
text
stringlengths 7
318k
| id
stringlengths 14
166
| metadata
dict | __index_level_0__
int64 0
439
|
|---|---|---|---|
# (Gluon) ResNet
**Residual Networks**, or **ResNets**, learn residual functions with reference to the layer inputs, instead of learning unreferenced functions. Instead of hoping each few stacked layers directly fit a desired underlying mapping, residual nets let these layers fit a residual mapping. They stack [residual blocks](https://paperswithcode.com/method/residual-block) ontop of each other to form network: e.g. a ResNet-50 has fifty layers using these blocks.
The weights from this model were ported from [Gluon](https://cv.gluon.ai/model_zoo/classification.html).
{% include 'code_snippets.md' %}
## How do I train this model?
You can follow the [timm recipe scripts](https://rwightman.github.io/pytorch-image-models/scripts/) for training a new model afresh.
## Citation
```BibTeX
@article{DBLP:journals/corr/HeZRS15,
author = {Kaiming He and
Xiangyu Zhang and
Shaoqing Ren and
Jian Sun},
title = {Deep Residual Learning for Image Recognition},
journal = {CoRR},
volume = {abs/1512.03385},
year = {2015},
url = {http://arxiv.org/abs/1512.03385},
archivePrefix = {arXiv},
eprint = {1512.03385},
timestamp = {Wed, 17 Apr 2019 17:23:45 +0200},
biburl = {https://dblp.org/rec/journals/corr/HeZRS15.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
<!--
Type: model-index
Collections:
- Name: Gloun ResNet
Paper:
Title: Deep Residual Learning for Image Recognition
URL: https://paperswithcode.com/paper/deep-residual-learning-for-image-recognition
Models:
- Name: gluon_resnet101_v1b
In Collection: Gloun ResNet
Metadata:
FLOPs: 10068547584
Parameters: 44550000
File Size: 178723172
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: gluon_resnet101_v1b
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/gluon_resnet.py#L89
Weights: https://github.com/rwightman/pytorch-pretrained-gluonresnet/releases/download/v0.1/gluon_resnet101_v1b-3b017079.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 79.3%
Top 5 Accuracy: 94.53%
- Name: gluon_resnet101_v1c
In Collection: Gloun ResNet
Metadata:
FLOPs: 10376567296
Parameters: 44570000
File Size: 178802575
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: gluon_resnet101_v1c
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/gluon_resnet.py#L113
Weights: https://github.com/rwightman/pytorch-pretrained-gluonresnet/releases/download/v0.1/gluon_resnet101_v1c-1f26822a.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 79.53%
Top 5 Accuracy: 94.59%
- Name: gluon_resnet101_v1d
In Collection: Gloun ResNet
Metadata:
FLOPs: 10377018880
Parameters: 44570000
File Size: 178802755
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: gluon_resnet101_v1d
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/gluon_resnet.py#L138
Weights: https://github.com/rwightman/pytorch-pretrained-gluonresnet/releases/download/v0.1/gluon_resnet101_v1d-0f9c8644.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 80.4%
Top 5 Accuracy: 95.02%
- Name: gluon_resnet101_v1s
In Collection: Gloun ResNet
Metadata:
FLOPs: 11805511680
Parameters: 44670000
File Size: 179221777
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: gluon_resnet101_v1s
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/gluon_resnet.py#L166
Weights: https://github.com/rwightman/pytorch-pretrained-gluonresnet/releases/download/v0.1/gluon_resnet101_v1s-60fe0cc1.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 80.29%
Top 5 Accuracy: 95.16%
- Name: gluon_resnet152_v1b
In Collection: Gloun ResNet
Metadata:
FLOPs: 14857660416
Parameters: 60190000
File Size: 241534001
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: gluon_resnet152_v1b
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/gluon_resnet.py#L97
Weights: https://github.com/rwightman/pytorch-pretrained-gluonresnet/releases/download/v0.1/gluon_resnet152_v1b-c1edb0dd.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 79.69%
Top 5 Accuracy: 94.73%
- Name: gluon_resnet152_v1c
In Collection: Gloun ResNet
Metadata:
FLOPs: 15165680128
Parameters: 60210000
File Size: 241613404
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: gluon_resnet152_v1c
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/gluon_resnet.py#L121
Weights: https://github.com/rwightman/pytorch-pretrained-gluonresnet/releases/download/v0.1/gluon_resnet152_v1c-a3bb0b98.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 79.91%
Top 5 Accuracy: 94.85%
- Name: gluon_resnet152_v1d
In Collection: Gloun ResNet
Metadata:
FLOPs: 15166131712
Parameters: 60210000
File Size: 241613584
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: gluon_resnet152_v1d
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/gluon_resnet.py#L147
Weights: https://github.com/rwightman/pytorch-pretrained-gluonresnet/releases/download/v0.1/gluon_resnet152_v1d-bd354e12.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 80.48%
Top 5 Accuracy: 95.2%
- Name: gluon_resnet152_v1s
In Collection: Gloun ResNet
Metadata:
FLOPs: 16594624512
Parameters: 60320000
File Size: 242032606
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: gluon_resnet152_v1s
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/gluon_resnet.py#L175
Weights: https://github.com/rwightman/pytorch-pretrained-gluonresnet/releases/download/v0.1/gluon_resnet152_v1s-dcc41b81.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 81.02%
Top 5 Accuracy: 95.42%
- Name: gluon_resnet18_v1b
In Collection: Gloun ResNet
Metadata:
FLOPs: 2337073152
Parameters: 11690000
File Size: 46816736
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: gluon_resnet18_v1b
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/gluon_resnet.py#L65
Weights: https://github.com/rwightman/pytorch-pretrained-gluonresnet/releases/download/v0.1/gluon_resnet18_v1b-0757602b.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 70.84%
Top 5 Accuracy: 89.76%
- Name: gluon_resnet34_v1b
In Collection: Gloun ResNet
Metadata:
FLOPs: 4718469120
Parameters: 21800000
File Size: 87295112
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: gluon_resnet34_v1b
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/gluon_resnet.py#L73
Weights: https://github.com/rwightman/pytorch-pretrained-gluonresnet/releases/download/v0.1/gluon_resnet34_v1b-c6d82d59.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 74.59%
Top 5 Accuracy: 92.0%
- Name: gluon_resnet50_v1b
In Collection: Gloun ResNet
Metadata:
FLOPs: 5282531328
Parameters: 25560000
File Size: 102493763
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: gluon_resnet50_v1b
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/gluon_resnet.py#L81
Weights: https://github.com/rwightman/pytorch-pretrained-gluonresnet/releases/download/v0.1/gluon_resnet50_v1b-0ebe02e2.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 77.58%
Top 5 Accuracy: 93.72%
- Name: gluon_resnet50_v1c
In Collection: Gloun ResNet
Metadata:
FLOPs: 5590551040
Parameters: 25580000
File Size: 102573166
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: gluon_resnet50_v1c
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/gluon_resnet.py#L105
Weights: https://github.com/rwightman/pytorch-pretrained-gluonresnet/releases/download/v0.1/gluon_resnet50_v1c-48092f55.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 78.01%
Top 5 Accuracy: 93.99%
- Name: gluon_resnet50_v1d
In Collection: Gloun ResNet
Metadata:
FLOPs: 5591002624
Parameters: 25580000
File Size: 102573346
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: gluon_resnet50_v1d
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/gluon_resnet.py#L129
Weights: https://github.com/rwightman/pytorch-pretrained-gluonresnet/releases/download/v0.1/gluon_resnet50_v1d-818a1b1b.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 79.06%
Top 5 Accuracy: 94.46%
- Name: gluon_resnet50_v1s
In Collection: Gloun ResNet
Metadata:
FLOPs: 7019495424
Parameters: 25680000
File Size: 102992368
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: gluon_resnet50_v1s
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/gluon_resnet.py#L156
Weights: https://github.com/rwightman/pytorch-pretrained-gluonresnet/releases/download/v0.1/gluon_resnet50_v1s-1762acc0.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 78.7%
Top 5 Accuracy: 94.25%
-->
| pytorch-image-models/docs/models/.templates/models/gloun-resnet.md/0 | {
"file_path": "pytorch-image-models/docs/models/.templates/models/gloun-resnet.md",
"repo_id": "pytorch-image-models",
"token_count": 6383
} | 170 |
# MobileNet v3
**MobileNetV3** is a convolutional neural network that is designed for mobile phone CPUs. The network design includes the use of a [hard swish activation](https://paperswithcode.com/method/hard-swish) and [squeeze-and-excitation](https://paperswithcode.com/method/squeeze-and-excitation-block) modules in the [MBConv blocks](https://paperswithcode.com/method/inverted-residual-block).
{% include 'code_snippets.md' %}
## How do I train this model?
You can follow the [timm recipe scripts](https://rwightman.github.io/pytorch-image-models/scripts/) for training a new model afresh.
## Citation
```BibTeX
@article{DBLP:journals/corr/abs-1905-02244,
author = {Andrew Howard and
Mark Sandler and
Grace Chu and
Liang{-}Chieh Chen and
Bo Chen and
Mingxing Tan and
Weijun Wang and
Yukun Zhu and
Ruoming Pang and
Vijay Vasudevan and
Quoc V. Le and
Hartwig Adam},
title = {Searching for MobileNetV3},
journal = {CoRR},
volume = {abs/1905.02244},
year = {2019},
url = {http://arxiv.org/abs/1905.02244},
archivePrefix = {arXiv},
eprint = {1905.02244},
timestamp = {Tue, 12 Jan 2021 15:30:06 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-1905-02244.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
<!--
Type: model-index
Collections:
- Name: MobileNet V3
Paper:
Title: Searching for MobileNetV3
URL: https://paperswithcode.com/paper/searching-for-mobilenetv3
Models:
- Name: mobilenetv3_large_100
In Collection: MobileNet V3
Metadata:
FLOPs: 287193752
Parameters: 5480000
File Size: 22076443
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Dense Connections
- Depthwise Separable Convolution
- Dropout
- Global Average Pooling
- Hard Swish
- Inverted Residual Block
- ReLU
- Residual Connection
- Softmax
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Techniques:
- RMSProp
- Weight Decay
Training Data:
- ImageNet
Training Resources: 4x4 TPU Pod
ID: mobilenetv3_large_100
LR: 0.1
Dropout: 0.8
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 4096
Image Size: '224'
Weight Decay: 1.0e-05
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/mobilenetv3.py#L363
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/mobilenetv3_large_100_ra-f55367f5.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 75.77%
Top 5 Accuracy: 92.54%
- Name: mobilenetv3_rw
In Collection: MobileNet V3
Metadata:
FLOPs: 287190638
Parameters: 5480000
File Size: 22064048
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Dense Connections
- Depthwise Separable Convolution
- Dropout
- Global Average Pooling
- Hard Swish
- Inverted Residual Block
- ReLU
- Residual Connection
- Softmax
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Techniques:
- RMSProp
- Weight Decay
Training Data:
- ImageNet
Training Resources: 4x4 TPU Pod
ID: mobilenetv3_rw
LR: 0.1
Dropout: 0.8
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 4096
Image Size: '224'
Weight Decay: 1.0e-05
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/mobilenetv3.py#L384
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/mobilenetv3_100-35495452.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 75.62%
Top 5 Accuracy: 92.71%
-->
| pytorch-image-models/docs/models/.templates/models/mobilenet-v3.md/0 | {
"file_path": "pytorch-image-models/docs/models/.templates/models/mobilenet-v3.md",
"repo_id": "pytorch-image-models",
"token_count": 1755
} | 171 |
# SK-ResNet
**SK ResNet** is a variant of a [ResNet](https://www.paperswithcode.com/method/resnet) that employs a [Selective Kernel](https://paperswithcode.com/method/selective-kernel) unit. In general, all the large kernel convolutions in the original bottleneck blocks in ResNet are replaced by the proposed [SK convolutions](https://paperswithcode.com/method/selective-kernel-convolution), enabling the network to choose appropriate receptive field sizes in an adaptive manner.
{% include 'code_snippets.md' %}
## How do I train this model?
You can follow the [timm recipe scripts](https://rwightman.github.io/pytorch-image-models/scripts/) for training a new model afresh.
## Citation
```BibTeX
@misc{li2019selective,
title={Selective Kernel Networks},
author={Xiang Li and Wenhai Wang and Xiaolin Hu and Jian Yang},
year={2019},
eprint={1903.06586},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
<!--
Type: model-index
Collections:
- Name: SKResNet
Paper:
Title: Selective Kernel Networks
URL: https://paperswithcode.com/paper/selective-kernel-networks
Models:
- Name: skresnet18
In Collection: SKResNet
Metadata:
FLOPs: 2333467136
Parameters: 11960000
File Size: 47923238
Architecture:
- Convolution
- Dense Connections
- Global Average Pooling
- Max Pooling
- Residual Connection
- Selective Kernel
- Softmax
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x GPUs
ID: skresnet18
LR: 0.1
Epochs: 100
Layers: 18
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 256
Image Size: '224'
Weight Decay: 4.0e-05
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/a7f95818e44b281137503bcf4b3e3e94d8ffa52f/timm/models/sknet.py#L148
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/skresnet18_ra-4eec2804.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 73.03%
Top 5 Accuracy: 91.17%
- Name: skresnet34
In Collection: SKResNet
Metadata:
FLOPs: 4711849952
Parameters: 22280000
File Size: 89299314
Architecture:
- Convolution
- Dense Connections
- Global Average Pooling
- Max Pooling
- Residual Connection
- Selective Kernel
- Softmax
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x GPUs
ID: skresnet34
LR: 0.1
Epochs: 100
Layers: 34
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 256
Image Size: '224'
Weight Decay: 4.0e-05
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/a7f95818e44b281137503bcf4b3e3e94d8ffa52f/timm/models/sknet.py#L165
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/skresnet34_ra-bdc0ccde.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 76.93%
Top 5 Accuracy: 93.32%
-->
| pytorch-image-models/docs/models/.templates/models/skresnet.md/0 | {
"file_path": "pytorch-image-models/docs/models/.templates/models/skresnet.md",
"repo_id": "pytorch-image-models",
"token_count": 1276
} | 172 |
# Xception
**Xception** is a convolutional neural network architecture that relies solely on [depthwise separable convolution layers](https://paperswithcode.com/method/depthwise-separable-convolution).
The weights from this model were ported from [Tensorflow/Models](https://github.com/tensorflow/models).
{% include 'code_snippets.md' %}
## How do I train this model?
You can follow the [timm recipe scripts](https://rwightman.github.io/pytorch-image-models/scripts/) for training a new model afresh.
## Citation
```BibTeX
@article{DBLP:journals/corr/ZagoruykoK16,
@misc{chollet2017xception,
title={Xception: Deep Learning with Depthwise Separable Convolutions},
author={François Chollet},
year={2017},
eprint={1610.02357},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
<!--
Type: model-index
Collections:
- Name: Xception
Paper:
Title: 'Xception: Deep Learning with Depthwise Separable Convolutions'
URL: https://paperswithcode.com/paper/xception-deep-learning-with-depthwise
Models:
- Name: xception
In Collection: Xception
Metadata:
FLOPs: 10600506792
Parameters: 22860000
File Size: 91675053
Architecture:
- 1x1 Convolution
- Convolution
- Dense Connections
- Depthwise Separable Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: xception
Crop Pct: '0.897'
Image Size: '299'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/xception.py#L229
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-cadene/xception-43020ad28.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 79.05%
Top 5 Accuracy: 94.4%
- Name: xception41
In Collection: Xception
Metadata:
FLOPs: 11681983232
Parameters: 26970000
File Size: 108422028
Architecture:
- 1x1 Convolution
- Convolution
- Dense Connections
- Depthwise Separable Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: xception41
Crop Pct: '0.903'
Image Size: '299'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/xception_aligned.py#L181
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_xception_41-e6439c97.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 78.54%
Top 5 Accuracy: 94.28%
- Name: xception65
In Collection: Xception
Metadata:
FLOPs: 17585702144
Parameters: 39920000
File Size: 160536780
Architecture:
- 1x1 Convolution
- Convolution
- Dense Connections
- Depthwise Separable Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: xception65
Crop Pct: '0.903'
Image Size: '299'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/xception_aligned.py#L200
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_xception_65-c9ae96e8.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 79.55%
Top 5 Accuracy: 94.66%
- Name: xception71
In Collection: Xception
Metadata:
FLOPs: 22817346560
Parameters: 42340000
File Size: 170295556
Architecture:
- 1x1 Convolution
- Convolution
- Dense Connections
- Depthwise Separable Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: xception71
Crop Pct: '0.903'
Image Size: '299'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/xception_aligned.py#L219
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_xception_71-8eec7df1.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 79.88%
Top 5 Accuracy: 94.93%
-->
| pytorch-image-models/docs/models/.templates/models/xception.md/0 | {
"file_path": "pytorch-image-models/docs/models/.templates/models/xception.md",
"repo_id": "pytorch-image-models",
"token_count": 1874
} | 173 |
# CSP-ResNet
**CSPResNet** is a convolutional neural network where we apply the Cross Stage Partial Network (CSPNet) approach to [ResNet](https://paperswithcode.com/method/resnet). The CSPNet partitions the feature map of the base layer into two parts and then merges them through a cross-stage hierarchy. The use of a split and merge strategy allows for more gradient flow through the network.
## How do I use this model on an image?
To load a pretrained model:
```py
>>> import timm
>>> model = timm.create_model('cspresnet50', pretrained=True)
>>> model.eval()
```
To load and preprocess the image:
```py
>>> import urllib
>>> from PIL import Image
>>> from timm.data import resolve_data_config
>>> from timm.data.transforms_factory import create_transform
>>> config = resolve_data_config({}, model=model)
>>> transform = create_transform(**config)
>>> url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
>>> urllib.request.urlretrieve(url, filename)
>>> img = Image.open(filename).convert('RGB')
>>> tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```py
>>> import torch
>>> with torch.no_grad():
... out = model(tensor)
>>> probabilities = torch.nn.functional.softmax(out[0], dim=0)
>>> print(probabilities.shape)
>>> # prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```py
>>> # Get imagenet class mappings
>>> url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
>>> urllib.request.urlretrieve(url, filename)
>>> with open("imagenet_classes.txt", "r") as f:
... categories = [s.strip() for s in f.readlines()]
>>> # Print top categories per image
>>> top5_prob, top5_catid = torch.topk(probabilities, 5)
>>> for i in range(top5_prob.size(0)):
... print(categories[top5_catid[i]], top5_prob[i].item())
>>> # prints class names and probabilities like:
>>> # [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `cspresnet50`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](../feature_extraction), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```py
>>> model = timm.create_model('cspresnet50', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](../scripts) for training a new model afresh.
## Citation
```BibTeX
@misc{wang2019cspnet,
title={CSPNet: A New Backbone that can Enhance Learning Capability of CNN},
author={Chien-Yao Wang and Hong-Yuan Mark Liao and I-Hau Yeh and Yueh-Hua Wu and Ping-Yang Chen and Jun-Wei Hsieh},
year={2019},
eprint={1911.11929},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
<!--
Type: model-index
Collections:
- Name: CSP ResNet
Paper:
Title: 'CSPNet: A New Backbone that can Enhance Learning Capability of CNN'
URL: https://paperswithcode.com/paper/cspnet-a-new-backbone-that-can-enhance
Models:
- Name: cspresnet50
In Collection: CSP ResNet
Metadata:
FLOPs: 5924992000
Parameters: 21620000
File Size: 86679303
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Techniques:
- Label Smoothing
- Polynomial Learning Rate Decay
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
ID: cspresnet50
LR: 0.1
Layers: 50
Crop Pct: '0.887'
Momentum: 0.9
Batch Size: 128
Image Size: '256'
Weight Decay: 0.005
Interpolation: bilinear
Training Steps: 8000000
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/cspnet.py#L415
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/cspresnet50_ra-d3e8d487.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 79.57%
Top 5 Accuracy: 94.71%
--> | pytorch-image-models/hfdocs/source/models/csp-resnet.mdx/0 | {
"file_path": "pytorch-image-models/hfdocs/source/models/csp-resnet.mdx",
"repo_id": "pytorch-image-models",
"token_count": 1706
} | 174 |
# RegNetX
**RegNetX** is a convolutional network design space with simple, regular models with parameters: depth \\( d \\), initial width \\( w\_{0} > 0 \\), and slope \\( w\_{a} > 0 \\), and generates a different block width \\( u\_{j} \\) for each block \\( j < d \\). The key restriction for the RegNet types of model is that there is a linear parameterisation of block widths (the design space only contains models with this linear structure):
\\( \\) u\_{j} = w\_{0} + w\_{a}\cdot{j} \\( \\)
For **RegNetX** we have additional restrictions: we set \\( b = 1 \\) (the bottleneck ratio), \\( 12 \leq d \leq 28 \\), and \\( w\_{m} \geq 2 \\) (the width multiplier).
## How do I use this model on an image?
To load a pretrained model:
```py
>>> import timm
>>> model = timm.create_model('regnetx_002', pretrained=True)
>>> model.eval()
```
To load and preprocess the image:
```py
>>> import urllib
>>> from PIL import Image
>>> from timm.data import resolve_data_config
>>> from timm.data.transforms_factory import create_transform
>>> config = resolve_data_config({}, model=model)
>>> transform = create_transform(**config)
>>> url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
>>> urllib.request.urlretrieve(url, filename)
>>> img = Image.open(filename).convert('RGB')
>>> tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```py
>>> import torch
>>> with torch.no_grad():
... out = model(tensor)
>>> probabilities = torch.nn.functional.softmax(out[0], dim=0)
>>> print(probabilities.shape)
>>> # prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```py
>>> # Get imagenet class mappings
>>> url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
>>> urllib.request.urlretrieve(url, filename)
>>> with open("imagenet_classes.txt", "r") as f:
... categories = [s.strip() for s in f.readlines()]
>>> # Print top categories per image
>>> top5_prob, top5_catid = torch.topk(probabilities, 5)
>>> for i in range(top5_prob.size(0)):
... print(categories[top5_catid[i]], top5_prob[i].item())
>>> # prints class names and probabilities like:
>>> # [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `regnetx_002`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](../feature_extraction), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```py
>>> model = timm.create_model('regnetx_002', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](../scripts) for training a new model afresh.
## Citation
```BibTeX
@misc{radosavovic2020designing,
title={Designing Network Design Spaces},
author={Ilija Radosavovic and Raj Prateek Kosaraju and Ross Girshick and Kaiming He and Piotr Dollár},
year={2020},
eprint={2003.13678},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
<!--
Type: model-index
Collections:
- Name: RegNetX
Paper:
Title: Designing Network Design Spaces
URL: https://paperswithcode.com/paper/designing-network-design-spaces
Models:
- Name: regnetx_002
In Collection: RegNetX
Metadata:
FLOPs: 255276032
Parameters: 2680000
File Size: 10862199
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Dense Connections
- Global Average Pooling
- Grouped Convolution
- ReLU
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA V100 GPUs
ID: regnetx_002
Epochs: 100
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 1024
Image Size: '224'
Weight Decay: 5.0e-05
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/regnet.py#L337
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-regnet/regnetx_002-e7e85e5c.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 68.75%
Top 5 Accuracy: 88.56%
- Name: regnetx_004
In Collection: RegNetX
Metadata:
FLOPs: 510619136
Parameters: 5160000
File Size: 20841309
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Dense Connections
- Global Average Pooling
- Grouped Convolution
- ReLU
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA V100 GPUs
ID: regnetx_004
Epochs: 100
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 1024
Image Size: '224'
Weight Decay: 5.0e-05
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/regnet.py#L343
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-regnet/regnetx_004-7d0e9424.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 72.39%
Top 5 Accuracy: 90.82%
- Name: regnetx_006
In Collection: RegNetX
Metadata:
FLOPs: 771659136
Parameters: 6200000
File Size: 24965172
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Dense Connections
- Global Average Pooling
- Grouped Convolution
- ReLU
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA V100 GPUs
ID: regnetx_006
Epochs: 100
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 1024
Image Size: '224'
Weight Decay: 5.0e-05
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/regnet.py#L349
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-regnet/regnetx_006-85ec1baa.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 73.84%
Top 5 Accuracy: 91.68%
- Name: regnetx_008
In Collection: RegNetX
Metadata:
FLOPs: 1027038208
Parameters: 7260000
File Size: 29235944
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Dense Connections
- Global Average Pooling
- Grouped Convolution
- ReLU
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA V100 GPUs
ID: regnetx_008
Epochs: 100
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 1024
Image Size: '224'
Weight Decay: 5.0e-05
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/regnet.py#L355
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-regnet/regnetx_008-d8b470eb.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 75.05%
Top 5 Accuracy: 92.34%
- Name: regnetx_016
In Collection: RegNetX
Metadata:
FLOPs: 2059337856
Parameters: 9190000
File Size: 36988158
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Dense Connections
- Global Average Pooling
- Grouped Convolution
- ReLU
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA V100 GPUs
ID: regnetx_016
Epochs: 100
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 1024
Image Size: '224'
Weight Decay: 5.0e-05
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/regnet.py#L361
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-regnet/regnetx_016-65ca972a.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 76.95%
Top 5 Accuracy: 93.43%
- Name: regnetx_032
In Collection: RegNetX
Metadata:
FLOPs: 4082555904
Parameters: 15300000
File Size: 61509573
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Dense Connections
- Global Average Pooling
- Grouped Convolution
- ReLU
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA V100 GPUs
ID: regnetx_032
Epochs: 100
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 512
Image Size: '224'
Weight Decay: 5.0e-05
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/regnet.py#L367
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-regnet/regnetx_032-ed0c7f7e.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 78.15%
Top 5 Accuracy: 94.09%
- Name: regnetx_040
In Collection: RegNetX
Metadata:
FLOPs: 5095167744
Parameters: 22120000
File Size: 88844824
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Dense Connections
- Global Average Pooling
- Grouped Convolution
- ReLU
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA V100 GPUs
ID: regnetx_040
Epochs: 100
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 512
Image Size: '224'
Weight Decay: 5.0e-05
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/regnet.py#L373
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-regnet/regnetx_040-73c2a654.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 78.48%
Top 5 Accuracy: 94.25%
- Name: regnetx_064
In Collection: RegNetX
Metadata:
FLOPs: 8303405824
Parameters: 26210000
File Size: 105184854
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Dense Connections
- Global Average Pooling
- Grouped Convolution
- ReLU
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA V100 GPUs
ID: regnetx_064
Epochs: 100
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 512
Image Size: '224'
Weight Decay: 5.0e-05
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/regnet.py#L379
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-regnet/regnetx_064-29278baa.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 79.06%
Top 5 Accuracy: 94.47%
- Name: regnetx_080
In Collection: RegNetX
Metadata:
FLOPs: 10276726784
Parameters: 39570000
File Size: 158720042
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Dense Connections
- Global Average Pooling
- Grouped Convolution
- ReLU
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA V100 GPUs
ID: regnetx_080
Epochs: 100
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 512
Image Size: '224'
Weight Decay: 5.0e-05
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/regnet.py#L385
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-regnet/regnetx_080-7c7fcab1.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 79.21%
Top 5 Accuracy: 94.55%
- Name: regnetx_120
In Collection: RegNetX
Metadata:
FLOPs: 15536378368
Parameters: 46110000
File Size: 184866342
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Dense Connections
- Global Average Pooling
- Grouped Convolution
- ReLU
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA V100 GPUs
ID: regnetx_120
Epochs: 100
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 512
Image Size: '224'
Weight Decay: 5.0e-05
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/regnet.py#L391
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-regnet/regnetx_120-65d5521e.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 79.61%
Top 5 Accuracy: 94.73%
- Name: regnetx_160
In Collection: RegNetX
Metadata:
FLOPs: 20491740672
Parameters: 54280000
File Size: 217623862
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Dense Connections
- Global Average Pooling
- Grouped Convolution
- ReLU
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA V100 GPUs
ID: regnetx_160
Epochs: 100
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 512
Image Size: '224'
Weight Decay: 5.0e-05
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/regnet.py#L397
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-regnet/regnetx_160-c98c4112.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 79.84%
Top 5 Accuracy: 94.82%
- Name: regnetx_320
In Collection: RegNetX
Metadata:
FLOPs: 40798958592
Parameters: 107810000
File Size: 431962133
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Dense Connections
- Global Average Pooling
- Grouped Convolution
- ReLU
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA V100 GPUs
ID: regnetx_320
Epochs: 100
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 256
Image Size: '224'
Weight Decay: 5.0e-05
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/regnet.py#L403
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-regnet/regnetx_320-8ea38b93.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 80.25%
Top 5 Accuracy: 95.03%
-->
| pytorch-image-models/hfdocs/source/models/regnetx.mdx/0 | {
"file_path": "pytorch-image-models/hfdocs/source/models/regnetx.mdx",
"repo_id": "pytorch-image-models",
"token_count": 6574
} | 175 |
# SWSL ResNet
**Residual Networks**, or **ResNets**, learn residual functions with reference to the layer inputs, instead of learning unreferenced functions. Instead of hoping each few stacked layers directly fit a desired underlying mapping, residual nets let these layers fit a residual mapping. They stack [residual blocks](https://paperswithcode.com/method/residual-block) ontop of each other to form network: e.g. a ResNet-50 has fifty layers using these blocks.
The models in this collection utilise semi-weakly supervised learning to improve the performance of the model. The approach brings important gains to standard architectures for image, video and fine-grained classification.
Please note the CC-BY-NC 4.0 license on theses weights, non-commercial use only.
## How do I use this model on an image?
To load a pretrained model:
```py
>>> import timm
>>> model = timm.create_model('swsl_resnet18', pretrained=True)
>>> model.eval()
```
To load and preprocess the image:
```py
>>> import urllib
>>> from PIL import Image
>>> from timm.data import resolve_data_config
>>> from timm.data.transforms_factory import create_transform
>>> config = resolve_data_config({}, model=model)
>>> transform = create_transform(**config)
>>> url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
>>> urllib.request.urlretrieve(url, filename)
>>> img = Image.open(filename).convert('RGB')
>>> tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```py
>>> import torch
>>> with torch.no_grad():
... out = model(tensor)
>>> probabilities = torch.nn.functional.softmax(out[0], dim=0)
>>> print(probabilities.shape)
>>> # prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```py
>>> # Get imagenet class mappings
>>> url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
>>> urllib.request.urlretrieve(url, filename)
>>> with open("imagenet_classes.txt", "r") as f:
... categories = [s.strip() for s in f.readlines()]
>>> # Print top categories per image
>>> top5_prob, top5_catid = torch.topk(probabilities, 5)
>>> for i in range(top5_prob.size(0)):
... print(categories[top5_catid[i]], top5_prob[i].item())
>>> # prints class names and probabilities like:
>>> # [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `swsl_resnet18`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](../feature_extraction), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```py
>>> model = timm.create_model('swsl_resnet18', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](../scripts) for training a new model afresh.
## Citation
```BibTeX
@article{DBLP:journals/corr/abs-1905-00546,
author = {I. Zeki Yalniz and
Herv{\'{e}} J{\'{e}}gou and
Kan Chen and
Manohar Paluri and
Dhruv Mahajan},
title = {Billion-scale semi-supervised learning for image classification},
journal = {CoRR},
volume = {abs/1905.00546},
year = {2019},
url = {http://arxiv.org/abs/1905.00546},
archivePrefix = {arXiv},
eprint = {1905.00546},
timestamp = {Mon, 28 Sep 2020 08:19:37 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-1905-00546.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
<!--
Type: model-index
Collections:
- Name: SWSL ResNet
Paper:
Title: Billion-scale semi-supervised learning for image classification
URL: https://paperswithcode.com/paper/billion-scale-semi-supervised-learning-for
Models:
- Name: swsl_resnet18
In Collection: SWSL ResNet
Metadata:
FLOPs: 2337073152
Parameters: 11690000
File Size: 46811375
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- IG-1B-Targeted
- ImageNet
Training Resources: 64x GPUs
ID: swsl_resnet18
LR: 0.0015
Epochs: 30
Layers: 18
Crop Pct: '0.875'
Batch Size: 1536
Image Size: '224'
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/resnet.py#L954
Weights: https://dl.fbaipublicfiles.com/semiweaksupervision/model_files/semi_weakly_supervised_resnet18-118f1556.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 73.28%
Top 5 Accuracy: 91.76%
- Name: swsl_resnet50
In Collection: SWSL ResNet
Metadata:
FLOPs: 5282531328
Parameters: 25560000
File Size: 102480594
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- IG-1B-Targeted
- ImageNet
Training Resources: 64x GPUs
ID: swsl_resnet50
LR: 0.0015
Epochs: 30
Layers: 50
Crop Pct: '0.875'
Batch Size: 1536
Image Size: '224'
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/resnet.py#L965
Weights: https://dl.fbaipublicfiles.com/semiweaksupervision/model_files/semi_weakly_supervised_resnet50-16a12f1b.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 81.14%
Top 5 Accuracy: 95.97%
--> | pytorch-image-models/hfdocs/source/models/swsl-resnet.mdx/0 | {
"file_path": "pytorch-image-models/hfdocs/source/models/swsl-resnet.mdx",
"repo_id": "pytorch-image-models",
"token_count": 2442
} | 176 |
# Results
CSV files containing an ImageNet-1K and out-of-distribution (OOD) test set validation results for all models with pretrained weights is located in the repository [results folder](https://github.com/rwightman/pytorch-image-models/tree/master/results).
## Self-trained Weights
The table below includes ImageNet-1k validation results of model weights that I've trained myself. It is not updated as frequently as the csv results outputs linked above.
|Model | Acc@1 (Err) | Acc@5 (Err) | Param # (M) | Interpolation | Image Size |
|---|---|---|---|---|---|
| efficientnet_b3a | 82.242 (17.758) | 96.114 (3.886) | 12.23 | bicubic | 320 (1.0 crop) |
| efficientnet_b3 | 82.076 (17.924) | 96.020 (3.980) | 12.23 | bicubic | 300 |
| regnet_32 | 82.002 (17.998) | 95.906 (4.094) | 19.44 | bicubic | 224 |
| skresnext50d_32x4d | 81.278 (18.722) | 95.366 (4.634) | 27.5 | bicubic | 288 (1.0 crop) |
| seresnext50d_32x4d | 81.266 (18.734) | 95.620 (4.380) | 27.6 | bicubic | 224 |
| efficientnet_b2a | 80.608 (19.392) | 95.310 (4.690) | 9.11 | bicubic | 288 (1.0 crop) |
| resnet50d | 80.530 (19.470) | 95.160 (4.840) | 25.6 | bicubic | 224 |
| mixnet_xl | 80.478 (19.522) | 94.932 (5.068) | 11.90 | bicubic | 224 |
| efficientnet_b2 | 80.402 (19.598) | 95.076 (4.924) | 9.11 | bicubic | 260 |
| seresnet50 | 80.274 (19.726) | 95.070 (4.930) | 28.1 | bicubic | 224 |
| skresnext50d_32x4d | 80.156 (19.844) | 94.642 (5.358) | 27.5 | bicubic | 224 |
| cspdarknet53 | 80.058 (19.942) | 95.084 (4.916) | 27.6 | bicubic | 256 |
| cspresnext50 | 80.040 (19.960) | 94.944 (5.056) | 20.6 | bicubic | 224 |
| resnext50_32x4d | 79.762 (20.238) | 94.600 (5.400) | 25 | bicubic | 224 |
| resnext50d_32x4d | 79.674 (20.326) | 94.868 (5.132) | 25.1 | bicubic | 224 |
| cspresnet50 | 79.574 (20.426) | 94.712 (5.288) | 21.6 | bicubic | 256 |
| ese_vovnet39b | 79.320 (20.680) | 94.710 (5.290) | 24.6 | bicubic | 224 |
| resnetblur50 | 79.290 (20.710) | 94.632 (5.368) | 25.6 | bicubic | 224 |
| dpn68b | 79.216 (20.784) | 94.414 (5.586) | 12.6 | bicubic | 224 |
| resnet50 | 79.038 (20.962) | 94.390 (5.610) | 25.6 | bicubic | 224 |
| mixnet_l | 78.976 (21.024 | 94.184 (5.816) | 7.33 | bicubic | 224 |
| efficientnet_b1 | 78.692 (21.308) | 94.086 (5.914) | 7.79 | bicubic | 240 |
| efficientnet_es | 78.066 (21.934) | 93.926 (6.074) | 5.44 | bicubic | 224 |
| seresnext26t_32x4d | 77.998 (22.002) | 93.708 (6.292) | 16.8 | bicubic | 224 |
| seresnext26tn_32x4d | 77.986 (22.014) | 93.746 (6.254) | 16.8 | bicubic | 224 |
| efficientnet_b0 | 77.698 (22.302) | 93.532 (6.468) | 5.29 | bicubic | 224 |
| seresnext26d_32x4d | 77.602 (22.398) | 93.608 (6.392) | 16.8 | bicubic | 224 |
| mobilenetv2_120d | 77.294 (22.706 | 93.502 (6.498) | 5.8 | bicubic | 224 |
| mixnet_m | 77.256 (22.744) | 93.418 (6.582) | 5.01 | bicubic | 224 |
| resnet34d | 77.116 (22.884) | 93.382 (6.618) | 21.8 | bicubic | 224 |
| seresnext26_32x4d | 77.104 (22.896) | 93.316 (6.684) | 16.8 | bicubic | 224 |
| skresnet34 | 76.912 (23.088) | 93.322 (6.678) | 22.2 | bicubic | 224 |
| ese_vovnet19b_dw | 76.798 (23.202) | 93.268 (6.732) | 6.5 | bicubic | 224 |
| resnet26d | 76.68 (23.32) | 93.166 (6.834) | 16 | bicubic | 224 |
| densenetblur121d | 76.576 (23.424) | 93.190 (6.810) | 8.0 | bicubic | 224 |
| mobilenetv2_140 | 76.524 (23.476) | 92.990 (7.010) | 6.1 | bicubic | 224 |
| mixnet_s | 75.988 (24.012) | 92.794 (7.206) | 4.13 | bicubic | 224 |
| mobilenetv3_large_100 | 75.766 (24.234) | 92.542 (7.458) | 5.5 | bicubic | 224 |
| mobilenetv3_rw | 75.634 (24.366) | 92.708 (7.292) | 5.5 | bicubic | 224 |
| mnasnet_a1 | 75.448 (24.552) | 92.604 (7.396) | 3.89 | bicubic | 224 |
| resnet26 | 75.292 (24.708) | 92.57 (7.43) | 16 | bicubic | 224 |
| fbnetc_100 | 75.124 (24.876) | 92.386 (7.614) | 5.6 | bilinear | 224 |
| resnet34 | 75.110 (24.890) | 92.284 (7.716) | 22 | bilinear | 224 |
| mobilenetv2_110d | 75.052 (24.948) | 92.180 (7.820) | 4.5 | bicubic | 224 |
| seresnet34 | 74.808 (25.192) | 92.124 (7.876) | 22 | bilinear | 224 |
| mnasnet_b1 | 74.658 (25.342) | 92.114 (7.886) | 4.38 | bicubic | 224 |
| spnasnet_100 | 74.084 (25.916) | 91.818 (8.182) | 4.42 | bilinear | 224 |
| skresnet18 | 73.038 (26.962) | 91.168 (8.832) | 11.9 | bicubic | 224 |
| mobilenetv2_100 | 72.978 (27.022) | 91.016 (8.984) | 3.5 | bicubic | 224 |
| resnet18d | 72.260 (27.740) | 90.696 (9.304) | 11.7 | bicubic | 224 |
| seresnet18 | 71.742 (28.258) | 90.334 (9.666) | 11.8 | bicubic | 224 |
## Ported and Other Weights
For weights ported from other deep learning frameworks (Tensorflow, MXNet GluonCV) or copied from other PyTorch sources, please see the full results tables for ImageNet and various OOD test sets at in the [results tables](https://github.com/rwightman/pytorch-image-models/tree/master/results).
Model code .py files contain links to original sources of models and weights.
| pytorch-image-models/hfdocs/source/results.mdx/0 | {
"file_path": "pytorch-image-models/hfdocs/source/results.mdx",
"repo_id": "pytorch-image-models",
"token_count": 2259
} | 177 |
import logging
from .constants import *
_logger = logging.getLogger(__name__)
def resolve_data_config(
args=None,
pretrained_cfg=None,
model=None,
use_test_size=False,
verbose=False
):
assert model or args or pretrained_cfg, "At least one of model, args, or pretrained_cfg required for data config."
args = args or {}
pretrained_cfg = pretrained_cfg or {}
if not pretrained_cfg and model is not None and hasattr(model, 'pretrained_cfg'):
pretrained_cfg = model.pretrained_cfg
data_config = {}
# Resolve input/image size
in_chans = 3
if args.get('in_chans', None) is not None:
in_chans = args['in_chans']
elif args.get('chans', None) is not None:
in_chans = args['chans']
input_size = (in_chans, 224, 224)
if args.get('input_size', None) is not None:
assert isinstance(args['input_size'], (tuple, list))
assert len(args['input_size']) == 3
input_size = tuple(args['input_size'])
in_chans = input_size[0] # input_size overrides in_chans
elif args.get('img_size', None) is not None:
assert isinstance(args['img_size'], int)
input_size = (in_chans, args['img_size'], args['img_size'])
else:
if use_test_size and pretrained_cfg.get('test_input_size', None) is not None:
input_size = pretrained_cfg['test_input_size']
elif pretrained_cfg.get('input_size', None) is not None:
input_size = pretrained_cfg['input_size']
data_config['input_size'] = input_size
# resolve interpolation method
data_config['interpolation'] = 'bicubic'
if args.get('interpolation', None):
data_config['interpolation'] = args['interpolation']
elif pretrained_cfg.get('interpolation', None):
data_config['interpolation'] = pretrained_cfg['interpolation']
# resolve dataset + model mean for normalization
data_config['mean'] = IMAGENET_DEFAULT_MEAN
if args.get('mean', None) is not None:
mean = tuple(args['mean'])
if len(mean) == 1:
mean = tuple(list(mean) * in_chans)
else:
assert len(mean) == in_chans
data_config['mean'] = mean
elif pretrained_cfg.get('mean', None):
data_config['mean'] = pretrained_cfg['mean']
# resolve dataset + model std deviation for normalization
data_config['std'] = IMAGENET_DEFAULT_STD
if args.get('std', None) is not None:
std = tuple(args['std'])
if len(std) == 1:
std = tuple(list(std) * in_chans)
else:
assert len(std) == in_chans
data_config['std'] = std
elif pretrained_cfg.get('std', None):
data_config['std'] = pretrained_cfg['std']
# resolve default inference crop
crop_pct = DEFAULT_CROP_PCT
if args.get('crop_pct', None):
crop_pct = args['crop_pct']
else:
if use_test_size and pretrained_cfg.get('test_crop_pct', None):
crop_pct = pretrained_cfg['test_crop_pct']
elif pretrained_cfg.get('crop_pct', None):
crop_pct = pretrained_cfg['crop_pct']
data_config['crop_pct'] = crop_pct
# resolve default crop percentage
crop_mode = DEFAULT_CROP_MODE
if args.get('crop_mode', None):
crop_mode = args['crop_mode']
elif pretrained_cfg.get('crop_mode', None):
crop_mode = pretrained_cfg['crop_mode']
data_config['crop_mode'] = crop_mode
if verbose:
_logger.info('Data processing configuration for current model + dataset:')
for n, v in data_config.items():
_logger.info('\t%s: %s' % (n, str(v)))
return data_config
def resolve_model_data_config(
model,
args=None,
pretrained_cfg=None,
use_test_size=False,
verbose=False,
):
""" Resolve Model Data Config
This is equivalent to resolve_data_config() but with arguments re-ordered to put model first.
Args:
model (nn.Module): the model instance
args (dict): command line arguments / configuration in dict form (overrides pretrained_cfg)
pretrained_cfg (dict): pretrained model config (overrides pretrained_cfg attached to model)
use_test_size (bool): use the test time input resolution (if one exists) instead of default train resolution
verbose (bool): enable extra logging of resolved values
Returns:
dictionary of config
"""
return resolve_data_config(
args=args,
pretrained_cfg=pretrained_cfg,
model=model,
use_test_size=use_test_size,
verbose=verbose,
)
| pytorch-image-models/timm/data/config.py/0 | {
"file_path": "pytorch-image-models/timm/data/config.py",
"repo_id": "pytorch-image-models",
"token_count": 1927
} | 178 |
""" Dataset reader for HF IterableDataset
"""
import math
import os
from itertools import repeat, chain
from typing import Optional
import torch
import torch.distributed as dist
from PIL import Image
try:
import datasets
from datasets.distributed import split_dataset_by_node
from datasets.splits import SplitInfo
except ImportError as e:
print("Please install Hugging Face datasets package `pip install datasets`.")
raise e
from .class_map import load_class_map
from .reader import Reader
from .shared_count import SharedCount
SHUFFLE_SIZE = int(os.environ.get('HFIDS_SHUFFLE_SIZE', 4096))
class ReaderHfids(Reader):
def __init__(
self,
name: str,
root: Optional[str] = None,
split: str = 'train',
is_training: bool = False,
batch_size: int = 1,
download: bool = False,
repeats: int = 0,
seed: int = 42,
class_map: Optional[dict] = None,
input_key: str = 'image',
input_img_mode: str = 'RGB',
target_key: str = 'label',
target_img_mode: str = '',
shuffle_size: Optional[int] = None,
num_samples: Optional[int] = None,
):
super().__init__()
self.root = root
self.split = split
self.is_training = is_training
self.batch_size = batch_size
self.download = download
self.repeats = repeats
self.common_seed = seed # a seed that's fixed across all worker / distributed instances
self.shuffle_size = shuffle_size or SHUFFLE_SIZE
self.input_key = input_key
self.input_img_mode = input_img_mode
self.target_key = target_key
self.target_img_mode = target_img_mode
self.builder = datasets.load_dataset_builder(name, cache_dir=root)
if download:
self.builder.download_and_prepare()
split_info: Optional[SplitInfo] = None
if self.builder.info.splits and split in self.builder.info.splits:
if isinstance(self.builder.info.splits[split], SplitInfo):
split_info: Optional[SplitInfo] = self.builder.info.splits[split]
if num_samples:
self.num_samples = num_samples
elif split_info and split_info.num_examples:
self.num_samples = split_info.num_examples
else:
raise ValueError(
"Dataset length is unknown, please pass `num_samples` explicitely. "
"The number of steps needs to be known in advance for the learning rate scheduler."
)
self.remap_class = False
if class_map:
self.class_to_idx = load_class_map(class_map)
self.remap_class = True
else:
self.class_to_idx = {}
# Distributed world state
self.dist_rank = 0
self.dist_num_replicas = 1
if dist.is_available() and dist.is_initialized() and dist.get_world_size() > 1:
self.dist_rank = dist.get_rank()
self.dist_num_replicas = dist.get_world_size()
# Attributes that are updated in _lazy_init
self.worker_info = None
self.worker_id = 0
self.num_workers = 1
self.global_worker_id = 0
self.global_num_workers = 1
# Initialized lazily on each dataloader worker process
self.ds: Optional[datasets.IterableDataset] = None
self.epoch = SharedCount()
def set_epoch(self, count):
# to update the shuffling effective_seed = seed + epoch
self.epoch.value = count
def set_loader_cfg(
self,
num_workers: Optional[int] = None,
):
if self.ds is not None:
return
if num_workers is not None:
self.num_workers = num_workers
self.global_num_workers = self.dist_num_replicas * self.num_workers
def _lazy_init(self):
""" Lazily initialize worker (in worker processes)
"""
if self.worker_info is None:
worker_info = torch.utils.data.get_worker_info()
if worker_info is not None:
self.worker_info = worker_info
self.worker_id = worker_info.id
self.num_workers = worker_info.num_workers
self.global_num_workers = self.dist_num_replicas * self.num_workers
self.global_worker_id = self.dist_rank * self.num_workers + self.worker_id
if self.download:
dataset = self.builder.as_dataset(split=self.split)
# to distribute evenly to workers
ds = dataset.to_iterable_dataset(num_shards=self.global_num_workers)
else:
# in this case the number of shard is determined by the number of remote files
ds = self.builder.as_streaming_dataset(split=self.split)
if self.is_training:
# will shuffle the list of shards and use a shuffle buffer
ds = ds.shuffle(seed=self.common_seed, buffer_size=self.shuffle_size)
# Distributed:
# The dataset has a number of shards that is a factor of `dist_num_replicas` (i.e. if `ds.n_shards % dist_num_replicas == 0`),
# so the shards are evenly assigned across the nodes.
# If it's not the case for dataset streaming, each node keeps 1 example out of `dist_num_replicas`, skipping the other examples.
# Workers:
# In a node, datasets.IterableDataset assigns the shards assigned to the node as evenly as possible to workers.
self.ds = split_dataset_by_node(ds, rank=self.dist_rank, world_size=self.dist_num_replicas)
def _num_samples_per_worker(self):
num_worker_samples = \
max(1, self.repeats) * self.num_samples / max(self.global_num_workers, self.dist_num_replicas)
if self.is_training or self.dist_num_replicas > 1:
num_worker_samples = math.ceil(num_worker_samples)
if self.is_training and self.batch_size is not None:
num_worker_samples = math.ceil(num_worker_samples / self.batch_size) * self.batch_size
return int(num_worker_samples)
def __iter__(self):
if self.ds is None:
self._lazy_init()
self.ds.set_epoch(self.epoch.value)
target_sample_count = self._num_samples_per_worker()
sample_count = 0
if self.is_training:
ds_iter = chain.from_iterable(repeat(self.ds))
else:
ds_iter = iter(self.ds)
for sample in ds_iter:
input_data: Image.Image = sample[self.input_key]
if self.input_img_mode and input_data.mode != self.input_img_mode:
input_data = input_data.convert(self.input_img_mode)
target_data = sample[self.target_key]
if self.target_img_mode:
assert isinstance(target_data, Image.Image), "target_img_mode is specified but target is not an image"
if target_data.mode != self.target_img_mode:
target_data = target_data.convert(self.target_img_mode)
elif self.remap_class:
target_data = self.class_to_idx[target_data]
yield input_data, target_data
sample_count += 1
if self.is_training and sample_count >= target_sample_count:
break
def __len__(self):
num_samples = self._num_samples_per_worker() * self.num_workers
return num_samples
def _filename(self, index, basename=False, absolute=False):
assert False, "Not supported" # no random access to examples
def filenames(self, basename=False, absolute=False):
""" Return all filenames in dataset, overrides base"""
if self.ds is None:
self._lazy_init()
names = []
for sample in self.ds:
if 'file_name' in sample:
name = sample['file_name']
elif 'filename' in sample:
name = sample['filename']
elif 'id' in sample:
name = sample['id']
elif 'image_id' in sample:
name = sample['image_id']
else:
assert False, "No supported name field present"
names.append(name)
return names | pytorch-image-models/timm/data/readers/reader_hfids.py/0 | {
"file_path": "pytorch-image-models/timm/data/readers/reader_hfids.py",
"repo_id": "pytorch-image-models",
"token_count": 3722
} | 179 |
from typing import Optional
import torch
import torch.nn as nn
import torch.nn.functional as F
from .config import use_fused_attn
from .mlp import Mlp
from .weight_init import trunc_normal_tf_
class AttentionPoolLatent(nn.Module):
""" Attention pooling w/ latent query
"""
fused_attn: torch.jit.Final[bool]
def __init__(
self,
in_features: int,
out_features: int = None,
embed_dim: int = None,
num_heads: int = 8,
mlp_ratio: float = 4.0,
qkv_bias: bool = True,
qk_norm: bool = False,
latent_len: int = 1,
latent_dim: int = None,
pos_embed: str = '',
pool_type: str = 'token',
norm_layer: Optional[nn.Module] = None,
drop: float = 0.0,
):
super().__init__()
embed_dim = embed_dim or in_features
out_features = out_features or in_features
assert embed_dim % num_heads == 0
self.num_heads = num_heads
self.head_dim = embed_dim // num_heads
self.scale = self.head_dim ** -0.5
self.pool = pool_type
self.fused_attn = use_fused_attn()
if pos_embed == 'abs':
spatial_len = self.feat_size
self.pos_embed = nn.Parameter(torch.zeros(spatial_len, in_features))
else:
self.pos_embed = None
self.latent_dim = latent_dim or embed_dim
self.latent_len = latent_len
self.latent = nn.Parameter(torch.zeros(1, self.latent_len, embed_dim))
self.q = nn.Linear(embed_dim, embed_dim, bias=qkv_bias)
self.kv = nn.Linear(embed_dim, embed_dim * 2, bias=qkv_bias)
self.q_norm = norm_layer(self.head_dim) if qk_norm else nn.Identity()
self.k_norm = norm_layer(self.head_dim) if qk_norm else nn.Identity()
self.proj = nn.Linear(embed_dim, embed_dim)
self.proj_drop = nn.Dropout(drop)
self.norm = norm_layer(out_features) if norm_layer is not None else nn.Identity()
self.mlp = Mlp(embed_dim, int(embed_dim * mlp_ratio))
self.init_weights()
def init_weights(self):
if self.pos_embed is not None:
trunc_normal_tf_(self.pos_embed, std=self.pos_embed.shape[1] ** -0.5)
trunc_normal_tf_(self.latent, std=self.latent_dim ** -0.5)
def forward(self, x):
B, N, C = x.shape
if self.pos_embed is not None:
# FIXME interpolate
x = x + self.pos_embed.unsqueeze(0).to(x.dtype)
q_latent = self.latent.expand(B, -1, -1)
q = self.q(q_latent).reshape(B, self.latent_len, self.num_heads, self.head_dim).transpose(1, 2)
kv = self.kv(x).reshape(B, N, 2, self.num_heads, self.head_dim).permute(2, 0, 3, 1, 4)
k, v = kv.unbind(0)
q, k = self.q_norm(q), self.k_norm(k)
if self.fused_attn:
x = F.scaled_dot_product_attention(q, k, v)
else:
q = q * self.scale
attn = q @ k.transpose(-2, -1)
attn = attn.softmax(dim=-1)
x = attn @ v
x = x.transpose(1, 2).reshape(B, self.latent_len, C)
x = self.proj(x)
x = self.proj_drop(x)
x = x + self.mlp(self.norm(x))
# optional pool if latent seq_len > 1 and pooled output is desired
if self.pool == 'token':
x = x[:, 0]
elif self.pool == 'avg':
x = x.mean(1)
return x | pytorch-image-models/timm/layers/attention_pool.py/0 | {
"file_path": "pytorch-image-models/timm/layers/attention_pool.py",
"repo_id": "pytorch-image-models",
"token_count": 1758
} | 180 |
"""
ECA module from ECAnet
paper: ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks
https://arxiv.org/abs/1910.03151
Original ECA model borrowed from https://github.com/BangguWu/ECANet
Modified circular ECA implementation and adaption for use in timm package
by Chris Ha https://github.com/VRandme
Original License:
MIT License
Copyright (c) 2019 BangguWu, Qilong Wang
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
"""
import math
from torch import nn
import torch.nn.functional as F
from .create_act import create_act_layer
from .helpers import make_divisible
class EcaModule(nn.Module):
"""Constructs an ECA module.
Args:
channels: Number of channels of the input feature map for use in adaptive kernel sizes
for actual calculations according to channel.
gamma, beta: when channel is given parameters of mapping function
refer to original paper https://arxiv.org/pdf/1910.03151.pdf
(default=None. if channel size not given, use k_size given for kernel size.)
kernel_size: Adaptive selection of kernel size (default=3)
gamm: used in kernel_size calc, see above
beta: used in kernel_size calc, see above
act_layer: optional non-linearity after conv, enables conv bias, this is an experiment
gate_layer: gating non-linearity to use
"""
def __init__(
self, channels=None, kernel_size=3, gamma=2, beta=1, act_layer=None, gate_layer='sigmoid',
rd_ratio=1/8, rd_channels=None, rd_divisor=8, use_mlp=False):
super(EcaModule, self).__init__()
if channels is not None:
t = int(abs(math.log(channels, 2) + beta) / gamma)
kernel_size = max(t if t % 2 else t + 1, 3)
assert kernel_size % 2 == 1
padding = (kernel_size - 1) // 2
if use_mlp:
# NOTE 'mlp' mode is a timm experiment, not in paper
assert channels is not None
if rd_channels is None:
rd_channels = make_divisible(channels * rd_ratio, divisor=rd_divisor)
act_layer = act_layer or nn.ReLU
self.conv = nn.Conv1d(1, rd_channels, kernel_size=1, padding=0, bias=True)
self.act = create_act_layer(act_layer)
self.conv2 = nn.Conv1d(rd_channels, 1, kernel_size=kernel_size, padding=padding, bias=True)
else:
self.conv = nn.Conv1d(1, 1, kernel_size=kernel_size, padding=padding, bias=False)
self.act = None
self.conv2 = None
self.gate = create_act_layer(gate_layer)
def forward(self, x):
y = x.mean((2, 3)).view(x.shape[0], 1, -1) # view for 1d conv
y = self.conv(y)
if self.conv2 is not None:
y = self.act(y)
y = self.conv2(y)
y = self.gate(y).view(x.shape[0], -1, 1, 1)
return x * y.expand_as(x)
EfficientChannelAttn = EcaModule # alias
class CecaModule(nn.Module):
"""Constructs a circular ECA module.
ECA module where the conv uses circular padding rather than zero padding.
Unlike the spatial dimension, the channels do not have inherent ordering nor
locality. Although this module in essence, applies such an assumption, it is unnecessary
to limit the channels on either "edge" from being circularly adapted to each other.
This will fundamentally increase connectivity and possibly increase performance metrics
(accuracy, robustness), without significantly impacting resource metrics
(parameter size, throughput,latency, etc)
Args:
channels: Number of channels of the input feature map for use in adaptive kernel sizes
for actual calculations according to channel.
gamma, beta: when channel is given parameters of mapping function
refer to original paper https://arxiv.org/pdf/1910.03151.pdf
(default=None. if channel size not given, use k_size given for kernel size.)
kernel_size: Adaptive selection of kernel size (default=3)
gamm: used in kernel_size calc, see above
beta: used in kernel_size calc, see above
act_layer: optional non-linearity after conv, enables conv bias, this is an experiment
gate_layer: gating non-linearity to use
"""
def __init__(self, channels=None, kernel_size=3, gamma=2, beta=1, act_layer=None, gate_layer='sigmoid'):
super(CecaModule, self).__init__()
if channels is not None:
t = int(abs(math.log(channels, 2) + beta) / gamma)
kernel_size = max(t if t % 2 else t + 1, 3)
has_act = act_layer is not None
assert kernel_size % 2 == 1
# PyTorch circular padding mode is buggy as of pytorch 1.4
# see https://github.com/pytorch/pytorch/pull/17240
# implement manual circular padding
self.padding = (kernel_size - 1) // 2
self.conv = nn.Conv1d(1, 1, kernel_size=kernel_size, padding=0, bias=has_act)
self.gate = create_act_layer(gate_layer)
def forward(self, x):
y = x.mean((2, 3)).view(x.shape[0], 1, -1)
# Manually implement circular padding, F.pad does not seemed to be bugged
y = F.pad(y, (self.padding, self.padding), mode='circular')
y = self.conv(y)
y = self.gate(y).view(x.shape[0], -1, 1, 1)
return x * y.expand_as(x)
CircularEfficientChannelAttn = CecaModule
| pytorch-image-models/timm/layers/eca.py/0 | {
"file_path": "pytorch-image-models/timm/layers/eca.py",
"repo_id": "pytorch-image-models",
"token_count": 2411
} | 181 |
""" PyTorch Mixed Convolution
Paper: MixConv: Mixed Depthwise Convolutional Kernels (https://arxiv.org/abs/1907.09595)
Hacked together by / Copyright 2020 Ross Wightman
"""
import torch
from torch import nn as nn
from .conv2d_same import create_conv2d_pad
def _split_channels(num_chan, num_groups):
split = [num_chan // num_groups for _ in range(num_groups)]
split[0] += num_chan - sum(split)
return split
class MixedConv2d(nn.ModuleDict):
""" Mixed Grouped Convolution
Based on MDConv and GroupedConv in MixNet impl:
https://github.com/tensorflow/tpu/blob/master/models/official/mnasnet/mixnet/custom_layers.py
"""
def __init__(self, in_channels, out_channels, kernel_size=3,
stride=1, padding='', dilation=1, depthwise=False, **kwargs):
super(MixedConv2d, self).__init__()
kernel_size = kernel_size if isinstance(kernel_size, list) else [kernel_size]
num_groups = len(kernel_size)
in_splits = _split_channels(in_channels, num_groups)
out_splits = _split_channels(out_channels, num_groups)
self.in_channels = sum(in_splits)
self.out_channels = sum(out_splits)
for idx, (k, in_ch, out_ch) in enumerate(zip(kernel_size, in_splits, out_splits)):
conv_groups = in_ch if depthwise else 1
# use add_module to keep key space clean
self.add_module(
str(idx),
create_conv2d_pad(
in_ch, out_ch, k, stride=stride,
padding=padding, dilation=dilation, groups=conv_groups, **kwargs)
)
self.splits = in_splits
def forward(self, x):
x_split = torch.split(x, self.splits, 1)
x_out = [c(x_split[i]) for i, c in enumerate(self.values())]
x = torch.cat(x_out, 1)
return x
| pytorch-image-models/timm/layers/mixed_conv2d.py/0 | {
"file_path": "pytorch-image-models/timm/layers/mixed_conv2d.py",
"repo_id": "pytorch-image-models",
"token_count": 834
} | 182 |
""" Split Attention Conv2d (for ResNeSt Models)
Paper: `ResNeSt: Split-Attention Networks` - /https://arxiv.org/abs/2004.08955
Adapted from original PyTorch impl at https://github.com/zhanghang1989/ResNeSt
Modified for torchscript compat, performance, and consistency with timm by Ross Wightman
"""
import torch
import torch.nn.functional as F
from torch import nn
from .helpers import make_divisible
class RadixSoftmax(nn.Module):
def __init__(self, radix, cardinality):
super(RadixSoftmax, self).__init__()
self.radix = radix
self.cardinality = cardinality
def forward(self, x):
batch = x.size(0)
if self.radix > 1:
x = x.view(batch, self.cardinality, self.radix, -1).transpose(1, 2)
x = F.softmax(x, dim=1)
x = x.reshape(batch, -1)
else:
x = torch.sigmoid(x)
return x
class SplitAttn(nn.Module):
"""Split-Attention (aka Splat)
"""
def __init__(self, in_channels, out_channels=None, kernel_size=3, stride=1, padding=None,
dilation=1, groups=1, bias=False, radix=2, rd_ratio=0.25, rd_channels=None, rd_divisor=8,
act_layer=nn.ReLU, norm_layer=None, drop_layer=None, **kwargs):
super(SplitAttn, self).__init__()
out_channels = out_channels or in_channels
self.radix = radix
mid_chs = out_channels * radix
if rd_channels is None:
attn_chs = make_divisible(in_channels * radix * rd_ratio, min_value=32, divisor=rd_divisor)
else:
attn_chs = rd_channels * radix
padding = kernel_size // 2 if padding is None else padding
self.conv = nn.Conv2d(
in_channels, mid_chs, kernel_size, stride, padding, dilation,
groups=groups * radix, bias=bias, **kwargs)
self.bn0 = norm_layer(mid_chs) if norm_layer else nn.Identity()
self.drop = drop_layer() if drop_layer is not None else nn.Identity()
self.act0 = act_layer(inplace=True)
self.fc1 = nn.Conv2d(out_channels, attn_chs, 1, groups=groups)
self.bn1 = norm_layer(attn_chs) if norm_layer else nn.Identity()
self.act1 = act_layer(inplace=True)
self.fc2 = nn.Conv2d(attn_chs, mid_chs, 1, groups=groups)
self.rsoftmax = RadixSoftmax(radix, groups)
def forward(self, x):
x = self.conv(x)
x = self.bn0(x)
x = self.drop(x)
x = self.act0(x)
B, RC, H, W = x.shape
if self.radix > 1:
x = x.reshape((B, self.radix, RC // self.radix, H, W))
x_gap = x.sum(dim=1)
else:
x_gap = x
x_gap = x_gap.mean((2, 3), keepdim=True)
x_gap = self.fc1(x_gap)
x_gap = self.bn1(x_gap)
x_gap = self.act1(x_gap)
x_attn = self.fc2(x_gap)
x_attn = self.rsoftmax(x_attn).view(B, -1, 1, 1)
if self.radix > 1:
out = (x * x_attn.reshape((B, self.radix, RC // self.radix, 1, 1))).sum(dim=1)
else:
out = x * x_attn
return out.contiguous()
| pytorch-image-models/timm/layers/split_attn.py/0 | {
"file_path": "pytorch-image-models/timm/layers/split_attn.py",
"repo_id": "pytorch-image-models",
"token_count": 1533
} | 183 |
""" EfficientNet, MobileNetV3, etc Builder
Assembles EfficieNet and related network feature blocks from string definitions.
Handles stride, dilation calculations, and selects feature extraction points.
Hacked together by / Copyright 2019, Ross Wightman
"""
import logging
import math
import re
from copy import deepcopy
from functools import partial
from typing import Any, Dict, List
import torch.nn as nn
from ._efficientnet_blocks import *
from timm.layers import CondConv2d, get_condconv_initializer, get_act_layer, get_attn, make_divisible
__all__ = ["EfficientNetBuilder", "decode_arch_def", "efficientnet_init_weights",
'resolve_bn_args', 'resolve_act_layer', 'round_channels', 'BN_MOMENTUM_TF_DEFAULT', 'BN_EPS_TF_DEFAULT']
_logger = logging.getLogger(__name__)
_DEBUG_BUILDER = False
# Defaults used for Google/Tensorflow training of mobile networks /w RMSprop as per
# papers and TF reference implementations. PT momentum equiv for TF decay is (1 - TF decay)
# NOTE: momentum varies btw .99 and .9997 depending on source
# .99 in official TF TPU impl
# .9997 (/w .999 in search space) for paper
BN_MOMENTUM_TF_DEFAULT = 1 - 0.99
BN_EPS_TF_DEFAULT = 1e-3
_BN_ARGS_TF = dict(momentum=BN_MOMENTUM_TF_DEFAULT, eps=BN_EPS_TF_DEFAULT)
BlockArgs = List[List[Dict[str, Any]]]
def get_bn_args_tf():
return _BN_ARGS_TF.copy()
def resolve_bn_args(kwargs):
bn_args = {}
bn_momentum = kwargs.pop('bn_momentum', None)
if bn_momentum is not None:
bn_args['momentum'] = bn_momentum
bn_eps = kwargs.pop('bn_eps', None)
if bn_eps is not None:
bn_args['eps'] = bn_eps
return bn_args
def resolve_act_layer(kwargs, default='relu'):
return get_act_layer(kwargs.pop('act_layer', default))
def round_channels(channels, multiplier=1.0, divisor=8, channel_min=None, round_limit=0.9):
"""Round number of filters based on depth multiplier."""
if not multiplier:
return channels
return make_divisible(channels * multiplier, divisor, channel_min, round_limit=round_limit)
def _log_info_if(msg, condition):
if condition:
_logger.info(msg)
def _parse_ksize(ss):
if ss.isdigit():
return int(ss)
else:
return [int(k) for k in ss.split('.')]
def _decode_block_str(block_str):
""" Decode block definition string
Gets a list of block arg (dicts) through a string notation of arguments.
E.g. ir_r2_k3_s2_e1_i32_o16_se0.25_noskip
All args can exist in any order with the exception of the leading string which
is assumed to indicate the block type.
leading string - block type (
ir = InvertedResidual, ds = DepthwiseSep, dsa = DeptwhiseSep with pw act, cn = ConvBnAct)
r - number of repeat blocks,
k - kernel size,
s - strides (1-9),
e - expansion ratio,
c - output channels,
se - squeeze/excitation ratio
n - activation fn ('re', 'r6', 'hs', or 'sw')
Args:
block_str: a string representation of block arguments.
Returns:
A list of block args (dicts)
Raises:
ValueError: if the string def not properly specified (TODO)
"""
assert isinstance(block_str, str)
ops = block_str.split('_')
block_type = ops[0] # take the block type off the front
ops = ops[1:]
options = {}
skip = None
for op in ops:
# string options being checked on individual basis, combine if they grow
if op == 'noskip':
skip = False # force no skip connection
elif op == 'skip':
skip = True # force a skip connection
elif op.startswith('n'):
# activation fn
key = op[0]
v = op[1:]
if v == 're':
value = get_act_layer('relu')
elif v == 'r6':
value = get_act_layer('relu6')
elif v == 'hs':
value = get_act_layer('hard_swish')
elif v == 'sw':
value = get_act_layer('swish') # aka SiLU
elif v == 'mi':
value = get_act_layer('mish')
else:
continue
options[key] = value
else:
# all numeric options
splits = re.split(r'(\d.*)', op)
if len(splits) >= 2:
key, value = splits[:2]
options[key] = value
# if act_layer is None, the model default (passed to model init) will be used
act_layer = options['n'] if 'n' in options else None
exp_kernel_size = _parse_ksize(options['a']) if 'a' in options else 1
pw_kernel_size = _parse_ksize(options['p']) if 'p' in options else 1
force_in_chs = int(options['fc']) if 'fc' in options else 0 # FIXME hack to deal with in_chs issue in TPU def
num_repeat = int(options['r'])
# each type of block has different valid arguments, fill accordingly
block_args = dict(
block_type=block_type,
out_chs=int(options['c']),
stride=int(options['s']),
act_layer=act_layer,
)
if block_type == 'ir':
block_args.update(dict(
dw_kernel_size=_parse_ksize(options['k']),
exp_kernel_size=exp_kernel_size,
pw_kernel_size=pw_kernel_size,
exp_ratio=float(options['e']),
se_ratio=float(options['se']) if 'se' in options else 0.,
noskip=skip is False,
))
if 'cc' in options:
block_args['num_experts'] = int(options['cc'])
elif block_type == 'ds' or block_type == 'dsa':
block_args.update(dict(
dw_kernel_size=_parse_ksize(options['k']),
pw_kernel_size=pw_kernel_size,
se_ratio=float(options['se']) if 'se' in options else 0.,
pw_act=block_type == 'dsa',
noskip=block_type == 'dsa' or skip is False,
))
elif block_type == 'er':
block_args.update(dict(
exp_kernel_size=_parse_ksize(options['k']),
pw_kernel_size=pw_kernel_size,
exp_ratio=float(options['e']),
force_in_chs=force_in_chs,
se_ratio=float(options['se']) if 'se' in options else 0.,
noskip=skip is False,
))
elif block_type == 'cn':
block_args.update(dict(
kernel_size=int(options['k']),
skip=skip is True,
))
else:
assert False, 'Unknown block type (%s)' % block_type
if 'gs' in options:
block_args['group_size'] = options['gs']
return block_args, num_repeat
def _scale_stage_depth(stack_args, repeats, depth_multiplier=1.0, depth_trunc='ceil'):
""" Per-stage depth scaling
Scales the block repeats in each stage. This depth scaling impl maintains
compatibility with the EfficientNet scaling method, while allowing sensible
scaling for other models that may have multiple block arg definitions in each stage.
"""
# We scale the total repeat count for each stage, there may be multiple
# block arg defs per stage so we need to sum.
num_repeat = sum(repeats)
if depth_trunc == 'round':
# Truncating to int by rounding allows stages with few repeats to remain
# proportionally smaller for longer. This is a good choice when stage definitions
# include single repeat stages that we'd prefer to keep that way as long as possible
num_repeat_scaled = max(1, round(num_repeat * depth_multiplier))
else:
# The default for EfficientNet truncates repeats to int via 'ceil'.
# Any multiplier > 1.0 will result in an increased depth for every stage.
num_repeat_scaled = int(math.ceil(num_repeat * depth_multiplier))
# Proportionally distribute repeat count scaling to each block definition in the stage.
# Allocation is done in reverse as it results in the first block being less likely to be scaled.
# The first block makes less sense to repeat in most of the arch definitions.
repeats_scaled = []
for r in repeats[::-1]:
rs = max(1, round((r / num_repeat * num_repeat_scaled)))
repeats_scaled.append(rs)
num_repeat -= r
num_repeat_scaled -= rs
repeats_scaled = repeats_scaled[::-1]
# Apply the calculated scaling to each block arg in the stage
sa_scaled = []
for ba, rep in zip(stack_args, repeats_scaled):
sa_scaled.extend([deepcopy(ba) for _ in range(rep)])
return sa_scaled
def decode_arch_def(
arch_def,
depth_multiplier=1.0,
depth_trunc='ceil',
experts_multiplier=1,
fix_first_last=False,
group_size=None,
):
""" Decode block architecture definition strings -> block kwargs
Args:
arch_def: architecture definition strings, list of list of strings
depth_multiplier: network depth multiplier
depth_trunc: networ depth truncation mode when applying multiplier
experts_multiplier: CondConv experts multiplier
fix_first_last: fix first and last block depths when multiplier is applied
group_size: group size override for all blocks that weren't explicitly set in arch string
Returns:
list of list of block kwargs
"""
arch_args = []
if isinstance(depth_multiplier, tuple):
assert len(depth_multiplier) == len(arch_def)
else:
depth_multiplier = (depth_multiplier,) * len(arch_def)
for stack_idx, (block_strings, multiplier) in enumerate(zip(arch_def, depth_multiplier)):
assert isinstance(block_strings, list)
stack_args = []
repeats = []
for block_str in block_strings:
assert isinstance(block_str, str)
ba, rep = _decode_block_str(block_str)
if ba.get('num_experts', 0) > 0 and experts_multiplier > 1:
ba['num_experts'] *= experts_multiplier
if group_size is not None:
ba.setdefault('group_size', group_size)
stack_args.append(ba)
repeats.append(rep)
if fix_first_last and (stack_idx == 0 or stack_idx == len(arch_def) - 1):
arch_args.append(_scale_stage_depth(stack_args, repeats, 1.0, depth_trunc))
else:
arch_args.append(_scale_stage_depth(stack_args, repeats, multiplier, depth_trunc))
return arch_args
class EfficientNetBuilder:
""" Build Trunk Blocks
This ended up being somewhat of a cross between
https://github.com/tensorflow/tpu/blob/master/models/official/mnasnet/mnasnet_models.py
and
https://github.com/facebookresearch/maskrcnn-benchmark/blob/master/maskrcnn_benchmark/modeling/backbone/fbnet_builder.py
"""
def __init__(self, output_stride=32, pad_type='', round_chs_fn=round_channels, se_from_exp=False,
act_layer=None, norm_layer=None, se_layer=None, drop_path_rate=0., feature_location=''):
self.output_stride = output_stride
self.pad_type = pad_type
self.round_chs_fn = round_chs_fn
self.se_from_exp = se_from_exp # calculate se channel reduction from expanded (mid) chs
self.act_layer = act_layer
self.norm_layer = norm_layer
self.se_layer = get_attn(se_layer)
try:
self.se_layer(8, rd_ratio=1.0) # test if attn layer accepts rd_ratio arg
self.se_has_ratio = True
except TypeError:
self.se_has_ratio = False
self.drop_path_rate = drop_path_rate
if feature_location == 'depthwise':
# old 'depthwise' mode renamed 'expansion' to match TF impl, old expansion mode didn't make sense
_logger.warning("feature_location=='depthwise' is deprecated, using 'expansion'")
feature_location = 'expansion'
self.feature_location = feature_location
assert feature_location in ('bottleneck', 'expansion', '')
self.verbose = _DEBUG_BUILDER
# state updated during build, consumed by model
self.in_chs = None
self.features = []
def _make_block(self, ba, block_idx, block_count):
drop_path_rate = self.drop_path_rate * block_idx / block_count
bt = ba.pop('block_type')
ba['in_chs'] = self.in_chs
ba['out_chs'] = self.round_chs_fn(ba['out_chs'])
if 'force_in_chs' in ba and ba['force_in_chs']:
# NOTE this is a hack to work around mismatch in TF EdgeEffNet impl
ba['force_in_chs'] = self.round_chs_fn(ba['force_in_chs'])
ba['pad_type'] = self.pad_type
# block act fn overrides the model default
ba['act_layer'] = ba['act_layer'] if ba['act_layer'] is not None else self.act_layer
assert ba['act_layer'] is not None
ba['norm_layer'] = self.norm_layer
ba['drop_path_rate'] = drop_path_rate
if bt != 'cn':
se_ratio = ba.pop('se_ratio')
if se_ratio and self.se_layer is not None:
if not self.se_from_exp:
# adjust se_ratio by expansion ratio if calculating se channels from block input
se_ratio /= ba.get('exp_ratio', 1.0)
if self.se_has_ratio:
ba['se_layer'] = partial(self.se_layer, rd_ratio=se_ratio)
else:
ba['se_layer'] = self.se_layer
if bt == 'ir':
_log_info_if(' InvertedResidual {}, Args: {}'.format(block_idx, str(ba)), self.verbose)
block = CondConvResidual(**ba) if ba.get('num_experts', 0) else InvertedResidual(**ba)
elif bt == 'ds' or bt == 'dsa':
_log_info_if(' DepthwiseSeparable {}, Args: {}'.format(block_idx, str(ba)), self.verbose)
block = DepthwiseSeparableConv(**ba)
elif bt == 'er':
_log_info_if(' EdgeResidual {}, Args: {}'.format(block_idx, str(ba)), self.verbose)
block = EdgeResidual(**ba)
elif bt == 'cn':
_log_info_if(' ConvBnAct {}, Args: {}'.format(block_idx, str(ba)), self.verbose)
block = ConvBnAct(**ba)
else:
assert False, 'Uknkown block type (%s) while building model.' % bt
self.in_chs = ba['out_chs'] # update in_chs for arg of next block
return block
def __call__(self, in_chs, model_block_args):
""" Build the blocks
Args:
in_chs: Number of input-channels passed to first block
model_block_args: A list of lists, outer list defines stages, inner
list contains strings defining block configuration(s)
Return:
List of block stacks (each stack wrapped in nn.Sequential)
"""
_log_info_if('Building model trunk with %d stages...' % len(model_block_args), self.verbose)
self.in_chs = in_chs
total_block_count = sum([len(x) for x in model_block_args])
total_block_idx = 0
current_stride = 2
current_dilation = 1
stages = []
if model_block_args[0][0]['stride'] > 1:
# if the first block starts with a stride, we need to extract first level feat from stem
feature_info = dict(module='bn1', num_chs=in_chs, stage=0, reduction=current_stride)
self.features.append(feature_info)
# outer list of block_args defines the stacks
for stack_idx, stack_args in enumerate(model_block_args):
last_stack = stack_idx + 1 == len(model_block_args)
_log_info_if('Stack: {}'.format(stack_idx), self.verbose)
assert isinstance(stack_args, list)
blocks = []
# each stack (stage of blocks) contains a list of block arguments
for block_idx, block_args in enumerate(stack_args):
last_block = block_idx + 1 == len(stack_args)
_log_info_if(' Block: {}'.format(block_idx), self.verbose)
assert block_args['stride'] in (1, 2)
if block_idx >= 1: # only the first block in any stack can have a stride > 1
block_args['stride'] = 1
extract_features = False
if last_block:
next_stack_idx = stack_idx + 1
extract_features = next_stack_idx >= len(model_block_args) or \
model_block_args[next_stack_idx][0]['stride'] > 1
next_dilation = current_dilation
if block_args['stride'] > 1:
next_output_stride = current_stride * block_args['stride']
if next_output_stride > self.output_stride:
next_dilation = current_dilation * block_args['stride']
block_args['stride'] = 1
_log_info_if(' Converting stride to dilation to maintain output_stride=={}'.format(
self.output_stride), self.verbose)
else:
current_stride = next_output_stride
block_args['dilation'] = current_dilation
if next_dilation != current_dilation:
current_dilation = next_dilation
# create the block
block = self._make_block(block_args, total_block_idx, total_block_count)
blocks.append(block)
# stash feature module name and channel info for model feature extraction
if extract_features:
feature_info = dict(
stage=stack_idx + 1,
reduction=current_stride,
**block.feature_info(self.feature_location),
)
leaf_name = feature_info.get('module', '')
if leaf_name:
feature_info['module'] = '.'.join([f'blocks.{stack_idx}.{block_idx}', leaf_name])
else:
assert last_block
feature_info['module'] = f'blocks.{stack_idx}'
self.features.append(feature_info)
total_block_idx += 1 # incr global block idx (across all stacks)
stages.append(nn.Sequential(*blocks))
return stages
def _init_weight_goog(m, n='', fix_group_fanout=True):
""" Weight initialization as per Tensorflow official implementations.
Args:
m (nn.Module): module to init
n (str): module name
fix_group_fanout (bool): enable correct (matching Tensorflow TPU impl) fanout calculation w/ group convs
Handles layers in EfficientNet, EfficientNet-CondConv, MixNet, MnasNet, MobileNetV3, etc:
* https://github.com/tensorflow/tpu/blob/master/models/official/mnasnet/mnasnet_model.py
* https://github.com/tensorflow/tpu/blob/master/models/official/efficientnet/efficientnet_model.py
"""
if isinstance(m, CondConv2d):
fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
if fix_group_fanout:
fan_out //= m.groups
init_weight_fn = get_condconv_initializer(
lambda w: nn.init.normal_(w, 0, math.sqrt(2.0 / fan_out)), m.num_experts, m.weight_shape)
init_weight_fn(m.weight)
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, nn.Conv2d):
fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
if fix_group_fanout:
fan_out //= m.groups
nn.init.normal_(m.weight, 0, math.sqrt(2.0 / fan_out))
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, nn.BatchNorm2d):
nn.init.ones_(m.weight)
nn.init.zeros_(m.bias)
elif isinstance(m, nn.Linear):
fan_out = m.weight.size(0) # fan-out
fan_in = 0
if 'routing_fn' in n:
fan_in = m.weight.size(1)
init_range = 1.0 / math.sqrt(fan_in + fan_out)
nn.init.uniform_(m.weight, -init_range, init_range)
nn.init.zeros_(m.bias)
def efficientnet_init_weights(model: nn.Module, init_fn=None):
init_fn = init_fn or _init_weight_goog
for n, m in model.named_modules():
init_fn(m, n)
| pytorch-image-models/timm/models/_efficientnet_builder.py/0 | {
"file_path": "pytorch-image-models/timm/models/_efficientnet_builder.py",
"repo_id": "pytorch-image-models",
"token_count": 9013
} | 184 |
""" Bring-Your-Own-Attention Network
A flexible network w/ dataclass based config for stacking NN blocks including
self-attention (or similar) layers.
Currently used to implement experimental variants of:
* Bottleneck Transformers
* Lambda ResNets
* HaloNets
Consider all of the models definitions here as experimental WIP and likely to change.
Hacked together by / copyright Ross Wightman, 2021.
"""
from timm.data import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD
from ._builder import build_model_with_cfg
from ._registry import register_model, generate_default_cfgs
from .byobnet import ByoBlockCfg, ByoModelCfg, ByobNet, interleave_blocks
__all__ = []
model_cfgs = dict(
botnet26t=ByoModelCfg(
blocks=(
ByoBlockCfg(type='bottle', d=2, c=256, s=1, gs=0, br=0.25),
ByoBlockCfg(type='bottle', d=2, c=512, s=2, gs=0, br=0.25),
interleave_blocks(types=('bottle', 'self_attn'), d=2, c=1024, s=2, gs=0, br=0.25),
ByoBlockCfg(type='self_attn', d=2, c=2048, s=2, gs=0, br=0.25),
),
stem_chs=64,
stem_type='tiered',
stem_pool='maxpool',
fixed_input_size=True,
self_attn_layer='bottleneck',
self_attn_kwargs=dict()
),
sebotnet33ts=ByoModelCfg(
blocks=(
ByoBlockCfg(type='bottle', d=2, c=256, s=1, gs=0, br=0.25),
interleave_blocks(types=('bottle', 'self_attn'), every=[2], d=3, c=512, s=2, gs=0, br=0.25),
interleave_blocks(types=('bottle', 'self_attn'), every=[2], d=3, c=1024, s=2, gs=0, br=0.25),
ByoBlockCfg('self_attn', d=2, c=1536, s=2, gs=0, br=0.333),
),
stem_chs=64,
stem_type='tiered',
stem_pool='',
act_layer='silu',
num_features=1280,
attn_layer='se',
self_attn_layer='bottleneck',
self_attn_kwargs=dict()
),
botnet50ts=ByoModelCfg(
blocks=(
ByoBlockCfg(type='bottle', d=3, c=256, s=1, gs=0, br=0.25),
interleave_blocks(types=('bottle', 'self_attn'), every=4, d=4, c=512, s=2, gs=0, br=0.25),
interleave_blocks(types=('bottle', 'self_attn'), d=6, c=1024, s=2, gs=0, br=0.25),
interleave_blocks(types=('bottle', 'self_attn'), d=3, c=2048, s=2, gs=0, br=0.25),
),
stem_chs=64,
stem_type='tiered',
stem_pool='maxpool',
act_layer='silu',
fixed_input_size=True,
self_attn_layer='bottleneck',
self_attn_kwargs=dict()
),
eca_botnext26ts=ByoModelCfg(
blocks=(
ByoBlockCfg(type='bottle', d=2, c=256, s=1, gs=16, br=0.25),
ByoBlockCfg(type='bottle', d=2, c=512, s=2, gs=16, br=0.25),
interleave_blocks(types=('bottle', 'self_attn'), d=2, c=1024, s=2, gs=16, br=0.25),
ByoBlockCfg(type='self_attn', d=2, c=2048, s=2, gs=16, br=0.25),
),
stem_chs=64,
stem_type='tiered',
stem_pool='maxpool',
fixed_input_size=True,
act_layer='silu',
attn_layer='eca',
self_attn_layer='bottleneck',
self_attn_kwargs=dict(dim_head=16)
),
halonet_h1=ByoModelCfg(
blocks=(
ByoBlockCfg(type='self_attn', d=3, c=64, s=1, gs=0, br=1.0),
ByoBlockCfg(type='self_attn', d=3, c=128, s=2, gs=0, br=1.0),
ByoBlockCfg(type='self_attn', d=10, c=256, s=2, gs=0, br=1.0),
ByoBlockCfg(type='self_attn', d=3, c=512, s=2, gs=0, br=1.0),
),
stem_chs=64,
stem_type='7x7',
stem_pool='maxpool',
self_attn_layer='halo',
self_attn_kwargs=dict(block_size=8, halo_size=3),
),
halonet26t=ByoModelCfg(
blocks=(
ByoBlockCfg(type='bottle', d=2, c=256, s=1, gs=0, br=0.25),
ByoBlockCfg(type='bottle', d=2, c=512, s=2, gs=0, br=0.25),
interleave_blocks(types=('bottle', 'self_attn'), d=2, c=1024, s=2, gs=0, br=0.25),
ByoBlockCfg(type='self_attn', d=2, c=2048, s=2, gs=0, br=0.25),
),
stem_chs=64,
stem_type='tiered',
stem_pool='maxpool',
self_attn_layer='halo',
self_attn_kwargs=dict(block_size=8, halo_size=2)
),
sehalonet33ts=ByoModelCfg(
blocks=(
ByoBlockCfg(type='bottle', d=2, c=256, s=1, gs=0, br=0.25),
interleave_blocks(types=('bottle', 'self_attn'), every=[2], d=3, c=512, s=2, gs=0, br=0.25),
interleave_blocks(types=('bottle', 'self_attn'), every=[2], d=3, c=1024, s=2, gs=0, br=0.25),
ByoBlockCfg('self_attn', d=2, c=1536, s=2, gs=0, br=0.333),
),
stem_chs=64,
stem_type='tiered',
stem_pool='',
act_layer='silu',
num_features=1280,
attn_layer='se',
self_attn_layer='halo',
self_attn_kwargs=dict(block_size=8, halo_size=3)
),
halonet50ts=ByoModelCfg(
blocks=(
ByoBlockCfg(type='bottle', d=3, c=256, s=1, gs=0, br=0.25),
interleave_blocks(
types=('bottle', 'self_attn'), every=4, d=4, c=512, s=2, gs=0, br=0.25,
self_attn_layer='halo', self_attn_kwargs=dict(block_size=8, halo_size=3, num_heads=4)),
interleave_blocks(types=('bottle', 'self_attn'), d=6, c=1024, s=2, gs=0, br=0.25),
interleave_blocks(types=('bottle', 'self_attn'), d=3, c=2048, s=2, gs=0, br=0.25),
),
stem_chs=64,
stem_type='tiered',
stem_pool='maxpool',
act_layer='silu',
self_attn_layer='halo',
self_attn_kwargs=dict(block_size=8, halo_size=3)
),
eca_halonext26ts=ByoModelCfg(
blocks=(
ByoBlockCfg(type='bottle', d=2, c=256, s=1, gs=16, br=0.25),
ByoBlockCfg(type='bottle', d=2, c=512, s=2, gs=16, br=0.25),
interleave_blocks(types=('bottle', 'self_attn'), d=2, c=1024, s=2, gs=16, br=0.25),
ByoBlockCfg(type='self_attn', d=2, c=2048, s=2, gs=16, br=0.25),
),
stem_chs=64,
stem_type='tiered',
stem_pool='maxpool',
act_layer='silu',
attn_layer='eca',
self_attn_layer='halo',
self_attn_kwargs=dict(block_size=8, halo_size=2, dim_head=16)
),
lambda_resnet26t=ByoModelCfg(
blocks=(
ByoBlockCfg(type='bottle', d=2, c=256, s=1, gs=0, br=0.25),
ByoBlockCfg(type='bottle', d=2, c=512, s=2, gs=0, br=0.25),
interleave_blocks(types=('bottle', 'self_attn'), d=2, c=1024, s=2, gs=0, br=0.25),
ByoBlockCfg(type='self_attn', d=2, c=2048, s=2, gs=0, br=0.25),
),
stem_chs=64,
stem_type='tiered',
stem_pool='maxpool',
self_attn_layer='lambda',
self_attn_kwargs=dict(r=9)
),
lambda_resnet50ts=ByoModelCfg(
blocks=(
ByoBlockCfg(type='bottle', d=3, c=256, s=1, gs=0, br=0.25),
interleave_blocks(types=('bottle', 'self_attn'), every=4, d=4, c=512, s=2, gs=0, br=0.25),
interleave_blocks(types=('bottle', 'self_attn'), d=6, c=1024, s=2, gs=0, br=0.25),
interleave_blocks(types=('bottle', 'self_attn'), d=3, c=2048, s=2, gs=0, br=0.25),
),
stem_chs=64,
stem_type='tiered',
stem_pool='maxpool',
act_layer='silu',
self_attn_layer='lambda',
self_attn_kwargs=dict(r=9)
),
lambda_resnet26rpt_256=ByoModelCfg(
blocks=(
ByoBlockCfg(type='bottle', d=2, c=256, s=1, gs=0, br=0.25),
ByoBlockCfg(type='bottle', d=2, c=512, s=2, gs=0, br=0.25),
interleave_blocks(types=('bottle', 'self_attn'), d=2, c=1024, s=2, gs=0, br=0.25),
ByoBlockCfg(type='self_attn', d=2, c=2048, s=2, gs=0, br=0.25),
),
stem_chs=64,
stem_type='tiered',
stem_pool='maxpool',
self_attn_layer='lambda',
self_attn_kwargs=dict(r=None)
),
# experimental
haloregnetz_b=ByoModelCfg(
blocks=(
ByoBlockCfg(type='bottle', d=2, c=48, s=2, gs=16, br=3),
ByoBlockCfg(type='bottle', d=6, c=96, s=2, gs=16, br=3),
interleave_blocks(types=('bottle', 'self_attn'), every=3, d=12, c=192, s=2, gs=16, br=3),
ByoBlockCfg('self_attn', d=2, c=288, s=2, gs=16, br=3),
),
stem_chs=32,
stem_pool='',
downsample='',
num_features=1536,
act_layer='silu',
attn_layer='se',
attn_kwargs=dict(rd_ratio=0.25),
block_kwargs=dict(bottle_in=True, linear_out=True),
self_attn_layer='halo',
self_attn_kwargs=dict(block_size=7, halo_size=2, qk_ratio=0.33)
),
# experimental
lamhalobotnet50ts=ByoModelCfg(
blocks=(
ByoBlockCfg(type='bottle', d=3, c=256, s=1, gs=0, br=0.25),
interleave_blocks(
types=('bottle', 'self_attn'), d=4, c=512, s=2, gs=0, br=0.25,
self_attn_layer='lambda', self_attn_kwargs=dict(r=13)),
interleave_blocks(
types=('bottle', 'self_attn'), d=6, c=1024, s=2, gs=0, br=0.25,
self_attn_layer='halo', self_attn_kwargs=dict(halo_size=3)),
interleave_blocks(
types=('bottle', 'self_attn'), d=3, c=2048, s=2, gs=0, br=0.25,
self_attn_layer='bottleneck', self_attn_kwargs=dict()),
),
stem_chs=64,
stem_type='tiered',
stem_pool='',
act_layer='silu',
),
halo2botnet50ts=ByoModelCfg(
blocks=(
ByoBlockCfg(type='bottle', d=3, c=256, s=1, gs=0, br=0.25),
interleave_blocks(
types=('bottle', 'self_attn'), d=4, c=512, s=2, gs=0, br=0.25,
self_attn_layer='halo', self_attn_kwargs=dict(halo_size=3)),
interleave_blocks(
types=('bottle', 'self_attn'), d=6, c=1024, s=2, gs=0, br=0.25,
self_attn_layer='halo', self_attn_kwargs=dict(halo_size=3)),
interleave_blocks(
types=('bottle', 'self_attn'), d=3, c=2048, s=2, gs=0, br=0.25,
self_attn_layer='bottleneck', self_attn_kwargs=dict()),
),
stem_chs=64,
stem_type='tiered',
stem_pool='',
act_layer='silu',
),
)
def _create_byoanet(variant, cfg_variant=None, pretrained=False, **kwargs):
return build_model_with_cfg(
ByobNet, variant, pretrained,
model_cfg=model_cfgs[variant] if not cfg_variant else model_cfgs[cfg_variant],
feature_cfg=dict(flatten_sequential=True),
**kwargs,
)
def _cfg(url='', **kwargs):
return {
'url': url, 'num_classes': 1000, 'input_size': (3, 224, 224), 'pool_size': (7, 7),
'crop_pct': 0.95, 'interpolation': 'bicubic',
'mean': IMAGENET_DEFAULT_MEAN, 'std': IMAGENET_DEFAULT_STD,
'first_conv': 'stem.conv1.conv', 'classifier': 'head.fc',
'fixed_input_size': False, 'min_input_size': (3, 224, 224),
**kwargs
}
default_cfgs = generate_default_cfgs({
# GPU-Efficient (ResNet) weights
'botnet26t_256.c1_in1k': _cfg(
url='https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-attn-weights/botnet26t_c1_256-167a0e9f.pth',
hf_hub_id='timm/',
fixed_input_size=True, input_size=(3, 256, 256), pool_size=(8, 8)),
'sebotnet33ts_256.a1h_in1k': _cfg(
url='https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-attn-weights/sebotnet33ts_a1h2_256-957e3c3e.pth',
hf_hub_id='timm/',
fixed_input_size=True, input_size=(3, 256, 256), pool_size=(8, 8), crop_pct=0.94),
'botnet50ts_256.untrained': _cfg(
fixed_input_size=True, input_size=(3, 256, 256), pool_size=(8, 8)),
'eca_botnext26ts_256.c1_in1k': _cfg(
url='https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-attn-weights/eca_botnext26ts_c_256-95a898f6.pth',
hf_hub_id='timm/',
fixed_input_size=True, input_size=(3, 256, 256), pool_size=(8, 8)),
'halonet_h1.untrained': _cfg(input_size=(3, 256, 256), pool_size=(8, 8), min_input_size=(3, 256, 256)),
'halonet26t.a1h_in1k': _cfg(
url='https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-attn-weights/halonet26t_a1h_256-3083328c.pth',
hf_hub_id='timm/',
input_size=(3, 256, 256), pool_size=(8, 8), min_input_size=(3, 256, 256)),
'sehalonet33ts.ra2_in1k': _cfg(
url='https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-attn-weights/sehalonet33ts_256-87e053f9.pth',
hf_hub_id='timm/',
input_size=(3, 256, 256), pool_size=(8, 8), min_input_size=(3, 256, 256), crop_pct=0.94),
'halonet50ts.a1h_in1k': _cfg(
url='https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-attn-weights/halonet50ts_a1h2_256-f3a3daee.pth',
hf_hub_id='timm/',
input_size=(3, 256, 256), pool_size=(8, 8), min_input_size=(3, 256, 256), crop_pct=0.94),
'eca_halonext26ts.c1_in1k': _cfg(
url='https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-attn-weights/eca_halonext26ts_c_256-06906299.pth',
hf_hub_id='timm/',
input_size=(3, 256, 256), pool_size=(8, 8), min_input_size=(3, 256, 256), crop_pct=0.94),
'lambda_resnet26t.c1_in1k': _cfg(
url='https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-attn-weights/lambda_resnet26t_c_256-e5a5c857.pth',
hf_hub_id='timm/',
min_input_size=(3, 128, 128), input_size=(3, 256, 256), pool_size=(8, 8), crop_pct=0.94),
'lambda_resnet50ts.a1h_in1k': _cfg(
url='https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-attn-weights/lambda_resnet50ts_a1h_256-b87370f7.pth',
hf_hub_id='timm/',
min_input_size=(3, 128, 128), input_size=(3, 256, 256), pool_size=(8, 8)),
'lambda_resnet26rpt_256.c1_in1k': _cfg(
url='https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-attn-weights/lambda_resnet26rpt_c_256-ab00292d.pth',
hf_hub_id='timm/',
fixed_input_size=True, input_size=(3, 256, 256), pool_size=(8, 8), crop_pct=0.94),
'haloregnetz_b.ra3_in1k': _cfg(
url='https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-attn-weights/haloregnetz_c_raa_256-c8ad7616.pth',
hf_hub_id='timm/',
mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5),
first_conv='stem.conv', input_size=(3, 224, 224), pool_size=(7, 7), min_input_size=(3, 224, 224), crop_pct=0.94),
'lamhalobotnet50ts_256.a1h_in1k': _cfg(
url='https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-attn-weights/lamhalobotnet50ts_a1h2_256-fe3d9445.pth',
hf_hub_id='timm/',
fixed_input_size=True, input_size=(3, 256, 256), pool_size=(8, 8)),
'halo2botnet50ts_256.a1h_in1k': _cfg(
url='https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-attn-weights/halo2botnet50ts_a1h2_256-fd9c11a3.pth',
hf_hub_id='timm/',
fixed_input_size=True, input_size=(3, 256, 256), pool_size=(8, 8)),
})
@register_model
def botnet26t_256(pretrained=False, **kwargs) -> ByobNet:
""" Bottleneck Transformer w/ ResNet26-T backbone.
"""
kwargs.setdefault('img_size', 256)
return _create_byoanet('botnet26t_256', 'botnet26t', pretrained=pretrained, **kwargs)
@register_model
def sebotnet33ts_256(pretrained=False, **kwargs) -> ByobNet:
""" Bottleneck Transformer w/ a ResNet33-t backbone, SE attn for non Halo blocks, SiLU,
"""
return _create_byoanet('sebotnet33ts_256', 'sebotnet33ts', pretrained=pretrained, **kwargs)
@register_model
def botnet50ts_256(pretrained=False, **kwargs) -> ByobNet:
""" Bottleneck Transformer w/ ResNet50-T backbone, silu act.
"""
kwargs.setdefault('img_size', 256)
return _create_byoanet('botnet50ts_256', 'botnet50ts', pretrained=pretrained, **kwargs)
@register_model
def eca_botnext26ts_256(pretrained=False, **kwargs) -> ByobNet:
""" Bottleneck Transformer w/ ResNet26-T backbone, silu act.
"""
kwargs.setdefault('img_size', 256)
return _create_byoanet('eca_botnext26ts_256', 'eca_botnext26ts', pretrained=pretrained, **kwargs)
@register_model
def halonet_h1(pretrained=False, **kwargs) -> ByobNet:
""" HaloNet-H1. Halo attention in all stages as per the paper.
NOTE: This runs very slowly!
"""
return _create_byoanet('halonet_h1', pretrained=pretrained, **kwargs)
@register_model
def halonet26t(pretrained=False, **kwargs) -> ByobNet:
""" HaloNet w/ a ResNet26-t backbone. Halo attention in final two stages
"""
return _create_byoanet('halonet26t', pretrained=pretrained, **kwargs)
@register_model
def sehalonet33ts(pretrained=False, **kwargs) -> ByobNet:
""" HaloNet w/ a ResNet33-t backbone, SE attn for non Halo blocks, SiLU, 1-2 Halo in stage 2,3,4.
"""
return _create_byoanet('sehalonet33ts', pretrained=pretrained, **kwargs)
@register_model
def halonet50ts(pretrained=False, **kwargs) -> ByobNet:
""" HaloNet w/ a ResNet50-t backbone, silu act. Halo attention in final two stages
"""
return _create_byoanet('halonet50ts', pretrained=pretrained, **kwargs)
@register_model
def eca_halonext26ts(pretrained=False, **kwargs) -> ByobNet:
""" HaloNet w/ a ResNet26-t backbone, silu act. Halo attention in final two stages
"""
return _create_byoanet('eca_halonext26ts', pretrained=pretrained, **kwargs)
@register_model
def lambda_resnet26t(pretrained=False, **kwargs) -> ByobNet:
""" Lambda-ResNet-26-T. Lambda layers w/ conv pos in last two stages.
"""
return _create_byoanet('lambda_resnet26t', pretrained=pretrained, **kwargs)
@register_model
def lambda_resnet50ts(pretrained=False, **kwargs) -> ByobNet:
""" Lambda-ResNet-50-TS. SiLU act. Lambda layers w/ conv pos in last two stages.
"""
return _create_byoanet('lambda_resnet50ts', pretrained=pretrained, **kwargs)
@register_model
def lambda_resnet26rpt_256(pretrained=False, **kwargs) -> ByobNet:
""" Lambda-ResNet-26-R-T. Lambda layers w/ rel pos embed in last two stages.
"""
kwargs.setdefault('img_size', 256)
return _create_byoanet('lambda_resnet26rpt_256', pretrained=pretrained, **kwargs)
@register_model
def haloregnetz_b(pretrained=False, **kwargs) -> ByobNet:
""" Halo + RegNetZ
"""
return _create_byoanet('haloregnetz_b', pretrained=pretrained, **kwargs)
@register_model
def lamhalobotnet50ts_256(pretrained=False, **kwargs) -> ByobNet:
""" Combo Attention (Lambda + Halo + Bot) Network
"""
return _create_byoanet('lamhalobotnet50ts_256', 'lamhalobotnet50ts', pretrained=pretrained, **kwargs)
@register_model
def halo2botnet50ts_256(pretrained=False, **kwargs) -> ByobNet:
""" Combo Attention (Halo + Halo + Bot) Network
"""
return _create_byoanet('halo2botnet50ts_256', 'halo2botnet50ts', pretrained=pretrained, **kwargs)
| pytorch-image-models/timm/models/byoanet.py/0 | {
"file_path": "pytorch-image-models/timm/models/byoanet.py",
"repo_id": "pytorch-image-models",
"token_count": 9703
} | 185 |
""" EfficientFormer-V2
@article{
li2022rethinking,
title={Rethinking Vision Transformers for MobileNet Size and Speed},
author={Li, Yanyu and Hu, Ju and Wen, Yang and Evangelidis, Georgios and Salahi, Kamyar and Wang, Yanzhi and Tulyakov, Sergey and Ren, Jian},
journal={arXiv preprint arXiv:2212.08059},
year={2022}
}
Significantly refactored and cleaned up for timm from original at: https://github.com/snap-research/EfficientFormer
Original code licensed Apache 2.0, Copyright (c) 2022 Snap Inc.
Modifications and timm support by / Copyright 2023, Ross Wightman
"""
import math
from functools import partial
from typing import Dict
import torch
import torch.nn as nn
from timm.data import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD
from timm.layers import create_conv2d, create_norm_layer, get_act_layer, get_norm_layer, ConvNormAct
from timm.layers import DropPath, trunc_normal_, to_2tuple, to_ntuple, ndgrid
from ._builder import build_model_with_cfg
from ._manipulate import checkpoint_seq
from ._registry import generate_default_cfgs, register_model
EfficientFormer_width = {
'L': (40, 80, 192, 384), # 26m 83.3% 6attn
'S2': (32, 64, 144, 288), # 12m 81.6% 4attn dp0.02
'S1': (32, 48, 120, 224), # 6.1m 79.0
'S0': (32, 48, 96, 176), # 75.0 75.7
}
EfficientFormer_depth = {
'L': (5, 5, 15, 10), # 26m 83.3%
'S2': (4, 4, 12, 8), # 12m
'S1': (3, 3, 9, 6), # 79.0
'S0': (2, 2, 6, 4), # 75.7
}
EfficientFormer_expansion_ratios = {
'L': (4, 4, (4, 4, 4, 4, 3, 3, 3, 3, 3, 3, 3, 4, 4, 4, 4), (4, 4, 4, 3, 3, 3, 3, 4, 4, 4)),
'S2': (4, 4, (4, 4, 3, 3, 3, 3, 3, 3, 4, 4, 4, 4), (4, 4, 3, 3, 3, 3, 4, 4)),
'S1': (4, 4, (4, 4, 3, 3, 3, 3, 4, 4, 4), (4, 4, 3, 3, 4, 4)),
'S0': (4, 4, (4, 3, 3, 3, 4, 4), (4, 3, 3, 4)),
}
class ConvNorm(nn.Module):
def __init__(
self,
in_channels,
out_channels,
kernel_size=1,
stride=1,
padding='',
dilation=1,
groups=1,
bias=True,
norm_layer='batchnorm2d',
norm_kwargs=None,
):
norm_kwargs = norm_kwargs or {}
super(ConvNorm, self).__init__()
self.conv = create_conv2d(
in_channels,
out_channels,
kernel_size,
stride=stride,
padding=padding,
dilation=dilation,
groups=groups,
bias=bias,
)
self.bn = create_norm_layer(norm_layer, out_channels, **norm_kwargs)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
return x
class Attention2d(torch.nn.Module):
attention_bias_cache: Dict[str, torch.Tensor]
def __init__(
self,
dim=384,
key_dim=32,
num_heads=8,
attn_ratio=4,
resolution=7,
act_layer=nn.GELU,
stride=None,
):
super().__init__()
self.num_heads = num_heads
self.scale = key_dim ** -0.5
self.key_dim = key_dim
resolution = to_2tuple(resolution)
if stride is not None:
resolution = tuple([math.ceil(r / stride) for r in resolution])
self.stride_conv = ConvNorm(dim, dim, kernel_size=3, stride=stride, groups=dim)
self.upsample = nn.Upsample(scale_factor=stride, mode='bilinear')
else:
self.stride_conv = None
self.upsample = None
self.resolution = resolution
self.N = self.resolution[0] * self.resolution[1]
self.d = int(attn_ratio * key_dim)
self.dh = int(attn_ratio * key_dim) * num_heads
self.attn_ratio = attn_ratio
kh = self.key_dim * self.num_heads
self.q = ConvNorm(dim, kh)
self.k = ConvNorm(dim, kh)
self.v = ConvNorm(dim, self.dh)
self.v_local = ConvNorm(self.dh, self.dh, kernel_size=3, groups=self.dh)
self.talking_head1 = nn.Conv2d(self.num_heads, self.num_heads, kernel_size=1)
self.talking_head2 = nn.Conv2d(self.num_heads, self.num_heads, kernel_size=1)
self.act = act_layer()
self.proj = ConvNorm(self.dh, dim, 1)
pos = torch.stack(ndgrid(torch.arange(self.resolution[0]), torch.arange(self.resolution[1]))).flatten(1)
rel_pos = (pos[..., :, None] - pos[..., None, :]).abs()
rel_pos = (rel_pos[0] * self.resolution[1]) + rel_pos[1]
self.attention_biases = torch.nn.Parameter(torch.zeros(num_heads, self.N))
self.register_buffer('attention_bias_idxs', torch.LongTensor(rel_pos), persistent=False)
self.attention_bias_cache = {} # per-device attention_biases cache (data-parallel compat)
@torch.no_grad()
def train(self, mode=True):
super().train(mode)
if mode and self.attention_bias_cache:
self.attention_bias_cache = {} # clear ab cache
def get_attention_biases(self, device: torch.device) -> torch.Tensor:
if torch.jit.is_tracing() or self.training:
return self.attention_biases[:, self.attention_bias_idxs]
else:
device_key = str(device)
if device_key not in self.attention_bias_cache:
self.attention_bias_cache[device_key] = self.attention_biases[:, self.attention_bias_idxs]
return self.attention_bias_cache[device_key]
def forward(self, x):
B, C, H, W = x.shape
if self.stride_conv is not None:
x = self.stride_conv(x)
q = self.q(x).reshape(B, self.num_heads, -1, self.N).permute(0, 1, 3, 2)
k = self.k(x).reshape(B, self.num_heads, -1, self.N).permute(0, 1, 2, 3)
v = self.v(x)
v_local = self.v_local(v)
v = v.reshape(B, self.num_heads, -1, self.N).permute(0, 1, 3, 2)
attn = (q @ k) * self.scale
attn = attn + self.get_attention_biases(x.device)
attn = self.talking_head1(attn)
attn = attn.softmax(dim=-1)
attn = self.talking_head2(attn)
x = (attn @ v).transpose(2, 3)
x = x.reshape(B, self.dh, self.resolution[0], self.resolution[1]) + v_local
if self.upsample is not None:
x = self.upsample(x)
x = self.act(x)
x = self.proj(x)
return x
class LocalGlobalQuery(torch.nn.Module):
def __init__(self, in_dim, out_dim):
super().__init__()
self.pool = nn.AvgPool2d(1, 2, 0)
self.local = nn.Conv2d(in_dim, in_dim, kernel_size=3, stride=2, padding=1, groups=in_dim)
self.proj = ConvNorm(in_dim, out_dim, 1)
def forward(self, x):
local_q = self.local(x)
pool_q = self.pool(x)
q = local_q + pool_q
q = self.proj(q)
return q
class Attention2dDownsample(torch.nn.Module):
attention_bias_cache: Dict[str, torch.Tensor]
def __init__(
self,
dim=384,
key_dim=16,
num_heads=8,
attn_ratio=4,
resolution=7,
out_dim=None,
act_layer=nn.GELU,
):
super().__init__()
self.num_heads = num_heads
self.scale = key_dim ** -0.5
self.key_dim = key_dim
self.resolution = to_2tuple(resolution)
self.resolution2 = tuple([math.ceil(r / 2) for r in self.resolution])
self.N = self.resolution[0] * self.resolution[1]
self.N2 = self.resolution2[0] * self.resolution2[1]
self.d = int(attn_ratio * key_dim)
self.dh = int(attn_ratio * key_dim) * num_heads
self.attn_ratio = attn_ratio
self.out_dim = out_dim or dim
kh = self.key_dim * self.num_heads
self.q = LocalGlobalQuery(dim, kh)
self.k = ConvNorm(dim, kh, 1)
self.v = ConvNorm(dim, self.dh, 1)
self.v_local = ConvNorm(self.dh, self.dh, kernel_size=3, stride=2, groups=self.dh)
self.act = act_layer()
self.proj = ConvNorm(self.dh, self.out_dim, 1)
self.attention_biases = nn.Parameter(torch.zeros(num_heads, self.N))
k_pos = torch.stack(ndgrid(torch.arange(self.resolution[0]), torch.arange(self.resolution[1]))).flatten(1)
q_pos = torch.stack(ndgrid(
torch.arange(0, self.resolution[0], step=2),
torch.arange(0, self.resolution[1], step=2)
)).flatten(1)
rel_pos = (q_pos[..., :, None] - k_pos[..., None, :]).abs()
rel_pos = (rel_pos[0] * self.resolution[1]) + rel_pos[1]
self.register_buffer('attention_bias_idxs', rel_pos, persistent=False)
self.attention_bias_cache = {} # per-device attention_biases cache (data-parallel compat)
@torch.no_grad()
def train(self, mode=True):
super().train(mode)
if mode and self.attention_bias_cache:
self.attention_bias_cache = {} # clear ab cache
def get_attention_biases(self, device: torch.device) -> torch.Tensor:
if torch.jit.is_tracing() or self.training:
return self.attention_biases[:, self.attention_bias_idxs]
else:
device_key = str(device)
if device_key not in self.attention_bias_cache:
self.attention_bias_cache[device_key] = self.attention_biases[:, self.attention_bias_idxs]
return self.attention_bias_cache[device_key]
def forward(self, x):
B, C, H, W = x.shape
q = self.q(x).reshape(B, self.num_heads, -1, self.N2).permute(0, 1, 3, 2)
k = self.k(x).reshape(B, self.num_heads, -1, self.N).permute(0, 1, 2, 3)
v = self.v(x)
v_local = self.v_local(v)
v = v.reshape(B, self.num_heads, -1, self.N).permute(0, 1, 3, 2)
attn = (q @ k) * self.scale
attn = attn + self.get_attention_biases(x.device)
attn = attn.softmax(dim=-1)
x = (attn @ v).transpose(2, 3)
x = x.reshape(B, self.dh, self.resolution2[0], self.resolution2[1]) + v_local
x = self.act(x)
x = self.proj(x)
return x
class Downsample(nn.Module):
def __init__(
self,
in_chs,
out_chs,
kernel_size=3,
stride=2,
padding=1,
resolution=7,
use_attn=False,
act_layer=nn.GELU,
norm_layer=nn.BatchNorm2d,
):
super().__init__()
kernel_size = to_2tuple(kernel_size)
stride = to_2tuple(stride)
padding = to_2tuple(padding)
norm_layer = norm_layer or nn.Identity()
self.conv = ConvNorm(
in_chs,
out_chs,
kernel_size=kernel_size,
stride=stride,
padding=padding,
norm_layer=norm_layer,
)
if use_attn:
self.attn = Attention2dDownsample(
dim=in_chs,
out_dim=out_chs,
resolution=resolution,
act_layer=act_layer,
)
else:
self.attn = None
def forward(self, x):
out = self.conv(x)
if self.attn is not None:
return self.attn(x) + out
return out
class ConvMlpWithNorm(nn.Module):
"""
Implementation of MLP with 1*1 convolutions.
