 9, 9]
Можно увидеть, что последовательности разбиваются на пары 1 и 8, 2 и 7, 3 и 6, 4 и 5. В каждой из пар сохраняется та же самая последовательность, но они представляют собой реверсированные копии друг друга, за исключением последнего элемента, который связан с множителем, равным основанию системы счисления - 1.
Также отметим, что при умножении на основание системы счисления -1 цифровой корень будет равен основанию системы счисления - 1. При умножении на 1 значение цифрового корня второго множителя сохраняется.
Визуализация последовательностей:
Последовательности для множителей 1, 2, 3, 4. Они же являются зеркальными для 8, 7, 6, 5.Последовательности можно рассмотреть как множество всех возможных замкнутых фигур с количеством точек, равным основанию системы счисления - 1, начиная с правильного n-угольника. Исключением является множитель, который не является взаимно простым с основанием системы счисления - 1, в данном случае это 3 и 6.
Для нахождения последовательности любой линии можно записать формулу:
Если записать эти значения как множество пересечений всех множителей, мы получим в результате [ведический квадрат](https://en.wikipedia.org/wiki/Vedic_square).
Ведический квадрат для десятичной системы счисления.Подмножество данного ведического квадрата формирует собой [латинский квадрат](https://ru.wikipedia.org/wiki/%D0%9B%D0%B0%D1%82%D0%B8%D0%BD%D1%81%D0%BA%D0%B8%D0%B9_%D0%BA%D0%B2%D0%B0%D0%B4%D1%80%D0%B0%D1%82). Чтобы получить его, нужно вычеркнуть элементы, равные основанию системы счисления - 1.
Приведение ведического квадрата к латинскому квадрату в десятичной системе счисления.В результате мы получим:
Подмножество ведического квадрата, составляющее латинский квадрат в десятичной системе счисления.Если переставить некоторые из его строчек местами, мы получим последовательность циклических чисел. О том, каким образом должны быть осуществлены перестановки строчек, будет рассказано ниже при исследовании других операций с цифровым корнем.
Ниже приведена ещё одна картинка ведических квадратов для систем счисления 100 и 1000. Белым отмечены самые большие значения клеток - соответствующие основанию системы счисления - 1, черным - самые маленькие, соответствующие 1.
Ведические квадраты для систем счисления 100 и 1000.Теперь вернемся к произведению. Цифровой корень произведения одиночных цифр в заданной системе счисления вычисляется при помощи соответствующего ведического квадрата.
Для вычисления цифрового корня произведения двух чисел, которые содержат больше одной цифры, для начала нужно вычислить цифровой корень каждой из этих цифр, и после этого воспользоваться ведической площадью.
**Операция деления**
Рассмотрим те числа, которые дают при делении непериодические дроби, это 2, 5, 4, 8.
Для того чтобы быть уверенными, что мы не допускаем ошибок, воспользуемся уже выведенными правилами и умножим результат деления на 1000; так как цифровой корень 1000 равен 1, то произведение будет иметь тот же самый цифровой корень.
Таблица деления для делителей, которые взаимно просты с десятичной системой счисления.
```
base = 10
divisors = [2, 4, 5, 8]
for j in divisors:
print()
for i in range(1, base):
value = (digitalRoot(int((i / j) * (base ** 3)), base))
print('dr(',i, '/', j, ') =', value, ' ', end='')
```
Тут бросаются в глаза несколько закономерностей. Число 9 не только при умножении, но и при делении приводит к значению цифрового корня, равному 9. Интересное происходит также с числами 3 и 6, эти числа как при умножении, так и при делении дают абсолютно одинаковые значения цифрового корня.
Запишем в таблицу череду делений:
2) [5, 1, 6, 2, 7, 3, 8, 4, 9] - Эта последовательность встречалась в множителе 5
4) [7, 5, 3, 1, 8, 6, 4, 2, 9] - Эта последовательность встречалась в множителе 7
5) [2, 4, 6, 8, 1, 3, 5, 7, 9] - Эта последовательность встречалась в множителе 2
8) [8, 7, 6, 5, 4, 3, 2, 1, 9] - Эта последовательность встречалась в множителе 8
Операция деления для цифрового корня определена только для делителей, которые не являются взаимно простыми с основанием системы счисления.
Операция возведения в степень
-----------------------------
Таблица возведения в степень:
Таблица возведения в степень в десятичной системе счисления.
