
problem_id
stringlengths 18
22
| source
stringclasses 1
value | task_type
stringclasses 1
value | in_source_id
stringlengths 13
58
| prompt
stringlengths 1.71k
18.9k
| golden_diff
stringlengths 145
5.13k
| verification_info
stringlengths 465
23.6k
| num_tokens_prompt
int64 556
4.1k
| num_tokens_diff
int64 47
1.02k
|
|---|---|---|---|---|---|---|---|---|
gh_patches_debug_15401 | rasdani/github-patches | git_diff | pytorch__text-1912 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
todo-decorator-remove-solved
Removed the code as the issue is closed.
</issue>
<code>
[start of torchtext/datasets/multi30k.py]
1 import os
2 from functools import partial
3 from typing import Union, Tuple
4
5 from torchtext._internal.module_utils import is_module_available
6 from torchtext.data.datasets_utils import (
7 _wrap_split_argument,
8 _create_dataset_directory,
9 )
10
11 if is_module_available("torchdata"):
12 from torchdata.datapipes.iter import FileOpener, IterableWrapper
13 from torchtext._download_hooks import HttpReader
14
15 # TODO: Update URL to original once the server is back up (see https://github.com/pytorch/text/issues/1756)
16 URL = {
17 "train": r"https://raw.githubusercontent.com/neychev/small_DL_repo/master/datasets/Multi30k/training.tar.gz",
18 "valid": r"https://raw.githubusercontent.com/neychev/small_DL_repo/master/datasets/Multi30k/validation.tar.gz",
19 "test": r"https://raw.githubusercontent.com/neychev/small_DL_repo/master/datasets/Multi30k/mmt16_task1_test.tar.gz",
20 }
21
22 MD5 = {
23 "train": "20140d013d05dd9a72dfde46478663ba05737ce983f478f960c1123c6671be5e",
24 "valid": "a7aa20e9ebd5ba5adce7909498b94410996040857154dab029851af3a866da8c",
25 "test": "6d1ca1dba99e2c5dd54cae1226ff11c2551e6ce63527ebb072a1f70f72a5cd36",
26 }
27
28 _PREFIX = {
29 "train": "train",
30 "valid": "val",
31 "test": "test",
32 }
33
34 NUM_LINES = {
35 "train": 29000,
36 "valid": 1014,
37 "test": 1000,
38 }
39
40 DATASET_NAME = "Multi30k"
41
42
43 def _filepath_fn(root, split, _=None):
44 return os.path.join(root, os.path.basename(URL[split]))
45
46
47 def _decompressed_filepath_fn(root, split, language_pair, i, _):
48 return os.path.join(root, f"{_PREFIX[split]}.{language_pair[i]}")
49
50
51 def _filter_fn(split, language_pair, i, x):
52 return f"{_PREFIX[split]}.{language_pair[i]}" in x[0]
53
54
55 @_create_dataset_directory(dataset_name=DATASET_NAME)
56 @_wrap_split_argument(("train", "valid", "test"))
57 def Multi30k(root: str, split: Union[Tuple[str], str], language_pair: Tuple[str] = ("de", "en")):
58 """Multi30k dataset
59
60 .. warning::
61
62 using datapipes is still currently subject to a few caveats. if you wish
63 to use this dataset with shuffling, multi-processing, or distributed
64 learning, please see :ref:`this note <datapipes_warnings>` for further
65 instructions.
66
67 For additional details refer to https://www.statmt.org/wmt16/multimodal-task.html#task1
68
69 Number of lines per split:
70 - train: 29000
71 - valid: 1014
72 - test: 1000
73
74 Args:
75 root: Directory where the datasets are saved. Default: os.path.expanduser('~/.torchtext/cache')
76 split: split or splits to be returned. Can be a string or tuple of strings. Default: ('train', 'valid', 'test')
77 language_pair: tuple or list containing src and tgt language. Available options are ('de','en') and ('en', 'de')
78
79 :return: DataPipe that yields tuple of source and target sentences
80 :rtype: (str, str)
81 """
82
83 assert len(language_pair) == 2, "language_pair must contain only 2 elements: src and tgt language respectively"
84 assert tuple(sorted(language_pair)) == (
85 "de",
86 "en",
87 ), "language_pair must be either ('de','en') or ('en', 'de')"
88
89 if not is_module_available("torchdata"):
90 raise ModuleNotFoundError(
91 "Package `torchdata` not found. Please install following instructions at https://github.com/pytorch/data"
92 )
93
94 url_dp = IterableWrapper([URL[split]])
95
96 cache_compressed_dp = url_dp.on_disk_cache(
97 filepath_fn=partial(_filepath_fn, root, split),
98 hash_dict={_filepath_fn(root, split): MD5[split]},
99 hash_type="sha256",
100 )
101 cache_compressed_dp = HttpReader(cache_compressed_dp).end_caching(mode="wb", same_filepath_fn=True)
102
103 cache_compressed_dp_1, cache_compressed_dp_2 = cache_compressed_dp.fork(num_instances=2)
104
105 src_cache_decompressed_dp = cache_compressed_dp_1.on_disk_cache(
106 filepath_fn=partial(_decompressed_filepath_fn, root, split, language_pair, 0)
107 )
108 src_cache_decompressed_dp = (
109 FileOpener(src_cache_decompressed_dp, mode="b")
110 .load_from_tar()
111 .filter(partial(_filter_fn, split, language_pair, 0))
112 )
113 src_cache_decompressed_dp = src_cache_decompressed_dp.end_caching(mode="wb", same_filepath_fn=True)
114
115 tgt_cache_decompressed_dp = cache_compressed_dp_2.on_disk_cache(
116 filepath_fn=partial(_decompressed_filepath_fn, root, split, language_pair, 1)
117 )
118 tgt_cache_decompressed_dp = (
119 FileOpener(tgt_cache_decompressed_dp, mode="b")
120 .load_from_tar()
121 .filter(partial(_filter_fn, split, language_pair, 1))
122 )
123 tgt_cache_decompressed_dp = tgt_cache_decompressed_dp.end_caching(mode="wb", same_filepath_fn=True)
124
125 src_data_dp = FileOpener(src_cache_decompressed_dp, encoding="utf-8").readlines(
126 return_path=False, strip_newline=True
127 )
128 tgt_data_dp = FileOpener(tgt_cache_decompressed_dp, encoding="utf-8").readlines(
129 return_path=False, strip_newline=True
130 )
131
132 return src_data_dp.zip(tgt_data_dp).shuffle().set_shuffle(False).sharding_filter()
133
[end of torchtext/datasets/multi30k.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/torchtext/datasets/multi30k.py b/torchtext/datasets/multi30k.py
--- a/torchtext/datasets/multi30k.py
+++ b/torchtext/datasets/multi30k.py
@@ -12,11 +12,10 @@
from torchdata.datapipes.iter import FileOpener, IterableWrapper
from torchtext._download_hooks import HttpReader
-# TODO: Update URL to original once the server is back up (see https://github.com/pytorch/text/issues/1756)
URL = {
- "train": r"https://raw.githubusercontent.com/neychev/small_DL_repo/master/datasets/Multi30k/training.tar.gz",
- "valid": r"https://raw.githubusercontent.com/neychev/small_DL_repo/master/datasets/Multi30k/validation.tar.gz",
- "test": r"https://raw.githubusercontent.com/neychev/small_DL_repo/master/datasets/Multi30k/mmt16_task1_test.tar.gz",
+ "train": "http://www.quest.dcs.shef.ac.uk/wmt16_files_mmt/training.tar.gz",
+ "valid": "http://www.quest.dcs.shef.ac.uk/wmt16_files_mmt/validation.tar.gz",
+ "test": "http://www.quest.dcs.shef.ac.uk/wmt16_files_mmt/mmt16_task1_test.tar.gz",
}
MD5 = {
| {"golden_diff": "diff --git a/torchtext/datasets/multi30k.py b/torchtext/datasets/multi30k.py\n--- a/torchtext/datasets/multi30k.py\n+++ b/torchtext/datasets/multi30k.py\n@@ -12,11 +12,10 @@\n from torchdata.datapipes.iter import FileOpener, IterableWrapper\n from torchtext._download_hooks import HttpReader\n \n-# TODO: Update URL to original once the server is back up (see https://github.com/pytorch/text/issues/1756)\n URL = {\n- \"train\": r\"https://raw.githubusercontent.com/neychev/small_DL_repo/master/datasets/Multi30k/training.tar.gz\",\n- \"valid\": r\"https://raw.githubusercontent.com/neychev/small_DL_repo/master/datasets/Multi30k/validation.tar.gz\",\n- \"test\": r\"https://raw.githubusercontent.com/neychev/small_DL_repo/master/datasets/Multi30k/mmt16_task1_test.tar.gz\",\n+ \"train\": \"http://www.quest.dcs.shef.ac.uk/wmt16_files_mmt/training.tar.gz\",\n+ \"valid\": \"http://www.quest.dcs.shef.ac.uk/wmt16_files_mmt/validation.tar.gz\",\n+ \"test\": \"http://www.quest.dcs.shef.ac.uk/wmt16_files_mmt/mmt16_task1_test.tar.gz\",\n }\n \n MD5 = {\n", "issue": "todo-decorator-remove-solved\nRemoved the code as the issue is closed.\n", "before_files": [{"content": "import os\nfrom functools import partial\nfrom typing import Union, Tuple\n\nfrom torchtext._internal.module_utils import is_module_available\nfrom torchtext.data.datasets_utils import (\n _wrap_split_argument,\n _create_dataset_directory,\n)\n\nif is_module_available(\"torchdata\"):\n from torchdata.datapipes.iter import FileOpener, IterableWrapper\n from torchtext._download_hooks import HttpReader\n\n# TODO: Update URL to original once the server is back up (see https://github.com/pytorch/text/issues/1756)\nURL = {\n \"train\": r\"https://raw.githubusercontent.com/neychev/small_DL_repo/master/datasets/Multi30k/training.tar.gz\",\n \"valid\": r\"https://raw.githubusercontent.com/neychev/small_DL_repo/master/datasets/Multi30k/validation.tar.gz\",\n \"test\": r\"https://raw.githubusercontent.com/neychev/small_DL_repo/master/datasets/Multi30k/mmt16_task1_test.tar.gz\",\n}\n\nMD5 = {\n \"train\": \"20140d013d05dd9a72dfde46478663ba05737ce983f478f960c1123c6671be5e\",\n \"valid\": \"a7aa20e9ebd5ba5adce7909498b94410996040857154dab029851af3a866da8c\",\n \"test\": \"6d1ca1dba99e2c5dd54cae1226ff11c2551e6ce63527ebb072a1f70f72a5cd36\",\n}\n\n_PREFIX = {\n \"train\": \"train\",\n \"valid\": \"val\",\n \"test\": \"test\",\n}\n\nNUM_LINES = {\n \"train\": 29000,\n \"valid\": 1014,\n \"test\": 1000,\n}\n\nDATASET_NAME = \"Multi30k\"\n\n\ndef _filepath_fn(root, split, _=None):\n return os.path.join(root, os.path.basename(URL[split]))\n\n\ndef _decompressed_filepath_fn(root, split, language_pair, i, _):\n return os.path.join(root, f\"{_PREFIX[split]}.{language_pair[i]}\")\n\n\ndef _filter_fn(split, language_pair, i, x):\n return f\"{_PREFIX[split]}.{language_pair[i]}\" in x[0]\n\n\n@_create_dataset_directory(dataset_name=DATASET_NAME)\n@_wrap_split_argument((\"train\", \"valid\", \"test\"))\ndef Multi30k(root: str, split: Union[Tuple[str], str], language_pair: Tuple[str] = (\"de\", \"en\")):\n \"\"\"Multi30k dataset\n\n .. warning::\n\n using datapipes is still currently subject to a few caveats. if you wish\n to use this dataset with shuffling, multi-processing, or distributed\n learning, please see :ref:`this note <datapipes_warnings>` for further\n instructions.\n\n For additional details refer to https://www.statmt.org/wmt16/multimodal-task.html#task1\n\n Number of lines per split:\n - train: 29000\n - valid: 1014\n - test: 1000\n\n Args:\n root: Directory where the datasets are saved. Default: os.path.expanduser('~/.torchtext/cache')\n split: split or splits to be returned. Can be a string or tuple of strings. Default: ('train', 'valid', 'test')\n language_pair: tuple or list containing src and tgt language. Available options are ('de','en') and ('en', 'de')\n\n :return: DataPipe that yields tuple of source and target sentences\n :rtype: (str, str)\n \"\"\"\n\n assert len(language_pair) == 2, \"language_pair must contain only 2 elements: src and tgt language respectively\"\n assert tuple(sorted(language_pair)) == (\n \"de\",\n \"en\",\n ), \"language_pair must be either ('de','en') or ('en', 'de')\"\n\n if not is_module_available(\"torchdata\"):\n raise ModuleNotFoundError(\n \"Package `torchdata` not found. Please install following instructions at https://github.com/pytorch/data\"\n )\n\n url_dp = IterableWrapper([URL[split]])\n\n cache_compressed_dp = url_dp.on_disk_cache(\n filepath_fn=partial(_filepath_fn, root, split),\n hash_dict={_filepath_fn(root, split): MD5[split]},\n hash_type=\"sha256\",\n )\n cache_compressed_dp = HttpReader(cache_compressed_dp).end_caching(mode=\"wb\", same_filepath_fn=True)\n\n cache_compressed_dp_1, cache_compressed_dp_2 = cache_compressed_dp.fork(num_instances=2)\n\n src_cache_decompressed_dp = cache_compressed_dp_1.on_disk_cache(\n filepath_fn=partial(_decompressed_filepath_fn, root, split, language_pair, 0)\n )\n src_cache_decompressed_dp = (\n FileOpener(src_cache_decompressed_dp, mode=\"b\")\n .load_from_tar()\n .filter(partial(_filter_fn, split, language_pair, 0))\n )\n src_cache_decompressed_dp = src_cache_decompressed_dp.end_caching(mode=\"wb\", same_filepath_fn=True)\n\n tgt_cache_decompressed_dp = cache_compressed_dp_2.on_disk_cache(\n filepath_fn=partial(_decompressed_filepath_fn, root, split, language_pair, 1)\n )\n tgt_cache_decompressed_dp = (\n FileOpener(tgt_cache_decompressed_dp, mode=\"b\")\n .load_from_tar()\n .filter(partial(_filter_fn, split, language_pair, 1))\n )\n tgt_cache_decompressed_dp = tgt_cache_decompressed_dp.end_caching(mode=\"wb\", same_filepath_fn=True)\n\n src_data_dp = FileOpener(src_cache_decompressed_dp, encoding=\"utf-8\").readlines(\n return_path=False, strip_newline=True\n )\n tgt_data_dp = FileOpener(tgt_cache_decompressed_dp, encoding=\"utf-8\").readlines(\n return_path=False, strip_newline=True\n )\n\n return src_data_dp.zip(tgt_data_dp).shuffle().set_shuffle(False).sharding_filter()\n", "path": "torchtext/datasets/multi30k.py"}]} | 2,277 | 324 |
gh_patches_debug_17570 | rasdani/github-patches | git_diff | bridgecrewio__checkov-3644 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
CKV_ARGO_1 / CKV_ARGO_2 - false positives for kinds Application / ApplicationSet / AppProject
**Describe the issue**
CKV_ARGO_1 / CKV_ARGO_2 checks trigger false positives for argocd kinds Application / ApplicationSet / AppProject
**Examples**
```yaml
# AppProject
---
apiVersion: argoproj.io/v1alpha1
kind: AppProject
metadata:
name: default
spec:
clusterResourceWhitelist:
- group: "*"
kind: "*"
destinations:
- namespace: "*"
server: "*"
sourceRepos:
- "*"
```
```yaml
# Application
---
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: cert-manager
spec:
destination:
namespace: cert-manager
server: https://kubernetes.default.svc
project: default
source:
chart: cert-manager
helm:
values: |
installCRDs: true
prometheus:
enabled: false
repoURL: https://charts.jetstack.io
targetRevision: v1.9.0
syncPolicy:
automated:
prune: true
selfHeal: true
syncOptions:
- CreateNamespace=true
```
```yaml
# ApplicationSet
---
apiVersion: argoproj.io/v1alpha1
kind: ApplicationSet
metadata:
name: cert-manager
spec:
generators:
- matrix:
generators:
- list:
elements:
- env: dev
- env: qa
- env: preprod
- env: demo
- env: training
template:
metadata:
name: "cert-manager-{{env}}"
spec:
project: "{{env}}"
source:
chart: cert-manager
helm:
values: |
installCRDs: true
prometheus:
enabled: false
repoURL: https://charts.jetstack.io
targetRevision: v1.9.0
destination:
namespace: "cert-manager-{{env}}"
server: https://kubernetes.default.svc
```
**Version (please complete the following information):**
- 2.1.207
</issue>
<code>
[start of checkov/argo_workflows/runner.py]
1 from __future__ import annotations
2
3 import re
4 from pathlib import Path
5 from typing import TYPE_CHECKING, Any
6
7 from checkov.common.images.image_referencer import ImageReferencer, Image
8 from checkov.common.output.report import CheckType
9 from checkov.yaml_doc.runner import Runner as YamlRunner
10
11 # Import of the checks registry for a specific resource type
12 from checkov.argo_workflows.checks.registry import registry as template_registry
13
14 if TYPE_CHECKING:
15 from checkov.common.checks.base_check_registry import BaseCheckRegistry
16
17 API_VERSION_PATTERN = re.compile(r"^apiVersion:\s*argoproj.io/", re.MULTILINE)
18
19
20 class Runner(YamlRunner, ImageReferencer):
21 check_type = CheckType.ARGO_WORKFLOWS # noqa: CCE003 # a static attribute
22
23 block_type_registries = { # noqa: CCE003 # a static attribute
24 "template": template_registry,
25 }
26
27 def require_external_checks(self) -> bool:
28 return False
29
30 def import_registry(self) -> BaseCheckRegistry:
31 return self.block_type_registries["template"]
32
33 def _parse_file(
34 self, f: str, file_content: str | None = None
35 ) -> tuple[dict[str, Any] | list[dict[str, Any]], list[tuple[int, str]]] | None:
36 content = self._get_workflow_file_content(file_path=f)
37 if content:
38 return super()._parse_file(f=f, file_content=content)
39
40 return None
41
42 def _get_workflow_file_content(self, file_path: str) -> str | None:
43 if not file_path.endswith((".yaml", ",yml")):
44 return None
45
46 content = Path(file_path).read_text()
47 match = re.search(API_VERSION_PATTERN, content)
48 if match:
49 return content
50
51 return None
52
53 def is_workflow_file(self, file_path: str) -> bool:
54 return self._get_workflow_file_content(file_path=file_path) is not None
55
56 def get_images(self, file_path: str) -> set[Image]:
57 """Get container images mentioned in a file
58
59 Argo Workflows file can have a job and services run within a container.
60
61 in the following sample file we can see a node:14.16 image:
62
63 apiVersion: argoproj.io/v1alpha1
64 kind: Workflow
65 metadata:
66 generateName: template-defaults-
67 spec:
68 entrypoint: main
69 templates:
70 - name: main
71 steps:
72 - - name: retry-backoff
73 template: retry-backoff
74 - - name: whalesay
75 template: whalesay
76
77 - name: whalesay
78 container:
79 image: argoproj/argosay:v2
80 command: [cowsay]
81 args: ["hello world"]
82
83 - name: retry-backoff
84 container:
85 image: python:alpine3.6
86 command: ["python", -c]
87 # fail with a 66% probability
88 args: ["import random; import sys; exit_code = random.choice([0, 1, 1]); sys.exit(exit_code)"]
89
90 Source: https://github.com/argoproj/argo-workflows/blob/master/examples/template-defaults.yaml
91
92 :return: List of container image short ids mentioned in the file.
93 Example return value for a file with node:14.16 image: ['sha256:6a353e22ce']
94 """
95
96 images: set[Image] = set()
97 parsed_file = self._parse_file(file_path)
98
99 if not parsed_file:
100 return images
101
102 workflow, workflow_line_numbers = parsed_file
103
104 if not isinstance(workflow, dict):
105 # make type checking happy
106 return images
107
108 spec = workflow.get("spec")
109 if spec:
110 templates = spec.get("templates")
111 if isinstance(templates, list):
112 for template in templates:
113 container = template.get("container")
114 if container:
115 image = self.extract_image(file_path=file_path, container=container)
116 if image:
117 images.add(image)
118 script = template.get("script")
119 if script:
120 image = self.extract_image(file_path=file_path, container=script)
121 if image:
122 images.add(image)
123
124 return images
125
126 def extract_image(self, file_path: str, container: dict[str, Any]) -> Image | None:
127 image_name = container.get("image")
128 if image_name and isinstance(image_name, str):
129 start_line = container.get("__startline__", 0)
130 end_line = container.get("__endline__", 0)
131 return Image(
132 file_path=file_path,
133 name=image_name,
134 start_line=start_line,
135 end_line=end_line,
136 )
137
138 return None
139
[end of checkov/argo_workflows/runner.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/checkov/argo_workflows/runner.py b/checkov/argo_workflows/runner.py
--- a/checkov/argo_workflows/runner.py
+++ b/checkov/argo_workflows/runner.py
@@ -15,6 +15,7 @@
from checkov.common.checks.base_check_registry import BaseCheckRegistry
API_VERSION_PATTERN = re.compile(r"^apiVersion:\s*argoproj.io/", re.MULTILINE)
+KIND_PATTERN = re.compile(r"^kind:\s*Workflow", re.MULTILINE)
class Runner(YamlRunner, ImageReferencer):
@@ -44,9 +45,12 @@
return None
content = Path(file_path).read_text()
- match = re.search(API_VERSION_PATTERN, content)
- if match:
- return content
+ match_api = re.search(API_VERSION_PATTERN, content)
+ if match_api:
+ match_kind = re.search(KIND_PATTERN, content)
+ if match_kind:
+ # only scan Argo Workflows
+ return content
return None
| {"golden_diff": "diff --git a/checkov/argo_workflows/runner.py b/checkov/argo_workflows/runner.py\n--- a/checkov/argo_workflows/runner.py\n+++ b/checkov/argo_workflows/runner.py\n@@ -15,6 +15,7 @@\n from checkov.common.checks.base_check_registry import BaseCheckRegistry\n \n API_VERSION_PATTERN = re.compile(r\"^apiVersion:\\s*argoproj.io/\", re.MULTILINE)\n+KIND_PATTERN = re.compile(r\"^kind:\\s*Workflow\", re.MULTILINE)\n \n \n class Runner(YamlRunner, ImageReferencer):\n@@ -44,9 +45,12 @@\n return None\n \n content = Path(file_path).read_text()\n- match = re.search(API_VERSION_PATTERN, content)\n- if match:\n- return content\n+ match_api = re.search(API_VERSION_PATTERN, content)\n+ if match_api:\n+ match_kind = re.search(KIND_PATTERN, content)\n+ if match_kind:\n+ # only scan Argo Workflows\n+ return content\n \n return None\n", "issue": "CKV_ARGO_1 / CKV_ARGO_2 - false positives for kinds Application / ApplicationSet / AppProject\n**Describe the issue**\r\nCKV_ARGO_1 / CKV_ARGO_2 checks trigger false positives for argocd kinds Application / ApplicationSet / AppProject\r\n\r\n**Examples**\r\n```yaml\r\n# AppProject\r\n---\r\napiVersion: argoproj.io/v1alpha1\r\nkind: AppProject\r\nmetadata:\r\n name: default\r\nspec:\r\n clusterResourceWhitelist:\r\n - group: \"*\"\r\n kind: \"*\"\r\n destinations:\r\n - namespace: \"*\"\r\n server: \"*\"\r\n sourceRepos:\r\n - \"*\"\r\n```\r\n```yaml\r\n# Application\r\n---\r\napiVersion: argoproj.io/v1alpha1\r\nkind: Application\r\nmetadata:\r\n name: cert-manager\r\nspec:\r\n destination:\r\n namespace: cert-manager\r\n server: https://kubernetes.default.svc\r\n project: default\r\n source:\r\n chart: cert-manager\r\n helm:\r\n values: |\r\n installCRDs: true\r\n\r\n prometheus:\r\n enabled: false\r\n\r\n repoURL: https://charts.jetstack.io\r\n targetRevision: v1.9.0\r\n syncPolicy:\r\n automated:\r\n prune: true\r\n selfHeal: true\r\n syncOptions:\r\n - CreateNamespace=true\r\n```\r\n```yaml\r\n# ApplicationSet\r\n---\r\napiVersion: argoproj.io/v1alpha1\r\nkind: ApplicationSet\r\nmetadata:\r\n name: cert-manager\r\nspec:\r\n generators:\r\n - matrix:\r\n generators:\r\n - list:\r\n elements:\r\n - env: dev\r\n - env: qa\r\n - env: preprod\r\n - env: demo\r\n - env: training\r\n template:\r\n metadata:\r\n name: \"cert-manager-{{env}}\"\r\n spec:\r\n project: \"{{env}}\"\r\n source:\r\n chart: cert-manager\r\n helm:\r\n values: |\r\n installCRDs: true\r\n\r\n prometheus:\r\n enabled: false\r\n\r\n repoURL: https://charts.jetstack.io\r\n targetRevision: v1.9.0\r\n destination:\r\n namespace: \"cert-manager-{{env}}\"\r\n server: https://kubernetes.default.svc\r\n```\r\n\r\n**Version (please complete the following information):**\r\n - 2.1.207\r\n \r\n\n", "before_files": [{"content": "from __future__ import annotations\n\nimport re\nfrom pathlib import Path\nfrom typing import TYPE_CHECKING, Any\n\nfrom checkov.common.images.image_referencer import ImageReferencer, Image\nfrom checkov.common.output.report import CheckType\nfrom checkov.yaml_doc.runner import Runner as YamlRunner\n\n# Import of the checks registry for a specific resource type\nfrom checkov.argo_workflows.checks.registry import registry as template_registry\n\nif TYPE_CHECKING:\n from checkov.common.checks.base_check_registry import BaseCheckRegistry\n\nAPI_VERSION_PATTERN = re.compile(r\"^apiVersion:\\s*argoproj.io/\", re.MULTILINE)\n\n\nclass Runner(YamlRunner, ImageReferencer):\n check_type = CheckType.ARGO_WORKFLOWS # noqa: CCE003 # a static attribute\n\n block_type_registries = { # noqa: CCE003 # a static attribute\n \"template\": template_registry,\n }\n\n def require_external_checks(self) -> bool:\n return False\n\n def import_registry(self) -> BaseCheckRegistry:\n return self.block_type_registries[\"template\"]\n\n def _parse_file(\n self, f: str, file_content: str | None = None\n ) -> tuple[dict[str, Any] | list[dict[str, Any]], list[tuple[int, str]]] | None:\n content = self._get_workflow_file_content(file_path=f)\n if content:\n return super()._parse_file(f=f, file_content=content)\n\n return None\n\n def _get_workflow_file_content(self, file_path: str) -> str | None:\n if not file_path.endswith((\".yaml\", \",yml\")):\n return None\n\n content = Path(file_path).read_text()\n match = re.search(API_VERSION_PATTERN, content)\n if match:\n return content\n\n return None\n\n def is_workflow_file(self, file_path: str) -> bool:\n return self._get_workflow_file_content(file_path=file_path) is not None\n\n def get_images(self, file_path: str) -> set[Image]:\n \"\"\"Get container images mentioned in a file\n\n Argo Workflows file can have a job and services run within a container.\n\n in the following sample file we can see a node:14.16 image:\n\n apiVersion: argoproj.io/v1alpha1\n kind: Workflow\n metadata:\n generateName: template-defaults-\n spec:\n entrypoint: main\n templates:\n - name: main\n steps:\n - - name: retry-backoff\n template: retry-backoff\n - - name: whalesay\n template: whalesay\n\n - name: whalesay\n container:\n image: argoproj/argosay:v2\n command: [cowsay]\n args: [\"hello world\"]\n\n - name: retry-backoff\n container:\n image: python:alpine3.6\n command: [\"python\", -c]\n # fail with a 66% probability\n args: [\"import random; import sys; exit_code = random.choice([0, 1, 1]); sys.exit(exit_code)\"]\n\n Source: https://github.com/argoproj/argo-workflows/blob/master/examples/template-defaults.yaml\n\n :return: List of container image short ids mentioned in the file.\n Example return value for a file with node:14.16 image: ['sha256:6a353e22ce']\n \"\"\"\n\n images: set[Image] = set()\n parsed_file = self._parse_file(file_path)\n\n if not parsed_file:\n return images\n\n workflow, workflow_line_numbers = parsed_file\n\n if not isinstance(workflow, dict):\n # make type checking happy\n return images\n\n spec = workflow.get(\"spec\")\n if spec:\n templates = spec.get(\"templates\")\n if isinstance(templates, list):\n for template in templates:\n container = template.get(\"container\")\n if container:\n image = self.extract_image(file_path=file_path, container=container)\n if image:\n images.add(image)\n script = template.get(\"script\")\n if script:\n image = self.extract_image(file_path=file_path, container=script)\n if image:\n images.add(image)\n\n return images\n\n def extract_image(self, file_path: str, container: dict[str, Any]) -> Image | None:\n image_name = container.get(\"image\")\n if image_name and isinstance(image_name, str):\n start_line = container.get(\"__startline__\", 0)\n end_line = container.get(\"__endline__\", 0)\n return Image(\n file_path=file_path,\n name=image_name,\n start_line=start_line,\n end_line=end_line,\n )\n\n return None\n", "path": "checkov/argo_workflows/runner.py"}]} | 2,407 | 233 |
gh_patches_debug_27074 | rasdani/github-patches | git_diff | OCA__social-937 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[14.0] mail_debrand empty content for sign up
Using mail_debrand, the content of the mail sent at sign up is empty (headers and footer are properly filled) :
```html
<!-- CONTENT -->
<tr>
<td align="center" style="min-width: 590px;">
<table border="0" cellpadding="0" cellspacing="0" width="590" style="min-width: 590px; background-color: white; padding: 0px 8px 0px 8px; border-collapse:separate;">
<tr><td valign="top" style="font-size: 13px;">
</td></tr>
<tr><td style="text-align:center;">
<hr width="100%" style="background-color:rgb(204,204,204);border:medium none;clear:both;display:block;font-size:0px;min-height:1px;line-height:0; margin: 16px 0px 16px 0px;">
</td></tr>
</table>
</td>
</tr>
```
Without mail_debrand module installed I get the following content :
```html
<!-- CONTENT -->
<tr>
<td align="center" style="min-width: 590px;">
<table border="0" cellpadding="0" cellspacing="0" width="590" style="min-width: 590px; background-color: white; padding: 0px 8px 0px 8px; border-collapse:separate;">
<tr><td valign="top" style="font-size: 13px;">
<div>
Cher(e) test,<br/><br/>
Vous avez été invité par Admin LE FILAMENT à rejoindre Odoo.
<div style="margin: 16px 0px 16px 0px;">
<a href="removed_url" style="background-color: #875A7B; padding: 8px 16px 8px 16px; text-decoration: none; color: #fff; border-radius: 5px; font-size:13px;">
Accepter l'invitation
</a>
</div>
Votre nom de domaine Odoo est: <b><a href="removed_url">removed_url</a></b><br/>
Votre courriel de connection est: <b><a href="removed_url" target="_blank">removed_email</a></b><br/><br/>
Jamais entendu parler d'Odoo? C’est un logiciel de gestion tout-en-un apprécié par plus de 3 millions d’utilisateurs. Il améliorera considérablement votre expérience de travail et augmentera votre productivité.
<br/><br/>
Faites un tour dans la section <a href="https://www.odoo.com/page/tour?utm_source=db&utm_medium=auth" style="color: #875A7B;">Odoo Tour</a> afin de découvrir l'outil.
<br/><br/>
Enjoy Odoo!<br/>
--<br/>L'équipe LE FILAMENT
</div>
</td></tr>
<tr><td style="text-align:center;">
<hr width="100%" style="background-color:rgb(204,204,204);border:medium none;clear:both;display:block;font-size:0px;min-height:1px;line-height:0; margin: 16px 0px 16px 0px;"/>
</td></tr>
</table>
</td>
</tr>
```
The issue seems related to this block : https://github.com/OCA/social/blob/02467d14fa4b2ade959ced981f3a0411d46e1d26/mail_debrand/models/mail_render_mixin.py#L51-L52 where the full div is removed because of Odoo tour section.
I am not sure how to address this without breaking the way this module works for other mail templates, any idea would be welcome !
</issue>
<code>
[start of mail_debrand/__manifest__.py]
1 # Copyright 2016 Tecnativa - Jairo Llopis
2 # Copyright 2017 Tecnativa - Pedro M. Baeza
3 # Copyright 2019 ForgeFlow S.L. - Lois Rilo <[email protected]>
4 # 2020 NextERP Romania
5 # Copyright 2021 Tecnativa - João Marques
6 # License AGPL-3.0 or later (http://www.gnu.org/licenses/agpl.html).
7
8 {
9 "name": "Mail Debrand",
10 "summary": """Remove Odoo branding in sent emails
11 Removes anchor <a href odoo.com togheder with it's parent
12 ( for powerd by) form all the templates
13 removes any 'odoo' that are in tempalte texts > 20characters
14 """,
15 "version": "14.0.2.2.1",
16 "category": "Social Network",
17 "website": "https://github.com/OCA/social",
18 "author": """Tecnativa, ForgeFlow, Onestein, Sodexis, Nexterp Romania,
19 Odoo Community Association (OCA)""",
20 "license": "AGPL-3",
21 "installable": True,
22 "depends": ["mail"],
23 "development_status": "Production/Stable",
24 "maintainers": ["pedrobaeza", "joao-p-marques"],
25 }
26
[end of mail_debrand/__manifest__.py]
[start of mail_debrand/models/mail_render_mixin.py]
1 # Copyright 2019 O4SB - Graeme Gellatly
2 # Copyright 2019 Tecnativa - Ernesto Tejeda
3 # Copyright 2020 Onestein - Andrea Stirpe
4 # Copyright 2021 Tecnativa - João Marques
5 # License AGPL-3.0 or later (http://www.gnu.org/licenses/agpl.html).
6 import re
7
8 from lxml import etree, html
9
10 from odoo import api, models
11
12
13 class MailRenderMixin(models.AbstractModel):
14 _inherit = "mail.render.mixin"
15
16 def remove_href_odoo(
17 self, value, remove_parent=True, remove_before=False, to_keep=None
18 ):
19 if len(value) < 20:
20 return value
21 # value can be bytes type; ensure we get a proper string
22 if type(value) is bytes:
23 value = value.decode()
24 has_odoo_link = re.search(r"<a\s(.*)odoo\.com", value, flags=re.IGNORECASE)
25 if has_odoo_link:
26 # We don't want to change what was explicitly added in the message body,
27 # so we will only change what is before and after it.
28 if to_keep:
29 value = value.replace(to_keep, "<body_msg></body_msg>")
30 tree = html.fromstring(value)
31 odoo_anchors = tree.xpath('//a[contains(@href,"odoo.com")]')
32 for elem in odoo_anchors:
33 parent = elem.getparent()
34 previous = elem.getprevious()
35 if remove_before and not remove_parent and previous is not None:
36 # remove 'using' that is before <a and after </span>
37 previous.tail = ""
38 if remove_parent and len(parent.getparent()):
39 # anchor <a href odoo has a parent powered by that must be removed
40 parent.getparent().remove(parent)
41 else:
42 if parent.tag == "td": # also here can be powered by
43 parent.getparent().remove(parent)
44 else:
45 parent.remove(elem)
46 value = etree.tostring(
47 tree, pretty_print=True, method="html", encoding="unicode"
48 )
49 if to_keep:
50 value = value.replace("<body_msg></body_msg>", to_keep)
51 return value
52
53 @api.model
54 def _render_template(
55 self,
56 template_src,
57 model,
58 res_ids,
59 engine="jinja",
60 add_context=None,
61 post_process=False,
62 ):
63 """replace anything that is with odoo in templates
64 if is a <a that contains odoo will delete it completly
65 original:
66 Render the given string on records designed by model / res_ids using
67 the given rendering engine. Currently only jinja is supported.
68
69 :param str template_src: template text to render (jinja) or (qweb)
70 this could be cleaned but hey, we are in a rush
71 :param str model: model name of records on which we want to perform rendering
72 :param list res_ids: list of ids of records (all belonging to same model)
73 :param string engine: jinja
74 :param post_process: perform rendered str / html post processing (see
75 ``_render_template_postprocess``)
76
77 :return dict: {res_id: string of rendered template based on record}"""
78 orginal_rendered = super()._render_template(
79 template_src,
80 model,
81 res_ids,
82 engine=engine,
83 add_context=add_context,
84 post_process=post_process,
85 )
86
87 for key in res_ids:
88 orginal_rendered[key] = self.remove_href_odoo(orginal_rendered[key])
89
90 return orginal_rendered
91
92 def _replace_local_links(self, html, base_url=None):
93 message = super()._replace_local_links(html)
94 message = re.sub(
95 r"""(Powered by\s(.*)Odoo</a>)""", "<div> </div>", message
96 )
97 return message
98
[end of mail_debrand/models/mail_render_mixin.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/mail_debrand/__manifest__.py b/mail_debrand/__manifest__.py
--- a/mail_debrand/__manifest__.py
+++ b/mail_debrand/__manifest__.py
@@ -20,6 +20,9 @@
"license": "AGPL-3",
"installable": True,
"depends": ["mail"],
+ "data": [
+ "data/ir_config_parameter.xml",
+ ],
"development_status": "Production/Stable",
"maintainers": ["pedrobaeza", "joao-p-marques"],
}
diff --git a/mail_debrand/models/mail_render_mixin.py b/mail_debrand/models/mail_render_mixin.py
--- a/mail_debrand/models/mail_render_mixin.py
+++ b/mail_debrand/models/mail_render_mixin.py
@@ -22,6 +22,23 @@
if type(value) is bytes:
value = value.decode()
has_odoo_link = re.search(r"<a\s(.*)odoo\.com", value, flags=re.IGNORECASE)
+ extra_regex_to_skip = (
+ self.env["ir.config_parameter"]
+ .sudo()
+ .get_param("mail_debrand.extra_regex_to_skip", "False")
+ )
+ # value is required field on ir config_parameter, so we have added
+ # safety check for "False"
+ if (
+ has_odoo_link
+ and extra_regex_to_skip
+ and extra_regex_to_skip.strip().lower() != "false"
+ ):
+ # check each regex to be skipped
+ for regex in extra_regex_to_skip.split(","):
+ if re.search(r"{}".format(regex), value, flags=re.IGNORECASE):
+ has_odoo_link = False
+ break
if has_odoo_link:
# We don't want to change what was explicitly added in the message body,
# so we will only change what is before and after it.
| {"golden_diff": "diff --git a/mail_debrand/__manifest__.py b/mail_debrand/__manifest__.py\n--- a/mail_debrand/__manifest__.py\n+++ b/mail_debrand/__manifest__.py\n@@ -20,6 +20,9 @@\n \"license\": \"AGPL-3\",\n \"installable\": True,\n \"depends\": [\"mail\"],\n+ \"data\": [\n+ \"data/ir_config_parameter.xml\",\n+ ],\n \"development_status\": \"Production/Stable\",\n \"maintainers\": [\"pedrobaeza\", \"joao-p-marques\"],\n }\ndiff --git a/mail_debrand/models/mail_render_mixin.py b/mail_debrand/models/mail_render_mixin.py\n--- a/mail_debrand/models/mail_render_mixin.py\n+++ b/mail_debrand/models/mail_render_mixin.py\n@@ -22,6 +22,23 @@\n if type(value) is bytes:\n value = value.decode()\n has_odoo_link = re.search(r\"<a\\s(.*)odoo\\.com\", value, flags=re.IGNORECASE)\n+ extra_regex_to_skip = (\n+ self.env[\"ir.config_parameter\"]\n+ .sudo()\n+ .get_param(\"mail_debrand.extra_regex_to_skip\", \"False\")\n+ )\n+ # value is required field on ir config_parameter, so we have added\n+ # safety check for \"False\"\n+ if (\n+ has_odoo_link\n+ and extra_regex_to_skip\n+ and extra_regex_to_skip.strip().lower() != \"false\"\n+ ):\n+ # check each regex to be skipped\n+ for regex in extra_regex_to_skip.split(\",\"):\n+ if re.search(r\"{}\".format(regex), value, flags=re.IGNORECASE):\n+ has_odoo_link = False\n+ break\n if has_odoo_link:\n # We don't want to change what was explicitly added in the message body,\n # so we will only change what is before and after it.\n", "issue": "[14.0] mail_debrand empty content for sign up\nUsing mail_debrand, the content of the mail sent at sign up is empty (headers and footer are properly filled) :\r\n```html\r\n <!-- CONTENT -->\r\n <tr>\r\n <td align=\"center\" style=\"min-width: 590px;\">\r\n <table border=\"0\" cellpadding=\"0\" cellspacing=\"0\" width=\"590\" style=\"min-width: 590px; background-color: white; padding: 0px 8px 0px 8px; border-collapse:separate;\">\r\n <tr><td valign=\"top\" style=\"font-size: 13px;\">\r\n </td></tr>\r\n <tr><td style=\"text-align:center;\">\r\n <hr width=\"100%\" style=\"background-color:rgb(204,204,204);border:medium none;clear:both;display:block;font-size:0px;min-height:1px;line-height:0; margin: 16px 0px 16px 0px;\">\r\n </td></tr>\r\n </table>\r\n </td>\r\n </tr>\r\n```\r\n\r\nWithout mail_debrand module installed I get the following content : \r\n```html\r\n <!-- CONTENT -->\r\n <tr>\r\n <td align=\"center\" style=\"min-width: 590px;\">\r\n <table border=\"0\" cellpadding=\"0\" cellspacing=\"0\" width=\"590\" style=\"min-width: 590px; background-color: white; padding: 0px 8px 0px 8px; border-collapse:separate;\">\r\n <tr><td valign=\"top\" style=\"font-size: 13px;\">\r\n <div>\r\n Cher(e) test,<br/><br/>\r\n Vous avez \u00e9t\u00e9 invit\u00e9 par Admin LE FILAMENT \u00e0 rejoindre Odoo.\r\n <div style=\"margin: 16px 0px 16px 0px;\">\r\n <a href=\"removed_url\" style=\"background-color: #875A7B; padding: 8px 16px 8px 16px; text-decoration: none; color: #fff; border-radius: 5px; font-size:13px;\">\r\n Accepter l'invitation\r\n </a>\r\n </div>\r\n Votre nom de domaine Odoo est: <b><a href=\"removed_url\">removed_url</a></b><br/>\r\n Votre courriel de connection est: <b><a href=\"removed_url\" target=\"_blank\">removed_email</a></b><br/><br/>\r\n Jamais entendu parler d'Odoo? C\u2019est un logiciel de gestion tout-en-un appr\u00e9ci\u00e9 par plus de 3 millions d\u2019utilisateurs. Il am\u00e9liorera consid\u00e9rablement votre exp\u00e9rience de travail et augmentera votre productivit\u00e9.\r\n <br/><br/>\r\n Faites un tour dans la section <a href=\"https://www.odoo.com/page/tour?utm_source=db&utm_medium=auth\" style=\"color: #875A7B;\">Odoo Tour</a> afin de d\u00e9couvrir l'outil.\r\n <br/><br/>\r\n Enjoy Odoo!<br/>\r\n --<br/>L'\u00e9quipe LE FILAMENT \r\n </div>\r\n </td></tr>\r\n <tr><td style=\"text-align:center;\">\r\n <hr width=\"100%\" style=\"background-color:rgb(204,204,204);border:medium none;clear:both;display:block;font-size:0px;min-height:1px;line-height:0; margin: 16px 0px 16px 0px;\"/>\r\n </td></tr>\r\n </table>\r\n </td>\r\n </tr>\r\n```\r\n\r\nThe issue seems related to this block : https://github.com/OCA/social/blob/02467d14fa4b2ade959ced981f3a0411d46e1d26/mail_debrand/models/mail_render_mixin.py#L51-L52 where the full div is removed because of Odoo tour section.\r\n\r\nI am not sure how to address this without breaking the way this module works for other mail templates, any idea would be welcome !\n", "before_files": [{"content": "# Copyright 2016 Tecnativa - Jairo Llopis\n# Copyright 2017 Tecnativa - Pedro M. Baeza\n# Copyright 2019 ForgeFlow S.L. - Lois Rilo <[email protected]>\n# 2020 NextERP Romania\n# Copyright 2021 Tecnativa - Jo\u00e3o Marques\n# License AGPL-3.0 or later (http://www.gnu.org/licenses/agpl.html).\n\n{\n \"name\": \"Mail Debrand\",\n \"summary\": \"\"\"Remove Odoo branding in sent emails\n Removes anchor <a href odoo.com togheder with it's parent\n ( for powerd by) form all the templates\n removes any 'odoo' that are in tempalte texts > 20characters\n \"\"\",\n \"version\": \"14.0.2.2.1\",\n \"category\": \"Social Network\",\n \"website\": \"https://github.com/OCA/social\",\n \"author\": \"\"\"Tecnativa, ForgeFlow, Onestein, Sodexis, Nexterp Romania,\n Odoo Community Association (OCA)\"\"\",\n \"license\": \"AGPL-3\",\n \"installable\": True,\n \"depends\": [\"mail\"],\n \"development_status\": \"Production/Stable\",\n \"maintainers\": [\"pedrobaeza\", \"joao-p-marques\"],\n}\n", "path": "mail_debrand/__manifest__.py"}, {"content": "# Copyright 2019 O4SB - Graeme Gellatly\n# Copyright 2019 Tecnativa - Ernesto Tejeda\n# Copyright 2020 Onestein - Andrea Stirpe\n# Copyright 2021 Tecnativa - Jo\u00e3o Marques\n# License AGPL-3.0 or later (http://www.gnu.org/licenses/agpl.html).\nimport re\n\nfrom lxml import etree, html\n\nfrom odoo import api, models\n\n\nclass MailRenderMixin(models.AbstractModel):\n _inherit = \"mail.render.mixin\"\n\n def remove_href_odoo(\n self, value, remove_parent=True, remove_before=False, to_keep=None\n ):\n if len(value) < 20:\n return value\n # value can be bytes type; ensure we get a proper string\n if type(value) is bytes:\n value = value.decode()\n has_odoo_link = re.search(r\"<a\\s(.*)odoo\\.com\", value, flags=re.IGNORECASE)\n if has_odoo_link:\n # We don't want to change what was explicitly added in the message body,\n # so we will only change what is before and after it.\n if to_keep:\n value = value.replace(to_keep, \"<body_msg></body_msg>\")\n tree = html.fromstring(value)\n odoo_anchors = tree.xpath('//a[contains(@href,\"odoo.com\")]')\n for elem in odoo_anchors:\n parent = elem.getparent()\n previous = elem.getprevious()\n if remove_before and not remove_parent and previous is not None:\n # remove 'using' that is before <a and after </span>\n previous.tail = \"\"\n if remove_parent and len(parent.getparent()):\n # anchor <a href odoo has a parent powered by that must be removed\n parent.getparent().remove(parent)\n else:\n if parent.tag == \"td\": # also here can be powered by\n parent.getparent().remove(parent)\n else:\n parent.remove(elem)\n value = etree.tostring(\n tree, pretty_print=True, method=\"html\", encoding=\"unicode\"\n )\n if to_keep:\n value = value.replace(\"<body_msg></body_msg>\", to_keep)\n return value\n\n @api.model\n def _render_template(\n self,\n template_src,\n model,\n res_ids,\n engine=\"jinja\",\n add_context=None,\n post_process=False,\n ):\n \"\"\"replace anything that is with odoo in templates\n if is a <a that contains odoo will delete it completly\n original:\n Render the given string on records designed by model / res_ids using\n the given rendering engine. Currently only jinja is supported.\n\n :param str template_src: template text to render (jinja) or (qweb)\n this could be cleaned but hey, we are in a rush\n :param str model: model name of records on which we want to perform rendering\n :param list res_ids: list of ids of records (all belonging to same model)\n :param string engine: jinja\n :param post_process: perform rendered str / html post processing (see\n ``_render_template_postprocess``)\n\n :return dict: {res_id: string of rendered template based on record}\"\"\"\n orginal_rendered = super()._render_template(\n template_src,\n model,\n res_ids,\n engine=engine,\n add_context=add_context,\n post_process=post_process,\n )\n\n for key in res_ids:\n orginal_rendered[key] = self.remove_href_odoo(orginal_rendered[key])\n\n return orginal_rendered\n\n def _replace_local_links(self, html, base_url=None):\n message = super()._replace_local_links(html)\n message = re.sub(\n r\"\"\"(Powered by\\s(.*)Odoo</a>)\"\"\", \"<div> </div>\", message\n )\n return message\n", "path": "mail_debrand/models/mail_render_mixin.py"}]} | 2,873 | 422 |
gh_patches_debug_9212 | rasdani/github-patches | git_diff | jazzband__pip-tools-956 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add python 3.8 support
#### What's the problem this feature will solve?
<!-- What are you trying to do, that you are unable to achieve with pip-tools as it currently stands? -->
Python 3.8 is released, so it's time to support it.
#### Describe the solution you'd like
<!-- A clear and concise description of what you want to happen. -->
1. add "py37" env to `tox.ini`
1. remove 3.8-dev from `.travis.yml`
1. add "Programming Language :: Python :: 3.8" classifier to `setup.py`
1. add "3.8" dimension to `.travis.yml` (supported, see https://travis-ci.community/t/add-python-3-8-support/5463)
1. add "py37" dimension to `.appveyor.yml` (not supported yet, but will be on the nex image update, tracking issue: https://github.com/appveyor/ci/issues/3142)
1. add "3.8" to python-version list in `.github/workflows/cron.yml` (not supported yet, tracking issue: https://github.com/actions/setup-python/issues/30)
<!-- Provide examples of real-world use cases that this would enable and how it solves the problem described above. -->
#### Alternative Solutions
<!-- Have you tried to workaround the problem using pip-tools or other tools? Or a different approach to solving this issue? Please elaborate here. -->
N/A
#### Additional context
<!-- Add any other context, links, etc. about the feature here. -->
https://discuss.python.org/t/python-3-8-0-is-now-available/2478
</issue>
<code>
[start of setup.py]
1 """
2 pip-tools keeps your pinned dependencies fresh.
3 """
4 from os.path import abspath, dirname, join
5
6 from setuptools import find_packages, setup
7
8
9 def read_file(filename):
10 """Read the contents of a file located relative to setup.py"""
11 with open(join(abspath(dirname(__file__)), filename)) as thefile:
12 return thefile.read()
13
14
15 setup(
16 name="pip-tools",
17 use_scm_version=True,
18 url="https://github.com/jazzband/pip-tools/",
19 license="BSD",
20 author="Vincent Driessen",
21 author_email="[email protected]",
22 description=__doc__.strip(),
23 long_description=read_file("README.rst"),
24 long_description_content_type="text/x-rst",
25 packages=find_packages(exclude=["tests"]),
26 package_data={},
27 python_requires=">=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*, !=3.4.*",
28 setup_requires=["setuptools_scm"],
29 install_requires=["click>=6", "six"],
30 zip_safe=False,
31 entry_points={
32 "console_scripts": [
33 "pip-compile = piptools.scripts.compile:cli",
34 "pip-sync = piptools.scripts.sync:cli",
35 ]
36 },
37 platforms="any",
38 classifiers=[
39 "Development Status :: 5 - Production/Stable",
40 "Intended Audience :: Developers",
41 "Intended Audience :: System Administrators",
42 "License :: OSI Approved :: BSD License",
43 "Operating System :: OS Independent",
44 "Programming Language :: Python",
45 "Programming Language :: Python :: 2",
46 "Programming Language :: Python :: 2.7",
47 "Programming Language :: Python :: 3",
48 "Programming Language :: Python :: 3.5",
49 "Programming Language :: Python :: 3.6",
50 "Programming Language :: Python :: 3.7",
51 "Programming Language :: Python :: Implementation :: CPython",
52 "Programming Language :: Python :: Implementation :: PyPy",
53 "Topic :: System :: Systems Administration",
54 ],
55 )
56
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -48,6 +48,7 @@
"Programming Language :: Python :: 3.5",
"Programming Language :: Python :: 3.6",
"Programming Language :: Python :: 3.7",
+ "Programming Language :: Python :: 3.8",
"Programming Language :: Python :: Implementation :: CPython",
"Programming Language :: Python :: Implementation :: PyPy",
"Topic :: System :: Systems Administration",
| {"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -48,6 +48,7 @@\n \"Programming Language :: Python :: 3.5\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n+ \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: Implementation :: CPython\",\n \"Programming Language :: Python :: Implementation :: PyPy\",\n \"Topic :: System :: Systems Administration\",\n", "issue": "Add python 3.8 support\n#### What's the problem this feature will solve?\r\n<!-- What are you trying to do, that you are unable to achieve with pip-tools as it currently stands? -->\r\n\r\nPython 3.8 is released, so it's time to support it. \r\n\r\n#### Describe the solution you'd like\r\n<!-- A clear and concise description of what you want to happen. -->\r\n\r\n1. add \"py37\" env to `tox.ini`\r\n1. remove 3.8-dev from `.travis.yml`\r\n1. add \"Programming Language :: Python :: 3.8\" classifier to `setup.py`\r\n1. add \"3.8\" dimension to `.travis.yml` (supported, see https://travis-ci.community/t/add-python-3-8-support/5463)\r\n1. add \"py37\" dimension to `.appveyor.yml` (not supported yet, but will be on the nex image update, tracking issue: https://github.com/appveyor/ci/issues/3142)\r\n1. add \"3.8\" to python-version list in `.github/workflows/cron.yml` (not supported yet, tracking issue: https://github.com/actions/setup-python/issues/30)\r\n\r\n<!-- Provide examples of real-world use cases that this would enable and how it solves the problem described above. -->\r\n\r\n#### Alternative Solutions\r\n<!-- Have you tried to workaround the problem using pip-tools or other tools? Or a different approach to solving this issue? Please elaborate here. -->\r\n\r\nN/A\r\n\r\n#### Additional context\r\n<!-- Add any other context, links, etc. about the feature here. -->\r\n\r\nhttps://discuss.python.org/t/python-3-8-0-is-now-available/2478\n", "before_files": [{"content": "\"\"\"\npip-tools keeps your pinned dependencies fresh.\n\"\"\"\nfrom os.path import abspath, dirname, join\n\nfrom setuptools import find_packages, setup\n\n\ndef read_file(filename):\n \"\"\"Read the contents of a file located relative to setup.py\"\"\"\n with open(join(abspath(dirname(__file__)), filename)) as thefile:\n return thefile.read()\n\n\nsetup(\n name=\"pip-tools\",\n use_scm_version=True,\n url=\"https://github.com/jazzband/pip-tools/\",\n license=\"BSD\",\n author=\"Vincent Driessen\",\n author_email=\"[email protected]\",\n description=__doc__.strip(),\n long_description=read_file(\"README.rst\"),\n long_description_content_type=\"text/x-rst\",\n packages=find_packages(exclude=[\"tests\"]),\n package_data={},\n python_requires=\">=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*, !=3.4.*\",\n setup_requires=[\"setuptools_scm\"],\n install_requires=[\"click>=6\", \"six\"],\n zip_safe=False,\n entry_points={\n \"console_scripts\": [\n \"pip-compile = piptools.scripts.compile:cli\",\n \"pip-sync = piptools.scripts.sync:cli\",\n ]\n },\n platforms=\"any\",\n classifiers=[\n \"Development Status :: 5 - Production/Stable\",\n \"Intended Audience :: Developers\",\n \"Intended Audience :: System Administrators\",\n \"License :: OSI Approved :: BSD License\",\n \"Operating System :: OS Independent\",\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 2\",\n \"Programming Language :: Python :: 2.7\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.5\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: Implementation :: CPython\",\n \"Programming Language :: Python :: Implementation :: PyPy\",\n \"Topic :: System :: Systems Administration\",\n ],\n)\n", "path": "setup.py"}]} | 1,430 | 114 |
gh_patches_debug_37695 | rasdani/github-patches | git_diff | Qiskit__qiskit-8625 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Flipping of gate direction in Transpiler for CZ gate
### What should we add?
The current version of the transpiler raises the following error when attempting to set the basis gate of a backend as `cz`
` 'Flipping of gate direction is only supported for CX, ECR, and RZX at this time, not cz.' `
As far as I'm aware and through my own testing flipping of a CZ should be easy to implement as it's "flip" produces the same unitary operator. There is no direct identity needed.
If this could get added that would be great! I would have done this via a pull request myself but it seems "too easy" of a solution that I must be missing something.
The Qiskit file that would need changing.
https://github.com/Qiskit/qiskit-terra/blob/1312624309526812eb62b97e0d47699d46649a25/qiskit/transpiler/passes/utils/gate_direction.py
</issue>
<code>
[start of qiskit/transpiler/passes/utils/gate_direction.py]
1 # This code is part of Qiskit.
2 #
3 # (C) Copyright IBM 2017, 2021.
4 #
5 # This code is licensed under the Apache License, Version 2.0. You may
6 # obtain a copy of this license in the LICENSE.txt file in the root directory
7 # of this source tree or at http://www.apache.org/licenses/LICENSE-2.0.
8 #
9 # Any modifications or derivative works of this code must retain this
10 # copyright notice, and modified files need to carry a notice indicating
11 # that they have been altered from the originals.
12
13 """Rearrange the direction of the cx nodes to match the directed coupling map."""
14
15 from math import pi
16
17 from qiskit.transpiler.layout import Layout
18 from qiskit.transpiler.basepasses import TransformationPass
19 from qiskit.transpiler.exceptions import TranspilerError
20
21 from qiskit.circuit import QuantumRegister
22 from qiskit.dagcircuit import DAGCircuit
23 from qiskit.circuit.library.standard_gates import RYGate, HGate, CXGate, ECRGate, RZXGate
24
25
26 class GateDirection(TransformationPass):
27 """Modify asymmetric gates to match the hardware coupling direction.
28
29 This pass makes use of the following identities::
30
31 ┌───┐┌───┐┌───┐
32 q_0: ──■── q_0: ┤ H ├┤ X ├┤ H ├
33 ┌─┴─┐ = ├───┤└─┬─┘├───┤
34 q_1: ┤ X ├ q_1: ┤ H ├──■──┤ H ├
35 └───┘ └───┘ └───┘
36
37 ┌──────┐ ┌───────────┐┌──────┐┌───┐
38 q_0: ┤0 ├ q_0: ┤ RY(-pi/2) ├┤1 ├┤ H ├
39 │ ECR │ = └┬──────────┤│ ECR │├───┤
40 q_1: ┤1 ├ q_1: ─┤ RY(pi/2) ├┤0 ├┤ H ├
41 └──────┘ └──────────┘└──────┘└───┘
42
43 ┌──────┐ ┌───┐┌──────┐┌───┐
44 q_0: ┤0 ├ q_0: ┤ H ├┤1 ├┤ H ├
45 │ RZX │ = ├───┤│ RZX │├───┤
46 q_1: ┤1 ├ q_1: ┤ H ├┤0 ├┤ H ├
47 └──────┘ └───┘└──────┘└───┘
48 """
49
50 def __init__(self, coupling_map, target=None):
51 """GateDirection pass.
52
53 Args:
54 coupling_map (CouplingMap): Directed graph represented a coupling map.
55 target (Target): The backend target to use for this pass. If this is specified
56 it will be used instead of the coupling map
57 """
58 super().__init__()
59 self.coupling_map = coupling_map
60 self.target = target
61
62 # Create the replacement dag and associated register.
63 self._cx_dag = DAGCircuit()
64 qr = QuantumRegister(2)
65 self._cx_dag.add_qreg(qr)
66 self._cx_dag.apply_operation_back(HGate(), [qr[0]], [])
67 self._cx_dag.apply_operation_back(HGate(), [qr[1]], [])
68 self._cx_dag.apply_operation_back(CXGate(), [qr[1], qr[0]], [])
69 self._cx_dag.apply_operation_back(HGate(), [qr[0]], [])
70 self._cx_dag.apply_operation_back(HGate(), [qr[1]], [])
71
72 self._ecr_dag = DAGCircuit()
73 qr = QuantumRegister(2)
74 self._ecr_dag.add_qreg(qr)
75 self._ecr_dag.apply_operation_back(RYGate(-pi / 2), [qr[0]], [])
76 self._ecr_dag.apply_operation_back(RYGate(pi / 2), [qr[1]], [])
77 self._ecr_dag.apply_operation_back(ECRGate(), [qr[1], qr[0]], [])
78 self._ecr_dag.apply_operation_back(HGate(), [qr[0]], [])
79 self._ecr_dag.apply_operation_back(HGate(), [qr[1]], [])
80
81 @staticmethod
82 def _rzx_dag(parameter):
83 _rzx_dag = DAGCircuit()
84 qr = QuantumRegister(2)
85 _rzx_dag.add_qreg(qr)
86 _rzx_dag.apply_operation_back(HGate(), [qr[0]], [])
87 _rzx_dag.apply_operation_back(HGate(), [qr[1]], [])
88 _rzx_dag.apply_operation_back(RZXGate(parameter), [qr[1], qr[0]], [])
89 _rzx_dag.apply_operation_back(HGate(), [qr[0]], [])
90 _rzx_dag.apply_operation_back(HGate(), [qr[1]], [])
91 return _rzx_dag
92
93 def run(self, dag):
94 """Run the GateDirection pass on `dag`.
95
96 Flips the cx nodes to match the directed coupling map. Modifies the
97 input dag.
98
99 Args:
100 dag (DAGCircuit): DAG to map.
101
102 Returns:
103 DAGCircuit: The rearranged dag for the coupling map
104
105 Raises:
106 TranspilerError: If the circuit cannot be mapped just by flipping the
107 cx nodes.
108 """
109 trivial_layout = Layout.generate_trivial_layout(*dag.qregs.values())
110 layout_map = trivial_layout.get_virtual_bits()
111 if len(dag.qregs) > 1:
112 raise TranspilerError(
113 "GateDirection expects a single qreg input DAG,"
114 "but input DAG had qregs: {}.".format(dag.qregs)
115 )
116 if self.target is None:
117 cmap_edges = set(self.coupling_map.get_edges())
118 if not cmap_edges:
119 return dag
120
121 self.coupling_map.compute_distance_matrix()
122
123 dist_matrix = self.coupling_map.distance_matrix
124
125 for node in dag.two_qubit_ops():
126 control = node.qargs[0]
127 target = node.qargs[1]
128
129 physical_q0 = layout_map[control]
130 physical_q1 = layout_map[target]
131
132 if dist_matrix[physical_q0, physical_q1] != 1:
133 raise TranspilerError(
134 "The circuit requires a connection between physical "
135 "qubits %s and %s" % (physical_q0, physical_q1)
136 )
137
138 if (physical_q0, physical_q1) not in cmap_edges:
139 if node.name == "cx":
140 dag.substitute_node_with_dag(node, self._cx_dag)
141 elif node.name == "ecr":
142 dag.substitute_node_with_dag(node, self._ecr_dag)
143 elif node.name == "rzx":
144 dag.substitute_node_with_dag(node, self._rzx_dag(*node.op.params))
145 else:
146 raise TranspilerError(
147 f"Flipping of gate direction is only supported "
148 f"for CX, ECR, and RZX at this time, not {node.name}."
149 )
150 else:
151 # TODO: Work with the gate instances and only use names as look up keys.
152 # This will require iterating over the target names to build a mapping
153 # of names to gates that implement CXGate, ECRGate, RZXGate (including
154 # fixed angle variants)
155 for node in dag.two_qubit_ops():
156 control = node.qargs[0]
157 target = node.qargs[1]
158
159 physical_q0 = layout_map[control]
160 physical_q1 = layout_map[target]
161
162 if node.name == "cx":
163 if (physical_q0, physical_q1) in self.target["cx"]:
164 continue
165 if (physical_q1, physical_q0) in self.target["cx"]:
166 dag.substitute_node_with_dag(node, self._cx_dag)
167 else:
168 raise TranspilerError(
169 "The circuit requires a connection between physical "
170 "qubits %s and %s for cx" % (physical_q0, physical_q1)
171 )
172 elif node.name == "ecr":
173 if (physical_q0, physical_q1) in self.target["ecr"]:
174 continue
175 if (physical_q1, physical_q0) in self.target["ecr"]:
176 dag.substitute_node_with_dag(node, self._ecr_dag)
177 else:
178 raise TranspilerError(
179 "The circuit requires a connection between physical "
180 "qubits %s and %s for ecr" % (physical_q0, physical_q1)
181 )
182 elif node.name == "rzx":
183 if (physical_q0, physical_q1) in self.target["rzx"]:
184 continue
185 if (physical_q1, physical_q0) in self.target["rzx"]:
186 dag.substitute_node_with_dag(node, self._rzx_dag(*node.op.params))
187 else:
188 raise TranspilerError(
189 "The circuit requires a connection between physical "
190 "qubits %s and %s for rzx" % (physical_q0, physical_q1)
191 )
192 else:
193 raise TranspilerError(
194 f"Flipping of gate direction is only supported "
195 f"for CX, ECR, and RZX at this time, not {node.name}."
196 )
197 return dag
198
[end of qiskit/transpiler/passes/utils/gate_direction.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/qiskit/transpiler/passes/utils/gate_direction.py b/qiskit/transpiler/passes/utils/gate_direction.py
--- a/qiskit/transpiler/passes/utils/gate_direction.py
+++ b/qiskit/transpiler/passes/utils/gate_direction.py
@@ -20,7 +20,7 @@
from qiskit.circuit import QuantumRegister
from qiskit.dagcircuit import DAGCircuit
-from qiskit.circuit.library.standard_gates import RYGate, HGate, CXGate, ECRGate, RZXGate
+from qiskit.circuit.library.standard_gates import RYGate, HGate, CXGate, CZGate, ECRGate, RZXGate
class GateDirection(TransformationPass):
@@ -78,6 +78,11 @@
self._ecr_dag.apply_operation_back(HGate(), [qr[0]], [])
self._ecr_dag.apply_operation_back(HGate(), [qr[1]], [])
+ self._cz_dag = DAGCircuit()
+ qr = QuantumRegister(2)
+ self._cz_dag.add_qreg(qr)
+ self._cz_dag.apply_operation_back(CZGate(), [qr[1], qr[0]], [])
+
@staticmethod
def _rzx_dag(parameter):
_rzx_dag = DAGCircuit()
@@ -138,6 +143,8 @@
if (physical_q0, physical_q1) not in cmap_edges:
if node.name == "cx":
dag.substitute_node_with_dag(node, self._cx_dag)
+ elif node.name == "cz":
+ dag.substitute_node_with_dag(node, self._cz_dag)
elif node.name == "ecr":
dag.substitute_node_with_dag(node, self._ecr_dag)
elif node.name == "rzx":
@@ -169,6 +176,16 @@
"The circuit requires a connection between physical "
"qubits %s and %s for cx" % (physical_q0, physical_q1)
)
+ elif node.name == "cz":
+ if (physical_q0, physical_q1) in self.target["cz"]:
+ continue
+ if (physical_q1, physical_q0) in self.target["cz"]:
+ dag.substitute_node_with_dag(node, self._cz_dag)
+ else:
+ raise TranspilerError(
+ "The circuit requires a connection between physical "
+ "qubits %s and %s for cz" % (physical_q0, physical_q1)
+ )
elif node.name == "ecr":
if (physical_q0, physical_q1) in self.target["ecr"]:
continue
| {"golden_diff": "diff --git a/qiskit/transpiler/passes/utils/gate_direction.py b/qiskit/transpiler/passes/utils/gate_direction.py\n--- a/qiskit/transpiler/passes/utils/gate_direction.py\n+++ b/qiskit/transpiler/passes/utils/gate_direction.py\n@@ -20,7 +20,7 @@\n \n from qiskit.circuit import QuantumRegister\n from qiskit.dagcircuit import DAGCircuit\n-from qiskit.circuit.library.standard_gates import RYGate, HGate, CXGate, ECRGate, RZXGate\n+from qiskit.circuit.library.standard_gates import RYGate, HGate, CXGate, CZGate, ECRGate, RZXGate\n \n \n class GateDirection(TransformationPass):\n@@ -78,6 +78,11 @@\n self._ecr_dag.apply_operation_back(HGate(), [qr[0]], [])\n self._ecr_dag.apply_operation_back(HGate(), [qr[1]], [])\n \n+ self._cz_dag = DAGCircuit()\n+ qr = QuantumRegister(2)\n+ self._cz_dag.add_qreg(qr)\n+ self._cz_dag.apply_operation_back(CZGate(), [qr[1], qr[0]], [])\n+\n @staticmethod\n def _rzx_dag(parameter):\n _rzx_dag = DAGCircuit()\n@@ -138,6 +143,8 @@\n if (physical_q0, physical_q1) not in cmap_edges:\n if node.name == \"cx\":\n dag.substitute_node_with_dag(node, self._cx_dag)\n+ elif node.name == \"cz\":\n+ dag.substitute_node_with_dag(node, self._cz_dag)\n elif node.name == \"ecr\":\n dag.substitute_node_with_dag(node, self._ecr_dag)\n elif node.name == \"rzx\":\n@@ -169,6 +176,16 @@\n \"The circuit requires a connection between physical \"\n \"qubits %s and %s for cx\" % (physical_q0, physical_q1)\n )\n+ elif node.name == \"cz\":\n+ if (physical_q0, physical_q1) in self.target[\"cz\"]:\n+ continue\n+ if (physical_q1, physical_q0) in self.target[\"cz\"]:\n+ dag.substitute_node_with_dag(node, self._cz_dag)\n+ else:\n+ raise TranspilerError(\n+ \"The circuit requires a connection between physical \"\n+ \"qubits %s and %s for cz\" % (physical_q0, physical_q1)\n+ )\n elif node.name == \"ecr\":\n if (physical_q0, physical_q1) in self.target[\"ecr\"]:\n continue\n", "issue": "Flipping of gate direction in Transpiler for CZ gate\n### What should we add?\n\nThe current version of the transpiler raises the following error when attempting to set the basis gate of a backend as `cz` \r\n\r\n` 'Flipping of gate direction is only supported for CX, ECR, and RZX at this time, not cz.' `\r\n\r\nAs far as I'm aware and through my own testing flipping of a CZ should be easy to implement as it's \"flip\" produces the same unitary operator. There is no direct identity needed. \r\n\r\nIf this could get added that would be great! I would have done this via a pull request myself but it seems \"too easy\" of a solution that I must be missing something.\r\n\r\nThe Qiskit file that would need changing. \r\nhttps://github.com/Qiskit/qiskit-terra/blob/1312624309526812eb62b97e0d47699d46649a25/qiskit/transpiler/passes/utils/gate_direction.py\r\n\r\n\n", "before_files": [{"content": "# This code is part of Qiskit.\n#\n# (C) Copyright IBM 2017, 2021.\n#\n# This code is licensed under the Apache License, Version 2.0. You may\n# obtain a copy of this license in the LICENSE.txt file in the root directory\n# of this source tree or at http://www.apache.org/licenses/LICENSE-2.0.\n#\n# Any modifications or derivative works of this code must retain this\n# copyright notice, and modified files need to carry a notice indicating\n# that they have been altered from the originals.\n\n\"\"\"Rearrange the direction of the cx nodes to match the directed coupling map.\"\"\"\n\nfrom math import pi\n\nfrom qiskit.transpiler.layout import Layout\nfrom qiskit.transpiler.basepasses import TransformationPass\nfrom qiskit.transpiler.exceptions import TranspilerError\n\nfrom qiskit.circuit import QuantumRegister\nfrom qiskit.dagcircuit import DAGCircuit\nfrom qiskit.circuit.library.standard_gates import RYGate, HGate, CXGate, ECRGate, RZXGate\n\n\nclass GateDirection(TransformationPass):\n \"\"\"Modify asymmetric gates to match the hardware coupling direction.\n\n This pass makes use of the following identities::\n\n \u250c\u2500\u2500\u2500\u2510\u250c\u2500\u2500\u2500\u2510\u250c\u2500\u2500\u2500\u2510\n q_0: \u2500\u2500\u25a0\u2500\u2500 q_0: \u2524 H \u251c\u2524 X \u251c\u2524 H \u251c\n \u250c\u2500\u2534\u2500\u2510 = \u251c\u2500\u2500\u2500\u2524\u2514\u2500\u252c\u2500\u2518\u251c\u2500\u2500\u2500\u2524\n q_1: \u2524 X \u251c q_1: \u2524 H \u251c\u2500\u2500\u25a0\u2500\u2500\u2524 H \u251c\n \u2514\u2500\u2500\u2500\u2518 \u2514\u2500\u2500\u2500\u2518 \u2514\u2500\u2500\u2500\u2518\n\n \u250c\u2500\u2500\u2500\u2500\u2500\u2500\u2510 \u250c\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2510\u250c\u2500\u2500\u2500\u2500\u2500\u2500\u2510\u250c\u2500\u2500\u2500\u2510\n q_0: \u25240 \u251c q_0: \u2524 RY(-pi/2) \u251c\u25241 \u251c\u2524 H \u251c\n \u2502 ECR \u2502 = \u2514\u252c\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2524\u2502 ECR \u2502\u251c\u2500\u2500\u2500\u2524\n q_1: \u25241 \u251c q_1: \u2500\u2524 RY(pi/2) \u251c\u25240 \u251c\u2524 H \u251c\n \u2514\u2500\u2500\u2500\u2500\u2500\u2500\u2518 \u2514\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2518\u2514\u2500\u2500\u2500\u2500\u2500\u2500\u2518\u2514\u2500\u2500\u2500\u2518\n\n \u250c\u2500\u2500\u2500\u2500\u2500\u2500\u2510 \u250c\u2500\u2500\u2500\u2510\u250c\u2500\u2500\u2500\u2500\u2500\u2500\u2510\u250c\u2500\u2500\u2500\u2510\n q_0: \u25240 \u251c q_0: \u2524 H \u251c\u25241 \u251c\u2524 H \u251c\n \u2502 RZX \u2502 = \u251c\u2500\u2500\u2500\u2524\u2502 RZX \u2502\u251c\u2500\u2500\u2500\u2524\n q_1: \u25241 \u251c q_1: \u2524 H \u251c\u25240 \u251c\u2524 H \u251c\n \u2514\u2500\u2500\u2500\u2500\u2500\u2500\u2518 \u2514\u2500\u2500\u2500\u2518\u2514\u2500\u2500\u2500\u2500\u2500\u2500\u2518\u2514\u2500\u2500\u2500\u2518\n \"\"\"\n\n def __init__(self, coupling_map, target=None):\n \"\"\"GateDirection pass.\n\n Args:\n coupling_map (CouplingMap): Directed graph represented a coupling map.\n target (Target): The backend target to use for this pass. If this is specified\n it will be used instead of the coupling map\n \"\"\"\n super().__init__()\n self.coupling_map = coupling_map\n self.target = target\n\n # Create the replacement dag and associated register.\n self._cx_dag = DAGCircuit()\n qr = QuantumRegister(2)\n self._cx_dag.add_qreg(qr)\n self._cx_dag.apply_operation_back(HGate(), [qr[0]], [])\n self._cx_dag.apply_operation_back(HGate(), [qr[1]], [])\n self._cx_dag.apply_operation_back(CXGate(), [qr[1], qr[0]], [])\n self._cx_dag.apply_operation_back(HGate(), [qr[0]], [])\n self._cx_dag.apply_operation_back(HGate(), [qr[1]], [])\n\n self._ecr_dag = DAGCircuit()\n qr = QuantumRegister(2)\n self._ecr_dag.add_qreg(qr)\n self._ecr_dag.apply_operation_back(RYGate(-pi / 2), [qr[0]], [])\n self._ecr_dag.apply_operation_back(RYGate(pi / 2), [qr[1]], [])\n self._ecr_dag.apply_operation_back(ECRGate(), [qr[1], qr[0]], [])\n self._ecr_dag.apply_operation_back(HGate(), [qr[0]], [])\n self._ecr_dag.apply_operation_back(HGate(), [qr[1]], [])\n\n @staticmethod\n def _rzx_dag(parameter):\n _rzx_dag = DAGCircuit()\n qr = QuantumRegister(2)\n _rzx_dag.add_qreg(qr)\n _rzx_dag.apply_operation_back(HGate(), [qr[0]], [])\n _rzx_dag.apply_operation_back(HGate(), [qr[1]], [])\n _rzx_dag.apply_operation_back(RZXGate(parameter), [qr[1], qr[0]], [])\n _rzx_dag.apply_operation_back(HGate(), [qr[0]], [])\n _rzx_dag.apply_operation_back(HGate(), [qr[1]], [])\n return _rzx_dag\n\n def run(self, dag):\n \"\"\"Run the GateDirection pass on `dag`.\n\n Flips the cx nodes to match the directed coupling map. Modifies the\n input dag.\n\n Args:\n dag (DAGCircuit): DAG to map.\n\n Returns:\n DAGCircuit: The rearranged dag for the coupling map\n\n Raises:\n TranspilerError: If the circuit cannot be mapped just by flipping the\n cx nodes.\n \"\"\"\n trivial_layout = Layout.generate_trivial_layout(*dag.qregs.values())\n layout_map = trivial_layout.get_virtual_bits()\n if len(dag.qregs) > 1:\n raise TranspilerError(\n \"GateDirection expects a single qreg input DAG,\"\n \"but input DAG had qregs: {}.\".format(dag.qregs)\n )\n if self.target is None:\n cmap_edges = set(self.coupling_map.get_edges())\n if not cmap_edges:\n return dag\n\n self.coupling_map.compute_distance_matrix()\n\n dist_matrix = self.coupling_map.distance_matrix\n\n for node in dag.two_qubit_ops():\n control = node.qargs[0]\n target = node.qargs[1]\n\n physical_q0 = layout_map[control]\n physical_q1 = layout_map[target]\n\n if dist_matrix[physical_q0, physical_q1] != 1:\n raise TranspilerError(\n \"The circuit requires a connection between physical \"\n \"qubits %s and %s\" % (physical_q0, physical_q1)\n )\n\n if (physical_q0, physical_q1) not in cmap_edges:\n if node.name == \"cx\":\n dag.substitute_node_with_dag(node, self._cx_dag)\n elif node.name == \"ecr\":\n dag.substitute_node_with_dag(node, self._ecr_dag)\n elif node.name == \"rzx\":\n dag.substitute_node_with_dag(node, self._rzx_dag(*node.op.params))\n else:\n raise TranspilerError(\n f\"Flipping of gate direction is only supported \"\n f\"for CX, ECR, and RZX at this time, not {node.name}.\"\n )\n else:\n # TODO: Work with the gate instances and only use names as look up keys.\n # This will require iterating over the target names to build a mapping\n # of names to gates that implement CXGate, ECRGate, RZXGate (including\n # fixed angle variants)\n for node in dag.two_qubit_ops():\n control = node.qargs[0]\n target = node.qargs[1]\n\n physical_q0 = layout_map[control]\n physical_q1 = layout_map[target]\n\n if node.name == \"cx\":\n if (physical_q0, physical_q1) in self.target[\"cx\"]:\n continue\n if (physical_q1, physical_q0) in self.target[\"cx\"]:\n dag.substitute_node_with_dag(node, self._cx_dag)\n else:\n raise TranspilerError(\n \"The circuit requires a connection between physical \"\n \"qubits %s and %s for cx\" % (physical_q0, physical_q1)\n )\n elif node.name == \"ecr\":\n if (physical_q0, physical_q1) in self.target[\"ecr\"]:\n continue\n if (physical_q1, physical_q0) in self.target[\"ecr\"]:\n dag.substitute_node_with_dag(node, self._ecr_dag)\n else:\n raise TranspilerError(\n \"The circuit requires a connection between physical \"\n \"qubits %s and %s for ecr\" % (physical_q0, physical_q1)\n )\n elif node.name == \"rzx\":\n if (physical_q0, physical_q1) in self.target[\"rzx\"]:\n continue\n if (physical_q1, physical_q0) in self.target[\"rzx\"]:\n dag.substitute_node_with_dag(node, self._rzx_dag(*node.op.params))\n else:\n raise TranspilerError(\n \"The circuit requires a connection between physical \"\n \"qubits %s and %s for rzx\" % (physical_q0, physical_q1)\n )\n else:\n raise TranspilerError(\n f\"Flipping of gate direction is only supported \"\n f\"for CX, ECR, and RZX at this time, not {node.name}.\"\n )\n return dag\n", "path": "qiskit/transpiler/passes/utils/gate_direction.py"}]} | 3,381 | 609 |
gh_patches_debug_23998 | rasdani/github-patches | git_diff | dotkom__onlineweb4-203 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Auth templates does not use crispy forms
https://github.com/dotKom/onlineweb4/commit/26ae7847c2907895e6842061a848a2c0f47090a0
Håvard did some weird shit. Undo this and test that it still works.
</issue>
<code>
[start of apps/authentication/urls.py]
1 # -*- coding: utf-8 -*-
2
3 from django.conf.urls import patterns, url
4
5 urlpatterns = patterns('apps.authentication.views',
6 url(r'^login/$', 'login', name='auth_login'),
7 url(r'^logout/$', 'logout', name='auth_logout'),
8 url(r'^register/$', 'register', name='auth_register'),
9 url(r'^verify/(\w+)/$', 'verify', name='auth_verify'),
10 url(r'^recover/$', 'recover', name='auth_recover'),
11 url(r'^set_password/(\w+)/$', 'set_password', name='auth_set_password'),
12 )
13
[end of apps/authentication/urls.py]
[start of apps/authentication/forms.py]
1 # -*- coding: utf-8 -*-
2
3 import datetime
4 import re
5
6 from django import forms
7 from django.contrib import auth
8
9 from apps.authentication.models import OnlineUser as User
10
11 class LoginForm(forms.Form):
12 username = forms.CharField(widget=forms.TextInput(), label="Username", max_length=50)
13 password = forms.CharField(widget=forms.PasswordInput(render_value=False), label="Password")
14 user = None
15
16 def clean(self):
17 if self._errors:
18 return
19
20 user = auth.authenticate(username=self.cleaned_data['username'], password=self.cleaned_data['password'])
21
22 if user:
23 if user.is_active:
24 self.user = user
25 else:
26 self._errors['username'] = self.error_class(["Your account is inactive, try to recover it."])
27 else:
28 self._errors['username'] = self.error_class(["The account does not exist, or username/password combination is incorrect."])
29 return self.cleaned_data
30
31 def login(self, request):
32 try:
33 User.objects.get(username=request.POST['username'])
34 except:
35 return False
36 if self.is_valid():
37 auth.login(request, self.user)
38 request.session.set_expiry(0)
39 return True
40 return False
41
42 class RegisterForm(forms.Form):
43 username = forms.CharField(label="Username", max_length=20)
44 first_name = forms.CharField(label="First name", max_length=50)
45 last_name = forms.CharField(label="Last name", max_length=50)
46 email = forms.EmailField(label="Email", max_length=50)
47 password = forms.CharField(widget=forms.PasswordInput(render_value=False), label="Password")
48 repeat_password = forms.CharField(widget=forms.PasswordInput(render_value=False), label="Repeat password")
49 address = forms.CharField(label="Address", max_length=50)
50 zip_code = forms.CharField(label="ZIP code", max_length=4)
51 phone = forms.CharField(label="Phone number", max_length=20)
52
53 def clean(self):
54 super(RegisterForm, self).clean()
55 if self.is_valid():
56 cleaned_data = self.cleaned_data
57
58 # Check passwords
59 if cleaned_data['password'] != cleaned_data['repeat_password']:
60 self._errors['repeat_password'] = self.error_class(["Passwords did not match."])
61
62 # Check username
63 username = cleaned_data['username']
64 if User.objects.filter(username=username).count() > 0:
65 self._errors['username'] = self.error_class(["There is already a user with that username."])
66 if not re.match("^[a-zA-Z0-9_-]+$", username):
67 self._errors['username'] = self.error_class(["Your desired username contains illegal characters. Valid: a-Z 0-9 - _"])
68
69 # Check email
70 email = cleaned_data['email']
71 if User.objects.filter(email=email).count() > 0:
72 self._errors['email'] = self.error_class(["There is already a user with that email."])
73
74 # ZIP code digits only
75 zip_code = cleaned_data['zip_code']
76 if len(zip_code) != 4 or not zip_code.isdigit():
77 self._errors['zip_code'] = self.error_class(["The ZIP code must be 4 digit number."])
78
79 return cleaned_data
80
81 class RecoveryForm(forms.Form):
82 email = forms.EmailField(label="Email", max_length=50)
83
84 class ChangePasswordForm(forms.Form):
85 old_password = forms.CharField(widget=forms.PasswordInput(render_value=False), label="Old password", required=False)
86 new_password = forms.CharField(widget=forms.PasswordInput(render_value=False), label="New password")
87 repeat_password = forms.CharField(widget=forms.PasswordInput(render_value=False), label="Repeat new password")
88
89 def clean(self):
90 super(ChangePasswordForm, self).clean()
91 if self.is_valid():
92 cleaned_data = self.cleaned_data
93
94 # Check passwords
95 if cleaned_data['new_password'] != cleaned_data['repeat_password']:
96 self._errors['repeat_password'] = self.error_class(["Passwords did not match."])
97
98 return cleaned_data
99
[end of apps/authentication/forms.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/apps/authentication/forms.py b/apps/authentication/forms.py
--- a/apps/authentication/forms.py
+++ b/apps/authentication/forms.py
@@ -82,7 +82,6 @@
email = forms.EmailField(label="Email", max_length=50)
class ChangePasswordForm(forms.Form):
- old_password = forms.CharField(widget=forms.PasswordInput(render_value=False), label="Old password", required=False)
new_password = forms.CharField(widget=forms.PasswordInput(render_value=False), label="New password")
repeat_password = forms.CharField(widget=forms.PasswordInput(render_value=False), label="Repeat new password")
diff --git a/apps/authentication/urls.py b/apps/authentication/urls.py
--- a/apps/authentication/urls.py
+++ b/apps/authentication/urls.py
@@ -6,7 +6,7 @@
url(r'^login/$', 'login', name='auth_login'),
url(r'^logout/$', 'logout', name='auth_logout'),
url(r'^register/$', 'register', name='auth_register'),
- url(r'^verify/(\w+)/$', 'verify', name='auth_verify'),
+ url(r'^verify/(?P<token>\w+)/$', 'verify', name='auth_verify'),
url(r'^recover/$', 'recover', name='auth_recover'),
- url(r'^set_password/(\w+)/$', 'set_password', name='auth_set_password'),
+ url(r'^set_password/(?P<token>\w+)/$', 'set_password', name='auth_set_password'),
)
| {"golden_diff": "diff --git a/apps/authentication/forms.py b/apps/authentication/forms.py\n--- a/apps/authentication/forms.py\n+++ b/apps/authentication/forms.py\n@@ -82,7 +82,6 @@\n email = forms.EmailField(label=\"Email\", max_length=50)\n \n class ChangePasswordForm(forms.Form):\n- old_password = forms.CharField(widget=forms.PasswordInput(render_value=False), label=\"Old password\", required=False)\n new_password = forms.CharField(widget=forms.PasswordInput(render_value=False), label=\"New password\")\n repeat_password = forms.CharField(widget=forms.PasswordInput(render_value=False), label=\"Repeat new password\")\n \ndiff --git a/apps/authentication/urls.py b/apps/authentication/urls.py\n--- a/apps/authentication/urls.py\n+++ b/apps/authentication/urls.py\n@@ -6,7 +6,7 @@\n url(r'^login/$', 'login', name='auth_login'),\n url(r'^logout/$', 'logout', name='auth_logout'),\n url(r'^register/$', 'register', name='auth_register'),\n- url(r'^verify/(\\w+)/$', 'verify', name='auth_verify'),\n+ url(r'^verify/(?P<token>\\w+)/$', 'verify', name='auth_verify'),\n url(r'^recover/$', 'recover', name='auth_recover'),\n- url(r'^set_password/(\\w+)/$', 'set_password', name='auth_set_password'),\n+ url(r'^set_password/(?P<token>\\w+)/$', 'set_password', name='auth_set_password'),\n )\n", "issue": "Auth templates does not use crispy forms\nhttps://github.com/dotKom/onlineweb4/commit/26ae7847c2907895e6842061a848a2c0f47090a0\n\nH\u00e5vard did some weird shit. Undo this and test that it still works.\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\nfrom django.conf.urls import patterns, url\n\nurlpatterns = patterns('apps.authentication.views',\n url(r'^login/$', 'login', name='auth_login'),\n url(r'^logout/$', 'logout', name='auth_logout'),\n url(r'^register/$', 'register', name='auth_register'),\n url(r'^verify/(\\w+)/$', 'verify', name='auth_verify'),\n url(r'^recover/$', 'recover', name='auth_recover'),\n url(r'^set_password/(\\w+)/$', 'set_password', name='auth_set_password'),\n)\n", "path": "apps/authentication/urls.py"}, {"content": "# -*- coding: utf-8 -*-\n\nimport datetime\nimport re\n\nfrom django import forms\nfrom django.contrib import auth\n\nfrom apps.authentication.models import OnlineUser as User\n\nclass LoginForm(forms.Form):\n username = forms.CharField(widget=forms.TextInput(), label=\"Username\", max_length=50)\n password = forms.CharField(widget=forms.PasswordInput(render_value=False), label=\"Password\")\n user = None\n\n def clean(self):\n if self._errors:\n return\n \n user = auth.authenticate(username=self.cleaned_data['username'], password=self.cleaned_data['password'])\n\n if user:\n if user.is_active:\n self.user = user\n else:\n self._errors['username'] = self.error_class([\"Your account is inactive, try to recover it.\"])\n else:\n self._errors['username'] = self.error_class([\"The account does not exist, or username/password combination is incorrect.\"])\n return self.cleaned_data\n\n def login(self, request):\n try:\n User.objects.get(username=request.POST['username'])\n except:\n return False\n if self.is_valid():\n auth.login(request, self.user)\n request.session.set_expiry(0)\n return True\n return False\n\nclass RegisterForm(forms.Form):\n username = forms.CharField(label=\"Username\", max_length=20)\n first_name = forms.CharField(label=\"First name\", max_length=50)\n last_name = forms.CharField(label=\"Last name\", max_length=50)\n email = forms.EmailField(label=\"Email\", max_length=50)\n password = forms.CharField(widget=forms.PasswordInput(render_value=False), label=\"Password\")\n repeat_password = forms.CharField(widget=forms.PasswordInput(render_value=False), label=\"Repeat password\")\n address = forms.CharField(label=\"Address\", max_length=50)\n zip_code = forms.CharField(label=\"ZIP code\", max_length=4)\n phone = forms.CharField(label=\"Phone number\", max_length=20)\n \n def clean(self):\n super(RegisterForm, self).clean()\n if self.is_valid():\n cleaned_data = self.cleaned_data\n\n # Check passwords\n if cleaned_data['password'] != cleaned_data['repeat_password']:\n self._errors['repeat_password'] = self.error_class([\"Passwords did not match.\"])\n\n # Check username\n username = cleaned_data['username']\n if User.objects.filter(username=username).count() > 0:\n self._errors['username'] = self.error_class([\"There is already a user with that username.\"])\n if not re.match(\"^[a-zA-Z0-9_-]+$\", username):\n self._errors['username'] = self.error_class([\"Your desired username contains illegal characters. Valid: a-Z 0-9 - _\"])\n\n # Check email\n email = cleaned_data['email']\n if User.objects.filter(email=email).count() > 0:\n self._errors['email'] = self.error_class([\"There is already a user with that email.\"])\n\n # ZIP code digits only\n zip_code = cleaned_data['zip_code']\n if len(zip_code) != 4 or not zip_code.isdigit():\n self._errors['zip_code'] = self.error_class([\"The ZIP code must be 4 digit number.\"])\n\n return cleaned_data \n\nclass RecoveryForm(forms.Form):\n email = forms.EmailField(label=\"Email\", max_length=50)\n\nclass ChangePasswordForm(forms.Form):\n old_password = forms.CharField(widget=forms.PasswordInput(render_value=False), label=\"Old password\", required=False)\n new_password = forms.CharField(widget=forms.PasswordInput(render_value=False), label=\"New password\")\n repeat_password = forms.CharField(widget=forms.PasswordInput(render_value=False), label=\"Repeat new password\")\n\n def clean(self):\n super(ChangePasswordForm, self).clean()\n if self.is_valid():\n cleaned_data = self.cleaned_data\n\n # Check passwords\n if cleaned_data['new_password'] != cleaned_data['repeat_password']:\n self._errors['repeat_password'] = self.error_class([\"Passwords did not match.\"])\n\n return cleaned_data\n", "path": "apps/authentication/forms.py"}]} | 1,819 | 315 |
gh_patches_debug_18058 | rasdani/github-patches | git_diff | cloudtools__troposphere-1287 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add 'Kind' property to AWS::AppSync::Resolver
https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-resource-appsync-resolver.html#cfn-appsync-resolver-kind
The Kind property is required when using the new PipelineConfig feature for AppSync.
There are only two allowable values, PIPELINE or UNIT. The property is not required if using the standard resolvers.
</issue>
<code>
[start of troposphere/appsync.py]
1 # Copyright (c) 2012-2017, Mark Peek <[email protected]>
2 # All rights reserved.
3 #
4 # See LICENSE file for full license.
5
6 from . import AWSObject, AWSProperty
7 from .validators import boolean, integer
8
9
10 class ApiKey(AWSObject):
11 resource_type = "AWS::AppSync::ApiKey"
12
13 props = {
14 'ApiId': (basestring, True),
15 'Description': (basestring, False),
16 'Expires': (integer, False),
17 }
18
19
20 class DynamoDBConfig(AWSProperty):
21 props = {
22 'AwsRegion': (basestring, True),
23 'TableName': (basestring, True),
24 'UseCallerCredentials': (boolean, False),
25 }
26
27
28 class ElasticsearchConfig(AWSProperty):
29 props = {
30 'AwsRegion': (basestring, True),
31 'Endpoint': (basestring, True),
32 }
33
34
35 class AwsIamConfig(AWSProperty):
36 props = {
37 'SigningRegion': (basestring, False),
38 'SigningServiceName': (basestring, False),
39 }
40
41
42 class AuthorizationConfig(AWSProperty):
43 props = {
44 'AuthorizationType': (basestring, True),
45 'AwsIamConfig': (AwsIamConfig, False),
46 }
47
48
49 class HttpConfig(AWSProperty):
50 props = {
51 'AuthorizationConfig': (AuthorizationConfig, False),
52 'Endpoint': (basestring, True),
53 }
54
55
56 class LambdaConfig(AWSProperty):
57 props = {
58 'LambdaFunctionArn': (basestring, True),
59 }
60
61
62 class RdsHttpEndpointConfig(AWSProperty):
63 props = {
64 'AwsRegion': (basestring, False),
65 'DbClusterIdentifier': (basestring, False),
66 'DatabaseName': (basestring, False),
67 'Schema': (basestring, False),
68 'AwsSecretStoreArn': (basestring, False),
69 }
70
71
72 class RelationalDatabaseConfig(AWSProperty):
73 props = {
74 'RelationalDatasourceType': (basestring, False),
75 'RdsHttpEndpointConfig': (RdsHttpEndpointConfig, False),
76 }
77
78
79 class DataSource(AWSObject):
80 resource_type = "AWS::AppSync::DataSource"
81
82 props = {
83 'ApiId': (basestring, True),
84 'Description': (basestring, False),
85 'DynamoDBConfig': (DynamoDBConfig, False),
86 'ElasticsearchConfig': (ElasticsearchConfig, False),
87 'HttpConfig': (HttpConfig, False),
88 'LambdaConfig': (LambdaConfig, False),
89 'Name': (basestring, True),
90 'ServiceRoleArn': (basestring, False),
91 'Type': (basestring, True),
92 'RelationalDatabaseConfig': (RelationalDatabaseConfig, False),
93 }
94
95
96 class LogConfig(AWSProperty):
97 props = {
98 'CloudWatchLogsRoleArn': (basestring, False),
99 'FieldLogLevel': (basestring, False),
100 }
101
102
103 class OpenIDConnectConfig(AWSProperty):
104 props = {
105 'AuthTTL': (float, False),
106 'ClientId': (basestring, False),
107 'IatTTL': (float, False),
108 'Issuer': (basestring, True),
109 }
110
111
112 class UserPoolConfig(AWSProperty):
113 props = {
114 'AppIdClientRegex': (basestring, False),
115 'AwsRegion': (basestring, False),
116 'DefaultAction': (basestring, False),
117 'UserPoolId': (basestring, False),
118 }
119
120
121 class GraphQLApi(AWSObject):
122 resource_type = "AWS::AppSync::GraphQLApi"
123
124 props = {
125 'AuthenticationType': (basestring, True),
126 'LogConfig': (LogConfig, False),
127 'Name': (basestring, True),
128 'OpenIDConnectConfig': (OpenIDConnectConfig, False),
129 'UserPoolConfig': (UserPoolConfig, False),
130 }
131
132
133 class GraphQLSchema(AWSObject):
134 resource_type = "AWS::AppSync::GraphQLSchema"
135
136 props = {
137 'ApiId': (basestring, True),
138 'Definition': (basestring, False),
139 'DefinitionS3Location': (basestring, False),
140 }
141
142
143 class PipelineConfig(AWSProperty):
144 props = {
145 'Functions': ([basestring], False),
146 }
147
148
149 class Resolver(AWSObject):
150 resource_type = "AWS::AppSync::Resolver"
151
152 props = {
153 'ApiId': (basestring, True),
154 'DataSourceName': (basestring, True),
155 'FieldName': (basestring, True),
156 'PipelineConfig': (PipelineConfig, False),
157 'RequestMappingTemplate': (basestring, False),
158 'RequestMappingTemplateS3Location': (basestring, False),
159 'ResponseMappingTemplate': (basestring, False),
160 'ResponseMappingTemplateS3Location': (basestring, False),
161 'TypeName': (basestring, True),
162 }
163
164
165 class FunctionConfiguration(AWSObject):
166 resource_type = "AWS::AppSync::FunctionConfiguration"
167
168 props = {
169 'ApiId': (basestring, True),
170 'Name': (basestring, False),
171 'Description': (basestring, False),
172 'DataSourceName': (basestring, False),
173 'FunctionVersion': (basestring, False),
174 'RequestMappingTemplate': (basestring, False),
175 'RequestMappingTemplateS3Location': (basestring, False),
176 'ResponseMappingTemplate': (basestring, False),
177 'ResponseMappingTemplateS3Location': (basestring, False),
178 }
179
[end of troposphere/appsync.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/troposphere/appsync.py b/troposphere/appsync.py
--- a/troposphere/appsync.py
+++ b/troposphere/appsync.py
@@ -7,6 +7,13 @@
from .validators import boolean, integer
+def resolver_kind_validator(x):
+ valid_types = ["UNIT", "PIPELINE"]
+ if x not in valid_types:
+ raise ValueError("Kind must be one of: %s" % ", ".join(valid_types))
+ return x
+
+
class ApiKey(AWSObject):
resource_type = "AWS::AppSync::ApiKey"
@@ -153,6 +160,7 @@
'ApiId': (basestring, True),
'DataSourceName': (basestring, True),
'FieldName': (basestring, True),
+ 'Kind': (resolver_kind_validator, False),
'PipelineConfig': (PipelineConfig, False),
'RequestMappingTemplate': (basestring, False),
'RequestMappingTemplateS3Location': (basestring, False),
| {"golden_diff": "diff --git a/troposphere/appsync.py b/troposphere/appsync.py\n--- a/troposphere/appsync.py\n+++ b/troposphere/appsync.py\n@@ -7,6 +7,13 @@\n from .validators import boolean, integer\n \n \n+def resolver_kind_validator(x):\n+ valid_types = [\"UNIT\", \"PIPELINE\"]\n+ if x not in valid_types:\n+ raise ValueError(\"Kind must be one of: %s\" % \", \".join(valid_types))\n+ return x\n+\n+\n class ApiKey(AWSObject):\n resource_type = \"AWS::AppSync::ApiKey\"\n \n@@ -153,6 +160,7 @@\n 'ApiId': (basestring, True),\n 'DataSourceName': (basestring, True),\n 'FieldName': (basestring, True),\n+ 'Kind': (resolver_kind_validator, False),\n 'PipelineConfig': (PipelineConfig, False),\n 'RequestMappingTemplate': (basestring, False),\n 'RequestMappingTemplateS3Location': (basestring, False),\n", "issue": "Add 'Kind' property to AWS::AppSync::Resolver\nhttps://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-resource-appsync-resolver.html#cfn-appsync-resolver-kind\r\n\r\nThe Kind property is required when using the new PipelineConfig feature for AppSync.\r\n\r\nThere are only two allowable values, PIPELINE or UNIT. The property is not required if using the standard resolvers.\n", "before_files": [{"content": "# Copyright (c) 2012-2017, Mark Peek <[email protected]>\n# All rights reserved.\n#\n# See LICENSE file for full license.\n\nfrom . import AWSObject, AWSProperty\nfrom .validators import boolean, integer\n\n\nclass ApiKey(AWSObject):\n resource_type = \"AWS::AppSync::ApiKey\"\n\n props = {\n 'ApiId': (basestring, True),\n 'Description': (basestring, False),\n 'Expires': (integer, False),\n }\n\n\nclass DynamoDBConfig(AWSProperty):\n props = {\n 'AwsRegion': (basestring, True),\n 'TableName': (basestring, True),\n 'UseCallerCredentials': (boolean, False),\n }\n\n\nclass ElasticsearchConfig(AWSProperty):\n props = {\n 'AwsRegion': (basestring, True),\n 'Endpoint': (basestring, True),\n }\n\n\nclass AwsIamConfig(AWSProperty):\n props = {\n 'SigningRegion': (basestring, False),\n 'SigningServiceName': (basestring, False),\n }\n\n\nclass AuthorizationConfig(AWSProperty):\n props = {\n 'AuthorizationType': (basestring, True),\n 'AwsIamConfig': (AwsIamConfig, False),\n }\n\n\nclass HttpConfig(AWSProperty):\n props = {\n 'AuthorizationConfig': (AuthorizationConfig, False),\n 'Endpoint': (basestring, True),\n }\n\n\nclass LambdaConfig(AWSProperty):\n props = {\n 'LambdaFunctionArn': (basestring, True),\n }\n\n\nclass RdsHttpEndpointConfig(AWSProperty):\n props = {\n 'AwsRegion': (basestring, False),\n 'DbClusterIdentifier': (basestring, False),\n 'DatabaseName': (basestring, False),\n 'Schema': (basestring, False),\n 'AwsSecretStoreArn': (basestring, False),\n }\n\n\nclass RelationalDatabaseConfig(AWSProperty):\n props = {\n 'RelationalDatasourceType': (basestring, False),\n 'RdsHttpEndpointConfig': (RdsHttpEndpointConfig, False),\n }\n\n\nclass DataSource(AWSObject):\n resource_type = \"AWS::AppSync::DataSource\"\n\n props = {\n 'ApiId': (basestring, True),\n 'Description': (basestring, False),\n 'DynamoDBConfig': (DynamoDBConfig, False),\n 'ElasticsearchConfig': (ElasticsearchConfig, False),\n 'HttpConfig': (HttpConfig, False),\n 'LambdaConfig': (LambdaConfig, False),\n 'Name': (basestring, True),\n 'ServiceRoleArn': (basestring, False),\n 'Type': (basestring, True),\n 'RelationalDatabaseConfig': (RelationalDatabaseConfig, False),\n }\n\n\nclass LogConfig(AWSProperty):\n props = {\n 'CloudWatchLogsRoleArn': (basestring, False),\n 'FieldLogLevel': (basestring, False),\n }\n\n\nclass OpenIDConnectConfig(AWSProperty):\n props = {\n 'AuthTTL': (float, False),\n 'ClientId': (basestring, False),\n 'IatTTL': (float, False),\n 'Issuer': (basestring, True),\n }\n\n\nclass UserPoolConfig(AWSProperty):\n props = {\n 'AppIdClientRegex': (basestring, False),\n 'AwsRegion': (basestring, False),\n 'DefaultAction': (basestring, False),\n 'UserPoolId': (basestring, False),\n }\n\n\nclass GraphQLApi(AWSObject):\n resource_type = \"AWS::AppSync::GraphQLApi\"\n\n props = {\n 'AuthenticationType': (basestring, True),\n 'LogConfig': (LogConfig, False),\n 'Name': (basestring, True),\n 'OpenIDConnectConfig': (OpenIDConnectConfig, False),\n 'UserPoolConfig': (UserPoolConfig, False),\n }\n\n\nclass GraphQLSchema(AWSObject):\n resource_type = \"AWS::AppSync::GraphQLSchema\"\n\n props = {\n 'ApiId': (basestring, True),\n 'Definition': (basestring, False),\n 'DefinitionS3Location': (basestring, False),\n }\n\n\nclass PipelineConfig(AWSProperty):\n props = {\n 'Functions': ([basestring], False),\n }\n\n\nclass Resolver(AWSObject):\n resource_type = \"AWS::AppSync::Resolver\"\n\n props = {\n 'ApiId': (basestring, True),\n 'DataSourceName': (basestring, True),\n 'FieldName': (basestring, True),\n 'PipelineConfig': (PipelineConfig, False),\n 'RequestMappingTemplate': (basestring, False),\n 'RequestMappingTemplateS3Location': (basestring, False),\n 'ResponseMappingTemplate': (basestring, False),\n 'ResponseMappingTemplateS3Location': (basestring, False),\n 'TypeName': (basestring, True),\n }\n\n\nclass FunctionConfiguration(AWSObject):\n resource_type = \"AWS::AppSync::FunctionConfiguration\"\n\n props = {\n 'ApiId': (basestring, True),\n 'Name': (basestring, False),\n 'Description': (basestring, False),\n 'DataSourceName': (basestring, False),\n 'FunctionVersion': (basestring, False),\n 'RequestMappingTemplate': (basestring, False),\n 'RequestMappingTemplateS3Location': (basestring, False),\n 'ResponseMappingTemplate': (basestring, False),\n 'ResponseMappingTemplateS3Location': (basestring, False),\n }\n", "path": "troposphere/appsync.py"}]} | 2,263 | 226 |
gh_patches_debug_1594 | rasdani/github-patches | git_diff | pypa__setuptools-2897 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[FR] User configurable get_requires_for_build_wheel and get_requires_for_build_sdist
### What's the problem this feature will solve?
https://github.com/pypa/setuptools/issues/2823 proposes to remove the legacy `setup_requires` option. Currently, `setup_requires` can be set statically (which has been replaced by the `requires` key in `pyproject.toml`), or dynamically during the running of the `setup.py` file. This latter method of dynamically setting the build requirements can be replaced more cleanly by the two optional PEP 517 hooks `get_requires_for_build_wheel` and `get_requires_for_build_sdist`. Currently setuptools does not allow users to override and/or set the output of these hooks.
### Describe the solution you'd like
I'm not proposing a specific solution (I suspect the best solution will be the one that best matches what users need, and aligns with the internal design of setuptools), but here are three possible designs:
1. Add two new arguments to `setuptools.setup`: `sdist_requires` and `wheel_requires`. These would be lists of requirements, similar to `install_requirements`. This would likely be the least change to existing setup.py files, but what that implies for the internal flow of setuptools is unclear. Additionally, this does not pass `config_settings` to the user code, which could be desired by users. It would be assumed that the presence of `sdist_requires` and `wheel_requires` would override `setup_requires` whilst that option was allowed.
2. Like 1, but instead of the options being lists of requirements, instead a function matching the interface of the PEP 517 hooks would be given. This does require more changes to user code, but means that the user code can handle `config_settings`. I'm not sure there's much difference between 1 and 2 from a setuptools internal-design perspective though (as both are being handled completely within the `setup.py` module).
3. Add `sdist_requires` and `wheel_requires` to `setup.cfg`. The values would follow the same format as `build-backend` from PEP 517, with the callables being pointed to matching the interface of the relevant hook. Depending on the internals of setuptools, this could allow setuptools to only run the `setup.py` file on the mandatory hooks.
### Alternative Solutions
_No response_
### Additional context
This came from https://github.com/pypa/setuptools/issues/2823, from what I can see there's not been a discussion around this.
I'm also not aware of build backends using this in anger, last time I surveyed the ecosystem none of the backends provided a way to set this, so I wouldn't be surprised if this causes some breakage in some frontends (even if it is part of PEP 517).
### Code of Conduct
- [X] I agree to follow the PSF Code of Conduct
</issue>
<code>
[start of docs/conf.py]
1 extensions = ['sphinx.ext.autodoc', 'jaraco.packaging.sphinx', 'rst.linker']
2
3 master_doc = "index"
4
5 link_files = {
6 '../CHANGES.rst': dict(
7 using=dict(
8 BB='https://bitbucket.org',
9 GH='https://github.com',
10 ),
11 replace=[
12 dict(
13 pattern=r'(Issue )?#(?P<issue>\d+)',
14 url='{package_url}/issues/{issue}',
15 ),
16 dict(
17 pattern=r'BB Pull Request ?#(?P<bb_pull_request>\d+)',
18 url='{BB}/pypa/setuptools/pull-request/{bb_pull_request}',
19 ),
20 dict(
21 pattern=r'Distribute #(?P<distribute>\d+)',
22 url='{BB}/tarek/distribute/issue/{distribute}',
23 ),
24 dict(
25 pattern=r'Buildout #(?P<buildout>\d+)',
26 url='{GH}/buildout/buildout/issues/{buildout}',
27 ),
28 dict(
29 pattern=r'Old Setuptools #(?P<old_setuptools>\d+)',
30 url='http://bugs.python.org/setuptools/issue{old_setuptools}',
31 ),
32 dict(
33 pattern=r'Jython #(?P<jython>\d+)',
34 url='http://bugs.jython.org/issue{jython}',
35 ),
36 dict(
37 pattern=r'(Python #|bpo-)(?P<python>\d+)',
38 url='http://bugs.python.org/issue{python}',
39 ),
40 dict(
41 pattern=r'Interop #(?P<interop>\d+)',
42 url='{GH}/pypa/interoperability-peps/issues/{interop}',
43 ),
44 dict(
45 pattern=r'Pip #(?P<pip>\d+)',
46 url='{GH}/pypa/pip/issues/{pip}',
47 ),
48 dict(
49 pattern=r'Packaging #(?P<packaging>\d+)',
50 url='{GH}/pypa/packaging/issues/{packaging}',
51 ),
52 dict(
53 pattern=r'[Pp]ackaging (?P<packaging_ver>\d+(\.\d+)+)',
54 url='{GH}/pypa/packaging/blob/{packaging_ver}/CHANGELOG.rst',
55 ),
56 dict(
57 pattern=r'PEP[- ](?P<pep_number>\d+)',
58 url='https://www.python.org/dev/peps/pep-{pep_number:0>4}/',
59 ),
60 dict(
61 pattern=r'setuptools_svn #(?P<setuptools_svn>\d+)',
62 url='{GH}/jaraco/setuptools_svn/issues/{setuptools_svn}',
63 ),
64 dict(
65 pattern=r'pypa/distutils#(?P<distutils>\d+)',
66 url='{GH}/pypa/distutils/issues/{distutils}',
67 ),
68 dict(
69 pattern=r'pypa/distutils@(?P<distutils_commit>[\da-f]+)',
70 url='{GH}/pypa/distutils/commit/{distutils_commit}',
71 ),
72 dict(
73 pattern=r'^(?m)((?P<scm_version>v?\d+(\.\d+){1,2}))\n[-=]+\n',
74 with_scm='{text}\n{rev[timestamp]:%d %b %Y}\n',
75 ),
76 ],
77 ),
78 }
79
80 # Be strict about any broken references:
81 nitpicky = True
82
83 # Include Python intersphinx mapping to prevent failures
84 # jaraco/skeleton#51
85 extensions += ['sphinx.ext.intersphinx']
86 intersphinx_mapping = {
87 'python': ('https://docs.python.org/3', None),
88 }
89
90 intersphinx_mapping.update({
91 'pypa-build': ('https://pypa-build.readthedocs.io/en/latest/', None)
92 })
93
94 # Add support for linking usernames
95 github_url = 'https://github.com'
96 github_sponsors_url = f'{github_url}/sponsors'
97 extlinks = {
98 'user': (f'{github_sponsors_url}/%s', '@'), # noqa: WPS323
99 }
100 extensions += ['sphinx.ext.extlinks']
101
102 # Ref: https://github.com/python-attrs/attrs/pull/571/files\
103 # #diff-85987f48f1258d9ee486e3191495582dR82
104 default_role = 'any'
105
106 # HTML theme
107 html_theme = 'furo'
108 html_logo = "images/logo.svg"
109
110 html_theme_options = {
111 "sidebar_hide_name": True,
112 "light_css_variables": {
113 "color-brand-primary": "#336790", # "blue"
114 "color-brand-content": "#336790",
115 },
116 "dark_css_variables": {
117 "color-brand-primary": "#E5B62F", # "yellow"
118 "color-brand-content": "#E5B62F",
119 },
120 }
121
122 # Add support for inline tabs
123 extensions += ['sphinx_inline_tabs']
124
125 # Support for distutils
126
127 # Ref: https://stackoverflow.com/a/30624034/595220
128 nitpick_ignore = [
129 ('c:func', 'SHGetSpecialFolderPath'), # ref to MS docs
130 ('envvar', 'DISTUTILS_DEBUG'), # undocumented
131 ('envvar', 'HOME'), # undocumented
132 ('envvar', 'PLAT'), # undocumented
133 ('py:attr', 'CCompiler.language_map'), # undocumented
134 ('py:attr', 'CCompiler.language_order'), # undocumented
135 ('py:class', 'distutils.dist.Distribution'), # undocumented
136 ('py:class', 'distutils.extension.Extension'), # undocumented
137 ('py:class', 'BorlandCCompiler'), # undocumented
138 ('py:class', 'CCompiler'), # undocumented
139 ('py:class', 'CygwinCCompiler'), # undocumented
140 ('py:class', 'distutils.dist.DistributionMetadata'), # undocumented
141 ('py:class', 'FileList'), # undocumented
142 ('py:class', 'IShellLink'), # ref to MS docs
143 ('py:class', 'MSVCCompiler'), # undocumented
144 ('py:class', 'OptionDummy'), # undocumented
145 ('py:class', 'UnixCCompiler'), # undocumented
146 ('py:exc', 'CompileError'), # undocumented
147 ('py:exc', 'DistutilsExecError'), # undocumented
148 ('py:exc', 'DistutilsFileError'), # undocumented
149 ('py:exc', 'LibError'), # undocumented
150 ('py:exc', 'LinkError'), # undocumented
151 ('py:exc', 'PreprocessError'), # undocumented
152 ('py:func', 'distutils.CCompiler.new_compiler'), # undocumented
153 # undocumented:
154 ('py:func', 'distutils.dist.DistributionMetadata.read_pkg_file'),
155 ('py:func', 'distutils.file_util._copy_file_contents'), # undocumented
156 ('py:func', 'distutils.log.debug'), # undocumented
157 ('py:func', 'distutils.spawn.find_executable'), # undocumented
158 ('py:func', 'distutils.spawn.spawn'), # undocumented
159 # TODO: check https://docutils.rtfd.io in the future
160 ('py:mod', 'docutils'), # there's no Sphinx site documenting this
161 ]
162
163 # Allow linking objects on other Sphinx sites seamlessly:
164 intersphinx_mapping.update(
165 python=('https://docs.python.org/3', None),
166 python2=('https://docs.python.org/2', None),
167 )
168
169 # Add support for the unreleased "next-version" change notes
170 extensions += ['sphinxcontrib.towncrier']
171 # Extension needs a path from here to the towncrier config.
172 towncrier_draft_working_directory = '..'
173 # Avoid an empty section for unpublished changes.
174 towncrier_draft_include_empty = False
175
176 extensions += ['jaraco.tidelift']
177
178 # Add icons (aka "favicons") to documentation
179 extensions += ['sphinx-favicon']
180 html_static_path = ['images'] # should contain the folder with icons
181
182 # List of dicts with <link> HTML attributes
183 # static-file points to files in the html_static_path (href is computed)
184 favicons = [
185 { # "Catch-all" goes first, otherwise some browsers will overwrite
186 "rel": "icon",
187 "type": "image/svg+xml",
188 "static-file": "logo-symbol-only.svg",
189 "sizes": "any"
190 },
191 { # Version with thicker strokes for better visibility at smaller sizes
192 "rel": "icon",
193 "type": "image/svg+xml",
194 "static-file": "favicon.svg",
195 "sizes": "16x16 24x24 32x32 48x48"
196 },
197 # rel="apple-touch-icon" does not support SVG yet
198 ]
199
200 intersphinx_mapping['pip'] = 'https://pip.pypa.io/en/latest', None
201
[end of docs/conf.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/docs/conf.py b/docs/conf.py
--- a/docs/conf.py
+++ b/docs/conf.py
@@ -95,6 +95,7 @@
github_sponsors_url = f'{github_url}/sponsors'
extlinks = {
'user': (f'{github_sponsors_url}/%s', '@'), # noqa: WPS323
+ 'pypi': ('https://pypi.org/project/%s', '%s'),
}
extensions += ['sphinx.ext.extlinks']
| {"golden_diff": "diff --git a/docs/conf.py b/docs/conf.py\n--- a/docs/conf.py\n+++ b/docs/conf.py\n@@ -95,6 +95,7 @@\n github_sponsors_url = f'{github_url}/sponsors'\n extlinks = {\n 'user': (f'{github_sponsors_url}/%s', '@'), # noqa: WPS323\n+ 'pypi': ('https://pypi.org/project/%s', '%s'),\n }\n extensions += ['sphinx.ext.extlinks']\n", "issue": "[FR] User configurable get_requires_for_build_wheel and get_requires_for_build_sdist\n### What's the problem this feature will solve?\n\nhttps://github.com/pypa/setuptools/issues/2823 proposes to remove the legacy `setup_requires` option. Currently, `setup_requires` can be set statically (which has been replaced by the `requires` key in `pyproject.toml`), or dynamically during the running of the `setup.py` file. This latter method of dynamically setting the build requirements can be replaced more cleanly by the two optional PEP 517 hooks `get_requires_for_build_wheel` and `get_requires_for_build_sdist`. Currently setuptools does not allow users to override and/or set the output of these hooks.\n\n### Describe the solution you'd like\n\nI'm not proposing a specific solution (I suspect the best solution will be the one that best matches what users need, and aligns with the internal design of setuptools), but here are three possible designs:\r\n\r\n1. Add two new arguments to `setuptools.setup`: `sdist_requires` and `wheel_requires`. These would be lists of requirements, similar to `install_requirements`. This would likely be the least change to existing setup.py files, but what that implies for the internal flow of setuptools is unclear. Additionally, this does not pass `config_settings` to the user code, which could be desired by users. It would be assumed that the presence of `sdist_requires` and `wheel_requires` would override `setup_requires` whilst that option was allowed.\r\n\r\n2. Like 1, but instead of the options being lists of requirements, instead a function matching the interface of the PEP 517 hooks would be given. This does require more changes to user code, but means that the user code can handle `config_settings`. I'm not sure there's much difference between 1 and 2 from a setuptools internal-design perspective though (as both are being handled completely within the `setup.py` module).\r\n\r\n3. Add `sdist_requires` and `wheel_requires` to `setup.cfg`. The values would follow the same format as `build-backend` from PEP 517, with the callables being pointed to matching the interface of the relevant hook. Depending on the internals of setuptools, this could allow setuptools to only run the `setup.py` file on the mandatory hooks.\n\n### Alternative Solutions\n\n_No response_\n\n### Additional context\n\nThis came from https://github.com/pypa/setuptools/issues/2823, from what I can see there's not been a discussion around this.\r\n\r\nI'm also not aware of build backends using this in anger, last time I surveyed the ecosystem none of the backends provided a way to set this, so I wouldn't be surprised if this causes some breakage in some frontends (even if it is part of PEP 517).\n\n### Code of Conduct\n\n- [X] I agree to follow the PSF Code of Conduct\n", "before_files": [{"content": "extensions = ['sphinx.ext.autodoc', 'jaraco.packaging.sphinx', 'rst.linker']\n\nmaster_doc = \"index\"\n\nlink_files = {\n '../CHANGES.rst': dict(\n using=dict(\n BB='https://bitbucket.org',\n GH='https://github.com',\n ),\n replace=[\n dict(\n pattern=r'(Issue )?#(?P<issue>\\d+)',\n url='{package_url}/issues/{issue}',\n ),\n dict(\n pattern=r'BB Pull Request ?#(?P<bb_pull_request>\\d+)',\n url='{BB}/pypa/setuptools/pull-request/{bb_pull_request}',\n ),\n dict(\n pattern=r'Distribute #(?P<distribute>\\d+)',\n url='{BB}/tarek/distribute/issue/{distribute}',\n ),\n dict(\n pattern=r'Buildout #(?P<buildout>\\d+)',\n url='{GH}/buildout/buildout/issues/{buildout}',\n ),\n dict(\n pattern=r'Old Setuptools #(?P<old_setuptools>\\d+)',\n url='http://bugs.python.org/setuptools/issue{old_setuptools}',\n ),\n dict(\n pattern=r'Jython #(?P<jython>\\d+)',\n url='http://bugs.jython.org/issue{jython}',\n ),\n dict(\n pattern=r'(Python #|bpo-)(?P<python>\\d+)',\n url='http://bugs.python.org/issue{python}',\n ),\n dict(\n pattern=r'Interop #(?P<interop>\\d+)',\n url='{GH}/pypa/interoperability-peps/issues/{interop}',\n ),\n dict(\n pattern=r'Pip #(?P<pip>\\d+)',\n url='{GH}/pypa/pip/issues/{pip}',\n ),\n dict(\n pattern=r'Packaging #(?P<packaging>\\d+)',\n url='{GH}/pypa/packaging/issues/{packaging}',\n ),\n dict(\n pattern=r'[Pp]ackaging (?P<packaging_ver>\\d+(\\.\\d+)+)',\n url='{GH}/pypa/packaging/blob/{packaging_ver}/CHANGELOG.rst',\n ),\n dict(\n pattern=r'PEP[- ](?P<pep_number>\\d+)',\n url='https://www.python.org/dev/peps/pep-{pep_number:0>4}/',\n ),\n dict(\n pattern=r'setuptools_svn #(?P<setuptools_svn>\\d+)',\n url='{GH}/jaraco/setuptools_svn/issues/{setuptools_svn}',\n ),\n dict(\n pattern=r'pypa/distutils#(?P<distutils>\\d+)',\n url='{GH}/pypa/distutils/issues/{distutils}',\n ),\n dict(\n pattern=r'pypa/distutils@(?P<distutils_commit>[\\da-f]+)',\n url='{GH}/pypa/distutils/commit/{distutils_commit}',\n ),\n dict(\n pattern=r'^(?m)((?P<scm_version>v?\\d+(\\.\\d+){1,2}))\\n[-=]+\\n',\n with_scm='{text}\\n{rev[timestamp]:%d %b %Y}\\n',\n ),\n ],\n ),\n}\n\n# Be strict about any broken references:\nnitpicky = True\n\n# Include Python intersphinx mapping to prevent failures\n# jaraco/skeleton#51\nextensions += ['sphinx.ext.intersphinx']\nintersphinx_mapping = {\n 'python': ('https://docs.python.org/3', None),\n}\n\nintersphinx_mapping.update({\n 'pypa-build': ('https://pypa-build.readthedocs.io/en/latest/', None)\n})\n\n# Add support for linking usernames\ngithub_url = 'https://github.com'\ngithub_sponsors_url = f'{github_url}/sponsors'\nextlinks = {\n 'user': (f'{github_sponsors_url}/%s', '@'), # noqa: WPS323\n}\nextensions += ['sphinx.ext.extlinks']\n\n# Ref: https://github.com/python-attrs/attrs/pull/571/files\\\n# #diff-85987f48f1258d9ee486e3191495582dR82\ndefault_role = 'any'\n\n# HTML theme\nhtml_theme = 'furo'\nhtml_logo = \"images/logo.svg\"\n\nhtml_theme_options = {\n \"sidebar_hide_name\": True,\n \"light_css_variables\": {\n \"color-brand-primary\": \"#336790\", # \"blue\"\n \"color-brand-content\": \"#336790\",\n },\n \"dark_css_variables\": {\n \"color-brand-primary\": \"#E5B62F\", # \"yellow\"\n \"color-brand-content\": \"#E5B62F\",\n },\n}\n\n# Add support for inline tabs\nextensions += ['sphinx_inline_tabs']\n\n# Support for distutils\n\n# Ref: https://stackoverflow.com/a/30624034/595220\nnitpick_ignore = [\n ('c:func', 'SHGetSpecialFolderPath'), # ref to MS docs\n ('envvar', 'DISTUTILS_DEBUG'), # undocumented\n ('envvar', 'HOME'), # undocumented\n ('envvar', 'PLAT'), # undocumented\n ('py:attr', 'CCompiler.language_map'), # undocumented\n ('py:attr', 'CCompiler.language_order'), # undocumented\n ('py:class', 'distutils.dist.Distribution'), # undocumented\n ('py:class', 'distutils.extension.Extension'), # undocumented\n ('py:class', 'BorlandCCompiler'), # undocumented\n ('py:class', 'CCompiler'), # undocumented\n ('py:class', 'CygwinCCompiler'), # undocumented\n ('py:class', 'distutils.dist.DistributionMetadata'), # undocumented\n ('py:class', 'FileList'), # undocumented\n ('py:class', 'IShellLink'), # ref to MS docs\n ('py:class', 'MSVCCompiler'), # undocumented\n ('py:class', 'OptionDummy'), # undocumented\n ('py:class', 'UnixCCompiler'), # undocumented\n ('py:exc', 'CompileError'), # undocumented\n ('py:exc', 'DistutilsExecError'), # undocumented\n ('py:exc', 'DistutilsFileError'), # undocumented\n ('py:exc', 'LibError'), # undocumented\n ('py:exc', 'LinkError'), # undocumented\n ('py:exc', 'PreprocessError'), # undocumented\n ('py:func', 'distutils.CCompiler.new_compiler'), # undocumented\n # undocumented:\n ('py:func', 'distutils.dist.DistributionMetadata.read_pkg_file'),\n ('py:func', 'distutils.file_util._copy_file_contents'), # undocumented\n ('py:func', 'distutils.log.debug'), # undocumented\n ('py:func', 'distutils.spawn.find_executable'), # undocumented\n ('py:func', 'distutils.spawn.spawn'), # undocumented\n # TODO: check https://docutils.rtfd.io in the future\n ('py:mod', 'docutils'), # there's no Sphinx site documenting this\n]\n\n# Allow linking objects on other Sphinx sites seamlessly:\nintersphinx_mapping.update(\n python=('https://docs.python.org/3', None),\n python2=('https://docs.python.org/2', None),\n)\n\n# Add support for the unreleased \"next-version\" change notes\nextensions += ['sphinxcontrib.towncrier']\n# Extension needs a path from here to the towncrier config.\ntowncrier_draft_working_directory = '..'\n# Avoid an empty section for unpublished changes.\ntowncrier_draft_include_empty = False\n\nextensions += ['jaraco.tidelift']\n\n# Add icons (aka \"favicons\") to documentation\nextensions += ['sphinx-favicon']\nhtml_static_path = ['images'] # should contain the folder with icons\n\n# List of dicts with <link> HTML attributes\n# static-file points to files in the html_static_path (href is computed)\nfavicons = [\n { # \"Catch-all\" goes first, otherwise some browsers will overwrite\n \"rel\": \"icon\",\n \"type\": \"image/svg+xml\",\n \"static-file\": \"logo-symbol-only.svg\",\n \"sizes\": \"any\"\n },\n { # Version with thicker strokes for better visibility at smaller sizes\n \"rel\": \"icon\",\n \"type\": \"image/svg+xml\",\n \"static-file\": \"favicon.svg\",\n \"sizes\": \"16x16 24x24 32x32 48x48\"\n },\n # rel=\"apple-touch-icon\" does not support SVG yet\n]\n\nintersphinx_mapping['pip'] = 'https://pip.pypa.io/en/latest', None\n", "path": "docs/conf.py"}]} | 3,607 | 109 |
gh_patches_debug_19269 | rasdani/github-patches | git_diff | huggingface__transformers-12930 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Feature request: Show command line argument defaults
# 🚀 Feature request
When running with `--help`, show the default values for command line arguments.
## Motivation
There are dozens of command line arguments. When I'm trying to figure out how to run a script, I often want to know what value is being used when I don't specify it. But running with `--help` doesn't show the default values unless it's explicitly written in the description (which is only for three of them for the example script I'm using).
For example, `--evaluation_strategy`
```
--evaluation_strategy {no,steps,epoch}
The evaluation strategy to use.
```
This ends up being a bit of a frustrating user experience. The two ways I currently use to find the value are:
1. Run the script again without `--help` and log all the arguments (done in the examples). This shows the assigned value, which will be the default if not passed. However, it doesn't show the description of what it does.
2. Go to the documentation. This will show the default value and a more thorough description, but requires opening a web browser and Googling to find the right page.
In other Python projects, I use the `argparse.ArgumentDefaultsHelpFormatter`, which automatically displays default values in the `--help` message along with their descriptions.
```python
parser = argparse.ArgumentParser(
formatter_class=argparse.ArgumentDefaultsHelpFormatter
)
```
I wonder whether the Huggingface arguments could support the same feature?
Many thanks for considering this!
</issue>
<code>
[start of src/transformers/hf_argparser.py]
1 # Copyright 2020 The HuggingFace Team. All rights reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import dataclasses
16 import json
17 import re
18 import sys
19 from argparse import ArgumentParser, ArgumentTypeError
20 from enum import Enum
21 from pathlib import Path
22 from typing import Any, Iterable, List, NewType, Optional, Tuple, Union
23
24
25 DataClass = NewType("DataClass", Any)
26 DataClassType = NewType("DataClassType", Any)
27
28
29 # From https://stackoverflow.com/questions/15008758/parsing-boolean-values-with-argparse
30 def string_to_bool(v):
31 if isinstance(v, bool):
32 return v
33 if v.lower() in ("yes", "true", "t", "y", "1"):
34 return True
35 elif v.lower() in ("no", "false", "f", "n", "0"):
36 return False
37 else:
38 raise ArgumentTypeError(
39 f"Truthy value expected: got {v} but expected one of yes/no, true/false, t/f, y/n, 1/0 (case insensitive)."
40 )
41
42
43 class HfArgumentParser(ArgumentParser):
44 """
45 This subclass of `argparse.ArgumentParser` uses type hints on dataclasses to generate arguments.
46
47 The class is designed to play well with the native argparse. In particular, you can add more (non-dataclass backed)
48 arguments to the parser after initialization and you'll get the output back after parsing as an additional
49 namespace. Optional: To create sub argument groups use the `_argument_group_name` attribute in the dataclass.
50 """
51
52 dataclass_types: Iterable[DataClassType]
53
54 def __init__(self, dataclass_types: Union[DataClassType, Iterable[DataClassType]], **kwargs):
55 """
56 Args:
57 dataclass_types:
58 Dataclass type, or list of dataclass types for which we will "fill" instances with the parsed args.
59 kwargs:
60 (Optional) Passed to `argparse.ArgumentParser()` in the regular way.
61 """
62 super().__init__(**kwargs)
63 if dataclasses.is_dataclass(dataclass_types):
64 dataclass_types = [dataclass_types]
65 self.dataclass_types = dataclass_types
66 for dtype in self.dataclass_types:
67 self._add_dataclass_arguments(dtype)
68
69 def _add_dataclass_arguments(self, dtype: DataClassType):
70 if hasattr(dtype, "_argument_group_name"):
71 parser = self.add_argument_group(dtype._argument_group_name)
72 else:
73 parser = self
74 for field in dataclasses.fields(dtype):
75 if not field.init:
76 continue
77 field_name = f"--{field.name}"
78 kwargs = field.metadata.copy()
79 # field.metadata is not used at all by Data Classes,
80 # it is provided as a third-party extension mechanism.
81 if isinstance(field.type, str):
82 raise ImportError(
83 "This implementation is not compatible with Postponed Evaluation of Annotations (PEP 563),"
84 "which can be opted in from Python 3.7 with `from __future__ import annotations`."
85 "We will add compatibility when Python 3.9 is released."
86 )
87 typestring = str(field.type)
88 for prim_type in (int, float, str):
89 for collection in (List,):
90 if (
91 typestring == f"typing.Union[{collection[prim_type]}, NoneType]"
92 or typestring == f"typing.Optional[{collection[prim_type]}]"
93 ):
94 field.type = collection[prim_type]
95 if (
96 typestring == f"typing.Union[{prim_type.__name__}, NoneType]"
97 or typestring == f"typing.Optional[{prim_type.__name__}]"
98 ):
99 field.type = prim_type
100
101 if isinstance(field.type, type) and issubclass(field.type, Enum):
102 kwargs["choices"] = [x.value for x in field.type]
103 kwargs["type"] = type(kwargs["choices"][0])
104 if field.default is not dataclasses.MISSING:
105 kwargs["default"] = field.default
106 else:
107 kwargs["required"] = True
108 elif field.type is bool or field.type == Optional[bool]:
109 if field.default is True:
110 parser.add_argument(f"--no_{field.name}", action="store_false", dest=field.name, **kwargs)
111
112 # Hack because type=bool in argparse does not behave as we want.
113 kwargs["type"] = string_to_bool
114 if field.type is bool or (field.default is not None and field.default is not dataclasses.MISSING):
115 # Default value is False if we have no default when of type bool.
116 default = False if field.default is dataclasses.MISSING else field.default
117 # This is the value that will get picked if we don't include --field_name in any way
118 kwargs["default"] = default
119 # This tells argparse we accept 0 or 1 value after --field_name
120 kwargs["nargs"] = "?"
121 # This is the value that will get picked if we do --field_name (without value)
122 kwargs["const"] = True
123 elif (
124 hasattr(field.type, "__origin__") and re.search(r"^typing\.List\[(.*)\]$", str(field.type)) is not None
125 ):
126 kwargs["nargs"] = "+"
127 kwargs["type"] = field.type.__args__[0]
128 assert all(
129 x == kwargs["type"] for x in field.type.__args__
130 ), f"{field.name} cannot be a List of mixed types"
131 if field.default_factory is not dataclasses.MISSING:
132 kwargs["default"] = field.default_factory()
133 elif field.default is dataclasses.MISSING:
134 kwargs["required"] = True
135 else:
136 kwargs["type"] = field.type
137 if field.default is not dataclasses.MISSING:
138 kwargs["default"] = field.default
139 elif field.default_factory is not dataclasses.MISSING:
140 kwargs["default"] = field.default_factory()
141 else:
142 kwargs["required"] = True
143 parser.add_argument(field_name, **kwargs)
144
145 def parse_args_into_dataclasses(
146 self, args=None, return_remaining_strings=False, look_for_args_file=True, args_filename=None
147 ) -> Tuple[DataClass, ...]:
148 """
149 Parse command-line args into instances of the specified dataclass types.
150
151 This relies on argparse's `ArgumentParser.parse_known_args`. See the doc at:
152 docs.python.org/3.7/library/argparse.html#argparse.ArgumentParser.parse_args
153
154 Args:
155 args:
156 List of strings to parse. The default is taken from sys.argv. (same as argparse.ArgumentParser)
157 return_remaining_strings:
158 If true, also return a list of remaining argument strings.
159 look_for_args_file:
160 If true, will look for a ".args" file with the same base name as the entry point script for this
161 process, and will append its potential content to the command line args.
162 args_filename:
163 If not None, will uses this file instead of the ".args" file specified in the previous argument.
164
165 Returns:
166 Tuple consisting of:
167
168 - the dataclass instances in the same order as they were passed to the initializer.abspath
169 - if applicable, an additional namespace for more (non-dataclass backed) arguments added to the parser
170 after initialization.
171 - The potential list of remaining argument strings. (same as argparse.ArgumentParser.parse_known_args)
172 """
173 if args_filename or (look_for_args_file and len(sys.argv)):
174 if args_filename:
175 args_file = Path(args_filename)
176 else:
177 args_file = Path(sys.argv[0]).with_suffix(".args")
178
179 if args_file.exists():
180 fargs = args_file.read_text().split()
181 args = fargs + args if args is not None else fargs + sys.argv[1:]
182 # in case of duplicate arguments the first one has precedence
183 # so we append rather than prepend.
184 namespace, remaining_args = self.parse_known_args(args=args)
185 outputs = []
186 for dtype in self.dataclass_types:
187 keys = {f.name for f in dataclasses.fields(dtype) if f.init}
188 inputs = {k: v for k, v in vars(namespace).items() if k in keys}
189 for k in keys:
190 delattr(namespace, k)
191 obj = dtype(**inputs)
192 outputs.append(obj)
193 if len(namespace.__dict__) > 0:
194 # additional namespace.
195 outputs.append(namespace)
196 if return_remaining_strings:
197 return (*outputs, remaining_args)
198 else:
199 if remaining_args:
200 raise ValueError(f"Some specified arguments are not used by the HfArgumentParser: {remaining_args}")
201
202 return (*outputs,)
203
204 def parse_json_file(self, json_file: str) -> Tuple[DataClass, ...]:
205 """
206 Alternative helper method that does not use `argparse` at all, instead loading a json file and populating the
207 dataclass types.
208 """
209 data = json.loads(Path(json_file).read_text())
210 outputs = []
211 for dtype in self.dataclass_types:
212 keys = {f.name for f in dataclasses.fields(dtype) if f.init}
213 inputs = {k: v for k, v in data.items() if k in keys}
214 obj = dtype(**inputs)
215 outputs.append(obj)
216 return (*outputs,)
217
218 def parse_dict(self, args: dict) -> Tuple[DataClass, ...]:
219 """
220 Alternative helper method that does not use `argparse` at all, instead uses a dict and populating the dataclass
221 types.
222 """
223 outputs = []
224 for dtype in self.dataclass_types:
225 keys = {f.name for f in dataclasses.fields(dtype) if f.init}
226 inputs = {k: v for k, v in args.items() if k in keys}
227 obj = dtype(**inputs)
228 outputs.append(obj)
229 return (*outputs,)
230
[end of src/transformers/hf_argparser.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/src/transformers/hf_argparser.py b/src/transformers/hf_argparser.py
--- a/src/transformers/hf_argparser.py
+++ b/src/transformers/hf_argparser.py
@@ -16,7 +16,7 @@
import json
import re
import sys
-from argparse import ArgumentParser, ArgumentTypeError
+from argparse import ArgumentDefaultsHelpFormatter, ArgumentParser, ArgumentTypeError
from enum import Enum
from pathlib import Path
from typing import Any, Iterable, List, NewType, Optional, Tuple, Union
@@ -59,6 +59,9 @@
kwargs:
(Optional) Passed to `argparse.ArgumentParser()` in the regular way.
"""
+ # To make the default appear when using --help
+ if "formatter_class" not in kwargs:
+ kwargs["formatter_class"] = ArgumentDefaultsHelpFormatter
super().__init__(**kwargs)
if dataclasses.is_dataclass(dataclass_types):
dataclass_types = [dataclass_types]
| {"golden_diff": "diff --git a/src/transformers/hf_argparser.py b/src/transformers/hf_argparser.py\n--- a/src/transformers/hf_argparser.py\n+++ b/src/transformers/hf_argparser.py\n@@ -16,7 +16,7 @@\n import json\n import re\n import sys\n-from argparse import ArgumentParser, ArgumentTypeError\n+from argparse import ArgumentDefaultsHelpFormatter, ArgumentParser, ArgumentTypeError\n from enum import Enum\n from pathlib import Path\n from typing import Any, Iterable, List, NewType, Optional, Tuple, Union\n@@ -59,6 +59,9 @@\n kwargs:\n (Optional) Passed to `argparse.ArgumentParser()` in the regular way.\n \"\"\"\n+ # To make the default appear when using --help\n+ if \"formatter_class\" not in kwargs:\n+ kwargs[\"formatter_class\"] = ArgumentDefaultsHelpFormatter\n super().__init__(**kwargs)\n if dataclasses.is_dataclass(dataclass_types):\n dataclass_types = [dataclass_types]\n", "issue": "Feature request: Show command line argument defaults\n# \ud83d\ude80 Feature request\r\n\r\nWhen running with `--help`, show the default values for command line arguments.\r\n\r\n## Motivation\r\n\r\nThere are dozens of command line arguments. When I'm trying to figure out how to run a script, I often want to know what value is being used when I don't specify it. But running with `--help` doesn't show the default values unless it's explicitly written in the description (which is only for three of them for the example script I'm using).\r\n\r\nFor example, `--evaluation_strategy`\r\n\r\n```\r\n --evaluation_strategy {no,steps,epoch}\r\n The evaluation strategy to use.\r\n```\r\n\r\nThis ends up being a bit of a frustrating user experience. The two ways I currently use to find the value are:\r\n\r\n1. Run the script again without `--help` and log all the arguments (done in the examples). This shows the assigned value, which will be the default if not passed. However, it doesn't show the description of what it does.\r\n\r\n2. Go to the documentation. This will show the default value and a more thorough description, but requires opening a web browser and Googling to find the right page.\r\n\r\nIn other Python projects, I use the `argparse.ArgumentDefaultsHelpFormatter`, which automatically displays default values in the `--help` message along with their descriptions.\r\n\r\n```python\r\nparser = argparse.ArgumentParser(\r\n formatter_class=argparse.ArgumentDefaultsHelpFormatter\r\n)\r\n```\r\n\r\nI wonder whether the Huggingface arguments could support the same feature?\r\n\r\nMany thanks for considering this!\n", "before_files": [{"content": "# Copyright 2020 The HuggingFace Team. All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport dataclasses\nimport json\nimport re\nimport sys\nfrom argparse import ArgumentParser, ArgumentTypeError\nfrom enum import Enum\nfrom pathlib import Path\nfrom typing import Any, Iterable, List, NewType, Optional, Tuple, Union\n\n\nDataClass = NewType(\"DataClass\", Any)\nDataClassType = NewType(\"DataClassType\", Any)\n\n\n# From https://stackoverflow.com/questions/15008758/parsing-boolean-values-with-argparse\ndef string_to_bool(v):\n if isinstance(v, bool):\n return v\n if v.lower() in (\"yes\", \"true\", \"t\", \"y\", \"1\"):\n return True\n elif v.lower() in (\"no\", \"false\", \"f\", \"n\", \"0\"):\n return False\n else:\n raise ArgumentTypeError(\n f\"Truthy value expected: got {v} but expected one of yes/no, true/false, t/f, y/n, 1/0 (case insensitive).\"\n )\n\n\nclass HfArgumentParser(ArgumentParser):\n \"\"\"\n This subclass of `argparse.ArgumentParser` uses type hints on dataclasses to generate arguments.\n\n The class is designed to play well with the native argparse. In particular, you can add more (non-dataclass backed)\n arguments to the parser after initialization and you'll get the output back after parsing as an additional\n namespace. Optional: To create sub argument groups use the `_argument_group_name` attribute in the dataclass.\n \"\"\"\n\n dataclass_types: Iterable[DataClassType]\n\n def __init__(self, dataclass_types: Union[DataClassType, Iterable[DataClassType]], **kwargs):\n \"\"\"\n Args:\n dataclass_types:\n Dataclass type, or list of dataclass types for which we will \"fill\" instances with the parsed args.\n kwargs:\n (Optional) Passed to `argparse.ArgumentParser()` in the regular way.\n \"\"\"\n super().__init__(**kwargs)\n if dataclasses.is_dataclass(dataclass_types):\n dataclass_types = [dataclass_types]\n self.dataclass_types = dataclass_types\n for dtype in self.dataclass_types:\n self._add_dataclass_arguments(dtype)\n\n def _add_dataclass_arguments(self, dtype: DataClassType):\n if hasattr(dtype, \"_argument_group_name\"):\n parser = self.add_argument_group(dtype._argument_group_name)\n else:\n parser = self\n for field in dataclasses.fields(dtype):\n if not field.init:\n continue\n field_name = f\"--{field.name}\"\n kwargs = field.metadata.copy()\n # field.metadata is not used at all by Data Classes,\n # it is provided as a third-party extension mechanism.\n if isinstance(field.type, str):\n raise ImportError(\n \"This implementation is not compatible with Postponed Evaluation of Annotations (PEP 563),\"\n \"which can be opted in from Python 3.7 with `from __future__ import annotations`.\"\n \"We will add compatibility when Python 3.9 is released.\"\n )\n typestring = str(field.type)\n for prim_type in (int, float, str):\n for collection in (List,):\n if (\n typestring == f\"typing.Union[{collection[prim_type]}, NoneType]\"\n or typestring == f\"typing.Optional[{collection[prim_type]}]\"\n ):\n field.type = collection[prim_type]\n if (\n typestring == f\"typing.Union[{prim_type.__name__}, NoneType]\"\n or typestring == f\"typing.Optional[{prim_type.__name__}]\"\n ):\n field.type = prim_type\n\n if isinstance(field.type, type) and issubclass(field.type, Enum):\n kwargs[\"choices\"] = [x.value for x in field.type]\n kwargs[\"type\"] = type(kwargs[\"choices\"][0])\n if field.default is not dataclasses.MISSING:\n kwargs[\"default\"] = field.default\n else:\n kwargs[\"required\"] = True\n elif field.type is bool or field.type == Optional[bool]:\n if field.default is True:\n parser.add_argument(f\"--no_{field.name}\", action=\"store_false\", dest=field.name, **kwargs)\n\n # Hack because type=bool in argparse does not behave as we want.\n kwargs[\"type\"] = string_to_bool\n if field.type is bool or (field.default is not None and field.default is not dataclasses.MISSING):\n # Default value is False if we have no default when of type bool.\n default = False if field.default is dataclasses.MISSING else field.default\n # This is the value that will get picked if we don't include --field_name in any way\n kwargs[\"default\"] = default\n # This tells argparse we accept 0 or 1 value after --field_name\n kwargs[\"nargs\"] = \"?\"\n # This is the value that will get picked if we do --field_name (without value)\n kwargs[\"const\"] = True\n elif (\n hasattr(field.type, \"__origin__\") and re.search(r\"^typing\\.List\\[(.*)\\]$\", str(field.type)) is not None\n ):\n kwargs[\"nargs\"] = \"+\"\n kwargs[\"type\"] = field.type.__args__[0]\n assert all(\n x == kwargs[\"type\"] for x in field.type.__args__\n ), f\"{field.name} cannot be a List of mixed types\"\n if field.default_factory is not dataclasses.MISSING:\n kwargs[\"default\"] = field.default_factory()\n elif field.default is dataclasses.MISSING:\n kwargs[\"required\"] = True\n else:\n kwargs[\"type\"] = field.type\n if field.default is not dataclasses.MISSING:\n kwargs[\"default\"] = field.default\n elif field.default_factory is not dataclasses.MISSING:\n kwargs[\"default\"] = field.default_factory()\n else:\n kwargs[\"required\"] = True\n parser.add_argument(field_name, **kwargs)\n\n def parse_args_into_dataclasses(\n self, args=None, return_remaining_strings=False, look_for_args_file=True, args_filename=None\n ) -> Tuple[DataClass, ...]:\n \"\"\"\n Parse command-line args into instances of the specified dataclass types.\n\n This relies on argparse's `ArgumentParser.parse_known_args`. See the doc at:\n docs.python.org/3.7/library/argparse.html#argparse.ArgumentParser.parse_args\n\n Args:\n args:\n List of strings to parse. The default is taken from sys.argv. (same as argparse.ArgumentParser)\n return_remaining_strings:\n If true, also return a list of remaining argument strings.\n look_for_args_file:\n If true, will look for a \".args\" file with the same base name as the entry point script for this\n process, and will append its potential content to the command line args.\n args_filename:\n If not None, will uses this file instead of the \".args\" file specified in the previous argument.\n\n Returns:\n Tuple consisting of:\n\n - the dataclass instances in the same order as they were passed to the initializer.abspath\n - if applicable, an additional namespace for more (non-dataclass backed) arguments added to the parser\n after initialization.\n - The potential list of remaining argument strings. (same as argparse.ArgumentParser.parse_known_args)\n \"\"\"\n if args_filename or (look_for_args_file and len(sys.argv)):\n if args_filename:\n args_file = Path(args_filename)\n else:\n args_file = Path(sys.argv[0]).with_suffix(\".args\")\n\n if args_file.exists():\n fargs = args_file.read_text().split()\n args = fargs + args if args is not None else fargs + sys.argv[1:]\n # in case of duplicate arguments the first one has precedence\n # so we append rather than prepend.\n namespace, remaining_args = self.parse_known_args(args=args)\n outputs = []\n for dtype in self.dataclass_types:\n keys = {f.name for f in dataclasses.fields(dtype) if f.init}\n inputs = {k: v for k, v in vars(namespace).items() if k in keys}\n for k in keys:\n delattr(namespace, k)\n obj = dtype(**inputs)\n outputs.append(obj)\n if len(namespace.__dict__) > 0:\n # additional namespace.\n outputs.append(namespace)\n if return_remaining_strings:\n return (*outputs, remaining_args)\n else:\n if remaining_args:\n raise ValueError(f\"Some specified arguments are not used by the HfArgumentParser: {remaining_args}\")\n\n return (*outputs,)\n\n def parse_json_file(self, json_file: str) -> Tuple[DataClass, ...]:\n \"\"\"\n Alternative helper method that does not use `argparse` at all, instead loading a json file and populating the\n dataclass types.\n \"\"\"\n data = json.loads(Path(json_file).read_text())\n outputs = []\n for dtype in self.dataclass_types:\n keys = {f.name for f in dataclasses.fields(dtype) if f.init}\n inputs = {k: v for k, v in data.items() if k in keys}\n obj = dtype(**inputs)\n outputs.append(obj)\n return (*outputs,)\n\n def parse_dict(self, args: dict) -> Tuple[DataClass, ...]:\n \"\"\"\n Alternative helper method that does not use `argparse` at all, instead uses a dict and populating the dataclass\n types.\n \"\"\"\n outputs = []\n for dtype in self.dataclass_types:\n keys = {f.name for f in dataclasses.fields(dtype) if f.init}\n inputs = {k: v for k, v in args.items() if k in keys}\n obj = dtype(**inputs)\n outputs.append(obj)\n return (*outputs,)\n", "path": "src/transformers/hf_argparser.py"}]} | 3,682 | 220 |
gh_patches_debug_60844 | rasdani/github-patches | git_diff | uclapi__uclapi-128 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[Bug] Search People should return HTTP status 400 when query is missing
Currently, the `/search/people` returns a HTTP 200 code when even for an incorrect API request. For example, if you leave out the `query` param it returns the following body:
```json
{ "error": "No query provided", "ok": false}
```
Yet, the HTTP status code is 200, while it should be 400.
</issue>
<code>
[start of backend/uclapi/search/views.py]
1 from rest_framework.decorators import api_view
2 from django.http import JsonResponse
3
4 from roombookings.decorators import does_token_exist, log_api_call, throttle
5
6 import os
7 import requests
8
9
10 @api_view(['GET'])
11 @does_token_exist
12 @throttle
13 @log_api_call
14 def people(request):
15 if "query" not in request.GET:
16 return JsonResponse({
17 "ok": False,
18 "error": "No query provided"
19 })
20
21 query = request.GET["query"]
22
23 url = (
24 "{}?{}={}"
25 .format(
26 os.environ["SEARCH_API_URL"],
27 os.environ["SEARCH_API_QUERY_PARAMS"],
28 query,
29 )
30 )
31
32 r = requests.get(url)
33
34 results = r.json()["response"]["resultPacket"]["results"][:20]
35
36 def serialize_person(person):
37 return {
38 "name": person["title"],
39 "department": person["metaData"].get("7", ""),
40 "email": person["metaData"].get("E", ""),
41 "status": person["metaData"].get("g", ""),
42 }
43
44 people = [serialize_person(person) for person in results]
45
46 return JsonResponse({
47 "ok": True,
48 "people": people
49 })
50
[end of backend/uclapi/search/views.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/backend/uclapi/search/views.py b/backend/uclapi/search/views.py
--- a/backend/uclapi/search/views.py
+++ b/backend/uclapi/search/views.py
@@ -13,10 +13,12 @@
@log_api_call
def people(request):
if "query" not in request.GET:
- return JsonResponse({
+ response = JsonResponse({
"ok": False,
- "error": "No query provided"
+ "error": "No query provided."
})
+ response.status_code = 400
+ return response
query = request.GET["query"]
| {"golden_diff": "diff --git a/backend/uclapi/search/views.py b/backend/uclapi/search/views.py\n--- a/backend/uclapi/search/views.py\n+++ b/backend/uclapi/search/views.py\n@@ -13,10 +13,12 @@\n @log_api_call\n def people(request):\n if \"query\" not in request.GET:\n- return JsonResponse({\n+ response = JsonResponse({\n \"ok\": False,\n- \"error\": \"No query provided\"\n+ \"error\": \"No query provided.\"\n })\n+ response.status_code = 400\n+ return response\n \n query = request.GET[\"query\"]\n", "issue": "[Bug] Search People should return HTTP status 400 when query is missing\nCurrently, the `/search/people` returns a HTTP 200 code when even for an incorrect API request. For example, if you leave out the `query` param it returns the following body:\r\n\r\n```json\r\n{ \"error\": \"No query provided\", \"ok\": false}\r\n```\r\n\r\nYet, the HTTP status code is 200, while it should be 400.\r\n\n", "before_files": [{"content": "from rest_framework.decorators import api_view\nfrom django.http import JsonResponse\n\nfrom roombookings.decorators import does_token_exist, log_api_call, throttle\n\nimport os\nimport requests\n\n\n@api_view(['GET'])\n@does_token_exist\n@throttle\n@log_api_call\ndef people(request):\n if \"query\" not in request.GET:\n return JsonResponse({\n \"ok\": False,\n \"error\": \"No query provided\"\n })\n\n query = request.GET[\"query\"]\n\n url = (\n \"{}?{}={}\"\n .format(\n os.environ[\"SEARCH_API_URL\"],\n os.environ[\"SEARCH_API_QUERY_PARAMS\"],\n query,\n )\n )\n\n r = requests.get(url)\n\n results = r.json()[\"response\"][\"resultPacket\"][\"results\"][:20]\n\n def serialize_person(person):\n return {\n \"name\": person[\"title\"],\n \"department\": person[\"metaData\"].get(\"7\", \"\"),\n \"email\": person[\"metaData\"].get(\"E\", \"\"),\n \"status\": person[\"metaData\"].get(\"g\", \"\"),\n }\n\n people = [serialize_person(person) for person in results]\n\n return JsonResponse({\n \"ok\": True,\n \"people\": people\n })\n", "path": "backend/uclapi/search/views.py"}]} | 995 | 136 |
gh_patches_debug_14186 | rasdani/github-patches | git_diff | bokeh__bokeh-4129 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Docs for styling selection overlays
There is currently no way to style the box or poly overlays that various selection tools use.
</issue>
<code>
[start of sphinx/source/docs/user_guide/source_examples/styling_tool_overlays.py]
1 import numpy as np
2
3 from bokeh.models import BoxSelectTool, BoxZoomTool, LassoSelectTool
4 from bokeh.plotting import figure, output_file, show
5
6 output_file("styling_tool_overlays.html")
7
8 x = np.random.random(size=200)
9 y = np.random.random(size=200)
10
11 # Basic plot setup
12 plot = figure(width=400, height=400, title='Select and Zoom',
13 tools="box_select,box_zoom,lasso_select,reset")
14
15 plot.circle(x, y, size=5)
16
17 plot.select_one(BoxSelectTool).overlay.fill_color = "firebrick"
18 plot.select_one(BoxSelectTool).overlay.line_color = None
19
20 plot.select_one(BoxZoomTool).overlay.line_color = "olive"
21 plot.select_one(BoxZoomTool).overlay.line_width = 8
22 plot.select_one(BoxZoomTool).overlay.line_dash = "solid"
23 plot.select_one(BoxZoomTool).overlay.fill_color = None
24
25 plot.select_one(LassoSelectTool).overlay.line_dash = [10, 10]
26
27 show(plot)
[end of sphinx/source/docs/user_guide/source_examples/styling_tool_overlays.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/sphinx/source/docs/user_guide/source_examples/styling_tool_overlays.py b/sphinx/source/docs/user_guide/source_examples/styling_tool_overlays.py
--- a/sphinx/source/docs/user_guide/source_examples/styling_tool_overlays.py
+++ b/sphinx/source/docs/user_guide/source_examples/styling_tool_overlays.py
@@ -14,14 +14,18 @@
plot.circle(x, y, size=5)
-plot.select_one(BoxSelectTool).overlay.fill_color = "firebrick"
-plot.select_one(BoxSelectTool).overlay.line_color = None
+select_overlay = plot.select_one(BoxSelectTool).overlay
-plot.select_one(BoxZoomTool).overlay.line_color = "olive"
-plot.select_one(BoxZoomTool).overlay.line_width = 8
-plot.select_one(BoxZoomTool).overlay.line_dash = "solid"
-plot.select_one(BoxZoomTool).overlay.fill_color = None
+select_overlay.fill_color = "firebrick"
+select_overlay.line_color = None
+
+zoom_overlay = plot.select_one(BoxZoomTool).overlay
+
+zoom_overlay.line_color = "olive"
+zoom_overlay.line_width = 8
+zoom_overlay.line_dash = "solid"
+zoom_overlay.fill_color = None
plot.select_one(LassoSelectTool).overlay.line_dash = [10, 10]
-show(plot)
\ No newline at end of file
+show(plot)
| {"golden_diff": "diff --git a/sphinx/source/docs/user_guide/source_examples/styling_tool_overlays.py b/sphinx/source/docs/user_guide/source_examples/styling_tool_overlays.py\n--- a/sphinx/source/docs/user_guide/source_examples/styling_tool_overlays.py\n+++ b/sphinx/source/docs/user_guide/source_examples/styling_tool_overlays.py\n@@ -14,14 +14,18 @@\n \n plot.circle(x, y, size=5)\n \n-plot.select_one(BoxSelectTool).overlay.fill_color = \"firebrick\"\n-plot.select_one(BoxSelectTool).overlay.line_color = None\n+select_overlay = plot.select_one(BoxSelectTool).overlay\n \n-plot.select_one(BoxZoomTool).overlay.line_color = \"olive\"\n-plot.select_one(BoxZoomTool).overlay.line_width = 8\n-plot.select_one(BoxZoomTool).overlay.line_dash = \"solid\"\n-plot.select_one(BoxZoomTool).overlay.fill_color = None\n+select_overlay.fill_color = \"firebrick\"\n+select_overlay.line_color = None\n+\n+zoom_overlay = plot.select_one(BoxZoomTool).overlay\n+\n+zoom_overlay.line_color = \"olive\"\n+zoom_overlay.line_width = 8\n+zoom_overlay.line_dash = \"solid\"\n+zoom_overlay.fill_color = None\n \n plot.select_one(LassoSelectTool).overlay.line_dash = [10, 10]\n \n-show(plot)\n\\ No newline at end of file\n+show(plot)\n", "issue": "Docs for styling selection overlays\nThere is currently no way to style the box or poly overlays that various selection tools use. \n\n", "before_files": [{"content": "import numpy as np\n\nfrom bokeh.models import BoxSelectTool, BoxZoomTool, LassoSelectTool\nfrom bokeh.plotting import figure, output_file, show\n\noutput_file(\"styling_tool_overlays.html\")\n\nx = np.random.random(size=200)\ny = np.random.random(size=200)\n\n# Basic plot setup\nplot = figure(width=400, height=400, title='Select and Zoom',\n tools=\"box_select,box_zoom,lasso_select,reset\")\n\nplot.circle(x, y, size=5)\n\nplot.select_one(BoxSelectTool).overlay.fill_color = \"firebrick\"\nplot.select_one(BoxSelectTool).overlay.line_color = None\n\nplot.select_one(BoxZoomTool).overlay.line_color = \"olive\"\nplot.select_one(BoxZoomTool).overlay.line_width = 8\nplot.select_one(BoxZoomTool).overlay.line_dash = \"solid\"\nplot.select_one(BoxZoomTool).overlay.fill_color = None\n\nplot.select_one(LassoSelectTool).overlay.line_dash = [10, 10]\n\nshow(plot)", "path": "sphinx/source/docs/user_guide/source_examples/styling_tool_overlays.py"}]} | 857 | 302 |
gh_patches_debug_24561 | rasdani/github-patches | git_diff | microsoft__playwright-python-345 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Inspect fails to retrieve module inside frozen app
# Description of the issue
when freezing playwright with [pyinstaller](https://github.com/pyinstaller/pyinstaller) the assertion in [`get_file_dirname`](https://github.com/microsoft/playwright-python/blob/master/playwright/path_utils.py#L19-L24) fails
```
File "main.py", line 6, in <module>
with sync_playwright() as p:
File "playwright/__init__.py", line 34, in sync_playwright
File "playwright/main.py", line 81, in __init__
File "playwright/main.py", line 76, in run_driver
File "asyncio/base_events.py", line 587, in run_until_complete
File "playwright/main.py", line 44, in run_driver_async
File "playwright/main.py", line 36, in compute_driver_executable
File "playwright/path_utils.py", line 23, in get_file_dirname
AssertionError
```
The reason is that the inspect module fails to find the module on the following lines inside [`get_file_dirname`](https://github.com/microsoft/playwright-python/blob/master/playwright/path_utils.py#L19-L24)
```python
frame = inspect.stack()[1]
module = inspect.getmodule(frame[0])
```
# Context information
* version of python: 3.7.9
* version of pyinstaller: 4.1
* version of playwright-python: Version 0.162.1
* platform: GNU/Linux (Ubuntu 18.04 LTS)
# Reproducing the bug
install packages
$ pip install playwright pyinstaller
install the browsers inside playwright
$ PLAYWRIGHT_BROWSERS_PATH=0 python -m playwright install
create `main.py`
```python
# main.py
import sys
from pathlib import Path
from playwright import sync_playwright
with sync_playwright() as p:
for browser_type in [p.chromium]:
browser = browser_type.launch(
headless=False,
executablePath=Path(sys.modules['playwright'].__file__).parent / 'driver' / '.local-browsers' / 'chromium-827102' / 'chrome-linux' / 'chrome')
page = browser.newPage()
page.goto('http://whatsmyuseragent.org/')
page.screenshot(path=f'example-{browser_type.name}.png')
browser.close()
```
freeze into single binary file with pyinstaller
$ pyinstaller -F main.py --add-data /path/to/lib/python3.7/site-packages/playwright/driver:playwright/driver
execute the binary file
```
$ ./dist/main
Traceback (most recent call last):
File "main.py", line 6, in <module>
with sync_playwright() as p:
File "playwright/__init__.py", line 34, in sync_playwright
File "playwright/main.py", line 81, in __init__
File "playwright/main.py", line 76, in run_driver
File "asyncio/base_events.py", line 587, in run_until_complete
File "playwright/main.py", line 44, in run_driver_async
File "playwright/main.py", line 36, in compute_driver_executable
File "playwright/path_utils.py", line 23, in get_file_dirname
AssertionError
```
# Proposed solution
The problem can be fixed by changing [`get_file_dirname`](https://github.com/microsoft/playwright-python/blob/master/playwright/path_utils.py#L19-L24) with
```python
import inspect
import sys
from pathlib import Path
def get_file_dirname() -> Path:
"""Returns the callee (`__file__`) directory name"""
module_name = inspect.currentframe().f_back.f_globals["__name__"]
module = sys.modules[module_name]
assert module
return Path(module.__file__).parent.absolute()
```
</issue>
<code>
[start of playwright/main.py]
1 # Copyright (c) Microsoft Corporation.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import asyncio
16 import os
17 import subprocess
18 import sys
19 from pathlib import Path
20 from typing import Any
21
22 from greenlet import greenlet
23
24 from playwright.async_api import Playwright as AsyncPlaywright
25 from playwright.connection import Connection
26 from playwright.helper import Error
27 from playwright.object_factory import create_remote_object
28 from playwright.path_utils import get_file_dirname
29 from playwright.playwright import Playwright
30 from playwright.sync_api import Playwright as SyncPlaywright
31
32
33 def compute_driver_executable() -> Path:
34 package_path = get_file_dirname()
35 platform = sys.platform
36 if platform == "win32":
37 return package_path / "driver" / "playwright-cli.exe"
38 return package_path / "driver" / "playwright-cli"
39
40
41 class SyncPlaywrightContextManager:
42 def __init__(self) -> None:
43 self._playwright: SyncPlaywright
44
45 def __enter__(self) -> SyncPlaywright:
46 def greenlet_main() -> None:
47 loop = None
48 own_loop = None
49 try:
50 loop = asyncio.get_running_loop()
51 except RuntimeError:
52 loop = asyncio.new_event_loop()
53 own_loop = loop
54
55 if loop.is_running():
56 raise Error("Can only run one Playwright at a time.")
57
58 loop.run_until_complete(self._connection.run_as_sync())
59
60 if own_loop:
61 loop.run_until_complete(loop.shutdown_asyncgens())
62 loop.close()
63
64 dispatcher_fiber = greenlet(greenlet_main)
65 self._connection = Connection(
66 dispatcher_fiber, create_remote_object, compute_driver_executable()
67 )
68
69 g_self = greenlet.getcurrent()
70
71 def callback_wrapper(playwright_impl: Playwright) -> None:
72 self._playwright = SyncPlaywright(playwright_impl)
73 g_self.switch()
74
75 self._connection.call_on_object_with_known_name("Playwright", callback_wrapper)
76
77 dispatcher_fiber.switch()
78 playwright = self._playwright
79 playwright.stop = self.__exit__ # type: ignore
80 return playwright
81
82 def start(self) -> SyncPlaywright:
83 return self.__enter__()
84
85 def __exit__(self, *args: Any) -> None:
86 self._connection.stop_sync()
87
88
89 class AsyncPlaywrightContextManager:
90 def __init__(self) -> None:
91 self._connection: Connection
92
93 async def __aenter__(self) -> AsyncPlaywright:
94 self._connection = Connection(
95 None, create_remote_object, compute_driver_executable()
96 )
97 loop = asyncio.get_running_loop()
98 self._connection._loop = loop
99 loop.create_task(self._connection.run())
100 playwright = AsyncPlaywright(
101 await self._connection.wait_for_object_with_known_name("Playwright")
102 )
103 playwright.stop = self.__aexit__ # type: ignore
104 return playwright
105
106 async def start(self) -> AsyncPlaywright:
107 return await self.__aenter__()
108
109 async def __aexit__(self, *args: Any) -> None:
110 self._connection.stop_async()
111
112
113 if sys.version_info.major == 3 and sys.version_info.minor == 7:
114 if sys.platform == "win32":
115 # Use ProactorEventLoop in 3.7, which is default in 3.8
116 asyncio.set_event_loop_policy(asyncio.WindowsProactorEventLoopPolicy())
117 else:
118 # Prevent Python 3.7 from throwing on Linux:
119 # RuntimeError: Cannot add child handler, the child watcher does not have a loop attached
120 asyncio.get_event_loop()
121 asyncio.get_child_watcher()
122
123
124 def main() -> None:
125 driver_executable = compute_driver_executable()
126 my_env = os.environ.copy()
127 my_env["PW_CLI_TARGET_LANG"] = "python"
128 subprocess.run([str(driver_executable), *sys.argv[1:]], env=my_env)
129
[end of playwright/main.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/playwright/main.py b/playwright/main.py
--- a/playwright/main.py
+++ b/playwright/main.py
@@ -13,6 +13,7 @@
# limitations under the License.
import asyncio
+import inspect
import os
import subprocess
import sys
@@ -21,18 +22,18 @@
from greenlet import greenlet
+import playwright
from playwright.async_api import Playwright as AsyncPlaywright
from playwright.connection import Connection
from playwright.helper import Error
from playwright.object_factory import create_remote_object
-from playwright.path_utils import get_file_dirname
from playwright.playwright import Playwright
from playwright.sync_api import Playwright as SyncPlaywright
from playwright.sync_base import dispatcher_fiber, set_dispatcher_fiber
def compute_driver_executable() -> Path:
- package_path = get_file_dirname()
+ package_path = Path(inspect.getfile(playwright)).parent
platform = sys.platform
if platform == "win32":
return package_path / "driver" / "playwright-cli.exe"
| {"golden_diff": "diff --git a/playwright/main.py b/playwright/main.py\n--- a/playwright/main.py\n+++ b/playwright/main.py\n@@ -13,6 +13,7 @@\n # limitations under the License.\n \n import asyncio\n+import inspect\n import os\n import subprocess\n import sys\n@@ -21,18 +22,18 @@\n \n from greenlet import greenlet\n \n+import playwright\n from playwright.async_api import Playwright as AsyncPlaywright\n from playwright.connection import Connection\n from playwright.helper import Error\n from playwright.object_factory import create_remote_object\n-from playwright.path_utils import get_file_dirname\n from playwright.playwright import Playwright\n from playwright.sync_api import Playwright as SyncPlaywright\n from playwright.sync_base import dispatcher_fiber, set_dispatcher_fiber\n \n \n def compute_driver_executable() -> Path:\n- package_path = get_file_dirname()\n+ package_path = Path(inspect.getfile(playwright)).parent\n platform = sys.platform\n if platform == \"win32\":\n return package_path / \"driver\" / \"playwright-cli.exe\"\n", "issue": "Inspect fails to retrieve module inside frozen app\n# Description of the issue\r\n\r\nwhen freezing playwright with [pyinstaller](https://github.com/pyinstaller/pyinstaller) the assertion in [`get_file_dirname`](https://github.com/microsoft/playwright-python/blob/master/playwright/path_utils.py#L19-L24) fails\r\n\r\n```\r\n File \"main.py\", line 6, in <module>\r\n with sync_playwright() as p:\r\n File \"playwright/__init__.py\", line 34, in sync_playwright\r\n File \"playwright/main.py\", line 81, in __init__\r\n File \"playwright/main.py\", line 76, in run_driver\r\n File \"asyncio/base_events.py\", line 587, in run_until_complete\r\n File \"playwright/main.py\", line 44, in run_driver_async\r\n File \"playwright/main.py\", line 36, in compute_driver_executable\r\n File \"playwright/path_utils.py\", line 23, in get_file_dirname\r\nAssertionError\r\n```\r\n\r\nThe reason is that the inspect module fails to find the module on the following lines inside [`get_file_dirname`](https://github.com/microsoft/playwright-python/blob/master/playwright/path_utils.py#L19-L24)\r\n\r\n```python\r\nframe = inspect.stack()[1]\r\nmodule = inspect.getmodule(frame[0])\r\n```\r\n\r\n# Context information\r\n\r\n* version of python: 3.7.9\r\n* version of pyinstaller: 4.1\r\n* version of playwright-python: Version 0.162.1\r\n* platform: GNU/Linux (Ubuntu 18.04 LTS)\r\n\r\n# Reproducing the bug\r\n\r\ninstall packages\r\n\r\n $ pip install playwright pyinstaller\r\n\r\ninstall the browsers inside playwright\r\n\r\n $ PLAYWRIGHT_BROWSERS_PATH=0 python -m playwright install\r\n\r\ncreate `main.py`\r\n\r\n```python\r\n# main.py\r\nimport sys\r\nfrom pathlib import Path\r\nfrom playwright import sync_playwright\r\n\r\nwith sync_playwright() as p:\r\n for browser_type in [p.chromium]:\r\n browser = browser_type.launch(\r\n headless=False,\r\n executablePath=Path(sys.modules['playwright'].__file__).parent / 'driver' / '.local-browsers' / 'chromium-827102' / 'chrome-linux' / 'chrome')\r\n page = browser.newPage()\r\n page.goto('http://whatsmyuseragent.org/')\r\n page.screenshot(path=f'example-{browser_type.name}.png')\r\n browser.close()\r\n```\r\n\r\nfreeze into single binary file with pyinstaller\r\n\r\n $ pyinstaller -F main.py --add-data /path/to/lib/python3.7/site-packages/playwright/driver:playwright/driver\r\n\r\nexecute the binary file\r\n\r\n```\r\n$ ./dist/main \r\nTraceback (most recent call last):\r\n File \"main.py\", line 6, in <module>\r\n with sync_playwright() as p:\r\n File \"playwright/__init__.py\", line 34, in sync_playwright\r\n File \"playwright/main.py\", line 81, in __init__\r\n File \"playwright/main.py\", line 76, in run_driver\r\n File \"asyncio/base_events.py\", line 587, in run_until_complete\r\n File \"playwright/main.py\", line 44, in run_driver_async\r\n File \"playwright/main.py\", line 36, in compute_driver_executable\r\n File \"playwright/path_utils.py\", line 23, in get_file_dirname\r\nAssertionError\r\n```\r\n\r\n# Proposed solution\r\n\r\nThe problem can be fixed by changing [`get_file_dirname`](https://github.com/microsoft/playwright-python/blob/master/playwright/path_utils.py#L19-L24) with\r\n\r\n```python\r\nimport inspect\r\nimport sys\r\nfrom pathlib import Path\r\n\r\ndef get_file_dirname() -> Path:\r\n \"\"\"Returns the callee (`__file__`) directory name\"\"\"\r\n module_name = inspect.currentframe().f_back.f_globals[\"__name__\"]\r\n module = sys.modules[module_name]\r\n assert module\r\n return Path(module.__file__).parent.absolute()\r\n```\n", "before_files": [{"content": "# Copyright (c) Microsoft Corporation.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport asyncio\nimport os\nimport subprocess\nimport sys\nfrom pathlib import Path\nfrom typing import Any\n\nfrom greenlet import greenlet\n\nfrom playwright.async_api import Playwright as AsyncPlaywright\nfrom playwright.connection import Connection\nfrom playwright.helper import Error\nfrom playwright.object_factory import create_remote_object\nfrom playwright.path_utils import get_file_dirname\nfrom playwright.playwright import Playwright\nfrom playwright.sync_api import Playwright as SyncPlaywright\n\n\ndef compute_driver_executable() -> Path:\n package_path = get_file_dirname()\n platform = sys.platform\n if platform == \"win32\":\n return package_path / \"driver\" / \"playwright-cli.exe\"\n return package_path / \"driver\" / \"playwright-cli\"\n\n\nclass SyncPlaywrightContextManager:\n def __init__(self) -> None:\n self._playwright: SyncPlaywright\n\n def __enter__(self) -> SyncPlaywright:\n def greenlet_main() -> None:\n loop = None\n own_loop = None\n try:\n loop = asyncio.get_running_loop()\n except RuntimeError:\n loop = asyncio.new_event_loop()\n own_loop = loop\n\n if loop.is_running():\n raise Error(\"Can only run one Playwright at a time.\")\n\n loop.run_until_complete(self._connection.run_as_sync())\n\n if own_loop:\n loop.run_until_complete(loop.shutdown_asyncgens())\n loop.close()\n\n dispatcher_fiber = greenlet(greenlet_main)\n self._connection = Connection(\n dispatcher_fiber, create_remote_object, compute_driver_executable()\n )\n\n g_self = greenlet.getcurrent()\n\n def callback_wrapper(playwright_impl: Playwright) -> None:\n self._playwright = SyncPlaywright(playwright_impl)\n g_self.switch()\n\n self._connection.call_on_object_with_known_name(\"Playwright\", callback_wrapper)\n\n dispatcher_fiber.switch()\n playwright = self._playwright\n playwright.stop = self.__exit__ # type: ignore\n return playwright\n\n def start(self) -> SyncPlaywright:\n return self.__enter__()\n\n def __exit__(self, *args: Any) -> None:\n self._connection.stop_sync()\n\n\nclass AsyncPlaywrightContextManager:\n def __init__(self) -> None:\n self._connection: Connection\n\n async def __aenter__(self) -> AsyncPlaywright:\n self._connection = Connection(\n None, create_remote_object, compute_driver_executable()\n )\n loop = asyncio.get_running_loop()\n self._connection._loop = loop\n loop.create_task(self._connection.run())\n playwright = AsyncPlaywright(\n await self._connection.wait_for_object_with_known_name(\"Playwright\")\n )\n playwright.stop = self.__aexit__ # type: ignore\n return playwright\n\n async def start(self) -> AsyncPlaywright:\n return await self.__aenter__()\n\n async def __aexit__(self, *args: Any) -> None:\n self._connection.stop_async()\n\n\nif sys.version_info.major == 3 and sys.version_info.minor == 7:\n if sys.platform == \"win32\":\n # Use ProactorEventLoop in 3.7, which is default in 3.8\n asyncio.set_event_loop_policy(asyncio.WindowsProactorEventLoopPolicy())\n else:\n # Prevent Python 3.7 from throwing on Linux:\n # RuntimeError: Cannot add child handler, the child watcher does not have a loop attached\n asyncio.get_event_loop()\n asyncio.get_child_watcher()\n\n\ndef main() -> None:\n driver_executable = compute_driver_executable()\n my_env = os.environ.copy()\n my_env[\"PW_CLI_TARGET_LANG\"] = \"python\"\n subprocess.run([str(driver_executable), *sys.argv[1:]], env=my_env)\n", "path": "playwright/main.py"}]} | 2,642 | 231 |
gh_patches_debug_30614 | rasdani/github-patches | git_diff | cloud-custodian__cloud-custodian-6996 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
c7n mailer dependency has a high vulnerability
### Describe the bug
c7n mailer depends on starkbank-ecdsa==1.1.1
This library at this version has been found to have a high vulnerability.
https://github.com/advisories/GHSA-9wx7-jrvc-28mm
The version has been fixed in version 2.0.1
### What did you expect to happen?
No vulnerabilities found in dependency libraries
### Cloud Provider
Amazon Web Services (AWS)
### Cloud Custodian version and dependency information
```shell
Custodian: 0.9.13
Python: 3.9.7 (default, Sep 1 2021, 14:45:30)
[GCC 10.3.1 20210424]
Platform: posix.uname_result(sysname='Linux', nodename='b82f5787903f', release='5.11.0-1016-aws', version='#17~20.04.1-Ubuntu SMP Thu Aug 12 05:39:36 UTC 2021', machine='x86_64')
Using venv: False
Docker: True
Installed:
argcomplete==1.12.3
attrs==21.2.0
boto3==1.17.102
botocore==1.20.102
importlib-metadata==4.6.0
jmespath==0.10.0
jsonschema==3.2.0
pyrsistent==0.18.0
python-dateutil==2.8.1
pyyaml==5.4.1
s3transfer==0.4.2
setuptools==57.4.0
six==1.16.0
tabulate==0.8.9
typing-extensions==3.10.0.0
urllib3==1.26.6
zipp==3.4.1
```
### Policy
_No response_
### Relevant log/traceback output
```shell
Trivy output:
Python (python-pkg)
===================
Total: 1 (UNKNOWN: 0, LOW: 0, MEDIUM: 0, HIGH: 1, CRITICAL: 0)
+-----------------+---------------------+----------+-------------------+---------------+----------------------------------------------+
| LIBRARY | VULNERABILITY ID | SEVERITY | INSTALLED VERSION | FIXED VERSION | TITLE |
+-----------------+---------------------+----------+-------------------+---------------+----------------------------------------------+
| starkbank-ecdsa | GHSA-9wx7-jrvc-28mm | HIGH | 1.1.1 | 2.0.1 | Signature verification vulnerability |
| | | | | | in Stark Bank ecdsa libraries |
| | | | | | -->github.com/advisories/GHSA-9wx7-jrvc-28mm |
+-----------------+---------------------+----------+-------------------+---------------+----------------------------------------------+
```
```
### Extra information or context
_No response_
</issue>
<code>
[start of tools/dev/poetrypkg.py]
1 # Copyright The Cloud Custodian Authors.
2 # SPDX-License-Identifier: Apache-2.0
3 """
4 Supplemental tooling for managing custodian packaging.
5
6 Has various workarounds for poetry
7 """
8 from collections import defaultdict
9 import click
10 import os
11 import sys
12 import toml
13 from pathlib import Path
14
15
16 @click.group()
17 def cli():
18 """Custodian Python Packaging Utility
19
20 some simple tooling to sync poetry files to setup/pip
21 """
22 # If there is a global installation of poetry, prefer that.
23 poetry_python_lib = Path(os.path.expanduser('~/.poetry/lib'))
24 if poetry_python_lib.exists():
25 sys.path.insert(0, os.path.realpath(poetry_python_lib))
26 # poetry env vendored deps
27 sys.path.insert(
28 0,
29 os.path.join(poetry_python_lib, 'poetry', '_vendor', 'py{}.{}'.format(
30 sys.version_info.major, sys.version_info.minor)))
31
32 # If there is a global installation of poetry, prefer that.
33 cur_poetry_python_lib = Path(os.path.expanduser('~/.local/share/pypoetry/venv/lib'))
34 if cur_poetry_python_lib.exists():
35 sys.path.insert(
36 0,
37 str(list(cur_poetry_python_lib.glob('*'))[0] / "site-packages"))
38
39
40 # Override the poetry base template as all our readmes files
41 # are in markdown format.
42 #
43 # Pull request submitted upstream to correctly autodetect
44 # https://github.com/python-poetry/poetry/pull/1994
45 #
46 SETUP_TEMPLATE = """\
47 # -*- coding: utf-8 -*-
48 from setuptools import setup
49
50 {before}
51 setup_kwargs = {{
52 'name': {name!r},
53 'version': {version!r},
54 'description': {description!r},
55 'license': 'Apache-2.0',
56 'classifiers': [
57 'License :: OSI Approved :: Apache Software License',
58 'Topic :: System :: Systems Administration',
59 'Topic :: System :: Distributed Computing'
60 ],
61 'long_description': {long_description!r},
62 'long_description_content_type': 'text/markdown',
63 'author': {author!r},
64 'author_email': {author_email!r},
65 'maintainer': {maintainer!r},
66 'maintainer_email': {maintainer_email!r},
67 'url': {url!r},
68 {extra}
69 }}
70 {after}
71
72 setup(**setup_kwargs)
73 """
74
75
76 @cli.command()
77 @click.option('-p', '--package-dir', type=click.Path())
78 @click.option('-f', '--version-file', type=click.Path())
79 def gen_version_file(package_dir, version_file):
80 data = toml.load(Path(str(package_dir)) / 'pyproject.toml')
81 version = data['tool']['poetry']['version']
82 with open(version_file, 'w') as fh:
83 fh.write('# Generated via tools/dev/poetrypkg.py\n')
84 fh.write('version = "{}"\n'.format(version))
85
86
87 @cli.command()
88 @click.option('-p', '--package-dir', type=click.Path())
89 def gen_setup(package_dir):
90 """Generate a setup suitable for dev compatibility with pip.