Input: tensor with shape [B, C, H, W]
"""
def __init__(
self,
in_features,
hidden_features=None,
out_features=None,
act_layer=nn.GELU,
norm_layer=nn.BatchNorm2d,
drop=0.,
mid_conv=False,
):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = ConvNormAct(
in_features, hidden_features, 1,
bias=True, norm_layer=norm_layer, act_layer=act_layer)
if mid_conv:
self.mid = ConvNormAct(
hidden_features, hidden_features, 3,
groups=hidden_features, bias=True, norm_layer=norm_layer, act_layer=act_layer)
else:
self.mid = nn.Identity()
self.drop1 = nn.Dropout(drop)
self.fc2 = ConvNorm(hidden_features, out_features, 1, norm_layer=norm_layer)
self.drop2 = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.mid(x)
x = self.drop1(x)
x = self.fc2(x)
x = self.drop2(x)
return x
class LayerScale2d(nn.Module):
def __init__(self, dim, init_values=1e-5, inplace=False):
super().__init__()
self.inplace = inplace
self.gamma = nn.Parameter(init_values * torch.ones(dim))
def forward(self, x):
gamma = self.gamma.view(1, -1, 1, 1)
return x.mul_(gamma) if self.inplace else x * gamma
class EfficientFormerV2Block(nn.Module):
def __init__(
self,
dim,
mlp_ratio=4.,
act_layer=nn.GELU,
norm_layer=nn.BatchNorm2d,
proj_drop=0.,
drop_path=0.,
layer_scale_init_value=1e-5,
resolution=7,
stride=None,
use_attn=True,
):
super().__init__()
if use_attn:
self.token_mixer = Attention2d(
dim,
resolution=resolution,
act_layer=act_layer,
stride=stride,
)
self.ls1 = LayerScale2d(
dim, layer_scale_init_value) if layer_scale_init_value is not None else nn.Identity()
self.drop_path1 = DropPath(drop_path) if drop_path > 0. else nn.Identity()
else:
self.token_mixer = None
self.ls1 = None
self.drop_path1 = None
self.mlp = ConvMlpWithNorm(
in_features=dim,
hidden_features=int(dim * mlp_ratio),
act_layer=act_layer,
norm_layer=norm_layer,
drop=proj_drop,
mid_conv=True,
)
self.ls2 = LayerScale2d(
dim, layer_scale_init_value) if layer_scale_init_value is not None else nn.Identity()
self.drop_path2 = DropPath(drop_path) if drop_path > 0. else nn.Identity()
def forward(self, x):
if self.token_mixer is not None:
x = x + self.drop_path1(self.ls1(self.token_mixer(x)))
x = x + self.drop_path2(self.ls2(self.mlp(x)))
return x
class Stem4(nn.Sequential):
def __init__(self, in_chs, out_chs, act_layer=nn.GELU, norm_layer=nn.BatchNorm2d):
super().__init__()
self.stride = 4
self.conv1 = ConvNormAct(
in_chs, out_chs // 2, kernel_size=3, stride=2, padding=1, bias=True,
norm_layer=norm_layer, act_layer=act_layer
)
self.conv2 = ConvNormAct(
out_chs // 2, out_chs, kernel_size=3, stride=2, padding=1, bias=True,
norm_layer=norm_layer, act_layer=act_layer
)
class EfficientFormerV2Stage(nn.Module):
def __init__(
self,
dim,
dim_out,
depth,
resolution=7,
downsample=True,
block_stride=None,
downsample_use_attn=False,
block_use_attn=False,
num_vit=1,
mlp_ratio=4.,
proj_drop=.0,
drop_path=0.,
layer_scale_init_value=1e-5,
act_layer=nn.GELU,
norm_layer=nn.BatchNorm2d,
):
super().__init__()
self.grad_checkpointing = False
mlp_ratio = to_ntuple(depth)(mlp_ratio)
resolution = to_2tuple(resolution)
if downsample:
self.downsample = Downsample(
dim,
dim_out,
use_attn=downsample_use_attn,
resolution=resolution,
norm_layer=norm_layer,
act_layer=act_layer,
)
dim = dim_out
resolution = tuple([math.ceil(r / 2) for r in resolution])
else:
assert dim == dim_out
self.downsample = nn.Identity()
blocks = []
for block_idx in range(depth):
remain_idx = depth - num_vit - 1
b = EfficientFormerV2Block(
dim,
resolution=resolution,
stride=block_stride,
mlp_ratio=mlp_ratio[block_idx],
use_attn=block_use_attn and block_idx > remain_idx,
proj_drop=proj_drop,
drop_path=drop_path[block_idx],
layer_scale_init_value=layer_scale_init_value,
act_layer=act_layer,
norm_layer=norm_layer,
)
blocks += [b]
self.blocks = nn.Sequential(*blocks)
def forward(self, x):
x = self.downsample(x)
if self.grad_checkpointing and not torch.jit.is_scripting():
x = checkpoint_seq(self.blocks, x)
else:
x = self.blocks(x)
return x
class EfficientFormerV2(nn.Module):
def __init__(
self,
depths,
in_chans=3,
img_size=224,
global_pool='avg',
embed_dims=None,
downsamples=None,
mlp_ratios=4,
norm_layer='batchnorm2d',
norm_eps=1e-5,
act_layer='gelu',
num_classes=1000,
drop_rate=0.,
proj_drop_rate=0.,
drop_path_rate=0.,
layer_scale_init_value=1e-5,
num_vit=0,
distillation=True,
):
super().__init__()
assert global_pool in ('avg', '')
self.num_classes = num_classes
self.global_pool = global_pool
self.feature_info = []
img_size = to_2tuple(img_size)
norm_layer = partial(get_norm_layer(norm_layer), eps=norm_eps)
act_layer = get_act_layer(act_layer)
self.stem = Stem4(in_chans, embed_dims[0], act_layer=act_layer, norm_layer=norm_layer)
prev_dim = embed_dims[0]
stride = 4
num_stages = len(depths)
dpr = [x.tolist() for x in torch.linspace(0, drop_path_rate, sum(depths)).split(depths)]
downsamples = downsamples or (False,) + (True,) * (len(depths) - 1)
mlp_ratios = to_ntuple(num_stages)(mlp_ratios)
stages = []
for i in range(num_stages):
curr_resolution = tuple([math.ceil(s / stride) for s in img_size])
stage = EfficientFormerV2Stage(
prev_dim,
embed_dims[i],
depth=depths[i],
resolution=curr_resolution,
downsample=downsamples[i],
block_stride=2 if i == 2 else None,
downsample_use_attn=i >= 3,
block_use_attn=i >= 2,
num_vit=num_vit,
mlp_ratio=mlp_ratios[i],
proj_drop=proj_drop_rate,
drop_path=dpr[i],
layer_scale_init_value=layer_scale_init_value,
act_layer=act_layer,
norm_layer=norm_layer,
)
if downsamples[i]:
stride *= 2
prev_dim = embed_dims[i]
self.feature_info += [dict(num_chs=prev_dim, reduction=stride, module=f'stages.{i}')]
stages.append(stage)
self.stages = nn.Sequential(*stages)
# Classifier head
self.num_features = embed_dims[-1]
self.norm = norm_layer(embed_dims[-1])
self.head_drop = nn.Dropout(drop_rate)
self.head = nn.Linear(embed_dims[-1], num_classes) if num_classes > 0 else nn.Identity()
self.dist = distillation
if self.dist:
self.head_dist = nn.Linear(embed_dims[-1], num_classes) if num_classes > 0 else nn.Identity()
else:
self.head_dist = None
self.apply(self.init_weights)
self.distilled_training = False
# init for classification
def init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
@torch.jit.ignore
def no_weight_decay(self):
return {k for k, _ in self.named_parameters() if 'attention_biases' in k}
@torch.jit.ignore
def group_matcher(self, coarse=False):
matcher = dict(
stem=r'^stem', # stem and embed
blocks=[(r'^stages\.(\d+)', None), (r'^norm', (99999,))]
)
return matcher
@torch.jit.ignore
def set_grad_checkpointing(self, enable=True):
for s in self.stages:
s.grad_checkpointing = enable
@torch.jit.ignore
def get_classifier(self):
return self.head, self.head_dist
def reset_classifier(self, num_classes, global_pool=None):
self.num_classes = num_classes
if global_pool is not None:
self.global_pool = global_pool
self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()
self.head_dist = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()
@torch.jit.ignore
def set_distilled_training(self, enable=True):
self.distilled_training = enable
def forward_features(self, x):
x = self.stem(x)
x = self.stages(x)
x = self.norm(x)
return x
def forward_head(self, x, pre_logits: bool = False):
if self.global_pool == 'avg':
x = x.mean(dim=(2, 3))
x = self.head_drop(x)
if pre_logits:
return x
x, x_dist = self.head(x), self.head_dist(x)
if self.distilled_training and self.training and not torch.jit.is_scripting():
# only return separate classification predictions when training in distilled mode
return x, x_dist
else:
# during standard train/finetune, inference average the classifier predictions
return (x + x_dist) / 2
def forward(self, x):
x = self.forward_features(x)
x = self.forward_head(x)
return x
def _cfg(url='', **kwargs):
return {
'url': url,
'num_classes': 1000, 'input_size': (3, 224, 224), 'pool_size': None, 'fixed_input_size': True,
'crop_pct': .95, 'interpolation': 'bicubic',
'mean': IMAGENET_DEFAULT_MEAN, 'std': IMAGENET_DEFAULT_STD,
'classifier': ('head', 'head_dist'), 'first_conv': 'stem.conv1.conv',
**kwargs
}
default_cfgs = generate_default_cfgs({
'efficientformerv2_s0.snap_dist_in1k': _cfg(
hf_hub_id='timm/',
),
'efficientformerv2_s1.snap_dist_in1k': _cfg(
hf_hub_id='timm/',
),
'efficientformerv2_s2.snap_dist_in1k': _cfg(
hf_hub_id='timm/',
),
'efficientformerv2_l.snap_dist_in1k': _cfg(
hf_hub_id='timm/',
),
})
def _create_efficientformerv2(variant, pretrained=False, **kwargs):
out_indices = kwargs.pop('out_indices', (0, 1, 2, 3))
model = build_model_with_cfg(
EfficientFormerV2, variant, pretrained,
feature_cfg=dict(flatten_sequential=True, out_indices=out_indices),
**kwargs)
return model
@register_model
def efficientformerv2_s0(pretrained=False, **kwargs) -> EfficientFormerV2:
model_args = dict(
depths=EfficientFormer_depth['S0'],
embed_dims=EfficientFormer_width['S0'],
num_vit=2,
drop_path_rate=0.0,
mlp_ratios=EfficientFormer_expansion_ratios['S0'],
)
return _create_efficientformerv2('efficientformerv2_s0', pretrained=pretrained, **dict(model_args, **kwargs))
@register_model
def efficientformerv2_s1(pretrained=False, **kwargs) -> EfficientFormerV2:
model_args = dict(
depths=EfficientFormer_depth['S1'],
embed_dims=EfficientFormer_width['S1'],
num_vit=2,
drop_path_rate=0.0,
mlp_ratios=EfficientFormer_expansion_ratios['S1'],
)
return _create_efficientformerv2('efficientformerv2_s1', pretrained=pretrained, **dict(model_args, **kwargs))
@register_model
def efficientformerv2_s2(pretrained=False, **kwargs) -> EfficientFormerV2:
model_args = dict(
depths=EfficientFormer_depth['S2'],
embed_dims=EfficientFormer_width['S2'],
num_vit=4,
drop_path_rate=0.02,
mlp_ratios=EfficientFormer_expansion_ratios['S2'],
)
return _create_efficientformerv2('efficientformerv2_s2', pretrained=pretrained, **dict(model_args, **kwargs))
@register_model
def efficientformerv2_l(pretrained=False, **kwargs) -> EfficientFormerV2:
model_args = dict(
depths=EfficientFormer_depth['L'],
embed_dims=EfficientFormer_width['L'],
num_vit=6,
drop_path_rate=0.1,
mlp_ratios=EfficientFormer_expansion_ratios['L'],
)
return _create_efficientformerv2('efficientformerv2_l', pretrained=pretrained, **dict(model_args, **kwargs))
| pytorch-image-models/timm/models/efficientformer_v2.py/0 | {
"file_path": "pytorch-image-models/timm/models/efficientformer_v2.py",
"repo_id": "pytorch-image-models",
"token_count": 12721
} | 186 |
"""
InceptionNeXt paper: https://arxiv.org/abs/2303.16900
Original implementation & weights from: https://github.com/sail-sg/inceptionnext
"""
from functools import partial
import torch
import torch.nn as nn
from timm.data import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD
from timm.layers import trunc_normal_, DropPath, to_2tuple, get_padding, SelectAdaptivePool2d
from ._builder import build_model_with_cfg
from ._manipulate import checkpoint_seq
from ._registry import register_model, generate_default_cfgs
class InceptionDWConv2d(nn.Module):
""" Inception depthwise convolution
"""
def __init__(
self,
in_chs,
square_kernel_size=3,
band_kernel_size=11,
branch_ratio=0.125,
dilation=1,
):
super().__init__()
gc = int(in_chs * branch_ratio) # channel numbers of a convolution branch
square_padding = get_padding(square_kernel_size, dilation=dilation)
band_padding = get_padding(band_kernel_size, dilation=dilation)
self.dwconv_hw = nn.Conv2d(
gc, gc, square_kernel_size,
padding=square_padding, dilation=dilation, groups=gc)
self.dwconv_w = nn.Conv2d(
gc, gc, (1, band_kernel_size),
padding=(0, band_padding), dilation=(1, dilation), groups=gc)
self.dwconv_h = nn.Conv2d(
gc, gc, (band_kernel_size, 1),
padding=(band_padding, 0), dilation=(dilation, 1), groups=gc)
self.split_indexes = (in_chs - 3 * gc, gc, gc, gc)
def forward(self, x):
x_id, x_hw, x_w, x_h = torch.split(x, self.split_indexes, dim=1)
return torch.cat((
x_id,
self.dwconv_hw(x_hw),
self.dwconv_w(x_w),
self.dwconv_h(x_h)
), dim=1,
)
class ConvMlp(nn.Module):
""" MLP using 1x1 convs that keeps spatial dims
copied from timm: https://github.com/huggingface/pytorch-image-models/blob/v0.6.11/timm/models/layers/mlp.py
"""
def __init__(
self,
in_features,
hidden_features=None,
out_features=None,
act_layer=nn.ReLU,
norm_layer=None,
bias=True,
drop=0.,
):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
bias = to_2tuple(bias)
self.fc1 = nn.Conv2d(in_features, hidden_features, kernel_size=1, bias=bias[0])
self.norm = norm_layer(hidden_features) if norm_layer else nn.Identity()
self.act = act_layer()
self.drop = nn.Dropout(drop)
self.fc2 = nn.Conv2d(hidden_features, out_features, kernel_size=1, bias=bias[1])
def forward(self, x):
x = self.fc1(x)
x = self.norm(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
return x
class MlpClassifierHead(nn.Module):
""" MLP classification head
"""
def __init__(
self,
dim,
num_classes=1000,
pool_type='avg',
mlp_ratio=3,
act_layer=nn.GELU,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
drop=0.,
bias=True
):
super().__init__()
self.global_pool = SelectAdaptivePool2d(pool_type=pool_type, flatten=True)
in_features = dim * self.global_pool.feat_mult()
hidden_features = int(mlp_ratio * in_features)
self.fc1 = nn.Linear(in_features, hidden_features, bias=bias)
self.act = act_layer()
self.norm = norm_layer(hidden_features)
self.fc2 = nn.Linear(hidden_features, num_classes, bias=bias)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.global_pool(x)
x = self.fc1(x)
x = self.act(x)
x = self.norm(x)
x = self.drop(x)
x = self.fc2(x)
return x
class MetaNeXtBlock(nn.Module):
""" MetaNeXtBlock Block
Args:
dim (int): Number of input channels.
drop_path (float): Stochastic depth rate. Default: 0.0
ls_init_value (float): Init value for Layer Scale. Default: 1e-6.
"""
def __init__(
self,
dim,
dilation=1,
token_mixer=InceptionDWConv2d,
norm_layer=nn.BatchNorm2d,
mlp_layer=ConvMlp,
mlp_ratio=4,
act_layer=nn.GELU,
ls_init_value=1e-6,
drop_path=0.,
):
super().__init__()
self.token_mixer = token_mixer(dim, dilation=dilation)
self.norm = norm_layer(dim)
self.mlp = mlp_layer(dim, int(mlp_ratio * dim), act_layer=act_layer)
self.gamma = nn.Parameter(ls_init_value * torch.ones(dim)) if ls_init_value else None
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
def forward(self, x):
shortcut = x
x = self.token_mixer(x)
x = self.norm(x)
x = self.mlp(x)
if self.gamma is not None:
x = x.mul(self.gamma.reshape(1, -1, 1, 1))
x = self.drop_path(x) + shortcut
return x
class MetaNeXtStage(nn.Module):
def __init__(
self,
in_chs,
out_chs,
stride=2,
depth=2,
dilation=(1, 1),
drop_path_rates=None,
ls_init_value=1.0,
token_mixer=InceptionDWConv2d,
act_layer=nn.GELU,
norm_layer=None,
mlp_ratio=4,
):
super().__init__()
self.grad_checkpointing = False
if stride > 1 or dilation[0] != dilation[1]:
self.downsample = nn.Sequential(
norm_layer(in_chs),
nn.Conv2d(
in_chs,
out_chs,
kernel_size=2,
stride=stride,
dilation=dilation[0],
),
)
else:
self.downsample = nn.Identity()
drop_path_rates = drop_path_rates or [0.] * depth
stage_blocks = []
for i in range(depth):
stage_blocks.append(MetaNeXtBlock(
dim=out_chs,
dilation=dilation[1],
drop_path=drop_path_rates[i],
ls_init_value=ls_init_value,
token_mixer=token_mixer,
act_layer=act_layer,
norm_layer=norm_layer,
mlp_ratio=mlp_ratio,
))
self.blocks = nn.Sequential(*stage_blocks)
def forward(self, x):
x = self.downsample(x)
if self.grad_checkpointing and not torch.jit.is_scripting():
x = checkpoint_seq(self.blocks, x)
else:
x = self.blocks(x)
return x
class MetaNeXt(nn.Module):
r""" MetaNeXt
A PyTorch impl of : `InceptionNeXt: When Inception Meets ConvNeXt` - https://arxiv.org/abs/2303.16900
Args:
in_chans (int): Number of input image channels. Default: 3
num_classes (int): Number of classes for classification head. Default: 1000
depths (tuple(int)): Number of blocks at each stage. Default: (3, 3, 9, 3)
dims (tuple(int)): Feature dimension at each stage. Default: (96, 192, 384, 768)
token_mixers: Token mixer function. Default: nn.Identity
norm_layer: Normalization layer. Default: nn.BatchNorm2d
act_layer: Activation function for MLP. Default: nn.GELU
mlp_ratios (int or tuple(int)): MLP ratios. Default: (4, 4, 4, 3)
head_fn: classifier head
drop_rate (float): Head dropout rate
drop_path_rate (float): Stochastic depth rate. Default: 0.
ls_init_value (float): Init value for Layer Scale. Default: 1e-6.
"""
def __init__(
self,
in_chans=3,
num_classes=1000,
global_pool='avg',
output_stride=32,
depths=(3, 3, 9, 3),
dims=(96, 192, 384, 768),
token_mixers=InceptionDWConv2d,
norm_layer=nn.BatchNorm2d,
act_layer=nn.GELU,
mlp_ratios=(4, 4, 4, 3),
head_fn=MlpClassifierHead,
drop_rate=0.,
drop_path_rate=0.,
ls_init_value=1e-6,
):
super().__init__()
num_stage = len(depths)
if not isinstance(token_mixers, (list, tuple)):
token_mixers = [token_mixers] * num_stage
if not isinstance(mlp_ratios, (list, tuple)):
mlp_ratios = [mlp_ratios] * num_stage
self.num_classes = num_classes
self.global_pool = global_pool
self.drop_rate = drop_rate
self.feature_info = []
self.stem = nn.Sequential(
nn.Conv2d(in_chans, dims[0], kernel_size=4, stride=4),
norm_layer(dims[0])
)
dp_rates = [x.tolist() for x in torch.linspace(0, drop_path_rate, sum(depths)).split(depths)]
prev_chs = dims[0]
curr_stride = 4
dilation = 1
# feature resolution stages, each consisting of multiple residual blocks
self.stages = nn.Sequential()
for i in range(num_stage):
stride = 2 if curr_stride == 2 or i > 0 else 1
if curr_stride >= output_stride and stride > 1:
dilation *= stride
stride = 1
curr_stride *= stride
first_dilation = 1 if dilation in (1, 2) else 2
out_chs = dims[i]
self.stages.append(MetaNeXtStage(
prev_chs,
out_chs,
stride=stride if i > 0 else 1,
dilation=(first_dilation, dilation),
depth=depths[i],
drop_path_rates=dp_rates[i],
ls_init_value=ls_init_value,
act_layer=act_layer,
token_mixer=token_mixers[i],
norm_layer=norm_layer,
mlp_ratio=mlp_ratios[i],
))
prev_chs = out_chs
self.feature_info += [dict(num_chs=prev_chs, reduction=curr_stride, module=f'stages.{i}')]
self.num_features = prev_chs
if self.num_classes > 0:
if issubclass(head_fn, MlpClassifierHead):
assert self.global_pool, 'Cannot disable global pooling with MLP head present.'
self.head = head_fn(self.num_features, num_classes, pool_type=self.global_pool, drop=drop_rate)
else:
if self.global_pool:
self.head = SelectAdaptivePool2d(pool_type=self.global_pool, flatten=True)
else:
self.head = nn.Identity()
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, (nn.Conv2d, nn.Linear)):
trunc_normal_(m.weight, std=.02)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
@torch.jit.ignore
def group_matcher(self, coarse=False):
return dict(
stem=r'^stem',
blocks=r'^stages\.(\d+)' if coarse else [
(r'^stages\.(\d+)\.downsample', (0,)), # blocks
(r'^stages\.(\d+)\.blocks\.(\d+)', None),
]
)
@torch.jit.ignore
def get_classifier(self):
return self.head.fc2
def reset_classifier(self, num_classes=0, global_pool=None, head_fn=MlpClassifierHead):
if global_pool is not None:
self.global_pool = global_pool
if num_classes > 0:
if issubclass(head_fn, MlpClassifierHead):
assert self.global_pool, 'Cannot disable global pooling with MLP head present.'
self.head = head_fn(self.num_features, num_classes, pool_type=self.global_pool, drop=self.drop_rate)
else:
if self.global_pool:
self.head = SelectAdaptivePool2d(pool_type=self.global_pool, flatten=True)
else:
self.head = nn.Identity()
@torch.jit.ignore
def set_grad_checkpointing(self, enable=True):
for s in self.stages:
s.grad_checkpointing = enable
@torch.jit.ignore
def no_weight_decay(self):
return set()
def forward_features(self, x):
x = self.stem(x)
x = self.stages(x)
return x
def forward_head(self, x, pre_logits: bool = False):
if pre_logits:
if hasattr(self.head, 'global_pool'):
x = self.head.global_pool(x)
return x
return self.head(x)
def forward(self, x):
x = self.forward_features(x)
x = self.forward_head(x)
return x
def _cfg(url='', **kwargs):
return {
'url': url,
'num_classes': 1000, 'input_size': (3, 224, 224), 'pool_size': (7, 7),
'crop_pct': 0.875, 'interpolation': 'bicubic',
'mean': IMAGENET_DEFAULT_MEAN, 'std': IMAGENET_DEFAULT_STD,
'first_conv': 'stem.0', 'classifier': 'head.fc2',
**kwargs
}
default_cfgs = generate_default_cfgs({
'inception_next_tiny.sail_in1k': _cfg(
hf_hub_id='timm/',
# url='https://github.com/sail-sg/inceptionnext/releases/download/model/inceptionnext_tiny.pth',
),
'inception_next_small.sail_in1k': _cfg(
hf_hub_id='timm/',
# url='https://github.com/sail-sg/inceptionnext/releases/download/model/inceptionnext_small.pth',
),
'inception_next_base.sail_in1k': _cfg(
hf_hub_id='timm/',
# url='https://github.com/sail-sg/inceptionnext/releases/download/model/inceptionnext_base.pth',
crop_pct=0.95,
),
'inception_next_base.sail_in1k_384': _cfg(
hf_hub_id='timm/',
# url='https://github.com/sail-sg/inceptionnext/releases/download/model/inceptionnext_base_384.pth',
input_size=(3, 384, 384), pool_size=(12, 12), crop_pct=1.0,
),
})
def _create_inception_next(variant, pretrained=False, **kwargs):
model = build_model_with_cfg(
MetaNeXt, variant, pretrained,
feature_cfg=dict(out_indices=(0, 1, 2, 3), flatten_sequential=True),
**kwargs,
)
return model
@register_model
def inception_next_tiny(pretrained=False, **kwargs):
model_args = dict(
depths=(3, 3, 9, 3), dims=(96, 192, 384, 768),
token_mixers=InceptionDWConv2d,
)
return _create_inception_next('inception_next_tiny', pretrained=pretrained, **dict(model_args, **kwargs))
@register_model
def inception_next_small(pretrained=False, **kwargs):
model_args = dict(
depths=(3, 3, 27, 3), dims=(96, 192, 384, 768),
token_mixers=InceptionDWConv2d,
)
return _create_inception_next('inception_next_small', pretrained=pretrained, **dict(model_args, **kwargs))
@register_model
def inception_next_base(pretrained=False, **kwargs):
model_args = dict(
depths=(3, 3, 27, 3), dims=(128, 256, 512, 1024),
token_mixers=InceptionDWConv2d,
)
return _create_inception_next('inception_next_base', pretrained=pretrained, **dict(model_args, **kwargs))
| pytorch-image-models/timm/models/inception_next.py/0 | {
"file_path": "pytorch-image-models/timm/models/inception_next.py",
"repo_id": "pytorch-image-models",
"token_count": 7709
} | 187 |
"""
pnasnet5large implementation grabbed from Cadene's pretrained models
Additional credit to https://github.com/creafz
https://github.com/Cadene/pretrained-models.pytorch/blob/master/pretrainedmodels/models/pnasnet.py
"""
from collections import OrderedDict
from functools import partial
import torch
import torch.nn as nn
import torch.nn.functional as F
from timm.layers import ConvNormAct, create_conv2d, create_pool2d, create_classifier
from ._builder import build_model_with_cfg
from ._registry import register_model, generate_default_cfgs
__all__ = ['PNASNet5Large']
class SeparableConv2d(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride, padding=''):
super(SeparableConv2d, self).__init__()
self.depthwise_conv2d = create_conv2d(
in_channels, in_channels, kernel_size=kernel_size,
stride=stride, padding=padding, groups=in_channels)
self.pointwise_conv2d = create_conv2d(
in_channels, out_channels, kernel_size=1, padding=padding)
def forward(self, x):
x = self.depthwise_conv2d(x)
x = self.pointwise_conv2d(x)
return x
class BranchSeparables(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride=1, stem_cell=False, padding=''):
super(BranchSeparables, self).__init__()
middle_channels = out_channels if stem_cell else in_channels
self.act_1 = nn.ReLU()
self.separable_1 = SeparableConv2d(
in_channels, middle_channels, kernel_size, stride=stride, padding=padding)
self.bn_sep_1 = nn.BatchNorm2d(middle_channels, eps=0.001)
self.act_2 = nn.ReLU()
self.separable_2 = SeparableConv2d(
middle_channels, out_channels, kernel_size, stride=1, padding=padding)
self.bn_sep_2 = nn.BatchNorm2d(out_channels, eps=0.001)
def forward(self, x):
x = self.act_1(x)
x = self.separable_1(x)
x = self.bn_sep_1(x)
x = self.act_2(x)
x = self.separable_2(x)
x = self.bn_sep_2(x)
return x
class ActConvBn(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride=1, padding=''):
super(ActConvBn, self).__init__()
self.act = nn.ReLU()
self.conv = create_conv2d(
in_channels, out_channels, kernel_size=kernel_size, stride=stride, padding=padding)
self.bn = nn.BatchNorm2d(out_channels, eps=0.001)
def forward(self, x):
x = self.act(x)
x = self.conv(x)
x = self.bn(x)
return x
class FactorizedReduction(nn.Module):
def __init__(self, in_channels, out_channels, padding=''):
super(FactorizedReduction, self).__init__()
self.act = nn.ReLU()
self.path_1 = nn.Sequential(OrderedDict([
('avgpool', nn.AvgPool2d(1, stride=2, count_include_pad=False)),
('conv', create_conv2d(in_channels, out_channels // 2, kernel_size=1, padding=padding)),
]))
self.path_2 = nn.Sequential(OrderedDict([
('pad', nn.ZeroPad2d((-1, 1, -1, 1))), # shift
('avgpool', nn.AvgPool2d(1, stride=2, count_include_pad=False)),
('conv', create_conv2d(in_channels, out_channels // 2, kernel_size=1, padding=padding)),
]))
self.final_path_bn = nn.BatchNorm2d(out_channels, eps=0.001)
def forward(self, x):
x = self.act(x)
x_path1 = self.path_1(x)
x_path2 = self.path_2(x)
out = self.final_path_bn(torch.cat([x_path1, x_path2], 1))
return out
class CellBase(nn.Module):
def cell_forward(self, x_left, x_right):
x_comb_iter_0_left = self.comb_iter_0_left(x_left)
x_comb_iter_0_right = self.comb_iter_0_right(x_left)
x_comb_iter_0 = x_comb_iter_0_left + x_comb_iter_0_right
x_comb_iter_1_left = self.comb_iter_1_left(x_right)
x_comb_iter_1_right = self.comb_iter_1_right(x_right)
x_comb_iter_1 = x_comb_iter_1_left + x_comb_iter_1_right
x_comb_iter_2_left = self.comb_iter_2_left(x_right)
x_comb_iter_2_right = self.comb_iter_2_right(x_right)
x_comb_iter_2 = x_comb_iter_2_left + x_comb_iter_2_right
x_comb_iter_3_left = self.comb_iter_3_left(x_comb_iter_2)
x_comb_iter_3_right = self.comb_iter_3_right(x_right)
x_comb_iter_3 = x_comb_iter_3_left + x_comb_iter_3_right
x_comb_iter_4_left = self.comb_iter_4_left(x_left)
if self.comb_iter_4_right is not None:
x_comb_iter_4_right = self.comb_iter_4_right(x_right)
else:
x_comb_iter_4_right = x_right
x_comb_iter_4 = x_comb_iter_4_left + x_comb_iter_4_right
x_out = torch.cat([x_comb_iter_0, x_comb_iter_1, x_comb_iter_2, x_comb_iter_3, x_comb_iter_4], 1)
return x_out
class CellStem0(CellBase):
def __init__(self, in_chs_left, out_chs_left, in_chs_right, out_chs_right, pad_type=''):
super(CellStem0, self).__init__()
self.conv_1x1 = ActConvBn(in_chs_right, out_chs_right, kernel_size=1, padding=pad_type)
self.comb_iter_0_left = BranchSeparables(
in_chs_left, out_chs_left, kernel_size=5, stride=2, stem_cell=True, padding=pad_type)
self.comb_iter_0_right = nn.Sequential(OrderedDict([
('max_pool', create_pool2d('max', 3, stride=2, padding=pad_type)),
('conv', create_conv2d(in_chs_left, out_chs_left, kernel_size=1, padding=pad_type)),
('bn', nn.BatchNorm2d(out_chs_left, eps=0.001)),
]))
self.comb_iter_1_left = BranchSeparables(
out_chs_right, out_chs_right, kernel_size=7, stride=2, padding=pad_type)
self.comb_iter_1_right = create_pool2d('max', 3, stride=2, padding=pad_type)
self.comb_iter_2_left = BranchSeparables(
out_chs_right, out_chs_right, kernel_size=5, stride=2, padding=pad_type)
self.comb_iter_2_right = BranchSeparables(
out_chs_right, out_chs_right, kernel_size=3, stride=2, padding=pad_type)
self.comb_iter_3_left = BranchSeparables(
out_chs_right, out_chs_right, kernel_size=3, padding=pad_type)
self.comb_iter_3_right = create_pool2d('max', 3, stride=2, padding=pad_type)
self.comb_iter_4_left = BranchSeparables(
in_chs_right, out_chs_right, kernel_size=3, stride=2, stem_cell=True, padding=pad_type)
self.comb_iter_4_right = ActConvBn(
out_chs_right, out_chs_right, kernel_size=1, stride=2, padding=pad_type)
def forward(self, x_left):
x_right = self.conv_1x1(x_left)
x_out = self.cell_forward(x_left, x_right)
return x_out
class Cell(CellBase):
def __init__(
self,
in_chs_left,
out_chs_left,
in_chs_right,
out_chs_right,
pad_type='',
is_reduction=False,
match_prev_layer_dims=False,
):
super(Cell, self).__init__()
# If `is_reduction` is set to `True` stride 2 is used for
# convolution and pooling layers to reduce the spatial size of
# the output of a cell approximately by a factor of 2.
stride = 2 if is_reduction else 1
# If `match_prev_layer_dimensions` is set to `True`
# `FactorizedReduction` is used to reduce the spatial size
# of the left input of a cell approximately by a factor of 2.
self.match_prev_layer_dimensions = match_prev_layer_dims
if match_prev_layer_dims:
self.conv_prev_1x1 = FactorizedReduction(in_chs_left, out_chs_left, padding=pad_type)
else:
self.conv_prev_1x1 = ActConvBn(in_chs_left, out_chs_left, kernel_size=1, padding=pad_type)
self.conv_1x1 = ActConvBn(in_chs_right, out_chs_right, kernel_size=1, padding=pad_type)
self.comb_iter_0_left = BranchSeparables(
out_chs_left, out_chs_left, kernel_size=5, stride=stride, padding=pad_type)
self.comb_iter_0_right = create_pool2d('max', 3, stride=stride, padding=pad_type)
self.comb_iter_1_left = BranchSeparables(
out_chs_right, out_chs_right, kernel_size=7, stride=stride, padding=pad_type)
self.comb_iter_1_right = create_pool2d('max', 3, stride=stride, padding=pad_type)
self.comb_iter_2_left = BranchSeparables(
out_chs_right, out_chs_right, kernel_size=5, stride=stride, padding=pad_type)
self.comb_iter_2_right = BranchSeparables(
out_chs_right, out_chs_right, kernel_size=3, stride=stride, padding=pad_type)
self.comb_iter_3_left = BranchSeparables(out_chs_right, out_chs_right, kernel_size=3)
self.comb_iter_3_right = create_pool2d('max', 3, stride=stride, padding=pad_type)
self.comb_iter_4_left = BranchSeparables(
out_chs_left, out_chs_left, kernel_size=3, stride=stride, padding=pad_type)
if is_reduction:
self.comb_iter_4_right = ActConvBn(
out_chs_right, out_chs_right, kernel_size=1, stride=stride, padding=pad_type)
else:
self.comb_iter_4_right = None
def forward(self, x_left, x_right):
x_left = self.conv_prev_1x1(x_left)
x_right = self.conv_1x1(x_right)
x_out = self.cell_forward(x_left, x_right)
return x_out
class PNASNet5Large(nn.Module):
def __init__(
self,
num_classes=1000,
in_chans=3,
output_stride=32,
drop_rate=0.,
global_pool='avg',
pad_type='',
):
super(PNASNet5Large, self).__init__()
self.num_classes = num_classes
self.num_features = 4320
assert output_stride == 32
self.conv_0 = ConvNormAct(
in_chans, 96, kernel_size=3, stride=2, padding=0,
norm_layer=partial(nn.BatchNorm2d, eps=0.001, momentum=0.1), apply_act=False)
self.cell_stem_0 = CellStem0(
in_chs_left=96, out_chs_left=54, in_chs_right=96, out_chs_right=54, pad_type=pad_type)
self.cell_stem_1 = Cell(
in_chs_left=96, out_chs_left=108, in_chs_right=270, out_chs_right=108, pad_type=pad_type,
match_prev_layer_dims=True, is_reduction=True)
self.cell_0 = Cell(
in_chs_left=270, out_chs_left=216, in_chs_right=540, out_chs_right=216, pad_type=pad_type,
match_prev_layer_dims=True)
self.cell_1 = Cell(
in_chs_left=540, out_chs_left=216, in_chs_right=1080, out_chs_right=216, pad_type=pad_type)
self.cell_2 = Cell(
in_chs_left=1080, out_chs_left=216, in_chs_right=1080, out_chs_right=216, pad_type=pad_type)
self.cell_3 = Cell(
in_chs_left=1080, out_chs_left=216, in_chs_right=1080, out_chs_right=216, pad_type=pad_type)
self.cell_4 = Cell(
in_chs_left=1080, out_chs_left=432, in_chs_right=1080, out_chs_right=432, pad_type=pad_type,
is_reduction=True)
self.cell_5 = Cell(
in_chs_left=1080, out_chs_left=432, in_chs_right=2160, out_chs_right=432, pad_type=pad_type,
match_prev_layer_dims=True)
self.cell_6 = Cell(
in_chs_left=2160, out_chs_left=432, in_chs_right=2160, out_chs_right=432, pad_type=pad_type)
self.cell_7 = Cell(
in_chs_left=2160, out_chs_left=432, in_chs_right=2160, out_chs_right=432, pad_type=pad_type)
self.cell_8 = Cell(
in_chs_left=2160, out_chs_left=864, in_chs_right=2160, out_chs_right=864, pad_type=pad_type,
is_reduction=True)
self.cell_9 = Cell(
in_chs_left=2160, out_chs_left=864, in_chs_right=4320, out_chs_right=864, pad_type=pad_type,
match_prev_layer_dims=True)
self.cell_10 = Cell(
in_chs_left=4320, out_chs_left=864, in_chs_right=4320, out_chs_right=864, pad_type=pad_type)
self.cell_11 = Cell(
in_chs_left=4320, out_chs_left=864, in_chs_right=4320, out_chs_right=864, pad_type=pad_type)
self.act = nn.ReLU()
self.feature_info = [
dict(num_chs=96, reduction=2, module='conv_0'),
dict(num_chs=270, reduction=4, module='cell_stem_1.conv_1x1.act'),
dict(num_chs=1080, reduction=8, module='cell_4.conv_1x1.act'),
dict(num_chs=2160, reduction=16, module='cell_8.conv_1x1.act'),
dict(num_chs=4320, reduction=32, module='act'),
]
self.global_pool, self.head_drop, self.last_linear = create_classifier(
self.num_features, self.num_classes, pool_type=global_pool, drop_rate=drop_rate)
@torch.jit.ignore
def group_matcher(self, coarse=False):
return dict(stem=r'^conv_0|cell_stem_[01]', blocks=r'^cell_(\d+)')
@torch.jit.ignore
def set_grad_checkpointing(self, enable=True):
assert not enable, 'gradient checkpointing not supported'
@torch.jit.ignore
def get_classifier(self):
return self.last_linear
def reset_classifier(self, num_classes, global_pool='avg'):
self.num_classes = num_classes
self.global_pool, self.last_linear = create_classifier(
self.num_features, self.num_classes, pool_type=global_pool)
def forward_features(self, x):
x_conv_0 = self.conv_0(x)
x_stem_0 = self.cell_stem_0(x_conv_0)
x_stem_1 = self.cell_stem_1(x_conv_0, x_stem_0)
x_cell_0 = self.cell_0(x_stem_0, x_stem_1)
x_cell_1 = self.cell_1(x_stem_1, x_cell_0)
x_cell_2 = self.cell_2(x_cell_0, x_cell_1)
x_cell_3 = self.cell_3(x_cell_1, x_cell_2)
x_cell_4 = self.cell_4(x_cell_2, x_cell_3)
x_cell_5 = self.cell_5(x_cell_3, x_cell_4)
x_cell_6 = self.cell_6(x_cell_4, x_cell_5)
x_cell_7 = self.cell_7(x_cell_5, x_cell_6)
x_cell_8 = self.cell_8(x_cell_6, x_cell_7)
x_cell_9 = self.cell_9(x_cell_7, x_cell_8)
x_cell_10 = self.cell_10(x_cell_8, x_cell_9)
x_cell_11 = self.cell_11(x_cell_9, x_cell_10)
x = self.act(x_cell_11)
return x
def forward_head(self, x, pre_logits: bool = False):
x = self.global_pool(x)
x = self.head_drop(x)
return x if pre_logits else self.last_linear(x)
def forward(self, x):
x = self.forward_features(x)
x = self.forward_head(x)
return x
def _create_pnasnet(variant, pretrained=False, **kwargs):
return build_model_with_cfg(
PNASNet5Large,
variant,
pretrained,
feature_cfg=dict(feature_cls='hook', no_rewrite=True), # not possible to re-write this model
**kwargs,
)
default_cfgs = generate_default_cfgs({
'pnasnet5large.tf_in1k': {
'hf_hub_id': 'timm/',
'input_size': (3, 331, 331),
'pool_size': (11, 11),
'crop_pct': 0.911,
'interpolation': 'bicubic',
'mean': (0.5, 0.5, 0.5),
'std': (0.5, 0.5, 0.5),
'num_classes': 1000,
'first_conv': 'conv_0.conv',
'classifier': 'last_linear',
},
})
@register_model
def pnasnet5large(pretrained=False, **kwargs) -> PNASNet5Large:
r"""PNASNet-5 model architecture from the
`"Progressive Neural Architecture Search"
<https://arxiv.org/abs/1712.00559>`_ paper.
"""
model_kwargs = dict(pad_type='same', **kwargs)
return _create_pnasnet('pnasnet5large', pretrained, **model_kwargs)
| pytorch-image-models/timm/models/pnasnet.py/0 | {
"file_path": "pytorch-image-models/timm/models/pnasnet.py",
"repo_id": "pytorch-image-models",
"token_count": 7653
} | 188 |
""" Swin Transformer V2
A PyTorch impl of : `Swin Transformer V2: Scaling Up Capacity and Resolution`
- https://arxiv.org/abs/2111.09883
Code/weights from https://github.com/microsoft/Swin-Transformer, original copyright/license info below
Modifications and additions for timm hacked together by / Copyright 2022, Ross Wightman
"""
# --------------------------------------------------------
# Swin Transformer V2
# Copyright (c) 2022 Microsoft
# Licensed under The MIT License [see LICENSE for details]
# Written by Ze Liu
# --------------------------------------------------------
import math
from typing import Callable, Optional, Tuple, Union, Set, Dict
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.checkpoint as checkpoint
from timm.data import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD
from timm.layers import PatchEmbed, Mlp, DropPath, to_2tuple, trunc_normal_, _assert, ClassifierHead,\
resample_patch_embed, ndgrid
from ._builder import build_model_with_cfg
from ._features_fx import register_notrace_function
from ._registry import generate_default_cfgs, register_model, register_model_deprecations
__all__ = ['SwinTransformerV2'] # model_registry will add each entrypoint fn to this
_int_or_tuple_2_t = Union[int, Tuple[int, int]]
def window_partition(x: torch.Tensor, window_size: Tuple[int, int]) -> torch.Tensor:
"""
Args:
x: (B, H, W, C)
window_size (int): window size
Returns:
windows: (num_windows*B, window_size, window_size, C)
"""
B, H, W, C = x.shape
x = x.view(B, H // window_size[0], window_size[0], W // window_size[1], window_size[1], C)
windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size[0], window_size[1], C)
return windows
@register_notrace_function # reason: int argument is a Proxy
def window_reverse(windows: torch.Tensor, window_size: Tuple[int, int], img_size: Tuple[int, int]) -> torch.Tensor:
"""
Args:
windows: (num_windows * B, window_size[0], window_size[1], C)
window_size (Tuple[int, int]): Window size
img_size (Tuple[int, int]): Image size
Returns:
x: (B, H, W, C)
"""
H, W = img_size
C = windows.shape[-1]
x = windows.view(-1, H // window_size[0], W // window_size[1], window_size[0], window_size[1], C)
x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, H, W, C)
return x
class WindowAttention(nn.Module):
r""" Window based multi-head self attention (W-MSA) module with relative position bias.
It supports both of shifted and non-shifted window.
Args:
dim (int): Number of input channels.
window_size (tuple[int]): The height and width of the window.
num_heads (int): Number of attention heads.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
attn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0
proj_drop (float, optional): Dropout ratio of output. Default: 0.0
pretrained_window_size (tuple[int]): The height and width of the window in pre-training.
"""
def __init__(
self,
dim: int,
window_size: Tuple[int, int],
num_heads: int,
qkv_bias: bool = True,
attn_drop: float = 0.,
proj_drop: float = 0.,
pretrained_window_size: Tuple[int, int] = (0, 0),
) -> None:
super().__init__()
self.dim = dim
self.window_size = window_size # Wh, Ww
self.pretrained_window_size = pretrained_window_size
self.num_heads = num_heads
self.logit_scale = nn.Parameter(torch.log(10 * torch.ones((num_heads, 1, 1))))
# mlp to generate continuous relative position bias
self.cpb_mlp = nn.Sequential(
nn.Linear(2, 512, bias=True),
nn.ReLU(inplace=True),
nn.Linear(512, num_heads, bias=False)
)
# get relative_coords_table
relative_coords_h = torch.arange(-(self.window_size[0] - 1), self.window_size[0]).to(torch.float32)
relative_coords_w = torch.arange(-(self.window_size[1] - 1), self.window_size[1]).to(torch.float32)
relative_coords_table = torch.stack(ndgrid(relative_coords_h, relative_coords_w))
relative_coords_table = relative_coords_table.permute(1, 2, 0).contiguous().unsqueeze(0) # 1, 2*Wh-1, 2*Ww-1, 2
if pretrained_window_size[0] > 0:
relative_coords_table[:, :, :, 0] /= (pretrained_window_size[0] - 1)
relative_coords_table[:, :, :, 1] /= (pretrained_window_size[1] - 1)
else:
relative_coords_table[:, :, :, 0] /= (self.window_size[0] - 1)
relative_coords_table[:, :, :, 1] /= (self.window_size[1] - 1)
relative_coords_table *= 8 # normalize to -8, 8
relative_coords_table = torch.sign(relative_coords_table) * torch.log2(
torch.abs(relative_coords_table) + 1.0) / math.log2(8)
self.register_buffer("relative_coords_table", relative_coords_table, persistent=False)
# get pair-wise relative position index for each token inside the window
coords_h = torch.arange(self.window_size[0])
coords_w = torch.arange(self.window_size[1])
coords = torch.stack(ndgrid(coords_h, coords_w)) # 2, Wh, Ww
coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
relative_coords[:, :, 0] += self.window_size[0] - 1 # shift to start from 0
relative_coords[:, :, 1] += self.window_size[1] - 1
relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1
relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
self.register_buffer("relative_position_index", relative_position_index, persistent=False)
self.qkv = nn.Linear(dim, dim * 3, bias=False)
if qkv_bias:
self.q_bias = nn.Parameter(torch.zeros(dim))
self.register_buffer('k_bias', torch.zeros(dim), persistent=False)
self.v_bias = nn.Parameter(torch.zeros(dim))
else:
self.q_bias = None
self.k_bias = None
self.v_bias = None
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x: torch.Tensor, mask: Optional[torch.Tensor] = None) -> torch.Tensor:
"""
Args:
x: input features with shape of (num_windows*B, N, C)
mask: (0/-inf) mask with shape of (num_windows, Wh*Ww, Wh*Ww) or None
"""
B_, N, C = x.shape
qkv_bias = None
if self.q_bias is not None:
qkv_bias = torch.cat((self.q_bias, self.k_bias, self.v_bias))
qkv = F.linear(input=x, weight=self.qkv.weight, bias=qkv_bias)
qkv = qkv.reshape(B_, N, 3, self.num_heads, -1).permute(2, 0, 3, 1, 4)
q, k, v = qkv.unbind(0)
# cosine attention
attn = (F.normalize(q, dim=-1) @ F.normalize(k, dim=-1).transpose(-2, -1))
logit_scale = torch.clamp(self.logit_scale, max=math.log(1. / 0.01)).exp()
attn = attn * logit_scale
relative_position_bias_table = self.cpb_mlp(self.relative_coords_table).view(-1, self.num_heads)
relative_position_bias = relative_position_bias_table[self.relative_position_index.view(-1)].view(
self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1) # Wh*Ww,Wh*Ww,nH
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
relative_position_bias = 16 * torch.sigmoid(relative_position_bias)
attn = attn + relative_position_bias.unsqueeze(0)
if mask is not None:
num_win = mask.shape[0]
attn = attn.view(-1, num_win, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)
attn = attn.view(-1, self.num_heads, N, N)
attn = self.softmax(attn)
else:
attn = self.softmax(attn)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B_, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
class SwinTransformerV2Block(nn.Module):
""" Swin Transformer Block.
"""
def __init__(
self,
dim: int,
input_resolution: _int_or_tuple_2_t,
num_heads: int,
window_size: _int_or_tuple_2_t = 7,
shift_size: _int_or_tuple_2_t = 0,
mlp_ratio: float = 4.,
qkv_bias: bool = True,
proj_drop: float = 0.,
attn_drop: float = 0.,
drop_path: float = 0.,
act_layer: nn.Module = nn.GELU,
norm_layer: nn.Module = nn.LayerNorm,
pretrained_window_size: _int_or_tuple_2_t = 0,
) -> None:
"""
Args:
dim: Number of input channels.
input_resolution: Input resolution.
num_heads: Number of attention heads.
window_size: Window size.
shift_size: Shift size for SW-MSA.
mlp_ratio: Ratio of mlp hidden dim to embedding dim.
qkv_bias: If True, add a learnable bias to query, key, value.
proj_drop: Dropout rate.
attn_drop: Attention dropout rate.
drop_path: Stochastic depth rate.
act_layer: Activation layer.
norm_layer: Normalization layer.
pretrained_window_size: Window size in pretraining.
"""
super().__init__()
self.dim = dim
self.input_resolution = to_2tuple(input_resolution)
self.num_heads = num_heads
ws, ss = self._calc_window_shift(window_size, shift_size)
self.window_size: Tuple[int, int] = ws
self.shift_size: Tuple[int, int] = ss
self.window_area = self.window_size[0] * self.window_size[1]
self.mlp_ratio = mlp_ratio
self.attn = WindowAttention(
dim,
window_size=to_2tuple(self.window_size),
num_heads=num_heads,
qkv_bias=qkv_bias,
attn_drop=attn_drop,
proj_drop=proj_drop,
pretrained_window_size=to_2tuple(pretrained_window_size),
)
self.norm1 = norm_layer(dim)
self.drop_path1 = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.mlp = Mlp(
in_features=dim,
hidden_features=int(dim * mlp_ratio),
act_layer=act_layer,
drop=proj_drop,
)
self.norm2 = norm_layer(dim)
self.drop_path2 = DropPath(drop_path) if drop_path > 0. else nn.Identity()
if any(self.shift_size):
# calculate attention mask for SW-MSA
H, W = self.input_resolution
img_mask = torch.zeros((1, H, W, 1)) # 1 H W 1
cnt = 0
for h in (
slice(0, -self.window_size[0]),
slice(-self.window_size[0], -self.shift_size[0]),
slice(-self.shift_size[0], None)):
for w in (
slice(0, -self.window_size[1]),
slice(-self.window_size[1], -self.shift_size[1]),
slice(-self.shift_size[1], None)):
img_mask[:, h, w, :] = cnt
cnt += 1
mask_windows = window_partition(img_mask, self.window_size) # nW, window_size, window_size, 1
mask_windows = mask_windows.view(-1, self.window_area)
attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)
attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))
else:
attn_mask = None
self.register_buffer("attn_mask", attn_mask, persistent=False)
def _calc_window_shift(self,
target_window_size: _int_or_tuple_2_t,
target_shift_size: _int_or_tuple_2_t) -> Tuple[Tuple[int, int], Tuple[int, int]]:
target_window_size = to_2tuple(target_window_size)
target_shift_size = to_2tuple(target_shift_size)
window_size = [r if r <= w else w for r, w in zip(self.input_resolution, target_window_size)]
shift_size = [0 if r <= w else s for r, w, s in zip(self.input_resolution, window_size, target_shift_size)]
return tuple(window_size), tuple(shift_size)
def _attn(self, x: torch.Tensor) -> torch.Tensor:
B, H, W, C = x.shape
# cyclic shift
has_shift = any(self.shift_size)
if has_shift:
shifted_x = torch.roll(x, shifts=(-self.shift_size[0], -self.shift_size[1]), dims=(1, 2))
else:
shifted_x = x
# partition windows
x_windows = window_partition(shifted_x, self.window_size) # nW*B, window_size, window_size, C
x_windows = x_windows.view(-1, self.window_area, C) # nW*B, window_size*window_size, C
# W-MSA/SW-MSA
attn_windows = self.attn(x_windows, mask=self.attn_mask) # nW*B, window_size*window_size, C
# merge windows
attn_windows = attn_windows.view(-1, self.window_size[0], self.window_size[1], C)
shifted_x = window_reverse(attn_windows, self.window_size, self.input_resolution) # B H' W' C
# reverse cyclic shift
if has_shift:
x = torch.roll(shifted_x, shifts=self.shift_size, dims=(1, 2))
else:
x = shifted_x
return x
def forward(self, x: torch.Tensor) -> torch.Tensor:
B, H, W, C = x.shape
x = x + self.drop_path1(self.norm1(self._attn(x)))
x = x.reshape(B, -1, C)
x = x + self.drop_path2(self.norm2(self.mlp(x)))
x = x.reshape(B, H, W, C)
return x
class PatchMerging(nn.Module):
""" Patch Merging Layer.
"""
def __init__(self, dim: int, out_dim: Optional[int] = None, norm_layer: nn.Module = nn.LayerNorm) -> None:
"""
Args:
dim (int): Number of input channels.
out_dim (int): Number of output channels (or 2 * dim if None)
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
"""
super().__init__()
self.dim = dim
self.out_dim = out_dim or 2 * dim
self.reduction = nn.Linear(4 * dim, self.out_dim, bias=False)
self.norm = norm_layer(self.out_dim)
def forward(self, x: torch.Tensor) -> torch.Tensor:
B, H, W, C = x.shape
_assert(H % 2 == 0, f"x height ({H}) is not even.")
_assert(W % 2 == 0, f"x width ({W}) is not even.")
x = x.reshape(B, H // 2, 2, W // 2, 2, C).permute(0, 1, 3, 4, 2, 5).flatten(3)
x = self.reduction(x)
x = self.norm(x)
return x
class SwinTransformerV2Stage(nn.Module):
""" A Swin Transformer V2 Stage.
"""
def __init__(
self,
dim: int,
out_dim: int,
input_resolution: _int_or_tuple_2_t,
depth: int,
num_heads: int,
window_size: _int_or_tuple_2_t,
downsample: bool = False,
mlp_ratio: float = 4.,
qkv_bias: bool = True,
proj_drop: float = 0.,
attn_drop: float = 0.,
drop_path: float = 0.,
norm_layer: nn.Module = nn.LayerNorm,
pretrained_window_size: _int_or_tuple_2_t = 0,
output_nchw: bool = False,
) -> None:
"""
Args:
dim: Number of input channels.
out_dim: Number of output channels.
input_resolution: Input resolution.
depth: Number of blocks.
num_heads: Number of attention heads.
window_size: Local window size.
downsample: Use downsample layer at start of the block.
mlp_ratio: Ratio of mlp hidden dim to embedding dim.
qkv_bias: If True, add a learnable bias to query, key, value.
proj_drop: Projection dropout rate
attn_drop: Attention dropout rate.
drop_path: Stochastic depth rate.
norm_layer: Normalization layer.
pretrained_window_size: Local window size in pretraining.
output_nchw: Output tensors on NCHW format instead of NHWC.
"""
super().__init__()
self.dim = dim
self.input_resolution = input_resolution
self.output_resolution = tuple(i // 2 for i in input_resolution) if downsample else input_resolution
self.depth = depth
self.output_nchw = output_nchw
self.grad_checkpointing = False
window_size = to_2tuple(window_size)
shift_size = tuple([w // 2 for w in window_size])
# patch merging / downsample layer
if downsample:
self.downsample = PatchMerging(dim=dim, out_dim=out_dim, norm_layer=norm_layer)
else:
assert dim == out_dim
self.downsample = nn.Identity()
# build blocks
self.blocks = nn.ModuleList([
SwinTransformerV2Block(
dim=out_dim,
input_resolution=self.output_resolution,
num_heads=num_heads,
window_size=window_size,
shift_size=0 if (i % 2 == 0) else shift_size,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias,
proj_drop=proj_drop,
attn_drop=attn_drop,
drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path,
norm_layer=norm_layer,
pretrained_window_size=pretrained_window_size,
)
for i in range(depth)])
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.downsample(x)
for blk in self.blocks:
if self.grad_checkpointing and not torch.jit.is_scripting():
x = checkpoint.checkpoint(blk, x)
else:
x = blk(x)
return x
def _init_respostnorm(self) -> None:
for blk in self.blocks:
nn.init.constant_(blk.norm1.bias, 0)
nn.init.constant_(blk.norm1.weight, 0)
nn.init.constant_(blk.norm2.bias, 0)
nn.init.constant_(blk.norm2.weight, 0)
class SwinTransformerV2(nn.Module):
""" Swin Transformer V2
A PyTorch impl of : `Swin Transformer V2: Scaling Up Capacity and Resolution`
- https://arxiv.org/abs/2111.09883
"""
def __init__(
self,
img_size: _int_or_tuple_2_t = 224,
patch_size: int = 4,
in_chans: int = 3,
num_classes: int = 1000,
global_pool: str = 'avg',
embed_dim: int = 96,
depths: Tuple[int, ...] = (2, 2, 6, 2),
num_heads: Tuple[int, ...] = (3, 6, 12, 24),
window_size: _int_or_tuple_2_t = 7,
mlp_ratio: float = 4.,
qkv_bias: bool = True,
drop_rate: float = 0.,
proj_drop_rate: float = 0.,
attn_drop_rate: float = 0.,
drop_path_rate: float = 0.1,
norm_layer: Callable = nn.LayerNorm,
pretrained_window_sizes: Tuple[int, ...] = (0, 0, 0, 0),
**kwargs,
):
"""
Args:
img_size: Input image size.
patch_size: Patch size.
in_chans: Number of input image channels.
num_classes: Number of classes for classification head.
embed_dim: Patch embedding dimension.
depths: Depth of each Swin Transformer stage (layer).
num_heads: Number of attention heads in different layers.
window_size: Window size.
mlp_ratio: Ratio of mlp hidden dim to embedding dim.
qkv_bias: If True, add a learnable bias to query, key, value.
drop_rate: Head dropout rate.
proj_drop_rate: Projection dropout rate.
attn_drop_rate: Attention dropout rate.
drop_path_rate: Stochastic depth rate.
norm_layer: Normalization layer.
patch_norm: If True, add normalization after patch embedding.
pretrained_window_sizes: Pretrained window sizes of each layer.
output_fmt: Output tensor format if not None, otherwise output 'NHWC' by default.
"""
super().__init__()
self.num_classes = num_classes
assert global_pool in ('', 'avg')
self.global_pool = global_pool
self.output_fmt = 'NHWC'
self.num_layers = len(depths)
self.embed_dim = embed_dim
self.num_features = int(embed_dim * 2 ** (self.num_layers - 1))
self.feature_info = []
if not isinstance(embed_dim, (tuple, list)):
embed_dim = [int(embed_dim * 2 ** i) for i in range(self.num_layers)]
# split image into non-overlapping patches
self.patch_embed = PatchEmbed(
img_size=img_size,
patch_size=patch_size,
in_chans=in_chans,
embed_dim=embed_dim[0],
norm_layer=norm_layer,
output_fmt='NHWC',
)
dpr = [x.tolist() for x in torch.linspace(0, drop_path_rate, sum(depths)).split(depths)]
layers = []
in_dim = embed_dim[0]
scale = 1
for i in range(self.num_layers):
out_dim = embed_dim[i]
layers += [SwinTransformerV2Stage(
dim=in_dim,
out_dim=out_dim,
input_resolution=(
self.patch_embed.grid_size[0] // scale,
self.patch_embed.grid_size[1] // scale),
depth=depths[i],
downsample=i > 0,
num_heads=num_heads[i],
window_size=window_size,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias,
proj_drop=proj_drop_rate,
attn_drop=attn_drop_rate,
drop_path=dpr[i],
norm_layer=norm_layer,
pretrained_window_size=pretrained_window_sizes[i],
)]
in_dim = out_dim
if i > 0:
scale *= 2
self.feature_info += [dict(num_chs=out_dim, reduction=4 * scale, module=f'layers.{i}')]
self.layers = nn.Sequential(*layers)
self.norm = norm_layer(self.num_features)
self.head = ClassifierHead(
self.num_features,
num_classes,
pool_type=global_pool,
drop_rate=drop_rate,
input_fmt=self.output_fmt,
)
self.apply(self._init_weights)
for bly in self.layers:
bly._init_respostnorm()
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
@torch.jit.ignore
def no_weight_decay(self):
nod = set()
for n, m in self.named_modules():
if any([kw in n for kw in ("cpb_mlp", "logit_scale")]):
nod.add(n)
return nod
@torch.jit.ignore
def group_matcher(self, coarse=False):
return dict(
stem=r'^absolute_pos_embed|patch_embed', # stem and embed
blocks=r'^layers\.(\d+)' if coarse else [
(r'^layers\.(\d+).downsample', (0,)),
(r'^layers\.(\d+)\.\w+\.(\d+)', None),
(r'^norm', (99999,)),
]
)
@torch.jit.ignore
def set_grad_checkpointing(self, enable=True):
for l in self.layers:
l.grad_checkpointing = enable
@torch.jit.ignore
def get_classifier(self):
return self.head.fc
def reset_classifier(self, num_classes, global_pool=None):
self.num_classes = num_classes
self.head.reset(num_classes, global_pool)
def forward_features(self, x):
x = self.patch_embed(x)
x = self.layers(x)
x = self.norm(x)
return x
def forward_head(self, x, pre_logits: bool = False):
return self.head(x, pre_logits=True) if pre_logits else self.head(x)
def forward(self, x):
x = self.forward_features(x)
x = self.forward_head(x)
return x
def checkpoint_filter_fn(state_dict, model):
state_dict = state_dict.get('model', state_dict)
state_dict = state_dict.get('state_dict', state_dict)
native_checkpoint = 'head.fc.weight' in state_dict
out_dict = {}
import re
for k, v in state_dict.items():
if any([n in k for n in ('relative_position_index', 'relative_coords_table', 'attn_mask')]):
continue # skip buffers that should not be persistent
if 'patch_embed.proj.weight' in k:
_, _, H, W = model.patch_embed.proj.weight.shape
if v.shape[-2] != H or v.shape[-1] != W:
v = resample_patch_embed(
v,
(H, W),
interpolation='bicubic',
antialias=True,
verbose=True,
)
if not native_checkpoint:
# skip layer remapping for updated checkpoints
k = re.sub(r'layers.(\d+).downsample', lambda x: f'layers.{int(x.group(1)) + 1}.downsample', k)
k = k.replace('head.', 'head.fc.')
out_dict[k] = v
return out_dict
def _create_swin_transformer_v2(variant, pretrained=False, **kwargs):
default_out_indices = tuple(i for i, _ in enumerate(kwargs.get('depths', (1, 1, 1, 1))))
out_indices = kwargs.pop('out_indices', default_out_indices)
model = build_model_with_cfg(
SwinTransformerV2, variant, pretrained,
pretrained_filter_fn=checkpoint_filter_fn,
feature_cfg=dict(flatten_sequential=True, out_indices=out_indices),
**kwargs)
return model
def _cfg(url='', **kwargs):
return {
'url': url,
'num_classes': 1000, 'input_size': (3, 256, 256), 'pool_size': (8, 8),
'crop_pct': .9, 'interpolation': 'bicubic', 'fixed_input_size': True,
'mean': IMAGENET_DEFAULT_MEAN, 'std': IMAGENET_DEFAULT_STD,
'first_conv': 'patch_embed.proj', 'classifier': 'head.fc',
'license': 'mit', **kwargs
}
default_cfgs = generate_default_cfgs({
'swinv2_base_window12to16_192to256.ms_in22k_ft_in1k': _cfg(
hf_hub_id='timm/',
url='https://github.com/SwinTransformer/storage/releases/download/v2.0.0/swinv2_base_patch4_window12to16_192to256_22kto1k_ft.pth',
),
'swinv2_base_window12to24_192to384.ms_in22k_ft_in1k': _cfg(
hf_hub_id='timm/',
url='https://github.com/SwinTransformer/storage/releases/download/v2.0.0/swinv2_base_patch4_window12to24_192to384_22kto1k_ft.pth',
input_size=(3, 384, 384), pool_size=(12, 12), crop_pct=1.0,
),
'swinv2_large_window12to16_192to256.ms_in22k_ft_in1k': _cfg(
hf_hub_id='timm/',
url='https://github.com/SwinTransformer/storage/releases/download/v2.0.0/swinv2_large_patch4_window12to16_192to256_22kto1k_ft.pth',
),
'swinv2_large_window12to24_192to384.ms_in22k_ft_in1k': _cfg(
hf_hub_id='timm/',
url='https://github.com/SwinTransformer/storage/releases/download/v2.0.0/swinv2_large_patch4_window12to24_192to384_22kto1k_ft.pth',
input_size=(3, 384, 384), pool_size=(12, 12), crop_pct=1.0,
),
'swinv2_tiny_window8_256.ms_in1k': _cfg(
hf_hub_id='timm/',
url='https://github.com/SwinTransformer/storage/releases/download/v2.0.0/swinv2_tiny_patch4_window8_256.pth',
),
'swinv2_tiny_window16_256.ms_in1k': _cfg(
hf_hub_id='timm/',
url='https://github.com/SwinTransformer/storage/releases/download/v2.0.0/swinv2_tiny_patch4_window16_256.pth',
),
'swinv2_small_window8_256.ms_in1k': _cfg(
hf_hub_id='timm/',
url='https://github.com/SwinTransformer/storage/releases/download/v2.0.0/swinv2_small_patch4_window8_256.pth',
),
'swinv2_small_window16_256.ms_in1k': _cfg(
hf_hub_id='timm/',
url='https://github.com/SwinTransformer/storage/releases/download/v2.0.0/swinv2_small_patch4_window16_256.pth',
),
'swinv2_base_window8_256.ms_in1k': _cfg(
hf_hub_id='timm/',
url='https://github.com/SwinTransformer/storage/releases/download/v2.0.0/swinv2_base_patch4_window8_256.pth',
),
'swinv2_base_window16_256.ms_in1k': _cfg(
hf_hub_id='timm/',
url='https://github.com/SwinTransformer/storage/releases/download/v2.0.0/swinv2_base_patch4_window16_256.pth',
),
'swinv2_base_window12_192.ms_in22k': _cfg(
hf_hub_id='timm/',
url='https://github.com/SwinTransformer/storage/releases/download/v2.0.0/swinv2_base_patch4_window12_192_22k.pth',
num_classes=21841, input_size=(3, 192, 192), pool_size=(6, 6)
),
'swinv2_large_window12_192.ms_in22k': _cfg(
hf_hub_id='timm/',
url='https://github.com/SwinTransformer/storage/releases/download/v2.0.0/swinv2_large_patch4_window12_192_22k.pth',
num_classes=21841, input_size=(3, 192, 192), pool_size=(6, 6)
),
})
@register_model
def swinv2_tiny_window16_256(pretrained=False, **kwargs) -> SwinTransformerV2:
"""
"""
model_args = dict(window_size=16, embed_dim=96, depths=(2, 2, 6, 2), num_heads=(3, 6, 12, 24))
return _create_swin_transformer_v2(
'swinv2_tiny_window16_256', pretrained=pretrained, **dict(model_args, **kwargs))
@register_model
def swinv2_tiny_window8_256(pretrained=False, **kwargs) -> SwinTransformerV2:
"""
"""
model_args = dict(window_size=8, embed_dim=96, depths=(2, 2, 6, 2), num_heads=(3, 6, 12, 24))
return _create_swin_transformer_v2(
'swinv2_tiny_window8_256', pretrained=pretrained, **dict(model_args, **kwargs))
@register_model
def swinv2_small_window16_256(pretrained=False, **kwargs) -> SwinTransformerV2:
"""
"""
model_args = dict(window_size=16, embed_dim=96, depths=(2, 2, 18, 2), num_heads=(3, 6, 12, 24))
return _create_swin_transformer_v2(
'swinv2_small_window16_256', pretrained=pretrained, **dict(model_args, **kwargs))
@register_model
def swinv2_small_window8_256(pretrained=False, **kwargs) -> SwinTransformerV2:
"""
"""
model_args = dict(window_size=8, embed_dim=96, depths=(2, 2, 18, 2), num_heads=(3, 6, 12, 24))
return _create_swin_transformer_v2(
'swinv2_small_window8_256', pretrained=pretrained, **dict(model_args, **kwargs))
@register_model
def swinv2_base_window16_256(pretrained=False, **kwargs) -> SwinTransformerV2:
"""
"""
model_args = dict(window_size=16, embed_dim=128, depths=(2, 2, 18, 2), num_heads=(4, 8, 16, 32))
return _create_swin_transformer_v2(
'swinv2_base_window16_256', pretrained=pretrained, **dict(model_args, **kwargs))
@register_model
def swinv2_base_window8_256(pretrained=False, **kwargs) -> SwinTransformerV2:
"""
"""
model_args = dict(window_size=8, embed_dim=128, depths=(2, 2, 18, 2), num_heads=(4, 8, 16, 32))
return _create_swin_transformer_v2(
'swinv2_base_window8_256', pretrained=pretrained, **dict(model_args, **kwargs))
@register_model
def swinv2_base_window12_192(pretrained=False, **kwargs) -> SwinTransformerV2:
"""
"""
model_args = dict(window_size=12, embed_dim=128, depths=(2, 2, 18, 2), num_heads=(4, 8, 16, 32))
return _create_swin_transformer_v2(
'swinv2_base_window12_192', pretrained=pretrained, **dict(model_args, **kwargs))
@register_model
def swinv2_base_window12to16_192to256(pretrained=False, **kwargs) -> SwinTransformerV2:
"""
"""
model_args = dict(
window_size=16, embed_dim=128, depths=(2, 2, 18, 2), num_heads=(4, 8, 16, 32),
pretrained_window_sizes=(12, 12, 12, 6))
return _create_swin_transformer_v2(
'swinv2_base_window12to16_192to256', pretrained=pretrained, **dict(model_args, **kwargs))
@register_model
def swinv2_base_window12to24_192to384(pretrained=False, **kwargs) -> SwinTransformerV2:
"""
"""
model_args = dict(
window_size=24, embed_dim=128, depths=(2, 2, 18, 2), num_heads=(4, 8, 16, 32),
pretrained_window_sizes=(12, 12, 12, 6))
return _create_swin_transformer_v2(
'swinv2_base_window12to24_192to384', pretrained=pretrained, **dict(model_args, **kwargs))
@register_model
def swinv2_large_window12_192(pretrained=False, **kwargs) -> SwinTransformerV2:
"""
"""
model_args = dict(window_size=12, embed_dim=192, depths=(2, 2, 18, 2), num_heads=(6, 12, 24, 48))
return _create_swin_transformer_v2(
'swinv2_large_window12_192', pretrained=pretrained, **dict(model_args, **kwargs))
@register_model
def swinv2_large_window12to16_192to256(pretrained=False, **kwargs) -> SwinTransformerV2:
"""
"""
model_args = dict(
window_size=16, embed_dim=192, depths=(2, 2, 18, 2), num_heads=(6, 12, 24, 48),
pretrained_window_sizes=(12, 12, 12, 6))
return _create_swin_transformer_v2(
'swinv2_large_window12to16_192to256', pretrained=pretrained, **dict(model_args, **kwargs))
@register_model
def swinv2_large_window12to24_192to384(pretrained=False, **kwargs) -> SwinTransformerV2:
"""
"""
model_args = dict(
window_size=24, embed_dim=192, depths=(2, 2, 18, 2), num_heads=(6, 12, 24, 48),
pretrained_window_sizes=(12, 12, 12, 6))
return _create_swin_transformer_v2(
'swinv2_large_window12to24_192to384', pretrained=pretrained, **dict(model_args, **kwargs))
register_model_deprecations(__name__, {
'swinv2_base_window12_192_22k': 'swinv2_base_window12_192.ms_in22k',
'swinv2_base_window12to16_192to256_22kft1k': 'swinv2_base_window12to16_192to256.ms_in22k_ft_in1k',
'swinv2_base_window12to24_192to384_22kft1k': 'swinv2_base_window12to24_192to384.ms_in22k_ft_in1k',
'swinv2_large_window12_192_22k': 'swinv2_large_window12_192.ms_in22k',
'swinv2_large_window12to16_192to256_22kft1k': 'swinv2_large_window12to16_192to256.ms_in22k_ft_in1k',
'swinv2_large_window12to24_192to384_22kft1k': 'swinv2_large_window12to24_192to384.ms_in22k_ft_in1k',
})
| pytorch-image-models/timm/models/swin_transformer_v2.py/0 | {
"file_path": "pytorch-image-models/timm/models/swin_transformer_v2.py",
"repo_id": "pytorch-image-models",
"token_count": 16762
} | 189 |
""" Cross-Covariance Image Transformer (XCiT) in PyTorch
Paper:
- https://arxiv.org/abs/2106.09681
Same as the official implementation, with some minor adaptations, original copyright below
- https://github.com/facebookresearch/xcit/blob/master/xcit.py
Modifications and additions for timm hacked together by / Copyright 2021, Ross Wightman
"""
# Copyright (c) 2015-present, Facebook, Inc.
# All rights reserved.
import math
from functools import partial
import torch
import torch.nn as nn
from torch.utils.checkpoint import checkpoint
from timm.data import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD
from timm.layers import DropPath, trunc_normal_, to_2tuple
from ._builder import build_model_with_cfg
from ._features_fx import register_notrace_module
from ._registry import register_model, generate_default_cfgs, register_model_deprecations
from .cait import ClassAttn
from .vision_transformer import Mlp
__all__ = ['Xcit'] # model_registry will add each entrypoint fn to this
@register_notrace_module # reason: FX can't symbolically trace torch.arange in forward method
class PositionalEncodingFourier(nn.Module):
"""
Positional encoding relying on a fourier kernel matching the one used in the "Attention is all you Need" paper.
Based on the official XCiT code
- https://github.com/facebookresearch/xcit/blob/master/xcit.py
"""
def __init__(self, hidden_dim=32, dim=768, temperature=10000):
super().__init__()
self.token_projection = nn.Conv2d(hidden_dim * 2, dim, kernel_size=1)
self.scale = 2 * math.pi
self.temperature = temperature
self.hidden_dim = hidden_dim
self.dim = dim
self.eps = 1e-6
def forward(self, B: int, H: int, W: int):
device = self.token_projection.weight.device
dtype = self.token_projection.weight.dtype
y_embed = torch.arange(1, H + 1, device=device).to(torch.float32).unsqueeze(1).repeat(1, 1, W)
x_embed = torch.arange(1, W + 1, device=device).to(torch.float32).repeat(1, H, 1)
y_embed = y_embed / (y_embed[:, -1:, :] + self.eps) * self.scale
x_embed = x_embed / (x_embed[:, :, -1:] + self.eps) * self.scale
dim_t = torch.arange(self.hidden_dim, device=device).to(torch.float32)
dim_t = self.temperature ** (2 * torch.div(dim_t, 2, rounding_mode='floor') / self.hidden_dim)
pos_x = x_embed[:, :, :, None] / dim_t
pos_y = y_embed[:, :, :, None] / dim_t
pos_x = torch.stack([pos_x[:, :, :, 0::2].sin(), pos_x[:, :, :, 1::2].cos()], dim=4).flatten(3)
pos_y = torch.stack([pos_y[:, :, :, 0::2].sin(), pos_y[:, :, :, 1::2].cos()], dim=4).flatten(3)
pos = torch.cat((pos_y, pos_x), dim=3).permute(0, 3, 1, 2)
pos = self.token_projection(pos.to(dtype))
return pos.repeat(B, 1, 1, 1) # (B, C, H, W)
def conv3x3(in_planes, out_planes, stride=1):
"""3x3 convolution + batch norm"""
return torch.nn.Sequential(
nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(out_planes)
)
class ConvPatchEmbed(nn.Module):
"""Image to Patch Embedding using multiple convolutional layers"""
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768, act_layer=nn.GELU):
super().__init__()
img_size = to_2tuple(img_size)
num_patches = (img_size[1] // patch_size) * (img_size[0] // patch_size)
self.img_size = img_size
self.patch_size = patch_size
self.num_patches = num_patches
if patch_size == 16:
self.proj = torch.nn.Sequential(
conv3x3(in_chans, embed_dim // 8, 2),
act_layer(),
conv3x3(embed_dim // 8, embed_dim // 4, 2),
act_layer(),
conv3x3(embed_dim // 4, embed_dim // 2, 2),
act_layer(),
conv3x3(embed_dim // 2, embed_dim, 2),
)
elif patch_size == 8:
self.proj = torch.nn.Sequential(
conv3x3(in_chans, embed_dim // 4, 2),
act_layer(),
conv3x3(embed_dim // 4, embed_dim // 2, 2),
act_layer(),
conv3x3(embed_dim // 2, embed_dim, 2),
)
else:
raise('For convolutional projection, patch size has to be in [8, 16]')
def forward(self, x):
x = self.proj(x)
Hp, Wp = x.shape[2], x.shape[3]
x = x.flatten(2).transpose(1, 2) # (B, N, C)
return x, (Hp, Wp)
class LPI(nn.Module):
"""
Local Patch Interaction module that allows explicit communication between tokens in 3x3 windows to augment the
implicit communication performed by the block diagonal scatter attention. Implemented using 2 layers of separable
3x3 convolutions with GeLU and BatchNorm2d
"""
def __init__(self, in_features, out_features=None, act_layer=nn.GELU, kernel_size=3):
super().__init__()
out_features = out_features or in_features
padding = kernel_size // 2
self.conv1 = torch.nn.Conv2d(
in_features, in_features, kernel_size=kernel_size, padding=padding, groups=in_features)
self.act = act_layer()
self.bn = nn.BatchNorm2d(in_features)
self.conv2 = torch.nn.Conv2d(
in_features, out_features, kernel_size=kernel_size, padding=padding, groups=out_features)
def forward(self, x, H: int, W: int):
B, N, C = x.shape
x = x.permute(0, 2, 1).reshape(B, C, H, W)
x = self.conv1(x)
x = self.act(x)
x = self.bn(x)
x = self.conv2(x)
x = x.reshape(B, C, N).permute(0, 2, 1)
return x
class ClassAttentionBlock(nn.Module):
"""Class Attention Layer as in CaiT https://arxiv.org/abs/2103.17239"""
def __init__(
self,
dim,
num_heads,
mlp_ratio=4.,
qkv_bias=False,
proj_drop=0.,
attn_drop=0.,
drop_path=0.,
act_layer=nn.GELU,
norm_layer=nn.LayerNorm,
eta=1.,
tokens_norm=False,
):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = ClassAttn(
dim, num_heads=num_heads, qkv_bias=qkv_bias, attn_drop=attn_drop, proj_drop=proj_drop)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
self.mlp = Mlp(in_features=dim, hidden_features=int(dim * mlp_ratio), act_layer=act_layer, drop=proj_drop)
if eta is not None: # LayerScale Initialization (no layerscale when None)
self.gamma1 = nn.Parameter(eta * torch.ones(dim))
self.gamma2 = nn.Parameter(eta * torch.ones(dim))
else:
self.gamma1, self.gamma2 = 1.0, 1.0
# See https://github.com/rwightman/pytorch-image-models/pull/747#issuecomment-877795721
self.tokens_norm = tokens_norm
def forward(self, x):
x_norm1 = self.norm1(x)
x_attn = torch.cat([self.attn(x_norm1), x_norm1[:, 1:]], dim=1)
x = x + self.drop_path(self.gamma1 * x_attn)
if self.tokens_norm:
x = self.norm2(x)
else:
x = torch.cat([self.norm2(x[:, 0:1]), x[:, 1:]], dim=1)
x_res = x
cls_token = x[:, 0:1]
cls_token = self.gamma2 * self.mlp(cls_token)
x = torch.cat([cls_token, x[:, 1:]], dim=1)
x = x_res + self.drop_path(x)
return x
class XCA(nn.Module):
""" Cross-Covariance Attention (XCA)
Operation where the channels are updated using a weighted sum. The weights are obtained from the (softmax
normalized) Cross-covariance matrix (Q^T \\cdot K \\in d_h \\times d_h)
"""
def __init__(self, dim, num_heads=8, qkv_bias=False, attn_drop=0., proj_drop=0.):
super().__init__()
self.num_heads = num_heads
self.temperature = nn.Parameter(torch.ones(num_heads, 1, 1))
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x):
B, N, C = x.shape
# Result of next line is (qkv, B, num (H)eads, (C')hannels per head, N)
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 4, 1)
q, k, v = qkv.unbind(0) # make torchscript happy (cannot use tensor as tuple)
# Paper section 3.2 l2-Normalization and temperature scaling
q = torch.nn.functional.normalize(q, dim=-1)
k = torch.nn.functional.normalize(k, dim=-1)
attn = (q @ k.transpose(-2, -1)) * self.temperature
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
# (B, H, C', N), permute -> (B, N, H, C')
x = (attn @ v).permute(0, 3, 1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
@torch.jit.ignore
def no_weight_decay(self):
return {'temperature'}
class XCABlock(nn.Module):
def __init__(
self,
dim,
num_heads,
mlp_ratio=4.,
qkv_bias=False,
proj_drop=0.,
attn_drop=0.,
drop_path=0.,
act_layer=nn.GELU,
norm_layer=nn.LayerNorm,
eta=1.,
):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = XCA(dim, num_heads=num_heads, qkv_bias=qkv_bias, attn_drop=attn_drop, proj_drop=proj_drop)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm3 = norm_layer(dim)
self.local_mp = LPI(in_features=dim, act_layer=act_layer)
self.norm2 = norm_layer(dim)
self.mlp = Mlp(in_features=dim, hidden_features=int(dim * mlp_ratio), act_layer=act_layer, drop=proj_drop)
self.gamma1 = nn.Parameter(eta * torch.ones(dim))
self.gamma3 = nn.Parameter(eta * torch.ones(dim))
self.gamma2 = nn.Parameter(eta * torch.ones(dim))
def forward(self, x, H: int, W: int):
x = x + self.drop_path(self.gamma1 * self.attn(self.norm1(x)))
# NOTE official code has 3 then 2, so keeping it the same to be consistent with loaded weights
# See https://github.com/rwightman/pytorch-image-models/pull/747#issuecomment-877795721
x = x + self.drop_path(self.gamma3 * self.local_mp(self.norm3(x), H, W))
x = x + self.drop_path(self.gamma2 * self.mlp(self.norm2(x)))
return x
class Xcit(nn.Module):
"""
Based on timm and DeiT code bases
https://github.com/rwightman/pytorch-image-models/tree/master/timm
https://github.com/facebookresearch/deit/
"""
def __init__(
self,
img_size=224,
patch_size=16,
in_chans=3,
num_classes=1000,
global_pool='token',
embed_dim=768,
depth=12,
num_heads=12,
mlp_ratio=4.,
qkv_bias=True,
drop_rate=0.,
pos_drop_rate=0.,
proj_drop_rate=0.,
attn_drop_rate=0.,
drop_path_rate=0.,
act_layer=None,
norm_layer=None,
cls_attn_layers=2,
use_pos_embed=True,
eta=1.,
tokens_norm=False,
):
"""
Args:
img_size (int, tuple): input image size
patch_size (int): patch size
in_chans (int): number of input channels
num_classes (int): number of classes for classification head
embed_dim (int): embedding dimension
depth (int): depth of transformer
num_heads (int): number of attention heads
mlp_ratio (int): ratio of mlp hidden dim to embedding dim
qkv_bias (bool): enable bias for qkv if True
drop_rate (float): dropout rate after positional embedding, and in XCA/CA projection + MLP
pos_drop_rate: position embedding dropout rate
proj_drop_rate (float): projection dropout rate
attn_drop_rate (float): attention dropout rate
drop_path_rate (float): stochastic depth rate (constant across all layers)
norm_layer: (nn.Module): normalization layer
cls_attn_layers: (int) Depth of Class attention layers
use_pos_embed: (bool) whether to use positional encoding
eta: (float) layerscale initialization value
tokens_norm: (bool) Whether to normalize all tokens or just the cls_token in the CA
Notes:
- Although `layer_norm` is user specifiable, there are hard-coded `BatchNorm2d`s in the local patch
interaction (class LPI) and the patch embedding (class ConvPatchEmbed)
"""
super().__init__()
assert global_pool in ('', 'avg', 'token')
img_size = to_2tuple(img_size)
assert (img_size[0] % patch_size == 0) and (img_size[0] % patch_size == 0), \
'`patch_size` should divide image dimensions evenly'
norm_layer = norm_layer or partial(nn.LayerNorm, eps=1e-6)
act_layer = act_layer or nn.GELU
self.num_classes = num_classes
self.num_features = self.embed_dim = embed_dim
self.global_pool = global_pool
self.grad_checkpointing = False
self.patch_embed = ConvPatchEmbed(
img_size=img_size,
patch_size=patch_size,
in_chans=in_chans,
embed_dim=embed_dim,
act_layer=act_layer,
)
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
if use_pos_embed:
self.pos_embed = PositionalEncodingFourier(dim=embed_dim)
else:
self.pos_embed = None
self.pos_drop = nn.Dropout(p=pos_drop_rate)
self.blocks = nn.ModuleList([
XCABlock(
dim=embed_dim,
num_heads=num_heads,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias,
proj_drop=proj_drop_rate,
attn_drop=attn_drop_rate,
drop_path=drop_path_rate,
act_layer=act_layer,
norm_layer=norm_layer,
eta=eta,
)
for _ in range(depth)])
self.cls_attn_blocks = nn.ModuleList([
ClassAttentionBlock(
dim=embed_dim,
num_heads=num_heads,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias,
proj_drop=drop_rate,
attn_drop=attn_drop_rate,
act_layer=act_layer,
norm_layer=norm_layer,
eta=eta,
tokens_norm=tokens_norm,
)
for _ in range(cls_attn_layers)])
# Classifier head
self.norm = norm_layer(embed_dim)
self.head_drop = nn.Dropout(drop_rate)
self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()
# Init weights
trunc_normal_(self.cls_token, std=.02)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
@torch.jit.ignore
def no_weight_decay(self):
return {'pos_embed', 'cls_token'}
@torch.jit.ignore
def group_matcher(self, coarse=False):
return dict(
stem=r'^cls_token|pos_embed|patch_embed', # stem and embed
blocks=r'^blocks\.(\d+)',
cls_attn_blocks=[(r'^cls_attn_blocks\.(\d+)', None), (r'^norm', (99999,))]
)
@torch.jit.ignore
def set_grad_checkpointing(self, enable=True):
self.grad_checkpointing = enable
@torch.jit.ignore
def get_classifier(self):
return self.head
def reset_classifier(self, num_classes, global_pool=''):
self.num_classes = num_classes
if global_pool is not None:
assert global_pool in ('', 'avg', 'token')
self.global_pool = global_pool
self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()
def forward_features(self, x):
B = x.shape[0]
# x is (B, N, C). (Hp, Hw) is (height in units of patches, width in units of patches)
x, (Hp, Wp) = self.patch_embed(x)
if self.pos_embed is not None:
# `pos_embed` (B, C, Hp, Wp), reshape -> (B, C, N), permute -> (B, N, C)
pos_encoding = self.pos_embed(B, Hp, Wp).reshape(B, -1, x.shape[1]).permute(0, 2, 1)
x = x + pos_encoding
x = self.pos_drop(x)
for blk in self.blocks:
if self.grad_checkpointing and not torch.jit.is_scripting():
x = checkpoint(blk, x, Hp, Wp)
else:
x = blk(x, Hp, Wp)
x = torch.cat((self.cls_token.expand(B, -1, -1), x), dim=1)
for blk in self.cls_attn_blocks:
if self.grad_checkpointing and not torch.jit.is_scripting():
x = checkpoint(blk, x)
else:
x = blk(x)
x = self.norm(x)
return x
def forward_head(self, x, pre_logits: bool = False):
if self.global_pool:
x = x[:, 1:].mean(dim=1) if self.global_pool == 'avg' else x[:, 0]
x = self.head_drop(x)
return x if pre_logits else self.head(x)
def forward(self, x):
x = self.forward_features(x)
x = self.forward_head(x)
return x
def checkpoint_filter_fn(state_dict, model):
if 'model' in state_dict:
state_dict = state_dict['model']
# For consistency with timm's transformer models while being compatible with official weights source we rename
# pos_embeder to pos_embed. Also account for use_pos_embed == False
use_pos_embed = getattr(model, 'pos_embed', None) is not None
pos_embed_keys = [k for k in state_dict if k.startswith('pos_embed')]
for k in pos_embed_keys:
if use_pos_embed:
state_dict[k.replace('pos_embeder.', 'pos_embed.')] = state_dict.pop(k)
else:
del state_dict[k]
# timm's implementation of class attention in CaiT is slightly more efficient as it does not compute query vectors
# for all tokens, just the class token. To use official weights source we must split qkv into q, k, v
if 'cls_attn_blocks.0.attn.qkv.weight' in state_dict and 'cls_attn_blocks.0.attn.q.weight' in model.state_dict():
num_ca_blocks = len(model.cls_attn_blocks)
for i in range(num_ca_blocks):
qkv_weight = state_dict.pop(f'cls_attn_blocks.{i}.attn.qkv.weight')
qkv_weight = qkv_weight.reshape(3, -1, qkv_weight.shape[-1])
for j, subscript in enumerate('qkv'):
state_dict[f'cls_attn_blocks.{i}.attn.{subscript}.weight'] = qkv_weight[j]
qkv_bias = state_dict.pop(f'cls_attn_blocks.{i}.attn.qkv.bias', None)
if qkv_bias is not None:
qkv_bias = qkv_bias.reshape(3, -1)
for j, subscript in enumerate('qkv'):
state_dict[f'cls_attn_blocks.{i}.attn.{subscript}.bias'] = qkv_bias[j]
return state_dict
def _create_xcit(variant, pretrained=False, default_cfg=None, **kwargs):
if kwargs.get('features_only', None):
raise RuntimeError('features_only not implemented for Cross-Covariance Image Transformers models.')
model = build_model_with_cfg(
Xcit,
variant,
pretrained,
pretrained_filter_fn=checkpoint_filter_fn,
**kwargs,
)
return model
def _cfg(url='', **kwargs):
return {
'url': url,
'num_classes': 1000, 'input_size': (3, 224, 224), 'pool_size': None,
'crop_pct': 1.0, 'interpolation': 'bicubic', 'fixed_input_size': True,
'mean': IMAGENET_DEFAULT_MEAN, 'std': IMAGENET_DEFAULT_STD,
'first_conv': 'patch_embed.proj.0.0', 'classifier': 'head',
**kwargs
}
default_cfgs = generate_default_cfgs({
# Patch size 16
'xcit_nano_12_p16_224.fb_in1k': _cfg(
hf_hub_id='timm/',
url='https://dl.fbaipublicfiles.com/xcit/xcit_nano_12_p16_224.pth'),
'xcit_nano_12_p16_224.fb_dist_in1k': _cfg(
hf_hub_id='timm/',
url='https://dl.fbaipublicfiles.com/xcit/xcit_nano_12_p16_224_dist.pth'),
'xcit_nano_12_p16_384.fb_dist_in1k': _cfg(
hf_hub_id='timm/',
url='https://dl.fbaipublicfiles.com/xcit/xcit_nano_12_p16_384_dist.pth', input_size=(3, 384, 384)),
'xcit_tiny_12_p16_224.fb_in1k': _cfg(
hf_hub_id='timm/',
url='https://dl.fbaipublicfiles.com/xcit/xcit_tiny_12_p16_224.pth'),
'xcit_tiny_12_p16_224.fb_dist_in1k': _cfg(
hf_hub_id='timm/',
url='https://dl.fbaipublicfiles.com/xcit/xcit_tiny_12_p16_224_dist.pth'),
'xcit_tiny_12_p16_384.fb_dist_in1k': _cfg(
hf_hub_id='timm/',
url='https://dl.fbaipublicfiles.com/xcit/xcit_tiny_12_p16_384_dist.pth', input_size=(3, 384, 384)),
'xcit_tiny_24_p16_224.fb_in1k': _cfg(
hf_hub_id='timm/',
url='https://dl.fbaipublicfiles.com/xcit/xcit_tiny_24_p16_224.pth'),
'xcit_tiny_24_p16_224.fb_dist_in1k': _cfg(
hf_hub_id='timm/',
url='https://dl.fbaipublicfiles.com/xcit/xcit_tiny_24_p16_224_dist.pth'),
'xcit_tiny_24_p16_384.fb_dist_in1k': _cfg(
hf_hub_id='timm/',
url='https://dl.fbaipublicfiles.com/xcit/xcit_tiny_24_p16_384_dist.pth', input_size=(3, 384, 384)),
'xcit_small_12_p16_224.fb_in1k': _cfg(
hf_hub_id='timm/',
url='https://dl.fbaipublicfiles.com/xcit/xcit_small_12_p16_224.pth'),
'xcit_small_12_p16_224.fb_dist_in1k': _cfg(
hf_hub_id='timm/',
url='https://dl.fbaipublicfiles.com/xcit/xcit_small_12_p16_224_dist.pth'),
'xcit_small_12_p16_384.fb_dist_in1k': _cfg(
hf_hub_id='timm/',
url='https://dl.fbaipublicfiles.com/xcit/xcit_small_12_p16_384_dist.pth', input_size=(3, 384, 384)),
'xcit_small_24_p16_224.fb_in1k': _cfg(
hf_hub_id='timm/',
url='https://dl.fbaipublicfiles.com/xcit/xcit_small_24_p16_224.pth'),
'xcit_small_24_p16_224.fb_dist_in1k': _cfg(
hf_hub_id='timm/',
url='https://dl.fbaipublicfiles.com/xcit/xcit_small_24_p16_224_dist.pth'),
'xcit_small_24_p16_384.fb_dist_in1k': _cfg(
hf_hub_id='timm/',
url='https://dl.fbaipublicfiles.com/xcit/xcit_small_24_p16_384_dist.pth', input_size=(3, 384, 384)),
'xcit_medium_24_p16_224.fb_in1k': _cfg(
hf_hub_id='timm/',
url='https://dl.fbaipublicfiles.com/xcit/xcit_medium_24_p16_224.pth'),
'xcit_medium_24_p16_224.fb_dist_in1k': _cfg(
hf_hub_id='timm/',
url='https://dl.fbaipublicfiles.com/xcit/xcit_medium_24_p16_224_dist.pth'),
'xcit_medium_24_p16_384.fb_dist_in1k': _cfg(
hf_hub_id='timm/',
url='https://dl.fbaipublicfiles.com/xcit/xcit_medium_24_p16_384_dist.pth', input_size=(3, 384, 384)),
'xcit_large_24_p16_224.fb_in1k': _cfg(
hf_hub_id='timm/',
url='https://dl.fbaipublicfiles.com/xcit/xcit_large_24_p16_224.pth'),
'xcit_large_24_p16_224.fb_dist_in1k': _cfg(
hf_hub_id='timm/',
url='https://dl.fbaipublicfiles.com/xcit/xcit_large_24_p16_224_dist.pth'),
'xcit_large_24_p16_384.fb_dist_in1k': _cfg(
hf_hub_id='timm/',
url='https://dl.fbaipublicfiles.com/xcit/xcit_large_24_p16_384_dist.pth', input_size=(3, 384, 384)),
# Patch size 8
'xcit_nano_12_p8_224.fb_in1k': _cfg(
hf_hub_id='timm/',
url='https://dl.fbaipublicfiles.com/xcit/xcit_nano_12_p8_224.pth'),
'xcit_nano_12_p8_224.fb_dist_in1k': _cfg(
hf_hub_id='timm/',
url='https://dl.fbaipublicfiles.com/xcit/xcit_nano_12_p8_224_dist.pth'),
'xcit_nano_12_p8_384.fb_dist_in1k': _cfg(
hf_hub_id='timm/',
url='https://dl.fbaipublicfiles.com/xcit/xcit_nano_12_p8_384_dist.pth', input_size=(3, 384, 384)),
'xcit_tiny_12_p8_224.fb_in1k': _cfg(
hf_hub_id='timm/',
url='https://dl.fbaipublicfiles.com/xcit/xcit_tiny_12_p8_224.pth'),
'xcit_tiny_12_p8_224.fb_dist_in1k': _cfg(
hf_hub_id='timm/',
url='https://dl.fbaipublicfiles.com/xcit/xcit_tiny_12_p8_224_dist.pth'),
'xcit_tiny_12_p8_384.fb_dist_in1k': _cfg(
hf_hub_id='timm/',
url='https://dl.fbaipublicfiles.com/xcit/xcit_tiny_12_p8_384_dist.pth', input_size=(3, 384, 384)),
'xcit_tiny_24_p8_224.fb_in1k': _cfg(
hf_hub_id='timm/',
url='https://dl.fbaipublicfiles.com/xcit/xcit_tiny_24_p8_224.pth'),
'xcit_tiny_24_p8_224.fb_dist_in1k': _cfg(
hf_hub_id='timm/',
url='https://dl.fbaipublicfiles.com/xcit/xcit_tiny_24_p8_224_dist.pth'),
'xcit_tiny_24_p8_384.fb_dist_in1k': _cfg(
hf_hub_id='timm/',
url='https://dl.fbaipublicfiles.com/xcit/xcit_tiny_24_p8_384_dist.pth', input_size=(3, 384, 384)),
'xcit_small_12_p8_224.fb_in1k': _cfg(
hf_hub_id='timm/',
url='https://dl.fbaipublicfiles.com/xcit/xcit_small_12_p8_224.pth'),
'xcit_small_12_p8_224.fb_dist_in1k': _cfg(
hf_hub_id='timm/',
url='https://dl.fbaipublicfiles.com/xcit/xcit_small_12_p8_224_dist.pth'),
'xcit_small_12_p8_384.fb_dist_in1k': _cfg(
hf_hub_id='timm/',
url='https://dl.fbaipublicfiles.com/xcit/xcit_small_12_p8_384_dist.pth', input_size=(3, 384, 384)),
'xcit_small_24_p8_224.fb_in1k': _cfg(
hf_hub_id='timm/',
url='https://dl.fbaipublicfiles.com/xcit/xcit_small_24_p8_224.pth'),
'xcit_small_24_p8_224.fb_dist_in1k': _cfg(
hf_hub_id='timm/',
url='https://dl.fbaipublicfiles.com/xcit/xcit_small_24_p8_224_dist.pth'),
'xcit_small_24_p8_384.fb_dist_in1k': _cfg(
hf_hub_id='timm/',
url='https://dl.fbaipublicfiles.com/xcit/xcit_small_24_p8_384_dist.pth', input_size=(3, 384, 384)),
'xcit_medium_24_p8_224.fb_in1k': _cfg(
hf_hub_id='timm/',
url='https://dl.fbaipublicfiles.com/xcit/xcit_medium_24_p8_224.pth'),
'xcit_medium_24_p8_224.fb_dist_in1k': _cfg(
hf_hub_id='timm/',
url='https://dl.fbaipublicfiles.com/xcit/xcit_medium_24_p8_224_dist.pth'),
'xcit_medium_24_p8_384.fb_dist_in1k': _cfg(
hf_hub_id='timm/',
url='https://dl.fbaipublicfiles.com/xcit/xcit_medium_24_p8_384_dist.pth', input_size=(3, 384, 384)),
'xcit_large_24_p8_224.fb_in1k': _cfg(
hf_hub_id='timm/',
url='https://dl.fbaipublicfiles.com/xcit/xcit_large_24_p8_224.pth'),
'xcit_large_24_p8_224.fb_dist_in1k': _cfg(
hf_hub_id='timm/',
url='https://dl.fbaipublicfiles.com/xcit/xcit_large_24_p8_224_dist.pth'),
'xcit_large_24_p8_384.fb_dist_in1k': _cfg(
hf_hub_id='timm/',
url='https://dl.fbaipublicfiles.com/xcit/xcit_large_24_p8_384_dist.pth', input_size=(3, 384, 384)),
})
@register_model
def xcit_nano_12_p16_224(pretrained=False, **kwargs) -> Xcit:
model_args = dict(
patch_size=16, embed_dim=128, depth=12, num_heads=4, eta=1.0, tokens_norm=False)
model = _create_xcit('xcit_nano_12_p16_224', pretrained=pretrained, **dict(model_args, **kwargs))
return model
@register_model
def xcit_nano_12_p16_384(pretrained=False, **kwargs) -> Xcit:
model_args = dict(
patch_size=16, embed_dim=128, depth=12, num_heads=4, eta=1.0, tokens_norm=False, img_size=384)
model = _create_xcit('xcit_nano_12_p16_384', pretrained=pretrained, **dict(model_args, **kwargs))
return model
@register_model
def xcit_tiny_12_p16_224(pretrained=False, **kwargs) -> Xcit:
model_args = dict(
patch_size=16, embed_dim=192, depth=12, num_heads=4, eta=1.0, tokens_norm=True)
model = _create_xcit('xcit_tiny_12_p16_224', pretrained=pretrained, **dict(model_args, **kwargs))
return model
@register_model
def xcit_tiny_12_p16_384(pretrained=False, **kwargs) -> Xcit:
model_args = dict(
patch_size=16, embed_dim=192, depth=12, num_heads=4, eta=1.0, tokens_norm=True)
model = _create_xcit('xcit_tiny_12_p16_384', pretrained=pretrained, **dict(model_args, **kwargs))
return model
@register_model
def xcit_small_12_p16_224(pretrained=False, **kwargs) -> Xcit:
model_args = dict(
patch_size=16, embed_dim=384, depth=12, num_heads=8, eta=1.0, tokens_norm=True)
model = _create_xcit('xcit_small_12_p16_224', pretrained=pretrained, **dict(model_args, **kwargs))
return model
@register_model
def xcit_small_12_p16_384(pretrained=False, **kwargs) -> Xcit:
model_args = dict(
patch_size=16, embed_dim=384, depth=12, num_heads=8, eta=1.0, tokens_norm=True)
model = _create_xcit('xcit_small_12_p16_384', pretrained=pretrained, **dict(model_args, **kwargs))
return model
@register_model
def xcit_tiny_24_p16_224(pretrained=False, **kwargs) -> Xcit:
model_args = dict(
patch_size=16, embed_dim=192, depth=24, num_heads=4, eta=1e-5, tokens_norm=True)
model = _create_xcit('xcit_tiny_24_p16_224', pretrained=pretrained, **dict(model_args, **kwargs))
return model
@register_model
def xcit_tiny_24_p16_384(pretrained=False, **kwargs) -> Xcit:
model_args = dict(
patch_size=16, embed_dim=192, depth=24, num_heads=4, eta=1e-5, tokens_norm=True)
model = _create_xcit('xcit_tiny_24_p16_384', pretrained=pretrained, **dict(model_args, **kwargs))
return model
@register_model
def xcit_small_24_p16_224(pretrained=False, **kwargs) -> Xcit:
model_args = dict(
patch_size=16, embed_dim=384, depth=24, num_heads=8, eta=1e-5, tokens_norm=True)
model = _create_xcit('xcit_small_24_p16_224', pretrained=pretrained, **dict(model_args, **kwargs))
return model
@register_model
def xcit_small_24_p16_384(pretrained=False, **kwargs) -> Xcit:
model_args = dict(
patch_size=16, embed_dim=384, depth=24, num_heads=8, eta=1e-5, tokens_norm=True)
model = _create_xcit('xcit_small_24_p16_384', pretrained=pretrained, **dict(model_args, **kwargs))
return model
@register_model
def xcit_medium_24_p16_224(pretrained=False, **kwargs) -> Xcit:
model_args = dict(
patch_size=16, embed_dim=512, depth=24, num_heads=8, eta=1e-5, tokens_norm=True)
model = _create_xcit('xcit_medium_24_p16_224', pretrained=pretrained, **dict(model_args, **kwargs))
return model
@register_model
def xcit_medium_24_p16_384(pretrained=False, **kwargs) -> Xcit:
model_args = dict(
patch_size=16, embed_dim=512, depth=24, num_heads=8, eta=1e-5, tokens_norm=True)
model = _create_xcit('xcit_medium_24_p16_384', pretrained=pretrained, **dict(model_args, **kwargs))
return model
@register_model
def xcit_large_24_p16_224(pretrained=False, **kwargs) -> Xcit:
model_args = dict(
patch_size=16, embed_dim=768, depth=24, num_heads=16, eta=1e-5, tokens_norm=True)
model = _create_xcit('xcit_large_24_p16_224', pretrained=pretrained, **dict(model_args, **kwargs))
return model
@register_model
def xcit_large_24_p16_384(pretrained=False, **kwargs) -> Xcit:
model_args = dict(
patch_size=16, embed_dim=768, depth=24, num_heads=16, eta=1e-5, tokens_norm=True)
model = _create_xcit('xcit_large_24_p16_384', pretrained=pretrained, **dict(model_args, **kwargs))
return model
# Patch size 8x8 models
@register_model
def xcit_nano_12_p8_224(pretrained=False, **kwargs) -> Xcit:
model_args = dict(
patch_size=8, embed_dim=128, depth=12, num_heads=4, eta=1.0, tokens_norm=False)
model = _create_xcit('xcit_nano_12_p8_224', pretrained=pretrained, **dict(model_args, **kwargs))
return model
@register_model
def xcit_nano_12_p8_384(pretrained=False, **kwargs) -> Xcit:
model_args = dict(
patch_size=8, embed_dim=128, depth=12, num_heads=4, eta=1.0, tokens_norm=False)
model = _create_xcit('xcit_nano_12_p8_384', pretrained=pretrained, **dict(model_args, **kwargs))
return model
@register_model
def xcit_tiny_12_p8_224(pretrained=False, **kwargs) -> Xcit:
model_args = dict(
patch_size=8, embed_dim=192, depth=12, num_heads=4, eta=1.0, tokens_norm=True)
model = _create_xcit('xcit_tiny_12_p8_224', pretrained=pretrained, **dict(model_args, **kwargs))
return model
@register_model
def xcit_tiny_12_p8_384(pretrained=False, **kwargs) -> Xcit:
model_args = dict(
patch_size=8, embed_dim=192, depth=12, num_heads=4, eta=1.0, tokens_norm=True)
model = _create_xcit('xcit_tiny_12_p8_384', pretrained=pretrained, **dict(model_args, **kwargs))
return model
@register_model
def xcit_small_12_p8_224(pretrained=False, **kwargs) -> Xcit:
model_args = dict(
patch_size=8, embed_dim=384, depth=12, num_heads=8, eta=1.0, tokens_norm=True)
model = _create_xcit('xcit_small_12_p8_224', pretrained=pretrained, **dict(model_args, **kwargs))
return model
@register_model
def xcit_small_12_p8_384(pretrained=False, **kwargs) -> Xcit:
model_args = dict(
patch_size=8, embed_dim=384, depth=12, num_heads=8, eta=1.0, tokens_norm=True)
model = _create_xcit('xcit_small_12_p8_384', pretrained=pretrained, **dict(model_args, **kwargs))
return model
@register_model
def xcit_tiny_24_p8_224(pretrained=False, **kwargs) -> Xcit:
model_args = dict(
patch_size=8, embed_dim=192, depth=24, num_heads=4, eta=1e-5, tokens_norm=True)
model = _create_xcit('xcit_tiny_24_p8_224', pretrained=pretrained, **dict(model_args, **kwargs))
return model
@register_model
def xcit_tiny_24_p8_384(pretrained=False, **kwargs) -> Xcit:
model_args = dict(
patch_size=8, embed_dim=192, depth=24, num_heads=4, eta=1e-5, tokens_norm=True)
model = _create_xcit('xcit_tiny_24_p8_384', pretrained=pretrained, **dict(model_args, **kwargs))
return model
@register_model
def xcit_small_24_p8_224(pretrained=False, **kwargs) -> Xcit:
model_args = dict(
patch_size=8, embed_dim=384, depth=24, num_heads=8, eta=1e-5, tokens_norm=True)
model = _create_xcit('xcit_small_24_p8_224', pretrained=pretrained, **dict(model_args, **kwargs))
return model
@register_model
def xcit_small_24_p8_384(pretrained=False, **kwargs) -> Xcit:
model_args = dict(
patch_size=8, embed_dim=384, depth=24, num_heads=8, eta=1e-5, tokens_norm=True)
model = _create_xcit('xcit_small_24_p8_384', pretrained=pretrained, **dict(model_args, **kwargs))
return model
@register_model
def xcit_medium_24_p8_224(pretrained=False, **kwargs) -> Xcit:
model_args = dict(
patch_size=8, embed_dim=512, depth=24, num_heads=8, eta=1e-5, tokens_norm=True)
model = _create_xcit('xcit_medium_24_p8_224', pretrained=pretrained, **dict(model_args, **kwargs))
return model
@register_model
def xcit_medium_24_p8_384(pretrained=False, **kwargs) -> Xcit:
model_args = dict(
patch_size=8, embed_dim=512, depth=24, num_heads=8, eta=1e-5, tokens_norm=True)
model = _create_xcit('xcit_medium_24_p8_384', pretrained=pretrained, **dict(model_args, **kwargs))
return model
@register_model
def xcit_large_24_p8_224(pretrained=False, **kwargs) -> Xcit:
model_args = dict(
patch_size=8, embed_dim=768, depth=24, num_heads=16, eta=1e-5, tokens_norm=True)
model = _create_xcit('xcit_large_24_p8_224', pretrained=pretrained, **dict(model_args, **kwargs))
return model
@register_model
def xcit_large_24_p8_384(pretrained=False, **kwargs) -> Xcit:
model_args = dict(
patch_size=8, embed_dim=768, depth=24, num_heads=16, eta=1e-5, tokens_norm=True)
model = _create_xcit('xcit_large_24_p8_384', pretrained=pretrained, **dict(model_args, **kwargs))
return model
register_model_deprecations(__name__, {
# Patch size 16
'xcit_nano_12_p16_224_dist': 'xcit_nano_12_p16_224.fb_dist_in1k',
'xcit_nano_12_p16_384_dist': 'xcit_nano_12_p16_384.fb_dist_in1k',
'xcit_tiny_12_p16_224_dist': 'xcit_tiny_12_p16_224.fb_dist_in1k',
'xcit_tiny_12_p16_384_dist': 'xcit_tiny_12_p16_384.fb_dist_in1k',
'xcit_tiny_24_p16_224_dist': 'xcit_tiny_24_p16_224.fb_dist_in1k',
'xcit_tiny_24_p16_384_dist': 'xcit_tiny_24_p16_384.fb_dist_in1k',
'xcit_small_12_p16_224_dist': 'xcit_small_12_p16_224.fb_dist_in1k',
'xcit_small_12_p16_384_dist': 'xcit_small_12_p16_384.fb_dist_in1k',
'xcit_small_24_p16_224_dist': 'xcit_small_24_p16_224.fb_dist_in1k',
'xcit_small_24_p16_384_dist': 'xcit_small_24_p16_384.fb_dist_in1k',
'xcit_medium_24_p16_224_dist': 'xcit_medium_24_p16_224.fb_dist_in1k',
'xcit_medium_24_p16_384_dist': 'xcit_medium_24_p16_384.fb_dist_in1k',
'xcit_large_24_p16_224_dist': 'xcit_large_24_p16_224.fb_dist_in1k',
'xcit_large_24_p16_384_dist': 'xcit_large_24_p16_384.fb_dist_in1k',
# Patch size 8
'xcit_nano_12_p8_224_dist': 'xcit_nano_12_p8_224.fb_dist_in1k',
'xcit_nano_12_p8_384_dist': 'xcit_nano_12_p8_384.fb_dist_in1k',
'xcit_tiny_12_p8_224_dist': 'xcit_tiny_12_p8_224.fb_dist_in1k',
'xcit_tiny_12_p8_384_dist': 'xcit_tiny_12_p8_384.fb_dist_in1k',
'xcit_tiny_24_p8_224_dist': 'xcit_tiny_24_p8_224.fb_dist_in1k',
'xcit_tiny_24_p8_384_dist': 'xcit_tiny_24_p8_384.fb_dist_in1k',
'xcit_small_12_p8_224_dist': 'xcit_small_12_p8_224.fb_dist_in1k',
'xcit_small_12_p8_384_dist': 'xcit_small_12_p8_384.fb_dist_in1k',
'xcit_small_24_p8_224_dist': 'xcit_small_24_p8_224.fb_dist_in1k',
'xcit_small_24_p8_384_dist': 'xcit_small_24_p8_384.fb_dist_in1k',
'xcit_medium_24_p8_224_dist': 'xcit_medium_24_p8_224.fb_dist_in1k',
'xcit_medium_24_p8_384_dist': 'xcit_medium_24_p8_384.fb_dist_in1k',
'xcit_large_24_p8_224_dist': 'xcit_large_24_p8_224.fb_dist_in1k',
'xcit_large_24_p8_384_dist': 'xcit_large_24_p8_384.fb_dist_in1k',
})
| pytorch-image-models/timm/models/xcit.py/0 | {
"file_path": "pytorch-image-models/timm/models/xcit.py",
"repo_id": "pytorch-image-models",
"token_count": 18692
} | 190 |
""" Optimizer Factory w/ Custom Weight Decay
Hacked together by / Copyright 2021 Ross Wightman
"""
import logging
from itertools import islice
from typing import Optional, Callable, Tuple
import torch
import torch.nn as nn
import torch.optim as optim
from timm.models import group_parameters
from .adabelief import AdaBelief
from .adafactor import Adafactor
from .adahessian import Adahessian
from .adamp import AdamP
from .adan import Adan
from .lamb import Lamb
from .lars import Lars
from .lion import Lion
from .lookahead import Lookahead
from .madgrad import MADGRAD
from .nadam import Nadam
from .nadamw import NAdamW
from .nvnovograd import NvNovoGrad
from .radam import RAdam
from .rmsprop_tf import RMSpropTF
from .sgdp import SGDP
from .sgdw import SGDW
_logger = logging.getLogger(__name__)
# optimizers to default to multi-tensor
_DEFAULT_FOREACH = {
'lion',
}
def param_groups_weight_decay(
model: nn.Module,
weight_decay=1e-5,
no_weight_decay_list=()
):
no_weight_decay_list = set(no_weight_decay_list)
decay = []
no_decay = []
for name, param in model.named_parameters():
if not param.requires_grad:
continue
if param.ndim <= 1 or name.endswith(".bias") or name in no_weight_decay_list:
no_decay.append(param)
else:
decay.append(param)
return [
{'params': no_decay, 'weight_decay': 0.},
{'params': decay, 'weight_decay': weight_decay}]
def _group(it, size):
it = iter(it)
return iter(lambda: tuple(islice(it, size)), ())
def _layer_map(model, layers_per_group=12, num_groups=None):
def _in_head(n, hp):
if not hp:
return True
elif isinstance(hp, (tuple, list)):
return any([n.startswith(hpi) for hpi in hp])
else:
return n.startswith(hp)
head_prefix = getattr(model, 'pretrained_cfg', {}).get('classifier', None)
names_trunk = []
names_head = []
for n, _ in model.named_parameters():
names_head.append(n) if _in_head(n, head_prefix) else names_trunk.append(n)
# group non-head layers
num_trunk_layers = len(names_trunk)
if num_groups is not None:
layers_per_group = -(num_trunk_layers // -num_groups)
names_trunk = list(_group(names_trunk, layers_per_group))
num_trunk_groups = len(names_trunk)
layer_map = {n: i for i, l in enumerate(names_trunk) for n in l}
layer_map.update({n: num_trunk_groups for n in names_head})
return layer_map
def param_groups_layer_decay(
model: nn.Module,
weight_decay: float = 0.05,
no_weight_decay_list: Tuple[str] = (),
layer_decay: float = .75,
end_layer_decay: Optional[float] = None,
verbose: bool = False,
):
"""
Parameter groups for layer-wise lr decay & weight decay
Based on BEiT: https://github.com/microsoft/unilm/blob/master/beit/optim_factory.py#L58
"""
no_weight_decay_list = set(no_weight_decay_list)
param_group_names = {} # NOTE for debugging
param_groups = {}
if hasattr(model, 'group_matcher'):
# FIXME interface needs more work
layer_map = group_parameters(model, model.group_matcher(coarse=False), reverse=True)
else:
# fallback
layer_map = _layer_map(model)
num_layers = max(layer_map.values()) + 1
layer_max = num_layers - 1
layer_scales = list(layer_decay ** (layer_max - i) for i in range(num_layers))
for name, param in model.named_parameters():
if not param.requires_grad:
continue
# no decay: all 1D parameters and model specific ones
if param.ndim == 1 or name in no_weight_decay_list:
g_decay = "no_decay"
this_decay = 0.
else:
g_decay = "decay"
this_decay = weight_decay
layer_id = layer_map.get(name, layer_max)
group_name = "layer_%d_%s" % (layer_id, g_decay)
if group_name not in param_groups:
this_scale = layer_scales[layer_id]
param_group_names[group_name] = {
"lr_scale": this_scale,
"weight_decay": this_decay,
"param_names": [],
}
param_groups[group_name] = {
"lr_scale": this_scale,
"weight_decay": this_decay,
"params": [],
}
param_group_names[group_name]["param_names"].append(name)
param_groups[group_name]["params"].append(param)
if verbose:
import json
_logger.info("parameter groups: \n%s" % json.dumps(param_group_names, indent=2))
return list(param_groups.values())
def optimizer_kwargs(cfg):
""" cfg/argparse to kwargs helper
Convert optimizer args in argparse args or cfg like object to keyword args for updated create fn.
"""
kwargs = dict(
opt=cfg.opt,
lr=cfg.lr,
weight_decay=cfg.weight_decay,
momentum=cfg.momentum,
)
if getattr(cfg, 'opt_eps', None) is not None:
kwargs['eps'] = cfg.opt_eps
if getattr(cfg, 'opt_betas', None) is not None:
kwargs['betas'] = cfg.opt_betas
if getattr(cfg, 'layer_decay', None) is not None:
kwargs['layer_decay'] = cfg.layer_decay
if getattr(cfg, 'opt_args', None) is not None:
kwargs.update(cfg.opt_args)
if getattr(cfg, 'opt_foreach', None) is not None:
kwargs['foreach'] = cfg.opt_foreach
return kwargs
def create_optimizer(args, model, filter_bias_and_bn=True):
""" Legacy optimizer factory for backwards compatibility.
NOTE: Use create_optimizer_v2 for new code.
"""
return create_optimizer_v2(
model,
**optimizer_kwargs(cfg=args),
filter_bias_and_bn=filter_bias_and_bn,
)
def create_optimizer_v2(
model_or_params,
opt: str = 'sgd',
lr: Optional[float] = None,
weight_decay: float = 0.,
momentum: float = 0.9,
foreach: Optional[bool] = None,
filter_bias_and_bn: bool = True,
layer_decay: Optional[float] = None,
param_group_fn: Optional[Callable] = None,
**kwargs,
):
""" Create an optimizer.
TODO currently the model is passed in and all parameters are selected for optimization.
For more general use an interface that allows selection of parameters to optimize and lr groups, one of:
* a filter fn interface that further breaks params into groups in a weight_decay compatible fashion
* expose the parameters interface and leave it up to caller
Args:
model_or_params (nn.Module): model containing parameters to optimize
opt: name of optimizer to create
lr: initial learning rate
weight_decay: weight decay to apply in optimizer
momentum: momentum for momentum based optimizers (others may use betas via kwargs)
foreach: Enable / disable foreach (multi-tensor) operation if True / False. Choose safe default if None
filter_bias_and_bn: filter out bias, bn and other 1d params from weight decay
**kwargs: extra optimizer specific kwargs to pass through
Returns:
Optimizer
"""
if isinstance(model_or_params, nn.Module):
# a model was passed in, extract parameters and add weight decays to appropriate layers
no_weight_decay = {}
if hasattr(model_or_params, 'no_weight_decay'):
no_weight_decay = model_or_params.no_weight_decay()
if param_group_fn:
parameters = param_group_fn(model_or_params)
elif layer_decay is not None:
parameters = param_groups_layer_decay(
model_or_params,
weight_decay=weight_decay,
layer_decay=layer_decay,
no_weight_decay_list=no_weight_decay,
)
weight_decay = 0.
elif weight_decay and filter_bias_and_bn:
parameters = param_groups_weight_decay(model_or_params, weight_decay, no_weight_decay)
weight_decay = 0.
else:
parameters = model_or_params.parameters()
else:
# iterable of parameters or param groups passed in
parameters = model_or_params
opt_lower = opt.lower()
opt_split = opt_lower.split('_')
opt_lower = opt_split[-1]
if opt_lower.startswith('fused'):
try:
from apex.optimizers import FusedNovoGrad, FusedAdam, FusedLAMB, FusedSGD
has_apex = True
except ImportError:
has_apex = False
assert has_apex and torch.cuda.is_available(), 'APEX and CUDA required for fused optimizers'
if opt_lower.startswith('bnb'):
try:
import bitsandbytes as bnb
has_bnb = True
except ImportError:
has_bnb = False
assert has_bnb and torch.cuda.is_available(), 'bitsandbytes and CUDA required for bnb optimizers'
opt_args = dict(weight_decay=weight_decay, **kwargs)
if lr is not None:
opt_args.setdefault('lr', lr)
if foreach is None:
if opt in _DEFAULT_FOREACH:
opt_args.setdefault('foreach', True)
else:
opt_args['foreach'] = foreach
# basic SGD & related
if opt_lower == 'sgd' or opt_lower == 'nesterov':
# NOTE 'sgd' refers to SGD + nesterov momentum for legacy / backwards compat reasons
opt_args.pop('eps', None)
optimizer = optim.SGD(parameters, momentum=momentum, nesterov=True, **opt_args)
elif opt_lower == 'momentum':
opt_args.pop('eps', None)
optimizer = optim.SGD(parameters, momentum=momentum, nesterov=False, **opt_args)
elif opt_lower == 'sgdp':
optimizer = SGDP(parameters, momentum=momentum, nesterov=True, **opt_args)
elif opt_lower == 'sgdw' or opt_lower == 'nesterovw':
# NOTE 'sgd' refers to SGD + nesterov momentum for legacy / backwards compat reasons
opt_args.pop('eps', None)
optimizer = SGDW(parameters, momentum=momentum, nesterov=True, **opt_args)
elif opt_lower == 'momentumw':
opt_args.pop('eps', None)
optimizer = SGDW(parameters, momentum=momentum, nesterov=False, **opt_args)
# adaptive
elif opt_lower == 'adam':
optimizer = optim.Adam(parameters, **opt_args)
elif opt_lower == 'adamw':
optimizer = optim.AdamW(parameters, **opt_args)
elif opt_lower == 'adamp':
optimizer = AdamP(parameters, wd_ratio=0.01, nesterov=True, **opt_args)
elif opt_lower == 'nadam':
try:
# NOTE PyTorch >= 1.10 should have native NAdam
optimizer = optim.Nadam(parameters, **opt_args)
except AttributeError:
optimizer = Nadam(parameters, **opt_args)
elif opt_lower == 'nadamw':
optimizer = NAdamW(parameters, **opt_args)
elif opt_lower == 'radam':
optimizer = RAdam(parameters, **opt_args)
elif opt_lower == 'adamax':
optimizer = optim.Adamax(parameters, **opt_args)
elif opt_lower == 'adabelief':
optimizer = AdaBelief(parameters, rectify=False, **opt_args)
elif opt_lower == 'radabelief':
optimizer = AdaBelief(parameters, rectify=True, **opt_args)
elif opt_lower == 'adadelta':
optimizer = optim.Adadelta(parameters, **opt_args)
elif opt_lower == 'adagrad':
opt_args.setdefault('eps', 1e-8)
optimizer = optim.Adagrad(parameters, **opt_args)
elif opt_lower == 'adafactor':
optimizer = Adafactor(parameters, **opt_args)
elif opt_lower == 'adanp':
optimizer = Adan(parameters, no_prox=False, **opt_args)
elif opt_lower == 'adanw':
optimizer = Adan(parameters, no_prox=True, **opt_args)
elif opt_lower == 'lamb':
optimizer = Lamb(parameters, **opt_args)
elif opt_lower == 'lambc':
optimizer = Lamb(parameters, trust_clip=True, **opt_args)
elif opt_lower == 'larc':
optimizer = Lars(parameters, momentum=momentum, trust_clip=True, **opt_args)
elif opt_lower == 'lars':
optimizer = Lars(parameters, momentum=momentum, **opt_args)
elif opt_lower == 'nlarc':
optimizer = Lars(parameters, momentum=momentum, trust_clip=True, nesterov=True, **opt_args)
elif opt_lower == 'nlars':
optimizer = Lars(parameters, momentum=momentum, nesterov=True, **opt_args)
elif opt_lower == 'madgrad':
optimizer = MADGRAD(parameters, momentum=momentum, **opt_args)
elif opt_lower == 'madgradw':
optimizer = MADGRAD(parameters, momentum=momentum, decoupled_decay=True, **opt_args)
elif opt_lower == 'novograd' or opt_lower == 'nvnovograd':
optimizer = NvNovoGrad(parameters, **opt_args)
elif opt_lower == 'rmsprop':
optimizer = optim.RMSprop(parameters, alpha=0.9, momentum=momentum, **opt_args)
elif opt_lower == 'rmsproptf':
optimizer = RMSpropTF(parameters, alpha=0.9, momentum=momentum, **opt_args)
elif opt_lower == 'lion':
opt_args.pop('eps', None)
optimizer = Lion(parameters, **opt_args)
# second order
elif opt_lower == 'adahessian':
optimizer = Adahessian(parameters, **opt_args)
# NVIDIA fused optimizers, require APEX to be installed
elif opt_lower == 'fusedsgd':
opt_args.pop('eps', None)
optimizer = FusedSGD(parameters, momentum=momentum, nesterov=True, **opt_args)
elif opt_lower == 'fusedmomentum':
opt_args.pop('eps', None)
optimizer = FusedSGD(parameters, momentum=momentum, nesterov=False, **opt_args)
elif opt_lower == 'fusedadam':
optimizer = FusedAdam(parameters, adam_w_mode=False, **opt_args)
elif opt_lower == 'fusedadamw':
optimizer = FusedAdam(parameters, adam_w_mode=True, **opt_args)
elif opt_lower == 'fusedlamb':
optimizer = FusedLAMB(parameters, **opt_args)
elif opt_lower == 'fusednovograd':
opt_args.setdefault('betas', (0.95, 0.98))
optimizer = FusedNovoGrad(parameters, **opt_args)
# bitsandbytes optimizers, require bitsandbytes to be installed
elif opt_lower == 'bnbsgd':
opt_args.pop('eps', None)
optimizer = bnb.optim.SGD(parameters, momentum=momentum, nesterov=True, **opt_args)
elif opt_lower == 'bnbsgd8bit':
opt_args.pop('eps', None)
optimizer = bnb.optim.SGD8bit(parameters, momentum=momentum, nesterov=True, **opt_args)
elif opt_lower == 'bnbmomentum':
opt_args.pop('eps', None)
optimizer = bnb.optim.SGD(parameters, momentum=momentum, **opt_args)
elif opt_lower == 'bnbmomentum8bit':
opt_args.pop('eps', None)
optimizer = bnb.optim.SGD8bit(parameters, momentum=momentum, **opt_args)
elif opt_lower == 'bnbadam':
optimizer = bnb.optim.Adam(parameters, **opt_args)
elif opt_lower == 'bnbadam8bit':
optimizer = bnb.optim.Adam8bit(parameters, **opt_args)
elif opt_lower == 'bnbadamw':
optimizer = bnb.optim.AdamW(parameters, **opt_args)
elif opt_lower == 'bnbadamw8bit':
optimizer = bnb.optim.AdamW8bit(parameters, **opt_args)
elif opt_lower == 'bnblamb':
optimizer = bnb.optim.LAMB(parameters, **opt_args)
elif opt_lower == 'bnblamb8bit':
optimizer = bnb.optim.LAMB8bit(parameters, **opt_args)
elif opt_lower == 'bnblars':
optimizer = bnb.optim.LARS(parameters, **opt_args)
elif opt_lower == 'bnblarsb8bit':
optimizer = bnb.optim.LAMB8bit(parameters, **opt_args)
elif opt_lower == 'bnblion':
optimizer = bnb.optim.Lion(parameters, **opt_args)
elif opt_lower == 'bnblion8bit':
optimizer = bnb.optim.Lion8bit(parameters, **opt_args)
else:
assert False and "Invalid optimizer"
raise ValueError
if len(opt_split) > 1:
if opt_split[0] == 'lookahead':
optimizer = Lookahead(optimizer)
return optimizer
| pytorch-image-models/timm/optim/optim_factory.py/0 | {
"file_path": "pytorch-image-models/timm/optim/optim_factory.py",
"repo_id": "pytorch-image-models",
"token_count": 6927
} | 191 |
""" Checkpoint Saver
Track top-n training checkpoints and maintain recovery checkpoints on specified intervals.
