
licenses
sequencelengths 1
3
| version
stringclasses 677
values | tree_hash
stringlengths 40
40
| path
stringclasses 1
value | type
stringclasses 2
values | size
stringlengths 2
8
| text
stringlengths 25
67.1M
| package_name
stringlengths 2
41
| repo
stringlengths 33
86
|
|---|---|---|---|---|---|---|---|---|
[
"MIT"
] | 0.4.12 | dc182956229ff16d5a4d90a562035e633bd2561d | code | 4338 | function save(f::Stream{format"STL_ASCII"}, mesh::AbstractMesh)
io = stream(f)
points = decompose(Point3f, mesh)
faces = decompose(GLTriangleFace, mesh)
normals = decompose_normals(mesh)
n_points = length(points)
n_faces = length(faces)
# write the header
write(io,"solid vcg\n")
# write the data
for i = 1:n_faces
f = faces[i]
n = normals[f][1] # TODO: properly compute normal(f)
v1, v2, v3 = points[f]
@printf io " facet normal %e %e %e\n" n[1] n[2] n[3]
write(io," outer loop\n")
@printf io " vertex %e %e %e\n" v1[1] v1[2] v1[3]
@printf io " vertex %e %e %e\n" v2[1] v2[2] v2[3]
@printf io " vertex %e %e %e\n" v3[1] v3[2] v3[3]
write(io," endloop\n")
write(io," endfacet\n")
end
write(io,"endsolid vcg\n")
end
show(io::IO, ::MIME"model/stl+ascii", mesh::AbstractMesh) = save(io, mesh)
function save(f::Stream{format"STL_BINARY"}, mesh::AbstractMesh)
io = stream(f)
points = decompose(Point3f, mesh)
faces = decompose(GLTriangleFace, mesh)
normals = decompose_normals(mesh)
n_faces = length(faces)
# Implementation made according to https://en.wikipedia.org/wiki/STL_%28file_format%29#Binary_STL
for i in 1:80 # write empty header
write(io, 0x00)
end
write(io, UInt32(n_faces)) # write triangle count
for i = 1:n_faces
f = faces[i]
n = normals[f][1] # TODO: properly compute normal(f)
triangle = points[f]
foreach(j-> write(io, n[j]), 1:3)
for point in triangle
foreach(p-> write(io, p), point)
end
write(io, 0x0000) # write 16bit empty bit
end
end
function load(fs::Stream{format"STL_BINARY"}; facetype=GLTriangleFace,
pointtype=Point3f, normaltype=Vec3f)
#Binary STL
#https://en.wikipedia.org/wiki/STL_%28file_format%29#Binary_STL
io = stream(fs)
read(io, 80) # throw out header
triangle_count = read(io, UInt32)
faces = Array{facetype}(undef, triangle_count)
vertices = Array{pointtype}(undef, triangle_count * 3)
normals = Array{normaltype}(undef, triangle_count * 3)
i = 0
while !eof(io)
faces[i+1] = GLTriangleFace(i * 3 + 1, i * 3 + 2, i * 3 + 3)
normal = (read(io, Float32), read(io, Float32), read(io, Float32))
normals[i*3+1] = normaltype(normal...)
normals[i*3+2] = normals[i*3+1] # hurts, but we need per vertex normals
normals[i*3+3] = normals[i*3+1]
vertices[i*3+1] = pointtype(read(io, Float32), read(io, Float32), read(io, Float32))
vertices[i*3+2] = pointtype(read(io, Float32), read(io, Float32), read(io, Float32))
vertices[i*3+3] = pointtype(read(io, Float32), read(io, Float32), read(io, Float32))
skip(io, 2) # throwout 16bit attribute
i += 1
end
return Mesh(meta(vertices; normals=normals), faces)
end
function load(fs::Stream{format"STL_ASCII"}; facetype=GLTriangleFace,
pointtype=Point3f, normaltype=Vec3f, topology=false)
#ASCII STL
#https://en.wikipedia.org/wiki/STL_%28file_format%29#ASCII_STL
io = stream(fs)
points = pointtype[]
faces = facetype[]
normals = normaltype[]
vert_count = 0
vert_idx = [0, 0, 0]
while !eof(io)
line = split(lowercase(readline(io)))
if !isempty(line) && line[1] == "facet"
normal = normaltype(parse.(eltype(normaltype), line[3:5]))
readline(io) # Throw away outerloop
for i in 1:3
vertex = pointtype(parse.(eltype(pointtype),
split(readline(io))[2:4]))
if topology
idx = findfirst(vertices(mesh), vertex)
end
if topology && idx != 0
vert_idx[i] = idx
else
push!(points, vertex)
push!(normals, normal)
vert_count += 1
vert_idx[i] = vert_count
end
end
readline(io) # throwout endloop
readline(io) # throwout endfacet
push!(faces, TriangleFace{Int}(vert_idx...))
end
end
return Mesh(meta(points; normals=normals), faces)
end
| MeshIO | https://github.com/JuliaIO/MeshIO.jl.git |
|
[
"MIT"
] | 0.4.12 | dc182956229ff16d5a4d90a562035e633bd2561d | code | 7602 | using FileIO, GeometryBasics
using Test
const tf = joinpath(dirname(@__FILE__), "testfiles")
using MeshIO
function test_face_indices(mesh)
for face in faces(mesh)
for index in face
pass = firstindex(coordinates(mesh)) <= index <= lastindex(coordinates(mesh))
pass || return false
end
end
return true
end
@testset "MeshIO" begin
dirlen = 1.0f0
baselen = 0.02f0
mesh = [
Rect3f(Vec3f(baselen), Vec3f(dirlen, baselen, baselen)),
Rect3f(Vec3f(baselen), Vec3f(baselen, dirlen, baselen)),
Rect3f(Vec3f(baselen), Vec3f(baselen, baselen, dirlen))
]
uvn_mesh = merge(map(uv_normal_mesh, mesh))
mesh = merge(map(triangle_mesh, mesh))
mktempdir() do tmpdir
for ext in ["2dm", "off", "obj"]
@testset "load save $ext" begin
save(joinpath(tmpdir, "test.$ext"), mesh)
mesh_loaded = load(joinpath(tmpdir, "test.$ext"))
@test mesh_loaded == mesh
end
end
@testset "PLY ascii and binary" begin
f = File{format"PLY_ASCII"}(joinpath(tmpdir, "test.ply"))
save(f, mesh)
mesh_loaded = load(joinpath(tmpdir, "test.ply"))
@test mesh_loaded == mesh
save(File{format"PLY_BINARY"}(joinpath(tmpdir, "test.ply")), mesh)
end
@testset "STL ascii and binary" begin
save(File{format"STL_ASCII"}(joinpath(tmpdir, "test.stl")), mesh)
mesh_loaded = load(joinpath(tmpdir, "test.stl"))
@test Set(mesh.position) == Set(mesh_loaded.position)
save(File{format"STL_BINARY"}(joinpath(tmpdir, "test.stl")), mesh)
mesh_loaded = load(joinpath(tmpdir, "test.stl"))
@test Set(mesh.position) == Set(mesh_loaded.position)
end
@testset "load save OBJ" begin
save(joinpath(tmpdir, "test.obj"), uvn_mesh)
mesh_loaded = load(joinpath(tmpdir, "test.obj"))
@test mesh_loaded == uvn_mesh
end
end
@testset "Real world files" begin
@testset "STL" begin
msh = load(joinpath(tf, "ascii.stl"))
@test length(faces(msh)) == 12
@test length(coordinates(msh)) == 36
@test length(normals(msh)) == 36
@test test_face_indices(msh)
msh = load(joinpath(tf, "binary.stl"))
@test msh isa GLNormalMesh
@test length(faces(msh)) == 828
@test length(coordinates(msh)) == 2484
@test length(msh.normals) == 2484
@test test_face_indices(msh)
mktempdir() do tmpdir
save(File{format"STL_BINARY"}(joinpath(tmpdir, "test.stl")), msh)
msh1 = load(joinpath(tmpdir, "test.stl"))
@test msh1 isa GLNormalMesh
@test faces(msh) == faces(msh1)
@test coordinates(msh) == coordinates(msh1)
@test msh.normals == msh1.normals
end
msh = load(joinpath(tf, "binary_stl_from_solidworks.STL"))
@test msh isa GLNormalMesh
@test length(faces(msh)) == 12
@test length(coordinates(msh)) == 36
@test test_face_indices(msh)
# STL Import
msh = load(joinpath(tf, "cube_binary.stl"))
@test length(coordinates(msh)) == 36
@test length(faces(msh)) == 12
@test test_face_indices(msh)
msh = load(joinpath(tf, "cube.stl"))
@test length(coordinates(msh)) == 36
@test length(faces(msh)) == 12
@test test_face_indices(msh)
end
@testset "PLY" begin
msh = load(joinpath(tf, "ascii.ply"))
@test length(faces(msh)) == 36
@test test_face_indices(msh)
@test length(coordinates(msh)) == 72
msh = load(joinpath(tf, "binary.ply"))
@test length(faces(msh)) == 36
@test test_face_indices(msh)
@test length(coordinates(msh)) == 72
msh = load(joinpath(tf, "cube.ply")) # quads
@test length(coordinates(msh)) == 24
@test length(faces(msh)) == 12
@test test_face_indices(msh)
end
@testset "OFF" begin
msh = load(joinpath(tf, "test.off"))
@test length(faces(msh)) == 28
@test length(coordinates(msh)) == 20
@test test_face_indices(msh)
msh = load(joinpath(tf, "test2.off"))
@test length(faces(msh)) == 810
@test length(coordinates(msh)) == 405
@test test_face_indices(msh)
msh = load(joinpath(tf, "cube.off"))
@test length(faces(msh)) == 12
@test length(coordinates(msh)) == 8
@test test_face_indices(msh)
end
@testset "OBJ" begin
msh = load(joinpath(tf, "test.obj"))
@test length(faces(msh)) == 3954
@test length(coordinates(msh)) == 2519
@test length(normals(msh)) == 2519
@test test_face_indices(msh)
msh = load(joinpath(tf, "cube.obj")) # quads
@test length(faces(msh)) == 12
@test length(coordinates(msh)) == 8
@test test_face_indices(msh)
msh = load(joinpath(tf, "cube_uv.obj"))
@test typeof(msh.uv) == Vector{Vec{2,Float32}}
@test length(msh.uv) == 8
msh = load(joinpath(tf, "cube_uvw.obj"))
@test typeof(msh.uv) == Vector{Vec{3,Float32}}
@test length(msh.uv) == 8
msh = load(joinpath(tf, "polygonal_face.obj"))
@test length(faces(msh)) == 4
@test length(coordinates(msh)) == 6
@test test_face_indices(msh)
msh = load(joinpath(tf, "test_face_normal.obj"))
@test length(faces(msh)) == 1
@test length(coordinates(msh)) == 3
@test test_face_indices(msh)
end
@testset "2DM" begin
msh = load(joinpath(tf, "test.2dm"))
@test test_face_indices(msh)
end
@testset "GMSH" begin
msh = load(joinpath(tf, "cube.msh"))
@test length(faces(msh)) == 24
@test length(coordinates(msh)) == 14
@test test_face_indices(msh)
end
@testset "GTS" begin
# TODO: FileIO upstream
#msh = load(joinpath(tf, "sphere5.gts"))
#@test typeof(msh) == GLNormalMesh
#test_face_indices(msh)
end
@testset "Index remapping" begin
pos_faces = GLTriangleFace[(5, 6, 7), (5, 6, 8), (5, 7, 8)]
normal_faces = GLTriangleFace[(5, 6, 7), (3, 6, 8), (5, 7, 8)]
uv_faces = GLTriangleFace[(1, 2, 3), (4, 2, 5), (1, 3, 1)]
# unique combinations -> new indices
# 551 662 773 534 885 881 1 2 3 4 5 6 (or 0..5 with 0 based indices)
faces, maps = MeshIO.merge_vertex_attribute_indices(pos_faces, normal_faces, uv_faces)
@test length(faces) == 3
@test faces == GLTriangleFace[(1, 2, 3), (4, 2, 5), (1, 3, 6)]
# maps are structured as map[new_index] = old_index, so they grab the
# first/second/third index of the unique combinations above
# maps = (pos_map, normal_map, uv_map)
@test maps[1] == [5, 6, 7, 5, 8, 8]
@test maps[2] == [5, 6, 7, 3, 8, 8]
@test maps[3] == [1, 2, 3, 4, 5, 1]
end
end
end
| MeshIO | https://github.com/JuliaIO/MeshIO.jl.git |
|
[
"MIT"
] | 0.4.12 | dc182956229ff16d5a4d90a562035e633bd2561d | docs | 4075 | # MeshIO
[](http://codecov.io/github/JuliaIO/MeshIO.jl?branch=master)
[](https://coveralls.io/github/JuliaIO/MeshIO.jl?branch=master)
This package supports loading 3D model file formats: `obj`, `stl`, `ply`, `off` and `2DM`.
More 3D model formats will be supported in the future.
## Installation
Enter package mode in the Julia REPL and run the following command:
```Julia
pkg> add FileIO MeshIO
```
## Usage
Loading works over the [FileIO](https://github.com/JuliaIO/FileIO.jl) interface.
This means loading a mesh is as simple as this:
```Julia
using FileIO
mesh = load("path/to/mesh.obj")
```
Displaying a mesh can be achieved with [Makie](https://github.com/JuliaPlots/Makie.jl).
Functions for mesh manipulation can be found in [JuliaGeometry](https://github.com/JuliaGeometry)
## Additional Information
MeshIO now has the HomogenousMesh type. Name is still not settled, but it's supposed to be a dense mesh with all attributes either having the length of one (constant over the whole mesh) or the same length (per vertex).
This meshtype holds a large variability for all the different attribute mixtures that I've encountered while trying to visualize things over at GLVisualize. This is the best type I've found so far to encode this large variability, without an explosion of functions.
The focus is on conversion between different mesh types and creation of different mesh types.
This has led to some odd seeming design choices.
First, you can get an attribute via `decompose(::Type{AttributeType}, ::Mesh)`.
This will try to get this attribute, and if it has the wrong type try to convert it, or if it is not available try to create it.
So `decompose(Point3{Float32}, mesh)` on a mesh with vertices of type `Point3{Float64}` will return a vector of type `Point3{Float32}`.
Similarly, if you call `decompose(Normal{3, Float32}, mesh)` but the mesh doesn't have normals, it will call the function `normals(mesh.vertices, mesh.faces, Normal{3, Float32}`, which will create the normals for the mesh.
As most attributes are independent, this enables us to easily create all kinds of conversions.
Also, I can define `decompose` for arbitrary geometric types.
`decompose{T}(Point3{T}, r::Rectangle)` can actually return the needed vertices for a rectangle.
This together with `convert` enables us to create mesh primitives like this:
```Julia
MeshType(Cube(...))
MeshType(Sphere(...))
MeshType(Volume, 0.4f0) #0.4f0 => isovalue
```
Similarly, I can pass a meshtype to an IO function, which then parses only the attributes that I really need.
So passing `Mesh{Point3{Float32}, Face3{UInt32}}` to the obj importer will skip normals, uv coordinates etc, and automatically converts the given attributes to the right number type.
To put this one level further, the `Face` type has the index offset relative to Julia's indexing as a parameter (e.g. `Face3{T, 0}` is 1 indexed). Also, you can index into an array with this face type, and it will convert the indexes correctly while accessing the array. So something like this always works, independent of the underlying index offset:
```Julia
v1, v2, v3 = vertices[face]
```
Also, the importer is sensitive to this, so if you always want to work with 0-indexed faces (like it makes sense for opengl based visualizations), you can parse the mesh already as an 0-indexed mesh, by just defining the mesh format to use `Face3{T, -1}`. (only the OBJ importer yet)
Small example to demonstrate the advantage for IO:
```Julia
#Export takes any mesh
function write{M <: Mesh}(msh::M, fn::File{:ply_binary})
# even if the native mesh format doesn't have an array of dense points or faces, the correct ones will
# now be created, or converted:
vts = decompose(Point3{Float32}, msh) # I know ply_binary needs Point3{Float32}
fcs = decompose(Face3{Int32, -1}, msh) # And 0 indexed Int32 faces.
#write code...
end
```
| MeshIO | https://github.com/JuliaIO/MeshIO.jl.git |
|
[
"MIT"
] | 0.4.0 | d7a67c1c8ae6118f253a137ffa5291421e757a8a | code | 279 | # This file is a part of project JuliaFEM.
# License is MIT: see https://github.com/JuliaFEM/Materials.jl/blob/master/LICENSE
using Documenter
using Materials
deploydocs(
deps = Deps.pip("mkdocs", "python-markdown-math"),
repo = "github.com/JuliaFEM/Materials.jl.git")
| Materials | https://github.com/JuliaFEM/Materials.jl.git |
|
[
"MIT"
] | 0.4.0 | d7a67c1c8ae6118f253a137ffa5291421e757a8a | code | 239 | # This file is a part of project JuliaFEM.
# License is MIT: see https://github.com/JuliaFEM/Materials.jl/blob/master/LICENSE
using Documenter
using Materials
makedocs(
modules = [Materials],
checkdocs = :all,
strict = true)
| Materials | https://github.com/JuliaFEM/Materials.jl.git |
|
[
"MIT"
] | 0.4.0 | d7a67c1c8ae6118f253a137ffa5291421e757a8a | code | 9897 | # This file is a part of JuliaFEM.
# License is MIT: see https://github.com/JuliaFEM/Materials.jl/blob/master/LICENSE
#
# Some examples of how to use the Chaboche material model.
using Parameters
using ForwardDiff
using DelimitedFiles, Test
using Materials
function simple_integration_test()
parameters = ChabocheParameterState(E = 200.0e3,
nu = 0.3,
R0 = 100.0,
Kn = 100.0,
nn = 10.0,
C1 = 10000.0,
D1 = 100.0,
C2 = 50000.0,
D2 = 1000.0,
Q = 50.0,
b = 0.1)
dstrain_dtime = fromvoigt(Symm2{Float64}, 1e-3*[1.0, -0.3, -0.3, 0.0, 0.0, 0.0]; offdiagscale=2.0)
ddrivers = ChabocheDriverState(time=0.25, strain=0.25*dstrain_dtime)
chabmat = Chaboche(parameters=parameters, ddrivers=ddrivers)
@info "time = $(chabmat.drivers.time), stress = $(chabmat.variables.stress)"
integrate_material!(chabmat)
update_material!(chabmat)
@info "time = $(chabmat.drivers.time), stress = $(chabmat.variables.stress)"
chabmat.ddrivers = ddrivers
integrate_material!(chabmat)
update_material!(chabmat)
@info "time = $(chabmat.drivers.time), stress = $(chabmat.variables.stress)"
chabmat.ddrivers = ddrivers
integrate_material!(chabmat)
update_material!(chabmat)
@info "time = $(chabmat.drivers.time), stress = $(chabmat.variables.stress)"
end
simple_integration_test()
function test_chaboche()
path = joinpath(@__DIR__, "one_elem_disp_chaboche", "unitelement_results.rpt")
data = readdlm(path, Float64; skipstart=4)
ts = data[:,1]
s11_ = data[:,2]
s12_ = data[:,3]
s13_ = data[:,4]
s22_ = data[:,5]
s23_ = data[:,6]
s33_ = data[:,7]
e11_ = data[:,8]
e12_ = data[:,9]
e13_ = data[:,10]
e22_ = data[:,11]
e23_ = data[:,12]
e33_ = data[:,13]
strains = [[e11_[i], e22_[i], e33_[i], e23_[i], e13_[i], e12_[i]] for i in 1:length(ts)]
parameters = ChabocheParameterState(E = 200.0e3,
nu = 0.3,
R0 = 100.0,
Kn = 100.0,
nn = 10.0,
C1 = 10000.0,
D1 = 100.0,
C2 = 50000.0,
D2 = 1000.0,
Q = 50.0,
b = 0.1)
chabmat = Chaboche(parameters=parameters)
s33s = [chabmat.variables.stress[3,3]]
for i=2:length(ts)
dtime = ts[i]-ts[i-1]
dstrain = fromvoigt(Symm2{Float64}, strains[i]-strains[i-1]; offdiagscale=2.0)
chabmat.ddrivers = ChabocheDriverState(time = dtime, strain = dstrain)
integrate_material!(chabmat)
update_material!(chabmat)
push!(s33s, chabmat.variables.stress[3,3])
end
@test isapprox(s33s, s33_; rtol=0.01)
end
test_chaboche()
# Profile.clear_malloc_data()
# test_chaboche()
# using BenchmarkTools
# @btime test_chaboche()
function simple_integration_test_fd_tangent()
parameters = ChabocheParameterState(E = 200.0e3,
nu = 0.3,
R0 = 100.0,
Kn = 100.0,
nn = 10.0,
C1 = 10000.0,
D1 = 100.0,
C2 = 50000.0,
D2 = 1000.0,
Q = 50.0,
b = 0.1)
dstrain_dtime = fromvoigt(Symm2{Float64}, 1e-3*[1.0, -0.3, -0.3, 0.0, 0.0, 0.0]; offdiagscale=2.0)
ddrivers = ChabocheDriverState(time=0.25, strain=0.25*dstrain_dtime)
chabmat = Chaboche(parameters=parameters, ddrivers=ddrivers)
function get_stress(dstrain::Symm2)
chabmat.ddrivers.strain = dstrain
integrate_material!(chabmat)
return chabmat.variables_new.stress
end
# stress = get_stress(0.25*dstrain_dtime)
# @info "stress = $stress"
# https://kristofferc.github.io/Tensors.jl/stable/man/automatic_differentiation/
# TODO: doesn't work, a Nothing ends up in the type for some reason?
D, dstress = Tensors.gradient(get_stress, 0.25*dstrain_dtime, :all)
@info "D_mat = $(tovoigt(chabmat.variables_new.jacobian))"
@info "D = $(tovoigt(D))"
chabmat.variables_new = typeof(chabmat.variables_new)()
chabmat.ddrivers = ChabocheDriverState(time=0.25, strain=0.25*dstrain_dtime)
@info "time = $(chabmat.drivers.time), stress = $(chabmat.variables.stress)"
integrate_material!(chabmat)
update_material!(chabmat)
@info "time = $(chabmat.drivers.time), stress = $(chabmat.variables.stress)"
# stress = get_stress(0.25*dstrain_dtime)
# @info "stress = $stress"
D, dstress = Tensors.gradient(get_stress, 0.25*dstrain_dtime, :all)
@info "D = $(tovoigt(D))"
chabmat.variables_new = typeof(chabmat.variables_new)()
chabmat.ddrivers = ChabocheDriverState(time=0.25, strain=0.25*dstrain_dtime)
integrate_material!(chabmat)
update_material!(chabmat)
@info "time = $(chabmat.drivers.time), stress = $(chabmat.variables.stress)"
# stress = get_stress(0.25*dstrain_dtime)
# @info "stress = $stress"
D, dstress = Tensors.gradient(get_stress, 0.25*dstrain_dtime, :all)
@info "D = $(tovoigt(D))"
chabmat.variables_new = typeof(chabmat.variables_new)()
chabmat.ddrivers = ChabocheDriverState(time=0.25, strain=0.25*dstrain_dtime)
integrate_material!(chabmat)
update_material!(chabmat)
@info "time = $(chabmat.drivers.time), stress = $(chabmat.variables.stress)"
# stress = get_stress(0.25*dstrain_dtime)
# @info "stress = $stress"
D, dstress = Tensors.gradient(get_stress, 0.25*dstrain_dtime, :all)
@info "D = $(tovoigt(D))"
end
simple_integration_test_fd_tangent()
function simple_integration_test_fd_tangent2()
parameters = ChabocheParameterState(E = 200.0e3,
nu = 0.3,
R0 = 100.0,
Kn = 100.0,
nn = 10.0,
C1 = 10000.0,
D1 = 100.0,
C2 = 50000.0,
D2 = 1000.0,
Q = 50.0,
b = 0.1)
dstrain_dtime = fromvoigt(Symm2{Float64}, 1e-3*[1.0, -0.3, -0.3, 0.0, 0.0, 0.0]; offdiagscale=2.0)
ddrivers = ChabocheDriverState(time=0.25, strain=0.25*dstrain_dtime)
chabmat = Chaboche(parameters=parameters, ddrivers=ddrivers)
integrate_material!(chabmat)
update_material!(chabmat)
@info "time = $(chabmat.drivers.time), stress = $(chabmat.variables.stress)"
chabmat.ddrivers = ddrivers
integrate_material!(chabmat)
update_material!(chabmat)
@info "time = $(chabmat.drivers.time), stress = $(chabmat.variables.stress)"
chabmat.ddrivers = ddrivers
integrate_material!(chabmat)
g! = Materials.ChabocheModule.create_nonlinear_system_of_equations(chabmat)
x0 = [tovoigt(chabmat.variables_new.stress); chabmat.variables_new.R; tovoigt(chabmat.variables_new.X1); tovoigt(chabmat.variables_new.X2)]
drdx = ForwardDiff.jacobian(debang(g!), x0)
@info "size(drdx) = $(size(drdx))"
@info "drdx = $drdx"
@unpack E, nu, R0, Kn, nn, C1, D1, C2, D2, Q, b = parameters
mu = E/(2.0*(1.0+nu))
lambda = E*nu/((1.0+nu)*(1.0-2.0*nu))
jacobian = isotropic_elasticity_tensor(lambda, mu)
drde = zeros((19,6))
drde[1:6, 1:6] = -tovoigt(jacobian)
@info "drde = $drde"
@info "size(drde) = $(size(drde))"
jacobian2 = (drdx\drde)[1:6, 1:6]
@info "jacobian = $(tovoigt(jacobian))"
@info "jacobian2 = $jacobian2"
jacobian3 = (drdx[1:6, 1:6] + drdx[1:6,7:end]*(drdx[7:end,7:end]\-drdx[7:end, 1:6]))\drde[1:6, 1:6]
@info "jacobian3 = $jacobian3"
@info "jacobian4 = $(tovoigt(chabmat.variables_new.jacobian))"
update_material!(chabmat)
@info "time = $(chabmat.drivers.time), stress = $(chabmat.variables.stress)"
chabmat.ddrivers = ddrivers
integrate_material!(chabmat)
g! = Materials.ChabocheModule.create_nonlinear_system_of_equations(chabmat)
x0 = [tovoigt(chabmat.variables_new.stress); chabmat.variables_new.R; tovoigt(chabmat.variables_new.X1); tovoigt(chabmat.variables_new.X2)]
drdx = ForwardDiff.jacobian(debang(g!), x0)
@info "size(drdx) = $(size(drdx))"
@info "drdx = $drdx"
@unpack E, nu, R0, Kn, nn, C1, D1, C2, D2, Q, b = parameters
mu = E/(2.0*(1.0+nu))
lambda = E*nu/((1.0+nu)*(1.0-2.0*nu))
jacobian = isotropic_elasticity_tensor(lambda, mu)
drde = zeros((19,6))
drde[1:6, 1:6] = -tovoigt(jacobian)
@info "drde = $drde"
@info "size(drde) = $(size(drde))"
jacobian2 = (drdx\drde)[1:6, 1:6]
@info "jacobian = $(tovoigt(jacobian))"
@info "jacobian2 = $jacobian2"
jacobian3 = (drdx[1:6, 1:6] + drdx[1:6,7:end]*(drdx[7:end,7:end]\-drdx[7:end, 1:6]))\drde[1:6, 1:6]
@info "jacobian3 = $jacobian3"
@info "jacobian4 = $(tovoigt(chabmat.variables_new.jacobian))"
update_material!(chabmat)
@info "time = $(chabmat.drivers.time), stress = $(chabmat.variables.stress)"
end
simple_integration_test_fd_tangent2()
| Materials | https://github.com/JuliaFEM/Materials.jl.git |
|
[
"MIT"
] | 0.4.0 | d7a67c1c8ae6118f253a137ffa5291421e757a8a | code | 3697 | # This file is a part of JuliaFEM.
# License is MIT: see https://github.com/JuliaFEM/Materials.jl/blob/master/LICENSE
#
# Some performance benchmarks for the current design for AbstractMaterial.
mutable struct Variable{T}
value :: T
dvalue :: T
end
function Variable(x)
return Variable(x, zero(x))
end
reset!(v::Variable) = (v.dvalue = zero(v.value))
update!(v::Variable) = (v.value += v.dvalue; reset!(v))
update!(v::Variable{<:Array}) = v.value .+= v.dvalue
using Tensors
a = 1.0
b = [1.0, 2.0, 3.0]
c = Tensor{2, 3}([1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0, 9.0])
vara = Variable(a)
varb = Variable(b)
varc = Variable(c)
@info "Initial state: $vara"
vara.dvalue += rand()
@info "After setting dvalue: $vara"
update!(vara)
@info "After update!: $vara"
@info "Initial state: $varb"
varb.dvalue += rand(3)
@info "After setting dvalue: $varb"
update!(varb)
@info "After update!: $varb"
@info "Initial state: $varc"
varc.dvalue += Tensor{2,3}(rand(9))
@info "After setting dvalue: $varc"
update!(varc)
@info "After update!: $varc"
using BenchmarkTools
N = 1000
function bench_float64()
# Random walk test"
var = Variable(1.0)
for i in 1:N
var.dvalue += randn()
update!(var)
end
return var
end
function bench_array()
# Random walk test
var = Variable([1.0, 2.0, 3.0])
for i in 1:N
var.dvalue += randn(3)
update!(var)
end
return var
end
function bench_tensor()
# Random walk test
var = Variable(Tensor{2, 3}([1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0, 9.0]))
for i in 1:N
var.dvalue += randn(Tensor{2,3})
update!(var)
end
end
function bench_symtensor()
# Random walk test
var = Variable(Symm2([1.0, 2.0, 3.0, 4.0, 5.0, 6.0]))
for i in 1:N
var.dvalue += randn(Symm2{Float64})
update!(var)
end
end
# println("Benchmark Variable{Float64}")
# @btime bench_float64()
# println("Benchmark Variable{Array{Float64,1}}")
# @btime bench_array()
# println("Benchmark Variable{Tensor{2,3,Float64,9}}")
# @btime bench_tensor()
# println("Benchmark Variable{SymmetricTensor{2,3,Float64,6}}")
# @btime bench_symtensor()
abstract type AbstractVariableState end
mutable struct TestState <: AbstractVariableState
x :: Variable{Float64}
end
mutable struct VariableState <: AbstractVariableState
stress::Variable{SymmetricTensor{2,3,Float64,6}}
strain::Variable{SymmetricTensor{2,3,Float64,6}}
backstress1::Variable{SymmetricTensor{2,3,Float64,6}}
backstress2::Variable{SymmetricTensor{2,3,Float64,6}}
plastic_strain::Variable{SymmetricTensor{2,3,Float64,6}}
cumeq::Variable{Float64}
R::Variable{Float64}
end
function update!(state::T) where {T<:AbstractVariableState}
for fn in fieldnames(T)
update!(getfield(state, fn))
end
end
function bench_chaboche_style_variablestate()
stress = Variable(zero(Symm2))
strain = Variable(zero(Symm2))
backstress1 = Variable(zero(Symm2))
backstress2 = Variable(zero(Symm2))
plastic_strain = Variable(zero(Symm2))
cumeq = Variable(0.0)
R = Variable(0.0)
state = VariableState(stress, strain, backstress1,
backstress2, plastic_strain, cumeq, R)
for i in 1:N
state.stress.dvalue = randn(Symm2)
state.strain.dvalue = randn(Symm2)
state.backstress1.dvalue = randn(Symm2)
state.backstress2.dvalue = randn(Symm2)
state.plastic_strain.dvalue = randn(Symm2)
state.cumeq.dvalue = norm(state.plastic_strain.dvalue)
state.R.dvalue = randn()
update!(state)
end
return state
end
println("Benchmark Chaboche VariableState")
@btime bench_chaboche_style_variablestate()
| Materials | https://github.com/JuliaFEM/Materials.jl.git |
|
[
"MIT"
] | 0.4.0 | d7a67c1c8ae6118f253a137ffa5291421e757a8a | code | 2010 | # This file is a part of JuliaFEM.
# License is MIT: see https://github.com/JuliaFEM/Materials.jl/blob/master/LICENSE
#
# Some performance benchmarks for the current design for AbstractMaterialState.
using Tensors
using BenchmarkTools
abstract type AbstractMaterialState end
@generated function Base.:+(state::T, dstate::T) where {T <: AbstractMaterialState}
expr = [:(state.$p+ dstate.$p) for p in fieldnames(T)]
return :(T($(expr...)))
end
struct SomeState <: AbstractMaterialState
stress::Symm2{Float64}
end
state = SomeState(Symm2{Float64}([1.0, 2.0, 3.0, 4.0, 5.0, 6.0]))
N = 1000
function bench_state(N)
state = SomeState(Symm2{Float64}([1.0, 2.0, 3.0, 4.0, 5.0, 6.0]))
for i in 1:N
dstate = SomeState(randn(Symm2{Float64}))
state = state + dstate
end
return state
end
# println("Benchmark State{Symm2{Float64}}")
# @btime bench_state(N)
struct AnotherState <: AbstractMaterialState
stress::SymmetricTensor{2,3,Float64,6}
strain::SymmetricTensor{2,3,Float64,6}
backstress1::SymmetricTensor{2,3,Float64,6}
backstress2::SymmetricTensor{2,3,Float64,6}
plastic_strain::SymmetricTensor{2,3,Float64,6}
cumeq::Float64
R::Float64
end
function bench_chaboche_style_state(N)
stress = zero(Symm2)
strain = zero(Symm2)
backstress1 = zero(Symm2)
backstress2 = zero(Symm2)
plastic_strain = zero(Symm2)
cumeq = 0.0
R = 0.0
state = AnotherState(stress, strain, backstress1,
backstress2, plastic_strain, cumeq, R)
for i in 1:N
dstress = randn(Symm2)
dstrain = randn(Symm2)
dbackstress1 = randn(Symm2)
dbackstress2 = randn(Symm2)
dplastic_strain = randn(Symm2)
dcumeq = norm(dplastic_strain)
dR = randn()
dstate = AnotherState(dstress, dstrain, dbackstress1,
dbackstress2, dplastic_strain, dcumeq, dR)
state = state + dstate
end
return state
end
println("Benchmark Chaboche State")
@btime bench_chaboche_style_state(N)
| Materials | https://github.com/JuliaFEM/Materials.jl.git |
|
[
"MIT"
] | 0.4.0 | d7a67c1c8ae6118f253a137ffa5291421e757a8a | code | 6386 | # An example of the Chaboche material model using just 2-dimensional Arrays
# (no tensors or Materials.jl).
using LinearAlgebra
using Einsum
using Test
using NLsolve
using Plots
pyplot() # OLD BACKEND: plotly()
# Tensors
I_ = Matrix(1.0I,3,3) # Second order identity tensor
II = zeros(3,3,3,3)
@einsum II[i,j,k,l] = 0.5*(I_[i,k]*I_[j,l] + I_[i,l]*I_[j,k]) # Fourth order symmetric identity tensor
IxI = zeros(3,3,3,3)
@einsum IxI[i,j,k,l] = I_[i,j]*I_[k,l] # "Trace" tensor
P = II - 1/3*IxI # Deviatoric projection tensor
# Functions
function double_contraction(x::AbstractArray{<:Number,2},y::AbstractArray{<:Number,2})
return sum(x.*y)
end
function double_contraction(x::AbstractArray{<:Number,4},y::AbstractArray{<:Number,2})
retval = zeros(3,3)
@einsum retval[i,j] = x[i,j,k,l]*y[k,l]
return retval
end
A = rand(3,3) # Create Random second order tensor
A += A' # Symmetrize it
@test isapprox(double_contraction(II, A), A)
@test isapprox(double_contraction(IxI, A), I_*tr(A))
function deviator(x::AbstractArray{<:Number,2})
s = zeros(3,3)
@einsum s[i,j] = P[i,j,k,l]*x[k,l]
return s
end
function von_mises_stress(stress::AbstractArray{<:Number,2})
s = deviator(stress)
return sqrt(3/2*double_contraction(s,s))
end
S = [100 0 0; 0 0 0; 0 0 0]
@test isapprox(von_mises_stress(S), 100)
### Material parameters ###
# Isotropic elasticity: \dot{sigma} = \mathcal{C}:(\dot{\varepsilon}_{tot} - \dot{\varepsilon}_{pl})
E = 210000.0 # Young's modulus
nu = 0.3 # Poisson's ratio
K = E/(3*(1-2*nu)) # Bulk modulus
G = E/(2*(1+nu)) # Shear modulus
C = K*IxI + 2*G*P # Elasticity Tensor \mathcal{C}
@test isapprox(double_contraction(C, [0.001 0 0; 0 -nu*0.001 0; 0 0 -nu*0.001]), [E*0.001 0 0; 0 0 0; 0 0 0])
# Non-linear isotropic hardening: \dot{R} = b(Q-R)\dot{p}
# where \dot{p} = \sqrt{2/3 \dot{\varepsilon}_{pl}:\dot{\varepsilon}_{pl}}} - equivalent plastic strain rate
R0 = 100.0 # Initial proportionality limit
Q = 50.0 # Hardening magnitude
b = 0.1 # Hardening rate
# Non-linear kinematic hardening: \dot{X}_i = 2/3C_i\dot{p}(n - \frac{3D_i}{2C_i}X_i)
# where n = \frac{\partial f}{\partial \sigma} - plastic strain direction
# and X = \sum_{i=1}^N X_i
C_1 = 10000.0 # Slope parameter 1
D_1 = 100.0 # Rate parameter 1
C_2 = 50000.0 # Slope parameter 2
D_2 = 1000.0 # Rate parameter 2
# Viscoplasticity: Norton viscoplastic potential \phi = \frac{K_n}{n_n+1}\left( \frac{f}{K_n} \right)^{n_n+1}
# \dot{\varepsilon}_{pl} = \frac{\partial \phi}{\partial \sigma} = \frac{\partial \phi}{\partial f}\frac{\partial f}{\partial \sigma}
# => \dot{p} = \frac{\partial \phi}{\partial f} = \left( \frac{f}{K_n} \right)^n_n
# => n = \frac{\partial f}{\partial \sigma}
# => \dot{\varepsilon}_{pl} = \dot{p} n
K_n = 100.0 # Drag stress
n_n = 3.0 # Viscosity exponent
# Initialize variables
sigma = zeros(3,3)
R = R0
X_1 = zeros(3,3)
X_2 = zeros(3,3)
varepsilon_pl = zeros(3,3)
varepsilon_el = zeros(3,3)
t = 0.0
# Determine loading sequence
varepsilon_a = 0.01 # Strain amplitude
#varepsilon_tot(t) = sin(t)*[varepsilon_a 0 0; 0 -nu*varepsilon_a 0; 0 0 -nu*varepsilon_a]
dt = 0.01 # Time step
T0 = 1.0
T = 10.0 # Time span
# varepsilon_tot(t) = t/T*[varepsilon_a 0 0; 0 -nu*varepsilon_a 0; 0 0 -nu*varepsilon_a]
function varepsilon_tot(t)
if t<T0
return t/T0*[varepsilon_a 0 0; 0 -nu*varepsilon_a 0; 0 0 -nu*varepsilon_a]
else
return [varepsilon_a 0 0; 0 -nu*varepsilon_a 0; 0 0 -nu*varepsilon_a]
end
end
# Initialize result storage
ts = [t]
sigmas = [sigma]
Rs = [R]
X_1s = [X_1]
X_2s = [X_2]
varepsilon_pls = [varepsilon_pl]
varepsilon_els = [varepsilon_el]
# Time integration
while t < T
global t, sigma, R, X_1, X_2, varepsilon_pl, varepsilon_el, ts, sigmas, Rs, X_1s, X2_s, varepsilon_pls, varepsilon_els
global C, K_n, n_n, C_1, D_1, C_2, D_2, Q, b
# Store initial state
sigma_n = sigma
R_n = R
X_1n = X_1
X_2n = X_2
varepsilon_pln = varepsilon_pl
varepsilon_eln = varepsilon_el
t_n = t
# Increments
t = t + dt
dvarepsilon_tot = varepsilon_tot(t) - varepsilon_tot(t_n)
# Elastic trial
sigma_tr = sigma_n + double_contraction(C, dvarepsilon_tot)
# Check for yield
f_tr = von_mises_stress(sigma_tr - X_1 - X_2) - R
println("***************************************")
if f_tr <= 0 # Elastic step
# Update variables
println("Elastic step!")
sigma = sigma_tr
varepsilon_el += dvarepsilon_tot
else # Viscoplastic step
println("Viscoplastic step!")
function g!(F, x) # System of non-linear equations
sigma = reshape(x[1:9], 3,3)
R = x[10]
X_1 = reshape(x[11:19], 3,3)
X_2 = reshape(x[20:28], 3,3)
dotp = ((von_mises_stress(sigma - X_1 - X_2) - R)/K_n)^n_n
dp = dotp*dt
s = deviator(sigma - X_1 - X_2)
n = 3/2*s/von_mises_stress(sigma - X_1 - X_2)
dvarepsilon_pl = dp*n
f1 = vec(sigma_n - sigma + double_contraction(C, dvarepsilon_tot - dvarepsilon_pl))
f2 = R_n - R + b*(Q-R)*dp
f3 = vec(X_1n - X_1 + 2/3*C_1*dp*(n - 3*D_1/(2*C_1)*X_1))
f4 = vec(X_2n - X_2 + 2/3*C_2*dp*(n - 3*D_2/(2*C_2)*X_2))
F[:] = vec([f1; f2; f3; f4])
end
x0 = vec([vec(sigma_tr); R; vec(X_1); vec(X_2)])
F = similar(x0)
res = nlsolve(g!, x0)
x = res.zero
sigma = reshape(x[1:9],3,3)
R = x[10]
X_1 = reshape(x[11:19], 3,3)
X_2 = reshape(x[20:28], 3,3)
dotp = ((von_mises_stress(sigma - X_1 - X_2) - R)/K_n)^n_n
dp = dotp*dt
s = deviator(sigma - X_1 - X_2)
n = 3/2*s/von_mises_stress(sigma - X_1 - X_2)
dvarepsilon_pl = dp*n
varepsilon_pl += dvarepsilon_pl
varepsilon_el += dvarepsilon_tot - dvarepsilon_pl
end
# Store variables
push!(ts, t)
push!(sigmas, sigma)
push!(Rs, R)
push!(X_1s, X_1)
push!(X_2s, X_2)
push!(varepsilon_pls, varepsilon_pl)
push!(varepsilon_els, varepsilon_el)
end
qs = [von_mises_stress(sigma_i) for sigma_i in sigmas]
ps = [tr(sigma_i)/3 for sigma_i in sigmas]
xs = [von_mises_stress(X_1s[i] + X_2s[i]) for i in 1:length(ts)]
plot(ps, qs, label="Stress")
plot!(ps, xs+Rs, label="Static yield surface")
xlabel!("Hydrostatic stress")
ylabel!("Von Mises stress")
| Materials | https://github.com/JuliaFEM/Materials.jl.git |
|
[
"MIT"
] | 0.4.0 | d7a67c1c8ae6118f253a137ffa5291421e757a8a | code | 42802 | # This file is a part of JuliaFEM.
# License is MIT: see https://github.com/JuliaFEM/Materials.jl/blob/master/LICENSE
using Printf
using Tensors
using Plots
using Test
using DelimitedFiles
using Materials
pyplot()
let
# https://rosettacode.org/wiki/Align_columns#Julia
# left/right/center justification of strings:
ljust(s::String, width::Integer) = s * " "^max(0, width - length(s))
# rjust(s::String, width::Integer) = " "^max(0, width - length(s)) * s
# function center(s::String, width::Integer)
# pad = width - length(s)
# if pad <= 0
# return s
# else
# pad2 = div(pad, 2)
# return " "^pad2 * s * " "^(pad - pad2)
# end
# end
""" format_numbers(xx::Array{<:Real})
Format a rank-1 array of numbers to "%0.6g", align the ones column, and pad to the same length.
Return a rank-1 array of the resulting strings.
"""
function format_numbers(xx::Array{<:Real}) # TODO: extend to handle complex numbers, too
# - real numbers x for which |x| < 1 always have "0." at the start
# - e-notation always has a dot
function find_ones_column(s::String)
dot_column = findfirst(".", s)
ones_column = (dot_column !== nothing) ? (dot_column[1] - 1) : length(s)
@assert (ones_column isa Integer) "failed to detect column for ones"
return ones_column
end
ss = [@sprintf("%0.6g", x) for x in xx]
ones_columns = [find_ones_column(s) for s in ss]
ones_target_column = maximum(ones_columns)
left_pads = ones_target_column .- ones_columns
@assert all(p >= 0 for p in left_pads) "negative padding length"
ss = [" "^p * s for (s, p) in zip(ss, left_pads)]
max_length = maximum(length(s) for s in ss)
ss = [ljust(s, max_length) for s in ss]
return ss
end
function constant(value::Real)
function interpolate(x::Real)
# `x` may be a `ForwardDiff.Dual` even when `value` is a float.
return convert(typeof(x), value)
end
return interpolate
end
function capped_linear(x1::Real, y1::Real, x2::Real, y2::Real)
if x1 > x2
x1, x2 = x2, x1
y1, y2 = y2, y1
end
dx = x2 - x1
dx > 0 || error("must have x2 > x1")
dy = y2 - y1
function interpolate(x::Real)
alpha = (x - x1) / dx
alpha = max(0, min(alpha, 1))
return y1 + alpha * dy
end
return interpolate
end
"""Celsius to Kelvin."""
function K(degreesC::Real)
return degreesC + 273.15
end
"""Kelvin to Celsius."""
function degreesC(K::Real)
return K - 273.15
end
let T0 = K(20.0),
T1 = K(620.0),
# Thermal elongation, Eurocode, SFS-EN 1993-1-2, carbon steel
# 1.2e-5 * T[C°] + 0.4e-8 * T[C°]^2 - 2.416e-4
# α is the derivative of this.
#
# using SymPy
# @vars T real=true
# thermal_elongation = 1.2e-5 * T + 0.4e-8 * T^2 - 2.416e-4
# alpha = diff(thermal_elongation, T)
# alpha0 = subs(alpha, (T, 20)) # 1.216e-5
# alpha1 = subs(alpha, (T, 600)) # 1.680e-5
#
# See also:
# https://www.engineeringtoolbox.com/linear-expansion-coefficients-d_95.html
parameters = ChabocheThermalParameterState(theta0=T0,
E=capped_linear(T0, 200.0e3, T1, 100.0e3),
#nu=capped_linear(T0, 0.3, T1, 0.35),
nu=constant(0.3),
#alpha=capped_linear(T0, 1.216e-5, T1, 1.680e-5),
alpha=constant(1.216e-5),
R0=capped_linear(T0, 100.0, T1, 50.0),
# R0=constant(1000.0),
# viscous hardening in constant strain rate test: (tvp * ε')^(1/nn) * Kn
tvp=1000.0,
Kn=capped_linear(T0, 100.0, T1, 50.0),
nn=capped_linear(T0, 1.0, T1, 4.0),
# C1=constant(10000.0),
# D1=constant(100.0),
# C2=constant(50000.0),
# D2=constant(1000.0),
C1=constant(1000.0),
D1=constant(10.0),
C2=constant(0.0),
D2=constant(0.0),
C3=constant(0.0),
D3=constant(0.0),
# Q=capped_linear(T0, 50.0, T1, 10.0),
# b=capped_linear(T0, 100.0, T1, 0.01)),
Q=constant(0.0),
b=constant(0.0)),
# uniaxial pull test, so we set only dε11.
# stress_rate=10.0, # dσ/dt [MPa/s] (for stress-driven test)
strain_rate=1e-3, # dε/dt [1/s] (for strain-driven test)
strain_final=0.005, # when to stop the pull test
dt=0.05, # simulation timestep, [s]
# dstress11 = stress_rate * dt, # dσ11 during one timestep (stress-driven)
dstrain11 = strain_rate * dt, # dε11 during one timestep (strain-driven)
n_timesteps = Integer(round(strain_final / dstrain11)),
#constant_temperatures = range(T0, T1, length=3),
constant_temperatures = [K(20.0), K(150.0), K(300.0), K(620.0)],
timevar_temperature = range(T0, T0 + 130, length=n_timesteps + 1)
# TODO: Improve the plotting to use two separate figures so that we can plot these examples too
# TODO: (without making individual plots too small).
# TODO: Plots.jl can't currently do that; investigate whether the underlying PyPlot.jl can.
# p1 = plot() # make empty figure
#
#
# # --------------------------------------------------------------------------------
# # constant temperature, constant strain rate pull test
#
# println("Constant temperature tests")
# for T in constant_temperatures
# println("T = $(degreesC(T))°C")
# mat = ChabocheThermal(parameters=parameters)
# mat.drivers.temperature = T
# mat.ddrivers.temperature = 0
# stresses = [mat.variables.stress[1,1]]
# strains = [mat.drivers.strain[1,1]]
# for i in 1:n_timesteps
# uniaxial_increment!(mat, dstrain11, dt)
# # stress_driven_uniaxial_increment!(mat, dstress11, dt)
# update_material!(mat)
# push!(strains, mat.drivers.strain[1,1])
# push!(stresses, mat.variables.stress[1,1])
# end
# println(" ε11, σ11, at end of simulation")
# println(" $(strains[end]), $(stresses[end])")
# plot!(strains, stresses, label="\$\\sigma(\\varepsilon)\$ @ \$$(degreesC(T))°C\$")
# end
#
#
# # --------------------------------------------------------------------------------
# # varying temperature, constant strain rate pull test
#
# println("Time-varying temperature tests (activates ΔT terms)")
# println("T = $(degreesC(timevar_temperature[1]))°C ... $(degreesC(timevar_temperature[end]))°C, linear profile.")
# mat = ChabocheThermal(parameters=parameters)
# stresses = [mat.variables.stress[1,1]]
# strains = [mat.drivers.strain[1,1]]
# temperature_pairs = zip(timevar_temperature, timevar_temperature[2:end])
# for (Tcurr, Tnext) in temperature_pairs
# # println(" Tcurr = $(degreesC(Tcurr))°C, Tnext = $(degreesC(Tnext))°C, ΔT = $(Tnext - Tcurr)°C")
# mat.drivers.temperature = Tcurr
# mat.ddrivers.temperature = Tnext - Tcurr
# uniaxial_increment!(mat, dstrain11, dt)
# # stress_driven_uniaxial_increment!(mat, dstress11, dt)
# update_material!(mat)
# push!(strains, mat.drivers.strain[1,1])
# push!(stresses, mat.variables.stress[1,1])
# end
# println(" ε11, σ11, at end of simulation")
# println(" $(strains[end]), $(stresses[end])")
# plot!(strains, stresses, label="\$\\sigma(\\varepsilon)\$ @ $(degreesC(timevar_temperature[1]))°C ... $(degreesC(timevar_temperature[end]))°C")
#
# xlabel!("\$\\varepsilon\$")
# ylabel!("\$\\sigma\$")
# title!("Uniaxial pull test (strain-driven)")
#
#
# # --------------------------------------------------------------------------------
# # cyclic temperature/strain
# #
# # - boomerang/fan in elastic region, no hysteresis
# # - check that the endpoint stays the same
# # - It doesn't when temperature effects are enabled; linearly dt-dependent drift; from the integrator?
#
# println("Elastic behavior under cyclic loading")
# function halfcycle(x0, x1, n)
# return x0 .+ (x1 - x0) .* range(0, 1, length=n)
# end
# function cycle(x0, x1, halfn) # 2 * halfn - 1 steps in total (duplicate at middle omitted)
# return cat(halfcycle(x0, x1, halfn),
# halfcycle(x1, x0, halfn)[2:end],
# dims=1)
# end
#
# strain_rate = 1e-4 # uniaxial constant strain rate, [1/s]
# cycle_time = 10.0 # one complete cycle, [s]
# ncycles = 20
# n = 201 # points per half-cycle (including endpoints; so n - 1 timesteps per half-cycle)
#
# Ta = T0 # temperature at cycle start, [K]
# Tb = K(50.0) # temperature at maximum strain (at cycle halfway point), [K]
#
# # Observe that:
# strain_max = strain_rate * (cycle_time / 2)
# dt = cycle_time / (2 * (n - 1))
#
# description = "$(ncycles) cycles, εₘₐₓ = $(strain_max), Ta = $(degreesC(Ta))°C, Tb = $(degreesC(Tb))°C"
# println(" $(description)")
# mat = ChabocheThermal(parameters=parameters)
# stresses = [mat.variables.stress[1,1]]
# strains = [mat.drivers.strain[1,1]]
# temperatures = cycle(Ta, Tb, n)
# temperature_pairs = zip(temperatures, temperatures[2:end])
# dstrain11 = strain_rate * dt # = strain_rate * (cycle_time / 2) / (n - 1) = strain_max / (n - 1)
# dstrain11s = cat(repeat([dstrain11], n - 1),
# repeat([-dstrain11], n - 1),
# dims=1)
# for cycle in 1:ncycles
# cycle_str = @sprintf("%02d", cycle)
# println(" start cycle $(cycle_str), ε11 = $(strains[end]), σ11 = $(stresses[end])")
# for ((Tcurr, Tnext), dstrain) in zip(temperature_pairs, dstrain11s)
# mat.drivers.temperature = Tcurr
# mat.ddrivers.temperature = Tnext - Tcurr
# uniaxial_increment!(mat, dstrain, dt)
# # stress_driven_uniaxial_increment!(mat, dstress11, dt)
# update_material!(mat)
# push!(strains, mat.drivers.strain[1,1])
# push!(stresses, mat.variables.stress[1,1])
# end
# end
# println(" ε11, σ11, at end of simulation")
# println(" $(strains[end]), $(stresses[end])")
# # println(" $(mat.variables.plastic_strain[end])")
# p2 = plot(strains, stresses, label="\$\\sigma(\\varepsilon)\$")
#
# # plot!(xx2, yy2, label="...") # to add new curves into the same figure
# xlabel!("\$\\varepsilon\$")
# ylabel!("\$\\sigma\$")
# title!("Elastic test, $(description)")
#
#
# # --------------------------------------------------------------------------------
# # non-symmetric cyclic loading
# #
# # Strain-driven case. Should exhibit stress relaxation.
#
# println("Non-symmetric strain cycle")
# strain_rate = 1e-3 # uniaxial constant strain rate, [1/s]
# cycle_time = 5.0 # one complete cycle, [s]
# ncycles = 20
# n = 51 # points per half-cycle (including endpoints; so n - 1 timesteps per half-cycle)
#
# Ta = T0 # temperature at simulation start, [K]
# Tb = K(50.0) # temperature at maximum strain (at cycle halfway point), [K]
# Tm = Ta + (Tb - Ta) / 2 # temperature at start of each cycle, [K]
#
# strain_max = strain_rate * cycle_time # accounting for initial loading, too.
# dt = cycle_time / (2 * (n - 1))
#
# description = "$(ncycles) cycles, εₘₐₓ = $(strain_max), Ta = $(degreesC(Ta))°C, Tb = $(degreesC(Tb))°C"
# println(" $(description)")
# mat = ChabocheThermal(parameters=parameters) # TODO: always use the AF model here (one backstress).
# stresses = [mat.variables.stress[1,1]]
# strains = [mat.drivers.strain[1,1]]
#
# # initial loading
# temperatures = halfcycle(Ta, Tm, n)
# temperature_pairs = zip(temperatures, temperatures[2:end])
# dstrain11 = strain_rate * dt
# dstrain11s = repeat([dstrain11], n - 1)
#
# for ((Tcurr, Tnext), dstrain) in zip(temperature_pairs, dstrain11s)
# mat.drivers.temperature = Tcurr
# mat.ddrivers.temperature = Tnext - Tcurr
# uniaxial_increment!(mat, dstrain, dt)
# # stress_driven_uniaxial_increment!(mat, dstress11, dt)
# update_material!(mat)
# push!(strains, mat.drivers.strain[1,1])
# push!(stresses, mat.variables.stress[1,1])
# end
#
# # cycles
# eps0 = strains[end] # for marking the start of the first cycle in the figure
# sig0 = stresses[end]
# temperatures = cycle(Tm, Tb, n)
# temperature_pairs = zip(temperatures, temperatures[2:end])
# dstrain11 = strain_rate * dt
# dstrain11s = cat(repeat([dstrain11], n - 1),
# repeat([-dstrain11], n - 1),
# dims=1)
# cycle_midpoint = n - 1
#
# for cycle in 1:ncycles
# cycle_str = @sprintf("%02d", cycle)
# println(" cycle $(cycle_str)")
# data_to_print = []
# for (k, ((Tcurr, Tnext), dstrain)) in enumerate(zip(temperature_pairs, dstrain11s))
# if k == 1 || k == cycle_midpoint
# push!(data_to_print, (strains[end], stresses[end]))
# end
#
# mat.drivers.temperature = Tcurr
# mat.ddrivers.temperature = Tnext - Tcurr
# uniaxial_increment!(mat, dstrain, dt)
# # stress_driven_uniaxial_increment!(mat, dstress11, dt)
# update_material!(mat)
# push!(strains, mat.drivers.strain[1,1])
# push!(stresses, mat.variables.stress[1,1])
# end
#
# strains_to_print, stresses_to_print = (collect(col) for col in zip(data_to_print...))
# strains_to_print = format_numbers(strains_to_print)
# stresses_to_print = format_numbers(stresses_to_print)
# println(" start ε11 = $(strains_to_print[1]), σ11 = $(stresses_to_print[1])")
# println(" midpoint ε11 = $(strains_to_print[2]), σ11 = $(stresses_to_print[2])")
# end
#
# p3 = plot(strains, stresses, label="\$\\sigma(\\varepsilon)\$")
# scatter!([eps0], [sig0], markercolor=:blue, label="First cycle start")
# xlabel!("\$\\varepsilon\$")
# ylabel!("\$\\sigma\$")
# title!("Non-symmetric strain cycle, $(ncycles) cycles")
#
#
# # --------------------------------------------------------------------------------
# # stress-driven non-symmetric cycle
# #
# # - AF (Chaboche with one kinematic hardening backstress) should lead to constant
# # ratcheting strain per stress cycle.
#
# println("Non-symmetric stress cycle")
# stress_rate = 40.0 # uniaxial constant stress rate, [MPa/s]
# cycle_time = 5.0 # one complete cycle, [s]
# ncycles = 40
# n = 51 # points per half-cycle (including endpoints; so n - 1 timesteps per half-cycle)
#
# Ta = T0 # temperature at simulation start, [K]
# Tb = K(50.0) # temperature at maximum strain (at cycle halfway point), [K]
# Tm = Ta + (Tb - Ta) / 2 # temperature at start of each cycle, [K]
#
# strain_max = strain_rate * cycle_time # accounting for initial loading, too.
# dt = cycle_time / (2 * (n - 1))
#
# description = "$(ncycles) cycles, εₘₐₓ = $(strain_max), Ta = $(degreesC(Ta))°C, Tb = $(degreesC(Tb))°C"
# println(" $(description)")
# mat = ChabocheThermal(parameters=parameters) # TODO: always use the AF model here (one backstress).
# stresses = [mat.variables.stress[1,1]]
# strains = [mat.drivers.strain[1,1]]
#
# # initial loading
# temperatures = halfcycle(Ta, Tm, n)
# temperature_pairs = zip(temperatures, temperatures[2:end])
# dstress11 = stress_rate * dt
# dstress11s = repeat([dstress11], n - 1)
#
# for ((Tcurr, Tnext), dstress) in zip(temperature_pairs, dstress11s)
# mat.drivers.temperature = Tcurr
# mat.ddrivers.temperature = Tnext - Tcurr
# stress_driven_uniaxial_increment!(mat, dstress, dt)
# update_material!(mat)
# push!(strains, mat.drivers.strain[1,1])
# push!(stresses, mat.variables.stress[1,1])
# end
#
# # cycles
# eps0 = strains[end]
# sig0 = stresses[end]
# temperatures = cycle(Tm, Tb, n)
# temperature_pairs = zip(temperatures, temperatures[2:end])
# dstress11 = stress_rate * dt
# dstress11s = cat(repeat([dstress11], n - 1),
# repeat([-dstress11], n - 1),
# dims=1)
# cycle_midpoint = n - 1
#
# cycle_start_strains = convert(Array{Float64}, []) # TODO: what's the julianic way to do this?
# for cycle in 1:ncycles
# cycle_str = @sprintf("%02d", cycle)
# println(" cycle $(cycle_str)")
# push!(cycle_start_strains, strains[end])
# data_to_print = []
# for (k, ((Tcurr, Tnext), dstress)) in enumerate(zip(temperature_pairs, dstress11s))
# if k == 1 || k == cycle_midpoint
# push!(data_to_print, (strains[end], stresses[end]))
# end
#
# mat.drivers.temperature = Tcurr
# mat.ddrivers.temperature = Tnext - Tcurr
# stress_driven_uniaxial_increment!(mat, dstress, dt)
# update_material!(mat)
# push!(strains, mat.drivers.strain[1,1])
# push!(stresses, mat.variables.stress[1,1])
# end
#
# strains_to_print, stresses_to_print = (collect(col) for col in zip(data_to_print...))
# strains_to_print = format_numbers(strains_to_print)
# stresses_to_print = format_numbers(stresses_to_print)
# println(" start ε11 = $(strains_to_print[1]), σ11 = $(stresses_to_print[1])")
# println(" midpoint ε11 = $(strains_to_print[2]), σ11 = $(stresses_to_print[2])")
# end
#
# println("Strain at cycle start:")
# cycle_start_strains_to_print = format_numbers(cycle_start_strains)
# diffs = diff(cycle_start_strains)
# diffs_to_print = cat([nothing], format_numbers(diffs), dims=1)
# for (cycle, (strain, dstrain)) in enumerate(zip(cycle_start_strains_to_print, diffs))
# cycle_str = @sprintf("%02d", cycle)
# println(" cycle $(cycle_str), ε11 = $(strain), Δε11 w.r.t. previous cycle = $(dstrain)")
# end
#
# p4 = plot(strains, stresses, label="\$\\sigma(\\varepsilon)\$")
# scatter!([eps0], [sig0], markercolor=:blue, label="First cycle start")
# xlabel!("\$\\varepsilon\$")
# ylabel!("\$\\sigma\$")
# title!("Non-symmetric stress cycle, $(ncycles) cycles")
#
#
# # --------------------------------------------------------------------------------
# # TODO:
# # - more tests based on Bari's thesis
# # - we need to implement pure plasticity (compute dotp from the consistency condition)
# # in order to compare to Bari's results.
# #
# # 1 ksi = 6.8947572932 MPa
# #
# # From Bari's thesis, paper 1, p. 25 (PDF page 31):
# #
# # E = 26300 ksi = 181332.11681116 MPa
# # ν = 0.302
# # σ₀ = 18.8 ksi = 129.62143711216 MPa (initial yield)
# # C₁ = 60000 ksi = 413685.437592 MPa
# # C₂ = 12856 ksi = 88638.9997613792 MPa
# # C₃ = 455 ksi = 3137.1145684059998 MPa
# # γ₁ = 20000 (D₁ in Materials.jl)
# # γ₂ = 800
# # γ₃ = 9
# #
# # From the article text and figure captions, these values seem to be for CS1026 steel.
# #
# # c = 6.8947572932 # MPa/ksi
# # parameters = ChabocheThermalParameterState(theta0=T0,
# # E=constant(26300*c),
# # nu=constant(0.302),
# # alpha=constant(1.216e-5), # not used in tests based on Bari
# # R0=constant(18.8*c),
# # # viscous hardening in constant strain rate test: (tvp * ε')^(1/nn) * Kn
# # tvp=1000.0,
# # Kn=constant(0.0), # TODO
# # nn=constant(0.0), # TODO
# # C1=constant(60000*c),
# # D1=constant(20000),
# # C2=constant(12856*c),
# # D2=constant(800),
# # C3=constant(455*c),
# # D3=constant(9),
# # Q=constant(0.0),
# # b=constant(0.0))
#
# # --------------------------------------------------------------------------------
# # plot the results
#
# # https://docs.juliaplots.org/latest/layouts/
# plot(p1, p2, p3, p4, layout=(2, 2))
# Abaqus as reference point. Data provided by Joona.
# The data describes a strain-driven uniaxial cyclic push-pull test in the 22 direction.
# let path = joinpath("test_chabochethermal", "cyclic_notherm",
# "chabochethermal_cyclic_test_nktherm.rpt"),
let path = joinpath("test_chabochethermal", "chabochethermal_cyclic_test_no_autostep.rpt"),
data = readdlm(path, Float64; skipstart=4),
ts = data[:, 1],
e11_ = data[:, 2], # note Abaqus component ordering
e12_ = data[:, 3],
e13_ = data[:, 4],
e22_ = data[:, 5],
e23_ = data[:, 6],
e33_ = data[:, 7],
s11_ = data[:, 8],
s12_ = data[:, 9],
s13_ = data[:, 10],
s22_ = data[:, 11],
s23_ = data[:, 12],
s33_ = data[:, 13],
cumeq_ = data[:, 14],
temperature_ = data[:, 15],
# note our component ordering (standard Voigt)
strains = [[e11_[i], e22_[i], e33_[i], e23_[i], e13_[i], e12_[i]] for i in 1:length(ts)],
stresses = [[s11_[i], s22_[i], s33_[i], s23_[i], s13_[i], s12_[i]] for i in 1:length(ts)],
T0 = K(23.0),
T1 = K(400.0),
# original test
parameters = ChabocheThermalParameterState(theta0=T0,
E=capped_linear(T0, 200.0e3, T1, 120.0e3),
nu=capped_linear(T0, 0.3, T1, 0.45),
alpha=capped_linear(K(0.0), 1.0e-5, T1, 1.5e-5),
R0=capped_linear(T0, 100.0, T1, 50.0),
# viscous hardening in constant strain rate test: (tvp * ε')^(1/nn) * Kn
tvp=1.0,
Kn=capped_linear(T0, 50.0, T1, 250.0),
nn=capped_linear(T0, 10.0, T1, 3.0),
C1=capped_linear(T0, 100000.0, T1, 20000.0),
D1=constant(1000.0),
C2=capped_linear(T0, 10000.0, T1, 2000.0),
D2=constant(100.0),
C3=capped_linear(T0, 1000.0, T1, 200.0),
D3=constant(10.0),
Q=capped_linear(T0, 100.0, T1, 50.0),
b=capped_linear(T0, 50.0, T1, 10.0)),
# # DEBUG: notherm test data
# parameters = ChabocheThermalParameterState(theta0=T0,
# E=constant(200.0e3),
# nu=constant(0.3),
# alpha=constant(1.0e-5),
# R0=constant(100.0),
# tvp=1.0,
# Kn=constant(50.0),
# nn=constant(10.0),
# C1=constant(100000.0),
# D1=constant(1000.0),
# C2=constant(10000.0),
# D2=constant(100.0),
# C3=constant(1000.0),
# D3=constant(10.0),
# Q=constant(100.0),
# b=constant(50.0)),
# # DEBUG: ctherm test data
# parameters = ChabocheThermalParameterState(theta0=T0,
# E=constant(200.0e3),
# nu=constant(0.3),
# alpha=constant(1.0e-5),
# R0=constant(100.0),
# tvp=1.0,
# Kn=constant(50.0),
# nn=constant(10.0),
# C1=capped_linear(T0, 100000.0, T1, 20000.0),
# D1=constant(1000.0),
# C2=capped_linear(T0, 10000.0, T1, 2000.0),
# D2=constant(100.0),
# C3=capped_linear(T0, 1000.0, T1, 200.0),
# D3=constant(10.0),
# Q=constant(100.0),
# b=constant(50.0)),
# # DEBUG: nktherm test data
# parameters = ChabocheThermalParameterState(theta0=T0,
# E=constant(200.0e3),
# nu=constant(0.3),
# alpha=constant(1.0e-5),
# R0=constant(100.0),
# tvp=1.0,
# Kn=capped_linear(T0, 50.0, T1, 250.0),
# nn=capped_linear(T0, 10.0, T1, 3.0),
# C1=constant(100000.0),
# D1=constant(1000.0),
# C2=constant(10000.0),
# D2=constant(100.0),
# C3=constant(1000.0),
# D3=constant(10.0),
# Q=constant(100.0),
# b=constant(50.0)),
# # DEBUG: rqbtherm test data
# parameters = ChabocheThermalParameterState(theta0=T0,
# E=constant(200.0e3),
# nu=constant(0.3),
# alpha=constant(1.0e-5),
# R0=capped_linear(T0, 100.0, T1, 50.0),
# tvp=1.0,
# Kn=constant(50.0),
# nn=constant(10.0),
# C1=constant(100000.0),
# D1=constant(1000.0),
# C2=constant(10000.0),
# D2=constant(100.0),
# C3=constant(1000.0),
# D3=constant(10.0),
# Q=capped_linear(T0, 100.0, T1, 50.0),
# b=capped_linear(T0, 50.0, T1, 10.0)),
mat = ChabocheThermal(parameters=parameters)
time_pairs = zip(ts, ts[2:end])
strain_pairs = zip(strains, strains[2:end])
stress_pairs = zip(stresses, stresses[2:end])
thetas = [K(celsius) for celsius in temperature_]
temperature_pairs = zip(thetas, thetas[2:end])
# print(count(dt -> dt < 0.001, diff(ts)))
ts_output = [copy(mat.drivers.time)]
es = [copy(mat.drivers.strain)]
ss = [copy(mat.variables.stress)]
X1s = [copy(mat.variables.X1)]
X2s = [copy(mat.variables.X2)]
X3s = [copy(mat.variables.X3)]
Rs = [copy(mat.variables.R)]
flags = [false] # plastic response activation flag (computed from output)
for (step, ((tcurr_, tnext_), (Tcurr_, Tnext_), (ecurr_, enext_), (scurr_, snext_))) in enumerate(zip(time_pairs,
temperature_pairs,
strain_pairs,
stress_pairs))
print("$(step) out of $(length(time_pairs)), t = $(tcurr_)...\n")
cumeq_old = mat.variables.cumeq # for plastic response activation detection
dtime_ = tnext_ - tcurr_
dtemperature_ = Tnext_ - Tcurr_
dstrain_ = enext_ - ecurr_
dstress_ = snext_ - scurr_
if dtime_ < 1e-8
print(" zero Δt in input data, skipping\n")
continue
end
# Use a smaller timestep internally and gather results every N timesteps.
# We have just backward Euler for now, so the integrator is not very accurate.
# TODO: We offer this substepping possibility to obtain higher accuracy.
# TODO: We don't know what Abaqus internally does here when autostep is on.
# TODO: Likely, it uses some kind of error indicator and adapts the
# TODO: timestep size based on that.
# TODO: Should disable autostep and recompute the Abaqus reference results, so that we can be sure of what the results mean.
N = 1
for substep in 1:N
tcurr = tcurr_ + ((substep - 1) / N) * dtime_
tnext = tcurr_ + (substep / N) * dtime_
Tcurr = Tcurr_ + ((substep - 1) / N) * dtemperature_
Tnext = Tcurr_ + (substep / N) * dtemperature_
ecurr = ecurr_ + ((substep - 1) / N) * dstrain_
enext = ecurr_ + (substep / N) * dstrain_
scurr = scurr_ + ((substep - 1) / N) * dstress_
snext = scurr_ + (substep / N) * dstress_
dtime = tnext - tcurr
dtemperature = Tnext - Tcurr
mat.drivers.temperature = Tcurr # value at start of timestep
mat.ddrivers.time = dtime
mat.ddrivers.temperature = dtemperature
# # For reference only:
# # This is how we would use the whole strain tensor from the Abaqus data as driver.
# #
# dstrain = enext - ecurr
# mat.ddrivers.strain = fromvoigt(Symm2{Float64}, dstrain, offdiagscale=2.0)
# integrate_material!(mat)
# This one is the actual test setup.
# Strain-driven uniaxial pull test in 22 direction, using only ε22 data as driver.
#
# note: our component ordering (Julia's standard Voigt)
dstrain22 = (enext - ecurr)[2]
dstrain_knowns = [missing, dstrain22, missing, missing, missing, missing]
dstrain_initialguess = [-dstrain22 * mat.parameters.nu(Tcurr),
dstrain22,
-dstrain22 * mat.parameters.nu(Tcurr),
0.0, 0.0, 0.0]
general_increment!(mat, dstrain_knowns, dt, dstrain_initialguess)
# # For reference only:
# # This is how we would do this for a stress-driven test, using the σ22 data as driver.
# #
# # note: our component ordering (Julia's standard Voigt)
# dstress22 = (snext - scurr)[2]
# dstress_knowns = [missing, dstress22, missing, missing, missing, missing]
# dstrain22_initialguess = dstress22 / mat.parameters.E(Tcurr)
# dstrain_initialguess = [-dstrain22_initialguess * mat.parameters.nu(Tcurr),
# dstrain22_initialguess,
# -dstrain22_initialguess * mat.parameters.nu(Tcurr),
# 0.0, 0.0, 0.0]
# stress_driven_general_increment!(mat, dstress_knowns, dt, dstrain_initialguess)
update_material!(mat)
end
push!(ts_output, tnext_)
push!(es, copy(mat.drivers.strain))
push!(ss, copy(mat.variables.stress))
push!(X1s, copy(mat.variables.X1))
push!(X2s, copy(mat.variables.X2))
push!(X3s, copy(mat.variables.X3))
push!(Rs, copy(mat.variables.R))
plastic_active = (mat.variables.cumeq != cumeq_old)
push!(flags, plastic_active)
end
# print("reference\n")
# print(e33_)
# print("\nresult\n")
# print(e33s)
# @test isapprox(e33s, e33_; rtol=0.05)
# ------------------------------------------------------------
current_run = Int64[]
runs = Array{typeof(current_run), 1}()
if flags[1] # signal may be "on" at start
push!(current_run, 1)
end
for (k, (flag1, flag2)) in enumerate(zip(flags, flags[2:end]))
if flag2 && !flag1 # signal switches on in this interval
@assert length(current_run) == 0
push!(current_run, k + 1) # run starts at the edge where the signal is "on"
elseif flag1 && !flag2 # signal switches off in this interval
@assert length(current_run) == 1
push!(current_run, k) # run ends at the edge where the signal was last "on"
push!(runs, current_run)
current_run = Int64[]
end
end
if flags[end] # signal may be "on" at end
push!(current_run, length(flags))
push!(runs, current_run)
current_run = Int64[]
end
@assert length(current_run) == 0
# ------------------------------------------------------------
e11s = [strain[1,1] for strain in es]
e22s = [strain[2,2] for strain in es]
s11s = [stress[1,1] for stress in ss]
s22s = [stress[2,2] for stress in ss]
X1_11s = [X1[1,1] for X1 in X1s]
X1_22s = [X1[2,2] for X1 in X1s]
X2_11s = [X2[1,1] for X2 in X2s]
X2_22s = [X2[2,2] for X2 in X2s]
X3_11s = [X3[1,1] for X3 in X3s]
X3_22s = [X3[2,2] for X3 in X3s]
# debug
p1 = plot()
plot!(ts, e22_, label="\$\\varepsilon_{22}\$ (Abaqus)")
plot!(ts, e11_, label="\$\\varepsilon_{11}\$ (Abaqus)")
plot!(ts_output, e22s, label="\$\\varepsilon_{22}\$ (Materials.jl)")
plot!(ts_output, e11s, label="\$\\varepsilon_{11}\$ (Materials.jl)")
for (s, e) in runs
plot!(ts_output[s:e], e22s[s:e], linecolor=:black, label=nothing)
end
plot!([NaN], [NaN], linecolor=:black, label="plastic response active")
p2 = plot()
plot!(ts, s22_, label="\$\\sigma_{22}\$ [MPa] (Abaqus)")
plot!(ts, s11_, label="\$\\sigma_{11}\$ [MPa] (Abaqus)")
plot!(ts_output, s22s, label="\$\\sigma_{22}\$ [MPa] (Materials.jl)")
plot!(ts_output, s11s, label="\$\\sigma_{11}\$ [MPa] (Materials.jl)")
# scatter!(ts[flags], s22s[flags], markersize=3, markercolor=:black, markershape=:rect, label="in plastic region")
for (s, e) in runs
plot!(ts_output[s:e], s22s[s:e], linecolor=:black, label=nothing)
end
plot!([NaN], [NaN], linecolor=:black, label="plastic response active")
p3 = plot()
plot!(ts, temperature_, label="\$\\theta\$ [°C]")
plot!(ts_output, Rs, label="\$R\$ [MPa]") # stress-like, unrelated, but the range of values fits here best.
for (s, e) in runs
plot!(ts[s:e], temperature_[s:e], linecolor=:black, label=nothing)
end
plot!([NaN], [NaN], linecolor=:black, label="plastic response active")
p4 = plot()
plot!(e22_, s22_, label="22 (Abaqus)")
plot!(e22s, s22s, label="22 (Materials.jl)")
# plot!(e11_, s11_, label="11 (Abaqus)")
# plot!(e11s, s11s, label="11 (Materials.jl)")
plot(p1, p2, p3, p4, layout=(2, 2))
# p4 = plot()
# plot!(ts_output, X1_22s, label="\$(X_1)_{22}\$ [MPa]")
# plot!(ts_output, X1_11s, label="\$(X_1)_{11}\$ [MPa]")
# for (s, e) in runs
# plot!(ts_output[s:e], X1_22s[s:e], linecolor=:black, label=nothing)
# end
# plot!([NaN], [NaN], linecolor=:black, label="plastic response active")
#
# p5 = plot()
# plot!(ts_output, X2_22s, label="\$(X_2)_{22}\$ [MPa]")
# plot!(ts_output, X2_11s, label="\$(X_2)_{11}\$ [MPa]")
# for (s, e) in runs
# plot!(ts_output[s:e], X2_22s[s:e], linecolor=:black, label=nothing)
# end
# plot!([NaN], [NaN], linecolor=:black, label="plastic response active")
#
# p6 = plot()
# plot!(ts_output, X3_22s, label="\$(X_3)_{22}\$ [MPa]")
# plot!(ts_output, X3_11s, label="\$(X_3)_{11}\$ [MPa]")
# for (s, e) in runs
# plot!(ts_output[s:e], X3_22s[s:e], linecolor=:black, label=nothing)
# end
# plot!([NaN], [NaN], linecolor=:black, label="plastic response active")
#
# plot(p1, p2, p3, p4, p5, p6, layout=(2, 3))
end
end
end
| Materials | https://github.com/JuliaFEM/Materials.jl.git |
|
[
"MIT"
] | 0.4.0 | d7a67c1c8ae6118f253a137ffa5291421e757a8a | code | 3907 | # This file is a part of JuliaFEM.
# License is MIT: see https://github.com/JuliaFEM/Materials.jl/blob/master/LICENSE
#
# Low-level definitions for one_elem_disp_chaboche.jl.
mutable struct Continuum3D <: FieldProblem
material_model :: Symbol
end
Continuum3D() = Continuum3D(:PerfectPlastic)
FEMBase.get_unknown_field_name(::Continuum3D) = "displacement"
function FEMBase.assemble_elements!(problem::Problem{Continuum3D},
assembly::Assembly,
elements::Vector{Element{Hex8}},
time::Float64)
for element in elements
for ip in get_integration_points(element)
material = ip("material", time)
preprocess_increment!(material, element, ip, time)
end
end
bi = BasisInfo(Hex8)
dim = 3
nnodes = 8
ndofs = dim*nnodes
BL = zeros(6, ndofs)
Km = zeros(ndofs, ndofs)
f_int = zeros(ndofs)
f_ext = zeros(ndofs)
D = zeros(6, 6)
S = zeros(6)
dtime = 0.05
# super dirty hack
# data = first(elements).fields["displacement"].data
# if length(data) > 1
# time0 = data[end-1].first
# dtime = time - time0
# end
for element in elements
u = element("displacement", time)
fill!(Km, 0.0)
fill!(f_int, 0.0)
fill!(f_ext, 0.0)
for ip in get_integration_points(element)
J, detJ, N, dN = element_info!(bi, element, ip, time)
material = ip("material", time)
w = ip.weight*detJ
# Kinematic matrix, linear part
fill!(BL, 0.0)
for i=1:nnodes
BL[1, 3*(i-1)+1] = dN[1,i]
BL[2, 3*(i-1)+2] = dN[2,i]
BL[3, 3*(i-1)+3] = dN[3,i]
BL[4, 3*(i-1)+1] = dN[2,i]
BL[4, 3*(i-1)+2] = dN[1,i]
BL[5, 3*(i-1)+2] = dN[3,i]
BL[5, 3*(i-1)+3] = dN[2,i]
BL[6, 3*(i-1)+1] = dN[3,i]
BL[6, 3*(i-1)+3] = dN[1,i]
end
# Calculate stress response
integrate_material!(material)
D = material.jacobian
S = material.stress + material.dstress
#@info("material matrix", D)
# Material stiffness matrix
Km += w*BL'*D*BL
# Internal force vector
f_int += w*BL'*S
# External force vector
for i=1:dim
haskey(element, "displacement load $i") || continue
b = element("displacement load $i", ip, time)
f_ext[i:dim:end] += w*B*vec(N)
end
end
# add contributions to K, Kg, f
gdofs = get_gdofs(problem, element)
add!(assembly.K, gdofs, gdofs, Km)
add!(assembly.f, gdofs, f_ext - f_int)
end
return nothing
end
function FEMBase.assemble_elements!(problem::Problem{Continuum3D},
assembly::Assembly,
elements::Vector{Element{Quad4}},
time::Float64)
nnodes = 4
ndofs = 3
f = zeros(nnodes*ndofs)
bi = BasisInfo(Quad4)
for element in elements
fill!(f, 0.0)
for ip in get_integration_points(element)
J, detJ, N, dN = element_info!(bi, element, ip, time)
w = ip.weight*detJ
if haskey(element, "surface pressure")
J = element(ip, time, Val{:Jacobian})'
n = cross(J[:,1], J[:,2])
n /= norm(n)
# sign convention, positive pressure is towards surface
p = element("surface pressure", ip, time)
f += w*p*vec(n*N)
end
end
gdofs = get_gdofs(problem, element)
add!(assembly.f, gdofs, f)
end
return nothing
end
| Materials | https://github.com/JuliaFEM/Materials.jl.git |
|
[
"MIT"
] | 0.4.0 | d7a67c1c8ae6118f253a137ffa5291421e757a8a | code | 6150 | # This file is a part of JuliaFEM.
# License is MIT: see https://github.com/JuliaFEM/Materials.jl/blob/master/LICENSE
using JuliaFEM, FEMBase, LinearAlgebra, Materials, DelimitedFiles
include("continuum.jl")
X = Dict(
1 => [0.0, 0.0, 0.0],
2 => [1.0, 0.0, 0.0],
3 => [1.0, 1.0, 0.0],
4 => [0.0, 1.0, 0.0],
5 => [0.0, 0.0, 1.0],
6 => [1.0, 0.0, 1.0],
7 => [1.0, 1.0, 1.0],
8 => [0.0, 1.0, 1.0])
body_element = Element(Hex8, (1, 2, 3, 4, 5, 6, 7, 8))
body_elements = [body_element]
update!(body_elements, "geometry", X)
update!(body_elements, "youngs modulus", 200.0e3)
update!(body_elements, "poissons ratio", 0.3)
update!(body_elements, "yield stress", 100.0)
update!(body_elements, "K_n", 100.0)
update!(body_elements, "n_n", 10.0)
update!(body_elements, "C_1", 10000.0)
update!(body_elements, "D_1", 100.0)
update!(body_elements, "C_2", 50000.0)
update!(body_elements, "D_2", 1000.0)
update!(body_elements, "Q", 50.0)
update!(body_elements, "b", 0.1)
bc_element_1 = Element(Poi1, (1,))
bc_element_2 = Element(Poi1, (2,))
bc_element_3 = Element(Poi1, (3,))
bc_element_4 = Element(Poi1, (4,))
bc_element_5 = Element(Poi1, (5,))
bc_element_6 = Element(Poi1, (6,))
bc_element_7 = Element(Poi1, (7,))
bc_element_8 = Element(Poi1, (8,))
bc_elements = [bc_element_1, bc_element_2, bc_element_3, bc_element_4,
bc_element_5, bc_element_6, bc_element_7, bc_element_8]
update!(bc_elements, "geometry", X)
for element in (bc_element_1, bc_element_2, bc_element_3, bc_element_4)
update!(element, "displacement 3", 0.0)
end
for element in (bc_element_5, bc_element_6, bc_element_7, bc_element_8)
update!(element, "displacement 3", 0.0 => 0.0)
update!(element, "displacement 3", 1.0 => 5.0e-3)
update!(element, "displacement 3", 3.0 => -5.0e-3)
update!(element, "displacement 3", 5.0 => 5.0e-3)
update!(element, "displacement 3", 7.0 => -5.0e-3)
update!(element, "displacement 3", 9.0 => 5.0e-3)
update!(element, "displacement 3", 10.0 => 0.0)
end
update!(bc_element_1, "displacement 1", 0.0)
update!(bc_element_1, "displacement 2", 0.0)
update!(bc_element_2, "displacement 2", 0.0)
update!(bc_element_4, "displacement 1", 0.0)
update!(bc_element_5, "displacement 1", 0.0)
update!(bc_element_5, "displacement 2", 0.0)
update!(bc_element_6, "displacement 2", 0.0)
update!(bc_element_8, "displacement 1", 0.0)
#update!(bc_element_5, "displacement 1", 0.0)
#update!(bc_element_5, "displacement 2", 0.0)
#update!(bc_element_5, "displacement 3", 0.0 => 0.0)
#update!(bc_element_5, "displacement 3", 1.0 => 1.0e-3)
# Initialize material model to integration points
for ip in get_integration_points(body_element)
mat = Material(Chaboche, tuple())
mat.dtime = 0.05
Materials.initialize!(mat, body_element, ip, 0.0)
ip.fields["material"] = field(mat)
end
body = Problem(Continuum3D, "1 element problem", 3)
bc = Problem(Dirichlet, "fix displacement", 3, "displacement")
add_elements!(body, body_elements)
add_elements!(bc, bc_elements)
analysis = Analysis(Nonlinear, "solve problem")
# xdmf = Xdmf("results"; overwrite=true)
# add_results_writer!(analysis, xdmf)
add_problems!(analysis, body, bc)
# time_end = 1.0
time_end = 10.0
dtime = 0.05
for problem in get_problems(analysis)
FEMBase.initialize!(problem, analysis.properties.time)
end
while analysis.properties.time < time_end
analysis.properties.time += dtime
update!(body_element, "displacement", analysis.properties.time => Dict(j => zeros(3) for j in 1:8))
@info("time = $(analysis.properties.time)")
for element in body_elements
for ip in get_integration_points(element)
material = ip("material", analysis.properties.time)
preprocess_analysis!(material, element, ip, analysis.properties.time)
end
end
run!(analysis)
for element in body_elements
for ip in get_integration_points(element)
material = ip("material", analysis.properties.time)
postprocess_analysis!(material, element, ip, analysis.properties.time)
end
end
# update material internal parameters
end
# close(xdmf)
using Plots
if true
ip1 = first(get_integration_points(body_element))
t = range(0, stop=time_end, length=Int(time_end/dtime)+1)
s11(t) = ip1("stress", t)[1]
s22(t) = ip1("stress", t)[2]
s33(t) = ip1("stress", t)[3]
s12(t) = ip1("stress", t)[4]
s23(t) = ip1("stress", t)[5]
s31(t) = ip1("stress", t)[6]
e11(t) = ip1("strain", t)[1]
e22(t) = ip1("strain", t)[2]
e33(t) = ip1("strain", t)[3]
s(t) = ip1("stress", t)
function vmis(t)
s11, s22, s33, s12, s23, s31 = ip1("stress", t)
return sqrt(1/2*((s11-s22)^2 + (s22-s33)^2 + (s33-s11)^2 + 6*(s12^2+s23^2+s31^2)))
end
path = joinpath("one_elem_disp_chaboche", "unitelement_results.rpt")
data = readdlm(path, Float64; skipstart=4)
t_ = data[:,1]
s11_ = data[:,2]
s12_ = data[:,3]
s13_ = data[:,4]
s22_ = data[:,5]
s23_ = data[:,6]
s33_ = data[:,7]
e11_ = data[:,8]
e12_ = data[:,9]
e13_ = data[:,10]
e22_ = data[:,11]
e23_ = data[:,12]
e33_ = data[:,13]
plot(e11.(t), s11.(t), label="\$\\sigma_{11}\$", legend=:topleft,
fg_legend=:transparent, bg_legend=:transparent)
plot!(e22.(t), s22.(t), label="\$\\sigma_{22}\$")
plot!(e33.(t), s33.(t), linecolor=:red, label="\$\\sigma_{33}\$")
plot!(e11_, s11_, ls=:dash, label="\$\\sigma_{11} \\quad \\mathrm{Commercial}\$")
plot!(e22_, s22_, ls=:dash, label="\$\\sigma_{22} \\quad \\mathrm{Commercial}\$")
plot!(e33_, s33_, linecolor=:black, lw=1, ls=:dash,
label="\$\\sigma_{33} \\quad \\mathrm{Commercial}\$")
title!("Chaboche plasticity model\nOne element model with uniaxial stress")
# xlabel!("\$\\varepsilon\$")
# ylabel!("\$\\sigma\$")
# labels = ["s11" "s22" "s33" "s12" "s23" "s31"]
# plot(t, s11, title="stress at integration point 1", label="s11")
# plot!(t, s22, label="s22")
# plot!(t, s33, label="s33")
# plot!(t, s12, label="s12")
# plot!(t, s23, label="s23")
# plot!(t, s31, label="s31")
end
| Materials | https://github.com/JuliaFEM/Materials.jl.git |
|
[
"MIT"
] | 0.4.0 | d7a67c1c8ae6118f253a137ffa5291421e757a8a | code | 1675 | # This file is a part of JuliaFEM.
# License is MIT: see https://github.com/JuliaFEM/Materials.jl/blob/master/LICENSE
using Materials, FEMBase, LinearAlgebra
# Standard simulation of perfect plastic material model
analysis, problem, element, bc_elements, ip = get_material_analysis(:PerfectPlastic)
update!(element, "youngs modulus", 200.0e3)
update!(element, "poissons ratio", 0.3)
update!(element, "yield stress", 100.0)
for element in bc_elements
update!(element, "fixed displacement 3", 0.0 => 0.0)
update!(element, "fixed displacement 3", 1.0 => 1.0e-3)
update!(element, "fixed displacement 3", 2.0 => -1.0e-3)
update!(element, "fixed displacement 3", 3.0 => 1.0e-3)
end
analysis.properties.t1 = 3.0
analysis.properties.extrapolate_initial_guess = false
run!(analysis)
s11(t) = ip("stress", t)[1]
s22(t) = ip("stress", t)[2]
s33(t) = ip("stress", t)[3]
s12(t) = ip("stress", t)[4]
s23(t) = ip("stress", t)[5]
s31(t) = ip("stress", t)[6]
e11(t) = ip("strain", t)[1]
e22(t) = ip("strain", t)[2]
e33(t) = ip("strain", t)[3]
e12(t) = ip("strain", t)[4]
e23(t) = ip("strain", t)[5]
e31(t) = ip("strain", t)[6]
using Plots, Test
t = 0.0:0.1:3.0
@test isapprox(maximum(e33.(t)), 0.001)
@test isapprox(minimum(e33.(t)), -0.001)
@test isapprox(maximum(s33.(t)), 100.0)
@test isapprox(minimum(s33.(t)), -100.0)
plot(e11.(t), s11.(t), label="\$\\sigma_{11}\$")
plot!(e22.(t), s22.(t), label="\$\\sigma_{22}\$")
plot!(e33.(t), s33.(t), label="\$\\sigma_{33}\$")
title!("Stress-strain curve of perfect plastic material model, uniaxial strain")
ylabel!("Stress [MPa]")
xlabel!("Strain [str]")
savefig(joinpath("one_element_ideal_plastic/uniaxial_strain.svg"))
| Materials | https://github.com/JuliaFEM/Materials.jl.git |
|
[
"MIT"
] | 0.4.0 | d7a67c1c8ae6118f253a137ffa5291421e757a8a | code | 13766 | # This file is a part of JuliaFEM.
# License is MIT: see https://github.com/JuliaFEM/Materials.jl/blob/master/LICENSE
module DSAModule
using LinearAlgebra, ForwardDiff, Tensors, NLsolve, Parameters
import ..AbstractMaterial, ..AbstractMaterialState
import ..Utilities: Symm2, Symm4, isotropic_elasticity_tensor, lame, debang
import ..integrate_material! # for method extension
# parametrically polymorphic for any type representing ℝ
export GenericDSA, GenericDSADriverState, GenericDSAParameterState, GenericDSAVariableState
# specialization for Float64
export DSA, DSADriverState, DSAParameterState, DSAVariableState
@with_kw mutable struct GenericDSADriverState{T <: Real} <: AbstractMaterialState
time::T = zero(T)
strain::Symm2{T} = zero(Symm2{T})
end
"""Parameter state for DSA (dynamic strain aging) material.
This is similar to the Chaboche model, but with additional static recovery terms.
Parameters:
- `E`: Young's modulus
- `nu`: Poisson's ratio
- `R0`: initial yield strength
- `Kn`: plasticity multiplier divisor (drag stress)
- `nn`: plasticity multiplier exponent
- `C1`, `D1`: parameters governing behavior of backstress X1
- `C2`, `D2`: parameters governing behavior of backstress X2
- `Q`: shift parameter for yield strength evolution
- `b`: multiplier for yield strength evolution
- `w`: controls the average waiting time a dislocation is arrested at localized obstacles.
It represents a strain increment produced when all arrested
dislocations overcome localized obstacles, and move toward the next
pinned configuration.
In practice, this parameter controls how fast the effective aging time
reacts to plastic flow: \$\\dot{t}_a = 1 - t_a \\dot{p} / w\$
- `P1`, `P2`: controls the maximum hardening in the fully aged state.
Has the units of stress.
- `m`: controls the characteristic diffusion time. Depends on the type of diffusion.
The value `1/3` is thought to represent pipe diffusion along dislocation lines.
Another typical value is `2/3`.
- `m1`, `m2`: The exponent of the power-law type static recovery of backstresses.
The static recovery mechanism becomes activated at higher temperatures.
This parameter controls the secondary creep and constant slope relaxation of
stresses over a longer period of time. Higher values (>6..10) effectively
deactivate static recovery, whereas lower values (<5) activate it.
- `M1`, `M2`: The normalizer of the power-law type static recovery of backstresses.
Has the units of stress. Can be used to activate/deactivate static recovery.
Deactivation occurs with high values.
- `ba`: Controls the rate of evolution of aging stress to its asymptotic value.
Dimensionless. Similar to the isotropic hardening `b`.
- `xi`: Controls the magnitude of the Marquis effect from the aging stress.
The Marquis effect is that increased hardening due to aging shows as
increased relaxation.
Dimensionless. Support `[0,1]`.
At `0`, the aging stress contributes solely to the size of the yield surface `R`
(isotropic hardening).
At `1`, the aging stress contributes solely to the viscoplastic drag stress `K`.
"""
@with_kw struct GenericDSAParameterState{T <: Real} <: AbstractMaterialState
E::T = 0.0
nu::T = 0.0
R0::T = 0.0
Kn::T = 0.0
nn::T = 0.0
C1::T = 0.0
D1::T = 0.0
C2::T = 0.0
D2::T = 0.0
Q::T = 0.0
b::T = 0.0
w::T = 0.0
P1::T = 0.0
P2::T = 0.0
m::T = 0.0
m1::T = 0.0
m2::T = 0.0
M1::T = 0.0
M2::T = 0.0
ba::T = 0.0
xi::T = 0.0
end
"""Problem state for DSA material.
- `stress`: stress tensor
- `X1`: backstress 1
- `X2`: backstress 2
- `plastic_strain`: plastic part of strain tensor
- `cumeq`: cumulative equivalent plastic strain (scalar, ≥ 0)
- `R`: yield strength
- `ta`: effective aging time
- `Ra`: aging stress
- `jacobian`: ∂σij/∂εkl
"""
@with_kw struct GenericDSAVariableState{T <: Real} <: AbstractMaterialState
stress::Symm2{T} = zero(Symm2{T})
X1::Symm2{T} = zero(Symm2{T})
X2::Symm2{T} = zero(Symm2{T})
plastic_strain::Symm2{T} = zero(Symm2{T})
cumeq::T = zero(T)
R::T = zero(T)
ta::T = zero(T)
Ra::T = zero(T)
jacobian::Symm4{T} = zero(Symm4{T})
end
# TODO: Does this eventually need a {T}?
@with_kw struct DSAOptions <: AbstractMaterialState
nlsolve_method::Symbol = :trust_region
end
@with_kw mutable struct GenericDSA{T <: Real} <: AbstractMaterial
drivers::GenericDSADriverState{T} = GenericDSADriverState{T}()
ddrivers::GenericDSADriverState{T} = GenericDSADriverState{T}()
variables::GenericDSAVariableState{T} = GenericDSAVariableState{T}()
variables_new::GenericDSAVariableState{T} = GenericDSAVariableState{T}()
parameters::GenericDSAParameterState{T} = GenericDSAParameterState{T}()
dparameters::GenericDSAParameterState{T} = GenericDSAParameterState{T}()
options::DSAOptions = DSAOptions()
end
DSADriverState = GenericDSADriverState{Float64}
DSAParameterState = GenericDSAParameterState{Float64}
DSAVariableState = GenericDSAVariableState{Float64}
DSA = GenericDSA{Float64}
"""
state_to_vector(sigma::U, R::T, X1::U, X2::U, ta::T, Ra::T) where U <: Symm2{T} where T <: Real
Adaptor for `nlsolve`. Marshal the problem state into a `Vector`.
"""
function state_to_vector(sigma::U, R::T, X1::U, X2::U, ta::T, Ra::T) where U <: Symm2{T} where T <: Real
return [tovoigt(sigma); R; tovoigt(X1); tovoigt(X2); ta; Ra]::Vector{T}
end
"""
state_from_vector(x::AbstractVector{<:Real})
Adaptor for `nlsolve`. Unmarshal the problem state from a `Vector`.
"""
function state_from_vector(x::AbstractVector{T}) where T <: Real
sigma::Symm2{T} = fromvoigt(Symm2{T}, @view x[1:6])
R::T = x[7]
X1::Symm2{T} = fromvoigt(Symm2{T}, @view x[8:13])
X2::Symm2{T} = fromvoigt(Symm2{T}, @view x[14:19])
ta::T = x[20]
Ra::T = x[21]
return sigma, R, X1, X2, ta, Ra
end
"""
integrate_material!(material::GenericDSA{T}) where T <: Real
Material model with dynamic strain aging (DSA). This is similar to the Chaboche
material with two backstresses, with both kinematic and isotropic hardening, but
this model also features static recovery terms.
This model captures dynamic (and static) strain aging (DSA) induced hardening.
The related phenomena are:
- Portevin le Chatelier effect. Serrated yield, plastic instabilities.
- Discontinuous yielding
- Inverse strain rate sensitivity (inverse SRS)
- Secondary hardening in low cycle fatigue (LCF) tests
These typically occur in a certain temperature/strain rate regime, where the
dislocations are pinned due to the diffusion of solute atoms. In the most
effective conditions, the speed of diffusion is comparable to the applied
strain rate (speed of dislocations).
See:
J.-L. Chaboche, A. Gaubert, P. Kanouté, A. Longuet, F. Azzouz, M. Mazière.
Viscoplastic constitutive equations of combustion chamber materials including
cyclic hardening and dynamic strain aging. International Journal of Plasticity
46 (2013), 1--22. http://dx.doi.org/10.1016/j.ijplas.2012.09.011
Further reading:
M. Mazière, H. Dierke. Investigations on the Portevin Le Chatelier critical
strain in an aluminum alloy. Computational Materials Science 52(1) (2012),
68--72. https://doi.org/10.1016/j.commatsci.2011.05.039
"""
function integrate_material!(material::GenericDSA{T}) where T <: Real
p = material.parameters
v = material.variables
dd = material.ddrivers
d = material.drivers
@unpack E, nu, R0, Kn, nn, C1, D1, C2, D2, Q, b, w, P1, P2, m, m1, m2, M1, M2, ba, xi = p
lambda, mu = lame(E, nu)
@unpack strain, time = d
dstrain = dd.strain
dtime = dd.time
@unpack stress, X1, X2, plastic_strain, cumeq, R, jacobian, ta, Ra = v
# elastic part
jacobian = isotropic_elasticity_tensor(lambda, mu)
stress += dcontract(jacobian, dstrain)
# resulting deviatoric plastic stress (accounting for backstresses Xm)
seff_dev = dev(stress - X1 - X2)
# von Mises yield function
f = sqrt(1.5)*norm(seff_dev) - (R0 + R + (1 - xi) * Ra) # using elastic trial problem state
if f > 0.0
g! = create_nonlinear_system_of_equations(material)
x0 = state_to_vector(stress, R, X1, X2, ta + dtime, Ra)
res = nlsolve(g!, x0; method=material.options.nlsolve_method, autodiff = :forward)
converged(res) || error("Nonlinear system of equations did not converge!")
x = res.zero
stress, R, X1, X2, ta, Ra = state_from_vector(x)
# using the new problem state
seff_dev = dev(stress - X1 - X2)
f = sqrt(1.5)*norm(seff_dev) - (R0 + R + (1 - xi) * Ra)
dotp = ((f >= 0.0 ? f : 0.0) / (Kn + xi * Ra))^nn
dp = dotp*dtime
n = sqrt(1.5)*seff_dev/norm(seff_dev)
plastic_strain += dp*n
cumeq += dp
# Compute the new Jacobian, accounting for the plastic contribution.
drdx = ForwardDiff.jacobian(debang(g!), x)
drde = zeros((length(x), 6))
drde[1:6, 1:6] = -tovoigt(jacobian) # elastic Jacobian. Follows from the defn. of g!.
jacobian = fromvoigt(Symm4, (drdx\drde)[1:6, 1:6])
else
ta += dtime
end
variables_new = GenericDSAVariableState{T}(stress = stress,
X1 = X1,
X2 = X2,
R = R,
plastic_strain = plastic_strain,
cumeq = cumeq,
jacobian = jacobian,
ta = ta,
Ra = Ra)
material.variables_new = variables_new
return nothing
end
"""
create_nonlinear_system_of_equations(material::GenericDSA{T}) where T <: Real
Create and return an instance of the equation system for the incremental form of
the evolution equations of the DSA material.
Used internally for computing the plastic contribution in `integrate_material!`.
The input `material` represents the problem state at the end of the previous
timestep. The created equation system will hold its own copy of that state.
The equation system is represented as a mutating function `g!` that computes the
residual:
```julia
g!(F::V, x::V) where V <: AbstractVector{<:Real}
```
Both `F` (output) and `x` (input) are length-21 vectors containing
[sigma, R, X1, X2, ta, Ra], in that order. The tensor quantities
sigma, X1, X2 are encoded in Voigt format.
The function `g!` is intended to be handed over to `nlsolve`.
"""
function create_nonlinear_system_of_equations(material::GenericDSA{T}) where T <: Real
p = material.parameters
v = material.variables
dd = material.ddrivers
d = material.drivers
@unpack E, nu, R0, Kn, nn, C1, D1, C2, D2, Q, b, w, P1, P2, m, m1, m2, M1, M2, ba, xi = p
lambda, mu = lame(E, nu)
# Old problem state (i.e. the problem state at the time when this equation
# system instance was created).
#
# Note this does not include the elastic trial; this is the state at the
# end of the previous timestep.
@unpack strain, time = d
dstrain = dd.strain
dtime = dd.time
@unpack stress, X1, X2, plastic_strain, cumeq, R, ta, Ra = v
jacobian = isotropic_elasticity_tensor(lambda, mu)
# Compute the residual. F is output, x is filled by NLsolve.
# The solution is x = x* such that g(x*) = 0.
function g!(F::V, x::V) where V <: AbstractVector{<:Real}
stress_new, R_new, X1_new, X2_new, ta_new, Ra_new = state_from_vector(x) # tentative new values from nlsolve
seff_dev = dev(stress_new - X1_new - X2_new)
f = sqrt(1.5)*norm(seff_dev) - (R0 + R_new + (1 - xi) * Ra_new)
dotp = ((f >= 0.0 ? f : 0.0) / (Kn + xi * Ra_new))^nn
dp = dotp*dtime
n = sqrt(1.5)*seff_dev/norm(seff_dev)
# The equations are written in an incremental form.
# TODO: multiply the equations by -1 to make them easier to understand in the context of the rest of the model.
dstrain_plastic = dp*n
dstrain_elastic = dstrain - dstrain_plastic
tovoigt!(view(F, 1:6), stress - stress_new + dcontract(jacobian, dstrain_elastic))
F[7] = R - R_new + b*(Q - R_new)*dp
# HACK: The zero special case is needed here to make ForwardDiff happy.
#
# Otherwise, when ndX1_new = 0, the components 2:end of the automatic
# derivative of JX1_new will be NaN, which causes the calculation of the
# material jacobian to silently fail. This usually manifests itself as a
# mysterious convergence failure, when this model is used in the strain
# optimizer.
ndX1_new = norm(dev(X1_new))
if iszero(ndX1_new)
JX1_new = 0.0
else
JX1_new = sqrt(1.5) * ndX1_new
end
sr1_new = (JX1_new^(m1 - 1) * X1_new) / (M1^m1) # static recovery term
tovoigt!(view(F, 8:13), X1 - X1_new + dp*(2.0/3.0*C1*n - D1*X1_new) - dtime*sr1_new)
ndX2_new = norm(dev(X2_new))
if iszero(ndX2_new)
JX2_new = 0.0
else
JX2_new = sqrt(1.5) * ndX2_new
end
sr2_new = (JX2_new^(m2 - 1) * X2_new) / (M2^m2) # static recovery term
tovoigt!(view(F, 14:19), X2 - X2_new + dp*(2.0/3.0*C2*n - D2*X2_new) - dtime*sr2_new)
Ras = P1 * (1.0 - exp(-P2 * ta_new^m))
F[20] = ta - ta_new + dtime - (ta_new / w)*dp
F[21] = Ra - Ra_new + ba*(Ras - Ra_new)*dp
return nothing
end
return g!
end
end
| Materials | https://github.com/JuliaFEM/Materials.jl.git |
|
[
"MIT"
] | 0.4.0 | d7a67c1c8ae6118f253a137ffa5291421e757a8a | code | 3403 | # This file is a part of JuliaFEM.
# License is MIT: see https://github.com/JuliaFEM/Materials.jl/blob/master/LICENSE
module Materials
abstract type AbstractMaterial end
abstract type AbstractMaterialState end
export AbstractMaterial, AbstractMaterialState
export integrate_material!, update_material!, reset_material!
"""
:+(a::T, b::T) where T <: AbstractMaterialState
Fieldwise addition for material states.
"""
@generated function Base.:+(a::T, b::T) where T <: AbstractMaterialState
expr = [:(a.$p + b.$p) for p in fieldnames(T)]
return :(T($(expr...)))
end
"""
integrate_material!(material::AbstractMaterial)
Integrate one timestep. The input `material.variables` represents the old
problem state.
Abstract method. Must be implemented for each material type. When integration is
done, the method **must** write the new state into `material.variables_new`.
**Do not** write into `material.variables`; actually committing the timestep
(i.e. accepting that one step of time evolution and applying it permanently)
is the job of `update_material!`.
"""
function integrate_material!(material::M) where M <: AbstractMaterial
error("One needs to define how to integrate material $M!")
end
"""
update_material!(material::AbstractMaterial)
Commit the result of `integrate_material!`.
In `material`, we add `ddrivers` into `drivers`, `dparameters` into
`parameters`, and replace `variables` by `variables_new`. Then we
automatically invoke `reset_material!`.
"""
function update_material!(material::AbstractMaterial)
material.drivers += material.ddrivers
# material.parameters += material.dparameters # TODO: fix this
material.variables = material.variables_new
reset_material!(material)
return nothing
end
"""
reset_material!(material::AbstractMaterial)
In `material`, we zero out `ddrivers`, `dparameters` and `variables_new`. This
clears out the tentative state produced when a timestep has been computed, but
has not yet been committed.
Used internally by `update_material!`.
"""
function reset_material!(material::AbstractMaterial)
material.ddrivers = typeof(material.ddrivers)()
material.dparameters = typeof(material.dparameters)()
material.variables_new = typeof(material.variables_new)()
return nothing
end
include("utilities.jl")
using .Utilities
export Symm2, Symm4
export delta, II, IT, IS, IA, IV, ID, isotropic_elasticity_tensor, isotropic_compliance_tensor
export lame, delame, debang, find_root
include("perfectplastic.jl")
using .PerfectPlasticModule
export PerfectPlastic, PerfectPlasticDriverState, PerfectPlasticParameterState, PerfectPlasticVariableState
include("chaboche.jl")
using .ChabocheModule
export Chaboche, ChabocheDriverState, ChabocheParameterState, ChabocheVariableState
include("chabochethermal.jl")
using .ChabocheThermalModule
export ChabocheThermal, ChabocheThermalDriverState, ChabocheThermalParameterState, ChabocheThermalVariableState
include("memory.jl")
using .MemoryModule
export Memory, MemoryDriverState, MemoryParameterState, MemoryVariableState
include("DSA.jl")
using .DSAModule
export DSA, DSADriverState, DSAParameterState, DSAVariableState
include("increments.jl")
using .Increments
export uniaxial_increment!, biaxial_increment!, stress_driven_uniaxial_increment!,
general_increment!, stress_driven_general_increment!, general_mixed_increment!, find_dstrain!
end
| Materials | https://github.com/JuliaFEM/Materials.jl.git |
|
[
"MIT"
] | 0.4.0 | d7a67c1c8ae6118f253a137ffa5291421e757a8a | code | 11176 | # This file is a part of JuliaFEM.
# License is MIT: see https://github.com/JuliaFEM/Materials.jl/blob/master/LICENSE
module ChabocheModule
using LinearAlgebra, ForwardDiff, Tensors, NLsolve, Parameters
import ..AbstractMaterial, ..AbstractMaterialState
import ..Utilities: Symm2, Symm4, isotropic_elasticity_tensor, lame, debang
import ..integrate_material! # for method extension
# parametrically polymorphic for any type representing ℝ
export GenericChaboche, GenericChabocheDriverState, GenericChabocheParameterState, GenericChabocheVariableState
# specialization for Float64
export Chaboche, ChabocheDriverState, ChabocheParameterState, ChabocheVariableState
@with_kw mutable struct GenericChabocheDriverState{T <: Real} <: AbstractMaterialState
time::T = zero(T)
strain::Symm2{T} = zero(Symm2{T})
end
"""Parameter state for Chaboche material.
The classical viscoplastic material is a special case of this model with `C1 = C2 = 0`.
- `E`: Young's modulus
- `nu`: Poisson's ratio
- `R0`: initial yield strength
- `Kn`: plasticity multiplier divisor (drag stress)
- `nn`: plasticity multiplier exponent
- `C1`, `D1`: parameters governing behavior of backstress X1
- `C2`, `D2`: parameters governing behavior of backstress X2
- `Q`: hardening saturation state
- `b`: rate of convergence to hardening saturation
"""
@with_kw struct GenericChabocheParameterState{T <: Real} <: AbstractMaterialState
E::T = 0
nu::T = 0
R0::T = 0
Kn::T = 0
nn::T = 0
C1::T = 0
D1::T = 0
C2::T = 0
D2::T = 0
Q::T = 0
b::T = 0
end
"""Problem state for Chaboche material.
- `stress`: stress tensor
- `X1`: backstress 1
- `X2`: backstress 2
- `plastic_strain`: plastic part of strain tensor
- `cumeq`: cumulative equivalent plastic strain (scalar, ≥ 0)
- `R`: yield strength
- `jacobian`: ∂σij/∂εkl
"""
@with_kw struct GenericChabocheVariableState{T <: Real} <: AbstractMaterialState
stress::Symm2{T} = zero(Symm2{T})
X1::Symm2{T} = zero(Symm2{T})
X2::Symm2{T} = zero(Symm2{T})
plastic_strain::Symm2{T} = zero(Symm2{T})
cumeq::T = zero(T)
R::T = zero(T)
jacobian::Symm4{T} = zero(Symm4{T})
end
# TODO: Does this eventually need a {T}?
@with_kw struct ChabocheOptions <: AbstractMaterialState
nlsolve_method::Symbol = :trust_region
end
@with_kw mutable struct GenericChaboche{T <: Real} <: AbstractMaterial
drivers::GenericChabocheDriverState{T} = GenericChabocheDriverState{T}()
ddrivers::GenericChabocheDriverState{T} = GenericChabocheDriverState{T}()
variables::GenericChabocheVariableState{T} = GenericChabocheVariableState{T}()
variables_new::GenericChabocheVariableState{T} = GenericChabocheVariableState{T}()
parameters::GenericChabocheParameterState{T} = GenericChabocheParameterState{T}()
dparameters::GenericChabocheParameterState{T} = GenericChabocheParameterState{T}()
options::ChabocheOptions = ChabocheOptions()
end
ChabocheDriverState = GenericChabocheDriverState{Float64}
ChabocheParameterState = GenericChabocheParameterState{Float64}
ChabocheVariableState = GenericChabocheVariableState{Float64}
Chaboche = GenericChaboche{Float64}
"""
state_to_vector(sigma::U, R::T, X1::U, X2::U) where U <: Symm2{T} where T <: Real
Adaptor for `nlsolve`. Marshal the problem state into a `Vector`.
"""
function state_to_vector(sigma::U, R::T, X1::U, X2::U) where U <: Symm2{T} where T <: Real
return [tovoigt(sigma); R; tovoigt(X1); tovoigt(X2)]::Vector{T}
end
"""
state_from_vector(x::AbstractVector{<:Real})
Adaptor for `nlsolve`. Unmarshal the problem state from a `Vector`.
"""
function state_from_vector(x::AbstractVector{T}) where T <: Real
sigma::Symm2{T} = fromvoigt(Symm2{T}, @view x[1:6])
R::T = x[7]
X1::Symm2{T} = fromvoigt(Symm2{T}, @view x[8:13])
X2::Symm2{T} = fromvoigt(Symm2{T}, @view x[14:19])
return sigma, R, X1, X2
end
"""
integrate_material!(material::GenericChaboche{T}) where T <: Real
Chaboche material with two backstresses. Both kinematic and isotropic hardening.
See:
J.-L. Chaboche. Constitutive equations for cyclic plasticity and cyclic
viscoplasticity. International Journal of Plasticity 5(3) (1989), 247--302.
https://doi.org/10.1016/0749-6419(89)90015-6
Further reading:
J.-L. Chaboche. A review of some plasticity and viscoplasticity constitutive
theories. International Journal of Plasticity 24 (2008), 1642--1693.
https://dx.doi.org/10.1016/j.ijplas.2008.03.009
J.-L. Chaboche, A. Gaubert, P. Kanouté, A. Longuet, F. Azzouz, M. Mazière.
Viscoplastic constitutive equations of combustion chamber materials including
cyclic hardening and dynamic strain aging. International Journal of Plasticity
46 (2013), 1--22. https://dx.doi.org/10.1016/j.ijplas.2012.09.011
"""
function integrate_material!(material::GenericChaboche{T}) where T <: Real
p = material.parameters
v = material.variables
dd = material.ddrivers
d = material.drivers
@unpack E, nu, R0, Kn, nn, C1, D1, C2, D2, Q, b = p
lambda, mu = lame(E, nu)
@unpack strain, time = d
dstrain = dd.strain
dtime = dd.time
@unpack stress, X1, X2, plastic_strain, cumeq, R = v
# elastic part
jacobian = isotropic_elasticity_tensor(lambda, mu) # dσ/dε, i.e. ∂σij/∂εkl
stress += dcontract(jacobian, dstrain) # add the elastic stress increment, get the elastic trial stress
# resulting deviatoric plastic stress (accounting for backstresses Xm)
seff_dev = dev(stress - X1 - X2)
# von Mises yield function
f = sqrt(1.5)*norm(seff_dev) - (R0 + R) # using elastic trial problem state
if f > 0.0
g! = create_nonlinear_system_of_equations(material)
x0 = state_to_vector(stress, R, X1, X2)
res = nlsolve(g!, x0; method=material.options.nlsolve_method, autodiff=:forward) # user manual: https://github.com/JuliaNLSolvers/NLsolve.jl
converged(res) || error("Nonlinear system of equations did not converge!")
x = res.zero
stress, R, X1, X2 = state_from_vector(x)
# using the new problem state
seff_dev = dev(stress - X1 - X2)
f = sqrt(1.5)*norm(seff_dev) - (R0 + R)
dotp = ((f >= 0.0 ? f : 0.0)/Kn)^nn # power law viscoplasticity (Norton-Bailey type)
dp = dotp*dtime # |dε_p|, using backward Euler (dotp is ∂ε_p/∂t at the end of the timestep)
n = sqrt(1.5)*seff_dev/norm(seff_dev) # Chaboche: a (tensorial) unit direction, s.t. 2/3 * (n : n) = 1; also n = ∂f/∂σ.
plastic_strain += dp*n
cumeq += dp # cumulative equivalent plastic strain (note dp ≥ 0)
# Compute the new Jacobian, accounting for the plastic contribution. Because
# x ≡ [σ R X1 X2] (vector of length 19, with tensors encoded in Voigt format)
# we have
# dσ/dε = (dx/dε)[1:6,1:6]
# for which we can compute the LHS as follows:
# dx/dε = dx/dr dr/dε = inv(dr/dx) dr/dε ≡ (dr/dx) \ (dr/dε)
# where r = r(x) is the residual, given by the function g!. AD can get us dr/dx automatically,
# the other factor we will have to supply manually.
drdx = ForwardDiff.jacobian(debang(g!), x) # Array{19, 19}
drde = zeros((length(x),6)) # Array{19, 6}
drde[1:6, 1:6] = tovoigt(jacobian) # elastic Jacobian. Follows from the defn. of g!.
jacobian = fromvoigt(Symm4, (drdx\drde)[1:6, 1:6])
end
variables_new = GenericChabocheVariableState{T}(stress = stress,
X1 = X1,
X2 = X2,
R = R,
plastic_strain = plastic_strain,
cumeq = cumeq,
jacobian = jacobian)
material.variables_new = variables_new
return nothing
end
"""
create_nonlinear_system_of_equations(material::GenericChaboche{T}) where T <: Real
Create and return an instance of the equation system for the incremental form of
the evolution equations of the Chaboche material.