91 """
92 from poetry.core.masonry.builders import sdist
93 from poetry.factory import Factory
94
95 factory = Factory()
96 poetry = factory.create_poetry(package_dir)
97
98 # the alternative to monkey patching is carrying forward a
99 # 100 line method. See SETUP_TEMPLATE comments above.
100 sdist.SETUP = SETUP_TEMPLATE
101
102 class SourceDevBuilder(sdist.SdistBuilder):
103 # to enable poetry with a monorepo, we have internal deps
104 # as source path dev dependencies, when we go to generate
105 # setup.py we need to ensure that the source deps are
106 # recorded faithfully.
107
108 @classmethod
109 def convert_dependencies(cls, package, dependencies):
110 reqs, default = super().convert_dependencies(package, dependencies)
111 resolve_source_deps(poetry, package, reqs)
112 return reqs, default
113
114 builder = SourceDevBuilder(poetry, None, None)
115 setup_content = builder.build_setup()
116
117 with open(os.path.join(package_dir, 'setup.py'), 'wb') as fh:
118 fh.write(b'# Automatically generated from poetry/pyproject.toml\n')
119 fh.write(b'# flake8: noqa\n')
120 fh.write(setup_content)
121
122
123 @cli.command()
124 @click.option('-p', '--package-dir', type=click.Path())
125 @click.option('-o', '--output', default='setup.py')
126 def gen_frozensetup(package_dir, output):
127 """Generate a frozen setup suitable for distribution.
128 """
129 from poetry.core.masonry.builders import sdist
130 from poetry.factory import Factory
131
132 factory = Factory()
133 poetry = factory.create_poetry(package_dir)
134
135 sdist.SETUP = SETUP_TEMPLATE
136
137 class FrozenBuilder(sdist.SdistBuilder):
138
139 @classmethod
140 def convert_dependencies(cls, package, dependencies):
141 reqs, default = locked_deps(package, poetry)
142 resolve_source_deps(poetry, package, reqs, frozen=True)
143 return reqs, default
144
145 builder = FrozenBuilder(poetry, None, None)
146 setup_content = builder.build_setup()
147
148 with open(os.path.join(package_dir, output), 'wb') as fh:
149 fh.write(b'# Automatically generated from pyproject.toml\n')
150 fh.write(b'# flake8: noqa\n')
151 fh.write(setup_content)
152
153
154 def resolve_source_deps(poetry, package, reqs, frozen=False):
155 # find any source path dev deps and them and their recursive
156 # deps to reqs
157 if poetry.local_config['name'] not in (package.name, package.pretty_name):
158 return
159
160 source_deps = []
161 for dep_name, info in poetry.local_config.get('dev-dependencies', {}).items():
162 if isinstance(info, dict) and 'path' in info:
163 source_deps.append(dep_name)
164 if not source_deps:
165 return
166
167 from poetry.core.packages.dependency import Dependency
168
169 dep_map = {d['name']: d for d in poetry.locker.lock_data['package']}
170 seen = set(source_deps)
171 seen.add('setuptools')
172
173 prefix = '' if frozen else '^'
174 while source_deps:
175 dep = source_deps.pop()
176 if dep not in dep_map:
177 dep = dep.replace('_', '-')
178 version = dep_map[dep]['version']
179 reqs.append(Dependency(dep, '{}{}'.format(prefix, version)).to_pep_508())
180 for cdep, cversion in dep_map[dep].get('dependencies', {}).items():
181 if cdep in seen:
182 continue
183 source_deps.append(cdep)
184 seen.add(cdep)
185
186
187 def locked_deps(package, poetry):
188 reqs = []
189 packages = poetry.locker.locked_repository(False).packages
190 for p in packages:
191 dep = p.to_dependency()
192 line = "{}=={}".format(p.name, p.version)
193 requirement = dep.to_pep_508()
194 if ';' in requirement:
195 line += "; {}".format(requirement.split(";")[1].strip())
196 reqs.append(line)
197 return reqs, defaultdict(list)
198
199
200 if __name__ == '__main__':
201 cli()
202
[end of tools/dev/poetrypkg.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/tools/dev/poetrypkg.py b/tools/dev/poetrypkg.py
--- a/tools/dev/poetrypkg.py
+++ b/tools/dev/poetrypkg.py
@@ -123,7 +123,9 @@
@cli.command()
@click.option('-p', '--package-dir', type=click.Path())
@click.option('-o', '--output', default='setup.py')
-def gen_frozensetup(package_dir, output):
[email protected]('-x', '--exclude', multiple=True)
[email protected]('-r', '--remove', multiple=True)
+def gen_frozensetup(package_dir, output, exclude, remove):
"""Generate a frozen setup suitable for distribution.
"""
from poetry.core.masonry.builders import sdist
@@ -138,7 +140,7 @@
@classmethod
def convert_dependencies(cls, package, dependencies):
- reqs, default = locked_deps(package, poetry)
+ reqs, default = locked_deps(package, poetry, exclude, remove)
resolve_source_deps(poetry, package, reqs, frozen=True)
return reqs, default
@@ -184,10 +186,18 @@
seen.add(cdep)
-def locked_deps(package, poetry):
+def locked_deps(package, poetry, exclude=(), remove=()):
reqs = []
packages = poetry.locker.locked_repository(False).packages
+
+ project_deps = {
+ r.name: r for r in poetry.package.requires}
for p in packages:
+ if p.name in exclude:
+ reqs.append(project_deps[p.name].to_pep_508())
+ continue
+ if p.name in remove:
+ continue
dep = p.to_dependency()
line = "{}=={}".format(p.name, p.version)
requirement = dep.to_pep_508()
| {"golden_diff": "diff --git a/tools/dev/poetrypkg.py b/tools/dev/poetrypkg.py\n--- a/tools/dev/poetrypkg.py\n+++ b/tools/dev/poetrypkg.py\n@@ -123,7 +123,9 @@\n @cli.command()\n @click.option('-p', '--package-dir', type=click.Path())\n @click.option('-o', '--output', default='setup.py')\n-def gen_frozensetup(package_dir, output):\[email protected]('-x', '--exclude', multiple=True)\[email protected]('-r', '--remove', multiple=True)\n+def gen_frozensetup(package_dir, output, exclude, remove):\n \"\"\"Generate a frozen setup suitable for distribution.\n \"\"\"\n from poetry.core.masonry.builders import sdist\n@@ -138,7 +140,7 @@\n \n @classmethod\n def convert_dependencies(cls, package, dependencies):\n- reqs, default = locked_deps(package, poetry)\n+ reqs, default = locked_deps(package, poetry, exclude, remove)\n resolve_source_deps(poetry, package, reqs, frozen=True)\n return reqs, default\n \n@@ -184,10 +186,18 @@\n seen.add(cdep)\n \n \n-def locked_deps(package, poetry):\n+def locked_deps(package, poetry, exclude=(), remove=()):\n reqs = []\n packages = poetry.locker.locked_repository(False).packages\n+\n+ project_deps = {\n+ r.name: r for r in poetry.package.requires}\n for p in packages:\n+ if p.name in exclude:\n+ reqs.append(project_deps[p.name].to_pep_508())\n+ continue\n+ if p.name in remove:\n+ continue\n dep = p.to_dependency()\n line = \"{}=={}\".format(p.name, p.version)\n requirement = dep.to_pep_508()\n", "issue": "c7n mailer dependency has a high vulnerability\n### Describe the bug\n\nc7n mailer depends on starkbank-ecdsa==1.1.1\r\n\r\nThis library at this version has been found to have a high vulnerability.\r\n\r\nhttps://github.com/advisories/GHSA-9wx7-jrvc-28mm\r\n\r\nThe version has been fixed in version 2.0.1\r\n\n\n### What did you expect to happen?\n\nNo vulnerabilities found in dependency libraries\n\n### Cloud Provider\n\nAmazon Web Services (AWS)\n\n### Cloud Custodian version and dependency information\n\n```shell\nCustodian: 0.9.13\r\nPython: 3.9.7 (default, Sep 1 2021, 14:45:30)\r\n [GCC 10.3.1 20210424]\r\nPlatform: posix.uname_result(sysname='Linux', nodename='b82f5787903f', release='5.11.0-1016-aws', version='#17~20.04.1-Ubuntu SMP Thu Aug 12 05:39:36 UTC 2021', machine='x86_64')\r\nUsing venv: False\r\nDocker: True\r\nInstalled:\r\n\r\nargcomplete==1.12.3\r\nattrs==21.2.0\r\nboto3==1.17.102\r\nbotocore==1.20.102\r\nimportlib-metadata==4.6.0\r\njmespath==0.10.0\r\njsonschema==3.2.0\r\npyrsistent==0.18.0\r\npython-dateutil==2.8.1\r\npyyaml==5.4.1\r\ns3transfer==0.4.2\r\nsetuptools==57.4.0\r\nsix==1.16.0\r\ntabulate==0.8.9\r\ntyping-extensions==3.10.0.0\r\nurllib3==1.26.6\r\nzipp==3.4.1\n```\n\n\n### Policy\n\n_No response_\n\n### Relevant log/traceback output\n\n```shell\nTrivy output:\r\n\r\n\r\nPython (python-pkg)\r\n===================\r\nTotal: 1 (UNKNOWN: 0, LOW: 0, MEDIUM: 0, HIGH: 1, CRITICAL: 0)\r\n+-----------------+---------------------+----------+-------------------+---------------+----------------------------------------------+\r\n| LIBRARY | VULNERABILITY ID | SEVERITY | INSTALLED VERSION | FIXED VERSION | TITLE |\r\n+-----------------+---------------------+----------+-------------------+---------------+----------------------------------------------+\r\n| starkbank-ecdsa | GHSA-9wx7-jrvc-28mm | HIGH | 1.1.1 | 2.0.1 | Signature verification vulnerability |\r\n| | | | | | in Stark Bank ecdsa libraries |\r\n| | | | | | -->github.com/advisories/GHSA-9wx7-jrvc-28mm |\r\n+-----------------+---------------------+----------+-------------------+---------------+----------------------------------------------+\r\n```\n```\n\n\n### Extra information or context\n\n_No response_\n", "before_files": [{"content": "# Copyright The Cloud Custodian Authors.\n# SPDX-License-Identifier: Apache-2.0\n\"\"\"\nSupplemental tooling for managing custodian packaging.\n\nHas various workarounds for poetry\n\"\"\"\nfrom collections import defaultdict\nimport click\nimport os\nimport sys\nimport toml\nfrom pathlib import Path\n\n\[email protected]()\ndef cli():\n \"\"\"Custodian Python Packaging Utility\n\n some simple tooling to sync poetry files to setup/pip\n \"\"\"\n # If there is a global installation of poetry, prefer that.\n poetry_python_lib = Path(os.path.expanduser('~/.poetry/lib'))\n if poetry_python_lib.exists():\n sys.path.insert(0, os.path.realpath(poetry_python_lib))\n # poetry env vendored deps\n sys.path.insert(\n 0,\n os.path.join(poetry_python_lib, 'poetry', '_vendor', 'py{}.{}'.format(\n sys.version_info.major, sys.version_info.minor)))\n\n # If there is a global installation of poetry, prefer that.\n cur_poetry_python_lib = Path(os.path.expanduser('~/.local/share/pypoetry/venv/lib'))\n if cur_poetry_python_lib.exists():\n sys.path.insert(\n 0,\n str(list(cur_poetry_python_lib.glob('*'))[0] / \"site-packages\"))\n\n\n# Override the poetry base template as all our readmes files\n# are in markdown format.\n#\n# Pull request submitted upstream to correctly autodetect\n# https://github.com/python-poetry/poetry/pull/1994\n#\nSETUP_TEMPLATE = \"\"\"\\\n# -*- coding: utf-8 -*-\nfrom setuptools import setup\n\n{before}\nsetup_kwargs = {{\n 'name': {name!r},\n 'version': {version!r},\n 'description': {description!r},\n 'license': 'Apache-2.0',\n 'classifiers': [\n 'License :: OSI Approved :: Apache Software License',\n 'Topic :: System :: Systems Administration',\n 'Topic :: System :: Distributed Computing'\n ],\n 'long_description': {long_description!r},\n 'long_description_content_type': 'text/markdown',\n 'author': {author!r},\n 'author_email': {author_email!r},\n 'maintainer': {maintainer!r},\n 'maintainer_email': {maintainer_email!r},\n 'url': {url!r},\n {extra}\n}}\n{after}\n\nsetup(**setup_kwargs)\n\"\"\"\n\n\[email protected]()\[email protected]('-p', '--package-dir', type=click.Path())\[email protected]('-f', '--version-file', type=click.Path())\ndef gen_version_file(package_dir, version_file):\n data = toml.load(Path(str(package_dir)) / 'pyproject.toml')\n version = data['tool']['poetry']['version']\n with open(version_file, 'w') as fh:\n fh.write('# Generated via tools/dev/poetrypkg.py\\n')\n fh.write('version = \"{}\"\\n'.format(version))\n\n\[email protected]()\[email protected]('-p', '--package-dir', type=click.Path())\ndef gen_setup(package_dir):\n \"\"\"Generate a setup suitable for dev compatibility with pip.\n \"\"\"\n from poetry.core.masonry.builders import sdist\n from poetry.factory import Factory\n\n factory = Factory()\n poetry = factory.create_poetry(package_dir)\n\n # the alternative to monkey patching is carrying forward a\n # 100 line method. See SETUP_TEMPLATE comments above.\n sdist.SETUP = SETUP_TEMPLATE\n\n class SourceDevBuilder(sdist.SdistBuilder):\n # to enable poetry with a monorepo, we have internal deps\n # as source path dev dependencies, when we go to generate\n # setup.py we need to ensure that the source deps are\n # recorded faithfully.\n\n @classmethod\n def convert_dependencies(cls, package, dependencies):\n reqs, default = super().convert_dependencies(package, dependencies)\n resolve_source_deps(poetry, package, reqs)\n return reqs, default\n\n builder = SourceDevBuilder(poetry, None, None)\n setup_content = builder.build_setup()\n\n with open(os.path.join(package_dir, 'setup.py'), 'wb') as fh:\n fh.write(b'# Automatically generated from poetry/pyproject.toml\\n')\n fh.write(b'# flake8: noqa\\n')\n fh.write(setup_content)\n\n\[email protected]()\[email protected]('-p', '--package-dir', type=click.Path())\[email protected]('-o', '--output', default='setup.py')\ndef gen_frozensetup(package_dir, output):\n \"\"\"Generate a frozen setup suitable for distribution.\n \"\"\"\n from poetry.core.masonry.builders import sdist\n from poetry.factory import Factory\n\n factory = Factory()\n poetry = factory.create_poetry(package_dir)\n\n sdist.SETUP = SETUP_TEMPLATE\n\n class FrozenBuilder(sdist.SdistBuilder):\n\n @classmethod\n def convert_dependencies(cls, package, dependencies):\n reqs, default = locked_deps(package, poetry)\n resolve_source_deps(poetry, package, reqs, frozen=True)\n return reqs, default\n\n builder = FrozenBuilder(poetry, None, None)\n setup_content = builder.build_setup()\n\n with open(os.path.join(package_dir, output), 'wb') as fh:\n fh.write(b'# Automatically generated from pyproject.toml\\n')\n fh.write(b'# flake8: noqa\\n')\n fh.write(setup_content)\n\n\ndef resolve_source_deps(poetry, package, reqs, frozen=False):\n # find any source path dev deps and them and their recursive\n # deps to reqs\n if poetry.local_config['name'] not in (package.name, package.pretty_name):\n return\n\n source_deps = []\n for dep_name, info in poetry.local_config.get('dev-dependencies', {}).items():\n if isinstance(info, dict) and 'path' in info:\n source_deps.append(dep_name)\n if not source_deps:\n return\n\n from poetry.core.packages.dependency import Dependency\n\n dep_map = {d['name']: d for d in poetry.locker.lock_data['package']}\n seen = set(source_deps)\n seen.add('setuptools')\n\n prefix = '' if frozen else '^'\n while source_deps:\n dep = source_deps.pop()\n if dep not in dep_map:\n dep = dep.replace('_', '-')\n version = dep_map[dep]['version']\n reqs.append(Dependency(dep, '{}{}'.format(prefix, version)).to_pep_508())\n for cdep, cversion in dep_map[dep].get('dependencies', {}).items():\n if cdep in seen:\n continue\n source_deps.append(cdep)\n seen.add(cdep)\n\n\ndef locked_deps(package, poetry):\n reqs = []\n packages = poetry.locker.locked_repository(False).packages\n for p in packages:\n dep = p.to_dependency()\n line = \"{}=={}\".format(p.name, p.version)\n requirement = dep.to_pep_508()\n if ';' in requirement:\n line += \"; {}\".format(requirement.split(\";\")[1].strip())\n reqs.append(line)\n return reqs, defaultdict(list)\n\n\nif __name__ == '__main__':\n cli()\n", "path": "tools/dev/poetrypkg.py"}]} | 3,322 | 408 |
gh_patches_debug_64061 | rasdani/github-patches | git_diff | privacyidea__privacyidea-1978 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Missing requirement in setup.py
The `flask-versioned` package is missing in `setup.py`s `install_requires` list. When installing privacyIDEA via `setup.py` or `pip` this will break.
</issue>
<code>
[start of setup.py]
1 # -*- coding: utf-8 -*-
2 from __future__ import print_function
3 from setuptools import setup, find_packages
4 import os
5 import stat
6 import sys
7
8 #VERSION="2.1dev4"
9 VERSION="3.2"
10
11 # Taken from kennethreitz/requests/setup.py
12 package_directory = os.path.realpath(os.path.dirname(__file__))
13
14
15 def get_file_contents(file_path):
16 """Get the context of the file using full path name."""
17 content = ""
18 try:
19 full_path = os.path.join(package_directory, file_path)
20 content = open(full_path, 'r').read()
21 except:
22 print("### could not open file {0!r}".format(file_path), file=sys.stderr)
23 return content
24
25
26 def get_file_list(file_path):
27 full_path = os.path.join(package_directory, file_path)
28 file_list = os.listdir(full_path)
29 # now we need to add the path to the files
30 return [file_path + f for f in file_list]
31
32
33 install_requires = ["Flask>=0.10.1",
34 "Flask-Migrate>=1.2.0",
35 "Flask-SQLAlchemy>=2.0",
36 "Flask-Script>=2.0.5",
37 "Jinja2>=2.10.1",
38 "Mako>=0.9.1",
39 "PyMySQL>=0.6.6",
40 "Pillow>=6.2.1",
41 "PyJWT>=1.3.0",
42 "PyYAML>=5.1",
43 "SQLAlchemy>=1.3.0",
44 "Werkzeug>=0.10.4",
45 "alembic>=0.6.7",
46 "bcrypt>=1.1.0",
47 "beautifulsoup4>=4.3.2",
48 "ldap3>=2.6",
49 "netaddr>=0.7.12",
50 "passlib>=1.6.2",
51 "pyOpenSSL>=17.5",
52 "pyrad>=2.0",
53 "qrcode>=6.1",
54 "requests>=2.7.0",
55 "sqlsoup>=0.9.0",
56 "ecdsa>=0.13.3",
57 "lxml>=4.2.5",
58 "python-gnupg>=0.4.4",
59 "defusedxml>=0.4.1",
60 "flask-babel>=0.9",
61 "croniter>=0.3.8",
62 "oauth2client>=2.0.1",
63 "configobj>=5.0.6"
64 ]
65
66 # For python 2.6 we need additional dependency importlib
67 try:
68 import importlib
69 except ImportError:
70 install_requires.append('importlib')
71
72
73 def get_man_pages(dir):
74 """
75 Get man pages in a directory.
76 :param dir:
77 :return: list of file names
78 """
79 files = os.listdir(dir)
80 r_files = []
81 for file in files:
82 if file.endswith(".1"):
83 r_files.append(dir + "/" + file)
84 return r_files
85
86
87 def get_scripts(dir):
88 """
89 Get files that are executable
90 :param dir:
91 :return: list of file names
92 """
93 files = os.listdir(dir)
94 r_files = []
95 for file in files:
96 if os.stat(dir + "/" + file)[stat.ST_MODE] & stat.S_IEXEC:
97 r_files.append(dir + "/" + file)
98 return r_files
99
100
101 setup(
102 name='privacyIDEA',
103 version=VERSION,
104 description='privacyIDEA: identity, multifactor authentication (OTP), '
105 'authorization, audit',
106 author='privacyidea.org',
107 license='AGPLv3',
108 author_email='[email protected]',
109 url='http://www.privacyidea.org',
110 keywords='OTP, two factor authentication, management, security',
111 python_requires='>=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*, !=3.4.*',
112 packages=find_packages(),
113 scripts=["pi-manage"] + get_scripts("tools"),
114 extras_require={
115 'dev': ["Sphinx>=1.3.1",
116 "sphinxcontrib-httpdomain>=1.3.0"],
117 'test': ["coverage>=3.7.1",
118 "mock>=1.0.1",
119 "pyparsing>=2.0.3",
120 "nose>=1.3.4",
121 "responses>=0.4.0",
122 "six>=1.8.0"],
123 },
124 install_requires=install_requires,
125 include_package_data=True,
126 data_files=[('etc/privacyidea/',
127 ['deploy/apache/privacyideaapp.wsgi',
128 'deploy/privacyidea/dictionary']),
129 ('share/man/man1', get_man_pages("tools")),
130 ('lib/privacyidea/migrations',
131 ["migrations/alembic.ini",
132 "migrations/env.py",
133 "migrations/README",
134 "migrations/script.py.mako"]),
135 ('lib/privacyidea/migrations/versions',
136 get_file_list("migrations/versions/")),
137 ('lib/privacyidea/', ['requirements.txt'])
138 ],
139 classifiers=["Framework :: Flask",
140 "License :: OSI Approved :: "
141 "GNU Affero General Public License v3",
142 "Programming Language :: Python",
143 "Development Status :: 5 - Production/Stable",
144 "Topic :: Internet",
145 "Topic :: Security",
146 "Topic :: System ::"
147 " Systems Administration :: Authentication/Directory",
148 'Programming Language :: Python',
149 'Programming Language :: Python :: 2',
150 'Programming Language :: Python :: 2.7',
151 'Programming Language :: Python :: 3',
152 'Programming Language :: Python :: 3.5',
153 'Programming Language :: Python :: 3.6',
154 'Programming Language :: Python :: 3.7'
155 ],
156 #message_extractors={'privacyidea': [
157 # ('**.py', 'python', None),
158 # ('static/**.html', 'html', {'input_encoding': 'utf-8'})]},
159 zip_safe=False,
160 long_description=get_file_contents('README.rst')
161 )
162
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -60,7 +60,8 @@
"flask-babel>=0.9",
"croniter>=0.3.8",
"oauth2client>=2.0.1",
- "configobj>=5.0.6"
+ "configobj>=5.0.6",
+ "flask-versioned>=0.9.4"
]
# For python 2.6 we need additional dependency importlib
| {"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -60,7 +60,8 @@\n \"flask-babel>=0.9\",\n \"croniter>=0.3.8\",\n \"oauth2client>=2.0.1\",\n- \"configobj>=5.0.6\"\n+ \"configobj>=5.0.6\",\n+ \"flask-versioned>=0.9.4\"\n ]\n \n # For python 2.6 we need additional dependency importlib\n", "issue": "Missing requirement in setup.py\nThe `flask-versioned` package is missing in `setup.py`s `install_requires` list. When installing privacyIDEA via `setup.py` or `pip` this will break.\r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\nfrom __future__ import print_function\nfrom setuptools import setup, find_packages\nimport os\nimport stat\nimport sys\n\n#VERSION=\"2.1dev4\"\nVERSION=\"3.2\"\n\n# Taken from kennethreitz/requests/setup.py\npackage_directory = os.path.realpath(os.path.dirname(__file__))\n\n\ndef get_file_contents(file_path):\n \"\"\"Get the context of the file using full path name.\"\"\"\n content = \"\"\n try:\n full_path = os.path.join(package_directory, file_path)\n content = open(full_path, 'r').read()\n except:\n print(\"### could not open file {0!r}\".format(file_path), file=sys.stderr)\n return content\n\n\ndef get_file_list(file_path):\n full_path = os.path.join(package_directory, file_path)\n file_list = os.listdir(full_path)\n # now we need to add the path to the files\n return [file_path + f for f in file_list]\n\n\ninstall_requires = [\"Flask>=0.10.1\",\n \"Flask-Migrate>=1.2.0\",\n \"Flask-SQLAlchemy>=2.0\",\n \"Flask-Script>=2.0.5\",\n \"Jinja2>=2.10.1\",\n \"Mako>=0.9.1\",\n \"PyMySQL>=0.6.6\",\n \"Pillow>=6.2.1\",\n \"PyJWT>=1.3.0\",\n \"PyYAML>=5.1\",\n \"SQLAlchemy>=1.3.0\",\n \"Werkzeug>=0.10.4\",\n \"alembic>=0.6.7\",\n \"bcrypt>=1.1.0\",\n \"beautifulsoup4>=4.3.2\",\n \"ldap3>=2.6\",\n \"netaddr>=0.7.12\",\n \"passlib>=1.6.2\",\n \"pyOpenSSL>=17.5\",\n \"pyrad>=2.0\",\n \"qrcode>=6.1\",\n \"requests>=2.7.0\",\n \"sqlsoup>=0.9.0\",\n \"ecdsa>=0.13.3\",\n \"lxml>=4.2.5\",\n \"python-gnupg>=0.4.4\",\n \"defusedxml>=0.4.1\",\n \"flask-babel>=0.9\",\n \"croniter>=0.3.8\",\n \"oauth2client>=2.0.1\",\n \"configobj>=5.0.6\"\n ]\n\n# For python 2.6 we need additional dependency importlib\ntry:\n import importlib\nexcept ImportError:\n install_requires.append('importlib')\n\n\ndef get_man_pages(dir):\n \"\"\"\n Get man pages in a directory.\n :param dir: \n :return: list of file names\n \"\"\"\n files = os.listdir(dir)\n r_files = []\n for file in files:\n if file.endswith(\".1\"):\n r_files.append(dir + \"/\" + file)\n return r_files\n\n\ndef get_scripts(dir):\n \"\"\"\n Get files that are executable\n :param dir: \n :return: list of file names\n \"\"\"\n files = os.listdir(dir)\n r_files = []\n for file in files:\n if os.stat(dir + \"/\" + file)[stat.ST_MODE] & stat.S_IEXEC:\n r_files.append(dir + \"/\" + file)\n return r_files\n\n\nsetup(\n name='privacyIDEA',\n version=VERSION,\n description='privacyIDEA: identity, multifactor authentication (OTP), '\n 'authorization, audit',\n author='privacyidea.org',\n license='AGPLv3',\n author_email='[email protected]',\n url='http://www.privacyidea.org',\n keywords='OTP, two factor authentication, management, security',\n python_requires='>=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*, !=3.4.*',\n packages=find_packages(),\n scripts=[\"pi-manage\"] + get_scripts(\"tools\"),\n extras_require={\n 'dev': [\"Sphinx>=1.3.1\",\n \"sphinxcontrib-httpdomain>=1.3.0\"],\n 'test': [\"coverage>=3.7.1\",\n \"mock>=1.0.1\",\n \"pyparsing>=2.0.3\",\n \"nose>=1.3.4\",\n \"responses>=0.4.0\",\n \"six>=1.8.0\"],\n },\n install_requires=install_requires,\n include_package_data=True,\n data_files=[('etc/privacyidea/',\n ['deploy/apache/privacyideaapp.wsgi',\n 'deploy/privacyidea/dictionary']),\n ('share/man/man1', get_man_pages(\"tools\")),\n ('lib/privacyidea/migrations',\n [\"migrations/alembic.ini\",\n \"migrations/env.py\",\n \"migrations/README\",\n \"migrations/script.py.mako\"]),\n ('lib/privacyidea/migrations/versions',\n get_file_list(\"migrations/versions/\")),\n ('lib/privacyidea/', ['requirements.txt'])\n ],\n classifiers=[\"Framework :: Flask\",\n \"License :: OSI Approved :: \"\n \"GNU Affero General Public License v3\",\n \"Programming Language :: Python\",\n \"Development Status :: 5 - Production/Stable\",\n \"Topic :: Internet\",\n \"Topic :: Security\",\n \"Topic :: System ::\"\n \" Systems Administration :: Authentication/Directory\",\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7'\n ],\n #message_extractors={'privacyidea': [\n # ('**.py', 'python', None),\n # ('static/**.html', 'html', {'input_encoding': 'utf-8'})]},\n zip_safe=False,\n long_description=get_file_contents('README.rst')\n)\n", "path": "setup.py"}]} | 2,304 | 121 |
gh_patches_debug_19463 | rasdani/github-patches | git_diff | buildbot__buildbot-7050 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Bitbucket cloud status update returns 400 for status_key longer than 40 characters
When using a status_key for reporters.BitbucketStatusPush, there is no check whether it is longer than 40 characters, which appears to be the limit that Bitbucket cloud accepts.
This error appears in the log file in cases where status_key exceeds 40 characters:
`400: unable to upload Bitbucket status b'{"type": "error", "error": {"message": "key: Ensure this value has at most 40 characters (it has 48).", "fields": {"key": ["Ensure this value has at most 40 characters (it has 48)."]}}}'`
Checking the length for this field might be difficult during configuration checking time, since it might exceed 40 characters only after a certain amount of builds have been done ( e.g. with the value Interpolate("%(prop:buildername)s/%(prop:buildnumber)s") )
I would propose hashing the status_key in order to get predictable key lengths. sha1 happens to be 20 bytes long which is 40 characters in hexadecimal notation.
</issue>
<code>
[start of master/buildbot/reporters/bitbucket.py]
1 # This file is part of Buildbot. Buildbot is free software: you can
2 # redistribute it and/or modify it under the terms of the GNU General Public
3 # License as published by the Free Software Foundation, version 2.
4 #
5 # This program is distributed in the hope that it will be useful, but WITHOUT
6 # ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS
7 # FOR A PARTICULAR PURPOSE. See the GNU General Public License for more
8 # details.
9 #
10 # You should have received a copy of the GNU General Public License along with
11 # this program; if not, write to the Free Software Foundation, Inc., 51
12 # Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.
13 #
14 # Copyright Buildbot Team Members
15
16 from urllib.parse import urlparse
17
18 from twisted.internet import defer
19 from twisted.python import log
20
21 from buildbot import config
22 from buildbot.process.properties import Properties
23 from buildbot.process.properties import Property
24 from buildbot.process.results import SUCCESS
25 from buildbot.reporters.base import ReporterBase
26 from buildbot.reporters.generators.build import BuildStartEndStatusGenerator
27 from buildbot.reporters.message import MessageFormatter
28 from buildbot.util import httpclientservice
29
30 # Magic words understood by Butbucket REST API
31 BITBUCKET_INPROGRESS = 'INPROGRESS'
32 BITBUCKET_SUCCESSFUL = 'SUCCESSFUL'
33 BITBUCKET_FAILED = 'FAILED'
34
35 _BASE_URL = 'https://api.bitbucket.org/2.0/repositories'
36 _OAUTH_URL = 'https://bitbucket.org/site/oauth2/access_token'
37 _GET_TOKEN_DATA = {
38 'grant_type': 'client_credentials'
39 }
40
41
42 class BitbucketStatusPush(ReporterBase):
43 name = "BitbucketStatusPush"
44
45 def checkConfig(self, oauth_key=None, oauth_secret=None, auth=None, base_url=_BASE_URL,
46 oauth_url=_OAUTH_URL, debug=None, verify=None, status_key=None,
47 status_name=None, generators=None, **kwargs):
48 if auth is not None and (oauth_key is not None or oauth_secret is not None):
49 config.error('Either App Passwords or OAuth can be specified, not both')
50
51 if generators is None:
52 generators = self._create_default_generators()
53
54 super().checkConfig(generators=generators, **kwargs)
55 httpclientservice.HTTPClientService.checkAvailable(self.__class__.__name__)
56
57 @defer.inlineCallbacks
58 def reconfigService(self, oauth_key=None, oauth_secret=None, auth=None, base_url=_BASE_URL,
59 oauth_url=_OAUTH_URL, debug=None, verify=None, status_key=None,
60 status_name=None, generators=None, **kwargs):
61 oauth_key, oauth_secret = yield self.renderSecrets(oauth_key, oauth_secret)
62 self.auth = yield self.renderSecrets(auth)
63 self.base_url = base_url
64 self.debug = debug
65 self.verify = verify
66 self.status_key = status_key or Property('buildername')
67 self.status_name = status_name or Property('buildername')
68
69 if generators is None:
70 generators = self._create_default_generators()
71
72 yield super().reconfigService(generators=generators, **kwargs)
73
74 base_url = base_url.rstrip('/')
75
76 self._http = yield httpclientservice.HTTPClientService.getService(
77 self.master, base_url,
78 debug=self.debug, verify=self.verify, auth=self.auth)
79
80 self.oauthhttp = None
81 if self.auth is None:
82 self.oauthhttp = yield httpclientservice.HTTPClientService.getService(
83 self.master, oauth_url, auth=(oauth_key, oauth_secret),
84 debug=self.debug, verify=self.verify)
85
86 def _create_default_generators(self):
87 return [
88 BuildStartEndStatusGenerator(
89 start_formatter=MessageFormatter(subject="", template=''),
90 end_formatter=MessageFormatter(subject="", template='')
91 )
92 ]
93
94 @defer.inlineCallbacks
95 def sendMessage(self, reports):
96 # Only use OAuth if basic auth has not been specified
97 if not self.auth:
98 request = yield self.oauthhttp.post("", data=_GET_TOKEN_DATA)
99 if request.code != 200:
100 content = yield request.content()
101 log.msg(f"{request.code}: unable to authenticate to Bitbucket {content}")
102 return
103 token = (yield request.json())['access_token']
104 self._http.updateHeaders({'Authorization': f'Bearer {token}'})
105
106 build = reports[0]['builds'][0]
107 if build['complete']:
108 status = BITBUCKET_SUCCESSFUL if build['results'] == SUCCESS else BITBUCKET_FAILED
109 else:
110 status = BITBUCKET_INPROGRESS
111
112 props = Properties.fromDict(build['properties'])
113 props.master = self.master
114
115 body = {
116 'state': status,
117 'key': (yield props.render(self.status_key)),
118 'name': (yield props.render(self.status_name)),
119 'description': reports[0]['subject'],
120 'url': build['url']
121 }
122
123 for sourcestamp in build['buildset']['sourcestamps']:
124 if not sourcestamp['repository']:
125 log.msg(f"Empty repository URL for Bitbucket status {body}")
126 continue
127 owner, repo = self.get_owner_and_repo(sourcestamp['repository'])
128
129 endpoint = (owner, repo, 'commit', sourcestamp['revision'], 'statuses', 'build')
130 bitbucket_uri = f"/{'/'.join(endpoint)}"
131
132 if self.debug:
133 log.msg(f"Bitbucket status {bitbucket_uri} {body}")
134
135 response = yield self._http.post(bitbucket_uri, json=body)
136 if response.code not in (200, 201):
137 content = yield response.content()
138 log.msg(f"{response.code}: unable to upload Bitbucket status {content}")
139
140 def get_owner_and_repo(self, repourl):
141 """
142 Takes a git repository URL from Bitbucket and tries to determine the owner and repository
143 name
144 :param repourl: Bitbucket git repo in the form of
145 [email protected]:OWNER/REPONAME.git
146 https://bitbucket.org/OWNER/REPONAME.git
147 ssh://[email protected]/OWNER/REPONAME.git
148 https://api.bitbucket.org/2.0/repositories/OWNER/REPONAME
149 :return: owner, repo: The owner of the repository and the repository name
150 """
151 parsed = urlparse(repourl)
152
153 base_parsed = urlparse(self.base_url)
154 if parsed.path.startswith(base_parsed.path):
155 path = parsed.path.replace(base_parsed.path, "")
156 elif parsed.scheme:
157 path = parsed.path
158 else:
159 # we assume git@host:owner/repo.git here
160 path = parsed.path.split(':', 1)[-1]
161
162 path = path.lstrip('/')
163 if path.endswith('.git'):
164 path = path[:-4]
165 path = path.rstrip('/')
166
167 parts = path.split('/')
168
169 assert len(parts) == 2, 'OWNER/REPONAME is expected'
170
171 return parts
172
[end of master/buildbot/reporters/bitbucket.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/master/buildbot/reporters/bitbucket.py b/master/buildbot/reporters/bitbucket.py
--- a/master/buildbot/reporters/bitbucket.py
+++ b/master/buildbot/reporters/bitbucket.py
@@ -13,6 +13,7 @@
#
# Copyright Buildbot Team Members
+import hashlib
from urllib.parse import urlparse
from twisted.internet import defer
@@ -112,9 +113,16 @@
props = Properties.fromDict(build['properties'])
props.master = self.master
+ def key_hash(key):
+ sha_obj = hashlib.sha1()
+ sha_obj.update(key.encode('utf-8'))
+ return sha_obj.hexdigest()
+
+ status_key = yield props.render(self.status_key)
+
body = {
'state': status,
- 'key': (yield props.render(self.status_key)),
+ 'key': key_hash(status_key),
'name': (yield props.render(self.status_name)),
'description': reports[0]['subject'],
'url': build['url']
| {"golden_diff": "diff --git a/master/buildbot/reporters/bitbucket.py b/master/buildbot/reporters/bitbucket.py\n--- a/master/buildbot/reporters/bitbucket.py\n+++ b/master/buildbot/reporters/bitbucket.py\n@@ -13,6 +13,7 @@\n #\n # Copyright Buildbot Team Members\n \n+import hashlib\n from urllib.parse import urlparse\n \n from twisted.internet import defer\n@@ -112,9 +113,16 @@\n props = Properties.fromDict(build['properties'])\n props.master = self.master\n \n+ def key_hash(key):\n+ sha_obj = hashlib.sha1()\n+ sha_obj.update(key.encode('utf-8'))\n+ return sha_obj.hexdigest()\n+\n+ status_key = yield props.render(self.status_key)\n+\n body = {\n 'state': status,\n- 'key': (yield props.render(self.status_key)),\n+ 'key': key_hash(status_key),\n 'name': (yield props.render(self.status_name)),\n 'description': reports[0]['subject'],\n 'url': build['url']\n", "issue": "Bitbucket cloud status update returns 400 for status_key longer than 40 characters\nWhen using a status_key for reporters.BitbucketStatusPush, there is no check whether it is longer than 40 characters, which appears to be the limit that Bitbucket cloud accepts.\r\nThis error appears in the log file in cases where status_key exceeds 40 characters:\r\n`400: unable to upload Bitbucket status b'{\"type\": \"error\", \"error\": {\"message\": \"key: Ensure this value has at most 40 characters (it has 48).\", \"fields\": {\"key\": [\"Ensure this value has at most 40 characters (it has 48).\"]}}}'`\r\n\r\nChecking the length for this field might be difficult during configuration checking time, since it might exceed 40 characters only after a certain amount of builds have been done ( e.g. with the value Interpolate(\"%(prop:buildername)s/%(prop:buildnumber)s\") )\r\n\r\nI would propose hashing the status_key in order to get predictable key lengths. sha1 happens to be 20 bytes long which is 40 characters in hexadecimal notation.\n", "before_files": [{"content": "# This file is part of Buildbot. Buildbot is free software: you can\n# redistribute it and/or modify it under the terms of the GNU General Public\n# License as published by the Free Software Foundation, version 2.\n#\n# This program is distributed in the hope that it will be useful, but WITHOUT\n# ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS\n# FOR A PARTICULAR PURPOSE. See the GNU General Public License for more\n# details.\n#\n# You should have received a copy of the GNU General Public License along with\n# this program; if not, write to the Free Software Foundation, Inc., 51\n# Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.\n#\n# Copyright Buildbot Team Members\n\nfrom urllib.parse import urlparse\n\nfrom twisted.internet import defer\nfrom twisted.python import log\n\nfrom buildbot import config\nfrom buildbot.process.properties import Properties\nfrom buildbot.process.properties import Property\nfrom buildbot.process.results import SUCCESS\nfrom buildbot.reporters.base import ReporterBase\nfrom buildbot.reporters.generators.build import BuildStartEndStatusGenerator\nfrom buildbot.reporters.message import MessageFormatter\nfrom buildbot.util import httpclientservice\n\n# Magic words understood by Butbucket REST API\nBITBUCKET_INPROGRESS = 'INPROGRESS'\nBITBUCKET_SUCCESSFUL = 'SUCCESSFUL'\nBITBUCKET_FAILED = 'FAILED'\n\n_BASE_URL = 'https://api.bitbucket.org/2.0/repositories'\n_OAUTH_URL = 'https://bitbucket.org/site/oauth2/access_token'\n_GET_TOKEN_DATA = {\n 'grant_type': 'client_credentials'\n}\n\n\nclass BitbucketStatusPush(ReporterBase):\n name = \"BitbucketStatusPush\"\n\n def checkConfig(self, oauth_key=None, oauth_secret=None, auth=None, base_url=_BASE_URL,\n oauth_url=_OAUTH_URL, debug=None, verify=None, status_key=None,\n status_name=None, generators=None, **kwargs):\n if auth is not None and (oauth_key is not None or oauth_secret is not None):\n config.error('Either App Passwords or OAuth can be specified, not both')\n\n if generators is None:\n generators = self._create_default_generators()\n\n super().checkConfig(generators=generators, **kwargs)\n httpclientservice.HTTPClientService.checkAvailable(self.__class__.__name__)\n\n @defer.inlineCallbacks\n def reconfigService(self, oauth_key=None, oauth_secret=None, auth=None, base_url=_BASE_URL,\n oauth_url=_OAUTH_URL, debug=None, verify=None, status_key=None,\n status_name=None, generators=None, **kwargs):\n oauth_key, oauth_secret = yield self.renderSecrets(oauth_key, oauth_secret)\n self.auth = yield self.renderSecrets(auth)\n self.base_url = base_url\n self.debug = debug\n self.verify = verify\n self.status_key = status_key or Property('buildername')\n self.status_name = status_name or Property('buildername')\n\n if generators is None:\n generators = self._create_default_generators()\n\n yield super().reconfigService(generators=generators, **kwargs)\n\n base_url = base_url.rstrip('/')\n\n self._http = yield httpclientservice.HTTPClientService.getService(\n self.master, base_url,\n debug=self.debug, verify=self.verify, auth=self.auth)\n\n self.oauthhttp = None\n if self.auth is None:\n self.oauthhttp = yield httpclientservice.HTTPClientService.getService(\n self.master, oauth_url, auth=(oauth_key, oauth_secret),\n debug=self.debug, verify=self.verify)\n\n def _create_default_generators(self):\n return [\n BuildStartEndStatusGenerator(\n start_formatter=MessageFormatter(subject=\"\", template=''),\n end_formatter=MessageFormatter(subject=\"\", template='')\n )\n ]\n\n @defer.inlineCallbacks\n def sendMessage(self, reports):\n # Only use OAuth if basic auth has not been specified\n if not self.auth:\n request = yield self.oauthhttp.post(\"\", data=_GET_TOKEN_DATA)\n if request.code != 200:\n content = yield request.content()\n log.msg(f\"{request.code}: unable to authenticate to Bitbucket {content}\")\n return\n token = (yield request.json())['access_token']\n self._http.updateHeaders({'Authorization': f'Bearer {token}'})\n\n build = reports[0]['builds'][0]\n if build['complete']:\n status = BITBUCKET_SUCCESSFUL if build['results'] == SUCCESS else BITBUCKET_FAILED\n else:\n status = BITBUCKET_INPROGRESS\n\n props = Properties.fromDict(build['properties'])\n props.master = self.master\n\n body = {\n 'state': status,\n 'key': (yield props.render(self.status_key)),\n 'name': (yield props.render(self.status_name)),\n 'description': reports[0]['subject'],\n 'url': build['url']\n }\n\n for sourcestamp in build['buildset']['sourcestamps']:\n if not sourcestamp['repository']:\n log.msg(f\"Empty repository URL for Bitbucket status {body}\")\n continue\n owner, repo = self.get_owner_and_repo(sourcestamp['repository'])\n\n endpoint = (owner, repo, 'commit', sourcestamp['revision'], 'statuses', 'build')\n bitbucket_uri = f\"/{'/'.join(endpoint)}\"\n\n if self.debug:\n log.msg(f\"Bitbucket status {bitbucket_uri} {body}\")\n\n response = yield self._http.post(bitbucket_uri, json=body)\n if response.code not in (200, 201):\n content = yield response.content()\n log.msg(f\"{response.code}: unable to upload Bitbucket status {content}\")\n\n def get_owner_and_repo(self, repourl):\n \"\"\"\n Takes a git repository URL from Bitbucket and tries to determine the owner and repository\n name\n :param repourl: Bitbucket git repo in the form of\n [email protected]:OWNER/REPONAME.git\n https://bitbucket.org/OWNER/REPONAME.git\n ssh://[email protected]/OWNER/REPONAME.git\n https://api.bitbucket.org/2.0/repositories/OWNER/REPONAME\n :return: owner, repo: The owner of the repository and the repository name\n \"\"\"\n parsed = urlparse(repourl)\n\n base_parsed = urlparse(self.base_url)\n if parsed.path.startswith(base_parsed.path):\n path = parsed.path.replace(base_parsed.path, \"\")\n elif parsed.scheme:\n path = parsed.path\n else:\n # we assume git@host:owner/repo.git here\n path = parsed.path.split(':', 1)[-1]\n\n path = path.lstrip('/')\n if path.endswith('.git'):\n path = path[:-4]\n path = path.rstrip('/')\n\n parts = path.split('/')\n\n assert len(parts) == 2, 'OWNER/REPONAME is expected'\n\n return parts\n", "path": "master/buildbot/reporters/bitbucket.py"}]} | 2,701 | 225 |
gh_patches_debug_21288 | rasdani/github-patches | git_diff | qtile__qtile-4045 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
simple_key_binder doesn't work after using a KeyChord
### The issue:
Qtile 0.22.1, in logs no errors or warns.
simple_key_binder doesn't work after using a KeyChord.
If I use simple_key_binder to generate Group switching keys, then Group switching does not work after using KeyChord. I am forced to do reload_config.
For the solution, I had to use: for i in Groups.
I see: https://github.com/qtile/qtile/issues/3734
My full config (correct) and line: https://github.com/Koljasha/archlinux/blob/7bef1b8d4d4fc972cdcbfa90453b5967ff739227/config/qtile/config.py#L279
For error: uncomment L279, comment L281-L290
### Required:
- [X] I have searched past issues to see if this bug has already been reported.
</issue>
<code>
[start of libqtile/dgroups.py]
1 # Copyright (c) 2011-2012 Florian Mounier
2 # Copyright (c) 2012-2014 roger
3 # Copyright (c) 2012 Craig Barnes
4 # Copyright (c) 2012-2014 Tycho Andersen
5 # Copyright (c) 2013 Tao Sauvage
6 # Copyright (c) 2014 ramnes
7 # Copyright (c) 2014 Sebastian Kricner
8 # Copyright (c) 2014 Sean Vig
9 #
10 # Permission is hereby granted, free of charge, to any person obtaining a copy
11 # of this software and associated documentation files (the "Software"), to deal
12 # in the Software without restriction, including without limitation the rights
13 # to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
14 # copies of the Software, and to permit persons to whom the Software is
15 # furnished to do so, subject to the following conditions:
16 #
17 # The above copyright notice and this permission notice shall be included in
18 # all copies or substantial portions of the Software.
19 #
20 # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
21 # IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
22 # FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
23 # AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
24 # LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
25 # OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
26 # SOFTWARE.
27
28 import collections
29
30 import libqtile.hook
31 from libqtile.backend.base import Static
32 from libqtile.command import lazy
33 from libqtile.config import Group, Key, Match, Rule
34 from libqtile.log_utils import logger
35
36
37 def simple_key_binder(mod, keynames=None):
38 """Bind keys to mod+group position or to the keys specified as second argument"""
39
40 def func(dgroup):
41 # unbind all
42 for key in dgroup.keys[:]:
43 dgroup.qtile.ungrab_key(key)
44 dgroup.keys.remove(key)
45
46 if keynames:
47 keys = keynames
48 else:
49 # keys 1 to 9 and 0
50 keys = list(map(str, list(range(1, 10)) + [0]))
51
52 # bind all keys
53 for keyname, group in zip(keys, dgroup.qtile.groups):
54 name = group.name
55 key = Key([mod], keyname, lazy.group[name].toscreen())
56 key_s = Key([mod, "shift"], keyname, lazy.window.togroup(name))
57 key_c = Key([mod, "control"], keyname, lazy.group.switch_groups(name))
58 dgroup.keys.append(key)
59 dgroup.keys.append(key_s)
60 dgroup.keys.append(key_c)
61 dgroup.qtile.grab_key(key)
62 dgroup.qtile.grab_key(key_s)
63 dgroup.qtile.grab_key(key_c)
64
65 return func
66
67
68 class DGroups:
69 """Dynamic Groups"""
70
71 def __init__(self, qtile, dgroups, key_binder=None, delay=1):
72 self.qtile = qtile
73
74 self.groups = dgroups
75 self.groups_map = {}
76
77 self.rules = []
78 self.rules_map = {}
79 self.last_rule_id = 0
80
81 for rule in getattr(qtile.config, "dgroups_app_rules", []):
82 self.add_rule(rule)
83
84 self.keys = []
85
86 self.key_binder = key_binder
87
88 self._setup_hooks()
89 self._setup_groups()
90
91 self.delay = delay
92
93 self.timeout = {}
94
95 def add_rule(self, rule, last=True):
96 rule_id = self.last_rule_id
97 self.rules_map[rule_id] = rule
98 if last:
99 self.rules.append(rule)
100 else:
101 self.rules.insert(0, rule)
102 self.last_rule_id += 1
103 return rule_id
104
105 def remove_rule(self, rule_id):
106 rule = self.rules_map.get(rule_id)
107 if rule:
108 self.rules.remove(rule)
109 del self.rules_map[rule_id]
110 else:
111 logger.warning('Rule "%s" not found', rule_id)
112
113 def add_dgroup(self, group, start=False):
114 self.groups_map[group.name] = group
115 rule = Rule(group.matches, group=group.name)
116 self.rules.append(rule)
117 if start:
118 self.qtile.add_group(group.name, group.layout, group.layouts, group.label)
119
120 def _setup_groups(self):
121 for group in self.groups:
122 self.add_dgroup(group, group.init)
123
124 if group.spawn and not self.qtile.no_spawn:
125 if isinstance(group.spawn, str):
126 spawns = [group.spawn]
127 else:
128 spawns = group.spawn
129 for spawn in spawns:
130 pid = self.qtile.spawn(spawn)
131 self.add_rule(Rule(Match(net_wm_pid=pid), group.name))
132
133 def _setup_hooks(self):
134 libqtile.hook.subscribe.addgroup(self._addgroup)
135 libqtile.hook.subscribe.client_new(self._add)
136 libqtile.hook.subscribe.client_killed(self._del)
137 if self.key_binder:
138 libqtile.hook.subscribe.setgroup(lambda: self.key_binder(self))
139 libqtile.hook.subscribe.changegroup(lambda: self.key_binder(self))
140
141 def _addgroup(self, group_name):
142 if group_name not in self.groups_map:
143 self.add_dgroup(Group(group_name, persist=False))
144
145 def _add(self, client):
146 if client in self.timeout:
147 logger.debug("Remove dgroup source")
148 self.timeout.pop(client).cancel()
149
150 # ignore static windows
151 if isinstance(client, Static):
152 return
153
154 # ignore windows whose groups is already set (e.g. from another hook or
155 # when it was set on state restore)
156 if client.group is not None:
157 return
158
159 group_set = False
160 intrusive = False
161
162 for rule in self.rules:
163 # Matching Rules
164 if rule.matches(client):
165 if rule.group:
166 if rule.group in self.groups_map:
167 layout = self.groups_map[rule.group].layout
168 layouts = self.groups_map[rule.group].layouts
169 label = self.groups_map[rule.group].label
170 else:
171 layout = None
172 layouts = None
173 label = None
174 group_added = self.qtile.add_group(rule.group, layout, layouts, label)
175 client.togroup(rule.group)
176
177 group_set = True
178
179 group_obj = self.qtile.groups_map[rule.group]
180 group = self.groups_map.get(rule.group)
181 if group and group_added:
182 for k, v in list(group.layout_opts.items()):
183 if isinstance(v, collections.abc.Callable):
184 v(group_obj.layout)
185 else:
186 setattr(group_obj.layout, k, v)
187 affinity = group.screen_affinity
188 if affinity and len(self.qtile.screens) > affinity:
189 self.qtile.screens[affinity].set_group(group_obj)
190
191 if rule.float:
192 client.enable_floating()
193
194 if rule.intrusive:
195 intrusive = rule.intrusive
196
197 if rule.break_on_match:
198 break
199
200 # If app doesn't have a group
201 if not group_set:
202 current_group = self.qtile.current_group.name
203 if (
204 current_group in self.groups_map
205 and self.groups_map[current_group].exclusive
206 and not intrusive
207 ):
208
209 wm_class = client.get_wm_class()
210
211 if wm_class:
212 if len(wm_class) > 1:
213 wm_class = wm_class[1]
214 else:
215 wm_class = wm_class[0]
216
217 group_name = wm_class
218 else:
219 group_name = client.name or "Unnamed"
220
221 self.add_dgroup(Group(group_name, persist=False), start=True)
222 client.togroup(group_name)
223 self.sort_groups()
224
225 def sort_groups(self):
226 grps = self.qtile.groups
227 sorted_grps = sorted(grps, key=lambda g: self.groups_map[g.name].position)
228 if grps != sorted_grps:
229 self.qtile.groups = sorted_grps
230 libqtile.hook.fire("changegroup")
231
232 def _del(self, client):
233 # ignore static windows
234 if isinstance(client, Static):
235 return
236
237 group = client.group
238
239 def delete_client():
240 # Delete group if empty and don't persist
241 if (
242 group
243 and group.name in self.groups_map
244 and not self.groups_map[group.name].persist
245 and len(group.windows) <= 0
246 ):
247 self.qtile.delete_group(group.name)
248 self.sort_groups()
249 del self.timeout[client]
250
251 logger.debug("Deleting %s in %ss", group, self.delay)
252 self.timeout[client] = self.qtile.call_later(self.delay, delete_client)
253
[end of libqtile/dgroups.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/libqtile/dgroups.py b/libqtile/dgroups.py
--- a/libqtile/dgroups.py
+++ b/libqtile/dgroups.py
@@ -41,6 +41,7 @@
# unbind all
for key in dgroup.keys[:]:
dgroup.qtile.ungrab_key(key)
+ dgroup.qtile.config.keys.remove(key)
dgroup.keys.remove(key)
if keynames:
@@ -55,9 +56,8 @@
key = Key([mod], keyname, lazy.group[name].toscreen())
key_s = Key([mod, "shift"], keyname, lazy.window.togroup(name))
key_c = Key([mod, "control"], keyname, lazy.group.switch_groups(name))
- dgroup.keys.append(key)
- dgroup.keys.append(key_s)
- dgroup.keys.append(key_c)
+ dgroup.keys.extend([key, key_s, key_c])
+ dgroup.qtile.config.keys.extend([key, key_s, key_c])
dgroup.qtile.grab_key(key)
dgroup.qtile.grab_key(key_s)
dgroup.qtile.grab_key(key_c)
| {"golden_diff": "diff --git a/libqtile/dgroups.py b/libqtile/dgroups.py\n--- a/libqtile/dgroups.py\n+++ b/libqtile/dgroups.py\n@@ -41,6 +41,7 @@\n # unbind all\n for key in dgroup.keys[:]:\n dgroup.qtile.ungrab_key(key)\n+ dgroup.qtile.config.keys.remove(key)\n dgroup.keys.remove(key)\n \n if keynames:\n@@ -55,9 +56,8 @@\n key = Key([mod], keyname, lazy.group[name].toscreen())\n key_s = Key([mod, \"shift\"], keyname, lazy.window.togroup(name))\n key_c = Key([mod, \"control\"], keyname, lazy.group.switch_groups(name))\n- dgroup.keys.append(key)\n- dgroup.keys.append(key_s)\n- dgroup.keys.append(key_c)\n+ dgroup.keys.extend([key, key_s, key_c])\n+ dgroup.qtile.config.keys.extend([key, key_s, key_c])\n dgroup.qtile.grab_key(key)\n dgroup.qtile.grab_key(key_s)\n dgroup.qtile.grab_key(key_c)\n", "issue": "simple_key_binder doesn't work after using a KeyChord\n### The issue:\n\nQtile 0.22.1, in logs no errors or warns.\r\nsimple_key_binder doesn't work after using a KeyChord.\r\nIf I use simple_key_binder to generate Group switching keys, then Group switching does not work after using KeyChord. I am forced to do reload_config.\r\nFor the solution, I had to use: for i in Groups.\r\nI see: https://github.com/qtile/qtile/issues/3734\r\nMy full config (correct) and line: https://github.com/Koljasha/archlinux/blob/7bef1b8d4d4fc972cdcbfa90453b5967ff739227/config/qtile/config.py#L279\r\nFor error: uncomment L279, comment L281-L290\n\n### Required:\n\n- [X] I have searched past issues to see if this bug has already been reported.\n", "before_files": [{"content": "# Copyright (c) 2011-2012 Florian Mounier\n# Copyright (c) 2012-2014 roger\n# Copyright (c) 2012 Craig Barnes\n# Copyright (c) 2012-2014 Tycho Andersen\n# Copyright (c) 2013 Tao Sauvage\n# Copyright (c) 2014 ramnes\n# Copyright (c) 2014 Sebastian Kricner\n# Copyright (c) 2014 Sean Vig\n#\n# Permission is hereby granted, free of charge, to any person obtaining a copy\n# of this software and associated documentation files (the \"Software\"), to deal\n# in the Software without restriction, including without limitation the rights\n# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell\n# copies of the Software, and to permit persons to whom the Software is\n# furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice shall be included in\n# all copies or substantial portions of the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\n# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\n# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE\n# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\n# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,\n# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE\n# SOFTWARE.\n\nimport collections\n\nimport libqtile.hook\nfrom libqtile.backend.base import Static\nfrom libqtile.command import lazy\nfrom libqtile.config import Group, Key, Match, Rule\nfrom libqtile.log_utils import logger\n\n\ndef simple_key_binder(mod, keynames=None):\n \"\"\"Bind keys to mod+group position or to the keys specified as second argument\"\"\"\n\n def func(dgroup):\n # unbind all\n for key in dgroup.keys[:]:\n dgroup.qtile.ungrab_key(key)\n dgroup.keys.remove(key)\n\n if keynames:\n keys = keynames\n else:\n # keys 1 to 9 and 0\n keys = list(map(str, list(range(1, 10)) + [0]))\n\n # bind all keys\n for keyname, group in zip(keys, dgroup.qtile.groups):\n name = group.name\n key = Key([mod], keyname, lazy.group[name].toscreen())\n key_s = Key([mod, \"shift\"], keyname, lazy.window.togroup(name))\n key_c = Key([mod, \"control\"], keyname, lazy.group.switch_groups(name))\n dgroup.keys.append(key)\n dgroup.keys.append(key_s)\n dgroup.keys.append(key_c)\n dgroup.qtile.grab_key(key)\n dgroup.qtile.grab_key(key_s)\n dgroup.qtile.grab_key(key_c)\n\n return func\n\n\nclass DGroups:\n \"\"\"Dynamic Groups\"\"\"\n\n def __init__(self, qtile, dgroups, key_binder=None, delay=1):\n self.qtile = qtile\n\n self.groups = dgroups\n self.groups_map = {}\n\n self.rules = []\n self.rules_map = {}\n self.last_rule_id = 0\n\n for rule in getattr(qtile.config, \"dgroups_app_rules\", []):\n self.add_rule(rule)\n\n self.keys = []\n\n self.key_binder = key_binder\n\n self._setup_hooks()\n self._setup_groups()\n\n self.delay = delay\n\n self.timeout = {}\n\n def add_rule(self, rule, last=True):\n rule_id = self.last_rule_id\n self.rules_map[rule_id] = rule\n if last:\n self.rules.append(rule)\n else:\n self.rules.insert(0, rule)\n self.last_rule_id += 1\n return rule_id\n\n def remove_rule(self, rule_id):\n rule = self.rules_map.get(rule_id)\n if rule:\n self.rules.remove(rule)\n del self.rules_map[rule_id]\n else:\n logger.warning('Rule \"%s\" not found', rule_id)\n\n def add_dgroup(self, group, start=False):\n self.groups_map[group.name] = group\n rule = Rule(group.matches, group=group.name)\n self.rules.append(rule)\n if start:\n self.qtile.add_group(group.name, group.layout, group.layouts, group.label)\n\n def _setup_groups(self):\n for group in self.groups:\n self.add_dgroup(group, group.init)\n\n if group.spawn and not self.qtile.no_spawn:\n if isinstance(group.spawn, str):\n spawns = [group.spawn]\n else:\n spawns = group.spawn\n for spawn in spawns:\n pid = self.qtile.spawn(spawn)\n self.add_rule(Rule(Match(net_wm_pid=pid), group.name))\n\n def _setup_hooks(self):\n libqtile.hook.subscribe.addgroup(self._addgroup)\n libqtile.hook.subscribe.client_new(self._add)\n libqtile.hook.subscribe.client_killed(self._del)\n if self.key_binder:\n libqtile.hook.subscribe.setgroup(lambda: self.key_binder(self))\n libqtile.hook.subscribe.changegroup(lambda: self.key_binder(self))\n\n def _addgroup(self, group_name):\n if group_name not in self.groups_map:\n self.add_dgroup(Group(group_name, persist=False))\n\n def _add(self, client):\n if client in self.timeout:\n logger.debug(\"Remove dgroup source\")\n self.timeout.pop(client).cancel()\n\n # ignore static windows\n if isinstance(client, Static):\n return\n\n # ignore windows whose groups is already set (e.g. from another hook or\n # when it was set on state restore)\n if client.group is not None:\n return\n\n group_set = False\n intrusive = False\n\n for rule in self.rules:\n # Matching Rules\n if rule.matches(client):\n if rule.group:\n if rule.group in self.groups_map:\n layout = self.groups_map[rule.group].layout\n layouts = self.groups_map[rule.group].layouts\n label = self.groups_map[rule.group].label\n else:\n layout = None\n layouts = None\n label = None\n group_added = self.qtile.add_group(rule.group, layout, layouts, label)\n client.togroup(rule.group)\n\n group_set = True\n\n group_obj = self.qtile.groups_map[rule.group]\n group = self.groups_map.get(rule.group)\n if group and group_added:\n for k, v in list(group.layout_opts.items()):\n if isinstance(v, collections.abc.Callable):\n v(group_obj.layout)\n else:\n setattr(group_obj.layout, k, v)\n affinity = group.screen_affinity\n if affinity and len(self.qtile.screens) > affinity:\n self.qtile.screens[affinity].set_group(group_obj)\n\n if rule.float:\n client.enable_floating()\n\n if rule.intrusive:\n intrusive = rule.intrusive\n\n if rule.break_on_match:\n break\n\n # If app doesn't have a group\n if not group_set:\n current_group = self.qtile.current_group.name\n if (\n current_group in self.groups_map\n and self.groups_map[current_group].exclusive\n and not intrusive\n ):\n\n wm_class = client.get_wm_class()\n\n if wm_class:\n if len(wm_class) > 1:\n wm_class = wm_class[1]\n else:\n wm_class = wm_class[0]\n\n group_name = wm_class\n else:\n group_name = client.name or \"Unnamed\"\n\n self.add_dgroup(Group(group_name, persist=False), start=True)\n client.togroup(group_name)\n self.sort_groups()\n\n def sort_groups(self):\n grps = self.qtile.groups\n sorted_grps = sorted(grps, key=lambda g: self.groups_map[g.name].position)\n if grps != sorted_grps:\n self.qtile.groups = sorted_grps\n libqtile.hook.fire(\"changegroup\")\n\n def _del(self, client):\n # ignore static windows\n if isinstance(client, Static):\n return\n\n group = client.group\n\n def delete_client():\n # Delete group if empty and don't persist\n if (\n group\n and group.name in self.groups_map\n and not self.groups_map[group.name].persist\n and len(group.windows) <= 0\n ):\n self.qtile.delete_group(group.name)\n self.sort_groups()\n del self.timeout[client]\n\n logger.debug(\"Deleting %s in %ss\", group, self.delay)\n self.timeout[client] = self.qtile.call_later(self.delay, delete_client)\n", "path": "libqtile/dgroups.py"}]} | 3,360 | 258 |
gh_patches_debug_8429 | rasdani/github-patches | git_diff | scrapy__scrapy-1644 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
_monkeypatches.py: 'NoneType' object has no attribute 'startswith'
Did not try yet to come up with minimal example to demonstrate this issue but it is reproducible for me:
```
$> datalad --dbg crawl
Traceback (most recent call last):
File "/home/yoh/proj/datalad/datalad/venv-tests/bin/datalad", line 9, in <module>
load_entry_point('datalad==0.1.dev0', 'console_scripts', 'datalad')()
File "/home/yoh/proj/datalad/datalad/datalad/cmdline/main.py", line 199, in main
cmdlineargs.func(cmdlineargs)
File "/home/yoh/proj/datalad/datalad/datalad/interface/base.py", line 151, in call_from_parser
return self(**kwargs)
File "/home/yoh/proj/datalad/datalad/datalad/interface/crawl.py", line 44, in __call__
from datalad.crawler.pipeline import load_pipeline_from_config, get_pipeline_config_path
File "/home/yoh/proj/datalad/datalad/datalad/crawler/pipeline.py", line 21, in <module>
from .newmain import lgr
File "/home/yoh/proj/datalad/datalad/datalad/crawler/newmain.py", line 21, in <module>
from .nodes.matches import *
File "/home/yoh/proj/datalad/datalad/datalad/crawler/nodes/matches.py", line 18, in <module>
from scrapy.selector import Selector
File "/home/yoh/proj/datalad/datalad/venv-tests/local/lib/python2.7/site-packages/scrapy/__init__.py", line 27, in <module>
from . import _monkeypatches
File "/home/yoh/proj/datalad/datalad/venv-tests/local/lib/python2.7/site-packages/scrapy/_monkeypatches.py", line 24, in <module>
and getattr(v, '__module__', '').startswith('twisted'):
AttributeError: 'NoneType' object has no attribute 'startswith'
()
> /home/yoh/proj/datalad/datalad/venv-tests/local/lib/python2.7/site-packages/scrapy/_monkeypatches.py(24)<module>()
-> and getattr(v, '__module__', '').startswith('twisted'):
(Pdb) l
19 # to prevent bugs like Twisted#7989 while serializing requests
20 import twisted.persisted.styles # NOQA
21 # Remove only entries with twisted serializers for non-twisted types.
22 for k, v in frozenset(copyreg.dispatch_table.items()):
23 if not getattr(k, '__module__', '').startswith('twisted') \
24 -> and getattr(v, '__module__', '').startswith('twisted'):
25 copyreg.dispatch_table.pop(k)
[EOF]
(Pdb) p k
None
(Pdb) p v
None
(Pdb) p copyreg
None
```
not sure it came to it but the issue is (if I pdb before this madness happens):
```
(Pdb) p getattr(k, '__module__', '')
'__builtin__'
(Pdb) p getattr(v, '__module__', '')
None
(Pdb) p v
<function mpq_reducer at 0x7f474bb4ab90>
(Pdb) p v.__module__
None
(Pdb) p k, v
(<type 'mpq'>, <function mpq_reducer at 0x7f474bb4ab90>)
```
so assigned `__module__` is None. As a quick resolution wrapped into str() call to assure str there
```
and str(getattr(v, '__module__', '')).startswith('twisted'):
```
</issue>
<code>
[start of scrapy/_monkeypatches.py]
1 import sys
2 from six.moves import copyreg
3
4 if sys.version_info[0] == 2:
5 from urlparse import urlparse
6
7 # workaround for http://bugs.python.org/issue7904 - Python < 2.7
8 if urlparse('s3://bucket/key').netloc != 'bucket':
9 from urlparse import uses_netloc
10 uses_netloc.append('s3')
11
12 # workaround for http://bugs.python.org/issue9374 - Python < 2.7.4
13 if urlparse('s3://bucket/key?key=value').query != 'key=value':
14 from urlparse import uses_query
15 uses_query.append('s3')
16
17
18 # Undo what Twisted's perspective broker adds to pickle register
19 # to prevent bugs like Twisted#7989 while serializing requests
20 import twisted.persisted.styles # NOQA
21 # Remove only entries with twisted serializers for non-twisted types.
22 for k, v in frozenset(copyreg.dispatch_table.items()):
23 if not getattr(k, '__module__', '').startswith('twisted') \
24 and getattr(v, '__module__', '').startswith('twisted'):
25 copyreg.dispatch_table.pop(k)
26
[end of scrapy/_monkeypatches.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/scrapy/_monkeypatches.py b/scrapy/_monkeypatches.py
--- a/scrapy/_monkeypatches.py
+++ b/scrapy/_monkeypatches.py
@@ -20,6 +20,6 @@
import twisted.persisted.styles # NOQA
# Remove only entries with twisted serializers for non-twisted types.
for k, v in frozenset(copyreg.dispatch_table.items()):
- if not getattr(k, '__module__', '').startswith('twisted') \
- and getattr(v, '__module__', '').startswith('twisted'):
+ if not str(getattr(k, '__module__', '')).startswith('twisted') \
+ and str(getattr(v, '__module__', '')).startswith('twisted'):
copyreg.dispatch_table.pop(k)
| {"golden_diff": "diff --git a/scrapy/_monkeypatches.py b/scrapy/_monkeypatches.py\n--- a/scrapy/_monkeypatches.py\n+++ b/scrapy/_monkeypatches.py\n@@ -20,6 +20,6 @@\n import twisted.persisted.styles # NOQA\n # Remove only entries with twisted serializers for non-twisted types.\n for k, v in frozenset(copyreg.dispatch_table.items()):\n- if not getattr(k, '__module__', '').startswith('twisted') \\\n- and getattr(v, '__module__', '').startswith('twisted'):\n+ if not str(getattr(k, '__module__', '')).startswith('twisted') \\\n+ and str(getattr(v, '__module__', '')).startswith('twisted'):\n copyreg.dispatch_table.pop(k)\n", "issue": "_monkeypatches.py: 'NoneType' object has no attribute 'startswith'\nDid not try yet to come up with minimal example to demonstrate this issue but it is reproducible for me:\n\n```\n$> datalad --dbg crawl\nTraceback (most recent call last):\n File \"/home/yoh/proj/datalad/datalad/venv-tests/bin/datalad\", line 9, in <module>\n load_entry_point('datalad==0.1.dev0', 'console_scripts', 'datalad')()\n File \"/home/yoh/proj/datalad/datalad/datalad/cmdline/main.py\", line 199, in main\n cmdlineargs.func(cmdlineargs)\n File \"/home/yoh/proj/datalad/datalad/datalad/interface/base.py\", line 151, in call_from_parser\n return self(**kwargs)\n File \"/home/yoh/proj/datalad/datalad/datalad/interface/crawl.py\", line 44, in __call__\n from datalad.crawler.pipeline import load_pipeline_from_config, get_pipeline_config_path\n File \"/home/yoh/proj/datalad/datalad/datalad/crawler/pipeline.py\", line 21, in <module>\n from .newmain import lgr\n File \"/home/yoh/proj/datalad/datalad/datalad/crawler/newmain.py\", line 21, in <module>\n from .nodes.matches import *\n File \"/home/yoh/proj/datalad/datalad/datalad/crawler/nodes/matches.py\", line 18, in <module>\n from scrapy.selector import Selector\n File \"/home/yoh/proj/datalad/datalad/venv-tests/local/lib/python2.7/site-packages/scrapy/__init__.py\", line 27, in <module>\n from . import _monkeypatches\n File \"/home/yoh/proj/datalad/datalad/venv-tests/local/lib/python2.7/site-packages/scrapy/_monkeypatches.py\", line 24, in <module>\n and getattr(v, '__module__', '').startswith('twisted'):\nAttributeError: 'NoneType' object has no attribute 'startswith'\n()\n> /home/yoh/proj/datalad/datalad/venv-tests/local/lib/python2.7/site-packages/scrapy/_monkeypatches.py(24)<module>()\n-> and getattr(v, '__module__', '').startswith('twisted'):\n(Pdb) l\n 19 # to prevent bugs like Twisted#7989 while serializing requests\n 20 import twisted.persisted.styles # NOQA\n 21 # Remove only entries with twisted serializers for non-twisted types.\n 22 for k, v in frozenset(copyreg.dispatch_table.items()):\n 23 if not getattr(k, '__module__', '').startswith('twisted') \\\n 24 -> and getattr(v, '__module__', '').startswith('twisted'):\n 25 copyreg.dispatch_table.pop(k)\n[EOF]\n(Pdb) p k\nNone\n(Pdb) p v\nNone\n(Pdb) p copyreg\nNone\n```\n\nnot sure it came to it but the issue is (if I pdb before this madness happens):\n\n```\n(Pdb) p getattr(k, '__module__', '')\n'__builtin__'\n(Pdb) p getattr(v, '__module__', '')\nNone\n(Pdb) p v\n<function mpq_reducer at 0x7f474bb4ab90>\n(Pdb) p v.__module__\nNone\n(Pdb) p k, v\n(<type 'mpq'>, <function mpq_reducer at 0x7f474bb4ab90>)\n```\n\nso assigned `__module__` is None. As a quick resolution wrapped into str() call to assure str there\n\n```\nand str(getattr(v, '__module__', '')).startswith('twisted'):\n```\n\n", "before_files": [{"content": "import sys\nfrom six.moves import copyreg\n\nif sys.version_info[0] == 2:\n from urlparse import urlparse\n\n # workaround for http://bugs.python.org/issue7904 - Python < 2.7\n if urlparse('s3://bucket/key').netloc != 'bucket':\n from urlparse import uses_netloc\n uses_netloc.append('s3')\n\n # workaround for http://bugs.python.org/issue9374 - Python < 2.7.4\n if urlparse('s3://bucket/key?key=value').query != 'key=value':\n from urlparse import uses_query\n uses_query.append('s3')\n\n\n# Undo what Twisted's perspective broker adds to pickle register\n# to prevent bugs like Twisted#7989 while serializing requests\nimport twisted.persisted.styles # NOQA\n# Remove only entries with twisted serializers for non-twisted types.\nfor k, v in frozenset(copyreg.dispatch_table.items()):\n if not getattr(k, '__module__', '').startswith('twisted') \\\n and getattr(v, '__module__', '').startswith('twisted'):\n copyreg.dispatch_table.pop(k)\n", "path": "scrapy/_monkeypatches.py"}]} | 1,685 | 163 |
gh_patches_debug_50691 | rasdani/github-patches | git_diff | huggingface__diffusers-2003 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
issue with DDIM scheduler for google/ddpm-celebahq-256 example
### Describe the bug
Referring to the example "Unconditional Diffusion with discrete scheduler" at https://github.com/huggingface/diffusers#running-code
The comment says you can use `DDIMPipeline` but this fails to run on
(got an unexpected keyword argument `eta`).
Also, the `PNDMPipeline` runs but just returns noise.
### Reproduction
```
# !pip install diffusers["torch"]
from diffusers import DDPMPipeline, DDIMPipeline, PNDMPipeline
model_id = "google/ddpm-celebahq-256"
device = "cuda"
# load model and scheduler
#ddpm = DDPMPipeline.from_pretrained(model_id)
ddpm = DDIMPipeline.from_pretrained(model_id)
#ddpm = PNDMPipeline.from_pretrained(model_id)
# you can replace DDPMPipeline with DDIMPipeline or PNDMPipeline for faster inference
ddpm.to(device)
# run pipeline in inference (sample random noise and denoise)
image = ddpm().images[0]
image
```
### Logs
```shell
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Input In [21], in <cell line: 17>()
14 ddpm.to(device)
16 # run pipeline in inference (sample random noise and denoise)
---> 17 image = ddpm().images[0]
18 image
File /usr/local/lib/python3.9/dist-packages/torch/autograd/grad_mode.py:27, in _DecoratorContextManager.__call__.<locals>.decorate_context(*args, **kwargs)
24 @functools.wraps(func)
25 def decorate_context(*args, **kwargs):
26 with self.clone():
---> 27 return func(*args, **kwargs)
File /usr/local/lib/python3.9/dist-packages/diffusers/pipelines/ddim/pipeline_ddim.py:114, in DDIMPipeline.__call__(self, batch_size, generator, eta, num_inference_steps, use_clipped_model_output, output_type, return_dict, **kwargs)
109 model_output = self.unet(image, t).sample
111 # 2. predict previous mean of image x_t-1 and add variance depending on eta
112 # eta corresponds to η in paper and should be between [0, 1]
113 # do x_t -> x_t-1
--> 114 image = self.scheduler.step(
115 model_output, t, image, eta=eta, use_clipped_model_output=use_clipped_model_output, generator=generator
116 ).prev_sample
118 image = (image / 2 + 0.5).clamp(0, 1)
119 image = image.cpu().permute(0, 2, 3, 1).numpy()
File /usr/local/lib/python3.9/dist-packages/diffusers/schedulers/scheduling_ddpm.py:259, in DDPMScheduler.step(self, model_output, timestep, sample, generator, return_dict, **kwargs)
237 """
238 Predict the sample at the previous timestep by reversing the SDE. Core function to propagate the diffusion
239 process from the learned model outputs (most often the predicted noise).
(...)
253
254 """
255 message = (
256 "Please make sure to instantiate your scheduler with `prediction_type` instead. E.g. `scheduler ="
257 " DDPMScheduler.from_pretrained(<model_id>, prediction_type='epsilon')`."
258 )
--> 259 predict_epsilon = deprecate("predict_epsilon", "0.11.0", message, take_from=kwargs)
260 if predict_epsilon is not None:
261 new_config = dict(self.config)
File /usr/local/lib/python3.9/dist-packages/diffusers/utils/deprecation_utils.py:43, in deprecate(take_from, standard_warn, *args)
41 function = call_frame.function
42 key, value = next(iter(deprecated_kwargs.items()))
---> 43 raise TypeError(f"{function} in {filename} line {line_number-1} got an unexpected keyword argument `{key}`")
45 if len(values) == 0:
46 return
TypeError: step in /usr/local/lib/python3.9/dist-packages/diffusers/schedulers/scheduling_ddpm.py line 258 got an unexpected keyword argument `eta`
```
```
### System Info
- `diffusers` version: 0.10.2
- Platform: Linux-5.4.0-122-generic-x86_64-with-glibc2.31
- Python version: 3.9.13
- PyTorch version (GPU?): 1.12.0+cu116 (True)
- Huggingface_hub version: 0.11.1
- Transformers version: 4.20.1
- Using GPU in script?: Yes. P6000
- Using distributed or parallel set-up in script?: No
</issue>
<code>
[start of src/diffusers/pipelines/pndm/pipeline_pndm.py]
1 # Copyright 2022 The HuggingFace Team. All rights reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15
16 from typing import List, Optional, Tuple, Union
17
18 import torch
19
20 from ...models import UNet2DModel
21 from ...schedulers import PNDMScheduler
22 from ...utils import randn_tensor
23 from ..pipeline_utils import DiffusionPipeline, ImagePipelineOutput
24
25
26 class PNDMPipeline(DiffusionPipeline):
27 r"""
28 This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
29 library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
30
31 Parameters:
32 unet (`UNet2DModel`): U-Net architecture to denoise the encoded image latents.
33 scheduler ([`SchedulerMixin`]):
34 The `PNDMScheduler` to be used in combination with `unet` to denoise the encoded image.
35 """
36
37 unet: UNet2DModel
38 scheduler: PNDMScheduler
39
40 def __init__(self, unet: UNet2DModel, scheduler: PNDMScheduler):
41 super().__init__()
42 self.register_modules(unet=unet, scheduler=scheduler)
43
44 @torch.no_grad()
45 def __call__(
46 self,
47 batch_size: int = 1,
48 num_inference_steps: int = 50,
49 generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
50 output_type: Optional[str] = "pil",
51 return_dict: bool = True,
52 **kwargs,
53 ) -> Union[ImagePipelineOutput, Tuple]:
54 r"""
55 Args:
56 batch_size (`int`, `optional`, defaults to 1): The number of images to generate.
57 num_inference_steps (`int`, `optional`, defaults to 50):
58 The number of denoising steps. More denoising steps usually lead to a higher quality image at the
59 expense of slower inference.
60 generator (`torch.Generator`, `optional`): A [torch
61 generator](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make generation
62 deterministic.
63 output_type (`str`, `optional`, defaults to `"pil"`): The output format of the generate image. Choose
64 between [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
65 return_dict (`bool`, `optional`, defaults to `True`): Whether or not to return a
66 [`~pipelines.ImagePipelineOutput`] instead of a plain tuple.
67
68 Returns:
69 [`~pipelines.ImagePipelineOutput`] or `tuple`: [`~pipelines.utils.ImagePipelineOutput`] if `return_dict` is
70 True, otherwise a `tuple. When returning a tuple, the first element is a list with the generated images.
71 """
72 # For more information on the sampling method you can take a look at Algorithm 2 of
73 # the official paper: https://arxiv.org/pdf/2202.09778.pdf
74
75 # Sample gaussian noise to begin loop
76 image = randn_tensor(
77 (batch_size, self.unet.in_channels, self.unet.sample_size, self.unet.sample_size),
78 generator=generator,
79 device=self.device,
80 )
81
82 self.scheduler.set_timesteps(num_inference_steps)
83 for t in self.progress_bar(self.scheduler.timesteps):
84 model_output = self.unet(image, t).sample
85
86 image = self.scheduler.step(model_output, t, image).prev_sample
87
88 image = (image / 2 + 0.5).clamp(0, 1)
89 image = image.cpu().permute(0, 2, 3, 1).numpy()
90 if output_type == "pil":
91 image = self.numpy_to_pil(image)
92
93 if not return_dict:
94 return (image,)
95
96 return ImagePipelineOutput(images=image)
97
[end of src/diffusers/pipelines/pndm/pipeline_pndm.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/src/diffusers/pipelines/pndm/pipeline_pndm.py b/src/diffusers/pipelines/pndm/pipeline_pndm.py
--- a/src/diffusers/pipelines/pndm/pipeline_pndm.py
+++ b/src/diffusers/pipelines/pndm/pipeline_pndm.py
@@ -39,6 +39,9 @@
def __init__(self, unet: UNet2DModel, scheduler: PNDMScheduler):
super().__init__()
+
+ scheduler = PNDMScheduler.from_config(scheduler.config)
+
self.register_modules(unet=unet, scheduler=scheduler)
@torch.no_grad()
| {"golden_diff": "diff --git a/src/diffusers/pipelines/pndm/pipeline_pndm.py b/src/diffusers/pipelines/pndm/pipeline_pndm.py\n--- a/src/diffusers/pipelines/pndm/pipeline_pndm.py\n+++ b/src/diffusers/pipelines/pndm/pipeline_pndm.py\n@@ -39,6 +39,9 @@\n \n def __init__(self, unet: UNet2DModel, scheduler: PNDMScheduler):\n super().__init__()\n+\n+ scheduler = PNDMScheduler.from_config(scheduler.config)\n+\n self.register_modules(unet=unet, scheduler=scheduler)\n \n @torch.no_grad()\n", "issue": "issue with DDIM scheduler for google/ddpm-celebahq-256 example\n### Describe the bug\r\n\r\nReferring to the example \"Unconditional Diffusion with discrete scheduler\" at https://github.com/huggingface/diffusers#running-code\r\nThe comment says you can use `DDIMPipeline` but this fails to run on\r\n(got an unexpected keyword argument `eta`).\r\nAlso, the `PNDMPipeline` runs but just returns noise.\r\n\r\n### Reproduction\r\n\r\n```\r\n\r\n# !pip install diffusers[\"torch\"]\r\nfrom diffusers import DDPMPipeline, DDIMPipeline, PNDMPipeline\r\n\r\nmodel_id = \"google/ddpm-celebahq-256\"\r\ndevice = \"cuda\"\r\n\r\n# load model and scheduler\r\n\r\n#ddpm = DDPMPipeline.from_pretrained(model_id)\r\nddpm = DDIMPipeline.from_pretrained(model_id)\r\n#ddpm = PNDMPipeline.from_pretrained(model_id)\r\n\r\n# you can replace DDPMPipeline with DDIMPipeline or PNDMPipeline for faster inference\r\nddpm.to(device)\r\n\r\n# run pipeline in inference (sample random noise and denoise)\r\nimage = ddpm().images[0]\r\nimage\r\n```\r\n\r\n### Logs\r\n\r\n```shell\r\n---------------------------------------------------------------------------\r\nTypeError Traceback (most recent call last)\r\nInput In [21], in <cell line: 17>()\r\n 14 ddpm.to(device)\r\n 16 # run pipeline in inference (sample random noise and denoise)\r\n---> 17 image = ddpm().images[0]\r\n 18 image\r\n\r\nFile /usr/local/lib/python3.9/dist-packages/torch/autograd/grad_mode.py:27, in _DecoratorContextManager.__call__.<locals>.decorate_context(*args, **kwargs)\r\n 24 @functools.wraps(func)\r\n 25 def decorate_context(*args, **kwargs):\r\n 26 with self.clone():\r\n---> 27 return func(*args, **kwargs)\r\n\r\nFile /usr/local/lib/python3.9/dist-packages/diffusers/pipelines/ddim/pipeline_ddim.py:114, in DDIMPipeline.__call__(self, batch_size, generator, eta, num_inference_steps, use_clipped_model_output, output_type, return_dict, **kwargs)\r\n 109 model_output = self.unet(image, t).sample\r\n 111 # 2. predict previous mean of image x_t-1 and add variance depending on eta\r\n 112 # eta corresponds to \u03b7 in paper and should be between [0, 1]\r\n 113 # do x_t -> x_t-1\r\n--> 114 image = self.scheduler.step(\r\n 115 model_output, t, image, eta=eta, use_clipped_model_output=use_clipped_model_output, generator=generator\r\n 116 ).prev_sample\r\n 118 image = (image / 2 + 0.5).clamp(0, 1)\r\n 119 image = image.cpu().permute(0, 2, 3, 1).numpy()\r\n\r\nFile /usr/local/lib/python3.9/dist-packages/diffusers/schedulers/scheduling_ddpm.py:259, in DDPMScheduler.step(self, model_output, timestep, sample, generator, return_dict, **kwargs)\r\n 237 \"\"\"\r\n 238 Predict the sample at the previous timestep by reversing the SDE. Core function to propagate the diffusion\r\n 239 process from the learned model outputs (most often the predicted noise).\r\n (...)\r\n 253 \r\n 254 \"\"\"\r\n 255 message = (\r\n 256 \"Please make sure to instantiate your scheduler with `prediction_type` instead. E.g. `scheduler =\"\r\n 257 \" DDPMScheduler.from_pretrained(<model_id>, prediction_type='epsilon')`.\"\r\n 258 )\r\n--> 259 predict_epsilon = deprecate(\"predict_epsilon\", \"0.11.0\", message, take_from=kwargs)\r\n 260 if predict_epsilon is not None:\r\n 261 new_config = dict(self.config)\r\n\r\nFile /usr/local/lib/python3.9/dist-packages/diffusers/utils/deprecation_utils.py:43, in deprecate(take_from, standard_warn, *args)\r\n 41 function = call_frame.function\r\n 42 key, value = next(iter(deprecated_kwargs.items()))\r\n---> 43 raise TypeError(f\"{function} in {filename} line {line_number-1} got an unexpected keyword argument `{key}`\")\r\n 45 if len(values) == 0:\r\n 46 return\r\n\r\nTypeError: step in /usr/local/lib/python3.9/dist-packages/diffusers/schedulers/scheduling_ddpm.py line 258 got an unexpected keyword argument `eta`\r\n\r\n```\r\n```\r\n\r\n\r\n### System Info\r\n\r\n\r\n\r\n- `diffusers` version: 0.10.2\r\n- Platform: Linux-5.4.0-122-generic-x86_64-with-glibc2.31\r\n- Python version: 3.9.13\r\n- PyTorch version (GPU?): 1.12.0+cu116 (True)\r\n- Huggingface_hub version: 0.11.1\r\n- Transformers version: 4.20.1\r\n- Using GPU in script?: Yes. P6000\r\n- Using distributed or parallel set-up in script?: No\n", "before_files": [{"content": "# Copyright 2022 The HuggingFace Team. All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\nfrom typing import List, Optional, Tuple, Union\n\nimport torch\n\nfrom ...models import UNet2DModel\nfrom ...schedulers import PNDMScheduler\nfrom ...utils import randn_tensor\nfrom ..pipeline_utils import DiffusionPipeline, ImagePipelineOutput\n\n\nclass PNDMPipeline(DiffusionPipeline):\n r\"\"\"\n This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the\n library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)\n\n Parameters:\n unet (`UNet2DModel`): U-Net architecture to denoise the encoded image latents.\n scheduler ([`SchedulerMixin`]):\n The `PNDMScheduler` to be used in combination with `unet` to denoise the encoded image.\n \"\"\"\n\n unet: UNet2DModel\n scheduler: PNDMScheduler\n\n def __init__(self, unet: UNet2DModel, scheduler: PNDMScheduler):\n super().__init__()\n self.register_modules(unet=unet, scheduler=scheduler)\n\n @torch.no_grad()\n def __call__(\n self,\n batch_size: int = 1,\n num_inference_steps: int = 50,\n generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,\n output_type: Optional[str] = \"pil\",\n return_dict: bool = True,\n **kwargs,\n ) -> Union[ImagePipelineOutput, Tuple]:\n r\"\"\"\n Args:\n batch_size (`int`, `optional`, defaults to 1): The number of images to generate.\n num_inference_steps (`int`, `optional`, defaults to 50):\n The number of denoising steps. More denoising steps usually lead to a higher quality image at the\n expense of slower inference.\n generator (`torch.Generator`, `optional`): A [torch\n generator](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make generation\n deterministic.\n output_type (`str`, `optional`, defaults to `\"pil\"`): The output format of the generate image. Choose\n between [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.\n return_dict (`bool`, `optional`, defaults to `True`): Whether or not to return a\n [`~pipelines.ImagePipelineOutput`] instead of a plain tuple.\n\n Returns:\n [`~pipelines.ImagePipelineOutput`] or `tuple`: [`~pipelines.utils.ImagePipelineOutput`] if `return_dict` is\n True, otherwise a `tuple. When returning a tuple, the first element is a list with the generated images.\n \"\"\"\n # For more information on the sampling method you can take a look at Algorithm 2 of\n # the official paper: https://arxiv.org/pdf/2202.09778.pdf\n\n # Sample gaussian noise to begin loop\n image = randn_tensor(\n (batch_size, self.unet.in_channels, self.unet.sample_size, self.unet.sample_size),\n generator=generator,\n device=self.device,\n )\n\n self.scheduler.set_timesteps(num_inference_steps)\n for t in self.progress_bar(self.scheduler.timesteps):\n model_output = self.unet(image, t).sample\n\n image = self.scheduler.step(model_output, t, image).prev_sample\n\n image = (image / 2 + 0.5).clamp(0, 1)\n image = image.cpu().permute(0, 2, 3, 1).numpy()\n if output_type == \"pil\":\n image = self.numpy_to_pil(image)\n\n if not return_dict:\n return (image,)\n\n return ImagePipelineOutput(images=image)\n", "path": "src/diffusers/pipelines/pndm/pipeline_pndm.py"}]} | 2,913 | 150 |
gh_patches_debug_41775 | rasdani/github-patches | git_diff | kymatio__kymatio-185 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
sphinx-gallery: 2d/plot_filters
the wavelets does not display.
Please close this issue only when you're happy with the sphinx-gallery.
</issue>
<code>
[start of examples/2d/plot_filters.py]
1 """
2 Plot the 2D wavelet filters
3 ===========================
4 See :meth:`scattering.scattering1d.filter_bank` for more informations about the used wavelets.
5 """
6
7 import numpy as np
8 import matplotlib.pyplot as plt
9 from kymatio.scattering2d.filter_bank import filter_bank
10 from kymatio.scattering2d.utils import fft2
11
12
13 ###############################################################################
14 # Initial parameters of the filter bank
15 # -------------------------------------
16 M = 32
17 J = 3
18 L = 8
19 filters_set = filter_bank(M, M, J, L=L)
20
21
22 ###############################################################################
23 # Imshow complex images
24 # -------------------------------------
25 # Thanks to https://stackoverflow.com/questions/17044052/mathplotlib-imshow-complex-2d-array
26 from colorsys import hls_to_rgb
27 def colorize(z):
28 n, m = z.shape
29 c = np.zeros((n, m, 3))
30 c[np.isinf(z)] = (1.0, 1.0, 1.0)
31 c[np.isnan(z)] = (0.5, 0.5, 0.5)
32
33 idx = ~(np.isinf(z) + np.isnan(z))
34 A = (np.angle(z[idx]) + np.pi) / (2*np.pi)
35 A = (A + 0.5) % 1.0
36 B = 1.0/(1.0+abs(z[idx])**0.3)
37 c[idx] = [hls_to_rgb(a, b, 0.8) for a,b in zip(A,B)]
38 return c
39
40 fig, axs = plt.subplots(J+1, L, sharex=True, sharey=True)
41 plt.rc('text', usetex=True)
42 plt.rc('font', family='serif')
43
44 ###############################################################################
45 # Bandpass filters
46 # ----------------
47 # First, we display each wavelets according to each scale and orientation.
48 i=0
49 for filter in filters_set['psi']:
50 f_r = filter[0][...,0].numpy()
51 f_i = filter[0][..., 1].numpy()
52 f = f_r + 1j*f_i
53 filter_c = fft2(f)
54 filter_c = np.fft.fftshift(filter_c)
55 axs[i // L, i % L].imshow(colorize(filter_c))
56 axs[i // L, i % L].axis('off')
57 axs[i // L, i % L].set_title("$j = {}$ \n $\\theta={}".format(i // L, i % L))
58 i = i+1
59
60
61 # Add blanks for pretty display
62 for z in range(L):
63 axs[i // L, i % L].axis('off')
64 i = i+1
65
66 ###############################################################################
67 # Lowpass filter
68 # ----------------
69 # We finally display the Gaussian filter.
70 f_r = filters_set['phi'][0][...,0].numpy()
71 f_i = filters_set['phi'][0][..., 1].numpy()
72 f = f_r + 1j*f_i
73 filter_c = fft2(f)
74 filter_c = np.fft.fftshift(filter_c)
75 axs[J, L // 2].imshow(colorize(filter_c))
76
77 # Final caption.
78 fig.suptitle("Wavelets for each scales $j$ and angles $\\theta$ used, with the corresponding low-pass filter."
79 "\n The contrast corresponds to the amplitude and the color to the phase.", fontsize=13)
80
81
82 plt.show()
83
[end of examples/2d/plot_filters.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/examples/2d/plot_filters.py b/examples/2d/plot_filters.py
--- a/examples/2d/plot_filters.py
+++ b/examples/2d/plot_filters.py
@@ -1,11 +1,11 @@
"""
Plot the 2D wavelet filters
===========================
-See :meth:`scattering.scattering1d.filter_bank` for more informations about the used wavelets.
+See :meth:`kymatio.scattering2d.filter_bank` for more informations about the used wavelets.
"""
-import numpy as np
import matplotlib.pyplot as plt
+import numpy as np
from kymatio.scattering2d.filter_bank import filter_bank
from kymatio.scattering2d.utils import fft2
@@ -18,10 +18,9 @@
L = 8
filters_set = filter_bank(M, M, J, L=L)
-
###############################################################################
# Imshow complex images
-# -------------------------------------
+# ---------------------
# Thanks to https://stackoverflow.com/questions/17044052/mathplotlib-imshow-complex-2d-array
from colorsys import hls_to_rgb
def colorize(z):
@@ -37,14 +36,15 @@
c[idx] = [hls_to_rgb(a, b, 0.8) for a,b in zip(A,B)]
return c
-fig, axs = plt.subplots(J+1, L, sharex=True, sharey=True)
-plt.rc('text', usetex=True)
-plt.rc('font', family='serif')
-
###############################################################################
# Bandpass filters
# ----------------
-# First, we display each wavelets according to each scale and orientation.
+# First, we display each wavelet according to its scale and orientation.
+fig, axs = plt.subplots(J, L, sharex=True, sharey=True)
+fig.set_figheight(6)
+fig.set_figwidth(6)
+plt.rc('text', usetex=True)
+plt.rc('font', family='serif')
i=0
for filter in filters_set['psi']:
f_r = filter[0][...,0].numpy()
@@ -54,29 +54,30 @@
filter_c = np.fft.fftshift(filter_c)
axs[i // L, i % L].imshow(colorize(filter_c))
axs[i // L, i % L].axis('off')
- axs[i // L, i % L].set_title("$j = {}$ \n $\\theta={}".format(i // L, i % L))
+ axs[i // L, i % L].set_title("$j = {}$ \n $\\theta={}$".format(i // L, i % L))
i = i+1
-
-# Add blanks for pretty display
-for z in range(L):
- axs[i // L, i % L].axis('off')
- i = i+1
+fig.suptitle("Wavelets for each scales $j$ and angles $\\theta$ used."
+"\n Color saturation and color hue respectively denote complex magnitude and complex phase.", fontsize=13)
+fig.show()
###############################################################################
# Lowpass filter
-# ----------------
-# We finally display the Gaussian filter.
-f_r = filters_set['phi'][0][...,0].numpy()
+# --------------
+# We finally display the low-pass filter.
+plt.figure()
+plt.rc('text', usetex=True)
+plt.rc('font', family='serif')
+plt.axis('off')
+plt.set_cmap('gray_r')
+
+f_r = filters_set['phi'][0][..., 0].numpy()
f_i = filters_set['phi'][0][..., 1].numpy()
f = f_r + 1j*f_i
+
filter_c = fft2(f)
filter_c = np.fft.fftshift(filter_c)
-axs[J, L // 2].imshow(colorize(filter_c))
-
-# Final caption.
-fig.suptitle("Wavelets for each scales $j$ and angles $\\theta$ used, with the corresponding low-pass filter."
- "\n The contrast corresponds to the amplitude and the color to the phase.", fontsize=13)
-
-
-plt.show()
+plt.suptitle("The corresponding low-pass filter, also known as scaling function."
+"Color saturation and color hue respectively denote complex magnitude and complex phase", fontsize=13)
+filter_c = np.abs(filter_c)
+plt.imshow(filter_c)
| {"golden_diff": "diff --git a/examples/2d/plot_filters.py b/examples/2d/plot_filters.py\n--- a/examples/2d/plot_filters.py\n+++ b/examples/2d/plot_filters.py\n@@ -1,11 +1,11 @@\n \"\"\"\n Plot the 2D wavelet filters\n ===========================\n-See :meth:`scattering.scattering1d.filter_bank` for more informations about the used wavelets.\n+See :meth:`kymatio.scattering2d.filter_bank` for more informations about the used wavelets.\n \"\"\"\n \n-import numpy as np\n import matplotlib.pyplot as plt\n+import numpy as np\n from kymatio.scattering2d.filter_bank import filter_bank\n from kymatio.scattering2d.utils import fft2\n \n@@ -18,10 +18,9 @@\n L = 8\n filters_set = filter_bank(M, M, J, L=L)\n \n-\n ###############################################################################\n # Imshow complex images\n-# -------------------------------------\n+# ---------------------\n # Thanks to https://stackoverflow.com/questions/17044052/mathplotlib-imshow-complex-2d-array\n from colorsys import hls_to_rgb\n def colorize(z):\n@@ -37,14 +36,15 @@\n c[idx] = [hls_to_rgb(a, b, 0.8) for a,b in zip(A,B)]\n return c\n \n-fig, axs = plt.subplots(J+1, L, sharex=True, sharey=True)\n-plt.rc('text', usetex=True)\n-plt.rc('font', family='serif')\n-\n ###############################################################################\n # Bandpass filters\n # ----------------\n-# First, we display each wavelets according to each scale and orientation.\n+# First, we display each wavelet according to its scale and orientation.\n+fig, axs = plt.subplots(J, L, sharex=True, sharey=True)\n+fig.set_figheight(6)\n+fig.set_figwidth(6)\n+plt.rc('text', usetex=True)\n+plt.rc('font', family='serif')\n i=0\n for filter in filters_set['psi']:\n f_r = filter[0][...,0].numpy()\n@@ -54,29 +54,30 @@\n filter_c = np.fft.fftshift(filter_c)\n axs[i // L, i % L].imshow(colorize(filter_c))\n axs[i // L, i % L].axis('off')\n- axs[i // L, i % L].set_title(\"$j = {}$ \\n $\\\\theta={}\".format(i // L, i % L))\n+ axs[i // L, i % L].set_title(\"$j = {}$ \\n $\\\\theta={}$\".format(i // L, i % L))\n i = i+1\n \n-\n-# Add blanks for pretty display\n-for z in range(L):\n- axs[i // L, i % L].axis('off')\n- i = i+1\n+fig.suptitle(\"Wavelets for each scales $j$ and angles $\\\\theta$ used.\"\n+\"\\n Color saturation and color hue respectively denote complex magnitude and complex phase.\", fontsize=13)\n+fig.show()\n \n ###############################################################################\n # Lowpass filter\n-# ----------------\n-# We finally display the Gaussian filter.\n-f_r = filters_set['phi'][0][...,0].numpy()\n+# --------------\n+# We finally display the low-pass filter.\n+plt.figure()\n+plt.rc('text', usetex=True)\n+plt.rc('font', family='serif')\n+plt.axis('off')\n+plt.set_cmap('gray_r')\n+\n+f_r = filters_set['phi'][0][..., 0].numpy()\n f_i = filters_set['phi'][0][..., 1].numpy()\n f = f_r + 1j*f_i\n+\n filter_c = fft2(f)\n filter_c = np.fft.fftshift(filter_c)\n-axs[J, L // 2].imshow(colorize(filter_c))\n-\n-# Final caption.\n-fig.suptitle(\"Wavelets for each scales $j$ and angles $\\\\theta$ used, with the corresponding low-pass filter.\"\n- \"\\n The contrast corresponds to the amplitude and the color to the phase.\", fontsize=13)\n-\n-\n-plt.show()\n+plt.suptitle(\"The corresponding low-pass filter, also known as scaling function.\"\n+\"Color saturation and color hue respectively denote complex magnitude and complex phase\", fontsize=13)\n+filter_c = np.abs(filter_c)\n+plt.imshow(filter_c)\n", "issue": "sphinx-gallery: 2d/plot_filters\nthe wavelets does not display.\r\n\r\nPlease close this issue only when you're happy with the sphinx-gallery.\n", "before_files": [{"content": "\"\"\"\nPlot the 2D wavelet filters\n===========================\nSee :meth:`scattering.scattering1d.filter_bank` for more informations about the used wavelets.\n\"\"\"\n\nimport numpy as np\nimport matplotlib.pyplot as plt\nfrom kymatio.scattering2d.filter_bank import filter_bank\nfrom kymatio.scattering2d.utils import fft2\n\n\n###############################################################################\n# Initial parameters of the filter bank\n# -------------------------------------\nM = 32\nJ = 3\nL = 8\nfilters_set = filter_bank(M, M, J, L=L)\n\n\n###############################################################################\n# Imshow complex images\n# -------------------------------------\n# Thanks to https://stackoverflow.com/questions/17044052/mathplotlib-imshow-complex-2d-array\nfrom colorsys import hls_to_rgb\ndef colorize(z):\n n, m = z.shape\n c = np.zeros((n, m, 3))\n c[np.isinf(z)] = (1.0, 1.0, 1.0)\n c[np.isnan(z)] = (0.5, 0.5, 0.5)\n\n idx = ~(np.isinf(z) + np.isnan(z))\n A = (np.angle(z[idx]) + np.pi) / (2*np.pi)\n A = (A + 0.5) % 1.0\n B = 1.0/(1.0+abs(z[idx])**0.3)\n c[idx] = [hls_to_rgb(a, b, 0.8) for a,b in zip(A,B)]\n return c\n\nfig, axs = plt.subplots(J+1, L, sharex=True, sharey=True)\nplt.rc('text', usetex=True)\nplt.rc('font', family='serif')\n\n###############################################################################\n# Bandpass filters\n# ----------------\n# First, we display each wavelets according to each scale and orientation.\ni=0\nfor filter in filters_set['psi']:\n f_r = filter[0][...,0].numpy()\n f_i = filter[0][..., 1].numpy()\n f = f_r + 1j*f_i\n filter_c = fft2(f)\n filter_c = np.fft.fftshift(filter_c)\n axs[i // L, i % L].imshow(colorize(filter_c))\n axs[i // L, i % L].axis('off')\n axs[i // L, i % L].set_title(\"$j = {}$ \\n $\\\\theta={}\".format(i // L, i % L))\n i = i+1\n\n\n# Add blanks for pretty display\nfor z in range(L):\n axs[i // L, i % L].axis('off')\n i = i+1\n\n###############################################################################\n# Lowpass filter\n# ----------------\n# We finally display the Gaussian filter.\nf_r = filters_set['phi'][0][...,0].numpy()\nf_i = filters_set['phi'][0][..., 1].numpy()\nf = f_r + 1j*f_i\nfilter_c = fft2(f)\nfilter_c = np.fft.fftshift(filter_c)\naxs[J, L // 2].imshow(colorize(filter_c))\n\n# Final caption.\nfig.suptitle(\"Wavelets for each scales $j$ and angles $\\\\theta$ used, with the corresponding low-pass filter.\"\n \"\\n The contrast corresponds to the amplitude and the color to the phase.\", fontsize=13)\n\n\nplt.show()\n", "path": "examples/2d/plot_filters.py"}]} | 1,468 | 961 |
gh_patches_debug_31257 | rasdani/github-patches | git_diff | zestedesavoir__zds-site-5761 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Corriger et refactoriser remove_url_scheme et ses tests
On a une fonction utilitaire qui s'appelle [remove_url_scheme](https://github.com/zestedesavoir/zds-site/blob/03c8f316c46e51d42afb8b8d2d9553cdd8fb0f08/zds/utils/templatetags/remove_url_scheme.py#L9), qui permet d'enlever le schéma des urls (http ou https) et le nom du domaine, afin de toujours servir les ressources locales au site avec le bon protocole (http ou https).
**Description du problème**
Le problème actuellement, c'est qu'elle gère mal le nom du domaine spécifié dans l'environnement de dev, à savoir `ZDS_APP['site']['dns'] = 127.0.0.1:8000`, ce qui a pour effet de faire rater un des tests (zds.utils.tests.test_misc.Misc.test_remove_url_scheme), mais en **local seulement**, pas sur Travis. Il s'agit donc d'un faux positif sur l'environnement de dev, ce qui est pénible.
**Comportement attendu**
On devrait avoir le bon fonctionnement sur l'environnement de dev en gérant correctement le numéro de port à la fin de l'url. Au passage, on devrait aussi :
* utiliser `urllib.parse` au lieu du module de `six` ;
* réunir tous les tests de `remove_url_scheme` dans le bon fichier (actuellement c'est réparti dans `test_misc` et un fichier `test_remove_url_scheme`).
</issue>
<code>
[start of zds/utils/templatetags/remove_url_scheme.py]
1 from django import template
2 from django.conf import settings
3 from six.moves import urllib_parse as urlparse
4
5 register = template.Library()
6
7
8 @register.filter('remove_url_scheme')
9 def remove_url_scheme(input_url):
10 """
11 make every image url pointing to this website protocol independant so that if we use https, we are sure
12 that all our media are served with this protocol.
13
14 .. notice::
15
16 this also removes the ``settings.ZDS_APP['site']['dns']`` from the url.
17
18 :return: the url without its scheme, e.g. ``http://zestedesavoir.com/media/gallery/1/1.png`` becomes
19 ``/media/gallery/1/1.png``
20
21 """
22
23 schemeless_url = input_url[len(urlparse.urlparse(input_url).scheme):]
24 schemeless_url = schemeless_url[len('://'):] if schemeless_url.startswith('://') else schemeless_url
25 if schemeless_url.startswith(settings.ZDS_APP['site']['dns']):
26 return schemeless_url[len(settings.ZDS_APP['site']['dns']):]
27 return input_url
28
[end of zds/utils/templatetags/remove_url_scheme.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/zds/utils/templatetags/remove_url_scheme.py b/zds/utils/templatetags/remove_url_scheme.py
--- a/zds/utils/templatetags/remove_url_scheme.py
+++ b/zds/utils/templatetags/remove_url_scheme.py
@@ -1,27 +1,37 @@
+import urllib.parse
+
from django import template
from django.conf import settings
-from six.moves import urllib_parse as urlparse
register = template.Library()
@register.filter('remove_url_scheme')
-def remove_url_scheme(input_url):
+def remove_url_scheme(url):
"""
- make every image url pointing to this website protocol independant so that if we use https, we are sure
- that all our media are served with this protocol.
-
- .. notice::
+ Remove the scheme and hostname from a URL if it is internal, but leave it unchanged otherwise.
- this also removes the ``settings.ZDS_APP['site']['dns']`` from the url.
+ The internal hostname is determined using the value of ``ZDS_APP['site']['dns']``.
+ URLs with no scheme are accepted. URLs with no hostname are treated as internal.
- :return: the url without its scheme, e.g. ``http://zestedesavoir.com/media/gallery/1/1.png`` becomes
- ``/media/gallery/1/1.png``
+ For example, ``http://zestedesavoir.com/media/gallery/1/1.png`` becomes ``/media/gallery/1/1.png``,
+ whereas ``/media/gallery/1/1.png`` and ``example.com/media/gallery/1/1.png`` stay the same.
+ :return: the url without its scheme and hostname.
"""
- schemeless_url = input_url[len(urlparse.urlparse(input_url).scheme):]
- schemeless_url = schemeless_url[len('://'):] if schemeless_url.startswith('://') else schemeless_url
- if schemeless_url.startswith(settings.ZDS_APP['site']['dns']):
- return schemeless_url[len(settings.ZDS_APP['site']['dns']):]
- return input_url
+ # Parse URLs after adding a prefix if necessary (e.g 'zestedesavoir.com' becomes '//zestedesavoir.com')
+ url_normalized = url
+ if '//' not in url:
+ url_normalized = '//' + url
+ url_parsed = urllib.parse.urlsplit(url_normalized)
+
+ # Return external URLs unchanged
+ if url_parsed.netloc != settings.ZDS_APP['site']['dns']:
+ return url
+
+ # Clean internal URLs
+ url_noscheme = urllib.parse.urlunsplit(['', '', url_parsed.path, url_parsed.query, url_parsed.fragment])
+ url_cleaned = url_noscheme[0:] # remove first "/"
+
+ return url_cleaned
| {"golden_diff": "diff --git a/zds/utils/templatetags/remove_url_scheme.py b/zds/utils/templatetags/remove_url_scheme.py\n--- a/zds/utils/templatetags/remove_url_scheme.py\n+++ b/zds/utils/templatetags/remove_url_scheme.py\n@@ -1,27 +1,37 @@\n+import urllib.parse\n+\n from django import template\n from django.conf import settings\n-from six.moves import urllib_parse as urlparse\n \n register = template.Library()\n \n \n @register.filter('remove_url_scheme')\n-def remove_url_scheme(input_url):\n+def remove_url_scheme(url):\n \"\"\"\n- make every image url pointing to this website protocol independant so that if we use https, we are sure\n- that all our media are served with this protocol.\n-\n- .. notice::\n+ Remove the scheme and hostname from a URL if it is internal, but leave it unchanged otherwise.\n \n- this also removes the ``settings.ZDS_APP['site']['dns']`` from the url.\n+ The internal hostname is determined using the value of ``ZDS_APP['site']['dns']``.\n+ URLs with no scheme are accepted. URLs with no hostname are treated as internal.\n \n- :return: the url without its scheme, e.g. ``http://zestedesavoir.com/media/gallery/1/1.png`` becomes\n- ``/media/gallery/1/1.png``\n+ For example, ``http://zestedesavoir.com/media/gallery/1/1.png`` becomes ``/media/gallery/1/1.png``,\n+ whereas ``/media/gallery/1/1.png`` and ``example.com/media/gallery/1/1.png`` stay the same.\n \n+ :return: the url without its scheme and hostname.\n \"\"\"\n \n- schemeless_url = input_url[len(urlparse.urlparse(input_url).scheme):]\n- schemeless_url = schemeless_url[len('://'):] if schemeless_url.startswith('://') else schemeless_url\n- if schemeless_url.startswith(settings.ZDS_APP['site']['dns']):\n- return schemeless_url[len(settings.ZDS_APP['site']['dns']):]\n- return input_url\n+ # Parse URLs after adding a prefix if necessary (e.g 'zestedesavoir.com' becomes '//zestedesavoir.com')\n+ url_normalized = url\n+ if '//' not in url:\n+ url_normalized = '//' + url\n+ url_parsed = urllib.parse.urlsplit(url_normalized)\n+\n+ # Return external URLs unchanged\n+ if url_parsed.netloc != settings.ZDS_APP['site']['dns']:\n+ return url\n+\n+ # Clean internal URLs\n+ url_noscheme = urllib.parse.urlunsplit(['', '', url_parsed.path, url_parsed.query, url_parsed.fragment])\n+ url_cleaned = url_noscheme[0:] # remove first \"/\"\n+\n+ return url_cleaned\n", "issue": "Corriger et refactoriser remove_url_scheme et ses tests\nOn a une fonction utilitaire qui s'appelle [remove_url_scheme](https://github.com/zestedesavoir/zds-site/blob/03c8f316c46e51d42afb8b8d2d9553cdd8fb0f08/zds/utils/templatetags/remove_url_scheme.py#L9), qui permet d'enlever le sch\u00e9ma des urls (http ou https) et le nom du domaine, afin de toujours servir les ressources locales au site avec le bon protocole (http ou https).\r\n\r\n**Description du probl\u00e8me**\r\n\r\nLe probl\u00e8me actuellement, c'est qu'elle g\u00e8re mal le nom du domaine sp\u00e9cifi\u00e9 dans l'environnement de dev, \u00e0 savoir `ZDS_APP['site']['dns'] = 127.0.0.1:8000`, ce qui a pour effet de faire rater un des tests (zds.utils.tests.test_misc.Misc.test_remove_url_scheme), mais en **local seulement**, pas sur Travis. Il s'agit donc d'un faux positif sur l'environnement de dev, ce qui est p\u00e9nible.\r\n\r\n**Comportement attendu**\r\n\r\nOn devrait avoir le bon fonctionnement sur l'environnement de dev en g\u00e9rant correctement le num\u00e9ro de port \u00e0 la fin de l'url. Au passage, on devrait aussi :\r\n\r\n* utiliser `urllib.parse` au lieu du module de `six` ;\r\n* r\u00e9unir tous les tests de `remove_url_scheme` dans le bon fichier (actuellement c'est r\u00e9parti dans `test_misc` et un fichier `test_remove_url_scheme`).\r\n\n", "before_files": [{"content": "from django import template\nfrom django.conf import settings\nfrom six.moves import urllib_parse as urlparse\n\nregister = template.Library()\n\n\[email protected]('remove_url_scheme')\ndef remove_url_scheme(input_url):\n \"\"\"\n make every image url pointing to this website protocol independant so that if we use https, we are sure\n that all our media are served with this protocol.\n\n .. notice::\n\n this also removes the ``settings.ZDS_APP['site']['dns']`` from the url.\n\n :return: the url without its scheme, e.g. ``http://zestedesavoir.com/media/gallery/1/1.png`` becomes\n ``/media/gallery/1/1.png``\n\n \"\"\"\n\n schemeless_url = input_url[len(urlparse.urlparse(input_url).scheme):]\n schemeless_url = schemeless_url[len('://'):] if schemeless_url.startswith('://') else schemeless_url\n if schemeless_url.startswith(settings.ZDS_APP['site']['dns']):\n return schemeless_url[len(settings.ZDS_APP['site']['dns']):]\n return input_url\n", "path": "zds/utils/templatetags/remove_url_scheme.py"}]} | 1,193 | 625 |
gh_patches_debug_1206 | rasdani/github-patches | git_diff | scikit-image__scikit-image-3790 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
0.14.2 test suite fails with `NameError: global name 'osp'`
## Description
The test suite does not pass. As far as I know `osp` is a common alias for `os.path`. Is this a typo in the code? Or related to the base python version?
## Way to reproduce
```python
pytest -vv
```
## Version information
```python
2.7.16 (default, Mar 4 2019, 19:30:43)
[GCC 8.2.0]
Linux-4.20.2-gentoo-x86_64-Intel-R-_Core-TM-_i7-8550U_CPU_@_1.80GHz-with-gentoo-2.6
scikit-image version: 0.14.2
numpy version: 1.16.1
```
OR
```python
3.6.8 (default, Mar 4 2019, 19:32:41)
[GCC 8.2.0]
Linux-4.20.2-gentoo-x86_64-Intel-R-_Core-TM-_i7-8550U_CPU_@_1.80GHz-with-gentoo-2.6
scikit-image version: 0.14.2
numpy version: 1.16.1
```
## My output
[build.log](https://github.com/scikit-image/scikit-image/files/2937545/build.log)
</issue>
<code>
[start of skimage/__init__.py]
1 """Image Processing SciKit (Toolbox for SciPy)
2
3 ``scikit-image`` (a.k.a. ``skimage``) is a collection of algorithms for image
4 processing and computer vision.
5
6 The main package of ``skimage`` only provides a few utilities for converting
7 between image data types; for most features, you need to import one of the
8 following subpackages:
9
10 Subpackages
11 -----------
12 color
13 Color space conversion.
14 data
15 Test images and example data.
16 draw
17 Drawing primitives (lines, text, etc.) that operate on NumPy arrays.
18 exposure
19 Image intensity adjustment, e.g., histogram equalization, etc.
20 feature
21 Feature detection and extraction, e.g., texture analysis corners, etc.
22 filters
23 Sharpening, edge finding, rank filters, thresholding, etc.
24 graph
25 Graph-theoretic operations, e.g., shortest paths.
26 io
27 Reading, saving, and displaying images and video.
28 measure
29 Measurement of image properties, e.g., similarity and contours.
30 morphology
31 Morphological operations, e.g., opening or skeletonization.
32 novice
33 Simplified interface for teaching purposes.
34 restoration
35 Restoration algorithms, e.g., deconvolution algorithms, denoising, etc.
36 segmentation
37 Partitioning an image into multiple regions.
38 transform
39 Geometric and other transforms, e.g., rotation or the Radon transform.
40 util
41 Generic utilities.
42 viewer
43 A simple graphical user interface for visualizing results and exploring
44 parameters.
45
46 Utility Functions
47 -----------------
48 img_as_float
49 Convert an image to floating point format, with values in [0, 1].
50 Is similar to `img_as_float64`, but will not convert lower-precision
51 floating point arrays to `float64`.
52 img_as_float32
53 Convert an image to single-precision (32-bit) floating point format,
54 with values in [0, 1].
55 img_as_float64
56 Convert an image to double-precision (64-bit) floating point format,
57 with values in [0, 1].
58 img_as_uint
59 Convert an image to unsigned integer format, with values in [0, 65535].
60 img_as_int
61 Convert an image to signed integer format, with values in [-32768, 32767].
62 img_as_ubyte
63 Convert an image to unsigned byte format, with values in [0, 255].
64 img_as_bool
65 Convert an image to boolean format, with values either True or False.
66 dtype_limits
67 Return intensity limits, i.e. (min, max) tuple, of the image's dtype.
68
69 """
70
71 import imp
72 import functools
73 import warnings
74 import sys
75
76 __version__ = '0.14.3'
77
78
79 try:
80 imp.find_module('pytest')
81 except ImportError:
82 def _test(doctest=False, verbose=False):
83 """This would run all unit tests, but pytest couldn't be
84 imported so the test suite can not run.
85 """
86 raise ImportError("Could not load pytest. Unit tests not available.")
87
88 else:
89 def _test(doctest=False, verbose=False):
90 """Run all unit tests."""
91 import pytest
92 import warnings
93 args = ['--pyargs', 'skimage']
94 if verbose:
95 args.extend(['-v', '-s'])
96 if doctest:
97 args.extend(['--doctest-modules'])
98 # Make sure warnings do not break the doc tests
99 with warnings.catch_warnings():
100 warnings.simplefilter("ignore")
101 success = pytest.main(args)
102 else:
103 success = pytest.main(args)
104 # Return sys.exit code
105 if success:
106 return 0
107 else:
108 return 1
109
110
111 # do not use `test` as function name as this leads to a recursion problem with
112 # the nose test suite
113 test = _test
114 test_verbose = functools.partial(test, verbose=True)
115 test_verbose.__doc__ = test.__doc__
116 doctest = functools.partial(test, doctest=True)
117 doctest.__doc__ = doctest.__doc__
118 doctest_verbose = functools.partial(test, doctest=True, verbose=True)
119 doctest_verbose.__doc__ = doctest.__doc__
120
121
122 # Logic for checking for improper install and importing while in the source
123 # tree when package has not been installed inplace.
124 # Code adapted from scikit-learn's __check_build module.
125 _INPLACE_MSG = """
126 It appears that you are importing a local scikit-image source tree. For
127 this, you need to have an inplace install. Maybe you are in the source
128 directory and you need to try from another location."""
129
130 _STANDARD_MSG = """
131 Your install of scikit-image appears to be broken.
132 Try re-installing the package following the instructions at:
133 http://scikit-image.org/docs/stable/install.html """
134
135
136 def _raise_build_error(e):
137 # Raise a comprehensible error
138 local_dir = osp.split(__file__)[0]
139 msg = _STANDARD_MSG
140 if local_dir == "skimage":
141 # Picking up the local install: this will work only if the
142 # install is an 'inplace build'
143 msg = _INPLACE_MSG
144 raise ImportError("""%s
145 It seems that scikit-image has not been built correctly.
146 %s""" % (e, msg))
147
148 try:
149 # This variable is injected in the __builtins__ by the build
150 # process. It used to enable importing subpackages of skimage when
151 # the binaries are not built
152 __SKIMAGE_SETUP__
153 except NameError:
154 __SKIMAGE_SETUP__ = False
155
156 if __SKIMAGE_SETUP__:
157 sys.stderr.write('Partial import of skimage during the build process.\n')
158 # We are not importing the rest of the scikit during the build
159 # process, as it may not be compiled yet
160 else:
161 try:
162 from ._shared import geometry
163 del geometry
164 except ImportError as e:
165 _raise_build_error(e)
166 # All skimage root imports go here
167 from .util.dtype import (img_as_float32,
168 img_as_float64,
169 img_as_float,
170 img_as_int,
171 img_as_uint,
172 img_as_ubyte,
173 img_as_bool,
174 dtype_limits)
175
176 from .util.lookfor import lookfor
177 from .data import data_dir
178
179
180 del warnings, functools, imp, sys
181
[end of skimage/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/skimage/__init__.py b/skimage/__init__.py
--- a/skimage/__init__.py
+++ b/skimage/__init__.py
@@ -135,6 +135,7 @@
def _raise_build_error(e):
# Raise a comprehensible error
+ import os.path as osp
local_dir = osp.split(__file__)[0]
msg = _STANDARD_MSG
if local_dir == "skimage":
| {"golden_diff": "diff --git a/skimage/__init__.py b/skimage/__init__.py\n--- a/skimage/__init__.py\n+++ b/skimage/__init__.py\n@@ -135,6 +135,7 @@\n \n def _raise_build_error(e):\n # Raise a comprehensible error\n+ import os.path as osp\n local_dir = osp.split(__file__)[0]\n msg = _STANDARD_MSG\n if local_dir == \"skimage\":\n", "issue": "0.14.2 test suite fails with `NameError: global name 'osp'`\n## Description\r\n\r\nThe test suite does not pass. As far as I know `osp` is a common alias for `os.path`. Is this a typo in the code? Or related to the base python version?\r\n\r\n## Way to reproduce\r\n```python\r\npytest -vv\r\n```\r\n\r\n## Version information\r\n```python\r\n2.7.16 (default, Mar 4 2019, 19:30:43) \r\n[GCC 8.2.0]\r\nLinux-4.20.2-gentoo-x86_64-Intel-R-_Core-TM-_i7-8550U_CPU_@_1.80GHz-with-gentoo-2.6\r\nscikit-image version: 0.14.2\r\nnumpy version: 1.16.1\r\n```\r\nOR\r\n```python\r\n3.6.8 (default, Mar 4 2019, 19:32:41) \r\n[GCC 8.2.0]\r\nLinux-4.20.2-gentoo-x86_64-Intel-R-_Core-TM-_i7-8550U_CPU_@_1.80GHz-with-gentoo-2.6\r\nscikit-image version: 0.14.2\r\nnumpy version: 1.16.1\r\n```\r\n## My output\r\n[build.log](https://github.com/scikit-image/scikit-image/files/2937545/build.log)\r\n\r\n\r\n\n", "before_files": [{"content": "\"\"\"Image Processing SciKit (Toolbox for SciPy)\n\n``scikit-image`` (a.k.a. ``skimage``) is a collection of algorithms for image\nprocessing and computer vision.\n\nThe main package of ``skimage`` only provides a few utilities for converting\nbetween image data types; for most features, you need to import one of the\nfollowing subpackages:\n\nSubpackages\n-----------\ncolor\n Color space conversion.\ndata\n Test images and example data.\ndraw\n Drawing primitives (lines, text, etc.) that operate on NumPy arrays.\nexposure\n Image intensity adjustment, e.g., histogram equalization, etc.\nfeature\n Feature detection and extraction, e.g., texture analysis corners, etc.\nfilters\n Sharpening, edge finding, rank filters, thresholding, etc.\ngraph\n Graph-theoretic operations, e.g., shortest paths.\nio\n Reading, saving, and displaying images and video.\nmeasure\n Measurement of image properties, e.g., similarity and contours.\nmorphology\n Morphological operations, e.g., opening or skeletonization.\nnovice\n Simplified interface for teaching purposes.\nrestoration\n Restoration algorithms, e.g., deconvolution algorithms, denoising, etc.\nsegmentation\n Partitioning an image into multiple regions.\ntransform\n Geometric and other transforms, e.g., rotation or the Radon transform.\nutil\n Generic utilities.\nviewer\n A simple graphical user interface for visualizing results and exploring\n parameters.\n\nUtility Functions\n-----------------\nimg_as_float\n Convert an image to floating point format, with values in [0, 1].\n Is similar to `img_as_float64`, but will not convert lower-precision\n floating point arrays to `float64`.\nimg_as_float32\n Convert an image to single-precision (32-bit) floating point format,\n with values in [0, 1].\nimg_as_float64\n Convert an image to double-precision (64-bit) floating point format,\n with values in [0, 1].\nimg_as_uint\n Convert an image to unsigned integer format, with values in [0, 65535].\nimg_as_int\n Convert an image to signed integer format, with values in [-32768, 32767].\nimg_as_ubyte\n Convert an image to unsigned byte format, with values in [0, 255].\nimg_as_bool\n Convert an image to boolean format, with values either True or False.\ndtype_limits\n Return intensity limits, i.e. (min, max) tuple, of the image's dtype.\n\n\"\"\"\n\nimport imp\nimport functools\nimport warnings\nimport sys\n\n__version__ = '0.14.3'\n\n\ntry:\n imp.find_module('pytest')\nexcept ImportError:\n def _test(doctest=False, verbose=False):\n \"\"\"This would run all unit tests, but pytest couldn't be\n imported so the test suite can not run.\n \"\"\"\n raise ImportError(\"Could not load pytest. Unit tests not available.\")\n\nelse:\n def _test(doctest=False, verbose=False):\n \"\"\"Run all unit tests.\"\"\"\n import pytest\n import warnings\n args = ['--pyargs', 'skimage']\n if verbose:\n args.extend(['-v', '-s'])\n if doctest:\n args.extend(['--doctest-modules'])\n # Make sure warnings do not break the doc tests\n with warnings.catch_warnings():\n warnings.simplefilter(\"ignore\")\n success = pytest.main(args)\n else:\n success = pytest.main(args)\n # Return sys.exit code\n if success:\n return 0\n else:\n return 1\n\n\n# do not use `test` as function name as this leads to a recursion problem with\n# the nose test suite\ntest = _test\ntest_verbose = functools.partial(test, verbose=True)\ntest_verbose.__doc__ = test.__doc__\ndoctest = functools.partial(test, doctest=True)\ndoctest.__doc__ = doctest.__doc__\ndoctest_verbose = functools.partial(test, doctest=True, verbose=True)\ndoctest_verbose.__doc__ = doctest.__doc__\n\n\n# Logic for checking for improper install and importing while in the source\n# tree when package has not been installed inplace.\n# Code adapted from scikit-learn's __check_build module.\n_INPLACE_MSG = \"\"\"\nIt appears that you are importing a local scikit-image source tree. For\nthis, you need to have an inplace install. Maybe you are in the source\ndirectory and you need to try from another location.\"\"\"\n\n_STANDARD_MSG = \"\"\"\nYour install of scikit-image appears to be broken.\nTry re-installing the package following the instructions at:\nhttp://scikit-image.org/docs/stable/install.html \"\"\"\n\n\ndef _raise_build_error(e):\n # Raise a comprehensible error\n local_dir = osp.split(__file__)[0]\n msg = _STANDARD_MSG\n if local_dir == \"skimage\":\n # Picking up the local install: this will work only if the\n # install is an 'inplace build'\n msg = _INPLACE_MSG\n raise ImportError(\"\"\"%s\nIt seems that scikit-image has not been built correctly.\n%s\"\"\" % (e, msg))\n\ntry:\n # This variable is injected in the __builtins__ by the build\n # process. It used to enable importing subpackages of skimage when\n # the binaries are not built\n __SKIMAGE_SETUP__\nexcept NameError:\n __SKIMAGE_SETUP__ = False\n\nif __SKIMAGE_SETUP__:\n sys.stderr.write('Partial import of skimage during the build process.\\n')\n # We are not importing the rest of the scikit during the build\n # process, as it may not be compiled yet\nelse:\n try:\n from ._shared import geometry\n del geometry\n except ImportError as e:\n _raise_build_error(e)\n # All skimage root imports go here\n from .util.dtype import (img_as_float32,\n img_as_float64,\n img_as_float,\n img_as_int,\n img_as_uint,\n img_as_ubyte,\n img_as_bool,\n dtype_limits)\n\n from .util.lookfor import lookfor\n from .data import data_dir\n\n\ndel warnings, functools, imp, sys\n", "path": "skimage/__init__.py"}]} | 2,684 | 107 |
gh_patches_debug_3772 | rasdani/github-patches | git_diff | kivy__python-for-android-2123 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
TestGetSystemPythonExecutable.test_virtualenv test fail
The `TestGetSystemPythonExecutable.test_virtualenv` and `TestGetSystemPythonExecutable.test_venv` tests started failing all of a sudden.
Error was:
```
ModuleNotFoundError: No module named \'pytoml\'\n'
```
This ca be reproduced in local via:
```sh
pytest tests/test_pythonpackage_basic.py::TestGetSystemPythonExecutable::test_virtualenv
```
</issue>
<code>
[start of pythonforandroid/recipes/openssl/__init__.py]
1 from os.path import join
2
3 from pythonforandroid.recipe import Recipe
4 from pythonforandroid.util import current_directory
5 from pythonforandroid.logger import shprint
6 import sh
7
8
9 class OpenSSLRecipe(Recipe):
10 '''
11 The OpenSSL libraries for python-for-android. This recipe will generate the
12 following libraries as shared libraries (*.so):
13
14 - crypto
15 - ssl
16
17 The generated openssl libraries are versioned, where the version is the
18 recipe attribute :attr:`version` e.g.: ``libcrypto1.1.so``,
19 ``libssl1.1.so``...so...to link your recipe with the openssl libs,
20 remember to add the version at the end, e.g.:
21 ``-lcrypto1.1 -lssl1.1``. Or better, you could do it dynamically
22 using the methods: :meth:`include_flags`, :meth:`link_dirs_flags` and
23 :meth:`link_libs_flags`.
24
25 .. warning:: This recipe is very sensitive because is used for our core
26 recipes, the python recipes. The used API should match with the one
27 used in our python build, otherwise we will be unable to build the
28 _ssl.so python module.
29
30 .. versionchanged:: 0.6.0
31
32 - The gcc compiler has been deprecated in favour of clang and libraries
33 updated to version 1.1.1 (LTS - supported until 11th September 2023)
34 - Added two new methods to make easier to link with openssl:
35 :meth:`include_flags` and :meth:`link_flags`
36 - subclassed versioned_url
37 - Adapted method :meth:`select_build_arch` to API 21+
38 - Add ability to build a legacy version of the openssl libs when using
39 python2legacy or python3crystax.
40
41 .. versionchanged:: 2019.06.06.1.dev0
42
43 - Removed legacy version of openssl libraries
44
45 '''
46
47 version = '1.1'
48 '''the major minor version used to link our recipes'''
49
50 url_version = '1.1.1'
51 '''the version used to download our libraries'''
52
53 url = 'https://www.openssl.org/source/openssl-{url_version}.tar.gz'
54
55 built_libraries = {
56 'libcrypto{version}.so'.format(version=version): '.',
57 'libssl{version}.so'.format(version=version): '.',
58 }
59
60 @property
61 def versioned_url(self):
62 if self.url is None:
63 return None
64 return self.url.format(url_version=self.url_version)
65
66 def get_build_dir(self, arch):
67 return join(
68 self.get_build_container_dir(arch), self.name + self.version
69 )
70
71 def include_flags(self, arch):
72 '''Returns a string with the include folders'''
73 openssl_includes = join(self.get_build_dir(arch.arch), 'include')
74 return (' -I' + openssl_includes +
75 ' -I' + join(openssl_includes, 'internal') +
76 ' -I' + join(openssl_includes, 'openssl'))
77
78 def link_dirs_flags(self, arch):
79 '''Returns a string with the appropriate `-L<lib directory>` to link
80 with the openssl libs. This string is usually added to the environment
81 variable `LDFLAGS`'''
82 return ' -L' + self.get_build_dir(arch.arch)
83
84 def link_libs_flags(self):
85 '''Returns a string with the appropriate `-l<lib>` flags to link with
86 the openssl libs. This string is usually added to the environment
87 variable `LIBS`'''
88 return ' -lcrypto{version} -lssl{version}'.format(version=self.version)
89
90 def link_flags(self, arch):
91 '''Returns a string with the flags to link with the openssl libraries
92 in the format: `-L<lib directory> -l<lib>`'''
93 return self.link_dirs_flags(arch) + self.link_libs_flags()
94
95 def get_recipe_env(self, arch=None):
96 env = super().get_recipe_env(arch)
97 env['OPENSSL_VERSION'] = self.version
98 env['MAKE'] = 'make' # This removes the '-j5', which isn't safe
99 env['ANDROID_NDK'] = self.ctx.ndk_dir
100 return env
101
102 def select_build_arch(self, arch):
103 aname = arch.arch
104 if 'arm64' in aname:
105 return 'android-arm64'
106 if 'v7a' in aname:
107 return 'android-arm'
108 if 'arm' in aname:
109 return 'android'
110 if 'x86_64' in aname:
111 return 'android-x86_64'
112 if 'x86' in aname:
113 return 'android-x86'
114 return 'linux-armv4'
115
116 def build_arch(self, arch):
117 env = self.get_recipe_env(arch)
118 with current_directory(self.get_build_dir(arch.arch)):
119 # sh fails with code 255 trying to execute ./Configure
120 # so instead we manually run perl passing in Configure
121 perl = sh.Command('perl')
122 buildarch = self.select_build_arch(arch)
123 config_args = [
124 'shared',
125 'no-dso',
126 'no-asm',
127 buildarch,
128 '-D__ANDROID_API__={}'.format(self.ctx.ndk_api),
129 ]
130 shprint(perl, 'Configure', *config_args, _env=env)
131 self.apply_patch('disable-sover.patch', arch.arch)
132
133 shprint(sh.make, 'build_libs', _env=env)
134
135
136 recipe = OpenSSLRecipe()
137
[end of pythonforandroid/recipes/openssl/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/pythonforandroid/recipes/openssl/__init__.py b/pythonforandroid/recipes/openssl/__init__.py
--- a/pythonforandroid/recipes/openssl/__init__.py
+++ b/pythonforandroid/recipes/openssl/__init__.py
@@ -47,7 +47,7 @@
version = '1.1'
'''the major minor version used to link our recipes'''
- url_version = '1.1.1'
+ url_version = '1.1.1f'
'''the version used to download our libraries'''
url = 'https://www.openssl.org/source/openssl-{url_version}.tar.gz'
| {"golden_diff": "diff --git a/pythonforandroid/recipes/openssl/__init__.py b/pythonforandroid/recipes/openssl/__init__.py\n--- a/pythonforandroid/recipes/openssl/__init__.py\n+++ b/pythonforandroid/recipes/openssl/__init__.py\n@@ -47,7 +47,7 @@\n version = '1.1'\n '''the major minor version used to link our recipes'''\n \n- url_version = '1.1.1'\n+ url_version = '1.1.1f'\n '''the version used to download our libraries'''\n \n url = 'https://www.openssl.org/source/openssl-{url_version}.tar.gz'\n", "issue": "TestGetSystemPythonExecutable.test_virtualenv test fail\nThe `TestGetSystemPythonExecutable.test_virtualenv` and `TestGetSystemPythonExecutable.test_venv` tests started failing all of a sudden.\r\nError was:\r\n```\r\nModuleNotFoundError: No module named \\'pytoml\\'\\n'\r\n```\r\nThis ca be reproduced in local via:\r\n```sh\r\npytest tests/test_pythonpackage_basic.py::TestGetSystemPythonExecutable::test_virtualenv\r\n```\r\n\r\n\n", "before_files": [{"content": "from os.path import join\n\nfrom pythonforandroid.recipe import Recipe\nfrom pythonforandroid.util import current_directory\nfrom pythonforandroid.logger import shprint\nimport sh\n\n\nclass OpenSSLRecipe(Recipe):\n '''\n The OpenSSL libraries for python-for-android. This recipe will generate the\n following libraries as shared libraries (*.so):\n\n - crypto\n - ssl\n\n The generated openssl libraries are versioned, where the version is the\n recipe attribute :attr:`version` e.g.: ``libcrypto1.1.so``,\n ``libssl1.1.so``...so...to link your recipe with the openssl libs,\n remember to add the version at the end, e.g.:\n ``-lcrypto1.1 -lssl1.1``. Or better, you could do it dynamically\n using the methods: :meth:`include_flags`, :meth:`link_dirs_flags` and\n :meth:`link_libs_flags`.\n\n .. warning:: This recipe is very sensitive because is used for our core\n recipes, the python recipes. The used API should match with the one\n used in our python build, otherwise we will be unable to build the\n _ssl.so python module.\n\n .. versionchanged:: 0.6.0\n\n - The gcc compiler has been deprecated in favour of clang and libraries\n updated to version 1.1.1 (LTS - supported until 11th September 2023)\n - Added two new methods to make easier to link with openssl:\n :meth:`include_flags` and :meth:`link_flags`\n - subclassed versioned_url\n - Adapted method :meth:`select_build_arch` to API 21+\n - Add ability to build a legacy version of the openssl libs when using\n python2legacy or python3crystax.\n\n .. versionchanged:: 2019.06.06.1.dev0\n\n - Removed legacy version of openssl libraries\n\n '''\n\n version = '1.1'\n '''the major minor version used to link our recipes'''\n\n url_version = '1.1.1'\n '''the version used to download our libraries'''\n\n url = 'https://www.openssl.org/source/openssl-{url_version}.tar.gz'\n\n built_libraries = {\n 'libcrypto{version}.so'.format(version=version): '.',\n 'libssl{version}.so'.format(version=version): '.',\n }\n\n @property\n def versioned_url(self):\n if self.url is None:\n return None\n return self.url.format(url_version=self.url_version)\n\n def get_build_dir(self, arch):\n return join(\n self.get_build_container_dir(arch), self.name + self.version\n )\n\n def include_flags(self, arch):\n '''Returns a string with the include folders'''\n openssl_includes = join(self.get_build_dir(arch.arch), 'include')\n return (' -I' + openssl_includes +\n ' -I' + join(openssl_includes, 'internal') +\n ' -I' + join(openssl_includes, 'openssl'))\n\n def link_dirs_flags(self, arch):\n '''Returns a string with the appropriate `-L<lib directory>` to link\n with the openssl libs. This string is usually added to the environment\n variable `LDFLAGS`'''\n return ' -L' + self.get_build_dir(arch.arch)\n\n def link_libs_flags(self):\n '''Returns a string with the appropriate `-l<lib>` flags to link with\n the openssl libs. This string is usually added to the environment\n variable `LIBS`'''\n return ' -lcrypto{version} -lssl{version}'.format(version=self.version)\n\n def link_flags(self, arch):\n '''Returns a string with the flags to link with the openssl libraries\n in the format: `-L<lib directory> -l<lib>`'''\n return self.link_dirs_flags(arch) + self.link_libs_flags()\n\n def get_recipe_env(self, arch=None):\n env = super().get_recipe_env(arch)\n env['OPENSSL_VERSION'] = self.version\n env['MAKE'] = 'make' # This removes the '-j5', which isn't safe\n env['ANDROID_NDK'] = self.ctx.ndk_dir\n return env\n\n def select_build_arch(self, arch):\n aname = arch.arch\n if 'arm64' in aname:\n return 'android-arm64'\n if 'v7a' in aname:\n return 'android-arm'\n if 'arm' in aname:\n return 'android'\n if 'x86_64' in aname:\n return 'android-x86_64'\n if 'x86' in aname:\n return 'android-x86'\n return 'linux-armv4'\n\n def build_arch(self, arch):\n env = self.get_recipe_env(arch)\n with current_directory(self.get_build_dir(arch.arch)):\n # sh fails with code 255 trying to execute ./Configure\n # so instead we manually run perl passing in Configure\n perl = sh.Command('perl')\n buildarch = self.select_build_arch(arch)\n config_args = [\n 'shared',\n 'no-dso',\n 'no-asm',\n buildarch,\n '-D__ANDROID_API__={}'.format(self.ctx.ndk_api),\n ]\n shprint(perl, 'Configure', *config_args, _env=env)\n self.apply_patch('disable-sover.patch', arch.arch)\n\n shprint(sh.make, 'build_libs', _env=env)\n\n\nrecipe = OpenSSLRecipe()\n", "path": "pythonforandroid/recipes/openssl/__init__.py"}]} | 2,188 | 145 |
gh_patches_debug_10073 | rasdani/github-patches | git_diff | alltheplaces__alltheplaces-2457 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Spider sheetz is broken
During the global build at 2021-06-23-14-42-18, spider **sheetz** failed with **526 features** and **1 errors**.
Here's [the log](https://data.alltheplaces.xyz/runs/2021-06-23-14-42-18/logs/sheetz.txt) and [the output](https://data.alltheplaces.xyz/runs/2021-06-23-14-42-18/output/sheetz.geojson) ([on a map](https://data.alltheplaces.xyz/map.html?show=https://data.alltheplaces.xyz/runs/2021-06-23-14-42-18/output/sheetz.geojson))
</issue>
<code>
[start of locations/spiders/sheetz.py]
1 import json
2 import re
3 import scrapy
4 from locations.items import GeojsonPointItem
5
6
7 class SheetzSpider(scrapy.Spider):
8 name = "sheetz"
9 item_attributes = {'brand': "Sheetz"}
10 allowed_domains = ["orderz.sheetz.com"]
11 start_urls = (
12 "https://orderz.sheetz.com/sas/store",
13 )
14
15 def parse(self, response):
16 stores = json.loads(response.body_as_unicode())
17
18 for store in stores:
19 properties = {
20 'addr_full': store['address'],
21 'city': store['city'],
22 'state': store['state'],
23 'postcode': store['zip'],
24 'ref': store['storeNumber'],
25 'phone': store['phone'],
26 'website': 'https://orderz.sheetz.com/#/main/location/store/'+store['storeNumber'],
27 'lat': float(store['latitude']),
28 'lon': float(store['longitude']),
29 'opening_hours': '24/7' if store['open24x7'] else None,
30 'extras': {
31 'amenity:chargingstation': store['evCharger'],
32 'amenity:fuel': True,
33 'atm': store['atm'],
34 'car_wash': store['carWash'],
35 'fax': store['fax'] if 'fax' in store else None,
36 'fuel:diesel': store['diesel'],
37 'fuel:e15': store['e15'],
38 'fuel:e85': store['e85'],
39 'fuel:kerosene': store['kerosene'],
40 'fuel:propane': store['propane'],
41 }
42 }
43
44 yield GeojsonPointItem(**properties)
45
[end of locations/spiders/sheetz.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/locations/spiders/sheetz.py b/locations/spiders/sheetz.py
--- a/locations/spiders/sheetz.py
+++ b/locations/spiders/sheetz.py
@@ -22,7 +22,7 @@
'state': store['state'],
'postcode': store['zip'],
'ref': store['storeNumber'],
- 'phone': store['phone'],
+ 'phone': store.get('phone'),
'website': 'https://orderz.sheetz.com/#/main/location/store/'+store['storeNumber'],
'lat': float(store['latitude']),
'lon': float(store['longitude']),
| {"golden_diff": "diff --git a/locations/spiders/sheetz.py b/locations/spiders/sheetz.py\n--- a/locations/spiders/sheetz.py\n+++ b/locations/spiders/sheetz.py\n@@ -22,7 +22,7 @@\n 'state': store['state'],\n 'postcode': store['zip'],\n 'ref': store['storeNumber'],\n- 'phone': store['phone'],\n+ 'phone': store.get('phone'),\n 'website': 'https://orderz.sheetz.com/#/main/location/store/'+store['storeNumber'],\n 'lat': float(store['latitude']),\n 'lon': float(store['longitude']),\n", "issue": "Spider sheetz is broken\nDuring the global build at 2021-06-23-14-42-18, spider **sheetz** failed with **526 features** and **1 errors**.\n\nHere's [the log](https://data.alltheplaces.xyz/runs/2021-06-23-14-42-18/logs/sheetz.txt) and [the output](https://data.alltheplaces.xyz/runs/2021-06-23-14-42-18/output/sheetz.geojson) ([on a map](https://data.alltheplaces.xyz/map.html?show=https://data.alltheplaces.xyz/runs/2021-06-23-14-42-18/output/sheetz.geojson))\n", "before_files": [{"content": "import json\nimport re\nimport scrapy\nfrom locations.items import GeojsonPointItem\n\n\nclass SheetzSpider(scrapy.Spider):\n name = \"sheetz\"\n item_attributes = {'brand': \"Sheetz\"}\n allowed_domains = [\"orderz.sheetz.com\"]\n start_urls = (\n \"https://orderz.sheetz.com/sas/store\",\n )\n\n def parse(self, response):\n stores = json.loads(response.body_as_unicode())\n\n for store in stores:\n properties = {\n 'addr_full': store['address'],\n 'city': store['city'],\n 'state': store['state'],\n 'postcode': store['zip'],\n 'ref': store['storeNumber'],\n 'phone': store['phone'],\n 'website': 'https://orderz.sheetz.com/#/main/location/store/'+store['storeNumber'],\n 'lat': float(store['latitude']),\n 'lon': float(store['longitude']),\n 'opening_hours': '24/7' if store['open24x7'] else None,\n 'extras': {\n 'amenity:chargingstation': store['evCharger'],\n 'amenity:fuel': True,\n 'atm': store['atm'],\n 'car_wash': store['carWash'],\n 'fax': store['fax'] if 'fax' in store else None,\n 'fuel:diesel': store['diesel'],\n 'fuel:e15': store['e15'],\n 'fuel:e85': store['e85'],\n 'fuel:kerosene': store['kerosene'],\n 'fuel:propane': store['propane'],\n }\n }\n\n yield GeojsonPointItem(**properties)\n", "path": "locations/spiders/sheetz.py"}]} | 1,169 | 141 |
gh_patches_debug_8051 | rasdani/github-patches | git_diff | mne-tools__mne-bids-67 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
ADD: Configure CircleCI
So that we can check the artifacts tab for builds of the docs
</issue>
<code>
[start of setup.py]
1 #! /usr/bin/env python
2 from setuptools import setup
3
4 descr = """Experimental code for BIDS using MNE."""
5
6 DISTNAME = 'mne-bids'
7 DESCRIPTION = descr
8 MAINTAINER = 'Alexandre Gramfort'
9 MAINTAINER_EMAIL = '[email protected]'
10 URL = 'http://martinos.org/mne'
11 LICENSE = 'BSD (3-clause)'
12 DOWNLOAD_URL = 'http://github.com/mne-tools/mne-bids'
13 VERSION = '0.1.dev0'
14
15 if __name__ == "__main__":
16 setup(name=DISTNAME,
17 maintainer=MAINTAINER,
18 maintainer_email=MAINTAINER_EMAIL,
19 description=DESCRIPTION,
20 license=LICENSE,
21 url=URL,
22 version=VERSION,
23 download_url=DOWNLOAD_URL,
24 long_description=open('README.md').read(),
25 classifiers=[
26 'Intended Audience :: Science/Research',
27 'Intended Audience :: Developers',
28 'License :: OSI Approved',
29 'Programming Language :: Python',
30 'Topic :: Software Development',
31 'Topic :: Scientific/Engineering',
32 'Operating System :: Microsoft :: Windows',
33 'Operating System :: POSIX',
34 'Operating System :: Unix',
35 'Operating System :: MacOS',
36 ],
37 platforms='any',
38 packages=[
39 'mne_bids'
40 ],
41 scripts=['bin/mne_bids']
42 )
43
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -1,5 +1,5 @@
#! /usr/bin/env python
-from setuptools import setup
+from setuptools import setup, find_packages
descr = """Experimental code for BIDS using MNE."""
@@ -35,8 +35,6 @@
'Operating System :: MacOS',
],
platforms='any',
- packages=[
- 'mne_bids'
- ],
+ packages=find_packages(),
scripts=['bin/mne_bids']
-)
+ )
| {"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -1,5 +1,5 @@\n #! /usr/bin/env python\n-from setuptools import setup\n+from setuptools import setup, find_packages\n \n descr = \"\"\"Experimental code for BIDS using MNE.\"\"\"\n \n@@ -35,8 +35,6 @@\n 'Operating System :: MacOS',\n ],\n platforms='any',\n- packages=[\n- 'mne_bids'\n- ],\n+ packages=find_packages(),\n scripts=['bin/mne_bids']\n-)\n+ )\n", "issue": "ADD: Configure CircleCI\nSo that we can check the artifacts tab for builds of the docs\n", "before_files": [{"content": "#! /usr/bin/env python\nfrom setuptools import setup\n\ndescr = \"\"\"Experimental code for BIDS using MNE.\"\"\"\n\nDISTNAME = 'mne-bids'\nDESCRIPTION = descr\nMAINTAINER = 'Alexandre Gramfort'\nMAINTAINER_EMAIL = '[email protected]'\nURL = 'http://martinos.org/mne'\nLICENSE = 'BSD (3-clause)'\nDOWNLOAD_URL = 'http://github.com/mne-tools/mne-bids'\nVERSION = '0.1.dev0'\n\nif __name__ == \"__main__\":\n setup(name=DISTNAME,\n maintainer=MAINTAINER,\n maintainer_email=MAINTAINER_EMAIL,\n description=DESCRIPTION,\n license=LICENSE,\n url=URL,\n version=VERSION,\n download_url=DOWNLOAD_URL,\n long_description=open('README.md').read(),\n classifiers=[\n 'Intended Audience :: Science/Research',\n 'Intended Audience :: Developers',\n 'License :: OSI Approved',\n 'Programming Language :: Python',\n 'Topic :: Software Development',\n 'Topic :: Scientific/Engineering',\n 'Operating System :: Microsoft :: Windows',\n 'Operating System :: POSIX',\n 'Operating System :: Unix',\n 'Operating System :: MacOS',\n ],\n platforms='any',\n packages=[\n 'mne_bids'\n ],\n scripts=['bin/mne_bids']\n)\n", "path": "setup.py"}]} | 920 | 126 |
gh_patches_debug_36182 | rasdani/github-patches | git_diff | xorbitsai__inference-126 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
BUG: worker timeout when downloading a model
</issue>
<code>
[start of xinference/core/service.py]
1 # Copyright 2022-2023 XProbe Inc.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import asyncio
16 import time
17 from dataclasses import dataclass
18 from logging import getLogger
19 from typing import Callable, Dict, List, Optional, Set, Tuple
20
21 import xoscar as xo
22
23 from ..core import ModelActor
24 from ..model import ModelSpec
25 from .resource import ResourceStatus, gather_node_info
26
27 logger = getLogger(__name__)
28
29
30 DEFAULT_NODE_DEAD_TIMEOUT = 30
31 DEFAULT_NODE_CHECK_INTERVAL = 1
32
33
34 def log(func: Callable):
35 # TODO: support non-async function
36 import time
37 from functools import wraps
38
39 @wraps(func)
40 async def wrapped(*args, **kwargs):
41 logger.debug(f"Enter {func.__name__}, args: {args}, kwargs: {kwargs}")
42 start = time.time()
43 ret = await func(*args, **kwargs)
44 logger.debug(
45 f"Leave {func.__name__}, elapsed time: {int(time.time() - start)} ms"
46 )
47 return ret
48
49 return wrapped
50
51
52 @dataclass
53 class WorkerStatus:
54 update_time: float
55 status: Dict[str, ResourceStatus]
56
57
58 class SupervisorActor(xo.Actor):
59 def __init__(self):
60 super().__init__()
61 self._worker_address_to_worker: Dict[str, xo.ActorRefType[WorkerActor]] = {}
62 self._model_uid_to_worker: Dict[str, xo.ActorRefType[WorkerActor]] = {}
63 self._worker_status: Dict[str, WorkerStatus] = {}
64
65 @classmethod
66 def uid(cls) -> str:
67 return "supervisor"
68
69 async def __post_create__(self):
70 self._check_dead_nodes_task = asyncio.create_task(self._check_dead_nodes())
71
72 async def __pre_destroy__(self):
73 self._check_dead_nodes_task.cancel()
74
75 async def _choose_worker(self) -> xo.ActorRefType["WorkerActor"]:
76 # TODO: better allocation strategy.
77 min_running_model_count = None
78 target_worker = None
79 for worker in self._worker_address_to_worker.values():
80 running_model_count = await worker.get_model_count()
81 if (
82 min_running_model_count is None
83 or running_model_count < min_running_model_count
84 ):
85 min_running_model_count = running_model_count
86 target_worker = worker
87
88 if target_worker:
89 return target_worker
90
91 raise RuntimeError("No available worker found")
92
93 @log
94 async def launch_builtin_model(
95 self,
96 model_uid: str,
97 model_name: str,
98 model_size_in_billions: Optional[int],
99 model_format: Optional[str],
100 quantization: Optional[str],
101 **kwargs,
102 ) -> xo.ActorRefType["ModelActor"]:
103 assert model_uid not in self._model_uid_to_worker
104
105 worker_ref = await self._choose_worker()
106 model_ref = await worker_ref.launch_builtin_model(
107 model_uid=model_uid,
108 model_name=model_name,
109 model_size_in_billions=model_size_in_billions,
110 model_format=model_format,
111 quantization=quantization,
112 **kwargs,
113 )
114 self._model_uid_to_worker[model_uid] = worker_ref
115
116 return model_ref
117
118 async def _check_dead_nodes(self):
119 while True:
120 for address, status in self._worker_status.items():
121 if time.time() - status.update_time > DEFAULT_NODE_DEAD_TIMEOUT:
122 dead_models = []
123 for model_uid in self._model_uid_to_worker:
124 if self._model_uid_to_worker[model_uid].address == address:
125 dead_models.append(model_uid)
126 logger.error(
127 "Worker timeout. address: %s, influenced models: %s",
128 address,
129 dead_models,
130 )
131 self._worker_status.pop(address)
132 self._worker_address_to_worker.pop(address)
133 await asyncio.sleep(5)
134
135 @log
136 async def terminate_model(self, model_uid: str):
137 assert model_uid in self._model_uid_to_worker
138
139 worker_ref = self._model_uid_to_worker[model_uid]
140 await worker_ref.terminate_model(model_uid=model_uid)
141 del self._model_uid_to_worker[model_uid]
142
143 @log
144 async def get_model(self, model_uid: str) -> xo.ActorRefType["ModelActor"]:
145 worker_ref = self._model_uid_to_worker[model_uid]
146 return await worker_ref.get_model(model_uid=model_uid)
147
148 @log
149 async def describe_model(self, model_uid: str):
150 worker_ref = self._model_uid_to_worker[model_uid]
151 return await worker_ref.describe_model(model_uid=model_uid)
152
153 @log
154 async def list_models(self) -> List[Tuple[str, ModelSpec]]:
155 ret = []
156 for worker in self._worker_address_to_worker.values():
157 ret.extend(await worker.list_models())
158 return ret
159
160 @log
161 async def add_worker(self, worker_address: str):
162 assert worker_address not in self._worker_address_to_worker
163
164 worker_ref = await xo.actor_ref(address=worker_address, uid=WorkerActor.uid())
165 self._worker_address_to_worker[worker_address] = worker_ref
166
167 async def report_worker_status(
168 self, worker_address: str, status: Dict[str, ResourceStatus]
169 ):
170 self._worker_status[worker_address] = WorkerStatus(
171 update_time=time.time(), status=status
172 )
173
174
175 class WorkerActor(xo.Actor):
176 def __init__(self, supervisor_address: str, subpool_addresses: List[str]):
177 super().__init__()
178 self._supervisor_address = supervisor_address
179 self._supervisor_ref = None
180 self._model_uid_to_model: Dict[str, xo.ActorRefType["ModelActor"]] = {}
181 self._model_uid_to_model_spec: Dict[str, ModelSpec] = {}
182 self._subpool_address_to_model_uids: Dict[str, Set[str]] = dict(
183 [(subpool_address, set()) for subpool_address in subpool_addresses]
184 )
185 logger.debug(f"Worker actor initialized with subpools: {subpool_addresses}")
186
187 @classmethod
188 def uid(cls) -> str:
189 return "worker"
190
191 async def __post_create__(self):
192 self._supervisor_ref: xo.ActorRefType["SupervisorActor"] = await xo.actor_ref(
193 address=self._supervisor_address, uid=SupervisorActor.uid()
194 )
195 await self._supervisor_ref.add_worker(self.address)
196 self._upload_task = asyncio.create_task(self._periodical_report_status())
197
198 async def __pre_destroy__(self):
199 self._upload_task.cancel()
200
201 async def get_model_count(self) -> int:
202 return len(self._model_uid_to_model)
203
204 def _choose_subpool(self) -> str:
205 min_running_model_count = None
206 target_subpool_address = None
207 for subpool_address in self._subpool_address_to_model_uids:
208 running_model_count = len(
209 self._subpool_address_to_model_uids[subpool_address]
210 )
211 if (
212 min_running_model_count is None
213 or running_model_count < min_running_model_count
214 ):
215 min_running_model_count = running_model_count
216 target_subpool_address = subpool_address
217
218 if target_subpool_address:
219 logger.debug(
220 "Subpool selected: %s, running model count: %d",
221 target_subpool_address,
222 min_running_model_count,
223 )
224 return target_subpool_address
225
226 raise RuntimeError("No available slot found")
227
228 @log
229 async def launch_builtin_model(
230 self,
231 model_uid: str,
232 model_name: str,
233 model_size_in_billions: Optional[int],
234 model_format: Optional[str],
235 quantization: Optional[str],
236 **kwargs,
237 ) -> xo.ActorRefType["ModelActor"]:
238 assert model_uid not in self._model_uid_to_model
239
240 from ..model import MODEL_FAMILIES
241
242 for model_family in MODEL_FAMILIES:
243 model_spec = model_family.match(
244 model_name=model_name,
245 model_format=model_format,
246 model_size_in_billions=model_size_in_billions,
247 quantization=quantization,
248 )
249
250 if model_spec is None:
251 continue
252
253 cls = model_family.cls
254 save_path = model_family.cache(
255 model_spec.model_size_in_billions, model_spec.quantization
256 )
257 model = cls(model_uid, model_spec, save_path, kwargs)
258 subpool_address = self._choose_subpool()
259 model_ref = await xo.create_actor(
260 ModelActor, address=subpool_address, uid=model_uid, model=model
261 )
262 await model_ref.load()
263 self._model_uid_to_model[model_uid] = model_ref
264 self._model_uid_to_model_spec[model_uid] = model_spec
265 self._subpool_address_to_model_uids[subpool_address].add(model_uid)
266 return model_ref
267
268 raise ValueError(
269 f"Model not found, name: {model_name}, format: {model_format},"
270 f" size: {model_size_in_billions}, quantization: {quantization}"
271 )
272
273 @log
274 async def terminate_model(self, model_uid: str):
275 assert model_uid in self._model_uid_to_model
276
277 model_ref = self._model_uid_to_model[model_uid]
278 await xo.destroy_actor(model_ref)
279 del self._model_uid_to_model[model_uid]
280 del self._model_uid_to_model_spec[model_uid]
281 for subpool_address in self._subpool_address_to_model_uids:
282 if model_uid in self._subpool_address_to_model_uids[subpool_address]:
283 self._subpool_address_to_model_uids[subpool_address].remove(model_uid)
284
285 @log
286 async def list_models(self) -> List[Tuple[str, ModelSpec]]:
287 ret = []
288 for k, v in self._model_uid_to_model_spec.items():
289 ret.append((k, v))
290 return ret
291
292 @log
293 async def get_model(self, model_uid: str) -> xo.ActorRefType["ModelActor"]:
294 return self._model_uid_to_model[model_uid]
295
296 @log
297 async def describe_model(self, model_uid: str) -> ModelSpec:
298 return self._model_uid_to_model_spec[model_uid]
299
300 async def report_status(self):
301 status = await asyncio.to_thread(gather_node_info)
302 await self._supervisor_ref.report_worker_status(self.address, status)
303
304 async def _periodical_report_status(self):
305 while True:
306 try:
307 await self.report_status()
308 except asyncio.CancelledError: # pragma: no cover
309 break
310 except RuntimeError as ex: # pragma: no cover
311 if "cannot schedule new futures" not in str(ex):
312 # when atexit is triggered, the default pool might be shutdown
313 # and to_thread will fail
314 break
315 except (
316 Exception
317 ) as ex: # pragma: no cover # noqa: E722 # nosec # pylint: disable=bare-except
318 logger.error(f"Failed to upload node info: {ex}")
319 try:
320 await asyncio.sleep(DEFAULT_NODE_CHECK_INTERVAL)
321 except asyncio.CancelledError: # pragma: no cover
322 break
323
[end of xinference/core/service.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/xinference/core/service.py b/xinference/core/service.py
--- a/xinference/core/service.py
+++ b/xinference/core/service.py
@@ -90,7 +90,6 @@
raise RuntimeError("No available worker found")
- @log
async def launch_builtin_model(
self,
model_uid: str,
@@ -100,10 +99,22 @@
quantization: Optional[str],
**kwargs,
) -> xo.ActorRefType["ModelActor"]:
+ logger.debug(
+ (
+ f"Enter launch_builtin_model, model_uid: %s, model_name: %s, model_size: %s, "
+ f"model_format: %s, quantization: %s"
+ ),
+ model_uid,
+ model_name,
+ str(model_size_in_billions) if model_size_in_billions else "",
+ model_format,
+ quantization,
+ )
+
assert model_uid not in self._model_uid_to_worker
worker_ref = await self._choose_worker()
- model_ref = await worker_ref.launch_builtin_model(
+ model_ref = yield worker_ref.launch_builtin_model(
model_uid=model_uid,
model_name=model_name,
model_size_in_billions=model_size_in_billions,
@@ -111,9 +122,10 @@
quantization=quantization,
**kwargs,
)
+ # TODO: not protected.
self._model_uid_to_worker[model_uid] = worker_ref
- return model_ref
+ raise xo.Return(model_ref)
async def _check_dead_nodes(self):
while True:
@@ -250,10 +262,13 @@
if model_spec is None:
continue
- cls = model_family.cls
- save_path = model_family.cache(
- model_spec.model_size_in_billions, model_spec.quantization
+ save_path = await asyncio.to_thread(
+ model_family.cache,
+ model_spec.model_size_in_billions,
+ model_spec.quantization,
)
+
+ cls = model_family.cls
model = cls(model_uid, model_spec, save_path, kwargs)
subpool_address = self._choose_subpool()
model_ref = await xo.create_actor(
| {"golden_diff": "diff --git a/xinference/core/service.py b/xinference/core/service.py\n--- a/xinference/core/service.py\n+++ b/xinference/core/service.py\n@@ -90,7 +90,6 @@\n \n raise RuntimeError(\"No available worker found\")\n \n- @log\n async def launch_builtin_model(\n self,\n model_uid: str,\n@@ -100,10 +99,22 @@\n quantization: Optional[str],\n **kwargs,\n ) -> xo.ActorRefType[\"ModelActor\"]:\n+ logger.debug(\n+ (\n+ f\"Enter launch_builtin_model, model_uid: %s, model_name: %s, model_size: %s, \"\n+ f\"model_format: %s, quantization: %s\"\n+ ),\n+ model_uid,\n+ model_name,\n+ str(model_size_in_billions) if model_size_in_billions else \"\",\n+ model_format,\n+ quantization,\n+ )\n+\n assert model_uid not in self._model_uid_to_worker\n \n worker_ref = await self._choose_worker()\n- model_ref = await worker_ref.launch_builtin_model(\n+ model_ref = yield worker_ref.launch_builtin_model(\n model_uid=model_uid,\n model_name=model_name,\n model_size_in_billions=model_size_in_billions,\n@@ -111,9 +122,10 @@\n quantization=quantization,\n **kwargs,\n )\n+ # TODO: not protected.\n self._model_uid_to_worker[model_uid] = worker_ref\n \n- return model_ref\n+ raise xo.Return(model_ref)\n \n async def _check_dead_nodes(self):\n while True:\n@@ -250,10 +262,13 @@\n if model_spec is None:\n continue\n \n- cls = model_family.cls\n- save_path = model_family.cache(\n- model_spec.model_size_in_billions, model_spec.quantization\n+ save_path = await asyncio.to_thread(\n+ model_family.cache,\n+ model_spec.model_size_in_billions,\n+ model_spec.quantization,\n )\n+\n+ cls = model_family.cls\n model = cls(model_uid, model_spec, save_path, kwargs)\n subpool_address = self._choose_subpool()\n model_ref = await xo.create_actor(\n", "issue": "BUG: worker timeout when downloading a model\n\n", "before_files": [{"content": "# Copyright 2022-2023 XProbe Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport asyncio\nimport time\nfrom dataclasses import dataclass\nfrom logging import getLogger\nfrom typing import Callable, Dict, List, Optional, Set, Tuple\n\nimport xoscar as xo\n\nfrom ..core import ModelActor\nfrom ..model import ModelSpec\nfrom .resource import ResourceStatus, gather_node_info\n\nlogger = getLogger(__name__)\n\n\nDEFAULT_NODE_DEAD_TIMEOUT = 30\nDEFAULT_NODE_CHECK_INTERVAL = 1\n\n\ndef log(func: Callable):\n # TODO: support non-async function\n import time\n from functools import wraps\n\n @wraps(func)\n async def wrapped(*args, **kwargs):\n logger.debug(f\"Enter {func.__name__}, args: {args}, kwargs: {kwargs}\")\n start = time.time()\n ret = await func(*args, **kwargs)\n logger.debug(\n f\"Leave {func.__name__}, elapsed time: {int(time.time() - start)} ms\"\n )\n return ret\n\n return wrapped\n\n\n@dataclass\nclass WorkerStatus:\n update_time: float\n status: Dict[str, ResourceStatus]\n\n\nclass SupervisorActor(xo.Actor):\n def __init__(self):\n super().__init__()\n self._worker_address_to_worker: Dict[str, xo.ActorRefType[WorkerActor]] = {}\n self._model_uid_to_worker: Dict[str, xo.ActorRefType[WorkerActor]] = {}\n self._worker_status: Dict[str, WorkerStatus] = {}\n\n @classmethod\n def uid(cls) -> str:\n return \"supervisor\"\n\n async def __post_create__(self):\n self._check_dead_nodes_task = asyncio.create_task(self._check_dead_nodes())\n\n async def __pre_destroy__(self):\n self._check_dead_nodes_task.cancel()\n\n async def _choose_worker(self) -> xo.ActorRefType[\"WorkerActor\"]:\n # TODO: better allocation strategy.\n min_running_model_count = None\n target_worker = None\n for worker in self._worker_address_to_worker.values():\n running_model_count = await worker.get_model_count()\n if (\n min_running_model_count is None\n or running_model_count < min_running_model_count\n ):\n min_running_model_count = running_model_count\n target_worker = worker\n\n if target_worker:\n return target_worker\n\n raise RuntimeError(\"No available worker found\")\n\n @log\n async def launch_builtin_model(\n self,\n model_uid: str,\n model_name: str,\n model_size_in_billions: Optional[int],\n model_format: Optional[str],\n quantization: Optional[str],\n **kwargs,\n ) -> xo.ActorRefType[\"ModelActor\"]:\n assert model_uid not in self._model_uid_to_worker\n\n worker_ref = await self._choose_worker()\n model_ref = await worker_ref.launch_builtin_model(\n model_uid=model_uid,\n model_name=model_name,\n model_size_in_billions=model_size_in_billions,\n model_format=model_format,\n quantization=quantization,\n **kwargs,\n )\n self._model_uid_to_worker[model_uid] = worker_ref\n\n return model_ref\n\n async def _check_dead_nodes(self):\n while True:\n for address, status in self._worker_status.items():\n if time.time() - status.update_time > DEFAULT_NODE_DEAD_TIMEOUT:\n dead_models = []\n for model_uid in self._model_uid_to_worker:\n if self._model_uid_to_worker[model_uid].address == address:\n dead_models.append(model_uid)\n logger.error(\n \"Worker timeout. address: %s, influenced models: %s\",\n address,\n dead_models,\n )\n self._worker_status.pop(address)\n self._worker_address_to_worker.pop(address)\n await asyncio.sleep(5)\n\n @log\n async def terminate_model(self, model_uid: str):\n assert model_uid in self._model_uid_to_worker\n\n worker_ref = self._model_uid_to_worker[model_uid]\n await worker_ref.terminate_model(model_uid=model_uid)\n del self._model_uid_to_worker[model_uid]\n\n @log\n async def get_model(self, model_uid: str) -> xo.ActorRefType[\"ModelActor\"]:\n worker_ref = self._model_uid_to_worker[model_uid]\n return await worker_ref.get_model(model_uid=model_uid)\n\n @log\n async def describe_model(self, model_uid: str):\n worker_ref = self._model_uid_to_worker[model_uid]\n return await worker_ref.describe_model(model_uid=model_uid)\n\n @log\n async def list_models(self) -> List[Tuple[str, ModelSpec]]:\n ret = []\n for worker in self._worker_address_to_worker.values():\n ret.extend(await worker.list_models())\n return ret\n\n @log\n async def add_worker(self, worker_address: str):\n assert worker_address not in self._worker_address_to_worker\n\n worker_ref = await xo.actor_ref(address=worker_address, uid=WorkerActor.uid())\n self._worker_address_to_worker[worker_address] = worker_ref\n\n async def report_worker_status(\n self, worker_address: str, status: Dict[str, ResourceStatus]\n ):\n self._worker_status[worker_address] = WorkerStatus(\n update_time=time.time(), status=status\n )\n\n\nclass WorkerActor(xo.Actor):\n def __init__(self, supervisor_address: str, subpool_addresses: List[str]):\n super().__init__()\n self._supervisor_address = supervisor_address\n self._supervisor_ref = None\n self._model_uid_to_model: Dict[str, xo.ActorRefType[\"ModelActor\"]] = {}\n self._model_uid_to_model_spec: Dict[str, ModelSpec] = {}\n self._subpool_address_to_model_uids: Dict[str, Set[str]] = dict(\n [(subpool_address, set()) for subpool_address in subpool_addresses]\n )\n logger.debug(f\"Worker actor initialized with subpools: {subpool_addresses}\")\n\n @classmethod\n def uid(cls) -> str:\n return \"worker\"\n\n async def __post_create__(self):\n self._supervisor_ref: xo.ActorRefType[\"SupervisorActor\"] = await xo.actor_ref(\n address=self._supervisor_address, uid=SupervisorActor.uid()\n )\n await self._supervisor_ref.add_worker(self.address)\n self._upload_task = asyncio.create_task(self._periodical_report_status())\n\n async def __pre_destroy__(self):\n self._upload_task.cancel()\n\n async def get_model_count(self) -> int:\n return len(self._model_uid_to_model)\n\n def _choose_subpool(self) -> str:\n min_running_model_count = None\n target_subpool_address = None\n for subpool_address in self._subpool_address_to_model_uids:\n running_model_count = len(\n self._subpool_address_to_model_uids[subpool_address]\n )\n if (\n min_running_model_count is None\n or running_model_count < min_running_model_count\n ):\n min_running_model_count = running_model_count\n target_subpool_address = subpool_address\n\n if target_subpool_address:\n logger.debug(\n \"Subpool selected: %s, running model count: %d\",\n target_subpool_address,\n min_running_model_count,\n )\n return target_subpool_address\n\n raise RuntimeError(\"No available slot found\")\n\n @log\n async def launch_builtin_model(\n self,\n model_uid: str,\n model_name: str,\n model_size_in_billions: Optional[int],\n model_format: Optional[str],\n quantization: Optional[str],\n **kwargs,\n ) -> xo.ActorRefType[\"ModelActor\"]:\n assert model_uid not in self._model_uid_to_model\n\n from ..model import MODEL_FAMILIES\n\n for model_family in MODEL_FAMILIES:\n model_spec = model_family.match(\n model_name=model_name,\n model_format=model_format,\n model_size_in_billions=model_size_in_billions,\n quantization=quantization,\n )\n\n if model_spec is None:\n continue\n\n cls = model_family.cls\n save_path = model_family.cache(\n model_spec.model_size_in_billions, model_spec.quantization\n )\n model = cls(model_uid, model_spec, save_path, kwargs)\n subpool_address = self._choose_subpool()\n model_ref = await xo.create_actor(\n ModelActor, address=subpool_address, uid=model_uid, model=model\n )\n await model_ref.load()\n self._model_uid_to_model[model_uid] = model_ref\n self._model_uid_to_model_spec[model_uid] = model_spec\n self._subpool_address_to_model_uids[subpool_address].add(model_uid)\n return model_ref\n\n raise ValueError(\n f\"Model not found, name: {model_name}, format: {model_format},\"\n f\" size: {model_size_in_billions}, quantization: {quantization}\"\n )\n\n @log\n async def terminate_model(self, model_uid: str):\n assert model_uid in self._model_uid_to_model\n\n model_ref = self._model_uid_to_model[model_uid]\n await xo.destroy_actor(model_ref)\n del self._model_uid_to_model[model_uid]\n del self._model_uid_to_model_spec[model_uid]\n for subpool_address in self._subpool_address_to_model_uids:\n if model_uid in self._subpool_address_to_model_uids[subpool_address]:\n self._subpool_address_to_model_uids[subpool_address].remove(model_uid)\n\n @log\n async def list_models(self) -> List[Tuple[str, ModelSpec]]:\n ret = []\n for k, v in self._model_uid_to_model_spec.items():\n ret.append((k, v))\n return ret\n\n @log\n async def get_model(self, model_uid: str) -> xo.ActorRefType[\"ModelActor\"]:\n return self._model_uid_to_model[model_uid]\n\n @log\n async def describe_model(self, model_uid: str) -> ModelSpec:\n return self._model_uid_to_model_spec[model_uid]\n\n async def report_status(self):\n status = await asyncio.to_thread(gather_node_info)\n await self._supervisor_ref.report_worker_status(self.address, status)\n\n async def _periodical_report_status(self):\n while True:\n try:\n await self.report_status()\n except asyncio.CancelledError: # pragma: no cover\n break\n except RuntimeError as ex: # pragma: no cover\n if \"cannot schedule new futures\" not in str(ex):\n # when atexit is triggered, the default pool might be shutdown\n # and to_thread will fail\n break\n except (\n Exception\n ) as ex: # pragma: no cover # noqa: E722 # nosec # pylint: disable=bare-except\n logger.error(f\"Failed to upload node info: {ex}\")\n try:\n await asyncio.sleep(DEFAULT_NODE_CHECK_INTERVAL)\n except asyncio.CancelledError: # pragma: no cover\n break\n", "path": "xinference/core/service.py"}]} | 3,921 | 499 |
gh_patches_debug_29351 | rasdani/github-patches | git_diff | open-mmlab__mmdetection-10056 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Why using repeated dataset in val_dataloader ?
### Prerequisite
- [X] I have searched [Issues](https://github.com/open-mmlab/mmdetection/issues) and [Discussions](https://github.com/open-mmlab/mmdetection/discussions) but cannot get the expected help.
- [X] I have read the [FAQ documentation](https://mmdetection.readthedocs.io/en/latest/faq.html) but cannot get the expected help.
- [X] The bug has not been fixed in the [latest version (master)](https://github.com/open-mmlab/mmdetection) or [latest version (3.x)](https://github.com/open-mmlab/mmdetection/tree/dev-3.x).
### Task
I'm using the official example scripts/configs for the officially supported tasks/models/datasets.
### Branch
3.x branch https://github.com/open-mmlab/mmdetection/tree/3.x
### Environment
https://github.com/open-mmlab/mmdetection/blob/3.x/configs/common/ms_3x_coco-instance.py#L53
### Reproduces the problem - code sample
https://github.com/open-mmlab/mmdetection/blob/3.x/configs/common/ms_3x_coco-instance.py#L53
### Reproduces the problem - command or script
https://github.com/open-mmlab/mmdetection/blob/3.x/configs/common/ms_3x_coco-instance.py#L53
### Reproduces the problem - error message
https://github.com/open-mmlab/mmdetection/blob/3.x/configs/common/ms_3x_coco-instance.py#L53
### Additional information
https://github.com/open-mmlab/mmdetection/blob/3.x/configs/common/ms_3x_coco-instance.py#L53
</issue>
<code>
[start of configs/common/ms_3x_coco-instance.py]
1 _base_ = '../_base_/default_runtime.py'
2
3 # dataset settings
4 dataset_type = 'CocoDataset'
5 data_root = 'data/coco/'
6
7 # Example to use different file client
8 # Method 1: simply set the data root and let the file I/O module
9 # automatically infer from prefix (not support LMDB and Memcache yet)
10
11 # data_root = 's3://openmmlab/datasets/detection/coco/'
12
13 # Method 2: Use `backend_args`, `file_client_args` in versions before 3.0.0rc6
14 # backend_args = dict(
15 # backend='petrel',
16 # path_mapping=dict({
17 # './data/': 's3://openmmlab/datasets/detection/',
18 # 'data/': 's3://openmmlab/datasets/detection/'
19 # }))
20 backend_args = None
21
22 train_pipeline = [
23 dict(type='LoadImageFromFile', backend_args=backend_args),
24 dict(type='LoadAnnotations', with_bbox=True, with_mask=True),
25 dict(
26 type='RandomResize', scale=[(1333, 640), (1333, 800)],
27 keep_ratio=True),
28 dict(type='RandomFlip', prob=0.5),
29 dict(type='PackDetInputs')
30 ]
31 test_pipeline = [
32 dict(type='LoadImageFromFile', backend_args=backend_args),
33 dict(type='Resize', scale=(1333, 800), keep_ratio=True),
34 dict(type='LoadAnnotations', with_bbox=True, with_mask=True),
35 dict(
36 type='PackDetInputs',
37 meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
38 'scale_factor'))
39 ]
40 train_dataloader = dict(
41 batch_size=2,
42 num_workers=2,
43 persistent_workers=True,
44 sampler=dict(type='DefaultSampler', shuffle=True),
45 batch_sampler=dict(type='AspectRatioBatchSampler'),
46 dataset=dict(
47 type=dataset_type,
48 data_root=data_root,
49 ann_file='annotations/instances_train2017.json',
50 data_prefix=dict(img='train2017/'),
51 filter_cfg=dict(filter_empty_gt=True, min_size=32),
52 pipeline=train_pipeline,
53 backend_args=backend_args))
54 val_dataloader = dict(
55 batch_size=2,
56 num_workers=2,
57 persistent_workers=True,
58 drop_last=False,
59 sampler=dict(type='DefaultSampler', shuffle=False),
60 dataset=dict(
61 type='RepeatDataset',
62 times=3,
63 dataset=dict(
64 type=dataset_type,
65 data_root=data_root,
66 ann_file='annotations/instances_val2017.json',
67 data_prefix=dict(img='val2017/'),
68 test_mode=True,
69 pipeline=test_pipeline,
70 backend_args=backend_args)))
71 test_dataloader = val_dataloader
72
73 val_evaluator = dict(
74 type='CocoMetric',
75 ann_file=data_root + 'annotations/instances_val2017.json',
76 metric='bbox',
77 backend_args=backend_args)
78 test_evaluator = val_evaluator
79
80 # training schedule for 3x with `RepeatDataset`
81 train_cfg = dict(type='EpochBasedTrainLoop', max_epochs=12, val_interval=1)
82 val_cfg = dict(type='ValLoop')
83 test_cfg = dict(type='TestLoop')
84
85 # learning rate
86 # Experiments show that using milestones=[9, 11] has higher performance
87 param_scheduler = [
88 dict(
89 type='LinearLR', start_factor=0.001, by_epoch=False, begin=0, end=500),
90 dict(
91 type='MultiStepLR',
92 begin=0,
93 end=12,
94 by_epoch=True,
95 milestones=[9, 11],
96 gamma=0.1)
97 ]
98
99 # optimizer
100 optim_wrapper = dict(
101 type='OptimWrapper',
102 optimizer=dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001))
103
104 # Default setting for scaling LR automatically
105 # - `enable` means enable scaling LR automatically
106 # or not by default.