Hacked together by / Copyright 2020 Ross Wightman
"""
import glob
import operator
import os
import logging
import torch
from .model import unwrap_model, get_state_dict
_logger = logging.getLogger(__name__)
class CheckpointSaver:
def __init__(
self,
model,
optimizer,
args=None,
model_ema=None,
amp_scaler=None,
checkpoint_prefix='checkpoint',
recovery_prefix='recovery',
checkpoint_dir='',
recovery_dir='',
decreasing=False,
max_history=10,
unwrap_fn=unwrap_model):
# objects to save state_dicts of
self.model = model
self.optimizer = optimizer
self.args = args
self.model_ema = model_ema
self.amp_scaler = amp_scaler
# state
self.checkpoint_files = [] # (filename, metric) tuples in order of decreasing betterness
self.best_epoch = None
self.best_metric = None
self.curr_recovery_file = ''
self.last_recovery_file = ''
# config
self.checkpoint_dir = checkpoint_dir
self.recovery_dir = recovery_dir
self.save_prefix = checkpoint_prefix
self.recovery_prefix = recovery_prefix
self.extension = '.pth.tar'
self.decreasing = decreasing # a lower metric is better if True
self.cmp = operator.lt if decreasing else operator.gt # True if lhs better than rhs
self.max_history = max_history
self.unwrap_fn = unwrap_fn
assert self.max_history >= 1
def save_checkpoint(self, epoch, metric=None):
assert epoch >= 0
tmp_save_path = os.path.join(self.checkpoint_dir, 'tmp' + self.extension)
last_save_path = os.path.join(self.checkpoint_dir, 'last' + self.extension)
self._save(tmp_save_path, epoch, metric)
if os.path.exists(last_save_path):
os.unlink(last_save_path) # required for Windows support.
os.rename(tmp_save_path, last_save_path)
worst_file = self.checkpoint_files[-1] if self.checkpoint_files else None
if (len(self.checkpoint_files) < self.max_history
or metric is None or self.cmp(metric, worst_file[1])):
if len(self.checkpoint_files) >= self.max_history:
self._cleanup_checkpoints(1)
filename = '-'.join([self.save_prefix, str(epoch)]) + self.extension
save_path = os.path.join(self.checkpoint_dir, filename)
os.link(last_save_path, save_path)
self.checkpoint_files.append((save_path, metric))
self.checkpoint_files = sorted(
self.checkpoint_files, key=lambda x: x[1],
reverse=not self.decreasing) # sort in descending order if a lower metric is not better
checkpoints_str = "Current checkpoints:\n"
for c in self.checkpoint_files:
checkpoints_str += ' {}\n'.format(c)
_logger.info(checkpoints_str)
if metric is not None and (self.best_metric is None or self.cmp(metric, self.best_metric)):
self.best_epoch = epoch
self.best_metric = metric
best_save_path = os.path.join(self.checkpoint_dir, 'model_best' + self.extension)
if os.path.exists(best_save_path):
os.unlink(best_save_path)
os.link(last_save_path, best_save_path)
return (None, None) if self.best_metric is None else (self.best_metric, self.best_epoch)
def _save(self, save_path, epoch, metric=None):
save_state = {
'epoch': epoch,
'arch': type(self.model).__name__.lower(),
'state_dict': get_state_dict(self.model, self.unwrap_fn),
'optimizer': self.optimizer.state_dict(),
'version': 2, # version < 2 increments epoch before save
}
if self.args is not None:
save_state['arch'] = self.args.model
save_state['args'] = self.args
if self.amp_scaler is not None:
save_state[self.amp_scaler.state_dict_key] = self.amp_scaler.state_dict()
if self.model_ema is not None:
save_state['state_dict_ema'] = get_state_dict(self.model_ema, self.unwrap_fn)
if metric is not None:
save_state['metric'] = metric
torch.save(save_state, save_path)
def _cleanup_checkpoints(self, trim=0):
trim = min(len(self.checkpoint_files), trim)
delete_index = self.max_history - trim
if delete_index < 0 or len(self.checkpoint_files) <= delete_index:
return
to_delete = self.checkpoint_files[delete_index:]
for d in to_delete:
try:
_logger.debug("Cleaning checkpoint: {}".format(d))
os.remove(d[0])
except Exception as e:
_logger.error("Exception '{}' while deleting checkpoint".format(e))
self.checkpoint_files = self.checkpoint_files[:delete_index]
def save_recovery(self, epoch, batch_idx=0):
assert epoch >= 0
filename = '-'.join([self.recovery_prefix, str(epoch), str(batch_idx)]) + self.extension
save_path = os.path.join(self.recovery_dir, filename)
self._save(save_path, epoch)
if os.path.exists(self.last_recovery_file):
try:
_logger.debug("Cleaning recovery: {}".format(self.last_recovery_file))
os.remove(self.last_recovery_file)
except Exception as e:
_logger.error("Exception '{}' while removing {}".format(e, self.last_recovery_file))
self.last_recovery_file = self.curr_recovery_file
self.curr_recovery_file = save_path
def find_recovery(self):
recovery_path = os.path.join(self.recovery_dir, self.recovery_prefix)
files = glob.glob(recovery_path + '*' + self.extension)
files = sorted(files)
return files[0] if len(files) else ''
| pytorch-image-models/timm/utils/checkpoint_saver.py/0 | {
"file_path": "pytorch-image-models/timm/utils/checkpoint_saver.py",
"repo_id": "pytorch-image-models",
"token_count": 2818
} | 192 |
#!/usr/bin/env python3
""" ImageNet Validation Script
This is intended to be a lean and easily modifiable ImageNet validation script for evaluating pretrained
models or training checkpoints against ImageNet or similarly organized image datasets. It prioritizes
canonical PyTorch, standard Python style, and good performance. Repurpose as you see fit.
Hacked together by Ross Wightman (https://github.com/rwightman)
"""
import argparse
import csv
import glob
import json
import logging
import os
import time
from collections import OrderedDict
from contextlib import suppress
from functools import partial
import torch
import torch.nn as nn
import torch.nn.parallel
from timm.data import create_dataset, create_loader, resolve_data_config, RealLabelsImagenet
from timm.layers import apply_test_time_pool, set_fast_norm
from timm.models import create_model, load_checkpoint, is_model, list_models
from timm.utils import accuracy, AverageMeter, natural_key, setup_default_logging, set_jit_fuser, \
decay_batch_step, check_batch_size_retry, ParseKwargs, reparameterize_model
try:
from apex import amp
has_apex = True
except ImportError:
has_apex = False
has_native_amp = False
try:
if getattr(torch.cuda.amp, 'autocast') is not None:
has_native_amp = True
except AttributeError:
pass
try:
from functorch.compile import memory_efficient_fusion
has_functorch = True
except ImportError as e:
has_functorch = False
has_compile = hasattr(torch, 'compile')
_logger = logging.getLogger('validate')
parser = argparse.ArgumentParser(description='PyTorch ImageNet Validation')
parser.add_argument('data', nargs='?', metavar='DIR', const=None,
help='path to dataset (*deprecated*, use --data-dir)')
parser.add_argument('--data-dir', metavar='DIR',
help='path to dataset (root dir)')
parser.add_argument('--dataset', metavar='NAME', default='',
help='dataset type + name ("<type>/<name>") (default: ImageFolder or ImageTar if empty)')
parser.add_argument('--split', metavar='NAME', default='validation',
help='dataset split (default: validation)')
parser.add_argument('--num-samples', default=None, type=int,
metavar='N', help='Manually specify num samples in dataset split, for IterableDatasets.')
parser.add_argument('--dataset-download', action='store_true', default=False,
help='Allow download of dataset for torch/ and tfds/ datasets that support it.')
parser.add_argument('--class-map', default='', type=str, metavar='FILENAME',
help='path to class to idx mapping file (default: "")')
parser.add_argument('--input-key', default=None, type=str,
help='Dataset key for input images.')
parser.add_argument('--input-img-mode', default=None, type=str,
help='Dataset image conversion mode for input images.')
parser.add_argument('--target-key', default=None, type=str,
help='Dataset key for target labels.')
parser.add_argument('--model', '-m', metavar='NAME', default='dpn92',
help='model architecture (default: dpn92)')
parser.add_argument('--pretrained', dest='pretrained', action='store_true',
help='use pre-trained model')
parser.add_argument('-j', '--workers', default=4, type=int, metavar='N',
help='number of data loading workers (default: 4)')
parser.add_argument('-b', '--batch-size', default=256, type=int,
metavar='N', help='mini-batch size (default: 256)')
parser.add_argument('--img-size', default=None, type=int,
metavar='N', help='Input image dimension, uses model default if empty')
parser.add_argument('--in-chans', type=int, default=None, metavar='N',
help='Image input channels (default: None => 3)')
parser.add_argument('--input-size', default=None, nargs=3, type=int,
metavar='N N N', help='Input all image dimensions (d h w, e.g. --input-size 3 224 224), uses model default if empty')
parser.add_argument('--use-train-size', action='store_true', default=False,
help='force use of train input size, even when test size is specified in pretrained cfg')
parser.add_argument('--crop-pct', default=None, type=float,
metavar='N', help='Input image center crop pct')
parser.add_argument('--crop-mode', default=None, type=str,
metavar='N', help='Input image crop mode (squash, border, center). Model default if None.')
parser.add_argument('--crop-border-pixels', type=int, default=None,
help='Crop pixels from image border.')
parser.add_argument('--mean', type=float, nargs='+', default=None, metavar='MEAN',
help='Override mean pixel value of dataset')
parser.add_argument('--std', type=float, nargs='+', default=None, metavar='STD',
help='Override std deviation of of dataset')
parser.add_argument('--interpolation', default='', type=str, metavar='NAME',
help='Image resize interpolation type (overrides model)')
parser.add_argument('--num-classes', type=int, default=None,
help='Number classes in dataset')
parser.add_argument('--gp', default=None, type=str, metavar='POOL',
help='Global pool type, one of (fast, avg, max, avgmax, avgmaxc). Model default if None.')
parser.add_argument('--log-freq', default=10, type=int,
metavar='N', help='batch logging frequency (default: 10)')
parser.add_argument('--checkpoint', default='', type=str, metavar='PATH',
help='path to latest checkpoint (default: none)')
parser.add_argument('--num-gpu', type=int, default=1,
help='Number of GPUS to use')
parser.add_argument('--test-pool', dest='test_pool', action='store_true',
help='enable test time pool')
parser.add_argument('--no-prefetcher', action='store_true', default=False,
help='disable fast prefetcher')
parser.add_argument('--pin-mem', action='store_true', default=False,
help='Pin CPU memory in DataLoader for more efficient (sometimes) transfer to GPU.')
parser.add_argument('--channels-last', action='store_true', default=False,
help='Use channels_last memory layout')
parser.add_argument('--device', default='cuda', type=str,
help="Device (accelerator) to use.")
parser.add_argument('--amp', action='store_true', default=False,
help='use NVIDIA Apex AMP or Native AMP for mixed precision training')
parser.add_argument('--amp-dtype', default='float16', type=str,
help='lower precision AMP dtype (default: float16)')
parser.add_argument('--amp-impl', default='native', type=str,
help='AMP impl to use, "native" or "apex" (default: native)')
parser.add_argument('--tf-preprocessing', action='store_true', default=False,
help='Use Tensorflow preprocessing pipeline (require CPU TF installed')
parser.add_argument('--use-ema', dest='use_ema', action='store_true',
help='use ema version of weights if present')
parser.add_argument('--fuser', default='', type=str,
help="Select jit fuser. One of ('', 'te', 'old', 'nvfuser')")
parser.add_argument('--fast-norm', default=False, action='store_true',
help='enable experimental fast-norm')
parser.add_argument('--reparam', default=False, action='store_true',
help='Reparameterize model')
parser.add_argument('--model-kwargs', nargs='*', default={}, action=ParseKwargs)
scripting_group = parser.add_mutually_exclusive_group()
scripting_group.add_argument('--torchscript', default=False, action='store_true',
help='torch.jit.script the full model')
scripting_group.add_argument('--torchcompile', nargs='?', type=str, default=None, const='inductor',
help="Enable compilation w/ specified backend (default: inductor).")
scripting_group.add_argument('--aot-autograd', default=False, action='store_true',
help="Enable AOT Autograd support.")
parser.add_argument('--results-file', default='', type=str, metavar='FILENAME',
help='Output csv file for validation results (summary)')
parser.add_argument('--results-format', default='csv', type=str,
help='Format for results file one of (csv, json) (default: csv).')
parser.add_argument('--real-labels', default='', type=str, metavar='FILENAME',
help='Real labels JSON file for imagenet evaluation')
parser.add_argument('--valid-labels', default='', type=str, metavar='FILENAME',
help='Valid label indices txt file for validation of partial label space')
parser.add_argument('--retry', default=False, action='store_true',
help='Enable batch size decay & retry for single model validation')
def validate(args):
# might as well try to validate something
args.pretrained = args.pretrained or not args.checkpoint
args.prefetcher = not args.no_prefetcher
if torch.cuda.is_available():
torch.backends.cuda.matmul.allow_tf32 = True
torch.backends.cudnn.benchmark = True
device = torch.device(args.device)
# resolve AMP arguments based on PyTorch / Apex availability
use_amp = None
amp_autocast = suppress
if args.amp:
if args.amp_impl == 'apex':
assert has_apex, 'AMP impl specified as APEX but APEX is not installed.'
assert args.amp_dtype == 'float16'
use_amp = 'apex'
_logger.info('Validating in mixed precision with NVIDIA APEX AMP.')
else:
assert has_native_amp, 'Please update PyTorch to a version with native AMP (or use APEX).'
assert args.amp_dtype in ('float16', 'bfloat16')
use_amp = 'native'
amp_dtype = torch.bfloat16 if args.amp_dtype == 'bfloat16' else torch.float16
amp_autocast = partial(torch.autocast, device_type=device.type, dtype=amp_dtype)
_logger.info('Validating in mixed precision with native PyTorch AMP.')
else:
_logger.info('Validating in float32. AMP not enabled.')
if args.fuser:
set_jit_fuser(args.fuser)
if args.fast_norm:
set_fast_norm()
# create model
in_chans = 3
if args.in_chans is not None:
in_chans = args.in_chans
elif args.input_size is not None:
in_chans = args.input_size[0]
model = create_model(
args.model,
pretrained=args.pretrained,
num_classes=args.num_classes,
in_chans=in_chans,
global_pool=args.gp,
scriptable=args.torchscript,
**args.model_kwargs,
)
if args.num_classes is None:
assert hasattr(model, 'num_classes'), 'Model must have `num_classes` attr if not set on cmd line/config.'
args.num_classes = model.num_classes
if args.checkpoint:
load_checkpoint(model, args.checkpoint, args.use_ema)
if args.reparam:
model = reparameterize_model(model)
param_count = sum([m.numel() for m in model.parameters()])
_logger.info('Model %s created, param count: %d' % (args.model, param_count))
data_config = resolve_data_config(
vars(args),
model=model,
use_test_size=not args.use_train_size,
verbose=True,
)
test_time_pool = False
if args.test_pool:
model, test_time_pool = apply_test_time_pool(model, data_config)
model = model.to(device)
if args.channels_last:
model = model.to(memory_format=torch.channels_last)
if args.torchscript:
assert not use_amp == 'apex', 'Cannot use APEX AMP with torchscripted model'
model = torch.jit.script(model)
elif args.torchcompile:
assert has_compile, 'A version of torch w/ torch.compile() is required for --compile, possibly a nightly.'
torch._dynamo.reset()
model = torch.compile(model, backend=args.torchcompile)
elif args.aot_autograd:
assert has_functorch, "functorch is needed for --aot-autograd"
model = memory_efficient_fusion(model)
if use_amp == 'apex':
model = amp.initialize(model, opt_level='O1')
if args.num_gpu > 1:
model = torch.nn.DataParallel(model, device_ids=list(range(args.num_gpu)))
criterion = nn.CrossEntropyLoss().to(device)
root_dir = args.data or args.data_dir
if args.input_img_mode is None:
input_img_mode = 'RGB' if data_config['input_size'][0] == 3 else 'L'
else:
input_img_mode = args.input_img_mode
dataset = create_dataset(
root=root_dir,
name=args.dataset,
split=args.split,
download=args.dataset_download,
load_bytes=args.tf_preprocessing,
class_map=args.class_map,
num_samples=args.num_samples,
input_key=args.input_key,
input_img_mode=input_img_mode,
target_key=args.target_key,
)
if args.valid_labels:
with open(args.valid_labels, 'r') as f:
valid_labels = [int(line.rstrip()) for line in f]
else:
valid_labels = None
if args.real_labels:
real_labels = RealLabelsImagenet(dataset.filenames(basename=True), real_json=args.real_labels)
else:
real_labels = None
crop_pct = 1.0 if test_time_pool else data_config['crop_pct']
loader = create_loader(
dataset,
input_size=data_config['input_size'],
batch_size=args.batch_size,
use_prefetcher=args.prefetcher,
interpolation=data_config['interpolation'],
mean=data_config['mean'],
std=data_config['std'],
num_workers=args.workers,
crop_pct=crop_pct,
crop_mode=data_config['crop_mode'],
crop_border_pixels=args.crop_border_pixels,
pin_memory=args.pin_mem,
device=device,
tf_preprocessing=args.tf_preprocessing,
)
batch_time = AverageMeter()
losses = AverageMeter()
top1 = AverageMeter()
top5 = AverageMeter()
model.eval()
with torch.no_grad():
# warmup, reduce variability of first batch time, especially for comparing torchscript vs non
input = torch.randn((args.batch_size,) + tuple(data_config['input_size'])).to(device)
if args.channels_last:
input = input.contiguous(memory_format=torch.channels_last)
with amp_autocast():
model(input)
end = time.time()
for batch_idx, (input, target) in enumerate(loader):
if args.no_prefetcher:
target = target.to(device)
input = input.to(device)
if args.channels_last:
input = input.contiguous(memory_format=torch.channels_last)
# compute output
with amp_autocast():
output = model(input)
if valid_labels is not None:
output = output[:, valid_labels]
loss = criterion(output, target)
if real_labels is not None:
real_labels.add_result(output)
# measure accuracy and record loss
acc1, acc5 = accuracy(output.detach(), target, topk=(1, 5))
losses.update(loss.item(), input.size(0))
top1.update(acc1.item(), input.size(0))
top5.update(acc5.item(), input.size(0))
# measure elapsed time
batch_time.update(time.time() - end)
end = time.time()
if batch_idx % args.log_freq == 0:
_logger.info(
'Test: [{0:>4d}/{1}] '
'Time: {batch_time.val:.3f}s ({batch_time.avg:.3f}s, {rate_avg:>7.2f}/s) '
'Loss: {loss.val:>7.4f} ({loss.avg:>6.4f}) '
'Acc@1: {top1.val:>7.3f} ({top1.avg:>7.3f}) '
'Acc@5: {top5.val:>7.3f} ({top5.avg:>7.3f})'.format(
batch_idx,
len(loader),
batch_time=batch_time,
rate_avg=input.size(0) / batch_time.avg,
loss=losses,
top1=top1,
top5=top5
)
)
if real_labels is not None:
# real labels mode replaces topk values at the end
top1a, top5a = real_labels.get_accuracy(k=1), real_labels.get_accuracy(k=5)
else:
top1a, top5a = top1.avg, top5.avg
results = OrderedDict(
model=args.model,
top1=round(top1a, 4), top1_err=round(100 - top1a, 4),
top5=round(top5a, 4), top5_err=round(100 - top5a, 4),
param_count=round(param_count / 1e6, 2),
img_size=data_config['input_size'][-1],
crop_pct=crop_pct,
interpolation=data_config['interpolation'],
)
_logger.info(' * Acc@1 {:.3f} ({:.3f}) Acc@5 {:.3f} ({:.3f})'.format(
results['top1'], results['top1_err'], results['top5'], results['top5_err']))
return results
def _try_run(args, initial_batch_size):
batch_size = initial_batch_size
results = OrderedDict()
error_str = 'Unknown'
while batch_size:
args.batch_size = batch_size * args.num_gpu # multiply by num-gpu for DataParallel case
try:
if torch.cuda.is_available() and 'cuda' in args.device:
torch.cuda.empty_cache()
results = validate(args)
return results
except RuntimeError as e:
error_str = str(e)
_logger.error(f'"{error_str}" while running validation.')
if not check_batch_size_retry(error_str):
break
batch_size = decay_batch_step(batch_size)
_logger.warning(f'Reducing batch size to {batch_size} for retry.')
results['error'] = error_str
_logger.error(f'{args.model} failed to validate ({error_str}).')
return results
_NON_IN1K_FILTERS = ['*_in21k', '*_in22k', '*in12k', '*_dino', '*fcmae', '*seer']
def main():
setup_default_logging()
args = parser.parse_args()
model_cfgs = []
model_names = []
if os.path.isdir(args.checkpoint):
# validate all checkpoints in a path with same model
checkpoints = glob.glob(args.checkpoint + '/*.pth.tar')
checkpoints += glob.glob(args.checkpoint + '/*.pth')
model_names = list_models(args.model)
model_cfgs = [(args.model, c) for c in sorted(checkpoints, key=natural_key)]
else:
if args.model == 'all':
# validate all models in a list of names with pretrained checkpoints
args.pretrained = True
model_names = list_models(
pretrained=True,
exclude_filters=_NON_IN1K_FILTERS,
)
model_cfgs = [(n, '') for n in model_names]
elif not is_model(args.model):
# model name doesn't exist, try as wildcard filter
model_names = list_models(
args.model,
pretrained=True,
)
model_cfgs = [(n, '') for n in model_names]
if not model_cfgs and os.path.isfile(args.model):
with open(args.model) as f:
model_names = [line.rstrip() for line in f]
model_cfgs = [(n, None) for n in model_names if n]
if len(model_cfgs):
_logger.info('Running bulk validation on these pretrained models: {}'.format(', '.join(model_names)))
results = []
try:
initial_batch_size = args.batch_size
for m, c in model_cfgs:
args.model = m
args.checkpoint = c
r = _try_run(args, initial_batch_size)
if 'error' in r:
continue
if args.checkpoint:
r['checkpoint'] = args.checkpoint
results.append(r)
except KeyboardInterrupt as e:
pass
results = sorted(results, key=lambda x: x['top1'], reverse=True)
else:
if args.retry:
results = _try_run(args, args.batch_size)
else:
results = validate(args)
if args.results_file:
write_results(args.results_file, results, format=args.results_format)
# output results in JSON to stdout w/ delimiter for runner script
print(f'--result\n{json.dumps(results, indent=4)}')
def write_results(results_file, results, format='csv'):
with open(results_file, mode='w') as cf:
if format == 'json':
json.dump(results, cf, indent=4)
else:
if not isinstance(results, (list, tuple)):
results = [results]
if not results:
return
dw = csv.DictWriter(cf, fieldnames=results[0].keys())
dw.writeheader()
for r in results:
dw.writerow(r)
cf.flush()
if __name__ == '__main__':
main()
| pytorch-image-models/validate.py/0 | {
"file_path": "pytorch-image-models/validate.py",
"repo_id": "pytorch-image-models",
"token_count": 9310
} | 193 |
<div align="center">
<a href="https://www.youtube.com/watch?v=jlMAX2Oaht0">
<img width=560 width=315 alt="Making TGI deployment optimal" src="https://huggingface.co/datasets/Narsil/tgi_assets/resolve/main/thumbnail.png">
</a>
# Text Generation Inference
<a href="https://github.com/huggingface/text-generation-inference">
<img alt="GitHub Repo stars" src="https://img.shields.io/github/stars/huggingface/text-generation-inference?style=social">
</a>
<a href="https://huggingface.github.io/text-generation-inference">
<img alt="Swagger API documentation" src="https://img.shields.io/badge/API-Swagger-informational">
</a>
A Rust, Python and gRPC server for text generation inference. Used in production at [HuggingFace](https://huggingface.co)
to power Hugging Chat, the Inference API and Inference Endpoint.
</div>
## Table of contents
- [Get Started](#get-started)
- [API Documentation](#api-documentation)
- [Using a private or gated model](#using-a-private-or-gated-model)
- [A note on Shared Memory](#a-note-on-shared-memory-shm)
- [Distributed Tracing](#distributed-tracing)
- [Local Install](#local-install)
- [CUDA Kernels](#cuda-kernels)
- [Optimized architectures](#optimized-architectures)
- [Run Mistral](#run-a-model)
- [Run](#run)
- [Quantization](#quantization)
- [Develop](#develop)
- [Testing](#testing)
Text Generation Inference (TGI) is a toolkit for deploying and serving Large Language Models (LLMs). TGI enables high-performance text generation for the most popular open-source LLMs, including Llama, Falcon, StarCoder, BLOOM, GPT-NeoX, and [more](https://huggingface.co/docs/text-generation-inference/supported_models). TGI implements many features, such as:
- Simple launcher to serve most popular LLMs
- Production ready (distributed tracing with Open Telemetry, Prometheus metrics)
- Tensor Parallelism for faster inference on multiple GPUs
- Token streaming using Server-Sent Events (SSE)
- Continuous batching of incoming requests for increased total throughput
- Optimized transformers code for inference using [Flash Attention](https://github.com/HazyResearch/flash-attention) and [Paged Attention](https://github.com/vllm-project/vllm) on the most popular architectures
- Quantization with :
- [bitsandbytes](https://github.com/TimDettmers/bitsandbytes)
- [GPT-Q](https://arxiv.org/abs/2210.17323)
- [EETQ](https://github.com/NetEase-FuXi/EETQ)
- [AWQ](https://github.com/casper-hansen/AutoAWQ)
- [Safetensors](https://github.com/huggingface/safetensors) weight loading
- Watermarking with [A Watermark for Large Language Models](https://arxiv.org/abs/2301.10226)
- Logits warper (temperature scaling, top-p, top-k, repetition penalty, more details see [transformers.LogitsProcessor](https://huggingface.co/docs/transformers/internal/generation_utils#transformers.LogitsProcessor))
- Stop sequences
- Log probabilities
- Custom Prompt Generation: Easily generate text by providing custom prompts to guide the model's output
- Fine-tuning Support: Utilize fine-tuned models for specific tasks to achieve higher accuracy and performance
### Hardware support
- [Nvidia](https://github.com/huggingface/text-generation-inference/pkgs/container/text-generation-inference)
- [AMD](https://github.com/huggingface/text-generation-inference/pkgs/container/text-generation-inference) (-rocm)
- [Inferentia](https://github.com/huggingface/optimum-neuron/tree/main/text-generation-inference)
- [Intel GPU](https://github.com/huggingface/text-generation-inference/pull/1475)
- [Gaudi](https://github.com/huggingface/tgi-gaudi)
## Get Started
### Docker
For a detailed starting guide, please see the [Quick Tour](https://huggingface.co/docs/text-generation-inference/quicktour). The easiest way of getting started is using the official Docker container:
```shell
model=HuggingFaceH4/zephyr-7b-beta
volume=$PWD/data # share a volume with the Docker container to avoid downloading weights every run
docker run --gpus all --shm-size 1g -p 8080:80 -v $volume:/data ghcr.io/huggingface/text-generation-inference:1.4 --model-id $model
```
And then you can make requests like
```bash
curl 127.0.0.1:8080/generate \
-X POST \
-d '{"inputs":"What is Deep Learning?","parameters":{"max_new_tokens":20}}' \
-H 'Content-Type: application/json'
```
**Note:** To use NVIDIA GPUs, you need to install the [NVIDIA Container Toolkit](https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/install-guide.html). We also recommend using NVIDIA drivers with CUDA version 12.2 or higher. For running the Docker container on a machine with no GPUs or CUDA support, it is enough to remove the `--gpus all` flag and add `--disable-custom-kernels`, please note CPU is not the intended platform for this project, so performance might be subpar.
**Note:** TGI supports AMD Instinct MI210 and MI250 GPUs. Details can be found in the [Supported Hardware documentation](https://huggingface.co/docs/text-generation-inference/supported_models#supported-hardware). To use AMD GPUs, please use `docker run --device /dev/kfd --device /dev/dri --shm-size 1g -p 8080:80 -v $volume:/data ghcr.io/huggingface/text-generation-inference:1.4-rocm --model-id $model` instead of the command above.
To see all options to serve your models (in the [code](https://github.com/huggingface/text-generation-inference/blob/main/launcher/src/main.rs) or in the cli):
```
text-generation-launcher --help
```
### API documentation
You can consult the OpenAPI documentation of the `text-generation-inference` REST API using the `/docs` route.
The Swagger UI is also available at: [https://huggingface.github.io/text-generation-inference](https://huggingface.github.io/text-generation-inference).
### Using a private or gated model
You have the option to utilize the `HUGGING_FACE_HUB_TOKEN` environment variable for configuring the token employed by
`text-generation-inference`. This allows you to gain access to protected resources.
For example, if you want to serve the gated Llama V2 model variants:
1. Go to https://huggingface.co/settings/tokens
2. Copy your cli READ token
3. Export `HUGGING_FACE_HUB_TOKEN=<your cli READ token>`
or with Docker:
```shell
model=meta-llama/Llama-2-7b-chat-hf
volume=$PWD/data # share a volume with the Docker container to avoid downloading weights every run
token=<your cli READ token>
docker run --gpus all --shm-size 1g -e HUGGING_FACE_HUB_TOKEN=$token -p 8080:80 -v $volume:/data ghcr.io/huggingface/text-generation-inference:1.4 --model-id $model
```
### A note on Shared Memory (shm)
[`NCCL`](https://docs.nvidia.com/deeplearning/nccl/user-guide/docs/index.html) is a communication framework used by
`PyTorch` to do distributed training/inference. `text-generation-inference` make
use of `NCCL` to enable Tensor Parallelism to dramatically speed up inference for large language models.
In order to share data between the different devices of a `NCCL` group, `NCCL` might fall back to using the host memory if
peer-to-peer using NVLink or PCI is not possible.
To allow the container to use 1G of Shared Memory and support SHM sharing, we add `--shm-size 1g` on the above command.
If you are running `text-generation-inference` inside `Kubernetes`. You can also add Shared Memory to the container by
creating a volume with:
```yaml
- name: shm
emptyDir:
medium: Memory
sizeLimit: 1Gi
```
and mounting it to `/dev/shm`.
Finally, you can also disable SHM sharing by using the `NCCL_SHM_DISABLE=1` environment variable. However, note that
this will impact performance.
### Distributed Tracing
`text-generation-inference` is instrumented with distributed tracing using OpenTelemetry. You can use this feature
by setting the address to an OTLP collector with the `--otlp-endpoint` argument.
### Architecture

### Local install
You can also opt to install `text-generation-inference` locally.
First [install Rust](https://rustup.rs/) and create a Python virtual environment with at least
Python 3.9, e.g. using `conda`:
```shell
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
conda create -n text-generation-inference python=3.11
conda activate text-generation-inference
```
You may also need to install Protoc.
On Linux:
```shell
PROTOC_ZIP=protoc-21.12-linux-x86_64.zip
curl -OL https://github.com/protocolbuffers/protobuf/releases/download/v21.12/$PROTOC_ZIP
sudo unzip -o $PROTOC_ZIP -d /usr/local bin/protoc
sudo unzip -o $PROTOC_ZIP -d /usr/local 'include/*'
rm -f $PROTOC_ZIP
```
On MacOS, using Homebrew:
```shell
brew install protobuf
```
Then run:
```shell
BUILD_EXTENSIONS=True make install # Install repository and HF/transformer fork with CUDA kernels
text-generation-launcher --model-id mistralai/Mistral-7B-Instruct-v0.2
```
**Note:** on some machines, you may also need the OpenSSL libraries and gcc. On Linux machines, run:
```shell
sudo apt-get install libssl-dev gcc -y
```
## Optimized architectures
TGI works out of the box to serve optimized models for all modern models. They can be found in [this list](https://huggingface.co/docs/text-generation-inference/supported_models).
Other architectures are supported on a best-effort basis using:
`AutoModelForCausalLM.from_pretrained(<model>, device_map="auto")`
or
`AutoModelForSeq2SeqLM.from_pretrained(<model>, device_map="auto")`
## Run locally
### Run
```shell
text-generation-launcher --model-id mistralai/Mistral-7B-Instruct-v0.2
```
### Quantization
You can also quantize the weights with bitsandbytes to reduce the VRAM requirement:
```shell
text-generation-launcher --model-id mistralai/Mistral-7B-Instruct-v0.2 --quantize
```
4bit quantization is available using the [NF4 and FP4 data types from bitsandbytes](https://arxiv.org/pdf/2305.14314.pdf). It can be enabled by providing `--quantize bitsandbytes-nf4` or `--quantize bitsandbytes-fp4` as a command line argument to `text-generation-launcher`.
## Develop
```shell
make server-dev
make router-dev
```
## Testing
```shell
# python
make python-server-tests
make python-client-tests
# or both server and client tests
make python-tests
# rust cargo tests
make rust-tests
# integration tests
make integration-tests
```
| text-generation-inference/README.md/0 | {
"file_path": "text-generation-inference/README.md",
"repo_id": "text-generation-inference",
"token_count": 3286
} | 194 |
[tool.poetry]
name = "text-generation"
version = "0.6.1"
description = "Hugging Face Text Generation Python Client"
license = "Apache-2.0"
authors = ["Olivier Dehaene <[email protected]>"]
maintainers = ["Olivier Dehaene <[email protected]>"]
readme = "README.md"
homepage = "https://github.com/huggingface/text-generation-inference"
repository = "https://github.com/huggingface/text-generation-inference"
[tool.poetry.dependencies]
python = "^3.7"
pydantic = "> 1.10, < 3"
aiohttp = "^3.8"
huggingface-hub = ">= 0.12, < 1.0"
[tool.poetry.dev-dependencies]
pytest = "^6.2.5"
pytest-asyncio = "^0.17.2"
pytest-cov = "^3.0.0"
[tool.pytest.ini_options]
asyncio_mode = "auto"
[build-system]
requires = ["poetry-core>=1.0.0"]
build-backend = "poetry.core.masonry.api"
| text-generation-inference/clients/python/pyproject.toml/0 | {
"file_path": "text-generation-inference/clients/python/pyproject.toml",
"repo_id": "text-generation-inference",
"token_count": 336
} | 195 |
# Text-generation-launcher arguments
<!-- WRAP CODE BLOCKS -->
```shell
Text Generation Launcher
Usage: text-generation-launcher [OPTIONS]
Options:
```
## MODEL_ID
```shell
--model-id <MODEL_ID>
The name of the model to load. Can be a MODEL_ID as listed on <https://hf.co/models> like `gpt2` or `OpenAssistant/oasst-sft-1-pythia-12b`. Or it can be a local directory containing the necessary files as saved by `save_pretrained(...)` methods of transformers
[env: MODEL_ID=]
[default: bigscience/bloom-560m]
```
## REVISION
```shell
--revision <REVISION>
The actual revision of the model if you're referring to a model on the hub. You can use a specific commit id or a branch like `refs/pr/2`
[env: REVISION=]
```
## VALIDATION_WORKERS
```shell
--validation-workers <VALIDATION_WORKERS>
The number of tokenizer workers used for payload validation and truncation inside the router
[env: VALIDATION_WORKERS=]
[default: 2]
```
## SHARDED
```shell
--sharded <SHARDED>
Whether to shard the model across multiple GPUs By default text-generation-inference will use all available GPUs to run the model. Setting it to `false` deactivates `num_shard`
[env: SHARDED=]
[possible values: true, false]
```
## NUM_SHARD
```shell
--num-shard <NUM_SHARD>
The number of shards to use if you don't want to use all GPUs on a given machine. You can use `CUDA_VISIBLE_DEVICES=0,1 text-generation-launcher... --num_shard 2` and `CUDA_VISIBLE_DEVICES=2,3 text-generation-launcher... --num_shard 2` to launch 2 copies with 2 shard each on a given machine with 4 GPUs for instance
[env: NUM_SHARD=]
```
## QUANTIZE
```shell
--quantize <QUANTIZE>
Whether you want the model to be quantized
[env: QUANTIZE=]
Possible values:
- awq: 4 bit quantization. Requires a specific AWQ quantized model: https://hf.co/models?search=awq. Should replace GPTQ models wherever possible because of the better latency
- eetq: 8 bit quantization, doesn't require specific model. Should be a drop-in replacement to bitsandbytes with much better performance. Kernels are from https://github.com/NetEase-FuXi/EETQ.git
- gptq: 4 bit quantization. Requires a specific GTPQ quantized model: https://hf.co/models?search=gptq. text-generation-inference will use exllama (faster) kernels wherever possible, and use triton kernel (wider support) when it's not. AWQ has faster kernels
- bitsandbytes: Bitsandbytes 8bit. Can be applied on any model, will cut the memory requirement in half, but it is known that the model will be much slower to run than the native f16
- bitsandbytes-nf4: Bitsandbytes 4bit. Can be applied on any model, will cut the memory requirement by 4x, but it is known that the model will be much slower to run than the native f16
- bitsandbytes-fp4: Bitsandbytes 4bit. nf4 should be preferred in most cases but maybe this one has better perplexity performance for you model
```
## SPECULATE
```shell
--speculate <SPECULATE>
The number of input_ids to speculate on If using a medusa model, the heads will be picked up automatically Other wise, it will use n-gram speculation which is relatively free in terms of compute, but the speedup heavily depends on the task
[env: SPECULATE=]
```
## DTYPE
```shell
--dtype <DTYPE>
The dtype to be forced upon the model. This option cannot be used with `--quantize`
[env: DTYPE=]
[possible values: float16, bfloat16]
```
## TRUST_REMOTE_CODE
```shell
--trust-remote-code
Whether you want to execute hub modelling code. Explicitly passing a `revision` is encouraged when loading a model with custom code to ensure no malicious code has been contributed in a newer revision
[env: TRUST_REMOTE_CODE=]
```
## MAX_CONCURRENT_REQUESTS
```shell
--max-concurrent-requests <MAX_CONCURRENT_REQUESTS>
The maximum amount of concurrent requests for this particular deployment. Having a low limit will refuse clients requests instead of having them wait for too long and is usually good to handle backpressure correctly
[env: MAX_CONCURRENT_REQUESTS=]
[default: 128]
```
## MAX_BEST_OF
```shell
--max-best-of <MAX_BEST_OF>
This is the maximum allowed value for clients to set `best_of`. Best of makes `n` generations at the same time, and return the best in terms of overall log probability over the entire generated sequence
[env: MAX_BEST_OF=]
[default: 2]
```
## MAX_STOP_SEQUENCES
```shell
--max-stop-sequences <MAX_STOP_SEQUENCES>
This is the maximum allowed value for clients to set `stop_sequences`. Stop sequences are used to allow the model to stop on more than just the EOS token, and enable more complex "prompting" where users can preprompt the model in a specific way and define their "own" stop token aligned with their prompt
[env: MAX_STOP_SEQUENCES=]
[default: 4]
```
## MAX_TOP_N_TOKENS
```shell
--max-top-n-tokens <MAX_TOP_N_TOKENS>
This is the maximum allowed value for clients to set `top_n_tokens`. `top_n_tokens is used to return information about the the `n` most likely tokens at each generation step, instead of just the sampled token. This information can be used for downstream tasks like for classification or ranking
[env: MAX_TOP_N_TOKENS=]
[default: 5]
```
## MAX_INPUT_LENGTH
```shell
--max-input-length <MAX_INPUT_LENGTH>
This is the maximum allowed input length (expressed in number of tokens) for users. The larger this value, the longer prompt users can send which can impact the overall memory required to handle the load. Please note that some models have a finite range of sequence they can handle
[env: MAX_INPUT_LENGTH=]
[default: 1024]
```
## MAX_TOTAL_TOKENS
```shell
--max-total-tokens <MAX_TOTAL_TOKENS>
This is the most important value to set as it defines the "memory budget" of running clients requests. Clients will send input sequences and ask to generate `max_new_tokens` on top. with a value of `1512` users can send either a prompt of `1000` and ask for `512` new tokens, or send a prompt of `1` and ask for `1511` max_new_tokens. The larger this value, the larger amount each request will be in your RAM and the less effective batching can be
[env: MAX_TOTAL_TOKENS=]
[default: 2048]
```
## WAITING_SERVED_RATIO
```shell
--waiting-served-ratio <WAITING_SERVED_RATIO>
This represents the ratio of waiting queries vs running queries where you want to start considering pausing the running queries to include the waiting ones into the same batch. `waiting_served_ratio=1.2` Means when 12 queries are waiting and there's only 10 queries left in the current batch we check if we can fit those 12 waiting queries into the batching strategy, and if yes, then batching happens delaying the 10 running queries by a `prefill` run.
This setting is only applied if there is room in the batch as defined by `max_batch_total_tokens`.
[env: WAITING_SERVED_RATIO=]
[default: 1.2]
```
## MAX_BATCH_PREFILL_TOKENS
```shell
--max-batch-prefill-tokens <MAX_BATCH_PREFILL_TOKENS>
Limits the number of tokens for the prefill operation. Since this operation take the most memory and is compute bound, it is interesting to limit the number of requests that can be sent
[env: MAX_BATCH_PREFILL_TOKENS=]
[default: 4096]
```
## MAX_BATCH_TOTAL_TOKENS
```shell
--max-batch-total-tokens <MAX_BATCH_TOTAL_TOKENS>
**IMPORTANT** This is one critical control to allow maximum usage of the available hardware.
This represents the total amount of potential tokens within a batch. When using padding (not recommended) this would be equivalent of `batch_size` * `max_total_tokens`.
However in the non-padded (flash attention) version this can be much finer.
For `max_batch_total_tokens=1000`, you could fit `10` queries of `total_tokens=100` or a single query of `1000` tokens.
Overall this number should be the largest possible amount that fits the remaining memory (after the model is loaded). Since the actual memory overhead depends on other parameters like if you're using quantization, flash attention or the model implementation, text-generation-inference cannot infer this number automatically.
[env: MAX_BATCH_TOTAL_TOKENS=]
```
## MAX_WAITING_TOKENS
```shell
--max-waiting-tokens <MAX_WAITING_TOKENS>
This setting defines how many tokens can be passed before forcing the waiting queries to be put on the batch (if the size of the batch allows for it). New queries require 1 `prefill` forward, which is different from `decode` and therefore you need to pause the running batch in order to run `prefill` to create the correct values for the waiting queries to be able to join the batch.
With a value too small, queries will always "steal" the compute to run `prefill` and running queries will be delayed by a lot.
With a value too big, waiting queries could wait for a very long time before being allowed a slot in the running batch. If your server is busy that means that requests that could run in ~2s on an empty server could end up running in ~20s because the query had to wait for 18s.
This number is expressed in number of tokens to make it a bit more "model" agnostic, but what should really matter is the overall latency for end users.
[env: MAX_WAITING_TOKENS=]
[default: 20]
```
## HOSTNAME
```shell
--hostname <HOSTNAME>
The IP address to listen on
[env: HOSTNAME=]
[default: 0.0.0.0]
```
## PORT
```shell
-p, --port <PORT>
The port to listen on
[env: PORT=]
[default: 3000]
```
## SHARD_UDS_PATH
```shell
--shard-uds-path <SHARD_UDS_PATH>
The name of the socket for gRPC communication between the webserver and the shards
[env: SHARD_UDS_PATH=]
[default: /tmp/text-generation-server]
```
## MASTER_ADDR
```shell
--master-addr <MASTER_ADDR>
The address the master shard will listen on. (setting used by torch distributed)
[env: MASTER_ADDR=]
[default: localhost]
```
## MASTER_PORT
```shell
--master-port <MASTER_PORT>
The address the master port will listen on. (setting used by torch distributed)
[env: MASTER_PORT=]
[default: 29500]
```
## HUGGINGFACE_HUB_CACHE
```shell
--huggingface-hub-cache <HUGGINGFACE_HUB_CACHE>
The location of the huggingface hub cache. Used to override the location if you want to provide a mounted disk for instance
[env: HUGGINGFACE_HUB_CACHE=]
```
## WEIGHTS_CACHE_OVERRIDE
```shell
--weights-cache-override <WEIGHTS_CACHE_OVERRIDE>
The location of the huggingface hub cache. Used to override the location if you want to provide a mounted disk for instance
[env: WEIGHTS_CACHE_OVERRIDE=]
```
## DISABLE_CUSTOM_KERNELS
```shell
--disable-custom-kernels
For some models (like bloom), text-generation-inference implemented custom cuda kernels to speed up inference. Those kernels were only tested on A100. Use this flag to disable them if you're running on different hardware and encounter issues
[env: DISABLE_CUSTOM_KERNELS=]
```
## CUDA_MEMORY_FRACTION
```shell
--cuda-memory-fraction <CUDA_MEMORY_FRACTION>
Limit the CUDA available memory. The allowed value equals the total visible memory multiplied by cuda-memory-fraction
[env: CUDA_MEMORY_FRACTION=]
[default: 1.0]
```
## ROPE_SCALING
```shell
--rope-scaling <ROPE_SCALING>
Rope scaling will only be used for RoPE models and allow rescaling the position rotary to accomodate for larger prompts.
Goes together with `rope_factor`.
`--rope-factor 2.0` gives linear scaling with a factor of 2.0 `--rope-scaling dynamic` gives dynamic scaling with a factor of 1.0 `--rope-scaling linear` gives linear scaling with a factor of 1.0 (Nothing will be changed basically)
`--rope-scaling linear --rope-factor` fully describes the scaling you want
[env: ROPE_SCALING=]
[possible values: linear, dynamic]
```
## ROPE_FACTOR
```shell
--rope-factor <ROPE_FACTOR>
Rope scaling will only be used for RoPE models See `rope_scaling`
[env: ROPE_FACTOR=]
```
## JSON_OUTPUT
```shell
--json-output
Outputs the logs in JSON format (useful for telemetry)
[env: JSON_OUTPUT=]
```
## OTLP_ENDPOINT
```shell
--otlp-endpoint <OTLP_ENDPOINT>
[env: OTLP_ENDPOINT=]
```
## CORS_ALLOW_ORIGIN
```shell
--cors-allow-origin <CORS_ALLOW_ORIGIN>
[env: CORS_ALLOW_ORIGIN=]
```
## WATERMARK_GAMMA
```shell
--watermark-gamma <WATERMARK_GAMMA>
[env: WATERMARK_GAMMA=]
```
## WATERMARK_DELTA
```shell
--watermark-delta <WATERMARK_DELTA>
[env: WATERMARK_DELTA=]
```
## NGROK
```shell
--ngrok
Enable ngrok tunneling
[env: NGROK=]
```
## NGROK_AUTHTOKEN
```shell
--ngrok-authtoken <NGROK_AUTHTOKEN>
ngrok authentication token
[env: NGROK_AUTHTOKEN=]
```
## NGROK_EDGE
```shell
--ngrok-edge <NGROK_EDGE>
ngrok edge
[env: NGROK_EDGE=]
```
## TOKENIZER_CONFIG_PATH
```shell
--tokenizer-config-path <TOKENIZER_CONFIG_PATH>
The path to the tokenizer config file. This path is used to load the tokenizer configuration which may include a `chat_template`. If not provided, the default config will be used from the model hub
[env: TOKENIZER_CONFIG_PATH=]
```
## ENV
```shell
-e, --env
Display a lot of information about your runtime environment
```
## HELP
```shell
-h, --help
Print help (see a summary with '-h')
```
## VERSION
```shell
-V, --version
Print version
```
| text-generation-inference/docs/source/basic_tutorials/launcher.md/0 | {
"file_path": "text-generation-inference/docs/source/basic_tutorials/launcher.md",
"repo_id": "text-generation-inference",
"token_count": 5833
} | 196 |
{
"details": {
"best_of_sequences": null,
"finish_reason": "length",
"generated_tokens": 10,
"prefill": [
{
"id": 17934,
"logprob": null,
"text": "Pour"
},
{
"id": 49833,
"logprob": -10.5625,
"text": " dég"
},
{
"id": 21543,
"logprob": -0.14770508,
"text": "uster"
},
{
"id": 447,
"logprob": -1.9287109,
"text": " un"
},
{
"id": 46341,
"logprob": -15.4609375,
"text": " ort"
},
{
"id": 35567,
"logprob": -7.5585938,
"text": "olan"
},
{
"id": 15,
"logprob": -1.4003906,
"text": ","
},
{
"id": 1669,
"logprob": -1.5673828,
"text": " il"
},
{
"id": 11580,
"logprob": -0.94628906,
"text": " faut"
},
{
"id": 3913,
"logprob": -3.703125,
"text": " tout"
},
{
"id": 39261,
"logprob": -1.5732422,
"text": " d'abord"
}
],
"seed": 0,
"tokens": [
{
"id": 578,
"logprob": -1.6591797,
"special": false,
"text": " le"
},
{
"id": 5608,
"logprob": -2.4492188,
"special": false,
"text": " faire"
},
{
"id": 159570,
"logprob": -6.6835938,
"special": false,
"text": " réch"
},
{
"id": 810,
"logprob": 0.0,
"special": false,
"text": "au"
},
{
"id": 12736,
"logprob": 0.0,
"special": false,
"text": "ffer"
},
{
"id": 1742,
"logprob": -2.5175781,
"special": false,
"text": " au"
},
{
"id": 6105,
"logprob": -2.0078125,
"special": false,
"text": " bain"
},
{
"id": 88254,
"logprob": -0.12695312,
"special": false,
"text": "-mar"
},
{
"id": 641,
"logprob": 0.0,
"special": false,
"text": "ie"
},
{
"id": 2940,
"logprob": -3.5175781,
"special": false,
"text": " avec"
}
]
},
"generated_text": " le faire réchauffer au bain-marie avec"
}
| text-generation-inference/integration-tests/models/__snapshots__/test_bloom_560m/test_bloom_560m.json/0 | {
"file_path": "text-generation-inference/integration-tests/models/__snapshots__/test_bloom_560m/test_bloom_560m.json",
"repo_id": "text-generation-inference",
"token_count": 1544
} | 197 |
{
"details": {
"best_of_sequences": null,
"finish_reason": "length",
"generated_tokens": 10,
"prefill": [
{
"id": 1,
"logprob": null,
"text": "<s>"
},
{
"id": 4321,
"logprob": -9.59375,
"text": "Test"
},
{
"id": 2009,
"logprob": -9.6640625,
"text": "request"
}
],
"seed": null,
"tokens": [
{
"id": 29918,
"logprob": -2.3867188,
"special": false,
"text": "_"
},
{
"id": 5338,
"logprob": -2.8183594,
"special": false,
"text": "uri"
},
{
"id": 13,
"logprob": -1.6367188,
"special": false,
"text": "\n"
},
{
"id": 3057,
"logprob": -1.0527344,
"special": false,
"text": "Test"
},
{
"id": 2009,
"logprob": -0.6542969,
"special": false,
"text": " request"
},
{
"id": 29918,
"logprob": -0.056121826,
"special": false,
"text": "_"
},
{
"id": 5338,
"logprob": -0.01600647,
"special": false,
"text": "uri"
},
{
"id": 13,
"logprob": -0.87939453,
"special": false,
"text": "\n"
},
{
"id": 3057,
"logprob": -0.7529297,
"special": false,
"text": "Test"
},
{
"id": 2009,
"logprob": -0.2980957,
"special": false,
"text": " request"
}
]
},
"generated_text": "_uri\nTest request_uri\nTest request"
}
| text-generation-inference/integration-tests/models/__snapshots__/test_flash_llama_gptq/test_flash_llama_gptq.json/0 | {
"file_path": "text-generation-inference/integration-tests/models/__snapshots__/test_flash_llama_gptq/test_flash_llama_gptq.json",
"repo_id": "text-generation-inference",
"token_count": 1036
} | 198 |
{
"details": {
"best_of_sequences": null,
"finish_reason": "length",
"generated_tokens": 10,
"prefill": [
{
"id": 563,
"logprob": null,
"text": "def"
},
{
"id": 942,
"logprob": -5.1367188,
"text": " print"
},
{
"id": 62,
"logprob": -0.24450684,
"text": "_"
},
{
"id": 7196,
"logprob": -6.9609375,
"text": "hello"
}
],
"seed": null,
"tokens": [
{
"id": 1241,
"logprob": -0.9863281,
"special": false,
"text": "():"
},
{
"id": 258,
"logprob": -0.21447754,
"special": false,
"text": "\n "
},
{
"id": 942,
"logprob": -0.43701172,
"special": false,
"text": " print"
},
{
"id": 372,
"logprob": -0.5361328,
"special": false,
"text": "(\""
},
{
"id": 7371,
"logprob": -0.44555664,
"special": false,
"text": "Hello"
},
{
"id": 9956,
"logprob": -1.2412109,
"special": false,
"text": " World"
},
{
"id": 8657,
"logprob": -0.7583008,
"special": false,
"text": "!\")"
},
{
"id": 185,
"logprob": -0.76171875,
"special": false,
"text": "\n"
},
{
"id": 185,
"logprob": -0.20837402,
"special": false,
"text": "\n"
},
{
"id": 1018,
"logprob": -1.2470703,
"special": false,
"text": "print"
}
]
},
"generated_text": "():\n print(\"Hello World!\")\n\nprint"
}
| text-generation-inference/integration-tests/models/__snapshots__/test_flash_santacoder/test_flash_santacoder.json/0 | {
"file_path": "text-generation-inference/integration-tests/models/__snapshots__/test_flash_santacoder/test_flash_santacoder.json",
"repo_id": "text-generation-inference",
"token_count": 1111
} | 199 |
[
{
"details": {
"best_of_sequences": null,
"finish_reason": "length",
"generated_tokens": 10,
"prefill": [
{
"id": 50278,
"logprob": null,
"text": "<|USER|>"
},
{
"id": 1276,
"logprob": -4.5546875,
"text": "What"
},
{
"id": 434,
"logprob": -4.1953125,
"text": "'s"
},
{
"id": 634,
"logprob": -5.125,
"text": " your"
},
{
"id": 12315,
"logprob": -9.8828125,
"text": " mood"
},
{
"id": 3063,
"logprob": -3.9980469,
"text": " today"
},
{
"id": 32,
"logprob": -0.14672852,
"text": "?"
},
{
"id": 50279,
"logprob": -0.26489258,
"text": "<|ASSISTANT|>"
}
],
"seed": null,
"tokens": [
{
"id": 42,
"logprob": -0.8618164,
"special": false,
"text": "I"
},
{
"id": 1353,
"logprob": -0.9506836,
"special": false,
"text": "'m"
},
{
"id": 7016,
"logprob": -2.1738281,
"special": false,
"text": " sorry"
},
{
"id": 13,
"logprob": -0.0758667,
"special": false,
"text": ","
},
{
"id": 1394,
"logprob": -0.9135742,
"special": false,
"text": "You"
},
{
"id": 452,
"logprob": -1.1445312,
"special": false,
"text": " have"
},
{
"id": 247,
"logprob": -1.4375,
"special": false,
"text": " a"
},
{
"id": 4327,
"logprob": -1.1103516,
"special": false,
"text": " choice"
},
{
"id": 273,
"logprob": -1.0058594,
"special": false,
"text": " of"
},
{
"id": 752,
"logprob": -1.921875,
"special": false,
"text": " what"
}
]
},
"generated_text": "I'm sorry,You have a choice of what"
},
{
"details": {
"best_of_sequences": null,
"finish_reason": "length",
"generated_tokens": 10,
"prefill": [
{
"id": 50278,
"logprob": null,
"text": "<|USER|>"
},
{
"id": 1276,
"logprob": -4.5546875,
"text": "What"
},
{
"id": 434,
"logprob": -4.1953125,
"text": "'s"
},
{
"id": 634,
"logprob": -5.125,
"text": " your"
},
{
"id": 12315,
"logprob": -9.8828125,
"text": " mood"
},
{
"id": 3063,
"logprob": -3.9980469,
"text": " today"
},
{
"id": 32,
"logprob": -0.14672852,
"text": "?"
},
{
"id": 50279,
"logprob": -0.26489258,
"text": "<|ASSISTANT|>"
}
],
"seed": null,
"tokens": [
{
"id": 42,
"logprob": -0.8618164,
"special": false,
"text": "I"
},
{
"id": 1353,
"logprob": -0.9506836,
"special": false,
"text": "'m"
},
{
"id": 7016,
"logprob": -2.1738281,
"special": false,
"text": " sorry"
},
{
"id": 13,
"logprob": -0.0758667,
"special": false,
"text": ","
},
{
"id": 1394,
"logprob": -0.9135742,
"special": false,
"text": "You"
},
{
"id": 452,
"logprob": -1.1445312,
"special": false,
"text": " have"
},
{
"id": 247,
"logprob": -1.4375,
"special": false,
"text": " a"
},
{
"id": 4327,
"logprob": -1.1103516,
"special": false,
"text": " choice"
},
{
"id": 273,
"logprob": -1.0058594,
"special": false,
"text": " of"
},
{
"id": 752,
"logprob": -1.921875,
"special": false,
"text": " what"
}
]
},
"generated_text": "I'm sorry,You have a choice of what"
},
{
"details": {
"best_of_sequences": null,
"finish_reason": "length",
"generated_tokens": 10,
"prefill": [
{
"id": 50278,
"logprob": null,
"text": "<|USER|>"
},
{
"id": 1276,
"logprob": -4.5546875,
"text": "What"
},
{
"id": 434,
"logprob": -4.1953125,
"text": "'s"
},
{
"id": 634,
"logprob": -5.125,
"text": " your"
},
{
"id": 12315,
"logprob": -9.8828125,
"text": " mood"
},
{
"id": 3063,
"logprob": -3.9980469,
"text": " today"
},
{
"id": 32,
"logprob": -0.14672852,
"text": "?"
},
{
"id": 50279,
"logprob": -0.26489258,
"text": "<|ASSISTANT|>"
}
],
"seed": null,
"tokens": [
{
"id": 42,
"logprob": -0.8618164,
"special": false,
"text": "I"
},
{
"id": 1353,
"logprob": -0.9506836,
"special": false,
"text": "'m"
},
{
"id": 7016,
"logprob": -2.1738281,
"special": false,
"text": " sorry"
},
{
"id": 13,
"logprob": -0.0758667,
"special": false,
"text": ","
},
{
"id": 1394,
"logprob": -0.9135742,
"special": false,
"text": "You"
},
{
"id": 452,
"logprob": -1.1445312,
"special": false,
"text": " have"
},
{
"id": 247,
"logprob": -1.4375,
"special": false,
"text": " a"
},
{
"id": 4327,
"logprob": -1.1103516,
"special": false,
"text": " choice"
},
{
"id": 273,
"logprob": -1.0058594,
"special": false,
"text": " of"
},
{
"id": 752,
"logprob": -1.921875,
"special": false,
"text": " what"
}
]
},
"generated_text": "I'm sorry,You have a choice of what"
},
{
"details": {
"best_of_sequences": null,
"finish_reason": "length",
"generated_tokens": 10,
"prefill": [
{
"id": 50278,
"logprob": null,
"text": "<|USER|>"
},
{
"id": 1276,
"logprob": -4.5546875,
"text": "What"
},
{
"id": 434,
"logprob": -4.1953125,
"text": "'s"
},
{
"id": 634,
"logprob": -5.125,
"text": " your"
},
{
"id": 12315,
"logprob": -9.8828125,
"text": " mood"
},
{
"id": 3063,
"logprob": -3.9980469,
"text": " today"
},
{
"id": 32,
"logprob": -0.14672852,
"text": "?"
},
{
"id": 50279,
"logprob": -0.26489258,
"text": "<|ASSISTANT|>"
}
],
"seed": null,
"tokens": [
{
"id": 42,
"logprob": -0.8618164,
"special": false,
"text": "I"
},
{
"id": 1353,
"logprob": -0.9506836,
"special": false,
"text": "'m"
},
{
"id": 7016,
"logprob": -2.1738281,
"special": false,
"text": " sorry"
},
{
"id": 13,
"logprob": -0.0758667,
"special": false,
"text": ","
},
{
"id": 1394,
"logprob": -0.9135742,
"special": false,
"text": "You"
},
{
"id": 452,
"logprob": -1.1445312,
"special": false,
"text": " have"
},
{
"id": 247,
"logprob": -1.4375,
"special": false,
"text": " a"
},
{
"id": 4327,
"logprob": -1.1103516,
"special": false,
"text": " choice"
},
{
"id": 273,
"logprob": -1.0058594,
"special": false,
"text": " of"
},
{
"id": 752,
"logprob": -1.921875,
"special": false,
"text": " what"
}
]
},
"generated_text": "I'm sorry,You have a choice of what"
}
]
| text-generation-inference/integration-tests/models/__snapshots__/test_neox/test_neox_load.json/0 | {
"file_path": "text-generation-inference/integration-tests/models/__snapshots__/test_neox/test_neox_load.json",
"repo_id": "text-generation-inference",
"token_count": 6296
} | 200 |
import pytest
@pytest.fixture(scope="module")
def flash_phi_handle(launcher):
with launcher("microsoft/phi-2", num_shard=1) as handle:
yield handle
@pytest.fixture(scope="module")
async def flash_phi(flash_phi_handle):
await flash_phi_handle.health(300)
return flash_phi_handle.client
@pytest.mark.asyncio
@pytest.mark.private
async def test_flash_phi(flash_phi, response_snapshot):
response = await flash_phi.generate(
"Test request", max_new_tokens=10, decoder_input_details=True
)
assert response.details.generated_tokens == 10
assert response.generated_text == ': {request}")\n response = self'
assert response == response_snapshot
@pytest.mark.asyncio
@pytest.mark.private
async def test_flash_phi_all_params(flash_phi, response_snapshot):
response = await flash_phi.generate(
"Test request",
max_new_tokens=10,
repetition_penalty=1.2,
return_full_text=True,
stop_sequences=["network"],
temperature=0.5,
top_p=0.9,
top_k=10,
truncate=5,
typical_p=0.9,
watermark=True,
decoder_input_details=True,
seed=0,
)
assert response.details.generated_tokens == 6
assert response.generated_text == "Test request to send data over a network"
assert response == response_snapshot
@pytest.mark.asyncio
@pytest.mark.private
async def test_flash_phi_load(flash_phi, generate_load, response_snapshot):
responses = await generate_load(flash_phi, "Test request", max_new_tokens=10, n=4)
assert len(responses) == 4
assert all(
[r.generated_text == responses[0].generated_text for r in responses]
), f"{[r.generated_text for r in responses]}"
assert responses[0].generated_text == ': {request}")\n response = self'
assert responses == response_snapshot
| text-generation-inference/integration-tests/models/test_flash_phi.py/0 | {
"file_path": "text-generation-inference/integration-tests/models/test_flash_phi.py",
"repo_id": "text-generation-inference",
"token_count": 749
} | 201 |
use std::fmt;
use std::process::Command;
pub(crate) struct Env {
cargo_target: &'static str,
cargo_version: &'static str,
git_sha: &'static str,
docker_label: &'static str,
nvidia_env: String,
}
impl Env {
pub fn new() -> Self {
let nvidia_env = nvidia_smi();
Self {
nvidia_env: nvidia_env.unwrap_or("N/A".to_string()),
cargo_target: env!("VERGEN_CARGO_TARGET_TRIPLE"),
cargo_version: env!("VERGEN_RUSTC_SEMVER"),
git_sha: option_env!("VERGEN_GIT_SHA").unwrap_or("N/A"),
docker_label: option_env!("DOCKER_LABEL").unwrap_or("N/A"),
}
}
}
impl fmt::Display for Env {
fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result {
writeln!(f, "Runtime environment:")?;
writeln!(f, "Target: {}", self.cargo_target)?;
writeln!(f, "Cargo version: {}", self.cargo_version)?;
writeln!(f, "Commit sha: {}", self.git_sha)?;
writeln!(f, "Docker label: {}", self.docker_label)?;
write!(f, "nvidia-smi:\n{}", self.nvidia_env)?;
Ok(())
}
}
fn nvidia_smi() -> Option<String> {
let output = Command::new("nvidia-smi").output().ok()?;
let nvidia_smi = String::from_utf8(output.stdout).ok()?;
let output = nvidia_smi.replace('\n', "\n ");
Some(output.trim().to_string())
}
| text-generation-inference/launcher/src/env_runtime.rs/0 | {
"file_path": "text-generation-inference/launcher/src/env_runtime.rs",
"repo_id": "text-generation-inference",
"token_count": 650
} | 202 |
[package]
name = "grpc-metadata"
version = "0.1.0"
edition = "2021"
[dependencies]
opentelemetry = "^0.20"
tonic = "^0.10"
tracing = "^0.1"
tracing-opentelemetry = "^0.21"
| text-generation-inference/router/grpc-metadata/Cargo.toml/0 | {
"file_path": "text-generation-inference/router/grpc-metadata/Cargo.toml",
"repo_id": "text-generation-inference",
"token_count": 83
} | 203 |
flash_att_v2_commit_cuda := 02ac572f3ffc4f402e4183aaa6824b45859d3ed3
flash_att_v2_commit_rocm := 8736558c287ff2ef28b24878e42828c595ac3e69
flash-attention-v2-cuda:
# Clone flash attention
pip install -U packaging ninja --no-cache-dir
git clone https://github.com/HazyResearch/flash-attention.git flash-attention-v2
build-flash-attention-v2-cuda: flash-attention-v2-cuda
cd flash-attention-v2 && git fetch && git checkout $(flash_att_v2_commit_cuda)
cd flash-attention-v2 && git submodule update --init --recursive
cd flash-attention-v2 && python setup.py build
install-flash-attention-v2-cuda: build-flash-attention-v2-cuda
cd flash-attention-v2 && git submodule update --init --recursive && python setup.py install
flash-attention-v2-rocm:
# Clone flash attention
pip install -U packaging ninja --no-cache-dir
git clone https://github.com/fxmarty/flash-attention-rocm flash-attention-v2
build-flash-attention-v2-rocm: flash-attention-v2-rocm
cd flash-attention-v2 && git fetch && git checkout $(flash_att_v2_commit_rocm)
cd flash-attention-v2 && git submodule update --init --recursive
cd flash-attention-v2 && PYTORCH_ROCM_ARCH=gfx90a python setup.py build
install-flash-attention-v2-rocm: build-flash-attention-v2-rocm
cd flash-attention-v2 && git submodule update --init --recursive && python setup.py install
| text-generation-inference/server/Makefile-flash-att-v2/0 | {
"file_path": "text-generation-inference/server/Makefile-flash-att-v2",
"repo_id": "text-generation-inference",
"token_count": 496
} | 204 |
// Adapted from turboderp exllama: https://github.com/turboderp/exllama
#ifndef _hip_compat_cuh
#define _hip_compat_cuh
// Workaround for a bug in hipamd, backported from upstream, this is fixed in ROCm 5.6.
__device__ __forceinline__ __half __compat_hrcp(__half x) {
return __half_raw{
static_cast<_Float16>(__builtin_amdgcn_rcph(static_cast<__half_raw>(x).data))};
}
__device__ __forceinline__ __half2 __compat_h2rcp(__half2 x) {
return _Float16_2{static_cast<_Float16>(__builtin_amdgcn_rcph(x.x)),
static_cast<_Float16>(__builtin_amdgcn_rcph(x.y))};
}
#define hrcp __compat_hrcp
#define h2rcp __compat_h2rcp
// Automatic conversion of hipblasHgemm doesn't convert half to hipblasHalf.
__host__ __forceinline__ hipblasStatus_t __compat_hipblasHgemm(hipblasHandle_t handle,
hipblasOperation_t transA,
hipblasOperation_t transB,
int m,
int n,
int k,
const half* alpha,
const half* AP,
int lda,
const half* BP,
int ldb,
const half* beta,
half* CP,
int ldc) {
return hipblasHgemm(handle, transA, transB, m, n, k,
reinterpret_cast<const hipblasHalf *>(alpha),
reinterpret_cast<const hipblasHalf *>(AP), lda,
reinterpret_cast<const hipblasHalf *>(BP), ldb,
reinterpret_cast<const hipblasHalf *>(beta),
reinterpret_cast<hipblasHalf *>(CP), ldc);
}
#define hipblasHgemm __compat_hipblasHgemm
// Previous version of PyTorch were converting to rocBLAS instead of hipBLAS.
#define rocblas_handle hipblasHandle_t
#define rocblas_operation_none HIPBLAS_OP_N
#define rocblas_get_stream hipblasGetStream
#define rocblas_set_stream hipblasSetStream
#define rocblas_hgemm __compat_hipblasHgemm
#endif | text-generation-inference/server/exllama_kernels/exllama_kernels/hip_compat.cuh/0 | {
"file_path": "text-generation-inference/server/exllama_kernels/exllama_kernels/hip_compat.cuh",
"repo_id": "text-generation-inference",
"token_count": 1707
} | 205 |
#ifndef _qdq_3_cuh
#define _qdq_3_cuh
#include "qdq_util.cuh"
#include "../../config.h"
#if QMODE_3BIT == 1
// Permutation:
//
// v9997775 55333111 u8886664 44222000 (u, v lsb)
// vjjjhhhf ffdddbbb uiiiggge eecccaaa
// vtttrrrp ppnnnlll usssqqqo oommmkkk
__forceinline__ __device__ void shuffle_3bit_32
(
uint32_t* q,
int stride
)
{
uint32_t qa = q[0 * stride];
uint32_t qb = q[1 * stride];
uint32_t qc = q[2 * stride];
// qa: aa999888 77766655 54443332 22111000
// qb: lkkkjjji iihhhggg fffeeedd dcccbbba
// qc: vvvuuutt tsssrrrq qqpppooo nnnmmmll
uint32_t qd = qc >> 26;
qc <<= 4;
qc |= qb >> 28;
qb <<= 2;
qb |= qa >> 30;
// qa: ..999888 77766655 54443332 22111000
// qb: ..jjjiii hhhgggff feeedddc ccbbbaaa
// qc: ..tttsss rrrqqqpp pooonnnm mmlllkkk
// qd: vvvuuu
uint32_t za = 0;
uint32_t zb = 0;
uint32_t zc = 0;
for (int i = 0; i < 5; i++) { uint32_t t0 = qa & 0x07; uint32_t t1 = (qa & 0x38) >> 3; qa >>= 6; za |= (t0 << (i * 3)); za |= (t1 << (i * 3 + 16)); }
for (int i = 0; i < 5; i++) { uint32_t t0 = qb & 0x07; uint32_t t1 = (qb & 0x38) >> 3; qb >>= 6; zb |= (t0 << (i * 3)); zb |= (t1 << (i * 3 + 16)); }
for (int i = 0; i < 5; i++) { uint32_t t0 = qc & 0x07; uint32_t t1 = (qc & 0x38) >> 3; qc >>= 6; zc |= (t0 << (i * 3)); zc |= (t1 << (i * 3 + 16)); }
// za: 9997775 55333111 8886664 44222000
// zb: jjjhhhf ffdddbbb iiiggge eecccaaa
// zc: tttrrrp ppnnnlll sssqqqo oommmkkk
// qd: vvvuuu
za |= ((qd & 0x01) >> 0) << 15;
zb |= ((qd & 0x02) >> 1) << 15;
zc |= ((qd & 0x04) >> 2) << 15;
za |= ((qd & 0x08) >> 3) << 31;
zb |= ((qd & 0x10) >> 4) << 31;
zc |= ((qd & 0x20) >> 5) << 31;
// za: v9997775 55333111 u8886664 44222000 (u, v lsb)
// zb: vjjjhhhf ffdddbbb uiiiggge eecccaaa
// zc: vtttrrrp ppnnnlll usssqqqo oommmkkk
q[0 * stride] = za;
q[1 * stride] = zb;
q[2 * stride] = zc;
}
__forceinline__ __device__ void dequant_3bit_32
(
const uint32_t q_0,
const uint32_t q_1,
const uint32_t q_2,
half2 (&dq)[16],
int stride
)
{
const uint32_t c0 = 0x64006400;
const half y8_ = __float2half_rn(1.0f / 8.0f);
const half y64_ = __float2half_rn(1.0f / 64.0f);
const half2 y8 = __halves2half2(y8_, y8_);
const half2 y64 = __halves2half2(y64_, y64_);
const half z1_ = __float2half_rn(-1024.0f - 4.0f);
const half z8_ = __float2half_rn(-1024.0f / 8.0f - 4.0f);
const half z64_ = __float2half_rn(-1024.0f / 64.0f - 4.0f);
const half2 z1 = __halves2half2(z1_, z1_);
const half2 z8 = __halves2half2(z8_, z8_);
const half2 z64 = __halves2half2(z64_, z64_);
uint32_t qa = q_0;
uint32_t qb = q_1;
uint32_t qc = q_2;
half2_uint32 q0((qa & 0x00070007) | c0); // half2(q[ 0], q[ 1]) + 1024
half2_uint32 q1((qa & 0x00380038) | c0); // half2(q[ 2], q[ 3]) * 8 + 1024
qa >>= 6;
half2_uint32 q2((qa & 0x00070007) | c0); // half2(q[ 4], q[ 5]) + 1024
half2_uint32 q3((qa & 0x00380038) | c0); // half2(q[ 6], q[ 7]) * 8 + 1024
half2_uint32 q4((qa & 0x01c001c0) | c0); // half2(q[ 8], q[ 9]) * 64 + 1024
qa >>= 9;
qa &= 0x00010001;
half2_uint32 q5((qb & 0x00070007) | c0); // half2(q[10], q[11]) + 1024
half2_uint32 q6((qb & 0x00380038) | c0); // half2(q[12], q[13]) * 8 + 1024
qb >>= 6;
half2_uint32 q7((qb & 0x00070007) | c0); // half2(q[14], q[15]) + 1024
half2_uint32 q8((qb & 0x00380038) | c0); // half2(q[16], q[17]) * 8 + 1024
half2_uint32 q9((qb & 0x01c001c0) | c0); // half2(q[18], q[19]) * 64 + 1024
qb >>= 8;
qb &= 0x00020002;
half2_uint32 q10((qc & 0x00070007) | c0); // half2(q[20], q[21]) + 1024
half2_uint32 q11((qc & 0x00380038) | c0); // half2(q[22], q[23]) * 8 + 1024
qc >>= 6;
half2_uint32 q12((qc & 0x00070007) | c0); // half2(q[24], q[25]) + 1024
half2_uint32 q13((qc & 0x00380038) | c0); // half2(q[26], q[27]) * 8 + 1024
half2_uint32 q14((qc & 0x01c001c0) | c0); // half2(q[28], q[29]) * 64 + 1024
qc >>= 7;
qc &= 0x00040004;
half2_uint32 q15((qa | qb | qc) | c0);
dq[ 0] = __hadd2( q0.as_half2, z1);
dq[ 1] = __hfma2( q1.as_half2, y8, z8);
dq[ 2] = __hadd2( q2.as_half2, z1);
dq[ 3] = __hfma2( q3.as_half2, y8, z8);
dq[ 4] = __hfma2( q4.as_half2, y64, z64);
dq[ 5] = __hadd2( q5.as_half2, z1);
dq[ 6] = __hfma2( q6.as_half2, y8, z8);
dq[ 7] = __hadd2( q7.as_half2, z1);
dq[ 8] = __hfma2( q8.as_half2, y8, z8);
dq[ 9] = __hfma2( q9.as_half2, y64, z64);
dq[10] = __hadd2(q10.as_half2, z1);
dq[11] = __hfma2(q11.as_half2, y8, z8);
dq[12] = __hadd2(q12.as_half2, z1);
dq[13] = __hfma2(q13.as_half2, y8, z8);
dq[14] = __hfma2(q14.as_half2, y64, z64);
dq[15] = __hadd2(q15.as_half2, z1);
}
#else
__forceinline__ __device__ void shuffle_3bit_32
(
uint32_t* q,
int stride
)
{
}
__forceinline__ __device__ void dequant_3bit_32
(
const uint32_t q_0,
const uint32_t q_1,
const uint32_t q_2,
half2 (&dq)[16],
int stride
)
{
half dqh[32];
for (int i = 0; i < 10; i++) dqh[ i] = dq_ns(exb( q_0, i * 3 , 0x07), 4);
dqh[10 ] = dq_ns(exb(q_1, q_0, 30, 0x07), 4);
for (int i = 0; i < 10; i++) dqh[11 + i] = dq_ns(exb( q_1, i * 3 + 1, 0x07), 4);
dqh[21 ] = dq_ns(exb(q_2, q_1, 31, 0x07), 4);
for (int i = 0; i < 10; i++) dqh[22 + i] = dq_ns(exb( q_2, i * 3 + 2, 0x07), 4);
for (int i = 0; i < 16; i++) dq[i] = __halves2half2(dqh[i * 2], dqh[i * 2 + 1]);
}
#endif
#endif
| text-generation-inference/server/exllamav2_kernels/exllamav2_kernels/cuda/quant/qdq_3.cuh/0 | {
"file_path": "text-generation-inference/server/exllamav2_kernels/exllamav2_kernels/cuda/quant/qdq_3.cuh",
"repo_id": "text-generation-inference",
"token_count": 3335
} | 206 |
import pytest
import torch
from copy import copy
from transformers import AutoTokenizer
from text_generation_server.pb import generate_pb2
from text_generation_server.models.causal_lm import CausalLM, CausalLMBatch
@pytest.fixture(scope="session")
def default_causal_lm():
return CausalLM("gpt2")
@pytest.fixture(scope="session")
def gpt2_tokenizer():
tokenizer = AutoTokenizer.from_pretrained("gpt2", padding_side="left")
tokenizer.pad_token_id = 50256
return tokenizer
@pytest.fixture
def default_pb_request(default_pb_parameters, default_pb_stop_parameters):
return generate_pb2.Request(
id=0,
inputs="Test",
prefill_logprobs=True,
truncate=100,
parameters=default_pb_parameters,
stopping_parameters=default_pb_stop_parameters,
)
@pytest.fixture
def default_pb_batch(default_pb_request):
return generate_pb2.Batch(id=0, requests=[default_pb_request], size=1)
@pytest.fixture
def default_causal_lm_batch(default_pb_batch, gpt2_tokenizer):
return CausalLMBatch.from_pb(
default_pb_batch, gpt2_tokenizer, torch.float32, torch.device("cpu")
)
@pytest.fixture
def default_multi_requests_causal_lm_batch(default_pb_request, gpt2_tokenizer):
req_0 = copy(default_pb_request)
req_0.id = 1
req_1 = default_pb_request
req_1.id = 2
req_1.stopping_parameters.max_new_tokens = 5
batch_pb = generate_pb2.Batch(id=1, requests=[req_0, req_1], size=2)
return CausalLMBatch.from_pb(
batch_pb, gpt2_tokenizer, torch.float32, torch.device("cpu")
)
def test_batch_from_pb(default_pb_batch, default_causal_lm_batch):
batch = default_causal_lm_batch
assert batch.batch_id == default_pb_batch.id
assert batch.requests == default_pb_batch.requests
assert len(batch.input_ids) == default_pb_batch.size
assert batch.input_ids[0][-1] == 14402
assert torch.all(batch.input_ids[0][:-1] == 50256)
assert batch.attention_mask[0, 0] == 1
assert torch.all(batch.attention_mask[0, 1:] == 0)
assert batch.past_key_values is None
assert all(
[
torch.equal(input_ids, all_input_ids[:, 0])
for input_ids, all_input_ids in zip(batch.input_ids, batch.all_input_ids)
]
)
assert batch.input_lengths == [1]
assert len(batch) == default_pb_batch.size
assert len(batch.next_token_choosers) == len(batch.stopping_criterias) == len(batch)
assert batch.max_input_length == batch.input_lengths[0]
def test_batch_concatenate_no_prefill(default_causal_lm_batch):
with pytest.raises(ValueError):
CausalLMBatch.concatenate([default_causal_lm_batch, default_causal_lm_batch])
def test_causal_lm_batch_type(default_causal_lm):
assert default_causal_lm.batch_type == CausalLMBatch
def test_causal_lm_generate_token(default_causal_lm, default_causal_lm_batch):
sequence_length = len(default_causal_lm_batch.all_input_ids[0])
generations, next_batch, _ = default_causal_lm.generate_token(
default_causal_lm_batch
)
assert len(generations) == len(next_batch)
assert isinstance(next_batch, CausalLMBatch)
assert len(next_batch.all_input_ids) == len(next_batch)
assert len(next_batch.all_input_ids[0]) == sequence_length + 1
assert len(next_batch.attention_mask[0]) == 11
assert next_batch.all_input_ids[0][-1] == 13
assert next_batch.all_input_ids[0][-2] == 14402
assert torch.all(next_batch.all_input_ids[0][:-2] == 50256)
assert torch.all(next_batch.attention_mask[0][0:2] == 1)
assert torch.all(next_batch.attention_mask[0][2:] == 0)
assert next_batch.input_ids.shape == (len(next_batch), 1)
assert next_batch.input_ids[0, 0] == 13
assert next_batch.input_lengths == [2]
assert next_batch.max_input_length == next_batch.input_lengths[0]
assert next_batch.past_key_values is not None
assert all(
[p[0].shape == (1, 12, sequence_length, 64) for p in next_batch.past_key_values]
)
assert all(
[p[1].shape == (1, 12, sequence_length, 64) for p in next_batch.past_key_values]
)
assert all([generation.generated_text is None for generation in generations])
assert all([len(generation.prefill_tokens) == 1 for generation in generations])
assert all(
[
token_id.item() == 13
for generation in generations
for token_id in generation.tokens.token_ids
]
)
assert all(
[
token_text == "."
for generation in generations
for token_text in generation.tokens.texts
]
)
assert generations[0].request_id == 0
def test_causal_lm_generate_token_completion(
default_causal_lm, default_causal_lm_batch
):
next_batch = default_causal_lm_batch
for _ in range(default_causal_lm_batch.stopping_criterias[0].max_new_tokens - 1):
generations, next_batch, _ = default_causal_lm.generate_token(next_batch)
assert len(generations) == len(next_batch)
generations, next_batch, _ = default_causal_lm.generate_token(next_batch)
assert next_batch is None
assert len(generations) == 1
assert generations[0].generated_text.text == ".java:784) at net.minecraft."
assert generations[0].request_id == default_causal_lm_batch.requests[0].id
assert (
generations[0].generated_text.generated_tokens
== default_causal_lm_batch.stopping_criterias[0].max_new_tokens
)
def test_causal_lm_generate_token_completion_multi(
default_causal_lm, default_multi_requests_causal_lm_batch
):
next_batch = default_multi_requests_causal_lm_batch
for i in range(
default_multi_requests_causal_lm_batch.stopping_criterias[1].max_new_tokens - 1
):
generations, next_batch, _ = default_causal_lm.generate_token(next_batch)
assert len(generations) == len(next_batch)
generations, next_batch, _ = default_causal_lm.generate_token(next_batch)
assert next_batch is not None
assert len(generations) == 2
assert generations[1].generated_text.text == ".java:784)"
assert (
generations[1].request_id
== default_multi_requests_causal_lm_batch.requests[1].id
)
assert (
generations[1].generated_text.generated_tokens
== default_multi_requests_causal_lm_batch.stopping_criterias[1].max_new_tokens
)
# Copy stopping_criterias before filtering
stopping_criterias = (
default_multi_requests_causal_lm_batch.stopping_criterias.copy()
)
next_batch = next_batch.filter([next_batch.requests[0].id])
for _ in range(
stopping_criterias[0].max_new_tokens - stopping_criterias[1].max_new_tokens - 1
):
generations, next_batch, _ = default_causal_lm.generate_token(next_batch)
assert len(generations) == len(next_batch)
generations, next_batch, _ = default_causal_lm.generate_token(next_batch)
assert next_batch is None
assert len(generations) == 1
assert generations[0].generated_text.text == ".java:784) at net.minecraft."
assert (
generations[0].request_id
== default_multi_requests_causal_lm_batch.requests[0].id
)
assert (
generations[0].generated_text.generated_tokens
== default_multi_requests_causal_lm_batch.stopping_criterias[0].max_new_tokens
)
def test_batch_concatenate(
default_causal_lm, default_causal_lm_batch, default_multi_requests_causal_lm_batch
):
next_batch_0 = default_causal_lm_batch
_, next_batch_0, _ = default_causal_lm.generate_token(next_batch_0)
_, next_batch_0, _ = default_causal_lm.generate_token(next_batch_0)
next_batch_1 = default_multi_requests_causal_lm_batch
_, next_batch_1, _ = default_causal_lm.generate_token(next_batch_1)
# Clone past_key_values before concatenating to compare after,
# because they are removed from the concatenated batches
next_batch_0_past_key_values = [
(k.clone(), v.clone()) for (k, v) in next_batch_0.past_key_values
]
next_batch_1_past_key_values = [
(k.clone(), v.clone()) for (k, v) in next_batch_1.past_key_values
]
next_batch = CausalLMBatch.concatenate([next_batch_0, next_batch_1])
assert torch.equal(next_batch.all_input_ids[0], next_batch_0.all_input_ids[0])
assert torch.equal(next_batch.all_input_ids[1], next_batch_1.all_input_ids[0])
assert torch.equal(next_batch.all_input_ids[2], next_batch_1.all_input_ids[1])
assert torch.all(
next_batch.attention_mask[0, : -next_batch.padding_right_offset] == 1
)
assert torch.all(
next_batch.attention_mask[1:, 1 : -next_batch.padding_right_offset] == 1
)
assert torch.all(next_batch.attention_mask[1:, 3:] == 0)
assert next_batch.batch_id == 0
assert next_batch.input_ids[0, 0] == 12355
assert torch.all(next_batch.input_ids[1:] == 13)
assert next_batch.input_lengths == [3, 2, 2]
assert next_batch.max_input_length == 3
assert next_batch.requests[0] == next_batch_0.requests[0]
assert next_batch.requests[1:] == next_batch_1.requests
assert next_batch.next_token_choosers[0] == next_batch_0.next_token_choosers[0]
assert next_batch.next_token_choosers[1:] == next_batch_1.next_token_choosers
assert next_batch.stopping_criterias[0] == next_batch_0.stopping_criterias[0]
assert next_batch.stopping_criterias[1:] == next_batch_1.stopping_criterias
assert next_batch.past_key_values is not None
assert all([p[0].shape == (3, 12, 2, 64) for p in next_batch.past_key_values])
assert all([p[1].shape == (3, 12, 2, 64) for p in next_batch.past_key_values])
for i, past in enumerate(next_batch.past_key_values):
assert torch.equal(next_batch_0_past_key_values[i][0][0, :, -2:], past[0][0])
assert torch.equal(
next_batch_1_past_key_values[i][0][:, :, -1:], past[0][1:, :, -1:, :]
)
assert torch.equal(next_batch_0_past_key_values[i][1][0, :, -2:], past[1][0])
assert torch.equal(
next_batch_1_past_key_values[i][1][:, :, -1:], past[1][1:, :, -1:, :]
)
for _ in range(
default_multi_requests_causal_lm_batch.stopping_criterias[1].max_new_tokens - 2
):
generations, next_batch, _ = default_causal_lm.generate_token(next_batch)
assert len(generations) == len(next_batch)
generations, next_batch, _ = default_causal_lm.generate_token(next_batch)
assert next_batch is not None
assert len(generations) == 3
assert generations[2].generated_text.text == ".java:784)"
assert (
generations[2].request_id
== default_multi_requests_causal_lm_batch.requests[1].id
)
assert (
generations[2].generated_text.generated_tokens
== default_multi_requests_causal_lm_batch.stopping_criterias[1].max_new_tokens
)
next_batch = next_batch.filter(
[next_batch.requests[0].id, next_batch.requests[1].id]
)
for _ in range(
default_causal_lm_batch.stopping_criterias[0].max_new_tokens
- default_multi_requests_causal_lm_batch.stopping_criterias[1].max_new_tokens
- 2
):
generations, next_batch, _ = default_causal_lm.generate_token(next_batch)
assert len(generations) == len(next_batch)
generations, next_batch, _ = default_causal_lm.generate_token(next_batch)
assert next_batch is not None
assert len(generations) == 2
assert generations[0].generated_text.text == ".java:784) at net.minecraft."
assert generations[0].request_id == default_causal_lm_batch.requests[0].id
assert (
generations[0].generated_text.generated_tokens
== default_causal_lm_batch.stopping_criterias[0].max_new_tokens
)
next_batch = next_batch.filter([next_batch.requests[1].id])
for _ in range(
default_multi_requests_causal_lm_batch.stopping_criterias[0].max_new_tokens
- default_causal_lm_batch.stopping_criterias[0].max_new_tokens
- default_multi_requests_causal_lm_batch.stopping_criterias[1].max_new_tokens
- 4
):
generations, next_batch, _ = default_causal_lm.generate_token(next_batch)
assert len(generations) == len(next_batch)
generations, next_batch, _ = default_causal_lm.generate_token(next_batch)
assert next_batch is None
assert len(generations) == 1
assert generations[0].generated_text.text == ".java:784) at net.minecraft."
assert (
generations[0].request_id
== default_multi_requests_causal_lm_batch.requests[0].id
)
assert (
generations[0].generated_text.generated_tokens
== default_multi_requests_causal_lm_batch.stopping_criterias[0].max_new_tokens
)
| text-generation-inference/server/tests/models/test_causal_lm.py/0 | {
"file_path": "text-generation-inference/server/tests/models/test_causal_lm.py",
"repo_id": "text-generation-inference",
"token_count": 5345
} | 207 |
import torch
import time
from dataclasses import dataclass
from opentelemetry import trace
from transformers import AutoTokenizer, AutoModelForCausalLM, PreTrainedTokenizerBase
from typing import Optional, Tuple, List, Type, Dict
from text_generation_server.models import Model
from text_generation_server.utils.tokens import batch_top_tokens
from text_generation_server.models.types import (
Batch,
Tokens,
Generation,
GeneratedText,
)
from text_generation_server.pb import generate_pb2
from text_generation_server.utils import NextTokenChooser, StoppingCriteria, Sampling
tracer = trace.get_tracer(__name__)
@dataclass
class CausalLMBatch(Batch):
batch_id: int
requests: List[generate_pb2.Request]
requests_idx_mapping: Dict[int, int]
# Decoder values
input_ids: torch.Tensor
attention_mask: torch.Tensor
position_ids: torch.Tensor
past_key_values: Optional[List[Tuple]]
# All tokens
all_input_ids: List[torch.Tensor]
# Lengths of all generations present in the batch
input_lengths: List[int]
prefix_offsets: List[int]
read_offsets: List[int]
# Generation helpers
next_token_choosers: List[NextTokenChooser]
stopping_criterias: List[StoppingCriteria]
top_n_tokens: List[int]
top_n_tokens_tensor: torch.Tensor
# Metadata used for padding
max_input_length: int
padding_right_offset: int
# Maximum number of tokens this batch will grow to
max_tokens: int
# Past metadata
keys_head_dim_last: bool = True
def to_pb(self) -> generate_pb2.CachedBatch:
return generate_pb2.CachedBatch(
id=self.batch_id,
request_ids=[r.id for r in self.requests],
size=len(self),
max_tokens=self.max_tokens,
)
@classmethod
def from_pb(
cls,
pb: generate_pb2.Batch,
tokenizer: PreTrainedTokenizerBase,
dtype: torch.dtype,
device: torch.device,
) -> "CausalLMBatch":
inputs = []
next_token_choosers = []
stopping_criterias = []
top_n_tokens = []
prefix_offsets = []
read_offsets = []
requests_idx_mapping = {}
# Parse batch
max_truncation = 0
padding_right_offset = 0
max_decode_tokens = 0
for i, r in enumerate(pb.requests):
requests_idx_mapping[r.id] = i
inputs.append(r.inputs)
next_token_choosers.append(NextTokenChooser.from_pb(r.parameters, device))
stopping_criteria = StoppingCriteria.from_pb(
r.stopping_parameters, tokenizer
)
stopping_criterias.append(stopping_criteria)
top_n_tokens.append(r.top_n_tokens)
max_truncation = max(max_truncation, r.truncate)
max_decode_tokens += stopping_criteria.max_new_tokens
padding_right_offset = max(
padding_right_offset, stopping_criteria.max_new_tokens
)
tokenized_inputs = tokenizer(
inputs,
return_tensors="pt",
padding=True,
return_token_type_ids=False,
truncation=True,
max_length=max_truncation,
).to(device)
for _ in pb.requests:
input_len = tokenized_inputs["input_ids"].shape[1]
prefix_offsets.append(input_len - 5)
read_offsets.append(input_len)
input_lengths = tokenized_inputs["attention_mask"].sum(1)
max_input_length = input_lengths.max()
input_ids = tokenized_inputs["input_ids"]
# Allocate maximum attention_mask
attention_mask = input_ids.new_zeros(
(pb.size, max_input_length + padding_right_offset)
)
# Copy tokenizer attention_mask into fully allocated attention_mask
attention_mask[:, :max_input_length] = tokenized_inputs["attention_mask"]
position_ids = tokenized_inputs["attention_mask"].long().cumsum(-1) - 1
position_ids.masked_fill_(tokenized_inputs["attention_mask"] == 0, 1)
all_input_ids = tokenized_inputs["input_ids"].T.split(1, dim=1)
top_n_tokens_tensor = torch.tensor(
top_n_tokens, device=device, dtype=torch.int64
)
max_tokens = len(inputs) * (max_input_length + max_decode_tokens)
return cls(
batch_id=pb.id,
requests=pb.requests,
requests_idx_mapping=requests_idx_mapping,
input_ids=input_ids,
attention_mask=attention_mask,
position_ids=position_ids,
past_key_values=None,
all_input_ids=list(all_input_ids),
input_lengths=input_lengths.tolist(),
prefix_offsets=prefix_offsets,
read_offsets=read_offsets,
next_token_choosers=next_token_choosers,
stopping_criterias=stopping_criterias,
top_n_tokens=top_n_tokens,
top_n_tokens_tensor=top_n_tokens_tensor,
max_input_length=max_input_length.item(),
padding_right_offset=padding_right_offset,
max_tokens=max_tokens,
)
@tracer.start_as_current_span("filter")
def filter(self, request_ids: List[int]) -> Optional["CausalLMBatch"]:
if len(request_ids) == 0:
raise ValueError("Batch must have at least one request")
if len(request_ids) == len(self):
return self
keep_indices = []
# New values after filtering
requests_idx_mapping = {}
requests = []
input_lengths = []
prefix_offsets = []
read_offsets = []
all_input_ids = []
max_input_length = 0
next_token_choosers = []
stopping_criterias = []
top_n_tokens = []
total_remaining_decode_tokens = 0
new_padding_right_offset = 0
for i, request_id in enumerate(request_ids):
idx = self.requests_idx_mapping[request_id]
requests_idx_mapping[request_id] = i
keep_indices.append(idx)
requests.append(self.requests[idx])
prefix_offsets.append(self.prefix_offsets[idx])
read_offsets.append(self.read_offsets[idx])
all_input_ids.append(self.all_input_ids[idx])
request_input_length = self.input_lengths[idx]
input_lengths.append(request_input_length)
max_input_length = max(max_input_length, request_input_length)
next_token_choosers.append(self.next_token_choosers[idx])
stopping_criteria = self.stopping_criterias[idx]
stopping_criterias.append(stopping_criteria)
top_n_tokens.append(self.top_n_tokens[idx])
remaining_decode_tokens = (
stopping_criteria.max_new_tokens - stopping_criteria.current_tokens
)
total_remaining_decode_tokens += remaining_decode_tokens
new_padding_right_offset = max(
new_padding_right_offset, remaining_decode_tokens
)
# Apply indices to input_ids, attention mask, past key values and other items that need to be cached
input_ids = self.input_ids[keep_indices]
position_ids = self.position_ids[keep_indices]
self.attention_mask = self.attention_mask[
keep_indices,
-(self.padding_right_offset + max_input_length) : (
self.attention_mask.shape[1] - self.padding_right_offset
)
+ new_padding_right_offset,
]
# Ensure that past_key_values tensors can be updated in-place
if type(self.past_key_values[0]) == tuple:
self.past_key_values = [list(layer) for layer in self.past_key_values]
# Update tensors in-place to allow incremental garbage collection
past_kv_length = max_input_length - 1
for layer in self.past_key_values:
past_keys, past_values = layer
if len(past_keys.shape) == 3:
# Force past to be of dim [self_size, num_heads, ...] for easy indexing
past_keys = past_keys.view(len(self), -1, *past_keys.shape[-2:])
past_values = past_values.view(len(self), -1, *past_values.shape[-2:])
if self.keys_head_dim_last:
layer[0] = past_keys[keep_indices, :, -past_kv_length:, :]
else:
layer[0] = past_keys[keep_indices, :, :, -past_kv_length:]
del past_keys
layer[1] = past_values[keep_indices, :, -past_kv_length:, :]
del past_values
top_n_tokens_tensor = self.top_n_tokens_tensor[keep_indices]
max_tokens = len(request_ids) * max_input_length + total_remaining_decode_tokens
self.requests = requests
self.requests_idx_mapping = requests_idx_mapping
self.input_ids = input_ids
self.position_ids = position_ids
self.all_input_ids = all_input_ids
self.input_lengths = input_lengths
self.prefix_offsets = prefix_offsets
self.read_offsets = read_offsets
self.next_token_choosers = next_token_choosers
self.stopping_criterias = stopping_criterias
self.top_n_tokens = top_n_tokens
self.top_n_tokens_tensor = top_n_tokens_tensor
self.max_input_length = max_input_length
self.padding_right_offset = new_padding_right_offset
self.max_tokens = max_tokens
return self
@classmethod
@tracer.start_as_current_span("concatenate")
def concatenate(cls, batches: List["CausalLMBatch"]) -> "CausalLMBatch":
# Used for padding
total_batch_size = 0
max_input_length = 0
padding_right_offset = 0
for batch in batches:
total_batch_size += len(batch)
max_input_length = max(max_input_length, batch.max_input_length)
padding_right_offset = max(padding_right_offset, batch.padding_right_offset)
# Batch attributes
requests = []
requests_idx_mapping = {}
input_lengths = []
prefix_offsets = []
read_offsets = []
all_input_ids = []
next_token_choosers = []
stopping_criterias = []
top_n_tokens = []
max_tokens = 0
# Batch tensors
input_ids = None
attention_mask = None
position_ids = None
past_key_values = []
top_n_tokens_tensor = None
# Used for slicing correctly inside the tensors
# Equivalent to a cumsum on batch sizes
start_index = 0
for i, batch in enumerate(batches):
requests.extend(batch.requests)
input_lengths.extend(batch.input_lengths)
prefix_offsets.extend(batch.prefix_offsets)
read_offsets.extend(batch.read_offsets)
all_input_ids.extend(batch.all_input_ids)
next_token_choosers.extend(batch.next_token_choosers)
stopping_criterias.extend(batch.stopping_criterias)
top_n_tokens.extend(batch.top_n_tokens)
if i == 0:
requests_idx_mapping = batch.requests_idx_mapping
else:
# We need to offset the mapping for each batch by the cumulative batch size
for k, v in batch.requests_idx_mapping.items():
requests_idx_mapping[k] = v + start_index
# Slicing end index for this batch
end_index = start_index + len(batch)
# We only concatenate batches that did at least one step
if batch.past_key_values is None:
raise ValueError("only concatenate prefilled batches")
# Create empty tensor
# input_ids is always of shape [batch_size, 1]
# We do not need to pad it
if input_ids is None:
input_ids = batch.input_ids.new_empty((total_batch_size, 1))
# Copy to correct indices
input_ids[start_index:end_index] = batch.input_ids
# Create padded tensor
if attention_mask is None:
attention_mask = batch.attention_mask.new_zeros(
(total_batch_size, max_input_length + padding_right_offset),
)
if top_n_tokens_tensor is None:
top_n_tokens_tensor = batches[0].top_n_tokens_tensor.new_zeros(
total_batch_size,
)
top_n_tokens_tensor[start_index:end_index] = batch.top_n_tokens_tensor
# We need to slice the attention mask to remove padding from previous steps
# and to remove unused allocated space
left_offset = max_input_length - batch.max_input_length
batch_left_offset = (
batch.attention_mask.shape[1]
- batch.max_input_length
- batch.padding_right_offset
)
attention_mask[
start_index:end_index,
left_offset:-padding_right_offset,
] = batch.attention_mask[
:,
batch_left_offset : -batch.padding_right_offset,
]
# Create empty tensor
# position_ids is always of shape [batch_size, 1]
if position_ids is None:
position_ids = batch.position_ids.new_empty((total_batch_size, 1))
position_ids[start_index:end_index] = batch.position_ids
# Shenanigans to get dimensions because BLOOM outputs a past with a different shape
# BLOOM Keys: [batch_size * num_heads, head_dim, seq_length]
# BLOOM Values: [batch_size * num_heads, seq_length, head_dim]
# And ensure that we can update tensors in-place
if type(batch.past_key_values[0]) == tuple:
batch.past_key_values = [
[t.view(len(batch), -1, *t.shape[-2:]) for t in layer]
for layer in batch.past_key_values
]
elif len(batch.past_key_values[0][0].shape) == 3:
for layer in batch.past_key_values:
for k, t in enumerate(layer):
layer[k] = t.view(len(batch), -1, *t.shape[-2:])
# Add eventual padding tokens that were added while concatenating
max_tokens += batch.max_tokens + (
max_input_length - batch.max_input_length
) * len(batch)
start_index = end_index
first_past_kvs = batches[0].past_key_values
_, num_heads, padded_sequence_length, head_dim = first_past_kvs[0][1].shape
padded_past_values_shape = (
total_batch_size,
num_heads,
max_input_length - 1,
head_dim,
)
if batches[0].keys_head_dim_last:
padded_past_keys_shape = padded_past_values_shape
else:
# seq_length is last for BLOOM
padded_past_keys_shape = (
total_batch_size,
num_heads,
head_dim,
max_input_length - 1,
)
# Iterate over attention layers
# Concatenate past key values layer by layer to allow incremental garbage collection
for j in range(len(first_past_kvs)):
padded_past_keys = first_past_kvs[j][0].new_zeros(padded_past_keys_shape)
start_index = 0
for batch in batches:
past_keys = batch.past_key_values[j][0]
# Clear reference to the original tensor
batch.past_key_values[j][0] = None
# Slicing end index for this batch
end_index = start_index + len(batch)
# We slice the keys to remove the padding from previous batches
past_seq_len = batch.max_input_length - 1
if batch.keys_head_dim_last:
padded_past_keys[
start_index:end_index, :, -past_seq_len:, :
] = past_keys[:, :, -past_seq_len:, :]
else:
# BLOOM case
padded_past_keys[
start_index:end_index, :, :, -past_seq_len:
] = past_keys[:, :, :, -past_seq_len:]
del past_keys
start_index = end_index
padded_past_values = first_past_kvs[j][1].new_zeros(
padded_past_values_shape
)
start_index = 0
for batch in batches:
past_values = batch.past_key_values[j][1]
# Clear reference to the original tensor
batch.past_key_values[j][1] = None
# Slicing end index for this batch
end_index = start_index + len(batch)
# We slice the past values to remove the padding from previous batches
past_seq_len = batch.max_input_length - 1
padded_past_values[
start_index:end_index, :, -past_seq_len:, :
] = past_values[:, :, -past_seq_len:, :]
del past_values
# Update values
start_index = end_index
past_key_values.append([padded_past_keys, padded_past_values])
return cls(
batch_id=batches[0].batch_id,
requests=requests,
requests_idx_mapping=requests_idx_mapping,
input_ids=input_ids,
attention_mask=attention_mask,
position_ids=position_ids,
past_key_values=past_key_values,
all_input_ids=all_input_ids,
input_lengths=input_lengths,
prefix_offsets=prefix_offsets,
read_offsets=read_offsets,
next_token_choosers=next_token_choosers,
stopping_criterias=stopping_criterias,
top_n_tokens=top_n_tokens,
top_n_tokens_tensor=top_n_tokens_tensor,
max_input_length=max_input_length,
padding_right_offset=padding_right_offset,
keys_head_dim_last=batches[0].keys_head_dim_last,
max_tokens=max_tokens,
)
def __len__(self):
return len(self.requests)
class CausalLM(Model):
def __init__(
self,
model_id: str,
revision: Optional[str] = None,
quantize: Optional[str] = None,
dtype: Optional[torch.dtype] = None,
trust_remote_code: bool = False,
):
if torch.cuda.is_available():
device = torch.device("cuda")
dtype = torch.float16 if dtype is None else dtype
else:
if quantize:
raise ValueError("quantization is not available on CPU")
device = torch.device("cpu")
dtype = torch.float32 if dtype is None else dtype
tokenizer = AutoTokenizer.from_pretrained(
model_id,
revision=revision,
padding_side="left",
truncation_side="left",
trust_remote_code=trust_remote_code,
)
model = AutoModelForCausalLM.from_pretrained(
model_id,
revision=revision,
torch_dtype=dtype,
device_map="auto"
if torch.cuda.is_available() and torch.cuda.device_count() > 1
else None,
load_in_8bit=quantize == "bitsandbytes",
trust_remote_code=trust_remote_code,
)
if (
torch.cuda.is_available()
and torch.cuda.device_count() == 1
and quantize != "bitsandbytes"
):
model = model.cuda()
if tokenizer.pad_token_id is None:
if model.config.pad_token_id is not None:
tokenizer.pad_token_id = model.config.pad_token_id
elif model.config.eos_token_id is not None:
tokenizer.pad_token_id = model.config.eos_token_id
elif tokenizer.eos_token_id is not None:
tokenizer.pad_token_id = tokenizer.eos_token_id
else:
tokenizer.add_special_tokens({"pad_token": "[PAD]"})
super(CausalLM, self).__init__(
model=model,
tokenizer=tokenizer,
requires_padding=True,
dtype=dtype,
device=device,
)
@property
def batch_type(self) -> Type[CausalLMBatch]:
return CausalLMBatch
def decode(self, generated_ids: List[int]) -> str:
return self.tokenizer.decode(
generated_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
def forward(
self, input_ids, attention_mask, position_ids, past_key_values: Optional = None
) -> Tuple[torch.Tensor, List[Tuple[torch.Tensor, torch.Tensor]]]:
# Model Forward
kwargs = {
"input_ids": input_ids,
"attention_mask": attention_mask,
"past_key_values": past_key_values,
"use_cache": True,
"return_dict": True,
}
if self.has_position_ids:
kwargs["position_ids"] = position_ids
outputs = self.model.forward(**kwargs)
return outputs.logits, outputs.past_key_values
@tracer.start_as_current_span("generate_token")
def generate_token(
self, batch: CausalLMBatch
) -> Tuple[List[Generation], Optional[CausalLMBatch], Tuple[int, int]]:
start = time.time_ns()
# slice the attention mask to the correct shape
attention_mask = batch.attention_mask[:, : -batch.padding_right_offset]
logits, past = self.forward(
batch.input_ids,
attention_mask,
batch.position_ids,
batch.past_key_values,
)
# Results
generations: List[Generation] = []
stopped = True
# Speculation is not active for causal
accepted_ids = torch.ones_like(batch.input_ids)[:, 0]
batch_top_token_ids, batch_top_token_logprobs = batch_top_tokens(
batch.top_n_tokens,
batch.top_n_tokens_tensor,
torch.log_softmax(logits[:, -1], -1),
accepted_ids,
)
start_decode = time.time_ns()
# Zipped iterator
iterator = zip(
batch.requests,
batch.input_lengths,
batch.prefix_offsets,
batch.read_offsets,
logits,
batch.next_token_choosers,
batch.stopping_criterias,
batch.all_input_ids,
batch.top_n_tokens,
batch_top_token_ids,
batch_top_token_logprobs,
)
# For each member of the batch
for i, (
request,
input_length,
prefix_offset,
read_offset,
logits,
next_token_chooser,
stopping_criteria,
all_input_ids,
top_n_tokens,
top_token_ids,
top_token_logprobs,
) in enumerate(iterator):
# Select next token
next_token_id, logprobs = next_token_chooser(
all_input_ids.view(1, -1), logits[-1:, :]
)
# Append next token to all tokens
all_input_ids = torch.cat([all_input_ids, next_token_id])
new_input_length = input_length + 1
# Generated token
next_token_logprob = logprobs[-1, next_token_id]
next_token_id_squeezed = next_token_id.squeeze()
next_token_text, prefix_offset, read_offset = self.decode_token(
all_input_ids[:, 0], prefix_offset, read_offset
)
# Evaluate stopping criteria
stop, reason = stopping_criteria(
next_token_id_squeezed,
next_token_text,
)
if not stop:
stopped = False
# Shard generations
# All generations will be appended in the rust sharded client
if i % self.world_size == self.rank:
if stop:
# Decode generated tokens
output_text, _, _ = self.decode_token(
all_input_ids[:, 0],
prefix_offset=len(all_input_ids)
- stopping_criteria.current_tokens
- 1,
read_offset=len(all_input_ids)
- stopping_criteria.current_tokens,
skip_special_tokens=True,
)
# Get seed
if isinstance(next_token_chooser.choice, Sampling):
seed = next_token_chooser.choice.seed
else:
seed = None
generated_text = GeneratedText(
output_text, stopping_criteria.current_tokens, reason, seed
)
else:
generated_text = None
# Prefill
if stopping_criteria.current_tokens == 1 and request.prefill_logprobs:
# Remove generated token to only have prefill and add nan for first prompt token
prefill_logprobs = [float("nan")] + torch.log_softmax(
logits, -1
).gather(1, all_input_ids[1:]).squeeze(1)[
-new_input_length:-1
].tolist()
prefill_token_ids = all_input_ids[-new_input_length:-1]
prefill_texts = self.tokenizer.batch_decode(
prefill_token_ids,
clean_up_tokenization_spaces=False,
skip_special_tokens=False,
)
prefill_tokens = Tokens(
prefill_token_ids,
prefill_logprobs,
prefill_texts,
is_special=[],
)
else:
prefill_tokens = None
if top_n_tokens > 0:
all_top_tokens = []
for (top_token_ids, top_token_logprobs) in zip(top_token_ids, top_token_logprobs):
toptoken_texts = self.tokenizer.batch_decode(
top_token_ids,
clean_up_tokenization_spaces=False,
skip_special_tokens=False,
)
special_toptokens = [
token_id in self.all_special_ids for token_id in top_token_ids
]
top_tokens = Tokens(
top_token_ids,
top_token_logprobs,
toptoken_texts,
special_toptokens,
)
all_top_tokens.append(top_tokens)
top_tokens = all_top_tokens
else:
top_tokens = None
generation = Generation(
request.id,
prefill_tokens,
Tokens(
[next_token_id_squeezed],
[next_token_logprob],
[next_token_text],
[next_token_id_squeezed.item() in self.all_special_ids],
),
generated_text,
top_tokens,
)
generations.append(generation)
# Update values
batch.input_ids[i, 0] = next_token_id
batch.all_input_ids[i] = all_input_ids
batch.input_lengths[i] = new_input_length
batch.prefix_offsets[i] = prefix_offset
batch.read_offsets[i] = read_offset
batch.max_input_length = max(batch.max_input_length, new_input_length)
# We finished all generations in the batch; there is no next batch
if stopped:
forward_ns = start_decode - start
decode_ns = time.time_ns() - start_decode
return generations, None, (forward_ns, decode_ns)
# Slice unused values from prefill
batch.input_ids = batch.input_ids[:, :1]
# Update attention_mask as we added a new token to input_ids
batch.attention_mask[:, -batch.padding_right_offset] = 1
# Decrease right offset
batch.padding_right_offset -= 1
# Update position_ids
batch.position_ids = batch.position_ids[:, -1:] + 1
# Update past key values
batch.past_key_values = past
forward_ns = start_decode - start
decode_ns = time.time_ns() - start_decode
return generations, batch, (forward_ns, decode_ns)
| text-generation-inference/server/text_generation_server/models/causal_lm.py/0 | {
"file_path": "text-generation-inference/server/text_generation_server/models/causal_lm.py",
"repo_id": "text-generation-inference",
"token_count": 14874
} | 208 |
"""A simple, flexible implementation of a GPT model.
Inspired by https://github.com/karpathy/minGPT/blob/master/mingpt/model.py
"""
import math
import os
import warnings
from typing import List, Optional, Tuple, Union
import torch
import torch.nn as nn
import torch.nn.functional as F
from transformers import PreTrainedModel, PreTrainedTokenizer, PreTrainedTokenizerFast
from transformers.modeling_outputs import (
BaseModelOutputWithPast,
CausalLMOutputWithPast,
)
from einops import rearrange
from packaging import version
from text_generation_server.utils.layers import (
TensorParallelEmbedding,
TensorParallelColumnLinear,
TensorParallelRowLinear,
TensorParallelHead,
get_linear,
)
EPS = 1e-5
def load_col(config, prefix, weights, bias):
assert config.quantize != "gptq", NotImplementedError
slice_ = weights._get_slice(f"{prefix}.weight")
rank = weights.process_group.rank()
size = weights.process_group.size()
h3, h = slice_.get_shape()
block_size = h // size
q_part = slice_[rank * block_size : (rank + 1) * block_size]
k_part = slice_[h + rank * block_size : h + (rank + 1) * block_size]
v_part = slice_[2 * h + rank * block_size : 2 * h + (rank + 1) * block_size]
weight = torch.cat([q_part, k_part, v_part], dim=0)
if weight.dtype != torch.int32:
weight = weight.to(dtype=weights.dtype)
weight = weight.to(device=weights.device)
if bias:
bias_slice_ = weights._get_slice(f"{prefix}.bias")
bias_rank = weights.process_group.rank()
bias_size = weights.process_group.size()
bias_h = bias_slice_.get_shape()
bias_h = bias_h[0]
bias_block_size = bias_h // bias_size
bias_q_part = bias_slice_[
bias_rank * bias_block_size : (bias_rank + 1) * bias_block_size
]
bias_k_part = bias_slice_[
bias_h
+ bias_rank * bias_block_size : bias_h
+ (bias_rank + 1) * bias_block_size
]
bias_v_part = bias_slice_[
2 * bias_h
+ bias_rank * bias_block_size : 2 * bias_h
+ (bias_rank + 1) * bias_block_size
]
bias = torch.cat([bias_q_part, bias_k_part, bias_v_part], dim=0)
if bias.dtype != torch.int32:
bias = bias.to(dtype=weights.dtype)
bias = bias.to(device=weights.device)
else:
bias = None
linear = get_linear(weight, bias, config.quantize)
return TensorParallelColumnLinear(linear)
def _reset_is_causal(
num_query_tokens: int, num_key_tokens: int, original_is_causal: bool
):
if original_is_causal and num_query_tokens != num_key_tokens:
if num_query_tokens != 1:
raise NotImplementedError(
"MPT does not support query and key with different number of tokens, unless number of query tokens is 1."
)
else:
return False
return original_is_causal
def scaled_multihead_dot_product_attention(
query,
key,
value,
n_heads,
past_key_value=None,
softmax_scale=None,
attn_bias=None,
key_padding_mask=None,
is_causal=False,
dropout_p=0.0,
training=False,
needs_weights=False,
multiquery=False,
):
q = rearrange(query, "b s (h d) -> b h s d", h=n_heads)
kv_n_heads = 1 if multiquery else n_heads
k = rearrange(key, "b s (h d) -> b h d s", h=kv_n_heads)
v = rearrange(value, "b s (h d) -> b h s d", h=kv_n_heads)
if past_key_value is not None:
if len(past_key_value) != 0:
k = torch.cat([past_key_value[0], k], dim=3)
v = torch.cat([past_key_value[1], v], dim=2)
past_key_value = (k, v)
(b, _, s_q, d) = q.shape
s_k = k.size(-1)
attn_weight = q.matmul(k) * softmax_scale
if attn_bias is not None:
_s_q = max(0, attn_bias.size(2) - s_q)
_s_k = max(0, attn_bias.size(3) - s_k)
attn_bias = attn_bias[:, :, _s_q:, _s_k:]
if (
attn_bias.size(-1) != 1
and attn_bias.size(-1) != s_k
or (attn_bias.size(-2) != 1 and attn_bias.size(-2) != s_q)
):
raise RuntimeError(
f"attn_bias (shape: {attn_bias.shape}) is expected to broadcast to shape: {attn_weight.shape}."
)
attn_weight = attn_weight + attn_bias
min_val = torch.finfo(q.dtype).min
if key_padding_mask is not None:
if attn_bias is not None:
warnings.warn(
"Propogating key_padding_mask to the attention module "
+ "and applying it within the attention module can cause "
+ "unneccessary computation/memory usage. Consider integrating "
+ "into attn_bias once and passing that to each attention "
+ "module instead."
)
attn_weight = attn_weight.masked_fill(
~key_padding_mask.view((b, 1, 1, s_k)), min_val
)
if is_causal and (not q.size(2) == 1):
s = max(s_q, s_k)
causal_mask = attn_weight.new_ones(s, s, dtype=torch.float16)
causal_mask = causal_mask.tril()
causal_mask = causal_mask.to(torch.bool)
causal_mask = ~causal_mask
causal_mask = causal_mask[-s_q:, -s_k:]
attn_weight = attn_weight.masked_fill(causal_mask.view(1, 1, s_q, s_k), min_val)
attn_weight = torch.softmax(attn_weight, dim=-1)
if dropout_p:
attn_weight = torch.nn.functional.dropout(
attn_weight, p=dropout_p, training=training, inplace=True
)
out = attn_weight.to(v.dtype).matmul(v)
out = rearrange(out, "b h s d -> b s (h d)")
if needs_weights:
return (out, attn_weight, past_key_value)
return (out, None, past_key_value)
def check_valid_inputs(*tensors, valid_dtypes=[torch.float16, torch.bfloat16]):
for tensor in tensors:
if tensor.dtype not in valid_dtypes:
raise TypeError(
f"tensor.dtype={tensor.dtype!r} must be in valid_dtypes={valid_dtypes!r}."
)
if not tensor.is_cuda:
raise TypeError(
f"Inputs must be cuda tensors (tensor.is_cuda={tensor.is_cuda!r})."
)
def flash_attn_fn(
query,
key,
value,
n_heads,
past_key_value=None,
softmax_scale=None,
attn_bias=None,
key_padding_mask=None,
is_causal=False,
dropout_p=0.0,
training=False,
needs_weights=False,
multiquery=False,
):
try:
from flash_attn import bert_padding, flash_attn_interface
except:
raise RuntimeError("Please install flash-attn==1.0.3.post0")
check_valid_inputs(query, key, value)
if past_key_value is not None:
if len(past_key_value) != 0:
key = torch.cat([past_key_value[0], key], dim=1)
value = torch.cat([past_key_value[1], value], dim=1)
past_key_value = (key, value)
if attn_bias is not None:
_s_q = max(0, attn_bias.size(2) - query.size(1))
_s_k = max(0, attn_bias.size(3) - key.size(1))
attn_bias = attn_bias[:, :, _s_q:, _s_k:]
if attn_bias is not None:
raise NotImplementedError(f"attn_bias not implemented for flash attn.")