Used internally for computing the plastic contribution in `integrate_material!`.
The input `material` represents the problem state at the end of the previous
timestep. The created equation system will hold its own copy of that state.
The equation system is represented as a mutating function `g!` that computes the
residual:
```julia
g!(F::V, x::V) where V <: AbstractVector{<:Real}
```
Both `F` (output) and `x` (input) are length-19 vectors containing
[sigma, R, X1, X2], in that order. The tensor quantities sigma, X1,
X2 are encoded in Voigt format.
The function `g!` is intended to be handed over to `nlsolve`.
"""
function create_nonlinear_system_of_equations(material::GenericChaboche{T}) where T <: Real
p = material.parameters
v = material.variables
dd = material.ddrivers
d = material.drivers
@unpack E, nu, R0, Kn, nn, C1, D1, C2, D2, Q, b = p
lambda, mu = lame(E, nu)
# Old problem state (i.e. the problem state at the time when this equation
# system instance was created).
#
# Note this does not include the elastic trial; this is the state at the
# end of the previous timestep.
@unpack strain, time = d
dstrain = dd.strain
dtime = dd.time
@unpack stress, X1, X2, plastic_strain, cumeq, R = v
jacobian = isotropic_elasticity_tensor(lambda, mu)
# Compute the residual. F is output, x is filled by NLsolve.
# The solution is x = x* such that g(x*) = 0.
function g!(F::V, x::V) where V <: AbstractVector{<:Real}
stress_new, R_new, X1_new, X2_new = state_from_vector(x) # tentative new values from nlsolve
seff_dev = dev(stress_new - X1_new - X2_new)
f = sqrt(1.5)*norm(seff_dev) - (R0 + R_new)
dotp = ((f >= 0.0 ? f : 0.0)/Kn)^nn
dp = dotp*dtime
n = sqrt(1.5)*seff_dev/norm(seff_dev)
# The equations are written in an incremental form:
#
# Δσ = (∂σ/∂ε)_e : dε_e = (∂σ/∂ε)_e : (dε - dε_p) (components 1:6)
# ΔR = b (Q - R_new) |dε_p| (component 7)
# ΔX1 = (2/3) C1 |dε_p| (n - (3/2) (D1/C1) X1_new) (components 8:13)
# ΔX2 = (2/3) C2 |dε_p| (n - (3/2) (D2/C2) X2_new) (components 14:19)
#
# where
#
# Δ(...) = (...)_new - (...)_old
#
# Then move the terms on the RHS to the LHS to get the standard form, (stuff) = 0.
# Also, below we avoid the multiplication and division that cancel each other
# in the last terms of the equations for ΔX1 and ΔX2.
#
dstrain_plastic = dp*n
dstrain_elastic = dstrain - dstrain_plastic
tovoigt!(view(F, 1:6), stress_new - stress - dcontract(jacobian, dstrain_elastic))
F[7] = R_new - R - b*(Q - R_new)*dp
tovoigt!(view(F, 8:13), X1_new - X1 - dp*(2.0/3.0*C1*n - D1*X1_new))
tovoigt!(view(F, 14:19), X2_new - X2 - dp*(2.0/3.0*C2*n - D2*X2_new))
return nothing
end
return g!
end
end
| Materials | https://github.com/JuliaFEM/Materials.jl.git |
|
[
"MIT"
] | 0.4.0 | d7a67c1c8ae6118f253a137ffa5291421e757a8a | code | 43965 | # This file is a part of JuliaFEM.
# License is MIT: see https://github.com/JuliaFEM/Materials.jl/blob/master/LICENSE
module ChabocheThermalModule
using LinearAlgebra, ForwardDiff, Tensors, NLsolve, Parameters
import ..AbstractMaterial, ..AbstractMaterialState
import ..Utilities: Symm2, Symm4, isotropic_elasticity_tensor, isotropic_compliance_tensor, lame, debang
import ..integrate_material! # for method extension
# parametrically polymorphic for any type representing ℝ
export GenericChabocheThermal, GenericChabocheThermalDriverState, GenericChabocheThermalParameterState, GenericChabocheThermalVariableState
# specialization for Float64
export ChabocheThermal, ChabocheThermalDriverState, ChabocheThermalParameterState, ChabocheThermalVariableState
"""Rank-2 identity tensor in three spatial dimensions."""
I2 = Symm2(I(3))
@with_kw mutable struct GenericChabocheThermalDriverState{T <: Real} <: AbstractMaterialState
time::T = zero(T)
strain::Symm2{T} = zero(Symm2{T})
temperature::T = zero(T)
end
# TODO: hierarchize parameters: elasticity, kinematic hardening, isotropic hardening, ...
# plasticity: yield criterion, flow rule, hardening
"""Parameter state for ChabocheThermal material.
The classical viscoplastic material is a special case of this model with `C1 = C2 = C3 = 0`.
Maximum hardening for each backstress is `Cj / Dj`.
Any parameter that is a `Function` should takes a single argument, the absolute
temperature.
- `theta0`: reference temperature at which thermal expansion is considered zero
- `E`: Young's modulus [N/mm^2]
- `nu`: Poisson's ratio
- `alpha`: linear thermal expansion coefficient
- `R0`: initial yield strength
- `tvp`: viscoplastic pseudo-relaxation-time (has the units of time)
- `Kn`: drag stress (has the units of stress)
- `nn`: Norton-Bailey power law exponent
- `C1`, `D1`: parameters governing behavior of backstress X1.
C1 has the units of stress; D1 is dimensionless.
- `C2`, `D2`: parameters governing behavior of backstress X2.
- `C3`, `D3`: parameters governing behavior of backstress X3.
- `Q`: isotropic hardening saturation state (has the units of stress)
- `b`: rate of convergence to isotropic hardening saturation (dimensionless)
"""
@with_kw struct GenericChabocheThermalParameterState{T <: Real} <: AbstractMaterialState
theta0::T = zero(T) # reference temperature for thermal behavior
# basic material parameters
E::Function = (theta::Real -> zero(T))
nu::Function = (theta::Real -> zero(T))
alpha::Function = (theta::Real -> zero(T))
R0::Function = (theta::Real -> zero(T))
# parameters for viscoplastic overstress model
tvp::T = zero(T)
Kn::Function = (theta::Real -> zero(T))
nn::Function = (theta::Real -> zero(T))
# kinematic hardening parameters
C1::Function = (theta::Real -> zero(T))
D1::Function = (theta::Real -> zero(T))
C2::Function = (theta::Real -> zero(T))
D2::Function = (theta::Real -> zero(T))
C3::Function = (theta::Real -> zero(T))
D3::Function = (theta::Real -> zero(T))
# isotropic hardening parameters
Q::Function = (theta::Real -> zero(T))
b::Function = (theta::Real -> zero(T))
end
"""Problem state for ChabocheThermal material.
- `stress`: stress tensor
- `R`: yield strength (isotropic hardening)
- `X1`: backstress 1 (kinematic hardening)
- `X2`: backstress 2 (kinematic hardening)
- `X3`: backstress 3 (kinematic hardening)
- `plastic_strain`: plastic part of strain tensor
- `cumeq`: cumulative equivalent plastic strain (scalar, ≥ 0)
- `jacobian`: ∂σij/∂εkl (algorithmic)
The other `dXXXdYYY` properties are the algorithmic jacobians for the
indicated variables.
The elastic and thermal contributions to the strain tensor are not stored.
To get them:
θ₀ = ...
θ = ...
p = material.parameters
v = material.variables
C(θ) = compliance_tensor(p.E, p.nu, θ)
elastic_strain = dcontract(C(θ), v.stress)
thermal_strain = thermal_strain_tensor(p.alpha, θ₀, θ)
Then it holds that:
material.drivers.strain = elastic_strain + v.plastic_strain + thermal_strain
"""
@with_kw struct GenericChabocheThermalVariableState{T <: Real} <: AbstractMaterialState
stress::Symm2{T} = zero(Symm2{T})
R::T = zero(T)
X1::Symm2{T} = zero(Symm2{T})
X2::Symm2{T} = zero(Symm2{T})
X3::Symm2{T} = zero(Symm2{T})
plastic_strain::Symm2{T} = zero(Symm2{T})
cumeq::T = zero(T)
jacobian::Symm4{T} = zero(Symm4{T})
dRdstrain::Symm2{T} = zero(Symm2{T})
dX1dstrain::Symm4{T} = zero(Symm4{T})
dX2dstrain::Symm4{T} = zero(Symm4{T})
dX3dstrain::Symm4{T} = zero(Symm4{T})
dstressdtemperature::Symm2{T} = zero(Symm2{T})
dRdtemperature::T = zero(T)
dX1dtemperature::Symm2{T} = zero(Symm2{T})
dX2dtemperature::Symm2{T} = zero(Symm2{T})
dX3dtemperature::Symm2{T} = zero(Symm2{T})
end
# TODO: Does this eventually need a {T}?
@with_kw struct ChabocheThermalOptions <: AbstractMaterialState
nlsolve_method::Symbol = :trust_region
end
@with_kw mutable struct GenericChabocheThermal{T <: Real} <: AbstractMaterial
drivers::GenericChabocheThermalDriverState{T} = GenericChabocheThermalDriverState{T}()
ddrivers::GenericChabocheThermalDriverState{T} = GenericChabocheThermalDriverState{T}()
variables::GenericChabocheThermalVariableState{T} = GenericChabocheThermalVariableState{T}()
variables_new::GenericChabocheThermalVariableState{T} = GenericChabocheThermalVariableState{T}()
parameters::GenericChabocheThermalParameterState{T} = GenericChabocheThermalParameterState{T}()
dparameters::GenericChabocheThermalParameterState{T} = GenericChabocheThermalParameterState{T}()
options::ChabocheThermalOptions = ChabocheThermalOptions()
end
ChabocheThermalDriverState = GenericChabocheThermalDriverState{Float64}
ChabocheThermalParameterState = GenericChabocheThermalParameterState{Float64}
ChabocheThermalVariableState = GenericChabocheThermalVariableState{Float64}
ChabocheThermal = GenericChabocheThermal{Float64}
"""
state_to_vector(sigma::U, R::T, X1::U, X2::U, X3::U) where U <: Symm2{T} where T <: Real
Adaptor for `nlsolve`. Marshal the problem state into a `Vector`.
"""
function state_to_vector(sigma::U, R::T, X1::U, X2::U, X3::U) where U <: Symm2{T} where T <: Real
return [tovoigt(sigma); R; tovoigt(X1); tovoigt(X2); tovoigt(X3)]::Vector{T}
end
"""
state_from_vector(x::AbstractVector{<:Real})
Adaptor for `nlsolve`. Unmarshal the problem state from a `Vector`.
"""
function state_from_vector(x::AbstractVector{T}) where T <: Real
sigma::Symm2{T} = fromvoigt(Symm2{T}, @view x[1:6])
R::T = x[7]
X1::Symm2{T} = fromvoigt(Symm2{T}, @view x[8:13])
X2::Symm2{T} = fromvoigt(Symm2{T}, @view x[14:19])
X3::Symm2{T} = fromvoigt(Symm2{T}, @view x[20:25])
return sigma, R, X1, X2, X3
end
"""
elasticity_tensor(E::Function, nu::Function, theta::Real)
Usage example:
E(θ) = ...
ν(θ) = ...
D(θ) = elasticity_tensor(E, ν, θ)
dDdθ(θ) = gradient(D, θ)
"""
function elasticity_tensor(E::Function, nu::Function, theta::Real)
lambda, mu = lame(E(theta), nu(theta))
return isotropic_elasticity_tensor(lambda, mu)
end
"""
compliance_tensor(E::Function, nu::Function, theta::Real)
Usage example:
E(θ) = ...
ν(θ) = ...
C(θ) = compliance_tensor(E, ν, θ)
dCdθ(θ) = gradient(C, θ)
"""
function compliance_tensor(E::Function, nu::Function, theta::Real)
lambda, mu = lame(E(theta), nu(theta))
return isotropic_compliance_tensor(lambda, mu)
end
"""
thermal_strain_tensor(alpha::Function, theta0::Real, theta::Real)
Return the isotropic thermal strain tensor:
εth = α(θ) (θ - θ₀) I
Here `alpha` is the linear thermal expansion coefficient, and `theta0`
is a reference temperature, at which thermal expansion is considered zero.
Usage example:
α(θ) = ...
θ₀ = ...
εth(θ) = thermal_strain_tensor(α, θ₀, θ)
dεthdθ(θ) = gradient(εth, θ)
Given θ and Δθ, you can easily get the increment Δεth:
Δεth(θ, Δθ) = dεthdθ(θ) * Δθ
"""
function thermal_strain_tensor(alpha::Function, theta0::Real, theta::Real)
return alpha(theta) * (theta - theta0) * I2
end
# TODO: Add this interface to the general API in `AbstractMaterial`?
#
# We should be careful to accept also `ForwardDiff.Dual`, because this stuff
# gets differentiated when computing the jacobian of the residual.
# For `yield_jacobian`, that leads to nested uses of `ForwardDiff`.
"""
yield_criterion(state::GenericChabocheThermalVariableState{<:Real},
drivers::GenericChabocheThermalDriverState{<:Real},
parameters::GenericChabocheThermalParameterState{<:Real})
Temperature-dependent yield criterion. This particular one is the von Mises
criterion for a Chaboche model with thermal effects, three backstresses,
and isotropic hardening.
`state` should contain `stress`, `R`, `X1`, `X2`, `X3`.
`drivers` should contain `temperature`.
`parameters` should contain `R0`, a function of temperature.
Other properties of the structures are not used by this function.
The return value is a scalar, the value of the yield function `f`.
"""
function yield_criterion(state::GenericChabocheThermalVariableState{<:Real},
drivers::GenericChabocheThermalDriverState{<:Real},
parameters::GenericChabocheThermalParameterState{<:Real})
@unpack stress, R, X1, X2, X3 = state
@unpack temperature = drivers
@unpack R0 = parameters
# deviatoric part of stress, accounting for plastic backstresses Xm.
seff_dev = dev(stress - X1 - X2 - X3)
f = sqrt(1.5)*norm(seff_dev) - (R0(temperature) + R)
return f
end
"""
yield_jacobian(state::GenericChabocheThermalVariableState{<:Real},
drivers::GenericChabocheThermalDriverState{<:Real},
parameters::GenericChabocheThermalParameterState{<:Real})
Compute `n = ∂f/∂σ`.
`state` should contain `stress`, `R`, `X1`, `X2`, `X3`.
`drivers` should contain `temperature`.
`parameters` should contain `R0`, a function of temperature.
Other properties of the structures are not used by this function.
The return value is the symmetric rank-2 tensor `n`.
"""
function yield_jacobian(state::GenericChabocheThermalVariableState{<:Real},
drivers::GenericChabocheThermalDriverState{<:Real},
parameters::GenericChabocheThermalParameterState{<:Real})
# We only need ∂f/∂σ, so let's compute only that to make this run faster.
#
# # TODO: The `gradient` wrapper of `Tensors.jl` is nice, but it doesn't tag its Dual.
# #
# # When using `Tensors.gradient` in `yield_jacobian` (n = ∂f/∂σ), the
# # differentiation of `yield_criterion` with respect to stress doesn't work
# # when computing the temperature jacobian for the residual function, which
# # needs ∂n/∂θ = ∂²f/∂σ∂θ. `ForwardDiff` fails to find an ordering for the
# # `Dual` terms (the temperature Dual having a tag, but the stress Dual not).
# #
# # Using `ForwardDiff.jacobian` directly, both Duals are tagged, so this works.
#
# @unpack stress, R, X1, X2, X3 = state
# function f(stress::Symm2{<:Real})
# state = GenericChabocheThermalVariableState{eltype(stress)}(stress=stress,
# R=R,
# X1=X1,
# X2=X2,
# X3=X3)
# return yield_criterion(state, drivers, parameters)
# end
# return gradient(f, stress)
@unpack stress, R, X1, X2, X3 = state
marshal(tensor::Symm2) = tovoigt(tensor)
unmarshal(x::AbstractVector{T}) where T <: Real = fromvoigt(Symm2{T}, x)
function f(x::AbstractVector{<:Real}) # x = stress
state = GenericChabocheThermalVariableState{eltype(x)}(stress=unmarshal(x),
X1=X1,
X2=X2,
X3=X3,
R=R)
return [yield_criterion(state, drivers, parameters)]::Vector
end
J = ForwardDiff.jacobian(f, marshal(stress))
# The result is a row vector, so drop the singleton dimension.
return unmarshal(J[1,:])
end
"""
overstress_function(state::GenericChabocheThermalVariableState{<:Real},
drivers::GenericChabocheThermalDriverState{<:Real},
parameters::GenericChabocheThermalParameterState{<:Real})
Norton-Bailey type power law.
`parameters` should contain `tvp`, `Kn` and `nn`.
`drivers` should contain `temperature`.
Additionally, `state`, `drivers` and `parameters` will be passed to
`yield_criterion`.
The return value is `dotp` that can be used in `dp = dotp * dtime`.
"""
function overstress_function(state::GenericChabocheThermalVariableState{<:Real},
drivers::GenericChabocheThermalDriverState{<:Real},
parameters::GenericChabocheThermalParameterState{<:Real})
f = yield_criterion(state, drivers, parameters)
@unpack tvp, Kn, nn = parameters
@unpack temperature = drivers
K = Kn(temperature)
n = nn(temperature)
return 1 / tvp * ((f >= 0.0 ? f : 0.0) / K)^n
end
"""
integrate_material!(material::GenericChabocheThermal{T}) where T <: Real
Chaboche viscoplastic material with thermal effects. The model includes
kinematic hardening with three backstresses, and isotropic hardening.
Let the prime (') denote the time derivative. The evolution equations are:
σ' = D : εel' + dD/dθ : εel θ'
R' = b (Q - R) p'
Xj' = ((2/3) Cj n - Dj Xj) p' (no sum)
where j = 1, 2, 3. The strain consists of elastic, thermal and viscoplastic
contributions:
ε = εel + εth + εpl
Outside the elastic region, the viscoplastic strain response is given by:
εpl' = n p'
where
n = ∂f/∂σ
and p' obeys a Norton-Bailey power law:
p' = 1/tvp * (<f> / Kn)^nn
Here <...> are the Macaulay brackets (a.k.a. positive part), and
the yield criterion is of the von Mises type:
f = √(3/2 dev(σ_eff) : dev(σ_eff)) - (R0 + R)
σ_eff = σ - ∑ Xj
See:
J.-L. Chaboche. Constitutive equations for cyclic plasticity and cyclic
viscoplasticity. International Journal of Plasticity 5(3) (1989), 247--302.
https://doi.org/10.1016/0749-6419(89)90015-6
Further reading:
J.-L. Chaboche. A review of some plasticity and viscoplasticity constitutive
theories. International Journal of Plasticity 24 (2008), 1642--1693.
https://dx.doi.org/10.1016/j.ijplas.2008.03.009
J.-L. Chaboche, A. Gaubert, P. Kanouté, A. Longuet, F. Azzouz, M. Mazière.
Viscoplastic constitutive equations of combustion chamber materials including
cyclic hardening and dynamic strain aging. International Journal of Plasticity
46 (2013), 1--22. https://dx.doi.org/10.1016/j.ijplas.2012.09.011
"""
function integrate_material!(material::GenericChabocheThermal{T}) where T <: Real
p = material.parameters
v = material.variables
dd = material.ddrivers
d = material.drivers
theta0 = p.theta0
Ef = p.E
nuf = p.nu
alphaf = p.alpha
temperature = d.temperature
dstrain = dd.strain
dtime = dd.time
dtemperature = dd.temperature
@unpack stress, X1, X2, X3, plastic_strain, cumeq, R = v
VariableState{U} = GenericChabocheThermalVariableState{U}
DriverState{U} = GenericChabocheThermalDriverState{U}
ff(sigma, R, X1, X2, X3, theta) = yield_criterion(VariableState{T}(stress=sigma, R=R, X1=X1, X2=X2, X3=X3),
DriverState{T}(temperature=theta),
p)
# n = ∂f/∂σ
nf(sigma, R, X1, X2, X3, theta) = yield_jacobian(VariableState{T}(stress=sigma, R=R, X1=X1, X2=X2, X3=X3),
DriverState{T}(temperature=theta),
p)
# p' (dp = p' * dtime)
dotpf(sigma, R, X1, X2, X3, theta) = overstress_function(VariableState{T}(stress=sigma, R=R, X1=X1, X2=X2, X3=X3),
DriverState{T}(temperature=theta),
p)
# Compute the elastic trial stress.
#
# We compute the elastic trial stress increment by using data from the
# start of the timestep, so we have essentially a forward Euler predictor.
#
# Relevant equations (thermoelasto(-visco-)plastic model):
#
# ε = εel + εpl + εth
# σ = D : εel (Hooke's law)
#
# where D = D(θ) is the elastic stiffness tensor (symmetric, rank-4),
# and θ is the absolute temperature (scalar, θ > 0).
#
# Thus:
#
# Δσ = Δ(D : εel)
# = ΔD : εel + D : Δεel
# = (dD/dθ Δθ) : εel + D : Δεel
# = dD/dθ : εel Δθ + D : Δεel
#
# where the elastic strain increment
#
# Δεel = Δε - Δεpl - Δεth
#
# In the elastic trial step, we temporarily assume Δεpl = 0, so then:
#
# Δεel = Δε - Δεth
#
# The elastic stiffness tensor D is explicitly known. Its derivative dD/dθ
# we can obtain by autodiff. The temperature increment Δθ is a driver.
#
# What remains to consider are the various strains. Because we store the total
# stress σ, we can obtain the elastic strain εel by inverting Hooke's law:
#
# εel = C : σ
#
# where C = C(θ) is the elastic compliance tensor (i.e. the inverse of
# the elastic stiffness tensor D with respect to the double contraction),
# and σ is a known total stress. (We have it at the start of the timestep.)
#
# The total strain increment Δε is a driver. So we only need to obtain Δεth.
# The thermal strain εth is, generally speaking,
#
# εth = α(θ) (θ - θ₀)
#
# where α is the linear thermal expansion tensor (symmetric, rank-2), and
# θ₀ is a reference temperature, where thermal expansion is considered zero.
#
# We can autodiff this to obtain dεth/dθ. Then the thermal strain increment
# Δεth is just:
#
# Δεth = dεth/dθ Δθ
#
Cf(theta) = compliance_tensor(Ef, nuf, theta)
C = Cf(temperature)
elastic_strain = dcontract(C, stress)
# This is a function so we can autodiff it to get the algorithmic jacobian in the elastic region.
# Δσ = D : Δεel + dD/dθ : εel Δθ
function elastic_dstress(dstrain::Symm2{<:Real}, dtemperature::Real)
local temperature_new = temperature + dtemperature
thermal_strainf(theta) = thermal_strain_tensor(alphaf, theta0, theta)
thermal_dstrain = thermal_strainf(temperature_new) - thermal_strainf(temperature)
trial_elastic_dstrain = dstrain - thermal_dstrain
Df(theta) = elasticity_tensor(Ef, nuf, theta) # dσ/dε, i.e. ∂σij/∂εkl
dDdthetaf(theta) = gradient(Df, theta)
# Evaluating `Df` and `dDdthetaf` at `temperature_new` eliminates integrator drift
# in cyclic uniaxial loading conditions inside the elastic region.
# Note in the second term we use the *old* elastic strain.
return (dcontract(Df(temperature_new), trial_elastic_dstrain)
+ dcontract(dDdthetaf(temperature_new), elastic_strain) * dtemperature)
end
stress += elastic_dstress(dstrain, dtemperature)
# using elastic trial problem state
if true # ff(stress, R, X1, X2, X3, temperature) > 0.0 # plastic region
rx!, rdstrain, rtemperature = create_nonlinear_system_of_equations(material)
x0 = state_to_vector(stress, R, X1, X2, X3)
res = nlsolve(rx!, x0; method=material.options.nlsolve_method, autodiff=:forward) # user manual: https://github.com/JuliaNLSolvers/NLsolve.jl
converged(res) || error("Nonlinear system of equations did not converge!")
x = res.zero
stress, R, X1, X2, X3 = state_from_vector(x)
# using the new problem state
temperature_new = temperature + dtemperature
# Compute the new plastic strain
dotp = dotpf(stress, R, X1, X2, X3, temperature_new)
n = nf(stress, R, X1, X2, X3, temperature_new)
dp = dotp * dtime # Δp, using backward Euler (dotp is |∂εpl/∂t| at the end of the timestep)
plastic_strain += dp * n
cumeq += dp # cumulative equivalent plastic strain (note Δp ≥ 0)
# Compute the new algorithmic jacobian Jstrain by implicit differentiation of the residual function,
# using `ForwardDiff` to compute the derivatives. Details in `create_nonlinear_system_of_equations`.
# We compute ∂V/∂D ∀ V ∈ state, D ∈ drivers (excluding time).
drdx = ForwardDiff.jacobian(debang(rx!), x)
# Here we don't bother with offdiagscale, since this Voigt conversion is just a marshaling.
# All `rdstrain` does with the Voigt `dstrain` is to unmarshal it back into a tensor.
# All computations are performed in tensor format.
rdstrainf(dstrain) = rdstrain(stress, R, X1, X2, X3, dstrain) # at solution point
drdstrain = ForwardDiff.jacobian(rdstrainf, tovoigt(dstrain))
Jstrain = -drdx \ drdstrain
jacobian = fromvoigt(Symm4, Jstrain[1:6, 1:6])
dRdstrain = fromvoigt(Symm2, Jstrain[7, 1:6])
dX1dstrain = fromvoigt(Symm4, Jstrain[8:13, 1:6])
dX2dstrain = fromvoigt(Symm4, Jstrain[14:19, 1:6])
dX3dstrain = fromvoigt(Symm4, Jstrain[20:25, 1:6])
rtemperaturef(theta) = rtemperature(stress, R, X1, X2, X3, theta) # at solution point
drdtemperature = ForwardDiff.jacobian(rtemperaturef, [temperature_new])
Jtemperature = -drdx \ drdtemperature
dstressdtemperature = fromvoigt(Symm2, Jtemperature[1:6, 1])
dRdtemperature = Jtemperature[7, 1]
dX1dtemperature = fromvoigt(Symm2, Jtemperature[8:13, 1])
dX2dtemperature = fromvoigt(Symm2, Jtemperature[14:19, 1])
dX3dtemperature = fromvoigt(Symm2, Jtemperature[20:25, 1])
else # elastic region
# TODO: update R (thermal effects), see if Xs also need updating
jacobian = gradient(((dstrain) -> elastic_dstress(dstrain, dtemperature)),
dstrain)
dstressdtemperature = gradient(((dtemperature) -> elastic_dstress(dstrain, dtemperature)),
dtemperature)
# In the elastic region, the plastic variables stay constant,
# so their jacobians vanish.
dRdstrain = zero(Symm2{T})
dX1dstrain = zero(Symm4{T})
dX2dstrain = zero(Symm4{T})
dX3dstrain = zero(Symm4{T})
dRdtemperature = zero(T)
dX1dtemperature = zero(Symm2{T})
dX2dtemperature = zero(Symm2{T})
dX3dtemperature = zero(Symm2{T})
end
variables_new = VariableState{T}(stress=stress,
R=R,
X1=X1,
X2=X2,
X3=X3,
plastic_strain=plastic_strain,
cumeq=cumeq,
jacobian=jacobian,
dRdstrain=dRdstrain,
dX1dstrain=dX1dstrain,
dX2dstrain=dX2dstrain,
dX3dstrain=dX3dstrain,
dstressdtemperature=dstressdtemperature,
dRdtemperature=dRdtemperature,
dX1dtemperature=dX1dtemperature,
dX2dtemperature=dX2dtemperature,
dX3dtemperature=dX3dtemperature)
material.variables_new = variables_new
return nothing
end
"""
create_nonlinear_system_of_equations(material::GenericChabocheThermal{T}) where T <: Real
Create and return an instance of the equation system for the incremental form of
the evolution equations.
Used internally for computing the viscoplastic contribution in `integrate_material!`.
The input `material` represents the problem state at the end of the previous
timestep. The created equation system will hold its own copy of that state.
The equation system is represented as a mutating function `r!` that computes the
residual:
```julia
r!(F::V, x::V) where V <: AbstractVector{<:Real}
```
Both `F` (output) and `x` (input) are length-25 vectors containing
[sigma, R, X1, X2, X3], in that order. The tensor quantities sigma,
X1, X2, X3 are encoded in Voigt format.
The function `r!` is intended to be handed over to `nlsolve`.
"""
function create_nonlinear_system_of_equations(material::GenericChabocheThermal{T}) where T <: Real
p = material.parameters
v = material.variables
dd = material.ddrivers
d = material.drivers
theta0 = p.theta0
Ef = p.E
nuf = p.nu
alphaf = p.alpha
C1f = p.C1
D1f = p.D1
C2f = p.C2
D2f = p.D2
C3f = p.C3
D3f = p.D3
Qf = p.Q
bf = p.b
VariableState{U} = GenericChabocheThermalVariableState{U}
DriverState{U} = GenericChabocheThermalDriverState{U}
# n = ∂f/∂σ
nf(sigma, R, X1, X2, X3, theta) = yield_jacobian(VariableState{eltype(sigma)}(stress=sigma, R=R, X1=X1, X2=X2, X3=X3),
DriverState{typeof(theta)}(temperature=theta),
p)
# p' (dp = p' * dtime)
dotpf(sigma, R, X1, X2, X3, theta) = overstress_function(VariableState{eltype(sigma)}(stress=sigma, R=R, X1=X1, X2=X2, X3=X3),
DriverState{typeof(theta)}(temperature=theta),
p)
# Old problem state (i.e. the problem state at the time when this equation
# system instance was created).
#
# Note this does not include the elastic trial; this is the actual state
# at the end of the previous timestep.
temperature = d.temperature
dtime = dd.time
dtemperature = dd.temperature
@unpack stress, X1, X2, X3, plastic_strain, cumeq, R = v
# To compute Δσ (and thus σ_new) in the residual, we need the new elastic
# strain εel_new, as well as the elastic strain increment Δεel. By the
# definition of Δεel,
#
# εel_new = εel_old + Δεel
#
# The elastic strain isn't stored in the model, but the total stress is,
# so we can obtain εel_old from Hooke's law, using the old problem state.
#
# The other quantity we need is Δεel. Recall that, in general:
#
# Δεel = Δε - Δεpl - Δεth
#
# The total strain increment Δε is a driver. The (visco-)plastic model gives
# us Δεpl (iteratively). The thermal contribution Δεth we can obtain as before.
#
# Thus we obtain εel and Δεel, which we can use to compute the residual for
# the new total stress σ_new.
#
Cf(theta) = compliance_tensor(Ef, nuf, theta)
C = Cf(temperature)
elastic_strain_old = dcontract(C, stress)
# To solve the equation system, we need to parameterize the residual function
# by all unknowns.
#
# To obtain the algorithmic jacobian ∂(Δσ)/∂(Δε), first keep in mind that as
# far as the algorithm is concerned, σ_old and ε_old are constants. Therefore,
# ∂(...)/∂(Δσ) = ∂(...)/∂(σ_new), and similarly for Δε, ε_new.
#
# Let r denote the residual function. For simplicity, consider only the increments
# Δε, Δσ for now (we will generalize below). At a solution point, we have:
#
# r(Δε, Δσ) = 0
#
# **On the condition that** we stay on the solution surface - i.e. it remains true
# that r = 0 - let us consider what happens to Δσ when we change Δε. On the solution
# surface, we can locally consider Δσ as a function of Δε:
#
# Δσ = Δσ(Δε)
#
# Taking this into account, we differentiate both sides of r = 0 w.r.t. Δε:
#
# dr/d(Δε) = d(0)/d(Δε)
#
# which yields, by applying the chain rule on the LHS:
#
# ∂r/∂(Δε) + ∂r/∂(Δσ) d(Δσ)/d(Δε) = 0
#
# Solving for d(Δσ)/d(Δε) now yields:
#
# d(Δσ)/d(Δε) = -∂r/∂(Δσ) \ ∂r/∂(Δε)
#
# which we can compute as:
#
# d(Δσ)/d(Δε) = -∂r/∂σ_new \ ∂r/∂(Δε)
#
# This completes the solution for the jacobian of the simple two-variable
# case. We can extend the same strategy to compute the jacobian for our
# actual problem. At a solution point, the residual equation is:
#
# r(Δε, Δσ, ΔR, ΔX1, ΔX2, ΔX3) = 0
#
# Packing the state variables into the vector x ≡ [σ R X1 X2 X3] (with tensors
# encoded into Voigt notation), we can rewrite this as:
#
# r(Δε, Δx) = 0
#
# Proceeding as before, we differentiate both sides w.r.t. Δε:
#
# dr/d(Δε) = d(0)/d(Δε)
#
# Considering Δx as a function of Δε (locally, on the solution surface),
# and applying the chain rule, we have:
#
# ∂r/∂(Δε) + ∂r/∂(Δx) d(Δx)/d(Δε) = 0
#
# Solving for d(Δx)/d(Δε) (which contains d(Δσ)/d(Δε) in its [1:6, 1:6] block) yields:
#
# d(Δx)/d(Δε) = -∂r/∂(Δx) \ ∂r/∂(Δε)
#
# which we can compute as:
#
# d(Δx)/d(Δε) = -∂r/∂x_new \ ∂r/∂(Δε)
#
# So, we can autodiff the algorithm to obtain both RHS terms, if we
# parameterize the residual function twice: once by x_new (which is
# already needed for solving the nonlinear equation system), and
# once by Δε (keeping all other quantities constant).
#
# Note this is slightly expensive. ∂r/∂x_new is a 25×25 matrix,
# and ∂r/∂(Δε) is 25×6. So essentially, to obtain d(Δx)/d(Δε),
# from which we can read off d(Δσ)/d(Δε), we must solve six
# linear equation systems, each of size 25. (In a FEM solver,
# this must be done for each integration point.)
#
# But if we are willing to pay for that, we get the algorithmic jacobian
# exactly (up to the effects of finite precision arithmetic) - which gives
# us quadratic convergence in a FEM solver using this material model.
# Residual function. (Actual implementation in `r!`, below.)
#
# This variant is for solving the equation system. F is output, x is filled by NLsolve.
# The solution is x = x* such that g(x*) = 0.
#
# This is a mutating function for performance reasons.
#
# Parameterized by the whole new state x_new.
# We can also autodiff this at the solution point to obtain ∂r/∂x_new.
function rx!(F::V, x::V) where V <: AbstractVector{<:Real} # x = new state
# IMPORTANT: Careful here not to overwrite cell variables
# from the outer scope. (Those variables hold the *old* values
# at the start of the timestep.) Either use a new name, or use
# the `local` annotation.
stress_new, R_new, X1_new, X2_new, X3_new = state_from_vector(x)
r!(F, stress_new, R_new, X1_new, X2_new, X3_new, dd.strain, temperature + dtemperature)
return nothing
end
# Residual parameterized by Δε, for algorithmic jacobian computation.
# Autodiff this (w.r.t. strain) at the solution point to get ∂r/∂(Δε).
#
# This we only need to compute once per timestep, so this allocates
# the output array.
#
# The quantity w.r.t. which the function is to be autodiffed must be a
# parameter, so `ForwardDiff` can promote it to use dual numbers.
# So `dstrain` must be a parameter. But the old state (from `material`)
# is used in several internal computations above. So the value of `dstrain`
# given to this routine **must be** `material.ddrivers.strain`.
#
# We also need to pass the new state (the solution point) to the underlying
# residual function `r!`. Use the partial application pattern to provide that:
#
# r(dstrain) = rdstrain(stress, R, X1, X2, X3, dstrain)
# ForwardDiff.jacobian(r, tovoigt(dstrain))
function rdstrain(stress_new::Symm2{<:Real}, R_new::Real,
X1_new::Symm2{<:Real}, X2_new::Symm2{<:Real}, X3_new::Symm2{<:Real},
x::V) where V <: AbstractVector{<:Real} # x = dstrain
F = similar(x, eltype(x), (25,))
# We don't bother with offdiagscale, since this Voigt conversion is just a marshaling.
# All computations are performed in tensor format.
dstrain = fromvoigt(Symm2, x)
r!(F, stress_new, R_new, X1_new, X2_new, X3_new, dstrain, temperature + dtemperature)
return F
end
function rtemperature(stress_new::Symm2{<:Real}, R_new::Real,
X1_new::Symm2{<:Real}, X2_new::Symm2{<:Real}, X3_new::Symm2{<:Real},
x::V) where V <: AbstractVector{<:Real} # x = temperature_new
F = similar(x, eltype(x), (25,))
temperature_new = x[1]
r!(F, stress_new, R_new, X1_new, X2_new, X3_new, dd.strain, temperature_new)
return F
end
# TODO: decouple integrator
# The evolution equations are written in an incremental form:
#
# Δσ = D : Δεel + dD/dθ : εel Δθ (components 1:6)
# ΔR = b (Q - R_new) Δp (component 7)
# ΔXj = ((2/3) Cj n - Dj Xj_new) Δp (components 8:13, 14:19, 20:25) (no sum)
#
# where
#
# Δ(...) = (...)_new - (...)_old
#
# (Δp and n are described below.)
#
# Then in each equation, move the terms on the RHS to the LHS to get
# the standard form, (stuff) = 0. Then the LHS is the residual.
#
# The viscoplastic response is updated by:
#
# Δεpl = Δp n
#
# where
#
# Δp = p' Δt
# p' = 1/tvp * (<f> / Kn)^nn (Norton-Bailey power law; <...>: Macaulay brackets)
# f = √(3/2 dev(σ_eff) : dev(σ_eff)) - (R0 + R)
# σ_eff = σ - ∑ Xj
# n = ∂f/∂σ
#
# `F` is output, length 25.
function r!(F::V, stress_new::Symm2{<:Real}, R_new::Real,
X1_new::Symm2{<:Real}, X2_new::Symm2{<:Real}, X3_new::Symm2{<:Real},
dstrain::Symm2{<:Real}, temperature_new::Real) where {V <: AbstractVector{<:Real}}
# This stuff must be done here so we can autodiff it w.r.t. temperature_new.
thermal_strainf(theta) = thermal_strain_tensor(alphaf, theta0, theta)
# thermal_strain_derivative(theta) = gradient(thermal_strainf, theta)
# thermal_dstrain = thermal_strain_derivative(temperature_new) * (temperature_new - temperature)
thermal_dstrain = thermal_strainf(temperature_new) - thermal_strainf(temperature)
Df(theta) = elasticity_tensor(Ef, nuf, theta) # dσ/dε, i.e. ∂σij/∂εkl
dDdthetaf(theta) = gradient(Df, theta)
D = Df(temperature_new)
dDdtheta = dDdthetaf(temperature_new)
dotp = dotpf(stress_new, R_new, X1_new, X2_new, X3_new, temperature_new)
n = nf(stress_new, R_new, X1_new, X2_new, X3_new, temperature_new)
local dtemperature = temperature_new - temperature
# Hooke's law in elastic regime
#
# σ = D : ε_el
#
# leads to
#
# σ' = D : (ε_el)' + ∂D/∂θ : ε_el θ'
#
# We have postulated that the evolution equation for the stress
# remains the same also in the viscoplastic regime, but now
# plastic contributions to the total strain ε affect the
# elastic strain ε_el:
#
# ε = ε_el + ε_pl + ε_th
#
# so that
#
# ε_el = ε - ε_pl - ε_th
#
# and similarly for the increments. Note that the old elastic
# strain can be obtained by inverting Hooke's law at the old
# stress value.
#
dp = dotp * dtime
plastic_dstrain = dp * n
elastic_dstrain = dstrain - plastic_dstrain - thermal_dstrain
elastic_strain = elastic_strain_old + elastic_dstrain
# # σ' = D : (ε_el)' + ∂D/∂θ : ε_el θ'
# tovoigt!(view(F, 1:6),
# stress_new - stress
# - dcontract(D, elastic_dstrain)
# - dcontract(dDdtheta, elastic_strain) * dtemperature)
# σ = D : ε_el
tovoigt!(view(F, 1:6),
stress_new
- dcontract(D, elastic_strain))
# Reijo's equations (37) and (43), for exponentially saturating
# isotropic hardening, are:
#
# Kiso = Kiso∞ (1 - exp(-hiso κiso / Kiso∞))
# κiso' = 1 / tvp <fhat / σ0>^p
#
# Our equation for R in the case without thermal effects, where
# Q and b are constant, is:
#
# R' = b (Q - R) p'
#
# We identify (LHS Reijo's notation; RHS Materials.jl notation):
#
# Kiso = R, κiso = p, σ0 = Kn, p = nn
# TODO: is fhat our f? Looks a bit different.
#
# So in the notation used in Materials.jl:
#
# R = R∞ (1 - exp(-hiso p / R∞))
# p' = 1 / tvp <fhat / Kn>^nn
#
# which leads to
#
# R' = -R∞ * (-hiso p'/ R∞) exp(-hiso p / R∞)
# = hiso exp(-hiso p / R∞) p'
# = hiso (1 - R / R∞) p'
# = hiso p' / R∞ (R∞ - R)
# = (hiso / R∞) (R∞ - R) p'
# ≡ b (Q - R) p'
#
# where
#
# Q := R∞
# b := hiso / R∞
#
# Thus we can write
#
# R = Q (1 - exp(-b p))
#
#
# Now, if we model thermal effects by Q = Q(θ), b = b(θ), we have
#
# R' = ∂Q/∂θ θ' (1 - exp(-b p)) - Q (-b p)' exp(-b p)
# = ∂Q/∂θ θ' (1 - exp(-b p)) + Q (∂b/∂θ θ' p + b p') exp(-b p)
#
# Observe that
#
# Q exp(-b p) = Q - R
# 1 - exp(-b p) = R / Q
#
# so we can write
#
# R' = (∂Q/∂θ / Q) θ' R + (∂b/∂θ θ' p + b p') (Q - R)
# = b (Q - R) p' + ((∂Q/∂θ / Q) R + ∂b/∂θ (Q - R) p) θ'
#
# on the condition that Q ≠ 0.
#
# But that's a disaster when Q = 0 (no isotropic hardening),
# so let's use R / Q = 1 - exp(-b p) to obtain
#
# R' = b (Q - R) p' + (∂Q/∂θ (1 - exp(-b p)) + ∂b/∂θ (Q - R) p) θ'
#
# which is the form we use here.
#
Q = Qf(temperature_new)
b = bf(temperature_new)
dQdtheta = gradient(Qf, temperature_new)
dbdtheta = gradient(bf, temperature_new)
cumeq_new = v.cumeq + dp
# TODO: p (cumeq) accumulates too much error to be usable here.
# TODO: As t increases, R will drift until the solution becomes nonsense.
# TODO: So for now, we approximate ∂Q/∂θ = ∂b/∂θ = 0 to eliminate terms
# TODO: that depend on p. (p' is fine; computed afresh every timestep.)
# F[7] = R_new - R - (b*(Q - R_new) * dp
# + (dQdtheta * (1 - exp(-b * cumeq_new))
# + dbdtheta * (Q - R_new) * cumeq_new)
# * dtemperature) # numerically bad
# F[7] = R_new - R - b*(Q - R_new) * dp # original equation, no dependence on temperature
# # consistent, including effects of temperature (and numerically much better than the above)
# F[7] = R_new - R - (dQdtheta * dtemperature * (1 - exp(-b * cumeq_new))
# + Q * (dbdtheta * dtemperature * cumeq_new + b * dp) * exp(-b * cumeq_new))
# # equivalent with the previous one, no difference in numerical behavior either
F[7] = R_new - R - (b*(Q - R_new) * dp
+ (dQdtheta * (1 - exp(-b * cumeq_new))
+ Q * dbdtheta * cumeq_new * exp(-b * cumeq_new)) * dtemperature)
# Reijo's equations (44) and (38):
#
# κk' = εp' - 1 / tvp <fhat / σ0>^p (3 / Kk∞) Kk
# Kk = 2/3 hk κk
#
# In Materials.jl, we have:
#
# εp' = p' n
# p' = 1 / tvp <fhat / Kn>^nn
#
# so (in a mixed abuse of notation)
#
# κk' = p' n - p' (3 / Kk∞) Kk
# = p' (n - (3 / Kk∞) Kk)
#
# In the case without thermal effects, hk is a constant, so:
#
# Kk' = 2/3 hk κk'
# = 2/3 hk p' (n - (3 / Kk∞) Kk)
# = p' (2/3 hk n - (2 hk / Kk∞) Kk)
#
# The equation used in Materials.jl is:
#
# Xk' = p' (2/3 Ck n - Dk Xk)
#
# so we identify
#
# Xk = Kk, Ck = hk, Dk = 2 hk / Kk∞
#
#
# Now let us model thermal effects by Ck = Ck(θ), Dk = Dk(θ).
# In Materials.jl notation, we have:
#
# Kk∞ = 2 Ck / Dk
#
# when Dk ≠ 0, so if also Ck ≠ 0, then
#
# 3 / Kk∞ = 3/2 Dk / Ck
#
# We have:
#
# κk' = p' (n - 3/2 (Dk / Ck) Kk)
# Kk = 2/3 Ck κk
#
# Differentiating:
#
# Kk' = 2/3 (Ck' κk + Ck κk')
# = 2/3 (∂Ck/∂θ θ' κk + Ck κk')
# = 2/3 (∂Ck/∂θ θ' κk + p' (Ck n - 3/2 Dk Kk))
# = 2/3 ∂Ck/∂θ θ' κk + p' (2/3 Ck n - Dk Kk)
#
# To avoid the need to track the internal variables κk as part of the
# problem state, we can use:
#
# Kk = 2/3 Ck κk
#
# So whenever Ck ≠ 0,
#
# κk = 3/2 Kk / Ck
#
# Final result:
#
# Xk' = 2/3 ∂Ck/∂θ θ' κk + p' (2/3 Ck n - Dk Xk)
# = 2/3 ∂Ck/∂θ θ' (3/2 Xk / Ck) + p' (2/3 Ck n - Dk Xk)
# = (∂Ck/∂θ / Ck) Xk θ' + p' (2/3 Ck n - Dk Xk)
#
# ------------------------------------------------------------
#
# We identified Ck = hk, Dk = 2 hk / Kk∞. The special case
# Ck(θ) = Dk(θ) ≡ 0 corresponds to hk = 0, Kk∞ → +∞. Then we have:
#
# κk' = p' (n - (3 / Kk∞) Kk) → p' n
# Kk' ≡ 0
#
# Also, because Kk = 2/3 Ck κk, we have Kk ≡ 0.
#
# In this case we can discard the internal variables κk, because they
# only contribute to Kk.
#
# ------------------------------------------------------------
#
# Incremental form:
#
# ΔXk = 2/3 ∂Ck/∂θ Δθ κk + Δp (2/3 Ck n - Dk Xk)
# = 2/3 ∂Ck/∂θ Δθ (3/2 Xk / Ck) + Δp (2/3 Ck n - Dk Xk)
# = (∂Ck/∂θ / Ck) Xk Δθ + Δp (2/3 Ck n - Dk Xk)
#
C1 = C1f(temperature_new)
dC1dtheta = gradient(C1f, temperature_new)
logdiff1 = (C1 != 0.0) ? (dC1dtheta / C1) : 0.0
D1 = D1f(temperature_new)
C2 = C2f(temperature_new)
dC2dtheta = gradient(C2f, temperature_new)
logdiff2 = (C2 != 0.0) ? (dC2dtheta / C2) : 0.0
D2 = D2f(temperature_new)
C3 = C3f(temperature_new)
dC3dtheta = gradient(C3f, temperature_new)
logdiff3 = (C3 != 0.0) ? (dC3dtheta / C3) : 0.0
D3 = D3f(temperature_new)
tovoigt!(view(F, 8:13), X1_new - X1 - (logdiff1 * X1_new * dtemperature
+ dp*(2.0/3.0*C1*n - D1*X1_new)))
tovoigt!(view(F, 14:19), X2_new - X2 - (logdiff2 * X2_new * dtemperature
+ dp*(2.0/3.0*C2*n - D2*X2_new)))
tovoigt!(view(F, 20:25), X3_new - X3 - (logdiff3 * X3_new * dtemperature
+ dp*(2.0/3.0*C3*n - D3*X3_new)))
return nothing
end
return rx!, rdstrain, rtemperature
end
end
| Materials | https://github.com/JuliaFEM/Materials.jl.git |
|
[
"MIT"
] | 0.4.0 | d7a67c1c8ae6118f253a137ffa5291421e757a8a | code | 18408 | # This file is a part of JuliaFEM.
# License is MIT: see https://github.com/JuliaFEM/Materials.jl/blob/master/LICENSE
"""
The functions in this module are made to be able to easily simulate stress
states produced by some of the most common test machines.
Take for example the function `uniaxial_increment!`. In a push-pull machine
(with a smooth specimen), we know that the stress state is uniaxial (in the
measuring volume). Given the strain increment in the direction where the stress
is nonzero, we find a strain increment that produces zero stress in the other
directions. Similarly for the other functions.
"""
module Increments
import LinearAlgebra: norm
import Tensors: tovoigt, fromvoigt
import ..AbstractMaterial, ..integrate_material!
import ..Utilities: Symm2
export find_dstrain!, general_increment!, stress_driven_general_increment!,
general_mixed_increment!,
uniaxial_increment!, biaxial_increment!, stress_driven_uniaxial_increment!
"""
find_dstrain!(material::AbstractMaterial, dstrain::AbstractVector{<:Real},
dt::Real, update_dstrain!::Function;
max_iter::Integer=50, tol::Real=1e-9)
Find a compatible strain increment for `material`.
Chances are you'll only need to call this low-level function directly if you
want to implement new kinds of strain optimizers. See `general_increment!`
and `stress_driven_general_increment!` for usage examples.
This is the skeleton of the optimizer. The individual specific optimizer
functions (`update_dstrain!)` only need to define how to update `dstrain`.
The skeleton itself isn't a Newton-Raphson root finder. It just abstracts away
the iteration loop, convergence checking and data plumbing, so it can be used,
among other kinds, to conveniently implement Newton-Raphson root finders.
The `dstrain` supplied to this function is the initial guess for the
optimization. At each iteration, it must be updated by the user-defined
corrector `update_dstrain!`, whose call signature is:
update_dstrain!(dstrain::V, dstress::V, jacobian::AbstractArray{T})
where V <: AbstractVector{T} where T <: Real
-> err::Real
`dstrain` is the current value of the strain increment, in Voigt format.
Conversion to tensor format uses `offdiagscale=2.0`. The function must update
the Voigt format `dstrain` in-place.
`dstress = stress - stress0`, where `stress` is the stress state predicted by
integrating the material for one timestep of length `dt`, using the current
value of `dstrain` as a driving strain increment, and `stress0` is the stress
state stored in `materials.variables.stress`.
`jacobian` is ∂σij/∂εkl (`material.variables_new.jacobian`), as computed by the
material implementation. In many cases, the dstrain optimization can actually be
performed by a Newton-Raphson root finder, so we pass the jacobian to facilitate
writing the update formula for such a root finder.
The return value `err` must be an error measure (Real, >= 0).
The update is iterated at most `max_iter` times, until `err` falls below `tol`.
If `max_iter` is reached and the error measure is still `tol` or greater,
`ErrorException` is thrown.
To keep features orthogonal, the timestep is **not** committed automatically.
We call `integrate_material!`, but not `update_material!`. In other words,
we only update `material.variables_new`. To commit the timestep, call
`update_material!` after the optimizer is done.
"""
function find_dstrain!(material::AbstractMaterial, dstrain::AbstractVector{<:Real},
dt::Real, update_dstrain!::Function;
max_iter::Integer=50, tol::Real=1e-9)
stress0 = tovoigt(material.variables.stress) # stored
T = typeof(dstrain[1])
# @debug "---START---"
for i=1:max_iter
# @debug "$i, $dstrain, $stress0, $(material.variables.stress)"
material.ddrivers.time = dt
material.ddrivers.strain = fromvoigt(Symm2{T}, dstrain; offdiagscale=2.0)
integrate_material!(material)
stress = tovoigt(material.variables_new.stress) # predicted
dstress = stress - stress0
jacobian = tovoigt(material.variables_new.jacobian)
e = update_dstrain!(dstrain, dstress, jacobian)
if e < tol
return nothing
end
end
error("No convergence in strain increment")
end
# --------------------------------------------------------------------------------
"""
general_increment!(material::AbstractMaterial, dstrain_knowns::AbstractVector{Union{T, Missing}},
dstrain::AbstractVector{Union{T, Missing}}=dstrain_knowns,
max_iter::Integer=50, norm_acc::T=1e-9) where T <: Real
Find a compatible strain increment for `material`.
The material state (`material.variables`) and any non-`missing` components of
the *strain* increment `dstrain_knowns` are taken as prescribed. Any `missing`
components will be solved for.
This routine computes the `missing` components of the strain increment, such that
those components of the new stress state that correspond to the `missing` strain
increment components, remain at the old values stored in `material.variables.stress`.
(Often in practice, those old values are set to zero, allowing simulation of
uniaxial push-pull tests and similar.)
"New" stress state means the stress state after integrating the material by
one timestep of length `dt`.
The type of the initial guess `dstrain` is `AbstractVector{Union{T, Missing}}`
only so we can make it default to `dstrain_knowns`, which has that type. Any
`missing` components in the initial guess `dstrain` will be replaced by zeroes
before we invoke the solver.
See `find_dstrain!`.
"""
function general_increment!(material::AbstractMaterial,
dstrain_knowns::AbstractVector{<:Union{T, Missing}},
dt::Real,
dstrain::AbstractVector{<:Union{T, Missing}}=dstrain_knowns,
max_iter::Integer=50, norm_acc::T=1e-9) where T <: Real
function validate_size(name::String, v::AbstractVector)
if ndims(v) != 1 || size(v)[1] != 6
error("""Expected a length-6 vector for $(name), got $(typeof(v)) with size $(join(size(v), "×"))""")
end
end
validate_size("dstrain_knowns", dstrain_knowns)
validate_size("dstrain", dstrain)
dstrain_actual::AbstractVector{T} = T[((x !== missing) ? x : T(0)) for x in dstrain]
dstrain_knowns_idxs = Integer[k for k in 1:6 if dstrain_knowns[k] !== missing]
dstrain_unknown_idxs = setdiff(1:6, dstrain_knowns_idxs)
if length(dstrain_unknown_idxs) == 0
error("Optimizer needs at least one unknown dstrain component to solve for")
end
function update_dstrain!(dstrain::V, dstress::V, jacobian::AbstractArray{T}) where V <: AbstractVector{T} where T <: Real
# See the stress-driven routine (`stress_driven_general_increment!`) for the general idea
# of how this works. The differences to that algorithm are that:
#
# - We update only components whose dstrain is not prescribed.
# - We want all corresponding components of dstress to converge to zero in the
# surrounding Newton-Raphson iteration.
#
dstrain_correction = (-jacobian[dstrain_unknown_idxs, dstrain_unknown_idxs]
\ dstress[dstrain_unknown_idxs])
dstrain[dstrain_unknown_idxs] .+= dstrain_correction
return norm(dstrain_correction)
end
find_dstrain!(material, dstrain_actual, dt, update_dstrain!, max_iter=max_iter, tol=norm_acc)
dstrain[:] = dstrain_actual
return nothing
end
"""
stress_driven_general_increment!(material::AbstractMaterial,
dstress_knowns::AbstractVector{<:Union{T, Missing}},
dt::Real,
dstrain::AbstractVector{T},
max_iter::Integer=50, norm_acc::T=1e-9) where T <: Real
Find a compatible strain increment for `material`.
The material state (`material.variables`) and any non-`missing` components of
the *stress* increment `dstress_knowns` are taken as prescribed.
This routine computes a *strain* increment such that those components of the
new stress state, that correspond to non-`missing` components of `dstress_knowns`,
match those components of `material.variables.stress + dstress_knowns`.
For any `missing` components of `dstress_knowns`, the new stress state will match
the corresponding components of `material.variables.stress`. (So the `missing`
components act as if they were zero.)
*All* strain increment components will be solved for. If you need to prescribe
some of them, while also prescribing stresses, see `general_mixed_increment!`.
"New" stress state means the stress state after integrating the material by
one timestep of length `dt`.
`dstrain` is the initial guess for the strain increment.
See `find_dstrain!`.
"""
function stress_driven_general_increment!(material::AbstractMaterial,
dstress_knowns::AbstractVector{<:Union{T, Missing}},
dt::Real,
dstrain::AbstractVector{T},
max_iter::Integer=50, norm_acc::T=1e-9) where T <: Real
function validate_size(name::String, v::AbstractVector)
if ndims(v) != 1 || size(v)[1] != 6
error("""Expected a length-6 vector for $(name), got $(typeof(v)) with size $(join(size(v), "×"))""")
end
end
validate_size("dstress_knowns", dstress_knowns)
validate_size("dstrain", dstrain)
dstrain_actual::AbstractVector{T} = T[((x !== missing) ? x : T(0)) for x in dstrain]
dstress_knowns_idxs = Integer[k for k in 1:6 if dstress_knowns[k] !== missing]
function update_dstrain!(dstrain::V, dstress::V, jacobian::AbstractArray{T}) where V <: AbstractVector{T} where T <: Real
# For the stress-driven correction, we have
#
# dε = dε₀ + dεₐ
#
# where dε₀ is the dstrain currently suggested by the optimizer, and the adjustment dεₐ is
#
# dεₐ = -(∂σ/∂ε)⁻¹ dσₑ
# dσₑ = dσ - dσₖ
#
# Here dσₑ is the effective stress increment, and dσₖ is the prescribed
# (known) stress increment, which is zero for unknown dstress components.
# As the Newton-Raphson iteration proceeds, dσₑ will converge to zero.
#
# Mutation of `dstress` doesn't matter, since `dstress` is freshly generated at each iteration.
dstress[dstress_knowns_idxs] -= dstress_knowns[dstress_knowns_idxs]
dstrain_correction = -jacobian \ dstress
dstrain .+= dstrain_correction
return norm(dstrain_correction)
end
find_dstrain!(material, dstrain_actual, dt, update_dstrain!, max_iter=max_iter, tol=norm_acc)
dstrain[:] = dstrain_actual
return nothing
end
"""
general_mixed_increment!(material::AbstractMaterial,
dstrain_knowns::AbstractVector{<:Union{T, Missing}},
dstress_knowns::AbstractVector{<:Union{T, Missing}},
dt::Real,
dstrain::AbstractVector{<:Union{T, Missing}}=dstrain_knowns,
max_iter::Integer=50, norm_acc::T=1e-9) where T <: Real
Find a compatible strain increment for `material`. A combination of `general_increment!`
and `stress_driven_general_increment!`, which allows for loadings where some components
are strain-driven and some are stress-driven, such as the biaxial "bow-tie" and
"reverse bow-tie" loadings of:
Corona, E., Hassan, T. and Kyriakides, S. (1996) On the Performance of
Kinematic Hardening Rules in Predicting a Class of Biaxial Ratcheting
Histories. International Journal of Plasticity, Vol 12, pp. 117--145.
See also:
Bari, Shafiqul. (2001) Constitutive modeling for cyclic plasticity and ratcheting.
Ph.D. thesis, North Carolina State University.
which compares the response of several different plasticity models under these loadings.
Each known component must be either strain-driven or stress-driven, not both.
The combination of the known components of dstrain and dstress must describe a
valid material state. Otherwise the optimizer may fail to converge, or return
a nonsensical solution.
"""
function general_mixed_increment!(material::AbstractMaterial,
dstrain_knowns::AbstractVector{<:Union{T, Missing}},
dstress_knowns::AbstractVector{<:Union{T, Missing}},
dt::Real,
dstrain::AbstractVector{<:Union{T, Missing}}=dstrain_knowns,
max_iter::Integer=50, norm_acc::T=1e-9) where T <: Real
function validate_size(name::String, v::AbstractVector)
if ndims(v) != 1 || size(v)[1] != 6
error("""Expected a length-6 vector for $(name), got $(typeof(v)) with size $(join(size(v), "×"))""")
end
end
validate_size("dstrain_knowns", dstrain_knowns)
validate_size("dstress_knowns", dstress_knowns)
validate_size("dstrain", dstrain)
dstrain_actual::AbstractVector{T} = T[((x !== missing) ? x : T(0)) for x in dstrain]
dstrain_knowns_idxs = Integer[k for k in 1:6 if dstrain_knowns[k] !== missing]
dstress_knowns_idxs = Integer[k for k in 1:6 if dstress_knowns[k] !== missing]
dstrain_unknown_idxs = setdiff(1:6, dstrain_knowns_idxs)
if length(dstrain_unknown_idxs) == 0
error("Optimizer needs at least one unknown dstrain component to solve for")
end
# check that no component is being prescribed both ways
let bad_idxs = intersect(dstrain_knowns_idxs, dstress_knowns_idxs)
if length(bad_idxs) > 0
plural = (length(bad_idxs) != 1) ? "s" : ""
error("""Each known component must be either strain- or stress-driven, not both; please check the input for component$(plural) $(bad_idxs)""")
end
end
function update_dstrain!(dstrain::V, dstress::V, jacobian::AbstractArray{T}) where V <: AbstractVector{T} where T <: Real
# This update algorithm is a combination of those in `general_increment!`
# and `stress_driven_general_increment!`.
#
# - Like `general_increment!`, we update only components whose dstrain is not prescribed.
# - Like `stress_driven_general_increment!`, we allow for nonzero target dstress.
#
dstress[dstress_knowns_idxs] -= dstress_knowns[dstress_knowns_idxs]
dstrain_correction = -(jacobian[dstrain_unknown_idxs, dstrain_unknown_idxs]
\ dstress[dstrain_unknown_idxs])
dstrain[dstrain_unknown_idxs] .+= dstrain_correction
return norm(dstrain_correction)
end
find_dstrain!(material, dstrain_actual, dt, update_dstrain!, max_iter=max_iter, tol=norm_acc)
dstrain[:] = dstrain_actual
return nothing
end
# --------------------------------------------------------------------------------
"""
uniaxial_increment!(material::AbstractMaterial, dstrain11::Real, dt::Real;
dstrain::AbstractVector{<:Real}=[dstrain11, -0.3*dstrain11, -0.3*dstrain11, 0.0, 0.0, 0.0],
max_iter::Integer=50, norm_acc::Real=1e-9)
Find a compatible strain increment for `material`.
The material state (`material.variables`) and the component 11 of the *strain*
increment are taken as prescribed.
Convenience function; see `general_increment!`.
See `find_dstrain!`.
"""
function uniaxial_increment!(material::AbstractMaterial, dstrain11::Real, dt::Real;
dstrain::AbstractVector{<:Real}=[dstrain11, -0.3*dstrain11, -0.3*dstrain11, 0.0, 0.0, 0.0],
max_iter::Integer=50, norm_acc::Real=1e-9)
dstrain_knowns = [dstrain11, missing, missing, missing, missing, missing]
general_increment!(material, dstrain_knowns, dt, dstrain, max_iter, norm_acc)
return nothing
end
"""
biaxial_increment!(material::AbstractMaterial, dstrain11::Real, dstrain12::Real, dt::Real;
dstrain::AbstractVector{<:Real}=[dstrain11, -0.3*dstrain11, -0.3*dstrain11, 0, 0, dstrain12],
max_iter::Integer=50, norm_acc::Real=1e-9)
Find a compatible strain increment for `material`.
By "biaxial", we mean a stress state with one normal component and one shear
component.
The material state (`material.variables`) and the components 11 and 12 of the
*strain* increment are taken as prescribed.
Convenience function; see `general_increment!`.
See `find_dstrain!`.
"""
function biaxial_increment!(material::AbstractMaterial, dstrain11::Real, dstrain12::Real, dt::Real;
dstrain::AbstractVector{<:Real}=[dstrain11, -0.3*dstrain11, -0.3*dstrain11, 0, 0, dstrain12],
max_iter::Integer=50, norm_acc::Real=1e-9)
dstrain_knowns = [dstrain11, missing, missing, missing, missing, dstrain12]
general_increment!(material, dstrain_knowns, dt, dstrain, max_iter, norm_acc)
return nothing
end
"""
stress_driven_uniaxial_increment!(material::AbstractMaterial, dstress11::Real, dt::Real;
dstrain::AbstractVector{<:Real}=[dstress11/200e3, -0.3*dstress11/200e3, -0.3*dstress11/200e3, 0.0, 0.0, 0.0],
max_iter::Integer=50, norm_acc::Real=1e-9)
Find a compatible strain increment for `material`.
The material state (`material.variables`) and the component 11 of the *stress*
increment are taken as prescribed.
Convenience function; see `stress_driven_general_increment!`.
See `find_dstrain!`.
"""
function stress_driven_uniaxial_increment!(material::AbstractMaterial, dstress11::Real, dt::Real;
dstrain::AbstractVector{<:Real}=[dstress11/200e3, -0.3*dstress11/200e3, -0.3*dstress11/200e3, 0.0, 0.0, 0.0],
max_iter::Integer=50, norm_acc::Real=1e-9)
dstress_knowns = [dstress11, missing, missing, missing, missing, missing]
stress_driven_general_increment!(material, dstress_knowns, dt, dstrain, max_iter, norm_acc)
return nothing
end
end
| Materials | https://github.com/JuliaFEM/Materials.jl.git |
|
[
"MIT"
] | 0.4.0 | d7a67c1c8ae6118f253a137ffa5291421e757a8a | code | 12126 | # This file is a part of JuliaFEM.
# License is MIT: see https://github.com/JuliaFEM/Materials.jl/blob/master/LICENSE
module MemoryModule
using LinearAlgebra, ForwardDiff, Tensors, NLsolve, Parameters
import ..AbstractMaterial, ..AbstractMaterialState
import ..Utilities: Symm2, Symm4, isotropic_elasticity_tensor, lame, debang
import ..integrate_material! # for method extension
# parametrically polymorphic for any type representing ℝ
export GenericMemory, GenericMemoryDriverState, GenericMemoryParameterState, GenericMemoryVariableState
# specialization for Float64
export Memory, MemoryDriverState, MemoryParameterState, MemoryVariableState
@with_kw mutable struct GenericMemoryDriverState{T <: Real} <: AbstractMaterialState
time::T = zero(T)
strain::Symm2{T} = zero(Symm2{T})
end
"""Parameter state for Memory material.
- `E`: Young's modulus
- `nu`: Poisson's ratio
- `R0`: initial yield strength
- `Kn`: plasticity multiplier divisor (drag stress)
- `nn`: plasticity multiplier exponent
- `C1`, `D1`: parameters governing behavior of backstress X1
- `C2`, `D2`: parameters governing behavior of backstress X2
- `Q0`: The initial isotropic hardening saturation value. Has the units of stress.
- `QM`: The asymptotic isotropic hardening saturation value reached with high strain amplitude.
Has the units of stress.
- `mu`: Controls the rate of evolution of the strain-amplitude dependent isotropic hardening saturation value.
- `b`: Controls the rate of evolution for isotropic hardening.
- `eta`: Controls the balance between memory surface kinematic and isotropic hardening.
Dimensionless, support `[0,1]`.
At `0`, the memory surface hardens kinematically.
At `1`, the memory surface hardens isotropically.
Initially, the value `1/2` was used by several authors. Later, values `< 1/2` have been suggested
to capture the progressive process of memorization.
- `m`: memory evanescence exponent. Controls the non-linearity of the memory evanescence.
- `pt`: threshold of equivalent plastic strain, after which the memory evanescence starts.
- `xi`: memory evanescence strength multiplier.
"""
@with_kw struct GenericMemoryParameterState{T <: Real} <: AbstractMaterialState
E::T = 0.0
nu::T = 0.0
R0::T = 0.0
Kn::T = 0.0
nn::T = 0.0
C1::T = 0.0
D1::T = 0.0
C2::T = 0.0
D2::T = 0.0
Q0::T = 0.0
QM::T = 0.0
mu::T = 0.0
b::T = 0.0
eta::T = 0.0
m::T = 0.0
pt::T = 0.0
xi::T = 0.0
end
"""Problem state for Memory material.
- `stress`: stress tensor
- `X1`: backstress 1
- `X2`: backstress 2
- `plastic_strain`: plastic part of strain tensor
- `cumeq`: cumulative equivalent plastic strain (scalar, ≥ 0)
- `R`: yield strength
- `q`: size of the strain memory surface (~plastic strain amplitude)
- `zeta`: strain memory surface kinematic hardening variable
- `jacobian`: ∂σij/∂εkl
"""
@with_kw struct GenericMemoryVariableState{T <: Real} <: AbstractMaterialState
stress::Symm2{T} = zero(Symm2{T})
X1::Symm2{T} = zero(Symm2{T})
X2::Symm2{T} = zero(Symm2{T})
plastic_strain::Symm2{T} = zero(Symm2{T})
cumeq::T = zero(T)
R::T = zero(T)
q::T = zero(T)
zeta::Symm2{T} = zero(Symm2{T})
jacobian::Symm4{T} = zero(Symm4{T})
end
# TODO: Does this eventually need a {T}?
@with_kw struct MemoryOptions <: AbstractMaterialState
nlsolve_method::Symbol = :trust_region
end
@with_kw mutable struct GenericMemory{T <: Real} <: AbstractMaterial
drivers::GenericMemoryDriverState{T} = GenericMemoryDriverState{T}()
ddrivers::GenericMemoryDriverState{T} = GenericMemoryDriverState{T}()
variables::GenericMemoryVariableState{T} = GenericMemoryVariableState{T}()
variables_new::GenericMemoryVariableState{T} = GenericMemoryVariableState{T}()
parameters::GenericMemoryParameterState{T} = GenericMemoryParameterState{T}()
dparameters::GenericMemoryParameterState{T} = GenericMemoryParameterState{T}()
options::MemoryOptions = MemoryOptions()
end
MemoryDriverState = GenericMemoryDriverState{Float64}
MemoryParameterState = GenericMemoryParameterState{Float64}
MemoryVariableState = GenericMemoryVariableState{Float64}
Memory = GenericMemory{Float64}
"""
state_to_vector(sigma::U, R::T, X1::U, X2::U) where U <: Symm2{T} where T <: Real
Adaptor for `nlsolve`. Marshal the problem state into a `Vector`.
"""
function state_to_vector(sigma::U, R::T, X1::U, X2::U) where U <: Symm2{T} where T <: Real
return [tovoigt(sigma); R; tovoigt(X1); tovoigt(X2)]::Vector{T}
end
"""
state_from_vector(x::AbstractVector{<:Real})
Adaptor for `nlsolve`. Unmarshal the problem state from a `Vector`.
"""
function state_from_vector(x::AbstractVector{T}) where T <: Real
sigma::Symm2{T} = fromvoigt(Symm2{T}, @view x[1:6])
R::T = x[7]
X1::Symm2{T} = fromvoigt(Symm2{T}, @view x[8:13])
X2::Symm2{T} = fromvoigt(Symm2{T}, @view x[14:19])
return sigma, R, X1, X2
end
"""
strain_memory_explicit_update(q, zeta, plastic_strain, dp, cumeq, pt, n, eta, xi, m)
Internal helper function for what it says on the tin.
Return `(dq, dzeta)`, the computed increments for `q` and `zeta`
for the given input.
"""
function strain_memory_explicit_update(q, zeta, plastic_strain, dp, cumeq, pt, n, eta, xi, m)
dq = zero(q)
dzeta = zero(zeta)
JF = sqrt(1.5)*norm(dev(plastic_strain - zeta))
FF = 2.0/3.0*JF - q
if FF > 0.0
nF = 1.5*dev(plastic_strain - zeta)/JF
nnF = dcontract(n, nF)
if nnF > 0
dq = 2.0/3.0*eta*nnF*dp
dzeta = 2.0/3.0*(1.0 - eta)*nnF*nF*dp
end
else
# Memory evanescence term
if cumeq >= pt
dq = -xi*q^m*dp
end
end
return dq, dzeta
end
"""
integrate_material!(material::GenericMemory{T}) where T <: Real
Material model with a strain memory effect.
This is similar to the Chaboche material with two backstresses, with both
kinematic and isotropic hardening, but this model also features a strain
memory term.
Strain memory is used to be able to model strain amplitude-dependent isotropic
hardening. In practice, the transition from a tensile test curve to cyclic
behavior can be captured with this model.
See:
D. Nouailhas, J.-L. Chaboche, S. Savalle, G. Cailletaud. On the constitutive
equations for cyclic plasticity under nonproportional loading. International
Journal of Plasticity 1(4) (1985), 317--330.
https://doi.org/10.1016/0749-6419(85)90018-X
"""
function integrate_material!(material::GenericMemory{T}) where T <: Real
p = material.parameters
v = material.variables
dd = material.ddrivers
d = material.drivers
@unpack E, nu, R0, Kn, nn, C1, D1, C2, D2, Q0, QM, mu, b, eta, m, pt, xi = p
lambda, elastic_mu = lame(E, nu)
@unpack strain, time = d
dstrain = dd.strain
dtime = dd.time
@unpack stress, X1, X2, plastic_strain, cumeq, R, q, zeta, jacobian = v
# elastic part
jacobian = isotropic_elasticity_tensor(lambda, elastic_mu)
stress += dcontract(jacobian, dstrain)
# resulting deviatoric plastic stress (accounting for backstresses Xm)
seff_dev = dev(stress - X1 - X2)
# von Mises yield function
f = sqrt(1.5)*norm(seff_dev) - (R0 + R) # using elastic trial problem state
if f > 0.0
# Explicit update to memory-surface
g! = create_nonlinear_system_of_equations(material)
x0 = state_to_vector(stress, R, X1, X2)
res = nlsolve(g!, x0; method=material.options.nlsolve_method, autodiff = :forward)
converged(res) || error("Nonlinear system of equations did not converge!")
x = res.zero
stress, R, X1, X2 = state_from_vector(x)
# using the new problem state
seff_dev = dev(stress - X1 - X2)
f = sqrt(1.5)*norm(seff_dev) - (R0 + R)
dotp = ((f >= 0.0 ? f : 0.0)/Kn)^nn
dp = dotp*dtime
n = sqrt(1.5)*seff_dev/norm(seff_dev)
plastic_strain += dp*n
cumeq += dp
dq, dzeta = strain_memory_explicit_update(q, zeta, plastic_strain, dp, cumeq, pt, n, eta, xi, m)
q += dq
zeta += dzeta
# Compute the new Jacobian, accounting for the plastic contribution.
drdx = ForwardDiff.jacobian(debang(g!), x)
drde = zeros((length(x),6))
drde[1:6, 1:6] = -tovoigt(jacobian)
jacobian = fromvoigt(Symm4, (drdx\drde)[1:6, 1:6])
end
variables_new = GenericMemoryVariableState{T}(stress = stress,
X1 = X1,
X2 = X2,
R = R,
plastic_strain = plastic_strain,
cumeq = cumeq,
q = q,
zeta = zeta,
jacobian = jacobian)
material.variables_new = variables_new
return nothing
end
"""
create_nonlinear_system_of_equations(material::GenericMemory{T}) where T <: Real
Create and return an instance of the equation system for the incremental form of
the evolution equations of the Memory material.
Used internally for computing the plastic contribution in `integrate_material!`.
The input `material` represents the problem state at the end of the previous
timestep. The created equation system will hold its own copy of that state.
The equation system is represented as a mutating function `g!` that computes the
residual:
```julia
g!(F::V, x::V) where V <: AbstractVector{<:Real}
```
Both `F` (output) and `x` (input) are length-19 vectors containing
[sigma, R, X1, X2], in that order. The tensor quantities sigma, X1,
X2 are encoded in Voigt format.
The function `g!` is intended to be handed over to `nlsolve`.
"""
function create_nonlinear_system_of_equations(material::GenericMemory{T}) where T <: Real
p = material.parameters
v = material.variables
dd = material.ddrivers
d = material.drivers
@unpack E, nu, R0, Kn, nn, C1, D1, C2, D2, Q0, QM, mu, b, eta, m, pt, xi = p
lambda, elastic_mu = lame(E, nu)
# Old problem state (i.e. the problem state at the time when this equation
# system instance was created).
#
# Note this does not include the elastic trial; this is the state at the
# end of the previous timestep.
@unpack strain, time = d
dstrain = dd.strain
dtime = dd.time
@unpack stress, X1, X2, plastic_strain, cumeq, R, q, zeta, jacobian = v
jacobian = isotropic_elasticity_tensor(lambda, elastic_mu)
# Explicit update of memory surface.
#
# Compute the residual. F is output, x is filled by NLsolve.
# The solution is x = x* such that g(x*) = 0.
function g!(F::V, x::V) where V <: AbstractVector{<:Real}
stress_new, R_new, X1_new, X2_new = state_from_vector(x) # tentative new values from nlsolve
seff_dev = dev(stress_new - X1_new - X2_new)
f = sqrt(1.5)*norm(seff_dev) - (R0 + R_new)
dotp = ((f >= 0.0 ? f : 0.0)/Kn)^nn
dp = dotp*dtime
n = sqrt(1.5)*seff_dev/norm(seff_dev)
dstrain_plastic = dp*n
# Strain memory - explicit update
plastic_strain_new = plastic_strain + dstrain_plastic
dq, dzeta = strain_memory_explicit_update(q, zeta, plastic_strain_new, dp, cumeq, pt, n, eta, xi, m)
q_new = q + dq
zeta_new = zeta + dzeta
# The equations are written in an incremental form.
# TODO: multiply the equations by -1 to make them easier to understand in the context of the rest of the model.
dstrain_elastic = dstrain - dstrain_plastic
tovoigt!(view(F, 1:6), stress - stress_new + dcontract(jacobian, dstrain_elastic))
F[7] = R - R_new + b*((QM + (Q0 - QM)*exp(-2.0*mu*q_new)) - R_new)*dp
tovoigt!(view(F, 8:13), X1 - X1_new + dp*(2.0/3.0*C1*n - D1*X1_new))
tovoigt!(view(F, 14:19), X2 - X2_new + dp*(2.0/3.0*C2*n - D2*X2_new))
return nothing
end
return g!
end
end
| Materials | https://github.com/JuliaFEM/Materials.jl.git |
|
[
"MIT"
] | 0.4.0 | d7a67c1c8ae6118f253a137ffa5291421e757a8a | code | 5183 | # This file is a part of JuliaFEM.
# License is MIT: see https://github.com/JuliaFEM/Materials.jl/blob/master/LICENSE
module PerfectPlasticModule
using LinearAlgebra, ForwardDiff, Tensors, NLsolve, Parameters
import ..AbstractMaterial, ..AbstractMaterialState
import ..Utilities: Symm2, Symm4, isotropic_elasticity_tensor, IS, ID, lame
import ..integrate_material! # for method extension
# parametrically polymorphic for any type representing ℝ
export GenericPerfectPlastic, GenericPerfectPlasticDriverState, GenericPerfectPlasticParameterState, GenericPerfectPlasticVariableState
# specialization for Float64
export PerfectPlastic, PerfectPlasticDriverState, PerfectPlasticParameterState, PerfectPlasticVariableState
@with_kw mutable struct GenericPerfectPlasticDriverState{T <: Real} <: AbstractMaterialState
time::T = zero(T)
strain::Symm2{T} = zero(Symm2{T})
end
"""Parameter state for perfect plastic material.
- youngs_modulus
- poissons_ratio
- yield_stress
"""
@with_kw struct GenericPerfectPlasticParameterState{T <: Real} <: AbstractMaterialState
youngs_modulus::T = zero(T)
poissons_ratio::T = zero(T)
yield_stress::T = zero(T)
end
"""Problem state for perfect plastic material.
- `stress`: stress tensor
- `plastic_strain`: plastic part of strain tensor
- `cumeq`: cumulative equivalent plastic strain (scalar, ≥ 0)
- `jacobian`: ∂σij/∂εkl
"""
@with_kw struct GenericPerfectPlasticVariableState{T <: Real} <: AbstractMaterialState
stress::Symm2{T} = zero(Symm2{T})
plastic_strain::Symm2{T} = zero(Symm2{T})
cumeq::T = zero(T)
jacobian::Symm4{T} = zero(Symm4{T})
end
@with_kw mutable struct GenericPerfectPlastic{T <: Real} <: AbstractMaterial
drivers::GenericPerfectPlasticDriverState{T} = GenericPerfectPlasticDriverState{T}()
ddrivers::GenericPerfectPlasticDriverState{T} = GenericPerfectPlasticDriverState{T}()
variables::GenericPerfectPlasticVariableState{T} = GenericPerfectPlasticVariableState{T}()
variables_new::GenericPerfectPlasticVariableState{T} = GenericPerfectPlasticVariableState{T}()
parameters::GenericPerfectPlasticParameterState{T} = GenericPerfectPlasticParameterState{T}()
dparameters::GenericPerfectPlasticParameterState{T} = GenericPerfectPlasticParameterState{T}()
end
PerfectPlastic = GenericPerfectPlastic{Float64}
PerfectPlasticDriverState = GenericPerfectPlasticDriverState{Float64}
PerfectPlasticParameterState = GenericPerfectPlasticParameterState{Float64}
PerfectPlasticVariableState = GenericPerfectPlasticVariableState{Float64}
"""
integrate_material!(material::GenericPerfectPlastic)
Perfect plastic material: no hardening. The elastic region remains centered on the
origin, and retains its original size.
This is a standard basic plasticity model; see a textbook, such as:
J. C. Simo, T. J. R. Hughes. Computational Inelasticity. Interdisciplinary
Applied Mathematics volume 7. Springer. 1998. http://dx.doi.org/10.1007/b98904
The notation in the book somewhat differs from ours; see:
https://github.com/JuliaFEM/Materials.jl/pull/66#issuecomment-674786955
"""
function integrate_material!(material::GenericPerfectPlastic{T}) where T <: Real
p = material.parameters
v = material.variables
dd = material.ddrivers
d = material.drivers
E = p.youngs_modulus
nu = p.poissons_ratio
lambda, mu = lame(E, nu)
R0 = p.yield_stress
# @unpack strain, time = d # not needed for this material
dstrain = dd.strain
dtime = dd.time
@unpack stress, plastic_strain, cumeq, jacobian = v
jacobian = isotropic_elasticity_tensor(lambda, mu) # dσ/dε, i.e. ∂σij/∂εkl
stress += dcontract(jacobian, dstrain) # add the elastic stress increment, get the elastic trial stress
seff_dev = dev(stress)
f = sqrt(1.5)*norm(seff_dev) - R0 # von Mises yield function; f := J(seff_dev) - Y
if f > 0.0
# see Simo & Hughes ch. 3.1: radial return mapping, eq. (3.37)
dp = 1.0/(3.0*mu) * f
n = sqrt(1.5)*seff_dev/norm(seff_dev) # a (tensorial) unit direction, s.t. 2/3 * (n : n) = 1
plastic_strain += dp*n
cumeq += dp # cumulative equivalent plastic strain (note dp ≥ 0)
# Perfect plastic material: the stress state cannot be outside the yield surface.
# Project it back to the yield surface.
stress -= dcontract(jacobian, dp*n)
# Compute ∂σij/∂εkl, accounting for the plastic contribution.
# EE = IS + dp/R0 * (∂σ/∂ε)_e : ((3/2) ID - n ⊗ n)
EE = IS(T) + dp/R0 * dcontract(jacobian, 1.5*ID(T) - otimes(n,n)) # using the elastic jacobian
ED = dcontract(inv(EE), jacobian)
# J = ED - (ED : n) ⊗ (n : ED) / (n : ED : n)
jacobian = ED - otimes(dcontract(ED, n), dcontract(n, ED)) / dcontract(dcontract(n, ED), n)
end
variables_new = GenericPerfectPlasticVariableState(stress=stress,
plastic_strain=plastic_strain,
cumeq=cumeq,
jacobian=jacobian)
material.variables_new = variables_new
return nothing
end
end
| Materials | https://github.com/JuliaFEM/Materials.jl.git |
|
[
"MIT"
] | 0.4.0 | d7a67c1c8ae6118f253a137ffa5291421e757a8a | code | 6814 | # This file is a part of JuliaFEM.
# License is MIT: see https://github.com/JuliaFEM/Materials.jl/blob/master/LICENSE
module Utilities
using Tensors, ForwardDiff
export Symm2, Symm4
export delta, II, IT, IS, IA, IV, ID, isotropic_elasticity_tensor, isotropic_compliance_tensor
export lame, delame, debang, find_root
"""Symm2{T} is an alias for SymmetricTensor{2,3,T}."""
const Symm2{T} = SymmetricTensor{2,3,T}
"""Symm4{T} is an alias for SymmetricTensor{4,3,T}."""
const Symm4{T} = SymmetricTensor{4,3,T}
"""
delta(i::Integer, j::Integer)
Kronecker delta, defined by delta(i, j) = (i == j) ? 1 : 0.
"""
delta(i::T, j::T) where T <: Integer = (i == j) ? one(T) : zero(T)
# TODO: We could probably remove the type argument, and just let the results be
# inferred as Symm4{Int64}, Symm4{Rational{Int64}} and similar. Simpler to use,
# and those behave correctly in calculations with types involving other reals
# such as Float64.
# Performance implications? Is the Julia compiler smart enough to optimize?
"""
II(T::Type=Float64)
Rank-4 unit tensor, defined by II : A = A for any rank-2 tensor A.
"""
II(T::Type=Float64) = Symm4{T}((i,j,k,l) -> delta(i,k)*delta(j,l))
"""
IT(T::Type=Float64)
Rank-4 unit tensor, defined by IT : A = transpose(A) for any rank-2 tensor A.
"""
IT(T::Type=Float64) = Symm4{T}((i,j,k,l) -> delta(i,l)*delta(j,k))
"""
IS(T::Type=Float64)
Rank-4 unit tensor, symmetric. IS ≡ (1/2) (II + IT).
"""
IS(T::Type=Float64) = 1//2 * (II(T) + IT(T))
"""
IA(T::Type=Float64)
Rank-4 unit tensor, screw-symmetric. IA ≡ (1/2) (II - IT).
"""
IA(T::Type=Float64) = 1//2 * (II(T) - IT(T))
"""
IV(T::Type=Float64)
Rank-4 unit tensor, volumetric. IS ≡ (1/3) I ⊗ I, where I is the rank-2 unit tensor.
"""
IV(T::Type=Float64) = Symm4{T}((i,j,k,l) -> 1//3 * delta(i,j)*delta(k,l))
"""
ID(T::Type=Float64)
Rank-4 unit tensor, deviatoric. ID ≡ IS - IV.
"""
ID(T::Type=Float64) = IS(T) - IV(T)
# TODO: implement other symmetry groups, not just isotropic.
#
# Only 8 elastic symmetry groups exist, so we could implement all of them.
#
# The elasticity and compliance tensors are the inverses of each other, and the
# `inv` function can invert rank-4 tensors numerically. So we can use that,
# if one of these tensors is not easily available in analytical form for some
# symmetry group. Could also investigate if SymPy can invert them symbolically
# (possible at least in Voigt notation).
"""
isotropic_elasticity_tensor(lambda::T, mu::T) where T <: Real
Compute the elasticity tensor C(i,j,k,l) (rank 4, symmetric) for an isotropic
material having the Lamé parameters `lambda` and `mu`.
If you have (E, nu) instead, use `lame` to get (lambda, mu).
"""
isotropic_elasticity_tensor(lambda::T, mu::T) where T <: Real = 3 * lambda * IV(T) + 2 * mu * IS(T)
# TODO: check: original expr from upstream/master:
# g(i,j,k,l) = -lambda/(2.0*mu*(3.0*lambda + 2.0*mu))*delta(i,j)*delta(k,l) + 1.0/(4.0*mu)*(delta(i,k)*delta(j,l)+delta(i,l)*delta(j,k))
"""
isotropic_compliance_tensor(lambda::T, mu::T) where T <: Real
Compute the compliance tensor S(i,j,k,l) (rank 4, symmetric) for an isotropic
material having the Lamé parameters `lambda` and `mu`.
If you have (E, nu) instead, use `lame` to get (lambda, mu).
"""
isotropic_compliance_tensor(lambda::T, mu::T) where T <: Real = -3 * lambda / (2*mu * (3*lambda + 2*mu)) * IV(T) + 1 / (2*mu) * IS(T)
"""
lame(E::Real, nu::Real)
Convert elastic parameters (E, nu) of an isotropic material to Lamé parameters (lambda, mu).
See:
https://en.wikipedia.org/wiki/Template:Elastic_moduli
"""
function lame(E::Real, nu::Real)
lambda = E * nu / ((1 + nu) * (1 - 2 * nu))
mu = E / (2 * (1 + nu))
return lambda, mu
end
"""
delame(lambda::Real, mu::Real)
Convert Lamé parameters (lambda, mu) of an isotropic material to elastic parameters (E, nu).
See:
https://en.wikipedia.org/wiki/Template:Elastic_moduli
"""
function delame(lambda::Real, mu::Real)
E = mu * (3 * lambda + 2 * mu) / (lambda + mu)
nu = lambda / (2 * (lambda + mu))
return E, nu
end
"""
debang(f!::Function, ex=nothing)
Convert a mutating function into non-mutating form.
`f!` must be a two-argument mutating function, which writes the result into its
first argument. The result of `debang` is then `f`, a single-argument
non-mutating function that allocates and returns the result. Schematically,
`f!(out, x)` becomes `f(x)`.
When the type, size and shape of `out` is the same as those of `x`, it is enough
to supply just `f!`. When `f` is called, output will be allocated as `similar(x)`.
When the type, size and/or shape of `out` are different from those of `x`, then
an example instance of the correct type with the correct size and shape for the
output must be supplied, as debang's `ex` argument. When `f` is called, output
will be allocated as `similar(ex)`. The `ex` instance will be automatically kept
alive by the lexical closure of `f`.
# Note
While the type of `out` is known at compile time, the size and shape are
typically runtime properties, not encoded into the type. For example, arrays
have the number of dimensions as part of the type, but the length of each
dimension is only defined at run time, when an instance is created. This is why
the `ex` argument is needed.
# Etymology
By convention, mutating functions are marked with an exclamation mark, a.k.a.
bang. This function takes away the bang.
"""
function debang(f!::Function, ex=nothing)
if ex === nothing
function f(x)
out = similar(x)
f!(out, x)
return out
end
return f
else
# We use a different name to make incremental compilation happy.
function f_with_ex(x)
out = similar(ex)
f!(out, x)
return out
end
return f_with_ex
end
end
# This comes from the old viscoplastic.jl, and is currently unused.
# The original wording of the error message suggested this was planned to be used for "radial return".
"""A simple Newton solver for the vector x* such that f(x*) = 0.
The input `x` is the initial guess.
The default `dfdx=nothing` uses `ForwardDiff.jacobian` to compute the jacobian
automatically. In this case the output of `f` must be an `AbstractArray`.
`tol` is measured in the vector norm of the change in `x` between successive
iterations.
"""
function find_root(f::Function, x::AbstractVector{<:Real},
dfdx::Union{Function, Nothing}=nothing;
max_iter::Integer=50, tol::Real=1e-9)
if dfdx === nothing
dfdx = (x) -> ForwardDiff.jacobian(f, x)
end
for i=1:max_iter
dx = -dfdx(x) \ f(x)
x += dx
if norm(dx) < tol
return x
end
end
error("No convergence!")
end
end
| Materials | https://github.com/JuliaFEM/Materials.jl.git |
|
[
"MIT"
] | 0.4.0 | d7a67c1c8ae6118f253a137ffa5291421e757a8a | code | 1167 | # This file is a part of JuliaFEM.
# License is MIT: see https://github.com/JuliaFEM/Materials.jl/blob/master/LICENSE
using Materials, Test
@testset "Test Materials.jl" begin
@testset "test utilities" begin
include("test_utilities.jl")
end
@testset "test perfect plastic uniaxial stress" begin
include("test_perfectplastic.jl")
end
@testset "test perfect plastic pure shear" begin
include("test_perfectplastic_shear.jl")
end
@testset "test chaboche uniaxial stress" begin
include("test_chaboche.jl")
end
@testset "test chaboche pure shear" begin
include("test_chaboche_shear.jl")
end
@testset "test memory material model" begin
include("test_memory.jl")
end
@testset "test DSA material model" begin
include("test_DSA.jl")
end
@testset "test uniaxial increment" begin
include("test_uniaxial_increment.jl")
end
@testset "test biaxial increment" begin
include("test_biaxial_increment.jl")
end
@testset "test stress-driven uniaxial increment" begin
include("test_stress_driven_uniaxial_increment.jl")
end
end
| Materials | https://github.com/JuliaFEM/Materials.jl.git |
|
[
"MIT"
] | 0.4.0 | d7a67c1c8ae6118f253a137ffa5291421e757a8a | code | 20864 | # This file is a part of JuliaFEM.
# License is MIT: see https://github.com/JuliaFEM/Materials.jl/blob/master/LICENSE
using Tensors, Materials, Test
# TODO: Civilized way to place this wall of numbers at the end of the source file?
# TODO: Or maybe read the expected results from a text file, like the other tests do?
let stresses_expected = [[0.0, 0.0, 0.0, 0.0, 0.0, 0.0],
[10.0, 0.0, 0.0, 0.0, 0.0, 0.0],
[20.0, 0.0, 0.0, 0.0, 0.0, 0.0],
[30.0, 0.0, 0.0, 0.0, 0.0, 0.0],
[40.0, 0.0, 0.0, 0.0, 0.0, 0.0],
[50.0, 0.0, 0.0, 0.0, 0.0, 0.0],
[60.0, 0.0, 0.0, 0.0, 0.0, 0.0],
[70.0, 0.0, 0.0, 0.0, 0.0, 0.0],
[80.0, 0.0, 0.0, 0.0, 0.0, 0.0],
[90.0, 0.0, 0.0, 0.0, 0.0, 0.0],
[100.0, 0.0, 0.0, 0.0, 0.0, 0.0],
[110.0, 0.0, 0.0, 0.0, 0.0, 0.0],
[119.995, 0.0, 0.0, 0.0, 0.0, 0.0],
[129.743, 0.0, 0.0, 0.0, 0.0, 0.0],
[137.812, 0.0, 0.0, 0.0, 0.0, 0.0],
[143.250, 0.0, 0.0, 0.0, 0.0, 0.0],
[146.767, 0.0, 0.0, 0.0, 0.0, 0.0],
[149.313, 0.0, 0.0, 0.0, 0.0, 0.0],
[151.463, 0.0, 0.0, 0.0, 0.0, 0.0],
[153.465, 0.0, 0.0, 0.0, 0.0, 0.0],
[155.402, 0.0, 0.0, 0.0, 0.0, 0.0],
[157.301, 0.0, 0.0, 0.0, 0.0, 0.0],
[159.164, 0.0, 0.0, 0.0, 0.0, 0.0],
[160.991, 0.0, 0.0, 0.0, 0.0, 0.0],
[162.780, 0.0, 0.0, 0.0, 0.0, 0.0],
[164.529, 0.0, 0.0, 0.0, 0.0, 0.0],
[166.236, 0.0, 0.0, 0.0, 0.0, 0.0],
[167.902, 0.0, 0.0, 0.0, 0.0, 0.0],
[169.527, 0.0, 0.0, 0.0, 0.0, 0.0],
[171.110, 0.0, 0.0, 0.0, 0.0, 0.0],
[172.653, 0.0, 0.0, 0.0, 0.0, 0.0],
[174.155, 0.0, 0.0, 0.0, 0.0, 0.0],
[175.618, 0.0, 0.0, 0.0, 0.0, 0.0],
[177.042, 0.0, 0.0, 0.0, 0.0, 0.0],
[178.429, 0.0, 0.0, 0.0, 0.0, 0.0],
[179.779, 0.0, 0.0, 0.0, 0.0, 0.0],
[181.094, 0.0, 0.0, 0.0, 0.0, 0.0],
[182.373, 0.0, 0.0, 0.0, 0.0, 0.0],
[183.619, 0.0, 0.0, 0.0, 0.0, 0.0],
[184.833, 0.0, 0.0, 0.0, 0.0, 0.0],
[186.014, 0.0, 0.0, 0.0, 0.0, 0.0],
[0.0, 0.0, 0.0, 0.0, 0.0, 0.0],
[0.0, 0.0, 0.0, 0.0, 0.0, 0.0],
[10.0, 0.0, 0.0, 0.0, 0.0, 0.0],
[20.0, 0.0, 0.0, 0.0, 0.0, 0.0],
[30.0, 0.0, 0.0, 0.0, 0.0, 0.0],
[40.0, 0.0, 0.0, 0.0, 0.0, 0.0],
[50.0, 0.0, 0.0, 0.0, 0.0, 0.0],
[60.0, 0.0, 0.0, 0.0, 0.0, 0.0],
[70.0, 0.0, 0.0, 0.0, 0.0, 0.0],
[80.0, 0.0, 0.0, 0.0, 0.0, 0.0],
[90.0, 0.0, 0.0, 0.0, 0.0, 0.0],
[100.0, 0.0, 0.0, 0.0, 0.0, 0.0],
[110.0, 0.0, 0.0, 0.0, 0.0, 0.0],
[120.0, 0.0, 0.0, 0.0, 0.0, 0.0],
[130.0, 0.0, 0.0, 0.0, 0.0, 0.0],
[140.0, 0.0, 0.0, 0.0, 0.0, 0.0],
[150.0, 0.0, 0.0, 0.0, 0.0, 0.0],
[159.999, 0.0, 0.0, 0.0, 0.0, 0.0],
[169.920, 0.0, 0.0, 0.0, 0.0, 0.0],
[179.177, 0.0, 0.0, 0.0, 0.0, 0.0],
[187.533, 0.0, 0.0, 0.0, 0.0, 0.0],
[195.357, 0.0, 0.0, 0.0, 0.0, 0.0],
[202.848, 0.0, 0.0, 0.0, 0.0, 0.0],
[209.935, 0.0, 0.0, 0.0, 0.0, 0.0],
[216.120, 0.0, 0.0, 0.0, 0.0, 0.0],
[219.606, 0.0, 0.0, 0.0, 0.0, 0.0],
[216.262, 0.0, 0.0, 0.0, 0.0, 0.0],
[209.090, 0.0, 0.0, 0.0, 0.0, 0.0],
[203.945, 0.0, 0.0, 0.0, 0.0, 0.0],
[201.241, 0.0, 0.0, 0.0, 0.0, 0.0],
[200.038, 0.0, 0.0, 0.0, 0.0, 0.0],
[199.668, 0.0, 0.0, 0.0, 0.0, 0.0],
[199.760, 0.0, 0.0, 0.0, 0.0, 0.0],
[200.115, 0.0, 0.0, 0.0, 0.0, 0.0],
[200.622, 0.0, 0.0, 0.0, 0.0, 0.0],
[201.219, 0.0, 0.0, 0.0, 0.0, 0.0],
[201.867, 0.0, 0.0, 0.0, 0.0, 0.0],
[202.542, 0.0, 0.0, 0.0, 0.0, 0.0],
[203.231, 0.0, 0.0, 0.0, 0.0, 0.0],
[203.922, 0.0, 0.0, 0.0, 0.0, 0.0],
[204.611, 0.0, 0.0, 0.0, 0.0, 0.0],
[205.293, 0.0, 0.0, 0.0, 0.0, 0.0],
[205.967, 0.0, 0.0, 0.0, 0.0, 0.0],
[206.630, 0.0, 0.0, 0.0, 0.0, 0.0],
[207.282, 0.0, 0.0, 0.0, 0.0, 0.0],
[207.922, 0.0, 0.0, 0.0, 0.0, 0.0],
[208.551, 0.0, 0.0, 0.0, 0.0, 0.0],
[209.168, 0.0, 0.0, 0.0, 0.0, 0.0],
[209.774, 0.0, 0.0, 0.0, 0.0, 0.0],
[210.368, 0.0, 0.0, 0.0, 0.0, 0.0],
[210.952, 0.0, 0.0, 0.0, 0.0, 0.0],
[211.525, 0.0, 0.0, 0.0, 0.0, 0.0],
[212.087, 0.0, 0.0, 0.0, 0.0, 0.0],
[212.640, 0.0, 0.0, 0.0, 0.0, 0.0],
[213.183, 0.0, 0.0, 0.0, 0.0, 0.0],
[213.717, 0.0, 0.0, 0.0, 0.0, 0.0],
[214.242, 0.0, 0.0, 0.0, 0.0, 0.0],
[214.758, 0.0, 0.0, 0.0, 0.0, 0.0],
[215.266, 0.0, 0.0, 0.0, 0.0, 0.0],
[215.766, 0.0, 0.0, 0.0, 0.0, 0.0],
[216.259, 0.0, 0.0, 0.0, 0.0, 0.0],
[216.743, 0.0, 0.0, 0.0, 0.0, 0.0],
[217.221, 0.0, 0.0, 0.0, 0.0, 0.0],
[217.691, 0.0, 0.0, 0.0, 0.0, 0.0],
[218.155, 0.0, 0.0, 0.0, 0.0, 0.0],
[218.612, 0.0, 0.0, 0.0, 0.0, 0.0],
[219.063, 0.0, 0.0, 0.0, 0.0, 0.0],
[219.507, 0.0, 0.0, 0.0, 0.0, 0.0],
[219.946, 0.0, 0.0, 0.0, 0.0, 0.0],
[220.379, 0.0, 0.0, 0.0, 0.0, 0.0],
[220.807, 0.0, 0.0, 0.0, 0.0, 0.0],
[221.229, 0.0, 0.0, 0.0, 0.0, 0.0],
[221.646, 0.0, 0.0, 0.0, 0.0, 0.0],
[222.059, 0.0, 0.0, 0.0, 0.0, 0.0],
[222.466, 0.0, 0.0, 0.0, 0.0, 0.0],
[222.868, 0.0, 0.0, 0.0, 0.0, 0.0],
[223.266, 0.0, 0.0, 0.0, 0.0, 0.0],
[223.660, 0.0, 0.0, 0.0, 0.0, 0.0],
[224.049, 0.0, 0.0, 0.0, 0.0, 0.0],
[224.435, 0.0, 0.0, 0.0, 0.0, 0.0],
[224.816, 0.0, 0.0, 0.0, 0.0, 0.0]],
strains_expected = [[0.0, 0.0, 0.0, 0.0, 0.0, 0.0],
[0.00005, -0.00002, -0.00002, 0.0, 0.0, 0.0],
[0.00010, -0.00003, -0.00003, 0.0, 0.0, 0.0],
[0.00015, -0.00004, -0.00004, 0.0, 0.0, 0.0],
[0.00020, -0.00006, -0.00006, 0.0, 0.0, 0.0],
[0.00025, -0.00008, -0.00008, 0.0, 0.0, 0.0],
[0.00030, -0.00009, -0.00009, 0.0, 0.0, 0.0],
[0.00035, -0.00010, -0.00010, 0.0, 0.0, 0.0],
[0.00040, -0.00012, -0.00012, 0.0, 0.0, 0.0],
[0.00045, -0.00014, -0.00014, 0.0, 0.0, 0.0],
[0.00050, -0.00015, -0.00015, 0.0, 0.0, 0.0],
[0.00055, -0.00017, -0.00017, 0.0, 0.0, 0.0],
[0.00060, -0.00018, -0.00018, 0.0, 0.0, 0.0],
[0.00065, -0.00020, -0.00020, 0.0, 0.0, 0.0],
[0.00070, -0.00021, -0.00021, 0.0, 0.0, 0.0],
[0.00075, -0.00023, -0.00023, 0.0, 0.0, 0.0],
[0.00080, -0.00025, -0.00025, 0.0, 0.0, 0.0],
[0.00085, -0.00028, -0.00028, 0.0, 0.0, 0.0],
[0.00090, -0.00030, -0.00030, 0.0, 0.0, 0.0],
[0.00095, -0.00032, -0.00032, 0.0, 0.0, 0.0],
[0.00100, -0.00034, -0.00034, 0.0, 0.0, 0.0],
[0.00105, -0.00037, -0.00037, 0.0, 0.0, 0.0],
[0.00110, -0.00039, -0.00039, 0.0, 0.0, 0.0],
[0.00115, -0.00041, -0.00041, 0.0, 0.0, 0.0],
[0.00120, -0.00044, -0.00044, 0.0, 0.0, 0.0],
[0.00125, -0.00046, -0.00046, 0.0, 0.0, 0.0],
[0.00130, -0.00048, -0.00048, 0.0, 0.0, 0.0],
[0.00135, -0.00051, -0.00051, 0.0, 0.0, 0.0],
[0.00140, -0.00053, -0.00053, 0.0, 0.0, 0.0],
[0.00145, -0.00055, -0.00055, 0.0, 0.0, 0.0],
[0.00150, -0.00058, -0.00058, 0.0, 0.0, 0.0],
[0.00155, -0.00060, -0.00060, 0.0, 0.0, 0.0],
[0.00160, -0.00062, -0.00062, 0.0, 0.0, 0.0],
[0.00165, -0.00065, -0.00065, 0.0, 0.0, 0.0],
[0.00170, -0.00067, -0.00067, 0.0, 0.0, 0.0],
[0.00175, -0.00070, -0.00070, 0.0, 0.0, 0.0],
[0.00180, -0.00072, -0.00072, 0.0, 0.0, 0.0],
[0.00185, -0.00074, -0.00074, 0.0, 0.0, 0.0],
[0.00190, -0.00077, -0.00077, 0.0, 0.0, 0.0],
[0.00195, -0.00079, -0.00079, 0.0, 0.0, 0.0],
[0.00200, -0.00081, -0.00081, 0.0, 0.0, 0.0],
[0.00107, -0.00053, -0.00053, 0.0, 0.0, 0.0],
[0.00107, -0.00053, -0.00053, 0.0, 0.0, 0.0],
[0.00112, -0.00055, -0.00055, 0.0, 0.0, 0.0],
[0.00117, -0.00056, -0.00056, 0.0, 0.0, 0.0],
[0.00122, -0.00058, -0.00058, 0.0, 0.0, 0.0],
[0.00127, -0.00059, -0.00059, 0.0, 0.0, 0.0],
[0.00132, -0.00061, -0.00061, 0.0, 0.0, 0.0],
[0.00137, -0.00062, -0.00062, 0.0, 0.0, 0.0],
[0.00142, -0.00064, -0.00064, 0.0, 0.0, 0.0],
[0.00147, -0.00065, -0.00065, 0.0, 0.0, 0.0],
[0.00152, -0.00067, -0.00067, 0.0, 0.0, 0.0],
[0.00157, -0.00068, -0.00068, 0.0, 0.0, 0.0],
[0.00162, -0.00070, -0.00070, 0.0, 0.0, 0.0],
[0.00167, -0.00071, -0.00071, 0.0, 0.0, 0.0],
[0.00172, -0.00073, -0.00073, 0.0, 0.0, 0.0],
[0.00177, -0.00074, -0.00074, 0.0, 0.0, 0.0],
[0.00182, -0.00076, -0.00076, 0.0, 0.0, 0.0],
[0.00187, -0.00077, -0.00077, 0.0, 0.0, 0.0],
[0.00192, -0.00079, -0.00079, 0.0, 0.0, 0.0],
[0.00197, -0.00081, -0.00081, 0.0, 0.0, 0.0],
[0.00202, -0.00082, -0.00082, 0.0, 0.0, 0.0],
[0.00207, -0.00084, -0.00084, 0.0, 0.0, 0.0],
[0.00212, -0.00086, -0.00086, 0.0, 0.0, 0.0],
[0.00217, -0.00088, -0.00088, 0.0, 0.0, 0.0],
[0.00222, -0.00089, -0.00089, 0.0, 0.0, 0.0],
[0.00227, -0.00092, -0.00092, 0.0, 0.0, 0.0],
[0.00232, -0.00094, -0.00094, 0.0, 0.0, 0.0],
[0.00237, -0.00098, -0.00098, 0.0, 0.0, 0.0],
[0.00242, -0.00101, -0.00101, 0.0, 0.0, 0.0],
[0.00247, -0.00103, -0.00103, 0.0, 0.0, 0.0],
[0.00252, -0.00106, -0.00106, 0.0, 0.0, 0.0],
[0.00257, -0.00109, -0.00109, 0.0, 0.0, 0.0],
[0.00262, -0.00111, -0.00111, 0.0, 0.0, 0.0],
[0.00267, -0.00113, -0.00113, 0.0, 0.0, 0.0],
[0.00272, -0.00116, -0.00116, 0.0, 0.0, 0.0],
[0.00277, -0.00118, -0.00118, 0.0, 0.0, 0.0],
[0.00282, -0.00121, -0.00121, 0.0, 0.0, 0.0],
[0.00287, -0.00123, -0.00123, 0.0, 0.0, 0.0],
[0.00292, -0.00126, -0.00126, 0.0, 0.0, 0.0],
[0.00297, -0.00128, -0.00128, 0.0, 0.0, 0.0],
[0.00302, -0.00131, -0.00131, 0.0, 0.0, 0.0],
[0.00307, -0.00133, -0.00133, 0.0, 0.0, 0.0],
[0.00312, -0.00135, -0.00135, 0.0, 0.0, 0.0],
[0.00317, -0.00138, -0.00138, 0.0, 0.0, 0.0],
[0.00322, -0.00140, -0.00140, 0.0, 0.0, 0.0],
[0.00327, -0.00143, -0.00143, 0.0, 0.0, 0.0],
[0.00332, -0.00145, -0.00145, 0.0, 0.0, 0.0],
[0.00337, -0.00148, -0.00148, 0.0, 0.0, 0.0],
[0.00342, -0.00150, -0.00150, 0.0, 0.0, 0.0],
[0.00347, -0.00152, -0.00152, 0.0, 0.0, 0.0],
[0.00352, -0.00155, -0.00155, 0.0, 0.0, 0.0],
[0.00357, -0.00157, -0.00157, 0.0, 0.0, 0.0],
[0.00362, -0.00160, -0.00160, 0.0, 0.0, 0.0],
[0.00367, -0.00162, -0.00162, 0.0, 0.0, 0.0],
[0.00372, -0.00165, -0.00165, 0.0, 0.0, 0.0],
[0.00377, -0.00167, -0.00167, 0.0, 0.0, 0.0],
[0.00382, -0.00170, -0.00170, 0.0, 0.0, 0.0],
[0.00387, -0.00172, -0.00172, 0.0, 0.0, 0.0],
[0.00392, -0.00174, -0.00174, 0.0, 0.0, 0.0],
[0.00397, -0.00177, -0.00177, 0.0, 0.0, 0.0],
[0.00402, -0.00179, -0.00179, 0.0, 0.0, 0.0],
[0.00407, -0.00182, -0.00182, 0.0, 0.0, 0.0],
[0.00412, -0.00184, -0.00184, 0.0, 0.0, 0.0],
[0.00417, -0.00187, -0.00187, 0.0, 0.0, 0.0],
[0.00422, -0.00189, -0.00189, 0.0, 0.0, 0.0],
[0.00427, -0.00192, -0.00192, 0.0, 0.0, 0.0],
[0.00432, -0.00194, -0.00194, 0.0, 0.0, 0.0],
[0.00437, -0.00197, -0.00197, 0.0, 0.0, 0.0],
[0.00442, -0.00199, -0.00199, 0.0, 0.0, 0.0],
[0.00447, -0.00201, -0.00201, 0.0, 0.0, 0.0],
[0.00452, -0.00204, -0.00204, 0.0, 0.0, 0.0],
[0.00457, -0.00206, -0.00206, 0.0, 0.0, 0.0],
[0.00462, -0.00209, -0.00209, 0.0, 0.0, 0.0],
[0.00467, -0.00211, -0.00211, 0.0, 0.0, 0.0],
[0.00472, -0.00214, -0.00214, 0.0, 0.0, 0.0],
[0.00477, -0.00216, -0.00216, 0.0, 0.0, 0.0],
[0.00482, -0.00219, -0.00219, 0.0, 0.0, 0.0],
[0.00487, -0.00221, -0.00221, 0.0, 0.0, 0.0],
[0.00492, -0.00224, -0.00224, 0.0, 0.0, 0.0],
[0.00497, -0.00226, -0.00226, 0.0, 0.0, 0.0],
[0.00502, -0.00229, -0.00229, 0.0, 0.0, 0.0]],
parameters = DSAParameterState(E = 200.0e3,
nu = 0.3,
R0 = 100.0,
Kn = 100.0,
nn = 10.0,
C1 = 10000.0,
D1 = 100.0,
C2 = 50000.0,
D2 = 1000.0,
Q = 50.0,
b = 0.1,
w = 1e-5,
P1 = 200.0,
P2 = 1e-1,
m = 0.66,
m1 = 6.0,
m2 = 6.0,
M1 = 6000.0,
M2 = 6000.0,
ba = 1e4,
xi = 1.0),
material = DSA(parameters=parameters),
dtime = 0.25,
n_steps = 100,
n_interrupt = 40, # for interrupt-and-hold test
dstrain11 = 2e-4 * dtime, # Corresponds to 10 MPa elastic stress response
tostrain(tens::Symm2) = copy(tovoigt(tens; offdiagscale=2.0)),
tostress(tens::Symm2) = copy(tovoigt(tens)),
times = [material.drivers.time],
stresses = [tostress(material.variables.stress)],
strains = [tostrain(material.drivers.strain)],
Ras = [copy(material.variables.Ra)],
tas = [copy(material.variables.ta)],
cumeqs = [copy(material.variables.cumeq)]
function snapshot!()
push!(times, material.drivers.time)
push!(stresses, tostress(material.variables.stress))
push!(strains, tostrain(material.drivers.strain))
push!(Ras, material.variables.Ra)
push!(tas, material.variables.ta)
push!(cumeqs, copy(material.variables.cumeq))
end
# TODO: This doesn't actually test anything.
# # Uninterrupted test
# material2 = DSA(parameters = parameters)
# times2 = [material2.drivers.time]
# stresses2 = [tostress(material2.variables.stress)]
# strains2 = [tostrain(material2.drivers.strain)]
# for i in 1:n_steps
# uniaxial_increment!(material2, dstrain11, dtime)
# update_material!(material2)
# push!(times2, material2.drivers.time)
# push!(stresses2, copy(tovoigt(material2.variables.stress)))
# push!(strains2, copy(tovoigt(material2.drivers.strain; offdiagscale = 2.0)))
# end
# Interrupted test
for i in 1:n_interrupt
uniaxial_increment!(material, dstrain11, dtime)
update_material!(material)
snapshot!()
end
# Interrupt and hold
# Drive to zero stress
strain_at_stop = material.drivers.strain[1,1]
let dstress11 = -material.variables.stress[1,1]
stress_driven_uniaxial_increment!(material, dstress11, dtime)
end
update_material!(material)
snapshot!()
# Hold for 3600 seconds
stress_driven_uniaxial_increment!(material, 0.0, 3600)
update_material!(material)
snapshot!()
# Continue test
dstrain_extra = strain_at_stop - material.drivers.strain[1,1]
n_extra_steps = Int(ceil(dstrain_extra / dstrain11))
for i in (n_interrupt + 1):(n_steps + n_extra_steps)
uniaxial_increment!(material, dstrain11, dtime)
update_material!(material)
snapshot!()
end
for i in 1:length(times)
@test isapprox(stresses[i], stresses_expected[i]; atol = 1e-3)
@test isapprox(strains[i], strains_expected[i]; atol = 1e-5)
end
dcumeq = cumeqs[end] - cumeqs[end - 1]
@test dcumeq > 0
end
# Plotting
# using PyPlot
# x11 = [a[1] for a in strains]
# y11 = [a[1] for a in stresses]
# x112 = [a[1] for a in strains2]
# y112 = [a[1] for a in stresses2]
# RasNorm = [Ra / parameters.P1 for Ra in Ras]
# tasNorm = [ta / maximum(tas) for ta in tas]
# fig = figure("test_DSA.jl", figsize = (5, 12)) # Create a new blank figure
# subplot(211)
# plot(x11,y11, label = "interrupted")
# plot(x112,y112,linestyle = "--", label = "uninterrupted")
# title("test_DSA.jl")
# xlabel("Strain, \$\\varepsilon_{11}\$")
# ylabel("Stress, \$\\sigma_{11}\$")
# legend()
# subplot(212)
# plot(times, RasNorm, label = "\$R_a\$")
# plot(times, tasNorm, linestyle = "--", label = "\$t_a\$")
# xlim([3600.0, maximum(times)])
# title("Normalized Evolution of \$R_a\$ & \$t_a\$")
# xlabel("Time")
# ylabel("Ra, ta")
# legend()
# fig.canvas.draw() # Update the figure
# show()
# gcf()
| Materials | https://github.com/JuliaFEM/Materials.jl.git |
|
[
"MIT"
] | 0.4.0 | d7a67c1c8ae6118f253a137ffa5291421e757a8a | code | 1555 | # This file is a part of JuliaFEM.