107 # - `base_batch_size` = (8 GPUs) x (2 samples per GPU).
108 auto_scale_lr = dict(enable=False, base_batch_size=16)
109
[end of configs/common/ms_3x_coco-instance.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/configs/common/ms_3x_coco-instance.py b/configs/common/ms_3x_coco-instance.py
--- a/configs/common/ms_3x_coco-instance.py
+++ b/configs/common/ms_3x_coco-instance.py
@@ -43,31 +43,31 @@
persistent_workers=True,
sampler=dict(type='DefaultSampler', shuffle=True),
batch_sampler=dict(type='AspectRatioBatchSampler'),
- dataset=dict(
- type=dataset_type,
- data_root=data_root,
- ann_file='annotations/instances_train2017.json',
- data_prefix=dict(img='train2017/'),
- filter_cfg=dict(filter_empty_gt=True, min_size=32),
- pipeline=train_pipeline,
- backend_args=backend_args))
-val_dataloader = dict(
- batch_size=2,
- num_workers=2,
- persistent_workers=True,
- drop_last=False,
- sampler=dict(type='DefaultSampler', shuffle=False),
dataset=dict(
type='RepeatDataset',
times=3,
dataset=dict(
type=dataset_type,
data_root=data_root,
- ann_file='annotations/instances_val2017.json',
- data_prefix=dict(img='val2017/'),
- test_mode=True,
- pipeline=test_pipeline,
+ ann_file='annotations/instances_train2017.json',
+ data_prefix=dict(img='train2017/'),
+ filter_cfg=dict(filter_empty_gt=True, min_size=32),
+ pipeline=train_pipeline,
backend_args=backend_args)))
+val_dataloader = dict(
+ batch_size=1,
+ num_workers=2,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ ann_file='annotations/instances_val2017.json',
+ data_prefix=dict(img='val2017/'),
+ test_mode=True,
+ pipeline=test_pipeline,
+ backend_args=backend_args))
test_dataloader = val_dataloader
val_evaluator = dict(
| {"golden_diff": "diff --git a/configs/common/ms_3x_coco-instance.py b/configs/common/ms_3x_coco-instance.py\n--- a/configs/common/ms_3x_coco-instance.py\n+++ b/configs/common/ms_3x_coco-instance.py\n@@ -43,31 +43,31 @@\n persistent_workers=True,\n sampler=dict(type='DefaultSampler', shuffle=True),\n batch_sampler=dict(type='AspectRatioBatchSampler'),\n- dataset=dict(\n- type=dataset_type,\n- data_root=data_root,\n- ann_file='annotations/instances_train2017.json',\n- data_prefix=dict(img='train2017/'),\n- filter_cfg=dict(filter_empty_gt=True, min_size=32),\n- pipeline=train_pipeline,\n- backend_args=backend_args))\n-val_dataloader = dict(\n- batch_size=2,\n- num_workers=2,\n- persistent_workers=True,\n- drop_last=False,\n- sampler=dict(type='DefaultSampler', shuffle=False),\n dataset=dict(\n type='RepeatDataset',\n times=3,\n dataset=dict(\n type=dataset_type,\n data_root=data_root,\n- ann_file='annotations/instances_val2017.json',\n- data_prefix=dict(img='val2017/'),\n- test_mode=True,\n- pipeline=test_pipeline,\n+ ann_file='annotations/instances_train2017.json',\n+ data_prefix=dict(img='train2017/'),\n+ filter_cfg=dict(filter_empty_gt=True, min_size=32),\n+ pipeline=train_pipeline,\n backend_args=backend_args)))\n+val_dataloader = dict(\n+ batch_size=1,\n+ num_workers=2,\n+ persistent_workers=True,\n+ drop_last=False,\n+ sampler=dict(type='DefaultSampler', shuffle=False),\n+ dataset=dict(\n+ type=dataset_type,\n+ data_root=data_root,\n+ ann_file='annotations/instances_val2017.json',\n+ data_prefix=dict(img='val2017/'),\n+ test_mode=True,\n+ pipeline=test_pipeline,\n+ backend_args=backend_args))\n test_dataloader = val_dataloader\n \n val_evaluator = dict(\n", "issue": "Why using repeated dataset in val_dataloader ?\n### Prerequisite\n\n- [X] I have searched [Issues](https://github.com/open-mmlab/mmdetection/issues) and [Discussions](https://github.com/open-mmlab/mmdetection/discussions) but cannot get the expected help.\n- [X] I have read the [FAQ documentation](https://mmdetection.readthedocs.io/en/latest/faq.html) but cannot get the expected help.\n- [X] The bug has not been fixed in the [latest version (master)](https://github.com/open-mmlab/mmdetection) or [latest version (3.x)](https://github.com/open-mmlab/mmdetection/tree/dev-3.x).\n\n### Task\n\nI'm using the official example scripts/configs for the officially supported tasks/models/datasets.\n\n### Branch\n\n3.x branch https://github.com/open-mmlab/mmdetection/tree/3.x\n\n### Environment\n\nhttps://github.com/open-mmlab/mmdetection/blob/3.x/configs/common/ms_3x_coco-instance.py#L53\n\n### Reproduces the problem - code sample\n\nhttps://github.com/open-mmlab/mmdetection/blob/3.x/configs/common/ms_3x_coco-instance.py#L53\n\n### Reproduces the problem - command or script\n\nhttps://github.com/open-mmlab/mmdetection/blob/3.x/configs/common/ms_3x_coco-instance.py#L53\n\n### Reproduces the problem - error message\n\nhttps://github.com/open-mmlab/mmdetection/blob/3.x/configs/common/ms_3x_coco-instance.py#L53\n\n### Additional information\n\nhttps://github.com/open-mmlab/mmdetection/blob/3.x/configs/common/ms_3x_coco-instance.py#L53\n", "before_files": [{"content": "_base_ = '../_base_/default_runtime.py'\n\n# dataset settings\ndataset_type = 'CocoDataset'\ndata_root = 'data/coco/'\n\n# Example to use different file client\n# Method 1: simply set the data root and let the file I/O module\n# automatically infer from prefix (not support LMDB and Memcache yet)\n\n# data_root = 's3://openmmlab/datasets/detection/coco/'\n\n# Method 2: Use `backend_args`, `file_client_args` in versions before 3.0.0rc6\n# backend_args = dict(\n# backend='petrel',\n# path_mapping=dict({\n# './data/': 's3://openmmlab/datasets/detection/',\n# 'data/': 's3://openmmlab/datasets/detection/'\n# }))\nbackend_args = None\n\ntrain_pipeline = [\n dict(type='LoadImageFromFile', backend_args=backend_args),\n dict(type='LoadAnnotations', with_bbox=True, with_mask=True),\n dict(\n type='RandomResize', scale=[(1333, 640), (1333, 800)],\n keep_ratio=True),\n dict(type='RandomFlip', prob=0.5),\n dict(type='PackDetInputs')\n]\ntest_pipeline = [\n dict(type='LoadImageFromFile', backend_args=backend_args),\n dict(type='Resize', scale=(1333, 800), keep_ratio=True),\n dict(type='LoadAnnotations', with_bbox=True, with_mask=True),\n dict(\n type='PackDetInputs',\n meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',\n 'scale_factor'))\n]\ntrain_dataloader = dict(\n batch_size=2,\n num_workers=2,\n persistent_workers=True,\n sampler=dict(type='DefaultSampler', shuffle=True),\n batch_sampler=dict(type='AspectRatioBatchSampler'),\n dataset=dict(\n type=dataset_type,\n data_root=data_root,\n ann_file='annotations/instances_train2017.json',\n data_prefix=dict(img='train2017/'),\n filter_cfg=dict(filter_empty_gt=True, min_size=32),\n pipeline=train_pipeline,\n backend_args=backend_args))\nval_dataloader = dict(\n batch_size=2,\n num_workers=2,\n persistent_workers=True,\n drop_last=False,\n sampler=dict(type='DefaultSampler', shuffle=False),\n dataset=dict(\n type='RepeatDataset',\n times=3,\n dataset=dict(\n type=dataset_type,\n data_root=data_root,\n ann_file='annotations/instances_val2017.json',\n data_prefix=dict(img='val2017/'),\n test_mode=True,\n pipeline=test_pipeline,\n backend_args=backend_args)))\ntest_dataloader = val_dataloader\n\nval_evaluator = dict(\n type='CocoMetric',\n ann_file=data_root + 'annotations/instances_val2017.json',\n metric='bbox',\n backend_args=backend_args)\ntest_evaluator = val_evaluator\n\n# training schedule for 3x with `RepeatDataset`\ntrain_cfg = dict(type='EpochBasedTrainLoop', max_epochs=12, val_interval=1)\nval_cfg = dict(type='ValLoop')\ntest_cfg = dict(type='TestLoop')\n\n# learning rate\n# Experiments show that using milestones=[9, 11] has higher performance\nparam_scheduler = [\n dict(\n type='LinearLR', start_factor=0.001, by_epoch=False, begin=0, end=500),\n dict(\n type='MultiStepLR',\n begin=0,\n end=12,\n by_epoch=True,\n milestones=[9, 11],\n gamma=0.1)\n]\n\n# optimizer\noptim_wrapper = dict(\n type='OptimWrapper',\n optimizer=dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001))\n\n# Default setting for scaling LR automatically\n# - `enable` means enable scaling LR automatically\n# or not by default.\n# - `base_batch_size` = (8 GPUs) x (2 samples per GPU).\nauto_scale_lr = dict(enable=False, base_batch_size=16)\n", "path": "configs/common/ms_3x_coco-instance.py"}]} | 2,077 | 475 |
gh_patches_debug_21554 | rasdani/github-patches | git_diff | encode__httpx-697 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
AsnycIteratorStream should error if `__iter__` called twice.
For defensive programming, the `AsyncIteratorStream` implementation should track `.stream_consumed` in `__iter__`, and raise a `RuntimeError` if it is called twice.
</issue>
<code>
[start of httpx/content_streams.py]
1 import binascii
2 import mimetypes
3 import os
4 import typing
5 from io import BytesIO
6 from json import dumps as json_dumps
7 from pathlib import Path
8 from urllib.parse import urlencode
9
10 from .utils import format_form_param
11
12 RequestData = typing.Union[dict, str, bytes, typing.AsyncIterator[bytes]]
13
14 RequestFiles = typing.Dict[
15 str,
16 typing.Union[
17 # file (or str)
18 typing.Union[typing.IO[typing.AnyStr], typing.AnyStr],
19 # (filename, file (or str))
20 typing.Tuple[
21 typing.Optional[str], typing.Union[typing.IO[typing.AnyStr], typing.AnyStr],
22 ],
23 # (filename, file (or str), content_type)
24 typing.Tuple[
25 typing.Optional[str],
26 typing.Union[typing.IO[typing.AnyStr], typing.AnyStr],
27 typing.Optional[str],
28 ],
29 ],
30 ]
31
32
33 class ContentStream:
34 def get_headers(self) -> typing.Dict[str, str]:
35 """
36 Return a dictionary of headers that are implied by the encoding.
37 """
38 return {}
39
40 def can_replay(self) -> bool:
41 """
42 Return `True` if `__aiter__` can be called multiple times.
43
44 We need this in cases such determining if we can re-issue a request
45 body when we receive a redirect response.
46 """
47 return True
48
49 async def __aiter__(self) -> typing.AsyncIterator[bytes]:
50 yield b""
51
52 async def aclose(self) -> None:
53 pass
54
55
56 class ByteStream(ContentStream):
57 """
58 Request content encoded as plain bytes.
59 """
60
61 def __init__(self, body: typing.Union[str, bytes]) -> None:
62 self.body = body.encode("utf-8") if isinstance(body, str) else body
63
64 def get_headers(self) -> typing.Dict[str, str]:
65 if not self.body:
66 return {}
67 content_length = str(len(self.body))
68 return {"Content-Length": content_length}
69
70 async def __aiter__(self) -> typing.AsyncIterator[bytes]:
71 yield self.body
72
73
74 class AsyncIteratorStream(ContentStream):
75 """
76 Request content encoded as plain bytes, using an async byte iterator.
77 """
78
79 def __init__(
80 self, aiterator: typing.AsyncIterator[bytes], close_func: typing.Callable = None
81 ) -> None:
82 self.aiterator = aiterator
83 self.close_func = close_func
84
85 def can_replay(self) -> bool:
86 return False
87
88 def get_headers(self) -> typing.Dict[str, str]:
89 return {"Transfer-Encoding": "chunked"}
90
91 async def __aiter__(self) -> typing.AsyncIterator[bytes]:
92 async for part in self.aiterator:
93 yield part
94
95 async def aclose(self) -> None:
96 if self.close_func is not None:
97 await self.close_func()
98
99
100 class JSONStream(ContentStream):
101 """
102 Request content encoded as JSON.
103 """
104
105 def __init__(self, json: typing.Any) -> None:
106 self.body = json_dumps(json).encode("utf-8")
107
108 def get_headers(self) -> typing.Dict[str, str]:
109 content_length = str(len(self.body))
110 content_type = "application/json"
111 return {"Content-Length": content_length, "Content-Type": content_type}
112
113 async def __aiter__(self) -> typing.AsyncIterator[bytes]:
114 yield self.body
115
116
117 class URLEncodedStream(ContentStream):
118 """
119 Request content as URL encoded form data.
120 """
121
122 def __init__(self, data: dict) -> None:
123 self.body = urlencode(data, doseq=True).encode("utf-8")
124
125 def get_headers(self) -> typing.Dict[str, str]:
126 content_length = str(len(self.body))
127 content_type = "application/x-www-form-urlencoded"
128 return {"Content-Length": content_length, "Content-Type": content_type}
129
130 async def __aiter__(self) -> typing.AsyncIterator[bytes]:
131 yield self.body
132
133
134 class MultipartStream(ContentStream):
135 """
136 Request content as multipart encoded form data.
137 """
138
139 class DataField:
140 """
141 A single form field item, within a multipart form field.
142 """
143
144 def __init__(self, name: str, value: typing.Union[str, bytes]) -> None:
145 if not isinstance(name, str):
146 raise TypeError("Invalid type for name. Expected str.")
147 if not isinstance(value, (str, bytes)):
148 raise TypeError("Invalid type for value. Expected str or bytes.")
149 self.name = name
150 self.value = value
151
152 def render_headers(self) -> bytes:
153 name = format_form_param("name", self.name)
154 return b"".join([b"Content-Disposition: form-data; ", name, b"\r\n\r\n"])
155
156 def render_data(self) -> bytes:
157 return (
158 self.value
159 if isinstance(self.value, bytes)
160 else self.value.encode("utf-8")
161 )
162
163 class FileField:
164 """
165 A single file field item, within a multipart form field.
166 """
167
168 def __init__(
169 self, name: str, value: typing.Union[typing.IO[typing.AnyStr], tuple]
170 ) -> None:
171 self.name = name
172 if not isinstance(value, tuple):
173 self.filename = Path(str(getattr(value, "name", "upload"))).name
174 self.file = (
175 value
176 ) # type: typing.Union[typing.IO[str], typing.IO[bytes]]
177 self.content_type = self.guess_content_type()
178 else:
179 self.filename = value[0]
180 self.file = value[1]
181 self.content_type = (
182 value[2] if len(value) > 2 else self.guess_content_type()
183 )
184
185 def guess_content_type(self) -> typing.Optional[str]:
186 if self.filename:
187 return (
188 mimetypes.guess_type(self.filename)[0] or "application/octet-stream"
189 )
190 else:
191 return None
192
193 def render_headers(self) -> bytes:
194 parts = [
195 b"Content-Disposition: form-data; ",
196 format_form_param("name", self.name),
197 ]
198 if self.filename:
199 filename = format_form_param("filename", self.filename)
200 parts.extend([b"; ", filename])
201 if self.content_type is not None:
202 content_type = self.content_type.encode()
203 parts.extend([b"\r\nContent-Type: ", content_type])
204 parts.append(b"\r\n\r\n")
205 return b"".join(parts)
206
207 def render_data(self) -> bytes:
208 if isinstance(self.file, str):
209 content = self.file
210 else:
211 content = self.file.read()
212 return content.encode("utf-8") if isinstance(content, str) else content
213
214 def __init__(self, data: dict, files: dict, boundary: bytes = None) -> None:
215 body = BytesIO()
216 if boundary is None:
217 boundary = binascii.hexlify(os.urandom(16))
218
219 for field in self.iter_fields(data, files):
220 body.write(b"--%s\r\n" % boundary)
221 body.write(field.render_headers())
222 body.write(field.render_data())
223 body.write(b"\r\n")
224
225 body.write(b"--%s--\r\n" % boundary)
226
227 self.content_type = "multipart/form-data; boundary=%s" % boundary.decode(
228 "ascii"
229 )
230 self.body = body.getvalue()
231
232 def iter_fields(
233 self, data: dict, files: dict
234 ) -> typing.Iterator[typing.Union["FileField", "DataField"]]:
235 for name, value in data.items():
236 if isinstance(value, (list, dict)):
237 for item in value:
238 yield self.DataField(name=name, value=item)
239 else:
240 yield self.DataField(name=name, value=value)
241
242 for name, value in files.items():
243 yield self.FileField(name=name, value=value)
244
245 def get_headers(self) -> typing.Dict[str, str]:
246 content_length = str(len(self.body))
247 content_type = self.content_type
248 return {"Content-Length": content_length, "Content-Type": content_type}
249
250 async def __aiter__(self) -> typing.AsyncIterator[bytes]:
251 yield self.body
252
253
254 def encode(
255 data: RequestData = None,
256 files: RequestFiles = None,
257 json: typing.Any = None,
258 boundary: bytes = None,
259 ) -> ContentStream:
260 """
261 Handles encoding the given `data`, `files`, and `json`, returning
262 a `ContentStream` implementation.
263 """
264 if data is None:
265 if json is not None:
266 return JSONStream(json=json)
267 elif files:
268 return MultipartStream(data={}, files=files, boundary=boundary)
269 else:
270 return ByteStream(body=b"")
271 elif isinstance(data, dict):
272 if files is not None:
273 return MultipartStream(data=data, files=files, boundary=boundary)
274 else:
275 return URLEncodedStream(data=data)
276 elif isinstance(data, (str, bytes)):
277 return ByteStream(body=data)
278 else:
279 return AsyncIteratorStream(aiterator=data)
280
[end of httpx/content_streams.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/httpx/content_streams.py b/httpx/content_streams.py
--- a/httpx/content_streams.py
+++ b/httpx/content_streams.py
@@ -7,6 +7,7 @@
from pathlib import Path
from urllib.parse import urlencode
+from .exceptions import StreamConsumed
from .utils import format_form_param
RequestData = typing.Union[dict, str, bytes, typing.AsyncIterator[bytes]]
@@ -81,6 +82,7 @@
) -> None:
self.aiterator = aiterator
self.close_func = close_func
+ self.is_stream_consumed = False
def can_replay(self) -> bool:
return False
@@ -89,6 +91,9 @@
return {"Transfer-Encoding": "chunked"}
async def __aiter__(self) -> typing.AsyncIterator[bytes]:
+ if self.is_stream_consumed:
+ raise StreamConsumed()
+ self.is_stream_consumed = True
async for part in self.aiterator:
yield part
| {"golden_diff": "diff --git a/httpx/content_streams.py b/httpx/content_streams.py\n--- a/httpx/content_streams.py\n+++ b/httpx/content_streams.py\n@@ -7,6 +7,7 @@\n from pathlib import Path\n from urllib.parse import urlencode\n \n+from .exceptions import StreamConsumed\n from .utils import format_form_param\n \n RequestData = typing.Union[dict, str, bytes, typing.AsyncIterator[bytes]]\n@@ -81,6 +82,7 @@\n ) -> None:\n self.aiterator = aiterator\n self.close_func = close_func\n+ self.is_stream_consumed = False\n \n def can_replay(self) -> bool:\n return False\n@@ -89,6 +91,9 @@\n return {\"Transfer-Encoding\": \"chunked\"}\n \n async def __aiter__(self) -> typing.AsyncIterator[bytes]:\n+ if self.is_stream_consumed:\n+ raise StreamConsumed()\n+ self.is_stream_consumed = True\n async for part in self.aiterator:\n yield part\n", "issue": "AsnycIteratorStream should error if `__iter__` called twice.\nFor defensive programming, the `AsyncIteratorStream` implementation should track `.stream_consumed` in `__iter__`, and raise a `RuntimeError` if it is called twice.\n", "before_files": [{"content": "import binascii\nimport mimetypes\nimport os\nimport typing\nfrom io import BytesIO\nfrom json import dumps as json_dumps\nfrom pathlib import Path\nfrom urllib.parse import urlencode\n\nfrom .utils import format_form_param\n\nRequestData = typing.Union[dict, str, bytes, typing.AsyncIterator[bytes]]\n\nRequestFiles = typing.Dict[\n str,\n typing.Union[\n # file (or str)\n typing.Union[typing.IO[typing.AnyStr], typing.AnyStr],\n # (filename, file (or str))\n typing.Tuple[\n typing.Optional[str], typing.Union[typing.IO[typing.AnyStr], typing.AnyStr],\n ],\n # (filename, file (or str), content_type)\n typing.Tuple[\n typing.Optional[str],\n typing.Union[typing.IO[typing.AnyStr], typing.AnyStr],\n typing.Optional[str],\n ],\n ],\n]\n\n\nclass ContentStream:\n def get_headers(self) -> typing.Dict[str, str]:\n \"\"\"\n Return a dictionary of headers that are implied by the encoding.\n \"\"\"\n return {}\n\n def can_replay(self) -> bool:\n \"\"\"\n Return `True` if `__aiter__` can be called multiple times.\n\n We need this in cases such determining if we can re-issue a request\n body when we receive a redirect response.\n \"\"\"\n return True\n\n async def __aiter__(self) -> typing.AsyncIterator[bytes]:\n yield b\"\"\n\n async def aclose(self) -> None:\n pass\n\n\nclass ByteStream(ContentStream):\n \"\"\"\n Request content encoded as plain bytes.\n \"\"\"\n\n def __init__(self, body: typing.Union[str, bytes]) -> None:\n self.body = body.encode(\"utf-8\") if isinstance(body, str) else body\n\n def get_headers(self) -> typing.Dict[str, str]:\n if not self.body:\n return {}\n content_length = str(len(self.body))\n return {\"Content-Length\": content_length}\n\n async def __aiter__(self) -> typing.AsyncIterator[bytes]:\n yield self.body\n\n\nclass AsyncIteratorStream(ContentStream):\n \"\"\"\n Request content encoded as plain bytes, using an async byte iterator.\n \"\"\"\n\n def __init__(\n self, aiterator: typing.AsyncIterator[bytes], close_func: typing.Callable = None\n ) -> None:\n self.aiterator = aiterator\n self.close_func = close_func\n\n def can_replay(self) -> bool:\n return False\n\n def get_headers(self) -> typing.Dict[str, str]:\n return {\"Transfer-Encoding\": \"chunked\"}\n\n async def __aiter__(self) -> typing.AsyncIterator[bytes]:\n async for part in self.aiterator:\n yield part\n\n async def aclose(self) -> None:\n if self.close_func is not None:\n await self.close_func()\n\n\nclass JSONStream(ContentStream):\n \"\"\"\n Request content encoded as JSON.\n \"\"\"\n\n def __init__(self, json: typing.Any) -> None:\n self.body = json_dumps(json).encode(\"utf-8\")\n\n def get_headers(self) -> typing.Dict[str, str]:\n content_length = str(len(self.body))\n content_type = \"application/json\"\n return {\"Content-Length\": content_length, \"Content-Type\": content_type}\n\n async def __aiter__(self) -> typing.AsyncIterator[bytes]:\n yield self.body\n\n\nclass URLEncodedStream(ContentStream):\n \"\"\"\n Request content as URL encoded form data.\n \"\"\"\n\n def __init__(self, data: dict) -> None:\n self.body = urlencode(data, doseq=True).encode(\"utf-8\")\n\n def get_headers(self) -> typing.Dict[str, str]:\n content_length = str(len(self.body))\n content_type = \"application/x-www-form-urlencoded\"\n return {\"Content-Length\": content_length, \"Content-Type\": content_type}\n\n async def __aiter__(self) -> typing.AsyncIterator[bytes]:\n yield self.body\n\n\nclass MultipartStream(ContentStream):\n \"\"\"\n Request content as multipart encoded form data.\n \"\"\"\n\n class DataField:\n \"\"\"\n A single form field item, within a multipart form field.\n \"\"\"\n\n def __init__(self, name: str, value: typing.Union[str, bytes]) -> None:\n if not isinstance(name, str):\n raise TypeError(\"Invalid type for name. Expected str.\")\n if not isinstance(value, (str, bytes)):\n raise TypeError(\"Invalid type for value. Expected str or bytes.\")\n self.name = name\n self.value = value\n\n def render_headers(self) -> bytes:\n name = format_form_param(\"name\", self.name)\n return b\"\".join([b\"Content-Disposition: form-data; \", name, b\"\\r\\n\\r\\n\"])\n\n def render_data(self) -> bytes:\n return (\n self.value\n if isinstance(self.value, bytes)\n else self.value.encode(\"utf-8\")\n )\n\n class FileField:\n \"\"\"\n A single file field item, within a multipart form field.\n \"\"\"\n\n def __init__(\n self, name: str, value: typing.Union[typing.IO[typing.AnyStr], tuple]\n ) -> None:\n self.name = name\n if not isinstance(value, tuple):\n self.filename = Path(str(getattr(value, \"name\", \"upload\"))).name\n self.file = (\n value\n ) # type: typing.Union[typing.IO[str], typing.IO[bytes]]\n self.content_type = self.guess_content_type()\n else:\n self.filename = value[0]\n self.file = value[1]\n self.content_type = (\n value[2] if len(value) > 2 else self.guess_content_type()\n )\n\n def guess_content_type(self) -> typing.Optional[str]:\n if self.filename:\n return (\n mimetypes.guess_type(self.filename)[0] or \"application/octet-stream\"\n )\n else:\n return None\n\n def render_headers(self) -> bytes:\n parts = [\n b\"Content-Disposition: form-data; \",\n format_form_param(\"name\", self.name),\n ]\n if self.filename:\n filename = format_form_param(\"filename\", self.filename)\n parts.extend([b\"; \", filename])\n if self.content_type is not None:\n content_type = self.content_type.encode()\n parts.extend([b\"\\r\\nContent-Type: \", content_type])\n parts.append(b\"\\r\\n\\r\\n\")\n return b\"\".join(parts)\n\n def render_data(self) -> bytes:\n if isinstance(self.file, str):\n content = self.file\n else:\n content = self.file.read()\n return content.encode(\"utf-8\") if isinstance(content, str) else content\n\n def __init__(self, data: dict, files: dict, boundary: bytes = None) -> None:\n body = BytesIO()\n if boundary is None:\n boundary = binascii.hexlify(os.urandom(16))\n\n for field in self.iter_fields(data, files):\n body.write(b\"--%s\\r\\n\" % boundary)\n body.write(field.render_headers())\n body.write(field.render_data())\n body.write(b\"\\r\\n\")\n\n body.write(b\"--%s--\\r\\n\" % boundary)\n\n self.content_type = \"multipart/form-data; boundary=%s\" % boundary.decode(\n \"ascii\"\n )\n self.body = body.getvalue()\n\n def iter_fields(\n self, data: dict, files: dict\n ) -> typing.Iterator[typing.Union[\"FileField\", \"DataField\"]]:\n for name, value in data.items():\n if isinstance(value, (list, dict)):\n for item in value:\n yield self.DataField(name=name, value=item)\n else:\n yield self.DataField(name=name, value=value)\n\n for name, value in files.items():\n yield self.FileField(name=name, value=value)\n\n def get_headers(self) -> typing.Dict[str, str]:\n content_length = str(len(self.body))\n content_type = self.content_type\n return {\"Content-Length\": content_length, \"Content-Type\": content_type}\n\n async def __aiter__(self) -> typing.AsyncIterator[bytes]:\n yield self.body\n\n\ndef encode(\n data: RequestData = None,\n files: RequestFiles = None,\n json: typing.Any = None,\n boundary: bytes = None,\n) -> ContentStream:\n \"\"\"\n Handles encoding the given `data`, `files`, and `json`, returning\n a `ContentStream` implementation.\n \"\"\"\n if data is None:\n if json is not None:\n return JSONStream(json=json)\n elif files:\n return MultipartStream(data={}, files=files, boundary=boundary)\n else:\n return ByteStream(body=b\"\")\n elif isinstance(data, dict):\n if files is not None:\n return MultipartStream(data=data, files=files, boundary=boundary)\n else:\n return URLEncodedStream(data=data)\n elif isinstance(data, (str, bytes)):\n return ByteStream(body=data)\n else:\n return AsyncIteratorStream(aiterator=data)\n", "path": "httpx/content_streams.py"}]} | 3,299 | 226 |
gh_patches_debug_12829 | rasdani/github-patches | git_diff | feast-dev__feast-456 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Deduplicate example notebooks
Currently we have two sets of example notebooks for Feast
1. [Examples](https://github.com/gojek/feast/tree/master/examples/basic)
2. [Docker compose](https://github.com/gojek/feast/tree/master/infra/docker-compose/jupyter/notebooks)
The docker compose notebooks can be deduplicated so that all examples are only contained in the root of the project. This would make management easier.
</issue>
<code>
[start of sdk/python/setup.py]
1 # Copyright 2019 The Feast Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # https://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import os
16
17 from setuptools import find_packages, setup
18
19 NAME = "feast"
20 DESCRIPTION = "Python SDK for Feast"
21 URL = "https://github.com/gojek/feast"
22 AUTHOR = "Feast"
23 REQUIRES_PYTHON = ">=3.6.0"
24
25 REQUIRED = [
26 "Click==7.*",
27 "google-api-core==1.14.*",
28 "google-auth==1.6.*",
29 "google-cloud-bigquery==1.18.*",
30 "google-cloud-storage==1.20.*",
31 "google-cloud-core==1.0.*",
32 "googleapis-common-protos==1.*",
33 "google-cloud-bigquery-storage==0.7.*",
34 "grpcio==1.*",
35 "pandas==0.*",
36 "pandavro==1.5.*",
37 "protobuf>=3.10",
38 "PyYAML==5.1.*",
39 "fastavro==0.*",
40 "kafka-python==1.*",
41 "tabulate==0.8.*",
42 "toml==0.10.*",
43 "tqdm==4.*",
44 "pyarrow>=0.15.1",
45 "numpy",
46 "google",
47 "confluent_kafka",
48 ]
49
50 # README file from Feast repo root directory
51 README_FILE = os.path.join(os.path.dirname(__file__), "..", "..", "README.md")
52 with open(os.path.join(README_FILE), "r") as f:
53 LONG_DESCRIPTION = f.read()
54
55 setup(
56 name=NAME,
57 author=AUTHOR,
58 description=DESCRIPTION,
59 long_description=LONG_DESCRIPTION,
60 long_description_content_type="text/markdown",
61 python_requires=REQUIRES_PYTHON,
62 url=URL,
63 packages=find_packages(exclude=("tests",)),
64 install_requires=REQUIRED,
65 # https://stackoverflow.com/questions/28509965/setuptools-development-requirements
66 # Install dev requirements with: pip install -e .[dev]
67 extras_require={"dev": ["mypy-protobuf==1.*", "grpcio-testing==1.*"]},
68 include_package_data=True,
69 license="Apache",
70 classifiers=[
71 # Trove classifiers
72 # Full list: https://pypi.python.org/pypi?%3Aaction=list_classifiers
73 "License :: OSI Approved :: Apache Software License",
74 "Programming Language :: Python",
75 "Programming Language :: Python :: 3",
76 "Programming Language :: Python :: 3.6",
77 ],
78 entry_points={"console_scripts": ["feast=feast.cli:cli"]},
79 use_scm_version={"root": "../..", "relative_to": __file__},
80 setup_requires=["setuptools_scm"],
81 )
82
[end of sdk/python/setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/sdk/python/setup.py b/sdk/python/setup.py
--- a/sdk/python/setup.py
+++ b/sdk/python/setup.py
@@ -13,6 +13,7 @@
# limitations under the License.
import os
+import subprocess
from setuptools import find_packages, setup
@@ -48,7 +49,13 @@
]
# README file from Feast repo root directory
-README_FILE = os.path.join(os.path.dirname(__file__), "..", "..", "README.md")
+repo_root = (
+ subprocess.Popen(["git", "rev-parse", "--show-toplevel"], stdout=subprocess.PIPE)
+ .communicate()[0]
+ .rstrip()
+ .decode("utf-8")
+)
+README_FILE = os.path.join(repo_root, "README.md")
with open(os.path.join(README_FILE), "r") as f:
LONG_DESCRIPTION = f.read()
| {"golden_diff": "diff --git a/sdk/python/setup.py b/sdk/python/setup.py\n--- a/sdk/python/setup.py\n+++ b/sdk/python/setup.py\n@@ -13,6 +13,7 @@\n # limitations under the License.\n \n import os\n+import subprocess\n \n from setuptools import find_packages, setup\n \n@@ -48,7 +49,13 @@\n ]\n \n # README file from Feast repo root directory\n-README_FILE = os.path.join(os.path.dirname(__file__), \"..\", \"..\", \"README.md\")\n+repo_root = (\n+ subprocess.Popen([\"git\", \"rev-parse\", \"--show-toplevel\"], stdout=subprocess.PIPE)\n+ .communicate()[0]\n+ .rstrip()\n+ .decode(\"utf-8\")\n+)\n+README_FILE = os.path.join(repo_root, \"README.md\")\n with open(os.path.join(README_FILE), \"r\") as f:\n LONG_DESCRIPTION = f.read()\n", "issue": "Deduplicate example notebooks\nCurrently we have two sets of example notebooks for Feast\r\n1. [Examples](https://github.com/gojek/feast/tree/master/examples/basic)\r\n2. [Docker compose](https://github.com/gojek/feast/tree/master/infra/docker-compose/jupyter/notebooks)\r\n\r\nThe docker compose notebooks can be deduplicated so that all examples are only contained in the root of the project. This would make management easier.\n", "before_files": [{"content": "# Copyright 2019 The Feast Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport os\n\nfrom setuptools import find_packages, setup\n\nNAME = \"feast\"\nDESCRIPTION = \"Python SDK for Feast\"\nURL = \"https://github.com/gojek/feast\"\nAUTHOR = \"Feast\"\nREQUIRES_PYTHON = \">=3.6.0\"\n\nREQUIRED = [\n \"Click==7.*\",\n \"google-api-core==1.14.*\",\n \"google-auth==1.6.*\",\n \"google-cloud-bigquery==1.18.*\",\n \"google-cloud-storage==1.20.*\",\n \"google-cloud-core==1.0.*\",\n \"googleapis-common-protos==1.*\",\n \"google-cloud-bigquery-storage==0.7.*\",\n \"grpcio==1.*\",\n \"pandas==0.*\",\n \"pandavro==1.5.*\",\n \"protobuf>=3.10\",\n \"PyYAML==5.1.*\",\n \"fastavro==0.*\",\n \"kafka-python==1.*\",\n \"tabulate==0.8.*\",\n \"toml==0.10.*\",\n \"tqdm==4.*\",\n \"pyarrow>=0.15.1\",\n \"numpy\",\n \"google\",\n \"confluent_kafka\",\n]\n\n# README file from Feast repo root directory\nREADME_FILE = os.path.join(os.path.dirname(__file__), \"..\", \"..\", \"README.md\")\nwith open(os.path.join(README_FILE), \"r\") as f:\n LONG_DESCRIPTION = f.read()\n\nsetup(\n name=NAME,\n author=AUTHOR,\n description=DESCRIPTION,\n long_description=LONG_DESCRIPTION,\n long_description_content_type=\"text/markdown\",\n python_requires=REQUIRES_PYTHON,\n url=URL,\n packages=find_packages(exclude=(\"tests\",)),\n install_requires=REQUIRED,\n # https://stackoverflow.com/questions/28509965/setuptools-development-requirements\n # Install dev requirements with: pip install -e .[dev]\n extras_require={\"dev\": [\"mypy-protobuf==1.*\", \"grpcio-testing==1.*\"]},\n include_package_data=True,\n license=\"Apache\",\n classifiers=[\n # Trove classifiers\n # Full list: https://pypi.python.org/pypi?%3Aaction=list_classifiers\n \"License :: OSI Approved :: Apache Software License\",\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.6\",\n ],\n entry_points={\"console_scripts\": [\"feast=feast.cli:cli\"]},\n use_scm_version={\"root\": \"../..\", \"relative_to\": __file__},\n setup_requires=[\"setuptools_scm\"],\n)\n", "path": "sdk/python/setup.py"}]} | 1,503 | 192 |
gh_patches_debug_9337 | rasdani/github-patches | git_diff | svthalia__concrexit-2962 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Fix escaped HTML in promorequest email remarks field
### Describe the bug

</issue>
<code>
[start of website/promotion/emails.py]
1 """The emails defined by the promotion request package."""
2 import logging
3
4 from django.conf import settings
5
6 from promotion.models import PromotionRequest
7 from utils.snippets import send_email
8
9 logger = logging.getLogger(__name__)
10
11
12 def send_weekly_overview():
13 new_requests = PromotionRequest.new_requests.all()
14 upcoming_requests = PromotionRequest.upcoming_requests.all()
15
16 send_email(
17 to=[settings.PROMO_REQUEST_NOTIFICATION_ADDRESS],
18 subject="[PROMO] Weekly request overview",
19 txt_template="requests/weekly_overview.txt",
20 html_template="requests/weekly_overview.html",
21 context={
22 "new_requests": new_requests,
23 "upcoming_requests": upcoming_requests,
24 },
25 )
26
[end of website/promotion/emails.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/website/promotion/emails.py b/website/promotion/emails.py
--- a/website/promotion/emails.py
+++ b/website/promotion/emails.py
@@ -16,8 +16,8 @@
send_email(
to=[settings.PROMO_REQUEST_NOTIFICATION_ADDRESS],
subject="[PROMO] Weekly request overview",
- txt_template="requests/weekly_overview.txt",
- html_template="requests/weekly_overview.html",
+ txt_template="promotion/email/weekly_overview.txt",
+ html_template="promotion/email/weekly_overview.html",
context={
"new_requests": new_requests,
"upcoming_requests": upcoming_requests,
| {"golden_diff": "diff --git a/website/promotion/emails.py b/website/promotion/emails.py\n--- a/website/promotion/emails.py\n+++ b/website/promotion/emails.py\n@@ -16,8 +16,8 @@\n send_email(\n to=[settings.PROMO_REQUEST_NOTIFICATION_ADDRESS],\n subject=\"[PROMO] Weekly request overview\",\n- txt_template=\"requests/weekly_overview.txt\",\n- html_template=\"requests/weekly_overview.html\",\n+ txt_template=\"promotion/email/weekly_overview.txt\",\n+ html_template=\"promotion/email/weekly_overview.html\",\n context={\n \"new_requests\": new_requests,\n \"upcoming_requests\": upcoming_requests,\n", "issue": "Fix escaped HTML in promorequest email remarks field\n### Describe the bug\n\n", "before_files": [{"content": "\"\"\"The emails defined by the promotion request package.\"\"\"\nimport logging\n\nfrom django.conf import settings\n\nfrom promotion.models import PromotionRequest\nfrom utils.snippets import send_email\n\nlogger = logging.getLogger(__name__)\n\n\ndef send_weekly_overview():\n new_requests = PromotionRequest.new_requests.all()\n upcoming_requests = PromotionRequest.upcoming_requests.all()\n\n send_email(\n to=[settings.PROMO_REQUEST_NOTIFICATION_ADDRESS],\n subject=\"[PROMO] Weekly request overview\",\n txt_template=\"requests/weekly_overview.txt\",\n html_template=\"requests/weekly_overview.html\",\n context={\n \"new_requests\": new_requests,\n \"upcoming_requests\": upcoming_requests,\n },\n )\n", "path": "website/promotion/emails.py"}]} | 807 | 148 |
gh_patches_debug_22780 | rasdani/github-patches | git_diff | yt-project__yt-2754 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Matplotlib 3.3.0 Breaks _png
<!--To help us understand and resolve your issue, please fill out the form to
the best of your ability.-->
<!--You can feel free to delete the sections that do not apply.-->
### Bug report
**Bug summary**
Matplotlib 3.3.0 removed the internal `_png` module, which breaks
https://github.com/yt-project/yt/blob/yt-3.6.0/yt/utilities/png_writer.py#L13
See the last mention in https://matplotlib.org/3.3.0/api/api_changes.html#matplotlib-now-uses-pillow-to-save-and-read-pngs
**Code for reproduction**
Just saw this on our CI:
https://travis-ci.com/github/ECP-WarpX/WarpX/jobs/361956903
MPL 3.3.0 was release about 5hrs ago.
https://github.com/matplotlib/matplotlib/releases/tag/v3.3.0
**Actual outcome**
```
File "/home/travis/.local/lib/python3.6/site-packages/yt/utilities/png_writer.py", line 13, in <module>
import matplotlib._png as _png
ModuleNotFoundError: No module named 'matplotlib._png'
```
**Expected outcome**
:-)
**Version Information**
<!--Please specify your platform and versions of the relevant libraries you are
using:-->
* Operating System: Ubuntu 18.04
* Python Version: 3.6
* yt version: 3.6.0
Installed via `python -m pip install --upgrade cmake matplotlib mpi4py numpy scipy yt`.
**Work-Around**
Downgrade matplotlib via `python -m pip install --upgrade matplotlib==3.2.2`.
Exact details:
- https://travis-ci.com/github/ECP-WarpX/WarpX/jobs/361956903
- https://github.com/ECP-WarpX/WarpX/blob/384c6ab9a864d430868a39a065f4a1d4426231af/.travis.yml#L30-L31
</issue>
<code>
[start of yt/utilities/png_writer.py]
1 from io import BytesIO
2
3 import matplotlib._png as _png
4
5
6 def call_png_write_png(buffer, width, height, fileobj, dpi):
7 _png.write_png(buffer, fileobj, dpi)
8
9
10 def write_png(buffer, filename, dpi=100):
11 width = buffer.shape[1]
12 height = buffer.shape[0]
13 with open(filename, "wb") as fileobj:
14 call_png_write_png(buffer, width, height, fileobj, dpi)
15
16
17 def write_png_to_string(buffer, dpi=100, gray=0):
18 width = buffer.shape[1]
19 height = buffer.shape[0]
20 fileobj = BytesIO()
21 call_png_write_png(buffer, width, height, fileobj, dpi)
22 png_str = fileobj.getvalue()
23 fileobj.close()
24 return png_str
25
[end of yt/utilities/png_writer.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/yt/utilities/png_writer.py b/yt/utilities/png_writer.py
--- a/yt/utilities/png_writer.py
+++ b/yt/utilities/png_writer.py
@@ -1,24 +1,29 @@
from io import BytesIO
-import matplotlib._png as _png
+try:
+ # matplotlib switched from an internal submodule _png to using pillow (PIL)
+ # between v3.1.0 and v3.3.0
+ # So PIL should be available on any system where matplotlib._png doesn't exist
+ import matplotlib._png as _png
+except ImportError:
+ from PIL import Image
-def call_png_write_png(buffer, width, height, fileobj, dpi):
- _png.write_png(buffer, fileobj, dpi)
+def call_png_write_png(buffer, fileobj, dpi):
+ try:
+ _png.write_png(buffer, fileobj, dpi)
+ except NameError:
+ Image.fromarray(buffer).save(fileobj, dpi=(dpi, dpi))
def write_png(buffer, filename, dpi=100):
- width = buffer.shape[1]
- height = buffer.shape[0]
with open(filename, "wb") as fileobj:
- call_png_write_png(buffer, width, height, fileobj, dpi)
+ call_png_write_png(buffer, fileobj, dpi)
-def write_png_to_string(buffer, dpi=100, gray=0):
- width = buffer.shape[1]
- height = buffer.shape[0]
+def write_png_to_string(buffer, dpi=100):
fileobj = BytesIO()
- call_png_write_png(buffer, width, height, fileobj, dpi)
+ call_png_write_png(buffer, fileobj, dpi)
png_str = fileobj.getvalue()
fileobj.close()
return png_str
| {"golden_diff": "diff --git a/yt/utilities/png_writer.py b/yt/utilities/png_writer.py\n--- a/yt/utilities/png_writer.py\n+++ b/yt/utilities/png_writer.py\n@@ -1,24 +1,29 @@\n from io import BytesIO\n \n-import matplotlib._png as _png\n+try:\n+ # matplotlib switched from an internal submodule _png to using pillow (PIL)\n+ # between v3.1.0 and v3.3.0\n+ # So PIL should be available on any system where matplotlib._png doesn't exist\n+ import matplotlib._png as _png\n+except ImportError:\n+ from PIL import Image\n \n \n-def call_png_write_png(buffer, width, height, fileobj, dpi):\n- _png.write_png(buffer, fileobj, dpi)\n+def call_png_write_png(buffer, fileobj, dpi):\n+ try:\n+ _png.write_png(buffer, fileobj, dpi)\n+ except NameError:\n+ Image.fromarray(buffer).save(fileobj, dpi=(dpi, dpi))\n \n \n def write_png(buffer, filename, dpi=100):\n- width = buffer.shape[1]\n- height = buffer.shape[0]\n with open(filename, \"wb\") as fileobj:\n- call_png_write_png(buffer, width, height, fileobj, dpi)\n+ call_png_write_png(buffer, fileobj, dpi)\n \n \n-def write_png_to_string(buffer, dpi=100, gray=0):\n- width = buffer.shape[1]\n- height = buffer.shape[0]\n+def write_png_to_string(buffer, dpi=100):\n fileobj = BytesIO()\n- call_png_write_png(buffer, width, height, fileobj, dpi)\n+ call_png_write_png(buffer, fileobj, dpi)\n png_str = fileobj.getvalue()\n fileobj.close()\n return png_str\n", "issue": "Matplotlib 3.3.0 Breaks _png\n<!--To help us understand and resolve your issue, please fill out the form to\r\nthe best of your ability.-->\r\n<!--You can feel free to delete the sections that do not apply.-->\r\n\r\n### Bug report\r\n\r\n**Bug summary**\r\n\r\nMatplotlib 3.3.0 removed the internal `_png` module, which breaks\r\nhttps://github.com/yt-project/yt/blob/yt-3.6.0/yt/utilities/png_writer.py#L13\r\n\r\nSee the last mention in https://matplotlib.org/3.3.0/api/api_changes.html#matplotlib-now-uses-pillow-to-save-and-read-pngs\r\n\r\n**Code for reproduction**\r\n\r\nJust saw this on our CI:\r\nhttps://travis-ci.com/github/ECP-WarpX/WarpX/jobs/361956903\r\n\r\nMPL 3.3.0 was release about 5hrs ago.\r\nhttps://github.com/matplotlib/matplotlib/releases/tag/v3.3.0\r\n\r\n**Actual outcome**\r\n\r\n```\r\nFile \"/home/travis/.local/lib/python3.6/site-packages/yt/utilities/png_writer.py\", line 13, in <module>\r\n import matplotlib._png as _png\r\nModuleNotFoundError: No module named 'matplotlib._png'\r\n```\r\n\r\n**Expected outcome**\r\n\r\n:-)\r\n\r\n**Version Information**\r\n<!--Please specify your platform and versions of the relevant libraries you are\r\nusing:-->\r\n * Operating System: Ubuntu 18.04\r\n * Python Version: 3.6\r\n * yt version: 3.6.0\r\n\r\nInstalled via `python -m pip install --upgrade cmake matplotlib mpi4py numpy scipy yt`.\r\n\r\n**Work-Around**\r\n\r\nDowngrade matplotlib via `python -m pip install --upgrade matplotlib==3.2.2`.\r\n\r\nExact details:\r\n- https://travis-ci.com/github/ECP-WarpX/WarpX/jobs/361956903\r\n- https://github.com/ECP-WarpX/WarpX/blob/384c6ab9a864d430868a39a065f4a1d4426231af/.travis.yml#L30-L31\r\n\n", "before_files": [{"content": "from io import BytesIO\n\nimport matplotlib._png as _png\n\n\ndef call_png_write_png(buffer, width, height, fileobj, dpi):\n _png.write_png(buffer, fileobj, dpi)\n\n\ndef write_png(buffer, filename, dpi=100):\n width = buffer.shape[1]\n height = buffer.shape[0]\n with open(filename, \"wb\") as fileobj:\n call_png_write_png(buffer, width, height, fileobj, dpi)\n\n\ndef write_png_to_string(buffer, dpi=100, gray=0):\n width = buffer.shape[1]\n height = buffer.shape[0]\n fileobj = BytesIO()\n call_png_write_png(buffer, width, height, fileobj, dpi)\n png_str = fileobj.getvalue()\n fileobj.close()\n return png_str\n", "path": "yt/utilities/png_writer.py"}]} | 1,244 | 407 |
gh_patches_debug_19260 | rasdani/github-patches | git_diff | pypi__warehouse-3236 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
License metadata seems to be ignored
When I made the latest release of `python-dateutil`, it came along with a license change from BSD to Apache / BSD dual licensed. I updated the `license=` metadata in `setup.py`, but I forgot to update the trove classifiers.
[The page on PyPI](https://pypi.python.org/pypi/python-dateutil/2.7.0) shows the license as "Apache 2.0" as I would expect. [The page on warehouse](https://pypi.org/project/python-dateutil/) shows the license as "BSD License". I'm assuming it's pulling that from the trove classifier? Shouldn't it pull it from the `license` field if that is populated?
</issue>
<code>
[start of warehouse/packaging/views.py]
1 # Licensed under the Apache License, Version 2.0 (the "License");
2 # you may not use this file except in compliance with the License.
3 # You may obtain a copy of the License at
4 #
5 # http://www.apache.org/licenses/LICENSE-2.0
6 #
7 # Unless required by applicable law or agreed to in writing, software
8 # distributed under the License is distributed on an "AS IS" BASIS,
9 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
10 # See the License for the specific language governing permissions and
11 # limitations under the License.
12
13 from first import first
14 from pyramid.httpexceptions import HTTPMovedPermanently, HTTPNotFound
15 from pyramid.view import view_config
16 from sqlalchemy.orm.exc import NoResultFound
17
18 from warehouse.accounts.models import User
19 from warehouse.cache.origin import origin_cache
20 from warehouse.packaging.models import Release, Role
21
22
23 @view_config(
24 route_name="packaging.project",
25 renderer="packaging/detail.html",
26 decorator=[
27 origin_cache(
28 1 * 24 * 60 * 60, # 1 day
29 stale_while_revalidate=1 * 24 * 60 * 60, # 1 day
30 stale_if_error=5 * 24 * 60 * 60, # 5 days
31 ),
32 ],
33 )
34 def project_detail(project, request):
35 if project.name != request.matchdict.get("name", project.name):
36 return HTTPMovedPermanently(
37 request.current_route_path(name=project.name),
38 )
39
40 try:
41 release = (
42 request.db.query(Release)
43 .filter(Release.project == project)
44 .order_by(
45 Release.is_prerelease.nullslast(),
46 Release._pypi_ordering.desc())
47 .limit(1)
48 .one()
49 )
50 except NoResultFound:
51 return HTTPNotFound()
52
53 return release_detail(release, request)
54
55
56 @view_config(
57 route_name="packaging.release",
58 renderer="packaging/detail.html",
59 decorator=[
60 origin_cache(
61 1 * 24 * 60 * 60, # 1 day
62 stale_while_revalidate=1 * 24 * 60 * 60, # 1 day
63 stale_if_error=5 * 24 * 60 * 60, # 5 days
64 ),
65 ],
66 )
67 def release_detail(release, request):
68 project = release.project
69
70 # Check if the requested version is equivalent but not exactly the same as
71 # the release's version. Use `.get` because this view is used by
72 # `project_detail` and there may not be a version.
73 #
74 # This also handles the case where both the version and the project name
75 # need adjusted, and handles it in a single redirect.
76 if release.version != request.matchdict.get("version", release.version):
77 return HTTPMovedPermanently(
78 request.current_route_path(
79 name=project.name,
80 version=release.version,
81 ),
82 )
83
84 # It's possible that the requested version was correct (or not provided),
85 # but we still need to adjust the project name.
86 if project.name != request.matchdict.get("name", project.name):
87 return HTTPMovedPermanently(
88 request.current_route_path(name=project.name),
89 )
90
91 # Get all of the registered versions for this Project, in order of newest
92 # to oldest.
93 all_releases = (
94 request.db.query(Release)
95 .filter(Release.project == project)
96 .with_entities(
97 Release.version,
98 Release.is_prerelease,
99 Release.created)
100 .order_by(Release._pypi_ordering.desc())
101 .all()
102 )
103
104 # Get the latest non-prerelease of this Project, or the latest release if
105 # all releases are prereleases.
106 latest_release = first(
107 all_releases,
108 key=lambda r: not r.is_prerelease,
109 default=all_releases[0],
110 )
111
112 # Get all of the maintainers for this project.
113 maintainers = [
114 r.user
115 for r in (
116 request.db.query(Role)
117 .join(User)
118 .filter(Role.project == project)
119 .distinct(User.username)
120 .order_by(User.username)
121 .all()
122 )
123 ]
124
125 # Get the license from the classifiers or metadata, preferring classifiers.
126 license = None
127 if release.license:
128 # Make a best effort when the entire license text is given
129 # by using the first line only.
130 license = release.license.split('\n')[0]
131 license_classifiers = [c.split(" :: ")[-1] for c in release.classifiers
132 if c.startswith("License")]
133 if license_classifiers:
134 license = ', '.join(license_classifiers)
135
136 return {
137 "project": project,
138 "release": release,
139 "files": release.files.all(),
140 "latest_release": latest_release,
141 "all_releases": all_releases,
142 "maintainers": maintainers,
143 "license": license,
144 }
145
146
147 @view_config(
148 route_name="includes.edit-project-button",
149 renderer="includes/manage-project-button.html",
150 uses_session=True,
151 permission="manage",
152 )
153 def edit_project_button(project, request):
154 return {'project': project}
155
[end of warehouse/packaging/views.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/warehouse/packaging/views.py b/warehouse/packaging/views.py
--- a/warehouse/packaging/views.py
+++ b/warehouse/packaging/views.py
@@ -122,16 +122,21 @@
)
]
- # Get the license from the classifiers or metadata, preferring classifiers.
- license = None
- if release.license:
- # Make a best effort when the entire license text is given
- # by using the first line only.
- license = release.license.split('\n')[0]
- license_classifiers = [c.split(" :: ")[-1] for c in release.classifiers
- if c.startswith("License")]
- if license_classifiers:
- license = ', '.join(license_classifiers)
+ # Get the license from both the `Classifier` and `License` metadata fields
+ license_classifiers = ', '.join(
+ c.split(" :: ")[-1]
+ for c in release.classifiers
+ if c.startswith("License")
+ )
+
+ # Make a best effort when the entire license text is given by using the
+ # first line only.
+ short_license = release.license.split('\n')[0] if release.license else None
+
+ if license_classifiers and short_license:
+ license = f'{license_classifiers} ({short_license})'
+ else:
+ license = license_classifiers or short_license or None
return {
"project": project,
| {"golden_diff": "diff --git a/warehouse/packaging/views.py b/warehouse/packaging/views.py\n--- a/warehouse/packaging/views.py\n+++ b/warehouse/packaging/views.py\n@@ -122,16 +122,21 @@\n )\n ]\n \n- # Get the license from the classifiers or metadata, preferring classifiers.\n- license = None\n- if release.license:\n- # Make a best effort when the entire license text is given\n- # by using the first line only.\n- license = release.license.split('\\n')[0]\n- license_classifiers = [c.split(\" :: \")[-1] for c in release.classifiers\n- if c.startswith(\"License\")]\n- if license_classifiers:\n- license = ', '.join(license_classifiers)\n+ # Get the license from both the `Classifier` and `License` metadata fields\n+ license_classifiers = ', '.join(\n+ c.split(\" :: \")[-1]\n+ for c in release.classifiers\n+ if c.startswith(\"License\")\n+ )\n+\n+ # Make a best effort when the entire license text is given by using the\n+ # first line only.\n+ short_license = release.license.split('\\n')[0] if release.license else None\n+\n+ if license_classifiers and short_license:\n+ license = f'{license_classifiers} ({short_license})'\n+ else:\n+ license = license_classifiers or short_license or None\n \n return {\n \"project\": project,\n", "issue": "License metadata seems to be ignored\nWhen I made the latest release of `python-dateutil`, it came along with a license change from BSD to Apache / BSD dual licensed. I updated the `license=` metadata in `setup.py`, but I forgot to update the trove classifiers.\r\n\r\n[The page on PyPI](https://pypi.python.org/pypi/python-dateutil/2.7.0) shows the license as \"Apache 2.0\" as I would expect. [The page on warehouse](https://pypi.org/project/python-dateutil/) shows the license as \"BSD License\". I'm assuming it's pulling that from the trove classifier? Shouldn't it pull it from the `license` field if that is populated?\n", "before_files": [{"content": "# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom first import first\nfrom pyramid.httpexceptions import HTTPMovedPermanently, HTTPNotFound\nfrom pyramid.view import view_config\nfrom sqlalchemy.orm.exc import NoResultFound\n\nfrom warehouse.accounts.models import User\nfrom warehouse.cache.origin import origin_cache\nfrom warehouse.packaging.models import Release, Role\n\n\n@view_config(\n route_name=\"packaging.project\",\n renderer=\"packaging/detail.html\",\n decorator=[\n origin_cache(\n 1 * 24 * 60 * 60, # 1 day\n stale_while_revalidate=1 * 24 * 60 * 60, # 1 day\n stale_if_error=5 * 24 * 60 * 60, # 5 days\n ),\n ],\n)\ndef project_detail(project, request):\n if project.name != request.matchdict.get(\"name\", project.name):\n return HTTPMovedPermanently(\n request.current_route_path(name=project.name),\n )\n\n try:\n release = (\n request.db.query(Release)\n .filter(Release.project == project)\n .order_by(\n Release.is_prerelease.nullslast(),\n Release._pypi_ordering.desc())\n .limit(1)\n .one()\n )\n except NoResultFound:\n return HTTPNotFound()\n\n return release_detail(release, request)\n\n\n@view_config(\n route_name=\"packaging.release\",\n renderer=\"packaging/detail.html\",\n decorator=[\n origin_cache(\n 1 * 24 * 60 * 60, # 1 day\n stale_while_revalidate=1 * 24 * 60 * 60, # 1 day\n stale_if_error=5 * 24 * 60 * 60, # 5 days\n ),\n ],\n)\ndef release_detail(release, request):\n project = release.project\n\n # Check if the requested version is equivalent but not exactly the same as\n # the release's version. Use `.get` because this view is used by\n # `project_detail` and there may not be a version.\n #\n # This also handles the case where both the version and the project name\n # need adjusted, and handles it in a single redirect.\n if release.version != request.matchdict.get(\"version\", release.version):\n return HTTPMovedPermanently(\n request.current_route_path(\n name=project.name,\n version=release.version,\n ),\n )\n\n # It's possible that the requested version was correct (or not provided),\n # but we still need to adjust the project name.\n if project.name != request.matchdict.get(\"name\", project.name):\n return HTTPMovedPermanently(\n request.current_route_path(name=project.name),\n )\n\n # Get all of the registered versions for this Project, in order of newest\n # to oldest.\n all_releases = (\n request.db.query(Release)\n .filter(Release.project == project)\n .with_entities(\n Release.version,\n Release.is_prerelease,\n Release.created)\n .order_by(Release._pypi_ordering.desc())\n .all()\n )\n\n # Get the latest non-prerelease of this Project, or the latest release if\n # all releases are prereleases.\n latest_release = first(\n all_releases,\n key=lambda r: not r.is_prerelease,\n default=all_releases[0],\n )\n\n # Get all of the maintainers for this project.\n maintainers = [\n r.user\n for r in (\n request.db.query(Role)\n .join(User)\n .filter(Role.project == project)\n .distinct(User.username)\n .order_by(User.username)\n .all()\n )\n ]\n\n # Get the license from the classifiers or metadata, preferring classifiers.\n license = None\n if release.license:\n # Make a best effort when the entire license text is given\n # by using the first line only.\n license = release.license.split('\\n')[0]\n license_classifiers = [c.split(\" :: \")[-1] for c in release.classifiers\n if c.startswith(\"License\")]\n if license_classifiers:\n license = ', '.join(license_classifiers)\n\n return {\n \"project\": project,\n \"release\": release,\n \"files\": release.files.all(),\n \"latest_release\": latest_release,\n \"all_releases\": all_releases,\n \"maintainers\": maintainers,\n \"license\": license,\n }\n\n\n@view_config(\n route_name=\"includes.edit-project-button\",\n renderer=\"includes/manage-project-button.html\",\n uses_session=True,\n permission=\"manage\",\n)\ndef edit_project_button(project, request):\n return {'project': project}\n", "path": "warehouse/packaging/views.py"}]} | 2,193 | 334 |
gh_patches_debug_6317 | rasdani/github-patches | git_diff | DataDog__dd-trace-py-5558 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Algoliasearch non-text argument used in set_tag_str
See https://github.com/DataDog/dd-trace-py/pull/4727#issuecomment-1511668474, we changed a usage of `set_tag()` to `set_tag_str()` in our algoliasearch integration, but that patched function involves non-text arguments that `set_tag_str()` throws an error for.
</issue>
<code>
[start of ddtrace/contrib/algoliasearch/patch.py]
1 from ddtrace import config
2 from ddtrace.ext import SpanKind
3 from ddtrace.ext import SpanTypes
4 from ddtrace.internal.constants import COMPONENT
5 from ddtrace.internal.utils.wrappers import unwrap as _u
6 from ddtrace.pin import Pin
7 from ddtrace.vendor.wrapt import wrap_function_wrapper as _w
8
9 from .. import trace_utils
10 from ...constants import SPAN_KIND
11 from ...constants import SPAN_MEASURED_KEY
12
13
14 DD_PATCH_ATTR = "_datadog_patch"
15
16 SERVICE_NAME = "algoliasearch"
17 APP_NAME = "algoliasearch"
18
19 try:
20 import algoliasearch
21 from algoliasearch.version import VERSION
22
23 algoliasearch_version = tuple([int(i) for i in VERSION.split(".")])
24
25 # Default configuration
26 config._add("algoliasearch", dict(_default_service=SERVICE_NAME, collect_query_text=False))
27 except ImportError:
28 algoliasearch_version = (0, 0)
29
30
31 def patch():
32 if algoliasearch_version == (0, 0):
33 return
34
35 if getattr(algoliasearch, DD_PATCH_ATTR, False):
36 return
37
38 setattr(algoliasearch, "_datadog_patch", True)
39
40 pin = Pin()
41
42 if algoliasearch_version < (2, 0) and algoliasearch_version >= (1, 0):
43 _w(algoliasearch.index, "Index.search", _patched_search)
44 pin.onto(algoliasearch.index.Index)
45 elif algoliasearch_version >= (2, 0) and algoliasearch_version < (3, 0):
46 from algoliasearch import search_index
47
48 _w(algoliasearch, "search_index.SearchIndex.search", _patched_search)
49 pin.onto(search_index.SearchIndex)
50 else:
51 return
52
53
54 def unpatch():
55 if algoliasearch_version == (0, 0):
56 return
57
58 if getattr(algoliasearch, DD_PATCH_ATTR, False):
59 setattr(algoliasearch, DD_PATCH_ATTR, False)
60
61 if algoliasearch_version < (2, 0) and algoliasearch_version >= (1, 0):
62 _u(algoliasearch.index.Index, "search")
63 elif algoliasearch_version >= (2, 0) and algoliasearch_version < (3, 0):
64 from algoliasearch import search_index
65
66 _u(search_index.SearchIndex, "search")
67 else:
68 return
69
70
71 # DEV: this maps serves the dual purpose of enumerating the algoliasearch.search() query_args that
72 # will be sent along as tags, as well as converting arguments names into tag names compliant with
73 # tag naming recommendations set out here: https://docs.datadoghq.com/tagging/
74 QUERY_ARGS_DD_TAG_MAP = {
75 "page": "page",
76 "hitsPerPage": "hits_per_page",
77 "attributesToRetrieve": "attributes_to_retrieve",
78 "attributesToHighlight": "attributes_to_highlight",
79 "attributesToSnippet": "attributes_to_snippet",
80 "minWordSizefor1Typo": "min_word_size_for_1_typo",
81 "minWordSizefor2Typos": "min_word_size_for_2_typos",
82 "getRankingInfo": "get_ranking_info",
83 "aroundLatLng": "around_lat_lng",
84 "numericFilters": "numeric_filters",
85 "tagFilters": "tag_filters",
86 "queryType": "query_type",
87 "optionalWords": "optional_words",
88 "distinct": "distinct",
89 }
90
91
92 def _patched_search(func, instance, wrapt_args, wrapt_kwargs):
93 """
94 wrapt_args is called the way it is to distinguish it from the 'args'
95 argument to the algoliasearch.index.Index.search() method.
96 """
97
98 if algoliasearch_version < (2, 0) and algoliasearch_version >= (1, 0):
99 function_query_arg_name = "args"
100 elif algoliasearch_version >= (2, 0) and algoliasearch_version < (3, 0):
101 function_query_arg_name = "request_options"
102 else:
103 return func(*wrapt_args, **wrapt_kwargs)
104
105 pin = Pin.get_from(instance)
106 if not pin or not pin.enabled():
107 return func(*wrapt_args, **wrapt_kwargs)
108
109 with pin.tracer.trace(
110 "algoliasearch.search",
111 service=trace_utils.ext_service(pin, config.algoliasearch),
112 span_type=SpanTypes.HTTP,
113 ) as span:
114 span.set_tag_str(COMPONENT, config.algoliasearch.integration_name)
115
116 # set span.kind to the type of request being performed
117 span.set_tag_str(SPAN_KIND, SpanKind.CLIENT)
118
119 span.set_tag(SPAN_MEASURED_KEY)
120
121 if not span.sampled:
122 return func(*wrapt_args, **wrapt_kwargs)
123
124 if config.algoliasearch.collect_query_text:
125 span.set_tag_str("query.text", wrapt_kwargs.get("query", wrapt_args[0]))
126
127 query_args = wrapt_kwargs.get(function_query_arg_name, wrapt_args[1] if len(wrapt_args) > 1 else None)
128
129 if query_args and isinstance(query_args, dict):
130 for query_arg, tag_name in QUERY_ARGS_DD_TAG_MAP.items():
131 value = query_args.get(query_arg)
132 if value is not None:
133 span.set_tag_str("query.args.{}".format(tag_name), value)
134
135 # Result would look like this
136 # {
137 # 'hits': [
138 # {
139 # .... your search results ...
140 # }
141 # ],
142 # 'processingTimeMS': 1,
143 # 'nbHits': 1,
144 # 'hitsPerPage': 20,
145 # 'exhaustiveNbHits': true,
146 # 'params': 'query=xxx',
147 # 'nbPages': 1,
148 # 'query': 'xxx',
149 # 'page': 0
150 # }
151 result = func(*wrapt_args, **wrapt_kwargs)
152
153 if isinstance(result, dict):
154 if result.get("processingTimeMS", None) is not None:
155 span.set_metric("processing_time_ms", int(result["processingTimeMS"]))
156
157 if result.get("nbHits", None) is not None:
158 span.set_metric("number_of_hits", int(result["nbHits"]))
159
160 return result
161
[end of ddtrace/contrib/algoliasearch/patch.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/ddtrace/contrib/algoliasearch/patch.py b/ddtrace/contrib/algoliasearch/patch.py
--- a/ddtrace/contrib/algoliasearch/patch.py
+++ b/ddtrace/contrib/algoliasearch/patch.py
@@ -130,7 +130,7 @@
for query_arg, tag_name in QUERY_ARGS_DD_TAG_MAP.items():
value = query_args.get(query_arg)
if value is not None:
- span.set_tag_str("query.args.{}".format(tag_name), value)
+ span.set_tag("query.args.{}".format(tag_name), value)
# Result would look like this
# {
| {"golden_diff": "diff --git a/ddtrace/contrib/algoliasearch/patch.py b/ddtrace/contrib/algoliasearch/patch.py\n--- a/ddtrace/contrib/algoliasearch/patch.py\n+++ b/ddtrace/contrib/algoliasearch/patch.py\n@@ -130,7 +130,7 @@\n for query_arg, tag_name in QUERY_ARGS_DD_TAG_MAP.items():\n value = query_args.get(query_arg)\n if value is not None:\n- span.set_tag_str(\"query.args.{}\".format(tag_name), value)\n+ span.set_tag(\"query.args.{}\".format(tag_name), value)\n \n # Result would look like this\n # {\n", "issue": "Algoliasearch non-text argument used in set_tag_str\nSee https://github.com/DataDog/dd-trace-py/pull/4727#issuecomment-1511668474, we changed a usage of `set_tag()` to `set_tag_str()` in our algoliasearch integration, but that patched function involves non-text arguments that `set_tag_str()` throws an error for.\r\n\n", "before_files": [{"content": "from ddtrace import config\nfrom ddtrace.ext import SpanKind\nfrom ddtrace.ext import SpanTypes\nfrom ddtrace.internal.constants import COMPONENT\nfrom ddtrace.internal.utils.wrappers import unwrap as _u\nfrom ddtrace.pin import Pin\nfrom ddtrace.vendor.wrapt import wrap_function_wrapper as _w\n\nfrom .. import trace_utils\nfrom ...constants import SPAN_KIND\nfrom ...constants import SPAN_MEASURED_KEY\n\n\nDD_PATCH_ATTR = \"_datadog_patch\"\n\nSERVICE_NAME = \"algoliasearch\"\nAPP_NAME = \"algoliasearch\"\n\ntry:\n import algoliasearch\n from algoliasearch.version import VERSION\n\n algoliasearch_version = tuple([int(i) for i in VERSION.split(\".\")])\n\n # Default configuration\n config._add(\"algoliasearch\", dict(_default_service=SERVICE_NAME, collect_query_text=False))\nexcept ImportError:\n algoliasearch_version = (0, 0)\n\n\ndef patch():\n if algoliasearch_version == (0, 0):\n return\n\n if getattr(algoliasearch, DD_PATCH_ATTR, False):\n return\n\n setattr(algoliasearch, \"_datadog_patch\", True)\n\n pin = Pin()\n\n if algoliasearch_version < (2, 0) and algoliasearch_version >= (1, 0):\n _w(algoliasearch.index, \"Index.search\", _patched_search)\n pin.onto(algoliasearch.index.Index)\n elif algoliasearch_version >= (2, 0) and algoliasearch_version < (3, 0):\n from algoliasearch import search_index\n\n _w(algoliasearch, \"search_index.SearchIndex.search\", _patched_search)\n pin.onto(search_index.SearchIndex)\n else:\n return\n\n\ndef unpatch():\n if algoliasearch_version == (0, 0):\n return\n\n if getattr(algoliasearch, DD_PATCH_ATTR, False):\n setattr(algoliasearch, DD_PATCH_ATTR, False)\n\n if algoliasearch_version < (2, 0) and algoliasearch_version >= (1, 0):\n _u(algoliasearch.index.Index, \"search\")\n elif algoliasearch_version >= (2, 0) and algoliasearch_version < (3, 0):\n from algoliasearch import search_index\n\n _u(search_index.SearchIndex, \"search\")\n else:\n return\n\n\n# DEV: this maps serves the dual purpose of enumerating the algoliasearch.search() query_args that\n# will be sent along as tags, as well as converting arguments names into tag names compliant with\n# tag naming recommendations set out here: https://docs.datadoghq.com/tagging/\nQUERY_ARGS_DD_TAG_MAP = {\n \"page\": \"page\",\n \"hitsPerPage\": \"hits_per_page\",\n \"attributesToRetrieve\": \"attributes_to_retrieve\",\n \"attributesToHighlight\": \"attributes_to_highlight\",\n \"attributesToSnippet\": \"attributes_to_snippet\",\n \"minWordSizefor1Typo\": \"min_word_size_for_1_typo\",\n \"minWordSizefor2Typos\": \"min_word_size_for_2_typos\",\n \"getRankingInfo\": \"get_ranking_info\",\n \"aroundLatLng\": \"around_lat_lng\",\n \"numericFilters\": \"numeric_filters\",\n \"tagFilters\": \"tag_filters\",\n \"queryType\": \"query_type\",\n \"optionalWords\": \"optional_words\",\n \"distinct\": \"distinct\",\n}\n\n\ndef _patched_search(func, instance, wrapt_args, wrapt_kwargs):\n \"\"\"\n wrapt_args is called the way it is to distinguish it from the 'args'\n argument to the algoliasearch.index.Index.search() method.\n \"\"\"\n\n if algoliasearch_version < (2, 0) and algoliasearch_version >= (1, 0):\n function_query_arg_name = \"args\"\n elif algoliasearch_version >= (2, 0) and algoliasearch_version < (3, 0):\n function_query_arg_name = \"request_options\"\n else:\n return func(*wrapt_args, **wrapt_kwargs)\n\n pin = Pin.get_from(instance)\n if not pin or not pin.enabled():\n return func(*wrapt_args, **wrapt_kwargs)\n\n with pin.tracer.trace(\n \"algoliasearch.search\",\n service=trace_utils.ext_service(pin, config.algoliasearch),\n span_type=SpanTypes.HTTP,\n ) as span:\n span.set_tag_str(COMPONENT, config.algoliasearch.integration_name)\n\n # set span.kind to the type of request being performed\n span.set_tag_str(SPAN_KIND, SpanKind.CLIENT)\n\n span.set_tag(SPAN_MEASURED_KEY)\n\n if not span.sampled:\n return func(*wrapt_args, **wrapt_kwargs)\n\n if config.algoliasearch.collect_query_text:\n span.set_tag_str(\"query.text\", wrapt_kwargs.get(\"query\", wrapt_args[0]))\n\n query_args = wrapt_kwargs.get(function_query_arg_name, wrapt_args[1] if len(wrapt_args) > 1 else None)\n\n if query_args and isinstance(query_args, dict):\n for query_arg, tag_name in QUERY_ARGS_DD_TAG_MAP.items():\n value = query_args.get(query_arg)\n if value is not None:\n span.set_tag_str(\"query.args.{}\".format(tag_name), value)\n\n # Result would look like this\n # {\n # 'hits': [\n # {\n # .... your search results ...\n # }\n # ],\n # 'processingTimeMS': 1,\n # 'nbHits': 1,\n # 'hitsPerPage': 20,\n # 'exhaustiveNbHits': true,\n # 'params': 'query=xxx',\n # 'nbPages': 1,\n # 'query': 'xxx',\n # 'page': 0\n # }\n result = func(*wrapt_args, **wrapt_kwargs)\n\n if isinstance(result, dict):\n if result.get(\"processingTimeMS\", None) is not None:\n span.set_metric(\"processing_time_ms\", int(result[\"processingTimeMS\"]))\n\n if result.get(\"nbHits\", None) is not None:\n span.set_metric(\"number_of_hits\", int(result[\"nbHits\"]))\n\n return result\n", "path": "ddtrace/contrib/algoliasearch/patch.py"}]} | 2,437 | 150 |
gh_patches_debug_37913 | rasdani/github-patches | git_diff | google__osv.dev-316 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Make version indexes more scalable.
Currently, all indexes for package+version are stored in the same `Bug` entity.
This has large benefits in terms of read/write latency and consistency, but we are now seeing some entries with large fanout of these indexes (high package count x version count).
Some options here
- Use partial indexes (package count + version count) and rely on Datastore's zig zag merge. Will need to evaluate performance here.
- Break out indexes into its own separate entity.
</issue>
<code>
[start of gcp/api/server.py]
1 # Copyright 2021 Google LLC
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 """API server implementation."""
15
16 import argparse
17 from concurrent import futures
18 import functools
19 import logging
20 import os
21 import sys
22 import time
23
24 from google.cloud import ndb
25 import grpc
26 from packageurl import PackageURL
27
28 import osv
29 from osv import ecosystems
30 from osv import semver_index
31 import osv_service_v1_pb2
32 import osv_service_v1_pb2_grpc
33
34 _PROJECT = 'oss-vdb'
35 _OSS_FUZZ_TRACKER_URL = 'https://bugs.chromium.org/p/oss-fuzz/issues/detail?id='
36
37 _SHUTDOWN_GRACE_DURATION = 5
38
39 _AUTHORIZATION_HEADER_PREFIX = 'Bearer '
40 _EXPECTED_AUDIENCE = 'https://db.oss-fuzz.com'
41
42 _ndb_client = ndb.Client()
43
44
45 def ndb_context(func):
46 """Wrapper to create an NDB context."""
47
48 @functools.wraps(func)
49 def wrapper(*args, **kwargs):
50 with _ndb_client.context():
51 return func(*args, **kwargs)
52
53 return wrapper
54
55
56 class OSVServicer(osv_service_v1_pb2_grpc.OSVServicer):
57 """V1 OSV servicer."""
58
59 @ndb_context
60 def GetVulnById(self, request, context):
61 """Return a `Vulnerability` object for a given OSV ID.
62 """
63 bug = osv.Bug.get_by_id(request.id)
64 if not bug or bug.status == osv.BugStatus.UNPROCESSED:
65 context.abort(grpc.StatusCode.NOT_FOUND, 'Bug not found.')
66 return None
67
68 if not bug.public:
69 context.abort(grpc.StatusCode.PERMISSION_DENIED, 'Permission denied.')
70 return None
71
72 return bug_to_response(bug)
73
74 @ndb_context
75 def QueryAffected(self, request, context):
76 """Query vulnerabilities for a particular project at a given commit or
77 version."""
78 if request.query.HasField('package'):
79 package_name = request.query.package.name
80 ecosystem = request.query.package.ecosystem
81 purl = request.query.package.purl
82 else:
83 package_name = ''
84 ecosystem = ''
85 purl = ''
86
87 purl_version = None
88 if purl:
89 try:
90 parsed_purl = PackageURL.from_string(purl)
91 purl_version = parsed_purl.version
92 purl = _clean_purl(parsed_purl).to_string()
93 except ValueError:
94 context.abort(grpc.StatusCode.INVALID_ARGUMENT, 'Invalid Package URL.')
95 return None
96
97 if request.query.WhichOneof('param') == 'commit':
98 bugs = query_by_commit(request.query.commit, to_response=bug_to_response)
99 elif purl and purl_version:
100 bugs = query_by_version(
101 package_name,
102 ecosystem,
103 purl,
104 purl_version,
105 to_response=bug_to_response)
106 elif request.query.WhichOneof('param') == 'version':
107 bugs = query_by_version(
108 package_name,
109 ecosystem,
110 purl,
111 request.query.version,
112 to_response=bug_to_response)
113 else:
114 context.abort(grpc.StatusCode.INVALID_ARGUMENT, 'Invalid query.')
115 return None
116
117 return osv_service_v1_pb2.VulnerabilityList(vulns=bugs)
118
119 def GetVulnByIdNew(self, request, context):
120 """Return a `Vulnerability` object for a given OSV ID.
121 """
122 return self.GetVulnById(request, context)
123
124 def QueryAffectedNew(self, request, context):
125 """Query vulnerabilities for a particular project at a given commit or
126 version."""
127 return self.QueryAffected(request, context)
128
129
130 def bug_to_response(bug):
131 """Convert a Bug entity to a response object."""
132 return bug.to_vulnerability(include_source=True)
133
134
135 def _get_bugs(bug_ids, to_response=bug_to_response):
136 """Get bugs from bug ids."""
137 bugs = ndb.get_multi([ndb.Key(osv.Bug, bug_id) for bug_id in bug_ids])
138 return [
139 to_response(bug)
140 for bug in bugs
141 if bug and bug.status == osv.BugStatus.PROCESSED
142 ]
143
144
145 def _clean_purl(purl):
146 """Clean a purl object."""
147 values = purl.to_dict()
148 values.pop('version', None)
149 values.pop('subpath', None)
150 values.pop('qualifiers', None)
151 return PackageURL(**values)
152
153
154 def query_by_commit(commit, to_response=bug_to_response):
155 """Query by commit."""
156 query = osv.AffectedCommit.query(osv.AffectedCommit.commit == commit,
157 osv.AffectedCommit.public == True) # pylint: disable=singleton-comparison
158 bug_ids = []
159 for affected_commit in query:
160 bug_ids.append(affected_commit.bug_id)
161
162 return _get_bugs(bug_ids, to_response=to_response)
163
164
165 def _is_semver_affected(affected_packages, package_name, ecosystem, purl,
166 version):
167 """Returns whether or not the given version is within an affected SEMVER
168 range."""
169 version = semver_index.parse(version)
170
171 affected = False
172 for affected_package in affected_packages:
173 if package_name and package_name != affected_package.package.name:
174 continue
175
176 if ecosystem and ecosystem != affected_package.package.ecosystem:
177 continue
178
179 if purl and purl != affected_package.package.purl:
180 continue
181
182 for affected_range in affected_package.ranges:
183 if affected_range.type != 'SEMVER':
184 continue
185
186 for event in osv.sorted_events('', affected_range.type,
187 affected_range.events):
188 if (event.type == 'introduced' and
189 (event.value == '0' or version >= semver_index.parse(event.value))):
190 affected = True
191
192 if event.type == 'fixed' and version >= semver_index.parse(event.value):
193 affected = False
194
195 return affected
196
197
198 def _query_by_semver(query, package_name, ecosystem, purl, version):
199 """Query by semver."""
200 if not semver_index.is_valid(version):
201 return []
202
203 query = query.filter(
204 osv.Bug.semver_fixed_indexes > semver_index.normalize(version))
205
206 return [
207 bug for bug in query if _is_semver_affected(
208 bug.affected_packages, package_name, ecosystem, purl, version)
209 ]
210
211
212 def _query_by_generic_version(base_query, version):
213 """Query by generic version."""
214 # Try without normalizing.
215 query = base_query.filter(osv.Bug.affected_fuzzy == version)
216 results = list(query)
217 if results:
218 return results
219
220 # Try again after normalizing.
221 query = base_query.filter(
222 osv.Bug.affected_fuzzy == osv.normalize_tag(version))
223 return list(query)
224
225
226 def query_by_version(project,
227 ecosystem,
228 purl,
229 version,
230 to_response=bug_to_response):
231 """Query by (fuzzy) version."""
232 ecosystem_info = ecosystems.get(ecosystem)
233 is_semver = ecosystem_info and ecosystem_info.is_semver
234 if project:
235 query = osv.Bug.query(osv.Bug.status == osv.BugStatus.PROCESSED,
236 osv.Bug.project == project, osv.Bug.public == True) # pylint: disable=singleton-comparison
237 elif purl:
238 query = osv.Bug.query(osv.Bug.status == osv.BugStatus.PROCESSED,
239 osv.Bug.purl == purl, osv.Bug.public == True) # pylint: disable=singleton-comparison
240 else:
241 return []
242
243 if ecosystem:
244 query = query.filter(osv.Bug.ecosystem == ecosystem)
245
246 bugs = []
247 if ecosystem:
248 if is_semver:
249 # Ecosystem supports semver only.
250 bugs.extend(_query_by_semver(query, project, ecosystem, purl, version))
251 else:
252 bugs.extend(_query_by_generic_version(query, version))
253 else:
254 # Unspecified ecosystem. Try both.
255 bugs.extend(_query_by_semver(query, project, ecosystem, purl, version))
256 bugs.extend(_query_by_generic_version(query, version))
257
258 return [to_response(bug) for bug in bugs]
259
260
261 def serve(port):
262 """Configures and runs the bookstore API server."""
263 server = grpc.server(futures.ThreadPoolExecutor(max_workers=10))
264 osv_service_v1_pb2_grpc.add_OSVServicer_to_server(OSVServicer(), server)
265 server.add_insecure_port('[::]:{}'.format(port))
266 server.start()
267
268 print('Listening on port {}'.format(port))
269 try:
270 while True:
271 time.sleep(3600)
272 except KeyboardInterrupt:
273 server.stop(_SHUTDOWN_GRACE_DURATION)
274
275
276 def main():
277 """Entrypoint."""
278 logging.basicConfig(stream=sys.stderr)
279 logging.getLogger().setLevel(logging.INFO)
280
281 parser = argparse.ArgumentParser(
282 formatter_class=argparse.RawDescriptionHelpFormatter)
283 parser.add_argument(
284 '--port',
285 type=int,
286 default=None,
287 help='The port to listen on.'
288 'If arg is not set, will listen on the $PORT env var.'
289 'If env var is empty, defaults to 8000.')
290
291 args = parser.parse_args()
292 port = args.port
293 if not port:
294 port = os.environ.get('PORT')
295 if not port:
296 port = 8000
297
298 serve(port)
299
300
301 if __name__ == '__main__':
302 main()
303
[end of gcp/api/server.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/gcp/api/server.py b/gcp/api/server.py
--- a/gcp/api/server.py
+++ b/gcp/api/server.py
@@ -195,6 +195,36 @@
return affected
+def _is_version_affected(affected_packages,
+ package_name,
+ ecosystem,
+ purl,
+ version,
+ normalize=False):
+ """Returns whether or not the given version is within an affected ECOSYSTEM
+ range."""
+ for affected_package in affected_packages:
+ if package_name and package_name != affected_package.package.name:
+ continue
+
+ if ecosystem and ecosystem != affected_package.package.ecosystem:
+ continue
+
+ if purl and purl != affected_package.package.purl:
+ continue
+
+ if normalize:
+ if any(
+ osv.normalize_tag(version) == osv.normalize_tag(v)
+ for v in affected_package.versions):
+ return True
+ else:
+ if version in affected_package.versions:
+ return True
+
+ return False
+
+
def _query_by_semver(query, package_name, ecosystem, purl, version):
"""Query by semver."""
if not semver_index.is_valid(version):
@@ -209,18 +239,29 @@
]
-def _query_by_generic_version(base_query, version):
+def _query_by_generic_version(base_query, project, ecosystem, purl, version):
"""Query by generic version."""
# Try without normalizing.
query = base_query.filter(osv.Bug.affected_fuzzy == version)
- results = list(query)
+ results = [
+ bug for bug in query if _is_version_affected(
+ bug.affected_packages, project, ecosystem, purl, version)
+ ]
if results:
return results
# Try again after normalizing.
- query = base_query.filter(
- osv.Bug.affected_fuzzy == osv.normalize_tag(version))
- return list(query)
+ version = osv.normalize_tag(version)
+ query = base_query.filter(osv.Bug.affected_fuzzy == version)
+ return [
+ bug for bug in query if _is_version_affected(
+ bug.affected_packages,
+ project,
+ ecosystem,
+ purl,
+ version,
+ normalize=True)
+ ]
def query_by_version(project,
@@ -249,11 +290,13 @@
# Ecosystem supports semver only.
bugs.extend(_query_by_semver(query, project, ecosystem, purl, version))
else:
- bugs.extend(_query_by_generic_version(query, version))
+ bugs.extend(
+ _query_by_generic_version(query, project, ecosystem, purl, version))
else:
# Unspecified ecosystem. Try both.
bugs.extend(_query_by_semver(query, project, ecosystem, purl, version))
- bugs.extend(_query_by_generic_version(query, version))
+ bugs.extend(
+ _query_by_generic_version(query, project, ecosystem, purl, version))
return [to_response(bug) for bug in bugs]
| {"golden_diff": "diff --git a/gcp/api/server.py b/gcp/api/server.py\n--- a/gcp/api/server.py\n+++ b/gcp/api/server.py\n@@ -195,6 +195,36 @@\n return affected\n \n \n+def _is_version_affected(affected_packages,\n+ package_name,\n+ ecosystem,\n+ purl,\n+ version,\n+ normalize=False):\n+ \"\"\"Returns whether or not the given version is within an affected ECOSYSTEM\n+ range.\"\"\"\n+ for affected_package in affected_packages:\n+ if package_name and package_name != affected_package.package.name:\n+ continue\n+\n+ if ecosystem and ecosystem != affected_package.package.ecosystem:\n+ continue\n+\n+ if purl and purl != affected_package.package.purl:\n+ continue\n+\n+ if normalize:\n+ if any(\n+ osv.normalize_tag(version) == osv.normalize_tag(v)\n+ for v in affected_package.versions):\n+ return True\n+ else:\n+ if version in affected_package.versions:\n+ return True\n+\n+ return False\n+\n+\n def _query_by_semver(query, package_name, ecosystem, purl, version):\n \"\"\"Query by semver.\"\"\"\n if not semver_index.is_valid(version):\n@@ -209,18 +239,29 @@\n ]\n \n \n-def _query_by_generic_version(base_query, version):\n+def _query_by_generic_version(base_query, project, ecosystem, purl, version):\n \"\"\"Query by generic version.\"\"\"\n # Try without normalizing.\n query = base_query.filter(osv.Bug.affected_fuzzy == version)\n- results = list(query)\n+ results = [\n+ bug for bug in query if _is_version_affected(\n+ bug.affected_packages, project, ecosystem, purl, version)\n+ ]\n if results:\n return results\n \n # Try again after normalizing.\n- query = base_query.filter(\n- osv.Bug.affected_fuzzy == osv.normalize_tag(version))\n- return list(query)\n+ version = osv.normalize_tag(version)\n+ query = base_query.filter(osv.Bug.affected_fuzzy == version)\n+ return [\n+ bug for bug in query if _is_version_affected(\n+ bug.affected_packages,\n+ project,\n+ ecosystem,\n+ purl,\n+ version,\n+ normalize=True)\n+ ]\n \n \n def query_by_version(project,\n@@ -249,11 +290,13 @@\n # Ecosystem supports semver only.\n bugs.extend(_query_by_semver(query, project, ecosystem, purl, version))\n else:\n- bugs.extend(_query_by_generic_version(query, version))\n+ bugs.extend(\n+ _query_by_generic_version(query, project, ecosystem, purl, version))\n else:\n # Unspecified ecosystem. Try both.\n bugs.extend(_query_by_semver(query, project, ecosystem, purl, version))\n- bugs.extend(_query_by_generic_version(query, version))\n+ bugs.extend(\n+ _query_by_generic_version(query, project, ecosystem, purl, version))\n \n return [to_response(bug) for bug in bugs]\n", "issue": "Make version indexes more scalable.\nCurrently, all indexes for package+version are stored in the same `Bug` entity. \r\n\r\nThis has large benefits in terms of read/write latency and consistency, but we are now seeing some entries with large fanout of these indexes (high package count x version count).\r\n\r\nSome options here\r\n- Use partial indexes (package count + version count) and rely on Datastore's zig zag merge. Will need to evaluate performance here.\r\n- Break out indexes into its own separate entity. \n", "before_files": [{"content": "# Copyright 2021 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"API server implementation.\"\"\"\n\nimport argparse\nfrom concurrent import futures\nimport functools\nimport logging\nimport os\nimport sys\nimport time\n\nfrom google.cloud import ndb\nimport grpc\nfrom packageurl import PackageURL\n\nimport osv\nfrom osv import ecosystems\nfrom osv import semver_index\nimport osv_service_v1_pb2\nimport osv_service_v1_pb2_grpc\n\n_PROJECT = 'oss-vdb'\n_OSS_FUZZ_TRACKER_URL = 'https://bugs.chromium.org/p/oss-fuzz/issues/detail?id='\n\n_SHUTDOWN_GRACE_DURATION = 5\n\n_AUTHORIZATION_HEADER_PREFIX = 'Bearer '\n_EXPECTED_AUDIENCE = 'https://db.oss-fuzz.com'\n\n_ndb_client = ndb.Client()\n\n\ndef ndb_context(func):\n \"\"\"Wrapper to create an NDB context.\"\"\"\n\n @functools.wraps(func)\n def wrapper(*args, **kwargs):\n with _ndb_client.context():\n return func(*args, **kwargs)\n\n return wrapper\n\n\nclass OSVServicer(osv_service_v1_pb2_grpc.OSVServicer):\n \"\"\"V1 OSV servicer.\"\"\"\n\n @ndb_context\n def GetVulnById(self, request, context):\n \"\"\"Return a `Vulnerability` object for a given OSV ID.\n \"\"\"\n bug = osv.Bug.get_by_id(request.id)\n if not bug or bug.status == osv.BugStatus.UNPROCESSED:\n context.abort(grpc.StatusCode.NOT_FOUND, 'Bug not found.')\n return None\n\n if not bug.public:\n context.abort(grpc.StatusCode.PERMISSION_DENIED, 'Permission denied.')\n return None\n\n return bug_to_response(bug)\n\n @ndb_context\n def QueryAffected(self, request, context):\n \"\"\"Query vulnerabilities for a particular project at a given commit or\n version.\"\"\"\n if request.query.HasField('package'):\n package_name = request.query.package.name\n ecosystem = request.query.package.ecosystem\n purl = request.query.package.purl\n else:\n package_name = ''\n ecosystem = ''\n purl = ''\n\n purl_version = None\n if purl:\n try:\n parsed_purl = PackageURL.from_string(purl)\n purl_version = parsed_purl.version\n purl = _clean_purl(parsed_purl).to_string()\n except ValueError:\n context.abort(grpc.StatusCode.INVALID_ARGUMENT, 'Invalid Package URL.')\n return None\n\n if request.query.WhichOneof('param') == 'commit':\n bugs = query_by_commit(request.query.commit, to_response=bug_to_response)\n elif purl and purl_version:\n bugs = query_by_version(\n package_name,\n ecosystem,\n purl,\n purl_version,\n to_response=bug_to_response)\n elif request.query.WhichOneof('param') == 'version':\n bugs = query_by_version(\n package_name,\n ecosystem,\n purl,\n request.query.version,\n to_response=bug_to_response)\n else:\n context.abort(grpc.StatusCode.INVALID_ARGUMENT, 'Invalid query.')\n return None\n\n return osv_service_v1_pb2.VulnerabilityList(vulns=bugs)\n\n def GetVulnByIdNew(self, request, context):\n \"\"\"Return a `Vulnerability` object for a given OSV ID.\n \"\"\"\n return self.GetVulnById(request, context)\n\n def QueryAffectedNew(self, request, context):\n \"\"\"Query vulnerabilities for a particular project at a given commit or\n version.\"\"\"\n return self.QueryAffected(request, context)\n\n\ndef bug_to_response(bug):\n \"\"\"Convert a Bug entity to a response object.\"\"\"\n return bug.to_vulnerability(include_source=True)\n\n\ndef _get_bugs(bug_ids, to_response=bug_to_response):\n \"\"\"Get bugs from bug ids.\"\"\"\n bugs = ndb.get_multi([ndb.Key(osv.Bug, bug_id) for bug_id in bug_ids])\n return [\n to_response(bug)\n for bug in bugs\n if bug and bug.status == osv.BugStatus.PROCESSED\n ]\n\n\ndef _clean_purl(purl):\n \"\"\"Clean a purl object.\"\"\"\n values = purl.to_dict()\n values.pop('version', None)\n values.pop('subpath', None)\n values.pop('qualifiers', None)\n return PackageURL(**values)\n\n\ndef query_by_commit(commit, to_response=bug_to_response):\n \"\"\"Query by commit.\"\"\"\n query = osv.AffectedCommit.query(osv.AffectedCommit.commit == commit,\n osv.AffectedCommit.public == True) # pylint: disable=singleton-comparison\n bug_ids = []\n for affected_commit in query:\n bug_ids.append(affected_commit.bug_id)\n\n return _get_bugs(bug_ids, to_response=to_response)\n\n\ndef _is_semver_affected(affected_packages, package_name, ecosystem, purl,\n version):\n \"\"\"Returns whether or not the given version is within an affected SEMVER\n range.\"\"\"\n version = semver_index.parse(version)\n\n affected = False\n for affected_package in affected_packages:\n if package_name and package_name != affected_package.package.name:\n continue\n\n if ecosystem and ecosystem != affected_package.package.ecosystem:\n continue\n\n if purl and purl != affected_package.package.purl:\n continue\n\n for affected_range in affected_package.ranges:\n if affected_range.type != 'SEMVER':\n continue\n\n for event in osv.sorted_events('', affected_range.type,\n affected_range.events):\n if (event.type == 'introduced' and\n (event.value == '0' or version >= semver_index.parse(event.value))):\n affected = True\n\n if event.type == 'fixed' and version >= semver_index.parse(event.value):\n affected = False\n\n return affected\n\n\ndef _query_by_semver(query, package_name, ecosystem, purl, version):\n \"\"\"Query by semver.\"\"\"\n if not semver_index.is_valid(version):\n return []\n\n query = query.filter(\n osv.Bug.semver_fixed_indexes > semver_index.normalize(version))\n\n return [\n bug for bug in query if _is_semver_affected(\n bug.affected_packages, package_name, ecosystem, purl, version)\n ]\n\n\ndef _query_by_generic_version(base_query, version):\n \"\"\"Query by generic version.\"\"\"\n # Try without normalizing.\n query = base_query.filter(osv.Bug.affected_fuzzy == version)\n results = list(query)\n if results:\n return results\n\n # Try again after normalizing.\n query = base_query.filter(\n osv.Bug.affected_fuzzy == osv.normalize_tag(version))\n return list(query)\n\n\ndef query_by_version(project,\n ecosystem,\n purl,\n version,\n to_response=bug_to_response):\n \"\"\"Query by (fuzzy) version.\"\"\"\n ecosystem_info = ecosystems.get(ecosystem)\n is_semver = ecosystem_info and ecosystem_info.is_semver\n if project:\n query = osv.Bug.query(osv.Bug.status == osv.BugStatus.PROCESSED,\n osv.Bug.project == project, osv.Bug.public == True) # pylint: disable=singleton-comparison\n elif purl:\n query = osv.Bug.query(osv.Bug.status == osv.BugStatus.PROCESSED,\n osv.Bug.purl == purl, osv.Bug.public == True) # pylint: disable=singleton-comparison\n else:\n return []\n\n if ecosystem:\n query = query.filter(osv.Bug.ecosystem == ecosystem)\n\n bugs = []\n if ecosystem:\n if is_semver:\n # Ecosystem supports semver only.\n bugs.extend(_query_by_semver(query, project, ecosystem, purl, version))\n else:\n bugs.extend(_query_by_generic_version(query, version))\n else:\n # Unspecified ecosystem. Try both.\n bugs.extend(_query_by_semver(query, project, ecosystem, purl, version))\n bugs.extend(_query_by_generic_version(query, version))\n\n return [to_response(bug) for bug in bugs]\n\n\ndef serve(port):\n \"\"\"Configures and runs the bookstore API server.\"\"\"\n server = grpc.server(futures.ThreadPoolExecutor(max_workers=10))\n osv_service_v1_pb2_grpc.add_OSVServicer_to_server(OSVServicer(), server)\n server.add_insecure_port('[::]:{}'.format(port))\n server.start()\n\n print('Listening on port {}'.format(port))\n try:\n while True:\n time.sleep(3600)\n except KeyboardInterrupt:\n server.stop(_SHUTDOWN_GRACE_DURATION)\n\n\ndef main():\n \"\"\"Entrypoint.\"\"\"\n logging.basicConfig(stream=sys.stderr)\n logging.getLogger().setLevel(logging.INFO)\n\n parser = argparse.ArgumentParser(\n formatter_class=argparse.RawDescriptionHelpFormatter)\n parser.add_argument(\n '--port',\n type=int,\n default=None,\n help='The port to listen on.'\n 'If arg is not set, will listen on the $PORT env var.'\n 'If env var is empty, defaults to 8000.')\n\n args = parser.parse_args()\n port = args.port\n if not port:\n port = os.environ.get('PORT')\n if not port:\n port = 8000\n\n serve(port)\n\n\nif __name__ == '__main__':\n main()\n", "path": "gcp/api/server.py"}]} | 3,641 | 698 |
gh_patches_debug_19766 | rasdani/github-patches | git_diff | explosion__spaCy-1448 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
TokenVectorEncoder object is not iterable when running example in 2.0 alpha
Im trying to run one of the examples in 2.0.0 alpha, for extending a pre existing model with
custom ner tags avaliable here [1],
here is the error i get:
```
$ python train_new_entity_type.py en othersame
Creating initial model en
Traceback (most recent call last):
File "train_new_entity_type.py", line 124, in <module>
plac.call(main)
File "/home/data/experim/spc/sp2env/lib/python2.7/site-packages/plac_core.py", line 328, in call
cmd, result = parser.consume(arglist)
File "/home/data/experim/spc/sp2env/lib/python2.7/site-packages/plac_core.py", line 207, in consume
return cmd, self.func(*(args + varargs + extraopts), **kwargs)
File "train_new_entity_type.py", line 106, in main
train_ner(nlp, train_data, output_directory)
File "train_new_entity_type.py", line 53, in train_ner
optimizer = nlp.begin_training(lambda: [])
File "/home/data/experim/spc/sp2env/lib/python2.7/site-packages/spacy/language.py", line 410, in begin_training
for name, proc in self.pipeline:
TypeError: 'TokenVectorEncoder' object is not iterable
```
I expected to get this to work, as its already documented here [2],
all the models and spacy install are recent and fresh installs (21st october).
## Your Environment
```
Info about spaCy
Python version 2.7.13
Platform Linux-4.11.12-100.fc24.x86_64-x86_64-with-fedora-24-Twenty_Four
spaCy version 2.0.0a17
Location /home/data/experim/spc/sp2env/lib/python2.7/site-packages/spacy
Models en_core_web_sm, en_core_web_lg
```
* Operating System: Fedora Linux
* Python Version Used: Python 2.7.13 reproducible with 3.5.3
* spaCy Version Used: 2.0.0a17
* Environment Information:
[ 1] https://github.com/explosion/spaCy/blob/develop/examples/training/train_new_entity_type.py
[ 2] https://alpha.spacy.io/usage/training#example-new-entity-type
</issue>
<code>
[start of examples/training/train_new_entity_type.py]
1 #!/usr/bin/env python
2 # coding: utf8
3 """
4 Example of training an additional entity type
5
6 This script shows how to add a new entity type to an existing pre-trained NER
7 model. To keep the example short and simple, only four sentences are provided
8 as examples. In practice, you'll need many more — a few hundred would be a
9 good start. You will also likely need to mix in examples of other entity
10 types, which might be obtained by running the entity recognizer over unlabelled
11 sentences, and adding their annotations to the training set.
12
13 The actual training is performed by looping over the examples, and calling
14 `nlp.entity.update()`. The `update()` method steps through the words of the
15 input. At each word, it makes a prediction. It then consults the annotations
16 provided on the GoldParse instance, to see whether it was right. If it was
17 wrong, it adjusts its weights so that the correct action will score higher
18 next time.
19
20 After training your model, you can save it to a directory. We recommend
21 wrapping models as Python packages, for ease of deployment.
22
23 For more details, see the documentation:
24 * Training the Named Entity Recognizer: https://spacy.io/docs/usage/train-ner
25 * Saving and loading models: https://spacy.io/docs/usage/saving-loading
26
27 Developed for: spaCy 1.7.6
28 Last updated for: spaCy 2.0.0a13
29 """
30 from __future__ import unicode_literals, print_function
31
32 import random
33 from pathlib import Path
34 import random
35
36 import spacy
37 from spacy.gold import GoldParse, minibatch
38 from spacy.pipeline import NeuralEntityRecognizer
39 from spacy.pipeline import TokenVectorEncoder
40
41
42 def get_gold_parses(tokenizer, train_data):
43 '''Shuffle and create GoldParse objects'''
44 random.shuffle(train_data)
45 for raw_text, entity_offsets in train_data:
46 doc = tokenizer(raw_text)
47 gold = GoldParse(doc, entities=entity_offsets)
48 yield doc, gold
49
50
51 def train_ner(nlp, train_data, output_dir):
52 random.seed(0)
53 optimizer = nlp.begin_training(lambda: [])
54 nlp.meta['name'] = 'en_ent_animal'
55 for itn in range(50):
56 losses = {}
57 for batch in minibatch(get_gold_parses(nlp.make_doc, train_data), size=3):
58 docs, golds = zip(*batch)
59 nlp.update(docs, golds, losses=losses, sgd=optimizer, update_shared=True,
60 drop=0.35)
61 print(losses)
62 if not output_dir:
63 return
64 elif not output_dir.exists():
65 output_dir.mkdir()
66 nlp.to_disk(output_dir)
67
68
69 def main(model_name, output_directory=None):
70 print("Creating initial model", model_name)
71 nlp = spacy.blank(model_name)
72 if output_directory is not None:
73 output_directory = Path(output_directory)
74
75 train_data = [
76 (
77 "Horses are too tall and they pretend to care about your feelings",
78 [(0, 6, 'ANIMAL')],
79 ),
80 (
81 "Do they bite?",
82 [],
83 ),
84
85 (
86 "horses are too tall and they pretend to care about your feelings",
87 [(0, 6, 'ANIMAL')]
88 ),
89 (
90 "horses pretend to care about your feelings",
91 [(0, 6, 'ANIMAL')]
92 ),
93 (
94 "they pretend to care about your feelings, those horses",
95 [(48, 54, 'ANIMAL')]
96 ),
97 (
98 "horses?",
99 [(0, 6, 'ANIMAL')]
100 )
101
102 ]
103 nlp.pipeline.append(TokenVectorEncoder(nlp.vocab))
104 nlp.pipeline.append(NeuralEntityRecognizer(nlp.vocab))
105 nlp.pipeline[-1].add_label('ANIMAL')
106 train_ner(nlp, train_data, output_directory)
107
108 # Test that the entity is recognized
109 text = 'Do you like horses?'
110 print("Ents in 'Do you like horses?':")
111 doc = nlp(text)
112 for ent in doc.ents:
113 print(ent.label_, ent.text)
114 if output_directory:
115 print("Loading from", output_directory)
116 nlp2 = spacy.load(output_directory)
117 doc2 = nlp2('Do you like horses?')
118 for ent in doc2.ents:
119 print(ent.label_, ent.text)
120
121
122 if __name__ == '__main__':
123 import plac
124 plac.call(main)
125
[end of examples/training/train_new_entity_type.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/examples/training/train_new_entity_type.py b/examples/training/train_new_entity_type.py
--- a/examples/training/train_new_entity_type.py
+++ b/examples/training/train_new_entity_type.py
@@ -56,8 +56,7 @@
losses = {}
for batch in minibatch(get_gold_parses(nlp.make_doc, train_data), size=3):
docs, golds = zip(*batch)
- nlp.update(docs, golds, losses=losses, sgd=optimizer, update_shared=True,
- drop=0.35)
+ nlp.update(docs, golds, losses=losses, sgd=optimizer, drop=0.35)
print(losses)
if not output_dir:
return
@@ -100,9 +99,10 @@
)
]
- nlp.pipeline.append(TokenVectorEncoder(nlp.vocab))
- nlp.pipeline.append(NeuralEntityRecognizer(nlp.vocab))
- nlp.pipeline[-1].add_label('ANIMAL')
+ nlp.add_pipe(TokenVectorEncoder(nlp.vocab))
+ ner = NeuralEntityRecognizer(nlp.vocab)
+ ner.add_label('ANIMAL')
+ nlp.add_pipe(ner)
train_ner(nlp, train_data, output_directory)
# Test that the entity is recognized
| {"golden_diff": "diff --git a/examples/training/train_new_entity_type.py b/examples/training/train_new_entity_type.py\n--- a/examples/training/train_new_entity_type.py\n+++ b/examples/training/train_new_entity_type.py\n@@ -56,8 +56,7 @@\n losses = {}\n for batch in minibatch(get_gold_parses(nlp.make_doc, train_data), size=3):\n docs, golds = zip(*batch)\n- nlp.update(docs, golds, losses=losses, sgd=optimizer, update_shared=True,\n- drop=0.35)\n+ nlp.update(docs, golds, losses=losses, sgd=optimizer, drop=0.35)\n print(losses)\n if not output_dir:\n return\n@@ -100,9 +99,10 @@\n )\n \n ]\n- nlp.pipeline.append(TokenVectorEncoder(nlp.vocab))\n- nlp.pipeline.append(NeuralEntityRecognizer(nlp.vocab))\n- nlp.pipeline[-1].add_label('ANIMAL')\n+ nlp.add_pipe(TokenVectorEncoder(nlp.vocab))\n+ ner = NeuralEntityRecognizer(nlp.vocab)\n+ ner.add_label('ANIMAL')\n+ nlp.add_pipe(ner)\n train_ner(nlp, train_data, output_directory)\n \n # Test that the entity is recognized\n", "issue": "TokenVectorEncoder object is not iterable when running example in 2.0 alpha\n\r\nIm trying to run one of the examples in 2.0.0 alpha, for extending a pre existing model with \r\ncustom ner tags avaliable here [1], \r\nhere is the error i get: \r\n```\r\n$ python train_new_entity_type.py en othersame \r\nCreating initial model en\r\nTraceback (most recent call last):\r\n File \"train_new_entity_type.py\", line 124, in <module>\r\n plac.call(main)\r\n File \"/home/data/experim/spc/sp2env/lib/python2.7/site-packages/plac_core.py\", line 328, in call\r\n cmd, result = parser.consume(arglist)\r\n File \"/home/data/experim/spc/sp2env/lib/python2.7/site-packages/plac_core.py\", line 207, in consume\r\n return cmd, self.func(*(args + varargs + extraopts), **kwargs)\r\n File \"train_new_entity_type.py\", line 106, in main\r\n train_ner(nlp, train_data, output_directory)\r\n File \"train_new_entity_type.py\", line 53, in train_ner\r\n optimizer = nlp.begin_training(lambda: [])\r\n File \"/home/data/experim/spc/sp2env/lib/python2.7/site-packages/spacy/language.py\", line 410, in begin_training\r\n for name, proc in self.pipeline:\r\nTypeError: 'TokenVectorEncoder' object is not iterable\r\n```\r\nI expected to get this to work, as its already documented here [2],\r\nall the models and spacy install are recent and fresh installs (21st october). \r\n\r\n## Your Environment\r\n```\r\n Info about spaCy\r\n\r\n Python version 2.7.13 \r\n Platform Linux-4.11.12-100.fc24.x86_64-x86_64-with-fedora-24-Twenty_Four\r\n spaCy version 2.0.0a17 \r\n Location /home/data/experim/spc/sp2env/lib/python2.7/site-packages/spacy\r\n Models en_core_web_sm, en_core_web_lg\r\n```\r\n* Operating System: Fedora Linux\r\n* Python Version Used: Python 2.7.13 reproducible with 3.5.3\r\n* spaCy Version Used: 2.0.0a17\r\n* Environment Information: \r\n\r\n\r\n[ 1] https://github.com/explosion/spaCy/blob/develop/examples/training/train_new_entity_type.py\r\n[ 2] https://alpha.spacy.io/usage/training#example-new-entity-type\n", "before_files": [{"content": "#!/usr/bin/env python\n# coding: utf8\n\"\"\"\nExample of training an additional entity type\n\nThis script shows how to add a new entity type to an existing pre-trained NER\nmodel. To keep the example short and simple, only four sentences are provided\nas examples. In practice, you'll need many more \u2014 a few hundred would be a\ngood start. You will also likely need to mix in examples of other entity\ntypes, which might be obtained by running the entity recognizer over unlabelled\nsentences, and adding their annotations to the training set.\n\nThe actual training is performed by looping over the examples, and calling\n`nlp.entity.update()`. The `update()` method steps through the words of the\ninput. At each word, it makes a prediction. It then consults the annotations\nprovided on the GoldParse instance, to see whether it was right. If it was\nwrong, it adjusts its weights so that the correct action will score higher\nnext time.\n\nAfter training your model, you can save it to a directory. We recommend\nwrapping models as Python packages, for ease of deployment.\n\nFor more details, see the documentation:\n* Training the Named Entity Recognizer: https://spacy.io/docs/usage/train-ner\n* Saving and loading models: https://spacy.io/docs/usage/saving-loading\n\nDeveloped for: spaCy 1.7.6\nLast updated for: spaCy 2.0.0a13\n\"\"\"\nfrom __future__ import unicode_literals, print_function\n\nimport random\nfrom pathlib import Path\nimport random\n\nimport spacy\nfrom spacy.gold import GoldParse, minibatch\nfrom spacy.pipeline import NeuralEntityRecognizer\nfrom spacy.pipeline import TokenVectorEncoder\n\n\ndef get_gold_parses(tokenizer, train_data):\n '''Shuffle and create GoldParse objects'''\n random.shuffle(train_data)\n for raw_text, entity_offsets in train_data:\n doc = tokenizer(raw_text)\n gold = GoldParse(doc, entities=entity_offsets)\n yield doc, gold\n\n \ndef train_ner(nlp, train_data, output_dir):\n random.seed(0)\n optimizer = nlp.begin_training(lambda: [])\n nlp.meta['name'] = 'en_ent_animal'\n for itn in range(50):\n losses = {}\n for batch in minibatch(get_gold_parses(nlp.make_doc, train_data), size=3):\n docs, golds = zip(*batch)\n nlp.update(docs, golds, losses=losses, sgd=optimizer, update_shared=True,\n drop=0.35)\n print(losses)\n if not output_dir:\n return\n elif not output_dir.exists():\n output_dir.mkdir()\n nlp.to_disk(output_dir)\n\n\ndef main(model_name, output_directory=None):\n print(\"Creating initial model\", model_name)\n nlp = spacy.blank(model_name)\n if output_directory is not None:\n output_directory = Path(output_directory)\n\n train_data = [\n (\n \"Horses are too tall and they pretend to care about your feelings\",\n [(0, 6, 'ANIMAL')],\n ),\n (\n \"Do they bite?\", \n [],\n ),\n \n (\n \"horses are too tall and they pretend to care about your feelings\",\n [(0, 6, 'ANIMAL')]\n ),\n (\n \"horses pretend to care about your feelings\",\n [(0, 6, 'ANIMAL')]\n ),\n (\n \"they pretend to care about your feelings, those horses\",\n [(48, 54, 'ANIMAL')]\n ),\n (\n \"horses?\",\n [(0, 6, 'ANIMAL')]\n )\n\n ]\n nlp.pipeline.append(TokenVectorEncoder(nlp.vocab))\n nlp.pipeline.append(NeuralEntityRecognizer(nlp.vocab))\n nlp.pipeline[-1].add_label('ANIMAL')\n train_ner(nlp, train_data, output_directory)\n\n # Test that the entity is recognized\n text = 'Do you like horses?'\n print(\"Ents in 'Do you like horses?':\")\n doc = nlp(text)\n for ent in doc.ents:\n print(ent.label_, ent.text)\n if output_directory:\n print(\"Loading from\", output_directory)\n nlp2 = spacy.load(output_directory)\n doc2 = nlp2('Do you like horses?')\n for ent in doc2.ents:\n print(ent.label_, ent.text)\n\n\nif __name__ == '__main__':\n import plac\n plac.call(main)\n", "path": "examples/training/train_new_entity_type.py"}]} | 2,382 | 292 |
gh_patches_debug_25260 | rasdani/github-patches | git_diff | streamlit__streamlit-4525 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
st.json collapse parameter
_(Note, you don't have to fill out every section here. They're just here for guidance. That said, nicely detailed feature requests are more likely to get eng attention sooner)_
### Problem
Have a parameter for st.json(body, collapse) where the default is `False` but you can set it to `True`. This would allow developers to choose if the json file is expanded or collapsed when rendered on the Streamlit app.
Requested by a community member, link to forum post:
https://discuss.streamlit.io/t/json-collapse-option/17159
### Solution
**MVP:** a parameter to set the view of a json file on the first render in Streamlit
</issue>
<code>
[start of e2e/scripts/st_json.py]
1 # Copyright 2018-2022 Streamlit Inc.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import streamlit as st
16
17 data = {"foo": "bar"}
18 st.json(data)
19
[end of e2e/scripts/st_json.py]
[start of lib/streamlit/elements/json.py]
1 # Copyright 2018-2022 Streamlit Inc.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import json
16 from typing import cast
17
18 import streamlit
19 from streamlit.proto.Json_pb2 import Json as JsonProto
20 from streamlit.state import AutoSessionState
21
22
23 class JsonMixin:
24 def json(self, body):
25 """Display object or string as a pretty-printed JSON string.
26
27 Parameters
28 ----------
29 body : Object or str
30 The object to print as JSON. All referenced objects should be
31 serializable to JSON as well. If object is a string, we assume it
32 contains serialized JSON.
33
34 Example
35 -------
36 >>> st.json({
37 ... 'foo': 'bar',
38 ... 'baz': 'boz',
39 ... 'stuff': [
40 ... 'stuff 1',
41 ... 'stuff 2',
42 ... 'stuff 3',
43 ... 'stuff 5',
44 ... ],
45 ... })
46
47 .. output::
48 https://share.streamlit.io/streamlit/docs/main/python/api-examples-source/data.json.py
49 height: 385px
50
51 """
52 import streamlit as st
53
54 if isinstance(body, AutoSessionState):
55 body = body.to_dict()
56
57 if not isinstance(body, str):
58 try:
59 body = json.dumps(body, default=repr)
60 except TypeError as err:
61 st.warning(
62 "Warning: this data structure was not fully serializable as "
63 "JSON due to one or more unexpected keys. (Error was: %s)" % err
64 )
65 body = json.dumps(body, skipkeys=True, default=repr)
66
67 json_proto = JsonProto()
68 json_proto.body = body
69 return self.dg._enqueue("json", json_proto)
70
71 @property
72 def dg(self) -> "streamlit.delta_generator.DeltaGenerator":
73 """Get our DeltaGenerator."""
74 return cast("streamlit.delta_generator.DeltaGenerator", self)
75
[end of lib/streamlit/elements/json.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/e2e/scripts/st_json.py b/e2e/scripts/st_json.py
--- a/e2e/scripts/st_json.py
+++ b/e2e/scripts/st_json.py
@@ -16,3 +16,4 @@
data = {"foo": "bar"}
st.json(data)
+st.json(data, expanded=False)
diff --git a/lib/streamlit/elements/json.py b/lib/streamlit/elements/json.py
--- a/lib/streamlit/elements/json.py
+++ b/lib/streamlit/elements/json.py
@@ -21,7 +21,12 @@
class JsonMixin:
- def json(self, body):
+ def json(
+ self,
+ body,
+ *, # keyword-only arguments:
+ expanded=True,
+ ):
"""Display object or string as a pretty-printed JSON string.
Parameters
@@ -31,6 +36,11 @@
serializable to JSON as well. If object is a string, we assume it
contains serialized JSON.
+ expanded : bool
+ An optional boolean that allows the user to set whether the initial
+ state of this json element should be expanded. Defaults to True.
+ This argument can only be supplied by keyword.
+
Example
-------
>>> st.json({
@@ -66,6 +76,7 @@
json_proto = JsonProto()
json_proto.body = body
+ json_proto.expanded = expanded
return self.dg._enqueue("json", json_proto)
@property
| {"golden_diff": "diff --git a/e2e/scripts/st_json.py b/e2e/scripts/st_json.py\n--- a/e2e/scripts/st_json.py\n+++ b/e2e/scripts/st_json.py\n@@ -16,3 +16,4 @@\n \n data = {\"foo\": \"bar\"}\n st.json(data)\n+st.json(data, expanded=False)\ndiff --git a/lib/streamlit/elements/json.py b/lib/streamlit/elements/json.py\n--- a/lib/streamlit/elements/json.py\n+++ b/lib/streamlit/elements/json.py\n@@ -21,7 +21,12 @@\n \n \n class JsonMixin:\n- def json(self, body):\n+ def json(\n+ self,\n+ body,\n+ *, # keyword-only arguments:\n+ expanded=True,\n+ ):\n \"\"\"Display object or string as a pretty-printed JSON string.\n \n Parameters\n@@ -31,6 +36,11 @@\n serializable to JSON as well. If object is a string, we assume it\n contains serialized JSON.\n \n+ expanded : bool\n+ An optional boolean that allows the user to set whether the initial\n+ state of this json element should be expanded. Defaults to True.\n+ This argument can only be supplied by keyword.\n+\n Example\n -------\n >>> st.json({\n@@ -66,6 +76,7 @@\n \n json_proto = JsonProto()\n json_proto.body = body\n+ json_proto.expanded = expanded\n return self.dg._enqueue(\"json\", json_proto)\n \n @property\n", "issue": "st.json collapse parameter\n_(Note, you don't have to fill out every section here. They're just here for guidance. That said, nicely detailed feature requests are more likely to get eng attention sooner)_\r\n\r\n### Problem\r\n\r\nHave a parameter for st.json(body, collapse) where the default is `False` but you can set it to `True`. This would allow developers to choose if the json file is expanded or collapsed when rendered on the Streamlit app.\r\n\r\nRequested by a community member, link to forum post: \r\nhttps://discuss.streamlit.io/t/json-collapse-option/17159\r\n\r\n### Solution\r\n\r\n**MVP:** a parameter to set the view of a json file on the first render in Streamlit\r\n\r\n\n", "before_files": [{"content": "# Copyright 2018-2022 Streamlit Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport streamlit as st\n\ndata = {\"foo\": \"bar\"}\nst.json(data)\n", "path": "e2e/scripts/st_json.py"}, {"content": "# Copyright 2018-2022 Streamlit Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport json\nfrom typing import cast\n\nimport streamlit\nfrom streamlit.proto.Json_pb2 import Json as JsonProto\nfrom streamlit.state import AutoSessionState\n\n\nclass JsonMixin:\n def json(self, body):\n \"\"\"Display object or string as a pretty-printed JSON string.\n\n Parameters\n ----------\n body : Object or str\n The object to print as JSON. All referenced objects should be\n serializable to JSON as well. If object is a string, we assume it\n contains serialized JSON.\n\n Example\n -------\n >>> st.json({\n ... 'foo': 'bar',\n ... 'baz': 'boz',\n ... 'stuff': [\n ... 'stuff 1',\n ... 'stuff 2',\n ... 'stuff 3',\n ... 'stuff 5',\n ... ],\n ... })\n\n .. output::\n https://share.streamlit.io/streamlit/docs/main/python/api-examples-source/data.json.py\n height: 385px\n\n \"\"\"\n import streamlit as st\n\n if isinstance(body, AutoSessionState):\n body = body.to_dict()\n\n if not isinstance(body, str):\n try:\n body = json.dumps(body, default=repr)\n except TypeError as err:\n st.warning(\n \"Warning: this data structure was not fully serializable as \"\n \"JSON due to one or more unexpected keys. (Error was: %s)\" % err\n )\n body = json.dumps(body, skipkeys=True, default=repr)\n\n json_proto = JsonProto()\n json_proto.body = body\n return self.dg._enqueue(\"json\", json_proto)\n\n @property\n def dg(self) -> \"streamlit.delta_generator.DeltaGenerator\":\n \"\"\"Get our DeltaGenerator.\"\"\"\n return cast(\"streamlit.delta_generator.DeltaGenerator\", self)\n", "path": "lib/streamlit/elements/json.py"}]} | 1,578 | 336 |
gh_patches_debug_49868 | rasdani/github-patches | git_diff | fossasia__open-event-server-2599 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Import not working on Kubernetes deployment
The file upload for import is not working on Kubernetes deployment. (but works locally and on heroku)
</issue>
<code>
[start of app/helpers/storage.py]
1 import os
2 from base64 import b64encode
3 from shutil import copyfile, rmtree
4
5 from boto.gs.connection import GSConnection
6 from flask.ext.scrypt import generate_password_hash
7 from boto.s3.connection import S3Connection
8 from boto.s3.key import Key
9 from werkzeug.utils import secure_filename
10 import magic
11
12 from app.settings import get_settings
13
14 #################
15 # STORAGE SCHEMA
16 #################
17
18 UPLOAD_PATHS = {
19 'sessions': {
20 'video': 'events/{event_id}/sessions/{id}/video',
21 'audio': 'events/{event_id}/audios/{id}/audio',
22 'slides': 'events/{event_id}/slides/{id}/slides'
23 },
24 'speakers': {
25 'photo': 'events/{event_id}/speakers/{id}/photo',
26 'thumbnail': 'events/{event_id}/speakers/{id}/thumbnail',
27 'small': 'events/{event_id}/speakers/{id}/small',
28 'icon': 'events/{event_id}/speakers/{id}/icon'
29 },
30 'event': {
31 'logo': 'events/{event_id}/logo',
32 'background_url': 'events/{event_id}/background',
33 'thumbnail': 'events/{event_id}/thumbnail',
34 'large': 'events/{event_id}/large',
35 'icon': 'events/{event_id}/icon'
36 },
37 'sponsors': {
38 'logo': 'events/{event_id}/sponsors/{id}/logo'
39 },
40 'tracks': {
41 'track_image_url': 'events/{event_id}/tracks/{id}/track_image'
42 },
43 'user': {
44 'avatar': 'users/{user_id}/avatar',
45 'thumbnail': 'users/{user_id}/thumbnail',
46 'small': 'users/{user_id}/small',
47 'icon': 'users/{user_id}/icon'
48 },
49 'temp': {
50 'event': 'events/temp/{uuid}'
51 }
52 }
53
54
55 ################
56 # HELPER CLASSES
57 ################
58
59 class UploadedFile(object):
60 """
61 Helper for a disk-file to replicate request.files[ITEM] class
62 """
63 def __init__(self, file_path, filename):
64 self.file_path = file_path
65 self.filename = filename
66 self.file = open(file_path)
67
68 def save(self, new_path):
69 copyfile(self.file_path, new_path)
70
71 def read(self):
72 return self.file.read()
73
74 def __exit__(self, *args, **kwargs):
75 self.file.close()
76
77
78 class UploadedMemory(object):
79 """
80 Helper for a memory file to replicate request.files[ITEM] class
81 """
82 def __init__(self, data, filename):
83 self.data = data
84 self.filename = filename
85
86 def read(self):
87 return self.data
88
89 def save(self, path):
90 f = open(path, 'w')
91 f.write(self.data)
92 f.close()
93
94
95 #########
96 # MAIN
97 #########
98
99 def upload(uploaded_file, key, **kwargs):
100 """
101 Upload handler
102 """
103 # refresh settings
104 aws_bucket_name = get_settings()['aws_bucket_name']
105 aws_key = get_settings()['aws_key']
106 aws_secret = get_settings()['aws_secret']
107
108 gs_bucket_name = get_settings()['gs_bucket_name']
109 gs_key = get_settings()['gs_key']
110 gs_secret = get_settings()['gs_secret']
111
112 storage_place = get_settings()['storage_place']
113
114 # upload
115 if aws_bucket_name and aws_key and aws_secret and storage_place == 's3':
116 return upload_to_aws(aws_bucket_name, aws_key, aws_secret, uploaded_file, key, **kwargs)
117 elif gs_bucket_name and gs_key and gs_secret and storage_place == 'gs':
118 return upload_to_gs(gs_bucket_name, gs_key, gs_secret, uploaded_file, key, **kwargs)
119 else:
120 return upload_local(uploaded_file, key, **kwargs)
121
122
123 def upload_local(uploaded_file, key, **kwargs):
124 """
125 Uploads file locally. Base dir - static/media/
126 """
127 filename = secure_filename(uploaded_file.filename)
128 file_path = 'static/media/' + key + '/' + generate_hash(key) + '/' + filename
129 dir_path = file_path.rsplit('/', 1)[0]
130 # delete current
131 try:
132 rmtree(dir_path)
133 except OSError:
134 pass
135 # create dirs
136 if not os.path.isdir(dir_path):
137 os.makedirs(dir_path)
138 uploaded_file.save(file_path)
139 return '/serve_' + file_path
140
141
142 def upload_to_aws(bucket_name, aws_key, aws_secret, file, key, acl='public-read'):
143 """
144 Uploads to AWS at key
145 http://{bucket}.s3.amazonaws.com/{key}
146 """
147 conn = S3Connection(aws_key, aws_secret)
148 bucket = conn.get_bucket(bucket_name)
149 k = Key(bucket)
150 # generate key
151 filename = secure_filename(file.filename)
152 key_dir = key + '/' + generate_hash(key) + '/'
153 k.key = key_dir + filename
154 # delete old data
155 for item in bucket.list(prefix='/' + key_dir):
156 item.delete()
157 # set object settings
158
159 file_data = file.read()
160 file_mime = magic.from_buffer(file_data, mime=True)
161 size = len(file_data)
162 sent = k.set_contents_from_string(
163 file_data,
164 headers={
165 'Content-Disposition': 'attachment; filename=%s' % filename,
166 'Content-Type': '%s' % file_mime
167 }
168 )
169 k.set_acl(acl)
170 s3_url = 'https://%s.s3.amazonaws.com/' % bucket_name
171 if sent == size:
172 return s3_url + k.key
173 return False
174
175
176 def upload_to_gs(bucket_name, client_id, client_secret, file, key, acl='public-read'):
177 conn = GSConnection(client_id, client_secret)
178 bucket = conn.get_bucket(bucket_name)
179 k = Key(bucket)
180 # generate key
181 filename = secure_filename(file.filename)
182 key_dir = key + '/' + generate_hash(key) + '/'
183 k.key = key_dir + filename
184 # delete old data
185 for item in bucket.list(prefix='/' + key_dir):
186 item.delete()
187 # set object settings
188
189 file_data = file.read()
190 file_mime = magic.from_buffer(file_data, mime=True)
191 size = len(file_data)
192 sent = k.set_contents_from_string(
193 file_data,
194 headers={
195 'Content-Disposition': 'attachment; filename=%s' % filename,
196 'Content-Type': '%s' % file_mime
197 }
198 )
199 k.set_acl(acl)
200 gs_url = 'https://storage.googleapis.com/%s/' % bucket_name
201 if sent == size:
202 return gs_url + key
203 return False
204
205 # ########
206 # HELPERS
207 # ########
208
209
210 def generate_hash(key):
211 """
212 Generate hash for key
213 """
214 phash = generate_password_hash(key, get_settings()['secret'])
215 return b64encode(phash)[:10] # limit len to 10, is sufficient
216
[end of app/helpers/storage.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/app/helpers/storage.py b/app/helpers/storage.py
--- a/app/helpers/storage.py
+++ b/app/helpers/storage.py
@@ -199,7 +199,7 @@
k.set_acl(acl)
gs_url = 'https://storage.googleapis.com/%s/' % bucket_name
if sent == size:
- return gs_url + key
+ return gs_url + k.key
return False
# ########
| {"golden_diff": "diff --git a/app/helpers/storage.py b/app/helpers/storage.py\n--- a/app/helpers/storage.py\n+++ b/app/helpers/storage.py\n@@ -199,7 +199,7 @@\n k.set_acl(acl)\n gs_url = 'https://storage.googleapis.com/%s/' % bucket_name\n if sent == size:\n- return gs_url + key\n+ return gs_url + k.key\n return False\n \n # ########\n", "issue": "Import not working on Kubernetes deployment\nThe file upload for import is not working on Kubernetes deployment. (but works locally and on heroku)\r\n\r\n\n", "before_files": [{"content": "import os\nfrom base64 import b64encode\nfrom shutil import copyfile, rmtree\n\nfrom boto.gs.connection import GSConnection\nfrom flask.ext.scrypt import generate_password_hash\nfrom boto.s3.connection import S3Connection\nfrom boto.s3.key import Key\nfrom werkzeug.utils import secure_filename\nimport magic\n\nfrom app.settings import get_settings\n\n#################\n# STORAGE SCHEMA\n#################\n\nUPLOAD_PATHS = {\n 'sessions': {\n 'video': 'events/{event_id}/sessions/{id}/video',\n 'audio': 'events/{event_id}/audios/{id}/audio',\n 'slides': 'events/{event_id}/slides/{id}/slides'\n },\n 'speakers': {\n 'photo': 'events/{event_id}/speakers/{id}/photo',\n 'thumbnail': 'events/{event_id}/speakers/{id}/thumbnail',\n 'small': 'events/{event_id}/speakers/{id}/small',\n 'icon': 'events/{event_id}/speakers/{id}/icon'\n },\n 'event': {\n 'logo': 'events/{event_id}/logo',\n 'background_url': 'events/{event_id}/background',\n 'thumbnail': 'events/{event_id}/thumbnail',\n 'large': 'events/{event_id}/large',\n 'icon': 'events/{event_id}/icon'\n },\n 'sponsors': {\n 'logo': 'events/{event_id}/sponsors/{id}/logo'\n },\n 'tracks': {\n 'track_image_url': 'events/{event_id}/tracks/{id}/track_image'\n },\n 'user': {\n 'avatar': 'users/{user_id}/avatar',\n 'thumbnail': 'users/{user_id}/thumbnail',\n 'small': 'users/{user_id}/small',\n 'icon': 'users/{user_id}/icon'\n },\n 'temp': {\n 'event': 'events/temp/{uuid}'\n }\n}\n\n\n################\n# HELPER CLASSES\n################\n\nclass UploadedFile(object):\n \"\"\"\n Helper for a disk-file to replicate request.files[ITEM] class\n \"\"\"\n def __init__(self, file_path, filename):\n self.file_path = file_path\n self.filename = filename\n self.file = open(file_path)\n\n def save(self, new_path):\n copyfile(self.file_path, new_path)\n\n def read(self):\n return self.file.read()\n\n def __exit__(self, *args, **kwargs):\n self.file.close()\n\n\nclass UploadedMemory(object):\n \"\"\"\n Helper for a memory file to replicate request.files[ITEM] class\n \"\"\"\n def __init__(self, data, filename):\n self.data = data\n self.filename = filename\n\n def read(self):\n return self.data\n\n def save(self, path):\n f = open(path, 'w')\n f.write(self.data)\n f.close()\n\n\n#########\n# MAIN\n#########\n\ndef upload(uploaded_file, key, **kwargs):\n \"\"\"\n Upload handler\n \"\"\"\n # refresh settings\n aws_bucket_name = get_settings()['aws_bucket_name']\n aws_key = get_settings()['aws_key']\n aws_secret = get_settings()['aws_secret']\n\n gs_bucket_name = get_settings()['gs_bucket_name']\n gs_key = get_settings()['gs_key']\n gs_secret = get_settings()['gs_secret']\n\n storage_place = get_settings()['storage_place']\n\n # upload\n if aws_bucket_name and aws_key and aws_secret and storage_place == 's3':\n return upload_to_aws(aws_bucket_name, aws_key, aws_secret, uploaded_file, key, **kwargs)\n elif gs_bucket_name and gs_key and gs_secret and storage_place == 'gs':\n return upload_to_gs(gs_bucket_name, gs_key, gs_secret, uploaded_file, key, **kwargs)\n else:\n return upload_local(uploaded_file, key, **kwargs)\n\n\ndef upload_local(uploaded_file, key, **kwargs):\n \"\"\"\n Uploads file locally. Base dir - static/media/\n \"\"\"\n filename = secure_filename(uploaded_file.filename)\n file_path = 'static/media/' + key + '/' + generate_hash(key) + '/' + filename\n dir_path = file_path.rsplit('/', 1)[0]\n # delete current\n try:\n rmtree(dir_path)\n except OSError:\n pass\n # create dirs\n if not os.path.isdir(dir_path):\n os.makedirs(dir_path)\n uploaded_file.save(file_path)\n return '/serve_' + file_path\n\n\ndef upload_to_aws(bucket_name, aws_key, aws_secret, file, key, acl='public-read'):\n \"\"\"\n Uploads to AWS at key\n http://{bucket}.s3.amazonaws.com/{key}\n \"\"\"\n conn = S3Connection(aws_key, aws_secret)\n bucket = conn.get_bucket(bucket_name)\n k = Key(bucket)\n # generate key\n filename = secure_filename(file.filename)\n key_dir = key + '/' + generate_hash(key) + '/'\n k.key = key_dir + filename\n # delete old data\n for item in bucket.list(prefix='/' + key_dir):\n item.delete()\n # set object settings\n\n file_data = file.read()\n file_mime = magic.from_buffer(file_data, mime=True)\n size = len(file_data)\n sent = k.set_contents_from_string(\n file_data,\n headers={\n 'Content-Disposition': 'attachment; filename=%s' % filename,\n 'Content-Type': '%s' % file_mime\n }\n )\n k.set_acl(acl)\n s3_url = 'https://%s.s3.amazonaws.com/' % bucket_name\n if sent == size:\n return s3_url + k.key\n return False\n\n\ndef upload_to_gs(bucket_name, client_id, client_secret, file, key, acl='public-read'):\n conn = GSConnection(client_id, client_secret)\n bucket = conn.get_bucket(bucket_name)\n k = Key(bucket)\n # generate key\n filename = secure_filename(file.filename)\n key_dir = key + '/' + generate_hash(key) + '/'\n k.key = key_dir + filename\n # delete old data\n for item in bucket.list(prefix='/' + key_dir):\n item.delete()\n # set object settings\n\n file_data = file.read()\n file_mime = magic.from_buffer(file_data, mime=True)\n size = len(file_data)\n sent = k.set_contents_from_string(\n file_data,\n headers={\n 'Content-Disposition': 'attachment; filename=%s' % filename,\n 'Content-Type': '%s' % file_mime\n }\n )\n k.set_acl(acl)\n gs_url = 'https://storage.googleapis.com/%s/' % bucket_name\n if sent == size:\n return gs_url + key\n return False\n\n# ########\n# HELPERS\n# ########\n\n\ndef generate_hash(key):\n \"\"\"\n Generate hash for key\n \"\"\"\n phash = generate_password_hash(key, get_settings()['secret'])\n return b64encode(phash)[:10] # limit len to 10, is sufficient\n", "path": "app/helpers/storage.py"}]} | 2,636 | 96 |
gh_patches_debug_10345 | rasdani/github-patches | git_diff | DataDog__dd-trace-py-1393 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Profile exporter crashes when DD_VERSION is used
The profile exporter is crashing due to `DD_VERSION` not being encoded before generating the export request. Looking at the code the same applies probably to `DD_ENV` as well.
Lines missing `.decode("utf-8")`: https://github.com/DataDog/dd-trace-py/blob/6a14a9ba75a6866d968ddf0eb84b8fee5bd3f49c/ddtrace/profiling/exporter/http.py#L144-L150
**Sentry traceback**
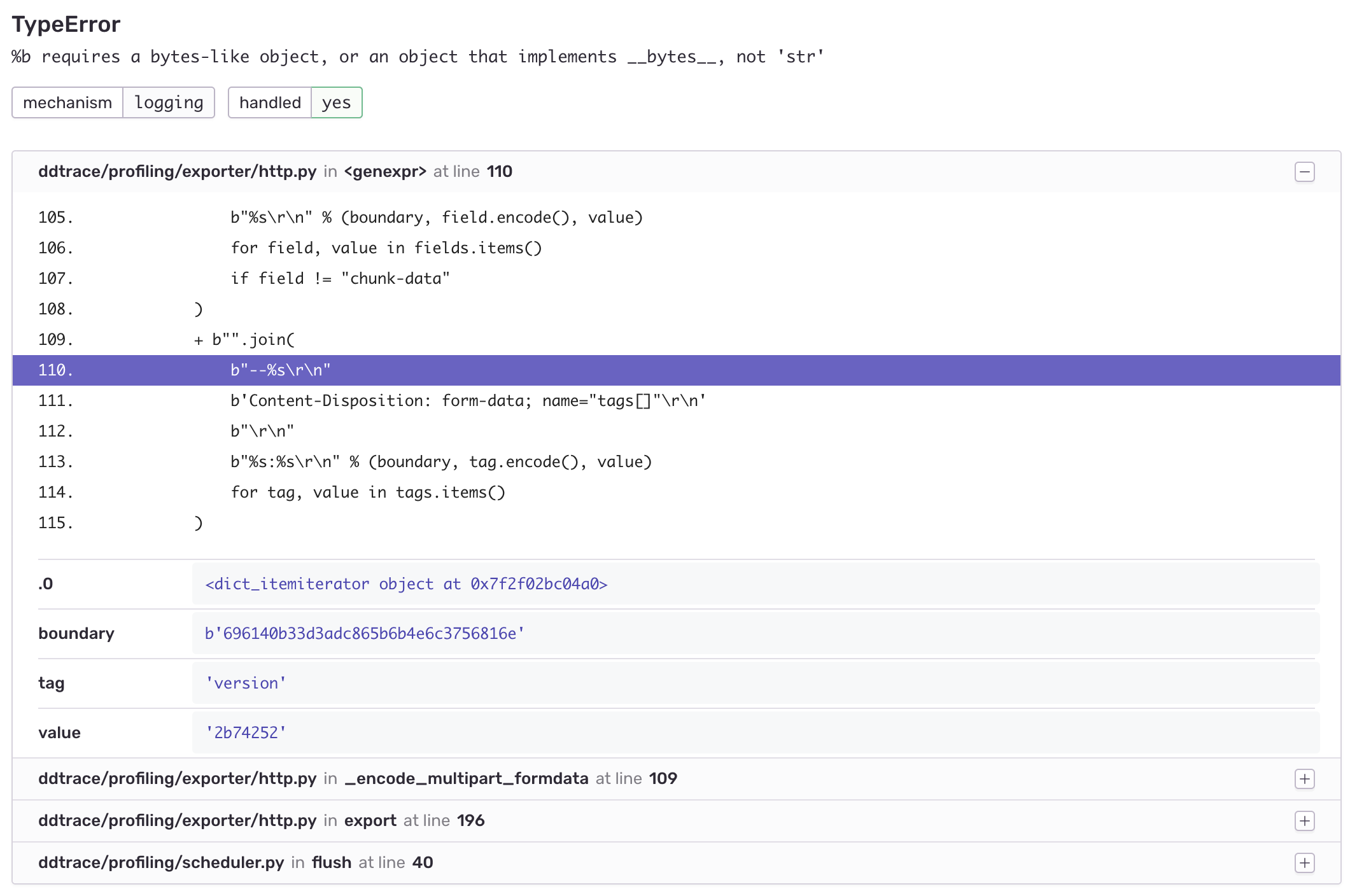
### Which version of dd-trace-py are you using?
0.37.0
### Which version of the libraries are you using?
N/A
### How can we reproduce your problem?
```
DD_VERSION=foobar pyddprofile ...
```
</issue>
<code>
[start of ddtrace/profiling/exporter/http.py]
1 # -*- encoding: utf-8 -*-
2 import binascii
3 import datetime
4 import gzip
5 import os
6 import platform
7 import uuid
8
9 import tenacity
10
11 from ddtrace.utils import deprecation
12 from ddtrace.utils.formats import parse_tags_str
13 from ddtrace.vendor import six
14 from ddtrace.vendor.six.moves import http_client
15 from ddtrace.vendor.six.moves.urllib import error
16 from ddtrace.vendor.six.moves.urllib import request
17
18 import ddtrace
19 from ddtrace.profiling import _attr
20 from ddtrace.profiling import _traceback
21 from ddtrace.profiling import exporter
22 from ddtrace.vendor import attr
23 from ddtrace.profiling.exporter import pprof
24
25
26 RUNTIME_ID = str(uuid.uuid4()).encode()
27 HOSTNAME = platform.node()
28 PYTHON_IMPLEMENTATION = platform.python_implementation().encode()
29 PYTHON_VERSION = platform.python_version().encode()
30
31
32 class InvalidEndpoint(exporter.ExportError):
33 pass
34
35
36 class RequestFailed(exporter.ExportError):
37 """Failed HTTP request."""
38
39 def __init__(self, response, content):
40 """Create a new failed request embedding response and content."""
41 self.response = response
42 self.content = content
43 super(RequestFailed, self).__init__(
44 "Error status code received from endpoint: %d: %s" % (response.status, content)
45 )
46
47
48 class UploadFailed(exporter.ExportError):
49 """Upload failure."""
50
51 def __init__(self, exception):
52 """Create a failed upload error based on raised exceptions."""
53 self.exception = exception
54 super(UploadFailed, self).__init__("Unable to upload: " + _traceback.format_exception(exception))
55
56
57 def _get_api_key():
58 legacy = _attr.from_env("DD_PROFILING_API_KEY", "", str)()
59 if legacy:
60 deprecation.deprecation("DD_PROFILING_API_KEY", "Use DD_API_KEY")
61 return legacy
62 return _attr.from_env("DD_API_KEY", "", str)()
63
64
65 ENDPOINT_TEMPLATE = "https://intake.profile.{}/v1/input"
66
67
68 def _get_endpoint():
69 legacy = _attr.from_env("DD_PROFILING_API_URL", "", str)()
70 if legacy:
71 deprecation.deprecation("DD_PROFILING_API_URL", "Use DD_SITE")
72 return legacy
73 site = _attr.from_env("DD_SITE", "datadoghq.com", str)()
74 return ENDPOINT_TEMPLATE.format(site)
75
76
77 def _get_service_name():
78 for service_name_var in ("DD_SERVICE", "DD_SERVICE_NAME", "DATADOG_SERVICE_NAME"):
79 service_name = os.environ.get(service_name_var)
80 if service_name is not None:
81 return service_name
82
83
84 @attr.s
85 class PprofHTTPExporter(pprof.PprofExporter):
86 """PProf HTTP exporter."""
87
88 endpoint = attr.ib(factory=_get_endpoint, type=str)
89 api_key = attr.ib(factory=_get_api_key, type=str)
90 timeout = attr.ib(factory=_attr.from_env("DD_PROFILING_API_TIMEOUT", 10, float), type=float)
91 service_name = attr.ib(factory=_get_service_name)
92 max_retry_delay = attr.ib(default=None)
93
94 def __attrs_post_init__(self):
95 if self.max_retry_delay is None:
96 self.max_retry_delay = self.timeout * 3
97
98 @staticmethod
99 def _encode_multipart_formdata(fields, tags):
100 boundary = binascii.hexlify(os.urandom(16))
101
102 # The body that is generated is very sensitive and must perfectly match what the server expects.
103 body = (
104 b"".join(
105 b"--%s\r\n"
106 b'Content-Disposition: form-data; name="%s"\r\n'
107 b"\r\n"
108 b"%s\r\n" % (boundary, field.encode(), value)
109 for field, value in fields.items()
110 if field != "chunk-data"
111 )
112 + b"".join(
113 b"--%s\r\n"
114 b'Content-Disposition: form-data; name="tags[]"\r\n'
115 b"\r\n"
116 b"%s:%s\r\n" % (boundary, tag.encode(), value)
117 for tag, value in tags.items()
118 )
119 + b"--"
120 + boundary
121 + b"\r\n"
122 b'Content-Disposition: form-data; name="chunk-data"; filename="profile.pb.gz"\r\n'
123 + b"Content-Type: application/octet-stream\r\n\r\n"
124 + fields["chunk-data"]
125 + b"\r\n--%s--\r\n" % boundary
126 )
127
128 content_type = b"multipart/form-data; boundary=%s" % boundary
129
130 return content_type, body
131
132 @staticmethod
133 def _get_tags(service):
134 tags = {
135 "service": service.encode("utf-8"),
136 "host": HOSTNAME.encode("utf-8"),
137 "runtime-id": RUNTIME_ID,
138 "language": b"python",
139 "runtime": PYTHON_IMPLEMENTATION,
140 "runtime_version": PYTHON_VERSION,
141 "profiler_version": ddtrace.__version__.encode("utf-8"),
142 }
143
144 version = os.environ.get("DD_VERSION")
145 if version:
146 tags["version"] = version
147
148 env = os.environ.get("DD_ENV")
149 if env:
150 tags["env"] = env
151
152 user_tags = parse_tags_str(os.environ.get("DD_TAGS", {}))
153 user_tags.update(parse_tags_str(os.environ.get("DD_PROFILING_TAGS", {})))
154 tags.update({k: six.ensure_binary(v) for k, v in user_tags.items()})
155 return tags
156
157 def export(self, events, start_time_ns, end_time_ns):
158 """Export events to an HTTP endpoint.
159
160 :param events: The event dictionary from a `ddtrace.profiling.recorder.Recorder`.
161 :param start_time_ns: The start time of recording.
162 :param end_time_ns: The end time of recording.
163 """
164 if not self.endpoint:
165 raise InvalidEndpoint("Endpoint is empty")
166
167 common_headers = {
168 "DD-API-KEY": self.api_key.encode(),
169 }
170
171 profile = super(PprofHTTPExporter, self).export(events, start_time_ns, end_time_ns)
172 s = six.BytesIO()
173 with gzip.GzipFile(fileobj=s, mode="wb") as gz:
174 gz.write(profile.SerializeToString())
175 fields = {
176 "runtime-id": RUNTIME_ID,
177 "recording-start": (
178 datetime.datetime.utcfromtimestamp(start_time_ns / 1e9).replace(microsecond=0).isoformat() + "Z"
179 ).encode(),
180 "recording-end": (
181 datetime.datetime.utcfromtimestamp(end_time_ns / 1e9).replace(microsecond=0).isoformat() + "Z"
182 ).encode(),
183 "runtime": PYTHON_IMPLEMENTATION,
184 "format": b"pprof",
185 "type": b"cpu+alloc+exceptions",
186 "chunk-data": s.getvalue(),
187 }
188
189 service_name = self.service_name or os.path.basename(profile.string_table[profile.mapping[0].filename])
190
191 content_type, body = self._encode_multipart_formdata(fields, tags=self._get_tags(service_name),)
192 headers = common_headers.copy()
193 headers["Content-Type"] = content_type
194
195 # urllib uses `POST` if `data` is supplied (Python 2 version does not handle `method` kwarg)
196 req = request.Request(self.endpoint, data=body, headers=headers)
197
198 retry = tenacity.Retrying(
199 # Retry after 1s, 2s, 4s, 8s with some randomness
200 wait=tenacity.wait_random_exponential(multiplier=0.5),
201 stop=tenacity.stop_after_delay(self.max_retry_delay),
202 retry=tenacity.retry_if_exception_type(
203 (error.HTTPError, error.URLError, http_client.HTTPException, OSError, IOError)
204 ),
205 )
206
207 try:
208 retry(request.urlopen, req, timeout=self.timeout)
209 except tenacity.RetryError as e:
210 raise UploadFailed(e.last_attempt.exception())
211
[end of ddtrace/profiling/exporter/http.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/ddtrace/profiling/exporter/http.py b/ddtrace/profiling/exporter/http.py
--- a/ddtrace/profiling/exporter/http.py
+++ b/ddtrace/profiling/exporter/http.py
@@ -143,11 +143,11 @@
version = os.environ.get("DD_VERSION")
if version:
- tags["version"] = version
+ tags["version"] = version.encode("utf-8")
env = os.environ.get("DD_ENV")
if env:
- tags["env"] = env
+ tags["env"] = env.encode("utf-8")
user_tags = parse_tags_str(os.environ.get("DD_TAGS", {}))
user_tags.update(parse_tags_str(os.environ.get("DD_PROFILING_TAGS", {})))
| {"golden_diff": "diff --git a/ddtrace/profiling/exporter/http.py b/ddtrace/profiling/exporter/http.py\n--- a/ddtrace/profiling/exporter/http.py\n+++ b/ddtrace/profiling/exporter/http.py\n@@ -143,11 +143,11 @@\n \n version = os.environ.get(\"DD_VERSION\")\n if version:\n- tags[\"version\"] = version\n+ tags[\"version\"] = version.encode(\"utf-8\")\n \n env = os.environ.get(\"DD_ENV\")\n if env:\n- tags[\"env\"] = env\n+ tags[\"env\"] = env.encode(\"utf-8\")\n \n user_tags = parse_tags_str(os.environ.get(\"DD_TAGS\", {}))\n user_tags.update(parse_tags_str(os.environ.get(\"DD_PROFILING_TAGS\", {})))\n", "issue": "Profile exporter crashes when DD_VERSION is used\nThe profile exporter is crashing due to `DD_VERSION` not being encoded before generating the export request. Looking at the code the same applies probably to `DD_ENV` as well.\r\n\r\nLines missing `.decode(\"utf-8\")`: https://github.com/DataDog/dd-trace-py/blob/6a14a9ba75a6866d968ddf0eb84b8fee5bd3f49c/ddtrace/profiling/exporter/http.py#L144-L150\r\n\r\n**Sentry traceback**\r\n\r\n\r\n### Which version of dd-trace-py are you using?\r\n\r\n0.37.0\r\n\r\n### Which version of the libraries are you using?\r\n\r\nN/A\r\n\r\n### How can we reproduce your problem?\r\n\r\n```\r\nDD_VERSION=foobar pyddprofile ...\r\n```\n", "before_files": [{"content": "# -*- encoding: utf-8 -*-\nimport binascii\nimport datetime\nimport gzip\nimport os\nimport platform\nimport uuid\n\nimport tenacity\n\nfrom ddtrace.utils import deprecation\nfrom ddtrace.utils.formats import parse_tags_str\nfrom ddtrace.vendor import six\nfrom ddtrace.vendor.six.moves import http_client\nfrom ddtrace.vendor.six.moves.urllib import error\nfrom ddtrace.vendor.six.moves.urllib import request\n\nimport ddtrace\nfrom ddtrace.profiling import _attr\nfrom ddtrace.profiling import _traceback\nfrom ddtrace.profiling import exporter\nfrom ddtrace.vendor import attr\nfrom ddtrace.profiling.exporter import pprof\n\n\nRUNTIME_ID = str(uuid.uuid4()).encode()\nHOSTNAME = platform.node()\nPYTHON_IMPLEMENTATION = platform.python_implementation().encode()\nPYTHON_VERSION = platform.python_version().encode()\n\n\nclass InvalidEndpoint(exporter.ExportError):\n pass\n\n\nclass RequestFailed(exporter.ExportError):\n \"\"\"Failed HTTP request.\"\"\"\n\n def __init__(self, response, content):\n \"\"\"Create a new failed request embedding response and content.\"\"\"\n self.response = response\n self.content = content\n super(RequestFailed, self).__init__(\n \"Error status code received from endpoint: %d: %s\" % (response.status, content)\n )\n\n\nclass UploadFailed(exporter.ExportError):\n \"\"\"Upload failure.\"\"\"\n\n def __init__(self, exception):\n \"\"\"Create a failed upload error based on raised exceptions.\"\"\"\n self.exception = exception\n super(UploadFailed, self).__init__(\"Unable to upload: \" + _traceback.format_exception(exception))\n\n\ndef _get_api_key():\n legacy = _attr.from_env(\"DD_PROFILING_API_KEY\", \"\", str)()\n if legacy:\n deprecation.deprecation(\"DD_PROFILING_API_KEY\", \"Use DD_API_KEY\")\n return legacy\n return _attr.from_env(\"DD_API_KEY\", \"\", str)()\n\n\nENDPOINT_TEMPLATE = \"https://intake.profile.{}/v1/input\"\n\n\ndef _get_endpoint():\n legacy = _attr.from_env(\"DD_PROFILING_API_URL\", \"\", str)()\n if legacy:\n deprecation.deprecation(\"DD_PROFILING_API_URL\", \"Use DD_SITE\")\n return legacy\n site = _attr.from_env(\"DD_SITE\", \"datadoghq.com\", str)()\n return ENDPOINT_TEMPLATE.format(site)\n\n\ndef _get_service_name():\n for service_name_var in (\"DD_SERVICE\", \"DD_SERVICE_NAME\", \"DATADOG_SERVICE_NAME\"):\n service_name = os.environ.get(service_name_var)\n if service_name is not None:\n return service_name\n\n\[email protected]\nclass PprofHTTPExporter(pprof.PprofExporter):\n \"\"\"PProf HTTP exporter.\"\"\"\n\n endpoint = attr.ib(factory=_get_endpoint, type=str)\n api_key = attr.ib(factory=_get_api_key, type=str)\n timeout = attr.ib(factory=_attr.from_env(\"DD_PROFILING_API_TIMEOUT\", 10, float), type=float)\n service_name = attr.ib(factory=_get_service_name)\n max_retry_delay = attr.ib(default=None)\n\n def __attrs_post_init__(self):\n if self.max_retry_delay is None:\n self.max_retry_delay = self.timeout * 3\n\n @staticmethod\n def _encode_multipart_formdata(fields, tags):\n boundary = binascii.hexlify(os.urandom(16))\n\n # The body that is generated is very sensitive and must perfectly match what the server expects.\n body = (\n b\"\".join(\n b\"--%s\\r\\n\"\n b'Content-Disposition: form-data; name=\"%s\"\\r\\n'\n b\"\\r\\n\"\n b\"%s\\r\\n\" % (boundary, field.encode(), value)\n for field, value in fields.items()\n if field != \"chunk-data\"\n )\n + b\"\".join(\n b\"--%s\\r\\n\"\n b'Content-Disposition: form-data; name=\"tags[]\"\\r\\n'\n b\"\\r\\n\"\n b\"%s:%s\\r\\n\" % (boundary, tag.encode(), value)\n for tag, value in tags.items()\n )\n + b\"--\"\n + boundary\n + b\"\\r\\n\"\n b'Content-Disposition: form-data; name=\"chunk-data\"; filename=\"profile.pb.gz\"\\r\\n'\n + b\"Content-Type: application/octet-stream\\r\\n\\r\\n\"\n + fields[\"chunk-data\"]\n + b\"\\r\\n--%s--\\r\\n\" % boundary\n )\n\n content_type = b\"multipart/form-data; boundary=%s\" % boundary\n\n return content_type, body\n\n @staticmethod\n def _get_tags(service):\n tags = {\n \"service\": service.encode(\"utf-8\"),\n \"host\": HOSTNAME.encode(\"utf-8\"),\n \"runtime-id\": RUNTIME_ID,\n \"language\": b\"python\",\n \"runtime\": PYTHON_IMPLEMENTATION,\n \"runtime_version\": PYTHON_VERSION,\n \"profiler_version\": ddtrace.__version__.encode(\"utf-8\"),\n }\n\n version = os.environ.get(\"DD_VERSION\")\n if version:\n tags[\"version\"] = version\n\n env = os.environ.get(\"DD_ENV\")\n if env:\n tags[\"env\"] = env\n\n user_tags = parse_tags_str(os.environ.get(\"DD_TAGS\", {}))\n user_tags.update(parse_tags_str(os.environ.get(\"DD_PROFILING_TAGS\", {})))\n tags.update({k: six.ensure_binary(v) for k, v in user_tags.items()})\n return tags\n\n def export(self, events, start_time_ns, end_time_ns):\n \"\"\"Export events to an HTTP endpoint.\n\n :param events: The event dictionary from a `ddtrace.profiling.recorder.Recorder`.\n :param start_time_ns: The start time of recording.\n :param end_time_ns: The end time of recording.\n \"\"\"\n if not self.endpoint:\n raise InvalidEndpoint(\"Endpoint is empty\")\n\n common_headers = {\n \"DD-API-KEY\": self.api_key.encode(),\n }\n\n profile = super(PprofHTTPExporter, self).export(events, start_time_ns, end_time_ns)\n s = six.BytesIO()\n with gzip.GzipFile(fileobj=s, mode=\"wb\") as gz:\n gz.write(profile.SerializeToString())\n fields = {\n \"runtime-id\": RUNTIME_ID,\n \"recording-start\": (\n datetime.datetime.utcfromtimestamp(start_time_ns / 1e9).replace(microsecond=0).isoformat() + \"Z\"\n ).encode(),\n \"recording-end\": (\n datetime.datetime.utcfromtimestamp(end_time_ns / 1e9).replace(microsecond=0).isoformat() + \"Z\"\n ).encode(),\n \"runtime\": PYTHON_IMPLEMENTATION,\n \"format\": b\"pprof\",\n \"type\": b\"cpu+alloc+exceptions\",\n \"chunk-data\": s.getvalue(),\n }\n\n service_name = self.service_name or os.path.basename(profile.string_table[profile.mapping[0].filename])\n\n content_type, body = self._encode_multipart_formdata(fields, tags=self._get_tags(service_name),)\n headers = common_headers.copy()\n headers[\"Content-Type\"] = content_type\n\n # urllib uses `POST` if `data` is supplied (Python\u00a02 version does not handle `method` kwarg)\n req = request.Request(self.endpoint, data=body, headers=headers)\n\n retry = tenacity.Retrying(\n # Retry after 1s, 2s, 4s, 8s with some randomness\n wait=tenacity.wait_random_exponential(multiplier=0.5),\n stop=tenacity.stop_after_delay(self.max_retry_delay),\n retry=tenacity.retry_if_exception_type(\n (error.HTTPError, error.URLError, http_client.HTTPException, OSError, IOError)\n ),\n )\n\n try:\n retry(request.urlopen, req, timeout=self.timeout)\n except tenacity.RetryError as e:\n raise UploadFailed(e.last_attempt.exception())\n", "path": "ddtrace/profiling/exporter/http.py"}]} | 3,037 | 175 |
gh_patches_debug_21934 | rasdani/github-patches | git_diff | Project-MONAI__MONAI-2254 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
ASPP type hints need to be updated
In ASPP (https://github.com/Project-MONAI/MONAI/blob/dev/monai/networks/blocks/aspp.py), the type hints of `acti_type` and `norm_type` are missing.
</issue>
<code>
[start of monai/networks/blocks/aspp.py]
1 # Copyright 2020 - 2021 MONAI Consortium
2 # Licensed under the Apache License, Version 2.0 (the "License");
3 # you may not use this file except in compliance with the License.
4 # You may obtain a copy of the License at
5 # http://www.apache.org/licenses/LICENSE-2.0
6 # Unless required by applicable law or agreed to in writing, software
7 # distributed under the License is distributed on an "AS IS" BASIS,
8 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
9 # See the License for the specific language governing permissions and
10 # limitations under the License.
11
12 from typing import Sequence
13
14 import torch
15 import torch.nn as nn
16
17 from monai.networks.blocks.convolutions import Convolution
18 from monai.networks.layers import same_padding
19 from monai.networks.layers.factories import Act, Conv, Norm
20
21
22 class SimpleASPP(nn.Module):
23 """
24 A simplified version of the atrous spatial pyramid pooling (ASPP) module.
25
26 Chen et al., Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation.
27 https://arxiv.org/abs/1802.02611
28
29 Wang et al., A Noise-robust Framework for Automatic Segmentation of COVID-19 Pneumonia Lesions
30 from CT Images. https://ieeexplore.ieee.org/document/9109297
31 """
32
33 def __init__(
34 self,
35 spatial_dims: int,
36 in_channels: int,
37 conv_out_channels: int,
38 kernel_sizes: Sequence[int] = (1, 3, 3, 3),
39 dilations: Sequence[int] = (1, 2, 4, 6),
40 norm_type=Norm.BATCH,
41 acti_type=Act.LEAKYRELU,
42 ) -> None:
43 """
44 Args:
45 spatial_dims: number of spatial dimensions, could be 1, 2, or 3.
46 in_channels: number of input channels.
47 conv_out_channels: number of output channels of each atrous conv.
48 The final number of output channels is conv_out_channels * len(kernel_sizes).
49 kernel_sizes: a sequence of four convolutional kernel sizes.
50 Defaults to (1, 3, 3, 3) for four (dilated) convolutions.
51 dilations: a sequence of four convolutional dilation parameters.
52 Defaults to (1, 2, 4, 6) for four (dilated) convolutions.
53 norm_type: final kernel-size-one convolution normalization type.
54 Defaults to batch norm.
55 acti_type: final kernel-size-one convolution activation type.
56 Defaults to leaky ReLU.
57
58 Raises:
59 ValueError: When ``kernel_sizes`` length differs from ``dilations``.
60
61 See also:
62
63 :py:class:`monai.networks.layers.Act`
64 :py:class:`monai.networks.layers.Conv`
65 :py:class:`monai.networks.layers.Norm`
66
67 """
68 super().__init__()
69 if len(kernel_sizes) != len(dilations):
70 raise ValueError(
71 "kernel_sizes and dilations length must match, "
72 f"got kernel_sizes={len(kernel_sizes)} dilations={len(dilations)}."
73 )
74 pads = tuple(same_padding(k, d) for k, d in zip(kernel_sizes, dilations))
75
76 self.convs = nn.ModuleList()
77 for k, d, p in zip(kernel_sizes, dilations, pads):
78 _conv = Conv[Conv.CONV, spatial_dims](
79 in_channels=in_channels, out_channels=conv_out_channels, kernel_size=k, dilation=d, padding=p
80 )
81 self.convs.append(_conv)
82
83 out_channels = conv_out_channels * len(pads) # final conv. output channels
84 self.conv_k1 = Convolution(
85 dimensions=spatial_dims,
86 in_channels=out_channels,
87 out_channels=out_channels,
88 kernel_size=1,
89 act=acti_type,
90 norm=norm_type,
91 )
92
93 def forward(self, x: torch.Tensor) -> torch.Tensor:
94 """
95 Args:
96 x: in shape (batch, channel, spatial_1[, spatial_2, ...]).
97 """
98 x_out = torch.cat([conv(x) for conv in self.convs], dim=1)
99 x_out = self.conv_k1(x_out)
100 return x_out
101
[end of monai/networks/blocks/aspp.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/monai/networks/blocks/aspp.py b/monai/networks/blocks/aspp.py
--- a/monai/networks/blocks/aspp.py
+++ b/monai/networks/blocks/aspp.py
@@ -9,14 +9,14 @@
# See the License for the specific language governing permissions and
# limitations under the License.
-from typing import Sequence
+from typing import Optional, Sequence, Tuple, Union
import torch
import torch.nn as nn
from monai.networks.blocks.convolutions import Convolution
from monai.networks.layers import same_padding
-from monai.networks.layers.factories import Act, Conv, Norm
+from monai.networks.layers.factories import Conv
class SimpleASPP(nn.Module):
@@ -37,8 +37,8 @@
conv_out_channels: int,
kernel_sizes: Sequence[int] = (1, 3, 3, 3),
dilations: Sequence[int] = (1, 2, 4, 6),
- norm_type=Norm.BATCH,
- acti_type=Act.LEAKYRELU,
+ norm_type: Optional[Union[Tuple, str]] = "BATCH",
+ acti_type: Optional[Union[Tuple, str]] = "LEAKYRELU",
) -> None:
"""
Args:
| {"golden_diff": "diff --git a/monai/networks/blocks/aspp.py b/monai/networks/blocks/aspp.py\n--- a/monai/networks/blocks/aspp.py\n+++ b/monai/networks/blocks/aspp.py\n@@ -9,14 +9,14 @@\n # See the License for the specific language governing permissions and\n # limitations under the License.\n \n-from typing import Sequence\n+from typing import Optional, Sequence, Tuple, Union\n \n import torch\n import torch.nn as nn\n \n from monai.networks.blocks.convolutions import Convolution\n from monai.networks.layers import same_padding\n-from monai.networks.layers.factories import Act, Conv, Norm\n+from monai.networks.layers.factories import Conv\n \n \n class SimpleASPP(nn.Module):\n@@ -37,8 +37,8 @@\n conv_out_channels: int,\n kernel_sizes: Sequence[int] = (1, 3, 3, 3),\n dilations: Sequence[int] = (1, 2, 4, 6),\n- norm_type=Norm.BATCH,\n- acti_type=Act.LEAKYRELU,\n+ norm_type: Optional[Union[Tuple, str]] = \"BATCH\",\n+ acti_type: Optional[Union[Tuple, str]] = \"LEAKYRELU\",\n ) -> None:\n \"\"\"\n Args:\n", "issue": "ASPP type hints need to be updated\nIn ASPP (https://github.com/Project-MONAI/MONAI/blob/dev/monai/networks/blocks/aspp.py), the type hints of `acti_type` and `norm_type` are missing.\n", "before_files": [{"content": "# Copyright 2020 - 2021 MONAI Consortium\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n# http://www.apache.org/licenses/LICENSE-2.0\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom typing import Sequence\n\nimport torch\nimport torch.nn as nn\n\nfrom monai.networks.blocks.convolutions import Convolution\nfrom monai.networks.layers import same_padding\nfrom monai.networks.layers.factories import Act, Conv, Norm\n\n\nclass SimpleASPP(nn.Module):\n \"\"\"\n A simplified version of the atrous spatial pyramid pooling (ASPP) module.\n\n Chen et al., Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation.\n https://arxiv.org/abs/1802.02611\n\n Wang et al., A Noise-robust Framework for Automatic Segmentation of COVID-19 Pneumonia Lesions\n from CT Images. https://ieeexplore.ieee.org/document/9109297\n \"\"\"\n\n def __init__(\n self,\n spatial_dims: int,\n in_channels: int,\n conv_out_channels: int,\n kernel_sizes: Sequence[int] = (1, 3, 3, 3),\n dilations: Sequence[int] = (1, 2, 4, 6),\n norm_type=Norm.BATCH,\n acti_type=Act.LEAKYRELU,\n ) -> None:\n \"\"\"\n Args:\n spatial_dims: number of spatial dimensions, could be 1, 2, or 3.\n in_channels: number of input channels.\n conv_out_channels: number of output channels of each atrous conv.\n The final number of output channels is conv_out_channels * len(kernel_sizes).\n kernel_sizes: a sequence of four convolutional kernel sizes.\n Defaults to (1, 3, 3, 3) for four (dilated) convolutions.\n dilations: a sequence of four convolutional dilation parameters.\n Defaults to (1, 2, 4, 6) for four (dilated) convolutions.\n norm_type: final kernel-size-one convolution normalization type.\n Defaults to batch norm.\n acti_type: final kernel-size-one convolution activation type.\n Defaults to leaky ReLU.\n\n Raises:\n ValueError: When ``kernel_sizes`` length differs from ``dilations``.\n\n See also:\n\n :py:class:`monai.networks.layers.Act`\n :py:class:`monai.networks.layers.Conv`\n :py:class:`monai.networks.layers.Norm`\n\n \"\"\"\n super().__init__()\n if len(kernel_sizes) != len(dilations):\n raise ValueError(\n \"kernel_sizes and dilations length must match, \"\n f\"got kernel_sizes={len(kernel_sizes)} dilations={len(dilations)}.\"\n )\n pads = tuple(same_padding(k, d) for k, d in zip(kernel_sizes, dilations))\n\n self.convs = nn.ModuleList()\n for k, d, p in zip(kernel_sizes, dilations, pads):\n _conv = Conv[Conv.CONV, spatial_dims](\n in_channels=in_channels, out_channels=conv_out_channels, kernel_size=k, dilation=d, padding=p\n )\n self.convs.append(_conv)\n\n out_channels = conv_out_channels * len(pads) # final conv. output channels\n self.conv_k1 = Convolution(\n dimensions=spatial_dims,\n in_channels=out_channels,\n out_channels=out_channels,\n kernel_size=1,\n act=acti_type,\n norm=norm_type,\n )\n\n def forward(self, x: torch.Tensor) -> torch.Tensor:\n \"\"\"\n Args:\n x: in shape (batch, channel, spatial_1[, spatial_2, ...]).\n \"\"\"\n x_out = torch.cat([conv(x) for conv in self.convs], dim=1)\n x_out = self.conv_k1(x_out)\n return x_out\n", "path": "monai/networks/blocks/aspp.py"}]} | 1,746 | 298 |
gh_patches_debug_50328 | rasdani/github-patches | git_diff | svthalia__concrexit-2198 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Change prefix of summaries on the website
### Is your feature request related to a problem? Please describe.
Titles of summaries usually say e.g. "Summary System Theory Summary", because people send in files called "System theory summary".
### Describe the solution you'd like
Titles can be changed by adding a semicolon after the first "summary", or by changing file titles.
### Motivation
It's much more clear.
</issue>
<code>
[start of website/education/views.py]
1 """Views provided by the education package."""
2 import os
3 from datetime import datetime, date
4
5 from django.contrib.auth.decorators import login_required
6 from django.contrib.messages.views import SuccessMessageMixin
7 from django.core.exceptions import PermissionDenied
8 from django.http import HttpResponse
9 from django.urls import reverse_lazy
10 from django.utils import timezone
11 from django.utils.decorators import method_decorator
12 from django.utils.translation import gettext_lazy as _
13 from django.views.generic import ListView, DetailView, CreateView, TemplateView
14 from django_sendfile import sendfile
15
16 from members.decorators import membership_required
17 from . import emails
18 from .forms import AddExamForm, AddSummaryForm
19 from .models import Category, Course, Exam, Summary
20
21
22 class CourseIndexView(ListView):
23 """Render an overview of the courses."""
24
25 queryset = Course.objects.filter(until=None)
26 template_name = "education/courses.html"
27
28 def get_ordering(self) -> str:
29 return "name"
30
31 def get_context_data(self, **kwargs) -> dict:
32 context = super().get_context_data(**kwargs)
33 context.update(
34 {
35 "courses": (
36 {
37 "course_code": x.course_code,
38 "name": x.name,
39 "categories": x.categories.all(),
40 "document_count": sum(
41 [
42 x.summary_set.filter(accepted=True).count(),
43 x.exam_set.filter(accepted=True).count(),
44 ]
45 + [
46 c.summary_set.filter(accepted=True).count()
47 + c.exam_set.filter(accepted=True).count()
48 for c in x.old_courses.all()
49 ]
50 ),
51 "url": x.get_absolute_url(),
52 }
53 for x in context["object_list"]
54 ),
55 "categories": Category.objects.all(),
56 }
57 )
58 return context
59
60
61 class CourseDetailView(DetailView):
62 """Render the detail page of one specific course."""
63
64 model = Course
65 context_object_name = "course"
66 template_name = "education/course.html"
67
68 def get_context_data(self, **kwargs) -> dict:
69 context = super().get_context_data(**kwargs)
70 obj = context["course"]
71 courses = list(obj.old_courses.all())
72 courses.append(obj)
73 items = {}
74 for course in courses:
75 for summary in course.summary_set.filter(accepted=True):
76 if summary.year not in items:
77 items[summary.year] = {
78 "summaries": [],
79 "exams": [],
80 "legacy": course if course.pk != obj.pk else None,
81 }
82 items[summary.year]["summaries"].append(
83 {
84 "year": summary.year,
85 "name": f'{_("Summary")} {summary.name}',
86 "language": summary.language,
87 "id": summary.id,
88 }
89 )
90 for exam in course.exam_set.filter(accepted=True):
91 if exam.year not in items:
92 items[exam.year] = {
93 "summaries": [],
94 "exams": [],
95 "legacy": course if course.pk != obj.pk else None,
96 }
97 items[exam.year]["exams"].append(
98 {
99 "type": "exam",
100 "year": exam.year,
101 "name": f"{exam.get_type_display()} {exam.name}",
102 "language": exam.language,
103 "id": exam.id,
104 }
105 )
106 context.update({"items": sorted(items.items(), key=lambda x: x[0])})
107 return context
108
109
110 @method_decorator(login_required, "dispatch")
111 @method_decorator(membership_required, "dispatch")
112 class ExamDetailView(DetailView):
113 """Fetch and output the specified exam."""
114
115 model = Exam
116
117 def get(self, request, *args, **kwargs) -> HttpResponse:
118 response = super().get(request, *args, **kwargs)
119 exam = response.context_data["object"]
120 exam.download_count += 1
121 exam.save()
122
123 ext = os.path.splitext(exam.file.path)[1]
124 filename = f"{exam.course.name}-exam{exam.year}{ext}"
125 return sendfile(
126 request, exam.file.path, attachment=True, attachment_filename=filename
127 )
128
129
130 @method_decorator(login_required, "dispatch")
131 @method_decorator(membership_required, "dispatch")
132 class SummaryDetailView(DetailView):
133 """Fetch and output the specified summary."""
134
135 model = Summary
136
137 def get(self, request, *args, **kwargs) -> HttpResponse:
138 response = super().get(request, *args, **kwargs)
139 obj = response.context_data["object"]
140 obj.download_count += 1
141 obj.save()
142
143 ext = os.path.splitext(obj.file.path)[1]
144 filename = f"{obj.course.name}-summary{obj.year}{ext}"
145 return sendfile(
146 request, obj.file.path, attachment=True, attachment_filename=filename
147 )
148
149
150 @method_decorator(login_required, "dispatch")
151 @method_decorator(membership_required, "dispatch")
152 class ExamCreateView(SuccessMessageMixin, CreateView):
153 """Render the form to submit a new exam."""
154
155 model = Exam
156 form_class = AddExamForm
157 template_name = "education/add_exam.html"
158 success_url = reverse_lazy("education:submit-exam")
159 success_message = _("Exam submitted successfully.")
160
161 def get_initial(self) -> dict:
162 initial = super().get_initial()
163 initial["exam_date"] = date.today()
164 initial["course"] = self.kwargs.get("pk", None)
165 return initial
166
167 def form_valid(self, form) -> HttpResponse:
168 self.object = form.save(commit=False)
169 self.object.uploader = self.request.member
170 self.object.uploader_date = datetime.now()
171 self.object.save()
172 emails.send_document_notification(self.object)
173 return super().form_valid(form)
174
175
176 @method_decorator(login_required, "dispatch")
177 @method_decorator(membership_required, "dispatch")
178 class SummaryCreateView(SuccessMessageMixin, CreateView):
179 """Render the form to submit a new summary."""
180
181 model = Summary
182 form_class = AddSummaryForm
183 template_name = "education/add_summary.html"
184 success_url = reverse_lazy("education:submit-summary")
185 success_message = _("Summary submitted successfully.")
186
187 def get_initial(self):
188 initial = super().get_initial()
189 initial["author"] = self.request.member.get_full_name()
190 initial["course"] = self.kwargs.get("pk", None)
191 return initial
192
193 def form_valid(self, form) -> HttpResponse:
194 self.object = form.save(commit=False)
195 self.object.uploader = self.request.member
196 self.object.uploader_date = datetime.now()
197 self.object.save()
198 emails.send_document_notification(self.object)
199 return super().form_valid(form)
200
201
202 @method_decorator(login_required, "dispatch")
203 class BookInfoView(TemplateView):
204 """Render a page with information about book sale.
205
206 Only available to members and to-be members
207 """
208
209 template_name = "education/books.html"
210
211 def dispatch(self, request, *args, **kwargs) -> HttpResponse:
212 if request.member.has_active_membership() or (
213 request.member.earliest_membership
214 and request.member.earliest_membership.since > timezone.now().date()
215 ):
216 return super().dispatch(request, *args, **kwargs)
217 raise PermissionDenied
218
219
220 class StudentParticipantView(TemplateView):
221 """Renders a page with information about student information."""