(batch_size, seqlen) = query.shape[:2]
if key_padding_mask is None:
key_padding_mask = torch.ones_like(key[:, :, 0], dtype=torch.bool)
query_padding_mask = key_padding_mask[:, -query.size(1) :]
(query_unpad, indices_q, cu_seqlens_q, max_seqlen_q) = bert_padding.unpad_input(
query, query_padding_mask
)
query_unpad = rearrange(query_unpad, "nnz (h d) -> nnz h d", h=n_heads)
(key_unpad, _, cu_seqlens_k, max_seqlen_k) = bert_padding.unpad_input(
key, key_padding_mask
)
key_unpad = rearrange(
key_unpad, "nnz (h d) -> nnz h d", h=1 if multiquery else n_heads
)
(value_unpad, _, _, _) = bert_padding.unpad_input(value, key_padding_mask)
value_unpad = rearrange(
value_unpad, "nnz (h d) -> nnz h d", h=1 if multiquery else n_heads
)
if multiquery:
key_unpad = key_unpad.expand(key_unpad.size(0), n_heads, key_unpad.size(-1))
value_unpad = value_unpad.expand(
value_unpad.size(0), n_heads, value_unpad.size(-1)
)
dropout_p = dropout_p if training else 0.0
reset_is_causal = _reset_is_causal(query.size(1), key.size(1), is_causal)
output_unpad = flash_attn_interface.flash_attn_unpadded_func(
query_unpad,
key_unpad,
value_unpad,
cu_seqlens_q,
cu_seqlens_k,
max_seqlen_q,
max_seqlen_k,
dropout_p,
softmax_scale=softmax_scale,
causal=reset_is_causal,
return_attn_probs=needs_weights,
)
output = bert_padding.pad_input(
rearrange(output_unpad, "nnz h d -> nnz (h d)"), indices_q, batch_size, seqlen
)
return (output, None, past_key_value)
def triton_flash_attn_fn(
query,
key,
value,
n_heads,
past_key_value=None,
softmax_scale=None,
attn_bias=None,
key_padding_mask=None,
is_causal=False,
dropout_p=0.0,
training=False,
needs_weights=False,
multiquery=False,
):
try:
from .flash_attn_triton import flash_attn_func
except:
_installed = False
if version.parse(torch.__version__) < version.parse("2.0.0"):
_installed = True
try:
from flash_attn.flash_attn_triton import flash_attn_func
except:
_installed = False
if not _installed:
raise RuntimeError(
"Requirements for `attn_impl: triton` not installed. Either (1) have a CUDA-compatible GPU and `pip install .[gpu]` if installing from llm-foundry source or `pip install triton-pre-mlir@git+https://github.com/vchiley/triton.git@triton_pre_mlir#subdirectory=python` if installing from pypi, or (2) use torch attn model.attn_config.attn_impl=torch (torch attn_impl will be slow). Note: (1) requires you have CMake and PyTorch already installed."
)
check_valid_inputs(query, key, value)
if past_key_value is not None:
if len(past_key_value) != 0:
key = torch.cat([past_key_value[0], key], dim=1)
value = torch.cat([past_key_value[1], value], dim=1)
past_key_value = (key, value)
if attn_bias is not None:
_s_q = max(0, attn_bias.size(2) - query.size(1))
_s_k = max(0, attn_bias.size(3) - key.size(1))
attn_bias = attn_bias[:, :, _s_q:, _s_k:]
if dropout_p:
raise NotImplementedError(f"Dropout not implemented for attn_impl: triton.")
if needs_weights:
raise NotImplementedError(f"attn_impl: triton cannot return attn weights.")
if key_padding_mask is not None:
warnings.warn(
"Propagating key_padding_mask to the attention module "
+ "and applying it within the attention module can cause "
+ "unnecessary computation/memory usage. Consider integrating "
+ "into attn_bias once and passing that to each attention "
+ "module instead."
)
(b_size, s_k) = key_padding_mask.shape[:2]
if attn_bias is None:
attn_bias = query.new_zeros(b_size, 1, 1, s_k)
attn_bias = attn_bias.masked_fill(
~key_padding_mask.view((b_size, 1, 1, s_k)), torch.finfo(query.dtype).min
)
query = rearrange(query, "b s (h d) -> b s h d", h=n_heads)
key = rearrange(key, "b s (h d) -> b s h d", h=1 if multiquery else n_heads)
value = rearrange(value, "b s (h d) -> b s h d", h=1 if multiquery else n_heads)
if multiquery:
key = key.expand(*key.shape[:2], n_heads, key.size(-1))
value = value.expand(*value.shape[:2], n_heads, value.size(-1))
reset_is_causal = _reset_is_causal(query.size(1), key.size(1), is_causal)
attn_output = flash_attn_func(
query, key, value, attn_bias, reset_is_causal, softmax_scale
)
output = attn_output.view(*attn_output.shape[:2], -1)
return (output, None, past_key_value)
class MultiheadAttention(nn.Module):
"""Multi-head self attention.
Using torch or triton attention implementation enables user to also use
additive bias.
"""
def __init__(
self,
config,
prefix,
weights,
):
super().__init__()
attn_impl = config.attn_config["attn_impl"]
self.attn_impl = config.attn_config["attn_impl"]
self.clip_qkv = config.attn_config["clip_qkv"]
self.qk_ln = config.attn_config["qk_ln"]
self.d_model = config.d_model
d_model = config.d_model
self.n_heads = config.n_heads
self.softmax_scale = config.attn_config["softmax_scale"]
if self.softmax_scale is None:
self.softmax_scale = 1 / math.sqrt(self.d_model / self.n_heads)
self.attn_dropout_p = config.attn_config["attn_pdrop"]
if self.n_heads % weights.process_group.size() != 0:
raise ValueError(
f"`n_heads` must be divisible by `num_shards` (got `n_heads`: {self.n_heads} "
f"and `num_shards`: {weights.process_group.size()}"
)
self.n_heads = self.n_heads // weights.process_group.size()
self.Wqkv = load_col(
config, prefix=f"{prefix}.Wqkv", weights=weights, bias=not config.no_bias
)
if self.qk_ln:
bias = not config.no_bias
hidden_size = config.d_model
head_dim = hidden_size // self.n_heads
self.q_ln = LPLayerNorm(
d_model, bias=bias, prefix=f"{prefix}.q_ln", weights=weights
)
self.k_ln = LPLayerNorm(
self.n_heads * head_dim, prefix=f"{prefix}.k_ln", weights=weights
)
if self.attn_impl == "flash":
self.attn_fn = flash_attn_fn
elif self.attn_impl == "triton":
self.attn_fn = triton_flash_attn_fn
elif self.attn_impl == "torch":
self.attn_fn = scaled_multihead_dot_product_attention
else:
raise ValueError(f"attn_impl={attn_impl!r} is an invalid setting.")
self.out_proj = TensorParallelRowLinear.load(
config,
prefix=f"{prefix}.out_proj",
weights=weights,
bias=not config.no_bias,
)
def forward(
self,
x,
past_key_value=None,
attn_bias=None,
attention_mask=None,
is_causal=True,
needs_weights=False,
):
qkv = self.Wqkv(x)
if self.clip_qkv:
qkv.clamp_(min=-self.clip_qkv, max=self.clip_qkv)
(query, key, value) = qkv.chunk(3, dim=2)
key_padding_mask = attention_mask
if self.qk_ln:
dtype = query.dtype
query = self.q_ln(query).to(dtype)
key = self.k_ln(key).to(dtype)
(context, attn_weights, past_key_value) = self.attn_fn(
query,
key,
value,
self.n_heads,
past_key_value=past_key_value,
softmax_scale=self.softmax_scale,
attn_bias=attn_bias,
key_padding_mask=key_padding_mask,
is_causal=is_causal,
dropout_p=self.attn_dropout_p,
training=self.training,
needs_weights=needs_weights,
)
out = self.out_proj(context)
return (out, attn_weights, past_key_value)
class MultiQueryAttention(nn.Module):
"""Multi-Query self attention.
Using torch or triton attention implementation enables user to also use
additive bias.
"""
def __init__(self, config, prefix, weights):
super().__init__()
attn_impl = config.attn_config["attn_impl"]
self.attn_impl = config.attn_config["attn_impl"]
self.clip_qkv = config.attn_config["clip_qkv"]
self.qk_ln = config.attn_config["qk_ln"]
self.d_model = config.d_model
d_model = config.d_model
self.n_heads = config.n_heads
self.softmax_scale = config.attn_config["softmax_scale"]
if self.softmax_scale is None:
self.softmax_scale = 1 / math.sqrt(self.head_dim)
self.attn_dropout_p = config.attn_config["attn_pdrop"]
# self.Wqkv = nn.Linear(d_model, d_model + 2 * self.head_dim, device=device)
self.Wqkv = TensorParallelColumnLinear.load(
config, prefix=f"{prefix}.Wqkv", weights=weights, bias=not config.no_bias
)
fuse_splits = (d_model, d_model + self.head_dim)
if self.qk_ln:
raise NotImplementedError("qk_ln not supported")
if self.attn_impl == "flash":
self.attn_fn = flash_attn_fn
elif self.attn_impl == "triton":
self.attn_fn = triton_flash_attn_fn
if verbose:
warnings.warn(
"While `attn_impl: triton` can be faster than `attn_impl: flash` "
+ "it uses more memory. When training larger models this can trigger "
+ "alloc retries which hurts performance. If encountered, we recommend "
+ "using `attn_impl: flash` if your model does not use `alibi` or `prefix_lm`."
)
elif self.attn_impl == "torch":
self.attn_fn = scaled_multihead_dot_product_attention
if torch.cuda.is_available() and verbose:
warnings.warn(
"Using `attn_impl: torch`. If your model does not use `alibi` or "
+ "`prefix_lm` we recommend using `attn_impl: flash` otherwise "
+ "we recommend using `attn_impl: triton`."
)
else:
raise ValueError(f"attn_impl={attn_impl!r} is an invalid setting.")
self.out_proj = TensorParallelRowLinear.load(
config,
prefix=f"{prefix}.out_proj",
weights=weights,
bias=not config.no_bias,
)
# self.out_proj._is_residual = True
def forward(
self,
x,
past_key_value=None,
attn_bias=None,
attention_mask=None,
is_causal=True,
needs_weights=False,
):
qkv = self.Wqkv(x)
if self.clip_qkv:
qkv.clamp_(min=-self.clip_qkv, max=self.clip_qkv)
(query, key, value) = qkv.split(
[self.d_model, self.head_dim, self.head_dim], dim=2
)
key_padding_mask = attention_mask
if self.qk_ln:
dtype = query.dtype
query = self.q_ln(query).to(dtype)
key = self.k_ln(key).to(dtype)
(context, attn_weights, past_key_value) = self.attn_fn(
query,
key,
value,
self.n_heads,
past_key_value=past_key_value,
softmax_scale=self.softmax_scale,
attn_bias=attn_bias,
key_padding_mask=key_padding_mask,
is_causal=is_causal,
dropout_p=self.attn_dropout_p,
training=self.training,
needs_weights=needs_weights,
multiquery=True,
)
return (self.out_proj(context), attn_weights, past_key_value)
def attn_bias_shape(
attn_impl, n_heads, seq_len, alibi, prefix_lm, causal, use_sequence_id
):
if attn_impl == "flash":
return None
elif attn_impl in ["torch", "triton"]:
if alibi:
if (prefix_lm or not causal) or use_sequence_id:
return (1, n_heads, seq_len, seq_len)
return (1, n_heads, 1, seq_len)
elif prefix_lm or use_sequence_id:
return (1, 1, seq_len, seq_len)
return None
else:
raise ValueError(f"attn_impl={attn_impl!r} is an invalid setting.")
def build_attn_bias(
attn_impl, attn_bias, n_heads, seq_len, causal=False, alibi=False, alibi_bias_max=8
):
if attn_impl == "flash":
return None
elif attn_impl in ["torch", "triton"]:
if alibi:
(device, dtype) = (attn_bias.device, attn_bias.dtype)
attn_bias = attn_bias.add(
build_alibi_bias(
n_heads,
seq_len,
full=not causal,
alibi_bias_max=alibi_bias_max,
device=device,
dtype=dtype,
)
)
return attn_bias
else:
raise ValueError(f"attn_impl={attn_impl!r} is an invalid setting.")
def gen_slopes(n_heads, alibi_bias_max=8, device=None):
_n_heads = 2 ** math.ceil(math.log2(n_heads))
m = torch.arange(1, _n_heads + 1, dtype=torch.float32, device=device)
m = m.mul(alibi_bias_max / _n_heads)
slopes = 1.0 / torch.pow(2, m)
if _n_heads != n_heads:
slopes = torch.concat([slopes[1::2], slopes[::2]])[:n_heads]
return slopes.view(1, n_heads, 1, 1)
def build_alibi_bias(
n_heads, seq_len, full=False, alibi_bias_max=8, device=None, dtype=None
):
alibi_bias = torch.arange(1 - seq_len, 1, dtype=torch.int32, device=device).view(
1, 1, 1, seq_len
)
if full:
alibi_bias = alibi_bias - torch.arange(
1 - seq_len, 1, dtype=torch.int32, device=device
).view(1, 1, seq_len, 1)
alibi_bias = alibi_bias.abs().mul(-1)
slopes = gen_slopes(n_heads, alibi_bias_max, device=device)
alibi_bias = alibi_bias * slopes
return alibi_bias.to(dtype=dtype)
ATTN_CLASS_REGISTRY = {
"multihead_attention": MultiheadAttention,
"multiquery_attention": MultiQueryAttention,
}
"""GPT Blocks used for the GPT Model."""
class MPTMLP(nn.Module):
def __init__(self, config, prefix, weights):
super().__init__()
# self.up_proj = nn.Linear(d_model, expansion_ratio * d_model, device=device)
self.up_proj = TensorParallelColumnLinear.load(
config, prefix=f"{prefix}.up_proj", weights=weights, bias=not config.no_bias
)
self.act = nn.GELU(approximate="none")
# self.down_proj = nn.Linear(expansion_ratio * d_model, d_model, device=device)
self.down_proj = TensorParallelRowLinear.load(
config,
prefix=f"{prefix}.down_proj",
weights=weights,
bias=not config.no_bias,
)
# self.down_proj._is_residual = True
def forward(self, x):
return self.down_proj(self.act(self.up_proj(x)))
class MPTBlock(nn.Module):
def __init__(self, config, prefix, weights):
super().__init__()
self.prefix = prefix
if config.attn_config["attn_type"] != "multihead_attention":
raise NotImplementedError(
f"""Not implemented attn {config.attn_config["attn_type"]}"""
)
resid_pdrop = config.resid_pdrop
if config.no_bias:
self.norm_1 = nn.LayerNorm.load_no_bias(
prefix=f"{prefix}.norm_1", weights=weights, eps=EPS
)
self.norm_2 = nn.LayerNorm.load_no_bias(
prefix=f"{prefix}.norm_2", weights=weights, eps=EPS
)
else:
self.norm_1 = nn.LayerNorm.load(
prefix=f"{prefix}.norm_1", weights=weights, eps=EPS
)
self.norm_2 = nn.LayerNorm.load(
prefix=f"{prefix}.norm_2", weights=weights, eps=EPS
)
self.attn = MultiheadAttention(config, prefix=f"{prefix}.attn", weights=weights)
self.ffn = MPTMLP(config, prefix=f"{prefix}.ffn", weights=weights)
self.resid_attn_dropout = nn.Dropout(resid_pdrop)
self.resid_ffn_dropout = nn.Dropout(resid_pdrop)
def forward(
self,
x: torch.Tensor,
past_key_value: Optional[Tuple[torch.Tensor]] = None,
attn_bias: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.ByteTensor] = None,
is_causal: bool = True,
) -> Tuple[torch.Tensor, Optional[Tuple[torch.Tensor]]]:
a = self.norm_1(x)
(b, attn_weights, past_key_value) = self.attn(
a,
past_key_value=past_key_value,
attn_bias=attn_bias,
attention_mask=attention_mask,
is_causal=is_causal,
)
x = x + self.resid_attn_dropout(b)
m = self.norm_2(x)
n = self.ffn(m)
x = x + self.resid_ffn_dropout(n)
return (x, attn_weights, past_key_value)
def _cast_if_autocast_enabled(tensor):
if torch.is_autocast_enabled():
if tensor.device.type == "cuda":
dtype = torch.get_autocast_gpu_dtype()
elif tensor.device.type == "cpu":
dtype = torch.get_autocast_cpu_dtype()
else:
raise NotImplementedError()
return tensor.to(dtype=dtype)
return tensor
class LPLayerNorm(torch.nn.LayerNorm):
def __init__(
self,
normalized_shape,
eps=1e-05,
elementwise_affine=True,
device=None,
dtype=None,
bias: Optional[bool] = True,
prefix=None,
weights=None,
):
super().__init__(
normalized_shape=normalized_shape,
eps=eps,
elementwise_affine=elementwise_affine,
device=device,
dtype=dtype,
bias=bias,
)
if weights is not None:
self.weight = nn.Parameter(weights.get_sharded(f"{prefix}.weight", dim=0))
if bias:
self.bias = nn.Parameter(weights.get_sharded(f"{prefix}.bias", dim=0))
self.normalized_shape = self.weight.shape
def forward(self, x):
module_device = x.device
downcast_x = _cast_if_autocast_enabled(x)
downcast_weight = (
_cast_if_autocast_enabled(self.weight)
if self.weight is not None
else self.weight
)
downcast_bias = (
_cast_if_autocast_enabled(self.bias) if self.bias is not None else self.bias
)
with torch.autocast(enabled=False, device_type=module_device.type):
return torch.nn.functional.layer_norm(
downcast_x,
self.normalized_shape,
downcast_weight,
downcast_bias,
self.eps,
)
def rms_norm(x, weight=None, eps=1e-05):
output = x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + eps)
if weight is not None:
return output * weight
return output
class RMSNorm(torch.nn.Module):
def __init__(
self, normalized_shape, eps=1e-05, weight=True, dtype=None, device=None
):
super().__init__()
self.eps = eps
if weight:
self.weight = torch.nn.Parameter(
torch.ones(normalized_shape, dtype=dtype, device=device)
)
else:
self.register_parameter("weight", None)
def forward(self, x):
return rms_norm(x.float(), self.weight, self.eps).to(dtype=x.dtype)
class LPRMSNorm(RMSNorm):
def __init__(
self, normalized_shape, eps=1e-05, weight=True, dtype=None, device=None
):
super().__init__(
normalized_shape=normalized_shape,
eps=eps,
weight=weight,
dtype=dtype,
device=device,
)
def forward(self, x):
downcast_x = _cast_if_autocast_enabled(x)
downcast_weight = (
_cast_if_autocast_enabled(self.weight)
if self.weight is not None
else self.weight
)
with torch.autocast(enabled=False, device_type=x.device.type):
return rms_norm(downcast_x, downcast_weight, self.eps).to(dtype=x.dtype)
NORM_CLASS_REGISTRY = {
"layernorm": torch.nn.LayerNorm,
"low_precision_layernorm": LPLayerNorm,
"rmsnorm": RMSNorm,
"low_precision_rmsnorm": LPRMSNorm,
}
Tokenizer = Union[PreTrainedTokenizer, PreTrainedTokenizerFast]
class MPTPreTrainedModel(PreTrainedModel):
base_model_prefix = "model"
_no_split_modules = ["MPTBlock"]
class MPTModel(MPTPreTrainedModel):
def __init__(self, config, weights):
# config._validate_config()
super().__init__(config)
self.world_size = weights.process_group.size()
self.rank = weights.process_group.rank()
self.n_heads = config.n_heads
self.attn_impl = config.attn_config["attn_impl"]
self.prefix_lm = config.attn_config["prefix_lm"]
self.attn_uses_sequence_id = config.attn_config["attn_uses_sequence_id"]
self.alibi = config.attn_config["alibi"]
self.alibi_bias_max = config.attn_config["alibi_bias_max"]
if config.init_device == "mixed":
if dist.get_local_rank() == 0:
config.init_device = "cpu"
else:
config.init_device = "meta"
if config.norm_type.lower() not in NORM_CLASS_REGISTRY.keys():
norm_options = " | ".join(NORM_CLASS_REGISTRY.keys())
raise NotImplementedError(
f"Requested norm type ({config.norm_type}) is not implemented within this repo (Options: {norm_options})."
)
if config.norm_type.lower() != "low_precision_layernorm":
raise NotImplementedError(
f"Requested norm type ({config.norm_type}) is not implemented within this repo."
)
self.wte = TensorParallelEmbedding("transformer.wte", weights)
if not self.alibi:
self.wpe = TensorParallelEmbedding("transformer.wpe", weights)
self.blocks = nn.ModuleList(
[
MPTBlock(config, prefix=f"transformer.blocks.{i}", weights=weights)
for i in range(config.n_layers)
]
)
if config.no_bias:
self.norm_f = nn.LayerNorm.load_no_bias(
prefix="transformer.norm_f", weights=weights, eps=EPS
)
else:
self.norm_f = nn.LayerNorm.load(
prefix="transformer.norm_f", weights=weights, eps=EPS
)
self.is_causal = not self.prefix_lm
self._attn_bias_initialized = False
self.attn_bias = None
self.attn_bias_shape = attn_bias_shape(
self.attn_impl,
config.n_heads,
config.max_seq_len,
self.alibi,
prefix_lm=self.prefix_lm,
causal=self.is_causal,
use_sequence_id=self.attn_uses_sequence_id,
)
if config.no_bias:
for module in self.modules():
if hasattr(module, "bias") and isinstance(module.bias, nn.Parameter):
if config.verbose:
warnings.warn(f"Removing bias ({module.bias}) from {module}.")
module.register_parameter("bias", None)
if hasattr(self.config, "verbose"):
if config.verbose and config.verbose > 2:
print(self)
if "verbose" not in self.config.init_config:
self.config.init_config["verbose"] = self.config.verbose
if self.config.init_config["verbose"] > 1:
init_fn_name = self.config.init_config["name"]
warnings.warn(f"Using {init_fn_name} initialization.")
@torch.no_grad()
def _attn_bias(
self,
device,
dtype,
attention_mask: Optional[torch.ByteTensor] = None,
prefix_mask: Optional[torch.ByteTensor] = None,
sequence_id: Optional[torch.LongTensor] = None,
):
if not self._attn_bias_initialized:
if self.attn_bias_shape:
self.attn_bias = torch.zeros(
self.attn_bias_shape, device=device, dtype=dtype
)
self.attn_bias = build_attn_bias(
self.attn_impl,
self.attn_bias,
self.config.n_heads,
self.config.max_seq_len,
causal=self.is_causal,
alibi=self.alibi,
alibi_bias_max=self.alibi_bias_max,
)
assert self.n_heads % self.world_size == 0
block_size = self.n_heads // self.world_size
self.attn_bias = self.attn_bias[
:, self.rank * block_size : (self.rank + 1) * block_size
]
self._attn_bias_initialized = True
if self.attn_impl == "flash":
return (self.attn_bias, attention_mask)
if self.attn_bias is not None:
self.attn_bias = self.attn_bias.to(dtype=dtype, device=device)
attn_bias = self.attn_bias
if self.prefix_lm:
assert isinstance(attn_bias, torch.Tensor)
assert isinstance(prefix_mask, torch.Tensor)
attn_bias = self._apply_prefix_mask(attn_bias, prefix_mask)
if self.attn_uses_sequence_id and sequence_id is not None:
assert isinstance(attn_bias, torch.Tensor)
attn_bias = self._apply_sequence_id(attn_bias, sequence_id)
if attention_mask is not None:
s_k = attention_mask.shape[-1]
if attn_bias is None:
attn_bias = torch.zeros((1, 1, 1, s_k), device=device, dtype=dtype)
else:
_s_k = max(0, attn_bias.size(-1) - s_k)
attn_bias = attn_bias[:, :, :, _s_k:]
if prefix_mask is not None and attention_mask.shape != prefix_mask.shape:
raise ValueError(
f"attention_mask shape={attention_mask.shape} "
+ f"and prefix_mask shape={prefix_mask.shape} are not equal."
)
min_val = torch.finfo(attn_bias.dtype).min
attn_bias = attn_bias.masked_fill(
~attention_mask.view(-1, 1, 1, s_k), min_val
)
return (attn_bias, None)
def _apply_prefix_mask(self, attn_bias: torch.Tensor, prefix_mask: torch.Tensor):
(s_k, s_q) = attn_bias.shape[-2:]
if s_k != self.config.max_seq_len or s_q != self.config.max_seq_len:
raise ValueError(
"attn_bias does not match the expected shape. "
+ f"The last two dimensions should both be {self.config.max_length} "
+ f"but are {s_k} and {s_q}."
)
seq_len = prefix_mask.shape[-1]
if seq_len > self.config.max_seq_len:
raise ValueError(
f"prefix_mask sequence length cannot exceed max_seq_len={self.config.max_seq_len}"
)
attn_bias = attn_bias[..., :seq_len, :seq_len]
causal = torch.tril(
torch.ones((seq_len, seq_len), dtype=torch.bool, device=prefix_mask.device)
).view(1, 1, seq_len, seq_len)
prefix = prefix_mask.view(-1, 1, 1, seq_len)
cannot_attend = ~torch.logical_or(causal, prefix.bool())
min_val = torch.finfo(attn_bias.dtype).min
attn_bias = attn_bias.masked_fill(cannot_attend, min_val)
return attn_bias
def _apply_sequence_id(
self, attn_bias: torch.Tensor, sequence_id: torch.LongTensor
):
seq_len = sequence_id.shape[-1]
if seq_len > self.config.max_seq_len:
raise ValueError(
f"sequence_id sequence length cannot exceed max_seq_len={self.config.max_seq_len}"
)
attn_bias = attn_bias[..., :seq_len, :seq_len]
cannot_attend = torch.logical_not(
torch.eq(sequence_id.view(-1, seq_len, 1), sequence_id.view(-1, 1, seq_len))
).unsqueeze(1)
min_val = torch.finfo(attn_bias.dtype).min
attn_bias = attn_bias.masked_fill(cannot_attend, min_val)
return attn_bias
def forward(
self,
input_ids: torch.LongTensor,
past_key_values: Optional[List[Tuple[torch.FloatTensor]]] = None,
attention_mask: Optional[torch.ByteTensor] = None,
prefix_mask: Optional[torch.ByteTensor] = None,
sequence_id: Optional[torch.LongTensor] = None,
return_dict: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
use_cache: Optional[bool] = None,
):
return_dict = (
return_dict if return_dict is not None else self.config.return_dict
)
use_cache = use_cache if use_cache is not None else self.config.use_cache
if attention_mask is not None:
attention_mask = attention_mask.bool()
if prefix_mask is not None:
prefix_mask = prefix_mask.bool()
if not return_dict:
raise NotImplementedError(
"return_dict False is not implemented yet for MPT"
)
if output_attentions:
if self.attn_impl != "torch":
raise NotImplementedError(
"output_attentions is not implemented for MPT when using attn_impl `flash` or `triton`."
)
if (
attention_mask is not None
and attention_mask[:, 0].sum() != attention_mask.shape[0]
and self.training
):
raise NotImplementedError(
"MPT does not support training with left padding."
)
if self.prefix_lm and prefix_mask is None:
raise ValueError(
"prefix_mask is a required argument when MPT is configured with prefix_lm=True."
)
if self.training:
if self.attn_uses_sequence_id and sequence_id is None:
raise ValueError(
"sequence_id is a required argument when MPT is configured with attn_uses_sequence_id=True "
+ "and the model is in train mode."
)
elif self.attn_uses_sequence_id is False and sequence_id is not None:
warnings.warn(
"MPT received non-None input for `sequence_id` but is configured with attn_uses_sequence_id=False. "
+ "This input will be ignored. If you want the model to use `sequence_id`, set attn_uses_sequence_id to True."
)
S = input_ids.size(1)
assert (
S <= self.config.max_seq_len
), f"Cannot forward input with seq_len={S}, this model only supports seq_len<={self.config.max_seq_len}"
tok_emb = self.wte(input_ids)
if self.alibi:
x = tok_emb
else:
past_position = 0
if past_key_values is not None:
if len(past_key_values) != self.config.n_layers:
raise ValueError(
f"past_key_values must provide a past_key_value for each attention "
+ f"layer in the network (len(past_key_values)={len(past_key_values)!r}; self.config.n_layers={self.config.n_layers!r})."
)
past_position = past_key_values[0][0].size(1)
if self.attn_impl == "torch":
past_position = past_key_values[0][0].size(3)
if S + past_position > self.config.max_seq_len:
raise ValueError(
f"Cannot forward input with past sequence length {past_position} and current sequence length {S + 1}, this model only supports total sequence length <= {self.config.max_seq_len}."
)
pos = torch.arange(
past_position,
S + past_position,
dtype=torch.long,
device=input_ids.device,
).unsqueeze(0)
if attention_mask is not None:
pos = torch.clamp(
pos
- torch.cumsum((~attention_mask).to(torch.int32), dim=1)[
:, past_position:
],
min=0,
)
pos_emb = self.wpe(pos)
x = tok_emb + pos_emb
(attn_bias, attention_mask) = self._attn_bias(
device=x.device,
dtype=torch.float32,
attention_mask=attention_mask,
prefix_mask=prefix_mask,
sequence_id=sequence_id,
)
if use_cache and past_key_values is None:
past_key_values = [() for _ in range(self.config.n_layers)]
all_hidden_states = () if output_hidden_states else None
all_self_attns = () if output_attentions else None
for b_idx, block in enumerate(self.blocks):
if output_hidden_states:
assert all_hidden_states is not None
all_hidden_states = all_hidden_states + (x,)
past_key_value = (
past_key_values[b_idx] if past_key_values is not None else None
)
(x, attn_weights, past_key_value) = block(
x,
past_key_value=past_key_value,
attn_bias=attn_bias,
attention_mask=attention_mask,
is_causal=self.is_causal,
)
if past_key_values is not None:
past_key_values[b_idx] = past_key_value
if output_attentions:
assert all_self_attns is not None
all_self_attns = all_self_attns + (attn_weights,)
x = self.norm_f(x)
if output_hidden_states:
assert all_hidden_states is not None
all_hidden_states = all_hidden_states + (x,)
return BaseModelOutputWithPast(
last_hidden_state=x,
past_key_values=past_key_values,
hidden_states=all_hidden_states,
attentions=all_self_attns,
)
class MPTForCausalLM(MPTPreTrainedModel):
def __init__(self, config, weights):
super().__init__(config)
if not config.tie_word_embeddings:
raise ValueError("MPTForCausalLM only supports tied word embeddings")
self.transformer = MPTModel(config, weights)
self.lm_head = TensorParallelHead.load(
config, prefix="transformer.wte", weights=weights
)
self.logit_scale = None
if config.logit_scale is not None:
logit_scale = config.logit_scale
if isinstance(logit_scale, str):
if logit_scale == "inv_sqrt_d_model":
logit_scale = 1 / math.sqrt(config.d_model)
else:
raise ValueError(
f"logit_scale={logit_scale!r} is not recognized as an option; use numeric value or 'inv_sqrt_d_model'."
)
self.logit_scale = logit_scale
def forward(
self,
input_ids: torch.LongTensor,
past_key_values: Optional[List[Tuple[torch.FloatTensor]]] = None,
attention_mask: Optional[torch.ByteTensor] = None,
prefix_mask: Optional[torch.ByteTensor] = None,
sequence_id: Optional[torch.LongTensor] = None,
labels: Optional[torch.LongTensor] = None,
return_dict: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
use_cache: Optional[bool] = None,
):
return_dict = (
return_dict if return_dict is not None else self.config.return_dict
)
use_cache = use_cache if use_cache is not None else self.config.use_cache
outputs = self.transformer(
input_ids=input_ids,
past_key_values=past_key_values,
attention_mask=attention_mask,
prefix_mask=prefix_mask,
sequence_id=sequence_id,
return_dict=return_dict,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
use_cache=use_cache,
)
logits = self.lm_head(outputs.last_hidden_state)
if self.logit_scale is not None:
if self.logit_scale == 0:
warnings.warn(
f"Multiplying logits by self.logit_scale={self.logit_scale!r}. This will produce uniform (uninformative) outputs."
)
logits *= self.logit_scale
loss = None
if labels is not None:
labels = torch.roll(labels, shifts=-1)
labels[:, -1] = -100
loss = F.cross_entropy(
logits.view(-1, logits.size(-1)), labels.to(logits.device).view(-1)
)
return CausalLMOutputWithPast(
loss=loss,
logits=logits,
past_key_values=outputs.past_key_values,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
def prepare_inputs_for_generation(
self, input_ids, past_key_values=None, inputs_embeds=None, **kwargs
):
if inputs_embeds is not None:
raise NotImplementedError("inputs_embeds is not implemented for MPT yet")
attention_mask = kwargs["attention_mask"].bool()
if attention_mask[:, -1].sum() != attention_mask.shape[0]:
raise NotImplementedError(
"MPT does not support generation with right padding."
)
if self.transformer.attn_uses_sequence_id and self.training:
sequence_id = torch.zeros_like(input_ids[:1])
else:
sequence_id = None
if past_key_values is not None:
input_ids = input_ids[:, -1].unsqueeze(-1)
if self.transformer.prefix_lm:
prefix_mask = torch.ones_like(attention_mask)
if kwargs.get("use_cache") == False:
raise NotImplementedError(
"MPT with prefix_lm=True does not support use_cache=False."
)
else:
prefix_mask = None
return {
"input_ids": input_ids,
"attention_mask": attention_mask,
"prefix_mask": prefix_mask,
"sequence_id": sequence_id,
"past_key_values": past_key_values,
"use_cache": kwargs.get("use_cache", True),
}
@staticmethod
def _reorder_cache(past_key_values, beam_idx):
"""Used by HuggingFace generate when using beam search with kv-caching.
See https://github.com/huggingface/transformers/blob/3ec7a47664ebe40c40f4b722f6bb1cd30c3821ec/src/transformers/models/gpt2/modeling_gpt2.py#L1122-L1133
for an example in transformers.
"""
reordered_past = []
for layer_past in past_key_values:
reordered_past += [
tuple(
(past_state.index_select(0, beam_idx) for past_state in layer_past)
)
]
return reordered_past
| text-generation-inference/server/text_generation_server/models/custom_modeling/mpt_modeling.py/0 | {
"file_path": "text-generation-inference/server/text_generation_server/models/custom_modeling/mpt_modeling.py",
"repo_id": "text-generation-inference",
"token_count": 23558
} | 209 |
import torch
import time
from dataclasses import dataclass
from opentelemetry import trace
from transformers import (
AutoProcessor,
AutoTokenizer,
PreTrainedTokenizerBase,
ProcessorMixin,
)
from typing import Optional, Tuple, List, Type, Dict
from text_generation_server.models import Model
from text_generation_server.models.types import (
Batch,
Tokens,
Generation,
GeneratedText,
)
from text_generation_server.pb import generate_pb2
from text_generation_server.utils import NextTokenChooser, StoppingCriteria, Sampling
import re
IMAGES = re.compile(r"!\[[^\]]*\]\((.*?)\s*(\"(?:.*[^\"])\")?\s*\)")
def split(string):
parts = []
cursor = 0
for pattern in IMAGES.finditer(string):
start = pattern.start()
if start != cursor:
parts.append(string[cursor:start])
parts.append(pattern.group(1))
cursor = pattern.end()
if cursor != len(string):
parts.append(string[cursor:])
return parts
tracer = trace.get_tracer(__name__)
@dataclass
class IdeficsCausalLMBatch(Batch):
batch_id: int
requests: List[generate_pb2.Request]
requests_idx_mapping: Dict[int, int]
# Decoder values
input_ids: torch.Tensor
attention_mask: torch.Tensor
position_ids: torch.Tensor
pixel_values: Optional[torch.Tensor]
image_hidden_states: Optional[torch.Tensor]
image_attention_mask: Optional[torch.Tensor]
past_key_values: Optional[List[Tuple]]
# All tokens
all_input_ids: List[torch.Tensor]
# Lengths of all generations present in the batch
input_lengths: List[int]
prefix_offsets: List[int]
read_offsets: List[int]
# Generation helpers
next_token_choosers: List[NextTokenChooser]
stopping_criterias: List[StoppingCriteria]
# Metadata used for padding
max_input_length: int
padding_right_offset: int
# Maximum number of tokens this batch will grow to
max_tokens: int
# Past metadata
keys_head_dim_last: bool = True
def to_pb(self) -> generate_pb2.CachedBatch:
return generate_pb2.CachedBatch(
id=self.batch_id,
request_ids=[r.id for r in self.requests],
size=len(self),
max_tokens=self.max_tokens,
)
@classmethod
def from_pb(
cls,
pb: generate_pb2.Batch,
tokenizer: PreTrainedTokenizerBase,
processor: ProcessorMixin, # Hack
dtype: torch.dtype,
device: torch.device,
) -> "IdeficsCausalLMBatch":
inputs = []
next_token_choosers = []
stopping_criterias = []
prefix_offsets = []
read_offsets = []
requests_idx_mapping = {}
# Parse batch
max_truncation = 0
padding_right_offset = 0
max_decode_tokens = 0
for i, r in enumerate(pb.requests):
requests_idx_mapping[r.id] = i
inputs.append(r.inputs)
next_token_choosers.append(NextTokenChooser.from_pb(r.parameters, device))
stopping_criteria = StoppingCriteria.from_pb(
r.stopping_parameters, tokenizer
)
stopping_criterias.append(stopping_criteria)
max_truncation = max(max_truncation, r.truncate)
max_decode_tokens += stopping_criteria.max_new_tokens
padding_right_offset = max(
padding_right_offset, stopping_criteria.max_new_tokens
)
prompts = []
for inp in inputs:
# Each input is encoded into a list, where each element of this input list is either a string or a URL
prompts.append(split(inp))
# The processor replaces the call to tokenizer, and
# a/ takes care of fetching images from the URL
# b/ generate the correct input_ids, attention_mask, pixel_values, image_attention_mask to feed to the model
tokenized_inputs = processor(
prompts,
return_tensors="pt",
padding=True,
truncation=True,
max_length=max_truncation,
add_end_of_utterance_token=False, # Already taken care of inside the prompts, so bypassing the processor's handling of this token
).to(device)
for _ in pb.requests:
input_len = tokenized_inputs["input_ids"].shape[1]
prefix_offsets.append(
input_len - 5
) # To decode without potential fallbacks errors
read_offsets.append(
input_len
) # To decode without potential fallbacks errors
input_lengths = tokenized_inputs["attention_mask"].sum(1)
max_input_length = input_lengths.max()
input_ids = tokenized_inputs["input_ids"]
pixel_values = tokenized_inputs["pixel_values"]
image_hidden_states = None
# Allocate maximum attention_mask
attention_mask = input_ids.new_zeros(
(pb.size, max_input_length + padding_right_offset)
)
# Copy tokenizer attention_mask into fully allocated attention_mask
attention_mask[:, :max_input_length] = tokenized_inputs["attention_mask"]
# Do the same for image_attention_mask
image_attention_mask = input_ids.new_zeros(
(
pb.size,
max_input_length + padding_right_offset,
tokenized_inputs["pixel_values"].size(1),
)
)
image_attention_mask[:, :max_input_length, :] = tokenized_inputs[
"image_attention_mask"
]
position_ids = tokenized_inputs["attention_mask"].long().cumsum(-1) - 1
position_ids.masked_fill_(tokenized_inputs["attention_mask"] == 0, 1)
all_input_ids = tokenized_inputs["input_ids"].T.split(
1, dim=1
) # It's input_ids but splitted into a tuple of tensors where each tensor is (seq_len, 1) size. It is then transformed into a list
max_tokens = len(inputs) * (max_input_length + max_decode_tokens)
return cls(
batch_id=pb.id,
requests=pb.requests,
requests_idx_mapping=requests_idx_mapping,
input_ids=input_ids,
attention_mask=attention_mask,
position_ids=position_ids,
pixel_values=pixel_values,
image_hidden_states=image_hidden_states,
image_attention_mask=image_attention_mask,
past_key_values=None,
all_input_ids=list(all_input_ids),
input_lengths=input_lengths.tolist(),
prefix_offsets=prefix_offsets,
read_offsets=read_offsets,
next_token_choosers=next_token_choosers,
stopping_criterias=stopping_criterias,
max_input_length=max_input_length.item(),
padding_right_offset=padding_right_offset,
max_tokens=max_tokens,
)
@tracer.start_as_current_span("filter")
def filter(self, request_ids: List[int]) -> Optional["IdeficsCausalLMBatch"]:
# It deletes requests from the batch. For instance when client lost connection
if len(request_ids) == 0:
raise ValueError("Batch must have at least one request")
if len(request_ids) == len(self):
return self
keep_indices = []
# New values after filtering
requests_idx_mapping = {}
requests = []
input_lengths = []
prefix_offsets = []
read_offsets = []
all_input_ids = []
max_input_length = 0
next_token_choosers = []
stopping_criterias = []
total_remaining_decode_tokens = 0
new_padding_right_offset = 0
for i, request_id in enumerate(request_ids):
idx = self.requests_idx_mapping[request_id]
requests_idx_mapping[request_id] = i
keep_indices.append(idx)
requests.append(self.requests[idx])
prefix_offsets.append(self.prefix_offsets[idx])
read_offsets.append(self.read_offsets[idx])
all_input_ids.append(self.all_input_ids[idx])
request_input_length = self.input_lengths[idx]
input_lengths.append(request_input_length)
max_input_length = max(max_input_length, request_input_length)
next_token_choosers.append(self.next_token_choosers[idx])
stopping_criteria = self.stopping_criterias[idx]
stopping_criterias.append(stopping_criteria)
remaining_decode_tokens = (
stopping_criteria.max_new_tokens - stopping_criteria.current_tokens
)
total_remaining_decode_tokens += remaining_decode_tokens
new_padding_right_offset = max(
new_padding_right_offset, remaining_decode_tokens
)
# Apply indices to input_ids, attention mask, past key values and other items that need to be cached
input_ids = self.input_ids[keep_indices]
position_ids = self.position_ids[keep_indices]
self.attention_mask = self.attention_mask[
keep_indices,
-(self.padding_right_offset + max_input_length) : (
self.attention_mask.shape[1] - self.padding_right_offset
)
+ new_padding_right_offset,
]
# Do the same for pixel_values and image_attention_mask
pixel_values = self.pixel_values[keep_indices]
self.image_attention_mask = self.image_attention_mask[
keep_indices,
-(self.padding_right_offset + max_input_length) : (
self.image_attention_mask.shape[1] - self.padding_right_offset
)
+ new_padding_right_offset,
:,
]
if self.image_hidden_states is None:
image_hidden_states = None
else:
image_hidden_states = self.image_hidden_states[keep_indices]
# Ensure that past_key_values tensors can be updated in-place
if type(self.past_key_values[0]) == tuple:
self.past_key_values = [list(layer) for layer in self.past_key_values]
# Update tensors in-place to allow incremental garbage collection
past_kv_length = max_input_length - 1
for layer in self.past_key_values:
past_keys, past_values = layer
if len(past_keys.shape) == 3:
# Force past to be of dim [self_size, num_heads, ...] for easy indexing
past_keys = past_keys.view(len(self), -1, *past_keys.shape[-2:])
past_values = past_values.view(len(self), -1, *past_values.shape[-2:])
if self.keys_head_dim_last:
layer[0] = past_keys[keep_indices, :, -past_kv_length:, :]
else:
layer[0] = past_keys[keep_indices, :, :, -past_kv_length:]
del past_keys
layer[1] = past_values[keep_indices, :, -past_kv_length:, :]
del past_values
max_tokens = len(request_ids) * max_input_length + total_remaining_decode_tokens
self.requests = requests
self.requests_idx_mapping = requests_idx_mapping
self.input_ids = input_ids
self.pixel_values = pixel_values
self.image_hidden_states = image_hidden_states
self.position_ids = position_ids
self.all_input_ids = all_input_ids
self.input_lengths = input_lengths
self.prefix_offsets = prefix_offsets
self.read_offsets = read_offsets
self.next_token_choosers = next_token_choosers
self.stopping_criterias = stopping_criterias
self.max_input_length = max_input_length
self.padding_right_offset = new_padding_right_offset
self.max_tokens = max_tokens
return self
@classmethod
@tracer.start_as_current_span("concatenate")
def concatenate(
cls, batches: List["IdeficsCausalLMBatch"]
) -> "IdeficsCausalLMBatch":
# It adds new requests to the batch
# Used for padding
total_batch_size = 0
max_input_length = 0
max_num_images = 0
padding_right_offset = 0
for batch in batches:
total_batch_size += len(batch)
max_input_length = max(max_input_length, batch.max_input_length)
max_num_images = max(max_num_images, batch.pixel_values.size(1))
padding_right_offset = max(padding_right_offset, batch.padding_right_offset)
# Batch attributes
requests = []
requests_idx_mapping = {}
input_lengths = []
prefix_offsets = []
read_offsets = []
all_input_ids = []
next_token_choosers = []
stopping_criterias = []
max_tokens = 0
# Batch tensors
input_ids = None
attention_mask = None
position_ids = None
pixel_values = None
image_hidden_states = None
image_attention_mask = None
past_key_values = []
# Used for slicing correctly inside the tensors
# Equivalent to a cumsum on batch sizes
start_index = 0
for i, batch in enumerate(batches):
requests.extend(batch.requests)
input_lengths.extend(batch.input_lengths)
prefix_offsets.extend(batch.prefix_offsets)
read_offsets.extend(batch.read_offsets)
all_input_ids.extend(batch.all_input_ids)
next_token_choosers.extend(batch.next_token_choosers)
stopping_criterias.extend(batch.stopping_criterias)
if i == 0:
requests_idx_mapping = batch.requests_idx_mapping
else:
# We need to offset the mapping for each batch by the cumulative batch size
for k, v in batch.requests_idx_mapping.items():
requests_idx_mapping[k] = v + start_index
# Slicing end index for this batch
end_index = start_index + len(batch)
# We only concatenate batches that did at least one step
if batch.past_key_values is None:
raise ValueError("only concatenate prefilled batches")
# Create empty tensor
# input_ids is always of shape [batch_size, 1]
# We do not need to pad it
if input_ids is None:
input_ids = batch.input_ids.new_empty((total_batch_size, 1))
# Copy to correct indices
input_ids[start_index:end_index] = batch.input_ids
# Create padded tensor
if attention_mask is None:
attention_mask = batch.attention_mask.new_zeros(
(total_batch_size, max_input_length + padding_right_offset),
)
curr_batch_max_num_images = batch.pixel_values.size(1)
if pixel_values is None:
pixel_values = batch.pixel_values.new_zeros(
(total_batch_size, max_num_images, 3, 224, 224)
)
pixel_values[
start_index:end_index, :curr_batch_max_num_images
] = batch.pixel_values
if image_attention_mask is None:
image_attention_mask = batch.image_attention_mask.new_zeros(
(
total_batch_size,
max_input_length + padding_right_offset,
max_num_images,
)
)
# We need to slice the attention mask to remove padding from previous steps
# and to remove unused allocated space
left_offset = max_input_length - batch.max_input_length
batch_left_offset = (
batch.attention_mask.shape[1]
- batch.max_input_length
- batch.padding_right_offset
)
attention_mask[
start_index:end_index,
left_offset:-padding_right_offset,
] = batch.attention_mask[
:,
batch_left_offset : -batch.padding_right_offset,
]
image_attention_mask[
start_index:end_index,
left_offset:-padding_right_offset,
:curr_batch_max_num_images,
] = batch.image_attention_mask[
:, batch_left_offset : -batch.padding_right_offset, :
]
# Create empty tensor
# position_ids is always of shape [batch_size, 1]
if position_ids is None:
position_ids = batch.position_ids.new_empty((total_batch_size, 1))
position_ids[start_index:end_index] = batch.position_ids
# Shenanigans to get dimensions because BLOOM outputs a past with a different shape
# BLOOM Keys: [batch_size * num_heads, head_dim, seq_length]
# BLOOM Values: [batch_size * num_heads, seq_length, head_dim]
# And ensure that we can update tensors in-place
if type(batch.past_key_values[0]) == tuple:
batch.past_key_values = [
[t.view(len(batch), -1, *t.shape[-2:]) for t in layer]
for layer in batch.past_key_values
]
elif len(batch.past_key_values[0][0].shape) == 3:
for layer in batch.past_key_values:
for k, t in enumerate(layer):
layer[k] = t.view(len(batch), -1, *t.shape[-2:])
# Add eventual padding tokens that were added while concatenating
max_tokens += batch.max_tokens + (
max_input_length - batch.max_input_length
) * len(batch)
start_index = end_index
first_past_kvs = batches[0].past_key_values
_, num_heads, padded_sequence_length, head_dim = first_past_kvs[0][1].shape
padded_past_values_shape = (
total_batch_size,
num_heads,
max_input_length - 1,
head_dim,
)
if batches[0].keys_head_dim_last:
padded_past_keys_shape = padded_past_values_shape
else:
# seq_length is last for BLOOM
padded_past_keys_shape = (
total_batch_size,
num_heads,
head_dim,
max_input_length - 1,
)
# Iterate over attention layers
# Concatenate past key values layer by layer to allow incremental garbage collection
for j in range(len(first_past_kvs)):
padded_past_keys = first_past_kvs[j][0].new_zeros(padded_past_keys_shape)
start_index = 0
for batch in batches:
past_keys = batch.past_key_values[j][0]
# Clear reference to the original tensor
batch.past_key_values[j][0] = None
# Slicing end index for this batch
end_index = start_index + len(batch)
# We slice the keys to remove the padding from previous batches
past_seq_len = batch.max_input_length - 1
if batch.keys_head_dim_last:
padded_past_keys[
start_index:end_index, :, -past_seq_len:, :
] = past_keys[:, :, -past_seq_len:, :]
else:
# BLOOM case
padded_past_keys[
start_index:end_index, :, :, -past_seq_len:
] = past_keys[:, :, :, -past_seq_len:]
del past_keys
start_index = end_index
padded_past_values = first_past_kvs[j][1].new_zeros(
padded_past_values_shape
)
start_index = 0
for batch in batches:
past_values = batch.past_key_values[j][1]
# Clear reference to the original tensor
batch.past_key_values[j][1] = None
# Slicing end index for this batch
end_index = start_index + len(batch)
# We slice the past values to remove the padding from previous batches
past_seq_len = batch.max_input_length - 1
padded_past_values[
start_index:end_index, :, -past_seq_len:, :
] = past_values[:, :, -past_seq_len:, :]
del past_values
# Update values
start_index = end_index
past_key_values.append([padded_past_keys, padded_past_values])
return cls(
batch_id=batches[0].batch_id,
requests=requests,
requests_idx_mapping=requests_idx_mapping,
input_ids=input_ids,
attention_mask=attention_mask,
position_ids=position_ids,
pixel_values=pixel_values,
image_hidden_states=image_hidden_states,
image_attention_mask=image_attention_mask,
past_key_values=past_key_values,
all_input_ids=all_input_ids,
input_lengths=input_lengths,
prefix_offsets=prefix_offsets,
read_offsets=read_offsets,
next_token_choosers=next_token_choosers,
stopping_criterias=stopping_criterias,
max_input_length=max_input_length,
padding_right_offset=padding_right_offset,
keys_head_dim_last=batches[0].keys_head_dim_last,
max_tokens=max_tokens,
)
def __len__(self):
return len(self.requests)
class IdeficsCausalLM(Model):
def __init__(
self,
model_id: str,
revision: Optional[str] = None,
quantize: Optional[str] = None,
dtype: Optional[torch.dtype] = None,
trust_remote_code: bool = False,
):
from text_generation_server.models.custom_modeling.idefics_modeling import (
IdeficsForVisionText2Text,
)
if torch.cuda.is_available():
device = torch.device("cuda")
dtype = torch.bfloat16 if dtype is None else dtype
else:
if quantize:
raise ValueError("quantization is not available on CPU")
device = torch.device("cpu")
dtype = torch.float32 if dtype is None else dtype
tokenizer = AutoTokenizer.from_pretrained(
model_id,
revision=revision,
padding_side="left",
truncation_side="left",
trust_remote_code=trust_remote_code,
)
self.processor = AutoProcessor.from_pretrained(
model_id,
revision=revision,
padding_side="left",
truncation_side="left",
trust_remote_code=trust_remote_code,
)
model = IdeficsForVisionText2Text.from_pretrained(
model_id,
revision=revision,
torch_dtype=dtype,
device_map="auto"
if torch.cuda.is_available() and torch.cuda.device_count() > 1
else None,
load_in_8bit=quantize == "bitsandbytes",
trust_remote_code=trust_remote_code,
)
if torch.cuda.is_available() and torch.cuda.device_count() == 1:
model = model.cuda()
if tokenizer.pad_token_id is None:
if model.config.pad_token_id is not None:
tokenizer.pad_token_id = model.config.pad_token_id
elif model.config.eos_token_id is not None:
tokenizer.pad_token_id = model.config.eos_token_id
elif tokenizer.eos_token_id is not None:
tokenizer.pad_token_id = tokenizer.eos_token_id
else:
tokenizer.add_special_tokens({"pad_token": "<unk>"})
super(IdeficsCausalLM, self).__init__(
model=model,
tokenizer=tokenizer,
requires_padding=True,
dtype=dtype,
device=device,
)
@property
def batch_type(self) -> Type[IdeficsCausalLMBatch]:
return IdeficsCausalLMBatch
def forward(
self,
input_ids,
attention_mask,
position_ids,
pixel_values,
image_hidden_states,
image_attention_mask,
past_key_values: Optional = None,
) -> Tuple[torch.Tensor, List[Tuple[torch.Tensor, torch.Tensor]]]:
# Model Forward
kwargs = {
"input_ids": input_ids,
"attention_mask": attention_mask,
"pixel_values": pixel_values,
"image_hidden_states": image_hidden_states,
"image_attention_mask": image_attention_mask,
"past_key_values": past_key_values,
"use_cache": True,
"return_dict": True,
}
if self.has_position_ids:
kwargs["position_ids"] = position_ids
outputs = self.model.forward(**kwargs)
return outputs.logits, outputs.past_key_values, outputs.image_hidden_states
@tracer.start_as_current_span("generate_token")
def generate_token(
self, batch: IdeficsCausalLMBatch
) -> Tuple[List[Generation], Optional[IdeficsCausalLMBatch], Tuple[int, int]]:
start = time.time_ns()
# slice the attention mask to the correct shape
attention_mask = batch.attention_mask[:, : -batch.padding_right_offset]
if batch.input_ids.size(1) == 1:
# THIS is a hack: when calling idefics.generate, the first time, we need the whole image_attention_mask (size bs x max_seq_len x max_num_images),
# but the subsequent times, we only need the last attention mask along the `max_seq_len` dimension
# this is due to the nature IDEFICS: it's an encoder decoder, and so when decoding, only the currently generated
# token need to attend to the encoder hidden states (i.e. the vision encoder)
# Also see seq2seq_lm.Seq2SeqLM.generate_token which has roughly the same logic
image_attention_mask = batch.image_attention_mask[
:, -(batch.padding_right_offset + 1)
].unsqueeze(1)
else:
image_attention_mask = batch.image_attention_mask[
:, : -batch.padding_right_offset
]
logits, past, image_hidden_states = self.forward(
input_ids=batch.input_ids,
attention_mask=attention_mask,
position_ids=batch.position_ids,
pixel_values=batch.pixel_values,
image_hidden_states=batch.image_hidden_states,
image_attention_mask=image_attention_mask,
past_key_values=batch.past_key_values,
)
# Hardcoded remove image tokens
logits[:, 32000:32001] = torch.finfo(logits.dtype).min
start_decode = time.time_ns()
# Results
generations: List[Generation] = []
stopped = True
# Zipped iterator
iterator = zip(
batch.requests,
batch.input_lengths,
batch.prefix_offsets,
batch.read_offsets,
logits,
batch.next_token_choosers,
batch.stopping_criterias,
batch.all_input_ids,
)
# For each member of the batch
for i, (
request,
input_length,
prefix_offset,
read_offset,
logits,
next_token_chooser,
stopping_criteria,
all_input_ids,
) in enumerate(iterator):
# Select next token
next_token_id, logprobs = next_token_chooser(
all_input_ids.view(1, -1), logits[-1:, :]
)
# Append next token to all tokens
all_input_ids = torch.cat([all_input_ids, next_token_id])
new_input_length = input_length + 1
# Generated token
next_token_logprob = logprobs[-1, next_token_id]
next_token_id_squeezed = next_token_id.squeeze()
next_token_text, prefix_offset, read_offset = self.decode_token(
all_input_ids[:, 0], prefix_offset, read_offset
)
# Evaluate stopping criteria
stop, reason = stopping_criteria(
next_token_id_squeezed,
next_token_text,
)
if not stop:
stopped = False
# Shard generations
# All generations will be appended in the rust sharded client
if i % self.world_size == self.rank:
if stop:
# Decode generated tokens
output_text, _, _ = self.decode_token(
all_input_ids[:, 0],
prefix_offset=len(all_input_ids)
- stopping_criteria.current_tokens
- 1,
read_offset=len(all_input_ids)
- stopping_criteria.current_tokens,
skip_special_tokens=True,
)
# Get seed
if isinstance(next_token_chooser.choice, Sampling):
seed = next_token_chooser.choice.seed
else:
seed = None
generated_text = GeneratedText(
output_text, stopping_criteria.current_tokens, reason, seed
)
else:
generated_text = None
# Prefill
if stopping_criteria.current_tokens == 1 and request.prefill_logprobs:
# Remove generated token to only have prefill and add nan for first prompt token
prefill_logprobs = [float("nan")] + torch.log_softmax(
logits, -1
).gather(1, all_input_ids[1:]).squeeze(1)[
-new_input_length:-1
].tolist()
prefill_token_ids = all_input_ids[-new_input_length:-1]
prefill_texts = self.tokenizer.batch_decode(
prefill_token_ids,
clean_up_tokenization_spaces=False,
skip_special_tokens=False,
)
prefill_tokens = Tokens(
prefill_token_ids,
prefill_logprobs,
prefill_texts,
is_special=[],
)
else:
prefill_tokens = None
top_tokens = None
generation = Generation(
request.id,
prefill_tokens,
Tokens(
[next_token_id_squeezed],
[next_token_logprob],
[next_token_text],
[next_token_id_squeezed.item() in self.all_special_ids],
),
generated_text,
top_tokens,
)
generations.append(generation)
# Update values
batch.input_ids[i, 0] = next_token_id
batch.all_input_ids[i] = all_input_ids
batch.input_lengths[i] = new_input_length
batch.prefix_offsets[i] = prefix_offset
batch.read_offsets[i] = read_offset
batch.max_input_length = max(batch.max_input_length, new_input_length)
# We finished all generations in the batch; there is no next batch
if stopped:
forward_ns = start_decode - start
decode_ns = time.time_ns() - start_decode
return generations, None, (forward_ns, decode_ns)
# Slice unused values from prefill
batch.input_ids = batch.input_ids[:, :1]
# Update attention_mask as we added a new token to input_ids
batch.attention_mask[:, -batch.padding_right_offset] = 1
batch.image_attention_mask[
:, -batch.padding_right_offset, :
] = batch.image_attention_mask[:, -(batch.padding_right_offset + 1), :]
# Decrease right offset
batch.padding_right_offset -= 1
# Update position_ids
batch.position_ids = batch.position_ids[:, -1:] + 1
# Update past key values
batch.past_key_values = past
batch.image_hidden_states = image_hidden_states
forward_ns = start_decode - start
decode_ns = time.time_ns() - start_decode
return generations, batch, (forward_ns, decode_ns)
| text-generation-inference/server/text_generation_server/models/idefics_causal_lm.py/0 | {
"file_path": "text-generation-inference/server/text_generation_server/models/idefics_causal_lm.py",
"repo_id": "text-generation-inference",
"token_count": 16143
} | 210 |
import os
import torch
from datetime import timedelta
from loguru import logger
# Tensor Parallelism settings
RANK = int(os.getenv("RANK", "0"))
WORLD_SIZE = int(os.getenv("WORLD_SIZE", "1"))
# CUDA memory fraction
MEMORY_FRACTION = float(os.getenv("CUDA_MEMORY_FRACTION", "1.0"))
class FakeBarrier:
def wait(self):
pass
class FakeGroup:
def __init__(self, rank, size):
self._rank = rank
self._size = size
def allreduce(self, *args, **kwargs):
return FakeBarrier()
def allgather(self, inputs, local_tensor, **kwargs):
assert (
len(inputs[0]) == len(local_tensor) == 1
), f"{len(inputs[0])} != {len(local_tensor)} != 1, and the FakeGroup is supposed to join on simple tensors"
for input_ in inputs:
input_[0].data = local_tensor[0].data
return FakeBarrier()
def barrier(self, *args, **kwargs):
return FakeBarrier()
def size(self):
return self._size
def rank(self):
return self._rank
def initialize_torch_distributed():
if torch.cuda.is_available():
from torch.distributed import ProcessGroupNCCL
# Set the device id.
assert WORLD_SIZE <= torch.cuda.device_count(), "Each process is one gpu"
device = RANK % torch.cuda.device_count()
torch.cuda.set_device(device)
torch.cuda.set_per_process_memory_fraction(MEMORY_FRACTION, device)
backend = "nccl"
options = ProcessGroupNCCL.Options()
options.is_high_priority_stream = True
options._timeout = timedelta(seconds=60)
else:
backend = "gloo"
options = None
if WORLD_SIZE == 1:
return FakeGroup(RANK, WORLD_SIZE), RANK, WORLD_SIZE
else:
if os.getenv("DEBUG", None) == "1":
return FakeGroup(RANK, WORLD_SIZE), RANK, WORLD_SIZE
if not torch.distributed.is_initialized():
# Call the init process.
torch.distributed.init_process_group(
backend=backend,
world_size=WORLD_SIZE,
rank=RANK,
timeout=timedelta(seconds=60),
pg_options=options,
)
else:
logger.warning("torch.distributed is already initialized.")
return torch.distributed.group.WORLD, RANK, WORLD_SIZE
| text-generation-inference/server/text_generation_server/utils/dist.py/0 | {
"file_path": "text-generation-inference/server/text_generation_server/utils/dist.py",
"repo_id": "text-generation-inference",
"token_count": 1042
} | 211 |
import re
from typing import Callable, List, Optional, Tuple
import torch
from text_generation_server.pb import generate_pb2
from text_generation_server.pb.generate_pb2 import FinishReason
from text_generation_server.utils.logits_process import (
HeterogeneousProcessorWrapper,
HeterogeneousRepetitionPenaltyLogitsProcessor,
HeterogeneousTemperatureLogitsWarper,
HeterogeneousTopKLogitsWarper,
HeterogeneousTopPLogitsWarper,
HeterogeneousTypicalLogitsWarper,
static_warper,
)
from text_generation_server.utils.watermark import WatermarkLogitsProcessor
from transformers import PreTrainedTokenizerBase, RepetitionPenaltyLogitsProcessor
class NextTokenChooser:
def __init__(
self,
watermark=False,
temperature=1.0,
repetition_penalty=1.0,
top_k=None,
top_p=None,
typical_p=None,
do_sample=False,
seed=0,
device="cpu",
):
self.watermark_processor = (
WatermarkLogitsProcessor(device=device) if watermark else None
)
self.repetition_processor = (
RepetitionPenaltyLogitsProcessor(penalty=repetition_penalty)
if repetition_penalty
else None
)
has_warpers = (
(temperature is not None and temperature != 1.0)
or (top_k is not None and top_k != 0)
or (top_p is not None and top_p < 1.0)
or (typical_p is not None and typical_p < 1.0)
)
if has_warpers:
self.static_warper = static_warper(
temperature=temperature, top_k=top_k, top_p=top_p, typical_p=typical_p
)
else:
self.static_warper = None
sampling = do_sample or has_warpers
self.choice = Sampling(seed, device) if sampling else Greedy()
def __call__(self, input_ids, scores):
if self.watermark_processor is not None:
scores = self.watermark_processor(input_ids, scores)
if self.repetition_processor is not None:
scores = self.repetition_processor(input_ids, scores)
if self.static_warper is None:
next_logprob = torch.log_softmax(scores, -1)
else:
scores, next_logprob = self.static_warper(scores)
next_id = self.choice(scores[-1]).view(1, 1)
return next_id, next_logprob
@classmethod
def from_pb(
cls,
pb: generate_pb2.NextTokenChooserParameters,
device: torch.device,
) -> "NextTokenChooser":
return NextTokenChooser(
watermark=pb.watermark,
temperature=pb.temperature,
repetition_penalty=pb.repetition_penalty,
top_k=pb.top_k,
top_p=pb.top_p,
typical_p=pb.typical_p,
do_sample=pb.do_sample,
seed=pb.seed,
device=device,
)
class StopSequenceCriteria:
def __init__(self, stop_sequence: str):
stop_sequence = re.escape(stop_sequence)
self.regex = re.compile(f"{stop_sequence}$")
def __call__(self, output: str) -> bool:
if self.regex.findall(output):
return True
return False
class StoppingCriteria:
def __init__(
self,
eos_token_id: int,
stop_sequence_criterias: List[StopSequenceCriteria],
max_new_tokens: int = 20,
ignore_eos_token: bool = False,
):
self.eos_token_id = eos_token_id
self.stop_sequence_criterias = stop_sequence_criterias
self.max_new_tokens = max_new_tokens
self.current_tokens = 0
self.current_output = ""
self.ignore_eos_token = ignore_eos_token
def __call__(self, last_token: int, last_output: str) -> Tuple[bool, Optional[str]]:
self.current_tokens += 1
if self.current_tokens >= self.max_new_tokens:
return True, FinishReason.FINISH_REASON_LENGTH
if not self.ignore_eos_token and last_token == self.eos_token_id:
return True, FinishReason.FINISH_REASON_EOS_TOKEN
if self.stop_sequence_criterias:
self.current_output += last_output
# There is no need to keep an output that is too long
if len(self.current_output) > 300:
# Slice to -200 to avoid doing it all the time
self.current_output = self.current_output[-200:]
for stop_sequence_criteria in self.stop_sequence_criterias:
if stop_sequence_criteria(self.current_output):
return True, FinishReason.FINISH_REASON_STOP_SEQUENCE
return False, None
@classmethod
def from_pb(
cls,
pb: generate_pb2.StoppingCriteriaParameters,
tokenizer: PreTrainedTokenizerBase,
) -> "StoppingCriteria":
stop_sequence_criterias = [
StopSequenceCriteria(sequence) for sequence in pb.stop_sequences
]
return StoppingCriteria(
tokenizer.eos_token_id,
stop_sequence_criterias,
pb.max_new_tokens,
pb.ignore_eos_token,
)
def create_n_gram_speculation(
input_ids: torch.Tensor,
next_ids: torch.Tensor,
accepted_ids: torch.Tensor,
speculate: int,
verbose: bool,
):
# Very trivial approach, find first match in the string.
# This is much less refined than actual n-gram but seems to work
# relatively OK in grounded mode and is by far much faster with
# much less worst case complexity as everything happens on device.
B = accepted_ids.shape[0]
device = input_ids.device
seeds = next_ids[accepted_ids.cumsum(dim=-1) - 1]
indices = (input_ids == seeds.unsqueeze(-1)).max(dim=1).indices + 1
all_indices = indices.unsqueeze(-1).expand(B, speculate) + torch.arange(
speculate, device=device
)
all_indices = torch.clamp(all_indices, max=input_ids.shape[1] - 1)
speculative_ids = input_ids.gather(dim=-1, index=all_indices)
return speculative_ids
class HeterogeneousNextTokenChooser:
def __init__(
self,
dtype: torch.dtype,
device: torch.device,
watermark: List[bool],
temperature: List[float],
repetition_penalty: List[float],
top_k: List[int],
top_p: List[float],
typical_p: List[float],
do_sample: List[bool],
seeds: List[int],
):
warpers = []
self.watermark_processor = (
HeterogeneousProcessorWrapper(
{
i: WatermarkLogitsProcessor(device=device)
for i, do_watermark in enumerate(watermark)
if do_watermark
}
)
if any(watermark)
else None
)
self.repetition_processor = (
HeterogeneousRepetitionPenaltyLogitsProcessor(
repetition_penalty, dtype, device
)
if any([x != 1.0 for x in repetition_penalty])
else None
)
if any([x != 1.0 for x in temperature]):
do_sample = [
sample or x != 1.0 for x, sample in zip(temperature, do_sample)
]
warpers.append(
HeterogeneousTemperatureLogitsWarper(temperature, dtype, device)
)
if any([x != 0 for x in top_k]):
do_sample = [sample or x != 0 for x, sample in zip(top_k, do_sample)]
warpers.append(HeterogeneousTopKLogitsWarper(top_k, device))
if any([x < 1.0 for x in top_p]):
do_sample = [sample or x < 1.0 for x, sample in zip(top_p, do_sample)]
warpers.append(HeterogeneousTopPLogitsWarper(top_p, dtype, device))
if any([x < 1.0 for x in typical_p]):
do_sample = [sample or x < 1.0 for x, sample in zip(typical_p, do_sample)]
warpers.append(HeterogeneousTypicalLogitsWarper(typical_p, dtype, device))
self.warpers = warpers
if any(do_sample):
self.choice = HeterogeneousSampling(do_sample, seeds, device)
else:
self.choice = Greedy()
self.seeds = seeds
self.do_sample = do_sample
self.dtype = dtype
self.device = device
def __call__(
self,
input_ids: torch.Tensor,
scores: torch.Tensor,
speculate: int,
speculated_ids: Optional[torch.Tensor] = None,
speculative_scores: Optional[torch.Tensor] = None,
verbose=False,
):
if speculated_ids is not None:
B = scores.shape[0] // (speculated_ids.shape[1] + 1)
S = speculated_ids.shape[1] + 1
scores = scores.view(B, S, -1)
else:
B = scores.shape[0]
S = 1
scores = scores.view(B, S, -1)
next_ids = torch.zeros((B, S), device=scores.device, dtype=torch.long)
for j in range(S):
_scores = scores[:, j]
if self.watermark_processor is not None:
_scores = self.watermark_processor(input_ids, _scores)
if self.repetition_processor is not None:
_scores = self.repetition_processor(input_ids, _scores)
for warper in self.warpers:
_scores = warper(input_ids, _scores)
_next_ids = self.choice(_scores)
scores[:, j] = _scores
next_ids[:, j] = _next_ids
next_ids = next_ids.view(B * S)
allscores = scores.view(B * S, -1)
alllogprobs = torch.log_softmax(allscores, -1)
if speculated_ids is not None:
accepted_ids = []
B = next_ids.shape[0] // (speculated_ids.shape[1] + 1)
S = speculated_ids.shape[1] + 1
indices = []
for i in range(B):
_next_ids = next_ids[i * S : (i + 1) * S]
_speculated_ids = speculated_ids[i]
validate_speculative = _next_ids[:-1] == _speculated_ids
index = i * S
accepted = 1
# First is always valid
indices.append(index)
for valid in validate_speculative.tolist():
if valid:
index += 1
accepted += 1
indices.append(index)
else:
break
accepted_ids.append(accepted)
accepted_ids = torch.tensor(
accepted_ids, device=input_ids.device, dtype=input_ids.dtype
)
next_ids = next_ids[indices]
logprobs = alllogprobs[indices]
indices = torch.arange(B, device=input_ids.device) * S
if speculative_scores is not None:
speculative_scores = speculative_scores[indices + accepted_ids - 1]
else:
accepted_ids = torch.ones_like(next_ids)
logprobs = alllogprobs
next_logprobs = torch.gather(logprobs, 1, next_ids.view(-1, 1)).view(-1)
if speculate > 0:
if speculative_scores is not None:
# Medusa provided some scores
speculative_ids = Greedy()(speculative_scores)
else:
# n-gram
speculative_ids = create_n_gram_speculation(
input_ids, next_ids, accepted_ids, speculate, verbose
)
else:
speculative_ids = None
return next_ids, next_logprobs, alllogprobs, accepted_ids, speculative_ids
def filter(self, indices):
if self.watermark_processor is not None:
self.watermark_processor = self.watermark_processor.filter(indices)
if self.repetition_processor is not None:
self.repetition_processor = self.repetition_processor.filter(indices)
filtered_warpers = []
for warper in self.warpers:
filtered_warper = warper.filter(indices)
if filtered_warper is not None:
filtered_warpers.append(filtered_warper)
self.warpers = filtered_warpers
self.seeds = [self.seeds[i] for i in indices]
self.do_sample = [self.do_sample[i] for i in indices]
if any(self.do_sample):
self.choice.filter(indices)
else:
self.choice = Greedy()
return self
@classmethod
def from_pb(
cls,
pb: List[generate_pb2.NextTokenChooserParameters],
dtype: torch.dtype,
device: torch.device,
) -> "HeterogeneousNextTokenChooser":
return HeterogeneousNextTokenChooser(
watermark=[pb_.watermark for pb_ in pb],
temperature=[pb_.temperature for pb_ in pb],
repetition_penalty=[pb_.repetition_penalty for pb_ in pb],
top_k=[pb_.top_k for pb_ in pb],
top_p=[pb_.top_p for pb_ in pb],
typical_p=[pb_.typical_p for pb_ in pb],
do_sample=[pb_.do_sample for pb_ in pb],
seeds=[pb_.seed for pb_ in pb],
device=device,
dtype=dtype,
)
class Sampling:
def __init__(self, seed: int, device: str = "cpu"):
self.generator = torch.Generator(device)
self.generator.manual_seed(seed)
self.seed = seed
def __call__(self, logits):
probs = torch.nn.functional.softmax(logits, -1)
# Avoid GPU<->CPU sync done by torch multinomial
# See: https://github.com/pytorch/pytorch/blob/925a3788ec5c06db62ca732a0e9425a26a00916f/aten/src/ATen/native/Distributions.cpp#L631-L637
q = torch.empty_like(probs).exponential_(1, generator=self.generator)
return probs.div_(q).argmax()
class Greedy:
def __call__(self, logits):
return logits.argmax(dim=-1)
class HeterogeneousSampling:
r"""
Mixed greedy and probabilistic sampling. Compute both and pick the right one for each sample.
"""
def __init__(self, do_sample: List[bool], seeds: List[int], device: torch.device):
self.seeds = seeds
self.greedy_indices = []
self.sampling_mapping = {}
for i, (sample, seed) in enumerate(zip(do_sample, seeds)):
if sample:
self.sampling_mapping[i] = Sampling(seed, device)
else:
self.greedy_indices.append(i)
self.greedy = Greedy()
def __call__(self, logits):
out = torch.empty(logits.shape[0], dtype=torch.int64, device=logits.device)
if self.greedy_indices:
# Computing for all indices is faster than slicing
torch.argmax(logits, -1, out=out)
for i, sampling in self.sampling_mapping.items():
out[i] = sampling(logits[i])
return out
def filter(self, indices):
new_greedy_indices = []
new_sampling_mapping = {}
for i, idx in enumerate(indices):
if idx in self.sampling_mapping:
new_sampling_mapping[i] = self.sampling_mapping[idx]
else:
new_greedy_indices.append(i)
self.greedy_indices = new_greedy_indices
self.sampling_mapping = new_sampling_mapping
return self
def batch_top_tokens(
top_n_tokens: List[int], top_n_tokens_tensor: torch.Tensor, logprobs: torch.Tensor, accepted_ids: torch.Tensor
) -> Tuple[List[List[List[int]]], List[List[List[float]]]]:
"""Find the top n most likely tokens for a batch of generations.
When multiple tokens have equal probabilities and they don't all fit, the
remaining tokens are also returned.
"""
max_top_n = max(top_n_tokens)
# Early exit when top_n_tokens is not used
if max_top_n == 0:
return [[[]]] * len(top_n_tokens), [[[]]] * len(top_n_tokens)
batch_size = accepted_ids.shape[0]
speculate_size = logprobs.shape[0] // batch_size
top_n_tokens_tensor = top_n_tokens_tensor.repeat_interleave(speculate_size)
# Ensure top_n doesn't exceed vocab size
top_n_tokens = [min(tok, logprobs.size(-1)) for tok in top_n_tokens for _ in range(speculate_size)]
# Parallel kthvalue adapted from https://discuss.pytorch.org/t/how-to-efficiently-get-the-k-th-largest-values-in-parallel/160529/2
# Sorted topk is faster than torch.sort() since we only need a small subset
sorted_top_k = torch.topk(logprobs, k=max_top_n, dim=-1, sorted=True).values
nth_highest = torch.gather(
sorted_top_k, 1, (top_n_tokens_tensor - 1).clip(min=0).unsqueeze(1)
)
nth_highest[nth_highest == -float("inf")] = torch.finfo(logprobs.dtype).min
# Find the new "fuzzy" top n values
top_n_indices = (logprobs >= nth_highest).nonzero()
_, top_n_ishes = torch.unique_consecutive(top_n_indices[:, 0], return_counts=True)
k = 1 if top_n_ishes.numel() == 0 else top_n_ishes.max()
# Take a new topk for these new max n values
top_k = torch.topk(logprobs, k=k, dim=1, sorted=True)
top_n_ishes = top_n_ishes.tolist()
top_indices = top_k.indices.tolist()
top_values = top_k.values.tolist()
batch_top_token_ids = []
batch_top_token_logprobs = []
accepted_ids_list = accepted_ids.tolist()
for i, n_accepted_ids in enumerate(accepted_ids_list):
start = speculate_size * i
stop = speculate_size * (i + 1)
_top_indices = top_indices[start: stop]
_top_values = top_values[start: stop]
_top_n_ishes = top_n_ishes[start: stop]
_top_n_tokens = top_n_tokens[start: stop]
_top_indices = _top_indices[:n_accepted_ids]
_top_values = _top_values[:n_accepted_ids]
_top_n_ishes = _top_n_ishes[:n_accepted_ids]
_top_n_tokens = _top_n_tokens[:n_accepted_ids]
row_top_token_ids = []
row_top_token_logprobs = []
for idxs, vals, n, req_n in zip(_top_indices, _top_values, _top_n_ishes, _top_n_tokens):
indices = idxs[:n] if req_n > 0 else []
values = vals[:n] if req_n > 0 else []
row_top_token_ids.append(indices)
row_top_token_logprobs.append(values)
batch_top_token_ids.append(row_top_token_ids)
batch_top_token_logprobs.append(row_top_token_logprobs)
return batch_top_token_ids, batch_top_token_logprobs
| text-generation-inference/server/text_generation_server/utils/tokens.py/0 | {
"file_path": "text-generation-inference/server/text_generation_server/utils/tokens.py",
"repo_id": "text-generation-inference",
"token_count": 8706
} | 212 |
# This CITATION.cff file was generated with cffinit.
# Visit https://bit.ly/cffinit to generate yours today!
cff-version: 1.2.0
title: HuggingFace's Tokenizers
message: >-
Fast State-of-the-Art Tokenizers optimized for Research
and Production.
type: software
authors:
- given-names: Anthony
family-names: Moi
email: [email protected]
affiliation: HuggingFace
- given-names: Nicolas
family-names: Patry
affiliation: HuggingFace
repository-code: 'https://github.com/huggingface/tokenizers'
url: 'https://github.com/huggingface/tokenizers'
repository: 'https://huggingface.co'
abstract: >-
Fast State-of-the-Art Tokenizers optimized for Research
and Production.
keywords:
- Rust
- Tokenizer
- NLP
license: Apache-2.0
commit: 37372b6
version: 0.13.4
date-released: '2023-04-05'
| tokenizers/CITATION.cff/0 | {
"file_path": "tokenizers/CITATION.cff",
"repo_id": "tokenizers",
"token_count": 293
} | 213 |
<p align="center">
<br>
<img src="https://huggingface.co/landing/assets/tokenizers/tokenizers-logo.png" width="600"/>
<br>
<p>
<p align="center">
<a href="https://badge.fury.io/js/tokenizers">
<img alt="Build" src="https://badge.fury.io/js/tokenizers.svg">
</a>
<a href="https://github.com/huggingface/tokenizers/blob/master/LICENSE">
<img alt="GitHub" src="https://img.shields.io/github/license/huggingface/tokenizers.svg?color=blue">
</a>
</p>
<br>
NodeJS implementation of today's most used tokenizers, with a focus on performance and
versatility. Bindings over the [Rust](https://github.com/huggingface/tokenizers/tree/master/tokenizers) implementation.
If you are interested in the High-level design, you can go check it there.
## Main features
- Train new vocabularies and tokenize using 4 pre-made tokenizers (Bert WordPiece and the 3
most common BPE versions).
- Extremely fast (both training and tokenization), thanks to the Rust implementation. Takes
less than 20 seconds to tokenize a GB of text on a server's CPU.
- Easy to use, but also extremely versatile.
- Designed for research and production.
- Normalization comes with alignments tracking. It's always possible to get the part of the
original sentence that corresponds to a given token.
- Does all the pre-processing: Truncate, Pad, add the special tokens your model needs.
## Installation
```bash
npm install tokenizers@latest
```
## Basic example
```ts
import { Tokenizer } from "tokenizers";
const tokenizer = await Tokenizer.fromFile("tokenizer.json");
const wpEncoded = await tokenizer.encode("Who is John?");
console.log(wpEncoded.getLength());
console.log(wpEncoded.getTokens());
console.log(wpEncoded.getIds());
console.log(wpEncoded.getAttentionMask());
console.log(wpEncoded.getOffsets());
console.log(wpEncoded.getOverflowing());
console.log(wpEncoded.getSpecialTokensMask());
console.log(wpEncoded.getTypeIds());
console.log(wpEncoded.getWordIds());
```
## License
[Apache License 2.0](../../LICENSE)
| tokenizers/bindings/node/README.md/0 | {
"file_path": "tokenizers/bindings/node/README.md",
"repo_id": "tokenizers",
"token_count": 651
} | 214 |
/* eslint-disable @typescript-eslint/no-explicit-any */
/* eslint-disable @typescript-eslint/no-empty-function */
import { TruncationStrategy, BPE, Encoding, AddedToken, Tokenizer } from '../../'
// jest.mock('../../bindings/tokenizer');
// jest.mock('../../bindings/models', () => ({
// __esModule: true,
// Model: jest.fn()
// }));
// Or:
// jest.mock('../../bindings/models', () => {
// return require('../../bindings/__mocks__/models');
// });
// const TokenizerMock = mocked(Tokenizer);
describe('AddedToken', () => {
it('instantiates with only content', () => {
const addToken = new AddedToken('test', false)
expect(addToken.constructor.name).toEqual('AddedToken')
})
it('instantiates with empty options', () => {
const addToken = new AddedToken('test', false, {})
expect(addToken.constructor.name).toEqual('AddedToken')
})
it('instantiates with options', () => {
const addToken = new AddedToken('test', false, {
leftStrip: true,
rightStrip: true,
singleWord: true,
})
expect(addToken.constructor.name).toEqual('AddedToken')
})
describe('getContent', () => {
it('returns the string content of AddedToken', () => {
const addedToken = new AddedToken('test', false)
expect(addedToken.getContent()).toEqual('test')
})
})
})
describe('Tokenizer', () => {
it('has expected methods', () => {
const model = BPE.empty()
const tokenizer = new Tokenizer(model)
expect(typeof Tokenizer.fromFile).toBe('function')
expect(typeof Tokenizer.fromString).toBe('function')
// expect(typeof Tokenizer.fromPretrained).toBe('function')
expect(typeof tokenizer.addSpecialTokens).toBe('function')
expect(typeof tokenizer.addTokens).toBe('function')
expect(typeof tokenizer.decode).toBe('function')
expect(typeof tokenizer.decodeBatch).toBe('function')
expect(typeof tokenizer.disablePadding).toBe('function')
expect(typeof tokenizer.disableTruncation).toBe('function')
expect(typeof tokenizer.encode).toBe('function')
expect(typeof tokenizer.encodeBatch).toBe('function')
expect(typeof tokenizer.getDecoder).toBe('function')
expect(typeof tokenizer.getNormalizer).toBe('function')
expect(typeof tokenizer.getPostProcessor).toBe('function')
expect(typeof tokenizer.getPreTokenizer).toBe('function')
expect(typeof tokenizer.getVocab).toBe('function')
expect(typeof tokenizer.getVocabSize).toBe('function')
expect(typeof tokenizer.idToToken).toBe('function')
expect(typeof tokenizer.runningTasks).toBe('function')
expect(typeof tokenizer.save).toBe('function')
expect(typeof tokenizer.setDecoder).toBe('function')
expect(typeof tokenizer.setModel).toBe('function')
expect(typeof tokenizer.setNormalizer).toBe('function')
expect(typeof tokenizer.setPadding).toBe('function')
expect(typeof tokenizer.setPostProcessor).toBe('function')
expect(typeof tokenizer.setPreTokenizer).toBe('function')
expect(typeof tokenizer.setTruncation).toBe('function')
expect(typeof tokenizer.tokenToId).toBe('function')
expect(typeof tokenizer.toString).toBe('function')
expect(typeof tokenizer.train).toBe('function')
})
// it('can be instantiated from the hub', async () => {
// let tokenizer: Tokenizer
// let output: Encoding
// tokenizer = Tokenizer.fromPretrained('bert-base-cased')
// output = await tokenizer.encode('Hey there dear friend!', null, { addSpecialTokens: false })
// expect(output.getTokens()).toEqual(['Hey', 'there', 'dear', 'friend', '!'])
// tokenizer = Tokenizer.fromPretrained('anthony/tokenizers-test')
// output = await tokenizer.encode('Hey there dear friend!', null, { addSpecialTokens: false })
// expect(output.getTokens()).toEqual(['hey', 'there', 'dear', 'friend', '!'])
// tokenizer = Tokenizer.fromPretrained('anthony/tokenizers-test', {
// revision: 'gpt-2',
// })
// output = await tokenizer.encode('Hey there dear friend!', null, { addSpecialTokens: false })
// expect(output.getTokens()).toEqual(['Hey', 'Ġthere', 'Ġdear', 'Ġfriend', '!'])
// }, 10000)
describe('addTokens', () => {
it('accepts a list of string as new tokens when initial model is empty', () => {
const model = BPE.empty()
const tokenizer = new Tokenizer(model)
const nbAdd = tokenizer.addTokens(['my', 'name', 'is', 'john', 'pair'])
expect(nbAdd).toBe(5)
})
it('accepts a list of AddedToken as new tokens when initial model is empty', () => {
const model = BPE.empty()
const tokenizer = new Tokenizer(model)
const addedToken = new AddedToken('test', false)
const nbAdd = tokenizer.addAddedTokens([addedToken])
expect(nbAdd).toBe(1)
})
})
describe('encode', () => {
let tokenizer: Tokenizer
beforeEach(() => {
// Clear all instances and calls to constructor and all methods:
// TokenizerMock.mockClear();
const model = BPE.empty()
tokenizer = new Tokenizer(model)
tokenizer.addTokens(['my', 'name', 'is', 'john', 'pair'])
})
it('accepts a pair of strings as parameters', async () => {
const encoding = await tokenizer.encode('my name is john', 'pair')
expect(encoding).toBeDefined()
})
it('accepts a string with a null pair', async () => {
const encoding = await tokenizer.encode('my name is john', null)
expect(encoding).toBeDefined()
})
// TODO
// it("throws if we try to encode a pre-tokenized string without isPretokenized=true", async () => {
// await expect((encode as any)(["my", "name", "is", "john"], null)).rejects.toThrow(
// "encode with isPreTokenized=false expect string"
// );
// });
// it("accepts a pre-tokenized string as parameter", async () => {
// const encoding = await tokenizer.encode(["my", "name", "is", "john"], undefined, {
// isPretokenized: true,
// });
// expect(encoding).toBeDefined();
// });
// it("throws if we try to encodeBatch pre-tokenized strings without isPretokenized=true", async () => {
// await expect((encodeBatch as any)([["my", "name", "is", "john"]])).rejects.toThrow(
// "encodeBatch with isPretokenized=false expects input to be `EncodeInput[]` " +
// "with `EncodeInput = string | [string, string]`"
// );
// });
// it("accepts a pre-tokenized input in encodeBatch", async () => {
// const encoding = await tokenizer.encodeBatch([["my", "name", "is", "john"]], {
// isPretokenized: true,
// });
// expect(encoding).toBeDefined();
// });
it('Encodes correctly if called with only one argument', async () => {
const encoded = await tokenizer.encode('my name is john')
expect(encoded.getIds()).toEqual([0, 1, 2, 3])
})
it('returns an Encoding', async () => {
const encoding = await tokenizer.encode('my name is john', 'pair')
expect(encoding.getAttentionMask()).toEqual([1, 1, 1, 1, 1])
const ids = encoding.getIds()
expect(Array.isArray(ids)).toBe(true)
expect(ids).toHaveLength(5)
for (const id of ids) {
expect(typeof id).toBe('number')
}
expect(encoding.getOffsets()).toEqual([
[0, 2],
[3, 7],
[8, 10],
[11, 15],
[0, 4],
])
expect(encoding.getOverflowing()).toEqual([])
expect(encoding.getSpecialTokensMask()).toEqual([0, 0, 0, 0, 0])
expect(encoding.getTokens()).toEqual(['my', 'name', 'is', 'john', 'pair'])
expect(encoding.getTypeIds()).toEqual([0, 0, 0, 0, 1])
})
describe('when truncation is enabled', () => {
it('truncates with default if no truncation options provided', async () => {
tokenizer.setTruncation(2)
const singleEncoding = await tokenizer.encode('my name is john', null)
expect(singleEncoding.getTokens()).toEqual(['my', 'name'])
const pairEncoding = await tokenizer.encode('my name is john', 'pair')
expect(pairEncoding.getTokens()).toEqual(['my', 'pair'])
})
it('throws an error with strategy `only_second` and no pair is encoded', async () => {
tokenizer.setTruncation(2, { strategy: TruncationStrategy.OnlySecond })
await expect(tokenizer.encode('my name is john', null)).rejects.toThrow(
'Truncation error: Second sequence not provided',
)
})
})
describe('when padding is enabled', () => {
it('does not pad anything with default options', async () => {
tokenizer.setPadding()
const singleEncoding = await tokenizer.encode('my name', null)
expect(singleEncoding.getTokens()).toEqual(['my', 'name'])
const pairEncoding = await tokenizer.encode('my name', 'pair')
expect(pairEncoding.getTokens()).toEqual(['my', 'name', 'pair'])
})
it('pads to the right by default', async () => {
tokenizer.setPadding({ maxLength: 5 })
const singleEncoding = await tokenizer.encode('my name', null)
expect(singleEncoding.getTokens()).toEqual(['my', 'name', '[PAD]', '[PAD]', '[PAD]'])
const pairEncoding = await tokenizer.encode('my name', 'pair')
expect(pairEncoding.getTokens()).toEqual(['my', 'name', 'pair', '[PAD]', '[PAD]'])
})
it('pads to multiple of the given value', async () => {
tokenizer.setPadding({ padToMultipleOf: 8 })
const singleEncoding = await tokenizer.encode('my name', null)
expect(singleEncoding.getTokens()).toHaveLength(8)
const pairEncoding = await tokenizer.encode('my name', 'pair')
expect(pairEncoding.getTokens()).toHaveLength(8)
})
})
})
describe('decode', () => {
let tokenizer: Tokenizer
beforeEach(() => {
const model = BPE.empty()
tokenizer = new Tokenizer(model)
tokenizer.addTokens(['my', 'name', 'is', 'john', 'pair'])
})
it('has its callback called with the decoded string', async () => {
const decode = tokenizer.decode.bind(tokenizer)
expect(await decode([0, 1, 2, 3], true)).toEqual('my name is john')
})
})
describe('decodeBatch', () => {
let tokenizer: Tokenizer
beforeEach(() => {
const model = BPE.empty()
tokenizer = new Tokenizer(model)
tokenizer.addTokens(['my', 'name', 'is', 'john', 'pair'])
})
it('has its callback called with the decoded string', async () => {
const decodeBatch = tokenizer.decodeBatch.bind(tokenizer)
expect(await decodeBatch([[0, 1, 2, 3], [4]], true)).toEqual(['my name is john', 'pair'])
})
})
describe('getVocab', () => {
it('accepts `undefined` as parameter', () => {
const model = BPE.empty()
const tokenizer = new Tokenizer(model)
expect(tokenizer.getVocab(undefined)).toBeDefined()
})
it('returns the vocabulary', () => {
const model = BPE.empty()
const tokenizer = new Tokenizer(model)
tokenizer.addTokens(['my', 'name', 'is', 'john'])
expect(tokenizer.getVocab(true)).toEqual({
my: 0,
name: 1,
is: 2,
john: 3,
})
})
})
describe('getVocabSize', () => {
it('accepts `undefined` as parameter', () => {
const model = BPE.empty()
const tokenizer = new Tokenizer(model)
expect(tokenizer.getVocabSize(undefined)).toBeDefined()
})
})
describe('setTruncation', () => {
it('returns the full truncation configuration', () => {
const model = BPE.empty()
const tokenizer = new Tokenizer(model)
tokenizer.setTruncation(2)
// TODO Return type is weird
// const expectedConfig: TruncationOptions = {
// maxLength: 2,
// strategy: TruncationStrategy.LongestFirst,
// stride: 0,
// direction: TruncationDirection.Right,
// };
// expect(truncation).toEqual(expectedConfig);
})
})
describe('setPadding', () => {
it('returns the full padding params', () => {
const model = BPE.empty()
const tokenizer = new Tokenizer(model)
tokenizer.setPadding()
// TODO Return type is weird
// const expectedConfig: PaddingOptions = {
// direction: PaddingDirection.Right,
// padId: 0,
// padToken: "[PAD]",
// padTypeId: 0,
// };
// expect(padding).toEqual(expectedConfig);
})
})
describe('postProcess', () => {
let tokenizer: Tokenizer
let firstEncoding: Encoding
let secondEncoding: Encoding
beforeAll(() => {
const model = BPE.empty()
tokenizer = new Tokenizer(model)
tokenizer.addTokens(['my', 'name', 'is', 'john', 'pair'])
})
beforeEach(async () => {
firstEncoding = await tokenizer.encode('my name is john', null)
secondEncoding = await tokenizer.encode('pair', null)
tokenizer.setTruncation(2)
tokenizer.setPadding({ maxLength: 5 })
})
it('returns correctly with a single Encoding param', () => {
const encoding = tokenizer.postProcess(firstEncoding)
expect(encoding.getTokens()).toEqual(['my', 'name', '[PAD]', '[PAD]', '[PAD]'])
})
it('returns correctly with `undefined` as second and third parameters', () => {
const encoding = tokenizer.postProcess(firstEncoding, undefined, undefined)
expect(encoding.getTokens()).toEqual(['my', 'name', '[PAD]', '[PAD]', '[PAD]'])
})
it('returns correctly with 2 encodings', () => {
const encoding = tokenizer.postProcess(firstEncoding, secondEncoding)
expect(encoding.getTokens()).toEqual(['my', 'pair', '[PAD]', '[PAD]', '[PAD]'])
})
})
})
| tokenizers/bindings/node/lib/bindings/tokenizer.test.ts/0 | {
"file_path": "tokenizers/bindings/node/lib/bindings/tokenizer.test.ts",
"repo_id": "tokenizers",
"token_count": 5268
} | 215 |
# `tokenizers-linux-arm64-musl`
This is the **aarch64-unknown-linux-musl** binary for `tokenizers`
| tokenizers/bindings/node/npm/linux-arm64-musl/README.md/0 | {
"file_path": "tokenizers/bindings/node/npm/linux-arm64-musl/README.md",
"repo_id": "tokenizers",
"token_count": 37
} | 216 |
use crate::tokenizer::PaddingOptions;
use napi::bindgen_prelude::*;
use napi_derive::napi;
use tokenizers::utils::truncation::TruncationDirection;
use tokenizers::Encoding;
#[napi(js_name = "Encoding")]
#[derive(Clone, Default)]
pub struct JsEncoding {
pub(crate) encoding: Option<Encoding>,
}
impl From<Encoding> for JsEncoding {
fn from(value: Encoding) -> Self {
Self {
encoding: Some(value),
}
}
}
impl TryFrom<JsEncoding> for Encoding {
type Error = Error;
fn try_from(value: JsEncoding) -> Result<Self> {
value
.encoding
.ok_or(Error::from_reason("Uninitialized encoding".to_string()))
}
}
#[napi(string_enum, js_name = "TruncationDirection")]
pub enum JsTruncationDirection {
Left,
Right,
}
impl From<JsTruncationDirection> for TruncationDirection {
fn from(value: JsTruncationDirection) -> Self {
match value {
JsTruncationDirection::Left => TruncationDirection::Left,
JsTruncationDirection::Right => TruncationDirection::Right,
}
}
}
impl TryFrom<String> for JsTruncationDirection {
type Error = Error;
fn try_from(value: String) -> Result<JsTruncationDirection> {
match value.as_str() {
"left" => Ok(JsTruncationDirection::Left),
"right" => Ok(JsTruncationDirection::Right),
s => Err(Error::from_reason(format!(
"{s:?} is not a valid direction"
))),
}
}
}
#[napi(string_enum, js_name = "TruncationStrategy")]
pub enum JsTruncationStrategy {
LongestFirst,
OnlyFirst,
OnlySecond,
}
impl From<JsTruncationStrategy> for tokenizers::TruncationStrategy {
fn from(value: JsTruncationStrategy) -> Self {
match value {
JsTruncationStrategy::LongestFirst => tokenizers::TruncationStrategy::LongestFirst,
JsTruncationStrategy::OnlyFirst => tokenizers::TruncationStrategy::OnlyFirst,
JsTruncationStrategy::OnlySecond => tokenizers::TruncationStrategy::OnlySecond,
}
}
}
#[napi]
impl JsEncoding {
#[napi(constructor)]
pub fn new() -> Self {
Self { encoding: None }
}
#[napi]
pub fn get_length(&self) -> u32 {
self
.encoding
.as_ref()
.expect("Uninitialized Encoding")
.get_ids()
.len() as u32
}
#[napi]
pub fn get_n_sequences(&self) -> u32 {
self
.encoding
.as_ref()
.expect("Uninitialized Encoding")
.n_sequences() as u32
}
#[napi]
pub fn get_ids(&self) -> Vec<u32> {
self
.encoding
.as_ref()
.expect("Uninitialized Encoding")
.get_ids()
.to_vec()
}
#[napi]
pub fn get_type_ids(&self) -> Vec<u32> {
self
.encoding
.as_ref()
.expect("Uninitialized Encoding")
.get_type_ids()
.to_vec()
}
#[napi]
pub fn get_attention_mask(&self) -> Vec<u32> {
self
.encoding
.as_ref()
.expect("Uninitialized Encoding")
.get_attention_mask()
.to_vec()
}
#[napi]
pub fn get_special_tokens_mask(&self) -> Vec<u32> {
self
.encoding
.as_ref()
.expect("Uninitialized Encoding")
.get_special_tokens_mask()
.to_vec()
}
#[napi]
pub fn get_tokens(&self) -> Vec<String> {
self
.encoding
.as_ref()
.expect("Uninitialized Encoding")
.get_tokens()
.to_vec()
}
#[napi]
pub fn get_offsets(&self) -> Vec<Vec<u32>> {
self
.encoding
.as_ref()
.expect("Uninitialized Encoding")
.get_offsets()
.iter()
.map(|(a, b)| vec![*a as u32, *b as u32])
.collect()
}
#[napi]
pub fn get_word_ids(&self) -> Vec<Option<u32>> {
self
.encoding
.as_ref()
.expect("Uninitialized Encoding")
.get_word_ids()
.to_vec()
}
#[napi]
pub fn char_to_token(&self, pos: u32, seq_id: Option<u32>) -> Option<u32> {
let seq_id = seq_id.unwrap_or(0);
self
.encoding
.as_ref()
.expect("Uninitialized Encoding")
.char_to_token(pos as usize, seq_id as usize)
.map(|i| i as u32)
}
#[napi]
pub fn char_to_word(&self, pos: u32, seq_id: Option<u32>) -> Option<u32> {
let seq_id = seq_id.unwrap_or(0);
self
.encoding
.as_ref()
.expect("Uninitialized Encoding")
.char_to_word(pos as usize, seq_id as usize)
}
#[napi]
pub fn pad(&mut self, length: u32, options: Option<PaddingOptions>) -> Result<()> {
let params: tokenizers::PaddingParams = options.unwrap_or_default().try_into()?;
self.encoding.as_mut().expect("Uninitialized Encoding").pad(
length as usize,
params.pad_id,
params.pad_type_id,
¶ms.pad_token,
params.direction,
);
Ok(())
}
#[napi]
pub fn truncate(
&mut self,
length: u32,
stride: Option<u32>,
direction: Option<Either<String, JsTruncationDirection>>,
) -> Result<()> {
let stride = stride.unwrap_or_default();
let direction = match direction {
None => TruncationDirection::Left,
Some(Either::A(s)) => match s.as_str() {
"left" => TruncationDirection::Left,
"right" => TruncationDirection::Right,
d => {
return Err(Error::from_reason(format!(
"{d} is not a valid truncation direction"
)));
}
},
Some(Either::B(t)) => t.into(),
};
self
.encoding
.as_mut()
.expect("Uninitialized Encoding")
.truncate(length as usize, stride as usize, direction);
Ok(())
}
#[napi(ts_return_type = "[number, number] | null | undefined")]
pub fn word_to_tokens(&self, env: Env, word: u32, seq_id: Option<u32>) -> Result<Option<Array>> {
let seq_id = seq_id.unwrap_or(0);
if let Some((a, b)) = self
.encoding
.as_ref()
.expect("Uninitialized Encoding")
.word_to_tokens(word, seq_id as usize)
{
let mut arr = env.create_array(2)?;
arr.set(0, env.create_uint32(a as u32)?)?;
arr.set(1, env.create_uint32(b as u32)?)?;
Ok(Some(arr))
} else {
Ok(None)
}
}
#[napi(ts_return_type = "[number, number] | null | undefined")]
pub fn word_to_chars(&self, env: Env, word: u32, seq_id: Option<u32>) -> Result<Option<Array>> {
let seq_id = seq_id.unwrap_or(0);
if let Some((a, b)) = self
.encoding
.as_ref()
.expect("Uninitialized Encoding")
.word_to_chars(word, seq_id as usize)
{
let mut arr = env.create_array(2)?;
arr.set(0, env.create_uint32(a as u32)?)?;
arr.set(1, env.create_uint32(b as u32)?)?;
Ok(Some(arr))
} else {
Ok(None)
}
}
#[napi(ts_return_type = "[number, [number, number]] | null | undefined")]
pub fn token_to_chars(&self, env: Env, token: u32) -> Result<Option<Array>> {
if let Some((_, (start, stop))) = self
.encoding
.as_ref()
.expect("Uninitialized Encoding")
.token_to_chars(token as usize)
{
let mut offsets = env.create_array(2)?;
offsets.set(0, env.create_uint32(start as u32)?)?;
offsets.set(1, env.create_uint32(stop as u32)?)?;
Ok(Some(offsets))
} else {
Ok(None)
}
}
#[napi]
pub fn token_to_word(&self, token: u32) -> Result<Option<u32>> {
if let Some((_, index)) = self
.encoding
.as_ref()
.expect("Uninitialized Encoding")
.token_to_word(token as usize)
{
Ok(Some(index))
} else {
Ok(None)
}
}
#[napi]
pub fn get_overflowing(&self) -> Vec<JsEncoding> {
self
.encoding
.as_ref()
.expect("Uninitialized Encoding")
.get_overflowing()
.clone()
.into_iter()
.map(|enc| JsEncoding {
encoding: Some(enc),
})
.collect()
}
#[napi]
pub fn get_sequence_ids(&self) -> Vec<Option<u32>> {
self
.encoding
.as_ref()
.expect("Uninitialized Encoding")
.get_sequence_ids()
.into_iter()
.map(|s| s.map(|id| id as u32))
.collect()
}
#[napi]
pub fn token_to_sequence(&self, token: u32) -> Option<u32> {
self
.encoding
.as_ref()
.expect("Uninitialized Encoding")
.token_to_sequence(token as usize)
.map(|s| s as u32)
}
}
| tokenizers/bindings/node/src/encoding.rs/0 | {
"file_path": "tokenizers/bindings/node/src/encoding.rs",
"repo_id": "tokenizers",
"token_count": 3778
} | 217 |
# Generated content DO NOT EDIT
class Decoder:
"""
Base class for all decoders
This class is not supposed to be instantiated directly. Instead, any implementation of
a Decoder will return an instance of this class when instantiated.
"""
def decode(self, tokens):
"""
Decode the given list of tokens to a final string
Args:
tokens (:obj:`List[str]`):
The list of tokens to decode
Returns:
:obj:`str`: The decoded string
"""
pass
class BPEDecoder(Decoder):
"""
BPEDecoder Decoder
Args:
suffix (:obj:`str`, `optional`, defaults to :obj:`</w>`):
The suffix that was used to caracterize an end-of-word. This suffix will
be replaced by whitespaces during the decoding
"""
def __init__(self, suffix="</w>"):
pass
def decode(self, tokens):
"""
Decode the given list of tokens to a final string
Args:
tokens (:obj:`List[str]`):
The list of tokens to decode
Returns:
:obj:`str`: The decoded string
"""
pass
class ByteFallback(Decoder):
"""
ByteFallback Decoder
ByteFallback is a simple trick which converts tokens looking like `<0x61>`
to pure bytes, and attempts to make them into a string. If the tokens
cannot be decoded you will get � instead for each inconvertable byte token
"""
def __init__(self):
pass
def decode(self, tokens):
"""
Decode the given list of tokens to a final string
Args:
tokens (:obj:`List[str]`):
The list of tokens to decode
Returns:
:obj:`str`: The decoded string
"""
pass
class ByteLevel(Decoder):
"""
ByteLevel Decoder
This decoder is to be used in tandem with the :class:`~tokenizers.pre_tokenizers.ByteLevel`
:class:`~tokenizers.pre_tokenizers.PreTokenizer`.
"""
def __init__(self):
pass
def decode(self, tokens):
"""
Decode the given list of tokens to a final string
Args:
tokens (:obj:`List[str]`):
The list of tokens to decode
Returns:
:obj:`str`: The decoded string
"""
pass
class CTC(Decoder):
"""
CTC Decoder
Args:
pad_token (:obj:`str`, `optional`, defaults to :obj:`<pad>`):
The pad token used by CTC to delimit a new token.
word_delimiter_token (:obj:`str`, `optional`, defaults to :obj:`|`):
The word delimiter token. It will be replaced by a <space>
cleanup (:obj:`bool`, `optional`, defaults to :obj:`True`):
Whether to cleanup some tokenization artifacts.
Mainly spaces before punctuation, and some abbreviated english forms.
"""
def __init__(self, pad_token="<pad>", word_delimiter_token="|", cleanup=True):
pass
def decode(self, tokens):
"""
Decode the given list of tokens to a final string
Args:
tokens (:obj:`List[str]`):
The list of tokens to decode
Returns:
:obj:`str`: The decoded string
"""
pass
class Fuse(Decoder):
"""
Fuse Decoder
Fuse simply fuses every token into a single string.
This is the last step of decoding, this decoder exists only if
there is need to add other decoders *after* the fusion
"""
def __init__(self):
pass
def decode(self, tokens):
"""
Decode the given list of tokens to a final string
Args:
tokens (:obj:`List[str]`):
The list of tokens to decode
Returns:
:obj:`str`: The decoded string
"""
pass
class Metaspace(Decoder):
"""
Metaspace Decoder
Args:
replacement (:obj:`str`, `optional`, defaults to :obj:`▁`):
The replacement character. Must be exactly one character. By default we
use the `▁` (U+2581) meta symbol (Same as in SentencePiece).
add_prefix_space (:obj:`bool`, `optional`, defaults to :obj:`True`):
Whether to add a space to the first word if there isn't already one. This
lets us treat `hello` exactly like `say hello`.
"""
def __init__(self, replacement="▁", add_prefix_space=True):
pass
def decode(self, tokens):
"""
Decode the given list of tokens to a final string
Args:
tokens (:obj:`List[str]`):
The list of tokens to decode
Returns:
:obj:`str`: The decoded string
"""
pass
class Replace(Decoder):
"""
Replace Decoder
This decoder is to be used in tandem with the :class:`~tokenizers.pre_tokenizers.Replace`
:class:`~tokenizers.pre_tokenizers.PreTokenizer`.
"""
def __init__(self, pattern, content):
pass
def decode(self, tokens):
"""
Decode the given list of tokens to a final string
Args:
tokens (:obj:`List[str]`):
The list of tokens to decode
Returns:
:obj:`str`: The decoded string
"""
pass
class Sequence(Decoder):
"""
Sequence Decoder
Args:
decoders (:obj:`List[Decoder]`)
The decoders that need to be chained
"""
def __init__(self, decoders):
pass
def decode(self, tokens):
"""
Decode the given list of tokens to a final string
Args:
tokens (:obj:`List[str]`):
The list of tokens to decode
Returns:
:obj:`str`: The decoded string
"""
pass
class Strip(Decoder):
"""
Strip normalizer
Strips n left characters of each token, or n right characters of each token
"""
def __init__(self, content, left=0, right=0):
pass
def decode(self, tokens):
"""
Decode the given list of tokens to a final string
Args:
tokens (:obj:`List[str]`):
The list of tokens to decode
Returns:
:obj:`str`: The decoded string
"""
pass
class WordPiece(Decoder):
"""
WordPiece Decoder
Args:
prefix (:obj:`str`, `optional`, defaults to :obj:`##`):
The prefix to use for subwords that are not a beginning-of-word
cleanup (:obj:`bool`, `optional`, defaults to :obj:`True`):
Whether to cleanup some tokenization artifacts. Mainly spaces before punctuation,
and some abbreviated english forms.
"""
def __init__(self, prefix="##", cleanup=True):
pass
def decode(self, tokens):
"""
Decode the given list of tokens to a final string
Args:
tokens (:obj:`List[str]`):
The list of tokens to decode
Returns:
:obj:`str`: The decoded string
"""
pass
| tokenizers/bindings/python/py_src/tokenizers/decoders/__init__.pyi/0 | {
"file_path": "tokenizers/bindings/python/py_src/tokenizers/decoders/__init__.pyi",
"repo_id": "tokenizers",
"token_count": 3115
} | 218 |
from .visualizer import Annotation, EncodingVisualizer
| tokenizers/bindings/python/py_src/tokenizers/tools/__init__.py/0 | {
"file_path": "tokenizers/bindings/python/py_src/tokenizers/tools/__init__.py",
"repo_id": "tokenizers",
"token_count": 13
} | 219 |
use std::sync::{Arc, RwLock};
use pyo3::exceptions;
use pyo3::prelude::*;
use pyo3::types::*;
use crate::error::ToPyResult;
use crate::utils::{PyNormalizedString, PyNormalizedStringRefMut, PyPattern};
use serde::ser::SerializeStruct;
use serde::{Deserialize, Deserializer, Serialize, Serializer};
use tk::normalizers::{
BertNormalizer, Lowercase, Nmt, NormalizerWrapper, Precompiled, Prepend, Replace, Strip,
StripAccents, NFC, NFD, NFKC, NFKD,
};
use tk::{NormalizedString, Normalizer};
use tokenizers as tk;
/// Represents the different kind of NormalizedString we can receive from Python:
/// - Owned: Created in Python and owned by Python
/// - RefMut: A mutable reference to a NormalizedString owned by Rust
#[derive(FromPyObject)]
enum PyNormalizedStringMut<'p> {
Owned(PyRefMut<'p, PyNormalizedString>),
RefMut(PyNormalizedStringRefMut),
}
impl PyNormalizedStringMut<'_> {
/// Normalized the underlying `NormalizedString` using the provided normalizer
pub fn normalize_with<N>(&mut self, normalizer: &N) -> PyResult<()>
where
N: Normalizer,
{
match self {
PyNormalizedStringMut::Owned(ref mut n) => normalizer.normalize(&mut n.normalized),
PyNormalizedStringMut::RefMut(n) => n.map_as_mut(|n| normalizer.normalize(n))?,
}
.map_err(|e| exceptions::PyException::new_err(format!("{}", e)))
}
}
/// Base class for all normalizers
///
/// This class is not supposed to be instantiated directly. Instead, any implementation of a
/// Normalizer will return an instance of this class when instantiated.
#[pyclass(dict, module = "tokenizers.normalizers", name = "Normalizer", subclass)]
#[derive(Clone, Serialize, Deserialize)]
pub struct PyNormalizer {
#[serde(flatten)]
pub(crate) normalizer: PyNormalizerTypeWrapper,
}
impl PyNormalizer {
pub(crate) fn new(normalizer: PyNormalizerTypeWrapper) -> Self {
PyNormalizer { normalizer }
}
pub(crate) fn get_as_subtype(&self, py: Python<'_>) -> PyResult<PyObject> {
let base = self.clone();
Ok(match self.normalizer {
PyNormalizerTypeWrapper::Sequence(_) => Py::new(py, (PySequence {}, base))?.into_py(py),
PyNormalizerTypeWrapper::Single(ref inner) => match &*inner.as_ref().read().unwrap() {
PyNormalizerWrapper::Custom(_) => Py::new(py, base)?.into_py(py),
PyNormalizerWrapper::Wrapped(ref inner) => match inner {
NormalizerWrapper::Sequence(_) => {
Py::new(py, (PySequence {}, base))?.into_py(py)
}
NormalizerWrapper::BertNormalizer(_) => {
Py::new(py, (PyBertNormalizer {}, base))?.into_py(py)
}
NormalizerWrapper::StripNormalizer(_) => {
Py::new(py, (PyBertNormalizer {}, base))?.into_py(py)
}
NormalizerWrapper::Prepend(_) => Py::new(py, (PyPrepend {}, base))?.into_py(py),
NormalizerWrapper::StripAccents(_) => {
Py::new(py, (PyStripAccents {}, base))?.into_py(py)
}
NormalizerWrapper::NFC(_) => Py::new(py, (PyNFC {}, base))?.into_py(py),
NormalizerWrapper::NFD(_) => Py::new(py, (PyNFD {}, base))?.into_py(py),
NormalizerWrapper::NFKC(_) => Py::new(py, (PyNFKC {}, base))?.into_py(py),
NormalizerWrapper::NFKD(_) => Py::new(py, (PyNFKD {}, base))?.into_py(py),
NormalizerWrapper::Lowercase(_) => {
Py::new(py, (PyLowercase {}, base))?.into_py(py)
}
NormalizerWrapper::Precompiled(_) => {
Py::new(py, (PyPrecompiled {}, base))?.into_py(py)
}
NormalizerWrapper::Replace(_) => Py::new(py, (PyReplace {}, base))?.into_py(py),
NormalizerWrapper::Nmt(_) => Py::new(py, (PyNmt {}, base))?.into_py(py),
},
},
})
}
}
impl Normalizer for PyNormalizer {
fn normalize(&self, normalized: &mut NormalizedString) -> tk::Result<()> {
self.normalizer.normalize(normalized)
}
}
#[pymethods]
impl PyNormalizer {
#[staticmethod]
fn custom(obj: PyObject) -> Self {
Self {
normalizer: PyNormalizerWrapper::Custom(CustomNormalizer::new(obj)).into(),
}
}
fn __getstate__(&self, py: Python) -> PyResult<PyObject> {
let data = serde_json::to_string(&self.normalizer).map_err(|e| {
exceptions::PyException::new_err(format!(
"Error while attempting to pickle Normalizer: {}",
e
))
})?;
Ok(PyBytes::new(py, data.as_bytes()).to_object(py))
}
fn __setstate__(&mut self, py: Python, state: PyObject) -> PyResult<()> {
match state.extract::<&PyBytes>(py) {
Ok(s) => {
self.normalizer = serde_json::from_slice(s.as_bytes()).map_err(|e| {
exceptions::PyException::new_err(format!(
"Error while attempting to unpickle Normalizer: {}",
e
))
})?;
Ok(())
}
Err(e) => Err(e),
}
}
/// Normalize a :class:`~tokenizers.NormalizedString` in-place
///
/// This method allows to modify a :class:`~tokenizers.NormalizedString` to
/// keep track of the alignment information. If you just want to see the result
/// of the normalization on a raw string, you can use
/// :meth:`~tokenizers.normalizers.Normalizer.normalize_str`
///
/// Args:
/// normalized (:class:`~tokenizers.NormalizedString`):
/// The normalized string on which to apply this
/// :class:`~tokenizers.normalizers.Normalizer`
#[pyo3(text_signature = "(self, normalized)")]
fn normalize(&self, mut normalized: PyNormalizedStringMut) -> PyResult<()> {
normalized.normalize_with(&self.normalizer)
}
/// Normalize the given string
///
/// This method provides a way to visualize the effect of a
/// :class:`~tokenizers.normalizers.Normalizer` but it does not keep track of the alignment
/// information. If you need to get/convert offsets, you can use
/// :meth:`~tokenizers.normalizers.Normalizer.normalize`
///
/// Args:
/// sequence (:obj:`str`):
/// A string to normalize
///
/// Returns:
/// :obj:`str`: A string after normalization
#[pyo3(text_signature = "(self, sequence)")]
fn normalize_str(&self, sequence: &str) -> PyResult<String> {
let mut normalized = NormalizedString::from(sequence);
ToPyResult(self.normalizer.normalize(&mut normalized)).into_py()?;
Ok(normalized.get().to_owned())
}
}
macro_rules! getter {
($self: ident, $variant: ident, $name: ident) => {{
let super_ = $self.as_ref();
if let PyNormalizerTypeWrapper::Single(ref norm) = super_.normalizer {
let wrapper = norm.read().unwrap();
if let PyNormalizerWrapper::Wrapped(NormalizerWrapper::$variant(o)) = (*wrapper).clone()
{
o.$name
} else {
unreachable!()
}
} else {
unreachable!()
}
}};
}
macro_rules! setter {
($self: ident, $variant: ident, $name: ident, $value: expr) => {{
let super_ = $self.as_ref();
if let PyNormalizerTypeWrapper::Single(ref norm) = super_.normalizer {
let mut wrapper = norm.write().unwrap();
if let PyNormalizerWrapper::Wrapped(NormalizerWrapper::$variant(ref mut o)) = *wrapper {
o.$name = $value;
}
}
}};
}
/// BertNormalizer
///
/// Takes care of normalizing raw text before giving it to a Bert model.
/// This includes cleaning the text, handling accents, chinese chars and lowercasing
///
/// Args:
/// clean_text (:obj:`bool`, `optional`, defaults to :obj:`True`):
/// Whether to clean the text, by removing any control characters
/// and replacing all whitespaces by the classic one.
///
/// handle_chinese_chars (:obj:`bool`, `optional`, defaults to :obj:`True`):
/// Whether to handle chinese chars by putting spaces around them.
///
/// strip_accents (:obj:`bool`, `optional`):
/// Whether to strip all accents. If this option is not specified (ie == None),
/// then it will be determined by the value for `lowercase` (as in the original Bert).
///
/// lowercase (:obj:`bool`, `optional`, defaults to :obj:`True`):
/// Whether to lowercase.
#[pyclass(extends=PyNormalizer, module = "tokenizers.normalizers", name = "BertNormalizer")]
pub struct PyBertNormalizer {}
#[pymethods]
impl PyBertNormalizer {
#[getter]
fn get_clean_text(self_: PyRef<Self>) -> bool {
getter!(self_, BertNormalizer, clean_text)
}
#[setter]
fn set_clean_text(self_: PyRef<Self>, clean_text: bool) {
setter!(self_, BertNormalizer, clean_text, clean_text);
}
#[getter]
fn get_handle_chinese_chars(self_: PyRef<Self>) -> bool {
getter!(self_, BertNormalizer, handle_chinese_chars)
}
#[setter]
fn set_handle_chinese_chars(self_: PyRef<Self>, handle_chinese_chars: bool) {
setter!(
self_,
BertNormalizer,
handle_chinese_chars,
handle_chinese_chars
);
}
#[getter]
fn get_strip_accents(self_: PyRef<Self>) -> Option<bool> {
getter!(self_, BertNormalizer, strip_accents)
}
#[setter]
fn set_strip_accents(self_: PyRef<Self>, strip_accents: Option<bool>) {
setter!(self_, BertNormalizer, strip_accents, strip_accents);
}
#[getter]
fn get_lowercase(self_: PyRef<Self>) -> bool {
getter!(self_, BertNormalizer, lowercase)
}
#[setter]
fn set_lowercase(self_: PyRef<Self>, lowercase: bool) {
setter!(self_, BertNormalizer, lowercase, lowercase)
}
#[new]
#[pyo3(signature = (
clean_text = true,
handle_chinese_chars = true,
strip_accents = None,
lowercase = true
),
text_signature = "(self, clean_text=True, handle_chinese_chars=True, strip_accents=None, lowercase=True)")]
fn new(
clean_text: bool,
handle_chinese_chars: bool,
strip_accents: Option<bool>,
lowercase: bool,
) -> (Self, PyNormalizer) {
let normalizer =
BertNormalizer::new(clean_text, handle_chinese_chars, strip_accents, lowercase);
(PyBertNormalizer {}, normalizer.into())
}
}
/// NFD Unicode Normalizer
#[pyclass(extends=PyNormalizer, module = "tokenizers.normalizers", name = "NFD")]
pub struct PyNFD {}
#[pymethods]
impl PyNFD {
#[new]
#[pyo3(text_signature = "(self)")]
fn new() -> (Self, PyNormalizer) {
(PyNFD {}, PyNormalizer::new(NFD.into()))
}
}
/// NFKD Unicode Normalizer
#[pyclass(extends=PyNormalizer, module = "tokenizers.normalizers", name = "NFKD")]
pub struct PyNFKD {}
#[pymethods]
impl PyNFKD {
#[new]
#[pyo3(text_signature = "(self)")]
fn new() -> (Self, PyNormalizer) {
(PyNFKD {}, NFKD.into())
}
}
/// NFC Unicode Normalizer
#[pyclass(extends=PyNormalizer, module = "tokenizers.normalizers", name = "NFC")]
pub struct PyNFC {}
#[pymethods]
impl PyNFC {
#[new]
#[pyo3(text_signature = "(self)")]
fn new() -> (Self, PyNormalizer) {
(PyNFC {}, NFC.into())
}
}
/// NFKC Unicode Normalizer
#[pyclass(extends=PyNormalizer, module = "tokenizers.normalizers", name = "NFKC")]
pub struct PyNFKC {}
#[pymethods]
impl PyNFKC {
#[new]
#[pyo3(text_signature = "(self)")]
fn new() -> (Self, PyNormalizer) {
(PyNFKC {}, NFKC.into())
}
}
/// Allows concatenating multiple other Normalizer as a Sequence.