# License is MIT: see https://github.com/JuliaFEM/Materials.jl/blob/master/LICENSE
using Test, Tensors
let dtime = 0.25,
parameters = ChabocheParameterState(E=200.0e3,
nu=0.3,
R0=100.0,
Kn=100.0,
nn=10.0,
C1=10000.0,
D1=100.0,
C2=50000.0,
D2=1000.0,
Q=50.0,
b=0.1),
mat = Chaboche(parameters = parameters),
dstrain11 = 1e-3*dtime,
dstrain12 = 1e-3*dtime,
dtimes = dtime*[1.0, 1.0, 1.0, 1.0, 4.0],
dstrains11 = dstrain11*[1.0, 1.0, 1.0, -1.0, -4.0],
dstrains12 = dstrain12*[1.0, 1.0, 1.0, -1.0, -4.0]
plastic_flow_occurred = zeros(Bool, length(dtimes) - 1)
for i in 1:length(dtimes)
dstrain11 = dstrains11[i]
dstrain12 = dstrains12[i]
dtime = dtimes[i]
biaxial_increment!(mat, dstrain11, dstrain12, dtime)
update_material!(mat)
if i > 1
plastic_flow_occurred[i-1] = (mat.variables.cumeq > 0.0)
end
@test !iszero(mat.variables.stress[1,1]) && !iszero(mat.variables.stress[1,2])
@test isapprox(tovoigt(mat.variables.stress)[2:5], zeros(4); atol=1e-8)
end
@test any(plastic_flow_occurred)
end
| Materials | https://github.com/JuliaFEM/Materials.jl.git |
|
[
"MIT"
] | 0.4.0 | d7a67c1c8ae6118f253a137ffa5291421e757a8a | code | 1670 | # This file is a part of JuliaFEM.
# License is MIT: see https://github.com/JuliaFEM/Materials.jl/blob/master/LICENSE
using Test, Tensors
using DelimitedFiles
let path = joinpath("test_chaboche", "unitelement_results.rpt"),
data = readdlm(path, Float64; skipstart=4),
ts = data[:,1],
s11_ = data[:,2],
s12_ = data[:,3],
s13_ = data[:,4],
s22_ = data[:,5],
s23_ = data[:,6],
s33_ = data[:,7],
e11_ = data[:,8],
e12_ = data[:,9],
e13_ = data[:,10],
e22_ = data[:,11],
e23_ = data[:,12],
e33_ = data[:,13],
strains = [[e11_[i], e22_[i], e33_[i], e23_[i], e13_[i], e12_[i]] for i in 1:length(ts)],
parameters = ChabocheParameterState(E=200.0e3,
nu=0.3,
R0=100.0,
Kn=100.0,
nn=10.0,
C1=10000.0,
D1=100.0,
C2=50000.0,
D2=1000.0,
Q=50.0,
b=0.1),
mat = Chaboche(parameters=parameters)
s33s = [mat.variables.stress[3,3]]
for i=2:length(ts)
dtime = ts[i] - ts[i-1]
dstrain = fromvoigt(Symm2{Float64}, strains[i] - strains[i-1]; offdiagscale=2.0)
mat.ddrivers = ChabocheDriverState(time = dtime, strain = dstrain)
integrate_material!(mat)
update_material!(mat)
push!(s33s, mat.variables.stress[3,3])
end
@test isapprox(s33s, s33_; rtol=0.05)
end
| Materials | https://github.com/JuliaFEM/Materials.jl.git |
|
[
"MIT"
] | 0.4.0 | d7a67c1c8ae6118f253a137ffa5291421e757a8a | code | 2882 | # This file is a part of JuliaFEM.
# License is MIT: see https://github.com/JuliaFEM/Materials.jl/blob/master/LICENSE
using Test, Tensors
let E = 200.0e3,
nu = 0.3,
yield_strength = 100.0,
parameters = ChabocheParameterState(E=E,
nu=nu,
R0=yield_strength, # yield in shear = R0 / sqrt(3)
Kn=100.0,
nn=3.0,
C1=0.0,
D1=100.0,
C2=0.0,
D2=1000.0,
Q=0.0,
b=0.1),
mat = Chaboche(parameters=parameters),
times = [0.0],
loads = [0.0],
dt = 1.0,
G = 0.5*E/(1+nu),
# vonMises = sqrt(3 J_2) = sqrt(3/2 tr(s^2)) = sqrt(3) |tau| = sqrt(3)*G*|gamma|
# gamma = 2 e12
# set vonMises = Y
gamma_yield = yield_strength/(sqrt(3)*G)
# Go to elastic border
push!(times, times[end] + dt)
push!(loads, loads[end] + gamma_yield*dt)
# Proceed to plastic flow
push!(times, times[end] + dt)
push!(loads, loads[end] + gamma_yield*dt)
# Reverse direction
push!(times, times[end] + dt)
push!(loads, loads[end] - gamma_yield*dt)
# Continue and pass yield criterion
push!(times, times[end] + dt)
push!(loads, loads[end] - gamma_yield*dt)
push!(times, times[end] + dt)
push!(loads, loads[end] - gamma_yield*dt)
eeqs = [mat.variables.cumeq]
stresses = [copy(tovoigt(mat.variables.stress))]
for i=2:length(times)
dtime = times[i] - times[i-1]
dstrain12 = loads[i] - loads[i-1]
dstrain_voigt = [0.0, 0.0, 0.0, 0.0, 0.0, dstrain12]
dstrain_tensor = fromvoigt(Symm2{Float64}, dstrain_voigt; offdiagscale=2.0)
mat.ddrivers = ChabocheDriverState(time=dtime, strain=dstrain_tensor)
integrate_material!(mat)
# @info "$i, $gamma_yield, $(mat.variables_new.stress[1,2]), $(2.0*mat.variables_new.plastic_strain[1,2])\n"
update_material!(mat)
push!(stresses, copy(tovoigt(mat.variables.stress)))
push!(eeqs, mat.variables.cumeq)
# @info "time = $(mat.time), stress = $(mat.stress), cumeq = $(mat.properties.cumulative_equivalent_plastic_strain))"
end
for i in 1:length(times)
@test isapprox(stresses[i][1:5], zeros(5); atol=1e-6)
end
s31 = [s[6] for s in stresses]
@test isapprox(s31[2], yield_strength/sqrt(3.0))
@test isapprox(s31[3]*sqrt(3.0), yield_strength + 100.0*((eeqs[3] - eeqs[2])/dt)^(1.0/3.0); rtol=1e-2)
@test isapprox(s31[4], s31[3] - G*gamma_yield*dt)
@test isapprox(s31[6]*sqrt(3.0), -(yield_strength + 100.0*((eeqs[6] - eeqs[5])/dt)^(1.0/3.0)); rtol=1e-2)
end
| Materials | https://github.com/JuliaFEM/Materials.jl.git |
|
[
"MIT"
] | 0.4.0 | d7a67c1c8ae6118f253a137ffa5291421e757a8a | code | 3272 | # This file is a part of JuliaFEM.
# License is MIT: see https://github.com/JuliaFEM/Materials.jl/blob/master/LICENSE
using Test, Tensors
let parameters = MemoryParameterState(E = 200.0e3,
nu = 0.3,
R0 = 100.0,
Kn = 20.0,
nn = 3.0,
C1 = 10000.0,
D1 = 100.0,
C2 = 50000.0,
D2 = 1000.0,
Q0 = 100.0,
QM = 500.0,
mu = 100.0,
b = 30.0,
eta = 0.5,
m = 0.5,
pt = 0.0,
xi = 0.3),
mat = Memory(parameters=parameters),
tostrain(tens::Symm2) = copy(tovoigt(tens; offdiagscale=2.0)),
tostress(tens::Symm2) = copy(tovoigt(tens)),
n_cycles = 30,
points_per_cycle = 40,
t = range(0.0; stop=Float64(n_cycles), length=n_cycles * points_per_cycle + 1),
dtime = t[end] / (length(t) - 1),
# We initialize these manually to automatically get the correct type.
times = [copy(mat.drivers.time)],
stresses = [tostress(mat.variables.stress)],
strains = [tostrain(mat.drivers.strain)],
plastic_strains = [tostrain(mat.variables.plastic_strain)],
cumeqs = [copy(mat.variables.cumeq)],
qs = [copy(mat.variables.q)],
Rs = [copy(mat.variables.R)],
zetas = [tostrain(mat.variables.zeta)]
function snapshot!()
push!(times, mat.drivers.time)
push!(stresses, tostress(mat.variables.stress))
push!(strains, tostrain(mat.drivers.strain))
push!(plastic_strains, tostrain(mat.variables.plastic_strain))
push!(cumeqs, copy(mat.variables.cumeq))
push!(qs, copy(mat.variables.q))
push!(Rs, copy(mat.variables.R))
push!(zetas, tostrain(mat.variables.zeta))
end
# Amplitude 1
ea = 0.003
strains11 = ea * sin.(2*pi*t)
for dstrain11 in diff(strains11)
uniaxial_increment!(mat, dstrain11, dtime)
update_material!(mat)
snapshot!()
end
R1 = copy(Rs[end])
# Amplitude 2
ea = 0.005
strains11 = ea * sin.(2*pi*t)
for dstrain11 in diff(strains11)
uniaxial_increment!(mat, dstrain11, dtime)
update_material!(mat)
snapshot!()
end
R2 = copy(Rs[end])
# Amplitude 3
ea = 0.007
strains11 = ea * sin.(2*pi*t)
for dstrain11 in diff(strains11)
uniaxial_increment!(mat, dstrain11, dtime)
update_material!(mat)
snapshot!()
end
R3 = copy(Rs[end])
# Amplitude 4 - evanescence
ea = 0.003
strains11 = ea * sin.(2*pi*t)
for _ in 1:3
for dstrain11 in diff(strains11)
uniaxial_increment!(mat, dstrain11, dtime)
update_material!(mat)
snapshot!()
end
end
R4 = copy(Rs[end])
@test R2 > R1
@test R3 > R2
@test R4 < R3
@test isapprox(R1, R4; atol=1.0)
end
| Materials | https://github.com/JuliaFEM/Materials.jl.git |
|
[
"MIT"
] | 0.4.0 | d7a67c1c8ae6118f253a137ffa5291421e757a8a | code | 2977 | # This file is a part of JuliaFEM.
# License is MIT: see https://github.com/JuliaFEM/Materials.jl/blob/master/LICENSE
using Test, Tensors
let nu = 0.3,
yield_strength=100.0,
parameters = PerfectPlasticParameterState(youngs_modulus=200.0e3,
poissons_ratio=nu,
yield_stress=yield_strength),
epsilon=1e-3,
mat, # scope the name to this level; actual definition follows later
tostrain(vec) = fromvoigt(Symm2, vec; offdiagscale=2.0),
tostress(vec) = fromvoigt(Symm2, vec),
uniaxial_stress(sigma) = tostress([sigma, 0, 0, 0, 0, 0])
let dtime=0.25
# elastic straining
dstrain_dtime = tostrain(epsilon*[1.0, -nu, -nu, 0.0, 0.0, 0.0])
ddrivers = PerfectPlasticDriverState(time=dtime, strain=dstrain_dtime*dtime)
mat = PerfectPlastic(parameters=parameters, ddrivers=ddrivers)
integrate_material!(mat)
update_material!(mat)
@test isapprox(mat.variables.stress, uniaxial_stress(yield_strength / 2))
mat.ddrivers = ddrivers
integrate_material!(mat)
update_material!(mat)
# We should now be at the yield surface.
@test isapprox(mat.variables.stress, uniaxial_stress(yield_strength))
@test isapprox(mat.variables.cumeq, 0.0; atol=1.0e-12)
# plastic straining
# von Mises material, plastically incompressible, so plastic nu=0.5.
dstrain_dtime = tostrain(epsilon*[1.0, -0.5, -0.5, 0.0, 0.0, 0.0])
ddrivers = PerfectPlasticDriverState(time=dtime, strain=dstrain_dtime*dtime)
mat.ddrivers = ddrivers
integrate_material!(mat)
update_material!(mat)
@test isapprox(mat.variables.stress, uniaxial_stress(yield_strength); atol=1.0e-12)
@test isapprox(mat.variables.cumeq, dtime*epsilon)
# return to elastic state
dstrain_dtime = tostrain(-epsilon*[1.0, -nu, -nu, 0.0, 0.0, 0.0])
ddrivers = PerfectPlasticDriverState(time=dtime, strain=dstrain_dtime*dtime)
mat.ddrivers = ddrivers
integrate_material!(mat)
update_material!(mat)
@test isapprox(mat.variables.stress, uniaxial_stress(yield_strength / 2); atol=1.0e-12)
end
let dtime=1.0
# loading in reverse direction to plastic state
# The 0.75 term: one 0.25 cancels the current elastic stress state,
# and the remaining 0.5 reaches the yield surface.
# The 0.25 term: plastic strain.
dstrain_dtime = (-0.75*tostrain(epsilon*[1.0, -nu, -nu, 0.0, 0.0, 0.0])
-0.25*tostrain(epsilon*[1.0, -0.5, -0.5, 0.0, 0.0, 0.0]))
ddrivers = PerfectPlasticDriverState(time=1.0, strain=dstrain_dtime*dtime)
mat.ddrivers = ddrivers
integrate_material!(mat)
integrate_material!(mat)
update_material!(mat)
@test isapprox(mat.variables.stress, uniaxial_stress(-yield_strength))
end
end
| Materials | https://github.com/JuliaFEM/Materials.jl.git |
|
[
"MIT"
] | 0.4.0 | d7a67c1c8ae6118f253a137ffa5291421e757a8a | code | 1987 | # This file is a part of JuliaFEM.
# License is MIT: see https://github.com/JuliaFEM/Materials.jl/blob/master/LICENSE
using Test, Tensors
let E = 200.0e3,
nu = 0.3,
yield_strength = 100.0,
parameters = PerfectPlasticParameterState(youngs_modulus=E,
poissons_ratio=nu,
yield_stress=yield_strength), # yield in shear = R0 / sqrt(3)
mat = PerfectPlastic(parameters=parameters),
times = [0.0],
loads = [0.0],
dt = 1.0,
G = 0.5*E/(1+nu),
# vonMises = sqrt(3 J_2) = sqrt(3/2 tr(s^2)) = sqrt(3) |tau| = sqrt(3)*G*|gamma|
# gamma = 2 e12
# set vonMises = Y
gamma_yield = yield_strength/(sqrt(3)*G)
# Go to elastic border
push!(times, times[end] + dt)
push!(loads, loads[end] + gamma_yield*dt)
# Proceed to plastic flow
push!(times, times[end] + dt)
push!(loads, loads[end] + gamma_yield*dt)
# Reverse direction
push!(times, times[end] + dt)
push!(loads, loads[end] - gamma_yield*dt)
# Continue and pass yield criterion
push!(times, times[end] + dt)
push!(loads, loads[end] - 2*gamma_yield*dt)
stresses = [copy(tovoigt(mat.variables.stress))]
for i=2:length(times)
dtime = times[i] - times[i-1]
dstrain31 = loads[i] - loads[i-1]
dstrain_voigt = [0.0, 0.0, 0.0, 0.0, 0.0, dstrain31]
dstrain_tensor = fromvoigt(Symm2{Float64}, dstrain_voigt; offdiagscale=2.0)
mat.ddrivers = PerfectPlasticDriverState(time=dtime, strain=dstrain_tensor)
integrate_material!(mat)
update_material!(mat)
push!(stresses, copy(tovoigt(mat.variables.stress)))
end
for i in 1:length(times)
@test isapprox(stresses[i][1:5], zeros(5); atol=1e-6)
end
let y = yield_strength/sqrt(3.0)
s31 = [s[6] for s in stresses]
s31_expected = [0.0, y, y, 0.0, -y]
@test isapprox(s31, s31_expected; rtol=1.0e-2)
end
end
| Materials | https://github.com/JuliaFEM/Materials.jl.git |
|
[
"MIT"
] | 0.4.0 | d7a67c1c8ae6118f253a137ffa5291421e757a8a | code | 2563 | # This file is a part of JuliaFEM.
# License is MIT: see https://github.com/JuliaFEM/Materials.jl/blob/master/LICENSE
using Test, Tensors
let dtime = 0.25,
R0 = 100.0,
parameters = ChabocheParameterState(E=200.0e3,
nu=0.3,
R0=R0,
Kn=100.0,
nn=10.0,
C1=10000.0,
D1=100.0,
C2=50000.0,
D2=1000.0,
Q=0.0,
b=0.1),
material = Chaboche(parameters=parameters),
times = [material.drivers.time],
stresses = [copy(tovoigt(material.variables.stress))],
strains = [copy(tovoigt(material.drivers.strain; offdiagscale=2.0))],
cumeqs = [copy(material.variables.cumeq)],
tostrain(vec) = fromvoigt(Symm2, vec; offdiagscale=2.0),
tostress(vec) = fromvoigt(Symm2, vec),
uniaxial_stress(sigma) = tostress([sigma, 0, 0, 0, 0, 0]),
stresses_expected = [uniaxial_stress(R0 / 2),
uniaxial_stress(R0),
uniaxial_stress(1.5 * R0),
uniaxial_stress(1.5 * R0),
uniaxial_stress(R0),
uniaxial_stress(-R0)],
dstress = R0 / 2,
dstresses11 = dstress*[1.0, 1.0, 1.0, 0.0, -1.0, -4.0]
dtimes = [dtime, dtime, dtime, 1e3, dtime, 1e3]
for i in 1:length(dtimes)
dstress11 = dstresses11[i]
dtime = dtimes[i]
stress_driven_uniaxial_increment!(material, dstress11, dtime)
update_material!(material)
push!(times, material.drivers.time)
push!(stresses, copy(tovoigt(material.variables.stress)))
push!(strains, copy(tovoigt(material.drivers.strain; offdiagscale=2.0)))
push!(cumeqs, copy(material.variables.cumeq))
@test isapprox(material.variables.stress, stresses_expected[i]; atol=1e-4)
end
# Plastic creep should have occurred at the portion of the test
# where the stress was held at 1.5*R0.
dstrain_creep = strains[5] - strains[4]
# von Mises material, so the plastic nu = 0.5.
@test isapprox(dstrain_creep[2], -dstrain_creep[1]*0.5; atol=1e-4) # ε22 = -0.5 ε11
@test isapprox(dstrain_creep[3], -dstrain_creep[1]*0.5; atol=1e-4) # ε33 = -0.5 ε11
dcumeq = cumeqs[end] - cumeqs[end-1]
@test dcumeq > 0
end
| Materials | https://github.com/JuliaFEM/Materials.jl.git |
|
[
"MIT"
] | 0.4.0 | d7a67c1c8ae6118f253a137ffa5291421e757a8a | code | 1690 | # This file is a part of JuliaFEM.
# License is MIT: see https://github.com/JuliaFEM/Materials.jl/blob/master/LICENSE
using Test, Tensors
let dtime = 0.25,
nu = 0.3,
R = 100.0,
parameters = PerfectPlasticParameterState(youngs_modulus=200.0e3,
poissons_ratio=nu,
yield_stress=R),
mat = PerfectPlastic(parameters=parameters),
tostrain(vec) = fromvoigt(Symm2, vec; offdiagscale=2.0),
tostress(vec) = fromvoigt(Symm2, vec),
uniaxial_stress(sigma) = tostress([sigma, 0, 0, 0, 0, 0]),
stresses_expected = [uniaxial_stress(R / 2),
uniaxial_stress(R),
uniaxial_stress(R),
uniaxial_stress(R / 2),
uniaxial_stress(-R)],
dstrain11 = 1e-3*dtime,
strains_expected = [tostrain(dstrain11*[1.0, -nu, -nu, 0.0, 0.0, 0.0]),
tostrain(dstrain11*[2, -2*nu, -2*nu, 0.0, 0.0, 0.0]),
tostrain(dstrain11*[3, -2*nu - 0.5, -2*nu - 0.5, 0.0, 0.0, 0.0]),
tostrain(dstrain11*[2, -nu - 0.5, -nu - 0.5, 0.0, 0.0, 0.0]),
tostrain(dstrain11*[-2, 2*nu, 2*nu, 0.0, 0.0, 0.0])],
dtimes = [dtime, dtime, dtime, dtime, 1.0],
dstrains11 = dstrain11*[1.0, 1.0, 1.0, -1.0, -4.0]
for i in 1:length(dtimes)
dstrain11 = dstrains11[i]
dtime = dtimes[i]
uniaxial_increment!(mat, dstrain11, dtime)
update_material!(mat)
@test isapprox(mat.variables.stress, stresses_expected[i])
@test isapprox(mat.drivers.strain, strains_expected[i])
end
end
| Materials | https://github.com/JuliaFEM/Materials.jl.git |
|
[
"MIT"
] | 0.4.0 | d7a67c1c8ae6118f253a137ffa5291421e757a8a | code | 2387 | # This file is a part of JuliaFEM.
# License is MIT: see https://github.com/JuliaFEM/Materials.jl/blob/master/LICENSE
using Test, Tensors, LinearAlgebra
# Kronecker delta
@test delta(1, 1) == 1
@test delta(1, 2) == 0
@test_throws MethodError delta(1.0, 2.0) # indices must be integers
@test_throws MethodError delta(1, BigInt(2)) # both must have the same type
@test delta(1, 2) isa Int # the output type matches the input
@test delta(BigInt(1), BigInt(2)) isa BigInt
# Various tensors
let Z3 = zeros(3, 3),
O3 = ones(3, 3)
@test isapprox(tovoigt(II()), I)
@test isapprox(tovoigt(IT()), [I Z3;
Z3 Z3])
@test isapprox(tovoigt(IS()), [I Z3;
Z3 1//2*I])
@test isapprox(tovoigt(IA()), [Z3 Z3;
Z3 1//2*I])
@test isapprox(tovoigt(IV()), [1//3*O3 Z3;
Z3 Z3])
@test isapprox(tovoigt(ID()), [(I - 1//3*O3) Z3;
Z3 1//2*I])
@test let lambda = 10.0,
mu = 1.0
isapprox(tovoigt(isotropic_elasticity_tensor(lambda, mu)), [(lambda*O3 + 2*mu*I) Z3;
Z3 mu*I])
end
end
# Lamé parameters for isotropic solids
@test all(isapprox(result, expected)
for (result, expected) in zip(lame(1e11, 0.3), (5.769230769230769e10, 3.846153846153846e10)))
@test all(isapprox(result, expected)
for (result, expected) in zip(delame(lame(1e11, 0.3)...), (1e11, 0.3)))
# Mutating function to non-mutating function conversion
let # introduce a local scope so the name `f!` is only defined locally for this test.
function f!(out, x)
out[:] = [sin(elt) for elt in x]
return nothing
end
let
out = [0.0]
@test all([f!(out, [pi/4]) == nothing,
isapprox(out, [1/sqrt(2)])])
end
let
out = [0.0]
f = debang(f!)
@test f isa Function
@test all([isapprox(f([pi/4]), [1/sqrt(2)]),
out == [0.0]])
end
end
# Newton root finder
let g(x) = [(1 - x[1]^2) + x[2]],
x0 = [0.8, 0.2]
@test !isapprox(g(x0), [0.0], atol=1e-15) # find_root should have to actually do something
@test isapprox(g(find_root(g, x0)), [0.0], atol=1e-15)
end
| Materials | https://github.com/JuliaFEM/Materials.jl.git |
|
[
"MIT"
] | 0.4.0 | d7a67c1c8ae6118f253a137ffa5291421e757a8a | docs | 1622 | # Materials.jl
A computational material models package for JuliaFEM, concentrating on plasticity and viscoplasticity.
The public API is defined in [src/Materials.jl](src/Materials.jl). For details, see the docstrings. For usage examples, see the [automated tests](test/).
[![][gitter-img]][gitter-url]
[![][travis-img]][travis-url]
[![][coveralls-img]][coveralls-url]
[![][docs-stable-img]][docs-stable-url]
[![][docs-latest-img]][docs-latest-url]
[![][issues-img]][issues-url]
[![][appveyor-img]][appveyor-url]


[gitter-img]: https://badges.gitter.im/Join%20Chat.svg
[gitter-url]: https://gitter.im/JuliaFEM/JuliaFEM.jl
[travis-img]: https://travis-ci.org/JuliaFEM/Materials.jl.svg?branch=master
[travis-url]: https://travis-ci.org/JuliaFEM/Materials.jl
[docs-stable-img]: https://img.shields.io/badge/docs-stable-blue.svg
[docs-stable-url]: https://juliafem.github.io/Materials.jl/stable
[docs-latest-img]: (https://img.shields.io/badge/docs-latest-blue.svg
[docs-latest-url]: https://juliafem.github.io/InterfaceMechanics.jl/latest
[coveralls-img]: https://coveralls.io/repos/github/JuliaFEM/Materials.jl/badge.svg?branch=master
[coveralls-url]: https://coveralls.io/github/JuliaFEM/Materials.jl?branch=master
[issues-img]: https://img.shields.io/github/issues/JuliaFEM/Materials.jl.svg
[issues-url]: https://github.com/JuliaFEM/Materials.jl/issues
[appveyor-img]: https://ci.appveyor.com/api/projects/status/akjpmgbfjv97t4ts?svg=true
[appveyor-url]: https://ci.appveyor.com/project/JuliaFEM/materials-jl
| Materials | https://github.com/JuliaFEM/Materials.jl.git |
|
[
"MIT"
] | 0.4.0 | d7a67c1c8ae6118f253a137ffa5291421e757a8a | docs | 195 | # Materials.jl documentation
```@contents
```
```@meta
DocTestSetup = quote
using Materials
end
```
## Types
```@autodocs
Modules = [Materials]
```
## Functions
## Index
```@index
```
| Materials | https://github.com/JuliaFEM/Materials.jl.git |
|
[
"MIT"
] | 0.1.0 | e25bfc35fe2f2be3a9aae6979daf51d8bc843add | code | 311 | using Documenter, ElectricWires
makedocs(
modules = [ElectricWires],
sitename = "ElectricWires.jl",
pages = Any[
"ElectricWires.jl"=>"index.md",
"API references"=>Any["api/materials.md", "api/cross_sections.md"],
],
)
deploydocs(repo = "github.com/ryd-yb/ElectricWires.jl.git") | ElectricWires | https://github.com/rydyb/ElectricWires.jl.git |
|
[
"MIT"
] | 0.1.0 | e25bfc35fe2f2be3a9aae6979daf51d8bc843add | code | 118 | module ElectricWires
using DynamicQuantities
include("profiles.jl")
include("materials.jl")
include("wire.jl")
end
| ElectricWires | https://github.com/rydyb/ElectricWires.jl.git |
|
[
"MIT"
] | 0.1.0 | e25bfc35fe2f2be3a9aae6979daf51d8bc843add | code | 1459 | """
Material{T}
A material with a name, resistivity, density, and heat capacity.
# Fields
- `resistivity::AbstractQuantity`: The resistivity of the material.
- `density::AbstractQuantity`: The density of the material.
- `heat_capacity::AbstractQuantity`: The heat capacity of the material.
"""
struct Material{T<:AbstractQuantity}
resistivity::T
density::T
heat_capacity::T
function Material(; resistivity::T, density::T, heat_capacity::T) where {T}
@assert dimension(resistivity) == dimension(u"Ω*m") "resistivity must have units of resistance times length"
@assert dimension(density) == dimension(u"g/cm^3") "density must have units of mass per volume"
@assert dimension(heat_capacity) == dimension(u"J/(g*K)") "heat capacity must have units of energy per mass per temperature"
@assert ustrip(heat_capacity) > 0 "heat_capacity must be positive"
@assert ustrip(resistivity) > 0 "resistivity must be positive"
@assert ustrip(density) > 0 "density must be positive"
new{T}(resistivity, density, heat_capacity)
end
end
export Material
export Cu
"""
Cu
Cu as instance of `Material` with properties from [Wikipedia][1].
[1]: https://en.wikipedia.org/wiki/Electrical_resistivity_and_conductivity#Resistivity_and_conductivity_of_various_materials
"""
const Cu = Material(;
resistivity = 1.68e-8u"Ω*m",
density = 8.96u"g/cm^3",
heat_capacity = 0.385u"J/(g*K)",
)
| ElectricWires | https://github.com/rydyb/ElectricWires.jl.git |
|
[
"MIT"
] | 0.1.0 | e25bfc35fe2f2be3a9aae6979daf51d8bc843add | code | 2174 | export Profile, CircularProfile, RectangularProfile, DifferenceProfile, RectangularHollowProfile
export area
"""
Profile
Abstract type for wire cross-sections.
"""
abstract type Profile end
"""
CircularProfile{T}
A circular wire cross-section.
# Fields
- `diameter::T`: The diameter of the wire.
"""
struct CircularProfile{T<:AbstractQuantity} <: Profile
diameter::T
function CircularProfile(; diameter::T) where {T}
@assert dimension(diameter) == dimension(u"m") "diameter must have units of length"
@assert ustrip(diameter) > 0 "diameter must be positive"
new{T}(diameter)
end
end
"""
RectangularProfile{T}
A rectangular wire cross-section.
# Fields
- `width::T`: The width of the wire.
- `height::T`: The height of the wire.
"""
struct RectangularProfile{T<:AbstractQuantity} <: Profile
width::T
height::T
function RectangularProfile(; width::T, height::T) where {T}
@assert dimension(width) == dimension(u"m") "width must have units of length"
@assert dimension(height) == dimension(u"m") "height must have units of length"
@assert ustrip(width) > 0 "width must be positive"
@assert ustrip(height) > 0 "height must be positive"
new{T}(width, height)
end
end
"""
DifferenceProfile{S1,S2}
A difference of two wire cross-sections.
# Fields
- `a::S1`: The first wire cross-section which is subtracted from.
- `b::S2`: The second wire cross-section which is subtracted.
"""
struct DifferenceProfile{S1<:Profile,S2<:Profile} <: Profile
a::S1
b::S2
end
RectangularHollowProfile(;
width::AbstractQuantity,
height::AbstractQuantity,
hole_diameter::AbstractQuantity,
) = DifferenceProfile(RectangularProfile(width = width, height = height), CircularProfile(diameter = hole_diameter))
"""
area(s::CrossSection)
Returns the area of the given wire cross-section.
# Arguments
- `s::Profile`: The wire cross-section.
# Returns
- `Unitful.Area`: The area of the wire cross-section.
"""
area(s::CircularProfile) = π * (s.diameter / 2)^2
area(s::RectangularProfile) = s.width * s.height
area(s::DifferenceProfile) = area(s.a) - area(s.b)
| ElectricWires | https://github.com/rydyb/ElectricWires.jl.git |
|
[
"MIT"
] | 0.1.0 | e25bfc35fe2f2be3a9aae6979daf51d8bc843add | code | 919 | export Wire
export weight, resistance, heat_capacity
"""
Wire{T}
A wire with a cross-section, material, and length.
# Fields
# - `profile::Profile`: The wire's cross-section.
# - `material::Material{T}`: The material of the wire.
# - `length::T`: The length of the wire.
"""
struct Wire{T<:AbstractQuantity}
profile::Profile
material::Material{T}
length::T
function Wire(; profile::Profile, material::Material{T}, length::T) where {T}
@assert dimension(length) == dimension(u"m") "length must have units of length"
@assert ustrip(length) > 0 "length must be positive"
new{T}(profile, material, length)
end
end
weight(w::Wire) = uconvert(us"g", w.length * area(w.profile) * w.material.density)
resistance(w::Wire) = uconvert(us"mΩ", w.length * w.material.resistivity / area(w.profile))
heat_capacity(w::Wire) = uconvert(us"J/K", w.material.heat_capacity * weight(w))
| ElectricWires | https://github.com/rydyb/ElectricWires.jl.git |
|
[
"MIT"
] | 0.1.0 | e25bfc35fe2f2be3a9aae6979daf51d8bc843add | code | 569 | @testset "Material" begin
m = Material(density = 8.96u"g/cm^3", resistivity=1u"Ω*m", heat_capacity=1u"J/(g*K)")
@test m.density == 8.96u"g/cm^3"
@test m.resistivity == 1u"Ω*m"
@test m.heat_capacity == 1u"J/(g*K)"
@test_throws AssertionError Material(density = 8.96u"m/s", resistivity=1u"Ω*m", heat_capacity=1u"J/(g*K)")
@test_throws AssertionError Material(density = 8.96u"g/cm^3", resistivity=1u"Ω", heat_capacity=1u"J/(g*K)")
@test_throws AssertionError Material(density = 8.96u"g/cm^3", resistivity=1u"Ω*m", heat_capacity=1u"J/K")
end
| ElectricWires | https://github.com/rydyb/ElectricWires.jl.git |
|
[
"MIT"
] | 0.1.0 | e25bfc35fe2f2be3a9aae6979daf51d8bc843add | code | 1398 | @testset "CircularProfile" begin
circ = CircularProfile(diameter = 1u"mm")
@test circ.diameter == 1u"mm"
@test_throws AssertionError CircularProfile(diameter = 1u"s")
end
@testset "RectangularProfile" begin
rect = RectangularProfile(width = 1u"mm", height = 2u"mm")
@test rect.width == 1u"mm"
@test rect.height == 2u"mm"
@test_throws AssertionError RectangularProfile(width = 1u"s", height = 1u"mm")
@test_throws AssertionError RectangularProfile(width = 1u"mm", height = 1u"s")
end
@testset "RectangularHollowCoreProfile" begin
recth = RectangularHollowProfile(width = 5u"mm", height = 5u"mm", hole_diameter = 2.7u"mm")
@test recth.a.width == 5u"mm"
@test recth.a.height == 5u"mm"
@test recth.b.diameter == 2.7u"mm"
@test_throws AssertionError RectangularHollowProfile(
width = 5u"s",
height = 5u"mm",
hole_diameter = 2.7u"mm",
)
@test_throws AssertionError RectangularHollowProfile(
width = 5u"mm",
height = 5u"s",
hole_diameter = 2.7u"mm",
)
@test_throws AssertionError RectangularHollowProfile(
width = 5u"mm",
height = 5u"mm",
hole_diameter = 2.7u"s",
)
@testset "area" begin
@test area(circ) ≈ 0.7854u"mm^2" rtol = 1e-4
@test area(rect) == 1u"mm^2"
@test area(recth) ≈ 19.27u"mm^2" rtol = 1e-2
end
end
| ElectricWires | https://github.com/rydyb/ElectricWires.jl.git |
|
[
"MIT"
] | 0.1.0 | e25bfc35fe2f2be3a9aae6979daf51d8bc843add | code | 316 | using ElectricWires
using Test
using DynamicQuantities
circ = CircularProfile(diameter = 1u"mm")
rect = RectangularProfile(width = 1u"mm", height = 1u"mm")
recth = RectangularHollowProfile(width = 5u"mm", height = 5u"mm", hole_diameter = 2.7u"mm")
include("profiles.jl")
include("materials.jl")
include("wire.jl")
| ElectricWires | https://github.com/rydyb/ElectricWires.jl.git |
|
[
"MIT"
] | 0.1.0 | e25bfc35fe2f2be3a9aae6979daf51d8bc843add | code | 636 | @testset "Wire" begin
cw = Wire(
profile = circ,
material = Cu,
length = 1u"m",
)
@test cw.profile.diameter == 1u"mm"
@test cw.material.density == 8.96u"g/cm^3"
rw = Wire(
profile = recth,
material = Cu,
length = 1u"m",
)
@testset "weight" begin
@test weight(cw) ≈ 7.04u"g" rtol = 1e-2
end
@testset "resistance" begin
@test resistance(cw) ≈ 21.39u"mΩ" rtol = 1e-2
@test resistance(rw) ≈ 0.8716u"mΩ" rtol = 1e-2
end
@testset "heat_capacity" begin
@test heat_capacity(rw) ≈ 66u"J/K" rtol = 1
end
end
| ElectricWires | https://github.com/rydyb/ElectricWires.jl.git |
|
[
"MIT"
] | 0.1.0 | e25bfc35fe2f2be3a9aae6979daf51d8bc843add | docs | 786 | # ElectricWires.jl
| **Build Status** | **Code Coverage** |
|:-----------------------------------------:|:-------------------------------:|
| [![][CI-img]][CI-url] | [![][codecov-img]][codecov-url] |
ElectricWires.jl is a Julia library that provides various types and functions for engineering wiring.
## Installation
```julia
using Pkg
Pkg.add("ElectricWires.jl")
```
## Usage
See the tests in `test`.
[CI-img]: https://github.com/ryd-yb/ElectricWires.jl/actions/workflows/CI.yml/badge.svg
[CI-url]: https://github.com/ryd-yb/ElectricWires.jl/actions/workflows/CI.yml
[codecov-img]: https://codecov.io/gh/ryd-yb/ElectricWires.jl/branch/main/graph/badge.svg?token=CNF55N4HDZ
[codecov-url]: https://codecov.io/gh/ryd-yb/ElectricWires.jl
| ElectricWires | https://github.com/rydyb/ElectricWires.jl.git |
|
[
"MIT"
] | 0.1.0 | e25bfc35fe2f2be3a9aae6979daf51d8bc843add | docs | 207 | # ElectricWires.jl
ElectricWires.jl is a Julia library that provides various types and functions for engineering heat transfer with fluids.
## Installation
```julia
using Pkg; Pkg.add("ElectricWires")
``` | ElectricWires | https://github.com/rydyb/ElectricWires.jl.git |
|
[
"MIT"
] | 0.1.0 | e25bfc35fe2f2be3a9aae6979daf51d8bc843add | docs | 294 | # Cross-sections
```@docs
ElectricWires.CrossSection
```
```@docs
ElectricWires.Circular
```
```@docs
ElectricWires.Rectangular
```
```@docs
ElectricWires.RectangularHollow
```
```@docs
ElectricWires.area
```
```@docs
ElectricWires.resistance
```
```@docs
ElectricWires.heat_capacity
``` | ElectricWires | https://github.com/rydyb/ElectricWires.jl.git |
|
[
"MIT"
] | 0.1.0 | e25bfc35fe2f2be3a9aae6979daf51d8bc843add | docs | 83 | # Materials
```@docs
ElectricWires.Material
```
```@docs
ElectricWires.Copper
``` | ElectricWires | https://github.com/rydyb/ElectricWires.jl.git |
|
[
"MIT"
] | 0.1.0 | e25bfc35fe2f2be3a9aae6979daf51d8bc843add | docs | 126 | # Properties
```@docs
ElectricWires.area
```
```@docs
ElectricWires.resistance
```
```@docs
ElectricWires.heat_capacity
``` | ElectricWires | https://github.com/rydyb/ElectricWires.jl.git |
|
[
"MIT"
] | 0.3.4 | f53e386411d9c596624bc254b13ce9aa31d5307a | code | 2109 | using AVLTrees, BenchmarkTools
using Random
using Plots
using DataFrames
function batch_insert!(t::AVLTree{K,D}, v::Vector{K}) where {K,D}
for i in v
insert!(t, i, i)
end
end
function batch_delete!(t::AVLTree{K,D}, v::Vector{K}) where {K,D}
for i in v
delete!(t, i)
end
end
function batch_find(t::AVLTree{K,D}, v::Vector{K}) where {K,D}
for i in v
i in t
end
end
insertion_vec = []
deletion_vec = []
search_vec = []
d = DataFrame((op=[], time=[], n=[]))
x = [1_000, 10_000, 100_000, 1_000_000, 10_000_000]
function prepare_t(t)
_t = deepcopy(t)
for i in nums_test
insert!(_t, i, i)
end
_t
end
for attempt in 1:1
for N in x
global t = AVLTree{Int64,Int64}()
rng = MersenneTwister(1111)
global nums_fill = rand(rng, Int64, N)
global nums_test = rand(rng, Int64, 10_000)
for i in nums_fill
insert!(t, i, i)
end
insertion = @benchmark batch_insert!(_t, nums_test) setup=(_t =deepcopy(t))
search = @benchmark batch_find(t, nums_test) setup=(_t = prepare_t(t))
deletion = @benchmark batch_delete!(t, nums_test) setup=(_t = prepare_t(t))
push!(d, ("insert", minimum(insertion).time, N))
push!(d, ("delete", minimum(deletion).time,N))
push!(d, ("search", minimum(search).time,N))
println("done $N")
end
end
c = combine(groupby(d, [:op,:n]), :time => minimum)
# plot(x, insertion_vec/1000, xscale=:log10, ylabel="us")
# plot(x, deletion_vec/1000, xscale=:log10, ylabel="us")
# plot(x, search_vec/1000, xscale=:log10, ylabel="us")
plot(
x,
[c[(c.op.=="insert"),:].time_minimum,c[(c.op.=="delete"),:].time_minimum, c[(c.op.=="search"),:].time_minimum],
xscale = :log10,
ylabel = "operation time [us]",
xlabel = "N",
xticks = [1e3, 1e4, 1e5, 1e6, 1e7],
markershape =[:diamond :utriangle :dtriangle],
labels= ["insert" "delete" "lookup"],
legend=:topleft,
)
savefig("branch_results_new2.svg")
savefig("result_new2.png")
using CSV
CSV.write("branch_results_new2.csv", c) | AVLTrees | https://github.com/krynju/AVLTrees.jl.git |
|
[
"MIT"
] | 0.3.4 | f53e386411d9c596624bc254b13ce9aa31d5307a | code | 307 | module AVLTrees
import Base: iterate, haskey, getkey, getindex, setindex!, length,
eltype, isempty, insert!, popfirst!, insert!, delete!
print, show, firstindex, pop!, popfirst!
include("node.jl")
include("tree.jl")
include("set.jl")
export AVLTree, AVLSet, findkey
end # module
| AVLTrees | https://github.com/krynju/AVLTrees.jl.git |
|
[
"MIT"
] | 0.3.4 | f53e386411d9c596624bc254b13ce9aa31d5307a | code | 669 |
"""
Node
struct
"""
mutable struct Node{K,D}
parent::Union{Node{K,D},Nothing}
left::Union{Node{K,D},Nothing}
right::Union{Node{K,D},Nothing}
key::K
bf::Int8
data::D
end # Node
Node{K,D}(key, data, parent) where {K,D} =
Node{K,D}(parent, nothing, nothing, key, Int8(0), data)
Node{K,D}(key, data) where {K,D} = Node{K,D}(key, data, nothing)
Node(key::K, data::D) where {K,D} = Node{K,D}(key, data)
Node(key::K, data::D, parent::Union{Node{K,D},Nothing}) where {K,D} =
Node{K,D}(key, data, parent)
Base.show(io::IO, ::MIME"text/plain", node::Node{K,D}) where {K,D} =
print(io, "Node{$(K),$(D)}: $(node.key) -> $(node.data)")
| AVLTrees | https://github.com/krynju/AVLTrees.jl.git |
|
[
"MIT"
] | 0.3.4 | f53e386411d9c596624bc254b13ce9aa31d5307a | code | 1747 | import Base: union, union!, setdiff, setdiff!, intersect!, intersect
struct AVLSet{K} <: AbstractSet{K}
tree::AVLTree{K,Nothing}
end
AVLSet() = AVLSet{Any}(AVLTree{Any,Nothing}())
AVLSet{K}() where {K} = AVLSet{K}(AVLTree{K,Nothing}())
function AVLSet(x::K) where {K <: AbstractVector}
t = AVLTree{eltype(x),Nothing}()
for i in x
insert!(t, i, nothing)
end
return AVLSet{eltype(x)}(t)
end
Base.eltype(::Type{AVLSet{K}}) where {K} = K
Base.length(set::AVLSet) = length(set.tree)
Base.in(x::K, set::AVLSet{K}) where {K} = x in set.tree
function iterate(set::AVLSet{K}) where {K}
ret = iterate(set.tree)
if ret === nothing return nothing else return (ret[1][1], ret[2]) end
end
function iterate(set::AVLSet{K}, node::Node{K,Nothing}) where {K}
ret = iterate(set.tree, node)
if ret === nothing return nothing else return (ret[1][1], ret[2]) end
end
Base.push!(set::AVLSet{K}, item::K) where {K} = insert!(set.tree, item, nothing)
Base.delete!(set::AVLSet{K}, item) where {K} = delete!(set.tree, item)
Base.union(set::AVLSet{K}, sets...) where {K} = union!(deepcopy(set), sets...)
function Base.union!(set::AVLSet{K}, sets...) where {K}
(key -> push!.(Ref(set), key)).(sets)
return set
end
Base.setdiff(set::AVLSet{K}, sets...) where {K} = setdiff!(deepcopy(set), sets...)
function Base.setdiff!(set::AVLSet{K}, sets...) where {K}
(key -> delete!.(Ref(set), key)).(sets)
return set
end
Base.intersect(set::AVLSet{K}, s::AbstractSet) where {K} = intersect!(deepcopy(set), s)
function Base.intersect!(set::AVLSet{K}, s::AbstractSet) where {K}
_set = collect(set)
for key in _set
if key ∉ s
delete!(set, key)
end
end
return set
end
| AVLTrees | https://github.com/krynju/AVLTrees.jl.git |
|
[
"MIT"
] | 0.3.4 | f53e386411d9c596624bc254b13ce9aa31d5307a | code | 11419 |
"""
AVLTree
struct
"""
mutable struct AVLTree{K,D}
root::Union{Node{K,D},Nothing}
end
AVLTree() = AVLTree{Any,Any}(nothing)
AVLTree{K,D}() where {K,D} = AVLTree{K,D}(nothing)
Base.eltype(::Type{AVLTree{K,D}}) where {K,D} = Tuple{K,D}
Base.getindex(tr::AVLTree{K,D}, k::K) where {K,D} = Base.getkey(tr, k)
Base.setindex!(tr::AVLTree{K,D}, k::K, d::D) where {K,D} = AVLTrees.insert!(tr, k, d)
Base.haskey(tr::AVLTree{K,D}, k::K) where {K,D} = !(find_node(tr, k) === nothing)
Base.length(tr::AVLTree{K,D}) where {K,D} = AVLTrees.size(tr)
Base.isempty(tr::AVLTree{K,D}) where {K,D} = tr.root === nothing
Base.in(x::K, tr::AVLTree{K,D}) where {K,D} = find_node(tr, x) !== nothing
function Base.getkey(tr::AVLTree{K,D}, k::K) where {K,D}
d = findkey(tr, k)
if d === nothing throw(KeyError(k)) else d end
end
function Base.size(tree::AVLTree)
return __size(tree.root)
end # function
@inline function __size(node::Union{Nothing,Node})
if node === nothing
return 0
end
return __size(node.left) + __size(node.right) + 1
end
"""
insert!(args)
documentation
"""
function Base.insert!(tree::AVLTree{K,D}, key, data) where {K,D}
parent = nothing
node = tree.root
while node !== nothing
parent = node
if key < node.key
node = node.left
elseif key > node.key
node = node.right
else
node.data = data
return
end
end
if parent === nothing
tree.root = Node{K,D}(key, data)
elseif key < parent.key
parent.left = Node{K,D}(key, data, parent)
balance_insertion(tree, parent, true)
elseif key > parent.key
parent.right = Node{K,D}(key, data, parent)
balance_insertion(tree, parent, false)
end
return
end # function
macro rebalance!(_tree, _node, _height_changed)
tree = esc(_tree)
node = esc(_node)
height_changed = esc(_height_changed)
return :(
if $(node).bf == 2
$(node), $(height_changed) = _rebalance_barrier_p2($(tree), $(node), $(node).right)
elseif $(node).bf == -2
$(node), $(height_changed) = _rebalance_barrier_m2($(tree), $(node), $(node).left)
else
$(height_changed) = $(node).bf == zero(Int8)
end
)
end
@inline function _rebalance_barrier_p2(tree::AVLTree{K,D}, node::Node{K,D}, node_right::Node{K,D}) where {K,D}
height_changed = node_right.bf != zero(Int8)
if node_right.bf == -one(Int8)
rotate_right(tree, node_right, node_right.left)
end
rotate_left(tree, node, node.right), height_changed
end
@inline function _rebalance_barrier_m2(tree::AVLTree{K,D}, node::Node{K,D}, node_left::Node{K,D}) where {K,D}
height_changed = node_left.bf != zero(Int8)
if node_left.bf == one(Int8)
rotate_left(tree, node_left, node_left.right)
end
rotate_right(tree, node, node.left), height_changed
end
"""
balance_insertion(tree::AVLTree{K,D},node::Node{K,D},left_insertion::Bool) where {K,D}
documentation
"""
@inline function balance_insertion(
tree::AVLTree{K,D},
node::Node{K,D},
left_insertion::Bool,
) where {K,D}
while true
node.bf += ifelse(left_insertion, -one(Int8), one(Int8))
height_changed = false
@rebalance!(tree, node, height_changed)
height_changed && break
node_parent = node.parent
if node_parent !== nothing
left_insertion = node_parent.left == node
node = node_parent
else
break
end
end
end # function
@inline function rotate_left(t::AVLTree{K,D}, x::Node{K,D}, x_right::Node{K,D}) where {K,D}
y = x_right
if y.left !== nothing
x.right = y.left
y.left.parent = x
else
x.right = nothing
end
y.left = x
xp = x.parent
if xp === nothing
t.root = y
else
if xp.left == x
xp.left = y
else
xp.right = y
end
end
y.parent = xp
x.parent = y
x.bf -= y.bf * (y.bf >= zero(Int8)) + one(Int8)
y.bf += x.bf * (x.bf < zero(Int8)) - one(Int8)
return y
end
@inline function rotate_right(t::AVLTree{K,D}, x::Node{K,D}, x_left::Node{K,D}) where {K,D}
y = x_left
if y.right !== nothing
x.left = y.right
y.right.parent = x
else
x.left = nothing
end
y.right = x
xp = x.parent
if xp === nothing
t.root = y
else
if xp.left == x
xp.left = y
else
xp.right = y
end
end
y.parent = xp
x.parent = y
x.bf -= y.bf * (y.bf < zero(Int8)) - one(Int8)
y.bf += x.bf * (x.bf >= zero(Int8)) + one(Int8)
return y
end
"""
delete!(tree::AVLTree{K,D}, node::Node{K,D}) where {K,D}
documentation
"""
function Base.delete!(tree::AVLTree{K,D}, node::Node{K,D}) where {K,D}
if node.left !== nothing
node_right = node.right
if node_right !== nothing
# left != nothing && right != nothing
temp = node_right
temp_left = temp.left
while temp_left !== nothing
temp = temp_left
temp_left = temp.left
end
# switch spots completely
node.key = temp.key
node.data = temp.data
delete!(tree, temp)
else
# left != nothing && right == nothing
dir = __parent_replace(tree, node, node.left)
balance_deletion(tree, node.parent, dir)
end
else
node_right = node.right
if node_right !== nothing
# left == nothing && right != nothing
dir = __parent_replace(tree, node, node_right)
balance_deletion(tree, node.parent, dir)
else
# left == nothing && right == nothing
dir = __parent_replace(tree, node, nothing)
balance_deletion(tree, node.parent, dir)
end
end
return
end # function
function Base.delete!(tree::AVLTree{K,D}, key::K) where {K,D}
node = find_node(tree, key)
if node !== nothing
delete!(tree, node)
end
end # function
@inline balance_deletion(tree::AVLTree, node::Nothing, left_delete::Bool) where {K,D} = return
@inline function balance_deletion(
tree::AVLTree{K,D},
node::Node{K,D},
left_delete::Bool,
) where {K,D}
while node !== nothing
node.bf += ifelse(left_delete, one(Int8), -one(Int8))
height_changed = false
@rebalance!(tree, node, height_changed)
!height_changed && break
node_parent = node.parent
if node_parent !== nothing
left_delete = node_parent.left == node
node = node_parent
else
break
end
end
end # function
# __parent_replace(tree::AVLTree{K,D}, node::Node{K,D}, replacement::Node{K,D})
#
# Replaces node with its only child. Used on nodes with a single child when erasing a node.
@inline function __parent_replace(
tree::AVLTree{K,D},
node::Node{K,D},
replacement::Node{K,D},
) where {K,D}
node_parent = node.parent
if node_parent !== nothing
replacement.parent = node_parent
if node_parent.right == node
node_parent.right = replacement
return false
else
node_parent.left = replacement
return true
end
else
replacement.parent = nothing
tree.root = replacement
return false
end
end # function
# __parent_replace(tree::AVLTree{K,D}, node::Node{K,D}, replacement::Nothing)
# Replaces node with nothing. Used on leaf nodes when erasing a node.
@inline function __parent_replace(
tree::AVLTree{K,D},
node::Node{K,D},
replacement::Nothing,
) where {K,D}
node_parent = node.parent
if node_parent !== nothing
if node_parent.right == node
node_parent.right = replacement
return false
else
node_parent.left = replacement
return true
end
else
tree.root = replacement
return false
end
end # function
"""
find(tree::AVLTree{K,D}, key::K) where {K,D}
Warning: do not use it to check whether `key` is in the `tree`.
It returns the node.data if found which can be `nothing`.
"""
@inline function findkey(tree::AVLTree{K,D}, key::K) where {K,D}
node = tree.root
while node !== nothing
if key < node.key
node = node.left
elseif key > node.key
node = node.right
else
return node.data
end
end
return nothing
end # function
"""
find_node(args)
"""
@inline function find_node(tree::AVLTree{K,D}, key::K) where {K,D}
node = tree.root
while node !== nothing
if key < node.key
node = node.left
elseif key > node.key
node = node.right
else
return node
end
end
return nothing
end # function
# Iteration interface
function Base.iterate(tree::AVLTree)
if tree.root === nothing
return nothing
end
node = tree.root
while node.left !== nothing
node = node.left
end
return (node.key, node.data), node
end
function Base.iterate(tree::AVLTree, node::Node)
if node.right !== nothing
node = node.right
while node.left !== nothing
node = node.left
end
else
prev = node
while node !== nothing && node.left != prev
prev = node
node = node.parent
end
end
if node === nothing
return nothing
end
return (node.key, node.data), node
end
# Pop and get methods
function Base.popfirst!(tree::AVLTree)
# traverse to left-most node
if tree.root === nothing
return
end
node = tree.root
while node.left !== nothing
node = node.left
end
# delete node and return data
node_data = node.data
delete!(tree, node)
return node_data
end
function Base.pop!(tree::AVLTree{K,D}, key::K) where {K,D}
node = AVLTrees.find_node(tree, key)
if node !== nothing
node_dat = node.data
delete!(tree, node)
return node_dat
else
return
end
end
function Base.firstindex(tree::AVLTree)
# traverse to left-most node
if tree.root === nothing
return
end
node = tree.root
while node.left !== nothing
node = node.left
end
# return node key
return node.key
end
## Print and Show methods
function Base.print(io::IO, tree::AVLTree{K,D}) where {K,D}
str_lst = Vector{String}()
for (k, v) in Base.Iterators.take(tree, 10)
push!(str_lst, "$k => $v")
end
print(io, "AVLTree{$K,$D}(")
print(io, join(str_lst, ", "))
length(str_lst) == 10 && print(io, ", ⋯ ")
print(io, ")")
end
function Base.show(io::IO, ::MIME"text/plain", tree::AVLTree{K,D}) where {K,D}
str_lst = Vector{String}()
indent_str = " "
for (k, v) in Base.Iterators.take(tree, 10)
push!(str_lst, indent_str * "$k => $v")
end
if length(str_lst) > 0
print(io, "AVLTree{$K,$D} with $(length(tree)) entries:\n")
print(io, join(str_lst, "\n"))
else
print(io, "AVLTree{$K,$D}()")
end
length(str_lst) == 10 && print(io, "\n", indent_str * "⋮ => ⋮ \n")
end
| AVLTrees | https://github.com/krynju/AVLTrees.jl.git |
|
[
"MIT"
] | 0.3.4 | f53e386411d9c596624bc254b13ce9aa31d5307a | code | 298 | @testset "node" begin
@testset "constructors" begin
n = AVLTrees.Node(10, 10)
@test n.key == 10
@test n.data == 10
@test isnothing(n.parent)
n1 = AVLTrees.Node(12, 12, n)
@test n1.parent == n
@test isnothing(n1.parent.parent)
end
end | AVLTrees | https://github.com/krynju/AVLTrees.jl.git |
|
[
"MIT"
] | 0.3.4 | f53e386411d9c596624bc254b13ce9aa31d5307a | code | 128 | using AVLTrees
using Test
@testset "AVLTrees.jl" begin
include("node.jl")
include("tree.jl")
include("set.jl")
end
| AVLTrees | https://github.com/krynju/AVLTrees.jl.git |
|
[
"MIT"
] | 0.3.4 | f53e386411d9c596624bc254b13ce9aa31d5307a | code | 1926 | @testset "set.jl" begin
@testset "basic" begin
s = AVLSet()
items = ["anything", "anything2"]
push!(s, items[1])
r = collect(s)
@test length(r) == 1
@test items[1] in r
push!(s, items[2])
r = collect(s)
@test length(r) == 2
@test all(items .∈ Ref(s))
@test all(items .∈ Ref(r))
delete!(s, items[1])
delete!(s, items[2])
@test isempty(s)
end
@testset "constructor with AbstractVector input" begin
items = rand(1_000)
s = AVLSet(items)
@test eltype(items) == eltype(s)
@test all(items .∈ Ref(s))
@test all(items .∈ Ref(collect(s)))
end
@testset "union" begin
a = rand(1:1000, 800)
b = rand(1:1000, 800)
avl_a = AVLSet(a)
avl_b = AVLSet(b)
sa = Set(a)
sb = Set(b)
@test union(avl_a, avl_b) == union(sa, sb)
@test union(avl_a, avl_a) == union(sa, sa)
@test union(avl_a, avl_b, avl_b) == union(sa, sb)
@test union(avl_a, sb, avl_b, avl_a, sb) == union(sa, sb)
@test union!(avl_a, avl_b) == union(sa, sb)
@test union!(avl_b, avl_a) == union(sa, sb)
end
@testset "setdiff" begin
a = rand(1:1000, 800)
b = rand(1:1000, 800)
avl_a = AVLSet(a)
avl_b = AVLSet(b)
sa = Set(a)
sb = Set(b)
@test setdiff(avl_a, avl_b, avl_b) == setdiff(sa, sb)
@test setdiff(avl_a, avl_a) == setdiff(sa, sa)
@test setdiff(avl_a, sb) == setdiff(sa, sb)
end
@testset "intersect" begin
a = rand(1:1000, 800)
b = rand(1:1000, 800)
avl_a = AVLSet(a)
avl_b = AVLSet(b)
sa = Set(a)
sb = Set(b)
@test intersect(avl_a, avl_b) == intersect(sa, sb)
@test intersect(avl_a, avl_a) == intersect(sa, sa)
end
end
| AVLTrees | https://github.com/krynju/AVLTrees.jl.git |
|
[
"MIT"
] | 0.3.4 | f53e386411d9c596624bc254b13ce9aa31d5307a | code | 4787 |
@testset "tree.jl" begin
@testset "root insertion test" begin
t = AVLTree{Int64,Int64}()
insert!(t, 1, 2)
@test !isnothing(t.root)
@test t.root.bf == 0
@test isnothing(t.root.right) && isnothing(t.root.left)
@test t.root.key == 1 && t.root.data == 2
@test size(t) == 1
insert!(t, 1, 10)
delete!(t, 999)
@test t.root.data == 10
@test size(t) == 1
end
@testset "left rotation test" begin
t = AVLTree{Int64,Int64}()
insert!(t, 1, 2)
insert!(t, 2, 2)
insert!(t, 3, 2)
@test t.root.bf == 0 && t.root.left.bf == 0 && t.root.right.bf == 0
@test t.root.key == 2 && t.root.left.key == 1 && t.root.right.key == 3
@test size(t) == 3
end
@testset "right rotation test" begin
t = AVLTree{Int64,Int64}()
insert!(t, 3, 2)
insert!(t, 2, 2)
insert!(t, 1, 2)
@test t.root.bf == 0 && t.root.left.bf == 0 && t.root.right.bf == 0
@test t.root.key == 2 && t.root.left.key == 1 && t.root.right.key == 3
@test size(t) == 3
end
@testset "left-right rotation test" begin
t = AVLTree{Int64,Int64}()
insert!(t, 3, 2)
insert!(t, 1, 2)
insert!(t, 2, 2)
@test t.root.bf == 0 && t.root.left.bf == 0 && t.root.right.bf == 0
@test t.root.key == 2 && t.root.left.key == 1 && t.root.right.key == 3
@test size(t) == 3
end
@testset "right-left rotation test" begin
t = AVLTree{Int64,Int64}()
insert!(t, 1, 2)
insert!(t, 3, 2)
insert!(t, 2, 2)
@test t.root.bf == 0 && t.root.left.bf == 0 && t.root.right.bf == 0
@test t.root.key == 2 && t.root.left.key == 1 && t.root.right.key == 3
@test size(t) == 3
end
@testset "tree{Any,Any} test" begin
t = AVLTree()
insert!(t, "item1", "item1")
@test t.root.key == "item1"
insert!(t, "item2", "item2")
insert!(t, "item3", "item3")
@test t.root.key == "item2"
@test size(t) == 3
end
@testset "fill test" begin
t = AVLTree{Int64,Int64}()
for i in rand(Int64, 100)
insert!(t, i, 0)
end
@test size(t) <= 100
end
@testset "delete basic" begin
t = AVLTree{Int64,Int64}()
insert!(t, 1, 2)
insert!(t, 2, 2)
insert!(t, 3, 2)
@test size(t) == 3
delete!(t, t.root.left)
@test isnothing(t.root.left)
@test t.root.bf == 1
@test size(t) == 2
delete!(t, t.root.right)
@test isnothing(t.root.right)
@test t.root.bf == 0
@test size(t) == 1
delete!(t, t.root)
@test size(t) == 0
@test isnothing(t.root)
end
@testset "fill and delete all test" begin
t = AVLTree{Int64,Int64}()
for i in rand(Int64, 100)
insert!(t, i, 0)
end
@test size(t) <= 100
while !isnothing(t.root)
delete!(t, t.root)
end
@test isnothing(t.root)
@test size(t) == 0
end
@testset "fill and delete keys test" begin
t = AVLTree{Int64,Int64}()
nums = rand(Int64, 100)
for i in nums
insert!(t, i, i)
end
@test size(t) <= 100
for i in nums
delete!(t, i)
end
@test size(t) == 0
@test isnothing(t.root)
end
@testset "findkey test" begin
t = AVLTree{Int64,Int64}()
for i = 1:1000
insert!(t, i, i)
end
@test size(t) == 1000
@test 500 == findkey(t, 500)
@test nothing == findkey(t, 1001)
@test size(t) == 1000
end
@testset "iteration test" begin
t = AVLTree{Int64,Int64}()
for i = 1:1000
insert!(t, i, i)
end
s1 = Set{Tuple{Int64,Int64}}([(_x,_x) for _x in 1:1000])
s2 = Set{Tuple{Int64,Int64}}()
for i in t
push!(s2,i)
end
@test s1 == s2
end
@testset "Base.*" begin
t = AVLTree{Int64, Int64}()
for i in 1:100
insert!(t, i, i)
end
@test eltype(t) == Tuple{Int64, Int64}
@test getindex.(Ref(t), 1:100) == 1:100
try
getindex(t, -100)
catch x
@test x == KeyError(-100)
end
setindex!(t, 10, -10)
@test t[10] == -10
@test haskey(t,10)
@test !haskey(t,-10)
@test length(t) == 100
t[-10] = -10
@test length(t) == 101
@test !isempty(t)
@test popfirst!(t) == -10
@test firstindex(t) == 1
t[10] = 10
@test pop!.(Ref(t), 1:100) == 1:100
end
end
| AVLTrees | https://github.com/krynju/AVLTrees.jl.git |
|
[
"MIT"
] | 0.3.4 | f53e386411d9c596624bc254b13ce9aa31d5307a | docs | 1295 | # AVLTrees
[](https://travis-ci.com/krynju/AVLTrees.jl)
[](https://codecov.io/gh/krynju/AVLTrees.jl)
AVL self-balancing tree written in pure Julia.
Implemented on raw heap assigned storage with minimal overhead coming from
balancing the tree itself. The tree node structure only has an additional Int8
keeping the balance factor. All balancing procedures are dynamically propagated
(no height calculations during balancing).
## Benchmark
An overview of performance is shown below. Times are shown for an average of 1000 operations made at N elements in the structure.
### Table
```julia
Row │ n insert[us] delete[us] search[us]
│ Any Float64? Float64? Float64?
─────┼────────────────────────────────────────────────
1 │ 1000 152.67 32.02 0.00222892
2 │ 10000 174.1 63.86 0.00227912
3 │ 100000 299.6 165.86 0.00235597
4 │ 1000000 629.11 524.92 0.00304124
5 │ 10000000 964.76 912.39 0.025
```
### Plot

| AVLTrees | https://github.com/krynju/AVLTrees.jl.git |
|
[
"MIT"
] | 0.1.0 | 47441aacebbc89a276d4c4cff49eab45cdf6b993 | code | 2411 | """
AdjustQuasiGLM(model, ϕ; level)
Estimates dispersion parameter, adjusts original GLM to reflect the dispersion and returns results in a pretty DataFrame.
Usage:
```julia-repl
AdjustQuasiGLM(model, ϕ; level)
```
Arguments:
- `model` : The `GLM` model.
- `data` : The `DataFrame` containing data that was used as input to the model.
- `level` : The desired degree of confidence.
"""
function AdjustQuasiGLM(model::StatsModels.TableRegressionModel, data::DataFrame; level::Real=0.95)
# Calculate Pearson residuals
resids = PearsonResiduals(model, data)
# Estimate dispersion parameter ϕ and take √ to convert to multiplier
ϕ = √EstimateDispersionParameter(resids, model)
# Correct standard errors and calculate updated test statistics, p-values, and confidence intervals
CorrectedOutputs = coefarray(model, ϕ; level)
levstr = isinteger(level * 100) ? string(Integer(level * 100)) : string(level * 100)
header = (["Parameter", "Estimate", "Std. Error", "t value", "Pr(>|t|)", "Lower $levstr%", "Upper $levstr%"])
#--------------------------------------------
# Organise results in a neat coeftable format
#--------------------------------------------
# Table formatting
ctf = TextFormat(
up_right_corner = ' ',
up_left_corner = ' ',
bottom_left_corner = ' ',
bottom_right_corner = ' ',
up_intersection = '─',
left_intersection = ' ',
right_intersection = ' ',
middle_intersection = '─',
bottom_intersection = '─',
column = ' ',
hlines = [ :begin, :header, :end]
)
# Render table
println("\nCoefficients:")
CorrectedOutputsPretty = PrettyTables.pretty_table(CorrectedOutputs; header = header, tf = ctf)
# Return results in a DataFrame for further use
CorrectedOutputs = DataFrame(CorrectedOutputs, :auto)
CorrectedOutputs = rename!(CorrectedOutputs, [:x1, :x2, :x3, :x4, :x5, :x6, :x7] .=> [Symbol(header[1]), Symbol(header[2]), Symbol(header[3]), Symbol(header[4]), Symbol(header[5]), Symbol(header[6]), Symbol(header[7])])
# Recode column types from `Any` to `String` for parameter names and `Float64` for values columns
for i in 2:size(header, 1)
CorrectedOutputs[!, i] = convert(Array{Float64, 1}, CorrectedOutputs[!, i])
end
CorrectedOutputs[!, 1] = convert(Array{String, 1}, CorrectedOutputs[!, 1])
return CorrectedOutputs
end
| QuasiGLM | https://github.com/hendersontrent/QuasiGLM.jl.git |
|
[
"MIT"
] | 0.1.0 | 47441aacebbc89a276d4c4cff49eab45cdf6b993 | code | 2526 | """
PearsonResiduals(model, data)
Calculates Pearson residuals between model predicted values and the actual response variable values.
Usage:
```julia-repl
PearsonResiduals(model, data)
```
Arguments:
- `model` : The `GLM` model.
- `data` : The `DataFrame` containing data that was used as input to the model.
"""
function PearsonResiduals(model::StatsModels.TableRegressionModel, data::DataFrame)
# Generate predictions
f_hat = predict(model)
# Parse response vector
y_name = string(formula(model).lhs)
y = Array(data[!, names(data, y_name)])
# Calculate residuals as per https://www.datascienceblog.net/post/machine-learning/interpreting_generalized_linear_models/
r = (y .- f_hat) ./ .√(f_hat)
r = sum(r .^ 2)
return r
end
"""
EstimateDispersionParameter(residuals, model)
Estimates the dispersion parameter ϕ by standardising the sum of squared Pearson residuals against the residual degrees of freedom.
Usage:
```julia-repl
EstimateDispersionParameter(residuals, model)
```
Arguments:
- `residuals` : The sum of squared Pearson residuals.
- `model` : The `GLM` model.
"""
function EstimateDispersionParameter(residuals::Float64, model::StatsModels.TableRegressionModel)
# Calculate dispersion/scale parameter estimate by dividing Pearson residuals by residual degrees of freedom
ϕ = residuals / (dof_residual(model) - 1) # This aligns calculation with R's df.residuals function
println("\nDispersion parameter (ϕ) for model taken to be " * string(round(ϕ, digits = 5)))
println("Standard errors are multiplied by " * string(round(sqrt(ϕ), digits = 5)) * " to adjust for dispersion parameter (ϕ)")
return ϕ
end
"""
coefarray(model, ϕ; level)
Calculates relevant statistics for inference based of estimates and dispersion-adjusted standard errors and returns results in a concatenated array.
Usage:
```julia-repl
coefarray(model, ϕ; level)
```
Arguments:
- `model` : The `GLM` model.
- `ϕ` : The estimated dispersion parameter.
- `level` : The desired degree of confidence.
"""
function coefarray(model::StatsModels.TableRegressionModel, ϕ::Real; level::Real=0.95)
# NOTE: Function modified from https://docs.juliahub.com/AxisIndices/AHOcZ/0.6.3/coeftable/
cc = coef(model)
se = stderror(model) * ϕ
tt = cc ./ se
p = ccdf.(Ref(FDist(1, dof_residual(model))), abs2.(tt))
ci = se * quantile(TDist(dof_residual(model)), (1 - level) / 2)
ct = hcat(coefnames(model), cc, se, tt, p, cc + ci, cc - ci)
return ct
end | QuasiGLM | https://github.com/hendersontrent/QuasiGLM.jl.git |
|
[
"MIT"
] | 0.1.0 | 47441aacebbc89a276d4c4cff49eab45cdf6b993 | code | 247 | module QuasiGLM
using DataFrames, Distributions, GLM, PrettyTables
include("PeripheralFunctions.jl")
include("AdjustQuasiGLM.jl")
# Exports
export PearsonResiduals
export EstimateDispersionParameter
export coefarray
export AdjustQuasiGLM
end
| QuasiGLM | https://github.com/hendersontrent/QuasiGLM.jl.git |
|
[
"MIT"
] | 0.1.0 | 47441aacebbc89a276d4c4cff49eab45cdf6b993 | code | 1868 | using DataFrames, CategoricalArrays, GLM, Distributions, PrettyTables, QuasiGLM, Test
#------------- Run package tests --------------
@testset "QuasiGLM.jl" begin
#-------------
# Quasipoisson
#-------------
# Define some data
dobson = DataFrame(Counts = [18,17,15,20,10,20,25,13,12], Outcome = categorical([1,2,3,1,2,3,1,2,3]), Treatment = categorical([1,1,1,2,2,2,3,3,3]))
# Fit Poisson model
gm = fit(GeneralizedLinearModel, @formula(Counts ~ Outcome + Treatment), dobson, Poisson())
# Correct standard errors using quasi correction
testOutputs = AdjustQuasiGLM(gm, dobson; level=0.95)
@test testOutputs isa DataFrames.DataFrame
#--------------
# Quasibinomial
#--------------
# Set up data and divide percentage by 100 to get proportion
blotchData = DataFrame(blotch = [0.05,0.00,1.25,2.50,5.50,1.00,5.00,5.00,17.50,0.00,0.05,1.25,0.50,1.00,5.00,0.10,10.00,25.00,0.00,0.05,2.50,0.01,6.00,5.00,5.00,5.00,42.50,0.10,0.30,16.60,3.00,1.10,5.00,5.00,5.00,50.00,0.25,0.75,2.50,2.50,2.50,5.00,50.00,25.00,37.50,0.05,0.30,2.50,0.01,8.00,5.00,10.00,75.00,95.00,0.50,3.00,0.00,25.00,16.50,10.00,50.00,50.00,62.50,1.30,7.50,20.00,55.00,29.50,5.00,25.00,75.00,95.00,1.50,1.00,37.50,5.00,20.00,50.00,50.00,75.00,95.00,1.50,12.70,26.25,40.00,43.50,75.00,75.00,75.00,95.00], variety = categorical(repeat([1,2,3,4,5,6,7,8,9], inner=1, outer=10)), site = categorical(repeat([1,2,3,4,5,6,7,8,9,10], inner=9, outer=1)))
blotchData.blotch = blotchData.blotch ./ 100
# Fit binomial model
gm2 = fit(GeneralizedLinearModel, @formula(blotch ~ variety + site), blotchData, Binomial())
# Correct standard errors using quasi correction
testOutputs2 = AdjustQuasiGLM(gm2, blotchData; level=0.95)
@test testOutputs2 isa DataFrames.DataFrame
end | QuasiGLM | https://github.com/hendersontrent/QuasiGLM.jl.git |
|
[
"MIT"
] | 0.1.0 | 47441aacebbc89a276d4c4cff49eab45cdf6b993 | docs | 4612 | # QuasiGLM
Adjust Poisson and Binomial Generalised Linear Models to their quasi equivalents for dispersed data
## Installation
You can install `QuasiGLM.jl` from the Julia Registry via:
```
using Pkg
Pkg.add("QuasiGLM")
```
## Motivation
`R` has an excellent interface for specifying [generalised linear models](https://en.wikipedia.org/wiki/Generalized_linear_model) (GLM) and its base functionality includes a wide variety of probability distributions and link functions. [`GLM.jl`](https://juliastats.org/GLM.jl/v0.11/) in `Julia` is also excellent, and boasts a similar interface to its `R` counterpart. However, in `GLM.jl`, two key model types are not readily available:
1. quasipoisson
2. quasibinomial
While neither defines an explicit probability distribution, these models are useful in a variety of contexts as they enable the modelling of overdispersion in data. If the data is indeed overdispersed, the estimated dispersion parameter will be >1. Failure to estimate and adjust for this dispersion may lead to inappropriate statistical inference.
`QuasiGLM.jl` is a simple package that provides intuitive one-line-of-code adjustments to existing Poisson and Binomial `GLM.jl` models to convert them to their quasi equivalents. It achieves this through estimating the dispersion parameter and using this to make adjustments to standard errors. These adjustments then flow through to updated test statistics, *p*-values, and confidence intervals.
## Usage
Here's a Poisson to quasipoisson conversion using the Dobson (1990) Page 93: Randomized Controlled Trial dataset (as presented in the [`GLM.jl` documentation](https://juliastats.org/GLM.jl/v0.11/#Fitting-GLM-models-1)).
```
using DataFrames, CategoricalArrays, GLM, QuasiGLM
dobson = DataFrame(Counts = [18,17,15,20,10,20,25,13,12], Outcome = categorical([1,2,3,1,2,3,1,2,3]), Treatment = categorical([1,1,1,2,2,2,3,3,3]))
gm = fit(GeneralizedLinearModel, @formula(Counts ~ Outcome + Treatment), dobson, Poisson())
testOutputs = AdjustQuasiGLM(gm, dobson; level=0.95)
```
And here's a binomial to quasibinomial example using the leaf blotch dataset (McCullagh and Nelder (1989, Ch. 9.2.4)) as seen in multiple textbooks and the [SAS documentation](https://support.sas.com/documentation/cdl/en/statug/63033/HTML/default/viewer.htm#statug_glimmix_sect016.htm):
```
using DataFrames, CategoricalArrays, GLM, QuasiGLM
blotchData = DataFrame(blotch = [0.05,0.00,1.25,2.50,5.50,1.00,5.00,5.00,17.50,0.00,0.05,1.25,0.50,1.00,5.00,0.10,10.00,25.00,0.00,0.05,2.50,0.01,6.00,5.00,5.00,5.00,42.50,0.10,0.30,16.60,3.00,1.10,5.00,5.00,5.00,50.00,0.25,0.75,2.50,2.50,2.50,5.00,50.00,25.00,37.50,0.05,0.30,2.50,0.01,8.00,5.00,10.00,75.00,95.00,0.50,3.00,0.00,25.00,16.50,10.00,50.00,50.00,62.50,1.30,7.50,20.00,55.00,29.50,5.00,25.00,75.00,95.00,1.50,1.00,37.50,5.00,20.00,50.00,50.00,75.00,95.00,1.50,12.70,26.25,40.00,43.50,75.00,75.00,75.00,95.00], variety = categorical(repeat([1,2,3,4,5,6,7,8,9], inner=1, outer=10)), site = categorical(repeat([1,2,3,4,5,6,7,8,9,10], inner=9, outer=1)))
blotchData.blotch = blotchData.blotch ./ 100
gm2 = fit(GeneralizedLinearModel, @formula(blotch ~ variety + site), blotchData, Binomial())
testOutputs2 = AdjustQuasiGLM(gm2, blotchData; level=0.95)
```
### Comparison to R results
Note that results do not exactly equal the `R` equivalent of GLMs fit with `quasibinomial` or `quasipoisson` families. While explorations are continuing, the discrepancy is believed to be the result of differences in optimisation methods in the GLM machinery and floating point calculations.
For example, in the quasipoisson example presented above, the dispersion parameter returned by `QuasiGLM.jl` and `R`'s `glm` function with quasipoisson family are equivalent, and the numerical values for the `Intercept` and `Outcome` in the summary coefficient table are also equivalent. However, the `Treatment` variable exhibits different coefficient estimates despite exhibiting the same standard error and *p*-values.
Here is the `R` code to test it:
```
dobson <- data.frame(Counts = c(18,17,15,20,10,20,25,13,12), Outcome = as.factor(c(1,2,3,1,2,3,1,2,3)), Treatment = as.factor(c(1,1,1,2,2,2,3,3,3)))
mod <- glm(Counts ~ Outcome + Treatment, dobson, family = quasipoisson)
summary(mod)
```
## Citation instructions
If you use `QuasiGLM.jl` in your work, please cite it using the following (included as BibTeX file in the package folder):
```
@Manual{QuasiGLM.jl,
title={{QuasiGLM.jl}},
author={Henderson, Trent},
year={2022},
month={2},
url={https://github.com/hendersontrent/QuasiGLM.jl}
}
```
| QuasiGLM | https://github.com/hendersontrent/QuasiGLM.jl.git |
|
[
"MIT"
] | 0.6.0 | d8f50cbc077c0992b472a07f99013cd5be80b11a | code | 2449 | # ------------------------------------------------------------------
# Licensed under the MIT License. See LICENCE in the project root.
# ------------------------------------------------------------------
module PlatformAware
using CpuId
using XMLDict
using TOML
using JSON
using Scratch
using Downloads
using InteractiveUtils
using HTTP
using Distributed
include("utils.jl")
# features (platform types)
include("features/features.jl") # platform types base
include("features/detection.jl") # feature detection
# quantifiers
include("features/quantifiers/atleast.jl")
include("features/quantifiers/atmost.jl")
include("features/quantifiers/macros.jl")
# qualifiers
include("features/qualifiers/general.jl")
include("features/qualifiers/common.jl")
include("features/qualifiers/ec2/ec2.jl")
include("features/qualifiers/gcp/gcp.jl")
include("features/qualifiers/nvidia/nvidia.jl")
include("features/qualifiers/intel/intel.jl")
include("features/qualifiers/intel/intel_accelerators_xeonphi.jl")
include("features/qualifiers/intel/intel_processors_atom.jl")
include("features/qualifiers/intel/intel_processors_celeron.jl")
include("features/qualifiers/intel/intel_processors_core.jl")
include("features/qualifiers/intel/intel_processors_itanium.jl")
include("features/qualifiers/intel/intel_processors_pentium.jl")
include("features/qualifiers/intel/intel_processors_xeon.jl")
include("features/qualifiers/amd/amd_processors.jl")
include("features/qualifiers/aws/aws_processors.jl")
include("features/qualifiers/amd/amd_accelerators.jl")
include("features/qualifiers/xilinx/xilinx.jl")
# main functionality (@platform macro and default types)
include("platform.jl")
function __init__()
load!()
end
export
@platform,
@quantifier,
@atleast,
@atmost,
@between,
@just,
@unlimited,
@api,
@assumption,
platform_feature,
platform_features,
PlatformType,
QuantifierFeature,
QualifierFeature,
Query,
Yes,
No,
Provider,
OnPremises,
CloudProvider,
MachineFamily,
MachineType,
Locale,
Manufacturer,
ProcessorMicroarchitecture,
ProcessorISA,
ProcessorSIMD,
Processor,
AcceleratorType,
AcceleratorArchitecture,
AcceleratorBackend,
Accelerator,
XPU,
GPU,
TPU,
IPU,
FPGA,
MIC,
InterconnectionTopology,
Interconnection,
StorageType,
StorageInterface,
MemoryType
end
| PlatformAware | https://github.com/PlatformAwareProgramming/PlatformAware.jl.git |
|
[
"MIT"
] | 0.6.0 | d8f50cbc077c0992b472a07f99013cd5be80b11a | code | 15511 | # ------------------------------------------------------------------
# Licensed under the MIT License. See LICENCE in the project root.
# ------------------------------------------------------------------
mutable struct PlatformFeatures
platform_feature_default_all
platform_feature_default
platform_feature_all
platform_feature
function PlatformFeatures()
new(Dict(),Dict(),Dict(),Dict())
end
end
state = PlatformFeatures()
defT =[
:node_count => Tuple{AtLeast1,AtMostInf,Q} where Q,
:node_threads_count => Tuple{AtLeast1,AtMostInf,Q} where Q,
:node_provider => Provider,
:node_virtual => Query,
:node_dedicated => Query,
:node_machinefamily => MachineFamily,
:node_machinetype => MachineType,
:node_vcpus_count => Tuple{AtLeast1,AtMostInf,Q} where Q,
:node_memory_size => Tuple{AtLeast0,AtMostInf,Q} where Q,
:node_memory_latency => Tuple{AtLeast0,AtMostInf,Q} where Q,
:node_memory_bandwidth => Tuple{AtLeast0,AtMostInf,Q} where Q,
:node_memory_type => MemoryType,
:node_memory_frequency => Tuple{AtLeast1,AtMostInf,Q} where Q,
:node_coworker_count => WorkerCount, # number of worker processes (i.e., julia -p N)
:processor_count => Tuple{AtLeast1,AtMostInf,Q} where Q,
:processor_manufacturer => Manufacturer,
:processor_microarchitecture => ProcessorMicroarchitecture,
:processor_simd => ProcessorSIMD,
:processor_isa => ProcessorISA,
:processor_tdp => Tuple{AtLeast0,AtMostInf,Q} where Q,
:processor_core_clock => Tuple{AtLeast0,AtMostInf,Q} where Q,
:processor_core_count => Tuple{AtLeast1,AtMostInf,Q} where Q,
:processor_core_threads_count => Tuple{AtLeast1,AtMostInf,Q} where Q,
# :processor_core_L1_mapping => :PC1M,
:processor_core_L1_size => Tuple{AtLeast0,AtMostInf,Q} where Q,
# :processor_core_L1_latency => :PC1T,
# :processor_core_L1_bandwidth => :PC1B,
# :processor_core_L1_linesize => :PC1L,
# :processor_core_L2_mapping => :PC2M,
:processor_core_L2_size => Tuple{AtLeast0,AtMostInf,Q} where Q,
# :processor_core_L2_latency => :PC2T,
# :processor_core_L2_bandwidth => :PC2B,
# :processor_core_L2_linesize => :PC2L,
# :processor_L3_mapping => :PC3M,
:processor_L3_size => Tuple{AtLeast0,AtMostInf,Q} where Q,
# :processor_L3_latency => :PC3T,
# :processor_L3_bandwidth => :PC3B,
# :processor_L3_linesize => :PC3L,
:processor => Processor,
:accelerator_count => Tuple{AtLeast0,AtMostInf,Q} where Q,
:accelerator_type => AcceleratorType,
:accelerator_manufacturer => Manufacturer,
:accelerator_interconnect => AcceleratorInterconnect,
:accelerator_api => Tuple{AcceleratorBackend,AcceleratorBackend,AcceleratorBackend,AcceleratorBackend,AcceleratorBackend,AcceleratorBackend,AcceleratorBackend},
:accelerator_architecture => AcceleratorArchitecture,
:accelerator_memory_size => Tuple{AtLeast0,AtMostInf,Q} where Q,
:accelerator_tdp => Tuple{AtLeast0,AtMostInf,Q} where Q,
:accelerator_processor => AcceleratorProcessor,
:accelerator_processor_count => Tuple{AtLeast1,AtMostInf,Q} where Q,
:accelerator_memory_type => MemoryType,
:accelerator => Accelerator,
:interconnection_startuptime => Tuple{AtLeast0,AtMostInf,Q} where Q,
:interconnection_latency => Tuple{AtLeast0,AtMostInf,Q} where Q,
:interconnection_bandwidth => Tuple{AtLeast0,AtMostInf,Q} where Q,
:interconnection_topology => InterconnectionTopology,
:interconnection_RDMA => Query,
:interconnection => Interconnection,
:storage_size => Tuple{AtLeast0,AtMostInf,Q} where Q,
:storage_latency => Tuple{AtLeast0,AtMostInf,Q} where Q,
:storage_bandwidth => Tuple{AtLeast0,AtMostInf,Q} where Q,
:storage_networkbandwidth => Tuple{AtLeast0,AtMostInf,Q} where Q,
:storage_type => StorageType,
:storage_interface => StorageInterface
]
state.platform_feature_default_all = Dict(defT...)
state.platform_feature_default = copy(state.platform_feature_default_all)
function setupWorkers(platform_description_dict, platform_feature)
try
colocated_procs = procs(myid())
node_coworker_count = if (1 in colocated_procs)
length(colocated_procs) - 1
else
length(colocated_procs)
end
vcount = platform_description_dict[:node_vcpus_count]
pcount = platform_description_dict[:processor_count]
ccount = pcount * platform_description_dict[:processor_core_count]
tcount = ccount * platform_description_dict[:processor_core_threads_count]
if vcount == node_coworker_count && platform_description_dict[:maintainer] == CloudProvider
platform_feature[:node_coworker_count] = PerVCPU
elseif (node_coworker_count = 0)
platform_feature[:node_coworker_count] = NoCoworkers
elseif node_coworker_count == 1
platform_feature[:node_coworker_count] = PerNode
elseif pcount == node_coworker_count
platform_feature[:node_coworker_count] = PerProcessor
elseif ccount == node_coworker_count
platform_feature[:node_coworker_count] = PerCore
elseif tcount == node_coworker_count
platform_feature[:node_coworker_count] = PerThread
else
platform_feature[:node_coworker_count] = Unmapped
end
catch _
platform_feature[:node_coworker_count] = NoCoworkers
end
end
function load!()
empty!(state.platform_feature_all)
platform_description_dict = readPlatormDescription()
platform_description_dict["node"]["node_count"] = try Distributed.nworkers() catch _ 1 end
platform_description_dict["node"]["node_threads_count"] = try Threads.nthreads() catch _ 1 end
loadFeatures!(platform_description_dict, state.platform_feature_default_all, state.platform_feature_all)
setupWorkers(platform_description_dict, state.platform_feature_all)
empty!(state.platform_feature)
for (k,v) in state.platform_feature_all
state.platform_feature[k] = v
end
end
# load!()
function update_platform_feature!(parameter_id, actual_type)
state.platform_feature[parameter_id] = actual_type
(parameter_id,actual_type)
end
function platform_feature(parameter_id)
state.platform_feature[parameter_id]
end
function platform_features()
state.platform_feature
end
function empty_platform_feature!()
empty!(state.platform_feature)
empty!(state.platform_feature_default)
end
function reset_platform_feature!()
for (k,v) in state.platform_feature_all
state.platform_feature[k] = v
end
for (k,v) in state.platform_feature_default_all
state.platform_feature_default[k] = v
end
keys(state.platform_feature)
end
function all_platform_feature!()
for (k,v) in state.platform_feature_all
if (!haskey(state.platform_feature, k))
state.platform_feature[k] = v
end
end
for (k,v) in state.platform_feature_default_all
state.platform_feature_default[k] = v
end
keys(state.platform_feature)
end
function default_platform_feature!()
for (k,v) in state.platform_feature_default_all
state.platform_feature[k] = v
end
for (k,v) in state.platform_feature_default_all
state.platform_feature_default[k] = v
end
keys(state.platform_feature)
end
function include_platform_feature!(f)
state.platform_feature[f] = state.platform_feature_all[f]
state.platform_feature_default[f] = state.platform_feature_default_all[f]
keys(state.platform_feature)
end
function platform_parameter_macro!(f)
if (f == :clear)
empty_platform_feature!()
elseif (f == :all)
all_platform_feature!()
elseif (f == :reset)
reset_platform_feature!()
elseif (f == :default)
default_platform_feature!()
elseif typeof(f) == Symbol
check_all(f)
include_platform_feature!(f)
elseif f.head == :(::)
x = f.args[2]
f = f.args[1]
check_all(f)
update_platform_feature!(f,getFeature(f, string(x), state.platform_feature_default_all, feature_type))
else
platform_syntax_message()
end
end
function platform_parameters_kernel(p_list)
# move p_list (p::T) to p_dict (p => T)
p_dict = Dict(); foreach(x->get!(p_dict, check(x.args[1]), x.args[2]), p_list)
# replace default types to required types in kernel platform parameters
r = []
for k in keys(state.platform_feature)
found = get(p_dict, k, nothing)
# found_v = !isnothing(found) && !(typeof(found) == Symbol) && ((found.head == :curly && length(found.args) == 2 && found.args[1] == :Type) || (found.head == :macrocall && length(found.args) > 0 && found.args[1] in [Symbol("@atleast"), Symbol("@atmost"), Symbol("@between"), Symbol("@just"), Symbol("@unrestricted")])) ? :(::$found) : :(::Type{<:$found})
found_v = :(::Type{<:$found})
v = state.platform_feature_default[k]
push!(r, isnothing(found) ? :(::Type{<:$v}) : found_v)
end
return r
end
function check_all(parameter_id)
if (!haskey(state.platform_feature_all,parameter_id))
throw(parameter_id)
end
parameter_id
end
function check(parameter_id)
if (!haskey(state.platform_feature,parameter_id))
throw(parameter_id)
end
parameter_id
end
global const can_add_parameter = Ref{Bool}(true)
function denyaddparameter!()
global can_add_parameter[] = false
end
function getaddparameter()
return can_add_parameter[]
end
macro platform(t, f, ff...)
try
if (length(ff) > 0)
platform_syntax_message()
return
end
if (t == :default)
# @platform default creates an entry function, called from outside, and a (default) kernel function
denyaddparameter!()
e = build_entry_function(f)
k = build_kernel_function(f)
return esc(:($e;$k))
#return k
elseif (t == :aware)
denyaddparameter!()
return esc(build_kernel_function(f))
elseif ((t == :parameter || t == :feature) && getaddparameter())
platform_parameter_macro!(f)
elseif ((t == :parameter || t == :feature) && !getaddparameter())
@info "cannot add parameters after including the first kernel method"
elseif (t == :assumption)
assumptions_dict[][f.args[1]] = f.args[2]
return nothing
else
platform_syntax_message()
end
catch e
@error e
platform_syntax_message()
end
end
const assumptions_dict = Ref(Dict{Symbol,Expr}())
function platform_syntax_message()
@info "usage: @platform [default | aware] <function declaration>"
@info " @platform feature [clear | all | reset]"
@info " @platform feature <feature name>"
@info " @platform feature <feature name> new_feature"
end
# build_entry_function
function build_entry_function(f::Expr)
# builds the entry function signature
(fname, fargs, kargs, fsign) = build_entry_signature(f.args[1])
# builds the entry function body
fbody = build_entry_body(fname, fargs, kargs)
# builds the :function node
Expr(:function, fsign, fbody)
end
function build_entry_signature(fsign::Expr)
fsign_args = copy(fsign.args)
# take the :call node arguments from inside the :where node if there is a where clause in the default kernel. where_vars == [] if it does not exist.
(call_node_args, where_vars) = fsign.head == :where ? (popfirst!(fsign_args).args, fsign_args) : (fsign_args, [])
# takes the name of the kernel (first argument to :call)
fname = popfirst!(call_node_args)
# look for the existence of keyword parameters (second argument to :call). keyword_parameters == [], if they do not exist.
keyword_parameters = length(call_node_args) > 1 && typeof(call_node_args[1]) == Expr && call_node_args[1].head == :parameters ? popfirst!(call_node_args).args : []
# takes a dictionary mapping par->actual_type and returns an expression :(par::actual_type)
# the remaining elements in call_node_args are the kernel parameters.
platform_parameters = map(p->Expr(:kw,Expr(:(::),p[1],Type{<:state.platform_feature_default[p[1]]}),p[2]), collect(state.platform_feature))
# rebuild the keyword parameters node for the entry function, including the platform_parameters
keyword_parameters_node = Expr(:parameters, platform_parameters..., keyword_parameters...)
# collect the identifiers of the kernel parameters
fargs = map(collect_arg_names, call_node_args)
# collect the identifiers of the keyword parameters
kargs = map(p -> p.args[1] , keyword_parameters)
# build the argument list of the call node (:call) of the entry function
new_call_node_args = [fname, keyword_parameters_node, call_node_args...]
return (fname, fargs, kargs, Expr(:where, Expr(:call, new_call_node_args...), where_vars...))
end
function build_entry_body(fname, fargs, kargs)
# takes the identifiers of the platform parameters
pargs = keys(state.platform_feature)
# builds the :parameters node for the keyword arguments of the kernel invocation (kargs), since the identifiers must be reerenced.
kargs = Expr(:parameters, map(p -> Expr(:kw, p, p), kargs)...)
# returns the :call node for the kernel invocation (note that platform arguments comes before kernel arguments)
Expr(:call, fname, kargs, pargs..., fargs...)
end
# build_kernel_function
function build_kernel_function(f::Expr)
# builds the kernel signature. The kernel's body (f.args[2]) is not modified.
fsign = build_kernel_signature(f.args[1])
# returns the :function node.
Expr(:function, fsign, f.args[2])
end
# the code is similar to the code of build_kernel_entry
function build_kernel_signature(fsign::Expr)
fsign_args = copy(fsign.args)
(call_node_args, where_vars) = fsign.head == :where ? (popfirst!(fsign_args).args, fsign_args) : (fsign_args, [])
fname = popfirst!(call_node_args)
keyword_parameters_node = length(call_node_args) > 0 && typeof(call_node_args[1]) == Expr && call_node_args[1].head == :parameters ? popfirst!(call_node_args) : nothing
# takes the platform parameters of the kernel
aware_parameters_args = []
if length(call_node_args) > 0
if typeof(call_node_args[1]) == Expr && call_node_args[1].head == :braces
aware_parameters_args = popfirst!(call_node_args).args
elseif typeof(call_node_args[1]) == Expr && call_node_args[1].head == :$
aware_parameters_args = assumptions_dict[][call_node_args[1].args[1]].args
popfirst!(call_node_args)
end
end
# inserts the kernel's platform parameters into the list platform parameters.
ppars = platform_parameters_kernel(aware_parameters_args)
new_call_node_args = isnothing(keyword_parameters_node) ? [fname, ppars..., call_node_args...] : [fname, keyword_parameters_node, ppars..., call_node_args...]
Expr(:where, Expr(:call, new_call_node_args...), where_vars...)
end
# utility functions
function collect_arg_names(par)
if (typeof(par) == Symbol)
par
elseif (par.head == :kw)
par.args[1].args[1]
elseif (par.head == :(::))
par.args[1]
elseif (par.head == :(...))
par.args[1]
end
end | PlatformAware | https://github.com/PlatformAwareProgramming/PlatformAware.jl.git |
|
[
"MIT"
] | 0.6.0 | d8f50cbc077c0992b472a07f99013cd5be80b11a | code | 2084 | # ------------------------------------------------------------------
# Licensed under the MIT License. See LICENCE in the project root.
# ------------------------------------------------------------------
function try_download(url,fname)
try
if (isfile(fname))
cp(fname,fname * ".backup", force=true)
end
Downloads.download(url, fname)
catch e
@info "error downloading $url."
if (isfile(fname) || isfile(fname * ".backup"))
@info " Using existing file $fname"
if (!isfile(fname))
cp(fname * ".backup", fname)
end
else
@info " Check internet connection and try again."
rethrow(e)
end
end
end
function readDB(filename)
d = Vector()
i=0
for ls in readlines(filename)
if i>0
l = split(ls,',')
ks = split(l[1],';')
d2 = d
for k in ks
next_d = nothing
for (key,value) in d
if (k == key)
next_d = value
end
end
if (isnothing(next_d))
next_d = Vector()
push!(d,(k,next_d))
end
d = next_d
end
push!(d,(l[2],tuple(l[2:length(l)]...)))
d = d2
end
i = i + 1
end
return d
end
function lookupDB(db, key)
d = db
while typeof(d) <: Vector
ks = d
found = false
for (k,v) in ks
if (occursin(k,key))
d = v; found = true
break
end
end
if !found return nothing end
end
return d
end
function readDB2(filename)
d = Dict()
i=0
for ls in readlines(filename)
l = split(ls,',')
if i==0
global columns = Vector()
for c in l
push!(columns, c)
end
elseif i>0
dd = Dict()
i = 1
for c in columns
dd[c] = l[i]
i = i + 1
end
d[l[1]] = dd
end
i = i + 1
end
return d
end | PlatformAware | https://github.com/PlatformAwareProgramming/PlatformAware.jl.git |
|
[
"MIT"
] | 0.6.0 | d8f50cbc077c0992b472a07f99013cd5be80b11a | code | 30937 | # ------------------------------------------------------------------
# Licensed under the MIT License. See LICENCE in the project root.
# ------------------------------------------------------------------
const processor_dict = Ref{Vector}()
const accelerator_dict = Ref{Vector}()
function loadDBs!()
database_path = @get_scratch!("database_path")
procdb_intel_url = "https://raw.githubusercontent.com/PlatformAwareProgramming/PlatformAware.jl/master/src/features/qualifiers/intel/db-processors.Intel.csv"
procdb_amd_url = "https://raw.githubusercontent.com/PlatformAwareProgramming/PlatformAware.jl/master/src/features/qualifiers/amd/db-processors.AMD.csv"
procdb_aws_url = "https://raw.githubusercontent.com/PlatformAwareProgramming/PlatformAware.jl/master/src/features/qualifiers/aws/db-processors.AWS.csv"
accdb_intel_url = "https://raw.githubusercontent.com/PlatformAwareProgramming/PlatformAware.jl/master/src/features/qualifiers/intel/db-accelerators.Intel.csv"
accdb_amd_url = "https://raw.githubusercontent.com/PlatformAwareProgramming/PlatformAware.jl/master/src/features/qualifiers/amd/db-accelerators.AMD.csv"
accdb_nvidia_url = "https://raw.githubusercontent.com/PlatformAwareProgramming/PlatformAware.jl/master/src/features/qualifiers/nvidia/db-accelerators.NVIDIA.csv"
# procdb_intel_fname = "/home/heron/Dropbox/Copy/ufc_mdcc_hpc/PlatformAware/PlatformAware.jl/src/features/qualifiers/intel/db-processors.Intel.csv" #joinpath(database_path,basename(procdb_intel_url))
# procdb_amd_fname = "/home/heron/Dropbox/Copy/ufc_mdcc_hpc/PlatformAware/PlatformAware.jl/src/features/qualifiers/amd/db-processors.AMD.csv" #joinpath(database_path,basename(procdb_amd_url))
# accdb_intel_fname = "/home/heron/Dropbox/Copy/ufc_mdcc_hpc/PlatformAware/PlatformAware.jl/src/features/qualifiers/intel/db-accelerators.Intel.csv" #joinpath(database_path,basename(accdb_intel_url))
# accdb_amd_fname = "/home/heron/Dropbox/Copy/ufc_mdcc_hpc/PlatformAware/PlatformAware.jl/src/features/qualifiers/amd/db-accelerators.AMD.csv" #joinpath(database_path,basename(accdb_amd_url))
# accdb_nvidia_fname = "/home/heron/Dropbox/Copy/ufc_mdcc_hpc/PlatformAware/PlatformAware.jl/src/features/qualifiers/nvidia/db-accelerators.NVIDIA.csv" #joinpath(database_path,basename(accdb_nvidia_url))
procdb_intel_fname = joinpath(database_path,basename(procdb_intel_url))
procdb_amd_fname = joinpath(database_path,basename(procdb_amd_url))
procdb_aws_fname = joinpath(database_path,basename(procdb_aws_url))
accdb_intel_fname = joinpath(database_path,basename(accdb_intel_url))
accdb_amd_fname = joinpath(database_path,basename(accdb_amd_url))
accdb_nvidia_fname = joinpath(database_path,basename(accdb_nvidia_url))
try_download(procdb_intel_url, procdb_intel_fname)
try_download(procdb_amd_url, procdb_amd_fname)
try_download(procdb_aws_url, procdb_aws_fname)
try_download(accdb_intel_url, accdb_intel_fname)
try_download(accdb_amd_url, accdb_amd_fname)
try_download(accdb_nvidia_url, accdb_nvidia_fname)
processor_dict_intel = readDB(procdb_intel_fname)
processor_dict_amd = readDB(procdb_amd_fname)
processor_dict_aws = readDB(procdb_aws_fname)
accelerator_dict_intel = readDB(accdb_intel_fname)
accelerator_dict_amd = readDB(accdb_amd_fname)
accelerator_dict_nvidia = readDB(accdb_nvidia_fname)
global processor_dict[] = vcat(processor_dict_amd, processor_dict_aws, processor_dict_intel)
global accelerator_dict[] = vcat(accelerator_dict_intel, accelerator_dict_amd, accelerator_dict_nvidia)
end
function get_info_dict(idtype)
command = `sudo lshw -xml -quiet -C $idtype`
xmlinfo = read(command, String)
xml_dict(xmlinfo)
end
function identifyComponent(idtype)
dict = get_info_dict(idtype)
l = Vector()
node = dict["list"]["node"]
if (typeof(node) == Vector{Any})
for v in enumerate(node)
push!(l,v[2])
end
else
push!(l,node)
end
return l
end
function identifySIMD(capabilities)
l = Vector()
# collect the supported SIMD extensions
for capacity in capabilities
if (occursin("avx512",capacity))
push!(l,:AVX512)
elseif (occursin("avx2",capacity))
push!(l,:AVX2)
elseif (occursin("avx",capacity))
push!(l,:AVX)
elseif (occursin("sse4_a",capacity))
push!(l,:SSE4a)
elseif (occursin("sse4_1",capacity))
push!(l,:SSE41)
elseif (occursin("sse4_2",capacity))
push!(l,:SSE42)
elseif (occursin("ssse3",capacity))
push!(l,:SSSE3)
elseif (occursin("sse3",capacity))
push!(l,:SSE3)
elseif (occursin("sse2",capacity))
push!(l,:SSE2)
elseif (occursin("sse",capacity))
push!(l,:SSE)
elseif (occursin("mmx",capacity))
push!(l,:MMX)
elseif (occursin("3dnowext",capacity))
push!(l,:Now3Dx)
elseif (occursin("3dnow",capacity))
push!(l,:Now3D)
end
end
# take the most advanced one (currently, only one is supported)
if (in(:AVX512,l))
return string(:AVX512)
elseif (in(:AVX2,l))
return string(:AVX2)
elseif (in(:AVX,l))
return string(:AVX)
elseif (in(:SSE4a,l))
return string(:SSE4a)
elseif (in(:SSE41,l))
return string(:SSE41)
elseif (in(:SSE42,l))
return string(:SSE42)
elseif (in(:SSSE3,l))
return string(:SSSE3)
elseif (in(:SSE3,l))
return string(:SSE3)
elseif (in(:SSE2,l))
return string(:SSE2)
elseif (in(:SSE,l))
return string(:SSE)
elseif (in(:MMX,l))
return string(:MMX)
else
return nothing
end
end
function identifySIMD_2(exts)
exts = split(exts,';')
if (!isnothing(exts))
if in("AVX-512",exts)
return string(:AVX512)
elseif in("AVX2", exts)
return string(:AVX2)
elseif in("SSE4.1",exts)
return string(:SSE_4_1)
elseif in("SSE4.2",exts)
return string(:SSE_4_2)
elseif in("SSSE3",exts)
return string(:SSSE_3)
elseif in("SSE3",exts)
return string(:SSE_3)
elseif in("SSE2",exts)
return string(:SSE_2)
elseif in("SSE", exts)
return string(:SSE)
elseif in("MMX", exts)
return string(:MMX)
else exts == "nothing"
return string(:ProcessorSIMD)
end
else
return string(:ProcessorSIMD)
end
end
function determineLevel(capabilities)
reduce(&, map(v -> in(v, capabilities), ["avx512f","avx512bw","avx512cd","avx512dq","avx512vl"])) ? 4 :
reduce(&, map(v -> in(v, capabilities), ["avx","avx2","bmi1","bmi2","f16c","fma","abm","movbe","xsave"])) ? 3 :
reduce(&, map(v -> in(v, capabilities), ["cx16","lahf_lm","popcnt","sse4_1","sse4_2","ssse3"])) ? 2 :
reduce(&, map(v -> in(v, capabilities), ["lm","cmov","cx8","fpu","fxsr","mmx","syscall","sse2"])) ? 1 :
0
end
function determineLevel_2()
reduce(&, CpuId.cpufeature.([:AVX512F,:AVX512BW,:AVX512CD,:AVX512DQ,:AVX512VL])) ? 4 :
reduce(&, CpuId.cpufeature.([:AVX,:AVX2,:BMI1,:BMI2,:F16C,:FMA3,#=:ABM,=#:MOVBE,:XSAVE])) ? 3 :
reduce(&, CpuId.cpufeature.([:CX16,#=:LAHF_LM,=#:POPCNT,:SSE41,:SSE42,:SSSE3])) ? 2 :
reduce(&, CpuId.cpufeature.([:LM,:CMOV,:CX8,:FPU,:FXSR,:MMX,:SYSCALL,:SSE2])) ? 1 :
0
end
# https://git.kernel.org/pub/scm/linux/kernel/git/stable/linux.git/tree/arch/
function identifyISA(capabilities)
for capacity in capabilities
if (occursin("x86-64",capacity))
level_dict = Dict(0 => string(:ISA_x86_64),
1 => string(:ISA_x86_64_v1),
2 => string(:ISA_x86_64_v2),
3 => string(:ISA_x86_64_v3),
4 => string(:ISA_x86_64_v4))
level = determineLevel(capabilities)
return level_dict[level]
elseif (occursin("x86-32",capacity))
return string(:ISA_x86_32)
elseif (occursin("amd64",capacity))
return string(:ISA_AMD_64)
elseif (occursin("ia64",capacity))
return string(:ISA_IA_64)
elseif (occursin("i386",capacity))
return string(:ISA_x86_32)
end
end
end
function identifyISA_2(isa)
if (isa == "64-bit")
level_dict = Dict(0 => string(:ISA_x86_64),
1 => string(:ISA_x86_64_v1),
2 => string(:ISA_x86_64_v2),
3 => string(:ISA_x86_64_v3),
4 => string(:ISA_x86_64_v4))
level = determineLevel_2()
return level_dict[level]
else (isa == "Itanium 64-bit")
return string(:ISA_IA_64)
end
end
#=
fn = open("src/features/qualifiers/database/processors/intel_processors_data.txt")
d = JSON.parse(fn)
close(fn)
fn_out = open("intel_processors_info.jl","w")
for p in d
if (haskey(p,"Processor Number"))
println(fn_out,
(haskey(p,"Product Collection") ? get(p,"Product Collection",nothing) : nothing,
haskey(p,"Processor Number") ? get(p,"Processor Number",nothing) : nothing,
haskey(p,"Total Cores") ? parse(Int64,get(p,"Total Cores",nothing)) : nothing,
haskey(p,"Processor Base Frequency") ? get(p,"Processor Base Frequency",nothing) : nothing,
haskey(p,"Total Threads") ? parse(Int64,get(p,"Total Threads",nothing)) : nothing,
haskey(p,"Instruction Set") ? get(p,"Instruction Set",nothing) : nothing,
haskey(p,"Instruction Set Extensions") ? split(replace(get(p,"Instruction Set Extensions",nothing),"Intel®"=>"", " "=>""),',') : nothing,
haskey(p,"Product Collection") ? replace(get(p,"Code Name",nothing),"Products formerly" => "", " " => "") : nothing))
else
end
end
close(fn_out)
=#
function identifyProcessorModel(processor_string)
lookupDB(processor_dict[], processor_string)
end
function identifyAcceleratorModel(accelerator_string)
lookupDB(accelerator_dict[], accelerator_string)
end
function getCoreClockString(clock_string)
if (!isnothing(clock_string))
clock_unit = match(r"GHz|MHz",clock_string)
clock_unit = isnothing(clock_unit) ? nothing : clock_unit.match
multiplier = Dict("GHz" => "G", "MHz" => "M", nothing => "")
result = match(r"^[-+]?[0-9]*\.?[0-9]+",clock_string)
isnothing(result) ? "unknown" : result.match * multiplier[clock_unit]
else
"unknown"
end
end
function identifySIMD_CpuId()
if CpuId.cpufeature(:AVX512F)
return string(:AVX512)
elseif CpuId.cpufeature(:AVX2)
return string(:AVX2)
elseif CpuId.cpufeature(:SSE41)
return "SSE_4_1"
elseif CpuId.cpufeature(:SSE42)
return "SSE_4_2"
elseif CpuId.cpufeature(:SSSE3)
return "SSSE_3"
elseif CpuId.cpufeature(:SSE3)
return "SSE_3"
elseif CpuId.cpufeature(:SSE2)
return "SSE_2"
elseif CpuId.cpufeature(:SSE)
return "SSE"
elseif CpuId.cpufeature(:MMX)
return "MMX"
else
return "ProcessorSIMD"
end
end
# using CpuId
function collectProcessorFeatures_CpuId()
processor_features = Dict{String,Any}()
processor_features["processor_count"] = CpuId.cpunodes()
processor_features["processor_core_count"] = CpuId.cpucores()
processor_features["processor_core_threads_count"] = CpuId.cputhreads()
processor_features["processor_core_clock"] = CpuId.cpu_base_frequency()
processor_features["processor_simd"] = identifySIMD_CpuId()
cache_config = CpuId.cachesize()
processor_features["processor_core_L1_size"] = cache_config[1]
processor_features["processor_core_L2_size"] = cache_config[2]
processor_features["processor_L3_size"] = cache_config[3]
processor_features["processor_manufacturer"] = string(CpuId.cpuvendor())
cpu_brand = string(CpuId.cpuvendor()) * " " * CpuId.cpubrand()
cpu_brand = replace(cpu_brand,"(tm)" => "","(TM)" => "", "(r)" => "", "(R)" => "")
proc_info = identifyProcessorModel(cpu_brand)
if (!isnothing(proc_info))
processor_features["processor_manufacturer"] = isnothing(processor_features["processor_manufacturer"]) ? proc_info[9] : processor_features["processor_manufacturer"]
processor_features["processor_core_clock"] = isnothing(processor_features["processor_core_clock"]) ? getCoreClockString(proc_info[3]) : processor_features["processor_core_clock"]
processor_features["processor_core_count"] = isnothing(processor_features["processor_core_count"]) ? parse(Int64,proc_info[2]) : processor_features["processor_core_count"]
processor_features["processor_core_threads_count"] = isnothing(processor_features["processor_core_threads_count"]) ? parse(Int64,proc_info[4]) : processor_features["processor_core_count"]
processor_features["processor_simd"] = isnothing(processor_features["processor_simd"]) ? identifySIMD_2(proc_info[6]) : processor_features["processor_simd"]
processor_features["processor_isa"] = identifyISA_2(proc_info[5])
processor_features["processor_microarchitecture"] = proc_info[7]
tdp = tryparse(Int64, proc_info[10])
processor_features["processor_tdp"] = isnothing(tdp) ? proc_info[11] : parse(Int64,proc_info[10])
processor_features["processor"] = proc_info[8]
end
return processor_features
end
# https://unix.stackexchange.com/questions/43539/what-do-the-flags-in-proc-cpuinfo-mean
# https://git.kernel.org/pub/scm/linux/kernel/git/stable/linux.git/tree/arch/x86/include/asm/cpufeatures.h
#=function collectProcessorFeatures(l)
processor_features_list = Dict{String,Any}()
i=1
for processor_info in l # take the first processor in the list, by supposing homogeneity.
processor_features = Dict{String,Any}()
get!(processor_features_list, string(i), processor_features)
processor_features["processor_count"] = 1
processor_features["processor_core_count"] = processor_info[2]
processor_features["processor_core_threads_count"] = processor_info[3]
processor_features["processor_core_clock"] = nothing
processor_features["processor_simd"] = identifySIMD(processor_info[4])
processor_features["processor_isa"] = identifyISA(processor_info[4])
processor_features["processor_core_L1_size"] = "unset" #TODO
processor_features["processor_core_L2_size"] = "unset" #TODO
processor_features["processor_L3_size"] = "unset" #TODO
# looking at the database
proc_info = identifyProcessorModel(processor_info[1])
if (!isnothing(proc_info))
processor_features["processor_manufacturer"] = proc_info[10]
processor_features["processor_core_clock"] = isnothing(processor_features["processor_core_clock"]) ? getCoreClockString(proc_info[3]) : processor_features["processor_core_clock"]
processor_features["processor_core_count"] = isnothing(processor_features["processor_core_count"]) ? proc_info[2] : processor_features["processor_core_count"]
processor_features["processor_core_threads_count"] = isnothing(processor_features["processor_core_threads_count"]) ? proc_info[4] : processor_features["processor_core_count"]
processor_features["processor_simd"] = isnothing(processor_features["processor_simd"]) ? identifySIMD_2(proc_info[6]) : processor_features["processor_simd"]
processor_features["processor_isa"] = isnothing(processor_features["processor_isa"]) ? identifyISA_2(proc_info[5]) : processor_features["processor_isa"]
processor_features["processor_microarchitecture"] = proc_info[7]
processor_features["processor_tdp"] = !isnothing(proc_info[9]) ? parse(Int64,match(r"[1-9]*",proc_info[11]).match) : nothing
processor_features["processor"] = proc_info[9]
end
i = i + 1
end
return length(processor_features_list) > 1 ? processor_features_list : processor_features_list["1"]
end
=#
function collectProcessorFeaturesDefault()
processor_features = Dict()
processor_features["processor_count"] = 1
processor_features["processor_core_count"] = 1
processor_features["processor_core_threads_count"] = 1
processor_features["processor_core_clock"] = "unset"
processor_features["processor_simd"] = "unset"
processor_features["processor_core_L1_size"] = "unset"
processor_features["processor_core_L2_size"] = "unset"
processor_features["processor_L3_size"] = "unset"
processor_features["processor_manufacturer"] = "unset"
processor_features["processor_tdp"] = "unset"
processor_features["processor"] = "unset"
return processor_features
end
# using CpuId (safe)
function identifyProcessor()
try
processor_features = collectProcessorFeatures_CpuId()
@info "Main processor detection succesful."
return processor_features
catch
@warn "Main processor detection failed."
@info "Detection of main processors failed. Using default features. You can setup manually."
return collectProcessorFeaturesDefault()
end
#=
l = Vector()
for p in identifyComponent("processor") # using lshw
lc = Vector()
for c in p["capabilities"]["capability"]
push!(lc,c[:id])
end
cdict = Dict()
for c in values(p["configuration"]["setting"])
get!(cdict,c[:id],c[:value])
end
processor_core_count = parse(Int64,cdict["enabledcores"])
processor_core_threads_count = parse(Int64,cdict["threads"])
push!(l,(p["product"],processor_core_count, processor_core_threads_count,lc))
end
collectProcessorFeatures(l)
=#
end
function collectAcceleratorFeatures(l)
accelerator_features = Dict()
# Return the first display device that is an accelerator.
# This is valid only for GPUs.
i = 1
for acc_brand in keys(l)
# looking at the database
acc_info = identifyAcceleratorModel(replace(acc_brand,"[" => "", "]" => "", "(" => "", ")" => "" ))
if (isnothing(acc_info))
continue
end
device = Dict()
accelerator_features[string(i)] = device
device["accelerator_count"] = l[acc_brand]
device["accelerator"] = acc_info[2]
device["accelerator_type"] = acc_info[3]
device["accelerator_manufacturer"] = acc_info[4]
device["accelerator_api"] = acc_info[5]
device["accelerator_architecture"] = acc_info[6]
device["accelerator_memory_size"] = acc_info[7]
device["accelerator_tdp"] = acc_info[8]
device["accelerator_processor_count"] = length(acc_info) > 8 ? acc_info[9] : "unset"
device["accelerator_processor"] = length(acc_info) > 9 ? acc_info[10] : "unset"
device["accelerator_memory_type"] = length(acc_info) > 10 ? acc_info[11] : "unset"
i = i + 1
end
return i > 1 ? accelerator_features["1"] : accelerator_features
end
function collectAcceleratorFeaturesDefault()
default_features = Dict()
default_features["accelerator_count"] = 0
default_features["accelerator"] = "unset"
default_features["accelerator_type"] = "unset"
default_features["accelerator_manufacturer"] = "unset"
default_features["accelerator_interconnect"] = "unset"
default_features["accelerator_api"] = "unset"
default_features["accelerator_architecture"] = "unset"
default_features["accelerator_memory_size"] = "unset"
default_features["accelerator_tdp"] = "unset"
default_features["accelerator_processor"] = "unset"
default_features["accelerator_processor_count"] = "unset"
default_features["accelerator_memory_type"] = "unset"
return default_features
end
function identifyAccelerator()
try
l = Dict()
for d in identifyComponent("display")
k = "$(d["vendor"]) $(d["product"])"
l[k] = haskey(l,k) ? l[k] + 1 : 1
end
accelerator_features = if (!isempty(l))
collectAcceleratorFeatures(l)
else
collectAcceleratorFeaturesDefault()
end
@info "Accelerator detection successful"
return accelerator_features
catch
@warn "Accelerator detection failed."