```
base = 10
.
for i in range(2, base - 2):
print()
for j in range(1, base - 1):
print('dr(', j ,'^', i, ') =', digitalRoot(i ** j, base), ' ', end='')
```
Здесь мы можем наблюдать цикличность.
При внимательном рассмотрении других систем счисления можно сделать вывод, что эта череда связана с формированием остатков от деления, и таким образом она связалась с моим любимым классом простых чисел - full reptend prime.
Для того чтобы пояснить это, рассмотрим операции возведения в степень в других системах счисления. Забегая вперед, скажу: наиболее интересными будут являться такие степени счисления, которые равны p^n + 1, где p — это простое число, а n - натуральное.
Рассмотрим систему счисления 8, череда его значений будет равна [1, 3, 2, 6, 4, 5]. Именно такие же остатки от деления мы получаем при делении числа в десятичной системе счисления.
![Деление 1 на 7 в столбик. Здесь мы можем наблюдать остатки от деления [1, 3, 2, 6, 4, 5]. ](https://habrastorage.org/r/w1560/getpro/habr/upload_files/740/9dc/7d8/7409dc7d835e4080385e4973454b939c.png "Деление 1 на 7 в столбик. Здесь мы можем наблюдать остатки от деления [1, 3, 2, 6, 4, 5]. ")Деление 1 на 7 в столбик. Здесь мы можем наблюдать остатки от деления [1, 3, 2, 6, 4, 5]. Последовательность полученная при возведении в степень, в восьмеричной системе счисления.Это свойство связано с тем, что вычисление цифрового корня можно осуществить при помощи альтернативной формулы расчета цифрового корня:
Ещё визуализации
----------------
Приведём ниже визуализации для операции возведения в степень для разных систем счисления, все они будут связанны с паттернами, образующимися в рациональных дробях 1/P, где P - это full reptend prime.
Остатки от деления, найденные в 6 системе счисления, связанные с числом 5.Остатки от деления, найденные в 10 системе счисления, связанные с квадратом числа 3.Остатки от деления, найденные в 12 системе счисления, связанные с числом 11.Остатки от деления, найденные в 14 системе счисления, связанные с числом 13.Остатки от деления, найденные в 18 системе счисления, связанные с числом 17.Остатки от деления, найденные в 20 системе счисления, связанные с числом 19.Остатки от деления, найденные в 26 системе счисления, связанные с квадратом числа 5.Остатки от деления, найденные в 28 системе счисления, связанные с кубом числа 3.Теперь приведём несколько картинок из ведических квадратов, принцип их формирования очень прост, потому ограничимся небольшим количеством:
Замкнутая фигура из 6 системы счисления, связана с числом 5.Замкнутые фигуры из 8 системы счисления, связанные с числом 7.Замкнутые фигуры из 12 системы счисления, связанные с числом 11.Образование циклических чисел при помощи ведической площади и остатков от деления
---------------------------------------------------------------------------------
После того как мы получили латинский квадрат из ведического квадрата, пронумеруем его строки последовательно:
Пронумерованный латинский квадрат.Теперь мы можем переставить строки на основании череды остатков от деления, таким образом мы получим последовательность циклических чисел. Напомню, остатки от деления были равны [1, 3, 2, 6, 4, 5]. В результате у нас получится следующая картина:
Перестановки в пронумерованном латинском квадрате, в результате мы получили циклическое число.Как можно наблюдать, первый столбец теперь представляет собой циклическое число 142857.
**Выводы**
Несмотря на плохую репутацию нумерологии, операции суммы цифр и цифрового корня имеют пусть не широкое, но всё же практическое применение.
Например, с помощью цифрового корня можно сформировать множество замкнутых n-вершинных звезд, многие из которых очень любят современные рок\метал группы :)
 Уроборос тут не случайно, о нем в следующей статье!")Пентаграмма - в представлении не нуждается :) Уроборос тут не случайно, о нем в следующей статье!Tool предпочитают 8 систему счисления, связанную с простым числом 7.Slipknot тяготеют к десятеричной системе счисления, связанной с квадратом числа 3.Как можно видеть, многие метал группы тоже любят теорию чисел!
Но лично я для своей метал группы решил выбрать анимированный логотип, составленный из одновременной визуализации периодических дробей, образованных из 90 рациональных дробей 1/91..90/91:
")Почему я выбрал число 91, которое является произведением 7 и 13? Речь об этом пойдет в следующей статье :)Если у кого-то есть дополнительная информация об описанных выше понятиях, пожалуйста присылайте её в комментарии, я буду очень благодарен!