222
223 template_name = "education/student_participation.html"
224
[end of website/education/views.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/website/education/views.py b/website/education/views.py
--- a/website/education/views.py
+++ b/website/education/views.py
@@ -82,7 +82,7 @@
items[summary.year]["summaries"].append(
{
"year": summary.year,
- "name": f'{_("Summary")} {summary.name}',
+ "name": summary.name,
"language": summary.language,
"id": summary.id,
}
| {"golden_diff": "diff --git a/website/education/views.py b/website/education/views.py\n--- a/website/education/views.py\n+++ b/website/education/views.py\n@@ -82,7 +82,7 @@\n items[summary.year][\"summaries\"].append(\n {\n \"year\": summary.year,\n- \"name\": f'{_(\"Summary\")} {summary.name}',\n+ \"name\": summary.name,\n \"language\": summary.language,\n \"id\": summary.id,\n }\n", "issue": "Change prefix of summaries on the website\n### Is your feature request related to a problem? Please describe.\r\nTitles of summaries usually say e.g. \"Summary System Theory Summary\", because people send in files called \"System theory summary\". \r\n\r\n### Describe the solution you'd like\r\nTitles can be changed by adding a semicolon after the first \"summary\", or by changing file titles. \r\n\r\n### Motivation\r\nIt's much more clear.\r\n\n", "before_files": [{"content": "\"\"\"Views provided by the education package.\"\"\"\nimport os\nfrom datetime import datetime, date\n\nfrom django.contrib.auth.decorators import login_required\nfrom django.contrib.messages.views import SuccessMessageMixin\nfrom django.core.exceptions import PermissionDenied\nfrom django.http import HttpResponse\nfrom django.urls import reverse_lazy\nfrom django.utils import timezone\nfrom django.utils.decorators import method_decorator\nfrom django.utils.translation import gettext_lazy as _\nfrom django.views.generic import ListView, DetailView, CreateView, TemplateView\nfrom django_sendfile import sendfile\n\nfrom members.decorators import membership_required\nfrom . import emails\nfrom .forms import AddExamForm, AddSummaryForm\nfrom .models import Category, Course, Exam, Summary\n\n\nclass CourseIndexView(ListView):\n \"\"\"Render an overview of the courses.\"\"\"\n\n queryset = Course.objects.filter(until=None)\n template_name = \"education/courses.html\"\n\n def get_ordering(self) -> str:\n return \"name\"\n\n def get_context_data(self, **kwargs) -> dict:\n context = super().get_context_data(**kwargs)\n context.update(\n {\n \"courses\": (\n {\n \"course_code\": x.course_code,\n \"name\": x.name,\n \"categories\": x.categories.all(),\n \"document_count\": sum(\n [\n x.summary_set.filter(accepted=True).count(),\n x.exam_set.filter(accepted=True).count(),\n ]\n + [\n c.summary_set.filter(accepted=True).count()\n + c.exam_set.filter(accepted=True).count()\n for c in x.old_courses.all()\n ]\n ),\n \"url\": x.get_absolute_url(),\n }\n for x in context[\"object_list\"]\n ),\n \"categories\": Category.objects.all(),\n }\n )\n return context\n\n\nclass CourseDetailView(DetailView):\n \"\"\"Render the detail page of one specific course.\"\"\"\n\n model = Course\n context_object_name = \"course\"\n template_name = \"education/course.html\"\n\n def get_context_data(self, **kwargs) -> dict:\n context = super().get_context_data(**kwargs)\n obj = context[\"course\"]\n courses = list(obj.old_courses.all())\n courses.append(obj)\n items = {}\n for course in courses:\n for summary in course.summary_set.filter(accepted=True):\n if summary.year not in items:\n items[summary.year] = {\n \"summaries\": [],\n \"exams\": [],\n \"legacy\": course if course.pk != obj.pk else None,\n }\n items[summary.year][\"summaries\"].append(\n {\n \"year\": summary.year,\n \"name\": f'{_(\"Summary\")} {summary.name}',\n \"language\": summary.language,\n \"id\": summary.id,\n }\n )\n for exam in course.exam_set.filter(accepted=True):\n if exam.year not in items:\n items[exam.year] = {\n \"summaries\": [],\n \"exams\": [],\n \"legacy\": course if course.pk != obj.pk else None,\n }\n items[exam.year][\"exams\"].append(\n {\n \"type\": \"exam\",\n \"year\": exam.year,\n \"name\": f\"{exam.get_type_display()} {exam.name}\",\n \"language\": exam.language,\n \"id\": exam.id,\n }\n )\n context.update({\"items\": sorted(items.items(), key=lambda x: x[0])})\n return context\n\n\n@method_decorator(login_required, \"dispatch\")\n@method_decorator(membership_required, \"dispatch\")\nclass ExamDetailView(DetailView):\n \"\"\"Fetch and output the specified exam.\"\"\"\n\n model = Exam\n\n def get(self, request, *args, **kwargs) -> HttpResponse:\n response = super().get(request, *args, **kwargs)\n exam = response.context_data[\"object\"]\n exam.download_count += 1\n exam.save()\n\n ext = os.path.splitext(exam.file.path)[1]\n filename = f\"{exam.course.name}-exam{exam.year}{ext}\"\n return sendfile(\n request, exam.file.path, attachment=True, attachment_filename=filename\n )\n\n\n@method_decorator(login_required, \"dispatch\")\n@method_decorator(membership_required, \"dispatch\")\nclass SummaryDetailView(DetailView):\n \"\"\"Fetch and output the specified summary.\"\"\"\n\n model = Summary\n\n def get(self, request, *args, **kwargs) -> HttpResponse:\n response = super().get(request, *args, **kwargs)\n obj = response.context_data[\"object\"]\n obj.download_count += 1\n obj.save()\n\n ext = os.path.splitext(obj.file.path)[1]\n filename = f\"{obj.course.name}-summary{obj.year}{ext}\"\n return sendfile(\n request, obj.file.path, attachment=True, attachment_filename=filename\n )\n\n\n@method_decorator(login_required, \"dispatch\")\n@method_decorator(membership_required, \"dispatch\")\nclass ExamCreateView(SuccessMessageMixin, CreateView):\n \"\"\"Render the form to submit a new exam.\"\"\"\n\n model = Exam\n form_class = AddExamForm\n template_name = \"education/add_exam.html\"\n success_url = reverse_lazy(\"education:submit-exam\")\n success_message = _(\"Exam submitted successfully.\")\n\n def get_initial(self) -> dict:\n initial = super().get_initial()\n initial[\"exam_date\"] = date.today()\n initial[\"course\"] = self.kwargs.get(\"pk\", None)\n return initial\n\n def form_valid(self, form) -> HttpResponse:\n self.object = form.save(commit=False)\n self.object.uploader = self.request.member\n self.object.uploader_date = datetime.now()\n self.object.save()\n emails.send_document_notification(self.object)\n return super().form_valid(form)\n\n\n@method_decorator(login_required, \"dispatch\")\n@method_decorator(membership_required, \"dispatch\")\nclass SummaryCreateView(SuccessMessageMixin, CreateView):\n \"\"\"Render the form to submit a new summary.\"\"\"\n\n model = Summary\n form_class = AddSummaryForm\n template_name = \"education/add_summary.html\"\n success_url = reverse_lazy(\"education:submit-summary\")\n success_message = _(\"Summary submitted successfully.\")\n\n def get_initial(self):\n initial = super().get_initial()\n initial[\"author\"] = self.request.member.get_full_name()\n initial[\"course\"] = self.kwargs.get(\"pk\", None)\n return initial\n\n def form_valid(self, form) -> HttpResponse:\n self.object = form.save(commit=False)\n self.object.uploader = self.request.member\n self.object.uploader_date = datetime.now()\n self.object.save()\n emails.send_document_notification(self.object)\n return super().form_valid(form)\n\n\n@method_decorator(login_required, \"dispatch\")\nclass BookInfoView(TemplateView):\n \"\"\"Render a page with information about book sale.\n\n Only available to members and to-be members\n \"\"\"\n\n template_name = \"education/books.html\"\n\n def dispatch(self, request, *args, **kwargs) -> HttpResponse:\n if request.member.has_active_membership() or (\n request.member.earliest_membership\n and request.member.earliest_membership.since > timezone.now().date()\n ):\n return super().dispatch(request, *args, **kwargs)\n raise PermissionDenied\n\n\nclass StudentParticipantView(TemplateView):\n \"\"\"Renders a page with information about student information.\"\"\"\n\n template_name = \"education/student_participation.html\"\n", "path": "website/education/views.py"}]} | 2,753 | 106 |
gh_patches_debug_25650 | rasdani/github-patches | git_diff | astronomer__astro-sdk-1374 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
All connections tested even though one's been specified
**Describe the bug**
I ran `astro flow validate --connection=<connection_id>` and all connections were tested even though I passed one conn id specifically.
**Version**
* Astro Runtime: 7.0.0
* Astro CLI: 1.8.3
**To Reproduce**
Steps to reproduce the behavior:
1. Update file `config/default/configuration.yml` as shown below:
```
connections:
- conn_id: sqlite_conn
conn_type: sqlite
host: /Users/magdagultekin/magda-dev/data/imdb.db
login: null
password: null
schema: null
- conn_id: sqlite_default
conn_type: sqlite
host: /tmp/sqlite.db
login: null
password: null
schema: null
```
4. Run `astro flow validate --connection=sqlite_default`
5. See message:
```
Validating connection(s) for environment 'default'
Validating connection sqlite_conn PASSED
Validating connection sqlite_default FAILED
```
**Expected behavior**
Only `sqlite_default` should be tested.
**Screenshots**

</issue>
<code>
[start of sql-cli/sql_cli/connections.py]
1 from __future__ import annotations
2
3 import os
4 from pathlib import Path
5
6 from airflow.models import Connection
7
8 from sql_cli.utils.rich import rprint
9
10 CONNECTION_ID_OUTPUT_STRING_WIDTH = 25
11
12
13 def validate_connections(connections: list[Connection], connection_id: str | None = None) -> None:
14 """
15 Validates that the given connections are valid and registers them to Airflow with replace policy for existing
16 connections.
17 """
18 for connection in connections:
19 os.environ[f"AIRFLOW_CONN_{connection.conn_id.upper()}"] = connection.get_uri()
20 status = "[bold green]PASSED[/bold green]" if _is_valid(connection) else "[bold red]FAILED[/bold red]"
21 rprint(f"Validating connection {connection.conn_id:{CONNECTION_ID_OUTPUT_STRING_WIDTH}}", status)
22
23 if connection_id and not any(connection.conn_id == connection_id for connection in connections):
24 rprint("[bold red]Error: Config file does not contain given connection[/bold red]", connection_id)
25
26
27 def _is_valid(connection: Connection) -> bool:
28 # Sqlite automatically creates the file if it does not exist,
29 # but our users might not expect that. They are referencing a database they expect to exist.
30 if connection.conn_type == "sqlite" and not Path(connection.host).is_file():
31 return False
32
33 success_status, _ = connection.test_connection()
34 return success_status
35
[end of sql-cli/sql_cli/connections.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/sql-cli/sql_cli/connections.py b/sql-cli/sql_cli/connections.py
--- a/sql-cli/sql_cli/connections.py
+++ b/sql-cli/sql_cli/connections.py
@@ -15,14 +15,17 @@
Validates that the given connections are valid and registers them to Airflow with replace policy for existing
connections.
"""
- for connection in connections:
- os.environ[f"AIRFLOW_CONN_{connection.conn_id.upper()}"] = connection.get_uri()
- status = "[bold green]PASSED[/bold green]" if _is_valid(connection) else "[bold red]FAILED[/bold red]"
- rprint(f"Validating connection {connection.conn_id:{CONNECTION_ID_OUTPUT_STRING_WIDTH}}", status)
-
if connection_id and not any(connection.conn_id == connection_id for connection in connections):
rprint("[bold red]Error: Config file does not contain given connection[/bold red]", connection_id)
+ for connection in connections:
+ if not connection_id or connection_id and connection.conn_id == connection_id:
+ os.environ[f"AIRFLOW_CONN_{connection.conn_id.upper()}"] = connection.get_uri()
+ status = (
+ "[bold green]PASSED[/bold green]" if _is_valid(connection) else "[bold red]FAILED[/bold red]"
+ )
+ rprint(f"Validating connection {connection.conn_id:{CONNECTION_ID_OUTPUT_STRING_WIDTH}}", status)
+
def _is_valid(connection: Connection) -> bool:
# Sqlite automatically creates the file if it does not exist,
| {"golden_diff": "diff --git a/sql-cli/sql_cli/connections.py b/sql-cli/sql_cli/connections.py\n--- a/sql-cli/sql_cli/connections.py\n+++ b/sql-cli/sql_cli/connections.py\n@@ -15,14 +15,17 @@\n Validates that the given connections are valid and registers them to Airflow with replace policy for existing\n connections.\n \"\"\"\n- for connection in connections:\n- os.environ[f\"AIRFLOW_CONN_{connection.conn_id.upper()}\"] = connection.get_uri()\n- status = \"[bold green]PASSED[/bold green]\" if _is_valid(connection) else \"[bold red]FAILED[/bold red]\"\n- rprint(f\"Validating connection {connection.conn_id:{CONNECTION_ID_OUTPUT_STRING_WIDTH}}\", status)\n-\n if connection_id and not any(connection.conn_id == connection_id for connection in connections):\n rprint(\"[bold red]Error: Config file does not contain given connection[/bold red]\", connection_id)\n \n+ for connection in connections:\n+ if not connection_id or connection_id and connection.conn_id == connection_id:\n+ os.environ[f\"AIRFLOW_CONN_{connection.conn_id.upper()}\"] = connection.get_uri()\n+ status = (\n+ \"[bold green]PASSED[/bold green]\" if _is_valid(connection) else \"[bold red]FAILED[/bold red]\"\n+ )\n+ rprint(f\"Validating connection {connection.conn_id:{CONNECTION_ID_OUTPUT_STRING_WIDTH}}\", status)\n+\n \n def _is_valid(connection: Connection) -> bool:\n # Sqlite automatically creates the file if it does not exist,\n", "issue": "All connections tested even though one's been specified\n**Describe the bug**\r\nI ran `astro flow validate --connection=<connection_id>` and all connections were tested even though I passed one conn id specifically. \r\n\r\n**Version**\r\n* Astro Runtime: 7.0.0\r\n* Astro CLI: 1.8.3\r\n\r\n**To Reproduce**\r\nSteps to reproduce the behavior:\r\n1. Update file `config/default/configuration.yml` as shown below:\r\n```\r\nconnections:\r\n - conn_id: sqlite_conn\r\n conn_type: sqlite\r\n host: /Users/magdagultekin/magda-dev/data/imdb.db\r\n login: null\r\n password: null\r\n schema: null\r\n - conn_id: sqlite_default\r\n conn_type: sqlite\r\n host: /tmp/sqlite.db\r\n login: null\r\n password: null\r\n schema: null\r\n```\r\n4. Run `astro flow validate --connection=sqlite_default`\r\n5. See message:\r\n```\r\nValidating connection(s) for environment 'default'\r\nValidating connection sqlite_conn PASSED\r\nValidating connection sqlite_default FAILED\r\n```\r\n\r\n**Expected behavior**\r\nOnly `sqlite_default` should be tested.\r\n\r\n**Screenshots**\r\n\r\n\r\n\n", "before_files": [{"content": "from __future__ import annotations\n\nimport os\nfrom pathlib import Path\n\nfrom airflow.models import Connection\n\nfrom sql_cli.utils.rich import rprint\n\nCONNECTION_ID_OUTPUT_STRING_WIDTH = 25\n\n\ndef validate_connections(connections: list[Connection], connection_id: str | None = None) -> None:\n \"\"\"\n Validates that the given connections are valid and registers them to Airflow with replace policy for existing\n connections.\n \"\"\"\n for connection in connections:\n os.environ[f\"AIRFLOW_CONN_{connection.conn_id.upper()}\"] = connection.get_uri()\n status = \"[bold green]PASSED[/bold green]\" if _is_valid(connection) else \"[bold red]FAILED[/bold red]\"\n rprint(f\"Validating connection {connection.conn_id:{CONNECTION_ID_OUTPUT_STRING_WIDTH}}\", status)\n\n if connection_id and not any(connection.conn_id == connection_id for connection in connections):\n rprint(\"[bold red]Error: Config file does not contain given connection[/bold red]\", connection_id)\n\n\ndef _is_valid(connection: Connection) -> bool:\n # Sqlite automatically creates the file if it does not exist,\n # but our users might not expect that. They are referencing a database they expect to exist.\n if connection.conn_type == \"sqlite\" and not Path(connection.host).is_file():\n return False\n\n success_status, _ = connection.test_connection()\n return success_status\n", "path": "sql-cli/sql_cli/connections.py"}]} | 1,219 | 338 |
gh_patches_debug_23145 | rasdani/github-patches | git_diff | alltheplaces__alltheplaces-881 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Jewel-Osco
https://local.jewelosco.com/index.html
Looks like it can probably just be added as a start url in the albertsons.py spider.
</issue>
<code>
[start of locations/spiders/albertsons.py]
1 import scrapy
2 import re
3 import json
4 from locations.items import GeojsonPointItem
5
6 DAY_MAPPING = {
7 'M': 'Mo',
8 'T': 'Tu',
9 'W': 'We',
10 'F': 'Fr',
11 'Sat': 'Sa',
12 'Sun': 'Su'
13 }
14
15
16 class AlbertsonsSpider(scrapy.Spider):
17
18 name = "albertsons"
19 allowed_domains = ["local.albertsons.com"]
20 download_delay = 0.5
21 start_urls = (
22 'https://local.albertsons.com/index.html',
23 )
24
25 def parse_stores(self, response):
26 ref = re.findall(r"[^(\/)]+.html$" ,response.url)
27 map_data = response.xpath('normalize-space(//script[@id="js-map-config-dir-map-desktop"]/text())').extract_first()
28 map_json= json.loads(map_data)
29 if(len(ref)>0):
30 ref = ref[0].split('.')[0]
31 properties = {
32 'addr_full': response.xpath('normalize-space(//span[@itemprop="streetAddress"]/span/text())').extract_first(),
33 'phone': response.xpath('normalize-space(//span[@itemprop="telephone"]/text())').extract_first(),
34 'city': response.xpath('normalize-space(//span[@itemprop="addressLocality"]/text())').extract_first(),
35 'state': response.xpath('normalize-space(//abbr[@itemprop="addressRegion"]/text())').extract_first(),
36 'postcode': response.xpath('normalize-space(//span[@itemprop="postalCode"]/text())').extract_first(),
37 'ref': ref,
38 'website': response.url,
39 'lat': float(map_json['locs'][0]['latitude']),
40 'lon': float(map_json['locs'][0]['longitude']),
41 }
42 hours = response.xpath('//div[@class="LocationInfo-right"]/div[1]/div[@class="LocationInfo-hoursTable"]/div[@class="c-location-hours-details-wrapper js-location-hours"]/table/tbody/tr/@content').extract()
43 if hours:
44 properties['opening_hours'] = " ;".join(hours)
45 yield GeojsonPointItem(**properties)
46
47 def parse_city_stores(self ,response):
48 stores = response.xpath('//div[@class="Teaser-content"]/h2/a/@href').extract()
49 for store in stores:
50 yield scrapy.Request(response.urljoin(store), callback=self.parse_stores)
51
52 def parse_state(self, response):
53 urls = response.xpath('//div[@class="c-directory-list-content-wrapper"]/ul/li/a/@href').extract()
54 for path in urls:
55 pattern = re.compile("^[a-z]{2}\/[^()]+\/[^()]+.html$")
56 if (pattern.match(path.strip())):
57 yield scrapy.Request(response.urljoin(path), callback=self.parse_stores)
58 else:
59 yield scrapy.Request(response.urljoin(path), callback=self.parse_city_stores)
60
61 def parse(self, response):
62 urls = response.xpath('//div[@class="c-directory-list-content-wrapper"]/ul/li/a/@href').extract()
63 for path in urls:
64 pattern = re.compile("^[a-z]{2}.html$")
65 pattern1 = re.compile("^[a-z]{2}\/[^()]+\/[^()]+.html$")
66 if(pattern.match(path.strip())):
67 yield scrapy.Request(response.urljoin(path), callback=self.parse_state)
68 elif(pattern1.match(path.strip())):
69 yield scrapy.Request(response.urljoin(path), callback=self.parse_stores)
70 else:
71 yield scrapy.Request(response.urljoin(path), callback=self.parse_city_stores)
72
[end of locations/spiders/albertsons.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/locations/spiders/albertsons.py b/locations/spiders/albertsons.py
--- a/locations/spiders/albertsons.py
+++ b/locations/spiders/albertsons.py
@@ -16,10 +16,14 @@
class AlbertsonsSpider(scrapy.Spider):
name = "albertsons"
- allowed_domains = ["local.albertsons.com"]
download_delay = 0.5
+ allowed_domains = [
+ "local.albertsons.com",
+ "local.jewelosco.com",
+ ]
start_urls = (
'https://local.albertsons.com/index.html',
+ 'https://local.jewelosco.com/index.html',
)
def parse_stores(self, response):
@@ -41,7 +45,7 @@
}
hours = response.xpath('//div[@class="LocationInfo-right"]/div[1]/div[@class="LocationInfo-hoursTable"]/div[@class="c-location-hours-details-wrapper js-location-hours"]/table/tbody/tr/@content').extract()
if hours:
- properties['opening_hours'] = " ;".join(hours)
+ properties['opening_hours'] = "; ".join(hours)
yield GeojsonPointItem(**properties)
def parse_city_stores(self ,response):
| {"golden_diff": "diff --git a/locations/spiders/albertsons.py b/locations/spiders/albertsons.py\n--- a/locations/spiders/albertsons.py\n+++ b/locations/spiders/albertsons.py\n@@ -16,10 +16,14 @@\n class AlbertsonsSpider(scrapy.Spider):\n \n name = \"albertsons\"\n- allowed_domains = [\"local.albertsons.com\"]\n download_delay = 0.5\n+ allowed_domains = [\n+ \"local.albertsons.com\",\n+ \"local.jewelosco.com\",\n+ ]\n start_urls = (\n 'https://local.albertsons.com/index.html',\n+ 'https://local.jewelosco.com/index.html',\n )\n \n def parse_stores(self, response):\n@@ -41,7 +45,7 @@\n }\n hours = response.xpath('//div[@class=\"LocationInfo-right\"]/div[1]/div[@class=\"LocationInfo-hoursTable\"]/div[@class=\"c-location-hours-details-wrapper js-location-hours\"]/table/tbody/tr/@content').extract()\n if hours:\n- properties['opening_hours'] = \" ;\".join(hours)\n+ properties['opening_hours'] = \"; \".join(hours)\n yield GeojsonPointItem(**properties)\n \n def parse_city_stores(self ,response):\n", "issue": "Jewel-Osco\nhttps://local.jewelosco.com/index.html\r\n\r\nLooks like it can probably just be added as a start url in the albertsons.py spider.\n", "before_files": [{"content": "import scrapy\nimport re\nimport json\nfrom locations.items import GeojsonPointItem\n\nDAY_MAPPING = {\n 'M': 'Mo',\n 'T': 'Tu',\n 'W': 'We',\n 'F': 'Fr',\n 'Sat': 'Sa',\n 'Sun': 'Su'\n}\n\n\nclass AlbertsonsSpider(scrapy.Spider):\n\n name = \"albertsons\"\n allowed_domains = [\"local.albertsons.com\"]\n download_delay = 0.5\n start_urls = (\n 'https://local.albertsons.com/index.html',\n )\n\n def parse_stores(self, response):\n ref = re.findall(r\"[^(\\/)]+.html$\" ,response.url)\n map_data = response.xpath('normalize-space(//script[@id=\"js-map-config-dir-map-desktop\"]/text())').extract_first()\n map_json= json.loads(map_data)\n if(len(ref)>0):\n ref = ref[0].split('.')[0]\n properties = {\n 'addr_full': response.xpath('normalize-space(//span[@itemprop=\"streetAddress\"]/span/text())').extract_first(),\n 'phone': response.xpath('normalize-space(//span[@itemprop=\"telephone\"]/text())').extract_first(),\n 'city': response.xpath('normalize-space(//span[@itemprop=\"addressLocality\"]/text())').extract_first(),\n 'state': response.xpath('normalize-space(//abbr[@itemprop=\"addressRegion\"]/text())').extract_first(),\n 'postcode': response.xpath('normalize-space(//span[@itemprop=\"postalCode\"]/text())').extract_first(),\n 'ref': ref,\n 'website': response.url,\n 'lat': float(map_json['locs'][0]['latitude']),\n 'lon': float(map_json['locs'][0]['longitude']),\n }\n hours = response.xpath('//div[@class=\"LocationInfo-right\"]/div[1]/div[@class=\"LocationInfo-hoursTable\"]/div[@class=\"c-location-hours-details-wrapper js-location-hours\"]/table/tbody/tr/@content').extract()\n if hours:\n properties['opening_hours'] = \" ;\".join(hours)\n yield GeojsonPointItem(**properties)\n\n def parse_city_stores(self ,response):\n stores = response.xpath('//div[@class=\"Teaser-content\"]/h2/a/@href').extract()\n for store in stores:\n yield scrapy.Request(response.urljoin(store), callback=self.parse_stores)\n\n def parse_state(self, response):\n urls = response.xpath('//div[@class=\"c-directory-list-content-wrapper\"]/ul/li/a/@href').extract()\n for path in urls:\n pattern = re.compile(\"^[a-z]{2}\\/[^()]+\\/[^()]+.html$\")\n if (pattern.match(path.strip())):\n yield scrapy.Request(response.urljoin(path), callback=self.parse_stores)\n else:\n yield scrapy.Request(response.urljoin(path), callback=self.parse_city_stores)\n\n def parse(self, response):\n urls = response.xpath('//div[@class=\"c-directory-list-content-wrapper\"]/ul/li/a/@href').extract()\n for path in urls:\n pattern = re.compile(\"^[a-z]{2}.html$\")\n pattern1 = re.compile(\"^[a-z]{2}\\/[^()]+\\/[^()]+.html$\")\n if(pattern.match(path.strip())):\n yield scrapy.Request(response.urljoin(path), callback=self.parse_state)\n elif(pattern1.match(path.strip())):\n yield scrapy.Request(response.urljoin(path), callback=self.parse_stores)\n else:\n yield scrapy.Request(response.urljoin(path), callback=self.parse_city_stores)\n", "path": "locations/spiders/albertsons.py"}]} | 1,471 | 284 |
gh_patches_debug_8006 | rasdani/github-patches | git_diff | tournesol-app__tournesol-1713 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[feat] Make `exclude_compared` configurable in user settings
</issue>
<code>
[start of backend/core/serializers/user_settings.py]
1 from django.utils.translation import gettext_lazy as _
2 from rest_framework import serializers
3 from rest_framework.serializers import ValidationError
4
5 from tournesol.models.poll import Poll
6 from tournesol.utils.video_language import ACCEPTED_LANGUAGE_CODES
7
8
9 class GeneralUserSettingsSerializer(serializers.Serializer):
10 """
11 The general user settings that are not related to Tournesol polls.
12 """
13
14 # The first element of the tuple should be an ISO 639-1 code.
15 NOTIFICATIONS_LANG = [
16 ("en", "en"),
17 ("fr", "fr"),
18 ]
19
20 notifications__lang = serializers.ChoiceField(
21 choices=NOTIFICATIONS_LANG, required=False
22 )
23 notifications_email__research = serializers.BooleanField(required=False)
24 notifications_email__new_features = serializers.BooleanField(required=False)
25
26
27 class GenericPollUserSettingsSerializer(serializers.Serializer):
28 """
29 The settings common to each poll.
30 """
31
32 COMPONENT_DISPLAY_STATE = [
33 ("ALWAYS", "always"),
34 ("EMBEDDED_ONLY", "embedded_only"),
35 ("WEBSITE_ONLY", "website_only"),
36 ("NEVER", "never"),
37 ]
38
39 comparison__criteria_order = serializers.ListField(
40 child=serializers.CharField(), required=False
41 )
42
43 comparison__fill_entity_selector = serializers.BooleanField(required=False)
44
45 comparison_ui__weekly_collective_goal_display = serializers.ChoiceField(
46 choices=COMPONENT_DISPLAY_STATE, allow_blank=True, required=False
47 )
48
49 rate_later__auto_remove = serializers.IntegerField(required=False)
50
51 def validate_comparison__criteria_order(self, criteria):
52 poll_name = self.context.get("poll_name", self._context["poll_name"])
53 poll = Poll.objects.get(name=poll_name)
54
55 if poll.main_criteria in criteria:
56 raise ValidationError(_("The main criterion cannot be in the list."))
57
58 if len(criteria) != len(set(criteria)):
59 raise ValidationError(_("The list cannot contain duplicates."))
60
61 for criterion in criteria:
62 if criterion not in poll.criterias_list:
63 raise ValidationError(
64 _("Unknown criterion: %(criterion)s.") % {"criterion": criterion}
65 )
66
67 return criteria
68
69 def validate_rate_later__auto_remove(self, value):
70 if value < 1:
71 raise ValidationError(_("This parameter cannot be lower than 1."))
72 return value
73
74
75 class VideosPollUserSettingsSerializer(GenericPollUserSettingsSerializer):
76 """
77 The settings specific to the `videos` poll.
78
79 Also inherit the settings common to each poll.
80 """
81
82 DEFAULT_DATE_CHOICES = [
83 ("TODAY", "today"),
84 ("WEEK", "week"),
85 ("MONTH", "month"),
86 ("YEAR", "year"),
87 ("ALL_TIME", "all_time"),
88 ]
89
90 recommendations__default_date = serializers.ChoiceField(
91 choices=DEFAULT_DATE_CHOICES, allow_blank=True, required=False
92 )
93 recommendations__default_languages = serializers.ListField(
94 child=serializers.CharField(), allow_empty=True, required=False
95 )
96 recommendations__default_unsafe = serializers.BooleanField(required=False)
97
98 def validate_recommendations__default_languages(self, default_languages):
99 for lang in default_languages:
100 if lang not in ACCEPTED_LANGUAGE_CODES:
101 raise ValidationError(_("Unknown language code: %(lang)s.") % {"lang": lang})
102
103 return default_languages
104
105
106 class TournesolUserSettingsSerializer(serializers.Serializer):
107 """
108 A representation of all user settings of the Tournesol project.
109
110 This representation includes poll-agnostic settings in addition to the
111 specific settings of each poll.
112 """
113
114 general = GeneralUserSettingsSerializer(required=False)
115 videos = VideosPollUserSettingsSerializer(required=False, context={"poll_name": "videos"})
116
117 def create(self, validated_data):
118 return validated_data
119
120 def update(self, instance, validated_data):
121 for scope, settings in self.validated_data.items():
122 if scope not in instance:
123 instance[scope] = {}
124 instance[scope].update(settings)
125 return instance
126
[end of backend/core/serializers/user_settings.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/backend/core/serializers/user_settings.py b/backend/core/serializers/user_settings.py
--- a/backend/core/serializers/user_settings.py
+++ b/backend/core/serializers/user_settings.py
@@ -94,6 +94,7 @@
child=serializers.CharField(), allow_empty=True, required=False
)
recommendations__default_unsafe = serializers.BooleanField(required=False)
+ recommendations__default_exclude_compared_entities = serializers.BooleanField(required=False)
def validate_recommendations__default_languages(self, default_languages):
for lang in default_languages:
| {"golden_diff": "diff --git a/backend/core/serializers/user_settings.py b/backend/core/serializers/user_settings.py\n--- a/backend/core/serializers/user_settings.py\n+++ b/backend/core/serializers/user_settings.py\n@@ -94,6 +94,7 @@\n child=serializers.CharField(), allow_empty=True, required=False\n )\n recommendations__default_unsafe = serializers.BooleanField(required=False)\n+ recommendations__default_exclude_compared_entities = serializers.BooleanField(required=False)\n \n def validate_recommendations__default_languages(self, default_languages):\n for lang in default_languages:\n", "issue": "[feat] Make `exclude_compared` configurable in user settings\n\n", "before_files": [{"content": "from django.utils.translation import gettext_lazy as _\nfrom rest_framework import serializers\nfrom rest_framework.serializers import ValidationError\n\nfrom tournesol.models.poll import Poll\nfrom tournesol.utils.video_language import ACCEPTED_LANGUAGE_CODES\n\n\nclass GeneralUserSettingsSerializer(serializers.Serializer):\n \"\"\"\n The general user settings that are not related to Tournesol polls.\n \"\"\"\n\n # The first element of the tuple should be an ISO 639-1 code.\n NOTIFICATIONS_LANG = [\n (\"en\", \"en\"),\n (\"fr\", \"fr\"),\n ]\n\n notifications__lang = serializers.ChoiceField(\n choices=NOTIFICATIONS_LANG, required=False\n )\n notifications_email__research = serializers.BooleanField(required=False)\n notifications_email__new_features = serializers.BooleanField(required=False)\n\n\nclass GenericPollUserSettingsSerializer(serializers.Serializer):\n \"\"\"\n The settings common to each poll.\n \"\"\"\n\n COMPONENT_DISPLAY_STATE = [\n (\"ALWAYS\", \"always\"),\n (\"EMBEDDED_ONLY\", \"embedded_only\"),\n (\"WEBSITE_ONLY\", \"website_only\"),\n (\"NEVER\", \"never\"),\n ]\n\n comparison__criteria_order = serializers.ListField(\n child=serializers.CharField(), required=False\n )\n\n comparison__fill_entity_selector = serializers.BooleanField(required=False)\n\n comparison_ui__weekly_collective_goal_display = serializers.ChoiceField(\n choices=COMPONENT_DISPLAY_STATE, allow_blank=True, required=False\n )\n\n rate_later__auto_remove = serializers.IntegerField(required=False)\n\n def validate_comparison__criteria_order(self, criteria):\n poll_name = self.context.get(\"poll_name\", self._context[\"poll_name\"])\n poll = Poll.objects.get(name=poll_name)\n\n if poll.main_criteria in criteria:\n raise ValidationError(_(\"The main criterion cannot be in the list.\"))\n\n if len(criteria) != len(set(criteria)):\n raise ValidationError(_(\"The list cannot contain duplicates.\"))\n\n for criterion in criteria:\n if criterion not in poll.criterias_list:\n raise ValidationError(\n _(\"Unknown criterion: %(criterion)s.\") % {\"criterion\": criterion}\n )\n\n return criteria\n\n def validate_rate_later__auto_remove(self, value):\n if value < 1:\n raise ValidationError(_(\"This parameter cannot be lower than 1.\"))\n return value\n\n\nclass VideosPollUserSettingsSerializer(GenericPollUserSettingsSerializer):\n \"\"\"\n The settings specific to the `videos` poll.\n\n Also inherit the settings common to each poll.\n \"\"\"\n\n DEFAULT_DATE_CHOICES = [\n (\"TODAY\", \"today\"),\n (\"WEEK\", \"week\"),\n (\"MONTH\", \"month\"),\n (\"YEAR\", \"year\"),\n (\"ALL_TIME\", \"all_time\"),\n ]\n\n recommendations__default_date = serializers.ChoiceField(\n choices=DEFAULT_DATE_CHOICES, allow_blank=True, required=False\n )\n recommendations__default_languages = serializers.ListField(\n child=serializers.CharField(), allow_empty=True, required=False\n )\n recommendations__default_unsafe = serializers.BooleanField(required=False)\n\n def validate_recommendations__default_languages(self, default_languages):\n for lang in default_languages:\n if lang not in ACCEPTED_LANGUAGE_CODES:\n raise ValidationError(_(\"Unknown language code: %(lang)s.\") % {\"lang\": lang})\n\n return default_languages\n\n\nclass TournesolUserSettingsSerializer(serializers.Serializer):\n \"\"\"\n A representation of all user settings of the Tournesol project.\n\n This representation includes poll-agnostic settings in addition to the\n specific settings of each poll.\n \"\"\"\n\n general = GeneralUserSettingsSerializer(required=False)\n videos = VideosPollUserSettingsSerializer(required=False, context={\"poll_name\": \"videos\"})\n\n def create(self, validated_data):\n return validated_data\n\n def update(self, instance, validated_data):\n for scope, settings in self.validated_data.items():\n if scope not in instance:\n instance[scope] = {}\n instance[scope].update(settings)\n return instance\n", "path": "backend/core/serializers/user_settings.py"}]} | 1,672 | 120 |
gh_patches_debug_5138 | rasdani/github-patches | git_diff | dask__dask-2634 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
String Accessors in Converted DataFrame Columns
Whenever I try to access strings in a dataframe which are previously converted to strings (ie. datall[['A']] = datall[['A']].applymap(str) and then datall['A']=datall['A'].str[:5]) I get a TypeError: 'StringAccessor' object has no attribute '__getitem__'.
This is reproducible as follows:
```
import pandas as pd
import dask.dataframe as dd
import numpy as np
def float_apply(x):
try:
return float(x)
except ValueError:
return float('nan')
def string_apply(x):
try:
return str(x)
except ValueError:
return str('nan')
df = pd.DataFrame(np.random.random_integers(0,6,size=(20, 6)), columns=list('ABCDEF'))
data = dd.from_pandas(df, npartitions = 2)
data=data.applymap(float_apply)
data[['A']] = data[['A']].applymap(string_apply)
data['A'] = data['A'].str[:1]
print data.compute()
```
This will work with pandas dataframes. If .compute() is run prior to this then it works fine but that is probably suboptimal for large datasets.
</issue>
<code>
[start of dask/dataframe/accessor.py]
1 from __future__ import absolute_import, division, print_function
2
3 import numpy as np
4 import pandas as pd
5 from toolz import partial
6
7 from ..utils import derived_from
8
9
10 def maybe_wrap_pandas(obj, x):
11 if isinstance(x, np.ndarray):
12 if isinstance(obj, pd.Series):
13 return pd.Series(x, index=obj.index, dtype=x.dtype)
14 return pd.Index(x)
15 return x
16
17
18 class Accessor(object):
19 """
20 Base class for pandas Accessor objects cat, dt, and str.
21
22 Notes
23 -----
24 Subclasses should define the following attributes:
25
26 * _accessor
27 * _accessor_name
28 """
29 _not_implemented = set()
30
31 def __init__(self, series):
32 from .core import Series
33 if not isinstance(series, Series):
34 raise ValueError('Accessor cannot be initialized')
35 self._validate(series)
36 self._series = series
37
38 def _validate(self, series):
39 pass
40
41 @staticmethod
42 def _delegate_property(obj, accessor, attr):
43 out = getattr(getattr(obj, accessor, obj), attr)
44 return maybe_wrap_pandas(obj, out)
45
46 @staticmethod
47 def _delegate_method(obj, accessor, attr, args, kwargs):
48 out = getattr(getattr(obj, accessor, obj), attr)(*args, **kwargs)
49 return maybe_wrap_pandas(obj, out)
50
51 def _property_map(self, attr):
52 meta = self._delegate_property(self._series._meta,
53 self._accessor_name, attr)
54 token = '%s-%s' % (self._accessor_name, attr)
55 return self._series.map_partitions(self._delegate_property,
56 self._accessor_name, attr,
57 token=token, meta=meta)
58
59 def _function_map(self, attr, *args, **kwargs):
60 meta = self._delegate_method(self._series._meta_nonempty,
61 self._accessor_name, attr, args, kwargs)
62 token = '%s-%s' % (self._accessor_name, attr)
63 return self._series.map_partitions(self._delegate_method,
64 self._accessor_name, attr, args,
65 kwargs, meta=meta, token=token)
66
67 @property
68 def _delegates(self):
69 return set(dir(self._accessor)).difference(self._not_implemented)
70
71 def __dir__(self):
72 o = self._delegates
73 o.update(self.__dict__)
74 o.update(dir(type(self)))
75 return list(o)
76
77 def __getattr__(self, key):
78 if key in self._delegates:
79 if isinstance(getattr(self._accessor, key), property):
80 return self._property_map(key)
81 else:
82 return partial(self._function_map, key)
83 else:
84 raise AttributeError(key)
85
86
87 class DatetimeAccessor(Accessor):
88 """ Accessor object for datetimelike properties of the Series values.
89
90 Examples
91 --------
92
93 >>> s.dt.microsecond # doctest: +SKIP
94 """
95 _accessor = pd.Series.dt
96 _accessor_name = 'dt'
97
98
99 class StringAccessor(Accessor):
100 """ Accessor object for string properties of the Series values.
101
102 Examples
103 --------
104
105 >>> s.str.lower() # doctest: +SKIP
106 """
107 _accessor = pd.Series.str
108 _accessor_name = 'str'
109 _not_implemented = {'get_dummies'}
110
111 def _validate(self, series):
112 if not series.dtype == 'object':
113 raise AttributeError("Can only use .str accessor with object dtype")
114
115 @derived_from(pd.core.strings.StringMethods)
116 def split(self, pat=None, n=-1):
117 return self._function_map('split', pat=pat, n=n)
118
[end of dask/dataframe/accessor.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/dask/dataframe/accessor.py b/dask/dataframe/accessor.py
--- a/dask/dataframe/accessor.py
+++ b/dask/dataframe/accessor.py
@@ -115,3 +115,12 @@
@derived_from(pd.core.strings.StringMethods)
def split(self, pat=None, n=-1):
return self._function_map('split', pat=pat, n=n)
+
+ def __getitem__(self, index):
+ return self._series.map_partitions(str_get, index,
+ meta=self._series._meta)
+
+
+def str_get(series, index):
+ """ Implements series.str[index] """
+ return series.str[index]
| {"golden_diff": "diff --git a/dask/dataframe/accessor.py b/dask/dataframe/accessor.py\n--- a/dask/dataframe/accessor.py\n+++ b/dask/dataframe/accessor.py\n@@ -115,3 +115,12 @@\n @derived_from(pd.core.strings.StringMethods)\n def split(self, pat=None, n=-1):\n return self._function_map('split', pat=pat, n=n)\n+\n+ def __getitem__(self, index):\n+ return self._series.map_partitions(str_get, index,\n+ meta=self._series._meta)\n+\n+\n+def str_get(series, index):\n+ \"\"\" Implements series.str[index] \"\"\"\n+ return series.str[index]\n", "issue": "String Accessors in Converted DataFrame Columns\nWhenever I try to access strings in a dataframe which are previously converted to strings (ie. datall[['A']] = datall[['A']].applymap(str) and then datall['A']=datall['A'].str[:5]) I get a TypeError: 'StringAccessor' object has no attribute '__getitem__'.\r\n\r\nThis is reproducible as follows:\r\n\r\n```\r\nimport pandas as pd\r\nimport dask.dataframe as dd\r\nimport numpy as np\r\n\r\ndef float_apply(x):\r\n try:\r\n return float(x)\r\n except ValueError:\r\n return float('nan')\r\n\r\ndef string_apply(x):\r\n try:\r\n return str(x)\r\n except ValueError:\r\n return str('nan')\r\n\r\ndf = pd.DataFrame(np.random.random_integers(0,6,size=(20, 6)), columns=list('ABCDEF'))\r\n\r\ndata = dd.from_pandas(df, npartitions = 2)\r\n\r\ndata=data.applymap(float_apply)\r\n\r\ndata[['A']] = data[['A']].applymap(string_apply)\r\ndata['A'] = data['A'].str[:1]\r\n\r\nprint data.compute()\r\n\r\n```\r\n\r\nThis will work with pandas dataframes. If .compute() is run prior to this then it works fine but that is probably suboptimal for large datasets.\n", "before_files": [{"content": "from __future__ import absolute_import, division, print_function\n\nimport numpy as np\nimport pandas as pd\nfrom toolz import partial\n\nfrom ..utils import derived_from\n\n\ndef maybe_wrap_pandas(obj, x):\n if isinstance(x, np.ndarray):\n if isinstance(obj, pd.Series):\n return pd.Series(x, index=obj.index, dtype=x.dtype)\n return pd.Index(x)\n return x\n\n\nclass Accessor(object):\n \"\"\"\n Base class for pandas Accessor objects cat, dt, and str.\n\n Notes\n -----\n Subclasses should define the following attributes:\n\n * _accessor\n * _accessor_name\n \"\"\"\n _not_implemented = set()\n\n def __init__(self, series):\n from .core import Series\n if not isinstance(series, Series):\n raise ValueError('Accessor cannot be initialized')\n self._validate(series)\n self._series = series\n\n def _validate(self, series):\n pass\n\n @staticmethod\n def _delegate_property(obj, accessor, attr):\n out = getattr(getattr(obj, accessor, obj), attr)\n return maybe_wrap_pandas(obj, out)\n\n @staticmethod\n def _delegate_method(obj, accessor, attr, args, kwargs):\n out = getattr(getattr(obj, accessor, obj), attr)(*args, **kwargs)\n return maybe_wrap_pandas(obj, out)\n\n def _property_map(self, attr):\n meta = self._delegate_property(self._series._meta,\n self._accessor_name, attr)\n token = '%s-%s' % (self._accessor_name, attr)\n return self._series.map_partitions(self._delegate_property,\n self._accessor_name, attr,\n token=token, meta=meta)\n\n def _function_map(self, attr, *args, **kwargs):\n meta = self._delegate_method(self._series._meta_nonempty,\n self._accessor_name, attr, args, kwargs)\n token = '%s-%s' % (self._accessor_name, attr)\n return self._series.map_partitions(self._delegate_method,\n self._accessor_name, attr, args,\n kwargs, meta=meta, token=token)\n\n @property\n def _delegates(self):\n return set(dir(self._accessor)).difference(self._not_implemented)\n\n def __dir__(self):\n o = self._delegates\n o.update(self.__dict__)\n o.update(dir(type(self)))\n return list(o)\n\n def __getattr__(self, key):\n if key in self._delegates:\n if isinstance(getattr(self._accessor, key), property):\n return self._property_map(key)\n else:\n return partial(self._function_map, key)\n else:\n raise AttributeError(key)\n\n\nclass DatetimeAccessor(Accessor):\n \"\"\" Accessor object for datetimelike properties of the Series values.\n\n Examples\n --------\n\n >>> s.dt.microsecond # doctest: +SKIP\n \"\"\"\n _accessor = pd.Series.dt\n _accessor_name = 'dt'\n\n\nclass StringAccessor(Accessor):\n \"\"\" Accessor object for string properties of the Series values.\n\n Examples\n --------\n\n >>> s.str.lower() # doctest: +SKIP\n \"\"\"\n _accessor = pd.Series.str\n _accessor_name = 'str'\n _not_implemented = {'get_dummies'}\n\n def _validate(self, series):\n if not series.dtype == 'object':\n raise AttributeError(\"Can only use .str accessor with object dtype\")\n\n @derived_from(pd.core.strings.StringMethods)\n def split(self, pat=None, n=-1):\n return self._function_map('split', pat=pat, n=n)\n", "path": "dask/dataframe/accessor.py"}]} | 1,863 | 152 |
gh_patches_debug_514 | rasdani/github-patches | git_diff | bookwyrm-social__bookwyrm-355 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
UndefinedTable: relation "bookwyrm_userrelationship" does not exist error
**Describe the bug**
I went to go load up the development env today after a little while of not using it and came across this error when I ran the `docker-compose run --rm web python manage.py migrate` cmd to keep up with new migrations:
```
docker-compose run --rm web python manage.py migrate
Creating bookwyrm_web_run ... done
Operations to perform:
Apply all migrations: admin, auth, bookwyrm, contenttypes, sessions
Running migrations:
Applying bookwyrm.0006_auto_20200221_1702_squashed_0064_merge_20201101_1913...Traceback (most recent call last):
File "/usr/local/lib/python3.9/site-packages/django/db/backends/utils.py", line 86, in _execute
return self.cursor.execute(sql, params)
psycopg2.errors.UndefinedTable: relation "bookwyrm_userrelationship" does not exist
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/app/manage.py", line 18, in <module>
execute_from_command_line(sys.argv)
File "/usr/local/lib/python3.9/site-packages/django/core/management/__init__.py", line 401, in execute_from_command_line
utility.execute()
File "/usr/local/lib/python3.9/site-packages/django/core/management/__init__.py", line 395, in execute
self.fetch_command(subcommand).run_from_argv(self.argv)
File "/usr/local/lib/python3.9/site-packages/django/core/management/base.py", line 328, in run_from_argv
self.execute(*args, **cmd_options)
File "/usr/local/lib/python3.9/site-packages/django/core/management/base.py", line 369, in execute
output = self.handle(*args, **options)
File "/usr/local/lib/python3.9/site-packages/django/core/management/base.py", line 83, in wrapped
res = handle_func(*args, **kwargs)
File "/usr/local/lib/python3.9/site-packages/django/core/management/commands/migrate.py", line 231, in handle
post_migrate_state = executor.migrate(
File "/usr/local/lib/python3.9/site-packages/django/db/migrations/executor.py", line 117, in migrate
state = self._migrate_all_forwards(state, plan, full_plan, fake=fake, fake_initial=fake_initial)
File "/usr/local/lib/python3.9/site-packages/django/db/migrations/executor.py", line 147, in _migrate_all_forwards
state = self.apply_migration(state, migration, fake=fake, fake_initial=fake_initial)
File "/usr/local/lib/python3.9/site-packages/django/db/migrations/executor.py", line 245, in apply_migration
state = migration.apply(state, schema_editor)
File "/usr/local/lib/python3.9/site-packages/django/db/migrations/migration.py", line 124, in apply
operation.database_forwards(self.app_label, schema_editor, old_state, project_state)
File "/usr/local/lib/python3.9/site-packages/django/db/migrations/operations/models.py", line 822, in database_forwards
schema_editor.add_constraint(model, self.constraint)
File "/usr/local/lib/python3.9/site-packages/django/db/backends/base/schema.py", line 362, in add_constraint
self.execute(sql)
File "/usr/local/lib/python3.9/site-packages/django/db/backends/base/schema.py", line 142, in execute
cursor.execute(sql, params)
File "/usr/local/lib/python3.9/site-packages/django/db/backends/utils.py", line 100, in execute
return super().execute(sql, params)
File "/usr/local/lib/python3.9/site-packages/django/db/backends/utils.py", line 68, in execute
return self._execute_with_wrappers(sql, params, many=False, executor=self._execute)
File "/usr/local/lib/python3.9/site-packages/django/db/backends/utils.py", line 77, in _execute_with_wrappers
return executor(sql, params, many, context)
File "/usr/local/lib/python3.9/site-packages/django/db/backends/utils.py", line 86, in _execute
return self.cursor.execute(sql, params)
File "/usr/local/lib/python3.9/site-packages/django/db/utils.py", line 90, in __exit__
raise dj_exc_value.with_traceback(traceback) from exc_value
File "/usr/local/lib/python3.9/site-packages/django/db/backends/utils.py", line 86, in _execute
return self.cursor.execute(sql, params)
django.db.utils.ProgrammingError: relation "bookwyrm_userrelationship" does not exist
```
**To Reproduce**
Run the `docker-compose run --rm web python manage.py migrate` command
**Expected behavior**
Migrations should run
**Desktop (please complete the following information):**
- OS: Mac OS
- Latest git pull
**Additional context**
I saw a commit with the msg "migrations are fucked" and I'm guessing you've experienced part of this problem before. Happy to provide any other context or try anything out here!
</issue>
<code>
[start of bookwyrm/settings.py]
1 ''' bookwyrm settings and configuration '''
2 import os
3
4 from environs import Env
5
6 env = Env()
7 DOMAIN = env('DOMAIN')
8
9 PAGE_LENGTH = env('PAGE_LENGTH', 15)
10
11 # celery
12 CELERY_BROKER = env('CELERY_BROKER')
13 CELERY_RESULT_BACKEND = env('CELERY_RESULT_BACKEND')
14 CELERY_ACCEPT_CONTENT = ['application/json']
15 CELERY_TASK_SERIALIZER = 'json'
16 CELERY_RESULT_SERIALIZER = 'json'
17
18 # Build paths inside the project like this: os.path.join(BASE_DIR, ...)
19 BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
20
21 # Quick-start development settings - unsuitable for production
22 # See https://docs.djangoproject.com/en/2.0/howto/deployment/checklist/
23
24 # SECURITY WARNING: keep the secret key used in production secret!
25 SECRET_KEY = env('SECRET_KEY')
26
27 # SECURITY WARNING: don't run with debug turned on in production!
28 DEBUG = env.bool('DEBUG', True)
29
30 ALLOWED_HOSTS = env.list('ALLOWED_HOSTS', ['*'])
31 OL_URL = env('OL_URL')
32
33 # Application definition
34
35 INSTALLED_APPS = [
36 'django.contrib.admin',
37 'django.contrib.auth',
38 'django.contrib.contenttypes',
39 'django.contrib.sessions',
40 'django.contrib.messages',
41 'django.contrib.staticfiles',
42 'django.contrib.humanize',
43 'bookwyrm',
44 'celery',
45 ]
46
47 MIDDLEWARE = [
48 'django.middleware.security.SecurityMiddleware',
49 'django.contrib.sessions.middleware.SessionMiddleware',
50 'django.middleware.common.CommonMiddleware',
51 'django.middleware.csrf.CsrfViewMiddleware',
52 'django.contrib.auth.middleware.AuthenticationMiddleware',
53 'django.contrib.messages.middleware.MessageMiddleware',
54 'django.middleware.clickjacking.XFrameOptionsMiddleware',
55 ]
56
57 ROOT_URLCONF = 'bookwyrm.urls'
58
59 TEMPLATES = [
60 {
61 'BACKEND': 'django.template.backends.django.DjangoTemplates',
62 'DIRS': ['templates'],
63 'APP_DIRS': True,
64 'OPTIONS': {
65 'context_processors': [
66 'django.template.context_processors.debug',
67 'django.template.context_processors.request',
68 'django.contrib.auth.context_processors.auth',
69 'django.contrib.messages.context_processors.messages',
70 ],
71 },
72 },
73 ]
74
75
76 WSGI_APPLICATION = 'bookwyrm.wsgi.application'
77
78
79 # Database
80 # https://docs.djangoproject.com/en/2.0/ref/settings/#databases
81
82 BOOKWYRM_DATABASE_BACKEND = env('BOOKWYRM_DATABASE_BACKEND', 'postgres')
83
84 BOOKWYRM_DBS = {
85 'postgres': {
86 'ENGINE': 'django.db.backends.postgresql_psycopg2',
87 'NAME': env('POSTGRES_DB', 'fedireads'),
88 'USER': env('POSTGRES_USER', 'fedireads'),
89 'PASSWORD': env('POSTGRES_PASSWORD', 'fedireads'),
90 'HOST': env('POSTGRES_HOST', ''),
91 'PORT': 5432
92 },
93 'sqlite': {
94 'ENGINE': 'django.db.backends.sqlite3',
95 'NAME': os.path.join(BASE_DIR, 'fedireads.db')
96 }
97 }
98
99 DATABASES = {
100 'default': BOOKWYRM_DBS[BOOKWYRM_DATABASE_BACKEND]
101 }
102
103
104 LOGIN_URL = '/login/'
105 AUTH_USER_MODEL = 'bookwyrm.User'
106
107 # Password validation
108 # https://docs.djangoproject.com/en/2.0/ref/settings/#auth-password-validators
109
110 AUTH_PASSWORD_VALIDATORS = [
111 {
112 'NAME': 'django.contrib.auth.password_validation.UserAttributeSimilarityValidator',
113 },
114 {
115 'NAME': 'django.contrib.auth.password_validation.MinimumLengthValidator',
116 },
117 {
118 'NAME': 'django.contrib.auth.password_validation.CommonPasswordValidator',
119 },
120 {
121 'NAME': 'django.contrib.auth.password_validation.NumericPasswordValidator',
122 },
123 ]
124
125
126 # Internationalization
127 # https://docs.djangoproject.com/en/2.0/topics/i18n/
128
129 LANGUAGE_CODE = 'en-us'
130
131 TIME_ZONE = 'UTC'
132
133 USE_I18N = True
134
135 USE_L10N = True
136
137 USE_TZ = True
138
139
140 # Static files (CSS, JavaScript, Images)
141 # https://docs.djangoproject.com/en/2.0/howto/static-files/
142
143 PROJECT_DIR = os.path.dirname(os.path.abspath(__file__))
144 STATIC_URL = '/static/'
145 STATIC_ROOT = os.path.join(BASE_DIR, env('STATIC_ROOT', 'static'))
146 MEDIA_URL = '/images/'
147 MEDIA_ROOT = os.path.join(BASE_DIR, env('MEDIA_ROOT', 'images'))
148
[end of bookwyrm/settings.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/bookwyrm/settings.py b/bookwyrm/settings.py
--- a/bookwyrm/settings.py
+++ b/bookwyrm/settings.py
@@ -40,6 +40,7 @@
'django.contrib.messages',
'django.contrib.staticfiles',
'django.contrib.humanize',
+ 'django_rename_app',
'bookwyrm',
'celery',
]
| {"golden_diff": "diff --git a/bookwyrm/settings.py b/bookwyrm/settings.py\n--- a/bookwyrm/settings.py\n+++ b/bookwyrm/settings.py\n@@ -40,6 +40,7 @@\n 'django.contrib.messages',\n 'django.contrib.staticfiles',\n 'django.contrib.humanize',\n+ 'django_rename_app',\n 'bookwyrm',\n 'celery',\n ]\n", "issue": "UndefinedTable: relation \"bookwyrm_userrelationship\" does not exist error\n**Describe the bug**\r\nI went to go load up the development env today after a little while of not using it and came across this error when I ran the `docker-compose run --rm web python manage.py migrate` cmd to keep up with new migrations:\r\n\r\n```\r\ndocker-compose run --rm web python manage.py migrate\r\nCreating bookwyrm_web_run ... done\r\nOperations to perform:\r\n Apply all migrations: admin, auth, bookwyrm, contenttypes, sessions\r\nRunning migrations:\r\n Applying bookwyrm.0006_auto_20200221_1702_squashed_0064_merge_20201101_1913...Traceback (most recent call last):\r\n File \"/usr/local/lib/python3.9/site-packages/django/db/backends/utils.py\", line 86, in _execute\r\n return self.cursor.execute(sql, params)\r\npsycopg2.errors.UndefinedTable: relation \"bookwyrm_userrelationship\" does not exist\r\n\r\n\r\nThe above exception was the direct cause of the following exception:\r\n\r\nTraceback (most recent call last):\r\n File \"/app/manage.py\", line 18, in <module>\r\n execute_from_command_line(sys.argv)\r\n File \"/usr/local/lib/python3.9/site-packages/django/core/management/__init__.py\", line 401, in execute_from_command_line\r\n utility.execute()\r\n File \"/usr/local/lib/python3.9/site-packages/django/core/management/__init__.py\", line 395, in execute\r\n self.fetch_command(subcommand).run_from_argv(self.argv)\r\n File \"/usr/local/lib/python3.9/site-packages/django/core/management/base.py\", line 328, in run_from_argv\r\n self.execute(*args, **cmd_options)\r\n File \"/usr/local/lib/python3.9/site-packages/django/core/management/base.py\", line 369, in execute\r\n output = self.handle(*args, **options)\r\n File \"/usr/local/lib/python3.9/site-packages/django/core/management/base.py\", line 83, in wrapped\r\n res = handle_func(*args, **kwargs)\r\n File \"/usr/local/lib/python3.9/site-packages/django/core/management/commands/migrate.py\", line 231, in handle\r\n post_migrate_state = executor.migrate(\r\n File \"/usr/local/lib/python3.9/site-packages/django/db/migrations/executor.py\", line 117, in migrate\r\n state = self._migrate_all_forwards(state, plan, full_plan, fake=fake, fake_initial=fake_initial)\r\n File \"/usr/local/lib/python3.9/site-packages/django/db/migrations/executor.py\", line 147, in _migrate_all_forwards\r\n state = self.apply_migration(state, migration, fake=fake, fake_initial=fake_initial)\r\n File \"/usr/local/lib/python3.9/site-packages/django/db/migrations/executor.py\", line 245, in apply_migration\r\n state = migration.apply(state, schema_editor)\r\n File \"/usr/local/lib/python3.9/site-packages/django/db/migrations/migration.py\", line 124, in apply\r\n operation.database_forwards(self.app_label, schema_editor, old_state, project_state)\r\n File \"/usr/local/lib/python3.9/site-packages/django/db/migrations/operations/models.py\", line 822, in database_forwards\r\n schema_editor.add_constraint(model, self.constraint)\r\n File \"/usr/local/lib/python3.9/site-packages/django/db/backends/base/schema.py\", line 362, in add_constraint\r\n self.execute(sql)\r\n File \"/usr/local/lib/python3.9/site-packages/django/db/backends/base/schema.py\", line 142, in execute\r\n cursor.execute(sql, params)\r\n File \"/usr/local/lib/python3.9/site-packages/django/db/backends/utils.py\", line 100, in execute\r\n return super().execute(sql, params)\r\n File \"/usr/local/lib/python3.9/site-packages/django/db/backends/utils.py\", line 68, in execute\r\n return self._execute_with_wrappers(sql, params, many=False, executor=self._execute)\r\n File \"/usr/local/lib/python3.9/site-packages/django/db/backends/utils.py\", line 77, in _execute_with_wrappers\r\n return executor(sql, params, many, context)\r\n File \"/usr/local/lib/python3.9/site-packages/django/db/backends/utils.py\", line 86, in _execute\r\n return self.cursor.execute(sql, params)\r\n File \"/usr/local/lib/python3.9/site-packages/django/db/utils.py\", line 90, in __exit__\r\n raise dj_exc_value.with_traceback(traceback) from exc_value\r\n File \"/usr/local/lib/python3.9/site-packages/django/db/backends/utils.py\", line 86, in _execute\r\n return self.cursor.execute(sql, params)\r\ndjango.db.utils.ProgrammingError: relation \"bookwyrm_userrelationship\" does not exist\r\n```\r\n\r\n**To Reproduce**\r\nRun the `docker-compose run --rm web python manage.py migrate` command\r\n\r\n**Expected behavior**\r\nMigrations should run\r\n\r\n**Desktop (please complete the following information):**\r\n - OS: Mac OS\r\n- Latest git pull\r\n\r\n**Additional context**\r\nI saw a commit with the msg \"migrations are fucked\" and I'm guessing you've experienced part of this problem before. Happy to provide any other context or try anything out here!\r\n\n", "before_files": [{"content": "''' bookwyrm settings and configuration '''\nimport os\n\nfrom environs import Env\n\nenv = Env()\nDOMAIN = env('DOMAIN')\n\nPAGE_LENGTH = env('PAGE_LENGTH', 15)\n\n# celery\nCELERY_BROKER = env('CELERY_BROKER')\nCELERY_RESULT_BACKEND = env('CELERY_RESULT_BACKEND')\nCELERY_ACCEPT_CONTENT = ['application/json']\nCELERY_TASK_SERIALIZER = 'json'\nCELERY_RESULT_SERIALIZER = 'json'\n\n# Build paths inside the project like this: os.path.join(BASE_DIR, ...)\nBASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))\n\n# Quick-start development settings - unsuitable for production\n# See https://docs.djangoproject.com/en/2.0/howto/deployment/checklist/\n\n# SECURITY WARNING: keep the secret key used in production secret!\nSECRET_KEY = env('SECRET_KEY')\n\n# SECURITY WARNING: don't run with debug turned on in production!\nDEBUG = env.bool('DEBUG', True)\n\nALLOWED_HOSTS = env.list('ALLOWED_HOSTS', ['*'])\nOL_URL = env('OL_URL')\n\n# Application definition\n\nINSTALLED_APPS = [\n 'django.contrib.admin',\n 'django.contrib.auth',\n 'django.contrib.contenttypes',\n 'django.contrib.sessions',\n 'django.contrib.messages',\n 'django.contrib.staticfiles',\n 'django.contrib.humanize',\n 'bookwyrm',\n 'celery',\n]\n\nMIDDLEWARE = [\n 'django.middleware.security.SecurityMiddleware',\n 'django.contrib.sessions.middleware.SessionMiddleware',\n 'django.middleware.common.CommonMiddleware',\n 'django.middleware.csrf.CsrfViewMiddleware',\n 'django.contrib.auth.middleware.AuthenticationMiddleware',\n 'django.contrib.messages.middleware.MessageMiddleware',\n 'django.middleware.clickjacking.XFrameOptionsMiddleware',\n]\n\nROOT_URLCONF = 'bookwyrm.urls'\n\nTEMPLATES = [\n {\n 'BACKEND': 'django.template.backends.django.DjangoTemplates',\n 'DIRS': ['templates'],\n 'APP_DIRS': True,\n 'OPTIONS': {\n 'context_processors': [\n 'django.template.context_processors.debug',\n 'django.template.context_processors.request',\n 'django.contrib.auth.context_processors.auth',\n 'django.contrib.messages.context_processors.messages',\n ],\n },\n },\n]\n\n\nWSGI_APPLICATION = 'bookwyrm.wsgi.application'\n\n\n# Database\n# https://docs.djangoproject.com/en/2.0/ref/settings/#databases\n\nBOOKWYRM_DATABASE_BACKEND = env('BOOKWYRM_DATABASE_BACKEND', 'postgres')\n\nBOOKWYRM_DBS = {\n 'postgres': {\n 'ENGINE': 'django.db.backends.postgresql_psycopg2',\n 'NAME': env('POSTGRES_DB', 'fedireads'),\n 'USER': env('POSTGRES_USER', 'fedireads'),\n 'PASSWORD': env('POSTGRES_PASSWORD', 'fedireads'),\n 'HOST': env('POSTGRES_HOST', ''),\n 'PORT': 5432\n },\n 'sqlite': {\n 'ENGINE': 'django.db.backends.sqlite3',\n 'NAME': os.path.join(BASE_DIR, 'fedireads.db')\n }\n}\n\nDATABASES = {\n 'default': BOOKWYRM_DBS[BOOKWYRM_DATABASE_BACKEND]\n}\n\n\nLOGIN_URL = '/login/'\nAUTH_USER_MODEL = 'bookwyrm.User'\n\n# Password validation\n# https://docs.djangoproject.com/en/2.0/ref/settings/#auth-password-validators\n\nAUTH_PASSWORD_VALIDATORS = [\n {\n 'NAME': 'django.contrib.auth.password_validation.UserAttributeSimilarityValidator',\n },\n {\n 'NAME': 'django.contrib.auth.password_validation.MinimumLengthValidator',\n },\n {\n 'NAME': 'django.contrib.auth.password_validation.CommonPasswordValidator',\n },\n {\n 'NAME': 'django.contrib.auth.password_validation.NumericPasswordValidator',\n },\n]\n\n\n# Internationalization\n# https://docs.djangoproject.com/en/2.0/topics/i18n/\n\nLANGUAGE_CODE = 'en-us'\n\nTIME_ZONE = 'UTC'\n\nUSE_I18N = True\n\nUSE_L10N = True\n\nUSE_TZ = True\n\n\n# Static files (CSS, JavaScript, Images)\n# https://docs.djangoproject.com/en/2.0/howto/static-files/\n\nPROJECT_DIR = os.path.dirname(os.path.abspath(__file__))\nSTATIC_URL = '/static/'\nSTATIC_ROOT = os.path.join(BASE_DIR, env('STATIC_ROOT', 'static'))\nMEDIA_URL = '/images/'\nMEDIA_ROOT = os.path.join(BASE_DIR, env('MEDIA_ROOT', 'images'))\n", "path": "bookwyrm/settings.py"}]} | 3,037 | 84 |
gh_patches_debug_4784 | rasdani/github-patches | git_diff | PaddlePaddle__PaddleSeg-134 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
评估时模型路径不存在直接报load op的错
</issue>
<code>
[start of pdseg/eval.py]
1 # coding: utf8
2 # copyright (c) 2019 PaddlePaddle Authors. All Rights Reserve.
3 #
4 # Licensed under the Apache License, Version 2.0 (the "License");
5 # you may not use this file except in compliance with the License.
6 # You may obtain a copy of the License at
7 #
8 # http://www.apache.org/licenses/LICENSE-2.0
9 #
10 # Unless required by applicable law or agreed to in writing, software
11 # distributed under the License is distributed on an "AS IS" BASIS,
12 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 # See the License for the specific language governing permissions and
14 # limitations under the License.
15
16 from __future__ import absolute_import
17 from __future__ import division
18 from __future__ import print_function
19
20 import os
21 # GPU memory garbage collection optimization flags
22 os.environ['FLAGS_eager_delete_tensor_gb'] = "0.0"
23
24 import sys
25 import time
26 import argparse
27 import functools
28 import pprint
29 import cv2
30 import numpy as np
31 import paddle
32 import paddle.fluid as fluid
33
34 from utils.config import cfg
35 from utils.timer import Timer, calculate_eta
36 from models.model_builder import build_model
37 from models.model_builder import ModelPhase
38 from reader import SegDataset
39 from metrics import ConfusionMatrix
40
41
42 def parse_args():
43 parser = argparse.ArgumentParser(description='PaddleSeg model evalution')
44 parser.add_argument(
45 '--cfg',
46 dest='cfg_file',
47 help='Config file for training (and optionally testing)',
48 default=None,
49 type=str)
50 parser.add_argument(
51 '--use_gpu',
52 dest='use_gpu',
53 help='Use gpu or cpu',
54 action='store_true',
55 default=False)
56 parser.add_argument(
57 '--use_mpio',
58 dest='use_mpio',
59 help='Use multiprocess IO or not',
60 action='store_true',
61 default=False)
62 parser.add_argument(
63 'opts',
64 help='See utils/config.py for all options',
65 default=None,
66 nargs=argparse.REMAINDER)
67 if len(sys.argv) == 1:
68 parser.print_help()
69 sys.exit(1)
70 return parser.parse_args()
71
72
73 def evaluate(cfg, ckpt_dir=None, use_gpu=False, use_mpio=False, **kwargs):
74 np.set_printoptions(precision=5, suppress=True)
75
76 startup_prog = fluid.Program()
77 test_prog = fluid.Program()
78 dataset = SegDataset(
79 file_list=cfg.DATASET.VAL_FILE_LIST,
80 mode=ModelPhase.EVAL,
81 data_dir=cfg.DATASET.DATA_DIR)
82
83 def data_generator():
84 #TODO: check is batch reader compatitable with Windows
85 if use_mpio:
86 data_gen = dataset.multiprocess_generator(
87 num_processes=cfg.DATALOADER.NUM_WORKERS,
88 max_queue_size=cfg.DATALOADER.BUF_SIZE)
89 else:
90 data_gen = dataset.generator()
91
92 for b in data_gen:
93 yield b[0], b[1], b[2]
94
95 py_reader, avg_loss, pred, grts, masks = build_model(
96 test_prog, startup_prog, phase=ModelPhase.EVAL)
97
98 py_reader.decorate_sample_generator(
99 data_generator, drop_last=False, batch_size=cfg.BATCH_SIZE)
100
101 # Get device environment
102 places = fluid.cuda_places() if use_gpu else fluid.cpu_places()
103 place = places[0]
104 dev_count = len(places)
105 print("#Device count: {}".format(dev_count))
106
107 exe = fluid.Executor(place)
108 exe.run(startup_prog)
109
110 test_prog = test_prog.clone(for_test=True)
111
112 ckpt_dir = cfg.TEST.TEST_MODEL if not ckpt_dir else ckpt_dir
113
114 if ckpt_dir is not None:
115 print('load test model:', ckpt_dir)
116 fluid.io.load_params(exe, ckpt_dir, main_program=test_prog)
117
118 # Use streaming confusion matrix to calculate mean_iou
119 np.set_printoptions(
120 precision=4, suppress=True, linewidth=160, floatmode="fixed")
121 conf_mat = ConfusionMatrix(cfg.DATASET.NUM_CLASSES, streaming=True)
122 fetch_list = [avg_loss.name, pred.name, grts.name, masks.name]
123 num_images = 0
124 step = 0
125 all_step = cfg.DATASET.TEST_TOTAL_IMAGES // cfg.BATCH_SIZE + 1
126 timer = Timer()
127 timer.start()
128 py_reader.start()
129 while True:
130 try:
131 step += 1
132 loss, pred, grts, masks = exe.run(
133 test_prog, fetch_list=fetch_list, return_numpy=True)
134
135 loss = np.mean(np.array(loss))
136
137 num_images += pred.shape[0]
138 conf_mat.calculate(pred, grts, masks)
139 _, iou = conf_mat.mean_iou()
140 _, acc = conf_mat.accuracy()
141
142 speed = 1.0 / timer.elapsed_time()
143
144 print(
145 "[EVAL]step={} loss={:.5f} acc={:.4f} IoU={:.4f} step/sec={:.2f} | ETA {}"
146 .format(step, loss, acc, iou, speed,
147 calculate_eta(all_step - step, speed)))
148 timer.restart()
149 sys.stdout.flush()
150 except fluid.core.EOFException:
151 break
152
153 category_iou, avg_iou = conf_mat.mean_iou()
154 category_acc, avg_acc = conf_mat.accuracy()
155 print("[EVAL]#image={} acc={:.4f} IoU={:.4f}".format(
156 num_images, avg_acc, avg_iou))
157 print("[EVAL]Category IoU:", category_iou)
158 print("[EVAL]Category Acc:", category_acc)
159 print("[EVAL]Kappa:{:.4f}".format(conf_mat.kappa()))
160
161 return category_iou, avg_iou, category_acc, avg_acc
162
163
164 def main():
165 args = parse_args()
166 if args.cfg_file is not None:
167 cfg.update_from_file(args.cfg_file)
168 if args.opts:
169 cfg.update_from_list(args.opts)
170 cfg.check_and_infer()
171 print(pprint.pformat(cfg))
172 evaluate(cfg, **args.__dict__)
173
174
175 if __name__ == '__main__':
176 main()
177
[end of pdseg/eval.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/pdseg/eval.py b/pdseg/eval.py
--- a/pdseg/eval.py
+++ b/pdseg/eval.py
@@ -111,6 +111,9 @@
ckpt_dir = cfg.TEST.TEST_MODEL if not ckpt_dir else ckpt_dir
+ if not os.path.exists(ckpt_dir):
+ raise ValueError('The TEST.TEST_MODEL {} is not found'.format(ckpt_dir))
+
if ckpt_dir is not None:
print('load test model:', ckpt_dir)
fluid.io.load_params(exe, ckpt_dir, main_program=test_prog)
| {"golden_diff": "diff --git a/pdseg/eval.py b/pdseg/eval.py\n--- a/pdseg/eval.py\n+++ b/pdseg/eval.py\n@@ -111,6 +111,9 @@\n \n ckpt_dir = cfg.TEST.TEST_MODEL if not ckpt_dir else ckpt_dir\n \n+ if not os.path.exists(ckpt_dir):\n+ raise ValueError('The TEST.TEST_MODEL {} is not found'.format(ckpt_dir))\n+\n if ckpt_dir is not None:\n print('load test model:', ckpt_dir)\n fluid.io.load_params(exe, ckpt_dir, main_program=test_prog)\n", "issue": "\u8bc4\u4f30\u65f6\u6a21\u578b\u8def\u5f84\u4e0d\u5b58\u5728\u76f4\u63a5\u62a5load op\u7684\u9519\n\n", "before_files": [{"content": "# coding: utf8\n# copyright (c) 2019 PaddlePaddle Authors. All Rights Reserve.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\n\nimport os\n# GPU memory garbage collection optimization flags\nos.environ['FLAGS_eager_delete_tensor_gb'] = \"0.0\"\n\nimport sys\nimport time\nimport argparse\nimport functools\nimport pprint\nimport cv2\nimport numpy as np\nimport paddle\nimport paddle.fluid as fluid\n\nfrom utils.config import cfg\nfrom utils.timer import Timer, calculate_eta\nfrom models.model_builder import build_model\nfrom models.model_builder import ModelPhase\nfrom reader import SegDataset\nfrom metrics import ConfusionMatrix\n\n\ndef parse_args():\n parser = argparse.ArgumentParser(description='PaddleSeg model evalution')\n parser.add_argument(\n '--cfg',\n dest='cfg_file',\n help='Config file for training (and optionally testing)',\n default=None,\n type=str)\n parser.add_argument(\n '--use_gpu',\n dest='use_gpu',\n help='Use gpu or cpu',\n action='store_true',\n default=False)\n parser.add_argument(\n '--use_mpio',\n dest='use_mpio',\n help='Use multiprocess IO or not',\n action='store_true',\n default=False)\n parser.add_argument(\n 'opts',\n help='See utils/config.py for all options',\n default=None,\n nargs=argparse.REMAINDER)\n if len(sys.argv) == 1:\n parser.print_help()\n sys.exit(1)\n return parser.parse_args()\n\n\ndef evaluate(cfg, ckpt_dir=None, use_gpu=False, use_mpio=False, **kwargs):\n np.set_printoptions(precision=5, suppress=True)\n\n startup_prog = fluid.Program()\n test_prog = fluid.Program()\n dataset = SegDataset(\n file_list=cfg.DATASET.VAL_FILE_LIST,\n mode=ModelPhase.EVAL,\n data_dir=cfg.DATASET.DATA_DIR)\n\n def data_generator():\n #TODO: check is batch reader compatitable with Windows\n if use_mpio:\n data_gen = dataset.multiprocess_generator(\n num_processes=cfg.DATALOADER.NUM_WORKERS,\n max_queue_size=cfg.DATALOADER.BUF_SIZE)\n else:\n data_gen = dataset.generator()\n\n for b in data_gen:\n yield b[0], b[1], b[2]\n\n py_reader, avg_loss, pred, grts, masks = build_model(\n test_prog, startup_prog, phase=ModelPhase.EVAL)\n\n py_reader.decorate_sample_generator(\n data_generator, drop_last=False, batch_size=cfg.BATCH_SIZE)\n\n # Get device environment\n places = fluid.cuda_places() if use_gpu else fluid.cpu_places()\n place = places[0]\n dev_count = len(places)\n print(\"#Device count: {}\".format(dev_count))\n\n exe = fluid.Executor(place)\n exe.run(startup_prog)\n\n test_prog = test_prog.clone(for_test=True)\n\n ckpt_dir = cfg.TEST.TEST_MODEL if not ckpt_dir else ckpt_dir\n\n if ckpt_dir is not None:\n print('load test model:', ckpt_dir)\n fluid.io.load_params(exe, ckpt_dir, main_program=test_prog)\n\n # Use streaming confusion matrix to calculate mean_iou\n np.set_printoptions(\n precision=4, suppress=True, linewidth=160, floatmode=\"fixed\")\n conf_mat = ConfusionMatrix(cfg.DATASET.NUM_CLASSES, streaming=True)\n fetch_list = [avg_loss.name, pred.name, grts.name, masks.name]\n num_images = 0\n step = 0\n all_step = cfg.DATASET.TEST_TOTAL_IMAGES // cfg.BATCH_SIZE + 1\n timer = Timer()\n timer.start()\n py_reader.start()\n while True:\n try:\n step += 1\n loss, pred, grts, masks = exe.run(\n test_prog, fetch_list=fetch_list, return_numpy=True)\n\n loss = np.mean(np.array(loss))\n\n num_images += pred.shape[0]\n conf_mat.calculate(pred, grts, masks)\n _, iou = conf_mat.mean_iou()\n _, acc = conf_mat.accuracy()\n\n speed = 1.0 / timer.elapsed_time()\n\n print(\n \"[EVAL]step={} loss={:.5f} acc={:.4f} IoU={:.4f} step/sec={:.2f} | ETA {}\"\n .format(step, loss, acc, iou, speed,\n calculate_eta(all_step - step, speed)))\n timer.restart()\n sys.stdout.flush()\n except fluid.core.EOFException:\n break\n\n category_iou, avg_iou = conf_mat.mean_iou()\n category_acc, avg_acc = conf_mat.accuracy()\n print(\"[EVAL]#image={} acc={:.4f} IoU={:.4f}\".format(\n num_images, avg_acc, avg_iou))\n print(\"[EVAL]Category IoU:\", category_iou)\n print(\"[EVAL]Category Acc:\", category_acc)\n print(\"[EVAL]Kappa:{:.4f}\".format(conf_mat.kappa()))\n\n return category_iou, avg_iou, category_acc, avg_acc\n\n\ndef main():\n args = parse_args()\n if args.cfg_file is not None:\n cfg.update_from_file(args.cfg_file)\n if args.opts:\n cfg.update_from_list(args.opts)\n cfg.check_and_infer()\n print(pprint.pformat(cfg))\n evaluate(cfg, **args.__dict__)\n\n\nif __name__ == '__main__':\n main()\n", "path": "pdseg/eval.py"}]} | 2,317 | 138 |
gh_patches_debug_16344 | rasdani/github-patches | git_diff | akvo__akvo-rsr-1875 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Project can only have one reporting organisation
## Test plan
1. Go to project editor and select 2 reporting organisations in section 3
2. _RESULT:_ a validation error should be shown
3. Remove one of the reporting organisations
4. _RESULT:_ the save should be successful
## Issue description
Validation error appears even if there's only one reporting organisation.
</issue>
<code>
[start of akvo/rsr/models/partnership.py]
1 # -*- coding: utf-8 -*-
2
3 # Akvo RSR is covered by the GNU Affero General Public License.
4 # See more details in the license.txt file located at the root folder of the Akvo RSR module.
5 # For additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.
6
7
8 from django.core.exceptions import ValidationError
9 from django.db import models
10 from django.utils.translation import ugettext_lazy as _
11
12 from ..fields import ValidXMLCharField
13
14
15 class Partnership(models.Model):
16 # the old way
17 FIELD_PARTNER = u'field'
18 FUNDING_PARTNER = u'funding'
19 SPONSOR_PARTNER = u'sponsor'
20 SUPPORT_PARTNER = u'support'
21 EXTENDING_PARTNER = u'extending'
22
23 PARTNER_TYPE_LIST = [
24 FIELD_PARTNER, FUNDING_PARTNER, SPONSOR_PARTNER, SUPPORT_PARTNER, EXTENDING_PARTNER
25 ]
26 PARTNER_LABELS = [
27 _(u'Implementing partner'),
28 _(u'Funding partner'),
29 _(u'Sponsor partner'),
30 _(u'Accountable partner'),
31 _(u'Extending partner'),
32 ]
33 PARTNER_TYPES = zip(PARTNER_TYPE_LIST, PARTNER_LABELS)
34
35 # the new way
36 IATI_FUNDING_PARTNER = 1
37 IATI_ACCOUNTABLE_PARTNER = 2
38 IATI_EXTENDING_PARTNER = 3
39 IATI_IMPLEMENTING_PARTNER = 4
40 AKVO_SPONSOR_PARTNER = 100 # not part of the IATI OrganisationRole codelist!
41 IATI_REPORTING_ORGANISATION = 101
42
43 # make sure the AKVO_SPONSOR_PARTNER is last in the list
44 IATI_ROLE_LIST = [
45 IATI_FUNDING_PARTNER, IATI_ACCOUNTABLE_PARTNER, IATI_EXTENDING_PARTNER,
46 IATI_IMPLEMENTING_PARTNER, AKVO_SPONSOR_PARTNER, IATI_REPORTING_ORGANISATION
47 ]
48 IATI_ROLE_LABELS = [
49 _(u'Funding partner'),
50 _(u'Accountable partner'),
51 _(u'Extending partner'),
52 _(u'Implementing partner'),
53 _(u'Sponsor partner'),
54 _(u'Reporting organisation'),
55 ]
56 IATI_ROLES = zip(IATI_ROLE_LIST, IATI_ROLE_LABELS)
57
58 # used when migrating
59 PARTNER_TYPES_TO_ROLES_MAP = {
60 FUNDING_PARTNER: IATI_FUNDING_PARTNER,
61 SUPPORT_PARTNER: IATI_ACCOUNTABLE_PARTNER,
62 FIELD_PARTNER: IATI_IMPLEMENTING_PARTNER,
63 SPONSOR_PARTNER: AKVO_SPONSOR_PARTNER,
64 }
65
66 # backwards compatibility
67 ROLES_TO_PARTNER_TYPES_MAP = {
68 IATI_FUNDING_PARTNER: FUNDING_PARTNER,
69 IATI_ACCOUNTABLE_PARTNER: SUPPORT_PARTNER,
70 IATI_EXTENDING_PARTNER: EXTENDING_PARTNER,
71 IATI_IMPLEMENTING_PARTNER: FIELD_PARTNER,
72 AKVO_SPONSOR_PARTNER: SPONSOR_PARTNER,
73 # TODO: not backwards compatible
74 IATI_REPORTING_ORGANISATION: u''
75 }
76
77 ALLIANCE_PARTNER = u'alliance'
78 KNOWLEDGE_PARTNER = u'knowledge'
79 NETWORK_PARTNER = u'network'
80
81 PARTNER_TYPE_EXTRAS_LIST = (ALLIANCE_PARTNER, KNOWLEDGE_PARTNER, NETWORK_PARTNER)
82 PARTNER_TYPE_EXTRA_LABELS = (
83 _(u'Alliance'),
84 _(u'Knowledge'),
85 _(u'Network')
86 )
87
88 PARTNER_TYPE_EXTRAS = zip(PARTNER_TYPE_EXTRAS_LIST, PARTNER_TYPE_EXTRA_LABELS)
89
90 organisation = models.ForeignKey(
91 'Organisation', verbose_name=_(u'organisation'), related_name='partnerships', null=True,
92 blank=False, help_text=_(u'Select an organisation that is taking an active role in the '
93 u'project.')
94 )
95 project = models.ForeignKey('Project', verbose_name=_(u'project'), related_name='partnerships')
96 iati_organisation_role = models.PositiveSmallIntegerField(
97 u'Organisation role', choices=IATI_ROLES, db_index=True, null=True)
98 # is_secondary_reporter is only used when the iati_organisation_role is set to
99 # IATI_REPORTING_ORGANISATION, thus the use of NullBooleanField
100 is_secondary_reporter = models.NullBooleanField(
101 _(u'secondary reporter'),
102 help_text=_(
103 u'This indicates whether the reporting organisation is a secondary publisher: '
104 u'publishing data for which it is not directly responsible.'
105 )
106 )
107 funding_amount = models.DecimalField(
108 _(u'funding amount'), max_digits=14, decimal_places=2, blank=True, null=True, db_index=True,
109 help_text=_(u'The funding amount of the partner.<br>'
110 u'Note that it\'s only possible to indicate a funding amount for funding '
111 u'partners.')
112 )
113 partner_type_extra = ValidXMLCharField(
114 _(u'partner type extra'), max_length=30, blank=True, null=True, choices=PARTNER_TYPE_EXTRAS,
115 help_text=_(u'RSR specific partner type.')
116 )
117 iati_activity_id = ValidXMLCharField(
118 _(u'IATI activity ID'), max_length=75, blank=True, null=True, db_index=True
119 )
120 internal_id = ValidXMLCharField(
121 _(u'Internal ID'), max_length=75, blank=True, null=True, db_index=True,
122 help_text=_(u'This field can be used to indicate an internal identifier that is used by '
123 u'the organisation for this project. (75 characters)')
124 )
125 iati_url = models.URLField(
126 blank=True,
127 help_text=_(
128 u'Please enter the URL for where the IATI Activity Id Funding details are published. '
129 u'For projects directly or indirectly funded by the Dutch Government, this should '
130 u'be the OpenAid.nl page. For other projects, an alternative URL can be used.'
131 )
132 )
133 related_activity_id = ValidXMLCharField(
134 _(u'related IATI activity ID'), max_length=50, blank=True
135 )
136
137 def iati_organisation_role_label(self):
138 return dict(self.IATI_ROLES)[self.iati_organisation_role]
139
140 def iati_role_to_partner_type(self):
141 if self.iati_organisation_role:
142 return self.ROLES_TO_PARTNER_TYPES_MAP[int(self.iati_organisation_role)]
143 else:
144 return None
145
146 class Meta:
147 app_label = 'rsr'
148 verbose_name = _(u'project partner')
149 verbose_name_plural = _(u'project partners')
150 ordering = ['iati_organisation_role']
151
152 def __unicode__(self):
153 if self.organisation:
154 if self.organisation.name:
155 organisation_unicode = self.organisation.name
156 elif self.organisation.long_name:
157 organisation_unicode = self.organisation.long_name
158 else:
159 organisation_unicode = u'%s' % _(u'Organisation name not specified')
160 else:
161 organisation_unicode = u'%s' % _(u'Organisation not specified')
162
163 if self.iati_organisation_role:
164 organisation_unicode += u' ({})'.format(
165 unicode(dict(self.IATI_ROLES)[self.iati_organisation_role])
166 )
167 return organisation_unicode
168
169 def clean(self):
170 # Don't allow multiple reporting organisations
171 reporting_orgs = self.project.partnerships.filter(
172 iati_organisation_role=self.IATI_REPORTING_ORGANISATION
173 )
174
175 if reporting_orgs:
176 raise ValidationError(
177 {'iati_organisation_role': u'%s' % _(u'Project can only have one reporting '
178 u'organisation')}
179 )
180
[end of akvo/rsr/models/partnership.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/akvo/rsr/models/partnership.py b/akvo/rsr/models/partnership.py
--- a/akvo/rsr/models/partnership.py
+++ b/akvo/rsr/models/partnership.py
@@ -168,12 +168,13 @@
def clean(self):
# Don't allow multiple reporting organisations
- reporting_orgs = self.project.partnerships.filter(
- iati_organisation_role=self.IATI_REPORTING_ORGANISATION
- )
-
- if reporting_orgs:
- raise ValidationError(
- {'iati_organisation_role': u'%s' % _(u'Project can only have one reporting '
- u'organisation')}
+ if self.iati_organisation_role == self.IATI_REPORTING_ORGANISATION:
+ reporting_orgs = self.project.partnerships.filter(
+ iati_organisation_role=self.IATI_REPORTING_ORGANISATION
)
+
+ if reporting_orgs.count() > 1:
+ raise ValidationError(
+ {'iati_organisation_role': u'%s' % _(u'Project can only have one reporting '
+ u'organisation')}
+ )
| {"golden_diff": "diff --git a/akvo/rsr/models/partnership.py b/akvo/rsr/models/partnership.py\n--- a/akvo/rsr/models/partnership.py\n+++ b/akvo/rsr/models/partnership.py\n@@ -168,12 +168,13 @@\n \n def clean(self):\n # Don't allow multiple reporting organisations\n- reporting_orgs = self.project.partnerships.filter(\n- iati_organisation_role=self.IATI_REPORTING_ORGANISATION\n- )\n-\n- if reporting_orgs:\n- raise ValidationError(\n- {'iati_organisation_role': u'%s' % _(u'Project can only have one reporting '\n- u'organisation')}\n+ if self.iati_organisation_role == self.IATI_REPORTING_ORGANISATION:\n+ reporting_orgs = self.project.partnerships.filter(\n+ iati_organisation_role=self.IATI_REPORTING_ORGANISATION\n )\n+\n+ if reporting_orgs.count() > 1:\n+ raise ValidationError(\n+ {'iati_organisation_role': u'%s' % _(u'Project can only have one reporting '\n+ u'organisation')}\n+ )\n", "issue": "Project can only have one reporting organisation\n## Test plan\n1. Go to project editor and select 2 reporting organisations in section 3\n2. _RESULT:_ a validation error should be shown\n3. Remove one of the reporting organisations\n4. _RESULT:_ the save should be successful\n## Issue description\n\nValidation error appears even if there's only one reporting organisation.\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Akvo RSR is covered by the GNU Affero General Public License.\n# See more details in the license.txt file located at the root folder of the Akvo RSR module.\n# For additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.\n\n\nfrom django.core.exceptions import ValidationError\nfrom django.db import models\nfrom django.utils.translation import ugettext_lazy as _\n\nfrom ..fields import ValidXMLCharField\n\n\nclass Partnership(models.Model):\n # the old way\n FIELD_PARTNER = u'field'\n FUNDING_PARTNER = u'funding'\n SPONSOR_PARTNER = u'sponsor'\n SUPPORT_PARTNER = u'support'\n EXTENDING_PARTNER = u'extending'\n\n PARTNER_TYPE_LIST = [\n FIELD_PARTNER, FUNDING_PARTNER, SPONSOR_PARTNER, SUPPORT_PARTNER, EXTENDING_PARTNER\n ]\n PARTNER_LABELS = [\n _(u'Implementing partner'),\n _(u'Funding partner'),\n _(u'Sponsor partner'),\n _(u'Accountable partner'),\n _(u'Extending partner'),\n ]\n PARTNER_TYPES = zip(PARTNER_TYPE_LIST, PARTNER_LABELS)\n\n # the new way\n IATI_FUNDING_PARTNER = 1\n IATI_ACCOUNTABLE_PARTNER = 2\n IATI_EXTENDING_PARTNER = 3\n IATI_IMPLEMENTING_PARTNER = 4\n AKVO_SPONSOR_PARTNER = 100 # not part of the IATI OrganisationRole codelist!\n IATI_REPORTING_ORGANISATION = 101\n\n # make sure the AKVO_SPONSOR_PARTNER is last in the list\n IATI_ROLE_LIST = [\n IATI_FUNDING_PARTNER, IATI_ACCOUNTABLE_PARTNER, IATI_EXTENDING_PARTNER,\n IATI_IMPLEMENTING_PARTNER, AKVO_SPONSOR_PARTNER, IATI_REPORTING_ORGANISATION\n ]\n IATI_ROLE_LABELS = [\n _(u'Funding partner'),\n _(u'Accountable partner'),\n _(u'Extending partner'),\n _(u'Implementing partner'),\n _(u'Sponsor partner'),\n _(u'Reporting organisation'),\n ]\n IATI_ROLES = zip(IATI_ROLE_LIST, IATI_ROLE_LABELS)\n\n # used when migrating\n PARTNER_TYPES_TO_ROLES_MAP = {\n FUNDING_PARTNER: IATI_FUNDING_PARTNER,\n SUPPORT_PARTNER: IATI_ACCOUNTABLE_PARTNER,\n FIELD_PARTNER: IATI_IMPLEMENTING_PARTNER,\n SPONSOR_PARTNER: AKVO_SPONSOR_PARTNER,\n }\n\n # backwards compatibility\n ROLES_TO_PARTNER_TYPES_MAP = {\n IATI_FUNDING_PARTNER: FUNDING_PARTNER,\n IATI_ACCOUNTABLE_PARTNER: SUPPORT_PARTNER,\n IATI_EXTENDING_PARTNER: EXTENDING_PARTNER,\n IATI_IMPLEMENTING_PARTNER: FIELD_PARTNER,\n AKVO_SPONSOR_PARTNER: SPONSOR_PARTNER,\n # TODO: not backwards compatible\n IATI_REPORTING_ORGANISATION: u''\n }\n\n ALLIANCE_PARTNER = u'alliance'\n KNOWLEDGE_PARTNER = u'knowledge'\n NETWORK_PARTNER = u'network'\n\n PARTNER_TYPE_EXTRAS_LIST = (ALLIANCE_PARTNER, KNOWLEDGE_PARTNER, NETWORK_PARTNER)\n PARTNER_TYPE_EXTRA_LABELS = (\n _(u'Alliance'),\n _(u'Knowledge'),\n _(u'Network')\n )\n\n PARTNER_TYPE_EXTRAS = zip(PARTNER_TYPE_EXTRAS_LIST, PARTNER_TYPE_EXTRA_LABELS)\n\n organisation = models.ForeignKey(\n 'Organisation', verbose_name=_(u'organisation'), related_name='partnerships', null=True,\n blank=False, help_text=_(u'Select an organisation that is taking an active role in the '\n u'project.')\n )\n project = models.ForeignKey('Project', verbose_name=_(u'project'), related_name='partnerships')\n iati_organisation_role = models.PositiveSmallIntegerField(\n u'Organisation role', choices=IATI_ROLES, db_index=True, null=True)\n # is_secondary_reporter is only used when the iati_organisation_role is set to\n # IATI_REPORTING_ORGANISATION, thus the use of NullBooleanField\n is_secondary_reporter = models.NullBooleanField(\n _(u'secondary reporter'),\n help_text=_(\n u'This indicates whether the reporting organisation is a secondary publisher: '\n u'publishing data for which it is not directly responsible.'\n )\n )\n funding_amount = models.DecimalField(\n _(u'funding amount'), max_digits=14, decimal_places=2, blank=True, null=True, db_index=True,\n help_text=_(u'The funding amount of the partner.<br>'\n u'Note that it\\'s only possible to indicate a funding amount for funding '\n u'partners.')\n )\n partner_type_extra = ValidXMLCharField(\n _(u'partner type extra'), max_length=30, blank=True, null=True, choices=PARTNER_TYPE_EXTRAS,\n help_text=_(u'RSR specific partner type.')\n )\n iati_activity_id = ValidXMLCharField(\n _(u'IATI activity ID'), max_length=75, blank=True, null=True, db_index=True\n )\n internal_id = ValidXMLCharField(\n _(u'Internal ID'), max_length=75, blank=True, null=True, db_index=True,\n help_text=_(u'This field can be used to indicate an internal identifier that is used by '\n u'the organisation for this project. (75 characters)')\n )\n iati_url = models.URLField(\n blank=True,\n help_text=_(\n u'Please enter the URL for where the IATI Activity Id Funding details are published. '\n u'For projects directly or indirectly funded by the Dutch Government, this should '\n u'be the OpenAid.nl page. For other projects, an alternative URL can be used.'\n )\n )\n related_activity_id = ValidXMLCharField(\n _(u'related IATI activity ID'), max_length=50, blank=True\n )\n\n def iati_organisation_role_label(self):\n return dict(self.IATI_ROLES)[self.iati_organisation_role]\n\n def iati_role_to_partner_type(self):\n if self.iati_organisation_role:\n return self.ROLES_TO_PARTNER_TYPES_MAP[int(self.iati_organisation_role)]\n else:\n return None\n\n class Meta:\n app_label = 'rsr'\n verbose_name = _(u'project partner')\n verbose_name_plural = _(u'project partners')\n ordering = ['iati_organisation_role']\n\n def __unicode__(self):\n if self.organisation:\n if self.organisation.name:\n organisation_unicode = self.organisation.name\n elif self.organisation.long_name:\n organisation_unicode = self.organisation.long_name\n else:\n organisation_unicode = u'%s' % _(u'Organisation name not specified')\n else:\n organisation_unicode = u'%s' % _(u'Organisation not specified')\n\n if self.iati_organisation_role:\n organisation_unicode += u' ({})'.format(\n unicode(dict(self.IATI_ROLES)[self.iati_organisation_role])\n )\n return organisation_unicode\n\n def clean(self):\n # Don't allow multiple reporting organisations\n reporting_orgs = self.project.partnerships.filter(\n iati_organisation_role=self.IATI_REPORTING_ORGANISATION\n )\n\n if reporting_orgs:\n raise ValidationError(\n {'iati_organisation_role': u'%s' % _(u'Project can only have one reporting '\n u'organisation')}\n )\n", "path": "akvo/rsr/models/partnership.py"}]} | 2,785 | 265 |
gh_patches_debug_25136 | rasdani/github-patches | git_diff | beeware__toga-1262 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Make app respond to Cmd-H, Cmd-Opt-H on macOS; add menu bar items
Toga apps do not respond to Cmd-H and Cmd-Opt-H on macOS and there are no options to hide the app or hide other apps on the application menu. These could be added to the `APP` command group in `toga-cocoa` so that they are always present for macOS apps, under a separate section. I could look into what this might require although I've no experience with ObjC and friends.
</issue>
<code>
[start of src/cocoa/toga_cocoa/app.py]
1 import asyncio
2 import inspect
3 import os
4 import sys
5 from urllib.parse import unquote, urlparse
6
7 from rubicon.objc.eventloop import CocoaLifecycle, EventLoopPolicy
8
9 import toga
10 from toga.handlers import wrapped_handler
11
12 from .keys import cocoa_key
13 from .libs import (
14 SEL,
15 NSMenu,
16 NSMenuItem,
17 NSURL,
18 NSAboutPanelOptionApplicationIcon,
19 NSAboutPanelOptionApplicationName,
20 NSAboutPanelOptionApplicationVersion,
21 NSApplication,
22 NSApplicationActivationPolicyRegular,
23 NSBundle,
24 NSCursor,
25 NSDocumentController,
26 NSMutableArray,
27 NSMutableDictionary,
28 NSNumber,
29 NSObject,
30 NSOpenPanel,
31 NSScreen,
32 NSString,
33 objc_method
34 )
35 from .window import Window
36
37
38 class MainWindow(Window):
39 def on_close(self):
40 self.interface.app.exit()
41
42
43 class AppDelegate(NSObject):
44 @objc_method
45 def applicationWillTerminate_(self, sender):
46 if self.interface.app.on_exit:
47 self.interface.app.on_exit(self.interface.app)
48
49 @objc_method
50 def applicationDidFinishLaunching_(self, notification):
51 self.native.activateIgnoringOtherApps(True)
52
53 @objc_method
54 def applicationOpenUntitledFile_(self, sender) -> bool:
55 self.impl.select_file()
56 return True
57
58 @objc_method
59 def addDocument_(self, document) -> None:
60 # print("Add Document", document)
61 super().addDocument_(document)
62
63 @objc_method
64 def applicationShouldOpenUntitledFile_(self, sender) -> bool:
65 return True
66
67 @objc_method
68 def application_openFiles_(self, app, filenames) -> None:
69 for i in range(0, len(filenames)):
70 filename = filenames[i]
71 # If you start your Toga application as `python myapp.py` or
72 # `myapp.py`, the name of the Python script is included as a
73 # filename to be processed. Inspect the stack, and ignore any
74 # "document" that matches the file doing the executing
75 if filename == inspect.stack(-1)[-1].filename:
76 continue
77
78 if isinstance(filename, NSString):
79 fileURL = NSURL.fileURLWithPath(filename)
80
81 elif isinstance(filename, NSURL):
82 # This case only exists because we aren't using the
83 # DocumentController to display the file open dialog.
84 # If we were, *all* filenames passed in would be
85 # string paths.
86 fileURL = filename
87 else:
88 return
89
90 self.impl.open_document(str(fileURL.absoluteString))
91
92 @objc_method
93 def selectMenuItem_(self, sender) -> None:
94 cmd = self.interface._impl._menu_items[sender]
95 if cmd.action:
96 cmd.action(None)
97
98
99 class App:
100 _MAIN_WINDOW_CLASS = MainWindow
101
102 def __init__(self, interface):
103 self.interface = interface
104 self.interface._impl = self
105
106 self._cursor_visible = True
107
108 asyncio.set_event_loop_policy(EventLoopPolicy())
109 self.loop = asyncio.get_event_loop()
110
111 def create(self):
112 self.native = NSApplication.sharedApplication
113 self.native.setActivationPolicy(NSApplicationActivationPolicyRegular)
114
115 icon = self.interface.icon.bind(self.interface.factory)
116 self.native.setApplicationIconImage_(icon.native)
117
118 self.resource_path = os.path.dirname(os.path.dirname(NSBundle.mainBundle.bundlePath))
119
120 self.appDelegate = AppDelegate.alloc().init()
121 self.appDelegate.impl = self
122 self.appDelegate.interface = self.interface
123 self.appDelegate.native = self.native
124 self.native.setDelegate_(self.appDelegate)
125
126 formal_name = self.interface.formal_name
127
128 self.interface.commands.add(
129 toga.Command(
130 lambda _: self.interface.about(),
131 'About ' + formal_name,
132 group=toga.Group.APP
133 ),
134 toga.Command(None, 'Preferences', group=toga.Group.APP),
135 # Quit should always be the last item, in a section on it's own
136 toga.Command(
137 lambda _: self.interface.exit(),
138 'Quit ' + formal_name,
139 shortcut=toga.Key.MOD_1 + 'q',
140 group=toga.Group.APP,
141 section=sys.maxsize
142 ),
143
144 toga.Command(
145 lambda _: self.interface.visit_homepage(),
146 'Visit homepage',
147 enabled=self.interface.home_page is not None,
148 group=toga.Group.HELP
149 )
150 )
151 self._create_app_commands()
152
153 # Call user code to populate the main window
154 self.interface.startup()
155
156 # Create the lookup table of menu items,
157 # then force the creation of the menus.
158 self.create_menus()
159
160 def _create_app_commands(self):
161 # No extra commands
162 pass
163
164 def create_menus(self):
165 # Recreate the menu
166 self._menu_items = {}
167 self._menu_groups = {}
168 menubar = NSMenu.alloc().initWithTitle('MainMenu')
169 submenu = None
170 for cmd in self.interface.commands:
171 if cmd == toga.GROUP_BREAK:
172 submenu = None
173 elif cmd == toga.SECTION_BREAK:
174 submenu.addItem_(NSMenuItem.separatorItem())
175 else:
176 submenu = self._submenu(cmd.group, menubar)
177
178 if cmd.shortcut:
179 key, modifier = cocoa_key(cmd.shortcut)
180 else:
181 key = ''
182 modifier = None
183
184 item = NSMenuItem.alloc().initWithTitle(
185 cmd.label,
186 action=SEL('selectMenuItem:'),
187 keyEquivalent=key,
188 )
189 if modifier is not None:
190 item.keyEquivalentModifierMask = modifier
191
192 cmd._impl.native.append(item)
193 self._menu_items[item] = cmd
194
195 # This line may appear redundant, but it triggers the logic
196 # to force the enabled status on the underlying widgets.
197 cmd.enabled = cmd.enabled
198 submenu.addItem(item)
199
200 # Set the menu for the app.
201 self.native.mainMenu = menubar
202
203 def _submenu(self, group, menubar):
204 """
205 Obtain the submenu representing the command group.
206
207 This will create the submenu if it doesn't exist. It will call itself
208 recursively to build the full path to menus inside submenus, returning
209 the "leaf" node in the submenu path. Once created, it caches the menu
210 that has been created for future lookup.
211 """
212 try:
213 return self._menu_groups[group]
214 except KeyError:
215 if group is None:
216 submenu = menubar
217 else:
218 parent_menu = self._submenu(group.parent, menubar)
219
220 menu_item = parent_menu.addItemWithTitle(
221 group.label, action=None, keyEquivalent=''
222 )
223 submenu = NSMenu.alloc().initWithTitle(group.label)
224 submenu.setAutoenablesItems(False)
225
226 parent_menu.setSubmenu(submenu, forItem=menu_item)
227
228 # Install the item in the group cache.
229 self._menu_groups[group] = submenu
230 return submenu
231
232 def main_loop(self):
233 # Stimulate the build of the app
234 self.create()
235
236 self.loop.run_forever(lifecycle=CocoaLifecycle(self.native))
237
238 def set_main_window(self, window):
239 pass
240
241 def show_about_dialog(self):
242 options = NSMutableDictionary.alloc().init()
243
244 options[NSAboutPanelOptionApplicationIcon] = self.interface.icon.bind(self.interface.factory).native
245
246 if self.interface.name is not None:
247 options[NSAboutPanelOptionApplicationName] = self.interface.name
248
249 if self.interface.version is not None:
250 options[NSAboutPanelOptionApplicationVersion] = self.interface.version
251
252 # The build number
253 # if self.interface.version is not None:
254 # options[NSAboutPanelOptionVersion] = "the build"
255
256 if self.interface.author is not None:
257 options["Copyright"] = "Copyright © {author}".format(
258 author=self.interface.author
259 )
260
261 self.native.orderFrontStandardAboutPanelWithOptions(options)
262
263 def exit(self):
264 self.native.terminate(None)
265
266 def set_on_exit(self, value):
267 pass
268
269 def current_window(self):
270 return self.native.keyWindow
271
272 def enter_full_screen(self, windows):
273 # If we're already in full screen mode, exit so that
274 # we can re-assign windows to screens.
275 if self.interface.is_full_screen:
276 self.interface.exit_full_screen()
277
278 opts = NSMutableDictionary.alloc().init()
279 opts.setObject(NSNumber.numberWithBool(True), forKey="NSFullScreenModeAllScreens")
280
281 for window, screen in zip(windows, NSScreen.screens):
282 window.content._impl.native.enterFullScreenMode(screen, withOptions=opts)
283 # Going full screen causes the window content to be re-homed
284 # in a NSFullScreenWindow; teach the new parent window
285 # about it's Toga representations.
286 window.content._impl.native.window._impl = window._impl
287 window.content._impl.native.window.interface = window
288
289 def exit_full_screen(self, windows):
290 opts = NSMutableDictionary.alloc().init()
291 opts.setObject(NSNumber.numberWithBool(True), forKey="NSFullScreenModeAllScreens")
292
293 for window in windows:
294 window.content._impl.native.exitFullScreenModeWithOptions(opts)
295
296 def show_cursor(self):
297 if not self._cursor_visible:
298 NSCursor.unhide()
299
300 self._cursor_visible = True
301
302 def hide_cursor(self):
303 if self._cursor_visible:
304 NSCursor.hide()
305
306 self._cursor_visible = False
307
308 def add_background_task(self, handler):
309 self.loop.call_soon(wrapped_handler(self, handler), self)
310
311
312 class DocumentApp(App):
313 def _create_app_commands(self):
314 self.interface.commands.add(
315 toga.Command(
316 lambda _: self.select_file(),
317 label='Open...',
318 shortcut=toga.Key.MOD_1 + 'o',
319 group=toga.Group.FILE,
320 section=0
321 ),
322 )
323
324 def select_file(self, **kwargs):
325 # FIXME This should be all we need; but for some reason, application types
326 # aren't being registered correctly..
327 # NSDocumentController.sharedDocumentController().openDocument_(None)
328
329 # ...so we do this instead.
330 panel = NSOpenPanel.openPanel()
331 # print("Open documents of type", NSDocumentController.sharedDocumentController().defaultType)
332
333 fileTypes = NSMutableArray.alloc().init()
334 for filetype in self.interface.document_types:
335 fileTypes.addObject(filetype)
336
337 NSDocumentController.sharedDocumentController.runModalOpenPanel(panel, forTypes=fileTypes)
338
339 # print("Untitled File opened?", panel.URLs)
340 self.appDelegate.application_openFiles_(None, panel.URLs)
341
342 def open_document(self, fileURL):
343 """Open a new document in this app.
344
345 Args:
346 fileURL (str): The URL/path to the file to add as a document.
347 """
348 # Convert a cocoa fileURL to a file path.
349 fileURL = fileURL.rstrip('/')
350 path = unquote(urlparse(fileURL).path)
351 extension = os.path.splitext(path)[1][1:]
352
353 # Create the document instance
354 DocType = self.interface.document_types[extension]
355 document = DocType(path, app=self.interface)
356 self.interface._documents.append(document)
357
358 # Show the document.
359 document.show()
360
[end of src/cocoa/toga_cocoa/app.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/src/cocoa/toga_cocoa/app.py b/src/cocoa/toga_cocoa/app.py
--- a/src/cocoa/toga_cocoa/app.py
+++ b/src/cocoa/toga_cocoa/app.py
@@ -131,8 +131,37 @@
'About ' + formal_name,
group=toga.Group.APP
),
- toga.Command(None, 'Preferences', group=toga.Group.APP),
- # Quit should always be the last item, in a section on it's own
+ toga.Command(
+ None,
+ 'Preferences',
+ shortcut=toga.Key.MOD_1 + ',',
+ group=toga.Group.APP,
+ section=20,
+ ),
+ toga.Command(
+ lambda _: self.native.hide(self.native),
+ 'Hide ' + formal_name,
+ shortcut=toga.Key.MOD_1 + 'h',
+ group=toga.Group.APP,
+ order=0,
+ section=sys.maxsize - 1,
+ ),
+ toga.Command(
+ lambda _: self.native.hideOtherApplications(self.native),
+ 'Hide Others',
+ shortcut=toga.Key.MOD_1 + toga.Key.MOD_2 + 'h',
+ group=toga.Group.APP,
+ order=1,
+ section=sys.maxsize - 1,
+ ),
+ toga.Command(
+ lambda _: self.native.unhideAllApplications(self.native),
+ 'Show All',
+ group=toga.Group.APP,
+ order=2,
+ section=sys.maxsize - 1,
+ ),
+ # Quit should always be the last item, in a section on its own
toga.Command(
lambda _: self.interface.exit(),
'Quit ' + formal_name,
| {"golden_diff": "diff --git a/src/cocoa/toga_cocoa/app.py b/src/cocoa/toga_cocoa/app.py\n--- a/src/cocoa/toga_cocoa/app.py\n+++ b/src/cocoa/toga_cocoa/app.py\n@@ -131,8 +131,37 @@\n 'About ' + formal_name,\n group=toga.Group.APP\n ),\n- toga.Command(None, 'Preferences', group=toga.Group.APP),\n- # Quit should always be the last item, in a section on it's own\n+ toga.Command(\n+ None,\n+ 'Preferences',\n+ shortcut=toga.Key.MOD_1 + ',',\n+ group=toga.Group.APP,\n+ section=20,\n+ ),\n+ toga.Command(\n+ lambda _: self.native.hide(self.native),\n+ 'Hide ' + formal_name,\n+ shortcut=toga.Key.MOD_1 + 'h',\n+ group=toga.Group.APP,\n+ order=0,\n+ section=sys.maxsize - 1,\n+ ),\n+ toga.Command(\n+ lambda _: self.native.hideOtherApplications(self.native),\n+ 'Hide Others',\n+ shortcut=toga.Key.MOD_1 + toga.Key.MOD_2 + 'h',\n+ group=toga.Group.APP,\n+ order=1,\n+ section=sys.maxsize - 1,\n+ ),\n+ toga.Command(\n+ lambda _: self.native.unhideAllApplications(self.native),\n+ 'Show All',\n+ group=toga.Group.APP,\n+ order=2,\n+ section=sys.maxsize - 1,\n+ ),\n+ # Quit should always be the last item, in a section on its own\n toga.Command(\n lambda _: self.interface.exit(),\n 'Quit ' + formal_name,\n", "issue": "Make app respond to Cmd-H, Cmd-Opt-H on macOS; add menu bar items\nToga apps do not respond to Cmd-H and Cmd-Opt-H on macOS and there are no options to hide the app or hide other apps on the application menu. These could be added to the `APP` command group in `toga-cocoa` so that they are always present for macOS apps, under a separate section. I could look into what this might require although I've no experience with ObjC and friends.\n", "before_files": [{"content": "import asyncio\nimport inspect\nimport os\nimport sys\nfrom urllib.parse import unquote, urlparse\n\nfrom rubicon.objc.eventloop import CocoaLifecycle, EventLoopPolicy\n\nimport toga\nfrom toga.handlers import wrapped_handler\n\nfrom .keys import cocoa_key\nfrom .libs import (\n SEL,\n NSMenu,\n NSMenuItem,\n NSURL,\n NSAboutPanelOptionApplicationIcon,\n NSAboutPanelOptionApplicationName,\n NSAboutPanelOptionApplicationVersion,\n NSApplication,\n NSApplicationActivationPolicyRegular,\n NSBundle,\n NSCursor,\n NSDocumentController,\n NSMutableArray,\n NSMutableDictionary,\n NSNumber,\n NSObject,\n NSOpenPanel,\n NSScreen,\n NSString,\n objc_method\n)\nfrom .window import Window\n\n\nclass MainWindow(Window):\n def on_close(self):\n self.interface.app.exit()\n\n\nclass AppDelegate(NSObject):\n @objc_method\n def applicationWillTerminate_(self, sender):\n if self.interface.app.on_exit:\n self.interface.app.on_exit(self.interface.app)\n\n @objc_method\n def applicationDidFinishLaunching_(self, notification):\n self.native.activateIgnoringOtherApps(True)\n\n @objc_method\n def applicationOpenUntitledFile_(self, sender) -> bool:\n self.impl.select_file()\n return True\n\n @objc_method\n def addDocument_(self, document) -> None:\n # print(\"Add Document\", document)\n super().addDocument_(document)\n\n @objc_method\n def applicationShouldOpenUntitledFile_(self, sender) -> bool:\n return True\n\n @objc_method\n def application_openFiles_(self, app, filenames) -> None:\n for i in range(0, len(filenames)):\n filename = filenames[i]\n # If you start your Toga application as `python myapp.py` or\n # `myapp.py`, the name of the Python script is included as a\n # filename to be processed. Inspect the stack, and ignore any\n # \"document\" that matches the file doing the executing\n if filename == inspect.stack(-1)[-1].filename:\n continue\n\n if isinstance(filename, NSString):\n fileURL = NSURL.fileURLWithPath(filename)\n\n elif isinstance(filename, NSURL):\n # This case only exists because we aren't using the\n # DocumentController to display the file open dialog.\n # If we were, *all* filenames passed in would be\n # string paths.\n fileURL = filename\n else:\n return\n\n self.impl.open_document(str(fileURL.absoluteString))\n\n @objc_method\n def selectMenuItem_(self, sender) -> None:\n cmd = self.interface._impl._menu_items[sender]\n if cmd.action:\n cmd.action(None)\n\n\nclass App:\n _MAIN_WINDOW_CLASS = MainWindow\n\n def __init__(self, interface):\n self.interface = interface\n self.interface._impl = self\n\n self._cursor_visible = True\n\n asyncio.set_event_loop_policy(EventLoopPolicy())\n self.loop = asyncio.get_event_loop()\n\n def create(self):\n self.native = NSApplication.sharedApplication\n self.native.setActivationPolicy(NSApplicationActivationPolicyRegular)\n\n icon = self.interface.icon.bind(self.interface.factory)\n self.native.setApplicationIconImage_(icon.native)\n\n self.resource_path = os.path.dirname(os.path.dirname(NSBundle.mainBundle.bundlePath))\n\n self.appDelegate = AppDelegate.alloc().init()\n self.appDelegate.impl = self\n self.appDelegate.interface = self.interface\n self.appDelegate.native = self.native\n self.native.setDelegate_(self.appDelegate)\n\n formal_name = self.interface.formal_name\n\n self.interface.commands.add(\n toga.Command(\n lambda _: self.interface.about(),\n 'About ' + formal_name,\n group=toga.Group.APP\n ),\n toga.Command(None, 'Preferences', group=toga.Group.APP),\n # Quit should always be the last item, in a section on it's own\n toga.Command(\n lambda _: self.interface.exit(),\n 'Quit ' + formal_name,\n shortcut=toga.Key.MOD_1 + 'q',\n group=toga.Group.APP,\n section=sys.maxsize\n ),\n\n toga.Command(\n lambda _: self.interface.visit_homepage(),\n 'Visit homepage',\n enabled=self.interface.home_page is not None,\n group=toga.Group.HELP\n )\n )\n self._create_app_commands()\n\n # Call user code to populate the main window\n self.interface.startup()\n\n # Create the lookup table of menu items,\n # then force the creation of the menus.\n self.create_menus()\n\n def _create_app_commands(self):\n # No extra commands\n pass\n\n def create_menus(self):\n # Recreate the menu\n self._menu_items = {}\n self._menu_groups = {}\n menubar = NSMenu.alloc().initWithTitle('MainMenu')\n submenu = None\n for cmd in self.interface.commands:\n if cmd == toga.GROUP_BREAK:\n submenu = None\n elif cmd == toga.SECTION_BREAK:\n submenu.addItem_(NSMenuItem.separatorItem())\n else:\n submenu = self._submenu(cmd.group, menubar)\n\n if cmd.shortcut:\n key, modifier = cocoa_key(cmd.shortcut)\n else:\n key = ''\n modifier = None\n\n item = NSMenuItem.alloc().initWithTitle(\n cmd.label,\n action=SEL('selectMenuItem:'),\n keyEquivalent=key,\n )\n if modifier is not None:\n item.keyEquivalentModifierMask = modifier\n\n cmd._impl.native.append(item)\n self._menu_items[item] = cmd\n\n # This line may appear redundant, but it triggers the logic\n # to force the enabled status on the underlying widgets.\n cmd.enabled = cmd.enabled\n submenu.addItem(item)\n\n # Set the menu for the app.\n self.native.mainMenu = menubar\n\n def _submenu(self, group, menubar):\n \"\"\"\n Obtain the submenu representing the command group.\n\n This will create the submenu if it doesn't exist. It will call itself\n recursively to build the full path to menus inside submenus, returning\n the \"leaf\" node in the submenu path. Once created, it caches the menu\n that has been created for future lookup.\n \"\"\"\n try:\n return self._menu_groups[group]\n except KeyError:\n if group is None:\n submenu = menubar\n else:\n parent_menu = self._submenu(group.parent, menubar)\n\n menu_item = parent_menu.addItemWithTitle(\n group.label, action=None, keyEquivalent=''\n )\n submenu = NSMenu.alloc().initWithTitle(group.label)\n submenu.setAutoenablesItems(False)\n\n parent_menu.setSubmenu(submenu, forItem=menu_item)\n\n # Install the item in the group cache.\n self._menu_groups[group] = submenu\n return submenu\n\n def main_loop(self):\n # Stimulate the build of the app\n self.create()\n\n self.loop.run_forever(lifecycle=CocoaLifecycle(self.native))\n\n def set_main_window(self, window):\n pass\n\n def show_about_dialog(self):\n options = NSMutableDictionary.alloc().init()\n\n options[NSAboutPanelOptionApplicationIcon] = self.interface.icon.bind(self.interface.factory).native\n\n if self.interface.name is not None:\n options[NSAboutPanelOptionApplicationName] = self.interface.name\n\n if self.interface.version is not None:\n options[NSAboutPanelOptionApplicationVersion] = self.interface.version\n\n # The build number\n # if self.interface.version is not None:\n # options[NSAboutPanelOptionVersion] = \"the build\"\n\n if self.interface.author is not None:\n options[\"Copyright\"] = \"Copyright \u00a9 {author}\".format(\n author=self.interface.author\n )\n\n self.native.orderFrontStandardAboutPanelWithOptions(options)\n\n def exit(self):\n self.native.terminate(None)\n\n def set_on_exit(self, value):\n pass\n\n def current_window(self):\n return self.native.keyWindow\n\n def enter_full_screen(self, windows):\n # If we're already in full screen mode, exit so that\n # we can re-assign windows to screens.\n if self.interface.is_full_screen:\n self.interface.exit_full_screen()\n\n opts = NSMutableDictionary.alloc().init()\n opts.setObject(NSNumber.numberWithBool(True), forKey=\"NSFullScreenModeAllScreens\")\n\n for window, screen in zip(windows, NSScreen.screens):\n window.content._impl.native.enterFullScreenMode(screen, withOptions=opts)\n # Going full screen causes the window content to be re-homed\n # in a NSFullScreenWindow; teach the new parent window\n # about it's Toga representations.\n window.content._impl.native.window._impl = window._impl\n window.content._impl.native.window.interface = window\n\n def exit_full_screen(self, windows):\n opts = NSMutableDictionary.alloc().init()\n opts.setObject(NSNumber.numberWithBool(True), forKey=\"NSFullScreenModeAllScreens\")\n\n for window in windows:\n window.content._impl.native.exitFullScreenModeWithOptions(opts)\n\n def show_cursor(self):\n if not self._cursor_visible:\n NSCursor.unhide()\n\n self._cursor_visible = True\n\n def hide_cursor(self):\n if self._cursor_visible:\n NSCursor.hide()\n\n self._cursor_visible = False\n\n def add_background_task(self, handler):\n self.loop.call_soon(wrapped_handler(self, handler), self)\n\n\nclass DocumentApp(App):\n def _create_app_commands(self):\n self.interface.commands.add(\n toga.Command(\n lambda _: self.select_file(),\n label='Open...',\n shortcut=toga.Key.MOD_1 + 'o',\n group=toga.Group.FILE,\n section=0\n ),\n )\n\n def select_file(self, **kwargs):\n # FIXME This should be all we need; but for some reason, application types\n # aren't being registered correctly..\n # NSDocumentController.sharedDocumentController().openDocument_(None)\n\n # ...so we do this instead.\n panel = NSOpenPanel.openPanel()\n # print(\"Open documents of type\", NSDocumentController.sharedDocumentController().defaultType)\n\n fileTypes = NSMutableArray.alloc().init()\n for filetype in self.interface.document_types:\n fileTypes.addObject(filetype)\n\n NSDocumentController.sharedDocumentController.runModalOpenPanel(panel, forTypes=fileTypes)\n\n # print(\"Untitled File opened?\", panel.URLs)\n self.appDelegate.application_openFiles_(None, panel.URLs)\n\n def open_document(self, fileURL):\n \"\"\"Open a new document in this app.\n\n Args:\n fileURL (str): The URL/path to the file to add as a document.\n \"\"\"\n # Convert a cocoa fileURL to a file path.\n fileURL = fileURL.rstrip('/')\n path = unquote(urlparse(fileURL).path)\n extension = os.path.splitext(path)[1][1:]\n\n # Create the document instance\n DocType = self.interface.document_types[extension]\n document = DocType(path, app=self.interface)\n self.interface._documents.append(document)\n\n # Show the document.\n document.show()\n", "path": "src/cocoa/toga_cocoa/app.py"}]} | 4,028 | 386 |
gh_patches_debug_12646 | rasdani/github-patches | git_diff | wagtail__wagtail-9572 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[Nightly] Image upload broken for some images
### Issue Summary
In the current Nightly version, it is no longer possible for me to upload an image. Maybe it is already known or fixed, but I preferred to report it.
```text
Internal Server Error: /admin/images/multiple/add/
Traceback (most recent call last):
File "/wagtailNightly/.env/lib/python3.10/site-packages/django/core/handlers/exception.py", line 55, in inner
response = get_response(request)
File "/wagtailNightly/.env/lib/python3.10/site-packages/django/core/handlers/base.py", line 197, in _get_response
response = wrapped_callback(request, *callback_args, **callback_kwargs)
File "/wagtailNightly/.env/lib/python3.10/site-packages/django/views/decorators/cache.py", line 62, in _wrapped_view_func
response = view_func(request, *args, **kwargs)
File "/wagtailNightly/.env/lib/python3.10/site-packages/wagtail/admin/urls/__init__.py", line 170, in wrapper
return view_func(request, *args, **kwargs)
File "/wagtailNightly/.env/lib/python3.10/site-packages/wagtail/admin/auth.py", line 205, in decorated_view
return view_func(request, *args, **kwargs)
File "/wagtailNightly/.env/lib/python3.10/site-packages/django/views/generic/base.py", line 103, in view
return self.dispatch(request, *args, **kwargs)
File "/wagtailNightly/.env/lib/python3.10/site-packages/django/utils/decorators.py", line 46, in _wrapper
return bound_method(*args, **kwargs)
File "/wagtailNightly/.env/lib/python3.10/site-packages/django/views/decorators/vary.py", line 21, in inner_func
response = func(*args, **kwargs)
File "/wagtailNightly/.env/lib/python3.10/site-packages/wagtail/admin/views/generic/multiple_upload.py", line 44, in dispatch
return super().dispatch(request)
File "/wagtailNightly/.env/lib/python3.10/site-packages/wagtail/admin/views/generic/permissions.py", line 36, in dispatch
return super().dispatch(request, *args, **kwargs)
File "/wagtailNightly/.env/lib/python3.10/site-packages/django/views/generic/base.py", line 142, in dispatch
return handler(request, *args, **kwargs)
File "/wagtailNightly/.env/lib/python3.10/site-packages/wagtail/admin/views/generic/multiple_upload.py", line 144, in post
if form.is_valid():
File "/wagtailNightly/.env/lib/python3.10/site-packages/django/forms/forms.py", line 205, in is_valid
return self.is_bound and not self.errors
File "/wagtailNightly/.env/lib/python3.10/site-packages/django/forms/forms.py", line 200, in errors
self.full_clean()
File "/wagtailNightly/.env/lib/python3.10/site-packages/django/forms/forms.py", line 437, in full_clean
self._clean_fields()
File "/wagtailNightly/.env/lib/python3.10/site-packages/django/forms/forms.py", line 447, in _clean_fields
value = field.clean(value, bf.initial)
File "/wagtailNightly/.env/lib/python3.10/site-packages/django/forms/fields.py", line 678, in clean
return super().clean(data)
File "/wagtailNightly/.env/lib/python3.10/site-packages/django/forms/fields.py", line 198, in clean
value = self.to_python(value)
File "/wagtailNightly/.env/lib/python3.10/site-packages/wagtail/images/fields.py", line 156, in to_python
self.check_image_pixel_size(f)
File "/wagtailNightly/.env/lib/python3.10/site-packages/wagtail/images/fields.py", line 107, in check_image_pixel_size
width, height = f.image.get_size()
File "/wagtailNightly/.env/lib/python3.10/site-packages/willow/image.py", line 78, in wrapper
image = converter(image)
File "/wagtailNightly/.env/lib/python3.10/site-packages/willow/plugins/pillow.py", line 248, in open
image_file.f.seek(0)
AttributeError: 'str' object has no attribute 'seek'
[01/Nov/2022 10:28:08] "POST /admin/images/multiple/add/ HTTP/1.1" 500 150299
```
### Steps to Reproduce
1. Start a new project with `wagtail start myproject`
2. Install the nightly version `pip install https://releases.wagtail.org/nightly/dist/wagtail-4.2.dev20221101-py3-none-any.whl`
3. Start the server and open the wagtail admin interface
4. Click on `Images` in the left sidebar
5. Upload an image
Any other relevant information. For example, why do you consider this a bug and what did you expect to happen instead?
- I have confirmed that this issue can be reproduced as described on a fresh Wagtail project: yes
### Technical details
- Python version: 3.10.8
- Django version: 4.1.1
- Wagtail version: 4.2.dev20221101
- Browser version: Firefox 106 and Chrome 107
</issue>
<code>
[start of wagtail/images/fields.py]
1 import os
2 from io import BytesIO
3
4 import willow
5 from django.conf import settings
6 from django.core.exceptions import ValidationError
7 from django.core.validators import FileExtensionValidator
8 from django.forms.fields import FileField, ImageField
9 from django.template.defaultfilters import filesizeformat
10 from django.utils.translation import gettext_lazy as _
11
12 ALLOWED_EXTENSIONS = ["gif", "jpg", "jpeg", "png", "webp"]
13 SUPPORTED_FORMATS_TEXT = _("GIF, JPEG, PNG, WEBP")
14
15
16 class WagtailImageField(ImageField):
17 default_validators = [FileExtensionValidator(ALLOWED_EXTENSIONS)]
18
19 def __init__(self, *args, **kwargs):
20 super().__init__(*args, **kwargs)
21
22 # Get max upload size from settings
23 self.max_upload_size = getattr(
24 settings, "WAGTAILIMAGES_MAX_UPLOAD_SIZE", 10 * 1024 * 1024
25 )
26 self.max_image_pixels = getattr(
27 settings, "WAGTAILIMAGES_MAX_IMAGE_PIXELS", 128 * 1000000
28 )
29 max_upload_size_text = filesizeformat(self.max_upload_size)
30
31 # Help text
32 if self.max_upload_size is not None:
33 self.help_text = _(
34 "Supported formats: %(supported_formats)s. Maximum filesize: %(max_upload_size)s."
35 ) % {
36 "supported_formats": SUPPORTED_FORMATS_TEXT,
37 "max_upload_size": max_upload_size_text,
38 }
39 else:
40 self.help_text = _("Supported formats: %(supported_formats)s.") % {
41 "supported_formats": SUPPORTED_FORMATS_TEXT,
42 }
43
44 # Error messages
45 self.error_messages["invalid_image_extension"] = (
46 _("Not a supported image format. Supported formats: %s.")
47 % SUPPORTED_FORMATS_TEXT
48 )
49
50 self.error_messages["invalid_image_known_format"] = _(
51 "Not a valid .%s image. The extension does not match the file format (%s)"
52 )
53
54 self.error_messages["file_too_large"] = (
55 _("This file is too big (%%s). Maximum filesize %s.") % max_upload_size_text
56 )
57
58 self.error_messages["file_too_many_pixels"] = (
59 _("This file has too many pixels (%%s). Maximum pixels %s.")
60 % self.max_image_pixels
61 )
62
63 self.error_messages["file_too_large_unknown_size"] = (
64 _("This file is too big. Maximum filesize %s.") % max_upload_size_text
65 )
66
67 def check_image_file_format(self, f):
68 # Check file extension
69 extension = os.path.splitext(f.name)[1].lower()[1:]
70
71 if extension not in ALLOWED_EXTENSIONS:
72 raise ValidationError(
73 self.error_messages["invalid_image_extension"],
74 code="invalid_image_extension",
75 )
76
77 if extension == "jpg":
78 extension = "jpeg"
79
80 # Check that the internal format matches the extension
81 # It is possible to upload PSD files if their extension is set to jpg, png or gif. This should catch them out
82 if extension != f.image.format_name:
83 raise ValidationError(
84 self.error_messages["invalid_image_known_format"]
85 % (extension, f.image.format_name),
86 code="invalid_image_known_format",
87 )
88
89 def check_image_file_size(self, f):
90 # Upload size checking can be disabled by setting max upload size to None
91 if self.max_upload_size is None:
92 return
93
94 # Check the filesize
95 if f.size > self.max_upload_size:
96 raise ValidationError(
97 self.error_messages["file_too_large"] % (filesizeformat(f.size),),
98 code="file_too_large",
99 )
100
101 def check_image_pixel_size(self, f):
102 # Upload pixel size checking can be disabled by setting max upload pixel to None
103 if self.max_image_pixels is None:
104 return
105
106 # Check the pixel size
107 width, height = f.image.get_size()
108 frames = f.image.get_frame_count()
109 num_pixels = width * height * frames
110
111 if num_pixels > self.max_image_pixels:
112 raise ValidationError(
113 self.error_messages["file_too_many_pixels"] % (num_pixels),
114 code="file_too_many_pixels",
115 )
116
117 def to_python(self, data):
118 """
119 Check that the file-upload field data contains a valid image (GIF, JPG,
120 PNG, etc. -- whatever Willow supports). Overridden from ImageField to use
121 Willow instead of Pillow as the image library in order to enable SVG support.
122 """
123 f = FileField.to_python(self, data)
124 if f is None:
125 return None
126
127 # We need to get a file object for Pillow. We might have a path or we might
128 # have to read the data into memory.
129 if hasattr(data, "temporary_file_path"):
130 file = data.temporary_file_path()
131 else:
132 if hasattr(data, "read"):
133 file = BytesIO(data.read())
134 else:
135 file = BytesIO(data["content"])
136
137 try:
138 # Annotate the python representation of the FileField with the image
139 # property so subclasses can reuse it for their own validation
140 f.image = willow.Image.open(file)
141 f.content_type = image_format_name_to_content_type(f.image.format_name)
142
143 except Exception as exc:
144 # Willow doesn't recognize it as an image.
145 raise ValidationError(
146 self.error_messages["invalid_image"],
147 code="invalid_image",
148 ) from exc
149
150 if hasattr(f, "seek") and callable(f.seek):
151 f.seek(0)
152
153 if f is not None:
154 self.check_image_file_size(f)
155 self.check_image_file_format(f)
156 self.check_image_pixel_size(f)
157
158 return f
159
160
161 def image_format_name_to_content_type(image_format_name):
162 """
163 Convert a Willow image format name to a content type.
164 TODO: Replace once https://github.com/wagtail/Willow/pull/102 and
165 a new Willow release is out
166 """
167 if image_format_name == "svg":
168 return "image/svg+xml"
169 elif image_format_name == "jpeg":
170 return "image/jpeg"
171 elif image_format_name == "png":
172 return "image/png"
173 elif image_format_name == "gif":
174 return "image/gif"
175 elif image_format_name == "bmp":
176 return "image/bmp"
177 elif image_format_name == "tiff":
178 return "image/tiff"
179 elif image_format_name == "webp":
180 return "image/webp"
181 else:
182 raise ValueError("Unknown image format name")
183
[end of wagtail/images/fields.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/wagtail/images/fields.py b/wagtail/images/fields.py
--- a/wagtail/images/fields.py
+++ b/wagtail/images/fields.py
@@ -124,10 +124,11 @@
if f is None:
return None
- # We need to get a file object for Pillow. We might have a path or we might
- # have to read the data into memory.
+ # We need to get a file object for Pillow. When we get a path, we need to open
+ # the file first. And we have to read the data into memory to pass to Willow.
if hasattr(data, "temporary_file_path"):
- file = data.temporary_file_path()
+ with open(data.temporary_file_path(), "rb") as fh:
+ file = BytesIO(fh.read())
else:
if hasattr(data, "read"):
file = BytesIO(data.read())
| {"golden_diff": "diff --git a/wagtail/images/fields.py b/wagtail/images/fields.py\n--- a/wagtail/images/fields.py\n+++ b/wagtail/images/fields.py\n@@ -124,10 +124,11 @@\n if f is None:\n return None\n \n- # We need to get a file object for Pillow. We might have a path or we might\n- # have to read the data into memory.\n+ # We need to get a file object for Pillow. When we get a path, we need to open\n+ # the file first. And we have to read the data into memory to pass to Willow.\n if hasattr(data, \"temporary_file_path\"):\n- file = data.temporary_file_path()\n+ with open(data.temporary_file_path(), \"rb\") as fh:\n+ file = BytesIO(fh.read())\n else:\n if hasattr(data, \"read\"):\n file = BytesIO(data.read())\n", "issue": "[Nightly] Image upload broken for some images\n### Issue Summary\r\n\r\nIn the current Nightly version, it is no longer possible for me to upload an image. Maybe it is already known or fixed, but I preferred to report it.\r\n\r\n```text\r\nInternal Server Error: /admin/images/multiple/add/\r\nTraceback (most recent call last):\r\n File \"/wagtailNightly/.env/lib/python3.10/site-packages/django/core/handlers/exception.py\", line 55, in inner\r\n response = get_response(request)\r\n File \"/wagtailNightly/.env/lib/python3.10/site-packages/django/core/handlers/base.py\", line 197, in _get_response\r\n response = wrapped_callback(request, *callback_args, **callback_kwargs)\r\n File \"/wagtailNightly/.env/lib/python3.10/site-packages/django/views/decorators/cache.py\", line 62, in _wrapped_view_func\r\n response = view_func(request, *args, **kwargs)\r\n File \"/wagtailNightly/.env/lib/python3.10/site-packages/wagtail/admin/urls/__init__.py\", line 170, in wrapper\r\n return view_func(request, *args, **kwargs)\r\n File \"/wagtailNightly/.env/lib/python3.10/site-packages/wagtail/admin/auth.py\", line 205, in decorated_view\r\n return view_func(request, *args, **kwargs)\r\n File \"/wagtailNightly/.env/lib/python3.10/site-packages/django/views/generic/base.py\", line 103, in view\r\n return self.dispatch(request, *args, **kwargs)\r\n File \"/wagtailNightly/.env/lib/python3.10/site-packages/django/utils/decorators.py\", line 46, in _wrapper\r\n return bound_method(*args, **kwargs)\r\n File \"/wagtailNightly/.env/lib/python3.10/site-packages/django/views/decorators/vary.py\", line 21, in inner_func\r\n response = func(*args, **kwargs)\r\n File \"/wagtailNightly/.env/lib/python3.10/site-packages/wagtail/admin/views/generic/multiple_upload.py\", line 44, in dispatch\r\n return super().dispatch(request)\r\n File \"/wagtailNightly/.env/lib/python3.10/site-packages/wagtail/admin/views/generic/permissions.py\", line 36, in dispatch\r\n return super().dispatch(request, *args, **kwargs)\r\n File \"/wagtailNightly/.env/lib/python3.10/site-packages/django/views/generic/base.py\", line 142, in dispatch\r\n return handler(request, *args, **kwargs)\r\n File \"/wagtailNightly/.env/lib/python3.10/site-packages/wagtail/admin/views/generic/multiple_upload.py\", line 144, in post\r\n if form.is_valid():\r\n File \"/wagtailNightly/.env/lib/python3.10/site-packages/django/forms/forms.py\", line 205, in is_valid\r\n return self.is_bound and not self.errors\r\n File \"/wagtailNightly/.env/lib/python3.10/site-packages/django/forms/forms.py\", line 200, in errors\r\n self.full_clean()\r\n File \"/wagtailNightly/.env/lib/python3.10/site-packages/django/forms/forms.py\", line 437, in full_clean\r\n self._clean_fields()\r\n File \"/wagtailNightly/.env/lib/python3.10/site-packages/django/forms/forms.py\", line 447, in _clean_fields\r\n value = field.clean(value, bf.initial)\r\n File \"/wagtailNightly/.env/lib/python3.10/site-packages/django/forms/fields.py\", line 678, in clean\r\n return super().clean(data)\r\n File \"/wagtailNightly/.env/lib/python3.10/site-packages/django/forms/fields.py\", line 198, in clean\r\n value = self.to_python(value)\r\n File \"/wagtailNightly/.env/lib/python3.10/site-packages/wagtail/images/fields.py\", line 156, in to_python\r\n self.check_image_pixel_size(f)\r\n File \"/wagtailNightly/.env/lib/python3.10/site-packages/wagtail/images/fields.py\", line 107, in check_image_pixel_size\r\n width, height = f.image.get_size()\r\n File \"/wagtailNightly/.env/lib/python3.10/site-packages/willow/image.py\", line 78, in wrapper\r\n image = converter(image)\r\n File \"/wagtailNightly/.env/lib/python3.10/site-packages/willow/plugins/pillow.py\", line 248, in open\r\n image_file.f.seek(0)\r\nAttributeError: 'str' object has no attribute 'seek'\r\n[01/Nov/2022 10:28:08] \"POST /admin/images/multiple/add/ HTTP/1.1\" 500 150299\r\n```\r\n\r\n### Steps to Reproduce\r\n\r\n1. Start a new project with `wagtail start myproject`\r\n2. Install the nightly version `pip install https://releases.wagtail.org/nightly/dist/wagtail-4.2.dev20221101-py3-none-any.whl`\r\n3. Start the server and open the wagtail admin interface\r\n4. Click on `Images` in the left sidebar\r\n5. Upload an image\r\n\r\nAny other relevant information. For example, why do you consider this a bug and what did you expect to happen instead?\r\n\r\n- I have confirmed that this issue can be reproduced as described on a fresh Wagtail project: yes\r\n\r\n### Technical details\r\n\r\n- Python version: 3.10.8\r\n- Django version: 4.1.1\r\n- Wagtail version: 4.2.dev20221101\r\n- Browser version: Firefox 106 and Chrome 107\r\n\n", "before_files": [{"content": "import os\nfrom io import BytesIO\n\nimport willow\nfrom django.conf import settings\nfrom django.core.exceptions import ValidationError\nfrom django.core.validators import FileExtensionValidator\nfrom django.forms.fields import FileField, ImageField\nfrom django.template.defaultfilters import filesizeformat\nfrom django.utils.translation import gettext_lazy as _\n\nALLOWED_EXTENSIONS = [\"gif\", \"jpg\", \"jpeg\", \"png\", \"webp\"]\nSUPPORTED_FORMATS_TEXT = _(\"GIF, JPEG, PNG, WEBP\")\n\n\nclass WagtailImageField(ImageField):\n default_validators = [FileExtensionValidator(ALLOWED_EXTENSIONS)]\n\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n\n # Get max upload size from settings\n self.max_upload_size = getattr(\n settings, \"WAGTAILIMAGES_MAX_UPLOAD_SIZE\", 10 * 1024 * 1024\n )\n self.max_image_pixels = getattr(\n settings, \"WAGTAILIMAGES_MAX_IMAGE_PIXELS\", 128 * 1000000\n )\n max_upload_size_text = filesizeformat(self.max_upload_size)\n\n # Help text\n if self.max_upload_size is not None:\n self.help_text = _(\n \"Supported formats: %(supported_formats)s. Maximum filesize: %(max_upload_size)s.\"\n ) % {\n \"supported_formats\": SUPPORTED_FORMATS_TEXT,\n \"max_upload_size\": max_upload_size_text,\n }\n else:\n self.help_text = _(\"Supported formats: %(supported_formats)s.\") % {\n \"supported_formats\": SUPPORTED_FORMATS_TEXT,\n }\n\n # Error messages\n self.error_messages[\"invalid_image_extension\"] = (\n _(\"Not a supported image format. Supported formats: %s.\")\n % SUPPORTED_FORMATS_TEXT\n )\n\n self.error_messages[\"invalid_image_known_format\"] = _(\n \"Not a valid .%s image. The extension does not match the file format (%s)\"\n )\n\n self.error_messages[\"file_too_large\"] = (\n _(\"This file is too big (%%s). Maximum filesize %s.\") % max_upload_size_text\n )\n\n self.error_messages[\"file_too_many_pixels\"] = (\n _(\"This file has too many pixels (%%s). Maximum pixels %s.\")\n % self.max_image_pixels\n )\n\n self.error_messages[\"file_too_large_unknown_size\"] = (\n _(\"This file is too big. Maximum filesize %s.\") % max_upload_size_text\n )\n\n def check_image_file_format(self, f):\n # Check file extension\n extension = os.path.splitext(f.name)[1].lower()[1:]\n\n if extension not in ALLOWED_EXTENSIONS:\n raise ValidationError(\n self.error_messages[\"invalid_image_extension\"],\n code=\"invalid_image_extension\",\n )\n\n if extension == \"jpg\":\n extension = \"jpeg\"\n\n # Check that the internal format matches the extension\n # It is possible to upload PSD files if their extension is set to jpg, png or gif. This should catch them out\n if extension != f.image.format_name:\n raise ValidationError(\n self.error_messages[\"invalid_image_known_format\"]\n % (extension, f.image.format_name),\n code=\"invalid_image_known_format\",\n )\n\n def check_image_file_size(self, f):\n # Upload size checking can be disabled by setting max upload size to None\n if self.max_upload_size is None:\n return\n\n # Check the filesize\n if f.size > self.max_upload_size:\n raise ValidationError(\n self.error_messages[\"file_too_large\"] % (filesizeformat(f.size),),\n code=\"file_too_large\",\n )\n\n def check_image_pixel_size(self, f):\n # Upload pixel size checking can be disabled by setting max upload pixel to None\n if self.max_image_pixels is None:\n return\n\n # Check the pixel size\n width, height = f.image.get_size()\n frames = f.image.get_frame_count()\n num_pixels = width * height * frames\n\n if num_pixels > self.max_image_pixels:\n raise ValidationError(\n self.error_messages[\"file_too_many_pixels\"] % (num_pixels),\n code=\"file_too_many_pixels\",\n )\n\n def to_python(self, data):\n \"\"\"\n Check that the file-upload field data contains a valid image (GIF, JPG,\n PNG, etc. -- whatever Willow supports). Overridden from ImageField to use\n Willow instead of Pillow as the image library in order to enable SVG support.\n \"\"\"\n f = FileField.to_python(self, data)\n if f is None:\n return None\n\n # We need to get a file object for Pillow. We might have a path or we might\n # have to read the data into memory.\n if hasattr(data, \"temporary_file_path\"):\n file = data.temporary_file_path()\n else:\n if hasattr(data, \"read\"):\n file = BytesIO(data.read())\n else:\n file = BytesIO(data[\"content\"])\n\n try:\n # Annotate the python representation of the FileField with the image\n # property so subclasses can reuse it for their own validation\n f.image = willow.Image.open(file)\n f.content_type = image_format_name_to_content_type(f.image.format_name)\n\n except Exception as exc:\n # Willow doesn't recognize it as an image.\n raise ValidationError(\n self.error_messages[\"invalid_image\"],\n code=\"invalid_image\",\n ) from exc\n\n if hasattr(f, \"seek\") and callable(f.seek):\n f.seek(0)\n\n if f is not None:\n self.check_image_file_size(f)\n self.check_image_file_format(f)\n self.check_image_pixel_size(f)\n\n return f\n\n\ndef image_format_name_to_content_type(image_format_name):\n \"\"\"\n Convert a Willow image format name to a content type.\n TODO: Replace once https://github.com/wagtail/Willow/pull/102 and\n a new Willow release is out\n \"\"\"\n if image_format_name == \"svg\":\n return \"image/svg+xml\"\n elif image_format_name == \"jpeg\":\n return \"image/jpeg\"\n elif image_format_name == \"png\":\n return \"image/png\"\n elif image_format_name == \"gif\":\n return \"image/gif\"\n elif image_format_name == \"bmp\":\n return \"image/bmp\"\n elif image_format_name == \"tiff\":\n return \"image/tiff\"\n elif image_format_name == \"webp\":\n return \"image/webp\"\n else:\n raise ValueError(\"Unknown image format name\")\n", "path": "wagtail/images/fields.py"}]} | 3,730 | 208 |
gh_patches_debug_24408 | rasdani/github-patches | git_diff | certbot__certbot-1160 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Standalone should verify ports for suported challenges only
I ran the following commands and both complained that nginx was already using port 80.
`./letsencrypt-auto --standalone --dvsni-port 63443 --server https://acme-v01.api.letsencrypt.org/directory auth`
`./letsencrypt-auto --standalone --dvsni-port 63443 --server https://acme-v01.api.letsencrypt.org/directory --standalone-supported-challenges dvsni auth`
I was under the impression that using `--dvsni-port` would force dvsni only.
I had to supply a fake port with `--simple-http-port 9999` with the second commad to get a certificate.
I'm using haproxy in the front to redirect *.acme.invalid to port 63443.
</issue>
<code>
[start of letsencrypt/plugins/standalone.py]
1 """Standalone Authenticator."""
2 import argparse
3 import collections
4 import logging
5 import random
6 import socket
7 import threading
8
9 import OpenSSL
10 import six
11 import zope.interface
12
13 from acme import challenges
14 from acme import crypto_util as acme_crypto_util
15 from acme import standalone as acme_standalone
16
17 from letsencrypt import achallenges
18 from letsencrypt import errors
19 from letsencrypt import interfaces
20
21 from letsencrypt.plugins import common
22 from letsencrypt.plugins import util
23
24 logger = logging.getLogger(__name__)
25
26
27 class ServerManager(object):
28 """Standalone servers manager.
29
30 Manager for `ACMEServer` and `ACMETLSServer` instances.
31
32 `certs` and `simple_http_resources` correspond to
33 `acme.crypto_util.SSLSocket.certs` and
34 `acme.crypto_util.SSLSocket.simple_http_resources` respectively. All
35 created servers share the same certificates and resources, so if
36 you're running both TLS and non-TLS instances, SimpleHTTP handlers
37 will serve the same URLs!
38
39 """
40 _Instance = collections.namedtuple("_Instance", "server thread")
41
42 def __init__(self, certs, simple_http_resources):
43 self._instances = {}
44 self.certs = certs
45 self.simple_http_resources = simple_http_resources
46
47 def run(self, port, challenge_type):
48 """Run ACME server on specified ``port``.
49
50 This method is idempotent, i.e. all calls with the same pair of
51 ``(port, challenge_type)`` will reuse the same server.
52
53 :param int port: Port to run the server on.
54 :param challenge_type: Subclass of `acme.challenges.Challenge`,
55 either `acme.challenge.SimpleHTTP` or `acme.challenges.DVSNI`.
56
57 :returns: Server instance.
58 :rtype: ACMEServerMixin
59
60 """
61 assert challenge_type in (challenges.DVSNI, challenges.SimpleHTTP)
62 if port in self._instances:
63 return self._instances[port].server
64
65 address = ("", port)
66 try:
67 if challenge_type is challenges.DVSNI:
68 server = acme_standalone.DVSNIServer(address, self.certs)
69 else: # challenges.SimpleHTTP
70 server = acme_standalone.SimpleHTTPServer(
71 address, self.simple_http_resources)
72 except socket.error as error:
73 raise errors.StandaloneBindError(error, port)
74
75 thread = threading.Thread(target=server.serve_forever2)
76 thread.start()
77
78 # if port == 0, then random free port on OS is taken
79 # pylint: disable=no-member
80 real_port = server.socket.getsockname()[1]
81 self._instances[real_port] = self._Instance(server, thread)
82 return server
83
84 def stop(self, port):
85 """Stop ACME server running on the specified ``port``.
86
87 :param int port:
88
89 """
90 instance = self._instances[port]
91 logger.debug("Stopping server at %s:%d...",
92 *instance.server.socket.getsockname()[:2])
93 instance.server.shutdown2()
94 instance.thread.join()
95 del self._instances[port]
96
97 def running(self):
98 """Return all running instances.
99
100 Once the server is stopped using `stop`, it will not be
101 returned.
102
103 :returns: Mapping from ``port`` to ``server``.
104 :rtype: tuple
105
106 """
107 return dict((port, instance.server) for port, instance
108 in six.iteritems(self._instances))
109
110
111 SUPPORTED_CHALLENGES = set([challenges.DVSNI, challenges.SimpleHTTP])
112
113
114 def supported_challenges_validator(data):
115 """Supported challenges validator for the `argparse`.
116
117 It should be passed as `type` argument to `add_argument`.
118
119 """
120 challs = data.split(",")
121 unrecognized = [name for name in challs
122 if name not in challenges.Challenge.TYPES]
123 if unrecognized:
124 raise argparse.ArgumentTypeError(
125 "Unrecognized challenges: {0}".format(", ".join(unrecognized)))
126
127 choices = set(chall.typ for chall in SUPPORTED_CHALLENGES)
128 if not set(challs).issubset(choices):
129 raise argparse.ArgumentTypeError(
130 "Plugin does not support the following (valid) "
131 "challenges: {0}".format(", ".join(set(challs) - choices)))
132
133 return data
134
135
136 class Authenticator(common.Plugin):
137 """Standalone Authenticator.
138
139 This authenticator creates its own ephemeral TCP listener on the
140 necessary port in order to respond to incoming DVSNI and SimpleHTTP
141 challenges from the certificate authority. Therefore, it does not
142 rely on any existing server program.
143
144 """
145 zope.interface.implements(interfaces.IAuthenticator)
146 zope.interface.classProvides(interfaces.IPluginFactory)
147
148 description = "Standalone Authenticator"
149
150 def __init__(self, *args, **kwargs):
151 super(Authenticator, self).__init__(*args, **kwargs)
152
153 # one self-signed key for all DVSNI and SimpleHTTP certificates
154 self.key = OpenSSL.crypto.PKey()
155 self.key.generate_key(OpenSSL.crypto.TYPE_RSA, bits=2048)
156 # TODO: generate only when the first SimpleHTTP challenge is solved
157 self.simple_http_cert = acme_crypto_util.gen_ss_cert(
158 self.key, domains=["temp server"])
159
160 self.served = collections.defaultdict(set)
161
162 # Stuff below is shared across threads (i.e. servers read
163 # values, main thread writes). Due to the nature of CPython's
164 # GIL, the operations are safe, c.f.
165 # https://docs.python.org/2/faq/library.html#what-kinds-of-global-value-mutation-are-thread-safe
166 self.certs = {}
167 self.simple_http_resources = set()
168
169 self.servers = ServerManager(self.certs, self.simple_http_resources)
170
171 @classmethod
172 def add_parser_arguments(cls, add):
173 add("supported-challenges", help="Supported challenges, "
174 "order preferences are randomly chosen.",
175 type=supported_challenges_validator, default=",".join(
176 sorted(chall.typ for chall in SUPPORTED_CHALLENGES)))
177
178 @property
179 def supported_challenges(self):
180 """Challenges supported by this plugin."""
181 return set(challenges.Challenge.TYPES[name] for name in
182 self.conf("supported-challenges").split(","))
183
184 def more_info(self): # pylint: disable=missing-docstring
185 return self.__doc__
186
187 def prepare(self): # pylint: disable=missing-docstring
188 pass
189
190 def get_chall_pref(self, domain):
191 # pylint: disable=unused-argument,missing-docstring
192 chall_pref = list(self.supported_challenges)
193 random.shuffle(chall_pref) # 50% for each challenge
194 return chall_pref
195
196 def perform(self, achalls): # pylint: disable=missing-docstring
197 if any(util.already_listening(port) for port in
198 (self.config.dvsni_port, self.config.simple_http_port)):
199 raise errors.MisconfigurationError(
200 "At least one of the (possibly) required ports is "
201 "already taken.")
202
203 try:
204 return self.perform2(achalls)
205 except errors.StandaloneBindError as error:
206 display = zope.component.getUtility(interfaces.IDisplay)
207
208 if error.socket_error.errno == socket.errno.EACCES:
209 display.notification(
210 "Could not bind TCP port {0} because you don't have "
211 "the appropriate permissions (for example, you "
212 "aren't running this program as "
213 "root).".format(error.port))
214 elif error.socket_error.errno == socket.errno.EADDRINUSE:
215 display.notification(
216 "Could not bind TCP port {0} because it is already in "
217 "use by another process on this system (such as a web "
218 "server). Please stop the program in question and then "
219 "try again.".format(error.port))
220 else:
221 raise # XXX: How to handle unknown errors in binding?
222
223 def perform2(self, achalls):
224 """Perform achallenges without IDisplay interaction."""
225 responses = []
226
227 for achall in achalls:
228 if isinstance(achall, achallenges.SimpleHTTP):
229 server = self.servers.run(
230 self.config.simple_http_port, challenges.SimpleHTTP)
231 response, validation = achall.gen_response_and_validation(
232 tls=False)
233 self.simple_http_resources.add(
234 acme_standalone.SimpleHTTPRequestHandler.SimpleHTTPResource(
235 chall=achall.chall, response=response,
236 validation=validation))
237 cert = self.simple_http_cert
238 domain = achall.domain
239 else: # DVSNI
240 server = self.servers.run(self.config.dvsni_port, challenges.DVSNI)
241 response, cert, _ = achall.gen_cert_and_response(self.key)
242 domain = response.z_domain
243 self.certs[domain] = (self.key, cert)
244 self.served[server].add(achall)
245 responses.append(response)
246
247 return responses
248
249 def cleanup(self, achalls): # pylint: disable=missing-docstring
250 # reduce self.served and close servers if none challenges are served
251 for server, server_achalls in self.served.items():
252 for achall in achalls:
253 if achall in server_achalls:
254 server_achalls.remove(achall)
255 for port, server in six.iteritems(self.servers.running()):
256 if not self.served[server]:
257 self.servers.stop(port)
258
[end of letsencrypt/plugins/standalone.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/letsencrypt/plugins/standalone.py b/letsencrypt/plugins/standalone.py
--- a/letsencrypt/plugins/standalone.py
+++ b/letsencrypt/plugins/standalone.py
@@ -181,6 +181,15 @@
return set(challenges.Challenge.TYPES[name] for name in
self.conf("supported-challenges").split(","))
+ @property
+ def _necessary_ports(self):
+ necessary_ports = set()
+ if challenges.SimpleHTTP in self.supported_challenges:
+ necessary_ports.add(self.config.simple_http_port)
+ if challenges.DVSNI in self.supported_challenges:
+ necessary_ports.add(self.config.dvsni_port)
+ return necessary_ports
+
def more_info(self): # pylint: disable=missing-docstring
return self.__doc__
@@ -194,8 +203,7 @@
return chall_pref
def perform(self, achalls): # pylint: disable=missing-docstring
- if any(util.already_listening(port) for port in
- (self.config.dvsni_port, self.config.simple_http_port)):
+ if any(util.already_listening(port) for port in self._necessary_ports):
raise errors.MisconfigurationError(
"At least one of the (possibly) required ports is "
"already taken.")
| {"golden_diff": "diff --git a/letsencrypt/plugins/standalone.py b/letsencrypt/plugins/standalone.py\n--- a/letsencrypt/plugins/standalone.py\n+++ b/letsencrypt/plugins/standalone.py\n@@ -181,6 +181,15 @@\n return set(challenges.Challenge.TYPES[name] for name in\n self.conf(\"supported-challenges\").split(\",\"))\n \n+ @property\n+ def _necessary_ports(self):\n+ necessary_ports = set()\n+ if challenges.SimpleHTTP in self.supported_challenges:\n+ necessary_ports.add(self.config.simple_http_port)\n+ if challenges.DVSNI in self.supported_challenges:\n+ necessary_ports.add(self.config.dvsni_port)\n+ return necessary_ports\n+\n def more_info(self): # pylint: disable=missing-docstring\n return self.__doc__\n \n@@ -194,8 +203,7 @@\n return chall_pref\n \n def perform(self, achalls): # pylint: disable=missing-docstring\n- if any(util.already_listening(port) for port in\n- (self.config.dvsni_port, self.config.simple_http_port)):\n+ if any(util.already_listening(port) for port in self._necessary_ports):\n raise errors.MisconfigurationError(\n \"At least one of the (possibly) required ports is \"\n \"already taken.\")\n", "issue": "Standalone should verify ports for suported challenges only\nI ran the following commands and both complained that nginx was already using port 80.\n`./letsencrypt-auto --standalone --dvsni-port 63443 --server https://acme-v01.api.letsencrypt.org/directory auth`\n`./letsencrypt-auto --standalone --dvsni-port 63443 --server https://acme-v01.api.letsencrypt.org/directory --standalone-supported-challenges dvsni auth`\n\nI was under the impression that using `--dvsni-port` would force dvsni only.\n\nI had to supply a fake port with `--simple-http-port 9999` with the second commad to get a certificate.\n\nI'm using haproxy in the front to redirect *.acme.invalid to port 63443.\n\n", "before_files": [{"content": "\"\"\"Standalone Authenticator.\"\"\"\nimport argparse\nimport collections\nimport logging\nimport random\nimport socket\nimport threading\n\nimport OpenSSL\nimport six\nimport zope.interface\n\nfrom acme import challenges\nfrom acme import crypto_util as acme_crypto_util\nfrom acme import standalone as acme_standalone\n\nfrom letsencrypt import achallenges\nfrom letsencrypt import errors\nfrom letsencrypt import interfaces\n\nfrom letsencrypt.plugins import common\nfrom letsencrypt.plugins import util\n\nlogger = logging.getLogger(__name__)\n\n\nclass ServerManager(object):\n \"\"\"Standalone servers manager.\n\n Manager for `ACMEServer` and `ACMETLSServer` instances.\n\n `certs` and `simple_http_resources` correspond to\n `acme.crypto_util.SSLSocket.certs` and\n `acme.crypto_util.SSLSocket.simple_http_resources` respectively. All\n created servers share the same certificates and resources, so if\n you're running both TLS and non-TLS instances, SimpleHTTP handlers\n will serve the same URLs!\n\n \"\"\"\n _Instance = collections.namedtuple(\"_Instance\", \"server thread\")\n\n def __init__(self, certs, simple_http_resources):\n self._instances = {}\n self.certs = certs\n self.simple_http_resources = simple_http_resources\n\n def run(self, port, challenge_type):\n \"\"\"Run ACME server on specified ``port``.\n\n This method is idempotent, i.e. all calls with the same pair of\n ``(port, challenge_type)`` will reuse the same server.\n\n :param int port: Port to run the server on.\n :param challenge_type: Subclass of `acme.challenges.Challenge`,\n either `acme.challenge.SimpleHTTP` or `acme.challenges.DVSNI`.\n\n :returns: Server instance.\n :rtype: ACMEServerMixin\n\n \"\"\"\n assert challenge_type in (challenges.DVSNI, challenges.SimpleHTTP)\n if port in self._instances:\n return self._instances[port].server\n\n address = (\"\", port)\n try:\n if challenge_type is challenges.DVSNI:\n server = acme_standalone.DVSNIServer(address, self.certs)\n else: # challenges.SimpleHTTP\n server = acme_standalone.SimpleHTTPServer(\n address, self.simple_http_resources)\n except socket.error as error:\n raise errors.StandaloneBindError(error, port)\n\n thread = threading.Thread(target=server.serve_forever2)\n thread.start()\n\n # if port == 0, then random free port on OS is taken\n # pylint: disable=no-member\n real_port = server.socket.getsockname()[1]\n self._instances[real_port] = self._Instance(server, thread)\n return server\n\n def stop(self, port):\n \"\"\"Stop ACME server running on the specified ``port``.\n\n :param int port:\n\n \"\"\"\n instance = self._instances[port]\n logger.debug(\"Stopping server at %s:%d...\",\n *instance.server.socket.getsockname()[:2])\n instance.server.shutdown2()\n instance.thread.join()\n del self._instances[port]\n\n def running(self):\n \"\"\"Return all running instances.\n\n Once the server is stopped using `stop`, it will not be\n returned.\n\n :returns: Mapping from ``port`` to ``server``.\n :rtype: tuple\n\n \"\"\"\n return dict((port, instance.server) for port, instance\n in six.iteritems(self._instances))\n\n\nSUPPORTED_CHALLENGES = set([challenges.DVSNI, challenges.SimpleHTTP])\n\n\ndef supported_challenges_validator(data):\n \"\"\"Supported challenges validator for the `argparse`.\n\n It should be passed as `type` argument to `add_argument`.\n\n \"\"\"\n challs = data.split(\",\")\n unrecognized = [name for name in challs\n if name not in challenges.Challenge.TYPES]\n if unrecognized:\n raise argparse.ArgumentTypeError(\n \"Unrecognized challenges: {0}\".format(\", \".join(unrecognized)))\n\n choices = set(chall.typ for chall in SUPPORTED_CHALLENGES)\n if not set(challs).issubset(choices):\n raise argparse.ArgumentTypeError(\n \"Plugin does not support the following (valid) \"\n \"challenges: {0}\".format(\", \".join(set(challs) - choices)))\n\n return data\n\n\nclass Authenticator(common.Plugin):\n \"\"\"Standalone Authenticator.\n\n This authenticator creates its own ephemeral TCP listener on the\n necessary port in order to respond to incoming DVSNI and SimpleHTTP\n challenges from the certificate authority. Therefore, it does not\n rely on any existing server program.\n\n \"\"\"\n zope.interface.implements(interfaces.IAuthenticator)\n zope.interface.classProvides(interfaces.IPluginFactory)\n\n description = \"Standalone Authenticator\"\n\n def __init__(self, *args, **kwargs):\n super(Authenticator, self).__init__(*args, **kwargs)\n\n # one self-signed key for all DVSNI and SimpleHTTP certificates\n self.key = OpenSSL.crypto.PKey()\n self.key.generate_key(OpenSSL.crypto.TYPE_RSA, bits=2048)\n # TODO: generate only when the first SimpleHTTP challenge is solved\n self.simple_http_cert = acme_crypto_util.gen_ss_cert(\n self.key, domains=[\"temp server\"])\n\n self.served = collections.defaultdict(set)\n\n # Stuff below is shared across threads (i.e. servers read\n # values, main thread writes). Due to the nature of CPython's\n # GIL, the operations are safe, c.f.\n # https://docs.python.org/2/faq/library.html#what-kinds-of-global-value-mutation-are-thread-safe\n self.certs = {}\n self.simple_http_resources = set()\n\n self.servers = ServerManager(self.certs, self.simple_http_resources)\n\n @classmethod\n def add_parser_arguments(cls, add):\n add(\"supported-challenges\", help=\"Supported challenges, \"\n \"order preferences are randomly chosen.\",\n type=supported_challenges_validator, default=\",\".join(\n sorted(chall.typ for chall in SUPPORTED_CHALLENGES)))\n\n @property\n def supported_challenges(self):\n \"\"\"Challenges supported by this plugin.\"\"\"\n return set(challenges.Challenge.TYPES[name] for name in\n self.conf(\"supported-challenges\").split(\",\"))\n\n def more_info(self): # pylint: disable=missing-docstring\n return self.__doc__\n\n def prepare(self): # pylint: disable=missing-docstring\n pass\n\n def get_chall_pref(self, domain):\n # pylint: disable=unused-argument,missing-docstring\n chall_pref = list(self.supported_challenges)\n random.shuffle(chall_pref) # 50% for each challenge\n return chall_pref\n\n def perform(self, achalls): # pylint: disable=missing-docstring\n if any(util.already_listening(port) for port in\n (self.config.dvsni_port, self.config.simple_http_port)):\n raise errors.MisconfigurationError(\n \"At least one of the (possibly) required ports is \"\n \"already taken.\")\n\n try:\n return self.perform2(achalls)\n except errors.StandaloneBindError as error:\n display = zope.component.getUtility(interfaces.IDisplay)\n\n if error.socket_error.errno == socket.errno.EACCES:\n display.notification(\n \"Could not bind TCP port {0} because you don't have \"\n \"the appropriate permissions (for example, you \"\n \"aren't running this program as \"\n \"root).\".format(error.port))\n elif error.socket_error.errno == socket.errno.EADDRINUSE:\n display.notification(\n \"Could not bind TCP port {0} because it is already in \"\n \"use by another process on this system (such as a web \"\n \"server). Please stop the program in question and then \"\n \"try again.\".format(error.port))\n else:\n raise # XXX: How to handle unknown errors in binding?\n\n def perform2(self, achalls):\n \"\"\"Perform achallenges without IDisplay interaction.\"\"\"\n responses = []\n\n for achall in achalls:\n if isinstance(achall, achallenges.SimpleHTTP):\n server = self.servers.run(\n self.config.simple_http_port, challenges.SimpleHTTP)\n response, validation = achall.gen_response_and_validation(\n tls=False)\n self.simple_http_resources.add(\n acme_standalone.SimpleHTTPRequestHandler.SimpleHTTPResource(\n chall=achall.chall, response=response,\n validation=validation))\n cert = self.simple_http_cert\n domain = achall.domain\n else: # DVSNI\n server = self.servers.run(self.config.dvsni_port, challenges.DVSNI)\n response, cert, _ = achall.gen_cert_and_response(self.key)\n domain = response.z_domain\n self.certs[domain] = (self.key, cert)\n self.served[server].add(achall)\n responses.append(response)\n\n return responses\n\n def cleanup(self, achalls): # pylint: disable=missing-docstring\n # reduce self.served and close servers if none challenges are served\n for server, server_achalls in self.served.items():\n for achall in achalls:\n if achall in server_achalls:\n server_achalls.remove(achall)\n for port, server in six.iteritems(self.servers.running()):\n if not self.served[server]:\n self.servers.stop(port)\n", "path": "letsencrypt/plugins/standalone.py"}]} | 3,462 | 300 |
gh_patches_debug_31086 | rasdani/github-patches | git_diff | activeloopai__deeplake-242 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Caching fails on windows with s3://
### Describe the issue
Caching path fails on windows
```python3
import hub
ds = hub.load("eurosat/eurosat-rgb") # is not loaded
```
Error shown
```
OSError: [WinError 123] The filename, directory name, or volume label syntax is incorrect: 'C:\\Users\\Folder/.activeloop/cache/s3:'
```
Likely caused by converting Linux style paths to windows.
</issue>
<code>
[start of hub/store/store.py]
1 import posixpath
2 import shutil
3 from hub.store.cache import Cache
4 from hub.store.lru_cache import LRUCache
5
6 from hub.client.hub_control import HubControlClient
7 import configparser
8 from typing import MutableMapping, Tuple
9
10 import fsspec
11 import gcsfs
12 import zarr
13 from hub.store.azure_fs import AzureBlobFileSystem
14 import os
15 import re
16
17
18 def _connect(tag):
19 """Connects to the backend and receives credentials"""
20
21 creds = HubControlClient().get_config()
22 dataset = HubControlClient().get_dataset_path(tag)
23
24 # If dataset is in DB then return the path
25 # Otherwise construct the path from the tag
26 if dataset and "path" in dataset:
27 path = dataset["path"]
28 else:
29 sub_tags = tag.split("/")
30 # Get repository path from the cred location
31 path = "/".join(creds["bucket"].split("/")[:-1])
32 path = f"{path}/{sub_tags[0]}/{sub_tags[-1]}"
33 return path, creds
34
35
36 def get_fs_and_path(url: str, token=None) -> Tuple[fsspec.AbstractFileSystem, str]:
37 if url.startswith("s3://"):
38 token = token or dict()
39 token = read_aws_creds(token) if isinstance(token, str) else token
40 return (
41 fsspec.filesystem(
42 "s3",
43 key=token.get("aws_access_key_id"),
44 secret=token.get("aws_secret_access_key"),
45 token=token.get("aws_session_token"),
46 ),
47 url[5:],
48 )
49 elif url.startswith("gcs://"):
50 return gcsfs.GCSFileSystem(token=token), url[6:]
51 elif url.find("blob.core.windows.net/") != -1:
52 account_name = url.split(".")[0]
53 account_name = account_name[8:] if url.startswith("https://") else account_name
54 return (
55 AzureBlobFileSystem(
56 account_name=account_name,
57 account_key=token.get("account_key"),
58 ),
59 url[url.find("blob.core.windows.net/") + 22 :],
60 )
61 elif (
62 url.startswith("../")
63 or url.startswith("./")
64 or url.startswith("/")
65 or url.startswith("~/")
66 ):
67 return fsspec.filesystem("file"), url
68 elif (
69 # windows local file system
70 re.search("^[A-Za-z]:", url)
71 ):
72 return fsspec.filesystem("file"), url
73 else:
74 # TOOD check if url is username/dataset:version
75 url, creds = _connect(url)
76 fs = fsspec.filesystem(
77 "s3",
78 key=creds["access_key"],
79 secret=creds["secret_key"],
80 token=creds["session_token"],
81 client_kwargs={
82 "endpoint_url": creds["endpoint"],
83 "region_name": creds["region"],
84 },
85 )
86 return (fs, url)
87
88
89 def read_aws_creds(filepath: str):
90 parser = configparser.ConfigParser()
91 parser.read(filepath)
92 return {section: dict(parser.items(section)) for section in parser.sections()}
93
94
95 def _get_storage_map(fs, path):
96 return StorageMapWrapperWithCommit(fs.get_mapper(path, check=False, create=False))
97
98
99 def get_storage_map(fs, path, memcache=2 ** 26, lock=True, storage_cache=2 ** 28):
100 store = _get_storage_map(fs, path)
101 cache_path = posixpath.expanduser(posixpath.join("~/.activeloop/cache/", path))
102 if storage_cache and storage_cache > 0:
103 os.makedirs(cache_path, exist_ok=True)
104 store = LRUCache(
105 zarr.LMDBStore(cache_path, buffers=True, lock=lock), store, storage_cache
106 )
107 if memcache and memcache > 0:
108 store = LRUCache(zarr.MemoryStore(), store, memcache)
109 return store
110
111
112 class StorageMapWrapperWithCommit(MutableMapping):
113 def __init__(self, map):
114 self._map = map
115 self.root = self._map.root
116
117 def __getitem__(self, slice_):
118 return self._map[slice_]
119
120 def __setitem__(self, slice_, value):
121 self._map[slice_] = value
122
123 def __delitem__(self, slice_):
124 del self._map[slice_]
125
126 def __len__(self):
127 return len(self._map)
128
129 def __iter__(self):
130 yield from self._map
131
132 def flush(self):
133 pass
134
135 def commit(self):
136 """ Deprecated alias to flush()"""
137 self.flush()
138
139 def close(self):
140 pass
141
142 def __enter__(self):
143 return self
144
145 def __exit__(self, exc_type, exc_value, exc_traceback):
146 self.close()
147
[end of hub/store/store.py]
[start of hub/store/lru_cache.py]
1 from collections import OrderedDict
2 from collections.abc import MutableMapping
3
4 # from multiprocessing import Lock
5
6 import fcntl
7 import hashlib
8 import uuid
9
10
11 class SystemMutex:
12 def __init__(self, name=str(uuid.uuid4())):
13 self.name = name
14 self._lockid = hashlib.sha1(self.name.encode("utf8")).hexdigest()
15
16 def __enter__(self):
17 self.fp = open(f"/tmp/.lock-{self._lockid}.lck", "wb")
18 fcntl.flock(self.fp.fileno(), fcntl.LOCK_EX)
19
20 def __exit__(self, _type, value, tb):
21 fcntl.flock(self.fp.fileno(), fcntl.LOCK_UN)
22 self.fp.close()
23
24
25 class DummyLock:
26 def __init__(self):
27 pass
28
29 def __enter__(self):
30 return self
31
32 def __exit__(self, *args):
33 pass
34
35
36 Lock = DummyLock
37
38
39 class LRUCache(MutableMapping):
40 def __init__(
41 self,
42 cache_storage: MutableMapping,
43 actual_storage: MutableMapping,
44 max_size,
45 ):
46 """Creates LRU cache using cache_storage and actual_storage containers
47 max_size -> maximum cache size that is allowed
48 """
49 self._dirty = set()
50 self._mutex = Lock()
51 self._max_size = max_size
52 self._cache_storage = cache_storage
53 self._actual_storage = actual_storage
54 self._total_cached = 0
55 self._cached_items = OrderedDict()
56 # assert len(self._cache_storage) == 0, "Initially cache storage should be empty"
57
58 @property
59 def cache_storage(self):
60 """Storage which is used for caching
61 Returns MutableMapping
62 """
63 return self._cache_storage
64
65 @property
66 def actual_storage(self):
67 """Storage which is used for actual storing (not caching)
68 Returns MutableMapping
69 """
70 return self._actual_storage
71
72 def __enter__(self):
73 return self
74
75 def __exit__(self, *args):
76 self.close()
77
78 def _flush_dirty(self):
79 for item in self._dirty:
80 self._actual_storage[item] = self._cache_storage[item]
81 self._dirty.clear()
82
83 def flush(self):
84 self._flush_dirty()
85 if hasattr(self._cache_storage, "flush"):
86 self._cache_storage.flush()
87 if hasattr(self._actual_storage, "flush"):
88 self._actual_storage.flush()
89
90 def close(self):
91 self._flush_dirty()
92 if hasattr(self._cache_storage, "close"):
93 self._cache_storage.close()
94 if hasattr(self._actual_storage, "close"):
95 self._actual_storage.close()
96
97 def commit(self):
98 self.close()
99
100 def __getitem__(self, key):
101 """ Gets item and puts it in the cache if not there """
102 with self._mutex:
103 if key in self._cached_items:
104 self._cached_items.move_to_end(key)
105 return self._cache_storage[key]
106 else:
107 result = self._actual_storage[key]
108 self._free_memory(len(result))
109 self._append_cache(key, result)
110 return result
111
112 def __setitem__(self, key, value):
113 """ Sets item and puts it in the cache if not there"""
114 with self._mutex:
115 if key in self._cached_items:
116 self._total_cached -= self._cached_items.pop(key)
117 self._free_memory(len(value))
118 self._append_cache(key, value)
119 if key not in self._dirty:
120 self._dirty.add(key)
121
122 def __delitem__(self, key):
123 deleted_from_cache = False
124 with self._mutex:
125 if key in self._cached_items:
126 self._total_cached -= self._cached_items.pop(key)
127 del self._cache_storage[key]
128 self._dirty.discard(key)
129 deleted_from_cache = True
130 try:
131 del self._actual_storage[key]
132 except KeyError:
133 if not deleted_from_cache:
134 raise
135
136 def __len__(self):
137 return len(
138 self.actual_storage
139 ) # TODO: In future might need to fix this to return proper len
140
141 def __iter__(self):
142 cached_keys = set(self._dirty)
143 for i in self.actual_storage:
144 cached_keys.discard(i)
145 yield i
146 yield from sorted(cached_keys)
147
148 def _free_memory(self, extra_size):
149 while (
150 self._total_cached > 0 and extra_size + self._total_cached > self._max_size
151 ):
152 item, itemsize = self._cached_items.popitem(last=False)
153 if item in self._dirty:
154 self._actual_storage[item] = self._cache_storage[item]
155 self._dirty.discard(item)
156 del self._cache_storage[item]
157 self._total_cached -= itemsize
158
159 def _append_cache(self, key, value):
160 self._total_cached += len(value)
161 self._cached_items[key] = len(value)
162 self._cache_storage[key] = value
163
[end of hub/store/lru_cache.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/hub/store/lru_cache.py b/hub/store/lru_cache.py
--- a/hub/store/lru_cache.py
+++ b/hub/store/lru_cache.py
@@ -3,25 +3,10 @@
# from multiprocessing import Lock
-import fcntl
import hashlib
import uuid
-class SystemMutex:
- def __init__(self, name=str(uuid.uuid4())):
- self.name = name
- self._lockid = hashlib.sha1(self.name.encode("utf8")).hexdigest()
-
- def __enter__(self):
- self.fp = open(f"/tmp/.lock-{self._lockid}.lck", "wb")
- fcntl.flock(self.fp.fileno(), fcntl.LOCK_EX)
-
- def __exit__(self, _type, value, tb):
- fcntl.flock(self.fp.fileno(), fcntl.LOCK_UN)
- self.fp.close()
-
-
class DummyLock:
def __init__(self):
pass
diff --git a/hub/store/store.py b/hub/store/store.py
--- a/hub/store/store.py
+++ b/hub/store/store.py
@@ -96,9 +96,32 @@
return StorageMapWrapperWithCommit(fs.get_mapper(path, check=False, create=False))
+def get_cache_path(path, cache_folder="~/.activeloop/cache/"):
+ if (
+ path.startswith("s3://")
+ or path.startswith("gcs://")
+ ):
+ path = '//'.join(path.split("//")[1:])
+ elif (
+ path.startswith("../")
+ or path.startswith("./")
+ or path.startswith("/")
+ or path.startswith("~/")
+ ):
+ path = "/".join(path.split("/")[1:])
+ elif path.find("://") != -1:
+ path = path.split("://")[-1]
+ elif path.find(":\\") != -1:
+ path = path.split(":\\")[-1]
+ else:
+ # path is username/dataset or username/dataset:version
+ path = path.replace(':', '/')
+ return os.path.expanduser(posixpath.join(cache_folder, path))
+
+
def get_storage_map(fs, path, memcache=2 ** 26, lock=True, storage_cache=2 ** 28):
store = _get_storage_map(fs, path)
- cache_path = posixpath.expanduser(posixpath.join("~/.activeloop/cache/", path))
+ cache_path = get_cache_path(path)
if storage_cache and storage_cache > 0:
os.makedirs(cache_path, exist_ok=True)
store = LRUCache(
| {"golden_diff": "diff --git a/hub/store/lru_cache.py b/hub/store/lru_cache.py\n--- a/hub/store/lru_cache.py\n+++ b/hub/store/lru_cache.py\n@@ -3,25 +3,10 @@\n \n # from multiprocessing import Lock\n \n-import fcntl\n import hashlib\n import uuid\n \n \n-class SystemMutex:\n- def __init__(self, name=str(uuid.uuid4())):\n- self.name = name\n- self._lockid = hashlib.sha1(self.name.encode(\"utf8\")).hexdigest()\n-\n- def __enter__(self):\n- self.fp = open(f\"/tmp/.lock-{self._lockid}.lck\", \"wb\")\n- fcntl.flock(self.fp.fileno(), fcntl.LOCK_EX)\n-\n- def __exit__(self, _type, value, tb):\n- fcntl.flock(self.fp.fileno(), fcntl.LOCK_UN)\n- self.fp.close()\n-\n-\n class DummyLock:\n def __init__(self):\n pass\ndiff --git a/hub/store/store.py b/hub/store/store.py\n--- a/hub/store/store.py\n+++ b/hub/store/store.py\n@@ -96,9 +96,32 @@\n return StorageMapWrapperWithCommit(fs.get_mapper(path, check=False, create=False))\n \n \n+def get_cache_path(path, cache_folder=\"~/.activeloop/cache/\"):\n+ if (\n+ path.startswith(\"s3://\")\n+ or path.startswith(\"gcs://\")\n+ ):\n+ path = '//'.join(path.split(\"//\")[1:])\n+ elif (\n+ path.startswith(\"../\")\n+ or path.startswith(\"./\")\n+ or path.startswith(\"/\")\n+ or path.startswith(\"~/\")\n+ ):\n+ path = \"/\".join(path.split(\"/\")[1:])\n+ elif path.find(\"://\") != -1:\n+ path = path.split(\"://\")[-1]\n+ elif path.find(\":\\\\\") != -1:\n+ path = path.split(\":\\\\\")[-1]\n+ else:\n+ # path is username/dataset or username/dataset:version\n+ path = path.replace(':', '/')\n+ return os.path.expanduser(posixpath.join(cache_folder, path))\n+\n+\n def get_storage_map(fs, path, memcache=2 ** 26, lock=True, storage_cache=2 ** 28):\n store = _get_storage_map(fs, path)\n- cache_path = posixpath.expanduser(posixpath.join(\"~/.activeloop/cache/\", path))\n+ cache_path = get_cache_path(path)\n if storage_cache and storage_cache > 0:\n os.makedirs(cache_path, exist_ok=True)\n store = LRUCache(\n", "issue": "Caching fails on windows with s3://\n### Describe the issue\r\n\r\nCaching path fails on windows\r\n\r\n```python3\r\nimport hub\r\nds = hub.load(\"eurosat/eurosat-rgb\") # is not loaded\r\n```\r\n\r\nError shown\r\n```\r\nOSError: [WinError 123] The filename, directory name, or volume label syntax is incorrect: 'C:\\\\Users\\\\Folder/.activeloop/cache/s3:'\r\n```\r\n\r\nLikely caused by converting Linux style paths to windows.\n", "before_files": [{"content": "import posixpath\nimport shutil\nfrom hub.store.cache import Cache\nfrom hub.store.lru_cache import LRUCache\n\nfrom hub.client.hub_control import HubControlClient\nimport configparser\nfrom typing import MutableMapping, Tuple\n\nimport fsspec\nimport gcsfs\nimport zarr\nfrom hub.store.azure_fs import AzureBlobFileSystem\nimport os\nimport re\n\n\ndef _connect(tag):\n \"\"\"Connects to the backend and receives credentials\"\"\"\n\n creds = HubControlClient().get_config()\n dataset = HubControlClient().get_dataset_path(tag)\n\n # If dataset is in DB then return the path\n # Otherwise construct the path from the tag\n if dataset and \"path\" in dataset:\n path = dataset[\"path\"]\n else:\n sub_tags = tag.split(\"/\")\n # Get repository path from the cred location\n path = \"/\".join(creds[\"bucket\"].split(\"/\")[:-1])\n path = f\"{path}/{sub_tags[0]}/{sub_tags[-1]}\"\n return path, creds\n\n\ndef get_fs_and_path(url: str, token=None) -> Tuple[fsspec.AbstractFileSystem, str]:\n if url.startswith(\"s3://\"):\n token = token or dict()\n token = read_aws_creds(token) if isinstance(token, str) else token\n return (\n fsspec.filesystem(\n \"s3\",\n key=token.get(\"aws_access_key_id\"),\n secret=token.get(\"aws_secret_access_key\"),\n token=token.get(\"aws_session_token\"),\n ),\n url[5:],\n )\n elif url.startswith(\"gcs://\"):\n return gcsfs.GCSFileSystem(token=token), url[6:]\n elif url.find(\"blob.core.windows.net/\") != -1:\n account_name = url.split(\".\")[0]\n account_name = account_name[8:] if url.startswith(\"https://\") else account_name\n return (\n AzureBlobFileSystem(\n account_name=account_name,\n account_key=token.get(\"account_key\"),\n ),\n url[url.find(\"blob.core.windows.net/\") + 22 :],\n )\n elif (\n url.startswith(\"../\")\n or url.startswith(\"./\")\n or url.startswith(\"/\")\n or url.startswith(\"~/\")\n ):\n return fsspec.filesystem(\"file\"), url\n elif (\n # windows local file system\n re.search(\"^[A-Za-z]:\", url)\n ):\n return fsspec.filesystem(\"file\"), url\n else:\n # TOOD check if url is username/dataset:version\n url, creds = _connect(url)\n fs = fsspec.filesystem(\n \"s3\",\n key=creds[\"access_key\"],\n secret=creds[\"secret_key\"],\n token=creds[\"session_token\"],\n client_kwargs={\n \"endpoint_url\": creds[\"endpoint\"],\n \"region_name\": creds[\"region\"],\n },\n )\n return (fs, url)\n\n\ndef read_aws_creds(filepath: str):\n parser = configparser.ConfigParser()\n parser.read(filepath)\n return {section: dict(parser.items(section)) for section in parser.sections()}\n\n\ndef _get_storage_map(fs, path):\n return StorageMapWrapperWithCommit(fs.get_mapper(path, check=False, create=False))\n\n\ndef get_storage_map(fs, path, memcache=2 ** 26, lock=True, storage_cache=2 ** 28):\n store = _get_storage_map(fs, path)\n cache_path = posixpath.expanduser(posixpath.join(\"~/.activeloop/cache/\", path))\n if storage_cache and storage_cache > 0:\n os.makedirs(cache_path, exist_ok=True)\n store = LRUCache(\n zarr.LMDBStore(cache_path, buffers=True, lock=lock), store, storage_cache\n )\n if memcache and memcache > 0:\n store = LRUCache(zarr.MemoryStore(), store, memcache)\n return store\n\n\nclass StorageMapWrapperWithCommit(MutableMapping):\n def __init__(self, map):\n self._map = map\n self.root = self._map.root\n\n def __getitem__(self, slice_):\n return self._map[slice_]\n\n def __setitem__(self, slice_, value):\n self._map[slice_] = value\n\n def __delitem__(self, slice_):\n del self._map[slice_]\n\n def __len__(self):\n return len(self._map)\n\n def __iter__(self):\n yield from self._map\n\n def flush(self):\n pass\n\n def commit(self):\n \"\"\" Deprecated alias to flush()\"\"\"\n self.flush()\n\n def close(self):\n pass\n\n def __enter__(self):\n return self\n\n def __exit__(self, exc_type, exc_value, exc_traceback):\n self.close()\n", "path": "hub/store/store.py"}, {"content": "from collections import OrderedDict\nfrom collections.abc import MutableMapping\n\n# from multiprocessing import Lock\n\nimport fcntl\nimport hashlib\nimport uuid\n\n\nclass SystemMutex:\n def __init__(self, name=str(uuid.uuid4())):\n self.name = name\n self._lockid = hashlib.sha1(self.name.encode(\"utf8\")).hexdigest()\n\n def __enter__(self):\n self.fp = open(f\"/tmp/.lock-{self._lockid}.lck\", \"wb\")\n fcntl.flock(self.fp.fileno(), fcntl.LOCK_EX)\n\n def __exit__(self, _type, value, tb):\n fcntl.flock(self.fp.fileno(), fcntl.LOCK_UN)\n self.fp.close()\n\n\nclass DummyLock:\n def __init__(self):\n pass\n\n def __enter__(self):\n return self\n\n def __exit__(self, *args):\n pass\n\n\nLock = DummyLock\n\n\nclass LRUCache(MutableMapping):\n def __init__(\n self,\n cache_storage: MutableMapping,\n actual_storage: MutableMapping,\n max_size,\n ):\n \"\"\"Creates LRU cache using cache_storage and actual_storage containers\n max_size -> maximum cache size that is allowed\n \"\"\"\n self._dirty = set()\n self._mutex = Lock()\n self._max_size = max_size\n self._cache_storage = cache_storage\n self._actual_storage = actual_storage\n self._total_cached = 0\n self._cached_items = OrderedDict()\n # assert len(self._cache_storage) == 0, \"Initially cache storage should be empty\"\n\n @property\n def cache_storage(self):\n \"\"\"Storage which is used for caching\n Returns MutableMapping\n \"\"\"\n return self._cache_storage\n\n @property\n def actual_storage(self):\n \"\"\"Storage which is used for actual storing (not caching)\n Returns MutableMapping\n \"\"\"\n return self._actual_storage\n\n def __enter__(self):\n return self\n\n def __exit__(self, *args):\n self.close()\n\n def _flush_dirty(self):\n for item in self._dirty:\n self._actual_storage[item] = self._cache_storage[item]\n self._dirty.clear()\n\n def flush(self):\n self._flush_dirty()\n if hasattr(self._cache_storage, \"flush\"):\n self._cache_storage.flush()\n if hasattr(self._actual_storage, \"flush\"):\n self._actual_storage.flush()\n\n def close(self):\n self._flush_dirty()\n if hasattr(self._cache_storage, \"close\"):\n self._cache_storage.close()\n if hasattr(self._actual_storage, \"close\"):\n self._actual_storage.close()\n\n def commit(self):\n self.close()\n\n def __getitem__(self, key):\n \"\"\" Gets item and puts it in the cache if not there \"\"\"\n with self._mutex:\n if key in self._cached_items:\n self._cached_items.move_to_end(key)\n return self._cache_storage[key]\n else:\n result = self._actual_storage[key]\n self._free_memory(len(result))\n self._append_cache(key, result)\n return result\n\n def __setitem__(self, key, value):\n \"\"\" Sets item and puts it in the cache if not there\"\"\"\n with self._mutex:\n if key in self._cached_items:\n self._total_cached -= self._cached_items.pop(key)\n self._free_memory(len(value))\n self._append_cache(key, value)\n if key not in self._dirty:\n self._dirty.add(key)\n\n def __delitem__(self, key):\n deleted_from_cache = False\n with self._mutex:\n if key in self._cached_items:\n self._total_cached -= self._cached_items.pop(key)\n del self._cache_storage[key]\n self._dirty.discard(key)\n deleted_from_cache = True\n try:\n del self._actual_storage[key]\n except KeyError:\n if not deleted_from_cache:\n raise\n\n def __len__(self):\n return len(\n self.actual_storage\n ) # TODO: In future might need to fix this to return proper len\n\n def __iter__(self):\n cached_keys = set(self._dirty)\n for i in self.actual_storage:\n cached_keys.discard(i)\n yield i\n yield from sorted(cached_keys)\n\n def _free_memory(self, extra_size):\n while (\n self._total_cached > 0 and extra_size + self._total_cached > self._max_size\n ):\n item, itemsize = self._cached_items.popitem(last=False)\n if item in self._dirty:\n self._actual_storage[item] = self._cache_storage[item]\n self._dirty.discard(item)\n del self._cache_storage[item]\n self._total_cached -= itemsize\n\n def _append_cache(self, key, value):\n self._total_cached += len(value)\n self._cached_items[key] = len(value)\n self._cache_storage[key] = value\n", "path": "hub/store/lru_cache.py"}]} | 3,494 | 579 |
gh_patches_debug_47937 | rasdani/github-patches | git_diff | apluslms__a-plus-1310 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Users should not be able to edit content hierarchy
Typically the A+ course content structure is configured from a JSON file generated by gitmanager. However, the teachers have possibility to edit the attributes also in the Edit course / Content view, including the parent learning object. By editing the parent selection it is possible to create a circular reference loop between two learning objects pointing to each other as a parent, that leads to excessive number of database operations, and as a result, leading the system to become unusable due to heavy database load.