@info "Detection of accelerators failed. Using default features. You can setup manually."
return collectAcceleratorFeaturesDefault()
end
end
#=
function identifyMemoryBank!(l,node)
size = 0
if ("node" in keys(node[2]))
if (typeof(node[2]["node"]) == Vector{Any})
for v2 in enumerate(node[2]["node"])
if ("description" in keys(v2[2]))
size = parse(Int64,v2[2]["size"][""])
push!(l, (v2[2]["description"],size))
end
end
else
if ("description" in keys(node[2]["node"]))
size = parse(Int64,node[2]["node"]["size"][""])
push!(l, (node[2]["node"]["description"],size))
end
end
end
end
=#
function getMemorySize(mem_size)
try
size_unit = match(r"KB|MB|GB|TB",mem_size)
size_unit = isnothing(size_unit) ? nothing : size_unit.match
multiplier = Dict("KB" => 2^10, "MB" => 2^20, "GB" => 2^30, "TB" => 2^40, nothing => 1)
return parse(Int64,match(r"^[-+]?[0-9]*\.?[0-9]+",mem_size).match) * multiplier[size_unit]
catch error
@warn string(error)
return "unknown"
end
end
function getMemorySpeed(mem_speed)
try
speed_unit = match(r"MT/s|GT/s|MHz|GHz",mem_speed)
speed_unit = isnothing(speed_unit) ? nothing : speed_unit.match
multiplier = Dict("MT/s" => 1, "GT/s" => 2^10, "MHz" => 1, "GHz" => 2^10, nothing => 1)
return parse(Int64,match(r"^[-+]?[0-9]*\.?[0-9]+",mem_speed).match) * multiplier[speed_unit]
catch error
@warn string(error)
return "unknown"
end
end
# using dmidecode
function collectMemoryFeatures(dict_list)
# dict_list is a dictionary with the memory banks returned by "dmidecode".
# It is assumed that all banks have the same characteristics.
# the total memory size is the sum of the size of memory banks.
memory_features = Dict()
memory_features["node_memory_size"] = 0
for (k,dict) in dict_list
memory_features["node_memory_type"] = !haskey(dict,"Type") || dict["Type"] == "Unknown" ? "unknown" : dict["Type"]
memory_features["node_memory_frequency"] = !haskey(dict,"Speed") || dict["Speed"] == "Unknown" ? "unknown" : getMemorySpeed(dict["Speed"])
memory_features["node_memory_size"] = !haskey(dict,"Size") || dict["Size"] == "Unknown" ? "unknown" : memory_features["node_memory_size"] + getMemorySize(dict["Size"])
memory_features["node_memory_latency"] = "unset"
memory_features["node_memory_bandwidth"] = !haskey(dict,"Configured Memory Speed") || dict["Configured Memory Speed"] == "Unknown" ? "unknown" : getMemorySpeed(dict["Configured Memory Speed"])
end
return memory_features
end
function collectMemoryFeaturesDefault()
memory_features = Dict()
memory_features["node_memory_size"] = 0
memory_features["node_memory_type"] = "unknown"
memory_features["node_memory_frequency"] = "unknown"
memory_features["node_memory_size"] = "unknown"
memory_features["node_memory_latency"] = "unknown"
memory_features["node_memory_bandwidth"] = "unknown"
return memory_features
end
# using dmidecode (unsafe ! text output)
function identifyMemory()
try
command = `sudo dmidecode -t memory`
l = split(replace(read(command, String),"\t"=>""),'\n')
d1 = Dict()
i=0
j=0
for s in l
if s == "Memory Device"
i = i + 1; j = j + 1
d1[j] = Dict()
else
if (i>0 && in(':',s))
ss = split(s,':')
d1[j][strip(ss[1])] = strip(ss[2])
elseif (i>0 && !in(':',s))
i=0
end
end
end
memory_features = collectMemoryFeatures(d1)
@info "Memory detection successfull."
return memory_features
catch
@warn "Memory detection failed."
@info "Detection of memory features failed. Using default features. You can setup manually."
return collectMemoryFeaturesDefault()
end
#=dict = get_info_dict("memory")
l = Vector()
node = dict["list"]["node"]
if (typeof(node) == Vector{Any})
for v1 in enumerate(node)
identifyMemoryBank!(l,v1)
end
else
identifyMemoryBank!(l,node)
end
return l
=#
end
# using lsblk (safe - JSON output)
function identifyStorage()
storage_features = Dict()
try
command = `lsblk --json -d --bytes -o rota,size,tran,type`
dict = JSON.parse(read(command, String))
i = 1
for device in dict["blockdevices"]
if (device["type"] == "disk")
storage_device = Dict()
storage_features[string(i)] = storage_device
storage_type = device["rota"] ? "StorageType_HDD" : "StorageType_SSD";
storage_interface = isnothing(device["tran"]) ? "unknown" : uppercase(device["tran"])
storage_size = device["size"]
storage_latency = "unset"
storage_bandwidth = "unset"
storage_networkbandwidth = "unset"
storage_device["storage_type"] = storage_type
storage_device["storage_interface"] = storage_interface
storage_device["storage_size"] = storage_size
storage_device["storage_latency"] = storage_latency
storage_device["storage_bandwidth"] = storage_bandwidth
storage_device["storage_networkbandwidth"] = storage_networkbandwidth
i = i + 1
end
end
@info "Storage detection successfull."
catch
@warn "Storage detection failed."
@info "Detection of storage features failed. Using default features. You can setup manually."
# default
storage_features["storage_type"] = "unset"
storage_features["storage_interface"] = "unset"
storage_features["storage_size"] = "unset"
storage_features["storage_latency"] = "unset"
storage_features["storage_bandwidth"] = "unset"
storage_features["storage_networkbandwidth"] = "unset"
end
return length(storage_features) > 1 ? storage_features : storage_features["1"]
end
# TODO
function identityInterconnection()
@warn "Interconnection detection failed"
@info "Detection of interconnection features (for cluster computing) not yet implemented. Using default features."
@info "You can setup interconnection features manually."
interconnection_features = Dict()
interconnection_features["interconnection_startuptime"] = "unset"
interconnection_features["interconnection_latency"] = "unset"
interconnection_features["interconnection_bandwidth"] = "unset"
interconnection_features["interconnection_topology"] = "unset"
interconnection_features["interconnection_RDMA"] = "unset"
interconnection_features["interconnection"] = "unset"
return interconnection_features
end
function identifyNode()
node_features = Dict()
node_features["node_count"] = 1
node_features["node_threads_count"] = 1
node_features["node_provider"] = "OnPremises"
node_features["node_virtual"] = "No"
node_features["node_dedicated"] = "No"
node_features["node_machinefamily"] = "unset"
node_features["node_machinetype"] = "unset"
node_features["node_vcpus_count"] = "unset"
for p in subtypes(CloudProvider)
@info "Checking $(string(p)) provider."
ok = getNodeFeatures(p, node_features)
if (isnothing(ok))
@info "$(string(p)) provider failed"
else
@info "$(string(p)) provider succesful"
end;
end
@info "Node identification complete."
return node_features
end
function addNodeFeatures!(platform_features, node_features)
platform_features["node"] = node_features
end
function addProcessorFeatures!(platform_features, processor_features)
platform_features["processor"] = processor_features
end
function addAcceleratorFeatures!(platform_features, accelerator_features)
platform_features["accelerator"] = accelerator_features
end
function addMemoryFeatures!(platform_features, memory_features)
platform_features["memory"] = memory_features
end
function addStorageFeatures!(platform_features, storage_features)
platform_features["storage"] = storage_features
end
function addInterconnectionFeatures!(platform_features, interconnection_features)
platform_features["interconnection"] = interconnection_features
end
function setup()
platform_features = Dict()
node_features = nothing
@sync begin
@async begin @info "Started node identification."; node_features = identifyNode() end
@async begin
@info "Started processor detection."; processor_features = identifyProcessor();
@info "Started accelerator detection."; accelerator_features = identifyAccelerator()
@info "Started memory system detection."; memory_features = identifyMemory()
@info "Started storage detection."; storage_features = identifyStorage()
@info "Started interconnection detection."; interconnection_features = identityInterconnection()
addProcessorFeatures!(platform_features, processor_features)
addAcceleratorFeatures!(platform_features, accelerator_features)
addMemoryFeatures!(platform_features, memory_features)
addStorageFeatures!(platform_features, storage_features)
addInterconnectionFeatures!(platform_features, interconnection_features)
end
end
addNodeFeatures!(platform_features, node_features)
if (!isfile("Platform.toml"))
@sync begin
Threads.@spawn begin
fn = open("Platform.toml","w")
TOML.print(fn, platform_features)
close(fn)
end
end
@info "The platform description file (Platform.toml) was created in the current folder."
@info "You can move it to your preferred target."
@info "Platform.toml will be searched in the following locations:"
@info " 1) A file path pointed by a PLATFORM_DESCRIPTION environment variable;"
@info " 2) The current directory;"
@info " 3) The /etc directory."
else
TOML.print(stdout, platform_features)
@info "A platform description file (Platform.toml) already exists in the current folder. It will not be removed or overwritten."
@info "You can see above the Platform.toml content calculated by the feature detection processing."
end
end
| PlatformAware | https://github.com/PlatformAwareProgramming/PlatformAware.jl.git |
|
[
"MIT"
] | 0.6.0 | d8f50cbc077c0992b472a07f99013cd5be80b11a | code | 9720 | # ------------------------------------------------------------------
# Licensed under the MIT License. See LICENCE in the project root.
# ------------------------------------------------------------------
abstract type PlatformType end
abstract type QuantifierFeature <: PlatformType end
abstract type QualifierFeature <: PlatformType end
@enum FeatureType qualifier=1 api_qualifier quantifier
export FeatureType
global feature_type = Dict(
:node_count => quantifier,
:node_threads_count => quantifier,
:node_provider => qualifier,
:node_virtual => qualifier,
:node_dedicated => qualifier,
:node_machinefamily => qualifier,
:node_machinetype => qualifier,
:node_vcpus_count => quantifier,
:node_memory_size => quantifier,
:node_memory_latency => quantifier,
:node_memory_bandwidth => quantifier,
:node_memory_type => qualifier,
:node_memory_frequency => quantifier,
:node_coworker_count => qualifier,
:processor_count => quantifier,
:processor_manufacturer => qualifier,
:processor_microarchitecture => qualifier,
:processor_simd => qualifier,
:processor_isa => qualifier,
:processor_tdp => quantifier,
:processor_core_clock => quantifier,
:processor_core_count => quantifier,
:processor_core_threads_count => quantifier,
# :processor_core_L1_mapping => ,
:processor_core_L1_size => quantifier,
# :processor_core_L1_latency => ,
# :processor_core_L1_bandwidth => ,
# :processor_core_L1_linesize => ,
# :processor_core_L2_mapping => ,
:processor_core_L2_size => quantifier,
# :processor_core_L2_latency => ,
# :processor_core_L2_bandwidth => ,
# :processor_core_L2_linesize => ,
# :processor_L3_mapping => ,
:processor_L3_size => quantifier,
# :processor_L3_latency => ,
# :processor_L3_bandwidth => ,
# :processor_L3_linesize => ,
:processor => qualifier,
:accelerator_count => quantifier,
:accelerator_manufacturer => qualifier,
:accelerator_interconnect => qualifier,
:accelerator_type => qualifier,
:accelerator_architecture => qualifier,
:accelerator_api => api_qualifier,
:accelerator_memory_size => quantifier,
:accelerator_tdp => quantifier,
:accelerator_processor => qualifier,
:accelerator_processor_count => quantifier,
:accelerator_memory_type => qualifier,
:accelerator => qualifier,
:interconnection_startuptime => quantifier,
:interconnection_latency => quantifier,
:interconnection_bandwidth => quantifier,
:interconnection_topology => qualifier,
:interconnection_RDMA => qualifier,
:interconnection => qualifier,
:storage_size => quantifier,
:storage_latency => quantifier,
:storage_bandwidth => quantifier,
:storage_networkbandwidth => quantifier,
:storage_type => qualifier,
:storage_interface => qualifier
)
function readPlatormDescription()
# read the platform description file (default to the current directory)
filename = get(ENV,"PLATFORM_DESCRIPTION","Platform.toml")
@info "reading platform description at $filename"
platform_description_toml =
try
io = open(filename)
read(io,String)
catch
default_location = "/etc/Platform.toml"
try
# defaul system location
io = open(default_location)
contents = read(io,String)
close(io)
contents
catch
@info "The platform description file (Platform.toml) was not found."
@info "Using default platform features (calling default kernels)."
@info "A Platform.toml file may be created by calling PlatformAware.setup()"
dpf_path = @get_scratch!("default_platform_path")
dpf_url = "https://raw.githubusercontent.com/PlatformAwareProgramming/PlatformAware.jl/master/src/features/default/Platform.toml"
dpf_fname = joinpath(dpf_path, basename(dpf_url))
try_download(dpf_url, dpf_fname)
read(dpf_fname,String)
end
end
TOML.parse(platform_description_toml)
end
get_quantifier_from_number(n) = get_quantifier_from_number(n,'.')
function get_quantifier_from_number(n, d)
if n >= 1.0
magnitude = Dict(0 => "", 1 => "K", 2 => "M", 3 => "G", 4 => "T", 5 => "P", 6 => "E")
l = log(2,n)
a = floor(l)
b = isinteger(l) ? a : a + 1;
# the following loop separates a and b in multiplier*magnitude.
if d == '<'
a_str = "AtLeast0"
else
# let A = 2^a
m1=0
while a>9
# loop invariant: A = 2^a * 2^(10*m)
a = a - 10
m1 = m1 + 1
end
if n==0.5
@info n, d
end
a_str = "AtLeast" * string(Integer(2^a)) * magnitude[m1]
end
if d == '>'
b_str = "AtMostInf"
else
m2=0
while b>9
# loop invariant: A = 2^a * 2^(10*m)
b = b - 10
m2 = m2 + 1
end
b_str = "AtMost" * string(Integer(2^b)) * magnitude[m2]
end
elseif n < 1.0
#TODO: consider 'n', 'u', and 'm' multipliers.
a_str = "AtLeast0"
b_str = "AtMost1"
else
a_str = "AtLeast0"
b_str = "AtMost0"
end
a_type = getfield(@__MODULE__, Meta.parse(a_str))
b_type = getfield(@__MODULE__, Meta.parse(b_str))
Tuple{a_type,b_type,n}
end
mag_mult = Dict('n' => 2^(-30), 'u' => 2^(-20), 'm' => 2^(-10), 'K' => 2^10, 'M' => 2^20, 'G' => 2^30, 'T' => 2^40, 'P'=> 2^50, 'E' => 2^60)
function get_quantifier_from_string(nn)
d = nn[1]
if d in ['<','>']
n = nn[2:length(nn)]
else
n = nn
end
m = n[length(n)]
v1 = get(mag_mult,m,1)
v0 = v1 == 1 ? parse(Float64,n) : parse(Float64,n[1:length(n)-1])
get_quantifier_from_number(v0*v1, d)
end
function get_quantifier(feature)
if (typeof(feature) <: Number)
get_quantifier_from_number(feature)
else #if (typeof(feature) == String)
get_quantifier_from_string(feature)
end
end
function get_qualifier(feature)
getfield(@__MODULE__, Meta.parse(feature))
end
function check_blank_feature(parameter_id, feature, platform_feature_default)
if (feature == "na")
platform_feature_default[parameter_id]
elseif (feature == "unset")
platform_feature_default[parameter_id]
elseif (feature == "unknown")
platform_feature_default[parameter_id]
elseif (feature == "ignore")
platform_feature_default[parameter_id]
else
nothing
end
end
function identifyAPI_oldversion(api_string)
dt = AcceleratorBackend
api_type = get_qualifier(api_string)
if (startswith(api_string, "CUDA")) return Tuple{api_type,dt,dt,dt,dt,dt,dt}
elseif (startswith(api_string, "OpenCL")) return Tuple{dt,api_type,dt,dt,dt,dt,dt}
elseif (startswith(api_string, "OpenACC")) return Tuple{dt,dt,api_type,dt,dt,dt,dt}
elseif (startswith(api_string, "OneAPI")) return Tuple{dt,dt,dt,api_type,dt,dt,dt}
elseif (startswith(api_string, "OpenGL")) return Tuple{dt,dt,dt,dt,api_type,dt,dt}
elseif (startswith(api_string, "Vulkan")) return Tuple{dt,dt,dt,dt,dt,api_type,dt}
elseif (startswith(api_string, "DirectX")) return Tuple{dt,dt,dt,dt,dt,dt,api_type}
else return Tuple{dt,dt,dt,dt,dt,dt}
end
end
function get_api_qualifier(api_string)
apis = split(api_string,';')
if length(apis) == 1
return identifyAPI_oldversion(api_string)
end
cuda_api = get_qualifier(apis[1] in ["na","unset","unknown","ignore"] ? "AcceleratorBackend" : apis[1])
opencl_api = get_qualifier(apis[2] in ["na","unset","unknown","ignore"] ? "AcceleratorBackend" : apis[2])
openacc_api = get_qualifier(apis[3] in ["na","unset","unknown","ignore"] ? "AcceleratorBackend" : apis[3])
oneapi_api = get_qualifier(apis[4] in ["na","unset","unknown","ignore"] ? "AcceleratorBackend" : apis[4])
opengl_api = get_qualifier(apis[5] in ["na","unset","unknown","ignore"] ? "AcceleratorBackend" : apis[5])
vulkan_api = get_qualifier(apis[6] in ["na","unset","unknown","ignore"] ? "AcceleratorBackend" : apis[6])
directx_api = get_qualifier(apis[7] in ["na","unset","unknown","ignore"] ? "AcceleratorBackend" : apis[7])
Tuple{cuda_api,opencl_api,openacc_api,oneapi_api,opengl_api,vulkan_api,directx_api}
end
function loadFeaturesSection!(dict, platform_feature, platform_feature_default)
if ("1" in keys(dict))
dict = dict["1"]
end
for (parameter_id, feature) in dict
p = Meta.parse(parameter_id)
platform_feature[p]= getFeature(p, feature, platform_feature_default, feature_type)
end
end
function getFeature(p, feature, platform_feature_default, feature_type)
try
return getfield(@__MODULE__, Meta.parse(feature))
catch(_)
end
v0 = check_blank_feature(p, feature, platform_feature_default)
return if isnothing(v0)
feature_type[p] == qualifier ? get_qualifier(feature) : feature_type[p] == api_qualifier ? get_api_qualifier(feature) : get_quantifier(feature)
else
v0
end
end
function loadFeatures!(dict, platform_feature_default, platform_feature)
loadDBs!()
for key in ["node", "processor", "accelerator", "memory", "storage", "interconnection"]
loadFeaturesSection!(dict[key], platform_feature, platform_feature_default)
end
end | PlatformAware | https://github.com/PlatformAwareProgramming/PlatformAware.jl.git |
|
[
"MIT"
] | 0.6.0 | d8f50cbc077c0992b472a07f99013cd5be80b11a | code | 5008 | # ------------------------------------------------------------------
# Licensed under the MIT License. See LICENCE in the project root.
# ------------------------------------------------------------------
# OpenCL
abstract type OpenCL_API <: AcceleratorBackend end
abstract type OpenCL_1_0 <: OpenCL_API end
abstract type OpenCL_1_1 <: OpenCL_1_0 end
abstract type OpenCL_1_2 <: OpenCL_1_1 end
abstract type OpenCL_2_0 <: OpenCL_1_2 end
abstract type OpenCL_2_1 <: OpenCL_2_0 end
abstract type OpenCL_2_2 <: OpenCL_2_1 end
abstract type OpenCL_3_0 <: OpenCL_2_2 end
export OpenCL_API, OpenCL_1_0, OpenCL_1_1, OpenCL_1_2, OpenCL_2_0, OpenCL_2_1, OpenCL_2_2, OpenCL_3_0
# OpenGL
abstract type OpenGL_API <: AcceleratorBackend end
abstract type OpenGL_4_6 <: OpenGL_API end
export OpenGL_API, OpenGL_4_6
# Vulkan
abstract type Vulkan_API <: AcceleratorBackend end
abstract type Vulkan_1_1 <: Vulkan_API end
abstract type Vulkan_1_2 <: Vulkan_1_1 end
abstract type Vulkan_1_3 <: Vulkan_1_2 end
export Vulkan_API, Vulkan_1_1, Vulkan_1_2, Vulkan_1_3
# DirectX
abstract type DirectX_API <: AcceleratorBackend end
abstract type DirectX_11_0 <: DirectX_API end
abstract type DirectX_12_1 <: DirectX_11_0 end
abstract type DirectX_12_2 <: DirectX_12_1 end
export DirectX_API, DirectX_11_0, DirectX_12_1, DirectX_12_2
# SIMD extensions
abstract type Now3D <: ProcessorSIMD end
abstract type Now3Dx <: Now3D end
abstract type MMX <: ProcessorSIMD end
abstract type SSE <: ProcessorSIMD end
abstract type SSE_2 <: SSE end; const SSE2 = SSE_2
abstract type SSE_3 <: SSE_2 end; const SSE3 = SSE_3
abstract type SSSE_3 <: SSE_3 end; const SSSE3 = SSSE_3
abstract type SSE_4 <: SSSE_3 end; const SSE4 = SSE_4
abstract type SSE_4_1 <: SSE_4 end
abstract type SSE_4_2 <: SSE_4 end
abstract type SSE_4a <: SSE_3 end
abstract type AVX <: ProcessorSIMD end
abstract type AVX2 <: AVX end
abstract type AVX512 <: AVX2 end # https://en.wikipedia.org/wiki/AVX-512
export Now3D, Now3Dx, MMX, SSE, SSE_2, SSE2, SSE_3, SSE3, SSSE_3, SSSE3, SSE_4, SSE4, SSE_4_1, SSE_4_2, AVX, AVX2, AVX512
# Memory types
abstract type RAM <: MemoryType end
abstract type SDRAM <: RAM end
abstract type DDR2 <: SDRAM end
abstract type DDR3 <: SDRAM end
abstract type DDR3L <: SDRAM end
abstract type DDR4 <: SDRAM end
abstract type LPDDR4 <: SDRAM end
abstract type LPDDR4X <: SDRAM end
abstract type DDR5 <: SDRAM end
abstract type LPDDR5 <: SDRAM end
abstract type DDR_SDRAM <: SDRAM end
abstract type GDDR2 <: SDRAM end
abstract type GDDR3 <: SDRAM end
abstract type GDDR4 <: SDRAM end
abstract type GDDR5 <: SDRAM end
abstract type GDDR5X <: SDRAM end
abstract type GDDR6 <: SDRAM end
abstract type GDDR6X <: SDRAM end
abstract type HBM2 <: SDRAM end
abstract type HBM2e <: SDRAM end
abstract type HBM3 <: SDRAM end
abstract type HBM_PIM <: SDRAM end
export RAM, DDR2, DDR3, DDR33L, DDR4, LPDDR4, LPDDR4X, DDR5, LPDDR5
export DDR_SDRAM, GDDR2, GDDR3, GDDR4, GDDR5, GDDR5X, GDDR6, GDDR6X
# Storage types
abstract type StorageType_SSD <: StorageType end
abstract type StorageType_HDD <: StorageType end
export Storage_SSD, Storage_HDD
# Storage interfaces
abstract type StorageInterface_SATA <: StorageInterface end
abstract type StorageInterface_IDE <: StorageInterface end; const StorageInterface_PATA = StorageInterface_IDE
abstract type StorageInterface_SAS <: StorageInterface end
abstract type StorageInterface_SCSI <: StorageInterface end
abstract type StorageInterface_FC <: StorageInterface end
export StorageInterface_SATA, StorageInterface_IDE, StorageInterface_SAS, StorageInterface_SCSI, StorageInterface_FC
# cache mappings
abstract type CacheMapping_Direct <: CacheMapping end
abstract type CacheMapping_FullyAssociative <: CacheMapping end
abstract type CacheMapping_SetAssociative8 <: CacheMapping end
abstract type CacheMapping_SetAssociative12 <: CacheMapping end
export CacheMapping_Direct, CacheMapping_FullyAssociative, CacheMapping_SetAssociative8, CacheMapping_SetAssociative12
# processor ISA
# https://git.kernel.org/pub/scm/linux/kernel/git/stable/linux.git/tree/arch/
abstract type ISA_x86_32 <: ProcessorISA end
const ISA_x86 = ISA_x86_32
abstract type ISA_x86_64 <: ISA_x86_32 end
const ISA_AMD_64 = ISA_x86_64
abstract type ISA_x86_64_v1 <: ISA_x86_64 end
abstract type ISA_x86_64_v2 <: ISA_x86_64_v1 end
abstract type ISA_x86_64_v3 <: ISA_x86_64_v2 end
abstract type ISA_x86_64_v4 <: ISA_x86_64_v3 end
abstract type ISA_IA_64 <: ProcessorISA end
export ISA_x86_32, ISA_x86, ISA_x86_64, ISA_AMD_64, ISA_x86_64_v1, ISA_x86_64_v2, ISA_x86_64_v3, ISA_x86_64_v4, ISA_IA_64
# TODO: ARM !!!
abstract type WorkerCount end
abstract type NoCoworkers <: WorkerCount end
abstract type PerNode <: WorkerCount end
abstract type PerProcessor <: WorkerCount end
abstract type PerCore <: WorkerCount end
abstract type PerThread <: WorkerCount end
abstract type PerVCPU <: WorkerCount end
abstract type Unmapped <: WorkerCount end
export PerNode, PerProcessor, PerCore, PerThread, PerVCPU | PlatformAware | https://github.com/PlatformAwareProgramming/PlatformAware.jl.git |
|
[
"MIT"
] | 0.6.0 | d8f50cbc077c0992b472a07f99013cd5be80b11a | code | 3215 | # ------------------------------------------------------------------
# Licensed under the MIT License. See LICENCE in the project root.
# ------------------------------------------------------------------
# query
abstract type Query <: QualifierFeature end
abstract type Yes <: Query end
abstract type No <: Query end
# maintainer
abstract type Provider <: QualifierFeature end
abstract type OnPremises <: Provider end
abstract type CloudProvider <: Provider end
# machine
abstract type MachineFamily <: QualifierFeature end
abstract type MachineType <: QualifierFeature end
# locale
abstract type Locale <: QualifierFeature end
# manufacturer
abstract type Manufacturer <: QualifierFeature end
# processor
abstract type ProcessorMicroarchitecture <: QualifierFeature end
abstract type ProcessorISA <: QualifierFeature end
abstract type ProcessorSIMD <: ProcessorISA end
abstract type Processor end
# accelerator
abstract type AcceleratorInterconnect <: QualifierFeature end
abstract type AcceleratorType <: QualifierFeature end
abstract type AcceleratorArchitecture <: QualifierFeature end
abstract type AcceleratorBackend <: QualifierFeature end
abstract type AcceleratorProcessor <: QualifierFeature end
abstract type Accelerator <: QualifierFeature end
abstract type XPU <: AcceleratorType end
abstract type GPU <: XPU end
abstract type TPU <: XPU end
abstract type IPU <: XPU end
abstract type FPGA <: AcceleratorType end
abstract type MIC <: AcceleratorType end
abstract type PCIe <: AcceleratorInterconnect end
abstract type NVLink <: AcceleratorInterconnect end
abstract type NVLink_V1 <: NVLink end
abstract type NVLink_V2 <: NVLink end
abstract type NVLink_SLI <: NVLink end
abstract type NVSwitch <: AcceleratorInterconnect end
abstract type GPUDirect <: AcceleratorInterconnect end
#interconnection
abstract type InterconnectionTopology <: QualifierFeature end
abstract type Interconnection <: QualifierFeature end
# storage
abstract type StorageType <: QualifierFeature end
abstract type StorageInterface <: QualifierFeature end
# memory system
abstract type MemoryType <: QualifierFeature end
# cache
abstract type CacheMapping <: QualifierFeature end
function apitype(api, version_number)
version = isnothing(version_number) ? "API" : string(version_number)
version = replace(version, "." => "_")
dt = AcceleratorBackend
if (api == :CUDA) return Tuple{get_qualifier("CUDA_$version"),dt,dt,dt,dt,dt,dt}
elseif (api == :OpenCL) return Tuple{dt,get_qualifier("OpenCL_$version"),dt,dt,dt,dt,dt}
elseif (api == :OpenACC) return Tuple{dt,dt,get_qualifier("OpenACC_$version"),dt,dt,dt,dt}
elseif (api == :OneAPI) return Tuple{dt,dt,dt,get_qualifier("OneAPI_$version"),dt,dt,dt}
elseif (api == :OpenGL) return Tuple{dt,dt,dt,dt,get_qualifier("OpenGL_$version"),dt,dt}
elseif (api == :Vulkan) return Tuple{dt,dt,dt,dt,dt,get_qualifier("Vulkan_$version"),dt}
elseif (api == :DirectX) return Tuple{dt,dt,dt,dt,dt,dt,get_qualifier("DirectX_$version")}
else return Tuple{dt,dt,dt,dt,dt,dt}
end
end
macro api(api, version_number)
apitype(api,version_number)
end
macro api(api)
apitype(api,nothing)
end
| PlatformAware | https://github.com/PlatformAwareProgramming/PlatformAware.jl.git |
|
[
"MIT"
] | 0.6.0 | d8f50cbc077c0992b472a07f99013cd5be80b11a | code | 18444 | # ------------------------------------------------------------------
# Licensed under the MIT License. See LICENCE in the project root.
# ------------------------------------------------------------------
# GPU architectures
abstract type AMDGPUArchitecture <: AcceleratorArchitecture end
export AMDGPUArchitecture
abstract type CDNA <: AMDGPUArchitecture end
abstract type CDNA_1_0 <: CDNA end; const CDNA1 = CDNA_1_0
abstract type CDNA_2_0 <: CDNA end; const CDNA2 = CDNA_2_0
export CDNA, CDNA_1_0, CDNA_2_0, CDNA1, CDNA2
abstract type RDNA <: AMDGPUArchitecture end
abstract type RDNA_1_0 <: RDNA end; const RDNA1 = RDNA_1_0
abstract type RDNA_2_0 <: RDNA_1_0 end; const RDNA2 = RDNA_2_0
abstract type RDNA_3_0 <: RDNA_2_0 end; const RDNA3 = RDNA_3_0
export RDNA, RDNA_1_0, RDNA_2_0, RDNA_3_0, RDNA1, RDNA2, RDNA3
abstract type GCN <: AMDGPUArchitecture end
abstract type GCN_1_0 <: GCN end; const CGN1 = GCN_1_0
abstract type GCN_2_0 <: GCN_1_0 end; const GCN2 = GCN_2_0
abstract type GCN_3_0 <: GCN_2_0 end; const GCN3 = GCN_3_0
abstract type GCN_4_0 <: GCN_3_0 end; const GCN4 = GCN_4_0; const Polaris = GCN4
abstract type GCN_5_0 <: GCN_4_0 end; const GCN5 = GCN_5_0; const Vega = GCN5
abstract type GCN_5_1 <: GCN_5_0 end; const Vega20 = GCN_5_1
export GCN, GCN_1_0, GCN_2_0, GCN_3_0, GCN_4_0, GCN_5_0, GCN_5_1, GCN1, GCN2, GCN3, GCN4, Polaris, GCN5, Vega, Vega20
abstract type TeraScale <: AMDGPUArchitecture end
abstract type TeraScale_1_0 <: TeraScale end; const TeraScale1 = TeraScale_1_0
abstract type TeraScale_2_0 <: TeraScale_1_0 end; const TeraScale2 = TeraScale_2_0
abstract type TeraScale_3_0 <: TeraScale_2_0 end; const TeraScale3 = TeraScale_3_0
export TeraScale, TeraScale_1_0, TeraScale_2_0, TeraScale_3_0, TeraScale1, TeraScale2, TeraScale3
# Accelerators
abstract type AMDAccelerator <: Accelerator end
# families 1
abstract type AMDRadeon <: AMDAccelerator end
abstract type AMDRadeon_Vega <: AMDRadeon end
abstract type AMDRadeon_PRO <: AMDRadeon end
abstract type AMDInstinct <: AMDAccelerator end
abstract type AMDFirePro <: AMDAccelerator end
# families 2
abstract type AMDRadeon_Vega2 <: AMDRadeon end
abstract type AMDRadeon_Vega_RX <: AMDRadeon_Vega end
abstract type AMDRadeon_RX_6000 <: AMDRadeon end
abstract type AMDRadeon_RX_6000S <: AMDRadeon_RX_6000 end
abstract type AMDRadeon_RX_6000M <: AMDRadeon_RX_6000 end
abstract type AMDRadeon_R9 <: AMDRadeon end
abstract type AMDRadeon_R7 <: AMDRadeon end
abstract type AMDRadeon_R5 <: AMDRadeon end
abstract type AMDRadeon_HD <: AMDRadeon end
abstract type AMDRadeon_600 <: AMDRadeon end
abstract type AMDRadeon_5700 <: AMDRadeon end
abstract type AMDRadeon_5600 <: AMDRadeon end
abstract type AMDRadeon_5500 <: AMDRadeon end
abstract type AMDRadeon_5300 <: AMDRadeon end
abstract type AMDRadeon_5000M <: AMDRadeon end
abstract type AMDRadeon_500 <: AMDRadeon end
abstract type AMDRadeon_400 <: AMDRadeon end
# families 2
abstract type AMDRadeon_500X <: AMDRadeon_500 end
abstract type ATIRadeon_HD_5000 <: AMDRadeon_HD end
abstract type AMDRadeon_HD_6000 <: AMDRadeon_HD end
abstract type AMDRadeon_HD_7000 <: AMDRadeon_HD end
abstract type AMDRadeon_HD_8000M <: AMDRadeon_HD end
abstract type AMDRadeon_R5_200 <: AMDRadeon_R5 end
abstract type AMDRadeon_R5_300 <: AMDRadeon_R5 end
abstract type AMDRadeon_R7_200 <: AMDRadeon_R7 end
abstract type AMDRadeon_R7_300 <: AMDRadeon_R7 end
abstract type AMDRadeon_R9_200 <: AMDRadeon_R9 end
abstract type AMDRadeon_R9_300 <: AMDRadeon_R9 end
abstract type AMDRadeon_R9_Fury <: AMDRadeon_R9 end
abstract type AMDRadeon_RX_400 <: AMDRadeon_400 end
abstract type AMDRadeon_RX_500 <: AMDRadeon_500 end
abstract type AMDRadeon_RX_5000M <: AMDRadeon_5000M end
abstract type AMDRadeon_RX_500X <: AMDRadeon_500 end
abstract type AMDRadeon_RX_5300 <: AMDRadeon_5300 end
abstract type AMDRadeon_RX_5500 <: AMDRadeon_5500 end
abstract type AMDRadeon_RX_5600 <: AMDRadeon_5600 end
abstract type AMDRadeon_RX_5700 <: AMDRadeon_5700 end
abstract type AMDRadeon_RX_6400 <: AMDRadeon_RX_6000 end
abstract type AMDRadeon_RX_6500 <: AMDRadeon_RX_6000 end
abstract type AMDRadeon_RX_6600 <: AMDRadeon_RX_6000 end
abstract type AMDRadeon_RX_6700 <: AMDRadeon_RX_6000 end
abstract type AMDRadeon_RX_6800 <: AMDRadeon_RX_6000 end
abstract type AMDRadeon_RX_6900 <: AMDRadeon_RX_6000 end
abstract type AMDRadeon_RX_Vega <: AMDRadeon_Vega_RX end
abstract type AMDRadeon_PRO_V <: AMDRadeon_PRO end
abstract type AMDInstinct_MI <: AMDInstinct end
abstract type AMDRadeon_PRO_W6000 <: AMDRadeon_PRO end
abstract type AMDRadeon_PRO_W6000_Mobile <: AMDRadeon_PRO end
abstract type AMDRadeon_PRO_VII <: AMDRadeon_PRO end
abstract type AMDRadeon_PRO_W5000 <: AMDRadeon_PRO end
abstract type AMDRadeon_PRO_W5000_Mobile <: AMDRadeon_PRO end
abstract type AMDRadeon_PRO_WX_x200 <: AMDRadeon_PRO end
abstract type AMDRadeon_PRO_WX_x100 <: AMDRadeon_PRO end
abstract type AMDFirePro_Wx100 <: AMDFirePro end
abstract type AMDFirePro_Wx000 <: AMDFirePro end
abstract type AMDFirePro_S <: AMDFirePro end
abstract type AMDFirePro_R <: AMDFirePro end
abstract type AMDFirePro_Mobility <: AMDFirePro end
abstract type AMDFirePro_MultiView <: AMDFirePro end
# models
abstract type AMDInstinct_MI250X <: AMDInstinct_MI end
abstract type AMDInstinct_MI250 <: AMDInstinct_MI end
abstract type AMDInstinct_MI210 <: AMDInstinct_MI end
abstract type AMDInstinct_MI100 <: AMDInstinct_MI end
abstract type AMDInstinct_MI60 <: AMDInstinct_MI end
abstract type AMDInstinct_MI50_32GB <: AMDInstinct_MI end
abstract type AMDInstinct_MI50_16GB <: AMDInstinct_MI end
abstract type AMDInstinct_MI25 <: AMDInstinct_MI end
abstract type AMDInstinct_MI8 <: AMDInstinct_MI end
abstract type AMDInstinct_MI6 <: AMDInstinct_MI end
abstract type AMDRadeonPRO_V_250 <: AMDRadeon_PRO_V end
abstract type AMDRadeon_PRO_V620 <: AMDRadeon_PRO_V end
abstract type AMDRadeon_PRO_W6800 <: AMDRadeon_PRO_W6000 end
abstract type AMDRadeon_PRO_W6600 <: AMDRadeon_PRO_W6000 end
abstract type AMDRadeon_PRO_V520 <: AMDRadeon_PRO_V end
abstract type AMDRadeon_PRO_W6600M <: AMDRadeon_PRO_W6000_Mobile end
abstract type AMDRadeon_PRO_W6400 <: AMDRadeon_PRO_W6000 end
abstract type AMDRadeon_PRO_W6500M <: AMDRadeon_PRO_W6000_Mobile end
abstract type AMDRadeon_PRO_W5700 <: AMDRadeon_PRO_W5000 end
abstract type AMDRadeon_PRO_W5500 <: AMDRadeon_PRO_W5000 end
abstract type AMDRadeon_PRO_W6300M <: AMDRadeon_PRO_W6000_Mobile end
abstract type AMDRadeon_PRO_WX_8200 <: AMDRadeon_PRO_WX_x200 end
abstract type AMDRadeon_PRO_WX_3200 <: AMDRadeon_PRO_WX_x200 end
abstract type AMDRadeon_PRO_SSG <: AMDRadeon_PRO end
abstract type AMDRadeon_Vega_Frontier <: AMDRadeon_PRO end
abstract type AMDRadeon_PRO_Duo <: AMDRadeon_PRO end
abstract type AMDRadeon_PRO_WX_9100 <: AMDRadeon_PRO_WX_x100 end
abstract type AMDRadeon_PRO_WX_7100 <: AMDRadeon_PRO_WX_x100 end
abstract type AMDRadeon_PRO_WX_5100 <: AMDRadeon_PRO_WX_x100 end
abstract type AMDRadeon_PRO_WX_4100 <: AMDRadeon_PRO_WX_x100 end
abstract type AMDRadeon_PRO_WX_3100 <: AMDRadeon_PRO_WX_x100 end
abstract type AMDRadeon_PRO_WX_2100 <: AMDRadeon_PRO_WX_x100 end
abstract type AMDFirePro_W9100_32GB <: AMDFirePro_Wx100 end
abstract type AMDFirePro_W9100 <: AMDFirePro_Wx100 end
abstract type AMDFirePro_W8100 <: AMDFirePro_Wx100 end
abstract type AMDFirePro_W7100 <: AMDFirePro_Wx100 end
abstract type AMDFirePro_W5100 <: AMDFirePro_Wx100 end
abstract type AMDFirePro_W4300 <: AMDFirePro_Wx100 end
abstract type AMDFirePro_W4100 <: AMDFirePro_Wx100 end
abstract type AMDFirePro_W2100 <: AMDFirePro_Wx100 end
abstract type AMDFirePro_W9000 <: AMDFirePro_Wx000 end
abstract type AMDFirePro_W8000 <: AMDFirePro_Wx000 end
abstract type AMDFirePro_W7000 <: AMDFirePro_Wx000 end
abstract type AMDFirePro_W5000 <: AMDFirePro_Wx000 end
abstract type AMDFirePro_W5000_DVI <: AMDFirePro_Wx000 end
abstract type AMDFirePro_W600 <: AMDFirePro_Wx000 end
abstract type AMDFirePro_S10000 <: AMDFirePro_S end
abstract type AMDFirePro_S10000_12GB <: AMDFirePro_S end
abstract type AMDFirePro_S9300_x2 <: AMDFirePro_S end
abstract type AMDFirePro_S9170 <: AMDFirePro_S end
abstract type AMDFirePro_S9150 <: AMDFirePro_S end
abstract type AMDFirePro_S9100 <: AMDFirePro_S end
abstract type AMDFirePro_S9050 <: AMDFirePro_S end
abstract type AMDFirePro_S9000 <: AMDFirePro_S end
abstract type AMDFirePro_S7150_x2 <: AMDFirePro_S end
abstract type AMDFirePro_S7150 <: AMDFirePro_S end
abstract type AMDFirePro_S7100X <: AMDFirePro_S end
abstract type AMDFirePro_S7000 <: AMDFirePro_S end
abstract type AMDFirePro_S4000X <: AMDFirePro_S end
abstract type AMDRadeon_PRO_W5500M <: AMDRadeon_PRO_W5000_Mobile end
abstract type AMDFirePro_R5000 <: AMDFirePro_R end
abstract type AMDFirePro_W7170M <: AMDFirePro_Mobility end
abstract type AMDFirePro_W6150M <: AMDFirePro_Mobility end
abstract type AMDFirePro_W5170M <: AMDFirePro_Mobility end
abstract type AMDFirePro_W5130M <: AMDFirePro_Mobility end
abstract type AMDFirePro_W4190M <: AMDFirePro_Mobility end
abstract type AMDFirePro_W4170M <: AMDFirePro_Mobility end
abstract type AMDFirePro_2460 <: AMDFirePro_MultiView end
abstract type AMDFirePro_2270_x1 <: AMDFirePro_MultiView end
abstract type AMDFirePro_2270_1GB <: AMDFirePro_MultiView end
abstract type AMDFirePro_2270 <: AMDFirePro_MultiView end
abstract type AMDRadeon_RX_6950_XT <: AMDRadeon_RX_6900 end
abstract type AMDRadeon_RX_6900_XT <: AMDRadeon_RX_6900 end
abstract type AMDRadeon_RX_6800_XT <: AMDRadeon_RX_6800 end
abstract type AMDRadeon_RX_6850M_XT <: AMDRadeon_RX_6000M end
abstract type AMDRadeon_RX_6750_XT <: AMDRadeon_RX_6700 end
abstract type AMDRadeon_RX_6800S <: AMDRadeon_RX_6000S end
abstract type AMDRadeon_RX_6700_XT <: AMDRadeon_RX_6700 end
abstract type AMDRadeon_RX_6650_XT <: AMDRadeon_RX_6600 end
abstract type AMDRadeon_RX_6800M <: AMDRadeon_RX_6000M end
abstract type AMDRadeon_RX_6600_XT <: AMDRadeon_RX_6600 end
abstract type AMDRadeon_RX_6700M <: AMDRadeon_RX_6000M end
abstract type AMDRadeon_RX_5700_XT <: AMDRadeon_RX_5700 end
abstract type AMDRadeon_RX_6500_XT <: AMDRadeon_RX_6500 end
abstract type AMDRadeon_RX_6650M_XT <: AMDRadeon_RX_6000M end
abstract type AMDRadeon_VII <: AMDRadeon_Vega2 end
abstract type AMDRadeon_RX_6650M <: AMDRadeon_RX_6000M end
abstract type AMDRadeon_RX_5600_XT <: AMDRadeon_RX_5600 end
abstract type AMDRadeon_RX_6600M <: AMDRadeon_RX_6000M end
abstract type AMDRadeon_RX_5500_XT <: AMDRadeon_RX_5500 end
abstract type AMDRadeon_RX_5700M <: AMDRadeon_RX_5000M end
abstract type AMDRadeon_RX_6500M <: AMDRadeon_RX_6000M end
abstract type AMDRadeon_RX_5600M <: AMDRadeon_RX_5000M end
abstract type AMDRadeon_RX_Vega_64_L <: AMDRadeon_RX_Vega end
abstract type AMDRadeon_RX_6300M <: AMDRadeon_RX_6000M end
abstract type AMDRadeon_RX_6700S <: AMDRadeon_RX_6000S end
abstract type AMDRadeon_RX_5500M <: AMDRadeon_RX_5000M end
abstract type AMDRadeon_RX_5300M <: AMDRadeon_RX_5000M end
abstract type AMDRadeon_RX_Vega_64 <: AMDRadeon_RX_Vega end
abstract type AMDRadeon_RX_Vega_56 <: AMDRadeon_RX_Vega end
abstract type AMDRadeon_RX_6600S <: AMDRadeon_RX_6000S end
abstract type AMDRadeon_RX_590 <: AMDRadeon_RX_500 end
abstract type AMDRadeon_RX_640 <: AMDRadeon_600 end
abstract type AMDRadeon_RX_580 <: AMDRadeon_RX_500 end
abstract type AMDRadeon_RX_580X <: AMDRadeon_RX_500X end
abstract type AMDRadeon_RX_570 <: AMDRadeon_RX_500 end
abstract type AMDRadeon_630 <: AMDRadeon_600 end
abstract type AMDRadeon_RX_570X <: AMDRadeon_RX_500X end
abstract type AMDRadeon_RX_560 <: AMDRadeon_RX_500 end
abstract type AMDRadeon_625 <: AMDRadeon_600 end
abstract type AMDRadeon_RX_560X <: AMDRadeon_RX_500X end
abstract type AMDRadeon_RX_550 <: AMDRadeon_RX_500 end
abstract type AMDRadeon_620 <: AMDRadeon_600 end
abstract type AMDRadeon_RX_550X <: AMDRadeon_RX_500X end
abstract type AMDRadeon_RX_540 <: AMDRadeon_RX_500 end
abstract type AMDRadeon_610 <: AMDRadeon_600 end
abstract type AMDRadeon_550X <: AMDRadeon_500X end
abstract type AMDRadeon_RX_540X <: AMDRadeon_RX_500X end
abstract type AMDRadeon_540 <: AMDRadeon_500 end
abstract type AMDRadeon_540X <: AMDRadeon_500X end
abstract type AMDRadeon_535 <: AMDRadeon_500 end
abstract type AMDRadeon_530 <: AMDRadeon_500 end
abstract type AMDRadeon_520 <: AMDRadeon_500 end
abstract type AMDRadeon_RX_480 <: AMDRadeon_RX_400 end
abstract type AMDRadeon_RX_470 <: AMDRadeon_RX_400 end
abstract type AMDRadeon_RX_460 <: AMDRadeon_RX_400 end
abstract type AMDRadeon_R9_Fury_X <: AMDRadeon_R9_Fury end
abstract type AMDRadeon_R9_Nano <: AMDRadeon_R9_Fury end
abstract type AMDRadeon_R9_390X <: AMDRadeon_R9_300 end
abstract type AMDRadeon_R9_390 <: AMDRadeon_R9_300 end
abstract type AMDRadeon_R9_380X <: AMDRadeon_R9_300 end
abstract type AMDRadeon_R9_380 <: AMDRadeon_R9_300 end
abstract type AMDRadeon_R9_M395X <: AMDRadeon_R9_300 end
abstract type AMDRadeon_R9_M395 <: AMDRadeon_R9_300 end
abstract type AMDRadeon_R9_M390X <: AMDRadeon_R9_300 end
abstract type AMDRadeon_R9_M390 <: AMDRadeon_R9_300 end
abstract type AMDRadeon_R9_M385X <: AMDRadeon_R9_300 end
abstract type AMDRadeon_R9_M385 <: AMDRadeon_R9_300 end
abstract type AMDRadeon_R9_M380 <: AMDRadeon_R9_300 end
abstract type AMDRadeon_R9_M375X <: AMDRadeon_R9_300 end
abstract type AMDRadeon_R9_M375 <: AMDRadeon_R9_300 end
abstract type AMDRadeon_R9_M365X <: AMDRadeon_R9_300 end
abstract type AMDRadeon_R9_M360 <: AMDRadeon_R9_300 end
abstract type AMDRadeon_R9_295X2 <: AMDRadeon_R9_200 end
abstract type AMDRadeon_R9_290X <: AMDRadeon_R9_200 end
abstract type AMDRadeon_R9_290 <: AMDRadeon_R9_200 end
abstract type AMDRadeon_R9_285 <: AMDRadeon_R9_200 end
abstract type AMDRadeon_R9_280X <: AMDRadeon_R9_200 end
abstract type AMDRadeon_R9_280 <: AMDRadeon_R9_200 end
abstract type AMDRadeon_R9_270X <: AMDRadeon_R9_200 end
abstract type AMDRadeon_R9_270 <: AMDRadeon_R9_200 end
abstract type AMDRadeon_R9_M295X <: AMDRadeon_R9_200 end
abstract type AMDRadeon_R9_M290X <: AMDRadeon_R9_200 end
abstract type AMDRadeon_R9_M285X <: AMDRadeon_R9_200 end
abstract type AMDRadeon_R9_M280X <: AMDRadeon_R9_200 end
abstract type AMDRadeon_R9_M280 <: AMDRadeon_R9_200 end
abstract type AMDRadeon_R9_M275X <: AMDRadeon_R9_200 end
abstract type AMDRadeon_R9_M270X <: AMDRadeon_R9_200 end
abstract type AMDRadeon_R9_M265X <: AMDRadeon_R9_200 end
abstract type AMDRadeon_R7_370 <: AMDRadeon_R7_300 end
abstract type AMDRadeon_R7_360 <: AMDRadeon_R7_300 end
abstract type AMDRadeon_R7_M380 <: AMDRadeon_R7_300 end
abstract type AMDRadeon_R7_M375 <: AMDRadeon_R7_300 end
abstract type AMDRadeon_R7_M370 <: AMDRadeon_R7_300 end
abstract type AMDRadeon_R7_M365X <: AMDRadeon_R7_300 end
abstract type AMDRadeon_R7_M365 <: AMDRadeon_R7_300 end
abstract type AMDRadeon_R7_M360 <: AMDRadeon_R7_300 end
abstract type AMDRadeon_R7_M350 <: AMDRadeon_R7_300 end
abstract type AMDRadeon_R7_M340 <: AMDRadeon_R7_300 end
abstract type AMDRadeon_R7_265 <: AMDRadeon_R7_200 end
abstract type AMDRadeon_R7_260X <: AMDRadeon_R7_200 end
abstract type AMDRadeon_R7_260 <: AMDRadeon_R7_200 end
abstract type AMDRadeon_R7_250X <: AMDRadeon_R7_200 end
abstract type AMDRadeon_R7_250 <: AMDRadeon_R7_200 end
abstract type AMDRadeon_R7_240 <: AMDRadeon_R7_200 end
abstract type AMDRadeon_R7_M270 <: AMDRadeon_R7_200 end
abstract type AMDRadeon_R7_M265X <: AMDRadeon_R7_200 end
abstract type AMDRadeon_R7_M265AE <: AMDRadeon_R7_200 end
abstract type AMDRadeon_R7_M265 <: AMDRadeon_R7_200 end
abstract type AMDRadeon_R7_M260X <: AMDRadeon_R7_200 end
abstract type AMDRadeon_R7_M260 <: AMDRadeon_R7_200 end
abstract type AMDRadeon_R5_M335X <: AMDRadeon_R5_300 end
abstract type AMDRadeon_R5_M335 <: AMDRadeon_R5_300 end
abstract type AMDRadeon_R5_M330 <: AMDRadeon_R5_300 end
abstract type AMDRadeon_R5_M320 <: AMDRadeon_R5_300 end
abstract type AMDRadeon_R5_M315 <: AMDRadeon_R5_300 end
abstract type AMDRadeon_R5_235 <: AMDRadeon_R5_200 end
abstract type AMDRadeon_R5_230 <: AMDRadeon_R5_200 end
abstract type AMDRadeon_R5_M255X <: AMDRadeon_R5_200 end
abstract type AMDRadeon_R5_M255 <: AMDRadeon_R5_200 end
abstract type AMDRadeon_R5_M240X <: AMDRadeon_R5_200 end
abstract type AMDRadeon_R5_M240 <: AMDRadeon_R5_200 end
abstract type AMDRadeon_R5_M230 <: AMDRadeon_R5_200 end
abstract type AMDRadeon_HD_8970M <: AMDRadeon_HD_8000M end
abstract type AMDRadeon_HD_8870M <: AMDRadeon_HD_8000M end
abstract type AMDRadeon_HD_8850M <: AMDRadeon_HD_8000M end
abstract type AMDRadeon_HD_8830M <: AMDRadeon_HD_8000M end
abstract type AMDRadeon_HD_8790M <: AMDRadeon_HD_8000M end
abstract type AMDRadeon_HD_8770M <: AMDRadeon_HD_8000M end
abstract type AMDRadeon_HD_8750M <: AMDRadeon_HD_8000M end
abstract type AMDRadeon_HD_8730M <: AMDRadeon_HD_8000M end
abstract type AMDRadeon_HD_8690M <: AMDRadeon_HD_8000M end
abstract type AMDRadeon_HD_8670M <: AMDRadeon_HD_8000M end
abstract type AMDRadeon_HD_8590M <: AMDRadeon_HD_8000M end
abstract type AMDRadeon_HD_8570M <: AMDRadeon_HD_8000M end
abstract type AMDRadeon_HD_7990 <: AMDRadeon_HD_7000 end
abstract type AMDRadeon_HD_7970_GE <: AMDRadeon_HD_7000 end
abstract type AMDRadeon_HD_7970 <: AMDRadeon_HD_7000 end
abstract type AMDRadeon_HD_7950 <: AMDRadeon_HD_7000 end
abstract type AMDRadeon_HD_7870_GE <: AMDRadeon_HD_7000 end
abstract type AMDRadeon_HD_7850 <: AMDRadeon_HD_7000 end
abstract type AMDRadeon_HD_7790 <: AMDRadeon_HD_7000 end
abstract type AMDRadeon_HD_7770_GE <: AMDRadeon_HD_7000 end
abstract type AMDRadeon_HD_7750 <: AMDRadeon_HD_7000 end
abstract type AMDRadeon_HD_7730 <: AMDRadeon_HD_7000 end
abstract type AMDRadeon_HD_6970 <: AMDRadeon_HD_6000 end
abstract type AMDRadeon_HD_6950 <: AMDRadeon_HD_6000 end
abstract type AMDRadeon_HD_6870 <: AMDRadeon_HD_6000 end
abstract type AMDRadeon_HD_6850 <: AMDRadeon_HD_6000 end
abstract type AMDRadeon_HD_6770 <: AMDRadeon_HD_6000 end
abstract type AMDRadeon_HD_6750 <: AMDRadeon_HD_6000 end
abstract type AMDRadeon_HD_6670 <: AMDRadeon_HD_6000 end
abstract type AMDRadeon_HD_6570 <: AMDRadeon_HD_6000 end
abstract type AMDRadeon_HD_6450 <: AMDRadeon_HD_6000 end
abstract type ATIRadeon_HD_5970 <: ATIRadeon_HD_5000 end
abstract type ATIRadeon_HD_5870 <: ATIRadeon_HD_5000 end
abstract type ATIRadeon_HD_5850 <: ATIRadeon_HD_5000 end
abstract type ATIRadeon_HD_5830 <: ATIRadeon_HD_5000 end
abstract type ATIRadeon_HD_5770 <: ATIRadeon_HD_5000 end
abstract type ATIRadeon_HD_5750 <: ATIRadeon_HD_5000 end
abstract type ATIRadeon_HD_5670 <: ATIRadeon_HD_5000 end
abstract type ATIRadeon_HD_5570 <: ATIRadeon_HD_5000 end
abstract type ATIRadeon_HD_5450 <: ATIRadeon_HD_5000 end | PlatformAware | https://github.com/PlatformAwareProgramming/PlatformAware.jl.git |
|
[
"MIT"
] | 0.6.0 | d8f50cbc077c0992b472a07f99013cd5be80b11a | code | 41939 | # ------------------------------------------------------------------
# Licensed under the MIT License. See LICENCE in the project root.
# ------------------------------------------------------------------
abstract type AMD <: Manufacturer end; export AMD
# AMD Processors - source: https://www.amd.com/en/products/specifications/processors
abstract type AMDProcessor <: Processor end; export AMDProcessor
# AMD Microarchictetures (from 2010)
abstract type AMDMicroarchitecture <: ProcessorMicroarchitecture end
abstract type K6 <: AMDMicroarchitecture end
abstract type K7 <: AMDMicroarchitecture end
abstract type K8 <: AMDMicroarchitecture end
const Hammer = K8
abstract type K10 <: AMDMicroarchitecture end
abstract type Zen <: AMDMicroarchitecture end
abstract type Zen2 <: AMDMicroarchitecture end
abstract type Zen3 <: AMDMicroarchitecture end
abstract type Zen4 <: AMDMicroarchitecture end
abstract type Zen4c <: Zen4 end
abstract type Zen5 <: AMDMicroarchitecture end
abstract type Bobcat <: AMDMicroarchitecture end
abstract type Bulldozer <: AMDMicroarchitecture end
abstract type Piledriver <: AMDMicroarchitecture end
abstract type Steamroller <: AMDMicroarchitecture end
abstract type Excavator <: AMDMicroarchitecture end
abstract type Jaguar <: AMDMicroarchitecture end
abstract type Puma <: AMDMicroarchitecture end
# Families
abstract type AMD_ASeries <: AMDProcessor end # AMD A-Series Processors
abstract type AMD_ASeries_PRO <: AMD_ASeries end # AMD PRO A-Series Processors
abstract type AMDAthlon <: AMDProcessor end # AMD Athlon™ Processors
abstract type AMDAthlon_PRO <: AMDAthlon end # AMD Athlon™ PRO Processors
abstract type AMD_ESeries <: AMDProcessor end # AMD E-Series Processors
abstract type AMDEPYC <: AMDProcessor end # AMD EPYC™
abstract type AMD_FX <: AMDProcessor end # AMD FX-Series Processors
abstract type AMDOpteron <: AMDProcessor end # AMD Opteron™
abstract type AMDPhenom <: AMDProcessor end # AMD Phenom™
abstract type AMDRyzen <: AMDProcessor end # AMD Ryzen™ Processors
abstract type AMDRyzen_PRO <: AMDRyzen end # AMD Ryzen™ PRO Processors
abstract type AMDSempron <: AMDProcessor end # AMD Sempron™
abstract type AMDTurion <: AMDProcessor end # AMD Turion™
#Lines
abstract type AMD_3000 <: AMDProcessor end # AMD 3000 Series Mobile Processors with Radeon™ Graphics
abstract type AMD_A12 <: AMD_ASeries end # AMD A12-Series APU
abstract type AMD_A10 <: AMD_ASeries end # AMD A10-Series APU
abstract type AMD_A8 <: AMD_ASeries end # AMD A8-Series APU
abstract type AMD_A6 <: AMD_ASeries end # AMD A6-Series APU
abstract type AMD_A9 <: AMD_ASeries end # AMD A9-Series APU
abstract type AMD_A4 <: AMD_ASeries end # AMD A4-Series APU
abstract type AMD_A10_Business <: AMD_ASeries end # AMD Business Class - Quad-Core A10-Series APU
abstract type AMD_A8_Business <: AMD_ASeries end # AMD Business Class - Quad-Core A8-Series APU
abstract type AMD_A6_Business <: AMD_ASeries end # AMD Business Class - Dual-Core A6-Series APU
abstract type AMDAthlon_PRO_3000 <: AMDAthlon_PRO end # AMD Athlon™ PRO 3000 Series Desktop Processors
abstract type AMDAthlon_PRO_Vega <: AMDAthlon_PRO end # AMD Athlon™ PRO Desktop Processors with Radeon™ Vega Graphics
abstract type AMDAthlon_Vega <: AMDAthlon end # AMD Athlon™ Desktop Processors with Radeon™ Vega Graphics
abstract type AMDAthlon_3000G <: AMDAthlon end # AMD Athlon™ 3000 G-Series Desktop Processors with Radeon™ Graphics
abstract type AMDAthlonII_X4 <: AMDAthlon end # AMD Athlon™ II X4
abstract type AMDAthlonII_X3 <: AMDAthlon end # AMD Athlon™ II X3
abstract type AMDAthlonII_X2 <: AMDAthlon end # AMD Athlon™ II X2
abstract type AMDAthlon_X4 <: AMDAthlon end # AMD Athlon™ X4
abstract type AMDAthlon_APU <: AMDAthlon end # AMD Athlon™ Quad-Core APU
abstract type AMD_E2 <: AMD_ESeries end # AMD E2-Series APU
abstract type AMD_E1 <: AMD_ESeries end # AMD E1-Series APU
abstract type AMDEPYC_7003 <: AMDEPYC end # AMD EPYC™ 7003 Series
abstract type AMDEPYC_7003_VCache <: AMDEPYC_7003 end # AMD EPYC™ 7003 Series with AMD 3D V-Cache™
abstract type AMDEPYC_7002 <: AMDEPYC end # AMD EPYC™ 7002 Series
abstract type AMDEPYC_7001 <: AMDEPYC end # AMD EPYC™ 7001 Series
abstract type AMDEPYC_9R14 <: AMDEPYC end
abstract type AMDEPYC_7B13 <: AMDEPYC end
abstract type AMDEPYC_7R13 <: AMDEPYC end
abstract type AMDEPYC_7R32 <: AMDEPYC end
abstract type AMD_FX_8_Black <: AMD_FX end # AMD FX 8-Core Black Edition Processors
abstract type AMD_FX_6_Black <: AMD_FX end # AMD FX 6-Core Black Edition Processors
abstract type AMD_FX_4_Black <: AMD_FX end # AMD FX 4-Core Black Edition Processors
abstract type AMDOpteron_X1100 <: AMDOpteron end # AMD Opteron™ X1100 Series Processors
abstract type AMDOpteron_6300 <: AMDOpteron end # AMD Opteron™ 6300 Series Processor
abstract type AMDOpteron_6200 <: AMDOpteron end # AMD Opteron™ 6200 Series Processor
abstract type AMDOpteron_6100 <: AMDOpteron end # AMD Opteron™ 6100 Series Processor
abstract type AMDOpteron_4300 <: AMDOpteron end # AMD Opteron™ 4300 Series Processor
abstract type AMDOpteron_4200 <: AMDOpteron end # AMD Opteron™ 4200 Series Processor
abstract type AMDOpteron_3300 <: AMDOpteron end # AMD Opteron™ 3300 Series Processor
abstract type AMDOpteron_3200 <: AMDOpteron end # AMD Opteron™ 3200 Series Processor
abstract type AMDOpteron_X2100 <: AMDOpteron end # AMD Opteron™ X2100 Series APU
abstract type AMDPhenom_II_X6 <: AMDPhenom end # AMD Phenom™ II X6
abstract type AMDPhenom_II_X4 <: AMDPhenom end # AMD Phenom™ II X4
abstract type AMDPhenom_II_X4_Black <: AMDPhenom end # AMD Phenom™ II X4 Black
abstract type AMDPhenom_II_X2 <: AMDPhenom end # AMD Phenom™ II X2
abstract type AMDPhenom_II_X2_Black <: AMDPhenom end # AMD Phenom™ II X2 Black
abstract type AMDPhenom_II_Black <: AMDPhenom end # AMD Phenom™ II Black Edition Quad-Core Mobile Processors
abstract type AMDPhenom_II_QuadCore <: AMDPhenom end # AMD Phenom™ II Quad-Core Mobile Processors
abstract type AMDPhenom_II_TripleCore <: AMDPhenom end # AMD Phenom™ II Triple-Core Mobile Processors
abstract type AMDPhenom_II_DualCore <: AMDPhenom end # AMD Phenom™ II Dual-Core Mobile Processors
abstract type AMDPhenom_X4 <: AMDPhenom end # AMD Business Class - AMD Phenom™ X4 Quad-Core
abstract type AMDPhenom_X3 <: AMDPhenom end # AMD Business Class - AMD Phenom™ X3 Triple-Core
abstract type AMDPhenom_X2 <: AMDPhenom end # AMD Business Class - AMD Ph enom™ X2 Dual-Core
abstract type AMD_A4_PRO <: AMD_ASeries_PRO end # AMD PRO A-Series A4 APU
abstract type AMD_A6_PRO <: AMD_ASeries_PRO end # AMD PRO A-Series A6 APU
abstract type AMD_A12_PRO <: AMD_ASeries_PRO end # AMD PRO A-Series A12 APU
abstract type AMD_A10_PRO <: AMD_ASeries_PRO end # AMD PRO A-Series A10 APU
abstract type AMD_A8_PRO <: AMD_ASeries_PRO end # AMD PRO A-Series A8 APU
abstract type AMDRyzen_PRO_Threadripper_5000_WX <: AMDRyzen_PRO end # AMD Ryzen™ Threadripper™ PRO 5000 WX-Series
abstract type AMDRyzen_PRO_Threadripper <: AMDRyzen_PRO end # AMD Ryzen™ Threadripper™ PRO Processors
abstract type AMDRyzen_PRO_9 <: AMDRyzen_PRO end # AMD Ryzen™ 9 PRO Desktop Processors
abstract type AMDRyzen_PRO_9_D <: AMDRyzen_PRO_9 end # AMD Ryzen™ 9 PRO Desktop Processors
abstract type AMDRyzen_PRO_9_6000 <: AMDRyzen_PRO end # AMD Ryzen™ 9 PRO 6000 Series Mobile Processors
abstract type AMDRyzen_PRO_9_6000_M <: AMDRyzen_PRO_9_6000 end # AMD Ryzen™ 9 PRO 6000 Series Mobile Processors
abstract type AMDRyzen_PRO_7 <: AMDRyzen_PRO end # AMD Ryzen™ 7 PRO Desktop Processors
abstract type AMDRyzen_PRO_7_D <: AMDRyzen_PRO_7 end # AMD Ryzen™ 7 PRO Desktop Processors
abstract type AMDRyzen_PRO_7_Vega <: AMDRyzen_PRO end # AMD Ryzen™ 7 PRO Mobile Processors with Radeon™ Vega Graphics
abstract type AMDRyzen_PRO_7_Vega_M <: AMDRyzen_PRO_7_Vega end # AMD Ryzen™ 7 PRO Mobile Processors with Radeon™ Vega Graphics
abstract type AMDRyzen_PRO_7_5000 <: AMDRyzen_PRO end # AMD Ryzen™ 7 PRO 5000 Series Desktop Processors
abstract type AMDRyzen_PRO_7_5000_D <: AMDRyzen_PRO_7_5000 end # AMD Ryzen™ 7 PRO 5000 Series Desktop Processors
abstract type AMDRyzen_PRO_7_5000_M <: AMDRyzen_PRO_7_5000 end # AMD Ryzen™ 7 PRO 5000 Series Mobile Processors
abstract type AMDRyzen_PRO_7_4000 <: AMDRyzen_PRO end # AMD Ryzen™ 7 PRO 4000 Series Desktop Processors
abstract type AMDRyzen_PRO_7_4000_D <: AMDRyzen_PRO_7_4000 end # AMD Ryzen™ 7 PRO 4000 Series Desktop Processors
abstract type AMDRyzen_PRO_7_4000_M <: AMDRyzen_PRO_7_4000 end # AMD Ryzen™ 7 PRO 4000 Series Mobile Processors
abstract type AMDRyzen_PRO_7_6000 <: AMDRyzen_PRO end # AMD Ryzen™ 7 PRO 6000 Series Mobile Processors
abstract type AMDRyzen_PRO_7_6000_M <: AMDRyzen_PRO_7_6000 end # AMD Ryzen™ 7 PRO 6000 Series Mobile Processors
abstract type AMDRyzen_PRO_5 <: AMDRyzen_PRO end # AMD Ryzen™ 5 PRO Desktop Processors
abstract type AMDRyzen_PRO_5_D <: AMDRyzen_PRO_5 end # AMD Ryzen™ 5 PRO Desktop Processors
abstract type AMDRyzen_PRO_5_Vega <: AMDRyzen_PRO end # AMD Ryzen™ 5 PRO Desktop Processors with Radeon™ Vega Graphics
abstract type AMDRyzen_PRO_5_3000 <: AMDRyzen_PRO end # AMD Ryzen™ 5 PRO 3000 Series Desktop Processors
abstract type AMDRyzen_PRO_5_4000 <: AMDRyzen_PRO end # AMD Ryzen™ 5 PRO 4000 Series Desktop Processors
abstract type AMDRyzen_PRO_5_5000 <: AMDRyzen_PRO end # AMD Ryzen™ 5 PRO 5000 Series Mobile Processors
abstract type AMDRyzen_PRO_5_6000 <: AMDRyzen_PRO end # AMD Ryzen™ 5 PRO 5000 Series Desktop Processors
abstract type AMDRyzen_PRO_3 <: AMDRyzen_PRO end # AMD Ryzen™ 3 PRO Desktop Processors
abstract type AMDRyzen_PRO_3_Vega <: AMDRyzen_PRO end # AMD Ryzen™ 3 PRO Desktop Processors with Radeon™ Vega Graphics
abstract type AMDRyzen_PRO_3_4000 <: AMDRyzen_PRO end # AMD Ryzen™ 3 PRO 4000 Series Desktop Processors
abstract type AMDRyzen_PRO_3_5000 <: AMDRyzen_PRO end # AMD Ryzen™ 3 PRO 5000 Series Desktop Processors
abstract type AMDRyzen_9 <: AMDRyzen end # AMD Ryzen™ 9 Desktop Processors
abstract type AMDRyzen_7 <: AMDRyzen end # AMD Ryzen™ 7 Desktop Processors
abstract type AMDRyzen_5 <: AMDRyzen end # AMD Ryzen™ 5 Desktop Processors
abstract type AMDRyzen_Threadripper <: AMDRyzen end # AMD Ryzen™ Threadripper™ Processors
abstract type AMDRyzen_3 <: AMDRyzen end # AMD Ryzen™ 3 Mobile Processors with Radeon™ Graphics
abstract type AMDRyzen_7_5000G <: AMDRyzen_7 end # AMD Ryzen™ 7 5000 G-Series Desktop Processors with Radeon™ Graphics
abstract type AMDRyzen_5_5000G <: AMDRyzen_5 end # AMD Ryzen™ 5 5000 G-Series Desktop Processors with Radeon™ Graphics
abstract type AMDRyzen_3_5000G <: AMDRyzen_3 end # AMD Ryzen™ 3 5000 G-Series Desktop Processors with Radeon™ Graphics
abstract type AMDRyzen_7_4000G <: AMDRyzen_7 end # AMD Ryzen™ 7 4000 G-Series Desktop Processors with Radeon™ Graphics
abstract type AMDRyzen_5_4000G <: AMDRyzen_5 end # AMD Ryzen™ 5 4000 G-Series Desktop Processors with Radeon™ Graphics
abstract type AMDRyzen_3_4000G <: AMDRyzen_3 end # AMD Ryzen™ 3 4000 G-Series Desktop Processors with Radeon™ Graphics
abstract type AMDRyzen_5_Vega <: AMDRyzen_5 end # AMD Ryzen™ 5 Desktop Processors with Radeon™ Vega Graphics
abstract type AMDRyzen_7_Surface <: AMDRyzen_7 end # AMD Ryzen™ 7 Mobile Processors with Radeon™ Graphics Microsoft Surface® Edition
abstract type AMDRyzen_5_Surface <: AMDRyzen_5 end # AMD Ryzen™ 5 Mobile Processors with Radeon™ Graphics Microsoft Surface® Edition
abstract type AMDRyzen_7_RXVega11_Surface <: AMDRyzen_7 end # AMD Ryzen™ 7 Mobile Processors with Radeon™ RX Vega 11 Graphics Microsoft Surface® Edition
abstract type AMDRyzen_3_Vega <: AMDRyzen_3 end # AMD Ryzen™ 3 Desktop Processors with Radeon™ Vega Graphics
abstract type AMDRyzen_7_RXVega <: AMDRyzen_7 end # AMD Ryzen™ 7 Mobile Processors with Radeon™ RX Vega Graphics
abstract type AMDRyzen_5_Vega_9_Surface <: AMDRyzen_5 end # AMD Ryzen™ 5 Mobile Processors with Radeon™ Vega 9 Graphics Microsoft Surface® Edition
abstract type AMDSempron_Quad_APU <: AMDSempron end # AMD Sempron™ Quad-Core APU
abstract type AMDSempron_Dual_APU <: AMDSempron end # AMD Sempron™ Dual-Core APU
abstract type AMDTurion_64_X2 <: AMDTurion end # AMD Turion™ 64 X2 Dual-Core Mobile Technology
# models
abstract type AMDAthlon_II_X2_255e <: AMDAthlonII_X2 end
abstract type AMDAthlon_II_X3_460 <: AMDAthlonII_X3 end
abstract type AMDAthlon_II_X3_425e <: AMDAthlonII_X3 end
abstract type AMDAthlon_II_X4_631 <: AMDAthlonII_X4 end
abstract type AMDAthlon_II_X4_638 <: AMDAthlonII_X4 end
abstract type AMDAthlon_II_X4_641 <: AMDAthlonII_X4 end
abstract type AMDAthlon_II_X4_620e <: AMDAthlonII_X4 end
abstract type AMDAthlon_X4_740 <: AMDAthlon_X4 end
abstract type AMDAthlon_X4_750 <: AMDAthlon_X4 end
abstract type AMDAthlon_X4_750K <: AMDAthlon_X4 end
abstract type AMDAthlon_X4_760K <: AMDAthlon_X4 end
abstract type AMDAthlon_X4_845 <: AMDAthlon_X4 end
abstract type AMDAthlon_X4_860K <: AMDAthlon_X4 end
abstract type AMDAthlon_X4_870K <: AMDAthlon_X4 end
abstract type AMDAthlon_X4_880K <: AMDAthlon_X4 end
abstract type AMDPhenom_X2_B57 <: AMDPhenom_X2 end
abstract type AMDPhenom_X2_B59 <: AMDPhenom_X2 end
abstract type AMDPhenom_X2_B60 <: AMDPhenom_X2 end
abstract type AMDPhenom_X3_B75 <: AMDPhenom_X3 end
abstract type AMDPhenom_X3_B77 <: AMDPhenom_X3 end
abstract type AMDPhenom_X4_B95 <: AMDPhenom_X4 end
abstract type AMDPhenom_X4_B97 <: AMDPhenom_X4 end
abstract type AMDPhenom_X4_B99 <: AMDPhenom_X4 end
abstract type AMD_E1_7010 <: AMD_E1 end
abstract type AMD_E1_Micro_6200T <: AMD_E1 end
abstract type AMD_E1_2100 <: AMD_E1 end
abstract type AMD_E1_2200 <: AMD_E1 end
abstract type AMD_E1_2500 <: AMD_E1 end
abstract type AMD_E1_6010 <: AMD_E1 end
abstract type AMD_E2_7110 <: AMD_E2 end
abstract type AMD_E2_3000 <: AMD_E2 end
abstract type AMD_E2_3800 <: AMD_E2 end
abstract type AMD_E2_6110 <: AMD_E2 end
abstract type AMD_FX_4100 <: AMD_FX_4_Black end
abstract type AMD_FX_4130 <: AMD_FX_4_Black end
abstract type AMD_FX_4170 <: AMD_FX_4_Black end
abstract type AMD_FX_4300 <: AMD_FX_4_Black end
abstract type AMD_FX_4320 <: AMD_FX_4_Black end
abstract type AMD_FX_4350 <: AMD_FX_4_Black end
abstract type AMD_FX_6100 <: AMD_FX_6_Black end
abstract type AMD_FX_6200 <: AMD_FX_6_Black end
abstract type AMD_FX_6300 <: AMD_FX_6_Black end
abstract type AMD_FX_6350 <: AMD_FX_6_Black end
abstract type AMD_FX_8120 <: AMD_FX_8_Black end
abstract type AMD_FX_8150 <: AMD_FX_8_Black end
abstract type AMD_FX_8300 <: AMD_FX_8_Black end
abstract type AMD_FX_8310 <: AMD_FX_8_Black end
abstract type AMD_FX_8320 <: AMD_FX_8_Black end
abstract type AMD_FX_8320E <: AMD_FX_8_Black end
abstract type AMD_FX_8350 <: AMD_FX_8_Black end
abstract type AMD_FX_8370 <: AMD_FX_8_Black end
abstract type AMD_FX_8370E <: AMD_FX_8_Black end
abstract type AMD_FX_9370 <: AMD_FX_8_Black end
abstract type AMD_FX_9590 <: AMD_FX_8_Black end
abstract type AMD_FX_8800P <: AMD_FX end
abstract type AMD_FX_7500 <: AMD_FX end
abstract type AMD_FX_7600P <: AMD_FX end
abstract type AMDOpteron_3280 <: AMDOpteron_3200 end
abstract type AMDOpteron_3250 <: AMDOpteron_3200 end
abstract type AMDOpteron_3260 <: AMDOpteron_3200 end
abstract type AMDOpteron_3365 <: AMDOpteron_3300 end
abstract type AMDOpteron_3380 <: AMDOpteron_3300 end
abstract type AMDOpteron_3320 <: AMDOpteron_3300 end
abstract type AMDOpteron_3350 <: AMDOpteron_3300 end
abstract type AMDOpteron_4226 <: AMDOpteron_4200 end
abstract type AMDOpteron_4234 <: AMDOpteron_4200 end
abstract type AMDOpteron_4238 <: AMDOpteron_4200 end
abstract type AMDOpteron_4240 <: AMDOpteron_4200 end
abstract type AMDOpteron_4280 <: AMDOpteron_4200 end
abstract type AMDOpteron_4284 <: AMDOpteron_4200 end
abstract type AMDOpteron_4228 <: AMDOpteron_4200 end
abstract type AMDOpteron_4230 <: AMDOpteron_4200 end
abstract type AMDOpteron_4256 <: AMDOpteron_4200 end
abstract type AMDOpteron_4274 <: AMDOpteron_4200 end
abstract type AMDOpteron_4276 <: AMDOpteron_4200 end
abstract type AMDOpteron_4334 <: AMDOpteron_4300 end
abstract type AMDOpteron_4340 <: AMDOpteron_4300 end
abstract type AMDOpteron_4365 <: AMDOpteron_4300 end
abstract type AMDOpteron_4386 <: AMDOpteron_4300 end
abstract type AMDOpteron_4310 <: AMDOpteron_4300 end
abstract type AMDOpteron_4332 <: AMDOpteron_4300 end
abstract type AMDOpteron_4376 <: AMDOpteron_4300 end
abstract type AMDOpteron_6140 <: AMDOpteron_6100 end
abstract type AMDOpteron_6176 <: AMDOpteron_6100 end
abstract type AMDOpteron_6132 <: AMDOpteron_6100 end
abstract type AMDOpteron_6166 <: AMDOpteron_6100 end
abstract type AMDOpteron_6180 <: AMDOpteron_6100 end
abstract type AMDOpteron_6204 <: AMDOpteron_6200 end
abstract type AMDOpteron_6212 <: AMDOpteron_6200 end
abstract type AMDOpteron_6220 <: AMDOpteron_6200 end
abstract type AMDOpteron_6234 <: AMDOpteron_6200 end
abstract type AMDOpteron_6238 <: AMDOpteron_6200 end
abstract type AMDOpteron_6272 <: AMDOpteron_6200 end
abstract type AMDOpteron_6274 <: AMDOpteron_6200 end
abstract type AMDOpteron_6276 <: AMDOpteron_6200 end
abstract type AMDOpteron_6278 <: AMDOpteron_6200 end
abstract type AMDOpteron_6262 <: AMDOpteron_6200 end
abstract type AMDOpteron_6282 <: AMDOpteron_6200 end
abstract type AMDOpteron_6284 <: AMDOpteron_6200 end
abstract type AMDOpteron_6308 <: AMDOpteron_6300 end
abstract type AMDOpteron_6320 <: AMDOpteron_6300 end
abstract type AMDOpteron_6328 <: AMDOpteron_6300 end
abstract type AMDOpteron_6344 <: AMDOpteron_6300 end
abstract type AMDOpteron_6348 <: AMDOpteron_6300 end
abstract type AMDOpteron_6376 <: AMDOpteron_6300 end
abstract type AMDOpteron_6378 <: AMDOpteron_6300 end
abstract type AMDOpteron_6380 <: AMDOpteron_6300 end
abstract type AMDOpteron_6338P <: AMDOpteron_6300 end
abstract type AMDOpteron_6366 <: AMDOpteron_6300 end
abstract type AMDOpteron_6370P <: AMDOpteron_6300 end
abstract type AMDOpteron_6386 <: AMDOpteron_6300 end
abstract type AMDOpteron_X1150 <: AMDOpteron_X1100 end
abstract type AMDPhenom_II_X940 <: AMDPhenom_II_Black end
abstract type AMDPhenom_II_N640 <: AMDPhenom_II_DualCore end
abstract type AMDPhenom_II_N660 <: AMDPhenom_II_DualCore end
abstract type AMDPhenom_II_P650 <: AMDPhenom_II_DualCore end
abstract type AMDPhenom_II_N960 <: AMDPhenom_II_QuadCore end
abstract type AMDPhenom_II_N970 <: AMDPhenom_II_QuadCore end
abstract type AMDPhenom_II_N870 <: AMDPhenom_II_TripleCore end
abstract type AMDPhenom_II_P860 <: AMDPhenom_II_TripleCore end
abstract type AMDPhenom_II_X2_565 <: AMDPhenom_II_X2 end
abstract type AMDPhenom_II_X2_Black_555 <: AMDPhenom_II_X2_Black end
abstract type AMDPhenom_II_X2_Black_565 <: AMDPhenom_II_X2_Black end
abstract type AMDPhenom_II_X2_Black_570 <: AMDPhenom_II_X2_Black end
abstract type AMDPhenom_II_840 <: AMDPhenom_II_X4 end
abstract type AMDPhenom_II_850 <: AMDPhenom_II_X4 end
abstract type AMDPhenom_II_965 <: AMDPhenom_II_X4_Black end
abstract type AMDPhenom_II_975 <: AMDPhenom_II_X4_Black end
abstract type AMDPhenom_II_980 <: AMDPhenom_II_X4_Black end
abstract type AMDPhenom_II_960T <: AMDPhenom_II_X4_Black end
abstract type AMDPhenom_II_1045T <: AMDPhenom_II_X6 end
abstract type AMDPhenom_II_1075T <: AMDPhenom_II_X6 end
abstract type AMDSempron_2800plus <: AMDSempron end
abstract type AMDTurion_TL52 <: AMDTurion_64_X2 end
abstract type AMDTurion_TL56 <: AMDTurion_64_X2 end
abstract type AMDTurion_TL60 <: AMDTurion_64_X2 end
abstract type AMDTurion_TL64 <: AMDTurion_64_X2 end
abstract type AMD_3015Ce <: AMD_3000 end
abstract type AMD_3015e <: AMD_3000 end
abstract type AMD_3020e <: AMD_3000 end
abstract type AMD_A10_6_8700P_APU <: AMD_A10 end
abstract type AMD_A10_6700 <: AMD_A10 end
abstract type AMD_A10_6700T <: AMD_A10 end
abstract type AMD_A10_6790B <: AMD_A10_Business end
abstract type AMD_A10_6790K <: AMD_A10 end
abstract type AMD_A10_6800B <: AMD_A10_Business end
abstract type AMD_A10_6800K <: AMD_A10 end
abstract type AMD_A10_7_9600P_APU <: AMD_A10 end
abstract type AMD_A10_7_9630P_APU <: AMD_A10 end
abstract type AMD_A10_7_9700_APU <: AMD_A10 end
abstract type AMD_A10_7_9700E_APU <: AMD_A10 end
abstract type AMD_A10_7300 <: AMD_A10 end
abstract type AMD_A10_7400P <: AMD_A10 end
abstract type AMD_A10_7700K <: AMD_A10 end
abstract type AMD_A10_7800 <: AMD_A10 end
abstract type AMD_A10_7850K <: AMD_A10 end
abstract type AMD_A10_7860K <: AMD_A10 end
abstract type AMD_A10_7870K <: AMD_A10 end
abstract type AMD_A10_7890K <: AMD_A10 end
abstract type AMD_A10_8700P <: AMD_A10 end
abstract type AMD_A10_Micro_6700T <: AMD_A10 end
abstract type AMD_A10_PRO_7350B <: AMD_A10 end
abstract type AMD_A10_PRO_7800B <: AMD_A10 end
abstract type AMD_A10_PRO_7850B <: AMD_A10 end
abstract type AMD_A12_7_9700P_APU <: AMD_A12 end
abstract type AMD_A12_7_9730P_APU <: AMD_A12 end
abstract type AMD_A12_7_9800_APU <: AMD_A12 end
abstract type AMD_A12_7_9800E_APU <: AMD_A12 end
abstract type AMD_A4_5000 <: AMD_A4 end
abstract type AMD_A4_5100 <: AMD_A4 end
abstract type AMD_A4_6210 <: AMD_A4 end
abstract type AMD_A4_6300 <: AMD_A4 end
abstract type AMD_A4_6320 <: AMD_A4 end
abstract type AMD_A4_7_9120_APU <: AMD_A4 end
abstract type AMD_A4_7_9120C_APU <: AMD_A4 end
abstract type AMD_A4_7_9125_APU <: AMD_A4 end
abstract type AMD_A4_7210 <: AMD_A4 end
abstract type AMD_A4_7300 <: AMD_A4 end
abstract type AMD_A4_Micro_6400T <: AMD_A4 end
abstract type AMD_A4_PRO_3340B <: AMD_A4 end
abstract type AMD_A4_PRO_3350B <: AMD_A4 end
abstract type AMD_A4_PRO_7300B <: AMD_A4 end
abstract type AMD_A4_PRO_7350B <: AMD_A4 end
abstract type AMD_A6_5200 <: AMD_A6 end
abstract type AMD_A6_5200M <: AMD_A6 end
abstract type AMD_A6_5350M <: AMD_A6 end
abstract type AMD_A6_6310 <: AMD_A6 end
abstract type AMD_A6_6400B <: AMD_A6_Business end
abstract type AMD_A6_6400K <: AMD_A6 end
abstract type AMD_A6_6420B <: AMD_A6_Business end
abstract type AMD_A6_6420K <: AMD_A6 end
abstract type AMD_A6_7_9210_APU <: AMD_A6 end
abstract type AMD_A6_7_9220_APU <: AMD_A6 end
abstract type AMD_A6_7_9220C_APU <: AMD_A6 end
abstract type AMD_A6_7_9225_APU <: AMD_A6 end
abstract type AMD_A6_7_9500_APU <: AMD_A6 end
abstract type AMD_A6_7_9500E_APU <: AMD_A6 end
abstract type AMD_A6_7_9550_APU <: AMD_A6 end
abstract type AMD_A6_7000 <: AMD_A6 end
abstract type AMD_A6_7310 <: AMD_A6 end
abstract type AMD_A6_7400K <: AMD_A6 end
abstract type AMD_A6_7470K <: AMD_A6 end
abstract type AMD_A6_8500P <: AMD_A6 end
abstract type AMD_A6_PRO_7050B <: AMD_A6 end
abstract type AMD_A6_PRO_7400B <: AMD_A6 end
abstract type AMD_A8_6_8600P_APU <: AMD_A8 end
abstract type AMD_A8_6410 <: AMD_A8 end
abstract type AMD_A8_6500 <: AMD_A8 end
abstract type AMD_A8_6500B <: AMD_A8_Business end
abstract type AMD_A8_6500T <: AMD_A8 end
abstract type AMD_A8_6600K <: AMD_A8 end
abstract type AMD_A8_7_9600_APU <: AMD_A8 end
abstract type AMD_A8_7100 <: AMD_A8 end
abstract type AMD_A8_7200P <: AMD_A8 end
abstract type AMD_A8_7410 <: AMD_A8 end
abstract type AMD_A8_7600 <: AMD_A8 end
abstract type AMD_A8_7650K <: AMD_A8 end
abstract type AMD_A8_7670K <: AMD_A8 end
abstract type AMD_A8_8600P <: AMD_A8 end
abstract type AMD_A8_PRO_7150B <: AMD_A8 end
abstract type AMD_A8_PRO_7600B <: AMD_A8 end
abstract type AMD_A9_7_9410_APU <: AMD_A9 end
abstract type AMD_A9_7_9420_APU <: AMD_A9 end
abstract type AMD_A9_7_9425_APU <: AMD_A9 end
abstract type AMD_E2_7_9010_APU <: AMD_E2 end
abstract type AMD_FX_6_8800P_APU <: AMD_FX end
abstract type AMD_FX_7_9800P_APU <: AMD_FX end
abstract type AMD_FX_7_9830P_APU <: AMD_FX end
abstract type AMD_A10_PRO_6_8700B_APU <: AMD_A10 end
abstract type AMD_A10_PRO_6_8730B_APU <: AMD_A10 end
abstract type AMD_A10_PRO_6_8750B_APU <: AMD_A10 end
abstract type AMD_A10_PRO_6_8770_APU <: AMD_A10 end
abstract type AMD_A10_PRO_6_8770E_APU <: AMD_A10 end
abstract type AMD_A10_PRO_6_8850B_APU <: AMD_A10 end
abstract type AMD_A10_PRO_7_9700_APU <: AMD_A10 end
abstract type AMD_A10_PRO_7_9700B_APU <: AMD_A10 end
abstract type AMD_A10_PRO_7_9700E_APU <: AMD_A10 end
abstract type AMD_A10_PRO_7_9730B_APU <: AMD_A10 end
abstract type AMD_A12_PRO_6_8800B_APU <: AMD_A12 end
abstract type AMD_A12_PRO_6_8830B_APU <: AMD_A12 end
abstract type AMD_A12_PRO_6_8870_APU <: AMD_A12 end
abstract type AMD_A12_PRO_6_8870E_APU <: AMD_A12 end
abstract type AMD_A12_PRO_7_9800_APU <: AMD_A12 end
abstract type AMD_A12_PRO_7_9800B_APU <: AMD_A12 end
abstract type AMD_A12_PRO_7_9800E_APU <: AMD_A12 end
abstract type AMD_A12_PRO_7_9830B_APU <: AMD_A12 end
abstract type AMD_A4_PRO_6_8350B_APU <: AMD_A4 end
abstract type AMD_A4_PRO_7_4350B_APU <: AMD_A4 end
abstract type AMD_A4_PRO_7_5350B_APU <: AMD_A4 end
abstract type AMD_A6_PRO_6_8500B_APU <: AMD_A6 end
abstract type AMD_A6_PRO_6_8530B_APU <: AMD_A6 end
abstract type AMD_A6_PRO_6_8550B_APU <: AMD_A6 end
abstract type AMD_A6_PRO_6_8570_APU <: AMD_A6 end
abstract type AMD_A6_PRO_6_8570E_APU <: AMD_A6 end
abstract type AMD_A6_PRO_7_7350B_APU <: AMD_A6 end
abstract type AMD_A6_PRO_7_8350B_APU <: AMD_A6 end
abstract type AMD_A6_PRO_7_9500_APU <: AMD_A6 end
abstract type AMD_A6_PRO_7_9500B_APU <: AMD_A6 end
abstract type AMD_A6_PRO_7_9500E_APU <: AMD_A6 end
abstract type AMD_A8_PRO_6_8600B_APU <: AMD_A8 end
abstract type AMD_A8_PRO_6_8650B_APU <: AMD_A8 end
abstract type AMD_A8_PRO_7_9600_APU <: AMD_A8 end
abstract type AMD_A8_PRO_7_9600B_APU <: AMD_A8 end
abstract type AMD_A8_PRO_7_9630B <: AMD_A8 end
abstract type AMDAthlon_200GE <: AMDAthlon_Vega end
abstract type AMDAthlon_220GE <: AMDAthlon_Vega end
abstract type AMDAthlon_240GE <: AMDAthlon_Vega end
abstract type AMDAthlon_300GE <: AMDAthlon_Vega end
abstract type AMDAthlon_300U <: AMDAthlon_Vega end
abstract type AMDAthlon_320GE <: AMDAthlon_Vega end
abstract type AMDAthlon_5150_APU <: AMDAthlon_APU end
abstract type AMDAthlon_5350_APU <: AMDAthlon_APU end
abstract type AMDAthlon_5370_APU <: AMDAthlon_APU end
abstract type AMDAthlon_7_X4_940 <: AMDAthlon_X4 end
abstract type AMDAthlon_7_X4_950 <: AMDAthlon_X4 end
abstract type AMDAthlon_7_X4_970 <: AMDAthlon_X4 end
abstract type AMDAthlon_Gold_3150C <: AMDAthlon end
abstract type AMDAthlon_Gold_3150G <: AMDAthlon_3000G end
abstract type AMDAthlon_Gold_3150GE <: AMDAthlon_3000G end
abstract type AMDAthlon_Gold_3150U <: AMDAthlon end
abstract type AMDAthlon_Gold_PRO_3150G <: AMDAthlon_PRO_3000 end
abstract type AMDAthlon_Gold_PRO_3150GE <: AMDAthlon_PRO_3000 end
abstract type AMDAthlon_PRO_200GE <: AMDAthlon_PRO_Vega end
abstract type AMDAthlon_PRO_200U <: AMDAthlon_PRO_Vega end
abstract type AMDAthlon_PRO_300GE <: AMDAthlon_PRO_Vega end
abstract type AMDAthlon_PRO_300U <: AMDAthlon_PRO_Vega end
abstract type AMDAthlon_PRO_3045B <: AMDAthlon_PRO end
abstract type AMDAthlon_PRO_3145B <: AMDAthlon_PRO end
abstract type AMDAthlon_Silver_3050C <: AMDAthlon end
abstract type AMDAthlon_Silver_3050e <: AMDAthlon end
abstract type AMDAthlon_Silver_3050GE <: AMDAthlon_3000G end
abstract type AMDAthlon_Silver_3050U <: AMDAthlon end
abstract type AMDAthlon_Silver_PRO_3125GE <: AMDAthlon_PRO_3000 end
abstract type AMDEPYC_7232P <: AMDEPYC_7002 end
abstract type AMDEPYC_7251 <: AMDEPYC_7001 end
abstract type AMDEPYC_7252 <: AMDEPYC_7002 end
abstract type AMDEPYC_7261 <: AMDEPYC_7001 end
abstract type AMDEPYC_7262 <: AMDEPYC_7002 end
abstract type AMDEPYC_7272 <: AMDEPYC_7002 end
abstract type AMDEPYC_7281 <: AMDEPYC_7001 end
abstract type AMDEPYC_7282 <: AMDEPYC_7002 end
abstract type AMDEPYC_72F3 <: AMDEPYC_7003 end
abstract type AMDEPYC_7301 <: AMDEPYC_7001 end
abstract type AMDEPYC_7302 <: AMDEPYC_7002 end
abstract type AMDEPYC_7302P <: AMDEPYC_7002 end
abstract type AMDEPYC_7313 <: AMDEPYC_7003 end
abstract type AMDEPYC_7313P <: AMDEPYC_7003 end
abstract type AMDEPYC_7343 <: AMDEPYC_7003 end
abstract type AMDEPYC_7351 <: AMDEPYC_7001 end
abstract type AMDEPYC_7351P <: AMDEPYC_7001 end
abstract type AMDEPYC_7352 <: AMDEPYC_7002 end
abstract type AMDEPYC_7371 <: AMDEPYC_7001 end
abstract type AMDEPYC_7373X <: AMDEPYC_7003_VCache end
abstract type AMDEPYC_73F3 <: AMDEPYC_7003 end
abstract type AMDEPYC_7401 <: AMDEPYC_7001 end
abstract type AMDEPYC_7401P <: AMDEPYC_7001 end
abstract type AMDEPYC_7402 <: AMDEPYC_7002 end
abstract type AMDEPYC_7402P <: AMDEPYC_7002 end
abstract type AMDEPYC_7413 <: AMDEPYC_7003 end
abstract type AMDEPYC_7443 <: AMDEPYC_7003 end
abstract type AMDEPYC_7443P <: AMDEPYC_7003 end
abstract type AMDEPYC_7451 <: AMDEPYC_7001 end
abstract type AMDEPYC_7452 <: AMDEPYC_7002 end
abstract type AMDEPYC_7453 <: AMDEPYC_7003 end
abstract type AMDEPYC_7473X <: AMDEPYC_7003_VCache end
abstract type AMDEPYC_74F3 <: AMDEPYC_7003 end
abstract type AMDEPYC_7501 <: AMDEPYC_7001 end
abstract type AMDEPYC_7502 <: AMDEPYC_7002 end
abstract type AMDEPYC_7502P <: AMDEPYC_7002 end
abstract type AMDEPYC_7513 <: AMDEPYC_7003 end
abstract type AMDEPYC_7532 <: AMDEPYC_7002 end
abstract type AMDEPYC_7542 <: AMDEPYC_7002 end
abstract type AMDEPYC_7543 <: AMDEPYC_7003 end
abstract type AMDEPYC_7543P <: AMDEPYC_7003 end
abstract type AMDEPYC_7551 <: AMDEPYC_7001 end
abstract type AMDEPYC_7551P <: AMDEPYC_7001 end
abstract type AMDEPYC_7552 <: AMDEPYC_7002 end
abstract type AMDEPYC_7571 <: AMDEPYC_7003_VCache end
abstract type AMDEPYC_7573X <: AMDEPYC_7003_VCache end
abstract type AMDEPYC_75F3 <: AMDEPYC_7003 end
abstract type AMDEPYC_7601 <: AMDEPYC_7001 end
abstract type AMDEPYC_7642 <: AMDEPYC_7002 end
abstract type AMDEPYC_7643 <: AMDEPYC_7003 end
abstract type AMDEPYC_7662 <: AMDEPYC_7002 end
abstract type AMDEPYC_7663 <: AMDEPYC_7003 end
abstract type AMDEPYC_7702 <: AMDEPYC_7002 end
abstract type AMDEPYC_7702P <: AMDEPYC_7002 end
abstract type AMDEPYC_7713 <: AMDEPYC_7003 end
abstract type AMDEPYC_7713P <: AMDEPYC_7003 end
abstract type AMDEPYC_7742 <: AMDEPYC_7002 end
abstract type AMDEPYC_7763 <: AMDEPYC_7003 end
abstract type AMDEPYC_7773X <: AMDEPYC_7003_VCache end
abstract type AMDEPYC_7F32 <: AMDEPYC_7002 end
abstract type AMDEPYC_7F52 <: AMDEPYC_7002 end
abstract type AMDEPYC_7F72 <: AMDEPYC_7002 end
abstract type AMDEPYC_7H12 <: AMDEPYC_7002 end
abstract type AMDOpteron_X2150_APU <: AMDOpteron_X2100 end
abstract type AMDOpteron_X2170 <: AMDOpteron_X2100 end
abstract type AMDRyzen_3_1200 <: AMDRyzen_3 end
abstract type AMDRyzen_3_1300X <: AMDRyzen_3 end
abstract type AMDRyzen_3_2200G <: AMDRyzen_3_Vega end
abstract type AMDRyzen_3_2200GE <: AMDRyzen_3_Vega end
abstract type AMDRyzen_3_2200U <: AMDRyzen_3_Vega end
abstract type AMDRyzen_3_2300U <: AMDRyzen_3_Vega end
abstract type AMDRyzen_3_2300X <: AMDRyzen_3 end
abstract type AMDRyzen_3_3100 <: AMDRyzen_3 end
abstract type AMDRyzen_3_3200G <: AMDRyzen_3_Vega end
abstract type AMDRyzen_3_3200GE <: AMDRyzen_3_Vega end
abstract type AMDRyzen_3_3200U <: AMDRyzen_3_Vega end
abstract type AMDRyzen_3_3250C <: AMDRyzen_3 end
abstract type AMDRyzen_3_3250U <: AMDRyzen_3 end
abstract type AMDRyzen_3_3300U <: AMDRyzen_3_Vega end
abstract type AMDRyzen_3_3300X <: AMDRyzen_3 end
abstract type AMDRyzen_3_3350U <: AMDRyzen_3_Vega end
abstract type AMDRyzen_3_4100 <: AMDRyzen_3 end
abstract type AMDRyzen_3_4300G <: AMDRyzen_3_4000G end
abstract type AMDRyzen_3_4300GE <: AMDRyzen_3_4000G end
abstract type AMDRyzen_3_4300U <: AMDRyzen_3 end
abstract type AMDRyzen_3_5125C <: AMDRyzen_3 end
abstract type AMDRyzen_3_5300G <: AMDRyzen_3_5000G end
abstract type AMDRyzen_3_5300GE <: AMDRyzen_3_5000G end
abstract type AMDRyzen_3_5300U <: AMDRyzen_3 end
abstract type AMDRyzen_3_5400U <: AMDRyzen_3 end
abstract type AMDRyzen_3_5425C <: AMDRyzen_3 end
abstract type AMDRyzen_3_5425U <: AMDRyzen_3 end
abstract type AMDRyzen_3_PRO_1200 <: AMDRyzen_PRO_3 end
abstract type AMDRyzen_3_PRO_1300 <: AMDRyzen_PRO_3 end
abstract type AMDRyzen_3_PRO_2200G <: AMDRyzen_PRO_3_Vega end
abstract type AMDRyzen_3_PRO_2200GE <: AMDRyzen_PRO_3_Vega end
abstract type AMDRyzen_3_PRO_2300U <: AMDRyzen_PRO_3_Vega end
abstract type AMDRyzen_3_PRO_3200G <: AMDRyzen_PRO_3_Vega end
abstract type AMDRyzen_3_PRO_3200GE <: AMDRyzen_PRO_3_Vega end
abstract type AMDRyzen_3_PRO_3300U <: AMDRyzen_PRO_3_Vega end
abstract type AMDRyzen_3_PRO_4350G <: AMDRyzen_PRO_3_4000 end
abstract type AMDRyzen_3_PRO_4350GE <: AMDRyzen_PRO_3_4000 end
abstract type AMDRyzen_3_PRO_4450U <: AMDRyzen_PRO_3_4000 end
abstract type AMDRyzen_3_PRO_5350G <: AMDRyzen_PRO_3_5000 end
abstract type AMDRyzen_3_PRO_5350GE <: AMDRyzen_PRO_3_5000 end
abstract type AMDRyzen_3_PRO_5450U <: AMDRyzen_PRO_3_5000 end
abstract type AMDRyzen_3_PRO_5475U <: AMDRyzen_PRO_3_5000 end
abstract type AMDRyzen_5_1400 <: AMDRyzen_5 end
abstract type AMDRyzen_5_1500X <: AMDRyzen_5 end
abstract type AMDRyzen_5_1600 <: AMDRyzen_5 end
abstract type AMDRyzen_5_1600_AF <: AMDRyzen_5 end
abstract type AMDRyzen_5_1600X <: AMDRyzen_5 end
abstract type AMDRyzen_5_2400G <: AMDRyzen_5_Vega end
abstract type AMDRyzen_5_2400GE <: AMDRyzen_5_Vega end
abstract type AMDRyzen_5_2500U <: AMDRyzen_5_Vega end
abstract type AMDRyzen_5_2500X <: AMDRyzen_5 end
abstract type AMDRyzen_5_2600 <: AMDRyzen_5 end
abstract type AMDRyzen_5_2600E <: AMDRyzen_5 end
abstract type AMDRyzen_5_2600H <: AMDRyzen_5_Vega end
abstract type AMDRyzen_5_2600X <: AMDRyzen_5 end
abstract type AMDRyzen_5_3400G <: AMDRyzen_5_Vega end
abstract type AMDRyzen_5_3400GE <: AMDRyzen_5_Vega end
abstract type AMDRyzen_5_3450U <: AMDRyzen_5_Vega end
abstract type AMDRyzen_5_3500 <: AMDRyzen_5 end
abstract type AMDRyzen_5_3500C <: AMDRyzen_5 end
abstract type AMDRyzen_5_3500U <: AMDRyzen_5_Vega end
abstract type AMDRyzen_5_3550H <: AMDRyzen_5_Vega end
abstract type AMDRyzen_5_3580U <: AMDRyzen_5_Vega_9_Surface end
abstract type AMDRyzen_5_3600 <: AMDRyzen_5 end
abstract type AMDRyzen_5_3600X <: AMDRyzen_5 end
abstract type AMDRyzen_5_3600XT <: AMDRyzen_5 end
abstract type AMDRyzen_5_4500 <: AMDRyzen_5 end
abstract type AMDRyzen_5_4500U <: AMDRyzen_5 end
abstract type AMDRyzen_5_4600G <: AMDRyzen_5_4000G end
abstract type AMDRyzen_5_4600GE <: AMDRyzen_5_4000G end
abstract type AMDRyzen_5_4600H <: AMDRyzen_5 end
abstract type AMDRyzen_5_4600U <: AMDRyzen_5 end
abstract type AMDRyzen_5_4680U <: AMDRyzen_5_Surface end
abstract type AMDRyzen_5_5500 <: AMDRyzen_5 end
abstract type AMDRyzen_5_5500U <: AMDRyzen_5 end
abstract type AMDRyzen_5_5560U <: AMDRyzen_5 end
abstract type AMDRyzen_5_5600 <: AMDRyzen_5 end
abstract type AMDRyzen_5_5600G <: AMDRyzen_5_5000G end
abstract type AMDRyzen_5_5600GE <: AMDRyzen_5_5000G end
abstract type AMDRyzen_5_5600H <: AMDRyzen_5 end
abstract type AMDRyzen_5_5600HS <: AMDRyzen_5 end
abstract type AMDRyzen_5_5600U <: AMDRyzen_5 end
abstract type AMDRyzen_5_5600X <: AMDRyzen_5 end
abstract type AMDRyzen_5_5625C <: AMDRyzen_5 end
abstract type AMDRyzen_5_5625U <: AMDRyzen_5 end
abstract type AMDRyzen_5_6600H <: AMDRyzen_5 end
abstract type AMDRyzen_5_6600HS <: AMDRyzen_5 end
abstract type AMDRyzen_5_6600U <: AMDRyzen_5 end
abstract type AMDRyzen_5_PRO_1500 <: AMDRyzen_PRO_5 end
abstract type AMDRyzen_5_PRO_1600 <: AMDRyzen_PRO_5 end
abstract type AMDRyzen_5_PRO_2400G <: AMDRyzen_PRO_5_Vega end
abstract type AMDRyzen_5_PRO_2400GE <: AMDRyzen_PRO_5_Vega end
abstract type AMDRyzen_5_PRO_2500U <: AMDRyzen_PRO_5_Vega end
abstract type AMDRyzen_5_PRO_2600 <: AMDRyzen_PRO_5 end
abstract type AMDRyzen_5_PRO_3350G <: AMDRyzen_PRO_5_3000 end
abstract type AMDRyzen_5_PRO_3350GE <: AMDRyzen_PRO_5_3000 end
abstract type AMDRyzen_5_PRO_3400G <: AMDRyzen_PRO_5_Vega end
abstract type AMDRyzen_5_PRO_3400GE <: AMDRyzen_PRO_5_Vega end
abstract type AMDRyzen_5_PRO_3500U <: AMDRyzen_PRO_5_Vega end
abstract type AMDRyzen_5_PRO_3600 <: AMDRyzen_PRO_5 end
abstract type AMDRyzen_5_PRO_4650G <: AMDRyzen_PRO_5_4000 end
abstract type AMDRyzen_5_PRO_4650GE <: AMDRyzen_PRO_5_4000 end
abstract type AMDRyzen_5_PRO_4650U <: AMDRyzen_PRO_5_4000 end
abstract type AMDRyzen_5_PRO_5650G <: AMDRyzen_PRO_5_6000 end
abstract type AMDRyzen_5_PRO_5650GE <: AMDRyzen_PRO_5_6000 end
abstract type AMDRyzen_5_PRO_5650U <: AMDRyzen_PRO_5_5000 end
abstract type AMDRyzen_5_PRO_5675U <: AMDRyzen_PRO_5_5000 end
abstract type AMDRyzen_5_PRO_6650H <: AMDRyzen_PRO_5_6000 end
abstract type AMDRyzen_5_PRO_6650HS <: AMDRyzen_PRO_5_6000 end
abstract type AMDRyzen_5_PRO_6650U <: AMDRyzen_PRO_5_6000 end
abstract type AMDRyzen_7_1700 <: AMDRyzen_7 end
abstract type AMDRyzen_7_1700X <: AMDRyzen_7 end
abstract type AMDRyzen_7_1800X <: AMDRyzen_7 end
abstract type AMDRyzen_7_2700 <: AMDRyzen_7 end
abstract type AMDRyzen_7_2700E <: AMDRyzen_7 end
abstract type AMDRyzen_7_2700U <: AMDRyzen_7_RXVega end
abstract type AMDRyzen_7_2700X <: AMDRyzen_7 end
abstract type AMDRyzen_7_2800H <: AMDRyzen_7_RXVega end
abstract type AMDRyzen_7_3700C <: AMDRyzen_7 end
abstract type AMDRyzen_7_3700U <: AMDRyzen_7_RXVega end
abstract type AMDRyzen_7_3700X <: AMDRyzen_7 end
abstract type AMDRyzen_7_3750H <: AMDRyzen_7_RXVega end
abstract type AMDRyzen_7_3780U <: AMDRyzen_7_RXVega11_Surface end
abstract type AMDRyzen_7_3800X <: AMDRyzen_7 end
abstract type AMDRyzen_7_3800XT <: AMDRyzen_7 end
abstract type AMDRyzen_7_4700G <: AMDRyzen_7_4000G end
abstract type AMDRyzen_7_4700GE <: AMDRyzen_7_4000G end
abstract type AMDRyzen_7_4700U <: AMDRyzen_7 end
abstract type AMDRyzen_7_4800H <: AMDRyzen_7 end
abstract type AMDRyzen_7_4800HS <: AMDRyzen_7 end
abstract type AMDRyzen_7_4800U <: AMDRyzen_7 end
abstract type AMDRyzen_7_4980U <: AMDRyzen_7_Surface end
abstract type AMDRyzen_7_5700G <: AMDRyzen_7_5000G end
abstract type AMDRyzen_7_5700GE <: AMDRyzen_7_5000G end
abstract type AMDRyzen_7_5700U <: AMDRyzen_7 end
abstract type AMDRyzen_7_5700X <: AMDRyzen_7 end
abstract type AMDRyzen_7_5800 <: AMDRyzen_7 end
abstract type AMDRyzen_7_5800H <: AMDRyzen_7 end
abstract type AMDRyzen_7_5800HS <: AMDRyzen_7 end
abstract type AMDRyzen_7_5800U <: AMDRyzen_7 end
abstract type AMDRyzen_7_5800X <: AMDRyzen_7 end
abstract type AMDRyzen_7_5800X3D <: AMDRyzen_7 end
abstract type AMDRyzen_7_5825C <: AMDRyzen_7 end
abstract type AMDRyzen_7_5825U <: AMDRyzen_7 end
abstract type AMDRyzen_7_6800H <: AMDRyzen_7 end
abstract type AMDRyzen_7_6800HS <: AMDRyzen_7 end
abstract type AMDRyzen_7_6800U <: AMDRyzen_7 end
abstract type AMDRyzen_7_PRO_1700 <: AMDRyzen_PRO_7 end
abstract type AMDRyzen_7_PRO_1700X <: AMDRyzen_PRO_7 end
abstract type AMDRyzen_7_PRO_2700 <: AMDRyzen_PRO_7 end
abstract type AMDRyzen_7_PRO_2700U <: AMDRyzen_PRO_7_Vega end
abstract type AMDRyzen_7_PRO_2700X <: AMDRyzen_PRO_7 end
abstract type AMDRyzen_7_PRO_3700 <: AMDRyzen_PRO_7 end
abstract type AMDRyzen_7_PRO_3700U <: AMDRyzen_PRO_7_Vega end
abstract type AMDRyzen_7_PRO_4750G <: AMDRyzen_PRO_7_4000 end
abstract type AMDRyzen_7_PRO_4750GE <: AMDRyzen_PRO_7_4000 end
abstract type AMDRyzen_7_PRO_4750U <: AMDRyzen_PRO_7_4000 end
abstract type AMDRyzen_7_PRO_5750G <: AMDRyzen_PRO_7_5000 end
abstract type AMDRyzen_7_PRO_5750GE <: AMDRyzen_PRO_7_5000 end
abstract type AMDRyzen_7_PRO_5850U <: AMDRyzen_PRO_7_5000 end
abstract type AMDRyzen_7_PRO_5875U <: AMDRyzen_PRO_7_5000 end
abstract type AMDRyzen_7_PRO_6850H <: AMDRyzen_PRO_7_6000 end
abstract type AMDRyzen_7_PRO_6850HS <: AMDRyzen_PRO_7_6000 end
abstract type AMDRyzen_7_PRO_6850U <: AMDRyzen_PRO_7_6000 end
abstract type AMDRyzen_9_3900 <: AMDRyzen_9 end
abstract type AMDRyzen_9_3900X <: AMDRyzen_9 end
abstract type AMDRyzen_9_3900XT <: AMDRyzen_9 end
abstract type AMDRyzen_9_3950X <: AMDRyzen_9 end
abstract type AMDRyzen_9_4900H <: AMDRyzen_9 end
abstract type AMDRyzen_9_4900HS <: AMDRyzen_9 end
abstract type AMDRyzen_9_5900 <: AMDRyzen_9 end
abstract type AMDRyzen_9_5900HS <: AMDRyzen_9 end
abstract type AMDRyzen_9_5900HX <: AMDRyzen_9 end
abstract type AMDRyzen_9_5900X <: AMDRyzen_9 end
abstract type AMDRyzen_9_5950X <: AMDRyzen_9 end
abstract type AMDRyzen_9_5980HS <: AMDRyzen_9 end
abstract type AMDRyzen_9_5980HX <: AMDRyzen_9 end
abstract type AMDRyzen_9_6900HS <: AMDRyzen_9 end
abstract type AMDRyzen_9_6900HX <: AMDRyzen_9 end
abstract type AMDRyzen_9_6980HS <: AMDRyzen_9 end
abstract type AMDRyzen_9_6980HX <: AMDRyzen_9 end
abstract type AMDRyzen_9_PRO_3900 <: AMDRyzen_PRO_9 end
abstract type AMDRyzen_9_PRO_6950H <: AMDRyzen_PRO_9_6000 end
abstract type AMDRyzen_9_PRO_6950HS <: AMDRyzen_PRO_9_6000 end
abstract type AMDRyzen_Threadripper_1900X <: AMDRyzen_Threadripper end
abstract type AMDRyzen_Threadripper_1920X <: AMDRyzen_Threadripper end
abstract type AMDRyzen_Threadripper_1950X <: AMDRyzen_Threadripper end
abstract type AMDRyzen_Threadripper_2920X <: AMDRyzen_Threadripper end
abstract type AMDRyzen_Threadripper_2950X <: AMDRyzen_Threadripper end
abstract type AMDRyzen_Threadripper_2970WX <: AMDRyzen_Threadripper end
abstract type AMDRyzen_Threadripper_2990WX <: AMDRyzen_Threadripper end
abstract type AMDRyzen_Threadripper_3960X <: AMDRyzen_Threadripper end
abstract type AMDRyzen_Threadripper_3970X <: AMDRyzen_Threadripper end
abstract type AMDRyzen_Threadripper_3990X <: AMDRyzen_Threadripper end
abstract type AMDRyzen_Threadripper_PRO_3945WX <: AMDRyzen_PRO_Threadripper end
abstract type AMDRyzen_Threadripper_PRO_3955WX <: AMDRyzen_PRO_Threadripper end
abstract type AMDRyzen_Threadripper_PRO_3975WX <: AMDRyzen_PRO_Threadripper end
abstract type AMDRyzen_Threadripper_PRO_3995WX <: AMDRyzen_PRO_Threadripper end
abstract type AMDRyzen_Threadripper_PRO_5945WX <: AMDRyzen_PRO_Threadripper_5000_WX end
abstract type AMDRyzen_Threadripper_PRO_5955WX <: AMDRyzen_PRO_Threadripper_5000_WX end
abstract type AMDRyzen_Threadripper_PRO_5965WX <: AMDRyzen_PRO_Threadripper_5000_WX end
abstract type AMDRyzen_Threadripper_PRO_5975WX <: AMDRyzen_PRO_Threadripper_5000_WX end
abstract type AMDRyzen_Threadripper_PRO_5995WX <: AMDRyzen_PRO_Threadripper_5000_WX end
abstract type AMDSempron_2650_APU <: AMDSempron_Dual_APU end
abstract type AMDSempron_3850_APU <: AMDSempron_Quad_APU end | PlatformAware | https://github.com/PlatformAwareProgramming/PlatformAware.jl.git |
|
[
"MIT"
] | 0.6.0 | d8f50cbc077c0992b472a07f99013cd5be80b11a | code | 529 | abstract type AWS <: Manufacturer end; export AWS
abstract type AWSProcessor <: Processor end; export AWSProcessor
abstract type AWSMicroarchitecture <: ProcessorMicroarchitecture end
abstract type AWSGravitonMicroarchitecture <: AWSMicroarchitecture end
abstract type AWSGraviton1 <: AWSProcessor end; export AWSGraviton1
abstract type AWSGraviton2 <: AWSProcessor end; export AWSGraviton2
abstract type AWSGraviton3 <: AWSProcessor end; export AWSGraviton3
abstract type AWSGraviton4 <: AWSProcessor end; export AWSGraviton4 | PlatformAware | https://github.com/PlatformAwareProgramming/PlatformAware.jl.git |
|
[
"MIT"
] | 0.6.0 | d8f50cbc077c0992b472a07f99013cd5be80b11a | code | 42253 | # ------------------------------------------------------------------