Надеюсь, что вам было интересно, большое спасибо за внимание! | https://habr.com/ru/post/556564/ | null | ru | null |
# Как Microsoft забыла про полмира или читайте сообщения об ошибках
Нет, это статья не про то, какой огромный и злобный монстр компания Microsoft. И как она опять обижает пользователей. А про то, как исправить досадный изъян, появившийся с последним, августовским обновлением **Power BI Desktop** c включённой поддержкой **Python**, а именно проблемы с визуализацией в локализованных версиях PBI, в частности **[matplotlib](https://ru.wikipedia.org/wiki/Matplotlib)**.
В первой декаде августа Microsoft выпустила давно и с нетерпением ожидавшийся релиз своего действительно замечательного BI-продукта с поддержкой языка [Python](https://ru.wikipedia.org/wiki/Python). На момент написания статьи эта функциональность находится в разделе предварительных возможностей (т.е. просто бета-версия).
Я давно и с удовольствием использую Power BI в своей работе (и как аналитик данных и как разработчик BI). Всегда стараюсь попробовать новинки функциональности, которые щедро анонсируются в разделе предварительных версий. И, надо отдать должное команде разработки Microsoft, это почти всегда добротные, пригодные к работе версии фич, опций и визуализаций.
Особенно ожидалось BI-сообществом включение в Power BI поддержки Python. Не то, чтобы встроенной функциональности Power BI не хватало для реализации самых заковыристых задач, решаемых BI-системами. Около 250 функций встроенного языка запросов [DAX](https://ru.wikipedia.org/wiki/DAX_(%D1%8F%D0%B7%D1%8B%D0%BA_%D0%B7%D0%B0%D0%BF%D1%80%D0%BE%D1%81%D0%BE%D0%B2)) и ещё более семисот функций Power Query позволяли решать практически любые задачи BI, от получения данных из самых разных источников, построения модели данных и до поддержки визуализаций и отчётов. В прошлом году была добавлена поддержка языка R, что резко расширило возможности Power BI в плане выполнения научных расчётов, новых визуализаций и даже машинного обучения.
Однако не секрет, что на сегодняшний день лидером в среде Data Science среди языков программирования является именно Python. И включение этого языка в BI-экосистему Microsoft превращает Power BI в эдакий швейцарский нож для подготовки, анализа и финального представления данных. С полноценной поддержкой четырёх специализированных языков (DAX, Power Query /M, R, Python) и ограниченной, в рамках необходимой функциональности SQL и MDX. Некоторые гики прикручивают ещё JavaScript, но это отдельный разговор.
Не являясь практикующим разработчиком Python, я всё же с нетерпением включил экспериментальную поддержку Python, чтобы протестировать новые, открывающиеся горизонты. Установил галочку в меню последнего релиза PBI и перезагрузил приложение. Подробнее о подключении и настройке можно прочитать в [блоге Microsoft](https://powerbi.microsoft.com/en-us/blog/pythonblogepisode1/).
У меня уже была установлена предыдущая версия Python и я решил рискнуть и не заморачиваться с установкой новой. В итоге в источниках данных появился новый коннектор – «Скрипт Pyton», а на панели визуализаций новая иконка [**Py**].
Однако на этом этапе пайтоновский код не выполнялся. Не буду описывать все перипетии, связанные с попыткой запустить в знакомом мне окружении и Power BI незнакомый (почти) Python.

Как бы то ни было, даже чистая установка сборки Anaconda с огромным количеством предустановленных библиотек, продвинутым менеджером пакетов и т. п. практически ни на йоту не продвинули меня к заветным «картинкам». Разные версии Python выдавали на мой тестовый код разные сообщения об ошибках, и я был слегка обескуражен. Поиск Google по этим сообщениям тоже не давал адекватных результатов. Недавно появившийся на портале, в сообществе Power BI (<https://community.powerbi.com>) запрос датского пользователя о похожей проблеме натолкнул на давно зревшую мысль – дело не в мой конфигурации компьютера с гремучей смесью установленного ПО (причём проверял я на разных своих машинах, но на них везде – гремучая смесь, только разная). Дело в локализации.
Когда стало ясно, в какую сторону смотреть, на уточнённые запросы стали попадаться более вменяемые ответы поисковиков. Но смысл был везде один: «В текущей версии Power BI нельзя использовать формат чисел с десятичной запятой, а только с десятичной точкой, совместно с Python. Ждите обновлённой версии или меняйте формат представления чисел».
В Power BI поменять формат числа можно за пару секунд через меню, но что делать с тоннами готовых отчётов и исходными данными? Овчинка тут явно не стоила выделки.