Easy approach would be to just disable the possibility to modify the parent selection. Later, it might be useful to think more thoroughly how important it is allow editing the content structure in this view, while the main form of course configuration should be through the JSON configuration.
</issue>
<code>
[start of edit_course/exercise_forms.py]
1 import logging
2 from typing import Any, Dict, List
3
4 from django import forms
5 from django.utils.translation import gettext_lazy as _
6
7 from course.models import CourseModule, LearningObjectCategory
8 from exercise.models import LearningObject, CourseChapter, BaseExercise, \
9 LTIExercise, StaticExercise, ExerciseWithAttachment, RevealRule, \
10 LTI1p3Exercise
11 from lib.widgets import DateTimeLocalInput
12 from .course_forms import FieldsetModelForm
13
14 from exercise.exercisecollection_models import ExerciseCollection
15
16 logger = logging.getLogger("aplus.exercise")
17
18 COMMON_FIELDS = [
19 'status',
20 'audience',
21 'category',
22 'course_module',
23 'parent',
24 'order',
25 'url',
26 ]
27 SERVICE_FIELDS = [
28 'service_url',
29 'name',
30 'description',
31 ]
32 EXERCISE_FIELDS = [
33 'max_submissions',
34 'max_points',
35 'difficulty',
36 'points_to_pass',
37 'allow_assistant_viewing',
38 'allow_assistant_grading',
39 'min_group_size',
40 'max_group_size',
41 'model_answers',
42 'templates',
43 'grading_mode',
44 ]
45
46
47 class LearningObjectMixin:
48
49 def init_fields(self, **kwargs):
50 self.lobject = kwargs.get('instance')
51 self.fields["category"].queryset = LearningObjectCategory.objects.filter(
52 course_instance=self.lobject.course_instance)
53 self.fields["course_module"].queryset = CourseModule.objects.filter(
54 course_instance=self.lobject.course_instance)
55 self.fields["parent"].queryset = LearningObject.objects\
56 .exclude(id=self.lobject.id)\
57 .filter(course_module=self.lobject.course_module)
58
59 @property
60 def remote_service_head(self):
61 return True
62
63 def get_hierarchy_fieldset(self):
64 return { 'legend':_('HIERARCHY'), 'fields':self.get_fields('status',
65 'audience', 'category','course_module','parent','order','url') }
66
67 def get_content_fieldset(self, *add):
68 return { 'legend':_('CONTENT'), 'fields':self.get_fields('name',
69 'description', *add) }
70
71
72 class CourseChapterForm(LearningObjectMixin, FieldsetModelForm):
73
74 class Meta:
75 model = CourseChapter
76 fields = COMMON_FIELDS + SERVICE_FIELDS + [
77 'use_wide_column',
78 'generate_table_of_contents'
79 ]
80
81 def __init__(self, *args, **kwargs):
82 super().__init__(*args, **kwargs)
83 self.init_fields(**kwargs)
84
85 def get_fieldsets(self):
86 return [
87 self.get_hierarchy_fieldset(),
88 self.get_content_fieldset(
89 'use_wide_column', 'generate_table_of_contents'),
90 ]
91
92
93 class RevealRuleForm(FieldsetModelForm):
94 # This form is only used internally by BaseExerciseForm.
95
96 class Meta:
97 model = RevealRule
98 fields = ['trigger', 'delay_minutes', 'time', 'currently_revealed']
99 widgets = {'time': DateTimeLocalInput}
100
101 def __init__(self, *args: Any, **kwargs: Any) -> None:
102 super().__init__(*args, **kwargs)
103 self.fields['trigger'].widget.attrs['data-trigger'] = True
104 # Visibility rules for the form fields. Each of the following fields is
105 # only visible when one of their specified values is selected from the
106 # trigger dropdown. See edit_model.html.
107 self.fields['currently_revealed'].widget.attrs['data-visible-triggers'] = [
108 RevealRule.TRIGGER.MANUAL.value,
109 ]
110 self.fields['time'].widget.attrs['data-visible-triggers'] = [
111 RevealRule.TRIGGER.TIME.value,
112 ]
113 self.fields['delay_minutes'].widget.attrs['data-visible-triggers'] = [
114 RevealRule.TRIGGER.DEADLINE.value,
115 RevealRule.TRIGGER.DEADLINE_ALL.value,
116 RevealRule.TRIGGER.DEADLINE_OR_FULL_POINTS.value,
117 ]
118
119 def clean(self) -> Dict[str, Any]:
120 result = super().clean()
121 errors = {}
122 trigger = self.cleaned_data.get('trigger')
123 if trigger == RevealRule.TRIGGER.TIME:
124 time = self.cleaned_data.get('time')
125 if time is None:
126 errors['time'] = _(
127 'ERROR_REQUIRED_WITH_SELECTED_TRIGGER'
128 )
129 if errors:
130 raise forms.ValidationError(errors)
131 return result
132
133
134 class BaseExerciseForm(LearningObjectMixin, FieldsetModelForm):
135
136 class Meta:
137 model = BaseExercise
138 fields = COMMON_FIELDS + SERVICE_FIELDS + EXERCISE_FIELDS
139
140 def __init__(self, *args: Any, **kwargs: Any) -> None:
141 super().__init__(*args, **kwargs)
142 self.init_fields(**kwargs)
143
144 # This form contains two embedded RevealRuleForms.
145 self.submission_feedback_form = RevealRuleForm(
146 data=kwargs.get('data'),
147 instance=self.instance.active_submission_feedback_reveal_rule,
148 prefix='submission_feedback',
149 )
150 self.model_solutions_form = RevealRuleForm(
151 data=kwargs.get('data'),
152 instance=self.instance.active_model_solutions_reveal_rule,
153 prefix='model_solutions',
154 )
155
156 def get_fieldsets(self) -> List[Dict[str, Any]]:
157 return [
158 self.get_hierarchy_fieldset(),
159 self.get_content_fieldset('model_answers', 'templates'),
160 { 'legend':_('GRADING'), 'fields':self.get_fields('max_submissions',
161 'max_points','points_to_pass', 'difficulty',
162 'allow_assistant_viewing','allow_assistant_grading','grading_mode') },
163 { 'legend':_('GROUPS'), 'fields':self.get_fields('min_group_size',
164 'max_group_size') },
165 { 'legend':_('REVEAL_SUBMISSION_FEEDBACK'), 'fields':self.submission_feedback_form },
166 { 'legend':_('REVEAL_MODEL_SOLUTIONS'), 'fields':self.model_solutions_form },
167 ]
168
169 def is_valid(self) -> bool:
170 return (
171 super().is_valid()
172 and self.submission_feedback_form.is_valid()
173 and self.model_solutions_form.is_valid()
174 )
175
176 def save(self, *args: Any, **kwargs: Any) -> Any:
177 # Save the reveal rules only if they have been changed.
178 # If they were not changed, we can keep using the default rule and
179 # there's no need to save a new RevealRule.
180 if self.submission_feedback_form.has_changed():
181 self.instance.submission_feedback_reveal_rule = (
182 self.submission_feedback_form.save(*args, **kwargs)
183 )
184 if self.model_solutions_form.has_changed():
185 self.instance.model_solutions_reveal_rule = (
186 self.model_solutions_form.save(*args, **kwargs)
187 )
188 return super().save(*args, **kwargs)
189
190
191 class LTIExerciseForm(BaseExerciseForm):
192
193 class Meta:
194 model = LTIExercise
195 fields = COMMON_FIELDS + SERVICE_FIELDS + EXERCISE_FIELDS + [
196 'lti_service',
197 'context_id',
198 'resource_link_id',
199 'resource_link_title',
200 'aplus_get_and_post',
201 'open_in_iframe',
202 ]
203
204 @property
205 def remote_service_head(self):
206 return False
207
208 def get_content_fieldset(self, *add):
209 return super().get_content_fieldset('lti_service','context_id',
210 'resource_link_id','resource_link_title',
211 'aplus_get_and_post','open_in_iframe','service_url')
212
213
214 class LTI1p3ExerciseForm(BaseExerciseForm):
215
216 class Meta:
217 model = LTI1p3Exercise
218 fields = COMMON_FIELDS + SERVICE_FIELDS + EXERCISE_FIELDS + [
219 'lti_service',
220 'custom',
221 'open_in_iframe',
222 ]
223
224 @property
225 def remote_service_head(self) -> bool:
226 return False
227
228 def get_content_fieldset(self, *add) -> Dict[str, Any]:
229 return super().get_content_fieldset('lti_service', 'custom', 'open_in_iframe')
230
231
232 class ExerciseWithAttachmentForm(BaseExerciseForm):
233 multipart = True
234
235 class Meta:
236 model = ExerciseWithAttachment
237 fields = COMMON_FIELDS + SERVICE_FIELDS + EXERCISE_FIELDS + [
238 'content',
239 'files_to_submit',
240 'attachment',
241 ]
242
243 def get_content_fieldset(self, *add):
244 return super().get_content_fieldset(
245 'content', 'files_to_submit', 'attachment')
246
247
248 class StaticExerciseForm(BaseExerciseForm):
249
250 class Meta:
251 model = StaticExercise
252 fields = COMMON_FIELDS + EXERCISE_FIELDS + [
253 'name',
254 'description',
255 'exercise_page_content',
256 'submission_page_content',
257 ]
258
259 @property
260 def remote_service_head(self):
261 return False
262
263 def get_content_fieldset(self, *add):
264 return super().get_content_fieldset(
265 'exercise_page_content', 'submission_page_content')
266
267 class ExerciseCollectionExerciseForm(BaseExerciseForm):
268
269 class Meta:
270 model = ExerciseCollection
271 fields = COMMON_FIELDS + EXERCISE_FIELDS + SERVICE_FIELDS + \
272 ['target_category']
273
274 def get_content_fieldset(self, *add):
275 return super().get_content_fieldset('target_category')
276
[end of edit_course/exercise_forms.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/edit_course/exercise_forms.py b/edit_course/exercise_forms.py
--- a/edit_course/exercise_forms.py
+++ b/edit_course/exercise_forms.py
@@ -55,6 +55,8 @@
self.fields["parent"].queryset = LearningObject.objects\
.exclude(id=self.lobject.id)\
.filter(course_module=self.lobject.course_module)
+ self.fields['parent'].widget.attrs.update(
+ {'readonly': True, 'disabled': True})
@property
def remote_service_head(self):
| {"golden_diff": "diff --git a/edit_course/exercise_forms.py b/edit_course/exercise_forms.py\n--- a/edit_course/exercise_forms.py\n+++ b/edit_course/exercise_forms.py\n@@ -55,6 +55,8 @@\n self.fields[\"parent\"].queryset = LearningObject.objects\\\n .exclude(id=self.lobject.id)\\\n .filter(course_module=self.lobject.course_module)\n+ self.fields['parent'].widget.attrs.update(\n+ {'readonly': True, 'disabled': True})\n \n @property\n def remote_service_head(self):\n", "issue": "Users should not be able to edit content hierarchy\nTypically the A+ course content structure is configured from a JSON file generated by gitmanager. However, the teachers have possibility to edit the attributes also in the Edit course / Content view, including the parent learning object. By editing the parent selection it is possible to create a circular reference loop between two learning objects pointing to each other as a parent, that leads to excessive number of database operations, and as a result, leading the system to become unusable due to heavy database load.\r\n\r\nEasy approach would be to just disable the possibility to modify the parent selection. Later, it might be useful to think more thoroughly how important it is allow editing the content structure in this view, while the main form of course configuration should be through the JSON configuration.\n", "before_files": [{"content": "import logging\nfrom typing import Any, Dict, List\n\nfrom django import forms\nfrom django.utils.translation import gettext_lazy as _\n\nfrom course.models import CourseModule, LearningObjectCategory\nfrom exercise.models import LearningObject, CourseChapter, BaseExercise, \\\n LTIExercise, StaticExercise, ExerciseWithAttachment, RevealRule, \\\n LTI1p3Exercise\nfrom lib.widgets import DateTimeLocalInput\nfrom .course_forms import FieldsetModelForm\n\nfrom exercise.exercisecollection_models import ExerciseCollection\n\nlogger = logging.getLogger(\"aplus.exercise\")\n\nCOMMON_FIELDS = [\n 'status',\n 'audience',\n 'category',\n 'course_module',\n 'parent',\n 'order',\n 'url',\n]\nSERVICE_FIELDS = [\n 'service_url',\n 'name',\n 'description',\n]\nEXERCISE_FIELDS = [\n 'max_submissions',\n 'max_points',\n 'difficulty',\n 'points_to_pass',\n 'allow_assistant_viewing',\n 'allow_assistant_grading',\n 'min_group_size',\n 'max_group_size',\n 'model_answers',\n 'templates',\n 'grading_mode',\n]\n\n\nclass LearningObjectMixin:\n\n def init_fields(self, **kwargs):\n self.lobject = kwargs.get('instance')\n self.fields[\"category\"].queryset = LearningObjectCategory.objects.filter(\n course_instance=self.lobject.course_instance)\n self.fields[\"course_module\"].queryset = CourseModule.objects.filter(\n course_instance=self.lobject.course_instance)\n self.fields[\"parent\"].queryset = LearningObject.objects\\\n .exclude(id=self.lobject.id)\\\n .filter(course_module=self.lobject.course_module)\n\n @property\n def remote_service_head(self):\n return True\n\n def get_hierarchy_fieldset(self):\n return { 'legend':_('HIERARCHY'), 'fields':self.get_fields('status',\n 'audience', 'category','course_module','parent','order','url') }\n\n def get_content_fieldset(self, *add):\n return { 'legend':_('CONTENT'), 'fields':self.get_fields('name',\n 'description', *add) }\n\n\nclass CourseChapterForm(LearningObjectMixin, FieldsetModelForm):\n\n class Meta:\n model = CourseChapter\n fields = COMMON_FIELDS + SERVICE_FIELDS + [\n 'use_wide_column',\n 'generate_table_of_contents'\n ]\n\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n self.init_fields(**kwargs)\n\n def get_fieldsets(self):\n return [\n self.get_hierarchy_fieldset(),\n self.get_content_fieldset(\n 'use_wide_column', 'generate_table_of_contents'),\n ]\n\n\nclass RevealRuleForm(FieldsetModelForm):\n # This form is only used internally by BaseExerciseForm.\n\n class Meta:\n model = RevealRule\n fields = ['trigger', 'delay_minutes', 'time', 'currently_revealed']\n widgets = {'time': DateTimeLocalInput}\n\n def __init__(self, *args: Any, **kwargs: Any) -> None:\n super().__init__(*args, **kwargs)\n self.fields['trigger'].widget.attrs['data-trigger'] = True\n # Visibility rules for the form fields. Each of the following fields is\n # only visible when one of their specified values is selected from the\n # trigger dropdown. See edit_model.html.\n self.fields['currently_revealed'].widget.attrs['data-visible-triggers'] = [\n RevealRule.TRIGGER.MANUAL.value,\n ]\n self.fields['time'].widget.attrs['data-visible-triggers'] = [\n RevealRule.TRIGGER.TIME.value,\n ]\n self.fields['delay_minutes'].widget.attrs['data-visible-triggers'] = [\n RevealRule.TRIGGER.DEADLINE.value,\n RevealRule.TRIGGER.DEADLINE_ALL.value,\n RevealRule.TRIGGER.DEADLINE_OR_FULL_POINTS.value,\n ]\n\n def clean(self) -> Dict[str, Any]:\n result = super().clean()\n errors = {}\n trigger = self.cleaned_data.get('trigger')\n if trigger == RevealRule.TRIGGER.TIME:\n time = self.cleaned_data.get('time')\n if time is None:\n errors['time'] = _(\n 'ERROR_REQUIRED_WITH_SELECTED_TRIGGER'\n )\n if errors:\n raise forms.ValidationError(errors)\n return result\n\n\nclass BaseExerciseForm(LearningObjectMixin, FieldsetModelForm):\n\n class Meta:\n model = BaseExercise\n fields = COMMON_FIELDS + SERVICE_FIELDS + EXERCISE_FIELDS\n\n def __init__(self, *args: Any, **kwargs: Any) -> None:\n super().__init__(*args, **kwargs)\n self.init_fields(**kwargs)\n\n # This form contains two embedded RevealRuleForms.\n self.submission_feedback_form = RevealRuleForm(\n data=kwargs.get('data'),\n instance=self.instance.active_submission_feedback_reveal_rule,\n prefix='submission_feedback',\n )\n self.model_solutions_form = RevealRuleForm(\n data=kwargs.get('data'),\n instance=self.instance.active_model_solutions_reveal_rule,\n prefix='model_solutions',\n )\n\n def get_fieldsets(self) -> List[Dict[str, Any]]:\n return [\n self.get_hierarchy_fieldset(),\n self.get_content_fieldset('model_answers', 'templates'),\n { 'legend':_('GRADING'), 'fields':self.get_fields('max_submissions',\n 'max_points','points_to_pass', 'difficulty',\n 'allow_assistant_viewing','allow_assistant_grading','grading_mode') },\n { 'legend':_('GROUPS'), 'fields':self.get_fields('min_group_size',\n 'max_group_size') },\n { 'legend':_('REVEAL_SUBMISSION_FEEDBACK'), 'fields':self.submission_feedback_form },\n { 'legend':_('REVEAL_MODEL_SOLUTIONS'), 'fields':self.model_solutions_form },\n ]\n\n def is_valid(self) -> bool:\n return (\n super().is_valid()\n and self.submission_feedback_form.is_valid()\n and self.model_solutions_form.is_valid()\n )\n\n def save(self, *args: Any, **kwargs: Any) -> Any:\n # Save the reveal rules only if they have been changed.\n # If they were not changed, we can keep using the default rule and\n # there's no need to save a new RevealRule.\n if self.submission_feedback_form.has_changed():\n self.instance.submission_feedback_reveal_rule = (\n self.submission_feedback_form.save(*args, **kwargs)\n )\n if self.model_solutions_form.has_changed():\n self.instance.model_solutions_reveal_rule = (\n self.model_solutions_form.save(*args, **kwargs)\n )\n return super().save(*args, **kwargs)\n\n\nclass LTIExerciseForm(BaseExerciseForm):\n\n class Meta:\n model = LTIExercise\n fields = COMMON_FIELDS + SERVICE_FIELDS + EXERCISE_FIELDS + [\n 'lti_service',\n 'context_id',\n 'resource_link_id',\n 'resource_link_title',\n 'aplus_get_and_post',\n 'open_in_iframe',\n ]\n\n @property\n def remote_service_head(self):\n return False\n\n def get_content_fieldset(self, *add):\n return super().get_content_fieldset('lti_service','context_id',\n 'resource_link_id','resource_link_title',\n 'aplus_get_and_post','open_in_iframe','service_url')\n\n\nclass LTI1p3ExerciseForm(BaseExerciseForm):\n\n class Meta:\n model = LTI1p3Exercise\n fields = COMMON_FIELDS + SERVICE_FIELDS + EXERCISE_FIELDS + [\n 'lti_service',\n 'custom',\n 'open_in_iframe',\n ]\n\n @property\n def remote_service_head(self) -> bool:\n return False\n\n def get_content_fieldset(self, *add) -> Dict[str, Any]:\n return super().get_content_fieldset('lti_service', 'custom', 'open_in_iframe')\n\n\nclass ExerciseWithAttachmentForm(BaseExerciseForm):\n multipart = True\n\n class Meta:\n model = ExerciseWithAttachment\n fields = COMMON_FIELDS + SERVICE_FIELDS + EXERCISE_FIELDS + [\n 'content',\n 'files_to_submit',\n 'attachment',\n ]\n\n def get_content_fieldset(self, *add):\n return super().get_content_fieldset(\n 'content', 'files_to_submit', 'attachment')\n\n\nclass StaticExerciseForm(BaseExerciseForm):\n\n class Meta:\n model = StaticExercise\n fields = COMMON_FIELDS + EXERCISE_FIELDS + [\n 'name',\n 'description',\n 'exercise_page_content',\n 'submission_page_content',\n ]\n\n @property\n def remote_service_head(self):\n return False\n\n def get_content_fieldset(self, *add):\n return super().get_content_fieldset(\n 'exercise_page_content', 'submission_page_content')\n\nclass ExerciseCollectionExerciseForm(BaseExerciseForm):\n\n class Meta:\n model = ExerciseCollection\n fields = COMMON_FIELDS + EXERCISE_FIELDS + SERVICE_FIELDS + \\\n ['target_category']\n\n def get_content_fieldset(self, *add):\n return super().get_content_fieldset('target_category')\n", "path": "edit_course/exercise_forms.py"}]} | 3,407 | 116 |
gh_patches_debug_7501 | rasdani/github-patches | git_diff | mindsdb__mindsdb-1667 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add new method to return the columns for ClickHouse datasources :electric_plug: :1234:
When MindsDB creates a new ClickHouse datasource we get information for columns by fetching all datasources. The problem here is that if datasource is big it takes a lot of time. We need a new get_columns method to return the columns name per datasource. The PR should include this method inside the ClickHouse class.
## Steps :male_detective: :female_detective:
- Implement in https://github.com/mindsdb/mindsdb/blob/staging/mindsdb/integrations/clickhouse/clickhouse.py#L25
- Push to staging branch
## Additional rewards :1st_place_medal:
Each code PR brings :three: point for entry into the draw for a :computer: Deep Learning Laptop powered by the NVIDIA RTX 3080 Max-Q GPU or other swag :shirt: :bear: . For more info check out https://mindsdb.com/hacktoberfest/
</issue>
<code>
[start of mindsdb/integrations/clickhouse/clickhouse.py]
1 import requests
2 from lightwood.api import dtype
3 from mindsdb.integrations.base import Integration
4 from mindsdb.utilities.log import log
5
6
7 class ClickhouseConnectionChecker:
8 def __init__(self, **kwargs):
9 self.host = kwargs.get("host")
10 self.port = kwargs.get("port")
11 self.user = kwargs.get("user")
12 self.password = kwargs.get("password")
13
14 def check_connection(self):
15 try:
16 res = requests.post(f"http://{self.host}:{self.port}",
17 data="select 1;",
18 params={'user': self.user, 'password': self.password})
19 connected = res.status_code == 200
20 except Exception:
21 connected = False
22 return connected
23
24
25 class Clickhouse(Integration, ClickhouseConnectionChecker):
26 def __init__(self, config, name, db_info):
27 super().__init__(config, name)
28 self.user = db_info.get('user', 'default')
29 self.password = db_info.get('password', None)
30 self.host = db_info.get('host')
31 self.port = db_info.get('port')
32
33 def _to_clickhouse_table(self, dtype_dict, predicted_cols, columns):
34 subtype_map = {
35 dtype.integer: 'Nullable(Int64)',
36 dtype.float: 'Nullable(Float64)',
37 dtype.binary: 'Nullable(UInt8)',
38 dtype.date: 'Nullable(Date)',
39 dtype.datetime: 'Nullable(Datetime)',
40 dtype.binary: 'Nullable(String)',
41 dtype.categorical: 'Nullable(String)',
42 dtype.tags: 'Nullable(String)',
43 dtype.image: 'Nullable(String)',
44 dtype.video: 'Nullable(String)',
45 dtype.audio: 'Nullable(String)',
46 dtype.short_text: 'Nullable(String)',
47 dtype.rich_text: 'Nullable(String)',
48 dtype.array: 'Nullable(String)'
49 }
50
51 column_declaration = []
52 for name in columns:
53 try:
54 col_subtype = dtype_dict[name]
55 new_type = subtype_map[col_subtype]
56 column_declaration.append(f' `{name}` {new_type} ')
57 if name in predicted_cols:
58 column_declaration.append(f' `{name}_original` {new_type} ')
59 except Exception as e:
60 log.error(f'Error: can not determine clickhouse data type for column {name}: {e}')
61
62 return column_declaration
63
64 def _query(self, query):
65 params = {'user': self.user}
66
67 if self.password is not None:
68 params['password'] = self.password
69
70 host = self.host
71 port = self.port
72
73 response = requests.post(f'http://{host}:{port}', data=query, params=params)
74
75 if response.status_code != 200:
76 raise Exception(f'Error: {response.content}\nQuery:{query}')
77
78 return response
79
80 def _get_mysql_user(self):
81 return f"{self.config['api']['mysql']['user']}_{self.name}"
82
83 def _escape_table_name(self, name):
84 return '`' + name.replace('`', '\\`') + '`'
85
86 def setup(self):
87 self._query(f'DROP DATABASE IF EXISTS {self.mindsdb_database}')
88 self._query(f'CREATE DATABASE IF NOT EXISTS {self.mindsdb_database}')
89
90 msqyl_conn = self.config['api']['mysql']['host'] + ':' + str(self.config['api']['mysql']['port'])
91 msqyl_pass = self.config['api']['mysql']['password']
92 msqyl_user = self._get_mysql_user()
93
94 q = f"""
95 CREATE TABLE IF NOT EXISTS {self.mindsdb_database}.predictors (
96 name String,
97 status String,
98 accuracy String,
99 predict String,
100 select_data_query String,
101 external_datasource String,
102 training_options String
103 ) ENGINE=MySQL('{msqyl_conn}', 'mindsdb', 'predictors', '{msqyl_user}', '{msqyl_pass}')
104 """
105 self._query(q)
106 q = f"""
107 CREATE TABLE IF NOT EXISTS {self.mindsdb_database}.commands (
108 command String
109 ) ENGINE=MySQL('{msqyl_conn}', 'mindsdb', 'commands', '{msqyl_user}', '{msqyl_pass}')
110 """
111 self._query(q)
112
113 def register_predictors(self, model_data_arr):
114 for model_meta in model_data_arr:
115 name = self._escape_table_name(model_meta['name'])
116
117 predict = model_meta['predict']
118 if not isinstance(predict, list):
119 predict = [predict]
120
121 columns_sql = ','.join(self._to_clickhouse_table(
122 model_meta['dtype_dict'],
123 predict,
124 list(model_meta['dtype_dict'].keys())
125 ))
126 columns_sql += ',`when_data` Nullable(String)'
127 columns_sql += ',`select_data_query` Nullable(String)'
128 columns_sql += ',`external_datasource` Nullable(String)'
129 for col in predict:
130 columns_sql += f',`{col}_confidence` Nullable(Float64)'
131
132 if model_meta['dtype_dict'][col] in (dtype.integer, dtype.float):
133 columns_sql += f',`{col}_min` Nullable(Float64)'
134 columns_sql += f',`{col}_max` Nullable(Float64)'
135 columns_sql += f',`{col}_explain` Nullable(String)'
136
137 msqyl_conn = self.config['api']['mysql']['host'] + ':' + str(self.config['api']['mysql']['port'])
138 msqyl_pass = self.config['api']['mysql']['password']
139 msqyl_user = self._get_mysql_user()
140
141 self.unregister_predictor(model_meta['name'])
142 q = f"""
143 CREATE TABLE {self.mindsdb_database}.{name}
144 ({columns_sql}
145 ) ENGINE=MySQL('{msqyl_conn}', 'mindsdb', {name}, '{msqyl_user}', '{msqyl_pass}')
146 """
147 self._query(q)
148
149 def unregister_predictor(self, name):
150 q = f"""
151 drop table if exists {self.mindsdb_database}.{self._escape_table_name(name)};
152 """
153 self._query(q)
154
155 def get_tables_list(self):
156 q = f"""SELECT database, table
157 FROM system.parts
158 WHERE active and database NOT IN ('system', 'mdb_system')
159 GROUP BY database, table
160 ORDER BY database, table;"""
161 tables_list = self._query(q)
162 tables= [f"{table[0]}.{table[1]}" for table in tables_list]
163 return tables
[end of mindsdb/integrations/clickhouse/clickhouse.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/mindsdb/integrations/clickhouse/clickhouse.py b/mindsdb/integrations/clickhouse/clickhouse.py
--- a/mindsdb/integrations/clickhouse/clickhouse.py
+++ b/mindsdb/integrations/clickhouse/clickhouse.py
@@ -160,4 +160,12 @@
ORDER BY database, table;"""
tables_list = self._query(q)
tables= [f"{table[0]}.{table[1]}" for table in tables_list]
- return tables
\ No newline at end of file
+ return tables
+
+ def get_columns(self,query):
+ q = f"SELECT * FROM ({query}) LIMIT 1 FORMAT JSON"
+ query_result = self._query(q).json()
+ columns_info = query_result['meta']
+ columns= [column['name'] for column in columns_info]
+ return columns
+
| {"golden_diff": "diff --git a/mindsdb/integrations/clickhouse/clickhouse.py b/mindsdb/integrations/clickhouse/clickhouse.py\n--- a/mindsdb/integrations/clickhouse/clickhouse.py\n+++ b/mindsdb/integrations/clickhouse/clickhouse.py\n@@ -160,4 +160,12 @@\n ORDER BY database, table;\"\"\"\n tables_list = self._query(q)\n tables= [f\"{table[0]}.{table[1]}\" for table in tables_list]\n- return tables\n\\ No newline at end of file\n+ return tables\n+\n+ def get_columns(self,query):\n+ q = f\"SELECT * FROM ({query}) LIMIT 1 FORMAT JSON\"\n+ query_result = self._query(q).json()\n+ columns_info = query_result['meta']\n+ columns= [column['name'] for column in columns_info]\n+ return columns\n+\n", "issue": "Add new method to return the columns for ClickHouse datasources :electric_plug: :1234: \nWhen MindsDB creates a new ClickHouse datasource we get information for columns by fetching all datasources. The problem here is that if datasource is big it takes a lot of time. We need a new get_columns method to return the columns name per datasource. The PR should include this method inside the ClickHouse class.\r\n\r\n## Steps :male_detective: :female_detective: \r\n\r\n- Implement in https://github.com/mindsdb/mindsdb/blob/staging/mindsdb/integrations/clickhouse/clickhouse.py#L25\r\n- Push to staging branch\r\n\r\n## Additional rewards :1st_place_medal: \r\n\r\nEach code PR brings :three: point for entry into the draw for a :computer: Deep Learning Laptop powered by the NVIDIA RTX 3080 Max-Q GPU or other swag :shirt: :bear: . For more info check out https://mindsdb.com/hacktoberfest/\r\n \r\n\r\n\n", "before_files": [{"content": "import requests\nfrom lightwood.api import dtype\nfrom mindsdb.integrations.base import Integration\nfrom mindsdb.utilities.log import log\n\n\nclass ClickhouseConnectionChecker:\n def __init__(self, **kwargs):\n self.host = kwargs.get(\"host\")\n self.port = kwargs.get(\"port\")\n self.user = kwargs.get(\"user\")\n self.password = kwargs.get(\"password\")\n\n def check_connection(self):\n try:\n res = requests.post(f\"http://{self.host}:{self.port}\",\n data=\"select 1;\",\n params={'user': self.user, 'password': self.password})\n connected = res.status_code == 200\n except Exception:\n connected = False\n return connected\n\n\nclass Clickhouse(Integration, ClickhouseConnectionChecker):\n def __init__(self, config, name, db_info):\n super().__init__(config, name)\n self.user = db_info.get('user', 'default')\n self.password = db_info.get('password', None)\n self.host = db_info.get('host')\n self.port = db_info.get('port')\n\n def _to_clickhouse_table(self, dtype_dict, predicted_cols, columns):\n subtype_map = {\n dtype.integer: 'Nullable(Int64)',\n dtype.float: 'Nullable(Float64)',\n dtype.binary: 'Nullable(UInt8)',\n dtype.date: 'Nullable(Date)',\n dtype.datetime: 'Nullable(Datetime)',\n dtype.binary: 'Nullable(String)',\n dtype.categorical: 'Nullable(String)',\n dtype.tags: 'Nullable(String)',\n dtype.image: 'Nullable(String)',\n dtype.video: 'Nullable(String)',\n dtype.audio: 'Nullable(String)',\n dtype.short_text: 'Nullable(String)',\n dtype.rich_text: 'Nullable(String)',\n dtype.array: 'Nullable(String)'\n }\n\n column_declaration = []\n for name in columns:\n try:\n col_subtype = dtype_dict[name]\n new_type = subtype_map[col_subtype]\n column_declaration.append(f' `{name}` {new_type} ')\n if name in predicted_cols:\n column_declaration.append(f' `{name}_original` {new_type} ')\n except Exception as e:\n log.error(f'Error: can not determine clickhouse data type for column {name}: {e}')\n\n return column_declaration\n\n def _query(self, query):\n params = {'user': self.user}\n\n if self.password is not None:\n params['password'] = self.password\n\n host = self.host\n port = self.port\n\n response = requests.post(f'http://{host}:{port}', data=query, params=params)\n\n if response.status_code != 200:\n raise Exception(f'Error: {response.content}\\nQuery:{query}')\n\n return response\n\n def _get_mysql_user(self):\n return f\"{self.config['api']['mysql']['user']}_{self.name}\"\n\n def _escape_table_name(self, name):\n return '`' + name.replace('`', '\\\\`') + '`'\n\n def setup(self):\n self._query(f'DROP DATABASE IF EXISTS {self.mindsdb_database}')\n self._query(f'CREATE DATABASE IF NOT EXISTS {self.mindsdb_database}')\n\n msqyl_conn = self.config['api']['mysql']['host'] + ':' + str(self.config['api']['mysql']['port'])\n msqyl_pass = self.config['api']['mysql']['password']\n msqyl_user = self._get_mysql_user()\n\n q = f\"\"\"\n CREATE TABLE IF NOT EXISTS {self.mindsdb_database}.predictors (\n name String,\n status String,\n accuracy String,\n predict String,\n select_data_query String,\n external_datasource String,\n training_options String\n ) ENGINE=MySQL('{msqyl_conn}', 'mindsdb', 'predictors', '{msqyl_user}', '{msqyl_pass}')\n \"\"\"\n self._query(q)\n q = f\"\"\"\n CREATE TABLE IF NOT EXISTS {self.mindsdb_database}.commands (\n command String\n ) ENGINE=MySQL('{msqyl_conn}', 'mindsdb', 'commands', '{msqyl_user}', '{msqyl_pass}')\n \"\"\"\n self._query(q)\n\n def register_predictors(self, model_data_arr):\n for model_meta in model_data_arr:\n name = self._escape_table_name(model_meta['name'])\n\n predict = model_meta['predict']\n if not isinstance(predict, list):\n predict = [predict]\n\n columns_sql = ','.join(self._to_clickhouse_table(\n model_meta['dtype_dict'],\n predict,\n list(model_meta['dtype_dict'].keys())\n ))\n columns_sql += ',`when_data` Nullable(String)'\n columns_sql += ',`select_data_query` Nullable(String)'\n columns_sql += ',`external_datasource` Nullable(String)'\n for col in predict:\n columns_sql += f',`{col}_confidence` Nullable(Float64)'\n\n if model_meta['dtype_dict'][col] in (dtype.integer, dtype.float):\n columns_sql += f',`{col}_min` Nullable(Float64)'\n columns_sql += f',`{col}_max` Nullable(Float64)'\n columns_sql += f',`{col}_explain` Nullable(String)'\n\n msqyl_conn = self.config['api']['mysql']['host'] + ':' + str(self.config['api']['mysql']['port'])\n msqyl_pass = self.config['api']['mysql']['password']\n msqyl_user = self._get_mysql_user()\n\n self.unregister_predictor(model_meta['name'])\n q = f\"\"\"\n CREATE TABLE {self.mindsdb_database}.{name}\n ({columns_sql}\n ) ENGINE=MySQL('{msqyl_conn}', 'mindsdb', {name}, '{msqyl_user}', '{msqyl_pass}')\n \"\"\"\n self._query(q)\n\n def unregister_predictor(self, name):\n q = f\"\"\"\n drop table if exists {self.mindsdb_database}.{self._escape_table_name(name)};\n \"\"\"\n self._query(q)\n\n def get_tables_list(self):\n q = f\"\"\"SELECT database, table\n FROM system.parts\n WHERE active and database NOT IN ('system', 'mdb_system')\n GROUP BY database, table\n ORDER BY database, table;\"\"\"\n tables_list = self._query(q)\n tables= [f\"{table[0]}.{table[1]}\" for table in tables_list]\n return tables", "path": "mindsdb/integrations/clickhouse/clickhouse.py"}]} | 2,520 | 206 |
gh_patches_debug_22993 | rasdani/github-patches | git_diff | inducer__relate-169 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Datetime shown not localized.
As one of my student complaints, his browser is using en_US locale, however, the datetime shown in RELATE is in zh_CN format. Although he can understand Chinese, however, that will cause problem in other circumstances.
The reason of problem lies in [this PR](https://github.com/inducer/relate/pull/39) I provided. It uses setting.LANGUAGE_CODE to determine the locale show in browser.
I found I've made it too complicated in that PR, and it quite simple to modify that method using built-in method `django.utils.formats`, and the result is itself locale aware.
I'll create a PR later to fix it.
</issue>
<code>
[start of relate/utils.py]
1 # -*- coding: utf-8 -*-
2
3 from __future__ import division
4
5 __copyright__ = "Copyright (C) 2014 Andreas Kloeckner"
6
7 __license__ = """
8 Permission is hereby granted, free of charge, to any person obtaining a copy
9 of this software and associated documentation files (the "Software"), to deal
10 in the Software without restriction, including without limitation the rights
11 to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
12 copies of the Software, and to permit persons to whom the Software is
13 furnished to do so, subject to the following conditions:
14
15 The above copyright notice and this permission notice shall be included in
16 all copies or substantial portions of the Software.
17
18 THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
19 IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
20 FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
21 AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
22 LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
23 OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
24 THE SOFTWARE.
25 """
26
27
28 import six
29 import django.forms as forms
30
31
32 class StyledForm(forms.Form):
33 def __init__(self, *args, **kwargs):
34 from crispy_forms.helper import FormHelper
35 self.helper = FormHelper()
36 self.helper.form_class = "form-horizontal"
37 self.helper.label_class = "col-lg-2"
38 self.helper.field_class = "col-lg-8"
39
40 super(StyledForm, self).__init__(*args, **kwargs)
41
42
43 class StyledInlineForm(forms.Form):
44 def __init__(self, *args, **kwargs):
45 from crispy_forms.helper import FormHelper
46 self.helper = FormHelper()
47 self.helper.form_class = "form-inline"
48 self.helper.label_class = "sr-only"
49
50 super(StyledInlineForm, self).__init__(*args, **kwargs)
51
52
53 class StyledModelForm(forms.ModelForm):
54 def __init__(self, *args, **kwargs):
55 from crispy_forms.helper import FormHelper
56 self.helper = FormHelper()
57 self.helper.form_class = "form-horizontal"
58 self.helper.label_class = "col-lg-2"
59 self.helper.field_class = "col-lg-8"
60
61 super(StyledModelForm, self).__init__(*args, **kwargs)
62
63
64 def settings_context_processor(request):
65 from django.conf import settings
66 return {
67 "student_sign_in_view": "relate-sign_in_choice",
68 "relate_sign_in_by_email_enabled":
69 settings.RELATE_SIGN_IN_BY_EMAIL_ENABLED,
70 "relate_registration_enabled":
71 settings.RELATE_REGISTRATION_ENABLED,
72 "relate_sign_in_by_exam_tickets_enabled":
73 settings.RELATE_SIGN_IN_BY_EXAM_TICKETS_ENABLED,
74 "relate_sign_in_by_saml2_enabled":
75 settings.RELATE_SIGN_IN_BY_SAML2_ENABLED,
76 "maintenance_mode": settings.RELATE_MAINTENANCE_MODE,
77 "site_announcement": getattr(settings, "RELATE_SITE_ANNOUNCEMENT", None),
78 }
79
80
81 def as_local_time(datetime):
82 """Takes an timezone-aware datetime and applies the server timezone."""
83 from django.conf import settings
84 from pytz import timezone
85 tz = timezone(settings.TIME_ZONE)
86 return datetime.astimezone(tz)
87
88
89 def localize_datetime(datetime):
90 """Takes an timezone-naive datetime and applies the server timezone."""
91 from django.conf import settings
92 from pytz import timezone
93 tz = timezone(settings.TIME_ZONE)
94 return tz.localize(datetime)
95
96
97 def local_now():
98 from django.conf import settings
99 from pytz import timezone
100 tz = timezone(settings.TIME_ZONE)
101 from datetime import datetime
102 return tz.localize(datetime.now())
103
104
105 def format_datetime_local(datetime, format='medium'):
106 """Format the output of a datetime object to a localized string"""
107 from babel.dates import format_datetime
108 from django.conf import settings
109 from django.utils.translation.trans_real import to_locale
110 # See http://babel.pocoo.org/docs/api/dates/#date-and-time-formatting
111 # for customizing the output format.
112 try:
113 locale = to_locale(settings.LANGUAGE_CODE)
114 except ValueError:
115 locale = "en_US"
116
117 result = format_datetime(datetime, format, locale=locale)
118
119 return result
120
121
122 # {{{ dict_to_struct
123
124 class Struct(object):
125 def __init__(self, entries):
126 for name, val in six.iteritems(entries):
127 self.__dict__[name] = val
128
129 def __repr__(self):
130 return repr(self.__dict__)
131
132
133 def dict_to_struct(data):
134 if isinstance(data, list):
135 return [dict_to_struct(d) for d in data]
136 elif isinstance(data, dict):
137 return Struct({k: dict_to_struct(v) for k, v in six.iteritems(data)})
138 else:
139 return data
140
141
142 def struct_to_dict(data):
143 return dict(
144 (name, val)
145 for name, val in six.iteritems(data.__dict__)
146 if not name.startswith("_"))
147
148 # }}}
149
150
151 def retry_transaction(f, args, kwargs={}, max_tries=None, serializable=None):
152 from django.db import transaction
153 from django.db.utils import OperationalError
154
155 if max_tries is None:
156 max_tries = 5
157 if serializable is None:
158 serializable = False
159
160 assert max_tries > 0
161 while True:
162 try:
163 with transaction.atomic():
164 if serializable:
165 from django.db import connections, DEFAULT_DB_ALIAS
166 conn = connections[DEFAULT_DB_ALIAS]
167 if conn.vendor == "postgresql":
168 cursor = conn.cursor()
169 cursor.execute(
170 "SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;")
171
172 return f(*args, **kwargs)
173 except OperationalError:
174 max_tries -= 1
175 if not max_tries:
176 raise
177
178
179 class retry_transaction_decorator(object):
180 def __init__(self, max_tries=None, serializable=None):
181 self.max_tries = max_tries
182 self.serializable = serializable
183
184 def __call__(self, f):
185 from functools import update_wrapper
186
187 def wrapper(*args, **kwargs):
188 return retry_transaction(f, args, kwargs,
189 max_tries=self.max_tries,
190 serializable=self.serializable)
191
192 update_wrapper(wrapper, f)
193 return wrapper
194
195
196 # {{{ hang debugging
197
198 def dumpstacks(signal, frame):
199 import threading
200 import sys
201 import traceback
202
203 id2name = dict([(th.ident, th.name) for th in threading.enumerate()])
204 code = []
205 for threadId, stack in sys._current_frames().items():
206 code.append("\n# Thread: %s(%d)" % (id2name.get(threadId, ""), threadId))
207 for filename, lineno, name, line in traceback.extract_stack(stack):
208 code.append('File: "%s", line %d, in %s' % (filename, lineno, name))
209 if line:
210 code.append(" %s" % (line.strip()))
211 print("\n".join(code))
212
213 if 0:
214 import signal
215 import os
216 print("*** HANG DUMP HANDLER ACTIVATED: 'kill -USR1 %s' to dump stacks"
217 % os.getpid())
218 signal.signal(signal.SIGUSR1, dumpstacks)
219
220 # }}}
221
222
223 # {{{ convert django language name to js styled language name
224
225 def to_js_lang_name(dj_lang_name):
226 """
227 Turns a django language name (en-us) into a js styled language
228 name (en-US).
229 """
230 p = dj_lang_name.find('-')
231 if p >= 0:
232 return dj_lang_name[:p].lower() + '-' + dj_lang_name[p + 1:].upper()
233 else:
234 return dj_lang_name.lower()
235
236 # }}}
237
238 # vim: foldmethod=marker
239
[end of relate/utils.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/relate/utils.py b/relate/utils.py
--- a/relate/utils.py
+++ b/relate/utils.py
@@ -102,21 +102,29 @@
return tz.localize(datetime.now())
-def format_datetime_local(datetime, format='medium'):
- """Format the output of a datetime object to a localized string"""
- from babel.dates import format_datetime
- from django.conf import settings
- from django.utils.translation.trans_real import to_locale
- # See http://babel.pocoo.org/docs/api/dates/#date-and-time-formatting
- # for customizing the output format.
- try:
- locale = to_locale(settings.LANGUAGE_CODE)
- except ValueError:
- locale = "en_US"
+def format_datetime_local(datetime, format='DATETIME_FORMAT'):
+ """
+ Format a datetime object to a localized string via python.
+
+ Note: The datetime rendered in template is itself locale aware.
+ A custom format must be defined in settings.py.
+ When a custom format uses a same name with an existing built-in
+ format, it will be overrided by built-in format if l10n
+ is enabled.
+ """
+
+ fmt = format
- result = format_datetime(datetime, format, locale=locale)
+ from django.utils import formats
+ from django.utils.dateformat import format
- return result
+ try:
+ return formats.date_format(datetime, fmt)
+ except AttributeError:
+ try:
+ return format(datetime, fmt)
+ except AttributeError:
+ return formats.date_format(datetime, "DATETIME_FORMAT")
# {{{ dict_to_struct
| {"golden_diff": "diff --git a/relate/utils.py b/relate/utils.py\n--- a/relate/utils.py\n+++ b/relate/utils.py\n@@ -102,21 +102,29 @@\n return tz.localize(datetime.now())\n \n \n-def format_datetime_local(datetime, format='medium'):\n- \"\"\"Format the output of a datetime object to a localized string\"\"\"\n- from babel.dates import format_datetime\n- from django.conf import settings\n- from django.utils.translation.trans_real import to_locale\n- # See http://babel.pocoo.org/docs/api/dates/#date-and-time-formatting\n- # for customizing the output format.\n- try:\n- locale = to_locale(settings.LANGUAGE_CODE)\n- except ValueError:\n- locale = \"en_US\"\n+def format_datetime_local(datetime, format='DATETIME_FORMAT'):\n+ \"\"\"\n+ Format a datetime object to a localized string via python.\n+\n+ Note: The datetime rendered in template is itself locale aware.\n+ A custom format must be defined in settings.py. \n+ When a custom format uses a same name with an existing built-in\n+ format, it will be overrided by built-in format if l10n\n+ is enabled.\n+ \"\"\"\n+\n+ fmt = format\n \n- result = format_datetime(datetime, format, locale=locale)\n+ from django.utils import formats\n+ from django.utils.dateformat import format\n \n- return result\n+ try:\n+ return formats.date_format(datetime, fmt)\n+ except AttributeError:\n+ try:\n+ return format(datetime, fmt)\n+ except AttributeError:\n+ return formats.date_format(datetime, \"DATETIME_FORMAT\")\n \n \n # {{{ dict_to_struct\n", "issue": "Datetime shown not localized.\nAs one of my student complaints, his browser is using en_US locale, however, the datetime shown in RELATE is in zh_CN format. Although he can understand Chinese, however, that will cause problem in other circumstances. \n\nThe reason of problem lies in [this PR](https://github.com/inducer/relate/pull/39) I provided. It uses setting.LANGUAGE_CODE to determine the locale show in browser. \n\nI found I've made it too complicated in that PR, and it quite simple to modify that method using built-in method `django.utils.formats`, and the result is itself locale aware.\n\nI'll create a PR later to fix it.\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\nfrom __future__ import division\n\n__copyright__ = \"Copyright (C) 2014 Andreas Kloeckner\"\n\n__license__ = \"\"\"\nPermission is hereby granted, free of charge, to any person obtaining a copy\nof this software and associated documentation files (the \"Software\"), to deal\nin the Software without restriction, including without limitation the rights\nto use, copy, modify, merge, publish, distribute, sublicense, and/or sell\ncopies of the Software, and to permit persons to whom the Software is\nfurnished to do so, subject to the following conditions:\n\nThe above copyright notice and this permission notice shall be included in\nall copies or substantial portions of the Software.\n\nTHE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\nIMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\nFITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE\nAUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\nLIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,\nOUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN\nTHE SOFTWARE.\n\"\"\"\n\n\nimport six\nimport django.forms as forms\n\n\nclass StyledForm(forms.Form):\n def __init__(self, *args, **kwargs):\n from crispy_forms.helper import FormHelper\n self.helper = FormHelper()\n self.helper.form_class = \"form-horizontal\"\n self.helper.label_class = \"col-lg-2\"\n self.helper.field_class = \"col-lg-8\"\n\n super(StyledForm, self).__init__(*args, **kwargs)\n\n\nclass StyledInlineForm(forms.Form):\n def __init__(self, *args, **kwargs):\n from crispy_forms.helper import FormHelper\n self.helper = FormHelper()\n self.helper.form_class = \"form-inline\"\n self.helper.label_class = \"sr-only\"\n\n super(StyledInlineForm, self).__init__(*args, **kwargs)\n\n\nclass StyledModelForm(forms.ModelForm):\n def __init__(self, *args, **kwargs):\n from crispy_forms.helper import FormHelper\n self.helper = FormHelper()\n self.helper.form_class = \"form-horizontal\"\n self.helper.label_class = \"col-lg-2\"\n self.helper.field_class = \"col-lg-8\"\n\n super(StyledModelForm, self).__init__(*args, **kwargs)\n\n\ndef settings_context_processor(request):\n from django.conf import settings\n return {\n \"student_sign_in_view\": \"relate-sign_in_choice\",\n \"relate_sign_in_by_email_enabled\":\n settings.RELATE_SIGN_IN_BY_EMAIL_ENABLED,\n \"relate_registration_enabled\":\n settings.RELATE_REGISTRATION_ENABLED,\n \"relate_sign_in_by_exam_tickets_enabled\":\n settings.RELATE_SIGN_IN_BY_EXAM_TICKETS_ENABLED,\n \"relate_sign_in_by_saml2_enabled\":\n settings.RELATE_SIGN_IN_BY_SAML2_ENABLED,\n \"maintenance_mode\": settings.RELATE_MAINTENANCE_MODE,\n \"site_announcement\": getattr(settings, \"RELATE_SITE_ANNOUNCEMENT\", None),\n }\n\n\ndef as_local_time(datetime):\n \"\"\"Takes an timezone-aware datetime and applies the server timezone.\"\"\"\n from django.conf import settings\n from pytz import timezone\n tz = timezone(settings.TIME_ZONE)\n return datetime.astimezone(tz)\n\n\ndef localize_datetime(datetime):\n \"\"\"Takes an timezone-naive datetime and applies the server timezone.\"\"\"\n from django.conf import settings\n from pytz import timezone\n tz = timezone(settings.TIME_ZONE)\n return tz.localize(datetime)\n\n\ndef local_now():\n from django.conf import settings\n from pytz import timezone\n tz = timezone(settings.TIME_ZONE)\n from datetime import datetime\n return tz.localize(datetime.now())\n\n\ndef format_datetime_local(datetime, format='medium'):\n \"\"\"Format the output of a datetime object to a localized string\"\"\"\n from babel.dates import format_datetime\n from django.conf import settings\n from django.utils.translation.trans_real import to_locale\n # See http://babel.pocoo.org/docs/api/dates/#date-and-time-formatting\n # for customizing the output format.\n try:\n locale = to_locale(settings.LANGUAGE_CODE)\n except ValueError:\n locale = \"en_US\"\n\n result = format_datetime(datetime, format, locale=locale)\n\n return result\n\n\n# {{{ dict_to_struct\n\nclass Struct(object):\n def __init__(self, entries):\n for name, val in six.iteritems(entries):\n self.__dict__[name] = val\n\n def __repr__(self):\n return repr(self.__dict__)\n\n\ndef dict_to_struct(data):\n if isinstance(data, list):\n return [dict_to_struct(d) for d in data]\n elif isinstance(data, dict):\n return Struct({k: dict_to_struct(v) for k, v in six.iteritems(data)})\n else:\n return data\n\n\ndef struct_to_dict(data):\n return dict(\n (name, val)\n for name, val in six.iteritems(data.__dict__)\n if not name.startswith(\"_\"))\n\n# }}}\n\n\ndef retry_transaction(f, args, kwargs={}, max_tries=None, serializable=None):\n from django.db import transaction\n from django.db.utils import OperationalError\n\n if max_tries is None:\n max_tries = 5\n if serializable is None:\n serializable = False\n\n assert max_tries > 0\n while True:\n try:\n with transaction.atomic():\n if serializable:\n from django.db import connections, DEFAULT_DB_ALIAS\n conn = connections[DEFAULT_DB_ALIAS]\n if conn.vendor == \"postgresql\":\n cursor = conn.cursor()\n cursor.execute(\n \"SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;\")\n\n return f(*args, **kwargs)\n except OperationalError:\n max_tries -= 1\n if not max_tries:\n raise\n\n\nclass retry_transaction_decorator(object):\n def __init__(self, max_tries=None, serializable=None):\n self.max_tries = max_tries\n self.serializable = serializable\n\n def __call__(self, f):\n from functools import update_wrapper\n\n def wrapper(*args, **kwargs):\n return retry_transaction(f, args, kwargs,\n max_tries=self.max_tries,\n serializable=self.serializable)\n\n update_wrapper(wrapper, f)\n return wrapper\n\n\n# {{{ hang debugging\n\ndef dumpstacks(signal, frame):\n import threading\n import sys\n import traceback\n\n id2name = dict([(th.ident, th.name) for th in threading.enumerate()])\n code = []\n for threadId, stack in sys._current_frames().items():\n code.append(\"\\n# Thread: %s(%d)\" % (id2name.get(threadId, \"\"), threadId))\n for filename, lineno, name, line in traceback.extract_stack(stack):\n code.append('File: \"%s\", line %d, in %s' % (filename, lineno, name))\n if line:\n code.append(\" %s\" % (line.strip()))\n print(\"\\n\".join(code))\n\nif 0:\n import signal\n import os\n print(\"*** HANG DUMP HANDLER ACTIVATED: 'kill -USR1 %s' to dump stacks\"\n % os.getpid())\n signal.signal(signal.SIGUSR1, dumpstacks)\n\n# }}}\n\n\n# {{{ convert django language name to js styled language name\n\ndef to_js_lang_name(dj_lang_name):\n \"\"\"\n Turns a django language name (en-us) into a js styled language\n name (en-US).\n \"\"\"\n p = dj_lang_name.find('-')\n if p >= 0:\n return dj_lang_name[:p].lower() + '-' + dj_lang_name[p + 1:].upper()\n else:\n return dj_lang_name.lower()\n\n# }}}\n\n# vim: foldmethod=marker\n", "path": "relate/utils.py"}]} | 2,995 | 373 |
gh_patches_debug_8046 | rasdani/github-patches | git_diff | conda__conda-build-526 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
AppVeyor: Commit message with braces -> failed build
https://ci.appveyor.com/project/mpi4py/mpi4py/build/2.0.0a0-13/job/0q0w2g5o32qk3m94#L522
PS: I got a warning about conda-build being outdated. Isn't `conda update --all` supposed to update it? Maybe conflicting versions with dependencies?
</issue>
<code>
[start of conda_build/windows.py]
1 from __future__ import absolute_import, division, print_function
2
3 import os
4 import sys
5 import shutil
6 from os.path import dirname, isdir, isfile, join, exists
7
8 import conda.config as cc
9 from conda.compat import iteritems
10
11 from conda_build.config import config
12 from conda_build import environ
13 from conda_build import source
14 from conda_build.utils import _check_call
15
16 try:
17 import psutil
18 except ImportError:
19 psutil = None
20
21 assert sys.platform == 'win32'
22
23
24 def fix_staged_scripts():
25 """
26 Fixes scripts which have been installed unix-style to have a .bat
27 helper
28 """
29 scripts_dir = join(config.build_prefix, 'Scripts')
30 if not isdir(scripts_dir):
31 return
32 for fn in os.listdir(scripts_dir):
33 # process all the extensionless files
34 if not isfile(join(scripts_dir, fn)) or '.' in fn:
35 continue
36
37 with open(join(scripts_dir, fn)) as f:
38 line = f.readline().lower()
39 # If it's a #!python script
40 if not (line.startswith('#!') and 'python' in line.lower()):
41 continue
42 print('Adjusting unix-style #! script %s, '
43 'and adding a .bat file for it' % fn)
44 # copy it with a .py extension (skipping that first #! line)
45 with open(join(scripts_dir, fn + '-script.py'), 'w') as fo:
46 fo.write(f.read())
47 # now create the .exe file
48 shutil.copyfile(join(dirname(__file__),
49 'cli-%d.exe' % (8 * tuple.__itemsize__)),
50 join(scripts_dir, fn + '.exe'))
51
52 # remove the original script
53 os.remove(join(scripts_dir, fn))
54
55
56 def msvc_env_cmd():
57 if 'ProgramFiles(x86)' in os.environ:
58 program_files = os.environ['ProgramFiles(x86)']
59 else:
60 program_files = os.environ['ProgramFiles']
61
62 localappdata = os.environ.get("localappdata")
63
64 if config.PY3K:
65 vcvarsall = os.path.join(program_files,
66 r'Microsoft Visual Studio 10.0'
67 r'\VC\vcvarsall.bat')
68 else:
69 vcvarsall = os.path.join(program_files,
70 r'Microsoft Visual Studio 9.0'
71 r'\VC\vcvarsall.bat')
72
73 # Try the Microsoft Visual C++ Compiler for Python 2.7
74 if not isfile(vcvarsall) and localappdata and not config.PY3K:
75 vcvarsall = os.path.join(localappdata, "Programs", "Common",
76 "Microsoft", "Visual C++ for Python", "9.0", "vcvarsall.bat")
77 if not isfile(vcvarsall) and program_files and not config.PY3K:
78 vcvarsall = os.path.join(program_files, 'Common Files',
79 'Microsoft', 'Visual C++ for Python', "9.0", "vcvarsall.bat")
80 if not isfile(vcvarsall):
81 print("Warning: Couldn't find Visual Studio: %r" % vcvarsall)
82 return ''
83
84 return '''\
85 call "%s" %s
86 ''' % (vcvarsall, {32: 'x86', 64: 'amd64'}[cc.bits])
87
88
89 def kill_processes():
90 if psutil is None:
91 return
92 for n in psutil.get_pid_list():
93 try:
94 p = psutil.Process(n)
95 if p.name.lower() == 'msbuild.exe':
96 print('Terminating:', p.name)
97 p.terminate()
98 except:
99 continue
100
101
102 def build(m):
103 env = dict(os.environ)
104 env.update(environ.get_dict(m))
105
106 for name in 'BIN', 'INC', 'LIB':
107 path = env['LIBRARY_' + name]
108 if not isdir(path):
109 os.makedirs(path)
110
111 src_dir = source.get_dir()
112 bld_bat = join(m.path, 'bld.bat')
113 if exists(bld_bat):
114 with open(bld_bat) as fi:
115 data = fi.read()
116 with open(join(src_dir, 'bld.bat'), 'w') as fo:
117 fo.write(msvc_env_cmd())
118 for kv in iteritems(env):
119 fo.write('set %s=%s\n' % kv)
120 # more debuggable with echo on
121 fo.write('@echo on\n')
122 fo.write("REM ===== end generated header =====\n")
123 fo.write(data)
124
125 cmd = [os.environ['COMSPEC'], '/c', 'call', 'bld.bat']
126 _check_call(cmd, cwd=src_dir)
127 kill_processes()
128 fix_staged_scripts()
129
[end of conda_build/windows.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/conda_build/windows.py b/conda_build/windows.py
--- a/conda_build/windows.py
+++ b/conda_build/windows.py
@@ -116,7 +116,7 @@
with open(join(src_dir, 'bld.bat'), 'w') as fo:
fo.write(msvc_env_cmd())
for kv in iteritems(env):
- fo.write('set %s=%s\n' % kv)
+ fo.write('set "%s=%s"\n' % kv)
# more debuggable with echo on
fo.write('@echo on\n')
fo.write("REM ===== end generated header =====\n")
| {"golden_diff": "diff --git a/conda_build/windows.py b/conda_build/windows.py\n--- a/conda_build/windows.py\n+++ b/conda_build/windows.py\n@@ -116,7 +116,7 @@\n with open(join(src_dir, 'bld.bat'), 'w') as fo:\n fo.write(msvc_env_cmd())\n for kv in iteritems(env):\n- fo.write('set %s=%s\\n' % kv)\n+ fo.write('set \"%s=%s\"\\n' % kv)\n # more debuggable with echo on\n fo.write('@echo on\\n')\n fo.write(\"REM ===== end generated header =====\\n\")\n", "issue": "AppVeyor: Commit message with braces -> failed build\nhttps://ci.appveyor.com/project/mpi4py/mpi4py/build/2.0.0a0-13/job/0q0w2g5o32qk3m94#L522\n\nPS: I got a warning about conda-build being outdated. Isn't `conda update --all` supposed to update it? Maybe conflicting versions with dependencies?\n\n", "before_files": [{"content": "from __future__ import absolute_import, division, print_function\n\nimport os\nimport sys\nimport shutil\nfrom os.path import dirname, isdir, isfile, join, exists\n\nimport conda.config as cc\nfrom conda.compat import iteritems\n\nfrom conda_build.config import config\nfrom conda_build import environ\nfrom conda_build import source\nfrom conda_build.utils import _check_call\n\ntry:\n import psutil\nexcept ImportError:\n psutil = None\n\nassert sys.platform == 'win32'\n\n\ndef fix_staged_scripts():\n \"\"\"\n Fixes scripts which have been installed unix-style to have a .bat\n helper\n \"\"\"\n scripts_dir = join(config.build_prefix, 'Scripts')\n if not isdir(scripts_dir):\n return\n for fn in os.listdir(scripts_dir):\n # process all the extensionless files\n if not isfile(join(scripts_dir, fn)) or '.' in fn:\n continue\n\n with open(join(scripts_dir, fn)) as f:\n line = f.readline().lower()\n # If it's a #!python script\n if not (line.startswith('#!') and 'python' in line.lower()):\n continue\n print('Adjusting unix-style #! script %s, '\n 'and adding a .bat file for it' % fn)\n # copy it with a .py extension (skipping that first #! line)\n with open(join(scripts_dir, fn + '-script.py'), 'w') as fo:\n fo.write(f.read())\n # now create the .exe file\n shutil.copyfile(join(dirname(__file__),\n 'cli-%d.exe' % (8 * tuple.__itemsize__)),\n join(scripts_dir, fn + '.exe'))\n\n # remove the original script\n os.remove(join(scripts_dir, fn))\n\n\ndef msvc_env_cmd():\n if 'ProgramFiles(x86)' in os.environ:\n program_files = os.environ['ProgramFiles(x86)']\n else:\n program_files = os.environ['ProgramFiles']\n\n localappdata = os.environ.get(\"localappdata\")\n\n if config.PY3K:\n vcvarsall = os.path.join(program_files,\n r'Microsoft Visual Studio 10.0'\n r'\\VC\\vcvarsall.bat')\n else:\n vcvarsall = os.path.join(program_files,\n r'Microsoft Visual Studio 9.0'\n r'\\VC\\vcvarsall.bat')\n\n # Try the Microsoft Visual C++ Compiler for Python 2.7\n if not isfile(vcvarsall) and localappdata and not config.PY3K:\n vcvarsall = os.path.join(localappdata, \"Programs\", \"Common\",\n \"Microsoft\", \"Visual C++ for Python\", \"9.0\", \"vcvarsall.bat\")\n if not isfile(vcvarsall) and program_files and not config.PY3K:\n vcvarsall = os.path.join(program_files, 'Common Files',\n 'Microsoft', 'Visual C++ for Python', \"9.0\", \"vcvarsall.bat\")\n if not isfile(vcvarsall):\n print(\"Warning: Couldn't find Visual Studio: %r\" % vcvarsall)\n return ''\n\n return '''\\\ncall \"%s\" %s\n''' % (vcvarsall, {32: 'x86', 64: 'amd64'}[cc.bits])\n\n\ndef kill_processes():\n if psutil is None:\n return\n for n in psutil.get_pid_list():\n try:\n p = psutil.Process(n)\n if p.name.lower() == 'msbuild.exe':\n print('Terminating:', p.name)\n p.terminate()\n except:\n continue\n\n\ndef build(m):\n env = dict(os.environ)\n env.update(environ.get_dict(m))\n\n for name in 'BIN', 'INC', 'LIB':\n path = env['LIBRARY_' + name]\n if not isdir(path):\n os.makedirs(path)\n\n src_dir = source.get_dir()\n bld_bat = join(m.path, 'bld.bat')\n if exists(bld_bat):\n with open(bld_bat) as fi:\n data = fi.read()\n with open(join(src_dir, 'bld.bat'), 'w') as fo:\n fo.write(msvc_env_cmd())\n for kv in iteritems(env):\n fo.write('set %s=%s\\n' % kv)\n # more debuggable with echo on\n fo.write('@echo on\\n')\n fo.write(\"REM ===== end generated header =====\\n\")\n fo.write(data)\n\n cmd = [os.environ['COMSPEC'], '/c', 'call', 'bld.bat']\n _check_call(cmd, cwd=src_dir)\n kill_processes()\n fix_staged_scripts()\n", "path": "conda_build/windows.py"}]} | 1,957 | 141 |
gh_patches_debug_20839 | rasdani/github-patches | git_diff | mdn__kuma-7759 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Make /$locale/search.json redirect
**Summary**
We get a lot of `NoReverseMatch` on URLs like https://developer.mozilla.org/en-US/search.json
That endpoint disappeared when we switched to the new search API.
Let's make it redirect.
**Additional context**
https://sentry.prod.mozaws.net/operations/mdn-prod/issues/10482841/
</issue>
<code>
[start of kuma/search/views.py]
1 from urllib.parse import parse_qs, urlencode
2
3 from django.shortcuts import render
4 from django.urls import reverse_lazy
5 from django.views.decorators.cache import never_cache
6 from django.views.decorators.http import require_GET
7 from django.views.generic import RedirectView
8 from ratelimit.decorators import ratelimit
9
10 from kuma.api.v1.search import search as search_api
11 from kuma.core.decorators import shared_cache_control
12
13
14 # Since the search endpoint accepts user input (via query parameters) and its
15 # response is compressed, use rate limiting to mitigate the BREACH attack
16 # (see http://breachattack.com/). It still needs to allow a user to click
17 # the filter switches (bug 1426968).
18 # Alternate: forbid gzip by setting Content-Encoding: identity
19 @never_cache
20 @require_GET
21 @ratelimit(key="user_or_ip", rate="25/m", block=True)
22 def search(request, *args, **kwargs):
23 """
24 The search view.
25
26 --2021-- THIS VIEW IS A HACK! --2021--
27 This Django view exists to server-side render the search results page.
28 But we're moving the search result page to Yari and that one will use a XHR
29 request (to /api/v1/search) from a skeleton page (aka. SPA).
30 But as a way to get to that, we need to transition from the old to the new.
31 So, this page uses the Django view in kuma.api.v1.search.search, which
32 returns a special `JsonResponse` instance whose data we can pluck out
33 to our needs for this old view.
34 Once we've fully moved to the Yari (static + XHR to v1 API) site-search,
35 we can comfortably delete this view.
36 """
37 # The underlying v1 API supports searching without a 'q' but the web
38 # UI doesn't. For example, the search input field requires a value.
39 # So we match that here too.
40 if not request.GET.get("q", "").strip():
41 status = 400
42 context = {"results": {}}
43 else:
44 # TODO consider, if the current locale is *not* en-US, that we force
45 # it to do a search in both locales.
46 # This might come in handy for people searching in a locale where
47 # there's very little results but they'd be happy to get the en-US ones.
48 response = search_api(request, *args, **kwargs)
49 results = response.data
50
51 error = None
52 status = response.status_code
53
54 # Determine if there were validation errors
55 if status == 400:
56 error = ""
57 for key, messages in results["errors"].items():
58 for message in messages:
59 error += f"{key}: {message['message']}\n"
60 else:
61 # Have to rearrange the 'results' in a way the old search expects it.
62 # ...which is as follows:
63 # - `count`: integer number of matched documents
64 # - `previous`: a URL or empty string
65 # - `next`: a URL or empty string
66 # - `query`: string
67 # - `start`: pagination number
68 # - `end`: pagination number
69 # - `documents`:
70 # - `title`
71 # - `locale`
72 # - `slug`
73 # - `excerpt`: string of safe HTML
74 next_url = ""
75 previous_url = ""
76 page = results["metadata"]["page"]
77 size = results["metadata"]["size"]
78 count = results["metadata"]["total"]["value"]
79 query_string = request.META.get("QUERY_STRING")
80 query_string_parsed = parse_qs(query_string)
81 if (page + 1) * size < count:
82 query_string_parsed["page"] = f"{page + 1}"
83 next_url = f"?{urlencode(query_string_parsed, True)}"
84 if page > 1:
85 if page == 2:
86 del query_string_parsed["page"]
87 else:
88 query_string_parsed["page"] = f"{page - 1}"
89 previous_url = f"?{urlencode(query_string_parsed, True)}"
90
91 results = {
92 "count": count,
93 "next": next_url,
94 "previous": previous_url,
95 "query": request.GET.get("q"),
96 "start": (page - 1) * size + 1,
97 "end": page * size,
98 "documents": [
99 {
100 "title": x["title"],
101 "slug": x["slug"],
102 "locale": x["locale"],
103 "excerpt": "<br>".join(x["highlight"].get("body", [])),
104 }
105 for x in results["documents"]
106 ],
107 }
108
109 context = {"results": {"results": None if error else results, "error": error}}
110 return render(request, "search/react.html", context, status=status)
111
112
113 class SearchRedirectView(RedirectView):
114 permanent = True
115
116 def get_redirect_url(self, *args, **kwargs):
117 query_string = self.request.META.get("QUERY_STRING")
118 url = reverse_lazy(
119 "api.v1.search", kwargs={"locale": self.request.LANGUAGE_CODE}
120 )
121 if query_string:
122 url += "?" + query_string
123 return url
124
125
126 @shared_cache_control(s_maxage=60 * 60 * 24 * 7)
127 def plugin(request):
128 """Render an OpenSearch Plugin."""
129 return render(
130 request,
131 "search/plugin.html",
132 {"locale": request.LANGUAGE_CODE},
133 content_type="application/opensearchdescription+xml",
134 )
135
[end of kuma/search/views.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/kuma/search/views.py b/kuma/search/views.py
--- a/kuma/search/views.py
+++ b/kuma/search/views.py
@@ -1,5 +1,6 @@
from urllib.parse import parse_qs, urlencode
+from django.conf import settings
from django.shortcuts import render
from django.urls import reverse_lazy
from django.views.decorators.cache import never_cache
@@ -115,11 +116,14 @@
def get_redirect_url(self, *args, **kwargs):
query_string = self.request.META.get("QUERY_STRING")
- url = reverse_lazy(
- "api.v1.search", kwargs={"locale": self.request.LANGUAGE_CODE}
- )
- if query_string:
- url += "?" + query_string
+ url = reverse_lazy("api.v1.search")
+ qs = parse_qs(query_string)
+ # If you used `/en-Us/search.json` you can skip the `?locale=`
+ # because the default locale in `/api/v1/search` is `en-US`.
+ if self.request.LANGUAGE_CODE.lower() != settings.LANGUAGE_CODE.lower():
+ qs["locale"] = self.request.LANGUAGE_CODE
+ if qs:
+ url += "?" + urlencode(qs, True)
return url
| {"golden_diff": "diff --git a/kuma/search/views.py b/kuma/search/views.py\n--- a/kuma/search/views.py\n+++ b/kuma/search/views.py\n@@ -1,5 +1,6 @@\n from urllib.parse import parse_qs, urlencode\n \n+from django.conf import settings\n from django.shortcuts import render\n from django.urls import reverse_lazy\n from django.views.decorators.cache import never_cache\n@@ -115,11 +116,14 @@\n \n def get_redirect_url(self, *args, **kwargs):\n query_string = self.request.META.get(\"QUERY_STRING\")\n- url = reverse_lazy(\n- \"api.v1.search\", kwargs={\"locale\": self.request.LANGUAGE_CODE}\n- )\n- if query_string:\n- url += \"?\" + query_string\n+ url = reverse_lazy(\"api.v1.search\")\n+ qs = parse_qs(query_string)\n+ # If you used `/en-Us/search.json` you can skip the `?locale=`\n+ # because the default locale in `/api/v1/search` is `en-US`.\n+ if self.request.LANGUAGE_CODE.lower() != settings.LANGUAGE_CODE.lower():\n+ qs[\"locale\"] = self.request.LANGUAGE_CODE\n+ if qs:\n+ url += \"?\" + urlencode(qs, True)\n return url\n", "issue": "Make /$locale/search.json redirect\n**Summary**\r\nWe get a lot of `NoReverseMatch` on URLs like https://developer.mozilla.org/en-US/search.json\r\nThat endpoint disappeared when we switched to the new search API. \r\nLet's make it redirect. \r\n\r\n\r\n**Additional context**\r\nhttps://sentry.prod.mozaws.net/operations/mdn-prod/issues/10482841/\r\n\n", "before_files": [{"content": "from urllib.parse import parse_qs, urlencode\n\nfrom django.shortcuts import render\nfrom django.urls import reverse_lazy\nfrom django.views.decorators.cache import never_cache\nfrom django.views.decorators.http import require_GET\nfrom django.views.generic import RedirectView\nfrom ratelimit.decorators import ratelimit\n\nfrom kuma.api.v1.search import search as search_api\nfrom kuma.core.decorators import shared_cache_control\n\n\n# Since the search endpoint accepts user input (via query parameters) and its\n# response is compressed, use rate limiting to mitigate the BREACH attack\n# (see http://breachattack.com/). It still needs to allow a user to click\n# the filter switches (bug 1426968).\n# Alternate: forbid gzip by setting Content-Encoding: identity\n@never_cache\n@require_GET\n@ratelimit(key=\"user_or_ip\", rate=\"25/m\", block=True)\ndef search(request, *args, **kwargs):\n \"\"\"\n The search view.\n\n --2021-- THIS VIEW IS A HACK! --2021--\n This Django view exists to server-side render the search results page.\n But we're moving the search result page to Yari and that one will use a XHR\n request (to /api/v1/search) from a skeleton page (aka. SPA).\n But as a way to get to that, we need to transition from the old to the new.\n So, this page uses the Django view in kuma.api.v1.search.search, which\n returns a special `JsonResponse` instance whose data we can pluck out\n to our needs for this old view.\n Once we've fully moved to the Yari (static + XHR to v1 API) site-search,\n we can comfortably delete this view.\n \"\"\"\n # The underlying v1 API supports searching without a 'q' but the web\n # UI doesn't. For example, the search input field requires a value.\n # So we match that here too.\n if not request.GET.get(\"q\", \"\").strip():\n status = 400\n context = {\"results\": {}}\n else:\n # TODO consider, if the current locale is *not* en-US, that we force\n # it to do a search in both locales.\n # This might come in handy for people searching in a locale where\n # there's very little results but they'd be happy to get the en-US ones.\n response = search_api(request, *args, **kwargs)\n results = response.data\n\n error = None\n status = response.status_code\n\n # Determine if there were validation errors\n if status == 400:\n error = \"\"\n for key, messages in results[\"errors\"].items():\n for message in messages:\n error += f\"{key}: {message['message']}\\n\"\n else:\n # Have to rearrange the 'results' in a way the old search expects it.\n # ...which is as follows:\n # - `count`: integer number of matched documents\n # - `previous`: a URL or empty string\n # - `next`: a URL or empty string\n # - `query`: string\n # - `start`: pagination number\n # - `end`: pagination number\n # - `documents`:\n # - `title`\n # - `locale`\n # - `slug`\n # - `excerpt`: string of safe HTML\n next_url = \"\"\n previous_url = \"\"\n page = results[\"metadata\"][\"page\"]\n size = results[\"metadata\"][\"size\"]\n count = results[\"metadata\"][\"total\"][\"value\"]\n query_string = request.META.get(\"QUERY_STRING\")\n query_string_parsed = parse_qs(query_string)\n if (page + 1) * size < count:\n query_string_parsed[\"page\"] = f\"{page + 1}\"\n next_url = f\"?{urlencode(query_string_parsed, True)}\"\n if page > 1:\n if page == 2:\n del query_string_parsed[\"page\"]\n else:\n query_string_parsed[\"page\"] = f\"{page - 1}\"\n previous_url = f\"?{urlencode(query_string_parsed, True)}\"\n\n results = {\n \"count\": count,\n \"next\": next_url,\n \"previous\": previous_url,\n \"query\": request.GET.get(\"q\"),\n \"start\": (page - 1) * size + 1,\n \"end\": page * size,\n \"documents\": [\n {\n \"title\": x[\"title\"],\n \"slug\": x[\"slug\"],\n \"locale\": x[\"locale\"],\n \"excerpt\": \"<br>\".join(x[\"highlight\"].get(\"body\", [])),\n }\n for x in results[\"documents\"]\n ],\n }\n\n context = {\"results\": {\"results\": None if error else results, \"error\": error}}\n return render(request, \"search/react.html\", context, status=status)\n\n\nclass SearchRedirectView(RedirectView):\n permanent = True\n\n def get_redirect_url(self, *args, **kwargs):\n query_string = self.request.META.get(\"QUERY_STRING\")\n url = reverse_lazy(\n \"api.v1.search\", kwargs={\"locale\": self.request.LANGUAGE_CODE}\n )\n if query_string:\n url += \"?\" + query_string\n return url\n\n\n@shared_cache_control(s_maxage=60 * 60 * 24 * 7)\ndef plugin(request):\n \"\"\"Render an OpenSearch Plugin.\"\"\"\n return render(\n request,\n \"search/plugin.html\",\n {\"locale\": request.LANGUAGE_CODE},\n content_type=\"application/opensearchdescription+xml\",\n )\n", "path": "kuma/search/views.py"}]} | 2,139 | 279 |
gh_patches_debug_32307 | rasdani/github-patches | git_diff | pwndbg__pwndbg-1912 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Refactor symbol.py skipped exceptions
The list created here: https://github.com/pwndbg/pwndbg/blob/85eb6c8bf9c59280f82f2168048071de104cd9dc/pwndbg/gdblib/symbol.py#L123-L140
should be a global variable and should be created with `(item1, item2, ...)` instead of appending to a list. The comments should still stand.
If anyone wants to go ahead and refactor it, please send a PR :).
</issue>
<code>
[start of pwndbg/gdblib/symbol.py]
1 """
2 Looking up addresses for function names / symbols, and
3 vice-versa.
4
5 Uses IDA when available if there isn't sufficient symbol
6 information available.
7 """
8 from __future__ import annotations
9
10 import re
11
12 import gdb
13
14 import pwndbg.gdblib.android
15 import pwndbg.gdblib.arch
16 import pwndbg.gdblib.elf
17 import pwndbg.gdblib.events
18 import pwndbg.gdblib.file
19 import pwndbg.gdblib.memory
20 import pwndbg.gdblib.qemu
21 import pwndbg.gdblib.remote
22 import pwndbg.gdblib.stack
23 import pwndbg.gdblib.vmmap
24 import pwndbg.ida
25 import pwndbg.lib.cache
26
27
28 def _get_debug_file_directory():
29 """
30 Retrieve the debug file directory path.
31
32 The debug file directory path ('show debug-file-directory') is a comma-
33 separated list of directories which GDB will look in to find the binaries
34 currently loaded.
35 """
36 result = gdb.execute("show debug-file-directory", to_string=True, from_tty=False)
37 expr = r'The directory where separate debug symbols are searched for is "(.*)".\n'
38
39 match = re.search(expr, result)
40
41 if match:
42 return match.group(1)
43 return ""
44
45
46 def _set_debug_file_directory(d) -> None:
47 gdb.execute(f"set debug-file-directory {d}", to_string=True, from_tty=False)
48
49
50 def _add_debug_file_directory(d) -> None:
51 current = _get_debug_file_directory()
52 if current:
53 _set_debug_file_directory(f"{current}:{d}")
54 else:
55 _set_debug_file_directory(d)
56
57
58 if "/usr/lib/debug" not in _get_debug_file_directory():
59 _add_debug_file_directory("/usr/lib/debug")
60
61
62 @pwndbg.lib.cache.cache_until("objfile")
63 def get(address: int, gdb_only=False) -> str:
64 """
65 Retrieve the name for the symbol located at `address` - either from GDB or from IDA sync
66 Passing `gdb_only=True`
67 """
68 # Note: we do not return "" on `address < pwndbg.gdblib.memory.MMAP_MIN_ADDR`
69 # because this may be used to find out the symbol name on PIE binaries that weren't started yet
70 # and then their symbol addresses can be found by GDB on their (non-rebased) offsets
71
72 # Fast path: GDB's `info symbol` returns 'Numeric constant too large' here
73 if address >= ((1 << 64) - 1):
74 return ""
75
76 # This sucks, but there's not a GDB API for this.
77 result = gdb.execute("info symbol %#x" % int(address), to_string=True, from_tty=False)
78
79 if not gdb_only and result.startswith("No symbol"):
80 address = int(address)
81 exe = pwndbg.gdblib.elf.exe()
82 if exe:
83 exe_map = pwndbg.gdblib.vmmap.find(exe.address)
84 if exe_map and address in exe_map:
85 res = pwndbg.ida.Name(address) or pwndbg.ida.GetFuncOffset(address)
86 return res or ""
87
88 # If there are newlines, which means that there are multiple symbols for the address
89 # then use the first one (see also #1610)
90 result = result[: result.index("\n")]
91
92 # See https://github.com/bminor/binutils-gdb/blob/d1702fea87aa62dff7de465464097dba63cc8c0f/gdb/printcmd.c#L1594-L1624
93 # The most often encountered formats looks like this:
94 # "main in section .text of /bin/bash"
95 # "main + 3 in section .text of /bin/bash"
96 # "system + 1 in section .text of /lib/x86_64-linux-gnu/libc.so.6"
97 # "No symbol matches system-1"
98 # But there are some others that we have to account for as well
99 if " in section " in result:
100 loc_string, _ = result.split(" in section ")
101 elif " in load address range of " in result:
102 loc_string, _ = result.split(" in load address range of ")
103 elif " overlay section " in result:
104 result, _ = result.split(" overlay section ")
105 loc_string, _ = result.split(" in ")
106 else:
107 loc_string = ""
108
109 # If there is 'main + 87' we want to replace it with 'main+87' etc.
110 return loc_string.replace(" + ", "+")
111
112
113 @pwndbg.lib.cache.cache_until("objfile")
114 def address(symbol: str) -> int:
115 """
116 Get the address for `symbol`
117 """
118 try:
119 symbol_obj = gdb.lookup_symbol(symbol)[0]
120 if symbol_obj:
121 return int(symbol_obj.value().address)
122 except gdb.error as e:
123 # Symbol lookup only throws exceptions on errors, not if it failed to
124 # lookup a symbol. We want to raise these errors so we can handle them
125 # properly, but there are some we haven't figured out how to fix yet, so
126 # we ignore those here
127 skipped_exceptions = []
128
129 # This is exception is being thrown by the Go typeinfo tests, we should
130 # investigate why this is happening and see if we can explicitly check
131 # for it with `gdb.selected_frame()`
132 skipped_exceptions.append("No frame selected")
133
134 # If we try to look up a TLS variable when there is no TLS, this
135 # exception occurs. Ideally we should come up with a way to check for
136 # this case before calling `gdb.lookup_symbol`
137 skipped_exceptions.append("Cannot find thread-local")
138
139 # This reproduced on GDB 12.1 and caused #1878
140 skipped_exceptions.append("symbol requires a frame to compute its value")
141
142 if all(x not in str(e) for x in skipped_exceptions):
143 raise e
144
145 try:
146 # Unfortunately, `gdb.lookup_symbol` does not seem to handle all
147 # symbols, so we need to fallback to using `gdb.parse_and_eval`. See
148 # https://sourceware.org/pipermail/gdb/2022-October/050362.html
149 # (We tried parsing the output of the `info address` before, but there were some issues. See #1628 and #1666)
150 if "\\" in symbol:
151 # Is it possible that happens? Probably not, but just in case
152 raise ValueError(f"Symbol {symbol!r} contains a backslash")
153 sanitized_symbol_name = symbol.replace("'", "\\'")
154 return int(gdb.parse_and_eval(f"&'{sanitized_symbol_name}'"))
155
156 except gdb.error:
157 return None
158
159
160 @pwndbg.lib.cache.cache_until("objfile", "thread")
161 def static_linkage_symbol_address(symbol: str) -> int:
162 """
163 Get the address for static linkage `symbol`
164 """
165
166 try:
167 symbol_obj = gdb.lookup_static_symbol(symbol)
168 return int(symbol_obj.value().address) if symbol_obj else None
169 except gdb.error:
170 return None
171
172
173 @pwndbg.lib.cache.cache_until("stop", "start")
174 def selected_frame_source_absolute_filename():
175 """
176 Retrieve the symbol table’s source absolute file name from the selected frame.
177
178 In case of missing symbol table or frame information, None is returned.
179 """
180 try:
181 frame = gdb.selected_frame()
182 except gdb.error:
183 return None
184
185 if not frame:
186 return None
187
188 sal = frame.find_sal()
189 if not sal:
190 return None
191
192 symtab = sal.symtab
193 if not symtab:
194 return None
195
196 return symtab.fullname()
197
198
199 def parse_and_eval(expression: str) -> gdb.Value | None:
200 """Error handling wrapper for GDBs parse_and_eval function"""
201 try:
202 return gdb.parse_and_eval(expression)
203 except gdb.error:
204 return None
205
[end of pwndbg/gdblib/symbol.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/pwndbg/gdblib/symbol.py b/pwndbg/gdblib/symbol.py
--- a/pwndbg/gdblib/symbol.py
+++ b/pwndbg/gdblib/symbol.py
@@ -24,6 +24,25 @@
import pwndbg.ida
import pwndbg.lib.cache
+# Symbol lookup only throws exceptions on errors, not if it failed to
+# look up a symbol. We want to raise these errors so we can handle them
+# properly, but there are some we haven't figured out how to fix yet, so
+# we ignore those here
+skipped_exceptions = None
+
+skipped_exceptions = (
+ # This exception is being thrown by the Go typeinfo tests, we should
+ # investigate why this is happening and see if we can explicitly check
+ # for it with `gdb.selected_frame()`
+ "No frame selected",
+ # If we try to look up a TLS variable when there is no TLS, this
+ # exception occurs. Ideally we should come up with a way to check for
+ # this case before calling `gdb.lookup_symbol`
+ "Cannot find thread-local",
+ # This reproduced on GDB 12.1 and caused #1878
+ "Symbol requires a frame to compute its value",
+)
+
def _get_debug_file_directory():
"""
@@ -120,25 +139,6 @@
if symbol_obj:
return int(symbol_obj.value().address)
except gdb.error as e:
- # Symbol lookup only throws exceptions on errors, not if it failed to
- # lookup a symbol. We want to raise these errors so we can handle them
- # properly, but there are some we haven't figured out how to fix yet, so
- # we ignore those here
- skipped_exceptions = []
-
- # This is exception is being thrown by the Go typeinfo tests, we should
- # investigate why this is happening and see if we can explicitly check
- # for it with `gdb.selected_frame()`
- skipped_exceptions.append("No frame selected")
-
- # If we try to look up a TLS variable when there is no TLS, this
- # exception occurs. Ideally we should come up with a way to check for
- # this case before calling `gdb.lookup_symbol`
- skipped_exceptions.append("Cannot find thread-local")
-
- # This reproduced on GDB 12.1 and caused #1878
- skipped_exceptions.append("symbol requires a frame to compute its value")
-
if all(x not in str(e) for x in skipped_exceptions):
raise e
| {"golden_diff": "diff --git a/pwndbg/gdblib/symbol.py b/pwndbg/gdblib/symbol.py\n--- a/pwndbg/gdblib/symbol.py\n+++ b/pwndbg/gdblib/symbol.py\n@@ -24,6 +24,25 @@\n import pwndbg.ida\n import pwndbg.lib.cache\n \n+# Symbol lookup only throws exceptions on errors, not if it failed to\n+# look up a symbol. We want to raise these errors so we can handle them\n+# properly, but there are some we haven't figured out how to fix yet, so\n+# we ignore those here\n+skipped_exceptions = None\n+\n+skipped_exceptions = (\n+ # This exception is being thrown by the Go typeinfo tests, we should\n+ # investigate why this is happening and see if we can explicitly check\n+ # for it with `gdb.selected_frame()`\n+ \"No frame selected\",\n+ # If we try to look up a TLS variable when there is no TLS, this\n+ # exception occurs. Ideally we should come up with a way to check for\n+ # this case before calling `gdb.lookup_symbol`\n+ \"Cannot find thread-local\",\n+ # This reproduced on GDB 12.1 and caused #1878\n+ \"Symbol requires a frame to compute its value\",\n+)\n+\n \n def _get_debug_file_directory():\n \"\"\"\n@@ -120,25 +139,6 @@\n if symbol_obj:\n return int(symbol_obj.value().address)\n except gdb.error as e:\n- # Symbol lookup only throws exceptions on errors, not if it failed to\n- # lookup a symbol. We want to raise these errors so we can handle them\n- # properly, but there are some we haven't figured out how to fix yet, so\n- # we ignore those here\n- skipped_exceptions = []\n-\n- # This is exception is being thrown by the Go typeinfo tests, we should\n- # investigate why this is happening and see if we can explicitly check\n- # for it with `gdb.selected_frame()`\n- skipped_exceptions.append(\"No frame selected\")\n-\n- # If we try to look up a TLS variable when there is no TLS, this\n- # exception occurs. Ideally we should come up with a way to check for\n- # this case before calling `gdb.lookup_symbol`\n- skipped_exceptions.append(\"Cannot find thread-local\")\n-\n- # This reproduced on GDB 12.1 and caused #1878\n- skipped_exceptions.append(\"symbol requires a frame to compute its value\")\n-\n if all(x not in str(e) for x in skipped_exceptions):\n raise e\n", "issue": "Refactor symbol.py skipped exceptions\nThe list created here: https://github.com/pwndbg/pwndbg/blob/85eb6c8bf9c59280f82f2168048071de104cd9dc/pwndbg/gdblib/symbol.py#L123-L140\r\n\r\nshould be a global variable and should be created with `(item1, item2, ...)` instead of appending to a list. The comments should still stand.\r\n\r\nIf anyone wants to go ahead and refactor it, please send a PR :).\r\n\n", "before_files": [{"content": "\"\"\"\nLooking up addresses for function names / symbols, and\nvice-versa.\n\nUses IDA when available if there isn't sufficient symbol\ninformation available.\n\"\"\"\nfrom __future__ import annotations\n\nimport re\n\nimport gdb\n\nimport pwndbg.gdblib.android\nimport pwndbg.gdblib.arch\nimport pwndbg.gdblib.elf\nimport pwndbg.gdblib.events\nimport pwndbg.gdblib.file\nimport pwndbg.gdblib.memory\nimport pwndbg.gdblib.qemu\nimport pwndbg.gdblib.remote\nimport pwndbg.gdblib.stack\nimport pwndbg.gdblib.vmmap\nimport pwndbg.ida\nimport pwndbg.lib.cache\n\n\ndef _get_debug_file_directory():\n \"\"\"\n Retrieve the debug file directory path.\n\n The debug file directory path ('show debug-file-directory') is a comma-\n separated list of directories which GDB will look in to find the binaries\n currently loaded.\n \"\"\"\n result = gdb.execute(\"show debug-file-directory\", to_string=True, from_tty=False)\n expr = r'The directory where separate debug symbols are searched for is \"(.*)\".\\n'\n\n match = re.search(expr, result)\n\n if match:\n return match.group(1)\n return \"\"\n\n\ndef _set_debug_file_directory(d) -> None:\n gdb.execute(f\"set debug-file-directory {d}\", to_string=True, from_tty=False)\n\n\ndef _add_debug_file_directory(d) -> None:\n current = _get_debug_file_directory()\n if current:\n _set_debug_file_directory(f\"{current}:{d}\")\n else:\n _set_debug_file_directory(d)\n\n\nif \"/usr/lib/debug\" not in _get_debug_file_directory():\n _add_debug_file_directory(\"/usr/lib/debug\")\n\n\[email protected]_until(\"objfile\")\ndef get(address: int, gdb_only=False) -> str:\n \"\"\"\n Retrieve the name for the symbol located at `address` - either from GDB or from IDA sync\n Passing `gdb_only=True`\n \"\"\"\n # Note: we do not return \"\" on `address < pwndbg.gdblib.memory.MMAP_MIN_ADDR`\n # because this may be used to find out the symbol name on PIE binaries that weren't started yet\n # and then their symbol addresses can be found by GDB on their (non-rebased) offsets\n\n # Fast path: GDB's `info symbol` returns 'Numeric constant too large' here\n if address >= ((1 << 64) - 1):\n return \"\"\n\n # This sucks, but there's not a GDB API for this.\n result = gdb.execute(\"info symbol %#x\" % int(address), to_string=True, from_tty=False)\n\n if not gdb_only and result.startswith(\"No symbol\"):\n address = int(address)\n exe = pwndbg.gdblib.elf.exe()\n if exe:\n exe_map = pwndbg.gdblib.vmmap.find(exe.address)\n if exe_map and address in exe_map:\n res = pwndbg.ida.Name(address) or pwndbg.ida.GetFuncOffset(address)\n return res or \"\"\n\n # If there are newlines, which means that there are multiple symbols for the address\n # then use the first one (see also #1610)\n result = result[: result.index(\"\\n\")]\n\n # See https://github.com/bminor/binutils-gdb/blob/d1702fea87aa62dff7de465464097dba63cc8c0f/gdb/printcmd.c#L1594-L1624\n # The most often encountered formats looks like this:\n # \"main in section .text of /bin/bash\"\n # \"main + 3 in section .text of /bin/bash\"\n # \"system + 1 in section .text of /lib/x86_64-linux-gnu/libc.so.6\"\n # \"No symbol matches system-1\"\n # But there are some others that we have to account for as well\n if \" in section \" in result:\n loc_string, _ = result.split(\" in section \")\n elif \" in load address range of \" in result:\n loc_string, _ = result.split(\" in load address range of \")\n elif \" overlay section \" in result:\n result, _ = result.split(\" overlay section \")\n loc_string, _ = result.split(\" in \")\n else:\n loc_string = \"\"\n\n # If there is 'main + 87' we want to replace it with 'main+87' etc.\n return loc_string.replace(\" + \", \"+\")\n\n\[email protected]_until(\"objfile\")\ndef address(symbol: str) -> int:\n \"\"\"\n Get the address for `symbol`\n \"\"\"\n try:\n symbol_obj = gdb.lookup_symbol(symbol)[0]\n if symbol_obj:\n return int(symbol_obj.value().address)\n except gdb.error as e:\n # Symbol lookup only throws exceptions on errors, not if it failed to\n # lookup a symbol. We want to raise these errors so we can handle them\n # properly, but there are some we haven't figured out how to fix yet, so\n # we ignore those here\n skipped_exceptions = []\n\n # This is exception is being thrown by the Go typeinfo tests, we should\n # investigate why this is happening and see if we can explicitly check\n # for it with `gdb.selected_frame()`\n skipped_exceptions.append(\"No frame selected\")\n\n # If we try to look up a TLS variable when there is no TLS, this\n # exception occurs. Ideally we should come up with a way to check for\n # this case before calling `gdb.lookup_symbol`\n skipped_exceptions.append(\"Cannot find thread-local\")\n\n # This reproduced on GDB 12.1 and caused #1878\n skipped_exceptions.append(\"symbol requires a frame to compute its value\")\n\n if all(x not in str(e) for x in skipped_exceptions):\n raise e\n\n try:\n # Unfortunately, `gdb.lookup_symbol` does not seem to handle all\n # symbols, so we need to fallback to using `gdb.parse_and_eval`. See\n # https://sourceware.org/pipermail/gdb/2022-October/050362.html\n # (We tried parsing the output of the `info address` before, but there were some issues. See #1628 and #1666)\n if \"\\\\\" in symbol:\n # Is it possible that happens? Probably not, but just in case\n raise ValueError(f\"Symbol {symbol!r} contains a backslash\")\n sanitized_symbol_name = symbol.replace(\"'\", \"\\\\'\")\n return int(gdb.parse_and_eval(f\"&'{sanitized_symbol_name}'\"))\n\n except gdb.error:\n return None\n\n\[email protected]_until(\"objfile\", \"thread\")\ndef static_linkage_symbol_address(symbol: str) -> int:\n \"\"\"\n Get the address for static linkage `symbol`\n \"\"\"\n\n try:\n symbol_obj = gdb.lookup_static_symbol(symbol)\n return int(symbol_obj.value().address) if symbol_obj else None\n except gdb.error:\n return None\n\n\[email protected]_until(\"stop\", \"start\")\ndef selected_frame_source_absolute_filename():\n \"\"\"\n Retrieve the symbol table\u2019s source absolute file name from the selected frame.\n\n In case of missing symbol table or frame information, None is returned.\n \"\"\"\n try:\n frame = gdb.selected_frame()\n except gdb.error:\n return None\n\n if not frame:\n return None\n\n sal = frame.find_sal()\n if not sal:\n return None\n\n symtab = sal.symtab\n if not symtab:\n return None\n\n return symtab.fullname()\n\n\ndef parse_and_eval(expression: str) -> gdb.Value | None:\n \"\"\"Error handling wrapper for GDBs parse_and_eval function\"\"\"\n try:\n return gdb.parse_and_eval(expression)\n except gdb.error:\n return None\n", "path": "pwndbg/gdblib/symbol.py"}]} | 2,949 | 592 |
gh_patches_debug_4542 | rasdani/github-patches | git_diff | open-mmlab__mmpretrain-122 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
mmcls/models/losses/eval_metrics.py confusion_matrix
confusion_matrix[target_label.long(), pred_label.long()] += 1
I think this code is wrong, 【target_label.long(), pred_label.long()】 will list all the coordinates that need + 1, but only once + 1 will work
it should be:
`for t, p in zip(target_label, pred_label):
confusion_matrix[t.long(), p.long()] += 1 `
</issue>
<code>
[start of mmcls/models/losses/eval_metrics.py]
1 import numpy as np
2 import torch
3
4
5 def calculate_confusion_matrix(pred, target):
6 if isinstance(pred, np.ndarray) and isinstance(target, np.ndarray):
7 pred = torch.from_numpy(pred)
8 target = torch.from_numpy(target)
9 elif not (isinstance(pred, torch.Tensor)
10 and isinstance(target, torch.Tensor)):
11 raise TypeError('pred and target should both be'
12 'torch.Tensor or np.ndarray')
13 _, pred_label = pred.topk(1, dim=1)
14 num_classes = pred.size(1)
15 pred_label = pred_label.view(-1)
16 target_label = target.view(-1)
17 assert len(pred_label) == len(target_label)
18 confusion_matrix = torch.zeros(num_classes, num_classes)
19 with torch.no_grad():
20 confusion_matrix[target_label.long(), pred_label.long()] += 1
21 return confusion_matrix
22
23
24 def precision(pred, target):
25 """Calculate macro-averaged precision according to the prediction and target
26
27 Args:
28 pred (torch.Tensor | np.array): The model prediction.
29 target (torch.Tensor | np.array): The target of each prediction.
30
31 Returns:
32 float: The function will return a single float as precision.
33 """
34 confusion_matrix = calculate_confusion_matrix(pred, target)
35 with torch.no_grad():
36 res = confusion_matrix.diag() / torch.clamp(
37 confusion_matrix.sum(0), min=1)
38 res = res.mean().item() * 100
39 return res
40
41
42 def recall(pred, target):
43 """Calculate macro-averaged recall according to the prediction and target
44
45 Args:
46 pred (torch.Tensor | np.array): The model prediction.
47 target (torch.Tensor | np.array): The target of each prediction.
48
49 Returns:
50 float: The function will return a single float as recall.
51 """
52 confusion_matrix = calculate_confusion_matrix(pred, target)
53 with torch.no_grad():
54 res = confusion_matrix.diag() / torch.clamp(
55 confusion_matrix.sum(1), min=1)
56 res = res.mean().item() * 100
57 return res
58
59
60 def f1_score(pred, target):
61 """Calculate macro-averaged F1 score according to the prediction and target
62
63 Args:
64 pred (torch.Tensor | np.array): The model prediction.
65 target (torch.Tensor | np.array): The target of each prediction.
66
67 Returns:
68 float: The function will return a single float as F1 score.
69 """
70 confusion_matrix = calculate_confusion_matrix(pred, target)
71 with torch.no_grad():
72 precision = confusion_matrix.diag() / torch.clamp(
73 confusion_matrix.sum(1), min=1)
74 recall = confusion_matrix.diag() / torch.clamp(
75 confusion_matrix.sum(0), min=1)
76 res = 2 * precision * recall / torch.clamp(
77 precision + recall, min=1e-20)
78 res = torch.where(torch.isnan(res), torch.full_like(res, 0), res)
79 res = res.mean().item() * 100
80 return res
81
[end of mmcls/models/losses/eval_metrics.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/mmcls/models/losses/eval_metrics.py b/mmcls/models/losses/eval_metrics.py
--- a/mmcls/models/losses/eval_metrics.py
+++ b/mmcls/models/losses/eval_metrics.py
@@ -17,7 +17,8 @@
assert len(pred_label) == len(target_label)
confusion_matrix = torch.zeros(num_classes, num_classes)
with torch.no_grad():
- confusion_matrix[target_label.long(), pred_label.long()] += 1
+ for t, p in zip(target_label, pred_label):
+ confusion_matrix[t.long(), p.long()] += 1
return confusion_matrix
| {"golden_diff": "diff --git a/mmcls/models/losses/eval_metrics.py b/mmcls/models/losses/eval_metrics.py\n--- a/mmcls/models/losses/eval_metrics.py\n+++ b/mmcls/models/losses/eval_metrics.py\n@@ -17,7 +17,8 @@\n assert len(pred_label) == len(target_label)\n confusion_matrix = torch.zeros(num_classes, num_classes)\n with torch.no_grad():\n- confusion_matrix[target_label.long(), pred_label.long()] += 1\n+ for t, p in zip(target_label, pred_label):\n+ confusion_matrix[t.long(), p.long()] += 1\n return confusion_matrix\n", "issue": "mmcls/models/losses/eval_metrics.py confusion_matrix\nconfusion_matrix[target_label.long(), pred_label.long()] += 1\r\nI think this code is wrong, \u3010target_label.long(), pred_label.long()\u3011 will list all the coordinates that need + 1, but only once + 1 will work\r\nit should be:\r\n`for t, p in zip(target_label, pred_label):\r\n confusion_matrix[t.long(), p.long()] += 1 `\r\n\n", "before_files": [{"content": "import numpy as np\nimport torch\n\n\ndef calculate_confusion_matrix(pred, target):\n if isinstance(pred, np.ndarray) and isinstance(target, np.ndarray):\n pred = torch.from_numpy(pred)\n target = torch.from_numpy(target)\n elif not (isinstance(pred, torch.Tensor)\n and isinstance(target, torch.Tensor)):\n raise TypeError('pred and target should both be'\n 'torch.Tensor or np.ndarray')\n _, pred_label = pred.topk(1, dim=1)\n num_classes = pred.size(1)\n pred_label = pred_label.view(-1)\n target_label = target.view(-1)\n assert len(pred_label) == len(target_label)\n confusion_matrix = torch.zeros(num_classes, num_classes)\n with torch.no_grad():\n confusion_matrix[target_label.long(), pred_label.long()] += 1\n return confusion_matrix\n\n\ndef precision(pred, target):\n \"\"\"Calculate macro-averaged precision according to the prediction and target\n\n Args:\n pred (torch.Tensor | np.array): The model prediction.\n target (torch.Tensor | np.array): The target of each prediction.\n\n Returns:\n float: The function will return a single float as precision.\n \"\"\"\n confusion_matrix = calculate_confusion_matrix(pred, target)\n with torch.no_grad():\n res = confusion_matrix.diag() / torch.clamp(\n confusion_matrix.sum(0), min=1)\n res = res.mean().item() * 100\n return res\n\n\ndef recall(pred, target):\n \"\"\"Calculate macro-averaged recall according to the prediction and target\n\n Args:\n pred (torch.Tensor | np.array): The model prediction.\n target (torch.Tensor | np.array): The target of each prediction.\n\n Returns:\n float: The function will return a single float as recall.\n \"\"\"\n confusion_matrix = calculate_confusion_matrix(pred, target)\n with torch.no_grad():\n res = confusion_matrix.diag() / torch.clamp(\n confusion_matrix.sum(1), min=1)\n res = res.mean().item() * 100\n return res\n\n\ndef f1_score(pred, target):\n \"\"\"Calculate macro-averaged F1 score according to the prediction and target\n\n Args:\n pred (torch.Tensor | np.array): The model prediction.\n target (torch.Tensor | np.array): The target of each prediction.\n\n Returns:\n float: The function will return a single float as F1 score.\n \"\"\"\n confusion_matrix = calculate_confusion_matrix(pred, target)\n with torch.no_grad():\n precision = confusion_matrix.diag() / torch.clamp(\n confusion_matrix.sum(1), min=1)\n recall = confusion_matrix.diag() / torch.clamp(\n confusion_matrix.sum(0), min=1)\n res = 2 * precision * recall / torch.clamp(\n precision + recall, min=1e-20)\n res = torch.where(torch.isnan(res), torch.full_like(res, 0), res)\n res = res.mean().item() * 100\n return res\n", "path": "mmcls/models/losses/eval_metrics.py"}]} | 1,449 | 142 |
gh_patches_debug_37892 | rasdani/github-patches | git_diff | ansible__ansible-39424 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Template module not accepting source that contains UTF8 characters
##### ISSUE TYPE
- Bug Report
##### COMPONENT NAME
template
##### ANSIBLE VERSION
```
$ ansible --version
ansible 2.3.1.0
config file = /work/ansible/configuration/ansible.cfg
configured module search path = Default w/o overrides
python version = 2.7.5 (default, Nov 6 2016, 00:28:07) [GCC 4.8.5 20150623 (Red Hat 4.8.5-11)]
```
##### OS / ENVIRONMENT
Ansible runs on CentOS 7.3
Target system on RHEL 6.9
##### SUMMARY
This looks like bug #10110:
Using the template module, when the source name contains an UTF8 character, the module fails with the following error.
Replacing template: with copy:, there is no error (the "copy" module has been used for more than a year and is just now being replaced by template).
If there is UTF8 only in the destination name, there is no error.
##### STEPS TO REPRODUCE
This sample triggers the error:
```
- name: Test UTF8
template:
src: "/tmp/ééé"
dest: "/tmp/eee"
```
This sample works:
```
- name: Test UTF8
template:
src: "/tmp/eee"
dest: "/tmp/ééé"
```
##### EXPECTED RESULTS
The template being copied to the target.
##### ACTUAL RESULTS
```
TASK [task : Test UTF8 *********************************************************************************************
[WARNING]: Failure using method (v2_runner_item_on_failed) in callback plugin (<ansible.plugins.callback.default.CallbackModule object at 0x35eb190>):
'ascii' codec can't decode byte 0xc3 in position 22: ordinal not in range(128
```
</issue>
<code>
[start of lib/ansible/plugins/action/template.py]
1 # (c) 2015, Michael DeHaan <[email protected]>
2 #
3 # This file is part of Ansible
4 #
5 # Ansible is free software: you can redistribute it and/or modify
6 # it under the terms of the GNU General Public License as published by
7 # the Free Software Foundation, either version 3 of the License, or
8 # (at your option) any later version.
9 #
10 # Ansible is distributed in the hope that it will be useful,
11 # but WITHOUT ANY WARRANTY; without even the implied warranty of
12 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
13 # GNU General Public License for more details.
14 #
15 # You should have received a copy of the GNU General Public License
16 # along with Ansible. If not, see <http://www.gnu.org/licenses/>.
17 from __future__ import (absolute_import, division, print_function)
18 __metaclass__ = type
19
20 import os
21 import shutil
22 import stat
23 import tempfile
24
25 from ansible import constants as C
26 from ansible.config.manager import ensure_type
27 from ansible.errors import AnsibleError, AnsibleFileNotFound, AnsibleAction, AnsibleActionFail
28 from ansible.module_utils._text import to_bytes, to_text
29 from ansible.module_utils.parsing.convert_bool import boolean
30 from ansible.module_utils.six import string_types
31 from ansible.plugins.action import ActionBase
32 from ansible.template import generate_ansible_template_vars
33
34
35 class ActionModule(ActionBase):
36
37 TRANSFERS_FILES = True
38 DEFAULT_NEWLINE_SEQUENCE = "\n"
39
40 def run(self, tmp=None, task_vars=None):
41 ''' handler for template operations '''
42
43 if task_vars is None:
44 task_vars = dict()
45
46 result = super(ActionModule, self).run(tmp, task_vars)
47 del tmp # tmp no longer has any effect
48
49 source = self._task.args.get('src', None)
50 dest = self._task.args.get('dest', None)
51 force = boolean(self._task.args.get('force', True), strict=False)
52 follow = boolean(self._task.args.get('follow', False), strict=False)
53 state = self._task.args.get('state', None)
54 newline_sequence = self._task.args.get('newline_sequence', self.DEFAULT_NEWLINE_SEQUENCE)
55 variable_start_string = self._task.args.get('variable_start_string', None)
56 variable_end_string = self._task.args.get('variable_end_string', None)
57 block_start_string = self._task.args.get('block_start_string', None)
58 block_end_string = self._task.args.get('block_end_string', None)
59 trim_blocks = boolean(self._task.args.get('trim_blocks', True), strict=False)
60 lstrip_blocks = boolean(self._task.args.get('lstrip_blocks', False), strict=False)
61
62 # Option `lstrip_blocks' was added in Jinja2 version 2.7.
63 if lstrip_blocks:
64 try:
65 import jinja2.defaults
66 except ImportError:
67 raise AnsibleError('Unable to import Jinja2 defaults for determing Jinja2 features.')
68
69 try:
70 jinja2.defaults.LSTRIP_BLOCKS
71 except AttributeError:
72 raise AnsibleError("Option `lstrip_blocks' is only available in Jinja2 versions >=2.7")
73
74 wrong_sequences = ["\\n", "\\r", "\\r\\n"]
75 allowed_sequences = ["\n", "\r", "\r\n"]
76
77 # We need to convert unescaped sequences to proper escaped sequences for Jinja2
78 if newline_sequence in wrong_sequences:
79 newline_sequence = allowed_sequences[wrong_sequences.index(newline_sequence)]
80
81 try:
82 for s_type in ('source', 'dest', 'state', 'newline_sequence', 'variable_start_string', 'variable_end_string', 'block_start_string',
83 'block_end_string'):
84 value = locals()[s_type]
85 value = ensure_type(value, 'string')
86 if value is not None and not isinstance(value, string_types):
87 raise AnsibleActionFail("%s is expected to be a string, but got %s instead" % (s_type, type(value)))
88 locals()[s_type] = value
89
90 for b_type in ('force', 'follow', 'trim_blocks'):
91 value = locals()[b_type]
92 value = ensure_type(value, 'string')
93 if value is not None and not isinstance(value, bool):
94 raise AnsibleActionFail("%s is expected to be a boolean, but got %s instead" % (b_type, type(value)))
95 locals()[b_type] = value
96
97 if state is not None:
98 raise AnsibleActionFail("'state' cannot be specified on a template")
99 elif source is None or dest is None:
100 raise AnsibleActionFail("src and dest are required")
101 elif newline_sequence not in allowed_sequences:
102 raise AnsibleActionFail("newline_sequence needs to be one of: \n, \r or \r\n")
103 else:
104 try:
105 source = self._find_needle('templates', source)
106 except AnsibleError as e:
107 raise AnsibleActionFail(to_text(e))
108
109 mode = self._task.args.get('mode', None)
110 if mode == 'preserve':
111 mode = '0%03o' % stat.S_IMODE(os.stat(source).st_mode)
112
113 # Get vault decrypted tmp file
114 try:
115 tmp_source = self._loader.get_real_file(source)
116 except AnsibleFileNotFound as e:
117 raise AnsibleActionFail("could not find src=%s, %s" % (source, to_text(e)))
118
119 # template the source data locally & get ready to transfer
120 try:
121 with open(tmp_source, 'r') as f:
122 template_data = to_text(f.read())
123
124 # set jinja2 internal search path for includes
125 searchpath = task_vars.get('ansible_search_path', [])
126 searchpath.extend([self._loader._basedir, os.path.dirname(source)])
127
128 # We want to search into the 'templates' subdir of each search path in
129 # addition to our original search paths.
130 newsearchpath = []
131 for p in searchpath:
132 newsearchpath.append(os.path.join(p, 'templates'))
133 newsearchpath.append(p)
134 searchpath = newsearchpath
135
136 self._templar.environment.loader.searchpath = searchpath
137 self._templar.environment.newline_sequence = newline_sequence
138 if block_start_string is not None:
139 self._templar.environment.block_start_string = block_start_string
140 if block_end_string is not None:
141 self._templar.environment.block_end_string = block_end_string
142 if variable_start_string is not None:
143 self._templar.environment.variable_start_string = variable_start_string
144 if variable_end_string is not None:
145 self._templar.environment.variable_end_string = variable_end_string
146 self._templar.environment.trim_blocks = trim_blocks
147 self._templar.environment.lstrip_blocks = lstrip_blocks
148
149 # add ansible 'template' vars
150 temp_vars = task_vars.copy()
151 temp_vars.update(generate_ansible_template_vars(source))
152
153 old_vars = self._templar._available_variables
154 self._templar.set_available_variables(temp_vars)
155 resultant = self._templar.do_template(template_data, preserve_trailing_newlines=True, escape_backslashes=False)
156 self._templar.set_available_variables(old_vars)
157 except AnsibleAction:
158 raise
159 except Exception as e:
160 raise AnsibleActionFail("%s: %s" % (type(e).__name__, to_text(e)))
161 finally:
162 self._loader.cleanup_tmp_file(tmp_source)
163
164 new_task = self._task.copy()
165 # mode is either the mode from task.args or the mode of the source file if the task.args
166 # mode == 'preserve'
167 new_task.args['mode'] = mode
168 new_task.args.pop('newline_sequence', None)
169 new_task.args.pop('block_start_string', None)
170 new_task.args.pop('block_end_string', None)
171 new_task.args.pop('variable_start_string', None)
172 new_task.args.pop('variable_end_string', None)
173 new_task.args.pop('trim_blocks', None)
174 new_task.args.pop('lstrip_blocks', None)
175
176 local_tempdir = tempfile.mkdtemp(dir=C.DEFAULT_LOCAL_TMP)
177
178 try:
179 result_file = os.path.join(local_tempdir, os.path.basename(source))
180 with open(result_file, 'wb') as f:
181 f.write(to_bytes(resultant, errors='surrogate_or_strict'))
182
183 new_task.args.update(
184 dict(
185 src=result_file,
186 dest=dest,
187 follow=follow,
188 ),
189 )
190 copy_action = self._shared_loader_obj.action_loader.get('copy',
191 task=new_task,
192 connection=self._connection,
193 play_context=self._play_context,
194 loader=self._loader,
195 templar=self._templar,
196 shared_loader_obj=self._shared_loader_obj)
197 result.update(copy_action.run(task_vars=task_vars))
198 finally:
199 shutil.rmtree(local_tempdir)
200
201 except AnsibleAction as e:
202 result.update(e.result)
203 finally:
204 self._remove_tmp_path(self._connection._shell.tmpdir)
205
206 return result
207
[end of lib/ansible/plugins/action/template.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/lib/ansible/plugins/action/template.py b/lib/ansible/plugins/action/template.py
--- a/lib/ansible/plugins/action/template.py
+++ b/lib/ansible/plugins/action/template.py
@@ -115,11 +115,12 @@
tmp_source = self._loader.get_real_file(source)
except AnsibleFileNotFound as e:
raise AnsibleActionFail("could not find src=%s, %s" % (source, to_text(e)))
+ b_tmp_source = to_bytes(tmp_source, errors='surrogate_or_strict')
# template the source data locally & get ready to transfer
try:
- with open(tmp_source, 'r') as f:
- template_data = to_text(f.read())
+ with open(b_tmp_source, 'rb') as f:
+ template_data = to_text(f.read(), errors='surrogate_or_strict')
# set jinja2 internal search path for includes
searchpath = task_vars.get('ansible_search_path', [])
@@ -159,7 +160,7 @@
except Exception as e:
raise AnsibleActionFail("%s: %s" % (type(e).__name__, to_text(e)))
finally:
- self._loader.cleanup_tmp_file(tmp_source)
+ self._loader.cleanup_tmp_file(b_tmp_source)
new_task = self._task.copy()
# mode is either the mode from task.args or the mode of the source file if the task.args
@@ -177,7 +178,7 @@
try:
result_file = os.path.join(local_tempdir, os.path.basename(source))
- with open(result_file, 'wb') as f:
+ with open(to_bytes(result_file, errors='surrogate_or_strict'), 'wb') as f:
f.write(to_bytes(resultant, errors='surrogate_or_strict'))
new_task.args.update(
@@ -196,7 +197,7 @@
shared_loader_obj=self._shared_loader_obj)
result.update(copy_action.run(task_vars=task_vars))
finally:
- shutil.rmtree(local_tempdir)
+ shutil.rmtree(to_bytes(local_tempdir, errors='surrogate_or_strict'))
except AnsibleAction as e:
result.update(e.result)
| {"golden_diff": "diff --git a/lib/ansible/plugins/action/template.py b/lib/ansible/plugins/action/template.py\n--- a/lib/ansible/plugins/action/template.py\n+++ b/lib/ansible/plugins/action/template.py\n@@ -115,11 +115,12 @@\n tmp_source = self._loader.get_real_file(source)\n except AnsibleFileNotFound as e:\n raise AnsibleActionFail(\"could not find src=%s, %s\" % (source, to_text(e)))\n+ b_tmp_source = to_bytes(tmp_source, errors='surrogate_or_strict')\n \n # template the source data locally & get ready to transfer\n try:\n- with open(tmp_source, 'r') as f:\n- template_data = to_text(f.read())\n+ with open(b_tmp_source, 'rb') as f:\n+ template_data = to_text(f.read(), errors='surrogate_or_strict')\n \n # set jinja2 internal search path for includes\n searchpath = task_vars.get('ansible_search_path', [])\n@@ -159,7 +160,7 @@\n except Exception as e:\n raise AnsibleActionFail(\"%s: %s\" % (type(e).__name__, to_text(e)))\n finally:\n- self._loader.cleanup_tmp_file(tmp_source)\n+ self._loader.cleanup_tmp_file(b_tmp_source)\n \n new_task = self._task.copy()\n # mode is either the mode from task.args or the mode of the source file if the task.args\n@@ -177,7 +178,7 @@\n \n try:\n result_file = os.path.join(local_tempdir, os.path.basename(source))\n- with open(result_file, 'wb') as f:\n+ with open(to_bytes(result_file, errors='surrogate_or_strict'), 'wb') as f:\n f.write(to_bytes(resultant, errors='surrogate_or_strict'))\n \n new_task.args.update(\n@@ -196,7 +197,7 @@\n shared_loader_obj=self._shared_loader_obj)\n result.update(copy_action.run(task_vars=task_vars))\n finally:\n- shutil.rmtree(local_tempdir)\n+ shutil.rmtree(to_bytes(local_tempdir, errors='surrogate_or_strict'))\n \n except AnsibleAction as e:\n result.update(e.result)\n", "issue": "Template module not accepting source that contains UTF8 characters\n##### ISSUE TYPE\r\n - Bug Report\r\n\r\n##### COMPONENT NAME\r\ntemplate\r\n\r\n##### ANSIBLE VERSION\r\n```\r\n$ ansible --version\r\nansible 2.3.1.0\r\n config file = /work/ansible/configuration/ansible.cfg\r\n configured module search path = Default w/o overrides\r\n python version = 2.7.5 (default, Nov 6 2016, 00:28:07) [GCC 4.8.5 20150623 (Red Hat 4.8.5-11)]\r\n```\r\n\r\n##### OS / ENVIRONMENT\r\nAnsible runs on CentOS 7.3\r\nTarget system on RHEL 6.9\r\n\r\n##### SUMMARY\r\nThis looks like bug #10110:\r\nUsing the template module, when the source name contains an UTF8 character, the module fails with the following error.\r\nReplacing template: with copy:, there is no error (the \"copy\" module has been used for more than a year and is just now being replaced by template).\r\nIf there is UTF8 only in the destination name, there is no error.\r\n\r\n\r\n##### STEPS TO REPRODUCE\r\n\r\nThis sample triggers the error:\r\n```\r\n- name: Test UTF8\r\n template:\r\n src: \"/tmp/\u00e9\u00e9\u00e9\"\r\n dest: \"/tmp/eee\"\r\n```\r\nThis sample works:\r\n```\r\n- name: Test UTF8\r\n template:\r\n src: \"/tmp/eee\"\r\n dest: \"/tmp/\u00e9\u00e9\u00e9\"\r\n```\r\n\r\n\r\n##### EXPECTED RESULTS\r\nThe template being copied to the target.\r\n\r\n##### ACTUAL RESULTS\r\n\r\n```\r\nTASK [task : Test UTF8 *********************************************************************************************\r\n[WARNING]: Failure using method (v2_runner_item_on_failed) in callback plugin (<ansible.plugins.callback.default.CallbackModule object at 0x35eb190>):\r\n'ascii' codec can't decode byte 0xc3 in position 22: ordinal not in range(128\r\n```\r\n\n", "before_files": [{"content": "# (c) 2015, Michael DeHaan <[email protected]>\n#\n# This file is part of Ansible\n#\n# Ansible is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# Ansible is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with Ansible. If not, see <http://www.gnu.org/licenses/>.\nfrom __future__ import (absolute_import, division, print_function)\n__metaclass__ = type\n\nimport os\nimport shutil\nimport stat\nimport tempfile\n\nfrom ansible import constants as C\nfrom ansible.config.manager import ensure_type\nfrom ansible.errors import AnsibleError, AnsibleFileNotFound, AnsibleAction, AnsibleActionFail\nfrom ansible.module_utils._text import to_bytes, to_text\nfrom ansible.module_utils.parsing.convert_bool import boolean\nfrom ansible.module_utils.six import string_types\nfrom ansible.plugins.action import ActionBase\nfrom ansible.template import generate_ansible_template_vars\n\n\nclass ActionModule(ActionBase):\n\n TRANSFERS_FILES = True\n DEFAULT_NEWLINE_SEQUENCE = \"\\n\"\n\n def run(self, tmp=None, task_vars=None):\n ''' handler for template operations '''\n\n if task_vars is None:\n task_vars = dict()\n\n result = super(ActionModule, self).run(tmp, task_vars)\n del tmp # tmp no longer has any effect\n\n source = self._task.args.get('src', None)\n dest = self._task.args.get('dest', None)\n force = boolean(self._task.args.get('force', True), strict=False)\n follow = boolean(self._task.args.get('follow', False), strict=False)\n state = self._task.args.get('state', None)\n newline_sequence = self._task.args.get('newline_sequence', self.DEFAULT_NEWLINE_SEQUENCE)\n variable_start_string = self._task.args.get('variable_start_string', None)\n variable_end_string = self._task.args.get('variable_end_string', None)\n block_start_string = self._task.args.get('block_start_string', None)\n block_end_string = self._task.args.get('block_end_string', None)\n trim_blocks = boolean(self._task.args.get('trim_blocks', True), strict=False)\n lstrip_blocks = boolean(self._task.args.get('lstrip_blocks', False), strict=False)\n\n # Option `lstrip_blocks' was added in Jinja2 version 2.7.\n if lstrip_blocks:\n try:\n import jinja2.defaults\n except ImportError:\n raise AnsibleError('Unable to import Jinja2 defaults for determing Jinja2 features.')\n\n try:\n jinja2.defaults.LSTRIP_BLOCKS\n except AttributeError:\n raise AnsibleError(\"Option `lstrip_blocks' is only available in Jinja2 versions >=2.7\")\n\n wrong_sequences = [\"\\\\n\", \"\\\\r\", \"\\\\r\\\\n\"]\n allowed_sequences = [\"\\n\", \"\\r\", \"\\r\\n\"]\n\n # We need to convert unescaped sequences to proper escaped sequences for Jinja2\n if newline_sequence in wrong_sequences:\n newline_sequence = allowed_sequences[wrong_sequences.index(newline_sequence)]\n\n try:\n for s_type in ('source', 'dest', 'state', 'newline_sequence', 'variable_start_string', 'variable_end_string', 'block_start_string',\n 'block_end_string'):\n value = locals()[s_type]\n value = ensure_type(value, 'string')\n if value is not None and not isinstance(value, string_types):\n raise AnsibleActionFail(\"%s is expected to be a string, but got %s instead\" % (s_type, type(value)))\n locals()[s_type] = value\n\n for b_type in ('force', 'follow', 'trim_blocks'):\n value = locals()[b_type]\n value = ensure_type(value, 'string')\n if value is not None and not isinstance(value, bool):\n raise AnsibleActionFail(\"%s is expected to be a boolean, but got %s instead\" % (b_type, type(value)))\n locals()[b_type] = value\n\n if state is not None:\n raise AnsibleActionFail(\"'state' cannot be specified on a template\")\n elif source is None or dest is None:\n raise AnsibleActionFail(\"src and dest are required\")\n elif newline_sequence not in allowed_sequences:\n raise AnsibleActionFail(\"newline_sequence needs to be one of: \\n, \\r or \\r\\n\")\n else:\n try:\n source = self._find_needle('templates', source)\n except AnsibleError as e:\n raise AnsibleActionFail(to_text(e))\n\n mode = self._task.args.get('mode', None)\n if mode == 'preserve':\n mode = '0%03o' % stat.S_IMODE(os.stat(source).st_mode)\n\n # Get vault decrypted tmp file\n try:\n tmp_source = self._loader.get_real_file(source)\n except AnsibleFileNotFound as e:\n raise AnsibleActionFail(\"could not find src=%s, %s\" % (source, to_text(e)))\n\n # template the source data locally & get ready to transfer\n try:\n with open(tmp_source, 'r') as f:\n template_data = to_text(f.read())\n\n # set jinja2 internal search path for includes\n searchpath = task_vars.get('ansible_search_path', [])\n searchpath.extend([self._loader._basedir, os.path.dirname(source)])\n\n # We want to search into the 'templates' subdir of each search path in\n # addition to our original search paths.\n newsearchpath = []\n for p in searchpath:\n newsearchpath.append(os.path.join(p, 'templates'))\n newsearchpath.append(p)\n searchpath = newsearchpath\n\n self._templar.environment.loader.searchpath = searchpath\n self._templar.environment.newline_sequence = newline_sequence\n if block_start_string is not None:\n self._templar.environment.block_start_string = block_start_string\n if block_end_string is not None:\n self._templar.environment.block_end_string = block_end_string\n if variable_start_string is not None:\n self._templar.environment.variable_start_string = variable_start_string\n if variable_end_string is not None:\n self._templar.environment.variable_end_string = variable_end_string\n self._templar.environment.trim_blocks = trim_blocks\n self._templar.environment.lstrip_blocks = lstrip_blocks\n\n # add ansible 'template' vars\n temp_vars = task_vars.copy()\n temp_vars.update(generate_ansible_template_vars(source))\n\n old_vars = self._templar._available_variables\n self._templar.set_available_variables(temp_vars)\n resultant = self._templar.do_template(template_data, preserve_trailing_newlines=True, escape_backslashes=False)\n self._templar.set_available_variables(old_vars)\n except AnsibleAction:\n raise\n except Exception as e:\n raise AnsibleActionFail(\"%s: %s\" % (type(e).__name__, to_text(e)))\n finally:\n self._loader.cleanup_tmp_file(tmp_source)\n\n new_task = self._task.copy()\n # mode is either the mode from task.args or the mode of the source file if the task.args\n # mode == 'preserve'\n new_task.args['mode'] = mode\n new_task.args.pop('newline_sequence', None)\n new_task.args.pop('block_start_string', None)\n new_task.args.pop('block_end_string', None)\n new_task.args.pop('variable_start_string', None)\n new_task.args.pop('variable_end_string', None)\n new_task.args.pop('trim_blocks', None)\n new_task.args.pop('lstrip_blocks', None)\n\n local_tempdir = tempfile.mkdtemp(dir=C.DEFAULT_LOCAL_TMP)\n\n try:\n result_file = os.path.join(local_tempdir, os.path.basename(source))\n with open(result_file, 'wb') as f:\n f.write(to_bytes(resultant, errors='surrogate_or_strict'))\n\n new_task.args.update(\n dict(\n src=result_file,\n dest=dest,\n follow=follow,\n ),\n )\n copy_action = self._shared_loader_obj.action_loader.get('copy',\n task=new_task,\n connection=self._connection,\n play_context=self._play_context,\n loader=self._loader,\n templar=self._templar,\n shared_loader_obj=self._shared_loader_obj)\n result.update(copy_action.run(task_vars=task_vars))\n finally:\n shutil.rmtree(local_tempdir)\n\n except AnsibleAction as e:\n result.update(e.result)\n finally:\n self._remove_tmp_path(self._connection._shell.tmpdir)\n\n return result\n", "path": "lib/ansible/plugins/action/template.py"}]} | 3,444 | 493 |
gh_patches_debug_28395 | rasdani/github-patches | git_diff | pantsbuild__pants-16264 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Not able to load resources when using pants vs sbt
**Describe the bug**
When using sbt we are able to call `Thread.currentThread().getContextClassLoader().getResources` and get a list of URLs. When using pants the list is empty.
This at the moment limits us from using Flyway with pants.
**Pants version**
2.13.0a1 and main.
**OS**
MacOS
**Additional info**
Example repo to reproduce the issue:
https://github.com/somdoron/test-pants-resources
I think the issue is, that pants only compress files in the resources zip file and not the directories.
</issue>
<code>
[start of src/python/pants/jvm/resources.py]
1 # Copyright 2021 Pants project contributors (see CONTRIBUTORS.md).
2 # Licensed under the Apache License, Version 2.0 (see LICENSE).
3
4 import itertools
5 import logging
6 from itertools import chain
7
8 from pants.core.target_types import ResourcesFieldSet, ResourcesGeneratorFieldSet
9 from pants.core.util_rules import stripped_source_files
10 from pants.core.util_rules.source_files import SourceFilesRequest
11 from pants.core.util_rules.stripped_source_files import StrippedSourceFiles
12 from pants.core.util_rules.system_binaries import ZipBinary
13 from pants.engine.fs import Digest, MergeDigests
14 from pants.engine.internals.selectors import MultiGet
15 from pants.engine.process import Process, ProcessResult
16 from pants.engine.rules import Get, collect_rules, rule
17 from pants.engine.target import SourcesField
18 from pants.engine.unions import UnionRule
19 from pants.jvm import compile
20 from pants.jvm.compile import (
21 ClasspathDependenciesRequest,
22 ClasspathEntry,
23 ClasspathEntryRequest,
24 ClasspathEntryRequests,
25 CompileResult,
26 FallibleClasspathEntries,
27 FallibleClasspathEntry,
28 )
29 from pants.jvm.strip_jar.strip_jar import StripJarRequest
30 from pants.jvm.subsystems import JvmSubsystem
31 from pants.util.logging import LogLevel
32
33 logger = logging.getLogger(__name__)
34
35
36 class JvmResourcesRequest(ClasspathEntryRequest):
37 field_sets = (
38 ResourcesFieldSet,
39 ResourcesGeneratorFieldSet,
40 )
41
42
43 @rule(desc="Assemble resources")
44 async def assemble_resources_jar(
45 zip: ZipBinary,
46 jvm: JvmSubsystem,
47 request: JvmResourcesRequest,
48 ) -> FallibleClasspathEntry:
49 # Request the component's direct dependency classpath, and additionally any prerequisite.
50 # Filter out any dependencies that are generated by our current target so that each resource
51 # only appears in a single input JAR.
52 # NOTE: Generated dependencies will have the same dependencies as the current target, so we
53 # don't need to inspect those dependencies.
54 optional_prereq_request = [*((request.prerequisite,) if request.prerequisite else ())]
55 fallibles = await MultiGet(
56 Get(FallibleClasspathEntries, ClasspathEntryRequests(optional_prereq_request)),
57 Get(FallibleClasspathEntries, ClasspathDependenciesRequest(request, ignore_generated=True)),
58 )
59 direct_dependency_classpath_entries = FallibleClasspathEntries(
60 itertools.chain(*fallibles)
61 ).if_all_succeeded()
62
63 if direct_dependency_classpath_entries is None:
64 return FallibleClasspathEntry(
65 description=str(request.component),
66 result=CompileResult.DEPENDENCY_FAILED,
67 output=None,
68 exit_code=1,
69 )
70
71 source_files = await Get(
72 StrippedSourceFiles,
73 SourceFilesRequest([tgt.get(SourcesField) for tgt in request.component.members]),
74 )
75
76 output_filename = f"{request.component.representative.address.path_safe_spec}.resources.jar"
77 output_files = [output_filename]
78
79 resources_jar_input_digest = source_files.snapshot.digest
80 resources_jar_result = await Get(
81 ProcessResult,
82 Process(
83 argv=[
84 zip.path,
85 output_filename,
86 *source_files.snapshot.files,
87 ],
88 description="Build resources JAR for {request.component}",
89 input_digest=resources_jar_input_digest,
90 output_files=output_files,
91 level=LogLevel.DEBUG,
92 ),
93 )
94
95 output_digest = resources_jar_result.output_digest
96 if jvm.reproducible_jars:
97 output_digest = await Get(Digest, StripJarRequest(output_digest, tuple(output_files)))
98 cpe = ClasspathEntry(output_digest, output_files, [])
99
100 merged_cpe_digest = await Get(
101 Digest,
102 MergeDigests(chain((cpe.digest,), (i.digest for i in direct_dependency_classpath_entries))),
103 )
104
105 merged_cpe = ClasspathEntry.merge(
106 digest=merged_cpe_digest, entries=[cpe, *direct_dependency_classpath_entries]
107 )
108
109 return FallibleClasspathEntry(output_filename, CompileResult.SUCCEEDED, merged_cpe, 0)
110
111
112 def rules():
113 return [
114 *collect_rules(),
115 *compile.rules(),
116 *stripped_source_files.rules(),
117 UnionRule(ClasspathEntryRequest, JvmResourcesRequest),
118 ]
119
[end of src/python/pants/jvm/resources.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/src/python/pants/jvm/resources.py b/src/python/pants/jvm/resources.py
--- a/src/python/pants/jvm/resources.py
+++ b/src/python/pants/jvm/resources.py
@@ -4,6 +4,7 @@
import itertools
import logging
from itertools import chain
+from pathlib import Path
from pants.core.target_types import ResourcesFieldSet, ResourcesGeneratorFieldSet
from pants.core.util_rules import stripped_source_files
@@ -76,6 +77,13 @@
output_filename = f"{request.component.representative.address.path_safe_spec}.resources.jar"
output_files = [output_filename]
+ # #16231: Valid JAR files need the directories of each resource file as well as the files
+ # themselves.
+
+ paths = {Path(filename) for filename in source_files.snapshot.files}
+ directories = {parent for path in paths for parent in path.parents}
+ input_files = {str(path) for path in chain(paths, directories)}
+
resources_jar_input_digest = source_files.snapshot.digest
resources_jar_result = await Get(
ProcessResult,
@@ -83,7 +91,7 @@
argv=[
zip.path,
output_filename,
- *source_files.snapshot.files,
+ *sorted(input_files),
],
description="Build resources JAR for {request.component}",
input_digest=resources_jar_input_digest,
| {"golden_diff": "diff --git a/src/python/pants/jvm/resources.py b/src/python/pants/jvm/resources.py\n--- a/src/python/pants/jvm/resources.py\n+++ b/src/python/pants/jvm/resources.py\n@@ -4,6 +4,7 @@\n import itertools\n import logging\n from itertools import chain\n+from pathlib import Path\n \n from pants.core.target_types import ResourcesFieldSet, ResourcesGeneratorFieldSet\n from pants.core.util_rules import stripped_source_files\n@@ -76,6 +77,13 @@\n output_filename = f\"{request.component.representative.address.path_safe_spec}.resources.jar\"\n output_files = [output_filename]\n \n+ # #16231: Valid JAR files need the directories of each resource file as well as the files\n+ # themselves.\n+\n+ paths = {Path(filename) for filename in source_files.snapshot.files}\n+ directories = {parent for path in paths for parent in path.parents}\n+ input_files = {str(path) for path in chain(paths, directories)}\n+\n resources_jar_input_digest = source_files.snapshot.digest\n resources_jar_result = await Get(\n ProcessResult,\n@@ -83,7 +91,7 @@\n argv=[\n zip.path,\n output_filename,\n- *source_files.snapshot.files,\n+ *sorted(input_files),\n ],\n description=\"Build resources JAR for {request.component}\",\n input_digest=resources_jar_input_digest,\n", "issue": "Not able to load resources when using pants vs sbt\n**Describe the bug**\r\nWhen using sbt we are able to call `Thread.currentThread().getContextClassLoader().getResources` and get a list of URLs. When using pants the list is empty. \r\n\r\nThis at the moment limits us from using Flyway with pants.\r\n\r\n**Pants version**\r\n2.13.0a1 and main.\r\n\r\n**OS**\r\nMacOS\r\n\r\n**Additional info**\r\nExample repo to reproduce the issue:\r\nhttps://github.com/somdoron/test-pants-resources\r\n\r\nI think the issue is, that pants only compress files in the resources zip file and not the directories.\n", "before_files": [{"content": "# Copyright 2021 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\nimport itertools\nimport logging\nfrom itertools import chain\n\nfrom pants.core.target_types import ResourcesFieldSet, ResourcesGeneratorFieldSet\nfrom pants.core.util_rules import stripped_source_files\nfrom pants.core.util_rules.source_files import SourceFilesRequest\nfrom pants.core.util_rules.stripped_source_files import StrippedSourceFiles\nfrom pants.core.util_rules.system_binaries import ZipBinary\nfrom pants.engine.fs import Digest, MergeDigests\nfrom pants.engine.internals.selectors import MultiGet\nfrom pants.engine.process import Process, ProcessResult\nfrom pants.engine.rules import Get, collect_rules, rule\nfrom pants.engine.target import SourcesField\nfrom pants.engine.unions import UnionRule\nfrom pants.jvm import compile\nfrom pants.jvm.compile import (\n ClasspathDependenciesRequest,\n ClasspathEntry,\n ClasspathEntryRequest,\n ClasspathEntryRequests,\n CompileResult,\n FallibleClasspathEntries,\n FallibleClasspathEntry,\n)\nfrom pants.jvm.strip_jar.strip_jar import StripJarRequest\nfrom pants.jvm.subsystems import JvmSubsystem\nfrom pants.util.logging import LogLevel\n\nlogger = logging.getLogger(__name__)\n\n\nclass JvmResourcesRequest(ClasspathEntryRequest):\n field_sets = (\n ResourcesFieldSet,\n ResourcesGeneratorFieldSet,\n )\n\n\n@rule(desc=\"Assemble resources\")\nasync def assemble_resources_jar(\n zip: ZipBinary,\n jvm: JvmSubsystem,\n request: JvmResourcesRequest,\n) -> FallibleClasspathEntry:\n # Request the component's direct dependency classpath, and additionally any prerequisite.\n # Filter out any dependencies that are generated by our current target so that each resource\n # only appears in a single input JAR.\n # NOTE: Generated dependencies will have the same dependencies as the current target, so we\n # don't need to inspect those dependencies.\n optional_prereq_request = [*((request.prerequisite,) if request.prerequisite else ())]\n fallibles = await MultiGet(\n Get(FallibleClasspathEntries, ClasspathEntryRequests(optional_prereq_request)),\n Get(FallibleClasspathEntries, ClasspathDependenciesRequest(request, ignore_generated=True)),\n )\n direct_dependency_classpath_entries = FallibleClasspathEntries(\n itertools.chain(*fallibles)\n ).if_all_succeeded()\n\n if direct_dependency_classpath_entries is None:\n return FallibleClasspathEntry(\n description=str(request.component),\n result=CompileResult.DEPENDENCY_FAILED,\n output=None,\n exit_code=1,\n )\n\n source_files = await Get(\n StrippedSourceFiles,\n SourceFilesRequest([tgt.get(SourcesField) for tgt in request.component.members]),\n )\n\n output_filename = f\"{request.component.representative.address.path_safe_spec}.resources.jar\"\n output_files = [output_filename]\n\n resources_jar_input_digest = source_files.snapshot.digest\n resources_jar_result = await Get(\n ProcessResult,\n Process(\n argv=[\n zip.path,\n output_filename,\n *source_files.snapshot.files,\n ],\n description=\"Build resources JAR for {request.component}\",\n input_digest=resources_jar_input_digest,\n output_files=output_files,\n level=LogLevel.DEBUG,\n ),\n )\n\n output_digest = resources_jar_result.output_digest\n if jvm.reproducible_jars:\n output_digest = await Get(Digest, StripJarRequest(output_digest, tuple(output_files)))\n cpe = ClasspathEntry(output_digest, output_files, [])\n\n merged_cpe_digest = await Get(\n Digest,\n MergeDigests(chain((cpe.digest,), (i.digest for i in direct_dependency_classpath_entries))),\n )\n\n merged_cpe = ClasspathEntry.merge(\n digest=merged_cpe_digest, entries=[cpe, *direct_dependency_classpath_entries]\n )\n\n return FallibleClasspathEntry(output_filename, CompileResult.SUCCEEDED, merged_cpe, 0)\n\n\ndef rules():\n return [\n *collect_rules(),\n *compile.rules(),\n *stripped_source_files.rules(),\n UnionRule(ClasspathEntryRequest, JvmResourcesRequest),\n ]\n", "path": "src/python/pants/jvm/resources.py"}]} | 1,821 | 307 |
gh_patches_debug_24844 | rasdani/github-patches | git_diff | easybuilders__easybuild-easyblocks-2022 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
numexpr can't be installed as an extension
The reason is two-fold:
As an extension this is not executed:
https://github.com/easybuilders/easybuild-easyblocks/blob/develop/easybuild/easyblocks/n/numexpr.py#L59
And therefore the variable is not defined, it is built without VML, and it would fail on the sanity check.
With that fixed, there is another more convoluted issue. The sanity check executed follows this order:
1. Sanity check in `numexpr.py`
2. Sanity check in `pythonpackage`
3. Sanity check in `extensioneasyblock`
4. Sanity check in `easyblock`
5. Sanity check in `extensioneasyblock` again
6. And finally sanity check in `easyblock` again, where it fails
5 and 6 happens due to this condition:
https://github.com/easybuilders/easybuild-framework/blob/develop/easybuild/framework/extensioneasyblock.py#L154
Without the `custom_commands` it works just fine. But that should be ok.
The log does not help much, but shows that there is a weird issue (sanity checked passed, and then failed):
```
== 2020-03-26 20:57:10,714 run.py:200 DEBUG run_cmd: running cmd python -c 'import numexpr; assert(numexpr.use_vml)' (in /gpfs/software/juwels/stages/Devel-2019a/software/Jupyter/2019a-gcccoremkl-8.3.0-2019.3.199-devel2-Python-3.6.8)
== 2020-03-26 20:57:10,715 run.py:219 INFO running cmd: python -c 'import numexpr; assert(numexpr.use_vml)'
== 2020-03-26 20:57:11,196 run.py:536 DEBUG cmd "python -c 'import numexpr; assert(numexpr.use_vml)'" exited with exit code 0 and output:
== 2020-03-26 20:57:11,196 run.py:570 DEBUG Using default regular expression: (?<![(,-]|\w)(?:error|segmentation fault|failed)(?![(,-]|\.?\w)
== 2020-03-26 20:57:11,197 easyblock.py:2574 INFO sanity check command python -c 'import numexpr; assert(numexpr.use_vml)' ran successfully! (output: )
== 2020-03-26 20:57:11,198 easyblock.py:2595 DEBUG Skipping RPATH sanity check
== 2020-03-26 20:57:11,198 easyblock.py:2601 DEBUG Sanity check passed!
== 2020-03-26 20:57:11,198 extensioneasyblock.py:160 INFO Sanity check for numexpr successful!
== 2020-03-26 20:57:11,199 easyblock.py:2473 WARNING failing sanity check for 'numexpr' extension: (see log for details)
== 2020-03-26 20:57:11,199 easyblock.py:2479 WARNING extensions sanity check failed for 1 extensions:
```
The funny bit. If I wrap this condition https://github.com/easybuilders/easybuild-framework/blob/develop/easybuild/framework/easyblock.py#L2622 like this:
```
print("before extension easyblock failed message: "+str(self.sanity_check_fail_msgs))
# also run sanity check for extensions (unless we are an extension ourselves)
if not extension:
self._sanity_check_step_extensions()
print("after extension easyblock failed message: "+str(self.sanity_check_fail_msgs))
```
I get this output:
```
before extension easyblock failed message: []
after extension easyblock failed message: []
after extension easyblock failed message: ['extensions sanity check failed for 1 extensions: numexpr', "failing sanity check for 'numexpr' extension: (see log for details)"]
```
Note the 2 "after" with a single "before". It is late and I am tired and hungry, but that looks pretty weird to me and I am starting to believe in leprechauns
</issue>
<code>
[start of easybuild/easyblocks/n/numexpr.py]
1 ##
2 # Copyright 2019-2020 Ghent University
3 #
4 # This file is part of EasyBuild,
5 # originally created by the HPC team of Ghent University (http://ugent.be/hpc/en),
6 # with support of Ghent University (http://ugent.be/hpc),
7 # the Flemish Supercomputer Centre (VSC) (https://www.vscentrum.be),
8 # Flemish Research Foundation (FWO) (http://www.fwo.be/en)
9 # and the Department of Economy, Science and Innovation (EWI) (http://www.ewi-vlaanderen.be/en).
10 #
11 # https://github.com/easybuilders/easybuild
12 #
13 # EasyBuild is free software: you can redistribute it and/or modify
14 # it under the terms of the GNU General Public License as published by
15 # the Free Software Foundation v2.
16 #
17 # EasyBuild is distributed in the hope that it will be useful,
18 # but WITHOUT ANY WARRANTY; without even the implied warranty of
19 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
20 # GNU General Public License for more details.
21 #
22 # You should have received a copy of the GNU General Public License
23 # along with EasyBuild. If not, see <http://www.gnu.org/licenses/>.
24 ##
25 """
26 EasyBuild support for building and installing numexpr, implemented as an easyblock
27 """
28 import os
29
30 from easybuild.easyblocks.generic.pythonpackage import PythonPackage
31 from easybuild.tools.filetools import write_file
32 from easybuild.tools.modules import get_software_root
33 from easybuild.tools.systemtools import get_cpu_features
34
35
36 class EB_numexpr(PythonPackage):
37 """Support for building/installing numexpr."""
38
39 @staticmethod
40 def extra_options():
41 """Override some custom easyconfig parameters specifically for numexpr."""
42 extra_vars = PythonPackage.extra_options()
43
44 extra_vars['download_dep_fail'][0] = True
45 extra_vars['use_pip'][0] = True
46
47 return extra_vars
48
49 def __init__(self, *args, **kwargs):
50 """Initialisation of custom class variables for numexpr."""
51 super(EB_numexpr, self).__init__(*args, **kwargs)
52
53 self.imkl_root = None
54
55 def prepare_step(self, *args, **kwargs):
56 """Prepare environment for building and installing numexpr."""
57 super(EB_numexpr, self).prepare_step(*args, **kwargs)
58
59 self.imkl_root = get_software_root('imkl')
60
61 def configure_step(self):
62 """Custom configuration procedure for numexpr."""
63 super(EB_numexpr, self).configure_step()
64
65 # if Intel MKL is available, set up site.cfg such that the right VML library is used;
66 # this makes a *big* difference in terms of performance;
67 # see also https://github.com/pydata/numexpr/blob/master/site.cfg.example
68 if self.imkl_root:
69
70 # figure out which VML library to link to
71 cpu_features = get_cpu_features()
72 if 'avx512f' in cpu_features:
73 mkl_vml_lib = 'mkl_vml_avx512'
74 elif 'avx2' in cpu_features:
75 mkl_vml_lib = 'mkl_vml_avx2'
76 elif 'avx' in cpu_features:
77 mkl_vml_lib = 'mkl_vml_avx'
78 else:
79 # use default kernels as fallback for non-AVX systems
80 mkl_vml_lib = 'mkl_vml_def'
81
82 mkl_libs = ['mkl_intel_lp64', 'mkl_intel_thread', 'mkl_core', 'mkl_def', mkl_vml_lib, 'mkl_rt', 'iomp5']
83
84 mkl_lib_dirs = [
85 os.path.join(self.imkl_root, 'mkl', 'lib', 'intel64'),
86 os.path.join(self.imkl_root, 'lib', 'intel64'),
87 ]
88
89 site_cfg_txt = '\n'.join([
90 "[mkl]",
91 "include_dirs = %s" % os.path.join(self.imkl_root, 'mkl', 'include'),
92 "library_dirs = %s" % ':'.join(mkl_lib_dirs),
93 "mkl_libs = %s" % ', '.join(mkl_libs),
94 ])
95 write_file('site.cfg', site_cfg_txt)
96
97 def sanity_check_step(self):
98 """Custom sanity check for numexpr."""
99
100 custom_commands = []
101
102 # if Intel MKL is available, make sure VML is used
103 if self.imkl_root:
104 custom_commands.append("python -c 'import numexpr; assert(numexpr.use_vml)'")
105
106 super(EB_numexpr, self).sanity_check_step(custom_commands=custom_commands)
107
[end of easybuild/easyblocks/n/numexpr.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/easybuild/easyblocks/n/numexpr.py b/easybuild/easyblocks/n/numexpr.py
--- a/easybuild/easyblocks/n/numexpr.py
+++ b/easybuild/easyblocks/n/numexpr.py
@@ -52,16 +52,12 @@
self.imkl_root = None
- def prepare_step(self, *args, **kwargs):
- """Prepare environment for building and installing numexpr."""
- super(EB_numexpr, self).prepare_step(*args, **kwargs)
-
- self.imkl_root = get_software_root('imkl')
-
def configure_step(self):
"""Custom configuration procedure for numexpr."""
super(EB_numexpr, self).configure_step()
+ self.imkl_root = get_software_root('imkl')
+
# if Intel MKL is available, set up site.cfg such that the right VML library is used;
# this makes a *big* difference in terms of performance;
# see also https://github.com/pydata/numexpr/blob/master/site.cfg.example
@@ -103,4 +99,4 @@
if self.imkl_root:
custom_commands.append("python -c 'import numexpr; assert(numexpr.use_vml)'")
- super(EB_numexpr, self).sanity_check_step(custom_commands=custom_commands)
+ return super(EB_numexpr, self).sanity_check_step(custom_commands=custom_commands)
| {"golden_diff": "diff --git a/easybuild/easyblocks/n/numexpr.py b/easybuild/easyblocks/n/numexpr.py\n--- a/easybuild/easyblocks/n/numexpr.py\n+++ b/easybuild/easyblocks/n/numexpr.py\n@@ -52,16 +52,12 @@\n \n self.imkl_root = None\n \n- def prepare_step(self, *args, **kwargs):\n- \"\"\"Prepare environment for building and installing numexpr.\"\"\"\n- super(EB_numexpr, self).prepare_step(*args, **kwargs)\n-\n- self.imkl_root = get_software_root('imkl')\n-\n def configure_step(self):\n \"\"\"Custom configuration procedure for numexpr.\"\"\"\n super(EB_numexpr, self).configure_step()\n \n+ self.imkl_root = get_software_root('imkl')\n+\n # if Intel MKL is available, set up site.cfg such that the right VML library is used;\n # this makes a *big* difference in terms of performance;\n # see also https://github.com/pydata/numexpr/blob/master/site.cfg.example\n@@ -103,4 +99,4 @@\n if self.imkl_root:\n custom_commands.append(\"python -c 'import numexpr; assert(numexpr.use_vml)'\")\n \n- super(EB_numexpr, self).sanity_check_step(custom_commands=custom_commands)\n+ return super(EB_numexpr, self).sanity_check_step(custom_commands=custom_commands)\n", "issue": "numexpr can't be installed as an extension\nThe reason is two-fold:\r\n\r\nAs an extension this is not executed:\r\n\r\nhttps://github.com/easybuilders/easybuild-easyblocks/blob/develop/easybuild/easyblocks/n/numexpr.py#L59\r\n\r\nAnd therefore the variable is not defined, it is built without VML, and it would fail on the sanity check.\r\n\r\nWith that fixed, there is another more convoluted issue. The sanity check executed follows this order:\r\n\r\n1. Sanity check in `numexpr.py`\r\n2. Sanity check in `pythonpackage`\r\n3. Sanity check in `extensioneasyblock`\r\n4. Sanity check in `easyblock`\r\n5. Sanity check in `extensioneasyblock` again\r\n6. And finally sanity check in `easyblock` again, where it fails\r\n\r\n5 and 6 happens due to this condition:\r\n\r\nhttps://github.com/easybuilders/easybuild-framework/blob/develop/easybuild/framework/extensioneasyblock.py#L154\r\n\r\nWithout the `custom_commands` it works just fine. But that should be ok.\r\n\r\nThe log does not help much, but shows that there is a weird issue (sanity checked passed, and then failed):\r\n\r\n```\r\n== 2020-03-26 20:57:10,714 run.py:200 DEBUG run_cmd: running cmd python -c 'import numexpr; assert(numexpr.use_vml)' (in /gpfs/software/juwels/stages/Devel-2019a/software/Jupyter/2019a-gcccoremkl-8.3.0-2019.3.199-devel2-Python-3.6.8)\r\n== 2020-03-26 20:57:10,715 run.py:219 INFO running cmd: python -c 'import numexpr; assert(numexpr.use_vml)'\r\n== 2020-03-26 20:57:11,196 run.py:536 DEBUG cmd \"python -c 'import numexpr; assert(numexpr.use_vml)'\" exited with exit code 0 and output:\r\n\r\n== 2020-03-26 20:57:11,196 run.py:570 DEBUG Using default regular expression: (?<![(,-]|\\w)(?:error|segmentation fault|failed)(?![(,-]|\\.?\\w)\r\n== 2020-03-26 20:57:11,197 easyblock.py:2574 INFO sanity check command python -c 'import numexpr; assert(numexpr.use_vml)' ran successfully! (output: )\r\n== 2020-03-26 20:57:11,198 easyblock.py:2595 DEBUG Skipping RPATH sanity check\r\n== 2020-03-26 20:57:11,198 easyblock.py:2601 DEBUG Sanity check passed!\r\n== 2020-03-26 20:57:11,198 extensioneasyblock.py:160 INFO Sanity check for numexpr successful!\r\n== 2020-03-26 20:57:11,199 easyblock.py:2473 WARNING failing sanity check for 'numexpr' extension: (see log for details)\r\n== 2020-03-26 20:57:11,199 easyblock.py:2479 WARNING extensions sanity check failed for 1 extensions:\r\n```\r\n\r\nThe funny bit. If I wrap this condition https://github.com/easybuilders/easybuild-framework/blob/develop/easybuild/framework/easyblock.py#L2622 like this:\r\n\r\n```\r\n print(\"before extension easyblock failed message: \"+str(self.sanity_check_fail_msgs))\r\n # also run sanity check for extensions (unless we are an extension ourselves)\r\n if not extension:\r\n self._sanity_check_step_extensions()\r\n print(\"after extension easyblock failed message: \"+str(self.sanity_check_fail_msgs))\r\n```\r\n\r\nI get this output:\r\n\r\n```\r\nbefore extension easyblock failed message: []\r\nafter extension easyblock failed message: []\r\nafter extension easyblock failed message: ['extensions sanity check failed for 1 extensions: numexpr', \"failing sanity check for 'numexpr' extension: (see log for details)\"]\r\n```\r\n\r\nNote the 2 \"after\" with a single \"before\". It is late and I am tired and hungry, but that looks pretty weird to me and I am starting to believe in leprechauns\n", "before_files": [{"content": "##\n# Copyright 2019-2020 Ghent University\n#\n# This file is part of EasyBuild,\n# originally created by the HPC team of Ghent University (http://ugent.be/hpc/en),\n# with support of Ghent University (http://ugent.be/hpc),\n# the Flemish Supercomputer Centre (VSC) (https://www.vscentrum.be),\n# Flemish Research Foundation (FWO) (http://www.fwo.be/en)\n# and the Department of Economy, Science and Innovation (EWI) (http://www.ewi-vlaanderen.be/en).\n#\n# https://github.com/easybuilders/easybuild\n#\n# EasyBuild is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation v2.\n#\n# EasyBuild is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with EasyBuild. If not, see <http://www.gnu.org/licenses/>.\n##\n\"\"\"\nEasyBuild support for building and installing numexpr, implemented as an easyblock\n\"\"\"\nimport os\n\nfrom easybuild.easyblocks.generic.pythonpackage import PythonPackage\nfrom easybuild.tools.filetools import write_file\nfrom easybuild.tools.modules import get_software_root\nfrom easybuild.tools.systemtools import get_cpu_features\n\n\nclass EB_numexpr(PythonPackage):\n \"\"\"Support for building/installing numexpr.\"\"\"\n\n @staticmethod\n def extra_options():\n \"\"\"Override some custom easyconfig parameters specifically for numexpr.\"\"\"\n extra_vars = PythonPackage.extra_options()\n\n extra_vars['download_dep_fail'][0] = True\n extra_vars['use_pip'][0] = True\n\n return extra_vars\n\n def __init__(self, *args, **kwargs):\n \"\"\"Initialisation of custom class variables for numexpr.\"\"\"\n super(EB_numexpr, self).__init__(*args, **kwargs)\n\n self.imkl_root = None\n\n def prepare_step(self, *args, **kwargs):\n \"\"\"Prepare environment for building and installing numexpr.\"\"\"\n super(EB_numexpr, self).prepare_step(*args, **kwargs)\n\n self.imkl_root = get_software_root('imkl')\n\n def configure_step(self):\n \"\"\"Custom configuration procedure for numexpr.\"\"\"\n super(EB_numexpr, self).configure_step()\n\n # if Intel MKL is available, set up site.cfg such that the right VML library is used;\n # this makes a *big* difference in terms of performance;\n # see also https://github.com/pydata/numexpr/blob/master/site.cfg.example\n if self.imkl_root:\n\n # figure out which VML library to link to\n cpu_features = get_cpu_features()\n if 'avx512f' in cpu_features:\n mkl_vml_lib = 'mkl_vml_avx512'\n elif 'avx2' in cpu_features:\n mkl_vml_lib = 'mkl_vml_avx2'\n elif 'avx' in cpu_features:\n mkl_vml_lib = 'mkl_vml_avx'\n else:\n # use default kernels as fallback for non-AVX systems\n mkl_vml_lib = 'mkl_vml_def'\n\n mkl_libs = ['mkl_intel_lp64', 'mkl_intel_thread', 'mkl_core', 'mkl_def', mkl_vml_lib, 'mkl_rt', 'iomp5']\n\n mkl_lib_dirs = [\n os.path.join(self.imkl_root, 'mkl', 'lib', 'intel64'),\n os.path.join(self.imkl_root, 'lib', 'intel64'),\n ]\n\n site_cfg_txt = '\\n'.join([\n \"[mkl]\",\n \"include_dirs = %s\" % os.path.join(self.imkl_root, 'mkl', 'include'),\n \"library_dirs = %s\" % ':'.join(mkl_lib_dirs),\n \"mkl_libs = %s\" % ', '.join(mkl_libs),\n ])\n write_file('site.cfg', site_cfg_txt)\n\n def sanity_check_step(self):\n \"\"\"Custom sanity check for numexpr.\"\"\"\n\n custom_commands = []\n\n # if Intel MKL is available, make sure VML is used\n if self.imkl_root:\n custom_commands.append(\"python -c 'import numexpr; assert(numexpr.use_vml)'\")\n\n super(EB_numexpr, self).sanity_check_step(custom_commands=custom_commands)\n", "path": "easybuild/easyblocks/n/numexpr.py"}]} | 2,814 | 322 |
gh_patches_debug_20578 | rasdani/github-patches | git_diff | google__osv.dev-482 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
PURLs for scoped NPM packages are invalid
The package URLs for scoped NPM packages (e.g. [`@hapi/hoek`](https://osv.dev/vulnerability/GHSA-22h7-7wwg-qmgg)) are invalid. Parsing them with any package URL library fails.
According to [the spec](https://github.com/package-url/purl-spec/blob/master/PURL-SPECIFICATION.rst#rules-for-each-purl-component), segments in the namespace (here: `@hapi`) must be percent-encdoded.
So
```
pkg:npm/@hapi/hoek
```
should be
```
pkg:npm/%40hapi/hoek
```
On the same note, the name segment must be percent-encoded, too. I haven't encountered a PURL in OSV where the package name contains characters that'd need encoding, but if this is done for the namespace, it should be considered for the name as well.
</issue>
<code>
[start of lib/osv/purl_helpers.py]
1 # Copyright 2022 Google LLC
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 """PURL conversion utilities."""
15
16 PURL_ECOSYSTEMS = {
17 'crates.io': 'cargo',
18 'Hex': 'hex',
19 'Go': 'golang',
20 'Maven': 'maven',
21 'NuGet': 'nuget',
22 'npm': 'npm',
23 'Packagist': 'composer',
24 'OSS-Fuzz': 'generic',
25 'PyPI': 'pypi',
26 'RubyGems': 'gem',
27 }
28
29
30 def package_to_purl(ecosystem, package_name):
31 """Convert a ecosystem and package name to PURL."""
32 purl_type = PURL_ECOSYSTEMS.get(ecosystem)
33 if not purl_type:
34 return None
35
36 if purl_type == 'maven':
37 # PURLs use / to separate the group ID and the artifact ID.
38 package_name = package_name.replace(':', '/', 1)
39
40 return f'pkg:{purl_type}/{package_name}'
41
[end of lib/osv/purl_helpers.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/lib/osv/purl_helpers.py b/lib/osv/purl_helpers.py
--- a/lib/osv/purl_helpers.py
+++ b/lib/osv/purl_helpers.py
@@ -13,6 +13,8 @@
# limitations under the License.
"""PURL conversion utilities."""
+from urllib.parse import quote
+
PURL_ECOSYSTEMS = {
'crates.io': 'cargo',
'Hex': 'hex',
@@ -27,6 +29,12 @@
}
+def _url_encode(package_name):
+ """URL encode a PURL `namespace/name` or `name`."""
+ parts = package_name.split('/')
+ return '/'.join(quote(p) for p in parts)
+
+
def package_to_purl(ecosystem, package_name):
"""Convert a ecosystem and package name to PURL."""
purl_type = PURL_ECOSYSTEMS.get(ecosystem)
@@ -37,4 +45,4 @@
# PURLs use / to separate the group ID and the artifact ID.
package_name = package_name.replace(':', '/', 1)
- return f'pkg:{purl_type}/{package_name}'
+ return f'pkg:{purl_type}/{_url_encode(package_name)}'
| {"golden_diff": "diff --git a/lib/osv/purl_helpers.py b/lib/osv/purl_helpers.py\n--- a/lib/osv/purl_helpers.py\n+++ b/lib/osv/purl_helpers.py\n@@ -13,6 +13,8 @@\n # limitations under the License.\n \"\"\"PURL conversion utilities.\"\"\"\n \n+from urllib.parse import quote\n+\n PURL_ECOSYSTEMS = {\n 'crates.io': 'cargo',\n 'Hex': 'hex',\n@@ -27,6 +29,12 @@\n }\n \n \n+def _url_encode(package_name):\n+ \"\"\"URL encode a PURL `namespace/name` or `name`.\"\"\"\n+ parts = package_name.split('/')\n+ return '/'.join(quote(p) for p in parts)\n+\n+\n def package_to_purl(ecosystem, package_name):\n \"\"\"Convert a ecosystem and package name to PURL.\"\"\"\n purl_type = PURL_ECOSYSTEMS.get(ecosystem)\n@@ -37,4 +45,4 @@\n # PURLs use / to separate the group ID and the artifact ID.\n package_name = package_name.replace(':', '/', 1)\n \n- return f'pkg:{purl_type}/{package_name}'\n+ return f'pkg:{purl_type}/{_url_encode(package_name)}'\n", "issue": "PURLs for scoped NPM packages are invalid\nThe package URLs for scoped NPM packages (e.g. [`@hapi/hoek`](https://osv.dev/vulnerability/GHSA-22h7-7wwg-qmgg)) are invalid. Parsing them with any package URL library fails.\r\n\r\nAccording to [the spec](https://github.com/package-url/purl-spec/blob/master/PURL-SPECIFICATION.rst#rules-for-each-purl-component), segments in the namespace (here: `@hapi`) must be percent-encdoded.\r\n\r\nSo\r\n\r\n```\r\npkg:npm/@hapi/hoek\r\n```\r\n\r\nshould be\r\n\r\n```\r\npkg:npm/%40hapi/hoek\r\n```\r\n\r\nOn the same note, the name segment must be percent-encoded, too. I haven't encountered a PURL in OSV where the package name contains characters that'd need encoding, but if this is done for the namespace, it should be considered for the name as well.\n", "before_files": [{"content": "# Copyright 2022 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"PURL conversion utilities.\"\"\"\n\nPURL_ECOSYSTEMS = {\n 'crates.io': 'cargo',\n 'Hex': 'hex',\n 'Go': 'golang',\n 'Maven': 'maven',\n 'NuGet': 'nuget',\n 'npm': 'npm',\n 'Packagist': 'composer',\n 'OSS-Fuzz': 'generic',\n 'PyPI': 'pypi',\n 'RubyGems': 'gem',\n}\n\n\ndef package_to_purl(ecosystem, package_name):\n \"\"\"Convert a ecosystem and package name to PURL.\"\"\"\n purl_type = PURL_ECOSYSTEMS.get(ecosystem)\n if not purl_type:\n return None\n\n if purl_type == 'maven':\n # PURLs use / to separate the group ID and the artifact ID.\n package_name = package_name.replace(':', '/', 1)\n\n return f'pkg:{purl_type}/{package_name}'\n", "path": "lib/osv/purl_helpers.py"}]} | 1,161 | 276 |
gh_patches_debug_12874 | rasdani/github-patches | git_diff | vyperlang__vyper-1078 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Cannot convert to address
### Version Information
* vyper Version: 0.2.0b4
### What's your issue about?
Vyper disallows converting to an address. This is a problem because sometimes we need to process stuff from bytes to an address.
#### Cute Animal Picture

</issue>
<code>
[start of vyper/types/convert.py]
1 import ast
2 import warnings
3
4 from vyper.functions.signature import (
5 signature
6 )
7 from vyper.parser.parser_utils import (
8 LLLnode,
9 getpos,
10 byte_array_to_num
11 )
12 from vyper.exceptions import (
13 InvalidLiteralException,
14 TypeMismatchException,
15 ParserException,
16 )
17 from vyper.types import (
18 BaseType,
19 )
20 from vyper.types import (
21 get_type,
22 )
23 from vyper.utils import (
24 DECIMAL_DIVISOR,
25 MemoryPositions,
26 SizeLimits
27 )
28
29
30 @signature(('uint256', 'bytes32', 'bytes'), '*')
31 def to_int128(expr, args, kwargs, context):
32 in_node = args[0]
33 typ, len = get_type(in_node)
34 if typ in ('uint256', 'bytes32'):
35 if in_node.typ.is_literal and not SizeLimits.in_bounds('int128', in_node.value):
36 raise InvalidLiteralException("Number out of range: {}".format(in_node.value), expr)
37 return LLLnode.from_list(
38 ['clamp', ['mload', MemoryPositions.MINNUM], in_node,
39 ['mload', MemoryPositions.MAXNUM]], typ=BaseType('int128', in_node.typ.unit), pos=getpos(expr)
40 )
41 else:
42 return byte_array_to_num(in_node, expr, 'int128')
43
44
45 @signature(('num_literal', 'int128', 'bytes32', 'address'), '*')
46 def to_uint256(expr, args, kwargs, context):
47 in_node = args[0]
48 input_type, len = get_type(in_node)
49
50 if isinstance(in_node, int):
51 if not SizeLimits.in_bounds('uint256', in_node):
52 raise InvalidLiteralException("Number out of range: {}".format(in_node))
53 _unit = in_node.typ.unit if input_type == 'int128' else None
54 return LLLnode.from_list(in_node, typ=BaseType('uint256', _unit), pos=getpos(expr))
55
56 elif isinstance(in_node, LLLnode) and input_type in ('int128', 'num_literal'):
57 _unit = in_node.typ.unit if input_type == 'int128' else None
58 return LLLnode.from_list(['clampge', in_node, 0], typ=BaseType('uint256', _unit), pos=getpos(expr))
59
60 elif isinstance(in_node, LLLnode) and input_type in ('bytes32', 'address'):
61 return LLLnode(value=in_node.value, args=in_node.args, typ=BaseType('uint256'), pos=getpos(expr))
62
63 else:
64 raise InvalidLiteralException("Invalid input for uint256: %r" % in_node, expr)
65
66
67 @signature(('int128', 'uint256'), '*')
68 def to_decimal(expr, args, kwargs, context):
69 input = args[0]
70 if input.typ.typ == 'uint256':
71 return LLLnode.from_list(
72 ['uclample', ['mul', input, DECIMAL_DIVISOR], ['mload', MemoryPositions.MAXDECIMAL]],
73 typ=BaseType('decimal', input.typ.unit, input.typ.positional), pos=getpos(expr)
74 )
75 else:
76 return LLLnode.from_list(
77 ['mul', input, DECIMAL_DIVISOR],
78 typ=BaseType('decimal', input.typ.unit, input.typ.positional),
79 pos=getpos(expr)
80 )
81
82
83 @signature(('int128', 'uint256', 'address', 'bytes'), '*')
84 def to_bytes32(expr, args, kwargs, context):
85 in_arg = args[0]
86 typ, _len = get_type(in_arg)
87
88 if typ == 'bytes':
89
90 if _len > 32:
91 raise TypeMismatchException("Unable to convert bytes[{}] to bytes32, max length is too large.".format(len))
92
93 if in_arg.location == "memory":
94 return LLLnode.from_list(
95 ['mload', ['add', in_arg, 32]], typ=BaseType('bytes32')
96 )
97 elif in_arg.location == "storage":
98 return LLLnode.from_list(
99 ['sload', ['add', ['sha3_32', in_arg], 1]], typ=BaseType('bytes32')
100 )
101
102 else:
103 return LLLnode(value=in_arg.value, args=in_arg.args, typ=BaseType('bytes32'), pos=getpos(expr))
104
105
106 def convert(expr, context):
107
108 if isinstance(expr.args[1], ast.Str):
109 warnings.warn(
110 "String parameter has been removed, see VIP1026). "
111 "Use a vyper type instead.",
112 DeprecationWarning
113 )
114
115 if isinstance(expr.args[1], ast.Name):
116 output_type = expr.args[1].id
117 else:
118 raise ParserException("Invalid conversion type, use valid vyper type.", expr)
119
120 if output_type in conversion_table:
121 return conversion_table[output_type](expr, context)
122 else:
123 raise ParserException("Conversion to {} is invalid.".format(output_type), expr)
124
125
126 conversion_table = {
127 'int128': to_int128,
128 'uint256': to_uint256,
129 'decimal': to_decimal,
130 'bytes32': to_bytes32,
131 }
132
[end of vyper/types/convert.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/vyper/types/convert.py b/vyper/types/convert.py
--- a/vyper/types/convert.py
+++ b/vyper/types/convert.py
@@ -103,6 +103,13 @@
return LLLnode(value=in_arg.value, args=in_arg.args, typ=BaseType('bytes32'), pos=getpos(expr))
+@signature(('bytes32'), '*')
+def to_address(expr, args, kwargs, context):
+ in_arg = args[0]
+
+ return LLLnode(value=in_arg.value, args=in_arg.args, typ=BaseType('address'), pos=getpos(expr))
+
+
def convert(expr, context):
if isinstance(expr.args[1], ast.Str):
@@ -128,4 +135,5 @@
'uint256': to_uint256,
'decimal': to_decimal,
'bytes32': to_bytes32,
+ 'address': to_address,
}
| {"golden_diff": "diff --git a/vyper/types/convert.py b/vyper/types/convert.py\n--- a/vyper/types/convert.py\n+++ b/vyper/types/convert.py\n@@ -103,6 +103,13 @@\n return LLLnode(value=in_arg.value, args=in_arg.args, typ=BaseType('bytes32'), pos=getpos(expr))\n \n \n+@signature(('bytes32'), '*')\n+def to_address(expr, args, kwargs, context):\n+ in_arg = args[0]\n+\n+ return LLLnode(value=in_arg.value, args=in_arg.args, typ=BaseType('address'), pos=getpos(expr))\n+\n+\n def convert(expr, context):\n \n if isinstance(expr.args[1], ast.Str):\n@@ -128,4 +135,5 @@\n 'uint256': to_uint256,\n 'decimal': to_decimal,\n 'bytes32': to_bytes32,\n+ 'address': to_address,\n }\n", "issue": "Cannot convert to address\n### Version Information\r\n\r\n* vyper Version: 0.2.0b4\r\n\r\n### What's your issue about?\r\nVyper disallows converting to an address. This is a problem because sometimes we need to process stuff from bytes to an address.\r\n\r\n#### Cute Animal Picture\r\n\n", "before_files": [{"content": "import ast\nimport warnings\n\nfrom vyper.functions.signature import (\n signature\n)\nfrom vyper.parser.parser_utils import (\n LLLnode,\n getpos,\n byte_array_to_num\n)\nfrom vyper.exceptions import (\n InvalidLiteralException,\n TypeMismatchException,\n ParserException,\n)\nfrom vyper.types import (\n BaseType,\n)\nfrom vyper.types import (\n get_type,\n)\nfrom vyper.utils import (\n DECIMAL_DIVISOR,\n MemoryPositions,\n SizeLimits\n)\n\n\n@signature(('uint256', 'bytes32', 'bytes'), '*')\ndef to_int128(expr, args, kwargs, context):\n in_node = args[0]\n typ, len = get_type(in_node)\n if typ in ('uint256', 'bytes32'):\n if in_node.typ.is_literal and not SizeLimits.in_bounds('int128', in_node.value):\n raise InvalidLiteralException(\"Number out of range: {}\".format(in_node.value), expr)\n return LLLnode.from_list(\n ['clamp', ['mload', MemoryPositions.MINNUM], in_node,\n ['mload', MemoryPositions.MAXNUM]], typ=BaseType('int128', in_node.typ.unit), pos=getpos(expr)\n )\n else:\n return byte_array_to_num(in_node, expr, 'int128')\n\n\n@signature(('num_literal', 'int128', 'bytes32', 'address'), '*')\ndef to_uint256(expr, args, kwargs, context):\n in_node = args[0]\n input_type, len = get_type(in_node)\n\n if isinstance(in_node, int):\n if not SizeLimits.in_bounds('uint256', in_node):\n raise InvalidLiteralException(\"Number out of range: {}\".format(in_node))\n _unit = in_node.typ.unit if input_type == 'int128' else None\n return LLLnode.from_list(in_node, typ=BaseType('uint256', _unit), pos=getpos(expr))\n\n elif isinstance(in_node, LLLnode) and input_type in ('int128', 'num_literal'):\n _unit = in_node.typ.unit if input_type == 'int128' else None\n return LLLnode.from_list(['clampge', in_node, 0], typ=BaseType('uint256', _unit), pos=getpos(expr))\n\n elif isinstance(in_node, LLLnode) and input_type in ('bytes32', 'address'):\n return LLLnode(value=in_node.value, args=in_node.args, typ=BaseType('uint256'), pos=getpos(expr))\n\n else:\n raise InvalidLiteralException(\"Invalid input for uint256: %r\" % in_node, expr)\n\n\n@signature(('int128', 'uint256'), '*')\ndef to_decimal(expr, args, kwargs, context):\n input = args[0]\n if input.typ.typ == 'uint256':\n return LLLnode.from_list(\n ['uclample', ['mul', input, DECIMAL_DIVISOR], ['mload', MemoryPositions.MAXDECIMAL]],\n typ=BaseType('decimal', input.typ.unit, input.typ.positional), pos=getpos(expr)\n )\n else:\n return LLLnode.from_list(\n ['mul', input, DECIMAL_DIVISOR],\n typ=BaseType('decimal', input.typ.unit, input.typ.positional),\n pos=getpos(expr)\n )\n\n\n@signature(('int128', 'uint256', 'address', 'bytes'), '*')\ndef to_bytes32(expr, args, kwargs, context):\n in_arg = args[0]\n typ, _len = get_type(in_arg)\n\n if typ == 'bytes':\n\n if _len > 32:\n raise TypeMismatchException(\"Unable to convert bytes[{}] to bytes32, max length is too large.\".format(len))\n\n if in_arg.location == \"memory\":\n return LLLnode.from_list(\n ['mload', ['add', in_arg, 32]], typ=BaseType('bytes32')\n )\n elif in_arg.location == \"storage\":\n return LLLnode.from_list(\n ['sload', ['add', ['sha3_32', in_arg], 1]], typ=BaseType('bytes32')\n )\n\n else:\n return LLLnode(value=in_arg.value, args=in_arg.args, typ=BaseType('bytes32'), pos=getpos(expr))\n\n\ndef convert(expr, context):\n\n if isinstance(expr.args[1], ast.Str):\n warnings.warn(\n \"String parameter has been removed, see VIP1026). \"\n \"Use a vyper type instead.\",\n DeprecationWarning\n )\n\n if isinstance(expr.args[1], ast.Name):\n output_type = expr.args[1].id\n else:\n raise ParserException(\"Invalid conversion type, use valid vyper type.\", expr)\n\n if output_type in conversion_table:\n return conversion_table[output_type](expr, context)\n else:\n raise ParserException(\"Conversion to {} is invalid.\".format(output_type), expr)\n\n\nconversion_table = {\n 'int128': to_int128,\n 'uint256': to_uint256,\n 'decimal': to_decimal,\n 'bytes32': to_bytes32,\n}\n", "path": "vyper/types/convert.py"}]} | 2,092 | 215 |
gh_patches_debug_903 | rasdani/github-patches | git_diff | lra__mackup-1412 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
AssertionError on Ubuntu 18.04.2 LTS, Mackup 0.8.25, Python 3.6.7
I'm trying to `mackup restore` on a machine running
- Ubuntu 18.04.2 LTS
- Mackup 0.8.25
- Python 3.6.7
It fails immediately with the following:
```
Traceback (most recent call last):
File "/home/REDACTED/.pyenv/versions/3.6.7/bin/mackup", line 10, in <module>
sys.exit(main())
File "/home/REDACTED/.pyenv/versions/3.6.7/lib/python3.6/site-packages/mackup/main.py", line 102, in main
verbose)
File "/home/REDACTED/.pyenv/versions/3.6.7/lib/python3.6/site-packages/mackup/application.py", line 26, in __init__
assert isinstance(files, set)
AssertionError
```
I sync via dropbox, and to debug I made a tar.gz of the original mackup folder and copied/extracted it directly with no luck :( Not sure how to proceed to debug further, I've also tried `mackup restore -v` with no luck.