# Licensed under the MIT License. See LICENCE in the project root.
# ------------------------------------------------------------------
# maintainer types
abstract type AmazonEC2 <: CloudProvider end; export AmazonEC2
# locale types
# machine family types
abstract type EC2Family <: MachineFamily end
abstract type EC2Family_General <: EC2Family end
abstract type EC2Family_Compute <: EC2Family end
abstract type EC2Family_Accelerated <: EC2Family end
abstract type EC2Family_Memory <: EC2Family end
abstract type EC2Family_Storage <: EC2Family end
# machine type types and sizes
abstract type EC2Type <: MachineType end
## general purpose instances
abstract type EC2Type_MAC <: EC2Type end
abstract type EC2Type_MAC1 <: EC2Type_MAC end
abstract type EC2Type_MAC2 <: EC2Type_MAC end
abstract type EC2Type_MAC1_Metal <: EC2Type_MAC1 end
abstract type EC2Type_MAC2_Metal <: EC2Type_MAC2 end
abstract type EC2Type_T4G <: EC2Type end
abstract type EC2Type_T4G_Nano <: EC2Type_T4G end
abstract type EC2Type_T4G_Micro <: EC2Type_T4G end
abstract type EC2Type_T4G_Small <: EC2Type_T4G end
abstract type EC2Type_T4G_Large <: EC2Type_T4G end
abstract type EC2Type_T4G_Medium <: EC2Type_T4G end
abstract type EC2Type_T4G_xLarge <: EC2Type_T4G end
abstract type EC2Type_T4G_2xLarge <: EC2Type_T4G end
abstract type EC2Type_T3 <: EC2Type end
abstract type EC2Type_T3A <: EC2Type_T3 end
abstract type EC2Type_T3_Nano <: EC2Type_T3 end
abstract type EC2Type_T3_Micro <: EC2Type_T3 end
abstract type EC2Type_T3_Small <: EC2Type_T3 end
abstract type EC2Type_T3_Large <: EC2Type_T3 end
abstract type EC2Type_T3_Medium <: EC2Type_T3 end
abstract type EC2Type_T3_xLarge <: EC2Type_T3 end
abstract type EC2Type_T3_2xLarge <: EC2Type_T3 end
abstract type EC2Type_T3A_Nano <: EC2Type_T3A end
abstract type EC2Type_T3A_Micro <: EC2Type_T3A end
abstract type EC2Type_T3A_Small <: EC2Type_T3A end
abstract type EC2Type_T3A_Large <: EC2Type_T3A end
abstract type EC2Type_T3A_Medium <: EC2Type_T3A end
abstract type EC2Type_T3A_xLarge <: EC2Type_T3A end
abstract type EC2Type_T3A_2xLarge <: EC2Type_T3A end
abstract type EC2Type_T1 <: EC2Type end
abstract type EC2Type_T1_Micro <: EC2Type_T1 end
abstract type EC2Type_T2 <: EC2Type end
abstract type EC2Type_T2_Nano <: EC2Type_T2 end
abstract type EC2Type_T2_Micro <: EC2Type_T2 end
abstract type EC2Type_T2_Small <: EC2Type_T2 end
abstract type EC2Type_T2_Large <: EC2Type_T2 end
abstract type EC2Type_T2_Medium <: EC2Type_T2 end
abstract type EC2Type_T2_xLarge <: EC2Type_T2 end
abstract type EC2Type_T2_2xLarge <: EC2Type_T2 end
abstract type EC2Type_M6 <: EC2Type end
abstract type EC2Type_M6G <: EC2Type_M6 end
abstract type EC2Type_M6I <: EC2Type_M6 end
abstract type EC2Type_M6A <: EC2Type_M6 end
abstract type EC2Type_M6GD <: EC2Type_M6G end
abstract type EC2Type_M6ID <: EC2Type_M6I end
abstract type EC2Type_M6G_Metal <: EC2Type_M6G end
abstract type EC2Type_M6G_Large <: EC2Type_M6G end
abstract type EC2Type_M6G_Medium <: EC2Type_M6G end
abstract type EC2Type_M6G_xLarge <: EC2Type_M6G end
abstract type EC2Type_M6G_2xLarge <: EC2Type_M6G end
abstract type EC2Type_M6G_4xLarge <: EC2Type_M6G end
abstract type EC2Type_M6G_8xLarge <: EC2Type_M6G end
abstract type EC2Type_M6G_12xLarge <: EC2Type_M6G end
abstract type EC2Type_M6G_16xLarge <: EC2Type_M6G end
abstract type EC2Type_M6GD_Metal <: EC2Type_M6GD end
abstract type EC2Type_M6GD_Large <: EC2Type_M6GD end
abstract type EC2Type_M6GD_Medium <: EC2Type_M6GD end
abstract type EC2Type_M6GD_xLarge <: EC2Type_M6GD end
abstract type EC2Type_M6GD_2xLarge <: EC2Type_M6GD end
abstract type EC2Type_M6GD_4xLarge <: EC2Type_M6GD end
abstract type EC2Type_M6GD_8xLarge <: EC2Type_M6GD end
abstract type EC2Type_M6GD_12xLarge <: EC2Type_M6GD end
abstract type EC2Type_M6GD_16xLarge <: EC2Type_M6GD end
abstract type EC2Type_M6I_Metal <: EC2Type_M6I end
abstract type EC2Type_M6I_Large <: EC2Type_M6I end
abstract type EC2Type_M6I_xLarge <: EC2Type_M6I end
abstract type EC2Type_M6I_2xLarge <: EC2Type_M6I end
abstract type EC2Type_M6I_4xLarge <: EC2Type_M6I end
abstract type EC2Type_M6I_8xLarge <: EC2Type_M6I end
abstract type EC2Type_M6I_12xLarge <: EC2Type_M6I end
abstract type EC2Type_M6I_16xLarge <: EC2Type_M6I end
abstract type EC2Type_M6I_24xLarge <: EC2Type_M6I end
abstract type EC2Type_M6I_32xLarge <: EC2Type_M6I end
abstract type EC2Type_M6ID_Metal <: EC2Type_M6ID end
abstract type EC2Type_M6ID_Large <: EC2Type_M6ID end
abstract type EC2Type_M6ID_xLarge <: EC2Type_M6ID end
abstract type EC2Type_M6ID_2xLarge <: EC2Type_M6ID end
abstract type EC2Type_M6ID_4xLarge <: EC2Type_M6ID end
abstract type EC2Type_M6ID_8xLarge <: EC2Type_M6ID end
abstract type EC2Type_M6ID_12xLarge <: EC2Type_M6ID end
abstract type EC2Type_M6ID_16xLarge <: EC2Type_M6ID end
abstract type EC2Type_M6ID_24xLarge <: EC2Type_M6ID end
abstract type EC2Type_M6ID_32xLarge <: EC2Type_M6ID end
abstract type EC2Type_M6A_Metal <: EC2Type_M6A end
abstract type EC2Type_M6A_Large <: EC2Type_M6A end
abstract type EC2Type_M6A_xLarge <: EC2Type_M6A end
abstract type EC2Type_M6A_2xLarge <: EC2Type_M6A end
abstract type EC2Type_M6A_4xLarge <: EC2Type_M6A end
abstract type EC2Type_M6A_8xLarge <: EC2Type_M6A end
abstract type EC2Type_M6A_12xLarge <: EC2Type_M6A end
abstract type EC2Type_M6A_16xLarge <: EC2Type_M6A end
abstract type EC2Type_M6A_24xLarge <: EC2Type_M6A end
abstract type EC2Type_M6A_32xLarge <: EC2Type_M6A end
abstract type EC2Type_M6A_48xLarge <: EC2Type_M6A end
abstract type EC2Type_M5 <: EC2Type end
abstract type EC2Type_M5D <: EC2Type_M5 end
abstract type EC2Type_M5A <: EC2Type_M5 end
abstract type EC2Type_M5N <: EC2Type_M5 end
abstract type EC2Type_M5ZN <: EC2Type_M5 end
abstract type EC2Type_M5AD <: EC2Type_M5A end
abstract type EC2Type_M5DN <: EC2Type_M5N end
abstract type EC2Type_M5_Metal <: EC2Type_M5 end
abstract type EC2Type_M5_Large <: EC2Type_M5 end
abstract type EC2Type_M5_xLarge <: EC2Type_M5 end
abstract type EC2Type_M5_2xLarge <: EC2Type_M5 end
abstract type EC2Type_M5_4xLarge <: EC2Type_M5 end
abstract type EC2Type_M5_8xLarge <: EC2Type_M5 end
abstract type EC2Type_M5_12xLarge <: EC2Type_M5 end
abstract type EC2Type_M5_16xLarge <: EC2Type_M5 end
abstract type EC2Type_M5_24xLarge <: EC2Type_M5 end
abstract type EC2Type_M5D_Metal <: EC2Type_M5D end
abstract type EC2Type_M5D_Large <: EC2Type_M5D end
abstract type EC2Type_M5D_xLarge <: EC2Type_M5D end
abstract type EC2Type_M5D_2xLarge <: EC2Type_M5D end
abstract type EC2Type_M5D_4xLarge <: EC2Type_M5D end
abstract type EC2Type_M5D_8xLarge <: EC2Type_M5D end
abstract type EC2Type_M5D_12xLarge <: EC2Type_M5D end
abstract type EC2Type_M5D_16xLarge <: EC2Type_M5D end
abstract type EC2Type_M5D_24xLarge <: EC2Type_M5D end
abstract type EC2Type_M5A_Large <: EC2Type_M5A end
abstract type EC2Type_M5A_xLarge <: EC2Type_M5A end
abstract type EC2Type_M5A_2xLarge <: EC2Type_M5A end
abstract type EC2Type_M5A_4xLarge <: EC2Type_M5A end
abstract type EC2Type_M5A_8xLarge <: EC2Type_M5A end
abstract type EC2Type_M5A_12xLarge <: EC2Type_M5A end
abstract type EC2Type_M5A_16xLarge <: EC2Type_M5A end
abstract type EC2Type_M5A_24xLarge <: EC2Type_M5A end
abstract type EC2Type_M5AD_Large <: EC2Type_M5AD end
abstract type EC2Type_M5AD_xLarge <: EC2Type_M5AD end
abstract type EC2Type_M5AD_2xLarge <: EC2Type_M5AD end
abstract type EC2Type_M5AD_4xLarge <: EC2Type_M5AD end
abstract type EC2Type_M5AD_8xLarge <: EC2Type_M5AD end
abstract type EC2Type_M5AD_12xLarge <: EC2Type_M5AD end
abstract type EC2Type_M5AD_16xLarge <: EC2Type_M5AD end
abstract type EC2Type_M5AD_24xLarge <: EC2Type_M5AD end
abstract type EC2Type_M5N_Metal <: EC2Type_M5N end
abstract type EC2Type_M5N_Large <: EC2Type_M5N end
abstract type EC2Type_M5N_xLarge <: EC2Type_M5N end
abstract type EC2Type_M5N_2xLarge <: EC2Type_M5N end
abstract type EC2Type_M5N_4xLarge <: EC2Type_M5N end
abstract type EC2Type_M5N_8xLarge <: EC2Type_M5N end
abstract type EC2Type_M5N_12xLarge <: EC2Type_M5N end
abstract type EC2Type_M5N_16xLarge <: EC2Type_M5N end
abstract type EC2Type_M5N_24xLarge <: EC2Type_M5N end
abstract type EC2Type_M5DN_Metal <: EC2Type_M5DN end
abstract type EC2Type_M5DN_Large <: EC2Type_M5DN end
abstract type EC2Type_M5DN_xLarge <: EC2Type_M5DN end
abstract type EC2Type_M5DN_2xLarge <: EC2Type_M5DN end
abstract type EC2Type_M5DN_4xLarge <: EC2Type_M5DN end
abstract type EC2Type_M5DN_8xLarge <: EC2Type_M5DN end
abstract type EC2Type_M5DN_12xLarge <: EC2Type_M5DN end
abstract type EC2Type_M5DN_16xLarge <: EC2Type_M5DN end
abstract type EC2Type_M5DN_24xLarge <: EC2Type_M5DN end
abstract type EC2Type_M5ZN_Metal <: EC2Type_M5ZN end
abstract type EC2Type_M5ZN_Large <: EC2Type_M5ZN end
abstract type EC2Type_M5ZN_xLarge <: EC2Type_M5ZN end
abstract type EC2Type_M5ZN_2xLarge <: EC2Type_M5ZN end
abstract type EC2Type_M5ZN_3xLarge <: EC2Type_M5ZN end
abstract type EC2Type_M5ZN_6xLarge <: EC2Type_M5ZN end
abstract type EC2Type_M5ZN_12xLarge <: EC2Type_M5ZN end
abstract type EC2Type_M1 <: EC2Type end
abstract type EC2Type_M1_Small <: EC2Type_M1 end
abstract type EC2Type_M1_Medium <: EC2Type_M1 end
abstract type EC2Type_M1_Large <: EC2Type_M1 end
abstract type EC2Type_M1_xLarge <: EC2Type_M1 end
abstract type EC2Type_M2 <: EC2Type end
abstract type EC2Type_M2_xLarge <: EC2Type_M2 end
abstract type EC2Type_M2_2xLarge <: EC2Type_M2 end
abstract type EC2Type_M2_4xLarge <: EC2Type_M2 end
abstract type EC2Type_M3 <: EC2Type end
abstract type EC2Type_M3_Medium <: EC2Type_M3 end
abstract type EC2Type_M3_Large <: EC2Type_M3 end
abstract type EC2Type_M3_xLarge <: EC2Type_M3 end
abstract type EC2Type_M3_2xLarge <: EC2Type_M3 end
abstract type EC2Type_M3_4xLarge <: EC2Type_M3 end
abstract type EC2Type_M4 <: EC2Type end
abstract type EC2Type_M4_Large <: EC2Type_M4 end
abstract type EC2Type_M4_xLarge <: EC2Type_M4 end
abstract type EC2Type_M4_2xLarge <: EC2Type_M4 end
abstract type EC2Type_M4_4xLarge <: EC2Type_M4 end
abstract type EC2Type_M4_10xLarge <: EC2Type_M4 end
abstract type EC2Type_M4_16xLarge <: EC2Type_M4 end
abstract type EC2Type_A1 <: EC2Type end
abstract type EC2Type_A1_Metal <: EC2Type_A1 end
abstract type EC2Type_A1_Large <: EC2Type_A1 end
abstract type EC2Type_A1_Medium <: EC2Type_A1 end
abstract type EC2Type_A1_xLarge <: EC2Type_A1 end
abstract type EC2Type_A1_2xLarge <: EC2Type_A1 end
abstract type EC2Type_A1_4xLarge <: EC2Type_A1 end
## compute optimized instances
abstract type EC2Type_CR1 <: EC2Type end
abstract type EC2Type_CR1_8xLarge <: EC2Type_CR1 end
abstract type EC2Type_CC2 <: EC2Type end
abstract type EC2Type_CC2_8xLarge <: EC2Type_CC2 end
abstract type EC2Type_C7A <: EC2Type end
abstract type EC2Type_C7G <: EC2Type end
abstract type EC2Type_C7GD <: EC2Type end
abstract type EC2Type_C7GN <: EC2Type end
abstract type EC2Type_C7I <: EC2Type end
abstract type EC2Type_HPC7A <: EC2Type end
abstract type EC2Type_HPC7G <: EC2Type end
abstract type EC2Type_C7A_12xLarge <: EC2Type_C7A end
abstract type EC2Type_C7A_16xLarge <: EC2Type_C7A end
abstract type EC2Type_C7A_24xLarge <: EC2Type_C7A end
abstract type EC2Type_C7A_2xLarge <: EC2Type_C7A end
abstract type EC2Type_C7A_32xLarge <: EC2Type_C7A end
abstract type EC2Type_C7A_48xLarge <: EC2Type_C7A end
abstract type EC2Type_C7A_4xLarge <: EC2Type_C7A end
abstract type EC2Type_C7A_8xLarge <: EC2Type_C7A end
abstract type EC2Type_C7A_Large <: EC2Type_C7A end
abstract type EC2Type_C7A_Medium <: EC2Type_C7A end
abstract type EC2Type_C7A_Metal_48xl <: EC2Type_C7A end
abstract type EC2Type_C7A_xLarge <: EC2Type_C7A end
abstract type EC2Type_C7G_12xLarge <: EC2Type_C7G end
abstract type EC2Type_C7G_16xLarge <: EC2Type_C7G end
abstract type EC2Type_C7G_2xLarge <: EC2Type_C7G end
abstract type EC2Type_C7G_4xLarge <: EC2Type_C7G end
abstract type EC2Type_C7G_8xLarge <: EC2Type_C7G end
abstract type EC2Type_C7G_Large <: EC2Type_C7G end
abstract type EC2Type_C7G_Medium <: EC2Type_C7G end
abstract type EC2Type_C7G_Metal <: EC2Type_C7G end
abstract type EC2Type_C7G_xLarge <: EC2Type_C7G end
abstract type EC2Type_C7GD_12xLarge <: EC2Type_C7GD end
abstract type EC2Type_C7GD_16xLarge <: EC2Type_C7GD end
abstract type EC2Type_C7GD_2xLarge <: EC2Type_C7GD end
abstract type EC2Type_C7GD_4xLarge <: EC2Type_C7GD end
abstract type EC2Type_C7GD_8xLarge <: EC2Type_C7GD end
abstract type EC2Type_C7GD_Large <: EC2Type_C7GD end
abstract type EC2Type_C7GD_Medium <: EC2Type_C7GD end
abstract type EC2Type_C7GD_Metal <: EC2Type_C7GD end
abstract type EC2Type_C7GD_xLarge <: EC2Type_C7GD end
abstract type EC2Type_C7GN_12xLarge <: EC2Type_C7GN end
abstract type EC2Type_C7GN_16xLarge <: EC2Type_C7GN end
abstract type EC2Type_C7GN_2xLarge <: EC2Type_C7GN end
abstract type EC2Type_C7GN_4xLarge <: EC2Type_C7GN end
abstract type EC2Type_C7GN_8xLarge <: EC2Type_C7GN end
abstract type EC2Type_C7GN_Large <: EC2Type_C7GN end
abstract type EC2Type_C7GN_Medium <: EC2Type_C7GN end
abstract type EC2Type_C7GN_Metal <: EC2Type_C7GN end
abstract type EC2Type_C7GN_xLarge <: EC2Type_C7GN end
abstract type EC2Type_C7I_12xLarge <: EC2Type_C7I end
abstract type EC2Type_C7I_16xLarge <: EC2Type_C7I end
abstract type EC2Type_C7I_24xLarge <: EC2Type_C7I end
abstract type EC2Type_C7I_2xLarge <: EC2Type_C7I end
abstract type EC2Type_C7I_48xLarge <: EC2Type_C7I end
abstract type EC2Type_C7I_4xLarge <: EC2Type_C7I end
abstract type EC2Type_C7I_8xLarge <: EC2Type_C7I end
abstract type EC2Type_C7I_Large <: EC2Type_C7I end
abstract type EC2Type_C7I_Metal_24xl <: EC2Type_C7I end
abstract type EC2Type_C7I_Metal_48xl <: EC2Type_C7I end
abstract type EC2Type_C7I_xLarge <: EC2Type_C7I end
abstract type EC2Type_HPC7A_12xLarge <: EC2Type_HPC7A end
abstract type EC2Type_HPC7A_24xLarge <: EC2Type_HPC7A end
abstract type EC2Type_HPC7A_48xLarge <: EC2Type_HPC7A end
abstract type EC2Type_HPC7A_96xLarge <: EC2Type_HPC7A end
abstract type EC2Type_HPC7G_16xLarge <: EC2Type_HPC7G end
abstract type EC2Type_HPC7G_4xLarge <: EC2Type_HPC7G end
abstract type EC2Type_HPC7G_8xLarge <: EC2Type_HPC7G end
abstract type EC2Type_C6 <: EC2Type end
abstract type EC2Type_C6G <: EC2Type_C6 end
abstract type EC2Type_C6GN <: EC2Type_C6 end
abstract type EC2Type_C6I <: EC2Type_C6 end
abstract type EC2Type_C6A <: EC2Type_C6 end
abstract type EC2Type_C6GD <: EC2Type_C6G end
abstract type EC2Type_C6ID <: EC2Type_C6I end
abstract type EC2Type_C6G_Metal <: EC2Type_C6G end
abstract type EC2Type_C6G_Large <: EC2Type_C6G end
abstract type EC2Type_C6G_Medium <: EC2Type_C6G end
abstract type EC2Type_C6G_xLarge <: EC2Type_C6G end
abstract type EC2Type_C6G_2xLarge <: EC2Type_C6G end
abstract type EC2Type_C6G_4xLarge <: EC2Type_C6G end
abstract type EC2Type_C6G_8xLarge <: EC2Type_C6G end
abstract type EC2Type_C6G_12xLarge <: EC2Type_C6G end
abstract type EC2Type_C6G_16xLarge <: EC2Type_C6G end
abstract type EC2Type_C6GD_Metal <: EC2Type_C6GD end
abstract type EC2Type_C6GD_Large <: EC2Type_C6GD end
abstract type EC2Type_C6GD_Medium <: EC2Type_C6GD end
abstract type EC2Type_C6GD_xLarge <: EC2Type_C6GD end
abstract type EC2Type_C6GD_2xLarge <: EC2Type_C6GD end
abstract type EC2Type_C6GD_4xLarge <: EC2Type_C6GD end
abstract type EC2Type_C6GD_8xLarge <: EC2Type_C6GD end
abstract type EC2Type_C6GD_12xLarge <: EC2Type_C6G end
abstract type EC2Type_C6GD_16xLarge <: EC2Type_C6G end
abstract type EC2Type_C6GN_Large <: EC2Type_C6GN end
abstract type EC2Type_C6GN_Medium <: EC2Type_C6GN end
abstract type EC2Type_C6GN_xLarge <: EC2Type_C6GN end
abstract type EC2Type_C6GN_2xLarge <: EC2Type_C6GN end
abstract type EC2Type_C6GN_4xLarge <: EC2Type_C6GN end
abstract type EC2Type_C6GN_8xLarge <: EC2Type_C6GN end
abstract type EC2Type_C6GN_12xLarge <: EC2Type_C6GN end
abstract type EC2Type_C6GN_16xLarge <: EC2Type_C6GN end
abstract type EC2Type_C6I_Metal <: EC2Type_C6I end
abstract type EC2Type_C6I_Large <: EC2Type_C6I end
abstract type EC2Type_C6I_xLarge <: EC2Type_C6I end
abstract type EC2Type_C6I_2xLarge <: EC2Type_C6I end
abstract type EC2Type_C6I_4xLarge <: EC2Type_C6I end
abstract type EC2Type_C6I_8xLarge <: EC2Type_C6I end
abstract type EC2Type_C6I_12xLarge <: EC2Type_C6I end
abstract type EC2Type_C6I_16xLarge <: EC2Type_C6I end
abstract type EC2Type_C6I_24xLarge <: EC2Type_C6I end
abstract type EC2Type_C6I_32xLarge <: EC2Type_C6I end
abstract type EC2Type_C6ID_Metal <: EC2Type_C6ID end
abstract type EC2Type_C6ID_Large <: EC2Type_C6ID end
abstract type EC2Type_C6ID_xLarge <: EC2Type_C6ID end
abstract type EC2Type_C6ID_2xLarge <: EC2Type_C6ID end
abstract type EC2Type_C6ID_4xLarge <: EC2Type_C6ID end
abstract type EC2Type_C6ID_8xLarge <: EC2Type_C6ID end
abstract type EC2Type_C6ID_12xLarge <: EC2Type_C6ID end
abstract type EC2Type_C6ID_16xLarge <: EC2Type_C6ID end
abstract type EC2Type_C6ID_24xLarge <: EC2Type_C6ID end
abstract type EC2Type_C6ID_32xLarge <: EC2Type_C6ID end
abstract type EC2Type_C6A_Metal <: EC2Type_C6A end
abstract type EC2Type_C6A_Large <: EC2Type_C6A end
abstract type EC2Type_C6A_xLarge <: EC2Type_C6A end
abstract type EC2Type_C6A_2xLarge <: EC2Type_C6A end
abstract type EC2Type_C6A_4xLarge <: EC2Type_C6A end
abstract type EC2Type_C6A_8xLarge <: EC2Type_C6A end
abstract type EC2Type_C6A_12xLarge <: EC2Type_C6A end
abstract type EC2Type_C6A_16xLarge <: EC2Type_C6A end
abstract type EC2Type_C6A_24xLarge <: EC2Type_C6A end
abstract type EC2Type_C6A_32xLarge <: EC2Type_C6A end
abstract type EC2Type_C6A_48xLarge <: EC2Type_C6A end
abstract type EC2Type_HPC6A <: EC2Type end
abstract type EC2Type_HPC6A_48xLarge <: EC2Type_HPC6A end
abstract type EC2Type_C5 <: EC2Type end
abstract type EC2Type_C5D <: EC2Type_C5 end
abstract type EC2Type_C5A <: EC2Type_C5 end
abstract type EC2Type_C5N <: EC2Type_C5 end
abstract type EC2Type_C5AD <: EC2Type_C5A end
abstract type EC2Type_C5_Metal <: EC2Type_C5 end
abstract type EC2Type_C5_Large <: EC2Type_C5 end
abstract type EC2Type_C5_xLarge <: EC2Type_C5 end
abstract type EC2Type_C5_2xLarge <: EC2Type_C5 end
abstract type EC2Type_C5_4xLarge <: EC2Type_C5 end
abstract type EC2Type_C5_9xLarge <: EC2Type_C5 end
abstract type EC2Type_C5_12xLarge <: EC2Type_C5 end
abstract type EC2Type_C5_18xLarge <: EC2Type_C5 end
abstract type EC2Type_C5_24xLarge <: EC2Type_C5 end
abstract type EC2Type_C5D_Metal <: EC2Type_C5D end
abstract type EC2Type_C5D_Large <: EC2Type_C5D end
abstract type EC2Type_C5D_xLarge <: EC2Type_C5D end
abstract type EC2Type_C5D_2xLarge <: EC2Type_C5D end
abstract type EC2Type_C5D_4xLarge <: EC2Type_C5D end
abstract type EC2Type_C5D_9xLarge <: EC2Type_C5D end
abstract type EC2Type_C5D_12xLarge <: EC2Type_C5D end
abstract type EC2Type_C5D_18xLarge <: EC2Type_C5D end
abstract type EC2Type_C5D_24xLarge <: EC2Type_C5D end
abstract type EC2Type_C5A_Large <: EC2Type_C5A end
abstract type EC2Type_C5A_xLarge <: EC2Type_C5A end
abstract type EC2Type_C5A_2xLarge <: EC2Type_C5A end
abstract type EC2Type_C5A_4xLarge <: EC2Type_C5A end
abstract type EC2Type_C5A_8xLarge <: EC2Type_C5A end
abstract type EC2Type_C5A_12xLarge <: EC2Type_C5A end
abstract type EC2Type_C5A_16xLarge <: EC2Type_C5A end
abstract type EC2Type_C5A_24xLarge <: EC2Type_C5A end
abstract type EC2Type_C5AD_Large <: EC2Type_C5AD end
abstract type EC2Type_C5AD_xLarge <: EC2Type_C5AD end
abstract type EC2Type_C5AD_2xLarge <: EC2Type_C5AD end
abstract type EC2Type_C5AD_4xLarge <: EC2Type_C5AD end
abstract type EC2Type_C5AD_8xLarge <: EC2Type_C5AD end
abstract type EC2Type_C5AD_12xLarge <: EC2Type_C5AD end
abstract type EC2Type_C5AD_16xLarge <: EC2Type_C5AD end
abstract type EC2Type_C5AD_24xLarge <: EC2Type_C5AD end
abstract type EC2Type_C5N_Metal <: EC2Type_C5N end
abstract type EC2Type_C5N_Large <: EC2Type_C5N end
abstract type EC2Type_C5N_xLarge <: EC2Type_C5N end
abstract type EC2Type_C5N_2xLarge <: EC2Type_C5N end
abstract type EC2Type_C5N_4xLarge <: EC2Type_C5N end
abstract type EC2Type_C5N_9xLarge <: EC2Type_C5N end
abstract type EC2Type_C5N_18xLarge <: EC2Type_C5N end
abstract type EC2Type_C4 <: EC2Type end
abstract type EC2Type_C4_Large <: EC2Type_C4 end
abstract type EC2Type_C4_xLarge <: EC2Type_C4 end
abstract type EC2Type_C4_2xLarge <: EC2Type_C4 end
abstract type EC2Type_C4_4xLarge <: EC2Type_C4 end
abstract type EC2Type_C4_8xLarge <: EC2Type_C4 end
abstract type EC2Type_C3 <: EC2Type end
abstract type EC2Type_C3_Large <: EC2Type_C3 end
abstract type EC2Type_C3_xLarge <: EC2Type_C3 end
abstract type EC2Type_C3_2xLarge <: EC2Type_C3 end
abstract type EC2Type_C3_4xLarge <: EC2Type_C3 end
abstract type EC2Type_C3_8xLarge <: EC2Type_C3 end
abstract type EC2Type_C1 <: EC2Type end
abstract type EC2Type_C1_Large <: EC2Type_C1 end
abstract type EC2Type_C1_Medium <: EC2Type_C1 end
abstract type EC2Type_C1_xLarge <: EC2Type_C1 end
## memory optimized instances
abstract type EC2Type_R6 <: EC2Type end
abstract type EC2Type_R6A <: EC2Type_R6 end
abstract type EC2Type_R6G <: EC2Type_R6 end
abstract type EC2Type_R6I <: EC2Type_R6 end
abstract type EC2Type_R6GD <: EC2Type_R6G end
abstract type EC2Type_R6ID <: EC2Type_R6I end
abstract type EC2Type_R6A_Metal <: EC2Type_R6A end
abstract type EC2Type_R6A_Large <: EC2Type_R6A end
abstract type EC2Type_R6A_xLarge <: EC2Type_R6A end
abstract type EC2Type_R6A_2xLarge <: EC2Type_R6A end
abstract type EC2Type_R6A_4xLarge <: EC2Type_R6A end
abstract type EC2Type_R6A_8xLarge <: EC2Type_R6A end
abstract type EC2Type_R6A_12xLarge <: EC2Type_R6A end
abstract type EC2Type_R6A_16xLarge <: EC2Type_R6A end
abstract type EC2Type_R6A_24xLarge <: EC2Type_R6A end
abstract type EC2Type_R6A_32xLarge <: EC2Type_R6A end
abstract type EC2Type_R6A_48xLarge <: EC2Type_R6A end
abstract type EC2Type_R6G_Metal <: EC2Type_R6G end
abstract type EC2Type_R6G_Large <: EC2Type_R6G end
abstract type EC2Type_R6G_Medium <: EC2Type_R6G end
abstract type EC2Type_R6G_xLarge <: EC2Type_R6G end
abstract type EC2Type_R6G_2xLarge <: EC2Type_R6G end
abstract type EC2Type_R6G_4xLarge <: EC2Type_R6G end
abstract type EC2Type_R6G_8xLarge <: EC2Type_R6G end
abstract type EC2Type_R6G_12xLarge <: EC2Type_R6G end
abstract type EC2Type_R6G_16xLarge <: EC2Type_R6G end
abstract type EC2Type_R6GD_Metal <: EC2Type_R6GD end
abstract type EC2Type_R6GD_Large <: EC2Type_R6GD end
abstract type EC2Type_R6GD_Medium <: EC2Type_R6GD end
abstract type EC2Type_R6GD_xLarge <: EC2Type_R6GD end
abstract type EC2Type_R6GD_2xLarge <: EC2Type_R6GD end
abstract type EC2Type_R6GD_4xLarge <: EC2Type_R6GD end
abstract type EC2Type_R6GD_8xLarge <: EC2Type_R6GD end
abstract type EC2Type_R6GD_12xLarge <: EC2Type_R6GD end
abstract type EC2Type_R6GD_16xLarge <: EC2Type_R6GD end
abstract type EC2Type_R6I_Metal <: EC2Type_R6I end
abstract type EC2Type_R6I_Large <: EC2Type_R6I end
abstract type EC2Type_R6I_xLarge <: EC2Type_R6I end
abstract type EC2Type_R6I_2xLarge <: EC2Type_R6I end
abstract type EC2Type_R6I_4xLarge <: EC2Type_R6I end
abstract type EC2Type_R6I_8xLarge <: EC2Type_R6I end
abstract type EC2Type_R6I_12xLarge <: EC2Type_R6I end
abstract type EC2Type_R6I_16xLarge <: EC2Type_R6I end
abstract type EC2Type_R6I_24xLarge <: EC2Type_R6I end
abstract type EC2Type_R6I_32xLarge <: EC2Type_R6I end
abstract type EC2Type_R6ID_Metal <: EC2Type_R6ID end
abstract type EC2Type_R6ID_Large <: EC2Type_R6ID end
abstract type EC2Type_R6ID_xLarge <: EC2Type_R6ID end
abstract type EC2Type_R6ID_2xLarge <: EC2Type_R6ID end
abstract type EC2Type_R6ID_4xLarge <: EC2Type_R6ID end
abstract type EC2Type_R6ID_8xLarge <: EC2Type_R6ID end
abstract type EC2Type_R6ID_12xLarge <: EC2Type_R6ID end
abstract type EC2Type_R6ID_16xLarge <: EC2Type_R6ID end
abstract type EC2Type_R6ID_24xLarge <: EC2Type_R6ID end
abstract type EC2Type_R6ID_32xLarge <: EC2Type_R6ID end
abstract type EC2Type_R5 <: EC2Type end
abstract type EC2Type_R5D <: EC2Type_R5 end
abstract type EC2Type_R5A <: EC2Type_R5 end
abstract type EC2Type_R5B <: EC2Type_R5 end
abstract type EC2Type_R5N <: EC2Type_R5 end
abstract type EC2Type_R5AD <: EC2Type_R5A end
abstract type EC2Type_R5DN <: EC2Type_R5N end
abstract type EC2Type_R5_Metal <: EC2Type_R5 end
abstract type EC2Type_R5_Large <: EC2Type_R5 end
abstract type EC2Type_R5_xLarge <: EC2Type_R5 end
abstract type EC2Type_R5_2xLarge <: EC2Type_R5 end
abstract type EC2Type_R5_4xLarge <: EC2Type_R5 end
abstract type EC2Type_R5_8xLarge <: EC2Type_R5 end
abstract type EC2Type_R5_12xLarge <: EC2Type_R5 end
abstract type EC2Type_R5_16xLarge <: EC2Type_R5 end
abstract type EC2Type_R5_24xLarge <: EC2Type_R5 end
abstract type EC2Type_R5D_Metal <: EC2Type_R5D end
abstract type EC2Type_R5D_Large <: EC2Type_R5D end
abstract type EC2Type_R5D_xLarge <: EC2Type_R5D end
abstract type EC2Type_R5D_2xLarge <: EC2Type_R5D end
abstract type EC2Type_R5D_4xLarge <: EC2Type_R5D end
abstract type EC2Type_R5D_8xLarge <: EC2Type_R5D end
abstract type EC2Type_R5D_12xLarge <: EC2Type_R5D end
abstract type EC2Type_R5D_16xLarge <: EC2Type_R5D end
abstract type EC2Type_R5D_24xLarge <: EC2Type_R5D end
abstract type EC2Type_R5A_Large <: EC2Type_R5A end
abstract type EC2Type_R5A_xLarge <: EC2Type_R5A end
abstract type EC2Type_R5A_2xLarge <: EC2Type_R5A end
abstract type EC2Type_R5A_4xLarge <: EC2Type_R5A end
abstract type EC2Type_R5A_8xLarge <: EC2Type_R5A end
abstract type EC2Type_R5A_12xLarge <: EC2Type_R5A end
abstract type EC2Type_R5A_16xLarge <: EC2Type_R5A end
abstract type EC2Type_R5A_24xLarge <: EC2Type_R5A end
abstract type EC2Type_R5AD_Large <: EC2Type_R5AD end
abstract type EC2Type_R5AD_xLarge <: EC2Type_R5AD end
abstract type EC2Type_R5AD_2xLarge <: EC2Type_R5AD end
abstract type EC2Type_R5AD_4xLarge <: EC2Type_R5AD end
abstract type EC2Type_R5AD_8xLarge <: EC2Type_R5AD end
abstract type EC2Type_R5AD_12xLarge <: EC2Type_R5AD end
abstract type EC2Type_R5AD_16xLarge <: EC2Type_R5AD end
abstract type EC2Type_R5AD_24xLarge <: EC2Type_R5AD end
abstract type EC2Type_R5B_Metal <: EC2Type_R5B end
abstract type EC2Type_R5B_Large <: EC2Type_R5B end
abstract type EC2Type_R5B_xLarge <: EC2Type_R5B end
abstract type EC2Type_R5B_2xLarge <: EC2Type_R5B end
abstract type EC2Type_R5B_4xLarge <: EC2Type_R5B end
abstract type EC2Type_R5B_8xLarge <: EC2Type_R5B end
abstract type EC2Type_R5B_12xLarge <: EC2Type_R5B end
abstract type EC2Type_R5B_16xLarge <: EC2Type_R5B end
abstract type EC2Type_R5B_24xLarge <: EC2Type_R5B end
abstract type EC2Type_R5N_Metal <: EC2Type_R5N end
abstract type EC2Type_R5N_Large <: EC2Type_R5N end
abstract type EC2Type_R5N_xLarge <: EC2Type_R5N end
abstract type EC2Type_R5N_2xLarge <: EC2Type_R5N end
abstract type EC2Type_R5N_4xLarge <: EC2Type_R5N end
abstract type EC2Type_R5N_8xLarge <: EC2Type_R5N end
abstract type EC2Type_R5N_12xLarge <: EC2Type_R5N end
abstract type EC2Type_R5N_16xLarge <: EC2Type_R5N end
abstract type EC2Type_R5N_24xLarge <: EC2Type_R5N end
abstract type EC2Type_R5DN_Metal <: EC2Type_R5DN end
abstract type EC2Type_R5DN_Large <: EC2Type_R5DN end
abstract type EC2Type_R5DN_xLarge <: EC2Type_R5DN end
abstract type EC2Type_R5DN_2xLarge <: EC2Type_R5DN end
abstract type EC2Type_R5DN_4xLarge <: EC2Type_R5DN end
abstract type EC2Type_R5DN_8xLarge <: EC2Type_R5DN end
abstract type EC2Type_R5DN_12xLarge <: EC2Type_R5DN end
abstract type EC2Type_R5DN_16xLarge <: EC2Type_R5DN end
abstract type EC2Type_R5DN_24xLarge <: EC2Type_R5DN end
abstract type EC2Type_R3 <: EC2Type end
abstract type EC2Type_R3_Large <: EC2Type_R3 end
abstract type EC2Type_R3_xLarge <: EC2Type_R3 end
abstract type EC2Type_R3_2xLarge <: EC2Type_R3 end
abstract type EC2Type_R3_4xLarge <: EC2Type_R3 end
abstract type EC2Type_R3_8xLarge <: EC2Type_R3 end
abstract type EC2Type_R4 <: EC2Type end
abstract type EC2Type_R4_Large <: EC2Type_R4 end
abstract type EC2Type_R4_xLarge <: EC2Type_R4 end
abstract type EC2Type_R4_2xLarge <: EC2Type_R4 end
abstract type EC2Type_R4_4xLarge <: EC2Type_R4 end
abstract type EC2Type_R4_8xLarge <: EC2Type_R4 end
abstract type EC2Type_R4_16xLarge <: EC2Type_R4 end
abstract type EC2Type_X2 <: EC2Type end
abstract type EC2Type_X2GD <: EC2Type_X2 end
abstract type EC2Type_X2IDN <: EC2Type_X2 end
abstract type EC2Type_X2IEDN <: EC2Type_X2 end
abstract type EC2Type_X2IEZN <: EC2Type_X2 end
abstract type EC2Type_X2GD_Metal <: EC2Type_X2GD end
abstract type EC2Type_X2GD_Large <: EC2Type_X2GD end
abstract type EC2Type_X2GD_Medium <: EC2Type_X2GD end
abstract type EC2Type_X2GD_xLarge <: EC2Type_X2GD end
abstract type EC2Type_X2GD_2xLarge <: EC2Type_X2GD end
abstract type EC2Type_X2GD_4xLarge <: EC2Type_X2GD end
abstract type EC2Type_X2GD_8xLarge <: EC2Type_X2GD end
abstract type EC2Type_X2GD_12xLarge <: EC2Type_X2GD end
abstract type EC2Type_X2GD_16xLarge <: EC2Type_X2GD end
abstract type EC2Type_X2IDN_Metal <: EC2Type_X2IDN end
abstract type EC2Type_X2IDN_16xLarge <: EC2Type_X2IDN end
abstract type EC2Type_X2IDN_24xLarge <: EC2Type_X2IDN end
abstract type EC2Type_X2IDN_32xLarge <: EC2Type_X2IDN end
abstract type EC2Type_X2IEDN_Metal <: EC2Type_X2IEDN end
abstract type EC2Type_X2IEDN_xLarge <: EC2Type_X2IEDN end
abstract type EC2Type_X2IEDN_2xLarge <: EC2Type_X2IEDN end
abstract type EC2Type_X2IEDN_4xLarge <: EC2Type_X2IEDN end
abstract type EC2Type_X2IEDN_8xLarge <: EC2Type_X2IEDN end
abstract type EC2Type_X2IEDN_16xLarge <: EC2Type_X2IEDN end
abstract type EC2Type_X2IEDN_24xLarge <: EC2Type_X2IEDN end
abstract type EC2Type_X2IEDN_32xLarge <: EC2Type_X2IEDN end
abstract type EC2Type_X2IEZN_Metal <: EC2Type_X2IEZN end
abstract type EC2Type_X2IEZN_2xLarge <: EC2Type_X2IEZN end
abstract type EC2Type_X2IEZN_4xLarge <: EC2Type_X2IEZN end
abstract type EC2Type_X2IEZN_6xLarge <: EC2Type_X2IEZN end
abstract type EC2Type_X2IEZN_8xLarge <: EC2Type_X2IEZN end
abstract type EC2Type_X2IEZN_12xLarge <: EC2Type_X2IEZN end
abstract type EC2Type_X1 <: EC2Type end
abstract type EC2Type_X1E <: EC2Type_X1 end
abstract type EC2Type_X1E_xLarge <: EC2Type_X1E end
abstract type EC2Type_X1E_2xLarge <: EC2Type_X1E end
abstract type EC2Type_X1E_4xLarge <: EC2Type_X1E end
abstract type EC2Type_X1E_8xLarge <: EC2Type_X1E end
abstract type EC2Type_X1E_16xLarge <: EC2Type_X1E end
abstract type EC2Type_X1E_32xLarge <: EC2Type_X1E end
abstract type EC2Type_X1_16xLarge <: EC2Type_X1 end
abstract type EC2Type_X1_32xLarge <: EC2Type_X1 end
abstract type EC2Type_U <: EC2Type end
abstract type EC2Type_U3TB1 <: EC2Type_U end
abstract type EC2Type_U6TB1 <: EC2Type_U end
abstract type EC2Type_U9TB1 <: EC2Type_U end
abstract type EC2Type_U12TB1 <: EC2Type_U end
abstract type EC2Type_U18TB1 <: EC2Type_U end
abstract type EC2Type_U24TB1 <: EC2Type_U end
abstract type EC2Type_U3TB1_56xLarge <: EC2Type_U3TB1 end
abstract type EC2Type_U6TB1_Metal <: EC2Type_U6TB1 end
abstract type EC2Type_U6TB1_56xLarge <: EC2Type_U6TB1 end
abstract type EC2Type_U6TB1_112xLarge <: EC2Type_U6TB1 end
abstract type EC2Type_U9TB1_Metal <: EC2Type_U9TB1 end
abstract type EC2Type_U9TB1_112xLarge <: EC2Type_U9TB1 end
abstract type EC2Type_U12TB1_Metal <: EC2Type_U12TB1 end
abstract type EC2Type_U12TB1_112xLarge <: EC2Type_U12TB1 end
abstract type EC2Type_U18TB1_Metal <: EC2Type_U18TB1 end
abstract type EC2Type_U24TB1_Metal <: EC2Type_U24TB1 end
abstract type EC2Type_Z1D <: EC2Type end
abstract type EC2Type_Z1D_Metal <: EC2Type_Z1D end
abstract type EC2Type_Z1D_Large <: EC2Type_Z1D end
abstract type EC2Type_Z1D_xLarge <: EC2Type_Z1D end
abstract type EC2Type_Z1D_2xLarge <: EC2Type_Z1D end
abstract type EC2Type_Z1D_3xLarge <: EC2Type_Z1D end
abstract type EC2Type_Z1D_6xLarge <: EC2Type_Z1D end
abstract type EC2Type_Z1D_12xLarge <: EC2Type_Z1D end
## accelerated computing instances
abstract type EC2Type_P4D <: EC2Type end
abstract type EC2Type_P4DE <: EC2Type_P4D end
abstract type EC2Type_P4D_24xLarge <: EC2Type_P4D end
abstract type EC2Type_P4DE_24xLarge <: EC2Type_P4DE end # instance type in preview
abstract type EC2Type_P3 <: EC2Type end
abstract type EC2Type_P3DN <: EC2Type_P3 end
abstract type EC2Type_P3_2xLarge <: EC2Type_P3 end
abstract type EC2Type_P3_8xLarge <: EC2Type_P3 end
abstract type EC2Type_P3_16xLarge <: EC2Type_P3 end
abstract type EC2Type_P3DN_24xLarge <: EC2Type_P3DN end
abstract type EC2Type_P2 <: EC2Type end
abstract type EC2Type_P2_xLarge <: EC2Type_P2 end
abstract type EC2Type_P2_8xLarge <: EC2Type_P2 end
abstract type EC2Type_P2_16xLarge <: EC2Type_P2 end
abstract type EC2Type_DL1 <: EC2Type end
abstract type EC2Type_DL1_24xLarge <: EC2Type_DL1 end
abstract type EC2Type_INF1 <: EC2Type end
abstract type EC2Type_INF1_xLarge <: EC2Type_INF1 end
abstract type EC2Type_INF1_2xLarge <: EC2Type_INF1 end
abstract type EC2Type_INF1_6xLarge <: EC2Type_INF1 end
abstract type EC2Type_INF1_24xLarge <: EC2Type_INF1 end
abstract type EC2Type_G5 <: EC2Type end
abstract type EC2Type_G5G <: EC2Type_G5 end
abstract type EC2Type_G5_xLarge <: EC2Type_G5 end
abstract type EC2Type_G5_2xLarge <: EC2Type_G5 end
abstract type EC2Type_G5_4xLarge <: EC2Type_G5 end
abstract type EC2Type_G5_8xLarge <: EC2Type_G5 end
abstract type EC2Type_G5_12xLarge <: EC2Type_G5 end
abstract type EC2Type_G5_16xLarge <: EC2Type_G5 end
abstract type EC2Type_G5_24xLarge <: EC2Type_G5 end
abstract type EC2Type_G5_48xLarge <: EC2Type_G5 end
abstract type EC2Type_G5G_Metal <: EC2Type_G5G end
abstract type EC2Type_G5G_xLarge <: EC2Type_G5G end
abstract type EC2Type_G5G_2xLarge <: EC2Type_G5G end
abstract type EC2Type_G5G_4xLarge <: EC2Type_G5G end
abstract type EC2Type_G5G_8xLarge <: EC2Type_G5G end
abstract type EC2Type_G5G_16xLarge <: EC2Type_G5G end
abstract type EC2Type_G6 <: EC2Type end
abstract type EC2Type_G6_xLarge <: EC2Type_G6 end
abstract type EC2Type_G6_2xLarge <: EC2Type_G6 end
abstract type EC2Type_G6_4xLarge <: EC2Type_G6 end
abstract type EC2Type_G6_8xLarge <: EC2Type_G6 end
abstract type EC2Type_G6_12xLarge <: EC2Type_G6 end
abstract type EC2Type_G6_16xLarge <: EC2Type_G6 end
abstract type EC2Type_G6_24xLarge <: EC2Type_G6 end
abstract type EC2Type_G6_48xLarge <: EC2Type_G6 end
abstract type EC2Type_G4 <: EC2Type end
abstract type EC2Type_G4DN <: EC2Type_G4 end
abstract type EC2Type_G4AD <: EC2Type_G4 end
abstract type EC2Type_G4DN_Metal <: EC2Type_G4DN end
abstract type EC2Type_G4DN_xLarge <: EC2Type_G4DN end
abstract type EC2Type_G4DN_2xLarge <: EC2Type_G4DN end
abstract type EC2Type_G4DN_4xLarge <: EC2Type_G4DN end
abstract type EC2Type_G4DN_8xLarge <: EC2Type_G4DN end
abstract type EC2Type_G4DN_12xLarge <: EC2Type_G4DN end
abstract type EC2Type_G4DN_16xLarge <: EC2Type_G4DN end
abstract type EC2Type_G4AD_xLarge <: EC2Type_G4AD end
abstract type EC2Type_G4AD_2xLarge <: EC2Type_G4AD end
abstract type EC2Type_G4AD_4xLarge <: EC2Type_G4AD end
abstract type EC2Type_G4AD_8xLarge <: EC2Type_G4AD end
abstract type EC2Type_G4AD_16xLarge <: EC2Type_G4AD end
abstract type EC2Type_G3 <: EC2Type end
abstract type EC2Type_G3S <: EC2Type_G3 end
abstract type EC2Type_G3_4xLarge <: EC2Type_G3 end
abstract type EC2Type_G3_8xLarge <: EC2Type_G3 end
abstract type EC2Type_G3_16xLarge <: EC2Type_G3 end
abstract type EC2Type_G3S_xLarge <: EC2Type_G3S end
abstract type EC2Type_G2 <: EC2Type end
abstract type EC2Type_G2_2xLarge <: EC2Type_G2 end
abstract type EC2Type_G2_8xLarge <: EC2Type_G2 end
abstract type EC2Type_F1 <: EC2Type end
abstract type EC2Type_F1_2xLarge <: EC2Type_F1 end
abstract type EC2Type_F1_4xLarge <: EC2Type_F1 end
abstract type EC2Type_F1_16xLarge <: EC2Type_F1 end
abstract type EC2Type_VT1 <: EC2Type end
abstract type EC2Type_VT1_3xLarge <: EC2Type_VT1 end
abstract type EC2Type_VT1_6xLarge <: EC2Type_VT1 end
abstract type EC2Type_VT1_24xLarge <: EC2Type_VT1 end
## storage optimized instances
abstract type EC2Type_IM4GN <: EC2Type end
abstract type EC2Type_IM4GN_Large <: EC2Type_IM4GN end
abstract type EC2Type_IM4GN_xLarge <: EC2Type_IM4GN end
abstract type EC2Type_IM4GN_2xLarge <: EC2Type_IM4GN end
abstract type EC2Type_IM4GN_4xLarge <: EC2Type_IM4GN end
abstract type EC2Type_IM4GN_8xLarge <: EC2Type_IM4GN end
abstract type EC2Type_IM4GN_16xLarge <: EC2Type_IM4GN end
abstract type EC2Type_IS4GEN <: EC2Type end
abstract type EC2Type_IS4GEN_Large <: EC2Type_IS4GEN end
abstract type EC2Type_IS4GEN_Medium <: EC2Type_IS4GEN end
abstract type EC2Type_IS4GEN_xLarge <: EC2Type_IS4GEN end
abstract type EC2Type_IS4GEN_2xLarge <: EC2Type_IS4GEN end
abstract type EC2Type_IS4GEN_4xLarge <: EC2Type_IS4GEN end
abstract type EC2Type_IS4GEN_8xLarge <: EC2Type_IS4GEN end
abstract type EC2Type_I4I <: EC2Type end
abstract type EC2Type_I4I_Metal <: EC2Type_I4I end
abstract type EC2Type_I4I_Large <: EC2Type_I4I end
abstract type EC2Type_I4I_xLarge <: EC2Type_I4I end
abstract type EC2Type_I4I_2xLarge <: EC2Type_I4I end
abstract type EC2Type_I4I_4xLarge <: EC2Type_I4I end
abstract type EC2Type_I4I_8xLarge <: EC2Type_I4I end
abstract type EC2Type_I4I_16xLarge <: EC2Type_I4I end
abstract type EC2Type_I4I_32xLarge <: EC2Type_I4I end
abstract type EC2Type_I3 <: EC2Type end
abstract type EC2Type_I3EN <: EC2Type_I3 end
abstract type EC2Type_I3_Metal <: EC2Type_I3 end
abstract type EC2Type_I3_Large <: EC2Type_I3 end
abstract type EC2Type_I3_xLarge <: EC2Type_I3 end
abstract type EC2Type_I3_2xLarge <: EC2Type_I3 end
abstract type EC2Type_I3_4xLarge <: EC2Type_I3 end
abstract type EC2Type_I3_8xLarge <: EC2Type_I3 end
abstract type EC2Type_I3_16xLarge <: EC2Type_I3 end
abstract type EC2Type_I3EN_Metal <: EC2Type_I3EN end
abstract type EC2Type_I3EN_Large <: EC2Type_I3EN end
abstract type EC2Type_I3EN_xLarge <: EC2Type_I3EN end
abstract type EC2Type_I3EN_2xLarge <: EC2Type_I3EN end
abstract type EC2Type_I3EN_3xLarge <: EC2Type_I3EN end
abstract type EC2Type_I3EN_6xLarge <: EC2Type_I3EN end
abstract type EC2Type_I3EN_12xLarge <: EC2Type_I3EN end
abstract type EC2Type_I3EN_24xLarge <: EC2Type_I3EN end
abstract type EC2Type_I2 <: EC2Type end
abstract type EC2Type_I2_Large <: EC2Type_I2 end
abstract type EC2Type_I2_xLarge <: EC2Type_I2 end
abstract type EC2Type_I2_2xLarge <: EC2Type_I2 end
abstract type EC2Type_I2_4xLarge <: EC2Type_I2 end
abstract type EC2Type_I2_8xLarge <: EC2Type_I2 end
abstract type EC2Type_D2 <: EC2Type end
abstract type EC2Type_D2_xLarge <: EC2Type_D2 end
abstract type EC2Type_D2_2xLarge <: EC2Type_D2 end
abstract type EC2Type_D2_4xLarge <: EC2Type_D2 end
abstract type EC2Type_D2_8xLarge <: EC2Type_D2 end
abstract type EC2Type_D3 <: EC2Type end
abstract type EC2Type_D3EN <: EC2Type_D3 end
abstract type EC2Type_D3_xLarge <: EC2Type_D3 end
abstract type EC2Type_D3_2xLarge <: EC2Type_D3 end
abstract type EC2Type_D3_4xLarge <: EC2Type_D3 end
abstract type EC2Type_D3_8xLarge <: EC2Type_D3 end
abstract type EC2Type_D3EN_xLarge <: EC2Type_D3EN end
abstract type EC2Type_D3EN_2xLarge <: EC2Type_D3EN end
abstract type EC2Type_D3EN_4xLarge <: EC2Type_D3EN end
abstract type EC2Type_D3EN_6xLarge <: EC2Type_D3EN end
abstract type EC2Type_D3EN_8xLarge <: EC2Type_D3EN end
abstract type EC2Type_D3EN_12xLarge <: EC2Type_D3EN end
abstract type EC2Type_H1 <: EC2Type end
abstract type EC2Type_H1_2xLarge <: EC2Type_H1 end
abstract type EC2Type_H1_4xLarge <: EC2Type_H1 end
abstract type EC2Type_H1_8xLarge <: EC2Type_H1 end
abstract type EC2Type_H1_16xLarge <: EC2Type_H1 end
abstract type EC2Type_HS1 <: EC2Type end
abstract type EC2Type_HS1_8xLarge <: EC2Type_HS1 end
# storage types
abstract type StorageType_EC2_EBSOnly <: StorageType end
abstract type StorageType_EC2_NVMeSSD <: StorageType_SSD end
# network performance
abstract type NetworkPerformance_EC2 end
abstract type NetworkPerformance_EC2_Low <: NetworkPerformance_EC2 end
abstract type NetworkPerformance_EC2_High <: NetworkPerformance_EC2 end
abstract type NetworkPerformance_EC2_Moderate <: NetworkPerformance_EC2 end
abstract type NetworkPerformance_EC2_LowModerate <: NetworkPerformance_EC2 end
##
function get_instance_info(provider::Type{<:AmazonEC2})
instance_id = try
JSON.parse(String(HTTP.request("GET", "http://169.254.169.254/latest/dynamic/instance-identity/document"; connect_timeout=5, readtimeout=5).body))
# return instance_info["instanceType"], instance_info["region"]
catch e
return nothing
end
machinetype_dict_ec2 = readCloudInstancesDB(provider)
instance_info = machinetype_dict_ec2[instance_id["instanceType"]]
return instance_info
end
function readCloudInstancesDB(::Type{<:AmazonEC2})
database_path = @get_scratch!("database_path")
machinetypedb_ec2_url = "https://raw.githubusercontent.com/PlatformAwareProgramming/PlatformAware.jl/master/src/features/qualifiers/ec2/db-machinetypes.ec2.csv"
machinetypedb_ec2_fname = joinpath(database_path,basename(machinetypedb_ec2_url))
#machinetypedb_ec2_fname = "/home/heron/Dropbox/Copy/ufc_mdcc_hpc/PlatformAware/PlatformAware.jl/src/features/qualifiers/ec2/db-machinetypes.ec2.csv"
try_download(machinetypedb_ec2_url, machinetypedb_ec2_fname)
machinetype_dict_ec2 = readDB2(machinetypedb_ec2_fname)
return machinetype_dict_ec2
end
# AWS EC2 locale types
abstract type EC2Zone end
abstract type EC2Zone_US end
abstract type EC2Zone_Europe end
abstract type EC2Zone_USEast1 <: EC2Zone end # Norte da Vírginia
abstract type EC2Zone_USEast1_bos_1a <: EC2Zone_USEast1 end # Boston
abstract type EC2Zone_USEast1_chi_1a <: EC2Zone_USEast1 end # ?
abstract type EC2Zone_USEast1_dfw_1a <: EC2Zone_USEast1 end # ?
function getInstanceLocaleType(::Type{<:AmazonEC2}, locale_desc)
EC2InstanceZoneDict[locale_desc]
end
EC2InstanceZoneDict = Dict(
"us-east-1" => EC2Zone_USEast1,
"us-east-1-bos-1a" => EC2Zone_USEast1_bos_1a,
"us-east-1-chi-1a" => EC2Zone_USEast1_chi_1a,
"us-east-1-dfw-1a" => EC2Zone_USEast1_dfw_1a
# ...
)
function getNodeFeatures(provider::Type{<:AmazonEC2}, node_features)
instance_info = get_instance_info(provider)
if (!isnothing(instance_info))
node_features["node_count"] = 1
node_features["node_threads_count"] = 1
node_features["node_provider"] = "AmazonEC2"
node_features["node_virtual"] = "Yes"
node_features["node_dedicated"] = "Yes" # ???
node_features["node_machinefamily"] = instance_info["node_machinefamily"]
node_features["node_machinetype"] = instance_info["node_machinesize"]
node_features["node_vcpus_count"] = instance_info["node_vcpus_count"]
end
return instance_info
end
| PlatformAware | https://github.com/PlatformAwareProgramming/PlatformAware.jl.git |
|
[
"MIT"
] | 0.6.0 | d8f50cbc077c0992b472a07f99013cd5be80b11a | code | 14143 | # ------------------------------------------------------------------
# Licensed under the MIT License. See LICENCE in the project root.
# ------------------------------------------------------------------
# maintaner types
abstract type GoogleCloud <: CloudProvider end; export GoogleCloud
# locale types
# machine family types
abstract type GCPFamily <: MachineFamily end
abstract type GCPFamily_General <: GCPFamily end
abstract type GCPFamily_Compute <: GCPFamily end
abstract type GCPFamily_Memory <: GCPFamily end
abstract type GCPFamily_Accelerated <: GCPFamily end
# machine types
abstract type GCPType <: MachineType end
# general purpose machine types
abstract type GCPType_E2 <: GCPType end
abstract type GCPType_E2_Standard <: GCPType_E2 end
abstract type GCPType_E2_Highmem <: GCPType_E2 end
abstract type GCPType_E2_Highcpu <: GCPType_E2 end
abstract type GCPType_E2_Micro <: GCPType_E2 end
abstract type GCPType_E2_Small <: GCPType_E2 end
abstract type GCPType_E2_Medium <: GCPType_E2 end
abstract type GCPType_E2_Standard2 <: GCPType_E2_Standard end
abstract type GCPType_E2_Standard4 <: GCPType_E2_Standard end
abstract type GCPType_E2_Standard8 <: GCPType_E2_Standard end
abstract type GCPType_E2_Standard16 <: GCPType_E2_Standard end
abstract type GCPType_E2_Standard32 <: GCPType_E2_Standard end
abstract type GCPType_E2_Highmem2 <: GCPType_E2_Highmem end
abstract type GCPType_E2_Highmem4 <: GCPType_E2_Highmem end
abstract type GCPType_E2_Highmem8 <: GCPType_E2_Highmem end
abstract type GCPType_E2_Highmem16 <: GCPType_E2_Highmem end
abstract type GCPType_E2_Highcpu2 <: GCPType_E2_Highcpu end
abstract type GCPType_E2_Highcpu4 <: GCPType_E2_Highcpu end
abstract type GCPType_E2_Highcpu8 <: GCPType_E2_Highcpu end
abstract type GCPType_E2_Highcpu16 <: GCPType_E2_Highcpu end
abstract type GCPType_E2_Highcpu32 <: GCPType_E2_Highcpu end
abstract type GCPType_N2 <: GCPType end
abstract type GCPType_N2_Standard <: GCPType_N2 end
abstract type GCPType_N2_Highmem <: GCPType_N2 end
abstract type GCPType_N2_Highcpu <: GCPType_N2 end
abstract type GCPType_N2_Standard2 <: GCPType_N2_Standard end
abstract type GCPType_N2_Standard4 <: GCPType_N2_Standard end
abstract type GCPType_N2_Standard8 <: GCPType_N2_Standard end
abstract type GCPType_N2_Standard16 <: GCPType_N2_Standard end
abstract type GCPType_N2_Standard32 <: GCPType_N2_Standard end
abstract type GCPType_N2_Standard48 <: GCPType_N2_Standard end
abstract type GCPType_N2_Standard64 <: GCPType_N2_Standard end
abstract type GCPType_N2_Standard80 <: GCPType_N2_Standard end
abstract type GCPType_N2_Standard96 <: GCPType_N2_Standard end
abstract type GCPType_N2_Standard128 <: GCPType_N2_Standard end
abstract type GCPType_N2_Highmem2 <: GCPType_N2_Highmem end
abstract type GCPType_N2_Highmem4 <: GCPType_N2_Highmem end
abstract type GCPType_N2_Highmem8 <: GCPType_N2_Highmem end
abstract type GCPType_N2_Highmem16 <: GCPType_N2_Highmem end
abstract type GCPType_N2_Highmem32 <: GCPType_N2_Highmem end
abstract type GCPType_N2_Highmem48 <: GCPType_N2_Highmem end
abstract type GCPType_N2_Highmem64 <: GCPType_N2_Highmem end
abstract type GCPType_N2_Highmem80 <: GCPType_N2_Highmem end
abstract type GCPType_N2_Highmem96 <: GCPType_N2_Highmem end
abstract type GCPType_N2_Highmem128 <: GCPType_N2_Highmem end
abstract type GCPType_N2_Highcpu2 <: GCPType_N2_Highcpu end
abstract type GCPType_N2_Highcpu4 <: GCPType_N2_Highcpu end
abstract type GCPType_N2_Highcpu8 <: GCPType_N2_Highcpu end
abstract type GCPType_N2_Highcpu16 <: GCPType_N2_Highcpu end
abstract type GCPType_N2_Highcpu32 <: GCPType_N2_Highcpu end
abstract type GCPType_N2_Highcpu48 <: GCPType_N2_Highcpu end
abstract type GCPType_N2_Highcpu64 <: GCPType_N2_Highcpu end
abstract type GCPType_N2_Highcpu80 <: GCPType_N2_Highcpu end
abstract type GCPType_N2_Highcpu96 <: GCPType_N2_Highcpu end
abstract type GCPType_N2D <: GCPType end
abstract type GCPType_N2D_Standard <: GCPType_N2D end
abstract type GCPType_N2D_Highmem <: GCPType_N2D end
abstract type GCPType_N2D_Highcpu <: GCPType_N2D end
abstract type GCPType_N2D_Standard2 <: GCPType_N2D_Standard end
abstract type GCPType_N2D_Standard4 <: GCPType_N2D_Standard end
abstract type GCPType_N2D_Standard8 <: GCPType_N2D_Standard end
abstract type GCPType_N2D_Standard16 <: GCPType_N2D_Standard end
abstract type GCPType_N2D_Standard32 <: GCPType_N2D_Standard end
abstract type GCPType_N2D_Standard48 <: GCPType_N2D_Standard end
abstract type GCPType_N2D_Standard64 <: GCPType_N2D_Standard end
abstract type GCPType_N2D_Standard80 <: GCPType_N2D_Standard end
abstract type GCPType_N2D_Standard96 <: GCPType_N2D_Standard end
abstract type GCPType_N2D_Standard128 <: GCPType_N2D_Standard end
abstract type GCPType_N2D_Standard224 <: GCPType_N2D_Standard end
abstract type GCPType_N2D_Highmem2 <: GCPType_N2D_Highmem end
abstract type GCPType_N2D_Highmem4 <: GCPType_N2D_Highmem end
abstract type GCPType_N2D_Highmem8 <: GCPType_N2D_Highmem end
abstract type GCPType_N2D_Highmem16 <: GCPType_N2D_Highmem end
abstract type GCPType_N2D_Highmem32 <: GCPType_N2D_Highmem end
abstract type GCPType_N2D_Highmem48 <: GCPType_N2D_Highmem end
abstract type GCPType_N2D_Highmem64 <: GCPType_N2D_Highmem end
abstract type GCPType_N2D_Highmem80 <: GCPType_N2D_Highmem end
abstract type GCPType_N2D_Highmem96 <: GCPType_N2D_Highmem end
abstract type GCPType_N2D_Highcpu2 <: GCPType_N2D_Highcpu end
abstract type GCPType_N2D_Highcpu4 <: GCPType_N2D_Highcpu end
abstract type GCPType_N2D_Highcpu8 <: GCPType_N2D_Highcpu end
abstract type GCPType_N2D_Highcpu16 <: GCPType_N2D_Highcpu end
abstract type GCPType_N2D_Highcpu32 <: GCPType_N2D_Highcpu end
abstract type GCPType_N2D_Highcpu48 <: GCPType_N2D_Highcpu end
abstract type GCPType_N2D_Highcpu64 <: GCPType_N2D_Highcpu end
abstract type GCPType_N2D_Highcpu80 <: GCPType_N2D_Highcpu end
abstract type GCPType_N2D_Highcpu96 <: GCPType_N2D_Highcpu end
abstract type GCPType_N2D_Highcpu128 <: GCPType_N2D_Highcpu end
abstract type GCPType_N2D_Highcpu224 <: GCPType_N2D_Highcpu end
abstract type GCPType_T2D <: GCPType end
abstract type GCPType_T2D_Standard <: GCPType_T2D end
abstract type GCPType_T2D_Standard1 <: GCPType_T2D_Standard end
abstract type GCPType_T2D_Standard2 <: GCPType_T2D_Standard end
abstract type GCPType_T2D_Standard4 <: GCPType_T2D_Standard end
abstract type GCPType_T2D_Standard8 <: GCPType_T2D_Standard end
abstract type GCPType_T2D_Standard16 <: GCPType_T2D_Standard end
abstract type GCPType_T2D_Standard32 <: GCPType_T2D_Standard end
abstract type GCPType_T2D_Standard48 <: GCPType_T2D_Standard end
abstract type GCPType_T2D_Standard60 <: GCPType_T2D_Standard end
abstract type GCPType_T2A <: GCPType end
abstract type GCPType_T2A_Standard <: GCPType_T2A end
abstract type GCPType_T2A_Standard1 <: GCPType_T2A_Standard end
abstract type GCPType_T2A_Standard2 <: GCPType_T2A_Standard end
abstract type GCPType_T2A_Standard4 <: GCPType_T2A_Standard end
abstract type GCPType_T2A_Standard8 <: GCPType_T2A_Standard end
abstract type GCPType_T2A_Standard16 <: GCPType_T2A_Standard end
abstract type GCPType_T2A_Standard32 <: GCPType_T2A_Standard end
abstract type GCPType_T2A_Standard48 <: GCPType_T2A_Standard end
abstract type GCPType_N1 <: GCPType end
abstract type GCPType_N1_Standard <: GCPType_N1 end
abstract type GCPType_N1_Highmem <: GCPType_N1 end
abstract type GCPType_N1_Highcpu <: GCPType_N1 end
abstract type GCPType_F1_Micro <: GCPType_N1 end
abstract type GCPType_G1_Small <: GCPType_N1 end
abstract type GCPType_N1_Standard1 <: GCPType_N1_Standard end
abstract type GCPType_N1_Standard2 <: GCPType_N1_Standard end
abstract type GCPType_N1_Standard4 <: GCPType_N1_Standard end
abstract type GCPType_N1_Standard8 <: GCPType_N1_Standard end
abstract type GCPType_N1_Standard16 <: GCPType_N1_Standard end
abstract type GCPType_N1_Standard32 <: GCPType_N1_Standard end
abstract type GCPType_N1_Standard64 <: GCPType_N1_Standard end
abstract type GCPType_N1_Standard96 <: GCPType_N1_Standard end
abstract type GCPType_N1_Highmem2 <: GCPType_N1_Highmem end
abstract type GCPType_N1_Highmem4 <: GCPType_N1_Highmem end
abstract type GCPType_N1_Highmem8 <: GCPType_N1_Highmem end
abstract type GCPType_N1_Highmem16 <: GCPType_N1_Highmem end
abstract type GCPType_N1_Highmem32 <: GCPType_N1_Highmem end
abstract type GCPType_N1_Highmem64 <: GCPType_N1_Highmem end
abstract type GCPType_N1_Highmem96 <: GCPType_N1_Highmem end
abstract type GCPType_N1_Highcpu2 <: GCPType_N1_Highcpu end
abstract type GCPType_N1_Highcpu4 <: GCPType_N1_Highcpu end
abstract type GCPType_N1_Highcpu8 <: GCPType_N1_Highcpu end
abstract type GCPType_N1_Highcpu16 <: GCPType_N1_Highcpu end
abstract type GCPType_N1_Highcpu32 <: GCPType_N1_Highcpu end
abstract type GCPType_N1_Highcpu64 <: GCPType_N1_Highcpu end
abstract type GCPType_N1_Highcpu96 <: GCPType_N1_Highcpu end
# compute optimized machine types
abstract type GCPType_C2 <: GCPType end
abstract type GCPType_C2_Standard <: GCPType_C2 end
abstract type GCPType_C2_Standard4 <: GCPType_C2_Standard end
abstract type GCPType_C2_Standard8 <: GCPType_C2_Standard end
abstract type GCPType_C2_Standard16 <: GCPType_C2_Standard end
abstract type GCPType_C2_Standard30 <: GCPType_C2_Standard end
abstract type GCPType_C2_Standard60 <: GCPType_C2_Standard end
abstract type GCPType_C2D <: GCPType end
abstract type GCPType_C2D_Standard <: GCPType_C2D end
abstract type GCPType_C2D_Highmem <: GCPType_C2D end
abstract type GCPType_C2D_Highcpu <: GCPType_C2D end
abstract type GCPType_C2D_Standard2 <: GCPType_C2D_Standard end
abstract type GCPType_C2D_Standard4 <: GCPType_C2D_Standard end
abstract type GCPType_C2D_Standard8 <: GCPType_C2D_Standard end
abstract type GCPType_C2D_Standard16 <: GCPType_C2D_Standard end
abstract type GCPType_C2D_Standard32 <: GCPType_C2D_Standard end
abstract type GCPType_C2D_Standard56 <: GCPType_C2D_Standard end
abstract type GCPType_C2D_Standard112 <: GCPType_C2D_Standard end
abstract type GCPType_C2D_Highcpu2 <: GCPType_C2D_Highcpu end
abstract type GCPType_C2D_Highcpu4 <: GCPType_C2D_Highcpu end
abstract type GCPType_C2D_Highcpu8 <: GCPType_C2D_Highcpu end
abstract type GCPType_C2D_Highcpu16 <: GCPType_C2D_Highcpu end
abstract type GCPType_C2D_Highcpu32 <: GCPType_C2D_Highcpu end
abstract type GCPType_C2D_Highcpu56 <: GCPType_C2D_Highcpu end
abstract type GCPType_C2D_Highcpu112 <: GCPType_C2D_Highcpu end
abstract type GCPType_C2D_Highmem2 <: GCPType_C2D_Highmem end
abstract type GCPType_C2D_Highmem4 <: GCPType_C2D_Highmem end
abstract type GCPType_C2D_Highmem8 <: GCPType_C2D_Highmem end
abstract type GCPType_C2D_Highmem16 <: GCPType_C2D_Highmem end
abstract type GCPType_C2D_Highmem32 <: GCPType_C2D_Highmem end
abstract type GCPType_C2D_Highmem56 <: GCPType_C2D_Highmem end
abstract type GCPType_C2D_Highmem112 <: GCPType_C2D_Highmem end
# memory optimized machine types
abstract type GCPType_M1 <: GCPType end
abstract type GCPType_M1_Ultramem40 <: GCPType_M1 end
abstract type GCPType_M1_Ultramem80 <: GCPType_M1 end
abstract type GCPType_M1_Ultramem160 <: GCPType_M1 end
abstract type GCPType_M1_Megamem96 <: GCPType_M1 end
abstract type GCPType_M2 <: GCPType end
abstract type GCPType_M2_Ultramem208 <: GCPType_M2 end
abstract type GCPType_M2_Ultramem416 <: GCPType_M2 end
abstract type GCPType_M2_Megamem416 <: GCPType_M2 end
abstract type GCPType_M2_Hypermem416 <: GCPType_M2 end
abstract type GCPType_M3 <: GCPType end
abstract type GCPType_M3_Ultramem32 <: GCPType_M3 end
abstract type GCPType_M3_Ultramem64 <: GCPType_M3 end
abstract type GCPType_M3_Ultramem128 <: GCPType_M3 end
abstract type GCPType_M3_Megamem64 <: GCPType_M3 end
abstract type GCPType_M3_Megamem128 <: GCPType_M3 end
# accelerator optimized machine types
abstract type GCPType_A2 <: GCPType end
abstract type GCPType_G2 <: GCPType end
abstract type GCPType_A2_Highgpu1G <: GCPType_A2 end
abstract type GCPType_A2_Highgpu2G <: GCPType_A2 end
abstract type GCPType_A2_Highgpu4G <: GCPType_A2 end
abstract type GCPType_A2_Highgpu8G <: GCPType_A2 end
abstract type GCPType_A2_Megagpu16G <: GCPType_A2 end
abstract type GCPType_A2_Ultragpu1G <: GCPType_A2 end
abstract type GCPType_A2_Ultragpu2G <: GCPType_A2 end
abstract type GCPType_A2_Ultragpu4G <: GCPType_A2 end
abstract type GCPType_A2_Ultragpu8G <: GCPType_A2 end
abstract type GCPType_G2_Standard4 <: GCPType_G2 end
abstract type GCPType_G2_Standard8 <: GCPType_G2 end
abstract type GCPType_G2_Standard12 <: GCPType_G2 end
abstract type GCPType_G2_Standard16 <: GCPType_G2 end
abstract type GCPType_G2_Standard24 <: GCPType_G2 end
abstract type GCPType_G2_Standard32 <: GCPType_G2 end
abstract type GCPType_G2_Standard48 <: GCPType_G2 end
abstract type GCPType_G2_Standard96 <: GCPType_G2 end
# machine size types
function getNodeFeatures(provider::Type{<:GoogleCloud}, node_features)
nothing
end
function getMachineType(provider::Type{<:GoogleCloud})
machine_type_url = "http://metadata.google.internal/computeMetadata/v1/instance/machine-type"
machine_type =
try
return last(split(String(HTTP.request("GET", machine_type_url, ["Metadata-Flavor" => "Google"]).body), "/"))
catch e
return nothing
end
end
function getDiskInfo(provider::Type{<:GoogleCloud})
disk_info_url = "http://metadata.google.internal/computeMetadata/v1/instance/disks/?recursive=true"
disk_info =
try
return JSON.parse(String(HTTP.request("GET", disk_info_url, ["Metadata-Flavor" => "Google"]).body))
catch e
return nothing
end
end
function readCloudInstancesDB(::Type{<:GoogleCloud})
database_path = @get_scratch!("database_path")
machinetypedb_gcp_url = "https://raw.githubusercontent.com/PlatformAwareProgramming/PlatformAware.jl/master/src/features/qualifiers/gcp/db-machinetypes.gcp.csv"
machinetypedb_gcp_fname = joinpath(database_path,basename(machinetypedb_gcp_url))
#machinetypedb_gcp_fname = "/home/heron/Dropbox/Copy/ufc_mdcc_hpc/PlatformAware/PlatformAware.jl/src/features/qualifiers/gcp/db-machinetypes.gcp.csv"
try_download(machinetypedb_gcp_url, machinetypedb_gcp_fname)
machinetype_dict_gcp = readDB2(machinetypedb_gcp_fname)
return machinetype_dict_gcp
end
| PlatformAware | https://github.com/PlatformAwareProgramming/PlatformAware.jl.git |
|
[
"MIT"
] | 0.6.0 | d8f50cbc077c0992b472a07f99013cd5be80b11a | code | 4412 | # ------------------------------------------------------------------
# Licensed under the MIT License. See LICENCE in the project root.
# ------------------------------------------------------------------
abstract type Intel <: Manufacturer end; export Intel
# Processor models (source: https://ark.intel.com)
abstract type IntelProcessor <: Processor end; export IntelProcessor
# Microarchictetures (from 2010)
abstract type IntelMicroarchitecture <: ProcessorMicroarchitecture end
abstract type Westmere <: IntelMicroarchitecture end
abstract type Saltwell <: IntelMicroarchitecture end
abstract type SandyBridge <: IntelMicroarchitecture end
abstract type IvyBridge <: IntelMicroarchitecture end
abstract type Silvermont <: IntelMicroarchitecture end
abstract type BayTrail <: Silvermont end
abstract type Haswell <: IntelMicroarchitecture end
abstract type Broadwell <: IntelMicroarchitecture end
abstract type Airmont <: IntelMicroarchitecture end
abstract type Skylake <: IntelMicroarchitecture end
abstract type Goldmont <: IntelMicroarchitecture end
abstract type KabyLake <: IntelMicroarchitecture end
abstract type GoldmontPlus <: IntelMicroarchitecture end
abstract type CoffeeLake <: IntelMicroarchitecture end
abstract type CannonLake <: IntelMicroarchitecture end
abstract type SunnyCove <: IntelMicroarchitecture end
abstract type CometLake <: IntelMicroarchitecture end
abstract type IceLake <: IntelMicroarchitecture end
abstract type Tremont <: IntelMicroarchitecture end
abstract type TigerLake <: IntelMicroarchitecture end
abstract type CascadeLake <: IntelMicroarchitecture end
abstract type WillowCove <: IntelMicroarchitecture end
abstract type AlderLake <: IntelMicroarchitecture end
abstract type CypressCove <: IntelMicroarchitecture end
abstract type GoldenCove <: IntelMicroarchitecture end
abstract type Gracemont <: IntelMicroarchitecture end
abstract type WhiskeyLake <: IntelMicroarchitecture end
abstract type RocketLake <: IntelMicroarchitecture end
abstract type HewittLake <: IntelMicroarchitecture end
abstract type CooperLake <: IntelMicroarchitecture end
abstract type ElkhartLake <: IntelMicroarchitecture end
abstract type JasperLake <: IntelMicroarchitecture end
abstract type GeminiLake <: IntelMicroarchitecture end
abstract type GeminiLakeRefresh <: GeminiLake end
abstract type ApolloLake <: IntelMicroarchitecture end
abstract type Braswell <: IntelMicroarchitecture end
abstract type AmberLake <: IntelMicroarchitecture end
abstract type Kittson <: IntelMicroarchitecture end
abstract type Poulson <: IntelMicroarchitecture end
abstract type CrystalWell <: IntelMicroarchitecture end
abstract type DevilsCanyon <: IntelMicroarchitecture end
abstract type Centerton <: IntelMicroarchitecture end
abstract type SnowRidge <: IntelMicroarchitecture end
abstract type Cedarview <: IntelMicroarchitecture end
abstract type ParkerRidge <: IntelMicroarchitecture end
abstract type Denverton <: IntelMicroarchitecture end
abstract type Rangeley <: IntelMicroarchitecture end
abstract type Avoton <: IntelMicroarchitecture end
abstract type Tukwila <: IntelMicroarchitecture end
abstract type Montvale <: IntelMicroarchitecture end
abstract type Montecito <: IntelMicroarchitecture end
export Westmere,
Saltwell,
SandyBridge,
SandyBridgeEP,
IvyBridge,
Silvermont,
Haswell,
Broadwell,
Airmont,
Skylake,
Goldmont,
KabyLake,
CascadeLake,
GoldmontPlus,
CoffeeLake,
CannonLake,
SunnyCove,
CometLake,
IceLake,
Tremont,
TigerLake,
WillowCove,
AlderLake,
CypressCove,
GoldenCove,
Gracemont,
Kittson,
Poulson,
Tukwila,
Montvale,
Montecito,
WhiskeyLake,
HewittLake,
CooperLake,
ElkhartLake,
JasperLake,
GeminiLake,
GeminiLakeRefresh,
ApolloLake,
Braswell,
AmberLake,
CrystalWell,
DevilsCanyon,
Centerton,
SnowRidge,
Cedarview,
ParkerRidge,
Denverton,
Rangeley,
Avoton
# Intel Accelerators
abstract type IntelAccelerator <: Accelerator end
abstract type IntelAcceleratorArchitecture <: AcceleratorArchitecture end; export IntelAcceleratorArchitecture
| PlatformAware | https://github.com/PlatformAwareProgramming/PlatformAware.jl.git |
|
[
"MIT"
] | 0.6.0 | d8f50cbc077c0992b472a07f99013cd5be80b11a | code | 2382 | # ------------------------------------------------------------------
# Licensed under the MIT License. See LICENCE in the project root.
# ------------------------------------------------------------------
abstract type KnightsLanding <: IntelAcceleratorArchitecture end; export KnightsLanding
abstract type KnightsCorner <: IntelAcceleratorArchitecture end; export KnightsCorner
abstract type KnightsMill <: IntelAcceleratorArchitecture end; export KnightsMill
abstract type IntelXeonPhi <: IntelAccelerator end; export IntelXeonPhi
abstract type IntelXeonPhi_72x5 <: IntelXeonPhi end; export IntelXeonPhi_72x5
abstract type IntelXeonPhi_x100 <: IntelXeonPhi end; export IntelXeonPhi_x100
abstract type IntelXeonPhi_x200 <: IntelXeonPhi end; export IntelXeonPhi_x200
abstract type IntelXeonPhi_7120A <: IntelXeonPhi_x100 end; export IntelXeonPhi_7120A
abstract type IntelXeonPhi_7120D <: IntelXeonPhi_x100 end; export IntelXeonPhi_7120D
abstract type IntelXeonPhi_3120A <: IntelXeonPhi_x100 end; export IntelXeonPhi_3120A
abstract type IntelXeonPhi_3120P <: IntelXeonPhi_x100 end; export IntelXeonPhi_3120P
abstract type IntelXeonPhi_5120D <: IntelXeonPhi_x100 end; export IntelXeonPhi_5120D
abstract type IntelXeonPhi_7120P <: IntelXeonPhi_x100 end; export IntelXeonPhi_7120P
abstract type IntelXeonPhi_7120X <: IntelXeonPhi_x100 end; export IntelXeonPhi_7120X
abstract type IntelXeonPhi_5110P <: IntelXeonPhi_x100 end; export IntelXeonPhi_5110P
abstract type IntelXeonPhi_7210 <: IntelXeonPhi_x200 end; export IntelXeonPhi_7210
abstract type IntelXeonPhi_7210F <: IntelXeonPhi_x200 end; export IntelXeonPhi_7210F
abstract type IntelXeonPhi_7230 <: IntelXeonPhi_x200 end; export IntelXeonPhi_7230
abstract type IntelXeonPhi_7230F <: IntelXeonPhi_x200 end; export IntelXeonPhi_7230F
abstract type IntelXeonPhi_7250 <: IntelXeonPhi_x200 end; export IntelXeonPhi_7250
abstract type IntelXeonPhi_7250F <: IntelXeonPhi_x200 end; export IntelXeonPhi_7250F
abstract type IntelXeonPhi_7290 <: IntelXeonPhi_x200 end; export IntelXeonPhi_7290
abstract type IntelXeonPhi_7290F <: IntelXeonPhi_x200 end; export IntelXeonPhi_7290F
abstract type IntelXeonPhi_7235 <: IntelXeonPhi_72x5 end; export IntelXeonPhi_7235
abstract type IntelXeonPhi_7285 <: IntelXeonPhi_72x5 end; export IntelXeonPhi_7285
abstract type IntelXeonPhi_7295 <: IntelXeonPhi_72x5 end; export IntelXeonPhi_7295
| PlatformAware | https://github.com/PlatformAwareProgramming/PlatformAware.jl.git |
|
[
"MIT"
] | 0.6.0 | d8f50cbc077c0992b472a07f99013cd5be80b11a | code | 10251 | # ------------------------------------------------------------------
# Licensed under the MIT License. See LICENCE in the project root.
# ------------------------------------------------------------------
## Atom processors
abstract type IntelAtom <: IntelProcessor end; export IntelAtom
abstract type IntelAtom_C <: IntelAtom end; export IntelAtom_C
abstract type IntelAtom_D <: IntelAtom end; export IntelAtom_D
abstract type IntelAtom_E <: IntelAtom end; export IntelAtom_E
abstract type IntelAtom_N <: IntelAtom end; export IntelAtom_N
abstract type IntelAtom_P <: IntelAtom end; export IntelAtom_P
abstract type IntelAtom_S <: IntelAtom end; export IntelAtom_S
abstract type IntelAtom_X <: IntelAtom end; export IntelAtom_X
abstract type IntelAtom_Z <: IntelAtom end; export IntelAtom_Z
# Atom processor models
abstract type IntelAtom_C5115 <: IntelAtom_C end; export IntelAtom_C5115
abstract type IntelAtom_C5125 <: IntelAtom_C end; export IntelAtom_C5125
abstract type IntelAtom_C5310 <: IntelAtom_C end; export IntelAtom_C5310
abstract type IntelAtom_C5315 <: IntelAtom_C end; export IntelAtom_C5315
abstract type IntelAtom_C5320 <: IntelAtom_C end; export IntelAtom_C5320
abstract type IntelAtom_C5325 <: IntelAtom_C end; export IntelAtom_C5325
abstract type IntelAtom_C3338R <: IntelAtom_C end; export IntelAtom_C3338R
abstract type IntelAtom_C3436L <: IntelAtom_C end; export IntelAtom_C3436L
abstract type IntelAtom_C3558R <: IntelAtom_C end; export IntelAtom_C3558R
abstract type IntelAtom_C3758R <: IntelAtom_C end; export IntelAtom_C3758R
abstract type IntelAtom_C3336 <: IntelAtom_C end; export IntelAtom_C3336
abstract type IntelAtom_C3308 <: IntelAtom_C end; export IntelAtom_C3308
abstract type IntelAtom_C3508 <: IntelAtom_C end; export IntelAtom_C3508
abstract type IntelAtom_C3538 <: IntelAtom_C end; export IntelAtom_C3538
abstract type IntelAtom_C3558 <: IntelAtom_C end; export IntelAtom_C3558
abstract type IntelAtom_C3708 <: IntelAtom_C end; export IntelAtom_C3708
abstract type IntelAtom_C3750 <: IntelAtom_C end; export IntelAtom_C3750
abstract type IntelAtom_C3758 <: IntelAtom_C end; export IntelAtom_C3758
abstract type IntelAtom_C3808 <: IntelAtom_C end; export IntelAtom_C3808
abstract type IntelAtom_C3830 <: IntelAtom_C end; export IntelAtom_C3830
abstract type IntelAtom_C3850 <: IntelAtom_C end; export IntelAtom_C3850
abstract type IntelAtom_C3858 <: IntelAtom_C end; export IntelAtom_C3858
abstract type IntelAtom_C3950 <: IntelAtom_C end; export IntelAtom_C3950
abstract type IntelAtom_C3955 <: IntelAtom_C end; export IntelAtom_C3955
abstract type IntelAtom_C3958 <: IntelAtom_C end; export IntelAtom_C3958
abstract type IntelAtom_C2316 <: IntelAtom_C end; export IntelAtom_C2316
abstract type IntelAtom_C2516 <: IntelAtom_C end; export IntelAtom_C2516
abstract type IntelAtom_C3338 <: IntelAtom_C end; export IntelAtom_C3338
abstract type IntelAtom_C2308 <: IntelAtom_C end; export IntelAtom_C2308
abstract type IntelAtom_C2508 <: IntelAtom_C end; export IntelAtom_C2508
abstract type IntelAtom_C2338 <: IntelAtom_C end; export IntelAtom_C2338
abstract type IntelAtom_C2350 <: IntelAtom_C end; export IntelAtom_C2350
abstract type IntelAtom_C2358 <: IntelAtom_C end; export IntelAtom_C2358
abstract type IntelAtom_C2518 <: IntelAtom_C end; export IntelAtom_C2518
abstract type IntelAtom_C2530 <: IntelAtom_C end; export IntelAtom_C2530
abstract type IntelAtom_C2538 <: IntelAtom_C end; export IntelAtom_C2538
abstract type IntelAtom_C2550 <: IntelAtom_C end; export IntelAtom_C2550
abstract type IntelAtom_C2558 <: IntelAtom_C end; export IntelAtom_C2558
abstract type IntelAtom_C2718 <: IntelAtom_C end; export IntelAtom_C2718
abstract type IntelAtom_C2730 <: IntelAtom_C end; export IntelAtom_C2730
abstract type IntelAtom_C2738 <: IntelAtom_C end; export IntelAtom_C2738
abstract type IntelAtom_C2750 <: IntelAtom_C end; export IntelAtom_C2750
abstract type IntelAtom_C2758 <: IntelAtom_C end; export IntelAtom_C2758
abstract type IntelAtom_D2550 <: IntelAtom_D end; export IntelAtom_D2550
abstract type IntelAtom_D2500 <: IntelAtom_D end; export IntelAtom_D2500
abstract type IntelAtom_D2700 <: IntelAtom_D end; export IntelAtom_D2700
abstract type IntelAtom_E3805 <: IntelAtom_E end; export IntelAtom_E3805
abstract type IntelAtom_E3815 <: IntelAtom_E end; export IntelAtom_E3815
abstract type IntelAtom_E3825 <: IntelAtom_E end; export IntelAtom_E3825
abstract type IntelAtom_E3826 <: IntelAtom_E end; export IntelAtom_E3826
abstract type IntelAtom_E3827 <: IntelAtom_E end; export IntelAtom_E3827
abstract type IntelAtom_E3845 <: IntelAtom_E end; export IntelAtom_E3845
abstract type IntelAtom_N2600 <: IntelAtom_N end; export IntelAtom_N2600
abstract type IntelAtom_N2800 <: IntelAtom_N end; export IntelAtom_N2800
abstract type IntelAtom_P5322 <: IntelAtom_P end; export IntelAtom_P5322
abstract type IntelAtom_P5332 <: IntelAtom_P end; export IntelAtom_P5332
abstract type IntelAtom_P5342 <: IntelAtom_P end; export IntelAtom_P5342
abstract type IntelAtom_P5352 <: IntelAtom_P end; export IntelAtom_P5352
abstract type IntelAtom_P5362 <: IntelAtom_P end; export IntelAtom_P5362
abstract type IntelAtom_P5721 <: IntelAtom_P end; export IntelAtom_P5721
abstract type IntelAtom_P5731 <: IntelAtom_P end; export IntelAtom_P5731
abstract type IntelAtom_P5742 <: IntelAtom_P end; export IntelAtom_P5742
abstract type IntelAtom_P5752 <: IntelAtom_P end; export IntelAtom_P5752
abstract type IntelAtom_P5921B <: IntelAtom_P end; export IntelAtom_P5921B
abstract type IntelAtom_P5931B <: IntelAtom_P end; export IntelAtom_P5931B
abstract type IntelAtom_P5942B <: IntelAtom_P end; export IntelAtom_P5942B
abstract type IntelAtom_P5962B <: IntelAtom_P end; export IntelAtom_P5962B
abstract type IntelAtom_S1220 <: IntelAtom_S end; export IntelAtom_S1220
abstract type IntelAtom_S1240 <: IntelAtom_S end; export IntelAtom_S1240
abstract type IntelAtom_S1260 <: IntelAtom_S end; export IntelAtom_S1260
abstract type IntelAtom_6200FE <: IntelAtom_X end; export IntelAtom_6200FE
abstract type IntelAtom_6211E <: IntelAtom_X end; export IntelAtom_6211E
abstract type IntelAtom_6212RE <: IntelAtom_X end; export IntelAtom_6212RE
abstract type IntelAtom_6413E <: IntelAtom_X end; export IntelAtom_6413E
abstract type IntelAtom_6414RE <: IntelAtom_X end; export IntelAtom_6414RE
abstract type IntelAtom_6425E <: IntelAtom_X end; export IntelAtom_6425E
abstract type IntelAtom_6425RE <: IntelAtom_X end; export IntelAtom_6425RE
abstract type IntelAtom_6427FE <: IntelAtom_X end; export IntelAtom_6427FE
abstract type IntelAtom_x3_3205RK <: IntelAtom_X end; export IntelAtom_x3_3205RK
abstract type IntelAtom_x3_C3235RK <: IntelAtom_X end; export IntelAtom_x3_C3235RK
abstract type IntelAtom_x3_C3265RK <: IntelAtom_X end; export IntelAtom_x3_C3265RK
abstract type IntelAtom_x3_C3295RK <: IntelAtom_X end; export IntelAtom_x3_C3295RK
abstract type IntelAtom_E3930 <: IntelAtom_X end; export IntelAtom_E3930
abstract type IntelAtom_E3940 <: IntelAtom_X end; export IntelAtom_E3940
abstract type IntelAtom_E3950 <: IntelAtom_X end; export IntelAtom_E3950
abstract type IntelAtom_x5_Z8550 <: IntelAtom_X end; export IntelAtom_x5_Z8550
abstract type IntelAtom_x7_Z8750 <: IntelAtom_X end; export IntelAtom_x7_Z8750
abstract type IntelAtom_x5_Z8330 <: IntelAtom_X end; export IntelAtom_x5_Z8330
abstract type IntelAtom_x5_Z8350 <: IntelAtom_X end; export IntelAtom_x5_Z8350
abstract type IntelAtom_E8000 <: IntelAtom_X end; export IntelAtom_E8000
abstract type IntelAtom_x3_C3200RK <: IntelAtom_X end; export IntelAtom_x3_C3200RK
abstract type IntelAtom_x3_C3405 <: IntelAtom_X end; export IntelAtom_x3_C3405
abstract type IntelAtom_x3_C3230RK <: IntelAtom_X end; export IntelAtom_x3_C3230RK
abstract type IntelAtom_x3_C3445 <: IntelAtom_X end; export IntelAtom_x3_C3445
abstract type IntelAtom_x5_Z8300 <: IntelAtom_X end; export IntelAtom_x5_Z8300
abstract type IntelAtom_x5_Z8500 <: IntelAtom_X end; export IntelAtom_x5_Z8500
abstract type IntelAtom_x7_Z8700 <: IntelAtom_X end; export IntelAtom_x7_Z8700
abstract type IntelAtom_Z3590 <: IntelAtom_Z end; export IntelAtom_Z3590
abstract type IntelAtom_Z3570 <: IntelAtom_Z end; export IntelAtom_Z3570
abstract type IntelAtom_Z3736F <: IntelAtom_Z end; export IntelAtom_Z3736F
abstract type IntelAtom_Z3736G <: IntelAtom_Z end; export IntelAtom_Z3736G
abstract type IntelAtom_Z3530 <: IntelAtom_Z end; export IntelAtom_Z3530
abstract type IntelAtom_Z3785 <: IntelAtom_Z end; export IntelAtom_Z3785
abstract type IntelAtom_Z3560 <: IntelAtom_Z end; export IntelAtom_Z3560
abstract type IntelAtom_Z3580 <: IntelAtom_Z end; export IntelAtom_Z3580
abstract type IntelAtom_Z3735F <: IntelAtom_Z end; export IntelAtom_Z3735F
abstract type IntelAtom_Z3735G <: IntelAtom_Z end; export IntelAtom_Z3735G
abstract type IntelAtom_Z3460 <: IntelAtom_Z end; export IntelAtom_Z3460
abstract type IntelAtom_Z3480 <: IntelAtom_Z end; export IntelAtom_Z3480
abstract type IntelAtom_Z3735D <: IntelAtom_Z end; export IntelAtom_Z3735D
abstract type IntelAtom_Z3735E <: IntelAtom_Z end; export IntelAtom_Z3735E
abstract type IntelAtom_Z3775D <: IntelAtom_Z end; export IntelAtom_Z3775D
abstract type IntelAtom_Z3795 <: IntelAtom_Z end; export IntelAtom_Z3795
abstract type IntelAtom_Z3745 <: IntelAtom_Z end; export IntelAtom_Z3745
abstract type IntelAtom_Z3745D <: IntelAtom_Z end; export IntelAtom_Z3745D
abstract type IntelAtom_Z3775 <: IntelAtom_Z end; export IntelAtom_Z3775
abstract type IntelAtom_Z3740 <: IntelAtom_Z end; export IntelAtom_Z3740
abstract type IntelAtom_Z3740D <: IntelAtom_Z end; export IntelAtom_Z3740D
abstract type IntelAtom_Z3770 <: IntelAtom_Z end; export IntelAtom_Z3770
abstract type IntelAtom_Z3770D <: IntelAtom_Z end; export IntelAtom_Z3770D
abstract type IntelAtom_Z2520 <: IntelAtom_Z end; export IntelAtom_Z2520
abstract type IntelAtom_Z2560 <: IntelAtom_Z end; export IntelAtom_Z2560
abstract type IntelAtom_Z2580 <: IntelAtom_Z end; export IntelAtom_Z2580
abstract type IntelAtom_Z2420 <: IntelAtom_Z end; export IntelAtom_Z2420
abstract type IntelAtom_Z2480 <: IntelAtom_Z end; export IntelAtom_Z2480
abstract type IntelAtom_Z2760 <: IntelAtom_Z end; export IntelAtom_Z2760
abstract type IntelAtom_Z2460 <: IntelAtom_Z end; export IntelAtom_Z2460
| PlatformAware | https://github.com/PlatformAwareProgramming/PlatformAware.jl.git |
|
[
"MIT"
] | 0.6.0 | d8f50cbc077c0992b472a07f99013cd5be80b11a | code | 11964 | # ------------------------------------------------------------------
# Licensed under the MIT License. See LICENCE in the project root.
# ------------------------------------------------------------------
## Celeron processors
abstract type IntelCeleron <: IntelProcessor end
abstract type IntelCeleron_G <: IntelCeleron end
abstract type IntelCeleron_J <: IntelCeleron end
abstract type IntelCeleron_N <: IntelCeleron end
abstract type IntelCeleron_7000 <: IntelCeleron end
abstract type IntelCeleron_6000 <: IntelCeleron end
abstract type IntelCeleron_5000 <: IntelCeleron end
abstract type IntelCeleron_4000 <: IntelCeleron end
abstract type IntelCeleron_3000 <: IntelCeleron end
abstract type IntelCeleron_2000 <: IntelCeleron end
abstract type IntelCeleron_1000 <: IntelCeleron end
export IntelCeleron,
IntelCeleron_1000,
IntelCeleron_2000,
IntelCeleron_3000,
IntelCeleron_4000,
IntelCeleron_5000,
IntelCeleron_6000,
IntelCeleron_7000,
IntelCeleron_G,
IntelCeleron_J,
IntelCeleron_N
# Celeron processor models
abstract type IntelCeleron_7305 <: IntelCeleron_7000 end; export IntelCeleron_7305
abstract type IntelCeleron_6305 <: IntelCeleron_6000 end; export IntelCeleron_6305
abstract type IntelCeleron_4305U <: IntelCeleron_4000 end; export IntelCeleron_4305U
abstract type IntelCeleron_G6900 <: IntelCeleron_G end; export IntelCeleron_G6900
abstract type IntelCeleron_G6900E <: IntelCeleron_G end; export IntelCeleron_G6900E
abstract type IntelCeleron_G6900T <: IntelCeleron_G end; export IntelCeleron_G6900T
abstract type IntelCeleron_G6900TE <: IntelCeleron_G end; export IntelCeleron_G6900TE
abstract type IntelCeleron_G5905 <: IntelCeleron_G end; export IntelCeleron_G5905
abstract type IntelCeleron_G5905T <: IntelCeleron_G end; export IntelCeleron_G5905T
abstract type IntelCeleron_G5925 <: IntelCeleron_G end; export IntelCeleron_G5925
abstract type IntelCeleron_G5900 <: IntelCeleron_G end; export IntelCeleron_G5900
abstract type IntelCeleron_G5900E <: IntelCeleron_G end; export IntelCeleron_G5900E
abstract type IntelCeleron_G5900T <: IntelCeleron_G end; export IntelCeleron_G5900T
abstract type IntelCeleron_G5900TE <: IntelCeleron_G end; export IntelCeleron_G5900TE
abstract type IntelCeleron_G5920 <: IntelCeleron_G end; export IntelCeleron_G5920
abstract type IntelCeleron_G4930E <: IntelCeleron_G end; export IntelCeleron_G4930E
abstract type IntelCeleron_G4932E <: IntelCeleron_G end; export IntelCeleron_G4932E
abstract type IntelCeleron_G4930 <: IntelCeleron_G end; export IntelCeleron_G4930
abstract type IntelCeleron_G4930T <: IntelCeleron_G end; export IntelCeleron_G4930T
abstract type IntelCeleron_G4950 <: IntelCeleron_G end; export IntelCeleron_G4950
abstract type IntelCeleron_G4900 <: IntelCeleron_G end; export IntelCeleron_G4900
abstract type IntelCeleron_G4900T <: IntelCeleron_G end; export IntelCeleron_G4900T
abstract type IntelCeleron_G4920 <: IntelCeleron_G end; export IntelCeleron_G4920
abstract type IntelCeleron_G3930E <: IntelCeleron_G end; export IntelCeleron_G3930E
abstract type IntelCeleron_G3930TE <: IntelCeleron_G end; export IntelCeleron_G3930TE
abstract type IntelCeleron_G3930 <: IntelCeleron_G end; export IntelCeleron_G3930
abstract type IntelCeleron_G3930T <: IntelCeleron_G end; export IntelCeleron_G3930T
abstract type IntelCeleron_G3950 <: IntelCeleron_G end; export IntelCeleron_G3950
abstract type IntelCeleron_G3900E <: IntelCeleron_G end; export IntelCeleron_G3900E
abstract type IntelCeleron_G3902E <: IntelCeleron_G end; export IntelCeleron_G3902E
abstract type IntelCeleron_G3900 <: IntelCeleron_G end; export IntelCeleron_G3900
abstract type IntelCeleron_G3900T <: IntelCeleron_G end; export IntelCeleron_G3900T
abstract type IntelCeleron_G3900TE <: IntelCeleron_G end; export IntelCeleron_G3900TE
abstract type IntelCeleron_G3920 <: IntelCeleron_G end; export IntelCeleron_G3920
abstract type IntelCeleron_G1840 <: IntelCeleron_G end; export IntelCeleron_G1840
abstract type IntelCeleron_G1840T <: IntelCeleron_G end; export IntelCeleron_G1840T
abstract type IntelCeleron_G1850 <: IntelCeleron_G end; export IntelCeleron_G1850
abstract type IntelCeleron_G1820TE <: IntelCeleron_G end; export IntelCeleron_G1820TE
abstract type IntelCeleron_G1820 <: IntelCeleron_G end; export IntelCeleron_G1820
abstract type IntelCeleron_G1820T <: IntelCeleron_G end; export IntelCeleron_G1820T
abstract type IntelCeleron_G1830 <: IntelCeleron_G end; export IntelCeleron_G1830
abstract type IntelCeleron_G1620T <: IntelCeleron_G end; export IntelCeleron_G1620T
abstract type IntelCeleron_G1630 <: IntelCeleron_G end; export IntelCeleron_G1630
abstract type IntelCeleron_G1610 <: IntelCeleron_G end; export IntelCeleron_G1610
abstract type IntelCeleron_G1610T <: IntelCeleron_G end; export IntelCeleron_G1610T
abstract type IntelCeleron_G1620 <: IntelCeleron_G end; export IntelCeleron_G1620
abstract type IntelCeleron_J6412 <: IntelCeleron_J end; export IntelCeleron_J6412
abstract type IntelCeleron_J6413 <: IntelCeleron_J end; export IntelCeleron_J6413
abstract type IntelCeleron_J4025 <: IntelCeleron_J end; export IntelCeleron_J4025
abstract type IntelCeleron_J4125 <: IntelCeleron_J end; export IntelCeleron_J4125
abstract type IntelCeleron_J3355E <: IntelCeleron_J end; export IntelCeleron_J3355E
abstract type IntelCeleron_J3455E <: IntelCeleron_J end; export IntelCeleron_J3455E
abstract type IntelCeleron_J4005 <: IntelCeleron_J end; export IntelCeleron_J4005
abstract type IntelCeleron_J4105 <: IntelCeleron_J end; export IntelCeleron_J4105
abstract type IntelCeleron_J3355 <: IntelCeleron_J end; export IntelCeleron_J3355
abstract type IntelCeleron_J3455 <: IntelCeleron_J end; export IntelCeleron_J3455
abstract type IntelCeleron_J3060 <: IntelCeleron_J end; export IntelCeleron_J3060
abstract type IntelCeleron_J3160 <: IntelCeleron_J end; export IntelCeleron_J3160
abstract type IntelCeleron_J1800 <: IntelCeleron_J end; export IntelCeleron_J1800
abstract type IntelCeleron_J1900 <: IntelCeleron_J end; export IntelCeleron_J1900
abstract type IntelCeleron_J1750 <: IntelCeleron_J end; export IntelCeleron_J1750
abstract type IntelCeleron_J1850 <: IntelCeleron_J end; export IntelCeleron_J1850
abstract type IntelCeleron_N6210 <: IntelCeleron_N end; export IntelCeleron_N6210
abstract type IntelCeleron_N4500 <: IntelCeleron_N end; export IntelCeleron_N4500
abstract type IntelCeleron_N4505 <: IntelCeleron_N end; export IntelCeleron_N4505
abstract type IntelCeleron_N5100 <: IntelCeleron_N end; export IntelCeleron_N5100
abstract type IntelCeleron_N5105 <: IntelCeleron_N end; export IntelCeleron_N5105
abstract type IntelCeleron_N6211 <: IntelCeleron_N end; export IntelCeleron_N6211
abstract type IntelCeleron_N4020 <: IntelCeleron_N end; export IntelCeleron_N4020
abstract type IntelCeleron_N4120 <: IntelCeleron_N end; export IntelCeleron_N4120
abstract type IntelCeleron_N3350E <: IntelCeleron_N end; export IntelCeleron_N3350E
abstract type IntelCeleron_N4000 <: IntelCeleron_N end; export IntelCeleron_N4000
abstract type IntelCeleron_N4100 <: IntelCeleron_N end; export IntelCeleron_N4100
abstract type IntelCeleron_N3350 <: IntelCeleron_N end; export IntelCeleron_N3350
abstract type IntelCeleron_N3450 <: IntelCeleron_N end; export IntelCeleron_N3450
abstract type IntelCeleron_N3010 <: IntelCeleron_N end; export IntelCeleron_N3010
abstract type IntelCeleron_N3060 <: IntelCeleron_N end; export IntelCeleron_N3060
abstract type IntelCeleron_N3160 <: IntelCeleron_N end; export IntelCeleron_N3160
abstract type IntelCeleron_N3000 <: IntelCeleron_N end; export IntelCeleron_N3000
abstract type IntelCeleron_N3050 <: IntelCeleron_N end; export IntelCeleron_N3050
abstract type IntelCeleron_N3150 <: IntelCeleron_N end; export IntelCeleron_N3150
abstract type IntelCeleron_N2808 <: IntelCeleron_N end; export IntelCeleron_N2808
abstract type IntelCeleron_N2840 <: IntelCeleron_N end; export IntelCeleron_N2840
abstract type IntelCeleron_N2940 <: IntelCeleron_N end; export IntelCeleron_N2940
abstract type IntelCeleron_N2807 <: IntelCeleron_N end; export IntelCeleron_N2807
abstract type IntelCeleron_N2830 <: IntelCeleron_N end; export IntelCeleron_N2830
abstract type IntelCeleron_N2930 <: IntelCeleron_N end; export IntelCeleron_N2930
abstract type IntelCeleron_N2806 <: IntelCeleron_N end; export IntelCeleron_N2806
abstract type IntelCeleron_N2815 <: IntelCeleron_N end; export IntelCeleron_N2815
abstract type IntelCeleron_N2820 <: IntelCeleron_N end; export IntelCeleron_N2820
abstract type IntelCeleron_N2920 <: IntelCeleron_N end; export IntelCeleron_N2920
abstract type IntelCeleron_N2805 <: IntelCeleron_N end; export IntelCeleron_N2805
abstract type IntelCeleron_N2810 <: IntelCeleron_N end; export IntelCeleron_N2810
abstract type IntelCeleron_N2910 <: IntelCeleron_N end; export IntelCeleron_N2910
abstract type IntelCeleron_7305E <: IntelCeleron_7000 end; export IntelCeleron_7305E
abstract type IntelCeleron_7300 <: IntelCeleron_7000 end; export IntelCeleron_7300
abstract type IntelCeleron_6600HE <: IntelCeleron_6000 end; export IntelCeleron_6600HE
abstract type IntelCeleron_6305E <: IntelCeleron_6000 end; export IntelCeleron_6305E
abstract type IntelCeleron_5305U <: IntelCeleron_5000 end; export IntelCeleron_5305U
abstract type IntelCeleron_5205U <: IntelCeleron_5000 end; export IntelCeleron_5205U
abstract type IntelCeleron_4305UE <: IntelCeleron_4000 end; export IntelCeleron_4305UE
abstract type IntelCeleron_4205U <: IntelCeleron_4000 end; export IntelCeleron_4205U
abstract type IntelCeleron_3867U <: IntelCeleron_3000 end; export IntelCeleron_3867U
abstract type IntelCeleron_3965Y <: IntelCeleron_3000 end; export IntelCeleron_3965Y
abstract type IntelCeleron_3865U <: IntelCeleron_3000 end; export IntelCeleron_3865U
abstract type IntelCeleron_3965U <: IntelCeleron_3000 end; export IntelCeleron_3965U
abstract type IntelCeleron_3855U <: IntelCeleron_3000 end; export IntelCeleron_3855U
abstract type IntelCeleron_3955U <: IntelCeleron_3000 end; export IntelCeleron_3955U
abstract type IntelCeleron_3215U <: IntelCeleron_3000 end; export IntelCeleron_3215U
abstract type IntelCeleron_3765U <: IntelCeleron_3000 end; export IntelCeleron_3765U
abstract type IntelCeleron_3205U <: IntelCeleron_3000 end; export IntelCeleron_3205U
abstract type IntelCeleron_3755U <: IntelCeleron_3000 end; export IntelCeleron_3755U
abstract type IntelCeleron_2970M <: IntelCeleron_2000 end; export IntelCeleron_2970M
abstract type IntelCeleron_2000E <: IntelCeleron_2000 end; export IntelCeleron_2000E
abstract type IntelCeleron_2002E <: IntelCeleron_2000 end; export IntelCeleron_2002E
abstract type IntelCeleron_2957U <: IntelCeleron_2000 end; export IntelCeleron_2957U
abstract type IntelCeleron_2961Y <: IntelCeleron_2000 end; export IntelCeleron_2961Y
abstract type IntelCeleron_2981U <: IntelCeleron_2000 end; export IntelCeleron_2981U
abstract type IntelCeleron_2950M <: IntelCeleron_2000 end; export IntelCeleron_2950M
abstract type IntelCeleron_2955U <: IntelCeleron_2000 end; export IntelCeleron_2955U
abstract type IntelCeleron_2980U <: IntelCeleron_2000 end; export IntelCeleron_2980U
abstract type IntelCeleron_1005M <: IntelCeleron_1000 end; export IntelCeleron_1005M
abstract type IntelCeleron_1017U <: IntelCeleron_1000 end; export IntelCeleron_1017U
abstract type IntelCeleron_1019Y <: IntelCeleron_1000 end; export IntelCeleron_1019Y
abstract type IntelCeleron_1000M <: IntelCeleron_1000 end; export IntelCeleron_1000M
abstract type IntelCeleron_1007U <: IntelCeleron_1000 end; export IntelCeleron_1007U
abstract type IntelCeleron_1020E <: IntelCeleron_1000 end; export IntelCeleron_1020E
abstract type IntelCeleron_1020M <: IntelCeleron_1000 end; export IntelCeleron_1020M
abstract type IntelCeleron_1037U <: IntelCeleron_1000 end; export IntelCeleron_1037U
abstract type IntelCeleron_1047UE <: IntelCeleron_1000 end; export IntelCeleron_1047UE
| PlatformAware | https://github.com/PlatformAwareProgramming/PlatformAware.jl.git |
|
[
"MIT"
] | 0.6.0 | d8f50cbc077c0992b472a07f99013cd5be80b11a | code | 56699 | # ------------------------------------------------------------------