/// All the normalizers run in sequence in the given order
///
/// Args:
/// normalizers (:obj:`List[Normalizer]`):
/// A list of Normalizer to be run as a sequence
#[pyclass(extends=PyNormalizer, module = "tokenizers.normalizers", name = "Sequence")]
pub struct PySequence {}
#[pymethods]
impl PySequence {
#[new]
#[pyo3(text_signature = None)]
fn new(normalizers: &PyList) -> PyResult<(Self, PyNormalizer)> {
let mut sequence = Vec::with_capacity(normalizers.len());
for n in normalizers.iter() {
let normalizer: PyRef<PyNormalizer> = n.extract()?;
match &normalizer.normalizer {
PyNormalizerTypeWrapper::Sequence(inner) => sequence.extend(inner.iter().cloned()),
PyNormalizerTypeWrapper::Single(inner) => sequence.push(inner.clone()),
}
}
Ok((
PySequence {},
PyNormalizer::new(PyNormalizerTypeWrapper::Sequence(sequence)),
))
}
fn __getnewargs__<'p>(&self, py: Python<'p>) -> &'p PyTuple {
PyTuple::new(py, [PyList::empty(py)])
}
fn __len__(&self) -> usize {
0
}
}
/// Lowercase Normalizer
#[pyclass(extends=PyNormalizer, module = "tokenizers.normalizers", name = "Lowercase")]
pub struct PyLowercase {}
#[pymethods]
impl PyLowercase {
#[new]
#[pyo3(text_signature = "(self)")]
fn new() -> (Self, PyNormalizer) {
(PyLowercase {}, Lowercase.into())
}
}
/// Strip normalizer
#[pyclass(extends=PyNormalizer, module = "tokenizers.normalizers", name = "Strip")]
pub struct PyStrip {}
#[pymethods]
impl PyStrip {
#[getter]
fn get_left(self_: PyRef<Self>) -> bool {
getter!(self_, StripNormalizer, strip_left)
}
#[setter]
fn set_left(self_: PyRef<Self>, left: bool) {
setter!(self_, StripNormalizer, strip_left, left)
}
#[getter]
fn get_right(self_: PyRef<Self>) -> bool {
getter!(self_, StripNormalizer, strip_right)
}
#[setter]
fn set_right(self_: PyRef<Self>, right: bool) {
setter!(self_, StripNormalizer, strip_right, right)
}
#[new]
#[pyo3(signature = (left = true, right = true), text_signature = "(self, left=True, right=True)")]
fn new(left: bool, right: bool) -> (Self, PyNormalizer) {
(PyStrip {}, Strip::new(left, right).into())
}
}
/// Prepend normalizer
#[pyclass(extends=PyNormalizer, module = "tokenizers.normalizers", name = "Prepend")]
pub struct PyPrepend {}
#[pymethods]
impl PyPrepend {
#[getter]
fn get_prepend(self_: PyRef<Self>) -> String {
getter!(self_, Prepend, prepend)
}
#[setter]
fn set_prepend(self_: PyRef<Self>, prepend: String) {
setter!(self_, Prepend, prepend, prepend)
}
#[new]
#[pyo3(signature = (prepend="▁".to_string()), text_signature = "(self, prepend)")]
fn new(prepend: String) -> (Self, PyNormalizer) {
(PyPrepend {}, Prepend::new(prepend).into())
}
}
/// StripAccents normalizer
#[pyclass(extends=PyNormalizer, module = "tokenizers.normalizers", name = "StripAccents")]
pub struct PyStripAccents {}
#[pymethods]
impl PyStripAccents {
#[new]
#[pyo3(text_signature = "(self)")]
fn new() -> (Self, PyNormalizer) {
(PyStripAccents {}, StripAccents.into())
}
}
/// Nmt normalizer
#[pyclass(extends=PyNormalizer, module = "tokenizers.normalizers", name = "Nmt")]
pub struct PyNmt {}
#[pymethods]
impl PyNmt {
#[new]
#[pyo3(text_signature = "(self)")]
fn new() -> (Self, PyNormalizer) {
(PyNmt {}, Nmt.into())
}
}
/// Precompiled normalizer
/// Don't use manually it is used for compatiblity for SentencePiece.
#[pyclass(extends=PyNormalizer, module = "tokenizers.normalizers", name = "Precompiled")]
pub struct PyPrecompiled {}
#[pymethods]
impl PyPrecompiled {
#[new]
#[pyo3(text_signature = "(self, precompiled_charsmap)")]
fn new(py_precompiled_charsmap: &PyBytes) -> PyResult<(Self, PyNormalizer)> {
let precompiled_charsmap: &[u8] = FromPyObject::extract(py_precompiled_charsmap)?;
Ok((
PyPrecompiled {},
Precompiled::from(precompiled_charsmap)
.map_err(|e| {
exceptions::PyException::new_err(format!(
"Error while attempting to build Precompiled normalizer: {}",
e
))
})?
.into(),
))
}
}
/// Replace normalizer
#[pyclass(extends=PyNormalizer, module = "tokenizers.normalizers", name = "Replace")]
pub struct PyReplace {}
#[pymethods]
impl PyReplace {
#[new]
#[pyo3(text_signature = "(self, pattern, content)")]
fn new(pattern: PyPattern, content: String) -> PyResult<(Self, PyNormalizer)> {
Ok((
PyReplace {},
ToPyResult(Replace::new(pattern, content)).into_py()?.into(),
))
}
}
#[derive(Debug, Clone)]
pub(crate) struct CustomNormalizer {
inner: PyObject,
}
impl CustomNormalizer {
pub fn new(inner: PyObject) -> Self {
Self { inner }
}
}
impl tk::tokenizer::Normalizer for CustomNormalizer {
fn normalize(&self, normalized: &mut NormalizedString) -> tk::Result<()> {
Python::with_gil(|py| {
let normalized = PyNormalizedStringRefMut::new(normalized);
let py_normalized = self.inner.as_ref(py);
py_normalized.call_method("normalize", (normalized.get(),), None)?;
Ok(())
})
}
}
impl Serialize for CustomNormalizer {
fn serialize<S>(&self, _serializer: S) -> Result<S::Ok, S::Error>
where
S: Serializer,
{
Err(serde::ser::Error::custom(
"Custom Normalizer cannot be serialized",
))
}
}
impl<'de> Deserialize<'de> for CustomNormalizer {
fn deserialize<D>(_deserializer: D) -> Result<Self, D::Error>
where
D: Deserializer<'de>,
{
Err(serde::de::Error::custom(
"Custom Normalizer cannot be deserialized",
))
}
}
#[derive(Debug, Clone, Deserialize)]
#[serde(untagged)]
pub(crate) enum PyNormalizerWrapper {
Custom(CustomNormalizer),
Wrapped(NormalizerWrapper),
}
impl Serialize for PyNormalizerWrapper {
fn serialize<S>(&self, serializer: S) -> Result<<S as Serializer>::Ok, <S as Serializer>::Error>
where
S: Serializer,
{
match self {
PyNormalizerWrapper::Wrapped(inner) => inner.serialize(serializer),
PyNormalizerWrapper::Custom(inner) => inner.serialize(serializer),
}
}
}
#[derive(Debug, Clone, Deserialize)]
#[serde(untagged)]
pub(crate) enum PyNormalizerTypeWrapper {
Sequence(Vec<Arc<RwLock<PyNormalizerWrapper>>>),
Single(Arc<RwLock<PyNormalizerWrapper>>),
}
impl Serialize for PyNormalizerTypeWrapper {
fn serialize<S>(&self, serializer: S) -> Result<S::Ok, S::Error>
where
S: Serializer,
{
match self {
PyNormalizerTypeWrapper::Sequence(seq) => {
let mut ser = serializer.serialize_struct("Sequence", 2)?;
ser.serialize_field("type", "Sequence")?;
ser.serialize_field("normalizers", seq)?;
ser.end()
}
PyNormalizerTypeWrapper::Single(inner) => inner.serialize(serializer),
}
}
}
impl<I> From<I> for PyNormalizerWrapper
where
I: Into<NormalizerWrapper>,
{
fn from(norm: I) -> Self {
PyNormalizerWrapper::Wrapped(norm.into())
}
}
impl<I> From<I> for PyNormalizerTypeWrapper
where
I: Into<PyNormalizerWrapper>,
{
fn from(norm: I) -> Self {
PyNormalizerTypeWrapper::Single(Arc::new(RwLock::new(norm.into())))
}
}
impl<I> From<I> for PyNormalizer
where
I: Into<NormalizerWrapper>,
{
fn from(norm: I) -> Self {
PyNormalizer {
normalizer: norm.into().into(),
}
}
}
impl Normalizer for PyNormalizerTypeWrapper {
fn normalize(&self, normalized: &mut NormalizedString) -> tk::Result<()> {
match self {
PyNormalizerTypeWrapper::Single(inner) => inner.read().unwrap().normalize(normalized),
PyNormalizerTypeWrapper::Sequence(inner) => inner
.iter()
.try_for_each(|n| n.read().unwrap().normalize(normalized)),
}
}
}
impl Normalizer for PyNormalizerWrapper {
fn normalize(&self, normalized: &mut NormalizedString) -> tk::Result<()> {
match self {
PyNormalizerWrapper::Wrapped(inner) => inner.normalize(normalized),
PyNormalizerWrapper::Custom(inner) => inner.normalize(normalized),
}
}
}
/// Normalizers Module
#[pymodule]
pub fn normalizers(_py: Python, m: &PyModule) -> PyResult<()> {
m.add_class::<PyNormalizer>()?;
m.add_class::<PyBertNormalizer>()?;
m.add_class::<PyNFD>()?;
m.add_class::<PyNFKD>()?;
m.add_class::<PyNFC>()?;
m.add_class::<PyNFKC>()?;
m.add_class::<PySequence>()?;
m.add_class::<PyLowercase>()?;
m.add_class::<PyStrip>()?;
m.add_class::<PyStripAccents>()?;
m.add_class::<PyPrepend>()?;
m.add_class::<PyNmt>()?;
m.add_class::<PyPrecompiled>()?;
m.add_class::<PyReplace>()?;
Ok(())
}
#[cfg(test)]
mod test {
use pyo3::prelude::*;
use tk::normalizers::unicode::{NFC, NFKC};
use tk::normalizers::utils::Sequence;
use tk::normalizers::NormalizerWrapper;
use crate::normalizers::{PyNormalizer, PyNormalizerTypeWrapper, PyNormalizerWrapper};
#[test]
fn get_subtype() {
Python::with_gil(|py| {
let py_norm = PyNormalizer::new(NFC.into());
let py_nfc = py_norm.get_as_subtype(py).unwrap();
assert_eq!("NFC", py_nfc.as_ref(py).get_type().name().unwrap());
})
}
#[test]
fn serialize() {
let py_wrapped: PyNormalizerWrapper = NFKC.into();
let py_ser = serde_json::to_string(&py_wrapped).unwrap();
let rs_wrapped = NormalizerWrapper::NFKC(NFKC);
let rs_ser = serde_json::to_string(&rs_wrapped).unwrap();
assert_eq!(py_ser, rs_ser);
let py_norm: PyNormalizer = serde_json::from_str(&rs_ser).unwrap();
match py_norm.normalizer {
PyNormalizerTypeWrapper::Single(inner) => match *inner.as_ref().read().unwrap() {
PyNormalizerWrapper::Wrapped(NormalizerWrapper::NFKC(_)) => {}
_ => panic!("Expected NFKC"),
},
_ => panic!("Expected wrapped, not sequence."),
}
let py_seq: PyNormalizerWrapper = Sequence::new(vec![NFC.into(), NFKC.into()]).into();
let py_wrapper_ser = serde_json::to_string(&py_seq).unwrap();
let rs_wrapped = NormalizerWrapper::Sequence(Sequence::new(vec![NFC.into(), NFKC.into()]));
let rs_ser = serde_json::to_string(&rs_wrapped).unwrap();
assert_eq!(py_wrapper_ser, rs_ser);
let py_seq = PyNormalizer::new(py_seq.into());
let py_ser = serde_json::to_string(&py_seq).unwrap();
assert_eq!(py_wrapper_ser, py_ser);
let rs_seq = Sequence::new(vec![NFC.into(), NFKC.into()]);
let rs_ser = serde_json::to_string(&rs_seq).unwrap();
assert_eq!(py_wrapper_ser, rs_ser);
}
#[test]
fn deserialize_sequence() {
let string = r#"{"type": "NFKC"}"#;
let normalizer: PyNormalizer = serde_json::from_str(string).unwrap();
match normalizer.normalizer {
PyNormalizerTypeWrapper::Single(inner) => match *inner.as_ref().read().unwrap() {
PyNormalizerWrapper::Wrapped(NormalizerWrapper::NFKC(_)) => {}
_ => panic!("Expected NFKC"),
},
_ => panic!("Expected wrapped, not sequence."),
}
let sequence_string = format!(r#"{{"type": "Sequence", "normalizers": [{}]}}"#, string);
let normalizer: PyNormalizer = serde_json::from_str(&sequence_string).unwrap();
match normalizer.normalizer {
PyNormalizerTypeWrapper::Single(inner) => match &*inner.as_ref().read().unwrap() {
PyNormalizerWrapper::Wrapped(NormalizerWrapper::Sequence(sequence)) => {
let normalizers = sequence.get_normalizers();
assert_eq!(normalizers.len(), 1);
match normalizers[0] {
NormalizerWrapper::NFKC(_) => {}
_ => panic!("Expected NFKC"),
}
}
_ => panic!("Expected sequence"),
},
_ => panic!("Expected single"),
};
}
}
| tokenizers/bindings/python/src/normalizers.rs/0 | {
"file_path": "tokenizers/bindings/python/src/normalizers.rs",
"repo_id": "tokenizers",
"token_count": 11191
} | 220 |
import pytest
from tokenizers import BertWordPieceTokenizer
from ..utils import bert_files, data_dir
class TestEncoding:
@pytest.fixture(scope="class")
def encodings(self, bert_files):
tokenizer = BertWordPieceTokenizer.from_file(bert_files["vocab"])
single_encoding = tokenizer.encode("I love HuggingFace")
pair_encoding = tokenizer.encode("I love HuggingFace", "Do you?")
return single_encoding, pair_encoding
def test_sequence_ids(self, encodings):
single, pair = encodings
assert single.sequence_ids == [None, 0, 0, 0, 0, None]
assert pair.sequence_ids == [None, 0, 0, 0, 0, None, 1, 1, 1, None]
def test_n_sequences(self, encodings):
single, pair = encodings
assert single.n_sequences == 1
assert pair.n_sequences == 2
def test_word_to_tokens(self, encodings):
single, pair = encodings
assert single.tokens == ["[CLS]", "i", "love", "hugging", "##face", "[SEP]"]
assert single.word_to_tokens(0) == (1, 2)
assert pair.tokens == [
"[CLS]",
"i",
"love",
"hugging",
"##face",
"[SEP]",
"do",
"you",
"?",
"[SEP]",
]
assert pair.word_to_tokens(0) == (1, 2)
assert pair.word_to_tokens(0, 0) == (1, 2)
assert pair.word_to_tokens(6, 0) == None
assert pair.word_to_tokens(0, 1) == (6, 7)
def test_word_to_chars(self, encodings):
single, pair = encodings
assert single.word_to_chars(2) == (7, 18)
assert pair.word_to_chars(2) == (7, 18)
assert pair.word_to_chars(2, 0) == (7, 18)
assert pair.word_to_chars(2, 1) == (6, 7)
def test_token_to_sequence(self, encodings):
single, pair = encodings
assert single.token_to_sequence(2) == 0
assert pair.token_to_sequence(2) == 0
assert pair.token_to_sequence(0) == None
assert pair.token_to_sequence(5) == None
assert pair.token_to_sequence(6) == 1
assert pair.token_to_sequence(8) == 1
assert pair.token_to_sequence(9) == None
assert pair.token_to_sequence(1200) == None
def test_token_to_chars(self, encodings):
single, pair = encodings
assert single.token_to_chars(0) == None
assert single.token_to_chars(2) == (2, 6)
assert pair.token_to_chars(2) == (2, 6)
assert pair.token_to_chars(5) == None
assert pair.token_to_chars(6) == (0, 2)
def test_token_to_word(self, encodings):
single, pair = encodings
assert single.token_to_word(0) == None
assert single.token_to_word(1) == 0
assert single.token_to_word(4) == 2
assert pair.token_to_word(1) == 0
assert pair.token_to_word(4) == 2
assert pair.token_to_word(5) == None
assert pair.token_to_word(6) == 0
assert pair.token_to_word(7) == 1
def test_char_to_token(self, encodings):
single, pair = encodings
assert single.char_to_token(0) == 1
assert pair.char_to_token(0) == 1
assert pair.char_to_token(0, 0) == 1
assert pair.char_to_token(1, 0) == None
assert pair.char_to_token(0, 1) == 6
assert pair.char_to_token(2, 1) == None
def test_char_to_word(self, encodings):
single, pair = encodings
assert single.char_to_word(0) == 0
assert single.char_to_word(1) == None
assert pair.char_to_word(2) == 1
assert pair.char_to_word(2, 0) == 1
assert pair.char_to_word(2, 1) == None
assert pair.char_to_word(3, 1) == 1
def test_truncation(self, encodings):
single, _ = encodings
single.truncate(2, 1, "right")
assert single.tokens == ["[CLS]", "i"]
assert single.overflowing[0].tokens == ["i", "love"]
def test_invalid_truncate_direction(self, encodings):
single, _ = encodings
with pytest.raises(ValueError) as excinfo:
single.truncate(2, 1, "not_a_direction")
assert "Invalid truncation direction value : not_a_direction" == str(excinfo.value)
| tokenizers/bindings/python/tests/bindings/test_encoding.py/0 | {
"file_path": "tokenizers/bindings/python/tests/bindings/test_encoding.py",
"repo_id": "tokenizers",
"token_count": 1991
} | 221 |
import os
import pytest
from tokenizers import SentencePieceBPETokenizer, SentencePieceUnigramTokenizer
class TestSentencePieceBPE:
def test_train_from_iterator(self):
text = ["A first sentence", "Another sentence", "And a last one"]
tokenizer = SentencePieceBPETokenizer()
tokenizer.train_from_iterator(text, show_progress=False)
output = tokenizer.encode("A sentence")
assert output.tokens == ["▁A", "▁sentence"]
class TestSentencePieceUnigram:
def test_train(self, tmpdir):
p = tmpdir.mkdir("tmpdir").join("file.txt")
p.write("A first sentence\nAnother sentence\nAnd a last one")
tokenizer = SentencePieceUnigramTokenizer()
tokenizer.train(files=str(p), show_progress=False)
output = tokenizer.encode("A sentence")
assert output.tokens == ["▁A", "▁", "s", "en", "t", "en", "c", "e"]
with pytest.raises(Exception) as excinfo:
_ = tokenizer.encode("A sentence 🤗")
assert str(excinfo.value) == "Encountered an unknown token but `unk_id` is missing"
def test_train_with_unk_token(self, tmpdir):
p = tmpdir.mkdir("tmpdir").join("file.txt")
p.write("A first sentence\nAnother sentence\nAnd a last one")
tokenizer = SentencePieceUnigramTokenizer()
tokenizer.train(files=str(p), show_progress=False, special_tokens=["<unk>"], unk_token="<unk>")
output = tokenizer.encode("A sentence 🤗")
assert output.ids[-1] == 0
assert output.tokens == ["▁A", "▁", "s", "en", "t", "en", "c", "e", "▁", "🤗"]
def test_train_from_iterator(self):
text = ["A first sentence", "Another sentence", "And a last one"]
tokenizer = SentencePieceUnigramTokenizer()
tokenizer.train_from_iterator(text, show_progress=False)
output = tokenizer.encode("A sentence")
assert output.tokens == ["▁A", "▁", "s", "en", "t", "en", "c", "e"]
with pytest.raises(Exception) as excinfo:
_ = tokenizer.encode("A sentence 🤗")
assert str(excinfo.value) == "Encountered an unknown token but `unk_id` is missing"
def test_train_from_iterator_with_unk_token(self):
text = ["A first sentence", "Another sentence", "And a last one"]
tokenizer = SentencePieceUnigramTokenizer()
tokenizer.train_from_iterator(
text, vocab_size=100, show_progress=False, special_tokens=["<unk>"], unk_token="<unk>"
)
output = tokenizer.encode("A sentence 🤗")
assert output.ids[-1] == 0
assert output.tokens == ["▁A", "▁", "s", "en", "t", "en", "c", "e", "▁", "🤗"]
| tokenizers/bindings/python/tests/implementations/test_sentencepiece.py/0 | {
"file_path": "tokenizers/bindings/python/tests/implementations/test_sentencepiece.py",
"repo_id": "tokenizers",
"token_count": 1122
} | 222 |
# Trainers
<tokenizerslangcontent>
<python>
## BpeTrainer
[[autodoc]] tokenizers.trainers.BpeTrainer
## UnigramTrainer
[[autodoc]] tokenizers.trainers.UnigramTrainer
## WordLevelTrainer
[[autodoc]] tokenizers.trainers.WordLevelTrainer
## WordPieceTrainer
[[autodoc]] tokenizers.trainers.WordPieceTrainer
</python>
<rust>
The Rust API Reference is available directly on the [Docs.rs](https://docs.rs/tokenizers/latest/tokenizers/) website.
</rust>
<node>
The node API has not been documented yet.
</node>
</tokenizerslangcontent> | tokenizers/docs/source-doc-builder/api/trainers.mdx/0 | {
"file_path": "tokenizers/docs/source-doc-builder/api/trainers.mdx",
"repo_id": "tokenizers",
"token_count": 183
} | 223 |
/* Our DOM objects */
/* Version control */
.selectors {
margin-bottom: 10px;
}
.dropdown-button {
display: inline-block;
width: 50%;
background-color: #6670FF;
color: white;
border: none;
padding: 5px;
font-size: 15px;
cursor: pointer;
}
.dropdown-button:hover, .dropdown-button:focus, .dropdown-button.active {
background-color: #A6B0FF;
}
.dropdown-button.active {
background-color: #7988FF;
}
.menu-dropdown {
display: none;
background-color: #7988FF;
min-width: 160px;
overflow: auto;
font-size: 15px;
padding: 10px 0;
}
.menu-dropdown a {
color: white;
padding: 3px 4px;
text-decoration: none;
display: block;
}
.menu-dropdown a:hover {
background-color: #A6B0FF;
}
.dropdown-link.active {
background-color: #A6B0FF;
}
.show {
display: block;
}
/* The literal code blocks */
.rst-content tt.literal, .rst-content tt.literal, .rst-content code.literal {
color: #6670FF;
}
/* To keep the logo centered */
.wy-side-scroll {
width: auto;
font-size: 20px;
}
/* The div that holds the Hugging Face logo */
.HuggingFaceDiv {
width: 100%
}
/* The research field on top of the toc tree */
.wy-side-nav-search{
padding-top: 0;
background-color: #6670FF;
}
/* The toc tree */
.wy-nav-side{
background-color: #6670FF;
padding-bottom: 0;
}
/* The section headers in the toc tree */
.wy-menu-vertical p.caption{
background-color: #4d59ff;
line-height: 40px;
}
/* The selected items in the toc tree */
.wy-menu-vertical li.current{
background-color: #A6B0FF;
}
/* When a list item that does belong to the selected block from the toc tree is hovered */
.wy-menu-vertical li.current a:hover{
background-color: #B6C0FF;
}
/* When a list item that does NOT belong to the selected block from the toc tree is hovered. */
.wy-menu-vertical li a:hover{
background-color: #A7AFFB;
}
/* The text items on the toc tree */
.wy-menu-vertical a {
color: #FFFFDD;
font-family: Calibre-Light, sans-serif;
}
.wy-menu-vertical header, .wy-menu-vertical p.caption{
color: white;
font-family: Calibre-Light, sans-serif;
}
/* The color inside the selected toc tree block */
.wy-menu-vertical li.toctree-l2 a, .wy-menu-vertical li.toctree-l3 a, .wy-menu-vertical li.toctree-l4 a {
color: black;
}
/* Inside the depth-2 selected toc tree block */
.wy-menu-vertical li.toctree-l2.current>a {
background-color: #B6C0FF
}
.wy-menu-vertical li.toctree-l2.current li.toctree-l3>a {
background-color: #C6D0FF
}
/* Inside the depth-3 selected toc tree block */
.wy-menu-vertical li.toctree-l3.current li.toctree-l4>a{
background-color: #D6E0FF
}
/* Inside code snippets */
.rst-content dl:not(.docutils) dt{
font-size: 15px;
}
/* Links */
a {
color: #6670FF;
}
/* Content bars */
.rst-content dl:not(.docutils) dt {
background-color: rgba(251, 141, 104, 0.1);
border-right: solid 2px #FB8D68;
border-left: solid 2px #FB8D68;
color: #FB8D68;
font-family: Calibre-Light, sans-serif;
border-top: none;
font-style: normal !important;
}
/* Expand button */
.wy-menu-vertical li.toctree-l2 span.toctree-expand,
.wy-menu-vertical li.on a span.toctree-expand, .wy-menu-vertical li.current>a span.toctree-expand,
.wy-menu-vertical li.toctree-l3 span.toctree-expand{
color: black;
}
/* Max window size */
.wy-nav-content{
max-width: 1200px;
}
/* Mobile header */
.wy-nav-top{
background-color: #6670FF;
}
/* Source spans */
.rst-content .viewcode-link, .rst-content .viewcode-back{
color: #6670FF;
font-size: 110%;
letter-spacing: 2px;
text-transform: uppercase;
}
/* It would be better for table to be visible without horizontal scrolling */
.wy-table-responsive table td, .wy-table-responsive table th{
white-space: normal;
}
.footer {
margin-top: 20px;
}
.footer__Social {
display: flex;
flex-direction: row;
}
.footer__CustomImage {
margin: 2px 5px 0 0;
}
/* class and method names in doc */
.rst-content dl:not(.docutils) tt.descname, .rst-content dl:not(.docutils) tt.descclassname, .rst-content dl:not(.docutils) tt.descname, .rst-content dl:not(.docutils) code.descname, .rst-content dl:not(.docutils) tt.descclassname, .rst-content dl:not(.docutils) code.descclassname{
font-family: Calibre, sans-serif;
font-size: 20px !important;
}
/* class name in doc*/
.rst-content dl:not(.docutils) tt.descname, .rst-content dl:not(.docutils) tt.descname, .rst-content dl:not(.docutils) code.descname{
margin-right: 10px;
font-family: Calibre-Medium, sans-serif;
}
/* Method and class parameters */
.sig-param{
line-height: 23px;
}
/* Class introduction "class" string at beginning */
.rst-content dl:not(.docutils) .property{
font-size: 18px;
color: black;
}
/* FONTS */
body{
font-family: Calibre, sans-serif;
font-size: 16px;
}
h1 {
font-family: Calibre-Thin, sans-serif;
font-size: 70px;
}
h2, .rst-content .toctree-wrapper p.caption, h3, h4, h5, h6, legend{
font-family: Calibre-Medium, sans-serif;
}
@font-face {
font-family: Calibre-Medium;
src: url(./Calibre-Medium.otf);
font-weight:400;
}
@font-face {
font-family: Calibre;
src: url(./Calibre-Regular.otf);
font-weight:400;
}
@font-face {
font-family: Calibre-Light;
src: url(./Calibre-Light.ttf);
font-weight:400;
}
@font-face {
font-family: Calibre-Thin;
src: url(./Calibre-Thin.otf);
font-weight:400;
}
/**
* Nav Links to other parts of huggingface.co
*/
div.hf-menu {
position: absolute;
top: 0;
right: 0;
padding-top: 20px;
padding-right: 20px;
z-index: 1000;
}
div.hf-menu a {
font-size: 14px;
letter-spacing: 0.3px;
text-transform: uppercase;
color: white;
-webkit-font-smoothing: antialiased;
background: linear-gradient(0deg, #6671ffb8, #9a66ffb8 50%);
padding: 10px 16px 6px 16px;
border-radius: 3px;
margin-left: 12px;
position: relative;
}
div.hf-menu a:active {
top: 1px;
}
@media (min-width: 768px) and (max-width: 1860px) {
.wy-breadcrumbs {
margin-top: 32px;
}
}
@media (max-width: 768px) {
div.hf-menu {
display: none;
}
}
| tokenizers/docs/source/_static/css/huggingface.css/0 | {
"file_path": "tokenizers/docs/source/_static/css/huggingface.css",
"repo_id": "tokenizers",
"token_count": 2708
} | 224 |
Training from memory
----------------------------------------------------------------------------------------------------
In the `Quicktour <quicktour>`__, we saw how to build and train a tokenizer using text files,
but we can actually use any Python Iterator. In this section we'll see a few different ways of
training our tokenizer.
For all the examples listed below, we'll use the same :class:`~tokenizers.Tokenizer` and
:class:`~tokenizers.trainers.Trainer`, built as following:
.. literalinclude:: ../../../../bindings/python/tests/documentation/test_tutorial_train_from_iterators.py
:language: python
:start-after: START init_tokenizer_trainer
:end-before: END init_tokenizer_trainer
:dedent: 8
This tokenizer is based on the :class:`~tokenizers.models.Unigram` model. It takes care of
normalizing the input using the NFKC Unicode normalization method, and uses a
:class:`~tokenizers.pre_tokenizers.ByteLevel` pre-tokenizer with the corresponding decoder.
For more information on the components used here, you can check `here <components>`__
The most basic way
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
As you probably guessed already, the easiest way to train our tokenizer is by using a :obj:`List`:
.. literalinclude:: ../../../../bindings/python/tests/documentation/test_tutorial_train_from_iterators.py
:language: python
:start-after: START train_basic
:end-before: END train_basic
:dedent: 8
Easy, right? You can use anything working as an iterator here, be it a :obj:`List`, :obj:`Tuple`,
or a :obj:`np.Array`. Anything works as long as it provides strings.
Using the 🤗 Datasets library
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
An awesome way to access one of the many datasets that exist out there is by using the 🤗 Datasets
library. For more information about it, you should check
`the official documentation here <https://huggingface.co/docs/datasets/>`__.
Let's start by loading our dataset:
.. literalinclude:: ../../../../bindings/python/tests/documentation/test_tutorial_train_from_iterators.py
:language: python
:start-after: START load_dataset
:end-before: END load_dataset
:dedent: 8
The next step is to build an iterator over this dataset. The easiest way to do this is probably by
using a generator:
.. literalinclude:: ../../../../bindings/python/tests/documentation/test_tutorial_train_from_iterators.py
:language: python
:start-after: START def_batch_iterator
:end-before: END def_batch_iterator
:dedent: 8
As you can see here, for improved efficiency we can actually provide a batch of examples used
to train, instead of iterating over them one by one. By doing so, we can expect performances very
similar to those we got while training directly from files.
With our iterator ready, we just need to launch the training. In order to improve the look of our
progress bars, we can specify the total length of the dataset:
.. literalinclude:: ../../../../bindings/python/tests/documentation/test_tutorial_train_from_iterators.py
:language: python
:start-after: START train_datasets
:end-before: END train_datasets
:dedent: 8
And that's it!
Using gzip files
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Since gzip files in Python can be used as iterators, it is extremely simple to train on such files:
.. literalinclude:: ../../../../bindings/python/tests/documentation/test_tutorial_train_from_iterators.py
:language: python
:start-after: START single_gzip
:end-before: END single_gzip
:dedent: 8
Now if we wanted to train from multiple gzip files, it wouldn't be much harder:
.. literalinclude:: ../../../../bindings/python/tests/documentation/test_tutorial_train_from_iterators.py
:language: python
:start-after: START multi_gzip
:end-before: END multi_gzip
:dedent: 8
And voilà!
| tokenizers/docs/source/tutorials/python/training_from_memory.rst/0 | {
"file_path": "tokenizers/docs/source/tutorials/python/training_from_memory.rst",
"repo_id": "tokenizers",
"token_count": 1149
} | 225 |
mod utils;
use tokenizers::models::bpe::{Vocab, BPE};
use tokenizers::Tokenizer;
use wasm_bindgen::prelude::*;
// When the `wee_alloc` feature is enabled, use `wee_alloc` as the global
// allocator.
#[cfg(feature = "wee_alloc")]
#[global_allocator]
static ALLOC: wee_alloc::WeeAlloc = wee_alloc::WeeAlloc::INIT;
#[wasm_bindgen]
pub fn tokenize(string: &str) -> Vec<u32> {
let vocab: Vocab = vec![
("a".to_string(), 0),
("##b".to_string(), 1),
("##c".to_string(), 2),
("ab".to_string(), 3),
("abc".to_string(), 4),
]
.into_iter()
.collect();
let merges = vec![
("a".to_string(), "##b".to_string()),
("ab".to_string(), "##c".to_string()),
];
let bpe = BPE::builder()
.vocab_and_merges(vocab, merges)
.unk_token("[UNK]".to_string())
.continuing_subword_prefix("##".to_string())
.build()
.unwrap();
let tokenizer = Tokenizer::new(bpe);
tokenizer
.encode(string, false)
.unwrap()
.get_ids()
.into_iter()
.cloned()
.collect()
}
| tokenizers/tokenizers/examples/unstable_wasm/src/lib.rs/0 | {
"file_path": "tokenizers/tokenizers/examples/unstable_wasm/src/lib.rs",
"repo_id": "tokenizers",
"token_count": 543
} | 226 |
//!
//! This is the CLI binary for the Tokenizers project
//!
use clap::{Parser, Subcommand};
use std::io::{self, BufRead, Write};
use tokenizers::models::bpe::BPE;
use tokenizers::pre_tokenizers::byte_level::ByteLevel;
use tokenizers::tokenizer::{AddedToken, Result};
use tokenizers::Tokenizer;
/// Generate custom Tokenizers or use existing ones
#[derive(Parser, Debug)]
#[command(author, version)]
struct Args {
#[command(subcommand)]
command: Command,
}
#[derive(Subcommand, Debug)]
enum Command {
Shell {
/// Path to the vocab.json file
vocab: String,
/// Path to the merges.txt file
merges: String,
},
}
fn shell(vocab: &str, merges: &str) -> Result<()> {
let bpe = BPE::from_file(vocab, merges).build()?;
let mut tokenizer = Tokenizer::new(bpe);
tokenizer
.with_pre_tokenizer(ByteLevel::default())
.with_decoder(ByteLevel::default());
tokenizer.add_tokens(&[AddedToken::from(String::from("ing"), false).single_word(false)]);
tokenizer
.add_special_tokens(&[AddedToken::from(String::from("[ENT]"), true).single_word(true)]);
let stdin = io::stdin();
let mut handle = stdin.lock();
let mut buffer = String::new();
loop {
buffer.clear();
print!("\nEnter some text to tokenize:\n> ");
io::stdout().flush()?;
handle.read_line(&mut buffer)?;
let buffer = buffer.trim_end();
let timer = std::time::Instant::now();
let encoded = tokenizer.encode(buffer.to_owned(), false)?;
let elapsed = timer.elapsed();
println!("\nInput:\t\t{}", buffer);
println!("Tokens:\t\t{:?}", encoded.get_tokens());
println!("IDs:\t\t{:?}", encoded.get_ids());
println!("Offsets:\t{:?}", encoded.get_offsets());
println!(
"Decoded:\t{}",
tokenizer.decode(encoded.get_ids(), true).unwrap()
);
println!("Tokenized in {:?}", elapsed);
}
}
fn main() -> Result<()> {
let args = Args::parse();
match args.command {
Command::Shell { vocab, merges } => shell(&vocab, &merges),
}
}
| tokenizers/tokenizers/src/cli.rs/0 | {
"file_path": "tokenizers/tokenizers/src/cli.rs",
"repo_id": "tokenizers",
"token_count": 900
} | 227 |
use rand::distributions::WeightedIndex;
use rand::prelude::*;
use std::cell::RefCell;
use std::cmp::{min, Ordering};
use std::collections::BinaryHeap;
use std::rc::Rc;
type NodeRef = Rc<RefCell<Node>>;
type HypothesisRef = Rc<RefCell<Hypothesis>>;
type Agenda = BinaryHeap<Hypothesis>;
struct Hypothesis {
node_ref: NodeRef,
next: Option<HypothesisRef>,
fx: f64,
gx: f64,
}
impl Hypothesis {
pub fn new(node_ref: NodeRef, next: Option<HypothesisRef>, fx: f64, gx: f64) -> Self {
Self {
node_ref,
next,
fx,
gx,
}
}
}
impl PartialEq for Hypothesis {
fn eq(&self, other: &Self) -> bool {
self.fx == other.fx
}
}
impl Eq for Hypothesis {}
impl PartialOrd for Hypothesis {
fn partial_cmp(&self, other: &Self) -> Option<Ordering> {
Some(self.cmp(other))
}
}
// TODO Maybe use Ordered Floats (https://docs.rs/ordered-float/1.0.2/ordered_float/)
impl Ord for Hypothesis {
fn cmp(&self, other: &Self) -> Ordering {
if self.fx < other.fx {
Ordering::Less
} else {
Ordering::Greater
}
}
}
/// Structure to implement Viterbi algorithm to find the best encoding, or sample
/// from all possible encodings of a given sentence.
#[derive(Debug)]
pub struct Lattice<'a> {
pub(super) sentence: &'a str,
len: usize,
nodes: Vec<NodeRef>,
pub(super) begin_nodes: Vec<Vec<NodeRef>>,
pub(super) end_nodes: Vec<Vec<NodeRef>>,
_bos_id: usize,
_eos_id: usize,
}
impl std::fmt::Display for Lattice<'_> {
fn fmt(&self, f: &mut std::fmt::Formatter) -> std::fmt::Result {
let display_pieces = |nodes: &Vec<Vec<NodeRef>>| {
nodes
.iter()
.map(|l| {
l.iter()
.map(|n| self.piece(&n.borrow()))
.collect::<Vec<_>>()
})
.collect::<Vec<_>>()
};
f.debug_struct("Lattice")
.field("sentence", &self.sentence)
.field("begin_nodes", &display_pieces(&self.begin_nodes))
.field("end_nodes", &display_pieces(&self.end_nodes))
.finish()
}
}
/// A node from the lattice, that helps reconstruct the underlying `String`
#[derive(Debug, Clone)]
pub struct Node {
// Vocabulary id
pub(super) id: usize,
// Local lattice identifier
pub(super) node_id: usize,
pos: usize,
length: usize,
prev: Option<NodeRef>,
backtrace_score: f64,
score: f64,
}
impl PartialEq for Node {
fn eq(&self, other: &Node) -> bool {
self.id == other.id
}
}
impl Node {
pub fn new(id: usize, node_id: usize, pos: usize, length: usize, score: f64) -> Self {
Self {
id,
node_id,
pos,
length,
prev: None,
score,
backtrace_score: 0.0,
}
}
}
/// Returns log(exp(x) + exp(y)).
/// if init_mode is true, returns log(exp(y)) == y.
/// log(\sum_i exp(a[i])) can be computed as
/// for (int i = 0; i < a.size(); ++i)
/// x = LogSumExp(x, a[i], i == 0);
fn log_sum_exp(x: f64, y: f64, init_mode: bool) -> f64 {
if init_mode {
y
} else {
let (vmin, vmax) = if x > y { (y, x) } else { (x, y) };
let k_minus_log_epsilon = 50.0;
if vmax > vmin + k_minus_log_epsilon {
vmax
} else {
vmax + ((vmin - vmax).exp() + 1.0).ln()
}
}
}
impl<'a> Lattice<'a> {
pub fn from(sentence: &'a str, bos_id: usize, eos_id: usize) -> Self {
let len = sentence.len();
let k_reserved_node_size = 16;
// We are adding 2 tokens, bos and eos
let mut nodes: Vec<NodeRef> = Vec::with_capacity(k_reserved_node_size);
let mut begin_nodes = vec![Vec::with_capacity(k_reserved_node_size); len + 1];
let mut end_nodes = vec![Vec::with_capacity(k_reserved_node_size); len + 1];
let bos = Rc::new(RefCell::new(Node::new(bos_id, 0, 0, 0, 0.0)));
let eos = Rc::new(RefCell::new(Node::new(eos_id, 1, len, 0, 0.0)));
begin_nodes[len].push(Rc::clone(&eos));
end_nodes[0].push(Rc::clone(&bos));
nodes.push(bos);
nodes.push(eos);
Self {
sentence,
len,
nodes,
begin_nodes,
end_nodes,
_bos_id: bos_id,
_eos_id: eos_id,
}
}
pub fn insert(&mut self, pos: usize, length: usize, score: f64, id: usize) {
let node_id = self.nodes.len();
let node = Rc::new(RefCell::new(Node::new(id, node_id, pos, length, score)));
self.begin_nodes[pos].push(Rc::clone(&node));
self.end_nodes[pos + length].push(Rc::clone(&node));
self.nodes.push(node);
}
pub fn viterbi(&mut self) -> Vec<NodeRef> {
let len = self.len;
let mut pos = 0;
while pos <= len {
if self.begin_nodes[pos].is_empty() {
return vec![];
}
for rnode in &self.begin_nodes[pos] {
rnode.borrow_mut().prev = None;
let mut best_score = 0.0;
let mut best_node: Option<NodeRef> = None;
for lnode in &self.end_nodes[pos] {
let score = lnode.borrow().backtrace_score + rnode.borrow().score;
if best_node.is_none() || score > best_score {
// TODO can we remove this clone ?
best_node = Some(lnode.clone());
best_score = score
}
}
match best_node {
Some(bnode) => {
rnode.borrow_mut().prev = Some(Rc::clone(&bnode));
rnode.borrow_mut().backtrace_score = best_score;
}
None => return vec![],
}
}
if let Some(c) = self.sentence[pos..].chars().next() {
pos += c.len_utf8();
} else {
break;
}
}
let mut results: Vec<NodeRef> = vec![];
let root = self.begin_nodes[len][0].borrow();
let prev = root.prev.as_ref();
if prev.is_none() {
return vec![];
}
let mut node: NodeRef = prev.unwrap().clone();
while node.borrow().prev.is_some() {
results.push(node.clone());
let n = node.borrow().clone();
node = n.prev.as_ref().unwrap().clone();
}
results.reverse();
results
}
pub fn piece(&self, node: &Node) -> String {
self.sentence[node.pos..node.pos + node.length].to_owned()
}
pub fn tokens(&mut self) -> Vec<String> {
self.viterbi()
.iter()
.map(|node| self.piece(&node.borrow()))
.collect()
}
pub fn nbest(&mut self, n: usize) -> Vec<Vec<NodeRef>> {
match n {
0 => vec![],
1 => vec![self.viterbi()],
_ => {
// let k_reserved_hypothesis_size = 512;
let mut agenda: Agenda = BinaryHeap::new();
let mut hypotheses: Vec<Vec<NodeRef>> = vec![];
let eos = self.eos_node();
let score = eos.borrow().score;
let hypo = Hypothesis::new(eos, None, score, score);
agenda.push(hypo);
// Fill backtrace scores
self.viterbi();
while !agenda.is_empty() {
let top = Rc::new(RefCell::new(agenda.pop().unwrap()));
let node = Rc::clone(&top.borrow().node_ref);
if node.borrow().id == self.bos_node().borrow().id {
let mut hypothesis = vec![];
let mut next: HypothesisRef =
Rc::clone(top.borrow().next.as_ref().unwrap());
while next.borrow().next.is_some() {
hypothesis.push(next.borrow().node_ref.clone());
let c: HypothesisRef = next.clone();
// let c: Ref<Hypothesis> = next.clone().borrow();
next = Rc::clone(c.borrow().next.as_ref().unwrap());
}
hypotheses.push(hypothesis);
if hypotheses.len() == n {
return hypotheses;
}
} else {
for lnode in &self.end_nodes[node.borrow().pos] {
let top_gx = top.borrow().gx;
let fx = lnode.borrow().backtrace_score + top_gx;
let gx = lnode.borrow().score + top_gx;
let hyp =
Hypothesis::new(Rc::clone(lnode), Some(Rc::clone(&top)), fx, gx);
agenda.push(hyp);
}
// When the input is too long or contains duplicated phrases,
// `agenda` will get extremely big. Here we avoid this case by
// dynamically shrinking the agenda.
let k_max_agenda_size = 100_000;
let k_min_agenda_size = 512;
if agenda.len() > k_max_agenda_size {
let mut new_agenda = BinaryHeap::new();
let len = min(k_min_agenda_size, n * 10);
for _i in 0..len {
new_agenda.push(agenda.pop().unwrap());
}
agenda = new_agenda;
}
}
}
hypotheses
}
}
}
pub fn nbest_tokens(&mut self, n: usize) -> Vec<Vec<String>> {
self.nbest(n)
.iter()
.map(|v| v.iter().map(|node| self.piece(&node.borrow())).collect())
.collect()
}
pub fn len(&self) -> usize {
self.len
}
pub fn is_empty(&self) -> bool {
self.len == 0
}
pub fn bos_node(&self) -> NodeRef {
Rc::clone(&self.end_nodes[0][0])
}
pub fn eos_node(&self) -> NodeRef {
Rc::clone(&self.begin_nodes[self.len][0])
}
pub fn surface(&self, n: usize) -> &str {
match self.sentence.char_indices().nth(n) {
Some((pos, _)) => &self.sentence[pos..],
None => "",
}
}
pub fn sentence(&self) -> &str {
self.sentence
}
pub fn populate_marginal(&self, freq: f64, expected: &mut [f64]) -> f64 {
let len = self.len();
let n_nodes = self.nodes.len();
let mut alpha = vec![0.0; n_nodes];
let mut beta = vec![0.0; n_nodes];
for pos in 0..=len {
for rnode in &self.begin_nodes[pos] {
for lnode in &self.end_nodes[pos] {
let lid = lnode.borrow().node_id;
let rid = rnode.borrow().node_id;
alpha[rid] = log_sum_exp(
alpha[rid],
lnode.borrow().score + alpha[lid],
*lnode == self.end_nodes[pos][0],
);
}
}
}
for pos in (0..=len).rev() {
// let rpos = len - pos;
for lnode in &self.end_nodes[pos] {
for rnode in &self.begin_nodes[pos] {
let lid = lnode.borrow().node_id;
let rid = rnode.borrow().node_id;
beta[lid] = log_sum_exp(
beta[lid],
rnode.borrow().score + beta[rid],
*rnode == self.begin_nodes[pos][0],
);
}
}
}
let eos_id = self.begin_nodes[len][0].borrow().node_id;
let z = alpha[eos_id];
for pos in 0..len {
for node in &self.begin_nodes[pos] {
let node_id = node.borrow().node_id;
let id = node.borrow().id;
let a = alpha[node_id];
let b = beta[node_id];
let total = a + node.borrow().score + b - z;
let update = freq * total.exp();
expected[id] += update;
}
}
freq * z
}
pub fn sample(&self, theta: f64) -> Vec<NodeRef> {
let len = self.len();
if len == 0 {
return vec![];
}
let mut alpha = vec![0.0; self.nodes.len()];
for pos in 0..=len {
for rnode in &self.begin_nodes[pos] {
for lnode in &self.end_nodes[pos] {
let lid = lnode.borrow().node_id;
let rid = rnode.borrow().node_id;
alpha[rid] = log_sum_exp(
alpha[rid],
theta * (lnode.borrow().score + alpha[lid]),
*lnode == self.end_nodes[pos][0],
);
}
}
}
let mut rng = thread_rng();
let mut results: Vec<NodeRef> = vec![];
let mut probs: Vec<f64> = vec![];
let mut z = alpha[self.eos_node().borrow().node_id];
let mut node = self.eos_node();
loop {
probs.clear();
let pos = node.borrow().pos;
for lnode in &self.end_nodes[pos] {
let lid = lnode.borrow().node_id;
probs.push((alpha[lid] + theta * lnode.borrow().score - z).exp())
}
let dist = WeightedIndex::new(&probs).unwrap();
let index = dist.sample(&mut rng);
node = Rc::clone(&self.end_nodes[pos][index]);
if node == self.bos_node() {
break;
}
z = alpha[node.borrow().node_id];
results.push(Rc::clone(&node));
}
results.reverse();
results
}
pub fn sample_token(&self, theta: f64) -> Vec<String> {
self.sample(theta)
.iter()
.map(|node| self.piece(&node.borrow()))
.collect()
}
}
#[cfg(test)]
mod tests {
use super::*;
use assert_approx_eq::assert_approx_eq;
#[test]
fn set_sentence() {
let lattice = Lattice::from("", 1, 2);
assert_eq!(lattice.len(), 0);
let lattice = Lattice::from("", 1, 2);
assert_eq!(lattice.len(), 0);
assert_eq!(lattice.sentence(), "");
assert_eq!(lattice.surface(0), "");
let lattice = Lattice::from("test", 1, 2);
assert_eq!(lattice.len(), 4);
assert_eq!(lattice.sentence(), "test");
assert_eq!(lattice.surface(0), "test");
assert_eq!(lattice.surface(1), "est");
assert_eq!(lattice.surface(2), "st");
assert_eq!(lattice.surface(3), "t");
let bos = lattice.bos_node();
let eos = lattice.eos_node();
assert_eq!(bos.borrow().id, 1);
assert_eq!(eos.borrow().id, 2);
assert_eq!(
lattice.end_nodes[0].first().unwrap().borrow().id,
bos.borrow().id
);
assert_eq!(
lattice.begin_nodes[4].first().unwrap().borrow().id,
eos.borrow().id
);
let lattice = Lattice::from("テストab", 1, 2);
assert_eq!(lattice.len(), 11);
assert_eq!(lattice.sentence(), "テストab");
assert_eq!(lattice.surface(0), "テストab");
assert_eq!(lattice.surface(1), "ストab");
assert_eq!(lattice.surface(2), "トab");
assert_eq!(lattice.surface(3), "ab");
assert_eq!(lattice.surface(4), "b");
}
#[test]
fn insert_test() {
let mut lattice = Lattice::from("ABあい", 1, 2);
lattice.insert(0, 1, 0.0, 3);
lattice.insert(1, 1, 0.0, 4);
lattice.insert(2, 3, 0.0, 5);
lattice.insert(5, 3, 0.0, 6);
lattice.insert(0, 2, 0.0, 7);
lattice.insert(1, 4, 0.0, 8);
lattice.insert(2, 6, 0.0, 9);
// 0 & 1 are bos and eos
let node0 = lattice.nodes[2].borrow();
let node1 = lattice.nodes[3].borrow();
let node2 = lattice.nodes[4].borrow();
let node3 = lattice.nodes[5].borrow();
let node4 = lattice.nodes[6].borrow();
let node5 = lattice.nodes[7].borrow();
let node6 = lattice.nodes[8].borrow();
assert_eq!(lattice.piece(&node0), "A");
assert_eq!(lattice.piece(&node1), "B");
assert_eq!(lattice.piece(&node2), "あ");
assert_eq!(lattice.piece(&node3), "い");
assert_eq!(lattice.piece(&node4), "AB");
assert_eq!(lattice.piece(&node5), "Bあ");
assert_eq!(lattice.piece(&node6), "あい");
assert_eq!(node0.pos, 0);
assert_eq!(node1.pos, 1);
assert_eq!(node2.pos, 2);
assert_eq!(node3.pos, 5);
assert_eq!(node4.pos, 0);
assert_eq!(node5.pos, 1);
assert_eq!(node6.pos, 2);
assert_eq!(node0.length, 1);
assert_eq!(node1.length, 1);
assert_eq!(node2.length, 3);
assert_eq!(node3.length, 3);
assert_eq!(node4.length, 2);
assert_eq!(node5.length, 4);
assert_eq!(node6.length, 6);
assert_eq!(lattice.bos_node().borrow().id, 1);
assert_eq!(lattice.eos_node().borrow().id, 2);
assert_eq!(node0.id, 3);
assert_eq!(node1.id, 4);
assert_eq!(node2.id, 5);
assert_eq!(node3.id, 6);
assert_eq!(node4.id, 7);
assert_eq!(node5.id, 8);
assert_eq!(node6.id, 9);
assert_eq!(lattice.begin_nodes[0].len(), 2);
assert_eq!(lattice.begin_nodes[1].len(), 2);
assert_eq!(lattice.begin_nodes[2].len(), 2);
assert_eq!(lattice.begin_nodes[5].len(), 1);
assert_eq!(lattice.begin_nodes[8].len(), 1);
assert_eq!(lattice.end_nodes[0].len(), 1);
assert_eq!(lattice.end_nodes[1].len(), 1);
assert_eq!(lattice.end_nodes[2].len(), 2);
assert_eq!(lattice.end_nodes[5].len(), 2);
assert_eq!(lattice.end_nodes[8].len(), 2);
assert_eq!(lattice.begin_nodes[0][0].borrow().id, node0.id);
assert_eq!(lattice.begin_nodes[0][1].borrow().id, node4.id);
assert_eq!(lattice.begin_nodes[1][0].borrow().id, node1.id);
assert_eq!(lattice.begin_nodes[1][1].borrow().id, node5.id);
assert_eq!(lattice.begin_nodes[2][0].borrow().id, node2.id);
assert_eq!(lattice.begin_nodes[2][1].borrow().id, node6.id);
assert_eq!(lattice.begin_nodes[5][0].borrow().id, node3.id);
assert_eq!(
lattice.eos_node().borrow().id,
lattice.begin_nodes[8][0].borrow().id
);
assert_eq!(
lattice.bos_node().borrow().id,
lattice.end_nodes[0][0].borrow().id
);
assert_eq!(node0.id, lattice.end_nodes[1][0].borrow().id);
assert_eq!(node1.id, lattice.end_nodes[2][0].borrow().id);
assert_eq!(node4.id, lattice.end_nodes[2][1].borrow().id);
assert_eq!(node2.id, lattice.end_nodes[5][0].borrow().id);
assert_eq!(node5.id, lattice.end_nodes[5][1].borrow().id);
assert_eq!(node3.id, lattice.end_nodes[8][0].borrow().id);
assert_eq!(node6.id, lattice.end_nodes[8][1].borrow().id);
}
#[test]
fn test_viterbi() {
let mut lattice = Lattice::from("ABC", 1, 2);
assert_eq!(lattice.viterbi(), vec![]);
// Still incomplete
lattice.insert(0, 1, 0.0, 3);
assert_eq!(lattice.viterbi(), vec![]);
lattice.insert(1, 1, 0.0, 4);
lattice.insert(2, 1, 0.0, 5);
// XXX: In sentence piece this is not tested, still incomplete ?
assert_eq!(lattice.viterbi().len(), 3);
}
#[test]
fn test_viterbi2() {
let mut lattice = Lattice::from("ABC", 1, 2);
lattice.insert(0, 1, 0.0, 3);
lattice.insert(1, 1, 0.0, 4);
lattice.insert(2, 1, 0.0, 5);
assert_eq!(lattice.tokens(), ["A", "B", "C"]);
lattice.insert(0, 2, 2.0, 6);
assert_eq!(lattice.tokens(), ["AB", "C"]);
lattice.insert(1, 2, 5.0, 7);
assert_eq!(lattice.tokens(), ["A", "BC"]);
lattice.insert(0, 3, 10.0, 8);
assert_eq!(lattice.tokens(), ["ABC"]);
}
#[test]
fn test_nbest() {
let mut lattice = Lattice::from("ABC", 1, 2);
lattice.insert(0, 1, 0.0, 3);
lattice.insert(1, 1, 0.0, 4);
lattice.insert(2, 1, 0.0, 5);
lattice.insert(0, 2, 2.0, 6);
lattice.insert(1, 2, 5.0, 7);
lattice.insert(0, 3, 10.0, 8);
let nbests = lattice.nbest_tokens(10);
assert_eq!(
nbests,
vec![
vec!["ABC"],
vec!["A", "BC"],
vec!["AB", "C"],
vec!["A", "B", "C"]
]
);
assert!(lattice.nbest_tokens(0).is_empty());
assert_eq!(lattice.nbest_tokens(1), vec![vec!["ABC"]]);
}
#[test]
fn test_log_sum_exp() {
let mut x = 0.0;
let v: Vec<f64> = vec![1.0, 2.0, 3.0];
for (i, y) in v.iter().enumerate() {
x = log_sum_exp(x, *y, i == 0);
}
assert_approx_eq!(x, v.iter().map(|n| n.exp()).sum::<f64>().ln(), 0.001);
}
#[test]
fn test_populate() {
let mut lattice = Lattice::from("ABC", 1, 2);
lattice.insert(0, 1, 1.0, 3); // A
lattice.insert(1, 1, 1.2, 4); // B
lattice.insert(2, 1, 2.5, 5); // C
lattice.insert(0, 2, 3.0, 6); // AB
lattice.insert(1, 2, 4.0, 7); // BC
lattice.insert(0, 3, 2.0, 8); // ABC
let mut probs = vec![0.0; 9];
let p1 = (1.0_f64 + 1.2 + 2.5).exp();
let p2 = (3.0_f64 + 2.5).exp();
let p3 = (1.0_f64 + 4.0).exp();
let p4 = 2.0_f64.exp();
let z = p1 + p2 + p3 + p4;
let log_z = lattice.populate_marginal(1.0, &mut probs);
assert_approx_eq!(log_z, z.ln(), 0.001);
assert_approx_eq!(probs[0], 0.0, 0.001);
assert_approx_eq!(probs[1], 0.0, 0.001);
assert_approx_eq!(probs[2], 0.0, 0.001);
assert_approx_eq!(probs[3], (p1 + p3) / z, 0.001);
assert_approx_eq!(probs[4], (p1) / z, 0.001);
assert_approx_eq!(probs[5], (p1 + p2) / z, 0.001);
assert_approx_eq!(probs[6], (p2) / z, 0.001);
assert_approx_eq!(probs[7], (p3) / z, 0.001);
assert_approx_eq!(probs[8], (p4) / z, 0.001);
}
}
| tokenizers/tokenizers/src/models/unigram/lattice.rs/0 | {
"file_path": "tokenizers/tokenizers/src/models/unigram/lattice.rs",
"repo_id": "tokenizers",
"token_count": 12682
} | 228 |
use crate::tokenizer::pattern::Pattern;
use crate::tokenizer::Decoder;
use crate::tokenizer::{NormalizedString, Normalizer, Result};
use crate::utils::SysRegex;
use serde::{Deserialize, Serialize};
/// Represents the different patterns that `Replace` can use
#[derive(Debug, Clone, PartialEq, Serialize, Deserialize, Eq)]
pub enum ReplacePattern {
String(String),
Regex(String),
}
impl From<String> for ReplacePattern {
fn from(v: String) -> Self {
Self::String(v)
}
}
impl From<&str> for ReplacePattern {
fn from(v: &str) -> Self {
Self::String(v.to_owned())
}
}
/// We use this custom deserializer to provide the value for `regex` for `Replace`
#[doc(hidden)]
#[derive(Deserialize)]
#[serde(tag = "type")]
struct ReplaceDeserializer {
pattern: ReplacePattern,
content: String,
}
impl std::convert::TryFrom<ReplaceDeserializer> for Replace {
type Error = Box<dyn std::error::Error + Send + Sync>;
fn try_from(v: ReplaceDeserializer) -> Result<Self> {
Self::new(v.pattern, v.content)
}
}
/// This normalizer will take a `pattern` (for now only a String)
/// and replace every occurrence with `content`.
#[derive(Debug, Serialize, Deserialize)]
#[serde(tag = "type", try_from = "ReplaceDeserializer")]
pub struct Replace {
pattern: ReplacePattern,
content: String,
#[serde(skip)]
regex: SysRegex,
}
impl Clone for Replace {
fn clone(&self) -> Self {
Self::new(self.pattern.clone(), &self.content).unwrap()
}
}
impl PartialEq for Replace {
fn eq(&self, other: &Self) -> bool {
self.pattern == other.pattern && self.content == other.content
}
}
impl Replace {
pub fn new<I: Into<ReplacePattern>, C: Into<String>>(pattern: I, content: C) -> Result<Self> {
let pattern: ReplacePattern = pattern.into();
let regex = match &pattern {
ReplacePattern::String(s) => SysRegex::new(®ex::escape(s))?,
ReplacePattern::Regex(r) => SysRegex::new(r)?,
};
Ok(Self {
pattern,
content: content.into(),
regex,
})
}
}
impl Normalizer for Replace {
fn normalize(&self, normalized: &mut NormalizedString) -> Result<()> {
normalized.replace(&self.regex, &self.content)
}
}
impl Decoder for Replace {
fn decode_chain(&self, tokens: Vec<String>) -> Result<Vec<String>> {
tokens
.into_iter()
.map(|token| -> Result<String> {
let mut new_token = "".to_string();
for ((start, stop), is_match) in (&self.regex).find_matches(&token)? {
if is_match {
new_token.push_str(&self.content);
} else {
new_token.push_str(&token[start..stop]);
}
}
Ok(new_token)
})
.collect()
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn test_replace() {
let original = "This is a ''test''";
let normalized = "This is a \"test\"";
let mut n = NormalizedString::from(original);
Replace::new("''", "\"").unwrap().normalize(&mut n).unwrap();
assert_eq!(&n.get(), &normalized);
}
#[test]
fn test_replace_regex() {
let original = "This is a test";
let normalized = "This is a test";
let mut n = NormalizedString::from(original);
Replace::new(ReplacePattern::Regex(r"\s+".into()), ' ')
.unwrap()
.normalize(&mut n)
.unwrap();
assert_eq!(&n.get(), &normalized);
}
#[test]
fn serialization() {
let replace = Replace::new("Hello", "Hey").unwrap();
let replace_s = r#"{"type":"Replace","pattern":{"String":"Hello"},"content":"Hey"}"#;
assert_eq!(serde_json::to_string(&replace).unwrap(), replace_s);
assert_eq!(serde_json::from_str::<Replace>(replace_s).unwrap(), replace);
let replace = Replace::new(ReplacePattern::Regex(r"\s+".into()), ' ').unwrap();
let replace_s = r#"{"type":"Replace","pattern":{"Regex":"\\s+"},"content":" "}"#;
assert_eq!(serde_json::to_string(&replace).unwrap(), replace_s);
assert_eq!(serde_json::from_str::<Replace>(replace_s).unwrap(), replace);
}
#[test]
fn test_replace_decode() {
let original = vec!["hello".to_string(), "_hello".to_string()];
let replace = Replace::new("_", " ").unwrap();
assert_eq!(
replace.decode_chain(original).unwrap(),
vec!["hello", " hello"]
);
}
}
| tokenizers/tokenizers/src/normalizers/replace.rs/0 | {
"file_path": "tokenizers/tokenizers/src/normalizers/replace.rs",
"repo_id": "tokenizers",
"token_count": 2048
} | 229 |
use regex::Regex;
use crate::tokenizer::{
pattern::Invert, PreTokenizedString, PreTokenizer, Result, SplitDelimiterBehavior,
};
use crate::utils::macro_rules_attribute;
#[derive(Clone, Debug, PartialEq, Eq)]
#[macro_rules_attribute(impl_serde_type!)]
pub struct Whitespace;
impl Default for Whitespace {
fn default() -> Self {
Self
}
}
impl PreTokenizer for Whitespace {
fn pre_tokenize(&self, pretokenized: &mut PreTokenizedString) -> Result<()> {
lazy_static! {
static ref RE: Regex = Regex::new(r"\w+|[^\w\s]+").unwrap();
}
let re_ref: &Regex = &RE;
pretokenized.split(|_, normalized| {
normalized.split(Invert(re_ref), SplitDelimiterBehavior::Removed)
})
}
}
#[derive(Copy, Clone, Debug, PartialEq, Eq)]
#[macro_rules_attribute(impl_serde_type!)]
pub struct WhitespaceSplit;
impl PreTokenizer for WhitespaceSplit {
fn pre_tokenize(&self, pretokenized: &mut PreTokenizedString) -> Result<()> {
pretokenized.split(|_, normalized| {
normalized.split(char::is_whitespace, SplitDelimiterBehavior::Removed)
})
}
}
#[cfg(test)]
mod tests {
use super::*;
use crate::{OffsetReferential, OffsetType, PreTokenizer};
#[test]
fn basic() {
let tests = vec![
(
"Hey man!",
vec![("Hey", (0, 3)), ("man", (4, 7)), ("!", (7, 8))],
),
(
"How are you doing?",
vec![
("How", (0, 3)),
("are", (4, 7)),
("you", (8, 11)),
("doing", (12, 17)),
("?", (17, 18)),
],
),
("\n", vec![]),
];
let pretok = Whitespace {};
for (s, res) in tests {
let mut pretokenized = PreTokenizedString::from(s);
pretok.pre_tokenize(&mut pretokenized).unwrap();
assert_eq!(
pretokenized
.get_splits(OffsetReferential::Original, OffsetType::Byte)
.into_iter()
.map(|(s, o, _)| (s, o))
.collect::<Vec<_>>(),
res
);
}
}
#[test]
fn whitespace_split() {
let tests = vec![
("Hey man!", vec![("Hey", (0, 3)), ("man!", (4, 8))]),
(
"Hey, man, Good?",
vec![("Hey,", (0, 4)), ("man,", (5, 9)), ("Good?", (10, 15))],
),
];
let pretok = WhitespaceSplit;
for (s, res) in tests {
let mut pretokenized = PreTokenizedString::from(s);
pretok.pre_tokenize(&mut pretokenized).unwrap();
assert_eq!(
pretokenized
.get_splits(OffsetReferential::Original, OffsetType::Byte)
.into_iter()
.map(|(s, o, _)| (s, o))
.collect::<Vec<_>>(),
res
);
}
}
}
| tokenizers/tokenizers/src/pre_tokenizers/whitespace.rs/0 | {
"file_path": "tokenizers/tokenizers/src/pre_tokenizers/whitespace.rs",
"repo_id": "tokenizers",
"token_count": 1660
} | 230 |
//! This comes from the Rust libcore and is duplicated here because it is not exported
//! (cf <https://github.com/rust-lang/rust/blob/25091ed9b7739e12466fb2490baa1e8a2815121c/src/libcore/iter/adapters/mod.rs#L2664>)
//! We are now using the version from <https://stackoverflow.com/questions/44544323/how-to-unzip-a-sequence-of-resulta-b-e-to-a-veca-vecb-and-stop-on-f>
//! because the one from the libcore seems to cause overflowing stacks in some cases
//! It also contains a lines_with_ending that copies std::io::BufRead but keeps line endings.
use std::io::BufRead;
pub struct ResultShunt<I, E> {
iter: I,
error: Option<E>,
}
impl<I, T, E> ResultShunt<I, E>
where
I: Iterator<Item = Result<T, E>>,
{
/// Process the given iterator as if it yielded a `T` instead of a
/// `Result<T, _>`. Any errors will stop the inner iterator and
/// the overall result will be an error.
pub fn process<F, U>(iter: I, mut f: F) -> Result<U, E>
where
F: FnMut(&mut Self) -> U,
{
let mut shunt = ResultShunt::new(iter);
let value = f(shunt.by_ref());
shunt.reconstruct(value)
}
fn new(iter: I) -> Self {
ResultShunt { iter, error: None }
}
/// Consume the adapter and rebuild a `Result` value. This should
/// *always* be called, otherwise any potential error would be
/// lost.
fn reconstruct<U>(self, val: U) -> Result<U, E> {
match self.error {
None => Ok(val),
Some(e) => Err(e),
}
}
}
impl<I, T, E> Iterator for ResultShunt<I, E>
where
I: Iterator<Item = Result<T, E>>,
{
type Item = T;
fn next(&mut self) -> Option<Self::Item> {
match self.iter.next() {
Some(Ok(v)) => Some(v),
Some(Err(e)) => {
self.error = Some(e);
None
}
None => None,
}
}
}
/// Copied from std::io::BufRead but keep newline characters.
#[derive(Debug)]
pub struct Lines<B> {
buf: B,
}
pub trait LinesWithEnding<B> {
fn lines_with_ending(self) -> Lines<B>;
}
impl<B> LinesWithEnding<B> for B
where
B: BufRead,
{
fn lines_with_ending(self) -> Lines<B> {
Lines::<B> { buf: self }
}
}
impl<B: BufRead> Iterator for Lines<B> {
type Item = std::io::Result<String>;
fn next(&mut self) -> Option<Self::Item> {
let mut buf = String::new();
match self.buf.read_line(&mut buf) {
Ok(0) => None,
Ok(_n) => {
// if buf.ends_with('\n') {
// buf.pop();
// if buf.ends_with('\r') {
// buf.pop();
// }
// }
Some(Ok(buf))
}
Err(e) => Some(Err(e)),
}
}
}
| tokenizers/tokenizers/src/utils/iter.rs/0 | {
"file_path": "tokenizers/tokenizers/src/utils/iter.rs",
"repo_id": "tokenizers",
"token_count": 1339
} | 231 |
version: 2.1
setup: true
orbs:
continuation: circleci/[email protected]
parameters:
nightly:
type: boolean
default: false
jobs:
# Ensure running with CircleCI/huggingface
check_circleci_user:
docker:
- image: cimg/python:3.8.12
parallelism: 1
steps:
- run: echo $CIRCLE_PROJECT_USERNAME
- run: |
if [ "$CIRCLE_PROJECT_USERNAME" = "huggingface" ]; then
exit 0
else
echo "The CI is running under $CIRCLE_PROJECT_USERNAME personal account. Please follow https://support.circleci.com/hc/en-us/articles/360008097173-Troubleshooting-why-pull-requests-are-not-triggering-jobs-on-my-organization- to fix it."; exit -1
fi
# Fetch the tests to run
fetch_tests:
working_directory: ~/transformers
docker:
- image: cimg/python:3.8.12
parallelism: 1
steps:
- checkout
- run: pip install --upgrade --upgrade-strategy eager pip
- run: pip install -U --upgrade-strategy eager GitPython
- run: pip install -U --upgrade-strategy eager .
- run: mkdir -p test_preparation
- run: python utils/tests_fetcher.py | tee tests_fetched_summary.txt
- store_artifacts:
path: ~/transformers/tests_fetched_summary.txt
- run: |
if [ -f test_list.txt ]; then
cp test_list.txt test_preparation/test_list.txt
else
touch test_preparation/test_list.txt
fi
- run: |
if [ -f examples_test_list.txt ]; then
mv examples_test_list.txt test_preparation/examples_test_list.txt
else
touch test_preparation/examples_test_list.txt
fi
- run: |
if [ -f filtered_test_list_cross_tests.txt ]; then
mv filtered_test_list_cross_tests.txt test_preparation/filtered_test_list_cross_tests.txt
else
touch test_preparation/filtered_test_list_cross_tests.txt
fi
- run: |
if [ -f doctest_list.txt ]; then
cp doctest_list.txt test_preparation/doctest_list.txt
else
touch test_preparation/doctest_list.txt
fi
- run: |
if [ -f test_repo_utils.txt ]; then
mv test_repo_utils.txt test_preparation/test_repo_utils.txt
else
touch test_preparation/test_repo_utils.txt
fi
- run: python utils/tests_fetcher.py --filter_tests
- run: |
if [ -f test_list.txt ]; then
mv test_list.txt test_preparation/filtered_test_list.txt
else
touch test_preparation/filtered_test_list.txt
fi
- store_artifacts:
path: test_preparation/test_list.txt
- store_artifacts:
path: test_preparation/doctest_list.txt
- store_artifacts:
path: ~/transformers/test_preparation/filtered_test_list.txt
- store_artifacts:
path: test_preparation/examples_test_list.txt
- run: python .circleci/create_circleci_config.py --fetcher_folder test_preparation
- run: |
if [ ! -s test_preparation/generated_config.yml ]; then
echo "No tests to run, exiting early!"
circleci-agent step halt
fi
- run: cp test_preparation/generated_config.yml test_preparation/generated_config.txt
- store_artifacts:
path: test_preparation/generated_config.txt
- store_artifacts:
path: test_preparation/filtered_test_list_cross_tests.txt
- continuation/continue:
configuration_path: test_preparation/generated_config.yml
# To run all tests for the nightly build
fetch_all_tests:
working_directory: ~/transformers
docker:
- image: cimg/python:3.8.12
parallelism: 1
steps:
- checkout
- run: pip install --upgrade --upgrade-strategy eager pip
- run: pip install -U --upgrade-strategy eager GitPython
- run: pip install -U --upgrade-strategy eager .
- run: |
mkdir test_preparation
echo -n "tests" > test_preparation/test_list.txt
echo -n "all" > test_preparation/examples_test_list.txt
echo -n "tests/repo_utils" > test_preparation/test_repo_utils.txt
- run: |
echo -n "tests" > test_list.txt
python utils/tests_fetcher.py --filter_tests
mv test_list.txt test_preparation/filtered_test_list.txt
- run: python .circleci/create_circleci_config.py --fetcher_folder test_preparation
- run: cp test_preparation/generated_config.yml test_preparation/generated_config.txt
- store_artifacts:
path: test_preparation/generated_config.txt
- continuation/continue:
configuration_path: test_preparation/generated_config.yml
check_code_quality:
working_directory: ~/transformers
docker:
- image: cimg/python:3.8.12
resource_class: large
environment:
TRANSFORMERS_IS_CI: yes
PYTEST_TIMEOUT: 120
parallelism: 1
steps:
- checkout
- restore_cache:
keys:
- v0.7-code_quality-pip-{{ checksum "setup.py" }}
- v0.7-code-quality-pip
- restore_cache:
keys:
- v0.7-code_quality-site-packages-{{ checksum "setup.py" }}
- v0.7-code-quality-site-packages
- run: pip install --upgrade --upgrade-strategy eager pip
- run: pip install -U --upgrade-strategy eager .[all,quality]
- save_cache:
key: v0.7-code_quality-pip-{{ checksum "setup.py" }}
paths:
- '~/.cache/pip'
- save_cache:
key: v0.7-code_quality-site-packages-{{ checksum "setup.py" }}
paths:
- '~/.pyenv/versions/'
- run:
name: Show installed libraries and their versions
command: pip freeze | tee installed.txt
- store_artifacts:
path: ~/transformers/installed.txt
- run: ruff check examples tests src utils
- run: ruff format tests src utils --check
- run: python utils/custom_init_isort.py --check_only
- run: python utils/sort_auto_mappings.py --check_only
- run: python utils/check_doc_toc.py
check_repository_consistency:
working_directory: ~/transformers
docker:
- image: cimg/python:3.8.12
resource_class: large
environment:
TRANSFORMERS_IS_CI: yes
PYTEST_TIMEOUT: 120
parallelism: 1
steps:
- checkout
- restore_cache:
keys:
- v0.7-repository_consistency-pip-{{ checksum "setup.py" }}
- v0.7-repository_consistency-pip
- restore_cache:
keys:
- v0.7-repository_consistency-site-packages-{{ checksum "setup.py" }}
- v0.7-repository_consistency-site-packages
- run: pip install --upgrade --upgrade-strategy eager pip
- run: pip install -U --upgrade-strategy eager .[all,quality]
- save_cache:
key: v0.7-repository_consistency-pip-{{ checksum "setup.py" }}
paths:
- '~/.cache/pip'
- save_cache:
key: v0.7-repository_consistency-site-packages-{{ checksum "setup.py" }}
paths:
- '~/.pyenv/versions/'
- run:
name: Show installed libraries and their versions
command: pip freeze | tee installed.txt
- store_artifacts:
path: ~/transformers/installed.txt
- run: python utils/check_copies.py
- run: python utils/check_table.py
- run: python utils/check_dummies.py
- run: python utils/check_repo.py
- run: python utils/check_inits.py
- run: python utils/check_config_docstrings.py
- run: python utils/check_config_attributes.py
- run: python utils/check_doctest_list.py
- run: make deps_table_check_updated
- run: python utils/update_metadata.py --check-only
- run: python utils/check_task_guides.py
- run: python utils/check_docstrings.py
- run: python utils/check_support_list.py
workflows:
version: 2
setup_and_quality:
when:
not: <<pipeline.parameters.nightly>>
jobs:
- check_circleci_user
- check_code_quality
- check_repository_consistency
- fetch_tests
nightly:
when: <<pipeline.parameters.nightly>>
jobs:
- check_circleci_user
- check_code_quality
- check_repository_consistency
- fetch_all_tests | transformers/.circleci/config.yml/0 | {
"file_path": "transformers/.circleci/config.yml",
"repo_id": "transformers",
"token_count": 5200
} | 232 |
FROM google/cloud-sdk:slim
# Build args.
ARG GITHUB_REF=refs/heads/main
# TODO: This Dockerfile installs pytorch/xla 3.6 wheels. There are also 3.7
# wheels available; see below.
ENV PYTHON_VERSION=3.6
RUN apt-get update && apt-get install -y --no-install-recommends \
build-essential \
cmake \
git \
curl \
ca-certificates
# Install conda and python.
# NOTE new Conda does not forward the exit status... https://github.com/conda/conda/issues/8385
RUN curl -o ~/miniconda.sh https://repo.anaconda.com/miniconda/Miniconda3-4.7.12-Linux-x86_64.sh && \
chmod +x ~/miniconda.sh && \
~/miniconda.sh -b && \
rm ~/miniconda.sh
ENV PATH=/root/miniconda3/bin:$PATH
RUN conda create -y --name container python=$PYTHON_VERSION
# Run the rest of commands within the new conda env.
# Use absolute path to appease Codefactor.
SHELL ["/root/miniconda3/bin/conda", "run", "-n", "container", "/bin/bash", "-c"]
RUN conda install -y python=$PYTHON_VERSION mkl
RUN pip uninstall -y torch && \
# Python 3.7 wheels are available. Replace cp36-cp36m with cp37-cp37m
gsutil cp 'gs://tpu-pytorch/wheels/torch-nightly-cp${PYTHON_VERSION/./}-cp${PYTHON_VERSION/./}m-linux_x86_64.whl' . && \
gsutil cp 'gs://tpu-pytorch/wheels/torch_xla-nightly-cp${PYTHON_VERSION/./}-cp${PYTHON_VERSION/./}m-linux_x86_64.whl' . && \
gsutil cp 'gs://tpu-pytorch/wheels/torchvision-nightly-cp${PYTHON_VERSION/./}-cp${PYTHON_VERSION/./}m-linux_x86_64.whl' . && \
pip install 'torch-nightly-cp${PYTHON_VERSION/./}-cp${PYTHON_VERSION/./}m-linux_x86_64.whl' && \
pip install 'torch_xla-nightly-cp${PYTHON_VERSION/./}-cp${PYTHON_VERSION/./}m-linux_x86_64.whl' && \
pip install 'torchvision-nightly-cp${PYTHON_VERSION/./}-cp${PYTHON_VERSION/./}m-linux_x86_64.whl' && \
rm 'torch-nightly-cp${PYTHON_VERSION/./}-cp${PYTHON_VERSION/./}m-linux_x86_64.whl' && \
rm 'torch_xla-nightly-cp${PYTHON_VERSION/./}-cp${PYTHON_VERSION/./}m-linux_x86_64.whl' && \
rm 'torchvision-nightly-cp${PYTHON_VERSION/./}-cp${PYTHON_VERSION/./}m-linux_x86_64.whl' && \
apt-get install -y libomp5
ENV LD_LIBRARY_PATH=root/miniconda3/envs/container/lib
# Install huggingface/transformers at the current PR, plus dependencies.
RUN git clone https://github.com/huggingface/transformers.git && \
cd transformers && \
git fetch origin $GITHUB_REF:CI && \
git checkout CI && \
cd .. && \
pip install ./transformers && \
pip install -r ./transformers/examples/pytorch/_test_requirements.txt && \
pip install pytest
RUN python -c "import torch_xla; print(torch_xla.__version__)"
RUN python -c "import transformers as trf; print(trf.__version__)"
RUN conda init bash
COPY docker-entrypoint.sh /usr/local/bin/
RUN chmod +x /usr/local/bin/docker-entrypoint.sh
ENTRYPOINT ["/usr/local/bin/docker-entrypoint.sh"]
CMD ["bash"]
| transformers/docker/transformers-pytorch-tpu/Dockerfile/0 | {
"file_path": "transformers/docker/transformers-pytorch-tpu/Dockerfile",
"repo_id": "transformers",
"token_count": 1235
} | 233 |
<!---
Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Installation
Installieren Sie 🤗 Transformers für die Deep-Learning-Bibliothek, mit der Sie arbeiten, richten Sie Ihren Cache ein und konfigurieren Sie 🤗 Transformers optional für den Offline-Betrieb.
🤗 Transformers wurde unter Python 3.6+, PyTorch 1.1.0+, TensorFlow 2.0+, und Flax getestet. Folgen Sie den Installationsanweisungen unten für die von Ihnen verwendete Deep-Learning-Bibliothek:
* [PyTorch](https://pytorch.org/get-started/locally/) installation instructions.
* [TensorFlow 2.0](https://www.tensorflow.org/install/pip) installation instructions.
* [Flax](https://flax.readthedocs.io/en/latest/) installation instructions.
## Installation mit pip
Sie sollten 🤗 Transformers in einer [virtuellen Umgebung](https://docs.python.org/3/library/venv.html) installieren. Wenn Sie mit virtuellen Python-Umgebungen nicht vertraut sind, werfen Sie einen Blick auf diese [Anleitung](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/). Eine virtuelle Umgebung macht es einfacher, verschiedene Projekte zu verwalten und Kompatibilitätsprobleme zwischen Abhängigkeiten zu vermeiden.
Beginnen wir mit der Erstellung einer virtuellen Umgebung in Ihrem Projektverzeichnis:
```bash
python -m venv .env
```
Aktivieren wir die virtuelle Umgebung. Unter Linux und MacOs:
```bash
source .env/bin/activate
```
Aktivieren wir die virtuelle Umgebung unter Windows
```bash
.env/Scripts/activate
```
Jetzt können wir die 🤗 Transformers mit dem folgenden Befehl installieren:
```bash
pip install transformers
```
Bei reiner CPU-Unterstützung können wir 🤗 Transformers und eine Deep-Learning-Bibliothek bequem in einer Zeile installieren. Installieren wir zum Beispiel 🤗 Transformers und PyTorch mit:
```bash
pip install transformers[torch]
```
🤗 Transformers und TensorFlow 2.0:
```bash
pip install transformers[tf-cpu]
```
🤗 Transformers und Flax:
```bash
pip install transformers[flax]
```
Überprüfen wir abschließend, ob 🤗 Transformers ordnungsgemäß installiert wurde, indem wir den folgenden Befehl ausführen. Es wird ein vortrainiertes Modell heruntergeladen:
```bash
python -c "from transformers import pipeline; print(pipeline('sentiment-analysis')('we love you'))"
```
Dann wird die Kategorie und die Wahrscheinlichkeit ausgegeben:
```bash
[{'label': 'POSITIVE', 'score': 0.9998704791069031}]
```
## Installation aus dem Code
Installieren wir 🤗 Transformers aus dem Quellcode mit dem folgenden Befehl:
```bash
pip install git+https://github.com/huggingface/transformers
```
Dieser Befehl installiert die aktuelle `main` Version und nicht die neueste `stable` Version. Die `main`-Version ist nützlich, um mit den neuesten Entwicklungen Schritt zu halten. Zum Beispiel, wenn ein Fehler seit der letzten offiziellen Version behoben wurde, aber eine neue Version noch nicht veröffentlicht wurde. Das bedeutet jedoch, dass die "Hauptversion" nicht immer stabil ist. Wir bemühen uns, die Hauptversion einsatzbereit zu halten, und die meisten Probleme werden normalerweise innerhalb weniger Stunden oder eines Tages behoben. Wenn Sie auf ein Problem stoßen, öffnen Sie bitte ein [Issue] (https://github.com/huggingface/transformers/issues), damit wir es noch schneller beheben können!
Überprüfen wir, ob 🤗 Transformers richtig installiert wurde, indem Sie den folgenden Befehl ausführen:
```bash
python -c "from transformers import pipeline; print(pipeline('sentiment-analysis')('I love you'))"
```
## Editierbare Installation
Sie benötigen eine bearbeitbare Installation, wenn Sie:
* die "Haupt"-Version des Quellcodes verwenden möchten.
* Zu 🤗 Transformers beitragen und Änderungen am Code testen wollen.
Klonen Sie das Repository und installieren 🤗 Transformers mit den folgenden Befehlen:
```bash
git clone https://github.com/huggingface/transformers.git
cd transformers
pip install -e .
```
Diese Befehle verknüpfen den Ordner, in den Sie das Repository geklont haben, mit den Pfaden Ihrer Python-Bibliotheken. Python wird nun in dem Ordner suchen, in den Sie geklont haben, zusätzlich zu den normalen Bibliothekspfaden. Wenn zum Beispiel Ihre Python-Pakete normalerweise in `~/anaconda3/envs/main/lib/python3.7/site-packages/` installiert sind, wird Python auch den Ordner durchsuchen, in den Sie geklont haben: `~/transformers/`.
<Tip warning={true}>
Sie müssen den Ordner `transformers` behalten, wenn Sie die Bibliothek weiter verwenden wollen.
</Tip>
Jetzt können Sie Ihren Klon mit dem folgenden Befehl ganz einfach auf die neueste Version von 🤗 Transformers aktualisieren:
```bash
cd ~/transformers/
git pull
```
Ihre Python-Umgebung wird beim nächsten Ausführen die `main`-Version von 🤗 Transformers finden.
## Installation mit conda
Installation von dem conda Kanal `conda-forge`:
```bash
conda install conda-forge::transformers
```
## Cache Einrichtung
Vorgefertigte Modelle werden heruntergeladen und lokal zwischengespeichert unter: `~/.cache/huggingface/hub`. Dies ist das Standardverzeichnis, das durch die Shell-Umgebungsvariable "TRANSFORMERS_CACHE" vorgegeben ist. Unter Windows wird das Standardverzeichnis durch `C:\Benutzer\Benutzername\.cache\huggingface\hub` angegeben. Sie können die unten aufgeführten Shell-Umgebungsvariablen - in der Reihenfolge ihrer Priorität - ändern, um ein anderes Cache-Verzeichnis anzugeben:
1. Shell-Umgebungsvariable (Standard): `HUGGINGFACE_HUB_CACHE` oder `TRANSFORMERS_CACHE`.
2. Shell-Umgebungsvariable: `HF_HOME`.
3. Shell-Umgebungsvariable: `XDG_CACHE_HOME` + `/huggingface`.
<Tip>
Transformers verwendet die Shell-Umgebungsvariablen `PYTORCH_TRANSFORMERS_CACHE` oder `PYTORCH_PRETRAINED_BERT_CACHE`, wenn Sie von einer früheren Iteration dieser Bibliothek kommen und diese Umgebungsvariablen gesetzt haben, sofern Sie nicht die Shell-Umgebungsvariable `TRANSFORMERS_CACHE` angeben.
</Tip>
## Offline Modus
Transformers ist in der Lage, in einer Firewall- oder Offline-Umgebung zu laufen, indem es nur lokale Dateien verwendet. Setzen Sie die Umgebungsvariable `TRANSFORMERS_OFFLINE=1`, um dieses Verhalten zu aktivieren.
<Tip>
Fügen sie [🤗 Datasets](https://huggingface.co/docs/datasets/) zu Ihrem Offline-Trainingsworkflow hinzufügen, indem Sie die Umgebungsvariable `HF_DATASETS_OFFLINE=1` setzen.
</Tip>
So würden Sie beispielsweise ein Programm in einem normalen Netzwerk mit einer Firewall für externe Instanzen mit dem folgenden Befehl ausführen:
```bash
python examples/pytorch/translation/run_translation.py --model_name_or_path t5-small --dataset_name wmt16 --dataset_config ro-en ...
```
Führen Sie das gleiche Programm in einer Offline-Instanz mit aus:
```bash
HF_DATASETS_OFFLINE=1 TRANSFORMERS_OFFLINE=1 \
python examples/pytorch/translation/run_translation.py --model_name_or_path t5-small --dataset_name wmt16 --dataset_config ro-en ...
```
Das Skript sollte nun laufen, ohne sich aufzuhängen oder eine Zeitüberschreitung abzuwarten, da es weiß, dass es nur nach lokalen Dateien suchen soll.
### Abrufen von Modellen und Tokenizern zur Offline-Verwendung
Eine andere Möglichkeit, 🤗 Transformers offline zu verwenden, besteht darin, die Dateien im Voraus herunterzuladen und dann auf ihren lokalen Pfad zu verweisen, wenn Sie sie offline verwenden müssen. Es gibt drei Möglichkeiten, dies zu tun:
* Laden Sie eine Datei über die Benutzeroberfläche des [Model Hub](https://huggingface.co/models) herunter, indem Sie auf das ↓-Symbol klicken.

* Verwenden Sie den [PreTrainedModel.from_pretrained] und [PreTrainedModel.save_pretrained] Workflow:
1. Laden Sie Ihre Dateien im Voraus mit [`PreTrainedModel.from_pretrained`] herunter:
```py
>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
>>> tokenizer = AutoTokenizer.from_pretrained("bigscience/T0_3B")
>>> model = AutoModelForSeq2SeqLM.from_pretrained("bigscience/T0_3B")
```
2. Speichern Sie Ihre Dateien in einem bestimmten Verzeichnis mit [`PreTrainedModel.save_pretrained`]:
```py
>>> tokenizer.save_pretrained("./your/path/bigscience_t0")
>>> model.save_pretrained("./your/path/bigscience_t0")
```
3. Wenn Sie nun offline sind, laden Sie Ihre Dateien mit [`PreTrainedModel.from_pretrained`] aus dem bestimmten Verzeichnis:
```py
>>> tokenizer = AutoTokenizer.from_pretrained("./your/path/bigscience_t0")
>>> model = AutoModel.from_pretrained("./your/path/bigscience_t0")
```
* Programmatisches Herunterladen von Dateien mit der [huggingface_hub](https://github.com/huggingface/huggingface_hub/tree/main/src/huggingface_hub) Bibliothek:
1. Installieren Sie die "huggingface_hub"-Bibliothek in Ihrer virtuellen Umgebung:
```bash
python -m pip install huggingface_hub
```
2. Verwenden Sie die Funktion [`hf_hub_download`](https://huggingface.co/docs/hub/adding-a-library#download-files-from-the-hub), um eine Datei in einen bestimmten Pfad herunterzuladen. Der folgende Befehl lädt zum Beispiel die Datei "config.json" aus dem Modell [T0](https://huggingface.co/bigscience/T0_3B) in den gewünschten Pfad herunter:
```py
>>> from huggingface_hub import hf_hub_download
>>> hf_hub_download(repo_id="bigscience/T0_3B", filename="config.json", cache_dir="./your/path/bigscience_t0")
```
Sobald Ihre Datei heruntergeladen und lokal zwischengespeichert ist, geben Sie den lokalen Pfad an, um sie zu laden und zu verwenden:
```py
>>> from transformers import AutoConfig
>>> config = AutoConfig.from_pretrained("./your/path/bigscience_t0/config.json")
```
<Tip>
Weitere Informationen zum Herunterladen von Dateien, die auf dem Hub gespeichert sind, finden Sie im Abschnitt [Wie man Dateien vom Hub herunterlädt] (https://huggingface.co/docs/hub/how-to-downstream).
</Tip>
| transformers/docs/source/de/installation.md/0 | {
"file_path": "transformers/docs/source/de/installation.md",
"repo_id": "transformers",
"token_count": 3991
} | 234 |
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# How to add a model to 🤗 Transformers?
The 🤗 Transformers library is often able to offer new models thanks to community contributors. But this can be a challenging project and requires an in-depth knowledge of the 🤗 Transformers library and the model to implement. At Hugging Face, we're trying to empower more of the community to actively add models and we've put together this guide to walk you through the process of adding a PyTorch model (make sure you have [PyTorch installed](https://pytorch.org/get-started/locally/)).
<Tip>
If you're interested in implementing a TensorFlow model, take a look at the [How to convert a 🤗 Transformers model to TensorFlow](add_tensorflow_model) guide!
</Tip>
Along the way, you'll:
- get insights into open-source best practices
- understand the design principles behind one of the most popular deep learning libraries
- learn how to efficiently test large models
- learn how to integrate Python utilities like `black`, `ruff`, and `make fix-copies` to ensure clean and readable code
A Hugging Face team member will be available to help you along the way so you'll never be alone. 🤗 ❤️
To get started, open a [New model addition](https://github.com/huggingface/transformers/issues/new?assignees=&labels=New+model&template=new-model-addition.yml) issue for the model you want to see in 🤗 Transformers. If you're not especially picky about contributing a specific model, you can filter by the [New model label](https://github.com/huggingface/transformers/labels/New%20model) to see if there are any unclaimed model requests and work on it.
Once you've opened a new model request, the first step is to get familiar with 🤗 Transformers if you aren't already!
## General overview of 🤗 Transformers
First, you should get a general overview of 🤗 Transformers. 🤗 Transformers is a very opinionated library, so there is a
chance that you don't agree with some of the library's philosophies or design choices. From our experience, however, we
found that the fundamental design choices and philosophies of the library are crucial to efficiently scale 🤗
Transformers while keeping maintenance costs at a reasonable level.
A good first starting point to better understand the library is to read the [documentation of our philosophy](philosophy). As a result of our way of working, there are some choices that we try to apply to all models:
- Composition is generally favored over-abstraction
- Duplicating code is not always bad if it strongly improves the readability or accessibility of a model
- Model files are as self-contained as possible so that when you read the code of a specific model, you ideally only
have to look into the respective `modeling_....py` file.
In our opinion, the library's code is not just a means to provide a product, *e.g.* the ability to use BERT for
inference, but also as the very product that we want to improve. Hence, when adding a model, the user is not only the
person who will use your model, but also everybody who will read, try to understand, and possibly tweak your code.
With this in mind, let's go a bit deeper into the general library design.
### Overview of models
To successfully add a model, it is important to understand the interaction between your model and its config,
[`PreTrainedModel`], and [`PretrainedConfig`]. For exemplary purposes, we will
call the model to be added to 🤗 Transformers `BrandNewBert`.
Let's take a look:
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers_overview.png"/>
As you can see, we do make use of inheritance in 🤗 Transformers, but we keep the level of abstraction to an absolute
minimum. There are never more than two levels of abstraction for any model in the library. `BrandNewBertModel`
inherits from `BrandNewBertPreTrainedModel` which in turn inherits from [`PreTrainedModel`] and
that's it. As a general rule, we want to make sure that a new model only depends on
[`PreTrainedModel`]. The important functionalities that are automatically provided to every new
model are [`~PreTrainedModel.from_pretrained`] and
[`~PreTrainedModel.save_pretrained`], which are used for serialization and deserialization. All of the
other important functionalities, such as `BrandNewBertModel.forward` should be completely defined in the new
`modeling_brand_new_bert.py` script. Next, we want to make sure that a model with a specific head layer, such as
`BrandNewBertForMaskedLM` does not inherit from `BrandNewBertModel`, but rather uses `BrandNewBertModel`
as a component that can be called in its forward pass to keep the level of abstraction low. Every new model requires a
configuration class, called `BrandNewBertConfig`. This configuration is always stored as an attribute in
[`PreTrainedModel`], and thus can be accessed via the `config` attribute for all classes
inheriting from `BrandNewBertPreTrainedModel`:
```python
model = BrandNewBertModel.from_pretrained("brandy/brand_new_bert")
model.config # model has access to its config
```
Similar to the model, the configuration inherits basic serialization and deserialization functionalities from
[`PretrainedConfig`]. Note that the configuration and the model are always serialized into two
different formats - the model to a *pytorch_model.bin* file and the configuration to a *config.json* file. Calling
[`~PreTrainedModel.save_pretrained`] will automatically call
[`~PretrainedConfig.save_pretrained`], so that both model and configuration are saved.
### Code style
When coding your new model, keep in mind that Transformers is an opinionated library and we have a few quirks of our
own regarding how code should be written :-)
1. The forward pass of your model should be fully written in the modeling file while being fully independent of other
models in the library. If you want to reuse a block from another model, copy the code and paste it with a
`# Copied from` comment on top (see [here](https://github.com/huggingface/transformers/blob/v4.17.0/src/transformers/models/roberta/modeling_roberta.py#L160)
for a good example and [there](pr_checks#check-copies) for more documentation on Copied from).
2. The code should be fully understandable, even by a non-native English speaker. This means you should pick
descriptive variable names and avoid abbreviations. As an example, `activation` is preferred to `act`.
One-letter variable names are strongly discouraged unless it's an index in a for loop.
3. More generally we prefer longer explicit code to short magical one.
4. Avoid subclassing `nn.Sequential` in PyTorch but subclass `nn.Module` and write the forward pass, so that anyone
using your code can quickly debug it by adding print statements or breaking points.
5. Your function signature should be type-annotated. For the rest, good variable names are way more readable and
understandable than type annotations.
### Overview of tokenizers
Not quite ready yet :-( This section will be added soon!
## Step-by-step recipe to add a model to 🤗 Transformers
Everyone has different preferences of how to port a model so it can be very helpful for you to take a look at summaries
of how other contributors ported models to Hugging Face. Here is a list of community blog posts on how to port a model:
1. [Porting GPT2 Model](https://medium.com/huggingface/from-tensorflow-to-pytorch-265f40ef2a28) by [Thomas](https://huggingface.co/thomwolf)
2. [Porting WMT19 MT Model](https://huggingface.co/blog/porting-fsmt) by [Stas](https://huggingface.co/stas)
From experience, we can tell you that the most important things to keep in mind when adding a model are:
- Don't reinvent the wheel! Most parts of the code you will add for the new 🤗 Transformers model already exist
somewhere in 🤗 Transformers. Take some time to find similar, already existing models and tokenizers you can copy
from. [grep](https://www.gnu.org/software/grep/) and [rg](https://github.com/BurntSushi/ripgrep) are your
friends. Note that it might very well happen that your model's tokenizer is based on one model implementation, and
your model's modeling code on another one. *E.g.* FSMT's modeling code is based on BART, while FSMT's tokenizer code
is based on XLM.
- It's more of an engineering challenge than a scientific challenge. You should spend more time creating an
efficient debugging environment rather than trying to understand all theoretical aspects of the model in the paper.
- Ask for help, when you're stuck! Models are the core component of 🤗 Transformers so we at Hugging Face are more
than happy to help you at every step to add your model. Don't hesitate to ask if you notice you are not making
progress.
In the following, we try to give you a general recipe that we found most useful when porting a model to 🤗 Transformers.
The following list is a summary of everything that has to be done to add a model and can be used by you as a To-Do
List:
☐ (Optional) Understood the model's theoretical aspects<br>
☐ Prepared 🤗 Transformers dev environment<br>
☐ Set up debugging environment of the original repository<br>
☐ Created script that successfully runs the `forward()` pass using the original repository and checkpoint<br>
☐ Successfully added the model skeleton to 🤗 Transformers<br>
☐ Successfully converted original checkpoint to 🤗 Transformers checkpoint<br>
☐ Successfully ran `forward()` pass in 🤗 Transformers that gives identical output to original checkpoint<br>
☐ Finished model tests in 🤗 Transformers<br>
☐ Successfully added tokenizer in 🤗 Transformers<br>
☐ Run end-to-end integration tests<br>
☐ Finished docs<br>
☐ Uploaded model weights to the Hub<br>
☐ Submitted the pull request<br>
☐ (Optional) Added a demo notebook
To begin with, we usually recommend starting by getting a good theoretical understanding of `BrandNewBert`. However,
if you prefer to understand the theoretical aspects of the model *on-the-job*, then it is totally fine to directly dive
into the `BrandNewBert`'s code-base. This option might suit you better if your engineering skills are better than
your theoretical skill, if you have trouble understanding `BrandNewBert`'s paper, or if you just enjoy programming
much more than reading scientific papers.
### 1. (Optional) Theoretical aspects of BrandNewBert
You should take some time to read *BrandNewBert's* paper, if such descriptive work exists. There might be large
sections of the paper that are difficult to understand. If this is the case, this is fine - don't worry! The goal is
not to get a deep theoretical understanding of the paper, but to extract the necessary information required to
effectively re-implement the model in 🤗 Transformers. That being said, you don't have to spend too much time on the
theoretical aspects, but rather focus on the practical ones, namely:
- What type of model is *brand_new_bert*? BERT-like encoder-only model? GPT2-like decoder-only model? BART-like
encoder-decoder model? Look at the [model_summary](model_summary) if you're not familiar with the differences between those.
- What are the applications of *brand_new_bert*? Text classification? Text generation? Seq2Seq tasks, *e.g.,*
summarization?
- What is the novel feature of the model that makes it different from BERT/GPT-2/BART?
- Which of the already existing [🤗 Transformers models](https://huggingface.co/transformers/#contents) is most
similar to *brand_new_bert*?
- What type of tokenizer is used? A sentencepiece tokenizer? Word piece tokenizer? Is it the same tokenizer as used
for BERT or BART?
After you feel like you have gotten a good overview of the architecture of the model, you might want to write to the
Hugging Face team with any questions you might have. This might include questions regarding the model's architecture,
its attention layer, etc. We will be more than happy to help you.
### 2. Next prepare your environment
1. Fork the [repository](https://github.com/huggingface/transformers) by clicking on the ‘Fork' button on the
repository's page. This creates a copy of the code under your GitHub user account.
2. Clone your `transformers` fork to your local disk, and add the base repository as a remote:
```bash
git clone https://github.com/[your Github handle]/transformers.git
cd transformers
git remote add upstream https://github.com/huggingface/transformers.git
```
3. Set up a development environment, for instance by running the following command:
```bash
python -m venv .env
source .env/bin/activate
pip install -e ".[dev]"
```
Depending on your OS, and since the number of optional dependencies of Transformers is growing, you might get a
failure with this command. If that's the case make sure to install the Deep Learning framework you are working with
(PyTorch, TensorFlow and/or Flax) then do:
```bash
pip install -e ".[quality]"
```
which should be enough for most use cases. You can then return to the parent directory
```bash
cd ..
```
4. We recommend adding the PyTorch version of *brand_new_bert* to Transformers. To install PyTorch, please follow the
instructions on https://pytorch.org/get-started/locally/.
**Note:** You don't need to have CUDA installed. Making the new model work on CPU is sufficient.
5. To port *brand_new_bert*, you will also need access to its original repository:
```bash
git clone https://github.com/org_that_created_brand_new_bert_org/brand_new_bert.git
cd brand_new_bert
pip install -e .
```
Now you have set up a development environment to port *brand_new_bert* to 🤗 Transformers.
### 3.-4. Run a pretrained checkpoint using the original repository
At first, you will work on the original *brand_new_bert* repository. Often, the original implementation is very
“researchy”. Meaning that documentation might be lacking and the code can be difficult to understand. But this should
be exactly your motivation to reimplement *brand_new_bert*. At Hugging Face, one of our main goals is to *make people
stand on the shoulders of giants* which translates here very well into taking a working model and rewriting it to make
it as **accessible, user-friendly, and beautiful** as possible. This is the number-one motivation to re-implement
models into 🤗 Transformers - trying to make complex new NLP technology accessible to **everybody**.
You should start thereby by diving into the original repository.
Successfully running the official pretrained model in the original repository is often **the most difficult** step.
From our experience, it is very important to spend some time getting familiar with the original code-base. You need to
figure out the following:
- Where to find the pretrained weights?
- How to load the pretrained weights into the corresponding model?
- How to run the tokenizer independently from the model?
- Trace one forward pass so that you know which classes and functions are required for a simple forward pass. Usually,
you only have to reimplement those functions.
- Be able to locate the important components of the model: Where is the model's class? Are there model sub-classes,
*e.g.* EncoderModel, DecoderModel? Where is the self-attention layer? Are there multiple different attention layers,
*e.g.* *self-attention*, *cross-attention*...?
- How can you debug the model in the original environment of the repo? Do you have to add *print* statements, can you
work with an interactive debugger like *ipdb*, or should you use an efficient IDE to debug the model, like PyCharm?
It is very important that before you start the porting process, you can **efficiently** debug code in the original
repository! Also, remember that you are working with an open-source library, so do not hesitate to open an issue, or
even a pull request in the original repository. The maintainers of this repository are most likely very happy about
someone looking into their code!
At this point, it is really up to you which debugging environment and strategy you prefer to use to debug the original
model. We strongly advise against setting up a costly GPU environment, but simply work on a CPU both when starting to
dive into the original repository and also when starting to write the 🤗 Transformers implementation of the model. Only
at the very end, when the model has already been successfully ported to 🤗 Transformers, one should verify that the
model also works as expected on GPU.
In general, there are two possible debugging environments for running the original model
- [Jupyter notebooks](https://jupyter.org/) / [google colab](https://colab.research.google.com/notebooks/intro.ipynb)
- Local python scripts.
Jupyter notebooks have the advantage that they allow for cell-by-cell execution which can be helpful to better split
logical components from one another and to have faster debugging cycles as intermediate results can be stored. Also,
notebooks are often easier to share with other contributors, which might be very helpful if you want to ask the Hugging
Face team for help. If you are familiar with Jupyter notebooks, we strongly recommend you work with them.
The obvious disadvantage of Jupyter notebooks is that if you are not used to working with them you will have to spend
some time adjusting to the new programming environment and you might not be able to use your known debugging tools
anymore, like `ipdb`.
For each code-base, a good first step is always to load a **small** pretrained checkpoint and to be able to reproduce a
single forward pass using a dummy integer vector of input IDs as an input. Such a script could look like this (in
pseudocode):
```python
model = BrandNewBertModel.load_pretrained_checkpoint("/path/to/checkpoint/")
input_ids = [0, 4, 5, 2, 3, 7, 9] # vector of input ids
original_output = model.predict(input_ids)
```
Next, regarding the debugging strategy, there are generally a few from which to choose from:
- Decompose the original model into many small testable components and run a forward pass on each of those for
verification
- Decompose the original model only into the original *tokenizer* and the original *model*, run a forward pass on
those, and use intermediate print statements or breakpoints for verification
Again, it is up to you which strategy to choose. Often, one or the other is advantageous depending on the original code
base.
If the original code-base allows you to decompose the model into smaller sub-components, *e.g.* if the original
code-base can easily be run in eager mode, it is usually worth the effort to do so. There are some important advantages
to taking the more difficult road in the beginning:
- at a later stage when comparing the original model to the Hugging Face implementation, you can verify automatically
for each component individually that the corresponding component of the 🤗 Transformers implementation matches instead
of relying on visual comparison via print statements
- it can give you some rope to decompose the big problem of porting a model into smaller problems of just porting
individual components and thus structure your work better
- separating the model into logical meaningful components will help you to get a better overview of the model's design
and thus to better understand the model
- at a later stage those component-by-component tests help you to ensure that no regression occurs as you continue
changing your code
[Lysandre's](https://gist.github.com/LysandreJik/db4c948f6b4483960de5cbac598ad4ed) integration checks for ELECTRA
gives a nice example of how this can be done.
However, if the original code-base is very complex or only allows intermediate components to be run in a compiled mode,
it might be too time-consuming or even impossible to separate the model into smaller testable sub-components. A good
example is [T5's MeshTensorFlow](https://github.com/tensorflow/mesh/tree/master/mesh_tensorflow) library which is
very complex and does not offer a simple way to decompose the model into its sub-components. For such libraries, one
often relies on verifying print statements.
No matter which strategy you choose, the recommended procedure is often the same that you should start to debug the
starting layers first and the ending layers last.
It is recommended that you retrieve the output, either by print statements or sub-component functions, of the following
layers in the following order:
1. Retrieve the input IDs passed to the model
2. Retrieve the word embeddings
3. Retrieve the input of the first Transformer layer
4. Retrieve the output of the first Transformer layer
5. Retrieve the output of the following n - 1 Transformer layers
6. Retrieve the output of the whole BrandNewBert Model
Input IDs should thereby consists of an array of integers, *e.g.* `input_ids = [0, 4, 4, 3, 2, 4, 1, 7, 19]`
The outputs of the following layers often consist of multi-dimensional float arrays and can look like this:
```
[[
[-0.1465, -0.6501, 0.1993, ..., 0.1451, 0.3430, 0.6024],
[-0.4417, -0.5920, 0.3450, ..., -0.3062, 0.6182, 0.7132],
[-0.5009, -0.7122, 0.4548, ..., -0.3662, 0.6091, 0.7648],
...,
[-0.5613, -0.6332, 0.4324, ..., -0.3792, 0.7372, 0.9288],
[-0.5416, -0.6345, 0.4180, ..., -0.3564, 0.6992, 0.9191],
[-0.5334, -0.6403, 0.4271, ..., -0.3339, 0.6533, 0.8694]]],
```
We expect that every model added to 🤗 Transformers passes a couple of integration tests, meaning that the original
model and the reimplemented version in 🤗 Transformers have to give the exact same output up to a precision of 0.001!
Since it is normal that the exact same model written in different libraries can give a slightly different output
depending on the library framework, we accept an error tolerance of 1e-3 (0.001). It is not enough if the model gives
nearly the same output, they have to be almost identical. Therefore, you will certainly compare the intermediate
outputs of the 🤗 Transformers version multiple times against the intermediate outputs of the original implementation of
*brand_new_bert* in which case an **efficient** debugging environment of the original repository is absolutely
important. Here is some advice to make your debugging environment as efficient as possible.
- Find the best way of debugging intermediate results. Is the original repository written in PyTorch? Then you should
probably take the time to write a longer script that decomposes the original model into smaller sub-components to
retrieve intermediate values. Is the original repository written in Tensorflow 1? Then you might have to rely on
TensorFlow print operations like [tf.print](https://www.tensorflow.org/api_docs/python/tf/print) to output
intermediate values. Is the original repository written in Jax? Then make sure that the model is **not jitted** when
running the forward pass, *e.g.* check-out [this link](https://github.com/google/jax/issues/196).
- Use the smallest pretrained checkpoint you can find. The smaller the checkpoint, the faster your debug cycle
becomes. It is not efficient if your pretrained model is so big that your forward pass takes more than 10 seconds.
In case only very large checkpoints are available, it might make more sense to create a dummy model in the new
environment with randomly initialized weights and save those weights for comparison with the 🤗 Transformers version
of your model
- Make sure you are using the easiest way of calling a forward pass in the original repository. Ideally, you want to
find the function in the original repository that **only** calls a single forward pass, *i.e.* that is often called
`predict`, `evaluate`, `forward` or `__call__`. You don't want to debug a function that calls `forward`
multiple times, *e.g.* to generate text, like `autoregressive_sample`, `generate`.
- Try to separate the tokenization from the model's *forward* pass. If the original repository shows examples where
you have to input a string, then try to find out where in the forward call the string input is changed to input ids
and start from this point. This might mean that you have to possibly write a small script yourself or change the
original code so that you can directly input the ids instead of an input string.
- Make sure that the model in your debugging setup is **not** in training mode, which often causes the model to yield
random outputs due to multiple dropout layers in the model. Make sure that the forward pass in your debugging
environment is **deterministic** so that the dropout layers are not used. Or use *transformers.utils.set_seed*
if the old and new implementations are in the same framework.
The following section gives you more specific details/tips on how you can do this for *brand_new_bert*.
### 5.-14. Port BrandNewBert to 🤗 Transformers
Next, you can finally start adding new code to 🤗 Transformers. Go into the clone of your 🤗 Transformers' fork:
```bash
cd transformers
```
In the special case that you are adding a model whose architecture exactly matches the model architecture of an
existing model you only have to add a conversion script as described in [this section](#write-a-conversion-script).
In this case, you can just re-use the whole model architecture of the already existing model.
Otherwise, let's start generating a new model. You have two choices here:
- `transformers-cli add-new-model-like` to add a new model like an existing one
- `transformers-cli add-new-model` to add a new model from our template (will look like BERT or Bart depending on the type of model you select)
In both cases, you will be prompted with a questionnaire to fill in the basic information of your model. The second command requires to install `cookiecutter`, you can find more information on it [here](https://github.com/huggingface/transformers/tree/main/templates/adding_a_new_model).
**Open a Pull Request on the main huggingface/transformers repo**
Before starting to adapt the automatically generated code, now is the time to open a “Work in progress (WIP)” pull
request, *e.g.* “[WIP] Add *brand_new_bert*”, in 🤗 Transformers so that you and the Hugging Face team can work
side-by-side on integrating the model into 🤗 Transformers.
You should do the following:
1. Create a branch with a descriptive name from your main branch
```bash
git checkout -b add_brand_new_bert
```
2. Commit the automatically generated code:
```bash
git add .
git commit
```
3. Fetch and rebase to current main
```bash
git fetch upstream
git rebase upstream/main
```
4. Push the changes to your account using:
```bash
git push -u origin a-descriptive-name-for-my-changes
```
5. Once you are satisfied, go to the webpage of your fork on GitHub. Click on “Pull request”. Make sure to add the
GitHub handle of some members of the Hugging Face team as reviewers, so that the Hugging Face team gets notified for
future changes.
6. Change the PR into a draft by clicking on “Convert to draft” on the right of the GitHub pull request web page.
In the following, whenever you have made some progress, don't forget to commit your work and push it to your account so
that it shows in the pull request. Additionally, you should make sure to update your work with the current main from
time to time by doing:
```bash
git fetch upstream
git merge upstream/main
```
In general, all questions you might have regarding the model or your implementation should be asked in your PR and
discussed/solved in the PR. This way, the Hugging Face team will always be notified when you are committing new code or
if you have a question. It is often very helpful to point the Hugging Face team to your added code so that the Hugging
Face team can efficiently understand your problem or question.
To do so, you can go to the “Files changed” tab where you see all of your changes, go to a line regarding which you
want to ask a question, and click on the “+” symbol to add a comment. Whenever a question or problem has been solved,
you can click on the “Resolve” button of the created comment.
In the same way, the Hugging Face team will open comments when reviewing your code. We recommend asking most questions
on GitHub on your PR. For some very general questions that are not very useful for the public, feel free to ping the
Hugging Face team by Slack or email.
**5. Adapt the generated models code for brand_new_bert**
At first, we will focus only on the model itself and not care about the tokenizer. All the relevant code should be
found in the generated files `src/transformers/models/brand_new_bert/modeling_brand_new_bert.py` and
`src/transformers/models/brand_new_bert/configuration_brand_new_bert.py`.
Now you can finally start coding :). The generated code in
`src/transformers/models/brand_new_bert/modeling_brand_new_bert.py` will either have the same architecture as BERT if
it's an encoder-only model or BART if it's an encoder-decoder model. At this point, you should remind yourself what
you've learned in the beginning about the theoretical aspects of the model: *How is the model different from BERT or
BART?*". Implement those changes which often means changing the *self-attention* layer, the order of the normalization
layer, etc… Again, it is often useful to look at the similar architecture of already existing models in Transformers to
get a better feeling of how your model should be implemented.
**Note** that at this point, you don't have to be very sure that your code is fully correct or clean. Rather, it is
advised to add a first *unclean*, copy-pasted version of the original code to
`src/transformers/models/brand_new_bert/modeling_brand_new_bert.py` until you feel like all the necessary code is
added. From our experience, it is much more efficient to quickly add a first version of the required code and
improve/correct the code iteratively with the conversion script as described in the next section. The only thing that
has to work at this point is that you can instantiate the 🤗 Transformers implementation of *brand_new_bert*, *i.e.* the
following command should work:
```python
from transformers import BrandNewBertModel, BrandNewBertConfig
model = BrandNewBertModel(BrandNewBertConfig())
```
The above command will create a model according to the default parameters as defined in `BrandNewBertConfig()` with
random weights, thus making sure that the `init()` methods of all components works.
Note that all random initialization should happen in the `_init_weights` method of your `BrandnewBertPreTrainedModel`
class. It should initialize all leaf modules depending on the variables of the config. Here is an example with the
BERT `_init_weights` method:
```py
def _init_weights(self, module):
"""Initialize the weights"""
if isinstance(module, nn.Linear):
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
if module.bias is not None:
module.bias.data.zero_()
elif isinstance(module, nn.Embedding):
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
if module.padding_idx is not None:
module.weight.data[module.padding_idx].zero_()
elif isinstance(module, nn.LayerNorm):
module.bias.data.zero_()
module.weight.data.fill_(1.0)
```
You can have some more custom schemes if you need a special initialization for some modules. For instance, in
`Wav2Vec2ForPreTraining`, the last two linear layers need to have the initialization of the regular PyTorch `nn.Linear`
but all the other ones should use an initialization as above. This is coded like this:
```py
def _init_weights(self, module):
"""Initialize the weights"""
if isinstance(module, Wav2Vec2ForPreTraining):
module.project_hid.reset_parameters()
module.project_q.reset_parameters()
module.project_hid._is_hf_initialized = True
module.project_q._is_hf_initialized = True
elif isinstance(module, nn.Linear):
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
if module.bias is not None:
module.bias.data.zero_()
```
The `_is_hf_initialized` flag is internally used to make sure we only initialize a submodule once. By setting it to
`True` for `module.project_q` and `module.project_hid`, we make sure the custom initialization we did is not overridden later on,
the `_init_weights` function won't be applied to them.
**6. Write a conversion script**
Next, you should write a conversion script that lets you convert the checkpoint you used to debug *brand_new_bert* in
the original repository to a checkpoint compatible with your just created 🤗 Transformers implementation of
*brand_new_bert*. It is not advised to write the conversion script from scratch, but rather to look through already
existing conversion scripts in 🤗 Transformers for one that has been used to convert a similar model that was written in
the same framework as *brand_new_bert*. Usually, it is enough to copy an already existing conversion script and
slightly adapt it for your use case. Don't hesitate to ask the Hugging Face team to point you to a similar already
existing conversion script for your model.
- If you are porting a model from TensorFlow to PyTorch, a good starting point might be BERT's conversion script [here](https://github.com/huggingface/transformers/blob/7acfa95afb8194f8f9c1f4d2c6028224dbed35a2/src/transformers/models/bert/modeling_bert.py#L91)
- If you are porting a model from PyTorch to PyTorch, a good starting point might be BART's conversion script [here](https://github.com/huggingface/transformers/blob/main/src/transformers/models/bart/convert_bart_original_pytorch_checkpoint_to_pytorch.py)
In the following, we'll quickly explain how PyTorch models store layer weights and define layer names. In PyTorch, the
name of a layer is defined by the name of the class attribute you give the layer. Let's define a dummy model in
PyTorch, called `SimpleModel` as follows:
```python
from torch import nn
class SimpleModel(nn.Module):
def __init__(self):
super().__init__()
self.dense = nn.Linear(10, 10)
self.intermediate = nn.Linear(10, 10)
self.layer_norm = nn.LayerNorm(10)
```
Now we can create an instance of this model definition which will fill all weights: `dense`, `intermediate`,
`layer_norm` with random weights. We can print the model to see its architecture
```python
model = SimpleModel()
print(model)
```
This will print out the following:
```
SimpleModel(
(dense): Linear(in_features=10, out_features=10, bias=True)
(intermediate): Linear(in_features=10, out_features=10, bias=True)
(layer_norm): LayerNorm((10,), eps=1e-05, elementwise_affine=True)
)
```
We can see that the layer names are defined by the name of the class attribute in PyTorch. You can print out the weight
values of a specific layer:
```python
print(model.dense.weight.data)
```
to see that the weights were randomly initialized
```
tensor([[-0.0818, 0.2207, -0.0749, -0.0030, 0.0045, -0.1569, -0.1598, 0.0212,
-0.2077, 0.2157],
[ 0.1044, 0.0201, 0.0990, 0.2482, 0.3116, 0.2509, 0.2866, -0.2190,
0.2166, -0.0212],
[-0.2000, 0.1107, -0.1999, -0.3119, 0.1559, 0.0993, 0.1776, -0.1950,
-0.1023, -0.0447],
[-0.0888, -0.1092, 0.2281, 0.0336, 0.1817, -0.0115, 0.2096, 0.1415,
-0.1876, -0.2467],
[ 0.2208, -0.2352, -0.1426, -0.2636, -0.2889, -0.2061, -0.2849, -0.0465,
0.2577, 0.0402],
[ 0.1502, 0.2465, 0.2566, 0.0693, 0.2352, -0.0530, 0.1859, -0.0604,
0.2132, 0.1680],
[ 0.1733, -0.2407, -0.1721, 0.1484, 0.0358, -0.0633, -0.0721, -0.0090,
0.2707, -0.2509],
[-0.1173, 0.1561, 0.2945, 0.0595, -0.1996, 0.2988, -0.0802, 0.0407,
0.1829, -0.1568],
[-0.1164, -0.2228, -0.0403, 0.0428, 0.1339, 0.0047, 0.1967, 0.2923,
0.0333, -0.0536],
[-0.1492, -0.1616, 0.1057, 0.1950, -0.2807, -0.2710, -0.1586, 0.0739,
0.2220, 0.2358]]).