</issue>
<code>
[start of mackup/appsdb.py]
1 """
2 The applications database.
3
4 The Applications Database provides an easy to use interface to load application
5 data from the Mackup Database (files).
6 """
7 import os
8
9 try:
10 import configparser
11 except ImportError:
12 import ConfigParser as configparser
13
14
15 from .constants import APPS_DIR
16 from .constants import CUSTOM_APPS_DIR
17
18
19 class ApplicationsDatabase(object):
20
21 """Database containing all the configured applications."""
22
23 def __init__(self):
24 """Create a ApplicationsDatabase instance."""
25 # Build the dict that will contain the properties of each application
26 self.apps = dict()
27
28 for config_file in ApplicationsDatabase.get_config_files():
29 config = configparser.SafeConfigParser(allow_no_value=True)
30
31 # Needed to not lowercase the configuration_files in the ini files
32 config.optionxform = str
33
34 if config.read(config_file):
35 # Get the filename without the directory name
36 filename = os.path.basename(config_file)
37 # The app name is the cfg filename with the extension
38 app_name = filename[:-len('.cfg')]
39
40 # Start building a dict for this app
41 self.apps[app_name] = dict()
42
43 # Add the fancy name for the app, for display purpose
44 app_pretty_name = config.get('application', 'name')
45 self.apps[app_name]['name'] = app_pretty_name
46
47 # Add the configuration files to sync
48 self.apps[app_name]['configuration_files'] = set()
49 if config.has_section('configuration_files'):
50 for path in config.options('configuration_files'):
51 if path.startswith('/'):
52 raise ValueError('Unsupported absolute path: {}'
53 .format(path))
54 self.apps[app_name]['configuration_files'].add(path)
55
56 # Add the XDG configuration files to sync
57 home = os.path.expanduser('~/')
58 failobj = "{}.config".format(home)
59 xdg_config_home = os.environ.get('XDG_CONFIG_HOME', failobj)
60 if not xdg_config_home.startswith(home):
61 raise ValueError('$XDG_CONFIG_HOME: {} must be '
62 'somewhere within your home '
63 'directory: {}'
64 .format(xdg_config_home, home))
65 if config.has_section('xdg_configuration_files'):
66 for path in config.options('xdg_configuration_files'):
67 if path.startswith('/'):
68 raise ValueError('Unsupported absolute path: '
69 '{}'
70 .format(path))
71 path = os.path.join(xdg_config_home, path)
72 path = path.replace(home, '')
73 (self.apps[app_name]['configuration_files']
74 .add(path))
75
76 @staticmethod
77 def get_config_files():
78 """
79 Return the application configuration files.
80
81 Return a list of configuration files describing the apps supported by
82 Mackup. The files returned are absolute full path to those files.
83 e.g. /usr/lib/mackup/applications/bash.cfg
84
85 Only one config file per application should be returned, custom config
86 having a priority over stock config.
87
88 Returns:
89 set of strings.
90 """
91 # Configure the config parser
92 apps_dir = os.path.join(os.path.dirname(os.path.realpath(__file__)),
93 APPS_DIR)
94 custom_apps_dir = os.path.join(os.environ['HOME'], CUSTOM_APPS_DIR)
95
96 # List of stock application config files
97 config_files = set()
98
99 # Temp list of user added app config file names
100 custom_files = set()
101
102 # Get the list of custom application config files first
103 if os.path.isdir(custom_apps_dir):
104 for filename in os.listdir(custom_apps_dir):
105 if filename.endswith('.cfg'):
106 config_files.add(os.path.join(custom_apps_dir,
107 filename))
108 # Also add it to the set of custom apps, so that we don't
109 # add the stock config for the same app too
110 custom_files.add(filename)
111
112 # Add the default provided app config files, but only if those are not
113 # customized, as we don't want to overwrite custom app config.
114 for filename in os.listdir(apps_dir):
115 if filename.endswith('.cfg') and filename not in custom_files:
116 config_files.add(os.path.join(apps_dir, filename))
117
118 return config_files
119
120 def get_name(self, name):
121 """
122 Return the fancy name of an application.
123
124 Args:
125 name (str)
126
127 Returns:
128 str
129 """
130 return self.apps[name]['name']
131
132 def get_files(self, name):
133 """
134 Return the list of config files of an application.
135
136 Args:
137 name (str)
138
139 Returns:
140 set of str.
141 """
142 return sorted(self.apps[name]['configuration_files'])
143
144 def get_app_names(self):
145 """
146 Return application names.
147
148 Return the list of application names that are available in the
149 database.
150
151 Returns:
152 set of str.
153 """
154 app_names = set()
155 for name in self.apps:
156 app_names.add(name)
157
158 return app_names
159
160 def get_pretty_app_names(self):
161 """
162 Return the list of pretty app names that are available in the database.
163
164 Returns:
165 set of str.
166 """
167 pretty_app_names = set()
168 for app_name in self.get_app_names():
169 pretty_app_names.add(self.get_name(app_name))
170
171 return pretty_app_names
172
[end of mackup/appsdb.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/mackup/appsdb.py b/mackup/appsdb.py
--- a/mackup/appsdb.py
+++ b/mackup/appsdb.py
@@ -139,7 +139,7 @@
Returns:
set of str.
"""
- return sorted(self.apps[name]['configuration_files'])
+ return self.apps[name]['configuration_files']
def get_app_names(self):
"""
| {"golden_diff": "diff --git a/mackup/appsdb.py b/mackup/appsdb.py\n--- a/mackup/appsdb.py\n+++ b/mackup/appsdb.py\n@@ -139,7 +139,7 @@\n Returns:\n set of str.\n \"\"\"\n- return sorted(self.apps[name]['configuration_files'])\n+ return self.apps[name]['configuration_files']\n \n def get_app_names(self):\n \"\"\"\n", "issue": "AssertionError on Ubuntu 18.04.2 LTS, Mackup 0.8.25, Python 3.6.7\nI'm trying to `mackup restore` on a machine running\r\n\r\n- Ubuntu 18.04.2 LTS\r\n- Mackup 0.8.25\r\n- Python 3.6.7\r\n\r\nIt fails immediately with the following:\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"/home/REDACTED/.pyenv/versions/3.6.7/bin/mackup\", line 10, in <module>\r\n sys.exit(main())\r\n File \"/home/REDACTED/.pyenv/versions/3.6.7/lib/python3.6/site-packages/mackup/main.py\", line 102, in main\r\n verbose)\r\n File \"/home/REDACTED/.pyenv/versions/3.6.7/lib/python3.6/site-packages/mackup/application.py\", line 26, in __init__\r\n assert isinstance(files, set)\r\nAssertionError\r\n```\r\n\r\nI sync via dropbox, and to debug I made a tar.gz of the original mackup folder and copied/extracted it directly with no luck :( Not sure how to proceed to debug further, I've also tried `mackup restore -v` with no luck.\n", "before_files": [{"content": "\"\"\"\nThe applications database.\n\nThe Applications Database provides an easy to use interface to load application\ndata from the Mackup Database (files).\n\"\"\"\nimport os\n\ntry:\n import configparser\nexcept ImportError:\n import ConfigParser as configparser\n\n\nfrom .constants import APPS_DIR\nfrom .constants import CUSTOM_APPS_DIR\n\n\nclass ApplicationsDatabase(object):\n\n \"\"\"Database containing all the configured applications.\"\"\"\n\n def __init__(self):\n \"\"\"Create a ApplicationsDatabase instance.\"\"\"\n # Build the dict that will contain the properties of each application\n self.apps = dict()\n\n for config_file in ApplicationsDatabase.get_config_files():\n config = configparser.SafeConfigParser(allow_no_value=True)\n\n # Needed to not lowercase the configuration_files in the ini files\n config.optionxform = str\n\n if config.read(config_file):\n # Get the filename without the directory name\n filename = os.path.basename(config_file)\n # The app name is the cfg filename with the extension\n app_name = filename[:-len('.cfg')]\n\n # Start building a dict for this app\n self.apps[app_name] = dict()\n\n # Add the fancy name for the app, for display purpose\n app_pretty_name = config.get('application', 'name')\n self.apps[app_name]['name'] = app_pretty_name\n\n # Add the configuration files to sync\n self.apps[app_name]['configuration_files'] = set()\n if config.has_section('configuration_files'):\n for path in config.options('configuration_files'):\n if path.startswith('/'):\n raise ValueError('Unsupported absolute path: {}'\n .format(path))\n self.apps[app_name]['configuration_files'].add(path)\n\n # Add the XDG configuration files to sync\n home = os.path.expanduser('~/')\n failobj = \"{}.config\".format(home)\n xdg_config_home = os.environ.get('XDG_CONFIG_HOME', failobj)\n if not xdg_config_home.startswith(home):\n raise ValueError('$XDG_CONFIG_HOME: {} must be '\n 'somewhere within your home '\n 'directory: {}'\n .format(xdg_config_home, home))\n if config.has_section('xdg_configuration_files'):\n for path in config.options('xdg_configuration_files'):\n if path.startswith('/'):\n raise ValueError('Unsupported absolute path: '\n '{}'\n .format(path))\n path = os.path.join(xdg_config_home, path)\n path = path.replace(home, '')\n (self.apps[app_name]['configuration_files']\n .add(path))\n\n @staticmethod\n def get_config_files():\n \"\"\"\n Return the application configuration files.\n\n Return a list of configuration files describing the apps supported by\n Mackup. The files returned are absolute full path to those files.\n e.g. /usr/lib/mackup/applications/bash.cfg\n\n Only one config file per application should be returned, custom config\n having a priority over stock config.\n\n Returns:\n set of strings.\n \"\"\"\n # Configure the config parser\n apps_dir = os.path.join(os.path.dirname(os.path.realpath(__file__)),\n APPS_DIR)\n custom_apps_dir = os.path.join(os.environ['HOME'], CUSTOM_APPS_DIR)\n\n # List of stock application config files\n config_files = set()\n\n # Temp list of user added app config file names\n custom_files = set()\n\n # Get the list of custom application config files first\n if os.path.isdir(custom_apps_dir):\n for filename in os.listdir(custom_apps_dir):\n if filename.endswith('.cfg'):\n config_files.add(os.path.join(custom_apps_dir,\n filename))\n # Also add it to the set of custom apps, so that we don't\n # add the stock config for the same app too\n custom_files.add(filename)\n\n # Add the default provided app config files, but only if those are not\n # customized, as we don't want to overwrite custom app config.\n for filename in os.listdir(apps_dir):\n if filename.endswith('.cfg') and filename not in custom_files:\n config_files.add(os.path.join(apps_dir, filename))\n\n return config_files\n\n def get_name(self, name):\n \"\"\"\n Return the fancy name of an application.\n\n Args:\n name (str)\n\n Returns:\n str\n \"\"\"\n return self.apps[name]['name']\n\n def get_files(self, name):\n \"\"\"\n Return the list of config files of an application.\n\n Args:\n name (str)\n\n Returns:\n set of str.\n \"\"\"\n return sorted(self.apps[name]['configuration_files'])\n\n def get_app_names(self):\n \"\"\"\n Return application names.\n\n Return the list of application names that are available in the\n database.\n\n Returns:\n set of str.\n \"\"\"\n app_names = set()\n for name in self.apps:\n app_names.add(name)\n\n return app_names\n\n def get_pretty_app_names(self):\n \"\"\"\n Return the list of pretty app names that are available in the database.\n\n Returns:\n set of str.\n \"\"\"\n pretty_app_names = set()\n for app_name in self.get_app_names():\n pretty_app_names.add(self.get_name(app_name))\n\n return pretty_app_names\n", "path": "mackup/appsdb.py"}]} | 2,359 | 91 |
gh_patches_debug_21469 | rasdani/github-patches | git_diff | cupy__cupy-1999 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Device-to-host copy in `examples/stream/cupy_memcpy.py` is not asynchronous
I've interested in asynchronous memcpy for better performance. I checked the `cupy_memcpy.py` sample, and noticed that the last line `x_pinned_cpu = x_gpu.get()` [1] shouldn't work asynchronously. Unfortunately I don't know how to properly fix it.
One issue is trivial: this line re-binds the variable `x_pinned_cpu`, instead of updating the value bound to this variable.
But there is another more tricky problem. The function `cupy.ndarray.get` creates the new `numpy.ndarray` instance by calling `numpy.empty`, and passes the new host pointer to the `copy_to_host_async` function [2]. IIUC, as the new array not allocated in pinned memory, the copy couldn't be asynchronous with other computations at the GPU.
* [1] https://github.com/cupy/cupy/blob/v5.0.0rc1/examples/stream/cupy_memcpy.py#L24
* [2] https://github.com/cupy/cupy/blob/v5.0.0rc1/cupy/core/core.pyx#L1805
</issue>
<code>
[start of examples/stream/cupy_memcpy.py]
1 # nvprof --print-gpu-trace python examples/stream/cupy_memcpy.py
2 import cupy
3 import numpy
4
5 pinned_memory_pool = cupy.cuda.PinnedMemoryPool()
6 cupy.cuda.set_pinned_memory_allocator(pinned_memory_pool.malloc)
7
8
9 def _pin_memory(array):
10 mem = cupy.cuda.alloc_pinned_memory(array.nbytes)
11 ret = numpy.frombuffer(mem, array.dtype, array.size).reshape(array.shape)
12 ret[...] = array
13 return ret
14
15
16 x_cpu = numpy.array([1, 2, 3], dtype=numpy.float32)
17 x_pinned_cpu = _pin_memory(x_cpu)
18 x_gpu = cupy.core.ndarray((3,), dtype=numpy.float32)
19 with cupy.cuda.stream.Stream():
20 x_gpu.set(x_pinned_cpu)
21
22 stream = cupy.cuda.stream.Stream()
23 stream.use()
24 x_pinned_cpu = x_gpu.get()
25
[end of examples/stream/cupy_memcpy.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/examples/stream/cupy_memcpy.py b/examples/stream/cupy_memcpy.py
--- a/examples/stream/cupy_memcpy.py
+++ b/examples/stream/cupy_memcpy.py
@@ -13,12 +13,38 @@
return ret
-x_cpu = numpy.array([1, 2, 3], dtype=numpy.float32)
-x_pinned_cpu = _pin_memory(x_cpu)
-x_gpu = cupy.core.ndarray((3,), dtype=numpy.float32)
-with cupy.cuda.stream.Stream():
- x_gpu.set(x_pinned_cpu)
-
-stream = cupy.cuda.stream.Stream()
-stream.use()
-x_pinned_cpu = x_gpu.get()
+SIZE = 1024 * 1024
+x_cpu_src = numpy.arange(SIZE, dtype=numpy.float32)
+x_gpu_src = cupy.arange(SIZE, dtype=numpy.float32)
+
+
+# synchronous
+stream = cupy.cuda.Stream.null
+start = stream.record()
+x_gpu_dst = cupy.empty(x_cpu_src.shape, x_cpu_src.dtype)
+x_gpu_dst.set(x_cpu_src)
+x_cpu_dst = x_gpu_src.get()
+end = stream.record()
+
+print('Synchronous Device to Host / Host to Device (ms)')
+print(cupy.cuda.get_elapsed_time(start, end))
+
+
+# asynchronous
+x_gpu_dst = cupy.empty(x_cpu_src.shape, x_cpu_src.dtype)
+x_cpu_dst = numpy.empty(x_gpu_src.shape, x_gpu_src.dtype)
+
+x_pinned_cpu_src = _pin_memory(x_cpu_src)
+x_pinned_cpu_dst = _pin_memory(x_cpu_dst)
+
+with cupy.cuda.stream.Stream() as stream_htod:
+ start = stream_htod.record()
+ x_gpu_dst.set(x_pinned_cpu_src)
+ with cupy.cuda.stream.Stream() as stream_dtoh:
+ x_gpu_src.get(out=x_pinned_cpu_dst)
+ stream_dtoh.synchronize()
+ stream_htod.synchronize()
+ end = stream_htod.record()
+
+print('Asynchronous Device to Host / Host to Device (ms)')
+print(cupy.cuda.get_elapsed_time(start, end))
| {"golden_diff": "diff --git a/examples/stream/cupy_memcpy.py b/examples/stream/cupy_memcpy.py\n--- a/examples/stream/cupy_memcpy.py\n+++ b/examples/stream/cupy_memcpy.py\n@@ -13,12 +13,38 @@\n return ret\n \n \n-x_cpu = numpy.array([1, 2, 3], dtype=numpy.float32)\n-x_pinned_cpu = _pin_memory(x_cpu)\n-x_gpu = cupy.core.ndarray((3,), dtype=numpy.float32)\n-with cupy.cuda.stream.Stream():\n- x_gpu.set(x_pinned_cpu)\n-\n-stream = cupy.cuda.stream.Stream()\n-stream.use()\n-x_pinned_cpu = x_gpu.get()\n+SIZE = 1024 * 1024\n+x_cpu_src = numpy.arange(SIZE, dtype=numpy.float32)\n+x_gpu_src = cupy.arange(SIZE, dtype=numpy.float32)\n+\n+\n+# synchronous\n+stream = cupy.cuda.Stream.null\n+start = stream.record()\n+x_gpu_dst = cupy.empty(x_cpu_src.shape, x_cpu_src.dtype)\n+x_gpu_dst.set(x_cpu_src)\n+x_cpu_dst = x_gpu_src.get()\n+end = stream.record()\n+\n+print('Synchronous Device to Host / Host to Device (ms)')\n+print(cupy.cuda.get_elapsed_time(start, end))\n+\n+\n+# asynchronous\n+x_gpu_dst = cupy.empty(x_cpu_src.shape, x_cpu_src.dtype)\n+x_cpu_dst = numpy.empty(x_gpu_src.shape, x_gpu_src.dtype)\n+\n+x_pinned_cpu_src = _pin_memory(x_cpu_src)\n+x_pinned_cpu_dst = _pin_memory(x_cpu_dst)\n+\n+with cupy.cuda.stream.Stream() as stream_htod:\n+ start = stream_htod.record()\n+ x_gpu_dst.set(x_pinned_cpu_src)\n+ with cupy.cuda.stream.Stream() as stream_dtoh:\n+ x_gpu_src.get(out=x_pinned_cpu_dst)\n+ stream_dtoh.synchronize()\n+ stream_htod.synchronize()\n+ end = stream_htod.record()\n+\n+print('Asynchronous Device to Host / Host to Device (ms)')\n+print(cupy.cuda.get_elapsed_time(start, end))\n", "issue": "Device-to-host copy in `examples/stream/cupy_memcpy.py` is not asynchronous\nI've interested in asynchronous memcpy for better performance. I checked the `cupy_memcpy.py` sample, and noticed that the last line `x_pinned_cpu = x_gpu.get()` [1] shouldn't work asynchronously. Unfortunately I don't know how to properly fix it.\r\n\r\nOne issue is trivial: this line re-binds the variable `x_pinned_cpu`, instead of updating the value bound to this variable.\r\n\r\nBut there is another more tricky problem. The function `cupy.ndarray.get` creates the new `numpy.ndarray` instance by calling `numpy.empty`, and passes the new host pointer to the `copy_to_host_async` function [2]. IIUC, as the new array not allocated in pinned memory, the copy couldn't be asynchronous with other computations at the GPU.\r\n\r\n* [1] https://github.com/cupy/cupy/blob/v5.0.0rc1/examples/stream/cupy_memcpy.py#L24\r\n* [2] https://github.com/cupy/cupy/blob/v5.0.0rc1/cupy/core/core.pyx#L1805\n", "before_files": [{"content": "# nvprof --print-gpu-trace python examples/stream/cupy_memcpy.py\nimport cupy\nimport numpy\n\npinned_memory_pool = cupy.cuda.PinnedMemoryPool()\ncupy.cuda.set_pinned_memory_allocator(pinned_memory_pool.malloc)\n\n\ndef _pin_memory(array):\n mem = cupy.cuda.alloc_pinned_memory(array.nbytes)\n ret = numpy.frombuffer(mem, array.dtype, array.size).reshape(array.shape)\n ret[...] = array\n return ret\n\n\nx_cpu = numpy.array([1, 2, 3], dtype=numpy.float32)\nx_pinned_cpu = _pin_memory(x_cpu)\nx_gpu = cupy.core.ndarray((3,), dtype=numpy.float32)\nwith cupy.cuda.stream.Stream():\n x_gpu.set(x_pinned_cpu)\n\nstream = cupy.cuda.stream.Stream()\nstream.use()\nx_pinned_cpu = x_gpu.get()\n", "path": "examples/stream/cupy_memcpy.py"}]} | 1,010 | 460 |
gh_patches_debug_20024 | rasdani/github-patches | git_diff | liqd__a4-meinberlin-3503 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
DataError: value too long for type character varying(100)
Sentry Issue: [MEINBERLIN-DEV-2Z](https://sentry.liqd.net/organizations/liqd/issues/1357/?referrer=github_integration)
```
StringDataRightTruncation: value too long for type character varying(100)
File "django/db/backends/utils.py", line 84, in _execute
return self.cursor.execute(sql, params)
DataError: value too long for type character varying(100)
(29 additional frame(s) were not displayed)
...
File "django/db/backends/utils.py", line 67, in execute
return self._execute_with_wrappers(sql, params, many=False, executor=self._execute)
File "django/db/backends/utils.py", line 76, in _execute_with_wrappers
return executor(sql, params, many, context)
File "django/db/backends/utils.py", line 84, in _execute
return self.cursor.execute(sql, params)
File "django/db/utils.py", line 89, in __exit__
raise dj_exc_value.with_traceback(traceback) from exc_value
File "django/db/backends/utils.py", line 84, in _execute
return self.cursor.execute(sql, params)
Internal Server Error: /api/organisations/1/bplan/
```
</issue>
<code>
[start of meinberlin/apps/bplan/serializers.py]
1 import datetime
2 import imghdr
3 import posixpath
4 import tempfile
5 from urllib.parse import urlparse
6
7 import requests
8 from django.apps import apps
9 from django.conf import settings
10 from django.contrib.sites.models import Site
11 from django.core.exceptions import ValidationError
12 from django.core.files.images import ImageFile
13 from django.urls import reverse
14 from django.utils import timezone
15 from django.utils.translation import ugettext as _
16 from rest_framework import serializers
17
18 from adhocracy4.dashboard import components
19 from adhocracy4.dashboard import signals as a4dashboard_signals
20 from adhocracy4.images.validators import validate_image
21 from adhocracy4.modules import models as module_models
22 from adhocracy4.phases import models as phase_models
23 from adhocracy4.projects import models as project_models
24
25 from .models import Bplan
26 from .phases import StatementPhase
27
28 BPLAN_EMBED = '<iframe height="500" style="width: 100%; min-height: 300px; ' \
29 'max-height: 100vh" src="{}" frameborder="0"></iframe>'
30 DOWNLOAD_IMAGE_SIZE_LIMIT_BYTES = 10 * 1024 * 1024
31
32
33 class BplanSerializer(serializers.ModelSerializer):
34 id = serializers.IntegerField(required=False)
35
36 # make write_only for consistency reasons
37 start_date = serializers.DateTimeField(write_only=True)
38 end_date = serializers.DateTimeField(write_only=True)
39 image_url = serializers.URLField(required=False, write_only=True)
40 image_copyright = serializers.CharField(required=False, write_only=True,
41 source='tile_image_copyright',
42 allow_blank=True,
43 max_length=120)
44 embed_code = serializers.SerializerMethodField()
45
46 class Meta:
47 model = Bplan
48 fields = (
49 'id', 'name', 'identifier', 'description', 'url',
50 'office_worker_email', 'is_draft', 'start_date', 'end_date',
51 'image_url', 'image_copyright', 'embed_code'
52 )
53 extra_kwargs = {
54 # write_only for consistency reasons
55 'is_draft': {'default': False, 'write_only': True},
56 'name': {'write_only': True},
57 'description': {'write_only': True},
58 'url': {'write_only': True},
59 'office_worker_email': {'write_only': True},
60 'identifier': {'write_only': True}
61 }
62
63 def create(self, validated_data):
64 orga_pk = self._context.get('organisation_pk', None)
65 orga_model = apps.get_model(settings.A4_ORGANISATIONS_MODEL)
66 orga = orga_model.objects.get(pk=orga_pk)
67 validated_data['organisation'] = orga
68
69 start_date = validated_data['start_date']
70 end_date = validated_data['end_date']
71
72 image_url = validated_data.pop('image_url', None)
73 if image_url:
74 validated_data['tile_image'] = \
75 self._download_image_from_url(image_url)
76
77 bplan = super().create(validated_data)
78 self._create_module_and_phase(bplan, start_date, end_date)
79 self._send_project_created_signal(bplan)
80 return bplan
81
82 def _create_module_and_phase(self, bplan, start_date, end_date):
83 module = module_models.Module.objects.create(
84 name=bplan.slug + '_module',
85 weight=1,
86 project=bplan,
87 )
88
89 phase_content = StatementPhase()
90 phase_models.Phase.objects.create(
91 name=_('Bplan statement phase'),
92 description=_('Bplan statement phase'),
93 type=phase_content.identifier,
94 module=module,
95 start_date=start_date,
96 end_date=end_date
97 )
98
99 def update(self, instance, validated_data):
100 start_date = validated_data.get('start_date', None)
101 end_date = validated_data.get('end_date', None)
102 if start_date or end_date:
103 self._update_phase(instance, start_date, end_date)
104 if end_date and end_date > timezone.localtime(timezone.now()):
105 instance.is_archived = False
106
107 image_url = validated_data.pop('image_url', None)
108 if image_url:
109 validated_data['tile_image'] = \
110 self._download_image_from_url(image_url)
111
112 instance = super().update(instance, validated_data)
113
114 self._send_component_updated_signal(instance)
115 return instance
116
117 def _update_phase(self, bplan, start_date, end_date):
118 module = module_models.Module.objects.get(project=bplan)
119 phase = phase_models.Phase.objects.get(module=module)
120 if start_date:
121 phase.start_date = start_date
122 if end_date:
123 phase.end_date = end_date
124 phase.save()
125
126 def get_embed_code(self, bplan):
127 url = self._get_absolute_url(bplan)
128 embed = BPLAN_EMBED.format(url)
129 return embed
130
131 def _get_absolute_url(self, bplan):
132 site_url = Site.objects.get_current().domain
133 embed_url = reverse('embed-project', kwargs={'slug': bplan.slug, })
134 url = 'https://{}{}'.format(site_url, embed_url)
135 return url
136
137 def _download_image_from_url(self, url):
138 parsed_url = urlparse(url)
139 file_name = None
140 try:
141 r = requests.get(url, stream=True, timeout=10)
142 downloaded_bytes = 0
143 with tempfile.TemporaryFile() as f:
144 for chunk in r.iter_content(chunk_size=1024):
145 downloaded_bytes += len(chunk)
146 if downloaded_bytes > DOWNLOAD_IMAGE_SIZE_LIMIT_BYTES:
147 raise serializers.ValidationError(
148 'Image too large to download {}'.format(url))
149 if chunk:
150 f.write(chunk)
151 file_name = self._generate_image_filename(parsed_url.path, f)
152 self._image_storage.save(file_name, f)
153 except Exception:
154 if file_name:
155 self._image_storage.delete(file_name)
156 raise serializers.ValidationError(
157 'Failed to download image {}'.format(url))
158
159 try:
160 self._validate_image(file_name)
161 except ValidationError as e:
162 self._image_storage.delete(file_name)
163 raise serializers.ValidationError(e)
164
165 return file_name
166
167 def _validate_image(self, file_name):
168 image_file = self._image_storage.open(file_name, 'rb')
169 image = ImageFile(image_file, file_name)
170 config = settings.IMAGE_ALIASES.get('*', {})
171 config.update(settings.IMAGE_ALIASES['tileimage'])
172 validate_image(image, **config)
173
174 @property
175 def _image_storage(self):
176 return project_models.Project._meta.get_field('tile_image').storage
177
178 @property
179 def _image_upload_to(self):
180 return project_models.Project._meta.get_field('tile_image').upload_to
181
182 def _generate_image_filename(self, url_path, file):
183 if callable(self._image_upload_to):
184 raise Exception('Callable upload_to fields are not supported')
185
186 root_path, extension = posixpath.splitext(url_path)
187 if file:
188 # Workaround: imghdr expects the files position on 0
189 file.seek(0)
190 extension = imghdr.what(file) or 'jpeg'
191
192 basename = posixpath.basename(root_path)
193 if not basename:
194 basename = 'bplan'
195
196 dirname = datetime.datetime.now().strftime(self._image_upload_to)
197 filename = posixpath.join(dirname, basename + '.' + extension)
198
199 return self._image_storage.get_available_name(filename)
200
201 def _send_project_created_signal(self, bplan):
202 a4dashboard_signals.project_created.send(
203 sender=self.__class__,
204 project=bplan,
205 user=self.context['request'].user
206 )
207
208 def _send_component_updated_signal(self, bplan):
209 component = components.projects['bplan']
210 a4dashboard_signals.project_component_updated.send(
211 sender=self.__class__,
212 project=bplan,
213 component=component,
214 user=self.context['request'].user
215 )
216
[end of meinberlin/apps/bplan/serializers.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/meinberlin/apps/bplan/serializers.py b/meinberlin/apps/bplan/serializers.py
--- a/meinberlin/apps/bplan/serializers.py
+++ b/meinberlin/apps/bplan/serializers.py
@@ -36,11 +36,18 @@
# make write_only for consistency reasons
start_date = serializers.DateTimeField(write_only=True)
end_date = serializers.DateTimeField(write_only=True)
- image_url = serializers.URLField(required=False, write_only=True)
- image_copyright = serializers.CharField(required=False, write_only=True,
- source='tile_image_copyright',
- allow_blank=True,
- max_length=120)
+ image_url = serializers.URLField(
+ required=False,
+ write_only=True,
+ max_length=(project_models.Project._meta.
+ get_field('tile_image').max_length))
+ image_copyright = serializers.CharField(
+ required=False,
+ write_only=True,
+ source='tile_image_copyright',
+ allow_blank=True,
+ max_length=(project_models.Project._meta.
+ get_field('tile_image_copyright').max_length))
embed_code = serializers.SerializerMethodField()
class Meta:
| {"golden_diff": "diff --git a/meinberlin/apps/bplan/serializers.py b/meinberlin/apps/bplan/serializers.py\n--- a/meinberlin/apps/bplan/serializers.py\n+++ b/meinberlin/apps/bplan/serializers.py\n@@ -36,11 +36,18 @@\n # make write_only for consistency reasons\n start_date = serializers.DateTimeField(write_only=True)\n end_date = serializers.DateTimeField(write_only=True)\n- image_url = serializers.URLField(required=False, write_only=True)\n- image_copyright = serializers.CharField(required=False, write_only=True,\n- source='tile_image_copyright',\n- allow_blank=True,\n- max_length=120)\n+ image_url = serializers.URLField(\n+ required=False,\n+ write_only=True,\n+ max_length=(project_models.Project._meta.\n+ get_field('tile_image').max_length))\n+ image_copyright = serializers.CharField(\n+ required=False,\n+ write_only=True,\n+ source='tile_image_copyright',\n+ allow_blank=True,\n+ max_length=(project_models.Project._meta.\n+ get_field('tile_image_copyright').max_length))\n embed_code = serializers.SerializerMethodField()\n \n class Meta:\n", "issue": "DataError: value too long for type character varying(100)\nSentry Issue: [MEINBERLIN-DEV-2Z](https://sentry.liqd.net/organizations/liqd/issues/1357/?referrer=github_integration)\n\n```\nStringDataRightTruncation: value too long for type character varying(100)\n\n File \"django/db/backends/utils.py\", line 84, in _execute\n return self.cursor.execute(sql, params)\n\nDataError: value too long for type character varying(100)\n\n(29 additional frame(s) were not displayed)\n...\n File \"django/db/backends/utils.py\", line 67, in execute\n return self._execute_with_wrappers(sql, params, many=False, executor=self._execute)\n File \"django/db/backends/utils.py\", line 76, in _execute_with_wrappers\n return executor(sql, params, many, context)\n File \"django/db/backends/utils.py\", line 84, in _execute\n return self.cursor.execute(sql, params)\n File \"django/db/utils.py\", line 89, in __exit__\n raise dj_exc_value.with_traceback(traceback) from exc_value\n File \"django/db/backends/utils.py\", line 84, in _execute\n return self.cursor.execute(sql, params)\n\nInternal Server Error: /api/organisations/1/bplan/\n```\n", "before_files": [{"content": "import datetime\nimport imghdr\nimport posixpath\nimport tempfile\nfrom urllib.parse import urlparse\n\nimport requests\nfrom django.apps import apps\nfrom django.conf import settings\nfrom django.contrib.sites.models import Site\nfrom django.core.exceptions import ValidationError\nfrom django.core.files.images import ImageFile\nfrom django.urls import reverse\nfrom django.utils import timezone\nfrom django.utils.translation import ugettext as _\nfrom rest_framework import serializers\n\nfrom adhocracy4.dashboard import components\nfrom adhocracy4.dashboard import signals as a4dashboard_signals\nfrom adhocracy4.images.validators import validate_image\nfrom adhocracy4.modules import models as module_models\nfrom adhocracy4.phases import models as phase_models\nfrom adhocracy4.projects import models as project_models\n\nfrom .models import Bplan\nfrom .phases import StatementPhase\n\nBPLAN_EMBED = '<iframe height=\"500\" style=\"width: 100%; min-height: 300px; ' \\\n 'max-height: 100vh\" src=\"{}\" frameborder=\"0\"></iframe>'\nDOWNLOAD_IMAGE_SIZE_LIMIT_BYTES = 10 * 1024 * 1024\n\n\nclass BplanSerializer(serializers.ModelSerializer):\n id = serializers.IntegerField(required=False)\n\n # make write_only for consistency reasons\n start_date = serializers.DateTimeField(write_only=True)\n end_date = serializers.DateTimeField(write_only=True)\n image_url = serializers.URLField(required=False, write_only=True)\n image_copyright = serializers.CharField(required=False, write_only=True,\n source='tile_image_copyright',\n allow_blank=True,\n max_length=120)\n embed_code = serializers.SerializerMethodField()\n\n class Meta:\n model = Bplan\n fields = (\n 'id', 'name', 'identifier', 'description', 'url',\n 'office_worker_email', 'is_draft', 'start_date', 'end_date',\n 'image_url', 'image_copyright', 'embed_code'\n )\n extra_kwargs = {\n # write_only for consistency reasons\n 'is_draft': {'default': False, 'write_only': True},\n 'name': {'write_only': True},\n 'description': {'write_only': True},\n 'url': {'write_only': True},\n 'office_worker_email': {'write_only': True},\n 'identifier': {'write_only': True}\n }\n\n def create(self, validated_data):\n orga_pk = self._context.get('organisation_pk', None)\n orga_model = apps.get_model(settings.A4_ORGANISATIONS_MODEL)\n orga = orga_model.objects.get(pk=orga_pk)\n validated_data['organisation'] = orga\n\n start_date = validated_data['start_date']\n end_date = validated_data['end_date']\n\n image_url = validated_data.pop('image_url', None)\n if image_url:\n validated_data['tile_image'] = \\\n self._download_image_from_url(image_url)\n\n bplan = super().create(validated_data)\n self._create_module_and_phase(bplan, start_date, end_date)\n self._send_project_created_signal(bplan)\n return bplan\n\n def _create_module_and_phase(self, bplan, start_date, end_date):\n module = module_models.Module.objects.create(\n name=bplan.slug + '_module',\n weight=1,\n project=bplan,\n )\n\n phase_content = StatementPhase()\n phase_models.Phase.objects.create(\n name=_('Bplan statement phase'),\n description=_('Bplan statement phase'),\n type=phase_content.identifier,\n module=module,\n start_date=start_date,\n end_date=end_date\n )\n\n def update(self, instance, validated_data):\n start_date = validated_data.get('start_date', None)\n end_date = validated_data.get('end_date', None)\n if start_date or end_date:\n self._update_phase(instance, start_date, end_date)\n if end_date and end_date > timezone.localtime(timezone.now()):\n instance.is_archived = False\n\n image_url = validated_data.pop('image_url', None)\n if image_url:\n validated_data['tile_image'] = \\\n self._download_image_from_url(image_url)\n\n instance = super().update(instance, validated_data)\n\n self._send_component_updated_signal(instance)\n return instance\n\n def _update_phase(self, bplan, start_date, end_date):\n module = module_models.Module.objects.get(project=bplan)\n phase = phase_models.Phase.objects.get(module=module)\n if start_date:\n phase.start_date = start_date\n if end_date:\n phase.end_date = end_date\n phase.save()\n\n def get_embed_code(self, bplan):\n url = self._get_absolute_url(bplan)\n embed = BPLAN_EMBED.format(url)\n return embed\n\n def _get_absolute_url(self, bplan):\n site_url = Site.objects.get_current().domain\n embed_url = reverse('embed-project', kwargs={'slug': bplan.slug, })\n url = 'https://{}{}'.format(site_url, embed_url)\n return url\n\n def _download_image_from_url(self, url):\n parsed_url = urlparse(url)\n file_name = None\n try:\n r = requests.get(url, stream=True, timeout=10)\n downloaded_bytes = 0\n with tempfile.TemporaryFile() as f:\n for chunk in r.iter_content(chunk_size=1024):\n downloaded_bytes += len(chunk)\n if downloaded_bytes > DOWNLOAD_IMAGE_SIZE_LIMIT_BYTES:\n raise serializers.ValidationError(\n 'Image too large to download {}'.format(url))\n if chunk:\n f.write(chunk)\n file_name = self._generate_image_filename(parsed_url.path, f)\n self._image_storage.save(file_name, f)\n except Exception:\n if file_name:\n self._image_storage.delete(file_name)\n raise serializers.ValidationError(\n 'Failed to download image {}'.format(url))\n\n try:\n self._validate_image(file_name)\n except ValidationError as e:\n self._image_storage.delete(file_name)\n raise serializers.ValidationError(e)\n\n return file_name\n\n def _validate_image(self, file_name):\n image_file = self._image_storage.open(file_name, 'rb')\n image = ImageFile(image_file, file_name)\n config = settings.IMAGE_ALIASES.get('*', {})\n config.update(settings.IMAGE_ALIASES['tileimage'])\n validate_image(image, **config)\n\n @property\n def _image_storage(self):\n return project_models.Project._meta.get_field('tile_image').storage\n\n @property\n def _image_upload_to(self):\n return project_models.Project._meta.get_field('tile_image').upload_to\n\n def _generate_image_filename(self, url_path, file):\n if callable(self._image_upload_to):\n raise Exception('Callable upload_to fields are not supported')\n\n root_path, extension = posixpath.splitext(url_path)\n if file:\n # Workaround: imghdr expects the files position on 0\n file.seek(0)\n extension = imghdr.what(file) or 'jpeg'\n\n basename = posixpath.basename(root_path)\n if not basename:\n basename = 'bplan'\n\n dirname = datetime.datetime.now().strftime(self._image_upload_to)\n filename = posixpath.join(dirname, basename + '.' + extension)\n\n return self._image_storage.get_available_name(filename)\n\n def _send_project_created_signal(self, bplan):\n a4dashboard_signals.project_created.send(\n sender=self.__class__,\n project=bplan,\n user=self.context['request'].user\n )\n\n def _send_component_updated_signal(self, bplan):\n component = components.projects['bplan']\n a4dashboard_signals.project_component_updated.send(\n sender=self.__class__,\n project=bplan,\n component=component,\n user=self.context['request'].user\n )\n", "path": "meinberlin/apps/bplan/serializers.py"}]} | 3,079 | 269 |
gh_patches_debug_14223 | rasdani/github-patches | git_diff | ibis-project__ibis-2556 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
CLN: Remove or consolidate dev dependencies from setup.py and environment.yml
I noticed in https://github.com/ibis-project/ibis/pull/2547#issue-529169508 that the dev dependencies are not in sync in https://github.com/ibis-project/ibis/blob/master/setup.py#L63 and https://github.com/ibis-project/ibis/blob/master/environment.yml#L24
`environment.yml` looks more up to date; the dev dependencies in `setup.py` should either be synced with that file or just removed.
</issue>
<code>
[start of setup.py]
1 #!/usr/bin/env python
2 """Ibis setup module."""
3 import pathlib
4 import sys
5
6 from setuptools import find_packages, setup
7
8 import versioneer
9
10 LONG_DESCRIPTION = """
11 Ibis is a productivity-centric Python big data framework.
12
13 See http://ibis-project.org
14 """
15
16 VERSION = sys.version_info.major, sys.version_info.minor
17
18 impala_requires = ['hdfs>=2.0.16', 'sqlalchemy>=1.1,<1.3.7', 'requests']
19 impala_requires.append('impyla[kerberos]>=0.15.0')
20
21 sqlite_requires = ['sqlalchemy>=1.1,<1.3.7']
22 postgres_requires = sqlite_requires + ['psycopg2']
23 mysql_requires = sqlite_requires + ['pymysql']
24
25 omniscidb_requires = ['pymapd==0.24', 'pyarrow']
26 kerberos_requires = ['requests-kerberos']
27 visualization_requires = ['graphviz']
28 clickhouse_requires = [
29 'clickhouse-driver>=0.1.3',
30 'clickhouse-cityhash',
31 ]
32 bigquery_requires = [
33 'google-cloud-bigquery[bqstorage,pandas]>=1.12.0,<2.0.0dev',
34 'pydata-google-auth',
35 ]
36 hdf5_requires = ['tables>=3.0.0']
37
38 parquet_requires = ['pyarrow>=0.12.0']
39 spark_requires = ['pyspark>=2.4.3']
40
41 geospatial_requires = ['geoalchemy2', 'geopandas', 'shapely']
42
43 dask_requires = [
44 'dask[dataframe, array]',
45 ]
46
47 all_requires = (
48 impala_requires
49 + postgres_requires
50 + omniscidb_requires
51 + mysql_requires
52 + kerberos_requires
53 + visualization_requires
54 + clickhouse_requires
55 + bigquery_requires
56 + hdf5_requires
57 + parquet_requires
58 + spark_requires
59 + geospatial_requires
60 + dask_requires
61 )
62
63 develop_requires = all_requires + [
64 'black',
65 'click',
66 'pydocstyle==4.0.1',
67 'flake8',
68 'isort',
69 'mypy',
70 'pre-commit',
71 'pygit2',
72 'pytest>=4.5',
73 ]
74
75 install_requires = [
76 line.strip()
77 for line in pathlib.Path(__file__)
78 .parent.joinpath('requirements.txt')
79 .read_text()
80 .splitlines()
81 ]
82
83 setup(
84 name='ibis-framework',
85 url='https://github.com/ibis-project/ibis',
86 packages=find_packages(),
87 version=versioneer.get_version(),
88 cmdclass=versioneer.get_cmdclass(),
89 install_requires=install_requires,
90 python_requires='>=3.7',
91 extras_require={
92 'all': all_requires,
93 'develop': develop_requires,
94 'impala': impala_requires,
95 'kerberos': kerberos_requires,
96 'postgres': postgres_requires,
97 'omniscidb': omniscidb_requires,
98 'mysql': mysql_requires,
99 'sqlite': sqlite_requires,
100 'visualization': visualization_requires,
101 'clickhouse': clickhouse_requires,
102 'bigquery': bigquery_requires,
103 'hdf5': hdf5_requires,
104 'parquet': parquet_requires,
105 'spark': spark_requires,
106 'geospatial': geospatial_requires,
107 'dask': dask_requires,
108 },
109 description="Productivity-centric Python Big Data Framework",
110 long_description=LONG_DESCRIPTION,
111 classifiers=[
112 'Development Status :: 4 - Beta',
113 'Operating System :: OS Independent',
114 'Intended Audience :: Science/Research',
115 'Programming Language :: Python',
116 'Programming Language :: Python :: 3',
117 'Topic :: Scientific/Engineering',
118 ],
119 license='Apache License, Version 2.0',
120 maintainer="Phillip Cloud",
121 maintainer_email="[email protected]",
122 )
123
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -60,18 +60,6 @@
+ dask_requires
)
-develop_requires = all_requires + [
- 'black',
- 'click',
- 'pydocstyle==4.0.1',
- 'flake8',
- 'isort',
- 'mypy',
- 'pre-commit',
- 'pygit2',
- 'pytest>=4.5',
-]
-
install_requires = [
line.strip()
for line in pathlib.Path(__file__)
@@ -90,7 +78,6 @@
python_requires='>=3.7',
extras_require={
'all': all_requires,
- 'develop': develop_requires,
'impala': impala_requires,
'kerberos': kerberos_requires,
'postgres': postgres_requires,
| {"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -60,18 +60,6 @@\n + dask_requires\n )\n \n-develop_requires = all_requires + [\n- 'black',\n- 'click',\n- 'pydocstyle==4.0.1',\n- 'flake8',\n- 'isort',\n- 'mypy',\n- 'pre-commit',\n- 'pygit2',\n- 'pytest>=4.5',\n-]\n-\n install_requires = [\n line.strip()\n for line in pathlib.Path(__file__)\n@@ -90,7 +78,6 @@\n python_requires='>=3.7',\n extras_require={\n 'all': all_requires,\n- 'develop': develop_requires,\n 'impala': impala_requires,\n 'kerberos': kerberos_requires,\n 'postgres': postgres_requires,\n", "issue": "CLN: Remove or consolidate dev dependencies from setup.py and environment.yml\nI noticed in https://github.com/ibis-project/ibis/pull/2547#issue-529169508 that the dev dependencies are not in sync in https://github.com/ibis-project/ibis/blob/master/setup.py#L63 and https://github.com/ibis-project/ibis/blob/master/environment.yml#L24\r\n\r\n`environment.yml` looks more up to date; the dev dependencies in `setup.py` should either be synced with that file or just removed.\n", "before_files": [{"content": "#!/usr/bin/env python\n\"\"\"Ibis setup module.\"\"\"\nimport pathlib\nimport sys\n\nfrom setuptools import find_packages, setup\n\nimport versioneer\n\nLONG_DESCRIPTION = \"\"\"\nIbis is a productivity-centric Python big data framework.\n\nSee http://ibis-project.org\n\"\"\"\n\nVERSION = sys.version_info.major, sys.version_info.minor\n\nimpala_requires = ['hdfs>=2.0.16', 'sqlalchemy>=1.1,<1.3.7', 'requests']\nimpala_requires.append('impyla[kerberos]>=0.15.0')\n\nsqlite_requires = ['sqlalchemy>=1.1,<1.3.7']\npostgres_requires = sqlite_requires + ['psycopg2']\nmysql_requires = sqlite_requires + ['pymysql']\n\nomniscidb_requires = ['pymapd==0.24', 'pyarrow']\nkerberos_requires = ['requests-kerberos']\nvisualization_requires = ['graphviz']\nclickhouse_requires = [\n 'clickhouse-driver>=0.1.3',\n 'clickhouse-cityhash',\n]\nbigquery_requires = [\n 'google-cloud-bigquery[bqstorage,pandas]>=1.12.0,<2.0.0dev',\n 'pydata-google-auth',\n]\nhdf5_requires = ['tables>=3.0.0']\n\nparquet_requires = ['pyarrow>=0.12.0']\nspark_requires = ['pyspark>=2.4.3']\n\ngeospatial_requires = ['geoalchemy2', 'geopandas', 'shapely']\n\ndask_requires = [\n 'dask[dataframe, array]',\n]\n\nall_requires = (\n impala_requires\n + postgres_requires\n + omniscidb_requires\n + mysql_requires\n + kerberos_requires\n + visualization_requires\n + clickhouse_requires\n + bigquery_requires\n + hdf5_requires\n + parquet_requires\n + spark_requires\n + geospatial_requires\n + dask_requires\n)\n\ndevelop_requires = all_requires + [\n 'black',\n 'click',\n 'pydocstyle==4.0.1',\n 'flake8',\n 'isort',\n 'mypy',\n 'pre-commit',\n 'pygit2',\n 'pytest>=4.5',\n]\n\ninstall_requires = [\n line.strip()\n for line in pathlib.Path(__file__)\n .parent.joinpath('requirements.txt')\n .read_text()\n .splitlines()\n]\n\nsetup(\n name='ibis-framework',\n url='https://github.com/ibis-project/ibis',\n packages=find_packages(),\n version=versioneer.get_version(),\n cmdclass=versioneer.get_cmdclass(),\n install_requires=install_requires,\n python_requires='>=3.7',\n extras_require={\n 'all': all_requires,\n 'develop': develop_requires,\n 'impala': impala_requires,\n 'kerberos': kerberos_requires,\n 'postgres': postgres_requires,\n 'omniscidb': omniscidb_requires,\n 'mysql': mysql_requires,\n 'sqlite': sqlite_requires,\n 'visualization': visualization_requires,\n 'clickhouse': clickhouse_requires,\n 'bigquery': bigquery_requires,\n 'hdf5': hdf5_requires,\n 'parquet': parquet_requires,\n 'spark': spark_requires,\n 'geospatial': geospatial_requires,\n 'dask': dask_requires,\n },\n description=\"Productivity-centric Python Big Data Framework\",\n long_description=LONG_DESCRIPTION,\n classifiers=[\n 'Development Status :: 4 - Beta',\n 'Operating System :: OS Independent',\n 'Intended Audience :: Science/Research',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 3',\n 'Topic :: Scientific/Engineering',\n ],\n license='Apache License, Version 2.0',\n maintainer=\"Phillip Cloud\",\n maintainer_email=\"[email protected]\",\n)\n", "path": "setup.py"}]} | 1,767 | 196 |
gh_patches_debug_16105 | rasdani/github-patches | git_diff | comic__grand-challenge.org-1812 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Increase width of algorithm result table
The table on the algorithm results page can become wider than the page container if the name of the scan is very long. The user then has to scroll to the right to see the "Open Result in Viewer" button, which is quite confusing.

</issue>
<code>
[start of app/grandchallenge/core/context_processors.py]
1 import logging
2
3 from django.conf import settings
4 from guardian.shortcuts import get_perms
5 from guardian.utils import get_anonymous_user
6
7 from grandchallenge.blogs.models import Post
8 from grandchallenge.policies.models import Policy
9
10 logger = logging.getLogger(__name__)
11
12
13 def challenge(request):
14 try:
15 challenge = request.challenge
16
17 if challenge is None:
18 return {}
19
20 except AttributeError:
21 logger.warning(f"Could not get challenge for request: {request}")
22 return {}
23
24 try:
25 user = request.user
26 except AttributeError:
27 user = get_anonymous_user()
28
29 return {
30 "challenge": challenge,
31 "challenge_perms": get_perms(user, challenge),
32 "user_is_participant": challenge.is_participant(user),
33 "pages": challenge.page_set.all(),
34 }
35
36
37 def deployment_info(*_, **__):
38 return {
39 "google_analytics_id": settings.GOOGLE_ANALYTICS_ID,
40 "geochart_api_key": settings.GOOGLE_MAPS_API_KEY,
41 "COMMIT_ID": settings.COMMIT_ID,
42 }
43
44
45 def debug(*_, **__):
46 return {
47 "DEBUG": settings.DEBUG,
48 "ACTSTREAM_ENABLE": settings.ACTSTREAM_ENABLE,
49 }
50
51
52 def sentry_dsn(*_, **__):
53 return {
54 "SENTRY_DSN": settings.SENTRY_DSN,
55 "SENTRY_ENABLE_JS_REPORTING": settings.SENTRY_ENABLE_JS_REPORTING,
56 }
57
58
59 def footer_links(*_, **__):
60 return {
61 "policy_pages": Policy.objects.all(),
62 "blog_posts": Post.objects.filter(published=True),
63 }
64
[end of app/grandchallenge/core/context_processors.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/app/grandchallenge/core/context_processors.py b/app/grandchallenge/core/context_processors.py
--- a/app/grandchallenge/core/context_processors.py
+++ b/app/grandchallenge/core/context_processors.py
@@ -5,6 +5,7 @@
from guardian.utils import get_anonymous_user
from grandchallenge.blogs.models import Post
+from grandchallenge.participants.models import RegistrationRequest
from grandchallenge.policies.models import Policy
logger = logging.getLogger(__name__)
@@ -31,6 +32,9 @@
"challenge_perms": get_perms(user, challenge),
"user_is_participant": challenge.is_participant(user),
"pages": challenge.page_set.all(),
+ "pending_requests": challenge.registrationrequest_set.filter(
+ status=RegistrationRequest.PENDING
+ ),
}
| {"golden_diff": "diff --git a/app/grandchallenge/core/context_processors.py b/app/grandchallenge/core/context_processors.py\n--- a/app/grandchallenge/core/context_processors.py\n+++ b/app/grandchallenge/core/context_processors.py\n@@ -5,6 +5,7 @@\n from guardian.utils import get_anonymous_user\n \n from grandchallenge.blogs.models import Post\n+from grandchallenge.participants.models import RegistrationRequest\n from grandchallenge.policies.models import Policy\n \n logger = logging.getLogger(__name__)\n@@ -31,6 +32,9 @@\n \"challenge_perms\": get_perms(user, challenge),\n \"user_is_participant\": challenge.is_participant(user),\n \"pages\": challenge.page_set.all(),\n+ \"pending_requests\": challenge.registrationrequest_set.filter(\n+ status=RegistrationRequest.PENDING\n+ ),\n }\n", "issue": "Increase width of algorithm result table\nThe table on the algorithm results page can become wider than the page container if the name of the scan is very long. The user then has to scroll to the right to see the \"Open Result in Viewer\" button, which is quite confusing.\r\n\r\n\n", "before_files": [{"content": "import logging\n\nfrom django.conf import settings\nfrom guardian.shortcuts import get_perms\nfrom guardian.utils import get_anonymous_user\n\nfrom grandchallenge.blogs.models import Post\nfrom grandchallenge.policies.models import Policy\n\nlogger = logging.getLogger(__name__)\n\n\ndef challenge(request):\n try:\n challenge = request.challenge\n\n if challenge is None:\n return {}\n\n except AttributeError:\n logger.warning(f\"Could not get challenge for request: {request}\")\n return {}\n\n try:\n user = request.user\n except AttributeError:\n user = get_anonymous_user()\n\n return {\n \"challenge\": challenge,\n \"challenge_perms\": get_perms(user, challenge),\n \"user_is_participant\": challenge.is_participant(user),\n \"pages\": challenge.page_set.all(),\n }\n\n\ndef deployment_info(*_, **__):\n return {\n \"google_analytics_id\": settings.GOOGLE_ANALYTICS_ID,\n \"geochart_api_key\": settings.GOOGLE_MAPS_API_KEY,\n \"COMMIT_ID\": settings.COMMIT_ID,\n }\n\n\ndef debug(*_, **__):\n return {\n \"DEBUG\": settings.DEBUG,\n \"ACTSTREAM_ENABLE\": settings.ACTSTREAM_ENABLE,\n }\n\n\ndef sentry_dsn(*_, **__):\n return {\n \"SENTRY_DSN\": settings.SENTRY_DSN,\n \"SENTRY_ENABLE_JS_REPORTING\": settings.SENTRY_ENABLE_JS_REPORTING,\n }\n\n\ndef footer_links(*_, **__):\n return {\n \"policy_pages\": Policy.objects.all(),\n \"blog_posts\": Post.objects.filter(published=True),\n }\n", "path": "app/grandchallenge/core/context_processors.py"}]} | 1,120 | 170 |
gh_patches_debug_1255 | rasdani/github-patches | git_diff | ivy-llc__ivy-17989 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
fmax
</issue>
<code>
[start of ivy/functional/frontends/paddle/tensor/math.py]
1 # global
2 import ivy
3 from ivy.func_wrapper import with_unsupported_dtypes, with_supported_dtypes
4 from ivy.functional.frontends.paddle.func_wrapper import to_ivy_arrays_and_back
5
6
7 @with_unsupported_dtypes({"2.5.0 and below": ("float16", "bfloat16")}, "paddle")
8 @to_ivy_arrays_and_back
9 def sin(x, name=None):
10 return ivy.sin(x)
11
12
13 @with_unsupported_dtypes({"2.5.0 and below": ("float16", "bfloat16")}, "paddle")
14 @to_ivy_arrays_and_back
15 def cos(x, name=None):
16 return ivy.cos(x)
17
18
19 @with_unsupported_dtypes({"2.5.0 and below": ("float16", "bfloat16")}, "paddle")
20 @to_ivy_arrays_and_back
21 def acos(x, name=None):
22 return ivy.acos(x)
23
24
25 @with_unsupported_dtypes({"2.5.0 and below": ("float16", "bfloat16")}, "paddle")
26 @to_ivy_arrays_and_back
27 def cosh(x, name=None):
28 return ivy.cosh(x)
29
30
31 @with_supported_dtypes({"2.5.0 and below": ("float32", "float64")}, "paddle")
32 @to_ivy_arrays_and_back
33 def tanh(x, name=None):
34 return ivy.tanh(x)
35
36
37 @with_unsupported_dtypes({"2.5.0 and below": ("float16", "bfloat16")}, "paddle")
38 @to_ivy_arrays_and_back
39 def acosh(x, name=None):
40 return ivy.acosh(x)
41
42
43 @with_supported_dtypes({"2.5.0 and below": ("float32", "float64")}, "paddle")
44 @to_ivy_arrays_and_back
45 def asin(x, name=None):
46 return ivy.asin(x)
47
48
49 @with_unsupported_dtypes({"2.5.0 and below": ("float16", "bfloat16")}, "paddle")
50 @to_ivy_arrays_and_back
51 def log(x, name=None):
52 return ivy.log(x)
53
54
55 @with_unsupported_dtypes({"2.5.0 and below": ("float16", "bfloat16")}, "paddle")
56 @to_ivy_arrays_and_back
57 def divide(x, y, name=None):
58 return ivy.divide(x, y)
59
60
61 @with_unsupported_dtypes({"2.5.0 and below": ("float16", "bfloat16")}, "paddle")
62 @to_ivy_arrays_and_back
63 def abs(x, name=None):
64 return ivy.abs(x)
65
66
67 @with_unsupported_dtypes({"2.5.0 and below": ("float16", "bfloat16")}, "paddle")
68 @to_ivy_arrays_and_back
69 def multiply(x, y, name=None):
70 return ivy.multiply(x, y)
71
72
73 @with_unsupported_dtypes(
74 {"2.5.0 and below": ("bool", "unsigned", "int8", "float16", "bfloat16")}, "paddle"
75 )
76 @to_ivy_arrays_and_back
77 def add(x, y, name=None):
78 return ivy.add(x, y)
79
80
81 @with_unsupported_dtypes({"2.5.0 and below": ("float16", "bfloat16")}, "paddle")
82 @to_ivy_arrays_and_back
83 def subtract(x, y, name=None):
84 return ivy.subtract(x, y)
85
86
87 @with_supported_dtypes({"2.5.0 and below": ("float32", "float64")}, "paddle")
88 @to_ivy_arrays_and_back
89 def sqrt(x, name=None):
90 return ivy.sqrt(x)
91
92
93 @with_unsupported_dtypes({"2.5.0 and below": ("float16", "bfloat16")}, "paddle")
94 @to_ivy_arrays_and_back
95 def atanh(x, name=None):
96 return ivy.atanh(x)
97
98
99 @with_unsupported_dtypes({"2.5.0 and below": ("float16", "bfloat16")}, "paddle")
100 @to_ivy_arrays_and_back
101 def atan(x, name=None):
102 return ivy.atan(x)
103
104
105 @with_unsupported_dtypes({"2.5.0 and below": ("float16", "bfloat16")}, "paddle")
106 @to_ivy_arrays_and_back
107 def round(x, name=None):
108 return ivy.round(x)
109
110
111 @with_unsupported_dtypes({"2.5.0 and below": ("float16", "bfloat16")}, "paddle")
112 @to_ivy_arrays_and_back
113 def ceil(x, name=None):
114 return ivy.ceil(x)
115
116
117 @with_supported_dtypes({"2.5.0 and below": ("float32", "float64")}, "paddle")
118 @to_ivy_arrays_and_back
119 def sinh(x, name=None):
120 return ivy.sinh(x)
121
122
123 @with_unsupported_dtypes({"2.5.0 and below": ("float16", "bfloat16")}, "paddle")
124 @to_ivy_arrays_and_back
125 def pow(x, y, name=None):
126 return ivy.pow(x, y)
127
128
129 @with_unsupported_dtypes({"2.4.2 and below": ("int16", "float16")}, "paddle")
130 @to_ivy_arrays_and_back
131 def conj(x, name=None):
132 return ivy.conj(x)
133
134
135 @with_unsupported_dtypes({"2.4.2 and below": ("float16", "bfloat16")}, "paddle")
136 @to_ivy_arrays_and_back
137 def floor(x, name=None):
138 return ivy.floor(x)
139
140
141 @with_unsupported_dtypes({"2.5.0 and below": ("float16", "bfloat16")}, "paddle")
142 @to_ivy_arrays_and_back
143 def remainder(x, y, name=None):
144 return ivy.remainder(x, y)
145
146
147 @with_unsupported_dtypes({"2.5.0 and below": ("float16", "bfloat16")}, "paddle")
148 @to_ivy_arrays_and_back
149 def log2(x, name=None):
150 return ivy.log2(x)
151
152
153 @with_unsupported_dtypes({"2.5.0 and below": ("float16", "bfloat16")}, "paddle")
154 @to_ivy_arrays_and_back
155 def log1p(x, name=None):
156 return ivy.log1p(x)
157
158
159 @with_unsupported_dtypes({"2.5.0 and below": ("float16", "bfloat16")}, "paddle")
160 @to_ivy_arrays_and_back
161 def rad2deg(x, name=None):
162 return ivy.rad2deg(x)
163
164
165 @with_unsupported_dtypes({"2.5.0 and below": ("float16", "bfloat16")}, "paddle")
166 @to_ivy_arrays_and_back
167 def deg2rad(x, name=None):
168 return ivy.deg2rad(x)
169
170
171 @with_unsupported_dtypes({"2.5.0 and below": ("float16", "bfloat16")}, "paddle")
172 @to_ivy_arrays_and_back
173 def gcd(x, y, name=None):
174 return ivy.gcd(x, y)
175
176
177 @with_unsupported_dtypes({"2.5.0 and below": ("float16", "bfloat16")}, "paddle")
178 @to_ivy_arrays_and_back
179 def tan(x, name=None):
180 return ivy.tan(x)
181
182
183 @with_unsupported_dtypes({"2.4.2 and below": ("float16", "bfloat16")}, "paddle")
184 @to_ivy_arrays_and_back
185 def atan2(x, y, name=None):
186 return ivy.atan2(x, y)
187
188
189 @with_supported_dtypes({"2.5.0 and below": ("float32", "float64")}, "paddle")
190 @to_ivy_arrays_and_back
191 def square(x, name=None):
192 return ivy.square(x)
193
194
195 @with_unsupported_dtypes({"2.5.0 and below": ("float16", "bfloat16")}, "paddle")
196 @to_ivy_arrays_and_back
197 def sign(x, name=None):
198 return ivy.sign(x)
199
200
201 @with_unsupported_dtypes({"2.4.2 and below": ("float16", "bfloat16")}, "paddle")
202 @to_ivy_arrays_and_back
203 def neg(x, name=None):
204 return ivy.negative(x)
205
206
207 @with_supported_dtypes({"2.5.0 and below": ("float32", "float64")}, "paddle")
208 @to_ivy_arrays_and_back
209 def exp(x, name=None):
210 return ivy.exp(x)
211
212
213 @with_supported_dtypes(
214 {
215 "2.4.2 and below": (
216 "float32",
217 "float64",
218 "int32",
219 "int64",
220 "complex64",
221 "complex128",
222 )
223 },
224 "paddle",
225 )
226 @to_ivy_arrays_and_back
227 def cumprod(x, dim=None, dtype=None, name=None):
228 return ivy.cumprod(x, axis=dim, dtype=dtype)
229
230
231 @with_unsupported_dtypes({"2.5.0 and below": ("float16", "bfloat16")}, "paddle")
232 @to_ivy_arrays_and_back
233 def reciprocal(x, name=None):
234 return ivy.reciprocal(x)
235
236
237 @with_supported_dtypes(
238 {"2.5.0 and below": ("complex64", "complex128", "float32", "float64")},
239 "paddle",
240 )
241 @to_ivy_arrays_and_back
242 def angle(x, name=None):
243 return ivy.angle(x)
244
245
246 @with_unsupported_dtypes({"2.5.0 and below": "bfloat16"}, "paddle")
247 @to_ivy_arrays_and_back
248 def fmin(x, y, name=None):
249 return ivy.fmin(x, y)
250
251
252 @with_unsupported_dtypes({"2.5.0 and below": ("float16", "bfloat16")}, "paddle")
253 @to_ivy_arrays_and_back
254 def logit(x, eps=None, name=None):
255 return ivy.logit(x, eps=eps)
256
[end of ivy/functional/frontends/paddle/tensor/math.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/ivy/functional/frontends/paddle/tensor/math.py b/ivy/functional/frontends/paddle/tensor/math.py
--- a/ivy/functional/frontends/paddle/tensor/math.py
+++ b/ivy/functional/frontends/paddle/tensor/math.py
@@ -253,3 +253,9 @@
@to_ivy_arrays_and_back
def logit(x, eps=None, name=None):
return ivy.logit(x, eps=eps)
+
+
+@with_unsupported_dtypes({"2.5.0 and below": "bfloat16"}, "paddle")
+@to_ivy_arrays_and_back
+def fmax(x, y, name=None):
+ return ivy.fmax(x, y)
| {"golden_diff": "diff --git a/ivy/functional/frontends/paddle/tensor/math.py b/ivy/functional/frontends/paddle/tensor/math.py\n--- a/ivy/functional/frontends/paddle/tensor/math.py\n+++ b/ivy/functional/frontends/paddle/tensor/math.py\n@@ -253,3 +253,9 @@\n @to_ivy_arrays_and_back\n def logit(x, eps=None, name=None):\n return ivy.logit(x, eps=eps)\n+\n+\n+@with_unsupported_dtypes({\"2.5.0 and below\": \"bfloat16\"}, \"paddle\")\n+@to_ivy_arrays_and_back\n+def fmax(x, y, name=None):\n+ return ivy.fmax(x, y)\n", "issue": "fmax\n\n", "before_files": [{"content": "# global\nimport ivy\nfrom ivy.func_wrapper import with_unsupported_dtypes, with_supported_dtypes\nfrom ivy.functional.frontends.paddle.func_wrapper import to_ivy_arrays_and_back\n\n\n@with_unsupported_dtypes({\"2.5.0 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef sin(x, name=None):\n return ivy.sin(x)\n\n\n@with_unsupported_dtypes({\"2.5.0 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef cos(x, name=None):\n return ivy.cos(x)\n\n\n@with_unsupported_dtypes({\"2.5.0 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef acos(x, name=None):\n return ivy.acos(x)\n\n\n@with_unsupported_dtypes({\"2.5.0 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef cosh(x, name=None):\n return ivy.cosh(x)\n\n\n@with_supported_dtypes({\"2.5.0 and below\": (\"float32\", \"float64\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef tanh(x, name=None):\n return ivy.tanh(x)\n\n\n@with_unsupported_dtypes({\"2.5.0 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef acosh(x, name=None):\n return ivy.acosh(x)\n\n\n@with_supported_dtypes({\"2.5.0 and below\": (\"float32\", \"float64\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef asin(x, name=None):\n return ivy.asin(x)\n\n\n@with_unsupported_dtypes({\"2.5.0 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef log(x, name=None):\n return ivy.log(x)\n\n\n@with_unsupported_dtypes({\"2.5.0 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef divide(x, y, name=None):\n return ivy.divide(x, y)\n\n\n@with_unsupported_dtypes({\"2.5.0 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef abs(x, name=None):\n return ivy.abs(x)\n\n\n@with_unsupported_dtypes({\"2.5.0 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef multiply(x, y, name=None):\n return ivy.multiply(x, y)\n\n\n@with_unsupported_dtypes(\n {\"2.5.0 and below\": (\"bool\", \"unsigned\", \"int8\", \"float16\", \"bfloat16\")}, \"paddle\"\n)\n@to_ivy_arrays_and_back\ndef add(x, y, name=None):\n return ivy.add(x, y)\n\n\n@with_unsupported_dtypes({\"2.5.0 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef subtract(x, y, name=None):\n return ivy.subtract(x, y)\n\n\n@with_supported_dtypes({\"2.5.0 and below\": (\"float32\", \"float64\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef sqrt(x, name=None):\n return ivy.sqrt(x)\n\n\n@with_unsupported_dtypes({\"2.5.0 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef atanh(x, name=None):\n return ivy.atanh(x)\n\n\n@with_unsupported_dtypes({\"2.5.0 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef atan(x, name=None):\n return ivy.atan(x)\n\n\n@with_unsupported_dtypes({\"2.5.0 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef round(x, name=None):\n return ivy.round(x)\n\n\n@with_unsupported_dtypes({\"2.5.0 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef ceil(x, name=None):\n return ivy.ceil(x)\n\n\n@with_supported_dtypes({\"2.5.0 and below\": (\"float32\", \"float64\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef sinh(x, name=None):\n return ivy.sinh(x)\n\n\n@with_unsupported_dtypes({\"2.5.0 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef pow(x, y, name=None):\n return ivy.pow(x, y)\n\n\n@with_unsupported_dtypes({\"2.4.2 and below\": (\"int16\", \"float16\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef conj(x, name=None):\n return ivy.conj(x)\n\n\n@with_unsupported_dtypes({\"2.4.2 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef floor(x, name=None):\n return ivy.floor(x)\n\n\n@with_unsupported_dtypes({\"2.5.0 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef remainder(x, y, name=None):\n return ivy.remainder(x, y)\n\n\n@with_unsupported_dtypes({\"2.5.0 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef log2(x, name=None):\n return ivy.log2(x)\n\n\n@with_unsupported_dtypes({\"2.5.0 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef log1p(x, name=None):\n return ivy.log1p(x)\n\n\n@with_unsupported_dtypes({\"2.5.0 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef rad2deg(x, name=None):\n return ivy.rad2deg(x)\n\n\n@with_unsupported_dtypes({\"2.5.0 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef deg2rad(x, name=None):\n return ivy.deg2rad(x)\n\n\n@with_unsupported_dtypes({\"2.5.0 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef gcd(x, y, name=None):\n return ivy.gcd(x, y)\n\n\n@with_unsupported_dtypes({\"2.5.0 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef tan(x, name=None):\n return ivy.tan(x)\n\n\n@with_unsupported_dtypes({\"2.4.2 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef atan2(x, y, name=None):\n return ivy.atan2(x, y)\n\n\n@with_supported_dtypes({\"2.5.0 and below\": (\"float32\", \"float64\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef square(x, name=None):\n return ivy.square(x)\n\n\n@with_unsupported_dtypes({\"2.5.0 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef sign(x, name=None):\n return ivy.sign(x)\n\n\n@with_unsupported_dtypes({\"2.4.2 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef neg(x, name=None):\n return ivy.negative(x)\n\n\n@with_supported_dtypes({\"2.5.0 and below\": (\"float32\", \"float64\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef exp(x, name=None):\n return ivy.exp(x)\n\n\n@with_supported_dtypes(\n {\n \"2.4.2 and below\": (\n \"float32\",\n \"float64\",\n \"int32\",\n \"int64\",\n \"complex64\",\n \"complex128\",\n )\n },\n \"paddle\",\n)\n@to_ivy_arrays_and_back\ndef cumprod(x, dim=None, dtype=None, name=None):\n return ivy.cumprod(x, axis=dim, dtype=dtype)\n\n\n@with_unsupported_dtypes({\"2.5.0 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef reciprocal(x, name=None):\n return ivy.reciprocal(x)\n\n\n@with_supported_dtypes(\n {\"2.5.0 and below\": (\"complex64\", \"complex128\", \"float32\", \"float64\")},\n \"paddle\",\n)\n@to_ivy_arrays_and_back\ndef angle(x, name=None):\n return ivy.angle(x)\n\n\n@with_unsupported_dtypes({\"2.5.0 and below\": \"bfloat16\"}, \"paddle\")\n@to_ivy_arrays_and_back\ndef fmin(x, y, name=None):\n return ivy.fmin(x, y)\n\n\n@with_unsupported_dtypes({\"2.5.0 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef logit(x, eps=None, name=None):\n return ivy.logit(x, eps=eps)\n", "path": "ivy/functional/frontends/paddle/tensor/math.py"}]} | 3,539 | 164 |
gh_patches_debug_26483 | rasdani/github-patches | git_diff | getnikola__nikola-3482 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add full GLOBAL_CONTEXT support to the post_list plugin
<!--
Before creating an issue:
* make sure you are using an up-to-date version of Nikola
* search for existing issues that might be related
Describe your requested features as precisely as possible. -->
I've got some data and functions in `GLOBAL_CONTEXT` that I'd like to use in a custom post list template. Right now, it appears that only the locale's date format is passed along to the template context.
Would you accept a PR to make all of the `GLOBAL_CONTEXT` available to the plugin?
</issue>
<code>
[start of nikola/plugins/shortcode/post_list.py]
1 # -*- coding: utf-8 -*-
2
3 # Copyright © 2013-2020 Udo Spallek, Roberto Alsina and others.
4
5 # Permission is hereby granted, free of charge, to any
6 # person obtaining a copy of this software and associated
7 # documentation files (the "Software"), to deal in the
8 # Software without restriction, including without limitation
9 # the rights to use, copy, modify, merge, publish,
10 # distribute, sublicense, and/or sell copies of the
11 # Software, and to permit persons to whom the Software is
12 # furnished to do so, subject to the following conditions:
13 #
14 # The above copyright notice and this permission notice
15 # shall be included in all copies or substantial portions of
16 # the Software.
17 #
18 # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY
19 # KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE
20 # WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR
21 # PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS
22 # OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR
23 # OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR
24 # OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
25 # SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
26
27 """Post list shortcode."""
28
29
30 import operator
31 import os
32 import uuid
33
34 import natsort
35
36 from nikola import utils
37 from nikola.packages.datecond import date_in_range
38 from nikola.plugin_categories import ShortcodePlugin
39
40
41 class PostListShortcode(ShortcodePlugin):
42 """Provide a shortcode to create a list of posts.
43
44 Post List
45 =========
46 :Directive Arguments: None.
47 :Directive Options: lang, start, stop, reverse, sort, date, tags, categories, sections, slugs, post_type, template, id
48 :Directive Content: None.
49
50 The posts appearing in the list can be filtered by options.
51 *List slicing* is provided with the *start*, *stop* and *reverse* options.
52
53 The following not required options are recognized:
54
55 ``start`` : integer
56 The index of the first post to show.
57 A negative value like ``-3`` will show the *last* three posts in the
58 post-list.
59 Defaults to None.
60
61 ``stop`` : integer
62 The index of the last post to show.
63 A value negative value like ``-1`` will show every post, but not the
64 *last* in the post-list.
65 Defaults to None.
66
67 ``reverse`` : flag
68 Reverse the order of the post-list.
69 Defaults is to not reverse the order of posts.
70
71 ``sort`` : string
72 Sort post list by one of each post's attributes, usually ``title`` or a
73 custom ``priority``. Defaults to None (chronological sorting).
74
75 ``date`` : string
76 Show posts that match date range specified by this option. Format:
77
78 * comma-separated clauses (AND)
79 * clause: attribute comparison_operator value (spaces optional)
80 * attribute: year, month, day, hour, month, second, weekday, isoweekday; or empty for full datetime
81 * comparison_operator: == != <= >= < >
82 * value: integer, 'now', 'today', or dateutil-compatible date input
83
84 ``tags`` : string [, string...]
85 Filter posts to show only posts having at least one of the ``tags``.
86 Defaults to None.
87
88 ``require_all_tags`` : flag
89 Change tag filter behaviour to show only posts that have all specified ``tags``.
90 Defaults to False.
91
92 ``categories`` : string [, string...]
93 Filter posts to show only posts having one of the ``categories``.
94 Defaults to None.
95
96 ``sections`` : string [, string...]
97 Filter posts to show only posts having one of the ``sections``.
98 Defaults to None.
99
100 ``slugs`` : string [, string...]
101 Filter posts to show only posts having at least one of the ``slugs``.
102 Defaults to None.
103
104 ``post_type`` (or ``type``) : string
105 Show only ``posts``, ``pages`` or ``all``.
106 Replaces ``all``. Defaults to ``posts``.
107
108 ``lang`` : string
109 The language of post *titles* and *links*.
110 Defaults to default language.
111
112 ``template`` : string
113 The name of an alternative template to render the post-list.
114 Defaults to ``post_list_directive.tmpl``
115
116 ``id`` : string
117 A manual id for the post list.
118 Defaults to a random name composed by 'post_list_' + uuid.uuid4().hex.
119 """
120
121 name = "post_list"
122
123 def set_site(self, site):
124 """Set the site."""
125 super().set_site(site)
126 site.register_shortcode('post-list', self.handler)
127
128 def handler(self, start=None, stop=None, reverse=False, tags=None, require_all_tags=False, categories=None,
129 sections=None, slugs=None, post_type='post', type=False,
130 lang=None, template='post_list_directive.tmpl', sort=None,
131 id=None, data=None, state=None, site=None, date=None, filename=None, post=None):
132 """Generate HTML for post-list."""
133 if lang is None:
134 lang = utils.LocaleBorg().current_lang
135 if site.invariant: # for testing purposes
136 post_list_id = id or 'post_list_' + 'fixedvaluethatisnotauuid'
137 else:
138 post_list_id = id or 'post_list_' + uuid.uuid4().hex
139
140 # Get post from filename if available
141 if filename:
142 self_post = site.post_per_input_file.get(filename)
143 else:
144 self_post = None
145
146 if self_post:
147 self_post.register_depfile("####MAGIC####TIMELINE", lang=lang)
148
149 # If we get strings for start/stop, make them integers
150 if start is not None:
151 start = int(start)
152 if stop is not None:
153 stop = int(stop)
154
155 # Parse tags/categories/sections/slugs (input is strings)
156 categories = [c.strip().lower() for c in categories.split(',')] if categories else []
157 sections = [s.strip().lower() for s in sections.split(',')] if sections else []
158 slugs = [s.strip() for s in slugs.split(',')] if slugs else []
159
160 filtered_timeline = []
161 posts = []
162 step = None if reverse is False else -1
163
164 if type is not False:
165 post_type = type
166
167 if post_type == 'page' or post_type == 'pages':
168 timeline = [p for p in site.timeline if not p.use_in_feeds]
169 elif post_type == 'all':
170 timeline = [p for p in site.timeline]
171 else: # post
172 timeline = [p for p in site.timeline if p.use_in_feeds]
173
174 # self_post should be removed from timeline because this is redundant
175 timeline = [p for p in timeline if p.source_path != filename]
176
177 if categories:
178 timeline = [p for p in timeline if p.meta('category', lang=lang).lower() in categories]
179
180 if sections:
181 timeline = [p for p in timeline if p.section_name(lang).lower() in sections]
182
183 if tags:
184 tags = {t.strip().lower() for t in tags.split(',')}
185 if require_all_tags:
186 compare = set.issubset
187 else:
188 compare = operator.and_
189 for post in timeline:
190 post_tags = {t.lower() for t in post.tags}
191 if compare(tags, post_tags):
192 filtered_timeline.append(post)
193 else:
194 filtered_timeline = timeline
195
196 if sort:
197 filtered_timeline = natsort.natsorted(filtered_timeline, key=lambda post: post.meta[lang][sort], alg=natsort.ns.F | natsort.ns.IC)
198
199 if date:
200 _now = utils.current_time()
201 filtered_timeline = [p for p in filtered_timeline if date_in_range(utils.html_unescape(date), p.date, now=_now)]
202
203 for post in filtered_timeline[start:stop:step]:
204 if slugs:
205 cont = True
206 for slug in slugs:
207 if slug == post.meta('slug'):
208 cont = False
209
210 if cont:
211 continue
212
213 bp = post.translated_base_path(lang)
214 if os.path.exists(bp) and state:
215 state.document.settings.record_dependencies.add(bp)
216 elif os.path.exists(bp) and self_post:
217 self_post.register_depfile(bp, lang=lang)
218
219 posts += [post]
220
221 template_deps = site.template_system.template_deps(template)
222 if state:
223 # Register template as a dependency (Issue #2391)
224 for d in template_deps:
225 state.document.settings.record_dependencies.add(d)
226 elif self_post:
227 for d in template_deps:
228 self_post.register_depfile(d, lang=lang)
229
230 template_data = {
231 'lang': lang,
232 'posts': posts,
233 # Need to provide str, not TranslatableSetting (Issue #2104)
234 'date_format': site.GLOBAL_CONTEXT.get('date_format')[lang],
235 'post_list_id': post_list_id,
236 'messages': site.MESSAGES,
237 '_link': site.link,
238 }
239 output = site.template_system.render_template(
240 template, None, template_data)
241 return output, template_deps
242
243
244 # Request file name from shortcode (Issue #2412)
245 PostListShortcode.handler.nikola_shortcode_pass_filename = True
246
[end of nikola/plugins/shortcode/post_list.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/nikola/plugins/shortcode/post_list.py b/nikola/plugins/shortcode/post_list.py
--- a/nikola/plugins/shortcode/post_list.py
+++ b/nikola/plugins/shortcode/post_list.py
@@ -145,6 +145,7 @@
if self_post:
self_post.register_depfile("####MAGIC####TIMELINE", lang=lang)
+ self_post.register_depfile("####MAGIC####CONFIG:GLOBAL_CONTEXT", lang=lang)
# If we get strings for start/stop, make them integers
if start is not None:
@@ -227,7 +228,8 @@
for d in template_deps:
self_post.register_depfile(d, lang=lang)
- template_data = {
+ template_data = site.GLOBAL_CONTEXT.copy()
+ template_data.update({
'lang': lang,
'posts': posts,
# Need to provide str, not TranslatableSetting (Issue #2104)
@@ -235,7 +237,7 @@
'post_list_id': post_list_id,
'messages': site.MESSAGES,
'_link': site.link,
- }
+ })
output = site.template_system.render_template(
template, None, template_data)
return output, template_deps
| {"golden_diff": "diff --git a/nikola/plugins/shortcode/post_list.py b/nikola/plugins/shortcode/post_list.py\n--- a/nikola/plugins/shortcode/post_list.py\n+++ b/nikola/plugins/shortcode/post_list.py\n@@ -145,6 +145,7 @@\n \n if self_post:\n self_post.register_depfile(\"####MAGIC####TIMELINE\", lang=lang)\n+ self_post.register_depfile(\"####MAGIC####CONFIG:GLOBAL_CONTEXT\", lang=lang)\n \n # If we get strings for start/stop, make them integers\n if start is not None:\n@@ -227,7 +228,8 @@\n for d in template_deps:\n self_post.register_depfile(d, lang=lang)\n \n- template_data = {\n+ template_data = site.GLOBAL_CONTEXT.copy()\n+ template_data.update({\n 'lang': lang,\n 'posts': posts,\n # Need to provide str, not TranslatableSetting (Issue #2104)\n@@ -235,7 +237,7 @@\n 'post_list_id': post_list_id,\n 'messages': site.MESSAGES,\n '_link': site.link,\n- }\n+ })\n output = site.template_system.render_template(\n template, None, template_data)\n return output, template_deps\n", "issue": "Add full GLOBAL_CONTEXT support to the post_list plugin\n<!--\r\nBefore creating an issue:\r\n* make sure you are using an up-to-date version of Nikola\r\n* search for existing issues that might be related\r\n\r\nDescribe your requested features as precisely as possible. -->\r\n\r\nI've got some data and functions in `GLOBAL_CONTEXT` that I'd like to use in a custom post list template. Right now, it appears that only the locale's date format is passed along to the template context.\r\n\r\nWould you accept a PR to make all of the `GLOBAL_CONTEXT` available to the plugin?\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Copyright \u00a9 2013-2020 Udo Spallek, Roberto Alsina and others.\n\n# Permission is hereby granted, free of charge, to any\n# person obtaining a copy of this software and associated\n# documentation files (the \"Software\"), to deal in the\n# Software without restriction, including without limitation\n# the rights to use, copy, modify, merge, publish,\n# distribute, sublicense, and/or sell copies of the\n# Software, and to permit persons to whom the Software is\n# furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice\n# shall be included in all copies or substantial portions of\n# the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY\n# KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE\n# WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR\n# PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS\n# OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR\n# OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR\n# OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE\n# SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.\n\n\"\"\"Post list shortcode.\"\"\"\n\n\nimport operator\nimport os\nimport uuid\n\nimport natsort\n\nfrom nikola import utils\nfrom nikola.packages.datecond import date_in_range\nfrom nikola.plugin_categories import ShortcodePlugin\n\n\nclass PostListShortcode(ShortcodePlugin):\n \"\"\"Provide a shortcode to create a list of posts.\n\n Post List\n =========\n :Directive Arguments: None.\n :Directive Options: lang, start, stop, reverse, sort, date, tags, categories, sections, slugs, post_type, template, id\n :Directive Content: None.\n\n The posts appearing in the list can be filtered by options.\n *List slicing* is provided with the *start*, *stop* and *reverse* options.\n\n The following not required options are recognized:\n\n ``start`` : integer\n The index of the first post to show.\n A negative value like ``-3`` will show the *last* three posts in the\n post-list.\n Defaults to None.\n\n ``stop`` : integer\n The index of the last post to show.\n A value negative value like ``-1`` will show every post, but not the\n *last* in the post-list.\n Defaults to None.\n\n ``reverse`` : flag\n Reverse the order of the post-list.\n Defaults is to not reverse the order of posts.\n\n ``sort`` : string\n Sort post list by one of each post's attributes, usually ``title`` or a\n custom ``priority``. Defaults to None (chronological sorting).\n\n ``date`` : string\n Show posts that match date range specified by this option. Format:\n\n * comma-separated clauses (AND)\n * clause: attribute comparison_operator value (spaces optional)\n * attribute: year, month, day, hour, month, second, weekday, isoweekday; or empty for full datetime\n * comparison_operator: == != <= >= < >\n * value: integer, 'now', 'today', or dateutil-compatible date input\n\n ``tags`` : string [, string...]\n Filter posts to show only posts having at least one of the ``tags``.\n Defaults to None.\n\n ``require_all_tags`` : flag\n Change tag filter behaviour to show only posts that have all specified ``tags``.\n Defaults to False.\n\n ``categories`` : string [, string...]\n Filter posts to show only posts having one of the ``categories``.\n Defaults to None.\n\n ``sections`` : string [, string...]\n Filter posts to show only posts having one of the ``sections``.\n Defaults to None.\n\n ``slugs`` : string [, string...]\n Filter posts to show only posts having at least one of the ``slugs``.\n Defaults to None.\n\n ``post_type`` (or ``type``) : string\n Show only ``posts``, ``pages`` or ``all``.\n Replaces ``all``. Defaults to ``posts``.\n\n ``lang`` : string\n The language of post *titles* and *links*.\n Defaults to default language.\n\n ``template`` : string\n The name of an alternative template to render the post-list.\n Defaults to ``post_list_directive.tmpl``\n\n ``id`` : string\n A manual id for the post list.\n Defaults to a random name composed by 'post_list_' + uuid.uuid4().hex.\n \"\"\"\n\n name = \"post_list\"\n\n def set_site(self, site):\n \"\"\"Set the site.\"\"\"\n super().set_site(site)\n site.register_shortcode('post-list', self.handler)\n\n def handler(self, start=None, stop=None, reverse=False, tags=None, require_all_tags=False, categories=None,\n sections=None, slugs=None, post_type='post', type=False,\n lang=None, template='post_list_directive.tmpl', sort=None,\n id=None, data=None, state=None, site=None, date=None, filename=None, post=None):\n \"\"\"Generate HTML for post-list.\"\"\"\n if lang is None:\n lang = utils.LocaleBorg().current_lang\n if site.invariant: # for testing purposes\n post_list_id = id or 'post_list_' + 'fixedvaluethatisnotauuid'\n else:\n post_list_id = id or 'post_list_' + uuid.uuid4().hex\n\n # Get post from filename if available\n if filename:\n self_post = site.post_per_input_file.get(filename)\n else:\n self_post = None\n\n if self_post:\n self_post.register_depfile(\"####MAGIC####TIMELINE\", lang=lang)\n\n # If we get strings for start/stop, make them integers\n if start is not None:\n start = int(start)\n if stop is not None:\n stop = int(stop)\n\n # Parse tags/categories/sections/slugs (input is strings)\n categories = [c.strip().lower() for c in categories.split(',')] if categories else []\n sections = [s.strip().lower() for s in sections.split(',')] if sections else []\n slugs = [s.strip() for s in slugs.split(',')] if slugs else []\n\n filtered_timeline = []\n posts = []\n step = None if reverse is False else -1\n\n if type is not False:\n post_type = type\n\n if post_type == 'page' or post_type == 'pages':\n timeline = [p for p in site.timeline if not p.use_in_feeds]\n elif post_type == 'all':\n timeline = [p for p in site.timeline]\n else: # post\n timeline = [p for p in site.timeline if p.use_in_feeds]\n\n # self_post should be removed from timeline because this is redundant\n timeline = [p for p in timeline if p.source_path != filename]\n\n if categories:\n timeline = [p for p in timeline if p.meta('category', lang=lang).lower() in categories]\n\n if sections:\n timeline = [p for p in timeline if p.section_name(lang).lower() in sections]\n\n if tags:\n tags = {t.strip().lower() for t in tags.split(',')}\n if require_all_tags:\n compare = set.issubset\n else:\n compare = operator.and_\n for post in timeline:\n post_tags = {t.lower() for t in post.tags}\n if compare(tags, post_tags):\n filtered_timeline.append(post)\n else:\n filtered_timeline = timeline\n\n if sort:\n filtered_timeline = natsort.natsorted(filtered_timeline, key=lambda post: post.meta[lang][sort], alg=natsort.ns.F | natsort.ns.IC)\n\n if date:\n _now = utils.current_time()\n filtered_timeline = [p for p in filtered_timeline if date_in_range(utils.html_unescape(date), p.date, now=_now)]\n\n for post in filtered_timeline[start:stop:step]:\n if slugs:\n cont = True\n for slug in slugs:\n if slug == post.meta('slug'):\n cont = False\n\n if cont:\n continue\n\n bp = post.translated_base_path(lang)\n if os.path.exists(bp) and state:\n state.document.settings.record_dependencies.add(bp)\n elif os.path.exists(bp) and self_post:\n self_post.register_depfile(bp, lang=lang)\n\n posts += [post]\n\n template_deps = site.template_system.template_deps(template)\n if state:\n # Register template as a dependency (Issue #2391)\n for d in template_deps:\n state.document.settings.record_dependencies.add(d)\n elif self_post:\n for d in template_deps:\n self_post.register_depfile(d, lang=lang)\n\n template_data = {\n 'lang': lang,\n 'posts': posts,\n # Need to provide str, not TranslatableSetting (Issue #2104)\n 'date_format': site.GLOBAL_CONTEXT.get('date_format')[lang],\n 'post_list_id': post_list_id,\n 'messages': site.MESSAGES,\n '_link': site.link,\n }\n output = site.template_system.render_template(\n template, None, template_data)\n return output, template_deps\n\n\n# Request file name from shortcode (Issue #2412)\nPostListShortcode.handler.nikola_shortcode_pass_filename = True\n", "path": "nikola/plugins/shortcode/post_list.py"}]} | 3,362 | 288 |
gh_patches_debug_25878 | rasdani/github-patches | git_diff | alltheplaces__alltheplaces-7567 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
primanti_bros_us: switch to YextSpider as Where2GetIt seemingly no longer used
The store locator at `https://restaurants.primantibros.com/search` now uses Yext APIs for querying store locations, not Where2GetIt.
</issue>
<code>
[start of locations/spiders/primanti_bros_us.py]
1 from locations.categories import Extras, apply_yes_no
2 from locations.hours import DAYS_FULL, OpeningHours
3 from locations.storefinders.where2getit import Where2GetItSpider
4
5
6 class PrimantiBrosUSSpider(Where2GetItSpider):
7 name = "primanti_bros_us"
8 item_attributes = {"brand": "Primanti Bros", "brand_wikidata": "Q7243049"}
9 api_brand_name = "primantibros"
10 api_key = "7CDBB1A2-4AC6-11EB-932C-8917919C4603"
11
12 def parse_item(self, item, location):
13 item["ref"] = location["uid"]
14 item["street_address"] = ", ".join(filter(None, [location.get("address1"), location.get("address2")]))
15 item["website"] = location.get("menuurl")
16 item["opening_hours"] = OpeningHours()
17 hours_string = ""
18 for day_name in DAYS_FULL:
19 hours_string = f"{hours_string} {day_name}: " + location["{}hours".format(day_name.lower())]
20 item["opening_hours"].add_ranges_from_string(hours_string)
21 apply_yes_no(Extras.DRIVE_THROUGH, item, location["has_drive_through"] == "1", False)
22 yield item
23
[end of locations/spiders/primanti_bros_us.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/locations/spiders/primanti_bros_us.py b/locations/spiders/primanti_bros_us.py
--- a/locations/spiders/primanti_bros_us.py
+++ b/locations/spiders/primanti_bros_us.py
@@ -1,22 +1,18 @@
-from locations.categories import Extras, apply_yes_no
-from locations.hours import DAYS_FULL, OpeningHours
-from locations.storefinders.where2getit import Where2GetItSpider
+from locations.categories import Categories
+from locations.storefinders.yext import YextSpider
-class PrimantiBrosUSSpider(Where2GetItSpider):
+class PrimantiBrosUSSpider(YextSpider):
name = "primanti_bros_us"
- item_attributes = {"brand": "Primanti Bros", "brand_wikidata": "Q7243049"}
- api_brand_name = "primantibros"
- api_key = "7CDBB1A2-4AC6-11EB-932C-8917919C4603"
+ item_attributes = {"brand": "Primanti Bros", "brand_wikidata": "Q7243049", "extras": Categories.RESTAURANT.value}
+ api_key = "7515c25fc685bbdd7c5975b6573c6912"
+ api_version = "20220511"
def parse_item(self, item, location):
- item["ref"] = location["uid"]
- item["street_address"] = ", ".join(filter(None, [location.get("address1"), location.get("address2")]))
- item["website"] = location.get("menuurl")
- item["opening_hours"] = OpeningHours()
- hours_string = ""
- for day_name in DAYS_FULL:
- hours_string = f"{hours_string} {day_name}: " + location["{}hours".format(day_name.lower())]
- item["opening_hours"].add_ranges_from_string(hours_string)
- apply_yes_no(Extras.DRIVE_THROUGH, item, location["has_drive_through"] == "1", False)
+ if "test-location" in item["ref"]:
+ return
+ item["ref"] = location.get("c_pagesURL")
+ item["name"] = location.get("c_searchName")
+ item["website"] = location.get("c_pagesURL")
+ item.pop("twitter", None)
yield item
| {"golden_diff": "diff --git a/locations/spiders/primanti_bros_us.py b/locations/spiders/primanti_bros_us.py\n--- a/locations/spiders/primanti_bros_us.py\n+++ b/locations/spiders/primanti_bros_us.py\n@@ -1,22 +1,18 @@\n-from locations.categories import Extras, apply_yes_no\n-from locations.hours import DAYS_FULL, OpeningHours\n-from locations.storefinders.where2getit import Where2GetItSpider\n+from locations.categories import Categories\n+from locations.storefinders.yext import YextSpider\n \n \n-class PrimantiBrosUSSpider(Where2GetItSpider):\n+class PrimantiBrosUSSpider(YextSpider):\n name = \"primanti_bros_us\"\n- item_attributes = {\"brand\": \"Primanti Bros\", \"brand_wikidata\": \"Q7243049\"}\n- api_brand_name = \"primantibros\"\n- api_key = \"7CDBB1A2-4AC6-11EB-932C-8917919C4603\"\n+ item_attributes = {\"brand\": \"Primanti Bros\", \"brand_wikidata\": \"Q7243049\", \"extras\": Categories.RESTAURANT.value}\n+ api_key = \"7515c25fc685bbdd7c5975b6573c6912\"\n+ api_version = \"20220511\"\n \n def parse_item(self, item, location):\n- item[\"ref\"] = location[\"uid\"]\n- item[\"street_address\"] = \", \".join(filter(None, [location.get(\"address1\"), location.get(\"address2\")]))\n- item[\"website\"] = location.get(\"menuurl\")\n- item[\"opening_hours\"] = OpeningHours()\n- hours_string = \"\"\n- for day_name in DAYS_FULL:\n- hours_string = f\"{hours_string} {day_name}: \" + location[\"{}hours\".format(day_name.lower())]\n- item[\"opening_hours\"].add_ranges_from_string(hours_string)\n- apply_yes_no(Extras.DRIVE_THROUGH, item, location[\"has_drive_through\"] == \"1\", False)\n+ if \"test-location\" in item[\"ref\"]:\n+ return\n+ item[\"ref\"] = location.get(\"c_pagesURL\")\n+ item[\"name\"] = location.get(\"c_searchName\")\n+ item[\"website\"] = location.get(\"c_pagesURL\")\n+ item.pop(\"twitter\", None)\n yield item\n", "issue": "primanti_bros_us: switch to YextSpider as Where2GetIt seemingly no longer used\nThe store locator at `https://restaurants.primantibros.com/search` now uses Yext APIs for querying store locations, not Where2GetIt.\n", "before_files": [{"content": "from locations.categories import Extras, apply_yes_no\nfrom locations.hours import DAYS_FULL, OpeningHours\nfrom locations.storefinders.where2getit import Where2GetItSpider\n\n\nclass PrimantiBrosUSSpider(Where2GetItSpider):\n name = \"primanti_bros_us\"\n item_attributes = {\"brand\": \"Primanti Bros\", \"brand_wikidata\": \"Q7243049\"}\n api_brand_name = \"primantibros\"\n api_key = \"7CDBB1A2-4AC6-11EB-932C-8917919C4603\"\n\n def parse_item(self, item, location):\n item[\"ref\"] = location[\"uid\"]\n item[\"street_address\"] = \", \".join(filter(None, [location.get(\"address1\"), location.get(\"address2\")]))\n item[\"website\"] = location.get(\"menuurl\")\n item[\"opening_hours\"] = OpeningHours()\n hours_string = \"\"\n for day_name in DAYS_FULL:\n hours_string = f\"{hours_string} {day_name}: \" + location[\"{}hours\".format(day_name.lower())]\n item[\"opening_hours\"].add_ranges_from_string(hours_string)\n apply_yes_no(Extras.DRIVE_THROUGH, item, location[\"has_drive_through\"] == \"1\", False)\n yield item\n", "path": "locations/spiders/primanti_bros_us.py"}]} | 929 | 564 |
gh_patches_debug_20381 | rasdani/github-patches | git_diff | scoutapp__scout_apm_python-663 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Track when an exception occurs in a Celery task
Similar to how we do this in other libraries
`tracked_request.tag("error", "true")`
</issue>
<code>
[start of src/scout_apm/celery.py]
1 # coding=utf-8
2 from __future__ import absolute_import, division, print_function, unicode_literals
3
4 import datetime as dt
5
6 from celery.signals import before_task_publish, task_postrun, task_prerun
7
8 import scout_apm.core
9 from scout_apm.compat import datetime_to_timestamp
10 from scout_apm.core.config import scout_config
11 from scout_apm.core.tracked_request import TrackedRequest
12
13
14 def before_task_publish_callback(headers=None, properties=None, **kwargs):
15 if "scout_task_start" not in headers:
16 headers["scout_task_start"] = datetime_to_timestamp(dt.datetime.utcnow())
17
18
19 def task_prerun_callback(task=None, **kwargs):
20 tracked_request = TrackedRequest.instance()
21 tracked_request.is_real_request = True
22
23 start = getattr(task.request, "scout_task_start", None)
24 if start is not None:
25 now = datetime_to_timestamp(dt.datetime.utcnow())
26 try:
27 queue_time = now - start
28 except TypeError:
29 pass
30 else:
31 tracked_request.tag("queue_time", queue_time)
32
33 task_id = getattr(task.request, "id", None)
34 if task_id:
35 tracked_request.tag("task_id", task_id)
36 parent_task_id = getattr(task.request, "parent_id", None)
37 if parent_task_id:
38 tracked_request.tag("parent_task_id", parent_task_id)
39
40 delivery_info = task.request.delivery_info
41 tracked_request.tag("is_eager", delivery_info.get("is_eager", False))
42 tracked_request.tag("exchange", delivery_info.get("exchange", "unknown"))
43 tracked_request.tag("priority", delivery_info.get("priority", "unknown"))
44 tracked_request.tag("routing_key", delivery_info.get("routing_key", "unknown"))
45 tracked_request.tag("queue", delivery_info.get("queue", "unknown"))
46
47 tracked_request.start_span(operation=("Job/" + task.name))
48
49
50 def task_postrun_callback(task=None, **kwargs):
51 tracked_request = TrackedRequest.instance()
52 tracked_request.stop_span()
53
54
55 def install(app=None):
56 if app is not None:
57 copy_configuration(app)
58
59 installed = scout_apm.core.install()
60 if not installed:
61 return
62
63 before_task_publish.connect(before_task_publish_callback)
64 task_prerun.connect(task_prerun_callback)
65 task_postrun.connect(task_postrun_callback)
66
67
68 def copy_configuration(app):
69 prefix = "scout_"
70 prefix_len = len(prefix)
71
72 to_set = {}
73 for key, value in app.conf.items():
74 key_lower = key.lower()
75 if key_lower.startswith(prefix) and len(key_lower) > prefix_len:
76 scout_key = key_lower[prefix_len:]
77 to_set[scout_key] = value
78
79 scout_config.set(**to_set)
80
81
82 def uninstall():
83 before_task_publish.disconnect(before_task_publish_callback)
84 task_prerun.disconnect(task_prerun_callback)
85 task_postrun.disconnect(task_postrun_callback)
86
[end of src/scout_apm/celery.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/src/scout_apm/celery.py b/src/scout_apm/celery.py
--- a/src/scout_apm/celery.py
+++ b/src/scout_apm/celery.py
@@ -3,7 +3,7 @@
import datetime as dt
-from celery.signals import before_task_publish, task_postrun, task_prerun
+from celery.signals import before_task_publish, task_failure, task_postrun, task_prerun
import scout_apm.core
from scout_apm.compat import datetime_to_timestamp
@@ -52,6 +52,11 @@
tracked_request.stop_span()
+def task_failure_callback(task_id=None, **kwargs):
+ tracked_request = TrackedRequest.instance()
+ tracked_request.tag("error", "true")
+
+
def install(app=None):
if app is not None:
copy_configuration(app)
@@ -62,6 +67,7 @@
before_task_publish.connect(before_task_publish_callback)
task_prerun.connect(task_prerun_callback)
+ task_failure.connect(task_failure_callback)
task_postrun.connect(task_postrun_callback)
| {"golden_diff": "diff --git a/src/scout_apm/celery.py b/src/scout_apm/celery.py\n--- a/src/scout_apm/celery.py\n+++ b/src/scout_apm/celery.py\n@@ -3,7 +3,7 @@\n \n import datetime as dt\n \n-from celery.signals import before_task_publish, task_postrun, task_prerun\n+from celery.signals import before_task_publish, task_failure, task_postrun, task_prerun\n \n import scout_apm.core\n from scout_apm.compat import datetime_to_timestamp\n@@ -52,6 +52,11 @@\n tracked_request.stop_span()\n \n \n+def task_failure_callback(task_id=None, **kwargs):\n+ tracked_request = TrackedRequest.instance()\n+ tracked_request.tag(\"error\", \"true\")\n+\n+\n def install(app=None):\n if app is not None:\n copy_configuration(app)\n@@ -62,6 +67,7 @@\n \n before_task_publish.connect(before_task_publish_callback)\n task_prerun.connect(task_prerun_callback)\n+ task_failure.connect(task_failure_callback)\n task_postrun.connect(task_postrun_callback)\n", "issue": "Track when an exception occurs in a Celery task\nSimilar to how we do this in other libraries\r\n`tracked_request.tag(\"error\", \"true\")`\r\n\n", "before_files": [{"content": "# coding=utf-8\nfrom __future__ import absolute_import, division, print_function, unicode_literals\n\nimport datetime as dt\n\nfrom celery.signals import before_task_publish, task_postrun, task_prerun\n\nimport scout_apm.core\nfrom scout_apm.compat import datetime_to_timestamp\nfrom scout_apm.core.config import scout_config\nfrom scout_apm.core.tracked_request import TrackedRequest\n\n\ndef before_task_publish_callback(headers=None, properties=None, **kwargs):\n if \"scout_task_start\" not in headers:\n headers[\"scout_task_start\"] = datetime_to_timestamp(dt.datetime.utcnow())\n\n\ndef task_prerun_callback(task=None, **kwargs):\n tracked_request = TrackedRequest.instance()\n tracked_request.is_real_request = True\n\n start = getattr(task.request, \"scout_task_start\", None)\n if start is not None:\n now = datetime_to_timestamp(dt.datetime.utcnow())\n try:\n queue_time = now - start\n except TypeError:\n pass\n else:\n tracked_request.tag(\"queue_time\", queue_time)\n\n task_id = getattr(task.request, \"id\", None)\n if task_id:\n tracked_request.tag(\"task_id\", task_id)\n parent_task_id = getattr(task.request, \"parent_id\", None)\n if parent_task_id:\n tracked_request.tag(\"parent_task_id\", parent_task_id)\n\n delivery_info = task.request.delivery_info\n tracked_request.tag(\"is_eager\", delivery_info.get(\"is_eager\", False))\n tracked_request.tag(\"exchange\", delivery_info.get(\"exchange\", \"unknown\"))\n tracked_request.tag(\"priority\", delivery_info.get(\"priority\", \"unknown\"))\n tracked_request.tag(\"routing_key\", delivery_info.get(\"routing_key\", \"unknown\"))\n tracked_request.tag(\"queue\", delivery_info.get(\"queue\", \"unknown\"))\n\n tracked_request.start_span(operation=(\"Job/\" + task.name))\n\n\ndef task_postrun_callback(task=None, **kwargs):\n tracked_request = TrackedRequest.instance()\n tracked_request.stop_span()\n\n\ndef install(app=None):\n if app is not None:\n copy_configuration(app)\n\n installed = scout_apm.core.install()\n if not installed:\n return\n\n before_task_publish.connect(before_task_publish_callback)\n task_prerun.connect(task_prerun_callback)\n task_postrun.connect(task_postrun_callback)\n\n\ndef copy_configuration(app):\n prefix = \"scout_\"\n prefix_len = len(prefix)\n\n to_set = {}\n for key, value in app.conf.items():\n key_lower = key.lower()\n if key_lower.startswith(prefix) and len(key_lower) > prefix_len:\n scout_key = key_lower[prefix_len:]\n to_set[scout_key] = value\n\n scout_config.set(**to_set)\n\n\ndef uninstall():\n before_task_publish.disconnect(before_task_publish_callback)\n task_prerun.disconnect(task_prerun_callback)\n task_postrun.disconnect(task_postrun_callback)\n", "path": "src/scout_apm/celery.py"}]} | 1,372 | 248 |
gh_patches_debug_29666 | rasdani/github-patches | git_diff | cupy__cupy-7597 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
`pip install cupy-wheel` - "not a valid wheel filename"
### Description
When I try to `pip install cupy-wheel` I get the error `cupy_wheel<...>.whl is not a valid wheel filename`.
### To Reproduce
```bash
pip install cupy-wheel
```
OS: Windows 10
Python: 3.8.9
pip: 23.1.2
CUDA: CUDA 11.7
### Installation
None
### Environment
Unable to install using `cupy-wheel`. Can install using `pip install cupy-cuda11x`.
### Additional Information
_No response_
</issue>
<code>
[start of install/universal_pkg/setup.py]
1 import ctypes
2 import pkg_resources
3 import os
4 import sys
5 from typing import Dict, List, Optional
6
7 from setuptools import setup
8
9
10 VERSION = '13.0.0a1'
11
12 # List of packages supported by this version of CuPy.
13 PACKAGES = [
14 'cupy-cuda102',
15 'cupy-cuda110',
16 'cupy-cuda111',
17 'cupy-cuda11x',
18 'cupy-cuda12x',
19 'cupy-rocm-4-3',
20 'cupy-rocm-5-0',
21 ]
22
23 # List of packages NOT supported by this version of CuPy.
24 PACKAGES_OUTDATED = [
25 'cupy-cuda80',
26 'cupy-cuda90',
27 'cupy-cuda91',
28 'cupy-cuda92',
29 'cupy-cuda100',
30 'cupy-cuda101',
31 'cupy-cuda112',
32 'cupy-cuda113',
33 'cupy-cuda114',
34 'cupy-cuda115',
35 'cupy-cuda116',
36 'cupy-cuda117',
37 'cupy-rocm-4-0',
38 'cupy-rocm-4-2',
39 ]
40
41 # List of sdist packages.
42 PACKAGES_SDIST = [
43 'cupy',
44 ]
45
46
47 class AutoDetectionFailed(Exception):
48 def __str__(self) -> str:
49 return f'''
50 ============================================================
51 {super().__str__()}
52 ============================================================
53 '''
54
55
56 def _log(msg: str) -> None:
57 sys.stdout.write(f'[cupy-wheel] {msg}\n')
58 sys.stdout.flush()
59
60
61 def _get_version_from_library(
62 libnames: List[str],
63 funcname: str,
64 nvrtc: bool = False,
65 ) -> Optional[int]:
66 """Returns the library version from list of candidate libraries."""
67
68 for libname in libnames:
69 try:
70 _log(f'Looking for library: {libname}')
71 runtime_so = ctypes.CDLL(libname)
72 break
73 except Exception as e:
74 _log(f'Failed to open {libname}: {e}')
75 else:
76 _log('No more candidate library to find')
77 return None
78
79 func = getattr(runtime_so, funcname, None)
80 if func is None:
81 raise AutoDetectionFailed(
82 f'{libname}: {func} could not be found')
83 func.restype = ctypes.c_int
84
85 if nvrtc:
86 # nvrtcVersion
87 func.argtypes = [
88 ctypes.POINTER(ctypes.c_int),
89 ctypes.POINTER(ctypes.c_int),
90 ]
91 major = ctypes.c_int()
92 minor = ctypes.c_int()
93 retval = func(major, minor)
94 version = major.value * 1000 + minor.value * 10
95 else:
96 # cudaRuntimeGetVersion
97 func.argtypes = [
98 ctypes.POINTER(ctypes.c_int),
99 ]
100 version_ref = ctypes.c_int()
101 retval = func(version_ref)
102 version = version_ref.value
103
104 if retval != 0: # NVRTC_SUCCESS or cudaSuccess
105 raise AutoDetectionFailed(
106 f'{libname}: {func} returned error: {retval}')
107 _log(f'Detected version: {version}')
108 return version
109
110
111 def _setup_win32_dll_directory() -> None:
112 if not hasattr(os, 'add_dll_directory'):
113 # Python 3.7 or earlier.
114 return
115 cuda_path = os.environ.get('CUDA_PATH', None)
116 if cuda_path is None:
117 _log('CUDA_PATH is not set.'
118 'cupy-wheel may not be able to discover NVRTC to probe version')
119 return
120 os.add_dll_directory(os.path.join(cuda_path, 'bin')) # type: ignore[attr-defined] # NOQA
121
122
123 def _get_cuda_version() -> Optional[int]:
124 """Returns the detected CUDA version or None."""
125
126 if sys.platform == 'linux':
127 libnames = [
128 'libnvrtc.so.12',
129 'libnvrtc.so.11.2',
130 'libnvrtc.so.11.1',
131 'libnvrtc.so.11.0',
132 'libnvrtc.so.10.2',
133 ]
134 elif sys.platform == 'win32':
135 libnames = [
136 'nvrtc64_120_0.dll',
137 'nvrtc64_112_0.dll',
138 'nvrtc64_111_0.dll',
139 'nvrtc64_110_0.dll',
140 'nvrtc64_102_0.dll',
141 ]
142 _setup_win32_dll_directory()
143 else:
144 _log(f'CUDA detection unsupported on platform: {sys.platform}')
145 return None
146 _log(f'Trying to detect CUDA version from libraries: {libnames}')
147 version = _get_version_from_library(libnames, 'nvrtcVersion', True)
148 return version
149
150
151 def _get_rocm_version() -> Optional[int]:
152 """Returns the detected ROCm version or None."""
153 if sys.platform == 'linux':
154 libnames = ['libamdhip64.so']
155 else:
156 _log(f'ROCm detection unsupported on platform: {sys.platform}')
157 return None
158 version = _get_version_from_library(libnames, 'hipRuntimeGetVersion')
159 return version
160
161
162 def _find_installed_packages() -> List[str]:
163 """Returns the list of CuPy packages installed in the environment."""
164
165 found = []
166 for pkg in (PACKAGES + PACKAGES_OUTDATED + PACKAGES_SDIST):
167 try:
168 pkg_resources.get_distribution(pkg)
169 found.append(pkg)
170 except pkg_resources.DistributionNotFound:
171 pass
172 return found
173
174
175 def _cuda_version_to_package(ver: int) -> str:
176 if ver < 10020:
177 raise AutoDetectionFailed(
178 f'Your CUDA version ({ver}) is too old.')
179 elif ver < 11000:
180 # CUDA 10.2
181 suffix = '102'
182 elif ver < 11010:
183 # CUDA 11.0
184 suffix = '110'
185 elif ver < 11020:
186 # CUDA 11.1
187 suffix = '111'
188 elif ver < 12000:
189 # CUDA 11.2 ~ 11.x
190 suffix = '11x'
191 elif ver < 13000:
192 # CUDA 12.x
193 suffix = '12x'
194 else:
195 raise AutoDetectionFailed(
196 f'Your CUDA version ({ver}) is too new.')
197 return f'cupy-cuda{suffix}'
198
199
200 def _rocm_version_to_package(ver: int) -> str:
201 """
202 ROCm 4.0.x = 3212
203 ROCm 4.1.x = 3241
204 ROCm 4.2.0 = 3275
205 ROCm 4.3.0 = 40321300
206 ROCm 4.3.1 = 40321331
207 ROCm 4.5.0 = 40421401
208 ROCm 4.5.1 = 40421432
209 ROCm 5.0.0 = 50013601
210 ROCm 5.1.0 = 50120531
211 """
212 if 4_03_00000 <= ver < 4_04_00000:
213 # ROCm 4.3
214 suffix = '4-3'
215 elif 5_00_00000 <= ver < 5_01_00000:
216 # ROCm 5.0
217 suffix = '5-0'
218 else:
219 raise AutoDetectionFailed(
220 f'Your ROCm version ({ver}) is unsupported.')
221 return f'cupy-rocm-{suffix}'
222
223
224 def infer_best_package() -> str:
225 """Returns the appropriate CuPy wheel package name for the environment."""
226
227 # Find the existing CuPy wheel installation.
228 installed = _find_installed_packages()
229 if 1 < len(installed):
230 raise AutoDetectionFailed(
231 'You have multiple CuPy packages installed: \n'
232 f' {installed}\n'
233 'Please uninstall all of them first, then try reinstalling.')
234
235 elif 1 == len(installed):
236 if installed[0] in PACKAGES_SDIST:
237 raise AutoDetectionFailed(
238 'You already have CuPy installed via source'
239 ' (pip install cupy).')
240 if installed[0] in PACKAGES_OUTDATED:
241 raise AutoDetectionFailed(
242 f'You have CuPy package "{installed[0]}" installed, but the'
243 f' package is not available for version {VERSION}.\n'
244 'Hint: cupy-cuda{112~117} has been merged to cupy-cuda11x in '
245 'CuPy v11. Uninstall the package and try again.')
246 return installed[0]
247
248 # Try CUDA.
249 version = _get_cuda_version()
250 if version is not None:
251 return _cuda_version_to_package(version)
252
253 # Try ROCm.
254 version = _get_rocm_version()
255 if version is not None:
256 return _rocm_version_to_package(version)
257
258 raise AutoDetectionFailed(
259 'Unable to detect NVIDIA CUDA or AMD ROCm installation.')
260
261
262 def _get_cmdclass(tag: str) -> Dict[str, type]:
263 try:
264 import wheel.bdist_wheel
265 except ModuleNotFoundError:
266 return {}
267
268 class bdist_wheel_with_tag(wheel.bdist_wheel.bdist_wheel): # type: ignore[misc] # NOQA
269 def initialize_options(self) -> None:
270 super().initialize_options()
271 self.build_number = f'0_{tag}'
272
273 return {"bdist_wheel": bdist_wheel_with_tag}
274
275
276 #
277 # Entrypoint
278 #
279
280 def main() -> None:
281 if os.environ.get('CUPY_UNIVERSAL_PKG_BUILD', None) is None:
282 package = infer_best_package()
283 requires = f'{package}=={VERSION}'
284 _log(f'Installing package: {requires}')
285 install_requires = [requires]
286 tag = package
287 else:
288 _log('Building cupy-wheel package for release.')
289 install_requires = []
290 tag = '0'
291
292 setup(
293 name='cupy-wheel',
294 version=f'{VERSION}',
295 install_requires=install_requires,
296 cmdclass=_get_cmdclass(tag),
297 )
298
299
300 if __name__ == '__main__':
301 main()
302
[end of install/universal_pkg/setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/install/universal_pkg/setup.py b/install/universal_pkg/setup.py
--- a/install/universal_pkg/setup.py
+++ b/install/universal_pkg/setup.py
@@ -2,12 +2,13 @@
import pkg_resources
import os
import sys
-from typing import Dict, List, Optional
+from typing import List, Optional
from setuptools import setup
VERSION = '13.0.0a1'
+META_VERSION = VERSION
# List of packages supported by this version of CuPy.
PACKAGES = [
@@ -259,20 +260,6 @@
'Unable to detect NVIDIA CUDA or AMD ROCm installation.')
-def _get_cmdclass(tag: str) -> Dict[str, type]:
- try:
- import wheel.bdist_wheel
- except ModuleNotFoundError:
- return {}
-
- class bdist_wheel_with_tag(wheel.bdist_wheel.bdist_wheel): # type: ignore[misc] # NOQA
- def initialize_options(self) -> None:
- super().initialize_options()
- self.build_number = f'0_{tag}'
-
- return {"bdist_wheel": bdist_wheel_with_tag}
-
-
#
# Entrypoint
#
@@ -283,17 +270,14 @@
requires = f'{package}=={VERSION}'
_log(f'Installing package: {requires}')
install_requires = [requires]
- tag = package
else:
_log('Building cupy-wheel package for release.')
install_requires = []
- tag = '0'
setup(
name='cupy-wheel',
- version=f'{VERSION}',
+ version=META_VERSION,
install_requires=install_requires,
- cmdclass=_get_cmdclass(tag),
)
| {"golden_diff": "diff --git a/install/universal_pkg/setup.py b/install/universal_pkg/setup.py\n--- a/install/universal_pkg/setup.py\n+++ b/install/universal_pkg/setup.py\n@@ -2,12 +2,13 @@\n import pkg_resources\n import os\n import sys\n-from typing import Dict, List, Optional\n+from typing import List, Optional\n \n from setuptools import setup\n \n \n VERSION = '13.0.0a1'\n+META_VERSION = VERSION\n \n # List of packages supported by this version of CuPy.\n PACKAGES = [\n@@ -259,20 +260,6 @@\n 'Unable to detect NVIDIA CUDA or AMD ROCm installation.')\n \n \n-def _get_cmdclass(tag: str) -> Dict[str, type]:\n- try:\n- import wheel.bdist_wheel\n- except ModuleNotFoundError:\n- return {}\n-\n- class bdist_wheel_with_tag(wheel.bdist_wheel.bdist_wheel): # type: ignore[misc] # NOQA\n- def initialize_options(self) -> None:\n- super().initialize_options()\n- self.build_number = f'0_{tag}'\n-\n- return {\"bdist_wheel\": bdist_wheel_with_tag}\n-\n-\n #\n # Entrypoint\n #\n@@ -283,17 +270,14 @@\n requires = f'{package}=={VERSION}'\n _log(f'Installing package: {requires}')\n install_requires = [requires]\n- tag = package\n else:\n _log('Building cupy-wheel package for release.')\n install_requires = []\n- tag = '0'\n \n setup(\n name='cupy-wheel',\n- version=f'{VERSION}',\n+ version=META_VERSION,\n install_requires=install_requires,\n- cmdclass=_get_cmdclass(tag),\n )\n", "issue": "`pip install cupy-wheel` - \"not a valid wheel filename\"\n### Description\n\nWhen I try to `pip install cupy-wheel` I get the error `cupy_wheel<...>.whl is not a valid wheel filename`.\n\n### To Reproduce\n\n```bash\r\npip install cupy-wheel\r\n```\r\nOS: Windows 10\r\nPython: 3.8.9\r\npip: 23.1.2\r\nCUDA: CUDA 11.7\n\n### Installation\n\nNone\n\n### Environment\n\nUnable to install using `cupy-wheel`. Can install using `pip install cupy-cuda11x`.\n\n### Additional Information\n\n_No response_\n", "before_files": [{"content": "import ctypes\nimport pkg_resources\nimport os\nimport sys\nfrom typing import Dict, List, Optional\n\nfrom setuptools import setup\n\n\nVERSION = '13.0.0a1'\n\n# List of packages supported by this version of CuPy.\nPACKAGES = [\n 'cupy-cuda102',\n 'cupy-cuda110',\n 'cupy-cuda111',\n 'cupy-cuda11x',\n 'cupy-cuda12x',\n 'cupy-rocm-4-3',\n 'cupy-rocm-5-0',\n]\n\n# List of packages NOT supported by this version of CuPy.\nPACKAGES_OUTDATED = [\n 'cupy-cuda80',\n 'cupy-cuda90',\n 'cupy-cuda91',\n 'cupy-cuda92',\n 'cupy-cuda100',\n 'cupy-cuda101',\n 'cupy-cuda112',\n 'cupy-cuda113',\n 'cupy-cuda114',\n 'cupy-cuda115',\n 'cupy-cuda116',\n 'cupy-cuda117',\n 'cupy-rocm-4-0',\n 'cupy-rocm-4-2',\n]\n\n# List of sdist packages.\nPACKAGES_SDIST = [\n 'cupy',\n]\n\n\nclass AutoDetectionFailed(Exception):\n def __str__(self) -> str:\n return f'''\n============================================================\n{super().__str__()}\n============================================================\n'''\n\n\ndef _log(msg: str) -> None:\n sys.stdout.write(f'[cupy-wheel] {msg}\\n')\n sys.stdout.flush()\n\n\ndef _get_version_from_library(\n libnames: List[str],\n funcname: str,\n nvrtc: bool = False,\n) -> Optional[int]:\n \"\"\"Returns the library version from list of candidate libraries.\"\"\"\n\n for libname in libnames:\n try:\n _log(f'Looking for library: {libname}')\n runtime_so = ctypes.CDLL(libname)\n break\n except Exception as e:\n _log(f'Failed to open {libname}: {e}')\n else:\n _log('No more candidate library to find')\n return None\n\n func = getattr(runtime_so, funcname, None)\n if func is None:\n raise AutoDetectionFailed(\n f'{libname}: {func} could not be found')\n func.restype = ctypes.c_int\n\n if nvrtc:\n # nvrtcVersion\n func.argtypes = [\n ctypes.POINTER(ctypes.c_int),\n ctypes.POINTER(ctypes.c_int),\n ]\n major = ctypes.c_int()\n minor = ctypes.c_int()\n retval = func(major, minor)\n version = major.value * 1000 + minor.value * 10\n else:\n # cudaRuntimeGetVersion\n func.argtypes = [\n ctypes.POINTER(ctypes.c_int),\n ]\n version_ref = ctypes.c_int()\n retval = func(version_ref)\n version = version_ref.value\n\n if retval != 0: # NVRTC_SUCCESS or cudaSuccess\n raise AutoDetectionFailed(\n f'{libname}: {func} returned error: {retval}')\n _log(f'Detected version: {version}')\n return version\n\n\ndef _setup_win32_dll_directory() -> None:\n if not hasattr(os, 'add_dll_directory'):\n # Python 3.7 or earlier.\n return\n cuda_path = os.environ.get('CUDA_PATH', None)\n if cuda_path is None:\n _log('CUDA_PATH is not set.'\n 'cupy-wheel may not be able to discover NVRTC to probe version')\n return\n os.add_dll_directory(os.path.join(cuda_path, 'bin')) # type: ignore[attr-defined] # NOQA\n\n\ndef _get_cuda_version() -> Optional[int]:\n \"\"\"Returns the detected CUDA version or None.\"\"\"\n\n if sys.platform == 'linux':\n libnames = [\n 'libnvrtc.so.12',\n 'libnvrtc.so.11.2',\n 'libnvrtc.so.11.1',\n 'libnvrtc.so.11.0',\n 'libnvrtc.so.10.2',\n ]\n elif sys.platform == 'win32':\n libnames = [\n 'nvrtc64_120_0.dll',\n 'nvrtc64_112_0.dll',\n 'nvrtc64_111_0.dll',\n 'nvrtc64_110_0.dll',\n 'nvrtc64_102_0.dll',\n ]\n _setup_win32_dll_directory()\n else:\n _log(f'CUDA detection unsupported on platform: {sys.platform}')\n return None\n _log(f'Trying to detect CUDA version from libraries: {libnames}')\n version = _get_version_from_library(libnames, 'nvrtcVersion', True)\n return version\n\n\ndef _get_rocm_version() -> Optional[int]:\n \"\"\"Returns the detected ROCm version or None.\"\"\"\n if sys.platform == 'linux':\n libnames = ['libamdhip64.so']\n else:\n _log(f'ROCm detection unsupported on platform: {sys.platform}')\n return None\n version = _get_version_from_library(libnames, 'hipRuntimeGetVersion')\n return version\n\n\ndef _find_installed_packages() -> List[str]:\n \"\"\"Returns the list of CuPy packages installed in the environment.\"\"\"\n\n found = []\n for pkg in (PACKAGES + PACKAGES_OUTDATED + PACKAGES_SDIST):\n try:\n pkg_resources.get_distribution(pkg)\n found.append(pkg)\n except pkg_resources.DistributionNotFound:\n pass\n return found\n\n\ndef _cuda_version_to_package(ver: int) -> str:\n if ver < 10020:\n raise AutoDetectionFailed(\n f'Your CUDA version ({ver}) is too old.')\n elif ver < 11000:\n # CUDA 10.2\n suffix = '102'\n elif ver < 11010:\n # CUDA 11.0\n suffix = '110'\n elif ver < 11020:\n # CUDA 11.1\n suffix = '111'\n elif ver < 12000:\n # CUDA 11.2 ~ 11.x\n suffix = '11x'\n elif ver < 13000:\n # CUDA 12.x\n suffix = '12x'\n else:\n raise AutoDetectionFailed(\n f'Your CUDA version ({ver}) is too new.')\n return f'cupy-cuda{suffix}'\n\n\ndef _rocm_version_to_package(ver: int) -> str:\n \"\"\"\n ROCm 4.0.x = 3212\n ROCm 4.1.x = 3241\n ROCm 4.2.0 = 3275\n ROCm 4.3.0 = 40321300\n ROCm 4.3.1 = 40321331\n ROCm 4.5.0 = 40421401\n ROCm 4.5.1 = 40421432\n ROCm 5.0.0 = 50013601\n ROCm 5.1.0 = 50120531\n \"\"\"\n if 4_03_00000 <= ver < 4_04_00000:\n # ROCm 4.3\n suffix = '4-3'\n elif 5_00_00000 <= ver < 5_01_00000:\n # ROCm 5.0\n suffix = '5-0'\n else:\n raise AutoDetectionFailed(\n f'Your ROCm version ({ver}) is unsupported.')\n return f'cupy-rocm-{suffix}'\n\n\ndef infer_best_package() -> str:\n \"\"\"Returns the appropriate CuPy wheel package name for the environment.\"\"\"\n\n # Find the existing CuPy wheel installation.\n installed = _find_installed_packages()\n if 1 < len(installed):\n raise AutoDetectionFailed(\n 'You have multiple CuPy packages installed: \\n'\n f' {installed}\\n'\n 'Please uninstall all of them first, then try reinstalling.')\n\n elif 1 == len(installed):\n if installed[0] in PACKAGES_SDIST:\n raise AutoDetectionFailed(\n 'You already have CuPy installed via source'\n ' (pip install cupy).')\n if installed[0] in PACKAGES_OUTDATED:\n raise AutoDetectionFailed(\n f'You have CuPy package \"{installed[0]}\" installed, but the'\n f' package is not available for version {VERSION}.\\n'\n 'Hint: cupy-cuda{112~117} has been merged to cupy-cuda11x in '\n 'CuPy v11. Uninstall the package and try again.')\n return installed[0]\n\n # Try CUDA.\n version = _get_cuda_version()\n if version is not None:\n return _cuda_version_to_package(version)\n\n # Try ROCm.\n version = _get_rocm_version()\n if version is not None:\n return _rocm_version_to_package(version)\n\n raise AutoDetectionFailed(\n 'Unable to detect NVIDIA CUDA or AMD ROCm installation.')\n\n\ndef _get_cmdclass(tag: str) -> Dict[str, type]:\n try:\n import wheel.bdist_wheel\n except ModuleNotFoundError:\n return {}\n\n class bdist_wheel_with_tag(wheel.bdist_wheel.bdist_wheel): # type: ignore[misc] # NOQA\n def initialize_options(self) -> None:\n super().initialize_options()\n self.build_number = f'0_{tag}'\n\n return {\"bdist_wheel\": bdist_wheel_with_tag}\n\n\n#\n# Entrypoint\n#\n\ndef main() -> None:\n if os.environ.get('CUPY_UNIVERSAL_PKG_BUILD', None) is None:\n package = infer_best_package()\n requires = f'{package}=={VERSION}'\n _log(f'Installing package: {requires}')\n install_requires = [requires]\n tag = package\n else:\n _log('Building cupy-wheel package for release.')\n install_requires = []\n tag = '0'\n\n setup(\n name='cupy-wheel',\n version=f'{VERSION}',\n install_requires=install_requires,\n cmdclass=_get_cmdclass(tag),\n )\n\n\nif __name__ == '__main__':\n main()\n", "path": "install/universal_pkg/setup.py"}]} | 3,854 | 386 |
gh_patches_debug_12634 | rasdani/github-patches | git_diff | saleor__saleor-2201 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Unable to add a new address on checkout of digital goods
### What I'm trying to achieve
Enter a new billing address on checkout when ordering a digital good.
### Steps to reproduce the problem
1. Make sure you have a default billing address;
1. Add to cart a book;
1. Go to checkout;
1. At billing address step, create a new address with a different country;
1. Correct any errors if the default billing address fields differs from the new country;
1. Place order;
1. Shipping address should not have been created.
### What I expected to happen
Have the new address as billing address on order.
### What happened instead/how it failed
Got no address created, and got the previous address as billing address for order.
</issue>
<code>
[start of saleor/checkout/views/summary.py]
1 from django.contrib import messages
2 from django.shortcuts import redirect
3 from django.template.response import TemplateResponse
4 from django.utils.translation import pgettext, pgettext_lazy
5
6 from ...account.forms import get_address_form
7 from ...account.models import Address
8 from ...core.exceptions import InsufficientStock
9 from ...order.emails import send_order_confirmation
10 from ..forms import (
11 AnonymousUserBillingForm, BillingAddressesForm,
12 BillingWithoutShippingAddressForm, NoteForm)
13
14
15 def create_order(checkout):
16 """Finalize a checkout session and create an order.
17
18 This is a helper function.
19
20 `checkout` is a `saleor.checkout.core.Checkout` instance.
21 """
22 order = checkout.create_order()
23 if not order:
24 return None, redirect('checkout:summary')
25 checkout.clear_storage()
26 checkout.cart.clear()
27 user = None if checkout.user.is_anonymous else checkout.user
28 msg = pgettext_lazy('Order status history entry', 'Order was placed')
29 order.history.create(user=user, content=msg)
30 send_order_confirmation.delay(order.pk)
31 return order, redirect('order:payment', token=order.token)
32
33
34 def handle_order_placement(request, checkout):
35 """Try to create an order and redirect the user as necessary.
36
37 This is a helper function.
38 """
39 try:
40 order, redirect_url = create_order(checkout)
41 except InsufficientStock:
42 return redirect('cart:index')
43 if not order:
44 msg = pgettext('Checkout warning', 'Please review your checkout.')
45 messages.warning(request, msg)
46 return redirect_url
47
48
49 def get_billing_forms_with_shipping(
50 data, addresses, billing_address, shipping_address):
51 """Get billing form based on a the current billing and shipping data."""
52 if billing_address == shipping_address:
53 address_form, preview = get_address_form(
54 data, country_code=shipping_address.country.code,
55 autocomplete_type='billing',
56 initial={'country': shipping_address.country.code},
57 instance=None)
58 addresses_form = BillingAddressesForm(
59 data, additional_addresses=addresses, initial={
60 'address': BillingAddressesForm.SHIPPING_ADDRESS})
61 elif billing_address.id is None:
62 address_form, preview = get_address_form(
63 data, country_code=billing_address.country.code,
64 autocomplete_type='billing',
65 initial={'country': billing_address.country.code},
66 instance=billing_address)
67 addresses_form = BillingAddressesForm(
68 data, additional_addresses=addresses, initial={
69 'address': BillingAddressesForm.NEW_ADDRESS})
70 else:
71 address_form, preview = get_address_form(
72 data, country_code=billing_address.country.code,
73 autocomplete_type='billing',
74 initial={'country': billing_address.country})
75 addresses_form = BillingAddressesForm(
76 data, additional_addresses=addresses, initial={
77 'address': billing_address.id})
78 if addresses_form.is_valid() and not preview:
79 address_id = addresses_form.cleaned_data['address']
80 if address_id == BillingAddressesForm.SHIPPING_ADDRESS:
81 return address_form, addresses_form, shipping_address
82 elif address_id != BillingAddressesForm.NEW_ADDRESS:
83 address = addresses.get(id=address_id)
84 return address_form, addresses_form, address
85 elif address_form.is_valid():
86 return address_form, addresses_form, address_form.instance
87 return address_form, addresses_form, None
88
89
90 def summary_with_shipping_view(request, checkout):
91 """Display order summary with billing forms for a logged in user.
92
93 Will create an order if all data is valid.
94 """
95 note_form = NoteForm(request.POST or None, checkout=checkout)
96 if note_form.is_valid():
97 note_form.set_checkout_note()
98
99 if request.user.is_authenticated:
100 additional_addresses = request.user.addresses.all()
101 else:
102 additional_addresses = Address.objects.none()
103 address_form, addresses_form, address = get_billing_forms_with_shipping(
104 request.POST or None, additional_addresses,
105 checkout.billing_address or Address(country=request.country),
106 checkout.shipping_address)
107 if address is not None:
108 checkout.billing_address = address
109 return handle_order_placement(request, checkout)
110 return TemplateResponse(
111 request, 'checkout/summary.html', context={
112 'addresses_form': addresses_form, 'address_form': address_form,
113 'checkout': checkout,
114 'additional_addresses': additional_addresses,
115 'note_form': note_form})
116
117
118 def anonymous_summary_without_shipping(request, checkout):
119 """Display order summary with billing forms for an unauthorized user.
120
121 Will create an order if all data is valid.
122 """
123 note_form = NoteForm(request.POST or None, checkout=checkout)
124 if note_form.is_valid():
125 note_form.set_checkout_note()
126 user_form = AnonymousUserBillingForm(
127 request.POST or None, initial={'email': checkout.email})
128 billing_address = checkout.billing_address
129 if billing_address:
130 address_form, preview = get_address_form(
131 request.POST or None, country_code=billing_address.country.code,
132 autocomplete_type='billing', instance=billing_address)
133 else:
134 address_form, preview = get_address_form(
135 request.POST or None, country_code=request.country.code,
136 autocomplete_type='billing', initial={'country': request.country})
137 if all([user_form.is_valid(), address_form.is_valid()]) and not preview:
138 checkout.email = user_form.cleaned_data['email']
139 checkout.billing_address = address_form.instance
140 return handle_order_placement(request, checkout)
141 return TemplateResponse(
142 request, 'checkout/summary_without_shipping.html', context={
143 'user_form': user_form, 'address_form': address_form,
144 'checkout': checkout,
145 'note_form': note_form})
146
147
148 def summary_without_shipping(request, checkout):
149 """Display order summary for cases where shipping is not required.
150
151 Will create an order if all data is valid.
152 """
153 note_form = NoteForm(request.POST or None, checkout=checkout)
154 if note_form.is_valid():
155 note_form.set_checkout_note()
156
157 billing_address = checkout.billing_address
158 user_addresses = request.user.addresses.all()
159 if billing_address and billing_address.id:
160 address_form, preview = get_address_form(
161 request.POST or None, autocomplete_type='billing',
162 initial={'country': request.country},
163 country_code=billing_address.country.code,
164 instance=billing_address)
165 addresses_form = BillingWithoutShippingAddressForm(
166 request.POST or None, additional_addresses=user_addresses,
167 initial={'address': billing_address.id})
168 elif billing_address:
169 address_form, preview = get_address_form(
170 request.POST or None, autocomplete_type='billing',
171 instance=billing_address,
172 country_code=billing_address.country.code)
173 addresses_form = BillingWithoutShippingAddressForm(
174 request.POST or None, additional_addresses=user_addresses)
175 else:
176 address_form, preview = get_address_form(
177 request.POST or None, autocomplete_type='billing',
178 initial={'country': request.country},
179 country_code=request.country.code)
180 addresses_form = BillingWithoutShippingAddressForm(
181 request.POST or None, additional_addresses=user_addresses)
182
183 if addresses_form.is_valid():
184 address_id = addresses_form.cleaned_data['address']
185 if address_id != BillingWithoutShippingAddressForm.NEW_ADDRESS:
186 checkout.billing_address = user_addresses.get(id=address_id)
187 return handle_order_placement(request, checkout)
188 elif address_form.is_valid() and not preview:
189 checkout.billing_address = address_form.instance
190 return handle_order_placement(request, checkout)
191 return TemplateResponse(
192 request, 'checkout/summary_without_shipping.html', context={
193 'addresses_form': addresses_form, 'address_form': address_form,
194 'checkout': checkout, 'additional_addresses': user_addresses,
195 'note_form': note_form})
196
[end of saleor/checkout/views/summary.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/saleor/checkout/views/summary.py b/saleor/checkout/views/summary.py
--- a/saleor/checkout/views/summary.py
+++ b/saleor/checkout/views/summary.py
@@ -160,8 +160,7 @@
address_form, preview = get_address_form(
request.POST or None, autocomplete_type='billing',
initial={'country': request.country},
- country_code=billing_address.country.code,
- instance=billing_address)
+ country_code=billing_address.country.code)
addresses_form = BillingWithoutShippingAddressForm(
request.POST or None, additional_addresses=user_addresses,
initial={'address': billing_address.id})
| {"golden_diff": "diff --git a/saleor/checkout/views/summary.py b/saleor/checkout/views/summary.py\n--- a/saleor/checkout/views/summary.py\n+++ b/saleor/checkout/views/summary.py\n@@ -160,8 +160,7 @@\n address_form, preview = get_address_form(\n request.POST or None, autocomplete_type='billing',\n initial={'country': request.country},\n- country_code=billing_address.country.code,\n- instance=billing_address)\n+ country_code=billing_address.country.code)\n addresses_form = BillingWithoutShippingAddressForm(\n request.POST or None, additional_addresses=user_addresses,\n initial={'address': billing_address.id})\n", "issue": "Unable to add a new address on checkout of digital goods\n\r\n\r\n### What I'm trying to achieve\r\n\r\nEnter a new billing address on checkout when ordering a digital good.\r\n\r\n### Steps to reproduce the problem\r\n\r\n1. Make sure you have a default billing address;\r\n1. Add to cart a book;\r\n1. Go to checkout;\r\n1. At billing address step, create a new address with a different country;\r\n1. Correct any errors if the default billing address fields differs from the new country;\r\n1. Place order;\r\n1. Shipping address should not have been created.\r\n\r\n### What I expected to happen\r\nHave the new address as billing address on order.\r\n\r\n### What happened instead/how it failed\r\nGot no address created, and got the previous address as billing address for order.\r\n\n", "before_files": [{"content": "from django.contrib import messages\nfrom django.shortcuts import redirect\nfrom django.template.response import TemplateResponse\nfrom django.utils.translation import pgettext, pgettext_lazy\n\nfrom ...account.forms import get_address_form\nfrom ...account.models import Address\nfrom ...core.exceptions import InsufficientStock\nfrom ...order.emails import send_order_confirmation\nfrom ..forms import (\n AnonymousUserBillingForm, BillingAddressesForm,\n BillingWithoutShippingAddressForm, NoteForm)\n\n\ndef create_order(checkout):\n \"\"\"Finalize a checkout session and create an order.\n\n This is a helper function.\n\n `checkout` is a `saleor.checkout.core.Checkout` instance.\n \"\"\"\n order = checkout.create_order()\n if not order:\n return None, redirect('checkout:summary')\n checkout.clear_storage()\n checkout.cart.clear()\n user = None if checkout.user.is_anonymous else checkout.user\n msg = pgettext_lazy('Order status history entry', 'Order was placed')\n order.history.create(user=user, content=msg)\n send_order_confirmation.delay(order.pk)\n return order, redirect('order:payment', token=order.token)\n\n\ndef handle_order_placement(request, checkout):\n \"\"\"Try to create an order and redirect the user as necessary.\n\n This is a helper function.\n \"\"\"\n try:\n order, redirect_url = create_order(checkout)\n except InsufficientStock:\n return redirect('cart:index')\n if not order:\n msg = pgettext('Checkout warning', 'Please review your checkout.')\n messages.warning(request, msg)\n return redirect_url\n\n\ndef get_billing_forms_with_shipping(\n data, addresses, billing_address, shipping_address):\n \"\"\"Get billing form based on a the current billing and shipping data.\"\"\"\n if billing_address == shipping_address:\n address_form, preview = get_address_form(\n data, country_code=shipping_address.country.code,\n autocomplete_type='billing',\n initial={'country': shipping_address.country.code},\n instance=None)\n addresses_form = BillingAddressesForm(\n data, additional_addresses=addresses, initial={\n 'address': BillingAddressesForm.SHIPPING_ADDRESS})\n elif billing_address.id is None:\n address_form, preview = get_address_form(\n data, country_code=billing_address.country.code,\n autocomplete_type='billing',\n initial={'country': billing_address.country.code},\n instance=billing_address)\n addresses_form = BillingAddressesForm(\n data, additional_addresses=addresses, initial={\n 'address': BillingAddressesForm.NEW_ADDRESS})\n else:\n address_form, preview = get_address_form(\n data, country_code=billing_address.country.code,\n autocomplete_type='billing',\n initial={'country': billing_address.country})\n addresses_form = BillingAddressesForm(\n data, additional_addresses=addresses, initial={\n 'address': billing_address.id})\n if addresses_form.is_valid() and not preview:\n address_id = addresses_form.cleaned_data['address']\n if address_id == BillingAddressesForm.SHIPPING_ADDRESS:\n return address_form, addresses_form, shipping_address\n elif address_id != BillingAddressesForm.NEW_ADDRESS:\n address = addresses.get(id=address_id)\n return address_form, addresses_form, address\n elif address_form.is_valid():\n return address_form, addresses_form, address_form.instance\n return address_form, addresses_form, None\n\n\ndef summary_with_shipping_view(request, checkout):\n \"\"\"Display order summary with billing forms for a logged in user.\n\n Will create an order if all data is valid.\n \"\"\"\n note_form = NoteForm(request.POST or None, checkout=checkout)\n if note_form.is_valid():\n note_form.set_checkout_note()\n\n if request.user.is_authenticated:\n additional_addresses = request.user.addresses.all()\n else:\n additional_addresses = Address.objects.none()\n address_form, addresses_form, address = get_billing_forms_with_shipping(\n request.POST or None, additional_addresses,\n checkout.billing_address or Address(country=request.country),\n checkout.shipping_address)\n if address is not None:\n checkout.billing_address = address\n return handle_order_placement(request, checkout)\n return TemplateResponse(\n request, 'checkout/summary.html', context={\n 'addresses_form': addresses_form, 'address_form': address_form,\n 'checkout': checkout,\n 'additional_addresses': additional_addresses,\n 'note_form': note_form})\n\n\ndef anonymous_summary_without_shipping(request, checkout):\n \"\"\"Display order summary with billing forms for an unauthorized user.\n\n Will create an order if all data is valid.\n \"\"\"\n note_form = NoteForm(request.POST or None, checkout=checkout)\n if note_form.is_valid():\n note_form.set_checkout_note()\n user_form = AnonymousUserBillingForm(\n request.POST or None, initial={'email': checkout.email})\n billing_address = checkout.billing_address\n if billing_address:\n address_form, preview = get_address_form(\n request.POST or None, country_code=billing_address.country.code,\n autocomplete_type='billing', instance=billing_address)\n else:\n address_form, preview = get_address_form(\n request.POST or None, country_code=request.country.code,\n autocomplete_type='billing', initial={'country': request.country})\n if all([user_form.is_valid(), address_form.is_valid()]) and not preview:\n checkout.email = user_form.cleaned_data['email']\n checkout.billing_address = address_form.instance\n return handle_order_placement(request, checkout)\n return TemplateResponse(\n request, 'checkout/summary_without_shipping.html', context={\n 'user_form': user_form, 'address_form': address_form,\n 'checkout': checkout,\n 'note_form': note_form})\n\n\ndef summary_without_shipping(request, checkout):\n \"\"\"Display order summary for cases where shipping is not required.\n\n Will create an order if all data is valid.\n \"\"\"\n note_form = NoteForm(request.POST or None, checkout=checkout)\n if note_form.is_valid():\n note_form.set_checkout_note()\n\n billing_address = checkout.billing_address\n user_addresses = request.user.addresses.all()\n if billing_address and billing_address.id:\n address_form, preview = get_address_form(\n request.POST or None, autocomplete_type='billing',\n initial={'country': request.country},\n country_code=billing_address.country.code,\n instance=billing_address)\n addresses_form = BillingWithoutShippingAddressForm(\n request.POST or None, additional_addresses=user_addresses,\n initial={'address': billing_address.id})\n elif billing_address:\n address_form, preview = get_address_form(\n request.POST or None, autocomplete_type='billing',\n instance=billing_address,\n country_code=billing_address.country.code)\n addresses_form = BillingWithoutShippingAddressForm(\n request.POST or None, additional_addresses=user_addresses)\n else:\n address_form, preview = get_address_form(\n request.POST or None, autocomplete_type='billing',\n initial={'country': request.country},\n country_code=request.country.code)\n addresses_form = BillingWithoutShippingAddressForm(\n request.POST or None, additional_addresses=user_addresses)\n\n if addresses_form.is_valid():\n address_id = addresses_form.cleaned_data['address']\n if address_id != BillingWithoutShippingAddressForm.NEW_ADDRESS:\n checkout.billing_address = user_addresses.get(id=address_id)\n return handle_order_placement(request, checkout)\n elif address_form.is_valid() and not preview:\n checkout.billing_address = address_form.instance\n return handle_order_placement(request, checkout)\n return TemplateResponse(\n request, 'checkout/summary_without_shipping.html', context={\n 'addresses_form': addresses_form, 'address_form': address_form,\n 'checkout': checkout, 'additional_addresses': user_addresses,\n 'note_form': note_form})\n", "path": "saleor/checkout/views/summary.py"}]} | 2,787 | 148 |
gh_patches_debug_5122 | rasdani/github-patches | git_diff | liqd__a4-meinberlin-3044 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[dev/stage] auto-fill-in overwrites my bplan-name
**URL:** https://meinberlin-stage.liqd.net/dashboard/projects/caro-testing-new-bplan-mail-2/bplan/
**user:** initiator addin bplan
**expected behaviour:** I can use autofill to add my mail-address
**behaviour:** if I do so, the title of bplan is overwritten by my name but as it is far up the form I don't notice it.
**important screensize:**
**device & browser:** mac, chrome
**Comment/Question:** is that even something we can influence?
Screenshot?
<img width="673" alt="Bildschirmfoto 2020-07-10 um 11 02 30" src="https://user-images.githubusercontent.com/35491681/87137579-6b0eaf80-c29d-11ea-928f-c888dc8eb430.png">
<img width="673" alt="Bildschirmfoto 2020-07-10 um 11 06 10" src="https://user-images.githubusercontent.com/35491681/87137586-6cd87300-c29d-11ea-965d-74b4ecba8bc8.png">
</issue>
<code>
[start of meinberlin/apps/bplan/forms.py]
1 from django import forms
2
3 from meinberlin.apps.extprojects.forms import ExternalProjectCreateForm
4 from meinberlin.apps.extprojects.forms import ExternalProjectForm
5
6 from . import models
7
8
9 class StatementForm(forms.ModelForm):
10 class Meta:
11 model = models.Statement
12 fields = ['name', 'email', 'statement',
13 'street_number', 'postal_code_city']
14
15
16 class BplanProjectCreateForm(ExternalProjectCreateForm):
17
18 class Meta:
19 model = models.Bplan
20 fields = ['name', 'description', 'tile_image', 'tile_image_copyright']
21
22
23 class BplanProjectForm(ExternalProjectForm):
24
25 class Meta:
26 model = models.Bplan
27 fields = ['name', 'identifier', 'url', 'description', 'tile_image',
28 'tile_image_copyright', 'is_archived', 'office_worker_email',
29 'start_date', 'end_date']
30 required_for_project_publish = ['name', 'url', 'description',
31 'office_worker_email']
32
[end of meinberlin/apps/bplan/forms.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/meinberlin/apps/bplan/forms.py b/meinberlin/apps/bplan/forms.py
--- a/meinberlin/apps/bplan/forms.py
+++ b/meinberlin/apps/bplan/forms.py
@@ -29,3 +29,9 @@
'start_date', 'end_date']
required_for_project_publish = ['name', 'url', 'description',
'office_worker_email']
+
+ def __init__(self, *args, **kwargs):
+ super().__init__(*args, **kwargs)
+ self.fields['name'].widget.attrs.update({
+ 'autocomplete': 'off', 'autofill': 'off'
+ })
| {"golden_diff": "diff --git a/meinberlin/apps/bplan/forms.py b/meinberlin/apps/bplan/forms.py\n--- a/meinberlin/apps/bplan/forms.py\n+++ b/meinberlin/apps/bplan/forms.py\n@@ -29,3 +29,9 @@\n 'start_date', 'end_date']\n required_for_project_publish = ['name', 'url', 'description',\n 'office_worker_email']\n+\n+ def __init__(self, *args, **kwargs):\n+ super().__init__(*args, **kwargs)\n+ self.fields['name'].widget.attrs.update({\n+ 'autocomplete': 'off', 'autofill': 'off'\n+ })\n", "issue": "[dev/stage] auto-fill-in overwrites my bplan-name\n**URL:** https://meinberlin-stage.liqd.net/dashboard/projects/caro-testing-new-bplan-mail-2/bplan/\r\n**user:** initiator addin bplan\r\n**expected behaviour:** I can use autofill to add my mail-address\r\n**behaviour:** if I do so, the title of bplan is overwritten by my name but as it is far up the form I don't notice it.\r\n**important screensize:**\r\n**device & browser:** mac, chrome\r\n**Comment/Question:** is that even something we can influence?\r\n\r\nScreenshot?\r\n<img width=\"673\" alt=\"Bildschirmfoto 2020-07-10 um 11 02 30\" src=\"https://user-images.githubusercontent.com/35491681/87137579-6b0eaf80-c29d-11ea-928f-c888dc8eb430.png\">\r\n<img width=\"673\" alt=\"Bildschirmfoto 2020-07-10 um 11 06 10\" src=\"https://user-images.githubusercontent.com/35491681/87137586-6cd87300-c29d-11ea-965d-74b4ecba8bc8.png\">\r\n\r\n\n", "before_files": [{"content": "from django import forms\n\nfrom meinberlin.apps.extprojects.forms import ExternalProjectCreateForm\nfrom meinberlin.apps.extprojects.forms import ExternalProjectForm\n\nfrom . import models\n\n\nclass StatementForm(forms.ModelForm):\n class Meta:\n model = models.Statement\n fields = ['name', 'email', 'statement',\n 'street_number', 'postal_code_city']\n\n\nclass BplanProjectCreateForm(ExternalProjectCreateForm):\n\n class Meta:\n model = models.Bplan\n fields = ['name', 'description', 'tile_image', 'tile_image_copyright']\n\n\nclass BplanProjectForm(ExternalProjectForm):\n\n class Meta:\n model = models.Bplan\n fields = ['name', 'identifier', 'url', 'description', 'tile_image',\n 'tile_image_copyright', 'is_archived', 'office_worker_email',\n 'start_date', 'end_date']\n required_for_project_publish = ['name', 'url', 'description',\n 'office_worker_email']\n", "path": "meinberlin/apps/bplan/forms.py"}]} | 1,132 | 146 |
gh_patches_debug_5041 | rasdani/github-patches | git_diff | dask__dask-256 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
dot_graph does not work in stable version
I try to generate visual graphs as [described in documentation](http://dask.pydata.org/en/latest/inspect.html), but get:
`'module' object has no attribute 'to_pydot'`
The graphviz is installed with homebrew. Dask is installed from conda (latest stable release):
```
In [15]: dask.__version__
Out[15]: '0.5.0'
```
The code and traceback are below (I had to replace `blockshape` with `chunks`, otherwise it did not create task graph):
``` python
In [1]:
import dask.array as da
from dask.dot import dot_graph
In [2]:
x = da.ones((5, 15), chunks=(5, 5))
In [5]:
d = (x + 1).dask
In [6]:
dot_graph(d)
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-6-c797e633866d> in <module>()
----> 1 dot_graph(d)
/Users/koldunov/miniconda/lib/python2.7/site-packages/dask/dot.pyc in dot_graph(d, filename, **kwargs)
73 def dot_graph(d, filename='mydask', **kwargs):
74 dg = to_networkx(d, **kwargs)
---> 75 write_networkx_to_dot(dg, filename=filename)
76
77
/Users/koldunov/miniconda/lib/python2.7/site-packages/dask/dot.pyc in write_networkx_to_dot(dg, filename)
61 def write_networkx_to_dot(dg, filename='mydask'):
62 import os
---> 63 p = nx.to_pydot(dg)
64 p.set_rankdir('BT')
65 with open(filename + '.dot', 'w') as f:
AttributeError: 'module' object has no attribute 'to_pydot'
```
</issue>
<code>
[start of dask/dot.py]
1 from __future__ import absolute_import, division, print_function
2
3 import networkx as nx
4 from dask.core import istask, get_dependencies
5
6
7 def make_hashable(x):
8 try:
9 hash(x)
10 return x
11 except TypeError:
12 return hash(str(x))
13
14
15 def lower(func):
16 while hasattr(func, 'func'):
17 func = func.func
18 return func
19
20 def name(func):
21 try:
22 return lower(func).__name__
23 except AttributeError:
24 return 'func'
25
26
27 def to_networkx(d, data_attributes=None, function_attributes=None):
28 if data_attributes is None:
29 data_attributes = dict()
30 if function_attributes is None:
31 function_attributes = dict()
32
33 g = nx.DiGraph()
34
35 for k, v in sorted(d.items(), key=lambda x: x[0]):
36 g.add_node(k, shape='box', **data_attributes.get(k, dict()))
37 if istask(v):
38 func, args = v[0], v[1:]
39 func_node = make_hashable((v, 'function'))
40 g.add_node(func_node,
41 shape='circle',
42 label=name(func),
43 **function_attributes.get(k, dict()))
44 g.add_edge(func_node, k)
45 for dep in sorted(get_dependencies(d, k)):
46 arg2 = make_hashable(dep)
47 g.add_node(arg2,
48 label=str(dep),
49 shape='box',
50 **data_attributes.get(dep, dict()))
51 g.add_edge(arg2, func_node)
52 else:
53 if v not in d:
54 g.add_node(k, label='%s=%s' % (k, v), **data_attributes.get(k, dict()))
55 else: # alias situation
56 g.add_edge(v, k)
57
58 return g
59
60
61 def write_networkx_to_dot(dg, filename='mydask'):
62 import os
63 p = nx.to_pydot(dg)
64 p.set_rankdir('BT')
65 with open(filename + '.dot', 'w') as f:
66 f.write(p.to_string())
67
68 os.system('dot -Tpdf %s.dot -o %s.pdf' % (filename, filename))
69 os.system('dot -Tpng %s.dot -o %s.png' % (filename, filename))
70 print("Writing graph to %s.pdf" % filename)
71
72
73 def dot_graph(d, filename='mydask', **kwargs):
74 dg = to_networkx(d, **kwargs)
75 write_networkx_to_dot(dg, filename=filename)
76
77
78 if __name__ == '__main__':
79 def add(x, y):
80 return x + y
81 def inc(x):
82 return x + 1
83
84 dsk = {'x': 1, 'y': (inc, 'x'),
85 'a': 2, 'b': (inc, 'a'),
86 'z': (add, 'y', 'b')}
87
88 dot_graph(dsk)
89
[end of dask/dot.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/dask/dot.py b/dask/dot.py
--- a/dask/dot.py
+++ b/dask/dot.py
@@ -60,7 +60,11 @@
def write_networkx_to_dot(dg, filename='mydask'):
import os
- p = nx.to_pydot(dg)
+ try:
+ p = nx.to_pydot(dg)
+ except AttributeError:
+ raise ImportError("Can not find pydot module. Please install.\n"
+ " pip install pydot")
p.set_rankdir('BT')
with open(filename + '.dot', 'w') as f:
f.write(p.to_string())
| {"golden_diff": "diff --git a/dask/dot.py b/dask/dot.py\n--- a/dask/dot.py\n+++ b/dask/dot.py\n@@ -60,7 +60,11 @@\n \n def write_networkx_to_dot(dg, filename='mydask'):\n import os\n- p = nx.to_pydot(dg)\n+ try:\n+ p = nx.to_pydot(dg)\n+ except AttributeError:\n+ raise ImportError(\"Can not find pydot module. Please install.\\n\"\n+ \" pip install pydot\")\n p.set_rankdir('BT')\n with open(filename + '.dot', 'w') as f:\n f.write(p.to_string())\n", "issue": "dot_graph does not work in stable version\nI try to generate visual graphs as [described in documentation](http://dask.pydata.org/en/latest/inspect.html), but get:\n`'module' object has no attribute 'to_pydot'`\n\nThe graphviz is installed with homebrew. Dask is installed from conda (latest stable release):\n\n```\nIn [15]: dask.__version__\n\nOut[15]: '0.5.0'\n```\n\nThe code and traceback are below (I had to replace `blockshape` with `chunks`, otherwise it did not create task graph):\n\n``` python\nIn [1]: \nimport dask.array as da\nfrom dask.dot import dot_graph\nIn [2]:\n\nx = da.ones((5, 15), chunks=(5, 5))\nIn [5]:\n\nd = (x + 1).dask\nIn [6]:\n\ndot_graph(d)\n---------------------------------------------------------------------------\nAttributeError Traceback (most recent call last)\n<ipython-input-6-c797e633866d> in <module>()\n----> 1 dot_graph(d)\n\n/Users/koldunov/miniconda/lib/python2.7/site-packages/dask/dot.pyc in dot_graph(d, filename, **kwargs)\n 73 def dot_graph(d, filename='mydask', **kwargs):\n 74 dg = to_networkx(d, **kwargs)\n---> 75 write_networkx_to_dot(dg, filename=filename)\n 76 \n 77 \n\n/Users/koldunov/miniconda/lib/python2.7/site-packages/dask/dot.pyc in write_networkx_to_dot(dg, filename)\n 61 def write_networkx_to_dot(dg, filename='mydask'):\n 62 import os\n---> 63 p = nx.to_pydot(dg)\n 64 p.set_rankdir('BT')\n 65 with open(filename + '.dot', 'w') as f:\n\nAttributeError: 'module' object has no attribute 'to_pydot'\n```\n\n", "before_files": [{"content": "from __future__ import absolute_import, division, print_function\n\nimport networkx as nx\nfrom dask.core import istask, get_dependencies\n\n\ndef make_hashable(x):\n try:\n hash(x)\n return x\n except TypeError:\n return hash(str(x))\n\n\ndef lower(func):\n while hasattr(func, 'func'):\n func = func.func\n return func\n\ndef name(func):\n try:\n return lower(func).__name__\n except AttributeError:\n return 'func'\n\n\ndef to_networkx(d, data_attributes=None, function_attributes=None):\n if data_attributes is None:\n data_attributes = dict()\n if function_attributes is None:\n function_attributes = dict()\n\n g = nx.DiGraph()\n\n for k, v in sorted(d.items(), key=lambda x: x[0]):\n g.add_node(k, shape='box', **data_attributes.get(k, dict()))\n if istask(v):\n func, args = v[0], v[1:]\n func_node = make_hashable((v, 'function'))\n g.add_node(func_node,\n shape='circle',\n label=name(func),\n **function_attributes.get(k, dict()))\n g.add_edge(func_node, k)\n for dep in sorted(get_dependencies(d, k)):\n arg2 = make_hashable(dep)\n g.add_node(arg2,\n label=str(dep),\n shape='box',\n **data_attributes.get(dep, dict()))\n g.add_edge(arg2, func_node)\n else:\n if v not in d:\n g.add_node(k, label='%s=%s' % (k, v), **data_attributes.get(k, dict()))\n else: # alias situation\n g.add_edge(v, k)\n\n return g\n\n\ndef write_networkx_to_dot(dg, filename='mydask'):\n import os\n p = nx.to_pydot(dg)\n p.set_rankdir('BT')\n with open(filename + '.dot', 'w') as f:\n f.write(p.to_string())\n\n os.system('dot -Tpdf %s.dot -o %s.pdf' % (filename, filename))\n os.system('dot -Tpng %s.dot -o %s.png' % (filename, filename))\n print(\"Writing graph to %s.pdf\" % filename)\n\n\ndef dot_graph(d, filename='mydask', **kwargs):\n dg = to_networkx(d, **kwargs)\n write_networkx_to_dot(dg, filename=filename)\n\n\nif __name__ == '__main__':\n def add(x, y):\n return x + y\n def inc(x):\n return x + 1\n\n dsk = {'x': 1, 'y': (inc, 'x'),\n 'a': 2, 'b': (inc, 'a'),\n 'z': (add, 'y', 'b')}\n\n dot_graph(dsk)\n", "path": "dask/dot.py"}]} | 1,781 | 151 |
gh_patches_debug_18251 | rasdani/github-patches | git_diff | qtile__qtile-2924 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Docs are failing to build (again)
See: https://readthedocs.org/projects/qtile/builds/15011707/
Looks like this is a dependency issue related to pywlroots.
</issue>
<code>
[start of docs/conf.py]
1 # -*- coding: utf-8 -*-
2 #
3 # Qtile documentation build configuration file, created by
4 # sphinx-quickstart on Sat Feb 11 15:20:21 2012.
5 #
6 # This file is execfile()d with the current directory set to its containing dir.
7 #
8 # Note that not all possible configuration values are present in this
9 # autogenerated file.
10 #
11 # All configuration values have a default; values that are commented out
12 # serve to show the default.
13
14 import os
15 import setuptools_scm
16 import sys
17 from unittest.mock import MagicMock
18
19
20 class Mock(MagicMock):
21 # xcbq does a dir() on objects and pull stuff out of them and tries to sort
22 # the result. MagicMock has a bunch of stuff that can't be sorted, so let's
23 # like about dir().
24 def __dir__(self):
25 return []
26
27 MOCK_MODULES = [
28 'libqtile._ffi_pango',
29 'libqtile.backend.x11._ffi_xcursors',
30 'libqtile.widget._pulse_audio',
31 'cairocffi',
32 'cairocffi.xcb',
33 'cairocffi.pixbuf',
34 'cffi',
35 'dateutil',
36 'dateutil.parser',
37 'dbus_next',
38 'dbus_next.aio',
39 'dbus_next.errors',
40 'dbus_next.service',
41 'dbus_next.constants',
42 'iwlib',
43 'keyring',
44 'mpd',
45 'psutil',
46 'trollius',
47 'xcffib',
48 'xcffib.randr',
49 'xcffib.render',
50 'xcffib.wrappers',
51 'xcffib.xfixes',
52 'xcffib.xinerama',
53 'xcffib.xproto',
54 'xdg.IconTheme',
55 ]
56 sys.modules.update((mod_name, Mock()) for mod_name in MOCK_MODULES)
57
58 # If extensions (or modules to document with autodoc) are in another directory,
59 # add these directories to sys.path here. If the directory is relative to the
60 # documentation root, use os.path.abspath to make it absolute, like shown here.
61 sys.path.insert(0, os.path.abspath('.'))
62 sys.path.insert(0, os.path.abspath('../'))
63
64 # -- General configuration -----------------------------------------------------
65
66 # If your documentation needs a minimal Sphinx version, state it here.
67 #needs_sphinx = '1.0'
68
69 # Add any Sphinx extension module names here, as strings. They can be extensions
70 # coming with Sphinx (named 'sphinx.ext.*') or your custom ones.
71 extensions = [
72 'sphinx.ext.autodoc',
73 'sphinx.ext.autosummary',
74 'sphinx.ext.coverage',
75 'sphinx.ext.graphviz',
76 'sphinx.ext.todo',
77 'sphinx.ext.viewcode',
78 'sphinxcontrib.seqdiag',
79 'sphinx_qtile',
80 'numpydoc',
81 ]
82
83 numpydoc_show_class_members = False
84
85 # Add any paths that contain templates here, relative to this directory.
86 templates_path = []
87
88 # The suffix of source filenames.
89 source_suffix = '.rst'
90
91 # The encoding of source files.
92 #source_encoding = 'utf-8-sig'
93
94 # The master toctree document.
95 master_doc = 'index'
96
97 # General information about the project.
98 project = u'Qtile'
99 copyright = u'2008-2021, Aldo Cortesi and contributers'
100
101 # The version info for the project you're documenting, acts as replacement for
102 # |version| and |release|, also used in various other places throughout the
103 # built documents.
104 #
105 # The short X.Y version.
106 version = setuptools_scm.get_version(root="..")
107 # The full version, including alpha/beta/rc tags.
108 release = version
109
110 # The language for content autogenerated by Sphinx. Refer to documentation
111 # for a list of supported languages.
112 #language = None
113
114 # There are two options for replacing |today|: either, you set today to some
115 # non-false value, then it is used:
116 #today = ''
117 # Else, today_fmt is used as the format for a strftime call.
118 #today_fmt = '%B %d, %Y'
119
120 # List of patterns, relative to source directory, that match files and
121 # directories to ignore when looking for source files.
122 exclude_patterns = ['_build']
123
124 # The reST default role (used for this markup: `text`) to use for all documents.
125 #default_role = None
126
127 # If true, '()' will be appended to :func: etc. cross-reference text.
128 #add_function_parentheses = True
129
130 # If true, the current module name will be prepended to all description
131 # unit titles (such as .. function::).
132 #add_module_names = True
133
134 # If true, sectionauthor and moduleauthor directives will be shown in the
135 # output. They are ignored by default.
136 #show_authors = False
137
138 # The name of the Pygments (syntax highlighting) style to use.
139 pygments_style = 'sphinx'
140
141 # A list of ignored prefixes for module index sorting.
142 #modindex_common_prefix = []
143
144 # If true, `todo` and `todoList` produce output, else they produce nothing.
145 todo_include_todos = True
146
147
148 # -- Options for HTML output --------fautod-------------------------------------------
149
150 # The theme to use for HTML and HTML Help pages. See the documentation for
151 # a list of builtin themes.
152 #html_theme = 'default'
153
154 # Theme options are theme-specific and customize the look and feel of a theme
155 # further. For a list of options available for each theme, see the
156 # documentation.
157 #html_theme_options = {}
158
159 # Add any paths that contain custom themes here, relative to this directory.
160 #html_theme_path = []
161
162 # The name for this set of Sphinx documents. If None, it defaults to
163 # "<project> v<release> documentation".
164 #html_title = None
165
166 # A shorter title for the navigation bar. Default is the same as html_title.
167 #html_short_title = None
168
169 # The name of an image file (relative to this directory) to place at the top
170 # of the sidebar.
171 #html_logo = None
172
173 # The name of an image file (within the static path) to use as favicon of the
174 # docs. This file should be a Windows icon file (.ico) being 16x16 or 32x32
175 # pixels large.
176 html_favicon = '_static/favicon.ico'
177
178 # Add any paths that contain custom static files (such as style sheets) here,
179 # relative to this directory. They are copied after the builtin static files,
180 # so a file named "default.css" will overwrite the builtin "default.css".
181 html_static_path = ['_static']
182
183 # If not '', a 'Last updated on:' timestamp is inserted at every page bottom,
184 # using the given strftime format.
185 #html_last_updated_fmt = '%b %d, %Y'
186
187 # If true, SmartyPants will be used to convert quotes and dashes to
188 # typographically correct entities.
189 #html_use_smartypants = True
190
191 # Custom sidebar templates, maps document names to template names.
192 #html_sidebars = {}
193
194 # Additional templates that should be rendered to pages, maps page names to
195 # template names.
196 #html_additional_pages = {'index': 'index.html'}
197
198 # If false, no module index is generated.
199 #html_domain_indices = True
200
201 # If false, no index is generated.
202 html_use_index = True
203
204 # If true, the index is split into individual pages for each letter.
205 #html_split_index = False
206
207 # If true, links to the reST sources are added to the pages.
208 #html_show_sourcelink = True
209
210 # If true, "Created using Sphinx" is shown in the HTML footer. Default is True.
211 #html_show_sphinx = True
212
213 # If true, "(C) Copyright ..." is shown in the HTML footer. Default is True.
214 #html_show_copyright = True
215
216 # If true, an OpenSearch description file will be output, and all pages will
217 # contain a <link> tag referring to it. The value of this option must be the
218 # base URL from which the finished HTML is served.
219 #html_use_opensearch = ''
220
221 # This is the file name suffix for HTML files (e.g. ".xhtml").
222 #html_file_suffix = None
223
224 # Output file base name for HTML help builder.
225 htmlhelp_basename = 'Qtiledoc'
226
227
228 # -- Options for LaTeX output --------------------------------------------------
229
230 latex_elements = {
231 # The paper size ('letterpaper' or 'a4paper').
232 #'papersize': 'letterpaper',
233
234 # The font size ('10pt', '11pt' or '12pt').
235 #'pointsize': '10pt',
236
237 # Additional stuff for the LaTeX preamble.
238 #'preamble': '',
239 }
240
241 # Grouping the document tree into LaTeX files. List of tuples
242 # (source start file, target name, title, author, documentclass [howto/manual]).
243 latex_documents = [
244 ('index', 'Qtile.tex', u'Qtile Documentation',
245 u'Aldo Cortesi', 'manual'),
246 ]
247
248 # The name of an image file (relative to this directory) to place at the top of
249 # the title page.
250 #latex_logo = None
251
252 # For "manual" documents, if this is true, then toplevel headings are parts,
253 # not chapters.
254 #latex_use_parts = False
255
256 # If true, show page references after internal links.
257 #latex_show_pagerefs = False
258
259 # If true, show URL addresses after external links.
260 #latex_show_urls = False
261
262 # Documents to append as an appendix to all manuals.
263 #latex_appendices = []
264
265 # If false, no module index is generated.
266 #latex_domain_indices = True
267
268
269 # -- Options for manual page output --------------------------------------------
270
271 # One entry per manual page. List of tuples
272 # (source start file, name, description, authors, manual section).
273 #man_pages = []
274
275 # If true, show URL addresses after external links.
276 #man_show_urls = False
277
278
279 # -- Options for Texinfo output ------------------------------------------------
280
281 # Grouping the document tree into Texinfo files. List of tuples
282 # (source start file, target name, title, author,
283 # dir menu entry, description, category)
284 texinfo_documents = [
285 ('index', 'Qtile', u'Qtile Documentation',
286 u'Aldo Cortesi', 'Qtile', 'A hackable tiling window manager.',
287 'Miscellaneous'),
288 ]
289
290 # Documents to append as an appendix to all manuals.
291 #texinfo_appendices = []
292
293 # If false, no module index is generated.
294 #texinfo_domain_indices = True
295
296 # How to display URL addresses: 'footnote', 'no', or 'inline'.
297 #texinfo_show_urls = 'footnote'
298
299 # only import and set the theme if we're building docs locally
300 if not os.environ.get('READTHEDOCS'):
301 import sphinx_rtd_theme
302 html_theme = 'sphinx_rtd_theme'
303 html_theme_path = [sphinx_rtd_theme.get_html_theme_path()]
304
305
306 graphviz_dot_args = ['-Lg']
307
308 # A workaround for the responsive tables always having annoying scrollbars.