# Licensed under the MIT License. See LICENCE in the project root.
# ------------------------------------------------------------------
### Core processors
abstract type IntelCore <: IntelProcessor end
#### Core X processors
abstract type IntelCore_X <: IntelCore end
#### Core i9 processors
abstract type IntelCore_i9 <: IntelCore end
abstract type IntelCore_i9_g8 <: IntelCore_i9 end
abstract type IntelCore_i9_g9 <: IntelCore_i9 end
abstract type IntelCore_i9_g10 <: IntelCore_i9 end
abstract type IntelCore_i9_g11 <: IntelCore_i9 end
abstract type IntelCore_i9_g12 <: IntelCore_i9 end
#### Core i7 processors
abstract type IntelCore_i7 <: IntelCore end
abstract type IntelCore_i7_g4 <: IntelCore_i7 end
abstract type IntelCore_i7_g5 <: IntelCore_i7 end
abstract type IntelCore_i7_g6 <: IntelCore_i7 end
abstract type IntelCore_i7_g7 <: IntelCore_i7 end
abstract type IntelCore_i7_g8 <: IntelCore_i7 end
abstract type IntelCore_i7_g9 <: IntelCore_i7 end
abstract type IntelCore_i7_g10 <: IntelCore_i7 end
abstract type IntelCore_i7_g11 <: IntelCore_i7 end
abstract type IntelCore_i7_g12 <: IntelCore_i7 end
#### Core i5 processors
abstract type IntelCore_i5 <: IntelCore end
abstract type IntelCore_i5_g4 <: IntelCore_i5 end
abstract type IntelCore_i5_g5 <: IntelCore_i5 end
abstract type IntelCore_i5_g6 <: IntelCore_i5 end
abstract type IntelCore_i5_g7 <: IntelCore_i5 end
abstract type IntelCore_i5_g8 <: IntelCore_i5 end
abstract type IntelCore_i5_g9 <: IntelCore_i5 end
abstract type IntelCore_i5_g10 <: IntelCore_i5 end
abstract type IntelCore_i5_g11 <: IntelCore_i5 end
abstract type IntelCore_i5_g12 <: IntelCore_i5 end
#### Core i3 processors
abstract type IntelCore_i3 <: IntelCore end
abstract type IntelCore_i3_g4 <: IntelCore_i3 end
abstract type IntelCore_i3_g5 <: IntelCore_i3 end
abstract type IntelCore_i3_g6 <: IntelCore_i3 end
abstract type IntelCore_i3_g7 <: IntelCore_i3 end
abstract type IntelCore_i3_g8 <: IntelCore_i3 end
abstract type IntelCore_i3_g9 <: IntelCore_i3 end
abstract type IntelCore_i3_g10 <: IntelCore_i3 end
abstract type IntelCore_i3_g11 <: IntelCore_i3 end
abstract type IntelCore_i3_g12 <: IntelCore_i3 end
#### Core M processors
abstract type IntelCore_M <: IntelCore end
abstract type IntelCore_M_g5 <: IntelCore_M end
abstract type IntelCore_M_g6 <: IntelCore_M end
abstract type IntelCore_M_g7 <: IntelCore_M end
abstract type IntelCore_M_g8 <: IntelCore_M end
export IntelCore,
IntelCore_i3,
IntelCore_i3_g12,
IntelCore_i3_g11,
IntelCore_i3_g10,
IntelCore_i3_g9,
IntelCore_i3_g8,
IntelCore_i3_g7,
IntelCore_i3_g6,
IntelCore_i3_g5,
IntelCore_i3_g4,
IntelCore_i5,
IntelCore_i5_g12,
IntelCore_i5_g11,
IntelCore_i5_g10,
IntelCore_i5_g9,
IntelCore_i5_g8,
IntelCore_i5_g7,
IntelCore_i5_g6,
IntelCore_i5_g5,
IntelCore_i5_g4,
IntelCore_i7,
IntelCore_i7_g12,
IntelCore_i7_g11,
IntelCore_i7_g10,
IntelCore_i7_g9,
IntelCore_i7_g8,
IntelCore_i7_g7,
IntelCore_i7_g6,
IntelCore_i7_g5,
IntelCore_i7_g4,
IntelCore_i9,
IntelCore_i9_g12,
IntelCore_i9_g11,
IntelCore_i9_g10,
IntelCore_i9_g9,
IntelCore_i9_g8,
IntelCore_X,
IntelCore_i9_10900X,
IntelCore_M,
IntelCore_M_g8,
IntelCore_M_g7,
IntelCore_M_g6,
IntelCore_M_g5,
IntelCore_i7_7500U
# Processor models
abstract type IntelCore_i5_11300H <: IntelCore_i5_g11 end; export IntelCore_i5_11300H
abstract type IntelCore_i5_1140G7 <: IntelCore_i5_g11 end; export IntelCore_i5_1140G7
abstract type IntelCore_i5_1145G7 <: IntelCore_i5_g11 end; export IntelCore_i5_1145G7
abstract type IntelCore_i7_11370H <: IntelCore_i7_g11 end; export IntelCore_i7_11370H
abstract type IntelCore_i7_11375H <: IntelCore_i7_g11 end; export IntelCore_i7_11375H
abstract type IntelCore_i7_1180G7 <: IntelCore_i7_g11 end; export IntelCore_i7_1180G7
abstract type IntelCore_i5_1145G7E <: IntelCore_i5_g11 end; export IntelCore_i5_1145G7E
abstract type IntelCore_i5_1145GRE <: IntelCore_i5_g11 end; export IntelCore_i5_1145GRE
abstract type IntelCore_i7_1185G7E <: IntelCore_i7_g11 end; export IntelCore_i7_1185G7E
abstract type IntelCore_i7_1185GRE <: IntelCore_i7_g11 end; export IntelCore_i7_1185GRE
abstract type IntelCore_i5_1130G7 <: IntelCore_i5_g11 end; export IntelCore_i5_1130G7
abstract type IntelCore_i5_1135G7 <: IntelCore_i5_g11 end; export IntelCore_i5_1135G7
abstract type IntelCore_i7_1160G7 <: IntelCore_i7_g11 end; export IntelCore_i7_1160G7
abstract type IntelCore_i7_1165G7 <: IntelCore_i7_g11 end; export IntelCore_i7_1165G7
abstract type IntelCore_i7_1185G7 <: IntelCore_i7_g11 end; export IntelCore_i7_1185G7
abstract type IntelCore_i3_1215U <: IntelCore_i3_g12 end; export IntelCore_i3_1215U
abstract type IntelCore_i5_1235U <: IntelCore_i5_g12 end; export IntelCore_i5_1235U
abstract type IntelCore_i7_1255U <: IntelCore_i7_g12 end; export IntelCore_i7_1255U
abstract type IntelCore_i5_1245U <: IntelCore_i5_g12 end; export IntelCore_i5_1245U
abstract type IntelCore_i7_1265U <: IntelCore_i7_g12 end; export IntelCore_i7_1265U
abstract type IntelCore_i7_12700 <: IntelCore_i7_g12 end; export IntelCore_i7_12700
abstract type IntelCore_i9_12900 <: IntelCore_i9_g12 end; export IntelCore_i9_12900
abstract type IntelCore_i7_11700B <: IntelCore_i7_g11 end; export IntelCore_i7_11700B
abstract type IntelCore_i9_11900KB <: IntelCore_i9_g11 end; export IntelCore_i9_11900KB
abstract type IntelCore_i3_1115G4 <: IntelCore_i3_g11 end; export IntelCore_i3_1115G4
abstract type IntelCore_i5_9300H <: IntelCore_i5_g9 end; export IntelCore_i5_9300H
abstract type IntelCore_i7_9750H <: IntelCore_i7_g9 end; export IntelCore_i7_9750H
abstract type IntelCore_i9_9980HK <: IntelCore_i9_g9 end; export IntelCore_i9_9980HK
abstract type IntelCore_i7_9850H <: IntelCore_i7_g9 end; export IntelCore_i7_9850H
abstract type IntelCore_i3_8145U <: IntelCore_i3_g8 end; export IntelCore_i3_8145U
abstract type IntelCore_i5_8265U <: IntelCore_i5_g8 end; export IntelCore_i5_8265U
abstract type IntelCore_i7_8565U <: IntelCore_i7_g8 end; export IntelCore_i7_8565U
abstract type IntelCore_i5_8365U <: IntelCore_i5_g8 end; export IntelCore_i5_8365U
abstract type IntelCore_i7_8665U <: IntelCore_i7_g8 end; export IntelCore_i7_8665U
abstract type IntelCore_i3_10110U <: IntelCore_i3_g10 end; export IntelCore_i3_10110U
abstract type IntelCore_i5_10210U <: IntelCore_i5_g10 end; export IntelCore_i5_10210U
abstract type IntelCore_i7_10710U <: IntelCore_i7_g10 end; export IntelCore_i7_10710U
abstract type IntelCore_i7_8559U <: IntelCore_i7_g8 end; export IntelCore_i7_8559U
abstract type IntelCore_i3_8109U <: IntelCore_i3_g8 end; export IntelCore_i3_8109U
abstract type IntelCore_i5_8259U <: IntelCore_i5_g8 end; export IntelCore_i5_8259U
abstract type IntelCore_i7_8705G <: IntelCore_i7_g8 end; export IntelCore_i7_8705G
abstract type IntelCore_i7_8809G <: IntelCore_i7_g8 end; export IntelCore_i7_8809G
abstract type IntelCore_i5_7300U <: IntelCore_i5_g7 end; export IntelCore_i5_7300U
abstract type IntelCore_i3_7100U <: IntelCore_i3_g7 end; export IntelCore_i3_7100U
abstract type IntelCore_i7_7567U <: IntelCore_i7_g7 end; export IntelCore_i7_7567U
abstract type IntelCore_i5_7260U <: IntelCore_i5_g7 end; export IntelCore_i5_7260U
abstract type IntelCore_i3_6157U <: IntelCore_i3_g6 end; export IntelCore_i3_6157U
abstract type IntelCore_i3_6167U <: IntelCore_i3_g6 end; export IntelCore_i3_6167U
abstract type IntelCore_i5_6267U <: IntelCore_i5_g5 end; export IntelCore_i5_6267U
abstract type IntelCore_i5_6287U <: IntelCore_i5_g5 end; export IntelCore_i5_6287U
abstract type IntelCore_i7_6567U <: IntelCore_i7_g6 end; export IntelCore_i7_6567U
abstract type IntelCore_i7_6660U <: IntelCore_i7_g6 end; export IntelCore_i7_6660U
abstract type IntelCore_i5_6260U <: IntelCore_i5_g5 end; export IntelCore_i5_6260U
abstract type IntelCore_i5_6360U <: IntelCore_i5_g5 end; export IntelCore_i5_6360U
abstract type IntelCore_i7_6560U <: IntelCore_i7_g6 end; export IntelCore_i7_6560U
abstract type IntelCore_i7_6650U <: IntelCore_i7_g6 end; export IntelCore_i7_6650U
abstract type IntelCore_i3_5157U <: IntelCore_i3_g5 end; export IntelCore_i3_5157U
abstract type IntelCore_i5_5257U <: IntelCore_i5_g5 end; export IntelCore_i5_5257U
abstract type IntelCore_i5_5287U <: IntelCore_i5_g5 end; export IntelCore_i5_5287U
abstract type IntelCore_i7_5557U <: IntelCore_i7_g5 end; export IntelCore_i7_5557U
abstract type IntelCore_i5_4278U <: IntelCore_i5_g4 end; export IntelCore_i5_4278U
abstract type IntelCore_i5_4308U <: IntelCore_i5_g4 end; export IntelCore_i5_4308U
abstract type IntelCore_i7_4578U <: IntelCore_i7_g4 end; export IntelCore_i7_4578U
abstract type IntelCore_i3_4158U <: IntelCore_i3_g4 end; export IntelCore_i3_4158U
abstract type IntelCore_i5_4258U <: IntelCore_i5_g4 end; export IntelCore_i5_4258U
abstract type IntelCore_i5_4288U <: IntelCore_i5_g4 end; export IntelCore_i5_4288U
abstract type IntelCore_i7_4558U <: IntelCore_i7_g4 end; export IntelCore_i7_4558U
abstract type IntelCore_i5_8279U <: IntelCore_i5_g8 end; export IntelCore_i5_8279U
abstract type IntelCore_i7_8569U <: IntelCore_i7_g8 end; export IntelCore_i7_8569U
abstract type IntelCore_i5_8269U <: IntelCore_i5_g8 end; export IntelCore_i5_8269U
abstract type IntelCore_i3_7167U <: IntelCore_i3_g7 end; export IntelCore_i3_7167U
abstract type IntelCore_i5_7267U <: IntelCore_i5_g7 end; export IntelCore_i5_7267U
abstract type IntelCore_i5_7287U <: IntelCore_i5_g7 end; export IntelCore_i5_7287U
abstract type IntelCore_i5_8257U <: IntelCore_i5_g8 end; export IntelCore_i5_8257U
abstract type IntelCore_i7_8557U <: IntelCore_i7_g8 end; export IntelCore_i7_8557U
abstract type IntelCore_i5_7360U <: IntelCore_i5_g7 end; export IntelCore_i5_7360U
abstract type IntelCore_i7_7560U <: IntelCore_i7_g7 end; export IntelCore_i7_7560U
abstract type IntelCore_i7_7660U <: IntelCore_i7_g7 end; export IntelCore_i7_7660U
abstract type IntelCore_i5_1038NG7 <: IntelCore_i5_g10 end; export IntelCore_i5_1038NG7
abstract type IntelCore_i7_1068NG7 <: IntelCore_i7_g10 end; export IntelCore_i7_1068NG7
abstract type IntelCore_i3_1000G4 <: IntelCore_i3_g10 end; export IntelCore_i3_1000G4
abstract type IntelCore_i5_1030G4 <: IntelCore_i5_g10 end; export IntelCore_i5_1030G4
abstract type IntelCore_i5_1030G7 <: IntelCore_i5_g10 end; export IntelCore_i5_1030G7
abstract type IntelCore_i5_1035G4 <: IntelCore_i5_g10 end; export IntelCore_i5_1035G4
abstract type IntelCore_i5_1035G7 <: IntelCore_i5_g10 end; export IntelCore_i5_1035G7
abstract type IntelCore_i7_1060G7 <: IntelCore_i7_g10 end; export IntelCore_i7_1060G7
abstract type IntelCore_i7_1065G7 <: IntelCore_i7_g10 end; export IntelCore_i7_1065G7
abstract type IntelCore_i5_8305G <: IntelCore_i5_g8 end; export IntelCore_i5_8305G
abstract type IntelCore_i7_8706G <: IntelCore_i7_g8 end; export IntelCore_i7_8706G
abstract type IntelCore_i7_8709G <: IntelCore_i7_g8 end; export IntelCore_i7_8709G
abstract type IntelCore_i3_7100 <: IntelCore_i3_g7 end; export IntelCore_i3_7100
abstract type IntelCore_i3_7100E <: IntelCore_i3_g7 end; export IntelCore_i3_7100E
abstract type IntelCore_i3_7100H <: IntelCore_i3_g7 end; export IntelCore_i3_7100H
abstract type IntelCore_i3_7100T <: IntelCore_i3_g7 end; export IntelCore_i3_7100T
abstract type IntelCore_i3_7101E <: IntelCore_i3_g7 end; export IntelCore_i3_7101E
abstract type IntelCore_i3_7101TE <: IntelCore_i3_g7 end; export IntelCore_i3_7101TE
abstract type IntelCore_i3_7102E <: IntelCore_i3_g7 end; export IntelCore_i3_7102E
abstract type IntelCore_i3_7300 <: IntelCore_i3_g7 end; export IntelCore_i3_7300
abstract type IntelCore_i3_7300T <: IntelCore_i3_g7 end; export IntelCore_i3_7300T
abstract type IntelCore_i3_7320 <: IntelCore_i3_g7 end; export IntelCore_i3_7320
abstract type IntelCore_i3_7350K <: IntelCore_i3_g7 end; export IntelCore_i3_7350K
abstract type IntelCore_i5_7300HQ <: IntelCore_i5_g7 end; export IntelCore_i5_7300HQ
abstract type IntelCore_i5_7400 <: IntelCore_i5_g7 end; export IntelCore_i5_7400
abstract type IntelCore_i5_7400T <: IntelCore_i5_g7 end; export IntelCore_i5_7400T
abstract type IntelCore_i5_7440EQ <: IntelCore_i5_g7 end; export IntelCore_i5_7440EQ
abstract type IntelCore_i5_7440HQ <: IntelCore_i5_g7 end; export IntelCore_i5_7440HQ
abstract type IntelCore_i5_7442EQ <: IntelCore_i5_g7 end; export IntelCore_i5_7442EQ
abstract type IntelCore_i5_7500 <: IntelCore_i5_g7 end; export IntelCore_i5_7500
abstract type IntelCore_i5_7500T <: IntelCore_i5_g7 end; export IntelCore_i5_7500T
abstract type IntelCore_i5_7600 <: IntelCore_i5_g7 end; export IntelCore_i5_7600
abstract type IntelCore_i5_7600K <: IntelCore_i5_g7 end; export IntelCore_i5_7600K
abstract type IntelCore_i5_7600T <: IntelCore_i5_g7 end; export IntelCore_i5_7600T
abstract type IntelCore_i7_7700 <: IntelCore_i7_g7 end; export IntelCore_i7_7700
abstract type IntelCore_i7_7700HQ <: IntelCore_i7_g7 end; export IntelCore_i7_7700HQ
abstract type IntelCore_i7_7700K <: IntelCore_i7_g7 end; export IntelCore_i7_7700K
abstract type IntelCore_i7_7700T <: IntelCore_i7_g7 end; export IntelCore_i7_7700T
abstract type IntelCore_i7_7820EQ <: IntelCore_i7_g7 end; export IntelCore_i7_7820EQ
abstract type IntelCore_i7_7820HK <: IntelCore_i7_g7 end; export IntelCore_i7_7820HK
abstract type IntelCore_i7_7820HQ <: IntelCore_i7_g7 end; export IntelCore_i7_7820HQ
abstract type IntelCore_i7_7920HQ <: IntelCore_i7_g7 end; export IntelCore_i7_7920HQ
abstract type IntelCore_i3_7020U <: IntelCore_i3_g7 end; export IntelCore_i3_7020U
abstract type IntelCore_i3_7130U <: IntelCore_i3_g7 end; export IntelCore_i3_7130U
abstract type IntelCore_i7_7600U <: IntelCore_i7_g7 end; export IntelCore_i7_7600U
abstract type IntelCore_i5_7200U <: IntelCore_i5_g7 end; export IntelCore_i5_7200U
abstract type IntelCore_i7_7500U <: IntelCore_i7_g7 end; export IntelCore_i7_7500U
abstract type IntelCore_M3_7Y32 <: IntelCore_M_g7 end; export IntelCore_M3_7Y32
abstract type IntelCore_i5_7Y57 <: IntelCore_i5_g7 end; export IntelCore_i5_7Y57
abstract type IntelCore_i5_7Y54 <: IntelCore_i5_g7 end; export IntelCore_i5_7Y54
abstract type IntelCore_i7_7Y75 <: IntelCore_i7_g7 end; export IntelCore_i7_7Y75
abstract type IntelCore_M3_7Y30 <: IntelCore_M_g7 end; export IntelCore_M3_7Y30
abstract type IntelCore_i3_6100E <: IntelCore_i3_g6 end; export IntelCore_i3_6100E
abstract type IntelCore_i3_6100TE <: IntelCore_i3_g6 end; export IntelCore_i3_6100TE
abstract type IntelCore_i3_6102E <: IntelCore_i3_g6 end; export IntelCore_i3_6102E
abstract type IntelCore_i5_6440EQ <: IntelCore_i5_g5 end; export IntelCore_i5_6440EQ
abstract type IntelCore_i5_6442EQ <: IntelCore_i5_g5 end; export IntelCore_i5_6442EQ
abstract type IntelCore_i5_6500TE <: IntelCore_i5_g5 end; export IntelCore_i5_6500TE
abstract type IntelCore_i7_6700TE <: IntelCore_i7_g6 end; export IntelCore_i7_6700TE
abstract type IntelCore_i7_6820EQ <: IntelCore_i7_g6 end; export IntelCore_i7_6820EQ
abstract type IntelCore_i7_6822EQ <: IntelCore_i7_g6 end; export IntelCore_i7_6822EQ
abstract type IntelCore_i3_6100 <: IntelCore_i3_g6 end; export IntelCore_i3_6100
abstract type IntelCore_i3_6100H <: IntelCore_i3_g6 end; export IntelCore_i3_6100H
abstract type IntelCore_i3_6100T <: IntelCore_i3_g6 end; export IntelCore_i3_6100T
abstract type IntelCore_i3_6300 <: IntelCore_i3_g6 end; export IntelCore_i3_6300
abstract type IntelCore_i3_6300T <: IntelCore_i3_g6 end; export IntelCore_i3_6300T
abstract type IntelCore_i3_6320 <: IntelCore_i3_g6 end; export IntelCore_i3_6320
abstract type IntelCore_i5_6300HQ <: IntelCore_i5_g5 end; export IntelCore_i5_6300HQ
abstract type IntelCore_i5_6400 <: IntelCore_i5_g5 end; export IntelCore_i5_6400
abstract type IntelCore_i5_6400T <: IntelCore_i5_g5 end; export IntelCore_i5_6400T
abstract type IntelCore_i5_6440HQ <: IntelCore_i5_g5 end; export IntelCore_i5_6440HQ
abstract type IntelCore_i5_6500 <: IntelCore_i5_g5 end; export IntelCore_i5_6500
abstract type IntelCore_i5_6500T <: IntelCore_i5_g5 end; export IntelCore_i5_6500T
abstract type IntelCore_i5_6600 <: IntelCore_i5_g5 end; export IntelCore_i5_6600
abstract type IntelCore_i5_6600T <: IntelCore_i5_g5 end; export IntelCore_i5_6600T
abstract type IntelCore_i7_6700 <: IntelCore_i7_g6 end; export IntelCore_i7_6700
abstract type IntelCore_i7_6700HQ <: IntelCore_i7_g6 end; export IntelCore_i7_6700HQ
abstract type IntelCore_i7_6700T <: IntelCore_i7_g6 end; export IntelCore_i7_6700T
abstract type IntelCore_i7_6820HK <: IntelCore_i7_g6 end; export IntelCore_i7_6820HK
abstract type IntelCore_i7_6820HQ <: IntelCore_i7_g6 end; export IntelCore_i7_6820HQ
abstract type IntelCore_i7_6920HQ <: IntelCore_i7_g6 end; export IntelCore_i7_6920HQ
abstract type IntelCore_i5_6600K <: IntelCore_i5_g5 end; export IntelCore_i5_6600K
abstract type IntelCore_i7_6700K <: IntelCore_i7_g6 end; export IntelCore_i7_6700K
abstract type IntelCore_i3_6006U <: IntelCore_i3_g6 end; export IntelCore_i3_6006U
abstract type IntelCore_i3_6100U <: IntelCore_i3_g6 end; export IntelCore_i3_6100U
abstract type IntelCore_i5_6200U <: IntelCore_i5_g5 end; export IntelCore_i5_6200U
abstract type IntelCore_i5_6300U <: IntelCore_i5_g5 end; export IntelCore_i5_6300U
abstract type IntelCore_i7_6500U <: IntelCore_i7_g6 end; export IntelCore_i7_6500U
abstract type IntelCore_i7_6600U <: IntelCore_i7_g6 end; export IntelCore_i7_6600U
abstract type IntelCore_M3_6Y30 <: IntelCore_M_g6 end; export IntelCore_M3_6Y30
abstract type IntelCore_M5_6Y54 <: IntelCore_M_g6 end; export IntelCore_M5_6Y54
abstract type IntelCore_M5_6Y57 <: IntelCore_M_g6 end; export IntelCore_M5_6Y57
abstract type IntelCore_M7_6Y75 <: IntelCore_M_g6 end; export IntelCore_M7_6Y75
abstract type IntelCore_i3_6098P <: IntelCore_i3_g6 end; export IntelCore_i3_6098P
abstract type IntelCore_i5_6402P <: IntelCore_i5_g5 end; export IntelCore_i5_6402P
abstract type IntelCore_i5_5250U <: IntelCore_i5_g5 end; export IntelCore_i5_5250U
abstract type IntelCore_i5_5350U <: IntelCore_i5_g5 end; export IntelCore_i5_5350U
abstract type IntelCore_i7_5550U <: IntelCore_i7_g5 end; export IntelCore_i7_5550U
abstract type IntelCore_i7_5650U <: IntelCore_i7_g5 end; export IntelCore_i7_5650U
abstract type IntelCore_i3_5015U <: IntelCore_i3_g5 end; export IntelCore_i3_5015U
abstract type IntelCore_i3_5020U <: IntelCore_i3_g5 end; export IntelCore_i3_5020U
abstract type IntelCore_i3_5005U <: IntelCore_i3_g5 end; export IntelCore_i3_5005U
abstract type IntelCore_i3_5010U <: IntelCore_i3_g5 end; export IntelCore_i3_5010U
abstract type IntelCore_i5_5200U <: IntelCore_i5_g5 end; export IntelCore_i5_5200U
abstract type IntelCore_i5_5300U <: IntelCore_i5_g5 end; export IntelCore_i5_5300U
abstract type IntelCore_i7_5500U <: IntelCore_i7_g5 end; export IntelCore_i7_5500U
abstract type IntelCore_i7_5600U <: IntelCore_i7_g5 end; export IntelCore_i7_5600U
abstract type IntelCore_5Y10c <: IntelCore_M_g5 end; export IntelCore_5Y10c
abstract type IntelCore_5Y31 <: IntelCore_M_g5 end; export IntelCore_5Y31
abstract type IntelCore_5Y51 <: IntelCore_M_g5 end; export IntelCore_5Y51
abstract type IntelCore_5Y71 <: IntelCore_M_g5 end; export IntelCore_5Y71
abstract type IntelCore_5Y10 <: IntelCore_M_g5 end; export IntelCore_5Y10
abstract type IntelCore_5Y10a <: IntelCore_M_g5 end; export IntelCore_5Y10a
abstract type IntelCore_5Y70 <: IntelCore_M_g5 end; export IntelCore_5Y70
abstract type IntelCore_i5_4260U <: IntelCore_i5_g4 end; export IntelCore_i5_4260U
abstract type IntelCore_i5_4360U <: IntelCore_i5_g4 end; export IntelCore_i5_4360U
abstract type IntelCore_i5_4250U <: IntelCore_i5_g4 end; export IntelCore_i5_4250U
abstract type IntelCore_i5_4350U <: IntelCore_i5_g4 end; export IntelCore_i5_4350U
abstract type IntelCore_i7_4550U <: IntelCore_i7_g4 end; export IntelCore_i7_4550U
abstract type IntelCore_i7_4650U <: IntelCore_i7_g4 end; export IntelCore_i7_4650U
abstract type IntelCore_i3_4370T <: IntelCore_i3_g4 end; export IntelCore_i3_4370T
abstract type IntelCore_i7_4720HQ <: IntelCore_i7_g4 end; export IntelCore_i7_4720HQ
abstract type IntelCore_i7_4722HQ <: IntelCore_i7_g4 end; export IntelCore_i7_4722HQ
abstract type IntelCore_i3_4360T <: IntelCore_i3_g4 end; export IntelCore_i3_4360T
abstract type IntelCore_i3_4370 <: IntelCore_i3_g4 end; export IntelCore_i3_4370
abstract type IntelCore_i5_4210H <: IntelCore_i5_g4 end; export IntelCore_i5_4210H
abstract type IntelCore_i5_4690K <: IntelCore_i5_g4 end; export IntelCore_i5_4690K
abstract type IntelCore_i7_4790K <: IntelCore_i7_g4 end; export IntelCore_i7_4790K
abstract type IntelCore_i3_4340TE <: IntelCore_i3_g4 end; export IntelCore_i3_4340TE
abstract type IntelCore_i3_4350 <: IntelCore_i3_g4 end; export IntelCore_i3_4350
abstract type IntelCore_i3_4350T <: IntelCore_i3_g4 end; export IntelCore_i3_4350T
abstract type IntelCore_i3_4360 <: IntelCore_i3_g4 end; export IntelCore_i3_4360
abstract type IntelCore_i5_4460 <: IntelCore_i5_g4 end; export IntelCore_i5_4460
abstract type IntelCore_i5_4460S <: IntelCore_i5_g4 end; export IntelCore_i5_4460S
abstract type IntelCore_i5_4460T <: IntelCore_i5_g4 end; export IntelCore_i5_4460T
abstract type IntelCore_i5_4590 <: IntelCore_i5_g4 end; export IntelCore_i5_4590
abstract type IntelCore_i5_4590S <: IntelCore_i5_g4 end; export IntelCore_i5_4590S
abstract type IntelCore_i5_4590T <: IntelCore_i5_g4 end; export IntelCore_i5_4590T
abstract type IntelCore_i5_4690 <: IntelCore_i5_g4 end; export IntelCore_i5_4690
abstract type IntelCore_i5_4690S <: IntelCore_i5_g4 end; export IntelCore_i5_4690S
abstract type IntelCore_i5_4690T <: IntelCore_i5_g4 end; export IntelCore_i5_4690T
abstract type IntelCore_i7_4785T <: IntelCore_i7_g4 end; export IntelCore_i7_4785T
abstract type IntelCore_i7_4790 <: IntelCore_i7_g4 end; export IntelCore_i7_4790
abstract type IntelCore_i7_4790S <: IntelCore_i7_g4 end; export IntelCore_i7_4790S
abstract type IntelCore_i7_4790T <: IntelCore_i7_g4 end; export IntelCore_i7_4790T
abstract type IntelCore_i3_4110E <: IntelCore_i3_g4 end; export IntelCore_i3_4110E
abstract type IntelCore_i3_4110M <: IntelCore_i3_g4 end; export IntelCore_i3_4110M
abstract type IntelCore_i3_4112E <: IntelCore_i3_g4 end; export IntelCore_i3_4112E
abstract type IntelCore_i5_4210M <: IntelCore_i5_g4 end; export IntelCore_i5_4210M
abstract type IntelCore_i5_4410E <: IntelCore_i5_g4 end; export IntelCore_i5_4410E
abstract type IntelCore_i5_4422E <: IntelCore_i5_g4 end; export IntelCore_i5_4422E
abstract type IntelCore_i7_4710HQ <: IntelCore_i7_g4 end; export IntelCore_i7_4710HQ
abstract type IntelCore_i7_4710MQ <: IntelCore_i7_g4 end; export IntelCore_i7_4710MQ
abstract type IntelCore_i7_4712HQ <: IntelCore_i7_g4 end; export IntelCore_i7_4712HQ
abstract type IntelCore_i7_4712MQ <: IntelCore_i7_g4 end; export IntelCore_i7_4712MQ
abstract type IntelCore_i5_4310M <: IntelCore_i5_g4 end; export IntelCore_i5_4310M
abstract type IntelCore_i5_4340M <: IntelCore_i5_g4 end; export IntelCore_i5_4340M
abstract type IntelCore_i7_4610M <: IntelCore_i7_g4 end; export IntelCore_i7_4610M
abstract type IntelCore_i7_4810MQ <: IntelCore_i7_g4 end; export IntelCore_i7_4810MQ
abstract type IntelCore_i7_4910MQ <: IntelCore_i7_g4 end; export IntelCore_i7_4910MQ
abstract type IntelCore_i7_4940MX <: IntelCore_X end; export IntelCore_i7_4940MX
abstract type IntelCore_i3_4000M <: IntelCore_i3_g4 end; export IntelCore_i3_4000M
abstract type IntelCore_i3_4100E <: IntelCore_i3_g4 end; export IntelCore_i3_4100E
abstract type IntelCore_i3_4100M <: IntelCore_i3_g4 end; export IntelCore_i3_4100M
abstract type IntelCore_i3_4102E <: IntelCore_i3_g4 end; export IntelCore_i3_4102E
abstract type IntelCore_i3_4330 <: IntelCore_i3_g4 end; export IntelCore_i3_4330
abstract type IntelCore_i3_4330T <: IntelCore_i3_g4 end; export IntelCore_i3_4330T
abstract type IntelCore_i3_4330TE <: IntelCore_i3_g4 end; export IntelCore_i3_4330TE
abstract type IntelCore_i3_4340 <: IntelCore_i3_g4 end; export IntelCore_i3_4340
abstract type IntelCore_i5_4200H <: IntelCore_i5_g4 end; export IntelCore_i5_4200H
abstract type IntelCore_i5_4200M <: IntelCore_i5_g4 end; export IntelCore_i5_4200M
abstract type IntelCore_i5_4300M <: IntelCore_i5_g4 end; export IntelCore_i5_4300M
abstract type IntelCore_i5_4330M <: IntelCore_i5_g4 end; export IntelCore_i5_4330M
abstract type IntelCore_i5_4400E <: IntelCore_i5_g4 end; export IntelCore_i5_4400E
abstract type IntelCore_i5_4402E <: IntelCore_i5_g4 end; export IntelCore_i5_4402E
abstract type IntelCore_i5_4440 <: IntelCore_i5_g4 end; export IntelCore_i5_4440
abstract type IntelCore_i5_4440S <: IntelCore_i5_g4 end; export IntelCore_i5_4440S
abstract type IntelCore_i7_4600M <: IntelCore_i7_g4 end; export IntelCore_i7_4600M
abstract type IntelCore_i7_4771 <: IntelCore_i7_g4 end; export IntelCore_i7_4771
abstract type IntelCore_i5_4430 <: IntelCore_i5_g4 end; export IntelCore_i5_4430
abstract type IntelCore_i5_4430S <: IntelCore_i5_g4 end; export IntelCore_i5_4430S
abstract type IntelCore_i5_4570 <: IntelCore_i5_g4 end; export IntelCore_i5_4570
abstract type IntelCore_i5_4570S <: IntelCore_i5_g4 end; export IntelCore_i5_4570S
abstract type IntelCore_i5_4570T <: IntelCore_i5_g4 end; export IntelCore_i5_4570T
abstract type IntelCore_i5_4570TE <: IntelCore_i5_g4 end; export IntelCore_i5_4570TE
abstract type IntelCore_i5_4670 <: IntelCore_i5_g4 end; export IntelCore_i5_4670
abstract type IntelCore_i5_4670K <: IntelCore_i5_g4 end; export IntelCore_i5_4670K
abstract type IntelCore_i5_4670S <: IntelCore_i5_g4 end; export IntelCore_i5_4670S
abstract type IntelCore_i5_4670T <: IntelCore_i5_g4 end; export IntelCore_i5_4670T
abstract type IntelCore_i7_4700EQ <: IntelCore_i7_g4 end; export IntelCore_i7_4700EQ
abstract type IntelCore_i7_4700HQ <: IntelCore_i7_g4 end; export IntelCore_i7_4700HQ
abstract type IntelCore_i7_4700MQ <: IntelCore_i7_g4 end; export IntelCore_i7_4700MQ
abstract type IntelCore_i7_4702HQ <: IntelCore_i7_g4 end; export IntelCore_i7_4702HQ
abstract type IntelCore_i7_4702MQ <: IntelCore_i7_g4 end; export IntelCore_i7_4702MQ
abstract type IntelCore_i7_4765T <: IntelCore_i7_g4 end; export IntelCore_i7_4765T
abstract type IntelCore_i7_4770 <: IntelCore_i7_g4 end; export IntelCore_i7_4770
abstract type IntelCore_i7_4770K <: IntelCore_i7_g4 end; export IntelCore_i7_4770K
abstract type IntelCore_i7_4770S <: IntelCore_i7_g4 end; export IntelCore_i7_4770S
abstract type IntelCore_i7_4770T <: IntelCore_i7_g4 end; export IntelCore_i7_4770T
abstract type IntelCore_i7_4770TE <: IntelCore_i7_g4 end; export IntelCore_i7_4770TE
abstract type IntelCore_i7_4800MQ <: IntelCore_i7_g4 end; export IntelCore_i7_4800MQ
abstract type IntelCore_i7_4900MQ <: IntelCore_i7_g4 end; export IntelCore_i7_4900MQ
abstract type IntelCore_i7_4930MX <: IntelCore_X end; export IntelCore_i7_4930MX
abstract type IntelCore_i3_4170 <: IntelCore_i3_g4 end; export IntelCore_i3_4170
abstract type IntelCore_i3_4170T <: IntelCore_i3_g4 end; export IntelCore_i3_4170T
abstract type IntelCore_i3_4160 <: IntelCore_i3_g4 end; export IntelCore_i3_4160
abstract type IntelCore_i3_4160T <: IntelCore_i3_g4 end; export IntelCore_i3_4160T
abstract type IntelCore_i3_4150 <: IntelCore_i3_g4 end; export IntelCore_i3_4150
abstract type IntelCore_i3_4150T <: IntelCore_i3_g4 end; export IntelCore_i3_4150T
abstract type IntelCore_i3_4025U <: IntelCore_i3_g4 end; export IntelCore_i3_4025U
abstract type IntelCore_i3_4030U <: IntelCore_i3_g4 end; export IntelCore_i3_4030U
abstract type IntelCore_i3_4120U <: IntelCore_i3_g4 end; export IntelCore_i3_4120U
abstract type IntelCore_i5_4210U <: IntelCore_i5_g4 end; export IntelCore_i5_4210U
abstract type IntelCore_i7_4510U <: IntelCore_i7_g4 end; export IntelCore_i7_4510U
abstract type IntelCore_i5_4310U <: IntelCore_i5_g4 end; export IntelCore_i5_4310U
abstract type IntelCore_i3_4005U <: IntelCore_i3_g4 end; export IntelCore_i3_4005U
abstract type IntelCore_i3_4130 <: IntelCore_i3_g4 end; export IntelCore_i3_4130
abstract type IntelCore_i3_4130T <: IntelCore_i3_g4 end; export IntelCore_i3_4130T
abstract type IntelCore_i5_4300U <: IntelCore_i5_g4 end; export IntelCore_i5_4300U
abstract type IntelCore_i7_4600U <: IntelCore_i7_g4 end; export IntelCore_i7_4600U
abstract type IntelCore_i3_4010U <: IntelCore_i3_g4 end; export IntelCore_i3_4010U
abstract type IntelCore_i3_4100U <: IntelCore_i3_g4 end; export IntelCore_i3_4100U
abstract type IntelCore_i5_4200U <: IntelCore_i5_g4 end; export IntelCore_i5_4200U
abstract type IntelCore_i7_4500U <: IntelCore_i7_g4 end; export IntelCore_i7_4500U
abstract type IntelCore_i3_4030Y <: IntelCore_i3_g4 end; export IntelCore_i3_4030Y
abstract type IntelCore_i5_4220Y <: IntelCore_i5_g4 end; export IntelCore_i5_4220Y
abstract type IntelCore_i3_4012Y <: IntelCore_i3_g4 end; export IntelCore_i3_4012Y
abstract type IntelCore_i3_4020Y <: IntelCore_i3_g4 end; export IntelCore_i3_4020Y
abstract type IntelCore_i5_4202Y <: IntelCore_i5_g4 end; export IntelCore_i5_4202Y
abstract type IntelCore_i5_4210Y <: IntelCore_i5_g4 end; export IntelCore_i5_4210Y
abstract type IntelCore_i5_4300Y <: IntelCore_i5_g4 end; export IntelCore_i5_4300Y
abstract type IntelCore_i5_4302Y <: IntelCore_i5_g4 end; export IntelCore_i5_4302Y
abstract type IntelCore_i7_4610Y <: IntelCore_i7_g4 end; export IntelCore_i7_4610Y
abstract type IntelCore_i3_4010Y <: IntelCore_i3_g4 end; export IntelCore_i3_4010Y
abstract type IntelCore_i5_4200Y <: IntelCore_i5_g4 end; export IntelCore_i5_4200Y
abstract type IntelCore_i7_3940XM <: IntelCore_X end; export IntelCore_i7_3940XM
abstract type IntelCore_i7_3920XM <: IntelCore_X end; export IntelCore_i7_3920XM
abstract type IntelCore_i5_1240P <: IntelCore_i5_g12 end; export IntelCore_i5_1240P
abstract type IntelCore_i7_1260P <: IntelCore_i7_g12 end; export IntelCore_i7_1260P
abstract type IntelCore_i5_11400H <: IntelCore_i5_g11 end; export IntelCore_i5_11400H
abstract type IntelCore_i7_11800H <: IntelCore_i7_g11 end; export IntelCore_i7_11800H
abstract type IntelCore_i3_10105 <: IntelCore_i3_g10 end; export IntelCore_i3_10105
abstract type IntelCore_i3_10105T <: IntelCore_i3_g10 end; export IntelCore_i3_10105T
abstract type IntelCore_i3_10305 <: IntelCore_i3_g10 end; export IntelCore_i3_10305
abstract type IntelCore_i3_10305T <: IntelCore_i3_g10 end; export IntelCore_i3_10305T
abstract type IntelCore_i3_10325 <: IntelCore_i3_g10 end; export IntelCore_i3_10325
abstract type IntelCore_i5_10505 <: IntelCore_i5_g10 end; export IntelCore_i5_10505
abstract type IntelCore_i9_10850K <: IntelCore_i9_g10 end; export IntelCore_i9_10850K
abstract type IntelCore_i3_10100 <: IntelCore_i3_g10 end; export IntelCore_i3_10100
abstract type IntelCore_i3_10100E <: IntelCore_i3_g10 end; export IntelCore_i3_10100E
abstract type IntelCore_i3_10100T <: IntelCore_i3_g10 end; export IntelCore_i3_10100T
abstract type IntelCore_i3_10100TE <: IntelCore_i3_g10 end; export IntelCore_i3_10100TE
abstract type IntelCore_i3_10300 <: IntelCore_i3_g10 end; export IntelCore_i3_10300
abstract type IntelCore_i3_10300T <: IntelCore_i3_g10 end; export IntelCore_i3_10300T
abstract type IntelCore_i3_10320 <: IntelCore_i3_g10 end; export IntelCore_i3_10320
abstract type IntelCore_i5_10400 <: IntelCore_i5_g10 end; export IntelCore_i5_10400
abstract type IntelCore_i5_10400T <: IntelCore_i5_g10 end; export IntelCore_i5_10400T
abstract type IntelCore_i5_10500 <: IntelCore_i5_g10 end; export IntelCore_i5_10500
abstract type IntelCore_i5_10500E <: IntelCore_i5_g10 end; export IntelCore_i5_10500E
abstract type IntelCore_i5_10500T <: IntelCore_i5_g10 end; export IntelCore_i5_10500T
abstract type IntelCore_i5_10500TE <: IntelCore_i5_g10 end; export IntelCore_i5_10500TE
abstract type IntelCore_i5_10600 <: IntelCore_i5_g10 end; export IntelCore_i5_10600
abstract type IntelCore_i5_10600K <: IntelCore_i5_g10 end; export IntelCore_i5_10600K
abstract type IntelCore_i5_10600T <: IntelCore_i5_g10 end; export IntelCore_i5_10600T
abstract type IntelCore_i7_10700 <: IntelCore_i7_g10 end; export IntelCore_i7_10700
abstract type IntelCore_i7_10700E <: IntelCore_i7_g10 end; export IntelCore_i7_10700E
abstract type IntelCore_i7_10700K <: IntelCore_i7_g10 end; export IntelCore_i7_10700K
abstract type IntelCore_i7_10700T <: IntelCore_i7_g10 end; export IntelCore_i7_10700T
abstract type IntelCore_i7_10700TE <: IntelCore_i7_g10 end; export IntelCore_i7_10700TE
abstract type IntelCore_i9_10900 <: IntelCore_i9_g10 end; export IntelCore_i9_10900
abstract type IntelCore_i9_10900E <: IntelCore_i9_g10 end; export IntelCore_i9_10900E
abstract type IntelCore_i9_10900K <: IntelCore_i9_g10 end; export IntelCore_i9_10900K
abstract type IntelCore_i9_10900T <: IntelCore_i9_g10 end; export IntelCore_i9_10900T
abstract type IntelCore_i9_10900TE <: IntelCore_i9_g10 end; export IntelCore_i9_10900TE
abstract type IntelCore_i9_9900KS <: IntelCore_i9_g9 end; export IntelCore_i9_9900KS
abstract type IntelCore_i3_9100E <: IntelCore_i3_g9 end; export IntelCore_i3_9100E
abstract type IntelCore_i3_9100HL <: IntelCore_i3_g9 end; export IntelCore_i3_9100HL
abstract type IntelCore_i3_9100TE <: IntelCore_i3_g9 end; export IntelCore_i3_9100TE
abstract type IntelCore_i5_9500E <: IntelCore_i5_g9 end; export IntelCore_i5_9500E
abstract type IntelCore_i5_9500TE <: IntelCore_i5_g9 end; export IntelCore_i5_9500TE
abstract type IntelCore_i7_9700E <: IntelCore_i7_g9 end; export IntelCore_i7_9700E
abstract type IntelCore_i7_9700TE <: IntelCore_i7_g9 end; export IntelCore_i7_9700TE
abstract type IntelCore_i7_9850HE <: IntelCore_i7_g9 end; export IntelCore_i7_9850HE
abstract type IntelCore_i7_9850HL <: IntelCore_i7_g9 end; export IntelCore_i7_9850HL
abstract type IntelCore_i3_9100 <: IntelCore_i3_g9 end; export IntelCore_i3_9100
abstract type IntelCore_i3_9100T <: IntelCore_i3_g9 end; export IntelCore_i3_9100T
abstract type IntelCore_i3_9300 <: IntelCore_i3_g9 end; export IntelCore_i3_9300
abstract type IntelCore_i3_9300T <: IntelCore_i3_g9 end; export IntelCore_i3_9300T
abstract type IntelCore_i3_9320 <: IntelCore_i3_g9 end; export IntelCore_i3_9320
abstract type IntelCore_i3_9350K <: IntelCore_i3_g9 end; export IntelCore_i3_9350K
abstract type IntelCore_i5_9400H <: IntelCore_i5_g9 end; export IntelCore_i5_9400H
abstract type IntelCore_i5_9400T <: IntelCore_i5_g9 end; export IntelCore_i5_9400T
abstract type IntelCore_i5_9500 <: IntelCore_i5_g9 end; export IntelCore_i5_9500
abstract type IntelCore_i5_9500T <: IntelCore_i5_g9 end; export IntelCore_i5_9500T
abstract type IntelCore_i5_9600 <: IntelCore_i5_g9 end; export IntelCore_i5_9600
abstract type IntelCore_i5_9600T <: IntelCore_i5_g9 end; export IntelCore_i5_9600T
abstract type IntelCore_i7_9700 <: IntelCore_i7_g9 end; export IntelCore_i7_9700
abstract type IntelCore_i7_9700T <: IntelCore_i7_g9 end; export IntelCore_i7_9700T
abstract type IntelCore_i9_9880H <: IntelCore_i9_g9 end; export IntelCore_i9_9880H
abstract type IntelCore_i9_9900 <: IntelCore_i9_g9 end; export IntelCore_i9_9900
abstract type IntelCore_i9_9900T <: IntelCore_i9_g9 end; export IntelCore_i9_9900T
abstract type IntelCore_i5_9400 <: IntelCore_i5_g9 end; export IntelCore_i5_9400
abstract type IntelCore_i5_9600K <: IntelCore_i5_g9 end; export IntelCore_i5_9600K
abstract type IntelCore_i7_9700K <: IntelCore_i7_g9 end; export IntelCore_i7_9700K
abstract type IntelCore_i9_9900K <: IntelCore_i9_g9 end; export IntelCore_i9_9900K
abstract type IntelCore_i3_8100B <: IntelCore_i3_g8 end; export IntelCore_i3_8100B
abstract type IntelCore_i3_8100H <: IntelCore_i3_g8 end; export IntelCore_i3_8100H
abstract type IntelCore_i7_8086K <: IntelCore_i7_g8 end; export IntelCore_i7_8086K
abstract type IntelCore_i3_8100T <: IntelCore_i3_g8 end; export IntelCore_i3_8100T
abstract type IntelCore_i3_8300 <: IntelCore_i3_g8 end; export IntelCore_i3_8300
abstract type IntelCore_i3_8300T <: IntelCore_i3_g8 end; export IntelCore_i3_8300T
abstract type IntelCore_i5_8300H <: IntelCore_i5_g8 end; export IntelCore_i5_8300H
abstract type IntelCore_i5_8400 <: IntelCore_i5_g8 end; export IntelCore_i5_8400
abstract type IntelCore_i5_8400B <: IntelCore_i5_g8 end; export IntelCore_i5_8400B
abstract type IntelCore_i5_8400H <: IntelCore_i5_g8 end; export IntelCore_i5_8400H
abstract type IntelCore_i5_8400T <: IntelCore_i5_g8 end; export IntelCore_i5_8400T
abstract type IntelCore_i5_8500 <: IntelCore_i5_g8 end; export IntelCore_i5_8500
abstract type IntelCore_i5_8500B <: IntelCore_i5_g8 end; export IntelCore_i5_8500B
abstract type IntelCore_i5_8500T <: IntelCore_i5_g8 end; export IntelCore_i5_8500T
abstract type IntelCore_i5_8600 <: IntelCore_i5_g8 end; export IntelCore_i5_8600
abstract type IntelCore_i5_8600T <: IntelCore_i5_g8 end; export IntelCore_i5_8600T
abstract type IntelCore_i7_8700 <: IntelCore_i7_g8 end; export IntelCore_i7_8700
abstract type IntelCore_i7_8700B <: IntelCore_i7_g8 end; export IntelCore_i7_8700B
abstract type IntelCore_i7_8700T <: IntelCore_i7_g8 end; export IntelCore_i7_8700T
abstract type IntelCore_i7_8750H <: IntelCore_i7_g8 end; export IntelCore_i7_8750H
abstract type IntelCore_i7_8850H <: IntelCore_i7_g8 end; export IntelCore_i7_8850H
abstract type IntelCore_i9_8950HK <: IntelCore_i9_g8 end; export IntelCore_i9_8950HK
abstract type IntelCore_i3_8100 <: IntelCore_i3_g8 end; export IntelCore_i3_8100
abstract type IntelCore_i3_8350K <: IntelCore_i3_g8 end; export IntelCore_i3_8350K
abstract type IntelCore_i5_8600K <: IntelCore_i5_g8 end; export IntelCore_i5_8600K
abstract type IntelCore_i7_8700K <: IntelCore_i7_g8 end; export IntelCore_i7_8700K
abstract type IntelCore_i3_8140U <: IntelCore_i3_g8 end; export IntelCore_i3_8140U
abstract type IntelCore_i5_8260U <: IntelCore_i5_g8 end; export IntelCore_i5_8260U
abstract type IntelCore_i3_8145UE <: IntelCore_i3_g8 end; export IntelCore_i3_8145UE
abstract type IntelCore_i5_8365UE <: IntelCore_i5_g8 end; export IntelCore_i5_8365UE
abstract type IntelCore_i7_8665UE <: IntelCore_i7_g8 end; export IntelCore_i7_8665UE
abstract type IntelCore_i3_8130U <: IntelCore_i3_g8 end; export IntelCore_i3_8130U
abstract type IntelCore_i5_8250U <: IntelCore_i5_g8 end; export IntelCore_i5_8250U
abstract type IntelCore_i5_8350U <: IntelCore_i5_g8 end; export IntelCore_i5_8350U
abstract type IntelCore_i7_8550U <: IntelCore_i7_g8 end; export IntelCore_i7_8550U
abstract type IntelCore_i7_8650U <: IntelCore_i7_g8 end; export IntelCore_i7_8650U
abstract type IntelCore_i5_8310Y <: IntelCore_i5_g8 end; export IntelCore_i5_8310Y
abstract type IntelCore_i5_8210Y <: IntelCore_i5_g8 end; export IntelCore_i5_8210Y
abstract type IntelCore_i3_10100Y <: IntelCore_i3_g10 end; export IntelCore_i3_10100Y
abstract type IntelCore_i5_8200Y <: IntelCore_i5_g8 end; export IntelCore_i5_8200Y
abstract type IntelCore_i7_8500Y <: IntelCore_i7_g8 end; export IntelCore_i7_8500Y
abstract type IntelCore_M3_8100Y <: IntelCore_M_g8 end; export IntelCore_M3_8100Y
abstract type IntelCore_i3_12300HE <: IntelCore_i3_g12 end; export IntelCore_i3_12300HE
abstract type IntelCore_i3_11100HE <: IntelCore_i3_g11 end; export IntelCore_i3_11100HE
abstract type IntelCore_i5_11500HE <: IntelCore_i5_g11 end; export IntelCore_i5_11500HE
abstract type IntelCore_i7_11850HE <: IntelCore_i7_g11 end; export IntelCore_i7_11850HE
abstract type IntelCore_i7_11600H <: IntelCore_i7_g11 end; export IntelCore_i7_11600H
abstract type IntelCore_i5_11260H <: IntelCore_i5_g11 end; export IntelCore_i5_11260H
abstract type IntelCore_i5_11500H <: IntelCore_i5_g11 end; export IntelCore_i5_11500H
abstract type IntelCore_i7_11850H <: IntelCore_i7_g11 end; export IntelCore_i7_11850H
abstract type IntelCore_i9_11900H <: IntelCore_i9_g11 end; export IntelCore_i9_11900H
abstract type IntelCore_i9_11950H <: IntelCore_i9_g11 end; export IntelCore_i9_11950H
abstract type IntelCore_i9_11980HK <: IntelCore_i9_g11 end; export IntelCore_i9_11980HK
abstract type IntelCore_i3_1115G4E <: IntelCore_i3_g11 end; export IntelCore_i3_1115G4E
abstract type IntelCore_i3_1115GRE <: IntelCore_i3_g11 end; export IntelCore_i3_1115GRE
abstract type IntelCore_i3_1120G4 <: IntelCore_i3_g11 end; export IntelCore_i3_1120G4
abstract type IntelCore_i3_1125G4 <: IntelCore_i3_g11 end; export IntelCore_i3_1125G4
abstract type IntelCore_i3_1110G4 <: IntelCore_i3_g11 end; export IntelCore_i3_1110G4
abstract type IntelCore_i5_10500H <: IntelCore_i5_g10 end; export IntelCore_i5_10500H
abstract type IntelCore_i7_10870H <: IntelCore_i7_g10 end; export IntelCore_i7_10870H
abstract type IntelCore_i5_10200H <: IntelCore_i5_g10 end; export IntelCore_i5_10200H
abstract type IntelCore_i5_10310U <: IntelCore_i5_g10 end; export IntelCore_i5_10310U
abstract type IntelCore_i7_10610U <: IntelCore_i7_g10 end; export IntelCore_i7_10610U
abstract type IntelCore_i7_10810U <: IntelCore_i7_g10 end; export IntelCore_i7_10810U
abstract type IntelCore_i9_10885H <: IntelCore_i9_g10 end; export IntelCore_i9_10885H
abstract type IntelCore_i5_10300H <: IntelCore_i5_g10 end; export IntelCore_i5_10300H
abstract type IntelCore_i5_10400H <: IntelCore_i5_g10 end; export IntelCore_i5_10400H
abstract type IntelCore_i7_10750H <: IntelCore_i7_g10 end; export IntelCore_i7_10750H
abstract type IntelCore_i7_10850H <: IntelCore_i7_g10 end; export IntelCore_i7_10850H
abstract type IntelCore_i7_10875H <: IntelCore_i7_g10 end; export IntelCore_i7_10875H
abstract type IntelCore_i9_10980HK <: IntelCore_i9_g10 end; export IntelCore_i9_10980HK
abstract type IntelCore_i3_10110Y <: IntelCore_i3_g10 end; export IntelCore_i3_10110Y
abstract type IntelCore_i5_10210Y <: IntelCore_i5_g10 end; export IntelCore_i5_10210Y
abstract type IntelCore_i5_10310Y <: IntelCore_i5_g10 end; export IntelCore_i5_10310Y
abstract type IntelCore_i7_10510U <: IntelCore_i7_g10 end; export IntelCore_i7_10510U
abstract type IntelCore_i7_10510Y <: IntelCore_i7_g10 end; export IntelCore_i7_10510Y
abstract type IntelCore_i3_1000G1 <: IntelCore_i3_g10 end; export IntelCore_i3_1000G1
abstract type IntelCore_i3_1005G1 <: IntelCore_i3_g10 end; export IntelCore_i3_1005G1
abstract type IntelCore_i5_1035G1 <: IntelCore_i5_g10 end; export IntelCore_i5_1035G1
abstract type IntelCore_i5_6585R <: IntelCore_i5_g5 end; export IntelCore_i5_6585R
abstract type IntelCore_i5_6685R <: IntelCore_i5_g5 end; export IntelCore_i5_6685R
abstract type IntelCore_i7_6785R <: IntelCore_i7_g6 end; export IntelCore_i7_6785R
abstract type IntelCore_i5_6350HQ <: IntelCore_i5_g5 end; export IntelCore_i5_6350HQ
abstract type IntelCore_i7_6770HQ <: IntelCore_i7_g6 end; export IntelCore_i7_6770HQ
abstract type IntelCore_i7_6870HQ <: IntelCore_i7_g6 end; export IntelCore_i7_6870HQ
abstract type IntelCore_i7_6970HQ <: IntelCore_i7_g6 end; export IntelCore_i7_6970HQ
abstract type IntelCore_i5_5350H <: IntelCore_i5_g5 end; export IntelCore_i5_5350H
abstract type IntelCore_i5_5575R <: IntelCore_i5_g5 end; export IntelCore_i5_5575R
abstract type IntelCore_i5_5675C <: IntelCore_i5_g5 end; export IntelCore_i5_5675C
abstract type IntelCore_i5_5675R <: IntelCore_i5_g5 end; export IntelCore_i5_5675R
abstract type IntelCore_i7_5700HQ <: IntelCore_i7_g5 end; export IntelCore_i7_5700HQ
abstract type IntelCore_i7_5750HQ <: IntelCore_i7_g5 end; export IntelCore_i7_5750HQ
abstract type IntelCore_i7_5775C <: IntelCore_i7_g5 end; export IntelCore_i7_5775C
abstract type IntelCore_i7_5775R <: IntelCore_i7_g5 end; export IntelCore_i7_5775R
abstract type IntelCore_i7_5850EQ <: IntelCore_i7_g5 end; export IntelCore_i7_5850EQ
abstract type IntelCore_i7_5850HQ <: IntelCore_i7_g5 end; export IntelCore_i7_5850HQ
abstract type IntelCore_i7_5950HQ <: IntelCore_i7_g5 end; export IntelCore_i7_5950HQ
abstract type IntelCore_i7_4770HQ <: IntelCore_i7_g4 end; export IntelCore_i7_4770HQ
abstract type IntelCore_i7_4870HQ <: IntelCore_i7_g4 end; export IntelCore_i7_4870HQ
abstract type IntelCore_i7_4980HQ <: IntelCore_i7_g4 end; export IntelCore_i7_4980HQ
abstract type IntelCore_i7_4760HQ <: IntelCore_i7_g4 end; export IntelCore_i7_4760HQ
abstract type IntelCore_i7_4860HQ <: IntelCore_i7_g4 end; export IntelCore_i7_4860HQ
abstract type IntelCore_i7_4960HQ <: IntelCore_i7_g4 end; export IntelCore_i7_4960HQ
abstract type IntelCore_i7_4750HQ <: IntelCore_i7_g4 end; export IntelCore_i7_4750HQ
abstract type IntelCore_i7_4850HQ <: IntelCore_i7_g4 end; export IntelCore_i7_4850HQ
abstract type IntelCore_i7_4950HQ <: IntelCore_i7_g4 end; export IntelCore_i7_4950HQ
abstract type IntelCore_i5_4570R <: IntelCore_i5_g4 end; export IntelCore_i5_4570R
abstract type IntelCore_i5_4670R <: IntelCore_i5_g4 end; export IntelCore_i5_4670R
abstract type IntelCore_i7_4770R <: IntelCore_i7_g4 end; export IntelCore_i7_4770R
abstract type IntelCore_i9_10900X <: IntelCore_X end; export IntelCore_i9_10900X
abstract type IntelCore_i9_10920X <: IntelCore_X end; export IntelCore_i9_10920X
abstract type IntelCore_i9_10940X <: IntelCore_X end; export IntelCore_i9_10940X
abstract type IntelCore_i9_10980XE <: IntelCore_X end; export IntelCore_i9_10980XE
abstract type IntelCore_i7_9800X <: IntelCore_X end; export IntelCore_i7_9800X
abstract type IntelCore_i9_9820X <: IntelCore_X end; export IntelCore_i9_9820X
abstract type IntelCore_i9_9900X <: IntelCore_X end; export IntelCore_i9_9900X
abstract type IntelCore_i9_9920X <: IntelCore_X end; export IntelCore_i9_9920X
abstract type IntelCore_i9_9940X <: IntelCore_X end; export IntelCore_i9_9940X
abstract type IntelCore_i9_9960X <: IntelCore_X end; export IntelCore_i9_9960X
abstract type IntelCore_i9_9980XE <: IntelCore_X end; export IntelCore_i9_9980XE
abstract type IntelCore_i9_7940X <: IntelCore_X end; export IntelCore_i9_7940X
abstract type IntelCore_i9_7960X <: IntelCore_X end; export IntelCore_i9_7960X
abstract type IntelCore_i9_7980XE <: IntelCore_X end; export IntelCore_i9_7980XE
abstract type IntelCore_i9_7920X <: IntelCore_X end; export IntelCore_i9_7920X
abstract type IntelCore_i5_7640X <: IntelCore_X end; export IntelCore_i5_7640X
abstract type IntelCore_i7_7740X <: IntelCore_X end; export IntelCore_i7_7740X
abstract type IntelCore_i7_7800X <: IntelCore_X end; export IntelCore_i7_7800X
abstract type IntelCore_i7_7820X <: IntelCore_X end; export IntelCore_i7_7820X
abstract type IntelCore_i9_7900X <: IntelCore_X end; export IntelCore_i9_7900X
abstract type IntelCore_i7_6800K <: IntelCore_X end; export IntelCore_i7_6800K
abstract type IntelCore_i7_6850K <: IntelCore_X end; export IntelCore_i7_6850K
abstract type IntelCore_i7_6900K <: IntelCore_X end; export IntelCore_i7_6900K
abstract type IntelCore_i7_6950X <: IntelCore_X end; export IntelCore_i7_6950X
abstract type IntelCore_i7_5820K <: IntelCore_X end; export IntelCore_i7_5820K
abstract type IntelCore_i7_5930K <: IntelCore_X end; export IntelCore_i7_5930K
abstract type IntelCore_i7_5960X <: IntelCore_X end; export IntelCore_i7_5960X
abstract type IntelCore_i7_4820K <: IntelCore_X end; export IntelCore_i7_4820K
abstract type IntelCore_i7_4930K <: IntelCore_X end; export IntelCore_i7_4930K
abstract type IntelCore_i7_4960X <: IntelCore_X end; export IntelCore_i7_4960X
abstract type IntelCore_i7_3970X <: IntelCore_X end; export IntelCore_i7_3970X
abstract type IntelCore_i7_3820 <: IntelCore_X end; export IntelCore_i7_3820
abstract type IntelCore_i7_3930K <: IntelCore_X end; export IntelCore_i7_3930K
abstract type IntelCore_i7_3960X <: IntelCore_X end; export IntelCore_i7_3960X
abstract type IntelCore_i9_12900HX <: IntelCore_i9_g12 end; export IntelCore_i9_12900HX
abstract type IntelCore_i9_12950HX <: IntelCore_i9_g12 end; export IntelCore_i9_12950HX
abstract type IntelCore_i9_12900KS <: IntelCore_i9_g12 end; export IntelCore_i9_12900KS
abstract type IntelCore_i9_12900E <: IntelCore_i9_g12 end; export IntelCore_i9_12900E
abstract type IntelCore_i9_12900F <: IntelCore_i9_g12 end; export IntelCore_i9_12900F
abstract type IntelCore_i9_12900H <: IntelCore_i9_g12 end; export IntelCore_i9_12900H
abstract type IntelCore_i9_12900HK <: IntelCore_i9_g12 end; export IntelCore_i9_12900HK
abstract type IntelCore_i9_12900T <: IntelCore_i9_g12 end; export IntelCore_i9_12900T
abstract type IntelCore_i9_12900TE <: IntelCore_i9_g12 end; export IntelCore_i9_12900TE
abstract type IntelCore_i9_12900K <: IntelCore_i9_g12 end; export IntelCore_i9_12900K
abstract type IntelCore_i9_12900KF <: IntelCore_i9_g12 end; export IntelCore_i9_12900KF
abstract type IntelCore_i9_11900 <: IntelCore_i9_g11 end; export IntelCore_i9_11900
abstract type IntelCore_i9_11900F <: IntelCore_i9_g11 end; export IntelCore_i9_11900F
abstract type IntelCore_i9_11900K <: IntelCore_i9_g11 end; export IntelCore_i9_11900K
abstract type IntelCore_i9_11900KF <: IntelCore_i9_g11 end; export IntelCore_i9_11900KF
abstract type IntelCore_i9_11900T <: IntelCore_i9_g11 end; export IntelCore_i9_11900T
abstract type IntelCore_i9_10900F <: IntelCore_i9_g10 end; export IntelCore_i9_10900F
abstract type IntelCore_i9_10900KF <: IntelCore_i9_g10 end; export IntelCore_i9_10900KF
abstract type IntelCore_i9_9900KF <: IntelCore_i9_g9 end; export IntelCore_i9_9900KF
abstract type IntelCore_i7_12650HX <: IntelCore_i7_g12 end; export IntelCore_i7_12650HX
abstract type IntelCore_i7_12800HX <: IntelCore_i7_g12 end; export IntelCore_i7_12800HX
abstract type IntelCore_i7_12850HX <: IntelCore_i7_g12 end; export IntelCore_i7_12850HX
abstract type IntelCore_i7_1265UE <: IntelCore_i7_g12 end; export IntelCore_i7_1265UE
abstract type IntelCore_i7_1270PE <: IntelCore_i7_g12 end; export IntelCore_i7_1270PE
abstract type IntelCore_i7_1250U <: IntelCore_i7_g12 end; export IntelCore_i7_1250U
abstract type IntelCore_i7_1260U <: IntelCore_i7_g12 end; export IntelCore_i7_1260U
abstract type IntelCore_i7_1270P <: IntelCore_i7_g12 end; export IntelCore_i7_1270P
abstract type IntelCore_i7_1280P <: IntelCore_i7_g12 end; export IntelCore_i7_1280P
abstract type IntelCore_i7_12650H <: IntelCore_i7_g12 end; export IntelCore_i7_12650H
abstract type IntelCore_i7_12700E <: IntelCore_i7_g12 end; export IntelCore_i7_12700E
abstract type IntelCore_i7_12700F <: IntelCore_i7_g12 end; export IntelCore_i7_12700F
abstract type IntelCore_i7_12700H <: IntelCore_i7_g12 end; export IntelCore_i7_12700H
abstract type IntelCore_i7_12700T <: IntelCore_i7_g12 end; export IntelCore_i7_12700T
abstract type IntelCore_i7_12700TE <: IntelCore_i7_g12 end; export IntelCore_i7_12700TE
abstract type IntelCore_i7_12800H <: IntelCore_i7_g12 end; export IntelCore_i7_12800H
abstract type IntelCore_i7_12800HE <: IntelCore_i7_g12 end; export IntelCore_i7_12800HE
abstract type IntelCore_i7_12700K <: IntelCore_i7_g12 end; export IntelCore_i7_12700K
abstract type IntelCore_i7_12700KF <: IntelCore_i7_g12 end; export IntelCore_i7_12700KF
abstract type IntelCore_i7_11390H <: IntelCore_i7_g11 end; export IntelCore_i7_11390H
abstract type IntelCore_i7_1195G7 <: IntelCore_i7_g11 end; export IntelCore_i7_1195G7
abstract type IntelCore_i7_11700 <: IntelCore_i7_g11 end; export IntelCore_i7_11700
abstract type IntelCore_i7_11700F <: IntelCore_i7_g11 end; export IntelCore_i7_11700F
abstract type IntelCore_i7_11700K <: IntelCore_i7_g11 end; export IntelCore_i7_11700K
abstract type IntelCore_i7_11700KF <: IntelCore_i7_g11 end; export IntelCore_i7_11700KF
abstract type IntelCore_i7_11700T <: IntelCore_i7_g11 end; export IntelCore_i7_11700T
abstract type IntelCore_i7_10700F <: IntelCore_i7_g10 end; export IntelCore_i7_10700F
abstract type IntelCore_i7_10700KF <: IntelCore_i7_g10 end; export IntelCore_i7_10700KF
abstract type IntelCore_i7_9700F <: IntelCore_i7_g9 end; export IntelCore_i7_9700F
abstract type IntelCore_i7_9750HF <: IntelCore_i7_g9 end; export IntelCore_i7_9750HF
abstract type IntelCore_i7_9700KF <: IntelCore_i7_g9 end; export IntelCore_i7_9700KF
abstract type IntelCore_i7_5700EQ <: IntelCore_i7_g5 end; export IntelCore_i7_5700EQ
abstract type IntelCore_i7_4700EC <: IntelCore_i7_g4 end; export IntelCore_i7_4700EC
abstract type IntelCore_i7_4702EC <: IntelCore_i7_g4 end; export IntelCore_i7_4702EC
abstract type IntelCore_i5_12450HX <: IntelCore_i5_g12 end; export IntelCore_i5_12450HX
abstract type IntelCore_i5_12600HX <: IntelCore_i5_g12 end; export IntelCore_i5_12600HX
abstract type IntelCore_i5_1245UE <: IntelCore_i5_g12 end; export IntelCore_i5_1245UE
abstract type IntelCore_i5_1250PE <: IntelCore_i5_g12 end; export IntelCore_i5_1250PE
abstract type IntelCore_i5_1230U <: IntelCore_i5_g12 end; export IntelCore_i5_1230U
abstract type IntelCore_i5_1240U <: IntelCore_i5_g12 end; export IntelCore_i5_1240U
abstract type IntelCore_i5_1250P <: IntelCore_i5_g12 end; export IntelCore_i5_1250P
abstract type IntelCore_i5_12400 <: IntelCore_i5_g12 end; export IntelCore_i5_12400
abstract type IntelCore_i5_12400F <: IntelCore_i5_g12 end; export IntelCore_i5_12400F
abstract type IntelCore_i5_12400T <: IntelCore_i5_g12 end; export IntelCore_i5_12400T
abstract type IntelCore_i5_12450H <: IntelCore_i5_g12 end; export IntelCore_i5_12450H
abstract type IntelCore_i5_12500 <: IntelCore_i5_g12 end; export IntelCore_i5_12500
abstract type IntelCore_i5_12500E <: IntelCore_i5_g12 end; export IntelCore_i5_12500E
abstract type IntelCore_i5_12500H <: IntelCore_i5_g12 end; export IntelCore_i5_12500H
abstract type IntelCore_i5_12500T <: IntelCore_i5_g12 end; export IntelCore_i5_12500T
abstract type IntelCore_i5_12500TE <: IntelCore_i5_g12 end; export IntelCore_i5_12500TE
abstract type IntelCore_i5_12600 <: IntelCore_i5_g12 end; export IntelCore_i5_12600
abstract type IntelCore_i5_12600H <: IntelCore_i5_g12 end; export IntelCore_i5_12600H
abstract type IntelCore_i5_12600HE <: IntelCore_i5_g12 end; export IntelCore_i5_12600HE
abstract type IntelCore_i5_12600T <: IntelCore_i5_g12 end; export IntelCore_i5_12600T
abstract type IntelCore_i5_12600K <: IntelCore_i5_g12 end; export IntelCore_i5_12600K
abstract type IntelCore_i5_12600KF <: IntelCore_i5_g12 end; export IntelCore_i5_12600KF
abstract type IntelCore_i5_11320H <: IntelCore_i5_g11 end; export IntelCore_i5_11320H
abstract type IntelCore_i5_1155G7 <: IntelCore_i5_g11 end; export IntelCore_i5_1155G7
abstract type IntelCore_i5_11400 <: IntelCore_i5_g11 end; export IntelCore_i5_11400
abstract type IntelCore_i5_11400F <: IntelCore_i5_g11 end; export IntelCore_i5_11400F
abstract type IntelCore_i5_11400T <: IntelCore_i5_g11 end; export IntelCore_i5_11400T
abstract type IntelCore_i5_11500 <: IntelCore_i5_g11 end; export IntelCore_i5_11500
abstract type IntelCore_i5_11500T <: IntelCore_i5_g11 end; export IntelCore_i5_11500T
abstract type IntelCore_i5_11600 <: IntelCore_i5_g11 end; export IntelCore_i5_11600
abstract type IntelCore_i5_11600K <: IntelCore_i5_g11 end; export IntelCore_i5_11600K
abstract type IntelCore_i5_11600KF <: IntelCore_i5_g11 end; export IntelCore_i5_11600KF
abstract type IntelCore_i5_11600T <: IntelCore_i5_g11 end; export IntelCore_i5_11600T
abstract type IntelCore_i5_10400F <: IntelCore_i5_g10 end; export IntelCore_i5_10400F
abstract type IntelCore_i5_10600KF <: IntelCore_i5_g10 end; export IntelCore_i5_10600KF
abstract type IntelCore_i5_9500F <: IntelCore_i5_g9 end; export IntelCore_i5_9500F
abstract type IntelCore_i5_9300HF <: IntelCore_i5_g9 end; export IntelCore_i5_9300HF
abstract type IntelCore_i5_9400F <: IntelCore_i5_g9 end; export IntelCore_i5_9400F
abstract type IntelCore_i5_9600KF <: IntelCore_i5_g9 end; export IntelCore_i5_9600KF
abstract type IntelCore_i5_4402EC <: IntelCore_i5_g4 end; export IntelCore_i5_4402EC
abstract type IntelCore_i3_1215UE <: IntelCore_i3_g12 end; export IntelCore_i3_1215UE
abstract type IntelCore_i3_1220PE <: IntelCore_i3_g12 end; export IntelCore_i3_1220PE
abstract type IntelCore_i3_1210U <: IntelCore_i3_g12 end; export IntelCore_i3_1210U
abstract type IntelCore_i3_1220P <: IntelCore_i3_g12 end; export IntelCore_i3_1220P
abstract type IntelCore_i3_12100 <: IntelCore_i3_g12 end; export IntelCore_i3_12100
abstract type IntelCore_i3_12100E <: IntelCore_i3_g12 end; export IntelCore_i3_12100E
abstract type IntelCore_i3_12100F <: IntelCore_i3_g12 end; export IntelCore_i3_12100F
abstract type IntelCore_i3_12100T <: IntelCore_i3_g12 end; export IntelCore_i3_12100T
abstract type IntelCore_i3_12100TE <: IntelCore_i3_g12 end; export IntelCore_i3_12100TE
abstract type IntelCore_i3_12300 <: IntelCore_i3_g12 end; export IntelCore_i3_12300
abstract type IntelCore_i3_12300T <: IntelCore_i3_g12 end; export IntelCore_i3_12300T
abstract type IntelCore_i3_10105F <: IntelCore_i3_g10 end; export IntelCore_i3_10105F
abstract type IntelCore_i3_10100F <: IntelCore_i3_g10 end; export IntelCore_i3_10100F
abstract type IntelCore_i3_9100F <: IntelCore_i3_g9 end; export IntelCore_i3_9100F
abstract type IntelCore_i3_9350KF <: IntelCore_i3_g9 end; export IntelCore_i3_9350KF
| PlatformAware | https://github.com/PlatformAwareProgramming/PlatformAware.jl.git |
|
[
"MIT"
] | 0.6.0 | d8f50cbc077c0992b472a07f99013cd5be80b11a | code | 2906 | # ------------------------------------------------------------------
# Licensed under the MIT License. See LICENCE in the project root.
# ------------------------------------------------------------------
## Itanium processors
abstract type IntelItanium <: IntelProcessor end
abstract type IntelItanium_9700 <: IntelItanium end
abstract type IntelItanium_9500 <: IntelItanium end
abstract type IntelItanium_9300 <: IntelItanium end
abstract type IntelItanium_9100 <: IntelItanium end
abstract type IntelItanium_9000 <: IntelItanium end
abstract type IntelItanium_FSB <: IntelItanium end
abstract type IntelItanium_FSB_400 <: IntelItanium_FSB end
abstract type IntelItanium_FSB_533 <: IntelItanium_FSB end
abstract type IntelItanium_FSB_677 <: IntelItanium_FSB end
export IntelItanium,
IntelItanium_9000,
IntelItanium_9100,
IntelItanium_9300,
IntelItanium_9500,
IntelItanium_9700,
IntelItanium_FSB,
IntelItanium_FSB_400,
IntelItanium_FSB_533,
IntelItanium_FSB_677
# Itanium processor models
abstract type IntelItanium_9720 <: IntelItanium_9700 end; export IntelItanium_9720
abstract type IntelItanium_9740 <: IntelItanium_9700 end; export IntelItanium_9740
abstract type IntelItanium_9750 <: IntelItanium_9700 end; export IntelItanium_9750
abstract type IntelItanium_9760 <: IntelItanium_9700 end; export IntelItanium_9760
abstract type IntelItanium_9520 <: IntelItanium_9500 end; export IntelItanium_9520
abstract type IntelItanium_9540 <: IntelItanium_9500 end; export IntelItanium_9540
abstract type IntelItanium_9550 <: IntelItanium_9500 end; export IntelItanium_9550
abstract type IntelItanium_9560 <: IntelItanium_9500 end; export IntelItanium_9560
abstract type IntelItanium_9310 <: IntelItanium_9300 end; export IntelItanium_9310
abstract type IntelItanium_9320 <: IntelItanium_9300 end; export IntelItanium_9320
abstract type IntelItanium_9330 <: IntelItanium_9300 end; export IntelItanium_9330
abstract type IntelItanium_9340 <: IntelItanium_9300 end; export IntelItanium_9340
abstract type IntelItanium_9350 <: IntelItanium_9300 end; export IntelItanium_9350
abstract type IntelItanium_9110N <: IntelItanium_9100 end; export IntelItanium_9110N
abstract type IntelItanium_9120N <: IntelItanium_9100 end; export IntelItanium_9120N
abstract type IntelItanium_9130M <: IntelItanium_9100 end; export IntelItanium_9130M
abstract type IntelItanium_9140M <: IntelItanium_9100 end; export IntelItanium_9140M
abstract type IntelItanium_9140N <: IntelItanium_9100 end; export IntelItanium_9140N
abstract type IntelItanium_9150M <: IntelItanium_9100 end; export IntelItanium_9150M
abstract type IntelItanium_9150N <: IntelItanium_9100 end; export IntelItanium_9150N
abstract type IntelItanium_9152M <: IntelItanium_9100 end; export IntelItanium_9152M
abstract type IntelItanium_9015 <: IntelItanium_9000 end; export IntelItanium_9015
| PlatformAware | https://github.com/PlatformAwareProgramming/PlatformAware.jl.git |
|
[
"MIT"
] | 0.6.0 | d8f50cbc077c0992b472a07f99013cd5be80b11a | code | 11348 | # ------------------------------------------------------------------
# Licensed under the MIT License. See LICENCE in the project root.
# ------------------------------------------------------------------
## Pentium processors
abstract type IntelPentium <: IntelProcessor end
abstract type IntelPentium_Gold <: IntelPentium end
abstract type IntelPentium_Silver <: IntelPentium end
abstract type IntelPentium_D <: IntelPentium end
abstract type IntelPentium_G <: IntelPentium end
abstract type IntelPentium_J <: IntelPentium end
abstract type IntelPentium_N <: IntelPentium end
abstract type IntelPentium_6800 <: IntelPentium end
abstract type IntelPentium_4000 <: IntelPentium end
abstract type IntelPentium_3000 <: IntelPentium end
abstract type IntelPentium_2000 <: IntelPentium end
abstract type IntelPentium_1000 <: IntelPentium end
export IntelPentium,
IntelPentium_1000,
IntelPentium_2000,
IntelPentium_3000,
IntelPentium_4000,
IntelPentium_6800,
IntelPentium_D,
IntelPentium_G,
IntelPentium_Gold,
IntelPentium_J,
IntelPentium_N,
IntelPentium_Silver
# Pentium processor models
abstract type IntelPentium_N3700 <: IntelPentium_N end; export IntelPentium_N3700
abstract type IntelPentium_G4600 <: IntelPentium_G end; export IntelPentium_G4600
abstract type IntelPentium_G4600T <: IntelPentium_G end; export IntelPentium_G4600T
abstract type IntelPentium_G4620 <: IntelPentium_G end; export IntelPentium_G4620
abstract type IntelPentium_4415Y <: IntelPentium_Gold end; export IntelPentium_4415Y
abstract type IntelPentium_4410Y <: IntelPentium_Gold end; export IntelPentium_4410Y
abstract type IntelPentium_4417U <: IntelPentium_Gold end; export IntelPentium_4417U
abstract type IntelPentium_4415U <: IntelPentium_Gold end; export IntelPentium_4415U
abstract type IntelPentium_G4560 <: IntelPentium_G end; export IntelPentium_G4560
abstract type IntelPentium_G4560T <: IntelPentium_G end; export IntelPentium_G4560T
abstract type IntelPentium_G4500 <: IntelPentium_G end; export IntelPentium_G4500
abstract type IntelPentium_G4500T <: IntelPentium_G end; export IntelPentium_G4500T
abstract type IntelPentium_G4520 <: IntelPentium_G end; export IntelPentium_G4520
abstract type IntelPentium_4405Y <: IntelPentium_4000 end; export IntelPentium_4405Y
abstract type IntelPentium_G4400TE <: IntelPentium_G end; export IntelPentium_G4400TE
abstract type IntelPentium_4405U <: IntelPentium_4000 end; export IntelPentium_4405U
abstract type IntelPentium_G4400 <: IntelPentium_G end; export IntelPentium_G4400
abstract type IntelPentium_G4400T <: IntelPentium_G end; export IntelPentium_G4400T
abstract type IntelPentium_N4200E <: IntelPentium_N end; export IntelPentium_N4200E
abstract type IntelPentium_J4205 <: IntelPentium_J end; export IntelPentium_J4205
abstract type IntelPentium_N4200 <: IntelPentium_N end; export IntelPentium_N4200
abstract type IntelPentium_3825U <: IntelPentium_3000 end; export IntelPentium_3825U
abstract type IntelPentium_3805U <: IntelPentium_3000 end; export IntelPentium_3805U
abstract type IntelPentium_G3260 <: IntelPentium_G end; export IntelPentium_G3260
abstract type IntelPentium_G3260T <: IntelPentium_G end; export IntelPentium_G3260T
abstract type IntelPentium_G3460T <: IntelPentium_G end; export IntelPentium_G3460T
abstract type IntelPentium_G3470 <: IntelPentium_G end; export IntelPentium_G3470
abstract type IntelPentium_G3250 <: IntelPentium_G end; export IntelPentium_G3250
abstract type IntelPentium_G3250T <: IntelPentium_G end; export IntelPentium_G3250T
abstract type IntelPentium_G3450T <: IntelPentium_G end; export IntelPentium_G3450T
abstract type IntelPentium_G3460 <: IntelPentium_G end; export IntelPentium_G3460
abstract type IntelPentium_G3258 <: IntelPentium_G end; export IntelPentium_G3258
abstract type IntelPentium_G3240 <: IntelPentium_G end; export IntelPentium_G3240
abstract type IntelPentium_G3240T <: IntelPentium_G end; export IntelPentium_G3240T
abstract type IntelPentium_G3440 <: IntelPentium_G end; export IntelPentium_G3440
abstract type IntelPentium_G3440T <: IntelPentium_G end; export IntelPentium_G3440T
abstract type IntelPentium_G3450 <: IntelPentium_G end; export IntelPentium_G3450
abstract type IntelPentium_3560M <: IntelPentium_3000 end; export IntelPentium_3560M
abstract type IntelPentium_3558U <: IntelPentium_3000 end; export IntelPentium_3558U
abstract type IntelPentium_3561Y <: IntelPentium_3000 end; export IntelPentium_3561Y
abstract type IntelPentium_3550M <: IntelPentium_3000 end; export IntelPentium_3550M
abstract type IntelPentium_3556U <: IntelPentium_3000 end; export IntelPentium_3556U
abstract type IntelPentium_3560Y <: IntelPentium_3000 end; export IntelPentium_3560Y
abstract type IntelPentium_G3220 <: IntelPentium_G end; export IntelPentium_G3220
abstract type IntelPentium_G3220T <: IntelPentium_G end; export IntelPentium_G3220T
abstract type IntelPentium_G3320TE <: IntelPentium_G end; export IntelPentium_G3320TE
abstract type IntelPentium_G3420 <: IntelPentium_G end; export IntelPentium_G3420
abstract type IntelPentium_G3420T <: IntelPentium_G end; export IntelPentium_G3420T
abstract type IntelPentium_G3430 <: IntelPentium_G end; export IntelPentium_G3430
abstract type IntelPentium_A1018 <: IntelPentium_1000 end; export IntelPentium_A1018
abstract type IntelPentium_2127U <: IntelPentium_2000 end; export IntelPentium_2127U
abstract type IntelPentium_G2030 <: IntelPentium_G end; export IntelPentium_G2030
abstract type IntelPentium_G2030T <: IntelPentium_G end; export IntelPentium_G2030T
abstract type IntelPentium_G2120T <: IntelPentium_G end; export IntelPentium_G2120T
abstract type IntelPentium_G2140 <: IntelPentium_G end; export IntelPentium_G2140
abstract type IntelPentium_2030M <: IntelPentium_2000 end; export IntelPentium_2030M
abstract type IntelPentium_G2010 <: IntelPentium_G end; export IntelPentium_G2010
abstract type IntelPentium_G2020 <: IntelPentium_G end; export IntelPentium_G2020
abstract type IntelPentium_G2020T <: IntelPentium_G end; export IntelPentium_G2020T
abstract type IntelPentium_G2130 <: IntelPentium_G end; export IntelPentium_G2130
abstract type IntelPentium_2129Y <: IntelPentium_2000 end; export IntelPentium_2129Y
abstract type IntelPentium_2020M <: IntelPentium_2000 end; export IntelPentium_2020M
abstract type IntelPentium_2117U <: IntelPentium_2000 end; export IntelPentium_2117U
abstract type IntelPentium_G2100T <: IntelPentium_G end; export IntelPentium_G2100T
abstract type IntelPentium_G2120 <: IntelPentium_G end; export IntelPentium_G2120
abstract type IntelPentium_A1020 <: IntelPentium_1000 end; export IntelPentium_A1020
abstract type IntelPentium_N3540 <: IntelPentium_N end; export IntelPentium_N3540
abstract type IntelPentium_N3530 <: IntelPentium_N end; export IntelPentium_N3530
abstract type IntelPentium_J2900 <: IntelPentium_J end; export IntelPentium_J2900
abstract type IntelPentium_N3520 <: IntelPentium_N end; export IntelPentium_N3520
abstract type IntelPentium_J2850 <: IntelPentium_J end; export IntelPentium_J2850
abstract type IntelPentium_N3510 <: IntelPentium_N end; export IntelPentium_N3510
abstract type IntelPentium_8500 <: IntelPentium_Gold end; export IntelPentium_8500
abstract type IntelPentium_8505 <: IntelPentium_Gold end; export IntelPentium_8505
abstract type IntelPentium_G7400 <: IntelPentium_Gold end; export IntelPentium_G7400
abstract type IntelPentium_G7400E <: IntelPentium_Gold end; export IntelPentium_G7400E
abstract type IntelPentium_G7400T <: IntelPentium_Gold end; export IntelPentium_G7400T
abstract type IntelPentium_G7400TE <: IntelPentium_Gold end; export IntelPentium_G7400TE
abstract type IntelPentium_G6405 <: IntelPentium_Gold end; export IntelPentium_G6405
abstract type IntelPentium_G6405T <: IntelPentium_Gold end; export IntelPentium_G6405T
abstract type IntelPentium_G6505 <: IntelPentium_Gold end; export IntelPentium_G6505
abstract type IntelPentium_G6505T <: IntelPentium_Gold end; export IntelPentium_G6505T
abstract type IntelPentium_G6605 <: IntelPentium_Gold end; export IntelPentium_G6605
abstract type IntelPentium_6500Y <: IntelPentium_Gold end; export IntelPentium_6500Y
abstract type IntelPentium_7505 <: IntelPentium_Gold end; export IntelPentium_7505
abstract type IntelPentium_G6400 <: IntelPentium_Gold end; export IntelPentium_G6400
abstract type IntelPentium_G6400E <: IntelPentium_Gold end; export IntelPentium_G6400E
abstract type IntelPentium_G6400T <: IntelPentium_Gold end; export IntelPentium_G6400T
abstract type IntelPentium_G6400TE <: IntelPentium_Gold end; export IntelPentium_G6400TE
abstract type IntelPentium_G6500 <: IntelPentium_Gold end; export IntelPentium_G6500
abstract type IntelPentium_G6500T <: IntelPentium_Gold end; export IntelPentium_G6500T
abstract type IntelPentium_G6600 <: IntelPentium_Gold end; export IntelPentium_G6600
abstract type IntelPentium_6405U <: IntelPentium_Gold end; export IntelPentium_6405U
abstract type IntelPentium_G5420 <: IntelPentium_Gold end; export IntelPentium_G5420
abstract type IntelPentium_G5420T <: IntelPentium_Gold end; export IntelPentium_G5420T
abstract type IntelPentium_G5600T <: IntelPentium_Gold end; export IntelPentium_G5600T
abstract type IntelPentium_G5620 <: IntelPentium_Gold end; export IntelPentium_G5620
abstract type IntelPentium_4425Y <: IntelPentium_Gold end; export IntelPentium_4425Y
abstract type IntelPentium_G5400 <: IntelPentium_Gold end; export IntelPentium_G5400
abstract type IntelPentium_G5400T <: IntelPentium_Gold end; export IntelPentium_G5400T
abstract type IntelPentium_G5500 <: IntelPentium_Gold end; export IntelPentium_G5500
abstract type IntelPentium_G5500T <: IntelPentium_Gold end; export IntelPentium_G5500T
abstract type IntelPentium_N6000 <: IntelPentium_Silver end; export IntelPentium_N6000
abstract type IntelPentium_N6005 <: IntelPentium_Silver end; export IntelPentium_N6005
abstract type IntelPentium_J5040 <: IntelPentium_Silver end; export IntelPentium_J5040
abstract type IntelPentium_N5030 <: IntelPentium_Silver end; export IntelPentium_N5030
abstract type IntelPentium_J5005 <: IntelPentium_Silver end; export IntelPentium_J5005
abstract type IntelPentium_N5000 <: IntelPentium_Silver end; export IntelPentium_N5000
abstract type IntelPentium_D1519 <: IntelPentium_D end; export IntelPentium_D1519
abstract type IntelPentium_D1507 <: IntelPentium_D end; export IntelPentium_D1507
abstract type IntelPentium_D1508 <: IntelPentium_D end; export IntelPentium_D1508
abstract type IntelPentium_D1509 <: IntelPentium_D end; export IntelPentium_D1509
abstract type IntelPentium_D1517 <: IntelPentium_D end; export IntelPentium_D1517
abstract type IntelPentium_J6426 <: IntelPentium_J end; export IntelPentium_J6426
abstract type IntelPentium_J3710 <: IntelPentium_J end; export IntelPentium_J3710
abstract type IntelPentium_N6415 <: IntelPentium_N end; export IntelPentium_N6415
abstract type IntelPentium_N3710 <: IntelPentium_N end; export IntelPentium_N3710
abstract type IntelPentium_6805 <: IntelPentium_6800 end; export IntelPentium_6805
abstract type IntelPentium_1405V2 <: IntelPentium_1000 end; export IntelPentium_1405V2
abstract type IntelPentium_1405 <: IntelPentium_1000 end; export IntelPentium_1405
abstract type IntelPentium_5405U <: IntelPentium_Gold end; export IntelPentium_5405U
| PlatformAware | https://github.com/PlatformAwareProgramming/PlatformAware.jl.git |
|
[
"MIT"
] | 0.6.0 | d8f50cbc077c0992b472a07f99013cd5be80b11a | code | 62826 | # ------------------------------------------------------------------