```
In the conversion script, you should fill those randomly initialized weights with the exact weights of the
corresponding layer in the checkpoint. *E.g.*
```python
# retrieve matching layer weights, e.g. by
# recursive algorithm
layer_name = "dense"
pretrained_weight = array_of_dense_layer
model_pointer = getattr(model, "dense")
model_pointer.weight.data = torch.from_numpy(pretrained_weight)
```
While doing so, you must verify that each randomly initialized weight of your PyTorch model and its corresponding
pretrained checkpoint weight exactly match in both **shape and name**. To do so, it is **necessary** to add assert
statements for the shape and print out the names of the checkpoints weights. E.g. you should add statements like:
```python
assert (
model_pointer.weight.shape == pretrained_weight.shape
), f"Pointer shape of random weight {model_pointer.shape} and array shape of checkpoint weight {pretrained_weight.shape} mismatched"
```
Besides, you should also print out the names of both weights to make sure they match, *e.g.*
```python
logger.info(f"Initialize PyTorch weight {layer_name} from {pretrained_weight.name}")
```
If either the shape or the name doesn't match, you probably assigned the wrong checkpoint weight to a randomly
initialized layer of the 🤗 Transformers implementation.
An incorrect shape is most likely due to an incorrect setting of the config parameters in `BrandNewBertConfig()` that
do not exactly match those that were used for the checkpoint you want to convert. However, it could also be that
PyTorch's implementation of a layer requires the weight to be transposed beforehand.
Finally, you should also check that **all** required weights are initialized and print out all checkpoint weights that
were not used for initialization to make sure the model is correctly converted. It is completely normal, that the
conversion trials fail with either a wrong shape statement or a wrong name assignment. This is most likely because either
you used incorrect parameters in `BrandNewBertConfig()`, have a wrong architecture in the 🤗 Transformers
implementation, you have a bug in the `init()` functions of one of the components of the 🤗 Transformers
implementation or you need to transpose one of the checkpoint weights.
This step should be iterated with the previous step until all weights of the checkpoint are correctly loaded in the
Transformers model. Having correctly loaded the checkpoint into the 🤗 Transformers implementation, you can then save
the model under a folder of your choice `/path/to/converted/checkpoint/folder` that should then contain both a
`pytorch_model.bin` file and a `config.json` file:
```python
model.save_pretrained("/path/to/converted/checkpoint/folder")
```
**7. Implement the forward pass**
Having managed to correctly load the pretrained weights into the 🤗 Transformers implementation, you should now make
sure that the forward pass is correctly implemented. In [Get familiar with the original repository](#34-run-a-pretrained-checkpoint-using-the-original-repository), you have already created a script that runs a forward
pass of the model using the original repository. Now you should write an analogous script using the 🤗 Transformers
implementation instead of the original one. It should look as follows:
```python
model = BrandNewBertModel.from_pretrained("/path/to/converted/checkpoint/folder")
input_ids = [0, 4, 4, 3, 2, 4, 1, 7, 19]
output = model(input_ids).last_hidden_states
```
It is very likely that the 🤗 Transformers implementation and the original model implementation don't give the exact
same output the very first time or that the forward pass throws an error. Don't be disappointed - it's expected! First,
you should make sure that the forward pass doesn't throw any errors. It often happens that the wrong dimensions are
used leading to a *Dimensionality mismatch* error or that the wrong data type object is used, *e.g.* `torch.long`
instead of `torch.float32`. Don't hesitate to ask the Hugging Face team for help, if you don't manage to solve
certain errors.
The final part to make sure the 🤗 Transformers implementation works correctly is to ensure that the outputs are
equivalent to a precision of `1e-3`. First, you should ensure that the output shapes are identical, *i.e.*
`outputs.shape` should yield the same value for the script of the 🤗 Transformers implementation and the original
implementation. Next, you should make sure that the output values are identical as well. This one of the most difficult
parts of adding a new model. Common mistakes why the outputs are not identical are:
- Some layers were not added, *i.e.* an *activation* layer was not added, or the residual connection was forgotten
- The word embedding matrix was not tied
- The wrong positional embeddings are used because the original implementation uses on offset
- Dropout is applied during the forward pass. To fix this make sure *model.training is False* and that no dropout
layer is falsely activated during the forward pass, *i.e.* pass *self.training* to [PyTorch's functional dropout](https://pytorch.org/docs/stable/nn.functional.html?highlight=dropout#torch.nn.functional.dropout)
The best way to fix the problem is usually to look at the forward pass of the original implementation and the 🤗
Transformers implementation side-by-side and check if there are any differences. Ideally, you should debug/print out
intermediate outputs of both implementations of the forward pass to find the exact position in the network where the 🤗
Transformers implementation shows a different output than the original implementation. First, make sure that the
hard-coded `input_ids` in both scripts are identical. Next, verify that the outputs of the first transformation of
the `input_ids` (usually the word embeddings) are identical. And then work your way up to the very last layer of the
network. At some point, you will notice a difference between the two implementations, which should point you to the bug
in the 🤗 Transformers implementation. From our experience, a simple and efficient way is to add many print statements
in both the original implementation and 🤗 Transformers implementation, at the same positions in the network
respectively, and to successively remove print statements showing the same values for intermediate presentations.
When you're confident that both implementations yield the same output, verify the outputs with
`torch.allclose(original_output, output, atol=1e-3)`, you're done with the most difficult part! Congratulations - the
work left to be done should be a cakewalk 😊.
**8. Adding all necessary model tests**
At this point, you have successfully added a new model. However, it is very much possible that the model does not yet
fully comply with the required design. To make sure, the implementation is fully compatible with 🤗 Transformers, all
common tests should pass. The Cookiecutter should have automatically added a test file for your model, probably under
the same `tests/models/brand_new_bert/test_modeling_brand_new_bert.py`. Run this test file to verify that all common
tests pass:
```bash
pytest tests/models/brand_new_bert/test_modeling_brand_new_bert.py
```
Having fixed all common tests, it is now crucial to ensure that all the nice work you have done is well tested, so that
- a) The community can easily understand your work by looking at specific tests of *brand_new_bert*
- b) Future changes to your model will not break any important feature of the model.
At first, integration tests should be added. Those integration tests essentially do the same as the debugging scripts
you used earlier to implement the model to 🤗 Transformers. A template of those model tests has already added by the
Cookiecutter, called `BrandNewBertModelIntegrationTests` and only has to be filled out by you. To ensure that those
tests are passing, run
```bash
RUN_SLOW=1 pytest -sv tests/models/brand_new_bert/test_modeling_brand_new_bert.py::BrandNewBertModelIntegrationTests
```
<Tip>
In case you are using Windows, you should replace `RUN_SLOW=1` with `SET RUN_SLOW=1`
</Tip>
Second, all features that are special to *brand_new_bert* should be tested additionally in a separate test under
`BrandNewBertModelTester`/``BrandNewBertModelTest`. This part is often forgotten but is extremely useful in two
ways:
- It helps to transfer the knowledge you have acquired during the model addition to the community by showing how the
special features of *brand_new_bert* should work.
- Future contributors can quickly test changes to the model by running those special tests.
**9. Implement the tokenizer**
Next, we should add the tokenizer of *brand_new_bert*. Usually, the tokenizer is equivalent to or very similar to an
already existing tokenizer of 🤗 Transformers.
It is very important to find/extract the original tokenizer file and to manage to load this file into the 🤗
Transformers' implementation of the tokenizer.
To ensure that the tokenizer works correctly, it is recommended to first create a script in the original repository
that inputs a string and returns the `input_ids``. It could look similar to this (in pseudo-code):
```python
input_str = "This is a long example input string containing special characters .$?-, numbers 2872 234 12 and words."
model = BrandNewBertModel.load_pretrained_checkpoint("/path/to/checkpoint/")
input_ids = model.tokenize(input_str)
```
You might have to take a deeper look again into the original repository to find the correct tokenizer function or you
might even have to do changes to your clone of the original repository to only output the `input_ids`. Having written
a functional tokenization script that uses the original repository, an analogous script for 🤗 Transformers should be
created. It should look similar to this:
```python
from transformers import BrandNewBertTokenizer
input_str = "This is a long example input string containing special characters .$?-, numbers 2872 234 12 and words."
tokenizer = BrandNewBertTokenizer.from_pretrained("/path/to/tokenizer/folder/")
input_ids = tokenizer(input_str).input_ids
```
When both `input_ids` yield the same values, as a final step a tokenizer test file should also be added.
Analogous to the modeling test files of *brand_new_bert*, the tokenization test files of *brand_new_bert* should
contain a couple of hard-coded integration tests.
**10. Run End-to-end integration tests**
Having added the tokenizer, you should also add a couple of end-to-end integration tests using both the model and the
tokenizer to `tests/models/brand_new_bert/test_modeling_brand_new_bert.py` in 🤗 Transformers.
Such a test should show on a meaningful
text-to-text sample that the 🤗 Transformers implementation works as expected. A meaningful text-to-text sample can
include *e.g.* a source-to-target-translation pair, an article-to-summary pair, a question-to-answer pair, etc… If none
of the ported checkpoints has been fine-tuned on a downstream task it is enough to simply rely on the model tests. In a
final step to ensure that the model is fully functional, it is advised that you also run all tests on GPU. It can
happen that you forgot to add some `.to(self.device)` statements to internal tensors of the model, which in such a
test would show in an error. In case you have no access to a GPU, the Hugging Face team can take care of running those
tests for you.
**11. Add Docstring**
Now, all the necessary functionality for *brand_new_bert* is added - you're almost done! The only thing left to add is
a nice docstring and a doc page. The Cookiecutter should have added a template file called
`docs/source/model_doc/brand_new_bert.md` that you should fill out. Users of your model will usually first look at
this page before using your model. Hence, the documentation must be understandable and concise. It is very useful for
the community to add some *Tips* to show how the model should be used. Don't hesitate to ping the Hugging Face team
regarding the docstrings.
Next, make sure that the docstring added to `src/transformers/models/brand_new_bert/modeling_brand_new_bert.py` is
correct and included all necessary inputs and outputs. We have a detailed guide about writing documentation and our docstring format [here](writing-documentation). It is always to good to remind oneself that documentation should
be treated at least as carefully as the code in 🤗 Transformers since the documentation is usually the first contact
point of the community with the model.
**Code refactor**
Great, now you have added all the necessary code for *brand_new_bert*. At this point, you should correct some potential
incorrect code style by running:
```bash
make style
```
and verify that your coding style passes the quality check:
```bash
make quality
```
There are a couple of other very strict design tests in 🤗 Transformers that might still be failing, which shows up in
the tests of your pull request. This is often because of some missing information in the docstring or some incorrect
naming. The Hugging Face team will surely help you if you're stuck here.
Lastly, it is always a good idea to refactor one's code after having ensured that the code works correctly. With all
tests passing, now it's a good time to go over the added code again and do some refactoring.
You have now finished the coding part, congratulation! 🎉 You are Awesome! 😎
**12. Upload the models to the model hub**
In this final part, you should convert and upload all checkpoints to the model hub and add a model card for each
uploaded model checkpoint. You can get familiar with the hub functionalities by reading our [Model sharing and uploading Page](model_sharing). You should work alongside the Hugging Face team here to decide on a fitting name for each
checkpoint and to get the required access rights to be able to upload the model under the author's organization of
*brand_new_bert*. The `push_to_hub` method, present in all models in `transformers`, is a quick and efficient way to push your checkpoint to the hub. A little snippet is pasted below:
```python
brand_new_bert.push_to_hub("brand_new_bert")
# Uncomment the following line to push to an organization.
# brand_new_bert.push_to_hub("<organization>/brand_new_bert")
```
It is worth spending some time to create fitting model cards for each checkpoint. The model cards should highlight the
specific characteristics of this particular checkpoint, *e.g.* On which dataset was the checkpoint
pretrained/fine-tuned on? On what down-stream task should the model be used? And also include some code on how to
correctly use the model.
**13. (Optional) Add notebook**
It is very helpful to add a notebook that showcases in-detail how *brand_new_bert* can be used for inference and/or
fine-tuned on a downstream task. This is not mandatory to merge your PR, but very useful for the community.
**14. Submit your finished PR**
You're done programming now and can move to the last step, which is getting your PR merged into main. Usually, the
Hugging Face team should have helped you already at this point, but it is worth taking some time to give your finished
PR a nice description and eventually add comments to your code, if you want to point out certain design choices to your
reviewer.
### Share your work!!
Now, it's time to get some credit from the community for your work! Having completed a model addition is a major
contribution to Transformers and the whole NLP community. Your code and the ported pre-trained models will certainly be
used by hundreds and possibly even thousands of developers and researchers. You should be proud of your work and share
your achievements with the community.
**You have made another model that is super easy to access for everyone in the community! 🤯**
| transformers/docs/source/en/add_new_model.md/0 | {
"file_path": "transformers/docs/source/en/add_new_model.md",
"repo_id": "transformers",
"token_count": 14076
} | 235 |
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Use tokenizers from 🤗 Tokenizers
The [`PreTrainedTokenizerFast`] depends on the [🤗 Tokenizers](https://huggingface.co/docs/tokenizers) library. The tokenizers obtained from the 🤗 Tokenizers library can be
loaded very simply into 🤗 Transformers.
Before getting in the specifics, let's first start by creating a dummy tokenizer in a few lines:
```python
>>> from tokenizers import Tokenizer
>>> from tokenizers.models import BPE
>>> from tokenizers.trainers import BpeTrainer
>>> from tokenizers.pre_tokenizers import Whitespace
>>> tokenizer = Tokenizer(BPE(unk_token="[UNK]"))
>>> trainer = BpeTrainer(special_tokens=["[UNK]", "[CLS]", "[SEP]", "[PAD]", "[MASK]"])
>>> tokenizer.pre_tokenizer = Whitespace()
>>> files = [...]
>>> tokenizer.train(files, trainer)
```
We now have a tokenizer trained on the files we defined. We can either continue using it in that runtime, or save it to
a JSON file for future re-use.
## Loading directly from the tokenizer object
Let's see how to leverage this tokenizer object in the 🤗 Transformers library. The
[`PreTrainedTokenizerFast`] class allows for easy instantiation, by accepting the instantiated
*tokenizer* object as an argument:
```python
>>> from transformers import PreTrainedTokenizerFast
>>> fast_tokenizer = PreTrainedTokenizerFast(tokenizer_object=tokenizer)
```
This object can now be used with all the methods shared by the 🤗 Transformers tokenizers! Head to [the tokenizer
page](main_classes/tokenizer) for more information.
## Loading from a JSON file
In order to load a tokenizer from a JSON file, let's first start by saving our tokenizer:
```python
>>> tokenizer.save("tokenizer.json")
```
The path to which we saved this file can be passed to the [`PreTrainedTokenizerFast`] initialization
method using the `tokenizer_file` parameter:
```python
>>> from transformers import PreTrainedTokenizerFast
>>> fast_tokenizer = PreTrainedTokenizerFast(tokenizer_file="tokenizer.json")
```
This object can now be used with all the methods shared by the 🤗 Transformers tokenizers! Head to [the tokenizer
page](main_classes/tokenizer) for more information.
| transformers/docs/source/en/fast_tokenizers.md/0 | {
"file_path": "transformers/docs/source/en/fast_tokenizers.md",
"repo_id": "transformers",
"token_count": 792
} | 236 |
<!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# BARTpho
## Overview
The BARTpho model was proposed in [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese](https://arxiv.org/abs/2109.09701) by Nguyen Luong Tran, Duong Minh Le and Dat Quoc Nguyen.
The abstract from the paper is the following:
*We present BARTpho with two versions -- BARTpho_word and BARTpho_syllable -- the first public large-scale monolingual
sequence-to-sequence models pre-trained for Vietnamese. Our BARTpho uses the "large" architecture and pre-training
scheme of the sequence-to-sequence denoising model BART, thus especially suitable for generative NLP tasks. Experiments
on a downstream task of Vietnamese text summarization show that in both automatic and human evaluations, our BARTpho
outperforms the strong baseline mBART and improves the state-of-the-art. We release BARTpho to facilitate future
research and applications of generative Vietnamese NLP tasks.*
This model was contributed by [dqnguyen](https://huggingface.co/dqnguyen). The original code can be found [here](https://github.com/VinAIResearch/BARTpho).
## Usage example
```python
>>> import torch
>>> from transformers import AutoModel, AutoTokenizer
>>> bartpho = AutoModel.from_pretrained("vinai/bartpho-syllable")
>>> tokenizer = AutoTokenizer.from_pretrained("vinai/bartpho-syllable")
>>> line = "Chúng tôi là những nghiên cứu viên."
>>> input_ids = tokenizer(line, return_tensors="pt")
>>> with torch.no_grad():
... features = bartpho(**input_ids) # Models outputs are now tuples
>>> # With TensorFlow 2.0+:
>>> from transformers import TFAutoModel
>>> bartpho = TFAutoModel.from_pretrained("vinai/bartpho-syllable")
>>> input_ids = tokenizer(line, return_tensors="tf")
>>> features = bartpho(**input_ids)
```
## Usage tips
- Following mBART, BARTpho uses the "large" architecture of BART with an additional layer-normalization layer on top of
both the encoder and decoder. Thus, usage examples in the [documentation of BART](bart), when adapting to use
with BARTpho, should be adjusted by replacing the BART-specialized classes with the mBART-specialized counterparts.
For example:
```python
>>> from transformers import MBartForConditionalGeneration
>>> bartpho = MBartForConditionalGeneration.from_pretrained("vinai/bartpho-syllable")
>>> TXT = "Chúng tôi là <mask> nghiên cứu viên."
>>> input_ids = tokenizer([TXT], return_tensors="pt")["input_ids"]
>>> logits = bartpho(input_ids).logits
>>> masked_index = (input_ids[0] == tokenizer.mask_token_id).nonzero().item()
>>> probs = logits[0, masked_index].softmax(dim=0)
>>> values, predictions = probs.topk(5)
>>> print(tokenizer.decode(predictions).split())
```
- This implementation is only for tokenization: "monolingual_vocab_file" consists of Vietnamese-specialized types
extracted from the pre-trained SentencePiece model "vocab_file" that is available from the multilingual XLM-RoBERTa.
Other languages, if employing this pre-trained multilingual SentencePiece model "vocab_file" for subword
segmentation, can reuse BartphoTokenizer with their own language-specialized "monolingual_vocab_file".
## BartphoTokenizer
[[autodoc]] BartphoTokenizer
| transformers/docs/source/en/model_doc/bartpho.md/0 | {
"file_path": "transformers/docs/source/en/model_doc/bartpho.md",
"repo_id": "transformers",
"token_count": 1166
} | 237 |
<!--Copyright 2023 The Intel Labs Team Authors, The Microsoft Research Team Authors and HuggingFace Inc. team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# BridgeTower
## Overview
The BridgeTower model was proposed in [BridgeTower: Building Bridges Between Encoders in Vision-Language Representative Learning](https://arxiv.org/abs/2206.08657) by Xiao Xu, Chenfei Wu, Shachar Rosenman, Vasudev Lal, Wanxiang Che, Nan Duan. The goal of this model is to build a
bridge between each uni-modal encoder and the cross-modal encoder to enable comprehensive and detailed interaction at each layer of the cross-modal encoder thus achieving remarkable performance on various downstream tasks with almost negligible additional performance and computational costs.
This paper has been accepted to the [AAAI'23](https://aaai.org/Conferences/AAAI-23/) conference.
The abstract from the paper is the following:
*Vision-Language (VL) models with the TWO-TOWER architecture have dominated visual-language representation learning in recent years.
Current VL models either use lightweight uni-modal encoders and learn to extract, align and fuse both modalities simultaneously in a deep cross-modal encoder, or feed the last-layer uni-modal representations from the deep pre-trained uni-modal encoders into the top cross-modal encoder.
Both approaches potentially restrict vision-language representation learning and limit model performance. In this paper, we propose BRIDGETOWER, which introduces multiple bridge layers that build a connection between the top layers of uni-modal encoders and each layer of the crossmodal encoder.
This enables effective bottom-up cross-modal alignment and fusion between visual and textual representations of different semantic levels of pre-trained uni-modal encoders in the cross-modal encoder. Pre-trained with only 4M images, BRIDGETOWER achieves state-of-the-art performance on various downstream vision-language tasks.
In particular, on the VQAv2 test-std set, BRIDGETOWER achieves an accuracy of 78.73%, outperforming the previous state-of-the-art model METER by 1.09% with the same pre-training data and almost negligible additional parameters and computational costs.
Notably, when further scaling the model, BRIDGETOWER achieves an accuracy of 81.15%, surpassing models that are pre-trained on orders-of-magnitude larger datasets.*
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/bridgetower_architecture%20.jpg"
alt="drawing" width="600"/>
<small> BridgeTower architecture. Taken from the <a href="https://arxiv.org/abs/2206.08657">original paper.</a> </small>
This model was contributed by [Anahita Bhiwandiwalla](https://huggingface.co/anahita-b), [Tiep Le](https://huggingface.co/Tile) and [Shaoyen Tseng](https://huggingface.co/shaoyent). The original code can be found [here](https://github.com/microsoft/BridgeTower).
## Usage tips and examples
BridgeTower consists of a visual encoder, a textual encoder and cross-modal encoder with multiple lightweight bridge layers.
The goal of this approach was to build a bridge between each uni-modal encoder and the cross-modal encoder to enable comprehensive and detailed interaction at each layer of the cross-modal encoder.
In principle, one can apply any visual, textual or cross-modal encoder in the proposed architecture.
The [`BridgeTowerProcessor`] wraps [`RobertaTokenizer`] and [`BridgeTowerImageProcessor`] into a single instance to both
encode the text and prepare the images respectively.
The following example shows how to run contrastive learning using [`BridgeTowerProcessor`] and [`BridgeTowerForContrastiveLearning`].
```python
>>> from transformers import BridgeTowerProcessor, BridgeTowerForContrastiveLearning
>>> import requests
>>> from PIL import Image
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> texts = ["An image of two cats chilling on a couch", "A football player scoring a goal"]
>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-large-itm-mlm-itc")
>>> model = BridgeTowerForContrastiveLearning.from_pretrained("BridgeTower/bridgetower-large-itm-mlm-itc")
>>> # forward pass
>>> scores = dict()
>>> for text in texts:
... # prepare inputs
... encoding = processor(image, text, return_tensors="pt")
... outputs = model(**encoding)
... scores[text] = outputs
```
The following example shows how to run image-text retrieval using [`BridgeTowerProcessor`] and [`BridgeTowerForImageAndTextRetrieval`].
```python
>>> from transformers import BridgeTowerProcessor, BridgeTowerForImageAndTextRetrieval
>>> import requests
>>> from PIL import Image
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> texts = ["An image of two cats chilling on a couch", "A football player scoring a goal"]
>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
>>> model = BridgeTowerForImageAndTextRetrieval.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
>>> # forward pass
>>> scores = dict()
>>> for text in texts:
... # prepare inputs
... encoding = processor(image, text, return_tensors="pt")
... outputs = model(**encoding)
... scores[text] = outputs.logits[0, 1].item()
```
The following example shows how to run masked language modeling using [`BridgeTowerProcessor`] and [`BridgeTowerForMaskedLM`].
```python
>>> from transformers import BridgeTowerProcessor, BridgeTowerForMaskedLM
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000360943.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
>>> text = "a <mask> looking out of the window"
>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
>>> model = BridgeTowerForMaskedLM.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
>>> # prepare inputs
>>> encoding = processor(image, text, return_tensors="pt")
>>> # forward pass
>>> outputs = model(**encoding)
>>> results = processor.decode(outputs.logits.argmax(dim=-1).squeeze(0).tolist())
>>> print(results)
.a cat looking out of the window.
```
Tips:
- This implementation of BridgeTower uses [`RobertaTokenizer`] to generate text embeddings and OpenAI's CLIP/ViT model to compute visual embeddings.
- Checkpoints for pre-trained [bridgeTower-base](https://huggingface.co/BridgeTower/bridgetower-base) and [bridgetower masked language modeling and image text matching](https://huggingface.co/BridgeTower/bridgetower-base-itm-mlm) are released.
- Please refer to [Table 5](https://arxiv.org/pdf/2206.08657.pdf) for BridgeTower's performance on Image Retrieval and other down stream tasks.
- The PyTorch version of this model is only available in torch 1.10 and higher.
## BridgeTowerConfig
[[autodoc]] BridgeTowerConfig
## BridgeTowerTextConfig
[[autodoc]] BridgeTowerTextConfig
## BridgeTowerVisionConfig
[[autodoc]] BridgeTowerVisionConfig
## BridgeTowerImageProcessor
[[autodoc]] BridgeTowerImageProcessor
- preprocess
## BridgeTowerProcessor
[[autodoc]] BridgeTowerProcessor
- __call__
## BridgeTowerModel
[[autodoc]] BridgeTowerModel
- forward
## BridgeTowerForContrastiveLearning
[[autodoc]] BridgeTowerForContrastiveLearning
- forward
## BridgeTowerForMaskedLM
[[autodoc]] BridgeTowerForMaskedLM
- forward
## BridgeTowerForImageAndTextRetrieval
[[autodoc]] BridgeTowerForImageAndTextRetrieval
- forward
| transformers/docs/source/en/model_doc/bridgetower.md/0 | {
"file_path": "transformers/docs/source/en/model_doc/bridgetower.md",
"repo_id": "transformers",
"token_count": 2392
} | 238 |
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# CPM
## Overview
The CPM model was proposed in [CPM: A Large-scale Generative Chinese Pre-trained Language Model](https://arxiv.org/abs/2012.00413) by Zhengyan Zhang, Xu Han, Hao Zhou, Pei Ke, Yuxian Gu, Deming Ye, Yujia Qin,
Yusheng Su, Haozhe Ji, Jian Guan, Fanchao Qi, Xiaozhi Wang, Yanan Zheng, Guoyang Zeng, Huanqi Cao, Shengqi Chen,
Daixuan Li, Zhenbo Sun, Zhiyuan Liu, Minlie Huang, Wentao Han, Jie Tang, Juanzi Li, Xiaoyan Zhu, Maosong Sun.
The abstract from the paper is the following:
*Pre-trained Language Models (PLMs) have proven to be beneficial for various downstream NLP tasks. Recently, GPT-3,
with 175 billion parameters and 570GB training data, drew a lot of attention due to the capacity of few-shot (even
zero-shot) learning. However, applying GPT-3 to address Chinese NLP tasks is still challenging, as the training corpus
of GPT-3 is primarily English, and the parameters are not publicly available. In this technical report, we release the
Chinese Pre-trained Language Model (CPM) with generative pre-training on large-scale Chinese training data. To the best
of our knowledge, CPM, with 2.6 billion parameters and 100GB Chinese training data, is the largest Chinese pre-trained
language model, which could facilitate several downstream Chinese NLP tasks, such as conversation, essay generation,
cloze test, and language understanding. Extensive experiments demonstrate that CPM achieves strong performance on many
NLP tasks in the settings of few-shot (even zero-shot) learning.*
This model was contributed by [canwenxu](https://huggingface.co/canwenxu). The original implementation can be found
here: https://github.com/TsinghuaAI/CPM-Generate
<Tip>
CPM's architecture is the same as GPT-2, except for tokenization method. Refer to [GPT-2 documentation](gpt2) for
API reference information.
</Tip>
## CpmTokenizer
[[autodoc]] CpmTokenizer
## CpmTokenizerFast
[[autodoc]] CpmTokenizerFast
| transformers/docs/source/en/model_doc/cpm.md/0 | {
"file_path": "transformers/docs/source/en/model_doc/cpm.md",
"repo_id": "transformers",
"token_count": 735
} | 239 |
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# FLAN-T5
## Overview
FLAN-T5 was released in the paper [Scaling Instruction-Finetuned Language Models](https://arxiv.org/pdf/2210.11416.pdf) - it is an enhanced version of T5 that has been finetuned in a mixture of tasks.
One can directly use FLAN-T5 weights without finetuning the model:
```python
>>> from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
>>> model = AutoModelForSeq2SeqLM.from_pretrained("google/flan-t5-small")
>>> tokenizer = AutoTokenizer.from_pretrained("google/flan-t5-small")
>>> inputs = tokenizer("A step by step recipe to make bolognese pasta:", return_tensors="pt")
>>> outputs = model.generate(**inputs)
>>> print(tokenizer.batch_decode(outputs, skip_special_tokens=True))
['Pour a cup of bolognese into a large bowl and add the pasta']
```
FLAN-T5 includes the same improvements as T5 version 1.1 (see [here](https://huggingface.co/docs/transformers/model_doc/t5v1.1) for the full details of the model's improvements.)
Google has released the following variants:
- [google/flan-t5-small](https://huggingface.co/google/flan-t5-small)
- [google/flan-t5-base](https://huggingface.co/google/flan-t5-base)
- [google/flan-t5-large](https://huggingface.co/google/flan-t5-large)
- [google/flan-t5-xl](https://huggingface.co/google/flan-t5-xl)
- [google/flan-t5-xxl](https://huggingface.co/google/flan-t5-xxl).
The original checkpoints can be found [here](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-t5-checkpoints).
<Tip>
Refer to [T5's documentation page](t5) for all API reference, code examples and notebooks. For more details regarding training and evaluation of the FLAN-T5, refer to the model card.
</Tip> | transformers/docs/source/en/model_doc/flan-t5.md/0 | {
"file_path": "transformers/docs/source/en/model_doc/flan-t5.md",
"repo_id": "transformers",
"token_count": 781
} | 240 |
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# GPT-NeoX-Japanese
## Overview
We introduce GPT-NeoX-Japanese, which is an autoregressive language model for Japanese, trained on top of [https://github.com/EleutherAI/gpt-neox](https://github.com/EleutherAI/gpt-neox).
Japanese is a unique language with its large vocabulary and a combination of hiragana, katakana, and kanji writing scripts.
To address this distinct structure of the Japanese language, we use a [special sub-word tokenizer](https://github.com/tanreinama/Japanese-BPEEncoder_V2). We are very grateful to *tanreinama* for open-sourcing this incredibly helpful tokenizer.
Following the recommendations from Google's research on [PaLM](https://ai.googleblog.com/2022/04/pathways-language-model-palm-scaling-to.html), we have removed bias parameters from transformer blocks, achieving better model performance. Please refer [this article](https://medium.com/ml-abeja/training-a-better-gpt-2-93b157662ae4) in detail.
Development of the model was led by [Shinya Otani](https://github.com/SO0529), [Takayoshi Makabe](https://github.com/spider-man-tm), [Anuj Arora](https://github.com/Anuj040), and [Kyo Hattori](https://github.com/go5paopao) from [ABEJA, Inc.](https://www.abejainc.com/). For more information on this model-building activity, please refer [here (ja)](https://tech-blog.abeja.asia/entry/abeja-gpt-project-202207).
### Usage example
The `generate()` method can be used to generate text using GPT NeoX Japanese model.
```python
>>> from transformers import GPTNeoXJapaneseForCausalLM, GPTNeoXJapaneseTokenizer
>>> model = GPTNeoXJapaneseForCausalLM.from_pretrained("abeja/gpt-neox-japanese-2.7b")
>>> tokenizer = GPTNeoXJapaneseTokenizer.from_pretrained("abeja/gpt-neox-japanese-2.7b")
>>> prompt = "人とAIが協調するためには、"
>>> input_ids = tokenizer(prompt, return_tensors="pt").input_ids
>>> gen_tokens = model.generate(
... input_ids,
... do_sample=True,
... temperature=0.9,
... max_length=100,
... )
>>> gen_text = tokenizer.batch_decode(gen_tokens, skip_special_tokens=True)[0]
>>> print(gen_text)
人とAIが協調するためには、AIと人が共存し、AIを正しく理解する必要があります。
```
## Resources
- [Causal language modeling task guide](../tasks/language_modeling)
## GPTNeoXJapaneseConfig
[[autodoc]] GPTNeoXJapaneseConfig
## GPTNeoXJapaneseTokenizer
[[autodoc]] GPTNeoXJapaneseTokenizer
## GPTNeoXJapaneseModel
[[autodoc]] GPTNeoXJapaneseModel
- forward
## GPTNeoXJapaneseForCausalLM
[[autodoc]] GPTNeoXJapaneseForCausalLM
- forward
| transformers/docs/source/en/model_doc/gpt_neox_japanese.md/0 | {
"file_path": "transformers/docs/source/en/model_doc/gpt_neox_japanese.md",
"repo_id": "transformers",
"token_count": 1075
} | 241 |
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Mask2Former
## Overview
The Mask2Former model was proposed in [Masked-attention Mask Transformer for Universal Image Segmentation](https://arxiv.org/abs/2112.01527) by Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar. Mask2Former is a unified framework for panoptic, instance and semantic segmentation and features significant performance and efficiency improvements over [MaskFormer](maskformer).
The abstract from the paper is the following:
*Image segmentation groups pixels with different semantics, e.g., category or instance membership. Each choice
of semantics defines a task. While only the semantics of each task differ, current research focuses on designing specialized architectures for each task. We present Masked-attention Mask Transformer (Mask2Former), a new architecture capable of addressing any image segmentation task (panoptic, instance or semantic). Its key components include masked attention, which extracts localized features by constraining cross-attention within predicted mask regions. In addition to reducing the research effort by at least three times, it outperforms the best specialized architectures by a significant margin on four popular datasets. Most notably, Mask2Former sets a new state-of-the-art for panoptic segmentation (57.8 PQ on COCO), instance segmentation (50.1 AP on COCO) and semantic segmentation (57.7 mIoU on ADE20K).*
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/mask2former_architecture.jpg" alt="drawing" width="600"/>
<small> Mask2Former architecture. Taken from the <a href="https://arxiv.org/abs/2112.01527">original paper.</a> </small>
This model was contributed by [Shivalika Singh](https://huggingface.co/shivi) and [Alara Dirik](https://huggingface.co/adirik). The original code can be found [here](https://github.com/facebookresearch/Mask2Former).
## Usage tips
- Mask2Former uses the same preprocessing and postprocessing steps as [MaskFormer](maskformer). Use [`Mask2FormerImageProcessor`] or [`AutoImageProcessor`] to prepare images and optional targets for the model.
- To get the final segmentation, depending on the task, you can call [`~Mask2FormerImageProcessor.post_process_semantic_segmentation`] or [`~Mask2FormerImageProcessor.post_process_instance_segmentation`] or [`~Mask2FormerImageProcessor.post_process_panoptic_segmentation`]. All three tasks can be solved using [`Mask2FormerForUniversalSegmentation`] output, panoptic segmentation accepts an optional `label_ids_to_fuse` argument to fuse instances of the target object/s (e.g. sky) together.
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with Mask2Former.
- Demo notebooks regarding inference + fine-tuning Mask2Former on custom data can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/Mask2Former).
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we will review it.
The resource should ideally demonstrate something new instead of duplicating an existing resource.
## Mask2FormerConfig
[[autodoc]] Mask2FormerConfig
## MaskFormer specific outputs
[[autodoc]] models.mask2former.modeling_mask2former.Mask2FormerModelOutput
[[autodoc]] models.mask2former.modeling_mask2former.Mask2FormerForUniversalSegmentationOutput
## Mask2FormerModel
[[autodoc]] Mask2FormerModel
- forward
## Mask2FormerForUniversalSegmentation
[[autodoc]] Mask2FormerForUniversalSegmentation
- forward
## Mask2FormerImageProcessor
[[autodoc]] Mask2FormerImageProcessor
- preprocess
- encode_inputs
- post_process_semantic_segmentation
- post_process_instance_segmentation
- post_process_panoptic_segmentation | transformers/docs/source/en/model_doc/mask2former.md/0 | {
"file_path": "transformers/docs/source/en/model_doc/mask2former.md",
"repo_id": "transformers",
"token_count": 1219
} | 242 |
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# OpenAI GPT
<div class="flex flex-wrap space-x-1">
<a href="https://huggingface.co/models?filter=openai-gpt">
<img alt="Models" src="https://img.shields.io/badge/All_model_pages-openai--gpt-blueviolet">
</a>
<a href="https://huggingface.co/spaces/docs-demos/openai-gpt">
<img alt="Spaces" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Spaces-blue">
</a>
</div>
## Overview
OpenAI GPT model was proposed in [Improving Language Understanding by Generative Pre-Training](https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf)
by Alec Radford, Karthik Narasimhan, Tim Salimans and Ilya Sutskever. It's a causal (unidirectional) transformer
pre-trained using language modeling on a large corpus will long range dependencies, the Toronto Book Corpus.
The abstract from the paper is the following:
*Natural language understanding comprises a wide range of diverse tasks such as textual entailment, question answering,
semantic similarity assessment, and document classification. Although large unlabeled text corpora are abundant,
labeled data for learning these specific tasks is scarce, making it challenging for discriminatively trained models to
perform adequately. We demonstrate that large gains on these tasks can be realized by generative pretraining of a
language model on a diverse corpus of unlabeled text, followed by discriminative fine-tuning on each specific task. In
contrast to previous approaches, we make use of task-aware input transformations during fine-tuning to achieve
effective transfer while requiring minimal changes to the model architecture. We demonstrate the effectiveness of our
approach on a wide range of benchmarks for natural language understanding. Our general task-agnostic model outperforms
discriminatively trained models that use architectures specifically crafted for each task, significantly improving upon
the state of the art in 9 out of the 12 tasks studied.*
[Write With Transformer](https://transformer.huggingface.co/doc/gpt) is a webapp created and hosted by Hugging Face
showcasing the generative capabilities of several models. GPT is one of them.
This model was contributed by [thomwolf](https://huggingface.co/thomwolf). The original code can be found [here](https://github.com/openai/finetune-transformer-lm).
## Usage tips
- GPT is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather than
the left.
- GPT was trained with a causal language modeling (CLM) objective and is therefore powerful at predicting the next
token in a sequence. Leveraging this feature allows GPT-2 to generate syntactically coherent text as it can be
observed in the *run_generation.py* example script.
Note:
If you want to reproduce the original tokenization process of the *OpenAI GPT* paper, you will need to install `ftfy`
and `SpaCy`:
```bash
pip install spacy ftfy==4.4.3
python -m spacy download en
```
If you don't install `ftfy` and `SpaCy`, the [`OpenAIGPTTokenizer`] will default to tokenize
using BERT's `BasicTokenizer` followed by Byte-Pair Encoding (which should be fine for most usage, don't worry).
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with OpenAI GPT. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
<PipelineTag pipeline="text-classification"/>
- A blog post on [outperforming OpenAI GPT-3 with SetFit for text-classification](https://www.philschmid.de/getting-started-setfit).
- See also: [Text classification task guide](../tasks/sequence_classification)
<PipelineTag pipeline="text-generation"/>
- A blog on how to [Finetune a non-English GPT-2 Model with Hugging Face](https://www.philschmid.de/fine-tune-a-non-english-gpt-2-model-with-huggingface).
- A blog on [How to generate text: using different decoding methods for language generation with Transformers](https://huggingface.co/blog/how-to-generate) with GPT-2.
- A blog on [Training CodeParrot 🦜 from Scratch](https://huggingface.co/blog/codeparrot), a large GPT-2 model.
- A blog on [Faster Text Generation with TensorFlow and XLA](https://huggingface.co/blog/tf-xla-generate) with GPT-2.
- A blog on [How to train a Language Model with Megatron-LM](https://huggingface.co/blog/megatron-training) with a GPT-2 model.
- A notebook on how to [finetune GPT2 to generate lyrics in the style of your favorite artist](https://colab.research.google.com/github/AlekseyKorshuk/huggingartists/blob/master/huggingartists-demo.ipynb). 🌎
- A notebook on how to [finetune GPT2 to generate tweets in the style of your favorite Twitter user](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb). 🌎
- [Causal language modeling](https://huggingface.co/course/en/chapter7/6?fw=pt#training-a-causal-language-model-from-scratch) chapter of the 🤗 Hugging Face Course.
- [`OpenAIGPTLMHeadModel`] is supported by this [causal language modeling example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/language-modeling#gpt-2gpt-and-causal-language-modeling), [text generation example script](https://github.com/huggingface/transformers/blob/main/examples/pytorch/text-generation/run_generation.py) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling.ipynb).
- [`TFOpenAIGPTLMHeadModel`] is supported by this [causal language modeling example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/language-modeling#run_clmpy) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling-tf.ipynb).
- See also: [Causal language modeling task guide](../tasks/language_modeling)
<PipelineTag pipeline="token-classification"/>
- A course material on [Byte-Pair Encoding tokenization](https://huggingface.co/course/en/chapter6/5).
## OpenAIGPTConfig
[[autodoc]] OpenAIGPTConfig
## OpenAIGPTTokenizer
[[autodoc]] OpenAIGPTTokenizer
- save_vocabulary
## OpenAIGPTTokenizerFast
[[autodoc]] OpenAIGPTTokenizerFast
## OpenAI specific outputs
[[autodoc]] models.openai.modeling_openai.OpenAIGPTDoubleHeadsModelOutput
[[autodoc]] models.openai.modeling_tf_openai.TFOpenAIGPTDoubleHeadsModelOutput
<frameworkcontent>
<pt>
## OpenAIGPTModel
[[autodoc]] OpenAIGPTModel
- forward
## OpenAIGPTLMHeadModel
[[autodoc]] OpenAIGPTLMHeadModel
- forward
## OpenAIGPTDoubleHeadsModel
[[autodoc]] OpenAIGPTDoubleHeadsModel
- forward
## OpenAIGPTForSequenceClassification
[[autodoc]] OpenAIGPTForSequenceClassification
- forward
</pt>
<tf>
## TFOpenAIGPTModel
[[autodoc]] TFOpenAIGPTModel
- call
## TFOpenAIGPTLMHeadModel
[[autodoc]] TFOpenAIGPTLMHeadModel
- call
## TFOpenAIGPTDoubleHeadsModel
[[autodoc]] TFOpenAIGPTDoubleHeadsModel
- call
## TFOpenAIGPTForSequenceClassification
[[autodoc]] TFOpenAIGPTForSequenceClassification
- call
</tf>
</frameworkcontent>
| transformers/docs/source/en/model_doc/openai-gpt.md/0 | {
"file_path": "transformers/docs/source/en/model_doc/openai-gpt.md",
"repo_id": "transformers",
"token_count": 2422
} | 243 |
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# ProphetNet
<div class="flex flex-wrap space-x-1">
<a href="https://huggingface.co/models?filter=prophetnet">
<img alt="Models" src="https://img.shields.io/badge/All_model_pages-prophetnet-blueviolet">
</a>
<a href="https://huggingface.co/spaces/docs-demos/prophetnet-large-uncased">
<img alt="Spaces" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Spaces-blue">
</a>
</div>
## Overview
The ProphetNet model was proposed in [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training,](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei
Zhang, Ming Zhou on 13 Jan, 2020.
ProphetNet is an encoder-decoder model and can predict n-future tokens for "ngram" language modeling instead of just
the next token.
The abstract from the paper is the following:
*In this paper, we present a new sequence-to-sequence pretraining model called ProphetNet, which introduces a novel
self-supervised objective named future n-gram prediction and the proposed n-stream self-attention mechanism. Instead of
the optimization of one-step ahead prediction in traditional sequence-to-sequence model, the ProphetNet is optimized by
n-step ahead prediction which predicts the next n tokens simultaneously based on previous context tokens at each time
step. The future n-gram prediction explicitly encourages the model to plan for the future tokens and prevent
overfitting on strong local correlations. We pre-train ProphetNet using a base scale dataset (16GB) and a large scale
dataset (160GB) respectively. Then we conduct experiments on CNN/DailyMail, Gigaword, and SQuAD 1.1 benchmarks for
abstractive summarization and question generation tasks. Experimental results show that ProphetNet achieves new
state-of-the-art results on all these datasets compared to the models using the same scale pretraining corpus.*
The Authors' code can be found [here](https://github.com/microsoft/ProphetNet).
## Usage tips
- ProphetNet is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather than
the left.
- The model architecture is based on the original Transformer, but replaces the “standard” self-attention mechanism in the decoder by a a main self-attention mechanism and a self and n-stream (predict) self-attention mechanism.
## Resources
- [Causal language modeling task guide](../tasks/language_modeling)
- [Translation task guide](../tasks/translation)
- [Summarization task guide](../tasks/summarization)
## ProphetNetConfig
[[autodoc]] ProphetNetConfig
## ProphetNetTokenizer
[[autodoc]] ProphetNetTokenizer
## ProphetNet specific outputs
[[autodoc]] models.prophetnet.modeling_prophetnet.ProphetNetSeq2SeqLMOutput
[[autodoc]] models.prophetnet.modeling_prophetnet.ProphetNetSeq2SeqModelOutput
[[autodoc]] models.prophetnet.modeling_prophetnet.ProphetNetDecoderModelOutput
[[autodoc]] models.prophetnet.modeling_prophetnet.ProphetNetDecoderLMOutput
## ProphetNetModel
[[autodoc]] ProphetNetModel
- forward
## ProphetNetEncoder
[[autodoc]] ProphetNetEncoder
- forward
## ProphetNetDecoder
[[autodoc]] ProphetNetDecoder
- forward
## ProphetNetForConditionalGeneration
[[autodoc]] ProphetNetForConditionalGeneration
- forward
## ProphetNetForCausalLM
[[autodoc]] ProphetNetForCausalLM
- forward
| transformers/docs/source/en/model_doc/prophetnet.md/0 | {
"file_path": "transformers/docs/source/en/model_doc/prophetnet.md",
"repo_id": "transformers",
"token_count": 1170
} | 244 |
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# SAM
## Overview
SAM (Segment Anything Model) was proposed in [Segment Anything](https://arxiv.org/pdf/2304.02643v1.pdf) by Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alex Berg, Wan-Yen Lo, Piotr Dollar, Ross Girshick.
The model can be used to predict segmentation masks of any object of interest given an input image.

The abstract from the paper is the following:
*We introduce the Segment Anything (SA) project: a new task, model, and dataset for image segmentation. Using our efficient model in a data collection loop, we built the largest segmentation dataset to date (by far), with over 1 billion masks on 11M licensed and privacy respecting images. The model is designed and trained to be promptable, so it can transfer zero-shot to new image distributions and tasks. We evaluate its capabilities on numerous tasks and find that its zero-shot performance is impressive -- often competitive with or even superior to prior fully supervised results. We are releasing the Segment Anything Model (SAM) and corresponding dataset (SA-1B) of 1B masks and 11M images at [https://segment-anything.com](https://segment-anything.com) to foster research into foundation models for computer vision.*
Tips:
- The model predicts binary masks that states the presence or not of the object of interest given an image.
- The model predicts much better results if input 2D points and/or input bounding boxes are provided
- You can prompt multiple points for the same image, and predict a single mask.
- Fine-tuning the model is not supported yet
- According to the paper, textual input should be also supported. However, at this time of writing this seems to be not supported according to [the official repository](https://github.com/facebookresearch/segment-anything/issues/4#issuecomment-1497626844).
This model was contributed by [ybelkada](https://huggingface.co/ybelkada) and [ArthurZ](https://huggingface.co/ArthurZ).
The original code can be found [here](https://github.com/facebookresearch/segment-anything).
Below is an example on how to run mask generation given an image and a 2D point:
```python
import torch
from PIL import Image
import requests
from transformers import SamModel, SamProcessor
device = "cuda" if torch.cuda.is_available() else "cpu"
model = SamModel.from_pretrained("facebook/sam-vit-huge").to(device)
processor = SamProcessor.from_pretrained("facebook/sam-vit-huge")
img_url = "https://huggingface.co/ybelkada/segment-anything/resolve/main/assets/car.png"
raw_image = Image.open(requests.get(img_url, stream=True).raw).convert("RGB")
input_points = [[[450, 600]]] # 2D location of a window in the image
inputs = processor(raw_image, input_points=input_points, return_tensors="pt").to(device)
with torch.no_grad():
outputs = model(**inputs)
masks = processor.image_processor.post_process_masks(
outputs.pred_masks.cpu(), inputs["original_sizes"].cpu(), inputs["reshaped_input_sizes"].cpu()
)
scores = outputs.iou_scores
```
You can also process your own masks alongside the input images in the processor to be passed to the model.
```python
import torch
from PIL import Image
import requests
from transformers import SamModel, SamProcessor
device = "cuda" if torch.cuda.is_available() else "cpu"
model = SamModel.from_pretrained("facebook/sam-vit-huge").to(device)
processor = SamProcessor.from_pretrained("facebook/sam-vit-huge")
img_url = "https://huggingface.co/ybelkada/segment-anything/resolve/main/assets/car.png"
raw_image = Image.open(requests.get(img_url, stream=True).raw).convert("RGB")
mask_url = "https://huggingface.co/ybelkada/segment-anything/resolve/main/assets/car.png"
segmentation_map = Image.open(requests.get(mask_url, stream=True).raw).convert("RGB")
input_points = [[[450, 600]]] # 2D location of a window in the image
inputs = processor(raw_image, input_points=input_points, segmentation_maps=mask, return_tensors="pt").to(device)
with torch.no_grad():
outputs = model(**inputs)
masks = processor.image_processor.post_process_masks(
outputs.pred_masks.cpu(), inputs["original_sizes"].cpu(), inputs["reshaped_input_sizes"].cpu()
)
scores = outputs.iou_scores
```
Resources:
- [Demo notebook](https://github.com/huggingface/notebooks/blob/main/examples/segment_anything.ipynb) for using the model.
- [Demo notebook](https://github.com/huggingface/notebooks/blob/main/examples/automatic_mask_generation.ipynb) for using the automatic mask generation pipeline.
- [Demo notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/SAM/Run_inference_with_MedSAM_using_HuggingFace_Transformers.ipynb) for inference with MedSAM, a fine-tuned version of SAM on the medical domain.
- [Demo notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/SAM/Fine_tune_SAM_(segment_anything)_on_a_custom_dataset.ipynb) for fine-tuning the model on custom data.
## SamConfig
[[autodoc]] SamConfig
## SamVisionConfig
[[autodoc]] SamVisionConfig
## SamMaskDecoderConfig
[[autodoc]] SamMaskDecoderConfig
## SamPromptEncoderConfig
[[autodoc]] SamPromptEncoderConfig
## SamProcessor
[[autodoc]] SamProcessor
## SamImageProcessor
[[autodoc]] SamImageProcessor
## SamModel
[[autodoc]] SamModel
- forward
## TFSamModel
[[autodoc]] TFSamModel
- call
| transformers/docs/source/en/model_doc/sam.md/0 | {
"file_path": "transformers/docs/source/en/model_doc/sam.md",
"repo_id": "transformers",
"token_count": 1871
} | 245 |
<!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# UniSpeech-SAT
## Overview
The UniSpeech-SAT model was proposed in [UniSpeech-SAT: Universal Speech Representation Learning with Speaker Aware
Pre-Training](https://arxiv.org/abs/2110.05752) by Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen,
Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu .
The abstract from the paper is the following:
*Self-supervised learning (SSL) is a long-standing goal for speech processing, since it utilizes large-scale unlabeled
data and avoids extensive human labeling. Recent years witness great successes in applying self-supervised learning in
speech recognition, while limited exploration was attempted in applying SSL for modeling speaker characteristics. In
this paper, we aim to improve the existing SSL framework for speaker representation learning. Two methods are
introduced for enhancing the unsupervised speaker information extraction. First, we apply the multi-task learning to
the current SSL framework, where we integrate the utterance-wise contrastive loss with the SSL objective function.
Second, for better speaker discrimination, we propose an utterance mixing strategy for data augmentation, where
additional overlapped utterances are created unsupervisedly and incorporate during training. We integrate the proposed
methods into the HuBERT framework. Experiment results on SUPERB benchmark show that the proposed system achieves
state-of-the-art performance in universal representation learning, especially for speaker identification oriented
tasks. An ablation study is performed verifying the efficacy of each proposed method. Finally, we scale up training
dataset to 94 thousand hours public audio data and achieve further performance improvement in all SUPERB tasks.*
This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten). The Authors' code can be
found [here](https://github.com/microsoft/UniSpeech/tree/main/UniSpeech-SAT).
## Usage tips
- UniSpeechSat is a speech model that accepts a float array corresponding to the raw waveform of the speech signal.
Please use [`Wav2Vec2Processor`] for the feature extraction.
- UniSpeechSat model can be fine-tuned using connectionist temporal classification (CTC) so the model output has to be
decoded using [`Wav2Vec2CTCTokenizer`].
- UniSpeechSat performs especially well on speaker verification, speaker identification, and speaker diarization tasks.
## Resources
- [Audio classification task guide](../tasks/audio_classification)
- [Automatic speech recognition task guide](../tasks/asr)
## UniSpeechSatConfig
[[autodoc]] UniSpeechSatConfig
## UniSpeechSat specific outputs
[[autodoc]] models.unispeech_sat.modeling_unispeech_sat.UniSpeechSatForPreTrainingOutput
## UniSpeechSatModel
[[autodoc]] UniSpeechSatModel
- forward
## UniSpeechSatForCTC
[[autodoc]] UniSpeechSatForCTC
- forward
## UniSpeechSatForSequenceClassification
[[autodoc]] UniSpeechSatForSequenceClassification
- forward
## UniSpeechSatForAudioFrameClassification
[[autodoc]] UniSpeechSatForAudioFrameClassification
- forward
## UniSpeechSatForXVector
[[autodoc]] UniSpeechSatForXVector
- forward
## UniSpeechSatForPreTraining
[[autodoc]] UniSpeechSatForPreTraining
- forward
| transformers/docs/source/en/model_doc/unispeech-sat.md/0 | {
"file_path": "transformers/docs/source/en/model_doc/unispeech-sat.md",
"repo_id": "transformers",
"token_count": 1045
} | 246 |
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# XLNet
<div class="flex flex-wrap space-x-1">
<a href="https://huggingface.co/models?filter=xlnet">
<img alt="Models" src="https://img.shields.io/badge/All_model_pages-xlnet-blueviolet">
</a>
<a href="https://huggingface.co/spaces/docs-demos/xlnet-base-cased">
<img alt="Spaces" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Spaces-blue">
</a>
</div>
## Overview
The XLNet model was proposed in [XLNet: Generalized Autoregressive Pretraining for Language Understanding](https://arxiv.org/abs/1906.08237) by Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov,
Quoc V. Le. XLnet is an extension of the Transformer-XL model pre-trained using an autoregressive method to learn
bidirectional contexts by maximizing the expected likelihood over all permutations of the input sequence factorization
order.
The abstract from the paper is the following:
*With the capability of modeling bidirectional contexts, denoising autoencoding based pretraining like BERT achieves
better performance than pretraining approaches based on autoregressive language modeling. However, relying on
corrupting the input with masks, BERT neglects dependency between the masked positions and suffers from a
pretrain-finetune discrepancy. In light of these pros and cons, we propose XLNet, a generalized autoregressive
pretraining method that (1) enables learning bidirectional contexts by maximizing the expected likelihood over all
permutations of the factorization order and (2) overcomes the limitations of BERT thanks to its autoregressive
formulation. Furthermore, XLNet integrates ideas from Transformer-XL, the state-of-the-art autoregressive model, into
pretraining. Empirically, under comparable experiment settings, XLNet outperforms BERT on 20 tasks, often by a large
margin, including question answering, natural language inference, sentiment analysis, and document ranking.*
This model was contributed by [thomwolf](https://huggingface.co/thomwolf). The original code can be found [here](https://github.com/zihangdai/xlnet/).
## Usage tips
- The specific attention pattern can be controlled at training and test time using the `perm_mask` input.
- Due to the difficulty of training a fully auto-regressive model over various factorization order, XLNet is pretrained
using only a sub-set of the output tokens as target which are selected with the `target_mapping` input.
- To use XLNet for sequential decoding (i.e. not in fully bi-directional setting), use the `perm_mask` and
`target_mapping` inputs to control the attention span and outputs (see examples in
*examples/pytorch/text-generation/run_generation.py*)
- XLNet is one of the few models that has no sequence length limit.
- XLNet is not a traditional autoregressive model but uses a training strategy that builds on that. It permutes the tokens in the sentence, then allows the model to use the last n tokens to predict the token n+1. Since this is all done with a mask, the sentence is actually fed in the model in the right order, but instead of masking the first n tokens for n+1, XLNet uses a mask that hides the previous tokens in some given permutation of 1,…,sequence length.
- XLNet also uses the same recurrence mechanism as Transformer-XL to build long-term dependencies.
## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
- [Question answering task guide](../tasks/question_answering)
- [Causal language modeling task guide](../tasks/language_modeling)
- [Multiple choice task guide](../tasks/multiple_choice)
## XLNetConfig
[[autodoc]] XLNetConfig
## XLNetTokenizer
[[autodoc]] XLNetTokenizer
- build_inputs_with_special_tokens
- get_special_tokens_mask
- create_token_type_ids_from_sequences
- save_vocabulary
## XLNetTokenizerFast
[[autodoc]] XLNetTokenizerFast
## XLNet specific outputs
[[autodoc]] models.xlnet.modeling_xlnet.XLNetModelOutput
[[autodoc]] models.xlnet.modeling_xlnet.XLNetLMHeadModelOutput
[[autodoc]] models.xlnet.modeling_xlnet.XLNetForSequenceClassificationOutput
[[autodoc]] models.xlnet.modeling_xlnet.XLNetForMultipleChoiceOutput
[[autodoc]] models.xlnet.modeling_xlnet.XLNetForTokenClassificationOutput
[[autodoc]] models.xlnet.modeling_xlnet.XLNetForQuestionAnsweringSimpleOutput
[[autodoc]] models.xlnet.modeling_xlnet.XLNetForQuestionAnsweringOutput
[[autodoc]] models.xlnet.modeling_tf_xlnet.TFXLNetModelOutput
[[autodoc]] models.xlnet.modeling_tf_xlnet.TFXLNetLMHeadModelOutput
[[autodoc]] models.xlnet.modeling_tf_xlnet.TFXLNetForSequenceClassificationOutput
[[autodoc]] models.xlnet.modeling_tf_xlnet.TFXLNetForMultipleChoiceOutput
[[autodoc]] models.xlnet.modeling_tf_xlnet.TFXLNetForTokenClassificationOutput
[[autodoc]] models.xlnet.modeling_tf_xlnet.TFXLNetForQuestionAnsweringSimpleOutput
<frameworkcontent>
<pt>
## XLNetModel
[[autodoc]] XLNetModel
- forward
## XLNetLMHeadModel
[[autodoc]] XLNetLMHeadModel
- forward
## XLNetForSequenceClassification
[[autodoc]] XLNetForSequenceClassification
- forward
## XLNetForMultipleChoice
[[autodoc]] XLNetForMultipleChoice
- forward
## XLNetForTokenClassification
[[autodoc]] XLNetForTokenClassification
- forward
## XLNetForQuestionAnsweringSimple
[[autodoc]] XLNetForQuestionAnsweringSimple
- forward
## XLNetForQuestionAnswering
[[autodoc]] XLNetForQuestionAnswering
- forward
</pt>
<tf>
## TFXLNetModel
[[autodoc]] TFXLNetModel
- call
## TFXLNetLMHeadModel
[[autodoc]] TFXLNetLMHeadModel
- call
## TFXLNetForSequenceClassification
[[autodoc]] TFXLNetForSequenceClassification
- call
## TFLNetForMultipleChoice
[[autodoc]] TFXLNetForMultipleChoice
- call
## TFXLNetForTokenClassification
[[autodoc]] TFXLNetForTokenClassification
- call
## TFXLNetForQuestionAnsweringSimple
[[autodoc]] TFXLNetForQuestionAnsweringSimple
- call
</tf>
</frameworkcontent> | transformers/docs/source/en/model_doc/xlnet.md/0 | {
"file_path": "transformers/docs/source/en/model_doc/xlnet.md",
"repo_id": "transformers",
"token_count": 2042
} | 247 |
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Optimize inference using torch.compile()
This guide aims to provide a benchmark on the inference speed-ups introduced with [`torch.compile()`](https://pytorch.org/tutorials/intermediate/torch_compile_tutorial.html) for [computer vision models in 🤗 Transformers](https://huggingface.co/models?pipeline_tag=image-classification&library=transformers&sort=trending).
## Benefits of torch.compile
Depending on the model and the GPU, `torch.compile()` yields up to 30% speed-up during inference. To use `torch.compile()`, simply install any version of `torch` above 2.0.
Compiling a model takes time, so it's useful if you are compiling the model only once instead of every time you infer.
To compile any computer vision model of your choice, call `torch.compile()` on the model as shown below:
```diff
from transformers import AutoModelForImageClassification
model = AutoModelForImageClassification.from_pretrained(MODEL_ID).to("cuda")
+ model = torch.compile(model)
```
`compile()` comes with multiple modes for compiling, which essentially differ in compilation time and inference overhead. `max-autotune` takes longer than `reduce-overhead` but results in faster inference. Default mode is fastest for compilation but is not as efficient compared to `reduce-overhead` for inference time. In this guide, we used the default mode. You can learn more about it [here](https://pytorch.org/get-started/pytorch-2.0/#user-experience).
We benchmarked `torch.compile` with different computer vision models, tasks, types of hardware, and batch sizes on `torch` version 2.0.1.
## Benchmarking code
Below you can find the benchmarking code for each task. We warm up the GPU before inference and take the mean time of 300 inferences, using the same image each time.
### Image Classification with ViT
```python
import torch
from PIL import Image
import requests
import numpy as np
from transformers import AutoImageProcessor, AutoModelForImageClassification
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
processor = AutoImageProcessor.from_pretrained("google/vit-base-patch16-224")
model = AutoModelForImageClassification.from_pretrained("google/vit-base-patch16-224").to("cuda")
model = torch.compile(model)
processed_input = processor(image, return_tensors='pt').to(device="cuda")
with torch.no_grad():
_ = model(**processed_input)
```
#### Object Detection with DETR
```python
from transformers import AutoImageProcessor, AutoModelForObjectDetection
processor = AutoImageProcessor.from_pretrained("facebook/detr-resnet-50")
model = AutoModelForObjectDetection.from_pretrained("facebook/detr-resnet-50").to("cuda")
model = torch.compile(model)
texts = ["a photo of a cat", "a photo of a dog"]
inputs = processor(text=texts, images=image, return_tensors="pt").to("cuda")
with torch.no_grad():
_ = model(**inputs)
```
#### Image Segmentation with Segformer
```python
from transformers import SegformerImageProcessor, SegformerForSemanticSegmentation
processor = SegformerImageProcessor.from_pretrained("nvidia/segformer-b0-finetuned-ade-512-512")
model = SegformerForSemanticSegmentation.from_pretrained("nvidia/segformer-b0-finetuned-ade-512-512").to("cuda")
model = torch.compile(model)
seg_inputs = processor(images=image, return_tensors="pt").to("cuda")
with torch.no_grad():
_ = model(**seg_inputs)
```
Below you can find the list of the models we benchmarked.
**Image Classification**
- [google/vit-base-patch16-224](https://huggingface.co/google/vit-base-patch16-224)
- [microsoft/beit-base-patch16-224-pt22k-ft22k](https://huggingface.co/microsoft/beit-base-patch16-224-pt22k-ft22k)
- [facebook/convnext-large-224](https://huggingface.co/facebook/convnext-large-224)
- [microsoft/resnet-50](https://huggingface.co/)
**Image Segmentation**
- [nvidia/segformer-b0-finetuned-ade-512-512](https://huggingface.co/nvidia/segformer-b0-finetuned-ade-512-512)
- [facebook/mask2former-swin-tiny-coco-panoptic](https://huggingface.co/facebook/mask2former-swin-tiny-coco-panoptic)
- [facebook/maskformer-swin-base-ade](https://huggingface.co/facebook/maskformer-swin-base-ade)
- [google/deeplabv3_mobilenet_v2_1.0_513](https://huggingface.co/google/deeplabv3_mobilenet_v2_1.0_513)
**Object Detection**
- [google/owlvit-base-patch32](https://huggingface.co/google/owlvit-base-patch32)
- [facebook/detr-resnet-101](https://huggingface.co/facebook/detr-resnet-101)
- [microsoft/conditional-detr-resnet-50](https://huggingface.co/microsoft/conditional-detr-resnet-50)
Below you can find visualization of inference durations with and without `torch.compile()` and percentage improvements for each model in different hardware and batch sizes.
<div class="flex">
<div>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/torch_compile/a100_batch_comp.png" />
</div>
<div>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/torch_compile/v100_batch_comp.png" />
</div>
<div>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/torch_compile/t4_batch_comp.png" />
</div>
</div>
<div class="flex">
<div>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/torch_compile/A100_1_duration.png" />
</div>
<div>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/torch_compile/A100_1_percentage.png" />
</div>
</div>
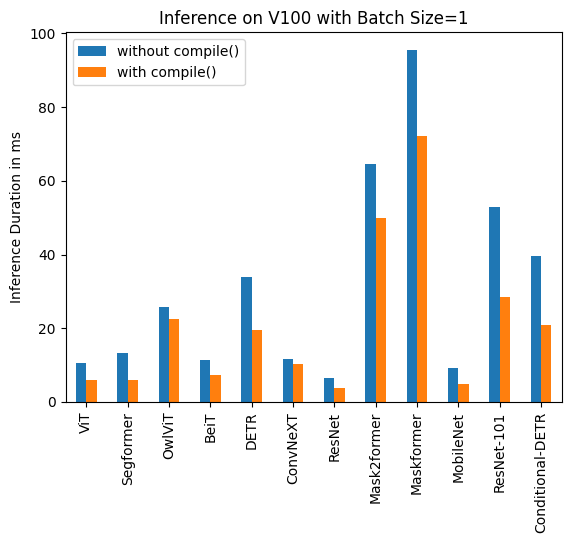
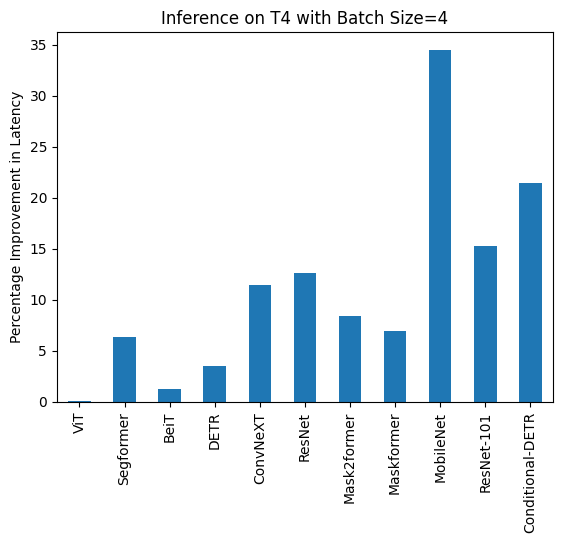
Below you can find inference durations in milliseconds for each model with and without `compile()`. Note that OwlViT results in OOM in larger batch sizes.
### A100 (batch size: 1)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 9.325 | 7.584 |
| Image Segmentation/Segformer | 11.759 | 10.500 |
| Object Detection/OwlViT | 24.978 | 18.420 |
| Image Classification/BeiT | 11.282 | 8.448 |
| Object Detection/DETR | 34.619 | 19.040 |
| Image Classification/ConvNeXT | 10.410 | 10.208 |
| Image Classification/ResNet | 6.531 | 4.124 |
| Image Segmentation/Mask2former | 60.188 | 49.117 |
| Image Segmentation/Maskformer | 75.764 | 59.487 |
| Image Segmentation/MobileNet | 8.583 | 3.974 |
| Object Detection/Resnet-101 | 36.276 | 18.197 |
| Object Detection/Conditional-DETR | 31.219 | 17.993 |
### A100 (batch size: 4)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 14.832 | 14.499 |
| Image Segmentation/Segformer | 18.838 | 16.476 |
| Image Classification/BeiT | 13.205 | 13.048 |
| Object Detection/DETR | 48.657 | 32.418|
| Image Classification/ConvNeXT | 22.940 | 21.631 |
| Image Classification/ResNet | 6.657 | 4.268 |
| Image Segmentation/Mask2former | 74.277 | 61.781 |
| Image Segmentation/Maskformer | 180.700 | 159.116 |
| Image Segmentation/MobileNet | 14.174 | 8.515 |
| Object Detection/Resnet-101 | 68.101 | 44.998 |
| Object Detection/Conditional-DETR | 56.470 | 35.552 |
### A100 (batch size: 16)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 40.944 | 40.010 |
| Image Segmentation/Segformer | 37.005 | 31.144 |
| Image Classification/BeiT | 41.854 | 41.048 |
| Object Detection/DETR | 164.382 | 161.902 |
| Image Classification/ConvNeXT | 82.258 | 75.561 |
| Image Classification/ResNet | 7.018 | 5.024 |
| Image Segmentation/Mask2former | 178.945 | 154.814 |
| Image Segmentation/Maskformer | 638.570 | 579.826 |
| Image Segmentation/MobileNet | 51.693 | 30.310 |
| Object Detection/Resnet-101 | 232.887 | 155.021 |
| Object Detection/Conditional-DETR | 180.491 | 124.032 |
### V100 (batch size: 1)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 10.495 | 6.00 |
| Image Segmentation/Segformer | 13.321 | 5.862 |
| Object Detection/OwlViT | 25.769 | 22.395 |
| Image Classification/BeiT | 11.347 | 7.234 |
| Object Detection/DETR | 33.951 | 19.388 |
| Image Classification/ConvNeXT | 11.623 | 10.412 |
| Image Classification/ResNet | 6.484 | 3.820 |
| Image Segmentation/Mask2former | 64.640 | 49.873 |
| Image Segmentation/Maskformer | 95.532 | 72.207 |
| Image Segmentation/MobileNet | 9.217 | 4.753 |
| Object Detection/Resnet-101 | 52.818 | 28.367 |
| Object Detection/Conditional-DETR | 39.512 | 20.816 |
### V100 (batch size: 4)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 15.181 | 14.501 |
| Image Segmentation/Segformer | 16.787 | 16.188 |
| Image Classification/BeiT | 15.171 | 14.753 |
| Object Detection/DETR | 88.529 | 64.195 |
| Image Classification/ConvNeXT | 29.574 | 27.085 |
| Image Classification/ResNet | 6.109 | 4.731 |
| Image Segmentation/Mask2former | 90.402 | 76.926 |
| Image Segmentation/Maskformer | 234.261 | 205.456 |
| Image Segmentation/MobileNet | 24.623 | 14.816 |
| Object Detection/Resnet-101 | 134.672 | 101.304 |
| Object Detection/Conditional-DETR | 97.464 | 69.739 |
### V100 (batch size: 16)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 52.209 | 51.633 |
| Image Segmentation/Segformer | 61.013 | 55.499 |
| Image Classification/BeiT | 53.938 | 53.581 |
| Object Detection/DETR | OOM | OOM |
| Image Classification/ConvNeXT | 109.682 | 100.771 |
| Image Classification/ResNet | 14.857 | 12.089 |
| Image Segmentation/Mask2former | 249.605 | 222.801 |
| Image Segmentation/Maskformer | 831.142 | 743.645 |
| Image Segmentation/MobileNet | 93.129 | 55.365 |
| Object Detection/Resnet-101 | 482.425 | 361.843 |
| Object Detection/Conditional-DETR | 344.661 | 255.298 |
### T4 (batch size: 1)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 16.520 | 15.786 |
| Image Segmentation/Segformer | 16.116 | 14.205 |
| Object Detection/OwlViT | 53.634 | 51.105 |
| Image Classification/BeiT | 16.464 | 15.710 |
| Object Detection/DETR | 73.100 | 53.99 |
| Image Classification/ConvNeXT | 32.932 | 30.845 |
| Image Classification/ResNet | 6.031 | 4.321 |
| Image Segmentation/Mask2former | 79.192 | 66.815 |
| Image Segmentation/Maskformer | 200.026 | 188.268 |
| Image Segmentation/MobileNet | 18.908 | 11.997 |
| Object Detection/Resnet-101 | 106.622 | 82.566 |
| Object Detection/Conditional-DETR | 77.594 | 56.984 |
### T4 (batch size: 4)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 43.653 | 43.626 |
| Image Segmentation/Segformer | 45.327 | 42.445 |
| Image Classification/BeiT | 52.007 | 51.354 |
| Object Detection/DETR | 277.850 | 268.003 |
| Image Classification/ConvNeXT | 119.259 | 105.580 |
| Image Classification/ResNet | 13.039 | 11.388 |
| Image Segmentation/Mask2former | 201.540 | 184.670 |
| Image Segmentation/Maskformer | 764.052 | 711.280 |
| Image Segmentation/MobileNet | 74.289 | 48.677 |
| Object Detection/Resnet-101 | 421.859 | 357.614 |
| Object Detection/Conditional-DETR | 289.002 | 226.945 |
### T4 (batch size: 16)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 163.914 | 160.907 |
| Image Segmentation/Segformer | 192.412 | 163.620 |
| Image Classification/BeiT | 188.978 | 187.976 |
| Object Detection/DETR | OOM | OOM |
| Image Classification/ConvNeXT | 422.886 | 388.078 |
| Image Classification/ResNet | 44.114 | 37.604 |
| Image Segmentation/Mask2former | 756.337 | 695.291 |
| Image Segmentation/Maskformer | 2842.940 | 2656.88 |
| Image Segmentation/MobileNet | 299.003 | 201.942 |
| Object Detection/Resnet-101 | 1619.505 | 1262.758 |
| Object Detection/Conditional-DETR | 1137.513 | 897.390|
## PyTorch Nightly
We also benchmarked on PyTorch nightly (2.1.0dev, find the wheel [here](https://download.pytorch.org/whl/nightly/cu118)) and observed improvement in latency both for uncompiled and compiled models.
### A100
| **Task/Model** | **Batch Size** | **torch 2.0 - no compile** | **torch 2.0 -<br> compile** |
|:---:|:---:|:---:|:---:|
| Image Classification/BeiT | Unbatched | 12.462 | 6.954 |
| Image Classification/BeiT | 4 | 14.109 | 12.851 |
| Image Classification/BeiT | 16 | 42.179 | 42.147 |
| Object Detection/DETR | Unbatched | 30.484 | 15.221 |
| Object Detection/DETR | 4 | 46.816 | 30.942 |
| Object Detection/DETR | 16 | 163.749 | 163.706 |
### T4
| **Task/Model** | **Batch Size** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|:---:|
| Image Classification/BeiT | Unbatched | 14.408 | 14.052 |
| Image Classification/BeiT | 4 | 47.381 | 46.604 |
| Image Classification/BeiT | 16 | 42.179 | 42.147 |
| Object Detection/DETR | Unbatched | 68.382 | 53.481 |
| Object Detection/DETR | 4 | 269.615 | 204.785 |
| Object Detection/DETR | 16 | OOM | OOM |
### V100
| **Task/Model** | **Batch Size** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|:---:|
| Image Classification/BeiT | Unbatched | 13.477 | 7.926 |
| Image Classification/BeiT | 4 | 15.103 | 14.378 |
| Image Classification/BeiT | 16 | 52.517 | 51.691 |
| Object Detection/DETR | Unbatched | 28.706 | 19.077 |
| Object Detection/DETR | 4 | 88.402 | 62.949|
| Object Detection/DETR | 16 | OOM | OOM |
## Reduce Overhead
We benchmarked `reduce-overhead` compilation mode for A100 and T4 in Nightly.
### A100
| **Task/Model** | **Batch Size** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|:---:|
| Image Classification/ConvNeXT | Unbatched | 11.758 | 7.335 |
| Image Classification/ConvNeXT | 4 | 23.171 | 21.490 |
| Image Classification/ResNet | Unbatched | 7.435 | 3.801 |
| Image Classification/ResNet | 4 | 7.261 | 2.187 |
| Object Detection/Conditional-DETR | Unbatched | 32.823 | 11.627 |
| Object Detection/Conditional-DETR | 4 | 50.622 | 33.831 |
| Image Segmentation/MobileNet | Unbatched | 9.869 | 4.244 |
| Image Segmentation/MobileNet | 4 | 14.385 | 7.946 |
### T4
| **Task/Model** | **Batch Size** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|:---:|
| Image Classification/ConvNeXT | Unbatched | 32.137 | 31.84 |
| Image Classification/ConvNeXT | 4 | 120.944 | 110.209 |
| Image Classification/ResNet | Unbatched | 9.761 | 7.698 |
| Image Classification/ResNet | 4 | 15.215 | 13.871 |
| Object Detection/Conditional-DETR | Unbatched | 72.150 | 57.660 |
| Object Detection/Conditional-DETR | 4 | 301.494 | 247.543 |
| Image Segmentation/MobileNet | Unbatched | 22.266 | 19.339 |
| Image Segmentation/MobileNet | 4 | 78.311 | 50.983 |
| transformers/docs/source/en/perf_torch_compile.md/0 | {
"file_path": "transformers/docs/source/en/perf_torch_compile.md",
"repo_id": "transformers",
"token_count": 5859
} | 248 |
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Train with a script
Along with the 🤗 Transformers [notebooks](./noteboks/README), there are also example scripts demonstrating how to train a model for a task with [PyTorch](https://github.com/huggingface/transformers/tree/main/examples/pytorch), [TensorFlow](https://github.com/huggingface/transformers/tree/main/examples/tensorflow), or [JAX/Flax](https://github.com/huggingface/transformers/tree/main/examples/flax).
You will also find scripts we've used in our [research projects](https://github.com/huggingface/transformers/tree/main/examples/research_projects) and [legacy examples](https://github.com/huggingface/transformers/tree/main/examples/legacy) which are mostly community contributed. These scripts are not actively maintained and require a specific version of 🤗 Transformers that will most likely be incompatible with the latest version of the library.
The example scripts are not expected to work out-of-the-box on every problem, and you may need to adapt the script to the problem you're trying to solve. To help you with this, most of the scripts fully expose how data is preprocessed, allowing you to edit it as necessary for your use case.
For any feature you'd like to implement in an example script, please discuss it on the [forum](https://discuss.huggingface.co/) or in an [issue](https://github.com/huggingface/transformers/issues) before submitting a Pull Request. While we welcome bug fixes, it is unlikely we will merge a Pull Request that adds more functionality at the cost of readability.
This guide will show you how to run an example summarization training script in [PyTorch](https://github.com/huggingface/transformers/tree/main/examples/pytorch/summarization) and [TensorFlow](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/summarization). All examples are expected to work with both frameworks unless otherwise specified.
## Setup
To successfully run the latest version of the example scripts, you have to **install 🤗 Transformers from source** in a new virtual environment:
```bash
git clone https://github.com/huggingface/transformers
cd transformers
pip install .
```
For older versions of the example scripts, click on the toggle below:
<details>
<summary>Examples for older versions of 🤗 Transformers</summary>
<ul>
<li><a href="https://github.com/huggingface/transformers/tree/v4.5.1/examples">v4.5.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.4.2/examples">v4.4.2</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.3.3/examples">v4.3.3</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.2.2/examples">v4.2.2</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.1.1/examples">v4.1.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.0.1/examples">v4.0.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.5.1/examples">v3.5.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.4.0/examples">v3.4.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.3.1/examples">v3.3.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.2.0/examples">v3.2.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.1.0/examples">v3.1.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.0.2/examples">v3.0.2</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.11.0/examples">v2.11.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.10.0/examples">v2.10.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.9.1/examples">v2.9.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.8.0/examples">v2.8.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.7.0/examples">v2.7.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.6.0/examples">v2.6.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.5.1/examples">v2.5.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.4.0/examples">v2.4.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.3.0/examples">v2.3.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.2.0/examples">v2.2.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.1.0/examples">v2.1.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.0.0/examples">v2.0.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v1.2.0/examples">v1.2.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v1.1.0/examples">v1.1.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v1.0.0/examples">v1.0.0</a></li>
</ul>
</details>
Then switch your current clone of 🤗 Transformers to a specific version, like v3.5.1 for example:
```bash
git checkout tags/v3.5.1
```
After you've setup the correct library version, navigate to the example folder of your choice and install the example specific requirements:
```bash
pip install -r requirements.txt
```
## Run a script
<frameworkcontent>
<pt>
The example script downloads and preprocesses a dataset from the 🤗 [Datasets](https://huggingface.co/docs/datasets/) library. Then the script fine-tunes a dataset with the [Trainer](https://huggingface.co/docs/transformers/main_classes/trainer) on an architecture that supports summarization. The following example shows how to fine-tune [T5-small](https://huggingface.co/t5-small) on the [CNN/DailyMail](https://huggingface.co/datasets/cnn_dailymail) dataset. The T5 model requires an additional `source_prefix` argument due to how it was trained. This prompt lets T5 know this is a summarization task.
```bash
python examples/pytorch/summarization/run_summarization.py \
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
```
</pt>
<tf>
The example script downloads and preprocesses a dataset from the 🤗 [Datasets](https://huggingface.co/docs/datasets/) library. Then the script fine-tunes a dataset using Keras on an architecture that supports summarization. The following example shows how to fine-tune [T5-small](https://huggingface.co/t5-small) on the [CNN/DailyMail](https://huggingface.co/datasets/cnn_dailymail) dataset. The T5 model requires an additional `source_prefix` argument due to how it was trained. This prompt lets T5 know this is a summarization task.
```bash
python examples/tensorflow/summarization/run_summarization.py \
--model_name_or_path t5-small \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 16 \
--num_train_epochs 3 \
--do_train \
--do_eval
```
</tf>
</frameworkcontent>
## Distributed training and mixed precision
The [Trainer](https://huggingface.co/docs/transformers/main_classes/trainer) supports distributed training and mixed precision, which means you can also use it in a script. To enable both of these features:
- Add the `fp16` argument to enable mixed precision.
- Set the number of GPUs to use with the `nproc_per_node` argument.
```bash
torchrun \
--nproc_per_node 8 pytorch/summarization/run_summarization.py \
--fp16 \
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
```
TensorFlow scripts utilize a [`MirroredStrategy`](https://www.tensorflow.org/guide/distributed_training#mirroredstrategy) for distributed training, and you don't need to add any additional arguments to the training script. The TensorFlow script will use multiple GPUs by default if they are available.
## Run a script on a TPU
<frameworkcontent>
<pt>
Tensor Processing Units (TPUs) are specifically designed to accelerate performance. PyTorch supports TPUs with the [XLA](https://www.tensorflow.org/xla) deep learning compiler (see [here](https://github.com/pytorch/xla/blob/master/README.md) for more details). To use a TPU, launch the `xla_spawn.py` script and use the `num_cores` argument to set the number of TPU cores you want to use.
```bash
python xla_spawn.py --num_cores 8 \
summarization/run_summarization.py \
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
```
</pt>
<tf>
Tensor Processing Units (TPUs) are specifically designed to accelerate performance. TensorFlow scripts utilize a [`TPUStrategy`](https://www.tensorflow.org/guide/distributed_training#tpustrategy) for training on TPUs. To use a TPU, pass the name of the TPU resource to the `tpu` argument.
```bash
python run_summarization.py \
--tpu name_of_tpu_resource \
--model_name_or_path t5-small \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 16 \
--num_train_epochs 3 \
--do_train \
--do_eval
```
</tf>
</frameworkcontent>
## Run a script with 🤗 Accelerate
🤗 [Accelerate](https://huggingface.co/docs/accelerate) is a PyTorch-only library that offers a unified method for training a model on several types of setups (CPU-only, multiple GPUs, TPUs) while maintaining complete visibility into the PyTorch training loop. Make sure you have 🤗 Accelerate installed if you don't already have it:
> Note: As Accelerate is rapidly developing, the git version of accelerate must be installed to run the scripts
```bash
pip install git+https://github.com/huggingface/accelerate
```
Instead of the `run_summarization.py` script, you need to use the `run_summarization_no_trainer.py` script. 🤗 Accelerate supported scripts will have a `task_no_trainer.py` file in the folder. Begin by running the following command to create and save a configuration file:
```bash
accelerate config
```
Test your setup to make sure it is configured correctly:
```bash
accelerate test
```
Now you are ready to launch the training:
```bash
accelerate launch run_summarization_no_trainer.py \
--model_name_or_path t5-small \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir ~/tmp/tst-summarization
```
## Use a custom dataset
The summarization script supports custom datasets as long as they are a CSV or JSON Line file. When you use your own dataset, you need to specify several additional arguments:
- `train_file` and `validation_file` specify the path to your training and validation files.
- `text_column` is the input text to summarize.
- `summary_column` is the target text to output.
A summarization script using a custom dataset would look like this:
```bash
python examples/pytorch/summarization/run_summarization.py \
--model_name_or_path t5-small \
--do_train \
--do_eval \
--train_file path_to_csv_or_jsonlines_file \
--validation_file path_to_csv_or_jsonlines_file \
--text_column text_column_name \
--summary_column summary_column_name \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--overwrite_output_dir \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--predict_with_generate
```
## Test a script
It is often a good idea to run your script on a smaller number of dataset examples to ensure everything works as expected before committing to an entire dataset which may take hours to complete. Use the following arguments to truncate the dataset to a maximum number of samples:
- `max_train_samples`
- `max_eval_samples`
- `max_predict_samples`
```bash
python examples/pytorch/summarization/run_summarization.py \
--model_name_or_path t5-small \
--max_train_samples 50 \
--max_eval_samples 50 \
--max_predict_samples 50 \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
```
Not all example scripts support the `max_predict_samples` argument. If you aren't sure whether your script supports this argument, add the `-h` argument to check:
```bash
examples/pytorch/summarization/run_summarization.py -h
```
## Resume training from checkpoint
Another helpful option to enable is resuming training from a previous checkpoint. This will ensure you can pick up where you left off without starting over if your training gets interrupted. There are two methods to resume training from a checkpoint.
The first method uses the `output_dir previous_output_dir` argument to resume training from the latest checkpoint stored in `output_dir`. In this case, you should remove `overwrite_output_dir`:
```bash
python examples/pytorch/summarization/run_summarization.py
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--output_dir previous_output_dir \
--predict_with_generate
```
The second method uses the `resume_from_checkpoint path_to_specific_checkpoint` argument to resume training from a specific checkpoint folder.
```bash
python examples/pytorch/summarization/run_summarization.py
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--resume_from_checkpoint path_to_specific_checkpoint \
--predict_with_generate
```
## Share your model
All scripts can upload your final model to the [Model Hub](https://huggingface.co/models). Make sure you are logged into Hugging Face before you begin:
```bash
huggingface-cli login
```
Then add the `push_to_hub` argument to the script. This argument will create a repository with your Hugging Face username and the folder name specified in `output_dir`.
To give your repository a specific name, use the `push_to_hub_model_id` argument to add it. The repository will be automatically listed under your namespace.
The following example shows how to upload a model with a specific repository name:
```bash
python examples/pytorch/summarization/run_summarization.py
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--push_to_hub \
--push_to_hub_model_id finetuned-t5-cnn_dailymail \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
``` | transformers/docs/source/en/run_scripts.md/0 | {
"file_path": "transformers/docs/source/en/run_scripts.md",
"repo_id": "transformers",
"token_count": 5851
} | 249 |
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Object detection
[[open-in-colab]]
Object detection is the computer vision task of detecting instances (such as humans, buildings, or cars) in an image. Object detection models receive an image as input and output
coordinates of the bounding boxes and associated labels of the detected objects. An image can contain multiple objects,
each with its own bounding box and a label (e.g. it can have a car and a building), and each object can
be present in different parts of an image (e.g. the image can have several cars).
This task is commonly used in autonomous driving for detecting things like pedestrians, road signs, and traffic lights.
Other applications include counting objects in images, image search, and more.
In this guide, you will learn how to:
1. Finetune [DETR](https://huggingface.co/docs/transformers/model_doc/detr), a model that combines a convolutional
backbone with an encoder-decoder Transformer, on the [CPPE-5](https://huggingface.co/datasets/cppe-5)
dataset.
2. Use your finetuned model for inference.
<Tip>
The task illustrated in this tutorial is supported by the following model architectures:
<!--This tip is automatically generated by `make fix-copies`, do not fill manually!-->
[Conditional DETR](../model_doc/conditional_detr), [Deformable DETR](../model_doc/deformable_detr), [DETA](../model_doc/deta), [DETR](../model_doc/detr), [Table Transformer](../model_doc/table-transformer), [YOLOS](../model_doc/yolos)
<!--End of the generated tip-->
</Tip>
Before you begin, make sure you have all the necessary libraries installed:
```bash
pip install -q datasets transformers evaluate timm albumentations
```
You'll use 🤗 Datasets to load a dataset from the Hugging Face Hub, 🤗 Transformers to train your model,
and `albumentations` to augment the data. `timm` is currently required to load a convolutional backbone for the DETR model.
We encourage you to share your model with the community. Log in to your Hugging Face account to upload it to the Hub.
When prompted, enter your token to log in:
```py
>>> from huggingface_hub import notebook_login
>>> notebook_login()
```
## Load the CPPE-5 dataset
The [CPPE-5 dataset](https://huggingface.co/datasets/cppe-5) contains images with
annotations identifying medical personal protective equipment (PPE) in the context of the COVID-19 pandemic.
Start by loading the dataset:
```py
>>> from datasets import load_dataset
>>> cppe5 = load_dataset("cppe-5")
>>> cppe5
DatasetDict({
train: Dataset({
features: ['image_id', 'image', 'width', 'height', 'objects'],
num_rows: 1000
})
test: Dataset({
features: ['image_id', 'image', 'width', 'height', 'objects'],
num_rows: 29
})
})
```
You'll see that this dataset already comes with a training set containing 1000 images and a test set with 29 images.
To get familiar with the data, explore what the examples look like.
```py
>>> cppe5["train"][0]
{'image_id': 15,
'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=943x663 at 0x7F9EC9E77C10>,
'width': 943,
'height': 663,
'objects': {'id': [114, 115, 116, 117],
'area': [3796, 1596, 152768, 81002],
'bbox': [[302.0, 109.0, 73.0, 52.0],
[810.0, 100.0, 57.0, 28.0],
[160.0, 31.0, 248.0, 616.0],
[741.0, 68.0, 202.0, 401.0]],
'category': [4, 4, 0, 0]}}
```
The examples in the dataset have the following fields:
- `image_id`: the example image id
- `image`: a `PIL.Image.Image` object containing the image
- `width`: width of the image
- `height`: height of the image
- `objects`: a dictionary containing bounding box metadata for the objects in the image:
- `id`: the annotation id
- `area`: the area of the bounding box
- `bbox`: the object's bounding box (in the [COCO format](https://albumentations.ai/docs/getting_started/bounding_boxes_augmentation/#coco) )
- `category`: the object's category, with possible values including `Coverall (0)`, `Face_Shield (1)`, `Gloves (2)`, `Goggles (3)` and `Mask (4)`
You may notice that the `bbox` field follows the COCO format, which is the format that the DETR model expects.
However, the grouping of the fields inside `objects` differs from the annotation format DETR requires. You will
need to apply some preprocessing transformations before using this data for training.
To get an even better understanding of the data, visualize an example in the dataset.
```py
>>> import numpy as np
>>> import os
>>> from PIL import Image, ImageDraw
>>> image = cppe5["train"][0]["image"]
>>> annotations = cppe5["train"][0]["objects"]
>>> draw = ImageDraw.Draw(image)
>>> categories = cppe5["train"].features["objects"].feature["category"].names
>>> id2label = {index: x for index, x in enumerate(categories, start=0)}
>>> label2id = {v: k for k, v in id2label.items()}
>>> for i in range(len(annotations["id"])):
... box = annotations["bbox"][i]
... class_idx = annotations["category"][i]
... x, y, w, h = tuple(box)
... # Check if coordinates are normalized or not
... if max(box) > 1.0:
... # Coordinates are un-normalized, no need to re-scale them
... x1, y1 = int(x), int(y)
... x2, y2 = int(x + w), int(y + h)
... else:
... # Coordinates are normalized, re-scale them
... x1 = int(x * width)
... y1 = int(y * height)
... x2 = int((x + w) * width)
... y2 = int((y + h) * height)
... draw.rectangle((x, y, x + w, y + h), outline="red", width=1)
... draw.text((x, y), id2label[class_idx], fill="white")
>>> image
```
<div class="flex justify-center">
<img src="https://i.imgur.com/TdaqPJO.png" alt="CPPE-5 Image Example"/>
</div>
To visualize the bounding boxes with associated labels, you can get the labels from the dataset's metadata, specifically
the `category` field.
You'll also want to create dictionaries that map a label id to a label class (`id2label`) and the other way around (`label2id`).
You can use them later when setting up the model. Including these maps will make your model reusable by others if you share
it on the Hugging Face Hub. Please note that, the part of above code that draws the bounding boxes assume that it is in `XYWH` (x,y co-ordinates and width and height of the box) format. It might not work for other formats like `(x1, y1, x2, y2)`.
As a final step of getting familiar with the data, explore it for potential issues. One common problem with datasets for
object detection is bounding boxes that "stretch" beyond the edge of the image. Such "runaway" bounding boxes can raise
errors during training and should be addressed at this stage. There are a few examples with this issue in this dataset.
To keep things simple in this guide, we remove these images from the data.
```py
>>> remove_idx = [590, 821, 822, 875, 876, 878, 879]
>>> keep = [i for i in range(len(cppe5["train"])) if i not in remove_idx]
>>> cppe5["train"] = cppe5["train"].select(keep)
```
## Preprocess the data
To finetune a model, you must preprocess the data you plan to use to match precisely the approach used for the pre-trained model.
[`AutoImageProcessor`] takes care of processing image data to create `pixel_values`, `pixel_mask`, and
`labels` that a DETR model can train with. The image processor has some attributes that you won't have to worry about:
- `image_mean = [0.485, 0.456, 0.406 ]`
- `image_std = [0.229, 0.224, 0.225]`
These are the mean and standard deviation used to normalize images during the model pre-training. These values are crucial
to replicate when doing inference or finetuning a pre-trained image model.
Instantiate the image processor from the same checkpoint as the model you want to finetune.
```py
>>> from transformers import AutoImageProcessor
>>> checkpoint = "facebook/detr-resnet-50"
>>> image_processor = AutoImageProcessor.from_pretrained(checkpoint)
```
Before passing the images to the `image_processor`, apply two preprocessing transformations to the dataset:
- Augmenting images
- Reformatting annotations to meet DETR expectations
First, to make sure the model does not overfit on the training data, you can apply image augmentation with any data augmentation library. Here we use [Albumentations](https://albumentations.ai/docs/) ...
This library ensures that transformations affect the image and update the bounding boxes accordingly.
The 🤗 Datasets library documentation has a detailed [guide on how to augment images for object detection](https://huggingface.co/docs/datasets/object_detection),
and it uses the exact same dataset as an example. Apply the same approach here, resize each image to (480, 480),
flip it horizontally, and brighten it:
```py
>>> import albumentations
>>> import numpy as np
>>> import torch
>>> transform = albumentations.Compose(
... [
... albumentations.Resize(480, 480),
... albumentations.HorizontalFlip(p=1.0),
... albumentations.RandomBrightnessContrast(p=1.0),
... ],
... bbox_params=albumentations.BboxParams(format="coco", label_fields=["category"]),
... )
```
The `image_processor` expects the annotations to be in the following format: `{'image_id': int, 'annotations': List[Dict]}`,
where each dictionary is a COCO object annotation. Let's add a function to reformat annotations for a single example:
```py
>>> def formatted_anns(image_id, category, area, bbox):
... annotations = []
... for i in range(0, len(category)):
... new_ann = {
... "image_id": image_id,
... "category_id": category[i],
... "isCrowd": 0,
... "area": area[i],
... "bbox": list(bbox[i]),
... }
... annotations.append(new_ann)
... return annotations
```
Now you can combine the image and annotation transformations to use on a batch of examples:
```py
>>> # transforming a batch
>>> def transform_aug_ann(examples):
... image_ids = examples["image_id"]
... images, bboxes, area, categories = [], [], [], []
... for image, objects in zip(examples["image"], examples["objects"]):
... image = np.array(image.convert("RGB"))[:, :, ::-1]
... out = transform(image=image, bboxes=objects["bbox"], category=objects["category"])
... area.append(objects["area"])
... images.append(out["image"])
... bboxes.append(out["bboxes"])
... categories.append(out["category"])
... targets = [
... {"image_id": id_, "annotations": formatted_anns(id_, cat_, ar_, box_)}
... for id_, cat_, ar_, box_ in zip(image_ids, categories, area, bboxes)
... ]
... return image_processor(images=images, annotations=targets, return_tensors="pt")
```
Apply this preprocessing function to the entire dataset using 🤗 Datasets [`~datasets.Dataset.with_transform`] method. This method applies
transformations on the fly when you load an element of the dataset.
At this point, you can check what an example from the dataset looks like after the transformations. You should see a tensor
with `pixel_values`, a tensor with `pixel_mask`, and `labels`.
```py
>>> cppe5["train"] = cppe5["train"].with_transform(transform_aug_ann)
>>> cppe5["train"][15]
{'pixel_values': tensor([[[ 0.9132, 0.9132, 0.9132, ..., -1.9809, -1.9809, -1.9809],
[ 0.9132, 0.9132, 0.9132, ..., -1.9809, -1.9809, -1.9809],
[ 0.9132, 0.9132, 0.9132, ..., -1.9638, -1.9638, -1.9638],
...,
[-1.5699, -1.5699, -1.5699, ..., -1.9980, -1.9980, -1.9980],
[-1.5528, -1.5528, -1.5528, ..., -1.9980, -1.9809, -1.9809],
[-1.5528, -1.5528, -1.5528, ..., -1.9980, -1.9809, -1.9809]],
[[ 1.3081, 1.3081, 1.3081, ..., -1.8431, -1.8431, -1.8431],
[ 1.3081, 1.3081, 1.3081, ..., -1.8431, -1.8431, -1.8431],
[ 1.3081, 1.3081, 1.3081, ..., -1.8256, -1.8256, -1.8256],
...,
[-1.3179, -1.3179, -1.3179, ..., -1.8606, -1.8606, -1.8606],
[-1.3004, -1.3004, -1.3004, ..., -1.8606, -1.8431, -1.8431],
[-1.3004, -1.3004, -1.3004, ..., -1.8606, -1.8431, -1.8431]],
[[ 1.4200, 1.4200, 1.4200, ..., -1.6476, -1.6476, -1.6476],
[ 1.4200, 1.4200, 1.4200, ..., -1.6476, -1.6476, -1.6476],
[ 1.4200, 1.4200, 1.4200, ..., -1.6302, -1.6302, -1.6302],
...,
[-1.0201, -1.0201, -1.0201, ..., -1.5604, -1.5604, -1.5604],
[-1.0027, -1.0027, -1.0027, ..., -1.5604, -1.5430, -1.5430],
[-1.0027, -1.0027, -1.0027, ..., -1.5604, -1.5430, -1.5430]]]),
'pixel_mask': tensor([[1, 1, 1, ..., 1, 1, 1],
[1, 1, 1, ..., 1, 1, 1],
[1, 1, 1, ..., 1, 1, 1],
...,
[1, 1, 1, ..., 1, 1, 1],
[1, 1, 1, ..., 1, 1, 1],
[1, 1, 1, ..., 1, 1, 1]]),
'labels': {'size': tensor([800, 800]), 'image_id': tensor([756]), 'class_labels': tensor([4]), 'boxes': tensor([[0.7340, 0.6986, 0.3414, 0.5944]]), 'area': tensor([519544.4375]), 'iscrowd': tensor([0]), 'orig_size': tensor([480, 480])}}
```
You have successfully augmented the individual images and prepared their annotations. However, preprocessing isn't
complete yet. In the final step, create a custom `collate_fn` to batch images together.
Pad images (which are now `pixel_values`) to the largest image in a batch, and create a corresponding `pixel_mask`
to indicate which pixels are real (1) and which are padding (0).
```py
>>> def collate_fn(batch):
... pixel_values = [item["pixel_values"] for item in batch]
... encoding = image_processor.pad(pixel_values, return_tensors="pt")
... labels = [item["labels"] for item in batch]
... batch = {}
... batch["pixel_values"] = encoding["pixel_values"]
... batch["pixel_mask"] = encoding["pixel_mask"]
... batch["labels"] = labels
... return batch
```
## Training the DETR model
You have done most of the heavy lifting in the previous sections, so now you are ready to train your model!
The images in this dataset are still quite large, even after resizing. This means that finetuning this model will
require at least one GPU.
Training involves the following steps:
1. Load the model with [`AutoModelForObjectDetection`] using the same checkpoint as in the preprocessing.
2. Define your training hyperparameters in [`TrainingArguments`].
3. Pass the training arguments to [`Trainer`] along with the model, dataset, image processor, and data collator.
4. Call [`~Trainer.train`] to finetune your model.
When loading the model from the same checkpoint that you used for the preprocessing, remember to pass the `label2id`
and `id2label` maps that you created earlier from the dataset's metadata. Additionally, we specify `ignore_mismatched_sizes=True` to replace the existing classification head with a new one.
```py
>>> from transformers import AutoModelForObjectDetection
>>> model = AutoModelForObjectDetection.from_pretrained(
... checkpoint,
... id2label=id2label,
... label2id=label2id,
... ignore_mismatched_sizes=True,
... )
```
In the [`TrainingArguments`] use `output_dir` to specify where to save your model, then configure hyperparameters as you see fit.
It is important you do not remove unused columns because this will drop the image column. Without the image column, you
can't create `pixel_values`. For this reason, set `remove_unused_columns` to `False`.
If you wish to share your model by pushing to the Hub, set `push_to_hub` to `True` (you must be signed in to Hugging
Face to upload your model).
```py
>>> from transformers import TrainingArguments
>>> training_args = TrainingArguments(
... output_dir="detr-resnet-50_finetuned_cppe5",
... per_device_train_batch_size=8,
... num_train_epochs=10,
... fp16=True,
... save_steps=200,
... logging_steps=50,
... learning_rate=1e-5,
... weight_decay=1e-4,
... save_total_limit=2,
... remove_unused_columns=False,
... push_to_hub=True,
... )
```
Finally, bring everything together, and call [`~transformers.Trainer.train`]:
```py
>>> from transformers import Trainer
>>> trainer = Trainer(
... model=model,
... args=training_args,
... data_collator=collate_fn,
... train_dataset=cppe5["train"],
... tokenizer=image_processor,
... )
>>> trainer.train()
```
If you have set `push_to_hub` to `True` in the `training_args`, the training checkpoints are pushed to the
Hugging Face Hub. Upon training completion, push the final model to the Hub as well by calling the [`~transformers.Trainer.push_to_hub`] method.
```py
>>> trainer.push_to_hub()
```
## Evaluate
Object detection models are commonly evaluated with a set of <a href="https://cocodataset.org/#detection-eval">COCO-style metrics</a>.
You can use one of the existing metrics implementations, but here you'll use the one from `torchvision` to evaluate the final
model that you pushed to the Hub.
To use the `torchvision` evaluator, you'll need to prepare a ground truth COCO dataset. The API to build a COCO dataset
requires the data to be stored in a certain format, so you'll need to save images and annotations to disk first. Just like
when you prepared your data for training, the annotations from the `cppe5["test"]` need to be formatted. However, images
should stay as they are.
The evaluation step requires a bit of work, but it can be split in three major steps.
First, prepare the `cppe5["test"]` set: format the annotations and save the data to disk.
```py
>>> import json
>>> # format annotations the same as for training, no need for data augmentation
>>> def val_formatted_anns(image_id, objects):
... annotations = []
... for i in range(0, len(objects["id"])):
... new_ann = {
... "id": objects["id"][i],
... "category_id": objects["category"][i],
... "iscrowd": 0,
... "image_id": image_id,
... "area": objects["area"][i],
... "bbox": objects["bbox"][i],
... }
... annotations.append(new_ann)
... return annotations
>>> # Save images and annotations into the files torchvision.datasets.CocoDetection expects
>>> def save_cppe5_annotation_file_images(cppe5):
... output_json = {}
... path_output_cppe5 = f"{os.getcwd()}/cppe5/"
... if not os.path.exists(path_output_cppe5):
... os.makedirs(path_output_cppe5)
... path_anno = os.path.join(path_output_cppe5, "cppe5_ann.json")
... categories_json = [{"supercategory": "none", "id": id, "name": id2label[id]} for id in id2label]
... output_json["images"] = []
... output_json["annotations"] = []
... for example in cppe5:
... ann = val_formatted_anns(example["image_id"], example["objects"])
... output_json["images"].append(
... {
... "id": example["image_id"],
... "width": example["image"].width,
... "height": example["image"].height,
... "file_name": f"{example['image_id']}.png",
... }
... )
... output_json["annotations"].extend(ann)
... output_json["categories"] = categories_json
... with open(path_anno, "w") as file:
... json.dump(output_json, file, ensure_ascii=False, indent=4)
... for im, img_id in zip(cppe5["image"], cppe5["image_id"]):
... path_img = os.path.join(path_output_cppe5, f"{img_id}.png")
... im.save(path_img)
... return path_output_cppe5, path_anno
```
Next, prepare an instance of a `CocoDetection` class that can be used with `cocoevaluator`.
```py
>>> import torchvision
>>> class CocoDetection(torchvision.datasets.CocoDetection):
... def __init__(self, img_folder, image_processor, ann_file):
... super().__init__(img_folder, ann_file)
... self.image_processor = image_processor
... def __getitem__(self, idx):
... # read in PIL image and target in COCO format
... img, target = super(CocoDetection, self).__getitem__(idx)
... # preprocess image and target: converting target to DETR format,
... # resizing + normalization of both image and target)
... image_id = self.ids[idx]
... target = {"image_id": image_id, "annotations": target}
... encoding = self.image_processor(images=img, annotations=target, return_tensors="pt")
... pixel_values = encoding["pixel_values"].squeeze() # remove batch dimension
... target = encoding["labels"][0] # remove batch dimension
... return {"pixel_values": pixel_values, "labels": target}
>>> im_processor = AutoImageProcessor.from_pretrained("devonho/detr-resnet-50_finetuned_cppe5")
>>> path_output_cppe5, path_anno = save_cppe5_annotation_file_images(cppe5["test"])
>>> test_ds_coco_format = CocoDetection(path_output_cppe5, im_processor, path_anno)
```
Finally, load the metrics and run the evaluation.
```py
>>> import evaluate
>>> from tqdm import tqdm
>>> model = AutoModelForObjectDetection.from_pretrained("devonho/detr-resnet-50_finetuned_cppe5")
>>> module = evaluate.load("ybelkada/cocoevaluate", coco=test_ds_coco_format.coco)
>>> val_dataloader = torch.utils.data.DataLoader(
... test_ds_coco_format, batch_size=8, shuffle=False, num_workers=4, collate_fn=collate_fn
... )
>>> with torch.no_grad():
... for idx, batch in enumerate(tqdm(val_dataloader)):
... pixel_values = batch["pixel_values"]
... pixel_mask = batch["pixel_mask"]
... labels = [
... {k: v for k, v in t.items()} for t in batch["labels"]
... ] # these are in DETR format, resized + normalized
... # forward pass
... outputs = model(pixel_values=pixel_values, pixel_mask=pixel_mask)
... orig_target_sizes = torch.stack([target["orig_size"] for target in labels], dim=0)
... results = im_processor.post_process(outputs, orig_target_sizes) # convert outputs of model to Pascal VOC format (xmin, ymin, xmax, ymax)
... module.add(prediction=results, reference=labels)
... del batch
>>> results = module.compute()
>>> print(results)
Accumulating evaluation results...
DONE (t=0.08s).
IoU metric: bbox
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.352
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.681
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.292
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.168
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.208
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.429
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.274
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.484
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.501
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.191
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.323
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.590
```
These results can be further improved by adjusting the hyperparameters in [`~transformers.TrainingArguments`]. Give it a go!
## Inference
Now that you have finetuned a DETR model, evaluated it, and uploaded it to the Hugging Face Hub, you can use it for inference.
The simplest way to try out your finetuned model for inference is to use it in a [`Pipeline`]. Instantiate a pipeline
for object detection with your model, and pass an image to it:
```py
>>> from transformers import pipeline
>>> import requests
>>> url = "https://i.imgur.com/2lnWoly.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> obj_detector = pipeline("object-detection", model="devonho/detr-resnet-50_finetuned_cppe5")
>>> obj_detector(image)
```
You can also manually replicate the results of the pipeline if you'd like:
```py
>>> image_processor = AutoImageProcessor.from_pretrained("devonho/detr-resnet-50_finetuned_cppe5")
>>> model = AutoModelForObjectDetection.from_pretrained("devonho/detr-resnet-50_finetuned_cppe5")
>>> with torch.no_grad():
... inputs = image_processor(images=image, return_tensors="pt")
... outputs = model(**inputs)
... target_sizes = torch.tensor([image.size[::-1]])
... results = image_processor.post_process_object_detection(outputs, threshold=0.5, target_sizes=target_sizes)[0]
>>> for score, label, box in zip(results["scores"], results["labels"], results["boxes"]):
... box = [round(i, 2) for i in box.tolist()]
... print(
... f"Detected {model.config.id2label[label.item()]} with confidence "
... f"{round(score.item(), 3)} at location {box}"
... )
Detected Coverall with confidence 0.566 at location [1215.32, 147.38, 4401.81, 3227.08]
Detected Mask with confidence 0.584 at location [2449.06, 823.19, 3256.43, 1413.9]
```
Let's plot the result:
```py
>>> draw = ImageDraw.Draw(image)
>>> for score, label, box in zip(results["scores"], results["labels"], results["boxes"]):
... box = [round(i, 2) for i in box.tolist()]
... x, y, x2, y2 = tuple(box)
... draw.rectangle((x, y, x2, y2), outline="red", width=1)
... draw.text((x, y), model.config.id2label[label.item()], fill="white")
>>> image
```
<div class="flex justify-center">
<img src="https://i.imgur.com/4QZnf9A.png" alt="Object detection result on a new image"/>
</div>
| transformers/docs/source/en/tasks/object_detection.md/0 | {
"file_path": "transformers/docs/source/en/tasks/object_detection.md",
"repo_id": "transformers",
"token_count": 9638
} | 250 |
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Export to TFLite
[TensorFlow Lite](https://www.tensorflow.org/lite/guide) is a lightweight framework for deploying machine learning models
on resource-constrained devices, such as mobile phones, embedded systems, and Internet of Things (IoT) devices.
TFLite is designed to optimize and run models efficiently on these devices with limited computational power, memory, and
power consumption.
A TensorFlow Lite model is represented in a special efficient portable format identified by the `.tflite` file extension.
🤗 Optimum offers functionality to export 🤗 Transformers models to TFLite through the `exporters.tflite` module.
For the list of supported model architectures, please refer to [🤗 Optimum documentation](https://huggingface.co/docs/optimum/exporters/tflite/overview).
To export a model to TFLite, install the required dependencies:
```bash
pip install optimum[exporters-tf]
```
To check out all available arguments, refer to the [🤗 Optimum docs](https://huggingface.co/docs/optimum/main/en/exporters/tflite/usage_guides/export_a_model),
or view help in command line:
```bash
optimum-cli export tflite --help
```
To export a model's checkpoint from the 🤗 Hub, for example, `bert-base-uncased`, run the following command:
```bash
optimum-cli export tflite --model bert-base-uncased --sequence_length 128 bert_tflite/
```
You should see the logs indicating progress and showing where the resulting `model.tflite` is saved, like this:
```bash
Validating TFLite model...
-[✓] TFLite model output names match reference model (logits)
- Validating TFLite Model output "logits":
-[✓] (1, 128, 30522) matches (1, 128, 30522)
-[x] values not close enough, max diff: 5.817413330078125e-05 (atol: 1e-05)
The TensorFlow Lite export succeeded with the warning: The maximum absolute difference between the output of the reference model and the TFLite exported model is not within the set tolerance 1e-05:
- logits: max diff = 5.817413330078125e-05.
The exported model was saved at: bert_tflite
```
The example above illustrates exporting a checkpoint from 🤗 Hub. When exporting a local model, first make sure that you
saved both the model's weights and tokenizer files in the same directory (`local_path`). When using CLI, pass the
`local_path` to the `model` argument instead of the checkpoint name on 🤗 Hub. | transformers/docs/source/en/tflite.md/0 | {
"file_path": "transformers/docs/source/en/tflite.md",
"repo_id": "transformers",
"token_count": 871
} | 251 |
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Compartir modelos personalizados
La biblioteca 🤗 Transformers está diseñada para ser fácilmente ampliable. Cada modelo está completamente codificado
sin abstracción en una subcarpeta determinada del repositorio, por lo que puedes copiar fácilmente un archivo del modelo
y ajustarlo según tus necesidades.
Si estás escribiendo un modelo completamente nuevo, podría ser más fácil comenzar desde cero. En este tutorial, te mostraremos
cómo escribir un modelo personalizado y su configuración para que pueda usarse dentro de Transformers, y cómo puedes compartirlo
con la comunidad (con el código en el que se basa) para que cualquiera pueda usarlo, incluso si no está presente en la biblioteca
🤗 Transformers.
Ilustraremos todo esto con un modelo ResNet, envolviendo la clase ResNet de la [biblioteca timm](https://github.com/rwightman/pytorch-image-models) en un [`PreTrainedModel`].
## Escribir una configuración personalizada
Antes de adentrarnos en el modelo, primero escribamos su configuración. La configuración de un modelo es un objeto que
contendrá toda la información necesaria para construir el modelo. Como veremos en la siguiente sección, el modelo solo puede
tomar un `config` para ser inicializado, por lo que realmente necesitamos que ese objeto esté lo más completo posible.
En nuestro ejemplo, tomaremos un par de argumentos de la clase ResNet que tal vez queramos modificar. Las diferentes
configuraciones nos darán los diferentes tipos de ResNet que son posibles. Luego simplemente almacenamos esos argumentos
después de verificar la validez de algunos de ellos.
```python
from transformers import PretrainedConfig
from typing import List
class ResnetConfig(PretrainedConfig):
model_type = "resnet"
def __init__(
self,
block_type="bottleneck",
layers: List[int] = [3, 4, 6, 3],
num_classes: int = 1000,
input_channels: int = 3,
cardinality: int = 1,
base_width: int = 64,
stem_width: int = 64,
stem_type: str = "",
avg_down: bool = False,
**kwargs,
):
if block_type not in ["basic", "bottleneck"]:
raise ValueError(f"`block_type` must be 'basic' or bottleneck', got {block_type}.")
if stem_type not in ["", "deep", "deep-tiered"]:
raise ValueError(f"`stem_type` must be '', 'deep' or 'deep-tiered', got {stem_type}.")
self.block_type = block_type
self.layers = layers
self.num_classes = num_classes
self.input_channels = input_channels
self.cardinality = cardinality
self.base_width = base_width
self.stem_width = stem_width
self.stem_type = stem_type
self.avg_down = avg_down
super().__init__(**kwargs)
```
Las tres cosas importantes que debes recordar al escribir tu propia configuración son las siguientes:
- tienes que heredar de `PretrainedConfig`,
- el `__init__` de tu `PretrainedConfig` debe aceptar cualquier `kwargs`,
- esos `kwargs` deben pasarse a la superclase `__init__`.
La herencia es para asegurarte de obtener toda la funcionalidad de la biblioteca 🤗 Transformers, mientras que las otras dos
restricciones provienen del hecho de que una `PretrainedConfig` tiene más campos que los que estás configurando. Al recargar una
`config` con el método `from_pretrained`, esos campos deben ser aceptados por tu `config` y luego enviados a la superclase.
Definir un `model_type` para tu configuración (en este caso `model_type="resnet"`) no es obligatorio, a menos que quieras
registrar tu modelo con las clases automáticas (ver la última sección).
Una vez hecho esto, puedes crear y guardar fácilmente tu configuración como lo harías con cualquier otra configuración de un
modelo de la biblioteca. Así es como podemos crear una configuración resnet50d y guardarla:
```py
resnet50d_config = ResnetConfig(block_type="bottleneck", stem_width=32, stem_type="deep", avg_down=True)
resnet50d_config.save_pretrained("custom-resnet")
```
Esto guardará un archivo llamado `config.json` dentro de la carpeta `custom-resnet`. Luego puedes volver a cargar tu configuración
con el método `from_pretrained`:
```py
resnet50d_config = ResnetConfig.from_pretrained("custom-resnet")
```
También puedes usar cualquier otro método de la clase [`PretrainedConfig`], como [`~PretrainedConfig.push_to_hub`], para cargar
directamente tu configuración en el Hub.
## Escribir un modelo personalizado
Ahora que tenemos nuestra configuración de ResNet, podemos seguir escribiendo el modelo. En realidad escribiremos dos: una que
extrae las características ocultas de un grupo de imágenes (como [`BertModel`]) y una que es adecuada para clasificación de
imagenes (como [`BertForSequenceClassification`]).
Como mencionamos antes, solo escribiremos un envoltura (_wrapper_) libre del modelo para simplificar este ejemplo. Lo único que debemos
hacer antes de escribir esta clase es un mapeo entre los tipos de bloques y las clases de bloques reales. Luego se define el
modelo desde la configuración pasando todo a la clase `ResNet`:
```py
from transformers import PreTrainedModel
from timm.models.resnet import BasicBlock, Bottleneck, ResNet
from .configuration_resnet import ResnetConfig
BLOCK_MAPPING = {"basic": BasicBlock, "bottleneck": Bottleneck}
class ResnetModel(PreTrainedModel):
config_class = ResnetConfig
def __init__(self, config):
super().__init__(config)
block_layer = BLOCK_MAPPING[config.block_type]
self.model = ResNet(
block_layer,
config.layers,
num_classes=config.num_classes,
in_chans=config.input_channels,
cardinality=config.cardinality,
base_width=config.base_width,
stem_width=config.stem_width,
stem_type=config.stem_type,
avg_down=config.avg_down,
)
def forward(self, tensor):
return self.model.forward_features(tensor)
```
Para el modelo que clasificará las imágenes, solo cambiamos el método de avance (es decir, el método `forward`):
```py
import torch
class ResnetModelForImageClassification(PreTrainedModel):
config_class = ResnetConfig
def __init__(self, config):
super().__init__(config)
block_layer = BLOCK_MAPPING[config.block_type]
self.model = ResNet(
block_layer,
config.layers,
num_classes=config.num_classes,
in_chans=config.input_channels,
cardinality=config.cardinality,
base_width=config.base_width,
stem_width=config.stem_width,
stem_type=config.stem_type,
avg_down=config.avg_down,
)
def forward(self, tensor, labels=None):
logits = self.model(tensor)
if labels is not None:
loss = torch.nn.cross_entropy(logits, labels)
return {"loss": loss, "logits": logits}
return {"logits": logits}
```
En ambos casos, observa cómo heredamos de `PreTrainedModel` y llamamos a la inicialización de la superclase con `config`
(un poco como cuando escribes `torch.nn.Module`). La línea que establece `config_class` no es obligatoria, a menos
que quieras registrar tu modelo con las clases automáticas (consulta la última sección).
<Tip>
Si tu modelo es muy similar a un modelo dentro de la biblioteca, puedes reutilizar la misma configuración de ese modelo.
</Tip>
Puedes hacer que tu modelo devuelva lo que quieras, pero devolver un diccionario como lo hicimos para
`ResnetModelForImageClassification`, con el `loss` incluido cuando se pasan las etiquetas, hará que tu modelo se pueda
usar directamente dentro de la clase [`Trainer`]. Usar otro formato de salida está bien, siempre y cuando estés planeando usar
tu propio bucle de entrenamiento u otra biblioteca para el entrenamiento.
Ahora que tenemos nuestra clase, vamos a crear un modelo:
```py
resnet50d = ResnetModelForImageClassification(resnet50d_config)
```
Nuevamente, puedes usar cualquiera de los métodos de [`PreTrainedModel`], como [`~PreTrainedModel.save_pretrained`] o
[`~PreTrainedModel.push_to_hub`]. Usaremos el segundo en la siguiente sección y veremos cómo pasar los pesos del modelo
con el código de nuestro modelo. Pero primero, carguemos algunos pesos previamente entrenados dentro de nuestro modelo.
En tu caso de uso, probablemente estarás entrenando tu modelo personalizado con tus propios datos. Para ir rápido en este
tutorial, usaremos la versión preentrenada de resnet50d. Dado que nuestro modelo es solo un envoltorio alrededor del resnet50d
original, será fácil transferir esos pesos:
```py
import timm
pretrained_model = timm.create_model("resnet50d", pretrained=True)
resnet50d.model.load_state_dict(pretrained_model.state_dict())
```
Ahora veamos cómo asegurarnos de que cuando hacemos [`~PreTrainedModel.save_pretrained`] o [`~PreTrainedModel.push_to_hub`],
se guarda el código del modelo.
## Enviar el código al _Hub_
<Tip warning={true}>
Esta _API_ es experimental y puede tener algunos cambios leves en las próximas versiones.