309 def setup(app):
310 app.add_css_file("no_scrollbars.css")
311
[end of docs/conf.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/docs/conf.py b/docs/conf.py
--- a/docs/conf.py
+++ b/docs/conf.py
@@ -43,7 +43,25 @@
'keyring',
'mpd',
'psutil',
- 'trollius',
+ 'pywayland',
+ 'pywayland.protocol.wayland',
+ 'pywayland.server',
+ 'wlroots',
+ 'wlroots.helper',
+ 'wlroots.util',
+ 'wlroots.util.box',
+ 'wlroots.util.clock',
+ 'wlroots.util.edges',
+ 'wlroots.util.region',
+ 'wlroots.wlr_types',
+ 'wlroots.wlr_types.cursor',
+ 'wlroots.wlr_types.keyboard',
+ 'wlroots.wlr_types.layer_shell_v1',
+ 'wlroots.wlr_types.output_management_v1',
+ 'wlroots.wlr_types.pointer_constraints_v1',
+ 'wlroots.wlr_types.server_decoration',
+ 'wlroots.wlr_types.virtual_keyboard_v1',
+ 'wlroots.wlr_types.xdg_shell',
'xcffib',
'xcffib.randr',
'xcffib.render',
@@ -52,6 +70,7 @@
'xcffib.xinerama',
'xcffib.xproto',
'xdg.IconTheme',
+ 'xkbcommon'
]
sys.modules.update((mod_name, Mock()) for mod_name in MOCK_MODULES)
| {"golden_diff": "diff --git a/docs/conf.py b/docs/conf.py\n--- a/docs/conf.py\n+++ b/docs/conf.py\n@@ -43,7 +43,25 @@\n 'keyring',\n 'mpd',\n 'psutil',\n- 'trollius',\n+ 'pywayland',\n+ 'pywayland.protocol.wayland',\n+ 'pywayland.server',\n+ 'wlroots',\n+ 'wlroots.helper',\n+ 'wlroots.util',\n+ 'wlroots.util.box',\n+ 'wlroots.util.clock',\n+ 'wlroots.util.edges',\n+ 'wlroots.util.region',\n+ 'wlroots.wlr_types',\n+ 'wlroots.wlr_types.cursor',\n+ 'wlroots.wlr_types.keyboard',\n+ 'wlroots.wlr_types.layer_shell_v1',\n+ 'wlroots.wlr_types.output_management_v1',\n+ 'wlroots.wlr_types.pointer_constraints_v1',\n+ 'wlroots.wlr_types.server_decoration',\n+ 'wlroots.wlr_types.virtual_keyboard_v1',\n+ 'wlroots.wlr_types.xdg_shell',\n 'xcffib',\n 'xcffib.randr',\n 'xcffib.render',\n@@ -52,6 +70,7 @@\n 'xcffib.xinerama',\n 'xcffib.xproto',\n 'xdg.IconTheme',\n+ 'xkbcommon'\n ]\n sys.modules.update((mod_name, Mock()) for mod_name in MOCK_MODULES)\n", "issue": "Docs are failing to build (again)\nSee: https://readthedocs.org/projects/qtile/builds/15011707/\r\n\r\nLooks like this is a dependency issue related to pywlroots.\r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n#\n# Qtile documentation build configuration file, created by\n# sphinx-quickstart on Sat Feb 11 15:20:21 2012.\n#\n# This file is execfile()d with the current directory set to its containing dir.\n#\n# Note that not all possible configuration values are present in this\n# autogenerated file.\n#\n# All configuration values have a default; values that are commented out\n# serve to show the default.\n\nimport os\nimport setuptools_scm\nimport sys\nfrom unittest.mock import MagicMock\n\n\nclass Mock(MagicMock):\n # xcbq does a dir() on objects and pull stuff out of them and tries to sort\n # the result. MagicMock has a bunch of stuff that can't be sorted, so let's\n # like about dir().\n def __dir__(self):\n return []\n\nMOCK_MODULES = [\n 'libqtile._ffi_pango',\n 'libqtile.backend.x11._ffi_xcursors',\n 'libqtile.widget._pulse_audio',\n 'cairocffi',\n 'cairocffi.xcb',\n 'cairocffi.pixbuf',\n 'cffi',\n 'dateutil',\n 'dateutil.parser',\n 'dbus_next',\n 'dbus_next.aio',\n 'dbus_next.errors',\n 'dbus_next.service',\n 'dbus_next.constants',\n 'iwlib',\n 'keyring',\n 'mpd',\n 'psutil',\n 'trollius',\n 'xcffib',\n 'xcffib.randr',\n 'xcffib.render',\n 'xcffib.wrappers',\n 'xcffib.xfixes',\n 'xcffib.xinerama',\n 'xcffib.xproto',\n 'xdg.IconTheme',\n]\nsys.modules.update((mod_name, Mock()) for mod_name in MOCK_MODULES)\n\n# If extensions (or modules to document with autodoc) are in another directory,\n# add these directories to sys.path here. If the directory is relative to the\n# documentation root, use os.path.abspath to make it absolute, like shown here.\nsys.path.insert(0, os.path.abspath('.'))\nsys.path.insert(0, os.path.abspath('../'))\n\n# -- General configuration -----------------------------------------------------\n\n# If your documentation needs a minimal Sphinx version, state it here.\n#needs_sphinx = '1.0'\n\n# Add any Sphinx extension module names here, as strings. They can be extensions\n# coming with Sphinx (named 'sphinx.ext.*') or your custom ones.\nextensions = [\n 'sphinx.ext.autodoc',\n 'sphinx.ext.autosummary',\n 'sphinx.ext.coverage',\n 'sphinx.ext.graphviz',\n 'sphinx.ext.todo',\n 'sphinx.ext.viewcode',\n 'sphinxcontrib.seqdiag',\n 'sphinx_qtile',\n 'numpydoc',\n]\n\nnumpydoc_show_class_members = False\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = []\n\n# The suffix of source filenames.\nsource_suffix = '.rst'\n\n# The encoding of source files.\n#source_encoding = 'utf-8-sig'\n\n# The master toctree document.\nmaster_doc = 'index'\n\n# General information about the project.\nproject = u'Qtile'\ncopyright = u'2008-2021, Aldo Cortesi and contributers'\n\n# The version info for the project you're documenting, acts as replacement for\n# |version| and |release|, also used in various other places throughout the\n# built documents.\n#\n# The short X.Y version.\nversion = setuptools_scm.get_version(root=\"..\")\n# The full version, including alpha/beta/rc tags.\nrelease = version\n\n# The language for content autogenerated by Sphinx. Refer to documentation\n# for a list of supported languages.\n#language = None\n\n# There are two options for replacing |today|: either, you set today to some\n# non-false value, then it is used:\n#today = ''\n# Else, today_fmt is used as the format for a strftime call.\n#today_fmt = '%B %d, %Y'\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\nexclude_patterns = ['_build']\n\n# The reST default role (used for this markup: `text`) to use for all documents.\n#default_role = None\n\n# If true, '()' will be appended to :func: etc. cross-reference text.\n#add_function_parentheses = True\n\n# If true, the current module name will be prepended to all description\n# unit titles (such as .. function::).\n#add_module_names = True\n\n# If true, sectionauthor and moduleauthor directives will be shown in the\n# output. They are ignored by default.\n#show_authors = False\n\n# The name of the Pygments (syntax highlighting) style to use.\npygments_style = 'sphinx'\n\n# A list of ignored prefixes for module index sorting.\n#modindex_common_prefix = []\n\n# If true, `todo` and `todoList` produce output, else they produce nothing.\ntodo_include_todos = True\n\n\n# -- Options for HTML output --------fautod-------------------------------------------\n\n# The theme to use for HTML and HTML Help pages. See the documentation for\n# a list of builtin themes.\n#html_theme = 'default'\n\n# Theme options are theme-specific and customize the look and feel of a theme\n# further. For a list of options available for each theme, see the\n# documentation.\n#html_theme_options = {}\n\n# Add any paths that contain custom themes here, relative to this directory.\n#html_theme_path = []\n\n# The name for this set of Sphinx documents. If None, it defaults to\n# \"<project> v<release> documentation\".\n#html_title = None\n\n# A shorter title for the navigation bar. Default is the same as html_title.\n#html_short_title = None\n\n# The name of an image file (relative to this directory) to place at the top\n# of the sidebar.\n#html_logo = None\n\n# The name of an image file (within the static path) to use as favicon of the\n# docs. This file should be a Windows icon file (.ico) being 16x16 or 32x32\n# pixels large.\nhtml_favicon = '_static/favicon.ico'\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\nhtml_static_path = ['_static']\n\n# If not '', a 'Last updated on:' timestamp is inserted at every page bottom,\n# using the given strftime format.\n#html_last_updated_fmt = '%b %d, %Y'\n\n# If true, SmartyPants will be used to convert quotes and dashes to\n# typographically correct entities.\n#html_use_smartypants = True\n\n# Custom sidebar templates, maps document names to template names.\n#html_sidebars = {}\n\n# Additional templates that should be rendered to pages, maps page names to\n# template names.\n#html_additional_pages = {'index': 'index.html'}\n\n# If false, no module index is generated.\n#html_domain_indices = True\n\n# If false, no index is generated.\nhtml_use_index = True\n\n# If true, the index is split into individual pages for each letter.\n#html_split_index = False\n\n# If true, links to the reST sources are added to the pages.\n#html_show_sourcelink = True\n\n# If true, \"Created using Sphinx\" is shown in the HTML footer. Default is True.\n#html_show_sphinx = True\n\n# If true, \"(C) Copyright ...\" is shown in the HTML footer. Default is True.\n#html_show_copyright = True\n\n# If true, an OpenSearch description file will be output, and all pages will\n# contain a <link> tag referring to it. The value of this option must be the\n# base URL from which the finished HTML is served.\n#html_use_opensearch = ''\n\n# This is the file name suffix for HTML files (e.g. \".xhtml\").\n#html_file_suffix = None\n\n# Output file base name for HTML help builder.\nhtmlhelp_basename = 'Qtiledoc'\n\n\n# -- Options for LaTeX output --------------------------------------------------\n\nlatex_elements = {\n# The paper size ('letterpaper' or 'a4paper').\n#'papersize': 'letterpaper',\n\n# The font size ('10pt', '11pt' or '12pt').\n#'pointsize': '10pt',\n\n# Additional stuff for the LaTeX preamble.\n#'preamble': '',\n}\n\n# Grouping the document tree into LaTeX files. List of tuples\n# (source start file, target name, title, author, documentclass [howto/manual]).\nlatex_documents = [\n ('index', 'Qtile.tex', u'Qtile Documentation',\n u'Aldo Cortesi', 'manual'),\n]\n\n# The name of an image file (relative to this directory) to place at the top of\n# the title page.\n#latex_logo = None\n\n# For \"manual\" documents, if this is true, then toplevel headings are parts,\n# not chapters.\n#latex_use_parts = False\n\n# If true, show page references after internal links.\n#latex_show_pagerefs = False\n\n# If true, show URL addresses after external links.\n#latex_show_urls = False\n\n# Documents to append as an appendix to all manuals.\n#latex_appendices = []\n\n# If false, no module index is generated.\n#latex_domain_indices = True\n\n\n# -- Options for manual page output --------------------------------------------\n\n# One entry per manual page. List of tuples\n# (source start file, name, description, authors, manual section).\n#man_pages = []\n\n# If true, show URL addresses after external links.\n#man_show_urls = False\n\n\n# -- Options for Texinfo output ------------------------------------------------\n\n# Grouping the document tree into Texinfo files. List of tuples\n# (source start file, target name, title, author,\n# dir menu entry, description, category)\ntexinfo_documents = [\n ('index', 'Qtile', u'Qtile Documentation',\n u'Aldo Cortesi', 'Qtile', 'A hackable tiling window manager.',\n 'Miscellaneous'),\n]\n\n# Documents to append as an appendix to all manuals.\n#texinfo_appendices = []\n\n# If false, no module index is generated.\n#texinfo_domain_indices = True\n\n# How to display URL addresses: 'footnote', 'no', or 'inline'.\n#texinfo_show_urls = 'footnote'\n\n# only import and set the theme if we're building docs locally\nif not os.environ.get('READTHEDOCS'):\n import sphinx_rtd_theme\n html_theme = 'sphinx_rtd_theme'\n html_theme_path = [sphinx_rtd_theme.get_html_theme_path()]\n\n\ngraphviz_dot_args = ['-Lg']\n\n# A workaround for the responsive tables always having annoying scrollbars.\ndef setup(app):\n app.add_css_file(\"no_scrollbars.css\")\n", "path": "docs/conf.py"}]} | 3,836 | 322 |
gh_patches_debug_20616 | rasdani/github-patches | git_diff | rasterio__rasterio-1259 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
examples/total.py won't run in Python3
The line `total /= 3` should read instead, `total = total / 3`.
</issue>
<code>
[start of examples/sieve.py]
1 #!/usr/bin/env python
2 #
3 # sieve: demonstrate sieving and polygonizing of raster features.
4
5 import subprocess
6
7 import numpy as np
8 import rasterio
9 from rasterio.features import sieve, shapes
10
11
12 # Register GDAL and OGR drivers.
13 with rasterio.Env():
14
15 # Read a raster to be sieved.
16 with rasterio.open('tests/data/shade.tif') as src:
17 shade = src.read(1)
18
19 # Print the number of shapes in the source raster.
20 print("Slope shapes: %d" % len(list(shapes(shade))))
21
22 # Sieve out features 13 pixels or smaller.
23 sieved = sieve(shade, 13, out=np.zeros(src.shape, src.dtypes[0]))
24
25 # Print the number of shapes in the sieved raster.
26 print("Sieved (13) shapes: %d" % len(list(shapes(sieved))))
27
28 # Write out the sieved raster.
29 kwargs = src.meta
30 kwargs['transform'] = kwargs.pop('affine')
31 with rasterio.open('example-sieved.tif', 'w', **kwargs) as dst:
32 dst.write(sieved, indexes=1)
33
34 # Dump out gdalinfo's report card and open (or "eog") the TIFF.
35 print(subprocess.check_output(
36 ['gdalinfo', '-stats', 'example-sieved.tif']))
37 subprocess.call(['open', 'example-sieved.tif'])
38
[end of examples/sieve.py]
[start of examples/total.py]
1 import numpy as np
2 import rasterio
3 import subprocess
4
5 with rasterio.Env(CPL_DEBUG=True):
6
7 # Read raster bands directly to Numpy arrays.
8 with rasterio.open('tests/data/RGB.byte.tif') as src:
9 r, g, b = src.read()
10
11 # Combine arrays using the 'iadd' ufunc. Expecting that the sum will
12 # exceed the 8-bit integer range, initialize it as 16-bit. Adding other
13 # arrays to it in-place converts those arrays up and preserves the type
14 # of the total array.
15 total = np.zeros(r.shape, dtype=rasterio.uint16)
16 for band in (r, g, b):
17 total += band
18 total /= 3
19
20 # Write the product as a raster band to a new 8-bit file. For keyword
21 # arguments, we start with the meta attributes of the source file, but
22 # then change the band count to 1, set the dtype to uint8, and specify
23 # LZW compression.
24 kwargs = src.meta
25 kwargs.update(
26 dtype=rasterio.uint8,
27 count=1,
28 compress='lzw')
29
30 with rasterio.open('example-total.tif', 'w', **kwargs) as dst:
31 dst.write(total.astype(rasterio.uint8), indexes=1)
32
33 # Dump out gdalinfo's report card and open the image.
34 info = subprocess.check_output(
35 ['gdalinfo', '-stats', 'example-total.tif'])
36 print(info)
37 subprocess.call(['open', 'example-total.tif'])
38
[end of examples/total.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/examples/sieve.py b/examples/sieve.py
--- a/examples/sieve.py
+++ b/examples/sieve.py
@@ -27,7 +27,7 @@
# Write out the sieved raster.
kwargs = src.meta
- kwargs['transform'] = kwargs.pop('affine')
+ kwargs['transform'] = rasterio.transform.guard_transform(kwargs['transform'])
with rasterio.open('example-sieved.tif', 'w', **kwargs) as dst:
dst.write(sieved, indexes=1)
diff --git a/examples/total.py b/examples/total.py
--- a/examples/total.py
+++ b/examples/total.py
@@ -1,3 +1,4 @@
+from __future__ import division
import numpy as np
import rasterio
import subprocess
@@ -15,7 +16,7 @@
total = np.zeros(r.shape, dtype=rasterio.uint16)
for band in (r, g, b):
total += band
- total /= 3
+ total = total // 3
# Write the product as a raster band to a new 8-bit file. For keyword
# arguments, we start with the meta attributes of the source file, but
| {"golden_diff": "diff --git a/examples/sieve.py b/examples/sieve.py\n--- a/examples/sieve.py\n+++ b/examples/sieve.py\n@@ -27,7 +27,7 @@\n \n # Write out the sieved raster.\n kwargs = src.meta\n- kwargs['transform'] = kwargs.pop('affine')\n+ kwargs['transform'] = rasterio.transform.guard_transform(kwargs['transform'])\n with rasterio.open('example-sieved.tif', 'w', **kwargs) as dst:\n dst.write(sieved, indexes=1)\n \ndiff --git a/examples/total.py b/examples/total.py\n--- a/examples/total.py\n+++ b/examples/total.py\n@@ -1,3 +1,4 @@\n+from __future__ import division\n import numpy as np\n import rasterio\n import subprocess\n@@ -15,7 +16,7 @@\n total = np.zeros(r.shape, dtype=rasterio.uint16)\n for band in (r, g, b):\n total += band\n- total /= 3\n+ total = total // 3\n \n # Write the product as a raster band to a new 8-bit file. For keyword\n # arguments, we start with the meta attributes of the source file, but\n", "issue": "examples/total.py won't run in Python3\nThe line `total /= 3` should read instead, `total = total / 3`.\r\n\n", "before_files": [{"content": "#!/usr/bin/env python\n#\n# sieve: demonstrate sieving and polygonizing of raster features.\n\nimport subprocess\n\nimport numpy as np\nimport rasterio\nfrom rasterio.features import sieve, shapes\n\n\n# Register GDAL and OGR drivers.\nwith rasterio.Env():\n\n # Read a raster to be sieved.\n with rasterio.open('tests/data/shade.tif') as src:\n shade = src.read(1)\n\n # Print the number of shapes in the source raster.\n print(\"Slope shapes: %d\" % len(list(shapes(shade))))\n\n # Sieve out features 13 pixels or smaller.\n sieved = sieve(shade, 13, out=np.zeros(src.shape, src.dtypes[0]))\n\n # Print the number of shapes in the sieved raster.\n print(\"Sieved (13) shapes: %d\" % len(list(shapes(sieved))))\n\n # Write out the sieved raster.\n kwargs = src.meta\n kwargs['transform'] = kwargs.pop('affine')\n with rasterio.open('example-sieved.tif', 'w', **kwargs) as dst:\n dst.write(sieved, indexes=1)\n\n# Dump out gdalinfo's report card and open (or \"eog\") the TIFF.\nprint(subprocess.check_output(\n ['gdalinfo', '-stats', 'example-sieved.tif']))\nsubprocess.call(['open', 'example-sieved.tif'])\n", "path": "examples/sieve.py"}, {"content": "import numpy as np\nimport rasterio\nimport subprocess\n\nwith rasterio.Env(CPL_DEBUG=True):\n\n # Read raster bands directly to Numpy arrays.\n with rasterio.open('tests/data/RGB.byte.tif') as src:\n r, g, b = src.read()\n\n # Combine arrays using the 'iadd' ufunc. Expecting that the sum will\n # exceed the 8-bit integer range, initialize it as 16-bit. Adding other\n # arrays to it in-place converts those arrays up and preserves the type\n # of the total array.\n total = np.zeros(r.shape, dtype=rasterio.uint16)\n for band in (r, g, b):\n total += band\n total /= 3\n\n # Write the product as a raster band to a new 8-bit file. For keyword\n # arguments, we start with the meta attributes of the source file, but\n # then change the band count to 1, set the dtype to uint8, and specify\n # LZW compression.\n kwargs = src.meta\n kwargs.update(\n dtype=rasterio.uint8,\n count=1,\n compress='lzw')\n\n with rasterio.open('example-total.tif', 'w', **kwargs) as dst:\n dst.write(total.astype(rasterio.uint8), indexes=1)\n\n# Dump out gdalinfo's report card and open the image.\ninfo = subprocess.check_output(\n ['gdalinfo', '-stats', 'example-total.tif'])\nprint(info)\nsubprocess.call(['open', 'example-total.tif'])\n", "path": "examples/total.py"}]} | 1,365 | 271 |
gh_patches_debug_58650 | rasdani/github-patches | git_diff | googleapis__google-api-python-client-295 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
BatchError is unprintable using default constructor (one string)
This one should be pretty simple, I hope.
Here's the constructor signature: `def __init__(self, reason, resp=None, content=None):`, which doesn't require `resp` to be defined, and I can see it is not defined most of the time, for example, in googleapiclient/http.py.
Then, given the representation method:
```
def __repr__(self):
return '<BatchError %s "%s">' % (self.resp.status, self.reason)
```
Which is also the string method:
```
__str__ = __repr__
```
This results in unprintable exceptions where `resp` is undefined, which is not very helpful when attempting to understand the error (e.g. #164).
</issue>
<code>
[start of googleapiclient/errors.py]
1 # Copyright 2014 Google Inc. All Rights Reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """Errors for the library.
16
17 All exceptions defined by the library
18 should be defined in this file.
19 """
20 from __future__ import absolute_import
21
22 __author__ = '[email protected] (Joe Gregorio)'
23
24 import json
25
26 # Oauth2client < 3 has the positional helper in 'util', >= 3 has it
27 # in '_helpers'.
28 try:
29 from oauth2client import util
30 except ImportError:
31 from oauth2client import _helpers as util
32
33
34 class Error(Exception):
35 """Base error for this module."""
36 pass
37
38
39 class HttpError(Error):
40 """HTTP data was invalid or unexpected."""
41
42 @util.positional(3)
43 def __init__(self, resp, content, uri=None):
44 self.resp = resp
45 if not isinstance(content, bytes):
46 raise TypeError("HTTP content should be bytes")
47 self.content = content
48 self.uri = uri
49
50 def _get_reason(self):
51 """Calculate the reason for the error from the response content."""
52 reason = self.resp.reason
53 try:
54 data = json.loads(self.content.decode('utf-8'))
55 if isinstance(data, dict):
56 reason = data['error']['message']
57 elif isinstance(data, list) and len(data) > 0:
58 first_error = data[0]
59 reason = first_error['error']['message']
60 except (ValueError, KeyError, TypeError):
61 pass
62 if reason is None:
63 reason = ''
64 return reason
65
66 def __repr__(self):
67 if self.uri:
68 return '<HttpError %s when requesting %s returned "%s">' % (
69 self.resp.status, self.uri, self._get_reason().strip())
70 else:
71 return '<HttpError %s "%s">' % (self.resp.status, self._get_reason())
72
73 __str__ = __repr__
74
75
76 class InvalidJsonError(Error):
77 """The JSON returned could not be parsed."""
78 pass
79
80
81 class UnknownFileType(Error):
82 """File type unknown or unexpected."""
83 pass
84
85
86 class UnknownLinkType(Error):
87 """Link type unknown or unexpected."""
88 pass
89
90
91 class UnknownApiNameOrVersion(Error):
92 """No API with that name and version exists."""
93 pass
94
95
96 class UnacceptableMimeTypeError(Error):
97 """That is an unacceptable mimetype for this operation."""
98 pass
99
100
101 class MediaUploadSizeError(Error):
102 """Media is larger than the method can accept."""
103 pass
104
105
106 class ResumableUploadError(HttpError):
107 """Error occured during resumable upload."""
108 pass
109
110
111 class InvalidChunkSizeError(Error):
112 """The given chunksize is not valid."""
113 pass
114
115 class InvalidNotificationError(Error):
116 """The channel Notification is invalid."""
117 pass
118
119 class BatchError(HttpError):
120 """Error occured during batch operations."""
121
122 @util.positional(2)
123 def __init__(self, reason, resp=None, content=None):
124 self.resp = resp
125 self.content = content
126 self.reason = reason
127
128 def __repr__(self):
129 return '<BatchError %s "%s">' % (self.resp.status, self.reason)
130
131 __str__ = __repr__
132
133
134 class UnexpectedMethodError(Error):
135 """Exception raised by RequestMockBuilder on unexpected calls."""
136
137 @util.positional(1)
138 def __init__(self, methodId=None):
139 """Constructor for an UnexpectedMethodError."""
140 super(UnexpectedMethodError, self).__init__(
141 'Received unexpected call %s' % methodId)
142
143
144 class UnexpectedBodyError(Error):
145 """Exception raised by RequestMockBuilder on unexpected bodies."""
146
147 def __init__(self, expected, provided):
148 """Constructor for an UnexpectedMethodError."""
149 super(UnexpectedBodyError, self).__init__(
150 'Expected: [%s] - Provided: [%s]' % (expected, provided))
151
[end of googleapiclient/errors.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/googleapiclient/errors.py b/googleapiclient/errors.py
--- a/googleapiclient/errors.py
+++ b/googleapiclient/errors.py
@@ -126,6 +126,9 @@
self.reason = reason
def __repr__(self):
+ if getattr(self.resp, 'status', None) is None:
+ return '<BatchError "%s">' % (self.reason)
+ else:
return '<BatchError %s "%s">' % (self.resp.status, self.reason)
__str__ = __repr__
| {"golden_diff": "diff --git a/googleapiclient/errors.py b/googleapiclient/errors.py\n--- a/googleapiclient/errors.py\n+++ b/googleapiclient/errors.py\n@@ -126,6 +126,9 @@\n self.reason = reason\n \n def __repr__(self):\n+ if getattr(self.resp, 'status', None) is None:\n+ return '<BatchError \"%s\">' % (self.reason)\n+ else:\n return '<BatchError %s \"%s\">' % (self.resp.status, self.reason)\n \n __str__ = __repr__\n", "issue": "BatchError is unprintable using default constructor (one string)\nThis one should be pretty simple, I hope.\n\nHere's the constructor signature: `def __init__(self, reason, resp=None, content=None):`, which doesn't require `resp` to be defined, and I can see it is not defined most of the time, for example, in googleapiclient/http.py.\n\nThen, given the representation method:\n\n```\ndef __repr__(self):\n return '<BatchError %s \"%s\">' % (self.resp.status, self.reason)\n```\n\nWhich is also the string method:\n\n```\n__str__ = __repr__\n```\n\nThis results in unprintable exceptions where `resp` is undefined, which is not very helpful when attempting to understand the error (e.g. #164).\n\n", "before_files": [{"content": "# Copyright 2014 Google Inc. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Errors for the library.\n\nAll exceptions defined by the library\nshould be defined in this file.\n\"\"\"\nfrom __future__ import absolute_import\n\n__author__ = '[email protected] (Joe Gregorio)'\n\nimport json\n\n# Oauth2client < 3 has the positional helper in 'util', >= 3 has it\n# in '_helpers'.\ntry:\n from oauth2client import util\nexcept ImportError:\n from oauth2client import _helpers as util\n\n\nclass Error(Exception):\n \"\"\"Base error for this module.\"\"\"\n pass\n\n\nclass HttpError(Error):\n \"\"\"HTTP data was invalid or unexpected.\"\"\"\n\n @util.positional(3)\n def __init__(self, resp, content, uri=None):\n self.resp = resp\n if not isinstance(content, bytes):\n raise TypeError(\"HTTP content should be bytes\")\n self.content = content\n self.uri = uri\n\n def _get_reason(self):\n \"\"\"Calculate the reason for the error from the response content.\"\"\"\n reason = self.resp.reason\n try:\n data = json.loads(self.content.decode('utf-8'))\n if isinstance(data, dict):\n reason = data['error']['message']\n elif isinstance(data, list) and len(data) > 0:\n first_error = data[0]\n reason = first_error['error']['message']\n except (ValueError, KeyError, TypeError):\n pass\n if reason is None:\n reason = ''\n return reason\n\n def __repr__(self):\n if self.uri:\n return '<HttpError %s when requesting %s returned \"%s\">' % (\n self.resp.status, self.uri, self._get_reason().strip())\n else:\n return '<HttpError %s \"%s\">' % (self.resp.status, self._get_reason())\n\n __str__ = __repr__\n\n\nclass InvalidJsonError(Error):\n \"\"\"The JSON returned could not be parsed.\"\"\"\n pass\n\n\nclass UnknownFileType(Error):\n \"\"\"File type unknown or unexpected.\"\"\"\n pass\n\n\nclass UnknownLinkType(Error):\n \"\"\"Link type unknown or unexpected.\"\"\"\n pass\n\n\nclass UnknownApiNameOrVersion(Error):\n \"\"\"No API with that name and version exists.\"\"\"\n pass\n\n\nclass UnacceptableMimeTypeError(Error):\n \"\"\"That is an unacceptable mimetype for this operation.\"\"\"\n pass\n\n\nclass MediaUploadSizeError(Error):\n \"\"\"Media is larger than the method can accept.\"\"\"\n pass\n\n\nclass ResumableUploadError(HttpError):\n \"\"\"Error occured during resumable upload.\"\"\"\n pass\n\n\nclass InvalidChunkSizeError(Error):\n \"\"\"The given chunksize is not valid.\"\"\"\n pass\n\nclass InvalidNotificationError(Error):\n \"\"\"The channel Notification is invalid.\"\"\"\n pass\n\nclass BatchError(HttpError):\n \"\"\"Error occured during batch operations.\"\"\"\n\n @util.positional(2)\n def __init__(self, reason, resp=None, content=None):\n self.resp = resp\n self.content = content\n self.reason = reason\n\n def __repr__(self):\n return '<BatchError %s \"%s\">' % (self.resp.status, self.reason)\n\n __str__ = __repr__\n\n\nclass UnexpectedMethodError(Error):\n \"\"\"Exception raised by RequestMockBuilder on unexpected calls.\"\"\"\n\n @util.positional(1)\n def __init__(self, methodId=None):\n \"\"\"Constructor for an UnexpectedMethodError.\"\"\"\n super(UnexpectedMethodError, self).__init__(\n 'Received unexpected call %s' % methodId)\n\n\nclass UnexpectedBodyError(Error):\n \"\"\"Exception raised by RequestMockBuilder on unexpected bodies.\"\"\"\n\n def __init__(self, expected, provided):\n \"\"\"Constructor for an UnexpectedMethodError.\"\"\"\n super(UnexpectedBodyError, self).__init__(\n 'Expected: [%s] - Provided: [%s]' % (expected, provided))\n", "path": "googleapiclient/errors.py"}]} | 2,006 | 124 |
gh_patches_debug_12722 | rasdani/github-patches | git_diff | oppia__oppia-15025 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Topic prerequisite skill checking is broken and prevents topic being published
**Describe the bug**
In a topic, chapters with prerequisite skills outside the topic make the topic unpublishable, because "this skill was not taught in any chapter before it". This behaviour is wrong because the validation error should only be triggered for skills that have been assigned to the topic currently being edited.
**To Reproduce**
Steps to reproduce the behavior:
1. Create topic P (the prerequisite topic) and topic M (the main topic).
2. Create skill S1 and assign it to P. Create skill S2 and assign it to M.
3. Create a chapter in topic M and assign it a prerequisite skill of S1, and an acquired skill of S2.
4. Save all changes.
5. Refresh the page and try to publish the topic. This is not possible because of a validation error: "The skill with id XYZ was specified as a prerequisite for Chapter Name but was not taught in any chapter before it.". See screenshot below:
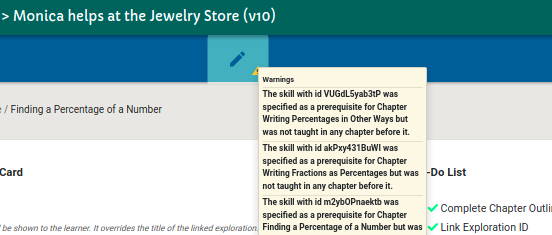
**Observed behavior**
The topic cannot be published, and further changes to the story/chapter cannot be saved, because the prerequisite skills include ones from outside the topic.
**Expected behavior**
The topic should be publishable. The validation message should **only** occur for skills that have been assigned to the main topic M, and not to other topics.
</issue>
<code>
[start of core/controllers/story_editor.py]
1 # Copyright 2018 The Oppia Authors. All Rights Reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS-IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """Controllers for the story editor."""
16
17 from __future__ import annotations
18
19 from core import feconf
20 from core import utils
21 from core.constants import constants
22 from core.controllers import acl_decorators
23 from core.controllers import base
24 from core.domain import classroom_services
25 from core.domain import skill_services
26 from core.domain import story_domain
27 from core.domain import story_fetchers
28 from core.domain import story_services
29 from core.domain import topic_fetchers
30 from core.domain import topic_services
31
32
33 class StoryEditorPage(base.BaseHandler):
34 """The editor page for a single story."""
35
36 URL_PATH_ARGS_SCHEMAS = {
37 'story_id': {
38 'schema': {
39 'type': 'basestring'
40 },
41 'validators': [{
42 'id': 'has_length',
43 'value': constants.STORY_ID_LENGTH
44 }]
45 }
46 }
47 HANDLER_ARGS_SCHEMAS = {
48 'GET': {}
49 }
50
51 @acl_decorators.can_edit_story
52 def get(self, _):
53 """Handles GET requests."""
54
55 self.render_template('story-editor-page.mainpage.html')
56
57
58 class EditableStoryDataHandler(base.BaseHandler):
59 """A data handler for stories which support writing."""
60
61 GET_HANDLER_ERROR_RETURN_TYPE = feconf.HANDLER_TYPE_JSON
62
63 def _require_valid_version(self, version_from_payload, story_version):
64 """Check that the payload version matches the given story
65 version.
66 """
67 if version_from_payload is None:
68 raise base.BaseHandler.InvalidInputException(
69 'Invalid POST request: a version must be specified.')
70
71 if version_from_payload != story_version:
72 raise base.BaseHandler.InvalidInputException(
73 'Trying to update version %s of story from version %s, '
74 'which is too old. Please reload the page and try again.'
75 % (story_version, version_from_payload))
76
77 @acl_decorators.can_edit_story
78 def get(self, story_id):
79 """Populates the data on the individual story page."""
80 story = story_fetchers.get_story_by_id(story_id, strict=False)
81 topic_id = story.corresponding_topic_id
82 topic = topic_fetchers.get_topic_by_id(topic_id, strict=False)
83 skill_ids = topic.get_all_skill_ids()
84 for node in story.story_contents.nodes:
85 for skill_id in node.prerequisite_skill_ids:
86 if skill_id not in skill_ids:
87 skill_ids.append(skill_id)
88
89 skill_summaries = skill_services.get_multi_skill_summaries(skill_ids)
90 skill_summary_dicts = [summary.to_dict() for summary in skill_summaries]
91 classroom_url_fragment = (
92 classroom_services.get_classroom_url_fragment_for_topic_id(
93 topic.id))
94
95 for story_reference in topic.canonical_story_references:
96 if story_reference.story_id == story_id:
97 story_is_published = story_reference.story_is_published
98
99 self.values.update({
100 'story': story.to_dict(),
101 'topic_name': topic.name,
102 'story_is_published': story_is_published,
103 'skill_summaries': skill_summary_dicts,
104 'topic_url_fragment': topic.url_fragment,
105 'classroom_url_fragment': classroom_url_fragment
106 })
107
108 self.render_json(self.values)
109
110 @acl_decorators.can_edit_story
111 def put(self, story_id):
112 """Updates properties of the given story."""
113 story = story_fetchers.get_story_by_id(story_id, strict=False)
114
115 version = self.payload.get('version')
116 self._require_valid_version(version, story.version)
117
118 commit_message = self.payload.get('commit_message')
119
120 if commit_message is None:
121 raise self.InvalidInputException(
122 'Expected a commit message but received none.')
123
124 if len(commit_message) > constants.MAX_COMMIT_MESSAGE_LENGTH:
125 raise self.InvalidInputException(
126 'Commit messages must be at most %s characters long.'
127 % constants.MAX_COMMIT_MESSAGE_LENGTH)
128
129 change_dicts = self.payload.get('change_dicts')
130 change_list = [
131 story_domain.StoryChange(change_dict)
132 for change_dict in change_dicts
133 ]
134 try:
135 # Update the Story and its corresponding TopicSummary.
136 topic_services.update_story_and_topic_summary(
137 self.user_id, story_id, change_list, commit_message,
138 story.corresponding_topic_id)
139 except utils.ValidationError as e:
140 raise self.InvalidInputException(e)
141
142 story_dict = story_fetchers.get_story_by_id(story_id).to_dict()
143
144 self.values.update({
145 'story': story_dict
146 })
147
148 self.render_json(self.values)
149
150 @acl_decorators.can_delete_story
151 def delete(self, story_id):
152 """Handles Delete requests."""
153 story_services.delete_story(self.user_id, story_id)
154 self.render_json(self.values)
155
156
157 class StoryPublishHandler(base.BaseHandler):
158 """A data handler for publishing and unpublishing stories."""
159
160 GET_HANDLER_ERROR_RETURN_TYPE = feconf.HANDLER_TYPE_JSON
161 URL_PATH_ARGS_SCHEMAS = {
162 'story_id': {
163 'schema': {
164 'type': 'basestring'
165 },
166 'validators': [{
167 'id': 'has_length',
168 'value': constants.STORY_ID_LENGTH
169 }]
170 }
171 }
172 HANDLER_ARGS_SCHEMAS = {
173 'PUT': {
174 'new_story_status_is_public': {
175 'schema': {
176 'type': 'bool'
177 },
178 }
179 }
180 }
181
182 @acl_decorators.can_edit_story
183 def put(self, story_id):
184 """Published/unpublished given story."""
185 story = story_fetchers.get_story_by_id(story_id, strict=False)
186 topic_id = story.corresponding_topic_id
187
188 new_story_status_is_public = self.normalized_payload.get(
189 'new_story_status_is_public')
190
191 if new_story_status_is_public:
192 topic_services.publish_story(topic_id, story_id, self.user_id)
193 else:
194 topic_services.unpublish_story(topic_id, story_id, self.user_id)
195
196 self.render_json(self.values)
197
198
199 class ValidateExplorationsHandler(base.BaseHandler):
200 """A data handler for validating the explorations in a story."""
201
202 GET_HANDLER_ERROR_RETURN_TYPE = feconf.HANDLER_TYPE_JSON
203
204 @acl_decorators.can_edit_story
205 def get(self, _):
206 """Handler that receives a list of exploration IDs, checks whether the
207 corresponding explorations are supported on mobile and returns the
208 validation error messages (if any).
209 """
210 comma_separated_exp_ids = self.request.get('comma_separated_exp_ids')
211 if not comma_separated_exp_ids:
212 raise self.InvalidInputException(
213 'Expected comma_separated_exp_ids parameter to be present.')
214 exp_ids = comma_separated_exp_ids.split(',')
215 validation_error_messages = (
216 story_services.validate_explorations_for_story(exp_ids, False))
217 self.values.update({
218 'validation_error_messages': validation_error_messages
219 })
220 self.render_json(self.values)
221
222
223 class StoryUrlFragmentHandler(base.BaseHandler):
224 """A data handler for checking if a story with given url fragment exists.
225 """
226
227 GET_HANDLER_ERROR_RETURN_TYPE = feconf.HANDLER_TYPE_JSON
228 URL_PATH_ARGS_SCHEMAS = {
229 'story_url_fragment': constants.SCHEMA_FOR_STORY_URL_FRAGMENTS
230 }
231 HANDLER_ARGS_SCHEMAS = {
232 'GET': {}
233 }
234
235 @acl_decorators.open_access
236 def get(self, story_url_fragment):
237 """Handler that receives a story url fragment and checks whether
238 a story with the same url fragment exists or not.
239 """
240 self.values.update({
241 'story_url_fragment_exists': (
242 story_services.does_story_exist_with_url_fragment(
243 story_url_fragment))
244 })
245 self.render_json(self.values)
246
[end of core/controllers/story_editor.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/core/controllers/story_editor.py b/core/controllers/story_editor.py
--- a/core/controllers/story_editor.py
+++ b/core/controllers/story_editor.py
@@ -81,10 +81,6 @@
topic_id = story.corresponding_topic_id
topic = topic_fetchers.get_topic_by_id(topic_id, strict=False)
skill_ids = topic.get_all_skill_ids()
- for node in story.story_contents.nodes:
- for skill_id in node.prerequisite_skill_ids:
- if skill_id not in skill_ids:
- skill_ids.append(skill_id)
skill_summaries = skill_services.get_multi_skill_summaries(skill_ids)
skill_summary_dicts = [summary.to_dict() for summary in skill_summaries]
| {"golden_diff": "diff --git a/core/controllers/story_editor.py b/core/controllers/story_editor.py\n--- a/core/controllers/story_editor.py\n+++ b/core/controllers/story_editor.py\n@@ -81,10 +81,6 @@\n topic_id = story.corresponding_topic_id\n topic = topic_fetchers.get_topic_by_id(topic_id, strict=False)\n skill_ids = topic.get_all_skill_ids()\n- for node in story.story_contents.nodes:\n- for skill_id in node.prerequisite_skill_ids:\n- if skill_id not in skill_ids:\n- skill_ids.append(skill_id)\n \n skill_summaries = skill_services.get_multi_skill_summaries(skill_ids)\n skill_summary_dicts = [summary.to_dict() for summary in skill_summaries]\n", "issue": "Topic prerequisite skill checking is broken and prevents topic being published\n**Describe the bug**\r\n\r\nIn a topic, chapters with prerequisite skills outside the topic make the topic unpublishable, because \"this skill was not taught in any chapter before it\". This behaviour is wrong because the validation error should only be triggered for skills that have been assigned to the topic currently being edited.\r\n\r\n**To Reproduce**\r\nSteps to reproduce the behavior:\r\n 1. Create topic P (the prerequisite topic) and topic M (the main topic).\r\n 2. Create skill S1 and assign it to P. Create skill S2 and assign it to M.\r\n 3. Create a chapter in topic M and assign it a prerequisite skill of S1, and an acquired skill of S2.\r\n 4. Save all changes.\r\n 5. Refresh the page and try to publish the topic. This is not possible because of a validation error: \"The skill with id XYZ was specified as a prerequisite for Chapter Name but was not taught in any chapter before it.\". See screenshot below:\r\n \r\n\r\n\r\n**Observed behavior**\r\nThe topic cannot be published, and further changes to the story/chapter cannot be saved, because the prerequisite skills include ones from outside the topic.\r\n\r\n**Expected behavior**\r\nThe topic should be publishable. The validation message should **only** occur for skills that have been assigned to the main topic M, and not to other topics.\r\n\n", "before_files": [{"content": "# Copyright 2018 The Oppia Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS-IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Controllers for the story editor.\"\"\"\n\nfrom __future__ import annotations\n\nfrom core import feconf\nfrom core import utils\nfrom core.constants import constants\nfrom core.controllers import acl_decorators\nfrom core.controllers import base\nfrom core.domain import classroom_services\nfrom core.domain import skill_services\nfrom core.domain import story_domain\nfrom core.domain import story_fetchers\nfrom core.domain import story_services\nfrom core.domain import topic_fetchers\nfrom core.domain import topic_services\n\n\nclass StoryEditorPage(base.BaseHandler):\n \"\"\"The editor page for a single story.\"\"\"\n\n URL_PATH_ARGS_SCHEMAS = {\n 'story_id': {\n 'schema': {\n 'type': 'basestring'\n },\n 'validators': [{\n 'id': 'has_length',\n 'value': constants.STORY_ID_LENGTH\n }]\n }\n }\n HANDLER_ARGS_SCHEMAS = {\n 'GET': {}\n }\n\n @acl_decorators.can_edit_story\n def get(self, _):\n \"\"\"Handles GET requests.\"\"\"\n\n self.render_template('story-editor-page.mainpage.html')\n\n\nclass EditableStoryDataHandler(base.BaseHandler):\n \"\"\"A data handler for stories which support writing.\"\"\"\n\n GET_HANDLER_ERROR_RETURN_TYPE = feconf.HANDLER_TYPE_JSON\n\n def _require_valid_version(self, version_from_payload, story_version):\n \"\"\"Check that the payload version matches the given story\n version.\n \"\"\"\n if version_from_payload is None:\n raise base.BaseHandler.InvalidInputException(\n 'Invalid POST request: a version must be specified.')\n\n if version_from_payload != story_version:\n raise base.BaseHandler.InvalidInputException(\n 'Trying to update version %s of story from version %s, '\n 'which is too old. Please reload the page and try again.'\n % (story_version, version_from_payload))\n\n @acl_decorators.can_edit_story\n def get(self, story_id):\n \"\"\"Populates the data on the individual story page.\"\"\"\n story = story_fetchers.get_story_by_id(story_id, strict=False)\n topic_id = story.corresponding_topic_id\n topic = topic_fetchers.get_topic_by_id(topic_id, strict=False)\n skill_ids = topic.get_all_skill_ids()\n for node in story.story_contents.nodes:\n for skill_id in node.prerequisite_skill_ids:\n if skill_id not in skill_ids:\n skill_ids.append(skill_id)\n\n skill_summaries = skill_services.get_multi_skill_summaries(skill_ids)\n skill_summary_dicts = [summary.to_dict() for summary in skill_summaries]\n classroom_url_fragment = (\n classroom_services.get_classroom_url_fragment_for_topic_id(\n topic.id))\n\n for story_reference in topic.canonical_story_references:\n if story_reference.story_id == story_id:\n story_is_published = story_reference.story_is_published\n\n self.values.update({\n 'story': story.to_dict(),\n 'topic_name': topic.name,\n 'story_is_published': story_is_published,\n 'skill_summaries': skill_summary_dicts,\n 'topic_url_fragment': topic.url_fragment,\n 'classroom_url_fragment': classroom_url_fragment\n })\n\n self.render_json(self.values)\n\n @acl_decorators.can_edit_story\n def put(self, story_id):\n \"\"\"Updates properties of the given story.\"\"\"\n story = story_fetchers.get_story_by_id(story_id, strict=False)\n\n version = self.payload.get('version')\n self._require_valid_version(version, story.version)\n\n commit_message = self.payload.get('commit_message')\n\n if commit_message is None:\n raise self.InvalidInputException(\n 'Expected a commit message but received none.')\n\n if len(commit_message) > constants.MAX_COMMIT_MESSAGE_LENGTH:\n raise self.InvalidInputException(\n 'Commit messages must be at most %s characters long.'\n % constants.MAX_COMMIT_MESSAGE_LENGTH)\n\n change_dicts = self.payload.get('change_dicts')\n change_list = [\n story_domain.StoryChange(change_dict)\n for change_dict in change_dicts\n ]\n try:\n # Update the Story and its corresponding TopicSummary.\n topic_services.update_story_and_topic_summary(\n self.user_id, story_id, change_list, commit_message,\n story.corresponding_topic_id)\n except utils.ValidationError as e:\n raise self.InvalidInputException(e)\n\n story_dict = story_fetchers.get_story_by_id(story_id).to_dict()\n\n self.values.update({\n 'story': story_dict\n })\n\n self.render_json(self.values)\n\n @acl_decorators.can_delete_story\n def delete(self, story_id):\n \"\"\"Handles Delete requests.\"\"\"\n story_services.delete_story(self.user_id, story_id)\n self.render_json(self.values)\n\n\nclass StoryPublishHandler(base.BaseHandler):\n \"\"\"A data handler for publishing and unpublishing stories.\"\"\"\n\n GET_HANDLER_ERROR_RETURN_TYPE = feconf.HANDLER_TYPE_JSON\n URL_PATH_ARGS_SCHEMAS = {\n 'story_id': {\n 'schema': {\n 'type': 'basestring'\n },\n 'validators': [{\n 'id': 'has_length',\n 'value': constants.STORY_ID_LENGTH\n }]\n }\n }\n HANDLER_ARGS_SCHEMAS = {\n 'PUT': {\n 'new_story_status_is_public': {\n 'schema': {\n 'type': 'bool'\n },\n }\n }\n }\n\n @acl_decorators.can_edit_story\n def put(self, story_id):\n \"\"\"Published/unpublished given story.\"\"\"\n story = story_fetchers.get_story_by_id(story_id, strict=False)\n topic_id = story.corresponding_topic_id\n\n new_story_status_is_public = self.normalized_payload.get(\n 'new_story_status_is_public')\n\n if new_story_status_is_public:\n topic_services.publish_story(topic_id, story_id, self.user_id)\n else:\n topic_services.unpublish_story(topic_id, story_id, self.user_id)\n\n self.render_json(self.values)\n\n\nclass ValidateExplorationsHandler(base.BaseHandler):\n \"\"\"A data handler for validating the explorations in a story.\"\"\"\n\n GET_HANDLER_ERROR_RETURN_TYPE = feconf.HANDLER_TYPE_JSON\n\n @acl_decorators.can_edit_story\n def get(self, _):\n \"\"\"Handler that receives a list of exploration IDs, checks whether the\n corresponding explorations are supported on mobile and returns the\n validation error messages (if any).\n \"\"\"\n comma_separated_exp_ids = self.request.get('comma_separated_exp_ids')\n if not comma_separated_exp_ids:\n raise self.InvalidInputException(\n 'Expected comma_separated_exp_ids parameter to be present.')\n exp_ids = comma_separated_exp_ids.split(',')\n validation_error_messages = (\n story_services.validate_explorations_for_story(exp_ids, False))\n self.values.update({\n 'validation_error_messages': validation_error_messages\n })\n self.render_json(self.values)\n\n\nclass StoryUrlFragmentHandler(base.BaseHandler):\n \"\"\"A data handler for checking if a story with given url fragment exists.\n \"\"\"\n\n GET_HANDLER_ERROR_RETURN_TYPE = feconf.HANDLER_TYPE_JSON\n URL_PATH_ARGS_SCHEMAS = {\n 'story_url_fragment': constants.SCHEMA_FOR_STORY_URL_FRAGMENTS\n }\n HANDLER_ARGS_SCHEMAS = {\n 'GET': {}\n }\n\n @acl_decorators.open_access\n def get(self, story_url_fragment):\n \"\"\"Handler that receives a story url fragment and checks whether\n a story with the same url fragment exists or not.\n \"\"\"\n self.values.update({\n 'story_url_fragment_exists': (\n story_services.does_story_exist_with_url_fragment(\n story_url_fragment))\n })\n self.render_json(self.values)\n", "path": "core/controllers/story_editor.py"}]} | 3,308 | 155 |
gh_patches_debug_14635 | rasdani/github-patches | git_diff | xorbitsai__inference-192 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
FEAT: support vicuna-v1.3 33B
</issue>
<code>
[start of xinference/model/llm/__init__.py]
1 # Copyright 2022-2023 XProbe Inc.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15
16 def install():
17 from .. import MODEL_FAMILIES, ModelFamily
18 from .chatglm import ChatglmCppChatModel
19 from .core import LlamaCppModel
20 from .orca import OrcaMiniGgml
21 from .pytorch.baichuan import BaichuanPytorch
22 from .pytorch.vicuna import VicunaCensoredPytorch
23 from .vicuna import VicunaCensoredGgml
24 from .wizardlm import WizardlmGgml
25
26 baichuan_url_generator = lambda model_size, quantization: (
27 f"https://huggingface.co/TheBloke/baichuan-llama-{model_size}B-GGML/resolve/main/"
28 f"baichuan-llama-{model_size}b.ggmlv3.{quantization}.bin"
29 )
30 MODEL_FAMILIES.append(
31 ModelFamily(
32 model_name="baichuan",
33 model_format="ggmlv3",
34 model_sizes_in_billions=[7],
35 quantizations=[
36 "q2_K",
37 "q3_K_L",
38 "q3_K_M",
39 "q3_K_S",
40 "q4_0",
41 "q4_1",
42 "q4_K_M",
43 "q4_K_S",
44 "q5_0",
45 "q5_1",
46 "q5_K_M",
47 "q5_K_S",
48 "q6_K",
49 "q8_0",
50 ],
51 url_generator=baichuan_url_generator,
52 cls=LlamaCppModel,
53 )
54 )
55
56 wizardlm_v1_0_url_generator = lambda model_size, quantization: (
57 f"https://huggingface.co/TheBloke/WizardLM-{model_size}B-V1.0-Uncensored-GGML/resolve/main/"
58 f"wizardlm-{model_size}b-v1.0-uncensored.ggmlv3.{quantization}.bin"
59 )
60 MODEL_FAMILIES.append(
61 ModelFamily(
62 model_name="wizardlm-v1.0",
63 model_sizes_in_billions=[7, 13, 33],
64 model_format="ggmlv3",
65 quantizations=[
66 "q2_K",
67 "q3_K_L",
68 "q3_K_M",
69 "q3_K_S",
70 "q4_0",
71 "q4_1",
72 "q4_K_M",
73 "q4_K_S",
74 "q5_0",
75 "q5_1",
76 "q5_K_M",
77 "q5_K_S",
78 "q6_K",
79 "q8_0",
80 ],
81 url_generator=wizardlm_v1_0_url_generator,
82 cls=WizardlmGgml,
83 ),
84 )
85
86 wizardlm_v1_1_url_generator = lambda model_size, quantization: (
87 f"https://huggingface.co/TheBloke/WizardLM-{model_size}B-V1.1-GGML/resolve/main/"
88 f"wizardlm-{model_size}b-v1.1.ggmlv3.{quantization}.bin"
89 )
90 MODEL_FAMILIES.append(
91 ModelFamily(
92 model_name="wizardlm-v1.1",
93 model_sizes_in_billions=[13],
94 model_format="ggmlv3",
95 quantizations=[
96 "q2_K",
97 "q3_K_L",
98 "q3_K_M",
99 "q3_K_S",
100 "q4_0",
101 "q4_1",
102 "q4_K_M",
103 "q4_K_S",
104 "q5_0",
105 "q5_1",
106 "q5_K_M",
107 "q5_K_S",
108 "q6_K",
109 "q8_0",
110 ],
111 url_generator=wizardlm_v1_1_url_generator,
112 cls=VicunaCensoredGgml, # according to https://huggingface.co/TheBloke/WizardLM-13B-V1.1-GGML
113 ),
114 )
115
116 vicuna_v1_3_url_generator = lambda model_size, quantization: (
117 "https://huggingface.co/TheBloke/vicuna-7B-v1.3-GGML/resolve/main/"
118 f"vicuna-7b-v1.3.ggmlv3.{quantization}.bin"
119 if model_size == 7
120 else (
121 "https://huggingface.co/TheBloke/vicuna-13b-v1.3.0-GGML/resolve/main/"
122 f"vicuna-13b-v1.3.0.ggmlv3.{quantization}.bin"
123 )
124 )
125 MODEL_FAMILIES.append(
126 ModelFamily(
127 model_name="vicuna-v1.3",
128 model_sizes_in_billions=[7, 13],
129 model_format="ggmlv3",
130 quantizations=[
131 "q2_K",
132 "q3_K_L",
133 "q3_K_M",
134 "q3_K_S",
135 "q4_0",
136 "q4_1",
137 "q4_K_M",
138 "q4_K_S",
139 "q5_0",
140 "q5_1",
141 "q5_K_M",
142 "q5_K_S",
143 "q6_K",
144 "q8_0",
145 ],
146 url_generator=vicuna_v1_3_url_generator,
147 cls=VicunaCensoredGgml,
148 ),
149 )
150
151 orca_url_generator = lambda model_size, quantization: (
152 f"https://huggingface.co/TheBloke/orca_mini_{model_size}B-GGML/resolve/main/orca-mini-"
153 f"{model_size}b.ggmlv3.{quantization}.bin"
154 )
155 MODEL_FAMILIES.append(
156 ModelFamily(
157 model_name="orca",
158 model_sizes_in_billions=[3, 7, 13],
159 model_format="ggmlv3",
160 quantizations=[
161 "q4_0",
162 "q4_1",
163 "q5_0",
164 "q5_1",
165 "q8_0",
166 ],
167 url_generator=orca_url_generator,
168 cls=OrcaMiniGgml,
169 )
170 )
171
172 chatglm_url_generator = lambda model_size, quantization: (
173 f"https://huggingface.co/Xorbits/chatglm-{model_size}B-GGML/resolve/main/"
174 f"chatglm-ggml-{quantization}.bin"
175 )
176 MODEL_FAMILIES.append(
177 ModelFamily(
178 model_name="chatglm",
179 model_sizes_in_billions=[6],
180 model_format="ggmlv3",
181 quantizations=[
182 "q4_0",
183 "q4_1",
184 "q5_0",
185 "q5_1",
186 "q8_0",
187 ],
188 url_generator=chatglm_url_generator,
189 cls=ChatglmCppChatModel,
190 )
191 )
192
193 chatglm2_url_generator = lambda model_size, quantization: (
194 f"https://huggingface.co/Xorbits/chatglm2-{model_size}B-GGML/resolve/main/"
195 f"chatglm2-ggml-{quantization}.bin"
196 )
197 MODEL_FAMILIES.append(
198 ModelFamily(
199 model_name="chatglm2",
200 model_sizes_in_billions=[6],
201 model_format="ggmlv3",
202 quantizations=[
203 "q4_0",
204 "q4_1",
205 "q5_0",
206 "q5_1",
207 "q8_0",
208 ],
209 url_generator=chatglm2_url_generator,
210 cls=ChatglmCppChatModel,
211 )
212 )
213
214 MODEL_FAMILIES.append(
215 ModelFamily(
216 model_name="baichuan-inc/Baichuan-7B",
217 model_sizes_in_billions=[7],
218 model_format="pytorch",
219 quantizations=None,
220 url_generator=None,
221 cls=BaichuanPytorch,
222 ),
223 )
224
225 MODEL_FAMILIES.append(
226 ModelFamily(
227 model_name="lmsys/vicuna-7b-v1.3",
228 model_sizes_in_billions=[7, 13],
229 model_format="pytorch",
230 quantizations=None,
231 url_generator=None,
232 cls=VicunaCensoredPytorch,
233 ),
234 )
235
[end of xinference/model/llm/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/xinference/model/llm/__init__.py b/xinference/model/llm/__init__.py
--- a/xinference/model/llm/__init__.py
+++ b/xinference/model/llm/__init__.py
@@ -88,12 +88,14 @@
else (
"https://huggingface.co/TheBloke/vicuna-13b-v1.3.0-GGML/resolve/main/"
f"vicuna-13b-v1.3.0.ggmlv3.{quantization}.bin"
+ if model_size == 13
+ else f"https://huggingface.co/TheBloke/vicuna-33B-GGML/resolve/main/vicuna-33b.ggmlv3.{quantization}.bin"
)
)
MODEL_FAMILIES.append(
ModelFamily(
model_name="vicuna-v1.3",
- model_sizes_in_billions=[7, 13],
+ model_sizes_in_billions=[7, 13, 33],
model_format="ggmlv3",
quantizations=[
"q2_K",
| {"golden_diff": "diff --git a/xinference/model/llm/__init__.py b/xinference/model/llm/__init__.py\n--- a/xinference/model/llm/__init__.py\n+++ b/xinference/model/llm/__init__.py\n@@ -88,12 +88,14 @@\n else (\n \"https://huggingface.co/TheBloke/vicuna-13b-v1.3.0-GGML/resolve/main/\"\n f\"vicuna-13b-v1.3.0.ggmlv3.{quantization}.bin\"\n+ if model_size == 13\n+ else f\"https://huggingface.co/TheBloke/vicuna-33B-GGML/resolve/main/vicuna-33b.ggmlv3.{quantization}.bin\"\n )\n )\n MODEL_FAMILIES.append(\n ModelFamily(\n model_name=\"vicuna-v1.3\",\n- model_sizes_in_billions=[7, 13],\n+ model_sizes_in_billions=[7, 13, 33],\n model_format=\"ggmlv3\",\n quantizations=[\n \"q2_K\",\n", "issue": "FEAT: support vicuna-v1.3 33B\n\n", "before_files": [{"content": "# Copyright 2022-2023 XProbe Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\ndef install():\n from .. import MODEL_FAMILIES, ModelFamily\n from .chatglm import ChatglmCppChatModel\n from .core import LlamaCppModel\n from .orca import OrcaMiniGgml\n from .pytorch.baichuan import BaichuanPytorch\n from .pytorch.vicuna import VicunaCensoredPytorch\n from .vicuna import VicunaCensoredGgml\n from .wizardlm import WizardlmGgml\n\n baichuan_url_generator = lambda model_size, quantization: (\n f\"https://huggingface.co/TheBloke/baichuan-llama-{model_size}B-GGML/resolve/main/\"\n f\"baichuan-llama-{model_size}b.ggmlv3.{quantization}.bin\"\n )\n MODEL_FAMILIES.append(\n ModelFamily(\n model_name=\"baichuan\",\n model_format=\"ggmlv3\",\n model_sizes_in_billions=[7],\n quantizations=[\n \"q2_K\",\n \"q3_K_L\",\n \"q3_K_M\",\n \"q3_K_S\",\n \"q4_0\",\n \"q4_1\",\n \"q4_K_M\",\n \"q4_K_S\",\n \"q5_0\",\n \"q5_1\",\n \"q5_K_M\",\n \"q5_K_S\",\n \"q6_K\",\n \"q8_0\",\n ],\n url_generator=baichuan_url_generator,\n cls=LlamaCppModel,\n )\n )\n\n wizardlm_v1_0_url_generator = lambda model_size, quantization: (\n f\"https://huggingface.co/TheBloke/WizardLM-{model_size}B-V1.0-Uncensored-GGML/resolve/main/\"\n f\"wizardlm-{model_size}b-v1.0-uncensored.ggmlv3.{quantization}.bin\"\n )\n MODEL_FAMILIES.append(\n ModelFamily(\n model_name=\"wizardlm-v1.0\",\n model_sizes_in_billions=[7, 13, 33],\n model_format=\"ggmlv3\",\n quantizations=[\n \"q2_K\",\n \"q3_K_L\",\n \"q3_K_M\",\n \"q3_K_S\",\n \"q4_0\",\n \"q4_1\",\n \"q4_K_M\",\n \"q4_K_S\",\n \"q5_0\",\n \"q5_1\",\n \"q5_K_M\",\n \"q5_K_S\",\n \"q6_K\",\n \"q8_0\",\n ],\n url_generator=wizardlm_v1_0_url_generator,\n cls=WizardlmGgml,\n ),\n )\n\n wizardlm_v1_1_url_generator = lambda model_size, quantization: (\n f\"https://huggingface.co/TheBloke/WizardLM-{model_size}B-V1.1-GGML/resolve/main/\"\n f\"wizardlm-{model_size}b-v1.1.ggmlv3.{quantization}.bin\"\n )\n MODEL_FAMILIES.append(\n ModelFamily(\n model_name=\"wizardlm-v1.1\",\n model_sizes_in_billions=[13],\n model_format=\"ggmlv3\",\n quantizations=[\n \"q2_K\",\n \"q3_K_L\",\n \"q3_K_M\",\n \"q3_K_S\",\n \"q4_0\",\n \"q4_1\",\n \"q4_K_M\",\n \"q4_K_S\",\n \"q5_0\",\n \"q5_1\",\n \"q5_K_M\",\n \"q5_K_S\",\n \"q6_K\",\n \"q8_0\",\n ],\n url_generator=wizardlm_v1_1_url_generator,\n cls=VicunaCensoredGgml, # according to https://huggingface.co/TheBloke/WizardLM-13B-V1.1-GGML\n ),\n )\n\n vicuna_v1_3_url_generator = lambda model_size, quantization: (\n \"https://huggingface.co/TheBloke/vicuna-7B-v1.3-GGML/resolve/main/\"\n f\"vicuna-7b-v1.3.ggmlv3.{quantization}.bin\"\n if model_size == 7\n else (\n \"https://huggingface.co/TheBloke/vicuna-13b-v1.3.0-GGML/resolve/main/\"\n f\"vicuna-13b-v1.3.0.ggmlv3.{quantization}.bin\"\n )\n )\n MODEL_FAMILIES.append(\n ModelFamily(\n model_name=\"vicuna-v1.3\",\n model_sizes_in_billions=[7, 13],\n model_format=\"ggmlv3\",\n quantizations=[\n \"q2_K\",\n \"q3_K_L\",\n \"q3_K_M\",\n \"q3_K_S\",\n \"q4_0\",\n \"q4_1\",\n \"q4_K_M\",\n \"q4_K_S\",\n \"q5_0\",\n \"q5_1\",\n \"q5_K_M\",\n \"q5_K_S\",\n \"q6_K\",\n \"q8_0\",\n ],\n url_generator=vicuna_v1_3_url_generator,\n cls=VicunaCensoredGgml,\n ),\n )\n\n orca_url_generator = lambda model_size, quantization: (\n f\"https://huggingface.co/TheBloke/orca_mini_{model_size}B-GGML/resolve/main/orca-mini-\"\n f\"{model_size}b.ggmlv3.{quantization}.bin\"\n )\n MODEL_FAMILIES.append(\n ModelFamily(\n model_name=\"orca\",\n model_sizes_in_billions=[3, 7, 13],\n model_format=\"ggmlv3\",\n quantizations=[\n \"q4_0\",\n \"q4_1\",\n \"q5_0\",\n \"q5_1\",\n \"q8_0\",\n ],\n url_generator=orca_url_generator,\n cls=OrcaMiniGgml,\n )\n )\n\n chatglm_url_generator = lambda model_size, quantization: (\n f\"https://huggingface.co/Xorbits/chatglm-{model_size}B-GGML/resolve/main/\"\n f\"chatglm-ggml-{quantization}.bin\"\n )\n MODEL_FAMILIES.append(\n ModelFamily(\n model_name=\"chatglm\",\n model_sizes_in_billions=[6],\n model_format=\"ggmlv3\",\n quantizations=[\n \"q4_0\",\n \"q4_1\",\n \"q5_0\",\n \"q5_1\",\n \"q8_0\",\n ],\n url_generator=chatglm_url_generator,\n cls=ChatglmCppChatModel,\n )\n )\n\n chatglm2_url_generator = lambda model_size, quantization: (\n f\"https://huggingface.co/Xorbits/chatglm2-{model_size}B-GGML/resolve/main/\"\n f\"chatglm2-ggml-{quantization}.bin\"\n )\n MODEL_FAMILIES.append(\n ModelFamily(\n model_name=\"chatglm2\",\n model_sizes_in_billions=[6],\n model_format=\"ggmlv3\",\n quantizations=[\n \"q4_0\",\n \"q4_1\",\n \"q5_0\",\n \"q5_1\",\n \"q8_0\",\n ],\n url_generator=chatglm2_url_generator,\n cls=ChatglmCppChatModel,\n )\n )\n\n MODEL_FAMILIES.append(\n ModelFamily(\n model_name=\"baichuan-inc/Baichuan-7B\",\n model_sizes_in_billions=[7],\n model_format=\"pytorch\",\n quantizations=None,\n url_generator=None,\n cls=BaichuanPytorch,\n ),\n )\n\n MODEL_FAMILIES.append(\n ModelFamily(\n model_name=\"lmsys/vicuna-7b-v1.3\",\n model_sizes_in_billions=[7, 13],\n model_format=\"pytorch\",\n quantizations=None,\n url_generator=None,\n cls=VicunaCensoredPytorch,\n ),\n )\n", "path": "xinference/model/llm/__init__.py"}]} | 3,108 | 259 |
gh_patches_debug_8817 | rasdani/github-patches | git_diff | svthalia__concrexit-1683 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
ValueError: day is out of range for month
In GitLab by _thaliatechnicie on Mar 4, 2020, 19:20
Sentry Issue: [CONCREXIT-24](https://sentry.io/organizations/thalia/issues/1538288408/?referrer=gitlab_integration)
```
ValueError: day is out of range for month
(11 additional frame(s) were not displayed)
...
File "rest_framework/serializers.py", line 260, in data
self._data = self.to_representation(self.instance)
File "rest_framework/serializers.py", line 529, in to_representation
ret[field.field_name] = field.to_representation(attribute)
File "rest_framework/fields.py", line 1905, in to_representation
return method(value)
File "members/api/serializers.py", line 93, in _achievements
return member_achievements(instance.user)
File "members/services.py", line 72, in member_achievements
earliest = earliest.replace(year=earliest.year + mentor_year.year)
```
</issue>
<code>
[start of website/members/services.py]
1 """Services defined in the members package."""
2 from datetime import date, datetime
3 from typing import Callable, List, Dict, Any
4
5 from django.conf import settings
6 from django.db.models import Q, Count
7 from django.utils import timezone
8 from django.utils.translation import gettext
9
10 from members import emails
11 from members.models import Membership, Member
12 from utils.snippets import datetime_to_lectureyear
13
14
15 def _member_group_memberships(
16 member: Member, condition: Callable[[Membership], bool]
17 ) -> Dict[str, Any]:
18 """Determine the group membership of a user based on a condition.
19
20 :return: Object with group memberships
21 """
22 memberships = member.membergroupmembership_set.all()
23 data = {}
24
25 for membership in memberships:
26 if not condition(membership):
27 continue
28 period = {
29 "since": membership.since,
30 "until": membership.until,
31 "chair": membership.chair,
32 }
33
34 if hasattr(membership.group, "board"):
35 period["role"] = membership.role
36
37 if membership.until is None and hasattr(membership.group, "board"):
38 period["until"] = membership.group.board.until
39
40 name = membership.group.name
41 if data.get(name):
42 data[name]["periods"].append(period)
43 if data[name]["earliest"] > period["since"]:
44 data[name]["earliest"] = period["since"]
45 if period["until"] is None or (
46 data[name]["latest"] is not None
47 and data[name]["latest"] < period["until"]
48 ):
49 data[name]["latest"] = period["until"]
50 data[name]["periods"].sort(key=lambda x: x["since"])
51 else:
52 data[name] = {
53 "pk": membership.group.pk,
54 "active": membership.group.active,
55 "name": name,
56 "periods": [period],
57 "url": settings.BASE_URL + membership.group.get_absolute_url(),
58 "earliest": period["since"],
59 "latest": period["until"],
60 }
61 return data
62
63
64 def member_achievements(member) -> List:
65 """Derive a list of achievements of a member.
66
67 Committee and board memberships + mentorships
68 """
69 achievements = _member_group_memberships(
70 member,
71 lambda membership: (
72 hasattr(membership.group, "board") or hasattr(membership.group, "committee")
73 ),
74 )
75
76 mentor_years = member.mentorship_set.all()
77 for mentor_year in mentor_years:
78 name = "Mentor in {}".format(mentor_year.year)
79 # Ensure mentorships appear last but are sorted
80 earliest = date.today()
81 earliest = earliest.replace(year=earliest.year + mentor_year.year)
82 if not achievements.get(name):
83 achievements[name] = {
84 "name": name,
85 "earliest": earliest,
86 }
87 return sorted(achievements.values(), key=lambda x: x["earliest"])
88
89
90 def member_societies(member) -> List:
91 """Derive a list of societies a member was part of."""
92 societies = _member_group_memberships(
93 member, lambda membership: (hasattr(membership.group, "society"))
94 )
95 return sorted(societies.values(), key=lambda x: x["earliest"])
96
97
98 def gen_stats_member_type() -> Dict[str, int]:
99 """Generate a dictionary where every key is a member type with the value being the number of current members of that type."""
100 data = {}
101 for key, display in Membership.MEMBERSHIP_TYPES:
102 data[str(display)] = (
103 Membership.objects.filter(since__lte=date.today())
104 .filter(Q(until__isnull=True) | Q(until__gt=date.today()))
105 .filter(type=key)
106 .count()
107 )
108 return data
109
110
111 def gen_stats_year() -> Dict[str, Dict[str, int]]:
112 """Generate list with 6 entries, where each entry represents the total amount of Thalia members in a year.
113
114 The sixth element contains all the multi-year students.
115 """
116 stats_year = {}
117 current_year = datetime_to_lectureyear(date.today())
118
119 for i in range(5):
120 new = {}
121 for key, _ in Membership.MEMBERSHIP_TYPES:
122 new[key] = (
123 Membership.objects.filter(user__profile__starting_year=current_year - i)
124 .filter(since__lte=date.today())
125 .filter(Q(until__isnull=True) | Q(until__gt=date.today()))
126 .filter(type=key)
127 .count()
128 )
129 stats_year[str(current_year - i)] = new
130
131 # Add multi year members
132 new = {}
133 for key, _ in Membership.MEMBERSHIP_TYPES:
134 new[key] = (
135 Membership.objects.filter(user__profile__starting_year__lt=current_year - 4)
136 .filter(since__lte=date.today())
137 .filter(Q(until__isnull=True) | Q(until__gt=date.today()))
138 .filter(type=key)
139 .count()
140 )
141 stats_year[str(gettext("Older"))] = new
142
143 return stats_year
144
145
146 def verify_email_change(change_request) -> None:
147 """Mark the email change request as verified.
148
149 :param change_request: the email change request
150 """
151 change_request.verified = True
152 change_request.save()
153
154 process_email_change(change_request)
155
156
157 def confirm_email_change(change_request) -> None:
158 """Mark the email change request as verified.
159
160 :param change_request: the email change request
161 """
162 change_request.confirmed = True
163 change_request.save()
164
165 process_email_change(change_request)
166
167
168 def process_email_change(change_request) -> None:
169 """Change the user's email address if the request was completed and send the completion email.
170
171 :param change_request: the email change request
172 """
173 if not change_request.completed:
174 return
175
176 member = change_request.member
177 member.email = change_request.email
178 member.save()
179
180 emails.send_email_change_completion_message(change_request)
181
182
183 def execute_data_minimisation(dry_run=False, members=None) -> List[Member]:
184 """Clean the profiles of members/users of whom the last membership ended at least 31 days ago.
185
186 :param dry_run: does not really remove data if True
187 :param members: queryset of members to process, optional
188 :return: list of processed members
189 """
190 if not members:
191 members = Member.objects
192 members = (
193 members.annotate(membership_count=Count("membership"))
194 .exclude(
195 (
196 Q(membership__until__isnull=True)
197 | Q(membership__until__gt=timezone.now().date())
198 )
199 & Q(membership_count__gt=0)
200 )
201 .distinct()
202 .prefetch_related("membership_set", "profile")
203 )
204 deletion_period = timezone.now().date() - timezone.timedelta(days=31)
205 processed_members = []
206 for member in members:
207 if (
208 member.latest_membership is None
209 or member.latest_membership.until <= deletion_period
210 ):
211 processed_members.append(member)
212 profile = member.profile
213 profile.student_number = None
214 profile.phone_number = None
215 profile.address_street = "<removed> 1"
216 profile.address_street2 = None
217 profile.address_postal_code = "<removed>"
218 profile.address_city = "<removed>"
219 profile.address_country = "NL"
220 profile.birthday = datetime(1900, 1, 1)
221 profile.emergency_contact_phone_number = None
222 profile.emergency_contact = None
223 member.bank_accounts.all().delete()
224 if not dry_run:
225 profile.save()
226
227 return processed_members
228
[end of website/members/services.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/website/members/services.py b/website/members/services.py
--- a/website/members/services.py
+++ b/website/members/services.py
@@ -79,6 +79,9 @@
# Ensure mentorships appear last but are sorted
earliest = date.today()
earliest = earliest.replace(year=earliest.year + mentor_year.year)
+ # Making sure it does not crash in leap years
+ if earliest.month == 2 and earliest.day == 29:
+ earliest = earliest.replace(day=28)
if not achievements.get(name):
achievements[name] = {
"name": name,
| {"golden_diff": "diff --git a/website/members/services.py b/website/members/services.py\n--- a/website/members/services.py\n+++ b/website/members/services.py\n@@ -79,6 +79,9 @@\n # Ensure mentorships appear last but are sorted\n earliest = date.today()\n earliest = earliest.replace(year=earliest.year + mentor_year.year)\n+ # Making sure it does not crash in leap years\n+ if earliest.month == 2 and earliest.day == 29:\n+ earliest = earliest.replace(day=28)\n if not achievements.get(name):\n achievements[name] = {\n \"name\": name,\n", "issue": "ValueError: day is out of range for month\nIn GitLab by _thaliatechnicie on Mar 4, 2020, 19:20\n\nSentry Issue: [CONCREXIT-24](https://sentry.io/organizations/thalia/issues/1538288408/?referrer=gitlab_integration)\n\n```\nValueError: day is out of range for month\n(11 additional frame(s) were not displayed)\n...\n File \"rest_framework/serializers.py\", line 260, in data\n self._data = self.to_representation(self.instance)\n File \"rest_framework/serializers.py\", line 529, in to_representation\n ret[field.field_name] = field.to_representation(attribute)\n File \"rest_framework/fields.py\", line 1905, in to_representation\n return method(value)\n File \"members/api/serializers.py\", line 93, in _achievements\n return member_achievements(instance.user)\n File \"members/services.py\", line 72, in member_achievements\n earliest = earliest.replace(year=earliest.year + mentor_year.year)\n```\n", "before_files": [{"content": "\"\"\"Services defined in the members package.\"\"\"\nfrom datetime import date, datetime\nfrom typing import Callable, List, Dict, Any\n\nfrom django.conf import settings\nfrom django.db.models import Q, Count\nfrom django.utils import timezone\nfrom django.utils.translation import gettext\n\nfrom members import emails\nfrom members.models import Membership, Member\nfrom utils.snippets import datetime_to_lectureyear\n\n\ndef _member_group_memberships(\n member: Member, condition: Callable[[Membership], bool]\n) -> Dict[str, Any]:\n \"\"\"Determine the group membership of a user based on a condition.\n\n :return: Object with group memberships\n \"\"\"\n memberships = member.membergroupmembership_set.all()\n data = {}\n\n for membership in memberships:\n if not condition(membership):\n continue\n period = {\n \"since\": membership.since,\n \"until\": membership.until,\n \"chair\": membership.chair,\n }\n\n if hasattr(membership.group, \"board\"):\n period[\"role\"] = membership.role\n\n if membership.until is None and hasattr(membership.group, \"board\"):\n period[\"until\"] = membership.group.board.until\n\n name = membership.group.name\n if data.get(name):\n data[name][\"periods\"].append(period)\n if data[name][\"earliest\"] > period[\"since\"]:\n data[name][\"earliest\"] = period[\"since\"]\n if period[\"until\"] is None or (\n data[name][\"latest\"] is not None\n and data[name][\"latest\"] < period[\"until\"]\n ):\n data[name][\"latest\"] = period[\"until\"]\n data[name][\"periods\"].sort(key=lambda x: x[\"since\"])\n else:\n data[name] = {\n \"pk\": membership.group.pk,\n \"active\": membership.group.active,\n \"name\": name,\n \"periods\": [period],\n \"url\": settings.BASE_URL + membership.group.get_absolute_url(),\n \"earliest\": period[\"since\"],\n \"latest\": period[\"until\"],\n }\n return data\n\n\ndef member_achievements(member) -> List:\n \"\"\"Derive a list of achievements of a member.\n\n Committee and board memberships + mentorships\n \"\"\"\n achievements = _member_group_memberships(\n member,\n lambda membership: (\n hasattr(membership.group, \"board\") or hasattr(membership.group, \"committee\")\n ),\n )\n\n mentor_years = member.mentorship_set.all()\n for mentor_year in mentor_years:\n name = \"Mentor in {}\".format(mentor_year.year)\n # Ensure mentorships appear last but are sorted\n earliest = date.today()\n earliest = earliest.replace(year=earliest.year + mentor_year.year)\n if not achievements.get(name):\n achievements[name] = {\n \"name\": name,\n \"earliest\": earliest,\n }\n return sorted(achievements.values(), key=lambda x: x[\"earliest\"])\n\n\ndef member_societies(member) -> List:\n \"\"\"Derive a list of societies a member was part of.\"\"\"\n societies = _member_group_memberships(\n member, lambda membership: (hasattr(membership.group, \"society\"))\n )\n return sorted(societies.values(), key=lambda x: x[\"earliest\"])\n\n\ndef gen_stats_member_type() -> Dict[str, int]:\n \"\"\"Generate a dictionary where every key is a member type with the value being the number of current members of that type.\"\"\"\n data = {}\n for key, display in Membership.MEMBERSHIP_TYPES:\n data[str(display)] = (\n Membership.objects.filter(since__lte=date.today())\n .filter(Q(until__isnull=True) | Q(until__gt=date.today()))\n .filter(type=key)\n .count()\n )\n return data\n\n\ndef gen_stats_year() -> Dict[str, Dict[str, int]]:\n \"\"\"Generate list with 6 entries, where each entry represents the total amount of Thalia members in a year.\n\n The sixth element contains all the multi-year students.\n \"\"\"\n stats_year = {}\n current_year = datetime_to_lectureyear(date.today())\n\n for i in range(5):\n new = {}\n for key, _ in Membership.MEMBERSHIP_TYPES:\n new[key] = (\n Membership.objects.filter(user__profile__starting_year=current_year - i)\n .filter(since__lte=date.today())\n .filter(Q(until__isnull=True) | Q(until__gt=date.today()))\n .filter(type=key)\n .count()\n )\n stats_year[str(current_year - i)] = new\n\n # Add multi year members\n new = {}\n for key, _ in Membership.MEMBERSHIP_TYPES:\n new[key] = (\n Membership.objects.filter(user__profile__starting_year__lt=current_year - 4)\n .filter(since__lte=date.today())\n .filter(Q(until__isnull=True) | Q(until__gt=date.today()))\n .filter(type=key)\n .count()\n )\n stats_year[str(gettext(\"Older\"))] = new\n\n return stats_year\n\n\ndef verify_email_change(change_request) -> None:\n \"\"\"Mark the email change request as verified.\n\n :param change_request: the email change request\n \"\"\"\n change_request.verified = True\n change_request.save()\n\n process_email_change(change_request)\n\n\ndef confirm_email_change(change_request) -> None:\n \"\"\"Mark the email change request as verified.\n\n :param change_request: the email change request\n \"\"\"\n change_request.confirmed = True\n change_request.save()\n\n process_email_change(change_request)\n\n\ndef process_email_change(change_request) -> None:\n \"\"\"Change the user's email address if the request was completed and send the completion email.\n\n :param change_request: the email change request\n \"\"\"\n if not change_request.completed:\n return\n\n member = change_request.member\n member.email = change_request.email\n member.save()\n\n emails.send_email_change_completion_message(change_request)\n\n\ndef execute_data_minimisation(dry_run=False, members=None) -> List[Member]:\n \"\"\"Clean the profiles of members/users of whom the last membership ended at least 31 days ago.\n\n :param dry_run: does not really remove data if True\n :param members: queryset of members to process, optional\n :return: list of processed members\n \"\"\"\n if not members:\n members = Member.objects\n members = (\n members.annotate(membership_count=Count(\"membership\"))\n .exclude(\n (\n Q(membership__until__isnull=True)\n | Q(membership__until__gt=timezone.now().date())\n )\n & Q(membership_count__gt=0)\n )\n .distinct()\n .prefetch_related(\"membership_set\", \"profile\")\n )\n deletion_period = timezone.now().date() - timezone.timedelta(days=31)\n processed_members = []\n for member in members:\n if (\n member.latest_membership is None\n or member.latest_membership.until <= deletion_period\n ):\n processed_members.append(member)\n profile = member.profile\n profile.student_number = None\n profile.phone_number = None\n profile.address_street = \"<removed> 1\"\n profile.address_street2 = None\n profile.address_postal_code = \"<removed>\"\n profile.address_city = \"<removed>\"\n profile.address_country = \"NL\"\n profile.birthday = datetime(1900, 1, 1)\n profile.emergency_contact_phone_number = None\n profile.emergency_contact = None\n member.bank_accounts.all().delete()\n if not dry_run:\n profile.save()\n\n return processed_members\n", "path": "website/members/services.py"}]} | 3,010 | 139 |
gh_patches_debug_7422 | rasdani/github-patches | git_diff | Lightning-AI__pytorch-lightning-1091 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Update CHANGELOG for 0.7.x
## 🐛 Bug
<!-- A clear and concise description of what the bug is. -->
Updated CHANGELOG according to the reset changes (about last two weeks) especially deprecated items like `data_loader` or `xxxxx_end`
### Additional context
<!-- Add any other context about the problem here. -->
https://github.com/PyTorchLightning/pytorch-lightning/milestone/4
</issue>
<code>
[start of pytorch_lightning/core/decorators.py]
1 import traceback
2 from functools import wraps
3 import warnings
4
5
6 def data_loader(fn):
7 """Decorator to make any fx with this use the lazy property.
8
9 :param fn:
10 :return:
11 """
12 w = 'data_loader decorator deprecated in 0.7.0. Will remove 0.9.0'
13 warnings.warn(w)
14
15 def inner_fx(self):
16 return fn(self)
17 return inner_fx
18
[end of pytorch_lightning/core/decorators.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/pytorch_lightning/core/decorators.py b/pytorch_lightning/core/decorators.py
--- a/pytorch_lightning/core/decorators.py
+++ b/pytorch_lightning/core/decorators.py
@@ -6,11 +6,10 @@
def data_loader(fn):
"""Decorator to make any fx with this use the lazy property.
- :param fn:
- :return:
+ Warnings:
+ This decorator deprecated in v0.7.0 and it will be removed v0.9.0.
"""
- w = 'data_loader decorator deprecated in 0.7.0. Will remove 0.9.0'
- warnings.warn(w)
+ warnings.warn('`data_loader` decorator deprecated in v0.7.0. Will be removed v0.9.0', DeprecationWarning)
def inner_fx(self):
return fn(self)
| {"golden_diff": "diff --git a/pytorch_lightning/core/decorators.py b/pytorch_lightning/core/decorators.py\n--- a/pytorch_lightning/core/decorators.py\n+++ b/pytorch_lightning/core/decorators.py\n@@ -6,11 +6,10 @@\n def data_loader(fn):\n \"\"\"Decorator to make any fx with this use the lazy property.\n \n- :param fn:\n- :return:\n+ Warnings:\n+ This decorator deprecated in v0.7.0 and it will be removed v0.9.0.\n \"\"\"\n- w = 'data_loader decorator deprecated in 0.7.0. Will remove 0.9.0'\n- warnings.warn(w)\n+ warnings.warn('`data_loader` decorator deprecated in v0.7.0. Will be removed v0.9.0', DeprecationWarning)\n \n def inner_fx(self):\n return fn(self)\n", "issue": "Update CHANGELOG for 0.7.x\n## \ud83d\udc1b Bug\r\n\r\n<!-- A clear and concise description of what the bug is. -->\r\n\r\nUpdated CHANGELOG according to the reset changes (about last two weeks) especially deprecated items like `data_loader` or `xxxxx_end`\r\n\r\n### Additional context\r\n\r\n<!-- Add any other context about the problem here. -->\r\n\r\nhttps://github.com/PyTorchLightning/pytorch-lightning/milestone/4\n", "before_files": [{"content": "import traceback\nfrom functools import wraps\nimport warnings\n\n\ndef data_loader(fn):\n \"\"\"Decorator to make any fx with this use the lazy property.\n\n :param fn:\n :return:\n \"\"\"\n w = 'data_loader decorator deprecated in 0.7.0. Will remove 0.9.0'\n warnings.warn(w)\n\n def inner_fx(self):\n return fn(self)\n return inner_fx\n", "path": "pytorch_lightning/core/decorators.py"}]} | 753 | 200 |
gh_patches_debug_12714 | rasdani/github-patches | git_diff | pypi__warehouse-12792 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Improve Alembic story
Fixes #10053.
Adds `alembic.ini`.
Runs `black` and `isort` after generating migrations.
</issue>
<code>
[start of warehouse/db.py]
1 # Licensed under the Apache License, Version 2.0 (the "License");
2 # you may not use this file except in compliance with the License.
3 # You may obtain a copy of the License at
4 #
5 # http://www.apache.org/licenses/LICENSE-2.0
6 #
7 # Unless required by applicable law or agreed to in writing, software
8 # distributed under the License is distributed on an "AS IS" BASIS,
9 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
10 # See the License for the specific language governing permissions and
11 # limitations under the License.
12
13 import functools
14 import logging
15
16 import alembic.config
17 import pyramid_retry
18 import sqlalchemy
19 import venusian
20 import zope.sqlalchemy
21
22 from sqlalchemy import event, inspect
23 from sqlalchemy.dialects.postgresql import UUID
24 from sqlalchemy.exc import IntegrityError, OperationalError
25 from sqlalchemy.ext.declarative import declarative_base # type: ignore
26 from sqlalchemy.orm import sessionmaker
27
28 from warehouse.metrics import IMetricsService
29 from warehouse.utils.attrs import make_repr
30
31 __all__ = ["includeme", "metadata", "ModelBase"]
32
33
34 logger = logging.getLogger(__name__)
35
36
37 DEFAULT_ISOLATION = "READ COMMITTED"
38
39
40 # On the surface this might seem wrong, because retrying a request whose data violates
41 # the constraints of the database doesn't seem like a useful endeavor. However what
42 # happens if you have two requests that are trying to insert a row, and that row
43 # contains a unique, user provided value, you can get into a race condition where both
44 # requests check the database, see nothing with that value exists, then both attempt to
45 # insert it. One of the requests will succeed, the other will fail with an
46 # IntegrityError. Retrying the request that failed will then have it see the object
47 # created by the other request, and will have it do the appropriate action in that case.
48 #
49 # The most common way to run into this, is when submitting a form in the browser, if the
50 # user clicks twice in rapid succession, the browser will send two almost identical
51 # requests at basically the same time.
52 #
53 # One possible issue that this raises, is that it will slow down "legitimate"
54 # IntegrityError because they'll have to fail multiple times before they ultimately
55 # fail. We consider this an acceptable trade off, because deterministic IntegrityError
56 # should be caught with proper validation prior to submitting records to the database
57 # anyways.
58 pyramid_retry.mark_error_retryable(IntegrityError)
59
60
61 # A generic wrapper exception that we'll raise when the database isn't available, we
62 # use this so we can catch it later and turn it into a generic 5xx error.
63 class DatabaseNotAvailableError(Exception):
64 ...
65
66
67 class ModelBase:
68 def __repr__(self):
69 inst = inspect(self)
70 self.__repr__ = make_repr(
71 *[c_attr.key for c_attr in inst.mapper.column_attrs], _self=self
72 )
73 return self.__repr__()
74
75
76 # The Global metadata object.
77 metadata = sqlalchemy.MetaData()
78
79
80 # Base class for models using declarative syntax
81 ModelBase = declarative_base(cls=ModelBase, metadata=metadata) # type: ignore
82
83
84 class Model(ModelBase):
85
86 __abstract__ = True
87
88 id = sqlalchemy.Column(
89 UUID(as_uuid=True),
90 primary_key=True,
91 server_default=sqlalchemy.text("gen_random_uuid()"),
92 )
93
94
95 # Create our session class here, this will stay stateless as we'll bind the
96 # engine to each new state we create instead of binding it to the session
97 # class.
98 Session = sessionmaker()
99
100
101 def listens_for(target, identifier, *args, **kwargs):
102 def deco(wrapped):
103 def callback(scanner, _name, wrapped):
104 wrapped = functools.partial(wrapped, scanner.config)
105 event.listen(target, identifier, wrapped, *args, **kwargs)
106
107 venusian.attach(wrapped, callback, category="warehouse")
108
109 return wrapped
110
111 return deco
112
113
114 def _configure_alembic(config):
115 alembic_cfg = alembic.config.Config()
116 alembic_cfg.set_main_option("script_location", "warehouse:migrations")
117 alembic_cfg.set_main_option("url", config.registry.settings["database.url"])
118 return alembic_cfg
119
120
121 def _create_session(request):
122 metrics = request.find_service(IMetricsService, context=None)
123 metrics.increment("warehouse.db.session.start")
124
125 # Create our connection, most likely pulling it from the pool of
126 # connections
127 try:
128 connection = request.registry["sqlalchemy.engine"].connect()
129 except OperationalError:
130 # When we tried to connection to PostgreSQL, our database was not available for
131 # some reason. We're going to log it here and then raise our error. Most likely
132 # this is a transient error that will go away.
133 logger.warning("Got an error connecting to PostgreSQL", exc_info=True)
134 metrics.increment("warehouse.db.session.error", tags=["error_in:connecting"])
135 raise DatabaseNotAvailableError()
136
137 # Now, create a session from our connection
138 session = Session(bind=connection)
139
140 # Register only this particular session with zope.sqlalchemy
141 zope.sqlalchemy.register(session, transaction_manager=request.tm)
142
143 # Setup a callback that will ensure that everything is cleaned up at the
144 # end of our connection.
145 @request.add_finished_callback
146 def cleanup(request):
147 metrics.increment("warehouse.db.session.finished")
148 session.close()
149 connection.close()
150
151 # Check if we're in read-only mode
152 from warehouse.admin.flags import AdminFlag, AdminFlagValue
153
154 flag = session.query(AdminFlag).get(AdminFlagValue.READ_ONLY.value)
155 if flag and flag.enabled:
156 request.tm.doom()
157
158 # Return our session now that it's created and registered
159 return session
160
161
162 def includeme(config):
163 # Add a directive to get an alembic configuration.
164 config.add_directive("alembic_config", _configure_alembic)
165
166 # Create our SQLAlchemy Engine.
167 config.registry["sqlalchemy.engine"] = sqlalchemy.create_engine(
168 config.registry.settings["database.url"],
169 isolation_level=DEFAULT_ISOLATION,
170 pool_size=35,
171 max_overflow=65,
172 pool_timeout=20,
173 )
174
175 # Register our request.db property
176 config.add_request_method(_create_session, name="db", reify=True)
177
[end of warehouse/db.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/warehouse/db.py b/warehouse/db.py
--- a/warehouse/db.py
+++ b/warehouse/db.py
@@ -115,6 +115,11 @@
alembic_cfg = alembic.config.Config()
alembic_cfg.set_main_option("script_location", "warehouse:migrations")
alembic_cfg.set_main_option("url", config.registry.settings["database.url"])
+ alembic_cfg.set_section_option("post_write_hooks", "hooks", "black, isort")
+ alembic_cfg.set_section_option("post_write_hooks", "black.type", "console_scripts")
+ alembic_cfg.set_section_option("post_write_hooks", "black.entrypoint", "black")
+ alembic_cfg.set_section_option("post_write_hooks", "isort.type", "console_scripts")
+ alembic_cfg.set_section_option("post_write_hooks", "isort.entrypoint", "isort")
return alembic_cfg
| {"golden_diff": "diff --git a/warehouse/db.py b/warehouse/db.py\n--- a/warehouse/db.py\n+++ b/warehouse/db.py\n@@ -115,6 +115,11 @@\n alembic_cfg = alembic.config.Config()\n alembic_cfg.set_main_option(\"script_location\", \"warehouse:migrations\")\n alembic_cfg.set_main_option(\"url\", config.registry.settings[\"database.url\"])\n+ alembic_cfg.set_section_option(\"post_write_hooks\", \"hooks\", \"black, isort\")\n+ alembic_cfg.set_section_option(\"post_write_hooks\", \"black.type\", \"console_scripts\")\n+ alembic_cfg.set_section_option(\"post_write_hooks\", \"black.entrypoint\", \"black\")\n+ alembic_cfg.set_section_option(\"post_write_hooks\", \"isort.type\", \"console_scripts\")\n+ alembic_cfg.set_section_option(\"post_write_hooks\", \"isort.entrypoint\", \"isort\")\n return alembic_cfg\n", "issue": "Improve Alembic story\nFixes #10053.\r\n\r\nAdds `alembic.ini`.\r\nRuns `black` and `isort` after generating migrations.\n", "before_files": [{"content": "# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport functools\nimport logging\n\nimport alembic.config\nimport pyramid_retry\nimport sqlalchemy\nimport venusian\nimport zope.sqlalchemy\n\nfrom sqlalchemy import event, inspect\nfrom sqlalchemy.dialects.postgresql import UUID\nfrom sqlalchemy.exc import IntegrityError, OperationalError\nfrom sqlalchemy.ext.declarative import declarative_base # type: ignore\nfrom sqlalchemy.orm import sessionmaker\n\nfrom warehouse.metrics import IMetricsService\nfrom warehouse.utils.attrs import make_repr\n\n__all__ = [\"includeme\", \"metadata\", \"ModelBase\"]\n\n\nlogger = logging.getLogger(__name__)\n\n\nDEFAULT_ISOLATION = \"READ COMMITTED\"\n\n\n# On the surface this might seem wrong, because retrying a request whose data violates\n# the constraints of the database doesn't seem like a useful endeavor. However what\n# happens if you have two requests that are trying to insert a row, and that row\n# contains a unique, user provided value, you can get into a race condition where both\n# requests check the database, see nothing with that value exists, then both attempt to\n# insert it. One of the requests will succeed, the other will fail with an\n# IntegrityError. Retrying the request that failed will then have it see the object\n# created by the other request, and will have it do the appropriate action in that case.\n#\n# The most common way to run into this, is when submitting a form in the browser, if the\n# user clicks twice in rapid succession, the browser will send two almost identical\n# requests at basically the same time.\n#\n# One possible issue that this raises, is that it will slow down \"legitimate\"\n# IntegrityError because they'll have to fail multiple times before they ultimately\n# fail. We consider this an acceptable trade off, because deterministic IntegrityError\n# should be caught with proper validation prior to submitting records to the database\n# anyways.\npyramid_retry.mark_error_retryable(IntegrityError)\n\n\n# A generic wrapper exception that we'll raise when the database isn't available, we\n# use this so we can catch it later and turn it into a generic 5xx error.\nclass DatabaseNotAvailableError(Exception):\n ...\n\n\nclass ModelBase:\n def __repr__(self):\n inst = inspect(self)\n self.__repr__ = make_repr(\n *[c_attr.key for c_attr in inst.mapper.column_attrs], _self=self\n )\n return self.__repr__()\n\n\n# The Global metadata object.\nmetadata = sqlalchemy.MetaData()\n\n\n# Base class for models using declarative syntax\nModelBase = declarative_base(cls=ModelBase, metadata=metadata) # type: ignore\n\n\nclass Model(ModelBase):\n\n __abstract__ = True\n\n id = sqlalchemy.Column(\n UUID(as_uuid=True),\n primary_key=True,\n server_default=sqlalchemy.text(\"gen_random_uuid()\"),\n )\n\n\n# Create our session class here, this will stay stateless as we'll bind the\n# engine to each new state we create instead of binding it to the session\n# class.\nSession = sessionmaker()\n\n\ndef listens_for(target, identifier, *args, **kwargs):\n def deco(wrapped):\n def callback(scanner, _name, wrapped):\n wrapped = functools.partial(wrapped, scanner.config)\n event.listen(target, identifier, wrapped, *args, **kwargs)\n\n venusian.attach(wrapped, callback, category=\"warehouse\")\n\n return wrapped\n\n return deco\n\n\ndef _configure_alembic(config):\n alembic_cfg = alembic.config.Config()\n alembic_cfg.set_main_option(\"script_location\", \"warehouse:migrations\")\n alembic_cfg.set_main_option(\"url\", config.registry.settings[\"database.url\"])\n return alembic_cfg\n\n\ndef _create_session(request):\n metrics = request.find_service(IMetricsService, context=None)\n metrics.increment(\"warehouse.db.session.start\")\n\n # Create our connection, most likely pulling it from the pool of\n # connections\n try:\n connection = request.registry[\"sqlalchemy.engine\"].connect()\n except OperationalError:\n # When we tried to connection to PostgreSQL, our database was not available for\n # some reason. We're going to log it here and then raise our error. Most likely\n # this is a transient error that will go away.\n logger.warning(\"Got an error connecting to PostgreSQL\", exc_info=True)\n metrics.increment(\"warehouse.db.session.error\", tags=[\"error_in:connecting\"])\n raise DatabaseNotAvailableError()\n\n # Now, create a session from our connection\n session = Session(bind=connection)\n\n # Register only this particular session with zope.sqlalchemy\n zope.sqlalchemy.register(session, transaction_manager=request.tm)\n\n # Setup a callback that will ensure that everything is cleaned up at the\n # end of our connection.\n @request.add_finished_callback\n def cleanup(request):\n metrics.increment(\"warehouse.db.session.finished\")\n session.close()\n connection.close()\n\n # Check if we're in read-only mode\n from warehouse.admin.flags import AdminFlag, AdminFlagValue\n\n flag = session.query(AdminFlag).get(AdminFlagValue.READ_ONLY.value)\n if flag and flag.enabled:\n request.tm.doom()\n\n # Return our session now that it's created and registered\n return session\n\n\ndef includeme(config):\n # Add a directive to get an alembic configuration.\n config.add_directive(\"alembic_config\", _configure_alembic)\n\n # Create our SQLAlchemy Engine.\n config.registry[\"sqlalchemy.engine\"] = sqlalchemy.create_engine(\n config.registry.settings[\"database.url\"],\n isolation_level=DEFAULT_ISOLATION,\n pool_size=35,\n max_overflow=65,\n pool_timeout=20,\n )\n\n # Register our request.db property\n config.add_request_method(_create_session, name=\"db\", reify=True)\n", "path": "warehouse/db.py"}]} | 2,367 | 211 |
gh_patches_debug_38787 | rasdani/github-patches | git_diff | Kinto__kinto-1284 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
500 when creating a new account with a POST and forgetting to put the ID
```
File "kinto/plugins/accounts/views.py", line 112, in process_record
if new[self.model.id_field] != self.request.selected_userid:
KeyError: 'id'
```
</issue>
<code>
[start of kinto/plugins/accounts/__init__.py]
1 from kinto.authorization import PERMISSIONS_INHERITANCE_TREE
2 from pyramid.exceptions import ConfigurationError
3
4
5 def includeme(config):
6 config.add_api_capability(
7 'accounts',
8 description='Manage user accounts.',
9 url='https://kinto.readthedocs.io/en/latest/api/1.x/accounts.html')
10
11 config.scan('kinto.plugins.accounts.views')
12
13 PERMISSIONS_INHERITANCE_TREE[''].update({
14 'account:create': {}
15 })
16 PERMISSIONS_INHERITANCE_TREE['account'] = {
17 'write': {'account': ['write']},
18 'read': {'account': ['write', 'read']}
19 }
20
21 # Add some safety to avoid weird behaviour with basicauth default policy.
22 settings = config.get_settings()
23 auth_policies = settings['multiauth.policies']
24 if 'basicauth' in auth_policies and 'account' in auth_policies:
25 if auth_policies.index('basicauth') < auth_policies.index('account'):
26 error_msg = ("'basicauth' should not be mentioned before 'account' "
27 "in 'multiauth.policies' setting.")
28 raise ConfigurationError(error_msg)
29
[end of kinto/plugins/accounts/__init__.py]
[start of kinto/plugins/accounts/views.py]
1 import bcrypt
2 import colander
3 from pyramid import httpexceptions
4 from pyramid.decorator import reify
5 from pyramid.security import Authenticated, Everyone
6 from pyramid.settings import aslist
7
8 from kinto.views import NameGenerator
9 from kinto.core import resource
10 from kinto.core.errors import raise_invalid, http_error
11
12
13 def _extract_posted_body_id(request):
14 try:
15 # Anonymous creation with POST.
16 return request.json['data']['id']
17 except (ValueError, KeyError):
18 # Bad POST data.
19 if request.method.lower() == 'post':
20 error_details = {
21 'name': 'data.id',
22 'description': 'data.id in body: Required'
23 }
24 raise_invalid(request, **error_details)
25 # Anonymous GET
26 error_msg = 'Cannot read accounts.'
27 raise http_error(httpexceptions.HTTPUnauthorized(), error=error_msg)
28
29
30 class AccountSchema(resource.ResourceSchema):
31 password = colander.SchemaNode(colander.String())
32
33
34 @resource.register()
35 class Account(resource.ShareableResource):
36
37 schema = AccountSchema
38
39 def __init__(self, request, context):
40 # Store if current user is administrator (before accessing get_parent_id())
41 allowed_from_settings = request.registry.settings.get('account_write_principals', [])
42 context.is_administrator = len(set(aslist(allowed_from_settings)) &
43 set(request.prefixed_principals)) > 0
44 # Shortcut to check if current is anonymous (before get_parent_id()).
45 context.is_anonymous = Authenticated not in request.effective_principals
46
47 super().__init__(request, context)
48
49 # Overwrite the current principal set by ShareableResource.
50 if self.model.current_principal == Everyone or context.is_administrator:
51 # Creation is anonymous, but author with write perm is this:
52 # XXX: only works if policy name is account in settings.
53 self.model.current_principal = 'account:{}'.format(self.model.parent_id)
54
55 @reify
56 def id_generator(self):
57 # This generator is used for ID validation.
58 return NameGenerator()
59
60 def get_parent_id(self, request):
61 # The whole challenge here is that we want to isolate what
62 # authenticated users can list, but give access to everything to
63 # administrators.
64 # Plus when anonymous create accounts, we have to set their parent id
65 # to the same value they would obtain when authenticated.
66 if self.context.is_administrator:
67 if self.context.on_collection:
68 # Accounts created by admin should have userid as parent.
69 if request.method.lower() == 'post':
70 return _extract_posted_body_id(request)
71 else:
72 # Admin see all accounts.
73 return '*'
74 else:
75 # No pattern matching for admin on single record.
76 return request.matchdict['id']
77
78 if not self.context.is_anonymous:
79 # Authenticated users see their own account only.
80 return request.selected_userid
81
82 # Anonymous creation with PUT.
83 if 'id' in request.matchdict:
84 return request.matchdict['id']
85
86 return _extract_posted_body_id(request)
87
88 def collection_post(self):
89 result = super(Account, self).collection_post()
90 if self.context.is_anonymous and self.request.response.status_code == 200:
91 error_details = {
92 'message': 'Account ID %r already exists' % result['data']['id']
93 }
94 raise http_error(httpexceptions.HTTPForbidden(), **error_details)
95 return result
96
97 def process_record(self, new, old=None):
98 new = super(Account, self).process_record(new, old)
99
100 # Store password safely in database as str
101 # (bcrypt.hashpw returns base64 bytes).
102 pwd_str = new["password"].encode(encoding='utf-8')
103 hashed = bcrypt.hashpw(pwd_str, bcrypt.gensalt())
104 new["password"] = hashed.decode(encoding='utf-8')
105
106 # Administrators can reach other accounts and anonymous have no
107 # selected_userid. So do not try to enforce.
108 if self.context.is_administrator or self.context.is_anonymous:
109 return new
110
111 # Otherwise, we force the id to match the authenticated username.
112 if new[self.model.id_field] != self.request.selected_userid:
113 error_details = {
114 'name': 'data.id',
115 'description': 'Username and account ID do not match.',
116 }
117 raise_invalid(self.request, **error_details)
118
119 return new
120
[end of kinto/plugins/accounts/views.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/kinto/plugins/accounts/__init__.py b/kinto/plugins/accounts/__init__.py
--- a/kinto/plugins/accounts/__init__.py
+++ b/kinto/plugins/accounts/__init__.py
@@ -26,3 +26,24 @@
error_msg = ("'basicauth' should not be mentioned before 'account' "
"in 'multiauth.policies' setting.")
raise ConfigurationError(error_msg)
+
+ # We assume anyone in account_create_principals is to create
+ # accounts for other people.
+ # No one can create accounts for other people unless they are an
+ # "admin", defined as someone matching account_write_principals.
+ # Therefore any account that is in account_create_principals
+ # should be in account_write_principals too.
+ creators = set(settings.get('account_create_principals', '').split())
+ admins = set(settings.get('account_write_principals', '').split())
+ cant_create_anything = creators.difference(admins)
+ # system.Everyone isn't an account.
+ cant_create_anything.discard('system.Everyone')
+ if cant_create_anything:
+ message = ('Configuration has some principals in account_create_principals '
+ 'but not in account_write_principals. These principals will only be '
+ 'able to create their own accounts. This may not be what you want.\n'
+ 'If you want these users to be able to create accounts for other users, '
+ 'add them to account_write_principals.\n'
+ 'Affected users: {}'.format(list(cant_create_anything)))
+
+ raise ConfigurationError(message)
diff --git a/kinto/plugins/accounts/views.py b/kinto/plugins/accounts/views.py
--- a/kinto/plugins/accounts/views.py
+++ b/kinto/plugins/accounts/views.py
@@ -27,6 +27,12 @@
raise http_error(httpexceptions.HTTPUnauthorized(), error=error_msg)
+class AccountIdGenerator(NameGenerator):
+ """Allow @ signs in account IDs."""
+
+ regexp = r'^[a-zA-Z0-9][.@a-zA-Z0-9_-]*$'
+
+
class AccountSchema(resource.ResourceSchema):
password = colander.SchemaNode(colander.String())
@@ -55,7 +61,7 @@
@reify
def id_generator(self):
# This generator is used for ID validation.
- return NameGenerator()
+ return AccountIdGenerator()
def get_parent_id(self, request):
# The whole challenge here is that we want to isolate what
@@ -108,6 +114,14 @@
if self.context.is_administrator or self.context.is_anonymous:
return new
+ # Do not let accounts be created without usernames.
+ if self.model.id_field not in new:
+ error_details = {
+ 'name': 'data.id',
+ 'description': 'Accounts must have an ID.',
+ }
+ raise_invalid(self.request, **error_details)
+
# Otherwise, we force the id to match the authenticated username.
if new[self.model.id_field] != self.request.selected_userid:
error_details = {
| {"golden_diff": "diff --git a/kinto/plugins/accounts/__init__.py b/kinto/plugins/accounts/__init__.py\n--- a/kinto/plugins/accounts/__init__.py\n+++ b/kinto/plugins/accounts/__init__.py\n@@ -26,3 +26,24 @@\n error_msg = (\"'basicauth' should not be mentioned before 'account' \"\n \"in 'multiauth.policies' setting.\")\n raise ConfigurationError(error_msg)\n+\n+ # We assume anyone in account_create_principals is to create\n+ # accounts for other people.\n+ # No one can create accounts for other people unless they are an\n+ # \"admin\", defined as someone matching account_write_principals.\n+ # Therefore any account that is in account_create_principals\n+ # should be in account_write_principals too.\n+ creators = set(settings.get('account_create_principals', '').split())\n+ admins = set(settings.get('account_write_principals', '').split())\n+ cant_create_anything = creators.difference(admins)\n+ # system.Everyone isn't an account.\n+ cant_create_anything.discard('system.Everyone')\n+ if cant_create_anything:\n+ message = ('Configuration has some principals in account_create_principals '\n+ 'but not in account_write_principals. These principals will only be '\n+ 'able to create their own accounts. This may not be what you want.\\n'\n+ 'If you want these users to be able to create accounts for other users, '\n+ 'add them to account_write_principals.\\n'\n+ 'Affected users: {}'.format(list(cant_create_anything)))\n+\n+ raise ConfigurationError(message)\ndiff --git a/kinto/plugins/accounts/views.py b/kinto/plugins/accounts/views.py\n--- a/kinto/plugins/accounts/views.py\n+++ b/kinto/plugins/accounts/views.py\n@@ -27,6 +27,12 @@\n raise http_error(httpexceptions.HTTPUnauthorized(), error=error_msg)\n \n \n+class AccountIdGenerator(NameGenerator):\n+ \"\"\"Allow @ signs in account IDs.\"\"\"\n+\n+ regexp = r'^[a-zA-Z0-9][.@a-zA-Z0-9_-]*$'\n+\n+\n class AccountSchema(resource.ResourceSchema):\n password = colander.SchemaNode(colander.String())\n \n@@ -55,7 +61,7 @@\n @reify\n def id_generator(self):\n # This generator is used for ID validation.\n- return NameGenerator()\n+ return AccountIdGenerator()\n \n def get_parent_id(self, request):\n # The whole challenge here is that we want to isolate what\n@@ -108,6 +114,14 @@\n if self.context.is_administrator or self.context.is_anonymous:\n return new\n \n+ # Do not let accounts be created without usernames.\n+ if self.model.id_field not in new:\n+ error_details = {\n+ 'name': 'data.id',\n+ 'description': 'Accounts must have an ID.',\n+ }\n+ raise_invalid(self.request, **error_details)\n+\n # Otherwise, we force the id to match the authenticated username.\n if new[self.model.id_field] != self.request.selected_userid:\n error_details = {\n", "issue": "500 when creating a new account with a POST and forgetting to put the ID\n```\r\n File \"kinto/plugins/accounts/views.py\", line 112, in process_record\r\n if new[self.model.id_field] != self.request.selected_userid:\r\nKeyError: 'id'\r\n```\n", "before_files": [{"content": "from kinto.authorization import PERMISSIONS_INHERITANCE_TREE\nfrom pyramid.exceptions import ConfigurationError\n\n\ndef includeme(config):\n config.add_api_capability(\n 'accounts',\n description='Manage user accounts.',\n url='https://kinto.readthedocs.io/en/latest/api/1.x/accounts.html')\n\n config.scan('kinto.plugins.accounts.views')\n\n PERMISSIONS_INHERITANCE_TREE[''].update({\n 'account:create': {}\n })\n PERMISSIONS_INHERITANCE_TREE['account'] = {\n 'write': {'account': ['write']},\n 'read': {'account': ['write', 'read']}\n }\n\n # Add some safety to avoid weird behaviour with basicauth default policy.\n settings = config.get_settings()\n auth_policies = settings['multiauth.policies']\n if 'basicauth' in auth_policies and 'account' in auth_policies:\n if auth_policies.index('basicauth') < auth_policies.index('account'):\n error_msg = (\"'basicauth' should not be mentioned before 'account' \"\n \"in 'multiauth.policies' setting.\")\n raise ConfigurationError(error_msg)\n", "path": "kinto/plugins/accounts/__init__.py"}, {"content": "import bcrypt\nimport colander\nfrom pyramid import httpexceptions\nfrom pyramid.decorator import reify\nfrom pyramid.security import Authenticated, Everyone\nfrom pyramid.settings import aslist\n\nfrom kinto.views import NameGenerator\nfrom kinto.core import resource\nfrom kinto.core.errors import raise_invalid, http_error\n\n\ndef _extract_posted_body_id(request):\n try:\n # Anonymous creation with POST.\n return request.json['data']['id']\n except (ValueError, KeyError):\n # Bad POST data.\n if request.method.lower() == 'post':\n error_details = {\n 'name': 'data.id',\n 'description': 'data.id in body: Required'\n }\n raise_invalid(request, **error_details)\n # Anonymous GET\n error_msg = 'Cannot read accounts.'\n raise http_error(httpexceptions.HTTPUnauthorized(), error=error_msg)\n\n\nclass AccountSchema(resource.ResourceSchema):\n password = colander.SchemaNode(colander.String())\n\n\[email protected]()\nclass Account(resource.ShareableResource):\n\n schema = AccountSchema\n\n def __init__(self, request, context):\n # Store if current user is administrator (before accessing get_parent_id())\n allowed_from_settings = request.registry.settings.get('account_write_principals', [])\n context.is_administrator = len(set(aslist(allowed_from_settings)) &\n set(request.prefixed_principals)) > 0\n # Shortcut to check if current is anonymous (before get_parent_id()).\n context.is_anonymous = Authenticated not in request.effective_principals\n\n super().__init__(request, context)\n\n # Overwrite the current principal set by ShareableResource.\n if self.model.current_principal == Everyone or context.is_administrator:\n # Creation is anonymous, but author with write perm is this:\n # XXX: only works if policy name is account in settings.\n self.model.current_principal = 'account:{}'.format(self.model.parent_id)\n\n @reify\n def id_generator(self):\n # This generator is used for ID validation.\n return NameGenerator()\n\n def get_parent_id(self, request):\n # The whole challenge here is that we want to isolate what\n # authenticated users can list, but give access to everything to\n # administrators.\n # Plus when anonymous create accounts, we have to set their parent id\n # to the same value they would obtain when authenticated.\n if self.context.is_administrator:\n if self.context.on_collection:\n # Accounts created by admin should have userid as parent.\n if request.method.lower() == 'post':\n return _extract_posted_body_id(request)\n else:\n # Admin see all accounts.\n return '*'\n else:\n # No pattern matching for admin on single record.\n return request.matchdict['id']\n\n if not self.context.is_anonymous:\n # Authenticated users see their own account only.\n return request.selected_userid\n\n # Anonymous creation with PUT.\n if 'id' in request.matchdict:\n return request.matchdict['id']\n\n return _extract_posted_body_id(request)\n\n def collection_post(self):\n result = super(Account, self).collection_post()\n if self.context.is_anonymous and self.request.response.status_code == 200:\n error_details = {\n 'message': 'Account ID %r already exists' % result['data']['id']\n }\n raise http_error(httpexceptions.HTTPForbidden(), **error_details)\n return result\n\n def process_record(self, new, old=None):\n new = super(Account, self).process_record(new, old)\n\n # Store password safely in database as str\n # (bcrypt.hashpw returns base64 bytes).\n pwd_str = new[\"password\"].encode(encoding='utf-8')\n hashed = bcrypt.hashpw(pwd_str, bcrypt.gensalt())\n new[\"password\"] = hashed.decode(encoding='utf-8')\n\n # Administrators can reach other accounts and anonymous have no\n # selected_userid. So do not try to enforce.\n if self.context.is_administrator or self.context.is_anonymous:\n return new\n\n # Otherwise, we force the id to match the authenticated username.\n if new[self.model.id_field] != self.request.selected_userid:\n error_details = {\n 'name': 'data.id',\n 'description': 'Username and account ID do not match.',\n }\n raise_invalid(self.request, **error_details)\n\n return new\n", "path": "kinto/plugins/accounts/views.py"}]} | 2,115 | 701 |
gh_patches_debug_30666 | rasdani/github-patches | git_diff | streamlit__streamlit-3106 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Missing "import urllib" in "streamlit hello" mapping/dataframe demo code
The mapping and dataframe demo (`streamlit hello`, select mapping option on left hand size, have "show code" checked) seems to be missing "import urllib" in the code section below the live demo;
The code uses `except urllib.error.URLError as e:` but urllib is never imported; copying and pasting the code into an app does show the import error.
Tested on streamlit 0.78.0, python 3.8.
EDIT 1: make it clearer
EDIT 2: Just realized the same thing happens for the Dataframe demo, edited.
</issue>
<code>
[start of lib/streamlit/hello/demos.py]
1 # Copyright 2018-2021 Streamlit Inc.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import urllib.error
16
17
18 def intro():
19 import streamlit as st
20
21 st.sidebar.success("Select a demo above.")
22
23 st.markdown(
24 """
25 Streamlit is an open-source app framework built specifically for
26 Machine Learning and Data Science projects.
27
28 **👈 Select a demo from the dropdown on the left** to see some examples
29 of what Streamlit can do!
30
31 ### Want to learn more?
32
33 - Check out [streamlit.io](https://streamlit.io)
34 - Jump into our [documentation](https://docs.streamlit.io)
35 - Ask a question in our [community
36 forums](https://discuss.streamlit.io)
37
38 ### See more complex demos
39
40 - Use a neural net to [analyze the Udacity Self-driving Car Image
41 Dataset] (https://github.com/streamlit/demo-self-driving)
42 - Explore a [New York City rideshare dataset]
43 (https://github.com/streamlit/demo-uber-nyc-pickups)
44 """
45 )
46
47
48 # Turn off black formatting for this function to present the user with more
49 # compact code.
50 # fmt: off
51 def mapping_demo():
52 import streamlit as st
53 import pandas as pd
54 import pydeck as pdk
55
56 @st.cache
57 def from_data_file(filename):
58 url = (
59 "https://raw.githubusercontent.com/streamlit/"
60 "example-data/master/hello/v1/%s" % filename)
61 return pd.read_json(url)
62
63 try:
64 ALL_LAYERS = {
65 "Bike Rentals": pdk.Layer(
66 "HexagonLayer",
67 data=from_data_file("bike_rental_stats.json"),
68 get_position=["lon", "lat"],
69 radius=200,
70 elevation_scale=4,
71 elevation_range=[0, 1000],
72 extruded=True,
73 ),
74 "Bart Stop Exits": pdk.Layer(
75 "ScatterplotLayer",
76 data=from_data_file("bart_stop_stats.json"),
77 get_position=["lon", "lat"],
78 get_color=[200, 30, 0, 160],
79 get_radius="[exits]",
80 radius_scale=0.05,
81 ),
82 "Bart Stop Names": pdk.Layer(
83 "TextLayer",
84 data=from_data_file("bart_stop_stats.json"),
85 get_position=["lon", "lat"],
86 get_text="name",
87 get_color=[0, 0, 0, 200],
88 get_size=15,
89 get_alignment_baseline="'bottom'",
90 ),
91 "Outbound Flow": pdk.Layer(
92 "ArcLayer",
93 data=from_data_file("bart_path_stats.json"),
94 get_source_position=["lon", "lat"],
95 get_target_position=["lon2", "lat2"],
96 get_source_color=[200, 30, 0, 160],
97 get_target_color=[200, 30, 0, 160],
98 auto_highlight=True,
99 width_scale=0.0001,
100 get_width="outbound",
101 width_min_pixels=3,
102 width_max_pixels=30,
103 ),
104 }
105 st.sidebar.markdown('### Map Layers')
106 selected_layers = [
107 layer for layer_name, layer in ALL_LAYERS.items()
108 if st.sidebar.checkbox(layer_name, True)]
109 if selected_layers:
110 st.pydeck_chart(pdk.Deck(
111 map_style="mapbox://styles/mapbox/light-v9",
112 initial_view_state={"latitude": 37.76,
113 "longitude": -122.4, "zoom": 11, "pitch": 50},
114 layers=selected_layers,
115 ))
116 else:
117 st.error("Please choose at least one layer above.")
118 except urllib.error.URLError as e:
119 st.error("""
120 **This demo requires internet access.**
121
122 Connection error: %s
123 """ % e.reason)
124 # fmt: on
125
126 # Turn off black formatting for this function to present the user with more
127 # compact code.
128 # fmt: off
129
130
131 def fractal_demo():
132 import streamlit as st
133 import numpy as np
134
135 # Interactive Streamlit elements, like these sliders, return their value.
136 # This gives you an extremely simple interaction model.
137 iterations = st.sidebar.slider("Level of detail", 2, 20, 10, 1)
138 separation = st.sidebar.slider("Separation", 0.7, 2.0, 0.7885)
139
140 # Non-interactive elements return a placeholder to their location
141 # in the app. Here we're storing progress_bar to update it later.
142 progress_bar = st.sidebar.progress(0)
143
144 # These two elements will be filled in later, so we create a placeholder
145 # for them using st.empty()
146 frame_text = st.sidebar.empty()
147 image = st.empty()
148
149 m, n, s = 960, 640, 400
150 x = np.linspace(-m / s, m / s, num=m).reshape((1, m))
151 y = np.linspace(-n / s, n / s, num=n).reshape((n, 1))
152
153 for frame_num, a in enumerate(np.linspace(0.0, 4 * np.pi, 100)):
154 # Here were setting value for these two elements.
155 progress_bar.progress(frame_num)
156 frame_text.text("Frame %i/100" % (frame_num + 1))
157
158 # Performing some fractal wizardry.
159 c = separation * np.exp(1j * a)
160 Z = np.tile(x, (n, 1)) + 1j * np.tile(y, (1, m))
161 C = np.full((n, m), c)
162 M = np.full((n, m), True, dtype=bool)
163 N = np.zeros((n, m))
164
165 for i in range(iterations):
166 Z[M] = Z[M] * Z[M] + C[M]
167 M[np.abs(Z) > 2] = False
168 N[M] = i
169
170 # Update the image placeholder by calling the image() function on it.
171 image.image(1.0 - (N / N.max()), use_column_width=True)
172
173 # We clear elements by calling empty on them.
174 progress_bar.empty()
175 frame_text.empty()
176
177 # Streamlit widgets automatically run the script from top to bottom. Since
178 # this button is not connected to any other logic, it just causes a plain
179 # rerun.
180 st.button("Re-run")
181
182
183 # fmt: on
184
185 # Turn off black formatting for this function to present the user with more
186 # compact code.
187 # fmt: off
188 def plotting_demo():
189 import streamlit as st
190 import time
191 import numpy as np
192
193 progress_bar = st.sidebar.progress(0)
194 status_text = st.sidebar.empty()
195 last_rows = np.random.randn(1, 1)
196 chart = st.line_chart(last_rows)
197
198 for i in range(1, 101):
199 new_rows = last_rows[-1, :] + np.random.randn(5, 1).cumsum(axis=0)
200 status_text.text("%i%% Complete" % i)
201 chart.add_rows(new_rows)
202 progress_bar.progress(i)
203 last_rows = new_rows
204 time.sleep(0.05)
205
206 progress_bar.empty()
207
208 # Streamlit widgets automatically run the script from top to bottom. Since
209 # this button is not connected to any other logic, it just causes a plain
210 # rerun.
211 st.button("Re-run")
212
213
214 # fmt: on
215
216 # Turn off black formatting for this function to present the user with more
217 # compact code.
218 # fmt: off
219 def data_frame_demo():
220 import streamlit as st
221 import pandas as pd
222 import altair as alt
223
224 @st.cache
225 def get_UN_data():
226 AWS_BUCKET_URL = "https://streamlit-demo-data.s3-us-west-2.amazonaws.com"
227 df = pd.read_csv(AWS_BUCKET_URL + "/agri.csv.gz")
228 return df.set_index("Region")
229
230 try:
231 df = get_UN_data()
232 countries = st.multiselect(
233 "Choose countries", list(df.index), ["China", "United States of America"]
234 )
235 if not countries:
236 st.error("Please select at least one country.")
237 else:
238 data = df.loc[countries]
239 data /= 1000000.0
240 st.write("### Gross Agricultural Production ($B)", data.sort_index())
241
242 data = data.T.reset_index()
243 data = pd.melt(data, id_vars=["index"]).rename(
244 columns={"index": "year", "value": "Gross Agricultural Product ($B)"}
245 )
246 chart = (
247 alt.Chart(data)
248 .mark_area(opacity=0.3)
249 .encode(
250 x="year:T",
251 y=alt.Y("Gross Agricultural Product ($B):Q", stack=None),
252 color="Region:N",
253 )
254 )
255 st.altair_chart(chart, use_container_width=True)
256 except urllib.error.URLError as e:
257 st.error(
258 """
259 **This demo requires internet access.**
260
261 Connection error: %s
262 """
263 % e.reason
264 )
265
266
267 # fmt: on
268
[end of lib/streamlit/hello/demos.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/lib/streamlit/hello/demos.py b/lib/streamlit/hello/demos.py
--- a/lib/streamlit/hello/demos.py
+++ b/lib/streamlit/hello/demos.py
@@ -12,8 +12,6 @@
# See the License for the specific language governing permissions and
# limitations under the License.
-import urllib.error
-
def intro():
import streamlit as st
@@ -53,6 +51,8 @@
import pandas as pd
import pydeck as pdk
+ from urllib.error import URLError
+
@st.cache
def from_data_file(filename):
url = (
@@ -115,7 +115,7 @@
))
else:
st.error("Please choose at least one layer above.")
- except urllib.error.URLError as e:
+ except URLError as e:
st.error("""
**This demo requires internet access.**
@@ -221,6 +221,8 @@
import pandas as pd
import altair as alt
+ from urllib.error import URLError
+
@st.cache
def get_UN_data():
AWS_BUCKET_URL = "https://streamlit-demo-data.s3-us-west-2.amazonaws.com"
@@ -253,7 +255,7 @@
)
)
st.altair_chart(chart, use_container_width=True)
- except urllib.error.URLError as e:
+ except URLError as e:
st.error(
"""
**This demo requires internet access.**
| {"golden_diff": "diff --git a/lib/streamlit/hello/demos.py b/lib/streamlit/hello/demos.py\n--- a/lib/streamlit/hello/demos.py\n+++ b/lib/streamlit/hello/demos.py\n@@ -12,8 +12,6 @@\n # See the License for the specific language governing permissions and\n # limitations under the License.\n \n-import urllib.error\n-\n \n def intro():\n import streamlit as st\n@@ -53,6 +51,8 @@\n import pandas as pd\n import pydeck as pdk\n \n+ from urllib.error import URLError\n+\n @st.cache\n def from_data_file(filename):\n url = (\n@@ -115,7 +115,7 @@\n ))\n else:\n st.error(\"Please choose at least one layer above.\")\n- except urllib.error.URLError as e:\n+ except URLError as e:\n st.error(\"\"\"\n **This demo requires internet access.**\n \n@@ -221,6 +221,8 @@\n import pandas as pd\n import altair as alt\n \n+ from urllib.error import URLError\n+\n @st.cache\n def get_UN_data():\n AWS_BUCKET_URL = \"https://streamlit-demo-data.s3-us-west-2.amazonaws.com\"\n@@ -253,7 +255,7 @@\n )\n )\n st.altair_chart(chart, use_container_width=True)\n- except urllib.error.URLError as e:\n+ except URLError as e:\n st.error(\n \"\"\"\n **This demo requires internet access.**\n", "issue": "Missing \"import urllib\" in \"streamlit hello\" mapping/dataframe demo code\nThe mapping and dataframe demo (`streamlit hello`, select mapping option on left hand size, have \"show code\" checked) seems to be missing \"import urllib\" in the code section below the live demo;\r\n\r\nThe code uses `except urllib.error.URLError as e:` but urllib is never imported; copying and pasting the code into an app does show the import error.\r\n\r\nTested on streamlit 0.78.0, python 3.8.\r\n\r\nEDIT 1: make it clearer\r\nEDIT 2: Just realized the same thing happens for the Dataframe demo, edited.\n", "before_files": [{"content": "# Copyright 2018-2021 Streamlit Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport urllib.error\n\n\ndef intro():\n import streamlit as st\n\n st.sidebar.success(\"Select a demo above.\")\n\n st.markdown(\n \"\"\"\n Streamlit is an open-source app framework built specifically for\n Machine Learning and Data Science projects.\n\n **\ud83d\udc48 Select a demo from the dropdown on the left** to see some examples\n of what Streamlit can do!\n\n ### Want to learn more?\n\n - Check out [streamlit.io](https://streamlit.io)\n - Jump into our [documentation](https://docs.streamlit.io)\n - Ask a question in our [community\n forums](https://discuss.streamlit.io)\n\n ### See more complex demos\n\n - Use a neural net to [analyze the Udacity Self-driving Car Image\n Dataset] (https://github.com/streamlit/demo-self-driving)\n - Explore a [New York City rideshare dataset]\n (https://github.com/streamlit/demo-uber-nyc-pickups)\n \"\"\"\n )\n\n\n# Turn off black formatting for this function to present the user with more\n# compact code.\n# fmt: off\ndef mapping_demo():\n import streamlit as st\n import pandas as pd\n import pydeck as pdk\n\n @st.cache\n def from_data_file(filename):\n url = (\n \"https://raw.githubusercontent.com/streamlit/\"\n \"example-data/master/hello/v1/%s\" % filename)\n return pd.read_json(url)\n\n try:\n ALL_LAYERS = {\n \"Bike Rentals\": pdk.Layer(\n \"HexagonLayer\",\n data=from_data_file(\"bike_rental_stats.json\"),\n get_position=[\"lon\", \"lat\"],\n radius=200,\n elevation_scale=4,\n elevation_range=[0, 1000],\n extruded=True,\n ),\n \"Bart Stop Exits\": pdk.Layer(\n \"ScatterplotLayer\",\n data=from_data_file(\"bart_stop_stats.json\"),\n get_position=[\"lon\", \"lat\"],\n get_color=[200, 30, 0, 160],\n get_radius=\"[exits]\",\n radius_scale=0.05,\n ),\n \"Bart Stop Names\": pdk.Layer(\n \"TextLayer\",\n data=from_data_file(\"bart_stop_stats.json\"),\n get_position=[\"lon\", \"lat\"],\n get_text=\"name\",\n get_color=[0, 0, 0, 200],\n get_size=15,\n get_alignment_baseline=\"'bottom'\",\n ),\n \"Outbound Flow\": pdk.Layer(\n \"ArcLayer\",\n data=from_data_file(\"bart_path_stats.json\"),\n get_source_position=[\"lon\", \"lat\"],\n get_target_position=[\"lon2\", \"lat2\"],\n get_source_color=[200, 30, 0, 160],\n get_target_color=[200, 30, 0, 160],\n auto_highlight=True,\n width_scale=0.0001,\n get_width=\"outbound\",\n width_min_pixels=3,\n width_max_pixels=30,\n ),\n }\n st.sidebar.markdown('### Map Layers')\n selected_layers = [\n layer for layer_name, layer in ALL_LAYERS.items()\n if st.sidebar.checkbox(layer_name, True)]\n if selected_layers:\n st.pydeck_chart(pdk.Deck(\n map_style=\"mapbox://styles/mapbox/light-v9\",\n initial_view_state={\"latitude\": 37.76,\n \"longitude\": -122.4, \"zoom\": 11, \"pitch\": 50},\n layers=selected_layers,\n ))\n else:\n st.error(\"Please choose at least one layer above.\")\n except urllib.error.URLError as e:\n st.error(\"\"\"\n **This demo requires internet access.**\n\n Connection error: %s\n \"\"\" % e.reason)\n# fmt: on\n\n# Turn off black formatting for this function to present the user with more\n# compact code.\n# fmt: off\n\n\ndef fractal_demo():\n import streamlit as st\n import numpy as np\n\n # Interactive Streamlit elements, like these sliders, return their value.\n # This gives you an extremely simple interaction model.\n iterations = st.sidebar.slider(\"Level of detail\", 2, 20, 10, 1)\n separation = st.sidebar.slider(\"Separation\", 0.7, 2.0, 0.7885)\n\n # Non-interactive elements return a placeholder to their location\n # in the app. Here we're storing progress_bar to update it later.\n progress_bar = st.sidebar.progress(0)\n\n # These two elements will be filled in later, so we create a placeholder\n # for them using st.empty()\n frame_text = st.sidebar.empty()\n image = st.empty()\n\n m, n, s = 960, 640, 400\n x = np.linspace(-m / s, m / s, num=m).reshape((1, m))\n y = np.linspace(-n / s, n / s, num=n).reshape((n, 1))\n\n for frame_num, a in enumerate(np.linspace(0.0, 4 * np.pi, 100)):\n # Here were setting value for these two elements.\n progress_bar.progress(frame_num)\n frame_text.text(\"Frame %i/100\" % (frame_num + 1))\n\n # Performing some fractal wizardry.\n c = separation * np.exp(1j * a)\n Z = np.tile(x, (n, 1)) + 1j * np.tile(y, (1, m))\n C = np.full((n, m), c)\n M = np.full((n, m), True, dtype=bool)\n N = np.zeros((n, m))\n\n for i in range(iterations):\n Z[M] = Z[M] * Z[M] + C[M]\n M[np.abs(Z) > 2] = False\n N[M] = i\n\n # Update the image placeholder by calling the image() function on it.\n image.image(1.0 - (N / N.max()), use_column_width=True)\n\n # We clear elements by calling empty on them.\n progress_bar.empty()\n frame_text.empty()\n\n # Streamlit widgets automatically run the script from top to bottom. Since\n # this button is not connected to any other logic, it just causes a plain\n # rerun.\n st.button(\"Re-run\")\n\n\n# fmt: on\n\n# Turn off black formatting for this function to present the user with more\n# compact code.\n# fmt: off\ndef plotting_demo():\n import streamlit as st\n import time\n import numpy as np\n\n progress_bar = st.sidebar.progress(0)\n status_text = st.sidebar.empty()\n last_rows = np.random.randn(1, 1)\n chart = st.line_chart(last_rows)\n\n for i in range(1, 101):\n new_rows = last_rows[-1, :] + np.random.randn(5, 1).cumsum(axis=0)\n status_text.text(\"%i%% Complete\" % i)\n chart.add_rows(new_rows)\n progress_bar.progress(i)\n last_rows = new_rows\n time.sleep(0.05)\n\n progress_bar.empty()\n\n # Streamlit widgets automatically run the script from top to bottom. Since\n # this button is not connected to any other logic, it just causes a plain\n # rerun.\n st.button(\"Re-run\")\n\n\n# fmt: on\n\n# Turn off black formatting for this function to present the user with more\n# compact code.\n# fmt: off\ndef data_frame_demo():\n import streamlit as st\n import pandas as pd\n import altair as alt\n\n @st.cache\n def get_UN_data():\n AWS_BUCKET_URL = \"https://streamlit-demo-data.s3-us-west-2.amazonaws.com\"\n df = pd.read_csv(AWS_BUCKET_URL + \"/agri.csv.gz\")\n return df.set_index(\"Region\")\n\n try:\n df = get_UN_data()\n countries = st.multiselect(\n \"Choose countries\", list(df.index), [\"China\", \"United States of America\"]\n )\n if not countries:\n st.error(\"Please select at least one country.\")\n else:\n data = df.loc[countries]\n data /= 1000000.0\n st.write(\"### Gross Agricultural Production ($B)\", data.sort_index())\n\n data = data.T.reset_index()\n data = pd.melt(data, id_vars=[\"index\"]).rename(\n columns={\"index\": \"year\", \"value\": \"Gross Agricultural Product ($B)\"}\n )\n chart = (\n alt.Chart(data)\n .mark_area(opacity=0.3)\n .encode(\n x=\"year:T\",\n y=alt.Y(\"Gross Agricultural Product ($B):Q\", stack=None),\n color=\"Region:N\",\n )\n )\n st.altair_chart(chart, use_container_width=True)\n except urllib.error.URLError as e:\n st.error(\n \"\"\"\n **This demo requires internet access.**\n\n Connection error: %s\n \"\"\"\n % e.reason\n )\n\n\n# fmt: on\n", "path": "lib/streamlit/hello/demos.py"}]} | 3,545 | 338 |
gh_patches_debug_24286 | rasdani/github-patches | git_diff | e-valuation__EvaP-1822 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Response status code of failed redemption is 200
As @niklasmohrin remarked in [#1790](https://github.com/e-valuation/EvaP/pull/1790/files#r962983692), in `evap.rewards.views.redeem_reward_points`, the status code of failed redemptions (e.g. due to `NotEnoughPoints` or `RedemptionEventExpired`) is set as 200 OK, even though no redemption points were saved.
Instead, the status code should be something like 400 Bad Request to underline that something went wrong.
@niklasmohrin added, that `assertContains`, used in some tests in `evap.rewards.tests.test_views.TestIndexView`, needs to adopted, as it asserts that the status code is 200 by default.
</issue>
<code>
[start of evap/rewards/views.py]
1 from datetime import datetime
2
3 from django.contrib import messages
4 from django.core.exceptions import BadRequest, SuspiciousOperation
5 from django.http import HttpResponse
6 from django.shortcuts import get_object_or_404, redirect, render
7 from django.utils.translation import get_language
8 from django.utils.translation import gettext as _
9 from django.views.decorators.http import require_POST
10
11 from evap.evaluation.auth import manager_required, reward_user_required
12 from evap.evaluation.models import Semester
13 from evap.evaluation.tools import AttachmentResponse, get_object_from_dict_pk_entry_or_logged_40x
14 from evap.rewards.exporters import RewardsExporter
15 from evap.rewards.forms import RewardPointRedemptionEventForm
16 from evap.rewards.models import (
17 NoPointsSelected,
18 NotEnoughPoints,
19 RedemptionEventExpired,
20 RewardPointGranting,
21 RewardPointRedemption,
22 RewardPointRedemptionEvent,
23 SemesterActivation,
24 )
25 from evap.rewards.tools import grant_eligible_reward_points_for_semester, reward_points_of_user, save_redemptions
26 from evap.staff.views import semester_view
27
28
29 @reward_user_required
30 def index(request):
31 if request.method == "POST":
32 redemptions = {}
33 try:
34 for key, value in request.POST.items():
35 if key.startswith("points-"):
36 event_id = int(key.rpartition("-")[2])
37 redemptions[event_id] = int(value)
38 except ValueError as e:
39 raise BadRequest from e
40
41 try:
42 save_redemptions(request, redemptions)
43 messages.success(request, _("You successfully redeemed your points."))
44 except (NoPointsSelected, NotEnoughPoints, RedemptionEventExpired) as error:
45 messages.warning(request, error)
46
47 total_points_available = reward_points_of_user(request.user)
48 reward_point_grantings = RewardPointGranting.objects.filter(user_profile=request.user)
49 reward_point_redemptions = RewardPointRedemption.objects.filter(user_profile=request.user)
50 events = RewardPointRedemptionEvent.objects.filter(redeem_end_date__gte=datetime.now()).order_by("date")
51
52 reward_point_actions = []
53 for granting in reward_point_grantings:
54 reward_point_actions.append(
55 (granting.granting_time, _("Reward for") + " " + granting.semester.name, granting.value, "")
56 )
57 for redemption in reward_point_redemptions:
58 reward_point_actions.append((redemption.redemption_time, redemption.event.name, "", redemption.value))
59
60 reward_point_actions.sort(key=lambda action: action[0], reverse=True)
61
62 template_data = dict(
63 reward_point_actions=reward_point_actions,
64 total_points_available=total_points_available,
65 events=events,
66 )
67 return render(request, "rewards_index.html", template_data)
68
69
70 @manager_required
71 def reward_point_redemption_events(request):
72 upcoming_events = RewardPointRedemptionEvent.objects.filter(redeem_end_date__gte=datetime.now()).order_by("date")
73 past_events = RewardPointRedemptionEvent.objects.filter(redeem_end_date__lt=datetime.now()).order_by("-date")
74 template_data = dict(upcoming_events=upcoming_events, past_events=past_events)
75 return render(request, "rewards_reward_point_redemption_events.html", template_data)
76
77
78 @manager_required
79 def reward_point_redemption_event_create(request):
80 event = RewardPointRedemptionEvent()
81 form = RewardPointRedemptionEventForm(request.POST or None, instance=event)
82
83 if form.is_valid():
84 form.save()
85 messages.success(request, _("Successfully created event."))
86 return redirect("rewards:reward_point_redemption_events")
87
88 return render(request, "rewards_reward_point_redemption_event_form.html", dict(form=form))
89
90
91 @manager_required
92 def reward_point_redemption_event_edit(request, event_id):
93 event = get_object_or_404(RewardPointRedemptionEvent, id=event_id)
94 form = RewardPointRedemptionEventForm(request.POST or None, instance=event)
95
96 if form.is_valid():
97 event = form.save()
98
99 messages.success(request, _("Successfully updated event."))
100 return redirect("rewards:reward_point_redemption_events")
101
102 return render(request, "rewards_reward_point_redemption_event_form.html", dict(event=event, form=form))
103
104
105 @require_POST
106 @manager_required
107 def reward_point_redemption_event_delete(request):
108 event = get_object_from_dict_pk_entry_or_logged_40x(RewardPointRedemptionEvent, request.POST, "event_id")
109
110 if not event.can_delete:
111 raise SuspiciousOperation("Deleting redemption event not allowed")
112 event.delete()
113 return HttpResponse() # 200 OK
114
115
116 @manager_required
117 def reward_point_redemption_event_export(request, event_id):
118 event = get_object_or_404(RewardPointRedemptionEvent, id=event_id)
119
120 filename = _("RewardPoints") + f"-{event.date}-{event.name}-{get_language()}.xls"
121 response = AttachmentResponse(filename, content_type="application/vnd.ms-excel")
122
123 RewardsExporter().export(response, event.redemptions_by_user())
124
125 return response
126
127
128 @manager_required
129 def semester_activation(request, semester_id, active):
130 semester = get_object_or_404(Semester, id=semester_id)
131 active = active == "on"
132
133 SemesterActivation.objects.update_or_create(semester=semester, defaults={"is_active": active})
134 if active:
135 grant_eligible_reward_points_for_semester(request, semester)
136
137 return semester_view(request=request, semester_id=semester_id)
138
[end of evap/rewards/views.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/evap/rewards/views.py b/evap/rewards/views.py
--- a/evap/rewards/views.py
+++ b/evap/rewards/views.py
@@ -28,6 +28,8 @@
@reward_user_required
def index(request):
+ # pylint: disable=too-many-locals
+ status = 200
if request.method == "POST":
redemptions = {}
try:
@@ -43,6 +45,7 @@
messages.success(request, _("You successfully redeemed your points."))
except (NoPointsSelected, NotEnoughPoints, RedemptionEventExpired) as error:
messages.warning(request, error)
+ status = 400
total_points_available = reward_points_of_user(request.user)
reward_point_grantings = RewardPointGranting.objects.filter(user_profile=request.user)
@@ -64,7 +67,7 @@
total_points_available=total_points_available,
events=events,
)
- return render(request, "rewards_index.html", template_data)
+ return render(request, "rewards_index.html", template_data, status=status)
@manager_required
| {"golden_diff": "diff --git a/evap/rewards/views.py b/evap/rewards/views.py\n--- a/evap/rewards/views.py\n+++ b/evap/rewards/views.py\n@@ -28,6 +28,8 @@\n \n @reward_user_required\n def index(request):\n+ # pylint: disable=too-many-locals\n+ status = 200\n if request.method == \"POST\":\n redemptions = {}\n try:\n@@ -43,6 +45,7 @@\n messages.success(request, _(\"You successfully redeemed your points.\"))\n except (NoPointsSelected, NotEnoughPoints, RedemptionEventExpired) as error:\n messages.warning(request, error)\n+ status = 400\n \n total_points_available = reward_points_of_user(request.user)\n reward_point_grantings = RewardPointGranting.objects.filter(user_profile=request.user)\n@@ -64,7 +67,7 @@\n total_points_available=total_points_available,\n events=events,\n )\n- return render(request, \"rewards_index.html\", template_data)\n+ return render(request, \"rewards_index.html\", template_data, status=status)\n \n \n @manager_required\n", "issue": "Response status code of failed redemption is 200\nAs @niklasmohrin remarked in [#1790](https://github.com/e-valuation/EvaP/pull/1790/files#r962983692), in `evap.rewards.views.redeem_reward_points`, the status code of failed redemptions (e.g. due to `NotEnoughPoints` or `RedemptionEventExpired`) is set as 200 OK, even though no redemption points were saved. \r\n\r\nInstead, the status code should be something like 400 Bad Request to underline that something went wrong.\r\n@niklasmohrin added, that `assertContains`, used in some tests in `evap.rewards.tests.test_views.TestIndexView`, needs to adopted, as it asserts that the status code is 200 by default.\n", "before_files": [{"content": "from datetime import datetime\n\nfrom django.contrib import messages\nfrom django.core.exceptions import BadRequest, SuspiciousOperation\nfrom django.http import HttpResponse\nfrom django.shortcuts import get_object_or_404, redirect, render\nfrom django.utils.translation import get_language\nfrom django.utils.translation import gettext as _\nfrom django.views.decorators.http import require_POST\n\nfrom evap.evaluation.auth import manager_required, reward_user_required\nfrom evap.evaluation.models import Semester\nfrom evap.evaluation.tools import AttachmentResponse, get_object_from_dict_pk_entry_or_logged_40x\nfrom evap.rewards.exporters import RewardsExporter\nfrom evap.rewards.forms import RewardPointRedemptionEventForm\nfrom evap.rewards.models import (\n NoPointsSelected,\n NotEnoughPoints,\n RedemptionEventExpired,\n RewardPointGranting,\n RewardPointRedemption,\n RewardPointRedemptionEvent,\n SemesterActivation,\n)\nfrom evap.rewards.tools import grant_eligible_reward_points_for_semester, reward_points_of_user, save_redemptions\nfrom evap.staff.views import semester_view\n\n\n@reward_user_required\ndef index(request):\n if request.method == \"POST\":\n redemptions = {}\n try:\n for key, value in request.POST.items():\n if key.startswith(\"points-\"):\n event_id = int(key.rpartition(\"-\")[2])\n redemptions[event_id] = int(value)\n except ValueError as e:\n raise BadRequest from e\n\n try:\n save_redemptions(request, redemptions)\n messages.success(request, _(\"You successfully redeemed your points.\"))\n except (NoPointsSelected, NotEnoughPoints, RedemptionEventExpired) as error:\n messages.warning(request, error)\n\n total_points_available = reward_points_of_user(request.user)\n reward_point_grantings = RewardPointGranting.objects.filter(user_profile=request.user)\n reward_point_redemptions = RewardPointRedemption.objects.filter(user_profile=request.user)\n events = RewardPointRedemptionEvent.objects.filter(redeem_end_date__gte=datetime.now()).order_by(\"date\")\n\n reward_point_actions = []\n for granting in reward_point_grantings:\n reward_point_actions.append(\n (granting.granting_time, _(\"Reward for\") + \" \" + granting.semester.name, granting.value, \"\")\n )\n for redemption in reward_point_redemptions:\n reward_point_actions.append((redemption.redemption_time, redemption.event.name, \"\", redemption.value))\n\n reward_point_actions.sort(key=lambda action: action[0], reverse=True)\n\n template_data = dict(\n reward_point_actions=reward_point_actions,\n total_points_available=total_points_available,\n events=events,\n )\n return render(request, \"rewards_index.html\", template_data)\n\n\n@manager_required\ndef reward_point_redemption_events(request):\n upcoming_events = RewardPointRedemptionEvent.objects.filter(redeem_end_date__gte=datetime.now()).order_by(\"date\")\n past_events = RewardPointRedemptionEvent.objects.filter(redeem_end_date__lt=datetime.now()).order_by(\"-date\")\n template_data = dict(upcoming_events=upcoming_events, past_events=past_events)\n return render(request, \"rewards_reward_point_redemption_events.html\", template_data)\n\n\n@manager_required\ndef reward_point_redemption_event_create(request):\n event = RewardPointRedemptionEvent()\n form = RewardPointRedemptionEventForm(request.POST or None, instance=event)\n\n if form.is_valid():\n form.save()\n messages.success(request, _(\"Successfully created event.\"))\n return redirect(\"rewards:reward_point_redemption_events\")\n\n return render(request, \"rewards_reward_point_redemption_event_form.html\", dict(form=form))\n\n\n@manager_required\ndef reward_point_redemption_event_edit(request, event_id):\n event = get_object_or_404(RewardPointRedemptionEvent, id=event_id)\n form = RewardPointRedemptionEventForm(request.POST or None, instance=event)\n\n if form.is_valid():\n event = form.save()\n\n messages.success(request, _(\"Successfully updated event.\"))\n return redirect(\"rewards:reward_point_redemption_events\")\n\n return render(request, \"rewards_reward_point_redemption_event_form.html\", dict(event=event, form=form))\n\n\n@require_POST\n@manager_required\ndef reward_point_redemption_event_delete(request):\n event = get_object_from_dict_pk_entry_or_logged_40x(RewardPointRedemptionEvent, request.POST, \"event_id\")\n\n if not event.can_delete:\n raise SuspiciousOperation(\"Deleting redemption event not allowed\")\n event.delete()\n return HttpResponse() # 200 OK\n\n\n@manager_required\ndef reward_point_redemption_event_export(request, event_id):\n event = get_object_or_404(RewardPointRedemptionEvent, id=event_id)\n\n filename = _(\"RewardPoints\") + f\"-{event.date}-{event.name}-{get_language()}.xls\"\n response = AttachmentResponse(filename, content_type=\"application/vnd.ms-excel\")\n\n RewardsExporter().export(response, event.redemptions_by_user())\n\n return response\n\n\n@manager_required\ndef semester_activation(request, semester_id, active):\n semester = get_object_or_404(Semester, id=semester_id)\n active = active == \"on\"\n\n SemesterActivation.objects.update_or_create(semester=semester, defaults={\"is_active\": active})\n if active:\n grant_eligible_reward_points_for_semester(request, semester)\n\n return semester_view(request=request, semester_id=semester_id)\n", "path": "evap/rewards/views.py"}]} | 2,201 | 255 |
gh_patches_debug_13133 | rasdani/github-patches | git_diff | scoutapp__scout_apm_python-701 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Bump core agent version to 1.4.0
Please update the Python agent dependency of core agent to core agent v1.4.0.
</issue>
<code>
[start of src/scout_apm/core/config.py]
1 # coding=utf-8
2 from __future__ import absolute_import, division, print_function, unicode_literals
3
4 import logging
5 import os
6 import re
7 import warnings
8
9 from scout_apm.compat import string_type
10 from scout_apm.core import platform_detection
11
12 logger = logging.getLogger(__name__)
13
14 key_regex = re.compile(r"[a-zA-Z0-9]{16}")
15
16
17 class ScoutConfig(object):
18 """
19 Configuration object for the ScoutApm agent.
20
21 Contains a list of configuration "layers". When a configuration key is
22 looked up, each layer is asked in turn if it knows the value. The first one
23 to answer affirmatively returns the value.
24 """
25
26 def __init__(self):
27 self.layers = [
28 Env(),
29 Python(),
30 Derived(self),
31 Defaults(),
32 Null(),
33 ]
34
35 def value(self, key):
36 value = self.locate_layer_for_key(key).value(key)
37 if key in CONVERSIONS:
38 return CONVERSIONS[key](value)
39 return value
40
41 def locate_layer_for_key(self, key):
42 for layer in self.layers:
43 if layer.has_config(key):
44 return layer
45
46 # Should be unreachable because Null returns None for all keys.
47 raise ValueError("key {!r} not found in any layer".format(key))
48
49 def log(self):
50 logger.debug("Configuration Loaded:")
51 for key in self.known_keys:
52 if key in self.secret_keys:
53 continue
54
55 layer = self.locate_layer_for_key(key)
56 logger.debug(
57 "%-9s: %s = %s",
58 layer.__class__.__name__,
59 key,
60 layer.value(key),
61 )
62
63 known_keys = [
64 "app_server",
65 "application_root",
66 "collect_remote_ip",
67 "core_agent_config_file",
68 "core_agent_dir",
69 "core_agent_download",
70 "core_agent_launch",
71 "core_agent_log_file",
72 "core_agent_log_level",
73 "core_agent_permissions",
74 "core_agent_socket_path",
75 "core_agent_version",
76 "disabled_instruments",
77 "download_url",
78 "framework",
79 "framework_version",
80 "hostname",
81 "ignore",
82 "key",
83 "log_level",
84 "monitor",
85 "name",
86 "revision_sha",
87 "scm_subdirectory",
88 "shutdown_message_enabled",
89 "shutdown_timeout_seconds",
90 ]
91
92 secret_keys = {"key"}
93
94 def core_agent_permissions(self):
95 try:
96 return int(str(self.value("core_agent_permissions")), 8)
97 except ValueError:
98 logger.exception(
99 "Invalid core_agent_permissions value, using default of 0o700"
100 )
101 return 0o700
102
103 @classmethod
104 def set(cls, **kwargs):
105 """
106 Sets a configuration value for the Scout agent. Values set here will
107 not override values set in ENV.
108 """
109 for key, value in kwargs.items():
110 SCOUT_PYTHON_VALUES[key] = value
111
112 @classmethod
113 def unset(cls, *keys):
114 """
115 Removes a configuration value for the Scout agent.
116 """
117 for key in keys:
118 SCOUT_PYTHON_VALUES.pop(key, None)
119
120 @classmethod
121 def reset_all(cls):
122 """
123 Remove all configuration settings set via `ScoutConfig.set(...)`.
124
125 This is meant for use in testing.
126 """
127 SCOUT_PYTHON_VALUES.clear()
128
129
130 # Module-level data, the ScoutConfig.set(key="value") adds to this
131 SCOUT_PYTHON_VALUES = {}
132
133
134 class Python(object):
135 """
136 A configuration overlay that lets other parts of python set values.
137 """
138
139 def has_config(self, key):
140 return key in SCOUT_PYTHON_VALUES
141
142 def value(self, key):
143 return SCOUT_PYTHON_VALUES[key]
144
145
146 class Env(object):
147 """
148 Reads configuration from environment by prefixing the key
149 requested with "SCOUT_"
150
151 Example: the `key` config looks for SCOUT_KEY
152 environment variable
153 """
154
155 def has_config(self, key):
156 env_key = self.modify_key(key)
157 return env_key in os.environ
158
159 def value(self, key):
160 env_key = self.modify_key(key)
161 return os.environ[env_key]
162
163 def modify_key(self, key):
164 env_key = ("SCOUT_" + key).upper()
165 return env_key
166
167
168 class Derived(object):
169 """
170 A configuration overlay that calculates from other values.
171 """
172
173 def __init__(self, config):
174 """
175 config argument is the overall ScoutConfig var, so we can lookup the
176 components of the derived info.
177 """
178 self.config = config
179
180 def has_config(self, key):
181 return self.lookup_func(key) is not None
182
183 def value(self, key):
184 return self.lookup_func(key)()
185
186 def lookup_func(self, key):
187 """
188 Returns the derive_#{key} function, or None if it isn't defined
189 """
190 func_name = "derive_" + key
191 return getattr(self, func_name, None)
192
193 def derive_core_agent_full_name(self):
194 triple = self.config.value("core_agent_triple")
195 if not platform_detection.is_valid_triple(triple):
196 warnings.warn("Invalid value for core_agent_triple: {}".format(triple))
197 return "{name}-{version}-{triple}".format(
198 name="scout_apm_core",
199 version=self.config.value("core_agent_version"),
200 triple=triple,
201 )
202
203 def derive_core_agent_triple(self):
204 return platform_detection.get_triple()
205
206
207 class Defaults(object):
208 """
209 Provides default values for important configurations
210 """
211
212 def __init__(self):
213 self.defaults = {
214 "app_server": "",
215 "application_root": os.getcwd(),
216 "collect_remote_ip": True,
217 "core_agent_dir": "/tmp/scout_apm_core",
218 "core_agent_download": True,
219 "core_agent_launch": True,
220 "core_agent_log_level": "info",
221 "core_agent_permissions": 700,
222 "core_agent_socket_path": "tcp://127.0.0.1:6590",
223 "core_agent_version": "v1.3.1", # can be an exact tag name, or 'latest'
224 "disabled_instruments": [],
225 "download_url": "https://s3-us-west-1.amazonaws.com/scout-public-downloads/apm_core_agent/release", # noqa: B950
226 "errors_batch_size": 5,
227 "errors_enabled": True,
228 "errors_ignored_exceptions": (),
229 "errors_host": "https://errors.scoutapm.com",
230 "framework": "",
231 "framework_version": "",
232 "hostname": None,
233 "key": "",
234 "monitor": False,
235 "name": "Python App",
236 "revision_sha": self._git_revision_sha(),
237 "scm_subdirectory": "",
238 "shutdown_message_enabled": True,
239 "shutdown_timeout_seconds": 2.0,
240 "uri_reporting": "filtered_params",
241 }
242
243 def _git_revision_sha(self):
244 # N.B. The environment variable SCOUT_REVISION_SHA may also be used,
245 # but that will be picked up by Env
246 return os.environ.get("HEROKU_SLUG_COMMIT", "")
247
248 def has_config(self, key):
249 return key in self.defaults
250
251 def value(self, key):
252 return self.defaults[key]
253
254
255 class Null(object):
256 """
257 Always answers that a key is present, but the value is None
258
259 Used as the last step of the layered configuration.
260 """
261
262 def has_config(self, key):
263 return True
264
265 def value(self, key):
266 return None
267
268
269 def convert_to_bool(value):
270 if isinstance(value, bool):
271 return value
272 if isinstance(value, string_type):
273 return value.lower() in ("yes", "true", "t", "1")
274 # Unknown type - default to false?
275 return False
276
277
278 def convert_to_float(value):
279 try:
280 return float(value)
281 except ValueError:
282 return 0.0
283
284
285 def convert_to_list(value):
286 if isinstance(value, list):
287 return value
288 if isinstance(value, tuple):
289 return list(value)
290 if isinstance(value, string_type):
291 # Split on commas
292 return [item.strip() for item in value.split(",") if item]
293 # Unknown type - default to empty?
294 return []
295
296
297 CONVERSIONS = {
298 "collect_remote_ip": convert_to_bool,
299 "core_agent_download": convert_to_bool,
300 "core_agent_launch": convert_to_bool,
301 "disabled_instruments": convert_to_list,
302 "ignore": convert_to_list,
303 "monitor": convert_to_bool,
304 "shutdown_message_enabled": convert_to_bool,
305 "shutdown_timeout_seconds": convert_to_float,
306 }
307
308
309 scout_config = ScoutConfig()
310
[end of src/scout_apm/core/config.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/src/scout_apm/core/config.py b/src/scout_apm/core/config.py
--- a/src/scout_apm/core/config.py
+++ b/src/scout_apm/core/config.py
@@ -220,7 +220,7 @@
"core_agent_log_level": "info",
"core_agent_permissions": 700,
"core_agent_socket_path": "tcp://127.0.0.1:6590",
- "core_agent_version": "v1.3.1", # can be an exact tag name, or 'latest'
+ "core_agent_version": "v1.4.0", # can be an exact tag name, or 'latest'
"disabled_instruments": [],
"download_url": "https://s3-us-west-1.amazonaws.com/scout-public-downloads/apm_core_agent/release", # noqa: B950
"errors_batch_size": 5,
| {"golden_diff": "diff --git a/src/scout_apm/core/config.py b/src/scout_apm/core/config.py\n--- a/src/scout_apm/core/config.py\n+++ b/src/scout_apm/core/config.py\n@@ -220,7 +220,7 @@\n \"core_agent_log_level\": \"info\",\n \"core_agent_permissions\": 700,\n \"core_agent_socket_path\": \"tcp://127.0.0.1:6590\",\n- \"core_agent_version\": \"v1.3.1\", # can be an exact tag name, or 'latest'\n+ \"core_agent_version\": \"v1.4.0\", # can be an exact tag name, or 'latest'\n \"disabled_instruments\": [],\n \"download_url\": \"https://s3-us-west-1.amazonaws.com/scout-public-downloads/apm_core_agent/release\", # noqa: B950\n \"errors_batch_size\": 5,\n", "issue": "Bump core agent version to 1.4.0\nPlease update the Python agent dependency of core agent to core agent v1.4.0.\n", "before_files": [{"content": "# coding=utf-8\nfrom __future__ import absolute_import, division, print_function, unicode_literals\n\nimport logging\nimport os\nimport re\nimport warnings\n\nfrom scout_apm.compat import string_type\nfrom scout_apm.core import platform_detection\n\nlogger = logging.getLogger(__name__)\n\nkey_regex = re.compile(r\"[a-zA-Z0-9]{16}\")\n\n\nclass ScoutConfig(object):\n \"\"\"\n Configuration object for the ScoutApm agent.\n\n Contains a list of configuration \"layers\". When a configuration key is\n looked up, each layer is asked in turn if it knows the value. The first one\n to answer affirmatively returns the value.\n \"\"\"\n\n def __init__(self):\n self.layers = [\n Env(),\n Python(),\n Derived(self),\n Defaults(),\n Null(),\n ]\n\n def value(self, key):\n value = self.locate_layer_for_key(key).value(key)\n if key in CONVERSIONS:\n return CONVERSIONS[key](value)\n return value\n\n def locate_layer_for_key(self, key):\n for layer in self.layers:\n if layer.has_config(key):\n return layer\n\n # Should be unreachable because Null returns None for all keys.\n raise ValueError(\"key {!r} not found in any layer\".format(key))\n\n def log(self):\n logger.debug(\"Configuration Loaded:\")\n for key in self.known_keys:\n if key in self.secret_keys:\n continue\n\n layer = self.locate_layer_for_key(key)\n logger.debug(\n \"%-9s: %s = %s\",\n layer.__class__.__name__,\n key,\n layer.value(key),\n )\n\n known_keys = [\n \"app_server\",\n \"application_root\",\n \"collect_remote_ip\",\n \"core_agent_config_file\",\n \"core_agent_dir\",\n \"core_agent_download\",\n \"core_agent_launch\",\n \"core_agent_log_file\",\n \"core_agent_log_level\",\n \"core_agent_permissions\",\n \"core_agent_socket_path\",\n \"core_agent_version\",\n \"disabled_instruments\",\n \"download_url\",\n \"framework\",\n \"framework_version\",\n \"hostname\",\n \"ignore\",\n \"key\",\n \"log_level\",\n \"monitor\",\n \"name\",\n \"revision_sha\",\n \"scm_subdirectory\",\n \"shutdown_message_enabled\",\n \"shutdown_timeout_seconds\",\n ]\n\n secret_keys = {\"key\"}\n\n def core_agent_permissions(self):\n try:\n return int(str(self.value(\"core_agent_permissions\")), 8)\n except ValueError:\n logger.exception(\n \"Invalid core_agent_permissions value, using default of 0o700\"\n )\n return 0o700\n\n @classmethod\n def set(cls, **kwargs):\n \"\"\"\n Sets a configuration value for the Scout agent. Values set here will\n not override values set in ENV.\n \"\"\"\n for key, value in kwargs.items():\n SCOUT_PYTHON_VALUES[key] = value\n\n @classmethod\n def unset(cls, *keys):\n \"\"\"\n Removes a configuration value for the Scout agent.\n \"\"\"\n for key in keys:\n SCOUT_PYTHON_VALUES.pop(key, None)\n\n @classmethod\n def reset_all(cls):\n \"\"\"\n Remove all configuration settings set via `ScoutConfig.set(...)`.\n\n This is meant for use in testing.\n \"\"\"\n SCOUT_PYTHON_VALUES.clear()\n\n\n# Module-level data, the ScoutConfig.set(key=\"value\") adds to this\nSCOUT_PYTHON_VALUES = {}\n\n\nclass Python(object):\n \"\"\"\n A configuration overlay that lets other parts of python set values.\n \"\"\"\n\n def has_config(self, key):\n return key in SCOUT_PYTHON_VALUES\n\n def value(self, key):\n return SCOUT_PYTHON_VALUES[key]\n\n\nclass Env(object):\n \"\"\"\n Reads configuration from environment by prefixing the key\n requested with \"SCOUT_\"\n\n Example: the `key` config looks for SCOUT_KEY\n environment variable\n \"\"\"\n\n def has_config(self, key):\n env_key = self.modify_key(key)\n return env_key in os.environ\n\n def value(self, key):\n env_key = self.modify_key(key)\n return os.environ[env_key]\n\n def modify_key(self, key):\n env_key = (\"SCOUT_\" + key).upper()\n return env_key\n\n\nclass Derived(object):\n \"\"\"\n A configuration overlay that calculates from other values.\n \"\"\"\n\n def __init__(self, config):\n \"\"\"\n config argument is the overall ScoutConfig var, so we can lookup the\n components of the derived info.\n \"\"\"\n self.config = config\n\n def has_config(self, key):\n return self.lookup_func(key) is not None\n\n def value(self, key):\n return self.lookup_func(key)()\n\n def lookup_func(self, key):\n \"\"\"\n Returns the derive_#{key} function, or None if it isn't defined\n \"\"\"\n func_name = \"derive_\" + key\n return getattr(self, func_name, None)\n\n def derive_core_agent_full_name(self):\n triple = self.config.value(\"core_agent_triple\")\n if not platform_detection.is_valid_triple(triple):\n warnings.warn(\"Invalid value for core_agent_triple: {}\".format(triple))\n return \"{name}-{version}-{triple}\".format(\n name=\"scout_apm_core\",\n version=self.config.value(\"core_agent_version\"),\n triple=triple,\n )\n\n def derive_core_agent_triple(self):\n return platform_detection.get_triple()\n\n\nclass Defaults(object):\n \"\"\"\n Provides default values for important configurations\n \"\"\"\n\n def __init__(self):\n self.defaults = {\n \"app_server\": \"\",\n \"application_root\": os.getcwd(),\n \"collect_remote_ip\": True,\n \"core_agent_dir\": \"/tmp/scout_apm_core\",\n \"core_agent_download\": True,\n \"core_agent_launch\": True,\n \"core_agent_log_level\": \"info\",\n \"core_agent_permissions\": 700,\n \"core_agent_socket_path\": \"tcp://127.0.0.1:6590\",\n \"core_agent_version\": \"v1.3.1\", # can be an exact tag name, or 'latest'\n \"disabled_instruments\": [],\n \"download_url\": \"https://s3-us-west-1.amazonaws.com/scout-public-downloads/apm_core_agent/release\", # noqa: B950\n \"errors_batch_size\": 5,\n \"errors_enabled\": True,\n \"errors_ignored_exceptions\": (),\n \"errors_host\": \"https://errors.scoutapm.com\",\n \"framework\": \"\",\n \"framework_version\": \"\",\n \"hostname\": None,\n \"key\": \"\",\n \"monitor\": False,\n \"name\": \"Python App\",\n \"revision_sha\": self._git_revision_sha(),\n \"scm_subdirectory\": \"\",\n \"shutdown_message_enabled\": True,\n \"shutdown_timeout_seconds\": 2.0,\n \"uri_reporting\": \"filtered_params\",\n }\n\n def _git_revision_sha(self):\n # N.B. The environment variable SCOUT_REVISION_SHA may also be used,\n # but that will be picked up by Env\n return os.environ.get(\"HEROKU_SLUG_COMMIT\", \"\")\n\n def has_config(self, key):\n return key in self.defaults\n\n def value(self, key):\n return self.defaults[key]\n\n\nclass Null(object):\n \"\"\"\n Always answers that a key is present, but the value is None\n\n Used as the last step of the layered configuration.\n \"\"\"\n\n def has_config(self, key):\n return True\n\n def value(self, key):\n return None\n\n\ndef convert_to_bool(value):\n if isinstance(value, bool):\n return value\n if isinstance(value, string_type):\n return value.lower() in (\"yes\", \"true\", \"t\", \"1\")\n # Unknown type - default to false?\n return False\n\n\ndef convert_to_float(value):\n try:\n return float(value)\n except ValueError:\n return 0.0\n\n\ndef convert_to_list(value):\n if isinstance(value, list):\n return value\n if isinstance(value, tuple):\n return list(value)\n if isinstance(value, string_type):\n # Split on commas\n return [item.strip() for item in value.split(\",\") if item]\n # Unknown type - default to empty?\n return []\n\n\nCONVERSIONS = {\n \"collect_remote_ip\": convert_to_bool,\n \"core_agent_download\": convert_to_bool,\n \"core_agent_launch\": convert_to_bool,\n \"disabled_instruments\": convert_to_list,\n \"ignore\": convert_to_list,\n \"monitor\": convert_to_bool,\n \"shutdown_message_enabled\": convert_to_bool,\n \"shutdown_timeout_seconds\": convert_to_float,\n}\n\n\nscout_config = ScoutConfig()\n", "path": "src/scout_apm/core/config.py"}]} | 3,310 | 212 |
gh_patches_debug_54565 | rasdani/github-patches | git_diff | dbt-labs__dbt-core-2832 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
set colorama upper bound to <0.4.4
colorama v0.4.4 (released in the last 24 hours) is missing an sdist, which trips up the homebrew packaging step of our [dbt release flow](https://github.com/fishtown-analytics/dbt-release/runs/1249693542). Let's set the [upper bound](https://github.com/fishtown-analytics/dbt/blob/dev/kiyoshi-kuromiya/core/setup.py#L67) to <0.4.4 instead of <0.5 for now.
</issue>
<code>
[start of core/setup.py]
1 #!/usr/bin/env python
2 import os
3 import sys
4
5 if sys.version_info < (3, 6):
6 print('Error: dbt does not support this version of Python.')
7 print('Please upgrade to Python 3.6 or higher.')
8 sys.exit(1)
9
10
11 from setuptools import setup
12 try:
13 from setuptools import find_namespace_packages
14 except ImportError:
15 # the user has a downlevel version of setuptools.
16 print('Error: dbt requires setuptools v40.1.0 or higher.')
17 print('Please upgrade setuptools with "pip install --upgrade setuptools" '
18 'and try again')
19 sys.exit(1)
20
21
22 def read(fname):
23 return open(os.path.join(os.path.dirname(__file__), fname)).read()
24
25
26 package_name = "dbt-core"
27 package_version = "0.18.1rc1"
28 description = """dbt (data build tool) is a command line tool that helps \
29 analysts and engineers transform data in their warehouse more effectively"""
30
31
32 setup(
33 name=package_name,
34 version=package_version,
35 description=description,
36 long_description=description,
37 author="Fishtown Analytics",
38 author_email="[email protected]",
39 url="https://github.com/fishtown-analytics/dbt",
40 packages=find_namespace_packages(include=['dbt', 'dbt.*']),
41 package_data={
42 'dbt': [
43 'include/index.html',
44 'include/global_project/dbt_project.yml',
45 'include/global_project/docs/*.md',
46 'include/global_project/macros/*.sql',
47 'include/global_project/macros/**/*.sql',
48 'include/global_project/macros/**/**/*.sql',
49 'py.typed',
50 ]
51 },
52 test_suite='test',
53 entry_points={
54 'console_scripts': [
55 'dbt = dbt.main:main',
56 ],
57 },
58 scripts=[
59 'scripts/dbt',
60 ],
61 install_requires=[
62 'Jinja2==2.11.2',
63 'PyYAML>=3.11',
64 'sqlparse>=0.2.3,<0.4',
65 'networkx>=2.3,<3',
66 'minimal-snowplow-tracker==0.0.2',
67 'colorama>=0.3.9,<0.5',
68 'agate>=1.6,<2',
69 'isodate>=0.6,<0.7',
70 'json-rpc>=1.12,<2',
71 'werkzeug>=0.15,<0.17',
72 'dataclasses==0.6;python_version<"3.7"',
73 'hologram==0.0.10',
74 'logbook>=1.5,<1.6',
75 'typing-extensions>=3.7.4,<3.8',
76 # the following are all to match snowflake-connector-python
77 'requests>=2.18.0,<2.24.0',
78 'idna<2.10',
79 'cffi>=1.9,<1.15',
80 ],
81 zip_safe=False,
82 classifiers=[
83 'Development Status :: 5 - Production/Stable',
84
85 'License :: OSI Approved :: Apache Software License',
86
87 'Operating System :: Microsoft :: Windows',
88 'Operating System :: MacOS :: MacOS X',
89 'Operating System :: POSIX :: Linux',
90
91 'Programming Language :: Python :: 3.6',
92 'Programming Language :: Python :: 3.7',
93 'Programming Language :: Python :: 3.8',
94 ],
95 python_requires=">=3.6.3",
96 )
97
[end of core/setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/core/setup.py b/core/setup.py
--- a/core/setup.py
+++ b/core/setup.py
@@ -64,7 +64,7 @@
'sqlparse>=0.2.3,<0.4',
'networkx>=2.3,<3',
'minimal-snowplow-tracker==0.0.2',
- 'colorama>=0.3.9,<0.5',
+ 'colorama>=0.3.9,<0.4.4',
'agate>=1.6,<2',
'isodate>=0.6,<0.7',
'json-rpc>=1.12,<2',
| {"golden_diff": "diff --git a/core/setup.py b/core/setup.py\n--- a/core/setup.py\n+++ b/core/setup.py\n@@ -64,7 +64,7 @@\n 'sqlparse>=0.2.3,<0.4',\n 'networkx>=2.3,<3',\n 'minimal-snowplow-tracker==0.0.2',\n- 'colorama>=0.3.9,<0.5',\n+ 'colorama>=0.3.9,<0.4.4',\n 'agate>=1.6,<2',\n 'isodate>=0.6,<0.7',\n 'json-rpc>=1.12,<2',\n", "issue": "set colorama upper bound to <0.4.4\ncolorama v0.4.4 (released in the last 24 hours) is missing an sdist, which trips up the homebrew packaging step of our [dbt release flow](https://github.com/fishtown-analytics/dbt-release/runs/1249693542). Let's set the [upper bound](https://github.com/fishtown-analytics/dbt/blob/dev/kiyoshi-kuromiya/core/setup.py#L67) to <0.4.4 instead of <0.5 for now.\n", "before_files": [{"content": "#!/usr/bin/env python\nimport os\nimport sys\n\nif sys.version_info < (3, 6):\n print('Error: dbt does not support this version of Python.')\n print('Please upgrade to Python 3.6 or higher.')\n sys.exit(1)\n\n\nfrom setuptools import setup\ntry:\n from setuptools import find_namespace_packages\nexcept ImportError:\n # the user has a downlevel version of setuptools.\n print('Error: dbt requires setuptools v40.1.0 or higher.')\n print('Please upgrade setuptools with \"pip install --upgrade setuptools\" '\n 'and try again')\n sys.exit(1)\n\n\ndef read(fname):\n return open(os.path.join(os.path.dirname(__file__), fname)).read()\n\n\npackage_name = \"dbt-core\"\npackage_version = \"0.18.1rc1\"\ndescription = \"\"\"dbt (data build tool) is a command line tool that helps \\\nanalysts and engineers transform data in their warehouse more effectively\"\"\"\n\n\nsetup(\n name=package_name,\n version=package_version,\n description=description,\n long_description=description,\n author=\"Fishtown Analytics\",\n author_email=\"[email protected]\",\n url=\"https://github.com/fishtown-analytics/dbt\",\n packages=find_namespace_packages(include=['dbt', 'dbt.*']),\n package_data={\n 'dbt': [\n 'include/index.html',\n 'include/global_project/dbt_project.yml',\n 'include/global_project/docs/*.md',\n 'include/global_project/macros/*.sql',\n 'include/global_project/macros/**/*.sql',\n 'include/global_project/macros/**/**/*.sql',\n 'py.typed',\n ]\n },\n test_suite='test',\n entry_points={\n 'console_scripts': [\n 'dbt = dbt.main:main',\n ],\n },\n scripts=[\n 'scripts/dbt',\n ],\n install_requires=[\n 'Jinja2==2.11.2',\n 'PyYAML>=3.11',\n 'sqlparse>=0.2.3,<0.4',\n 'networkx>=2.3,<3',\n 'minimal-snowplow-tracker==0.0.2',\n 'colorama>=0.3.9,<0.5',\n 'agate>=1.6,<2',\n 'isodate>=0.6,<0.7',\n 'json-rpc>=1.12,<2',\n 'werkzeug>=0.15,<0.17',\n 'dataclasses==0.6;python_version<\"3.7\"',\n 'hologram==0.0.10',\n 'logbook>=1.5,<1.6',\n 'typing-extensions>=3.7.4,<3.8',\n # the following are all to match snowflake-connector-python\n 'requests>=2.18.0,<2.24.0',\n 'idna<2.10',\n 'cffi>=1.9,<1.15',\n ],\n zip_safe=False,\n classifiers=[\n 'Development Status :: 5 - Production/Stable',\n\n 'License :: OSI Approved :: Apache Software License',\n\n 'Operating System :: Microsoft :: Windows',\n 'Operating System :: MacOS :: MacOS X',\n 'Operating System :: POSIX :: Linux',\n\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n 'Programming Language :: Python :: 3.8',\n ],\n python_requires=\">=3.6.3\",\n)\n", "path": "core/setup.py"}]} | 1,621 | 148 |
gh_patches_debug_13897 | rasdani/github-patches | git_diff | deis__deis-3272 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Domain name validation: w3.domain.com
I tried to add a domain to my app: `deis domains:add w3.domain.com`
and got the following error :
`{u'domain': [u'Hostname does not look valid.']}`
w3.domain.com is a valid domain.
</issue>
<code>
[start of controller/api/serializers.py]
1 """
2 Classes to serialize the RESTful representation of Deis API models.
3 """
4
5 from __future__ import unicode_literals
6
7 import json
8 import re
9
10 from django.conf import settings
11 from django.contrib.auth.models import User
12 from django.utils import timezone
13 from rest_framework import serializers
14 from rest_framework.validators import UniqueTogetherValidator
15
16 from api import models
17
18
19 PROCTYPE_MATCH = re.compile(r'^(?P<type>[a-z]+)')
20 MEMLIMIT_MATCH = re.compile(r'^(?P<mem>[0-9]+[BbKkMmGg])$')
21 CPUSHARE_MATCH = re.compile(r'^(?P<cpu>[0-9]+)$')
22 TAGKEY_MATCH = re.compile(r'^[a-z]+$')
23 TAGVAL_MATCH = re.compile(r'^\w+$')
24
25
26 class JSONFieldSerializer(serializers.Field):
27 def to_representation(self, obj):
28 return obj
29
30 def to_internal_value(self, data):
31 try:
32 val = json.loads(data)
33 except TypeError:
34 val = data
35 return val
36
37
38 class ModelSerializer(serializers.ModelSerializer):
39
40 uuid = serializers.ReadOnlyField()
41
42 def get_validators(self):
43 """
44 Hack to remove DRF's UniqueTogetherValidator when it concerns the UUID.
45
46 See https://github.com/deis/deis/pull/2898#discussion_r23105147
47 """
48 validators = super(ModelSerializer, self).get_validators()
49 for v in validators:
50 if isinstance(v, UniqueTogetherValidator) and 'uuid' in v.fields:
51 validators.remove(v)
52 return validators
53
54
55 class UserSerializer(serializers.ModelSerializer):
56 class Meta:
57 model = User
58 fields = ['email', 'username', 'password', 'first_name', 'last_name', 'is_superuser',
59 'is_staff', 'groups', 'user_permissions', 'last_login', 'date_joined',
60 'is_active']
61 read_only_fields = ['is_superuser', 'is_staff', 'groups',
62 'user_permissions', 'last_login', 'date_joined', 'is_active']
63 extra_kwargs = {'password': {'write_only': True}}
64
65 def create(self, validated_data):
66 now = timezone.now()
67 user = User(
68 email=validated_data.get('email'),
69 username=validated_data.get('username'),
70 last_login=now,
71 date_joined=now,
72 is_active=True
73 )
74 if validated_data.get('first_name'):
75 user.first_name = validated_data['first_name']
76 if validated_data.get('last_name'):
77 user.last_name = validated_data['last_name']
78 user.set_password(validated_data['password'])
79 # Make the first signup an admin / superuser
80 if not User.objects.filter(is_superuser=True).exists():
81 user.is_superuser = user.is_staff = True
82 user.save()
83 return user
84
85
86 class AdminUserSerializer(serializers.ModelSerializer):
87 """Serialize admin status for a User model."""
88
89 class Meta:
90 model = User
91 fields = ['username', 'is_superuser']
92 read_only_fields = ['username']
93
94
95 class AppSerializer(ModelSerializer):
96 """Serialize a :class:`~api.models.App` model."""
97
98 owner = serializers.ReadOnlyField(source='owner.username')
99 structure = JSONFieldSerializer(required=False)
100 created = serializers.DateTimeField(format=settings.DEIS_DATETIME_FORMAT, read_only=True)
101 updated = serializers.DateTimeField(format=settings.DEIS_DATETIME_FORMAT, read_only=True)
102
103 class Meta:
104 """Metadata options for a :class:`AppSerializer`."""
105 model = models.App
106 fields = ['uuid', 'id', 'owner', 'url', 'structure', 'created', 'updated']
107 read_only_fields = ['uuid']
108
109
110 class BuildSerializer(ModelSerializer):
111 """Serialize a :class:`~api.models.Build` model."""
112
113 app = serializers.SlugRelatedField(slug_field='id', queryset=models.App.objects.all())
114 owner = serializers.ReadOnlyField(source='owner.username')
115 procfile = JSONFieldSerializer(required=False)
116 created = serializers.DateTimeField(format=settings.DEIS_DATETIME_FORMAT, read_only=True)
117 updated = serializers.DateTimeField(format=settings.DEIS_DATETIME_FORMAT, read_only=True)
118
119 class Meta:
120 """Metadata options for a :class:`BuildSerializer`."""
121 model = models.Build
122 fields = ['owner', 'app', 'image', 'sha', 'procfile', 'dockerfile', 'created',
123 'updated', 'uuid']
124 read_only_fields = ['uuid']
125
126
127 class ConfigSerializer(ModelSerializer):
128 """Serialize a :class:`~api.models.Config` model."""
129
130 app = serializers.SlugRelatedField(slug_field='id', queryset=models.App.objects.all())
131 owner = serializers.ReadOnlyField(source='owner.username')
132 values = JSONFieldSerializer(required=False)
133 memory = JSONFieldSerializer(required=False)
134 cpu = JSONFieldSerializer(required=False)
135 tags = JSONFieldSerializer(required=False)
136 created = serializers.DateTimeField(format=settings.DEIS_DATETIME_FORMAT, read_only=True)
137 updated = serializers.DateTimeField(format=settings.DEIS_DATETIME_FORMAT, read_only=True)
138
139 class Meta:
140 """Metadata options for a :class:`ConfigSerializer`."""
141 model = models.Config
142
143 def validate_memory(self, value):
144 for k, v in value.items():
145 if v is None: # use NoneType to unset a value
146 continue
147 if not re.match(PROCTYPE_MATCH, k):
148 raise serializers.ValidationError("Process types can only contain [a-z]")
149 if not re.match(MEMLIMIT_MATCH, str(v)):
150 raise serializers.ValidationError(
151 "Limit format: <number><unit>, where unit = B, K, M or G")
152 return value
153
154 def validate_cpu(self, value):
155 for k, v in value.items():
156 if v is None: # use NoneType to unset a value
157 continue
158 if not re.match(PROCTYPE_MATCH, k):
159 raise serializers.ValidationError("Process types can only contain [a-z]")
160 shares = re.match(CPUSHARE_MATCH, str(v))
161 if not shares:
162 raise serializers.ValidationError("CPU shares must be an integer")
163 for v in shares.groupdict().values():
164 try:
165 i = int(v)
166 except ValueError:
167 raise serializers.ValidationError("CPU shares must be an integer")
168 if i > 1024 or i < 0:
169 raise serializers.ValidationError("CPU shares must be between 0 and 1024")
170 return value
171
172 def validate_tags(self, value):
173 for k, v in value.items():
174 if v is None: # use NoneType to unset a value
175 continue
176 if not re.match(TAGKEY_MATCH, k):
177 raise serializers.ValidationError("Tag keys can only contain [a-z]")
178 if not re.match(TAGVAL_MATCH, str(v)):
179 raise serializers.ValidationError("Invalid tag value")
180 return value
181
182
183 class ReleaseSerializer(ModelSerializer):
184 """Serialize a :class:`~api.models.Release` model."""
185
186 app = serializers.SlugRelatedField(slug_field='id', queryset=models.App.objects.all())
187 owner = serializers.ReadOnlyField(source='owner.username')
188 created = serializers.DateTimeField(format=settings.DEIS_DATETIME_FORMAT, read_only=True)
189 updated = serializers.DateTimeField(format=settings.DEIS_DATETIME_FORMAT, read_only=True)
190
191 class Meta:
192 """Metadata options for a :class:`ReleaseSerializer`."""
193 model = models.Release
194
195
196 class ContainerSerializer(ModelSerializer):
197 """Serialize a :class:`~api.models.Container` model."""
198
199 app = serializers.SlugRelatedField(slug_field='id', queryset=models.App.objects.all())
200 owner = serializers.ReadOnlyField(source='owner.username')
201 created = serializers.DateTimeField(format=settings.DEIS_DATETIME_FORMAT, read_only=True)
202 updated = serializers.DateTimeField(format=settings.DEIS_DATETIME_FORMAT, read_only=True)
203 release = serializers.SerializerMethodField()
204
205 class Meta:
206 """Metadata options for a :class:`ContainerSerializer`."""
207 model = models.Container
208 fields = ['owner', 'app', 'release', 'type', 'num', 'state', 'created', 'updated', 'uuid']
209
210 def get_release(self, obj):
211 return "v{}".format(obj.release.version)
212
213
214 class KeySerializer(ModelSerializer):
215 """Serialize a :class:`~api.models.Key` model."""
216
217 owner = serializers.ReadOnlyField(source='owner.username')
218 created = serializers.DateTimeField(format=settings.DEIS_DATETIME_FORMAT, read_only=True)
219 updated = serializers.DateTimeField(format=settings.DEIS_DATETIME_FORMAT, read_only=True)
220
221 class Meta:
222 """Metadata options for a KeySerializer."""