# Licensed under the MIT License. See LICENCE in the project root.
# ------------------------------------------------------------------
## Xeon processors
abstract type IntelXeon <: IntelProcessor end
abstract type IntelXeon_W <: IntelXeon end
abstract type IntelXeon_D <: IntelXeon end
abstract type IntelXeon_E <: IntelXeon end
abstract type IntelXeon_E3 <: IntelXeon_E end
abstract type IntelXeon_E3_v2 <: IntelXeon_E3 end
abstract type IntelXeon_E3_v3 <: IntelXeon_E3 end
abstract type IntelXeon_E3_v4 <: IntelXeon_E3 end
abstract type IntelXeon_E3_v5 <: IntelXeon_E3 end
abstract type IntelXeon_E3_v6 <: IntelXeon_E3 end
abstract type IntelXeon_E5 <: IntelXeon_E end
abstract type IntelXeon_E5_v2 <: IntelXeon_E5 end
abstract type IntelXeon_E5_v3 <: IntelXeon_E5 end
abstract type IntelXeon_E5_v4 <: IntelXeon_E5 end
abstract type IntelXeon_E5_v5 <: IntelXeon_E5 end
abstract type IntelXeon_E7 <: IntelXeon_E end
abstract type IntelXeon_E7_v2 <: IntelXeon_E7 end
abstract type IntelXeon_E7_v3 <: IntelXeon_E7 end
abstract type IntelXeon_E7_v4 <: IntelXeon_E7 end
abstract type IntelXeon_Scalable <: IntelXeon end
abstract type IntelXeon_Scalable_g2 <: IntelXeon_Scalable end
abstract type IntelXeon_Scalable_g3 <: IntelXeon_Scalable end
export IntelXeon,
IntelXeon_D,
IntelXeon_E,
IntelXeon_E3,
IntelXeon_E3_v2,
IntelXeon_E3_v3,
IntelXeon_E3_v4,
IntelXeon_E3_v5,
IntelXeon_E3_v6,
IntelXeon_E5,
IntelXeon_E5_v2,
IntelXeon_E5_v3,
IntelXeon_E5_v4,
IntelXeon_E5_v5,
IntelXeon_E7,
IntelXeon_E7_v2,
IntelXeon_E7_v3,
IntelXeon_E7_v4,
IntelXeon_Scalable,
IntelXeon_Scalable_g2,
IntelXeon_Scalable_g3,
IntelXeon_W
# Xeon processor models
abstract type IntelXeon_E_2286M <: IntelXeon_E end; export IntelXeon_E_2286M
abstract type IntelXeon_E3_1285V6 <: IntelXeon_E3_v6 end; export IntelXeon_E3_1285V6
abstract type IntelXeon_E3_1501LV6 <: IntelXeon_E3_v6 end; export IntelXeon_E3_1501LV6
abstract type IntelXeon_E3_1501MV6 <: IntelXeon_E3_v6 end; export IntelXeon_E3_1501MV6
abstract type IntelXeon_E3_1225V6 <: IntelXeon_E3_v6 end; export IntelXeon_E3_1225V6
abstract type IntelXeon_E3_1245V6 <: IntelXeon_E3_v6 end; export IntelXeon_E3_1245V6
abstract type IntelXeon_E3_1275V6 <: IntelXeon_E3_v6 end; export IntelXeon_E3_1275V6
abstract type IntelXeon_E3_1505LV6 <: IntelXeon_E3_v6 end; export IntelXeon_E3_1505LV6
abstract type IntelXeon_E3_1505MV6 <: IntelXeon_E3_v6 end; export IntelXeon_E3_1505MV6
abstract type IntelXeon_E3_1535MV6 <: IntelXeon_E3_v6 end; export IntelXeon_E3_1535MV6
abstract type IntelXeon_E3_1225V5 <: IntelXeon_E3_v5 end; export IntelXeon_E3_1225V5
abstract type IntelXeon_E3_1235LV5 <: IntelXeon_E3_v5 end; export IntelXeon_E3_1235LV5
abstract type IntelXeon_E3_1245V5 <: IntelXeon_E3_v5 end; export IntelXeon_E3_1245V5
abstract type IntelXeon_E3_1268LV5 <: IntelXeon_E3_v5 end; export IntelXeon_E3_1268LV5
abstract type IntelXeon_E3_1275V5 <: IntelXeon_E3_v5 end; export IntelXeon_E3_1275V5
abstract type IntelXeon_E3_1505LV5 <: IntelXeon_E3_v5 end; export IntelXeon_E3_1505LV5
abstract type IntelXeon_E3_1505MV5 <: IntelXeon_E3_v5 end; export IntelXeon_E3_1505MV5
abstract type IntelXeon_E3_1535MV5 <: IntelXeon_E3_v5 end; export IntelXeon_E3_1535MV5
abstract type IntelXeon_E3_1268LV3 <: IntelXeon_E3_v3 end; export IntelXeon_E3_1268LV3
abstract type IntelXeon_E3_1265LV2 <: IntelXeon_E3_v2 end; export IntelXeon_E3_1265LV2
abstract type IntelXeon_E3_1260L <: IntelXeon_E3 end; export IntelXeon_E3_1260L
abstract type IntelXeon_E3_1275LV3 <: IntelXeon_E3_v3 end; export IntelXeon_E3_1275LV3
abstract type IntelXeon_E3_1265Lv3 <: IntelXeon_E3_v3 end; export IntelXeon_E3_1265Lv3
abstract type IntelXeon_W_1250 <: IntelXeon_W end; export IntelXeon_W_1250
abstract type IntelXeon_W_1250P <: IntelXeon_W end; export IntelXeon_W_1250P
abstract type IntelXeon_W_1270 <: IntelXeon_W end; export IntelXeon_W_1270
abstract type IntelXeon_W_1270P <: IntelXeon_W end; export IntelXeon_W_1270P
abstract type IntelXeon_W_1290 <: IntelXeon_W end; export IntelXeon_W_1290
abstract type IntelXeon_W_1290P <: IntelXeon_W end; export IntelXeon_W_1290P
abstract type IntelXeon_W_1290T <: IntelXeon_W end; export IntelXeon_W_1290T
abstract type IntelXeon_E_2254ME <: IntelXeon_E end; export IntelXeon_E_2254ME
abstract type IntelXeon_E_2254ML <: IntelXeon_E end; export IntelXeon_E_2254ML
abstract type IntelXeon_E_2276ME <: IntelXeon_E end; export IntelXeon_E_2276ME
abstract type IntelXeon_E_2276ML <: IntelXeon_E end; export IntelXeon_E_2276ML
abstract type IntelXeon_E_2224G <: IntelXeon_E end; export IntelXeon_E_2224G
abstract type IntelXeon_E_2226G <: IntelXeon_E end; export IntelXeon_E_2226G
abstract type IntelXeon_E_2244G <: IntelXeon_E end; export IntelXeon_E_2244G
abstract type IntelXeon_E_2246G <: IntelXeon_E end; export IntelXeon_E_2246G
abstract type IntelXeon_E_2274G <: IntelXeon_E end; export IntelXeon_E_2274G
abstract type IntelXeon_E_2276G <: IntelXeon_E end; export IntelXeon_E_2276G
abstract type IntelXeon_E_2276M <: IntelXeon_E end; export IntelXeon_E_2276M
abstract type IntelXeon_E_2278G <: IntelXeon_E end; export IntelXeon_E_2278G
abstract type IntelXeon_E_2286G <: IntelXeon_E end; export IntelXeon_E_2286G
abstract type IntelXeon_E_2288G <: IntelXeon_E end; export IntelXeon_E_2288G
abstract type IntelXeon_E_2124G <: IntelXeon_E end; export IntelXeon_E_2124G
abstract type IntelXeon_E_2126G <: IntelXeon_E end; export IntelXeon_E_2126G
abstract type IntelXeon_E_2144G <: IntelXeon_E end; export IntelXeon_E_2144G
abstract type IntelXeon_E_2146G <: IntelXeon_E end; export IntelXeon_E_2146G
abstract type IntelXeon_E_2174G <: IntelXeon_E end; export IntelXeon_E_2174G
abstract type IntelXeon_E_2176G <: IntelXeon_E end; export IntelXeon_E_2176G
abstract type IntelXeon_E_2186G <: IntelXeon_E end; export IntelXeon_E_2186G
abstract type IntelXeon_E_2176M <: IntelXeon_E end; export IntelXeon_E_2176M
abstract type IntelXeon_E_2186M <: IntelXeon_E end; export IntelXeon_E_2186M
abstract type IntelXeon_W_1250E <: IntelXeon_W end; export IntelXeon_W_1250E
abstract type IntelXeon_W_1250TE <: IntelXeon_W end; export IntelXeon_W_1250TE
abstract type IntelXeon_W_1270E <: IntelXeon_W end; export IntelXeon_W_1270E
abstract type IntelXeon_W_1270TE <: IntelXeon_W end; export IntelXeon_W_1270TE
abstract type IntelXeon_W_1290E <: IntelXeon_W end; export IntelXeon_W_1290E
abstract type IntelXeon_W_1290TE <: IntelXeon_W end; export IntelXeon_W_1290TE
abstract type IntelXeon_E_2226GE <: IntelXeon_E end; export IntelXeon_E_2226GE
abstract type IntelXeon_E_2278GE <: IntelXeon_E end; export IntelXeon_E_2278GE
abstract type IntelXeon_E_2278GEL <: IntelXeon_E end; export IntelXeon_E_2278GEL
abstract type IntelXeon_W_11155MLE <: IntelXeon_W end; export IntelXeon_W_11155MLE
abstract type IntelXeon_W_11155MRE <: IntelXeon_W end; export IntelXeon_W_11155MRE
abstract type IntelXeon_W_11555MLE <: IntelXeon_W end; export IntelXeon_W_11555MLE
abstract type IntelXeon_W_11555MRE <: IntelXeon_W end; export IntelXeon_W_11555MRE
abstract type IntelXeon_W_11865MLE <: IntelXeon_W end; export IntelXeon_W_11865MLE
abstract type IntelXeon_W_11865MRE <: IntelXeon_W end; export IntelXeon_W_11865MRE
abstract type IntelXeon_W_11855M <: IntelXeon_W end; export IntelXeon_W_11855M
abstract type IntelXeon_W_11955M <: IntelXeon_W end; export IntelXeon_W_11955M
abstract type IntelXeon_W_10855M <: IntelXeon_W end; export IntelXeon_W_10855M
abstract type IntelXeon_W_10885M <: IntelXeon_W end; export IntelXeon_W_10885M
abstract type IntelXeon_E3_1565LV5 <: IntelXeon_E3_v5 end; export IntelXeon_E3_1565LV5
abstract type IntelXeon_E3_1578LV5 <: IntelXeon_E3_v5 end; export IntelXeon_E3_1578LV5
abstract type IntelXeon_E3_1585V5 <: IntelXeon_E3_v5 end; export IntelXeon_E3_1585V5
abstract type IntelXeon_E3_1585LV5 <: IntelXeon_E3_v5 end; export IntelXeon_E3_1585LV5
abstract type IntelXeon_E3_1515MV5 <: IntelXeon_E3_v5 end; export IntelXeon_E3_1515MV5
abstract type IntelXeon_E3_1545MV5 <: IntelXeon_E3_v5 end; export IntelXeon_E3_1545MV5
abstract type IntelXeon_E3_1575MV5 <: IntelXeon_E3_v5 end; export IntelXeon_E3_1575MV5
abstract type IntelXeon_5315Y <: IntelXeon_Scalable_g3 end; export IntelXeon_5315Y
abstract type IntelXeon_5317 <: IntelXeon_Scalable_g3 end; export IntelXeon_5317
abstract type IntelXeon_5318N <: IntelXeon_Scalable_g3 end; export IntelXeon_5318N
abstract type IntelXeon_5318S <: IntelXeon_Scalable_g3 end; export IntelXeon_5318S
abstract type IntelXeon_5318Y <: IntelXeon_Scalable_g3 end; export IntelXeon_5318Y
abstract type IntelXeon_5320 <: IntelXeon_Scalable_g3 end; export IntelXeon_5320
abstract type IntelXeon_5320T <: IntelXeon_Scalable_g3 end; export IntelXeon_5320T
abstract type IntelXeon_6312U <: IntelXeon_Scalable_g3 end; export IntelXeon_6312U
abstract type IntelXeon_6314U <: IntelXeon_Scalable_g3 end; export IntelXeon_6314U
abstract type IntelXeon_6326 <: IntelXeon_Scalable_g3 end; export IntelXeon_6326
abstract type IntelXeon_6330 <: IntelXeon_Scalable_g3 end; export IntelXeon_6330
abstract type IntelXeon_6330N <: IntelXeon_Scalable_g3 end; export IntelXeon_6330N
abstract type IntelXeon_6334 <: IntelXeon_Scalable_g3 end; export IntelXeon_6334
abstract type IntelXeon_6336Y <: IntelXeon_Scalable_g3 end; export IntelXeon_6336Y
abstract type IntelXeon_6338 <: IntelXeon_Scalable_g3 end; export IntelXeon_6338
abstract type IntelXeon_6338N <: IntelXeon_Scalable_g3 end; export IntelXeon_6338N
abstract type IntelXeon_6338T <: IntelXeon_Scalable_g3 end; export IntelXeon_6338T
abstract type IntelXeon_6342 <: IntelXeon_Scalable_g3 end; export IntelXeon_6342
abstract type IntelXeon_6346 <: IntelXeon_Scalable_g3 end; export IntelXeon_6346
abstract type IntelXeon_6348 <: IntelXeon_Scalable_g3 end; export IntelXeon_6348
abstract type IntelXeon_6354 <: IntelXeon_Scalable_g3 end; export IntelXeon_6354
abstract type IntelXeon_8351N <: IntelXeon_Scalable_g3 end; export IntelXeon_8351N
abstract type IntelXeon_8352M <: IntelXeon_Scalable_g3 end; export IntelXeon_8352M
abstract type IntelXeon_8352S <: IntelXeon_Scalable_g3 end; export IntelXeon_8352S
abstract type IntelXeon_8352V <: IntelXeon_Scalable_g3 end; export IntelXeon_8352V
abstract type IntelXeon_8352Y <: IntelXeon_Scalable_g3 end; export IntelXeon_8352Y
abstract type IntelXeon_8358 <: IntelXeon_Scalable_g3 end; export IntelXeon_8358
abstract type IntelXeon_8358P <: IntelXeon_Scalable_g3 end; export IntelXeon_8358P
abstract type IntelXeon_8362 <: IntelXeon_Scalable_g3 end; export IntelXeon_8362
abstract type IntelXeon_8368 <: IntelXeon_Scalable_g3 end; export IntelXeon_8368
abstract type IntelXeon_8368Q <: IntelXeon_Scalable_g3 end; export IntelXeon_8368Q
abstract type IntelXeon_8380 <: IntelXeon_Scalable_g3 end; export IntelXeon_8380
abstract type IntelXeon_4309Y <: IntelXeon_Scalable_g3 end; export IntelXeon_4309Y
abstract type IntelXeon_4310 <: IntelXeon_Scalable_g3 end; export IntelXeon_4310
abstract type IntelXeon_4310T <: IntelXeon_Scalable_g3 end; export IntelXeon_4310T
abstract type IntelXeon_4314 <: IntelXeon_Scalable_g3 end; export IntelXeon_4314
abstract type IntelXeon_4316 <: IntelXeon_Scalable_g3 end; export IntelXeon_4316
abstract type IntelXeon_6330H <: IntelXeon_Scalable_g3 end; export IntelXeon_6330H
abstract type IntelXeon_8356H <: IntelXeon_Scalable_g3 end; export IntelXeon_8356H
abstract type IntelXeon_8360H <: IntelXeon_Scalable_g3 end; export IntelXeon_8360H
abstract type IntelXeon_8360HL <: IntelXeon_Scalable_g3 end; export IntelXeon_8360HL
abstract type IntelXeon_5318H <: IntelXeon_Scalable_g3 end; export IntelXeon_5318H
abstract type IntelXeon_5320H <: IntelXeon_Scalable_g3 end; export IntelXeon_5320H
abstract type IntelXeon_6328H <: IntelXeon_Scalable_g3 end; export IntelXeon_6328H
abstract type IntelXeon_6328HL <: IntelXeon_Scalable_g3 end; export IntelXeon_6328HL
abstract type IntelXeon_6348H <: IntelXeon_Scalable_g3 end; export IntelXeon_6348H
abstract type IntelXeon_8353H <: IntelXeon_Scalable_g3 end; export IntelXeon_8353H
abstract type IntelXeon_8354H <: IntelXeon_Scalable_g3 end; export IntelXeon_8354H
abstract type IntelXeon_8375 <: IntelXeon_Scalable_g3 end; export IntelXeon_8375
abstract type IntelXeon_8375C <: IntelXeon_Scalable_g3 end; export IntelXeon_8375C
abstract type IntelXeon_8376H <: IntelXeon_Scalable_g3 end; export IntelXeon_8376H
abstract type IntelXeon_8376HL <: IntelXeon_Scalable_g3 end; export IntelXeon_8376HL
abstract type IntelXeon_8380H <: IntelXeon_Scalable_g3 end; export IntelXeon_8380H
abstract type IntelXeon_3206R <: IntelXeon_Scalable_g2 end; export IntelXeon_3206R
abstract type IntelXeon_5218R <: IntelXeon_Scalable_g2 end; export IntelXeon_5218R
abstract type IntelXeon_5220R <: IntelXeon_Scalable_g2 end; export IntelXeon_5220R
abstract type IntelXeon_6208U <: IntelXeon_Scalable_g2 end; export IntelXeon_6208U
abstract type IntelXeon_6226R <: IntelXeon_Scalable_g2 end; export IntelXeon_6226R
abstract type IntelXeon_6230R <: IntelXeon_Scalable_g2 end; export IntelXeon_6230R
abstract type IntelXeon_6238R <: IntelXeon_Scalable_g2 end; export IntelXeon_6238R
abstract type IntelXeon_6240R <: IntelXeon_Scalable_g2 end; export IntelXeon_6240R
abstract type IntelXeon_6242R <: IntelXeon_Scalable_g2 end; export IntelXeon_6242R
abstract type IntelXeon_6246R <: IntelXeon_Scalable_g2 end; export IntelXeon_6246R
abstract type IntelXeon_6248R <: IntelXeon_Scalable_g2 end; export IntelXeon_6248R
abstract type IntelXeon_6250 <: IntelXeon_Scalable_g2 end; export IntelXeon_6250
abstract type IntelXeon_6250L <: IntelXeon_Scalable_g2 end; export IntelXeon_6250L
abstract type IntelXeon_6256 <: IntelXeon_Scalable_g2 end; export IntelXeon_6256
abstract type IntelXeon_6258R <: IntelXeon_Scalable_g2 end; export IntelXeon_6258R
abstract type IntelXeon_4210R <: IntelXeon_Scalable_g2 end; export IntelXeon_4210R
abstract type IntelXeon_4210T <: IntelXeon_Scalable_g2 end; export IntelXeon_4210T
abstract type IntelXeon_4214R <: IntelXeon_Scalable_g2 end; export IntelXeon_4214R
abstract type IntelXeon_4215R <: IntelXeon_Scalable_g2 end; export IntelXeon_4215R
abstract type IntelXeon_9221 <: IntelXeon_Scalable_g2 end; export IntelXeon_9221
abstract type IntelXeon_9222 <: IntelXeon_Scalable_g2 end; export IntelXeon_9222
abstract type IntelXeon_3204 <: IntelXeon_Scalable_g2 end; export IntelXeon_3204
abstract type IntelXeon_5215 <: IntelXeon_Scalable_g2 end; export IntelXeon_5215
abstract type IntelXeon_5215L <: IntelXeon_Scalable_g2 end; export IntelXeon_5215L
abstract type IntelXeon_5217 <: IntelXeon_Scalable_g2 end; export IntelXeon_5217
abstract type IntelXeon_5218 <: IntelXeon_Scalable_g2 end; export IntelXeon_5218
abstract type IntelXeon_5218B <: IntelXeon_Scalable_g2 end; export IntelXeon_5218B
abstract type IntelXeon_5218N <: IntelXeon_Scalable_g2 end; export IntelXeon_5218N
abstract type IntelXeon_5218T <: IntelXeon_Scalable_g2 end; export IntelXeon_5218T
abstract type IntelXeon_5220 <: IntelXeon_Scalable_g2 end; export IntelXeon_5220
abstract type IntelXeon_5220S <: IntelXeon_Scalable_g2 end; export IntelXeon_5220S
abstract type IntelXeon_5220T <: IntelXeon_Scalable_g2 end; export IntelXeon_5220T
abstract type IntelXeon_5222 <: IntelXeon_Scalable_g2 end; export IntelXeon_5222
abstract type IntelXeon_6209U <: IntelXeon_Scalable_g2 end; export IntelXeon_6209U
abstract type IntelXeon_6210U <: IntelXeon_Scalable_g2 end; export IntelXeon_6210U
abstract type IntelXeon_6212U <: IntelXeon_Scalable_g2 end; export IntelXeon_6212U
abstract type IntelXeon_6222V <: IntelXeon_Scalable_g2 end; export IntelXeon_6222V
abstract type IntelXeon_6226 <: IntelXeon_Scalable_g2 end; export IntelXeon_6226
abstract type IntelXeon_6230 <: IntelXeon_Scalable_g2 end; export IntelXeon_6230
abstract type IntelXeon_6230N <: IntelXeon_Scalable_g2 end; export IntelXeon_6230N
abstract type IntelXeon_6230T <: IntelXeon_Scalable_g2 end; export IntelXeon_6230T
abstract type IntelXeon_6234 <: IntelXeon_Scalable_g2 end; export IntelXeon_6234
abstract type IntelXeon_6238 <: IntelXeon_Scalable_g2 end; export IntelXeon_6238
abstract type IntelXeon_6238L <: IntelXeon_Scalable_g2 end; export IntelXeon_6238L
abstract type IntelXeon_6238T <: IntelXeon_Scalable_g2 end; export IntelXeon_6238T
abstract type IntelXeon_6240 <: IntelXeon_Scalable_g2 end; export IntelXeon_6240
abstract type IntelXeon_6240L <: IntelXeon_Scalable_g2 end; export IntelXeon_6240L
abstract type IntelXeon_6240Y <: IntelXeon_Scalable_g2 end; export IntelXeon_6240Y
abstract type IntelXeon_6242 <: IntelXeon_Scalable_g2 end; export IntelXeon_6242
abstract type IntelXeon_6244 <: IntelXeon_Scalable_g2 end; export IntelXeon_6244
abstract type IntelXeon_6246 <: IntelXeon_Scalable_g2 end; export IntelXeon_6246
abstract type IntelXeon_6248 <: IntelXeon_Scalable_g2 end; export IntelXeon_6248
abstract type IntelXeon_6252 <: IntelXeon_Scalable_g2 end; export IntelXeon_6252
abstract type IntelXeon_6252N <: IntelXeon_Scalable_g2 end; export IntelXeon_6252N
abstract type IntelXeon_6254 <: IntelXeon_Scalable_g2 end; export IntelXeon_6254
abstract type IntelXeon_6262V <: IntelXeon_Scalable_g2 end; export IntelXeon_6262V
abstract type IntelXeon_8252 <: IntelXeon_Scalable_g2 end; export IntelXeon_8252
abstract type IntelXeon_8253 <: IntelXeon_Scalable_g2 end; export IntelXeon_8253
abstract type IntelXeon_8256 <: IntelXeon_Scalable_g2 end; export IntelXeon_8256
abstract type IntelXeon_8259 <: IntelXeon_Scalable_g2 end; export IntelXeon_8259
abstract type IntelXeon_8259CL <: IntelXeon_Scalable_g2 end; export IntelXeon_8259CL
abstract type IntelXeon_8260 <: IntelXeon_Scalable_g2 end; export IntelXeon_8260
abstract type IntelXeon_8260L <: IntelXeon_Scalable_g2 end; export IntelXeon_8260L
abstract type IntelXeon_8260Y <: IntelXeon_Scalable_g2 end; export IntelXeon_8260Y
abstract type IntelXeon_8268 <: IntelXeon_Scalable_g2 end; export IntelXeon_8268
abstract type IntelXeon_8270 <: IntelXeon_Scalable_g2 end; export IntelXeon_8270
abstract type IntelXeon_8275 <: IntelXeon_Scalable_g2 end; export IntelXeon_8275
abstract type IntelXeon_8275L <: IntelXeon_Scalable_g2 end; export IntelXeon_8275L
abstract type IntelXeon_8275CL <: IntelXeon_Scalable_g2 end; export IntelXeon_8275CL
abstract type IntelXeon_8276 <: IntelXeon_Scalable_g2 end; export IntelXeon_8276
abstract type IntelXeon_8276L <: IntelXeon_Scalable_g2 end; export IntelXeon_8276L
abstract type IntelXeon_8280 <: IntelXeon_Scalable_g2 end; export IntelXeon_8280
abstract type IntelXeon_8280L <: IntelXeon_Scalable_g2 end; export IntelXeon_8280L
abstract type IntelXeon_9242 <: IntelXeon_Scalable_g2 end; export IntelXeon_9242
abstract type IntelXeon_9282 <: IntelXeon_Scalable_g2 end; export IntelXeon_9282
abstract type IntelXeon_4208 <: IntelXeon_Scalable_g2 end; export IntelXeon_4208
abstract type IntelXeon_4209T <: IntelXeon_Scalable_g2 end; export IntelXeon_4209T
abstract type IntelXeon_4210 <: IntelXeon_Scalable_g2 end; export IntelXeon_4210
abstract type IntelXeon_4214 <: IntelXeon_Scalable_g2 end; export IntelXeon_4214
abstract type IntelXeon_4214Y <: IntelXeon_Scalable_g2 end; export IntelXeon_4214Y
abstract type IntelXeon_4215 <: IntelXeon_Scalable_g2 end; export IntelXeon_4215
abstract type IntelXeon_4216 <: IntelXeon_Scalable_g2 end; export IntelXeon_4216
abstract type IntelXeon_6138P <: IntelXeon_Scalable end; export IntelXeon_6138P
abstract type IntelXeon_3104 <: IntelXeon_Scalable end; export IntelXeon_3104
abstract type IntelXeon_3106 <: IntelXeon_Scalable end; export IntelXeon_3106
abstract type IntelXeon_5115 <: IntelXeon_Scalable end; export IntelXeon_5115
abstract type IntelXeon_5118 <: IntelXeon_Scalable end; export IntelXeon_5118
abstract type IntelXeon_5119T <: IntelXeon_Scalable end; export IntelXeon_5119T
abstract type IntelXeon_5120 <: IntelXeon_Scalable end; export IntelXeon_5120
abstract type IntelXeon_5120T <: IntelXeon_Scalable end; export IntelXeon_5120T
abstract type IntelXeon_5122 <: IntelXeon_Scalable end; export IntelXeon_5122
abstract type IntelXeon_6126 <: IntelXeon_Scalable end; export IntelXeon_6126
abstract type IntelXeon_6126F <: IntelXeon_Scalable end; export IntelXeon_6126F
abstract type IntelXeon_6126T <: IntelXeon_Scalable end; export IntelXeon_6126T
abstract type IntelXeon_6128 <: IntelXeon_Scalable end; export IntelXeon_6128
abstract type IntelXeon_6130 <: IntelXeon_Scalable end; export IntelXeon_6130
abstract type IntelXeon_6130F <: IntelXeon_Scalable end; export IntelXeon_6130F
abstract type IntelXeon_6130T <: IntelXeon_Scalable end; export IntelXeon_6130T
abstract type IntelXeon_6132 <: IntelXeon_Scalable end; export IntelXeon_6132
abstract type IntelXeon_6134 <: IntelXeon_Scalable end; export IntelXeon_6134
abstract type IntelXeon_6136 <: IntelXeon_Scalable end; export IntelXeon_6136
abstract type IntelXeon_6138 <: IntelXeon_Scalable end; export IntelXeon_6138
abstract type IntelXeon_6138F <: IntelXeon_Scalable end; export IntelXeon_6138F
abstract type IntelXeon_6138T <: IntelXeon_Scalable end; export IntelXeon_6138T
abstract type IntelXeon_6140 <: IntelXeon_Scalable end; export IntelXeon_6140
abstract type IntelXeon_6142 <: IntelXeon_Scalable end; export IntelXeon_6142
abstract type IntelXeon_6142F <: IntelXeon_Scalable end; export IntelXeon_6142F
abstract type IntelXeon_6144 <: IntelXeon_Scalable end; export IntelXeon_6144
abstract type IntelXeon_6146 <: IntelXeon_Scalable end; export IntelXeon_6146
abstract type IntelXeon_6148 <: IntelXeon_Scalable end; export IntelXeon_6148
abstract type IntelXeon_6148F <: IntelXeon_Scalable end; export IntelXeon_6148F
abstract type IntelXeon_6150 <: IntelXeon_Scalable end; export IntelXeon_6150
abstract type IntelXeon_6152 <: IntelXeon_Scalable end; export IntelXeon_6152
abstract type IntelXeon_6154 <: IntelXeon_Scalable end; export IntelXeon_6154
abstract type IntelXeon_8124M <: IntelXeon_Scalable end; export IntelXeon_8124M
abstract type IntelXeon_8151 <: IntelXeon_Scalable end; export IntelXeon_8151
abstract type IntelXeon_8153 <: IntelXeon_Scalable end; export IntelXeon_8153
abstract type IntelXeon_8156 <: IntelXeon_Scalable end; export IntelXeon_8156
abstract type IntelXeon_8158 <: IntelXeon_Scalable end; export IntelXeon_8158
abstract type IntelXeon_8160 <: IntelXeon_Scalable end; export IntelXeon_8160
abstract type IntelXeon_8160F <: IntelXeon_Scalable end; export IntelXeon_8160F
abstract type IntelXeon_8160T <: IntelXeon_Scalable end; export IntelXeon_8160T
abstract type IntelXeon_8164 <: IntelXeon_Scalable end; export IntelXeon_8164
abstract type IntelXeon_8168 <: IntelXeon_Scalable end; export IntelXeon_8168
abstract type IntelXeon_8170 <: IntelXeon_Scalable end; export IntelXeon_8170
abstract type IntelXeon_8175 <: IntelXeon_Scalable end; export IntelXeon_8175
abstract type IntelXeon_8176 <: IntelXeon_Scalable end; export IntelXeon_8176
abstract type IntelXeon_8176F <: IntelXeon_Scalable end; export IntelXeon_8176F
abstract type IntelXeon_8180 <: IntelXeon_Scalable end; export IntelXeon_8180
abstract type IntelXeon_4108 <: IntelXeon_Scalable end; export IntelXeon_4108
abstract type IntelXeon_4109T <: IntelXeon_Scalable end; export IntelXeon_4109T
abstract type IntelXeon_4110 <: IntelXeon_Scalable end; export IntelXeon_4110
abstract type IntelXeon_4112 <: IntelXeon_Scalable end; export IntelXeon_4112
abstract type IntelXeon_4114T <: IntelXeon_Scalable end; export IntelXeon_4114T
abstract type IntelXeon_4116 <: IntelXeon_Scalable end; export IntelXeon_4116
abstract type IntelXeon_4116T <: IntelXeon_Scalable end; export IntelXeon_4116T
abstract type IntelXeon_E_2314 <: IntelXeon_E end; export IntelXeon_E_2314
abstract type IntelXeon_E_2324G <: IntelXeon_E end; export IntelXeon_E_2324G
abstract type IntelXeon_E_2334 <: IntelXeon_E end; export IntelXeon_E_2334
abstract type IntelXeon_E_2336 <: IntelXeon_E end; export IntelXeon_E_2336
abstract type IntelXeon_E_2356G <: IntelXeon_E end; export IntelXeon_E_2356G
abstract type IntelXeon_E_2374G <: IntelXeon_E end; export IntelXeon_E_2374G
abstract type IntelXeon_E_2378 <: IntelXeon_E end; export IntelXeon_E_2378
abstract type IntelXeon_E_2378G <: IntelXeon_E end; export IntelXeon_E_2378G
abstract type IntelXeon_E_2386G <: IntelXeon_E end; export IntelXeon_E_2386G
abstract type IntelXeon_E_2388G <: IntelXeon_E end; export IntelXeon_E_2388G
abstract type IntelXeon_E_2224 <: IntelXeon_E end; export IntelXeon_E_2224
abstract type IntelXeon_E_2234 <: IntelXeon_E end; export IntelXeon_E_2234
abstract type IntelXeon_E_2236 <: IntelXeon_E end; export IntelXeon_E_2236
abstract type IntelXeon_E_2124 <: IntelXeon_E end; export IntelXeon_E_2124
abstract type IntelXeon_E_2134 <: IntelXeon_E end; export IntelXeon_E_2134
abstract type IntelXeon_E_2136 <: IntelXeon_E end; export IntelXeon_E_2136
abstract type IntelXeon_W_3323 <: IntelXeon_W end; export IntelXeon_W_3323
abstract type IntelXeon_W_3335 <: IntelXeon_W end; export IntelXeon_W_3335
abstract type IntelXeon_W_3345 <: IntelXeon_W end; export IntelXeon_W_3345
abstract type IntelXeon_W_3365 <: IntelXeon_W end; export IntelXeon_W_3365
abstract type IntelXeon_W_3375 <: IntelXeon_W end; export IntelXeon_W_3375
abstract type IntelXeon_W_1350 <: IntelXeon_W end; export IntelXeon_W_1350
abstract type IntelXeon_W_1350P <: IntelXeon_W end; export IntelXeon_W_1350P
abstract type IntelXeon_W_1370 <: IntelXeon_W end; export IntelXeon_W_1370
abstract type IntelXeon_W_1370P <: IntelXeon_W end; export IntelXeon_W_1370P
abstract type IntelXeon_W_1390 <: IntelXeon_W end; export IntelXeon_W_1390
abstract type IntelXeon_W_1390P <: IntelXeon_W end; export IntelXeon_W_1390P
abstract type IntelXeon_W_1390T <: IntelXeon_W end; export IntelXeon_W_1390T
abstract type IntelXeon_W_2223 <: IntelXeon_W end; export IntelXeon_W_2223
abstract type IntelXeon_W_2225 <: IntelXeon_W end; export IntelXeon_W_2225
abstract type IntelXeon_W_2235 <: IntelXeon_W end; export IntelXeon_W_2235
abstract type IntelXeon_W_2245 <: IntelXeon_W end; export IntelXeon_W_2245
abstract type IntelXeon_W_2255 <: IntelXeon_W end; export IntelXeon_W_2255
abstract type IntelXeon_W_2265 <: IntelXeon_W end; export IntelXeon_W_2265
abstract type IntelXeon_W_2275 <: IntelXeon_W end; export IntelXeon_W_2275
abstract type IntelXeon_W_2295 <: IntelXeon_W end; export IntelXeon_W_2295
abstract type IntelXeon_W_3223 <: IntelXeon_W end; export IntelXeon_W_3223
abstract type IntelXeon_W_3225 <: IntelXeon_W end; export IntelXeon_W_3225
abstract type IntelXeon_W_3235 <: IntelXeon_W end; export IntelXeon_W_3235
abstract type IntelXeon_W_3245 <: IntelXeon_W end; export IntelXeon_W_3245
abstract type IntelXeon_W_3245M <: IntelXeon_W end; export IntelXeon_W_3245M
abstract type IntelXeon_W_3265 <: IntelXeon_W end; export IntelXeon_W_3265
abstract type IntelXeon_W_3265M <: IntelXeon_W end; export IntelXeon_W_3265M
abstract type IntelXeon_W_3275 <: IntelXeon_W end; export IntelXeon_W_3275
abstract type IntelXeon_W_3275M <: IntelXeon_W end; export IntelXeon_W_3275M
abstract type IntelXeon_W_3175X <: IntelXeon_W end; export IntelXeon_W_3175X
abstract type IntelXeon_W_2123 <: IntelXeon_W end; export IntelXeon_W_2123
abstract type IntelXeon_W_2125 <: IntelXeon_W end; export IntelXeon_W_2125
abstract type IntelXeon_W_2133 <: IntelXeon_W end; export IntelXeon_W_2133
abstract type IntelXeon_W_2135 <: IntelXeon_W end; export IntelXeon_W_2135
abstract type IntelXeon_W_2145 <: IntelXeon_W end; export IntelXeon_W_2145
abstract type IntelXeon_W_2155 <: IntelXeon_W end; export IntelXeon_W_2155
abstract type IntelXeon_W_2175 <: IntelXeon_W end; export IntelXeon_W_2175
abstract type IntelXeon_W_2195 <: IntelXeon_W end; export IntelXeon_W_2195
abstract type IntelXeon_D_1702 <: IntelXeon_D end; export IntelXeon_D_1702
abstract type IntelXeon_D_1712TR <: IntelXeon_D end; export IntelXeon_D_1712TR
abstract type IntelXeon_D_1713NT <: IntelXeon_D end; export IntelXeon_D_1713NT
abstract type IntelXeon_D_1713NTE <: IntelXeon_D end; export IntelXeon_D_1713NTE
abstract type IntelXeon_D_1714 <: IntelXeon_D end; export IntelXeon_D_1714
abstract type IntelXeon_D_1715TER <: IntelXeon_D end; export IntelXeon_D_1715TER
abstract type IntelXeon_D_1718T <: IntelXeon_D end; export IntelXeon_D_1718T
abstract type IntelXeon_D_1722NE <: IntelXeon_D end; export IntelXeon_D_1722NE
abstract type IntelXeon_D_1726 <: IntelXeon_D end; export IntelXeon_D_1726
abstract type IntelXeon_D_1732TE <: IntelXeon_D end; export IntelXeon_D_1732TE
abstract type IntelXeon_D_1733NT <: IntelXeon_D end; export IntelXeon_D_1733NT
abstract type IntelXeon_D_1734NT <: IntelXeon_D end; export IntelXeon_D_1734NT
abstract type IntelXeon_D_1735TR <: IntelXeon_D end; export IntelXeon_D_1735TR
abstract type IntelXeon_D_1736 <: IntelXeon_D end; export IntelXeon_D_1736
abstract type IntelXeon_D_1736NT <: IntelXeon_D end; export IntelXeon_D_1736NT
abstract type IntelXeon_D_1739 <: IntelXeon_D end; export IntelXeon_D_1739
abstract type IntelXeon_D_1746TER <: IntelXeon_D end; export IntelXeon_D_1746TER
abstract type IntelXeon_D_1747NTE <: IntelXeon_D end; export IntelXeon_D_1747NTE
abstract type IntelXeon_D_1748TE <: IntelXeon_D end; export IntelXeon_D_1748TE
abstract type IntelXeon_D_1749NT <: IntelXeon_D end; export IntelXeon_D_1749NT
abstract type IntelXeon_D_2712T <: IntelXeon_D end; export IntelXeon_D_2712T
abstract type IntelXeon_D_2733NT <: IntelXeon_D end; export IntelXeon_D_2733NT
abstract type IntelXeon_D_2738 <: IntelXeon_D end; export IntelXeon_D_2738
abstract type IntelXeon_D_2752NTE <: IntelXeon_D end; export IntelXeon_D_2752NTE
abstract type IntelXeon_D_2752TER <: IntelXeon_D end; export IntelXeon_D_2752TER
abstract type IntelXeon_D_2753NT <: IntelXeon_D end; export IntelXeon_D_2753NT
abstract type IntelXeon_D_2766NT <: IntelXeon_D end; export IntelXeon_D_2766NT
abstract type IntelXeon_D_2775TE <: IntelXeon_D end; export IntelXeon_D_2775TE
abstract type IntelXeon_D_2776NT <: IntelXeon_D end; export IntelXeon_D_2776NT
abstract type IntelXeon_D_2779 <: IntelXeon_D end; export IntelXeon_D_2779
abstract type IntelXeon_D_2786NTE <: IntelXeon_D end; export IntelXeon_D_2786NTE
abstract type IntelXeon_D_2795NT <: IntelXeon_D end; export IntelXeon_D_2795NT
abstract type IntelXeon_D_2796NT <: IntelXeon_D end; export IntelXeon_D_2796NT
abstract type IntelXeon_D_2796TE <: IntelXeon_D end; export IntelXeon_D_2796TE
abstract type IntelXeon_D_2798NT <: IntelXeon_D end; export IntelXeon_D_2798NT
abstract type IntelXeon_D_2799 <: IntelXeon_D end; export IntelXeon_D_2799
abstract type IntelXeon_D_1602 <: IntelXeon_D end; export IntelXeon_D_1602
abstract type IntelXeon_D_1622 <: IntelXeon_D end; export IntelXeon_D_1622
abstract type IntelXeon_D_1623N <: IntelXeon_D end; export IntelXeon_D_1623N
abstract type IntelXeon_D_1627 <: IntelXeon_D end; export IntelXeon_D_1627
abstract type IntelXeon_D_1633N <: IntelXeon_D end; export IntelXeon_D_1633N
abstract type IntelXeon_D_1637 <: IntelXeon_D end; export IntelXeon_D_1637
abstract type IntelXeon_D_1649N <: IntelXeon_D end; export IntelXeon_D_1649N
abstract type IntelXeon_D_1653N <: IntelXeon_D end; export IntelXeon_D_1653N
abstract type IntelXeon_D_2123IT <: IntelXeon_D end; export IntelXeon_D_2123IT
abstract type IntelXeon_D_2141I <: IntelXeon_D end; export IntelXeon_D_2141I
abstract type IntelXeon_D_2142IT <: IntelXeon_D end; export IntelXeon_D_2142IT
abstract type IntelXeon_D_2143IT <: IntelXeon_D end; export IntelXeon_D_2143IT
abstract type IntelXeon_D_2145NT <: IntelXeon_D end; export IntelXeon_D_2145NT
abstract type IntelXeon_D_2161I <: IntelXeon_D end; export IntelXeon_D_2161I
abstract type IntelXeon_D_2163IT <: IntelXeon_D end; export IntelXeon_D_2163IT
abstract type IntelXeon_D_2166NT <: IntelXeon_D end; export IntelXeon_D_2166NT
abstract type IntelXeon_D_2173IT <: IntelXeon_D end; export IntelXeon_D_2173IT
abstract type IntelXeon_D_2177NT <: IntelXeon_D end; export IntelXeon_D_2177NT
abstract type IntelXeon_D_2183IT <: IntelXeon_D end; export IntelXeon_D_2183IT
abstract type IntelXeon_D_2187NT <: IntelXeon_D end; export IntelXeon_D_2187NT
abstract type IntelXeon_D_1513N <: IntelXeon_D end; export IntelXeon_D_1513N
abstract type IntelXeon_D_1523N <: IntelXeon_D end; export IntelXeon_D_1523N
abstract type IntelXeon_D_1533N <: IntelXeon_D end; export IntelXeon_D_1533N
abstract type IntelXeon_D_1543N <: IntelXeon_D end; export IntelXeon_D_1543N
abstract type IntelXeon_D_1553N <: IntelXeon_D end; export IntelXeon_D_1553N
abstract type IntelXeon_D_1529 <: IntelXeon_D end; export IntelXeon_D_1529
abstract type IntelXeon_D_1539 <: IntelXeon_D end; export IntelXeon_D_1539
abstract type IntelXeon_D_1559 <: IntelXeon_D end; export IntelXeon_D_1559
abstract type IntelXeon_D_1557 <: IntelXeon_D end; export IntelXeon_D_1557
abstract type IntelXeon_D_1567 <: IntelXeon_D end; export IntelXeon_D_1567
abstract type IntelXeon_D_1571 <: IntelXeon_D end; export IntelXeon_D_1571
abstract type IntelXeon_D_1577 <: IntelXeon_D end; export IntelXeon_D_1577
abstract type IntelXeon_D_1518 <: IntelXeon_D end; export IntelXeon_D_1518
abstract type IntelXeon_D_1521 <: IntelXeon_D end; export IntelXeon_D_1521
abstract type IntelXeon_D_1527 <: IntelXeon_D end; export IntelXeon_D_1527
abstract type IntelXeon_D_1528 <: IntelXeon_D end; export IntelXeon_D_1528
abstract type IntelXeon_D_1531 <: IntelXeon_D end; export IntelXeon_D_1531
abstract type IntelXeon_D_1537 <: IntelXeon_D end; export IntelXeon_D_1537
abstract type IntelXeon_D_1541 <: IntelXeon_D end; export IntelXeon_D_1541
abstract type IntelXeon_D_1548 <: IntelXeon_D end; export IntelXeon_D_1548
abstract type IntelXeon_D_1520 <: IntelXeon_D end; export IntelXeon_D_1520
abstract type IntelXeon_D_1540 <: IntelXeon_D end; export IntelXeon_D_1540
abstract type IntelXeon_E7_8894V4 <: IntelXeon_E7_v4 end; export IntelXeon_E7_8894V4
abstract type IntelXeon_E7_4809V4 <: IntelXeon_E7_v4 end; export IntelXeon_E7_4809V4
abstract type IntelXeon_E7_4820V4 <: IntelXeon_E7_v4 end; export IntelXeon_E7_4820V4
abstract type IntelXeon_E7_4830V4 <: IntelXeon_E7_v4 end; export IntelXeon_E7_4830V4
abstract type IntelXeon_E7_4850V4 <: IntelXeon_E7_v4 end; export IntelXeon_E7_4850V4
abstract type IntelXeon_E7_8860V4 <: IntelXeon_E7_v4 end; export IntelXeon_E7_8860V4
abstract type IntelXeon_E7_8867V4 <: IntelXeon_E7_v4 end; export IntelXeon_E7_8867V4
abstract type IntelXeon_E7_8870V4 <: IntelXeon_E7_v4 end; export IntelXeon_E7_8870V4
abstract type IntelXeon_E7_8880V4 <: IntelXeon_E7_v4 end; export IntelXeon_E7_8880V4
abstract type IntelXeon_E7_8890V4 <: IntelXeon_E7_v4 end; export IntelXeon_E7_8890V4
abstract type IntelXeon_E7_8891V4 <: IntelXeon_E7_v4 end; export IntelXeon_E7_8891V4
abstract type IntelXeon_E7_8893V4 <: IntelXeon_E7_v4 end; export IntelXeon_E7_8893V4
abstract type IntelXeon_E7_4809V3 <: IntelXeon_E7_v3 end; export IntelXeon_E7_4809V3
abstract type IntelXeon_E7_4820V3 <: IntelXeon_E7_v3 end; export IntelXeon_E7_4820V3
abstract type IntelXeon_E7_4830V3 <: IntelXeon_E7_v3 end; export IntelXeon_E7_4830V3
abstract type IntelXeon_E7_4850V3 <: IntelXeon_E7_v3 end; export IntelXeon_E7_4850V3
abstract type IntelXeon_E7_8860V3 <: IntelXeon_E7_v3 end; export IntelXeon_E7_8860V3
abstract type IntelXeon_E7_8867V3 <: IntelXeon_E7_v3 end; export IntelXeon_E7_8867V3
abstract type IntelXeon_E7_8870V3 <: IntelXeon_E7_v3 end; export IntelXeon_E7_8870V3
abstract type IntelXeon_E7_8880V3 <: IntelXeon_E7_v3 end; export IntelXeon_E7_8880V3
abstract type IntelXeon_E7_8880LV3 <: IntelXeon_E7_v3 end; export IntelXeon_E7_8880LV3
abstract type IntelXeon_E7_8890V3 <: IntelXeon_E7_v3 end; export IntelXeon_E7_8890V3
abstract type IntelXeon_E7_8891V3 <: IntelXeon_E7_v3 end; export IntelXeon_E7_8891V3
abstract type IntelXeon_E7_8893V3 <: IntelXeon_E7_v3 end; export IntelXeon_E7_8893V3
abstract type IntelXeon_E7_2850V2 <: IntelXeon_E7_v2 end; export IntelXeon_E7_2850V2
abstract type IntelXeon_E7_2870V2 <: IntelXeon_E7_v2 end; export IntelXeon_E7_2870V2
abstract type IntelXeon_E7_2880V2 <: IntelXeon_E7_v2 end; export IntelXeon_E7_2880V2
abstract type IntelXeon_E7_2890V2 <: IntelXeon_E7_v2 end; export IntelXeon_E7_2890V2
abstract type IntelXeon_E7_4809V2 <: IntelXeon_E7_v2 end; export IntelXeon_E7_4809V2
abstract type IntelXeon_E7_4820V2 <: IntelXeon_E7_v2 end; export IntelXeon_E7_4820V2
abstract type IntelXeon_E7_4830V2 <: IntelXeon_E7_v2 end; export IntelXeon_E7_4830V2
abstract type IntelXeon_E7_4850V2 <: IntelXeon_E7_v2 end; export IntelXeon_E7_4850V2
abstract type IntelXeon_E7_4860V2 <: IntelXeon_E7_v2 end; export IntelXeon_E7_4860V2
abstract type IntelXeon_E7_4870V2 <: IntelXeon_E7_v2 end; export IntelXeon_E7_4870V2
abstract type IntelXeon_E7_4880V2 <: IntelXeon_E7_v2 end; export IntelXeon_E7_4880V2
abstract type IntelXeon_E7_4890V2 <: IntelXeon_E7_v2 end; export IntelXeon_E7_4890V2
abstract type IntelXeon_E7_8850V2 <: IntelXeon_E7_v2 end; export IntelXeon_E7_8850V2
abstract type IntelXeon_E7_8857V2 <: IntelXeon_E7_v2 end; export IntelXeon_E7_8857V2
abstract type IntelXeon_E7_8870V2 <: IntelXeon_E7_v2 end; export IntelXeon_E7_8870V2
abstract type IntelXeon_E7_8880V2 <: IntelXeon_E7_v2 end; export IntelXeon_E7_8880V2
abstract type IntelXeon_E7_8880LV2 <: IntelXeon_E7_v2 end; export IntelXeon_E7_8880LV2
abstract type IntelXeon_E7_8890V2 <: IntelXeon_E7_v2 end; export IntelXeon_E7_8890V2
abstract type IntelXeon_E7_8891V2 <: IntelXeon_E7_v2 end; export IntelXeon_E7_8891V2
abstract type IntelXeon_E7_8893V2 <: IntelXeon_E7_v2 end; export IntelXeon_E7_8893V2
abstract type IntelXeon_E7_2803 <: IntelXeon_E7 end; export IntelXeon_E7_2803
abstract type IntelXeon_E7_2820 <: IntelXeon_E7 end; export IntelXeon_E7_2820
abstract type IntelXeon_E7_2830 <: IntelXeon_E7 end; export IntelXeon_E7_2830
abstract type IntelXeon_E7_2850 <: IntelXeon_E7 end; export IntelXeon_E7_2850
abstract type IntelXeon_E7_2860 <: IntelXeon_E7 end; export IntelXeon_E7_2860
abstract type IntelXeon_E7_2870 <: IntelXeon_E7 end; export IntelXeon_E7_2870
abstract type IntelXeon_E7_4807 <: IntelXeon_E7 end; export IntelXeon_E7_4807
abstract type IntelXeon_E7_4820 <: IntelXeon_E7 end; export IntelXeon_E7_4820
abstract type IntelXeon_E7_4830 <: IntelXeon_E7 end; export IntelXeon_E7_4830
abstract type IntelXeon_E7_4850 <: IntelXeon_E7 end; export IntelXeon_E7_4850
abstract type IntelXeon_E7_4860 <: IntelXeon_E7 end; export IntelXeon_E7_4860
abstract type IntelXeon_E7_4870 <: IntelXeon_E7 end; export IntelXeon_E7_4870
abstract type IntelXeon_E7_8830 <: IntelXeon_E7 end; export IntelXeon_E7_8830
abstract type IntelXeon_E7_8837 <: IntelXeon_E7 end; export IntelXeon_E7_8837
abstract type IntelXeon_E7_8850 <: IntelXeon_E7 end; export IntelXeon_E7_8850
abstract type IntelXeon_E7_8860 <: IntelXeon_E7 end; export IntelXeon_E7_8860
abstract type IntelXeon_E7_8867L <: IntelXeon_E7 end; export IntelXeon_E7_8867L
abstract type IntelXeon_E7_8870 <: IntelXeon_E7 end; export IntelXeon_E7_8870
abstract type IntelXeon_E5_2699AV4 <: IntelXeon_E5_v4 end; export IntelXeon_E5_2699AV4
abstract type IntelXeon_E5_2699RV4 <: IntelXeon_E5_v4 end; export IntelXeon_E5_2699RV4
abstract type IntelXeon_E5_4610V4 <: IntelXeon_E5_v4 end; export IntelXeon_E5_4610V4
abstract type IntelXeon_E5_4620V4 <: IntelXeon_E5_v4 end; export IntelXeon_E5_4620V4
abstract type IntelXeon_E5_4627V4 <: IntelXeon_E5_v4 end; export IntelXeon_E5_4627V4
abstract type IntelXeon_E5_4628LV4 <: IntelXeon_E5_v4 end; export IntelXeon_E5_4628LV4
abstract type IntelXeon_E5_4640V4 <: IntelXeon_E5_v4 end; export IntelXeon_E5_4640V4
abstract type IntelXeon_E5_4650V4 <: IntelXeon_E5_v4 end; export IntelXeon_E5_4650V4
abstract type IntelXeon_E5_4655V4 <: IntelXeon_E5_v4 end; export IntelXeon_E5_4655V4
abstract type IntelXeon_E5_4660V4 <: IntelXeon_E5_v4 end; export IntelXeon_E5_4660V4
abstract type IntelXeon_E5_4667V4 <: IntelXeon_E5_v4 end; export IntelXeon_E5_4667V4
abstract type IntelXeon_E5_4669V4 <: IntelXeon_E5_v4 end; export IntelXeon_E5_4669V4
abstract type IntelXeon_E5_1620V4 <: IntelXeon_E5_v4 end; export IntelXeon_E5_1620V4
abstract type IntelXeon_E5_1630V4 <: IntelXeon_E5_v4 end; export IntelXeon_E5_1630V4
abstract type IntelXeon_E5_1650V4 <: IntelXeon_E5_v4 end; export IntelXeon_E5_1650V4
abstract type IntelXeon_E5_1660V4 <: IntelXeon_E5_v4 end; export IntelXeon_E5_1660V4
abstract type IntelXeon_E5_1680V4 <: IntelXeon_E5_v4 end; export IntelXeon_E5_1680V4
abstract type IntelXeon_E5_2603V4 <: IntelXeon_E5_v4 end; export IntelXeon_E5_2603V4
abstract type IntelXeon_E5_2608LV4 <: IntelXeon_E5_v4 end; export IntelXeon_E5_2608LV4
abstract type IntelXeon_E5_2609V4 <: IntelXeon_E5_v4 end; export IntelXeon_E5_2609V4
abstract type IntelXeon_E5_2618LV4 <: IntelXeon_E5_v4 end; export IntelXeon_E5_2618LV4
abstract type IntelXeon_E5_2620V4 <: IntelXeon_E5_v4 end; export IntelXeon_E5_2620V4
abstract type IntelXeon_E5_2623V4 <: IntelXeon_E5_v4 end; export IntelXeon_E5_2623V4
abstract type IntelXeon_E5_2628LV4 <: IntelXeon_E5_v4 end; export IntelXeon_E5_2628LV4
abstract type IntelXeon_E5_2630V4 <: IntelXeon_E5_v4 end; export IntelXeon_E5_2630V4
abstract type IntelXeon_E5_2630LV4 <: IntelXeon_E5_v4 end; export IntelXeon_E5_2630LV4
abstract type IntelXeon_E5_2637V4 <: IntelXeon_E5_v4 end; export IntelXeon_E5_2637V4
abstract type IntelXeon_E5_2640V4 <: IntelXeon_E5_v4 end; export IntelXeon_E5_2640V4
abstract type IntelXeon_E5_2643V4 <: IntelXeon_E5_v4 end; export IntelXeon_E5_2643V4
abstract type IntelXeon_E5_2648LV4 <: IntelXeon_E5_v4 end; export IntelXeon_E5_2648LV4
abstract type IntelXeon_E5_2650V4 <: IntelXeon_E5_v4 end; export IntelXeon_E5_2650V4
abstract type IntelXeon_E5_2650LV4 <: IntelXeon_E5_v4 end; export IntelXeon_E5_2650LV4
abstract type IntelXeon_E5_2658V4 <: IntelXeon_E5_v4 end; export IntelXeon_E5_2658V4
abstract type IntelXeon_E5_2660V4 <: IntelXeon_E5_v4 end; export IntelXeon_E5_2660V4
abstract type IntelXeon_E5_2667V4 <: IntelXeon_E5_v4 end; export IntelXeon_E5_2667V4
abstract type IntelXeon_E5_2680V4 <: IntelXeon_E5_v4 end; export IntelXeon_E5_2680V4
abstract type IntelXeon_E5_2683V4 <: IntelXeon_E5_v4 end; export IntelXeon_E5_2683V4
abstract type IntelXeon_E5_2686V5 <: IntelXeon_E5_v5 end; export IntelXeon_E5_2686V5
abstract type IntelXeon_E5_2686V4 <: IntelXeon_E5_v4 end; export IntelXeon_E5_2686V4
abstract type IntelXeon_E5_2687WV4 <: IntelXeon_E5_v4 end; export IntelXeon_E5_2687WV4
abstract type IntelXeon_E5_2690V4 <: IntelXeon_E5_v4 end; export IntelXeon_E5_2690V4
abstract type IntelXeon_E5_2695V4 <: IntelXeon_E5_v4 end; export IntelXeon_E5_2695V4
abstract type IntelXeon_E5_2697V4 <: IntelXeon_E5_v4 end; export IntelXeon_E5_2697V4
abstract type IntelXeon_E5_2697AV4 <: IntelXeon_E5_v4 end; export IntelXeon_E5_2697AV4
abstract type IntelXeon_E5_2698V4 <: IntelXeon_E5_v4 end; export IntelXeon_E5_2698V4
abstract type IntelXeon_E5_2699V4 <: IntelXeon_E5_v4 end; export IntelXeon_E5_2699V4
abstract type IntelXeon_E5_4610V3 <: IntelXeon_E5_v3 end; export IntelXeon_E5_4610V3
abstract type IntelXeon_E5_4620V3 <: IntelXeon_E5_v3 end; export IntelXeon_E5_4620V3
abstract type IntelXeon_E5_4627V3 <: IntelXeon_E5_v3 end; export IntelXeon_E5_4627V3
abstract type IntelXeon_E5_4640V3 <: IntelXeon_E5_v3 end; export IntelXeon_E5_4640V3
abstract type IntelXeon_E5_4648V3 <: IntelXeon_E5_v3 end; export IntelXeon_E5_4648V3
abstract type IntelXeon_E5_4650V3 <: IntelXeon_E5_v3 end; export IntelXeon_E5_4650V3
abstract type IntelXeon_E5_4655V3 <: IntelXeon_E5_v3 end; export IntelXeon_E5_4655V3
abstract type IntelXeon_E5_4660V3 <: IntelXeon_E5_v3 end; export IntelXeon_E5_4660V3
abstract type IntelXeon_E5_4667V3 <: IntelXeon_E5_v3 end; export IntelXeon_E5_4667V3
abstract type IntelXeon_E5_4669V3 <: IntelXeon_E5_v3 end; export IntelXeon_E5_4669V3
abstract type IntelXeon_E5_2658AV3 <: IntelXeon_E5_v3 end; export IntelXeon_E5_2658AV3
abstract type IntelXeon_E5_1428LV3 <: IntelXeon_E5_v3 end; export IntelXeon_E5_1428LV3
abstract type IntelXeon_E5_2408LV3 <: IntelXeon_E5_v3 end; export IntelXeon_E5_2408LV3
abstract type IntelXeon_E5_2418LV3 <: IntelXeon_E5_v3 end; export IntelXeon_E5_2418LV3
abstract type IntelXeon_E5_2428LV3 <: IntelXeon_E5_v3 end; export IntelXeon_E5_2428LV3
abstract type IntelXeon_E5_2438LV3 <: IntelXeon_E5_v3 end; export IntelXeon_E5_2438LV3
abstract type IntelXeon_E5_1620V3 <: IntelXeon_E5_v3 end; export IntelXeon_E5_1620V3
abstract type IntelXeon_E5_1630V3 <: IntelXeon_E5_v3 end; export IntelXeon_E5_1630V3
abstract type IntelXeon_E5_1650V3 <: IntelXeon_E5_v3 end; export IntelXeon_E5_1650V3
abstract type IntelXeon_E5_1660V3 <: IntelXeon_E5_v3 end; export IntelXeon_E5_1660V3
abstract type IntelXeon_E5_1680V3 <: IntelXeon_E5_v3 end; export IntelXeon_E5_1680V3
abstract type IntelXeon_E5_2603V3 <: IntelXeon_E5_v3 end; export IntelXeon_E5_2603V3
abstract type IntelXeon_E5_2608LV3 <: IntelXeon_E5_v3 end; export IntelXeon_E5_2608LV3
abstract type IntelXeon_E5_2609V3 <: IntelXeon_E5_v3 end; export IntelXeon_E5_2609V3
abstract type IntelXeon_E5_2618LV3 <: IntelXeon_E5_v3 end; export IntelXeon_E5_2618LV3
abstract type IntelXeon_E5_2620V3 <: IntelXeon_E5_v3 end; export IntelXeon_E5_2620V3
abstract type IntelXeon_E5_2623V3 <: IntelXeon_E5_v3 end; export IntelXeon_E5_2623V3
abstract type IntelXeon_E5_2628LV3 <: IntelXeon_E5_v3 end; export IntelXeon_E5_2628LV3
abstract type IntelXeon_E5_2630V3 <: IntelXeon_E5_v3 end; export IntelXeon_E5_2630V3
abstract type IntelXeon_E5_2630LV3 <: IntelXeon_E5_v3 end; export IntelXeon_E5_2630LV3
abstract type IntelXeon_E5_2637V3 <: IntelXeon_E5_v3 end; export IntelXeon_E5_2637V3
abstract type IntelXeon_E5_2640V3 <: IntelXeon_E5_v3 end; export IntelXeon_E5_2640V3
abstract type IntelXeon_E5_2643V3 <: IntelXeon_E5_v3 end; export IntelXeon_E5_2643V3
abstract type IntelXeon_E5_2648LV3 <: IntelXeon_E5_v3 end; export IntelXeon_E5_2648LV3
abstract type IntelXeon_E5_2650V3 <: IntelXeon_E5_v3 end; export IntelXeon_E5_2650V3
abstract type IntelXeon_E5_2650LV3 <: IntelXeon_E5_v3 end; export IntelXeon_E5_2650LV3
abstract type IntelXeon_E5_2658V3 <: IntelXeon_E5_v3 end; export IntelXeon_E5_2658V3
abstract type IntelXeon_E5_2660V3 <: IntelXeon_E5_v3 end; export IntelXeon_E5_2660V3
abstract type IntelXeon_E5_2666V3 <: IntelXeon_E5_v3 end; export IntelXeon_E5_2666V3
abstract type IntelXeon_E5_2667V3 <: IntelXeon_E5_v3 end; export IntelXeon_E5_2667V3
abstract type IntelXeon_E5_2670V3 <: IntelXeon_E5_v3 end; export IntelXeon_E5_2670V3
abstract type IntelXeon_E5_2676V3 <: IntelXeon_E5_v3 end; export IntelXeon_E5_2676V3
abstract type IntelXeon_E5_2680V3 <: IntelXeon_E5_v3 end; export IntelXeon_E5_2680V3
abstract type IntelXeon_E5_2683V3 <: IntelXeon_E5_v3 end; export IntelXeon_E5_2683V3
abstract type IntelXeon_E5_2687WV3 <: IntelXeon_E5_v3 end; export IntelXeon_E5_2687WV3
abstract type IntelXeon_E5_2690V3 <: IntelXeon_E5_v3 end; export IntelXeon_E5_2690V3
abstract type IntelXeon_E5_2695V3 <: IntelXeon_E5_v3 end; export IntelXeon_E5_2695V3
abstract type IntelXeon_E5_2697V3 <: IntelXeon_E5_v3 end; export IntelXeon_E5_2697V3
abstract type IntelXeon_E5_2698V3 <: IntelXeon_E5_v3 end; export IntelXeon_E5_2698V3
abstract type IntelXeon_E5_2699V3 <: IntelXeon_E5_v3 end; export IntelXeon_E5_2699V3
abstract type IntelXeon_E5_4603V2 <: IntelXeon_E5_v2 end; export IntelXeon_E5_4603V2
abstract type IntelXeon_E5_4607V2 <: IntelXeon_E5_v2 end; export IntelXeon_E5_4607V2
abstract type IntelXeon_E5_4610V2 <: IntelXeon_E5_v2 end; export IntelXeon_E5_4610V2
abstract type IntelXeon_E5_4620V2 <: IntelXeon_E5_v2 end; export IntelXeon_E5_4620V2
abstract type IntelXeon_E5_4624LV2 <: IntelXeon_E5_v2 end; export IntelXeon_E5_4624LV2
abstract type IntelXeon_E5_4627V2 <: IntelXeon_E5_v2 end; export IntelXeon_E5_4627V2
abstract type IntelXeon_E5_4640V2 <: IntelXeon_E5_v2 end; export IntelXeon_E5_4640V2
abstract type IntelXeon_E5_4650V2 <: IntelXeon_E5_v2 end; export IntelXeon_E5_4650V2
abstract type IntelXeon_E5_4657LV2 <: IntelXeon_E5_v2 end; export IntelXeon_E5_4657LV2
abstract type IntelXeon_E5_1428LV2 <: IntelXeon_E5_v2 end; export IntelXeon_E5_1428LV2
abstract type IntelXeon_E5_2403V2 <: IntelXeon_E5_v2 end; export IntelXeon_E5_2403V2
abstract type IntelXeon_E5_2407V2 <: IntelXeon_E5_v2 end; export IntelXeon_E5_2407V2
abstract type IntelXeon_E5_2418LV2 <: IntelXeon_E5_v2 end; export IntelXeon_E5_2418LV2
abstract type IntelXeon_E5_2420V2 <: IntelXeon_E5_v2 end; export IntelXeon_E5_2420V2
abstract type IntelXeon_E5_2428LV2 <: IntelXeon_E5_v2 end; export IntelXeon_E5_2428LV2
abstract type IntelXeon_E5_2430V2 <: IntelXeon_E5_v2 end; export IntelXeon_E5_2430V2
abstract type IntelXeon_E5_2430LV2 <: IntelXeon_E5_v2 end; export IntelXeon_E5_2430LV2
abstract type IntelXeon_E5_2440V2 <: IntelXeon_E5_v2 end; export IntelXeon_E5_2440V2
abstract type IntelXeon_E5_2448LV2 <: IntelXeon_E5_v2 end; export IntelXeon_E5_2448LV2
abstract type IntelXeon_E5_2450V2 <: IntelXeon_E5_v2 end; export IntelXeon_E5_2450V2
abstract type IntelXeon_E5_2450LV2 <: IntelXeon_E5_v2 end; export IntelXeon_E5_2450LV2
abstract type IntelXeon_E5_2470V2 <: IntelXeon_E5_v2 end; export IntelXeon_E5_2470V2
abstract type IntelXeon_E5_1620V2 <: IntelXeon_E5_v2 end; export IntelXeon_E5_1620V2
abstract type IntelXeon_E5_1650V2 <: IntelXeon_E5_v2 end; export IntelXeon_E5_1650V2
abstract type IntelXeon_E5_1660V2 <: IntelXeon_E5_v2 end; export IntelXeon_E5_1660V2
abstract type IntelXeon_E5_2603V2 <: IntelXeon_E5_v2 end; export IntelXeon_E5_2603V2
abstract type IntelXeon_E5_2609V2 <: IntelXeon_E5_v2 end; export IntelXeon_E5_2609V2
abstract type IntelXeon_E5_2618LV2 <: IntelXeon_E5_v2 end; export IntelXeon_E5_2618LV2
abstract type IntelXeon_E5_2620V2 <: IntelXeon_E5_v2 end; export IntelXeon_E5_2620V2
abstract type IntelXeon_E5_2628LV2 <: IntelXeon_E5_v2 end; export IntelXeon_E5_2628LV2
abstract type IntelXeon_E5_2630V2 <: IntelXeon_E5_v2 end; export IntelXeon_E5_2630V2
abstract type IntelXeon_E5_2630LV2 <: IntelXeon_E5_v2 end; export IntelXeon_E5_2630LV2
abstract type IntelXeon_E5_2637V2 <: IntelXeon_E5_v2 end; export IntelXeon_E5_2637V2
abstract type IntelXeon_E5_2640V2 <: IntelXeon_E5_v2 end; export IntelXeon_E5_2640V2
abstract type IntelXeon_E5_2643V2 <: IntelXeon_E5_v2 end; export IntelXeon_E5_2643V2
abstract type IntelXeon_E5_2648LV2 <: IntelXeon_E5_v2 end; export IntelXeon_E5_2648LV2
abstract type IntelXeon_E5_2650V2 <: IntelXeon_E5_v2 end; export IntelXeon_E5_2650V2
abstract type IntelXeon_E5_2650LV2 <: IntelXeon_E5_v2 end; export IntelXeon_E5_2650LV2
abstract type IntelXeon_E5_2658V2 <: IntelXeon_E5_v2 end; export IntelXeon_E5_2658V2
abstract type IntelXeon_E5_2660V2 <: IntelXeon_E5_v2 end; export IntelXeon_E5_2660V2
abstract type IntelXeon_E5_2667V2 <: IntelXeon_E5_v2 end; export IntelXeon_E5_2667V2
abstract type IntelXeon_E5_2670V2 <: IntelXeon_E5_v2 end; export IntelXeon_E5_2670V2
abstract type IntelXeon_E5_2680V2 <: IntelXeon_E5_v2 end; export IntelXeon_E5_2680V2
abstract type IntelXeon_E5_2687WV2 <: IntelXeon_E5_v2 end; export IntelXeon_E5_2687WV2
abstract type IntelXeon_E5_2690V2 <: IntelXeon_E5_v2 end; export IntelXeon_E5_2690V2
abstract type IntelXeon_E5_2695V2 <: IntelXeon_E5_v2 end; export IntelXeon_E5_2695V2
abstract type IntelXeon_E5_2697V2 <: IntelXeon_E5_v2 end; export IntelXeon_E5_2697V2
abstract type IntelXeon_E5_1428L <: IntelXeon_E5 end; export IntelXeon_E5_1428L
abstract type IntelXeon_E5_2403 <: IntelXeon_E5 end; export IntelXeon_E5_2403
abstract type IntelXeon_E5_2407 <: IntelXeon_E5 end; export IntelXeon_E5_2407
abstract type IntelXeon_E5_2418L <: IntelXeon_E5 end; export IntelXeon_E5_2418L
abstract type IntelXeon_E5_2420 <: IntelXeon_E5 end; export IntelXeon_E5_2420
abstract type IntelXeon_E5_2428L <: IntelXeon_E5 end; export IntelXeon_E5_2428L
abstract type IntelXeon_E5_2430 <: IntelXeon_E5 end; export IntelXeon_E5_2430
abstract type IntelXeon_E5_2430L <: IntelXeon_E5 end; export IntelXeon_E5_2430L
abstract type IntelXeon_E5_2440 <: IntelXeon_E5 end; export IntelXeon_E5_2440
abstract type IntelXeon_E5_2448L <: IntelXeon_E5 end; export IntelXeon_E5_2448L
abstract type IntelXeon_E5_2450 <: IntelXeon_E5 end; export IntelXeon_E5_2450
abstract type IntelXeon_E5_2450L <: IntelXeon_E5 end; export IntelXeon_E5_2450L
abstract type IntelXeon_E5_2470 <: IntelXeon_E5 end; export IntelXeon_E5_2470
abstract type IntelXeon_E5_4603 <: IntelXeon_E5 end; export IntelXeon_E5_4603
abstract type IntelXeon_E5_4607 <: IntelXeon_E5 end; export IntelXeon_E5_4607
abstract type IntelXeon_E5_4610 <: IntelXeon_E5 end; export IntelXeon_E5_4610
abstract type IntelXeon_E5_4617 <: IntelXeon_E5 end; export IntelXeon_E5_4617
abstract type IntelXeon_E5_4620 <: IntelXeon_E5 end; export IntelXeon_E5_4620
abstract type IntelXeon_E5_4640 <: IntelXeon_E5 end; export IntelXeon_E5_4640
abstract type IntelXeon_E5_4650 <: IntelXeon_E5 end; export IntelXeon_E5_4650
abstract type IntelXeon_E5_4650L <: IntelXeon_E5 end; export IntelXeon_E5_4650L
abstract type IntelXeon_E5_1620 <: IntelXeon_E5 end; export IntelXeon_E5_1620
abstract type IntelXeon_E5_1650 <: IntelXeon_E5 end; export IntelXeon_E5_1650
abstract type IntelXeon_E5_1660 <: IntelXeon_E5 end; export IntelXeon_E5_1660
abstract type IntelXeon_E5_2603 <: IntelXeon_E5 end; export IntelXeon_E5_2603
abstract type IntelXeon_E5_2609 <: IntelXeon_E5 end; export IntelXeon_E5_2609
abstract type IntelXeon_E5_2620 <: IntelXeon_E5 end; export IntelXeon_E5_2620
abstract type IntelXeon_E5_2630 <: IntelXeon_E5 end; export IntelXeon_E5_2630
abstract type IntelXeon_E5_2630L <: IntelXeon_E5 end; export IntelXeon_E5_2630L
abstract type IntelXeon_E5_2637 <: IntelXeon_E5 end; export IntelXeon_E5_2637
abstract type IntelXeon_E5_2640 <: IntelXeon_E5 end; export IntelXeon_E5_2640
abstract type IntelXeon_E5_2643 <: IntelXeon_E5 end; export IntelXeon_E5_2643
abstract type IntelXeon_E5_2648L <: IntelXeon_E5 end; export IntelXeon_E5_2648L
abstract type IntelXeon_E5_2650 <: IntelXeon_E5 end; export IntelXeon_E5_2650
abstract type IntelXeon_E5_2650L <: IntelXeon_E5 end; export IntelXeon_E5_2650L
abstract type IntelXeon_E5_2658 <: IntelXeon_E5 end; export IntelXeon_E5_2658
abstract type IntelXeon_E5_2660 <: IntelXeon_E5 end; export IntelXeon_E5_2660
abstract type IntelXeon_E5_2665 <: IntelXeon_E5 end; export IntelXeon_E5_2665
abstract type IntelXeon_E5_2667 <: IntelXeon_E5 end; export IntelXeon_E5_2667
abstract type IntelXeon_E5_2670 <: IntelXeon_E5 end; export IntelXeon_E5_2670
abstract type IntelXeon_E5_2680 <: IntelXeon_E5 end; export IntelXeon_E5_2680
abstract type IntelXeon_E5_2687W <: IntelXeon_E5 end; export IntelXeon_E5_2687W
abstract type IntelXeon_E5_2690 <: IntelXeon_E5 end; export IntelXeon_E5_2690
abstract type IntelXeon_E3_1220V6 <: IntelXeon_E3_v6 end; export IntelXeon_E3_1220V6
abstract type IntelXeon_E3_1230V6 <: IntelXeon_E3_v6 end; export IntelXeon_E3_1230V6
abstract type IntelXeon_E3_1240V6 <: IntelXeon_E3_v6 end; export IntelXeon_E3_1240V6
abstract type IntelXeon_E3_1270V6 <: IntelXeon_E3_v6 end; export IntelXeon_E3_1270V6
abstract type IntelXeon_E3_1280V6 <: IntelXeon_E3_v6 end; export IntelXeon_E3_1280V6
abstract type IntelXeon_E3_1558LV5 <: IntelXeon_E3_v5 end; export IntelXeon_E3_1558LV5
abstract type IntelXeon_E3_1220V5 <: IntelXeon_E3_v5 end; export IntelXeon_E3_1220V5
abstract type IntelXeon_E3_1230V5 <: IntelXeon_E3_v5 end; export IntelXeon_E3_1230V5
abstract type IntelXeon_E3_1240V5 <: IntelXeon_E3_v5 end; export IntelXeon_E3_1240V5
abstract type IntelXeon_E3_1240LV5 <: IntelXeon_E3_v5 end; export IntelXeon_E3_1240LV5
abstract type IntelXeon_E3_1260LV5 <: IntelXeon_E3_v5 end; export IntelXeon_E3_1260LV5
abstract type IntelXeon_E3_1270V5 <: IntelXeon_E3_v5 end; export IntelXeon_E3_1270V5
abstract type IntelXeon_E3_1280V5 <: IntelXeon_E3_v5 end; export IntelXeon_E3_1280V5
abstract type IntelXeon_E3_1258LV4 <: IntelXeon_E3_v4 end; export IntelXeon_E3_1258LV4
abstract type IntelXeon_E3_1265LV4 <: IntelXeon_E3_v4 end; export IntelXeon_E3_1265LV4
abstract type IntelXeon_E3_1278LV4 <: IntelXeon_E3_v4 end; export IntelXeon_E3_1278LV4
abstract type IntelXeon_E3_1285V4 <: IntelXeon_E3_v4 end; export IntelXeon_E3_1285V4
abstract type IntelXeon_E3_1285LV4 <: IntelXeon_E3_v4 end; export IntelXeon_E3_1285LV4
abstract type IntelXeon_E3_1226V3 <: IntelXeon_E3_v3 end; export IntelXeon_E3_1226V3
abstract type IntelXeon_E3_1231V3 <: IntelXeon_E3_v3 end; export IntelXeon_E3_1231V3
abstract type IntelXeon_E3_1240LV3 <: IntelXeon_E3_v3 end; export IntelXeon_E3_1240LV3
abstract type IntelXeon_E3_1241V3 <: IntelXeon_E3_v3 end; export IntelXeon_E3_1241V3
abstract type IntelXeon_E3_1246V3 <: IntelXeon_E3_v3 end; export IntelXeon_E3_1246V3
abstract type IntelXeon_E3_1271V3 <: IntelXeon_E3_v3 end; export IntelXeon_E3_1271V3
abstract type IntelXeon_E3_1276V3 <: IntelXeon_E3_v3 end; export IntelXeon_E3_1276V3
abstract type IntelXeon_E3_1281V3 <: IntelXeon_E3_v3 end; export IntelXeon_E3_1281V3
abstract type IntelXeon_E3_1286V3 <: IntelXeon_E3_v3 end; export IntelXeon_E3_1286V3
abstract type IntelXeon_E3_1286LV3 <: IntelXeon_E3_v3 end; export IntelXeon_E3_1286LV3
abstract type IntelXeon_E3_1220LV3 <: IntelXeon_E3_v3 end; export IntelXeon_E3_1220LV3
abstract type IntelXeon_E3_1220_v3 <: IntelXeon_E3_v3 end; export IntelXeon_E3_1220_v3
abstract type IntelXeon_E3_1225V3 <: IntelXeon_E3_v3 end; export IntelXeon_E3_1225V3
abstract type IntelXeon_E3_1230_v3 <: IntelXeon_E3_v3 end; export IntelXeon_E3_1230_v3
abstract type IntelXeon_E3_1230Lv3 <: IntelXeon_E3_v3 end; export IntelXeon_E3_1230Lv3
abstract type IntelXeon_E3_1240_v3 <: IntelXeon_E3_v3 end; export IntelXeon_E3_1240_v3
abstract type IntelXeon_E3_1245_v3 <: IntelXeon_E3_v3 end; export IntelXeon_E3_1245_v3
abstract type IntelXeon_E3_1270_v3 <: IntelXeon_E3_v3 end; export IntelXeon_E3_1270_v3
abstract type IntelXeon_E3_1275_v3 <: IntelXeon_E3_v3 end; export IntelXeon_E3_1275_v3
abstract type IntelXeon_E3_1280_v3 <: IntelXeon_E3_v3 end; export IntelXeon_E3_1280_v3
abstract type IntelXeon_E3_1285_v3 <: IntelXeon_E3_v3 end; export IntelXeon_E3_1285_v3
abstract type IntelXeon_E3_1285Lv3 <: IntelXeon_E3_v3 end; export IntelXeon_E3_1285Lv3
abstract type IntelXeon_E3_1105CV2 <: IntelXeon_E3_v2 end; export IntelXeon_E3_1105CV2
abstract type IntelXeon_E3_1125CV2 <: IntelXeon_E3_v2 end; export IntelXeon_E3_1125CV2
abstract type IntelXeon_E3_1220V2 <: IntelXeon_E3_v2 end; export IntelXeon_E3_1220V2
abstract type IntelXeon_E3_1220LV2 <: IntelXeon_E3_v2 end; export IntelXeon_E3_1220LV2
abstract type IntelXeon_E3_1225V2 <: IntelXeon_E3_v2 end; export IntelXeon_E3_1225V2
abstract type IntelXeon_E3_1230V2 <: IntelXeon_E3_v2 end; export IntelXeon_E3_1230V2
abstract type IntelXeon_E3_1240V2 <: IntelXeon_E3_v2 end; export IntelXeon_E3_1240V2
abstract type IntelXeon_E3_1245V2 <: IntelXeon_E3_v2 end; export IntelXeon_E3_1245V2
abstract type IntelXeon_E3_1270V2 <: IntelXeon_E3_v2 end; export IntelXeon_E3_1270V2
abstract type IntelXeon_E3_1275V2 <: IntelXeon_E3_v2 end; export IntelXeon_E3_1275V2
abstract type IntelXeon_E3_1280V2 <: IntelXeon_E3_v2 end; export IntelXeon_E3_1280V2
abstract type IntelXeon_E3_1290V2 <: IntelXeon_E3_v2 end; export IntelXeon_E3_1290V2
abstract type IntelXeon_E3_1105C <: IntelXeon_E3 end; export IntelXeon_E3_1105C
abstract type IntelXeon_E3_1125C <: IntelXeon_E3 end; export IntelXeon_E3_1125C
abstract type IntelXeon_E3_1290 <: IntelXeon_E3 end; export IntelXeon_E3_1290
abstract type IntelXeon_E3_1220 <: IntelXeon_E3 end; export IntelXeon_E3_1220
abstract type IntelXeon_E3_1220L <: IntelXeon_E3 end; export IntelXeon_E3_1220L
abstract type IntelXeon_E3_1225 <: IntelXeon_E3 end; export IntelXeon_E3_1225
abstract type IntelXeon_E3_1230 <: IntelXeon_E3 end; export IntelXeon_E3_1230
abstract type IntelXeon_E3_1235 <: IntelXeon_E3 end; export IntelXeon_E3_1235
abstract type IntelXeon_E3_1240 <: IntelXeon_E3 end; export IntelXeon_E3_1240
abstract type IntelXeon_E3_1245 <: IntelXeon_E3 end; export IntelXeon_E3_1245
abstract type IntelXeon_E3_1270 <: IntelXeon_E3 end; export IntelXeon_E3_1270
abstract type IntelXeon_E3_1275 <: IntelXeon_E3 end; export IntelXeon_E3_1275
abstract type IntelXeon_E3_1280 <: IntelXeon_E3 end; export IntelXeon_E3_1280
| PlatformAware | https://github.com/PlatformAwareProgramming/PlatformAware.jl.git |
|
[
"MIT"
] | 0.6.0 | d8f50cbc077c0992b472a07f99013cd5be80b11a | code | 26602 | # ------------------------------------------------------------------
# Licensed under the MIT License. See LICENCE in the project root.
# ------------------------------------------------------------------
# abstract types
abstract type NVIDIA <: Manufacturer end; export NVIDIA
abstract type NVIDIAArchitecture <: AcceleratorArchitecture end; export NVIDIAArchitecture
abstract type Farenheit <: NVIDIAArchitecture end; export Farenheit
abstract type Celsius <: Farenheit end; export Celsius
abstract type Kelvin <: Celsius end; export Kelvin
abstract type Rankine <: Kelvin end; export Rankine
abstract type Curie <: Rankine end; export Curie
abstract type Tesla <: Curie end; export Tesla
abstract type Tesla2 <: Tesla end; export Tesla2
abstract type Fermi <: Tesla2 end; export Fermi
abstract type Kepler <: Fermi end; export Kepler
abstract type Kepler2 <: Kepler end; export Kepler2
abstract type Maxwell <: Kepler2 end; export Maxwell
abstract type Maxwell2 <: Maxwell end; export Maxwell2
abstract type Pascal <: Maxwell2 end; export Pascal
abstract type Volta <: Pascal end; export Volta
abstract type Turing <: Volta end; export Turing
abstract type Ampere <: Turing end; export Ampere
abstract type Ada <: Ampere end; export Ada
abstract type Hopper <: Ada end; export Hopper
# GPU processors
abstract type NVIDIAGPUProcessor <: AcceleratorProcessor end
abstract type GT200 <: NVIDIAGPUProcessor end; export GT200
abstract type GT200GL <: GT200 end; export GT200GL
abstract type G80 <: NVIDIAGPUProcessor end; export G80
abstract type GF100 <: NVIDIAGPUProcessor end; export GF100
abstract type GK104 <: NVIDIAGPUProcessor end; export GK104
abstract type GK110 <: NVIDIAGPUProcessor end; export GK110
abstract type GK110B <: GK110 end; export GK110B
abstract type GK210 <: NVIDIAGPUProcessor end; export GK210
abstract type GM107 <: NVIDIAGPUProcessor end; export GM107
abstract type GM200 <: NVIDIAGPUProcessor end; export GM200
abstract type GM204 <: NVIDIAGPUProcessor end; export GM206
abstract type GM204_995_A1 <: GM204 end; export GM204_995_A1
abstract type GM204_895_A1 <: GM204 end; export GM204_895_A1
abstract type GM206 <: NVIDIAGPUProcessor end; export GM206
abstract type GP100 <: NVIDIAGPUProcessor end; export GP100
abstract type GP100_890_A1 <: GP100 end; export GP100_890_A1
abstract type GP102 <: NVIDIAGPUProcessor end; export GP102
abstract type GP104 <: NVIDIAGPUProcessor end; export GP104
abstract type GP104_995_A1 <: GP104 end; export GP104_995_A1
abstract type GV100 <: NVIDIAGPUProcessor end; export GV100
abstract type GV100_895_A1 <: GV100 end; export GV100_895_A1
abstract type TU104_895_A1 <: NVIDIAGPUProcessor end; export TU104_895_A1
abstract type GA100 <: NVIDIAGPUProcessor end; export GA100
abstract type GA100_883AA_A1 <: GA100 end; export GA100_883AA_A1
abstract type GA102 <: NVIDIAGPUProcessor end; export GA102
abstract type GA102_890_A1 <: GA102 end; export GA102_890_A1
abstract type GA107 <: NVIDIAGPUProcessor end; export GA107
abstract type GH100 <: NVIDIAGPUProcessor end; export GH100
abstract type AD102 <: NVIDIAGPUProcessor end; export AD102
abstract type AD103 <: NVIDIAGPUProcessor end; export AD103
abstract type AD104 <: NVIDIAGPUProcessor end; export AD104
abstract type GA103S <: NVIDIAGPUProcessor end; export GA103S
abstract type GA104 <: NVIDIAGPUProcessor end; export GA104
abstract type GA106 <: NVIDIAGPUProcessor end; export GA106
abstract type GA107S <: NVIDIAGPUProcessor end; export GA107S
abstract type GF108 <: NVIDIAGPUProcessor end; export GF108
abstract type GF119 <: NVIDIAGPUProcessor end; export GF119
abstract type GK106 <: NVIDIAGPUProcessor end; export GK106
abstract type GK107 <: NVIDIAGPUProcessor end; export GK107
abstract type GK208B <: NVIDIAGPUProcessor end; export GK208B
abstract type GM108 <: NVIDIAGPUProcessor end; export GM108
abstract type GM108M <: NVIDIAGPUProcessor end; export GM108M
abstract type GM20B <: NVIDIAGPUProcessor end; export GM20B
abstract type GP106 <: NVIDIAGPUProcessor end; export GP106
abstract type GP107 <: NVIDIAGPUProcessor end; export GP107
abstract type GP108 <: NVIDIAGPUProcessor end; export GP108
abstract type GP108B <: NVIDIAGPUProcessor end; export GP108B
abstract type GP10B <: NVIDIAGPUProcessor end; export GP10B
abstract type GV10B <: NVIDIAGPUProcessor end; export GV10B
abstract type TU102 <: NVIDIAGPUProcessor end; export TU102
abstract type TU104 <: NVIDIAGPUProcessor end; export TU104
abstract type TU104B <: NVIDIAGPUProcessor end; export TU104B
abstract type TU106 <: NVIDIAGPUProcessor end; export TU106
abstract type TU106B <: NVIDIAGPUProcessor end; export TU106B
abstract type TU116 <: NVIDIAGPUProcessor end; export TU116
abstract type TU117 <: NVIDIAGPUProcessor end; export TU117
abstract type TU117B <: NVIDIAGPUProcessor end; export TU117B
# CUDA API
abstract type CUDA_API <: AcceleratorBackend end; export CUDA_API
abstract type CUDA_1_0 <: CUDA_API end; const CUDA1 = CUDA_1_0; export CUDA_1_0, CUDA1
abstract type CUDA_1_3 <: CUDA_1_0 end; export CUDA_1_3
abstract type CUDA_2_0 <: CUDA_1_3 end; const CUDA2 = CUDA_2_0; export CUDA_2_0, CUDA2
abstract type CUDA_2_1 <: CUDA_2_0 end; export CUDA_2_1
abstract type CUDA_3_0 <: CUDA_2_1 end; const CUDA3 = CUDA_3_0; export CUDA_3_0, CUDA3
abstract type CUDA_3_5 <: CUDA_3_0 end; export CUDA_3_5
abstract type CUDA_3_7 <: CUDA_3_5 end; export CUDA_3_7
abstract type CUDA_5_0 <: CUDA_3_7 end; export CUDA_5_2
abstract type CUDA_5_2 <: CUDA_5_0 end; export CUDA_5_0
abstract type CUDA_5_3 <: CUDA_5_2 end; export CUDA_5_3
abstract type CUDA_6_0 <: CUDA_5_3 end; const CUDA6 = CUDA_6_0; export CUDA_6_0, CUDA6
abstract type CUDA_6_1 <: CUDA_6_0 end; export CUDA_6_1
abstract type CUDA_6_2 <: CUDA_6_1 end; export CUDA_6_2
abstract type CUDA_7_0 <: CUDA_6_2 end; const CUDA7 = CUDA_7_0; export CUDA_7_0, CUDA7
abstract type CUDA_7_2 <: CUDA_7_0 end; export CUDA_7_2
abstract type CUDA_7_5 <: CUDA_7_2 end; export CUDA_7_5
abstract type CUDA_8_0 <: CUDA_7_5 end; const CUDA8 = CUDA_8_0; export CUDA_8_0, CUDA8
abstract type CUDA_8_6 <: CUDA_8_0 end; export CUDA_8_6
abstract type CUDA_8_9 <: CUDA_8_6 end; export CUDA_8_9
abstract type CUDA_9_0 <: CUDA_8_9 end; const CUDA9 = CUDA_9_0; export CUDA_9_0, CUDA9
# GPU models
abstract type NVIDIAAccelerator <: Accelerator end; export NVIDIAAccelerator
# GPU models (Tensor Core)
abstract type NVIDIATensorCore <: NVIDIAAccelerator end; export NVIDIATensorCore
abstract type NVIDIA_L4 <: NVIDIATensorCore end; export NVIDIA_L4 # 23/05/2024
abstract type NVIDIA_A10 <: NVIDIATensorCore end; export NVIDIA_A10
abstract type NVIDIA_A100 <: NVIDIATensorCore end; export NVIDIA_A100
abstract type NVIDIA_A10G <: NVIDIATensorCore end; export NVIDIA_A10G
abstract type NVIDIA_A16 <: NVIDIATensorCore end; export NVIDIA_A16
abstract type NVIDIA_A2 <: NVIDIATensorCore end; export NVIDIA_A2
abstract type NVIDIA_A30 <: NVIDIATensorCore end; export NVIDIA_A30
abstract type NVIDIA_A40 <: NVIDIATensorCore end; export NVIDIA_A40
abstract type NVIDIA_H100 <: NVIDIATensorCore end; export NVIDIA_H100
# GPU models (Tesla)
abstract type NVIDIATesla <: NVIDIAAccelerator end; export NVIDIATesla
abstract type NVIDIATesla_C870 <: NVIDIATesla end; export NVIDIATesla_C870
abstract type NVIDIATesla_D870 <: NVIDIATesla end; export NVIDIATesla_D870
abstract type NVIDIATesla_S870 <: NVIDIATesla end; export NVIDIATesla_S870
abstract type NVIDIATesla_S1070 <: NVIDIATesla end; export NVIDIATesla_S1070
abstract type NVIDIATesla_S1075 <: NVIDIATesla end; export NVIDIATesla_S1075
abstract type NVIDIATesla_C1060 <: NVIDIATesla end; export NVIDIATesla_C1060
abstract type NVIDIATesla_C2050 <: NVIDIATesla end; export NVIDIATesla_C2050
abstract type NVIDIATesla_M2050 <: NVIDIATesla end; export NVIDIATesla_M2050
abstract type NVIDIATesla_C2070 <: NVIDIATesla end; export NVIDIATesla_C2070
abstract type NVIDIATesla_C2075 <: NVIDIATesla end; export NVIDIATesla_C2075
abstract type NVIDIATesla_M2070 <: NVIDIATesla end; export NVIDIATesla_M2070
abstract type NVIDIATesla_M2070Q <: NVIDIATesla end; export NVIDIATesla_M2070Q
abstract type NVIDIATesla_M2090 <: NVIDIATesla end; export NVIDIATesla_M2090
abstract type NVIDIATesla_S2050 <: NVIDIATesla end; export NVIDIATesla_S2050
abstract type NVIDIATesla_S2070 <: NVIDIATesla end; export NVIDIATesla_S2070
abstract type NVIDIATesla_K10 <: NVIDIATesla end; export NVIDIATesla_K10
abstract type NVIDIATesla_K20 <: NVIDIATesla end; export NVIDIATesla_K20
abstract type NVIDIATesla_K20X <: NVIDIATesla end; export NVIDIATesla_K20X
abstract type NVIDIATesla_K40 <: NVIDIATesla end; export NVIDIATesla_K40
abstract type NVIDIATesla_K80 <: NVIDIATesla end; export NVIDIATesla_K80
abstract type NVIDIATesla_M6 <: NVIDIATesla end; export NVIDIATesla_M6
abstract type NVIDIATesla_M60 <: NVIDIATesla end; export NVIDIATesla_M60
abstract type NVIDIATesla_M4 <: NVIDIATesla end; export NVIDIATesla_M4
abstract type NVIDIATesla_M40 <: NVIDIATesla end; export NVIDIATesla_M40
abstract type NVIDIATesla_M10 <: NVIDIATesla end; export NVIDIATesla_M10
abstract type NVIDIATesla_P100 <: NVIDIATesla end; export NVIDIATesla_P100
abstract type NVIDIATesla_P4 <: NVIDIATesla end; export NVIDIATesla_P4
abstract type NVIDIATesla_P40 <: NVIDIATesla end; export NVIDIATesla_P40
abstract type NVIDIATesla_P6 <: NVIDIATesla end; export NVIDIATesla_P6
abstract type NVIDIATesla_V100 <: NVIDIATesla end; export NVIDIATesla_V100
abstract type NVIDIATesla_T4 <: NVIDIATesla end; export NVIDIATesla_T4
abstract type NVIDIATesla_A100 <: NVIDIATesla end; export NVIDIATesla_A100
abstract type NVIDIATesla_A40 <: NVIDIATesla end; export NVIDIATesla_A40
abstract type NVIDIATesla_A10 <: NVIDIATesla end; export NVIDIATesla_A10
abstract type NVIDIATesla_A16 <: NVIDIATesla end; export NVIDIATesla_A16
abstract type NVIDIATesla_A30 <: NVIDIATesla end; export NVIDIATesla_A30
abstract type NVIDIATesla_A2 <: NVIDIATesla end; export NVIDIATesla_A2
abstract type NVIDIATesla_H100 <: NVIDIATesla end; export NVIDIATesla_H100
abstract type NVIDIATesla_P10 <: NVIDIATesla end; export NVIDIATesla_P10
abstract type NVIDIATesla_PG500_216 <: NVIDIATesla end; export NVIDIATesla_PG500_216
abstract type NVIDIATesla_PG503_216 <: NVIDIATesla end; export NVIDIATesla_PG503_216
abstract type NVIDIATesla_V100S <: NVIDIATesla end; export NVIDIATesla_V100S
# GPU models (RTX)
abstract type NVIDIA_RTX <: NVIDIAAccelerator end; export NVIDIA_RTX
abstract type NVIDIA_RTX_A1000 <: NVIDIA_RTX end; export NVIDIA_RTX_A1000
abstract type NVIDIA_RTX_A2000 <: NVIDIA_RTX end; export NVIDIA_RTX_A2000
abstract type NVIDIA_RTX_A3000 <: NVIDIA_RTX end; export NVIDIA_RTX_A3000
abstract type NVIDIA_RTX_A4 <: NVIDIA_RTX end; export NVIDIA_RTX_A4
abstract type NVIDIA_RTX_A4000 <: NVIDIA_RTX end; export NVIDIA_RTX_A4000
abstract type NVIDIA_RTX_A4500 <: NVIDIA_RTX end; export NVIDIA_RTX_A4500
abstract type NVIDIA_RTX_A500 <: NVIDIA_RTX end; export NVIDIA_RTX_A500
abstract type NVIDIA_RTX_A5000 <: NVIDIA_RTX end; export NVIDIA_RTX_A5000
abstract type NVIDIA_RTX_A5500 <: NVIDIA_RTX end; export NVIDIA_RTX_A5500
abstract type NVIDIA_RTX_A6000 <: NVIDIA_RTX end; export NVIDIA_RTX_A6000
# GPU models (NVS)
abstract type NVIDIA_NVS <: NVIDIAAccelerator end; export NVIDIA_NVS
abstract type NVIDIA_NVS_810 <: NVIDIA_NVS end; export NVIDIA_NVS_810
# GPU models (Switch)
abstract type NVIDIA_Switch <: NVIDIAAccelerator end; export NVIDIA_Switch
# GPU models (P)
abstract type NVIDIA_P <: NVIDIAAccelerator end; export NVIDIA_P
abstract type NVIDIA_P102_100 <: NVIDIA_P end; export NVIDIA_P102_100
abstract type NVIDIA_P102_101 <: NVIDIA_P end; export NVIDIA_P102_101
abstract type NVIDIA_P104_100 <: NVIDIA_P end; export NVIDIA_P104_100
abstract type NVIDIA_P104_101 <: NVIDIA_P end; export NVIDIA_P104_101
abstract type NVIDIA_P106_090 <: NVIDIA_P end; export NVIDIA_P106_090
abstract type NVIDIA_P106_100 <: NVIDIA_P end; export NVIDIA_P106_100
abstract type NVIDIA_P106M <: NVIDIA_P end; export NVIDIA_P106M
abstract type NVIDIA_PG506_232 <: NVIDIA_P end; export NVIDIA_PG506_232
abstract type NVIDIA_PG506_242 <: NVIDIA_P end; export NVIDIA_PG506_242
# GPU models (T)
abstract type NVIDIA_T <: NVIDIAAccelerator end; export NVIDIA_T
abstract type NVIDIA_T1000 <: NVIDIA_T end; export NVIDIA_T1000
abstract type NVIDIA_T400 <: NVIDIA_T end; export NVIDIA_T400
abstract type NVIDIA_T500 <: NVIDIA_T end; export NVIDIA_T500
abstract type NVIDIA_T550 <: NVIDIA_T end; export NVIDIA_T550
abstract type NVIDIA_T600 <: NVIDIA_T end; export NVIDIA_T600
# GPU models (Titan)
abstract type NVIDIATitan <: NVIDIAAccelerator end; export NVIDIATitan
abstract type NVIDIATitan_RTX <: NVIDIATitan end; export NVIDIATitan_RTX
abstract type NVIDIATitan_V <: NVIDIATitan end; export NVIDIATitan_V
abstract type NVIDIATitan_X <: NVIDIATitan end; export NVIDIATitan_X
abstract type NVIDIATitan_Xp <: NVIDIATitan end; export NVIDIATitan_Xp
# GPU models (Grid)
abstract type NVIDIAGrid <: NVIDIAAccelerator end; export NVIDIAGrid
abstract type NVIDIAGrid_K520 <: NVIDIAGrid end; export NVIDIAGrid_K520
abstract type NVIDIAGrid_A100A <: NVIDIAGrid end; export NVIDIAGrid_A100A
abstract type NVIDIAGrid_A100B <: NVIDIAGrid end; export NVIDIAGrid_A100B
abstract type NVIDIAGrid_M10_8Q <: NVIDIAGrid end; export NVIDIAGrid_M10_8Q
abstract type NVIDIAGrid_M3_3020 <: NVIDIAGrid end; export NVIDIAGrid_M3_3020
abstract type NVIDIAGrid_M40 <: NVIDIAGrid end; export NVIDIAGrid_M40
abstract type NVIDIAGrid_M6_8Q <: NVIDIAGrid end; export NVIDIAGrid_M6_8Q
abstract type NVIDIAGrid_M60_1Q <: NVIDIAGrid end; export NVIDIAGrid_M60_1Q
abstract type NVIDIAGrid_M60_2Q <: NVIDIAGrid end; export NVIDIAGrid_M60_2Q
abstract type NVIDIAGrid_M60_4A <: NVIDIAGrid end; export NVIDIAGrid_M60_4A
abstract type NVIDIAGrid_M60_8Q <: NVIDIAGrid end; export NVIDIAGrid_M60_8Q
abstract type NVIDIAGrid_RTX_T10_16 <: NVIDIAGrid end; export NVIDIAGrid_RTX_T10_16
abstract type NVIDIAGrid_RTX_T10_2 <: NVIDIAGrid end; export NVIDIAGrid_RTX_T10_2
abstract type NVIDIAGrid_RTX_T10_4 <: NVIDIAGrid end; export NVIDIAGrid_RTX_T10_4
abstract type NVIDIAGrid_RTX_T10_8 <: NVIDIAGrid end; export NVIDIAGrid_RTX_T10_8
# GPU models (Quadro)
abstract type NVIDIAQuadro <: NVIDIAAccelerator end; export NVIDIAQuadro
abstract type NVIDIAQuadro_Plex <: NVIDIAAccelerator end; export NVIDIAQuadro_Plex
abstract type NVIDIAQuadro_2200_D2 <: NVIDIAQuadro_Plex end; export NVIDIAQuadro_2200_D2
abstract type NVIDIAQuadro_2200_S4 <: NVIDIAQuadro_Plex end; export NVIDIAQuadro_2200_S4
abstract type NVIDIAQuadro_GP100 <: NVIDIAQuadro end; export NVIDIAQuadro_GP100
abstract type NVIDIAQuadro_GV100 <: NVIDIAQuadro end; export NVIDIAQuadro_GV100
abstract type NVIDIAQuadro_K1200 <: NVIDIAQuadro end; export NVIDIAQuadro_K1200
abstract type NVIDIAQuadro_K620M <: NVIDIAQuadro end; export NVIDIAQuadro_K620M
abstract type NVIDIAQuadro_M1000M <: NVIDIAQuadro end; export NVIDIAQuadro_M1000M
abstract type NVIDIAQuadro_M1200 <: NVIDIAQuadro end; export NVIDIAQuadro_M1200
abstract type NVIDIAQuadro_M2000 <: NVIDIAQuadro end; export NVIDIAQuadro_M2000
abstract type NVIDIAQuadro_M2000M <: NVIDIAQuadro end; export NVIDIAQuadro_M2000M
abstract type NVIDIAQuadro_M2200 <: NVIDIAQuadro end; export NVIDIAQuadro_M2200
abstract type NVIDIAQuadro_M3000 <: NVIDIAQuadro end; export NVIDIAQuadro_M3000
abstract type NVIDIAQuadro_M3000M <: NVIDIAQuadro end; export NVIDIAQuadro_M3000M
abstract type NVIDIAQuadro_M4000 <: NVIDIAQuadro end; export NVIDIAQuadro_M4000
abstract type NVIDIAQuadro_M4000M <: NVIDIAQuadro end; export NVIDIAQuadro_M4000M
abstract type NVIDIAQuadro_M5000 <: NVIDIAQuadro end; export NVIDIAQuadro_M5000
abstract type NVIDIAQuadro_M5000M <: NVIDIAQuadro end; export NVIDIAQuadro_M5000M
abstract type NVIDIAQuadro_M500M <: NVIDIAQuadro end; export NVIDIAQuadro_M500M
abstract type NVIDIAQuadro_M520 <: NVIDIAQuadro end; export NVIDIAQuadro_M520
abstract type NVIDIAQuadro_M5500 <: NVIDIAQuadro end; export NVIDIAQuadro_M5500
abstract type NVIDIAQuadro_M6000 <: NVIDIAQuadro end; export NVIDIAQuadro_M6000
abstract type NVIDIAQuadro_M600M <: NVIDIAQuadro end; export NVIDIAQuadro_M600M
abstract type NVIDIAQuadro_M620 <: NVIDIAQuadro end; export NVIDIAQuadro_M620
abstract type NVIDIAQuadro_P1000 <: NVIDIAQuadro end; export NVIDIAQuadro_P1000
abstract type NVIDIAQuadro_P2000 <: NVIDIAQuadro end; export NVIDIAQuadro_P2000
abstract type NVIDIAQuadro_P2200 <: NVIDIAQuadro end; export NVIDIAQuadro_P2200
abstract type NVIDIAQuadro_P3000 <: NVIDIAQuadro end; export NVIDIAQuadro_P3000
abstract type NVIDIAQuadro_P3200 <: NVIDIAQuadro end; export NVIDIAQuadro_P3200
abstract type NVIDIAQuadro_P400 <: NVIDIAQuadro end; export NVIDIAQuadro_P400
abstract type NVIDIAQuadro_P4000 <: NVIDIAQuadro end; export NVIDIAQuadro_P4000
abstract type NVIDIAQuadro_P4200 <: NVIDIAQuadro end; export NVIDIAQuadro_P4200
abstract type NVIDIAQuadro_P500 <: NVIDIAQuadro end; export NVIDIAQuadro_P500
abstract type NVIDIAQuadro_P5000 <: NVIDIAQuadro end; export NVIDIAQuadro_P5000
abstract type NVIDIAQuadro_P520 <: NVIDIAQuadro end; export NVIDIAQuadro_P520
abstract type NVIDIAQuadro_P5200 <: NVIDIAQuadro end; export NVIDIAQuadro_P5200
abstract type NVIDIAQuadro_P600 <: NVIDIAQuadro end; export NVIDIAQuadro_P600
abstract type NVIDIAQuadro_P6000 <: NVIDIAQuadro end; export NVIDIAQuadro_P6000
abstract type NVIDIAQuadro_P620 <: NVIDIAQuadro end; export NVIDIAQuadro_P620
abstract type NVIDIAQuadro_RTX_3000 <: NVIDIAQuadro end; export NVIDIAQuadro_RTX_3000
abstract type NVIDIAQuadro_RTX_4000 <: NVIDIAQuadro end; export NVIDIAQuadro_RTX_4000
abstract type NVIDIAQuadro_RTX_5000 <: NVIDIAQuadro end; export NVIDIAQuadro_RTX_5000
abstract type NVIDIAQuadro_RTX_6000 <: NVIDIAQuadro end; export NVIDIAQuadro_RTX_6000
abstract type NVIDIAQuadro_RTX_8000 <: NVIDIAQuadro end; export NVIDIAQuadro_RTX_8000
abstract type NVIDIAQuadro_T1000 <: NVIDIAQuadro end; export NVIDIAQuadro_T1000
abstract type NVIDIAQuadro_T1200 <: NVIDIAQuadro end; export NVIDIAQuadro_T1200
abstract type NVIDIAQuadro_T2000 <: NVIDIAQuadro end; export NVIDIAQuadro_T2000
# GPU models (Jetson)
abstract type NVIDIAJetson <: NVIDIAAccelerator end; export NVIDIAJetson
abstract type NVIDIAJetson_Nano <: NVIDIAJetson end; export NVIDIAJetson_Nano
abstract type NVIDIAJetson_TX1 <: NVIDIAJetson end; export NVIDIAJetson_TX1
abstract type NVIDIAJetson_TX2 <: NVIDIAJetson end; export NVIDIAJetson_TX2
abstract type NVIDIAJetson_Xavier <: NVIDIAJetson end; export NVIDIAJetson_Xavier
# GPU models (Cmp)
abstract type NVIDIACmp <: NVIDIAAccelerator end; export NVIDIACmp
abstract type NVIDIACmp_170HX <: NVIDIACmp end; export NVIDIACmp_170HX
abstract type NVIDIACmp_30HX <: NVIDIACmp end; export NVIDIACmp_30HX
abstract type NVIDIACmp_40HX <: NVIDIACmp end; export NVIDIACmp_40HX
abstract type NVIDIACmp_50HX <: NVIDIACmp end; export NVIDIACmp_50HX
abstract type NVIDIACmp_70HX <: NVIDIACmp end; export NVIDIACmp_70HX
abstract type NVIDIACmp_90HX <: NVIDIACmp end; export NVIDIACmp_90HX
# GPU models (GeForce)
abstract type NVIDIAGeForce <: NVIDIAAccelerator end; export NVIDIA_GeForce
abstract type NVIDIAGeForce7 <: NVIDIAGeForce end; export NVIDIA_GeForce7
abstract type NVIDIAGeForce8 <: NVIDIAGeForce end; export NVIDIA_GeForce8
abstract type NVIDIAGeForce9 <: NVIDIAGeForce end; export NVIDIA_GeForce9
abstract type NVIDIAGeForce_GT <: NVIDIAGeForce end; export NVIDIAGeForce_GT
abstract type NVIDIAGeForce_MX <: NVIDIAGeForce end; export NVIDIAGeForce_MX
abstract type NVIDIAGeForce_GTX <: NVIDIAGeForce end; export NVIDIAGeForce_GTX
abstract type NVIDIAGeForce_RTX <: NVIDIAGeForce end; export NVIDIAGeForce_RTX
abstract type NVIDIAGeForce_GTX7Series <: NVIDIAGeForce_GTX end; export NVIDIAGeForce_GTX7Series
abstract type NVIDIAGeForce_GTX8Series <: NVIDIAGeForce_GTX end; export NVIDIAGeForce_GTX8Series
abstract type NVIDIAGeForce_GTX9Series <: NVIDIAGeForce_GTX end; export NVIDIAGeForce_GTX9Series
abstract type NVIDIAGeForce_GTX10Series <: NVIDIAGeForce_GTX end; export NVIDIAGeForce_GTX10Series
abstract type NVIDIAGeForce_GTX16Series <: NVIDIAGeForce_GTX end; export NVIDIAGeForce_GTX16Series
abstract type NVIDIAGeForce_RTX20Series <: NVIDIAGeForce_RTX end; export NVIDIAGeForce_RTX20Series
abstract type NVIDIAGeForce_RTX30Series <: NVIDIAGeForce_RTX end; export NVIDIAGeForce_RTX30Series
abstract type NVIDIAGeForce_RTX40Series <: NVIDIAGeForce_RTX end; export NVIDIAGeForce_RTX30Series
abstract type NVIDIAGeForce_710A <: NVIDIAGeForce7 end; export NVIDIAGeForce_710A
abstract type NVIDIAGeForce_810M <: NVIDIAGeForce8 end; export NVIDIAGeForce_810M
abstract type NVIDIAGeForce_820M <: NVIDIAGeForce8 end; export NVIDIAGeForce_820M
abstract type NVIDIAGeForce_845M <: NVIDIAGeForce8 end; export NVIDIAGeForce_845M
abstract type NVIDIAGeForce_910M <: NVIDIAGeForce9 end; export NVIDIAGeForce_910M
abstract type NVIDIAGeForce_920A <: NVIDIAGeForce9 end; export NVIDIAGeForce_920A
abstract type NVIDIAGeForce_920M <: NVIDIAGeForce9 end; export NVIDIAGeForce_920M
abstract type NVIDIAGeForce_920MX <: NVIDIAGeForce9 end; export NVIDIAGeForce_920MX
abstract type NVIDIAGeForce_930A <: NVIDIAGeForce9 end; export NVIDIAGeForce_930A
abstract type NVIDIAGeForce_930M <: NVIDIAGeForce9 end; export NVIDIAGeForce_930M
abstract type NVIDIAGeForce_930MX <: NVIDIAGeForce9 end; export NVIDIAGeForce_930MX
abstract type NVIDIAGeForce_940A <: NVIDIAGeForce9 end; export NVIDIAGeForce_940A
abstract type NVIDIAGeForce_940M <: NVIDIAGeForce9 end; export NVIDIAGeForce_940M
abstract type NVIDIAGeForce_940MX <: NVIDIAGeForce9 end; export NVIDIAGeForce_940MX
abstract type NVIDIAGeForce_945A <: NVIDIAGeForce9 end; export NVIDIAGeForce_945A
abstract type NVIDIAGeForce_945M <: NVIDIAGeForce9 end; export NVIDIAGeForce_945M
abstract type NVIDIAGeForce_GT_1010 <: NVIDIAGeForce_GT end; export NVIDIAGeForce_GT_1010
abstract type NVIDIAGeForce_GT_1030 <: NVIDIAGeForce_GT end; export NVIDIAGeForce_GT_1030
abstract type NVIDIAGeForce_GT_610 <: NVIDIAGeForce_GT end; export NVIDIAGeForce_GT_610
abstract type NVIDIAGeForce_GT_710 <: NVIDIAGeForce_GT end; export NVIDIAGeForce_GT_710
abstract type NVIDIAGeForce_GT_720 <: NVIDIAGeForce_GT end; export NVIDIAGeForce_GT_720
abstract type NVIDIAGeForce_GT_730 <: NVIDIAGeForce_GT end; export NVIDIAGeForce_GT_730
abstract type NVIDIAGeForce_GT_740 <: NVIDIAGeForce_GT end; export NVIDIAGeForce_GT_740
abstract type NVIDIAGeForce_GTX_1050 <: NVIDIAGeForce_GTX10Series end; export NVIDIAGeForce_GTX_1050
abstract type NVIDIAGeForce_GTX_1060 <: NVIDIAGeForce_GTX10Series end; export NVIDIAGeForce_GTX_1060
abstract type NVIDIAGeForce_GTX_1070 <: NVIDIAGeForce_GTX10Series end; export NVIDIAGeForce_GTX_1070
abstract type NVIDIAGeForce_GTX_1080 <: NVIDIAGeForce_GTX10Series end; export NVIDIAGeForce_GTX_1080
abstract type NVIDIAGeForce_GTX_1630 <: NVIDIAGeForce_GTX16Series end; export NVIDIAGeForce_GTX_1630
abstract type NVIDIAGeForce_GTX_1650 <: NVIDIAGeForce_GTX16Series end; export NVIDIAGeForce_GTX_1650
abstract type NVIDIAGeForce_GTX_1660 <: NVIDIAGeForce_GTX16Series end; export NVIDIAGeForce_GTX_1660
abstract type NVIDIAGeForce_GTX_750 <: NVIDIAGeForce_GTX7Series end; export NVIDIAGeForce_GTX_750
abstract type NVIDIAGeForce_GTX_760 <: NVIDIAGeForce_GTX7Series end; export NVIDIAGeForce_GTX_760
abstract type NVIDIAGeForce_GTX_860M <: NVIDIAGeForce_GTX8Series end; export NVIDIAGeForce_GTX_860M
abstract type NVIDIAGeForce_GTX_950 <: NVIDIAGeForce_GTX9Series end; export NVIDIAGeForce_GTX_950
abstract type NVIDIAGeForce_GTX_950A <: NVIDIAGeForce_GTX9Series end; export NVIDIAGeForce_GTX_950A
abstract type NVIDIAGeForce_GTX_950M <: NVIDIAGeForce_GTX9Series end; export NVIDIAGeForce_GTX_950M
abstract type NVIDIAGeForce_GTX_960 <: NVIDIAGeForce_GTX9Series end; export NVIDIAGeForce_GTX_960
abstract type NVIDIAGeForce_GTX_960A <: NVIDIAGeForce_GTX9Series end; export NVIDIAGeForce_GTX_960A
abstract type NVIDIAGeForce_GTX_960M <: NVIDIAGeForce_GTX9Series end; export NVIDIAGeForce_GTX_960M
abstract type NVIDIAGeForce_GTX_965M <: NVIDIAGeForce_GTX9Series end; export NVIDIAGeForce_GTX_965M
abstract type NVIDIAGeForce_GTX_980 <: NVIDIAGeForce_GTX9Series end; export NVIDIAGeForce_GTX_980
abstract type NVIDIAGeForce_GTX_980MX <: NVIDIAGeForce_GTX9Series end; export NVIDIAGeForce_GTX_980MX
abstract type NVIDIAGeForce_GTX_TITAN_X <: NVIDIAGeForce_GTX end; export NVIDIAGeForce_GTX_TITAN_X
abstract type NVIDIAGeForce_MX110 <: NVIDIAGeForce_MX end; export NVIDIAGeForce_MX110
abstract type NVIDIAGeForce_MX130 <: NVIDIAGeForce_MX end; export NVIDIAGeForce_MX130
abstract type NVIDIAGeForce_MX150 <: NVIDIAGeForce_MX end; export NVIDIAGeForce_MX150
abstract type NVIDIAGeForce_MX230 <: NVIDIAGeForce_MX end; export NVIDIAGeForce_MX230
abstract type NVIDIAGeForce_MX250 <: NVIDIAGeForce_MX end; export NVIDIAGeForce_MX250
abstract type NVIDIAGeForce_MX330 <: NVIDIAGeForce_MX end; export NVIDIAGeForce_MX330
abstract type NVIDIAGeForce_MX350 <: NVIDIAGeForce_MX end; export NVIDIAGeForce_MX350
abstract type NVIDIAGeForce_MX450 <: NVIDIAGeForce_MX end; export NVIDIAGeForce_MX450
abstract type NVIDIAGeForce_MX550 <: NVIDIAGeForce_MX end; export NVIDIAGeForce_MX550
abstract type NVIDIAGeForce_MX570 <: NVIDIAGeForce_MX end; export NVIDIAGeForce_MX570
abstract type NVIDIAGeForce_RTX_2050 <: NVIDIAGeForce_RTX20Series end; export NVIDIAGeForce_RTX_2050
abstract type NVIDIAGeForce_RTX_2060 <: NVIDIAGeForce_RTX20Series end; export NVIDIAGeForce_RTX_2060
abstract type NVIDIAGeForce_RTX_2070 <: NVIDIAGeForce_RTX20Series end; export NVIDIAGeForce_RTX_2070
abstract type NVIDIAGeForce_RTX_2080 <: NVIDIAGeForce_RTX20Series end; export NVIDIAGeForce_RTX_2080
abstract type NVIDIAGeForce_RTX_3050 <: NVIDIAGeForce_RTX30Series end; export NVIDIAGeForce_RTX_3050
abstract type NVIDIAGeForce_RTX_3060 <: NVIDIAGeForce_RTX30Series end; export NVIDIAGeForce_RTX_3060
abstract type NVIDIAGeForce_RTX_3070 <: NVIDIAGeForce_RTX30Series end; export NVIDIAGeForce_RTX_3070
abstract type NVIDIAGeForce_RTX_3080 <: NVIDIAGeForce_RTX30Series end; export NVIDIAGeForce_RTX_3080
abstract type NVIDIAGeForce_RTX_3090 <: NVIDIAGeForce_RTX30Series end; export NVIDIAGeForce_RTX_3090
abstract type NVIDIAGeForce_RTX_4060 <: NVIDIAGeForce_RTX40Series end; export NVIDIAGeForce_RTX_4060
abstract type NVIDIAGeForce_RTX_4070 <: NVIDIAGeForce_RTX40Series end; export NVIDIAGeForce_RTX_4070
abstract type NVIDIAGeForce_RTX_4080 <: NVIDIAGeForce_RTX40Series end; export NVIDIAGeForce_RTX_4080
abstract type NVIDIAGeForce_RTX_4090 <: NVIDIAGeForce_RTX40Series end; export NVIDIAGeForce_RTX_4090 | PlatformAware | https://github.com/PlatformAwareProgramming/PlatformAware.jl.git |
|
[
"MIT"
] | 0.6.0 | d8f50cbc077c0992b472a07f99013cd5be80b11a | code | 448 | # ------------------------------------------------------------------
# Licensed under the MIT License. See LICENCE in the project root.
# ------------------------------------------------------------------
abstract type Xilinx <: Manufacturer end; export Xilinx
abstract type UltrascalePlus_HBM_FPGA <: AcceleratorType end; export UltrascalePlus_HBM_FPGA
abstract type UltrascalePlus_VU9P <: AcceleratorType end; export UltrascalePlus_VU9P
#TODO | PlatformAware | https://github.com/PlatformAwareProgramming/PlatformAware.jl.git |
|
[
"MIT"
] | 0.6.0 | d8f50cbc077c0992b472a07f99013cd5be80b11a | code | 6414 | # ------------------------------------------------------------------
# Licensed under the MIT License. See LICENCE in the project root.
# ------------------------------------------------------------------
# automated declaration of at-least quantifier types
abstract type AtLeast0 <: QuantifierFeature end; export AtLeast0
let mul_super = 0
mag_ = ""
for mag in ["n", "u", "m", "", "K", "M", "G", "T", "P", "E"]
for mul in [1, 2, 4, 8, 16, 32, 64, 128, 256, 512]
mag_super = mul == 1 ? mag_ : mag
nm1 = Symbol("AtLeast" * string(mul) * mag)
nm2 = Symbol("AtLeast" * string(mul_super) * mag_super)
@eval abstract type $nm1 <: $nm2 end
@eval export $nm1
mul_super = mul
end
mag_ = mag
end
end
abstract type AtLeastInf <: AtLeast512E end
#=
abstract type AtLeast0 end # 0
abstract type AtLeast1n <: AtLeast0 end # 2^-30
abstract type AtLeast2n <: AtLeast1n end # 2^-29
abstract type AtLeast4n <: AtLeast2n end # 2^-28
abstract type AtLeast8n <: AtLeast4n end # 2^-27
abstract type AtLeast16n <: AtLeast8n end # 2^-26
abstract type AtLeast32n <: AtLeast16n end # 2^-25
abstract type AtLeast64n <: AtLeast32n end # 2^-24
abstract type AtLeast128n <: AtLeast64n end # 2^-23
abstract type AtLeast256n <: AtLeast128n end # 2^-22
abstract type AtLeast512n <: AtLeast256n end # 2^-21
abstract type AtLeast1u <: AtLeast512n end # 2^-20
abstract type AtLeast2u <: AtLeast1u end # 2^-19
abstract type AtLeast4u <: AtLeast2u end # 2^-18
abstract type AtLeast8u <: AtLeast4u end # 2^-17
abstract type AtLeast16u <: AtLeast8u end # 2^-16
abstract type AtLeast32u <: AtLeast16u end # 2^-15
abstract type AtLeast64u <: AtLeast32u end # 2^-14
abstract type AtLeast128u <: AtLeast64u end # 2^-13
abstract type AtLeast256u <: AtLeast128u end # 2^-12
abstract type AtLeast512u <: AtLeast256u end # 2^-11
abstract type AtLeast1m <: AtLeast512u end # 2^-10
abstract type AtLeast2m <: AtLeast1m end # 2^-9
abstract type AtLeast4m <: AtLeast2m end # 2^-8
abstract type AtLeast8m <: AtLeast4m end # 2^-7
abstract type AtLeast16m <: AtLeast8m end # 2^-6
abstract type AtLeast32m <: AtLeast16m end # 2^-5
abstract type AtLeast64m <: AtLeast32m end # 2^-4
abstract type AtLeast128m <: AtLeast64m end # 2^-3
abstract type AtLeast256m <: AtLeast128m end # 2^-2
abstract type AtLeast512m <: AtLeast256m end # 2^-1
abstract type AtLeast1 <: AtLeast512m end # 2^0
abstract type AtLeast2 <: AtLeast1 end # 2^1
abstract type AtLeast4 <: AtLeast2 end # 2^2
abstract type AtLeast8 <: AtLeast4 end # 2^3
abstract type AtLeast16 <: AtLeast8 end # 2^4
abstract type AtLeast32 <: AtLeast16 end # 2^5
abstract type AtLeast64 <: AtLeast32 end # 2^6
abstract type AtLeast128 <: AtLeast64 end # 2^7
abstract type AtLeast256 <: AtLeast128 end # 2^8
abstract type AtLeast512 <: AtLeast256 end # 2^9
abstract type AtLeast1K <: AtLeast512 end # 2^10
abstract type AtLeast2K <: AtLeast1K end # 2^11
abstract type AtLeast4K <: AtLeast2K end # 2^12
abstract type AtLeast8K <: AtLeast4K end # 2^13
abstract type AtLeast16K <: AtLeast8K end # 2^14
abstract type AtLeast32K <: AtLeast16K end # 2^15
abstract type AtLeast64K <: AtLeast32K end # 2^16
abstract type AtLeast128K <: AtLeast64K end # 2^17
abstract type AtLeast256K <: AtLeast128K end # 2^18
abstract type AtLeast512K <: AtLeast256K end # 2^19
abstract type AtLeast1M <: AtLeast512K end # 2^20
abstract type AtLeast2M <: AtLeast1M end # 2^21
abstract type AtLeast4M <: AtLeast2M end # 2^22
abstract type AtLeast8M <: AtLeast4M end # 2^23
abstract type AtLeast16M <: AtLeast8M end # 2^24
abstract type AtLeast32M <: AtLeast16M end # 2^25
abstract type AtLeast64M <: AtLeast32M end # 2^26
abstract type AtLeast128M <: AtLeast64M end # 2^27
abstract type AtLeast256M <: AtLeast128M end # 2^28
abstract type AtLeast512M <: AtLeast256M end # 2^29
abstract type AtLeast1G <: AtLeast512M end # 2^30
abstract type AtLeast2G <: AtLeast1G end # 2^31
abstract type AtLeast4G <: AtLeast2G end # 2^32
abstract type AtLeast8G <: AtLeast4G end # 2^33
abstract type AtLeast16G <: AtLeast8G end # 2^34
abstract type AtLeast32G <: AtLeast16G end # 2^35
abstract type AtLeast64G <: AtLeast32G end # 2^36
abstract type AtLeast128G <: AtLeast64G end # 2^37
abstract type AtLeast256G <: AtLeast128G end # 2^38
abstract type AtLeast512G <: AtLeast256G end # 2^39
abstract type AtLeast1T <: AtLeast512G end # 2^40
abstract type AtLeast2T <: AtLeast1T end # 2^41
abstract type AtLeast4T <: AtLeast2T end # 2^42
abstract type AtLeast8T <: AtLeast4T end # 2^43
abstract type AtLeast16T <: AtLeast8T end # 2^44
abstract type AtLeast32T <: AtLeast16T end # 2^45
abstract type AtLeast64T <: AtLeast32T end # 2^46
abstract type AtLeast128T <: AtLeast64T end # 2^47
abstract type AtLeast256T <: AtLeast128T end # 2^48
abstract type AtLeast512T <: AtLeast256T end # 2^49
abstract type AtLeast1P <: AtLeast512T end # 2^50
abstract type AtLeast2P <: AtLeast1P end # 2^51
abstract type AtLeast4P <: AtLeast2P end # 2^52
abstract type AtLeast8P <: AtLeast4P end # 2^53
abstract type AtLeast16P <: AtLeast8P end # 2^54
abstract type AtLeast32P <: AtLeast16P end # 2^55
abstract type AtLeast64P <: AtLeast32P end # 2^56
abstract type AtLeast128P <: AtLeast64P end # 2^57
abstract type AtLeast256P <: AtLeast128P end # 2^58
abstract type AtLeast512P <: AtLeast256P end # 2^59
abstract type AtLeast1E <: AtLeast512T end # 2^60
abstract type AtLeast2E <: AtLeast1E end # 2^61
abstract type AtLeast4E <: AtLeast2E end # 2^62
abstract type AtLeast8E <: AtLeast4E end # 2^63
abstract type AtLeast16E <: AtLeast8E end # 2^64
abstract type AtLeast32E <: AtLeast16E end # 2^65
abstract type AtLeast64E <: AtLeast32E end # 2^66
abstract type AtLeast128E <: AtLeast64E end # 2^67
abstract type AtLeast256E <: AtLeast128E end # 2^68
abstract type AtLeast512E <: AtLeast256E end # 2^69
# ...
abstract type AtLeastInf <: AtLeast512E end # ∞
=# | PlatformAware | https://github.com/PlatformAwareProgramming/PlatformAware.jl.git |
|
[
"MIT"
] | 0.6.0 | d8f50cbc077c0992b472a07f99013cd5be80b11a | code | 7366 | # ------------------------------------------------------------------
# Licensed under the MIT License. See LICENCE in the project root.
# ------------------------------------------------------------------
# automated declaration of at-most quantifier types
abstract type AtMostInf <: QuantifierFeature end; export AtMostInf
let mul_super = "Inf" ,
mag_ = "" ;
for mag in reverse(["n", "u", "m", "", "K", "M", "G", "T", "P", "E"])
for mul in reverse([1, 2, 4, 8, 16, 32, 64, 128, 256, 512])
mag_super = mul==512 ? mag_ : mag
nm1 = Symbol("AtMost" * string(mul) * mag)
nm2 = Symbol("AtMost" * string(mul_super) * mag_super)
@eval abstract type $nm1 <: $nm2 end
@eval export $nm1
mul_super = mul
end
mag_ = mag
end
end
abstract type AtMost0 <: AtMost1n end; export AtMost0
#=
abstract type AtMostInf end # ∞
abstract type AtMost512E <: AtMostInf end # 2^69
abstract type AtMost256E <: AtMost512E end # 2^68
abstract type AtMost128E <: AtMost256E end # 2^67
abstract type AtMost64E <: AtMost128E end # 2^66
abstract type AtMost32E <: AtMost64E end # 2^65
abstract type AtMost16E <: AtMost32E end # 2^64
abstract type AtMost8E <: AtMost16E end # 2^63
abstract type AtMost4E <: AtMost8E end # 2^62
abstract type AtMost2E <: AtMost4E end # 2^61
abstract type AtMost1E <: AtMost2E end # 2^60
abstract type AtMost512P <: AtMost1E end # 2^59
abstract type AtMost256P <: AtMost512P end # 2^58
abstract type AtMost128P <: AtMost256P end # 2^57
abstract type AtMost64P <: AtMost128P end # 2^56
abstract type AtMost32P <: AtMost64P end # 2^55
abstract type AtMost16P <: AtMost32P end # 2^54
abstract type AtMost8P <: AtMost16P end # 2^53
abstract type AtMost4P <: AtMost8P end # 2^52
abstract type AtMost2P <: AtMost4P end # 2^51
abstract type AtMost1P <: AtMost2P end # 2^50
abstract type AtMost512T <: AtMost1P end # 2^49
abstract type AtMost256T <: AtMost512T end # 2^48
abstract type AtMost128T <: AtMost256T end # 2^47
abstract type AtMost64T <: AtMost128T end # 2^46
abstract type AtMost32T <: AtMost64T end # 2^45
abstract type AtMost16T <: AtMost32T end # 2^44
abstract type AtMost8T <: AtMost16T end # 2^43
abstract type AtMost4T <: AtMost8T end # 2^42
abstract type AtMost2T <: AtMost4T end # 2^41
abstract type AtMost1T <: AtMost2T end # 2^40
abstract type AtMost512G <: AtMost1T end # 2^39
abstract type AtMost256G <: AtMost512G end # 2^38
abstract type AtMost128G <: AtMost256G end # 2^37
abstract type AtMost64G <: AtMost128G end # 2^36
abstract type AtMost32G <: AtMost64G end # 2^35
abstract type AtMost16G <: AtMost32G end # 2^34
abstract type AtMost8G <: AtMost16G end # 2^33
abstract type AtMost4G <: AtMost8G end # 2^32
abstract type AtMost2G <: AtMost4G end # 2^31
abstract type AtMost1G <: AtMost2G end # 2^30
abstract type AtMost512M <: AtMost1G end # 2^29
abstract type AtMost256M <: AtMost512M end # 2^28
abstract type AtMost128M <: AtMost256M end # 2^27
abstract type AtMost64M <: AtMost128M end # 2^26
abstract type AtMost32M <: AtMost64M end # 2^25
abstract type AtMost16M <: AtMost32M end # 2^24
abstract type AtMost8M <: AtMost16M end # 2^23
abstract type AtMost4M <: AtMost8M end # 2^22
abstract type AtMost2M <: AtMost4M end # 2^21
abstract type AtMost1M <: AtMost2M end # 2^20
abstract type AtMost512K <: AtMost1M end # 2^19
abstract type AtMost256K <: AtMost512K end # 2^18
abstract type AtMost128K <: AtMost256K end # 2^17
abstract type AtMost64K <: AtMost128K end # 2^16
abstract type AtMost32K <: AtMost64K end # 2^15
abstract type AtMost16K <: AtMost32K end # 2^14
abstract type AtMost8K <: AtMost16K end # 2^13
abstract type AtMost4K <: AtMost8K end # 2^12
abstract type AtMost2K <: AtMost4K end # 2^11
abstract type AtMost1K <: AtMost2K end # 2^10
abstract type AtMost512 <: AtMost1K end # 2^9
abstract type AtMost256 <: AtMost512 end # 2^8
abstract type AtMost128 <: AtMost256 end # 2^7
abstract type AtMost64 <: AtMost128 end # 2^6
abstract type AtMost32 <: AtMost64 end # 2^5
abstract type AtMost16 <: AtMost32 end # 2^4
abstract type AtMost8 <: AtMost16 end # 2^3
abstract type AtMost4 <: AtMost8 end # 2^2
abstract type AtMost2 <: AtMost4 end # 2^1
abstract type AtMost1 <: AtMost2 end # 2^0
abstract type AtMost512m <: AtMost1 end # 2^-1
abstract type AtMost256m <: AtMost512m end # 2^-2
abstract type AtMost128m <: AtMost256m end # 2^-3
abstract type AtMost64m <: AtMost128m end # 2^-4
abstract type AtMost32m <: AtMost64m end # 2^-5
abstract type AtMost16m <: AtMost32m end # 2^-6
abstract type AtMost8m <: AtMost16m end # 2^-7
abstract type AtMost4m <: AtMost8m end # 2^-8
abstract type AtMost2m <: AtMost4m end # 2^-9
abstract type AtMost1m <: AtMost2m end # 2^-10
abstract type AtMost512u <: AtMost1m end # 2^-11
abstract type AtMost256u <: AtMost512u end # 2^-12
abstract type AtMost128u <: AtMost256u end # 2^-13
abstract type AtMost64u <: AtMost128u end # 2^-14
abstract type AtMost32u <: AtMost64u end # 2^-15
abstract type AtMost16u <: AtMost32u end # 2^-16
abstract type AtMost8u <: AtMost16u end # 2^-17
abstract type AtMost4u <: AtMost8u end # 2^-18
abstract type AtMost2u <: AtMost4u end # 2^-19
abstract type AtMost1u <: AtMost2u end # 2^-20
abstract type AtMost512n <: AtMost1u end # 2^-21
abstract type AtMost256n <: AtMost512n end # 2^-22
abstract type AtMost128n <: AtMost256n end # 2^-23
abstract type AtMost64n <: AtMost128n end # 2^-24
abstract type AtMost32n <: AtMost64n end # 2^-25
abstract type AtMost16n <: AtMost32n end # 2^-26
abstract type AtMost8n <: AtMost16n end # 2^-27
abstract type AtMost4n <: AtMost8n end # 2^-28
abstract type AtMost2n <: AtMost4n end # 2^-29
abstract type AtMost1n <: AtMost2n end # 2^-30
abstract type AtMost0 <: AtMost1n end # 0
=#
| PlatformAware | https://github.com/PlatformAwareProgramming/PlatformAware.jl.git |
|
[
"MIT"
] | 0.6.0 | d8f50cbc077c0992b472a07f99013cd5be80b11a | code | 1992 | # ------------------------------------------------------------------
# Licensed under the MIT License. See LICENCE in the project root.
# ------------------------------------------------------------------
macro quantifier(n)
nn = eval(n)
get_quantifier(nn)
end
macro atleast(n)
N = n==:∞ || n==:inf ? "AtLeastInf" : "AtLeast" * string(n)
# Meta.parse("Type{<:Tuple{$N,AtMostInf,X} where X}")
Meta.parse("Tuple{$N,AtMostInf,X} where X")
end
macro atleast(n,x)
N = n==:∞ || n==:inf ? "AtLeastInf" : "AtLeast" * string(n)
# Meta.parse("Type{<:Tuple{$N,AtMostInf,$(x)}}")
Meta.parse("Tuple{$N,AtMostInf,$(x)}")
end
macro atmost(n)
N = n==:∞ || n==:inf ? "AtMostInf" : "AtMost" * string(n);
# Meta.parse("Type{<:Tuple{AtLeast0,$N,X} where X}")
Meta.parse("Tuple{AtLeast0,$N,X} where X")
end
macro atmost(n,x)
N = n==:∞ || n==:inf ? "AtMostInf" : "AtMost" * string(n);
# Meta.parse("Type{<:Tuple{AtLeast0,$N,$(x)}}")
Meta.parse("Tuple{AtLeast0,$N,$(x)}")
end
macro between(m,n)
M = m==:∞ || n==:inf ? "AtLeastInf" : "AtLeast" * string(m)
N = n==:∞ || n==:inf ? "AtMostInf" : "AtMost" * string(n)
# Meta.parse("Type{<:Tuple{$M,$N,X} where X}")
Meta.parse("Tuple{$M,$N,X} where X")
end
macro between(m,n,x)
M = m==:∞ || n==:inf ? "AtLeastInf" : "AtLeast" * string(m)
N = n==:∞ || n==:inf ? "AtMostInf" : "AtMost" * string(n)
# Meta.parse("Type{<:Tuple{$M,$N,$(x)}}")
Meta.parse("Tuple{$M,$N,$(x)}")
end
macro just(m)
M = m==:∞ || m==:inf ? "AtLeastInf" : "AtLeast" * string(m)
N = m==:∞ || m==:inf ? "AtMostInf" : "AtMost" * string(m)
# Meta.parse("Type{<:Tuple{$M,$N,X} where X}")
Meta.parse("Tuple{$M,$N,X} where X")
end
macro just(m,x)
M = m==:∞ || m==:inf ? "AtLeastInf" : "AtLeast" * string(m)
N = m==:∞ || m==:inf ? "AtMostInf" : "AtMost" * string(m)
# Meta.parse("Type{<:Tuple{$M,$N,$(x)}}")
Meta.parse("Tuple{$M,$N,$(x)}")
end
macro unrestricted()
@atleast 0
end | PlatformAware | https://github.com/PlatformAwareProgramming/PlatformAware.jl.git |
|
[
"MIT"
] | 0.6.0 | d8f50cbc077c0992b472a07f99013cd5be80b11a | code | 4051 | @testset "Basics" begin
@platform feature clear
#= for the first 5 kernels =#
@platform feature accelerator_count
@platform feature accelerator_manufacturer
@platform feature accelerator_api
@platform feature node_count
@platform feature processor
@platform feature accelerator_architecture
#= for all kernels =#
@platform feature node_memory_size
@platform feature processor_count
@platform feature processor_core_count
@platform feature interconnection_bandwidth
@platform feature interconnection_latency
@platform feature accelerator_type
@platform feature accelerator_memory_size
@platform feature processor_simd
# define a kernel
@platform default function kernel(x,y,args...; z=0, kwargs...)
println(z,": default implementation of kernel_example:")
end
# specify platform-aware implementations
@platform aware function kernel({accelerator_count::(@atleast 1)}, y, args...; z=1, kwargs...)
println(z,": kernel for 1 accelerators of unspecified kind")
end
@platform aware function kernel({accelerator_count::Tuple{AtLeast1,AtMostInf,C} #=(@atleast(1,C))=#,
accelerator_manufacturer::NVIDIA,
accelerator_api::(@api CUDA 6.0)},y,args...; z=2, kwargs...) where C
println(z,": kernel 1 for $C NVIDIA accelerators")
end
@platform aware function kernel({accelerator_count::Tuple{AtLeast1,AtMostInf,C}#=(@atleast(1,C))=#,
accelerator_manufacturer::NVIDIA,
accelerator_api::(@api CUDA 5.0)},y,args...; z=2, kwargs...) where C
println(z,": kernel 2 for $C NVIDIA accelerators")
end
@platform assumption some_cluster = {node_count::(@atleast 32), processor::IntelCore_i7_7500U}
@platform aware function kernel($some_cluster, x,y,args...; z=3, kwargs...)
println(z,": kernel optimized to the features of clusters with at least 32 nodes with Intel(R) Core(TM) i7-7500U processors")
end
@platform aware function kernel({accelerator_count::(@just 4),
accelerator_manufacturer::NVIDIA,
accelerator_architecture::Turing},
x,y,args...; z=4, kwargs...)
println(z,": kernel for exactly 4 accelerators of NVIDIA's Turing architecture")
end
@platform aware function kernel({node_count::(@between 8 16),
node_memory_size::(@atleast 16G),
processor_count::(@atleast 2),
processor_core_count::(@atleast 8),
interconnection_latency::(@atmost 32u),
interconnection_bandwidth::(@atleast 128G)
},
x,y,args...; z=5, kwargs...)
println(z,": kernel tuned for a cluster of 8 to 16 nodes having at least 2 processors with at least 8 cores each,")
println(z,": connected through an intereconnection having at most 32us latency and at least 128Gbs bandwidth.")
end
@platform aware function kernel({accelerator_count::(@atleast 1),
accelerator_type::FPGA,
accelerator_memory_size::(@atleast 16G),
processor_simd::AVX512,
node_memory_size::(@atleast 256G)
},
x,y,args...; z=6, kwargs...)
println(z,": kernel for a platform equipped with a FPGA accelerator with at least 16GB of memory,")
println(z,": a processor with AVX512 SIMD support, and 256GB of primary memory.")
end
kernel(@quantifier(7),1,2,3;z=10,kwargs=0)
kernel(@quantifier(18),1,2,3;z=10,kwargs=0)
end | PlatformAware | https://github.com/PlatformAwareProgramming/PlatformAware.jl.git |
|
[
"MIT"
] | 0.6.0 | d8f50cbc077c0992b472a07f99013cd5be80b11a | code | 223 | using PlatformAware
using Test
# list of tests
testfiles = [
"basics.jl"
]
@testset "PlatformAware.jl" begin
for testfile in testfiles
println("Testing $testfile...")
include(testfile)
end
end
| PlatformAware | https://github.com/PlatformAwareProgramming/PlatformAware.jl.git |
|
[
"MIT"
] | 0.6.0 | d8f50cbc077c0992b472a07f99013cd5be80b11a | docs | 16069 | # PlatformAware.jl
[](https://github.com/decarvalhojunior-fh/PlatformAware.jl/actions/workflows/TagBot.yml)
[](https://github.com/PlatformAwareProgramming/PlatformAware.jl/actions/workflows/CompatHelper.yml)
_A package for improving the practice of **platform-aware programming** in Julia_.
It helps HPC package developers write code for different versions of computationally intensive functions (kernels) according to different assumptions about the features of the execution platform.
# What is platform-aware programming ?
We define platform-aware programming as the practice of coding computationally intensive functions, called _kernels_, using the most appropriate abstractions and programming interfaces, as well as performance tuning techniques, to take better advantage of the features of the target execution platform. This is a well-known practice in programming for HPC applications.
Platform-aware programming is especially suitable when the developer is interested in employing heterogeneous computing resources, such as accelerators (e.g., GPUs, FPGAs, and MICs), especially in conjunction with multicore and cluster computing.
For example, suppose a package developer is interested in providing a specialized kernel implementation for [NVIDIA A100 Tensor Core GPUs](https://www.nvidia.com/en-us/data-center/a100), meeting the demand from users of a specific cloud provider offering virtual machines with accelerators of this model. The developer would like to use CUDA programming with this device's supported *computing capability* (8.0). However, other users may require support from other cloud providers that support different accelerator models, from different vendors (for example, [AMD Instinct™ MI210](https://www.amd.com/en/products/server-accelerators/amd-instinct-mi210) and [Intel® Agilex™ F-Series FPGA and SoC FPGA]( https://www.intel.com/content/www/us/en/products/details/fpga/agilex/f-series.html)). In this scenario, the developer will face the challenge of coding and deploying for multiple devices. This is a typical platform-aware programming scenario where _PlatformAware.jl_ should be useful, which is becoming increasingly common as the use of heterogeneous computing platforms increases to accelerate AI and data analytics applications.
## Target users
_PlatformAware.jl_ is aimed primarily at **_package developers_** dealing with HPC concerns, especially using heterogenous computing resources.
We assume that **_package users_** are only interested in using package operations without being concerned about how they are implemented.
# Usage tutorial
We present a simple example that readers may reproduce to test _PlatformAware.jl_ features.
Consider the problem of performing a convolution operation using a Fast Fourier Transform (FFT). To do this, the user can implement a ```fftconv``` function that uses a ```fft``` function offered by a user-defined package called _MyFFT.jl_, capable of performing the FFT on an accelerator (e.g., GPU) if it is present.
```julia
using MyFFT
fftconv(X,K) = fft(X) .* conj.(fft(K))
```
This tutorial shows how to create _MyFFT.jl_, demonstrating the basics of how to install _PlatformAware.jl_ and how to use it to create a platform-aware package.