</Tip>
Primero, asegúrate de que tu modelo esté completamente definido en un archivo `.py`. Puedes basarte en importaciones
relativas a otros archivos, siempre que todos los archivos estén en el mismo directorio (aún no admitimos submódulos
para esta característica). Para nuestro ejemplo, definiremos un archivo `modeling_resnet.py` y un archivo
`configuration_resnet.py` en una carpeta del directorio de trabajo actual llamado `resnet_model`. El archivo de configuración
contiene el código de `ResnetConfig` y el archivo del modelo contiene el código de `ResnetModel` y
`ResnetModelForImageClassification`.
```
.
└── resnet_model
├── __init__.py
├── configuration_resnet.py
└── modeling_resnet.py
```
El `__init__.py` puede estar vacío, solo está ahí para que Python detecte que `resnet_model` se puede usar como un módulo.
<Tip warning={true}>
Si copias archivos del modelo desde la biblioteca, deberás reemplazar todas las importaciones relativas en la parte superior
del archivo para importarlos desde el paquete `transformers`.
</Tip>
Ten en cuenta que puedes reutilizar (o subclasificar) una configuración o modelo existente.
Para compartir tu modelo con la comunidad, sigue estos pasos: primero importa el modelo y la configuración de ResNet desde
los archivos recién creados:
```py
from resnet_model.configuration_resnet import ResnetConfig
from resnet_model.modeling_resnet import ResnetModel, ResnetModelForImageClassification
```
Luego, debes decirle a la biblioteca que deseas copiar el código de esos objetos cuando usas el método `save_pretrained`
y registrarlos correctamente con una determinada clase automática (especialmente para modelos), simplemente ejecuta:
```py
ResnetConfig.register_for_auto_class()
ResnetModel.register_for_auto_class("AutoModel")
ResnetModelForImageClassification.register_for_auto_class("AutoModelForImageClassification")
```
Ten en cuenta que no es necesario especificar una clase automática para la configuración (solo hay una clase automática
para ellos, [`AutoConfig`]), pero es diferente para los modelos. Tu modelo personalizado podría ser adecuado para muchas
tareas diferentes, por lo que debes especificar cuál de las clases automáticas es la correcta para tu modelo.
A continuación, vamos a crear la configuración y los modelos como lo hicimos antes:
```py
resnet50d_config = ResnetConfig(block_type="bottleneck", stem_width=32, stem_type="deep", avg_down=True)
resnet50d = ResnetModelForImageClassification(resnet50d_config)
pretrained_model = timm.create_model("resnet50d", pretrained=True)
resnet50d.model.load_state_dict(pretrained_model.state_dict())
```
Ahora, para enviar el modelo al Hub, asegúrate de haber iniciado sesión. Ejecuta en tu terminal:
```bash
huggingface-cli login
```
o desde un _notebook_:
```py
from huggingface_hub import notebook_login
notebook_login()
```
Luego puedes ingresar a tu propio espacio (o una organización de la que seas miembro) de esta manera:
```py
resnet50d.push_to_hub("custom-resnet50d")
```
Además de los pesos del modelo y la configuración en formato json, esto también copió los archivos `.py` del modelo y la
configuración en la carpeta `custom-resnet50d` y subió el resultado al Hub. Puedes verificar el resultado en este
[repositorio de modelos](https://huggingface.co/sgugger/custom-resnet50d).
Consulta el tutorial sobre cómo [compartir modelos](model_sharing) para obtener más información sobre el método para subir modelos al Hub.
## Usar un modelo con código personalizado
Puedes usar cualquier configuración, modelo o _tokenizador_ con archivos de código personalizado en tu repositorio con las
clases automáticas y el método `from_pretrained`. Todos los archivos y códigos cargados en el Hub se analizan en busca de
malware (consulta la documentación de [seguridad del Hub](https://huggingface.co/docs/hub/security#malware-scanning) para
obtener más información), pero aún debes revisar el código del modelo y el autor para evitar la ejecución de código malicioso
en tu computadora. Configura `trust_remote_code=True` para usar un modelo con código personalizado:
```py
from transformers import AutoModelForImageClassification
model = AutoModelForImageClassification.from_pretrained("sgugger/custom-resnet50d", trust_remote_code=True)
```
También se recomienda encarecidamente pasar un _hash_ de confirmación como una "revisión" para asegurarte de que el autor
de los modelos no actualizó el código con algunas líneas nuevas maliciosas (a menos que confíes plenamente en los autores
de los modelos).
```py
commit_hash = "ed94a7c6247d8aedce4647f00f20de6875b5b292"
model = AutoModelForImageClassification.from_pretrained(
"sgugger/custom-resnet50d", trust_remote_code=True, revision=commit_hash
)
```
Ten en cuenta que al navegar por el historial de confirmaciones del repositorio del modelo en Hub, hay un botón para copiar
fácilmente el hash de confirmación de cualquier _commit_.
## Registrar un model con código personalizado a las clases automáticas
Si estás escribiendo una biblioteca que amplía 🤗 Transformers, es posible que quieras ampliar las clases automáticas para
incluir tu propio modelo. Esto es diferente de enviar el código al Hub en el sentido de que los usuarios necesitarán importar
tu biblioteca para obtener los modelos personalizados (al contrario de descargar automáticamente el código del modelo desde Hub).
Siempre que tu configuración tenga un atributo `model_type` que sea diferente de los tipos de modelos existentes, y que tus
clases modelo tengan los atributos `config_class` correctos, puedes agregarlos a las clases automáticas de la siguiente manera:
```py
from transformers import AutoConfig, AutoModel, AutoModelForImageClassification
AutoConfig.register("resnet", ResnetConfig)
AutoModel.register(ResnetConfig, ResnetModel)
AutoModelForImageClassification.register(ResnetConfig, ResnetModelForImageClassification)
```
Ten en cuenta que el primer argumento utilizado al registrar tu configuración personalizada en [`AutoConfig`] debe coincidir
con el `model_type` de tu configuración personalizada, y el primer argumento utilizado al registrar tus modelos personalizados
en cualquier clase del modelo automático debe coincidir con el `config_class ` de esos modelos.
| transformers/docs/source/es/custom_models.md/0 | {
"file_path": "transformers/docs/source/es/custom_models.md",
"repo_id": "transformers",
"token_count": 5983
} | 252 |
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Entrenamiento con scripts
Junto con los [notebooks](./noteboks/README) de 🤗 Transformers, también hay scripts con ejemplos que muestran cómo entrenar un modelo para una tarea en [PyTorch](https://github.com/huggingface/transformers/tree/main/examples/pytorch), [TensorFlow](https://github.com/huggingface/transformers/tree/main/examples/tensorflow), o [JAX/Flax](https://github.com/huggingface/transformers/tree/main/examples/flax).
También encontrarás scripts que hemos usado en nuestros [proyectos de investigación](https://github.com/huggingface/transformers/tree/main/examples/research_projects) y [ejemplos pasados](https://github.com/huggingface/transformers/tree/main/examples/legacy) que en su mayoría son aportados por la comunidad. Estos scripts no se mantienen activamente y requieren una versión específica de 🤗 Transformers que probablemente sea incompatible con la última versión de la biblioteca.
No se espera que los scripts de ejemplo funcionen de inmediato en todos los problemas, y es posible que debas adaptar el script al problema que estás tratando de resolver. Para ayudarte con esto, la mayoría de los scripts exponen completamente cómo se preprocesan los datos, lo que te permite editarlos según sea necesario para tu caso de uso.
Para cualquier característica que te gustaría implementar en un script de ejemplo, por favor discútelo en el [foro](https://discuss.huggingface.co/) o con un [issue](https://github.com/huggingface/transformers/issues) antes de enviar un Pull Request. Si bien agradecemos las correcciones de errores, es poco probable que fusionemos un Pull Request que agregue más funcionalidad a costa de la legibilidad.
Esta guía te mostrará cómo ejecutar un ejemplo de un script de entrenamiento para resumir texto en [PyTorch](https://github.com/huggingface/transformers/tree/main/examples/pytorch/summarization) y [TensorFlow](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/summarization). Se espera que todos los ejemplos funcionen con ambos frameworks a menos que se especifique lo contrario.
## Configuración
Para ejecutar con éxito la última versión de los scripts de ejemplo debes **instalar 🤗 Transformers desde su fuente** en un nuevo entorno virtual:
```bash
git clone https://github.com/huggingface/transformers
cd transformers
pip install .
```
Para versiones anteriores de los scripts de ejemplo, haz clic en alguno de los siguientes links:
<details>
<summary>Ejemplos de versiones anteriores de 🤗 Transformers</summary>
<ul>
<li><a href="https://github.com/huggingface/transformers/tree/v4.5.1/examples">v4.5.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.4.2/examples">v4.4.2</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.3.3/examples">v4.3.3</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.2.2/examples">v4.2.2</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.1.1/examples">v4.1.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.0.1/examples">v4.0.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.5.1/examples">v3.5.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.4.0/examples">v3.4.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.3.1/examples">v3.3.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.2.0/examples">v3.2.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.1.0/examples">v3.1.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.0.2/examples">v3.0.2</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.11.0/examples">v2.11.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.10.0/examples">v2.10.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.9.1/examples">v2.9.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.8.0/examples">v2.8.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.7.0/examples">v2.7.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.6.0/examples">v2.6.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.5.1/examples">v2.5.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.4.0/examples">v2.4.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.3.0/examples">v2.3.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.2.0/examples">v2.2.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.1.0/examples">v2.1.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.0.0/examples">v2.0.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v1.2.0/examples">v1.2.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v1.1.0/examples">v1.1.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v1.0.0/examples">v1.0.0</a></li>
</ul>
</details>
Luego cambia tu clon actual de 🤗 Transformers a una versión específica, por ejemplo v3.5.1:
```bash
git checkout tags/v3.5.1
```
Una vez que hayas configurado la versión correcta de la biblioteca, ve a la carpeta de ejemplo de tu elección e instala los requisitos específicos del ejemplo:
```bash
pip install -r requirements.txt
```
## Ejecutar un script
<frameworkcontent>
<pt>
El script de ejemplo descarga y preprocesa un conjunto de datos de la biblioteca 🤗 [Datasets](https://huggingface.co/docs/datasets/). Luego, el script ajusta un conjunto de datos con [Trainer](https://huggingface.co/docs/transformers/main_classes/trainer) en una arquitectura que soporta la tarea de resumen. El siguiente ejemplo muestra cómo ajustar un [T5-small](https://huggingface.co/t5-small) en el conjunto de datos [CNN/DailyMail](https://huggingface.co/datasets/cnn_dailymail). El modelo T5 requiere un argumento adicional `source_prefix` debido a cómo fue entrenado. Este aviso le permite a T5 saber que se trata de una tarea de resumir.
```bash
python examples/pytorch/summarization/run_summarization.py \
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
```
</pt>
<tf>
El script de ejemplo descarga y preprocesa un conjunto de datos de la biblioteca 🤗 [Datasets](https://huggingface.co/docs/datasets/). Luego, el script ajusta un conjunto de datos utilizando Keras en una arquitectura que soporta la tarea de resumir. El siguiente ejemplo muestra cómo ajustar un [T5-small](https://huggingface.co/t5-small) en el conjunto de datos [CNN/DailyMail](https://huggingface.co/datasets/cnn_dailymail). El modelo T5 requiere un argumento adicional `source_prefix` debido a cómo fue entrenado. Este aviso le permite a T5 saber que se trata de una tarea de resumir.
```bash
python examples/tensorflow/summarization/run_summarization.py \
--model_name_or_path t5-small \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 16 \
--num_train_epochs 3 \
--do_train \
--do_eval
```
</tf>
</frameworkcontent>
## Entrenamiento distribuido y de precisión mixta
[Trainer](https://huggingface.co/docs/transformers/main_classes/trainer) admite un entrenamiento distribuido y de precisión mixta, lo que significa que también puedes usarlo en un script. Para habilitar ambas características:
- Agrega el argumento `fp16` para habilitar la precisión mixta.
- Establece la cantidad de GPU que se usará con el argumento `nproc_per_node`.
```bash
torchrun \
--nproc_per_node 8 pytorch/summarization/run_summarization.py \
--fp16 \
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
```
Los scripts de TensorFlow utilizan [`MirroredStrategy`](https://www.tensorflow.org/guide/distributed_training#mirroredstrategy) para el entrenamiento distribuido, y no es necesario agregar argumentos adicionales al script de entrenamiento. El script de TensorFlow utilizará múltiples GPUs de forma predeterminada si están disponibles.
## Ejecutar un script en una TPU
<frameworkcontent>
<pt>
Las Unidades de Procesamiento de Tensor (TPUs) están diseñadas específicamente para acelerar el rendimiento. PyTorch admite TPU con el compilador de aprendizaje profundo [XLA](https://www.tensorflow.org/xla) (consulta [aquí](https://github.com/pytorch/xla/blob/master/README.md) para obtener más detalles). Para usar una TPU, inicia el script `xla_spawn.py` y usa el argumento `num_cores` para establecer la cantidad de núcleos de TPU que deseas usar.
```bash
python xla_spawn.py --num_cores 8 \
summarization/run_summarization.py \
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
```
</pt>
<tf>
Las Unidades de Procesamiento de Tensor (TPUs) están diseñadas específicamente para acelerar el rendimiento. TensorFlow utiliza [`TPUStrategy`](https://www.tensorflow.org/guide/distributed_training#tpustrategy) para entrenar en TPUs. Para usar una TPU, pasa el nombre del recurso de la TPU al argumento `tpu`
```bash
python run_summarization.py \
--tpu name_of_tpu_resource \
--model_name_or_path t5-small \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 16 \
--num_train_epochs 3 \
--do_train \
--do_eval
```
</tf>
</frameworkcontent>
## Ejecutar un script con 🤗 Accelerate
🤗 [Accelerate](https://huggingface.co/docs/accelerate) es una biblioteca exclusiva de PyTorch que ofrece un método unificado para entrenar un modelo en varios tipos de configuraciones (solo CPU, GPU múltiples, TPU) mientras mantiene una visibilidad completa en el ciclo de entrenamiento de PyTorch. Asegúrate de tener 🤗 Accelerate instalado si aún no lo tienes:
> Nota: Como Accelerate se está desarrollando rápidamente, debes instalar la versión git de Accelerate para ejecutar los scripts
```bash
pip install git+https://github.com/huggingface/accelerate
```
En lugar del script `run_summarization.py`, debes usar el script `run_summarization_no_trainer.py`. Los scripts compatibles con 🤗 Accelerate tendrán un archivo `task_no_trainer.py` en la carpeta. Comienza ejecutando el siguiente comando para crear y guardar un archivo de configuración:
```bash
accelerate config
```
Prueba tu configuración para asegurarte que está configurada correctamente:
```bash
accelerate test
```
Todo listo para iniciar el entrenamiento:
```bash
accelerate launch run_summarization_no_trainer.py \
--model_name_or_path t5-small \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir ~/tmp/tst-summarization
```
## Usar un conjunto de datos personalizado
El script de la tarea resumir admite conjuntos de datos personalizados siempre que sean un archivo CSV o JSON Line. Cuando uses tu propio conjunto de datos, necesitas especificar varios argumentos adicionales:
- `train_file` y `validation_file` especifican la ruta a tus archivos de entrenamiento y validación.
- `text_column` es el texto de entrada para resumir.
- `summary_column` es el texto de destino para la salida.
Un script para resumir que utiliza un conjunto de datos personalizado se vera así:
```bash
python examples/pytorch/summarization/run_summarization.py \
--model_name_or_path t5-small \
--do_train \
--do_eval \
--train_file path_to_csv_or_jsonlines_file \
--validation_file path_to_csv_or_jsonlines_file \
--text_column text_column_name \
--summary_column summary_column_name \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--overwrite_output_dir \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--predict_with_generate
```
## Prueba un script
A veces, es una buena idea ejecutar tu secuencia de comandos en una cantidad menor de ejemplos para asegurarte de que todo funciona como se espera antes de comprometerte con un conjunto de datos completo, lo que puede demorar horas en completarse. Utiliza los siguientes argumentos para truncar el conjunto de datos a un número máximo de muestras:
- `max_train_samples`
- `max_eval_samples`
- `max_predict_samples`
```bash
python examples/pytorch/summarization/run_summarization.py \
--model_name_or_path t5-small \
--max_train_samples 50 \
--max_eval_samples 50 \
--max_predict_samples 50 \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
```
No todos los scripts de ejemplo admiten el argumento `max_predict_samples`. Puede que desconozcas si la secuencia de comandos admite este argumento, agrega `-h` para verificar:
```bash
examples/pytorch/summarization/run_summarization.py -h
```
## Reanudar el entrenamiento desde el punto de control
Otra opción útil para habilitar es reanudar el entrenamiento desde un punto de control anterior. Esto asegurará que puedas continuar donde lo dejaste sin comenzar de nuevo si tu entrenamiento se interrumpe. Hay dos métodos para reanudar el entrenamiento desde un punto de control.
El primer método utiliza el argumento `output_dir previous_output_dir` para reanudar el entrenamiento desde el último punto de control almacenado en `output_dir`. En este caso, debes eliminar `overwrite_output_dir`:
```bash
python examples/pytorch/summarization/run_summarization.py
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--output_dir previous_output_dir \
--predict_with_generate
```
El segundo método utiliza el argumento `resume_from_checkpoint path_to_specific_checkpoint` para reanudar el entrenamiento desde una carpeta de punto de control específica.
```bash
python examples/pytorch/summarization/run_summarization.py
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--resume_from_checkpoint path_to_specific_checkpoint \
--predict_with_generate
```
## Comparte tu modelo
Todos los scripts pueden cargar tu modelo final en el [Model Hub](https://huggingface.co/models). Asegúrate de haber iniciado sesión en Hugging Face antes de comenzar:
```bash
huggingface-cli login
```
Luego agrega el argumento `push_to_hub` al script. Este argumento creará un repositorio con tu nombre de usuario Hugging Face y el nombre de la carpeta especificado en `output_dir`.
Para darle a tu repositorio un nombre específico, usa el argumento `push_to_hub_model_id` para añadirlo. El repositorio se incluirá automáticamente en tu namespace.
El siguiente ejemplo muestra cómo cargar un modelo con un nombre de repositorio específico:
```bash
python examples/pytorch/summarization/run_summarization.py
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--push_to_hub \
--push_to_hub_model_id finetuned-t5-cnn_dailymail \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
```
| transformers/docs/source/es/run_scripts.md/0 | {
"file_path": "transformers/docs/source/es/run_scripts.md",
"repo_id": "transformers",
"token_count": 6952
} | 253 |
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Visite rapide
[[open-in-colab]]
Soyez opérationnel avec 🤗 Transformers ! Que vous soyez un développeur ou un utilisateur lambda, cette visite rapide vous aidera à démarrer et vous montrera comment utiliser le [`pipeline`] pour l'inférence, charger un modèle pré-entraîné et un préprocesseur avec une [AutoClass](./model_doc/auto), et entraîner rapidement un modèle avec PyTorch ou TensorFlow. Si vous êtes un débutant, nous vous recommandons de consulter nos tutoriels ou notre [cours](https://huggingface.co/course/chapter1/1) suivant pour des explications plus approfondies des concepts présentés ici.
Avant de commencer, assurez-vous que vous avez installé toutes les bibliothèques nécessaires :
```bash
!pip install transformers datasets
```
Vous aurez aussi besoin d'installer votre bibliothèque d'apprentissage profond favorite :
<frameworkcontent>
<pt>
```bash
pip install torch
```
</pt>
<tf>
```bash
pip install tensorflow
```
</tf>
</frameworkcontent>
## Pipeline
<Youtube id="tiZFewofSLM"/>
Le [`pipeline`] est le moyen le plus simple d'utiliser un modèle pré-entraîné pour l'inférence. Vous pouvez utiliser le [`pipeline`] prêt à l'emploi pour de nombreuses tâches dans différentes modalités. Consultez le tableau ci-dessous pour connaître les tâches prises en charge :
| **Tâche** | **Description** | **Modalité** | **Identifiant du pipeline** |
|------------------------------|--------------------------------------------------------------------------------------------------------------|----------------------|-----------------------------------------------|
| Classification de texte | Attribue une catégorie à une séquence de texte donnée | Texte | pipeline(task="sentiment-analysis") |
| Génération de texte | Génère du texte à partir d'une consigne donnée | Texte | pipeline(task="text-generation") |
| Reconnaissance de token nommé | Attribue une catégorie à chaque token dans une séquence (personnes, organisation, localisation, etc.) | Texte | pipeline(task="ner") |
| Question réponse | Extrait une réponse du texte en fonction du contexte et d'une question | Texte | pipeline(task="question-answering") |
| Prédiction de token masqué | Prédit correctement le token masqué dans une séquence | Texte | pipeline(task="fill-mask") |
| Génération de résumé | Génère un résumé d'une séquence de texte donnée ou d'un document | Texte | pipeline(task="summarization") |
| Traduction | Traduit du texte d'un langage à un autre | Texte | pipeline(task="translation") |
| Classification d'image | Attribue une catégorie à une image | Image | pipeline(task="image-classification") |
| Segmentation d'image | Attribue une catégorie à chaque pixel d'une image (supporte la segmentation sémantique, panoptique et d'instance) | Image | pipeline(task="image-segmentation") |
| Détection d'objets | Prédit les délimitations et catégories d'objets dans une image | Image | pipeline(task="object-detection") |
| Classification d'audio | Attribue une catégorie à un fichier audio | Audio | pipeline(task="audio-classification") |
| Reconnaissance automatique de la parole | Extrait le discours d'un fichier audio en texte | Audio | pipeline(task="automatic-speech-recognition") |
| Question réponse visuels | Etant données une image et une question, répond correctement à une question sur l'image | Modalités multiples | pipeline(task="vqa") |
Commencez par créer une instance de [`pipeline`] et spécifiez la tâche pour laquelle vous souhaitez l'utiliser. Vous pouvez utiliser le [`pipeline`] pour n'importe laquelle des tâches mentionnées dans le tableau précédent. Pour obtenir une liste complète des tâches prises en charge, consultez la documentation de l'[API pipeline](./main_classes/pipelines). Dans ce guide, nous utiliserons le [`pipeline`] pour l'analyse des sentiments à titre d'exemple :
```py
>>> from transformers import pipeline
>>> classifier = pipeline("sentiment-analysis")
```
Le [`pipeline`] télécharge et stocke en cache un [modèle pré-entraîné](https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english) et un tokenizer par défaut pour l'analyse des sentiments. Vous pouvez maintenant utiliser le `classifier` sur le texte de votre choix :
```py
>>> classifier("We are very happy to show you the 🤗 Transformers library.")
[{'label': 'POSITIVE', 'score': 0.9998}]
```
Si vous voulez classifier plus qu'un texte, donnez une liste de textes au [`pipeline`] pour obtenir une liste de dictionnaires en retour :
```py
>>> results = classifier(["We are very happy to show you the 🤗 Transformers library.", "We hope you don't hate it."])
>>> for result in results:
... print(f"label: {result['label']}, avec le score de: {round(result['score'], 4)}")
label: POSITIVE, avec le score de: 0.9998
label: NEGATIVE, avec le score de: 0.5309
```
Le [`pipeline`] peut aussi itérer sur un jeu de données entier pour n'importe quelle tâche. Prenons par exemple la reconnaissance automatique de la parole :
```py
>>> import torch
>>> from transformers import pipeline
>>> speech_recognizer = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-base-960h")
```
Chargez un jeu de données audio (voir le 🤗 Datasets [Quick Start](https://huggingface.co/docs/datasets/quickstart#audio) pour plus de détails) sur lequel vous souhaitez itérer. Pour cet exemple, nous chargeons le jeu de données [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) :
```py
>>> from datasets import load_dataset, Audio
>>> dataset = load_dataset("PolyAI/minds14", name="en-US", split="train") # doctest: +IGNORE_RESULT
```
Vous devez vous assurer que le taux d'échantillonnage de l'ensemble de données correspond au taux d'échantillonnage sur lequel [`facebook/wav2vec2-base-960h`](https://huggingface.co/facebook/wav2vec2-base-960h) a été entraîné :
```py
>>> dataset = dataset.cast_column("audio", Audio(sampling_rate=speech_recognizer.feature_extractor.sampling_rate))
```
Les fichiers audio sont automatiquement chargés et rééchantillonnés lors de l'appel de la colonne `"audio"`.
Extrayez les tableaux de formes d'ondes brutes des quatre premiers échantillons et passez-les comme une liste au pipeline :
```py
>>> result = speech_recognizer(dataset[:4]["audio"])
>>> print([d["text"] for d in result])
['I WOULD LIKE TO SET UP A JOINT ACCOUNT WITH MY PARTNER HOW DO I PROCEED WITH DOING THAT', "FODING HOW I'D SET UP A JOIN TO HET WITH MY WIFE AND WHERE THE AP MIGHT BE", "I I'D LIKE TOY SET UP A JOINT ACCOUNT WITH MY PARTNER I'M NOT SEEING THE OPTION TO DO IT ON THE AP SO I CALLED IN TO GET SOME HELP CAN I JUST DO IT OVER THE PHONE WITH YOU AND GIVE YOU THE INFORMATION OR SHOULD I DO IT IN THE AP AND I'M MISSING SOMETHING UQUETTE HAD PREFERRED TO JUST DO IT OVER THE PHONE OF POSSIBLE THINGS", 'HOW DO I THURN A JOIN A COUNT']
```
Pour les ensembles de données plus importants où les entrées sont volumineuses (comme dans les domaines de la parole ou de la vision), utilisez plutôt un générateur au lieu d'une liste pour charger toutes les entrées en mémoire. Pour plus d'informations, consultez la documentation de l'[API pipeline](./main_classes/pipelines).
### Utiliser une autre modèle et tokenizer dans le pipeline
Le [`pipeline`] peut être utilisé avec n'importe quel modèle du [Hub](https://huggingface.co/models), ce qui permet d'adapter facilement le [`pipeline`] à d'autres cas d'utilisation. Par exemple, si vous souhaitez un modèle capable de traiter du texte français, utilisez les filtres du Hub pour trouver un modèle approprié. Le premier résultat renvoie un [modèle BERT](https://huggingface.co/nlptown/bert-base-multilingual-uncased-sentiment) multilingue finetuné pour l'analyse des sentiments que vous pouvez utiliser pour le texte français :
```py
>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
```
<frameworkcontent>
<pt>
Utilisez [`AutoModelForSequenceClassification`] et [`AutoTokenizer`] pour charger le modèle pré-entraîné et le tokenizer adapté (plus de détails sur une `AutoClass` dans la section suivante) :
```py
>>> from transformers import AutoTokenizer, AutoModelForSequenceClassification
>>> model = AutoModelForSequenceClassification.from_pretrained(model_name)
>>> tokenizer = AutoTokenizer.from_pretrained(model_name)
```
</pt>
<tf>
Utilisez [`TFAutoModelForSequenceClassification`] et [`AutoTokenizer`] pour charger le modèle pré-entraîné et le tokenizer adapté (plus de détails sur une `TFAutoClass` dans la section suivante) :
```py
>>> from transformers import AutoTokenizer, TFAutoModelForSequenceClassification
>>> model = TFAutoModelForSequenceClassification.from_pretrained(model_name)
>>> tokenizer = AutoTokenizer.from_pretrained(model_name)
```
</tf>
</frameworkcontent>
Spécifiez le modèle et le tokenizer dans le [`pipeline`], et utilisez le `classifier` sur le texte en français :
```py
>>> classifier = pipeline("sentiment-analysis", model=model, tokenizer=tokenizer)
>>> classifier("Nous sommes très heureux de vous présenter la bibliothèque 🤗 Transformers.")
[{'label': '5 stars', 'score': 0.7273}]
```
Si vous ne parvenez pas à trouver un modèle adapté à votre cas d'utilisation, vous devrez finetuner un modèle pré-entraîné sur vos données. Jetez un coup d'œil à notre [tutoriel sur le finetuning](./training) pour apprendre comment faire. Enfin, après avoir finetuné votre modèle pré-entraîné, pensez à [partager](./model_sharing) le modèle avec la communauté sur le Hub afin de démocratiser l'apprentissage automatique pour tous ! 🤗
## AutoClass
<Youtube id="AhChOFRegn4"/>
Les classes [`AutoModelForSequenceClassification`] et [`AutoTokenizer`] fonctionnent ensemble pour créer un [`pipeline`] comme celui que vous avez utilisé ci-dessus. Une [AutoClass](./model_doc/auto) est un raccourci qui récupère automatiquement l'architecture d'un modèle pré-entraîné à partir de son nom ou de son emplacement. Il vous suffit de sélectionner l'`AutoClass` appropriée à votre tâche et la classe de prétraitement qui lui est associée.
Reprenons l'exemple de la section précédente et voyons comment vous pouvez utiliser l'`AutoClass` pour reproduire les résultats du [`pipeline`].
### AutoTokenizer
Un tokenizer est chargé de prétraiter le texte pour en faire un tableau de chiffres qui servira d'entrée à un modèle. De nombreuses règles régissent le processus de tokenisation, notamment la manière de diviser un mot et le niveau auquel les mots doivent être divisés (pour en savoir plus sur la tokenisation, consultez le [résumé](./tokenizer_summary)). La chose la plus importante à retenir est que vous devez instancier un tokenizer avec le même nom de modèle pour vous assurer que vous utilisez les mêmes règles de tokenisation que celles avec lesquelles un modèle a été pré-entraîné.
Chargez un tokenizer avec [`AutoTokenizer`] :
```py
>>> from transformers import AutoTokenizer
>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
>>> tokenizer = AutoTokenizer.from_pretrained(model_name)
```
Passez votre texte au tokenizer :
```py
>>> encoding = tokenizer("We are very happy to show you the 🤗 Transformers library.")
>>> print(encoding)
{'input_ids': [101, 11312, 10320, 12495, 19308, 10114, 11391, 10855, 10103, 100, 58263, 13299, 119, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
```
Le tokenizer retourne un dictionnaire contenant :
* [input_ids](./glossary#input-ids): la représentation numérique des tokens.
* [attention_mask](.glossary#attention-mask): indique quels tokens doivent faire l'objet d'une attention particulière (plus particulièrement les tokens de remplissage).
Un tokenizer peut également accepter une liste de textes, et remplir et tronquer le texte pour retourner un échantillon de longueur uniforme :
<frameworkcontent>
<pt>
```py
>>> pt_batch = tokenizer(
... ["We are very happy to show you the 🤗 Transformers library.", "We hope you don't hate it."],
... padding=True,
... truncation=True,
... max_length=512,
... return_tensors="pt",
... )
```
</pt>
<tf>
```py
>>> tf_batch = tokenizer(
... ["We are very happy to show you the 🤗 Transformers library.", "We hope you don't hate it."],
... padding=True,
... truncation=True,
... max_length=512,
... return_tensors="tf",
... )
```
</tf>
</frameworkcontent>
<Tip>
Consultez le tutoriel [prétraitement](./preprocessing) pour plus de détails sur la tokenisation, et sur la manière d'utiliser un [`AutoImageProcessor`], un [`AutoFeatureExtractor`] et un [`AutoProcessor`] pour prétraiter les images, l'audio et les contenus multimodaux.
</Tip>
### AutoModel
<frameworkcontent>
<pt>
🤗 Transformers fournit un moyen simple et unifié de charger des instances pré-entraînées. Cela signifie que vous pouvez charger un [`AutoModel`] comme vous chargeriez un [`AutoTokenizer`]. La seule différence est de sélectionner l'[`AutoModel`] approprié pour la tâche. Pour une classification de texte (ou de séquence de textes), vous devez charger [`AutoModelForSequenceClassification`] :
```py
>>> from transformers import AutoModelForSequenceClassification
>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
>>> pt_model = AutoModelForSequenceClassification.from_pretrained(model_name)
```
<Tip>
Voir le [résumé de la tâche](./task_summary) pour vérifier si elle est prise en charge par une classe [`AutoModel`].
</Tip>
Maintenant, passez votre échantillon d'entrées prétraitées directement au modèle. Il vous suffit de décompresser le dictionnaire en ajoutant `**` :
```py
>>> pt_outputs = pt_model(**pt_batch)
```
Le modèle produit les activations finales dans l'attribut `logits`. Appliquez la fonction softmax aux `logits` pour récupérer les probabilités :
```py
>>> from torch import nn
>>> pt_predictions = nn.functional.softmax(pt_outputs.logits, dim=-1)
>>> print(pt_predictions)
tensor([[0.0021, 0.0018, 0.0115, 0.2121, 0.7725],
[0.2084, 0.1826, 0.1969, 0.1755, 0.2365]], grad_fn=<SoftmaxBackward0>)
```
</pt>
<tf>
🤗 Transformers fournit un moyen simple et unifié de charger des instances pré-entraînés. Cela signifie que vous pouvez charger un [`TFAutoModel`] comme vous chargeriez un [`AutoTokenizer`]. La seule différence est de sélectionner le [`TFAutoModel`] approprié pour la tâche. Pour une classification de texte (ou de séquence de textes), vous devez charger [`TFAutoModelForSequenceClassification`] :
```py
>>> from transformers import TFAutoModelForSequenceClassification
>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained(model_name)
```
<Tip>
Voir le [résumé de la tâche](./task_summary) pour vérifier si elle est prise en charge par une classe [`AutoModel`].
</Tip>
Passez maintenant votre échantillon d'entrées prétraitées directement au modèle en passant les clés du dictionnaire directement aux tensors :
```py
>>> tf_outputs = tf_model(tf_batch)
```
Le modèle produit les activations finales dans l'attribut `logits`. Appliquez la fonction softmax aux `logits` pour récupérer les probabilités :
```py
>>> import tensorflow as tf
>>> tf_predictions = tf.nn.softmax(tf_outputs.logits, axis=-1)
>>> tf_predictions # doctest: +IGNORE_RESULT
```
</tf>
</frameworkcontent>
<Tip>
Tous les modèles 🤗 Transformers (PyTorch ou TensorFlow) produisent les tensors *avant* la fonction d'activation finale (comme softmax) car la fonction d'activation finale est souvent fusionnée avec le calcul de la perte. Les structures produites par le modèle sont des classes de données spéciales, de sorte que leurs attributs sont autocomplétés dans un environnement de développement. Les structures produites par le modèle se comportent comme un tuple ou un dictionnaire (vous pouvez les indexer avec un entier, une tranche ou une chaîne), auquel cas les attributs qui sont None sont ignorés.
</Tip>
### Sauvegarder un modèle
<frameworkcontent>
<pt>
Une fois que votre modèle est finetuné, vous pouvez le sauvegarder avec son tokenizer en utilisant [`PreTrainedModel.save_pretrained`] :
```py
>>> pt_save_directory = "./pt_save_pretrained"
>>> tokenizer.save_pretrained(pt_save_directory) # doctest: +IGNORE_RESULT
>>> pt_model.save_pretrained(pt_save_directory)
```
Lorsque vous voulez réutiliser le modèle, rechargez-le avec [`PreTrainedModel.from_pretrained`] :
```py
>>> pt_model = AutoModelForSequenceClassification.from_pretrained("./pt_save_pretrained")
```
</pt>
<tf>
Une fois que votre modèle est finetuné, vous pouvez le sauvegarder avec son tokenizer en utilisant [`TFPreTrainedModel.save_pretrained`] :
```py
>>> tf_save_directory = "./tf_save_pretrained"
>>> tokenizer.save_pretrained(tf_save_directory) # doctest: +IGNORE_RESULT
>>> tf_model.save_pretrained(tf_save_directory)
```
Lorsque vous voulez réutiliser le modèle, rechargez-le avec [`TFPreTrainedModel.from_pretrained`] :
```py
>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained("./tf_save_pretrained")
```
</tf>
</frameworkcontent>
Une fonctionnalité particulièrement cool 🤗 Transformers est la possibilité d'enregistrer un modèle et de le recharger en tant que modèle PyTorch ou TensorFlow. Le paramètre `from_pt` ou `from_tf` permet de convertir le modèle d'un framework à l'autre :
<frameworkcontent>
<pt>
```py
>>> from transformers import AutoModel
>>> tokenizer = AutoTokenizer.from_pretrained(tf_save_directory)
>>> pt_model = AutoModelForSequenceClassification.from_pretrained(tf_save_directory, from_tf=True)
```
</pt>
<tf>
```py
>>> from transformers import TFAutoModel
>>> tokenizer = AutoTokenizer.from_pretrained(pt_save_directory)
>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained(pt_save_directory, from_pt=True)
```
</tf>
</frameworkcontent>
## Constructions de modèles personnalisés
Vous pouvez modifier la configuration du modèle pour changer la façon dont un modèle est construit. La configuration spécifie les attributs d'un modèle, tels que le nombre de couches ou de têtes d'attention. Vous partez de zéro lorsque vous initialisez un modèle à partir d'une configuration personnalisée. Les attributs du modèle sont initialisés de manière aléatoire et vous devrez entraîner le modèle avant de pouvoir l'utiliser pour obtenir des résultats significatifs.
Commencez par importer [`AutoConfig`], puis chargez le modèle pré-entraîné que vous voulez modifier. Dans [`AutoConfig.from_pretrained`], vous pouvez spécifier l'attribut que vous souhaitez modifier, tel que le nombre de têtes d'attention :
```py
>>> from transformers import AutoConfig
>>> my_config = AutoConfig.from_pretrained("distilbert-base-uncased", n_heads=12)
```
<frameworkcontent>
<pt>
Créez un modèle personnalisé à partir de votre configuration avec [`AutoModel.from_config`] :
```py
>>> from transformers import AutoModel
>>> my_model = AutoModel.from_config(my_config)
```
</pt>
<tf>
Créez un modèle personnalisé à partir de votre configuration avec [`TFAutoModel.from_config`] :
```py
>>> from transformers import TFAutoModel
>>> my_model = TFAutoModel.from_config(my_config)
```
</tf>
</frameworkcontent>
Consultez le guide [Créer une architecture personnalisée](./create_a_model) pour plus d'informations sur la création de configurations personnalisées.
## Trainer - une boucle d'entraînement optimisée par PyTorch
Tous les modèles sont des [`torch.nn.Module`](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) standard, vous pouvez donc les utiliser dans n'importe quelle boucle d'entraînement typique. Bien que vous puissiez écrire votre propre boucle d'entraînement, 🤗 Transformers fournit une classe [`Trainer`] pour PyTorch, qui contient la boucle d'entraînement de base et ajoute des fonctionnalités supplémentaires comme l'entraînement distribué, la précision mixte, et plus encore.
En fonction de votre tâche, vous passerez généralement les paramètres suivants à [`Trainer`] :
1. Un [`PreTrainedModel`] ou un [`torch.nn.Module`](https://pytorch.org/docs/stable/nn.html#torch.nn.Module):
```py
>>> from transformers import AutoModelForSequenceClassification
>>> model = AutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased")
```
2. [`TrainingArguments`] contient les hyperparamètres du modèle que vous pouvez changer comme le taux d'apprentissage, la taille de l'échantillon, et le nombre d'époques pour s'entraîner. Les valeurs par défaut sont utilisées si vous ne spécifiez pas d'hyperparamètres d'apprentissage :
```py
>>> from transformers import TrainingArguments
>>> training_args = TrainingArguments(
... output_dir="path/to/save/folder/",
... learning_rate=2e-5,
... per_device_train_batch_size=8,
... per_device_eval_batch_size=8,
... num_train_epochs=2,
... )
```
3. Une classe de prétraitement comme un tokenizer, un processeur d'images ou un extracteur de caractéristiques :
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
```
4. Chargez un jeu de données :
```py
>>> from datasets import load_dataset
>>> dataset = load_dataset("rotten_tomatoes") # doctest: +IGNORE_RESULT
```
5. Créez une fonction qui transforme le texte du jeu de données en token :
```py
>>> def tokenize_dataset(dataset):
... return tokenizer(dataset["text"])
```
Puis appliquez-la à l'intégralité du jeu de données avec [`~datasets.Dataset.map`]:
```py
>>> dataset = dataset.map(tokenize_dataset, batched=True)
```
6. Un [`DataCollatorWithPadding`] pour créer un échantillon d'exemples à partir de votre jeu de données :
```py
>>> from transformers import DataCollatorWithPadding
>>> data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
```
Maintenant, rassemblez tous ces éléments dans un [`Trainer`] :
```py
>>> from transformers import Trainer
>>> trainer = Trainer(
... model=model,
... args=training_args,
... train_dataset=dataset["train"],
... eval_dataset=dataset["test"],
... tokenizer=tokenizer,
... data_collator=data_collator,
... ) # doctest: +SKIP
```
Une fois que vous êtes prêt, appelez la fonction [`~Trainer.train`] pour commencer l'entraînement :
```py
>>> trainer.train() # doctest: +SKIP
```
<Tip>
Pour les tâches - comme la traduction ou la génération de résumé - qui utilisent un modèle séquence à séquence, utilisez plutôt les classes [`Seq2SeqTrainer`] et [`Seq2SeqTrainingArguments`].
</Tip>
Vous pouvez personnaliser le comportement de la boucle d'apprentissage en redéfinissant les méthodes à l'intérieur de [`Trainer`]. Cela vous permet de personnaliser des caractéristiques telles que la fonction de perte, l'optimiseur et le planificateur. Consultez la documentation de [`Trainer`] pour savoir quelles méthodes peuvent être redéfinies.
L'autre moyen de personnaliser la boucle d'apprentissage est d'utiliser les [Callbacks](./main_classes/callbacks). Vous pouvez utiliser les callbacks pour intégrer d'autres bibliothèques et inspecter la boucle d'apprentissage afin de suivre la progression ou d'arrêter l'apprentissage plus tôt. Les callbacks ne modifient rien dans la boucle d'apprentissage elle-même. Pour personnaliser quelque chose comme la fonction de perte, vous devez redéfinir le [`Trainer`] à la place.
## Entraînement avec TensorFlow
Tous les modèles sont des modèles standard [`tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model) afin qu'ils puissent être entraînés avec TensorFlow avec l'API [Keras](https://keras.io/). 🤗 Transformers fournit la fonction [`~TFPreTrainedModel.prepare_tf_dataset`] pour charger facilement votre jeu de données comme un `tf.data.Dataset` afin que vous puissiez commencer l'entraînement immédiatement avec les fonctions [`compile`](https://keras.io/api/models/model_training_apis/#compile-method) et [`fit`](https://keras.io/api/models/model_training_apis/#fit-method) de Keras.
1. Vous commencez avec un modèle [`TFPreTrainedModel`] ou [`tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model) :
```py
>>> from transformers import TFAutoModelForSequenceClassification
>>> model = TFAutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased")
```
2. Une classe de prétraitement comme un tokenizer, un processeur d'images ou un extracteur de caractéristiques :
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
```
3. Créez une fonction qui transforme le texte du jeu de données en token :
```py
>>> def tokenize_dataset(dataset):
... return tokenizer(dataset["text"]) # doctest: +SKIP
```
4. Appliquez le tokenizer à l'ensemble du jeu de données avec [`~datasets.Dataset.map`] et passez ensuite le jeu de données et le tokenizer à [`~TFPreTrainedModel.prepare_tf_dataset`]. Vous pouvez également modifier la taille de l'échantillon et mélanger le jeu de données ici si vous le souhaitez :
```py
>>> dataset = dataset.map(tokenize_dataset) # doctest: +SKIP
>>> tf_dataset = model.prepare_tf_dataset(
... dataset, batch_size=16, shuffle=True, tokenizer=tokenizer
... ) # doctest: +SKIP
```
5. Une fois que vous êtes prêt, appelez les fonctions `compile` et `fit` pour commencer l'entraînement :
```py
>>> from tensorflow.keras.optimizers import Adam
>>> model.compile(optimizer=Adam(3e-5))
>>> model.fit(dataset) # doctest: +SKIP
```
## Et après ?
Maintenant que vous avez terminé la visite rapide de 🤗 Transformers, consultez nos guides et apprenez à faire des choses plus spécifiques comme créer un modèle personnalisé, finetuner un modèle pour une tâche, et comment entraîner un modèle avec un script. Si vous souhaitez en savoir plus sur les concepts fondamentaux de 🤗 Transformers, jetez un œil à nos guides conceptuels !
| transformers/docs/source/fr/quicktour.md/0 | {
"file_path": "transformers/docs/source/fr/quicktour.md",
"repo_id": "transformers",
"token_count": 10715
} | 254 |
<!---
Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Installazione
Installa 🤗 Transformers per qualsiasi libreria di deep learning con cui stai lavorando, imposta la tua cache, e opzionalmente configura 🤗 Transformers per l'esecuzione offline.
🤗 Transformers è testato su Python 3.6+, PyTorch 1.1.0+, TensorFlow 2.0+, e Flax. Segui le istruzioni di installazione seguenti per la libreria di deep learning che stai utilizzando:
* [PyTorch](https://pytorch.org/get-started/locally/) istruzioni di installazione.
* [TensorFlow 2.0](https://www.tensorflow.org/install/pip) istruzioni di installazione.
* [Flax](https://flax.readthedocs.io/en/latest/) istruzioni di installazione.
## Installazione con pip
Puoi installare 🤗 Transformers in un [ambiente virtuale](https://docs.python.org/3/library/venv.html). Se non sei familiare con gli ambienti virtuali in Python, dai un'occhiata a questa [guida](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/). Un ambiente virtuale rende più semplice la gestione di progetti differenti, evitando problemi di compatibilità tra dipendenze.
Inizia creando un ambiente virtuale nella directory del tuo progetto:
```bash
python -m venv .env
```
Attiva l'ambiente virtuale:
```bash
source .env/bin/activate
```
Ora puoi procedere con l'installazione di 🤗 Transformers eseguendo il comando seguente:
```bash
pip install transformers
```
Per il solo supporto della CPU, puoi installare facilmente 🤗 Transformers e una libreria di deep learning in solo una riga. Ad esempio, installiamo 🤗 Transformers e PyTorch con:
```bash
pip install transformers[torch]
```
🤗 Transformers e TensorFlow 2.0:
```bash
pip install transformers[tf-cpu]
```
🤗 Transformers e Flax:
```bash
pip install transformers[flax]
```
Infine, verifica se 🤗 Transformers è stato installato in modo appropriato eseguendo il seguente comando. Questo scaricherà un modello pre-allenato:
```bash
python -c "from transformers import pipeline; print(pipeline('sentiment-analysis')('we love you'))"
```
Dopodiché stampa l'etichetta e il punteggio:
```bash
[{'label': 'POSITIVE', 'score': 0.9998704791069031}]
```
## Installazione dalla fonte
Installa 🤗 Transformers dalla fonte con il seguente comando:
```bash
pip install git+https://github.com/huggingface/transformers
```
Questo comando installa la versione `main` più attuale invece dell'ultima versione stabile. Questo è utile per stare al passo con gli ultimi sviluppi. Ad esempio, se un bug è stato sistemato da quando è uscita l'ultima versione ufficiale ma non è stata ancora rilasciata una nuova versione. Tuttavia, questo significa che questa versione `main` può non essere sempre stabile. Ci sforziamo per mantenere la versione `main` operativa, e la maggior parte dei problemi viene risolta in poche ore o in un giorno. Se riscontri un problema, per favore apri una [Issue](https://github.com/huggingface/transformers/issues) così possiamo sistemarlo ancora più velocemente!
Controlla se 🤗 Transformers è stata installata in modo appropriato con il seguente comando:
```bash
python -c "from transformers import pipeline; print(pipeline('sentiment-analysis')('I love you'))"
```
## Installazione modificabile
Hai bisogno di un'installazione modificabile se vuoi:
* Usare la versione `main` del codice dalla fonte.
* Contribuire a 🤗 Transformers e hai bisogno di testare i cambiamenti nel codice.
Clona il repository e installa 🤗 Transformers con i seguenti comandi:
```bash
git clone https://github.com/huggingface/transformers.git
cd transformers
pip install -e .
```
Questi comandi collegheranno la cartella in cui è stato clonato il repository e i path delle librerie Python. Python guarderà ora all'interno della cartella clonata, oltre ai normali path delle librerie. Per esempio, se i tuoi pacchetti Python sono installati tipicamente in `~/anaconda3/envs/main/lib/python3.7/site-packages/`, Python cercherà anche nella cartella clonata: `~/transformers/`.
<Tip warning={true}>
Devi tenere la cartella `transformers` se vuoi continuare ad utilizzare la libreria.
</Tip>
Ora puoi facilmente aggiornare il tuo clone all'ultima versione di 🤗 Transformers con il seguente comando:
```bash
cd ~/transformers/
git pull
```
Il tuo ambiente Python troverà la versione `main` di 🤗 Transformers alla prossima esecuzione.
## Installazione con conda
Installazione dal canale conda `conda-forge`:
```bash
conda install conda-forge::transformers
```
## Impostazione della cache
I modelli pre-allenati sono scaricati e memorizzati localmente nella cache in: `~/.cache/huggingface/transformers/`. Questa è la directory di default data dalla variabile d'ambiente della shell `TRANSFORMERS_CACHE`. Su Windows, la directory di default è data da `C:\Users\username\.cache\huggingface\transformers`. Puoi cambiare le variabili d'ambiente della shell indicate in seguito, in ordine di priorità, per specificare una directory differente per la cache:
1. Variabile d'ambiente della shell (default): `TRANSFORMERS_CACHE`.
2. Variabile d'ambiente della shell: `HF_HOME` + `transformers/`.
3. Variabile d'ambiente della shell: `XDG_CACHE_HOME` + `/huggingface/transformers`.
<Tip>
🤗 Transformers utilizzerà le variabili d'ambiente della shell `PYTORCH_TRANSFORMERS_CACHE` o `PYTORCH_PRETRAINED_BERT_CACHE` se si proviene da un'iterazione precedente di questa libreria e sono state impostate queste variabili d'ambiente, a meno che non si specifichi la variabile d'ambiente della shell `TRANSFORMERS_CACHE`.
</Tip>
## Modalità Offline
🤗 Transformers può essere eseguita in un ambiente firewalled o offline utilizzando solo file locali. Imposta la variabile d'ambiente `TRANSFORMERS_OFFLINE=1` per abilitare questo comportamento.
<Tip>
Aggiungi [🤗 Datasets](https://huggingface.co/docs/datasets/) al tuo flusso di lavoro offline di training impostando la variabile d'ambiente `HF_DATASETS_OFFLINE=1`.
</Tip>
Ad esempio, in genere si esegue un programma su una rete normale, protetta da firewall per le istanze esterne, con il seguente comando:
```bash
python examples/pytorch/translation/run_translation.py --model_name_or_path t5-small --dataset_name wmt16 --dataset_config ro-en ...
```
Esegui lo stesso programma in un'istanza offline con:
```bash
HF_DATASETS_OFFLINE=1 TRANSFORMERS_OFFLINE=1 \
python examples/pytorch/translation/run_translation.py --model_name_or_path t5-small --dataset_name wmt16 --dataset_config ro-en ...
```
Lo script viene ora eseguito senza bloccarsi o attendere il timeout, perché sa di dover cercare solo file locali.
### Ottenere modelli e tokenizer per l'uso offline
Un'altra opzione per utilizzare offline 🤗 Transformers è scaricare i file in anticipo, e poi puntare al loro path locale quando hai la necessità di utilizzarli offline. Ci sono tre modi per fare questo:
* Scarica un file tramite l'interfaccia utente sul [Model Hub](https://huggingface.co/models) premendo sull'icona ↓.

* Utilizza il flusso [`PreTrainedModel.from_pretrained`] e [`PreTrainedModel.save_pretrained`]:
1. Scarica i tuoi file in anticipo con [`PreTrainedModel.from_pretrained`]:
```py
>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
>>> tokenizer = AutoTokenizer.from_pretrained("bigscience/T0_3B")
>>> model = AutoModelForSeq2SeqLM.from_pretrained("bigscience/T0_3B")
```
2. Salva i tuoi file in una directory specificata con [`PreTrainedModel.save_pretrained`]:
```py
>>> tokenizer.save_pretrained("./il/tuo/path/bigscience_t0")
>>> model.save_pretrained("./il/tuo/path/bigscience_t0")
```
3. Ora quando sei offline, carica i tuoi file con [`PreTrainedModel.from_pretrained`] dalla directory specificata:
```py
>>> tokenizer = AutoTokenizer.from_pretrained("./il/tuo/path/bigscience_t0")
>>> model = AutoModel.from_pretrained("./il/tuo/path/bigscience_t0")
```
* Scarica in maniera programmatica i file con la libreria [huggingface_hub](https://github.com/huggingface/huggingface_hub/tree/main/src/huggingface_hub):
1. Installa la libreria `huggingface_hub` nel tuo ambiente virtuale:
```bash
python -m pip install huggingface_hub
```
2. Utilizza la funzione [`hf_hub_download`](https://huggingface.co/docs/hub/adding-a-library#download-files-from-the-hub) per scaricare un file in un path specifico. Per esempio, il seguente comando scarica il file `config.json` dal modello [T0](https://huggingface.co/bigscience/T0_3B) nel path che desideri:
```py
>>> from huggingface_hub import hf_hub_download
>>> hf_hub_download(repo_id="bigscience/T0_3B", filename="config.json", cache_dir="./il/tuo/path/bigscience_t0")
```
Una volta che il tuo file è scaricato e salvato in cache localmente, specifica il suo path locale per caricarlo e utilizzarlo:
```py
>>> from transformers import AutoConfig
>>> config = AutoConfig.from_pretrained("./il/tuo/path/bigscience_t0/config.json")
```
<Tip>
Fai riferimento alla sezione [How to download files from the Hub](https://huggingface.co/docs/hub/how-to-downstream) per avere maggiori dettagli su come scaricare modelli presenti sull Hub.
</Tip>
| transformers/docs/source/it/installation.md/0 | {
"file_path": "transformers/docs/source/it/installation.md",
"repo_id": "transformers",
"token_count": 3575
} | 255 |
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Quick tour
[[open-in-colab]]
Entra in azione con 🤗 Transformers! Inizia utilizzando [`pipeline`] per un'inferenza veloce, carica un modello pre-allenato e un tokenizer con una [AutoClass](./model_doc/auto) per risolvere i tuoi compiti legati a testo, immagini o audio.
<Tip>
Tutti gli esempi di codice presenti in questa documentazione hanno un pulsante in alto a sinistra che permette di selezionare tra PyTorch e TensorFlow. Se
questo non è presente, ci si aspetta che il codice funzioni per entrambi i backend senza alcun cambiamento.
</Tip>
## Pipeline
[`pipeline`] è il modo più semplice per utilizzare un modello pre-allenato per un dato compito.
<Youtube id="tiZFewofSLM"/>
La [`pipeline`] supporta molti compiti comuni:
**Testo**:
* Analisi del Sentimento (Sentiment Analysis, in inglese): classifica la polarità di un testo dato.
* Generazione del Testo (Text Generation, in inglese): genera del testo a partire da un dato input.
* Riconoscimento di Entità (Name Entity Recognition o NER, in inglese): etichetta ogni parola con l'entità che questa rappresenta (persona, data, luogo, ecc.).
* Rispondere a Domande (Question answering, in inglese): estrae la risposta da un contesto, dato del contesto e una domanda.
* Riempimento di Maschere (Fill-mask, in inglese): riempie gli spazi mancanti in un testo che ha parole mascherate.
* Riassumere (Summarization, in inglese): genera una sintesi di una lunga sequenza di testo o di un documento.
* Traduzione (Translation, in inglese): traduce un testo in un'altra lingua.
* Estrazione di Caratteristiche (Feature Extraction, in inglese): crea un tensore che rappresenta un testo.
**Immagini**:
* Classificazione di Immagini (Image Classification, in inglese): classifica un'immagine.
* Segmentazione di Immagini (Image Segmentation, in inglese): classifica ogni pixel di un'immagine.
* Rilevazione di Oggetti (Object Detection, in inglese): rileva oggetti all'interno di un'immagine.
**Audio**:
* Classificazione di Audio (Audio Classification, in inglese): assegna un'etichetta ad un segmento di audio dato.
* Riconoscimento Vocale Automatico (Automatic Speech Recognition o ASR, in inglese): trascrive il contenuto di un audio dato in un testo.
<Tip>
Per maggiori dettagli legati alla [`pipeline`] e ai compiti ad essa associati, fai riferimento alla documentazione [qui](./main_classes/pipelines).
</Tip>
### Utilizzo della Pipeline
Nel seguente esempio, utilizzerai la [`pipeline`] per l'analisi del sentimento.
Installa le seguenti dipendenze se non lo hai già fatto:
<frameworkcontent>
<pt>
```bash
pip install torch
```
</pt>
<tf>
```bash
pip install tensorflow
```
</tf>
</frameworkcontent>
Importa [`pipeline`] e specifica il compito che vuoi completare:
```py
>>> from transformers import pipeline
>>> classificatore = pipeline("sentiment-analysis", model="MilaNLProc/feel-it-italian-sentiment")
```
La pipeline scarica e salva il [modello pre-allenato](https://huggingface.co/MilaNLProc/feel-it-italian-sentiment) e il tokenizer per l'analisi del sentimento. Se non avessimo scelto un modello, la pipeline ne avrebbe scelto uno di default. Ora puoi utilizzare il `classifier` sul tuo testo obiettivo:
```py
>>> classificatore("Siamo molto felici di mostrarti la libreria 🤗 Transformers.")
[{'label': 'positive', 'score': 0.9997}]
```
Per più di una frase, passa una lista di frasi alla [`pipeline`] la quale restituirà una lista di dizionari:
```py
>>> risultati = classificatore(
... ["Siamo molto felici di mostrarti la libreria 🤗 Transformers.", "Speriamo te non la odierai."]
... )
>>> for risultato in risultati:
... print(f"etichetta: {risultato['label']}, con punteggio: {round(risultato['score'], 4)}")
etichetta: positive, con punteggio: 0.9998
etichetta: negative, con punteggio: 0.9998
```
La [`pipeline`] può anche iterare su un dataset intero. Inizia installando la libreria [🤗 Datasets](https://huggingface.co/docs/datasets/):
```bash
pip install datasets
```
Crea una [`pipeline`] con il compito che vuoi risolvere e con il modello che vuoi utilizzare.
```py
>>> import torch
>>> from transformers import pipeline
>>> riconoscitore_vocale = pipeline(
... "automatic-speech-recognition", model="radiogroup-crits/wav2vec2-xls-r-1b-italian-doc4lm-5gram"
... )
```
Poi, carica un dataset (vedi 🤗 Datasets [Quick Start](https://huggingface.co/docs/datasets/quickstart) per maggiori dettagli) sul quale vuoi iterare. Per esempio, carichiamo il dataset [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14):
```py
>>> from datasets import load_dataset, Audio
>>> dataset = load_dataset("PolyAI/minds14", name="it-IT", split="train") # doctest: +IGNORE_RESULT
```
Dobbiamo assicurarci che la frequenza di campionamento del set di dati corrisponda alla frequenza di campionamento con cui è stato addestrato `radiogroup-crits/wav2vec2-xls-r-1b-italian-doc4lm-5gram`.
```py
>>> dataset = dataset.cast_column("audio", Audio(sampling_rate=riconoscitore_vocale.feature_extractor.sampling_rate))
```
I file audio vengono caricati automaticamente e ri-campionati quando chiamiamo la colonna "audio".
Estraiamo i vettori delle forme d'onda grezze delle prime 4 osservazioni e passiamoli come lista alla pipeline:
```py
>>> risultato = riconoscitore_vocale(dataset[:4]["audio"])
>>> print([d["text"] for d in risultato])
['dovrei caricare dei soldi sul mio conto corrente', 'buongiorno e senza vorrei depositare denaro sul mio conto corrente come devo fare per cortesia', 'sì salve vorrei depositare del denaro sul mio conto', 'e buon pomeriggio vorrei depositare dei soldi sul mio conto bancario volleo sapere come posso fare se e posso farlo online ed un altro conto o andandoo tramite bancomut']
```
Per un dataset più grande dove gli input sono di dimensione maggiore (come nel parlato/audio o nella visione), dovrai passare un generatore al posto di una lista che carica tutti gli input in memoria. Guarda la [documentazione della pipeline](./main_classes/pipelines) per maggiori informazioni.
### Utilizzare un altro modello e tokenizer nella pipeline
La [`pipeline`] può ospitare qualsiasi modello del [Model Hub](https://huggingface.co/models), rendendo semplice l'adattamento della [`pipeline`] per altri casi d'uso. Per esempio, se si vuole un modello capace di trattare testo in francese, usa i tag presenti nel Model Hub in modo da filtrare per ottenere un modello appropriato. Il miglior risultato filtrato restituisce un modello multi-lingua [BERT model](https://huggingface.co/nlptown/bert-base-multilingual-uncased-sentiment) fine-tuned per l'analisi del sentimento. Ottimo, utilizziamo questo modello!
```py
>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
```
<frameworkcontent>
<pt>
Usa [`AutoModelForSequenceClassification`] e [`AutoTokenizer`] per caricare il modello pre-allenato e il suo tokenizer associato (maggiori informazioni su una `AutoClass` in seguito):
```py
>>> from transformers import AutoTokenizer, AutoModelForSequenceClassification
>>> model = AutoModelForSequenceClassification.from_pretrained(model_name)
>>> tokenizer = AutoTokenizer.from_pretrained(model_name)
```
</pt>
<tf>
Usa [`TFAutoModelForSequenceClassification`] e [`AutoTokenizer`] per caricare il modello pre-allenato e il suo tokenizer associato (maggiori informazioni su una `TFAutoClass` in seguito):
```py
>>> from transformers import AutoTokenizer, TFAutoModelForSequenceClassification
>>> model = TFAutoModelForSequenceClassification.from_pretrained(model_name)
>>> tokenizer = AutoTokenizer.from_pretrained(model_name)
```
</tf>
</frameworkcontent>
Poi puoi specificare il modello e il tokenizer nella [`pipeline`], e applicare il `classifier` sul tuo testo obiettivo:
```py
>>> classifier = pipeline("sentiment-analysis", model=model, tokenizer=tokenizer)
>>> classifier("Nous sommes très heureux de vous présenter la bibliothèque 🤗 Transformers.")
[{'label': '5 stars', 'score': 0.7273}]
```
Se non riesci a trovare un modello per il tuo caso d'uso, dovrai fare fine-tuning di un modello pre-allenato sui tuoi dati. Dai un'occhiata al nostro tutorial [fine-tuning tutorial](./training) per imparare come. Infine, dopo che hai completato il fine-tuning del tuo modello pre-allenato, considera per favore di condividerlo (vedi il tutorial [qui](./model_sharing)) con la comunità sul Model Hub per democratizzare l'NLP! 🤗
## AutoClass
<Youtube id="AhChOFRegn4"/>
Al suo interno, le classi [`AutoModelForSequenceClassification`] e [`AutoTokenizer`] lavorano assieme per dare potere alla [`pipeline`]. Una [AutoClass](./model_doc/auto) è una scorciatoia che automaticamente recupera l'architettura di un modello pre-allenato a partire dal suo nome o path. Hai solo bisogno di selezionare la `AutoClass` appropriata per il tuo compito e il suo tokenizer associato con [`AutoTokenizer`].
Ritorniamo al nostro esempio e vediamo come puoi utilizzare la `AutoClass` per replicare i risultati della [`pipeline`].
### AutoTokenizer
Un tokenizer è responsabile dell'elaborazione del testo in modo da trasformarlo in un formato comprensibile dal modello. Per prima cosa, il tokenizer dividerà il testo in parole chiamate *token*. Ci sono diverse regole che governano il processo di tokenizzazione, tra cui come dividere una parola e a quale livello (impara di più sulla tokenizzazione [qui](./tokenizer_summary)). La cosa più importante da ricordare comunque è che hai bisogno di inizializzare il tokenizer con lo stesso nome del modello in modo da assicurarti che stai utilizzando le stesse regole di tokenizzazione con cui il modello è stato pre-allenato.
Carica un tokenizer con [`AutoTokenizer`]:
```py
>>> from transformers import AutoTokenizer
>>> nome_del_modello = "nlptown/bert-base-multilingual-uncased-sentiment"
>>> tokenizer = AutoTokenizer.from_pretrained(nome_del_modello)
```
Dopodiché, il tokenizer converte i token in numeri in modo da costruire un tensore come input del modello. Questo è conosciuto come il *vocabolario* del modello.
Passa il tuo testo al tokenizer:
```py
>>> encoding = tokenizer("Siamo molto felici di mostrarti la libreria 🤗 Transformers.")
>>> print(encoding)
{'input_ids': [101, 56821, 10132, 14407, 13019, 13007, 10120, 47201, 10330, 10106, 91686, 100, 58263, 119, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
```
Il tokenizer restituirà un dizionario contenente:
* [input_ids](./glossary#input-ids): rappresentazioni numeriche dei tuoi token.
* [attention_mask](.glossary#attention-mask): indica quali token devono essere presi in considerazione.
Come con la [`pipeline`], il tokenizer accetterà una lista di input. In più, il tokenizer può anche completare (pad, in inglese) e troncare il testo in modo da restituire un lotto (batch, in inglese) di lunghezza uniforme:
<frameworkcontent>
<pt>
```py
>>> pt_batch = tokenizer(
... ["Siamo molto felici di mostrarti la libreria 🤗 Transformers.", "Speriamo te non la odierai."],
... padding=True,
... truncation=True,
... max_length=512,
... return_tensors="pt",
... )
```
</pt>
<tf>
```py
>>> tf_batch = tokenizer(
... ["Siamo molto felici di mostrarti la libreria 🤗 Transformers.", "Speriamo te non la odierai."],
... padding=True,
... truncation=True,
... max_length=512,
... return_tensors="tf",
... )
```
</tf>
</frameworkcontent>
Leggi il tutorial sul [preprocessing](./preprocessing) per maggiori dettagli sulla tokenizzazione.
### AutoModel
<frameworkcontent>
<pt>
🤗 Transformers fornisce un metodo semplice e unificato per caricare istanze pre-allenate. Questo significa che puoi caricare un [`AutoModel`] come caricheresti un [`AutoTokenizer`]. L'unica differenza è selezionare l'[`AutoModel`] corretto per il compito di interesse. Dato che stai facendo classificazione di testi, o sequenze, carica [`AutoModelForSequenceClassification`]:
```py
>>> from transformers import AutoModelForSequenceClassification
>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
>>> pt_model = AutoModelForSequenceClassification.from_pretrained(model_name)
```
<Tip>
Guarda il [task summary](./task_summary) per sapere quale classe di [`AutoModel`] utilizzare per quale compito.
</Tip>
Ora puoi passare il tuo lotto di input pre-processati direttamente al modello. Devi solo spacchettare il dizionario aggiungendo `**`:
```py
>>> pt_outputs = pt_model(**pt_batch)
```
Il modello produrrà le attivazioni finali nell'attributo `logits`. Applica la funzione softmax a `logits` per ottenere le probabilità:
```py
>>> from torch import nn
>>> pt_predictions = nn.functional.softmax(pt_outputs.logits, dim=-1)
>>> print(pt_predictions)
tensor([[0.0041, 0.0037, 0.0203, 0.2005, 0.7713],
[0.3766, 0.3292, 0.1832, 0.0558, 0.0552]], grad_fn=<SoftmaxBackward0>)
```
</pt>
<tf>
🤗 Transformers fornisce un metodo semplice e unificato per caricare istanze pre-allenate. Questo significa che puoi caricare un [`TFAutoModel`] come caricheresti un [`AutoTokenizer`]. L'unica differenza è selezionare il [`TFAutoModel`] corretto per il compito di interesse. Dato che stai facendo classificazione di testi, o sequenze, carica [`TFAutoModelForSequenceClassification`]:
```py
>>> from transformers import TFAutoModelForSequenceClassification
>>> nome_del_modello = "nlptown/bert-base-multilingual-uncased-sentiment"
>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained(nome_del_modello)
```
<Tip>
Guarda il [task summary](./task_summary) per sapere quale classe di [`AutoModel`] utilizzare per quale compito.
</Tip>
Ora puoi passare il tuo lotto di input pre-processati direttamente al modello passando le chiavi del dizionario al tensore:
```py
>>> tf_outputs = tf_model(tf_batch)
```
Il modello produrrà le attivazioni finali nell'attributo `logits`. Applica la funzione softmax a `logits` per ottenere le probabilità:
```py
>>> import tensorflow as tf
>>> tf_predictions = tf.nn.softmax(tf_outputs.logits, axis=-1)
>>> tf_predictions # doctest: +IGNORE_RESULT
```
</tf>
</frameworkcontent>
<Tip>
Tutti i modelli di 🤗 Transformers (PyTorch e TensorFlow) restituiscono i tensori *prima* della funzione finale
di attivazione (come la softmax) perché la funzione di attivazione finale viene spesso unita a quella di perdita.
</Tip>
I modelli sono [`torch.nn.Module`](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) o [`tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model) standard così puoi utilizzarli all'interno del tuo training loop usuale. Tuttavia, per rendere le cose più semplici, 🤗 Transformers fornisce una classe [`Trainer`] per PyTorch che aggiunge delle funzionalità per l'allenamento distribuito, precisione mista, e altro ancora. Per TensorFlow, puoi utilizzare il metodo `fit` di [Keras](https://keras.io/). Fai riferimento al [tutorial per il training](./training) per maggiori dettagli.
<Tip>
Gli output del modello di 🤗 Transformers sono delle dataclasses speciali in modo che i loro attributi vengano auto-completati all'interno di un IDE.
Gli output del modello si comportano anche come una tupla o un dizionario (ad esempio, puoi indicizzare con un intero, una slice o una stringa) nel qual caso gli attributi che sono `None` vengono ignorati.
</Tip>
### Salva un modello
<frameworkcontent>
<pt>
Una volta completato il fine-tuning del tuo modello, puoi salvarlo con il suo tokenizer utilizzando [`PreTrainedModel.save_pretrained`]:
```py
>>> pt_save_directory = "./pt_save_pretrained"
>>> tokenizer.save_pretrained(pt_save_directory) # doctest: +IGNORE_RESULT
>>> pt_model.save_pretrained(pt_save_directory)
```
Quando desideri utilizzare il tuo modello nuovamente, puoi ri-caricarlo con [`PreTrainedModel.from_pretrained`]:
```py
>>> pt_model = AutoModelForSequenceClassification.from_pretrained("./pt_save_pretrained")
```
</pt>
<tf>
Una volta completato il fine-tuning del tuo modello, puoi salvarlo con il suo tokenizer utilizzando [`TFPreTrainedModel.save_pretrained`]:
```py
>>> tf_save_directory = "./tf_save_pretrained"
>>> tokenizer.save_pretrained(tf_save_directory) # doctest: +IGNORE_RESULT
>>> tf_model.save_pretrained(tf_save_directory)
```
Quando desideri utilizzare il tuo modello nuovamente, puoi ri-caricarlo con [`TFPreTrainedModel.from_pretrained`]:
```py
>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained("./tf_save_pretrained")
```
</tf>
</frameworkcontent>
Una caratteristica particolarmente interessante di 🤗 Transformers è la sua abilità di salvare un modello e ri-caricarlo sia come modello di PyTorch che di TensorFlow. I parametri `from_pt` o `from_tf` possono convertire un modello da un framework all'altro:
<frameworkcontent>
<pt>
```py
>>> from transformers import AutoModel
>>> tokenizer = AutoTokenizer.from_pretrained(tf_save_directory)
>>> pt_model = AutoModelForSequenceClassification.from_pretrained(tf_save_directory, from_tf=True)
```
</pt>
<tf>
```py
>>> from transformers import TFAutoModel
>>> tokenizer = AutoTokenizer.from_pretrained(pt_save_directory)
>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained(pt_save_directory, from_pt=True)
```
</tf>
</frameworkcontent>
| transformers/docs/source/it/quicktour.md/0 | {
"file_path": "transformers/docs/source/it/quicktour.md",
"repo_id": "transformers",
"token_count": 6490
} | 256 |
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Sharing custom models
🤗 Transformersライブラリは、簡単に拡張できるように設計されています。すべてのモデルはリポジトリの特定のサブフォルダに完全にコード化されており、抽象化はありません。したがって、モデリングファイルをコピーして調整することが簡単です。
新しいモデルを書いている場合、ゼロから始める方が簡単かもしれません。このチュートリアルでは、カスタムモデルとその設定をどのように書き、Transformers内で使用できるようにし、コードに依存する共同体と共有する方法を説明します。ライブラリに存在しない場合でも、誰でも使用できるようにします。
これを実証するために、[timmライブラリ](https://github.com/rwightman/pytorch-image-models)のResNetクラスを[`PreTrainedModel`]にラップすることによって、ResNetモデルを使用します。
## Writing a custom configuration
モデルに取り組む前に、まずその設定を書きましょう。モデルの設定は、モデルを構築するために必要なすべての情報を含むオブジェクトです。次のセクションで見るように、モデルは初期化するために`config`しか受け取ることができないため、そのオブジェクトができるだけ完全である必要があります。
この例では、ResNetクラスのいくつかの引数を取得し、調整したいかもしれないとします。異なる設定は、異なるタイプのResNetを提供します。その後、これらの引数を確認した後、それらの引数を単に格納します。
```python
from transformers import PretrainedConfig
from typing import List
class ResnetConfig(PretrainedConfig):
model_type = "resnet"
def __init__(
self,
block_type="bottleneck",
layers: List[int] = [3, 4, 6, 3],
num_classes: int = 1000,
input_channels: int = 3,
cardinality: int = 1,
base_width: int = 64,
stem_width: int = 64,
stem_type: str = "",
avg_down: bool = False,
**kwargs,
):
if block_type not in ["basic", "bottleneck"]:
raise ValueError(f"`block_type` must be 'basic' or bottleneck', got {block_type}.")
if stem_type not in ["", "deep", "deep-tiered"]:
raise ValueError(f"`stem_type` must be '', 'deep' or 'deep-tiered', got {stem_type}.")
self.block_type = block_type
self.layers = layers
self.num_classes = num_classes
self.input_channels = input_channels
self.cardinality = cardinality
self.base_width = base_width
self.stem_width = stem_width
self.stem_type = stem_type
self.avg_down = avg_down
super().__init__(**kwargs)
```
重要なことを3つ覚えておくべきポイントは次のとおりです:
- `PretrainedConfig` を継承する必要があります。
- あなたの `PretrainedConfig` の `__init__` は任意の kwargs を受け入れる必要があります。
- これらの `kwargs` は親クラスの `__init__` に渡す必要があります。
継承は、🤗 Transformers ライブラリのすべての機能を取得できるようにするためです。他の2つの制約は、
`PretrainedConfig` が設定しているフィールド以外にも多くのフィールドを持っていることから来ています。
`from_pretrained` メソッドで設定を再ロードする場合、これらのフィールドはあなたの設定に受け入れられ、
その後、親クラスに送信される必要があります。
設定の `model_type` を定義すること(ここでは `model_type="resnet"`)は、
自動クラスにモデルを登録したい場合を除いては必須ではありません(最後のセクションを参照)。
これで、ライブラリの他のモデル設定と同様に、設定を簡単に作成して保存できます。
以下は、resnet50d 設定を作成して保存する方法の例です:
```py
resnet50d_config = ResnetConfig(block_type="bottleneck", stem_width=32, stem_type="deep", avg_down=True)
resnet50d_config.save_pretrained("custom-resnet")
```
これにより、`custom-resnet` フォルダ内に `config.json` という名前のファイルが保存されます。その後、`from_pretrained` メソッドを使用して構成を再ロードできます。
```py
resnet50d_config = ResnetConfig.from_pretrained("custom-resnet")
```
また、[`PretrainedConfig`] クラスの他のメソッドを使用することもできます。たとえば、[`~PretrainedConfig.push_to_hub`] を使用して、設定を直接 Hub にアップロードできます。
## Writing a custom model
ResNet の設定ができたので、モデルを書き始めることができます。実際には2つのモデルを書きます。1つはバッチの画像から隠れた特徴を抽出するモデル([`BertModel`] のようなもの)で、もう1つは画像分類に適したモデル([`BertForSequenceClassification`] のようなもの)です。
前述したように、この例をシンプルに保つために、モデルの緩いラッパーのみを書きます。このクラスを書く前に行う必要がある唯一のことは、ブロックタイプと実際のブロッククラスの間のマップです。その後、すべてを `ResNet` クラスに渡して設定からモデルを定義します:
```py
from transformers import PreTrainedModel
from timm.models.resnet import BasicBlock, Bottleneck, ResNet
from .configuration_resnet import ResnetConfig
BLOCK_MAPPING = {"basic": BasicBlock, "bottleneck": Bottleneck}
class ResnetModel(PreTrainedModel):
config_class = ResnetConfig
def __init__(self, config):
super().__init__(config)
block_layer = BLOCK_MAPPING[config.block_type]
self.model = ResNet(
block_layer,
config.layers,
num_classes=config.num_classes,
in_chans=config.input_channels,
cardinality=config.cardinality,
base_width=config.base_width,
stem_width=config.stem_width,
stem_type=config.stem_type,
avg_down=config.avg_down,
)
def forward(self, tensor):
return self.model.forward_features(tensor)
```
画像を分類するモデルの場合、forwardメソッドを変更するだけです:
```py
import torch
class ResnetModelForImageClassification(PreTrainedModel):
config_class = ResnetConfig
def __init__(self, config):
super().__init__(config)
block_layer = BLOCK_MAPPING[config.block_type]
self.model = ResNet(
block_layer,
config.layers,
num_classes=config.num_classes,
in_chans=config.input_channels,
cardinality=config.cardinality,
base_width=config.base_width,
stem_width=config.stem_width,
stem_type=config.stem_type,
avg_down=config.avg_down,
)
def forward(self, tensor, labels=None):
logits = self.model(tensor)
if labels is not None:
loss = torch.nn.cross_entropy(logits, labels)
return {"loss": loss, "logits": logits}
return {"logits": logits}
```
両方の場合、`PreTrainedModel`から継承し、`config`を使用してスーパークラスの初期化を呼び出します(通常の`torch.nn.Module`を書くときのような感じです)。
`config_class`を設定する行は必須ではありませんが、(最後のセクションを参照)、モデルを自動クラスに登録したい場合に使用できます。
<Tip>
モデルがライブラリ内のモデルと非常に似ている場合、このモデルと同じ構成を再利用できます。
</Tip>
モデルが返す内容は何でも構いませんが、ラベルが渡されるときに損失を含む辞書を返す(`ResnetModelForImageClassification`のように行ったもの)と、
モデルを[`Trainer`]クラス内で直接使用できるようになります。独自のトレーニングループまたは他のライブラリを使用する予定である限り、
別の出力形式を使用することも問題ありません。
さて、モデルクラスができたので、1つ作成しましょう:
```py
resnet50d = ResnetModelForImageClassification(resnet50d_config)
```
再度、[`PreTrainedModel`]のいずれかのメソッド、例えば[`~PreTrainedModel.save_pretrained`]や
[`~PreTrainedModel.push_to_hub`]などを使用できます。次のセクションでは、モデルの重みをコードと一緒に
Hugging Face Hub にプッシュする方法を見てみます。
しかし、まずはモデル内に事前学習済みの重みをロードしましょう。
独自のユースケースでは、おそらく独自のデータでカスタムモデルをトレーニングすることになるでしょう。
このチュートリアルではスピードアップのために、resnet50dの事前学習済みバージョンを使用します。
私たちのモデルはそれをラップするだけなので、これらの重みを転送するのは簡単です:
```py
import timm
pretrained_model = timm.create_model("resnet50d", pretrained=True)
resnet50d.model.load_state_dict(pretrained_model.state_dict())
```
さて、[`~PreTrainedModel.save_pretrained`]または[`~PreTrainedModel.push_to_hub`]を実行したときに、
モデルのコードが保存されるようにする方法を見てみましょう。
## Sending the code to the Hub
<Tip warning={true}>
このAPIは実験的であり、次のリリースでわずかな変更があるかもしれません。
</Tip>
まず、モデルが`.py`ファイルに完全に定義されていることを確認してください。
ファイルは相対インポートを他のファイルに依存できますが、すべてのファイルが同じディレクトリにある限り(まだこの機能ではサブモジュールはサポートしていません)、問題ありません。
この例では、現在の作業ディレクトリ内に名前が「resnet_model」のフォルダを作成し、その中に`modeling_resnet.py`ファイルと`configuration_resnet.py`ファイルを定義します。
構成ファイルには`ResnetConfig`のコードが含まれ、モデリングファイルには`ResnetModel`と`ResnetModelForImageClassification`のコードが含まれています。
```
.
└── resnet_model
├── __init__.py
├── configuration_resnet.py
└── modeling_resnet.py
```
`__init__.py`は空であっても問題ありません。Pythonが`resnet_model`をモジュールとして検出できるようにするために存在します。
<Tip warning={true}>
ライブラリからモデリングファイルをコピーする場合、ファイルの先頭にあるすべての相対インポートを`transformers`パッケージからインポートに置き換える必要があります。
</Tip>
既存の設定やモデルを再利用(またはサブクラス化)できることに注意してください。
コミュニティとモデルを共有するために、次の手順に従ってください:まず、新しく作成したファイルからResNetモデルと設定をインポートします:
```py
from resnet_model.configuration_resnet import ResnetConfig
from resnet_model.modeling_resnet import ResnetModel, ResnetModelForImageClassification
```
次に、`save_pretrained`メソッドを使用してこれらのオブジェクトのコードファイルをコピーし、特定のAutoクラス(特にモデルの場合)に正しく登録するようライブラリに指示する必要があります。次のように実行します:
```py
ResnetConfig.register_for_auto_class()
ResnetModel.register_for_auto_class("AutoModel")
ResnetModelForImageClassification.register_for_auto_class("AutoModelForImageClassification")
```
注意: 設定については自動クラスを指定する必要はありません(設定用の自動クラスは1つしかなく、[`AutoConfig`]です)が、
モデルについては異なります。カスタムモデルは多くの異なるタスクに適している可能性があるため、
モデルが正確な自動クラスのうちどれに適しているかを指定する必要があります。
次に、前述のように設定とモデルを作成しましょう:
```py
resnet50d_config = ResnetConfig(block_type="bottleneck", stem_width=32, stem_type="deep", avg_down=True)
resnet50d = ResnetModelForImageClassification(resnet50d_config)
pretrained_model = timm.create_model("resnet50d", pretrained=True)
resnet50d.model.load_state_dict(pretrained_model.state_dict())
```
モデルをHubに送信するには、ログインしていることを確認してください。ターミナルで次のコマンドを実行します:
```bash
huggingface-cli login
```
またはノートブックから:
```py
from huggingface_hub import notebook_login
notebook_login()
```
次に、次のようにして、独自の名前空間にプッシュできます(または、メンバーである組織にプッシュできます):
```py
resnet50d.push_to_hub("custom-resnet50d")
```
モデリングの重みとJSON形式の構成に加えて、このフォルダー「custom-resnet50d」内のモデリングおよび構成「.py」ファイルもコピーされ、結果はHubにアップロードされました。結果はこの[model repo](https://huggingface.co/sgugger/custom-resnet50d)で確認できます。
詳細については、[Hubへのプッシュ方法](model_sharing)を参照してください。
## Using a model with custom code
自動クラスと `from_pretrained` メソッドを使用して、リポジトリ内のカスタムコードファイルと共に任意の構成、モデル、またはトークナイザを使用できます。 Hubにアップロードされるすべてのファイルとコードはマルウェアのスキャンが実施されます(詳細は[Hubセキュリティ](https://huggingface.co/docs/hub/security#malware-scanning)ドキュメンテーションを参照してください)、しかし、依然として悪意のあるコードを実行しないために、モデルコードと作者を確認する必要があります。
`trust_remote_code=True` を設定してカスタムコードを持つモデルを使用できます:
```py
from transformers import AutoModelForImageClassification
model = AutoModelForImageClassification.from_pretrained("sgugger/custom-resnet50d", trust_remote_code=True)
```
コミットハッシュを「revision」として渡すことも強く推奨されています。これにより、モデルの作者がコードを悪意のある新しい行で更新しなかったことを確認できます(モデルの作者を完全に信頼している場合を除きます)。
```py
commit_hash = "ed94a7c6247d8aedce4647f00f20de6875b5b292"
model = AutoModelForImageClassification.from_pretrained(
"sgugger/custom-resnet50d", trust_remote_code=True, revision=commit_hash
)
```
モデルリポジトリのコミット履歴をブラウジングする際には、任意のコミットのコミットハッシュを簡単にコピーできるボタンがあります。
## Registering a model with custom code to the auto classes
🤗 Transformersを拡張するライブラリを作成している場合、独自のモデルを含めるために自動クラスを拡張したい場合があります。
これはコードをHubにプッシュすることとは異なり、ユーザーはカスタムモデルを取得するためにあなたのライブラリをインポートする必要があります
(Hubからモデルコードを自動的にダウンロードするのとは対照的です)。
構成に既存のモデルタイプと異なる `model_type` 属性がある限り、またあなたのモデルクラスが適切な `config_class` 属性を持っている限り、
次のようにそれらを自動クラスに追加できます:
```py
from transformers import AutoConfig, AutoModel, AutoModelForImageClassification
AutoConfig.register("resnet", ResnetConfig)
AutoModel.register(ResnetConfig, ResnetModel)
AutoModelForImageClassification.register(ResnetConfig, ResnetModelForImageClassification)
```
注意: `AutoConfig` にカスタム設定を登録する際の最初の引数は、カスタム設定の `model_type` と一致する必要があります。
また、任意の自動モデルクラスにカスタムモデルを登録する際の最初の引数は、それらのモデルの `config_class` と一致する必要があります。
| transformers/docs/source/ja/custom_models.md/0 | {
"file_path": "transformers/docs/source/ja/custom_models.md",
"repo_id": "transformers",
"token_count": 7501
} | 257 |
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Processors
Transformers ライブラリでは、プロセッサは 2 つの異なる意味を持ちます。
- [Wav2Vec2](../model_doc/wav2vec2) などのマルチモーダル モデルの入力を前処理するオブジェクト (音声とテキスト)
または [CLIP](../model_doc/clip) (テキストとビジョン)
- 古いバージョンのライブラリで GLUE または SQUAD のデータを前処理するために使用されていたオブジェクトは非推奨になりました。
## Multi-modal processors
マルチモーダル モデルでは、オブジェクトが複数のモダリティ (テキスト、
視覚と音声)。これは、2 つ以上の処理オブジェクトをグループ化するプロセッサーと呼ばれるオブジェクトによって処理されます。
トークナイザー (テキスト モダリティ用)、画像プロセッサー (視覚用)、特徴抽出器 (オーディオ用) など。
これらのプロセッサは、保存およびロード機能を実装する次の基本クラスを継承します。
[[autodoc]] ProcessorMixin
## Deprecated processors
すべてのプロセッサは、同じアーキテクチャに従っています。
[`~data.processors.utils.DataProcessor`]。プロセッサは次のリストを返します。
[`~data.processors.utils.InputExample`]。これら
[`~data.processors.utils.InputExample`] は次のように変換できます。
[`~data.processors.utils.Input features`] をモデルにフィードします。
[[autodoc]] data.processors.utils.DataProcessor
[[autodoc]] data.processors.utils.InputExample
[[autodoc]] data.processors.utils.InputFeatures
## GLUE
[一般言語理解評価 (GLUE)](https://gluebenchmark.com/) は、
既存の NLU タスクの多様なセットにわたるモデルのパフォーマンス。紙と同時発売された [GLUE: A
自然言語理解のためのマルチタスクベンチマークおよび分析プラットフォーム](https://openreview.net/pdf?id=rJ4km2R5t7)
このライブラリは、MRPC、MNLI、MNLI (不一致)、CoLA、SST2、STSB、
QQP、QNLI、RTE、WNLI。
それらのプロセッサは次のとおりです。
- [`~data.processors.utils.MrpcProcessor`]
- [`~data.processors.utils.MnliProcessor`]
- [`~data.processors.utils.MnliMismatchedProcessor`]
- [`~data.processors.utils.Sst2Processor`]
- [`~data.processors.utils.StsbProcessor`]
- [`~data.processors.utils.QqpProcessor`]
- [`~data.processors.utils.QnliProcessor`]
- [`~data.processors.utils.RteProcessor`]
- [`~data.processors.utils.WnliProcessor`]
さらに、次のメソッドを使用して、データ ファイルから値をロードし、それらをリストに変換することができます。
[`~data.processors.utils.InputExample`]。
[[autodoc]] data.processors.glue.glue_convert_examples_to_features
## XNLI
[クロスリンガル NLI コーパス (XNLI)](https://www.nyu.edu/projects/bowman/xnli/) は、
言語を超えたテキスト表現の品質。 XNLI は、[*MultiNLI*](http://www.nyu.edu/projects/bowman/multinli/) に基づくクラウドソースのデータセットです。テキストのペアには、15 個のテキスト含意アノテーションがラベル付けされています。
さまざまな言語 (英語などの高リソース言語とスワヒリ語などの低リソース言語の両方を含む)。
論文 [XNLI: Evaluating Cross-lingual Sentence Representations](https://arxiv.org/abs/1809.05053) と同時にリリースされました。
このライブラリは、XNLI データをロードするプロセッサをホストします。
- [`~data.processors.utils.XnliProcessor`]
テストセットにはゴールドラベルが付いているため、評価はテストセットで行われますのでご了承ください。
これらのプロセッサを使用する例は、[run_xnli.py](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-classification/run_xnli.py) スクリプトに示されています。
## SQuAD
[The Stanford Question Answering Dataset (SQuAD)](https://rajpurkar.github.io/SQuAD-explorer//) は、次のベンチマークです。
質問応答に関するモデルのパフォーマンスを評価します。 v1.1 と v2.0 の 2 つのバージョンが利用可能です。最初のバージョン
(v1.1) は、論文 [SQuAD: 100,000+ question for Machine Comprehension of Text](https://arxiv.org/abs/1606.05250) とともにリリースされました。 2 番目のバージョン (v2.0) は、論文 [Know What You Don't と同時にリリースされました。
知っておくべき: SQuAD の答えられない質問](https://arxiv.org/abs/1806.03822)。
このライブラリは、次の 2 つのバージョンのそれぞれのプロセッサをホストします。
### Processors
それらのプロセッサは次のとおりです。
- [`~data.processors.utils.SquadV1Processor`]
- [`~data.processors.utils.SquadV2Processor`]
どちらも抽象クラス [`~data.processors.utils.SquadProcessor`] を継承しています。
[[autodoc]] data.processors.squad.SquadProcessor
- all
さらに、次のメソッドを使用して、SQuAD の例を次の形式に変換できます。
モデルの入力として使用できる [`~data.processors.utils.SquadFeatures`]。
[[autodoc]] data.processors.squad.squad_convert_examples_to_features
これらのプロセッサと前述の方法は、データを含むファイルだけでなく、
*tensorflow_datasets* パッケージ。以下に例を示します。
### Example usage
以下にプロセッサを使用した例と、データ ファイルを使用した変換方法を示します。
```python
# Loading a V2 processor
processor = SquadV2Processor()
examples = processor.get_dev_examples(squad_v2_data_dir)
# Loading a V1 processor
processor = SquadV1Processor()
examples = processor.get_dev_examples(squad_v1_data_dir)
features = squad_convert_examples_to_features(
examples=examples,
tokenizer=tokenizer,
max_seq_length=max_seq_length,
doc_stride=args.doc_stride,
max_query_length=max_query_length,
is_training=not evaluate,
)
```
*tensorflow_datasets* の使用は、データ ファイルを使用するのと同じくらい簡単です。
```python
# tensorflow_datasets only handle Squad V1.
tfds_examples = tfds.load("squad")
examples = SquadV1Processor().get_examples_from_dataset(tfds_examples, evaluate=evaluate)
features = squad_convert_examples_to_features(
examples=examples,
tokenizer=tokenizer,
max_seq_length=max_seq_length,
doc_stride=args.doc_stride,
max_query_length=max_query_length,
is_training=not evaluate,
)
```
これらのプロセッサを使用する別の例は、[run_squad.py](https://github.com/huggingface/transformers/tree/main/examples/legacy/question-answering/run_squad.py) スクリプトに示されています。
| transformers/docs/source/ja/main_classes/processors.md/0 | {
"file_path": "transformers/docs/source/ja/main_classes/processors.md",
"repo_id": "transformers",
"token_count": 3103
} | 258 |
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# BertGeneration
## Overview
BertGeneration モデルは、次を使用してシーケンス間のタスクに利用できる BERT モデルです。
[Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) で提案されている [`EncoderDecoderModel`]
タスク、Sascha Rothe、Sishi Nagayan、Aliaksei Severyn 著。
論文の要約は次のとおりです。
*大規模なニューラル モデルの教師なし事前トレーニングは、最近、自然言語処理に革命をもたらしました。による
NLP 実践者は、公開されたチェックポイントからウォームスタートして、複数の項目で最先端の技術を推進してきました。
コンピューティング時間を大幅に節約しながらベンチマークを実行します。これまでのところ、主に自然言語に焦点を当ててきました。
タスクを理解する。この論文では、シーケンス生成のための事前トレーニングされたチェックポイントの有効性を実証します。私たちは
公開されている事前トレーニング済み BERT と互換性のある Transformer ベースのシーケンス間モデルを開発しました。
GPT-2 および RoBERTa チェックポイントを使用し、モデルの初期化の有用性について広範な実証研究を実施しました。
エンコーダとデコーダ、これらのチェックポイント。私たちのモデルは、機械翻訳に関する新しい最先端の結果をもたらします。
テキストの要約、文の分割、および文の融合。*
## Usage examples and tips
- モデルを [`EncoderDecoderModel`] と組み合わせて使用して、2 つの事前トレーニングされたモデルを活用できます。
後続の微調整のための BERT チェックポイント。
```python
>>> # leverage checkpoints for Bert2Bert model...
>>> # use BERT's cls token as BOS token and sep token as EOS token
>>> encoder = BertGenerationEncoder.from_pretrained("bert-large-uncased", bos_token_id=101, eos_token_id=102)
>>> # add cross attention layers and use BERT's cls token as BOS token and sep token as EOS token
>>> decoder = BertGenerationDecoder.from_pretrained(
... "bert-large-uncased", add_cross_attention=True, is_decoder=True, bos_token_id=101, eos_token_id=102
... )
>>> bert2bert = EncoderDecoderModel(encoder=encoder, decoder=decoder)
>>> # create tokenizer...
>>> tokenizer = BertTokenizer.from_pretrained("bert-large-uncased")
>>> input_ids = tokenizer(
... "This is a long article to summarize", add_special_tokens=False, return_tensors="pt"
... ).input_ids
>>> labels = tokenizer("This is a short summary", return_tensors="pt").input_ids
>>> # train...
>>> loss = bert2bert(input_ids=input_ids, decoder_input_ids=labels, labels=labels).loss
>>> loss.backward()
```
- 事前トレーニングされた [`EncoderDecoderModel`] もモデル ハブで直接利用できます。
```python
>>> # instantiate sentence fusion model
>>> sentence_fuser = EncoderDecoderModel.from_pretrained("google/roberta2roberta_L-24_discofuse")
>>> tokenizer = AutoTokenizer.from_pretrained("google/roberta2roberta_L-24_discofuse")
>>> input_ids = tokenizer(
... "This is the first sentence. This is the second sentence.", add_special_tokens=False, return_tensors="pt"
... ).input_ids
>>> outputs = sentence_fuser.generate(input_ids)
>>> print(tokenizer.decode(outputs[0]))
```
チップ:
- [`BertGenerationEncoder`] と [`BertGenerationDecoder`] は、
[`EncoderDecoder`] と組み合わせます。
- 要約、文の分割、文の融合、および翻訳の場合、入力に特別なトークンは必要ありません。
したがって、入力の末尾に EOS トークンを追加しないでください。
このモデルは、[patrickvonplaten](https://huggingface.co/patrickvonplaten) によって提供されました。元のコードは次のとおりです
[ここ](https://tfhub.dev/s?module-type=text-generation&subtype=module,placeholder) があります。
## BertGenerationConfig
[[autodoc]] BertGenerationConfig
## BertGenerationTokenizer
[[autodoc]] BertGenerationTokenizer
- save_vocabulary
## BertGenerationEncoder
[[autodoc]] BertGenerationEncoder
- forward
## BertGenerationDecoder
[[autodoc]] BertGenerationDecoder
- forward
| transformers/docs/source/ja/model_doc/bert-generation.md/0 | {
"file_path": "transformers/docs/source/ja/model_doc/bert-generation.md",
"repo_id": "transformers",
"token_count": 1962
} | 259 |
<!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# ByT5
## Overview
ByT5 モデルは、[ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://arxiv.org/abs/2105.13626) by Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir
Kale, Adam Roberts, Colin Raffel.
論文の要約は次のとおりです。
*最も広く使用されている事前トレーニング済み言語モデルは、単語またはサブワード単位に対応するトークンのシーケンスで動作します。
テキストをトークンのシーケンスとしてエンコードするには、トークナイザーが必要です。トークナイザーは通常、
モデル。代わりに生のテキスト (バイトまたは文字) を直接操作するトークンフリー モデルには多くの利点があります。
すぐに使用できるあらゆる言語のテキストを処理でき、ノイズに対してより堅牢であり、技術的負債を最小限に抑えます。
複雑でエラーが発生しやすいテキスト前処理パイプラインを削除します。バイトまたは文字列がトークンより長いため
トークンフリー モデルに関する過去の研究では、シーケンスのコストを償却するように設計された新しいモデル アーキテクチャが導入されることがよくありました。
生のテキストを直接操作します。この論文では、標準的な Transformer アーキテクチャが次のようなもので使用できることを示します。
バイトシーケンスを処理するための最小限の変更。パラメータ数の観点からトレードオフを注意深く特徴付けます。
FLOP のトレーニングと推論速度を調べ、バイトレベルのモデルがトークンレベルと競合できることを示します。
対応者。また、バイトレベルのモデルはノイズに対して大幅に堅牢であり、より優れたパフォーマンスを発揮することも示しています。
スペルと発音に敏感なタスク。私たちの貢献の一環として、新しいセットをリリースします。
T5 アーキテクチャに基づいた事前トレーニング済みのバイトレベルの Transformer モデルと、そこで使用されるすべてのコードとデータ
実験。*
このモデルは、[patrickvonplaten](https://huggingface.co/patrickvonplaten) によって提供されました。元のコードは次のとおりです
[ここ](https://github.com/google-research/byt5) にあります。
<Tip>
ByT5 のアーキテクチャは T5v1.1 モデルに基づいています。API リファレンスについては、[T5v1.1 のドキュメント ページ](t5v1.1) を参照してください。彼らは
モデルの入力を準備する方法が異なるだけです。以下のコード例を参照してください。
</Tip>
ByT5 は教師なしで事前トレーニングされているため、単一タスク中にタスク プレフィックスを使用する利点はありません。
微調整。マルチタスクの微調整を行う場合は、プレフィックスを使用する必要があります。
## Usage Examples
ByT5 は生の UTF-8 バイトで動作するため、トークナイザーなしで使用できます。
```python
>>> from transformers import T5ForConditionalGeneration
>>> import torch
>>> model = T5ForConditionalGeneration.from_pretrained("google/byt5-small")
>>> num_special_tokens = 3
>>> # Model has 3 special tokens which take up the input ids 0,1,2 of ByT5.
>>> # => Need to shift utf-8 character encodings by 3 before passing ids to model.
>>> input_ids = torch.tensor([list("Life is like a box of chocolates.".encode("utf-8"))]) + num_special_tokens
>>> labels = torch.tensor([list("La vie est comme une boîte de chocolat.".encode("utf-8"))]) + num_special_tokens
>>> loss = model(input_ids, labels=labels).loss
>>> loss.item()
2.66
```
ただし、バッチ推論とトレーニングの場合は、トークナイザーを使用することをお勧めします。
```python
>>> from transformers import T5ForConditionalGeneration, AutoTokenizer
>>> model = T5ForConditionalGeneration.from_pretrained("google/byt5-small")
>>> tokenizer = AutoTokenizer.from_pretrained("google/byt5-small")
>>> model_inputs = tokenizer(
... ["Life is like a box of chocolates.", "Today is Monday."], padding="longest", return_tensors="pt"
... )
>>> labels_dict = tokenizer(
... ["La vie est comme une boîte de chocolat.", "Aujourd'hui c'est lundi."], padding="longest", return_tensors="pt"
... )
>>> labels = labels_dict.input_ids
>>> loss = model(**model_inputs, labels=labels).loss
>>> loss.item()
17.9
```
[T5](t5) と同様に、ByT5 はスパンマスクノイズ除去タスクでトレーニングされました。しかし、
モデルはキャラクターに直接作用するため、事前トレーニングタスクは少し複雑です
違う。のいくつかの文字を破損してみましょう
`"The dog chases a ball in the park."`という文を入力し、ByT5 に予測してもらいます。
わたしたちのため。
```python
>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
>>> import torch
>>> tokenizer = AutoTokenizer.from_pretrained("google/byt5-base")
>>> model = AutoModelForSeq2SeqLM.from_pretrained("google/byt5-base")
>>> input_ids_prompt = "The dog chases a ball in the park."
>>> input_ids = tokenizer(input_ids_prompt).input_ids
>>> # Note that we cannot add "{extra_id_...}" to the string directly
>>> # as the Byte tokenizer would incorrectly merge the tokens
>>> # For ByT5, we need to work directly on the character level
>>> # Contrary to T5, ByT5 does not use sentinel tokens for masking, but instead
>>> # uses final utf character ids.
>>> # UTF-8 is represented by 8 bits and ByT5 has 3 special tokens.
>>> # => There are 2**8+2 = 259 input ids and mask tokens count down from index 258.
>>> # => mask to "The dog [258]a ball [257]park."
>>> input_ids = torch.tensor([input_ids[:8] + [258] + input_ids[14:21] + [257] + input_ids[28:]])
>>> input_ids
tensor([[ 87, 107, 104, 35, 103, 114, 106, 35, 258, 35, 100, 35, 101, 100, 111, 111, 257, 35, 115, 100, 117, 110, 49, 1]])
>>> # ByT5 produces only one char at a time so we need to produce many more output characters here -> set `max_length=100`.
>>> output_ids = model.generate(input_ids, max_length=100)[0].tolist()
>>> output_ids
[0, 258, 108, 118, 35, 119, 107, 104, 35, 114, 113, 104, 35, 122, 107, 114, 35, 103, 114, 104, 118, 257, 35, 108, 113, 35, 119, 107, 104, 35, 103, 108, 118, 102, 114, 256, 108, 113, 35, 119, 107, 104, 35, 115, 100, 117, 110, 49, 35, 87, 107, 104, 35, 103, 114, 106, 35, 108, 118, 35, 119, 107, 104, 35, 114, 113, 104, 35, 122, 107, 114, 35, 103, 114, 104, 118, 35, 100, 35, 101, 100, 111, 111, 35, 108, 113, 255, 35, 108, 113, 35, 119, 107, 104, 35, 115, 100, 117, 110, 49]
>>> # ^- Note how 258 descends to 257, 256, 255
>>> # Now we need to split on the sentinel tokens, let's write a short loop for this
>>> output_ids_list = []
>>> start_token = 0
>>> sentinel_token = 258
>>> while sentinel_token in output_ids:
... split_idx = output_ids.index(sentinel_token)
... output_ids_list.append(output_ids[start_token:split_idx])
... start_token = split_idx
... sentinel_token -= 1
>>> output_ids_list.append(output_ids[start_token:])
>>> output_string = tokenizer.batch_decode(output_ids_list)
>>> output_string
['<pad>', 'is the one who does', ' in the disco', 'in the park. The dog is the one who does a ball in', ' in the park.']
```
## ByT5Tokenizer
[[autodoc]] ByT5Tokenizer
詳細については、[`ByT5Tokenizer`] を参照してください。 | transformers/docs/source/ja/model_doc/byt5.md/0 | {
"file_path": "transformers/docs/source/ja/model_doc/byt5.md",
"repo_id": "transformers",
"token_count": 3268
} | 260 |
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# CTRL
<div class="flex flex-wrap space-x-1">
<a href="https://huggingface.co/models?filter=ctrl">
<img alt="Models" src="https://img.shields.io/badge/All_model_pages-ctrl-blueviolet">
</a>
<a href="https://huggingface.co/spaces/docs-demos/tiny-ctrl">
<img alt="Spaces" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Spaces-blue">
</a>
</div>
## Overview
CTRL モデルは、Nitish Shirish Keskar*、Bryan McCann*、Lav R. Varshney、Caiming Xiong, Richard Socher によって [CTRL: A Conditional Transformer Language Model for Controllable Generation](https://arxiv.org/abs/1909.05858) で提案されました。
リチャード・ソーチャー。これは、非常に大規模なコーパスの言語モデリングを使用して事前トレーニングされた因果的 (一方向) トランスフォーマーです
最初のトークンが制御コード (リンク、書籍、Wikipedia など) として予約されている、約 140 GB のテキスト データ。
論文の要約は次のとおりです。
*大規模な言語モデルは有望なテキスト生成機能を示していますが、ユーザーは特定の言語モデルを簡単に制御できません
生成されたテキストの側面。 16 億 3,000 万パラメータの条件付きトランスフォーマー言語モデルである CTRL をリリースします。
スタイル、コンテンツ、タスク固有の動作を制御する制御コードを条件付けるように訓練されています。制御コードは
生のテキストと自然に共生する構造から派生し、教師なし学習の利点を維持しながら、
テキスト生成をより明示的に制御できるようになります。これらのコードを使用すると、CTRL でどの部分が予測されるのかを予測することもできます。
トレーニング データにはシーケンスが与えられる可能性が最も高くなります。これにより、大量のデータを分析するための潜在的な方法が提供されます。
モデルベースのソース帰属を介して。*
このモデルは、[keskarnitishr](https://huggingface.co/keskarnitishr) によって提供されました。元のコードが見つかる
[こちら](https://github.com/salesforce/ctrl)。
## Usage tips
- CTRL は制御コードを利用してテキストを生成します。生成を特定の単語や文で開始する必要があります。
またはリンクして一貫したテキストを生成します。 [元の実装](https://github.com/salesforce/ctrl) を参照してください。
詳しくは。
- CTRL は絶対位置埋め込みを備えたモデルであるため、通常は入力を右側にパディングすることをお勧めします。
左。
- CTRL は因果言語モデリング (CLM) の目的でトレーニングされているため、次の予測に強力です。
シーケンス内のトークン。この機能を利用すると、CTRL は構文的に一貫したテキストを生成できるようになります。
*run_generation.py* サンプル スクリプトで確認できます。
- PyTorch モデルは、以前に計算されたキーと値のアテンション ペアである`past_key_values`を入力として受け取ることができます。
TensorFlow モデルは`past`を入力として受け入れます。 `past_key_values`値を使用すると、モデルが再計算されなくなります。
テキスト生成のコンテキストで事前に計算された値。 [`forward`](model_doc/ctrl#transformers.CTRLModel.forward) を参照してください。
この引数の使用法の詳細については、メソッドを参照してください。
## Resources
- [テキスト分類タスクガイド](../tasks/sequence_classification)
- [因果言語モデリング タスク ガイド](../tasks/language_modeling)
## CTRLConfig
[[autodoc]] CTRLConfig
## CTRLTokenizer
[[autodoc]] CTRLTokenizer
- save_vocabulary
<frameworkcontent>
<pt>
## CTRLModel
[[autodoc]] CTRLModel
- forward
## CTRLLMHeadModel
[[autodoc]] CTRLLMHeadModel
- forward
## CTRLForSequenceClassification
[[autodoc]] CTRLForSequenceClassification
- forward
</pt>
<tf>
## TFCTRLModel
[[autodoc]] TFCTRLModel
- call
## TFCTRLLMHeadModel
[[autodoc]] TFCTRLLMHeadModel
- call
## TFCTRLForSequenceClassification
[[autodoc]] TFCTRLForSequenceClassification
- call
</tf>
</frameworkcontent>
| transformers/docs/source/ja/model_doc/ctrl.md/0 | {
"file_path": "transformers/docs/source/ja/model_doc/ctrl.md",
"repo_id": "transformers",
"token_count": 2118
} | 261 |
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 推論のための多言語モデル
[[open-in-colab]]
🤗 Transformers にはいくつかの多言語モデルがあり、それらの推論の使用方法は単一言語モデルとは異なります。ただし、多言語モデルの使用方法がすべて異なるわけではありません。 [bert-base-multilingual-uncased](https://huggingface.co/bert-base-multilingual-uncased) などの一部のモデルは、単一言語モデルと同様に使用できます。 このガイドでは、推論のために使用方法が異なる多言語モデルをどのように使うかを示します。
## XLM
XLM には10の異なるチェックポイントがあり、そのうちの1つだけが単一言語です。 残りの9つのモデルチェックポイントは、言語埋め込みを使用するチェックポイントと使用しないチェックポイントの2つのカテゴリに分けることができます。
### 言語の埋め込みがある XLM
次の XLM モデルは、言語の埋め込みを使用して、推論で使用される言語を指定します。
- `xlm-mlm-ende-1024` (マスク化された言語モデリング、英語-ドイツ語)
- `xlm-mlm-enfr-1024` (マスク化された言語モデリング、英語-フランス語)
- `xlm-mlm-enro-1024` (マスク化された言語モデリング、英語-ルーマニア語)
- `xlm-mlm-xnli15-1024` (マスク化された言語モデリング、XNLI 言語)
- `xlm-mlm-tlm-xnli15-1024` (マスク化された言語モデリング + 翻訳 + XNLI 言語)
- `xlm-clm-enfr-1024` (因果言語モデリング、英語-フランス語)
- `xlm-clm-ende-1024` (因果言語モデリング、英語-ドイツ語)
言語の埋め込みは、モデルに渡される `input_ids` と同じ形状のテンソルとして表されます。 これらのテンソルの値は、使用される言語に依存し、トークナイザーの `lang2id` および `id2lang` 属性によって識別されます。
この例では、`xlm-clm-enfr-1024` チェックポイントをロードします (因果言語モデリング、英語-フランス語)。
```py
>>> import torch
>>> from transformers import XLMTokenizer, XLMWithLMHeadModel
>>> tokenizer = XLMTokenizer.from_pretrained("xlm-clm-enfr-1024")
>>> model = XLMWithLMHeadModel.from_pretrained("xlm-clm-enfr-1024")
```
トークナイザーの `lang2id` 属性は、このモデルの言語とその ID を表示します。
```py
>>> print(tokenizer.lang2id)
{'en': 0, 'fr': 1}
```
次に、入力例を作成します。
```py
>>> input_ids = torch.tensor([tokenizer.encode("Wikipedia was used to")]) # batch size of 1
```
言語 ID を `en` に設定し、それを使用して言語の埋め込みを定義します。 言語の埋め込みは、英語の言語 ID であるため、`0` で埋められたテンソルです。 このテンソルは `input_ids` と同じサイズにする必要があります。
```py
>>> language_id = tokenizer.lang2id["en"] # 0
>>> langs = torch.tensor([language_id] * input_ids.shape[1]) # torch.tensor([0, 0, 0, ..., 0])
>>> # We reshape it to be of size (batch_size, sequence_length)
>>> langs = langs.view(1, -1) # is now of shape [1, sequence_length] (we have a batch size of 1)
```
これで、`input_ids` と言語の埋め込みをモデルに渡すことができます。
```py
>>> outputs = model(input_ids, langs=langs)
```
[run_generation.py](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-generation/run_generation.py) スクリプトは、`xlm-clm` チェックポイントを使用して、言語が埋め込まれたテキストを生成できます。
### 言語の埋め込みがないXLM
次の XLM モデルは、推論中に言語の埋め込みを必要としません。
- `xlm-mlm-17-1280` (マスク化された言語モデリング、17の言語)
- `xlm-mlm-100-1280` (マスク化された言語モデリング、100の言語)
これらのモデルは、以前の XLM チェックポイントとは異なり、一般的な文の表現に使用されます。
## BERT
以下の BERT モデルは、多言語タスクに使用できます。
- `bert-base-multilingual-uncased` (マスク化された言語モデリング + 次の文の予測、102の言語)
- `bert-base-multilingual-cased` (マスク化された言語モデリング + 次の文の予測、104の言語)
これらのモデルは、推論中に言語の埋め込みを必要としません。 文脈から言語を識別し、それに応じて推測する必要があります。
## XLM-RoBERTa
次の XLM-RoBERTa モデルは、多言語タスクに使用できます。
- `xlm-roberta-base` (マスク化された言語モデリング、100の言語)
- `xlm-roberta-large` (マスク化された言語モデリング、100の言語)
XLM-RoBERTa は、100の言語で新しく作成およびクリーニングされた2.5 TB の CommonCrawl データでトレーニングされました。 これは、分類、シーケンスのラベル付け、質問応答などのダウンストリームタスクで、mBERT や XLM などの以前にリリースされた多言語モデルを大幅に改善します。
## M2M100
次の M2M100 モデルは、多言語翻訳に使用できます。
- `facebook/m2m100_418M` (翻訳)
- `facebook/m2m100_1.2B` (翻訳)
この例では、`facebook/m2m100_418M` チェックポイントをロードして、中国語から英語に翻訳します。 トークナイザーでソース言語を設定できます。
```py
>>> from transformers import M2M100ForConditionalGeneration, M2M100Tokenizer
>>> en_text = "Do not meddle in the affairs of wizards, for they are subtle and quick to anger."
>>> chinese_text = "不要插手巫師的事務, 因為他們是微妙的, 很快就會發怒."
>>> tokenizer = M2M100Tokenizer.from_pretrained("facebook/m2m100_418M", src_lang="zh")
>>> model = M2M100ForConditionalGeneration.from_pretrained("facebook/m2m100_418M")
```
テキストをトークン化します。
```py
>>> encoded_zh = tokenizer(chinese_text, return_tensors="pt")
```
M2M100 は、最初に生成されたトークンとしてターゲット言語 ID を強制的にターゲット言語に翻訳します。 英語に翻訳するには、`generate` メソッドで `forced_bos_token_id` を `en` に設定します。
```py
>>> generated_tokens = model.generate(**encoded_zh, forced_bos_token_id=tokenizer.get_lang_id("en"))
>>> tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
'Do not interfere with the matters of the witches, because they are delicate and will soon be angry.'
```
## MBart
多言語翻訳には、次の MBart モデルを使用できます。
- `facebook/mbart-large-50-one-to-many-mmt` (One-to-many multilingual machine translation, 50 languages)
- `facebook/mbart-large-50-many-to-many-mmt` (Many-to-many multilingual machine translation, 50 languages)
- `facebook/mbart-large-50-many-to-one-mmt` (Many-to-one multilingual machine translation, 50 languages)
- `facebook/mbart-large-50` (Multilingual translation, 50 languages)
- `facebook/mbart-large-cc25`
この例では、`facebook/mbart-large-50-many-to-many-mmt` チェックポイントをロードして、フィンランド語を英語に翻訳します。トークナイザーでソース言語を設定できます。
```py
>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
>>> en_text = "Do not meddle in the affairs of wizards, for they are subtle and quick to anger."
>>> fi_text = "Älä sekaannu velhojen asioihin, sillä ne ovat hienovaraisia ja nopeasti vihaisia."
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/mbart-large-50-many-to-many-mmt", src_lang="fi_FI")
>>> model = AutoModelForSeq2SeqLM.from_pretrained("facebook/mbart-large-50-many-to-many-mmt")
```
テキストをトークン化します。
```py
>>> encoded_en = tokenizer(en_text, return_tensors="pt")
```
MBart は、最初に生成されたトークンとしてターゲット言語 ID を強制的にターゲット言語に翻訳します。 英語に翻訳するには、`generate` メソッドで `forced_bos_token_id` を `en` に設定します。
```py
>>> generated_tokens = model.generate(**encoded_en, forced_bos_token_id=tokenizer.lang_code_to_id("en_XX"))
>>> tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
"Don't interfere with the wizard's affairs, because they are subtle, will soon get angry."
```
`facebook/mbart-large-50-many-to-one-mmt` チェックポイントを使用している場合、最初に生成されたトークンとしてターゲット言語 ID を強制する必要はありません。それ以外の場合、使用方法は同じです。 | transformers/docs/source/ja/multilingual.md/0 | {
"file_path": "transformers/docs/source/ja/multilingual.md",
"repo_id": "transformers",
"token_count": 4086
} | 262 |
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Video classification
[[open-in-colab]]
ビデオ分類は、ビデオ全体にラベルまたはクラスを割り当てるタスクです。ビデオには、各ビデオに 1 つのクラスのみが含まれることが期待されます。ビデオ分類モデルはビデオを入力として受け取り、ビデオがどのクラスに属するかについての予測を返します。これらのモデルを使用して、ビデオの内容を分類できます。ビデオ分類の実際のアプリケーションはアクション/アクティビティ認識であり、フィットネス アプリケーションに役立ちます。また、視覚障害のある人にとって、特に通勤時に役立ちます。
このガイドでは、次の方法を説明します。
1. [UCF101](https://www.crcv.ucf.edu/) のサブセットで [VideoMAE](https://huggingface.co/docs/transformers/main/en/model_doc/videomae) を微調整します。 data/UCF101.php) データセット。
2. 微調整したモデルを推論に使用します。
<Tip>
このチュートリアルで説明するタスクは、次のモデル アーキテクチャでサポートされています。
<!--This tip is automatically generated by `make fix-copies`, do not fill manually!-->
[TimeSformer](../model_doc/timesformer), [VideoMAE](../model_doc/videomae), [ViViT](../model_doc/vivit)
<!--End of the generated tip-->
</Tip>
始める前に、必要なライブラリがすべてインストールされていることを確認してください。
```bash
pip install -q pytorchvideo transformers evaluate
```
[PyTorchVideo](https://pytorchvideo.org/) (`pytorchvideo` と呼ばれます) を使用してビデオを処理し、準備します。
モデルをアップロードしてコミュニティと共有できるように、Hugging Face アカウントにログインすることをお勧めします。プロンプトが表示されたら、トークンを入力してログインします。
```py
>>> from huggingface_hub import notebook_login
>>> notebook_login()
```
## Load UCF101 dataset
まず、[UCF-101 データセット](https://www.crcv.ucf.edu/data/UCF101.php) のサブセットをロードします。これにより、完全なデータセットのトレーニングにさらに時間を費やす前に、実験してすべてが機能することを確認する機会が得られます。
```py
>>> from huggingface_hub import hf_hub_download
>>> hf_dataset_identifier = "sayakpaul/ucf101-subset"
>>> filename = "UCF101_subset.tar.gz"
>>> file_path = hf_hub_download(repo_id=hf_dataset_identifier, filename=filename, repo_type="dataset")
```
サブセットをダウンロードした後、圧縮アーカイブを抽出する必要があります。
```py
>>> import tarfile
>>> with tarfile.open(file_path) as t:
... t.extractall(".")
```
大まかに言うと、データセットは次のように構成されています。
```bash
UCF101_subset/
train/
BandMarching/
video_1.mp4
video_2.mp4
...
Archery
video_1.mp4
video_2.mp4
...
...
val/
BandMarching/
video_1.mp4
video_2.mp4
...
Archery
video_1.mp4
video_2.mp4
...
...
test/
BandMarching/
video_1.mp4
video_2.mp4
...
Archery
video_1.mp4
video_2.mp4
...
...
```
(`sorted`)された ビデオ パスは次のように表示されます。
```bash
...
'UCF101_subset/train/ApplyEyeMakeup/v_ApplyEyeMakeup_g07_c04.avi',
'UCF101_subset/train/ApplyEyeMakeup/v_ApplyEyeMakeup_g07_c06.avi',
'UCF101_subset/train/ApplyEyeMakeup/v_ApplyEyeMakeup_g08_c01.avi',
'UCF101_subset/train/ApplyEyeMakeup/v_ApplyEyeMakeup_g09_c02.avi',
'UCF101_subset/train/ApplyEyeMakeup/v_ApplyEyeMakeup_g09_c06.avi'
...
```
同じグループ/シーンに属するビデオ クリップがあり、ビデオ ファイル パスではグループが`g`で示されていることがわかります。たとえば、`v_ApplyEyeMakeup_g07_c04.avi`や`v_ApplyEyeMakeup_g07_c06.avi`などです。
検証と評価の分割では、[データ漏洩](https://www.kaggle.com/code/alexisbcook/data-leakage) を防ぐために、同じグループ/シーンからのビデオ クリップを使用しないでください。このチュートリアルで使用しているサブセットでは、この情報が考慮されています。
次に、データセット内に存在するラベルのセットを取得します。また、モデルを初期化するときに役立つ 2 つの辞書を作成します。
* `label2id`: クラス名を整数にマップします。
* `id2label`: 整数をクラス名にマッピングします。
```py
>>> class_labels = sorted({str(path).split("/")[2] for path in all_video_file_paths})
>>> label2id = {label: i for i, label in enumerate(class_labels)}
>>> id2label = {i: label for label, i in label2id.items()}
>>> print(f"Unique classes: {list(label2id.keys())}.")