223 model = models.Key
224
225
226 class DomainSerializer(ModelSerializer):
227 """Serialize a :class:`~api.models.Domain` model."""
228
229 app = serializers.SlugRelatedField(slug_field='id', queryset=models.App.objects.all())
230 owner = serializers.ReadOnlyField(source='owner.username')
231 created = serializers.DateTimeField(format=settings.DEIS_DATETIME_FORMAT, read_only=True)
232 updated = serializers.DateTimeField(format=settings.DEIS_DATETIME_FORMAT, read_only=True)
233
234 class Meta:
235 """Metadata options for a :class:`DomainSerializer`."""
236 model = models.Domain
237 fields = ['uuid', 'owner', 'created', 'updated', 'app', 'domain']
238
239 def validate_domain(self, value):
240 """
241 Check that the hostname is valid
242 """
243 if len(value) > 255:
244 raise serializers.ValidationError('Hostname must be 255 characters or less.')
245 if value[-1:] == ".":
246 value = value[:-1] # strip exactly one dot from the right, if present
247 labels = value.split('.')
248 if labels[0] == '*':
249 raise serializers.ValidationError(
250 'Adding a wildcard subdomain is currently not supported.')
251 allowed = re.compile("^(?!-)[a-z0-9-]{1,63}(?<!-)$", re.IGNORECASE)
252 for label in labels:
253 match = allowed.match(label)
254 if not match or '--' in label or label[-1].isdigit() or label.isdigit():
255 raise serializers.ValidationError('Hostname does not look valid.')
256 if models.Domain.objects.filter(domain=value).exists():
257 raise serializers.ValidationError(
258 "The domain {} is already in use by another app".format(value))
259 return value
260
261
262 class PushSerializer(ModelSerializer):
263 """Serialize a :class:`~api.models.Push` model."""
264
265 app = serializers.SlugRelatedField(slug_field='id', queryset=models.App.objects.all())
266 owner = serializers.ReadOnlyField(source='owner.username')
267 created = serializers.DateTimeField(format=settings.DEIS_DATETIME_FORMAT, read_only=True)
268 updated = serializers.DateTimeField(format=settings.DEIS_DATETIME_FORMAT, read_only=True)
269
270 class Meta:
271 """Metadata options for a :class:`PushSerializer`."""
272 model = models.Push
273 fields = ['uuid', 'owner', 'app', 'sha', 'fingerprint', 'receive_user', 'receive_repo',
274 'ssh_connection', 'ssh_original_command', 'created', 'updated']
275
[end of controller/api/serializers.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/controller/api/serializers.py b/controller/api/serializers.py
--- a/controller/api/serializers.py
+++ b/controller/api/serializers.py
@@ -251,7 +251,8 @@
allowed = re.compile("^(?!-)[a-z0-9-]{1,63}(?<!-)$", re.IGNORECASE)
for label in labels:
match = allowed.match(label)
- if not match or '--' in label or label[-1].isdigit() or label.isdigit():
+ if not match or '--' in label or label.isdigit() or \
+ len(labels) == 1 and any(char.isdigit() for char in label):
raise serializers.ValidationError('Hostname does not look valid.')
if models.Domain.objects.filter(domain=value).exists():
raise serializers.ValidationError(
| {"golden_diff": "diff --git a/controller/api/serializers.py b/controller/api/serializers.py\n--- a/controller/api/serializers.py\n+++ b/controller/api/serializers.py\n@@ -251,7 +251,8 @@\n allowed = re.compile(\"^(?!-)[a-z0-9-]{1,63}(?<!-)$\", re.IGNORECASE)\n for label in labels:\n match = allowed.match(label)\n- if not match or '--' in label or label[-1].isdigit() or label.isdigit():\n+ if not match or '--' in label or label.isdigit() or \\\n+ len(labels) == 1 and any(char.isdigit() for char in label):\n raise serializers.ValidationError('Hostname does not look valid.')\n if models.Domain.objects.filter(domain=value).exists():\n raise serializers.ValidationError(\n", "issue": "Domain name validation: w3.domain.com\nI tried to add a domain to my app: `deis domains:add w3.domain.com`\nand got the following error :\n`{u'domain': [u'Hostname does not look valid.']}`\nw3.domain.com is a valid domain.\n\n", "before_files": [{"content": "\"\"\"\nClasses to serialize the RESTful representation of Deis API models.\n\"\"\"\n\nfrom __future__ import unicode_literals\n\nimport json\nimport re\n\nfrom django.conf import settings\nfrom django.contrib.auth.models import User\nfrom django.utils import timezone\nfrom rest_framework import serializers\nfrom rest_framework.validators import UniqueTogetherValidator\n\nfrom api import models\n\n\nPROCTYPE_MATCH = re.compile(r'^(?P<type>[a-z]+)')\nMEMLIMIT_MATCH = re.compile(r'^(?P<mem>[0-9]+[BbKkMmGg])$')\nCPUSHARE_MATCH = re.compile(r'^(?P<cpu>[0-9]+)$')\nTAGKEY_MATCH = re.compile(r'^[a-z]+$')\nTAGVAL_MATCH = re.compile(r'^\\w+$')\n\n\nclass JSONFieldSerializer(serializers.Field):\n def to_representation(self, obj):\n return obj\n\n def to_internal_value(self, data):\n try:\n val = json.loads(data)\n except TypeError:\n val = data\n return val\n\n\nclass ModelSerializer(serializers.ModelSerializer):\n\n uuid = serializers.ReadOnlyField()\n\n def get_validators(self):\n \"\"\"\n Hack to remove DRF's UniqueTogetherValidator when it concerns the UUID.\n\n See https://github.com/deis/deis/pull/2898#discussion_r23105147\n \"\"\"\n validators = super(ModelSerializer, self).get_validators()\n for v in validators:\n if isinstance(v, UniqueTogetherValidator) and 'uuid' in v.fields:\n validators.remove(v)\n return validators\n\n\nclass UserSerializer(serializers.ModelSerializer):\n class Meta:\n model = User\n fields = ['email', 'username', 'password', 'first_name', 'last_name', 'is_superuser',\n 'is_staff', 'groups', 'user_permissions', 'last_login', 'date_joined',\n 'is_active']\n read_only_fields = ['is_superuser', 'is_staff', 'groups',\n 'user_permissions', 'last_login', 'date_joined', 'is_active']\n extra_kwargs = {'password': {'write_only': True}}\n\n def create(self, validated_data):\n now = timezone.now()\n user = User(\n email=validated_data.get('email'),\n username=validated_data.get('username'),\n last_login=now,\n date_joined=now,\n is_active=True\n )\n if validated_data.get('first_name'):\n user.first_name = validated_data['first_name']\n if validated_data.get('last_name'):\n user.last_name = validated_data['last_name']\n user.set_password(validated_data['password'])\n # Make the first signup an admin / superuser\n if not User.objects.filter(is_superuser=True).exists():\n user.is_superuser = user.is_staff = True\n user.save()\n return user\n\n\nclass AdminUserSerializer(serializers.ModelSerializer):\n \"\"\"Serialize admin status for a User model.\"\"\"\n\n class Meta:\n model = User\n fields = ['username', 'is_superuser']\n read_only_fields = ['username']\n\n\nclass AppSerializer(ModelSerializer):\n \"\"\"Serialize a :class:`~api.models.App` model.\"\"\"\n\n owner = serializers.ReadOnlyField(source='owner.username')\n structure = JSONFieldSerializer(required=False)\n created = serializers.DateTimeField(format=settings.DEIS_DATETIME_FORMAT, read_only=True)\n updated = serializers.DateTimeField(format=settings.DEIS_DATETIME_FORMAT, read_only=True)\n\n class Meta:\n \"\"\"Metadata options for a :class:`AppSerializer`.\"\"\"\n model = models.App\n fields = ['uuid', 'id', 'owner', 'url', 'structure', 'created', 'updated']\n read_only_fields = ['uuid']\n\n\nclass BuildSerializer(ModelSerializer):\n \"\"\"Serialize a :class:`~api.models.Build` model.\"\"\"\n\n app = serializers.SlugRelatedField(slug_field='id', queryset=models.App.objects.all())\n owner = serializers.ReadOnlyField(source='owner.username')\n procfile = JSONFieldSerializer(required=False)\n created = serializers.DateTimeField(format=settings.DEIS_DATETIME_FORMAT, read_only=True)\n updated = serializers.DateTimeField(format=settings.DEIS_DATETIME_FORMAT, read_only=True)\n\n class Meta:\n \"\"\"Metadata options for a :class:`BuildSerializer`.\"\"\"\n model = models.Build\n fields = ['owner', 'app', 'image', 'sha', 'procfile', 'dockerfile', 'created',\n 'updated', 'uuid']\n read_only_fields = ['uuid']\n\n\nclass ConfigSerializer(ModelSerializer):\n \"\"\"Serialize a :class:`~api.models.Config` model.\"\"\"\n\n app = serializers.SlugRelatedField(slug_field='id', queryset=models.App.objects.all())\n owner = serializers.ReadOnlyField(source='owner.username')\n values = JSONFieldSerializer(required=False)\n memory = JSONFieldSerializer(required=False)\n cpu = JSONFieldSerializer(required=False)\n tags = JSONFieldSerializer(required=False)\n created = serializers.DateTimeField(format=settings.DEIS_DATETIME_FORMAT, read_only=True)\n updated = serializers.DateTimeField(format=settings.DEIS_DATETIME_FORMAT, read_only=True)\n\n class Meta:\n \"\"\"Metadata options for a :class:`ConfigSerializer`.\"\"\"\n model = models.Config\n\n def validate_memory(self, value):\n for k, v in value.items():\n if v is None: # use NoneType to unset a value\n continue\n if not re.match(PROCTYPE_MATCH, k):\n raise serializers.ValidationError(\"Process types can only contain [a-z]\")\n if not re.match(MEMLIMIT_MATCH, str(v)):\n raise serializers.ValidationError(\n \"Limit format: <number><unit>, where unit = B, K, M or G\")\n return value\n\n def validate_cpu(self, value):\n for k, v in value.items():\n if v is None: # use NoneType to unset a value\n continue\n if not re.match(PROCTYPE_MATCH, k):\n raise serializers.ValidationError(\"Process types can only contain [a-z]\")\n shares = re.match(CPUSHARE_MATCH, str(v))\n if not shares:\n raise serializers.ValidationError(\"CPU shares must be an integer\")\n for v in shares.groupdict().values():\n try:\n i = int(v)\n except ValueError:\n raise serializers.ValidationError(\"CPU shares must be an integer\")\n if i > 1024 or i < 0:\n raise serializers.ValidationError(\"CPU shares must be between 0 and 1024\")\n return value\n\n def validate_tags(self, value):\n for k, v in value.items():\n if v is None: # use NoneType to unset a value\n continue\n if not re.match(TAGKEY_MATCH, k):\n raise serializers.ValidationError(\"Tag keys can only contain [a-z]\")\n if not re.match(TAGVAL_MATCH, str(v)):\n raise serializers.ValidationError(\"Invalid tag value\")\n return value\n\n\nclass ReleaseSerializer(ModelSerializer):\n \"\"\"Serialize a :class:`~api.models.Release` model.\"\"\"\n\n app = serializers.SlugRelatedField(slug_field='id', queryset=models.App.objects.all())\n owner = serializers.ReadOnlyField(source='owner.username')\n created = serializers.DateTimeField(format=settings.DEIS_DATETIME_FORMAT, read_only=True)\n updated = serializers.DateTimeField(format=settings.DEIS_DATETIME_FORMAT, read_only=True)\n\n class Meta:\n \"\"\"Metadata options for a :class:`ReleaseSerializer`.\"\"\"\n model = models.Release\n\n\nclass ContainerSerializer(ModelSerializer):\n \"\"\"Serialize a :class:`~api.models.Container` model.\"\"\"\n\n app = serializers.SlugRelatedField(slug_field='id', queryset=models.App.objects.all())\n owner = serializers.ReadOnlyField(source='owner.username')\n created = serializers.DateTimeField(format=settings.DEIS_DATETIME_FORMAT, read_only=True)\n updated = serializers.DateTimeField(format=settings.DEIS_DATETIME_FORMAT, read_only=True)\n release = serializers.SerializerMethodField()\n\n class Meta:\n \"\"\"Metadata options for a :class:`ContainerSerializer`.\"\"\"\n model = models.Container\n fields = ['owner', 'app', 'release', 'type', 'num', 'state', 'created', 'updated', 'uuid']\n\n def get_release(self, obj):\n return \"v{}\".format(obj.release.version)\n\n\nclass KeySerializer(ModelSerializer):\n \"\"\"Serialize a :class:`~api.models.Key` model.\"\"\"\n\n owner = serializers.ReadOnlyField(source='owner.username')\n created = serializers.DateTimeField(format=settings.DEIS_DATETIME_FORMAT, read_only=True)\n updated = serializers.DateTimeField(format=settings.DEIS_DATETIME_FORMAT, read_only=True)\n\n class Meta:\n \"\"\"Metadata options for a KeySerializer.\"\"\"\n model = models.Key\n\n\nclass DomainSerializer(ModelSerializer):\n \"\"\"Serialize a :class:`~api.models.Domain` model.\"\"\"\n\n app = serializers.SlugRelatedField(slug_field='id', queryset=models.App.objects.all())\n owner = serializers.ReadOnlyField(source='owner.username')\n created = serializers.DateTimeField(format=settings.DEIS_DATETIME_FORMAT, read_only=True)\n updated = serializers.DateTimeField(format=settings.DEIS_DATETIME_FORMAT, read_only=True)\n\n class Meta:\n \"\"\"Metadata options for a :class:`DomainSerializer`.\"\"\"\n model = models.Domain\n fields = ['uuid', 'owner', 'created', 'updated', 'app', 'domain']\n\n def validate_domain(self, value):\n \"\"\"\n Check that the hostname is valid\n \"\"\"\n if len(value) > 255:\n raise serializers.ValidationError('Hostname must be 255 characters or less.')\n if value[-1:] == \".\":\n value = value[:-1] # strip exactly one dot from the right, if present\n labels = value.split('.')\n if labels[0] == '*':\n raise serializers.ValidationError(\n 'Adding a wildcard subdomain is currently not supported.')\n allowed = re.compile(\"^(?!-)[a-z0-9-]{1,63}(?<!-)$\", re.IGNORECASE)\n for label in labels:\n match = allowed.match(label)\n if not match or '--' in label or label[-1].isdigit() or label.isdigit():\n raise serializers.ValidationError('Hostname does not look valid.')\n if models.Domain.objects.filter(domain=value).exists():\n raise serializers.ValidationError(\n \"The domain {} is already in use by another app\".format(value))\n return value\n\n\nclass PushSerializer(ModelSerializer):\n \"\"\"Serialize a :class:`~api.models.Push` model.\"\"\"\n\n app = serializers.SlugRelatedField(slug_field='id', queryset=models.App.objects.all())\n owner = serializers.ReadOnlyField(source='owner.username')\n created = serializers.DateTimeField(format=settings.DEIS_DATETIME_FORMAT, read_only=True)\n updated = serializers.DateTimeField(format=settings.DEIS_DATETIME_FORMAT, read_only=True)\n\n class Meta:\n \"\"\"Metadata options for a :class:`PushSerializer`.\"\"\"\n model = models.Push\n fields = ['uuid', 'owner', 'app', 'sha', 'fingerprint', 'receive_user', 'receive_repo',\n 'ssh_connection', 'ssh_original_command', 'created', 'updated']\n", "path": "controller/api/serializers.py"}]} | 3,635 | 176 |
gh_patches_debug_30520 | rasdani/github-patches | git_diff | ray-project__ray-4518 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[tune] Add `--output` to the Tune docs
We should add --output to the docs.
_Originally posted by @richardliaw in https://github.com/ray-project/ray/pull/4322#issuecomment-477903993_
cc @andrewztan
</issue>
<code>
[start of python/ray/tune/commands.py]
1 from __future__ import absolute_import
2 from __future__ import division
3 from __future__ import print_function
4
5 import glob
6 import json
7 import logging
8 import os
9 import sys
10 import subprocess
11 import operator
12 from datetime import datetime
13
14 import pandas as pd
15 from pandas.api.types import is_string_dtype, is_numeric_dtype
16 from ray.tune.util import flatten_dict
17 from ray.tune.result import TRAINING_ITERATION, MEAN_ACCURACY, MEAN_LOSS
18 from ray.tune.trial import Trial
19 try:
20 from tabulate import tabulate
21 except ImportError:
22 tabulate = None
23
24 logger = logging.getLogger(__name__)
25
26 EDITOR = os.getenv("EDITOR", "vim")
27
28 TIMESTAMP_FORMAT = "%Y-%m-%d %H:%M:%S (%A)"
29
30 DEFAULT_EXPERIMENT_INFO_KEYS = (
31 "trainable_name",
32 "experiment_tag",
33 "trial_id",
34 "status",
35 "last_update_time",
36 )
37
38 DEFAULT_RESULT_KEYS = (TRAINING_ITERATION, MEAN_ACCURACY, MEAN_LOSS)
39
40 DEFAULT_PROJECT_INFO_KEYS = (
41 "name",
42 "total_trials",
43 "running_trials",
44 "terminated_trials",
45 "error_trials",
46 "last_updated",
47 )
48
49 try:
50 TERM_HEIGHT, TERM_WIDTH = subprocess.check_output(["stty", "size"]).split()
51 TERM_HEIGHT, TERM_WIDTH = int(TERM_HEIGHT), int(TERM_WIDTH)
52 except subprocess.CalledProcessError:
53 TERM_HEIGHT, TERM_WIDTH = 100, 100
54
55 OPERATORS = {
56 '<': operator.lt,
57 '<=': operator.le,
58 '==': operator.eq,
59 '!=': operator.ne,
60 '>=': operator.ge,
61 '>': operator.gt,
62 }
63
64
65 def _check_tabulate():
66 """Checks whether tabulate is installed."""
67 if tabulate is None:
68 raise ImportError(
69 "Tabulate not installed. Please run `pip install tabulate`.")
70
71
72 def print_format_output(dataframe):
73 """Prints output of given dataframe to fit into terminal.
74
75 Returns:
76 table (pd.DataFrame): Final outputted dataframe.
77 dropped_cols (list): Columns dropped due to terminal size.
78 empty_cols (list): Empty columns (dropped on default).
79 """
80 print_df = pd.DataFrame()
81 dropped_cols = []
82 empty_cols = []
83 # column display priority is based on the info_keys passed in
84 for i, col in enumerate(dataframe):
85 if dataframe[col].isnull().all():
86 # Don't add col to print_df if is fully empty
87 empty_cols += [col]
88 continue
89
90 print_df[col] = dataframe[col]
91 test_table = tabulate(print_df, headers="keys", tablefmt="psql")
92 if str(test_table).index('\n') > TERM_WIDTH:
93 # Drop all columns beyond terminal width
94 print_df.drop(col, axis=1, inplace=True)
95 dropped_cols += list(dataframe.columns)[i:]
96 break
97
98 table = tabulate(
99 print_df, headers="keys", tablefmt="psql", showindex="never")
100
101 print(table)
102 if dropped_cols:
103 print("Dropped columns:", dropped_cols)
104 print("Please increase your terminal size to view remaining columns.")
105 if empty_cols:
106 print("Empty columns:", empty_cols)
107
108 return table, dropped_cols, empty_cols
109
110
111 def _get_experiment_state(experiment_path, exit_on_fail=False):
112 experiment_path = os.path.expanduser(experiment_path)
113 experiment_state_paths = glob.glob(
114 os.path.join(experiment_path, "experiment_state*.json"))
115 if not experiment_state_paths:
116 if exit_on_fail:
117 print("No experiment state found!")
118 sys.exit(0)
119 else:
120 return
121 experiment_filename = max(list(experiment_state_paths))
122
123 with open(experiment_filename) as f:
124 experiment_state = json.load(f)
125 return experiment_state
126
127
128 def list_trials(experiment_path,
129 sort=None,
130 output=None,
131 filter_op=None,
132 info_keys=DEFAULT_EXPERIMENT_INFO_KEYS,
133 result_keys=DEFAULT_RESULT_KEYS):
134 """Lists trials in the directory subtree starting at the given path.
135
136 Args:
137 experiment_path (str): Directory where trials are located.
138 Corresponds to Experiment.local_dir/Experiment.name.
139 sort (str): Key to sort by.
140 output (str): Name of file where output is saved.
141 filter_op (str): Filter operation in the format
142 "<column> <operator> <value>".
143 info_keys (list): Keys that are displayed.
144 result_keys (list): Keys of last result that are displayed.
145 """
146 _check_tabulate()
147 experiment_state = _get_experiment_state(
148 experiment_path, exit_on_fail=True)
149
150 checkpoint_dicts = experiment_state["checkpoints"]
151 checkpoint_dicts = [flatten_dict(g) for g in checkpoint_dicts]
152 checkpoints_df = pd.DataFrame(checkpoint_dicts)
153
154 result_keys = ["last_result:{}".format(k) for k in result_keys]
155 col_keys = [
156 k for k in list(info_keys) + result_keys if k in checkpoints_df
157 ]
158 checkpoints_df = checkpoints_df[col_keys]
159
160 if "last_update_time" in checkpoints_df:
161 with pd.option_context("mode.use_inf_as_null", True):
162 datetime_series = checkpoints_df["last_update_time"].dropna()
163
164 datetime_series = datetime_series.apply(
165 lambda t: datetime.fromtimestamp(t).strftime(TIMESTAMP_FORMAT))
166 checkpoints_df["last_update_time"] = datetime_series
167
168 if "logdir" in checkpoints_df:
169 # logdir often too verbose to view in table, so drop experiment_path
170 checkpoints_df["logdir"] = checkpoints_df["logdir"].str.replace(
171 experiment_path, '')
172
173 if filter_op:
174 col, op, val = filter_op.split(' ')
175 col_type = checkpoints_df[col].dtype
176 if is_numeric_dtype(col_type):
177 val = float(val)
178 elif is_string_dtype(col_type):
179 val = str(val)
180 # TODO(Andrew): add support for datetime and boolean
181 else:
182 raise ValueError("Unsupported dtype for '{}': {}".format(
183 val, col_type))
184 op = OPERATORS[op]
185 filtered_index = op(checkpoints_df[col], val)
186 checkpoints_df = checkpoints_df[filtered_index]
187
188 if sort:
189 if sort not in checkpoints_df:
190 raise KeyError("Sort Index '{}' not in: {}".format(
191 sort, list(checkpoints_df)))
192 checkpoints_df = checkpoints_df.sort_values(by=sort)
193
194 print_format_output(checkpoints_df)
195
196 if output:
197 experiment_path = os.path.expanduser(experiment_path)
198 output_path = os.path.join(experiment_path, output)
199 file_extension = os.path.splitext(output)[1].lower()
200 if file_extension in (".p", ".pkl", ".pickle"):
201 checkpoints_df.to_pickle(output_path)
202 elif file_extension == ".csv":
203 checkpoints_df.to_csv(output_path, index=False)
204 else:
205 raise ValueError("Unsupported filetype: {}".format(output))
206 print("Output saved at:", output_path)
207
208
209 def list_experiments(project_path,
210 sort=None,
211 output=None,
212 filter_op=None,
213 info_keys=DEFAULT_PROJECT_INFO_KEYS):
214 """Lists experiments in the directory subtree.
215
216 Args:
217 project_path (str): Directory where experiments are located.
218 Corresponds to Experiment.local_dir.
219 sort (str): Key to sort by.
220 output (str): Name of file where output is saved.
221 filter_op (str): Filter operation in the format
222 "<column> <operator> <value>".
223 info_keys (list): Keys that are displayed.
224 """
225 _check_tabulate()
226 base, experiment_folders, _ = next(os.walk(project_path))
227
228 experiment_data_collection = []
229
230 for experiment_dir in experiment_folders:
231 experiment_state = _get_experiment_state(
232 os.path.join(base, experiment_dir))
233 if not experiment_state:
234 logger.debug("No experiment state found in %s", experiment_dir)
235 continue
236
237 checkpoints = pd.DataFrame(experiment_state["checkpoints"])
238 runner_data = experiment_state["runner_data"]
239
240 # Format time-based values.
241 time_values = {
242 "start_time": runner_data.get("_start_time"),
243 "last_updated": experiment_state.get("timestamp"),
244 }
245
246 formatted_time_values = {
247 key: datetime.fromtimestamp(val).strftime(TIMESTAMP_FORMAT)
248 if val else None
249 for key, val in time_values.items()
250 }
251
252 experiment_data = {
253 "name": experiment_dir,
254 "total_trials": checkpoints.shape[0],
255 "running_trials": (checkpoints["status"] == Trial.RUNNING).sum(),
256 "terminated_trials": (
257 checkpoints["status"] == Trial.TERMINATED).sum(),
258 "error_trials": (checkpoints["status"] == Trial.ERROR).sum(),
259 }
260 experiment_data.update(formatted_time_values)
261 experiment_data_collection.append(experiment_data)
262
263 if not experiment_data_collection:
264 print("No experiments found!")
265 sys.exit(0)
266
267 info_df = pd.DataFrame(experiment_data_collection)
268 col_keys = [k for k in list(info_keys) if k in info_df]
269 if not col_keys:
270 print("None of keys {} in experiment data!".format(info_keys))
271 sys.exit(0)
272 info_df = info_df[col_keys]
273
274 if filter_op:
275 col, op, val = filter_op.split(' ')
276 col_type = info_df[col].dtype
277 if is_numeric_dtype(col_type):
278 val = float(val)
279 elif is_string_dtype(col_type):
280 val = str(val)
281 # TODO(Andrew): add support for datetime and boolean
282 else:
283 raise ValueError("Unsupported dtype for '{}': {}".format(
284 val, col_type))
285 op = OPERATORS[op]
286 filtered_index = op(info_df[col], val)
287 info_df = info_df[filtered_index]
288
289 if sort:
290 if sort not in info_df:
291 raise KeyError("Sort Index '{}' not in: {}".format(
292 sort, list(info_df)))
293 info_df = info_df.sort_values(by=sort)
294
295 print_format_output(info_df)
296
297 if output:
298 output_path = os.path.join(base, output)
299 file_extension = os.path.splitext(output)[1].lower()
300 if file_extension in (".p", ".pkl", ".pickle"):
301 info_df.to_pickle(output_path)
302 elif file_extension == ".csv":
303 info_df.to_csv(output_path, index=False)
304 else:
305 raise ValueError("Unsupported filetype: {}".format(output))
306 print("Output saved at:", output_path)
307
308
309 def add_note(path, filename="note.txt"):
310 """Opens a txt file at the given path where user can add and save notes.
311
312 Args:
313 path (str): Directory where note will be saved.
314 filename (str): Name of note. Defaults to "note.txt"
315 """
316 path = os.path.expanduser(path)
317 assert os.path.isdir(path), "{} is not a valid directory.".format(path)
318
319 filepath = os.path.join(path, filename)
320 exists = os.path.isfile(filepath)
321
322 try:
323 subprocess.call([EDITOR, filepath])
324 except Exception as exc:
325 logger.error("Editing note failed!")
326 raise exc
327 if exists:
328 print("Note updated at:", filepath)
329 else:
330 print("Note created at:", filepath)
331
[end of python/ray/tune/commands.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/python/ray/tune/commands.py b/python/ray/tune/commands.py
--- a/python/ray/tune/commands.py
+++ b/python/ray/tune/commands.py
@@ -194,16 +194,14 @@
print_format_output(checkpoints_df)
if output:
- experiment_path = os.path.expanduser(experiment_path)
- output_path = os.path.join(experiment_path, output)
file_extension = os.path.splitext(output)[1].lower()
if file_extension in (".p", ".pkl", ".pickle"):
- checkpoints_df.to_pickle(output_path)
+ checkpoints_df.to_pickle(output)
elif file_extension == ".csv":
- checkpoints_df.to_csv(output_path, index=False)
+ checkpoints_df.to_csv(output, index=False)
else:
raise ValueError("Unsupported filetype: {}".format(output))
- print("Output saved at:", output_path)
+ print("Output saved at:", output)
def list_experiments(project_path,
@@ -295,15 +293,14 @@
print_format_output(info_df)
if output:
- output_path = os.path.join(base, output)
file_extension = os.path.splitext(output)[1].lower()
if file_extension in (".p", ".pkl", ".pickle"):
- info_df.to_pickle(output_path)
+ info_df.to_pickle(output)
elif file_extension == ".csv":
- info_df.to_csv(output_path, index=False)
+ info_df.to_csv(output, index=False)
else:
raise ValueError("Unsupported filetype: {}".format(output))
- print("Output saved at:", output_path)
+ print("Output saved at:", output)
def add_note(path, filename="note.txt"):
| {"golden_diff": "diff --git a/python/ray/tune/commands.py b/python/ray/tune/commands.py\n--- a/python/ray/tune/commands.py\n+++ b/python/ray/tune/commands.py\n@@ -194,16 +194,14 @@\n print_format_output(checkpoints_df)\n \n if output:\n- experiment_path = os.path.expanduser(experiment_path)\n- output_path = os.path.join(experiment_path, output)\n file_extension = os.path.splitext(output)[1].lower()\n if file_extension in (\".p\", \".pkl\", \".pickle\"):\n- checkpoints_df.to_pickle(output_path)\n+ checkpoints_df.to_pickle(output)\n elif file_extension == \".csv\":\n- checkpoints_df.to_csv(output_path, index=False)\n+ checkpoints_df.to_csv(output, index=False)\n else:\n raise ValueError(\"Unsupported filetype: {}\".format(output))\n- print(\"Output saved at:\", output_path)\n+ print(\"Output saved at:\", output)\n \n \n def list_experiments(project_path,\n@@ -295,15 +293,14 @@\n print_format_output(info_df)\n \n if output:\n- output_path = os.path.join(base, output)\n file_extension = os.path.splitext(output)[1].lower()\n if file_extension in (\".p\", \".pkl\", \".pickle\"):\n- info_df.to_pickle(output_path)\n+ info_df.to_pickle(output)\n elif file_extension == \".csv\":\n- info_df.to_csv(output_path, index=False)\n+ info_df.to_csv(output, index=False)\n else:\n raise ValueError(\"Unsupported filetype: {}\".format(output))\n- print(\"Output saved at:\", output_path)\n+ print(\"Output saved at:\", output)\n \n \n def add_note(path, filename=\"note.txt\"):\n", "issue": "[tune] Add `--output` to the Tune docs\nWe should add --output to the docs.\r\n\r\n_Originally posted by @richardliaw in https://github.com/ray-project/ray/pull/4322#issuecomment-477903993_\r\n\r\ncc @andrewztan\n", "before_files": [{"content": "from __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\n\nimport glob\nimport json\nimport logging\nimport os\nimport sys\nimport subprocess\nimport operator\nfrom datetime import datetime\n\nimport pandas as pd\nfrom pandas.api.types import is_string_dtype, is_numeric_dtype\nfrom ray.tune.util import flatten_dict\nfrom ray.tune.result import TRAINING_ITERATION, MEAN_ACCURACY, MEAN_LOSS\nfrom ray.tune.trial import Trial\ntry:\n from tabulate import tabulate\nexcept ImportError:\n tabulate = None\n\nlogger = logging.getLogger(__name__)\n\nEDITOR = os.getenv(\"EDITOR\", \"vim\")\n\nTIMESTAMP_FORMAT = \"%Y-%m-%d %H:%M:%S (%A)\"\n\nDEFAULT_EXPERIMENT_INFO_KEYS = (\n \"trainable_name\",\n \"experiment_tag\",\n \"trial_id\",\n \"status\",\n \"last_update_time\",\n)\n\nDEFAULT_RESULT_KEYS = (TRAINING_ITERATION, MEAN_ACCURACY, MEAN_LOSS)\n\nDEFAULT_PROJECT_INFO_KEYS = (\n \"name\",\n \"total_trials\",\n \"running_trials\",\n \"terminated_trials\",\n \"error_trials\",\n \"last_updated\",\n)\n\ntry:\n TERM_HEIGHT, TERM_WIDTH = subprocess.check_output([\"stty\", \"size\"]).split()\n TERM_HEIGHT, TERM_WIDTH = int(TERM_HEIGHT), int(TERM_WIDTH)\nexcept subprocess.CalledProcessError:\n TERM_HEIGHT, TERM_WIDTH = 100, 100\n\nOPERATORS = {\n '<': operator.lt,\n '<=': operator.le,\n '==': operator.eq,\n '!=': operator.ne,\n '>=': operator.ge,\n '>': operator.gt,\n}\n\n\ndef _check_tabulate():\n \"\"\"Checks whether tabulate is installed.\"\"\"\n if tabulate is None:\n raise ImportError(\n \"Tabulate not installed. Please run `pip install tabulate`.\")\n\n\ndef print_format_output(dataframe):\n \"\"\"Prints output of given dataframe to fit into terminal.\n\n Returns:\n table (pd.DataFrame): Final outputted dataframe.\n dropped_cols (list): Columns dropped due to terminal size.\n empty_cols (list): Empty columns (dropped on default).\n \"\"\"\n print_df = pd.DataFrame()\n dropped_cols = []\n empty_cols = []\n # column display priority is based on the info_keys passed in\n for i, col in enumerate(dataframe):\n if dataframe[col].isnull().all():\n # Don't add col to print_df if is fully empty\n empty_cols += [col]\n continue\n\n print_df[col] = dataframe[col]\n test_table = tabulate(print_df, headers=\"keys\", tablefmt=\"psql\")\n if str(test_table).index('\\n') > TERM_WIDTH:\n # Drop all columns beyond terminal width\n print_df.drop(col, axis=1, inplace=True)\n dropped_cols += list(dataframe.columns)[i:]\n break\n\n table = tabulate(\n print_df, headers=\"keys\", tablefmt=\"psql\", showindex=\"never\")\n\n print(table)\n if dropped_cols:\n print(\"Dropped columns:\", dropped_cols)\n print(\"Please increase your terminal size to view remaining columns.\")\n if empty_cols:\n print(\"Empty columns:\", empty_cols)\n\n return table, dropped_cols, empty_cols\n\n\ndef _get_experiment_state(experiment_path, exit_on_fail=False):\n experiment_path = os.path.expanduser(experiment_path)\n experiment_state_paths = glob.glob(\n os.path.join(experiment_path, \"experiment_state*.json\"))\n if not experiment_state_paths:\n if exit_on_fail:\n print(\"No experiment state found!\")\n sys.exit(0)\n else:\n return\n experiment_filename = max(list(experiment_state_paths))\n\n with open(experiment_filename) as f:\n experiment_state = json.load(f)\n return experiment_state\n\n\ndef list_trials(experiment_path,\n sort=None,\n output=None,\n filter_op=None,\n info_keys=DEFAULT_EXPERIMENT_INFO_KEYS,\n result_keys=DEFAULT_RESULT_KEYS):\n \"\"\"Lists trials in the directory subtree starting at the given path.\n\n Args:\n experiment_path (str): Directory where trials are located.\n Corresponds to Experiment.local_dir/Experiment.name.\n sort (str): Key to sort by.\n output (str): Name of file where output is saved.\n filter_op (str): Filter operation in the format\n \"<column> <operator> <value>\".\n info_keys (list): Keys that are displayed.\n result_keys (list): Keys of last result that are displayed.\n \"\"\"\n _check_tabulate()\n experiment_state = _get_experiment_state(\n experiment_path, exit_on_fail=True)\n\n checkpoint_dicts = experiment_state[\"checkpoints\"]\n checkpoint_dicts = [flatten_dict(g) for g in checkpoint_dicts]\n checkpoints_df = pd.DataFrame(checkpoint_dicts)\n\n result_keys = [\"last_result:{}\".format(k) for k in result_keys]\n col_keys = [\n k for k in list(info_keys) + result_keys if k in checkpoints_df\n ]\n checkpoints_df = checkpoints_df[col_keys]\n\n if \"last_update_time\" in checkpoints_df:\n with pd.option_context(\"mode.use_inf_as_null\", True):\n datetime_series = checkpoints_df[\"last_update_time\"].dropna()\n\n datetime_series = datetime_series.apply(\n lambda t: datetime.fromtimestamp(t).strftime(TIMESTAMP_FORMAT))\n checkpoints_df[\"last_update_time\"] = datetime_series\n\n if \"logdir\" in checkpoints_df:\n # logdir often too verbose to view in table, so drop experiment_path\n checkpoints_df[\"logdir\"] = checkpoints_df[\"logdir\"].str.replace(\n experiment_path, '')\n\n if filter_op:\n col, op, val = filter_op.split(' ')\n col_type = checkpoints_df[col].dtype\n if is_numeric_dtype(col_type):\n val = float(val)\n elif is_string_dtype(col_type):\n val = str(val)\n # TODO(Andrew): add support for datetime and boolean\n else:\n raise ValueError(\"Unsupported dtype for '{}': {}\".format(\n val, col_type))\n op = OPERATORS[op]\n filtered_index = op(checkpoints_df[col], val)\n checkpoints_df = checkpoints_df[filtered_index]\n\n if sort:\n if sort not in checkpoints_df:\n raise KeyError(\"Sort Index '{}' not in: {}\".format(\n sort, list(checkpoints_df)))\n checkpoints_df = checkpoints_df.sort_values(by=sort)\n\n print_format_output(checkpoints_df)\n\n if output:\n experiment_path = os.path.expanduser(experiment_path)\n output_path = os.path.join(experiment_path, output)\n file_extension = os.path.splitext(output)[1].lower()\n if file_extension in (\".p\", \".pkl\", \".pickle\"):\n checkpoints_df.to_pickle(output_path)\n elif file_extension == \".csv\":\n checkpoints_df.to_csv(output_path, index=False)\n else:\n raise ValueError(\"Unsupported filetype: {}\".format(output))\n print(\"Output saved at:\", output_path)\n\n\ndef list_experiments(project_path,\n sort=None,\n output=None,\n filter_op=None,\n info_keys=DEFAULT_PROJECT_INFO_KEYS):\n \"\"\"Lists experiments in the directory subtree.\n\n Args:\n project_path (str): Directory where experiments are located.\n Corresponds to Experiment.local_dir.\n sort (str): Key to sort by.\n output (str): Name of file where output is saved.\n filter_op (str): Filter operation in the format\n \"<column> <operator> <value>\".\n info_keys (list): Keys that are displayed.\n \"\"\"\n _check_tabulate()\n base, experiment_folders, _ = next(os.walk(project_path))\n\n experiment_data_collection = []\n\n for experiment_dir in experiment_folders:\n experiment_state = _get_experiment_state(\n os.path.join(base, experiment_dir))\n if not experiment_state:\n logger.debug(\"No experiment state found in %s\", experiment_dir)\n continue\n\n checkpoints = pd.DataFrame(experiment_state[\"checkpoints\"])\n runner_data = experiment_state[\"runner_data\"]\n\n # Format time-based values.\n time_values = {\n \"start_time\": runner_data.get(\"_start_time\"),\n \"last_updated\": experiment_state.get(\"timestamp\"),\n }\n\n formatted_time_values = {\n key: datetime.fromtimestamp(val).strftime(TIMESTAMP_FORMAT)\n if val else None\n for key, val in time_values.items()\n }\n\n experiment_data = {\n \"name\": experiment_dir,\n \"total_trials\": checkpoints.shape[0],\n \"running_trials\": (checkpoints[\"status\"] == Trial.RUNNING).sum(),\n \"terminated_trials\": (\n checkpoints[\"status\"] == Trial.TERMINATED).sum(),\n \"error_trials\": (checkpoints[\"status\"] == Trial.ERROR).sum(),\n }\n experiment_data.update(formatted_time_values)\n experiment_data_collection.append(experiment_data)\n\n if not experiment_data_collection:\n print(\"No experiments found!\")\n sys.exit(0)\n\n info_df = pd.DataFrame(experiment_data_collection)\n col_keys = [k for k in list(info_keys) if k in info_df]\n if not col_keys:\n print(\"None of keys {} in experiment data!\".format(info_keys))\n sys.exit(0)\n info_df = info_df[col_keys]\n\n if filter_op:\n col, op, val = filter_op.split(' ')\n col_type = info_df[col].dtype\n if is_numeric_dtype(col_type):\n val = float(val)\n elif is_string_dtype(col_type):\n val = str(val)\n # TODO(Andrew): add support for datetime and boolean\n else:\n raise ValueError(\"Unsupported dtype for '{}': {}\".format(\n val, col_type))\n op = OPERATORS[op]\n filtered_index = op(info_df[col], val)\n info_df = info_df[filtered_index]\n\n if sort:\n if sort not in info_df:\n raise KeyError(\"Sort Index '{}' not in: {}\".format(\n sort, list(info_df)))\n info_df = info_df.sort_values(by=sort)\n\n print_format_output(info_df)\n\n if output:\n output_path = os.path.join(base, output)\n file_extension = os.path.splitext(output)[1].lower()\n if file_extension in (\".p\", \".pkl\", \".pickle\"):\n info_df.to_pickle(output_path)\n elif file_extension == \".csv\":\n info_df.to_csv(output_path, index=False)\n else:\n raise ValueError(\"Unsupported filetype: {}\".format(output))\n print(\"Output saved at:\", output_path)\n\n\ndef add_note(path, filename=\"note.txt\"):\n \"\"\"Opens a txt file at the given path where user can add and save notes.\n\n Args:\n path (str): Directory where note will be saved.\n filename (str): Name of note. Defaults to \"note.txt\"\n \"\"\"\n path = os.path.expanduser(path)\n assert os.path.isdir(path), \"{} is not a valid directory.\".format(path)\n\n filepath = os.path.join(path, filename)\n exists = os.path.isfile(filepath)\n\n try:\n subprocess.call([EDITOR, filepath])\n except Exception as exc:\n logger.error(\"Editing note failed!\")\n raise exc\n if exists:\n print(\"Note updated at:\", filepath)\n else:\n print(\"Note created at:\", filepath)\n", "path": "python/ray/tune/commands.py"}]} | 3,925 | 383 |
gh_patches_debug_27270 | rasdani/github-patches | git_diff | PaddlePaddle__PaddleNLP-2090 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
ann_utils 当 output_emb_size = 0 时报错
欢迎您反馈PaddleNLP使用问题,非常感谢您对PaddleNLP的贡献!
在留下您的问题时,辛苦您同步提供如下信息:
- 版本、环境信息
1)PaddleNLP和PaddlePaddle版本:请提供您的PaddleNLP和PaddlePaddle版本号,例如PaddleNLP 2.0.4,PaddlePaddle2.1.1
2)系统环境:请您描述系统类型,例如Linux/Windows/MacOS/,python版本
- 复现信息:如为报错,请给出复现环境、复现步骤
</issue>
<code>
[start of applications/neural_search/recall/in_batch_negative/ann_util.py]
1 # Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 # coding=UTF-8
16
17 import numpy as np
18 import hnswlib
19 from paddlenlp.utils.log import logger
20
21
22 def build_index(args, data_loader, model):
23
24 index = hnswlib.Index(space='ip', dim=args.output_emb_size)
25
26 # Initializing index
27 # max_elements - the maximum number of elements (capacity). Will throw an exception if exceeded
28 # during insertion of an element.
29 # The capacity can be increased by saving/loading the index, see below.
30 #
31 # ef_construction - controls index search speed/build speed tradeoff
32 #
33 # M - is tightly connected with internal dimensionality of the data. Strongly affects memory consumption (~M)
34 # Higher M leads to higher accuracy/run_time at fixed ef/efConstruction
35 index.init_index(
36 max_elements=args.hnsw_max_elements,
37 ef_construction=args.hnsw_ef,
38 M=args.hnsw_m)
39
40 # Controlling the recall by setting ef:
41 # higher ef leads to better accuracy, but slower search
42 index.set_ef(args.hnsw_ef)
43
44 # Set number of threads used during batch search/construction
45 # By default using all available cores
46 index.set_num_threads(16)
47
48 logger.info("start build index..........")
49
50 all_embeddings = []
51
52 for text_embeddings in model.get_semantic_embedding(data_loader):
53 all_embeddings.append(text_embeddings.numpy())
54
55 all_embeddings = np.concatenate(all_embeddings, axis=0)
56 index.add_items(all_embeddings)
57
58 logger.info("Total index number:{}".format(index.get_current_count()))
59
60 return index
61
[end of applications/neural_search/recall/in_batch_negative/ann_util.py]
[start of applications/question_answering/faq_system/ann_util.py]
1 # Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import numpy as np
16 import hnswlib
17 from paddlenlp.utils.log import logger
18
19
20 def build_index(args, data_loader, model):
21
22 index = hnswlib.Index(space='ip', dim=args.output_emb_size)
23
24 # Initializing index
25 # max_elements - the maximum number of elements (capacity). Will throw an exception if exceeded
26 # during insertion of an element.
27 # The capacity can be increased by saving/loading the index, see below.
28 #
29 # ef_construction - controls index search speed/build speed tradeoff
30 #
31 # M - is tightly connected with internal dimensionality of the data. Strongly affects memory consumption (~M)
32 # Higher M leads to higher accuracy/run_time at fixed ef/efConstruction
33 index.init_index(
34 max_elements=args.hnsw_max_elements,
35 ef_construction=args.hnsw_ef,
36 M=args.hnsw_m)
37
38 # Controlling the recall by setting ef:
39 # higher ef leads to better accuracy, but slower search
40 index.set_ef(args.hnsw_ef)
41
42 # Set number of threads used during batch search/construction
43 # By default using all available cores
44 index.set_num_threads(16)
45
46 logger.info("start build index..........")
47
48 all_embeddings = []
49
50 for text_embeddings in model.get_semantic_embedding(data_loader):
51 all_embeddings.append(text_embeddings.numpy())
52
53 all_embeddings = np.concatenate(all_embeddings, axis=0)
54 index.add_items(all_embeddings)
55
56 logger.info("Total index number:{}".format(index.get_current_count()))
57
58 return index
59
[end of applications/question_answering/faq_system/ann_util.py]
[start of applications/question_answering/faq_finance/ann_util.py]
1 # Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import numpy as np
16 import hnswlib
17 from paddlenlp.utils.log import logger
18
19
20 def build_index(args, data_loader, model):
21
22 index = hnswlib.Index(space='ip', dim=args.output_emb_size)
23
24 # Initializing index
25 # max_elements - the maximum number of elements (capacity). Will throw an exception if exceeded
26 # during insertion of an element.
27 # The capacity can be increased by saving/loading the index, see below.
28 #
29 # ef_construction - controls index search speed/build speed tradeoff
30 #
31 # M - is tightly connected with internal dimensionality of the data. Strongly affects memory consumption (~M)
32 # Higher M leads to higher accuracy/run_time at fixed ef/efConstruction
33 index.init_index(
34 max_elements=args.hnsw_max_elements,
35 ef_construction=args.hnsw_ef,
36 M=args.hnsw_m)
37
38 # Controlling the recall by setting ef:
39 # higher ef leads to better accuracy, but slower search
40 index.set_ef(args.hnsw_ef)
41
42 # Set number of threads used during batch search/construction
43 # By default using all available cores
44 index.set_num_threads(16)
45
46 logger.info("start build index..........")
47
48 all_embeddings = []
49
50 for text_embeddings in model.get_semantic_embedding(data_loader):
51 all_embeddings.append(text_embeddings.numpy())
52
53 all_embeddings = np.concatenate(all_embeddings, axis=0)
54 index.add_items(all_embeddings)
55
56 logger.info("Total index number:{}".format(index.get_current_count()))
57
58 return index
59
[end of applications/question_answering/faq_finance/ann_util.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/applications/neural_search/recall/in_batch_negative/ann_util.py b/applications/neural_search/recall/in_batch_negative/ann_util.py
--- a/applications/neural_search/recall/in_batch_negative/ann_util.py
+++ b/applications/neural_search/recall/in_batch_negative/ann_util.py
@@ -21,7 +21,9 @@
def build_index(args, data_loader, model):
- index = hnswlib.Index(space='ip', dim=args.output_emb_size)
+ index = hnswlib.Index(
+ space='ip',
+ dim=args.output_emb_size if args.output_emb_size > 0 else 768)
# Initializing index
# max_elements - the maximum number of elements (capacity). Will throw an exception if exceeded
diff --git a/applications/question_answering/faq_finance/ann_util.py b/applications/question_answering/faq_finance/ann_util.py
--- a/applications/question_answering/faq_finance/ann_util.py
+++ b/applications/question_answering/faq_finance/ann_util.py
@@ -19,7 +19,9 @@
def build_index(args, data_loader, model):
- index = hnswlib.Index(space='ip', dim=args.output_emb_size)
+ index = hnswlib.Index(
+ space='ip',
+ dim=args.output_emb_size if args.output_emb_size > 0 else 768)
# Initializing index
# max_elements - the maximum number of elements (capacity). Will throw an exception if exceeded
diff --git a/applications/question_answering/faq_system/ann_util.py b/applications/question_answering/faq_system/ann_util.py
--- a/applications/question_answering/faq_system/ann_util.py
+++ b/applications/question_answering/faq_system/ann_util.py
@@ -19,7 +19,9 @@
def build_index(args, data_loader, model):
- index = hnswlib.Index(space='ip', dim=args.output_emb_size)
+ index = hnswlib.Index(
+ space='ip',
+ dim=args.output_emb_size if args.output_emb_size > 0 else 768)
# Initializing index
# max_elements - the maximum number of elements (capacity). Will throw an exception if exceeded
| {"golden_diff": "diff --git a/applications/neural_search/recall/in_batch_negative/ann_util.py b/applications/neural_search/recall/in_batch_negative/ann_util.py\n--- a/applications/neural_search/recall/in_batch_negative/ann_util.py\n+++ b/applications/neural_search/recall/in_batch_negative/ann_util.py\n@@ -21,7 +21,9 @@\n \n def build_index(args, data_loader, model):\n \n- index = hnswlib.Index(space='ip', dim=args.output_emb_size)\n+ index = hnswlib.Index(\n+ space='ip',\n+ dim=args.output_emb_size if args.output_emb_size > 0 else 768)\n \n # Initializing index\n # max_elements - the maximum number of elements (capacity). Will throw an exception if exceeded\ndiff --git a/applications/question_answering/faq_finance/ann_util.py b/applications/question_answering/faq_finance/ann_util.py\n--- a/applications/question_answering/faq_finance/ann_util.py\n+++ b/applications/question_answering/faq_finance/ann_util.py\n@@ -19,7 +19,9 @@\n \n def build_index(args, data_loader, model):\n \n- index = hnswlib.Index(space='ip', dim=args.output_emb_size)\n+ index = hnswlib.Index(\n+ space='ip',\n+ dim=args.output_emb_size if args.output_emb_size > 0 else 768)\n \n # Initializing index\n # max_elements - the maximum number of elements (capacity). Will throw an exception if exceeded\ndiff --git a/applications/question_answering/faq_system/ann_util.py b/applications/question_answering/faq_system/ann_util.py\n--- a/applications/question_answering/faq_system/ann_util.py\n+++ b/applications/question_answering/faq_system/ann_util.py\n@@ -19,7 +19,9 @@\n \n def build_index(args, data_loader, model):\n \n- index = hnswlib.Index(space='ip', dim=args.output_emb_size)\n+ index = hnswlib.Index(\n+ space='ip',\n+ dim=args.output_emb_size if args.output_emb_size > 0 else 768)\n \n # Initializing index\n # max_elements - the maximum number of elements (capacity). Will throw an exception if exceeded\n", "issue": "ann_utils \u5f53 output_emb_size = 0 \u65f6\u62a5\u9519\n\u6b22\u8fce\u60a8\u53cd\u9988PaddleNLP\u4f7f\u7528\u95ee\u9898\uff0c\u975e\u5e38\u611f\u8c22\u60a8\u5bf9PaddleNLP\u7684\u8d21\u732e\uff01\r\n\u5728\u7559\u4e0b\u60a8\u7684\u95ee\u9898\u65f6\uff0c\u8f9b\u82e6\u60a8\u540c\u6b65\u63d0\u4f9b\u5982\u4e0b\u4fe1\u606f\uff1a\r\n- \u7248\u672c\u3001\u73af\u5883\u4fe1\u606f\r\n1\uff09PaddleNLP\u548cPaddlePaddle\u7248\u672c\uff1a\u8bf7\u63d0\u4f9b\u60a8\u7684PaddleNLP\u548cPaddlePaddle\u7248\u672c\u53f7\uff0c\u4f8b\u5982PaddleNLP 2.0.4\uff0cPaddlePaddle2.1.1\r\n2\uff09\u7cfb\u7edf\u73af\u5883\uff1a\u8bf7\u60a8\u63cf\u8ff0\u7cfb\u7edf\u7c7b\u578b\uff0c\u4f8b\u5982Linux/Windows/MacOS/\uff0cpython\u7248\u672c\r\n- \u590d\u73b0\u4fe1\u606f\uff1a\u5982\u4e3a\u62a5\u9519\uff0c\u8bf7\u7ed9\u51fa\u590d\u73b0\u73af\u5883\u3001\u590d\u73b0\u6b65\u9aa4\r\n\n", "before_files": [{"content": "# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n# coding=UTF-8\n\nimport numpy as np\nimport hnswlib\nfrom paddlenlp.utils.log import logger\n\n\ndef build_index(args, data_loader, model):\n\n index = hnswlib.Index(space='ip', dim=args.output_emb_size)\n\n # Initializing index\n # max_elements - the maximum number of elements (capacity). Will throw an exception if exceeded\n # during insertion of an element.\n # The capacity can be increased by saving/loading the index, see below.\n #\n # ef_construction - controls index search speed/build speed tradeoff\n #\n # M - is tightly connected with internal dimensionality of the data. Strongly affects memory consumption (~M)\n # Higher M leads to higher accuracy/run_time at fixed ef/efConstruction\n index.init_index(\n max_elements=args.hnsw_max_elements,\n ef_construction=args.hnsw_ef,\n M=args.hnsw_m)\n\n # Controlling the recall by setting ef:\n # higher ef leads to better accuracy, but slower search\n index.set_ef(args.hnsw_ef)\n\n # Set number of threads used during batch search/construction\n # By default using all available cores\n index.set_num_threads(16)\n\n logger.info(\"start build index..........\")\n\n all_embeddings = []\n\n for text_embeddings in model.get_semantic_embedding(data_loader):\n all_embeddings.append(text_embeddings.numpy())\n\n all_embeddings = np.concatenate(all_embeddings, axis=0)\n index.add_items(all_embeddings)\n\n logger.info(\"Total index number:{}\".format(index.get_current_count()))\n\n return index\n", "path": "applications/neural_search/recall/in_batch_negative/ann_util.py"}, {"content": "# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport numpy as np\nimport hnswlib\nfrom paddlenlp.utils.log import logger\n\n\ndef build_index(args, data_loader, model):\n\n index = hnswlib.Index(space='ip', dim=args.output_emb_size)\n\n # Initializing index\n # max_elements - the maximum number of elements (capacity). Will throw an exception if exceeded\n # during insertion of an element.\n # The capacity can be increased by saving/loading the index, see below.\n #\n # ef_construction - controls index search speed/build speed tradeoff\n #\n # M - is tightly connected with internal dimensionality of the data. Strongly affects memory consumption (~M)\n # Higher M leads to higher accuracy/run_time at fixed ef/efConstruction\n index.init_index(\n max_elements=args.hnsw_max_elements,\n ef_construction=args.hnsw_ef,\n M=args.hnsw_m)\n\n # Controlling the recall by setting ef:\n # higher ef leads to better accuracy, but slower search\n index.set_ef(args.hnsw_ef)\n\n # Set number of threads used during batch search/construction\n # By default using all available cores\n index.set_num_threads(16)\n\n logger.info(\"start build index..........\")\n\n all_embeddings = []\n\n for text_embeddings in model.get_semantic_embedding(data_loader):\n all_embeddings.append(text_embeddings.numpy())\n\n all_embeddings = np.concatenate(all_embeddings, axis=0)\n index.add_items(all_embeddings)\n\n logger.info(\"Total index number:{}\".format(index.get_current_count()))\n\n return index\n", "path": "applications/question_answering/faq_system/ann_util.py"}, {"content": "# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport numpy as np\nimport hnswlib\nfrom paddlenlp.utils.log import logger\n\n\ndef build_index(args, data_loader, model):\n\n index = hnswlib.Index(space='ip', dim=args.output_emb_size)\n\n # Initializing index\n # max_elements - the maximum number of elements (capacity). Will throw an exception if exceeded\n # during insertion of an element.\n # The capacity can be increased by saving/loading the index, see below.\n #\n # ef_construction - controls index search speed/build speed tradeoff\n #\n # M - is tightly connected with internal dimensionality of the data. Strongly affects memory consumption (~M)\n # Higher M leads to higher accuracy/run_time at fixed ef/efConstruction\n index.init_index(\n max_elements=args.hnsw_max_elements,\n ef_construction=args.hnsw_ef,\n M=args.hnsw_m)\n\n # Controlling the recall by setting ef:\n # higher ef leads to better accuracy, but slower search\n index.set_ef(args.hnsw_ef)\n\n # Set number of threads used during batch search/construction\n # By default using all available cores\n index.set_num_threads(16)\n\n logger.info(\"start build index..........\")\n\n all_embeddings = []\n\n for text_embeddings in model.get_semantic_embedding(data_loader):\n all_embeddings.append(text_embeddings.numpy())\n\n all_embeddings = np.concatenate(all_embeddings, axis=0)\n index.add_items(all_embeddings)\n\n logger.info(\"Total index number:{}\".format(index.get_current_count()))\n\n return index\n", "path": "applications/question_answering/faq_finance/ann_util.py"}]} | 2,536 | 512 |
gh_patches_debug_1577 | rasdani/github-patches | git_diff | elastic__apm-agent-python-1690 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
KeyError: 'db' for DroppedSpan when running scan query on Elasticsearch
**Describe the bug**: ...
Elastic APM fails with a `KeyError: db key not found`.
The application where this happens is a Django project that stores/reads data from Elasticsearch. I have APM enable (APM server and Elasticsearch cluster are both running on Elastic Cloud). The library fails with the aforementioned error (shown in the snippet and screenshots below) while running a scan query on Elasticsearch. It looks like it's dropping some spans, which ends up in this case:
```
hits = self._get_hits(result_data)
if hits:
span.context["db"]["rows_affected"] = hits
return result_data
```
here's a screenshot of what I see on the APM Error page:

Few variables from the context:

**To Reproduce**
Unfortunately, I don't have a reproducible snippet.
**Environment (please complete the following information)**
- OS: Linux (containerized)
- Python version: 3.9.15
- Framework and version [e.g. Django 2.1]:
- APM Server version: 7.17.4
- Agent version:
```
$ pip freeze | grep elastic
django-elasticsearch-dsl==7.2.2
elastic-apm==6.13.1
elasticsearch==7.17.4
elasticsearch-dsl==7.4.0
```
**Additional context**
Add any other context about the problem here.
</issue>
<code>
[start of elasticapm/instrumentation/packages/elasticsearch.py]
1 # BSD 3-Clause License
2 #
3 # Copyright (c) 2019, Elasticsearch BV
4 # All rights reserved.
5 #
6 # Redistribution and use in source and binary forms, with or without
7 # modification, are permitted provided that the following conditions are met:
8 #
9 # * Redistributions of source code must retain the above copyright notice, this
10 # list of conditions and the following disclaimer.
11 #
12 # * Redistributions in binary form must reproduce the above copyright notice,
13 # this list of conditions and the following disclaimer in the documentation
14 # and/or other materials provided with the distribution.
15 #
16 # * Neither the name of the copyright holder nor the names of its
17 # contributors may be used to endorse or promote products derived from
18 # this software without specific prior written permission.
19 #
20 # THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
21 # AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
22 # IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
23 # DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
24 # FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
25 # DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
26 # SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
27 # CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
28 # OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
29 # OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
30
31 from __future__ import absolute_import
32
33 import re
34 from typing import Optional
35 from urllib.parse import parse_qs, urlparse
36
37 import elasticapm
38 from elasticapm.instrumentation.packages.base import AbstractInstrumentedModule
39 from elasticapm.traces import DroppedSpan, execution_context
40 from elasticapm.utils.logging import get_logger
41
42 logger = get_logger("elasticapm.instrument")
43
44 should_capture_body_re = re.compile("/(_search|_msearch|_count|_async_search|_sql|_eql)(/|$)")
45
46
47 class ElasticsearchConnectionInstrumentation(AbstractInstrumentedModule):
48 name = "elasticsearch_connection"
49
50 def get_instrument_list(self):
51 try:
52 import elastic_transport # noqa: F401
53
54 return [
55 ("elastic_transport._node._http_urllib3", "Urllib3HttpNode.perform_request"),
56 ("elastic_transport._node._http_requests", "RequestsHttpNode.perform_request"),
57 ]
58 except ImportError:
59 return [
60 ("elasticsearch.connection.http_urllib3", "Urllib3HttpConnection.perform_request"),
61 ("elasticsearch.connection.http_requests", "RequestsHttpConnection.perform_request"),
62 ]
63
64 def call(self, module, method, wrapped, instance, args, kwargs):
65 span = execution_context.get_span()
66 if not span or isinstance(span, DroppedSpan):
67 return wrapped(*args, **kwargs)
68
69 self._update_context_by_request_data(span.context, instance, args, kwargs)
70
71 result = wrapped(*args, **kwargs)
72 if hasattr(result, "meta"): # elasticsearch-py 8.x+
73 status_code = result.meta.status
74 cluster = result.meta.headers.get("x-found-handling-cluster")
75 else:
76 status_code = result[0]
77 cluster = result[1].get("x-found-handling-cluster")
78 span.context["http"] = {"status_code": status_code}
79 if cluster:
80 span.context["db"] = {"instance": cluster}
81
82 return result
83
84 def _update_context_by_request_data(self, context, instance, args, kwargs):
85 args_len = len(args)
86 url = args[1] if args_len > 1 else kwargs.get("url")
87 params = args[2] if args_len > 2 else kwargs.get("params")
88 body_serialized = args[3] if args_len > 3 else kwargs.get("body")
89
90 if "?" in url and not params:
91 url, qs = url.split("?", 1)
92 params = {k: v[0] for k, v in parse_qs(qs).items()}
93
94 should_capture_body = bool(should_capture_body_re.search(url))
95
96 context["db"] = {"type": "elasticsearch"}
97 if should_capture_body:
98 query = []
99 # using both q AND body is allowed in some API endpoints / ES versions,
100 # but not in others. We simply capture both if they are there so the
101 # user can see it.
102 if params and "q" in params:
103 # 'q' may already be encoded to a byte string at this point.
104 # We assume utf8, which is the default
105 q = params["q"]
106 if isinstance(q, bytes):
107 q = q.decode("utf-8", errors="replace")
108 query.append("q=" + q)
109 if body_serialized:
110 if isinstance(body_serialized, bytes):
111 query.append(body_serialized.decode("utf-8", errors="replace"))
112 else:
113 query.append(body_serialized)
114 if query:
115 context["db"]["statement"] = "\n\n".join(query)
116
117 # ES5: `host` is URL, no `port` attribute
118 # ES6, ES7: `host` URL, `hostname` is host, `port` is port
119 # ES8: `host` is hostname, no `hostname` attribute, `port` is `port`
120 if not hasattr(instance, "port"):
121 # ES5, parse hostname and port from URL stored in `host`
122 parsed_url = urlparse(instance.host)
123 host = parsed_url.hostname
124 port = parsed_url.port
125 elif not hasattr(instance, "hostname"):
126 # ES8 (and up, one can hope)
127 host = instance.host
128 port = instance.port
129 else:
130 # ES6, ES7
131 host = instance.hostname
132 port = instance.port
133
134 context["destination"] = {"address": host, "port": port}
135
136
137 class ElasticsearchTransportInstrumentation(AbstractInstrumentedModule):
138 name = "elasticsearch_connection"
139
140 def get_instrument_list(self):
141 try:
142 import elastic_transport # noqa: F401
143
144 return [
145 ("elastic_transport", "Transport.perform_request"),
146 ]
147 except ImportError:
148 return [
149 ("elasticsearch.transport", "Transport.perform_request"),
150 ]
151
152 def call(self, module, method, wrapped, instance, args, kwargs):
153 with elasticapm.capture_span(
154 self._get_signature(args, kwargs),
155 span_type="db",
156 span_subtype="elasticsearch",
157 span_action="query",
158 extra={},
159 skip_frames=2,
160 leaf=True,
161 ) as span:
162 result_data = wrapped(*args, **kwargs)
163
164 hits = self._get_hits(result_data)
165 if hits:
166 span.context["db"]["rows_affected"] = hits
167
168 return result_data
169
170 def _get_signature(self, args, kwargs):
171 args_len = len(args)
172 http_method = args[0] if args_len else kwargs.get("method")
173 http_path = args[1] if args_len > 1 else kwargs.get("url")
174 http_path = http_path.split("?", 1)[0] # we don't want to capture a potential query string in the span name
175
176 return "ES %s %s" % (http_method, http_path)
177
178 def _get_hits(self, result) -> Optional[int]:
179 if getattr(result, "body", None) and "hits" in result.body: # ES >= 8
180 return result.body["hits"].get("total", {}).get("value")
181 elif isinstance(result, dict) and "hits" in result and "total" in result["hits"]:
182 return (
183 result["hits"]["total"]["value"]
184 if isinstance(result["hits"]["total"], dict)
185 else result["hits"]["total"]
186 )
187
[end of elasticapm/instrumentation/packages/elasticsearch.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/elasticapm/instrumentation/packages/elasticsearch.py b/elasticapm/instrumentation/packages/elasticsearch.py
--- a/elasticapm/instrumentation/packages/elasticsearch.py
+++ b/elasticapm/instrumentation/packages/elasticsearch.py
@@ -163,7 +163,7 @@
hits = self._get_hits(result_data)
if hits:
- span.context["db"]["rows_affected"] = hits
+ span.update_context("db", {"rows_affected": hits})
return result_data
| {"golden_diff": "diff --git a/elasticapm/instrumentation/packages/elasticsearch.py b/elasticapm/instrumentation/packages/elasticsearch.py\n--- a/elasticapm/instrumentation/packages/elasticsearch.py\n+++ b/elasticapm/instrumentation/packages/elasticsearch.py\n@@ -163,7 +163,7 @@\n \n hits = self._get_hits(result_data)\n if hits:\n- span.context[\"db\"][\"rows_affected\"] = hits\n+ span.update_context(\"db\", {\"rows_affected\": hits})\n \n return result_data\n", "issue": "KeyError: 'db' for DroppedSpan when running scan query on Elasticsearch\n**Describe the bug**: ...\r\n\r\nElastic APM fails with a `KeyError: db key not found`.\r\n\r\nThe application where this happens is a Django project that stores/reads data from Elasticsearch. I have APM enable (APM server and Elasticsearch cluster are both running on Elastic Cloud). The library fails with the aforementioned error (shown in the snippet and screenshots below) while running a scan query on Elasticsearch. It looks like it's dropping some spans, which ends up in this case:\r\n\r\n```\r\n hits = self._get_hits(result_data)\r\n if hits:\r\n span.context[\"db\"][\"rows_affected\"] = hits\r\n \r\n return result_data\r\n```\r\n\r\nhere's a screenshot of what I see on the APM Error page:\r\n\r\n\r\n\r\nFew variables from the context:\r\n\r\n\r\n\r\n\r\n**To Reproduce**\r\n\r\nUnfortunately, I don't have a reproducible snippet. \r\n\r\n**Environment (please complete the following information)**\r\n- OS: Linux (containerized)\r\n- Python version: 3.9.15\r\n- Framework and version [e.g. Django 2.1]:\r\n- APM Server version: 7.17.4\r\n- Agent version: \r\n\r\n```\r\n$ pip freeze | grep elastic\r\ndjango-elasticsearch-dsl==7.2.2\r\nelastic-apm==6.13.1\r\nelasticsearch==7.17.4\r\nelasticsearch-dsl==7.4.0\r\n```\r\n\r\n\r\n**Additional context**\r\n\r\nAdd any other context about the problem here.\r\n\r\n\n", "before_files": [{"content": "# BSD 3-Clause License\n#\n# Copyright (c) 2019, Elasticsearch BV\n# All rights reserved.\n#\n# Redistribution and use in source and binary forms, with or without\n# modification, are permitted provided that the following conditions are met:\n#\n# * Redistributions of source code must retain the above copyright notice, this\n# list of conditions and the following disclaimer.\n#\n# * Redistributions in binary form must reproduce the above copyright notice,\n# this list of conditions and the following disclaimer in the documentation\n# and/or other materials provided with the distribution.\n#\n# * Neither the name of the copyright holder nor the names of its\n# contributors may be used to endorse or promote products derived from\n# this software without specific prior written permission.\n#\n# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS \"AS IS\"\n# AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE\n# IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE\n# DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE\n# FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL\n# DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR\n# SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER\n# CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,\n# OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE\n# OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.\n\nfrom __future__ import absolute_import\n\nimport re\nfrom typing import Optional\nfrom urllib.parse import parse_qs, urlparse\n\nimport elasticapm\nfrom elasticapm.instrumentation.packages.base import AbstractInstrumentedModule\nfrom elasticapm.traces import DroppedSpan, execution_context\nfrom elasticapm.utils.logging import get_logger\n\nlogger = get_logger(\"elasticapm.instrument\")\n\nshould_capture_body_re = re.compile(\"/(_search|_msearch|_count|_async_search|_sql|_eql)(/|$)\")\n\n\nclass ElasticsearchConnectionInstrumentation(AbstractInstrumentedModule):\n name = \"elasticsearch_connection\"\n\n def get_instrument_list(self):\n try:\n import elastic_transport # noqa: F401\n\n return [\n (\"elastic_transport._node._http_urllib3\", \"Urllib3HttpNode.perform_request\"),\n (\"elastic_transport._node._http_requests\", \"RequestsHttpNode.perform_request\"),\n ]\n except ImportError:\n return [\n (\"elasticsearch.connection.http_urllib3\", \"Urllib3HttpConnection.perform_request\"),\n (\"elasticsearch.connection.http_requests\", \"RequestsHttpConnection.perform_request\"),\n ]\n\n def call(self, module, method, wrapped, instance, args, kwargs):\n span = execution_context.get_span()\n if not span or isinstance(span, DroppedSpan):\n return wrapped(*args, **kwargs)\n\n self._update_context_by_request_data(span.context, instance, args, kwargs)\n\n result = wrapped(*args, **kwargs)\n if hasattr(result, \"meta\"): # elasticsearch-py 8.x+\n status_code = result.meta.status\n cluster = result.meta.headers.get(\"x-found-handling-cluster\")\n else:\n status_code = result[0]\n cluster = result[1].get(\"x-found-handling-cluster\")\n span.context[\"http\"] = {\"status_code\": status_code}\n if cluster:\n span.context[\"db\"] = {\"instance\": cluster}\n\n return result\n\n def _update_context_by_request_data(self, context, instance, args, kwargs):\n args_len = len(args)\n url = args[1] if args_len > 1 else kwargs.get(\"url\")\n params = args[2] if args_len > 2 else kwargs.get(\"params\")\n body_serialized = args[3] if args_len > 3 else kwargs.get(\"body\")\n\n if \"?\" in url and not params:\n url, qs = url.split(\"?\", 1)\n params = {k: v[0] for k, v in parse_qs(qs).items()}\n\n should_capture_body = bool(should_capture_body_re.search(url))\n\n context[\"db\"] = {\"type\": \"elasticsearch\"}\n if should_capture_body:\n query = []\n # using both q AND body is allowed in some API endpoints / ES versions,\n # but not in others. We simply capture both if they are there so the\n # user can see it.\n if params and \"q\" in params:\n # 'q' may already be encoded to a byte string at this point.\n # We assume utf8, which is the default\n q = params[\"q\"]\n if isinstance(q, bytes):\n q = q.decode(\"utf-8\", errors=\"replace\")\n query.append(\"q=\" + q)\n if body_serialized:\n if isinstance(body_serialized, bytes):\n query.append(body_serialized.decode(\"utf-8\", errors=\"replace\"))\n else:\n query.append(body_serialized)\n if query:\n context[\"db\"][\"statement\"] = \"\\n\\n\".join(query)\n\n # ES5: `host` is URL, no `port` attribute\n # ES6, ES7: `host` URL, `hostname` is host, `port` is port\n # ES8: `host` is hostname, no `hostname` attribute, `port` is `port`\n if not hasattr(instance, \"port\"):\n # ES5, parse hostname and port from URL stored in `host`\n parsed_url = urlparse(instance.host)\n host = parsed_url.hostname\n port = parsed_url.port\n elif not hasattr(instance, \"hostname\"):\n # ES8 (and up, one can hope)\n host = instance.host\n port = instance.port\n else:\n # ES6, ES7\n host = instance.hostname\n port = instance.port\n\n context[\"destination\"] = {\"address\": host, \"port\": port}\n\n\nclass ElasticsearchTransportInstrumentation(AbstractInstrumentedModule):\n name = \"elasticsearch_connection\"\n\n def get_instrument_list(self):\n try:\n import elastic_transport # noqa: F401\n\n return [\n (\"elastic_transport\", \"Transport.perform_request\"),\n ]\n except ImportError:\n return [\n (\"elasticsearch.transport\", \"Transport.perform_request\"),\n ]\n\n def call(self, module, method, wrapped, instance, args, kwargs):\n with elasticapm.capture_span(\n self._get_signature(args, kwargs),\n span_type=\"db\",\n span_subtype=\"elasticsearch\",\n span_action=\"query\",\n extra={},\n skip_frames=2,\n leaf=True,\n ) as span:\n result_data = wrapped(*args, **kwargs)\n\n hits = self._get_hits(result_data)\n if hits:\n span.context[\"db\"][\"rows_affected\"] = hits\n\n return result_data\n\n def _get_signature(self, args, kwargs):\n args_len = len(args)\n http_method = args[0] if args_len else kwargs.get(\"method\")\n http_path = args[1] if args_len > 1 else kwargs.get(\"url\")\n http_path = http_path.split(\"?\", 1)[0] # we don't want to capture a potential query string in the span name\n\n return \"ES %s %s\" % (http_method, http_path)\n\n def _get_hits(self, result) -> Optional[int]:\n if getattr(result, \"body\", None) and \"hits\" in result.body: # ES >= 8\n return result.body[\"hits\"].get(\"total\", {}).get(\"value\")\n elif isinstance(result, dict) and \"hits\" in result and \"total\" in result[\"hits\"]:\n return (\n result[\"hits\"][\"total\"][\"value\"]\n if isinstance(result[\"hits\"][\"total\"], dict)\n else result[\"hits\"][\"total\"]\n )\n", "path": "elasticapm/instrumentation/packages/elasticsearch.py"}]} | 3,151 | 120 |
gh_patches_debug_14724 | rasdani/github-patches | git_diff | scikit-hep__pyhf-235 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
loosen numpy requirements for non-extra installs
# Description
we are pretty restrictive in the numpy version range due to trying to conform to TF's valid range, but TF is only one of the backends. If just installing `pip install pyhf` we should not force users to a speciic range unless we require the APIs
`numpy>=1.14.0` should be enough unless i'm missing something. @kratsg since you changed this last, any reason you see to restrict numpy further?
</issue>
<code>
[start of setup.py]
1 from setuptools import setup, find_packages
2 setup(
3 name = 'pyhf',
4 version = '0.0.15',
5 description = '(partial) pure python histfactory implementation',
6 url = '',
7 author = 'Lukas Heinrich',
8 author_email = '[email protected]',
9 packages = find_packages(),
10 include_package_data = True,
11 install_requires = [
12 'numpy<=1.14.5,>=1.14.3', # required by tensorflow, mxnet, and us
13 'scipy',
14 'click>=6.0', # for console scripts,
15 'tqdm', # for readxml
16 'six', # for modifiers
17 'jsonschema>=v3.0.0a2', # for utils, alpha-release for draft 6
18 ],
19 extras_require = {
20 'xmlimport': [
21 'uproot',
22 ],
23 'torch': [
24 'torch>=0.4.0'
25 ],
26 'mxnet':[
27 'mxnet>=1.0.0',
28 'requests<2.19.0,>=2.18.4',
29 'numpy<1.15.0,>=1.8.2',
30 'requests<2.19.0,>=2.18.4',
31 ],
32 'tensorflow':[
33 'tensorflow>=1.10.0',
34 'numpy<=1.14.5,>=1.13.3',
35 'setuptools<=39.1.0',
36 ],
37 'develop': [
38 'pyflakes',
39 'pytest>=3.5.1',
40 'pytest-cov>=2.5.1',
41 'pytest-benchmark[histogram]',
42 'pytest-console-scripts',
43 'python-coveralls',
44 'coverage>=4.0', # coveralls
45 'matplotlib',
46 'jupyter',
47 'uproot',
48 'papermill',
49 'graphviz',
50 'sphinx',
51 'sphinxcontrib-bibtex',
52 'sphinxcontrib-napoleon',
53 'sphinx_rtd_theme',
54 'nbsphinx',
55 'jsonpatch'
56 ]
57 },
58 entry_points = {
59 'console_scripts': ['pyhf=pyhf.commandline:pyhf']
60 },
61 dependency_links = [
62 ]
63 )
64
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -9,8 +9,7 @@
packages = find_packages(),
include_package_data = True,
install_requires = [
- 'numpy<=1.14.5,>=1.14.3', # required by tensorflow, mxnet, and us
- 'scipy',
+ 'scipy', # requires numpy, which is required by pyhf, tensorflow, and mxnet
'click>=6.0', # for console scripts,
'tqdm', # for readxml
'six', # for modifiers
@@ -31,7 +30,7 @@
],
'tensorflow':[
'tensorflow>=1.10.0',
- 'numpy<=1.14.5,>=1.13.3',
+ 'numpy<=1.14.5,>=1.14.0', # Lower of 1.14.0 instead of 1.13.3 to ensure doctest pass
'setuptools<=39.1.0',
],
'develop': [
| {"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -9,8 +9,7 @@\n packages = find_packages(),\n include_package_data = True,\n install_requires = [\n- 'numpy<=1.14.5,>=1.14.3', # required by tensorflow, mxnet, and us\n- 'scipy',\n+ 'scipy', # requires numpy, which is required by pyhf, tensorflow, and mxnet\n 'click>=6.0', # for console scripts,\n 'tqdm', # for readxml\n 'six', # for modifiers\n@@ -31,7 +30,7 @@\n ],\n 'tensorflow':[\n 'tensorflow>=1.10.0',\n- 'numpy<=1.14.5,>=1.13.3',\n+ 'numpy<=1.14.5,>=1.14.0', # Lower of 1.14.0 instead of 1.13.3 to ensure doctest pass\n 'setuptools<=39.1.0',\n ],\n 'develop': [\n", "issue": "loosen numpy requirements for non-extra installs\n# Description\r\n\r\nwe are pretty restrictive in the numpy version range due to trying to conform to TF's valid range, but TF is only one of the backends. If just installing `pip install pyhf` we should not force users to a speciic range unless we require the APIs\r\n\r\n`numpy>=1.14.0` should be enough unless i'm missing something. @kratsg since you changed this last, any reason you see to restrict numpy further?\n", "before_files": [{"content": "from setuptools import setup, find_packages\nsetup(\n name = 'pyhf',\n version = '0.0.15',\n description = '(partial) pure python histfactory implementation',\n url = '',\n author = 'Lukas Heinrich',\n author_email = '[email protected]',\n packages = find_packages(),\n include_package_data = True,\n install_requires = [\n 'numpy<=1.14.5,>=1.14.3', # required by tensorflow, mxnet, and us\n 'scipy',\n 'click>=6.0', # for console scripts,\n 'tqdm', # for readxml\n 'six', # for modifiers\n 'jsonschema>=v3.0.0a2', # for utils, alpha-release for draft 6\n ],\n extras_require = {\n 'xmlimport': [\n 'uproot',\n ],\n 'torch': [\n 'torch>=0.4.0'\n ],\n 'mxnet':[\n 'mxnet>=1.0.0',\n 'requests<2.19.0,>=2.18.4',\n 'numpy<1.15.0,>=1.8.2',\n 'requests<2.19.0,>=2.18.4',\n ],\n 'tensorflow':[\n 'tensorflow>=1.10.0',\n 'numpy<=1.14.5,>=1.13.3',\n 'setuptools<=39.1.0',\n ],\n 'develop': [\n 'pyflakes',\n 'pytest>=3.5.1',\n 'pytest-cov>=2.5.1',\n 'pytest-benchmark[histogram]',\n 'pytest-console-scripts',\n 'python-coveralls',\n 'coverage>=4.0', # coveralls\n 'matplotlib',\n 'jupyter',\n 'uproot',\n 'papermill',\n 'graphviz',\n 'sphinx',\n 'sphinxcontrib-bibtex',\n 'sphinxcontrib-napoleon',\n 'sphinx_rtd_theme',\n 'nbsphinx',\n 'jsonpatch'\n ]\n },\n entry_points = {\n 'console_scripts': ['pyhf=pyhf.commandline:pyhf']\n },\n dependency_links = [\n ]\n)\n", "path": "setup.py"}]} | 1,268 | 260 |
gh_patches_debug_38469 | rasdani/github-patches | git_diff | scrapy__scrapy-1267 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Backward incompatibility for relocated paths in settings
Reported by @dangra
This issue manifests when mixing old paths and new ones for extensions and middlewares (this can happen for example while using a newer version of Scrapy in a project that hasn't updated to the new paths yet). Since paths aren't normalized, the same component can be loaded twice.
Take these settings for example:
``` python
# scrapy/settings/default_settings.py
EXTENSIONS_BASE = {
'scrapy.extensions.debug.StackTraceDump': 100, # new path
}
```
``` python
# myproject/settings.py
EXTENSIONS = {
'scrapy.contrib.debug.StackTraceDump': 200, # old path
}
```
While merging both dictionaries to build the list of components, the same StackTraceDump class is going to be loaded twice since it appears in two different keys.
</issue>
<code>
[start of scrapy/utils/deprecate.py]
1 """Some helpers for deprecation messages"""
2
3 import warnings
4 import inspect
5 from scrapy.exceptions import ScrapyDeprecationWarning
6
7
8 def attribute(obj, oldattr, newattr, version='0.12'):
9 cname = obj.__class__.__name__
10 warnings.warn("%s.%s attribute is deprecated and will be no longer supported "
11 "in Scrapy %s, use %s.%s attribute instead" % \
12 (cname, oldattr, version, cname, newattr), ScrapyDeprecationWarning, stacklevel=3)
13
14
15 def create_deprecated_class(name, new_class, clsdict=None,
16 warn_category=ScrapyDeprecationWarning,
17 warn_once=True,
18 old_class_path=None,
19 new_class_path=None,
20 subclass_warn_message="{cls} inherits from "\
21 "deprecated class {old}, please inherit "\
22 "from {new}.",
23 instance_warn_message="{cls} is deprecated, "\
24 "instantiate {new} instead."):
25 """
26 Return a "deprecated" class that causes its subclasses to issue a warning.
27 Subclasses of ``new_class`` are considered subclasses of this class.
28 It also warns when the deprecated class is instantiated, but do not when
29 its subclasses are instantiated.
30
31 It can be used to rename a base class in a library. For example, if we
32 have
33
34 class OldName(SomeClass):
35 # ...
36
37 and we want to rename it to NewName, we can do the following::
38
39 class NewName(SomeClass):
40 # ...
41
42 OldName = create_deprecated_class('OldName', NewName)
43
44 Then, if user class inherits from OldName, warning is issued. Also, if
45 some code uses ``issubclass(sub, OldName)`` or ``isinstance(sub(), OldName)``
46 checks they'll still return True if sub is a subclass of NewName instead of
47 OldName.
48 """
49
50 class DeprecatedClass(new_class.__class__):
51
52 deprecated_class = None
53 warned_on_subclass = False
54
55 def __new__(metacls, name, bases, clsdict_):
56 cls = super(DeprecatedClass, metacls).__new__(metacls, name, bases, clsdict_)
57 if metacls.deprecated_class is None:
58 metacls.deprecated_class = cls
59 return cls
60
61 def __init__(cls, name, bases, clsdict_):
62 meta = cls.__class__
63 old = meta.deprecated_class
64 if old in bases and not (warn_once and meta.warned_on_subclass):
65 meta.warned_on_subclass = True
66 msg = subclass_warn_message.format(cls=_clspath(cls),
67 old=_clspath(old, old_class_path),
68 new=_clspath(new_class, new_class_path))
69 if warn_once:
70 msg += ' (warning only on first subclass, there may be others)'
71 warnings.warn(msg, warn_category, stacklevel=2)
72 super(DeprecatedClass, cls).__init__(name, bases, clsdict_)
73
74 # see http://www.python.org/dev/peps/pep-3119/#overloading-isinstance-and-issubclass
75 # and http://docs.python.org/2/reference/datamodel.html#customizing-instance-and-subclass-checks
76 # for implementation details
77 def __instancecheck__(cls, inst):
78 return any(cls.__subclasscheck__(c)
79 for c in {type(inst), inst.__class__})
80
81 def __subclasscheck__(cls, sub):
82 if cls is not DeprecatedClass.deprecated_class:
83 # we should do the magic only if second `issubclass` argument
84 # is the deprecated class itself - subclasses of the
85 # deprecated class should not use custom `__subclasscheck__`
86 # method.
87 return super(DeprecatedClass, cls).__subclasscheck__(sub)
88
89 if not inspect.isclass(sub):
90 raise TypeError("issubclass() arg 1 must be a class")
91
92 mro = getattr(sub, '__mro__', ())
93 return any(c in {cls, new_class} for c in mro)
94
95 def __call__(cls, *args, **kwargs):
96 old = DeprecatedClass.deprecated_class
97 if cls is old:
98 msg = instance_warn_message.format(cls=_clspath(cls, old_class_path),
99 new=_clspath(new_class, new_class_path))
100 warnings.warn(msg, warn_category, stacklevel=2)
101 return super(DeprecatedClass, cls).__call__(*args, **kwargs)
102
103 deprecated_cls = DeprecatedClass(name, (new_class,), clsdict or {})
104
105 try:
106 frm = inspect.stack()[1]
107 parent_module = inspect.getmodule(frm[0])
108 if parent_module is not None:
109 deprecated_cls.__module__ = parent_module.__name__
110 except Exception as e:
111 # Sometimes inspect.stack() fails (e.g. when the first import of
112 # deprecated class is in jinja2 template). __module__ attribute is not
113 # important enough to raise an exception as users may be unable
114 # to fix inspect.stack() errors.
115 warnings.warn("Error detecting parent module: %r" % e)
116
117 return deprecated_cls
118
119
120 def _clspath(cls, forced=None):
121 if forced is not None:
122 return forced
123 return '{}.{}'.format(cls.__module__, cls.__name__)
124
[end of scrapy/utils/deprecate.py]
[start of scrapy/utils/conf.py]
1 import os
2 import sys
3 from operator import itemgetter
4
5 import six
6 from six.moves.configparser import SafeConfigParser
7
8
9 def build_component_list(base, custom):
10 """Compose a component list based on a custom and base dict of components
11 (typically middlewares or extensions), unless custom is already a list, in
12 which case it's returned.
13 """
14 if isinstance(custom, (list, tuple)):
15 return custom
16 compdict = base.copy()
17 compdict.update(custom)
18 items = (x for x in six.iteritems(compdict) if x[1] is not None)
19 return [x[0] for x in sorted(items, key=itemgetter(1))]
20
21
22 def arglist_to_dict(arglist):
23 """Convert a list of arguments like ['arg1=val1', 'arg2=val2', ...] to a
24 dict
25 """
26 return dict(x.split('=', 1) for x in arglist)
27
28
29 def closest_scrapy_cfg(path='.', prevpath=None):
30 """Return the path to the closest scrapy.cfg file by traversing the current
31 directory and its parents
32 """
33 if path == prevpath:
34 return ''
35 path = os.path.abspath(path)
36 cfgfile = os.path.join(path, 'scrapy.cfg')
37 if os.path.exists(cfgfile):
38 return cfgfile
39 return closest_scrapy_cfg(os.path.dirname(path), path)
40
41
42 def init_env(project='default', set_syspath=True):
43 """Initialize environment to use command-line tool from inside a project
44 dir. This sets the Scrapy settings module and modifies the Python path to
45 be able to locate the project module.
46 """
47 cfg = get_config()
48 if cfg.has_option('settings', project):
49 os.environ['SCRAPY_SETTINGS_MODULE'] = cfg.get('settings', project)
50 closest = closest_scrapy_cfg()
51 if closest:
52 projdir = os.path.dirname(closest)
53 if set_syspath and projdir not in sys.path:
54 sys.path.append(projdir)
55
56
57 def get_config(use_closest=True):
58 """Get Scrapy config file as a SafeConfigParser"""
59 sources = get_sources(use_closest)
60 cfg = SafeConfigParser()
61 cfg.read(sources)
62 return cfg
63
64
65 def get_sources(use_closest=True):
66 xdg_config_home = os.environ.get('XDG_CONFIG_HOME') or \
67 os.path.expanduser('~/.config')
68 sources = ['/etc/scrapy.cfg', r'c:\scrapy\scrapy.cfg',
69 xdg_config_home + '/scrapy.cfg',
70 os.path.expanduser('~/.scrapy.cfg')]
71 if use_closest:
72 sources.append(closest_scrapy_cfg())
73 return sources
74
[end of scrapy/utils/conf.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/scrapy/utils/conf.py b/scrapy/utils/conf.py
--- a/scrapy/utils/conf.py
+++ b/scrapy/utils/conf.py
@@ -5,16 +5,30 @@
import six
from six.moves.configparser import SafeConfigParser
+from scrapy.utils.deprecate import update_classpath
-def build_component_list(base, custom):
+
+def build_component_list(base, custom, convert=update_classpath):
"""Compose a component list based on a custom and base dict of components
(typically middlewares or extensions), unless custom is already a list, in
which case it's returned.
"""
+
+ def _check_components(complist):
+ if len({convert(c) for c in complist}) != len(complist):
+ raise ValueError('Some paths in {!r} convert to the same object, '
+ 'please update your settings'.format(complist))
+
if isinstance(custom, (list, tuple)):
- return custom
- compdict = base.copy()
- compdict.update(custom)
+ _check_components(custom)
+ return type(custom)(convert(c) for c in custom)
+
+ def _map_keys(compdict):
+ _check_components(compdict)
+ return {convert(k): v for k, v in six.iteritems(compdict)}
+
+ compdict = _map_keys(base)
+ compdict.update(_map_keys(custom))
items = (x for x in six.iteritems(compdict) if x[1] is not None)
return [x[0] for x in sorted(items, key=itemgetter(1))]
diff --git a/scrapy/utils/deprecate.py b/scrapy/utils/deprecate.py
--- a/scrapy/utils/deprecate.py
+++ b/scrapy/utils/deprecate.py
@@ -121,3 +121,37 @@
if forced is not None:
return forced
return '{}.{}'.format(cls.__module__, cls.__name__)
+
+
+DEPRECATION_RULES = [
+ ('scrapy.contrib_exp.downloadermiddleware.decompression.', 'scrapy.downloadermiddlewares.decompression.'),
+ ('scrapy.contrib_exp.iterators.', 'scrapy.utils.iterators.'),
+ ('scrapy.contrib.downloadermiddleware.', 'scrapy.downloadermiddlewares.'),
+ ('scrapy.contrib.exporter.', 'scrapy.exporters.'),
+ ('scrapy.contrib.linkextractors.', 'scrapy.linkextractors.'),
+ ('scrapy.contrib.loader.processor.', 'scrapy.loader.processors.'),
+ ('scrapy.contrib.loader.', 'scrapy.loader.'),
+ ('scrapy.contrib.pipeline.', 'scrapy.pipelines.'),
+ ('scrapy.contrib.spidermiddleware.', 'scrapy.spidermiddlewares.'),
+ ('scrapy.contrib.spiders.', 'scrapy.spiders.'),
+ ('scrapy.contrib.', 'scrapy.extensions.'),
+ ('scrapy.command.', 'scrapy.commands.'),
+ ('scrapy.dupefilter.', 'scrapy.dupefilters.'),
+ ('scrapy.linkextractor.', 'scrapy.linkextractors.'),
+ ('scrapy.spider.', 'scrapy.spiders.'),
+ ('scrapy.squeue.', 'scrapy.squeues.'),
+ ('scrapy.statscol.', 'scrapy.statscollectors.'),
+ ('scrapy.utils.decorator.', 'scrapy.utils.decorators.'),
+ ('scrapy.spidermanager.SpiderManager', 'scrapy.spiderloader.SpiderLoader'),
+]
+
+
+def update_classpath(path):
+ """Update a deprecated path from an object with its new location"""
+ for prefix, replacement in DEPRECATION_RULES:
+ if path.startswith(prefix):
+ new_path = path.replace(prefix, replacement, 1)
+ warnings.warn("`{}` class is deprecated, use `{}` instead".format(path, new_path),
+ ScrapyDeprecationWarning)
+ return new_path
+ return path
| {"golden_diff": "diff --git a/scrapy/utils/conf.py b/scrapy/utils/conf.py\n--- a/scrapy/utils/conf.py\n+++ b/scrapy/utils/conf.py\n@@ -5,16 +5,30 @@\n import six\n from six.moves.configparser import SafeConfigParser\n \n+from scrapy.utils.deprecate import update_classpath\n \n-def build_component_list(base, custom):\n+\n+def build_component_list(base, custom, convert=update_classpath):\n \"\"\"Compose a component list based on a custom and base dict of components\n (typically middlewares or extensions), unless custom is already a list, in\n which case it's returned.\n \"\"\"\n+\n+ def _check_components(complist):\n+ if len({convert(c) for c in complist}) != len(complist):\n+ raise ValueError('Some paths in {!r} convert to the same object, '\n+ 'please update your settings'.format(complist))\n+\n if isinstance(custom, (list, tuple)):\n- return custom\n- compdict = base.copy()\n- compdict.update(custom)\n+ _check_components(custom)\n+ return type(custom)(convert(c) for c in custom)\n+\n+ def _map_keys(compdict):\n+ _check_components(compdict)\n+ return {convert(k): v for k, v in six.iteritems(compdict)}\n+\n+ compdict = _map_keys(base)\n+ compdict.update(_map_keys(custom))\n items = (x for x in six.iteritems(compdict) if x[1] is not None)\n return [x[0] for x in sorted(items, key=itemgetter(1))]\n \ndiff --git a/scrapy/utils/deprecate.py b/scrapy/utils/deprecate.py\n--- a/scrapy/utils/deprecate.py\n+++ b/scrapy/utils/deprecate.py\n@@ -121,3 +121,37 @@\n if forced is not None:\n return forced\n return '{}.{}'.format(cls.__module__, cls.__name__)\n+\n+\n+DEPRECATION_RULES = [\n+ ('scrapy.contrib_exp.downloadermiddleware.decompression.', 'scrapy.downloadermiddlewares.decompression.'),\n+ ('scrapy.contrib_exp.iterators.', 'scrapy.utils.iterators.'),\n+ ('scrapy.contrib.downloadermiddleware.', 'scrapy.downloadermiddlewares.'),\n+ ('scrapy.contrib.exporter.', 'scrapy.exporters.'),\n+ ('scrapy.contrib.linkextractors.', 'scrapy.linkextractors.'),\n+ ('scrapy.contrib.loader.processor.', 'scrapy.loader.processors.'),\n+ ('scrapy.contrib.loader.', 'scrapy.loader.'),\n+ ('scrapy.contrib.pipeline.', 'scrapy.pipelines.'),\n+ ('scrapy.contrib.spidermiddleware.', 'scrapy.spidermiddlewares.'),\n+ ('scrapy.contrib.spiders.', 'scrapy.spiders.'),\n+ ('scrapy.contrib.', 'scrapy.extensions.'),\n+ ('scrapy.command.', 'scrapy.commands.'),\n+ ('scrapy.dupefilter.', 'scrapy.dupefilters.'),\n+ ('scrapy.linkextractor.', 'scrapy.linkextractors.'),\n+ ('scrapy.spider.', 'scrapy.spiders.'),\n+ ('scrapy.squeue.', 'scrapy.squeues.'),\n+ ('scrapy.statscol.', 'scrapy.statscollectors.'),\n+ ('scrapy.utils.decorator.', 'scrapy.utils.decorators.'),\n+ ('scrapy.spidermanager.SpiderManager', 'scrapy.spiderloader.SpiderLoader'),\n+]\n+\n+\n+def update_classpath(path):\n+ \"\"\"Update a deprecated path from an object with its new location\"\"\"\n+ for prefix, replacement in DEPRECATION_RULES:\n+ if path.startswith(prefix):\n+ new_path = path.replace(prefix, replacement, 1)\n+ warnings.warn(\"`{}` class is deprecated, use `{}` instead\".format(path, new_path),\n+ ScrapyDeprecationWarning)\n+ return new_path\n+ return path\n", "issue": "Backward incompatibility for relocated paths in settings\nReported by @dangra\n\nThis issue manifests when mixing old paths and new ones for extensions and middlewares (this can happen for example while using a newer version of Scrapy in a project that hasn't updated to the new paths yet). Since paths aren't normalized, the same component can be loaded twice.\n\nTake these settings for example:\n\n``` python\n# scrapy/settings/default_settings.py\nEXTENSIONS_BASE = {\n 'scrapy.extensions.debug.StackTraceDump': 100, # new path\n} \n```\n\n``` python\n# myproject/settings.py\nEXTENSIONS = {\n 'scrapy.contrib.debug.StackTraceDump': 200, # old path\n}\n```\n\nWhile merging both dictionaries to build the list of components, the same StackTraceDump class is going to be loaded twice since it appears in two different keys. \n\n", "before_files": [{"content": "\"\"\"Some helpers for deprecation messages\"\"\"\n\nimport warnings\nimport inspect\nfrom scrapy.exceptions import ScrapyDeprecationWarning\n\n\ndef attribute(obj, oldattr, newattr, version='0.12'):\n cname = obj.__class__.__name__\n warnings.warn(\"%s.%s attribute is deprecated and will be no longer supported \"\n \"in Scrapy %s, use %s.%s attribute instead\" % \\\n (cname, oldattr, version, cname, newattr), ScrapyDeprecationWarning, stacklevel=3)\n\n\ndef create_deprecated_class(name, new_class, clsdict=None,\n warn_category=ScrapyDeprecationWarning,\n warn_once=True,\n old_class_path=None,\n new_class_path=None,\n subclass_warn_message=\"{cls} inherits from \"\\\n \"deprecated class {old}, please inherit \"\\\n \"from {new}.\",\n instance_warn_message=\"{cls} is deprecated, \"\\\n \"instantiate {new} instead.\"):\n \"\"\"\n Return a \"deprecated\" class that causes its subclasses to issue a warning.\n Subclasses of ``new_class`` are considered subclasses of this class.\n It also warns when the deprecated class is instantiated, but do not when\n its subclasses are instantiated.\n\n It can be used to rename a base class in a library. For example, if we\n have\n\n class OldName(SomeClass):\n # ...\n\n and we want to rename it to NewName, we can do the following::\n\n class NewName(SomeClass):\n # ...\n\n OldName = create_deprecated_class('OldName', NewName)\n\n Then, if user class inherits from OldName, warning is issued. Also, if\n some code uses ``issubclass(sub, OldName)`` or ``isinstance(sub(), OldName)``\n checks they'll still return True if sub is a subclass of NewName instead of\n OldName.\n \"\"\"\n\n class DeprecatedClass(new_class.__class__):\n\n deprecated_class = None\n warned_on_subclass = False\n\n def __new__(metacls, name, bases, clsdict_):\n cls = super(DeprecatedClass, metacls).__new__(metacls, name, bases, clsdict_)\n if metacls.deprecated_class is None:\n metacls.deprecated_class = cls\n return cls\n\n def __init__(cls, name, bases, clsdict_):\n meta = cls.__class__\n old = meta.deprecated_class\n if old in bases and not (warn_once and meta.warned_on_subclass):\n meta.warned_on_subclass = True\n msg = subclass_warn_message.format(cls=_clspath(cls),\n old=_clspath(old, old_class_path),\n new=_clspath(new_class, new_class_path))\n if warn_once:\n msg += ' (warning only on first subclass, there may be others)'\n warnings.warn(msg, warn_category, stacklevel=2)\n super(DeprecatedClass, cls).__init__(name, bases, clsdict_)\n\n # see http://www.python.org/dev/peps/pep-3119/#overloading-isinstance-and-issubclass\n # and http://docs.python.org/2/reference/datamodel.html#customizing-instance-and-subclass-checks\n # for implementation details\n def __instancecheck__(cls, inst):\n return any(cls.__subclasscheck__(c)\n for c in {type(inst), inst.__class__})\n\n def __subclasscheck__(cls, sub):\n if cls is not DeprecatedClass.deprecated_class:\n # we should do the magic only if second `issubclass` argument\n # is the deprecated class itself - subclasses of the\n # deprecated class should not use custom `__subclasscheck__`\n # method.\n return super(DeprecatedClass, cls).__subclasscheck__(sub)\n\n if not inspect.isclass(sub):\n raise TypeError(\"issubclass() arg 1 must be a class\")\n\n mro = getattr(sub, '__mro__', ())\n return any(c in {cls, new_class} for c in mro)\n\n def __call__(cls, *args, **kwargs):\n old = DeprecatedClass.deprecated_class\n if cls is old:\n msg = instance_warn_message.format(cls=_clspath(cls, old_class_path),\n new=_clspath(new_class, new_class_path))\n warnings.warn(msg, warn_category, stacklevel=2)\n return super(DeprecatedClass, cls).__call__(*args, **kwargs)\n\n deprecated_cls = DeprecatedClass(name, (new_class,), clsdict or {})\n\n try:\n frm = inspect.stack()[1]\n parent_module = inspect.getmodule(frm[0])\n if parent_module is not None:\n deprecated_cls.__module__ = parent_module.__name__\n except Exception as e:\n # Sometimes inspect.stack() fails (e.g. when the first import of\n # deprecated class is in jinja2 template). __module__ attribute is not\n # important enough to raise an exception as users may be unable\n # to fix inspect.stack() errors.\n warnings.warn(\"Error detecting parent module: %r\" % e)\n\n return deprecated_cls\n\n\ndef _clspath(cls, forced=None):\n if forced is not None:\n return forced\n return '{}.{}'.format(cls.__module__, cls.__name__)\n", "path": "scrapy/utils/deprecate.py"}, {"content": "import os\nimport sys\nfrom operator import itemgetter\n\nimport six\nfrom six.moves.configparser import SafeConfigParser\n\n\ndef build_component_list(base, custom):\n \"\"\"Compose a component list based on a custom and base dict of components\n (typically middlewares or extensions), unless custom is already a list, in\n which case it's returned.\n \"\"\"\n if isinstance(custom, (list, tuple)):\n return custom\n compdict = base.copy()\n compdict.update(custom)\n items = (x for x in six.iteritems(compdict) if x[1] is not None)\n return [x[0] for x in sorted(items, key=itemgetter(1))]\n\n\ndef arglist_to_dict(arglist):\n \"\"\"Convert a list of arguments like ['arg1=val1', 'arg2=val2', ...] to a\n dict\n \"\"\"\n return dict(x.split('=', 1) for x in arglist)\n\n\ndef closest_scrapy_cfg(path='.', prevpath=None):\n \"\"\"Return the path to the closest scrapy.cfg file by traversing the current\n directory and its parents\n \"\"\"\n if path == prevpath:\n return ''\n path = os.path.abspath(path)\n cfgfile = os.path.join(path, 'scrapy.cfg')\n if os.path.exists(cfgfile):\n return cfgfile\n return closest_scrapy_cfg(os.path.dirname(path), path)\n\n\ndef init_env(project='default', set_syspath=True):\n \"\"\"Initialize environment to use command-line tool from inside a project\n dir. This sets the Scrapy settings module and modifies the Python path to\n be able to locate the project module.\n \"\"\"\n cfg = get_config()\n if cfg.has_option('settings', project):\n os.environ['SCRAPY_SETTINGS_MODULE'] = cfg.get('settings', project)\n closest = closest_scrapy_cfg()\n if closest:\n projdir = os.path.dirname(closest)\n if set_syspath and projdir not in sys.path:\n sys.path.append(projdir)\n\n\ndef get_config(use_closest=True):\n \"\"\"Get Scrapy config file as a SafeConfigParser\"\"\"\n sources = get_sources(use_closest)\n cfg = SafeConfigParser()\n cfg.read(sources)\n return cfg\n\n\ndef get_sources(use_closest=True):\n xdg_config_home = os.environ.get('XDG_CONFIG_HOME') or \\\n os.path.expanduser('~/.config')\n sources = ['/etc/scrapy.cfg', r'c:\\scrapy\\scrapy.cfg',\n xdg_config_home + '/scrapy.cfg',\n os.path.expanduser('~/.scrapy.cfg')]\n if use_closest:\n sources.append(closest_scrapy_cfg())\n return sources\n", "path": "scrapy/utils/conf.py"}]} | 2,869 | 836 |
gh_patches_debug_24923 | rasdani/github-patches | git_diff | WeblateOrg__weblate-2306 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Vote for suggestion when adding duplicate
Currently duplicate suggestions are ignored, but it would be better if it would be accepted as upvote in case voting is enabled for given translation.
See also https://github.com/WeblateOrg/weblate/issues/1348#issuecomment-280706768
<bountysource-plugin>
---
Want to back this issue? **[Post a bounty on it!](https://www.bountysource.com/issues/42236397-vote-for-suggestion-when-adding-duplicate?utm_campaign=plugin&utm_content=tracker%2F253393&utm_medium=issues&utm_source=github)** We accept bounties via [Bountysource](https://www.bountysource.com/?utm_campaign=plugin&utm_content=tracker%2F253393&utm_medium=issues&utm_source=github).
</bountysource-plugin>
</issue>
<code>
[start of weblate/trans/models/suggestion.py]
1 # -*- coding: utf-8 -*-
2 #
3 # Copyright © 2012 - 2018 Michal Čihař <[email protected]>
4 #
5 # This file is part of Weblate <https://weblate.org/>
6 #
7 # This program is free software: you can redistribute it and/or modify
8 # it under the terms of the GNU General Public License as published by
9 # the Free Software Foundation, either version 3 of the License, or
10 # (at your option) any later version.
11 #
12 # This program is distributed in the hope that it will be useful,
13 # but WITHOUT ANY WARRANTY; without even the implied warranty of
14 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
15 # GNU General Public License for more details.
16 #
17 # You should have received a copy of the GNU General Public License
18 # along with this program. If not, see <https://www.gnu.org/licenses/>.
19 #
20
21 from __future__ import unicode_literals
22
23 from django.conf import settings
24 from django.db import models, transaction
25 from django.db.models import Count
26 from django.utils.encoding import python_2_unicode_compatible
27 from django.utils.translation import ugettext as _
28
29 from weblate.lang.models import Language
30 from weblate.trans.models.change import Change
31 from weblate.utils.unitdata import UnitData
32 from weblate.trans.mixins import UserDisplayMixin
33 from weblate.utils import messages
34 from weblate.utils.antispam import report_spam
35 from weblate.utils.fields import JSONField
36 from weblate.utils.state import STATE_TRANSLATED
37 from weblate.utils.request import get_ip_address
38
39
40 class SuggestionManager(models.Manager):
41 # pylint: disable=no-init
42
43 def add(self, unit, target, request, vote=False):
44 """Create new suggestion for this unit."""
45 user = request.user
46
47 same = self.filter(
48 target=target,
49 content_hash=unit.content_hash,
50 language=unit.translation.language,
51 project=unit.translation.component.project,
52 )
53
54 if same.exists() or (unit.target == target and not unit.fuzzy):
55 return False
56
57 # Create the suggestion
58 suggestion = self.create(
59 target=target,
60 content_hash=unit.content_hash,
61 language=unit.translation.language,
62 project=unit.translation.component.project,
63 user=user,
64 userdetails={
65 'address': get_ip_address(request),
66 'agent': request.META.get('HTTP_USER_AGENT', ''),
67 },
68 )
69
70 # Record in change
71 for aunit in suggestion.related_units:
72 Change.objects.create(
73 unit=aunit,
74 action=Change.ACTION_SUGGESTION,
75 user=user,
76 target=target,
77 author=user
78 )
79
80 # Add unit vote
81 if vote:
82 suggestion.add_vote(
83 unit.translation,
84 request,
85 True
86 )
87
88 # Notify subscribed users
89 from weblate.accounts.notifications import notify_new_suggestion
90 notify_new_suggestion(unit, suggestion, user)
91
92 # Update suggestion stats
93 if user is not None:
94 user.profile.suggested += 1
95 user.profile.save()
96
97 return True
98
99 def copy(self, project):
100 """Copy suggestions to new project
101
102 This is used on moving component to other project and ensures nothing
103 is lost. We don't actually look where the suggestion belongs as it
104 would make the operation really expensive and it should be done in the
105 cleanup cron job.
106 """
107 for suggestion in self.all():
108 Suggestion.objects.create(
109 project=project,
110 target=suggestion.target,
111 content_hash=suggestion.content_hash,
112 user=suggestion.user,
113 language=suggestion.language,
114 )
115
116
117 @python_2_unicode_compatible
118 class Suggestion(UnitData, UserDisplayMixin):
119 target = models.TextField()
120 user = models.ForeignKey(
121 settings.AUTH_USER_MODEL, null=True, blank=True,
122 on_delete=models.deletion.CASCADE
123 )
124 userdetails = JSONField()
125 language = models.ForeignKey(
126 Language, on_delete=models.deletion.CASCADE
127 )
128 timestamp = models.DateTimeField(auto_now_add=True)
129
130 votes = models.ManyToManyField(
131 settings.AUTH_USER_MODEL,
132 through='Vote',
133 related_name='user_votes'
134 )
135
136 objects = SuggestionManager()
137
138 class Meta(object):
139 app_label = 'trans'
140 ordering = ['-timestamp']
141 index_together = [
142 ('project', 'language', 'content_hash'),
143 ]
144
145 def __str__(self):
146 return 'suggestion for {0} by {1}'.format(
147 self.content_hash,
148 self.user.username if self.user else 'unknown',
149 )
150
151 @transaction.atomic
152 def accept(self, translation, request, permission='suggestion.accept'):
153 allunits = translation.unit_set.select_for_update().filter(
154 content_hash=self.content_hash,
155 )
156 failure = False
157 for unit in allunits:
158 if not request.user.has_perm(permission, unit):
159 failure = True
160 messages.error(request, _('Failed to accept suggestion!'))
161 continue
162
163 # Skip if there is no change
164 if unit.target == self.target and unit.state >= STATE_TRANSLATED:
165 continue
166
167 unit.target = self.target
168 unit.state = STATE_TRANSLATED
169 unit.save_backend(
170 request, change_action=Change.ACTION_ACCEPT, user=self.user
171 )
172
173 if not failure:
174 self.delete()
175
176 def delete_log(self, user, change=Change.ACTION_SUGGESTION_DELETE,
177 is_spam=False):
178 """Delete with logging change"""
179 if is_spam and self.userdetails:
180 report_spam(
181 self.userdetails['address'],
182 self.userdetails['agent'],
183 self.target
184 )
185 for unit in self.related_units:
186 Change.objects.create(
187 unit=unit,
188 action=change,
189 user=user,
190 target=self.target,
191 author=user
192 )
193 self.delete()
194
195 def get_num_votes(self):
196 """Return number of votes."""
197 votes = Vote.objects.filter(suggestion=self)
198 positive = votes.filter(positive=True).aggregate(Count('id'))
199 negative = votes.filter(positive=False).aggregate(Count('id'))
200 return positive['id__count'] - negative['id__count']
201
202 def add_vote(self, translation, request, positive):
203 """Add (or updates) vote for a suggestion."""
204 if not request.user.is_authenticated:
205 return
206
207 vote, created = Vote.objects.get_or_create(
208 suggestion=self,
209 user=request.user,
210 defaults={'positive': positive}
211 )
212 if not created or vote.positive != positive:
213 vote.positive = positive
214 vote.save()
215
216 # Automatic accepting
217 required_votes = translation.component.suggestion_autoaccept
218 if required_votes and self.get_num_votes() >= required_votes:
219 self.accept(translation, request, 'suggestion.vote')
220
221
222 @python_2_unicode_compatible
223 class Vote(models.Model):
224 """Suggestion voting."""
225 suggestion = models.ForeignKey(
226 Suggestion, on_delete=models.deletion.CASCADE
227 )
228 user = models.ForeignKey(
229 settings.AUTH_USER_MODEL, on_delete=models.deletion.CASCADE
230 )
231 positive = models.BooleanField(default=True)
232
233 class Meta(object):
234 unique_together = ('suggestion', 'user')
235 app_label = 'trans'
236
237 def __str__(self):
238 if self.positive:
239 vote = '+1'
240 else:
241 vote = '-1'
242 return '{0} for {1} by {2}'.format(
243 vote,
244 self.suggestion,
245 self.user.username,
246 )
247
[end of weblate/trans/models/suggestion.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/weblate/trans/models/suggestion.py b/weblate/trans/models/suggestion.py
--- a/weblate/trans/models/suggestion.py
+++ b/weblate/trans/models/suggestion.py
@@ -35,6 +35,7 @@
from weblate.utils.fields import JSONField
from weblate.utils.state import STATE_TRANSLATED
from weblate.utils.request import get_ip_address
+from django.core.exceptions import ObjectDoesNotExist
class SuggestionManager(models.Manager):
@@ -44,15 +45,22 @@
"""Create new suggestion for this unit."""
user = request.user
- same = self.filter(
- target=target,
- content_hash=unit.content_hash,
- language=unit.translation.language,
- project=unit.translation.component.project,
- )
+ try:
+ same = self.get(
+ target=target,
+ content_hash=unit.content_hash,
+ language=unit.translation.language,
+ project=unit.translation.component.project,
+ )
+
+ if same.user == user or not vote:
+ return False
+ else:
+ same.add_vote(unit.translation, request, True)
+ return False
- if same.exists() or (unit.target == target and not unit.fuzzy):
- return False
+ except ObjectDoesNotExist:
+ pass
# Create the suggestion
suggestion = self.create(
| {"golden_diff": "diff --git a/weblate/trans/models/suggestion.py b/weblate/trans/models/suggestion.py\n--- a/weblate/trans/models/suggestion.py\n+++ b/weblate/trans/models/suggestion.py\n@@ -35,6 +35,7 @@\n from weblate.utils.fields import JSONField\n from weblate.utils.state import STATE_TRANSLATED\n from weblate.utils.request import get_ip_address\n+from django.core.exceptions import ObjectDoesNotExist\n \n \n class SuggestionManager(models.Manager):\n@@ -44,15 +45,22 @@\n \"\"\"Create new suggestion for this unit.\"\"\"\n user = request.user\n \n- same = self.filter(\n- target=target,\n- content_hash=unit.content_hash,\n- language=unit.translation.language,\n- project=unit.translation.component.project,\n- )\n+ try:\n+ same = self.get(\n+ target=target,\n+ content_hash=unit.content_hash,\n+ language=unit.translation.language,\n+ project=unit.translation.component.project,\n+ )\n+\n+ if same.user == user or not vote:\n+ return False\n+ else:\n+ same.add_vote(unit.translation, request, True)\n+ return False\n \n- if same.exists() or (unit.target == target and not unit.fuzzy):\n- return False\n+ except ObjectDoesNotExist:\n+ pass\n \n # Create the suggestion\n suggestion = self.create(\n", "issue": "Vote for suggestion when adding duplicate\nCurrently duplicate suggestions are ignored, but it would be better if it would be accepted as upvote in case voting is enabled for given translation.\r\n\r\nSee also https://github.com/WeblateOrg/weblate/issues/1348#issuecomment-280706768\r\n\r\n<bountysource-plugin>\r\n\r\n---\r\nWant to back this issue? **[Post a bounty on it!](https://www.bountysource.com/issues/42236397-vote-for-suggestion-when-adding-duplicate?utm_campaign=plugin&utm_content=tracker%2F253393&utm_medium=issues&utm_source=github)** We accept bounties via [Bountysource](https://www.bountysource.com/?utm_campaign=plugin&utm_content=tracker%2F253393&utm_medium=issues&utm_source=github).\r\n</bountysource-plugin>\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n#\n# Copyright \u00a9 2012 - 2018 Michal \u010ciha\u0159 <[email protected]>\n#\n# This file is part of Weblate <https://weblate.org/>\n#\n# This program is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# This program is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with this program. If not, see <https://www.gnu.org/licenses/>.\n#\n\nfrom __future__ import unicode_literals\n\nfrom django.conf import settings\nfrom django.db import models, transaction\nfrom django.db.models import Count\nfrom django.utils.encoding import python_2_unicode_compatible\nfrom django.utils.translation import ugettext as _\n\nfrom weblate.lang.models import Language\nfrom weblate.trans.models.change import Change\nfrom weblate.utils.unitdata import UnitData\nfrom weblate.trans.mixins import UserDisplayMixin\nfrom weblate.utils import messages\nfrom weblate.utils.antispam import report_spam\nfrom weblate.utils.fields import JSONField\nfrom weblate.utils.state import STATE_TRANSLATED\nfrom weblate.utils.request import get_ip_address\n\n\nclass SuggestionManager(models.Manager):\n # pylint: disable=no-init\n\n def add(self, unit, target, request, vote=False):\n \"\"\"Create new suggestion for this unit.\"\"\"\n user = request.user\n\n same = self.filter(\n target=target,\n content_hash=unit.content_hash,\n language=unit.translation.language,\n project=unit.translation.component.project,\n )\n\n if same.exists() or (unit.target == target and not unit.fuzzy):\n return False\n\n # Create the suggestion\n suggestion = self.create(\n target=target,\n content_hash=unit.content_hash,\n language=unit.translation.language,\n project=unit.translation.component.project,\n user=user,\n userdetails={\n 'address': get_ip_address(request),\n 'agent': request.META.get('HTTP_USER_AGENT', ''),\n },\n )\n\n # Record in change\n for aunit in suggestion.related_units:\n Change.objects.create(\n unit=aunit,\n action=Change.ACTION_SUGGESTION,\n user=user,\n target=target,\n author=user\n )\n\n # Add unit vote\n if vote:\n suggestion.add_vote(\n unit.translation,\n request,\n True\n )\n\n # Notify subscribed users\n from weblate.accounts.notifications import notify_new_suggestion\n notify_new_suggestion(unit, suggestion, user)\n\n # Update suggestion stats\n if user is not None:\n user.profile.suggested += 1\n user.profile.save()\n\n return True\n\n def copy(self, project):\n \"\"\"Copy suggestions to new project\n\n This is used on moving component to other project and ensures nothing\n is lost. We don't actually look where the suggestion belongs as it\n would make the operation really expensive and it should be done in the\n cleanup cron job.\n \"\"\"\n for suggestion in self.all():\n Suggestion.objects.create(\n project=project,\n target=suggestion.target,\n content_hash=suggestion.content_hash,\n user=suggestion.user,\n language=suggestion.language,\n )\n\n\n@python_2_unicode_compatible\nclass Suggestion(UnitData, UserDisplayMixin):\n target = models.TextField()\n user = models.ForeignKey(\n settings.AUTH_USER_MODEL, null=True, blank=True,\n on_delete=models.deletion.CASCADE\n )\n userdetails = JSONField()\n language = models.ForeignKey(\n Language, on_delete=models.deletion.CASCADE\n )\n timestamp = models.DateTimeField(auto_now_add=True)\n\n votes = models.ManyToManyField(\n settings.AUTH_USER_MODEL,\n through='Vote',\n related_name='user_votes'\n )\n\n objects = SuggestionManager()\n\n class Meta(object):\n app_label = 'trans'\n ordering = ['-timestamp']\n index_together = [\n ('project', 'language', 'content_hash'),\n ]\n\n def __str__(self):\n return 'suggestion for {0} by {1}'.format(\n self.content_hash,\n self.user.username if self.user else 'unknown',\n )\n\n @transaction.atomic\n def accept(self, translation, request, permission='suggestion.accept'):\n allunits = translation.unit_set.select_for_update().filter(\n content_hash=self.content_hash,\n )\n failure = False\n for unit in allunits:\n if not request.user.has_perm(permission, unit):\n failure = True\n messages.error(request, _('Failed to accept suggestion!'))\n continue\n\n # Skip if there is no change\n if unit.target == self.target and unit.state >= STATE_TRANSLATED:\n continue\n\n unit.target = self.target\n unit.state = STATE_TRANSLATED\n unit.save_backend(\n request, change_action=Change.ACTION_ACCEPT, user=self.user\n )\n\n if not failure:\n self.delete()\n\n def delete_log(self, user, change=Change.ACTION_SUGGESTION_DELETE,\n is_spam=False):\n \"\"\"Delete with logging change\"\"\"\n if is_spam and self.userdetails:\n report_spam(\n self.userdetails['address'],\n self.userdetails['agent'],\n self.target\n )\n for unit in self.related_units:\n Change.objects.create(\n unit=unit,\n action=change,\n user=user,\n target=self.target,\n author=user\n )\n self.delete()\n\n def get_num_votes(self):\n \"\"\"Return number of votes.\"\"\"\n votes = Vote.objects.filter(suggestion=self)\n positive = votes.filter(positive=True).aggregate(Count('id'))\n negative = votes.filter(positive=False).aggregate(Count('id'))\n return positive['id__count'] - negative['id__count']\n\n def add_vote(self, translation, request, positive):\n \"\"\"Add (or updates) vote for a suggestion.\"\"\"\n if not request.user.is_authenticated:\n return\n\n vote, created = Vote.objects.get_or_create(\n suggestion=self,\n user=request.user,\n defaults={'positive': positive}\n )\n if not created or vote.positive != positive:\n vote.positive = positive\n vote.save()\n\n # Automatic accepting\n required_votes = translation.component.suggestion_autoaccept\n if required_votes and self.get_num_votes() >= required_votes:\n self.accept(translation, request, 'suggestion.vote')\n\n\n@python_2_unicode_compatible\nclass Vote(models.Model):\n \"\"\"Suggestion voting.\"\"\"\n suggestion = models.ForeignKey(\n Suggestion, on_delete=models.deletion.CASCADE\n )\n user = models.ForeignKey(\n settings.AUTH_USER_MODEL, on_delete=models.deletion.CASCADE\n )\n positive = models.BooleanField(default=True)\n\n class Meta(object):\n unique_together = ('suggestion', 'user')\n app_label = 'trans'\n\n def __str__(self):\n if self.positive:\n vote = '+1'\n else:\n vote = '-1'\n return '{0} for {1} by {2}'.format(\n vote,\n self.suggestion,\n self.user.username,\n )\n", "path": "weblate/trans/models/suggestion.py"}]} | 2,984 | 305 |
gh_patches_debug_25841 | rasdani/github-patches | git_diff | saleor__saleor-2825 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Turn Order.paymentStatus field into an enum
Currently `Order.status` is an `OrderStatus` enum but `Order.paymentStatus` is a `String`.
We should make both enums so clients can know all possible values up-front.
</issue>
<code>
[start of saleor/graphql/order/types.py]
1 import graphene
2 from graphene import relay
3
4 from ...order import OrderEvents, models
5 from ..account.types import User
6 from ..core.types.common import CountableDjangoObjectType
7 from ..core.types.money import Money, TaxedMoney
8 from decimal import Decimal
9
10 OrderEventsEnum = graphene.Enum.from_enum(OrderEvents)
11
12
13 class OrderEvent(CountableDjangoObjectType):
14 date = graphene.types.datetime.DateTime(
15 description='Date when event happened at in ISO 8601 format.')
16 type = OrderEventsEnum(description='Order event type')
17 user = graphene.Field(
18 User, id=graphene.Argument(graphene.ID),
19 description='User who performed the action.')
20 message = graphene.String(
21 description='Content of a note added to the order.')
22 email = graphene.String(description='Email of the customer')
23 email_type = graphene.String(
24 description='Type of an email sent to the customer')
25 amount = graphene.Float(description='Amount of money.')
26 quantity = graphene.Int(description='Number of items.')
27 composed_id = graphene.String(
28 description='Composed id of the Fulfillment.')
29
30 class Meta:
31 description = 'History log of the order.'
32 model = models.OrderEvent
33 interfaces = [relay.Node]
34 exclude_fields = ['order', 'parameters']
35
36 def resolve_email(self, info):
37 return self.parameters.get('email', None)
38
39 def resolve_email_type(self, info):
40 return self.parameters.get('email_type', None)
41
42 def resolve_amount(self, info):
43 amount = self.parameters.get('amount', None)
44 return Decimal(amount) if amount else None
45
46 def resolve_quantity(self, info):
47 quantity = self.parameters.get('quantity', None)
48 return int(quantity) if quantity else None
49
50 def resolve_message(self, info):
51 return self.parameters.get('message', None)
52
53 def resolve_composed_id(self, info):
54 return self.parameters.get('composed_id', None)
55
56
57 class Fulfillment(CountableDjangoObjectType):
58 status_display = graphene.String(
59 description='User-friendly fulfillment status.')
60
61 class Meta:
62 description = 'Represents order fulfillment.'
63 interfaces = [relay.Node]
64 model = models.Fulfillment
65 exclude_fields = ['order']
66
67 def resolve_status_display(self, info):
68 return self.get_status_display()
69
70
71 class FulfillmentLine(CountableDjangoObjectType):
72 class Meta:
73 description = 'Represents line of the fulfillment.'
74 interfaces = [relay.Node]
75 model = models.FulfillmentLine
76 exclude_fields = ['fulfillment']
77
78
79 class Order(CountableDjangoObjectType):
80 fulfillments = graphene.List(
81 Fulfillment,
82 required=True,
83 description='List of shipments for the order.')
84 is_paid = graphene.Boolean(
85 description='Informs if an order is fully paid.')
86 number = graphene.String(description='User-friendly number of an order.')
87 payment_status = graphene.String(description='Internal payment status.')
88 payment_status_display = graphene.String(
89 description='User-friendly payment status.')
90 subtotal = graphene.Field(
91 TaxedMoney,
92 description='The sum of line prices not including shipping.')
93 status_display = graphene.String(description='User-friendly order status.')
94 total_authorized = graphene.Field(
95 Money, description='Amount authorized for the order.')
96 total_captured = graphene.Field(
97 Money, description='Amount captured by payment.')
98 events = graphene.List(
99 OrderEvent,
100 description='List of events associated with the order.')
101 user_email = graphene.String(
102 required=False, description='Email address of the customer.')
103
104 class Meta:
105 description = 'Represents an order in the shop.'
106 interfaces = [relay.Node]
107 model = models.Order
108 exclude_fields = [
109 'shipping_price_gross', 'shipping_price_net', 'total_gross',
110 'total_net']
111
112 @staticmethod
113 def resolve_subtotal(obj, info):
114 return obj.get_subtotal()
115
116 @staticmethod
117 def resolve_total_authorized(obj, info):
118 payment = obj.get_last_payment()
119 if payment:
120 return payment.get_total_price().gross
121
122 @staticmethod
123 def resolve_total_captured(obj, info):
124 payment = obj.get_last_payment()
125 if payment:
126 return payment.get_captured_price()
127
128 @staticmethod
129 def resolve_fulfillments(obj, info):
130 return obj.fulfillments.all()
131
132 @staticmethod
133 def resolve_events(obj, info):
134 return obj.events.all()
135
136 @staticmethod
137 def resolve_is_paid(obj, info):
138 return obj.is_fully_paid()
139
140 @staticmethod
141 def resolve_number(obj, info):
142 return str(obj.pk)
143
144 @staticmethod
145 def resolve_payment_status(obj, info):
146 return obj.get_last_payment_status()
147
148 @staticmethod
149 def resolve_payment_status_display(obj, info):
150 return obj.get_last_payment_status_display()
151
152 @staticmethod
153 def resolve_status_display(obj, info):
154 return obj.get_status_display()
155
156 @staticmethod
157 def resolve_user_email(obj, info):
158 if obj.user_email:
159 return obj.user_email
160 if obj.user_id:
161 return obj.user.email
162 return None
163
164
165 class OrderLine(CountableDjangoObjectType):
166 class Meta:
167 description = 'Represents order line of particular order.'
168 model = models.OrderLine
169 interfaces = [relay.Node]
170 exclude_fields = [
171 'order', 'unit_price_gross', 'unit_price_net', 'variant']
172
[end of saleor/graphql/order/types.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/saleor/graphql/order/types.py b/saleor/graphql/order/types.py
--- a/saleor/graphql/order/types.py
+++ b/saleor/graphql/order/types.py
@@ -1,13 +1,18 @@
+from decimal import Decimal
+
import graphene
from graphene import relay
+from payments import PaymentStatus
from ...order import OrderEvents, models
from ..account.types import User
from ..core.types.common import CountableDjangoObjectType
from ..core.types.money import Money, TaxedMoney
-from decimal import Decimal
OrderEventsEnum = graphene.Enum.from_enum(OrderEvents)
+PaymentStatusEnum = graphene.Enum(
+ 'PaymentStatusEnum',
+ [(code.upper(), code) for code, name in PaymentStatus.CHOICES])
class OrderEvent(CountableDjangoObjectType):
@@ -84,7 +89,7 @@
is_paid = graphene.Boolean(
description='Informs if an order is fully paid.')
number = graphene.String(description='User-friendly number of an order.')
- payment_status = graphene.String(description='Internal payment status.')
+ payment_status = PaymentStatusEnum(description='Internal payment status.')
payment_status_display = graphene.String(
description='User-friendly payment status.')
subtotal = graphene.Field(
| {"golden_diff": "diff --git a/saleor/graphql/order/types.py b/saleor/graphql/order/types.py\n--- a/saleor/graphql/order/types.py\n+++ b/saleor/graphql/order/types.py\n@@ -1,13 +1,18 @@\n+from decimal import Decimal\n+\n import graphene\n from graphene import relay\n+from payments import PaymentStatus\n \n from ...order import OrderEvents, models\n from ..account.types import User\n from ..core.types.common import CountableDjangoObjectType\n from ..core.types.money import Money, TaxedMoney\n-from decimal import Decimal\n \n OrderEventsEnum = graphene.Enum.from_enum(OrderEvents)\n+PaymentStatusEnum = graphene.Enum(\n+ 'PaymentStatusEnum',\n+ [(code.upper(), code) for code, name in PaymentStatus.CHOICES])\n \n \n class OrderEvent(CountableDjangoObjectType):\n@@ -84,7 +89,7 @@\n is_paid = graphene.Boolean(\n description='Informs if an order is fully paid.')\n number = graphene.String(description='User-friendly number of an order.')\n- payment_status = graphene.String(description='Internal payment status.')\n+ payment_status = PaymentStatusEnum(description='Internal payment status.')\n payment_status_display = graphene.String(\n description='User-friendly payment status.')\n subtotal = graphene.Field(\n", "issue": "Turn Order.paymentStatus field into an enum\nCurrently `Order.status` is an `OrderStatus` enum but `Order.paymentStatus` is a `String`.\r\n\r\nWe should make both enums so clients can know all possible values up-front.\n", "before_files": [{"content": "import graphene\nfrom graphene import relay\n\nfrom ...order import OrderEvents, models\nfrom ..account.types import User\nfrom ..core.types.common import CountableDjangoObjectType\nfrom ..core.types.money import Money, TaxedMoney\nfrom decimal import Decimal\n\nOrderEventsEnum = graphene.Enum.from_enum(OrderEvents)\n\n\nclass OrderEvent(CountableDjangoObjectType):\n date = graphene.types.datetime.DateTime(\n description='Date when event happened at in ISO 8601 format.')\n type = OrderEventsEnum(description='Order event type')\n user = graphene.Field(\n User, id=graphene.Argument(graphene.ID),\n description='User who performed the action.')\n message = graphene.String(\n description='Content of a note added to the order.')\n email = graphene.String(description='Email of the customer')\n email_type = graphene.String(\n description='Type of an email sent to the customer')\n amount = graphene.Float(description='Amount of money.')\n quantity = graphene.Int(description='Number of items.')\n composed_id = graphene.String(\n description='Composed id of the Fulfillment.')\n\n class Meta:\n description = 'History log of the order.'\n model = models.OrderEvent\n interfaces = [relay.Node]\n exclude_fields = ['order', 'parameters']\n\n def resolve_email(self, info):\n return self.parameters.get('email', None)\n\n def resolve_email_type(self, info):\n return self.parameters.get('email_type', None)\n\n def resolve_amount(self, info):\n amount = self.parameters.get('amount', None)\n return Decimal(amount) if amount else None\n\n def resolve_quantity(self, info):\n quantity = self.parameters.get('quantity', None)\n return int(quantity) if quantity else None\n\n def resolve_message(self, info):\n return self.parameters.get('message', None)\n\n def resolve_composed_id(self, info):\n return self.parameters.get('composed_id', None)\n\n\nclass Fulfillment(CountableDjangoObjectType):\n status_display = graphene.String(\n description='User-friendly fulfillment status.')\n\n class Meta:\n description = 'Represents order fulfillment.'\n interfaces = [relay.Node]\n model = models.Fulfillment\n exclude_fields = ['order']\n\n def resolve_status_display(self, info):\n return self.get_status_display()\n\n\nclass FulfillmentLine(CountableDjangoObjectType):\n class Meta:\n description = 'Represents line of the fulfillment.'\n interfaces = [relay.Node]\n model = models.FulfillmentLine\n exclude_fields = ['fulfillment']\n\n\nclass Order(CountableDjangoObjectType):\n fulfillments = graphene.List(\n Fulfillment,\n required=True,\n description='List of shipments for the order.')\n is_paid = graphene.Boolean(\n description='Informs if an order is fully paid.')\n number = graphene.String(description='User-friendly number of an order.')\n payment_status = graphene.String(description='Internal payment status.')\n payment_status_display = graphene.String(\n description='User-friendly payment status.')\n subtotal = graphene.Field(\n TaxedMoney,\n description='The sum of line prices not including shipping.')\n status_display = graphene.String(description='User-friendly order status.')\n total_authorized = graphene.Field(\n Money, description='Amount authorized for the order.')\n total_captured = graphene.Field(\n Money, description='Amount captured by payment.')\n events = graphene.List(\n OrderEvent,\n description='List of events associated with the order.')\n user_email = graphene.String(\n required=False, description='Email address of the customer.')\n\n class Meta:\n description = 'Represents an order in the shop.'\n interfaces = [relay.Node]\n model = models.Order\n exclude_fields = [\n 'shipping_price_gross', 'shipping_price_net', 'total_gross',\n 'total_net']\n\n @staticmethod\n def resolve_subtotal(obj, info):\n return obj.get_subtotal()\n\n @staticmethod\n def resolve_total_authorized(obj, info):\n payment = obj.get_last_payment()\n if payment:\n return payment.get_total_price().gross\n\n @staticmethod\n def resolve_total_captured(obj, info):\n payment = obj.get_last_payment()\n if payment:\n return payment.get_captured_price()\n\n @staticmethod\n def resolve_fulfillments(obj, info):\n return obj.fulfillments.all()\n\n @staticmethod\n def resolve_events(obj, info):\n return obj.events.all()\n\n @staticmethod\n def resolve_is_paid(obj, info):\n return obj.is_fully_paid()\n\n @staticmethod\n def resolve_number(obj, info):\n return str(obj.pk)\n\n @staticmethod\n def resolve_payment_status(obj, info):\n return obj.get_last_payment_status()\n\n @staticmethod\n def resolve_payment_status_display(obj, info):\n return obj.get_last_payment_status_display()\n\n @staticmethod\n def resolve_status_display(obj, info):\n return obj.get_status_display()\n\n @staticmethod\n def resolve_user_email(obj, info):\n if obj.user_email:\n return obj.user_email\n if obj.user_id:\n return obj.user.email\n return None\n\n\nclass OrderLine(CountableDjangoObjectType):\n class Meta:\n description = 'Represents order line of particular order.'\n model = models.OrderLine\n interfaces = [relay.Node]\n exclude_fields = [\n 'order', 'unit_price_gross', 'unit_price_net', 'variant']\n", "path": "saleor/graphql/order/types.py"}]} | 2,157 | 269 |
gh_patches_debug_21966 | rasdani/github-patches | git_diff | ranaroussi__yfinance-1283 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Ticket data from different timezone are not aligned (bug introduced with #1085)
I am trying to find correlations between tickets in differnet timezone (one in the New York Stock exchange and the other in the London Stock Exchange). Due to changes to the timezone logic, the data in each row of `yfinance.download` are no longer the data of the Tickets at the same time. Using `ignore_tz=False` fixes this problem. This problem didn't exist with version `0.1.77` and previous. So I think by default `ignore_tz` should be set to `False` as that behaviour is consistent with the previous minor versions.
</issue>
<code>
[start of yfinance/multi.py]
1 #!/usr/bin/env python
2 # -*- coding: utf-8 -*-
3 #
4 # yfinance - market data downloader
5 # https://github.com/ranaroussi/yfinance
6 #
7 # Copyright 2017-2019 Ran Aroussi
8 #
9 # Licensed under the Apache License, Version 2.0 (the "License");
10 # you may not use this file except in compliance with the License.
11 # You may obtain a copy of the License at
12 #
13 # http://www.apache.org/licenses/LICENSE-2.0
14 #
15 # Unless required by applicable law or agreed to in writing, software
16 # distributed under the License is distributed on an "AS IS" BASIS,
17 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
18 # See the License for the specific language governing permissions and
19 # limitations under the License.
20 #
21
22 from __future__ import print_function
23
24 import time as _time
25 import multitasking as _multitasking
26 import pandas as _pd
27
28 from . import Ticker, utils
29 from . import shared
30
31
32 def download(tickers, start=None, end=None, actions=False, threads=True, ignore_tz=True,
33 group_by='column', auto_adjust=False, back_adjust=False, repair=False, keepna=False,
34 progress=True, period="max", show_errors=True, interval="1d", prepost=False,
35 proxy=None, rounding=False, timeout=10):
36 """Download yahoo tickers
37 :Parameters:
38 tickers : str, list
39 List of tickers to download
40 period : str
41 Valid periods: 1d,5d,1mo,3mo,6mo,1y,2y,5y,10y,ytd,max
42 Either Use period parameter or use start and end
43 interval : str
44 Valid intervals: 1m,2m,5m,15m,30m,60m,90m,1h,1d,5d,1wk,1mo,3mo
45 Intraday data cannot extend last 60 days
46 start: str
47 Download start date string (YYYY-MM-DD) or _datetime.
48 Default is 1900-01-01
49 end: str
50 Download end date string (YYYY-MM-DD) or _datetime.
51 Default is now
52 group_by : str
53 Group by 'ticker' or 'column' (default)
54 prepost : bool
55 Include Pre and Post market data in results?
56 Default is False
57 auto_adjust: bool
58 Adjust all OHLC automatically? Default is False
59 repair: bool
60 Detect currency unit 100x mixups and attempt repair
61 Default is False
62 keepna: bool
63 Keep NaN rows returned by Yahoo?
64 Default is False
65 actions: bool
66 Download dividend + stock splits data. Default is False
67 threads: bool / int
68 How many threads to use for mass downloading. Default is True
69 ignore_tz: bool
70 When combining from different timezones, ignore that part of datetime.
71 Default is True
72 proxy: str
73 Optional. Proxy server URL scheme. Default is None
74 rounding: bool
75 Optional. Round values to 2 decimal places?
76 show_errors: bool
77 Optional. Doesn't print errors if False
78 timeout: None or float
79 If not None stops waiting for a response after given number of
80 seconds. (Can also be a fraction of a second e.g. 0.01)
81 """
82
83 # create ticker list
84 tickers = tickers if isinstance(
85 tickers, (list, set, tuple)) else tickers.replace(',', ' ').split()
86
87 # accept isin as ticker
88 shared._ISINS = {}
89 _tickers_ = []
90 for ticker in tickers:
91 if utils.is_isin(ticker):
92 isin = ticker
93 ticker = utils.get_ticker_by_isin(ticker, proxy)
94 shared._ISINS[ticker] = isin
95 _tickers_.append(ticker)
96
97 tickers = _tickers_
98
99 tickers = list(set([ticker.upper() for ticker in tickers]))
100
101 if progress:
102 shared._PROGRESS_BAR = utils.ProgressBar(len(tickers), 'completed')
103
104 # reset shared._DFS
105 shared._DFS = {}
106 shared._ERRORS = {}
107
108 # download using threads
109 if threads:
110 if threads is True:
111 threads = min([len(tickers), _multitasking.cpu_count() * 2])
112 _multitasking.set_max_threads(threads)
113 for i, ticker in enumerate(tickers):
114 _download_one_threaded(ticker, period=period, interval=interval,
115 start=start, end=end, prepost=prepost,
116 actions=actions, auto_adjust=auto_adjust,
117 back_adjust=back_adjust, repair=repair, keepna=keepna,
118 progress=(progress and i > 0), proxy=proxy,
119 rounding=rounding, timeout=timeout)
120 while len(shared._DFS) < len(tickers):
121 _time.sleep(0.01)
122
123 # download synchronously
124 else:
125 for i, ticker in enumerate(tickers):
126 data = _download_one(ticker, period=period, interval=interval,
127 start=start, end=end, prepost=prepost,
128 actions=actions, auto_adjust=auto_adjust,
129 back_adjust=back_adjust, repair=repair, keepna=keepna,
130 proxy=proxy,
131 rounding=rounding, timeout=timeout)
132 shared._DFS[ticker.upper()] = data
133 if progress:
134 shared._PROGRESS_BAR.animate()
135
136 if progress:
137 shared._PROGRESS_BAR.completed()
138
139 if shared._ERRORS and show_errors:
140 print('\n%.f Failed download%s:' % (
141 len(shared._ERRORS), 's' if len(shared._ERRORS) > 1 else ''))
142 # print(shared._ERRORS)
143 print("\n".join(['- %s: %s' %
144 v for v in list(shared._ERRORS.items())]))
145
146 if ignore_tz:
147 for tkr in shared._DFS.keys():
148 if (shared._DFS[tkr] is not None) and (shared._DFS[tkr].shape[0] > 0):
149 shared._DFS[tkr].index = shared._DFS[tkr].index.tz_localize(None)
150
151 if len(tickers) == 1:
152 ticker = tickers[0]
153 return shared._DFS[shared._ISINS.get(ticker, ticker)]
154
155 try:
156 data = _pd.concat(shared._DFS.values(), axis=1, sort=True,
157 keys=shared._DFS.keys())
158 except Exception:
159 _realign_dfs()
160 data = _pd.concat(shared._DFS.values(), axis=1, sort=True,
161 keys=shared._DFS.keys())
162
163 # switch names back to isins if applicable
164 data.rename(columns=shared._ISINS, inplace=True)
165
166 if group_by == 'column':
167 data.columns = data.columns.swaplevel(0, 1)
168 data.sort_index(level=0, axis=1, inplace=True)
169
170 return data
171
172
173 def _realign_dfs():
174 idx_len = 0
175 idx = None
176
177 for df in shared._DFS.values():
178 if len(df) > idx_len:
179 idx_len = len(df)
180 idx = df.index
181
182 for key in shared._DFS.keys():
183 try:
184 shared._DFS[key] = _pd.DataFrame(
185 index=idx, data=shared._DFS[key]).drop_duplicates()
186 except Exception:
187 shared._DFS[key] = _pd.concat([
188 utils.empty_df(idx), shared._DFS[key].dropna()
189 ], axis=0, sort=True)
190
191 # remove duplicate index
192 shared._DFS[key] = shared._DFS[key].loc[
193 ~shared._DFS[key].index.duplicated(keep='last')]
194
195
196 @_multitasking.task
197 def _download_one_threaded(ticker, start=None, end=None,
198 auto_adjust=False, back_adjust=False, repair=False,
199 actions=False, progress=True, period="max",
200 interval="1d", prepost=False, proxy=None,
201 keepna=False, rounding=False, timeout=10):
202 try:
203 data = _download_one(ticker, start, end, auto_adjust, back_adjust, repair,
204 actions, period, interval, prepost, proxy, rounding,
205 keepna, timeout)
206 except Exception as e:
207 # glob try/except needed as current thead implementation breaks if exception is raised.
208 shared._DFS[ticker] = utils.empty_df()
209 shared._ERRORS[ticker] = repr(e)
210 else:
211 shared._DFS[ticker.upper()] = data
212 if progress:
213 shared._PROGRESS_BAR.animate()
214
215
216 def _download_one(ticker, start=None, end=None,
217 auto_adjust=False, back_adjust=False, repair=False,
218 actions=False, period="max", interval="1d",
219 prepost=False, proxy=None, rounding=False,
220 keepna=False, timeout=10):
221 return Ticker(ticker).history(
222 period=period, interval=interval,
223 start=start, end=end, prepost=prepost,
224 actions=actions, auto_adjust=auto_adjust,
225 back_adjust=back_adjust, repair=repair, proxy=proxy,
226 rounding=rounding, keepna=keepna, timeout=timeout,
227 debug=False, raise_errors=False # debug and raise_errors false to not log and raise errors in threads
228 )
229
[end of yfinance/multi.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/yfinance/multi.py b/yfinance/multi.py
--- a/yfinance/multi.py
+++ b/yfinance/multi.py
@@ -29,7 +29,7 @@
from . import shared
-def download(tickers, start=None, end=None, actions=False, threads=True, ignore_tz=True,
+def download(tickers, start=None, end=None, actions=False, threads=True, ignore_tz=False,
group_by='column', auto_adjust=False, back_adjust=False, repair=False, keepna=False,
progress=True, period="max", show_errors=True, interval="1d", prepost=False,
proxy=None, rounding=False, timeout=10):
@@ -68,7 +68,7 @@
How many threads to use for mass downloading. Default is True
ignore_tz: bool
When combining from different timezones, ignore that part of datetime.
- Default is True
+ Default is False
proxy: str
Optional. Proxy server URL scheme. Default is None
rounding: bool
| {"golden_diff": "diff --git a/yfinance/multi.py b/yfinance/multi.py\n--- a/yfinance/multi.py\n+++ b/yfinance/multi.py\n@@ -29,7 +29,7 @@\n from . import shared\n \n \n-def download(tickers, start=None, end=None, actions=False, threads=True, ignore_tz=True,\n+def download(tickers, start=None, end=None, actions=False, threads=True, ignore_tz=False,\n group_by='column', auto_adjust=False, back_adjust=False, repair=False, keepna=False,\n progress=True, period=\"max\", show_errors=True, interval=\"1d\", prepost=False,\n proxy=None, rounding=False, timeout=10):\n@@ -68,7 +68,7 @@\n How many threads to use for mass downloading. Default is True\n ignore_tz: bool\n When combining from different timezones, ignore that part of datetime.\n- Default is True\n+ Default is False\n proxy: str\n Optional. Proxy server URL scheme. Default is None\n rounding: bool\n", "issue": "Ticket data from different timezone are not aligned (bug introduced with #1085)\nI am trying to find correlations between tickets in differnet timezone (one in the New York Stock exchange and the other in the London Stock Exchange). Due to changes to the timezone logic, the data in each row of `yfinance.download` are no longer the data of the Tickets at the same time. Using `ignore_tz=False` fixes this problem. This problem didn't exist with version `0.1.77` and previous. So I think by default `ignore_tz` should be set to `False` as that behaviour is consistent with the previous minor versions. \n", "before_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n#\n# yfinance - market data downloader\n# https://github.com/ranaroussi/yfinance\n#\n# Copyright 2017-2019 Ran Aroussi\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n#\n\nfrom __future__ import print_function\n\nimport time as _time\nimport multitasking as _multitasking\nimport pandas as _pd\n\nfrom . import Ticker, utils\nfrom . import shared\n\n\ndef download(tickers, start=None, end=None, actions=False, threads=True, ignore_tz=True,\n group_by='column', auto_adjust=False, back_adjust=False, repair=False, keepna=False,\n progress=True, period=\"max\", show_errors=True, interval=\"1d\", prepost=False,\n proxy=None, rounding=False, timeout=10):\n \"\"\"Download yahoo tickers\n :Parameters:\n tickers : str, list\n List of tickers to download\n period : str\n Valid periods: 1d,5d,1mo,3mo,6mo,1y,2y,5y,10y,ytd,max\n Either Use period parameter or use start and end\n interval : str\n Valid intervals: 1m,2m,5m,15m,30m,60m,90m,1h,1d,5d,1wk,1mo,3mo\n Intraday data cannot extend last 60 days\n start: str\n Download start date string (YYYY-MM-DD) or _datetime.\n Default is 1900-01-01\n end: str\n Download end date string (YYYY-MM-DD) or _datetime.\n Default is now\n group_by : str\n Group by 'ticker' or 'column' (default)\n prepost : bool\n Include Pre and Post market data in results?\n Default is False\n auto_adjust: bool\n Adjust all OHLC automatically? Default is False\n repair: bool\n Detect currency unit 100x mixups and attempt repair\n Default is False\n keepna: bool\n Keep NaN rows returned by Yahoo?\n Default is False\n actions: bool\n Download dividend + stock splits data. Default is False\n threads: bool / int\n How many threads to use for mass downloading. Default is True\n ignore_tz: bool\n When combining from different timezones, ignore that part of datetime.\n Default is True\n proxy: str\n Optional. Proxy server URL scheme. Default is None\n rounding: bool\n Optional. Round values to 2 decimal places?\n show_errors: bool\n Optional. Doesn't print errors if False\n timeout: None or float\n If not None stops waiting for a response after given number of\n seconds. (Can also be a fraction of a second e.g. 0.01)\n \"\"\"\n\n # create ticker list\n tickers = tickers if isinstance(\n tickers, (list, set, tuple)) else tickers.replace(',', ' ').split()\n\n # accept isin as ticker\n shared._ISINS = {}\n _tickers_ = []\n for ticker in tickers:\n if utils.is_isin(ticker):\n isin = ticker\n ticker = utils.get_ticker_by_isin(ticker, proxy)\n shared._ISINS[ticker] = isin\n _tickers_.append(ticker)\n\n tickers = _tickers_\n\n tickers = list(set([ticker.upper() for ticker in tickers]))\n\n if progress:\n shared._PROGRESS_BAR = utils.ProgressBar(len(tickers), 'completed')\n\n # reset shared._DFS\n shared._DFS = {}\n shared._ERRORS = {}\n\n # download using threads\n if threads:\n if threads is True:\n threads = min([len(tickers), _multitasking.cpu_count() * 2])\n _multitasking.set_max_threads(threads)\n for i, ticker in enumerate(tickers):\n _download_one_threaded(ticker, period=period, interval=interval,\n start=start, end=end, prepost=prepost,\n actions=actions, auto_adjust=auto_adjust,\n back_adjust=back_adjust, repair=repair, keepna=keepna,\n progress=(progress and i > 0), proxy=proxy,\n rounding=rounding, timeout=timeout)\n while len(shared._DFS) < len(tickers):\n _time.sleep(0.01)\n\n # download synchronously\n else:\n for i, ticker in enumerate(tickers):\n data = _download_one(ticker, period=period, interval=interval,\n start=start, end=end, prepost=prepost,\n actions=actions, auto_adjust=auto_adjust,\n back_adjust=back_adjust, repair=repair, keepna=keepna,\n proxy=proxy,\n rounding=rounding, timeout=timeout)\n shared._DFS[ticker.upper()] = data\n if progress:\n shared._PROGRESS_BAR.animate()\n\n if progress:\n shared._PROGRESS_BAR.completed()\n\n if shared._ERRORS and show_errors:\n print('\\n%.f Failed download%s:' % (\n len(shared._ERRORS), 's' if len(shared._ERRORS) > 1 else ''))\n # print(shared._ERRORS)\n print(\"\\n\".join(['- %s: %s' %\n v for v in list(shared._ERRORS.items())]))\n\n if ignore_tz:\n for tkr in shared._DFS.keys():\n if (shared._DFS[tkr] is not None) and (shared._DFS[tkr].shape[0] > 0):\n shared._DFS[tkr].index = shared._DFS[tkr].index.tz_localize(None)\n\n if len(tickers) == 1:\n ticker = tickers[0]\n return shared._DFS[shared._ISINS.get(ticker, ticker)]\n\n try:\n data = _pd.concat(shared._DFS.values(), axis=1, sort=True,\n keys=shared._DFS.keys())\n except Exception:\n _realign_dfs()\n data = _pd.concat(shared._DFS.values(), axis=1, sort=True,\n keys=shared._DFS.keys())\n\n # switch names back to isins if applicable\n data.rename(columns=shared._ISINS, inplace=True)\n\n if group_by == 'column':\n data.columns = data.columns.swaplevel(0, 1)\n data.sort_index(level=0, axis=1, inplace=True)\n\n return data\n\n\ndef _realign_dfs():\n idx_len = 0\n idx = None\n\n for df in shared._DFS.values():\n if len(df) > idx_len:\n idx_len = len(df)\n idx = df.index\n\n for key in shared._DFS.keys():\n try:\n shared._DFS[key] = _pd.DataFrame(\n index=idx, data=shared._DFS[key]).drop_duplicates()\n except Exception:\n shared._DFS[key] = _pd.concat([\n utils.empty_df(idx), shared._DFS[key].dropna()\n ], axis=0, sort=True)\n\n # remove duplicate index\n shared._DFS[key] = shared._DFS[key].loc[\n ~shared._DFS[key].index.duplicated(keep='last')]\n\n\n@_multitasking.task\ndef _download_one_threaded(ticker, start=None, end=None,\n auto_adjust=False, back_adjust=False, repair=False,\n actions=False, progress=True, period=\"max\",\n interval=\"1d\", prepost=False, proxy=None,\n keepna=False, rounding=False, timeout=10):\n try:\n data = _download_one(ticker, start, end, auto_adjust, back_adjust, repair,\n actions, period, interval, prepost, proxy, rounding,\n keepna, timeout)\n except Exception as e:\n # glob try/except needed as current thead implementation breaks if exception is raised.\n shared._DFS[ticker] = utils.empty_df()\n shared._ERRORS[ticker] = repr(e)\n else:\n shared._DFS[ticker.upper()] = data\n if progress:\n shared._PROGRESS_BAR.animate()\n\n\ndef _download_one(ticker, start=None, end=None,\n auto_adjust=False, back_adjust=False, repair=False,\n actions=False, period=\"max\", interval=\"1d\",\n prepost=False, proxy=None, rounding=False,\n keepna=False, timeout=10):\n return Ticker(ticker).history(\n period=period, interval=interval,\n start=start, end=end, prepost=prepost,\n actions=actions, auto_adjust=auto_adjust,\n back_adjust=back_adjust, repair=repair, proxy=proxy,\n rounding=rounding, keepna=keepna, timeout=timeout,\n debug=False, raise_errors=False # debug and raise_errors false to not log and raise errors in threads\n )\n", "path": "yfinance/multi.py"}]} | 3,323 | 230 |
gh_patches_debug_4248 | rasdani/github-patches | git_diff | mindsdb__mindsdb-317 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Unbound local error
**Your Environment**
anaconda
* Python version: 3.7.4
* Pip version:19.2.2
* Operating system:Windows
* Python environment used (e.g. venv, conda): conda
* Mindsdb version you tried to install:1.6.15
* Additional info if applicable:
**Describe the bug**
got Unbound local error while running this example
[https://github.com/ZoranPandovski/mindsdb-examples/tree/master/air_quality](https://github.com/ZoranPandovski/mindsdb-examples/tree/master/air_quality)
**To Reproduce**
Steps to reproduce the behavior, for example:
1. clone the repository
2. Run that example code in a jupyter notebook and you should see the error as presented in the screenshot.
**Expected behavior**
It should start the training.
**Additional context**


</issue>
<code>
[start of mindsdb/libs/data_sources/file_ds.py]
1 import re
2 from io import BytesIO, StringIO
3 import csv
4 import codecs
5 import json
6 import traceback
7 import codecs
8
9 import pandas
10 from pandas.io.json import json_normalize
11 import requests
12
13 from mindsdb.libs.data_types.data_source import DataSource
14 from mindsdb.libs.data_types.mindsdb_logger import log
15
16
17 class FileDS(DataSource):
18
19 def cleanRow(self, row):
20 n_row = []
21 for cell in row:
22 if str(cell) in ['', ' ', ' ', 'NaN', 'nan', 'NA']:
23 cell = None
24 n_row.append(cell)
25
26 return n_row
27
28 def _getDataIo(self, file):
29 """
30 This gets a file either url or local file and defiens what the format is as well as dialect
31 :param file: file path or url
32 :return: data_io, format, dialect
33 """
34
35 ############
36 # get file as io object
37 ############
38
39 data = BytesIO()
40
41 # get data from either url or file load in memory
42 if file[:5] == 'http:' or file[:6] == 'https:':
43 r = requests.get(file, stream=True)
44 if r.status_code == 200:
45 for chunk in r:
46 data.write(chunk)
47 data.seek(0)
48
49 # else read file from local file system
50 else:
51 try:
52 data = open(file, 'rb')
53 except Exception as e:
54 error = 'Could not load file, possible exception : {exception}'.format(exception = e)
55 log.error(error)
56 raise ValueError(error)
57
58
59 dialect = None
60
61 ############
62 # check for file type
63 ############
64
65 # try to guess if its an excel file
66 xlsx_sig = b'\x50\x4B\x05\06'
67 xlsx_sig2 = b'\x50\x4B\x03\x04'
68 xls_sig = b'\x09\x08\x10\x00\x00\x06\x05\x00'
69
70 # different whence, offset, size for different types
71 excel_meta = [ ('xls', 0, 512, 8), ('xlsx', 2, -22, 4)]
72
73 for filename, whence, offset, size in excel_meta:
74
75 try:
76 data.seek(offset, whence) # Seek to the offset.
77 bytes = data.read(size) # Capture the specified number of bytes.
78 data.seek(0)
79 codecs.getencoder('hex')(bytes)
80
81 if bytes == xls_sig:
82 return data, 'xls', dialect
83 elif bytes == xlsx_sig:
84 return data, 'xlsx', dialect
85
86 except:
87 data.seek(0)
88
89 # if not excel it can be a json file or a CSV, convert from binary to stringio
90
91 byte_str = data.read()
92 # Move it to StringIO
93 try:
94 # Handle Microsoft's BOM "special" UTF-8 encoding
95 if byte_str.startswith(codecs.BOM_UTF8):
96 data = StringIO(byte_str.decode('utf-8-sig'))
97 else:
98 data = StringIO(byte_str.decode('utf-8'))
99
100 except:
101 log.error(traceback.format_exc())
102 log.error('Could not load into string')
103
104 # see if its JSON
105 buffer = data.read(100)
106 data.seek(0)
107 text = buffer.strip()
108 # analyze first n characters
109 if len(text) > 0:
110 text = text.strip()
111 # it it looks like a json, then try to parse it
112 if text != "" and ((text[0] == "{") or (text[0] == "[")):
113 try:
114 json.loads(data.read())
115 data.seek(0)
116 return data, 'json', dialect
117 except:
118 data.seek(0)
119 return data, None, dialect
120
121 # lets try to figure out if its a csv
122 try:
123 data.seek(0)
124 first_few_lines = []
125 i = 0
126 for line in data:
127 i += 1
128 first_few_lines.append(line)
129 if i > 0:
130 break
131
132 accepted_delimiters = [',','\t', ';']
133 dialect = csv.Sniffer().sniff(''.join(first_few_lines[0]), delimiters=accepted_delimiters)
134 data.seek(0)
135 # if csv dialect identified then return csv
136 if dialect:
137 return data, 'csv', dialect
138 else:
139 return data, None, dialect
140 except:
141 data.seek(0)
142 log.error('Could not detect format for this file')
143 log.error(traceback.format_exc())
144 # No file type identified
145 return data, None, dialect
146
147
148
149
150 def _setup(self,file, clean_rows = True, custom_parser = None):
151 """
152 Setup from file
153 :param file: fielpath or url
154 :param clean_rows: if you want to clean rows for strange null values
155 :param custom_parser: if you want to parse the file with some custom parser
156 """
157
158 col_map = {}
159 # get file data io, format and dialect
160 data, format, dialect = self._getDataIo(file)
161 data.seek(0) # make sure we are at 0 in file pointer
162
163 if format is None:
164 log.error('Could not laod file into any format, supported formats are csv, json, xls, xslx')
165
166 if custom_parser:
167 header, file_data = custom_parser(data, format)
168
169 elif format == 'csv':
170 csv_reader = list(csv.reader(data, dialect))
171 header = csv_reader[0]
172 file_data = csv_reader[1:]
173
174 elif format in ['xlsx', 'xls']:
175 data.seek(0)
176 df = pandas.read_excel(data)
177 header = df.columns.values.tolist()
178 file_data = df.values.tolist()
179
180 elif format == 'json':
181 data.seek(0)
182 json_doc = json.loads(data.read())
183 df = json_normalize(json_doc)
184 header = df.columns.values.tolist()
185 file_data = df.values.tolist()
186
187 for col in header:
188 col_map[col] = col
189
190 if clean_rows == True:
191 file_list_data = []
192 for row in file_data:
193 row = self.cleanRow(row)
194 file_list_data.append(row)
195 else:
196 file_list_data = file_data
197
198 try:
199 return pandas.DataFrame(file_list_data, columns=header), col_map
200 except:
201 return pandas.read_csv(file), col_map
202
[end of mindsdb/libs/data_sources/file_ds.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/mindsdb/libs/data_sources/file_ds.py b/mindsdb/libs/data_sources/file_ds.py
--- a/mindsdb/libs/data_sources/file_ds.py
+++ b/mindsdb/libs/data_sources/file_ds.py
@@ -124,8 +124,10 @@
first_few_lines = []
i = 0
for line in data:
- i += 1
+ if line in ['\r\n','\n']:
+ continue
first_few_lines.append(line)
+ i += 1
if i > 0:
break
| {"golden_diff": "diff --git a/mindsdb/libs/data_sources/file_ds.py b/mindsdb/libs/data_sources/file_ds.py\n--- a/mindsdb/libs/data_sources/file_ds.py\n+++ b/mindsdb/libs/data_sources/file_ds.py\n@@ -124,8 +124,10 @@\n first_few_lines = []\n i = 0\n for line in data:\n- i += 1\n+ if line in ['\\r\\n','\\n']:\n+ continue\n first_few_lines.append(line)\n+ i += 1\n if i > 0:\n break\n", "issue": "Unbound local error\n**Your Environment**\r\nanaconda \r\n* Python version: 3.7.4\r\n* Pip version:19.2.2\r\n* Operating system:Windows\r\n* Python environment used (e.g. venv, conda): conda\r\n* Mindsdb version you tried to install:1.6.15\r\n* Additional info if applicable:\r\n\r\n**Describe the bug**\r\ngot Unbound local error while running this example \r\n[https://github.com/ZoranPandovski/mindsdb-examples/tree/master/air_quality](https://github.com/ZoranPandovski/mindsdb-examples/tree/master/air_quality)\r\n**To Reproduce**\r\nSteps to reproduce the behavior, for example:\r\n1. clone the repository\r\n2. Run that example code in a jupyter notebook and you should see the error as presented in the screenshot.\r\n\r\n**Expected behavior**\r\nIt should start the training.\r\n\r\n**Additional context**\r\n\r\n\n", "before_files": [{"content": "import re\nfrom io import BytesIO, StringIO\nimport csv\nimport codecs\nimport json\nimport traceback\nimport codecs\n\nimport pandas\nfrom pandas.io.json import json_normalize\nimport requests\n\nfrom mindsdb.libs.data_types.data_source import DataSource\nfrom mindsdb.libs.data_types.mindsdb_logger import log\n\n\nclass FileDS(DataSource):\n\n def cleanRow(self, row):\n n_row = []\n for cell in row:\n if str(cell) in ['', ' ', ' ', 'NaN', 'nan', 'NA']:\n cell = None\n n_row.append(cell)\n\n return n_row\n\n def _getDataIo(self, file):\n \"\"\"\n This gets a file either url or local file and defiens what the format is as well as dialect\n :param file: file path or url\n :return: data_io, format, dialect\n \"\"\"\n\n ############\n # get file as io object\n ############\n\n data = BytesIO()\n\n # get data from either url or file load in memory\n if file[:5] == 'http:' or file[:6] == 'https:':\n r = requests.get(file, stream=True)\n if r.status_code == 200:\n for chunk in r:\n data.write(chunk)\n data.seek(0)\n\n # else read file from local file system\n else:\n try:\n data = open(file, 'rb')\n except Exception as e:\n error = 'Could not load file, possible exception : {exception}'.format(exception = e)\n log.error(error)\n raise ValueError(error)\n\n\n dialect = None\n\n ############\n # check for file type\n ############\n\n # try to guess if its an excel file\n xlsx_sig = b'\\x50\\x4B\\x05\\06'\n xlsx_sig2 = b'\\x50\\x4B\\x03\\x04'\n xls_sig = b'\\x09\\x08\\x10\\x00\\x00\\x06\\x05\\x00'\n\n # different whence, offset, size for different types\n excel_meta = [ ('xls', 0, 512, 8), ('xlsx', 2, -22, 4)]\n\n for filename, whence, offset, size in excel_meta:\n\n try:\n data.seek(offset, whence) # Seek to the offset.\n bytes = data.read(size) # Capture the specified number of bytes.\n data.seek(0)\n codecs.getencoder('hex')(bytes)\n\n if bytes == xls_sig:\n return data, 'xls', dialect\n elif bytes == xlsx_sig:\n return data, 'xlsx', dialect\n\n except:\n data.seek(0)\n\n # if not excel it can be a json file or a CSV, convert from binary to stringio\n\n byte_str = data.read()\n # Move it to StringIO\n try:\n # Handle Microsoft's BOM \"special\" UTF-8 encoding\n if byte_str.startswith(codecs.BOM_UTF8):\n data = StringIO(byte_str.decode('utf-8-sig'))\n else:\n data = StringIO(byte_str.decode('utf-8'))\n\n except:\n log.error(traceback.format_exc())\n log.error('Could not load into string')\n\n # see if its JSON\n buffer = data.read(100)\n data.seek(0)\n text = buffer.strip()\n # analyze first n characters\n if len(text) > 0:\n text = text.strip()\n # it it looks like a json, then try to parse it\n if text != \"\" and ((text[0] == \"{\") or (text[0] == \"[\")):\n try:\n json.loads(data.read())\n data.seek(0)\n return data, 'json', dialect\n except:\n data.seek(0)\n return data, None, dialect\n\n # lets try to figure out if its a csv\n try:\n data.seek(0)\n first_few_lines = []\n i = 0\n for line in data:\n i += 1\n first_few_lines.append(line)\n if i > 0:\n break\n\n accepted_delimiters = [',','\\t', ';']\n dialect = csv.Sniffer().sniff(''.join(first_few_lines[0]), delimiters=accepted_delimiters)\n data.seek(0)\n # if csv dialect identified then return csv\n if dialect:\n return data, 'csv', dialect\n else:\n return data, None, dialect\n except:\n data.seek(0)\n log.error('Could not detect format for this file')\n log.error(traceback.format_exc())\n # No file type identified\n return data, None, dialect\n\n\n\n\n def _setup(self,file, clean_rows = True, custom_parser = None):\n \"\"\"\n Setup from file\n :param file: fielpath or url\n :param clean_rows: if you want to clean rows for strange null values\n :param custom_parser: if you want to parse the file with some custom parser\n \"\"\"\n\n col_map = {}\n # get file data io, format and dialect\n data, format, dialect = self._getDataIo(file)\n data.seek(0) # make sure we are at 0 in file pointer\n\n if format is None:\n log.error('Could not laod file into any format, supported formats are csv, json, xls, xslx')\n\n if custom_parser:\n header, file_data = custom_parser(data, format)\n\n elif format == 'csv':\n csv_reader = list(csv.reader(data, dialect))\n header = csv_reader[0]\n file_data = csv_reader[1:]\n\n elif format in ['xlsx', 'xls']:\n data.seek(0)\n df = pandas.read_excel(data)\n header = df.columns.values.tolist()\n file_data = df.values.tolist()\n\n elif format == 'json':\n data.seek(0)\n json_doc = json.loads(data.read())\n df = json_normalize(json_doc)\n header = df.columns.values.tolist()\n file_data = df.values.tolist()\n\n for col in header:\n col_map[col] = col\n\n if clean_rows == True:\n file_list_data = []\n for row in file_data:\n row = self.cleanRow(row)\n file_list_data.append(row)\n else:\n file_list_data = file_data\n\n try:\n return pandas.DataFrame(file_list_data, columns=header), col_map\n except:\n return pandas.read_csv(file), col_map\n", "path": "mindsdb/libs/data_sources/file_ds.py"}]} | 2,794 | 131 |
gh_patches_debug_1393 | rasdani/github-patches | git_diff | pytorch__audio-1583 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Use of deprecated `AutoNonVariableTypeMode`.
`AutoNonVariableTypeMode` is deprecated and will be removed in PyTorch 1.10.
https://github.com/pytorch/audio/search?q=AutoNonVariableTypeMode
Migration: https://github.com/pytorch/pytorch/blob/master/docs/cpp/source/notes/inference_mode.rst#migration-guide-from-autononvariabletypemode
cc @carolineechen
</issue>
<code>
[start of torchaudio/__init__.py]
1 from . import extension # noqa: F401
2 from torchaudio._internal import module_utils as _mod_utils # noqa: F401
3 from torchaudio import (
4 compliance,
5 datasets,
6 functional,
7 kaldi_io,
8 utils,
9 sox_effects,
10 transforms,
11 )
12
13 from torchaudio.backend import (
14 list_audio_backends,
15 get_audio_backend,
16 set_audio_backend,
17 )
18
19 try:
20 from .version import __version__, git_version # noqa: F401
21 except ImportError:
22 pass
23
24 __all__ = [
25 'compliance',
26 'datasets',
27 'functional',
28 'kaldi_io',
29 'utils',
30 'sox_effects',
31 'transforms',
32 'list_audio_backends',
33 'get_audio_backend',
34 'set_audio_backend',
35 'save_encinfo',
36 'sox_signalinfo_t',
37 'sox_encodinginfo_t',
38 'get_sox_option_t',
39 'get_sox_encoding_t',
40 'get_sox_bool',
41 'SignalInfo',
42 'EncodingInfo',
43 ]
44
[end of torchaudio/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/torchaudio/__init__.py b/torchaudio/__init__.py
--- a/torchaudio/__init__.py
+++ b/torchaudio/__init__.py
@@ -32,12 +32,4 @@
'list_audio_backends',
'get_audio_backend',
'set_audio_backend',
- 'save_encinfo',
- 'sox_signalinfo_t',
- 'sox_encodinginfo_t',
- 'get_sox_option_t',
- 'get_sox_encoding_t',
- 'get_sox_bool',
- 'SignalInfo',
- 'EncodingInfo',
]
| {"golden_diff": "diff --git a/torchaudio/__init__.py b/torchaudio/__init__.py\n--- a/torchaudio/__init__.py\n+++ b/torchaudio/__init__.py\n@@ -32,12 +32,4 @@\n 'list_audio_backends',\n 'get_audio_backend',\n 'set_audio_backend',\n- 'save_encinfo',\n- 'sox_signalinfo_t',\n- 'sox_encodinginfo_t',\n- 'get_sox_option_t',\n- 'get_sox_encoding_t',\n- 'get_sox_bool',\n- 'SignalInfo',\n- 'EncodingInfo',\n ]\n", "issue": "Use of deprecated `AutoNonVariableTypeMode`.\n`AutoNonVariableTypeMode` is deprecated and will be removed in PyTorch 1.10.\r\n\r\nhttps://github.com/pytorch/audio/search?q=AutoNonVariableTypeMode\r\n\r\nMigration: https://github.com/pytorch/pytorch/blob/master/docs/cpp/source/notes/inference_mode.rst#migration-guide-from-autononvariabletypemode\r\n\r\ncc @carolineechen \n", "before_files": [{"content": "from . import extension # noqa: F401\nfrom torchaudio._internal import module_utils as _mod_utils # noqa: F401\nfrom torchaudio import (\n compliance,\n datasets,\n functional,\n kaldi_io,\n utils,\n sox_effects,\n transforms,\n)\n\nfrom torchaudio.backend import (\n list_audio_backends,\n get_audio_backend,\n set_audio_backend,\n)\n\ntry:\n from .version import __version__, git_version # noqa: F401\nexcept ImportError:\n pass\n\n__all__ = [\n 'compliance',\n 'datasets',\n 'functional',\n 'kaldi_io',\n 'utils',\n 'sox_effects',\n 'transforms',\n 'list_audio_backends',\n 'get_audio_backend',\n 'set_audio_backend',\n 'save_encinfo',\n 'sox_signalinfo_t',\n 'sox_encodinginfo_t',\n 'get_sox_option_t',\n 'get_sox_encoding_t',\n 'get_sox_bool',\n 'SignalInfo',\n 'EncodingInfo',\n]\n", "path": "torchaudio/__init__.py"}]} | 941 | 140 |
gh_patches_debug_4807 | rasdani/github-patches | git_diff | bridgecrewio__checkov-5045 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Update CKV_AZURE_43 `each.`
**Describe the issue**
CKV_AZURE_43 StorageAccountName.py VARIABLE_REFS list does not include the `each.` used with for_each meta argument to return UNKNOWN and currently returns FAILED check which is incorrect.
**Examples**
```
module "bootstrap" {
source = "../../modules/bootstrap"
for_each = var.bootstrap_storage
create_storage_account = try(each.value.create_storage, true)
name = each.value.name
resource_group_name = try(each.value.resource_group_name, local.resource_group.name)
location = var.location
storage_acl = try(each.value.storage_acl, false)
tags = var.tags
}
```
Within the bootstrap module - we use the `azurerm_storage_account` :
```
resource "azurerm_storage_account" "this" {
count = var.create_storage_account ? 1 : 0
name = var.name
location = var.location
resource_group_name = var.resource_group_name
min_tls_version = var.min_tls_version
account_replication_type = "LRS"
account_tier = "Standard"
tags = var.tags
queue_properties {
logging {
delete = true
read = true
write = true
version = "1.0"
retention_policy_days = var.retention_policy_days
}
}
network_rules {
default_action = var.storage_acl == true ? "Deny" : "Allow"
ip_rules = var.storage_acl == true ? var.storage_allow_inbound_public_ips : null
virtual_network_subnet_ids = var.storage_acl == true ? var.storage_allow_vnet_subnets : null
}
}
```
And Checkov returns this :
```
Check: CKV_AZURE_43: "Ensure Storage Accounts adhere to the naming rules"
FAILED for resource: module.bootstrap.azurerm_storage_account.this
File: /modules/bootstrap/main.tf:1-25
Calling File: /examples/standalone_vm/main.tf:192-204
Guide: https://docs.bridgecrew.io/docs/ensure-storage-accounts-adhere-to-the-naming-rules
```
**Version (please complete the following information):**
- Checkov Version 2.2.125
**Additional context**
</issue>
<code>
[start of checkov/terraform/checks/resource/azure/StorageAccountName.py]
1 import re
2 from typing import List, Dict, Any
3
4 from checkov.terraform.checks.resource.base_resource_check import BaseResourceCheck
5 from checkov.common.models.enums import CheckResult, CheckCategories
6
7 STO_NAME_REGEX = re.compile(r"^[a-z0-9]{3,24}$")
8 VARIABLE_REFS = ("local.", "module.", "var.", "random_string.", "random_id.", "random_integer.", "random_pet.",
9 "azurecaf_name")
10
11
12 class StorageAccountName(BaseResourceCheck):
13 def __init__(self) -> None:
14 name = "Ensure Storage Accounts adhere to the naming rules"
15 id = "CKV_AZURE_43"
16 supported_resources = ["azurerm_storage_account"]
17 categories = [CheckCategories.CONVENTION]
18 super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)
19
20 def scan_resource_conf(self, conf: Dict[str, Any]) -> CheckResult:
21 """
22 The Storage Account naming reference:
23 https://docs.microsoft.com/en-us/azure/storage/common/storage-account-overview#naming-storage-accounts
24 :param conf: azurerm_storage_account configuration
25 :return: <CheckResult>
26 """
27 name = conf.get("name")
28 if name:
29 name = str(name[0])
30 if any(x in name for x in VARIABLE_REFS):
31 # in the case we couldn't evaluate the name, just ignore
32 return CheckResult.UNKNOWN
33 if re.findall(STO_NAME_REGEX, str(conf["name"][0])):
34 return CheckResult.PASSED
35
36 return CheckResult.FAILED
37
38 def get_evaluated_keys(self) -> List[str]:
39 return ["name"]
40
41
42 check = StorageAccountName()
43
[end of checkov/terraform/checks/resource/azure/StorageAccountName.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/checkov/terraform/checks/resource/azure/StorageAccountName.py b/checkov/terraform/checks/resource/azure/StorageAccountName.py
--- a/checkov/terraform/checks/resource/azure/StorageAccountName.py
+++ b/checkov/terraform/checks/resource/azure/StorageAccountName.py
@@ -6,7 +6,7 @@
STO_NAME_REGEX = re.compile(r"^[a-z0-9]{3,24}$")
VARIABLE_REFS = ("local.", "module.", "var.", "random_string.", "random_id.", "random_integer.", "random_pet.",
- "azurecaf_name")
+ "azurecaf_name", "each.")
class StorageAccountName(BaseResourceCheck):
| {"golden_diff": "diff --git a/checkov/terraform/checks/resource/azure/StorageAccountName.py b/checkov/terraform/checks/resource/azure/StorageAccountName.py\n--- a/checkov/terraform/checks/resource/azure/StorageAccountName.py\n+++ b/checkov/terraform/checks/resource/azure/StorageAccountName.py\n@@ -6,7 +6,7 @@\n \n STO_NAME_REGEX = re.compile(r\"^[a-z0-9]{3,24}$\")\n VARIABLE_REFS = (\"local.\", \"module.\", \"var.\", \"random_string.\", \"random_id.\", \"random_integer.\", \"random_pet.\",\n- \"azurecaf_name\")\n+ \"azurecaf_name\", \"each.\")\n \n \n class StorageAccountName(BaseResourceCheck):\n", "issue": "Update CKV_AZURE_43 `each.`\n**Describe the issue**\r\nCKV_AZURE_43 StorageAccountName.py VARIABLE_REFS list does not include the `each.` used with for_each meta argument to return UNKNOWN and currently returns FAILED check which is incorrect.\r\n\r\n**Examples**\r\n\r\n```\r\nmodule \"bootstrap\" {\r\n source = \"../../modules/bootstrap\"\r\n\r\n for_each = var.bootstrap_storage\r\n\r\n create_storage_account = try(each.value.create_storage, true)\r\n name = each.value.name\r\n resource_group_name = try(each.value.resource_group_name, local.resource_group.name)\r\n location = var.location\r\n storage_acl = try(each.value.storage_acl, false)\r\n\r\n tags = var.tags\r\n}\r\n```\r\n\r\nWithin the bootstrap module - we use the `azurerm_storage_account` :\r\n\r\n```\r\nresource \"azurerm_storage_account\" \"this\" {\r\n count = var.create_storage_account ? 1 : 0\r\n\r\n name = var.name\r\n location = var.location\r\n resource_group_name = var.resource_group_name\r\n min_tls_version = var.min_tls_version\r\n account_replication_type = \"LRS\"\r\n account_tier = \"Standard\"\r\n tags = var.tags\r\n queue_properties {\r\n logging {\r\n delete = true\r\n read = true\r\n write = true\r\n version = \"1.0\"\r\n retention_policy_days = var.retention_policy_days\r\n }\r\n }\r\n network_rules {\r\n default_action = var.storage_acl == true ? \"Deny\" : \"Allow\"\r\n ip_rules = var.storage_acl == true ? var.storage_allow_inbound_public_ips : null\r\n virtual_network_subnet_ids = var.storage_acl == true ? var.storage_allow_vnet_subnets : null\r\n }\r\n}\r\n```\r\n\r\nAnd Checkov returns this :\r\n\r\n```\r\nCheck: CKV_AZURE_43: \"Ensure Storage Accounts adhere to the naming rules\"\r\n FAILED for resource: module.bootstrap.azurerm_storage_account.this\r\n File: /modules/bootstrap/main.tf:1-25\r\n Calling File: /examples/standalone_vm/main.tf:192-204\r\n Guide: https://docs.bridgecrew.io/docs/ensure-storage-accounts-adhere-to-the-naming-rules\r\n```\r\n\r\n**Version (please complete the following information):**\r\n - Checkov Version 2.2.125\r\n\r\n**Additional context**\r\n\n", "before_files": [{"content": "import re\nfrom typing import List, Dict, Any\n\nfrom checkov.terraform.checks.resource.base_resource_check import BaseResourceCheck\nfrom checkov.common.models.enums import CheckResult, CheckCategories\n\nSTO_NAME_REGEX = re.compile(r\"^[a-z0-9]{3,24}$\")\nVARIABLE_REFS = (\"local.\", \"module.\", \"var.\", \"random_string.\", \"random_id.\", \"random_integer.\", \"random_pet.\",\n \"azurecaf_name\")\n\n\nclass StorageAccountName(BaseResourceCheck):\n def __init__(self) -> None:\n name = \"Ensure Storage Accounts adhere to the naming rules\"\n id = \"CKV_AZURE_43\"\n supported_resources = [\"azurerm_storage_account\"]\n categories = [CheckCategories.CONVENTION]\n super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)\n\n def scan_resource_conf(self, conf: Dict[str, Any]) -> CheckResult:\n \"\"\"\n The Storage Account naming reference:\n https://docs.microsoft.com/en-us/azure/storage/common/storage-account-overview#naming-storage-accounts\n :param conf: azurerm_storage_account configuration\n :return: <CheckResult>\n \"\"\"\n name = conf.get(\"name\")\n if name:\n name = str(name[0])\n if any(x in name for x in VARIABLE_REFS):\n # in the case we couldn't evaluate the name, just ignore\n return CheckResult.UNKNOWN\n if re.findall(STO_NAME_REGEX, str(conf[\"name\"][0])):\n return CheckResult.PASSED\n\n return CheckResult.FAILED\n\n def get_evaluated_keys(self) -> List[str]:\n return [\"name\"]\n\n\ncheck = StorageAccountName()\n", "path": "checkov/terraform/checks/resource/azure/StorageAccountName.py"}]} | 1,519 | 156 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.