## Creating the _MyFFT.jl_ project
In the Julia REPL, as shown in the screenshot below, run ```] generate MyFFT.jl``` to create a new project called _MyFFT.jl_, run ```🔙cd("MyFFT.jl")``` to move to the directory of the created project, and ```] activate .``` to enable the current project (_MyFFT.jl_) in the current Julia REPL session.
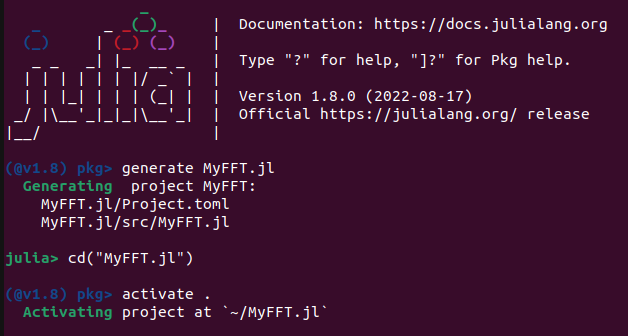
These operations create a standard _"hello world"_ project, with the contents of the following snapshot:
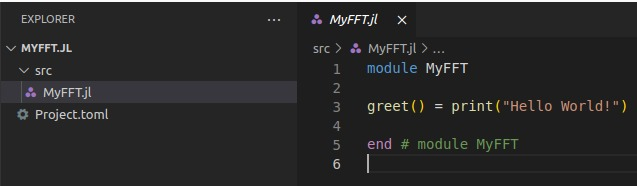
## Installing _PlatformAware.jl_
Before coding the platform-aware package, it is necessary to add _PlatormAware.jl_ as a dependency of _MyFFT.jl_ by running the following command in the Julia REPL:
```julia
] add PlatformAware
```
Now, load the _PlatfomAware.jl_ package (```using PlatformAware``` or ```import PlatformAware```) and read the output message:

_Platform.toml_ is the _platform description file_, containing a set of key-value pairs, each describing a feature of the underlying platform. It must be created by the user running ```PlatformWare.setup()```, which performs a sequence of feature detection operations on the platform.
_Platform.toml_ is written in a human-editable format. Therefore, it can be modified by users to add undetected platform features or ignore detected features.
## Sketching the _MyFFT.jl_ code
In order to implement the _fft_ kernel function, we edit the _src/MyFFT.jl_ file. First, we sketch the code of the _fft_ kernel methods:
```julia
module MyFFT
import PlatformAware
# setup platorm features (parameters)
@platform feature clear
@platform feature accelerator_count
@platform feature accelerator_api
# Fallback kernel
@platform default fft(X) = ...
# OpenCL kernel, to be called
@platform aware fft({accelerator_count::(@atleast 1), accelerator_api::(@api OpenCL)}, X) = ...
# CUDA kernel
@platform aware fft({accelerator_count::(@atleast 1), accelerator_api::(@api CUDA)},X) = ...
export fft
end
```
The sequence of ```@platorm feature``` macro declarations specifies the set of platform parameters that will be used by subsequent kernel method declarations, that is, the assumptions that will be made to distinguish them. You can refer to [this table](https://docs.google.com/spreadsheets/d/1n-c4b7RxUduaKV43XrTnt54w-SR1AXgVNI7dN2OkEUc/edit?usp=sharing) for a list of all supported _**platform parameters**_. By default, they are all included. In the case of ```fft```, the kernel methods are differentiated using only two parameters: ```accelerator_count``` and ```accelerator_api```. They denote, respectively, assumptions about the number of accelerator devices and the native API they support.
The ```@platorm default``` macro declares the _default kernel method_, which will be called if none of the assumptions of other kernel methods declared using ```@platform aware``` macro calls are valid. The default kernel must be unique to avoid ambiguity.
Finally, the kernels for accelerators that support OpenCL and CUDA APIs are declared using the macro ```@platform aware```. The list of platform parameters is declared just before the regular parameters, such as ```X```, in braces. Their types denote assumptions. For example, ```@atleast 1``` denotes a quantifier representing one or more units of a resource, while``` @api CUDA``` and ```@api OpenCL``` denote types of qualifiers that refer to the CUDA and OpenCL APIs.
The programmer must be careful not to declare kernel methods with overlapping assumptions in order to avoid ambiguities.
## Other dependencies
Before adding the code for the kernels, add the code to load their dependencies. This can be done directly by adding the following code to the _src/MyFFT.jl_ file, right after ```import PlatformAware```:
```julia
import CUDA
import OpenCL
import CLFFT
import FFTW
```
Also, you should add _CUDA.jl_, _OpenCL.jl_, _CLFFT.jl_, and _FFFT.jl_ as dependencies of _MyFFT.jl_. To do this, execute the following commands in the Julia REPL:
```julia
] add CUDA OpenCL CLFFT FFTW
```
> **NOTE**: [_CLFFT.jl_](https://github.com/JuliaGPU/CLFFT.jl) is not available on JuliaHub due to compatibility issues with recent versions of Julia. We're working with the CLFFT.jl maintainers to address this issue. If you have an error with the CLFFT dependency, point to our _CLFFT.jl_ fork by running ```add https://github.com/JuliaGPU/CLFFT.jl#master```.
As a performance optimization, we can take advantage of platform-aware features to selectively load dependencies, speeding up the loading of _MyFFT.jl_. To do this, we first declare a kernel function called ```which_api``` in _src/MyFFT.jl_, right after the ```@platform feature``` declaration:
```julia
@platform default which_api() = :fftw
@platform aware which_api({accelerator_api::(@api CUDA)}) = :cufft
@platform aware which_api({accelerator_api::(@api OpenCL)}) = :clfft
```
Next, we add the code for selective dependency loading:
```julia
api = which_api()
if (api == :cufft)
import CUDA
elseif (api == :clfft)
import OpenCL
import CLFFT
else # api == :fftw
import FFTW
end
```
## Full _src/MyFFT.jl_ code
Finally, we present the complete code for _src/MyFFT.jl_, with the implementation of the kernel methods:
```julia
module MyFFT
using PlatformAware
@platform feature clear
@platform feature accelerator_count
@platform feature accelerator_api
@platform default which_api() = :fftw
@platform aware which_api({accelerator_count::(@atleast 1), accelerator_api::(@api CUDA)}) = :cufft
@platform aware which_api({accelerator_count::(@atleast 1), accelerator_api::(@api OpenCL)}) = :clfft
api = which_api()
@info "seleted FFT API" api
if (api == :cufft)
using CUDA; const cufft = CUDA.CUFFT
elseif (api == :clfft)
using OpenCL
using CLFFT; const clfft = CLFFT
else # api == :fftw
using FFTW; const fftw = FFTW
end
# Fallback kernel
@platform default fft(X) = fftw.fft(X)
# OpenCL kernel
@platform aware function fft({accelerator_count::(@atleast 1), accelerator_api::(@api OpenCL)}, X)
T = eltype(X)
_, ctx, queue = cl.create_compute_context()
bufX = cl.Buffer(T, ctx, :copy, hostbuf=X)
p = clfft.Plan(T, ctx, size(X))
clfft.set_layout!(p, :interleaved, :interleaved)
clfft.set_result!(p, :inplace)
clfft.bake!(p, queue)
clfft.enqueue_transform(p, :forward, [queue], bufX, nothing)
reshape(cl.read(queue, bufX), size(X))
end
# CUDA kernel
@platform aware fft({accelerator_count::(@atleast 1), accelerator_api::(@api CUDA)},X) = cufft.fft(X |> CuArray)
export fft
end # module MyFFT
```
## Running and testing the _fft_ kernel methods
To test _fft_ in a convolution, open a Julia REPL session in the _MyFFT.jl_ directory and execute the following commands:
> **NOTE**: If you receive an ambiguity error after executing _fftconv_, don't panic ! Read the next paragraphs.
```julia
import Pkg; Pkg.activate(".")
using MyFFT
function fftconv(img,krn)
padkrn = zeros(size(img))
copyto!(padkrn,CartesianIndices(krn),krn,CartesianIndices(krn))
fft(img) .* conj.(fft(padkrn))
end
img = rand(Float64,(20,20,20)) # image
krn = rand(Float64,(4,4,4)) # kernel
fftconv(img,krn)
```
The _fft_ kernel method that corresponds to the current _Platform.toml_ will be selected. If _Platform.toml_ was not created before, the default kernel method will be selected. The reader can consult the _Platform.toml_ file to find out about the platform features detected by _PlatformAware.setup()_. The reader can also see the selected FFT API in the logging messages after ```using MyFFT```.
By carefully modifying the _Platform.toml_ file, the reader can test all kernel methods. For example, if an NVIDIA GPU was recognized by _PlatformAware.setup()_, the ```accelerator_api``` entry in _Platform.toml_ will probably include the supported CUDA and OpenCL versions. For example, for an NVIDIA GeForce 940MX GPU, ```accelerator_api = "CUDA_5_0;OpenCL_3_0;unset;unset;OpenGL_4_6;Vulkan_1_3;DirectX_11_0"```. This may lead to an ambiguity error, as multiple dispatch will not be able to distinguish between the OpenCL and CUDA kernel methods based on the ```accelerator_api``` parameter alone. In this case, there are two alternatives:
* To edit _Platform.toml_ by setting CUDA or OpenCL platform type (e.g. ```CUDA_5_0``` or ```OpenCL_3_0```) to ```unset``` in the ```accelerator_api``` entry, making it possible to select manually the kernel method that will be selected;
* To modify the CUDA kernel signature by including, for example, ```accelerator_manufacturer::NVIDIA``` in the list of platform parameters, so that NVIDIA GPUs will give preference to CUDA and OpenCL will be applied to accelerators of other vendors (recommended).
## A general guideline
Therefore, we suggest the following general guideline for package developers who want to take advantage of _PlatformWare.jl_.
1. Identify the _kernel functions_, that is, the functions with high computational requirements in your package, which are the natural candidates to exploit parallel computing, acceleration resources, or both.
2. Provide a default (fallback) method for each kernel function, using the ```@platform default``` macro.
3. Identify the target execution platforms to which you want to provide specialized methods for each kernel function. You can choose a set of execution platforms for all kernels, or you can select one or more platforms for each kernel independently. For helping your choice, look at the following information sources:
- the [table of supported _platform **parameters**_](https://docs.google.com/spreadsheets/d/1n-c4b7RxUduaKV43XrTnt54w-SR1AXgVNI7dN2OkEUc/edit?usp=sharing), which will help you to know which assumptions _PlatformAware.jl_ already allow you to make about the target execution platorm;
- the database of supported _platform **features**_, where the features of the models of processors and accelerators that are currently suported by _PlatformAware.jl_ are described:
- AMD [accelerators](https://github.com/PlatformAwareProgramming/PlatformAware.jl/blob/master/src/features/qualifiers/amd/db-accelerators.AMD.csv) and [processors](https://github.com/PlatformAwareProgramming/PlatformAware.jl/blob/master/src/features/qualifiers/amd/db-processors.AMD.csv);
- Intel [accelerators](https://github.com/PlatformAwareProgramming/PlatformAware.jl/blob/master/src/features/qualifiers/intel/db-accelerators.Intel.csv) and [processors](https://github.com/PlatformAwareProgramming/PlatformAware.jl/blob/master/src/features/qualifiers/intel/db-processors.Intel.csv);
- NVIDIA [accelerators](https://github.com/PlatformAwareProgramming/PlatformAware.jl/blob/master/src/features/qualifiers/nvidia/db-accelerators.NVIDIA.csv).
4. For each platform you select, define a set of assumptions about its features that will guide your implementation decisions. In fact, it is possible to define different assumptions for the same platform, leading to multiple implementations of a kernel for the same platform. For example, you might decide to implement different parallel algorithms to solve a problem according to the number of nodes and the interconnection characteristics of a cluster.
5. Provide platform-aware methods for each kernel function using the ```@platform aware``` macro.
6. After implementing and testing all platform-aware methods, you have a list of platform parameters that were used to make assumptions about the target execution platform(s). You can optionally instruct the _PlatformAware.jl_ to use only that parameters by using the ``@platform feature`` macro.
# Contributing
Contributions are very welcome, as are feature requests and suggestions.
Please [open an issue](https://github.com/PlatformAwareProgramming/PlatformAware.jl) if you encounter any problems.
# License
_PlatformAware.jl_ is licensed under the [MIT License](https://github.com/PlatformAwareProgramming/PlatformAware.jl/blob/master/LICENSE)
[build-img]: https://img.shields.io/github/workflow/status/JuliaEarth/ImageQuilting.jl/CI
[build-url]: https://github.com/PlatformAwareProgramming/PlatformAware.jl/actions
| PlatformAware | https://github.com/PlatformAwareProgramming/PlatformAware.jl.git |
|
[
"MIT"
] | 0.2.7 | e58d5904fa7ffa914a3eb60f8705e2ea3aaea1b9 | code | 538 | using Documenter
push!(LOAD_PATH, "../src/")
using LazyAlgebra
DEPLOYDOCS = (get(ENV, "CI", nothing) == "true")
makedocs(
sitename = "LazyAlgebra for Julia",
format = Documenter.HTML(
prettyurls = DEPLOYDOCS,
),
authors = "Éric Thiébaut and contributors",
pages = ["index.md", "install.md", "introduction.md",
"vectors.md", "sparse.md", "mappings.md",
"simplifications.md", "refs.md"]
)
if DEPLOYDOCS
deploydocs(
repo = "github.com/emmt/LazyAlgebra.jl.git",
)
end
| LazyAlgebra | https://github.com/emmt/LazyAlgebra.jl.git |
|
[
"MIT"
] | 0.2.7 | e58d5904fa7ffa914a3eb60f8705e2ea3aaea1b9 | code | 2802 | #
# LazyAlgebra.jl -
#
# A simple linear algebra system.
#
#-------------------------------------------------------------------------------
#
# This file is part of LazyAlgebra (https://github.com/emmt/LazyAlgebra.jl)
# released under the MIT "Expat" license.
#
# Copyright (c) 2017-2021 Éric Thiébaut.
#
module LazyAlgebra
export
CirculantConvolution,
CompressedSparseOperator,
CroppingOperator,
Diag,
Diff,
FFTOperator,
GeneralMatrix,
Gram,
Id,
Identity,
Jacobian,
LinearMapping,
Mapping,
NonuniformScaling,
RankOneOperator,
SingularSystem,
SparseOperator,
SparseOperatorCOO,
SparseOperatorCSC,
SparseOperatorCSR,
SymbolicLinearMapping,
SymbolicMapping,
SymmetricRankOneOperator,
ZeroPaddingOperator,
∇,
adjoint,
apply!,
apply,
coefficients,
col_size,
conjgrad!,
conjgrad,
diag,
gram,
input_eltype,
input_ndims,
input_size,
input_type,
is_diagonal,
is_endomorphism,
is_linear,
is_selfadjoint,
isone,
iszero,
jacobian,
lgemm!,
lgemm,
lgemv!,
lgemv,
multiplier,
ncols,
nnz,
nonzeros,
nrows,
output_eltype,
output_ndims,
output_size,
output_type,
row_size,
sparse,
terms,
unpack!,
unscaled,
unveil,
vcombine!,
vcombine,
vcopy!,
vcopy,
vcreate,
vdot,
vfill!,
vmul!,
vmul,
vnorm1,
vnorm2,
vnorminf,
vones,
vproduct!,
vproduct,
vscale!,
vscale,
vswap!,
vupdate!,
vzero!,
vzeros
using Printf
using ArrayTools
import Base: *, ∘, +, -, \, /, ==
import Base: Tuple, adjoint, inv, axes,
show, showerror, convert, eltype, ndims, size, length, stride, strides,
getindex, setindex!, eachindex, first, last, firstindex, lastindex,
one, zero, isone, iszero, @propagate_inbounds
# Import/using from LinearAlgebra, BLAS and SparseArrays.
using LinearAlgebra
import LinearAlgebra: UniformScaling, diag, ⋅, mul!, rmul!
using LinearAlgebra.BLAS
using LinearAlgebra.BLAS: libblas, @blasfunc,
BlasInt, BlasReal, BlasFloat, BlasComplex
using SparseArrays: sparse
include("types.jl")
include("traits.jl")
include("utils.jl")
include("methods.jl")
include("vectors.jl")
include("genmult.jl")
import .GenMult: lgemm!, lgemm, lgemv!, lgemv
include("blas.jl")
include("rules.jl")
include("mappings.jl")
include("foundations.jl")
include("sparse.jl")
using .SparseOperators
import .SparseOperators: unpack!
include("cropping.jl")
import .Cropping: CroppingOperator, ZeroPaddingOperator, defaultoffset
include("diff.jl")
import .FiniteDifferences: Diff
include("fft.jl")
import .FFTs: CirculantConvolution, FFTOperator
include("conjgrad.jl")
include("init.jl")
end
| LazyAlgebra | https://github.com/emmt/LazyAlgebra.jl.git |
|
[
"MIT"
] | 0.2.7 | e58d5904fa7ffa914a3eb60f8705e2ea3aaea1b9 | code | 2453 | #
# blas.jl -
#
# Code based on BLAS (Basic Linear Algebra Subroutines).
#
#-------------------------------------------------------------------------------
#
# This file is part of LazyAlgebra (https://github.com/emmt/LazyAlgebra.jl)
# released under the MIT "Expat" license.
#
# Copyright (c) 2017-2019 Éric Thiébaut.
#
# The idea is to generalize the dot product as follows:
#
# `vdot(x,y)` yields the sum of `conj(x[i])*y[i]` for each `i` in
# `eachindex(x,y)` providing `x` and `y` have the same dimensions
# (i.e., same `indices`).
#
# `A*x` yields the matrix-vector product providing that the trailing
# dimensions of `A` match the dimensions of `x`. The result has
# the same dimensions as the leading dimensions of `A`.
#
# We may want to use fast BLAS routines.
#
# According to the following timings (for n = 96 and 4 threads), the fastest
# method is the BLAS version of `apply!(,Adjoint,,)`. When looking at the
# loops, this is understandable as `apply!(,Adjoint,,)` is easier to
# parallelize than `apply!(,Direct,,)`. Note that Julia implementations are
# with SIMD and no bounds checking.
#
# A⋅x A'.x x'⋅y
# ---------------------------------
# BLAS 3.4 µs 2.0 µs 65 ns
# Julia 4.5 µs 24.2 μs 65 ns
const BlasVec{T} = Union{DenseVector{T},StridedVector{T}}
const BlasArr{T,N} = DenseArray{T,N}
for T in (Float32, Float64)
@eval begin
vdot(::Type{$T}, x::BlasVec{$T}, y::BlasVec{$T}) =
__call_blas_dot(BLAS.dot, x, y)
vdot(::Type{$T}, x::BlasArr{$T,N}, y::BlasArr{$T,N}) where {N} =
__call_blas_dot(BLAS.dot, x, y)
vdot(::Type{Complex{$T}}, x::BlasVec{Complex{$T}}, y::BlasVec{Complex{$T}}) =
__call_blas_dot(BLAS.dotc, x, y)
vdot(::Type{Complex{$T}}, x::BlasArr{Complex{$T},N}, y::BlasArr{Complex{$T},N}) where {N} =
__call_blas_dot(BLAS.dotc, x, y)
end
end
@inline function __call_blas_dot(f, x, y)
size(x) == size(y) || throw_dimensions_mismatch()
return f(length(x), pointer(x), stride(x, 1), pointer(y), stride(y, 1))
end
function vupdate!(y::BlasVec{T}, alpha::Real,
x::BlasVec{T}) where {T<:BlasFloat}
size(x) == size(y) || throw_dimensions_mismatch()
BLAS.axpy!(length(x), T(alpha),
pointer(x), stride(x, 1),
pointer(y), stride(y, 1))
return y
end
| LazyAlgebra | https://github.com/emmt/LazyAlgebra.jl.git |
|
[
"MIT"
] | 0.2.7 | e58d5904fa7ffa914a3eb60f8705e2ea3aaea1b9 | code | 9428 | #
# conjgrad.jl -
#
# Linear conjugate-gradient.
#
#-------------------------------------------------------------------------------
#
# This file is part of LazyAlgebra (https://github.com/emmt/LazyAlgebra.jl)
# released under the MIT "Expat" license.
#
# Copyright (c) 2017-2020 Éric Thiébaut.
#
struct WrappedLeftHandSideMatrix{T}
op::T
end
(obj::WrappedLeftHandSideMatrix)(dst, src) = apply!(dst, obj.op, src)
"""
```julia
conjgrad(A, b, x0=vzeros(b)) -> x
```
solves the symmetric linear system `A⋅x = b` starting at `x0` by means of the
iterative conjugate gradient method. The returned solution `x` is a new object
similar to `b` and to `x0`.
Argument `A` implements the symmetric positive definite linear mapping `A`, it
can be provided as a Julia array (interpreted as a general matrix, see
[`GeneralMatrix`](@ref)), as an instance of [`LinearMapping`](@ref) or as a
callable object (like a function) which is used as:
```julia
A(dst, src)
```
to overwrite `dst` with `A⋅src`. If `A` has been implemented as a callable
object, such that `A(x)` yields `A⋅x`, then call `conjgrad` with an
inline function:
```julia
conjgrad((dst,src) -> (dst .= A(src); return dst), b, ...)
```
See [`conjgrad!`](@ref) for accepted keywords and more details.
"""
conjgrad(A, b, x0; kwds...) =
conjgrad!(vcreate(b), A, b, x0; kwds...)
function conjgrad(A, b; kwds...)
x = vzeros(b)
return conjgrad!(x, A, b, x; kwds...)
end
"""
# Linear conjugate gradient
```julia
conjgrad!(x, A, b, [x0=vfill!(x,0), p, q, r]) -> x
```
finds an approximate solution to the symmetric linear system `A⋅x = b` starting
at `x0` by means of the iterative conjugate gradient method. The result is
stored in `x` which is returned.
Argument `A` implements the symmetric positive definite linear mapping `A`, it
can be provided as a Julia array (interpreted as a general matrix, see
[`GeneralMatrix`](@ref)), as an instance of [`LinearMapping`](@ref) or as a
callable object (like a function) which is used as:
```julia
A(dst, src)
```
to overwrite `dst` with `A⋅src`. If `A` has been implemented as a callable
object, such that `A(x)` yields `A⋅x`, then call `conjgrad!` with an inline
function:
```julia
conjgrad!(x, (dst,src) -> (dst .= A(src); return dst), b, ...)
```
If no initial variables are specified, the default is to start with all
variables set to zero.
Optional arguments `p`, `q` and `r` are writable workspace *vectors*. On
return, `p` is the last search direction, `q = A⋅p` and `r = b - A⋅xp` with
`xp` the previous or last solution. If provided, these workspaces must be
distinct. All *vectors* must have the same sizes. If all workspace vectors
are provided, no other memory allocation is necessary (unless `A` needs
to allocate some temporaries).
Provided `A` be positive definite, the solution `x` of the equations `A⋅x = b`
is also the minimum of the quadratic function:
f(x) = (1/2) x'⋅A⋅x - b'⋅x + ϵ
where `ϵ` is an arbitrary constant. The variations of `f(x)` between
successive iterations, the norm of the gradient of `f(x)` or the variations of
`x` may be used to decide the convergence of the algorithm (see keywords
`ftol`, `gtol` and `xtol` below).
## Saving memory
To save memory, `x` and `x0` can be the same object. Otherwise, if no
restarting occurs (see keyword `restart` below), `b` can also be the same as
`r` but this is not recommended.
## Keywords
There are several keywords to control the algorithm:
* Keyword `ftol` specifies the function tolerance for convergence. The
convergence is assumed as soon as the variation of the objective function
`f(x)` between two successive iterations is less or equal `ftol` times the
largest variation so far. By default, `ftol = 1e-8`.
* Keyword `gtol` specifies the gradient tolerances for convergence, it is a
tuple of two values `(gatol, grtol)` which are the absolute and relative
tolerances. Convergence occurs when the Euclidean norm of the residuals
(which is that of the gradient of the associated objective function) is less
or equal the largest of `gatol` and `grtol` times the Euclidean norm of the
initial residuals. By default, `gtol = (0.0, 0.0)`.
* Keyword `xtol` specifies the variables tolerance for convergence. The
convergence is assumed as soon as the Euclidean norm of the change of
variables is less or equal `xtol` times the Euclidean norm of the variables
`x`. By default, `xtol = 0`.
* Keyword `maxiter` specifies the maximum number of iterations which is
practically unlimited by default.
* Keyword `restart` may be set with the maximum number of iterations before
restarting the algorithm. By default, `restart` is set with the smallest of
`50` and the number of variables. Set `restart` to at least `maxiter` if you
do not want that any restarts ever occur.
* Keyword `strict` can be set to a boolean value (default is `true`) to specify
whether non-positive definite operator `A` throws a `NonPositiveDefinite`
exception or just returns the best solution found so far (with a warning if
`quiet` is false).
* Keyword `quiet` can be set to a boolean value (default is `false`) to specify
whether or not to print warning messages.
See also: [`conjgrad`][@ref).
"""
conjgrad!(x, A::Union{LinearMapping,AbstractArray}, b, args...; kwds...) =
conjgrad!(x, WrappedLeftHandSideMatrix(A), b, args...; kwds...)
function conjgrad!(x, A::Mapping, b, args...; kwds...)
is_linear(A) || bad_argument("`A` must be a linear map")
conjgrad!(x, WrappedLeftHandSideMatrix(A), b, args...; kwds...)
end
function conjgrad!(x, A, b, x0 = vfill!(x, 0),
p = vcreate(x), q = vcreate(x), r = vcreate(x);
ftol::Real = 1e-8,
gtol::NTuple{2,Real} = (0.0,0.0),
xtol::Real = 0.0,
maxiter::Integer = typemax(Int),
restart::Integer = min(50, length(b)),
verb::Bool = false,
io::IO = stdout,
quiet::Bool = false,
strict::Bool = true)
# Initialization.
0 ≤ ftol < 1 ||
bad_argument("bad function tolerance (ftol = ", ftol, ")")
gtol[1] ≥ 0 ||
bad_argument("bad gradient absolute tolerance (gtol[1] = ",
gtol[1], ")")
0 ≤ gtol[2] < 1 ||
bad_argument("bad gradient relative tolerance (gtol[2] = ",
gtol[2], ")")
0 ≤ xtol < 1 ||
bad_argument("bad variables tolerance (xtol = ", xtol, ")")
restart ≥ 1 ||
bad_argument("bad number of iterations for restarting (restart = ",
restart,")")
vcopy!(x, x0)
if maxiter < 1 && quiet && !verb
return x
end
if vnorm2(x) > 0 # cheap trick to check whether x is non-zero
# Compute r = b - A⋅x.
A(r, x)
vcombine!(r, 1, b, -1, r)
else
# Save applying A since x = 0.
vcopy!(r, b)
end
local rho :: Float64 = vdot(r, r)
local ftest :: Float64 = ftol
local gtest :: Float64 = max(gtol[1], gtol[2]*sqrt(rho))
local xtest :: Float64 = xtol
local psimax :: Float64 = 0
local psi :: Float64 = 0
local oldrho :: Float64
local gamma :: Float64
# Conjugate gradient iterations.
k = 0
while true
if verb
if k == 0
@printf(io, "# %s\n# %s\n",
"Iter. Δf(x) ||∇f(x)||",
"-------------------------------")
end
@printf(io, "%6d %12.4e %12.4e\n", k, psi, sqrt(rho))
end
k += 1
if sqrt(rho) ≤ gtest
# Normal convergence.
if verb
@printf(io, "# %s\n", "Convergence (gtest statisfied).")
end
break
elseif k > maxiter
verb && @printf(io, "# %s\n", "Too many iteration(s).")
quiet || warn("too many (", k, " conjugate gradient iteration(s)")
break
end
if rem(k, restart) == 1
# Restart or first iteration.
if k > 1
# Restart.
A(r, x)
vcombine!(r, 1, b, -1, r)
end
vcopy!(p, r)
else
beta = rho/oldrho
vcombine!(p, beta, p, +1, r)
end
# Compute optimal step size.
A(q, p)
gamma = vdot(p, q)
if gamma ≤ 0
verb && @printf(io, "# %s\n", "Operator is not positive definite.")
strict && throw(NonPositiveDefinite("in conjugate gradient"))
quiet || warn("operator is not positive definite")
break
end
alpha = rho/gamma
# Update variables and check for convergence.
vupdate!(x, +alpha, p)
psi = alpha*rho/2 # psi = f(x_{k}) - f(x_{k+1})
psimax = max(psi, psimax)
if psi ≤ ftest*psimax
# Normal convergence.
verb && @printf(io, "# %s\n", "Convergence (ftest statisfied).")
break
end
if xtest > 0 && alpha*vnorm2(p) ≤ xtest*vnorm2(x)
# Normal convergence.
verb && @printf(io, "# %s\n", "Convergence (xtest statisfied).")
break
end
# Update residuals and related quantities.
vupdate!(r, -alpha, q)
oldrho = rho
rho = vdot(r, r)
end
return x
end
| LazyAlgebra | https://github.com/emmt/LazyAlgebra.jl.git |
|
[
"MIT"
] | 0.2.7 | e58d5904fa7ffa914a3eb60f8705e2ea3aaea1b9 | code | 9385 | #
# cropping.jl -
#
# Provide zero-padding and cropping operators.
#
#-------------------------------------------------------------------------------
#
# This file is part of LazyAlgebra (https://github.com/emmt/LazyAlgebra.jl)
# released under the MIT "Expat" license.
#
# Copyright (c) 2019-2021, Éric Thiébaut.
#
module Cropping
# FIXME: add simplifying rules:
# Z'*Z = Id (not Z*Z' = Id) crop zero-padded array is identity
export
CroppingOperator,
ZeroPaddingOperator,
defaultoffset
using ArrayTools
using ..Foundations
using ..LazyAlgebra
using ..LazyAlgebra: bad_argument, bad_size
import ..LazyAlgebra: apply!, vcreate,
input_size, input_ndims, output_size, output_ndims
"""
CroppingOperator(outdims, inpdims, offset=defaultoffset(outdims,inpdims))
yields a linear map which implements cropping of arrays of size `inpdims` to
produce arrays of size `outdims`. By default, the output array is centered
with respect to the inpput array (using the same conventions as `fftshift`).
Optional argument `offset` can be used to specify a different relative
position. If `offset` is given, the output value at multi-dimensional index
`i` is given by input value at index `j = i + offset`.
The adjoint of a cropping operator is a zero-padding operator.
See also: [`ZeroPaddingOperator`](@ref).
"""
struct CroppingOperator{N} <: LinearMapping
outdims::NTuple{N,Int} # cropped dimensions
inpdims::NTuple{N,Int} # input dimensions
offset::CartesianIndex{N} # offset of cropped region w.r.t. input array
function CroppingOperator{N}(outdims::NTuple{N,Int},
inpdims::NTuple{N,Int}) where {N}
@inbounds for d in 1:N
1 ≤ outdims[d] || error("invalid output dimension(s)")
outdims[d] ≤ inpdims[d] ||
error(1 ≤ inpdims[d]
? "invalid input dimension(s)"
: "output dimensions must be less or equal input ones")
end
offset = defaultoffset(inpdims, outdims)
return new{N}(outdims, inpdims, offset)
end
function CroppingOperator{N}(outdims::NTuple{N,Int},
inpdims::NTuple{N,Int},
offset::CartesianIndex{N}) where {N}
@inbounds for d in 1:N
1 ≤ outdims[d] || error("invalid output dimension(s)")
outdims[d] ≤ inpdims[d] ||
error(1 ≤ inpdims[d]
? "invalid input dimension(s)"
: "output dimensions must less or equal input ones")
0 ≤ offset[d] ≤ inpdims[d] - outdims[d] ||
error("out of range offset(s)")
end
return new{N}(outdims, inpdims, offset)
end
end
@callable CroppingOperator
commonpart(C::CroppingOperator) = CartesianIndices(output_size(C))
offset(C::CroppingOperator) = C.offset
input_ndims(C::CroppingOperator{N}) where {N} = N
input_size(C::CroppingOperator) = C.inpdims
input_size(C::CroppingOperator, i...) = input_size(C)[i...]
output_ndims(C::CroppingOperator{N}) where {N} = N
output_size(C::CroppingOperator) = C.outdims
output_size(C::CroppingOperator, i...) = output_size(C)[i...]
# Union of acceptable types for the offset.
const Offset = Union{CartesianIndex,Integer,Tuple{Vararg{Integer}}}
CroppingOperator(outdims::ArraySize, inpdims::ArraySize) =
CroppingOperator(to_size(outdims), to_size(inpdims))
CroppingOperator(outdims::ArraySize, inpdims::ArraySize, offset::Offset) =
CroppingOperator(to_size(outdims), to_size(inpdims),
CartesianIndex(offset))
CroppingOperator(::Tuple{Vararg{Int}}, ::Tuple{Vararg{Int}}) =
error("numbers of output and input dimensions must be equal")
CroppingOperator(::Tuple{Vararg{Int}}, ::Tuple{Vararg{Int}}, ::CartesianIndex) =
error("numbers of output and input dimensions and offsets must be equal")
CroppingOperator(outdims::NTuple{N,Int}, inpdims::NTuple{N,Int}) where {N} =
CroppingOperator{N}(outdims, inpdims)
CroppingOperator(outdims::NTuple{N,Int}, inpdims::NTuple{N,Int},
offset::CartesianIndex{N}) where {N} =
CroppingOperator{N}(outdims, inpdims, offset)
function vcreate(::Type{Direct},
C::CroppingOperator{N},
x::AbstractArray{T,N},
scratch::Bool) where {T,N}
(scratch && isa(x, Array{T,N}) && input_size(C) == output_size(C)) ? x :
Array{T,N}(undef, output_size(C))
end
function vcreate(::Type{Adjoint},
C::CroppingOperator{N},
x::AbstractArray{T,N},
scratch::Bool) where {T,N}
(scratch && isa(x, Array{T,N}) && input_size(C) == output_size(C)) ? x :
Array{T,N}(undef, input_size(C))
end
# Apply cropping operation.
#
# for I in R
# J = I + K
# y[I] = α*x[J] + β*y[I]
# end
#
function apply!(α::Number,
::Type{Direct},
C::CroppingOperator{N},
x::AbstractArray{T,N},
scratch::Bool,
β::Number,
y::AbstractArray{T,N}) where {T,N}
has_standard_indexing(x) ||
bad_argument("input array has non-standard indexing")
size(x) == input_size(C) ||
bad_size("bad input array dimensions")
has_standard_indexing(y) ||
bad_argument("output array has non-standard indexing")
size(y) == output_size(C) ||
bad_size("bad output array dimensions")
if α == 0
β == 1 || vscale!(y, β)
else
k = offset(C)
I = commonpart(C)
if α == 1
if β == 0
@inbounds @simd for i in I
y[i] = x[i + k]
end
elseif β == 1
@inbounds @simd for i in I
y[i] += x[i + k]
end
else
beta = convert(T, β)
@inbounds @simd for i in I
y[i] = x[i + k] + beta*y[i]
end
end
else
alpha = convert(T, α)
if β == 0
@inbounds @simd for i in I
y[i] = alpha*x[i + k]
end
elseif β == 1
@inbounds @simd for i in I
y[i] += alpha*x[i + k]
end
else
beta = convert(T, β)
@inbounds @simd for i in I
y[i] = alpha*x[i + k] + beta*y[i]
end
end
end
end
return y
end
# Apply zero-padding operation.
#
# for i in I
# y[i + k] = α*x[i] + β*y[i + k]
# end
# # Plus y[i + k] *= β outside common region R
#
function apply!(α::Number,
::Type{Adjoint},
C::CroppingOperator{N},
x::AbstractArray{T,N},
scratch::Bool,
β::Number,
y::AbstractArray{T,N}) where {T,N}
has_standard_indexing(x) ||
bad_argument("input array has non-standard indexing")
size(x) == output_size(C) ||
bad_size("bad input array dimensions")
has_standard_indexing(y) ||
bad_argument("output array has non-standard indexing")
size(y) == input_size(C) ||
bad_size("bad output array dimensions")
β == 1 || vscale!(y, β)
if α != 0
k = offset(C)
I = commonpart(C)
if α == 1
if β == 0
@inbounds @simd for i in I
y[i + k] = x[i]
end
else
@inbounds @simd for i in I
y[i + k] += x[i]
end
end
else
alpha = convert(T, α)
if β == 0
@inbounds @simd for i in I
y[i + k] = alpha*x[i]
end
else
@inbounds @simd for i in I
y[i + k] += alpha*x[i]
end
end
end
end
return y
end
"""
ZeroPaddingOperator(outdims, inpdims, offset=defaultoffset(outdims,inpdims))
yields a linear map which implements zero-padding of arrays of size `inpdims`
to produce arrays of size `outdims`. By default, the input array is centered
with respect to the output array (using the same conventions as `fftshift`).
Optional argument `offset` can be used to specify a different relative
position. If `offset` is given, the input value at multi-dimensional index `j`
is copied at index `i = j + offset` in the result.
A zero-padding operator is implemented as the adjoint of a cropping operator.
See also: [`CroppingOperator`](@ref).
"""
ZeroPaddingOperator(outdims, inpdims) =
Adjoint(CroppingOperator(inpdims, outdims))
ZeroPaddingOperator(outdims, inpdims, offset) =
Adjoint(CroppingOperator(inpdims, outdims, offset))
"""
defaultoffset(dim1,dim2)
yields the index offset such that the centers (in the same sense as assumed by
`fftshift`) of dimensions of lengths `dim1` and `dim2` are coincident. If `off
= defaultoffset(dim1,dim2)` and `i2` is the index along `dim2`, then the index
along `dim1` is `i1 = i2 + off`.
"""
defaultoffset(dim1::Integer, dim2::Integer) =
(Int(dim1) >> 1) - (Int(dim2) >> 1)
defaultoffset(dims1::NTuple{N,Integer}, dims2::NTuple{N,Integer}) where {N} =
CartesianIndex(map(defaultoffset, dims1, dims2))
end # module
| LazyAlgebra | https://github.com/emmt/LazyAlgebra.jl.git |
|
[
"MIT"
] | 0.2.7 | e58d5904fa7ffa914a3eb60f8705e2ea3aaea1b9 | code | 44103 | #
# diff.jl -
#
# Implement finite differences operators.
#
#-------------------------------------------------------------------------------
#
# This file is part of LazyAlgebra (https://github.com/emmt/LazyAlgebra.jl)
# released under the MIT "Expat" license.
#
# Copyright (c) 2017-2021 Éric Thiébaut.
#
module FiniteDifferences
export Diff
using MayOptimize
using LazyAlgebra
using LazyAlgebra.Foundations
import LazyAlgebra: apply!, vcreate, identical
using Base: @propagate_inbounds
import Base: show
const ArrayAxis = AbstractUnitRange{Int}
const ArrayAxes{N} = NTuple{N,ArrayAxis}
"""
limits(r) -> (first(r), last(r))
yields the first and last value of the unit-range `r`.
"""
limits(r::AbstractUnitRange) = (first(r), last(r))
"""
Diff([opt::MayOptimize.Vectorize,] n=1, dims=:)
yields a linear mapping that computes a finite difference approximation of the
`n`-order derivative along the dimension(s) specified by `dims`. Arguments
`dims` is an integer, a tuple or a vector of integers specifying along which
dimension(s) to apply the operator or `:` to specify all dimensions. If
multiple dimensions are specified, the result is as if the operator is applied
separately on the specified dimension(s).
Optional argument `opt` is the optimization level and may be specified as the
first or last argument. By default, `opt` is assumed to be `Vectorize`,
however depending on the dimensions of the array, the dimensions of interest
and on the machine, setting `opt` to `InBounds` may be more efficient.
If `dims` is a scalar, the result, say `y`, of applying the finite difference
operator to an array, say `x`, has the same axes as `x`. Otherwise and even
though `x` has a single dimension or `dims` is a 1-tuple, `y` has one more
dimension than `x`, the last dimension of `y` is used to store the finite
differences along each dimensions specified by `dims` and the leading
dimensions of `y` are the same as the dimensions of `x`.
More specifically, the operator created by `Diff` implements **forward finite
differences** with **flat boundary conditions**, that is to say extrapolated
entries are assumed equal to the nearest entry.
"""
struct Diff{L,D,O<:OptimLevel} <: LinearMapping end
# L = level of differentiation
# D = list of dimensions along which compute the differences
# O = optimization level
# Constructors.
function Diff(n::Integer = 1,
dims::Union{Colon,Integer,Tuple{Vararg{Integer}},
AbstractVector{<:Integer}}=Colon(),
opt::Type{<:OptimLevel} = Vectorize)
return Diff{to_int(n), to_dims(dims), opt}()
end
function Diff(opt::Type{<:OptimLevel}, n::Integer = 1,
dims::Union{Colon,Integer,Tuple{Vararg{Integer}},
AbstractVector{<:Integer}}=Colon())
return Diff{to_int(n), to_dims(dims), opt}()
end
function Diff(n::Integer, opt::Type{<:OptimLevel})
return Diff{to_int(n), Colon, opt}()
end
# Make a finite difference operator callable.
@callable Diff
# Two finite difference operators are identical if they have the same level of
# differentiation and list of dimensions along which compute the differences.
# Their optimization levels may be different.
identical(::Diff{L,D}, ::Diff{L,D}) where {L,D} = true
# Print operator in such a way that is similar to how the operator would be
# created in Julia.
show(io::IO, ::Diff{L,D,Opt}) where {L,D,Opt} =
print(io, "Diff(", L, ',', (D === Colon ? ":" : D),',',
(Opt === Debug ? "Debug" :
Opt === InBounds ? "InBounds" :
Opt === Vectorize ? "Vectorize" : Opt), ')')
"""
differentiation_order(A)
yields the differentiation order of finite difference operator `A` (argument
can also be a type).
"""
differentiation_order(::Type{<:Diff{L,D,Opt}}) where {L,D,Opt} = L
"""
dimensions_of_interest(A)
yields the list of dimensions of interest of finite difference operator `A`
(argument can also be a type).
"""
dimensions_of_interest(::Type{<:Diff{L,D,Opt}}) where {L,D,Opt} = D
"""
optimization_level(A)
yields the optimization level for applying finite difference operator `A`
(argument can also be a type).
"""
optimization_level(::Type{<:Diff{L,D,Opt}}) where {L,D,Opt} = Opt
for f in (:differentiation_order,
:dimensions_of_interest,
:optimization_level)
@eval begin
$f(A::Diff) = $f(typeof(A))
$f(A::Gram{<:Diff}) = $f(typeof(A))
$f(::Type{<:Gram{T}}) where {T<:Diff} = $f(T)
end
end
# Convert argument to `Int`.
to_int(x::Int) = x
to_int(x::Integer) = Int(x)
# Convert argument to the type parameter which specifies the list of dimensions
# of interest.
to_dims(::Colon) = Colon
to_dims(x::Int) = x
to_dims(x::Integer) = to_int(x)
to_dims(x::Tuple{Vararg{Int}}) = x
to_dims(x::Tuple{Vararg{Integer}}) = map(to_int, x)
to_dims(x::AbstractVector{<:Integer}) = to_dims((x...,))
# Drop list of dimensions from type to avoid unecessary specializations.
anydims(::Diff{L,D,P}) where {L,D,P} = Diff{L,Any,P}()
anydims(::Gram{Diff{L,D,P}}) where {L,D,P} = gram(Diff{L,Any,P}())
# Applying a separable operator is split in several stages:
#
# 1. Check arguments (so that avoiding bound checking should be safe) and deal
# with the trivial cases α = 0 or no dimension of interest to apply the
# operation (to simplify subsequent stages).
#
# 2. If α is non-zero, dispatch on dimension(s) along which to apply the
# operation and on the specific values of the multipliers α and β.
#
# The second stage may be split in several sub-stages.
# Declare all possible signatures (not using unions) to avoid ambiguities.
for (P,A) in ((:Direct, :Diff),
(:Adjoint, :Diff),
(:Direct, :(Gram{<:Diff})))
@eval function apply!(α::Number,
P::Type{$P},
A::$A,
x::AbstractArray,
scratch::Bool,
β::Number,
y::AbstractArray)
inds, ndims = check_arguments(P, A, x, y)
if α == 0 || ndims < 1
# Get rid of this stupid case!
vscale!(y, β)
else
# Call unsafe_apply! to dispatch on the dimensions of interest and on
# the values of the multipliers.
unsafe_apply!(α, P, A, x, β, y, inds)
end
return y
end
end
# FIXME: This should not be necessary.
function apply!(α::Number,
::Type{<:Adjoint},
A::Gram{<:Diff},
x::AbstractArray,
scratch::Bool,
β::Number,
y::AbstractArray)
apply!(α, Direct, A, x, scratch, β, y)
end
function vcreate(::Type{Direct},
A::Diff{L,D,P},
x::AbstractArray{T,N},
scratch::Bool) where {L,D,P,T,N}
if D === Colon
return Array{T}(undef, size(x)..., N)
elseif isa(D, Tuple{Vararg{Int}})
return Array{T}(undef, size(x)..., length(D))
elseif isa(D, Int)
# if L === 1 && scratch && isa(x, Array)
# # First order finite difference along a single dimension.
# # Operation could be done in-place but we must preserve
# # type-stability.
# return x
#else
# return Array{T}(undef, size(x))
#end
return Array{T}(undef, size(x))
else
error("invalid list of dimensions")
end
end
function vcreate(::Type{Adjoint},
A::Diff{L,D,P},
x::AbstractArray{T,N},
scratch::Bool) where {L,D,P,T,N}
# Checking the validity of the argument dimensions is done by applying the
# opererator. In-place operation never possible, so ignore the scratch
# flag.
if D === Colon || isa(D, Tuple{Vararg{Int}})
return Array{T}(undef, size(x)[1:N-1])
elseif isa(D, Int)
return Array{T}(undef, size(x))
else
error("invalid list of dimensions")
end
end
#------------------------------------------------------------------------------
# CHECKING OF ARGUMENTS
"""
check_arguments(P, A, x, y) -> inds, ndims
checks that arguments `x` and `y` are valid for applying `P(A)`, with `A` a
separable operator, to `x` and store the result in `y`. The result is a
2-tuple, `inds` is the axes that the arguments have in common and `ndims` is
the number of dimensions of interest.
If this function returns normally, the caller may safely assume that index
bound checking is not needed; hence, this function must throw an exception if
the dimensions/indices of `x` and `y` are not compatible or if the dimensions
of interest in `A` are out of range. This function may also throw an exception
if the element types of `x` and `y` are not compatible.
This method must be specialized for the different types of separable operators.
"""
function check_arguments(P::Type{<:Union{Direct,Adjoint}},
A::Union{Diff{L,D},Gram{<:Diff{L,D}}},
x::AbstractArray,
y::AbstractArray) where {L,D}
inds = check_axes(P, A, axes(x), axes(y))
ndims = check_dimensions_of_interest(D, length(inds))
return inds, ndims
end
function check_axes(P::Type{<:Union{Direct,Adjoint}},
A::Diff{L,D},
xinds::ArrayAxes,
yinds::ArrayAxes) where {L,D}
if D === Colon || isa(D, Dims)
if P === Direct
length(yinds) == length(xinds) + 1 ||
throw_dimension_mismatch("output array must have one more dimension than input array")
N = (D === Colon ? length(xinds) : length(D))
yinds[end] == 1:N ||
throw_dimension_mismatch("last axis of output array must be 1:", N)
yinds[1:end-1] == xinds ||
throw_dimension_mismatch("leading axes must be identical")
return xinds
else
length(yinds) == length(xinds) - 1 ||
throw_dimension_mismatch("output array must have one less dimension than input array")
N = (D === Colon ? length(yinds) : length(D))
xinds[end] == 1:N ||
throw_dimension_mismatch("last axis of input array must be 1:", N)
xinds[1:end-1] == yinds ||
throw_dimension_mismatch("leading axes must be identical")
return yinds
end
elseif isa(D, Int)
xinds == yinds || throw_dimension_mismatch("array axes must be identical")
return xinds
else
throw(ArgumentError("invalid dimensions of interest"))
end
end
function check_axes(P::Type{<:Operations},
A::Gram{<:Diff},
xinds::ArrayAxes,
yinds::ArrayAxes)
xinds == yinds || throw_dimension_mismatch("array axes must be identical")
return xinds
end
check_dimensions_of_interest(::Type{Colon}, ndims::Int) = ndims
check_dimensions_of_interest(dim::Int, ndims::Int) = begin
1 ≤ dim ≤ ndims ||
throw_dimension_mismatch("out of range dimension ", dim,
"for ", ndims,"-dimensional arrays")
return 1
end
check_dimensions_of_interest(dims::Dims{N}, ndims::Int) where {N} = begin
for dim in dims
1 ≤ dim ≤ ndims ||
throw_dimension_mismatch("out of range dimension ", dim,
"for ", ndims,"-dimensional arrays")
end
return N
end
throw_dimension_mismatch(str::String) = throw(DimensionMismatch(str))
@noinline throw_dimension_mismatch(args...) =
throw_dimension_mismatch(string(args...))
#------------------------------------------------------------------------------
# Apply the operation along all dimensions of interest but one dimension at a
# time and knowing that α is not zero.
@generated function unsafe_apply!(α::Number,
::Type{P},
A::Diff{L,D},
x::AbstractArray,
β::Number,
y::AbstractArray,
inds::ArrayAxes{N}) where {L,D,N,
P<:Union{Direct,
Adjoint}}
# Allocate empty vector of statements.
exprs = Expr[]
# Discard type parameter specifying the dimensions of interest to avoid
# specialization on this parameter.
push!(exprs, :(B = anydims(A)))
# Dispatch on dimensions of interest.
if isa(D, Int)
# Arrays x and y have the same dimensions.
push!(exprs, :(unsafe_apply!(α, P, B, x, β, y,
inds[1:$(D-1)],
inds[$D],
inds[$(D+1):$N],
CartesianIndex())))
elseif D === Colon || isa(D, Dims)
# One of x or y (depending on whether the direct or the adjoint
# operator is applied) has an extra leading dimension used to store the
# result computed along a given dimension.
keep_beta = true # initially scale y by β
dims = (D === Colon ? (1:N) : D)
for l in 1:length(dims)
d = dims[l]
push!(exprs, :(unsafe_apply!(α, P, B, x,
$(keep_beta ? :β : 1), y,
inds[1:$(d-1)],
inds[$d],
inds[$(d+1):$N],
CartesianIndex($l))))
keep_beta = (P === Direct && A <: Diff)
end
else
# This should never happen.
return quote
error("invalid list of dimensions of interest")
end
end
return quote
$(Expr(:meta, :inline))
$(exprs...)
nothing
end
end
@generated function unsafe_apply!(α::Number,
::Type{P},
A::Gram{<:Diff{L,D}},
x::AbstractArray,
β::Number,
y::AbstractArray,
inds::ArrayAxes{N}) where {L,D,N,
P<:Direct}
# Allocate empty vector of statements.
exprs = Expr[]
# Discard type parameter specifying the dimensions of interest to avoid
# specialization on this parameter.
push!(exprs, :(B = anydims(A)))
# Dispatch on dimensions of interest. Arrays x and y have the same
# dimensions and there is no last index `l` to specify.
if isa(D, Int)
push!(exprs, :(unsafe_apply!(α, P, B, x, β, y,
inds[1:$(D-1)],
inds[$D],
inds[$(D+1):$N])))
elseif D === Colon || isa(D, Dims)
# β is set to 1 after first dimension of interest.
dims = (D === Colon ? (1:N) : D)
for l in 1:length(dims)
d = dims[l]
push!(exprs, :(unsafe_apply!(α, P, B, x,
$(l == 1 ? :β : 1), y,
inds[1:$(d-1)],
inds[$d],
inds[$(d+1):$N])))
end
else
# This should never happen.
return quote
error("invalid list of dimensions of interest")
end
end
return quote
$(Expr(:meta, :inline))
$(exprs...)
nothing
end
end
# Dispatch on multipliers values (α is not zero).
function unsafe_apply!(alpha::Number,
P::Type{<:Operations},
A::Union{Diff{L,Any,Opt},
Gram{Diff{L,Any,Opt}}},
x::AbstractArray,
beta::Number,
y::AbstractArray,
I::ArrayAxes,
J::ArrayAxis,
K::ArrayAxes,
l::CartesianIndex) where {L,Opt}
if alpha == 1
if beta == 0
unsafe_apply!(axpby_yields_x, 1, P, A, x, 0, y, I, J, K, l)
elseif beta == 1
unsafe_apply!(axpby_yields_xpy, 1, P, A, x, 1, y, I, J, K, l)
else
β = promote_multiplier(beta, y)
unsafe_apply!(axpby_yields_xpby, 1, P, A, x, β, y, I, J, K, l)
end
else
α = promote_multiplier(alpha, y)
if beta == 0
unsafe_apply!(axpby_yields_ax, α, P, A, x, 0, y, I, J, K, l)
elseif beta == 1
unsafe_apply!(axpby_yields_axpy, α, P, A, x, 1, y, I, J, K, l)
else
β = promote_multiplier(beta, y)
unsafe_apply!(axpby_yields_axpby, α, P, A, x, β, y, I, J, K, l)
end
end
nothing
end
# Dispatch on multipliers values (α is not zero) for Gram compositions of a
# finite difference operator.
function unsafe_apply!(alpha::Number,
P::Type{<:Operations},
A::Gram{<:Diff},
x::AbstractArray,
beta::Number,
y::AbstractArray,
I::ArrayAxes,
J::ArrayAxis,
K::ArrayAxes)
if alpha == 1
if beta == 0
unsafe_apply!(axpby_yields_x, 1, P, A, x, 0, y, I, J, K)
elseif beta == 1
unsafe_apply!(axpby_yields_xpy, 1, P, A, x, 1, y, I, J, K)
else
β = promote_multiplier(beta, y)
unsafe_apply!(axpby_yields_xpby, 1, P, A, x, β, y, I, J, K)
end
else
α = promote_multiplier(alpha, y)
if beta == 0
unsafe_apply!(axpby_yields_ax, α, P, A, x, 0, y, I, J, K)
elseif beta == 1
unsafe_apply!(axpby_yields_axpy, α, P, A, x, 1, y, I, J, K)
else
β = promote_multiplier(beta, y)
unsafe_apply!(axpby_yields_axpby, α, P, A, x, β, y, I, J, K)
end
end
nothing
end
#------------------------------------------------------------------------------
#
# The operator D implementing 1st order forward finite difference with flat
# boundary conditions and its adjoint D' are given by:
#
# D = [ -1 1 0 0
# 0 -1 1 0
# 0 0 -1 1
# 0 0 0 0];
#
# D' = [ -1 0 0 0
# 1 -1 0 0
# 0 1 -1 0
# 0 0 1 0];
#
# The row (for D) and column (for D') of zeros are to preserve the size. This
# is needed for multi-dimensional arrays when derivatives along each dimension
# are stored into a single array.
#
# Apply 1st order finite differences along 1st dimension:
#
function unsafe_apply!(f::Function,
α::Number,
::Type{Direct},
A::Diff{1,Any,Opt},
x::AbstractArray,
β::Number,
y::AbstractArray,
I::Tuple{},
J::ArrayAxis,
K::ArrayAxes,
l::CartesianIndex) where {Opt}
T = real(eltype(x))
jmin, jmax = limits(J)
if jmin ≤ jmax
@maybe_inbounds Opt for k in CartesianIndices(K)
@maybe_vectorized Opt for j in jmin:jmax-1
z = x[j+1,k] - x[j,k]
y[j,k,l] = f(α, z, β, y[j,k,l])
end
let j = jmax, z = zero(T)
y[j,k,l] = f(α, z, β, y[j,k,l])
end
end
end
nothing
end
#
# Apply 1st order finite differences along 2nd and subsequent dimensions:
#
function unsafe_apply!(f::Function,
α::Number,
::Type{Direct},
A::Diff{1,Any,Opt},
x::AbstractArray,
β::Number,
y::AbstractArray,
I::ArrayAxes,
J::ArrayAxis,
K::ArrayAxes,
l::CartesianIndex) where {Opt}
T = real(eltype(x))
jmin, jmax = limits(J)
if jmin ≤ jmax
@maybe_inbounds Opt for k in CartesianIndices(K)
for j in jmin:jmax-1
@maybe_vectorized Opt for i in CartesianIndices(I)
z = x[i,j+1,k] - x[i,j,k]
y[i,j,k,l] = f(α, z, β, y[i,j,k,l])
end
end
let j = jmax, z = zero(T)
@maybe_vectorized Opt for i in CartesianIndices(I)
y[i,j,k,l] = f(α, z, β, y[i,j,k,l])
end
end
end
end
nothing
end
#
# Apply adjoint of 1st order finite differences along 1st dimension:
#
function unsafe_apply!(f::Function,
α::Number,
::Type{Adjoint},
A::Diff{1,Any,Opt},
x::AbstractArray,
β::Number,
y::AbstractArray,
I::Tuple{},
J::ArrayAxis,
K::ArrayAxes,
l::CartesianIndex) where {Opt}
T = real(eltype(x))
jmin, jmax = limits(J)
if jmin < jmax
@maybe_inbounds Opt for k in CartesianIndices(K)
let j = jmin
z = -x[j,k,l]
y[j,k] = f(α, z, β, y[j,k])
end
@maybe_vectorized Opt for j in jmin+1:jmax-1
z = x[j-1,k,l] - x[j,k,l]
y[j,k] = f(α, z, β, y[j,k])
end
let j = jmax
z = x[j-1,k,l]
y[j,k] = f(α, z, β, y[j,k])
end
end
elseif jmin == jmax && β != 1
let j = jmin, z = zero(T)
@maybe_vectorized Opt for k in CartesianIndices(K)
y[j,k] = f(α, z, β, y[j,k])
end
end
end
nothing
end
#
# Apply adjoint of 1st order finite differences along 2nd and subsequent
# dimensions:
#
function unsafe_apply!(f::Function,
α::Number,
::Type{Adjoint},
A::Diff{1,Any,Opt},
x::AbstractArray,
β::Number,
y::AbstractArray,
I::ArrayAxes,
J::ArrayAxis,
K::ArrayAxes,
l::CartesianIndex) where {Opt}
T = real(eltype(x))
jmin, jmax = limits(J)
if jmin < jmax
@maybe_inbounds Opt for k in CartesianIndices(K)
let j = jmin
@maybe_vectorized Opt for i in CartesianIndices(I)
z = -x[i,j,k,l]
y[i,j,k] = f(α, z, β, y[i,j,k])
end
end
for j in jmin+1:jmax-1
@maybe_vectorized Opt for i in CartesianIndices(I)
z = x[i,j-1,k,l] - x[i,j,k,l]
y[i,j,k] = f(α, z, β, y[i,j,k])
end
end
let j = jmax
@maybe_vectorized Opt for i in CartesianIndices(I)
z = x[i,j-1,k,l]
y[i,j,k] = f(α, z, β, y[i,j,k])
end
end
end
elseif jmin == jmax && β != 1
let j = jmin, z = zero(T)
@maybe_inbounds Opt for k in CartesianIndices(K)
@maybe_vectorized Opt for i in CartesianIndices(I)
y[i,j,k] = f(α, z, β, y[i,j,k])
end
end
end
end
nothing
end
#
# The Gram composition D'*D of the 1st order forward finite differences D with
# flat boundary conditions writes:
#
# D'*D = [ 1 -1 0 0 0
# -1 2 -1 0 0
# 0 -1 2 -1 0
# 0 0 -1 2 -1
# 0 0 0 -1 1 ]
#
# Apply D'*D along 1st dimension:
#
function unsafe_apply!(f::Function,
α::Number,
::Type{<:Union{Direct,Adjoint}},
A::Gram{Diff{1,Any,Opt}},
x::AbstractArray,
β::Number,
y::AbstractArray,
I::Tuple{},
J::ArrayAxis,
K::ArrayAxes) where {Opt}
T = real(eltype(x))
jmin, jmax = limits(J)
if jmin < jmax
@maybe_inbounds Opt for k in CartesianIndices(K)
let j = jmin
z = x[j,k] - x[j+1,k]
y[j,k] = f(α, z, β, y[j,k])
end
@maybe_vectorized Opt for j in jmin+1:jmax-1
z = T(2)*x[j,k] - (x[j-1,k] + x[j+1,k])
y[j,k] = f(α, z, β, y[j,k])
end
let j = jmax
z = x[j,k] - x[j-1,k]
y[j,k] = f(α, z, β, y[j,k])
end
end
elseif jmin == jmax && β != 1
let j = jmin, z = zero(T)
@maybe_vectorized Opt for k in CartesianIndices(K)
y[j,k] = f(α, z, β, y[j,k])
end
end
end
nothing
end
#
# Apply D'*D along 2nd and subsequent dimensions:
#
function unsafe_apply!(f::Function,
α::Number,
::Type{<:Union{Direct,Adjoint}},
A::Gram{Diff{1,Any,Opt}},
x::AbstractArray,
β::Number,
y::AbstractArray,
I::ArrayAxes,
J::ArrayAxis,
K::ArrayAxes) where {Opt}
T = real(eltype(x))
jmin, jmax = limits(J)
if jmin < jmax
@maybe_inbounds Opt for k in CartesianIndices(K)
let j = jmin
@maybe_vectorized Opt for i in CartesianIndices(I)
z = x[i,j,k] - x[i,j+1,k]
y[i,j,k] = f(α, z, β, y[i,j,k])
end
end
for j in jmin+1:jmax-1
@maybe_vectorized Opt for i in CartesianIndices(I)
z = T(2)*x[i,j,k] - (x[i,j-1,k] + x[i,j+1,k])
y[i,j,k] = f(α, z, β, y[i,j,k])
end
end
let j = jmax
@maybe_vectorized Opt for i in CartesianIndices(I)
z = x[i,j,k] - x[i,j-1,k]
y[i,j,k] = f(α, z, β, y[i,j,k])
end
end
end
elseif jmin == jmax && β != 1
let j = jmin, z = zero(T)
@maybe_inbounds Opt for k in CartesianIndices(K)
@maybe_vectorized Opt for i in CartesianIndices(I)
y[i,j,k] = f(α, z, β, y[i,j,k])
end
end
end
end
nothing
end
#------------------------------------------------------------------------------
#
# 2nd order finite differences with flat boundary conditions are computed by:
#
# D = [-1 1 0 0 0 0
# 1 -2 1 0 0 0
# 0 1 -2 1 0 0
# 0 0 1 -2 1 0
# 0 0 0 1 -2 1
# 0 0 0 0 1 -1]
#
# Remarks:
#
# - Applying this operator on a single dimension is self-adjoint.
#
# - For a single dimension, this operator is the opposite of the Gram
# composition of 1st order finite differences (backward or forward).
#
# Apply 2nd order finite differences along 1st dimension:
#
function unsafe_apply!(f::Function,
α::Number,
::Type{Direct},
A::Diff{2,Any,Opt},
x::AbstractArray,
β::Number,
y::AbstractArray,
I::Tuple{},
J::ArrayAxis,
K::ArrayAxes,
l::CartesianIndex) where {Opt}
T = real(eltype(x))
jmin, jmax = limits(J)
if jmin < jmax
@maybe_inbounds Opt for k in CartesianIndices(K)
let j = jmin
z = x[j+1,k] - x[j,k]
y[j,k,l] = f(α, z, β, y[j,k,l])
end
@maybe_vectorized Opt for j in jmin+1:jmax-1
z = x[j-1,k] + x[j+1,k] - T(2)*x[j,k]
y[j,k,l] = f(α, z, β, y[j,k,l])
end
let j = jmax
z = x[j-1,k] - x[j,k]
y[j,k,l] = f(α, z, β, y[j,k,l])
end
end
elseif jmin == jmax && β != 1
let j = jmin, z = zero(T)
@maybe_vectorized Opt for k in CartesianIndices(K)
y[j,k,l] = f(α, z, β, y[j,k,l])
end
end
end
nothing
end
#
# Apply 2nd order finite differences along 2nd and subsequent dimensions:
#
function unsafe_apply!(f::Function,
α::Number,
::Type{Direct},
A::Diff{2,Any,Opt},
x::AbstractArray,
β::Number,
y::AbstractArray,
I::ArrayAxes,
J::ArrayAxis,
K::ArrayAxes,
l::CartesianIndex) where {Opt}
T = real(eltype(x))
jmin, jmax = limits(J)
if jmin < jmax
@maybe_inbounds Opt for k in CartesianIndices(K)
let j = jmin
@maybe_vectorized Opt for i in CartesianIndices(I)
z = x[i,j+1,k] - x[i,j,k]
y[i,j,k,l] = f(α, z, β, y[i,j,k,l])
end
end
for j in jmin+1:jmax-1
@maybe_vectorized Opt for i in CartesianIndices(I)
# Other possibility:
# z = (x[i,j-1,k] - x[i,j,k]) + (x[i,j+1,k] - x[i,j,k])
z = x[i,j-1,k] + x[i,j+1,k] - T(2)*x[i,j,k]
y[i,j,k,l] = f(α, z, β, y[i,j,k,l])
end
end
let j = jmax
@maybe_vectorized Opt for i in CartesianIndices(I)
z = x[i,j-1,k] - x[i,j,k]
y[i,j,k,l] = f(α, z, β, y[i,j,k,l])
end
end
end
elseif jmin == jmax && β != 1
let j = jmin, z = zero(T)
@maybe_inbounds Opt for k in CartesianIndices(K)
@maybe_vectorized Opt for i in CartesianIndices(I)
y[i,j,k,l] = f(α, z, β, y[i,j,k,l])
end
end
end
end
nothing
end
#
# Apply adjoint of 2nd order finite differences along 1st dimension:
#
function unsafe_apply!(f::Function,
α::Number,
::Type{Adjoint},
A::Diff{2,Any,Opt},
x::AbstractArray,
β::Number,
y::AbstractArray,
I::Tuple{},
J::ArrayAxis,
K::ArrayAxes,
l::CartesianIndex) where {Opt}
T = real(eltype(x))
jmin, jmax = limits(J)
if jmin < jmax
@maybe_inbounds Opt for k in CartesianIndices(K)
let j = jmin
z = x[j+1,k,l] - x[j,k,l]
y[j,k] = f(α, z, β, y[j,k])
end
@maybe_vectorized Opt for j in jmin+1:jmax-1
# Other possibility:
# z = (x[j-1,k,l] - x[j,k,l]) + (x[j+1,k,l] - x[j,k,l])
z = x[j-1,k,l] + x[j+1,k,l] - T(2)*x[j,k,l]
y[j,k] = f(α, z, β, y[j,k])
end
let j = jmax
z = x[j-1,k,l] - x[j,k,l]
y[j,k] = f(α, z, β, y[j,k])
end
end
elseif jmin == jmax && β != 1
let j = jmin, z = zero(T)
@maybe_vectorized Opt for k in CartesianIndices(K)
y[j,k] = f(α, z, β, y[j,k])
end
end
end
nothing
end
#
# Apply 2nd order finite differences along 2nd and subsequent dimensions:
#
function unsafe_apply!(f::Function,
α::Number,
::Type{Adjoint},
A::Diff{2,Any,Opt},
x::AbstractArray,
β::Number,
y::AbstractArray,
I::ArrayAxes,
J::ArrayAxis,
K::ArrayAxes,
l::CartesianIndex) where {Opt}
T = real(eltype(x))
jmin, jmax = limits(J)
if jmin < jmax
@maybe_inbounds Opt for k in CartesianIndices(K)
let j = jmin
@maybe_vectorized Opt for i in CartesianIndices(I)
z = x[i,j+1,k,l] - x[i,j,k,l]
y[i,j,k] = f(α, z, β, y[i,j,k])
end
end
for j in jmin+1:jmax-1
@maybe_vectorized Opt for i in CartesianIndices(I)
z = x[i,j-1,k,l] + x[i,j+1,k,l] - T(2)*x[i,j,k,l]
y[i,j,k] = f(α, z, β, y[i,j,k])
end
end
let j = jmax
@maybe_vectorized Opt for i in CartesianIndices(I)
z = x[i,j-1,k,l] - x[i,j,k,l]
y[i,j,k] = f(α, z, β, y[i,j,k])
end
end
end
elseif jmin == jmax && β != 1
let j = jmin, z = zero(T)
@maybe_inbounds Opt for k in CartesianIndices(K)
@maybe_vectorized Opt for i in CartesianIndices(I)
y[i,j,k] = f(α, z, β, y[i,j,k])
end
end
end
end
nothing
end
#
# The Gram composition of 2nd order finite differences writes:
#
# D'*D = [ 2 -3 1 0 0 0 (1)
# -3 6 -4 1 0 0 (2)
# 1 -4 6 -4 1 0 (3)
# 0 1 -4 6 -4 1 (3)
# 0 0 1 -4 6 -3 (4)
# 0 0 0 1 -3 2] (5)
#
# The above is for len ≥ 4, with len is the length of the dimension of
# interest, omitting the Eq. (5) for len = 4 and repeating Eq. (5) as necessary
# for the central rows for n ≥ 5. For len = 3:
#
# D'*D = [ 2 -3 1 (1)
# -3 6 -3 (6)
# 1 -3 2] (5)
#
# For len = 2:
#
# D'*D = [ 2 -2 (7)
# -2 2] (8)
#
# For len = 1, D = 0 and D'*D = 0 (the null 1×1 operator).
#
# Methods to apply the rows of D'D ():
#
# - Eq. (1), first row when len ≥ 3:
#
@inline @propagate_inbounds D2tD2_1(x::AbstractArray, j::Int, k) = begin
T = real(eltype(x))
T(2)*x[j,k] - T(3)*x[j+1,k] + x[j+2,k]
end
@inline @propagate_inbounds D2tD2_1(x::AbstractArray, i, j::Int, k) = begin
T = real(eltype(x))
T(2)*x[i,j,k] - T(3)*x[i,j+1,k] + x[i,j+2,k]
end
#
# - Eq. (2), second row when len ≥ 4:
#
@inline @propagate_inbounds D2tD2_2(x::AbstractArray, j::Int, k) = begin
T = real(eltype(x))
T(6)*x[j,k] - T(3)*x[j-1,k] - T(4)*x[j+1,k] + x[j+2,k]
end
@inline @propagate_inbounds D2tD2_2(x::AbstractArray, i, j::Int, k) = begin
T = real(eltype(x))
T(6)*x[i,j,k] - T(3)*x[i,j-1,k] - T(4)*x[i,j+1,k] + x[i,j+2,k]
end
#
# - Eq. (3), central rows when len ≥ 5:
#
@inline @propagate_inbounds D2tD2_3(x::AbstractArray, j::Int, k) = begin
T = real(eltype(x))
(x[j-2,k] + x[j+2,k]) + T(6)*x[j,k] - T(4)*(x[j-1,k] + x[j+1,k])
end
@inline @propagate_inbounds D2tD2_3(x::AbstractArray, i, j::Int, k) = begin
T = real(eltype(x))
(x[i,j-2,k] + x[i,j+2,k]) + T(6)*x[i,j,k] - T(4)*(x[i,j-1,k] + x[i,j+1,k])
end
#
# - Eq. (4), before last row when len ≥ 4:
#
@inline @propagate_inbounds D2tD2_4(x::AbstractArray, j::Int, k) = begin
T = real(eltype(x))
T(6)*x[j,k] - T(3)*x[j+1,k] - T(4)*x[j-1,k] + x[j-2,k]
end
@inline @propagate_inbounds D2tD2_4(x::AbstractArray, i, j::Int, k) = begin
T = real(eltype(x))
T(6)*x[i,j,k] - T(3)*x[i,j+1,k] - T(4)*x[i,j-1,k] + x[i,j-2,k]
end
#
# - Eq. (5), last row when len ≥ 3:
#
@inline @propagate_inbounds D2tD2_5(x::AbstractArray, j::Int, k) = begin
T = real(eltype(x))
T(2)*x[j,k] - T(3)*x[j-1,k] + x[j-2,k]
end
@inline @propagate_inbounds D2tD2_5(x::AbstractArray, i, j::Int, k) = begin
T = real(eltype(x))
T(2)*x[i,j,k] - T(3)*x[i,j-1,k] + x[i,j-2,k]
end
#
# - Eq. (6), central row when len = 3:
#
@inline @propagate_inbounds D2tD2_6(x::AbstractArray, j::Int, k) = begin
T = real(eltype(x))
T(6)*x[j,k] - T(3)*(x[j-1,k] + x[j+1,k])
end
@inline @propagate_inbounds D2tD2_6(x::AbstractArray, i, j::Int, k) = begin
T = real(eltype(x))
T(6)*x[i,j,k] - T(3)*(x[i,j-1,k] + x[i,j+1,k])
end
#
# - Eq. (7), first row when len = 2:
#
@inline @propagate_inbounds D2tD2_7(x::AbstractArray, j::Int, k) = begin
z = x[j,k] - x[j+1,k]
return z + z
end
@inline @propagate_inbounds D2tD2_7(x::AbstractArray, i, j::Int, k) = begin
z = x[i,j,k] - x[i,j+1,k]
return z + z
end
#
# - Eq. (8), last row when len = 2:
#
@inline @propagate_inbounds D2tD2_8(x::AbstractArray, j::Int, k) = begin
z = x[j,k] - x[j-1,k]
return z + z
end
@inline @propagate_inbounds D2tD2_8(x::AbstractArray, i, j::Int, k) = begin
z = x[i,j,k] - x[i,j-1,k]
return z + z
end
#
# Apply Gram composition of 2nd order finite differences along 1st dimension:
#
function unsafe_apply!(f::Function,
α::Number,
::Type{<:Union{Direct,Adjoint}},
A::Gram{Diff{2,Any,Opt}},
x::AbstractArray,
β::Number,
y::AbstractArray,
I::Tuple{},
J::ArrayAxis,
K::ArrayAxes) where {Opt}
T = real(eltype(x))
jmin, jmax = limits(J)
len = length(J)
if len ≥ 5
@maybe_inbounds Opt for k in CartesianIndices(K)
let j = jmin
y[j,k] = f(α, D2tD2_1(x,j,k), β, y[j,k])
end
let j = jmin+1
y[j,k] = f(α, D2tD2_2(x,j,k), β, y[j,k])
end
@maybe_vectorized Opt for j in jmin+2:jmax-2
y[j,k] = f(α, D2tD2_3(x,j,k), β, y[j,k])
end
let j = jmax-1
y[j,k] = f(α, D2tD2_4(x,j,k), β, y[j,k])
end
let j = jmax
y[j,k] = f(α, D2tD2_5(x,j,k), β, y[j,k])
end
end
elseif len == 4
@maybe_vectorized Opt for k in CartesianIndices(K)
let j = jmin
y[j,k] = f(α, D2tD2_1(x,j,k), β, y[j,k])
end
let j = jmin+1
y[j,k] = f(α, D2tD2_2(x,j,k), β, y[j,k])
end
let j = jmax-1
y[j,k] = f(α, D2tD2_4(x,j,k), β, y[j,k])
end
let j = jmax
y[j,k] = f(α, D2tD2_5(x,j,k), β, y[j,k])
end
end
elseif len == 3
@maybe_vectorized Opt for k in CartesianIndices(K)
let j = jmin
y[j,k] = f(α, D2tD2_1(x,j,k), β, y[j,k])
end
let j = jmin+1
y[j,k] = f(α, D2tD2_6(x,j,k), β, y[j,k])
end
let j = jmax
y[j,k] = f(α, D2tD2_5(x,j,k), β, y[j,k])
end
end
elseif len == 2
@maybe_vectorized Opt for k in CartesianIndices(K)
let j = jmin
y[j,k] = f(α, D2tD2_7(x,j,k), β, y[j,k])
end
let j = jmax
y[j,k] = f(α, D2tD2_8(x,j,k), β, y[j,k])
end
end
elseif len == 1 && β != 1
let j = jmin, z = zero(T)
@maybe_vectorized Opt for k in CartesianIndices(K)
y[j,k] = f(α, z, β, y[j,k])
end
end
end
nothing
end
#
# Apply Gram composition of 2nd order finite differences along 2nd and
# subsequent dimensions:
#
function unsafe_apply!(f::Function,
α::Number,
::Type{<:Union{Direct,Adjoint}},
A::Gram{Diff{2,Any,Opt}},
x::AbstractArray,
β::Number,
y::AbstractArray,
I::ArrayAxes,
J::ArrayAxis,
K::ArrayAxes) where {Opt}
T = real(eltype(x))
jmin, jmax = limits(J)
len = length(J)
if len ≥ 5
@maybe_inbounds Opt for k in CartesianIndices(K)
let j = jmin
@maybe_vectorized Opt for i in CartesianIndices(I)
y[i,j,k] = f(α, D2tD2_1(x,i,j,k), β, y[i,j,k])
end
end
let j = jmin+1
@maybe_vectorized Opt for i in CartesianIndices(I)
y[i,j,k] = f(α, D2tD2_2(x,i,j,k), β, y[i,j,k])
end
end
for j in jmin+2:jmax-2
@maybe_vectorized Opt for i in CartesianIndices(I)
y[i,j,k] = f(α, D2tD2_3(x,i,j,k), β, y[i,j,k])
end
end
let j = jmax-1
@maybe_vectorized Opt for i in CartesianIndices(I)
y[i,j,k] = f(α, D2tD2_4(x,i,j,k), β, y[i,j,k])
end
end
let j = jmax
@maybe_vectorized Opt for i in CartesianIndices(I)
y[i,j,k] = f(α, D2tD2_5(x,i,j,k), β, y[i,j,k])
end
end
end
elseif len == 4
@maybe_inbounds Opt for k in CartesianIndices(K)
let j = jmin
@maybe_vectorized Opt for i in CartesianIndices(I)
y[i,j,k] = f(α, D2tD2_1(x,i,j,k), β, y[i,j,k])
end
end
let j = jmin+1
@maybe_vectorized Opt for i in CartesianIndices(I)
y[i,j,k] = f(α, D2tD2_2(x,i,j,k), β, y[i,j,k])
end
end
let j = jmax-1
@maybe_vectorized Opt for i in CartesianIndices(I)
y[i,j,k] = f(α, D2tD2_4(x,i,j,k), β, y[i,j,k])
end
end
let j = jmax
@maybe_vectorized Opt for i in CartesianIndices(I)
y[i,j,k] = f(α, D2tD2_5(x,i,j,k), β, y[i,j,k])
end
end
end
elseif len == 3
@maybe_inbounds Opt for k in CartesianIndices(K)
let j = jmin
@maybe_vectorized Opt for i in CartesianIndices(I)
y[i,j,k] = f(α, D2tD2_1(x,i,j,k), β, y[i,j,k])
end
end
let j = jmin+1
@maybe_vectorized Opt for i in CartesianIndices(I)
y[i,j,k] = f(α, D2tD2_6(x,i,j,k), β, y[i,j,k])
end
end
let j = jmax
@maybe_vectorized Opt for i in CartesianIndices(I)
y[i,j,k] = f(α, D2tD2_5(x,i,j,k), β, y[i,j,k])
end
end
end
elseif len == 2
@maybe_inbounds Opt for k in CartesianIndices(K)
let j = jmin
@maybe_vectorized Opt for i in CartesianIndices(I)
y[i,j,k] = f(α, D2tD2_7(x,i,j,k), β, y[i,j,k])
end
end
let j = jmax
@maybe_vectorized Opt for i in CartesianIndices(I)
y[i,j,k] = f(α, D2tD2_8(x,i,j,k), β, y[i,j,k])
end
end
end
elseif len == 1 && β != 1
let j = jmin, z = zero(T)
@maybe_inbounds Opt for k in CartesianIndices(K)
@maybe_vectorized Opt for i in CartesianIndices(I)
y[i,j,k] = f(α, z, β, y[i,j,k])
end
end
end
end
nothing
end
end # module
| LazyAlgebra | https://github.com/emmt/LazyAlgebra.jl.git |
|
[
"MIT"
] | 0.2.7 | e58d5904fa7ffa914a3eb60f8705e2ea3aaea1b9 | code | 33017 | #
# fft.jl -
#
# Implementation of FFT and circulant convolution operators.
#
#------------------------------------------------------------------------------
#
# This file is part of LazyAlgebra (https://github.com/emmt/LazyAlgebra.jl)
# released under the MIT "Expat" license.
#
# Copyright (C) 2017-2021, Éric Thiébaut.
# Copyright (C) 2015-2016, Éric Thiébaut, Jonathan Léger & Matthew Ozon.
#
module FFTs
# Be nice with the caller: re-export `fftshift` and `ifftshift` but not `fft`,
# `ifft`, etc. as the `FFTOperator` is meant to replace them.
export
CirculantConvolution,
FFTOperator,
fftfreq,
fftshift,
goodfftdim,
goodfftdims,
ifftshift,
rfftdims
using ..Foundations
using ..LazyAlgebra
using ..LazyAlgebra:
@certify, bad_argument, bad_size, compose
import ..LazyAlgebra:
adjoint, apply!, vcreate, MorphismType, mul!,
input_size, input_ndims, input_eltype,
output_size, output_ndims, output_eltype,
identical
import Base: *, /, \, inv, show
using ArrayTools
import AbstractFFTs: Plan, fftshift, ifftshift
using FFTW
import FFTW: fftwNumber, fftwReal, fftwComplex, FFTWPlan, cFFTWPlan, rFFTWPlan
# All planning flags.
const PLANNING = (FFTW.ESTIMATE | FFTW.MEASURE | FFTW.PATIENT |
FFTW.EXHAUSTIVE | FFTW.WISDOM_ONLY)
# The time needed to allocate temporary arrays is negligible compared to the
# time taken to compute a FFT (e.g., 5µs to allocate a 256×256 array of double
# precision complexes versus 1.5ms to compute its FFT). We therefore do not
# store any temporary arrays in the FFT operator. Only the FFT plans are
# cached in the operator.
#------------------------------------------------------------------------------
# Extend LazyAlgebra framework for FFTW plans.
#
# This simplify a lot the implementation of FFT and circulant convolution
# operators without loss of performances.
macro checksize(name, arg, dims)
return quote
size($(esc(arg))) == $(esc(dims)) ||
bad_size($(esc(name)), " must have dimensions ", $(esc(dims)))
end
end
input_size(P::FFTWPlan) = P.sz
output_size(P::FFTWPlan) = P.osz
#input_strides(P::FFTWPlan) = P.istride
#output_strides(P::FFTWPlan) = P.ostride
flags(P::FFTWPlan) = P.flags
destroys_input(A::FFTWPlan) =
(flags(A) & (FFTW.PRESERVE_INPUT|FFTW.DESTROY_INPUT)) == FFTW.DESTROY_INPUT
preserves_input(A::FFTWPlan) =
(flags(A) & (FFTW.PRESERVE_INPUT|FFTW.DESTROY_INPUT)) == FFTW.PRESERVE_INPUT
# Extend `vcreate` for FFTW plans. Rationale: result must be of predictible type
# and checking input argument is skipped (this will be done by `apply!`).
#
# Create result for an in-place complex-complex forward/backward FFT
# transform.
function vcreate(::Type{Direct},
A::cFFTWPlan{Complex{T},K,true,N},
x::StridedArray{Complex{T},N},
scratch::Bool) where {T<:fftwReal,K,N}
return (scratch && isa(x, Array) ? x : Array{Complex{T}}(undef, output_size(A)))
end
# Create result for an out-of-place complex-complex forward/backward FFT
# transform.
function vcreate(::Type{Direct},
A::cFFTWPlan{Complex{T},K,false,N},
x::StridedArray{Complex{T},N},
scratch::Bool) where {T<:fftwReal,K,N}
return Array{Complex{T}}(undef, output_size(A))
end
# Create result for a real-complex or a complex-real forward/backward FFT
# transform. The result is necessarily a new array whatever the `scratch`
# flag.
function vcreate(::Type{Direct},
A::rFFTWPlan{T,K,false,N},
x::StridedArray{T,N},
scratch::Bool) where {T<:fftwReal,K,N}
return Array{Complex{T}}(undef, output_size(A))
end
function vcreate(::Type{Direct},
A::rFFTWPlan{Complex{T},K,false,N},
x::StridedArray{Complex{T},N},
scratch::Bool) where {T<:fftwReal,K,N}
return Array{T}(undef, output_size(A))
end
# Extend `apply!` for FFTW plans. We want to compute:
#
# y = α⋅F⋅x + β⋅y
#
# with as few temporaries as possible. If β = 0, then there are no needs
# to save the contents of y which can be used directly for the output of
# the transform. Extra checks are required to make sure the contents x is
# not damaged unless scratch is true. It tuns out that the implementation
# depends on the type of transform so several versions are coded below.
# Apply in-place complex-complex forward/backward FFT transform.
function apply!(α::Number,
::Type{Direct},
A::cFFTWPlan{Complex{T},K,true,N},
x::StridedArray{Complex{T},N},
scratch::Bool,
β::Number,
y::StridedArray{Complex{T},N}) where {T<:fftwReal,N,K}
@checksize "argument" x input_size(A)
@checksize "result" y output_size(A)
if α == 0
vscale!(y, β)
elseif β == 0
mul!(y, A, vscale!(y, α, x))
elseif scratch
vcombine!(y, α, mul!(x, A, x), β, y)
else
z = copy(x)
vcombine!(y, α, mul!(z, A, z), β, y)
end
return y
end
# Apply out-of-place complex-complex forward/backward FFT transform.
function apply!(α::Number,
::Type{Direct},
A::cFFTWPlan{Complex{T},K,false,N},
x::StridedArray{Complex{T},N},
scratch::Bool,
β::Number,
y::StridedArray{Complex{T},N}) where {T<:fftwReal,N,K}
@checksize "argument" x input_size(A)
@checksize "result" y output_size(A)
if α == 0
vscale!(y, β)
elseif β == 0
safe_mul!(y, A, x, scratch && x !== y)
α == 1 || vscale!(y, α)
else
vcombine!(y, α, safe_mul(A, x, scratch), β, y)
end
return y
end
# Apply real-to-complex forward transform. The transform is necessarily
# out-of-place.
function apply!(α::Number,
::Type{Direct},
A::rFFTWPlan{T,K,false,N},
x::StridedArray{T,N},
scratch::Bool,
β::Number,
y::StridedArray{Complex{T},N}) where {T<:fftwReal,K,N}
@checksize "argument" x input_size(A)
@checksize "result" y output_size(A)
if α == 0
vscale!(y, β)
elseif β == 0
safe_mul!(y, A, x, scratch)
α == 1 || vscale!(y, α)
else
vcombine!(y, α, safe_mul(A, x, scratch), β, y)
end
return y
end
# Apply complex-to-real (c2r) backward transform. Preserving input is not
# possible for multi-dimensional c2r transforms so we must copy the input
# argument x.
function apply!(α::Number,
::Type{Direct},
A::rFFTWPlan{Complex{T},K,false,N},
x::StridedArray{Complex{T},N},
scratch::Bool,
β::Number,
y::StridedArray{T,N}) where {T<:fftwReal,K,N}
@checksize "argument" x input_size(A)
@checksize "result" y output_size(A)
if α == 0
vscale!(y, β)
elseif β == 0
safe_mul!(y, A, x, scratch)
α == 1 || vscale!(y, α)
else
vcombine!(y, α, safe_mul(A, x, scratch), β, y)
end
return y
end
"""
```julia
safe_mul!(dest, A, src, scratch=false) -> dest
```
overwrite `dest` with the result of applying operator `A` to `src` and
returns `dest`. Unless `scratch` is true, it is guaranteed that `src` is
preserved which may involve making a temporary copy of it.
See also [`safe_mul`](@ref).
"""
function safe_mul!(dest::StridedArray{Complex{T},N},
A::cFFTWPlan{Complex{T},K,inplace,N},
src::StridedArray{Complex{T},N},
scratch::Bool = false) where {T<:fftwReal,K,inplace,N}
_safe_mul!(dest, A, src, scratch)
end
function safe_mul!(dest::StridedArray{Complex{T},N},
A::rFFTWPlan{T,K,inplace,N},
src::StridedArray{T,N},
scratch::Bool = false) where {T<:fftwReal,K,inplace,N}
_safe_mul!(dest, A, src, scratch)
end
function safe_mul!(dest::StridedArray{T,N},
A::rFFTWPlan{Complex{T},K,inplace,N},
src::StridedArray{Complex{T},N},
scratch::Bool = false) where {T<:fftwReal,K,inplace,N}
_safe_mul!(dest, A, src, scratch)
end
function _safe_mul!(dest::StridedArray, A::FFTWPlan,
src::StridedArray{T,N}, scratch::Bool) where {T,N}
if scratch || preserves_input(A)
mul!(dest, A, src)
else
mul!(dest, A, copy(src))
end
return dest
end
"""
```julia
safe_mul(A, x, scratch=false)
```
yields the result of applying operator `A` to `x`. Unless `scratch` is
true, it is guaranteed that input `x` is preserved which may involve making
a temporary copy of it.
See also [`safe_mul!`](@ref).
"""
function safe_mul(A::cFFTWPlan{Complex{T},K,inplace,N},
x::StridedArray{Complex{T},N},
scratch::Bool = false) where {T<:fftwReal,K,inplace,N}
y = Array{Complex{T},N}(undef, output_size(A))
safe_mul!(y, A, x, scratch)
end
function safe_mul(A::rFFTWPlan{T,K,inplace,N},
x::StridedArray{T,N},
scratch::Bool = false) where {T<:fftwReal,K,inplace,N}
y = Array{Complex{T},N}(undef, output_size(A))
safe_mul!(y, A, x, scratch)
end
function safe_mul(A::rFFTWPlan{Complex{T},K,inplace,N},
x::StridedArray{Complex{T},N},
scratch::Bool = false) where {T<:fftwReal,K,inplace,N}
y = Array{T,N}(undef, output_size(A))
safe_mul!(y, A, x, scratch)
end
#------------------------------------------------------------------------------
# FFT operator.
"""
```julia
FFTOperator(A) -> F
```
yields an FFT operator suitable for computing the fast Fourier transform of
arrays similar to `A`. The operator can also be specified by the
real/complex floating-point type of the elements of the arrays to transform
and their dimensions:
```julia
FFTOperator(T, dims) -> F
```
where `T` is one of `Float64`, `Float32` (for a real-complex FFT),
`Complex{Float64}`, `Complex{Float32}` (for a complex-complex FFT) and
`dims` gives the dimensions of the arrays to transform (by the `Direct` or
`InverseAdjoint` operation).
The interest of creating such an operator is that it caches the ressources
necessary for fast computation of the FFT and can be therefore *much*
faster than calling `fft`, `rfft`, `ifft`, etc. This is especially true on
small arrays. Keywords `flags` and `timelimit` may be used to specify
planning options and time limit to create the FFT plans (see
http://www.fftw.org/doc/Planner-Flags.html). The defaults are
`flags=FFTW.MEASURE` and no time limit.
An instance of `FFTOperator` is a linear mapping which can be used as any
other mapping:
```julia
F*x # yields the FFT of x
F'*x # yields the adjoint FFT applied to x, that is the backward FFT of x
F\\x # yields the inverse FFT of x
```
See also: [`fft`](@ref), [`plan_fft`](@ref), [`bfft`](@ref),
[`plan_bfft`](@ref), [`rfft`](@ref), [`plan_rfft`](@ref),
[`brfft`](@ref), [`plan_brfft`](@ref).
"""
struct FFTOperator{T<:fftwNumber, # element type of input
N, # number of dimensions
C<:fftwComplex, # element type of output
F<:Plan{T}, # type of forward plan
B<:Plan{C} # type of backward plan
} <: LinearMapping
ncols::Int # number of input elements
inpdims::NTuple{N,Int} # input dimensions
outdims::NTuple{N,Int} # output dimensions
forward::F # plan for forward transform
backward::B # plan for backward transform
end
# Real-to-complex FFT.
function FFTOperator(::Type{T},
dims::NTuple{N,Int};
timelimit::Real = FFTW.NO_TIMELIMIT,
flags::Integer = FFTW.MEASURE) where {T<:fftwReal,N}
# Check arguments and build dimension list of the result of the forward
# real-to-complex (r2c) transform.
planning = check_flags(flags)
ncols = check_size(dims)
zdims = rfftdims(dims)
# Compute the plans with suitable FFTW flags. The forward transform (r2c)
# must preserve its input, while the backward transform (c2r) may destroy
# it (in fact there are no input-preserving algorithms for
# multi-dimensional c2r transforms implemented in FFTW, see
# http://www.fftw.org/doc/Planner-Flags.html).
forward = plan_rfft(Array{T}(undef, dims);
flags = (planning | FFTW.PRESERVE_INPUT),
timelimit = timelimit)
backward = plan_brfft(Array{Complex{T}}(undef, zdims), dims[1];
flags = (planning | FFTW.DESTROY_INPUT),
timelimit = timelimit)
# Build operator.
F = typeof(forward)
B = typeof(backward)
return FFTOperator{T,N,Complex{T},F,B}(ncols, dims, zdims,
forward, backward)
end
# Complex-to-complex FFT.
function FFTOperator(::Type{T},
dims::NTuple{N,Int};
timelimit::Real = FFTW.NO_TIMELIMIT,
flags::Integer = FFTW.MEASURE) where {T<:fftwComplex,N}
# Check arguments. The input and output of the complex-to-complex
# transform have the same dimensions.
planning = check_flags(flags)
ncols = check_size(dims)
temp = Array{T}(undef, dims)
# Compute the plans with suitable FFTW flags. For maximum efficiency, the
# transforms are always applied in-place and thus cannot preserve their
# inputs.
forward = plan_fft!(temp; flags = (planning | FFTW.DESTROY_INPUT),
timelimit = timelimit)
backward = plan_bfft!(temp; flags = (planning | FFTW.DESTROY_INPUT),
timelimit = timelimit)
# Build operator.
F = typeof(forward)
B = typeof(backward)
return FFTOperator{T,N,T,F,B}(ncols, dims, dims, forward, backward)
end
@callable FFTOperator
# Constructor for dimensions not specified as a tuple.
FFTOperator(T::Type{<:fftwNumber}, dims::Integer...; kwds...) =
FFTOperator(T, dims; kwds...)
# The following 2 definitions are needed to avoid ambiguities.
FFTOperator(T::Type{<:fftwReal}, dims::Tuple{Vararg{Integer}}; kwds...) =
FFTOperator(T, to_size(dims); kwds...)
FFTOperator(T::Type{<:fftwComplex}, dims::Tuple{Vararg{Integer}}; kwds...) =
FFTOperator(T, to_size(dims); kwds...)
# Constructor for transforms applicable to a given array.
FFTOperator(A::DenseArray{T,N}; kwds...) where {T<:fftwNumber,N} =
FFTOperator(T, size(A); kwds...)
# Traits:
MorphismType(::FFTOperator{<:Complex}) = Endomorphism()
ncols(A::FFTOperator) = A.ncols
ncols(A::Adjoint{<:FFTOperator}) = ncols(unveil(A))
ncols(A::Inverse{<:FFTOperator}) = ncols(unveil(A))
ncols(A::InverseAdjoint{<:FFTOperator}) = ncols(unveil(A))
input_size(A::FFTOperator) = A.inpdims # FIXME: input_size(A.forward)
input_size(A::FFTOperator, i::Integer) = get_dimension(input_size(A), i)
output_size(A::FFTOperator) = A.outdims
output_size(A::FFTOperator, i::Integer) = get_dimension(output_size(A), i)
input_ndims(A::FFTOperator{T,N,C}) where {T,N,C} = N
output_ndims(A::FFTOperator{T,N,C}) where {T,N,C} = N
input_eltype(A::FFTOperator{T,N,C}) where {T,N,C} = T
output_eltype(A::FFTOperator{T,N,C}) where {T,N,C} = C
# 2 FFT operators can be considered the same if they operate on arguments with
# the same element type and the same dimensions. If the types do not match,
# the matching method is the one which return false, so it is only needed to
# implement the method for two arguments with the same types (omitting the type
# of the plans as it is irrelevant here).
identical(A::FFTOperator{T,N,C}, B::FFTOperator{T,N,C}) where {T,N,C} =
(input_size(A) == input_size(B))
show(io::IO, A::FFTOperator) = print(io, "FFT")
# Impose the following simplifying rules:
# inv(F) = n\F'
# ==> F⋅F' = F'⋅F = n⋅Id
# ==> inv(F⋅F') = inv(F'⋅F) = inv(F)⋅inv(F') = inv(F')⋅inv(F) = n\Id
*(A::Adjoint{F}, B::F) where {F<:FFTOperator} =
(identical(unveil(A), B) ? ncols(A)*Id : compose(A, B))
*(A::F, B::Adjoint{F}) where {F<:FFTOperator} =
(identical(A, unveil(B)) ? ncols(A)*Id : compose(A, B))
*(A::InverseAdjoint{F}, B::Inverse{F}) where {F<:FFTOperator} =
(identical(unveil(A), unveil(B)) ? (1//ncols(A))*Id : compose(A, B))
*(A::Inverse{F}, B::InverseAdjoint{F}) where {F<:FFTOperator} =
(identical(unveil(A), unveil(B)) ? (1//ncols(A))*Id : compose(A, B))
function vcreate(P::Type{<:Union{Direct,InverseAdjoint}},
A::FFTOperator{T,N,C},
x::DenseArray{T,N},
scratch::Bool) where {T,N,C}
vcreate(Direct, A.forward, x, scratch)
end
function vcreate(P::Type{<:Union{Adjoint,Inverse}},
A::FFTOperator{T,N,C},
x::DenseArray{C,N},
scratch::Bool) where {T,N,C}
vcreate(Direct, A.backward, x, scratch)
end
#
# In principle, FFTW plans can be applied to strided arrays (StridedArray) but
# this imposes that the arguments have the same strides. So for now, we choose
# to restrict arguments to arrays with contiguous elements (DenseArray).
#
function apply!(α::Number,
::Type{Direct},
A::FFTOperator{T,N,C},
x::DenseArray{T,N},
scratch::Bool,
β::Number,
y::DenseArray{C,N}) where {T,N,C}
return apply!(α, Direct, A.forward, x, scratch, β, y)
end
function apply!(α::Number,
::Type{Adjoint},
A::FFTOperator{T,N,C},
x::DenseArray{C,N},
scratch::Bool,
β::Number,
y::DenseArray{T,N}) where {T,N,C}
return apply!(α, Direct, A.backward, x, scratch, β, y)
end
function apply!(α::Number,
::Type{Inverse},
A::FFTOperator{T,N,C},
x::DenseArray{C,N},
scratch::Bool,
β::Number,
y::DenseArray{T,N}) where {T,N,C}
return apply!(α/ncols(A), Direct, A.backward, x, scratch, β, y)
end
function apply!(α::Number,
::Type{InverseAdjoint},
A::FFTOperator{T,N,C},
x::DenseArray{T,N},
scratch::Bool,
β::Number,
y::DenseArray{C,N}) where {T,N,C}
return apply!(α/ncols(A), Direct, A.forward, x, scratch, β, y)
end
#------------------------------------------------------------------------------
# Circulant convolution.
struct CirculantConvolution{T<:fftwNumber,N,
C<:fftwComplex,
F<:Plan{T},
B<:Plan{C}} <: LinearMapping
dims::NTuple{N,Int} # input/output dimensions
zdims::NTuple{N,Int} # complex dimensions
mtf::Array{C,N} # modulation transfer function
forward::F # plan for forward transform
backward::B # plan for backward transform
end
@callable CirculantConvolution
# Traits:
MorphismType(::CirculantConvolution) = Endomorphism()
# Basic methods for a linear operator on Julia's arrays.
input_size(H::CirculantConvolution) = H.dims
output_size(H::CirculantConvolution) = H.dims
input_size(H::CirculantConvolution, i::Integer) = get_dimension(H.dims, i)
output_size(H::CirculantConvolution, i::Integer) = get_dimension(H.dims, i)
input_ndims(H::CirculantConvolution{T,N}) where {T,N} = N
output_ndims(H::CirculantConvolution{T,N}) where {T,N} = N
input_eltype(H::CirculantConvolution{T,N}) where {T,N} = T
output_eltype(H::CirculantConvolution{T,N}) where {T,N} = T
# Basic methods for an array.
Base.eltype(H::CirculantConvolution{T,N}) where {T,N} = T
Base.size(H::CirculantConvolution{T,N}) where {T,N} =
ntuple(i -> H.dims[(i ≤ N ? i : i - N)], 2*N)
Base.size(H::CirculantConvolution{T,N}, i::Integer) where {T,N} =
(i < 1 ? bad_dimension_index() : i ≤ N ? H.dims[i] : i ≤ 2N ? H.dims[i-N] : 1)
Base.ndims(H::CirculantConvolution{T,N}) where {T,N} = 2*N
"""
# Circulant convolution operator
The circulant convolution operator `H` is defined by:
```julia
H = (1/n)*F'*Diag(mtf)*F
```
with `n` the number of elements, `F` the discrete Fourier transform operator
and `mtf` the modulation transfer function.
The operator `H` can be created by:
```julia
H = CirculantConvolution(psf; flags=FFTW.MEASURE, timelimit=Inf, shift=false)
```
where `psf` is the point spread function (PSF). Note that the PSF is assumed
to be centered according to the convention of the discrete Fourier transform.
You may use `ifftshift` or the keyword `shift` if the PSF is geometrically
centered:
```julia
H = CirculantConvolution(ifftshift(psf))
H = CirculantConvolution(psf, shift=true)
```
The following keywords can be specified:
* `shift` (`false` by default) indicates whether to apply `ifftshift` to `psf`.
* `normalize` (`false` by default) indicates whether to divide `psf` by the sum
of its values. This keyword is only available for real-valued PSF.
* `flags` is a bitwise-or of FFTW planner flags, defaulting to `FFTW.MEASURE`.
If the operator is to be used many times (as in iterative methods), it is
recommended to use at least `flags=FFTW.MEASURE` (the default) which
generally yields faster transforms compared to `flags=FFTW.ESTIMATE`.
* `timelimit` specifies a rough upper bound on the allowed planning time, in
seconds.
The operator can be used as a regular linear operator: `H(x)` or `H*x` to
compute the convolution of `x` and `H'(x)` or `H'*x` to apply the adjoint of
`H` to `x`.
For a slight improvement of performances, an array `y` to store the result of
the operation can be provided:
```julia
apply!(y, [P=Direct,] H, x) -> y
apply!(y, H, x)
apply!(y, H', x)
```
If provided, `y` must be at a different memory location than `x`.
""" CirculantConvolution
function CirculantConvolution(psf::AbstractArray{T,N};
kwds...) where {T<:fftwNumber,N}
CirculantConvolution(copy(psf); kwds...)
end
# Create a circular convolution operator for real arrays.
function CirculantConvolution(psf::DenseArray{T,N};
flags::Integer = FFTW.MEASURE,
normalize::Bool = false,
shift::Bool = false,
kwds...) where {T<:fftwReal,N}
# Check arguments and compute dimensions.
planning = check_flags(flags)
n = length(psf)
dims = size(psf)
zdims = rfftdims(dims)
# Allocate array for the scaled MTF, this array also serves as a workspace
# for planning operations which may destroy their input.
mtf = Array{Complex{T}}(undef, zdims)
# Compute the plans with suitable FFTW flags. The forward transform (r2c)
# must preserve its input, while the backward transform (c2r) may destroy
# it (in fact there are no input-preserving algorithms for
# multi-dimensional c2r transforms).
forward = safe_plan_rfft(psf; flags = (planning | FFTW.PRESERVE_INPUT), kwds...)
backward = plan_brfft(mtf, dims[1]; flags = (planning | FFTW.DESTROY_INPUT),
kwds...)
# Compute the scaled MTF *after* computing the plans.
mul!(mtf, forward, (shift ? ifftshift(psf) : psf))
if normalize
sum = mtf[1]
sum <= 0 && bad_argument("cannot normalize: sum(PSF) ≤ 0")
sum != 1 && vscale!(mtf, 1/sum)
end
# Build operator.
F = typeof(forward)
B = typeof(backward)
CirculantConvolution{T,N,Complex{T},F,B}(dims, zdims, mtf, forward, backward)
end
# Create a circular convolution operator for complex arrays (see
# docs/convolution.md for explanations).
function CirculantConvolution(psf::DenseArray{T,N};
flags::Integer = FFTW.MEASURE,
normalize::Bool = false,
shift::Bool = false,
kwds...) where {T<:fftwComplex,N}
# Check arguments and get dimensions.
@certify normalize == false "normalizing a complex PSF has no sense"
planning = check_flags(flags)
n = length(psf)
dims = size(psf)
# Allocate array for the scaled MTF, this array also serves as a workspace
# for planning operations which may destroy their input.
mtf = Array{T}(undef, dims)
# Compute the plans with FFTW flags suitable for out-of-place forward
# transform and in-place backward transform.
forward = plan_fft(mtf; flags = (planning | FFTW.PRESERVE_INPUT), kwds...)
backward = plan_bfft!(mtf; flags = (planning | FFTW.DESTROY_INPUT), kwds...)
# Compute the MTF *after* computing the plans.
mul!(mtf, forward, (shift ? ifftshift(psf) : psf))
# Build the operator.
F = typeof(forward)
B = typeof(backward)
CirculantConvolution{T,N,T,F,B}(dims, dims, mtf, forward, backward)
end
"""
`safe_plan_rfft(x; kwds...)` yields a FFTW plan for computing the real to
complex fast Fourier transform of `x`. This method is the same as `plan_rfft`
except that it makes sure that `x` is preserved.
"""
function safe_plan_rfft(x::AbstractArray{T,N}; flags::Integer = FFTW.MEASURE,
kwds...) where {T<:fftwReal,N}
planning = (flags & PLANNING)
if isa(x, StridedArray) && (planning == FFTW.ESTIMATE ||
planning == FFTW.WISDOM_ONLY)
return plan_rfft(x; flags=flags, kwds...)
else
return plan_rfft(Array{T}(undef, size(x)); flags=flags, kwds...)
end
end
function vcreate(::Type{<:Operations},
H::CirculantConvolution{T,N},
x::AbstractArray{T,N},
scratch::Bool) where {T<:fftwNumber,N}
return Array{T,N}(undef, H.dims)
end
function apply!(α::Number,
P::Type{<:Union{Direct,Adjoint}},
H::CirculantConvolution{Complex{T},N,Complex{T}},
x::AbstractArray{Complex{T},N},
scratch::Bool,
β::Number,
y::AbstractArray{Complex{T},N}) where {T<:fftwReal,N}
@certify !Base.has_offset_axes(x, y)
if α == 0
@certify size(y) == H.dims
vscale!(y, β)
else
n = length(x)
if β == 0
# Use y as a workspace.
mul!(y, H.forward, x) # out-of-place forward FFT of x in y
_apply!(y, α/n, P, H.mtf) # in-place multiply y by mtf/n
mul!(y, H.backward, y) # in-place backward FFT of y
else
# Must allocate a workspace.
z = Array{Complex{T}}(undef, H.zdims) # allocate temporary
mul!(z, H.forward, x) # out-of-place forward FFT of x in z
_apply!(z, α/n, P, H.mtf) # in-place multiply z by mtf/n
mul!(z, H.backward, z) # in-place backward FFT of z
vcombine!(y, 1, z, β, y)
end
end
return y
end
function apply!(α::Number,
P::Type{<:Union{Direct,Adjoint}},
H::CirculantConvolution{T,N,Complex{T}},
x::AbstractArray{T,N},
scratch::Bool,
β::Number,
y::AbstractArray{T,N}) where {T<:fftwReal,N}
@certify !Base.has_offset_axes(x, y)
if α == 0
@certify size(y) == H.dims
vscale!(y, β)
else
n = length(x)
z = Array{Complex{T}}(undef, H.zdims) # allocate temporary
mul!(z, H.forward, x) # out-of-place forward FFT of x in z
_apply!(z, α/n, P, H.mtf) # in-place multiply z by mtf/n
if β == 0
mul!(y, H.backward, z) # out-of-place backward FFT of z in y
else
w = Array{T}(undef, H.dims) # allocate another temporary
mul!(w, H.backward, z) # out-of-place backward FFT of z in y
vcombine!(y, 1, w, β, y)
end
end
return y
end
"""
```julia
_apply!(arr, α, P, mtf)
```
stores in `arr` the elementwise multiplication of `arr` by `α*mtf` if `P` is
`Direct` or by `α*conj(mtf)` if `P` is `Adjoint`. An error is thrown if the
arrays do not have the same dimensions. It is assumed that `α ≠ 0`.
"""
function _apply!(arr::AbstractArray{Complex{T},N},
α::Number, ::Type{Direct},
mtf::AbstractArray{Complex{T},N}) where {T,N}
@certify axes(arr) == axes(mtf)
if α == 1
@inbounds @simd for i in eachindex(arr, mtf)
arr[i] *= mtf[i]
end
else
alpha = promote_multiplier(α, T)
@inbounds @simd for i in eachindex(arr, mtf)
arr[i] *= alpha*mtf[i]
end
end
end
function _apply!(arr::AbstractArray{Complex{T},N},
α::Number, ::Type{Adjoint},
mtf::AbstractArray{Complex{T},N}) where {T,N}
@certify axes(arr) == axes(mtf)
if α == 1
@inbounds @simd for i in eachindex(arr, mtf)
arr[i] *= conj(mtf[i])
end
else
alpha = promote_multiplier(α, T)
@inbounds @simd for i in eachindex(arr, mtf)
arr[i] *= alpha*conj(mtf[i])
end
end
end
#------------------------------------------------------------------------------
# Utilities.
"""
`check_flags(flags)` checks whether `flags` is an allowed bitwise-or
combination of FFTW planner flags (see
http://www.fftw.org/doc/Planner-Flags.html) and returns the filtered flags.
"""
function check_flags(flags::Integer)
planning = flags & PLANNING
flags == planning ||
bad_argument("only FFTW planning flags can be specified")
return UInt32(planning)
end
"""
`get_dimension(dims, i)` yields the `i`-th dimension in tuple of integers
`dims`. Like for broadcasting rules, it is assumed that the length of
all dimensions after the last one are equal to 1.
"""
get_dimension(dims::NTuple{N,Int}, i::Integer) where {N} =
(i < 1 ? bad_dimension_index() : i ≤ N ? dims[i] : 1)
# FIXME: should be in ArrayTools
bad_dimension_index() = error("invalid dimension index")
"""
```julia
goodfftdim(len)
```
yields the smallest integer which is greater or equal `len` and which is a
multiple of powers of 2, 3 and/or 5. If argument is an array dimesion list
(i.e. a tuple of integers), a tuple of good FFT dimensions is returned.
Also see: [`goodfftdims`](@ref), [`rfftdims`](@ref), [`FFTOperator`](@ref).
"""
goodfftdim(len::Integer) = goodfftdim(Int(len))
goodfftdim(len::Int) = nextprod([2,3,5], len)
"""
```julia
goodfftdims(dims)
```
yields a list of dimensions suitable for computing the FFT of arrays whose
dimensions are `dims` (a tuple or a vector of integers).
Also see: [`goodfftdim`](@ref), [`rfftdims`](@ref), [`FFTOperator`](@ref).
"""
goodfftdims(dims::Integer...) = map(goodfftdim, dims)
goodfftdims(dims::Union{AbstractVector{<:Integer},Tuple{Vararg{Integer}}}) =
map(goodfftdim, dims)
"""
```julia
rfftdims(dims)
```
yields the dimensions of the complex array produced by a real-complex FFT of a
real array of size `dims`.
Also see: [`goodfftdim`](@ref), [`FFTOperator`](@ref).
"""
rfftdims(dims::Integer...) = rfftdims(dims)
rfftdims(dims::NTuple{N,Integer}) where {N} =
ntuple(d -> (d == 1 ? (Int(dims[d]) >>> 1) + 1 : Int(dims[d])), Val(N))
# Note: The above version is equivalent but much faster than
# ((dims[1] >>> 1) + 1, dims[2:end]...)
# which is not optimized out by the compiler.
"""
### Generate Discrete Fourier Transform frequency indexes or frequencies
Syntax:
```julia
k = fftfreq(dim)
f = fftfreq(dim, step)
```
With a single argument, the function returns a vector of `dim` values set with
the frequency indexes:
```
k = [0, 1, 2, ..., n-1, -n, ..., -2, -1] if dim = 2*n
k = [0, 1, 2, ..., n, -n, ..., -2, -1] if dim = 2*n + 1
```
depending whether `dim` is even or odd. These rules are compatible to what is
assumed by `fftshift` (which to see) in the sense that:
```
fftshift(fftfreq(dim)) = [-n, ..., -2, -1, 0, 1, 2, ...]
```
With two arguments, `step` is the sample spacing in the direct space and the
result is a floating point vector with `dim` elements set with the frequency
bin centers in cycles per unit of the sample spacing (with zero at the start).
For instance, if the sample spacing is in seconds, then the frequency unit is
cycles/second. This is equivalent to:
```
fftfreq(dim)/(dim*step)
```
See also: [`FFTOperator`](@ref), [`fftshift`](@ref).
"""
function fftfreq(_dim::Integer)
dim = Int(_dim)
n = div(dim, 2)
f = Array{Int}(undef, dim)
@inbounds begin
for k in 1:dim-n
f[k] = k - 1
end
for k in dim-n+1:dim
f[k] = k - (1 + dim)
end
end
return f
end
function fftfreq(_dim::Integer, step::Real)
dim = Int(_dim)
scl = Cdouble(1/(dim*step))
n = div(dim, 2)
f = Array{Cdouble}(undef, dim)
@inbounds begin
for k in 1:dim-n
f[k] = (k - 1)*scl
end
for k in dim-n+1:dim
f[k] = (k - (1 + dim))*scl
end
end
return f
end
end # module
| LazyAlgebra | https://github.com/emmt/LazyAlgebra.jl.git |
|
[
"MIT"
] | 0.2.7 | e58d5904fa7ffa914a3eb60f8705e2ea3aaea1b9 | code | 1759 | #
# foundations.jl -
#
# Sub-module exporting types and methods needed to extend or implement
# LazyAlgebra mappings.
#
#-------------------------------------------------------------------------------
#
# This file is part of LazyAlgebra (https://github.com/emmt/LazyAlgebra.jl)
# released under the MIT "Expat" license.
#
# Copyright (c) 2017-2021 Éric Thiébaut.
#
"""
using LazyAlgebra.Foundations
imports types and methods that may be useful to extend or implement
`LazyAlgebra` mappings.
"""
module Foundations
using ..LazyAlgebra
for sym in (Symbol("@callable"),
:Adjoint,
:AdjointInverse,
:DiagonalMapping,
:DiagonalType,
:Direct,
:Endomorphism,
:Inverse,
:InverseAdjoint,
:Linear,
:LinearType,
:Morphism,
:MorphismType,
:NonDiagonalMapping,
:NonLinear,
:NonSelfAdjoint,
:Operations,
:SelfAdjoint,
:SelfAdjointType,
:axpby_yields_zero,
:axpby_yields_y,
:axpby_yields_my,
:axpby_yields_by,
:axpby_yields_x,
:axpby_yields_xpy,
:axpby_yields_xmy,
:axpby_yields_xpby,
:axpby_yields_mx,
:axpby_yields_ymx,
:axpby_yields_mxmy,
:axpby_yields_bymx,
:axpby_yields_ax,
:axpby_yields_axpy,
:axpby_yields_axmy,
:axpby_yields_axpby,
:multiplier_type,
:multiplier_floatingpoint_type,
:promote_multiplier)
@eval begin
import ..LazyAlgebra: $sym
export $sym
end
end
end # module Foundations
| LazyAlgebra | https://github.com/emmt/LazyAlgebra.jl.git |
|
[
"MIT"
] | 0.2.7 | e58d5904fa7ffa914a3eb60f8705e2ea3aaea1b9 | code | 2056 | #
# genmult.jl -
#
# Generalized dot product by grouping consecutive dimensions.
#
#-------------------------------------------------------------------------------
#
# This file is part of LazyAlgebra (https://github.com/emmt/LazyAlgebra.jl)
# released under the MIT "Expat" license.
#
# Copyright (c) 2017-2020 Éric Thiébaut.
#
module GenMult
export
lgemm!,
lgemm,
lgemv!,
lgemv
using ..LazyAlgebra
using ..LazyAlgebra: Complexes, Floats, Reals, axes, promote_multiplier,
libblas, @blasfunc, BlasInt, BlasReal, BlasFloat, BlasComplex,
bad_argument, bad_size
using ArrayTools # for `cartesian_indices`, `is_flat_array`, etc.
using LinearAlgebra
using LinearAlgebra.BLAS
"""
```julia
Implementation(Val(:alg), args...)`
```
is used to quickly determine the most efficient implementation of the code to
use for algorithm `alg` with arguments `args...`. The returned value is one of
four possible singletons:
- `Blas()` when highly optimized BLAS code can be used. This is the preferred
implementation as it is assumed to be the fastest.
- `Basic()` when *vector* and *matrix* arguments have respectively one and two
dimensions.
- `Linear()` when *vector* and *matrix* arguments can be efficiently indexed
by, respectively, one and two linear indices.
- `Generic()` to use generic implementation which can accommodate from any type
of arguments and of multi-dimensional indices. This implementation should be
always safe to use and should provide the reference implementation of the
algorithm `alg`.
Whenever possible, the best implementation is automatically determined at
compilation time by calling this method.
"""
abstract type Implementation end
for S in (:Basic, :Blas, :Linear, :Generic)
@eval begin
struct $S <: Implementation end
@doc @doc(Implementation) $S
end
end
incompatible_dimensions() =
bad_size("incompatible dimensions")
invalid_transpose_character() =
bad_argument("invalid transpose character")
include("lgemv.jl")
include("lgemm.jl")
end # module
| LazyAlgebra | https://github.com/emmt/LazyAlgebra.jl.git |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.