# Unique classes: ['ApplyEyeMakeup', 'ApplyLipstick', 'Archery', 'BabyCrawling', 'BalanceBeam', 'BandMarching', 'BaseballPitch', 'Basketball', 'BasketballDunk', 'BenchPress'].
```
個性的なクラスが10種類あります。トレーニング セットには、クラスごとに 30 個のビデオがあります。
## Load a model to fine-tune
事前トレーニングされたチェックポイントとそれに関連する画像プロセッサからビデオ分類モデルをインスタンス化します。モデルのエンコーダーには事前トレーニングされたパラメーターが付属しており、分類ヘッドはランダムに初期化されます。画像プロセッサは、データセットの前処理パイプラインを作成するときに役立ちます。
```py
>>> from transformers import VideoMAEImageProcessor, VideoMAEForVideoClassification
>>> model_ckpt = "MCG-NJU/videomae-base"
>>> image_processor = VideoMAEImageProcessor.from_pretrained(model_ckpt)
>>> model = VideoMAEForVideoClassification.from_pretrained(
... model_ckpt,
... label2id=label2id,
... id2label=id2label,
... ignore_mismatched_sizes=True, # provide this in case you're planning to fine-tune an already fine-tuned checkpoint
... )
```
モデルのロード中に、次の警告が表示される場合があります。
```bash
Some weights of the model checkpoint at MCG-NJU/videomae-base were not used when initializing VideoMAEForVideoClassification: [..., 'decoder.decoder_layers.1.attention.output.dense.bias', 'decoder.decoder_layers.2.attention.attention.key.weight']
- This IS expected if you are initializing VideoMAEForVideoClassification from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing VideoMAEForVideoClassification from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Some weights of VideoMAEForVideoClassification were not initialized from the model checkpoint at MCG-NJU/videomae-base and are newly initialized: ['classifier.bias', 'classifier.weight']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
```
この警告は、一部の重み (たとえば、`classifier`層の重みとバイアス) を破棄し、他のいくつかの重み (新しい`classifier`層の重みとバイアス) をランダムに初期化していることを示しています。この場合、これは予想されることです。事前にトレーニングされた重みを持たない新しい頭部を追加しているため、推論に使用する前にこのモデルを微調整する必要があるとライブラリが警告します。これはまさに私たちが行おうとしているものです。する。
**注意** [このチェックポイント](https://huggingface.co/MCG-NJU/videomae-base-finetuned-kinetics) は、同様のダウンストリームで微調整されてチェックポイントが取得されたため、このタスクのパフォーマンスが向上することに注意してください。かなりのドメインの重複があるタスク。 `MCG-NJU/videomae-base-finetuned-kinetics` を微調整して取得した [このチェックポイント](https://huggingface.co/sayakpaul/videomae-base-finetuned-kinetics-finetuned-ucf101-subset) を確認できます。 -キネティクス`。
## Prepare the datasets for training
ビデオの前処理には、[PyTorchVideo ライブラリ](https://pytorchvideo.org/) を利用します。まず、必要な依存関係をインポートします。
```py
>>> import pytorchvideo.data
>>> from pytorchvideo.transforms import (
... ApplyTransformToKey,
... Normalize,
... RandomShortSideScale,
... RemoveKey,
... ShortSideScale,
... UniformTemporalSubsample,
... )
>>> from torchvision.transforms import (
... Compose,
... Lambda,
... RandomCrop,
... RandomHorizontalFlip,
... Resize,
... )
```
トレーニング データセットの変換には、均一な時間サブサンプリング、ピクセル正規化、ランダム クロッピング、およびランダムな水平反転を組み合わせて使用します。検証および評価のデータセット変換では、ランダムなトリミングと水平反転を除き、同じ変換チェーンを維持します。これらの変換の詳細については、[PyTorchVideo の公式ドキュメント](https://pytorchvideo.org) を参照してください。
事前トレーニングされたモデルに関連付けられた`image_processor`を使用して、次の情報を取得します。
* ビデオ フレームのピクセルが正規化される画像の平均値と標準偏差。
* ビデオ フレームのサイズが変更される空間解像度。
まず、いくつかの定数を定義します。
```py
>>> mean = image_processor.image_mean
>>> std = image_processor.image_std
>>> if "shortest_edge" in image_processor.size:
... height = width = image_processor.size["shortest_edge"]
>>> else:
... height = image_processor.size["height"]
... width = image_processor.size["width"]
>>> resize_to = (height, width)
>>> num_frames_to_sample = model.config.num_frames
>>> sample_rate = 4
>>> fps = 30
>>> clip_duration = num_frames_to_sample * sample_rate / fps
```
次に、データセット固有の変換とデータセットをそれぞれ定義します。トレーニングセットから始めます:
```py
>>> train_transform = Compose(
... [
... ApplyTransformToKey(
... key="video",
... transform=Compose(
... [
... UniformTemporalSubsample(num_frames_to_sample),
... Lambda(lambda x: x / 255.0),
... Normalize(mean, std),
... RandomShortSideScale(min_size=256, max_size=320),
... RandomCrop(resize_to),
... RandomHorizontalFlip(p=0.5),
... ]
... ),
... ),
... ]
... )
>>> train_dataset = pytorchvideo.data.Ucf101(
... data_path=os.path.join(dataset_root_path, "train"),
... clip_sampler=pytorchvideo.data.make_clip_sampler("random", clip_duration),
... decode_audio=False,
... transform=train_transform,
... )
```
同じ一連のワークフローを検証セットと評価セットに適用できます。
```py
>>> val_transform = Compose(
... [
... ApplyTransformToKey(
... key="video",
... transform=Compose(
... [
... UniformTemporalSubsample(num_frames_to_sample),
... Lambda(lambda x: x / 255.0),
... Normalize(mean, std),
... Resize(resize_to),
... ]
... ),
... ),
... ]
... )
>>> val_dataset = pytorchvideo.data.Ucf101(
... data_path=os.path.join(dataset_root_path, "val"),
... clip_sampler=pytorchvideo.data.make_clip_sampler("uniform", clip_duration),
... decode_audio=False,
... transform=val_transform,
... )
>>> test_dataset = pytorchvideo.data.Ucf101(
... data_path=os.path.join(dataset_root_path, "test"),
... clip_sampler=pytorchvideo.data.make_clip_sampler("uniform", clip_duration),
... decode_audio=False,
... transform=val_transform,
... )
```
**注意**: 上記のデータセット パイプラインは、[公式 PyTorchVideo サンプル](https://pytorchvideo.org/docs/tutorial_classification#dataset) から取得したものです。 [`pytorchvideo.data.Ucf101()`](https://pytorchvideo.readthedocs.io/en/latest/api/data/data.html#pytorchvideo.data.Ucf101) 関数を使用しています。 UCF-101 データセット。内部では、[`pytorchvideo.data.labeled_video_dataset.LabeledVideoDataset`](https://pytorchvideo.readthedocs.io/en/latest/api/data/data.html#pytorchvideo.data.LabeledVideoDataset) オブジェクトを返します。 `LabeledVideoDataset` クラスは、PyTorchVideo データセット内のすべてのビデオの基本クラスです。したがって、PyTorchVideo で既製でサポートされていないカスタム データセットを使用したい場合は、それに応じて `LabeledVideoDataset` クラスを拡張できます。詳細については、`data`API [ドキュメント](https://pytorchvideo.readthedocs.io/en/latest/api/data/data.html)を参照してください。また、データセットが同様の構造 (上に示したもの) に従っている場合は、`pytorchvideo.data.Ucf101()` を使用すると問題なく動作するはずです。
`num_videos` 引数にアクセスすると、データセット内のビデオの数を知ることができます。
```py
>>> print(train_dataset.num_videos, val_dataset.num_videos, test_dataset.num_videos)
# (300, 30, 75)
```
## Visualize the preprocessed video for better debugging
```py
>>> import imageio
>>> import numpy as np
>>> from IPython.display import Image
>>> def unnormalize_img(img):
... """Un-normalizes the image pixels."""
... img = (img * std) + mean
... img = (img * 255).astype("uint8")
... return img.clip(0, 255)
>>> def create_gif(video_tensor, filename="sample.gif"):
... """Prepares a GIF from a video tensor.
...
... The video tensor is expected to have the following shape:
... (num_frames, num_channels, height, width).
... """
... frames = []
... for video_frame in video_tensor:
... frame_unnormalized = unnormalize_img(video_frame.permute(1, 2, 0).numpy())
... frames.append(frame_unnormalized)
... kargs = {"duration": 0.25}
... imageio.mimsave(filename, frames, "GIF", **kargs)
... return filename
>>> def display_gif(video_tensor, gif_name="sample.gif"):
... """Prepares and displays a GIF from a video tensor."""
... video_tensor = video_tensor.permute(1, 0, 2, 3)
... gif_filename = create_gif(video_tensor, gif_name)
... return Image(filename=gif_filename)
>>> sample_video = next(iter(train_dataset))
>>> video_tensor = sample_video["video"]
>>> display_gif(video_tensor)
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/sample_gif.gif" alt="Person playing basketball"/>
</div>
## Train the model
🤗 Transformers の [`Trainer`](https://huggingface.co/docs/transformers/main_classes/trainer) をモデルのトレーニングに利用します。 `Trainer`をインスタンス化するには、トレーニング構成と評価メトリクスを定義する必要があります。最も重要なのは [`TrainingArguments`](https://huggingface.co/transformers/main_classes/trainer.html#transformers.TrainingArguments) で、これはトレーニングを構成するためのすべての属性を含むクラスです。モデルのチェックポイントを保存するために使用される出力フォルダー名が必要です。また、🤗 Hub 上のモデル リポジトリ内のすべての情報を同期するのにも役立ちます。
トレーニング引数のほとんどは一目瞭然ですが、ここで非常に重要なのは`remove_unused_columns=False`です。これにより、モデルの呼び出し関数で使用されない機能が削除されます。デフォルトでは`True`です。これは、通常、未使用の特徴列を削除し、モデルの呼び出し関数への入力を解凍しやすくすることが理想的であるためです。ただし、この場合、`pixel_values` (モデルが入力で期待する必須キーです) を作成するには、未使用の機能 (特に`video`) が必要です。
```py
>>> from transformers import TrainingArguments, Trainer
>>> model_name = model_ckpt.split("/")[-1]
>>> new_model_name = f"{model_name}-finetuned-ucf101-subset"
>>> num_epochs = 4
>>> args = TrainingArguments(
... new_model_name,
... remove_unused_columns=False,
... evaluation_strategy="epoch",
... save_strategy="epoch",
... learning_rate=5e-5,
... per_device_train_batch_size=batch_size,
... per_device_eval_batch_size=batch_size,
... warmup_ratio=0.1,
... logging_steps=10,
... load_best_model_at_end=True,
... metric_for_best_model="accuracy",
... push_to_hub=True,
... max_steps=(train_dataset.num_videos // batch_size) * num_epochs,
... )
```
`pytorchvideo.data.Ucf101()` によって返されるデータセットは `__len__` メソッドを実装していません。そのため、`TrainingArguments`をインスタンス化するときに`max_steps`を定義する必要があります。
次に、予測からメトリクスを計算する関数を定義する必要があります。これは、これからロードする`metric`を使用します。必要な前処理は、予測されたロジットの argmax を取得することだけです。
```py
import evaluate
metric = evaluate.load("accuracy")
def compute_metrics(eval_pred):
predictions = np.argmax(eval_pred.predictions, axis=1)
return metric.compute(predictions=predictions, references=eval_pred.label_ids)
```
**評価に関する注意事項**:
[VideoMAE 論文](https://arxiv.org/abs/2203.12602) では、著者は次の評価戦略を使用しています。彼らはテスト ビデオからのいくつかのクリップでモデルを評価し、それらのクリップにさまざまなクロップを適用して、合計スコアを報告します。ただし、単純さと簡潔さを保つために、このチュートリアルではそれを考慮しません。
また、サンプルをまとめてバッチ処理するために使用される `collate_fn` を定義します。各バッチは、`pixel_values` と `labels` という 2 つのキーで構成されます。
```py
>>> def collate_fn(examples):
... # permute to (num_frames, num_channels, height, width)
... pixel_values = torch.stack(
... [example["video"].permute(1, 0, 2, 3) for example in examples]
... )
... labels = torch.tensor([example["label"] for example in examples])
... return {"pixel_values": pixel_values, "labels": labels}
```
次に、これらすべてをデータセットとともに`Trainer`に渡すだけです。
```py
>>> trainer = Trainer(
... model,
... args,
... train_dataset=train_dataset,
... eval_dataset=val_dataset,
... tokenizer=image_processor,
... compute_metrics=compute_metrics,
... data_collator=collate_fn,
... )
```
すでにデータを前処理しているのに、なぜトークナイザーとして`image_processor`を渡したのか不思議に思うかもしれません。これは、イメージ プロセッサ構成ファイル (JSON として保存) もハブ上のリポジトリにアップロードされるようにするためだけです。
次に、`train` メソッドを呼び出してモデルを微調整します。
```py
>>> train_results = trainer.train()
```
トレーニングが完了したら、 [`~transformers.Trainer.push_to_hub`] メソッドを使用してモデルをハブに共有し、誰もがモデルを使用できるようにします。
```py
>>> trainer.push_to_hub()
```
## Inference
モデルを微調整したので、それを推論に使用できるようになりました。
推論のためにビデオをロードします。
```py
>>> sample_test_video = next(iter(test_dataset))
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/sample_gif_two.gif" alt="Teams playing basketball"/>
</div>
推論用に微調整されたモデルを試す最も簡単な方法は、それを [`pipeline`](https://huggingface.co/docs/transformers/main/en/main_classes/pipelines#transformers.VideoClassificationPipeline). で使用することです。モデルを使用してビデオ分類用の` pipeline`をインスタンス化し、それにビデオを渡します。
```py
>>> from transformers import pipeline
>>> video_cls = pipeline(model="my_awesome_video_cls_model")
>>> video_cls("https://huggingface.co/datasets/sayakpaul/ucf101-subset/resolve/main/v_BasketballDunk_g14_c06.avi")
[{'score': 0.9272987842559814, 'label': 'BasketballDunk'},
{'score': 0.017777055501937866, 'label': 'BabyCrawling'},
{'score': 0.01663011871278286, 'label': 'BalanceBeam'},
{'score': 0.009560945443809032, 'label': 'BandMarching'},
{'score': 0.0068979403004050255, 'label': 'BaseballPitch'}]
```
必要に応じて、`pipeline`の結果を手動で複製することもできます。
```py
>>> def run_inference(model, video):
... # (num_frames, num_channels, height, width)
... perumuted_sample_test_video = video.permute(1, 0, 2, 3)
... inputs = {
... "pixel_values": perumuted_sample_test_video.unsqueeze(0),
... "labels": torch.tensor(
... [sample_test_video["label"]]
... ), # this can be skipped if you don't have labels available.
... }
... device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
... inputs = {k: v.to(device) for k, v in inputs.items()}
... model = model.to(device)
... # forward pass
... with torch.no_grad():
... outputs = model(**inputs)
... logits = outputs.logits
... return logits
```
次に、入力をモデルに渡し、`logits `を返します。
```
>>> logits = run_inference(trained_model, sample_test_video["video"])
```
`logits` をデコードすると、次のようになります。
```py
>>> predicted_class_idx = logits.argmax(-1).item()
>>> print("Predicted class:", model.config.id2label[predicted_class_idx])
# Predicted class: BasketballDunk
```
| transformers/docs/source/ja/tasks/video_classification.md/0 | {
"file_path": "transformers/docs/source/ja/tasks/video_classification.md",
"repo_id": "transformers",
"token_count": 10073
} | 263 |
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Hugging Face Transformers를 추가하는 방법은 무엇인가요? [[how-to-add-a-model-to-transformers]]
Hugging Face Transformers 라이브러리는 커뮤니티 기여자들 덕분에 새로운 모델을 제공할 수 있는 경우가 많습니다. 하지만 이는 도전적인 프로젝트이며 Hugging Face Transformers 라이브러리와 구현할 모델에 대한 깊은 이해가 필요합니다. Hugging Face에서는 더 많은 커뮤니티 멤버가 모델을 적극적으로 추가할 수 있도록 지원하고자 하며, 이 가이드를 통해 PyTorch 모델을 추가하는 과정을 안내하고 있습니다 (PyTorch가 설치되어 있는지 확인해주세요).
<Tip>
TensorFlow 모델을 구현하고자 하는 경우 [🤗 Transformers 모델을 TensorFlow로 변환하는 방법](add_tensorflow_model) 가이드를 살펴보세요!
</Tip>
이 과정을 진행하면 다음과 같은 내용을 이해하게 됩니다:
- 오픈 소스의 모범 사례에 대한 통찰력을 얻습니다.
- 가장 인기 있는 딥러닝 라이브러리의 설계 원칙을 이해합니다.
- 대규모 모델을 효율적으로 테스트하는 방법을 배웁니다.
- `black`, `ruff`, `make fix-copies`와 같은 Python 유틸리티를 통합하여 깔끔하고 가독성 있는 코드를 작성하는 방법을 배웁니다.
Hugging Face 팀은 항상 도움을 줄 준비가 되어 있으므로 혼자가 아니라는 점을 기억하세요. 🤗 ❤️
시작에 앞서 🤗 Transformers에 원하는 모델을 추가하기 위해 [New model addition](https://github.com/huggingface/transformers/issues/new?assignees=&labels=New+model&template=new-model-addition.yml) 이슈를 열어야 합니다. 특정 모델을 기여하는 데 특별히 까다로운 기준을 가지지 않는 경우 [New model label](https://github.com/huggingface/transformers/labels/New%20model)을 필터링하여 요청되지 않은 모델이 있는지 확인하고 작업할 수 있습니다.
새로운 모델 요청을 열었다면 첫 번째 단계는 🤗 Transformers에 익숙해지는 것입니다!
## 🤗 Transformers의 전반적인 개요 [[general-overview-of-transformers]]
먼저 🤗 Transformers에 대한 전반적인 개요를 파악해야 합니다. 🤗 Transformers는 매우 주관적인 라이브러리이기 때문에 해당 라이브러리의 철학이나 설계 선택 사항에 동의하지 않을 수도 있습니다. 그러나 우리의 경험상 라이브러리의 기본적인 설계 선택과 철학은 🤗 Transformers의 규모를 효율적으로 확장하면서 유지 보수 비용을 합리적인 수준으로 유지하는 것입니다.
[라이브러리의 철학에 대한 문서](philosophy)를 읽는 것이 라이브러리를 더 잘 이해하는 좋은 시작점입니다. 모든 모델에 적용하려는 몇 가지 작업 방식에 대한 선택 사항이 있습니다:
- 일반적으로 추상화보다는 구성을 선호합니다.
- 코드를 복제하는 것이 항상 나쁜 것은 아닙니다. 코드의 가독성이나 접근성을 크게 향상시킨다면 복제하는 것은 좋습니다.
- 모델 파일은 가능한 한 독립적으로 유지되어야 합니다. 따라서 특정 모델의 코드를 읽을 때 해당 `modeling_....py` 파일만 확인하면 됩니다.
우리는 라이브러리의 코드가 제품을 제공하는 수단뿐만 아니라 개선하고자 하는 제품이라고도 생각합니다. 따라서 모델을 추가할 때, 사용자는 모델을 사용할 사람뿐만 아니라 코드를 읽고 이해하고 필요한 경우 조정할 수 있는 모든 사람까지도 포함한다는 점을 기억해야 합니다.
이를 염두에 두고 일반적인 라이브러리 설계에 대해 조금 더 자세히 알아보겠습니다.
### 모델 개요 [[overview-of-models]]
모델을 성공적으로 추가하려면 모델과 해당 구성인 [`PreTrainedModel`] 및 [`PretrainedConfig`] 간의 상호작용을 이해하는 것이 중요합니다. 예를 들어, 🤗 Transformers에 추가하려는 모델을 `BrandNewBert`라고 부르겠습니다.
다음을 살펴보겠습니다:
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers_overview.png"/>
보다시피, 🤗 Transformers에서는 상속을 사용하지만 추상화 수준을 최소한으로 유지합니다. 라이브러리의 어떤 모델에서도 두 수준 이상의 추상화가 존재하지 않습니다. `BrandNewBertModel`은 `BrandNewBertPreTrainedModel`에서 상속받고, 이 클래스는 [`PreTrainedModel`]에서 상속받습니다. 이로써 새로운 모델은 [`PreTrainedModel`]에만 의존하도록 하려고 합니다. 모든 새로운 모델에 자동으로 제공되는 중요한 기능은 [`~PreTrainedModel.from_pretrained`] 및 [`~PreTrainedModel.save_pretrained`]입니다. 이러한 기능 외에도 `BrandNewBertModel.forward`와 같은 다른 중요한 기능은 새로운 `modeling_brand_new_bert.py` 스크립트에서 완전히 정의되어야 합니다. 또한 `BrandNewBertForMaskedLM`과 같은 특정 헤드 레이어를 가진 모델은 `BrandNewBertModel`을 상속받지 않고 forward pass에서 호출할 수 있는 `BrandNewBertModel`을 사용하여 추상화 수준을 낮게 유지합니다. 모든 새로운 모델은 `BrandNewBertConfig`라는 구성 클래스를 필요로 합니다. 이 구성은 항상 [`PreTrainedModel`]의 속성으로 저장되며, 따라서 `BrandNewBertPreTrainedModel`을 상속받는 모든 클래스에서 `config` 속성을 통해 액세스할 수 있습니다:
```python
model = BrandNewBertModel.from_pretrained("brandy/brand_new_bert")
model.config # model has access to its config
```
모델과 마찬가지로 구성은 [`PretrainedConfig`]에서 기본 직렬화 및 역직렬화 기능을 상속받습니다. 구성과 모델은 항상 *pytorch_model.bin* 파일과 *config.json* 파일로 각각 별도로 직렬화됩니다. [`~PreTrainedModel.save_pretrained`]를 호출하면 자동으로 [`~PretrainedConfig.save_pretrained`]도 호출되므로 모델과 구성이 모두 저장됩니다.
### 코드 스타일 [[code-style]]
새로운 모델을 작성할 때, Transformers는 주관적인 라이브러리이며 몇 가지 독특한 코딩 스타일이 있습니다:
1. 모델의 forward pass는 모델 파일에 완전히 작성되어야 합니다. 라이브러리의 다른 모델에서 블록을 재사용하려면 코드를 복사하여 위에 `# Copied from` 주석과 함께 붙여넣으면 됩니다 (예: [여기](https://github.com/huggingface/transformers/blob/v4.17.0/src/transformers/models/roberta/modeling_roberta.py#L160)를 참조하세요).
2. 코드는 완전히 이해하기 쉬워야 합니다. 변수 이름을 명확하게 지정하고 약어를 사용하지 않는 것이 좋습니다. 예를 들어, `act`보다는 `activation`을 선호합니다. 한 글자 변수 이름은 루프의 인덱스인 경우를 제외하고 권장되지 않습니다.
3. 더 일반적으로, 짧은 마법 같은 코드보다는 길고 명시적인 코드를 선호합니다.
4. PyTorch에서 `nn.Sequential`을 하위 클래스로 만들지 말고 `nn.Module`을 하위 클래스로 만들고 forward pass를 작성하여 다른 사람이 코드를 빠르게 디버그할 수 있도록 합니다. print 문이나 중단점을 추가할 수 있습니다.
5. 함수 시그니처에는 타입 주석을 사용해야 합니다. 그 외에는 타입 주석보다 변수 이름이 훨씬 읽기 쉽고 이해하기 쉽습니다.
### 토크나이저 개요 [[overview-of-tokenizers]]
아직 준비되지 않았습니다 :-( 이 섹션은 곧 추가될 예정입니다!
## 🤗 Transformers에 모델 추가하는 단계별 방법 [[stepbystep-recipe-to-add-a-model-to-transformers]]
각자 모델을 이식하는 방법에 대한 선호가 다르기 때문에 다른 기여자들이 Hugging Face에 모델을 이식하는 방법에 대한 요약을 살펴보는 것이 매우 유용할 수 있습니다. 다음은 모델을 이식하는 방법에 대한 커뮤니티 블로그 게시물 목록입니다:
1. [GPT2 모델 이식하기](https://medium.com/huggingface/from-tensorflow-to-pytorch-265f40ef2a28) - [Thomas](https://huggingface.co/thomwolf)
2. [WMT19 MT 모델 이식하기](https://huggingface.co/blog/porting-fsmt) - [Stas](https://huggingface.co/stas)
경험상 모델을 추가할 때 주의해야 할 가장 중요한 사항은 다음과 같습니다:
- 같은 일을 반복하지 마세요! 새로운 🤗 Transformers 모델을 위해 추가할 코드의 대부분은 이미 🤗 Transformers 어딘가에 존재합니다. 이미 존재하는 복사할 수 있는 유사한 모델과 토크나이저를 찾는데 시간을 투자하세요. [grep](https://www.gnu.org/software/grep/)와 [rg](https://github.com/BurntSushi/ripgrep)를 참고하세요. 모델의 토크나이저가 한 모델을 기반으로 하고 모델링 코드가 다른 모델을 기반으로 하는 경우가 존재할 수도 있습니다. 예를 들어 FSMT의 모델링 코드는 BART를 기반으로 하고 FSMT의 토크나이저 코드는 XLM을 기반으로 합니다.
- 이것은 과학적인 도전보다는 공학적인 도전입니다. 논문의 모델의 모든 이론적 측면을 이해하려는 것보다 효율적인 디버깅 환경을 만드는 데 더 많은 시간을 소비해야 합니다.
- 막힐 때 도움을 요청하세요! 모델은 🤗 Transformers의 핵심 구성 요소이므로 Hugging Face의 우리는 당신이 모델을 추가하는 각 단계에서 기꺼이 도움을 줄 준비가 되어 있습니다. 진전이 없다고 느끼면 주저하지 말고 도움을 요청하세요.
다음에서는 모델을 🤗 Transformers로 이식하는 데 가장 유용한 일반적인 절차를 제공하려고 노력합니다.
다음 목록은 모델을 추가하는 데 수행해야 할 모든 작업의 요약이며 To-Do 목록으로 사용할 수 있습니다:
☐ (선택 사항) BrandNewBert의 이론적 측면 이해<br>
☐ Hugging Face 개발 환경 준비<br>
☐ 원본 리포지토리의 디버깅 환경 설정<br>
☐ 원본 리포지토리와 체크포인트를 사용하여 `forward()` pass가 성공적으로 실행되는 스크립트 작성<br>
☐ 🤗 Transformers에 모델 스켈레톤 성공적으로 추가<br>
☐ 원본 체크포인트를 🤗 Transformers 체크포인트로 성공적으로 변환<br>
☐ 🤗 Transformers에서 원본 체크포인트와 동일한 출력을 내주는 `forward()` pass 성공적으로 실행<br>
☐ 🤗 Transformers에서 모델 테스트 완료<br>
☐ 🤗 Transformers에 토크나이저 성공적으로 추가<br>
☐ 종단 간 통합 테스트 실행<br>
☐ 문서 작성 완료<br>
☐ 모델 가중치를 허브에 업로드<br>
☐ Pull request 제출<br>
☐ (선택 사항) 데모 노트북 추가
우선, 일반적으로는 `BrandNewBert`의 이론적인 이해로 시작하는 것을 권장합니다. 그러나 이론적 측면을 직접 이해하는 대신 *직접 해보면서* 모델의 이론적 측면을 이해하는 것을 선호하는 경우 바로 `BrandNewBert` 코드 베이스로 빠져드는 것도 괜찮습니다. 이 옵션은 엔지니어링 기술이 이론적 기술보다 더 뛰어난 경우, `BrandNewBert`의 논문을 이해하는 데 어려움이 있는 경우, 또는 과학적인 논문을 읽는 것보다 프로그래밍에 훨씬 더 흥미 있는 경우에 더 적합할 수 있습니다.
### 1. (선택 사항) BrandNewBert의 이론적 측면 [[1-optional-theoretical-aspects-of-brandnewbert]]
만약 그런 서술적인 작업이 존재한다면, *BrandNewBert*의 논문을 읽어보는 시간을 가져야 합니다. 이해하기 어려운 섹션이 많을 수 있습니다. 그렇더라도 걱정하지 마세요! 목표는 논문의 깊은 이론적 이해가 아니라 *BrandNewBert*를 🤗 Transformers에서 효과적으로 재구현하기 위해 필요한 정보를 추출하는 것입니다. 이를 위해 이론적 측면에 너무 많은 시간을 투자할 필요는 없지만 다음과 같은 실제적인 측면에 집중해야 합니다:
- *BrandNewBert*는 어떤 유형의 모델인가요? BERT와 유사한 인코더 모델인가요? GPT2와 유사한 디코더 모델인가요? BART와 유사한 인코더-디코더 모델인가요? 이들 간의 차이점에 익숙하지 않은 경우[model_summary](model_summary)를 참조하세요.
- *BrandNewBert*의 응용 분야는 무엇인가요? 텍스트 분류인가요? 텍스트 생성인가요? 요약과 같은 Seq2Seq 작업인가요?
- *brand_new_bert*와 BERT/GPT-2/BART의 차이점은 무엇인가요?
- *brand_new_bert*와 가장 유사한 [🤗 Transformers 모델](https://huggingface.co/transformers/#contents)은 무엇인가요?
- 어떤 종류의 토크나이저가 사용되나요? Sentencepiece 토크나이저인가요? Word piece 토크나이저인가요? BERT 또는 BART에 사용되는 동일한 토크나이저인가요?
모델의 아키텍처에 대해 충분히 이해했다는 생각이 든 후, 궁금한 사항이 있으면 Hugging Face 팀에 문의하십시오. 이는 모델의 아키텍처, 어텐션 레이어 등에 관한 질문을 포함할 수 있습니다. Hugging Face의 유지 관리자들은 보통 코드를 검토하는 것에 대해 매우 기뻐하므로 당신을 돕는 일을 매우 환영할 것입니다!
### 2. 개발 환경 설정 [[2-next-prepare-your-environment]]
1. 저장소 페이지에서 "Fork" 버튼을 클릭하여 저장소의 사본을 GitHub 사용자 계정으로 만듭니다.
2. `transformers` fork를 로컬 디스크에 클론하고 베이스 저장소를 원격 저장소로 추가합니다:
```bash
git clone https://github.com/[your Github handle]/transformers.git
cd transformers
git remote add upstream https://github.com/huggingface/transformers.git
```
3. 개발 환경을 설정합니다. 다음 명령을 실행하여 개발 환경을 설정할 수 있습니다:
```bash
python -m venv .env
source .env/bin/activate
pip install -e ".[dev]"
```
각 운영 체제에 따라 Transformers의 선택적 의존성이 개수가 증가하면 이 명령이 실패할 수 있습니다. 그런 경우에는 작업 중인 딥 러닝 프레임워크 (PyTorch, TensorFlow 및/또는 Flax)을 설치한 후, 다음 명령을 수행하면 됩니다:
```bash
pip install -e ".[quality]"
```
대부분의 경우에는 이것으로 충분합니다. 그런 다음 상위 디렉토리로 돌아갑니다.
```bash
cd ..
```
4. Transformers에 *brand_new_bert*의 PyTorch 버전을 추가하는 것을 권장합니다. PyTorch를 설치하려면 다음 링크의 지침을 따르십시오: https://pytorch.org/get-started/locally/.
**참고:** CUDA를 설치할 필요는 없습니다. 새로운 모델이 CPU에서 작동하도록 만드는 것으로 충분합니다.
5. *brand_new_bert*를 이식하기 위해서는 해당 원본 저장소에 접근할 수 있어야 합니다:
```bash
git clone https://github.com/org_that_created_brand_new_bert_org/brand_new_bert.git
cd brand_new_bert
pip install -e .
```
이제 *brand_new_bert*를 🤗 Transformers로 이식하기 위한 개발 환경을 설정하였습니다.
### 3.-4. 원본 저장소에서 사전 훈련된 체크포인트 실행하기 [[3.-4.-run-a-pretrained-checkpoint-using-the-original-repository]]
먼저, 원본 *brand_new_bert* 저장소에서 작업을 시작합니다. 원본 구현은 보통 "연구용"으로 많이 사용됩니다. 즉, 문서화가 부족하고 코드가 이해하기 어려울 수 있습니다. 그러나 이것이 바로 *brand_new_bert*를 다시 구현하려는 동기가 되어야 합니다. Hugging Face에서의 주요 목표 중 하나는 **거인의 어깨 위에 서는 것**이며, 이는 여기에서 쉽게 해석되어 동작하는 모델을 가져와서 가능한 한 **접근 가능하고 사용자 친화적이며 아름답게** 만드는 것입니다. 이것은 🤗 Transformers에서 모델을 다시 구현하는 가장 중요한 동기입니다 - 새로운 복잡한 NLP 기술을 **모두에게** 접근 가능하게 만드는 것을 목표로 합니다.
따라서 원본 저장소에 대해 자세히 살펴보는 것으로 시작해야 합니다.
원본 저장소에서 공식 사전 훈련된 모델을 성공적으로 실행하는 것은 종종 **가장 어려운** 단계입니다. 우리의 경험에 따르면, 원본 코드 베이스에 익숙해지는 데 시간을 투자하는 것이 매우 중요합니다. 다음을 파악해야 합니다:
- 사전 훈련된 가중치를 어디서 찾을 수 있는지?
- 사전 훈련된 가중치를 해당 모델에로드하는 방법은?
- 모델과 독립적으로 토크나이저를 실행하는 방법은?
- 간단한 forward pass에 필요한 클래스와 함수를 파악하기 위해 forward pass를 한 번 추적해 보세요. 일반적으로 해당 함수들만 다시 구현하면 됩니다.
- 모델의 중요한 구성 요소를 찾을 수 있어야 합니다. 모델 클래스는 어디에 있나요? 모델 하위 클래스(*EncoderModel*, *DecoderModel* 등)가 있나요? self-attention 레이어는 어디에 있나요? self-attention, cross-attention 등 여러 가지 다른 어텐션 레이어가 있나요?
- 원본 환경에서 모델을 디버그할 수 있는 방법은 무엇인가요? *print* 문을 추가해야 하나요? *ipdb*와 같은 대화식 디버거를 사용할 수 있나요? PyCharm과 같은 효율적인 IDE를 사용해 모델을 디버그할 수 있나요?
원본 저장소에서 코드를 이식하는 작업을 시작하기 전에 원본 저장소에서 코드를 **효율적으로** 디버그할 수 있어야 합니다! 또한, 오픈 소스 라이브러리로 작업하고 있다는 것을 기억해야 합니다. 따라서 원본 저장소에서 issue를 열거나 pull request를 열기를 주저하지 마십시오. 이 저장소의 유지 관리자들은 누군가가 자신들의 코드를 살펴본다는 것에 대해 매우 기뻐할 것입니다!
현재 시점에서, 원래 모델을 디버깅하기 위해 어떤 디버깅 환경과 전략을 선호하는지는 당신에게 달렸습니다. 우리는 고가의 GPU 환경을 구축하는 것은 비추천합니다. 대신, 원래 저장소로 들어가서 작업을 시작할 때와 🤗 Transformers 모델의 구현을 시작할 때에도 CPU에서 작업하는 것이 좋습니다. 모델이 이미 🤗 Transformers로 성공적으로 이식되었을 때에만 모델이 GPU에서도 예상대로 작동하는지 확인해야합니다.
일반적으로, 원래 모델을 실행하기 위한 두 가지 가능한 디버깅 환경이 있습니다.
- [Jupyter 노트북](https://jupyter.org/) / [Google Colab](https://colab.research.google.com/notebooks/intro.ipynb)
- 로컬 Python 스크립트
Jupyter 노트북의 장점은 셀 단위로 실행할 수 있다는 것입니다. 이는 논리적인 구성 요소를 더 잘 분리하고 중간 결과를 저장할 수 있으므로 디버깅 사이클이 더 빨라질 수 있습니다. 또한, 노트북은 다른 기여자와 쉽게 공유할 수 있으므로 Hugging Face 팀의 도움을 요청하려는 경우 매우 유용할 수 있습니다. Jupyter 노트북에 익숙하다면 이를 사용하는 것을 강력히 추천합니다.
Jupyter 노트북의 단점은 사용에 익숙하지 않은 경우 새로운 프로그래밍 환경에 적응하는 데 시간을 할애해야 하며, `ipdb`와 같은 알려진 디버깅 도구를 더 이상 사용할 수 없을 수도 있다는 것입니다.
각 코드 베이스에 대해 좋은 첫 번째 단계는 항상 **작은** 사전 훈련된 체크포인트를 로드하고 더미 정수 벡터 입력을 사용하여 단일 forward pass를 재현하는 것입니다. 이와 같은 스크립트는 다음과 같을 수 있습니다(의사 코드로 작성):
```python
model = BrandNewBertModel.load_pretrained_checkpoint("/path/to/checkpoint/")
input_ids = [0, 4, 5, 2, 3, 7, 9] # vector of input ids
original_output = model.predict(input_ids)
```
다음으로, 디버깅 전략에 대해 일반적으로 다음과 같은 몇 가지 선택지가 있습니다:
- 원본 모델을 많은 작은 테스트 가능한 구성 요소로 분해하고 각각에 대해 forward pass를 실행하여 검증합니다.
- 원본 모델을 원본 *tokenizer*과 원본 *model*로만 분해하고 해당 부분에 대해 forward pass를 실행한 후 검증을 위해 중간 출력(print 문 또는 중단점)을 사용합니다.
다시 말하지만, 어떤 전략을 선택할지는 당신에게 달려 있습니다. 원본 코드 베이스에 따라 하나 또는 다른 전략이 유리할 수 있습니다.
원본 코드 베이스를 모델의 작은 하위 구성 요소로 분해할 수 있는지 여부, 예를 들어 원본 코드 베이스가 즉시 실행 모드에서 간단히 실행될 수 있는 경우, 그런 경우에는 그 노력이 가치가 있다는 것이 일반적입니다. 초기에 더 어려운 방법을 선택하는 것에는 몇 가지 중요한 장점이 있습니다.
- 원본 모델을 🤗 Transformers 구현과 비교할 때 각 구성 요소가 일치하는지 자동으로 확인할 수 있습니다. 즉, 시각적인 비교(print 문을 통한 비교가 아닌) 대신 🤗 Transformers 구현과 그에 대응하는 원본 구성 요소가 일치하는지 확인할 수 있습니다.
- 전체 모델을 모듈별로, 즉 작은 구성 요소로 분해함으로써 모델을 이식하는 큰 문제를 단순히 개별 구성 요소를 이식하는 작은 문제로 분해할 수 있으므로 작업을 더 잘 구조화할 수 있습니다.
- 모델을 논리적으로 의미 있는 구성 요소로 분리하는 것은 모델의 설계에 대한 더 나은 개요를 얻고 모델을 더 잘 이해하는 데 도움이 됩니다.
- 이러한 구성 요소별 테스트를 통해 코드를 변경하면서 회귀가 발생하지 않도록 보장할 수 있습니다.
[Lysandre의 ELECTRA 통합 검사](https://gist.github.com/LysandreJik/db4c948f6b4483960de5cbac598ad4ed)는 이를 수행하는 좋은 예제입니다.
그러나 원본 코드 베이스가 매우 복잡하거나 중간 구성 요소를 컴파일된 모드에서 실행하는 것만 허용하는 경우, 모델을 테스트 가능한 작은 하위 구성 요소로 분해하는 것이 시간이 많이 소요되거나 불가능할 수도 있습니다. [T5의 MeshTensorFlow](https://github.com/tensorflow/mesh/tree/master/mesh_tensorflow) 라이브러리는 매우 복잡하며 모델을 하위 구성 요소로 분해하는 간단한 방법을 제공하지 않습니다. 이러한 라이브러리의 경우, 보통 print 문을 통해 확인합니다.
어떤 전략을 선택하더라도 권장되는 절차는 동일합니다. 먼저 시작 레이어를 디버그하고 마지막 레이어를 마지막에 디버그하는 것이 좋습니다.
다음 순서로 각 레이어의 출력을 검색하는 것이 좋습니다:
1. 모델에 전달된 입력 ID 가져오기
2. 워드 임베딩 가져오기
3. 첫 번째 Transformer 레이어의 입력 가져오기
4. 첫 번째 Transformer 레이어의 출력 가져오기
5. 다음 n-1개의 Transformer 레이어의 출력 가져오기
6. BrandNewBert 모델의 출력 가져오기
입력 ID는 정수 배열로 구성되며, 예를 들어 `input_ids = [0, 4, 4, 3, 2, 4, 1, 7, 19]`와 같을 수 있습니다.
다음 레이어의 출력은 종종 다차원 실수 배열로 구성되며, 다음과 같이 나타낼 수 있습니다:
```
[[
[-0.1465, -0.6501, 0.1993, ..., 0.1451, 0.3430, 0.6024],
[-0.4417, -0.5920, 0.3450, ..., -0.3062, 0.6182, 0.7132],
[-0.5009, -0.7122, 0.4548, ..., -0.3662, 0.6091, 0.7648],
...,
[-0.5613, -0.6332, 0.4324, ..., -0.3792, 0.7372, 0.9288],
[-0.5416, -0.6345, 0.4180, ..., -0.3564, 0.6992, 0.9191],
[-0.5334, -0.6403, 0.4271, ..., -0.3339, 0.6533, 0.8694]]],
```
🤗 Transformers에 추가되는 모든 모델은 통합 테스트를 통과해야 합니다. 즉, 원본 모델과 🤗 Transformers의 재구현 버전이 0.001의 정밀도로 정확히 동일한 출력을 내야 합니다! 동일한 모델이 다른 라이브러리에서 작성되었을 때 라이브러리 프레임워크에 따라 약간 다른 출력을 얻는 것은 정상이므로 1e-3(0.001)의 오차는 허용합니다. 거의 동일한 출력을 내는 것만으로는 충분하지 않으며, 완벽히 일치하는 수준이어야 합니다. 따라서 🤗 Transformers 버전의 중간 출력을 *brand_new_bert*의 원래 구현의 중간 출력과 여러 번 비교해야 합니다. 이 경우 원본 저장소의 **효율적인** 디버깅 환경이 절대적으로 중요합니다. 디버깅 환경을 가능한 한 효율적으로 만드는 몇 가지 조언을 제시합니다.
- 중간 결과를 디버그하는 가장 좋은 방법을 찾으세요. 원본 저장소가 PyTorch로 작성되었다면 원본 모델을 더 작은 하위 구성 요소로 분해하여 중간 값을 검색하는 긴 스크립트를 작성하는 것에 시간을 투자할 가치가 있습니다. 원본 저장소가 Tensorflow 1로 작성되었다면 [tf.print](https://www.tensorflow.org/api_docs/python/tf/print)와 같은 Tensorflow 출력 작업을 사용하여 중간 값을 출력해야 할 수도 있습니다. 원본 저장소가 Jax로 작성되었다면 forward pass를 실행할 때 모델이 **jit 되지 않도록** 해야 합니다. 예를 들어 [이 링크](https://github.com/google/jax/issues/196)를 확인해 보세요.
- 사용 가능한 가장 작은 사전 훈련된 체크포인트를 사용하세요. 체크포인트가 작을수록 디버그 사이클이 더 빨라집니다. 전반적으로 forward pass에 10초 이상이 걸리는 경우 효율적이지 않습니다. 매우 큰 체크포인트만 사용할 수 있는 경우, 새 환경에서 임의로 초기화된 가중치로 더미 모델을 만들고 해당 가중치를 🤗 Transformers 버전과 비교하기 위해 저장하는 것이 더 의미가 있을 수 있습니다.
- 디버깅 설정에서 가장 쉽게 forward pass를 호출하는 방법을 사용하세요. 원본 저장소에서 **단일** forward pass만 호출하는 함수를 찾는 것이 이상적입니다. 이 함수는 일반적으로 `predict`, `evaluate`, `forward`, `__call__`과 같이 호출됩니다. `autoregressive_sample`과 같은 텍스트 생성에서 `forward`를 여러 번 호출하여 텍스트를 생성하는 등의 작업을 수행하는 함수를 디버그하고 싶지 않을 것입니다.
- 토큰화 과정을 모델의 *forward* pass와 분리하려고 노력하세요. 원본 저장소에서 입력 문자열을 입력해야 하는 예제가 있는 경우, 입력 문자열이 입력 ID로 변경되는 순간을 찾아서 시작하세요. 이 경우 직접 ID를 입력할 수 있도록 작은 스크립트를 작성하거나 원본 코드를 수정해야 할 수도 있습니다.
- 디버깅 설정에서 모델이 훈련 모드가 아니라는 것을 확인하세요. 훈련 모드에서는 모델의 여러 드롭아웃 레이어 때문에 무작위 출력이 생성될 수 있습니다. 디버깅 환경에서 forward pass가 **결정론적**이도록 해야 합니다. 또는 동일한 프레임워크에 있는 경우 *transformers.utils.set_seed*를 사용하세요.
다음 섹션에서는 *brand_new_bert*에 대해 이 작업을 수행하는 데 더 구체적인 세부 사항/팁을 제공합니다.
### 5.-14. 🤗 Transformers에 BrandNewBert를 이식하기 [[5.-14.-port-brandnewbert-to-transformers]]
이제, 마침내 🤗 Transformers에 새로운 코드를 추가할 수 있습니다. 🤗 Transformers 포크의 클론으로 이동하세요:
```bash
cd transformers
```
다음과 같이 이미 존재하는 모델의 모델 아키텍처와 정확히 일치하는 모델을 추가하는 특별한 경우에는 [이 섹션](#write-a-conversion-script)에 설명된대로 변환 스크립트만 추가하면 됩니다. 이 경우에는 이미 존재하는 모델의 전체 모델 아키텍처를 그대로 재사용할 수 있습니다.
그렇지 않으면 새로운 모델 생성을 시작합시다. 여기에서 두 가지 선택지가 있습니다:
- `transformers-cli add-new-model-like`를 사용하여 기존 모델과 유사한 새로운 모델 추가하기
- `transformers-cli add-new-model`을 사용하여 템플릿을 기반으로 한 새로운 모델 추가하기 (선택한 모델 유형에 따라 BERT 또는 Bart와 유사한 모습일 것입니다)
두 경우 모두, 모델의 기본 정보를 입력하는 설문조사가 제시됩니다. 두 번째 명령어는 `cookiecutter`를 설치해야 합니다. 자세한 정보는 [여기](https://github.com/huggingface/transformers/tree/main/templates/adding_a_new_model)에서 확인할 수 있습니다.
**huggingface/transformers 메인 저장소에 Pull Request 열기**
자동으로 생성된 코드를 수정하기 전에, 지금은 "작업 진행 중 (WIP)" 풀 리퀘스트를 열기 위한 시기입니다. 예를 들어, 🤗 Transformers에 "*brand_new_bert* 추가"라는 제목의 "[WIP] Add *brand_new_bert*" 풀 리퀘스트를 엽니다. 이렇게 하면 당신과 Hugging Face 팀이 🤗 Transformers에 모델을 통합하는 작업을 함께할 수 있습니다.
다음을 수행해야 합니다:
1. 메인 브랜치에서 작업을 잘 설명하는 이름으로 브랜치 생성
```bash
git checkout -b add_brand_new_bert
```
2. 자동으로 생성된 코드 커밋
```bash
git add .
git commit
```
3. 현재 메인을 가져오고 리베이스
```bash
git fetch upstream
git rebase upstream/main
```
4. 변경 사항을 계정에 푸시
```bash
git push -u origin a-descriptive-name-for-my-changes
```
5. 만족스럽다면, GitHub에서 자신의 포크한 웹 페이지로 이동합니다. "Pull request"를 클릭합니다. Hugging Face 팀의 일부 멤버의 GitHub 핸들을 리뷰어로 추가하여 Hugging Face 팀이 앞으로의 변경 사항에 대해 알림을 받을 수 있도록 합니다.
6. GitHub 풀 리퀘스트 웹 페이지 오른쪽에 있는 "Convert to draft"를 클릭하여 PR을 초안으로 변경합니다.
다음으로, 어떤 진전을 이루었다면 작업을 커밋하고 계정에 푸시하여 풀 리퀘스트에 표시되도록 해야 합니다. 또한, 다음과 같이 현재 메인과 작업을 업데이트해야 합니다:
```bash
git fetch upstream
git merge upstream/main
```
일반적으로, 모델 또는 구현에 관한 모든 질문은 자신의 PR에서 해야 하며, PR에서 토론되고 해결되어야 합니다. 이렇게 하면 Hugging Face 팀이 새로운 코드를 커밋하거나 질문을 할 때 항상 알림을 받을 수 있습니다. Hugging Face 팀에게 문제 또는 질문을 효율적으로 이해할 수 있도록 추가한 코드를 명시하는 것이 도움이 될 때가 많습니다.
이를 위해, 변경 사항을 모두 볼 수 있는 "Files changed" 탭으로 이동하여 질문하고자 하는 줄로 이동한 다음 "+" 기호를 클릭하여 코멘트를 추가할 수 있습니다. 질문이나 문제가 해결되면, 생성된 코멘트의 "Resolve" 버튼을 클릭할 수 있습니다.
마찬가지로, Hugging Face 팀은 코드를 리뷰할 때 코멘트를 남길 것입니다. 우리는 PR에서 대부분의 질문을 GitHub에서 묻는 것을 권장합니다. 공개에 크게 도움이 되지 않는 매우 일반적인 질문의 경우, Slack이나 이메일을 통해 Hugging Face 팀에게 문의할 수 있습니다.
**5. brand_new_bert에 대해 생성된 모델 코드를 적용하기**
먼저, 우리는 모델 자체에만 초점을 맞추고 토크나이저에 대해서는 신경 쓰지 않을 것입니다. 모든 관련 코드는 다음의 생성된 파일에서 찾을 수 있습니다: `src/transformers/models/brand_new_bert/modeling_brand_new_bert.py` 및 `src/transformers/models/brand_new_bert/configuration_brand_new_bert.py`.
이제 마침내 코딩을 시작할 수 있습니다 :). `src/transformers/models/brand_new_bert/modeling_brand_new_bert.py`의 생성된 코드는 인코더 전용 모델인 경우 BERT와 동일한 아키텍처를 가지거나, 인코더-디코더 모델인 경우 BART와 동일한 아키텍처를 가질 것입니다. 이 시점에서, 모델의 이론적 측면에 대해 배운 내용을 다시 상기해야 합니다: *모델이 BERT 또는 BART와 어떻게 다른가요?*. 자주 변경해야 하는 것은 *self-attention* 레이어, 정규화 레이어의 순서 등을 변경하는 것입니다. 다시 말하지만, 자신의 모델을 구현하는 데 도움이 되도록 Transformers에서 이미 존재하는 모델의 유사한 아키텍처를 살펴보는 것이 유용할 수 있습니다.
**참고로** 이 시점에서, 코드가 완전히 정확하거나 깨끗하다고 확신할 필요는 없습니다. 오히려 처음에는 원본 코드의 첫 번째 *불완전하고* 복사된 버전을 `src/transformers/models/brand_new_bert/modeling_brand_new_bert.py`에 추가하는 것이 좋습니다. 필요한 모든 코드가 추가될 때까지 이러한 작업을 진행한 후, 다음 섹션에서 설명한 변환 스크립트를 사용하여 코드를 점진적으로 개선하고 수정하는 것이 훨씬 효율적입니다. 이 시점에서 작동해야 하는 유일한 것은 다음 명령이 작동하는 것입니다:
```python
from transformers import BrandNewBertModel, BrandNewBertConfig
model = BrandNewBertModel(BrandNewBertConfig())
```
위의 명령은 `BrandNewBertConfig()`에 정의된 기본 매개변수에 따라 무작위 가중치로 모델을 생성하며, 이로써 모든 구성 요소의 `init()` 메서드가 작동함을 보장합니다.
모든 무작위 초기화는 `BrandnewBertPreTrainedModel` 클래스의 `_init_weights` 메서드에서 수행되어야 합니다. 이 메서드는 구성 설정 변수에 따라 모든 리프 모듈을 초기화해야 합니다. BERT의 `_init_weights` 메서드 예제는 다음과 같습니다:
```py
def _init_weights(self, module):
"""Initialize the weights"""
if isinstance(module, nn.Linear):
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
if module.bias is not None:
module.bias.data.zero_()
elif isinstance(module, nn.Embedding):
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
if module.padding_idx is not None:
module.weight.data[module.padding_idx].zero_()
elif isinstance(module, nn.LayerNorm):
module.bias.data.zero_()
module.weight.data.fill_(1.0)
```
몇 가지 모듈에 대해 특별한 초기화가 필요한 경우 사용자 정의 방식을 사용할 수도 있습니다. 예를 들어, `Wav2Vec2ForPreTraining`에서 마지막 두 개의 선형 레이어는 일반적인 PyTorch `nn.Linear`의 초기화를 가져야 하지만, 다른 모든 레이어는 위와 같은 초기화를 사용해야 합니다. 이는 다음과 같이 코드화됩니다:
```py
def _init_weights(self, module):
"""Initialize the weights"""
if isinstance(module, Wav2Vec2ForPreTraining):
module.project_hid.reset_parameters()
module.project_q.reset_parameters()
module.project_hid._is_hf_initialized = True
module.project_q._is_hf_initialized = True
elif isinstance(module, nn.Linear):
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
if module.bias is not None:
module.bias.data.zero_()
```
`_is_hf_initialized` 플래그는 서브모듈을 한 번만 초기화하도록 내부적으로 사용됩니다. `module.project_q` 및 `module.project_hid`에 대해 `True`로 설정함으로써, 우리가 수행한 사용자 정의 초기화가 이후에 덮어쓰이지 않도록 합니다. 즉, `_init_weights` 함수가 이들에게 적용되지 않습니다.
**6. 변환 스크립트 작성하기**
다음으로, 디버그에 사용한 체크포인트를 기존 저장소에서 만든 🤗 Transformers 구현과 호환되는 체크포인트로 변환할 수 있는 변환 스크립트를 작성해야 합니다. 변환 스크립트를 처음부터 작성하는 것보다는 *brand_new_bert*와 동일한 프레임워크로 작성된 유사한 모델을 변환한 기존 변환 스크립트를 찾아보는 것이 좋습니다. 일반적으로 기존 변환 스크립트를 복사하여 사용 사례에 맞게 약간 수정하는 것으로 충분합니다. 모델에 대해 유사한 기존 변환 스크립트를 어디에서 찾을 수 있는지 Hugging Face 팀에게 문의하는 것을 망설이지 마세요.
- TensorFlow에서 PyTorch로 모델을 이전하는 경우, 좋은 참고 자료로 BERT의 변환 스크립트 [여기](https://github.com/huggingface/transformers/blob/7acfa95afb8194f8f9c1f4d2c6028224dbed35a2/src/transformers/models/bert/modeling_bert.py#L91)를 참조할 수 있습니다.
- PyTorch에서 PyTorch로 모델을 이전하는 경우, 좋은 참고 자료로 BART의 변환 스크립트 [여기](https://github.com/huggingface/transformers/blob/main/src/transformers/models/bart/convert_bart_original_pytorch_checkpoint_to_pytorch.py)를 참조할 수 있습니다.
다음에서는 PyTorch 모델이 레이어 가중치를 저장하고 레이어 이름을 정의하는 방법에 대해 간단히 설명하겠습니다. PyTorch에서 레이어의 이름은 레이어에 지정한 클래스 속성의 이름으로 정의됩니다. 다음과 같이 PyTorch에서 `SimpleModel`이라는 더미 모델을 정의해 봅시다:
```python
from torch import nn
class SimpleModel(nn.Module):
def __init__(self):
super().__init__()
self.dense = nn.Linear(10, 10)
self.intermediate = nn.Linear(10, 10)
self.layer_norm = nn.LayerNorm(10)
```
이제 이 모델 정의의 인스턴스를 생성할 수 있으며 `dense`, `intermediate`, `layer_norm` 등의 가중치가 랜덤하게 할당됩니다. 모델을 출력하여 아키텍처를 확인할 수 있습니다.
```python
model = SimpleModel()
print(model)
```
이는 다음과 같이 출력됩니다:
```
SimpleModel(
(dense): Linear(in_features=10, out_features=10, bias=True)
(intermediate): Linear(in_features=10, out_features=10, bias=True)
(layer_norm): LayerNorm((10,), eps=1e-05, elementwise_affine=True)
)
```
우리는 레이어의 이름이 PyTorch에서 클래스 속성의 이름으로 정의되어 있는 것을 볼 수 있습니다. 특정 레이어의 가중치 값을 출력하여 확인할 수 있습니다:
```python
print(model.dense.weight.data)
```
가중치가 무작위로 초기화되었음을 확인할 수 있습니다.
```
tensor([[-0.0818, 0.2207, -0.0749, -0.0030, 0.0045, -0.1569, -0.1598, 0.0212,
-0.2077, 0.2157],
[ 0.1044, 0.0201, 0.0990, 0.2482, 0.3116, 0.2509, 0.2866, -0.2190,
0.2166, -0.0212],
[-0.2000, 0.1107, -0.1999, -0.3119, 0.1559, 0.0993, 0.1776, -0.1950,
-0.1023, -0.0447],
[-0.0888, -0.1092, 0.2281, 0.0336, 0.1817, -0.0115, 0.2096, 0.1415,
-0.1876, -0.2467],
[ 0.2208, -0.2352, -0.1426, -0.2636, -0.2889, -0.2061, -0.2849, -0.0465,
0.2577, 0.0402],
[ 0.1502, 0.2465, 0.2566, 0.0693, 0.2352, -0.0530, 0.1859, -0.0604,
0.2132, 0.1680],
[ 0.1733, -0.2407, -0.1721, 0.1484, 0.0358, -0.0633, -0.0721, -0.0090,
0.2707, -0.2509],
[-0.1173, 0.1561, 0.2945, 0.0595, -0.1996, 0.2988, -0.0802, 0.0407,
0.1829, -0.1568],
[-0.1164, -0.2228, -0.0403, 0.0428, 0.1339, 0.0047, 0.1967, 0.2923,
0.0333, -0.0536],
[-0.1492, -0.1616, 0.1057, 0.1950, -0.2807, -0.2710, -0.1586, 0.0739,
0.2220, 0.2358]]).
```
변환 스크립트에서는 이러한 무작위로 초기화된 가중치를 체크포인트의 해당 레이어의 정확한 가중치로 채워야 합니다. 예를 들면 다음과 같습니다:
```python
# retrieve matching layer weights, e.g. by
# recursive algorithm
layer_name = "dense"
pretrained_weight = array_of_dense_layer
model_pointer = getattr(model, "dense")
model_pointer.weight.data = torch.from_numpy(pretrained_weight)
```
이렇게 하면 PyTorch 모델의 무작위로 초기화된 각 가중치와 해당 체크포인트 가중치가 **모양과 이름** 모두에서 정확히 일치하는지 확인해야 합니다. 이를 위해 모양에 대한 assert 문을 추가하고 체크포인트 가중치의 이름을 출력해야 합니다. 예를 들어 다음과 같은 문장을 추가해야 합니다:
```python
assert (
model_pointer.weight.shape == pretrained_weight.shape
), f"Pointer shape of random weight {model_pointer.shape} and array shape of checkpoint weight {pretrained_weight.shape} mismatched"
```
또한 두 가중치의 이름을 출력하여 일치하는지 확인해야 합니다. *예시*:
```python
logger.info(f"Initialize PyTorch weight {layer_name} from {pretrained_weight.name}")
```
모양 또는 이름이 일치하지 않는 경우, 랜덤으로 초기화된 레이어에 잘못된 체크포인트 가중치를 할당한 것으로 추측됩니다.
잘못된 모양은 `BrandNewBertConfig()`의 구성 매개변수 설정이 변환하려는 체크포인트에 사용된 설정과 정확히 일치하지 않기 때문일 가능성이 가장 큽니다. 그러나 PyTorch의 레이어 구현 자체에서 가중치를 전치해야 할 수도 있습니다.
마지막으로, **모든** 필요한 가중치가 초기화되었는지 확인하고 초기화에 사용되지 않은 모든 체크포인트 가중치를 출력하여 모델이 올바르게 변환되었는지 확인해야 합니다. 잘못된 모양 문장이나 잘못된 이름 할당으로 인해 변환 시도가 실패하는 것은 완전히 정상입니다. 이는 `BrandNewBertConfig()`에서 잘못된 매개변수를 사용하거나 🤗 Transformers 구현에서 잘못된 아키텍처, 🤗 Transformers 구현의 구성 요소 중 하나의 `init()` 함수에 버그가 있는 경우이거나 체크포인트 가중치 중 하나를 전치해야 하는 경우일 가능성이 가장 높습니다.
이 단계는 이전 단계와 함께 반복되어야 하며 모든 체크포인트의 가중치가 Transformers 모델에 올바르게 로드되었을 때까지 계속되어야 합니다. 🤗 Transformers 구현에 체크포인트를 올바르게 로드한 후에는 `/path/to/converted/checkpoint/folder`와 같은 원하는 폴더에 모델을 저장할 수 있어야 합니다. 해당 폴더에는 `pytorch_model.bin` 파일과 `config.json` 파일이 모두 포함되어야 합니다.
```python
model.save_pretrained("/path/to/converted/checkpoint/folder")
```
**7. 순방향 패스 구현하기**
🤗 Transformers 구현에 사전 훈련된 가중치를 정확하게 로드한 후에는 순방향 패스가 올바르게 구현되었는지 확인해야 합니다. [원본 저장소에 익숙해지기](#34-run-a-pretrained-checkpoint-using-the-original-repository)에서 이미 원본 저장소를 사용하여 모델의 순방향 패스를 실행하는 스크립트를 만들었습니다. 이제 원본 대신 🤗 Transformers 구현을 사용하는 유사한 스크립트를 작성해야 합니다. 다음과 같이 작성되어야 합니다:
```python
model = BrandNewBertModel.from_pretrained("/path/to/converted/checkpoint/folder")
input_ids = [0, 4, 4, 3, 2, 4, 1, 7, 19]
output = model(input_ids).last_hidden_states
```
🤗 Transformers 구현과 원본 모델 구현이 처음부터 정확히 동일한 출력을 제공하지 않거나 순방향 패스에서 오류가 발생할 가능성이 매우 높습니다. 실망하지 마세요. 예상된 일입니다! 먼저, 순방향 패스에서 오류가 발생하지 않도록 해야 합니다. 종종 잘못된 차원이 사용되어 *차원 불일치* 오류가 발생하거나 잘못된 데이터 유형 개체가 사용되는 경우가 있습니다. 예를 들면 `torch.long` 대신에 `torch.float32`가 사용된 경우입니다. 해결할 수 없는 오류가 발생하면 Hugging Face 팀에 도움을 요청하는 것이 좋습니다.
🤗 Transformers 구현이 올바르게 작동하는지 확인하는 마지막 단계는 출력이 `1e-3`의 정밀도로 동일한지 확인하는 것입니다. 먼저, 출력 모양이 동일하도록 보장해야 합니다. 즉, 🤗 Transformers 구현 스크립트와 원본 구현 사이에서 `outputs.shape`는 동일한 값을 반환해야 합니다. 그 다음으로, 출력 값이 동일하도록 해야 합니다. 이는 새로운 모델을 추가할 때 가장 어려운 부분 중 하나입니다. 출력이 동일하지 않은 일반적인 실수 사례는 다음과 같습니다:
- 일부 레이어가 추가되지 않았습니다. 즉, *활성화* 레이어가 추가되지 않았거나 잔차 연결이 빠졌습니다.
- 단어 임베딩 행렬이 연결되지 않았습니다.
- 잘못된 위치 임베딩이 사용되었습니다. 원본 구현에서는 오프셋을 사용합니다.
- 순방향 패스 중에 Dropout이 적용되었습니다. 이를 수정하려면 *model.training이 False*인지 확인하고 순방향 패스 중에 Dropout 레이어가 잘못 활성화되지 않도록 하세요. 즉, [PyTorch의 기능적 Dropout](https://pytorch.org/docs/stable/nn.functional.html?highlight=dropout#torch.nn.functional.dropout)에 *self.training*을 전달하세요.
문제를 해결하는 가장 좋은 방법은 일반적으로 원본 구현과 🤗 Transformers 구현의 순방향 패스를 나란히 놓고 차이점이 있는지 확인하는 것입니다. 이상적으로는 순방향 패스의 중간 출력을 디버그/출력하여 원본 구현과 🤗 Transformers 구현의 정확한 위치를 찾을 수 있어야 합니다. 먼저, 두 스크립트의 하드코딩된 `input_ids`가 동일한지 확인하세요. 다음으로, `input_ids`의 첫 번째 변환의 출력(일반적으로 단어 임베딩)이 동일한지 확인하세요. 그런 다음 네트워크의 가장 마지막 레이어까지 진행해보세요. 어느 시점에서 두 구현 사이에 차이가 있는 것을 알게 되는데, 이는 🤗 Transformers 구현의 버그 위치를 가리킬 것입니다. 저희 경험상으로는 원본 구현과 🤗 Transformers 구현 모두에서 동일한 위치에 많은 출력 문을 추가하고 이들의 중간 표현에 대해 동일한 값을 보이는 출력 문을 연속적으로 제거하는 것이 간단하고 효과적인 방법입니다.
`torch.allclose(original_output, output, atol=1e-3)`로 출력을 확인하여 두 구현이 동일한 출력을 하는 것을 확신한다면, 가장 어려운 부분은 끝났습니다! 축하드립니다. 남은 작업은 쉬운 일이 될 것입니다 😊.
**8. 필요한 모든 모델 테스트 추가하기**
이 시점에서 새로운 모델을 성공적으로 추가했습니다. 그러나 해당 모델이 요구되는 디자인에 완전히 부합하지 않을 수도 있습니다. 🤗 Transformers와 완벽하게 호환되는 구현인지 확인하기 위해 모든 일반 테스트를 통과해야 합니다. Cookiecutter는 아마도 모델을 위한 테스트 파일을 자동으로 추가했을 것입니다. 아마도 `tests/models/brand_new_bert/test_modeling_brand_new_bert.py`와 같은 경로에 위치할 것입니다. 이 테스트 파일을 실행하여 일반 테스트가 모두 통과하는지 확인하세요.
```bash
pytest tests/models/brand_new_bert/test_modeling_brand_new_bert.py
```
모든 일반 테스트를 수정한 후, 이제 수행한 작업을 충분히 테스트하여 다음 사항을 보장해야 합니다.
- a) 커뮤니티가 *brand_new_bert*의 특정 테스트를 살펴봄으로써 작업을 쉽게 이해할 수 있도록 함
- b) 모델에 대한 향후 변경 사항이 모델의 중요한 기능을 손상시키지 않도록 함
먼저 통합 테스트를 추가해야 합니다. 이러한 통합 테스트는 이전에 모델을 🤗 Transformers로 구현하기 위해 사용한 디버깅 스크립트와 동일한 작업을 수행합니다. Cookiecutter에 이미 이러한 모델 테스트의 템플릿인 `BrandNewBertModelIntegrationTests`가 추가되어 있으며, 여러분이 작성해야 할 내용으로만 채워 넣으면 됩니다. 이러한 테스트가 통과하는지 확인하려면 다음을 실행하세요.
```bash
RUN_SLOW=1 pytest -sv tests/models/brand_new_bert/test_modeling_brand_new_bert.py::BrandNewBertModelIntegrationTests
```
<Tip>
Windows를 사용하는 경우 `RUN_SLOW=1`을 `SET RUN_SLOW=1`로 바꿔야 합니다.
</Tip>
둘째로, *brand_new_bert*에 특화된 모든 기능도 별도의 테스트에서 추가로 테스트해야 합니다. 이 부분은 종종 잊히는데, 두 가지 측면에서 굉장히 유용합니다.
- *brand_new_bert*의 특수 기능이 어떻게 작동해야 하는지 보여줌으로써 커뮤니티에게 모델 추가 과정에서 습득한 지식을 전달하는 데 도움이 됩니다.
- 향후 기여자는 이러한 특수 테스트를 실행하여 모델에 대한 변경 사항을 빠르게 테스트할 수 있습니다.
**9. 토크나이저 구현하기**
다음으로, *brand_new_bert*의 토크나이저를 추가해야 합니다. 보통 토크나이저는 🤗 Transformers의 기존 토크나이저와 동일하거나 매우 유사합니다.
토크나이저가 올바르게 작동하는지 확인하기 위해 먼저 원본 리포지토리에서 문자열을 입력하고 `input_ids`를 반환하는 스크립트를 생성하는 것이 좋습니다. 다음과 같은 유사한 스크립트일 수 있습니다 (의사 코드로 작성):
```python
input_str = "This is a long example input string containing special characters .$?-, numbers 2872 234 12 and words."
model = BrandNewBertModel.load_pretrained_checkpoint("/path/to/checkpoint/")
input_ids = model.tokenize(input_str)
```
원본 리포지토리를 자세히 살펴보고 올바른 토크나이저 함수를 찾거나, 복제본에서 변경 사항을 적용하여 `input_ids`만 출력하도록 해야 합니다. 원본 리포지토리를 사용하는 기능적인 토큰화 스크립트를 작성한 후, 🤗 Transformers의 유사한 스크립트를 생성해야 합니다. 다음과 같이 작성되어야 합니다:
```python
from transformers import BrandNewBertTokenizer
input_str = "This is a long example input string containing special characters .$?-, numbers 2872 234 12 and words."
tokenizer = BrandNewBertTokenizer.from_pretrained("/path/to/tokenizer/folder/")
input_ids = tokenizer(input_str).input_ids
```
두 개의 `input_ids`가 동일한 값을 반환할 때, 마지막 단계로 토크나이저 테스트 파일도 추가해야 합니다.
*brand_new_bert*의 모델링 테스트 파일과 유사하게, *brand_new_bert*의 토크나이제이션 테스트 파일에는 몇 가지 하드코딩된 통합 테스트가 포함되어야 합니다.
**10. 종단 간 통합 테스트 실행**
토크나이저를 추가한 후에는 모델과 토크나이저를 사용하여 몇 가지 종단 간 통합 테스트를 추가해야 합니다. `tests/models/brand_new_bert/test_modeling_brand_new_bert.py`에 추가해주세요. 이러한 테스트는 🤗 Transformers 구현이 예상대로 작동하는지를 의미 있는 text-to-text 예시로 보여줘야 합니다. 그 예시로는 *예를 들어* source-to-target 번역 쌍, article-to-summary 쌍, question-to-answer 쌍 등이 포함될 수 있습니다. 불러온 체크포인트 중 어느 것도 다운스트림 작업에서 미세 조정되지 않았다면, 모델 테스트만으로 충분합니다. 모델이 완전히 기능을 갖추었는지 확인하기 위해 마지막 단계로 GPU에서 모든 테스트를 실행하는 것이 좋습니다. 모델의 내부 텐서의 일부에 `.to(self.device)` 문을 추가하는 것을 잊었을 수 있으며, 이 경우 테스트에서 오류로 표시됩니다. GPU에 액세스할 수 없는 경우, Hugging Face 팀이 테스트를 대신 실행할 수 있습니다.
**11. 기술문서 추가**
이제 *brand_new_bert*에 필요한 모든 기능이 추가되었습니다. 거의 끝났습니다! 추가해야 할 것은 멋진 기술문서과 기술문서 페이지입니다. Cookiecutter가 `docs/source/model_doc/brand_new_bert.md`라는 템플릿 파일을 추가해줬을 것입니다. 이 페이지를 사용하기 전에 모델을 사용하는 사용자들은 일반적으로 이 페이지를 먼저 확인합니다. 따라서 문서는 이해하기 쉽고 간결해야 합니다. 모델을 사용하는 방법을 보여주기 위해 *팁*을 추가하는 것이 커뮤니티에 매우 유용합니다. 독스트링에 관련하여 Hugging Face 팀에 문의하는 것을 주저하지 마세요.
다음으로, `src/transformers/models/brand_new_bert/modeling_brand_new_bert.py`에 추가된 독스트링이 올바르며 필요한 모든 입력 및 출력을 포함하도록 확인하세요. [여기](writing-documentation)에서 우리의 문서 작성 가이드와 독스트링 형식에 대한 상세 가이드가 있습니다. 문서는 일반적으로 커뮤니티와 모델의 첫 번째 접점이기 때문에, 문서는 적어도 코드만큼의 주의를 기울여야 합니다.
**코드 리팩토링**
좋아요, 이제 *brand_new_bert*를 위한 모든 필요한 코드를 추가했습니다. 이 시점에서 다음을 실행하여 잠재적으로 잘못된 코드 스타일을 수정해야 합니다:
그리고 코딩 스타일이 품질 점검을 통과하는지 확인하기 위해 다음을 실행하고 확인해야 합니다:
```bash
make style
```
🤗 Transformers에는 여전히 실패할 수 있는 몇 가지 매우 엄격한 디자인 테스트가 있습니다. 이는 독스트링에 누락된 정보나 잘못된 명명 때문에 종종 발생합니다. 여기서 막히면 Hugging Face 팀이 도움을 줄 것입니다.
```bash
make quality
```
마지막으로, 코드가 정확히 작동하는 것을 확인한 후에는 항상 코드를 리팩토링하는 것이 좋은 생각입니다. 모든 테스트가 통과된 지금은 추가한 코드를 다시 검토하고 리팩토링하는 좋은 시기입니다.
이제 코딩 부분을 완료했습니다. 축하합니다! 🎉 멋져요! 😎
**12. 모델을 모델 허브에 업로드하세요**
이 마지막 파트에서는 모든 체크포인트를 변환하여 모델 허브에 업로드하고 각 업로드된 모델 체크포인트에 대한 모델 카드를 추가해야 합니다. [Model sharing and uploading Page](model_sharing)를 읽고 허브 기능에 익숙해지세요. *brand_new_bert*의 저자 조직 아래에 모델을 업로드할 수 있는 필요한 액세스 권한을 얻기 위해 Hugging Face 팀과 협업해야 합니다. `transformers`의 모든 모델에 있는 `push_to_hub` 메서드는 체크포인트를 허브에 빠르고 효율적으로 업로드하는 방법입니다. 아래에 작은 코드 조각이 붙여져 있습니다:
각 체크포인트에 적합한 모델 카드를 만드는 데 시간을 할애하는 것은 가치가 있습니다. 모델 카드는 체크포인트의 특성을 강조해야 합니다. *예를 들어* 이 체크포인트는 어떤 데이터셋에서 사전 훈련/세부 훈련되었는지? 이 모델은 어떤 하위 작업에서 사용해야 하는지? 그리고 모델을 올바르게 사용하는 방법에 대한 몇 가지 코드도 포함해야 합니다.
```python
brand_new_bert.push_to_hub("brand_new_bert")
# Uncomment the following line to push to an organization.
# brand_new_bert.push_to_hub("<organization>/brand_new_bert")
```
**13. (선택 사항) 노트북 추가**
*brand_new_bert*를 다운스트림 작업에서 추론 또는 미세 조정에 사용하는 방법을 자세히 보여주는 노트북을 추가하는 것이 매우 유용합니다. 이것은 PR을 병합하는 데 필수적이지는 않지만 커뮤니티에 매우 유용합니다.
**14. 완료된 PR 제출**
이제 프로그래밍을 마쳤으며, 마지막 단계로 PR을 메인 브랜치에 병합해야 합니다. 보통 Hugging Face 팀은 이미 여기까지 도움을 주었을 것입니다. 그러나 PR에 멋진 설명을 추가하고 리뷰어에게 특정 디자인 선택 사항을 강조하려면 완료된 PR에 약간의 설명을 추가하는 시간을 할애하는 것이 가치가 있습니다.
### 작업물을 공유하세요!! [[share-your-work]]
이제 커뮤니티에서 작업물을 인정받을 시간입니다! 모델 추가 작업을 완료하는 것은 Transformers와 전체 NLP 커뮤니티에 큰 기여입니다. 당신의 코드와 이식된 사전 훈련된 모델은 수백, 심지어 수천 명의 개발자와 연구원에 의해 확실히 사용될 것입니다. 당신의 작업에 자랑스러워해야 하며 이를 커뮤니티와 공유해야 합니다.
**당신은 커뮤니티 내 모든 사람들에게 매우 쉽게 접근 가능한 또 다른 모델을 만들었습니다! 🤯**
| transformers/docs/source/ko/add_new_model.md/0 | {
"file_path": "transformers/docs/source/ko/add_new_model.md",
"repo_id": "transformers",
"token_count": 43460
} | 264 |
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# CPU에서 효율적인 훈련 [[efficient-training-on-cpu]]
이 가이드는 CPU에서 대규모 모델을 효율적으로 훈련하는 데 초점을 맞춥니다.
## IPEX와 혼합 정밀도 [[mixed-precision-with-ipex]]
IPEX는 AVX-512 이상을 지원하는 CPU에 최적화되어 있으며, AVX2만 지원하는 CPU에도 기능적으로 작동합니다. 따라서 AVX-512 이상의 Intel CPU 세대에서는 성능상 이점이 있을 것으로 예상되지만, AVX2만 지원하는 CPU (예: AMD CPU 또는 오래된 Intel CPU)의 경우에는 IPEX 아래에서 더 나은 성능을 보일 수 있지만 이는 보장되지 않습니다. IPEX는 Float32와 BFloat16를 모두 사용하여 CPU 훈련을 위한 성능 최적화를 제공합니다. BFloat16의 사용은 다음 섹션의 주요 초점입니다.
저정밀도 데이터 타입인 BFloat16은 3세대 Xeon® Scalable 프로세서 (코드명: Cooper Lake)에서 AVX512 명령어 집합을 네이티브로 지원해 왔으며, 다음 세대의 Intel® Xeon® Scalable 프로세서에서 Intel® Advanced Matrix Extensions (Intel® AMX) 명령어 집합을 지원하여 성능을 크게 향상시킬 예정입니다. CPU 백엔드의 자동 혼합 정밀도 기능은 PyTorch-1.10부터 활성화되었습니다. 동시에, Intel® Extension for PyTorch에서 BFloat16에 대한 CPU의 자동 혼합 정밀도 및 연산자의 BFloat16 최적화를 대규모로 활성화하고, PyTorch 마스터 브랜치로 부분적으로 업스트림을 반영했습니다. 사용자들은 IPEX 자동 혼합 정밀도를 사용하여 더 나은 성능과 사용자 경험을 얻을 수 있습니다.
[자동 혼합 정밀도](https://intel.github.io/intel-extension-for-pytorch/cpu/latest/tutorials/features/amp.html)에 대한 자세한 정보를 확인하십시오.
### IPEX 설치: [[ipex-installation]]
IPEX 릴리스는 PyTorch를 따라갑니다. pip를 통해 설치하려면:
| PyTorch Version | IPEX version |
| :---------------: | :----------: |
| 1.13 | 1.13.0+cpu |
| 1.12 | 1.12.300+cpu |
| 1.11 | 1.11.200+cpu |
| 1.10 | 1.10.100+cpu |
```
pip install intel_extension_for_pytorch==<version_name> -f https://developer.intel.com/ipex-whl-stable-cpu
```
[IPEX 설치](https://intel.github.io/intel-extension-for-pytorch/cpu/latest/tutorials/installation.html)에 대한 더 많은 접근 방법을 확인하십시오.
### Trainer에서의 사용법 [[usage-in-trainer]]
Trainer에서 IPEX의 자동 혼합 정밀도를 활성화하려면 사용자는 훈련 명령 인수에 `use_ipex`, `bf16`, `no_cuda`를 추가해야 합니다.
[Transformers 질문-응답](https://github.com/huggingface/transformers/tree/main/examples/pytorch/question-answering)의 사용 사례를 살펴보겠습니다.
- CPU에서 BF16 자동 혼합 정밀도를 사용하여 IPEX로 훈련하기:
<pre> python run_qa.py \
--model_name_or_path bert-base-uncased \
--dataset_name squad \
--do_train \
--do_eval \
--per_device_train_batch_size 12 \
--learning_rate 3e-5 \
--num_train_epochs 2 \
--max_seq_length 384 \
--doc_stride 128 \
--output_dir /tmp/debug_squad/ \
<b>--use_ipex \</b>
<b>--bf16 --no_cuda</b></pre>
### 실습 예시 [[practice-example]]
블로그: [Intel Sapphire Rapids로 PyTorch Transformers 가속화](https://huggingface.co/blog/intel-sapphire-rapids) | transformers/docs/source/ko/perf_train_cpu.md/0 | {
"file_path": "transformers/docs/source/ko/perf_train_cpu.md",
"repo_id": "transformers",
"token_count": 2390
} | 265 |
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 자동 음성 인식[[automatic-speech-recognition]]
[[open-in-colab]]
<Youtube id="TksaY_FDgnk"/>
자동 음성 인식(Automatic Speech Recognition, ASR)은 음성 신호를 텍스트로 변환하여 음성 입력 시퀀스를 텍스트 출력에 매핑합니다.
Siri와 Alexa와 같은 가상 어시스턴트는 ASR 모델을 사용하여 일상적으로 사용자를 돕고 있으며, 회의 중 라이브 캡션 및 메모 작성과 같은 유용한 사용자 친화적 응용 프로그램도 많이 있습니다.
이 가이드에서 소개할 내용은 아래와 같습니다:
1. [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) 데이터 세트에서 [Wav2Vec2](https://huggingface.co/facebook/wav2vec2-base)를 미세 조정하여 오디오를 텍스트로 변환합니다.
2. 미세 조정한 모델을 추론에 사용합니다.
<Tip>
이 튜토리얼에서 설명하는 작업은 다음 모델 아키텍처에 의해 지원됩니다:
<!--This tip is automatically generated by `make fix-copies`, do not fill manually!-->
[Data2VecAudio](../model_doc/data2vec-audio), [Hubert](../model_doc/hubert), [M-CTC-T](../model_doc/mctct), [SEW](../model_doc/sew), [SEW-D](../model_doc/sew-d), [UniSpeech](../model_doc/unispeech), [UniSpeechSat](../model_doc/unispeech-sat), [Wav2Vec2](../model_doc/wav2vec2), [Wav2Vec2-Conformer](../model_doc/wav2vec2-conformer), [WavLM](../model_doc/wavlm)
<!--End of the generated tip-->
</Tip>
시작하기 전에 필요한 모든 라이브러리가 설치되어 있는지 확인하세요:
```bash
pip install transformers datasets evaluate jiwer
```
Hugging Face 계정에 로그인하면 모델을 업로드하고 커뮤니티에 공유할 수 있습니다. 토큰을 입력하여 로그인하세요.
```py
>>> from huggingface_hub import notebook_login
>>> notebook_login()
```
## MInDS-14 데이터 세트 가져오기[[load-minds-14-dataset]]
먼저, 🤗 Datasets 라이브러리에서 [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) 데이터 세트의 일부분을 가져오세요.
이렇게 하면 전체 데이터 세트에 대한 훈련에 시간을 들이기 전에 모든 것이 작동하는지 실험하고 검증할 수 있습니다.
```py
>>> from datasets import load_dataset, Audio
>>> minds = load_dataset("PolyAI/minds14", name="en-US", split="train[:100]")
```
[`~Dataset.train_test_split`] 메소드를 사용하여 데이터 세트의 `train`을 훈련 세트와 테스트 세트로 나누세요:
```py
>>> minds = minds.train_test_split(test_size=0.2)
```
그리고 데이터 세트를 확인하세요:
```py
>>> minds
DatasetDict({
train: Dataset({
features: ['path', 'audio', 'transcription', 'english_transcription', 'intent_class', 'lang_id'],
num_rows: 16
})
test: Dataset({
features: ['path', 'audio', 'transcription', 'english_transcription', 'intent_class', 'lang_id'],
num_rows: 4
})
})
```
데이터 세트에는 `lang_id`와 `english_transcription`과 같은 유용한 정보가 많이 포함되어 있지만, 이 가이드에서는 `audio`와 `transcription`에 초점을 맞출 것입니다. 다른 열은 [`~datasets.Dataset.remove_columns`] 메소드를 사용하여 제거하세요:
```py
>>> minds = minds.remove_columns(["english_transcription", "intent_class", "lang_id"])
```
예시를 다시 한번 확인해보세요:
```py
>>> minds["train"][0]
{'audio': {'array': array([-0.00024414, 0. , 0. , ..., 0.00024414,
0.00024414, 0.00024414], dtype=float32),
'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~APP_ERROR/602ba9e2963e11ccd901cd4f.wav',
'sampling_rate': 8000},
'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~APP_ERROR/602ba9e2963e11ccd901cd4f.wav',
'transcription': "hi I'm trying to use the banking app on my phone and currently my checking and savings account balance is not refreshing"}
```
두 개의 필드가 있습니다:
- `audio`: 오디오 파일을 가져오고 리샘플링하기 위해 호출해야 하는 음성 신호의 1차원 `array(배열)`
- `transcription`: 목표 텍스트
## 전처리[[preprocess]]
다음으로 오디오 신호를 처리하기 위한 Wav2Vec2 프로세서를 가져옵니다:
```py
>>> from transformers import AutoProcessor
>>> processor = AutoProcessor.from_pretrained("facebook/wav2vec2-base")
```
MInDS-14 데이터 세트의 샘플링 레이트는 8000kHz이므로([데이터 세트 카드](https://huggingface.co/datasets/PolyAI/minds14)에서 확인), 사전 훈련된 Wav2Vec2 모델을 사용하려면 데이터 세트를 16000kHz로 리샘플링해야 합니다:
```py
>>> minds = minds.cast_column("audio", Audio(sampling_rate=16_000))
>>> minds["train"][0]
{'audio': {'array': array([-2.38064706e-04, -1.58618059e-04, -5.43987835e-06, ...,
2.78103951e-04, 2.38446111e-04, 1.18740834e-04], dtype=float32),
'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~APP_ERROR/602ba9e2963e11ccd901cd4f.wav',
'sampling_rate': 16000},
'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~APP_ERROR/602ba9e2963e11ccd901cd4f.wav',
'transcription': "hi I'm trying to use the banking app on my phone and currently my checking and savings account balance is not refreshing"}
```
위의 'transcription'에서 볼 수 있듯이 텍스트는 대문자와 소문자가 섞여 있습니다. Wav2Vec2 토크나이저는 대문자 문자에 대해서만 훈련되어 있으므로 텍스트가 토크나이저의 어휘와 일치하는지 확인해야 합니다:
```py
>>> def uppercase(example):
... return {"transcription": example["transcription"].upper()}
>>> minds = minds.map(uppercase)
```
이제 다음 작업을 수행할 전처리 함수를 만들어보겠습니다:
1. `audio` 열을 호출하여 오디오 파일을 가져오고 리샘플링합니다.
2. 오디오 파일에서 `input_values`를 추출하고 프로세서로 `transcription` 열을 토큰화합니다.
```py
>>> def prepare_dataset(batch):
... audio = batch["audio"]
... batch = processor(audio["array"], sampling_rate=audio["sampling_rate"], text=batch["transcription"])
... batch["input_length"] = len(batch["input_values"][0])
... return batch
```
전체 데이터 세트에 전처리 함수를 적용하려면 🤗 Datasets [`~datasets.Dataset.map`] 함수를 사용하세요. `num_proc` 매개변수를 사용하여 프로세스 수를 늘리면 `map`의 속도를 높일 수 있습니다. [`~datasets.Dataset.remove_columns`] 메소드를 사용하여 필요하지 않은 열을 제거하세요:
```py
>>> encoded_minds = minds.map(prepare_dataset, remove_columns=minds.column_names["train"], num_proc=4)
```
🤗 Transformers에는 자동 음성 인식용 데이터 콜레이터가 없으므로 예제 배치를 생성하려면 [`DataCollatorWithPadding`]을 조정해야 합니다. 이렇게 하면 데이터 콜레이터는 텍스트와 레이블을 배치에서 가장 긴 요소의 길이에 동적으로 패딩하여 길이를 균일하게 합니다. `tokenizer` 함수에서 `padding=True`를 설정하여 텍스트를 패딩할 수 있지만, 동적 패딩이 더 효율적입니다.
다른 데이터 콜레이터와 달리 이 특정 데이터 콜레이터는 `input_values`와 `labels`에 대해 다른 패딩 방법을 적용해야 합니다.
```py
>>> import torch
>>> from dataclasses import dataclass, field
>>> from typing import Any, Dict, List, Optional, Union
>>> @dataclass
... class DataCollatorCTCWithPadding:
... processor: AutoProcessor
... padding: Union[bool, str] = "longest"
... def __call__(self, features: List[Dict[str, Union[List[int], torch.Tensor]]]) -> Dict[str, torch.Tensor]:
... # 입력과 레이블을 분할합니다
... # 길이가 다르고, 각각 다른 패딩 방법을 사용해야 하기 때문입니다
... input_features = [{"input_values": feature["input_values"][0]} for feature in features]
... label_features = [{"input_ids": feature["labels"]} for feature in features]
... batch = self.processor.pad(input_features, padding=self.padding, return_tensors="pt")
... labels_batch = self.processor.pad(labels=label_features, padding=self.padding, return_tensors="pt")
... # 패딩에 대해 손실을 적용하지 않도록 -100으로 대체합니다
... labels = labels_batch["input_ids"].masked_fill(labels_batch.attention_mask.ne(1), -100)
... batch["labels"] = labels
... return batch
```
이제 `DataCollatorForCTCWithPadding`을 인스턴스화합니다:
```py
>>> data_collator = DataCollatorCTCWithPadding(processor=processor, padding="longest")
```
## 평가하기[[evaluate]]
훈련 중에 평가 지표를 포함하면 모델의 성능을 평가하는 데 도움이 되는 경우가 많습니다. 🤗 [Evaluate](https://huggingface.co/docs/evaluate/index) 라이브러리를 사용하면 평가 방법을 빠르게 불러올 수 있습니다.
이 작업에서는 [단어 오류율(Word Error Rate, WER)](https://huggingface.co/spaces/evaluate-metric/wer) 평가 지표를 가져옵니다.
(평가 지표를 불러오고 계산하는 방법은 🤗 Evaluate [둘러보기](https://huggingface.co/docs/evaluate/a_quick_tour)를 참조하세요):
```py
>>> import evaluate
>>> wer = evaluate.load("wer")
```
그런 다음 예측값과 레이블을 [`~evaluate.EvaluationModule.compute`]에 전달하여 WER을 계산하는 함수를 만듭니다:
```py
>>> import numpy as np
>>> def compute_metrics(pred):
... pred_logits = pred.predictions
... pred_ids = np.argmax(pred_logits, axis=-1)
... pred.label_ids[pred.label_ids == -100] = processor.tokenizer.pad_token_id
... pred_str = processor.batch_decode(pred_ids)
... label_str = processor.batch_decode(pred.label_ids, group_tokens=False)
... wer = wer.compute(predictions=pred_str, references=label_str)
... return {"wer": wer}
```
이제 `compute_metrics` 함수를 사용할 준비가 되었으며, 훈련을 설정할 때 이 함수로 되돌아올 것입니다.
## 훈련하기[[train]]
<frameworkcontent>
<pt>
<Tip>
[`Trainer`]로 모델을 미세 조정하는 것이 익숙하지 않다면, [여기](../training#train-with-pytorch-trainer)에서 기본 튜토리얼을 확인해보세요!
</Tip>
이제 모델 훈련을 시작할 준비가 되었습니다! [`AutoModelForCTC`]로 Wav2Vec2를 가져오세요. `ctc_loss_reduction` 매개변수로 CTC 손실에 적용할 축소(reduction) 방법을 지정하세요. 기본값인 합계 대신 평균을 사용하는 것이 더 좋은 경우가 많습니다:
```py
>>> from transformers import AutoModelForCTC, TrainingArguments, Trainer
>>> model = AutoModelForCTC.from_pretrained(
... "facebook/wav2vec2-base",
... ctc_loss_reduction="mean",
... pad_token_id=processor.tokenizer.pad_token_id,
... )
```
이제 세 단계만 남았습니다:
1. [`TrainingArguments`]에서 훈련 하이퍼파라미터를 정의하세요. `output_dir`은 모델을 저장할 경로를 지정하는 유일한 필수 매개변수입니다. `push_to_hub=True`를 설정하여 모델을 Hub에 업로드 할 수 있습니다(모델을 업로드하려면 Hugging Face에 로그인해야 합니다). [`Trainer`]는 각 에폭마다 WER을 평가하고 훈련 체크포인트를 저장합니다.
2. 모델, 데이터 세트, 토크나이저, 데이터 콜레이터, `compute_metrics` 함수와 함께 [`Trainer`]에 훈련 인수를 전달하세요.
3. [`~Trainer.train`]을 호출하여 모델을 미세 조정하세요.
```py
>>> training_args = TrainingArguments(
... output_dir="my_awesome_asr_mind_model",
... per_device_train_batch_size=8,
... gradient_accumulation_steps=2,
... learning_rate=1e-5,
... warmup_steps=500,
... max_steps=2000,
... gradient_checkpointing=True,
... fp16=True,
... group_by_length=True,
... evaluation_strategy="steps",
... per_device_eval_batch_size=8,
... save_steps=1000,
... eval_steps=1000,
... logging_steps=25,
... load_best_model_at_end=True,
... metric_for_best_model="wer",
... greater_is_better=False,
... push_to_hub=True,
... )
>>> trainer = Trainer(
... model=model,
... args=training_args,
... train_dataset=encoded_minds["train"],
... eval_dataset=encoded_minds["test"],
... tokenizer=processor.feature_extractor,
... data_collator=data_collator,
... compute_metrics=compute_metrics,
... )
>>> trainer.train()
```
훈련이 완료되면 모두가 모델을 사용할 수 있도록 [`~transformers.Trainer.push_to_hub`] 메소드를 사용하여 모델을 Hub에 공유하세요:
```py
>>> trainer.push_to_hub()
```
</pt>
</frameworkcontent>
<Tip>
자동 음성 인식을 위해 모델을 미세 조정하는 더 자세한 예제는 영어 자동 음성 인식을 위한 [블로그 포스트](https://huggingface.co/blog/fine-tune-wav2vec2-english)와 다국어 자동 음성 인식을 위한 [포스트](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2)를 참조하세요.
</Tip>
## 추론하기[[inference]]
좋아요, 이제 모델을 미세 조정했으니 추론에 사용할 수 있습니다!
추론에 사용할 오디오 파일을 가져오세요. 필요한 경우 오디오 파일의 샘플링 비율을 모델의 샘플링 레이트에 맞게 리샘플링하는 것을 잊지 마세요!
```py
>>> from datasets import load_dataset, Audio
>>> dataset = load_dataset("PolyAI/minds14", "en-US", split="train")
>>> dataset = dataset.cast_column("audio", Audio(sampling_rate=16000))
>>> sampling_rate = dataset.features["audio"].sampling_rate
>>> audio_file = dataset[0]["audio"]["path"]
```
추론을 위해 미세 조정된 모델을 시험해보는 가장 간단한 방법은 [`pipeline`]을 사용하는 것입니다. 모델을 사용하여 자동 음성 인식을 위한 `pipeline`을 인스턴스화하고 오디오 파일을 전달하세요:
```py
>>> from transformers import pipeline
>>> transcriber = pipeline("automatic-speech-recognition", model="stevhliu/my_awesome_asr_minds_model")
>>> transcriber(audio_file)
{'text': 'I WOUD LIKE O SET UP JOINT ACOUNT WTH Y PARTNER'}
```
<Tip>
텍스트로 변환된 결과가 꽤 괜찮지만 더 좋을 수도 있습니다! 더 나은 결과를 얻으려면 더 많은 예제로 모델을 미세 조정하세요!
</Tip>
`pipeline`의 결과를 수동으로 재현할 수도 있습니다:
<frameworkcontent>
<pt>
오디오 파일과 텍스트를 전처리하고 PyTorch 텐서로 `input`을 반환할 프로세서를 가져오세요:
```py
>>> from transformers import AutoProcessor
>>> processor = AutoProcessor.from_pretrained("stevhliu/my_awesome_asr_mind_model")
>>> inputs = processor(dataset[0]["audio"]["array"], sampling_rate=sampling_rate, return_tensors="pt")
```
입력을 모델에 전달하고 로짓을 반환하세요:
```py
>>> from transformers import AutoModelForCTC
>>> model = AutoModelForCTC.from_pretrained("stevhliu/my_awesome_asr_mind_model")
>>> with torch.no_grad():
... logits = model(**inputs).logits
```
가장 높은 확률의 `input_ids`를 예측하고, 프로세서를 사용하여 예측된 `input_ids`를 다시 텍스트로 디코딩하세요:
```py
>>> import torch
>>> predicted_ids = torch.argmax(logits, dim=-1)
>>> transcription = processor.batch_decode(predicted_ids)
>>> transcription
['I WOUL LIKE O SET UP JOINT ACOUNT WTH Y PARTNER']
```
</pt>
</frameworkcontent> | transformers/docs/source/ko/tasks/asr.md/0 | {
"file_path": "transformers/docs/source/ko/tasks/asr.md",
"repo_id": "transformers",
"token_count": 9668
} | 266 |
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 영상 분류 [[video-classification]]
[[open-in-colab]]
영상 분류는 영상 전체에 레이블 또는 클래스를 지정하는 작업입니다. 각 영상에는 하나의 클래스가 있을 것으로 예상됩니다. 영상 분류 모델은 영상을 입력으로 받아 어느 클래스에 속하는지에 대한 예측을 반환합니다. 이러한 모델은 영상이 어떤 내용인지 분류하는 데 사용될 수 있습니다. 영상 분류의 실제 응용 예는 피트니스 앱에서 유용한 동작 / 운동 인식 서비스가 있습니다. 이는 또한 시각 장애인이 이동할 때 보조하는데 사용될 수 있습니다
이 가이드에서는 다음을 수행하는 방법을 보여줍니다:
1. [UCF101](https://www.crcv.ucf.edu/data/UCF101.php) 데이터 세트의 하위 집합을 통해 [VideoMAE](https://huggingface.co/docs/transformers/main/en/model_doc/videomae) 모델을 미세 조정하기.
2. 미세 조정한 모델을 추론에 사용하기.
<Tip>
이 튜토리얼에서 설명하는 작업은 다음 모델 아키텍처에서 지원됩니다:
<!--This tip is automatically generated by `make fix-copies`, do not fill manually!-->
[TimeSformer](../model_doc/timesformer), [VideoMAE](../model_doc/videomae)
<!--End of the generated tip-->
</Tip>
시작하기 전에 필요한 모든 라이브러리가 설치되었는지 확인하세요:
```bash
pip install -q pytorchvideo transformers evaluate
```
영상을 처리하고 준비하기 위해 [PyTorchVideo](https://pytorchvideo.org/)(이하 `pytorchvideo`)를 사용합니다.
커뮤니티에 모델을 업로드하고 공유할 수 있도록 Hugging Face 계정에 로그인하는 것을 권장합니다. 프롬프트가 나타나면 토큰을 입력하여 로그인하세요:
```py
>>> from huggingface_hub import notebook_login
>>> notebook_login()
```
## UCF101 데이터셋 불러오기 [[load-ufc101-dataset]]
[UCF-101](https://www.crcv.ucf.edu/data/UCF101.php) 데이터 세트의 하위 집합(subset)을 불러오는 것으로 시작할 수 있습니다. 전체 데이터 세트를 학습하는데 더 많은 시간을 할애하기 전에 데이터의 하위 집합을 불러와 모든 것이 잘 작동하는지 실험하고 확인할 수 있습니다.
```py
>>> from huggingface_hub import hf_hub_download
>>> hf_dataset_identifier = "sayakpaul/ucf101-subset"
>>> filename = "UCF101_subset.tar.gz"
>>> file_path = hf_hub_download(repo_id=hf_dataset_identifier, filename=filename, repo_type="dataset")
```
데이터 세트의 하위 집합이 다운로드 되면, 압축된 파일의 압축을 해제해야 합니다:
```py
>>> import tarfile
>>> with tarfile.open(file_path) as t:
... t.extractall(".")
```
전체 데이터 세트는 다음과 같이 구성되어 있습니다.
```bash
UCF101_subset/
train/
BandMarching/
video_1.mp4
video_2.mp4
...
Archery
video_1.mp4
video_2.mp4
...
...
val/
BandMarching/
video_1.mp4
video_2.mp4
...
Archery
video_1.mp4
video_2.mp4
...
...
test/
BandMarching/
video_1.mp4
video_2.mp4
...
Archery
video_1.mp4
video_2.mp4
...
...
```
정렬된 영상의 경로는 다음과 같습니다:
```bash
...
'UCF101_subset/train/ApplyEyeMakeup/v_ApplyEyeMakeup_g07_c04.avi',
'UCF101_subset/train/ApplyEyeMakeup/v_ApplyEyeMakeup_g07_c06.avi',
'UCF101_subset/train/ApplyEyeMakeup/v_ApplyEyeMakeup_g08_c01.avi',
'UCF101_subset/train/ApplyEyeMakeup/v_ApplyEyeMakeup_g09_c02.avi',
'UCF101_subset/train/ApplyEyeMakeup/v_ApplyEyeMakeup_g09_c06.avi'
...
```
동일한 그룹/장면에 속하는 영상 클립은 파일 경로에서 `g`로 표시되어 있습니다. 예를 들면, `v_ApplyEyeMakeup_g07_c04.avi`와 `v_ApplyEyeMakeup_g07_c06.avi` 이 있습니다. 이 둘은 같은 그룹입니다.
검증 및 평가 데이터 분할을 할 때, [데이터 누출(data leakage)](https://www.kaggle.com/code/alexisbcook/data-leakage)을 방지하기 위해 동일한 그룹 / 장면의 영상 클립을 사용하지 않아야 합니다. 이 튜토리얼에서 사용하는 하위 집합은 이러한 정보를 고려하고 있습니다.
그 다음으로, 데이터 세트에 존재하는 라벨을 추출합니다. 또한, 모델을 초기화할 때 도움이 될 딕셔너리(dictionary data type)를 생성합니다.
* `label2id`: 클래스 이름을 정수에 매핑합니다.
* `id2label`: 정수를 클래스 이름에 매핑합니다.
```py
>>> class_labels = sorted({str(path).split("/")[2] for path in all_video_file_paths})
>>> label2id = {label: i for i, label in enumerate(class_labels)}
>>> id2label = {i: label for label, i in label2id.items()}
>>> print(f"Unique classes: {list(label2id.keys())}.")
# Unique classes: ['ApplyEyeMakeup', 'ApplyLipstick', 'Archery', 'BabyCrawling', 'BalanceBeam', 'BandMarching', 'BaseballPitch', 'Basketball', 'BasketballDunk', 'BenchPress'].
```
이 데이터 세트에는 총 10개의 고유한 클래스가 있습니다. 각 클래스마다 30개의 영상이 훈련 세트에 있습니다
## 미세 조정하기 위해 모델 가져오기 [[load-a-model-to-fine-tune]]
사전 훈련된 체크포인트와 체크포인트에 연관된 이미지 프로세서를 사용하여 영상 분류 모델을 인스턴스화합니다. 모델의 인코더에는 미리 학습된 매개변수가 제공되며, 분류 헤드(데이터를 분류하는 마지막 레이어)는 무작위로 초기화됩니다. 데이터 세트의 전처리 파이프라인을 작성할 때는 이미지 프로세서가 유용합니다.
```py
>>> from transformers import VideoMAEImageProcessor, VideoMAEForVideoClassification
>>> model_ckpt = "MCG-NJU/videomae-base"
>>> image_processor = VideoMAEImageProcessor.from_pretrained(model_ckpt)
>>> model = VideoMAEForVideoClassification.from_pretrained(
... model_ckpt,
... label2id=label2id,
... id2label=id2label,
... ignore_mismatched_sizes=True, # provide this in case you're planning to fine-tune an already fine-tuned checkpoint
... )
```
모델을 가져오는 동안, 다음과 같은 경고를 마주칠 수 있습니다:
```bash
Some weights of the model checkpoint at MCG-NJU/videomae-base were not used when initializing VideoMAEForVideoClassification: [..., 'decoder.decoder_layers.1.attention.output.dense.bias', 'decoder.decoder_layers.2.attention.attention.key.weight']
- This IS expected if you are initializing VideoMAEForVideoClassification from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing VideoMAEForVideoClassification from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Some weights of VideoMAEForVideoClassification were not initialized from the model checkpoint at MCG-NJU/videomae-base and are newly initialized: ['classifier.bias', 'classifier.weight']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
```
위 경고는 우리가 일부 가중치(예: `classifier` 층의 가중치와 편향)를 버리고 새로운 `classifier` 층의 가중치와 편향을 무작위로 초기화하고 있다는 것을 알려줍니다. 이 경우에는 미리 학습된 가중치가 없는 새로운 헤드를 추가하고 있으므로, 라이브러리가 모델을 추론에 사용하기 전에 미세 조정하라고 경고를 보내는 것은 당연합니다. 그리고 이제 우리는 이 모델을 미세 조정할 예정입니다.
**참고** 이 [체크포인트](https://huggingface.co/MCG-NJU/videomae-base-finetuned-kinetics)는 도메인이 많이 중첩된 유사한 다운스트림 작업에 대해 미세 조정하여 얻은 체크포인트이므로 이 작업에서 더 나은 성능을 보일 수 있습니다. `MCG-NJU/videomae-base-finetuned-kinetics` 데이터 세트를 미세 조정하여 얻은 [체크포인트](https://huggingface.co/sayakpaul/videomae-base-finetuned-kinetics-finetuned-ucf101-subset)도 있습니다.
## 훈련을 위한 데이터 세트 준비하기[[prepare-the-datasets-for-training]]
영상 전처리를 위해 [PyTorchVideo 라이브러리](https://pytorchvideo.org/)를 활용할 것입니다. 필요한 종속성을 가져오는 것으로 시작하세요.
```py
>>> import pytorchvideo.data
>>> from pytorchvideo.transforms import (
... ApplyTransformToKey,
... Normalize,
... RandomShortSideScale,
... RemoveKey,
... ShortSideScale,
... UniformTemporalSubsample,
... )
>>> from torchvision.transforms import (
... Compose,
... Lambda,
... RandomCrop,
... RandomHorizontalFlip,
... Resize,
... )
```
학습 데이터 세트 변환에는 '균일한 시간 샘플링(uniform temporal subsampling)', '픽셀 정규화(pixel normalization)', '랜덤 잘라내기(random cropping)' 및 '랜덤 수평 뒤집기(random horizontal flipping)'의 조합을 사용합니다. 검증 및 평가 데이터 세트 변환에는 '랜덤 잘라내기'와 '랜덤 뒤집기'를 제외한 동일한 변환 체인을 유지합니다. 이러한 변환에 대해 자세히 알아보려면 [PyTorchVideo 공식 문서](https://pytorchvideo.org)를 확인하세요.
사전 훈련된 모델과 관련된 이미지 프로세서를 사용하여 다음 정보를 얻을 수 있습니다:
* 영상 프레임 픽셀을 정규화하는 데 사용되는 이미지 평균과 표준 편차
* 영상 프레임이 조정될 공간 해상도
먼저, 몇 가지 상수를 정의합니다.
```py
>>> mean = image_processor.image_mean
>>> std = image_processor.image_std
>>> if "shortest_edge" in image_processor.size:
... height = width = image_processor.size["shortest_edge"]
>>> else:
... height = image_processor.size["height"]
... width = image_processor.size["width"]
>>> resize_to = (height, width)
>>> num_frames_to_sample = model.config.num_frames
>>> sample_rate = 4
>>> fps = 30
>>> clip_duration = num_frames_to_sample * sample_rate / fps
```
이제 데이터 세트에 특화된 전처리(transform)과 데이터 세트 자체를 정의합니다. 먼저 훈련 데이터 세트로 시작합니다:
```py
>>> train_transform = Compose(
... [
... ApplyTransformToKey(
... key="video",
... transform=Compose(
... [
... UniformTemporalSubsample(num_frames_to_sample),
... Lambda(lambda x: x / 255.0),
... Normalize(mean, std),
... RandomShortSideScale(min_size=256, max_size=320),
... RandomCrop(resize_to),
... RandomHorizontalFlip(p=0.5),
... ]
... ),
... ),
... ]
... )
>>> train_dataset = pytorchvideo.data.Ucf101(
... data_path=os.path.join(dataset_root_path, "train"),
... clip_sampler=pytorchvideo.data.make_clip_sampler("random", clip_duration),
... decode_audio=False,
... transform=train_transform,
... )
```
같은 방식의 작업 흐름을 검증과 평가 세트에도 적용할 수 있습니다.
```py
>>> val_transform = Compose(
... [
... ApplyTransformToKey(
... key="video",
... transform=Compose(
... [
... UniformTemporalSubsample(num_frames_to_sample),
... Lambda(lambda x: x / 255.0),
... Normalize(mean, std),
... Resize(resize_to),
... ]
... ),
... ),
... ]
... )
>>> val_dataset = pytorchvideo.data.Ucf101(
... data_path=os.path.join(dataset_root_path, "val"),
... clip_sampler=pytorchvideo.data.make_clip_sampler("uniform", clip_duration),
... decode_audio=False,
... transform=val_transform,
... )
>>> test_dataset = pytorchvideo.data.Ucf101(
... data_path=os.path.join(dataset_root_path, "test"),
... clip_sampler=pytorchvideo.data.make_clip_sampler("uniform", clip_duration),
... decode_audio=False,
... transform=val_transform,
... )
```
**참고**: 위의 데이터 세트의 파이프라인은 [공식 파이토치 예제](https://pytorchvideo.org/docs/tutorial_classification#dataset)에서 가져온 것입니다. 우리는 UCF-101 데이터셋에 맞게 [`pytorchvideo.data.Ucf101()`](https://pytorchvideo.readthedocs.io/en/latest/api/data/data.html#pytorchvideo.data.Ucf101) 함수를 사용하고 있습니다. 내부적으로 이 함수는 [`pytorchvideo.data.labeled_video_dataset.LabeledVideoDataset`](https://pytorchvideo.readthedocs.io/en/latest/api/data/data.html#pytorchvideo.data.LabeledVideoDataset) 객체를 반환합니다. `LabeledVideoDataset` 클래스는 PyTorchVideo 데이터셋에서 모든 영상 관련 작업의 기본 클래스입니다. 따라서 PyTorchVideo에서 미리 제공하지 않는 사용자 지정 데이터 세트를 사용하려면, 이 클래스를 적절하게 확장하면 됩니다. 더 자세한 사항이 알고 싶다면 `data` API [문서](https://pytorchvideo.readthedocs.io/en/latest/api/data/data.html) 를 참고하세요. 또한 위의 예시와 유사한 구조를 갖는 데이터 세트를 사용하고 있다면, `pytorchvideo.data.Ucf101()` 함수를 사용하는 데 문제가 없을 것입니다.
데이터 세트에 영상의 개수를 알기 위해 `num_videos` 인수에 접근할 수 있습니다.
```py
>>> print(train_dataset.num_videos, val_dataset.num_videos, test_dataset.num_videos)
# (300, 30, 75)
```
## 더 나은 디버깅을 위해 전처리 영상 시각화하기[[visualize-the-preprocessed-video-for-better-debugging]]
```py
>>> import imageio
>>> import numpy as np
>>> from IPython.display import Image
>>> def unnormalize_img(img):
... """Un-normalizes the image pixels."""
... img = (img * std) + mean
... img = (img * 255).astype("uint8")
... return img.clip(0, 255)
>>> def create_gif(video_tensor, filename="sample.gif"):
... """Prepares a GIF from a video tensor.
...
... The video tensor is expected to have the following shape:
... (num_frames, num_channels, height, width).
... """
... frames = []
... for video_frame in video_tensor:
... frame_unnormalized = unnormalize_img(video_frame.permute(1, 2, 0).numpy())
... frames.append(frame_unnormalized)
... kargs = {"duration": 0.25}
... imageio.mimsave(filename, frames, "GIF", **kargs)
... return filename
>>> def display_gif(video_tensor, gif_name="sample.gif"):
... """Prepares and displays a GIF from a video tensor."""
... video_tensor = video_tensor.permute(1, 0, 2, 3)
... gif_filename = create_gif(video_tensor, gif_name)
... return Image(filename=gif_filename)
>>> sample_video = next(iter(train_dataset))
>>> video_tensor = sample_video["video"]
>>> display_gif(video_tensor)
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/sample_gif.gif" alt="Person playing basketball"/>
</div>
## 모델 훈련하기[[train-the-model]]
🤗 Transformers의 [`Trainer`](https://huggingface.co/docs/transformers/main_classes/trainer)를 사용하여 모델을 훈련시켜보세요. `Trainer`를 인스턴스화하려면 훈련 설정과 평가 지표를 정의해야 합니다. 가장 중요한 것은 [`TrainingArguments`](https://huggingface.co/transformers/main_classes/trainer.html#transformers.TrainingArguments)입니다. 이 클래스는 훈련을 구성하는 모든 속성을 포함하며, 훈련 중 체크포인트를 저장할 출력 폴더 이름을 필요로 합니다. 또한 🤗 Hub의 모델 저장소의 모든 정보를 동기화하는 데 도움이 됩니다.
대부분의 훈련 인수는 따로 설명할 필요는 없습니다. 하지만 여기에서 중요한 인수는 `remove_unused_columns=False` 입니다. 이 인자는 모델의 호출 함수에서 사용되지 않는 모든 속성 열(columns)을 삭제합니다. 기본값은 일반적으로 True입니다. 이는 사용되지 않는 기능 열을 삭제하는 것이 이상적이며, 입력을 모델의 호출 함수로 풀기(unpack)가 쉬워지기 때문입니다. 하지만 이 경우에는 `pixel_values`(모델의 입력으로 필수적인 키)를 생성하기 위해 사용되지 않는 기능('video'가 특히 그렇습니다)이 필요합니다. 따라서 remove_unused_columns을 False로 설정해야 합니다.
```py
>>> from transformers import TrainingArguments, Trainer
>>> model_name = model_ckpt.split("/")[-1]
>>> new_model_name = f"{model_name}-finetuned-ucf101-subset"
>>> num_epochs = 4
>>> args = TrainingArguments(
... new_model_name,
... remove_unused_columns=False,
... evaluation_strategy="epoch",
... save_strategy="epoch",
... learning_rate=5e-5,
... per_device_train_batch_size=batch_size,
... per_device_eval_batch_size=batch_size,
... warmup_ratio=0.1,
... logging_steps=10,
... load_best_model_at_end=True,
... metric_for_best_model="accuracy",
... push_to_hub=True,
... max_steps=(train_dataset.num_videos // batch_size) * num_epochs,
... )
```
`pytorchvideo.data.Ucf101()` 함수로 반환되는 데이터 세트는 `__len__` 메소드가 이식되어 있지 않습니다. 따라서, `TrainingArguments`를 인스턴스화할 때 `max_steps`를 정의해야 합니다.
다음으로, 평가지표를 불러오고, 예측값에서 평가지표를 계산할 함수를 정의합니다. 필요한 전처리 작업은 예측된 로짓(logits)에 argmax 값을 취하는 것뿐입니다:
```py
import evaluate
metric = evaluate.load("accuracy")
def compute_metrics(eval_pred):
predictions = np.argmax(eval_pred.predictions, axis=1)
return metric.compute(predictions=predictions, references=eval_pred.label_ids)
```
**평가에 대한 참고사항**:
[VideoMAE 논문](https://arxiv.org/abs/2203.12602)에서 저자는 다음과 같은 평가 전략을 사용합니다. 테스트 영상에서 여러 클립을 선택하고 그 클립에 다양한 크롭을 적용하여 집계 점수를 보고합니다. 그러나 이번 튜토리얼에서는 간단함과 간결함을 위해 해당 전략을 고려하지 않습니다.
또한, 예제를 묶어서 배치를 형성하는 `collate_fn`을 정의해야합니다. 각 배치는 `pixel_values`와 `labels`라는 2개의 키로 구성됩니다.
```py
>>> def collate_fn(examples):
... # permute to (num_frames, num_channels, height, width)
... pixel_values = torch.stack(
... [example["video"].permute(1, 0, 2, 3) for example in examples]
... )
... labels = torch.tensor([example["label"] for example in examples])
... return {"pixel_values": pixel_values, "labels": labels}
```
그런 다음 이 모든 것을 데이터 세트와 함께 `Trainer`에 전달하기만 하면 됩니다:
```py
>>> trainer = Trainer(
... model,
... args,
... train_dataset=train_dataset,
... eval_dataset=val_dataset,
... tokenizer=image_processor,
... compute_metrics=compute_metrics,
... data_collator=collate_fn,
... )
```
데이터를 이미 처리했는데도 불구하고 `image_processor`를 토크나이저 인수로 넣은 이유는 JSON으로 저장되는 이미지 프로세서 구성 파일이 Hub의 저장소에 업로드되도록 하기 위함입니다.
`train` 메소드를 호출하여 모델을 미세 조정하세요:
```py
>>> train_results = trainer.train()
```
학습이 완료되면, 모델을 [`~transformers.Trainer.push_to_hub`] 메소드를 사용하여 허브에 공유하여 누구나 모델을 사용할 수 있도록 합니다:
```py
>>> trainer.push_to_hub()
```
## 추론하기[[inference]]
좋습니다. 이제 미세 조정된 모델을 추론하는 데 사용할 수 있습니다.
추론에 사용할 영상을 불러오세요:
```py
>>> sample_test_video = next(iter(test_dataset))
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/sample_gif_two.gif" alt="Teams playing basketball"/>
</div>
미세 조정된 모델을 추론에 사용하는 가장 간단한 방법은 [`pipeline`](https://huggingface.co/docs/transformers/main/en/main_classes/pipelines#transformers.VideoClassificationPipeline)에서 모델을 사용하는 것입니다. 모델로 영상 분류를 하기 위해 `pipeline`을 인스턴스화하고 영상을 전달하세요:
```py
>>> from transformers import pipeline
>>> video_cls = pipeline(model="my_awesome_video_cls_model")
>>> video_cls("https://huggingface.co/datasets/sayakpaul/ucf101-subset/resolve/main/v_BasketballDunk_g14_c06.avi")
[{'score': 0.9272987842559814, 'label': 'BasketballDunk'},
{'score': 0.017777055501937866, 'label': 'BabyCrawling'},
{'score': 0.01663011871278286, 'label': 'BalanceBeam'},
{'score': 0.009560945443809032, 'label': 'BandMarching'},
{'score': 0.0068979403004050255, 'label': 'BaseballPitch'}]
```
만약 원한다면 수동으로 `pipeline`의 결과를 재현할 수 있습니다:
```py
>>> def run_inference(model, video):
... # (num_frames, num_channels, height, width)
... perumuted_sample_test_video = video.permute(1, 0, 2, 3)
... inputs = {
... "pixel_values": perumuted_sample_test_video.unsqueeze(0),
... "labels": torch.tensor(
... [sample_test_video["label"]]
... ), # this can be skipped if you don't have labels available.
... }
... device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
... inputs = {k: v.to(device) for k, v in inputs.items()}
... model = model.to(device)
... # forward pass
... with torch.no_grad():
... outputs = model(**inputs)
... logits = outputs.logits
... return logits
```
모델에 입력값을 넣고 `logits`을 반환받으세요:
```
>>> logits = run_inference(trained_model, sample_test_video["video"])
```
`logits`을 디코딩하면, 우리는 다음 결과를 얻을 수 있습니다:
```py
>>> predicted_class_idx = logits.argmax(-1).item()
>>> print("Predicted class:", model.config.id2label[predicted_class_idx])
# Predicted class: BasketballDunk
```
| transformers/docs/source/ko/tasks/video_classification.md/0 | {
"file_path": "transformers/docs/source/ko/tasks/video_classification.md",
"repo_id": "transformers",
"token_count": 13653
} | 267 |
- sections:
- local: index
title: 🤗 Transformers
- local: quicktour
title: Tour rápido
- local: installation
title: Instalação
title: Início
- sections:
- local: pipeline_tutorial
title: Pipelines para inferência
- local: training
title: Fine-tuning de um modelo pré-treinado
- local: accelerate
title: Treinamento distribuído com 🤗 Accelerate
title: Tutoriais
- sections:
- local: fast_tokenizers
title: Usando os Tokenizers do 🤗 Tokenizers
- local: create_a_model
title: Criando uma arquitetura customizada
- local: custom_models
title: Compartilhando modelos customizados
- local: run_scripts
title: Treinamento a partir de um script
- local: converting_tensorflow_models
title: Convertendo checkpoints do TensorFlow para Pytorch
- local: serialization
title: Exportando modelos para ONNX
- sections:
- local: tasks/sequence_classification
title: Classificação de texto
- local: tasks/token_classification
title: Classificação de tokens
title: Fine-tuning para tarefas específicas
- local: multilingual
title: Modelos multilinguísticos para inferência
title: Guias práticos
| transformers/docs/source/pt/_toctree.yml/0 | {
"file_path": "transformers/docs/source/pt/_toctree.yml",
"repo_id": "transformers",
"token_count": 424
} | 268 |
- sections:
- local: index
title: 🤗 Transformers
- local: quicktour
title: త్వరిత పర్యటన
title: ప్రారంభించడానికి
| transformers/docs/source/te/_toctree.yml/0 | {
"file_path": "transformers/docs/source/te/_toctree.yml",
"repo_id": "transformers",
"token_count": 125
} | 269 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.