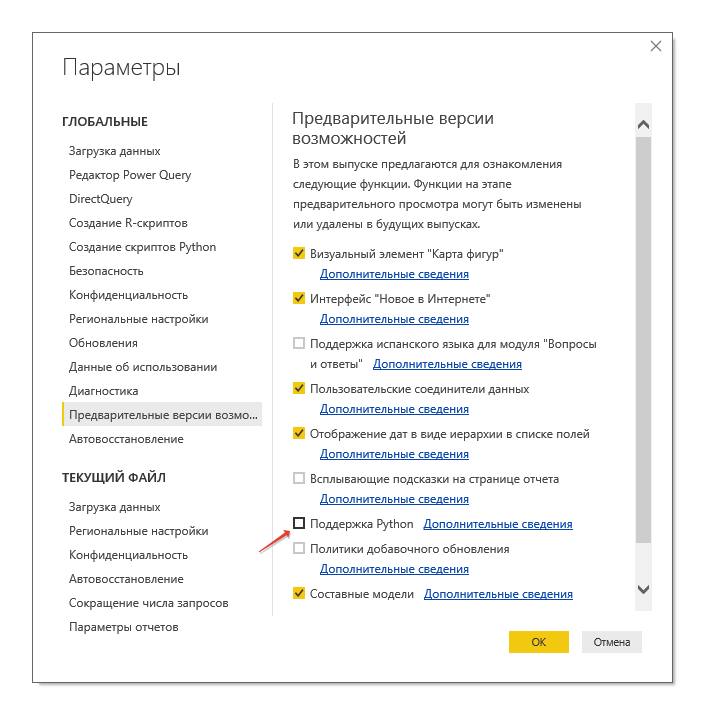
В этот момент все страждущие «питона под пауэр би» разделились на два лагеря: американцы и англичане с десятичной точкой и все остальные. Часть «оставшихся за бортом текущей версии» спешно переметнулась к первой группе, установив в качестве стандартного разделителя точку. Остальные понура принялись ждать исправленного релиза. Но т.к. это бета-версия и перевод в продуктовую функциональность может занять и два месяца и полгода, ожидать исправлений со дня на день точно не стоило.
И в этот момент я решил повнимательнее прочитать сообщение об ошибке:

Повнимательнее, потому что ошибка относилась не к моему коду, который в [Jypyter](https://ru.wikipedia.org/wiki/IPython) исполнялся как раз без ошибок и отображал все визуальные элементы без каких бы то ни было проблем. Проблема была вызвана дополнительным кодом, который Microsoft внедрила для интеграции Python с Power BI. А именно с вызовом библиотеки matplotlib (<https://ru.wikipedia.org/wiki/Matplotlib>) и конкретно функции pyplot (файл pyplot.py).
Но на то и ПО с открытым исходным кодом, чтобы запустить в него свои шаловливые ручонки. Недолго думая, открыв сто тридцати килобайтный код функции по приведённому в тексте ошибки адресу обнаружил, что сбой возникает при инициализации figManager.
В исходном коде библиотеки этот код на Python выглядит так:
```
figManager = new_figure_manager(num, figsize=figsize,
dpi=dpi,
facecolor=facecolor,
edgecolor=edgecolor,
frameon=frameon,
FigureClass=FigureClass,
**kwargs)
```
Соблюдая уважение к столь важной библиотеке я просто закомментировал код вызова проблемного параметра **figsize**, в который Microsoft передаёт в локализованных версиях четыре аргумента из Poiwer BI вместо двух, и передал этому параметру значение размеров визуализации по умолчанию.
Теперь этот код выглядит так:
```
figManager = new_figure_manager(num,
figsize=rcParams['figure.figsize'],
#figsize=figsize,
dpi=dpi,
facecolor=facecolor,
edgecolor=edgecolor,
frameon=frameon,
FigureClass=FigureClass,
**kwargs)
```
В актуальной сборке Anaconda это 542-549 строки. Если у вас другая версия библиотеки, просто поищите вхождение «figManager» и внесите необходимые изменения и сохраните исправленную библиотеку под тем же именем (для этого понадобятся права администратора).
После этого просто перезапустите код визуализации на исполнение и наслаждайтесь результатом… Ну, или подождите, пока гора не придёт к Магомету, точнее Microsoft к Python.
Юрий Колмаков ([McCow](https://habr.com/users/mccow/)) | https://habr.com/ru/post/421659/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.